Attention-Guided Generative Adversarial Networks for Unsupervised Image-to-Image Translation
注意力引导的生成对抗网络在无监督图像到图像转换中的应用
Abstract—The state-of-the-art approaches in Generative Adversarial Networks (GANs) are able to learn a mapping function from one image domain to another with unpaired image data. However, these methods often produce artifacts and can only be able to convert low-level information, but fail to transfer high-level semantic part of images. The reason is mainly that generators do not have the ability to detect the most discriminative semantic part of images, which thus makes the generated images with low-quality. To handle the limitation, in this paper we propose a novel Attention-Guided Generative Adversarial Network (AGGAN), which can detect the most disc rim i native semantic object and minimize changes of unwanted part for semantic manipulation problems without using extra data and models. The attention-guided generators in AGGAN are able to produce attention masks via a built-in attention mechanism, and then fuse the input image with the attention mask to obtain a target image with high-quality. Moreover, we propose a novel attention-guided disc rim in at or which only considers attended regions. The proposed AGGAN is trained by an end-to-end fashion with an adversarial loss, cycle-consistency loss, pixel loss and attention loss. Both qualitative and quantitative results demonstrate that our approach is effective to generate sharper and more accurate images than existing models. The code is available at https://github.com/Ha0Tang/Attention GAN.
摘要—生成对抗网络(GAN)的最先进方法能够利用不成对的图像数据学习从一个图像域到另一个图像域的映射函数。然而,这些方法常会产生伪影,且仅能转换低层次信息,无法传递图像的高层次语义部分。其主要原因在于生成器缺乏检测图像最具区分性语义部分的能力,从而导致生成图像质量低下。为解决这一局限,本文提出了一种新颖的注意力引导生成对抗网络(AGGAN),该网络无需使用额外数据和模型即可检测最具区分性的语义对象,并在语义操控问题中最小化非目标区域的变化。AGGAN中的注意力引导生成器通过内置注意力机制生成注意力掩码,随后将输入图像与注意力掩码融合以获得高质量目标图像。此外,我们提出了一种仅关注注意区域的新型注意力引导判别器。所提出的AGGAN采用端到端训练方式,结合对抗损失、循环一致性损失、像素损失和注意力损失进行优化。定性与定量结果表明,相较于现有模型,我们的方法能生成更清晰、更准确的图像。代码已开源:https://github.com/Ha0Tang/Attention_GAN。
Index Terms—GANs, Image-to-Image Translation, Attention
索引术语—GANs, 图像到图像转换, 注意力机制
I. INTRODUCTION
I. 引言
Recently, Generative Adversarial Networks (GANs) [8] have received considerable attention across many communities, e.g., computer vision, natural language processing, audio and video processing. GANs are generative models, which are particularly designed for image generation task. Recent works in computer vision, image processing and computer graphics have produced powerful translation systems in supervised settings such as Pix2pix [11], where the image pairs are required. However, the paired training data are usually difficult and expensive to obtain. Especially, the input-output pairs for images tasks such as artistic styli z ation can be even more difficult to acquire since the desired output is quite complex, typically requiring artistic authoring. To tackle this problem, CycleGAN [47], DualGAN [43] and DiscoGAN [13] provide an insight, in which the models can learn the mapping from one image domain to another one with unpaired image data.
近来,生成对抗网络 (GANs) [8] 在计算机视觉、自然语言处理、音视频处理等多个领域受到广泛关注。GANs 是专为图像生成任务设计的生成模型。近期在计算机视觉、图像处理和计算机图形学领域的研究已开发出强大的监督式转换系统,例如需要成对图像的 Pix2pix [11]。然而,成对训练数据通常难以获取且成本高昂。特别是艺术风格化等图像任务的输入-输出对更难获得,因为理想输出通常较为复杂,需要艺术创作。为解决这一问题,CycleGAN [47]、DualGAN [43] 和 DiscoGAN [13] 提出了一种创新思路:模型能够利用非成对图像数据学习不同图像域之间的映射关系。
Despite these efforts, image-to-image translation, e.g., converting a neutral expression to a happy expression, remains a challenging problem due to the fact that the facial expression changes are non-linear, unaligned and vary conditioned on the appearance of the face. Moreover, most previous models change unwanted objects during the translation stage and can also be easily affected by background changes. In order to address these limitations, Liang et al. propose the ContrastGAN [18], which uses object mask annotations from each dataset. In Contrast GAN, it first crops a part in the image according to the masks, and then makes translations and finally pastes it back. Promising results have been obtained from it, however it is hard to collect training data with object masks. More importantly, we have to make an assumption that the object shape should not change after applying semantic modification. Another option is to train an extra model to detect the object masks and fit them into the generated image patches [6], [12]. In this case, we need to increase the number of parameters of our network, which consequently increases the training complexity both in time and space.
尽管已有这些努力,图像到图像的转换(例如将中性表情转为快乐表情)仍是一个具有挑战性的问题,因为面部表情变化是非线性、未对齐的,且会因面部外观而呈现条件性差异。此外,多数现有模型在转换阶段会改变非目标对象,并易受背景变化干扰。为解决这些限制,Liang等人提出了ContrastGAN [18],该方法利用各数据集中的对象掩码标注:先根据掩码裁剪图像局部区域,完成转换后再将其粘贴回原位置。虽然该方法取得了显著效果,但带有对象掩码的训练数据难以收集。更重要的是,该方法需假设语义修改后对象形状保持不变。另一种方案是训练额外模型来检测对象掩码并将其适配到生成图像块中 [6][12],但这会增加网络参数量,进而提升训练在时间和空间维度上的复杂度。
To overcome the aforementioned issues, in this paper we propose a novel Attention-Guided Generative Adversarial Network (AGGAN) for the image translation problem without using extra data and models. The proposed AGGAN comprises of two generators and two disc rim in at or s, which is similar with CycleGAN [47]. Fig. 1 illustrates the differences between previous representative works and the proposed AGGAN. Two attention-guided generators in the proposed AGGAN have built-in attention modules, which can disentangle the discriminative semantic object and the unwanted part by producing a attention mask and a content mask. Then we fuse the input image with new patches produced through the attention mask to obtain high-quality results. We also constrain generators with pixel-wise and cycle-consistency loss function, which forces the generators to reduce changes. Moreover, we propose two novel attention-guided disc rim in at or s which aims to consider only the attended regions. The proposed AGGAN is trained by an end-to-end fashion, and can produce attention mask, content mask and targeted images at the same time. Experimental results on four public available datasets demonstrate that the proposed AGGAN is able to produce higher-quality images compared with the state-of-the-art methods.
为克服上述问题,本文提出了一种新型注意力引导生成对抗网络 (Attention-Guided Generative Adversarial Network, AGGAN) ,用于无需额外数据和模型的图像转换任务。所提出的 AGGAN 包含两个生成器和两个判别器,其结构与 CycleGAN [47] 类似。图 1 展示了先前代表性工作与本文提出的 AGGAN 之间的差异。AGGAN 中两个注意力引导生成器内置了注意力模块,通过生成注意力掩码和内容掩码来分离判别性语义对象与非目标区域。随后,我们将输入图像与通过注意力掩码生成的新图像块融合,以获得高质量结果。我们还通过逐像素损失和循环一致性损失函数约束生成器,迫使生成器减少变化。此外,我们提出了两种新型注意力引导判别器,其仅关注被注意力机制选定的区域。所提出的 AGGAN 采用端到端训练方式,可同时生成注意力掩码、内容掩码和目标图像。在四个公开数据集上的实验结果表明,与现有最优方法相比,AGGAN 能够生成更高质量的图像。
The contributions of this paper are summarized as follows: • We propose a novel Attention-Guided Generative Adversarial Network (AGGAN) for unsupervised image-to-image translation. • We propose a novel generator architecture with built-in at
本文的贡献总结如下:
- 我们提出了一种新颖的注意力引导生成对抗网络 (Attention-Guided Generative Adversarial Network, AGGAN) ,用于无监督图像到图像转换。
- 我们提出了一种新型生成器架构,内置注意力机制。

Fig. 1: Comparison of previous frameworks, e.g., CycleGAN [47], DualGAN [43] and DiscoGAN [13] (Left), and the proposed AGGAN (Right). The contribution of AGGAN is that the proposed generators can produce the attention mask $M_{x}$ and $M_{y}$ ) via the built-in attention module and then the produced attention mask and content mask mixed with the input image to obtain the targeted image. Moreover, we also propose two attention-guided disc rim in at or s $D_{X A}$ , $D_{Y A}$ , which aim to consider only the attended regions. Finally, for better optimizing the proposed AGGAN, we employ pixel loss, cycle-consistency loss and attention loss.
图 1: 现有框架(如CycleGAN [47]、DualGAN [43]和DiscoGAN [13])(左)与提出的AGGAN(右)对比。AGGAN的贡献在于:通过内置注意力模块,生成器可产生注意力掩码$M_{x}$和$M_{y}$,随后将生成的注意力掩码与内容掩码混合输入图像以获取目标图像。此外,我们还提出两个注意力引导判别器$D_{X A}$、$D_{Y A}$,其仅关注注意力区域。最后,为更好优化AGGAN,我们采用像素损失、循环一致性损失和注意力损失。
tention mechanism, which can detect the most disc rim i native semantic part of images in different domains. • We propose a novel attention-guided disc rim in at or which only consider the attended regions. Moreover, the proposed attention-guided generator and disc rim in at or can be easily used to other GAN models. • Extensive results demonstrate that the proposed AGGAN can generate sharper faces with clearer details and more realistic expressions compared with baseline models.
• 我们提出了一种新颖的注意力机制,能够检测不同领域中图像最具判别性的语义部分。
• 我们提出了一种新型的注意力引导判别器,仅关注被注意区域。此外,所提出的注意力引导生成器和判别器可轻松应用于其他GAN模型。
• 大量实验结果表明,与基线模型相比,提出的AGGAN能生成更清晰、细节更丰富且表情更逼真的人脸图像。
II. RELATED WORK
II. 相关工作
Generative Adversarial Networks (GANs) [8] are powerful generative models, which have achieved impressive results on different computer vision tasks, e.g., image generation [5], [27], [9], image editing [34], [35] and image inpainting [17], [10]. In order to generate meaningful images that meet user requirement, Conditional GAN (CGAN) [26] is proposed where the conditioned information is employed to guide the image generation process. The conditioned information can be discrete labels [28], text [22], [31], object keypoints [32], human skeleton [39] and reference images [11]. CGANs using a reference images as conditional information have tackled a lot of problems, e.g., text-to-image translation [22], image-toimage translation [11] and video-to-video translation [42].
生成对抗网络 (GANs) [8] 是一种强大的生成模型,在不同计算机视觉任务中取得了令人印象深刻的成果,例如图像生成 [5]、[27]、[9],图像编辑 [34]、[35] 以及图像修复 [17]、[10]。为了生成符合用户需求的有意义图像,研究者提出了条件生成对抗网络 (CGAN) [26],通过引入条件信息来指导图像生成过程。这些条件信息可以是离散标签 [28]、文本 [22]、[31]、物体关键点 [32]、人体骨架 [39] 或参考图像 [11]。以参考图像作为条件信息的 CGAN 已经解决了许多问题,例如文本到图像转换 [22]、图像到图像转换 [11] 以及视频到视频转换 [42]。
Image-to-Image Translation models learns a translation function using CNNs. Pix2pix [11] is a conditional framework using a CGAN to learn a mapping function from input to output images. Similar ideas have also been applied to many other tasks, such as generating photographs from sketches [33] or vice versa [38]. However, most of the tasks in the real world suffer from the constraint of having few or none of the paired input-output samples available. To overcome this limitation, unpaired image-to-image translation task has been proposed. Different from the prior works, unpaired image translation task try to learn the mapping function without the requirement of paired training data. Specifically, CycleGAN [47] learns the mappings between two image domains (i.e., a source domain $X$ to a target domain $Y$ ) instead of the paired images. Apart from CycleGAN, many other GAN variants are proposed to tackle the cross-domain problem. For example, to learn a common representation across domains, CoupledGAN [19] uses a weight-sharing strategy. The work of [37] utilizes some certain shared content features between input and output even though they may differ in style. Kim et al. [13] propose a method based on GANs that learns to discover relations between different domains. A model which can learn object transfiguration from two unpaired sets of images is presented in [46]. Tang et al. [41] propose $\mathbf{G}^{2}\mathbf{GAN}$ , which is a robust and scalable approach allowing to perform unpaired imageto-image translation for multiple domains. However, those models can be easily affected by unwanted content and cannot focus on the most disc rim i native semantic part of images during translation stage.
图像到图像翻译模型利用CNN学习翻译函数。Pix2pix [11] 是一个使用条件生成对抗网络(CGAN)学习从输入到输出图像映射函数的框架。类似思路也被应用于许多其他任务,例如从草图生成照片 [33] 或逆向操作 [38]。然而现实世界中的多数任务都面临配对输入-输出样本稀缺的约束。为突破这一限制,研究者提出了非配对图像翻译任务。
与先前工作不同,非配对图像翻译任务旨在无需配对训练数据的情况下学习映射函数。具体而言,CycleGAN [47] 学习的是两个图像域(即源域$X$到目标域$Y$)之间的映射,而非配对图像间的映射。除CycleGAN外,还有许多其他GAN变体被提出以解决跨域问题。例如,CoupledGAN [19] 采用权重共享策略来学习跨域共同表示。[37] 的研究则利用输入输出间某些特定的共享内容特征(尽管风格可能不同)。Kim等人 [13] 提出基于GAN的方法来发现不同域间的关系。[46] 展示了一个能从两组非配对图像中学习物体变形的模型。Tang等人 [41] 提出$\mathbf{G}^{2}\mathbf{GAN}$,这是一种鲁棒且可扩展的方法,可实现多域非配对图像翻译。然而这些模型容易受到无关内容干扰,在翻译阶段难以聚焦最具判别性的图像语义部分。
Attention-Guided Image-to-Image Translation. In order to fix the aforementioned limitations, Liang et al. propose Contrast GAN [18], which uses the object mask annotations from each dataset as extra input data. In this method, we have to make an assumption that after applying semantic changes an object shape does not change. Another method is to train another segmentation or attention model and fit it to the system. For instance, Mejjati et al. [25] propose an attention mechanisms that are jointly trained with the generators and disc rim in at or s. Chen et al. propose Attention GAN [6], which uses an extra attention network to generate attention maps, so that major attention can be paid to objects of interests. K as tani otis et al. [12] present ATAGAN, which use a teacher network to produce attention maps. Zhang et al. [45] propose the Self-Attention Generative Adversarial Networks (SAGAN) for image generation task. Qian et al. [30] employ a recurrent network to generate visual attention first and then transform a raindrop degraded image into a clean one. Tang et al. [40] propose a novel Multi-Channel Attention Selection GAN for the challenging cross-view image translation task. Sun et al. [36] generate a facial mask by using FCN [21] for face attribute manipulation.
注意力引导的图像到图像翻译。为解决上述限制,Liang等人提出了Contrast GAN [18],该方法将每个数据集中的物体掩码标注作为额外输入数据。此方法需假设语义变化后物体形状保持不变。另一种方案是训练独立的分割或注意力模型并集成至系统中。例如Mejjati等人[25]提出与生成器和判别器联合训练的注意力机制。Chen等人开发的Attention GAN [6]通过额外注意力网络生成注意力图,使系统聚焦于目标物体。Kastaniotis等人[12]提出的ATAGAN采用教师网络生成注意力图。Zhang等人[45]针对图像生成任务提出自注意力生成对抗网络(SAGAN)。Qian等人[30]先通过循环网络生成视觉注意力,再将雨滴退化图像恢复为清晰图像。Tang等人[40]针对跨视角图像翻译任务提出多通道注意力选择GAN。Sun等人[36]利用FCN[21]生成面部掩码以实现人脸属性编辑。
All these aforementioned methods employ extra networks or data to obtain attention masks, which increases the number of parameters, training time and storage space of the whole system. In this work, we propose the Attention-Guided Generative Adversarial Network (AGGAN), which can produce attention masks by the generators. For this purpose, we embed an attention method to the vanilla generator which means that we do not need any extra models to obtain the attention masks of objects of interests.
上述所有方法都采用额外网络或数据来获取注意力掩码,这增加了整个系统的参数量、训练时间和存储空间。本文提出注意力引导生成对抗网络 (AGGAN),可通过生成器直接生成注意力掩码。为此,我们在基础生成器中嵌入注意力机制,这意味着无需任何额外模型即可获取目标对象的注意力掩码。
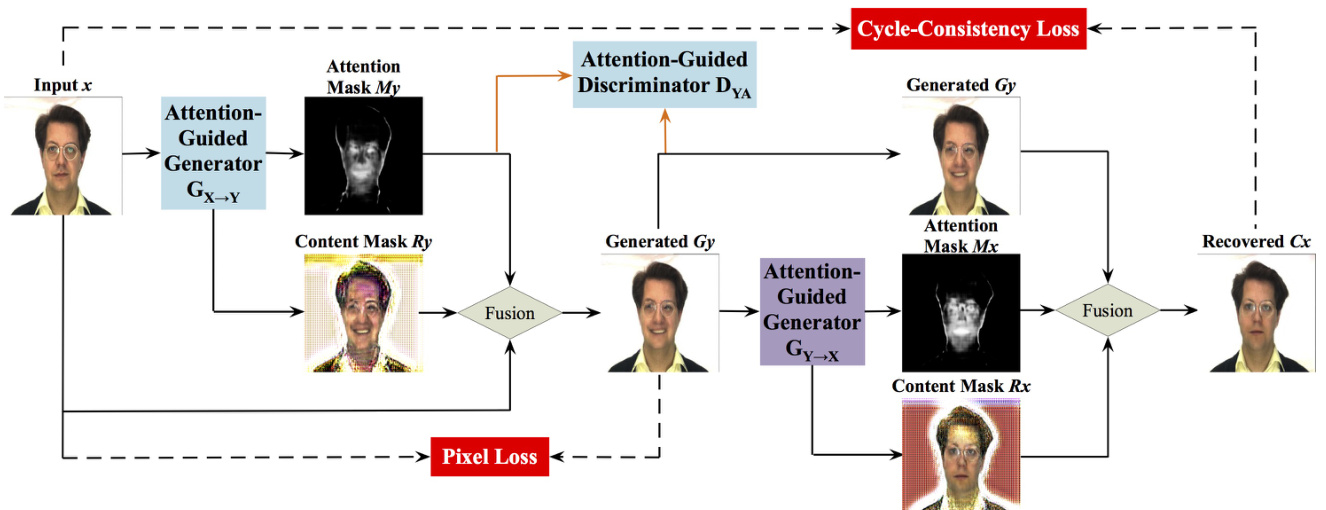
Fig. 2: The framework of the proposed AGGAN. Because of the space limitation, we only show one mapping in this figure, i.e., $x{\rightarrow}[M_{y},R_{y},G_{y}]{\rightarrow}C_{x}{\approx}x$ . We also have the other mapping, i.e., $y\rightarrow[M_{x},R_{x},G_{x}]\rightarrow C_{y}\approx y$ . The attention-guided generators have built-in attention mechanism, which can detect the most disc rim i native part of images. After that we mix the input image, content mask and the attention mask to synthesize the targeted image. Moreover, to distinguish only the most disc rim i native content, we also propose a attention-guided disc rim in at or $D_{Y A}$ . Note that our systems does not require supervision, i.e., no pairs of images of the same person with different expressions.
图 2: 提出的 AGGAN 框架。由于篇幅限制,本图仅展示一个映射关系,即 $x{\rightarrow}[M_{y},R_{y},G_{y}]{\rightarrow}C_{x}{\approx}x$ 。另一个映射关系为 $y\rightarrow[M_{x},R_{x},G_{x}]\rightarrow C_{y}\approx y$ 。注意力引导生成器内置注意力机制,可检测图像中最具判别性的区域。随后我们将输入图像、内容掩码和注意力掩码混合以合成目标图像。此外,为仅区分最具判别性的内容,我们还提出了注意力引导判别器 $D_{Y A}$ 。需注意本系统无需监督信号,即不需要同一人物不同表情的成对图像。
III. METHOD
III. 方法
We first start with the attention-guided generator and discriminator of the proposed Attention-Guided Generative Adversarial Network (AGGAN), and then introduce the loss function for better optimization of the model. Finally we present the implementation details of the whole model including network architecture and training procedure.
我们首先从所提出的注意力引导生成对抗网络 (AGGAN) 的注意力引导生成器和判别器开始,然后介绍用于更好优化模型的损失函数。最后我们展示整个模型的实现细节,包括网络架构和训练过程。
A. Attention-Guided Generator
A. 注意力引导生成器
GANs [8] are composed of two competing modules, i.e., the generator $G_{X\rightarrow Y}$ and the disc rim in at or $D_{Y}$ (where $X$ and $Y$ denote two different image domains), which are iterative ly trained competing against with each other in the manner of two-player minimax. More formally, let $x_{i}\in X$ and $y_{j}\in Y$ denote the training images in source and target image domain, respectively (for simplicity, we usually omit the subscript $i$ and $j$ ). For most current image translation models, e.g., CycleGAN [47] and DualGAN [43], they include two mappings $G_{X\rightarrow Y}{:}x{\rightarrow}G_{y}$ and $G_{Y\rightarrow X}{:}y\rightarrow G_{x}$ , and two corresponding adversarial disc rim in at or s $D_{X}$ and $D_{Y}$ . The generator $G_{X\rightarrow Y}$ maps $x$ from the source domain to the generated image $G_{y}$ in the target domain $Y$ and tries to fool the disc rim in at or $D_{Y}$ , whilst the $D_{Y}$ focuses on improving itself in order to be able to tell whether a sample is a generated sample or a real data sample. Similar to $G_{Y\rightarrow X}$ and $D_{X}$ .
GANs [8] 由两个相互竞争的模块组成,即生成器 $G_{X\rightarrow Y}$ 和判别器 $D_{Y}$ (其中 $X$ 和 $Y$ 表示两个不同的图像域),它们以双人极小极大博弈的方式迭代训练并相互对抗。更正式地说,令 $x_{i}\in X$ 和 $y_{j}\in Y$ 分别表示源图像域和目标图像域中的训练图像(为简化起见,通常省略下标 $i$ 和 $j$ )。对于当前大多数图像翻译模型(例如 CycleGAN [47] 和 DualGAN [43]),它们包含两个映射 $G_{X\rightarrow Y}{:}x{\rightarrow}G_{y}$ 和 $G_{Y\rightarrow X}{:}y\rightarrow G_{x}$ ,以及两个对应的对抗判别器 $D_{X}$ 和 $D_{Y}$ 。生成器 $G_{X\rightarrow Y}$ 将源域的 $x$ 映射到目标域 $Y$ 中的生成图像 $G_{y}$ ,并试图欺骗判别器 $D_{Y}$ ,而 $D_{Y}$ 则专注于提升自身能力以判断样本是生成样本还是真实数据样本。 $G_{Y\rightarrow X}$ 和 $D_{X}$ 的原理与之类似。
While for the proposed AGGAN, we intend to learn two mappings between domains $X$ and $Y$ via two generators with built-in attention mechanism, i.e., $G_{X\rightarrow Y};x{\rightarrow}[M_{y},R_{y},G_{y}]$ and $G_{Y\rightarrow X};y\rightarrow[M_{x},R_{x},G_{x}]$ , where $M_{x}$ and $M_{y}$ are the attention masks of images $x$ and $y$ , respectively; $R_{x}$ and $R_{y}$ are the content masks of images $x$ and $y$ , respectively; $G_{x}$ and $G_{y}$ are the generated images. The attention masks $M_{x}$ and $M_{y}$ define a per pixel intensity specifying to which extend each pixel of the content masks $R_{x}$ and $R_{y}$ will contribute in the final rendered image. In this way, the generator does not need to render static elements, and can focus exclusively on the pixels defining the facial movements, leading to sharper and more realistic synthetic images. After that, we fuse input image $x$ and the generated attention mask $M_{y}$ , and the content mask $R_{y}$ to obtain the targeted image $G_{y}$ . Through this way, we can disentangle the most disc rim i native semantic object and unwanted part of images. In Fig. 2, the attention-guided generators focus only on those regions of the image that are responsible of generating the novel expression such as eyes and mouth, and keep the rest parts of the image such as hair, glasses, clothes untouched. The higher intensity in the attention mask means the larger contribution for changing the expression.
而对于我们提出的AGGAN,旨在通过两个内置注意力机制的生成器学习域$X$和$Y$之间的双向映射:$G_{X\rightarrow Y};x{\rightarrow}[M_{y},R_{y},G_{y}]$与$G_{Y\rightarrow X};y\rightarrow[M_{x},R_{x},G_{x}]$。其中$M_{x}$和$M_{y}$分别是图像$x$和$y$的注意力掩膜;$R_{x}$和$R_{y}$是图像$x$和$y$的内容掩膜;$G_{x}$和$G_{y}$为生成图像。注意力掩膜$M_{x}$和$M_{y}$通过逐像素强度值,定义了内容掩膜$R_{x}$和$R_{y}$中各像素对最终合成图像的贡献程度。这种方式使生成器无需渲染静态元素,仅需聚焦于定义面部运动的像素,从而产生更清晰逼真的合成图像。随后,我们融合输入图像$x$与生成的注意力掩膜$M_{y}$、内容掩膜$R_{y}$来获得目标图像$G_{y}$。该方法能有效解耦图像中最具判别力的语义对象与无关区域。如图2所示,注意力引导的生成器仅聚焦于眼睛、嘴巴等生成新表情的关键区域,而保持头发、眼镜、衣物等其他部分不变。注意力掩膜中强度越高,表示该区域对表情变化的贡献越大。
To focus on the disc rim i native semantic parts in two different domains, we specifically designed two generators with built-in attention mechanism. By using this mechanism, generators can generate attention masks in two different domains. The input of each generator is a three-channel image, and the outputs of each generator are a attention mask and a content mask. Specifically, the input image of GX→Y is x∈RH×W ×3, and the outputs are the attention mask $M_{y}{\in}{0,{\ldots},1}^{H\times W}$ and content mask $R_{y}{\in}\mathbb{R}^{H\times W\times3}$ . Thus, we use the following formulation to calculate the final image $G_{y}$ ,
为了聚焦两个不同领域中具有区分性的语义部分,我们专门设计了两个内置注意力机制的生成器。通过该机制,生成器可在两个不同域中生成注意力掩码。每个生成器的输入为三通道图像,输出为注意力掩码和内容掩码。具体而言,生成器GX→Y的输入图像为x∈RH×W ×3,输出为注意力掩码$M_{y}{\in}{0,{\ldots},1}^{H\times W}$和内容掩码$R_{y}{\in}\mathbb{R}^{H\times W\times3}$。因此,我们采用以下公式计算最终图像$G_{y}$:
$$
G_{y}=R{y}M{y}+x(1-M{y}),
$$
where attention mask $M_{y}$ is copied into three-channel for multiplication purpose. The formulation for generator $G_{Y\rightarrow X}$ and input image $y$ is $G_{x}{=}R_{x}M_{x}{+}y(1{-}M_{x})$ . Intuitively, attention mask $M_{y}$ enables some specific areas where facial muscle changed to get more focus, applying it to the content mask $R_{y}$ can generate images with clear dynamic area and unclear static area. After that, what left is to enhance the static area, which should be similar between the generated image and the original real image. Therefore we can enhance the static area (basically it refers to background area) in the original real image $(1-M_{y})x$ and merge it to $R{y}M{y}$ to obtain final result $R_{y}M_{y}+x(1{-}M_{y})$ .
其中注意力掩码 $M_{y}$ 被复制为三通道以进行乘法运算。生成器 $G_{Y\rightarrow X}$ 和输入图像 $y$ 的公式为 $G_{x}{=}R_{x}M_{x}{+}y(1{-}M_{x})$ 。直观上,注意力掩码 $M_{y}$ 能使面部肌肉变化的特定区域获得更多关注,将其应用于内容掩码 $R_{y}$ 可生成动态区域清晰而静态区域模糊的图像。随后只需增强静态区域(通常指背景区域),该区域在生成图像与原始真实图像间应保持相似。因此我们可增强原始真实图像中的静态区域 $(1-M_{y})x$ 并将其与 $R_{y}M_{y}$ 融合,最终得到 $R_{y}M_{y}+x(1{-}M_{y})$ 。
B. Attention-Guided Disc rim in at or
B. 注意力引导判别器
Eq. (1) constrains the generators to act only on the attended regions. However, the disc rim in at or s currently consider the whole image. More specifically, the vanilla disc rim in at or $D_{Y}$ takes the generated image $G_{y}$ or the real image $y$ as input and tries to distinguish them. Similar to disc rim in at or $D_{X}$ , which tries to distinguish the generated image $G_{x}$ and the real image $x$ . To add attention mechanism to the disc rim in at or so that it only considers attended regions. We propose two attentionguided disc rim in at or s. The attention-guided disc rim in at or is structurally the same with the vanilla disc rim in at or but it also takes the attention mask as input. For attention-guided disc rim in at or $D_{Y A}$ , which tries to distinguish the fake image pairs $[M_{y},G_{y}]$ and the real image pairs $[M_{y},y]$ . Similar to $D_{X A}$ , which tries to distinguish the fake image pairs $[M_{x},G_{x}]$ and the real image pairs $[M_{x},x]$ . In this way, disc rim in at or s can focus on the most disc rim i native content.
式 (1) 约束生成器仅作用于注意力区域。然而当前判别器仍考虑整张图像。具体而言,原始判别器 $D_{Y}$ 以生成图像 $G_{y}$ 或真实图像 $y$ 作为输入进行区分。类似地,判别器 $D_{X}$ 用于区分生成图像 $G_{x}$ 与真实图像 $x$。
为使判别器仅关注注意力区域,我们提出两种注意力引导的判别器。其结构与原始判别器相同,但额外接收注意力掩模作为输入。注意力引导判别器 $D_{YA}$ 用于区分伪造图像对 $[M_{y},G_{y}]$ 与真实图像对 $[M_{y},y]$;类似地,$D_{XA}$ 用于区分伪造图像对 $[M_{x},G_{x}]$ 与真实图像对 $[M_{x},x]$。该方法可使判别器聚焦于最具判别力的内容。
C. Optimization Objective
C. 优化目标
Vanilla Adversarial Loss $\mathcal{L}{G A N}(G_{X\rightarrow Y},D_{Y})$ [8] can be formulated as follows:
普通对抗损失 $\mathcal{L}{G A N}(G_{X\rightarrow Y},D_{Y})$ [8] 可表述如下:
$$
\begin{array}{r l}{\mathcal{L}{G A N}(G_{X\rightarrow Y},D_{Y})=\mathbb{E}{y\sim p_{\mathrm{data}}(y)}\left[\log D_{Y}(y)\right]+}\ {\mathbb{E}{x\sim p_{\mathrm{data}}(x)}[\log(1-D_{Y}(G_{X\rightarrow Y}(x)))].}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{G A N}(G_{X\rightarrow Y},D_{Y})=\mathbb{E}{y\sim p_{\mathrm{data}}(y)}\left[\log D_{Y}(y)\right]+}\ &{\mathbb{E}{x\sim p_{\mathrm{data}}(x)}[\log(1-D_{Y}(G_{X\rightarrow Y}(x)))].}\end{array}
$$
$G_{X\rightarrow Y}$ tries to minimize the adversarial loss objective $\mathcal{L}{G A N}(G_{X\rightarrow Y},D_{Y})$ while $D_{Y}$ tries to maximize it. The target of $G_{X\rightarrow Y}$ is to generate an image $G_{y}{=}G_{X{\rightarrow}Y}(x)$ that looks similar to the images from domain $Y$ , while $D_{Y}$ aims to distinguish between the generated images $G_{X\rightarrow Y}(x)$ and the real images $y$ . A similar adversarial loss of Eq. (2) for mapping function $G_{Y\rightarrow X}$ and its disc rim in at or $D_{X}$ is defined as $\mathcal{L}{G A N}(G_{Y\rightarrow X},D_{X})=\mathbb{E}{x\sim p_{\mathrm{data}}(x)}[\log D_{X}(x)]+$ $\mathbb{E}{y\sim p_{\mathrm{data}}(y)}[\log(1-D_{X}(G_{Y\rightarrow X}(y)))]$ .
$G_{X\rightarrow Y}$ 试图最小化对抗损失目标 $\mathcal{L}{G A N}(G_{X\rightarrow Y},D_{Y})$,而 $D_{Y}$ 则试图最大化该目标。$G_{X\rightarrow Y}$ 的目标是生成图像 $G_{y}{=}G_{X{\rightarrow}Y}(x)$,使其看起来类似于域 $Y$ 中的图像,而 $D_{Y}$ 旨在区分生成的图像 $G_{X\rightarrow Y}(x)$ 和真实图像 $y$。对于映射函数 $G_{Y\rightarrow X}$ 及其判别器 $D_{X}$,定义了一个与式(2)类似的对抗损失:$\mathcal{L}{G A N}(G_{Y\rightarrow X},D_{X})=\mathbb{E}_{x\sim p_{\mathrm{data}}(x)}[\log D_{X}(x)]+$ $\mathbb{E}{y\sim p_{\mathrm{data}}(y)}[\log(1-D_{X}(G_{Y\rightarrow X}(y)))]$。
Attention-Guided Adversarial Loss. We propose the attention-guided adversarial loss for training the attentionguide disc rim in at or s. The min-max game between the attention-guided disc rim in at or $D_{Y A}$ and the generator $G_{X\rightarrow Y}$ is performed through the following objective functions:
注意力引导对抗损失。我们提出注意力引导对抗损失用于训练注意力引导判别器。注意力引导判别器 $D_{YA}$ 与生成器 $G_{X\rightarrow Y}$ 之间的最小-最大博弈通过以下目标函数实现:
$$
\begin{array}{r l}&{\mathcal{L}{A G A N}(G_{X\rightarrow Y},D_{Y A})=\mathbb{E}{y\sim p_{\mathrm{data}}(y)}\left[\log D_{Y A}([M_{y},y])\right]+}\ &{\mathbb{E}{x\sim p_{\mathrm{data}}(x)}[\log(1-D_{Y A}([M_{y},G_{X\rightarrow Y}(x)]))],}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{A G A N}(G{X\rightarrow Y},D_{Y A})=\mathbb{E}{y\sim p{\mathrm{data}}(y)}\left[\log D_{Y A}([M_{y},y])\right]+}\ &{\mathbb{E}{x\sim p{\mathrm{data}}(x)}[\log(1-D_{Y A}([M_{y},G_{X\rightarrow Y}(x)]))],}\end{array}
$$
where $D_{Y A}$ aims to distinguish between the generated image pairs $[M_{y},G_{X\rightarrow Y}(x)]$ and the real image pairs $[M_{y},y]$ . We also have another loss $\mathcal{L}{A G A N}(G_{Y\rightarrow X},D_{X A})$ for discriminator $D_{X A}$ and the generator $G_{Y\rightarrow X}$ .
其中 $D_{Y A}$ 旨在区分生成的图像对 $[M_{y},G_{X\rightarrow Y}(x)]$ 和真实图像对 $[M_{y},y]$ 。我们还为判别器 $D_{X A}$ 和生成器 $G_{Y\rightarrow X}$ 定义了另一个损失函数 $\mathcal{L}{A G A N}(G_{Y\rightarrow X},D_{X A})$ 。
Cycle-Consistency Loss. Note that CycleGAN [47] and DualGAN [43] are different from Pix2pix [11] as the training data in those models are unpaired. The cycle-consistency loss can be used to enforce forward and backward consistency. The cycle-consistency loss can be regarded as “pseudo” pairs of training data even though we do not have the corresponding data in the target domain which corresponds to the input data from the source domain. Thus, the loss function of cycleconsistency can be defined as:
循环一致性损失 (Cycle-Consistency Loss)。需要注意的是,CycleGAN [47] 和 DualGAN [43] 与 Pix2pix [11] 不同,因为这些模型的训练数据是非配对的。循环一致性损失可用于强化前向和后向一致性。即使我们没有目标域中与源域输入数据相对应的数据,循环一致性损失也可以被视为训练数据的"伪"配对。因此,循环一致性损失函数可以定义为:
$$
\begin{array}{r l}&{\mathcal{L}{c y c l e}(G_{X\rightarrow Y},G_{Y\rightarrow X})=}\ &{\mathbb{E}{x\sim p_{\mathrm{data}}(x)}[|G_{Y\rightarrow X}(G_{X\rightarrow Y}(x))-x|{1}]+}\ &{\mathbb{E}{y\sim p_{\mathrm{data}}(y)}[|G_{X\rightarrow Y}(G_{Y\rightarrow X}(y))-y|_{1}].}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{c y c l e}(G_{X\rightarrow Y},G_{Y\rightarrow X})=}\ &{\mathbb{E}{x\sim p_{\mathrm{data}}(x)}[|G_{Y\rightarrow X}(G_{X\rightarrow Y}(x))-x|{1}]+}\ &{\mathbb{E}{y\sim p_{\mathrm{data}}(y)}[|G_{X\rightarrow Y}(G_{Y\rightarrow X}(y))-y|_{1}].}\end{array}
$$
The reconstructed images $C_{x}{=}G_{Y\rightarrow X}(G_{X{\rightarrow}Y}(x))$ are closely matched to the input image $x$ , and similar to $G_{X\rightarrow Y}(G_{Y\rightarrow X}(y))$ and image $y$ .
重建图像 $C_{x}{=}G_{Y\rightarrow X}(G_{X{\rightarrow}Y}(x))$ 与输入图像 $x$ 高度匹配,且与 $G_{X\rightarrow Y}(G_{Y\rightarrow X}(y))$ 及图像 $y$ 相似。
Pixel Loss. To reduce changes and constrain generators, we adopt pixel loss between the input images and the generated images. We express this loss as:
像素损失 (Pixel Loss)。为了减少变化并约束生成器,我们采用输入图像与生成图像之间的像素损失。该损失函数表示为:
$$
\begin{array}{r}{\mathcal{L}{p i x e l}(G_{X\rightarrow Y},G_{Y\rightarrow X})=\mathbb{E}{x\sim p_{\mathrm{data}}(x)}[|G_{X\rightarrow Y}(x)-x|{1}]+}\ {\mathbb{E}{y\sim p_{\mathrm{data}}(y)}[|G_{Y\rightarrow X}(y)-y|{1}]._{\ell=1}.}\end{array}
$$
We adopt $L1$ distance as loss measurement in pixel loss. Note that the pixel loss usually used in the paired image-to-image translation models such as Pix2pix [11]. While we use it in our AGGAN for unpaired image-to-image translation task.
我们在像素损失中采用$L1$距离作为损失度量。需要注意的是,像素损失通常用于成对图像转换模型(如Pix2pix [11]),而我们在AGGAN中将其用于非成对图像转换任务。
Attention Loss. When training our AGGAN we do not have ground-truth annotation for the attention masks. They are learned from the resulting gradients of the attentionguided disc rim in at or s and the rest of the losses. However, the attention masks can easily saturate to 1 which makes the attention-guided generator has no effect as indicated in GANimation [29]. To prevent this situation, we perform a Total Variation Regular iz ation over attention masks $M_{y}$ and $M_{x}$ . The attention loss of mask $M_{x}$ therefore can be defined as:
注意力损失 (Attention Loss)。在训练我们的 AGGAN 时,我们没有注意力掩码 (attention masks) 的真实标注。它们是从注意力判别器 (attention-guided discriminators) 和其他损失的梯度中学习得到的。然而,注意力掩码很容易饱和到 1,这会使注意力引导生成器 (attention-guided generator) 失效,如 GANimation [29] 所述。为了防止这种情况,我们对注意力掩码 $M_{y}$ 和 $M_{x}$ 进行了总变分正则化 (Total Variation Regularization)。因此,掩码 $M_{x}$ 的注意力损失可以定义为:
$$
\begin{array}{r l r}{\lefteqn{\mathcal{L}{t v}(M_{x})=\displaystyle\sum_{w,h=1}^{W,H}|M_{x}(w+1,h,c)-M_{x}(w,h,c)|+}}\ &{}&{\quad\quad\quad|M_{x}(w,h+1,c)-M_{x}(w,h,c)|,}\end{array}
$$
$$
\begin{array}{r l r}{\lefteqn{\mathcal{L}{t v}(M_{x})=\displaystyle\sum_{w,h=1}^{W,H}|M_{x}(w+1,h,c)-M_{x}(w,h,c)|+}}\ &{}&{\quad\quad\quad|M_{x}(w,h+1,c)-M_{x}(w,h,c)|,}\end{array}
$$
where $W$ and $H$ are the width and height of $M_{x}$ .
其中 $W$ 和 $H$ 是 $M_{x}$ 的宽度和高度。
Full Objective. Thus, the complete objective loss of AGGAN can be formulated as follows:
完整目标。因此,AGGAN的完整目标损失可表述如下:
$$
\begin{array}{r l}&{\mathcal{L}(G_{X\to Y},G_{Y\to X},D_{X},D_{Y},D_{X A},D_{Y A})=}\ &{\lambda_{g a n}[\mathcal{L}{G A N}(G_{X\to Y},D_{Y})+\mathcal{L}{G A N}(G_{Y\to X},D_{X})+}\ {\mathcal{L}{A G A N}(G_{X\to Y},D_{Y A})+\mathcal{L}{A G A N}(G_{Y\to X},D_{X A})]+}\ &{\lambda_{c y c l e}\mathcal{L}{c y c l e}(G_{X\to Y},G_{Y\to X})+}\ {\lambda_{p i x e l}\mathcal{L}{p i x e l}(G_{X\to Y},G_{Y\to X})+\lambda_{t v}[\mathcal{L}{t v}(M_{x})+\mathcal{L}{t v}(M_{y})].}\end{array}
$$
where $\lambda_{g a n},\lambda_{c y c l e},\lambda_{p i x e l}$ and $\lambda_{t v}$ are parameters controlling the relative relation of objectives terms. We aim to solve:
其中 $\lambda_{g a n},\lambda_{c y c l e},\lambda_{p i x e l}$ 和 $\lambda_{t v}$ 是控制目标项相对关系的参数。我们的目标是求解:
$$
\begin{array}{r l}&{G_{X\rightarrow Y}^,G_{Y\rightarrow X}^=}\ &{\arg\underset{G_{Y\rightarrow X},D_{X},D_{Y},}{\operatorname{min}}\underset{G_{X\rightarrow Y},G_{Y\rightarrow X},D_{X},D_{Y},D_{X A},D_{Y A}).}{\arg}.}\end{array}
$$
$D$ . Implementation Details
$D$ . 实现细节
Network Architecture. For fair comparison, we use the generator architecture from CycleGAN [47]. We have slightly modified it for our task and the network architecture of the proposed generators is, $[c7s1_{-}64,d128,d256,R256,R256,R256,R256,R256,R256,R256,$ $u128,u64,c7s1_4]$ , where $c7s1_{-}k$ denotes a $7\times7$ Convolution-BatchNorm-ReLU layer with $k$ filters and stride 1. dk denotes a $3\times3$ Convolution-BatchNorm-ReLU layer with $k$ filters and stride 2. $R k$ represents a residual block that contains two $3\times3$ convolutional layers with stride 1 and the same number of filters on both layer. uk denotes a $3\times3$ fractional-strided-Convolution-BatchNorm-ReLU layer with $k$ filters and stride $1/2$ . The generator takes an 3-channel RGB image as input and outputs a single-channel attention mask and a 3-channel content mask.
网络架构。为了公平比较,我们采用CycleGAN [47]的生成器架构,并针对任务进行了微调。提出的生成器网络架构为:$[c7s1_{-}64,d128,d256,R256,R256,R256,R256,R256,R256,R256,$ $u128,u64,c7s1_4]$。其中$c7s1_{-}k$表示具有$k$个滤波器和步长1的$7\times7$卷积-批归一化-ReLU层,dk表示具有$k$个滤波器和步长2的$3\times3$卷积-批归一化-ReLU层,$R k$代表包含两个步长1且滤波器数量相同的$3\times3$卷积层的残差块,uk表示具有$k$个滤波器和步长$1/2$的$3\times3$分数步长卷积-批归一化-ReLU层。生成器以3通道RGB图像作为输入,输出单通道注意力掩码和3通道内容掩码。
For the vanilla disc rim in at or, we employ discriminator architecture in [11], [47], which is denoted as $[C64,C128,C256,C512,C512]$ , where $C k$ denotes a $4\times4$ Convolution-BatchNorm-LReLU layer with $k$ filters and stride 2. The differences between [11], [47] are that the BatchNorm is used for the first $C64$ . And for the last $C512$ , the stride is change to 1 and BatchNorm is not adopted. After the end of the disc rim in at or architecture, an adaptive average pooling layer and a convolution layer are applied to produce the final 1 dimensional output. For comparing the vanilla disc rim in at or and the proposed attention-guided disc rim in at or, we employ the same architecture as the proposed attentionguided disc rim in at or except the attention-guided disc rim in at or takes a attention mask and an image as inputs while the vanilla disc rim in at or only takes an image as input.
对于基础的判别器架构,我们采用[11]、[47]中提出的 $[C64,C128,C256,C512,C512]$ 结构,其中 $C k$ 表示包含 $k$ 个滤波器、步长为2的 $4\times4$ 卷积-批归一化-LReLU层。与[11]、[47]的区别在于:首个 $C64$ 层使用了批归一化;末层 $C512$ 的步长改为1且移除了批归一化。在判别器末端,通过自适应平均池化层和卷积层生成最终的一维输出。为对比基础判别器与提出的注意力引导判别器,两者采用相同架构,区别仅在于注意力引导判别器需同时接收注意力掩膜和图像作为输入,而基础判别器仅接收单张图像输入。
Training Strategy. We follow the standard optimization method from [8] to optimize the proposed AGGAN, i.e., we alternate between one gradient descent step on generators, then one step on disc rim in at or s. The proposed AGGAN is trained end-to-end fashion. Moreover, in order to slow down the rate of disc rim in at or s relative to generators we divide the objective by 2 while optimizing disc rim in at or s. We use a least square loss [23] to stabilize our model during training procedure similar to CycleGAN. The least square loss is more stable than the negative log likelihood objective in Eq. (2) and more faster than Wasser stein GAN (WGAN) [2] to converge. We also use a history of generated images to update disc rim in at or s similar to CycleGAN. Finally, we adopt a curriculum strategy for training stage, which makes we have a strong GAN loss at the beginning of training time. Eq. (7) then becomes,
训练策略。我们遵循[8]中的标准优化方法优化提出的AGGAN,即在生成器上执行一次梯度下降步骤,然后在判别器上执行一步优化。提出的AGGAN采用端到端方式进行训练。此外,为了减缓判别器相对于生成器的学习速度,我们在优化判别器时将目标函数除以2。与CycleGAN类似,我们使用最小二乘损失[23]来稳定训练过程中的模型。最小二乘损失比公式(2)中的负对数似然目标更稳定,且比Wasserstein GAN (WGAN) [2]收敛更快。我们还采用类似CycleGAN的方法,使用生成图像的历史记录来更新判别器。最后,我们在训练阶段采用课程策略,这使得训练初期具有更强的GAN损失。此时公式(7)变为,
$$
\begin{array}{r l}{\mathcal{L}(G_{X\rightarrow Y},G_{Y\rightarrow X},D_{X},D_{Y},D_{X A},D_{Y A})=}\ {[\lambda_{c y c l e}\mathcal{L}{c y c l e}(G_{X\rightarrow Y},G_{Y\rightarrow X})+}\ {\lambda_{p i x e l}\mathcal{L}{p i x e l}(G_{X\rightarrow Y},G_{Y\rightarrow X})]r+}\ {{\lambda_{g a n}[\mathcal{L}{G A N}(G_{X\rightarrow Y},D_{Y})+\mathcal{L}{G A N}(G_{Y\rightarrow X},D_{X})+}\ {\mathcal{L}{A G A N}(G_{X\rightarrow Y},D_{Y A})+\mathcal{L}{A G A N}(G_{Y\rightarrow X},D_{X A})]+}\ {\lambda_{t v}[\mathcal{L}{t v}(M_{x})+\mathcal{L}{t v}(M_{y})]}(1-r),}\end{array}
$$
where $r$ is a curriculum parameter to control the relation be- tween GAN loss and reconstruction loss (i.e, cycle-consistency loss and pixel loss) during curriculum period.
其中 $r$ 是课程参数,用于控制课程学习期间 GAN 损失与重建损失 (即循环一致性损失和像素损失) 之间的关系。
IV. EXPERIMENTAL RESULTS
IV. 实验结果
A. Experimental Setup
A. 实验设置
Dataset. We employ four public datasets to validate the proposed AGGAN. These datasets contains the faces with different races and they have different illumination, occlusion, pose conditions and backgrounds. (i) Large-scale Celeb Faces Attributes (CelebA) dataset [20] has more than 200K celebrity images with complex backgrounds. To evaluate the performance of the proposed method under the situation where training data is limited. We randomly select 1,000 neutral images and 1,000 smile images as training data, and another 1,000 neutral and 1,000 smile images as testing data. (ii) RaFD dataset [15] consists of 4,824 images collected from 67 participants. Each participant have eight facial expressions in three gaze directions, which are captured from three different angles. We employed all of the images for diversity expression generation task. (iii) AR Face [24] contains over 4,000 color images in which only 1,018 images have 4 different facial expressions, i.e., smile, anger, fear and neutral expression. We employ the images with the expression labels of smile and neutral to evaluate our method. (iv) Bu3dfe [44] is a 3D facial expression dataset including 100 subjects with 7 different expression categories. We employed the images with smile and neutral expressions as training and testing data.
数据集。我们采用四个公共数据集来验证所提出的AGGAN。这些数据集包含不同种族的人脸,具有不同的光照、遮挡、姿态条件和背景。(i) 大规模名人面部属性数据集CelebA [20]包含超过20万张复杂背景的名人图像。为评估所提方法在训练数据有限情况下的性能,我们随机选取1,000张中性表情图像和1,000张微笑图像作为训练数据,另选1,000张中性和1,000张微笑图像作为测试数据。(ii) RaFD数据集[15]包含从67名参与者收集的4,824张图像,每位参与者有8种面部表情和3个注视方向,并从3个不同角度拍摄。我们使用全部图像进行多样化表情生成任务。(iii) AR Face[24]包含4,000多张彩色图像,其中仅1,018张具有4种不同面部表情(微笑、愤怒、恐惧和中性表情)。我们使用带有微笑和中性表情标签的图像评估方法。(iv) Bu3dfe[44]是包含100名受试者的3D面部表情数据集,涵盖7种不同表情类别。我们采用微笑和中性表情图像作为训练和测试数据。
Parameter Setting. For all datasets, images are rescaled to $256\times256\times3$ and we do left-right flip for data augmentation. For optimization, all baselines and the proposed AGGAN are trained with batch size of 1. All models were trained for 200 epochs on AR Face, Bu3dfe and RaFD datasets, 80 epochs on CelebA dataset. For all the experiments, we set $\lambda_{c y c l e}{=}10$ , $\lambda_{g a n}{=}0.5$ , $\lambda_{p i x e l}{=}1$ and $\lambda_{t v}{=}1e{-}6$ . We set the number of image buffer to 50 similar in [47]. We use the Adam optimizer [14] with the momentum terms $\beta_{1}{=}0.5$ and $\beta_{2}{=}0.999$ . The initial learning rate for Adam optimizer is 0.0001. After 100 and 40 epochs for different datasets, the learning rate starts linearly decaying to 0. For $r$ in Eq. (9), we set it to 0.01 at the first 10 epochs. After curriculum period, we set $r$ to 0.5. The proposed AGGAN is implemented using public PyTorch framework. To speed up both training and testing processes, we use a Nvidia TITAN Xp GPU.
参数设置。对于所有数据集,图像均被缩放至$256\times256\times3$分辨率,并通过左右翻转进行数据增强。优化方面,所有基线模型和提出的AGGAN均采用批次大小为1进行训练。在AR Face、Bu3dfe和RaFD数据集上训练200轮次,CelebA数据集训练80轮次。所有实验中设定$\lambda_{cycle}{=}10$、$\lambda_{gan}{=}0.5$、$\lambda_{pixel}{=}1$和$\lambda_{tv}{=}1e{-}6$。参照[47]设置图像缓冲区数量为50。采用Adam优化器[14],动量项$\beta_{1}{=}0.5$和$\beta_{2}{=}0.999$,初始学习率为0.0001。不同数据集分别在100和40轮次后开始线性衰减学习率至0。式(9)中的$r$在前10轮次设为0.01,课程学习阶段结束后调整为0.5。所提AGGAN基于公开PyTorch框架实现,训练和测试过程均使用Nvidia TITAN Xp GPU加速。
Competing Models. We consider several state-of-the-art cross-domain image generation models as our baselines. (i) Unpaired image translation method: CycleGAN [47], DIAT [16], DiscoGAN [13], Distance GAN [4], Dist. $^+$ Cycle [4], Self Dist. [4], ComboGAN [1], StarGAN [7]; (ii) Paired image translation method: BicycleGAN [48], Pix2pix [11], Encoder-Decoder [11] and (iii) Label-, maskor attention-guided image translation method: IcGAN [28], Contrast GAN [18] and GANimation [29]. Note that the fully supervised Pix2pix, Encoder-Decoder (Enc.-Decoder) and BicycleGAN are trained with paired data on AR Face and Bu3dfe datasets. Since BicycleGAN can generate several different outputs with one single input image, we randomly select one output from them for fair comparison. To re-implement Contrast GAN, we use OpenFace [3] to obtain the face masks as extra input data. For a fair comparison, we implement all the baselines using the same setups as our approach.
竞争模型。我们选取了几种先进的跨域图像生成模型作为基线:(i) 无配对图像翻译方法:CycleGAN [47]、DIAT [16]、DiscoGAN [13]、Distance GAN [4]、Dist.$^+$Cycle [4]、Self Dist. [4]、ComboGAN [1]、StarGAN [7];(ii) 配对图像翻译方法:BicycleGAN [48]、Pix2pix [11]、Encoder-Decoder [11];(iii) 标签/掩码/注意力引导的图像翻译方法:IcGAN [28]、Contrast GAN [18] 和 GANimation [29]。需要注意的是,全监督模型 Pix2pix、Encoder-Decoder (Enc.-Decoder) 和 BicycleGAN 是在 AR Face 和 Bu3dfe 数据集上使用配对数据训练的。由于 BicycleGAN 能对单张输入图像生成多个不同输出,我们从中随机选取一个输出以进行公平比较。在复现 Contrast GAN 时,我们使用 OpenFace [3] 获取人脸掩模作为额外输入数据。为确保公平性,所有基线模型均采用与我们方法相同的配置实现。
Evaluation Metrics. We adopt Amazon Mechanical Turk (AMT) perceptual studies to evaluate the generated images. We gather data from 50 participants per algorithm we tested.
评估指标。我们采用Amazon Mechanical Turk (AMT) 感知研究来评估生成的图像。针对每个测试算法,我们从50名参与者处收集数据。

Fig. 3: Comparison with different baselines on Bu3dfe (Top) and AR Face (Bottom) datasets.
图 3: 在Bu3dfe(上)和AR Face(下)数据集上与不同基线的对比。

Fig. 4: Comparison with different baselines on CelebA dataset.
图 4: 在CelebA数据集上与不同基线的对比。

Fig. 5: Comparison with baselines on RaFD dataset.
图 5: RaFD数据集上与基线的对比。
Participants were shown a sequence of pairs of images, one real image and one fake (generated by our algorithm or a baseline), and asked to click on the image they thought was real. To seek a quantitative measure that does not require human participation, Mean Squared Error (MSE) and Peak Signal-to-Noise Ratio (PSNR) are employed.
参与者观看一系列图像对(一张真实图像和一张由我们的算法或基线生成的伪造图像),并被要求点击他们认为真实的图像。为了寻求无需人工参与的定量衡量标准,我们采用了均方误差 (MSE) 和峰值信噪比 (PSNR)。
B. Comparison with the State-of-the-Art
B. 与现有最优技术的对比
Bu3dfe&AR Face Dataset. Results of Bu3dfe and AR Face datasets are shown in Fig. 3. It is clear that the results of
Bu3dfe&AR Face数据集。Bu3dfe和AR Face数据集的结果如图3所示。显然,这些结果表明
Dist. $^+$ Cycle and Self Dist. cannot even generate human faces. DiscoGAN produce identical results regardless of the input faces, which suffers from mode collapse. While the results of DualGAN, Distance GAN, StarGAN, Pix2pix, EncoderDecoder and BicycleGAN tend to be blurry. While ComboGAN and Contrast GAN can produce the same identity but without expression changing. CycleGAN can generate sharper images, but the details of the generated faces are not convincing. Compared with all the baselines, the results of our AGGAN are more smooth, correct and with more details.
Dist. $^+$ Cycle 和 Self Dist. 甚至无法生成人脸。DiscoGAN 无论输入何种人脸都会产生相同结果,存在模式坍塌问题。而 DualGAN、Distance GAN、StarGAN、Pix2pix、EncoderDecoder 和 BicycleGAN 的结果往往模糊不清。ComboGAN 和 Contrast GAN 能生成相同身份特征但无法改变表情。CycleGAN 生成的图像更清晰,但人脸细节不够真实。与所有基线方法相比,我们的 AGGAN 生成结果更平滑、准确且细节更丰富。
CelebA Dataset. Since CelebA dataset do not provide paired data, thus we cannot conduct experiments on supervised methods. The results of CelebA dataset are shown in Fig. 4. We can see that only the proposed AGGAN can produce photorealistic faces with correct expressions. Thus, we can conclude that even though the subjects in the three datasets have different races, poses, skin colors, illumination conditions, occlusions and complex backgrounds, our method consistently generates more sharper images with correct expressions than the baseline models. Moreover, we observe that our AGGAN preforms better than other baselines when training data is limited, which also shows that our method is very robust.
CelebA数据集。由于CelebA数据集未提供配对数据,因此无法在监督方法上进行实验。CelebA数据集的结果如图4所示。可以看出,只有我们提出的AGGAN能够生成具有正确表情的逼真人脸。因此可以得出结论:尽管三个数据集的受试者在种族、姿态、肤色、光照条件、遮挡和复杂背景方面存在差异,我们的方法始终能比基线模型生成更清晰且表情正确的图像。此外,我们观察到当训练数据有限时,AGGAN的表现优于其他基线模型,这也表明我们的方法具有极强的鲁棒性。
RaFD Dataset. Our model can be easily extended to generate facial diversity expressions (e.g., sad, happy and fearful). To generate diversity expressions in one single model we employ the domain classification loss proposed in StarGAN.
RaFD数据集。我们的模型可以轻松扩展到生成多样化的面部表情(如悲伤、快乐和恐惧)。为了在单一模型中生成多样化表情,我们采用了StarGAN提出的域分类损失。
TABLE I: Quantitative comparison with different models. For all metrics except MSE, high is better.
表 1: 不同模型的定量比较。除MSE外,所有指标均为越高越好。
| 模型 | ARFace | Bu3dfe | CelebA | ||||
|---|---|---|---|---|---|---|---|
| AMT | PSNR | MSE | AMT | PSNR | MSE | AMT | |
| CycleGAN | 10.2 | 14.8142 | 2538.4 | 25.4 | 21.1369 | 602.1 | 34.6 |
| DualGAN | 1.3 | 14.7458 | 2545.7 | 4.1 | 21.0617 | 595.1 | 3.2 |
| DiscoGAN | 0.1 | 13.1547 | 3321.9 | 0.2 | 15.4010 | 2018.7 | 1.2 |
| ComboGAN | 1.5 | 14.7465 | 2550.6 | 28.7 | 20.7377 | 664.4 | 9.6 |
| DistanceGAN | 0.3 | 11.4983 | 4918.5 | 8.9 | 13.9514 | 3426.6 | 1.9 |
| Dist.+Cycle | 0.1 | 3.8632 | 27516.2 | 0.1 | 10.8042 | 6066.7 | 1.3 |
| Self Dist. | 0.1 | 3.8674 | 26775.4 | 0.1 | 6.6458 | 14184.2 | 1.2 |
| StarGAN | 1.6 | 13.5757 | 3360.2 | 5.3 | 20.8275 | 634.4 | 14.8 |
| ContrastGAN | 8.3 | 14.8495 | 2511.1 | 26.2 | 21.1205 | 607.8 | 25.1 |
| Pix2pix | 2.6 | 14.6118 | 2601.3 | 3.8 | 21.2864 | 580.6 | |
| Enc.-Decoder | 0.1 | 12.6660 | 3755.4 | 0.2 | 16.5609 | 1576.7 | |
| BicycleGAN | 1.5 | 14.7914 | 2541.8 | 3.2 | 19.1703 | 1045.4 | |
| AGGAN | 12.8 | 14.9187 | 2508.6 | 32.9 | 21.3247 | 574.5 | 38.9 |
TABLE II: Ablation study of AGGAN.
表 2: AGGAN消融实验
| 组件 | AMT | PSNR | MSE |
|---|---|---|---|
| 完整模型 | 12.8 | 14.9187 | 2508.6 |
| 完整模型-AD | 10.2 | 14.6352 | 2569.2 |
| 完整模型-AD-AG | 3.2 | 14.4646 | 2636.7 |
| 完整模型-AD-PL | 8.9 | 14.5128 | 2619.8 |
| 完整模型-AD-AL | 6.3 | 14.6129 | 2652.6 |
| 完整模型-AD-PL-AL | 5.2 | 14.3287 | 2787.3 |
The results compared against the baselines DIAT, CycleGAN, IcGAN, StarGAN and GANimation are shown in Fig. 5. For GANimation, we follow the authors’ instruction and use OpenFace [3] to obtain the action units of each face as extra input data. We observe that the proposed AGGAN achieves competitive results compared to GANimation.
与基线方法 DIAT、CycleGAN、IcGAN、StarGAN 和 GANimation 的对比结果如图 5 所示。对于 GANimation,我们遵循作者建议,使用 OpenFace [3] 获取每张人脸的动作单元作为额外输入数据。实验表明,我们提出的 AGGAN 取得了与 GANimation 相当的结果。
Quantitative Comparison on All Datasets. We also provide quantitative results on AR Face, Bu3dfe and CelebA datasets. As shown in Table I, we can see that the proposed AGGAN achieves best results on these datasets compared with competing models including fully-supervised methods Pix2pix, Encoder-Decoder, BicycleGAN, and mask-, label- conditional method, i.e., Contrast GAN.
全数据集定量对比。我们还在AR Face、Bu3dfe和CelebA数据集上提供了定量结果。如表1所示,与包括全监督方法Pix2pix、Encoder-Decoder、BicycleGAN以及掩码/标签条件方法Contrast GAN在内的竞争模型相比,我们提出的AGGAN在这些数据集上取得了最佳结果。
C. Model Analysis
C. 模型分析
Analysis of Model Component. In Table II and Fig. 6 we run ablation studies of our model on the AR Face dataset. We gradually remove components of the proposed AGGAN, i.e., Attention-guided Disc rim in at or (AD), Attention-guided Generator (AG), Attention Loss (AL), Pixel Loss (PL). We find that removing one of them substantially degrades results, which means all of them are critical to our results. Note that without AG we cannot generate the attention mask and content mask, as shown in Fig. 6
模型组件分析。在表II和图6中,我们在AR Face数据集上对模型进行了消融实验。我们逐步移除所提出的AGGAN的组件,即注意力引导判别器(AD)、注意力引导生成器(AG)、注意力损失(AL)、像素损失(PL)。实验表明移除任一组件都会显著降低结果质量,这意味着所有组件都对最终结果至关重要。值得注意的是,如图6所示,若移除AG组件将无法生成注意力掩码和内容掩码。
Attention/Content Mask Visualization. Instead of regressing a full image, our generator outputs two masks, a content mask and an attention mask. We also visualize the generation of both masks on RaFD dataset in Fig. 7. We observe that different expressions generate different attention masks and content masks. The proposed method makes the generator focus only on those disc rim i native regions of the image that are responsible of synthesizing the novel expression. The attention mask mainly focuses on the eyes and mouth, which means these parts are important for generating the novel expression.
注意力/内容掩码可视化。我们的生成器并非回归完整图像,而是输出两个掩码:内容掩码和注意力掩码。图7展示了在RaFD数据集上两种掩码的生成过程可视化。我们观察到不同表情会生成不同的注意力掩码和内容掩码。该方法使生成器仅聚焦于图像中负责合成新表情的判别性区域。注意力掩码主要集中于眼睛和嘴巴区域,表明这些部位对生成新表情至关重要。

Fig. 6: Ablation study on the AR Face dataset.
图 6: AR Face数据集消融实验研究。

Fig. 7: Visualization of attention mask and content attention generation on RaFD (Top), AR Face (Bottom-Left) and Bu3dfe (Bottom-Right) datasets.
图 7: RaFD (顶部)、AR Face (左下) 和 Bu3dfe (右下) 数据集上的注意力掩码与内容注意力生成可视化。
The proposed method also keeps the other elements of the image or unwanted part untouched. In Fig. 7 the unwanted part are hair, cheek, clothes and also background, which means these parts have no contribution in generating the novel expression. Methods without attention cannot learn the most disc rim i native part and the unwanted part as shown in Fig. 4. All existing methods failed to generate the novel expression, which means they treat the whole image as the unwanted part, while the proposed AGGAN can learn the novel expression, by distinguishing the disc rim i native part from the unwanted part. Moreover, we also present the generation of both masks on AR Face and Bu3dfe datasets epoch-by-epoch in Fig. 7. We can see that with the number of training epoch increases, the attention mask and the result become better, and the attention mask correlates well with image quality, which demonstrates that our method is effective.
所提出的方法还能保持图像其他部分或不需要区域不受影响。在图7中,不需要的区域包括头发、脸颊、衣物及背景,表明这些部分对生成新表情没有贡献。如图4所示,缺乏注意力机制的算法无法区分最具判别性的区域与干扰区域。现有方法均未能生成新表情,说明它们将整张图像视为干扰区域,而本文提出的AGGAN通过区分判别区域与干扰区域实现了新表情生成。此外,图7还展示了AR Face和Bu3dfe数据集上两种掩模的逐代生成过程。可见随着训练代次增加,注意力掩模和生成效果持续改善,且注意力掩模与图像质量高度相关,这验证了本方法的有效性。
Comparison of the Number of Parameters. The number of models for different $m$ image domains and the number of model parameters on RaFD is shown in Table III. Note that our performance is much better than these baselines and the number of parameters is comparable with Contrast GAN, while this model requires the object mask as extra data.
参数数量对比。表 III 展示了不同 $m$ 图像域模型在RaFD数据集上的参数数量。值得注意的是,我们的性能远优于这些基线模型,且参数数量与Contrast GAN相当,而后者需要物体掩码作为额外数据。
TABLE III: Comparison of the overall model capacity on RaFD Dataset $(\mathrm{m}{=}8)$ .
表 III: RaFD数据集上整体模型容量的比较 $(\mathrm{m}{=}8)$
| 方法 | 模型数量 | 参数量 |
|---|---|---|
| Pix2pix Encoder-Decoder BicycleGAN CycleGAN | m(m-1) m(m-1) m(m-1) m(m-1)/2 | 57.2M×56 41.9M×56 64.3M×56 52.6M×28 |
| DualGAN DiscoGAN DistanceGAN Dist.+ Cycle Self Dist. | m(m-1)/2 m(m-1)/2 m(m-1)/2 m(m-1)/2 m(m-1)/2 | 178.7M×28 16.6M×28 52.6M×28 52.6M×28 52.6M×28 |
| ComboGAN | m | 14.4M×8 |
| StarGAN ContrastGAN | 1 1 | 53.2M×1 52.6M×1 |
| AGGAN(本文) | 1 | 52.6M×1 |
V. CONCLUSION
V. 结论
We propose a novel AGGAN for unsupervised image-toimage translation. The generators in AGGAN have the built-in attention mechanism, which can detect the most disc rim i native part of images and produce the attention mask. Then the attention mask and the input image are combined to generate the targeted images with high-quality. We also propose a novel attention-guided disc rim in at or, which only focus on the attended content. The proposed AGGAN is trained by an end-toend fashion. Experimental results on four datasets demonstrate that AGGAN and the training strategy can generate compelling results with more convincing details and correct expressions than the state-of-the-art models.
我们提出了一种新型AGGAN用于无监督图像到图像转换。该模型的生成器内置注意力机制,能自动检测图像中最具区分性的区域并生成注意力掩码。随后通过结合注意力掩码与输入图像,生成高质量的目标图像。我们还创新性地设计了注意力引导判别器,使其仅聚焦于被关注的内容区域。整个AGGAN采用端到端方式进行训练。在四个数据集上的实验表明,相比现有最优模型,AGGAN及其训练策略能生成更具说服力的细节表现和更准确的特征表达。