Unified Keypoint-based Action Recognition Framework via Structured Keypoint Pooling
基于结构化关键点池化的统一关键点动作识别框架

Figure 1. Qualitative results of the proposed framework for the skeleton-based action recognition (top) and spatio-temporal localization task (bottom). The input keypoints and the estimated action labels are visualized in the figure. We achieve state-of-the-art accuracy for the recognition task while it runs ${\sim}1800\mathrm{FPS}$ on a single RTX 3080Ti GPU. In addition, the proposed method outperforms the state-of-the-art weakly supervised spatio-temporal localization methods. See the website for the demo video.
图 1: 基于骨架的动作识别(上)和时空定位任务(下)所提框架的定性结果。图中可视化展示了输入关键点与预测动作标签。该识别任务在单块RTX 3080Ti GPU上以${\sim}1800\mathrm{FPS}$运行时达到最优精度。此外,所提方法优于当前最先进的弱监督时空定位方法。演示视频详见项目网站。
Abstract
摘要
This paper simultaneously addresses three limitations associated with conventional skeleton-based action recognition; skeleton detection and tracking errors, poor variety of the targeted actions, as well as person-wise and frame-wise action recognition. A point cloud deep-learning paradigm is introduced to the action recognition, and a unified framework along with a novel deep neural network architecture called Structured Keypoint Pooling is proposed. The proposed method sparsely aggregates keypoint features in a cascaded manner based on prior knowledge of the data structure (which is inherent in skeletons), such as the instances and frames to which each keypoint belongs, and achieves robustness against input errors. Its less constrained and tracking-free architecture enables time-series keypoints consisting of human skeletons and nonhuman object contours to be efficiently treated as an input 3D point cloud and extends the variety of the targeted action. Furthermore, we propose a Pooling-Switching Trick inspired by Structured Keypoint Pooling. This trick switches the pooling kernels between the training and inference phases to detect person-wise and frame-wise actions in a weakly supervised manner using only video-level action labels. This trick enables our training scheme to naturally introduce novel data augmentation, which mixes multiple point clouds extracted from different videos. In the experiments, we comprehensively verify the effectiveness of the proposed method against the limitations, and the method outperforms state-of-the-art skeleton-based action recognition and spatio-temporal action localization methods.
本文同时解决了传统基于骨架的动作识别存在的三个局限性:骨架检测与跟踪误差、目标动作多样性不足,以及人物级和帧级动作识别问题。研究将点云深度学习范式引入动作识别领域,提出了一种统一框架及名为结构化关键点池化(Structured Keypoint Pooling)的新型深度神经网络架构。该方法基于数据结构先验知识(如骨架固有的实例与帧归属关系),以级联方式稀疏聚合关键点特征,从而实现对输入误差的鲁棒性。其弱约束且无需跟踪的架构设计,能够将人体骨架与非人物体轮廓组成的时间序列关键点高效处理为输入3D点云,从而扩展目标动作的多样性。此外,我们受结构化关键点池化启发提出池化切换技巧(Pooling-Switching Trick),通过在训练与推理阶段切换池化核,仅利用视频级动作标签即可实现弱监督的人物级和帧级动作检测。该技巧使训练方案能自然引入混合多源点云的新型数据增强策略。实验全面验证了所提方法针对上述局限性的有效性,其性能优于当前最先进的基于骨架的动作识别与时空动作定位方法。
1. Introduction
1. 引言
Recognizing the actions of a person in a video plays an essential role in various applications such as robotics [28, 41] and surveillance cameras [11, 25, 49]. The approach to the action recognition task differs depending on whether leveraging appearance information in a video or human skeletons1 detected in the video. The former appearancebased approaches [2,7,11,18,20–23,25,32,45,51,52,56,58] directly use video as an input to deep neural networks (DNNs) and thus even can recognize actions with relatively small movements. However, they are less robust to appearances of the people or scenes that differ from the training data [34, 55]. On the other hand, the latter skeleton-based approaches [5,9,10,13,17,29,33,34,49,57,60] are relatively robust to such appearance changes of a scene or a person because they only input low-information keypoints detected using the multi-person pose estimation methods [6, 42, 50].
识别视频中人物的动作在机器人技术[28, 41]和监控摄像头[11, 25, 49]等多种应用中起着至关重要的作用。动作识别任务的方法根据是否利用视频中的外观信息或检测到的人体骨骼1而有所不同。前者基于外观的方法[2,7,11,18,20–23,25,32,45,51,52,56,58]直接将视频作为深度神经网络(DNNs)的输入,因此甚至可以识别动作幅度相对较小的行为。然而,它们对于与训练数据中不同的人物或场景外观的鲁棒性较差[34, 55]。另一方面,后者基于骨骼的方法[5,9,10,13,17,29,33,34,49,57,60]对场景或人物的此类外观变化相对鲁棒,因为它们仅输入使用多人姿态估计方法[6, 42, 50]检测到的低信息量关键点。
Starting from ST-GCN [57], various skeleton-based approaches employing graph convolutional networks (GCNs) have emerged [5, 9, 10, 13, 33, 44]. These approaches model the relationship among keypoints by densely connecting them in a spatio-temporal space using GCNs, which treat every keypoint as a node at each time step. However, most approaches exhibit low s cal ability in practical scenarios, and further performance improvement is required since they exhibit three limitations regarding network architectures or their problem settings, as described below.
从ST-GCN [57]开始,出现了多种基于骨架的图卷积网络(GCN)方法[5, 9, 10, 13, 33, 44]。这些方法通过在时空空间中用GCN密集连接关键点来建模它们之间的关系,将每个时间步的每个关键点视为一个节点。然而,大多数方法在实际场景中表现出较低的可扩展性,并且由于在网络架构或问题设置方面存在以下三个局限性,需要进一步提升性能。
Skeleton Detection and Tracking Errors. Conventional GCN-based methods heavily rely on dense graphs, whose node keypoints are accurately detected and grouped by the same instance. These methods assume that the DNN features are correctly propagated. Therefore, if false positives (FPs) or false negatives (FNs) occur during keypoint detection, or if the multi-person pose tracking [39, 47] fails, such assumptions no longer hold, and the action recognition accuracy is degraded [17, 62].
骨架检测与追踪误差。传统基于GCN的方法严重依赖密集图结构,其节点关键点需被准确检测并由同一实例分组。这些方法假设DNN特征能够正确传播。因此,若关键点检测过程中出现误检(FP)或漏检(FN),或多人姿态追踪[39, 47]失败,此类假设将不再成立,动作识别精度会随之下降[17, 62]。
Poor Variety of the Targeted Actions. Conventional approaches limit the number of input skeletons to at most one or two. Therefore, the recognition of actions performed by many people or those interacting with nonhuman objects is an ill-posed problem. On the other hand, for a wide range of applications, it is desirable to eliminate such restrictions and target a variety of action categories.
目标动作多样性不足。传统方法将输入骨骼数量限制在一到两个以内,因此识别多人执行的动作或与非人物体交互的动作成为一个不适定问题。另一方面,对于广泛的应用场景而言,消除此类限制并覆盖多样化的动作类别具有重要价值。
Person-wise and Frame-wise Action Recognition. Conventional approaches classify an entire video into actions, while practical scenes are complex and include multiple persons performing different actions in different time windows. Hence, recognizing each person’s action for each frame (spatio-temporal action localization) is necessary.
人物级与帧级动作识别。传统方法将整个视频分类为动作类别,而实际场景复杂多样,常包含多人在不同时间窗口执行不同动作。因此,需要逐帧识别每个人的动作(时空动作定位)。
In this paper, a unified action recognition framework and a novel DNN architecture called Structured Keypoint Pooling, which enhances the applicability and s cal ability of the skeleton-based action recognition (see Fig. 1), is proposed to simultaneously address the above three limitations. Unlike previous methods, which concatenate the keypoint coordinates and input them into a DNN designed on a predefined graph structure of a skeleton, the proposed method introduces a point cloud deep-learning paradigm [37,38,61] to the action recognition and treats a set of keypoints as an input 3D point cloud. PointNet [37], which was proposed in such a paradigm, is an innovative research, whose output is permutation-invariant to the order of the input points. It extracts the features for each input point and sparsely aggregates them to the output feature vector using Max-Pooling. Unlike PointNet, the proposed network architecture aggregates the features extracted from the point cloud in a cascaded manner based on prior knowledge of the data structure, which is inherent in the point cloud, such as the frames or the detection results of the persons (instances) to which each keypoint belongs. As a result, it is less constrained than conventional approaches and tracking-free. Also, its feature propagation among keypoints is relatively sparse. Therefore, the range of the DNNs affected by the keypoint errors (e.g., FPs, FNs, and tracking errors) associated with the first robustness limitation can also be limited.
本文提出了一种统一的动作识别框架和一种名为结构化关键点池化的新型DNN架构(见图1),旨在同时解决上述三个局限性,从而提升基于骨架的动作识别的适用性和可扩展性。与以往方法(将关键点坐标拼接后输入预定义骨架图结构的DNN)不同,本方法将点云深度学习范式[37,38,61]引入动作识别领域,将关键点集合视为输入的三维点云。该范式下的开创性研究PointNet[37]具有输入点顺序无关的特性,它通过逐点提取特征并使用最大池化稀疏聚合为输出特征向量。不同于PointNet,本网络架构基于点云固有数据结构(如关键点所属的帧或人员实例检测结果)的先验知识,以级联方式聚合点云特征。因此,其约束条件少于传统方法且无需追踪,同时关键点间的特征传播相对稀疏,从而可将受关键点误差(如误检、漏检和追踪误差)影响的DNN范围控制在第一鲁棒性限制内。
In addition, the permutation-invariant property of the input in the proposed network architecture eliminates the constraints of the data structure and size (e.g., number of instances and pose tracking) found in the GCN-based methods. This property is exploited, and the nonhuman object keypoints2 defined on the contour of the objects are used as an input in addition to human skeletons. Thus, the second target-action limitation mentioned above is addressed by increasing the input information without relying on the appearances while avoiding over fitting on them [14,34,55].
此外,所提出网络架构中输入数据的置换不变性消除了基于GCN方法中数据结构与规模(如实例数量和姿态追踪)的限制。该特性被充分利用,除人体骨骼外还采用物体轮廓上定义的非人物体关键点作为输入。因此,上述第二个目标动作限制问题通过增加输入信息得到解决,既不依赖外观特征,又避免了对此类特征的过拟合 [14,34,55]。
Finally, the third multi-action limitation is addressed by extending the proposed network architecture concept to a weakly supervised spatio-temporal action localization, which only requires a video-level action label during training. This is achieved using the proposed PoolingSwitching Trick inspired by Structured Keypoint Pooling, which switches the pooling structures according to the training and inference phases. Furthermore, this poolingswitching technique naturally enables the proposed training scheme to introduce novel data augmentation, which mixes multiple point clouds extracted from different videos.
最后,针对第三个多动作限制问题,我们通过将提出的网络架构概念扩展到弱监督时空动作定位来解决,该方案在训练期间仅需视频级动作标签。这一目标通过受结构化关键点池化 (Structured Keypoint Pooling) 启发的池化切换技巧 (PoolingSwitching Trick) 实现,该技巧根据训练和推理阶段切换池化结构。此外,这种池化切换技术自然支持所提出的训练方案引入新颖的数据增强方法——即混合从不同视频中提取的多个点云。
In summary, our main contributions are three-fold: (1) We propose Structured Keypoint Pooling based on point cloud deep-learning in the context of action recognition. This method incorporates prior knowledge of the data structure to which each keypoint belongs into a DNN architecture as an inductive bias using a simple Max-Pooling operation. (2) In addition to the human skeletons, object keypoints are introduced as an additional input for skeletonbased action recognition. (3) A skeleton-based, weakly supervised spatio-temporal action localization is achieved by introducing a Pooling-Switching Trick, which exploits the feature aggregation scheme of Structured Keypoint Pooling.
总结而言,我们的主要贡献有三点:(1) 在动作识别领域,我们提出了基于点云深度学习的结构化关键点池化方法。该方法通过简单的最大池化操作,将每个关键点所属数据结构的先验知识作为归纳偏置融入DNN架构。(2) 除人体骨骼外,我们还引入了物体关键点作为基于骨骼的动作识别的额外输入。(3) 通过提出池化切换技巧(Pooling-Switching Trick),利用结构化关键点池化的特征聚合方案,实现了基于骨骼的弱监督时空动作定位。
2. Related Work
2. 相关工作
2.1. Action Recognition
2.1. 动作识别
Appearance-based Action Recognition. Numerous prior works rely on RGB images, which are used as inputs to DNNs [7, 20–23, 45, 51, 52, 56, 58]. In early deeplearning-based approaches, RGB and optical flow images are used as inputs to a 2D convolutional neural network (CNN) to explicitly model the appearance and motion features [45, 58]. The methods that extract spatio-temporal features using a 3D CNN obtain the motion feature extractors in a data-driven manner [7, 22, 51]. On the other hand, some studies have focused on reducing the computational cost and the number of parameters of a 3D CNN [20, 21, 52, 56]. Recently, methods that extract longrange features using the Transformer [53] have been proposed [2, 23, 32]. These appearance-based approaches have an advantage over skeleton-based methods because they use more detailed movement features.
基于外观的动作识别。许多先前的工作依赖于RGB图像,这些图像被用作DNN的输入 [7, 20–23, 45, 51, 52, 56, 58]。在早期的深度学习方法中,RGB和光流图像被用作2D卷积神经网络(CNN)的输入,以显式建模外观和运动特征 [45, 58]。使用3D CNN提取时空特征的方法以数据驱动的方式获得运动特征提取器 [7, 22, 51]。另一方面,一些研究专注于降低3D CNN的计算成本和参数数量 [20, 21, 52, 56]。最近,提出了使用Transformer提取长距离特征的方法 [2, 23, 32]。这些基于外观的方法相比基于骨架的方法具有优势,因为它们利用了更详细的运动特征。
Skeleton-based Action Recognition. Skeleton-based approaches have been actively investigated since STGCN [57], which models the relationships among timeseries keypoints using GCNs. Upon the ST-GCN, the robustness and performance of these approaches have been improved by extracting the features from distant keypoints in the spatio-temporal space [9, 10, 29, 33] or by employing efficient graph convolution layers [5, 60]. In these methods, the input skeleton sequences can capture only motion information that is immune to contextual nuisances such as background variation and lighting changes [14, 34, 55]. Despite their significant success, GCN-based methods exhibit the three limitations mentioned in Sec. 1.
基于骨架的动作识别。自STGCN [57] 以来,基于骨架的方法得到了广泛研究,该方法使用图卷积网络 (GCN) 建模时序关键点间的关系。在ST-GCN基础上,研究者通过从时空远距离关键点提取特征 [9, 10, 29, 33] 或采用高效图卷积层 [5, 60],提升了这些方法的鲁棒性和性能。这类方法的输入骨架序列仅能捕捉运动信息,对背景变化和光照差异等环境干扰具有免疫力 [14, 34, 55]。尽管取得显著成果,基于GCN的方法仍存在第1节所述的三大局限性。
SPIL [49], which uses an attention mechanism among keypoints, also handles skeleton sequences as an input 3D point cloud and competes with the proposed method only with respect to the network architecture concept. Unlike SPIL, the proposed method does not rely on such a redundant attention module. Instead, it introduces a simple and sparse feature aggregation structure, which exploits prior knowledge of the data structure to which each keypoint belongs as an inductive bias.
SPIL [49]通过关键点间的注意力机制处理骨架序列作为输入3D点云,仅在网络架构概念层面与所提方法形成竞争。与SPIL不同,所提方法无需依赖此类冗余注意力模块,而是采用简单稀疏的特征聚合结构,利用每个关键点所属数据结构的先验知识作为归纳偏置。
2.2. Spatio-temporal Action Localization
2.2. 时空动作定位
When multiple persons appearing in a video perform different actions in different time windows, according to the third multi-action limitation mentioned in Sec. 1, this can be handled as a spatio-temporal action localization task. In the fully-supervised setting, appearance-based approaches [27, 30, 36] have been proposed but require dense instance-level annotations during the training. To reduce the annotation cost, weakly supervised methods [3, 12, 19] use only a single label for the video as supervision. These methods employ the multiple instance learning framework [16] for the weakly supervised setting to which this study also focuses on. Unlike such appearance-based approaches, our input keypoint information is less sensitive to the appearance changes. In addition, weakly supervised learning is achieved using a simple Pooling-Switching Trick, which exploits our point cloud-based setting and only changes the pooling kernels between the training and inference phases.
当视频中出现多人在不同时间窗口执行不同动作时,根据第1节提到的第三个多动作限制条件,可将其视为时空动作定位任务处理。在全监督设定下,基于外观的方法[27,30,36]已被提出,但训练期间需要密集的实例级标注。为降低标注成本,弱监督方法[3,12,19]仅使用视频的单标签作为监督信号。这些方法采用多实例学习框架[16]应对弱监督设定,这也是本研究的主要关注点。与这类基于外观的方法不同,我们输入的关键点信息对外观变化较不敏感。此外,通过简单的池化切换技巧(Pooling-Switching Trick)实现弱监督学习,该技术利用了点云基础设定,仅需在训练和推理阶段切换池化核。
3. Proposed Framework
3. 提出的框架
3.1. Overview
3.1. 概述
The proposed network architecture and its components are shown in Fig. 2. One of our core ideas is the feature aggregation by a Max-Pooling operator based on groups belonging to the same instance or the same frame (referred to as local groups). Limiting the feature-propagation range to the local group is essentially similar to the convolution operation, which extracts the pixel features locally; this is introduced as an inductive bias in our model. The proposed model essentially consists of only a few conventional DNN modules; nevertheless, its original design and inputs contribute to a significant performance improvement. In the following, we describe the network architecture along its process and each component in detail.
提出的网络架构及其组件如图 2 所示。我们的核心思想之一是基于属于同一实例或同一帧的组(称为局部组)通过 Max-Pooling 算子进行特征聚合。将特征传播范围限制在局部组内本质上类似于卷积操作,后者在局部提取像素特征;这被作为归纳偏置引入我们的模型。该模型本质上仅由少量常规 DNN 模块组成;然而其原创性设计和输入带来了显著的性能提升。下文将按处理流程详细描述网络架构及各组件。
First, multi-person pose estimation and object keypoint detection are applied to the input video, and human joints as well as object contour points (collectively denoted as keypoints) are obtained. Then, the keypoints extracted from all frames in the video are treated as a point cloud and used as inputs to the network. Each keypoint is represented by a four-dimensional vector, which consists of the twodimensional image coordinates, the confidence score, and the category index of the instance in which the keypoint belongs (e.g., 0 denotes person, 1 denotes car, etc.). Each element of the input vector is normalized between 0 and 1.
首先,对输入视频应用多人姿态估计和物体关键点检测,获取人体关节和物体轮廓点(统称为关键点)。随后,将视频所有帧中提取的关键点视为点云并作为网络输入。每个关键点由一个四维向量表示,包含二维图像坐标、置信度分数以及该关键点所属实例的类别索引(例如0代表人,1代表汽车等)。输入向量的每个元素均归一化至0到1之间。
Structured Keypoint Pooling $f_{\theta}$ predicts logit $z$ , where $z\in\mathbb{R}^{C}$ for the action recognition task and for the training phase in a weakly supervised action localization task. As discussed later, $\boldsymbol{z}\in\bar{\mathbb{R}}^{F I\times C}$ for the inference phase in the action localization task. $F$ denotes the number of frames in the video clip, $I$ denotes the number of instances per frame, and $C$ denotes the number of target classes. $\theta$ in $f_{\theta}$ represents the trainable parameters, and $f_{\theta}$ mainly consists of MLP Blocks and Grouped Pool Blocks (GPB). During the training phase, the cross-entropy loss $L_{\theta}\left(\mathrm{softmax}(z),l\right)$ is computed using the softmax layer and the ground-truth action label l; $\theta$ is updated via back propagation.
结构化关键点池化 $f_{\theta}$ 预测逻辑值 $z$,其中在动作识别任务和弱监督动作定位任务的训练阶段 $z\in\mathbb{R}^{C}$。如后文所述,在动作定位任务的推理阶段 $\boldsymbol{z}\in\bar{\mathbb{R}}^{F I\times C}$。$F$ 表示视频片段中的帧数,$I$ 表示每帧的实例数,$C$ 表示目标类别数。$f_{\theta}$ 中的 $\theta$ 代表可训练参数,该函数主要由多层感知机模块 (MLP Blocks) 和分组池化模块 (Grouped Pool Blocks, GPB) 构成。训练阶段通过 softmax 层和真实动作标签 l 计算交叉熵损失 $L_{\theta}\left(\mathrm{softmax}(z),l\right)$,并通过反向传播更新 $\theta$。
The Point embedding layer embeds the input vector into a high-dimensional feature vector using multilayer perceptrons (MLPs). The weights of the MLP are shared across all keypoints. We adopt keypoint index encoding, which replaces the position in the original sinusoid positional encoding [53] with a keypoint index. The keypoint index represents its type, for example, 0 for the left shoulder and 1 for the right shoulder regarding the skeleton keypoints; also, it is 0 for up left and 1 for up right regarding these objects.
点嵌入层 (Point embedding layer) 通过多层感知机 (MLPs) 将输入向量嵌入到高维特征向量中。所有关键点共享该 MLP 的权重。我们采用关键点索引编码,用关键点索引取代原始正弦位置编码 [53] 中的位置信息。关键点索引代表其类型,例如:对于骨骼关键点,0 表示左肩,1 表示右肩;对于物体关键点,0 表示左上角,1 表示右上角。
The MLP Block computes the feature vectors considering the sparse relationships among them via Max-Pooling, and the GPB aggregates such feature vectors into local groups. Similar to keypoint index encoding, we adopt time index encoding, which encodes the frame index in the video clip. The feature vectors are finally aggregated by global max-pooling (GMPool) to generate a single feature vector for the entire video. The logit is predicted via the fullyconnected (FC) layers.
MLP块通过最大池化(Max-Pooling)计算考虑特征向量间稀疏关系的特征向量,GPB将这些特征向量聚合为局部组。与关键点索引编码类似,我们采用时间索引编码来对视频片段中的帧索引进行编码。最终通过全局最大池化(GMPool)聚合特征向量,生成代表整个视频的单一特征向量。逻辑值通过全连接(FC)层进行预测。
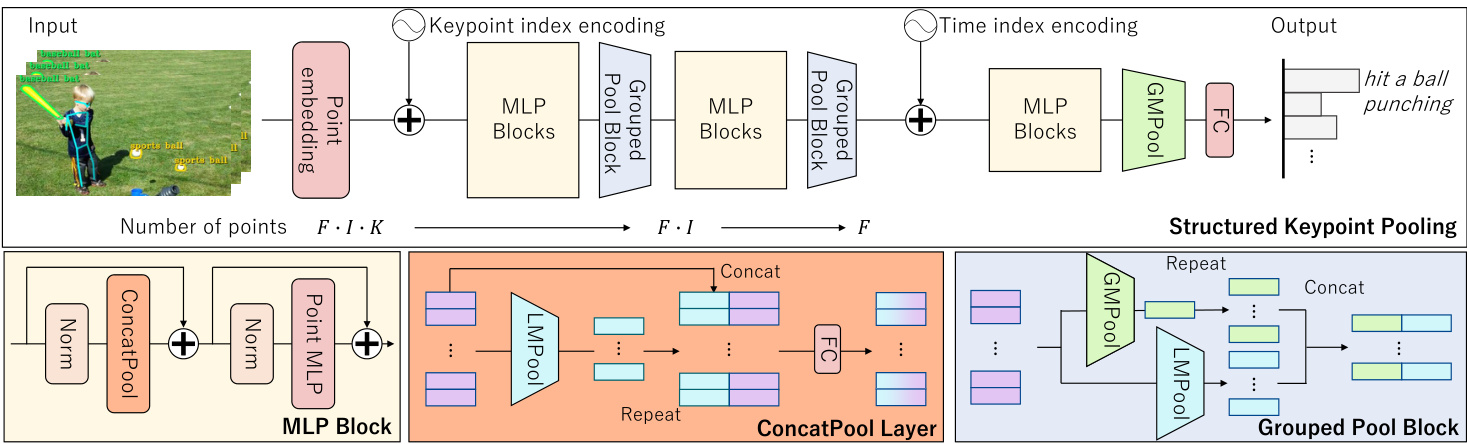
Figure 2. Overview of the Structured Keypoint Pooling network architecture (top) and its original components (bottom).
图 2: 结构化关键点池化网络架构概览(顶部)及其原始组件(底部)。
The reduction in the number of feature vectors by the GPB is described in the following. We denote $K$ as the number of keypoints per instance, in addition to $F$ and $I$ defined above. The number of keypoints input to the network is $F\cdot I\cdot K$ , which is reduced to $F\cdot I$ points by the first Grouped Pool Bock that aggregates $K$ keypoint-wise features into a single vector. Then, the second GPB that aggregates $I$ instance-wise features in a single vector reduces the number of points from $F\cdot I$ to $F$ .
以下描述GPB对特征向量数量的缩减过程。设每个实例的关键点数量为$K$,同时沿用之前定义的$F$和$I$。输入网络的关键点数量为$F\cdot I\cdot K$,经过首个分组池化块(GPB)将$K$个关键点特征聚合成单个向量后,数量降至$F\cdot I$。随后第二个GPB通过聚合$I$个实例特征,将点数从$F\cdot I$进一步缩减至$F$。
The Max-Pooling operator outputs a feature vector by selecting a maximum value for each dimension from $N$ input vectors. Therefore, elements from maximum $D$ points are selected ( $D$ is the feature dimension size of input vectors). As $N\gg D$ (e.g., $N=F\cdot I\cdot K=300\cdot2\cdot18$ , $D=512$ ) for the skeleton-based action recognition task, most points will be disregarded for the GMPool (pooling across all input points). Reducing the number of points $(N)$ by cascaded feature aggregation and limiting the pooling range using local max-pooling (LMPool), which applies Max-Pooling to each local group to which the input feature vectors belong, are helpful to generate informative and robust feature vectors. The effect of using this cascaded reduction during the feature extraction will be quantitatively verified in Sec. 4.6.
最大池化 (Max-Pooling) 算子通过从 $N$ 个输入向量中为每个维度选择最大值来输出特征向量。因此,会从最多 $D$ 个点中选择元素( $D$ 是输入向量的特征维度大小)。在基于骨架的动作识别任务中,由于 $N\gg D$(例如 $N=F\cdot I\cdot K=300\cdot2\cdot18$, $D=512$),大多数点将被全局最大池化 (GMPool) 忽略。通过级联特征聚合减少点的数量 $(N)$,并使用局部最大池化 (LMPool) 限制池化范围(对输入特征向量所属的每个局部组应用最大池化),有助于生成信息丰富且鲁棒的特征向量。第4.6节将定量验证在特征提取过程中使用这种级联缩减的效果。
The process in each block is invariant to the position and order of the input feature vectors, and the entire network can handle permutation-invariant inputs.
每个块中的处理过程对输入特征向量的位置和顺序保持不变,整个网络能够处理排列不变的输入。
3.2. Grouped Pool Block (GPB)
3.2. 分组池化块 (GPB)
The GPB consists of GMPool $\phi_{G}$ and LMPool $\phi_{L}$ . The first GPB outputs feature vectors containing the number of
GPB由GMPool $\phi_{G}$ 和LMPool $\phi_{L}$ 组成。第一个GPB输出的特征向量包含
instances in the video, and the subsequent GPB outputs feature vectors containing the number of frames.
视频中的实例,随后GPB输出包含帧数的特征向量。
The GPB can be expressed as follows:
GPB可表示为:
$$
Y={[{L}(X){j};{G}(X)]}_{j{1,...,M}}.
$$
$X$ and $Y$ are the matrices of the input and output feature vectors, respectively, as described below. $M$ denotes the number of local groups in $X$ ; $M=F\cdot I$ in the first block; $M=F$ in the second block. Therefore, the input feature vector $x_{i}\in X$ is grouped into $M$ local groups, and $X$ can be expressed by a concatenated matrix as follows:
$X$ 和 $Y$ 分别是输入和输出特征向量的矩阵,具体描述如下。$M$ 表示 $X$ 中的局部组数量;在第一个块中 $M=F\cdot I$;在第二个块中 $M=F$。因此,输入特征向量 $x_{i}\in X$ 被划分为 $M$ 个局部组,$X$ 可通过以下拼接矩阵表示:
$$
X=(x_{1},...,x_{N})^{T}=(X_{1};...;X_{M})^{T}.
$$
$$
X=(x_{1},...,x_{N})^{T}=(X_{1};...;X_{M})^{T}.
$$
Consequently, $Y$ is computed using the output vector $y_{j}$ as follows:
因此,$Y$ 通过输出向量 $y_{j}$ 计算如下:
$$
Y=\left(y_{1},\dots,y_{M}\right)^{T}.
$$
$$
Y=\left(y_{1},\dots,y_{M}\right)^{T}.
$$
In Eq. (1), we concatenate each feature vector $\phi_{L}\left(X\right){j}$ computed for the local group $j$ and the global feature vector $\phi_{G}\left(X\right)$ in a channel dimension. Also, LMPool $\phi_{L}(\cdot)$ can be expressed as follows:
在式 (1) 中,我们将为局部组 $j$ 计算的特征向量 $\phi_{L}\left(X\right){j}$ 与全局特征向量 $\phi_{G}\left(X\right)$ 在通道维度上进行拼接。同时,LMPool $\phi_{L}(\cdot)$ 可表示为:
$$
\phi_{L}\left(X\right)={\mathrm{MaxPool}(X_{j})}_{j={1,...,M}},
$$
$$
\phi_{L}\left(X\right)={\mathrm{MaxPool}(X_{j})}_{j={1,...,M}},
$$
where $\operatorname{MaxPool}(\cdot)$ is the operation used to obtain the max value for each channel from the feature vectors. GMPool $\phi_{G}(\cdot)$ is expressed as follows:
其中 $\operatorname{MaxPool}(\cdot)$ 是用于从特征向量中获取每个通道最大值的操作。GMPool $\phi_{G}(\cdot)$ 表达式如下:
$$
\phi_{G}(X)=\operatorname{MaxPool}(X).
$$
$$
\phi_{G}(X)=\operatorname{MaxPool}(X).
$$
3.3. MLP Block
3.3. MLP 模块
The MLP Block consists of two residual blocks. The first block models the relationship among feature vectors within each local group. The subsequent block applies MLPs for each feature vector. Each MLP block is repeated $r$ times.
MLP块由两个残差块组成。第一个块对每个局部组内的特征向量之间的关系进行建模。随后的块对每个特征向量应用MLP。每个MLP块重复$r$次。
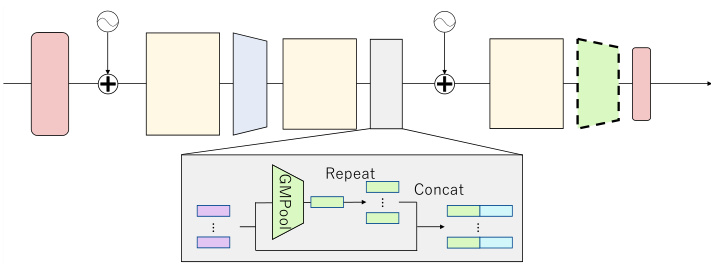
Figure 3. Pooling-Switching Trick for point cloud-based spatiotemporal action localization. The modules same as those in Fig. 2 are abbreviated with the same color. The dotted GMPool layer is only applied during the training phase.
图 3: 基于点云的时空动作定位的池化切换技巧。与图 2 中相同的模块用相同颜色简略表示。虚线标注的 GMPool 层仅在训练阶段使用。
The first residual block can be written using the input and output matrices $X$ and $Y$ , respectively, as follows:
第一个残差块可以用输入和输出矩阵 $X$ 和 $Y$ 表示如下:
$$
Y=\operatorname{ConcatPool}(\operatorname{Norm}(X))+X,
$$
$$
Y=\operatorname{ConcatPool}(\operatorname{Norm}(X))+X,
$$
where $\mathrm{Norm}(\cdot)$ is the normalization layer, and ConcatPool(·) is the learnable layer represented as ${ConcatPool}(X)={([x_{i};{L}(X){j_{i}}]W_{1})}{i\in{1,...,N}},$ (7) where $\sigma(\cdot)$ is a nonlinear activation function and $j_{i}^{\phantom{\dagger}}\in$ ${1,\ldots,M}$ is the local group index of the $i$ -th feature vector. $W_{1}\in\mathbb{R}^{2D\times D}$ is a learnable weight matrix, and $D$ is the number of channels of $X$ .
其中 $\mathrm{Norm}(\cdot)$ 是归一化层,ConcatPool(·) 是可学习层,表示为 ${ConcatPool}(X)={\sigma\left(\left[x_{i};{L}(X){j_{i}}]W_{1})}{i{1,...,N}},$ (7) 其中 $\sigma(\cdot)$ 是非线性激活函数,$j_{i}^{\phantom{\dagger}}\in$ ${1,\ldots,M}$ 是第 $i$ 个特征向量的局部组索引。$W_{1}\in\mathbb{R}^{2D\times D}$ 是可学习权重矩阵,$D$ 是 $X$ 的通道数。
The second residual block can be expressed as follows:
第二个残差块可以表示为:
$$
Y=\sigma\left(\mathrm{Norm}\left(X\right)W_{2}\right)W_{3}+X,
$$
$$
Y=\sigma\left(\mathrm{Norm}\left(X\right)W_{2}\right)W_{3}+X,
$$
where W2 RD×αD and $W_{3}\in\mathbb{R}^{\alpha D\times D}$ are learnable weight matrices, and $\alpha$ is the MLP expansion ratio.
其中 W2 ∈ ℝD×αD 和 $W_{3}\in\mathbb{R}^{\alpha D\times D}$ 是可学习的权重矩阵,$\alpha$ 是 MLP (Multilayer Perceptron) 的扩展比率。
3.4. Pooling-Switching Trick for Spatio-Temporal Action Localization
3.4. 时空动作定位的池化切换技巧
The proposed network architecture of the spatiotemporal action localization is shown in Fig. 3. To avoid aggregating instance-level features into frame-level features, the second GPB in Fig. 2 is changed. We propose a PoolingSwitching Trick, which switches the group of the pooling (kernel) from the training to the inference phases. This trick naturally enables our weakly supervised training scheme to introduce the proposed batch-mixing data augmentation.
时空动作定位的网络架构如图3所示。为避免将实例级特征聚合为帧级特征,图2中的第二个GPB被修改。我们提出了一种池化切换技巧(PoolingSwitching Trick),该技巧在训练和推理阶段切换池化(核)的分组。该技巧自然支持弱监督训练方案引入提出的批量混合数据增强方法。
Weakly Supervised Training. During the training, the loss is computed between the ground-truth action label assigned to the input video and the video-level logit predicted by aggregating instance-level features using the last GMPool. During the inference, the proposed method estimates the actions against targets different from the training, such as each instance, each frame, or each video, by switching the pooling kernel (target local group) at the last GMPool operation. For the spatio-temporal action localization task, the
弱监督训练。训练过程中,损失函数通过对比输入视频的真实动作标签与最后一个GMPool聚合实例级特征所预测的视频级logit来计算。推理时,该方法通过切换最后一个GMPool操作中的池化核(目标局部组),可针对不同于训练的目标(如每个实例、每帧或每个视频)进行动作估计。对于时空动作定位任务,
GMPool operation is simply removed from the network architecture (Fig. 3) to estimate the instance-level logit. The weights of the FC layer are shared across all targets.
GMPool操作简单地从网络架构中移除(图3)以估计实例级logit。FC层的权重在所有目标间共享。
Batch-Mixing Augmentation. To improve the localization robustness, we propose a novel data augmentation technique in the Pooling-Switching Trick. This technique mixes the point clouds extracted from different videos and promotes classifying multiple actions. Let X ∈ RF I×D and $l$ denote instance-level features and the corresponding ground-truth one-hot label, respectively. Two training samples $(X^{a},l^{a})$ and $(X^{b},l^{b})$ are mixed for augmentation.
批混合增强 (Batch-Mixing Augmentation)。为提高定位鲁棒性,我们在池化切换技巧 (Pooling-Switching Trick) 中提出了一种新颖的数据增强技术。该技术通过混合从不同视频中提取的点云数据来促进多动作分类。设 X ∈ RF I×D 和 $l$ 分别表示实例级特征及其对应的真实值独热标签,将两个训练样本 $(X^{a},l^{a})$ 和 $(X^{b},l^{b})$ 混合以实现数据增强。
First, we mask two training samples as follows:
首先,我们对两个训练样本进行如下掩码处理:
$$
{\hat{X}}^{a}=B\odot X^{a},{\hat{X}}^{b}=(1-B)\odot X^{b},
$$
$$
{\hat{X}}^{a}=B\odot X^{a},{\hat{X}}^{b}=(1-B)\odot X^{b},
$$
where $\boldsymbol{B}\in\mathbb{R}^{F I\times D}$ denotes a binary mask indicating which keypoint is used in the two samples. Each column vector in $B$ is 0 or 1, and $\odot$ denotes the element-wise multiplication. Also, the ground-truth label is mixed with a certain ratio $\lambda$ as follows:
其中 $\boldsymbol{B}\in\mathbb{R}^{F I\times D}$ 表示一个二元掩码 (binary mask),用于指示两个样本中使用了哪些关键点。$B$ 中的每个列向量为0或1,$\odot$ 表示逐元素乘法。此外,真实标签 (ground-truth label) 会以特定比例 $\lambda$ 进行混合,如下所示:
$$
{\hat{l}}=\lambda l^{a}+(1-\lambda)l^{b}.
$$
$$
{\hat{l}}=\lambda l^{a}+(1-\lambda)l^{b}.
$$
A random sampling of the mixing ratio $\lambda$ and the binary mask is followed to the CutMix strategy [59].
按照CutMix策略[59],随机采样混合比例$\lambda$和二元掩码。
Instead of aggregating a set of feature vectors in the global feature using GMPool within each training sample (intra-sample), GMPool (two green boxes in Fig. 3) aggregates between two training samples (inter-samples) to the global feature vector during the training phase as follows:
与在每个训练样本内(intra-sample)使用GMPool聚合一组特征向量到全局特征不同,GMPool(图3中的两个绿色方框)在训练阶段将两个训练样本间(inter-samples)的特征聚合到全局特征向量,具体方式如下:
$$
\phi_{G}\left(\hat{X}^{a},\hat{X}^{b}\right)=\mathrm{MaxPool}(\hat{X}^{a};\hat{X}^{b}).
$$
$$
\phi_{G}\left(\hat{X}^{a},\hat{X}^{b}\right)=\mathrm{MaxPool}(\hat{X}^{a};\hat{X}^{b}).
$$
Finally, the mixed logit $\hat{z}$ is predicted, and the cross-entropy loss $L_{\theta}\left(\operatorname{softmax}\left({\hat{z}}\right),{\hat{l}}\right)$ is computed.
最终,预测混合对数 $\hat{z}$,并计算交叉熵损失 $L_{\theta}\left(\operatorname{softmax}\left({\hat{z}}\right),{\hat{l}}\right)$。
4. Experiments
4. 实验
4.1. Datasets
4.1. 数据集
Kinetics-400. The Kinetics-400 [7] dataset is a large-scale video dataset collected from YouTube videos with 400 action classes. It contains 250K training and 19K validation 10-second video clips.
Kinetics-400。Kinetics-400 [7] 是一个从YouTube视频中收集的大规模视频数据集,包含400个动作类别。该数据集由25万段训练视频和1.9万段验证视频组成,每段视频时长为10秒。
UCF101 and HMDB51. The UCF101 [48] and HMDB51 [26] datasets contain 13K YouTube videos with 101 action labels and 6.7K videos with 51 action labels, respectively. We employ split1 for training and test data splitting, according to the previous work [17].
UCF101和HMDB51。UCF101 [48] 和HMDB51 [26] 数据集分别包含13K个带101种动作标签的YouTube视频和6.7K个带51种动作标签的视频。根据先前工作[17],我们采用split1划分训练集与测试集。
RWF-2000, Hockey-Fight, Crowd Violence, and Movies-Fight. The RWF-2000 [11], Hockey-Fight [4], Crowd Violence [24], and Movies-Fight [35] datasets are violence recognition datasets. These datasets contain two types of actions, violence and non-violence, with various people and backgrounds.
RWF-2000、Hockey-Fight、Crowd Violence和Movies-Fight。RWF-2000 [11]、Hockey-Fight [4]、Crowd Violence [24]和Movies-Fight [35]数据集是暴力行为识别数据集。这些数据集包含暴力和非暴力两类行为,涉及不同人群和背景。

Figure 4. Examples of human skeletons (blue) and eight object contour keypoints (green).
图 4: 人体骨架(蓝色)与八个物体轮廓关键点(绿色)示例。
Mimetics. The Mimetics dataset [55] contains 713 YouTube video clips of mimed actions that form a subset of 50 classes obtained from the Kinetics-400 dataset. This dataset evaluates human actions with out-of-context appearances different from the Kinetics-400 dataset, and thus the methods have been trained on only the Kinetics-400 dataset. Mixamo. The Mixamo dataset [15] is an action recognition dataset that was proposed for the evaluation of domain adaptation tasks. This dataset is synthetically generated using the Mixamo library [1]. The 3D virtual avatars perform 14 different actions with various backgrounds and objects. The dataset contains 24K 2D-rendered videos.
Mimetics。Mimetics数据集[55]包含713个YouTube视频片段,这些片段模仿了从Kinetics-400数据集中选取的50个类别的动作。该数据集评估了与Kinetics-400数据集不同的、脱离上下文的动作表现,因此相关方法仅基于Kinetics-400数据集进行训练。
Mixamo。Mixamo数据集[15]是为评估领域适应任务而提出的动作识别数据集,通过Mixamo库[1]合成生成。3D虚拟角色在多样化背景和物体交互下执行14种不同动作,共包含24K个2D渲染视频。
UCF101-24. The UCF101-24 dataset [48] is a subset of the UCF101 dataset. Its 24 class action labels are annotated for each bounding box in the videos. Following the standard practice [3, 12], we use the corrected annotation [46].
UCF101-24。UCF101-24数据集[48]是UCF101数据集的子集,其24类动作标签针对视频中每个边界框进行了标注。遵循标准实践[3, 12],我们使用校正后的标注[46]。
4.2. Evaluation Metrics
4.2. 评估指标
We employ Top-1 Accuracy $(%)$ (simply referred to as accuracy) as the evaluation metric for an action recognition task. For a spatio-temporal action localization task, we employ Video Average Precision (Video AP) $(%)$ with different 3D IoUs (0.2 and 0.5) as the evaluation metrics. We use a machine equipped with Intel i7-10700K CPU, 32GB RAM, and GeForce RTX 3080Ti GPU to compute the speed. See the supplementary material for the implementation details, the hyper parameters of the training, and data augmentations pertaining to all experiments.
我们采用Top-1准确率(%)(简称准确率)作为动作识别任务的评估指标。对于时空动作定位任务,我们采用不同3D IoU(0.2和0.5)下的视频平均精度(Video AP)(%)作为评估指标。使用配备Intel i7-10700K CPU、32GB内存和GeForce RTX 3080Ti GPU的机器计算速度。具体实现细节、训练超参数及所有实验相关的数据增强方法详见补充材料。
4.2.1 Keypoint Detectors
4.2.1 关键点检测器
PPNv2. The pose proposal networks (PPNv2) [42, 43] simultan e ou sly detect human skeletons and object keypoints located onto the object contours from an RGB image at a high speed. They are employed to generate keypoints in an experiment using object information as an input and consist of a Pelee backbone [54] trained on the MS-COCO dataset [31] with both human and object keypoint annotations. The definition of a human skeleton is the same as the OpenPose [6] definition. The object keypoints are defined as the eight extreme points on the contours with respect to the eight directions centered on the object (see Fig. 4). The input image is resized by $\mathrm{320\times224px^{2}}$ .
PPNv2。姿态提议网络 (PPNv2) [42, 43] 能够同时从RGB图像中高速检测人体骨骼和位于物体轮廓上的物体关键点。在实验中,它们被用于生成关键点,使用物体信息作为输入,并包含一个在MS-COCO数据集 [31] 上训练的Pelee骨干网络 [54],该数据集包含人体和物体关键点标注。人体骨骼的定义与OpenPose [6] 的定义相同。物体关键点被定义为物体轮廓上相对于以物体为中心的八个方向的八个极值点 (见图 4)。输入图像的大小调整为 $\mathrm{320\times224px^{2}}$。
HRNet. For a fair comparison with conventional skeletonbased approaches [17, 33, 34, 49], the HRNet [50] is also employed as the human keypoint detector. The HRNet is a Top-Down pose detector that achieves superior human pose estimation performance. However, its computational cost, which includes a human detector (Faster RCNN [40]), is expensive. We use publicly available HRNet skeletons [17] for the Kinetics-400, UCF101, and HMDB51 datasets. With the same setting [17], HRNet skeletons are generated for the RWF-2000, Hockey-Fight, Crowd Violence, Movies-Fight, and Mimetics datasets.
HRNet。为了与传统基于骨架的方法[17, 33, 34, 49]进行公平比较,本研究同样采用HRNet[50]作为人体关键点检测器。该网络是一种自上而下的姿态检测器,在人体姿态估计任务中表现出色,但其计算成本(包含Faster RCNN[40]人体检测器)较高。我们对Kinetics-400、UCF101和HMDB51数据集使用公开的HRNet骨架数据[17],并沿用相同设置[17]为RWF-2000、Hockey-Fight、Crowd Violence、Movies-Fight及Mimetics数据集生成HRNet骨架。

Figure 5. Comparison of the robustness against skeleton detection and tracking errors on the Kinetics-400 dataset. The methods are trained and evaluated using HRNet skeletons for a fair comparison.
图 5: Kinetics-400 数据集上针对骨架检测与跟踪错误的鲁棒性对比。为确保公平比较,所有方法均采用 HRNet 骨架进行训练和评估。
4.3. Skeleton-based Action Recognition Performance Comparisons on the Kinetics-400
4.3. 基于骨架的动作识别在Kinetics-400上的性能比较
In Tab. 1, the action recognition accuracy and the speed between the proposed method and conventional skeletonbased approaches are compared on the Kinetics-400 dataset. It can be observed that the proposed method (Ours w/ objects), which inputs both the skeleton and object keypoints detected by PPNv2, outperforms the conventional methods. Moreover, its accuracy is improved by 9.2 percentage-point by introducing object keypoints in addition to the skeletons (Ours w/o objects vs. Ours w/ objects). The qualitative results are shown in Fig. 1 (top).
在表1中,我们在Kinetics-400数据集上比较了所提方法与基于骨架的传统方法在动作识别准确率和速度上的表现。可以看出,同时输入骨架和PPNv2检测到的物体关键点的方法(Ours w/ objects)优于传统方法。此外,通过引入物体关键点(对比Ours w/o objects与Ours w/ objects),准确率提升了9.2个百分点。定性结果如图1(上)所示。
Compared with conventional methods that employ HRNet keypoints [50], the proposed method outperforms stateof-the-art (SoTA) methods [17, 33] (MS-G3D and PoseConv3D), while its runtime is 3x and 96x faster, respectively, than the runtime of these methods. Considering ablation studies, as discussed later, these results show that the proposed method overcomes both the first robustness and the second target-action limitations, mentioned in Sec. 1.
与采用HRNet关键点 [50] 的传统方法相比,所提方法在性能上超越了当前最优 (SoTA) 方法 [17, 33] (MS-G3D和PoseConv3D) ,且运行速度分别比这些方法快3倍和96倍。结合后文消融实验可知,这些结果表明所提方法同时克服了第1节提到的第一类鲁棒性限制和第二类目标动作限制。
4.4. Robustness against Skeleton Detection and Tracking Errors
4.4. 针对骨架检测与跟踪错误的鲁棒性
The robustness of the proposed method against skeleton detection errors (FPs, FNs, and tracking errors) is compared with that of the MS-G3D [33], which is the best-performing SoTA method considering both accuracy and runtime metrics, as shown in Tab. 1. Here, we synthetically generated three types of skeleton detection errors, FPs, FNs, and tracking errors. The FPs were generated by adding noise sampled from a normal distribution to the keypoint image coordinates. The FNs were generated by replacing the keypoint image coordinates and the confidence score with 0 using a certain ratio. The tracking errors were generated by switching the tracking indices with a certain interval. Note that the action recognition accuracy of GCN-based methods relies on tracking errors. On the other hand, the proposed method does not because the proposed network architecture is permutation-invariant for the input keypoints, and the tracking indices are not used.
所提方法对骨架检测错误(FP、FN和跟踪错误)的鲁棒性与MS-G3D [33]进行了对比(后者是综合考虑精度和运行时指标表现最优的SoTA方法),如表1所示。本文通过合成方式生成三类骨架检测错误:FP、FN和跟踪错误。FP通过向关键点图像坐标添加正态分布采样的噪声生成;FN通过以特定比例将关键点图像坐标和置信度置零生成;跟踪错误通过按固定间隔切换跟踪索引生成。需注意,基于GCN的方法其动作识别精度依赖于跟踪错误。而所提方法不受此影响,因为其网络架构对输入关键点具有排列不变性,且未使用跟踪索引。
Table 1. Speed/Accuracy comparison of SoTA skeleton-based action recognition methods on the Kinetics-400 dataset. Column Runtime shows the computation time of only the action recognition model. Column Total FPS shows the speed, including keypoint detection and action recognition. The joint-bone two-stream ensemble framework is employed for a fair comparison with conventional methods [17, 33, 44]. Additionally, we combine HRNet human joints and PPNv2 object keypoints, and the result is $61.4%$ ( $_{+11.1}$ percentage-point by using objects).
表 1: Kinetics-400数据集上基于骨架的动作识别先进方法的速度/准确率对比。Runtime列仅展示动作识别模型的计算时间,Total FPS列显示包含关键点检测和动作识别的整体速度。为与传统方法[17, 33, 44]公平比较,采用关节-骨骼双流集成框架。此外,我们结合HRNet人体关节和PPNv2物体关键点,最终结果为61.4%(使用物体关键点提升11.1个百分点)。
| 方法 | 准确率(%) | 关键点检测器 | COCO APkp(%) | 运行时间(ms) | 总帧率(FPS) |
|---|---|---|---|---|---|
| ST-GCN[57] 2s-AGCN[44] | 30.7 36.1 | OpenPose[6] | 56.3 | 4.0 27.6 | 85.4 84.8 |
| MS-G3D[33] MS-G3D[33] | 38.0 45.1 | OpenPose[6] | 56.3 | 28.2 28.2 | 84.8 8.8 |
| PoseConv3D[17] 无物体版 | 47.7 50.3 | HRNet[50] | 74.6 36.4 | 960.0 9.8 | 8.5 |
| 无物体版 含物体版 | 43.1 52.3 | HRNet[50] | 74.6 36.4 | 9.8 11.2 | 8.8 1913 |
Table 2. Ablation study of the GPB on the Kinetics-400 dataset with HRNet skeletons.
表 2: 基于HRNet骨架在Kinetics-400数据集上对GPB的消融研究
| Inst. | Frame | Acc. (%) | Runtime (ms) |
|---|---|---|---|
| 47.3 | 89.5 | ||
| √ | 48.6 | 7.2 | |
| √ | 48.5 | 4.9 |
Table 3. Ablation study of the object keypoint input on the Kinetics-400 dataset with PPNv2 keypoints.
表 3: 在 Kinetics-400 数据集上使用 PPNv2 关键点进行物体关键点输入的消融研究
| 类别 | 边界框 (Bbox) | 轮廓 (Contours) | 准确率 (%) |
|---|---|---|---|
| 1 | 41.2 | ||
| √ | √ | 48.6 | |
| √ | √ | 49.2 |
Table 4. Accuracy Comparison on UCF-101 (U), HMDB51 (HM), Mimetics (Mi), RWF-2000 (R), Hockey-Fight (Ho), Crowd Violence (C), and MoviesFight (MF) datasets.
表 4. 在 UCF-101 (U)、HMDB51 (HM)、Mimetics (Mi)、RWF-2000 (R)、Hockey-Fight (Ho)、Crowd Violence (C) 和 MoviesFight (MF) 数据集上的准确率对比。
| 方法 | 输入 | U | HM | Mi | R | Ho | C | MF |
|---|---|---|---|---|---|---|---|---|
| I3D [7] | RGB/ | 95.6 | 74.8 | 83.4 | 93.4 | 83.4 | 95.8 | |
| Flow Gated [11] | RGB/ | 87.3 | 98.0 | 88.8 | 97.3 | |||
| 3D ResNext[55] | RGB/ | 10.5 | ||||||
| SlowOnly[21] | RGB/ | 92.8 | 66.0 | |||||
| OmniSource[18] | RGB/ | 98.6 | 87.0 | |||||
| SIP-Net[55] | Skeleton | 14.2 | ||||||
| IntegralAction [34] | Skeleton | 15.3 | ||||||
| PoseConv3D[17] | Skeleton | 87.0 | 69.7 | |||||
| SPIL [49] | Skeleton | 89.3 | 96.8 | 94.5 | 98.5 | |||
| Ours | Skeleton | 87.8 | 70.9 | 21.2 | 93.4 | 99.5 | 94.7 | 99.0 |
Table 5. Domain shift experiment on the Mixamo dataset for training and the Kinetics-400 dataset for evaluation. Unsupervised (US) and weakly supervised (WS) domain adaptation (DA) methods are employed as a comparison.
表 5: 在Mixamo数据集上训练并在Kinetics-400数据集上评估的领域迁移实验。采用无监督(US)和弱监督(WS)领域自适应(DA)方法作为对比。
| 方法 DA | 输入 | 准确率(%) |
|---|---|---|
| I3D [7] | RGB | 11.2 |
| TA3N[8] US CO²A[15] | RGB | 10.0 16.4 |
| TA?N[8] WS CO2A [15] | RGB | 19.1 20.1 |
| Ours | Skeleton Skeleton+Object | 27.6 28.4 |
Table 6. Ablation study of the overall framework on the Kinetics-400 dataset with HRNet skeletons.
表 6: 基于 HRNet 骨架在 Kinetics-400 数据集上整体框架的消融研究
| GPB 设计 | MLP 块设计 |
|---|---|
| 仅 MLP | |
| 无 LMPool | 30.3 |
| 本方案 (含 GPB) | 44.5 |
Table 7. Comparison with SoTA weakly supervised spatio-temporal action localization methods on the UCF101-24 dataset.
表 7: 在UCF101-24数据集上与当前最优(SoTA)弱监督时空动作定位方法的对比
| 方法 | 输入 | AP@0.2 | AP@0.5 |
|---|---|---|---|
| Escorcia等[19] Cheron等[12] | RGB | 45.5 43.9 | 17.7 |
| Anurag等[3] 我们的方法(无混合增强) | 61.7 60.4 | 35.0 37.4 | |
| 我们的方法(含混合增强) | Skeleton | 61.8 | 38.0 |
4.5. Action Recognition Accuracy Comparison with Appearance-based Approaches
4.5. 基于外观方法的动作识别准确率对比
In Tab. 4, the performance of the proposed method is compared against that of both the SoTA skeleton-based and appearance-based approaches that use RGB and/or optical flow images as inputs. Here, for a fair comparison with SoTA skeleton-based approaches [17, 34, 49], only HRNet skeletons are used as input. HRNet exhibits a detection performance similar to that of conventional skeleton detection methods employed in these approaches.
在表4中,将所提方法与当前最先进的基于骨架和基于外观的方法进行了性能对比,这些方法使用RGB和/或光流图像作为输入。此处为了与最先进的基于骨架方法[17, 34, 49]进行公平比较,仅采用HRNet骨架作为输入。HRNet展现出的检测性能与这些方法采用的传统骨架检测技术相当。
Fig. 5 shows that the performance of the SoTA method (MS-G3D) is highly degraded by adding errors to the inputs. In contrast, since the performance degradation of the proposed method is relatively small, the proposed method is robust against skeleton detection and tracking errors, which are described as the first robustness limitation in Sec. 1.
图 5 表明,当前最优方法 (MS-G3D) 在输入数据中添加误差后性能大幅下降。相比之下,由于所提方法的性能下降相对较小,因此该方法对骨架检测和跟踪误差具有鲁棒性,这正是第1节所述的第一项鲁棒性限制。
The RWF-2000 dataset captures two actions (violence and non-violence) using surveillance cameras in a similar environment. In the Mimetics experiment, the DNNs are trained with the Kinetics-400 dataset, while the appearances of a person or a background are different from the Kinetics-400 in the evaluation videos. Hence, the skeletonbased approaches outperform the appearance-based approaches when the RWF-2000 and Mimetics datasets are employed. The opposite occurs when the UCF101 and HMDB51 datasets are employed. Conclusively, the performance of each of the two approaches depends on the pair of datasets employed. This result, that the appearance-based approaches are highly biased to background or person appearances, is also mentioned in previous studies [14,34,55].
RWF-2000数据集通过监控摄像头在相似环境中捕捉两种行为(暴力和非暴力)。在Mimetics实验中,DNN(深度神经网络)使用Kinetics-400数据集进行训练,而评估视频中人物或背景的外观与Kinetics-400存在差异。因此,当采用RWF-2000和Mimetics数据集时,基于骨架的方法优于基于外观的方法。而使用UCF101和HMDB51数据集时则出现相反结果。最终结论是,两种方法的性能表现取决于所采用的数据集组合。这一结果——即基于外观的方法对背景或人物外观存在高度偏差——在先前研究[14,34,55]中也有提及。
The proposed method outperforms the SoTA methods by a certain margin, except for UCF101 and HMDB51 datasets. In particular, the proposed method outperforms that of SPIL [49], which handles the sequential skeleton data as a point cloud on four violence recognition datasets.
所提方法在除UCF101和HMDB51数据集外的其他基准上均以一定优势超越当前最优方法(SoTA)。特别是在四个暴力识别数据集上,该方法对序列骨骼数据采用点云处理方式,性能优于SPIL [49]。
4.6. Ablation Studies
4.6. 消融实验
Effect of the GPB. An ablation study of the GPB, which aggregates keypoint features using prior knowledge of the keypoint belongings, instances, or frames, is shown in Tab. 2. Three models are compared; the model where the GPB is not applied at the two stages (instance-level and frame-level), the model where the GPB is applied only at the first stage, and the proposed model. Instead of not using the GPB, we concatenate the feature vector from GMPool and each input vector. It can be observed that the first GPB, which aggregates the features into the instance level, significantly improves the accuracy and speed. The second GPB mainly improves the runtime.
全局先验块(GPB)的效果。表2展示了GPB的消融实验结果,该模块利用关键点所属实例或帧的先验知识来聚合关键点特征。我们对比了三种模型:未在两阶段(实例级和帧级)应用GPB的模型、仅在首阶段应用GPB的模型,以及本文提出的完整模型。在不使用GPB时,我们将GMPool输出的特征向量与各输入向量进行拼接。实验表明,首个将特征聚合至实例级的GPB能显著提升精度与速度,而第二个GPB主要优化了运行效率。
Effect of Object Keypoints. Tab. 3 shows the results obtained using object categories and eight object contour keypoints as an additional input with the Kinetics-400 dataset. It can be observed that compared to the accuracy of the skeleton-only input $(41.2%)$ , the accuracy of the proposed model is improved when using object categories and four bounding box points $(48.6%)$ as an additional input. Furthermore, the accuracy is further improved by introducing eight object contour points $(49.2%)$ instead of bounding box points, and both the category and object contour points are informative of the action recognition task.
物体关键点的影响。表3展示了使用Kinetics-400数据集时,以物体类别和八个物体轮廓关键点作为额外输入所获得的结果。可以观察到,与仅使用骨架输入的准确率$(41.2%)$相比,当使用物体类别和四个边界框点$(48.6%)$作为额外输入时,所提模型的准确率有所提升。此外,通过引入八个物体轮廓点$(49.2%)$替代边界框点,准确率得到进一步提高,且类别和物体轮廓点都对动作识别任务具有信息量。
Ablation Study of the Overall Framework. An ablation study is performed to verify the GPB and MLP Block contributions in Tab. 6. Also, Tab. 6 includes the results of the model replacing our first MLP Block with the GCNbased MS-G3D module [33]. The simplest baseline (topleft cell) extracts point-wise features and aggregates them using MLPs and GMPool, respectively, similar to PointNet [37]. This baseline performs poorly; the GPB yields significant enhancement in accuracy $30.3%$ vs. $44.5%)$ ). Moreover, our method outperforms the version employing the MS-G3D module, which models the temporal information among keypoints $45.7%$ vs. $48.5%$ ).
整体框架消融研究。通过消融实验验证GPB和MLP模块的贡献,结果如 表 6 所示。 表 6 同时展示了用基于GCN的MS-G3D模块[33]替换首个MLP模块的模型结果。最简基线方案(左上单元格)采用类似PointNet[37]的方式提取逐点特征,并分别通过MLP和GMPool进行聚合。该基线表现较差:GPB模块带来显著精度提升 (30.3% vs. 44.5%)。此外,我们的方法优于采用MS-G3D模块建模关键点时序信息的版本 (45.7% vs. 48.5%)。
4.7. Domain Shift by Introducing Object
4.7. 通过引入对象引发的领域偏移
An accuracy comparison with and without using object keypoint information is summarized in Tab. 5. Here, the models are trained using a synthetically-created Mixamo dataset and evaluated using a real Kinetics dataset to reproduce a challenging, cross-dataset domain shift. In addition, the proposed method is compared with an appearance-based method [7] and the SoTA unsupervised and weakly supervised domain adaptation methods [8, 15].
使用与不使用物体关键点信息的准确率对比总结于表5。该实验采用合成生成的Mixamo数据集训练模型,并在真实Kinetics数据集上进行评估,以复现具有挑战性的跨数据集域偏移场景。此外,本文方法还与基于外观的方法[7]以及当前最先进的无监督和弱监督域适应方法[8, 15]进行了对比。
It can be observed that the accuracy is improved by introducing the proposed object keypoints $(27.6%$ vs. $28.4%\$ , and the variety of actions is expanded without over fitting (the second target-action limitation mentioned in Sec. 1). Furthermore, since the proposed method outperforms the appearance-based approaches without any domain adaptation or supervision of the target dataset (Kinetics-400), it is suitable for practical cases when the scene appearance differs between the training and inference phases.
可以观察到,通过引入所提出的物体关键点,准确率得到了提升(27.6% vs. 28.4%),同时动作多样性也得到了扩展且没有出现过拟合(即第1节提到的第二个目标-动作限制问题)。此外,由于该方法在没有任何目标数据集(Kinetics-400)领域适应或监督的情况下,表现优于基于外观的方法,因此适用于训练和推理阶段场景外观不同的实际场景。
4.8. Spatio-Temporal Action Localization
4.8. 时空动作定位
The weakly supervised spatio-temporal action localization accuracy is summarized in Tab. 7. Since no previous study addressed the task of using only skeletons as an input, the proposed method is compared against appearance-based approaches [3, 12, 19] and the evaluation protocol [3] is followed, although the UCF101 is an advantageous dataset for the appearance-based approaches shown in Tab. 4.
弱监督时空动作定位的准确率总结在表7中。由于之前没有研究仅使用骨架作为输入来解决该任务,因此将所提出的方法与基于外观的方法 [3, 12, 19] 进行了比较,并遵循了评估协议 [3] ,尽管UCF101是对基于外观的方法有利的数据集,如表4所示。
The proposed method without batch-mixing augmentation outperforms SoTA weakly supervised action localization methods with the $\mathrm{AP}@0.5$ metric. Furthermore, the proposed method outperforms these methods with both $\mathrm{AP}@0.2$ and $\mathrm{AP}@0.5$ metrics by introducing batch-mixing augmentation. Therefore, as mentioned in the third multiaction limitation in Sec. 1, the proposed method localizes the actions of each person in each frame. The qualitative results of the action localization are shown in Fig. 1 (bottom).
所提方法在没有使用批量混合增强 (batch-mixing augmentation) 的情况下,以 $\mathrm{AP}@0.5$ 指标超越了当前最先进 (SoTA) 的弱监督动作定位方法。此外,通过引入批量混合增强,所提方法在 $\mathrm{AP}@0.2$ 和 $\mathrm{AP}@0.5$ 指标上均优于这些方法。因此,如第1节第三个多动作限制所述,所提方法能定位每帧中每个人的动作。动作定位的定性结果如图 1 (bottom) 所示。
5. Conclusion
5. 结论
In this paper, a novel framework with a DNN architecture, Structured Keypoint Pooling, was proposed to address the limitations of conventional skeleton-based action recognition methods. Time-series keypoints consisting of human skeletons and nonhuman object contours were treated as an input 3D point cloud of the Structured Keypoint Pooling, which sparsely aggregates keypoint features into a cascaded manner based on prior knowledge of the data structure to which the keypoints belong. A Pooling-Switching Trick, which switches the aggregation target in the phases, and novel data augmentation, which mixes multiple point clouds, were also proposed. We comprehensively verified the effectiveness against the limitations using several action recognition and localization datasets. The experimental results demonstrated that the proposed method outperforms SoTA methods regarding both skeleton-based action recognition and spatio-temporal action localization tasks.
本文提出了一种采用DNN架构的新框架——结构化关键点池化(Structured Keypoint Pooling),以解决传统基于骨架的动作识别方法的局限性。该框架将人体骨架与非人物体轮廓组成的时间序列关键点作为输入3D点云,根据关键点所属数据结构的先验知识,以级联方式稀疏聚合关键点特征。同时提出了池化切换技巧(Pooling-Switching Trick)(通过阶段性地切换聚合目标)和混合多点云的新型数据增强方法。我们在多个动作识别与定位数据集上全面验证了该方法对局限性的改善效果。实验结果表明,所提方法在基于骨架的动作识别和时空动作定位任务上均优于当前最优(SoTA)方法。