PRCA: Fitting Black-Box Large Language Models for Retrieval Question Answering via Pluggable Reward-Driven Contextual Adapter
PRCA: 通过可插拔奖励驱动的上下文适配器适配黑盒大语言模型以用于检索问答
Haoyan Yang1,2†, Zhitao $\mathbf{Li}^{1}$ , Yong Zhang1, Jianzong Wang1∗, Ning Cheng1, Ming $\mathbf{Li^{1,3}}$ , Jing Xiao1
Haoyan Yang1,2†, Zhitao $\mathbf{Li}^{1}$, Yong Zhang1, Jianzong Wang1∗, Ning Cheng1, Ming $\mathbf{Li^{1,3}}$, Jing Xiao1
1Ping An Technology (Shenzhen) Co., Ltd., China 2New York University 3 University of Maryland jzwang@188.com
1平安科技(深圳)有限公司 2纽约大学 3马里兰大学 jzwang@188.com
Abstract
摘要
The Retrieval Question Answering (ReQA) task employs the retrieval-augmented framework, composed of a retriever and generator. The generator formulates the answer based on the documents retrieved by the retriever. Incorporating Large Language Models (LLMs) as generators is beneficial due to their advanced QA capabilities, but they are typically too large to be fine-tuned with budget constraints while some of them are only accessible via APIs. To tackle this issue and further improve ReQA performance, we propose a trainable Pluggable Reward-Driven Contextual Adapter (PRCA), keeping the generator as a black box. Positioned between the retriever and generator in a Pluggable manner, PRCA refines the retrieved information by operating in a tokenauto regressive strategy via maximizing rewards of the reinforcement learning phase. Our experiments validate PRCA’s effectiveness in enhancing ReQA performance on three datasets by up to $20%$ improvement to fit black-box LLMs into existing frameworks, demonstrating its considerable potential in the LLMs era.
检索式问答 (ReQA) 任务采用检索增强框架,由检索器和生成器组成。生成器根据检索器获取的文档生成答案。由于大语言模型具备先进的问答能力,将其作为生成器具有优势,但其参数量通常过大难以在有限预算下微调,且部分模型仅能通过API访问。为解决该问题并进一步提升ReQA性能,我们提出可训练的即插即用奖励驱动上下文适配器 (PRCA),将生成器视为黑盒。PRCA以即插即用方式部署于检索器与生成器之间,通过强化学习阶段奖励最大化的token自回归策略优化检索信息。实验证明PRCA能有效提升三个数据集的ReQA性能(最高达$20%$),使黑盒大语言模型适配现有框架,展现了其在LLM时代的巨大潜力。
1 Introduction
1 引言
Retrieval Question Answering (ReQA) tasks involve generating appropriate answers to given questions, utilizing relevant contextual documents. To achieve this, retrieval augmentation is employed (Chen et al., 2017; Pan et al., 2019; Izacard and Grave, 2021), and comprised of two key components: a retriever and a generator. The retriever’s role is to retrieve relevant documents from a large corpus in response to the question, while the generator uses this contextual information to formulate accurate answers. Such systems alleviate the problem of hallucinations (Shuster et al., 2021), thereby enhancing the overall accuracy of the output.
检索问答 (Retrieval Question Answering,ReQA) 任务旨在利用相关上下文文档为给定问题生成合适答案。为实现这一目标,系统采用检索增强技术 (Chen et al., 2017; Pan et al., 2019; Izacard and Grave, 2021) ,其核心包含两个组件:检索器与生成器。检索器负责从大规模语料库中检索与问题相关的文档,生成器则基于这些上下文信息构建准确答案。此类系统能有效缓解幻觉问题 (Shuster et al., 2021) ,从而提升输出结果的整体准确性。
Current Paradigm
当前范式
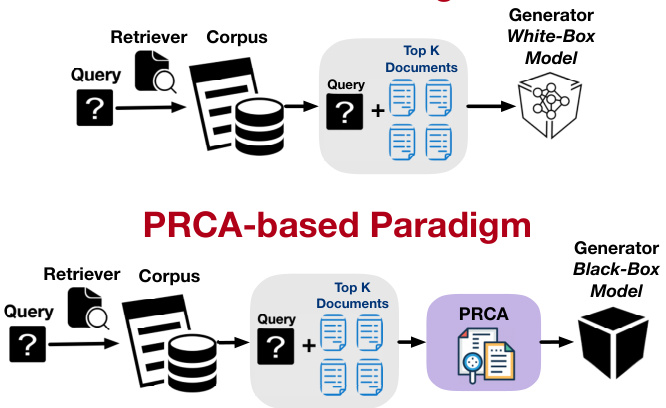
Figure 1: A comparison between two paradigms for information retrieval and generation. The upper section showcases the traditional method where a query is processed by a retriever that scans a corpus to fetch the Top-K documents and then fed to a white-box generator. The lower section introduces our proposed PRCA method, which processes extracted Top-K documents from the retriever before feeding them to black-box generator to achieve better performance for in-domain tasks.
图 1: 信息检索与生成的两种范式对比。上半部分展示了传统方法:查询由检索器处理,扫描语料库获取Top-K文档后输入白盒生成器。下半部分介绍我们提出的PRCA方法,该方法在将检索器提取的Top-K文档输入黑盒生成器前进行预处理,以提升领域内任务性能。
Recent advances in Large Language Models (LLMs) such as the generative pre-trained transformer (GPT) series (Brown et al., 2020; Ouyang et al., 2022; OpenAI, 2023) have demonstrated remarkable potential, notably in their zero-shot and few-shot abilities within the realm of QA tasks. Owing to these capabilities, LLMs are excellent choices as generators within the retrievalaugmented framework. However, due to the vast parameters of LLMs, fine-tuning them becomes exceedingly difficult within a limited computation budget. Furthermore, certain LLMs such as GPT-4 (OpenAI, 2023) are closed-source, making it impossible to fine-tune them. To achieve optimal results on specific datasets, fine-tuning retrievalaugmented models becomes necessary (Guu et al., 2020; Lewis et al., 2020b; An et al., 2021). Previ- ous attempts to integrate LLMs into the retrievalaugmented framework have met with partial success but also come with limitations. (Shi et al., 2023) utilized the logits from the final layer of the LLMs when calculating the loss function, which may not be available to certain powerful LLMs that served via APIs. (Ma et al., 2023) involved frequently invoking pricy LLMs and overlooked the impact of the input token length on the accuracy and effectiveness of the system.
近年来,大语言模型 (LLM) 如生成式预训练Transformer (GPT) 系列 (Brown et al., 2020; Ouyang et al., 2022; OpenAI, 2023) 取得了显著进展,尤其在问答任务中展现出卓越的零样本和少样本能力。凭借这些特性,大语言模型成为检索增强框架中生成器的理想选择。然而,由于大语言模型参数量庞大,在有限算力下进行微调极为困难。此外,GPT-4 (OpenAI, 2023) 等部分大语言模型未开源,导致无法微调。为在特定数据集上获得最优效果,对检索增强模型进行微调十分必要 (Guu et al., 2020; Lewis et al., 2020b; An et al., 2021)。此前将大语言模型融入检索增强框架的尝试虽取得部分成功,但仍存在局限。(Shi et al., 2023) 在计算损失函数时使用了大语言模型最后一层的logits,但通过API调用的某些强大模型可能无法提供该数据。(Ma et al., 2023) 需要频繁调用高成本的大语言模型,且忽视了输入token长度对系统准确性和效率的影响。
To overcome these hurdles, we propose a trainable Pluggable Reward-driven Context Adapter (PRCA) that enables one to fine-tune the adapter instead of LLMs under the retrieval-augmented framework on specific datasets and achieve higher performance. Furthermore, PRCA distills the retrieved documents information guided by rewards from the generator through reinforcement learning. The distillation of retrieval information through PRCA reduces the length of text input to the generator and constructs a context of superior quality, which mitigates the hallucination issues during the answer generation. As shown in Figure 1, PRCA is placed between the retriever and the generator, forming a PRCA-based Paradigm where both the generator and the retriever remain frozen. In general, the introduction of the PRCA-based paradigm brings the following advantages:
为克服这些障碍,我们提出了一种可训练的插件式奖励驱动上下文适配器(PRCA),它允许在特定数据集上基于检索增强框架微调解码器而非大语言模型,从而获得更高性能。此外,PRCA通过强化学习以生成器的奖励信号为指导,蒸馏检索文档信息。这种基于PRCA的检索信息蒸馏机制能缩短生成器的文本输入长度,并构建更高质量的上下文,从而缓解答案生成过程中的幻觉问题。如图1所示,PRCA被置于检索器与生成器之间,形成一种PRCA范式(PRCA-based Paradigm),其中生成器和检索器均保持冻结状态。总体而言,该范式的引入具有以下优势:
Black-box LLMs Integration With the use of PRCA, LLMs can be treated as a black box integrated into the retrieval-augmented framework, eliminating the need for resource-intensive finetuning and restrictions on closed-nature models.
大语言模型的黑箱集成
通过使用PRCA,大语言模型可作为黑箱集成到检索增强框架中,无需资源密集的微调,也不受闭源模型的限制。
Robustness PRCA serves as a pluggable adapter that is compatible with various retrievers and generators because PRCA-based paradigm keeps both the generator and retriever frozen.
鲁棒性 PRCA 作为一种可插拔适配器,能够兼容多种检索器和生成器,因为基于 PRCA 的范式保持生成器和检索器均处于冻结状态。
Efficiency The PRCA-based paradigm ensures the efficiency of the framework by reducing the text length inputted into the generator and can adapt to different retrieval corpus.
效率
基于PRCA的范式通过减少输入生成器的文本长度来确保框架的效率,并能适应不同的检索语料库。
2 Related Work
2 相关工作
2.1 The Potential of LLMs as Black-Box Models
2.1 大语言模型 (LLM) 作为黑盒模型的潜力
LLMs have demonstrated remarkable capabilities in downstream QA tasks, even in scenarios with limited or no training data (Wei et al., 2022). This emergence capability enables them to efficiently tackle such tasks, making them potential candidates for black-box models in inference. Furthermore, the non-open-source nature and large parameter size of these models further contribute to their inclination towards being perceived as black boxes.
大语言模型在下游问答任务中展现出卓越能力,即便在训练数据有限或缺失的场景下 [20]。这种涌现能力使其能高效应对此类任务,成为推理中黑盒模型的潜在候选者。此外,这些模型的非开源特性及庞大参数量进一步强化了其黑盒属性认知。
On one hand, LLMs like GPT-4 (OpenAI, 2023) and PaLM (Scao et al., 2023) have showcased impressive performance in QA tasks. However, their closed source nature restricts access to these models, making API-based utilization the only feasible option, thereby categorizing them as black-box models.
一方面,GPT-4 (OpenAI, 2023) 和 PaLM (Scao et al., 2023) 等大语言模型在问答任务中展现了令人印象深刻的表现。然而,它们的闭源特性限制了访问权限,使得基于 API 的使用成为唯一可行方案,从而将其归类为黑盒模型。
On the other hand, training LLMs, exemplified by models like Bloom (Scao et al., 2022) and GLM130B (Zeng et al., 2023), impose substantial computational demands. Specifically, training Bloom took 3.5 months using 384 NVIDIA A100 80GB GPUs. Similarly, GLM-130B requires a two-month training period on a cluster of 96 DGX-A100 GPU servers. These resource requirements make it extremely challenging for the majority of researchers to deploy these models. Moreover, LLMs exhibit rapid development speeds. For instance, from LLaMA (Touvron et al., 2023) to Alpaca (Taori et al., 2023) and now Vicuna (Peng et al., 2023), the iterations are completed within a month. It is evident that the speed of training models lags behind the pace of model iterations. Consequentially, tuning small-size adapters for any sequenceto-sequence LLMs on downstream tasks could be a simpler and more efficient approach.
另一方面,以Bloom (Scao等人, 2022) 和GLM130B (Zeng等人, 2023) 为代表的大语言模型训练需要巨大的计算资源。具体而言,训练Bloom耗时3.5个月,使用了384块NVIDIA A100 80GB GPU。同样地,GLM-130B需要在96台DGX-A100 GPU服务器集群上进行为期两个月的训练。这些资源需求使得大多数研究者难以部署这些模型。此外,大语言模型的发展速度极快。例如从LLaMA (Touvron等人, 2023) 到Alpaca (Taori等人, 2023) 再到Vicuna (Peng等人, 2023),迭代周期仅在一个月内完成。显然,模型训练速度已落后于迭代速度。因此,在下游任务中为任何序列到序列的大语言模型微调小型适配器可能是更简单高效的解决方案。
2.2 Retrieval-Augmented Framework
2.2 检索增强框架
Various retrieval augmented ideas have been progressively developed and applied to improve the performance in the ReQA task.
多种检索增强方法逐步发展并应用于提升ReQA任务性能。
In the initial stage of research, independent statistical similarity-base retrievers like TF-IDF (Sparck Jones, 1972) and BM25 (Robertson and Zaragoza, 2009) were used as fundamental retrieval engines. They helped in extracting the most relevant documents from the corpus for QA tasks (Chen et al., 2017; Izacard and Grave, 2021).
在研究初期阶段,独立统计相似性检索器如TF-IDF (Sparck Jones, 1972)和BM25 (Robertson and Zaragoza, 2009)被用作基础检索引擎。它们有助于从语料库中提取与问答任务最相关的文档 (Chen et al., 2017; Izacard and Grave, 2021)。
The concept of vector iz ation was subsequently introduced, where both questions and documents were represented as vectors, and vector similarity became a critical parameter for retrieval. This paradigm shift was led by methods such as dense retrieval, as embodied by DPR (Karpukhin et al., 2020). Models based on contrastive learning like SimCSE (Gao et al., 2021) and Contriver (Izacard et al., 2022a), along with sentence-level semantic models such as Sentence-BERT (Reimers and Gurevych, 2019), represented this era. These methods can be seen as pre-trained retrievers that boosted the effectiveness of the ReQA task.
向量化(vectorization)概念随后被引入,此时问题和文档都被表示为向量,而向量相似度成为检索的关键参数。这一范式转变由密集检索(dense retrieval)等方法引领,以DPR (Karpukhin等人,2020)为代表。基于对比学习的模型如SimCSE (Gao等人,2021)和Contriver (Izacard等人,2022a),以及句子级语义模型如Sentence-BERT (Reimers和Gurevych,2019)都是这一时期的代表。这些方法可视为预训练检索器,显著提升了ReQA任务的效果。
Further development led to the fusion of retrieval and generation components within the ReQA frameworks. This was implemented in systems like REALM (Guu et al., 2020) and RAG (Lewis et al., 2020b), where retrievers were co-trained with generators, further refining the performance in the ReQA task.
进一步的发展促成了ReQA框架中检索与生成组件的融合。这一理念在REALM (Guu et al., 2020) 和 RAG (Lewis et al., 2020b) 等系统中得到实现,这些系统通过联合训练检索器与生成器,进一步优化了ReQA任务的性能表现。
Recently, advanced approaches like Atlas (Izacard et al., 2022b) and RETRO (Borgeaud et al., 2022) have been introduced which could achieve performance comparable to large-scale models like Palm (Chowdhery et al., 2022) and GPT3 (Brown et al., 2020) with significantly fewer parameters.
近期,Atlas (Izacard等人,2022b) 和 RETRO (Borgeaud等人,2022) 等先进方法的提出,使得模型能以显著更少的参数量达到与 Palm (Chowdhery等人,2022) 和 GPT3 (Brown等人,2020) 等大规模模型相媲美的性能。
3 Methodology
3 方法论
3.1 Two-Stage Training for PRCA
3.1 PRCA 的两阶段训练
PRCA is designed to take sequences composed of the given query and the Top-K relevant documents retrieved by the retriever. The purpose of PRCA is to distill this collection of results, presenting a concise and effective context to the generator, while keeping both the retriever and the generator frozen. This PRCA-based paradigm introduces two challenges: the effectiveness of the retrieval cannot be directly evaluated due to its heavy dependence on the responses generated by the generator, and learning the mapping relationship between the generator’s outputs and the input sequence via back propagation is obstructed due to the black-box generator. To tackle these issues, we propose a twostage training strategy for PRCA, as illustrated in Figure 2. In the contextual stage, supervised learning is employed to train PRCA, encouraging it to output context-rich extractions from the input text. During the reward-driven stage, the generator is treated as a reward model. The difference between the generated answer and the ground truth serves as a reward signal to further train PRCA. This process effectively optimizes the information distillation to be more beneficial for the generator to answer accurately.
PRCA的设计目的是处理由给定查询和检索器(Retriever)返回的Top-K相关文档组成的序列。其核心在于提炼这组结果,为生成器(Generator)提供简洁有效的上下文,同时保持检索器和生成器的参数冻结。这种基于PRCA的范式带来两个挑战:由于检索效果高度依赖生成器的响应,无法直接评估检索质量;同时黑盒生成器阻碍了通过反向传播学习输出与输入序列间的映射关系。为解决这些问题,我们提出了如图2所示的两阶段训练策略。在上下文阶段,采用监督学习训练PRCA,使其能从输入文本中提取富含上下文的片段;在奖励驱动阶段,将生成器视为奖励模型,用生成答案与标准答案的差异作为奖励信号进一步优化PRCA,从而有效改进信息蒸馏过程,使其更有利于生成器给出准确回答。
3.2 Contextual Extraction Stage
3.2 上下文提取阶段
In the contextual extraction stage, we train PRCA to extract textual information. Given an input text $S_{\mathrm{input}}$ , PRCA generates an output sequence Cextracted, representing the context derived from the
在上下文提取阶段,我们训练PRCA来提取文本信息。给定输入文本$S_{\mathrm{input}}$,PRCA生成输出序列Cextracted,表示从
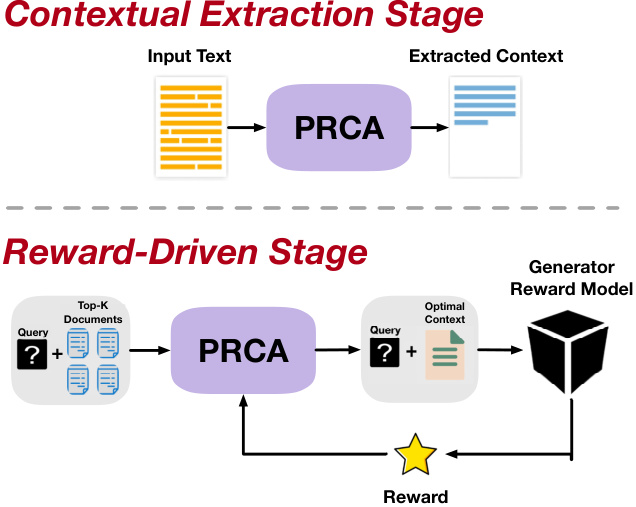
Figure 2: An illustration of the two-stage sequential training process for the PRCA. In the first “Contextual Extraction Stage”, PRCA module is pre-trained on domain abstract ive sum mari z ation tasks. The second “Reward-Driven Stage”, demonstrates the interaction between retrieved Top-K documents and the PRCA. Here, the PRCA refines the query using both the documents and the original query, producing an optimal context. This context is processed by a generator to obtain a reward, signifying the quality and relevance of the context, with the feedback loop aiding in further refining the model’s output and performance.
图 2: PRCA两阶段顺序训练流程示意图。在第一阶段"上下文提取阶段"中,PRCA模块在领域抽象摘要任务上进行预训练。第二阶段"奖励驱动阶段"展示了检索到的Top-K文档与PRCA的交互过程。此时,PRCA会结合文档和原始查询优化上下文,生成最优语境。该语境由生成器处理后获得奖励值,用于评估语境的质量和相关性,反馈循环机制可进一步优化模型输出和性能。
input text. The objective of the training process is to minimize the discrepancy between $C_{\mathrm{extracted}}$ and the ground truth context $C_{\mathrm{truth}}$ and the loss function is demonstrated as follows:
输入文本。训练过程的目标是最小化提取的上下文 $C_{\mathrm{extracted}}$ 与真实上下文 $C_{\mathrm{truth}}$ 之间的差异,损失函数如下所示:
$$
\operatorname*{min}_ {\theta}L(\theta)=-\frac{1}{N}\sum_{i=1}^{N}C_{\mathrm{truth}}^{(i)}\log(f_{\mathrm{PRCA}}(S_{\mathrm{input}}^{(i)};\theta))
$$
$$
\operatorname*{min}_ {\theta}L(\theta)=-\frac{1}{N}\sum_{i=1}^{N}C_{\mathrm{truth}}^{(i)}\log(f_{\mathrm{PRCA}}(S_{\mathrm{input}}^{(i)};\theta))
$$
where $\theta$ represents the parameters of PRCA
其中 $\theta$ 代表 PRCA 的参数
In the context extraction stage, PRCA is initialized from a BART-Large model pre-trained on CNN Daily Mail dataset (Lewis et al., 2020a).
在上下文提取阶段,PRCA从基于CNN Daily Mail数据集预训练的BART-Large模型初始化 (Lewis et al., 2020a)。
3.3 Reward-Driven Stage
3.3 奖励驱动阶段
In the reward-driven stage, the objective is to align the extracted context $C_{\mathrm{extracted}}$ from the previous stage with the downstream generator, ensuring that the text distilled by PRCA serves effectively to guide the generator’s answering. Given the blackbox nature of the generator, a direct update of PRCA is not feasible. Therefore, we resort to reinforcement learning to optimize PRCA’s parameters. Specifically, the generator offers rewards to guide the update of PRCA’s parameter, targeting to improve answer quality. The reward is based on the ROUGE-L score between the generated answer $O$ and the ground truth $O^{*}$ . Meanwhile, it’s vital that PRCA retains its skill of information extraction from long texts, as learned in the contextual extraction stage. Our objective is twofold: maximizing generator’s reward and maintaining similarity between updated and original parameters of PRCA after contextual extraction training. Catering to the reward-driven training where policy actions manipulate sequence tokens, policy optimization, particularly via Proximal Policy Optimization (PPO) (Schulman et al., 2017; Stiennon et al., 2020), is the preferred method. However, when employing a black-box generator as a reward model, we identify certain limitations of using PPO.
在奖励驱动的阶段,目标是将上一阶段提取的上下文 $C_{\mathrm{extracted}}$ 与下游生成器对齐,确保PRCA提炼的文本能有效指导生成器的回答。鉴于生成器的黑盒性质,直接更新PRCA不可行。因此,我们采用强化学习来优化PRCA的参数。具体而言,生成器通过提供奖励来指导PRCA参数的更新,旨在提升答案质量。该奖励基于生成答案 $O$ 与真实答案 $O^{*}$ 之间的ROUGE-L分数。同时,PRCA必须保留其在上下文提取阶段学习到的长文本信息提取能力。我们的目标有两个:最大化生成器的奖励,并保持PRCA在上下文提取训练后更新参数与原始参数的相似性。针对奖励驱动的训练,其中策略动作操作序列token,策略优化(特别是通过近端策略优化(PPO) (Schulman et al., 2017; Stiennon et al., 2020))是首选方法。然而,当使用黑盒生成器作为奖励模型时,我们发现PPO存在某些局限性。
In (2), we present the PPO’s objective function $J(\theta)$ . This function strives to optimize the advantage, a value derived from the Generalized Advantage Estimation (GAE) (Schulman et al., 2016). The GAE leverages both $\gamma$ and $\lambda$ as discounting factors, adjusting the estimated advantage based on the temporal difference $\delta_{t+l}^{V}$ , as depicted in (3). Here, $E_{t}[m i n(r_{t}(\theta)\cdot A_{t}^{G A E},c l i p(r_{t}(\theta),1-\epsilon,1+$ $\epsilon)\cdot A_{t}^{G A E})]$ captures the expected advantage. The clip function serves to prevent excessive policy updates by constraining the policy update step, ensuring stability in the learning process. The term $\beta(V(s_{t})-R_{t})^{2}$ is a squared-error term between $V(s_{t})$ and $R_{t}$ . This term seeks to minimize the difference between the predicted and actual value, ensuring accurate value predictions. However, the critic network $V$ is usually initialized to have the same parameter as the reward model (Yao et al., 2023; Fazzie et al., 2023), which is inapplicable when the reward models are black-boxed. Additionally, the APIs from vendors usually have limited amount of return parameters which may cause the computation of $R_{t}$ impossible.
在(2)中,我们提出了PPO的目标函数$J(\theta)$。该函数旨在优化优势值(advantage),该值源自广义优势估计(GAE) (Schulman等人,2016)。GAE利用$\gamma$和$\lambda$作为折扣因子,基于时序差分$\delta_{t+l}^{V}$调整估计优势值,如(3)所示。其中$E_{t}[min(r_{t}(\theta)\cdot A_{t}^{GAE},clip(r_{t}(\theta),1-\epsilon,1+$ $\epsilon)\cdot A_{t}^{GAE})]$表示期望优势值。clip函数通过限制策略更新步长来防止过度的策略更新,确保学习过程的稳定性。项$\beta(V(s_{t})-R_{t})^{2}$是$V(s_{t})$与$R_{t}$之间的平方误差项,旨在最小化预测值与实际值之间的差异,确保准确的价值预测。然而,评论家网络$V$通常被初始化为与奖励模型具有相同参数(Yao等人,2023;Fazzie等人,2023),当奖励模型为黑盒时这种方法不适用。此外,供应商提供的API通常返回参数有限,可能导致$R_{t}$无法计算。
$$
\begin{array}{r}{\underset{\theta}{\operatorname*{max}}J(\theta)=E_{t}[m i n(r_{t}(\theta)\cdot A_{t}^{G A E},\quad\quad\quad\quad\quad}\ {c l i p(r_{t}(\theta),1-\epsilon,1+\epsilon)\cdot A_{t}^{G A E})]}\ {\quad\quad-\beta(V(s_{t})-R_{t})^{2}\quad\quad\quad\quad(2)}\end{array}
$$
$$
\begin{array}{r}{\underset{\theta}{\operatorname*{max}}J(\theta)=E_{t}[m i n(r_{t}(\theta)\cdot A_{t}^{G A E},\quad\quad\quad\quad\quad}\ {c l i p(r_{t}(\theta),1-\epsilon,1+\epsilon)\cdot A_{t}^{G A E})]}\ {\quad\quad-\beta(V(s_{t})-R_{t})^{2}\quad\quad\quad\quad(2)}\end{array}
$$
where $\begin{array}{r}{r_{t}(\theta)=\frac{\pi_{\theta}(a_{t}|s_{t})}{\pi_{\theta_{o r i}}(a_{t}|s_{t})}}\end{array}$ is the ratio of the updated policy $\pi_{\theta}$ to the original policy $\pi_{\theta_{o r i}}~;~a_{t}$ represents the action (the next token); $s_{t}$ is the state (the sequence of previous tokens); $\epsilon$ is the clipping parameter; $V$ is a critic network; $V(s_{t})$ is the predicted value of state $s_{t};\beta$ is a coefficient that weights the squared-error term; $R_{t}$ is the expected return at time $t$ .
其中 $\begin{array}{r}{r_{t}(\theta)=\frac{\pi_{\theta}(a_{t}|s_{t})}{\pi_{\theta_{o r i}}(a_{t}|s_{t})}}\end{array}$ 表示更新后策略 $\pi_{\theta}$ 与原策略 $\pi_{\theta_{o r i}}$ 的比值; $a_{t}$ 表示动作(下一个token); $s_{t}$ 表示状态(先前token序列); $\epsilon$ 是截断参数; $V$ 是评判网络; $V(s_{t})$ 是状态 $s_{t}$ 的预测值; $\beta$ 是平方误差项的加权系数; $R_{t}$ 表示时刻 $t$ 的预期回报。
$$
A_{t}^{G A E(\gamma,\lambda)}=\sum_{l=0}^{T}(\gamma\lambda)^{l}\delta_{t+l}^{V}
$$
$$
A_{t}^{G A E(\gamma,\lambda)}=\sum_{l=0}^{T}(\gamma\lambda)^{l}\delta_{t+l}^{V}
$$
where δtV+l $\delta_{t+l}^{V}~=~R_{t+l}+\gamma V(s_{t+l+1})-V(s_{t+l})$ ; $\gamma$ and $\lambda$ as discounting and GAE parameters respectively.
其中 $\delta_{t+l}^{V}~=~R_{t+l}+\gamma V(s_{t+l+1})-V(s_{t+l})$;$\gamma$ 和 $\lambda$ 分别为折扣因子和广义优势估计(GAE)参数。
To tackle this issue, we introduce a strategy to estimate $R_{t}$ . In the PRCA, when the token $\langle E O S\rangle$ is generated, we can obtain the reward $R_{E O S}$ by comparing the generated answer against the ground truth. We consider it an accumulation of the reward $R_{t}$ achieved at each time step t for the generated token. As for $R_{t}$ , it serves as a target in $J(\theta)$ to train the critic network $V(s)$ for fitting, symbolizing the average reward of the current action, thereby assessing the advantage of the current policy. For each token, the greater the probability of generation, the more important this token is perceived by the current policy, so we consider its contribution to the total reward to be greater. Therefore, we regard the probability of generating each token as the weight of $R_{E O S}$ , and the representation of $R_{t}$ is given by the following:
为解决这一问题,我们引入了一种估计 $R_{t}$ 的策略。在PRCA中,当生成 $\langle E O S\rangle$ token时,通过将生成答案与标准答案对比可获得奖励 $R_{E O S}$ 。我们将其视为每个时间步t生成token所获奖励 $R_{t}$ 的累积值。对于 $R_{t}$ ,它在 $J(\theta)$ 中作为训练评论家网络 $V(s)$ 拟合的目标,表征当前动作的平均奖励,从而评估当前策略的优势。对于每个token,其生成概率越大,说明当前策略认为该token越重要,因此我们认为其对总奖励的贡献也越大。因此,我们将每个token的生成概率作为 $R_{E O S}$ 的权重, $R_{t}$ 的表达式如下:
$$
R_{t}=R_{E O S}*{\frac{e^{\pi_{\theta}(a_{t}|s_{t})}}{\sum_{t=1}^{K}e^{\pi_{\theta}(a_{t}|s_{t})}}}
$$
$$
R_{t}=R_{E O S}*{\frac{e^{\pi_{\theta}(a_{t}|s_{t})}}{\sum_{t=1}^{K}e^{\pi_{\theta}(a_{t}|s_{t})}}}
$$
$$
\begin{array}{r}{R_{E O S}=\mathrm{ROUGE}\mathrm{-L}(O,O^{*})}\ {-\beta\cdot D_{K L}(\pi_{\theta}||\pi_{\theta_{o r i}})}\end{array}
$$
$$
\begin{array}{r}{R_{E O S}=\mathrm{ROUGE}\mathrm{-L}(O,O^{*})}\ {-\beta\cdot D_{K L}(\pi_{\theta}||\pi_{\theta_{o r i}})}\end{array}
$$
$$
{\mathrm{ROUGE}}{\mathrm{-}}\mathrm{L}={\frac{\operatorname{LCS}(X,Y)}{\operatorname*{max}(|X|,|Y|)}}
$$
$$
{\mathrm{ROUGE}}{\mathrm{-}}\mathrm{L}={\frac{\operatorname{LCS}(X,Y)}{\operatorname*{max}(|X|,|Y|)}}
$$
where $K$ is the number of tokens in one generated context, $\operatorname{LCS}(X,Y)$ denotes the length of the longest common sub sequence between sequence $X$ and sequence $Y$ , and $|X|$ and $\vert Y\vert$ denote the lengths of sequences $X$ and $Y$ , respectively.
其中 $K$ 是生成上下文中的一个 token 数量,$\operatorname{LCS}(X,Y)$ 表示序列 $X$ 和序列 $Y$ 之间最长公共子序列的长度,$|X|$ 和 $\vert Y\vert$ 分别表示序列 $X$ 和 $Y$ 的长度。
This method mitigates the challenges associated with calculating $R_{t}$ when interpreting the blackbox generator as a reward model. A substantial advantage it confers is the requirement of invoking the reward model only once for each context generation. Compared to the original PPO that employs the reward model for every token computation, our approach reduces the reward model usage to $\frac{1}{K}$ , which is cost-effective especially when using LLMs as generators.
该方法缓解了将黑盒生成器视为奖励模型时计算$R_{t}$的挑战。其显著优势在于每个上下文生成只需调用一次奖励模型。相比原始PPO对每个token计算都使用奖励模型,我们的方法将奖励模型使用量降至$\frac{1}{K}$,这在采用大语言模型作为生成器时尤为经济高效。
Table 1: Overview of the data quantities used for training and testing across three benchmark datasets.
| Dataset | Train/Test | # of Q | #of C | #ofA |
| SQuAD | Train | 87.6k | 18.9k | 87.6k |
| Test | 10.6k | 2.1k | 10.6k | |
| HotpotQA | Train | 90.4k | 483.5k | 90.4k |
| Test | 7.4k | 66.5k | 7.4k | |
| TopiQCQA | Train | 45.5k | 45.5k | 45.5k |
| Test | 2.5k | 2.5k | 2.5k |
表 1: 三个基准数据集训练与测试使用的数据量概览
| 数据集 | 训练/测试 | # of Q | # of C | # of A |
|---|---|---|---|---|
| SQuAD | 训练 | 87.6k | 18.9k | 87.6k |
| 测试 | 10.6k | 2.1k | 10.6k | |
| HotpotQA | 训练 | 90.4k | 483.5k | 90.4k |
| 测试 | 7.4k | 66.5k | 7.4k | |
| TopiQCQA | 训练 | 45.5k | 45.5k | 45.5k |
| 测试 | 2.5k | 2.5k | 2.5k |
4 Experimental Setup
4 实验设置
4.1 Datasets
4.1 数据集
We performed our experiments on three QA datasets: SQuAD (Rajpurkar et al., 2016), HotpotQA (Yang et al., 2018) and TopiOCQA (Adlakha et al., 2022). The complexity of three datasets increases sequentially: SQuAD is a dataset that matches questions, documents, and answers in a one-to-one manner. HotpotQA is a multi-hop QA dataset, requiring the synthesis of correct answers from multiple documents. TopiOCQA is a conversational QA dataset with topic switching.
我们在三个问答数据集上进行了实验:SQuAD (Rajpurkar et al., 2016)、HotpotQA (Yang et al., 2018) 和 TopiOCQA (Adlakha et al., 2022)。这三个数据集的复杂度依次递增:SQuAD 是以一对一方式匹配问题、文档和答案的数据集;HotpotQA 是多跳问答数据集,需要从多篇文档中综合出正确答案;TopiOCQA 是支持主题切换的会话式问答数据集。
To align these datasets with our ReQA task, we reconstructed all three datasets into the form of $(Q,C,A)$ , where $Q$ and $A$ denote the question and answer pair, and $C$ represents a corpus composed of all the documents in the dataset respectively. In Table 1, we present the number of questions and answers employed in the PRCA training and testing phases for every dataset. Additionally, we provide the quantity of documents contained within each respective corpus.
为了使这些数据集与我们的ReQA任务对齐,我们将所有三个数据集重构为$(Q,C,A)$形式,其中$Q$和$A$表示问题和答案对,$C$代表由数据集中所有文档分别组成的语料库。在表1中,我们展示了每个数据集在PRCA训练和测试阶段使用的问题和答案数量。此外,我们还提供了每个语料库中包含的文档数量。
4.2 Baseline Retrievers and Generators
4.2 基线检索器和生成器
We conducted experiments with five different retrievers, specifically BM25 (Robertson and Zaragoza, 2009), Sentence Bert (Reimers and Gurevych, 2019), DPR (Karpukhin et al., 2020), SimCSE (Gao et al., 2021), and Contriver (Izacard et al., 2022a). We also utilized five generators which are T5-large (Raffel et al., 2020), Phoenix7B (Chen et al., 2023), Vicuna-7B (Peng et al., 2023), ChatGLM (Du et al., 2022) and GPT-3.5 1 to assess the effectiveness of PRCA. Note that both the retrievers and generators remain frozen through the experiment.
我们使用了五种不同的检索器进行实验,具体包括 BM25 (Robertson and Zaragoza, 2009)、Sentence Bert (Reimers and Gurevych, 2019)、DPR (Karpukhin et al., 2020)、SimCSE (Gao et al., 2021) 和 Contriver (Izacard et al., 2022a)。同时采用了五种生成器:T5-large (Raffel et al., 2020)、Phoenix7B (Chen et al., 2023)、Vicuna-7B (Peng et al., 2023)、ChatGLM (Du et al., 2022) 和 GPT-3.5 来评估 PRCA 的效果。需要注意的是,实验中所有检索器和生成器均保持冻结状态。
By pairing every retriever with each generator, we established a total of seventy-five baseline config u rations on three datasets. For each configuration, we evaluated the performance with and without the application of PRCA and the difference serves as an indicator of the effectiveness of our proposed approach.
通过将每个检索器与每个生成器配对,我们在三个数据集上共建立了七十五种基准配置。针对每种配置,我们评估了应用PRCA前后的性能差异,该差异作为衡量我们提出方法有效性的指标。
Table 2: Hyper parameters settings used in the experiments.
| Hyperparameters | Value |
| Learningrate | 5 ×10-5 |
| Batchsize | 1/2/4 |
| Numbeams | 3 |
| Temperature | 1 |
| Early Stopping | True |
| Topk | 0.0 |
| Topp | 1.0 |
表 2: 实验中使用的超参数设置。
| 超参数 | 值 |
|---|---|
| 学习率 (Learning rate) | 5 ×10-5 |
| 批量大小 (Batch size) | 1/2/4 |
| 束搜索数量 (Number beams) | 3 |
| 温度系数 (Temperature) | 1 |
| 早停机制 (Early Stopping) | True |
| Topk | 0.0 |
| Topp | 1.0 |
4.3 GPT-4 Assessment
4.3 GPT-4评估
Notably, we used GPT-4 for evaluation rather than traditional metrics like F1 and BLEU, as these metrics often misjudged semantically similar sentences. LLMs often output longer textual explanations for answers, even when the correct answer might be a word or two. Despite attempts to constrain an- swer lengths, the results weren’t ideal. We then evaluated predictions using both manual methods and GPT-4 against golden answers. GPT-4’s evaluations showed correctness rates of $96%$ , $93%$ , and $92%$ across three datasets, demonstrating its reliability and alignment with human judgment.
值得注意的是,我们使用GPT-4而非F1和BLEU等传统指标进行评估,因为这些指标经常误判语义相似的句子。大语言模型通常会输出较长的文本解释作为答案,即使正确答案可能仅为一两个单词。尽管尝试限制答案长度,结果仍不理想。随后,我们通过人工方法和GPT-4对照标准答案评估预测结果。GPT-4在三个数据集上的评估正确率分别为$96%$、$93%$和$92%$,证明了其可靠性与人类判断的一致性。
Specifically, the template for GPT-4 assessment is shown as follows. Finally, the accuracy rate of answering “Yes” is counted as the evaluation metric.
具体而言,GPT-4评估模板如下所示。最终统计回答"是"的准确率作为评估指标。
Template for GPT-4 Assessment
GPT-4 评估模板
Prompt: You are now an intelligent assessment assistant. Based on the question and the golden answer, judge whether the predicted answer correctly answers the question and give only a Yes or No.
提示:你现在是一位智能评估助手。根据问题和参考答案,判断预测答案是否正确回答了问题,并仅回答是或否。
Question: Golden Answer: Predicted Answer:
问题: 黄金答案: 预测答案:
Expected Output: Yes / No
预期输出: 是 / 否
4.4 Hyper parameter Configurations
4.4 超参数配置
To achieve optimal results in our PRCA training, careful selection of hyper parameters is pivotal. The
在我们的PRCA训练中,要取得最佳效果,超参数(hyper parameters)的精心选择至关重要。
Table 3: Comparative results of performance for different retriever and generator combinations in the presence and absence of PRCA integration. The results are based on the evaluation using three benchmark datasets: SQuAD, HotpotQA, and TopiOCQA, and focus on the selection of the Top-5 most relevant documents.
| Retriever | Generator | SQuAD | HotpotQA | TopiOCQA |
| BM25 | T5 | 0.74-0.03 | 0.35+0.01 | 0.27+0.08 |
| Phoenix | 0.61+0.02 | 0.31+0.09 | 0.25+0.03 | |
| Vicuna | 0.59+0.09 | 0.19+0.13 | 0.23+0.10 | |
| ChatGLM | 0.67+0.03 | 0.36+0.04 | 0.35+0.03 | |
| GPT-3.5 | 0.75+0.02 | 0.48+0.06 | 0.44+0.04 | |
| SentenceBert | T5 | 0.48-0.06 | 0.20+0.05 | 0.28+0.05 |
| Phoenix | 0.42+0.04 | 0.13+0.10 | 0.26+0.08 | |
| Vicuna | 0.36+0.09 | 0.22+0.03 | 0.23+0.05 | |
| ChatGLM | 0.57+0.04 | 0.16+0.08 | 0.28+0.04 | |
| GPT-3.5 | 0.6+0.02 | 0.34+0.03 | 0.47+0.03 | |
| DPR | T5 | 0.57+0 | 0.23+0.02 | 0.20+0.09 |
| Phoenix | 0.56+0.01 | 0.15+0.09 | 0.15+0.16 | |
| Vicuna | 0.42+0.06 | 0.16+0.11 | 0.15+0.14 | |
| ChatGLM | 0.53+0.0 | 0.16+0.04 | 0.31+0.07 | |
| GPT-3.5 | 0.69+0.04 | 0.41+0.02 | 0.34+0.06 | |
| SimSCE | T5 | 0.75+0.01 | 0.28+0.02 | 0.18+0.09 |
| Phoenix | 0.67+0.02 | 0.17+0.10 | 0.17+0.13 | |
| Vicuna | 0.47+0.06 | 0.19+0.06 | 0.10+0.20 | |
| ChatGLM | 0.75+0.05 | 0.17+0.05 | 0.21+0.06 | |
| GPT-3.5 | 0.77+0.04 | 0.37+0.05 | 0.31+0.06 | |
| Contriver | T5 | 0.80-0.08 | 0.35+0.03 | 0.18+0.11 |
| Phoenix | 0.69+0.02 | 0.10+0.11 | 0.16+0.18 | |
| Vicuna | 0.58+0.08 | 0.17+0.12 | 0.14+0.19 | |
| ChatGLM | 0.71+0.05 | 0.13+0.09 | 0.23+0.05 | |
| GPT-3.5 | 0.80+0.02 | 0.37+0.05 | 0.30+0.08 |
$\cdot_{+},$ indicates an improvement in performance metrics upon the incorporation of PRCA. The color coding provides a visual representation of the effect: Green signifies a positive enhancement in performance, while Red indicates a decrement.
表 3: 不同检索器与生成器组合在集成/未集成PRCA情况下的性能对比结果。该评估基于SQuAD、HotpotQA和TopiOCQA三个基准数据集,重点关注Top-5最相关文档的选择。
| 检索器 | 生成器 | SQuAD | HotpotQA | TopiOCQA |
|---|---|---|---|---|
| BM25 | T5 | 0.74-0.03 | 0.35+0.01 | 0.27+0.08 |
| Phoenix | 0.61+0.02 | 0.31+0.09 | 0.25+0.03 | |
| Vicuna | 0.59+0.09 | 0.19+0.13 | 0.23+0.10 | |
| ChatGLM | 0.67+0.03 | 0.36+0.04 | 0.35+0.03 | |
| GPT-3.5 | 0.75+0.02 | 0.48+0.06 | 0.44+0.04 | |
| SentenceBert | T5 | 0.48-0.06 | 0.20+0.05 | 0.28+0.05 |
| Phoenix | 0.42+0.04 | 0.13+0.10 | 0.26+0.08 | |
| Vicuna | 0.36+0.09 | 0.22+0.03 | 0.23+0.05 | |
| ChatGLM | 0.57+0.04 | 0.16+0.08 | 0.28+0.04 | |
| GPT-3.5 | 0.6+0.02 | 0.34+0.03 | 0.47+0.03 | |
| DPR | T5 | 0.57+0 | 0.23+0.02 | 0.20+0.09 |
| Phoenix | 0.56+0.01 | 0.15+0.09 | 0.15+0.16 | |
| Vicuna | 0.42+0.06 | 0.16+0.11 | 0.15+0.14 | |
| ChatGLM | 0.53+0.0 | 0.16+0.04 | 0.31+0.07 | |
| GPT-3.5 | 0.69+0.04 | 0.41+0.02 | 0.34+0.06 | |
| SimSCE | T5 | 0.75+0.01 | 0.28+0.02 | 0.18+0.09 |
| Phoenix | 0.67+0.02 | 0.17+0.10 | 0.17+0.13 | |
| Vicuna | 0.47+0.06 | 0.19+0.06 | 0.10+0.20 | |
| ChatGLM | 0.75+0.05 | 0.17+0.05 | 0.21+0.06 | |
| GPT-3.5 | 0.77+0.04 | 0.37+0.05 | 0.31+0.06 | |
| Contriver | T5 | 0.80-0.08 | 0.35+0.03 | 0.18+0.11 |
| Phoenix | 0.69+0.02 | 0.10+0.11 | 0.16+0.18 | |
| Vicuna | 0.58+0.08 | 0.17+0.12 | 0.14+0.19 | |
| ChatGLM | 0.71+0.05 | 0.13+0.09 | 0.23+0.05 | |
| GPT-3.5 | 0.80+0.02 | 0.37+0.05 | 0.30+0.08 |
$\cdot_{+}$表示集成PRCA后性能指标的提升。颜色编码提供直观效果:绿色表示性能正向增强,红色表示性能下降。
configuration settings employed in our experiment are stated in Table 2.
我们实验中采用的配置设置如表 2 所示。
5 Results and Analysis
5 结果与分析
5.1 Overall Performance
5.1 总体性能
As delineated in Table 3, among the seventy-five configurations, our experimental results suggest that the inclusion of PRCA improves performance in seventy-one configurations. On average, we observe an enhancement of $3%$ , $6%$ , and $9%$ on the SQuAD, HotpotQA, and TopiOCQA datasets, respectively. This demonstrates that PRCA possesses robustness and can enhance the performance of different combinations of retrievers and generators on the ReQA task. As illustrated in Figure 3, the improvements rendered by PRCA to the generators are significant across all three datasets. Particularly on the TopiOCQA dataset, the average improvement for generator Vicuna across five different retrievers reaches $14%$ . Notably, when SimSCE is the retriever, the enhancement offered by PRCA is $20%$ .
如表 3 所示,在七十五种配置中,我们的实验结果表明,加入 PRCA 在七十一种配置中提升了性能。平均而言,我们在 SQuAD、HotpotQA 和 TopiOCQA 数据集上分别观察到 $3%$、$6%$ 和 $9%$ 的提升。这表明 PRCA 具有鲁棒性,能够提升不同检索器与生成器组合在 ReQA 任务中的表现。如图 3 所示,PRCA 对生成器的改进在所有三个数据集上均显著。尤其在 TopiOCQA 数据集上,生成器 Vicuna 在五种不同检索器下的平均改进达到 $14%$。值得注意的是,当检索器为 SimSCE 时,PRCA 带来的提升高达 $20%$。
In Figure 3, we notice that the improvement to generator performance by PRCA across the three datasets is incremental, while the original performance of the generators across the three datasets is dec re mental without PRCA, correlating directly with the complexity of the datasets. This is because when faced with more complex issues, such as multi-hop questions in HotpotQA and topic transitions in multi-turn QA in TopiOCQA, PRCA reserves and integrates critical information which is beneficial for generators from the retrieved documents. This attribute of PRCA alleviate issues where generators struggle with lengthy texts, failing to answer questions correctly or producing halluci nations, thus enhancing performance.
在图3中,我们注意到PRCA对三个数据集上生成器性能的提升是递增的,而未经PRCA处理的生成器在三个数据集上的原始性能则随着数据集复杂度的增加而递减。这是因为当面对更复杂的问题时(如HotpotQA中的多跳问题和TopiOCQA中多轮问答的主题转换),PRCA会保留并整合检索文档中对生成器有益的关键信息。PRCA的这一特性缓解了生成器处理长文本时遇到的困难(如无法正确回答问题或产生幻觉),从而提升了性能。
However, the inclusion of PRCA has a negative effect on the performance of the generator T5 on the SQuAD dataset. This is because the SQuAD dataset is relatively simple, where the answer often directly corresponds to a phrase in the text. As an encoder-decoder architecture model, T5 tends to extract answers directly rather than infer in-depth based on the context. Therefore, without information distillation by PRCA from the retrieved documents, T5 performs well because its features fit well in handling this dataset, capable of directly extracting answers from the context. But under the effect of PRCA, the structure of the text might be altered, and T5’s direct answer extraction may lead to some errors, thereby reducing performance.
然而,PRCA的引入对生成器T5在SQuAD数据集上的性能产生了负面影响。这是因为SQuAD数据集相对简单,答案通常直接对应文本中的某个短语。作为编码器-解码器架构模型,T5倾向于直接提取答案,而非基于上下文进行深入推理。因此,在没有PRCA从检索文档中进行信息蒸馏的情况下,T5表现良好,因为其特征非常适合处理该数据集,能够直接从上下文中提取答案。但在PRCA的作用下,文本结构可能被改变,T5的直接答案提取可能导致一些错误,从而降低了性能。
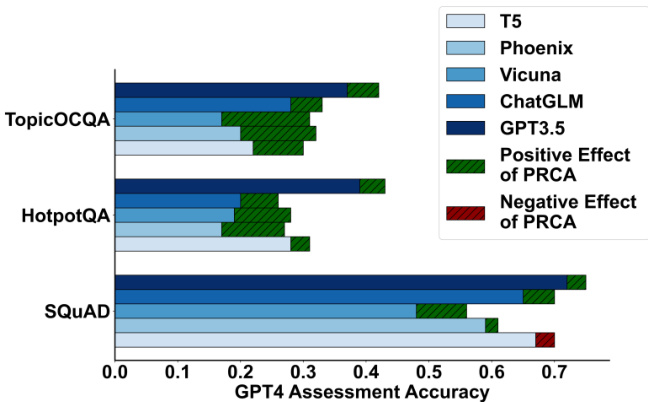
Figure 3: Comparison of performance of different generators (T5, Phoenix, Vicuna, ChatGLM, and GPT-3.5) on three benchmark datasets: SQuAD, HotpotQA, and TopicOCQA. The horizontal axis represents the GPT-4 assessment accuracy. Bars depict the performance levels of each generator, with green and red arrows indicating the enhanced or diminished effects due to PRCA integration, respectively.
图 3: 不同生成器 (T5、Phoenix、Vicuna、ChatGLM 和 GPT-3.5) 在三个基准数据集 (SQuAD、HotpotQA 和 TopicOCQA) 上的性能对比。横轴表示 GPT-4 评估准确率。柱状图展示各生成器的性能水平,绿色和红色箭头分别表示集成 PRCA 后产生的增强或削弱效果。
While in a few configurations, the characteristics of PRCA may have negative effects, for the vast majority of configurations, our experiments validate that under PRCA-based paradigm, PRCA can effectively enhance the performance in the ReQA task, demonstrating robustness.
虽然在某些配置中,PRCA的特性可能产生负面影响,但在绝大多数配置下,我们的实验验证了基于PRCA的范式能有效提升ReQA任务性能,展现出鲁棒性。
5.2 Efficiency of PRCA
5.2 PRCA的效率
PRCA represents an effective approach for enhancing the performance of the ReQA task without significantly increasing computational demand. Its efficiency is manifested in optimizing parameters to achieve superior results and in simplifying input text, thereby aiding generators in managing complex text.
PRCA代表了一种在不显著增加计算需求的情况下提升ReQA任务性能的有效方法。其效率体现在通过优化参数实现更优结果,以及简化输入文本从而帮助生成器处理复杂文本。
Parameter Efficiency Figure 4 portrays a comparative analysis between the generators, which gain the maximum improvements with PRCA, and the GPT-3.5 model which operates without PRCA, across 3 datasets. PRCA boasts roughly 0.4 billion parameters, the most significantly improved generators encompass about 7 billion parameters on average, while GPT-3.5 has approximately 1.75 trillion parameters. As demonstrated in Figure 4, with a marginal parameter increment, the performance of these generators improved by $12.0%$ , $27.1%$ , and $64.5%$ respectively. Hence, PRCA has great potential to be an efficient way to boost the performance of ReQA task while keeping computational resources consumption acceptable. During the inference process, a fully-trained PRCA will perform only standard forward propagation and hence introduce limited impact on inference latency. Our inference latency test on SQUAD was reported in Table 4. This low latency ensures that the system maintains a smooth process without significant delays after integrating PRCA, underscoring the high efficiency of PRCA in boosting system performance.
参数效率
图 4: 展示了采用PRCA后获得最大提升的生成器与未使用PRCA的GPT-3.5模型在3个数据集上的对比分析。PRCA仅包含约4亿参数,改进最显著的生成器平均约70亿参数,而GPT-3.5拥有约1.75万亿参数。如图4所示,在参数量小幅增加的情况下,这些生成器的性能分别提升了$12.0%$、$27.1%$和$64.5%$。因此,PRCA有望成为在保持计算资源消耗可控的同时显著提升ReQA任务性能的高效方案。推理过程中,完全训练后的PRCA仅执行标准前向传播,对推理延迟的影响有限。我们在SQUAD上的推理延迟测试结果见表4。这种低延迟特性确保系统在集成PRCA后仍能保持流畅运行,凸显了PRCA在提升系统性能方面的高效性。
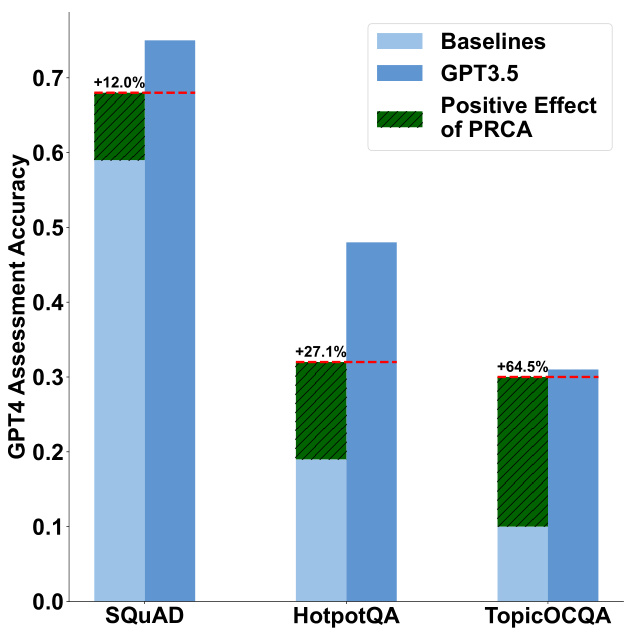
Figure 4: Performance comparison between PRCAenhanced baseline models and GPT-3.5 across SQuAD, HotpotQA, and TopicOCQA. Light and dark blue bars represent baseline and GPT-3.5 performance, while striped green indicates PRCA’s improvement.
图 4: PRCA增强基线模型与GPT-3.5在SQuAD、HotpotQA和TopicOCQA上的性能对比。浅蓝和深蓝色柱分别表示基线和GPT-3.5的性能,条纹绿色柱表示PRCA带来的提升。
Table 4: PRCA inference speed test results.
| Dataset | Precision | GPU | BatchSize | InferenceSpeed (token/s) |
| PRCA | float32 | A100 | 1 | 126 |
| PRCA | float32 | A100 | 2 | 231 |
| PRCA | float32 | A100 | 4 | 492 |
表 4: PRCA 推理速度测试结果。
| Dataset | Precision | GPU | BatchSize | InferenceSpeed (token/s) |
|---|---|---|---|---|
| PRCA | float32 | A100 | 1 | 126 |
| PRCA | float32 | A100 | 2 | 231 |
| PRCA | float32 | A100 | 4 | 492 |
Input Simplification As illustrated in Figure 5, we analyzed the relationship between reward and token count during reward-driven stage for a QA pair in the HotpotQA dataset, with and without PRCA. There’s a discernible difference in the reward trajectories with and without PRCA. Both reward curves ascend with the increase in token count, but the gradient of ascent with PRCA is noticeably steeper. This implies that when PRCA is in action, the generator reaches its optimal performance with a significantly reduced token count.
输入简化
如图5所示,我们分析了HotpotQA数据集中一个问答对在奖励驱动阶段有/无PRCA时奖励与token数量的关系。使用PRCA前后的奖励轨迹存在明显差异:两条奖励曲线均随token数量增加而上升,但采用PRCA时的上升梯度明显更陡。这表明当PRCA生效时,生成器能以显著减少的token数量达到最佳性能。

Figure 5: A depiction of reward trajectories over increasing token counts during the reward-driven stage for a QA pair within the HotpotQA dataset. Distinct lines represent rewards achieved with and without the implementation of PRCA, underscoring PRCA’s ability to extract more concise and high-quality text.
图 5: HotpotQA数据集中某问答对在奖励驱动阶段随token数量增加的奖励轨迹示意图。不同线条分别代表使用PRCA与未使用PRCA时获得的奖励,凸显PRCA能够提取更简洁、更高质量的文本。
Under the influence of PRCA, the generator can derive the correct answer with approximately four times fewer tokens. This indicates that PRCA can distill the retrieved text while ensuring the quality of the generated answer. This simplification process filters out redundant information, thereby promoting the generator to extract answers more accurately using a more streamlined context. Moreover, the reduction in token count enables the generator to process text faster and produce outputs more promptly. Overall, PRCA’s efficiency in information distillation greatly bolsters the generator’s capacity to manage and interpret complex text.
在PRCA的影响下,生成器能够以约四分之一数量的Token得出正确答案。这表明PRCA可以在确保生成答案质量的同时,对检索到的文本进行提炼。这一简化过程过滤了冗余信息,从而促使生成器利用更精简的上下文更准确地提取答案。此外,Token数量的减少使生成器能更快地处理文本并更迅速地生成输出。总体而言,PRCA在信息提炼上的高效性极大地增强了生成器管理和解析复杂文本的能力。
5.3 Impact of Top-K Selection
5.3 Top-K选择的影响
We conducted parameter sensitivity experiments to observe the performance of PRCA when the number of retrieved relevant documents changes. The results presented in Figure 6 show that on the SQuAD dataset, both the performance with and without PRCA improve as the number of retrieved documents increases, while the addition of PRCA consistently provides a positive effect across different Top-K values. Since the dataset is relatively simple, with the increased likelihood of the correct answer being included in the retrieved documents, both trends exhibit an upward trajectory.
我们进行了参数敏感性实验,以观察PRCA在检索相关文档数量变化时的性能表现。图6所示结果表明,在SQuAD数据集上,无论是否使用PRCA,性能都随着检索文档数量的增加而提升,而PRCA的加入在不同Top-K值下始终能带来积极效果。由于该数据集相对简单,随着检索文档中包含正确答案的概率增加,两种趋势均呈现上升轨迹。
In contrast, without the implementation of PRCA, there is a noticeable drop in performance on the HotpotQA and TopiOCQA datasets when more documents are added. This decline is attributed to the model’s diminishing capability to generate accurate answers to complex questions due to the rise in distracting information and the onset of hallucination problems. However, by implementing PRCA, these adverse effects are systematically alleviated, which not only reduces the onset of hallucinations but also enhances the generator’s ability to handle complex queries amidst distractions.
相比之下,若不实施PRCA,当添加更多文档时,HotpotQA和TopiOCQA数据集的性能会出现明显下降。这一现象归因于干扰信息增加和幻觉问题出现导致模型回答复杂问题的能力减弱。而通过采用PRCA,这些负面影响被系统性缓解——既减少了幻觉现象的发生,又提升了生成器在干扰环境下处理复杂查询的能力。

Figure 6: Comparison of performance with and without PRCA with the different number of retrieved documents.
图 6: 使用PRCA与不使用PRCA在不同检索文档数量下的性能对比
In general, at different Top-K values, PRCA demonstrates positive effects across all three datasets, thereby illustrating the universal applicability of PRCA regardless of the quantity of retrieved documents.
总体而言,在不同Top-K值下,PRCA在所有三个数据集上都展现出积极效果,从而证明了PRCA无论检索文档数量多少都具有普适性。
5.4 Case Study
5.4 案例研究
When answering the form of Mersenne primes problem, the retrieved text contains two distinct sources of information. One directly specifies the form as 2p-1, accurately reflecting the nature of Mersenne primes. The other source misguidedly introduces “factorial primes” as an answer. Without PRCA’s intervention, this diversion leads the generator astray, resulting in an erroneous answer of “factorial primes”. However, when PRCA is engaged, it sifts through the information, prioritizing the accurate context. This refined context extraction steers the generator towards the correct answer.
在回答梅森素数的形式问题时,检索到的文本包含两种不同信息来源。一种直接指明其形式为2p-1,准确反映了梅森素数的本质;另一种则错误地引入"阶乘素数"作为答案。若没有PRCA干预,这种干扰会导致生成器偏离正轨,最终输出错误的"阶乘素数"答案。但当PRCA介入时,它能筛选信息并优先处理准确上下文,这种精细化的上下文提取引导生成器得出正确答案。
Question:
问题:
Predicted Answer without PRCA: Factorial primes
未使用PRCA的预测答案:阶乘质数
Context through PRCA: Mersenne primes are prime numbers that are of the form 2p-1, where p is an arbitrary prime. The Lucas–Lehmer test is particularly fast for numbers of this form, so many of the largest primes found today are Mersenne primes.
通过PRCA的背景:梅森素数(Mersenne primes)是指形如2^p-1的素数,其中p为任意素数。对于这种形式的数字,卢卡斯-莱默检验(Lucas–Lehmer test)速度极快,因此当今发现的最大素数多为梅森素数。
Predicted Answer with PRCA: 2p-1
使用PRCA预测的答案:2p-1
Note: “–” denotes key information relevant to the question, “~” represents predicted answers.
注: "--" 表示与问题相关的关键信息, "~" 表示预测答案。
5.5 Ablation Study of PRCA
5.5 PRCA消融研究
We assessed the impact of PRCA on three datasets using the configurations from section 5.2, which showed maximum improvements. The evaluation is conducted with and without the reward-driven stage to observe the impact of PRCA on the performance. As illustrated in Figure 7, without the reward-driven training stage, the effect of PRCA on the entire configuration becomes adverse because PRCA merely simplifies the text without discerning which information is beneficial for the generator to answer questions, resulting in the omission of useful text. In contrast, once the training process incorporates the reward-driven stage, the quality of the context becomes directly aligned with reward values, assisting PRCA in more effectively distilling pertinent information. Therefore, the reward- driven stage is vital, allowing PRCA to retain key details while simplifying text, enhancing its overall effect.
我们采用第5.2节中提升效果最佳的配置,评估了PRCA在三个数据集上的影响。通过对比有无奖励驱动阶段的实验,观察PRCA对性能的作用。如图7所示,若缺少奖励驱动训练阶段,PRCA会对整体配置产生负面影响——因其仅简化文本而未识别哪些信息有助于生成器回答问题,导致有用文本被剔除。反之,当训练过程加入奖励驱动阶段后,上下文质量便直接与奖励值挂钩,帮助PRCA更有效地提炼相关信息。因此奖励驱动阶段至关重要,它使PRCA能在简化文本的同时保留关键细节,从而增强整体效果。

Figure 7: An illustration showcasing the impact of the reward-driven stage on PRCA’s performance.
图 7: 展示奖励驱动阶段对PRCA性能影响的示意图。
6 Conclusion
6 结论
In conclusion, this research successfully introduces a PRCA-based paradigm for ReQA tasks, tackling the inherent challenges of fine-tuning LLMs in the retrieval-enhancement framework, especially given their vast parameter size and closed-source natures. PRCA innovative ly distills retrieved documents via generator rewards, leading to a marked improvement in the ReQA task’s performance. Experimental outcomes consistently demonstrate the robustness and effectiveness of PRCA when paired with various retrievers and generators, indicating its potential to be widely deployed as an adapter on the ReQA task.
总之,本研究成功引入了一种基于PRCA的ReQA任务范式,解决了在大语言模型(LLM)微调过程中检索增强框架固有的挑战,尤其是针对其庞大参数量与闭源特性。PRCA创新性地通过生成器奖励对检索文档进行提炼,显著提升了ReQA任务的性能。实验结果表明,PRCA与不同检索器和生成器组合时均展现出稳定高效的表现,预示其作为适配器在ReQA任务中具备广泛部署潜力。
Limitations
局限性
While PRCA has shown effectiveness in improving ReQA task performance, it has limitations, including dependency on generators, convergence issues, and limited integration with retrievers. The reward during reinforcement learning training is derived from the generator, requiring PRCA retraining with different generators, which can be time-consuming. PRCA may also experience difficulties converging in a single training session, which impacts the stability and consistency of its performance. Lastly, PRCA’s operation as a pluggable adapter limits its ability to train jointly with retrievers, which means if the retrieval quality is not up to par, PRCA’s effectiveness could be compromised.
虽然PRCA在提升ReQA任务表现上显示出效果,但它存在若干局限性,包括对生成器的依赖、收敛性问题以及与检索器集成有限。强化学习训练期间的奖励源自生成器,这导致PRCA需要针对不同生成器重新训练,过程可能耗时。此外,PRCA在单次训练中可能出现收敛困难,影响其性能的稳定性和一致性。最后,PRCA作为可插拔适配器的运作方式限制了其与检索器联合训练的能力,这意味着若检索质量不达标,PRCA的效果可能受到影响。
Acknowledgement
致谢
Supported by the Key Research and Development Program of Guangdong Province (grant No. 2021 B 0101400003) and Corresponding author is Jianzong Wang (jzwang@188.com).
广东省重点领域研发计划项目(项目编号:2021B0101400003)资助,通信作者为Jianzong Wang(jzwang@188.com)。
References
参考文献
Vaibhav Adlakha, Shehzaad Dhuliawala, Kaheer Suleman, Harm de Vries, and Siva Reddy. 2022. TopiOCQA: Open-domain conversational question answering with topic switching. Transactions of the Association for Computational Linguistics, 10:468– 483.
Vaibhav Adlakha、Shehzaad Dhuliawala、Kaheer Suleman、Harm de Vries 和 Siva Reddy。2022. TopiOCQA: 支持主题切换的开放域对话问答。计算语言学协会汇刊,10:468–483。
Chenxin An, Ming Zhong, Zhichao Geng, Jianqiang Yang, and Xipeng Qiu. 2021. Retrieval sum: A retrieval enhanced framework for abstract ive summarization. CoRR, abs/2109.07943.
陈新安、钟鸣、耿志超、杨建强、邱锡鹏。2021。检索式摘要:一种用于抽象摘要的检索增强框架。CoRR, abs/2109.07943。
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack Rae, Erich Elsen, and Laurent Sifre. 2022. Improving language models by retrieving from trillions of tokens. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 2206–2240. PMLR.
Sebastian Borgeaud、Arthur Mensch、Jordan Hoffmann、Trevor Cai、Eliza Rutherford、Katie Millican、George Bm Van Den Driessche、Jean-Baptiste Lespiau、Bogdan Damoc、Aidan Clark、Diego De Las Casas、Aurelia Guy、Jacob Menick、Roman Ring、Tom Hennigan、Saffron Huang、Loren Maggiore、Chris Jones、Albin Cassirer、Andy Brock、Michela Paganini、Geoffrey Irving、Oriol Vinyals、Simon Osindero、Karen Simonyan、Jack Rae、Erich Elsen 和 Laurent Sifre。2022。通过从数万亿token中检索改进语言模型。载于《第39届国际机器学习会议论文集》,第162卷《机器学习研究论文集》,第2206–2240页。PMLR。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
Tom Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared D Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell、Sandhini Agarwal、Ariel Herbert-Voss、Gretchen Krueger、Tom Henighan、Rewon Child、Aditya Ramesh、Daniel Ziegler、Jeffrey Wu、Clemens Winter、Chris Hesse、Mark Chen、Eric Sigler、Mateusz Litwin、Scott Gray、Benjamin Chess、Jack Clark、Christopher Berner、Sam McCandlish、Alec Radford、Ilya Sutskever 和 Dario Amodei。2020. 大语言模型是少样本学习者。载于《神经信息处理系统进展》第33卷,第1877-1901页。Curran Associates公司。
Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading Wikipedia to answer opendomain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1870–1879, Vancouver, Canada. Association for Computational Linguistics.
Danqi Chen、Adam Fisch、Jason Weston和Antoine Bordes。2017。通过阅读维基百科回答开放域问题。载于《第55届计算语言学协会年会论文集(第一卷:长论文)》,第1870–1879页,加拿大温哥华。计算语言学协会。
Zhihong Chen, Feng Jiang, Junying Chen, Tiannan Wang, Fei Yu, Guiming Chen, Hongbo Zhang, Juhao Liang, Chen Zhang, Zhiyi Zhang, et al. 2023. Phoenix: Democratizing chatgpt across languages. arXiv preprint arXiv:2304.10453.
Zhihong Chen, Feng Jiang, Junying Chen, Tiannan Wang, Fei Yu, Guiming Chen, Hongbo Zhang, Juhao Liang, Chen Zhang, Zhiyi Zhang, 等. 2023. Phoenix: 实现ChatGPT跨语言民主化. arXiv预印本 arXiv:2304.10453.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
Aakanksha Chowdhery、Sharan Narang、Jacob Devlin、Maarten Bosma、Gaurav Mishra、Adam Roberts、Paul Barham、Hyung Won Chung、Charles Sutton、Sebastian Gehrmann 等. 2022. PaLM: 基于Pathways的大语言模型扩展. arXiv预印本 arXiv:2204.02311.
Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. 2022. GLM: General language model pre training with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335, Dublin, Ireland. Association for Computational Linguistics.
郑晓杜、余杰钱、肖刘、明丁、杰忠邱、志林杨和杰唐。2022。GLM:基于自回归空白填充的通用语言模型预训练。载于《第60届计算语言学协会年会论文集(第一卷:长论文)》,第320-335页,爱尔兰都柏林。计算语言学协会。
Fazzie, Frank Le eeee, BlueRum, ver217, ofey404, Wenhao Chen, Zangwei Zheng, and Xue Fuzhao. 2023. Colossal chat. https://github.com/hpcaitech/ ColossalAI/tree/main/applications/Chat.
Fazzie、Frank Le eeee、BlueRum、ver217、ofey404、Wenhao Chen、Zangwei Zheng 和 Xue Fuzhao。2023。Colossal chat。https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat。
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Tianyu Gao、Xingcheng Yao 和 Danqi Chen。2021. SimCSE:基于简单对比学习的句子嵌入方法。载于《2021年自然语言处理实证方法会议论文集》,第6894–6910页,线上会议及多米尼加共和国蓬塔卡纳。计算语言学协会。
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3929–3938. PMLR.
Kelvin Guu、Kenton Lee、Zora Tung、Panupong Pasupat 和 Mingwei Chang。2020. 检索增强的语言模型预训练。载于《第37届国际机器学习会议论文集》,第119卷《机器学习研究论文集》,第3929–3938页。PMLR。
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022a. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research, 08:1–21.
Gautier Izacard、Mathilde Caron、Lucas Hosseini、Sebastian Riedel、Piotr Bojanowski、Armand Joulin 和 Edouard Grave。2022a。基于对比学习的无监督密集信息检索。机器学习研究汇刊,08:1–21。
Gautier Izacard and Edouard Grave. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, Online. Association for Computational Linguistics.
Gautier Izacard 和 Edouard Grave. 2021. 利用生成模型结合段落检索实现开放域问答. 载于《第16届欧洲计算语言学协会会议论文集: 主卷》, 第874–880页, 线上会议. 计算语言学协会.
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2022b. Few-shot learning with retrieval augmented language models. arXiv preprint arXiv:2208.03299.
Gautier Izacard、Patrick Lewis、Maria Lomeli、Lucas Hosseini、Fabio Petroni、Timo Schick、Jane Dwivedi-Yu、Armand Joulin、Sebastian Riedel 和 Edouard Grave。2022b。基于检索增强语言模型的少样本学习。arXiv预印本 arXiv:2208.03299。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for opendomain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6769–6781, Online. Association for Computational Linguistics.
Vladimir Karpukhin、Barlas Oguz、Sewon Min、Patrick Lewis、Ledell Wu、Sergey Edunov、Danqi Chen 和 Wen-tau Yih。2020。开放域问答的密集段落检索 (Dense Passage Retrieval for Open-Domain Question Answering)。载于《2020年自然语言处理实证方法会议论文集》,第6769–6781页,线上会议。计算语言学协会。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Z ett le moyer. 2020a. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Veselin Stoyanov 和 Luke Zettlemoyer。2020a. BART: 面向自然语言生成、翻译与理解的去噪序列到序列预训练。载于《第58届计算语言学协会年会论文集》,第7871-7880页,线上会议。计算语言学协会。
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, Sebastian Riedel, and Douwe Kiela. 2020b. Retrieval-augmented generation for knowledgeintensive nlp tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459– 9474. Curran Associates, Inc.
Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel、Sebastian Riedel 和 Douwe Kiela。2020b. 面向知识密集型NLP任务的检索增强生成。载于《神经信息处理系统进展》第33卷,第9459-9474页。Curran Associates出版社。
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023. Query rewriting for retrievalaugmented large language models. arXiv preprint arXiv:2305.14283.
Xinbei Ma、Yeyun Gong、Pengcheng He、Hai Zhao和Nan Duan。2023。检索增强大语言模型的查询重写。arXiv预印本arXiv:2305.14283。
OpenAI. 2023. Gpt-4 technical report. arXiv preprint arXiv:2302.08774.
OpenAI. 2023. GPT-4技术报告. arXiv预印本 arXiv:2302.08774.
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, volume 35, pages 27730–27744. Curran Associates, Inc.
Long Ouyang、Jeffrey Wu、Xu Jiang、Diogo Almeida、Carroll Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray、John Schulman、Jacob Hilton、Fraser Kelton、Luke Miller、Maddie Simens、Amanda Askell、Peter Welinder、Paul F Christiano、Jan Leike 和 Ryan Lowe。2022。通过人类反馈训练语言模型遵循指令。收录于《神经信息处理系统进展》第35卷,第27730–27744页。Curran Associates公司。
Xiaoman Pan, Kai Sun, Dian Yu, Jianshu Chen, Heng Ji, Claire Cardie, and Dong Yu. 2019. Improving question answering with external knowledge. In Proceedings of the 2nd Workshop on Machine Reading for Question Answering, pages 27–37, Hong Kong, China. Association for Computational Linguistics.
潘小曼、孙凯、余典、陈建树、纪恒、Claire Cardie 和余栋。2019. 利用外部知识提升问答系统性能。载于《第二届机器阅读与问答研讨会论文集》,第27-37页,中国香港。计算语言学协会。
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Gal- ley, and Jianfeng Gao. 2023. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277.
Baolin Peng、Chunyan Li、Pengcheng He、Michel Galley 和 Jianfeng Gao。2023。使用 GPT-4 进行指令调优。arXiv 预印本 arXiv:2304.03277。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu。2020。探索迁移学习的极限:基于统一文本到文本Transformer的研究。Journal of Machine Learning Research,21(140):1–67。
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: $100{,}000+$ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas. Association for Computational Linguistics.
Pranav Rajpurkar、Jian Zhang、Konstantin Lopyrev 和 Percy Liang。2016. SQuAD: 面向机器理解文本的 $100{,}000+$ 问题集。载于《2016年自然语言处理实证方法会议论文集》,第2383–2392页,美国德克萨斯州奥斯汀。计算语言学协会。
Nils Reimers and Iryna Gurevych. 2019. SentenceBERT: Sentence embeddings using Siamese BERTnetworks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
Nils Reimers和Iryna Gurevych。2019。SentenceBERT:基于孪生BERT网络的句子嵌入方法。载于《2019年自然语言处理实证方法会议暨第九届自然语言处理国际联合会议论文集》,第3982-3992页,中国香港。计算语言学协会。
Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389.
Stephen Robertson 和 Hugo Zaragoza. 2009. 概率相关性框架: BM25 及后续发展. Foundations and Trends® in Information Retrieval, 3(4):333–389.
Teven Le Scao, Angela Fan, Christopher Akiki, El- lie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2022. Bloom: A 176bparameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé等. 2022. Bloom: 一个1760亿参数的开源多语言大语言模型. arXiv预印本 arXiv:2211.05100.
Teven Le Scao, Angela Fan, Christopher Akiki, El- lie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2023. Palm 2 technical report. ArXiv, abs/2305.10403.
Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilic, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé等. 2023. PaLM 2技术报告. ArXiv, abs/2305.10403.
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. 2016. Highdimensional continuous control using generalized advantage estimation. In The Fourth International Conference on Learning Representations.
John Schulman、Philipp Moritz、Sergey Levine、Michael I. Jordan和Pieter Abbeel。2016。基于广义优势估计的高维连续控制。发表于第四届国际学习表征会议。
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. CoRR, abs/1707.06347.
John Schulman、Filip Wolski、Prafulla Dhariwal、Alec Radford 和 Oleg Klimov。2017. 近端策略优化算法。CoRR, abs/1707.06347。
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. 2023. Replug: Retrievalaugmented black-box language models. arXiv preprint arXiv:2301.12652.
Weijia Shi、Sewon Min、Michihiro Yasunaga、Minjoon Seo、Rich James、Mike Lewis、Luke Zettlemoyer 和 Wen-tau Yih。2023。Replug: 检索增强的黑盒大语言模型。arXiv预印本 arXiv:2301.12652。
Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. 2021. Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3784–3803, Punta Cana, Dominican Republic. Association for Computational Linguistics.
Kurt Shuster、Spencer Poff、Moya Chen、Douwe Kiela 和 Jason Weston。2021. 检索增强减少对话中的幻觉。载于《计算语言学协会发现:EMNLP 2021》,第3784–3803页,多米尼加共和国蓬塔卡纳。计算语言学协会。
Karen Sparck Jones. 1972. A statistical interpretation of term specificity and its application in retrieval. Journal of Documentation, 28(1):11–21.
Karen Sparck Jones. 1972. 词项特异性的统计解释及其在检索中的应用. Journal of Documentation, 28(1):11–21.
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems, volume 33, pages 3008–3021. Curran Associates, Inc.
Nisan Stiennon、Long Ouyang、Jeffrey Wu、Daniel Ziegler、Ryan Lowe、Chelsea Voss、Alec Radford、Dario Amodei 和 Paul F Christiano。2020。基于人类反馈的摘要学习。《神经信息处理系统进展》第33卷,第3008–3021页。Curran Associates公司。
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. github.com/tatsu-lab/stanford alpaca.
Rohan Taori、Ishaan Gulrajani、Tianyi Zhang、Yann Dubois、Xuechen Li、Carlos Guestrin、Percy Liang 和 Tatsunori B. Hashimoto。2023。Stanford Alpaca: 一个遵循指令的 LLaMA 模型。https://github.com/tatsu-lab/stanford_alpaca。
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
Hugo Touvron、Thibaut Lavril、Gautier Izacard、Xavier Martinet、Marie-Anne Lachaux、Timothée Lacroix、Baptiste Rozière、Naman Goyal、Eric Hambro、Faisal Azhar 等. 2023. Llama: 开放高效的基础大语言模型. arXiv预印本 arXiv:2302.13971.
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022. Emergent abilities of large language models. Transactions on Machine Learning Research, 08:1–30. Survey Certification.
Jason Wei、Yi Tay、Rishi Bommasani、Colin Raffel、Barret Zoph、Sebastian Borgeaud、Dani Yogatama、Maarten Bosma、Denny Zhou、Donald Metzler、Ed H. Chi、Tatsunori Hashimoto、Oriol Vinyals、Percy Liang、Jeff Dean 和 William Fedus。2022。大语言模型 (Large Language Model) 的涌现能力。机器学习研究汇刊,08:1–30。调查认证。
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salak hut dino v, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explain able multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
Zhilin Yang、Peng Qi、Saizheng Zhang、Yoshua Bengio、William Cohen、Ruslan Salakhutdinov 和 Christopher D. Manning。2018. HotpotQA:一个支持多样化、可解释多跳问答的数据集。载于《2018年自然语言处理实证方法会议论文集》,第2369–2380页,比利时布鲁塞尔。计算语言学协会。
Zhewei Yao, Reza Yazdani Aminabadi, Olatunji Ruwase, Samyam Raj bh and ari, Xiaoxia Wu, Ammar Ahmad Awan, Jeff Rasley, Minjia Zhang, Conglong Li, Connor Holmes, Zhongzhu Zhou, Michael Wyatt, Molly Smith, Lev Kurilenko, Heyang Qin, Masahiro Tanaka, Shuai Che, Shuaiwen Leon Song, and Yuxiong He. 2023. DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales. arXiv preprint arXiv:2308.01320.
Zhewei Yao、Reza Yazdani Aminabadi、Olatunji Ruwase、Samyam Rajbhandari、Xiaoxia Wu、Ammar Ahmad Awan、Jeff Rasley、Minjia Zhang、Conglong Li、Connor Holmes、Zhongzhu Zhou、Michael Wyatt、Molly Smith、Lev Kurilenko、Heyang Qin、Masahiro Tanaka、Shuai Che、Shuaiwen Leon Song 和 Yuxiong He。2023。DeepSpeed-Chat:全规模高效、快速、经济地训练类ChatGPT模型的RLHF方法。arXiv预印本arXiv:2308.01320。
Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, Weng Lam Tam, Zixuan Ma, Yufei Xue, Jidong Zhai, Wenguang Chen, Zhiyuan Liu, Peng Zhang, Yuxiao Dong, and Jie Tang. 2023. GLM-130b: An open bilingual pre-trained model. In The Eleventh International Conference on Learning Representations.
Aohan Zeng、Xiao Liu、Zhengxiao Du、Zihan Wang、Hanyu Lai、Ming Ding、Zhuoyi Yang、Yifan Xu、Wendi Zheng、Xiao Xia、Weng Lam Tam、Zixuan Ma、Yufei Xue、Jidong Zhai、Wenguang Chen、Zhiyuan Liu、Peng Zhang、Yuxiao Dong 和 Jie Tang。2023。GLM-130b:一个开放的双语预训练模型。在第十一届国际学习表征会议中。