Long LL M Lingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
长文本大语言模型加速器:通过提示压缩在长上下文场景中优化大语言模型性能
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu Microsoft Corporation {hjiang,qianhuiwu,xufluo,dongsli,cyl,yuqyang,liliqiu}@microsoft.com
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu Microsoft Corporation {hjiang,qianhuiwu,xufluo,dongsli,cyl,yuqyang,liliqiu}@microsoft.com
Abstract
摘要
In long context scenarios, large language models (LLMs) face three main challenges: higher computational cost, performance reduction, and position bias. Research indicates that LLM performance hinges on the density and position of key information in the input prompt. In- spired by these findings, we propose LongLLMLingua for prompt compression towards improving LLMs’ perception of the key information to simultaneously address the three chal- lenges. Our extensive evaluation across various long context scenarios demonstrates that Long LL M Lingua not only enhances performance but also significantly reduces costs and latency. For instance, in the Natural Questions benchmark, Long LL M Lingua boosts performance by up to $21.4%$ with around 4x fewer tokens in GPT-3.5-Turbo, leading to substantial cost savings. It achieves a $94.0%$ cost reduction in the LooGLE benchmark. Moreover, when compressing prompts of about 10k tokens at ratios of $2\mathbf{x}{-}6\mathbf{x}$ , Long LL M Lingua can accelerate end-to-end latency by $1.4\mathrm{X}{-}2.6\mathrm{X}$ .1
在长上下文场景中,大语言模型(LLM)面临三大挑战:计算成本更高、性能下降以及位置偏差。研究表明,LLM性能取决于输入提示中关键信息的密度和位置。受此启发,我们提出LongLLMLingua进行提示压缩,以提升LLM对关键信息的感知能力,从而同时解决这三个问题。我们在多种长上下文场景中的广泛评估表明,LongLLMLingua不仅能提升性能,还可显著降低成本和延迟。例如在Natural Questions基准测试中,LongLLMLingua使用GPT-3.5-Turbo时以约4倍的token缩减量实现了高达$21.4%$的性能提升,带来显著成本节约。在LooGLE基准测试中实现了$94.0%$的成本降低。此外,当以$2\mathbf{x}{-}6\mathbf{x}$的压缩率处理约10k token的提示时,LongLLMLingua能将端到端延迟加速$1.4\mathrm{X}{-}2.6\mathrm{X}$。
1 Introduction
1 引言
Large language models (LLMs) have revolutionized user-oriented language technologies and are serving as crucial components in more and more applications. Carefully designing prompts is necessary to achieve better performance in specific downstream tasks. The commonly used technologies such as In-Context Learning (ICL) (Min et al., 2022; Dong et al., 2023), Retrieval Augment Generation (RAG) (Lewis et al., 2020; Asai et al., 2024), and Multi-turn Agent (Shen et al., 2024; Park et al., 2023; Wu et al., 2023a) are driving prompts to be increasingly longer, even reaching thousands of tokens. Scenarios such as multi-document question answering, code completion, and document summarization also necessitate the processing of long contexts.
大语言模型(LLM)彻底改变了面向用户的语言技术,正成为越来越多应用中的核心组件。为在特定下游任务中获得更优表现,精心设计提示词(prompt)至关重要。目前广泛使用的上下文学习(ICL) (Min et al., 2022; Dong et al., 2023)、检索增强生成(RAG) (Lewis et al., 2020; Asai et al., 2024)和多轮AI智能体(Shen et al., 2024; Park et al., 2023; Wu et al., 2023a)等技术推动提示词长度持续增长,甚至可达数千token。多文档问答、代码补全和文档摘要等场景同样需要处理长上下文。
There are three main challenges when LLMs are used in long context scenarios: (1) Higher computational costs, encompassing both financial and latency expenses. (2) Longer prompts introduce irrelevant and redundant information, which can weaken LLMs’ performance (Shi et al., 2023), as illustrated in Figure 1a. (3) LLMs exhibit position bias (Kamradt, 2023), also known as the "lost in the middle" issue (Liu et al., 2024), suggesting that the placement of key information within the prompt significantly affects LLMs’ performance. This is demonstrated by the purple curve in Figure 1b.
大语言模型在长上下文场景中应用时面临三大主要挑战:(1) 计算成本更高,包括资金和延迟开销。(2) 过长的提示会引入无关冗余信息,这会削弱大语言模型的性能 (Shi et al., 2023),如图 1a 所示。(3) 大语言模型存在位置偏差 (Kamradt, 2023),即"迷失在中间"问题 (Liu et al., 2024),表明关键信息在提示中的位置会显著影响模型表现,图 1b 中的紫色曲线印证了这一点。
Inspired by these observations, we propose Long LL M Lingua to address the three challenges. Specifically, we use LLMLingua (Jiang et al., 2023a) as the backbone for prompt compression to address the first challenge, i.e., reduce cost and latency. However, in the case of long contexts, the distribution of question-relevant key information in the prompt is generally dynamic and sparse. Existing prompt compression methods like LLMLingua (Jiang et al., 2023a) and Selective-Context (Li et al., 2023c) that often fail to consider question during compression, resulting in retention of excessive noise and decreased performance. LongLLMLingua aims to improve LLMs’ perception of key information pertinent to the question, thereby overcoming the noise and position bias issues in long contexts, shown in Figure 1b. The underlying principle of Long LL M Lingua is that small LM are inherently capable of capturing the distribution of key information relevant to a given question.
受这些观察启发,我们提出LongLLMLingua以解决这三个挑战。具体而言,我们采用LLMLingua (Jiang et al., 2023a) 作为提示压缩的骨干框架来应对第一个挑战(即降低成本和延迟)。但在长上下文场景中,问题相关关键信息在提示中的分布通常呈现动态稀疏特性。现有提示压缩方法如LLMLingua (Jiang et al., 2023a) 和Selective-Context (Li et al., 2023c) 往往未能在压缩过程中考虑问题相关性,导致保留过多噪声并降低性能。LongLLMLingua旨在提升大语言模型对问题关键信息的感知能力,从而克服长上下文中的噪声和位置偏差问题(如图1b所示)。其核心原理在于:小型语言模型天生具备捕捉给定问题相关关键信息分布的能力。
Our main contributions are five-fold: (1) We propose a question-aware coarse-to-fine compression method to improve the key information density in the prompt (Sec. 4.1); (2) We introduce a document reordering strategy to minimize position bias in LLMs. (Sec. 4.2); (3) We establish dynamic compression ratios for precise control between coarse and fine compression levels (Sec. 4.3); (4) We propose a post-compression sub sequence recovery strategy to improve the integrity of the key information (4.4). (5) We evaluate Long LL M Lingua across five benchmarks, i.e., Natural Questions (Liu et al., 2024), LongBench (Bai et al., 2023), Zero SCROLLS (Shaham et al., 2023), MuSicQue (Trivedi et al., 2022), and LooGLE (Li et al., 2023b), covering a variety of long context scenarios. Experimental results reveal that Long LL M Lingua’s compressed prompts outperform original prompts in terms of performance, cost efficiency, and system latency.
我们的主要贡献包括五个方面:(1) 提出一种问题感知的由粗到精压缩方法,以提高提示中的关键信息密度(第4.1节);(2) 引入文档重排序策略以最小化大语言模型中的位置偏差(第4.2节);(3) 建立动态压缩比实现粗粒度与细粒度压缩级别的精准控制(第4.3节);(4) 提出压缩后子序列恢复策略以提升关键信息完整性(第4.4节);(5) 在五个基准测试(Natural Questions (Liu et al., 2024)、LongBench (Bai et al., 2023)、Zero SCROLLS (Shaham et al., 2023)、MuSicQue (Trivedi et al., 2022) 和 LooGLE (Li et al., 2023b))上评估 Long LL M Lingua,覆盖多种长上下文场景。实验结果表明,压缩后提示在性能、成本效益和系统延迟方面均优于原始提示。
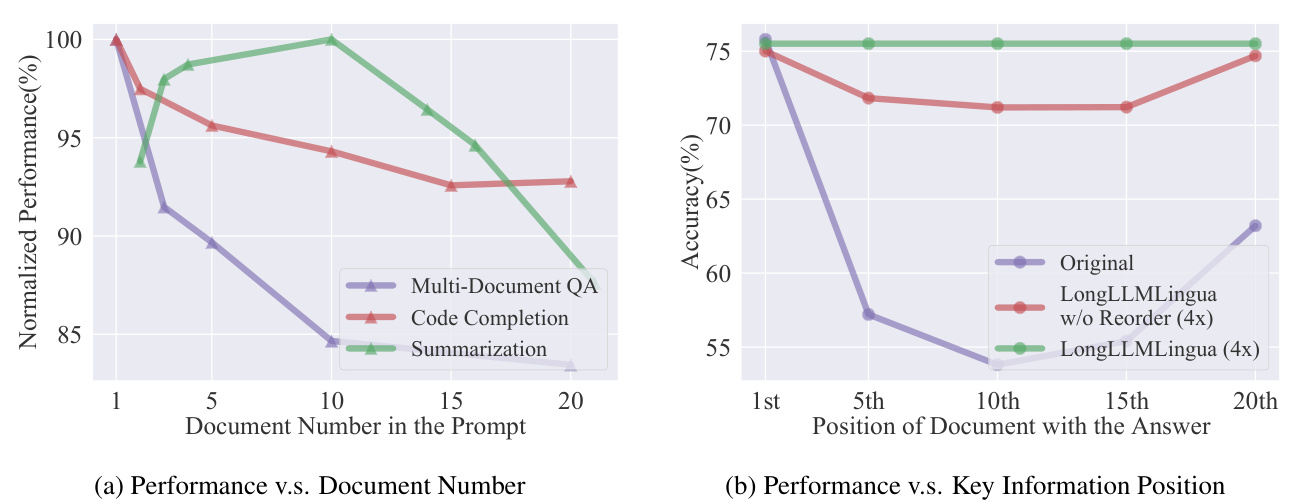
Figure 1: (a) LLMs’ performance in downstream tasks decreases with increased noise in prompts. In this case, we keep $k$ most relevant documents/paragraphs based on the ground-truth or Long LL M Lingua $r_{k}$ . A larger $k$ implies more noise introduced into the prompt. To improve the key information density in the prompt, we present question-aware coarse-to-fine compression. (b) LLMs’ ability to capture the relevant information depends on their positions in the prompt. To reduce information loss in the middle, we introduce a document reordering mechanism.
图 1: (a) 大语言模型在下游任务中的性能随着提示中噪声的增加而下降。在本例中, 我们基于真实值或 Long LL M Lingua $r_{k}$ 保留 $k$ 个最相关的文档/段落。更大的 $k$ 意味着提示中引入了更多噪声。为了提高提示中的关键信息密度, 我们提出了问题感知的由粗到细压缩方法。(b) 大语言模型捕获相关信息的能力取决于其在提示中的位置。为了减少中间位置的信息丢失, 我们引入了文档重排序机制。
2 Problem Formulation
2 问题描述
Following LLMLingua (Jiang et al., 2023a), we use $\mathbf{x}=(\mathbf{x}^{\mathrm{ins}},\mathbf{x}_ {1}^{\mathrm{doc}},\cdot\cdot\cdot,\mathbf{x}_ {K}^{\mathrm{doc}},\mathbf{x}^{\mathrm{que}})$ to represent a prompt, including the instruction $\mathbf{x}^{\mathrm{ins}}$ , $K$ documents $\mathbf{x}_{i}^{\mathrm{doc}}$ , and the question $\mathbf{x}^{\mathrm{que}}$ . However, this definition can be adjusted for specific scenarios. The objective of a prompt compression system can be formulated as:
遵循LLMLingua (Jiang et al., 2023a)的方法,我们使用$\mathbf{x}=(\mathbf{x}^{\mathrm{ins}},\mathbf{x}_ {1}^{\mathrm{doc}},\cdot\cdot\cdot,\mathbf{x}_ {K}^{\mathrm{doc}},\mathbf{x}^{\mathrm{que}})$表示一个提示(prompt),其中包含指令$\mathbf{x}^{\mathrm{ins}}$、$K$个文档$\mathbf{x}_{i}^{\mathrm{doc}}$以及问题$\mathbf{x}^{\mathrm{que}}$。不过,该定义可根据具体场景进行调整。提示压缩系统的目标可表述为:
$$
\operatorname*{min}_ {\widetilde{\mathbf{x}}}D_{\phi}\left(\mathbf{y},\widetilde{\mathbf{y}}\right)+\lambda|\widetilde{\mathbf{x}}|_{0},
$$
$$
\operatorname*{min}_ {\widetilde{\mathbf{x}}}D_{\phi}\left(\mathbf{y},\widetilde{\mathbf{y}}\right)+\lambda|\widetilde{\mathbf{x}}|_{0},
$$
where $\widetilde{\mathbf{x}}$ represents the compressed prompt, a tokenlevel seu b sequence of $\mathbf{x}$ . $\mathbf{y}$ and $\widetilde{\mathbf{y}}$ represent the LLM-generated results from $\mathbf{x}$ an de $\widetilde{\mathbf{x}}$ , respectively. $D_{\phi}$ measures the distance function, esuch as KL divergence. $\lambda$ serves as a hyper-parameter balancing the compression ratio. Additionally, this study explores a permutation operation space over the $K$ documents $({\bf x}_ {1}^{\mathrm{doc}},\cdot\cdot\cdot,{\bf x}_{K}^{\mathrm{doc}})$ for joint optimization.
其中 $\widetilde{\mathbf{x}}$ 表示压缩后的提示 (prompt),即 $\mathbf{x}$ 的一个 token 级子序列。$\mathbf{y}$ 和 $\widetilde{\mathbf{y}}$ 分别表示大语言模型基于 $\mathbf{x}$ 和 $\widetilde{\mathbf{x}}$ 生成的结果。$D_{\phi}$ 为距离度量函数,例如 KL 散度。$\lambda$ 是平衡压缩率的超参数。此外,本研究还探索了对 $K$ 个文档 $({\bf x}_ {1}^{\mathrm{doc}},\cdot\cdot\cdot,{\bf x}_{K}^{\mathrm{doc}})$ 进行排列组合的操作空间以实现联合优化。
3 Preliminary: LLMLingua
3 预备知识:LLMLingua
LLMLingua (Jiang et al., 2023a) utilizes a small language model $\mathcal{M}_ {S}$ to evaluate the perplexity of each prompt token, removing those with lower perplexities. This method is premised on the idea that tokens with lower perplexities have a negligible effect on the language model’s overall entropy gain, implying their removal slightly impacts the LLMs’ contextual understanding. This process is viewed as an application of "LM is Compression" (Delétang et al., 2023). LLMLingua include three key components: budget controller, iterative token-level prompt compression, and distribution alignment, highlighted by italic text in Figure 2. The budget controller assigns varying compression ratios to different parts of the prompt (i.e., instruction, demonstrations, question), implementing coarse-level prompt compression. Subsequent steps involve dividing intermediate results into segments and applying token-level compression iteratively, where each token’s perplexity based on preceding compressed segments. To aware different target LLMs, LLMLingua fine-tunes $\mathcal{M}_{S}$ using data from the target LLM.
LLMLingua (Jiang et al., 2023a) 利用一个小型语言模型 $\mathcal{M}_ {S}$ 来评估每个提示token的困惑度,并移除那些困惑度较低的token。该方法基于这样的前提:困惑度较低的token对语言模型整体熵增益的影响可以忽略不计,这意味着移除它们对大语言模型的上下文理解影响较小。这一过程被视为"LM is Compression" (Delétang et al., 2023) 理论的应用。LLMLingua包含三个关键组件:预算控制器、迭代式token级提示压缩和分布对齐(如图2中斜体文本所示)。预算控制器为提示的不同部分(即指令、示例、问题)分配不同的压缩比例,实现粗粒度的提示压缩。后续步骤包括将中间结果分段并迭代应用token级压缩,其中每个token的困惑度基于先前压缩的段落计算。为了使模型适配不同目标大语言模型,LLMLingua使用目标大语言模型的数据对 $\mathcal{M}_{S}$ 进行微调。
4 Long LL M Lingua
4 长文本大语言模型 Lingua
Long LL M Lingua builds on LLMLingua to better compress prompts in long context scenorias. It tack- les three main issues in handling lengthy contexts, as introduced in Sec. 1. This approach focuses on making LLMs more effective at recognizing key information related to the question in the prompt. It encompasses three perspectives and further incorporates a sub sequence recovery strategy, as shown in Figure 2, to enhance the accuracy and reliability of the information provided to users. In this section, we detail how each part of Long LL M Lingua works to improve the LLMs deal with long context.
Long LL M Lingua基于LLMLingua改进,旨在长上下文场景中更好地压缩提示。该方法针对第1节提出的处理长文本时的三个主要问题,重点提升大语言模型识别提示中与问题相关关键信息的能力。其包含三个优化视角,并进一步引入如图2所示的子序列恢复策略,以提高提供给用户信息的准确性和可靠性。本节将详细阐述Long LL M Lingua各模块如何协同提升大语言模型处理长文本的能力。
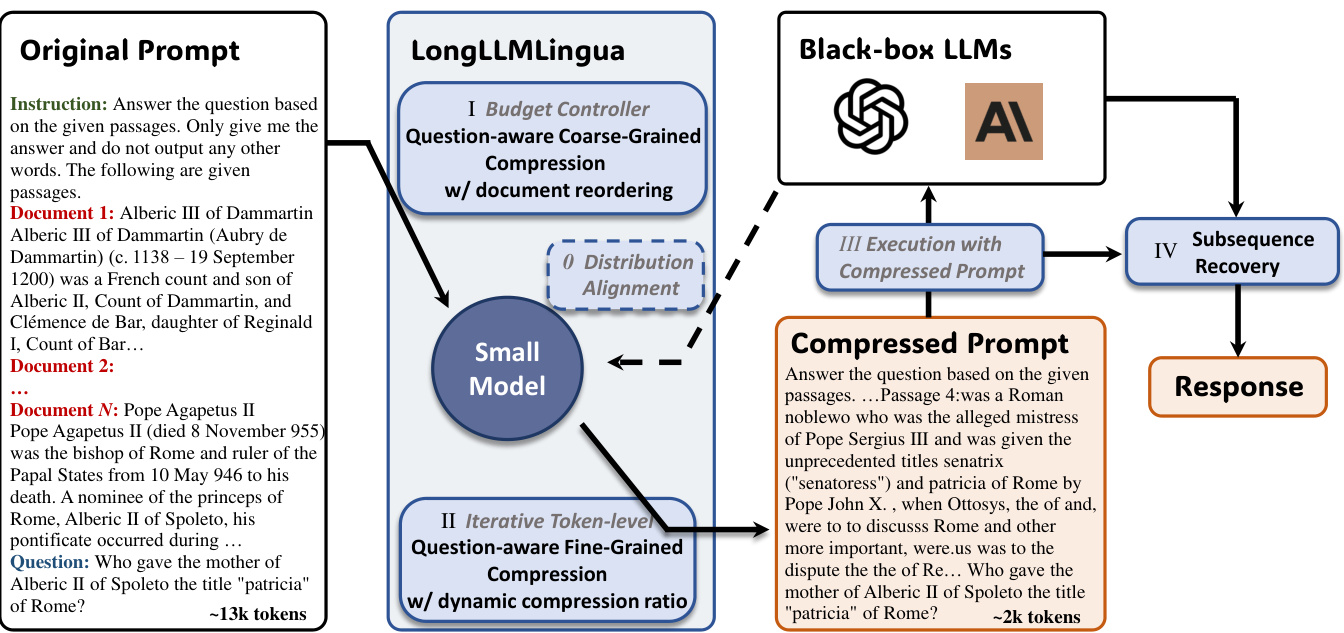
Figure 2: Framework of Long LL M Lingua. Gray Italic content: As in LLMLingua.
图 2: Long LLM Lingua框架。灰色斜体内容: 同LLMLingua。
4.1 How to improve key information density in the prompt?
4.1 如何提升提示中的关键信息密度
Question-Aware Coarse-Grained Compression In coarse-grained compression, we aim to figure out a metric $r_{k}$ to evaluate the importance of each document xdko ${\bf x}_ {k}^{\mathrm{doc}} = {x_{k,i}^{\mathrm{doc}}}_ {i=1}^{N_{k}}$ , where $N_{k}$ is the number of tokens in xdko c. We only keep xdko with higher $r_{k}$ as the intermediate compressed results. One approach to improve key information density in the compressed prompts is to calculate document-level perplexity conditioned on the question $p(\mathbf{x}_{k}^{\mathrm{doc}}|\mathbf{x}^{\mathrm{que}})$ . However, this method may not be effective because documents often contain a significant amount of irrelevant information. Even when conditioned on $\mathbf{x}^{\mathrm{que}}$ , the perplexity scores computed for entire documents may not be sufficiently distinct, rendering them an inadequate metric for document-level compression.
问题感知的粗粒度压缩
在粗粒度压缩中,我们的目标是找到一种度量标准$r_{k}$,用于评估每个文档${\bf x}_ {k}^{\mathrm{doc}} = {x_{k,i}^{\mathrm{doc}}}_ {i=1}^{N_{k}}$的重要性,其中$N_{k}$是文档中的token数量。我们仅保留$r_{k}$较高的文档作为中间压缩结果。一种提高压缩提示中关键信息密度的方法是计算文档在问题条件下的困惑度$p(\mathbf{x}_{k}^{\mathrm{doc}}|\mathbf{x}^{\mathrm{que}})$。然而,这种方法可能效果不佳,因为文档通常包含大量无关信息。即使在$\mathbf{x}^{\mathrm{que}}$条件下,对整个文档计算的困惑度分数可能区分度不足,使其无法作为文档级压缩的有效度量标准。
We propose to use the perplexity of the question xque conditioned on different contexts xdko $p(\mathbf{x}^{\mathrm{que}}|\mathbf{x}_ {k}^{\mathrm{doc}})$ to represent the association between them. We also append a restrictive statement2 $\mathbf{x}^{\mathrm{restrict}}$ after $\mathbf{x}^{\mathrm{que}}$ to strengthen the interconnection of $\mathbf{x}^{\mathrm{que}}$ and $\mathbf{x}_{k}^{\mathrm{doc}}$ . It can be regarded as a regularization term that mitigates the impact of hallucinations. This can be formulated as:
我们建议使用问题xque在不同上下文xdko条件下的困惑度$p(\mathbf{x}^{\mathrm{que}}|\mathbf{x}_ {k}^{\mathrm{doc}})$来表示它们之间的关联。同时,我们在$\mathbf{x}^{\mathrm{que}}$后添加限制性陈述$\mathbf{x}^{\mathrm{restrict}}$,以加强$\mathbf{x}^{\mathrm{que}}$与$\mathbf{x}_{k}^{\mathrm{doc}}$之间的关联。这可以视为一种正则化项,用于减轻幻觉效应的影响。其数学表达为:
$$
r_{k}=-\frac{1}{N_{c}}\sum_{i}^{N_{c}}\log p(x_{i}^{\mathrm{que,restrict}}|\mathbf{x}_{k}^{\mathrm{doc}}),
$$
$$
r_{k}=-\frac{1}{N_{c}}\sum_{i}^{N_{c}}\log p(x_{i}^{\mathrm{que,restrict}}|\mathbf{x}_{k}^{\mathrm{doc}}),
$$
where xque,restrict is the i-th token in the concatenated sequence of $\mathbf{x}^{\mathrm{que}}$ and $\mathbf{x}^{\mathrm{restrict}}$ and $N_{c}$ in the number of tokens.
其中,xque,restrict 是 $\mathbf{x}^{\mathrm{que}}$ 和 $\mathbf{x}^{\mathrm{restrict}}$ 拼接序列中的第 i 个 token,$N_{c}$ 是 token 的数量。
Figure 3a displays the recall distribution of different retrieval methods, including traditional relevance methos (BM25, Gzip (Jiang et al., 2023b)), embedding-based methods (OpenAI-embedding, Voyageai3, BGE-large-en v1.5 (Xiao et al., 2023), Sentence-BERT (Reimers and Gurevych, 2019), Jina (Günther et al., 2023)), and reranker methods (Cohere-Rerank4, BGE-llmembeder, BGE-Rankerlarge), which demonstrates that our coarse-level compression approach achieves the highest recall with different numbers of retained documents, suggesting that it preserves the most key information from the contexts in the compressed results.
图 3a: 展示了不同检索方法的召回率分布,包括传统相关性方法 (BM25, Gzip [Jiang et al., 2023b])、基于嵌入的方法 (OpenAI-embedding, Voyageai3, BGE-large-en v1.5 [Xiao et al., 2023], Sentence-BERT [Reimers and Gurevych, 2019], Jina [Günther et al., 2023]) 以及重排序方法 (Cohere-Rerank4, BGE-llmembeder, BGE-Rankerlarge)。结果表明,在不同保留文档数量的情况下,我们的粗粒度压缩方法实现了最高召回率,这表明它在压缩结果中保留了上下文中最关键的信息。
Question-Aware Fine-Grained Compression In fine-grained compression, we assess the importance of each token in the instruction $\mathbf{x}^{\mathrm{{ins}}}$ , the question $\mathbf{x}^{\mathrm{que}}$ , and $K^{\prime}$ documents ${\mathbf{x}_ {i}^{\mathrm{{doc}}}}_ {i=1}^{K^{\prime}}$ retained af- ter coarse-grained compression. We incorporate the iterative compression mechanism following LLMLingua and directly calculate token perplexities to compress $\mathbf{x}^{\mathrm{ins}}$ and $\mathbf{x}^{\mathrm{que}}$ . In this section, we investigate how to make the fine-grained token-level compression over ${\mathbf{x}_ {k}^{\mathrm{doc}}}_{k=1}^{K^{\prime}}$ aware of the question $\mathbf{x}^{\mathrm{que}}$ , so that the compressed results could contain more question-relevant key information.
问题感知的细粒度压缩
在细粒度压缩中,我们评估指令$\mathbf{x}^{\mathrm{ins}}$、问题$\mathbf{x}^{\mathrm{que}}$以及经过粗粒度压缩后保留的$K^{\prime}$篇文档${\mathbf{x}_ {i}^{\mathrm{doc}}}_ {i=1}^{K^{\prime}}$中每个token的重要性。我们采用LLMLingua的迭代压缩机制,直接计算token困惑度来压缩$\mathbf{x}^{\mathrm{ins}}$和$\mathbf{x}^{\mathrm{que}}$。本节重点研究如何让${\mathbf{x}_ {k}^{\mathrm{doc}}}_{k=1}^{K^{\prime}}$的细粒度token级压缩感知问题$\mathbf{x}^{\mathrm{que}}$,从而使压缩结果保留更多与问题相关的关键信息。
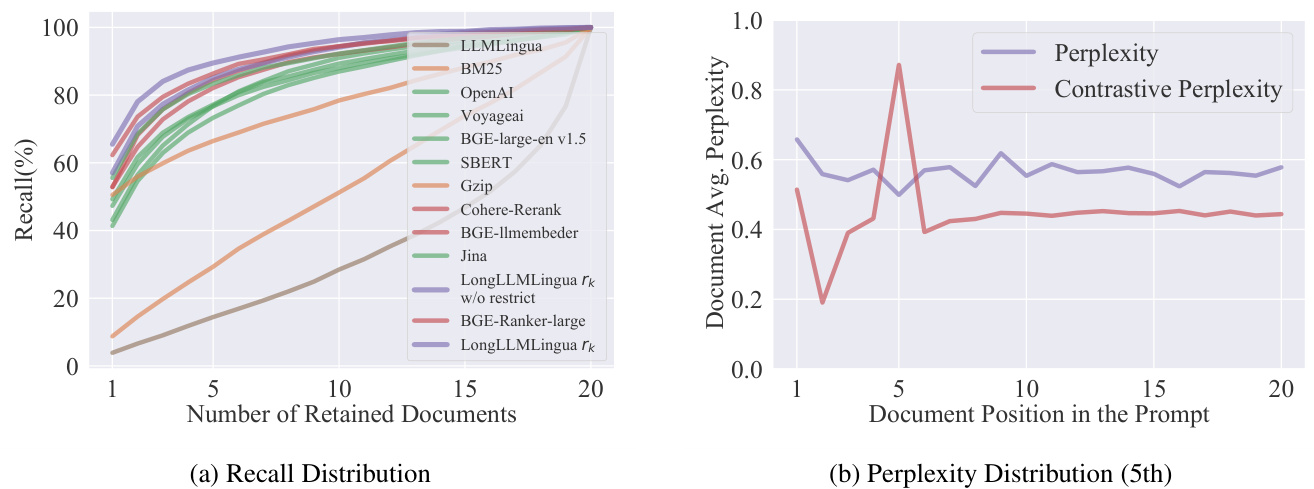
Figure 3: (a) Comparison of recall on Natural Questions Multi-documemnt QA dataset, which increases from top to bottom in terms of Recall $@1$ . Different colors represent different types of methods. Among them, yellow represents traditional relevance methods, green signifies embedding-based methods, and red denotes rerank-based methods. (b) Comparison between perplexities and contrastive perplexities of tokens in the prompt from Multi-documemnt QA dataset. The document containing the ground-truth information is located in the 5th position. More results on position can be found in the Appendix C.1.
图 3: (a) Natural Questions多文档问答数据集的召回率对比,按Recall $@1$ 从高到低排列。不同颜色代表不同类型的方法:黄色表示传统相关性方法,绿色代表基于嵌入的方法,红色表示基于重排序的方法。(b) 多文档问答数据集中提示文本token的困惑度与对比困惑度对比。包含真实信息的文档位于第5位。更多位置相关结果见附录C.1。
A straightforward solution for the awareness of $\mathbf{x}^{\mathrm{que}}$ is to simply concatenate it at the beginning of the whole context. However, this will result in low perplexities of relevant tokens in the context following the condition of question $\mathbf{x}^{\mathrm{que}}$ , further reducing their differentiation from other tokens.
对于感知 $\mathbf{x}^{\mathrm{que}}$ 的直观解决方案是直接将其拼接在整个上下文的开头。然而,这会导致在问题 $\mathbf{x}^{\mathrm{que}}$ 条件之后的上下文中相关 token 的困惑度降低,从而进一步减弱它们与其他 token 的区分度。
In this paper, we propose contrastive perplexity, i.e., the distribution shift caused by the condition of the question, to represent the association between the token and the question. The contrastive perplexity based importance metric $s_{i}$ for each token $x_{i}$ in ${\mathbf{x}_ {k}^{\mathrm{doc}}}_{k=1}^{K^{\prime}}$ can be formulated as:
在本文中,我们提出对比困惑度(即问题条件引起的分布偏移)来表示token与问题之间的关联性。基于对比困惑度的重要性度量$s_{i}$可表示为${\mathbf{x}_ {k}^{\mathrm{doc}}}_ {k=1}^{K^{\prime}}$中每个token$x_{i}$的公式:
$$
s_{i}=\mathrm{perplexity}(x_{i}|x_{<i})-\mathrm{perplexity}(x_{i}|x^{\mathrm{que}},x_{<i}).
$$
$$
s_{i}=\mathrm{perplexity}(x_{i}|x_{<i})-\mathrm{perplexity}(x_{i}|x^{\mathrm{que}},x_{<i}).
$$
Additionally, we provide the derivation of its mathematical significance in the Appendix A, concluding that it is equivalent to conditional pointwise mutual information (Church and Hanks, 1989).
此外,我们在附录A中提供了其数学意义的推导过程,并得出结论:它等同于条件点互信息 (Church and Hanks, 1989)。
Figure 3b illustrates the difference between perplexities and contrastive perplexities. The distribution of perplexities appears random, making it challenging to extract information related to the question. However, tokens with high contrastive perplexities tend to cluster near the ground-truth document, which contains information relevant to the question. This suggests that the proposed contrastive perplexity can better distinguish tokens relevant to the question, thus improving the key information density in the compressed results.
图 3b 展示了困惑度 (perplexity) 与对比困惑度 (contrastive perplexity) 的区别。困惑度分布呈现随机性,难以提取与问题相关的信息;而具有高对比困惑度的 token 往往聚集在包含问题相关信息的真实文档附近。这表明所提出的对比困惑度能更好地区分与问题相关的 token,从而提高压缩结果中的关键信息密度。
4.2 How to reduce information loss in the middle?
4.2 如何减少中间环节的信息损失?
As demonstrated in Figure 1b, LLM achieves the highest performance when relevant information occurs at the beginning and significantly degrades if relevant information is located in the middle of long contexts. After the coarse-grained compression, we have obtained a set of documents ${\mathbf{x}_ {k}^{\mathrm{{doc}}}}_ {k=1}^{K^{\prime}}$ with their corresponding importance scores ${r_{k}}_{k=1}^{K^{\prime}}$ indicating their association with the question $\mathbf{x}^{\mathrm{que}}$ . Therefore, we reorder documents using their importance scores to better leverage LLMs’ information perception difference in positions:
如图 1b 所示,当相关信息出现在开头时,大语言模型(LLM)表现最佳,而若相关信息位于长文本中间则性能显著下降。经过粗粒度压缩后,我们获得了一组文档 ${\mathbf{x}_ {k}^{\mathrm{{doc}}}}_ {k=1}^{K^{\prime}}$ 及其对应的重要性分数 ${r_{k}}_{k=1}^{K^{\prime}}$ ,这些分数表示它们与问题 $\mathbf{x}^{\mathrm{que}}$ 的关联程度。因此,我们根据重要性分数对文档重新排序,以更好地利用大语言模型在不同位置的信息感知差异:
$$
\begin{array}{r}{\left(\mathbf{x}^{\mathrm{ins}},\mathbf{x}_ {1}^{\mathrm{doc}},\cdot\cdot\cdot,\mathbf{x}_ {K^{\prime}}^{\mathrm{doc}},\mathbf{x}^{\mathrm{que}}\right)\xrightarrow[]{r_{k}}}\ {\left(\mathbf{x}^{\mathrm{ins}},\mathbf{x}_ {r1}^{\mathrm{doc}},\cdot\cdot\cdot,\mathbf{x}_{r K^{\prime}}^{\mathrm{doc}},\mathbf{x}^{\mathrm{que}}\right)}\end{array}
$$
$$
\begin{array}{r}{\left(\mathbf{x}^{\mathrm{ins}},\mathbf{x}_ {1}^{\mathrm{doc}},\cdot\cdot\cdot,\mathbf{x}_ {K^{\prime}}^{\mathrm{doc}},\mathbf{x}^{\mathrm{que}}\right)\xrightarrow[]{r_{k}}}\ {\left(\mathbf{x}^{\mathrm{ins}},\mathbf{x}_ {r1}^{\mathrm{doc}},\cdot\cdot\cdot,\mathbf{x}_{r K^{\prime}}^{\mathrm{doc}},\mathbf{x}^{\mathrm{que}}\right)}\end{array}
$$
4.3 How to achieve adaptive granular control during compression?
4.3 如何在压缩过程中实现自适应粒度控制?
In fine-grained compression, LLMLingua applies the same compression ratio over all documents obtained from budget controller. However, the key information density of different documents is different. The more relevant to the question a document
在细粒度压缩中,LLMLingua对所有从预算控制器获取的文档应用相同的压缩比例。然而,不同文档的关键信息密度存在差异。文档与问题的相关性越高

Figure 4: The example of Sub sequence Recovery, the red text represents the original text, and the blue text is the result after using the LLaMA 2-7B tokenizer.
图 4: 子序列恢复示例,红色文本代表原始文本,蓝色文本是使用LLaMA 2-7B分词器后的结果。
is, the more budget (i.e., lower compression ratio) we should allocate to it. Therefore, we bridge pression and use the importance scores ${r_{k}}_{k=1}^{K^{\prime}}$ obtained from coarse-grained compression to guide the budget allocation in fine-grained compression. In this way, we can achieve adaptive granular control on the whole.
具体而言,重要性越高的特征应分配越多预算(即更低压缩率)。因此,我们通过重要性分数${r_{k}}_{k=1}^{K^{\prime}}$建立粗粒度压缩与细粒度压缩之间的桥梁,用粗粒度阶段获得的重要性分数指导细粒度阶段的预算分配,从而实现整体自适应粒度控制。
Specifically, we first determine the initial budget for the retained documents5 $\tau^{\mathrm{doc}}$ using the budget controller of LLMLingua. During fine-grained compression, we follow the iterative token-level compression algorithm in LLMLingua but dynamdocument $\mathbf{x}_ {k}^{\mathrm{doc}}$ according to the rankin τ doc to each ex $I(r_{k})$ (e.g., 0, 1) of its importance score from the coarsegrained compression. In this paper, we employ a linear scheduler for the adaptive allocation. Budget of each token $x_{i}$ can be formulated as:
具体而言,我们首先利用LLMLingua的预算控制器确定保留文档的初始预算$\tau^{\mathrm{doc}}$。在细粒度压缩阶段,我们沿用LLMLingua的迭代token级压缩算法,但会基于粗粒度压缩获得的重要性分数$I(r_{k})$(例如0或1)动态调整文档$\mathbf{x}_ {k}^{\mathrm{doc}}$的预算分配$\tau^{\mathrm{doc}}$。本文采用线性调度器进行自适应分配,每个token$x_{i}$的预算可表示为:
The overall procedure includes: i) Iterate through tokens $y_{l}$ in LLMs’ response and select the longest substring $\widetilde{\pmb{y}}_ {\mathrm{key},l} = {y_{l},y_{l+1},...,y_{r}}$ that appears in the c oempressed prompt $\widetilde{x}$ . ii) Find the maximum common shortest subse qeuence $\pmb{x}_ {i,j}={x_{i},x_{i+1},...,x_{j}}$ in the original prompt $_ {x}$ , corresponding to the representation $\widetilde{\boldsymbol{y}}_ {\mathrm{key,\ell}}$ in the original prompt (accelerated using p reefix trees or sequence automata). iii) Replace the matched tokens $\widetilde{\pmb y}_ {\mathrm{key},l}$ in LLMs’ response with the corresponding s u eb sequence $\mathbf{\Delta}_ {x_{i,j}}$ from the original prompt. For more details, please refer to Algorithm 1.
整体流程包括:
i) 遍历大语言模型响应中的token $y_{l}$,选取在压缩提示 $\widetilde{x}$ 中出现的最长子串 $\widetilde{\pmb{y}}_ {\mathrm{key},l} = {y_{l},y_{l+1},...,y_{r}}$。
ii) 在原始提示 $_ {x}$ 中寻找与 $\widetilde{\boldsymbol{y}}_ {\mathrm{key,\ell}}$ 对应的最大公共最短子序列 $\pmb{x}_ {i,j}={x_{i},x_{i+1},...,x_{j}}$(使用前缀树或序列自动机加速)。
iii) 将大语言模型响应中匹配的token $\widetilde{\pmb y}_ {\mathrm{key},l}$ 替换为原始提示中的对应子序列 $\mathbf{\Delta}_ {x_{i,j}}$。具体细节请参阅算法1。
$$
\begin{array}{l}{\displaystyle\tau_{i}=\tau_{k}^{\mathrm{doc}},\quad\forall x_{i}\in\mathbf{x}_ {k}^{\mathrm{doc}},}\ {\displaystyle\tau_{k}^{\mathrm{doc}}=\operatorname*{max}(\operatorname*{min}((1-\frac{2I(r_{k})}{K^{\prime}})\delta\tau+\tau^{\mathrm{doc}},1),0),}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\tau_{i}=\tau_{k}^{\mathrm{doc}},\quad\forall x_{i}\in\mathbf{x}_ {k}^{\mathrm{doc}},}\ {\displaystyle\tau_{k}^{\mathrm{doc}}=\operatorname*{max}(\operatorname*{min}((1-\frac{2I(r_{k})}{K^{\prime}})\delta\tau+\tau^{\mathrm{doc}},1),0),}\end{array}
$$
where $i$ and $k$ is the index of token and document, $K^{\prime}$ denotes the number of documents, and $\delta\tau$ is a hyper-parameter that controls the overall budget for dynamic allocation.
其中 $i$ 和 $k$ 分别表示 token 和文档的索引,$K^{\prime}$ 表示文档数量,$\delta\tau$ 是控制动态分配总体预算的超参数。
4.4 How to improve the integrity of key information?
4.4 如何提升关键信息的完整性?
During the generation process, LLMs tend to replicate entities found in the prompt, such as names, places, and organizations. Compressing these entities at the token level doesn’t affect the LLMs’ understanding of semantic content but can lead to errors in the generated content.
在生成过程中,大语言模型倾向于复制提示中的实体,如人名、地点和组织机构。在token级别压缩这些实体不会影响大语言模型对语义内容的理解,但可能导致生成内容出现错误。
Therefore, we propose a sub sequence recovery method to restore the original content in LLMs’ responses. This method relies on the subsequence relationship among tokens in the original prompt, compressed prompt, and LLMs’ response, as shown in Figure 4.
因此,我们提出了一种子序列恢复方法,用于还原大语言模型响应中的原始内容。该方法依赖于原始提示、压缩提示和大语言模型响应中token之间的子序列关系,如图4所示。
Input: The original prompt $_{\mathbf{\delta}}$ ; the compressed prompt $\widetilde{x}$ ; the generation response of LLMs $\pmb{y}$ .
输入: 原始提示 $_{\mathbf{\delta}}$ ; 压缩提示 $\widetilde{x}$ ; 大语言模型的生成响应 $\pmb{y}$ 。
5 Experiments
5 实验
Here, we investigate: (1) How effective is Long LL M Lingua? (2) How efficient is LongLLMLingua?
我们研究以下问题:(1) LongLLMLingua 的效果如何?(2) LongLLMLingua 的效率如何?
Implementation details In this paper, we use GPT-3.5-Turbo $.0613^{6}$ and LongChat-13B-16k as the target LLMs, both accessible via OpenAI7 and Hugging Face 8. To ensure stable and reproducible results, we employ greedy decoding and set the temperature to 0 in all experiments. For the small language models used for compression, we apply LLaMA-2-7B-Chat9, which has been aligned by supervised fine-tuning and RLHF. We implement our approach with PyTorch 1.13.1 and HuggingFace Transformers. We set up hyper parameters following LLMLingua except for the segment size used in iterative token-level compression set to 200 here. More details are provided in Appendix B.
实现细节
本文采用 GPT-3.5-Turbo $.0613^{6}$ 和 LongChat-13B-16k 作为目标大语言模型,二者分别通过 OpenAI 和 Hugging Face 平台调用。为确保实验结果的稳定性与可复现性,所有实验均采用贪婪解码策略并将温度参数设为 0。用于压缩任务的小型语言模型选用经过监督微调与 RLHF 对齐的 LLaMA-2-7B-Chat,实验基于 PyTorch 1.13.1 和 HuggingFace Transformers 实现。超参数设置沿用 LLMLingua 方案,仅将迭代token级压缩中的分段尺寸调整为 200。更多细节详见附录 B。
Dataset & evaluation metric We use Natural Questions for the multi-document QA task, and use LongBench and Zero SCROLLS for general long context scenarios. We also test on multihop QA tasks using MuSiQue dataset (Trivedi et al., 2022), and long dependency QA tasks using LooGLE benchmark (Li et al., 2023b). Please refer to Appendix C for more details on datasets.
数据集与评估指标
我们使用Natural Questions进行多文档问答任务,并采用LongBench和Zero SCROLLS评估通用长文本场景。此外,基于MuSiQue数据集[20]测试多跳问答任务,使用LooGLE基准[21]评估长依赖问答任务。更多数据集细节详见附录C。
Baselines We include two sets of baselines in following experiments:
基线方法
我们在后续实验中包含两组基线方法:
(i) Retrieval-based Methods. We assess the question-document association in the prompt using five SoTA retrieval methods: BM25, Gzip (Jiang et al., 2023b), Sentence BERT (Reimers and Gurevych, 2019), OpenAI Embedding, and the Long LL M Lingua ranker’s important metric $r_{k}$ for coarse-grained compression. Notably, embedding model-based compression mirrors the method in Xu et al. (2024). We remove low-relevance sentences or paragraphs to meet compression limits, maintaining the original document sequence.
(i) 基于检索的方法。我们使用五种最先进的检索方法评估提示中的问题-文档关联性:BM25、Gzip (Jiang et al., 2023b)、Sentence BERT (Reimers and Gurevych, 2019)、OpenAI Embedding以及长文本大语言模型Lingua排序器的重要指标$r_{k}$(用于粗粒度压缩)。值得注意的是,基于嵌入模型的压缩方法遵循Xu et al. (2024)的方案。我们会移除低相关性的句子或段落以满足压缩限制,同时保持文档原始顺序。
(ii) Compression-based Methods. We compare our approach with two state-of-art methods for prompt compression, i.e., Selective Context (Li et al., 2023c) and LLMLingua (Jiang et al., 2023a). Both methods employ LLaMA-2-7B-Chat as the small language model for compression. In LLMLingua, a coarse-to-fine approach is used to handle constraints of compression ratio: the original prompt is first compressed to $k$ times the constraint at a coarse level, where $k$ is the granular control coefficient; token-level is then performed to reach the overall constraint. Our method follows the same coarse-to-fine logic to achieve the constraint.
(ii) 基于压缩的方法。我们将本方法与两种先进的提示词压缩方法进行比较,即 Selective Context (Li et al., 2023c) 和 LLMLingua (Jiang et al., 2023a)。两种方法均采用 LLaMA-2-7B-Chat 作为压缩用的小型语言模型。在 LLMLingua 中,采用由粗到精的方法处理压缩比约束:原始提示词首先在粗粒度层面被压缩至约束值的 $k$ 倍,其中 $k$ 为粒度控制系数;随后通过 token 级压缩达成整体约束。我们的方法遵循相同的由粗到精逻辑来实现约束。
Main results Table 1 and 2 present the performance of various methods under different compression constraints. There are multiple observations and conclusions: (1) Our Long LL M Lingua achieves the best performance across different tasks and constraints of compression ratios. Compared to the original prompt, our compressed prompt can derive higher performance with much lower cost. For example, Long LL M Lingua gains a performance boost of $21.4%$ on Natural Questions with the ground-truth document at the 10th position, while the number of tokens input to GPT3.5-Turbo is ${\sim}4\mathbf{X}$ less. (2) Compression-based methods like Selective Context (Li et al., 2023c) and LLMLingua (Jiang et al., 2023a) perform poorly on most tasks, especially those with abundant irrelevant information in the original prompt. This is due to their pure information entropy based compression mechanism, which includes too much noise in the compressed results and even leads to performance worse than the zero-shot setting, e.g., on Natural Questions. (3) Retrieval-based methods work well with low compression ratios. However, their performance declines as the compression progresses, e.g., $2x\rightarrow4x$ ; 3000 tokens $\rightarrow$ 2000 tokens. This may be caused by the decreased recall. Figure 3a is the illustration of cases on Natural Questions. (4) Long LL M Lingua as well as our coarse-grained compression metric $r_{k}$ only is much more robust than all other baselines under different tasks and compression constraints. With the increase of the compression ratio, e.g., $2x\rightarrow4x$ , Long LL M Lingua even achieves a little performance gain. We mainly owe this to the question-aware coarse-to-fine compression, which can better figure out the key information and reach a higher key information density with a higher compression ratio. (5) The proposed reordering method helps in not only our approach but also other baselines, well demonstrating its effectiveness. (6) Compared to the results with a 2,000 tokens constraint, overall performance of 3,000 tokens has improved. Long LL M Lingua sees an increase of 1.2 points in average score and a $1.6\mathrm{x}$ speedup in end-to-end latency. In this scenario, the recall rates of retrieval-based methods have increased, leading to a significant improvement in their accuracy. For example, BM25 achieves an average score of 48.9.
主要结果
表1和表2展示了不同方法在多种压缩约束下的性能表现。我们得出以下观察与结论:
(1) 我们的Long LLM Lingua在不同任务和压缩比约束下均取得最佳性能。相比原始提示,压缩后的提示能以更低成本获得更高性能。例如,在Natural Questions任务中,当真实文档位于第10位时,Long LLM Lingua性能提升达$21.4%$,而输入GPT-3.5 Turbo的token数量减少约${\sim}4\mathbf{X}$。
(2) 基于压缩的方法(如Selective Context [Li et al., 2023c]和LLMLingua [Jiang et al., 2023a])在多数任务中表现不佳,尤其当原始提示包含大量无关信息时。这源于其纯信息熵压缩机制会导致压缩结果包含过多噪声,甚至在Natural Questions等任务中表现差于零样本设置。
(3) 基于检索的方法在低压缩比下表现良好,但随着压缩程度加深(如$2x\rightarrow4x$;3000 token$\rightarrow$2000 token),性能会因召回率下降而降低。图3a展示了Natural Questions的案例。
(4) Long LLM Lingua及我们提出的粗粒度压缩指标$r_{k}$在不同任务和压缩约束下均展现出最强鲁棒性。当压缩比增大时(如$2x\rightarrow4x$),Long LLM Lingua甚至能实现小幅性能提升,这归功于问题感知的由粗到细压缩机制能更精准定位关键信息,从而在更高压缩比下保持关键信息密度。
(5) 提出的重排序方法不仅对我们的方法有效,也能提升其他基线性能,充分验证其有效性。
(6) 相比2000 token约束,3000 token约束下整体性能有所提升:Long LLM Lingua平均分提高1.2分,端到端延迟加速$1.6\mathrm{x}$。此场景下基于检索方法的召回率提升使其准确率显著改善,例如BM25平均分达到48.9。
In addition, we also present experimental results on datasets such as MuSicQue, LooGLE, ZEROSCROLLS, etc., in Appendix C.
此外,我们还在附录 C 中展示了 MuSicQue、LooGLE、ZEROSCROLLS 等数据集的实验结果。
Ablation study To evaluate the contributions of different components in Long LL M Lingua, we
消融实验
为了评估Long LL M Lingua中不同组件的贡献,我们
Table 1: Performance of different methods with different compression ratios (raw size / compressed size $=1/\tau$ ) on Natural Questions (20 documents) (Liu et al., 2024). Reorder: we reorder the documents with relevance metrics of different baselines as our document reordering strategy described in Sec. 4.2. In the case of OpenAI, it corresponds to Long Context Reorder 9 in the LangChain framework (Chase, 2022). For results reported under 1st to $20\mathrm{th}$ , we do not use the reordering strategy for all methods.
| Methods | 1st | GPT3.5-Turbo | LongChat-13b | Length | Latency | 10th 15th 20th Reorder|Tokens 1/T|Latency Speedup | ||||||||||||
| 5th | 10th 15th 20th Reorder|1st5th | |||||||||||||||||
| 2x constraint | ||||||||||||||||||
| Retrieval-basedMethods | ||||||||||||||||||
| BM25 | 53.749.347.9 | 949.9 | 46.9 | 50.3 | 50.9 44.9 44.1 | 42.9 | 43.2 | 46.0 | 1,545 | 1.9x | 2.1 | 1.9x | ||||||
| Gzip | 64.6 | 63.8 | 60.5 | 58.3 | 57.3 | 64.4 | 61.9 | 55.7 | 52.7 | 50.8 | 50.9 | 59.3 | 1,567 | 1.9x | 2.1 | 1.9x | ||
| SBERT | 72.5 | 67.9 | 63.3 | 65.0 | 66.2 | 68.7 | 65.8 | 357.5 | 54.9 | 53.4 | 55.7 | 61.4 | 1,549 | 1.9x | 2.2 | 1.9x | ||
| OpenAI | 73.0( | 65.6 | 66.5 | 65.4 | 65.5 | 69.9 | 65.9 | 57.5 | 56.2 | 54.2 | 55.7 | 61.7 | 1,550 | 1.9x | 4.9 | 0.8x | ||
| LongLLMLingua rk | 73.9 | 67.7 | 68.7 | 66.0 | 65.6 | 74.3 | 68.5 59.1 | 56.8 | 55.3 | 56.9 | 65.2 | 1,548 | 1.9x | 2.3 | 1.8x | |||
| Compression-basedMethods | ||||||||||||||||||
| Selective-Context | 45.4 39.033.8 | 333.5 | 41.5 | 53.2 26.3 25.4 24.2 | 33.3 | 1,478 | 2.0x | 7.4 | 0.6x | |||||||||
| LLMLingua | 39.7 39.5 40.4 | 37.1 | 42.3 | 41.5 | 38.7 37.3 | 35.7 | 34.1 | 37.5 | 37.1 | 1,410 | 2.1x | 2.8 | 1.5x | |||||
| LongLLMLingua | 77.272.9 | 70.8 | 70.5 | 70.6 | 76.2 | 68.7 | 59.4 | 57.3 | 55.9 | 58.4 | 66.1 | 1,429 | 2.1x | 2.9 | 1.4x | |||
| 4xconstraint | ||||||||||||||||||
| Retrieval-basedMethods | 3.7x | |||||||||||||||||
| BM25 | 40.638.638.2 37.4 | 36.6 | 36.3 | 39.5 37.5 36.8 36.4 | :35.5 | 37.7 | 798 | 1.5 | 2.7x | |||||||||
| Gzip | 63.1( | 61.0 59.8 | 61.1 | 60.1 | 62.3 | 57.6 52.9 | 51.0 | 50.1 | 50.4 | 57.2 | 824 | 3.6x | 1.5 | 2.7x | ||||
| SBERT | 66.9 | 61.1 | 59.0 | 61.2 | 60.3 | 64.4 | 62.6 56.6 | 55.1 | 53.9 | 55.0 | 59.1 | 808 | 3.6x | 1.6 | 2.5x | |||
| OpenAI | 63.8 | 64.6 | 65.4 | 64.1 | 63.7 | 63.7 | 61.2 56.0 | 55.1 | 54.4 | 55.0 | 58.8 | 804 | 3.7x | 4.3 | 1.0x | |||
| LongLLMLingua rk | 71.1 | 70.7 | 69.3 | 68.7 | 68.5 | 71.5 | 67.8 | 59.4 | 57.7 | 57.7 | 58.6 | 64.0 | 807 | 3.7x | 1.7 | 2.4x | ||
| Compression-basedMethods | ||||||||||||||||||
| 24.1 | 38.2 | 17.2 | 15.9 | 791 | 3.7x | 6.8 | 0.6x | |||||||||||
| Selective-Context LLMLingua | 31.4 19.5 24.7 | 25.5 27.5 23.5 | 26.5 | 43.8 30.0 | 27.0 | 32.1 | 30.82 | 29.9 | 16.0 28.9 | 27.3 32.4 | 30.5 | 775 | 3.8x | 1.8 | 2.2x | |||
| LongLLMLingua | 71.8 | 71.2 | 71.2 | 74.7 | 75.5 | 68.7 | 60.5 | 59.3 | 58.3 | 61.3 | 66.7 | 748 | 3.9x | 2.1 | 2.0x | |||
| Original Prompt | 75.0 | 55.0 | 2,946 | 4.1 | ||||||||||||||
| Zero-shot | 75.7 | 57.3 54.1 | 155.4 56.1 | 63.1 | - 68.6 | 557.455.3 | 352.5 35.0 | |||||||||||
表 1: 不同压缩比 (原始大小/压缩大小 $=1/\tau$) 下各方法在 Natural Questions (20篇文档) 上的性能表现 (Liu et al., 2024)。重排序: 我们使用不同基线相关性指标对文档进行重排序,具体策略如第4.2节所述。对于OpenAI,其对应LangChain框架中的Long Context Reorder 9 (Chase, 2022)。在报告第1至$20\mathrm{th}$位结果时,所有方法均未使用重排序策略。
| 方法 | 1st | GPT3.5-Turbo 5th | 10th 15th 20th 重排序 | LongChat-13b 1st5th | 10th 15th 20th 重排序 | 长度 | 延迟 | 加速比 | Token数 | 1/T | 延迟 | 加速比 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2x约束 | ||||||||||||
| 基于检索的方法 | ||||||||||||
| BM25 | 53.7 49.3 47.9 | 949.9 | 46.9 50.3 | 50.9 44.9 44.1 | 42.9 | 43.2 | 46.0 | 1,545 | 1.9x | 2.1 | 1.9x | |
| Gzip | 64.6 | 63.8 60.5 58.3 | 57.3 64.4 | 61.9 55.7 52.7 | 50.8 50.9 | 59.3 | 1,567 | 1.9x | 2.1 | 1.9x | ||
| SBERT | 72.5 | 67.9 63.3 65.0 | 66.2 68.7 | 65.8 357.5 54.9 | 53.4 55.7 | 61.4 | 1,549 | 1.9x | 2.2 | 1.9x | ||
| OpenAI | 73.0 | 65.6 66.5 65.4 | 65.5 69.9 | 65.9 57.5 56.2 | 54.2 55.7 | 61.7 | 1,550 | 1.9x | 4.9 | 0.8x | ||
| LongLLMLingua | 73.9 | 67.7 68.7 66.0 | 65.6 74.3 | 68.5 59.1 56.8 | 55.3 56.9 | 65.2 | 1,548 | 1.9x | 2.3 | 1.8x | ||
| 基于压缩的方法 | ||||||||||||
| Selective-Context | 45.4 39.0 33.8 | 333.5 | 41.5 | 53.2 26.3 25.4 24.2 | 33.3 | 1,478 | 2.0x | 7.4 | 0.6x | |||
| LLMLingua | 39.7 39.5 40.4 | 37.1 42.3 | 41.5 | 38.7 37.3 35.7 34.1 | 37.5 | 37.1 | 1,410 | 2.1x | 2.8 | 1.5x | ||
| LongLLMLingua | 77.2 72.9 70.8 | 70.5 70.6 | 76.2 68.7 | 59.4 57.3 55.9 58.4 | 66.1 | 1,429 | 2.1x | 2.9 | 1.4x | |||
| 4x约束 | ||||||||||||
| 基于检索的方法 | ||||||||||||
| BM25 | 40.6 38.6 38.2 | 37.4 | 36.6 36.3 | 39.5 37.5 36.8 36.4 | 35.5 | 37.7 | 798 | 3.7x | 1.5 | 2.7x | ||
| Gzip | 63.1 61.0 59.8 | 61.1 60.1 | 62.3 | 57.6 52.9 51.0 50.1 | 50.4 | 57.2 | 824 | 3.6x | 1.5 | 2.7x | ||
| SBERT | 66.9 | 61.1 59.0 61.2 | 60.3 64.4 | 62.6 56.6 55.1 | 53.9 55.0 | 59.1 | 808 | 3.6x | 1.6 | 2.5x | ||
| OpenAI | 63.8 | 64.6 65.4 64.1 | 63.7 63.7 | 61.2 56.0 55.1 | 54.4 55.0 | 58.8 | 804 | 3.7x | 4.3 | 1.0x | ||
| LongLLMLingua | 71.1 | 70.7 69.3 68.7 | 68.5 71.5 | 67.8 59.4 57.7 | 57.7 58.6 | 64.0 | 807 | 3.7x | 1.7 | 2.4x | ||
| 基于压缩的方法 | ||||||||||||
| Selective-Context | 24.1 | 38.2 | 17.2 15.9 | 791 | 3.7x | 6.8 | 0.6x | |||||
| LLMLingua | 31.4 | 19.5 24.7 25.5 | 27.5 23.5 | 26.5 43.8 30.0 | 27.0 32.1 30.82 29.9 | 16.0 | 28.9 | 27.3 | 32.4 | 30.5 | 775 | 3.8x |
| LongLLMLingua | 71.8 71.2 71.2 | 74.7 75.5 | 68.7 60.5 59.3 | 58.3 61.3 | 66.7 | 748 | 3.9x | 2.1 | 2.0x | |||
| 原始提示 | 75.0 | 55.0 | 2,946 | 4.1 | ||||||||
| 零样本 | 75.7 | 57.3 54.1 | 155.4 56.1 | 63.1 | - 68.6 557.4 55.3 | 352.5 | 35.0 |
introduce following variants of it for ablation study. (1) Variants about Question-aware Coarsegrained Compression, include: ours w/o Questionawareness, which calculates question-text relevance $r_{k}$ using information entropy in LLMLingua, ours w/ SBERT, which employs SBERT to compute rk, ours w/ p(xdko c|xique,restrict), which replace $p(x_{i}^{\mathrm{que,restrict}}|\mathbf{x}_ {k}^{\mathrm{doc}})$ with $p(\mathbf{x}_ {k}^{\mathrm{doc}}|x_{i}^{\mathrm{que,restrict}})$ in Eq. (2), and ours w/o restrict, which only calculates the conditional probability corresponding to $x^{\mathrm{que}}$ . (2) Ours w/o Question-aware Fine-grained, which disregards Eq. (3) and only applies Iterative Token-level Prompt Compression as LLMLingua. (3) Ours w/o Dynamic Compression Ratio, where all documents share the same compression ratio in fine-grained compression. (4) Ours w/o and (5) LLMLingua w/ Sub sequence Recovery, which either removes or adds the post-processing subsequence recovery strategy. (6) Ours w/ GPT2-small, which uses the GPT2-small model as the $\mathcal{M}_{S}$ .
为进行消融研究,我们引入以下变体:(1) 关于问题感知粗粒度压缩的变体,包括:ours w/o Questionawareness(在LLMLingua中使用信息熵计算问题-文本相关性 $r_{k}$),ours w/ SBERT(使用SBERT计算 $r_{k}$),ours w/ p(xdko c|xique,restrict)(将式(2)中的 $p(x_{i}^{\mathrm{que,restrict}}|\mathbf{x}_ {k}^{\mathrm{doc}})$ 替换为 $p(\mathbf{x}_ {k}^{\mathrm{doc}}|x_{i}^{\mathrm{que,restrict}})$),以及ours w/o restrict(仅计算与 $x^{\mathrm{que}}$ 对应的条件概率)。(2) Ours w/o Question-aware Fine-grained(忽略式(3),仅应用LLMLingua中的迭代Token级提示压缩)。(3) Ours w/o Dynamic Compression Ratio(在细粒度压缩中所有文档共享相同压缩比)。(4) Ours w/o 和 (5) LLMLingua w/ Sub sequence Recovery(分别移除或添加后处理的子序列恢复策略)。(6) Ours w/ GPT2-small(使用GPT2-small模型作为 $\mathcal{M}_{S}$)。
Table 3, 4, and 7 shows the results of the ablation study in difference tasks. In summary, removing any component proposed for Long LL M Lingua will lead to a performance drop regardless of the position of the ground-truth answer. This well validates the necessity and effectiveness of the proposed question-aware mechanism during coarse-to-fine compression, the dynamic compression ratio, and the sub sequence recovery strategy. It also shows that applying SBERT for coarse-grained compression will result in inferior performance, which implies the superiority of our question-aware imporplacing $p(x_{i}^{\mathrm{que,restrict}}|\mathbf{x}_ {k}^{\mathrm{doc}})$ with $p(\mathbf{x}_ {k}^{\mathrm{doc}}|x_{i}^{\mathrm{que,restrict}})$ can greatly affect performance due to the large noise in calculating $p(\mathbf{x}_{k}^{\mathrm{doc}})$ since the perplexity of document depends on many other information besides the question. Removing the restrictive statement can increase the hallucination of small language models, leading to a decrease in performance. Moreover, our sub sequence recovery strategy can also bring performance gains for LLMLingua. However, without our question-aware mechanism, results from LLMLingua are still less satisfactory. For more detailed cases, please go to Appendix E.
表 3、4 和 7 展示了不同任务中的消融研究结果。总体而言,无论真实答案的位置如何,移除 Long LLM Lingua 提出的任何组件都会导致性能下降。这充分验证了在粗到细压缩过程中提出的问题感知机制、动态压缩比和子序列恢复策略的必要性和有效性。研究还表明,使用 SBERT 进行粗粒度压缩会导致性能较差,这暗示了我们问题感知方法的优越性。将 $p(x_{i}^{\mathrm{que,restrict}}|\mathbf{x}_ {k}^{\mathrm{doc}})$ 替换为 $p(\mathbf{x}_ {k}^{\mathrm{doc}}|x_{i}^{\mathrm{que,restrict}})$ 会显著影响性能,因为在计算 $p(\mathbf{x}_{k}^{\mathrm{doc}})$ 时存在较大噪声(文档的复杂度取决于问题之外的许多其他信息)。移除限制性语句会增加小语言模型的幻觉,导致性能下降。此外,我们的子序列恢复策略也能为 LLMLingua 带来性能提升。然而,若缺少问题感知机制,LLMLingua 的结果仍不够理想。更多详细案例请参阅附录 E。
| Methods | |||||||||||
| 3,000 tokens constraint | |||||||||||
| Retrieval-basedMethods | |||||||||||
| BM25 | 32.3 | 34.3 | 25.3 | 57.9 | 45.1 | 48.9 | 40.6 | 3,417 | 3x | 7.5 7.7 | 2.1x 2.0x |
| SBERT OpenAI | 35.3 | 37.4 | 26.7 | 63.4 | 51.0 | 34.5 | 41.4 | 3,399 | 3x | 13.3 | 1.2x |
| LongLLMLingua rk | 34.5 37.6 | 38.6 42.9 | 26.8 26.9 | 63.4 68.2 | 49.6 49.9 | 37.6 53.4 | 41.7 46.5 | 3,421 3,424 | 3x 3x | 8.2 | 1.9x |
| Compression-basedMethods | |||||||||||
| Selective-Context | 23.3 | 39.2 | 25.0 | 23.8 | 27.5 | 53.1 | 32.0 | 3,328 | 3x | 50.6 | 0.3x |
| LLMLingua | 31.8 | 37.5 | 26.2 | 67.2 | 8.3 | 53.2 | 37.4 | 3,421 | 3x | 9.2 | 1.7x |
| LongLLMLingua | 40.7 | 46.2 | 27.2 | 70.6 | 53.0 | 55.2 | 48.8 | 3,283 | 3x | 10.0 | 1.6x |
| 2,000 tokens constraint | |||||||||||
| Retrieval-basedMethods BM25 | 29.4 | 21.2 | 19.5 | 12.4 | 29.1 | 23.6 | 1,985 | 5x | 4.6 | 3.4x | |
| SBERT | 30.1 33.8 | 35.9 | 25.9 | 23.5 | 18.0 | 17.8 | 25.8 | 1,947 | 5x | 4.8 | 3.4x |
| OpenAI | 34.3 | 36.3 | 24.7 | 32.4 | 26.3 | 24.8 | 29.8 | 1,991 | 5x | 10.4 | 1.5x |
| LongLLMLingua rk | 37.8 | 41.7 | 26.9 | 66.3 | 53.0 | 52.4 | 46.3 | 1,960 | 5x | 4.7 | 3.3x |
| Compression-basedMethods | |||||||||||
| Selective-Context | 16.2 | 34.8 | 24.4 | 15.7 | 8.4 | 49.2 | 24.8 | 1,925 | 5x | 47.1 | 0.3x |
| LLMLingua | 22.4 | 32.1 | 24.5 | 61.2 | 10.4 | 56.8 | 34.6 | 1,950 | 5x | 5.9 | 2.6x |
| LongLLMLingua | 39.9 | 43.2 | 27.4 | 69.8 | 53.0 | 56.7 | 48.3 | 1,822 | 6x | 6.1 | 2.6x |
| Original Prompt | 39.7 | 38.7 | 26.5 | 67.0 | 37.8 | 54.2 | 44.0 | 10,295 | 15.6 | ||
| Zero-shot | 15.6 | 31.3 | 15.6 | 40.7 | 1.6 | 36.2 | 23.5 | 214 | 48x | 1.6 | 9.8x |
Table 2: Performance of different methods under different compression ratios on LongBench (Bai et al., 2023) using GPT-3.5-Turbo in 2,000 tokens constraint.
| 方法 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3000 token限制 | |||||||||||
| 基于检索的方法 | |||||||||||
| BM25 | 32.3 | 34.3 | 25.3 | 57.9 | 45.1 | 48.9 | 40.6 | 3417 | 3x | 7.5 7.7 | 2.1x 2.0x |
| SBERT OpenAI | 35.3 | 37.4 | 26.7 | 63.4 | 51.0 | 34.5 | 41.4 | 3399 | 3x | 13.3 | 1.2x |
| LongLLMLingua rk | 34.5 37.6 | 38.6 42.9 | 26.8 26.9 | 63.4 68.2 | 49.6 49.9 | 37.6 53.4 | 41.7 46.5 | 3421 3424 | 3x 3x | 8.2 | 1.9x |
| 基于压缩的方法 | |||||||||||
| Selective-Context | 23.3 | 39.2 | 25.0 | 23.8 | 27.5 | 53.1 | 32.0 | 3328 | 3x | 50.6 | 0.3x |
| LLMLingua | 31.8 | 37.5 | 26.2 | 67.2 | 8.3 | 53.2 | 37.4 | 3421 | 3x | 9.2 | 1.7x |
| LongLLMLingua | 40.7 | 46.2 | 27.2 | 70.6 | 53.0 | 55.2 | 48.8 | 3283 | 3x | 10.0 | 1.6x |
| 2000 token限制 | |||||||||||
| 基于检索的方法 | |||||||||||
| BM25 | 29.4 | 21.2 | 19.5 | 12.4 | 29.1 | 23.6 | 1985 | 5x | 4.6 | 3.4x | |
| SBERT | 30.1 33.8 | 35.9 | 25.9 | 23.5 | 18.0 | 17.8 | 25.8 | 1947 | 5x | 4.8 | 3.4x |
| OpenAI | 34.3 | 36.3 | 24.7 | 32.4 | 26.3 | 24.8 | 29.8 | 1991 | 5x | 10.4 | 1.5x |
| LongLLMLingua rk | 37.8 | 41.7 | 26.9 | 66.3 | 53.0 | 52.4 | 46.3 | 1960 | 5x | 4.7 | 3.3x |
| 基于压缩的方法 | |||||||||||
| Selective-Context | 16.2 | 34.8 | 24.4 | 15.7 | 8.4 | 49.2 | 24.8 | 1925 | 5x | 47.1 | 0.3x |
| LLMLingua | 22.4 | 32.1 | 24.5 | 61.2 | 10.4 | 56.8 | 34.6 | 1950 | 5x | 5.9 | 2.6x |
| LongLLMLingua | 39.9 | 43.2 | 27.4 | 69.8 | 53.0 | 56.7 | 48.3 | 1822 | 6x | 6.1 | 2.6x |
| Original Prompt | 39.7 | 38.7 | 26.5 | 67.0 | 37.8 | 54.2 | 44.0 | 10295 | 15.6 | ||
| Zero-shot | 15.6 | 31.3 | 15.6 | 40.7 | 1.6 | 36.2 | 23.5 | 214 | 48x | 1.6 | 9.8x |
表 2: 使用GPT-3.5-Turbo在2000 token限制下不同方法在LongBench (Bai et al., 2023)上的性能表现。
Table 3: Ablation study on Natural Questions with $2\mathbf{x}$ constraint using GPT-3.5-Turbo.
| 1st5th10th15th20th LongLLMLingua 77.272.9 70.870.570.6 |
| Question-awareCoarse-grained -w/oQuestion-awareness 42.140.339.740.140.3 -W/SBERT 73.268.565.766.166.7 56.052.653.451.651.1 -w/orestrict 75.172.270.3 70.370.2 |
| -w/oQuestion-awareFine-grained75.871.068.968.469.3 -w/o Dynamic Compression Ratio 74.4 70.7 68.7 67.9 68.1 w/oSubsequenceRecovery 76.771.769.4 69.3 69.7 -w/DocumentReordering 76.276.276.276.276.2 |
| -w/GPT2-small 74.6 71.7 70.1 69.8 68.5 LLMLingua 39.739.540.437.142.3 - w/ Subsequence Recovery 43.8 44.1 43.5 43.3 44.4 |
表 3: 使用 GPT-3.5-Turbo 在 $2\mathbf{x}$ 约束下对 Natural Questions 进行的消融研究
| 1st | 5th | 10th | 15th | 20th | LongLLMLingua | 77.2 | 72.9 | 70.8 | 70.5 | 70.6 |
|---|---|---|---|---|---|---|---|---|---|---|
| Question-awareCoarse-grained -w/oQuestion-awareness | 42.1 | 40.3 | 39.7 | 40.1 | 40.3 | -W/SBERT | 73.2 | 68.5 | 65.7 | 66.1 |
| -w/oQuestion-awareFine-grained | 75.8 | 71.0 | 68.9 | 68.4 | 69.3 | -w/o Dynamic Compression Ratio | 74.4 | 70.7 | 68.7 | 67.9 |
| -w/GPT2-small | 74.6 | 71.7 | 70.1 | 69.8 | 68.5 | LLMLingua | 39.7 | 39.5 | 40.4 | 37.1 |
Latency evaluation We conducte end-to-end latency testing on a V100-32G, using the prompts from Multi-document QA, LongBench, and ZeroSCROLLS in the API call, and results are shown in Table 1, 2 and 6. The latency includes the time cost for prompt compression and the request time for LLMs, with multiple measurements taken and averaged over. Results demonstrate that LongLLMLingua does indeed speed up the overall inference under different compression ratios and scenarios. Moreover, with the compression ratio increasing, the acceleration effect becomes more pronounced up to 2.6x. However, the OpenAI embedding and Selective-Context results in longer latency time, due to repeated API calls and the sequential entropy calculation of semantic units, respectively.
延迟评估
我们在V100-32G上进行了端到端延迟测试,使用了Multi-document QA、LongBench和ZeroSCROLLS中的提示进行API调用,结果如表1、表2和表6所示。延迟包括提示压缩的时间成本和LLM的请求时间,经过多次测量取平均值。结果表明,LongLLMLingua在不同压缩比和场景下确实加速了整体推理。此外,随着压缩比的增加,加速效果最高可达2.6倍。然而,OpenAI嵌入和Selective-Context由于重复的API调用和语义单元的序列熵计算,分别导致了更长的延迟时间。
6 Related Works
6 相关工作
Long context for LLMs. Recent research has focused on expanding the window size of LLMs. Main approaches include: (1) Staged pre-training (Nijkamp et al., 2023) which gradually increases the context window; (2) Modifying (Press et al., 2022) or interpolating position em- beddings (Chen et al., 2023; Peng et al., 2024); (3) Using linear or sparse attention mechanisms (Ding et al., 2023; Sun et al., 2023); (4) Utilizing exter- nal memory modules for context storage (Bertsch et al., 2023; Tworkowski et al., 2023). While these methods address context window expansion, their impact on downstream task performance has yet to be discussed.
大语言模型的长上下文处理。近期研究主要聚焦于扩展大语言模型的窗口尺寸,主要方法包括:(1) 分阶段预训练 (Nijkamp et al., 2023) 逐步增大上下文窗口;(2) 修改 (Press et al., 2022) 或插值位置嵌入 (Chen et al., 2023; Peng et al., 2024);(3) 采用线性或稀疏注意力机制 (Ding et al., 2023; Sun et al., 2023);(4) 利用外部记忆模块存储上下文 (Bertsch et al., 2023; Tworkowski et al., 2023)。尽管这些方法解决了上下文窗口扩展问题,但其对下游任务性能的影响仍有待探讨。
Information distribution in prompt. Recent empirical experiments have shown that LLM performance decreases with less effective information in a prompt (Bai et al., 2023; Li et al., 2023a; Shi et al., 2023). Moreover, the position of relevant information in a prompt has a significant impact on performance (Wu et al., 2023b). Liu et al. (2024) suggests that LLMs have more difficulty comprehending information located in the middle of a prompt compared to those at the edges.
提示中的信息分布。最近的实证实验表明,随着提示中有效信息的减少,大语言模型的性能会下降 (Bai et al., 2023; Li et al., 2023a; Shi et al., 2023)。此外,提示中相关信息的位置对性能有显著影响 (Wu et al., 2023b)。Liu et al. (2024) 指出,与位于边缘的信息相比,大语言模型更难理解位于提示中间位置的信息。
Retrieval methods can be categorized as dense or sparse retrieval methods. Sparse retrieval methods, like BM25, determine the relevance between queries and documents based on n-gram information. Conversely, dense retrieval methods assess the relevance between queries and documents in latent space using embedding model (Reimers and Gurevych, 2019; Xiao et al., 2023; Günther et al., 2023) and reranker model (Xiao et al., 2023). Re- cently, Jiang et al. (2023b) proposed an unsupervised dense retrieval method that leverages traditional compression algorithms, such as gzip, and $\mathrm{k\Omega}$ -nearest neighbors.
检索方法可分为稠密检索和稀疏检索两类。稀疏检索方法(如BM25)基于n-gram信息判断查询与文档的相关性。相反,稠密检索方法通过嵌入模型(Reimers和Gurevych,2019;Xiao等,2023;Günther等,2023)和重排序模型(Xiao等,2023)在潜在空间中评估查询与文档的相关性。最近,Jiang等(2023b)提出了一种无监督稠密检索方法,该方法利用传统压缩算法(如gzip)和$\mathrm{k\Omega}$-近邻算法。
Prompt compression methods can be grouped into three main categories: (1) Token pruning (Goyal et al., 2020; Kim and Cho, 2021; Modar- ressi et al., 2022) and token merging (Bolya et al., 2023), which need model fine-tuning or intermediate results during inference and have been used with BERT-scale models. (2) Soft prompt tuning methods like GIST (Mu et al., 2023), AutoCompressor (Chevalier et al., 2023), and ICAE (Ge et al., 2024), which require LLMs’ parameter finetuning, making them suitable for specific domains but not directly applicable to black-box LLMs. (3) Information-entropy-based approaches such as Selective Context (Li et al., 2023c) and LLMLingua (Jiang et al., 2023a), which use a small language model to calculate the self-information or perplexity of each token in the original prompt and then remove tokens with lower perplexities.
提示词压缩方法可分为三大类:(1) Token剪枝 (Goyal et al., 2020; Kim and Cho, 2021; Modarressi et al., 2022) 和Token合并 (Bolya et al., 2023),这些方法需要模型微调或推理过程中的中间结果,已在BERT规模模型中应用。(2) 软提示调优方法如GIST (Mu et al., 2023)、AutoCompressor (Chevalier et al., 2023) 和ICAE (Ge et al., 2024),需要大语言模型参数微调,适用于特定领域但无法直接用于黑盒大语言模型。(3) 基于信息熵的方法如Selective Context (Li et al., 2023c) 和LLMLingua (Jiang et al., 2023a),使用小型语言模型计算原始提示中每个Token的自信息或困惑度,然后移除困惑度较低的Token。
7 Conclusion
7 结论
We propose Long LL M Lingua to address the three challenges, i.e., higher computational cost, performance reduction, and position bias for LLMs in long context scenarios. We develop LongLLMLingua from the perspective of efficient prompt compression, thus reducing computational cost. We further design four components, i.e., a questionaware coarse-to-fine compression method, a document reordering mechanism, dynamic compression ratios, and a sub sequence recovery strategy to improve LLMs’ perception of the key information, with which Long LL M Lingua demonstrate superior performance. Experiments on the multidocument QA, multi-hop QA, and long context benchmarks demonstrate that Long LL M Lingua compressed prompt can derive higher performance than original prompts while both API costs for inference and the end-to-end system latency are largely reduced.
我们提出LongLLMLingua来解决大语言模型在长上下文场景下面临的三大挑战:计算成本高、性能下降和位置偏差。该方案从高效提示压缩的角度切入以降低计算开销,并创新性地设计了四个核心组件:(1) 问题感知的由粗到细压缩方法,(2) 文档重排序机制,(3) 动态压缩比率,以及(4) 子序列恢复策略,从而显著提升大语言模型对关键信息的感知能力。在多文档问答、多跳问答和长上下文基准测试中,经LongLLMLingua压缩的提示不仅推理API成本大幅降低、端到端系统延迟显著减少,其性能表现更优于原始提示。
Limitation
局限性
Although previous experiments demonstrate Long LL M Lingua’s effectiveness and efficiency across a broad range of tasks, the method still has the following limitations: 1) Long LL M Lingua is a question-aware approach, meaning it requires re-compression for different questions, even with the same context, preventing caching of the context. Moreover, in terms of computational cost, Long LL M Lingua increases the computation by twice as much as LLMLingua. This can lead to greater overhead in real-world applications. However, this issue can be mitigated by extending the question-aware approach to a task-aware approach, allowing for reuse and caching. 2) While the effectiveness of Long LL M Lingua has been tested on a wide range of tasks, especially on the multi-hop QA dataset MuSicQue (Trivedi et al., 2022), its effectiveness might be impacted when the relationship between context and prompt is more complex and subtle due to the coarse-level question-aware approach.
尽管先前的实验证明了Long LL M Lingua在广泛任务中的有效性和效率,但该方法仍存在以下局限:1) Long LL M Lingua是一种问题感知方法,这意味着即使上下文相同,也需要针对不同问题重新压缩,无法缓存上下文。此外,在计算成本方面,Long LL M Lingua的计算量是LLMLingua的两倍,这在实际应用中可能导致更大开销。不过,通过将问题感知方法扩展为任务感知方法,可以实现复用和缓存,从而缓解该问题。2) 虽然Long LL M Lingua的有效性已在多种任务上得到验证(尤其在多跳问答数据集MuSicQue (Trivedi et al., 2022)上),但由于其粗粒度的问题感知特性,当上下文与提示间关系更为复杂微妙时,其效果可能会受到影响。
References
参考文献
Eleventh International Conference on Learning Represent at ions.
第十一届学习表征国际会议
Harrison Chase. 2022. LangChain.
Harrison Chase. 2022. LangChain.
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. 2023. Extending context window of large language models via positional interpolation. ArXiv preprint, abs/2306.15595.
Shouyuan Chen、Sherman Wong、Liangjian Chen 和 Yuandong Tian。2023。通过位置插值扩展大语言模型的上下文窗口。ArXiv预印本,abs/2306.15595。
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. 2023. Adapting language models to compress contexts. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3829–3846, Singapore. Association for Computational Linguistics.
Alexis Chevalier、Alexander Wettig、Anirudh Ajith 和 Danqi Chen。2023。使语言模型适应上下文压缩。载于《2023年自然语言处理实证方法会议论文集》,第3829-3846页,新加坡。计算语言学协会。
Kenneth Ward Church and Patrick Hanks. 1989. Word association norms, mutual information, and lexicography. In 27th Annual Meeting of the Association for Computational Linguistics, pages 76–83, Vancouver, British Columbia, Canada. Association for Computational Linguistics.
Kenneth Ward Church 和 Patrick Hanks. 1989. 词语关联规范、互信息和词典编纂. 见: 第27届计算语言学协会年会, 第76-83页, 加拿大不列颠哥伦比亚省温哥华. 计算语言学协会.
Grégoire Delétang, Anian Ruoss, Paul-Ambroise Duquenne, Elliot Catt, Tim Genewein, Christopher Mattern, Jordi Grau-Moya, Li Kevin Wenliang, Matthew Aitchison, Laurent Orseau, et al. 2023. Language modeling is compression. ArXiv preprint, abs/2309.10668.
Grégoire Delétang、Anian Ruoss、Paul-Ambroise Duquenne、Elliot Catt、Tim Genewein、Christopher Mattern、Jordi Grau-Moya、Li Kevin Wenliang、Matthew Aitchison、Laurent Orseau 等。2023. 语言建模即压缩。ArXiv 预印本,abs/2309.10668。
Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, and Furu Wei. 2023. Longnet: Scaling transformers to 1,000,000,000 tokens. ArXiv preprint, abs/2307.02486.
Jiayu Ding、Shuming Ma、Li Dong、Xingxing Zhang、Shaohan Huang、Wenhui Wang 和 Furu Wei。2023。LongNet:将Transformer扩展到10亿Token。ArXiv预印本,abs/2307.02486。
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiy- ong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2023. A survey for in-context learning. ArXiv preprint, abs/2301.00234.
董清秀、李磊、戴大迈、郑策、吴志勇、常宝宝、孙旭、徐晶晶、隋志芳。2023。上下文学习综述。ArXiv预印本,abs/2301.00234。
Tao Ge, Hu Jing, Lei Wang, Xun Wang, Si-Qing Chen, and Furu Wei. 2024. In-context auto encoder for context compression in a large language model. In The Twelfth International Conference on Learning Representations.
陶歌、胡静、王磊、王勋、陈思清和韦福如。2024. 大语言模型中的上下文自编码器用于上下文压缩。收录于第十二届国际学习表征会议。
Saurabh Goyal, Anamitra Roy Choudhury, Saurabh Raje, Venkatesan T. Cha kara var thy, Yogish Sabharwal, and Ashish Verma. 2020. Power-bert: Accelerating BERT inference via progressive word-vector elimination. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pages 3690–3699. PMLR.
Saurabh Goyal、Anamitra Roy Choudhury、Saurabh Raje、Venkatesan T. Chakravarthy、Yogish Sabharwal 和 Ashish Verma。2020。Power-bert:通过渐进式词向量消除加速 BERT 推理。载于《第 37 届国际机器学习会议论文集》(ICML 2020),2020 年 7 月 13-18 日,线上会议,《机器学习研究论文集》第 119 卷,第 3690–3699 页。PMLR。
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaed- dine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, and Han Xiao. 2023. Jina embeddings 2: 8192-token general-purpose text embeddings for long documents. ArXiv preprint, abs/2310.19923.
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaed-dine Abdessalem, Tanguy Abel, Mohammad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, and Han Xiao. 2023. Jina Embeddings 2: 支持8192 Token的长文档通用文本嵌入。ArXiv预印本, abs/2310.19923.
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research.
Gautier Izacard、Mathilde Caron、Lucas Hosseini、Sebastian Riedel、Piotr Bojanowski、Armand Joulin和Edouard Grave。2022。基于对比学习的无监督密集信息检索。机器学习研究汇刊。
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023a. LLMLingua: Compressing prompts for accelerated inference of large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13358–13376. Association for Computational Linguistics.
Huiqiang Jiang、Qianhui Wu、Chin-Yew Lin、Yuqing Yang 和 Lili Qiu。2023a。LLMLingua: 大语言模型加速推理的提示词压缩技术。载于《2023年自然语言处理实证方法会议论文集》,第13358–13376页。计算语言学协会。
Zhiying Jiang, Matthew Yang, Mikhail Tsirlin, Raphael Tang, Yiqin Dai, and Jimmy Lin. 2023b. “lowresource” text classification: A parameter-free classification method with compressors. In Findings of the Association for Computational Linguistics: ACL 2023, pages 6810–6828, Toronto, Canada. Associa- tion for Computational Linguistics.
Zhiying Jiang, Matthew Yang, Mikhail Tsirlin, Raphael Tang, Yiqin Dai, and Jimmy Lin. 2023b. "低资源"文本分类: 基于压缩器的无参数分类方法. 载于《计算语言学协会研究发现: ACL 2023》, 第6810–6828页, 加拿大多伦多. 计算语言学协会.
Greg Kamradt. 2023. Needle In A Haystack - Pressure Testing LLMs.
Greg Kamradt. 2023. 大海捞针 - 大语言模型压力测试
Gyuwan Kim and Kyunghyun Cho. 2021. Lengthadaptive transformer: Train once with length drop, use anytime with search. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6501–6511, Online. Association for Computational Linguistics.
Gyuwan Kim 和 Kyunghyun Cho. 2021. 长度自适应 Transformer (Length-adaptive Transformer): 训练时使用长度丢弃, 使用时任意搜索. 载于《第 59 届计算语言学协会年会暨第 11 届自然语言处理国际联合会议论文集 (第一卷: 长论文)》, 第 6501–6511 页, 线上会议. 计算语言学协会.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466.
Tom Kwiatkowski、Jennimaria Palomaki、Olivia Redfield、Michael Collins、Ankur Parikh、Chris Alberti、Danielle Epstein、Illia Polosukhin、Jacob Devlin、Kenton Lee、Kristina Toutanova、Llion Jones、Matthew Kelcey、Ming-Wei Chang、Andrew M. Dai、Jakob Uszkoreit、Quoc Le 和 Slav Petrov。2019。自然问题:问答研究的基准测试。《计算语言学协会汇刊》7:452-466。
Patrick S. H. Lewis, Ethan Perez, Aleksandra Pik- tus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock t s chel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
Patrick S. H. Lewis、Ethan Perez、Aleksandra Pikus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel、Sebastian Riedel 和 Douwe Kiela。2020。面向知识密集型 NLP 任务的检索增强生成。收录于《神经信息处理系统进展 33:2020 年神经信息处理系统年会 (NeurIPS 2020)》,2020 年 12 月 6-12 日,线上会议。
Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph E. Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. 2023a. How long can opensource llms truly promise on context length?
Dacheng Li、Rulin Shao、Anze Xie、Ying Sheng、Lianmin Zheng、Joseph E. Gonzalez、Ion Stoica、Xuezhe Ma 和 Hao Zhang。2023a。开源大语言模型 (LLM) 究竟能承诺多长的上下文?
Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. 2023b. Loogle: Can long-context language models understand long contexts? ArXiv preprint, abs/2311.04939.
Jiaqi Li, Mengmeng Wang, Zilong Zheng 和 Muhan Zhang. 2023b. Loogle: 长上下文语言模型能理解长上下文吗? ArXiv 预印本, abs/2311.04939.
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. 2023c. Compressing context to enhance inference efficiency of large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6342–6353, Singapore. Association for Computational Linguistics.
Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. 2023c. 压缩上下文提升大语言模型推理效率. 见: 2023年自然语言处理经验方法会议论文集, 第6342–6353页, 新加坡. 计算语言学协会.
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics, 12:157–173.
Nelson F. Liu、Kevin Lin、John Hewitt、Ashwin Paranjape、Michele Bevilacqua、Fabio Petroni 和 Percy Liang。2024。迷失在中间:语言模型如何利用长上下文。《计算语言学协会汇刊》12:157–173。
Sewon Min, Mike Lewis, Luke Z ett le moyer, and Hannaneh Hajishirzi. 2022. MetaICL: Learning to learn in context. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2791–2809, Seattle, United States. Association for Computational Linguistics.
Sewon Min、Mike Lewis、Luke Zettlemoyer 和 Hannaneh Hajishirzi。2022. MetaICL:学习在上下文中学习。载于《2022年北美计算语言学协会会议:人类语言技术论文集》,第2791–2809页,美国西雅图。计算语言学协会。
Ali Modarressi, Hosein Mohebbi, and Moham- mad Taher Pilehvar. 2022. AdapLeR: Speeding up inference by adaptive length reduction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1–15, Dublin, Ireland. Association for Computational Linguistics.
Ali Modarressi、Hosein Mohebbi和Mohammad Taher Pilehvar。2022。AdapLeR:通过自适应长度缩减加速推理。载于《第60届计算语言学协会年会论文集(第一卷:长论文)》,第1-15页,爱尔兰都柏林。计算语言学协会。
Jesse Mu, Xiang Lisa Li, and Noah Goodman. 2023. Learning to compress prompts with gist tokens. In Thirty-seventh Conference on Neural Information Processing Systems.
Jesse Mu、Xiang Lisa Li 和 Noah Goodman。2023。学习用要点token压缩提示。载于《第三十七届神经信息处理系统大会》。
Erik Nijkamp, Tian Xie, Hiroaki Hayashi, Bo Pang, Congying Xia, Chen Xing, Jesse Vig, Semih Yavuz, Philippe Laban, Ben Krause, Senthil Purush- walkam, Tong Niu, Wojciech Kryscinski, Lidiya Mu- rakhovs’ka, Prafulla Kumar Choubey, Alex Fabbri, Ye Liu, Rui Meng, Lifu Tu, Meghana Bhat, ChienSheng Wu, Silvio Savarese, Yingbo Zhou, Shafiq Joty, and Caiming Xiong. 2023. Xgen-7b technical report. ArXiv preprint, abs/2309.03450.
Erik Nijkamp、Tian Xie、Hiroaki Hayashi、Bo Pang、Congying Xia、Chen Xing、Jesse Vig、Semih Yavuz、Philippe Laban、Ben Krause、Senthil Purushwalkam、Tong Niu、Wojciech Kryscinski、Lidiya Murakhovs'ka、Prafulla Kumar Choubey、Alex Fabbri、Ye Liu、Rui Meng、Lifu Tu、Meghana Bhat、ChienSheng Wu、Silvio Savarese、Yingbo Zhou、Shafiq Joty 和 Caiming Xiong。2023。XGen-7B 技术报告。ArXiv 预印本,abs/2309.03450。
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST ’23, New York, NY, USA. Association for Computing Machinery.
Joon Sung Park、Joseph O'Brien、Carrie Jun Cai、Meredith Ringel Morris、Percy Liang 和 Michael S. Bernstein。2023. 生成式智能体 (Generative Agents):人类行为的交互式模拟。见《第36届ACM用户界面软件与技术研讨会论文集》(UIST '23),美国纽约州纽约市。ACM协会。
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. 2024. YaRN: Efficient context window ex- tension of large language models. In The Twelfth International Conference on Learning Representations.
Bowen Peng、Jeffrey Quesnelle、Honglu Fan 和 Enrico Shippole。2024。YaRN: 大语言模型的高效上下文窗口扩展。载于第十二届国际学习表征会议。
Ofir Press, Noah A. Smith, and Mike Lewis. 2022. Train short, test long: Attention with linear biases enables input length extrapolation. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
Ofir Press、Noah A. Smith 和 Mike Lewis。2022. 训练短序列,测试长序列:线性偏置注意力机制实现输入长度外推。载于《第十届国际学习表征会议》(ICLR 2022),虚拟会议,2022年4月25-29日。OpenReview.net。
Nils Reimers and Iryna Gurevych. 2019. SentenceBERT: Sentence embeddings using Siamese BERTnetworks. In Proceedings of the 2019 Conference on
Nils Reimers 和 Iryna Gurevych. 2019. SentenceBERT: 基于孪生BERT网络的句子嵌入方法. 见: 2019年会议论文集
Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
自然语言处理实证方法与第九届国际自然语言处理联合会议 (EMNLP-IJCNLP),第3982–3992页,中国香港。计算语言学协会。
Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. 2023. Zero SCROLLS: A zero-shot benchmark for long text understanding. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7977–7989, Singapore. Association for Computational Linguistics.
Uri Shaham、Maor Ivgi、Avia Efrat、Jonathan Berant 和 Omer Levy。2023。Zero SCROLLS:长文本理解的零样本基准测试。载于《计算语言学协会发现:EMNLP 2023》,第7977–7989页,新加坡。计算语言学协会。
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2024. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems, 36.
Yongliang Shen、Kaitao Song、Xu Tan、Dongsheng Li、Weiming Lu、Yueting Zhuang。2024。HuggingGPT:利用ChatGPT和Hugging Face生态解决AI任务。Advances in Neural Information Processing Systems,36。
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning, pages 31210–31227. PMLR.
Freda Shi、Xinyun Chen、Kanishka Misra、Nathan Scales、David Dohan、Ed H Chi、Nathanael Schärli 和 Denny Zhou。2023。大语言模型 (Large Language Model) 易受无关上下文干扰。见 International Conference on Machine Learning,第31210–31227页。PMLR。
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. 2023. Retentive network: A successor to transformer for large language models. ArXiv preprint, abs/2307.08621.
Yutao Sun、Li Dong、Shaohan Huang、Shuming Ma、Yuqing Xia、Jilong Xue、Jianyong Wang 和 Furu Wei。2023。Retentive网络:大语言模型中Transformer的继任者。ArXiv预印本,abs/2307.08621。
Harsh Trivedi, Niranjan Bala subramania n, Tushar Khot, and Ashish Sabharwal. 2022. MuSiQue: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554.
Harsh Trivedi、Niranjan Balasubramanian、Tushar Khot 和 Ashish Sabharwal。2022。MuSiQue:通过单跳问题组合实现的多跳问题。《计算语言学协会汇刊》10:539–554。
Szymon Tworkowski, Konrad Stanis ze w ski, Mikołaj Pacek, Yuhuai Wu, Henryk Micha lewski, and Piotr Milos. 2023. Focused transformer: Contrastive training for context scaling. In Thirty-seventh Conference on Neural Information Processing Systems.
Szymon Tworkowski、Konrad Staniszewski、Mikołaj Pacek、Yuhuai Wu、Henryk Michalewski 和 Piotr Miłoś。2023. 聚焦式Transformer (Focused Transformer):基于对比训练的上下文扩展方法。见于第三十七届神经信息处理系统大会。
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadal- lah, Ryen W White, Doug Burger, and Chi Wang. 2023a. Autogen: Enabling next-gen llm applica- tions via multi-agent conversation framework. ArXiv preprint, abs/2308.08155.
Qingyun Wu、Gagan Bansal、Jieyu Zhang、Yiran Wu、Beibin Li、Erkang Zhu、Li Jiang、Xiaoyun Zhang、Shaokun Zhang、Jiale Liu、Ahmed Hassan Awadallah、Ryen W White、Doug Burger 和 Chi Wang。2023a。Autogen: 通过多智能体对话框架实现下一代大语言模型应用。ArXiv预印本,abs/2308.08155。
Zhiyong Wu, Yaoxiang Wang, Jiacheng Ye, and Lingpeng Kong. 2023b. Self-adaptive in-context learning: An information compression perspective for incontext example selection and ordering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1423–1436, Toronto, Canada. Association for Computational Linguistics.
吴志勇、王耀翔、叶佳成和孔令鹏。2023b。自适应上下文学习:从信息压缩视角看上下文示例选择与排序。载于《第61届计算语言学协会年会论文集(第一卷:长论文)》,第1423–1436页,加拿大多伦多。计算语言学协会。
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Mu en nigh off. 2023. C-pack: Packaged resources to advance general chinese embedding. ArXiv preprint, abs/2309.07597.
Shitao Xiao、Zheng Liu、Peitian Zhang 和 Niklas Muennighoff。2023。C-pack: 推进通用中文嵌入的打包资源。ArXiv预印本,abs/2309.07597。
Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Subramania n, Evelina Bakhturina, Mohammad Shoeybi, and Bryan Catanzaro. 2024. Retrieval meets long context large language models. In The Twelfth International Conference on Learning Representations.
彭旭、魏平、吴先超、Lawrence McAfee、朱晨、刘子涵、Sandeep Subramanian、Evelina Bakhturina、Mohammad Shoeybi 和 Bryan Catanzaro。2024。检索遇见长上下文大语言模型。收录于第十二届国际学习表征会议。
A Derivation Of Question-Aware Fine-Grained Compression
问题感知细粒度压缩的推导
Based on the definition of Eq. (3), we can derive that,
根据式(3)的定义, 我们可以推导出,
$$
\begin{array}{r l}&{s_{i}=\mathrm{perplexity}(x_{i}|x_{<i})-\mathrm{perplexity}(x_{i}|x^{\mathrm{que}},x_{<i})}\ &{\quad=q(x_{i})\log p(x_{i}|x^{\mathrm{que}},x_{<i})-q(x_{i})\log p(x_{i}|x_{<i})}\ &{\quad=q(x_{i})\log\frac{p(x_{i}|x^{\mathrm{que}},x_{<i})}{p(x_{i}|x_{<i})}}\end{array}
$$
$$
\begin{array}{r l}&{s_{i}=\mathrm{perplexity}(x_{i}|x_{<i})-\mathrm{perplexity}(x_{i}|x^{\mathrm{que}},x_{<i})}\ &{\quad=q(x_{i})\log p(x_{i}|x^{\mathrm{que}},x_{<i})-q(x_{i})\log p(x_{i}|x_{<i})}\ &{\quad=q(x_{i})\log\frac{p(x_{i}|x^{\mathrm{que}},x_{<i})}{p(x_{i}|x_{<i})}}\end{array}
$$
In the actual calculation of perplexity, a log opera- tion is performed to avoid overflow, and $q(x_{i})$ represents the probability distribution of the groundtruth.
在实际计算困惑度时,为避免溢出会进行对数运算,其中$q(x_{i})$表示真实值的概率分布。
At the same time, we can derive the following expanded expression based on Bayes’ theorem.
同时,我们可以基于贝叶斯定理推导出以下扩展表达式。
$$
\begin{array}{r}{p(x^{\mathsf{q u e}}|x_{i},x_{<i})=\frac{p(x_{i}|x^{\mathsf{q u e}},x_{<i})p(x^{\mathsf{q u e}})}{p(x_{i}|x_{<i})}}\ {=p(x^{\mathsf{q u e}})\frac{p(x_{i}|x^{\mathsf{q u e}},x_{<i})}{p(x_{i}|x_{<i})}}\end{array}
$$
$$
\begin{array}{r}{p(x^{\mathsf{q u e}}|x_{i},x_{<i})=\frac{p(x_{i}|x^{\mathsf{q u e}},x_{<i})p(x^{\mathsf{q u e}})}{p(x_{i}|x_{<i})}}\ {=p(x^{\mathsf{q u e}})\frac{p(x_{i}|x^{\mathsf{q u e}},x_{<i})}{p(x_{i}|x_{<i})}}\end{array}
$$
The probability distribution $p(x^{\mathrm{que}})$ of the question and the ground-truth distribution $q(x_{i})$ of $x_{i}$ are constants, hence $s_{i}$ can be considered as the representation of Eq. (7).
问题和真实分布 $q(x_{i})$ 的概率分布 $p(x^{\mathrm{que}})$ 是常数,因此 $s_{i}$ 可视为式 (7) 的表示。
$$
s_{i}\propto p(x^{\mathrm{que}}|x_{i},x_{<i})
$$
$$
s_{i}\propto p(x^{\mathrm{que}}|x_{i},x_{<i})
$$
So we can utilize Eq. (3) to represent the probability distribution $p(\boldsymbol{x}^{\mathrm{que}}|\boldsymbol{x}_ {i},\boldsymbol{x}_ {<i})$ , which represents the condition likelihood of generating $x^{\mathrm{que}}$ given the token $x_{i}$ . Therefore, we can represent the tokenlevel sensitive distribution for the question $x^{\mathrm{que}}$ using just a single inference. For tokens that are unrelated to $x^{\mathrm{que}}$ , such as the tokens on the right side of Figure 3b, their original amount of information may be high, but the contrastive perplexity remains at a relatively low level. Finally, we observe that the form of contrastive perplexity is equivalent to conditional pointwise mutual information (Church and Hanks, 1989).
因此,我们可以利用方程(3)来表示概率分布 $p(\boldsymbol{x}^{\mathrm{que}}|\boldsymbol{x}_ {i},\boldsymbol{x}_ {<i})$ ,它表示在给定token $x_{i}$ 时生成 $x^{\mathrm{que}}$ 的条件似然。因此,我们仅需一次推理就能表示问题 $x^{\mathrm{que}}$ 的token级别敏感分布。对于与 $x^{\mathrm{que}}$ 无关的token(例如图3b右侧的token),它们原始的信息量可能较高,但对比困惑度仍保持在相对较低的水平。最后,我们注意到对比困惑度的形式等同于条件点互信息(Church and Hanks, 1989)[20]。
B Experiment Details
B 实验细节
B.1 Dataset Details
B.1 数据集详情
We use Natural Questions (Liu et al., 2024) for the multi-document QA task, MuSicQue (Trivedi et al.,
我们使用Natural Questions (Liu等人,2024) 进行多文档问答任务,MuSicQue (Trivedi等人,
- for the multi-hop QA task, and use LongBench (Bai et al., 2023), Zero SCROLLS (Shaham et al., 2023), LooGLE (Li et al., 2023b) for general long context scenarios. The specific details of the dataset are as follows:
- 用于多跳问答任务,并使用LongBench (Bai等人,2023)、Zero SCROLLS (Shaham等人,2023)、LooGLE (Li等人,2023b) 用于通用长上下文场景。数据集的具体细节如下:
Natural Questions multi-document QA A multi-document question-answering dataset, comprising 2,655 problems, was built by (Liu et al., 2024) based on the Natural Questions dataset (Kwiatkowski et al., 2019). This dataset provides a realistic retrieval-augmented generation setup that closely resembles commercial search and question-answering applications (e.g., Bing Chat). Each example in the dataset contains a question and k related documents, utilizing the Contriever retrieval system (Izacard et al., 2022), one of which includes a document with the correct answer. To perform this task, the model must access the document containing the answer within its input context and use it to answer the question. The dataset’s data is sourced from the Natural Questions dataset, which contains historical queries issued to the Google search engine and human-annotated answers extracted from Wikipedia. The average prompt token length in this benchmark is 2,946. For our experiments, we used the version provided by (Liu et al., 2024) that includes 20 documents 10. The dataset comprises five different ground truth document position settings in the prompt: 1st, 5th, 10th, 15th, and $20\mathrm{{th}}$ .
Natural Questions多文档问答
(Liu et al., 2024)基于Natural Questions数据集(Kwiatkowski et al., 2019)构建了一个包含2,655个问题的多文档问答数据集。该数据集提供了接近商业搜索和问答应用(如Bing Chat)的真实检索增强生成场景。每个示例包含一个问题及k篇相关文档(使用Contriever检索系统(Izacard et al., 2022)),其中必有一篇包含正确答案。执行该任务时,模型必须在其输入上下文中定位含答案的文档并据此回答问题。数据源自Natural Questions数据集,包含谷歌搜索引擎历史查询及人工标注的维基百科答案。该基准测试的平均提示token长度为2,946。我们采用(Liu et al., 2024)提供的包含20篇文档的版本,数据集中设置了五种真实答案文档位置:第1、5、10、15和$20\mathrm{{th}}$位。
LongBench A multi-task long context benchmark consists of 3,750 problems in English and includes six categories with a total of 16 tasks. These tasks encompass key long-text application scenarios, such as single-document QA, multi-document QA, sum mari z ation, few-shot learning, synthetic tasks, and code completion. The average prompt token length in this benchmark is 10,289. For our experiments, we used the English dataset and evaluation scripts provided by (Bai et al., 2023) for this benchmark 11.
LongBench 是一个多任务长上下文基准测试,包含 3,750 道英文题目,涵盖六大类别共 16 项任务。这些任务覆盖了关键的长文本应用场景,例如单文档问答、多文档问答、摘要生成、少样本学习、合成任务和代码补全。该基准测试的平均提示 token 长度为 10,289。在我们的实验中,我们使用了 (Bai et al., 2023) 为该基准测试提供的英文数据集和评估脚本 11。
Zero SCROLLS The multi-task long context benchmark consists of 4,378 problems, including four categories with a total of 10 tasks. These tasks cover sum mari z ation, question answering, aggregated sentiment classification, and information reordering. The average prompt token length in this benchmark is 9,788. For our experiments, we used the validation set and evaluation scripts provided by (Shaham et al., 2023) for this dataset12.
零滚动 (Zero SCROLLS) 多任务长上下文基准包含 4,378 个问题,涵盖四大类共 10 项任务。这些任务包括摘要生成、问答、聚合情感分类和信息重排序。该基准的平均提示词 (prompt token) 长度为 9,788。我们使用 (Shaham et al., 2023) 为该数据集提供的验证集和评估脚本进行实验[12]。
MuSiQue The multi-hop question-answer dataset is composed of 39,876, 4,834, and 4,918 problems in the training, validation, and testing datasets, respectively. This dataset requires the language model to conduct multiple inferences based on the content of several documents and provide corresponding answers, thereby necessitating a certain capability for global information processing. The average token length for prompts in this dataset is 2,477. For our experiments, we utilized the validation set and evaluation scripts provided by (Trivedi et al., 2022) for this dataset13.
MuSiQue 这个多跳问答数据集分别由训练集、验证集和测试集中的 39,876、4,834 和 4,918 个问题组成。该数据集要求语言模型基于多篇文档内容进行多次推理并给出相应答案,因此需要具备一定的全局信息处理能力。该数据集中提示的平均 token 长度为 2,477。在我们的实验中,我们使用了 (Trivedi et al., 2022) 为该数据集提供的验证集和评估脚本 [13]。
LooGLE The multi-task long context benchmark comprises 6,448 problems, divided into three categories: sum mari z ation, short dependency question answering, and long dependency question answering. The average prompt token length in this benchmark stands at 24,005. For our experiments, we focused on the long dependency question answering subset, which includes four types of tasks: information retrieval, timeline reordering, computation, and comprehension. This subset contains 1,101 problems. We utilized the evaluation scripts provided by (Li et al., 2023b) for this dataset14.
LooGLE多任务长上下文基准包含6,448个问题,分为三类:摘要生成、短依赖问答和长依赖问答。该基准的平均提示token长度为24,005。在我们的实验中,我们专注于长依赖问答子集,包含四种任务类型:信息检索、时间线重排序、计算和理解。该子集包含1,101个问题。我们使用了(Li et al., 2023b)为该数据集提供的评估脚本14。
B.2 Other Implementation Details
B.2 其他实现细节
All experiments were conducted using a Tesla V100 (32GB). We use tiktoken15 and GPT-3.5- Turbo model to count all the tokens. We set the granular control coefficient $k$ to 2. We use the pre-defined compression rates $\tau_{\mathrm{ins}}~=~0.85$ and $\tau_{\mathrm{que}}=0.9$ for instructions and questions. The segment size used in the iterative token-level compression is set to 200. The $\delta\tau$ used in dynamic compression ratio is set to 0.3. For a fair comparison, we only used reordering in the Natural Questions Multi-document QA and noted this in Table 1. We use “We can get the answer to this question in the given documents." as the guideline sentence in Eq. (3).
所有实验均使用 Tesla V100 (32GB) 进行。我们采用 tiktoken15 和 GPT-3.5-Turbo 模型统计所有 token。设置细粒度控制系数 $k$ 为 2,预定义指令和问题的压缩率分别为 $\tau_{\mathrm{ins}}~=~0.85$ 与 $\tau_{\mathrm{que}}=0.9$。迭代 token 级压缩的片段大小设为 200,动态压缩比参数 $\delta\tau$ 设为 0.3。为公平对比,仅在 Natural Questions 多文档问答任务中使用重排序策略,并在表 1 中予以标注。公式 (3) 中的引导句采用"我们可以在给定文档中找到此问题的答案"。
For the baselines experiment, we use the currently recommended strongest model, all-mpnetbase $\mathbf{\cdot}\mathbf{V}2^{16}$ , as the dense representation model for
在基线实验中,我们采用当前推荐的最强模型 all-mpnetbase $\mathbf{\cdot}\mathbf{V}2^{16}$ 作为稠密表示模型
Sentence BERT. We use the recommended “textembedding-ada-002" as the embedding model for OpenAI Embedding 17. We use the GPT2-dolly18 as the small language model in w/ GPT2-small ablation experiments.
Sentence BERT。我们使用官方推荐的"textembedding-ada-002"作为OpenAI Embedding[17]的嵌入模型。在w/ GPT2-small消融实验中,我们采用GPT2-dolly[18]作为小型语言模型。
C Additional Experimental Results
C 补充实验结果
C.1 Empirical Study of Question-aware Fine-grained Compression
C.1 问题感知细粒度压缩的实证研究
Figure 5 shows the distribution of the document’s average perplexity when the ground-truth is located at more positions within the prompt. As can be observed, as the context length increases, the original perplexity curve remains relatively stable. In unrelated documents, a higher perplexity is still retained, making it easier to remove relevant tokens from the related documents in the prompt compression process, thereby damaging the corresponding semantic information. Contrarily, contrastive perplexity shows an increase in perplexity in documents related to the question. According to the theoretical derivation in Appendix A, it’s known that contrastive perplexity characterizes the conditional probability of tokens corresponding to the question. The higher the relevance, the higher the contrastive perplexity, thereby retaining key information in the prompt compression process.
图 5 展示了当真实值位于提示词中更多位置时文档平均困惑度的分布情况。如图所示,随着上下文长度增加,原始困惑度曲线保持相对稳定。在无关文档中仍保留较高困惑度,使得在提示词压缩过程中更容易从相关文档中移除关联token,从而破坏相应语义信息。相反,对比困惑度在与问题相关的文档中呈现上升趋势。根据附录A的理论推导可知,对比困惑度表征了token对应问题的条件概率。相关性越高,对比困惑度就越高,从而在提示词压缩过程中保留关键信息。
C.2 Ablation in LongBench
C.2 LongBench消融实验
Table 4 presents the results from the ablation experiment in the LongBench long context benchmark. It can be observed that in various long context tasks: 1) Removing the question-aware coarse-grained, question-aware fine-grained, dynamic compression ratio, document reordering, and sub sequence recovery proposed by Long LL M Lingua all result in different degrees of performance drop. 2) Among these, question-aware coarse-grained is particularly important for document-based QA and synthetic tasks, with the maximum drop being 35.8 points; its impact on sum mari z ation and code tasks is relatively smaller. 3) The design of the conditional probability in the question-aware coarse-grained module improves the results in all tasks, including code completion, single-document questionanswer, and synthetic tasks. Changing the order of conditional probabilities or removing the restrict prompt both lead to varying degrees of performance decline. 4) Removing question-aware finegrained, dynamic compression ratio has a more significant impact on document-based QA and synthetic tasks. 5) The sub sequence recovery module can enhance reference-based tasks, but its improvement on tasks like sum mari z ation, code, synthetic, etc., is relatively smaller. 6) Document reordering is effective for all types of tasks. Reordering at the document level does not affect LLMs’ understanding of context information, even for timelinerelated tasks (see timeline reorder in LooGLE, Table 8). On the contrary, reordering can effectively alleviate the "lost in the middle" issue, thereby improving LLMs performance. 7) Using GPT2-small reduces the capture of effective tokens, but it can still achieve results close to or even slightly better than the original prompt.
表 4 展示了 LongBench 长上下文基准测试中的消融实验结果。可以观察到,在各种长上下文任务中:
- 移除 Long LL M Lingua 提出的问题感知粗粒度、问题感知细粒度、动态压缩比、文档重排序和子序列恢复都会导致不同程度的性能下降。
- 其中,问题感知粗粒度对基于文档的 QA 和合成任务尤为重要,最大下降达 35.8 分;其对摘要和代码任务的影响相对较小。
- 问题感知粗粒度模块中条件概率的设计提升了所有任务的结果,包括代码补全、单文档问答和合成任务。改变条件概率顺序或移除限制提示均会导致不同程度的性能下降。
- 移除问题感知细粒度、动态压缩比对基于文档的 QA 和合成任务影响更显著。
- 子序列恢复模块能提升基于参考的任务,但对摘要、代码、合成等任务的改进相对较小。
- 文档重排序对所有类型任务均有效。文档级别的重排序不会影响大语言模型对上下文信息的理解,即使是与时间线相关的任务 (参见 LooGLE 中的时间线重排序,表 8)。相反,重排序能有效缓解"迷失在中间"问题,从而提升大语言模型性能。
- 使用 GPT2-small 会减少有效 token 的捕获,但仍能取得接近甚至略优于原始提示的结果。

Figure 5: The distribution of document-level average perplexity when the ground-truth document is in different positions.
图 5: 真实文档位于不同位置时的文档级平均困惑度分布。
| Methods | SingleDoc MultiDoc Summ.FewShot Synth. | Code | AVG | Tokens | 1/T | ||||
| LongLLMLingua | 39.9 | 43.2 | 27.4 | 69.8 | 53.0 | 56.7 | 48.3 | 1,822 | 6x |
| Question-awareCoarse-grained | |||||||||
| -w/oQuestion-awareness | 27.1 | 38.7 | 25.4 | 62.0 | 18.0 | 53.3 | 37.4 | 1,945 | 5x |
| -W/SBERT doc|。 que,restrict | 34.0 22.5 | 38.7 | 24.1 | 57.9 | 32.5 | 31.1 | 36.4 | 1,790 | 6x |
| -w/ p(xkc -w/orestrict | 37.8 | 28.9 39.5 | 23.2 26.4 | 53.0 64.8 | 22.5 52.5 | 33.3 55.8 | 30.6 46.1 | 1,794 1,834 | 6x 6x |
| -w/oQuestion-awareFine-grained | 35.7 | 41.1 | 26.4 | 62.9 | 44.5 | 54.8 | 44.2 | 1,807 | 6x |
| - w/o Dynamic Compression Ratio | 36.1 | 40.6 | 26.9 | 67.2 | 48.0 | 55.8 | 45.7 | 1,851 | 6x |
| -w/oSubsequenceRecovery | 38.6 | 41.8 | 27.3 | 69.0 | 53.8 | 56.6 | 47.8 | 1,809 | 6x |
| -w/oDocumentReordering | 39.0 | 42.2 | 27.4 | 69.3 | 53.8 | 56.6 | 48.0 | 1,809 | 6x |
| - w/ GPT2-small | 35.9 | 39.4 | 25.0 | 60.6 | 42.0 | 55.4 | 43.0 | 1,892 | 5x |
Table 4: Ablation on LongBench (Bai et al., 2023) using GPT-3.5-Turbo in 2,000 tokens constraint.
| 方法 | 单文档 | 多文档 | 摘要 | 少样本 | 合成 | 代码 | 平均 | Token数 | 1/T |
|---|---|---|---|---|---|---|---|---|---|
| LongLLMLingua | 39.9 | 43.2 | 27.4 | 69.8 | 53.0 | 56.7 | 48.3 | 1,822 | 6x |
| 问题感知粗粒度 | - | - | - | - | - | - | - | - | - |
| -无问题感知 | 27.1 | 38.7 | 25.4 | 62.0 | 18.0 | 53.3 | 37.4 | 1,945 | 5x |
| -W/SBERT文档|问题限制 | 34.0 | 38.7 | 24.1 | 57.9 | 32.5 | 31.1 | 36.4 | 1,790 | 6x |
| -带p(xkc)无限制 | 37.8 | 39.5 | 26.4 | 64.8 | 52.5 | 55.8 | 46.1 | 1,834 | 6x |
| -无问题感知细粒度 | 35.7 | 41.1 | 26.4 | 62.9 | 44.5 | 54.8 | 44.2 | 1,807 | 6x |
| -无动态压缩比 | 36.1 | 40.6 | 26.9 | 67.2 | 48.0 | 55.8 | 45.7 | 1,851 | 6x |
| -无子序列恢复 | 38.6 | 41.8 | 27.3 | 69.0 | 53.8 | 56.6 | 47.8 | 1,809 | 6x |
| -无文档重排序 | 39.0 | 42.2 | 27.4 | 69.3 | 53.8 | 56.6 | 48.0 | 1,809 | 6x |
| -使用GPT2-small | 35.9 | 39.4 | 25.0 | 60.6 | 42.0 | 55.4 | 43.0 | 1,892 | 5x |
表 4: 基于GPT-3.5-Turbo在2,000 Token限制下的LongBench消融实验 (Bai et al., 2023)
C.3 LongBench Using LongChat-13b-16k
C.3 LongBench 使用 LongChat-13b-16k
Table 5 presents the experiment results in the LongBench long context benchmark using LongChat13b-16k. It can be seen that the compressed prompt can also achieve good results on other LLMs, such as LongChat-13b-16k. Specifically, 1) there is a maximum improvement of 15.5 points in synthetic tasks. Except for a slight drop in few-shot Learning, there is an improvement of 3-5 points in other tasks. 2) The performance trends of retrieval-based and compressed-based baselines are similar to the results in GPT-3.5-Turbo.
表 5: 展示了使用 LongChat13b-16k 在 LongBench 长上下文基准测试中的实验结果。可以看出,压缩提示 (compressed prompt) 在其他大语言模型 (如 LongChat-13b-16k) 上也能取得良好效果。具体表现为:1) 在合成任务中最高提升 15.5 分,除少样本学习 (few-shot Learning) 略有下降外,其他任务均有 3-5 分的提升;2) 基于检索和基于压缩的基线性能趋势与 GPT-3.5-Turbo 的结果相似。
C.4 Zero SCROLLS
C.4 零样本 SCROLLS
Table 6 presents a detailed performance breakdown on the Zero SCROLLS benchmark. It can be observed that in the four sum mari z ation tasks - GvRp, SSFD, QMsm, SQAL, Long LL M Lingua closely matches or slightly surpasses the original results under two compression constraints. Meanwhile, in the four long context QA tasks - Qsqr, Nrtv, QALT, $\mathrm{MuSQ}$ , there is a significant improvement. Notably, in the MuSiQue task, which is based on a question-answering dataset from books and movie scripts, there is a 2.1 point increase even under a 2,000 tokens constraint. It’s worth mentioning that MuSiQue is a multi-hop question-answering dataset that requires LLMs to utilize global information for long dependency QA. Long LL M Lingua can also improve by 3.5 points under a 6x compression ratio. In the two ordering tasks, $\mathrm{SpDg}$ and BkSS, Long LL M Lingua can better retain globally sensitive information, resulting in a 3.0 point improvement in BkSS after prompt compression.
表 6: 展示了在零样本 SCROLLS 基准测试上的详细性能分析。可以观察到,在四个摘要任务(GvRp、SSFD、QMsm、SQAL)中,Long LLM Lingua 在两种压缩约束下基本匹配或略微超过原始结果。同时,在四个长上下文问答任务(Qsqr、Nrtv、QALT、MuSQ)中则有显著提升。值得注意的是,在基于书籍和电影剧本问答数据集的 MuSiQue 任务中,即使在 2,000 tokens 限制下也能获得 2.1 分的提升。需要说明的是,MuSiQue 是一个多跳问答数据集,要求大语言模型利用全局信息进行长依赖问答。Long LLM Lingua 在 6 倍压缩率下还能提升 3.5 分。在两个排序任务(SpDg 和 BkSS)中,Long LLM Lingua 能更好地保留全局敏感信息,使得提示词压缩后在 BkSS 任务上获得 3.0 分的改进。
It’s important to note that although the Zero
需要注意的是,尽管零样本 (Zero-shot)
Table 5: Performance of different methods under different compression ratios on LongBench (Bai et al., 2023) using LongChat-13b in 2,000 tokens constraint.
| Methods | SingleDoc | MultiDoc Summ.FewShot Synth.( | Code | AVG | Tokens 1/T | ||||
| Original Prompt | 27.4 | 30.3 | 20.3 | 49.9 | 12.5 | 42.5 | 30.5 | 10,295 | |
| Retrieval-basedMethods | |||||||||
| BM25 | 2.4 | 2.6 | 16.4 | 8.7 | 0.0 | 44.7 | 12.5 | 1,985 | 5x |
| SBERT | 11.6 | 13.7 | 21.1 | 16.2 | 7.5 | 30.0 | 16.7 | 1,947 | 5x |
| LongLLMLingua rk | 30.3 | 32.4 | 24.5 | 41.0 | 27.5 | 38.1 | 32.3 | 1,960 | 5x |
| Compression-basedMethods | |||||||||
| Selective-Context | 16.1 | 23.5 | 21.8 | 21.4 | 2.5 | 35.9 | 20.2 | 1,925 | 5x |
| LLMLingua | 20.6 | 22.3 | 22.4 | 35.6 | 0.0 | 35.4 | 22.7 | 1,950 | 5x |
| LongLLMLingua | 31.3 | 34.6 | 24.6 | 46.1 | 27.8 | 48.8 | 35.5 | 1,822 | 6x |
表 5: 不同方法在 LongBench (Bai et al., 2023) 上使用 LongChat-13b 在 2,000 token 限制下的性能表现
| 方法 | SingleDoc | MultiDoc Summ. | FewShot Synth. | Code | AVG | Tokens | 1/T |
|---|---|---|---|---|---|---|---|
| Original Prompt | 27.4 | 30.3 | 20.3 | 49.9 | 12.5 | 42.5 | 30.5 |
| 基于检索的方法 | |||||||
| BM25 | 2.4 | 2.6 | 16.4 | 8.7 | 0.0 | 44.7 | 12.5 |
| SBERT | 11.6 | 13.7 | 21.1 | 16.2 | 7.5 | 30.0 | 16.7 |
| LongLLMLingua rk | 30.3 | 32.4 | 24.5 | 41.0 | 27.5 | 38.1 | 32.3 |
| 基于压缩的方法 | |||||||
| Selective-Context | 16.1 | 23.5 | 21.8 | 21.4 | 2.5 | 35.9 | 20.2 |
| LLMLingua | 20.6 | 22.3 | 22.4 | 35.6 | 0.0 | 35.4 | 22.7 |
| LongLLMLingua | 31.3 | 34.6 | 24.6 | 46.1 | 27.8 | 48.8 | 35.5 |
| Methods | |GvRp SSFD QMsm SQAL QALT Nrtv Qspr MuSQ SpDg BkSS AVG|Tokens 1/T |Latency Speedup | |||||||||||||||
| 3,000 tokens constraint | ||||||||||||||||
| Retrieval-basedMethods | ||||||||||||||||
| BM25 | 9.7 | 3.4 | 11.7 | 14.3 | 57.1 | 5.9 | 25.7 | 11.2 | 29.6 | 29.6 | 19.8 | 3,379 | 3x | 5.5 | 2.2x | |
| SBERT | 16.5 | 9.8 | 12.3 | 15.2 | 60.0 | 14.6 | 23.4 | 12.1 | 39.4 | 36.4 | 24.0 | 3,340 | 3x | 5.9 | 2.1x | |
| OpenAI | 14.3 | 8.3 | 12.0 | 15.3 | 66.7 | 13.3 | 24.3 | 11.7 | 31.2 | 26.4 | 22.4 | 3,362 | 3x | 11.7 | 1.0x | |
| LongLLMLingua rk| | 19.5 | 11.6 | 14.7 | 15.5 | 66.7 | 20.5 | 27.6 | 13.0 | 60.8 | 43.4 | 29.3 | 3,350 | 3x | 6.2 | 2.0x | |
| Compression-basedMethods | ||||||||||||||||
| Selective-Context | 20.8 | 9.1 | 11.7 | 13.4 | 50.0 | 9.8 | 26.1 | 11.0 | 46.0 | 9.5 | 20.7 | 3,460 | 3x | 54.2 | 0.2x | |
| LLMLingua | 18.7 | 10.0 | 14.9 | 16.8 | 61.9 | 26.9 | 27.2 | 23.4 | 62.9 | 44.5 | 30.7 | 3,366 | 3x | 7.4 | 1.7x | |
| LongLLMLingua | 22.1 | 12.8 | 15.9 | 17.1 | 67.0 | 27.8 | 31.3 | 23.9 | 65.8 | 46.5 | 33.0 | 3,431 | 3x | 8.2 | 1.5x | |
| Retrieval-basedMethods | ||||||||||||||||
| BM25 | 2.5 | 11.1 | 13.5 | 60.0 | 7.0 | 4.9 | 20.3 | 39.9 | 32.9 | 20.1 | ||||||
| SBERT | 8.8 10.2 | 7.9 | 13.7 | 13.2 | 60.0 | 8.1 | 10.8 | 1.7 | 37.2 | 42.8 | 20.5 | 1,799 1,773 | 5x 6x | 3.8 4.1 | 3.2x 3.0x | |
| OpenAI | 11.1 | 8.0 | 11.8 | 13.6 | 60.0 | 7.1 | 13.2 | 4.0 | 33.6 | 43.6 | 20.6 | 1,784 | 5x | 9.9 | 1.2x | |
| LongLLMLingua rk| | 18.2 | 9.8 | 12.3 | 15.9 | 57.1 | 10.1 | 17.8 | 7.3 | 57.7 | 42.3 | 24.9 | 1,771 | 6x | 4.7 | 2.6x | |
| Compression-basedMethods | ||||||||||||||||
| Selective-Context | 12.4 | 12.5 | 41.2 | 11.0 | ||||||||||||
| LLMLingua | 19.0 19.4 | 8.4 11.9 | 9.7 13.1 | 16.0 | 47.0 62.1 | 23.7 | 21.6 24.0 | 11.5 22.4 | 33.9 | 44.9 | 19.4 27.2 | 1,865 1,862 | 5x 5x | 47.5 4.8 | 0.3x 0.3x | |
| LongLLMLingua | 20.1 | 12.4 | 14.9 | 16.5 | 65.1 | 27.7 | 30.7 | 23.6 | 68.5 | 47.2 | 32.7 | |||||
| 1,826 | 6x | 5.2 | 2.3x | |||||||||||||
| Original Prompt Zero-shot | 21.8 9.4 | 12.1 3.0 | 17.9 8.6 | 17.4 11.4 | 66.7 42.9 | 25.3 10.6 | 29.8 12.4 | 20.0 5.5 | 69.7 4.2 | 44.1 0.0 | 32.5 | 9,788 | 12.2 1.0 | 12.2x | ||
Table 6: Performance breakdown of different methods under different compression ratios on Zero SCROLLS (Shaham et al., 2023) using GPT-3.5-Turbo.
表 6: 不同压缩比下各方法在 Zero SCROLLS (Shaham et al., 2023) 上使用 GPT-3.5-Turbo 的性能分解。
| 方法 | GvRp | SSFD | QMsm | SQAL | QALT | Nrtv | Qspr | MuSQ | SpDg | BkSS | AVG | Tokens | 1/T | Latency | Speedup |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3,000 tokens 约束 | |||||||||||||||
| 基于检索的方法 | |||||||||||||||
| BM25 | 9.7 | 3.4 | 11.7 | 14.3 | 57.1 | 5.9 | 25.7 | 11.2 | 29.6 | 29.6 | 19.8 | 3,379 | 3x | 5.5 | 2.2x |
| SBERT | 16.5 | 9.8 | 12.3 | 15.2 | 60.0 | 14.6 | 23.4 | 12.1 | 39.4 | 36.4 | 24.0 | 3,340 | 3x | 5.9 | 2.1x |
| OpenAI | 14.3 | 8.3 | 12.0 | 15.3 | 66.7 | 13.3 | 24.3 | 11.7 | 31.2 | 26.4 | 22.4 | 3,362 | 3x | 11.7 | 1.0x |
| LongLLMLingua rk | 19.5 | 11.6 | 14.7 | 15.5 | 66.7 | 20.5 | 27.6 | 13.0 | 60.8 | 43.4 | 29.3 | 3,350 | 3x | 6.2 | |
| 基于压缩的方法 | |||||||||||||||
| Selective-Context | 20.8 | 9.1 | 11.7 | 13.4 | 50.0 | 9.8 | 26.1 | 11.0 | 46.0 | 9.5 | 20.7 | 3,460 | 3x | 54.2 | 0.2x |
| LLMLingua | 18.7 | 10.0 | 14.9 | 16.8 | 61.9 | 26.9 | 27.2 | 23.4 | 62.9 | 44.5 | 30.7 | 3,366 | 3x | 7.4 | 1.7x |
| LongLLMLingua | 22.1 | 12.8 | 15.9 | 17.1 | 67.0 | 27.8 | 31.3 | 23.9 | 65.8 | 46.5 | 33.0 | 3,431 | 3x | 8.2 | 1.5x |
| 基于检索的方法 | |||||||||||||||
| BM25 | 2.5 | 11.1 | 13.5 | 60.0 | 7.0 | 4.9 | 20.3 | 39.9 | 32.9 | 20.1 | |||||
| SBERT | 8.8 10.2 | 7.9 | 13.7 | 13.2 | 60.0 | 8.1 | 10.8 | 1.7 | 37.2 | 42.8 | 20.5 | 1,799 1,773 | 5x 6x | 3.8 4.1 | 3.2x 3.0x |
| OpenAI | 11.1 | 8.0 | 11.8 | 13.6 | 60.0 | 7.1 | 13.2 | 4.0 | 33.6 | 43.6 | 20.6 | 1,784 | 5x | 9.9 | 1.2x |
| LongLLMLingua rk | 18.2 | 9.8 | 12.3 | 15.9 | 57.1 | 10.1 | 17.8 | 7.3 | 57.7 | 42.3 | 24.9 | 1,771 | 6x | 4.7 | |
| 基于压缩的方法 | |||||||||||||||
| Selective-Context | 12.4 | 12.5 | 41.2 | 11.0 | |||||||||||
| LLMLingua | 19.0 19.4 | 8.4 11.9 | 9.7 13.1 | 16.0 | 47.0 62.1 | 23.7 | 21.6 24.0 | 11.5 22.4 | 33.9 | 44.9 | 19.4 27.2 | 1,865 1,862 | 5x 5x | 47.5 4.8 | 0.3x 0.3x |
| LongLLMLingua | 20.1 | 12.4 | 14.9 | 16.5 | 65.1 | 27.7 | 30.7 | 23.6 | 68.5 | 47.2 | 32.7 | ||||
| 1,826 | 6x | 5.2 | 2.3x | ||||||||||||
| Original Prompt Zero-shot | 21.8 9.4 | 12.1 3.0 | 17.9 8.6 | 17.4 11.4 | 66.7 42.9 | 25.3 10.6 | 29.8 12.4 | 20.0 5.5 | 69.7 4.2 | 44.1 0.0 | 32.5 | 9,788 | 12.2 1.0 | 12.2x |
Scrolls validation dataset is relatively small, it still demonstrates conclusions similar to previous experimental observations across various methods and tasks. Furthermore, this study conducted an indepth analysis of the multi-hop QA task - MuSiQue, and another long context benchmark - LooGLE. The results can be found in Appendix C.5 and Appendix C.6.
Scrolls验证数据集虽然规模较小,但仍能得出与先前实验观察相似的结论,涵盖多种方法和任务。此外,本研究对多跳问答任务MuSiQue和另一个长上下文基准测试LooGLE进行了深入分析,具体结果详见附录C.5和附录C.6。
C.5 MuSiQue
C.5 MuSiQue
Table 7 presents the results from the MuSiQue multi-hop question-answer dataset. From the table, it can be observed that in the multi-hop QA task, requiring global information: 1) Long LL M Lingua can reduce noise in the prompt by eliminating irrelevant information and putting more related information at the beginning or end of the prompt, thereby improving performance by 5.4 points. 2) The performance drop is more pronounced for retrievalbased methods, particularly for n-gram-based methods like BM25. Due to long dependencies, direct matching information is lost, resulting in less relevant information being recalled. 3) The performance of compression-based methods is slightly different. Selective-Context does not distinguish between different modules’ sensitivity, resulting in a loss of question and instruction-related information, thereby leading to poorer performance. However, LLMLingua can still retain relevant key information at around a $2\mathbf{x}$ compression ratio. 4) The ablation experiments show that every module designed in Long LL M Lingua plays a role in the multi-hop task. The removal of the question-aware coarse-grained and w/ $p(\mathbf{x}_ {k}^{\mathrm{doc}}|x_{i}^{\mathrm{que,restrict}})$ modules, which have difficulty in perceiving the importance distribution of corresponding questions, can cause a drop of up to 8 points. Removing the restrict prompt in the question-aware coarse module can also cause a 2-point drop due to the hallucination issue of small LLM. In addition, removing question-aware fine-grained, dynamic compression ratio, and document reordering can all cause a drop of 0.5-2.8 points. 5) Moreover, if the small language model in Long LL M Lingua is replaced with GPT2-small, it can further improve the acceleration ratio and still achieve a result that is 2.6 points better than the original prompt.
表 7: MuSiQue多跳问答数据集的结果。从表中可以看出,在需要全局信息的多跳QA任务中:1) Long LL M Lingua通过消除无关信息并将更多相关信息置于提示的开头或结尾,可以减少提示中的噪声,从而将性能提升5.4分。2) 基于检索的方法性能下降更为明显,尤其是像BM25这样的基于n-gram的方法。由于长依赖关系,直接匹配信息丢失,导致召回的相关信息较少。3) 基于压缩的方法性能略有不同。Selective-Context无法区分不同模块的敏感性,导致问题和指令相关信息丢失,从而表现较差。然而,LLMLingua仍能在约$2\mathbf{x}$的压缩比下保留相关关键信息。4) 消融实验表明,Long LL M Lingua中设计的每个模块在多跳任务中都发挥了作用。移除难以感知相应问题重要性分布的问题感知粗粒度模块和w/ $p(\mathbf{x}_ {k}^{\mathrm{doc}}|x_{i}^{\mathrm{que,restrict}})$模块,可能导致高达8分的下降。移除问题感知粗粒度模块中的限制提示也会因小LLM的幻觉问题导致2分的下降。此外,移除问题感知细粒度、动态压缩比和文档重排序都会导致0.5-2.8分的下降。5) 此外,如果将Long LL M Lingua中的小语言模型替换为GPT2-small,可以进一步提高加速比,并且仍能获得比原始提示好2.6分的结果。
Table 7: Performance of different methods and ablation study on MuSicQue (Trivedi et al., 2022) with $2\mathbf{x}$ constraint using GPT-3.5-Turbo.
| Methods | F1Tokens 1/T |
| Original Prompt BM25 | 45.8 2,427 |
| SBERT | 28.5 1,295 1.9x 36.2 1,288 1.9x |
| LongLLMLingua rk | 46.3 1,295 1.9x |
| Selective-Context LLMLingua | 19.6 1,141 2.1x |
| LongLLMLingua | 40.1 1,110 2.2x |
| Question-awareCoarse-grained -w/oQuestion-awareness | 51.2 1,077 2.3x |
| -w/SBERT | 43.2 1,076 2.3x 47.3 1,070 2.3x |
| -w/o restrict | 44.0 1,066 2.3x 49.2 1,078 2.3x |
| - w/o Question-aware Fine-grained 48.4 1,118 2.2x | |
| -w/o Dynamic Compression Ratio 48.21,0902.2x | |
| -w/oSubsequence Recovery | 50.7 1,077 2.3x |
| -w/o Document Reordering - w/ GPT2-small | 49.2 1,077 2.3x 48.4 1,095 2.2x |
表 7: 不同方法及消融实验在 MuSicQue (Trivedi et al., 2022) 上的性能表现 (使用 GPT-3.5-Turbo 并施加 $2\mathbf{x}$ 约束)
| 方法 | F1Tokens 1/T |
|---|---|
| Original Prompt BM25 | 45.8 2,427 |
| SBERT | 28.5 1,295 1.9x 36.2 1,288 1.9x |
| LongLLMLingua rk | 46.3 1,295 1.9x |
| Selective-Context LLMLingua | 19.6 1,141 2.1x |
| LongLLMLingua | 40.1 1,110 2.2x |
| Question-awareCoarse-grained -w/oQuestion-awareness | 51.2 1,077 2.3x |
| -w/SBERT | 43.2 1,076 2.3x 47.3 1,070 2.3x |
| -w/o restrict | 44.0 1,066 2.3x 49.2 1,078 2.3x |
| - w/o Question-aware Fine-grained | 48.4 1,118 2.2x |
| -w/o Dynamic Compression Ratio | 48.2 1,090 2.2x |
| -w/oSubsequence Recovery | 50.7 1,077 2.3x |
| -w/o Document Reordering - w/ GPT2-small | 49.2 1,077 2.3x 48.4 1,095 2.2x |
timeline, it can effectively improve performance by alleviating the "lost in the middle" issue. 3) Retrieval-based methods tend to lose performance in tasks that have longer dependencies, such as computation and reasoning. 4) For compressionbased methods, due to the difficulty in perceiving question information, there tends to be a larger performance loss in retrieval tasks within long contexts.
时间线方面,它能通过缓解"迷失在中段"问题有效提升性能。3) 基于检索的方法在依赖链较长的任务(如计算和推理)中容易表现下降。4) 对于基于压缩的方法,由于难以感知问题信息,在长上下文检索任务中往往会出现较大的性能损失。
D Economic Cost
D 经济成本
Table 9 presents the estimated per 1,000 samples inference costs for various datasets, encompassing input prompts and generated output text, based on GPT-3.5-Turbo pricing19. Our approach demonstrates substantial savings in computational resources and monetary expenses, particularly in long context situations. Cost reductions of $\$3.3$ $(71.7%)$ , $\$28.5$ $(90.5%)$ , $\$27.4$ $(89.5%)$ , $\$2.0$ $(52.6%)$ , and $\$88.0$ $(94.0%)$ per 1,000 samples are observed for Multi-document QA, LongBench, Zero Scrolls, MuSiQue, and LooGLE, respectively.
表 9 展示了基于 GPT-3.5-Turbo 定价[19]的各种数据集每 1,000 样本的推理成本估算,包括输入提示和生成输出文本。我们的方法在计算资源和资金支出方面显示出显著节省,尤其在长上下文场景中。对于 Multi-document QA、LongBench、Zero Scrolls、MuSiQue 和 LooGLE 数据集,每 1,000 样本分别观察到成本降低 $3.3 (71.7%) 、$28.5 (90.5%) 、$27.4 (89.5%) 、$2.0 (52.6%) 和 $88.0 (94.0%) 。
E Ablation Analysis
E 消融分析
Figure 6 illustrates the compressed prompts from the Multi-document QA dataset, comparing the use of contrastive perplexity at a high compression ratio (30x). It shows that without question-aware token-level prompt compression, LongLLMLingua tends to compress key information, a tendency that becomes more pronounced at higher compression ratios. Conversely, employing contrastive perplexity allows for better detection of key information related to the question within the context, thus preserving key information within the compressed prompt.
图 6: 展示了多文档问答数据集中的压缩提示对比,在高压缩比(30x)下使用对比困惑度的效果。结果表明,若不采用问题感知的token级提示压缩,LongLLMLingua往往会压缩关键信息,且这种倾向在更高压缩比下更为明显。相反,采用对比困惑度能更好地检测上下文中与问题相关的关键信息,从而在压缩提示中保留关键内容。
C.6 LooGLE
C.6 LooGLE
Table 8 presents the experiment results in the LooGLE long dependency benchmark, which features longer prompts $(\sim30\mathrm{k})$ and more global dependencies. From the table, we can observe that: 1) Long LL M Lingua can effectively improve the performance of long context tasks by compressing prompts, even for long dependency tasks. The results show that Long LL M Lingua significantly improves performance in tasks such as retrieval, timeline reorder, and computation, with the maximum improvement reaching 15.9 points. 2) The document reorder in Long LL M Lingua is effective in all types of tasks, even in tasks highly related to the
表 8: 展示了LooGLE长依赖基准测试的实验结果,该基准测试以较长的提示词 $(\sim30\mathrm{k})$ 和更多全局依赖为特征。从表中我们可以观察到:1) Long LLM Lingua通过压缩提示词能有效提升长上下文任务性能,即便是长依赖任务也不例外。结果显示,Long LLM Lingua在检索、时间线重排和计算等任务中均显著提升性能,最大提升幅度达到15.9分。2) Long LLM Lingua中的文档重排功能对所有类型任务都有效,包括与...
F Cases Study
F 案例研究
Figures 7, 8, and 9 display the outcomes before and after compression, as well as the LLMs’ responses in various scenarios.
图 7、图 8 和图 9 展示了压缩前后的结果,以及大语言模型在不同场景下的响应。
Table 8: Performance of different methods on LooGLE (Li et al., 2023b) long dependency QA.
| Methods | Retrieval Timeline Reorder Computation Reasoning AVG Tokens 1/T | ||||||
| Retrieval-basedMethods | |||||||
| BM25 | 20.4 | 21.7 | 8.2 | 26.3 | 19.2 | 3,185 | 10x |
| SBERT | 28.9 | 21.1 | 10.7 | 27.2 | 22.0 | 3,169 | 10x |
| LongLLMLingua rk | 38.6 | 32.2 | 16.2 | 26.3 | 28.3 | 3,158 | 10x |
| Compression-basedMethods | |||||||
| Selective-Context | 16.7 | 5.0 | 2.3 | 17.6 | 10.4 | 3,710 | 8x |
| LLMLingua | 10.0 | 25.0 | 13.3 | 21.1 | 17.3 | 3,404 | 9x |
| LongLLMLingua | 40.0 | 35.0 | 19.7 | 33.6 | 32.1 | 3,121 | 10x |
| LongLLMLinguaw/oReorder | 39.3 | 33.8 | 18.7 | 31.6 | 30.9 | 3,119 | 10x |
| Original Prompt | 24.1 | 20.9 | 13.5 | 32.1 | 22.6 | 30,546 | |
| Zero-shot | 8.7 | 6.3 | 1.2 | 14.5 | 7.7 | 43 | 710x |
表 8: 不同方法在 LooGLE (Li et al., 2023b) 长依赖问答任务上的性能表现
| 方法 | 检索时间线重排序 | 计算推理 | AVG Tokens | 1/T |
|---|---|---|---|---|
| 基于检索的方法 | ||||
| BM25 | 20.4 | 21.7 | 8.2 | 26.3 |
| SBERT | 28.9 | 21.1 | 10.7 | 27.2 |
| LongLLMLingua rk | 38.6 | 32.2 | 16.2 | 26.3 |
| 基于压缩的方法 | ||||
| Selective-Context | 16.7 | 5.0 | 2.3 | 17.6 |
| LLMLingua | 10.0 | 25.0 | 13.3 | 21.1 |
| LongLLMLingua | 40.0 | 35.0 | 19.7 | 33.6 |
| LongLLMLingua (无重排序) | 39.3 | 33.8 | 18.7 | 31.6 |
| 原始提示 | 24.1 | 20.9 | 13.5 | 32.1 |
| 零样本 | 8.7 | 6.3 | 1.2 | 14.5 |
Table 9: The inference costs $\$$1 (per 1,000 samples) for various datasets using GPT-3.5-Turbo.
| Multi-document tQA | LongBench | ZeroScolls | MuSicQue | LooGLE | |
| Original | 4.6 | 31.5 | 30.6 | 3.8 | 93.6 |
| Ours | 1.3 (↓71.7%) | 3.0 (↓90.5%) | 3.2 (↓89.5%) | 1.8 (↓52.6%) | 5.6 (↓94.0%) |
表 9: 使用 GPT-3.5-Turbo 时各数据集的推理成本 $\$$1 (每 1,000 个样本)
Ours w/o Token-level Question-aware: Compressed Prompt:
无Token级问题感知的压缩提示:
Write a high-quality answer for the given question using only the provided search results (some of which might be irrelevant).
根据提供的搜索结果(部分可能无关)撰写高质量回答。
Document [1](: Physics)gen„ who received2K, which is ,73,0 in0. Johnen only to twice6. Mariaie won, for.g was, until 1 estate he. Two:Mayer (1963). As of 2017, the prize has been awarded Question: who got the first nobel prize in physics
文档 [1](: 物理学) 获得2K的gen„,即73,0中的0。Johnen仅两次获得6。Mariaie获胜,直到他拥有1处房产。两位:Mayer (1963)。截至2017年,该奖项已被颁发。问题:谁获得了第一个诺贝尔物理学奖
Answer:
回答:
LLMs’ Response: No answer found in the given search results.
大语言模型的回复:在给定的搜索结果中未找到答案。
Ours w/ Token-level Question-aware: Compressed Prompt:
Ours w/ Token-level Question-aware: 压缩提示 (Compressed Prompt):
Answer:
回答:
Original Prompt:
原始提示:
Document [1](Title: Dancing on Ice) It was confirmed on 25 January 2018, that Dancing on Ice had been recommissioned for an eleventh series to air in 2019
文档 [1](标题: Dancing on Ice) 2018年1月25日确认,《Dancing on Ice》已续订第十一季,将于2019年播出
Compressed Prompt:
压缩提示:
Please complete the code given below.
请补全下方给出的代码。
Next line of code:
下一行代码:
LLMs’ Response:
大语言模型的响应:
contact.set Last Message Transmitted(query.getEnd());\n
contact.set Last Message Transmitted(query.getEnd());
Ground Truth:
Ground Truth:
if (contact.set Last Message Transmitted(query.getEnd())) {
if (contact.setLastMessageTransmitted(query.getEnd())) {
Zero-shot LLMs’ Response: contact.remove Query(query);\n
零样本大语言模型响应:contact.remove Query(query);\n

Figure 9: Cases study on trec few-show learning in LongBench benchmark (Bai et al., 2023) in 2,000 constraint using GPT-3.5-Turbo.
图 9: LongBench基准测试(Bai et al., 2023)中trec少样本学习的案例研究(使用GPT-3.5-Turbo在2000 token限制下)