ERNIE-GEN: An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation
ERNIE-GEN: 面向自然语言生成的增强型多流预训练与微调框架
Abstract
摘要
Current pre-training works in natural language generation pay little attention to the problem of exposure bias on downstream tasks. To address this issue, we propose an enhanced multi-flow sequence to sequence pre-training and fine-tuning framework named ERNIE-GEN, which bridges the discrepancy between training and inference with an infilling generation mechanism and a noise-aware generation method. To make generation closer to human writing patterns, this framework introduces a span-by-span generation flow that trains the model to predict semantically-complete spans consecutively rather than predicting word by word. Unlike existing pre-training methods, ERNIE-GEN incorporates multi-granularity target sampling to construct pre-training data, which enhances the correlation between encoder and decoder. Experimental results demonstrate that ERNIE-GEN achieves state-of-the-art results with a much smaller amount of pre-training data and parameters on a range of language generation tasks, including abstract ive sum mari z ation (Gigaword and CNN/DailyMail), question generation (SQuAD), dialogue response generation (Persona-Chat) and generative question answering (CoQA). The source codes and pretrained models have been released at https://github. com/Paddle Paddle/ERNIE.
当前自然语言生成领域的预训练工作很少关注下游任务中的曝光偏差问题。为解决这一问题,我们提出了名为ERNIE-GEN的增强型多流程序列到序列预训练与微调框架,该框架通过填充生成机制和噪声感知生成方法弥合了训练与推理之间的差异。为使生成更接近人类写作模式,该框架引入了逐片段生成流程,训练模型连续预测语义完整的片段而非逐词预测。与现有预训练方法不同,ERNIE-GEN采用多粒度目标采样构建预训练数据,增强了编码器与解码器之间的关联性。实验结果表明,在抽象摘要生成(Gigaword和CNN/DailyMail)、问题生成(SQuAD)、对话响应生成(Persona-Chat)以及生成式问答(CoQA)等一系列语言生成任务中,ERNIE-GEN以更少的预训练数据和参数量取得了最先进的性能。源代码与预训练模型已发布于https://github.com/PaddlePaddle/ERNIE。
1 Introduction
1 引言
Pre-trained on large-scale unlabeled text corpora and finetuned on downstream tasks, self-supervised representation models such as GPT [Radford et al., 2018], BERT [Devlin et al., 2019] and XLNet [Yang et al., 2019b] have achieved remarkable improvements in natural language understanding (NLU). Different from encoder-only pre-training like BERT or decoder-only pre-training like GPT, natural language generation (NLG) relies on the sequence to sequence generation framework (seq2seq) which consists of a bidirectional encoder and a unidirectional decoder. Current pre-training works in NLG such as MASS [Song et al., 2019] and UNILM [Dong et al., 2019] mainly focus on jointly pre-training encoder and decoder on different self-supervised tasks. However, these works pay little attention to the exposure bias issue [Ranzato et al., 2016], a major drawback of teacher-forcing training. This issue is due to the fact that ground truth words are used during training, while generated words, whether predicted correctly or not, are used for inference where mistakes tend to accumulate. To alleviate this issue, we present ERNIE-GEN, an enhanced multi-flow seq2seq training framework characterized by a carefully-designed MultiFlow Attention architecture based on Transformer [Vaswani et al., 2017], as illustrated in Figure 2. ERNIE-GEN incorporates a novel infilling generation mechanism and a noiseaware generation method into pre-training and fine-tuning, which is proved to be effective through experiments in $\S4.3$ .
在大规模无标注文本语料上进行预训练并在下游任务上微调的自监督表示模型,如GPT [Radford et al., 2018]、BERT [Devlin et al., 2019]和XLNet [Yang et al., 2019b],在自然语言理解(NLU)领域取得了显著进步。与BERT这类仅编码器的预训练或GPT这类仅解码器的预训练不同,自然语言生成(NLG)依赖于由双向编码器和单向解码器组成的序列到序列生成框架(seq2seq)。当前NLG领域的预训练工作如MASS [Song et al., 2019]和UNILM [Dong et al., 2019]主要聚焦于在不同自监督任务上联合预训练编码器和解码器。然而,这些工作很少关注教师强制训练的主要缺陷——曝光偏差问题[Ranzato et al., 2016]。该问题源于训练时使用真实词汇,而推理时无论预测正确与否都使用生成词汇,导致错误容易累积。为缓解此问题,我们提出了ERNIE-GEN,这是一个基于Transformer [Vaswani et al., 2017]的多流注意力架构精心设计的增强型多流seq2seq训练框架,如图2所示。ERNIE-GEN将新颖的填充生成机制和噪声感知生成方法融入预训练与微调过程,其有效性通过$\S4.3$节的实验得到验证。
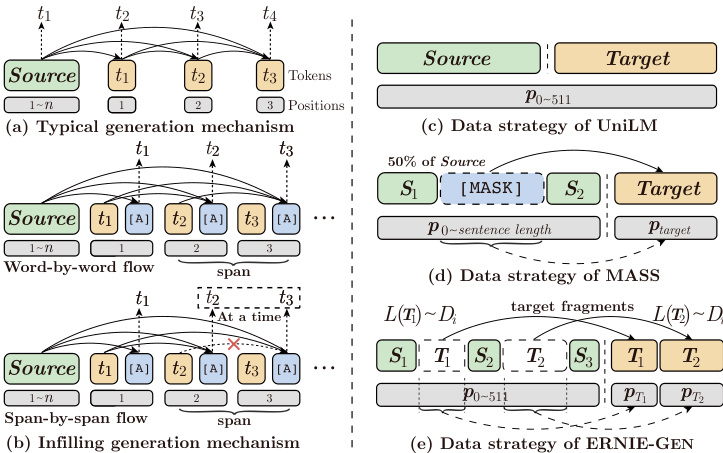
Figure 1: Schematic of two generation mechanisms (left) and data strategies for pre-training (right). Blocks in green, orange and blue denote source texts, target texts and artificial symbols.
图 1: 两种生成机制示意图 (左) 和预训练数据策略 (右)。绿色、橙色和蓝色区块分别表示源文本、目标文本和人工符号。
• Infilling generation. Instead of using last ground truth word in training or last generated word in inference, we adopt an inserted artificial symbol [ATTN] along with its position to gather history contextual representations at each step in both training and inference, which diverts model’s attention away from last word and coerces it into focusing on all former representations, thus alleviating negative influence of previous mistakes to subsequent generation, as shown in Figure 1(b).
• 填充生成 (Infilling generation)。与训练时使用最后一个真实词或推理时使用最后一个生成词不同,我们在训练和推理的每一步都插入一个人工符号 [ATTN] 及其位置来收集历史上下文表征。这种方法将模型的注意力从最后一个词转移开,迫使其关注所有先前的表征,从而减轻先前错误对后续生成的负面影响,如图 1(b) 所示。
• Noise-Aware generation. We corrupt the input target sequence by randomly replacing words to arbitrary words in the vocabulary. This setup, despite its simplicity, proves to be an effective way to make the model be aware of mistakes in training, so that the model is able to detect mistakes and ignore them during inference.
• 噪声感知生成 (Noise-Aware generation)。我们通过随机替换词汇表中的任意单词来破坏输入目标序列。尽管这种设置很简单,但事实证明,这是一种让模型意识到训练中错误的有效方法,从而使模型能够在推理过程中检测并忽略这些错误。
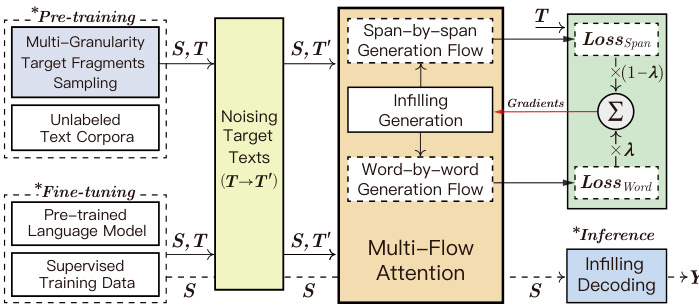
Figure 2: Overview of ERNIE-GEN framework. ${S,T}$ and $\mathbf{Y}$ donate source, target, and generated texts, $\pmb{T}^{\prime}$ is the noised version of $_{\pmb{T}}$ .
图 2: ERNIE-GEN 框架概览。${S,T}$ 和 $\mathbf{Y}$ 分别表示源文本、目标文本和生成文本,$\pmb{T}^{\prime}$ 是 $_{\pmb{T}}$ 的噪声版本。
Moreover, in light of the fact that entities, phrases and sentences in human writing are organized in a coherent manner, we incorporate a span-by-span generation task into ERNIEGEN as a new generation flow to train the model to predict semantically-complete spans consecutively rather than predicting word by word as traditional models do. This task is implemented through the infilling generation mechanism in parallel with an infilling-based word-by-word generation flow to facilitate convergence in training, as shown in Figure 1b.
此外,鉴于人类写作中的实体、短语和句子是以连贯方式组织的,我们在ERNIEGEN中引入了一个逐片段生成任务作为新的生成流程,训练模型连续预测语义完整的片段,而非像传统模型那样逐词预测。该任务通过填充生成机制实现,并与基于填充的逐词生成流程并行运行以促进训练收敛,如图1b所示。
In addition, as shown in Figure 1(c-d), recent pre-training works for NLG like UNILM and MASS only sample a single continuous segment as target sequence. However, this sampling method compromises the correlation between encoder and decoder when it comes to pre-training of long texts (typically 512 words), given that adjacent segments are often relevant semantically. ERNIE-GEN adopts a multi-granularity target fragments sampling strategy to force decoder to rely more on the encoder representations other than the previous generated words, thus enhancing the correlation between encoder and decoder, as shown in Figure 1e.
此外,如图 1(c-d) 所示,近期 UNILM 和 MASS 等自然语言生成 (NLG) 预训练工作仅采样单个连续片段作为目标序列。然而这种采样方法会损害长文本 (通常为 512 词) 预训练时编码器与解码器的关联性,因为相邻片段往往具有语义相关性。ERNIE-GEN 采用多粒度目标片段采样策略,迫使解码器更多地依赖编码器表征而非先前生成的词,从而增强编码器与解码器的关联性,如图 1e 所示。
Empirically, ERNIE-GEN is particularly effective and achieves state-of-the-art results on a range of NLG tasks including abstract ive sum mari z ation (Gigaword and CNN/DailyMail), question generation (SQuAD), dialogue response generation (Persona-Chat) and generative question answering (CoQA), utilizing a much smaller amount of pretraining data and parameters.
实证表明,ERNIE-GEN 在多项自然语言生成任务中表现尤为出色,仅使用少量预训练数据和参数,便在摘要生成 (Gigaword 和 CNN/DailyMail)、问题生成 (SQuAD)、对话响应生成 (Persona-Chat) 以及生成式问答 (CoQA) 任务上取得了最先进的结果。
2 Related Work
2 相关工作
Pre-training for NLP Tasks. Recently, pre-training methods have achieved state-of-the-art results in multiple NLU tasks. ELMo [Peters et al., 2018] pre-trains two unidirectional language models (LMs) with forward and backward direction respectively to feature downstream tasks. GPT utilizes an adjusted Transformer [Vaswani et al., 2017] to learn a forward LM and then fine-tunes the forward LM on supervised datasets. BERT proposes a masked language modeling (MLM) task to learn deep bidirectional representations. Nevertheless, above methods are usually implemented by just one encoder or decoder, which is less effective in encoder-decoder based generation tasks, thus several works have preliminarily explored the pre-training towards NLG by incorporating BERT’s MLM into the seq2seq framework and shown excellent performance on a range of generation tasks. MASS masks a consecutive fragment $(50%)$ of the input sentence with [MASK] symbols to predict. UNILM masks several words in the input sequence which is a pair of segments for encoder and decoder, and then predicts the masked words in accordance with BERT’s MLM.
自然语言处理任务的预训练。近年来,预训练方法在多项自然语言理解任务中取得了最先进的成果。ELMo [Peters et al., 2018] 分别通过前向和后向语言模型进行预训练,为下游任务提供特征表示。GPT 采用改进版 Transformer [Vaswani et al., 2017] 学习前向语言模型,然后在监督数据集上微调该模型。BERT 提出掩码语言建模 (MLM) 任务来学习深度双向表征。然而上述方法通常仅使用单个编码器或解码器实现,在基于编码器-解码器的生成任务中效果有限。为此,部分研究通过将 BERT 的 MLM 融入 seq2seq 框架,初步探索了面向自然语言生成的预训练方法,在一系列生成任务中展现出优异性能。MASS 使用 [MASK] 符号遮盖输入句中连续片段 $(50%)$ 进行预测。UNILM 对编码器-解码器双段输入序列中的多个词进行掩码,然后按照 BERT 的 MLM 方式预测被掩词汇。
Exposure Bias Issue. NLG tasks suffer from the exposure bias which is caused by teacher-forcing training. To address such issue, RNN-based variation al auto encoders (VAEs) are leveraged in [Yang et al., 2019a; Wang et al., 2019], whereas it requires inference for both posterior and prior distribution. Reinforcement learning is also adopted to text generation against exposure bias issue [Ranzato et al., 2016; Wang et al., 2018], which is, however, inefficient during training because of the word-by-word sampling procedure. These methods are inefficient and less practical for pretraining that relies on large-scale unlabeled text corpora.
曝光偏差问题。自然语言生成任务存在由教师强制训练导致的曝光偏差问题。为解决该问题,[Yang et al., 2019a; Wang et al., 2019] 采用了基于RNN的变分自编码器 (VAEs),但该方法需要同时推断后验分布和先验分布。强化学习也被用于对抗曝光偏差的文本生成任务 [Ranzato et al., 2016; Wang et al., 2018],然而由于逐词采样的训练过程,这类方法效率较低。这些方法对于依赖大规模无标注文本语料的预训练任务而言效率不足且实用性有限。
Span-level Pre-training. [Sun et al., 2019; Sun et al., 2020; Joshi et al., 2019] verify that predicting spans reaches substantially better performance on NLU tasks. Meanwhile, inspired by characteristics of human expression, we hope the model have the foresight to generate a semantically-complete span at each step rather than a word. Consequently, a spanby-span generating task is proposed to make the model capable of generating texts more human-like.
Span-level 预训练。 [Sun et al., 2019; Sun et al., 2020; Joshi et al., 2019] 验证了预测文本片段 (span) 在自然语言理解 (NLU) 任务中能显著提升性能。同时,受人类表达特点的启发,我们希望模型在每一步都能前瞻性地生成语义完整的片段而非单个词汇。因此,我们提出了逐片段生成任务,使模型能够生成更接近人类表达的文本。
3 Proposed Framework
3 提出的框架
Built on infilling generation mechanism, ERNIE-GEN adopts a Multi-Flow Attention architecture to train the model on word-by-word and span-by-span generation tasks in parallel. In this section, we describe ERNIE-GEN according to the training process shown in Figure 2.
基于填充生成机制,ERNIE-GEN采用多流注意力架构,在逐词生成和跨片段生成任务上并行训练模型。本节将根据图2所示的训练流程描述ERNIE-GEN。
3.1 Multi-Granularity Target Fragments
3.1 多粒度目标片段
Given an input sequence ${ S}~={s_{1},...,s_{n}}$ , we first sample a length distribution $D_{i}$ from a distribution set ${{D}}=$ ${D_{1},...,D_{|D|}}$ with probability $p_{i}$ for target fragments, and then select fragments according to $D_{i}$ in ${S}$ iterative ly until the fragment budget has been spent (e.g. $25%$ of ${S}$ ). We denote $S_{j}^{i}$ as the $j$ -th fragment which is sampled in length distribution $D_{i}$ . Sampled fragments are then removed from ${S}$ and stitched together to form target sequence ${T}=[T_{1},...,T_{k}]=$ $[S_{1}^{i},...,S_{k}^{i}]$ . We denote $S^{\prime}$ as the left input sequence after removing sampled fragments. ERNIE-GEN performs pretraining by predicting the fragmented target sequence ${T}$ and minimizing the negative log likelihood:
给定输入序列 ${\cal S}~={s_{1},...,s_{n}}$ ,首先从分布集 $\textbf{\textit{D}}=$ ${D_{1},...,D_{|D|}}$ 中按概率 $p_{i}$ 采样目标片段的长度分布 $D_{i}$ ,然后在 $\boldsymbol{S}$ 中根据 $D_{i}$ 迭代选择片段直至耗尽片段预算 (例如 $\pmb{S}$ 的 $25%$ )。将 $S_{j}^{i}$ 表示为按长度分布 $D_{i}$ 采样的第 $j$ 个片段。采样后的片段从 $\boldsymbol{S}$ 中移除并拼接形成目标序列 $\pmb{T}=[T_{1},...,T_{k}]=$ $[S_{1}^{i},...,S_{k}^{i}]$ 。用 $S^{\prime}$ 表示移除采样片段后剩余的输入序列。ERNIE-GEN通过预测分段目标序列 $\pmb{T}$ 并最小化负对数似然进行预训练:
$$
\begin{array}{l}{\displaystyle\mathcal{L}(\boldsymbol{\theta};\boldsymbol{S},D_{i})=-\mathrm{log}P(T|\boldsymbol{S}^{\prime},D_{i};\boldsymbol{\theta})}\ {\displaystyle=-\mathrm{log}\prod_{j=1}^{k}P(T_{j}|T_{<j},\boldsymbol{S}^{\prime},D_{i};\boldsymbol{\theta}).}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\mathcal{L}(\boldsymbol{\theta};\boldsymbol{S},D_{i})=-\mathrm{log}P(T|\boldsymbol{S}^{\prime},D_{i};\boldsymbol{\theta})}\ {\displaystyle=-\mathrm{log}\prod_{j=1}^{k}P(T_{j}|T_{<j},\boldsymbol{S}^{\prime},D_{i};\boldsymbol{\theta}).}\end{array}
$$
where the target sequence $\mathbf{\delta}{\mathbf{{T}}}$ is sorted by the positions of sampled fragments. For each fragment $\dot{T={t_{1},...,t_{|T|}}}$ in $\pmb{T}$ , we have $\begin{array}{r}{P(T)=\prod_{j=1}^{|T|}P(t_{j}|t_{<j})}\end{array}$ .
目标序列 $\mathbf{\delta}{\mathbf{{T}}}$ 按采样片段的位置排序。对于 $\pmb{T}$ 中的每个片段 $\dot{T={t_{1},...,t_{|T|}}}$ ,我们有 $\begin{array}{r}{P(T)=\prod_{j=1}^{|T|}P(t_{j}|t_{<j})}\end{array}$ 。
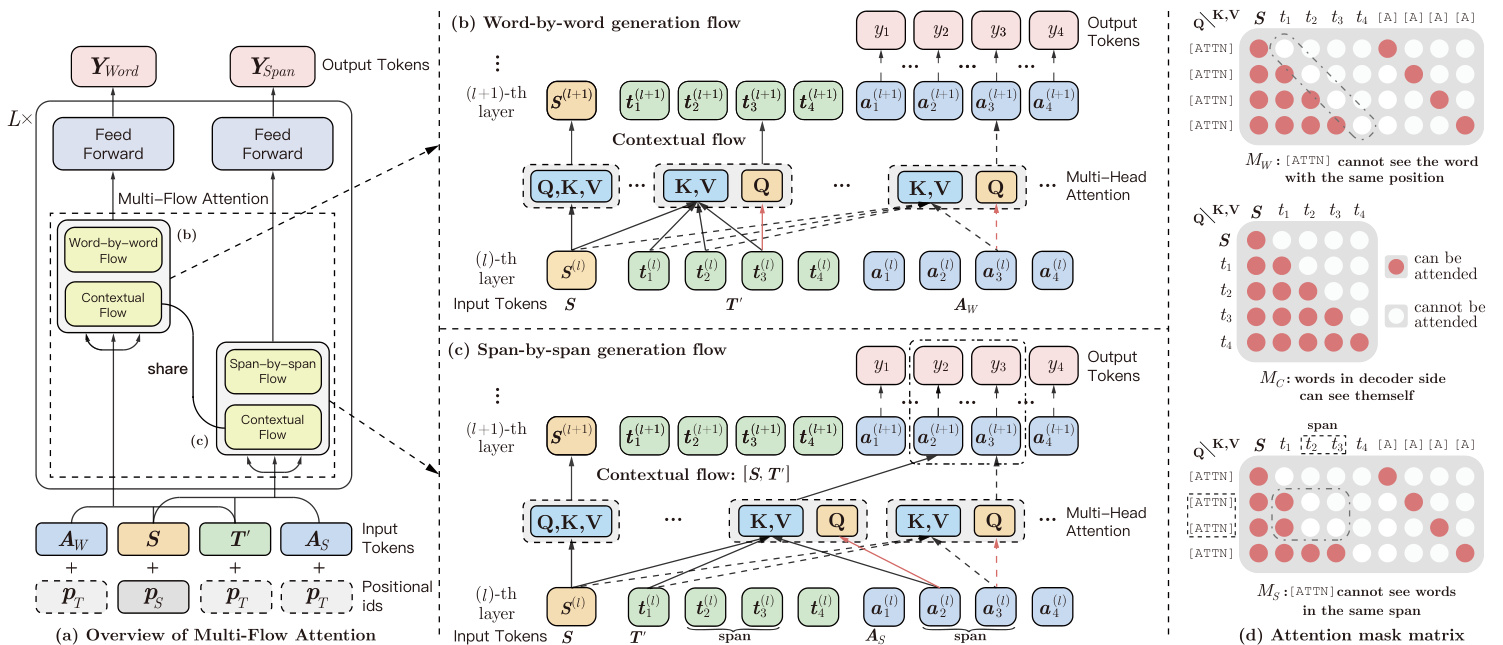
Figure 3: Illustration of the Multi-Flow Attention module. (a):Overview of multi-flow attention. The encoder and the decoder share the parameters of multi-layer Transformer. (b):Word-by-word generation flow with history contextual representations from Contextual Flow. (c):Spanby-span generation flow with shared Contextual Flow. (d):The attention mask matrixes of word-by-word generation flow $(M_{W})$ , contextual flow $(M_{C})$ and span-by-span generation flow $(M_{S})$ . The $i$ -th generated token $y_{i}$ is calculated by argmax(softmax( $\operatorname{Ec}(\pmb{a}_{i}^{(L-1)}))$ ).
图 3: 多流注意力模块示意图。(a): 多流注意力概览。编码器与解码器共享多层Transformer参数。(b): 基于上下文流历史表征的逐词生成流。(c): 共享上下文流的逐片段生成流。(d): 逐词生成流 $(M_{W})$、上下文流 $(M_{C})$ 和逐片段生成流 $(M_{S})$ 的注意力掩码矩阵。第 $i$ 个生成token $y_{i}$ 通过argmax(softmax( $\operatorname{Ec}(\pmb{a}_{i}^{(L-1)}))$ )计算得出。
Following preliminary trials, we set a hyper parameter $\gamma=$ 0.25, which denotes the ratio of length of all fragments to that of the input sequence $\pmb{S}$ . Besides, we introduce two uniform distributions $\bar{D}={U(1,4),U(4,32)}$ with probability of 0.4 and 0.6 respectively to sample fragments, which aims to learn representations from different perspectives. On the one hand, short fragments benefit learning of semantic relation between words; on the other hand, longer fragments help to memorize sentence-level expressions.
经过初步试验,我们将超参数设为 $\gamma=$ 0.25,该参数表示所有片段长度与输入序列 $\pmb{S}$ 长度的比值。此外,我们引入两个均匀分布 $\bar{D}={U(1,4),U(4,32)}$,分别以0.4和0.6的概率进行片段采样,旨在从不同角度学习表征。一方面,短片段有助于学习词语间的语义关系;另一方面,长片段有助于记忆句子级表达。
3.2 Noise-Aware Generation
3.2 噪声感知生成
To train a generation model which can detect the false prediction and mitigate its impact on subsequent generation, we corrupt the ground truth sequence $\mathbf{\delta}{\mathbf{{T}}}$ with a procedure where words are being replaced randomly, and the corrupted $\pmb{T}$ is represented as $\pmb{T}^{\prime}$ . There are two hyper parameters, $\rho_{p}$ and $\rho_{f}$ , denoting the noising rate in pre-training and fine-tuning respectively.
为了训练一个能够检测错误预测并减轻其对后续生成影响的生成模型,我们通过随机替换单词的方式对真实序列$\mathbf{\delta}{\mathbf{{T}}}$进行干扰,干扰后的$\pmb{T}$表示为$\pmb{T}^{\prime}$。该过程涉及两个超参数:$\rho_{p}$和$\rho_{f}$,分别表示预训练和微调阶段的噪声率。
3.3 Architecture: Multi-Flow Attention
3.3 架构:多流注意力机制
Formally, given a source sequence $S={s_{1},...,s_{n}}$ , a noised target sequence $\pmb{T}^{\prime}={t_{1},...,t_{m}}$ , we denote the inference of seq2seq network based on shared Transformer as follows:
给定源序列 $S={s_{1},...,s_{n}}$ 和带噪声的目标序列 $\pmb{T}^{\prime}={t_{1},...,t_{m}}$ ,我们将基于共享Transformer的seq2seq网络推理表示如下:
$$
\begin{array}{r}{{s}{i}^{(l+1)}\gets\mathtt{M H\mathrm{-}R t\mathrm{tn}}\big(Q={s}_{i}^{(l)},K V=S^{(l)}\big).}\end{array}
$$
$$
\begin{array}{r}{{s}{i}^{(l+1)}\gets\mathtt{M H\mathrm{-}R t\mathrm{tn}}\big(Q={s}_{i}^{(l)},K V=S^{(l)}\big).}\end{array}
$$
$$
\pmb{t}{i}^{(l+1)}\gets\mathtt{M H\mathrm{-}R t}\mathsf{t}\mathsf{t}\mathsf{n}(Q=\pmb{t}{i}^{(l)},K V=\left[\pmb{S}^{(l)},\pmb{t}_{\le i}^{(l)}\right]).
$$
$$
\pmb{t}{i}^{(l+1)}\gets\mathtt{M H\mathrm{-}R t}\mathsf{t}\mathsf{t}\mathsf{n}(Q=\pmb{t}{i}^{(l)},K V=\left[\pmb{S}^{(l)},\pmb{t}_{\le i}^{(l)}\right]).
$$
where $Q,K,V$ denote the query, key, and value in MultiHead attention [Vaswani et al., 2017]. $\mathbf{\pmb{\mathscr{s}}}{i}^{(l)}$ and $\pmb{t}_{i}^{(l)}$ indicate the $i$ -th vector representations of the $l$ -th layer of Multi-Head Attention for the encoder and the decoder respectively, $[\cdot]$ denotes the concatenation operation. In this work, we call the above procedure the Contextual Flow.
其中 $Q,K,V$ 表示多头注意力 (MultiHead attention) [Vaswani et al., 2017] 中的查询(query)、键(key)和值(value)。$\mathbf{\pmb{\mathscr{s}}}{i}^{(l)}$ 和 $\pmb{t}_{i}^{(l)}$ 分别表示编码器和解码器第 $l$ 层多头注意力的第 $i$ 个向量表示,$[\cdot]$ 表示拼接操作。在本研究中,我们将上述过程称为上下文流 (Contextual Flow)。
Word-by-word Generation Flow. Based on infilling generation mechanism, this flow utilizes an inserted [ATTN] symbol to gather history representations word by word (see Figure 1b). To facilitate this process, we place all inserted [ATTN] together to construct an artificial symbol sequence $A_{W}={~[{ATTN}]{1},...,[ATTN]_{m}}$ which has the same length as $\pmb{T}^{\prime}$ , as shown in Figure 3b. To be specific, the word-byword generation flow is updated as follow:
逐词生成流程。基于填充生成机制,该流程通过插入的[ATTN]符号逐词收集历史表征(见图1b)。为实现这一过程,我们将所有插入的[ATTN]集中排列,构建人工符号序列$A_{W}={~[{ATTN}]{1},...,[ATTN]_{m}}$,其长度与$\pmb{T}^{\prime}$相同,如图3b所示。具体而言,逐词生成流程按以下方式更新:
$$
\pmb{a}{i}^{(l+1)}\gets\mathtt{M H\mathrm{-}A t t n}(Q=\pmb{a}{i}^{(l)},K V=\left[\pmb{S}^{(l)},\pmb{t}{<i}^{(l)},\pmb{a}_{i}^{(l)}\right]).
$$
$$
\pmb{a}{i}^{(l+1)}\gets\mathtt{M H\mathrm{-}A t t n}(Q=\pmb{a}{i}^{(l)},K V=\left[\pmb{S}^{(l)},\pmb{t}{<i}^{(l)},\pmb{a}_{i}^{(l)}\right]).
$$
where ai(l) indicates the i-th vector representation of the l-th layer for the artificial symbol sequence $\pmb{A}_{W}$ .
其中ai(l)表示人工符号序列$\pmb{A}_{W}$第l层的第i个向量表示。
Span-by-span Generation Flow. Different from word-byword generation flow, span-by-span flow uses [ATTN] symbols to predict spans consecutively, as shown in Figure 3c. Formally, given a list of span boundaries $B={b_{1},...,b_{|B|}}$ , we conduct the span-by-span generation flow as:
分跨度生成流程。与逐词生成流程不同,分跨度流程使用[ATTN]符号连续预测跨度,如图3c所示。形式上,给定跨度边界列表$B={b_{1},...,b_{|B|}}$,我们执行分跨度生成流程如下:
$$
\pmb{a}{j}^{(l+1)}\gets\mathtt{M H\mathrm{-}A t t n}(Q=\pmb{a}{j}^{(l)},K V=\left[\pmb{S}^{(l)},\pmb{t}{<b_{i}}^{(l)},\pmb{a}_{j}^{(l)}\right]).
$$
$$
\pmb{a}{j}^{(l+1)}\gets\mathtt{M H\mathrm{-}A t t n}(Q=\pmb{a}{j}^{(l)},K V=\left[\pmb{S}^{(l)},\pmb{t}{<b_{i}}^{(l)},\pmb{a}_{j}^{(l)}\right]).
$$
where j ∈ [bi, bi+1), and a(jl) denotes the $(j-b_{i})$ -th vector representation of the $i$ -th span. Essentially, the model is trained to predict a whole span ${t_{b_{i}},...,t_{b_{i+1}-1}}$ with the same history context $[S,t_{<b_{i}}]$ . Instead of randomly sampling spans, we prefer sampling spans with semantical information and knowledge. Specifically, we consider the following two steps to sample spans consecutively in $\pmb{T}^{\prime}$ :
其中j ∈ [bi, bi+1),a(jl)表示第i个跨度的第$(j-b_{i})$个向量表示。本质上,模型被训练为预测整个跨度${t_{b_{i}},...,t_{b_{i+1}-1}}$,使用相同的历史上下文$[S,t_{<b_{i}}]$。我们不是随机采样跨度,而是倾向于采样具有语义信息和知识的跨度。具体来说,我们考虑以下两个步骤在$\pmb{T}^{\prime}$中连续采样跨度:
• Firstly, we implement a T-test to compute ${\bf t}$ -statistic scores of all bigrams and trigrams, which is based on an initial hypothesis $H_{0}$ : a random span of $n$ arbitrary words ${\pmb w}=$ ${w_{1},...,w_{n}}$ with probability $\begin{array}{r}{p^{\prime}(\pmb{w})=\prod_{i=1}^{n}\stackrel{\cdot}{p}(w_{i})}\end{array}$ cannot be a statistical $n$ -gram. The t-statistic sc ore is calculated by $\frac{\left(p(\pmb{w})-p^{\prime}(\pmb{w})\right)}{\sqrt{\sigma^{2}/N}}$ , where $\begin{array}{r}{p(\pmb{w})=\frac{\complement\mathrm{ount}(\pmb{w})}{N}}\end{array}$ and $\sigma^{2}=p(\pmb{w})(1-$ $p(\pmb{w}))$ , indicating the statistic probability and the standard deviation of $\mathbf{\nabla}_{\mathbf{\overrightarrow{\nabla}}\mathbf{\overrightarrow{\omega}}}$ respectively, $N$ denotes the total number of $n$ -grams appearing in the training data. According to the t-statistic scores, we select the top 200,000 bigrams, top 50,000 trigrams and all unigrams to construct a specific vocabulary of spans, which is represented as $V_{s p a n}$ .
• 首先,我们实施T检验来计算所有二元组和三元组的 ${\bf t}$ 统计量得分,其基于初始假设 $H_{0}$:由 $n$ 个任意单词 ${\pmb w}=$ ${w_{1},...,w_{n}}$ 组成的随机片段,其概率 $\begin{array}{r}{p^{\prime}(\pmb{w})=\prod_{i=1}^{n}\stackrel{\cdot}{p}(w_{i})}\end{array}$ 不可能构成统计意义上的 $n$-gram。t统计量得分通过 $\frac{\left(p(\pmb{w})-p^{\prime}(\pmb{w})\right)}{\sqrt{\sigma^{2}/N}}$ 计算,其中 $\begin{array}{r}{p(\pmb{w})=\frac{\complement\mathrm{ount}(\pmb{w})}{N}}\end{array}$ 和 $\sigma^{2}=p(\pmb{w})(1-$ $p(\pmb{w}))$ 分别表示统计概率和 $\mathbf{\nabla}_{\mathbf{\overrightarrow{\nabla}}\mathbf{\overrightarrow{\omega}}}$ 的标准差,$N$ 表示训练数据中出现的 $n$-gram 总数。根据t统计量得分,我们选取前200,000个二元组、前50,000个三元组及所有一元组构建特定片段词汇表,记为 $V_{s p a n}$。
• Secondly, we search the trigram, bigram and unigram in order, starting with current word until a span $n$ -gram, $n\leq$ 3) is retrieved in $V_{s p a n}$ .
• 其次,我们从当前词开始依次搜索三元组、二元组和一元组,直到在 $V_{span}$ 中检索到跨度为 $n$ 的语法单元( $n\leq$ 3)。
where $\boldsymbol{X}$ denotes the concatenation of $\boldsymbol{S}$ and $\pmb{T}^{\prime}$ , $X^{(l)}$ is the vector sequence of the $l$ -th layer for the contextual flow. ${\pmb A}{W}^{(l)},{\pmb A}_{S}^{(l)}$ are vector sequences of the $l$ -th layer for the wordby-word and span-by-span generation flow respectively. As shown in Figure 3d, attention mask matrix $M$ determines whether query and key can attend to each other by modifying the attention weight W=softmax( Q√KdT [Vaswani et al., 2017] . Specifically, $M$ is assigned as:
其中 $\boldsymbol{X}$ 表示 $\boldsymbol{S}$ 和 $\pmb{T}^{\prime}$ 的拼接,$X^{(l)}$ 是第 $l$ 层上下文流的向量序列。${\pmb A}{W}^{(l)},{\pmb A}_{S}^{(l)}$ 分别是第 $l$ 层逐词生成流和逐片段生成流的向量序列。如图 3d 所示,注意力掩码矩阵 $M$ 通过修改注意力权重 W=softmax( Q√KdT [Vaswani et al., 2017] 来决定查询和键是否可以相互关注。具体来说,$M$ 被赋值为:
$$
M_{i j}={0}{canbeattended}.
$$
While training, we add the loss of the word-by-word and span-by-span generation flow with an coefficient $\lambda$ :
训练时,我们以系数$\lambda$加权相加逐词生成和逐片段生成流程的损失值:
$$
\begin{array}{r l}&{\mathcal{L}(\pmb{T})=\lambda\mathcal{L}{W o r d}(\pmb{T})+(1-\lambda)\mathcal{L}{S p a n}(\pmb{T})}\ &{\quad\quad=-\lambda\mathrm{log}P(\pmb{T}|\pmb{A}{W}^{(L-1)})-(1-\lambda)\mathrm{log}P(\pmb{T}|\pmb{A}_{S}^{(L-1)}).}\end{array}
$$
where $\mathbf{\delta}_{\mathbf{T}}$ indicates the unnoised target sequence, and $\mathcal{L}(\cdot)$ denotes the cross entropy loss function. In detail, we set $\lambda=0.5$ and $\lambda=1.0$ respectively in pre-training and fine-tuning.
其中 $\mathbf{\delta}_{\mathbf{T}}$ 表示未加噪的目标序列,$\mathcal{L}(\cdot)$ 表示交叉熵损失函数。具体而言,我们在预训练和微调阶段分别设置 $\lambda=0.5$ 和 $\lambda=1.0$。
3.4 Inference: Infilling Decoding
3.4 推理:填充解码
During inference, the target sequence $\mathbf{\delta}_{\mathbf{{T}}}$ is unknown, we insert symbol [ATTN] step by step to gather the representation of history context instead of preparing an artificial symbol sequence $\pmb{A}$ in advance. Meanwhile, for the purpose of efficiency, we need to drop the inserted [ATTN] after inference at each step, as detailed in Figure 4.
在推理过程中,目标序列 $\mathbf{\delta}_{\mathbf{{T}}}$ 是未知的,我们逐步插入符号 [ATTN] 来收集历史上下文的表示,而不是预先准备人工符号序列 $\pmb{A}$。同时,出于效率考虑,我们需要在每一步推理后丢弃插入的 [ATTN],如图 4 所示。
4 Experiments
4 实验
In this section, we compare our ERNIE-GEN with previous works and conduct several ablation experiments to assess the performance of proposed methods in $\S3$ .
在本节中,我们将ERNIE-GEN与先前工作进行比较,并通过多项消融实验评估$\S3$中提出方法的性能。
4.1 Pre-training and Implementation
4.1 预训练与实现
Analogous to BERT and UNILM, ERNIE-GEN is trained on English Wikipedia and BookCorpus [Zhu et al., 2015], totaling 16GB. We also pre-train ERNIE-GEN on larger scaled text corpora, which is specifically described in appendix A. The input sequence is lowercased and truncated to a maximum length of 512. We train a base model ERNIE $\mathbf{GEN}_{B A S E}$ ( $L{=}12$ , $H{=}768$ , $_{A=12}$ , Total Parameters ${\bf\Gamma}=110\mathbf{M})^{.}$ 1 and a large model ERNIE $\mathbf{GEN}_{L A R G E}$ $\scriptstyle{\mathcal{L}}=24$ , $H{=}1024$ , $A{=}16$ , Total Parameters $\mathbf{\mu}=340\mathbf{M})$ with parameters initialized by $\mathbf{B}\mathbf{ERT}_{B A S E}$ and $\mathbf{B}\mathbf{ERT}_{L A R G E}$ respectively. Specifically, Adam optimizer with $\beta_{1}~=~0.9,\beta_{2}~=~0.99\dot{9},\dot{\epsilon}~=~10^{-9}$ is employed. The peak learning rate is 5e-5 with warmup over the first 4,000 steps and linear decay scheduling. The noising rate $\rho_{p}$ for pre-training is 0.05. Batches are organized by limiting the maximum number of tokens to 196,608. Pre-training experiments are carried out on Paddle Paddle platforms2 and Nvidia Tesla V100 GPU. By virtue of float16 mixed precision training, it takes almost 4 days for 400,000 steps to train ERNIE $\mathbf{GEN}_{B A S E}$ while almost 7 days for 450,000 steps to train ERNIE-GENLARGE.
与BERT和UNILM类似,ERNIE-GEN在英文维基百科和BookCorpus [Zhu et al., 2015]上进行训练,总计16GB。我们还在更大规模的文本语料库上对ERNIE-GEN进行了预训练,具体描述见附录A。输入序列被转换为小写并截断至最大长度512。我们训练了一个基础模型ERNIE $\mathbf{GEN}_{B A S E}$ ( $L{=}12$ , $H{=}768$ , $_{A=12}$ , 总参数量 ${\bf\Gamma}=110\mathbf{M})^{.}$ 1和一个大模型ERNIE $\mathbf{GEN}_{L A R G E}$ $\scriptstyle{\mathcal{L}}=24$ , $H{=}1024$ , $A{=}16$ , 总参数量 $\mathbf{\mu}=340\mathbf{M})$ ,参数分别由 $\mathbf{B}\mathbf{ERT}_{B A S E}$ 和 $\mathbf{B}\mathbf{ERT}_{L A R G E}$ 初始化。具体采用Adam优化器,参数为 $\beta_{1}~=~0.9,\beta_{2}~=~0.99\dot{9},\dot{\epsilon}~=~10^{-9}$ 。峰值学习率为5e-5,前4,000步进行预热并采用线性衰减调度。预训练的噪声率 $\rho_{p}$ 为0.05。通过限制最大token数为196,608来组织批次。预训练实验在Paddle Paddle平台2和Nvidia Tesla V100 GPU上进行。借助float16混合精度训练,ERNIE $\mathbf{GEN}_{B A S E}$ 训练400,000步耗时约4天,而ERNIE-GENLARGE训练450,000步耗时约7天。
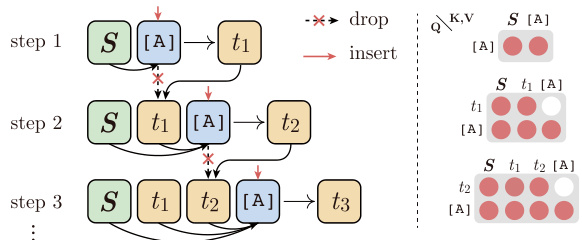
Figure 4: Schematic of infilling decoding: the particular procedures in infilling decoding including dropping and inserting (left) and the attention mask matrixes at each step (right).
图 4: 填充解码示意图:填充解码中的特定步骤包括丢弃和插入 (左) 以及每一步的注意力掩码矩阵 (右)。
4.2 Fine-tuning on Downstream Tasks
4.2 下游任务微调
Abstract ive Sum mari z ation aims at generating fluent and concise summaries without being constrained to extracting sub-sequences from the input articles. We execute experiments on Gigaword dataset [Rush et al., 2015] and CNN/DailyMail dataset [Hermann et al., 2015]. Gigaword dataset contains $3.8\mathbf{M}$ articles extracted from the Gigaword corpus, while CNN/DailyMail dataset consists of $93\mathrm{k\Omega}$ articles and $220\mathrm{k\Omega}$ articles from the CNN and Daily Mail respectively.
摘要式摘要旨在生成流畅简洁的摘要,而不受限于从输入文章中提取子序列。我们在Gigaword数据集[Rush等人,2015]和CNN/DailyMail数据集[Hermann等人,2015]上进行了实验。Gigaword数据集包含从Gigaword语料库中提取的$3.8\mathbf{M}$篇文章,而CNN/DailyMail数据集分别包含来自CNN和Daily Mail的$93\mathrm{k\Omega}$篇和$220\mathrm{k\Omega}$篇文章。
| 模型 | 数据参数量 | RG-1/RG-2/RG-L | |
|---|---|---|---|
| *10k训练样本:Gigaword10k | |||
| MASS [Song et al., 2019] | 18G | 160M | 25.03/9.48/23.48 |
| UNILM LARGE [Dong et al., 2019] | 16G | 340M | 32.96/14.68/30.56 |
| ERNIE-GEN BASE | 16G | 110M | 33.75/15.23/31.35 |
| ERNIE-GEN LARGE | 16G | 340M | 35.05/16.10/32.50 |
| *完整3.8M训练样本 | |||
| MASS [Song et al., 2019] | 18G | 160M | 37.66/18.53/34.89 |
| BERT SHARE [Rothe et al., 2019] | 16G | 110M | 38.13/19.81/35.62 |
| UNILM LARGE [Dong et al., 2019] | 16G | 340M | 38.45/19.45/35.75 |
| PEGASUS (c4) [Zhang et al., 2019] | 750G | 568M | 38.75/19.96/36.14 |
| PEGASUS (HugeNews) [Zhang et al., 2019] | 3.8T | 568M | 39.12/19.86/36.24 |
| ERNIE-GEN BASE | 16G | 110M | 38.83/20.04/36.20 |
| ERNIE-GEN LARGE | 16G | 340M | 39.25/20.25/36.53 |
Table 2: Comparison on Gigaword dataset with state-of-the-art results. Models in the upper block use 10k sample for fine-tuning. We also report the size of pre-training data and parameters utilized for each listed model (columns 2-3). RG is short for ROUGE.
表 2: Gigaword数据集与最先进结果的对比。上方模块中的模型使用1万样本进行微调。我们还列出了每个模型的预训练数据规模和参数量(第2-3列)。RG是ROUGE的缩写。
Table 1: Hyper paramters of fine-tuning for ERNIE $\mathrm{GEN}_{B A S E}$ and ERNIE-GENLARGE.
表 1: ERNIE $\mathrm{GEN}_{B A S E}$ 和 ERNIE-GENLARGE 微调的超参数
| 任务 | Epoch BASE | Epoch LARGE | LearningRate BASE | LearningRate LARGE | NoisingRate BASE | NoisingRate LARGE | DropoutRate BASE | DropoutRate LARGE | Batch Size | Label Smooth | Beam Size | Evaluation Metric |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SQuAD QG | 10 | 10 | 2.5e-5 | 1.5e-5 | 0.7 | 0.7 | 0.1 | 0.2 | 32 | 0.1 | 1 | BLEU-4, METEOR (MTR), ROUGE-L (RG-L) |
| CNN/DailyMail | 30 | 20 | 5e-5 | 4e-5 | 0.7 | 0.7 | 0.1 | 0.1 | 64 | 0.1 | 5 | ROUGE-F1 scores: |
| Gigaword | 10 | 5 | 3e-5 | 3e-5 | 0.5 | 0.6 | 0.1 | 0.2 | 128 | 0.1 | 5 | ROUGE-1 (RG-1), ROUGE-2 (RG-2), ROUGE-L (RG-L) |
| Persona-Chat | - | 30 | - | 1e-4 | - | 0.0 | - | 0.1 | 64 | 0.1 | 10 | BLEU-1, BLEU-2, Distinct-1, Distinct-2 |
| GenerativeCoQA | - | 10 | - | 1e-5 | - | 0.5 | - | 0.1 | 32 | 0.1 | 3 | F1-score |
Table 3: Evaluation results on CNN/DailyMail. C4 and HugeNews are two massive datasets of 750G and $3.8\mathrm{T}$ respectively.
| 模型 | 数据 | 参数量 | RG-1/RG-2/RG-L |
|---|---|---|---|
| BERTSHARE [Rothe et al., 2019] | 16G | 110M | 39.25/18.09/36.45 |
| BERTSUMABS [Liu and Lapata, 2019] | 16G | 110M | 41.72/19.39/38.76 |
| MASS [Song et al., 2019] | 18G | 160M | 42.12/19.50/39.01 |
| UNLMLARGE [Dong et al., 2019] | 16G | 340M | 43.33/20.21/40.51 |
| T5LARGE [Raffel et al., 2019] | 750G | 340M | 42.50/20.68/39.75 |
| T5xLARGE [Raffel et al., 2019] | 750G | 11B | 43.52/21.55/40.69 |
| BARTLARGE [Lewis et al., 2019] | 430G | 400M | 44.16/21.28/40.90 |
| PEGASUS(c4) [Zhang et al., 2019] | 750G | 568M | 43.90/21.20/40.76 |
| PEGASUS(HugeNews) [Zhang et al., 2019] | 3.8T | 568M | 44.17/21.47/41.11 |
| ERNIE-GENBASE | 16G | 110M | 42.30/19.92/39.68 |
| ERNIE-GENLARGE | 16G | 340M | 44.02/21.17/41.26 |
表 3: CNN/DailyMail 上的评估结果。C4 和 HugeNews 是两个大规模数据集,分别包含 750G 和 $3.8\mathrm{T}$ 数据。
The results on Gigaword task with two scales (10k and 3.8M) are presented in Table 2, and the fine-tuning settings are shown in Table 1. On the low-resource task (Gigaword 10k), ERNIE $\mathrm{GEN}{L A R G E}$ yields a gain of $+1.94$ ROUGEL compared with $\mathrm{UNILM}{L A R G E}$ . On the full training set, ERNIE $\mathbf{G}\mathbf{EN}{L A R G E}$ creates the state-of-the-art results, outperforming various previous methods. Specifically, ERNIE $\mathbf{GEN}_{B A S E}$ outperforms PEGASUS (568M and 750G) by using only 110M parameters and 16G training data.
在Gigaword任务上两个规模(10k和3.8M)的结果如表2所示,微调设置如表1所示。在低资源任务(Gigaword 10k)上,ERNIE $\mathrm{GEN}{L A R G E}$ 相比 $\mathrm{UNILM}{L A R G E}$ 实现了 $+1.94$ ROUGEL的提升。在全训练集上,ERNIE $\mathbf{G}\mathbf{EN}{L A R G E}$ 创造了最先进的结果,超越了多种先前方法。具体而言,ERNIE $\mathbf{GEN}{B A S E}$ 仅使用1.1亿参数和16G训练数据就超越了PEGASUS(5.68亿参数和750G数据)。
Table 3 shows the performance on CNN/DailyMail. With a similar amount of pre-training data and parameters, ERNIE $\mathbf{GEN}{B A S E}$ outperforms MASS by $+0.67$ ROUGE-L scores. Fairly compared with $\mathrm{UNILM}{L A R G E}$ , ERNIE $\mathbf{GEN}_{L A R G E}$ obtains substantial gain of $+0.73$ ROUGE-L scores. Meanwhile, in spite of small pre-training data and parameters, our large model also achieves state-of-the-art result on ROUGE-L and comparable performance on ROUGE-1/2.
表 3 展示了 CNN/DailyMail 数据集上的性能表现。在预训练数据量和参数量相近的情况下,ERNIE $\mathbf{GEN}{B A S E}$ 在 ROUGE-L 分数上比 MASS 高出 $+0.67$。与 $\mathrm{UNILM}{L A R G E}$ 进行公平对比时,ERNIE $\mathbf{GEN}_{L A R G E}$ 获得了 $+0.73$ 的 ROUGE-L 分数显著提升。同时,尽管预训练数据和参数量较小,我们的大型模型在 ROUGE-L 上仍取得了最先进的结果,并在 ROUGE-1/2 上表现出可比性能。
Question Generation is to generate a question according to a given input passage and a corresponding answer. We evaluate on the SQuAD 1.1 dataset [Rajpurkar et al., 2016] for question generation task (called SQuAD QG). Following UNILM, we redistribute the original dataset into a new training set and testing set with the original development set unchanged. We also conduct experiment with the reversed dev $\leftrightarrow$ test split as [Zhao et al., 2018] indicates. In Table 4, we present the results of ERNIE-GEN and several previous works. Again, ERNIE-GEN outperforms $\mathrm{UNILM}_{L A R G E}$ and achieves a new state-of-the-art result on question generation by giving $+1.82$ BLEU-4 scores.
问题生成 (Question Generation) 是根据给定的输入段落和对应答案生成问题的任务。我们在SQuAD 1.1数据集[Rajpurkar et al., 2016]上评估问题生成任务(称为SQuAD QG)。遵循UNILM的做法,我们将原始数据集重新划分为新的训练集和测试集,同时保持原始开发集不变。我们还按照[Zhao et al., 2018]的建议,进行了开发集$\leftrightarrow$测试集互换的实验。在表4中,我们展示了ERNIE-GEN与之前多项工作的结果。ERNIE-GEN再次超越了$\mathrm{UNILM}_{L A R G E}$,通过提升$+1.82$个BLEU-4分数,在问题生成任务上取得了新的最先进成果。
Table 4: Question generation results on SQuAD. Models in the upper block and the lower block use different $t e s t\leftrightarrow$ dev split method.
表 4: SQuAD上的问题生成结果。上区块和下区块的模型使用了不同的 $test\leftrightarrow$ dev 划分方法。
| 模型 | BLEU-4 | METEOR | ROUGE-L |
|---|---|---|---|
| SemQG [Zhang and Bansal, 2019] | 20.76 | 24.20 | 48.91 |
| UNILM LARGE [Dong et al., 2019] | 22.12 | 25.06 | 51.07 |
| ERNIE-GEN BASE (beam size = 1) | 22.28 | 25.13 | 50.58 |
| ERNIE-GEN LARGE (beam size = 1) | 24.03 | 26.31 | 52.36 |
| ERNIE-GEN LARGE (beam size = 5) | 25.40 | 26.92 | 52.84 |
| *Reversed test→dev split | |||
| MP-GSN [Zhao et al., 2018] | 16.38 | 20.25 | 44.48 |
| SemQG [Zhang and Bansal, 2019] | 20.76 | 24.20 | 48.91 |
| UnILM LARGE [Dong et al., 2019] | 23.75 | 25.61 | 52.04 |
| ERNIE-GEN BASE (beam size = 1) | 23.52 | 25.61 | 51.45 |
| ERNIE-GEN LARGE (beam size = 1) | 25.57 | 26.89 | 53.31 |
| ERNIE-GEN LARGE (beam size = 5) | 26.95 | 27.57 | 53.77 |
Table 5: Comparison with state-of-the-art results on Persona-Chat.
| 模型 | BLEU-1/2 | Distinct-1/2 |
|---|---|---|
| LIC [Bao et al., 2020] | 40.5/32.0 | 0.019/0.113 |
| PLATO w/ latent [Bao et al., 2020] | 45.8/35.7 | 0.012/0.064 |
| PLATO [Bao et al., 2020] | 40.6/31.5 | 0.021/0.121 |
| ERNIE-GEN LARGE | 46.8/36.4 | 0.023/0.168 |
表 5: Persona-Chat数据集上与其他先进结果的对比
Generative Question Answering / Dialogue Response in multi-turn conversations are challenging because of complex background knowledge and diverse utterances. We conduct an experiment on Persona-Chat dataset [Zhang et al., 2018] to generate responses according to given multi-turn conversations and persona profile. Table 5 shows that ERNIE-GEN outperforms current task-specific pre-training model on dialogue generation. Beside, we also execute an experiment on CoQA dataset [Reddy et al., 2019] to generate free-form an- swers for input questions and conversations. As shown in Table 6, our generative question answering model works considerably better than early works by $+2.0$ F1-scores.
生成式问答/多轮对话中的对话响应因复杂的背景知识和多样化的表达而具有挑战性。我们在Persona-Chat数据集[Zhang et al., 2018]上进行了实验,根据给定的多轮对话和人物画像生成响应。表5显示,ERNIE-GEN在对话生成任务上优于当前的任务特定预训练模型。此外,我们还在CoQA数据集[Reddy et al., 2019]上进行了实验,为输入问题和对话生成自由形式的答案。如表6所示,我们的生成式问答模型比早期工作显著提升了$+2.0$个F1分数。
Table 6: Generative question answering results on the development set of CoQA.
| 模型 | F1分数 |
|---|---|
| Seq2Seq [Reddy et al., 2019] | 27.5 |
| PGNet [Reddy et al., 2019] | 45.4 |
| UNILM LARGE [Dong et al., 2019] | 82.5 |
| ERNIE-GEN LARGE | 84.5 |
表 6: CoQA开发集上的生成式问答结果。
4.3 Ablation Studies
4.3 消融研究
To better understand the importance of each proposed generation methods, we conduct experiments concerning the following two aspects:
为了更好地理解每种提出的生成方法的重要性,我们围绕以下两个方面进行了实验:
• The robustness of infilling generation mechanism and noise-aware generation method against the exposure bias. • The effectiveness of span-by-span generation task and the complete ERNIE-GEN model.
• 填充生成机制和噪声感知生成方法对曝光偏差的鲁棒性。
• 逐片段生成任务及完整ERNIE-GEN模型的有效性。
In Table 8, we compare two ERNIE $\mathbf{GEN}_{B A S E}$ variants that are pre-trained with typical generation mechanism and infilling generation mechanism and that generate word by word. Row 1-3 shows that without noising ground truth texts, infilling generation outperforms typical generation
在表8中,我们比较了两种ERNIE $\mathbf{GEN}_{B A S E}$变体:一种采用典型生成机制预训练,另一种采用填充生成机制,两者均逐词生成。第1-3行显示,在不添加噪声的真实文本条件下,填充生成机制优于典型生成机制。

Figure 5: Results of ablation studies. (a):Comparisons between typical generation and infilling generation on Gigaword 10k and SQuAD QG with different fine-tuning noising rate $\rho_{f}$ . (b):Noising Analysis, average attention weights of source words, unnoised target words and noised target words for diverse fine-tuning noising rate $\rho_{f}$ . (c):Ablation study on Gigaword 10k, the $\mathbf{X}$ -axis shows fine-tuning epochs.
图 5: 消融实验结果。(a): 在Gigaword 10k和SQuAD QG数据集上,典型生成与填充生成的对比,采用不同微调噪声率$\rho_{f}$。(b): 噪声分析,展示不同微调噪声率$\rho_{f}$下源词、未加噪目标词和加噪目标词的平均注意力权重。(c): Gigaword 10k上的消融研究,$\mathbf{X}$轴表示微调周期数。
Table 7: Ablation study for ERNIE $\mathbf{GEN}{B A S E}$ and its variants. Particularly, We set $\rho_{p}=0.05$ in pre-training (row 1), while removing the span-by-span generation task (row 3), we set $\rho_{p}=0.2$ because the pre-training becomes easier.
| #微调方法 | 1噪声感知微调: 带噪声感知生成的微调 | 2掩码微调: 仅更新掩码词梯度 | ||||
|---|---|---|---|---|---|---|
| Gigaword10k | CNN/DailyMail10k | SQuADQG | Gigaword10k | CNN/DailyMail10k | SQuADQG | |
| #模型 | RG-1/RG-2/RG-L | RG-1/RG-2/RG-L | Bleu-4/MTR/RG-L | RG-1/RG-2/RG-L | RG-1/RG-2/RG-L | Bleu-4/MTR/RG-L |
| ERNIE-GEN | 33.75/15.23/31.35 | 39.92/17.46/37.40 | 23.52/25.61/51.45 | 33.30/15.04/31.22 | 39.54/17.61/37.00 | 22.99/25.14/51.31 |
| 2 | -噪声感知 | 33.57/15.15/31.28 | 39.78/17.63/37.23 | 23.40/25.50/51.36 | 33.01/14.94/31.00 | 39.53/17.61/36.97 |
| 3 | -逐片段生成 | 33.43/15.04/31.14 | 39.75/17.62/37.21 | 23.37/25.56/51.32 | 32.97/14.92/30.94 | 39.54/17.57/36.95 |
| 4 | -2和3 | 33.23/14.77/31.00 | 39.71/17.55/37.18 | 23.34/25.54/51.30 | 32.57/14.68/30.60 | 39.49/17.66/36.96 |
表 7: ERNIE $\mathbf{GEN}{B A S E}$ 及其变体的消融研究。特别地,在预训练中设置 $\rho_{p}=0.05$ (第1行),当移除逐片段生成任务时(第3行),我们设置 $\rho_{p}=0.2$ 因为预训练变得更容易。
| #任务 (指标) | 典型生成 | 填充生成 |
|---|---|---|
| 无噪声感知生成的微调 | ||
| GigaWord 10k (RG-1/RG-2/RG-L) | 32.98/14.67/30.5132.93/14.46/30.53 | |
| CNN/DM10K(RG-1/RG-2/RG-L) | 39.25/16.70/36.6539.56/16.93/36.94 | |
| SQuADQG (Bleu-4/MTR/RG-L) | 21.95/24.53/50.3422.13/24.66/50.51 | |
| 带噪声感知生成的微调 | ||
| 4 Gigaword 10k (RG-1/RG-2/RG-L) | 32.99/14.83/30.8433.23/14.77/31.00 | |
| 5 CNN/DM1OK(RG-1/RG-2/RG-L) | 39.34/17.30/36.7539.71/17.55/37.18 | |
| h SQuADQG (Bleu-4 /MTR /RG-L) | 23.23/25.47/51.2523.34/25.54/51.30 |
Table 8: Results of models pre-trained with typical generation and infilling generation. Tasks in the upper block are fine-tuned without noising, while the others are fine-tuned with noise-aware generation.
表 8: 典型生成与填充生成预训练模型结果。上方区块任务在无噪声条件下微调,其余任务采用噪声感知生成微调。
across tasks. Furthermore, both variants achieve remarkable improvements by fine-tuning with noise-aware generation method (row 4-6). Specifically, Figure 5a shows the re- sults with diverse choices of noising rate $\rho_{f}$ on two tasks, indicating that appropriate noising substantially benefits the training and alleviates the training-inference discrepancy. To further analyze the excellence of infilling generation mechanism with noising, we compute the average attention weights of source tokens, unnoised target tokens and noised target tokens in the last self-attention layer respectively on 1,000 samples. Average attention weights with diverse noising rate $\rho_{f}$ are shown in Figure 5b, which tells us that the model pays more attention on the decoder side to figure out noised points and assign them less attention weights as the noising rate $\rho_{f}$ increased in fine-tuning. Thereby, the model is able to detect and ignore the false predictions properly to alleviate accumulating mistakes while inference.
跨任务表现。此外,两种变体通过采用噪声感知生成方法进行微调均取得显著提升(第4-6行)。具体而言,图5a展示了两个任务在不同噪声率$\rho_{f}$选择下的结果,表明适当的噪声注入能有效促进训练并缓解训练-推理差异。为深入分析带噪声的填充生成机制优势,我们在最后自注意力层对1,000个样本分别计算了源token、未加噪目标token和加噪目标token的平均注意力权重。图5b呈现了不同噪声率$\rho_{f}$下的平均注意力权重分布,表明随着微调中噪声率$\rho_{f}$的提升,模型在解码端会更多关注噪声点并分配较低注意力权重。这使得模型能够有效检测并忽略错误预测,从而缓解推理过程中的错误累积问题。
In column 1 of Table 7, we compare four base size variants on three tasks. We see that noise-aware generation method and span-by-span generation task (rows 2-3 of Table 7) play an important role in ERNIE-GEN pre-training and significantly outperform the baseline model which is only pretrained with word-by-word infilling generation flow (row 4 of Table 7). After integrating noise-aware generation method and span-by-span generation task, ERNIE-GEN boosts the performance across all three tasks, as shown in row 1 of Table 7. In addition, UNILM is fine-tuned by masking words in the encoder and decoder to predict, which is also a case of noising for generation. To verify the idea that fine-tuning with masking language modeling like UNILM is inefficient due to the coupling of masking (noising) and predicting that only the masked (noised) position will be learned, we also list the fine-tuning results obtained by predicting masked words with masking probability of 0.7, as shown in column 2 of Table 7. We observe that our noise-aware generation method significantly outperforms the mask language modeling in seq2seq fine-tuning by predicting all words in the decoder side.
在表7的第1列中,我们比较了三种任务上的四种基础规模变体。可以看到,噪声感知生成方法和逐片段生成任务(表7的第2-3行)在ERNIE-GEN预训练中起关键作用,其表现显著优于仅采用逐词填充生成流程的基线模型(表7第4行)。整合这两项技术后,ERNIE-GEN在所有三项任务中均实现性能提升(如表7第1行所示)。此外,UNILM通过掩码编码器和解码器中的单词进行预测微调,这也属于生成噪声的案例。为验证"类似UNILM的掩码语言建模微调效率低下,因为掩码(噪声)与预测耦合导致仅学习被掩码(噪声)位置"的观点,我们同时列出了掩码概率为0.7时的微调结果(见表7第2列)。实验表明,我们的噪声感知生成方法通过预测解码端所有单词,显著优于序列到序列微调中的掩码语言建模。
5 Conclusions
5 结论
We present an enhanced multi-flow seq2seq pre-training and fine-tuning framework named ERNIE-GEN for language generation, which incorporates an infilling generation mechanism and a noise-aware generation method to alleviate the exposure bias. Besides, ERNIE-GEN integrates a new span-by- span generation task to train the model to generate texts like human writing, which further improves the performance on downstream tasks. Through extensive experiments, ERNIEGEN achieves state-of-the-art results on a range of NLG tasks. Future work includes incorporating reinforcement learning into pre-training for exposure bias and applying ERNIE-GEN to more NLG tasks such as machine translation.
我们提出了一种增强型多流序列到序列预训练与微调框架ERNIE-GEN,用于语言生成。该框架结合了填充生成机制和噪声感知生成方法,以缓解曝光偏差问题。此外,ERNIE-GEN整合了新的逐片段生成任务,通过模拟人类写作方式训练模型,从而进一步提升下游任务性能。大量实验表明,ERNIE-GEN在一系列自然语言生成任务中取得了最先进的结果。未来工作包括将强化学习引入预训练过程以解决曝光偏差问题,并将ERNIE-GEN应用于机器翻译等更多自然语言生成任务。
Acknowledgments
致谢
This work was supported by the National Key Research and Development Project of China (No. 2018 AAA 0101900).
本研究得到国家重点研发计划项目(No. 2018AAA0101900)资助。
[Zhang et al., 2019] Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter J Liu. Pegasus: Pre-training with extracted gap-sentences for abstract ive sum mari z ation. arXiv preprint arXiv:1912.08777, 2019.
[Zhang et al., 2019] Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J Liu. Pegasus: 基于抽取式间隔句预训练的抽象摘要生成. arXiv preprint arXiv:1912.08777, 2019.
[Zhao et al., 2018] Yao Zhao, Xiaochuan Ni, Yuanyuan Ding, and Qifa Ke. Paragraph-level neural question generation with maxout pointer and gated self-attention networks. In EMNLP, pages 3901–3910, 2018.
[Zhao et al., 2018] Yao Zhao, Xiaochuan Ni, Yuanyuan Ding, and Qifa Ke. 基于最大输出指针和门控自注意力网络的段落级神经问题生成。发表于EMNLP,第3901–3910页,2018。
[Zhu et al., 2015] Yukun Zhu, Ryan Kiros, Rich Zemel, Rus- lan Salak hut dino v, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards storylike visual explanations by watching movies and reading books. In ICCV, pages 19–27, 2015.
[Zhu et al., 2015] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 通过观看电影和阅读书籍实现书籍与电影的对齐:迈向故事化视觉解释. 收录于ICCV, 第19-27页, 2015.
A Appendix
A 附录
A.1 Pre-training on Large-scale Text Corpora
A.1 基于大规模文本语料的预训练
Recent works for pre-training verify that larger scaled pretraining corpora can improve the performances on downstream tasks. We pre-train ERNIE $\mathbf{GEN}{L A R G E}$ model on the 430GB text corpora with 1 epoch and 1M training steps. Our 430GB text corpora is extracted from the corpus used by RoBERTa [Liu et al., 2019], T5 [Raffel et al., 2019] and ALBERT [Lan et al., 2020]. We fine-tune ERNIE- $\mathbf{GEN}{L A R G E}$ on two abstract ive sum mari z ation datasets including Gigaword and CNN/Daily Mail, the evaluation results are reported in Table 9. Notice that the performance increase significantly as ERNIE $\mathbf{GEN}_{L A R G E}$ pre-trains on larger scaled text corpora.
近期研究表明,更大规模的预训练语料能提升下游任务性能。我们在430GB文本语料上对ERNIE $\mathbf{GEN}{L A R G E}$ 模型进行了1个周期和100万训练步的预训练。该语料源自RoBERTa [Liu et al., 2019]、T5 [Raffel et al., 2019]和ALBERT [Lan et al., 2020]使用的语料库。我们在Gigaword和CNN/Daily Mail两个摘要数据集上微调ERNIE-$\mathbf{GEN}{L A R G E}$,评估结果如 表 9 所示。值得注意的是,当ERNIE $\mathbf{GEN}_{L A R G E}$ 在更大规模语料上预训练时,性能显著提升。
Table 9: Evaluation results on Gigaword and CNN/DailyMail for pre-trained models using large-scale text corpora. ERNIE-GEN with the $^\ddag$ mark is pre-trained with the 430GB text corpora.
表 9: 基于大规模文本语料库的预训练模型在Gigaword和CNN/DailyMail上的评估结果。带有$^\ddag$标记的ERNIE-GEN使用430GB文本语料库进行预训练。
| 模型 | 数据参数量 | 模型参数量 | RG-1/RG-2/RG-L |
|---|---|---|---|
| *Gigaword10k | |||
| ERNIE-GENLARGE | 16G | 340M | 35.05/16.10/32.50 |
| ERNIE-GENILARGE | 430G | 340M | 35.51/16.79/33.23 |
| *Gigaword | |||
| PEGASUS(Cc4) [Zhang et al.,2019] | 750G | 568M | 38.75/19.96/36.14 |
| PEGASUS(HugeNews) [Zhang et al.,2019] | 3.8T | 568M | 39.12/19.86/36.24 |
| ERNIE-GENLARGE ERNIE-GENILARGE | 16G 430G | 340M 340M | 39.25/20.25/36.53 39.46/20.34/36.74 |
| *CNN/DailyMail | |||
| T5LARGE [Raffel et al., 2019] | 750G | 340M | 42.50/20.68/39.75 |
| T5xLARGE [Raffel et al.,2019] | 750G | 11B | 43.52/21.55/40.69 |
| BARTLARGE [Lewis et al., 2019] | 160G | 400M | 44.16/21.28/40.90 |
| PEGASUS(c4) [Zhang et al.,2019] | 750G | 568M | 43.90/21.20/40.76 |
| PEGASUS(HugeNews) [Zhang et al.,2019] | 3.8T | 568M | 44.17/21.47/41.11 |
| ERNIE-GENLARGE | 16G | 340M | 44.02/21.17/41.26 |
| ERNIE-GENILARGE | 430G | 340M | 44.31/21.35/41.60 |
We also fine-tune ERNIE-GEN on the SQuAD 1.1 dataset for question generation task, the results are presented in Table 10. We observe that larger scaled pre-training corpora can slightly improve the Rouge-L score and BLEU-4 score for the SQuAD dataset.
我们还在SQuAD 1.1数据集上对ERNIE-GEN进行了问题生成任务的微调,结果如表10所示。我们发现更大规模的预训练语料可以略微提升SQuAD数据集的Rouge-L分数和BLEU-4分数。
| 模型 | 数据 | 参数量 | BLEU-4 | METEOR | ROUGE-L |
|---|---|---|---|---|---|
| ERNIE-GENLARGE | 16G | 340M | 25.40 | 26.92 | 52.84 |
| ERNIE-GENILARGE | 430G | 340M | 25.41 | 52.84 | 25.91 |
| *测试集与开发集反转 | |||||
| ERNIE-GENLARGE | 16G | 340M | 26.95 | 27.57 | 53.77 |
| ERNIE-GENILARGE | 430G | 340M | 27.05 | 27.43 | 53.83 |
Table 10: Question generation results on SQuAD. ERNIE-GEN with the $^\ddag$ mark is pre-trained with the 430GB text corpora.
表 10: SQuAD上的问题生成结果。标有$^\ddag$的ERNIE-GEN使用了430GB文本语料库进行预训练。
The fine-tuning hyper parameters of ERNIE-GEN‡LARGE are presented in Table 11.
ERNIE-GEN‡LARGE的微调超参数如表11所示。
Table 11: Hyper parameters used for fine-tuning on CNN/DailyMail, Gigaword, and SQuAD QG.
| CNN/DailyMail | Gigaword | SQuADQG | |
|---|---|---|---|
| 学习率 (Learning rate) | 4e-5 | 3e-5 | 1.25e-5 |
| 批量大小 (Batch size) | 32 | 128 | 32 |
| 训练轮次 (Epochs) | 17 | 5 | 10 |
| 丢弃率 (Dropout rate) | 0.1 | 0.2 | 0.2 |
| 预热比例 (Warmup ratio) | 0.02 | 0.1 | 0.25 |
| 噪声率 (Noising rate) | 0.7 | 0.6 | 0.7 |
| 标签平滑 (Label smooth) | 0.1 | 0.1 | 0.1 |
| 集束大小 (Beam size) | 5 | 6 | 5 |
| 长度惩罚 (Length penalty) | 1.2 | 0.7 | 1.0 |
表 11: 在CNN/DailyMail、Gigaword和SQuAD QG上微调使用的超参数。