CoCa: Contrastive Captioners are Image-Text Foundation Models
CoCa: 对比式字幕生成器作为图文基础模型
Abstract
摘要
Exploring large-scale pretrained foundation models is of significant interest in computer vision because these models can be quickly transferred to many downstream tasks. This paper presents Contrastive Captioner (CoCa), a minimalist design to pretrain an image-text encoder-decoder foundation model jointly with contrastive loss and captioning loss, thereby subsuming model capabilities from contrastive approaches like CLIP and generative methods like SimVLM. In contrast to standard encoder-decoder transformers where all decoder layers attend to encoder outputs, CoCa omits cross-attention in the first half of decoder layers to encode unimodal text representations, and cascades the remaining decoder layers which cross-attend to the image encoder for multimodal image-text representations. We apply a contrastive loss between unimodal image and text embeddings, in addition to a captioning loss on the multimodal decoder outputs which predicts text tokens auto regressive ly. By sharing the same computational graph, the two training objectives are computed efficiently with minimal overhead. CoCa is pretrained end-to-end and from scratch on both web-scale alt-text data and annotated images by treating all labels simply as text, seamlessly unifying natural language supervision for representation learning. Empirically, CoCa achieves state-of-theart performance with zero-shot transfer or minimal task-specific adaptation on a broad range of downstream tasks, spanning visual recognition (ImageNet, Kinetics400/600/700, Moments-in-Time), crossmodal retrieval (MSCOCO, Flickr30K, MSR-VTT), multimodal understanding (VQA, SNLI-VE, NLVR2), and image captioning (MSCOCO, NoCaps). Notably on ImageNet classification, CoCa obtains $86.3%$ zero-shot top-1 accuracy, $90.6%$ with a frozen encoder and learned classification head, and new state-of-the-art $91.0%$ top-1 accuracy on ImageNet with a finetuned encoder.
探索大规模预训练基础模型对计算机视觉具有重要意义,因为这些模型可以快速迁移至众多下游任务。本文提出对比式描述生成器(CoCa),采用极简设计联合对比损失与描述生成损失预训练图文编码器-解码器基础模型,从而融合了CLIP等对比方法与SimVLM等生成方法的模型能力。不同于所有解码层都关注编码器输出的标准编码器-解码器Transformer,CoCa在前半部分解码层中省略交叉注意力以编码单模态文本表征,后半部分级联的解码层则通过交叉注意力处理图像编码器的多模态图文表征。我们在单模态图像与文本嵌入之间施加对比损失,同时对多模态解码器输出的自回归文本token预测施加描述生成损失。通过共享计算图,这两个训练目标能以最小开销高效计算。CoCa通过将所有标签视为文本,在网页规模替代文本数据和标注图像上实现了端到端的从头预训练,无缝统一了表征学习的自然语言监督机制。实证表明,CoCa在视觉识别(ImageNet、Kinetics400/600/700、Moments-in-Time)、跨模态检索(MSCOCO、Flickr30K、MSR-VTT)、多模态理解(VQA、SNLI-VE、NLVR2)和图像描述生成(MSCOCO、NoCaps)等广泛下游任务中,通过零样本迁移或最小化任务适配达到了最先进性能。特别在ImageNet分类任务上,CoCa实现了86.3%的零样本top-1准确率、90.6%(冻结编码器+可学习分类头)的准确率,并通过微调编码器创造了91.0%的ImageNet top-1准确率新纪录。
1 Introduction
1 引言
Deep learning has recently witnessed the rise of foundation language models [1] such as BERT [2], T5 [3], GPT-3 [4], where models are pretrained on web-scale data and demonstrate generic multitasking capabilities through zero-shot, few-shot or transfer learning. Compared with specialized individual models, pre training foundation models for massive downstream tasks can amortize training costs, providing opportunities to push the limits of model scale [5] for human-level intelligence.
深度学习领域近期见证了基础语言模型 [1] 的崛起,例如 BERT [2]、T5 [3]、GPT-3 [4]。这些模型通过网页规模数据进行预训练,并借助零样本 (zero-shot)、少样本 (few-shot) 或迁移学习展现出通用多任务处理能力。与专用独立模型相比,为海量下游任务预训练基础模型能够分摊训练成本,为突破模型规模极限 [5] 以实现人类水平智能提供了可能。
For vision and vision-language problems, several foundation model candidates have been explored: (1) Pioneering works [6, 7, 8] have shown the effectiveness of single-encoder models pretrained with cross-entropy loss on image classification datasets such as ImageNet [9]. The image encoder provides generic visual representations that can be adapted for various downstream tasks including image and video understanding [10, 11]. However, these models rely heavily on image annotations as labeled vectors and do not bake in knowledge of free-form human natural language, hindering their application to downstream tasks that involving both vision and language modalities. (2) Recently, a line of research [12, 13, 14] has shown the feasibility of image-text foundation model candidates by pre training two parallel encoders with a contrastive loss on web-scale noisy image-text pairs. In addition to the visual embeddings for vision-only tasks, the resulting dual-encoder models can additionally encode textual embeddings to the same latent space, enabling new crossmodal alignment capabilities such as zero-shot image classification and image-text retrieval. Nonetheless, these models are not directly applicable for joint vision-language understanding tasks such as visual question answering (VQA), due to missing joint components to learn fused image and text representations. (3) Another line of research [15, 16, 17] has explored generative pre training with encoder-decoder models to learn generic vision and multimodal representations. During pre training, the model takes images on the encoder side and applies Language Modeling (LM) loss (or PrefixLM [3, 16]) on the decoder outputs. For downstream tasks, the decoder outputs can then be used as joint representations for multimodal understanding tasks. While superior vision-language results [16] have been attained with pretrained encoder-decoder models, they do not produce text-only representations aligned with image embeddings, thereby being less feasible and efficient for crossmodal alignment tasks.
针对视觉与视觉-语言问题,研究者已探索了多种基础模型候选方案:(1) 开创性研究 [6,7,8] 证明了在ImageNet [9]等图像分类数据集上使用交叉熵损失预训练的单编码器模型的有效性。这种图像编码器提供的通用视觉表征可适配图像/视频理解 [10,11] 等多种下游任务。但这些模型严重依赖标注向量形式的图像注释,且未融入自由形式的人类自然语言知识,限制了其在涉及视觉与语言模态的下游任务中的应用。(2) 近期研究 [12,13,14] 通过在网络级噪声图像-文本对上使用对比损失预训练双并行编码器,验证了图文基础模型的可行性。除支持纯视觉任务的视觉嵌入外,所得双编码器模型还能将文本嵌入编码至相同潜在空间,实现零样本图像分类和图文检索等跨模态对齐能力。但由于缺乏学习融合图文表征的联合组件,这些模型无法直接应用于视觉问答(VQA)等联合视觉-语言理解任务。(3) 另一研究方向 [15,16,17] 探索了采用编码器-解码器模型进行生成式预训练,以学习通用视觉与多模态表征。预训练时模型在编码端输入图像,并在解码器输出端应用语言建模(LM)损失(或PrefixLM [3,16])。下游任务中,解码器输出可作为多模态理解任务的联合表征。虽然预训练编码器-解码器模型取得了卓越的视觉-语言效果 [16],但其无法生成与图像嵌入对齐的纯文本表征,因此在跨模态对齐任务中可行性及效率较低。
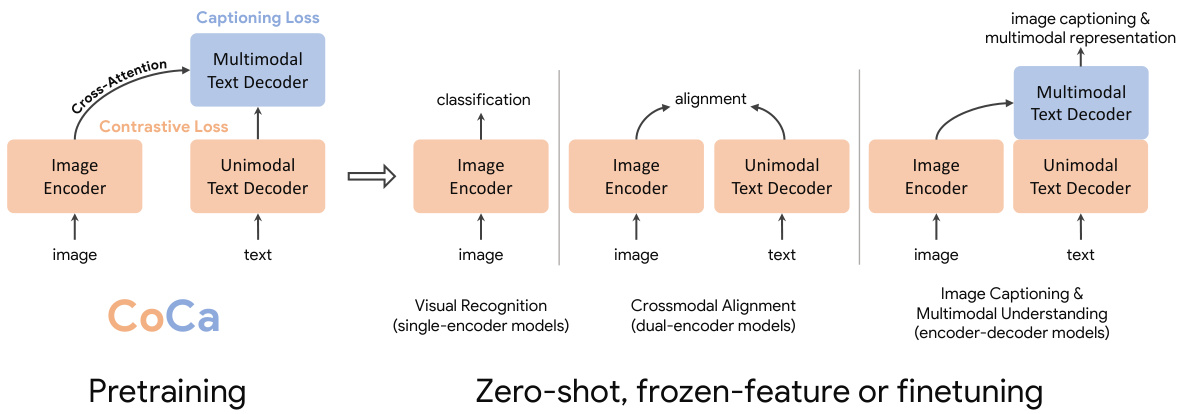
Figure 1: Overview of Contrastive Captioners (CoCa) pre training as image-text foundation models. The pretrained CoCa can be used for downstream tasks including visual recognition, vision-language alignment, image captioning and multimodal understanding with zero-shot transfer, frozen-feature evaluation or end-to-end finetuning.
图 1: 对比式描述生成器 (CoCa) 作为图文基础模型的预训练概览。预训练后的 CoCa 可用于下游任务,包括视觉识别、视觉-语言对齐、图像描述生成和多模态理解,支持零样本迁移、冻结特征评估或端到端微调。
In this work, we unify single-encoder, dual-encoder and encoder-decoder paradigms, and train one image-text foundation model that subsumes the capabilities of all three approaches. We propose a simple model family named Contrastive Captioners $\mathrm{(CoCa)}$ with a modified encoder-decoder architecture trained with both contrastive loss and captioning (generative) loss. As shown in Figure 1, we decouple the decoder transformer into two parts, a unimodal decoder and a multimodal decoder. We omit cross-attention in unimodal decoder layers to encode text-only representations, and cascade multimodal decoder layers cross-attending to image encoder outputs to learn multimodal image-text representations. We apply both the contrastive objective between outputs of the image encoder and unimodal text decoder, and the captioning objective at the output of the multimodal decoder. Furthermore, CoCa is trained on both image annotation data and noisy image-text data by treating all labels simply as text. The generative loss on image annotation text provides a fine-grained training signal similar to the single-encoder cross-entropy loss approach, effectively subsuming all three pre training paradigms into a single unified method.
在本工作中,我们统一了单编码器、双编码器和编码器-解码器范式,训练了一个包含这三种方法能力的图文基础模型。我们提出了一个名为对比字幕生成器 (CoCa) 的简单模型家族,采用改进的编码器-解码器架构,同时使用对比损失和字幕生成(生成式)损失进行训练。如图 1 所示,我们将解码器 Transformer 解耦为两部分:单模态解码器和多模态解码器。我们在单模态解码器层中省略交叉注意力以编码纯文本表示,并级联多模态解码器层对图像编码器输出进行交叉注意力学习多模态图文表示。我们在图像编码器和单模态文本解码器输出之间应用对比目标,同时在多模态解码器输出端应用字幕生成目标。此外,CoCa 通过将所有标签视为文本来同时训练图像标注数据和噪声图文数据。图像标注文本上的生成损失提供了类似于单编码器交叉熵损失方法的细粒度训练信号,有效地将所有三种预训练范式统一为单一方法。
The design of CoCa leverages contrastive learning for learning global representations and captioning for fine-grained region-level features, thereby benefiting tasks across all three categories shown in Figure 1. CoCa shows that a single pretrained model can outperform many specialized models using zero-shot transfer or minimal task-specific adaptation. For example, CoCa obtains $86.3%$ zero-shot accuracy on ImageNet and better zero-shot crossmodal retrieval on MSCOCO and Flickr $30\mathrm{k\Omega}$ . With a frozen-encoder, CoCa achieves $90.6%$ on ImageNet classification, $88.0%/88.5%/81.1%$ on Kinetics40/600/700 and $47.4%$ on Moments-in-Time. After lightweight finetuning, CoCa further achieves $91.0%$ on ImageNet, $82.3%$ on VQA and 120.6 CIDEr score on NoCaps.
CoCa的设计利用对比学习(contrastive learning)来学习全局表征,并通过描述任务获取细粒度区域级特征,从而提升图1所示三大类任务的性能。该研究表明,单一预训练模型通过零样本迁移或极少量任务适配,即可超越众多专用模型。例如:CoCa在ImageNet上实现86.3%的零样本准确率,在MSCOCO和Flickr30k上取得更优的零样本跨模态检索效果;采用冻结编码器时,其ImageNet分类准确率达90.6%,Kinetics40/600/700三数据集分别达到88.0%/88.5%/81.1%,Moments-in-Time数据集为47.4%;经轻量化微调后,ImageNet准确率提升至91.0%,VQA任务达82.3%,NoCaps数据集CIDEr分数达120.6。
2 Related Work
2 相关工作
Vision Pre training. Pre training ConvNets [18] or Transformers [19] on large-scale annotated data such as ImageNet [6, 7, 8], Instagram [20] or JFT [21] has become a popular strategy towards solving visual recognition problems including classification, localization, segmentation, video recognition, tracking and many other problems. Recently, self-supervised pre training approaches have also been explored. BEiT [22] proposes a masked image modeling task following BERT [2] in natural language processing, and uses quantized visual token ids as prediction targets. MAE [23] and SimMIM [24] remove the need for an image tokenizer and directly use a light-weight decoder or projection layer to regress pixel values. Nonetheless, these methods only learn models for the vision modality and thus they are not applicable to tasks that require joint reasoning over both image and text inputs.
视觉预训练。在大规模标注数据(如ImageNet [6, 7, 8]、Instagram [20] 或 JFT [21])上预训练ConvNets [18] 或 Transformer [19] 已成为解决分类、定位、分割、视频识别、跟踪等视觉识别问题的流行策略。近年来,自监督预训练方法也得到探索。BEiT [22] 提出了一种遵循自然语言处理中BERT [2] 的掩码图像建模任务,并使用量化视觉token id作为预测目标。MAE [23] 和 SimMIM [24] 则消除了对图像分词器的需求,直接通过轻量级解码器或投影层回归像素值。然而,这些方法仅学习视觉模态的模型,因此不适用于需要联合推理图像和文本输入的任务。
Vision-Language Pre training. In recent years, rapid progress has been made in vision-language pre training (VLP), which aims to jointly encode vision and language in a fusion model. Early work (e.g. LXMERT [25], UNITER [26], VinVL [27]) in this direction relies on pretrained object detection modules such as Fast(er) R-CNN [28] to extract visual representations. Later efforts such as ViLT [29] and VLMo [30] unify vision and language transformers, and train a multimodal transformer from scratch.
视觉语言预训练。近年来,视觉语言预训练(VLP)取得了快速进展,其目标是在一个融合模型中联合编码视觉和语言信息。该领域的早期工作(如LXMERT [25]、UNITER [26]、VinVL [27])依赖于预训练的目标检测模块(如Fast(er) R-CNN [28])来提取视觉表征。后续研究如ViLT [29]和VLMo [30]则统一了视觉与语言的Transformer架构,并从头开始训练多模态Transformer模型。
Image-Text Foundation Models. Recent work has proposed image-text foundation models that can subsume both vision and vision-language pre training. CLIP [12] and ALIGN [13] demonstrate that dual-encoder models pretrained with contrastive objectives on noisy image-text pairs can learn strong image and text representations for crossmodal alignment tasks and zero-shot image classification. Florence [14] further develops this method with unified contrastive objective [31], training foundation models that can be adapted for a wide range of vision and image-text benchmarks. To further improve zero-shot image classification accuracy, LiT [32] and BASIC [33] first pretrain model on an largescale image annotation dataset with cross-entropy and further finetune with contrastive loss on an noisy alt-text image dataset. Another line of research [16, 17, 34] proposes encoder-decoder models trained with generative losses and shows strong results in vision-language benchmarks while the visual encoder still performs competitively on image classification. In this work, we focus on training an image-text foundation model from scratch in a single pre training stage to unify these approaches. While recent works [35, 36, 37] have also explored image-text unification, they require multiple pre training stages of unimodal and multimodal modules to attain good performance. For example, ALBEF [36] combines contrastive loss with masked language modelling (MLM) with a dual-encoder design. However, our approach is simpler and more efficient to train while also enables more model capabilities: (1) CoCa only performs one forward and backward propagation for a batch of image-text pairs while ALBEF requires two (one on corrupted inputs and another without corruption), (2) CoCa is trained from scratch on the two objectives only while ALBEF is initialized from pretrained visual and textual encoders with additional training signals including momentum modules. (3) The decoder architecture with generative loss is preferred for natural language generation and thus directly enables image captioning and zero-shot learning [16].
图文基础模型。近期研究提出了能同时涵盖视觉与视觉语言预训练的图文基础模型。CLIP [12] 和 ALIGN [13] 证明,通过在噪声图文对上采用对比目标预训练的双编码器模型,可为跨模态对齐任务和零样本图像分类学习强大的图像与文本表征。Florence [14] 通过统一对比目标 [31] 进一步发展了该方法,训练出可适配多种视觉与图文基准的基础模型。为提升零样本图像分类准确率,LiT [32] 和 BASIC [33] 先在大型图像标注数据集上用交叉熵预训练模型,再在噪声替代文本图像数据集上用对比损失微调。另一研究方向 [16, 17, 34] 提出采用生成式损失训练的编码器-解码器模型,在视觉语言基准中表现优异,同时视觉编码器在图像分类任务中仍具竞争力。本文工作聚焦于通过单一预训练阶段从头训练图文基础模型以统一这些方法。虽然近期研究 [35, 36, 37] 也探索了图文统一,但它们需要多阶段预训练单模态与多模态模块以获得良好性能。例如 ALBEF [36] 在双编码器设计中结合了对比损失与掩码语言建模 (MLM)。但我们的方法训练更简单高效且具备更多能力:(1) CoCa 对批量图文对仅需一次前向与反向传播,而 ALBEF 需要两次(一次处理损坏输入,一次处理未损坏输入);(2) CoCa 仅针对两个目标从头训练,而 ALBEF 需从预训练的视觉与文本编码器初始化,并引入动量模块等额外训练信号;(3) 采用生成式损失的解码器架构更适用于自然语言生成,因此可直接支持图像描述生成和零样本学习 [16]。
3 Approach
3 方法
We begin with a review of three foundation model families that utilize natural language supervision differently: single-encoder classification pre training, dual-encoder contrastive learning, and encoderdecoder image captioning. We then introduce Contrastive Captioners (CoCa) that share the merits of both contrastive learning and image-to-caption generation under a simple architecture. We further discuss how CoCa models can quickly transfer to downstream tasks with zero-shot transfer or minimal task adaptation.
我们首先回顾三种利用自然语言监督方式不同的基础模型家族:单编码器分类预训练、双编码器对比学习和编码器-解码器图像描述生成。随后介绍对比式描述生成器(CoCa),该模型通过简洁架构同时具备对比学习和图像到描述生成的双重优势。进一步探讨CoCa模型如何通过零样本迁移或最小任务适配快速迁移至下游任务。
3.1 Natural Language Supervision
3.1 自然语言监督
Single-Encoder Classification. The classic single-encoder approach pretrains a visual encoder through image classification on a large crowd-sourced image annotation dataset (e.g., ImageNet [9], Instagram [20] or JFT [21]), where the vocabulary of annotation texts is usually fixed. These image annotations are usually mapped into discrete class vectors to learn with a cross-entropy loss as
单编码器分类。经典的单编码器方法通过在大型众包图像标注数据集(如ImageNet [9]、Instagram [20]或JFT [21])上进行图像分类来预训练视觉编码器,其中标注文本的词汇通常是固定的。这些图像标注通常被映射为离散的类别向量,通过交叉熵损失进行学习。
$$
\begin{array}{r}{\mathcal{L}{\mathrm{Cls}}=-p(y)\log q_{\theta}(x),}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{\mathrm{Cls}}=-p(y)\log q_{\theta}(x),}\end{array}
$$
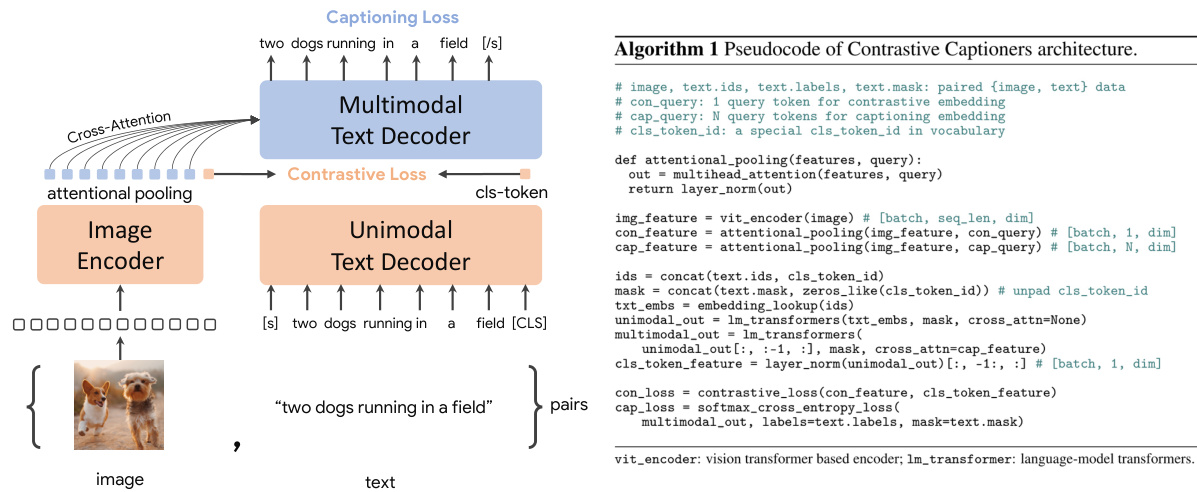
Figure 2: Detailed illustration of CoCa architecture and training objectives.
图 2: CoCa架构及训练目标的详细说明。
where $p(y)$ is a one-hot, multi-hot or smoothed label distribution from ground truth label $y$ . The learned image encoder is then used as a generic visual representation extractor for downstream tasks.
其中 $p(y)$ 是来自真实标签 $y$ 的独热 (one-hot) 、多热 (multi-hot) 或平滑标签分布。随后,学习到的图像编码器被用作下游任务的通用视觉表征提取器。
Dual-Encoder Contrastive Learning. Compared to pre training with single-encoder classification, which requires human-annotated labels and data cleaning, the dual-encoder approach exploits noisy web-scale text descriptions and introduces a learnable text tower to encode free-form texts. The two encoders are jointly optimized by contrasting the paired text against others in the sampled batch:
双编码器对比学习。与需要人工标注标签和数据清洗的单编码器分类预训练相比,双编码器方法利用噪声网络规模文本描述,并引入可学习的文本塔来编码自由格式文本。这两个编码器通过将配对文本与采样批次中的其他文本进行对比来联合优化:
$$
\mathcal{L}{\mathrm{Con}}=-\frac{1}{N}(\sum_{i}^{N}\log\frac{\exp(x_{i}^{\top}y_{i}/\sigma)}{\sum_{j=1}^{N}\exp(x_{i}^{\top}y_{j}/\sigma)}+\sum_{i}^{N}\log\frac{\exp(y_{i}^{\top}x_{i}/\sigma)}{\sum_{j=1}^{N}\exp(y_{i}^{\top}x_{j}/\sigma)}),
$$
$$
\mathcal{L}{\mathrm{Con}}=-\frac{1}{N}(\sum_{i}^{N}\log\frac{\exp(x_{i}^{\top}y_{i}/\sigma)}{\sum_{j=1}^{N}\exp(x_{i}^{\top}y_{j}/\sigma)}+\sum_{i}^{N}\log\frac{\exp(y_{i}^{\top}x_{i}/\sigma)}{\sum_{j=1}^{N}\exp(y_{i}^{\top}x_{j}/\sigma)}),
$$
where $x_{i}$ and $y_{j}$ are normalized embeddings of the image in the $i$ -th pair and that of the text in the $j$ -th pair. $N$ is the batch size, and $\sigma$ is the temperature to scale the logits. In addition to the image encoder, the dual-encoder approach also learns an aligned text encoder that enables crossmodal alignment applications such as image-text retrieval and zero-shot image classification. Empirical evidence shows zero-shot classification is more robust [12, 13, 38] on corrupted or out-of-distribution images.
其中 $x_{i}$ 和 $y_{j}$ 分别是第 $i$ 对图像和第 $j$ 对文本的归一化嵌入向量。$N$ 为批次大小,$\sigma$ 是用于缩放逻辑值的温度系数。除图像编码器外,双编码器方法还学习对齐的文本编码器,从而实现跨模态对齐应用(如图文检索和零样本图像分类)。实证研究表明,零样本分类在受损或分布外图像上具有更强鲁棒性 [12, 13, 38]。
Encoder-Decoder Captioning. While the dual-encoder approach encodes the text as a whole, the generative approach (a.k.a. captioner) aims for detailed granularity and requires the model to predict the exact tokenized texts of $y$ auto regressive ly. Following a standard encoder-decoder architecture, the image encoder provides latent encoded features (e.g., using a Vision Transformer [39] or ConvNets [40]) and the text decoder learns to maximize the conditional likelihood of the paired text $y$ under the forward auto regressive factorization:
编码器-解码器字幕生成。双编码器方法将文本作为一个整体进行编码,而生成式方法(又称字幕生成器)追求细粒度,要求模型以自回归方式预测 $y$ 的精确分词文本。遵循标准编码器-解码器架构,图像编码器提供潜在编码特征(例如使用Vision Transformer [39]或ConvNets [40]),文本解码器则学习在前向自回归分解下最大化配对文本 $y$ 的条件似然:
$$
\mathcal{L}{\mathrm{Cap}}=-\sum_{t=1}^{T}\log P_{\theta}(y_{t}|y_{<t},x).
$$
$$
\mathcal{L}{\mathrm{Cap}}=-\sum_{t=1}^{T}\log P_{\theta}(y_{t}|y_{<t},x).
$$
The encoder-decoder is trained with teacher-forcing [41] to parallel ize computation and maximize learning efficiency. Unlike prior methods, the captioner approach yields a joint image-text representation that can be used for vision-language understanding, and is also capable of image captioning applications with natural language generation.
编码器-解码器采用教师强制[41]进行训练,以实现并行计算并最大化学习效率。与先前方法不同,该字幕生成方法能产生可用于视觉语言理解的联合图像-文本表征,同时具备通过自然语言生成进行图像字幕应用的能力。
3.2 Contrastive Captioners Pre training
3.2 对比式字幕生成预训练
Figure 2 depicts the proposed contrastive captioner (CoCa): a simple encoder-decoder approach that seamlessly combines the three training paradigms. Similar to standard image-text encoderdecoder models, CoCa encodes images to latent representations by a neural network encoder, for example, vision transformer (ViT) [39] (used by default; it can also be other image encoders like ConvNets [40]), and decodes texts with a causal masking transformer decoder. Unlike standard decoder transformers, CoCa omits cross-attention in the first half of the decoder layers to encode unimodal text representations, and cascades the rest of the decoder layers, cross-attending to the image encoder for multimodal image-text representations. As a result, the CoCa decoder simultaneously produces both unimodal and multimodal text representations that allow us to apply both contrastive and generative objectives as
图 2: 展示了提出的对比式字幕生成器 (CoCa) : 一种无缝结合三种训练范式的简单编码器-解码器方法。与标准图文编码器-解码器模型类似,CoCa通过神经网络编码器 (如默认使用的视觉Transformer (ViT) [39] ,也可采用ConvNets [40] 等其他图像编码器) 将图像编码为潜在表征,并通过因果掩码Transformer解码器解码文本。不同于标准解码器Transformer,CoCa在前半部分解码层省略了交叉注意力以编码单模态文本表征,后半部分解码层则级联图像编码器的交叉注意力来生成多模态图文表征。因此,CoCa解码器能同步生成单模态和多模态文本表征,从而支持对比式和生成式目标函数的联合优化。
Table 1: Size variants of CoCa. Both image encoder and text decoder are Transformers [19, 39].
| 模型 | 图像编码器层数 | MLP | 参数量 | 单模态层数 | 多模态层数 | MLP | 参数量 | 隐藏层维度 | 注意力头数 | 总参数量 |
|---|---|---|---|---|---|---|---|---|---|---|
| CoCa-Base | 12 | 3072 | 86M | 12 | 12 | 3072 | 297M | 768 | 12 | 383M |
| CoCa-Large | 24 | 4096 | 303M | 12 | 12 | 4096 | 484M | 1024 | 16 | 787M |
| CoCa | 40 | 6144 | 1B | 18 | 18 | 5632 | 1.1B | 1408 | 16 | 2.1B |
表 1: CoCa的规模变体。图像编码器和文本解码器均采用Transformer结构 [19, 39]。
$$
\mathcal{L}{\mathrm{CoCa}}=\lambda_{\mathrm{Con}}\cdot\mathcal{L}{\mathrm{Con}}+\lambda_{\mathrm{Cap}}\cdot\mathcal{L}_{\mathrm{Cap}},
$$
$$
\mathcal{L}{\mathrm{CoCa}}=\lambda_{\mathrm{Con}}\cdot\mathcal{L}{\mathrm{Con}}+\lambda_{\mathrm{Cap}}\cdot\mathcal{L}_{\mathrm{Cap}},
$$
where $\lambda_{\mathrm{Con}}$ and $\lambda_{\mathrm{Cap}}$ are loss weighting hyper-parameters. We note that the single-encoder crossentropy classification objective can be interpreted as a special case of the generative approach applied on image annotation data, when the vocabulary is the set of all label names.
其中 $\lambda_{\mathrm{Con}}$ 和 $\lambda_{\mathrm{Cap}}$ 是损失加权超参数。我们注意到,当词汇表为所有标签名称的集合时,单编码器交叉熵分类目标可解释为应用于图像标注数据的生成式方法的一个特例。
Decoupled Text Decoder and CoCa Architecture. The captioning approach optimizes the conditional likelihood of text while the contrastive approach uses an unconditional text representation. To address this dilemma and combine these two methods into a single model, we propose a simple decoupled decoder design where we split the decoder into unimodal and multimodal components, by skipping the cross-attention mechanism in the unimodal decoder layers. That is, the bottom $n_{\mathrm{uni}}$ unimodal decoder layers encode the input text as latent vectors with causally-masked self-attention, and the top $n_{\mathrm{multi}}$ multimodal layers further apply causally-masked self-attention and together with cross-attention to the output of the visual encoder. All decoder layers prohibit tokens from attending to future tokens, and it is straightforward to use the multimodal text decoder output for the captioning objective ${\mathcal{L}}{\mathrm{Cap}}$ . For the contrastive objective $\mathcal{L}{\mathrm{Con}}$ , we append a learnable [CLS] token at the end of the input sentence and use its corresponding output of unimodal decoder as the text embedding. We split the decoder in half such that $n_{\mathrm{uni}}=n_{\mathrm{multi}}$ . Following ALIGN [13], we pretrain with image resolution of $288\times288$ and patch size $18\times18$ , resulting in a total of 256 image tokens. Our largest CoCa model ("CoCa" in short) follows the ViT-giant setup in [21] with 1B-parameters in the image encoder and 2.1B-parameters altogether with the text decoder. We also explore two smaller variants of “CoCa-Base” and “CoCa-Large” detailed in Table 1.
解耦文本解码器与CoCa架构。标题生成方法优化文本的条件似然,而对比方法使用无条件文本表示。为解决这一矛盾并将两种方法整合到单一模型中,我们提出简单的解耦解码器设计:通过跳过单模态解码器层的交叉注意力机制,将解码器拆分为单模态和多模态组件。具体而言,底部的$n_{\mathrm{uni}}$层单模态解码器通过因果掩码自注意力将输入文本编码为潜在向量,顶部的$n_{\mathrm{multi}}$层多模态解码器则进一步应用因果掩码自注意力,并与视觉编码器输出进行交叉注意力交互。所有解码器层均禁止token关注未来token,可直接使用多模态文本解码器输出来实现标题生成目标${\mathcal{L}}{\mathrm{Cap}}$。对于对比目标$\mathcal{L}{\mathrm{Con}}$,我们在输入句末添加可学习的[CLS]token,并使用其对应的单模态解码器输出作为文本嵌入。我们将解码器均等分割为$n_{\mathrm{uni}}=n_{\mathrm{multi}}$。遵循ALIGN [13]的方法,采用$288\times288$图像分辨率和$18\times18$的补丁尺寸进行预训练,共生成256个图像token。最大规模的CoCa模型(简称"CoCa")采用[21]中的ViT-giant配置,图像编码器含10亿参数,结合文本解码器总计21亿参数。我们还探索了"CoCa-Base"和"CoCa-Large"两个小型变体,详见表1。
Attention al Poolers. It is noteworthy that the contrastive loss uses a single embedding for each image while the decoder usually attends to a sequence of image output tokens in an encoder-decoder captioner [16]. Our preliminary experiments show that a single pooled image embedding helps visual recognition tasks as a global representation, while more visual tokens (thus more fine-grained) are beneficial for multimodal understanding tasks which require region-level features. Hence, CoCa adopts task-specific attention al pooling [42] to customize visual representations to be used for different types of training objectives and downstream tasks. Here, a pooler is a single multi-head attention layer with $n_{\mathrm{query}}$ learnable queries, with the encoder output as both keys and values. Through this, the model can learn to pool embeddings with different lengths for the two training objectives, as shown in Figure 2. The use of task-specific pooling not only addresses different needs for different tasks but also introduces the pooler as a natural task adapter. We use attention al poolers in pre training for generative loss $n_{\mathrm{query}}=256$ and contrastive loss $n_{\mathrm{query}}=1$ .
注意力池化器。值得注意的是,对比损失对每张图像使用单一嵌入向量,而解码器通常在编码器-解码器结构的字幕生成器[16]中处理一系列图像输出token。我们的初步实验表明,单一池化图像嵌入作为全局表征有助于视觉识别任务,而更多视觉token(即更细粒度)则对需要区域级特征的多模态理解任务更有利。因此,CoCa采用任务特定的注意力池化[42]来定制适用于不同类型训练目标和下游任务的视觉表征。这里的池化器是一个带$n_{\mathrm{query}}$个可学习查询的单层多头注意力机制,以编码器输出同时作为键和值。通过这种方式,模型可以学习为两种训练目标生成不同长度的嵌入向量,如图2所示。任务特定池化的使用不仅解决了不同任务的差异化需求,还将池化器自然地转化为任务适配器。在预训练中,我们为生成式损失($n_{\mathrm{query}}=256$)和对比损失($n_{\mathrm{query}}=1$)分别配置了注意力池化器。
Pre training Efficiency. A key benefit of the decoupled auto regressive decoder design is that it can compute two training losses considered efficiently. Since unidirectional language models are trained with causal masking on complete sentences, the decoder can efficiently generate outputs for both contrastive and generative losses with a single forward propagation (compared to two passes for a bidirectional approach [36]). Therefore, the majority of the compute is shared between the two losses and CoCa only induces minimal overhead compared to standard encoder-decoder models. On the other hand, while many existing methods [30, 32, 33, 35, 36, 37] train model components with multiple stages on various data sources and/or modalities, CoCa is pretrained end-to-end from scratch directly with various data sources (i.e., annotated images and noisy alt-text images) by treating all labels as texts for both contrastive and generative objectives.
预训练效率。解耦自回归解码器设计的一个关键优势在于能够高效计算两种训练损失。由于单向语言模型采用因果掩码在完整句子上训练,解码器仅需单次前向传播即可同时生成对比损失和生成损失的输出(而双向方法需要两次前向传播 [36])。因此两种损失的计算大部分是共享的,相比标准编码器-解码器模型,CoCa仅引入极小开销。另一方面,现有方法 [30, 32, 33, 35, 36, 37] 通常需要分多阶段训练模型组件并使用不同数据源和/或模态,而CoCa通过将所有标签视为文本(服务于对比和生成目标),直接端到端地从多种数据源(标注图像和含噪声替代文本图像)进行预训练。
3.3 Contrastive Captioners for Downstream Tasks
3.3 面向下游任务的对比式字幕生成器
Zero-shot Transfer. A pretrained CoCa model performs many tasks in a zero-shot manner by leveraging both image and text inputs, including zero-shot image classification, zero-shot image-text cross-retrieval, zero-shot video-text cross-retrieval. Following previous practices [12, 32], “zero-shot” here is different from classical zero-shot learning in that during pre training, the model may see relevant supervised information, but no supervised examples are used during the transfer protocol. For the pre training data, we follow strict de-duplication procedures introduced in [13, 32] to filter all near-domain examples to our downstream tasks.
零样本迁移。预训练的CoCa模型通过同时利用图像和文本输入,能以零样本方式执行多种任务,包括零样本图像分类、零样本图文交叉检索、零样本视频文本交叉检索。遵循先前实践 [12, 32],此处的"零样本"与传统零样本学习不同:在预训练阶段模型可能接触过相关监督信息,但在迁移协议中未使用任何监督样本。对于预训练数据,我们采用 [13, 32] 提出的严格去重流程,过滤所有与下游任务近似的域内样本。
Frozen-feature Evaluation. As discussed in the previous section, CoCa adopts task-specific attentional pooling [42] (pooler for brevity) to customize visual representations for different types downstream tasks while sharing the backbone encoder. This enables the model to obtain strong performance as a frozen encoder where we only learn a new pooler to aggregate features. It can also benefit to multi-task problems that share the same frozen image encoder computation but different task-specific heads. As also discussed in [23], linear-evaluation struggles to accurately measure learned representations and we find the attention al poolers are more practical for real-world applications.
冻结特征评估。如前一节所述,CoCa采用任务特定的注意力池化[42](简称pooler)来为不同类型的下游任务定制视觉表征,同时共享骨干编码器。这使得模型作为冻结编码器时仅需学习新的pooler来聚合特征,即可获得强劲性能。该方案同样适用于共享同一冻结图像编码器计算但采用不同任务特定头部的多任务场景。如[23]所述,线性评估难以准确衡量学习到的表征,我们发现注意力池化方案在实际应用中更具实用性。
CoCa for Video Action Recognition. We use a simple approach to enable a learned CoCa model for video action recognition tasks. We first take multiple frames of a video and feed each frame into the shared image encoder individually as shown in Figure 3. For frozenfeature evaluation or finetuning, we learn an additional pooler on top of the spatial and temporal feature tokens with a softmax cross-entropy loss. Note the pooler has a single query token thus the computation of pooling over all spatial and temporal tokens is not expensive. For zero-shot video-text retrieval, we use an even simpler approach by computing the mean embedding of 16 frames of the video (frames are uniformly sampled from a video). We also encode the captions of each video as target embeddings when computing retrieval metrics.
用于视频动作识别的CoCa。我们采用一种简单方法使训练好的CoCa模型能够处理视频动作识别任务。如图3所示,首先提取视频的多帧画面,将每帧图像分别输入共享的图像编码器。在冻结特征评估或微调阶段,我们会在空间和时间特征token之上学习一个带softmax交叉熵损失的附加池化器。请注意该池化器仅使用单个查询token,因此对所有时空token进行池化计算的开销并不大。对于零样本视频-文本检索任务,我们采用更简单的方法:计算视频16帧(从视频中均匀采样)的嵌入均值。在计算检索指标时,我们还会将每个视频的字幕编码为目标嵌入向量。
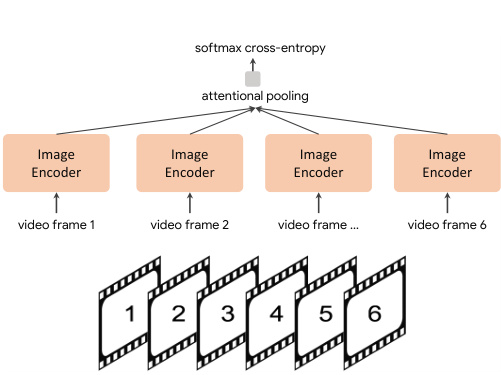
Figure 3: CoCa for video recognition.
图 3: 用于视频识别的 CoCa。
4 Experiments
4 实验
In this section, we first describe the details of our experimental setup. The main results are presented next organized as visual recognition tasks, crossmodal alignment tasks, image captioning and multimodal understanding tasks. Our main results are conducted under three categories for downstream tasks: zero-shot transfer, frozen-feature evaluation and finetuning. We also present ablation experiments including training objectives and architecture designs.
在本节中,我们首先描述实验设置的细节。随后按视觉识别任务、跨模态对齐任务、图像描述及多模态理解任务的分类呈现主要结果。下游任务主要分为三类进行评估:零样本迁移、冻结特征评估和微调。同时展示了包括训练目标和架构设计在内的消融实验。
4.1 Training Setup
4.1 训练设置
Data. As discussed in Section 3.2, CoCa is pretrained from scratch in a single stage on both webscale alt-text data and annotated images by treating all labels simply as texts. We use the JFT-3B dataset [21] with label names as the paired texts, and the ALIGN dataset [13] with noisy alt-texts. Similar to [33], we randomly shuffle and concatenate label names of each image in JFT together with a prompt sampled from [12]. An example of the resulting text label of a JFT image would look like “a photo of the cat, animal”. Unlike prior models [32, 33] that also use the combination of these two datasets, we train all model parameters from scratch at the same time without pre training an image encoder with supervised cross-entropy loss for simplicity and pre training efficiency. To ensure fair evaluation, we follow the strict de-duplication procedures introduced in [13, 32] to filter all near-domain examples (3.6M images are removed in total) to our downstream tasks. To tokenize text input, we use a sentence-piece model [43, 44] with a vocabulary size of 64k trained on the sampled pre training dataset.
数据。如第3.2节所述,CoCa通过将所有标签简单视为文本,在网页替代文本数据和标注图像上单阶段从头开始预训练。我们使用JFT-3B数据集[21](以标签名称作为配对文本)和ALIGN数据集[13](含噪声替代文本)。类似[33]的做法,我们将JFT中每张图像的标签名称随机打乱,并与从[12]采样的提示词拼接。例如JFT图像的生成文本标签可能呈现为"a photo of the cat, animal"。与同样使用这两个数据集组合的先前模型[32,33]不同,为简化流程并提升预训练效率,我们同时从头训练所有模型参数,而非先用监督交叉熵损失预训练图像编码器。为确保评估公平性,我们遵循[13,32]提出的严格去重流程,过滤所有近域样本(共移除360万张图像)以用于下游任务。文本输入的分词处理采用基于采样预训练数据集训练的句子片段模型[43,44],词表大小为64k。
Optimization. Our models are implemented in the Lingvo framework [45] with GSPMD [46, 47, 48, 49] for scaling performance. Following [33], we use a batch size of 65,536 image-text pairs, where half of each batch comes from JFT and ALIGN, respectively. All models are trained on the combined contrastive and captioning objectives in Eq.(4) for $500\mathrm{k}$ steps, roughly corresponding to 5 epochs on JFT and 10 epochs on ALIGN. As shown later in our studies, we find a larger captioning loss weight is better and thus $\lambda_{\mathrm{Cap}}=2.0$ and $\lambda_{\mathrm{Con}}=1.0$ . Following [13], we apply a contrastive loss with a trainable temperature $\tau$ with an initial value of 0.07. For memory efficiency, we use the Adafactor [50] optimizer with $\beta_{1}=0.9$ , $\beta_{2}=0.999$ and decoupled weight decay ratio of 0.01. We warm up the learning rate for the first $2%$ of training steps to a peak value of $8\times\mathrm{10^{-4}}$ , and linearly decay it afterwards. Pre training $\mathrm{{CoCa}}$ takes about 5 days on 2,048 CloudTPUv4 chips. Following [12, 13, 14], we continue pre training for one epoch on a higher resolution of $576\times576$ . For finetuning evaluation, we mainly follow simple protocols and directly train CoCa on downstream tasks without further metric-specific tuning like CIDEr scores (details in Appendix A and B).
优化。我们的模型基于 Lingvo 框架 [45] 实现,并采用 GSPMD [46, 47, 48, 49] 进行性能扩展。参照 [33],我们使用 65,536 个图文对作为批次大小,其中每批数据各半分别来自 JFT 和 ALIGN。所有模型均采用公式 (4) 中的对比学习与描述生成联合目标进行训练,共进行 $500\mathrm{k}$ 步,约相当于 JFT 的 5 个周期和 ALIGN 的 10 个周期。后续研究表明,增大描述生成损失权重效果更优,故设定 $\lambda_{\mathrm{Cap}}=2.0$ 和 $\lambda_{\mathrm{Con}}=1.0$。参照 [13],我们采用可训练温度参数 $\tau$ 的对比损失,初始值为 0.07。为提升内存效率,使用 Adafactor [50] 优化器,参数设为 $\beta_{1}=0.9$、$\beta_{2}=0.999$,解耦权重衰减率为 0.01。学习率在前 $2%$ 训练步数中线性预热至峰值 $8\times\mathrm{10^{-4}}$,之后线性衰减。$\mathrm{{CoCa}}$ 预训练在 2,048 块 CloudTPUv4 芯片上耗时约 5 天。遵循 [12, 13, 14] 方法,我们继续以 $576\times576$ 更高分辨率预训练一个周期。微调评估阶段主要采用简单协议,直接在下游任务上训练 CoCa,未针对 CIDEr 等指标进行额外调优(详见附录 A 和 B)。
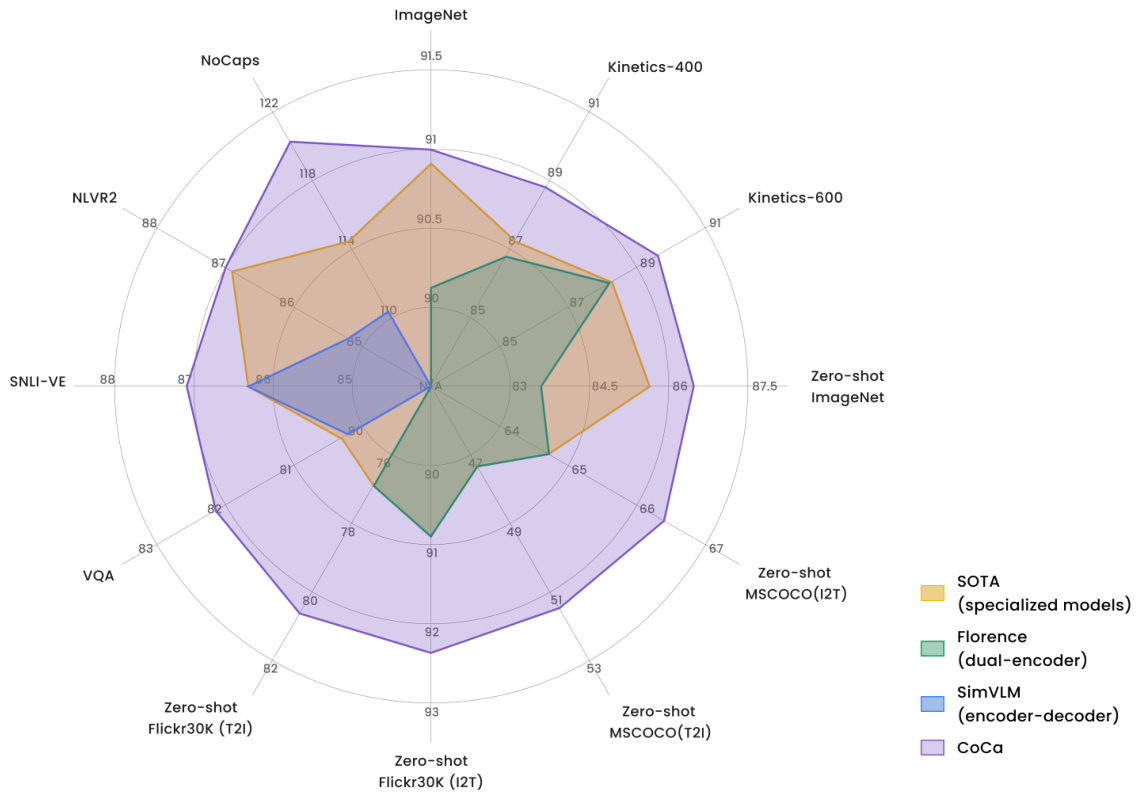
Figure 4: Comparison of CoCa with other image-text foundation models (without task-specific customization) and multiple state-of-the-art task-specialized models.
Table 2: Image classification and video action recognition with frozen encoder or finetuned encoder.
图 4: CoCa与其他图文基础模型(未进行任务定制)及多个最先进任务专用模型的对比。
| 模型 | ImageNet | 模型 | K-400 | K-600 | K-700 | Moments-in-Time |
|---|---|---|---|---|---|---|
| ALIGN[13] | 88.6 | ViViT[53] | 84.8 | 84.3 | 38.0 | |
| Florence[14] | 90.1 | MoViNet[54] | 81.5 | 84.8 | 79.4 | 40.2 |
| MetaPseudoLabels[51] | 90.2 | VATT[55] | 82.1 | 83.6 | 41.1 | |
| CoAtNet[10] | 90.9 | Florence[14] | 86.8 | 88.0 | ||
| ViT-G[21] | 90.5 | MaskFeat[56] | 87.0 | 88.3 | 80.4 | |
| + Model Soups[52] | 90.9 | CoVeR[11] | 87.2 | 87.9 | 78.5 | 46.1 |
| CoCa(frozen) | 90.6 | CoCa(frozen) | 88.0 | 88.5 | 81.1 | 47.4 |
| CoCa(finetuned) | 91.0 | CoCa(finetuned) | 88.9 | 89.4 | 82.7 | 49.0 |
表 2: 使用冻结编码器或微调编码器进行图像分类和视频动作识别的结果。
4.2 Main Results
4.2 主要结果
We extensively evaluate the capabilities of CoCa models on a wide range of downstream tasks as a pretrained foundation model. We mainly consider core tasks of three categories that examine (1)
我们广泛评估了CoCa模型作为预训练基础模型在多种下游任务上的能力。主要考察三类核心任务:(1)
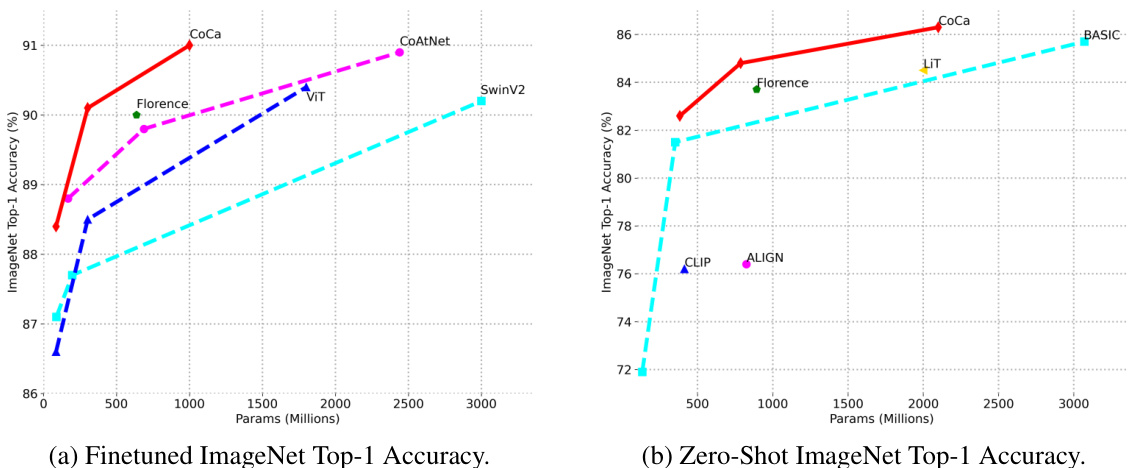
Figure 5: Image classification scaling performance of model sizes.
图 5: 不同模型尺寸的图像分类扩展性能。
visual recognition, (2) crossmodal alignment, and (3) image captioning and multimodal understanding capabilities. Since CoCa produces both aligned unimodal representations and fused multimodal embeddings at the same time, it is easily transferable to all three task groups with minimal adaption. Figure 4 summarizes the performance on key benchmarks of CoCa compared to other dual-encoder and encoder-decoder foundation models and state-of-the-art task-specialized methods. CoCa sets new state-of-the-art results on tasks of all three categories with a single pretrained checkpoint.
视觉识别、(2) 跨模态对齐、(3) 图像描述与多模态理解能力。由于CoCa能同时生成对齐的单模态表征和融合的多模态嵌入,只需极少量适配即可迁移至全部三类任务组。图4对比了CoCa与其他双编码器-解码器基础模型及专项最优方法在核心基准测试中的表现。CoCa仅用单一预训练检查点,就在全部三类任务中刷新了最优性能纪录。
4.2.1 Visual Recognition Tasks
4.2.1 视觉识别任务
Our visual recognition experiments are conducted on ImageNet [9] as image recognition benchmark, and multiple video datasets including Kinetics-400 [57], Kinetics-600 [58], Kinetics-700 [59], Moments-in-Time [60] as test-beds for video action recognition; it is noteworthy that CoCa pretrains on image data only, without accessing any extra video datasets. We apply the CoCa encoder on video frames individually (Section 3.3) without early fusion of temporal information, yet the resulting CoCa-for-Video model performs better than many spatio-temporal early-fused video models.
我们的视觉识别实验在ImageNet [9]作为图像识别基准,以及包括Kinetics-400 [57]、Kinetics-600 [58]、Kinetics-700 [59]、Moments-in-Time [60]在内的多个视频数据集上作为视频动作识别的测试平台进行;值得注意的是,CoCa仅使用图像数据进行预训练,未接触任何额外视频数据集。我们将CoCa编码器单独应用于视频帧(第3.3节),未对时序信息进行早期融合,但由此产生的CoCa-for-Video模型表现优于许多时空早期融合的视频模型。
Frozen-feature. We apply a pretrained frozen CoCa model on both image classification and video action recognition. The encoder is used for both tasks while the decoder is discarded. As discussed in Section 3.3, an attention al pooling is learned together with a softmax cross-entropy loss layer on top of the embedding outputs from CoCa encoder. For video classification, a single query-token is learned to weight outputs of all tokens of spatial patches $\times$ temporal frames. We set a learning rate of $5\times10^{-4}$ on both attention al pooler and softmax, batch size of 128, and a cosine learning rate schedule (details in Appendix A). For video action recognition, we compare CoCa with other approaches on the same setup (i.e., without extra supervised video data and without audio signals as model inputs). As shown in Table 2, without finetuning full encoder, CoCa already achieves competitive Top-1 classification accuracies compared to specialized image and outperforms prior state-of-the-art specialized methods on video tasks.
冻结特征。我们在图像分类和视频动作识别任务中应用了预训练且冻结参数的CoCa模型,编码器用于两项任务而解码器被弃用。如第3.3节所述,我们在CoCa编码器的嵌入输出层上联合学习了一个注意力池化层和softmax交叉熵损失层。对于视频分类,通过学习单个查询token (query-token) 来加权空间区块×时间帧的所有token输出。设置注意力池化器和softmax的学习率为$5×10^{-4}$,批量大小为128,并采用余弦学习率调度(详见附录A)。在视频动作识别任务中,我们在相同配置下(即不使用额外监督视频数据且不将音频信号作为模型输入)将CoCa与其他方法进行比较。如表2所示,在不微调完整编码器的情况下,CoCa已取得与专用图像模型相当的Top-1分类准确率,并在视频任务上超越了之前的专用最优方法。
Finetuning. Based on the architecture of frozen-feature evaluation, we further finetune CoCa encoders on image and video datasets individually with a smaller learning rate of $1\times10^{-4}$ . More experimental details are summarized in the Appendix A. The finetuned CoCa has improved performance across these tasks. Notably, CoCa obtains new state-of-the-art $91.0%$ Top-1 accuracy on ImageNet, as well as better video action recognition results compared with recent video approaches. More importantly, CoCa models use much less parameters than other methods in the visual encoder as shown in Figure 5a. These results suggest the proposed framework efficiently combines text training signals and thus is able to learn high-quality visual representation better than the classical single-encoder approach.
微调 (Finetuning)。基于冻结特征评估的架构,我们进一步在图像和视频数据集上分别对 CoCa 编码器进行微调,采用较小的学习率 $1\times10^{-4}$。更多实验细节总结在附录 A 中。微调后的 CoCa 在这些任务上均表现出性能提升。值得注意的是,CoCa 在 ImageNet 上取得了 91.0% 的最新 Top-1 准确率,同时在视频动作识别任务中也优于近期视频方法。更重要的是,如图 5a 所示,CoCa 模型的视觉编码器参数量远少于其他方法。这些结果表明,所提出的框架能高效结合文本训练信号,从而比经典的单编码器方法更能学习到高质量的视觉表征。
4.2.2 Crossmodal Alignment Tasks
4.2.2 跨模态对齐任务
Unlike other fusion-based foundation methods [16, 17, 35], CoCa is naturally applicable to crossmodal alignment tasks since it generates aligned image and text unimodal embeddings. In particular, we are interested in the zero-shot setting where all parameters are frozen after pre training and directly used to extract embeddings. Here, we use the same embeddings used for contrastive loss during pre training, and thus the multimodal text decoder is not used.
与其他基于融合的基础方法[16, 17, 35]不同,CoCa由于生成对齐的图像和文本单模态嵌入(embedding),天然适用于跨模态对齐任务。我们特别关注零样本(zero-shot)设置,其中所有参数在预训练后冻结,并直接用于提取嵌入。此处我们使用与预训练期间对比损失相同的嵌入,因此未使用多模态文本解码器。
| | Flickr30K (1K测试集) | | | | | | MSCOCO (5K测试集) | | | | | |
| | 图像→文本 | | | 文本→图像 | | | 图像→文本 | | | 文本→图像 | | |
| 模型 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| CLIP [12] | 88.0 | 98.7 | 99.4 | 68.7 | 90.6 | 95.2 | 58.4 | 81.5 | 88.1 | 37.8 | 62.4 | 72.2 |
| ALIGN [13] | 88.6 | 98.7 | 99.7 | 75.7 | 93.8 | 96.8 | 58.6 | 83.0 | 89.7 | 45.6 | 69.8 | 78.6 |
| FLAVA [35] | 67.7 | 94.0 | | 65.2 | 89.4 | | 42.7 | 76.8 | | 38.4 | 67.5 | = |
| FILIP [61] | 89.8 | 99.2 | 99.8 | 75.0 | 93.4 | 96.3 | 61.3 | 84.3 | 90.4 | 45.9 | 70.6 | 79.3 |
| Florence [14] | 90.9 | 99.1 | | 76.7 | 93.6 | | 64.7 | 85.9 | | 47.2 | 71.4 | |
| CoCa-Base | 89.8 | 98.8 | 99.8 | 76.8 | 93.7 | 96.8 | 63.8 | 84.7 | 90.7 | 47.5 | 72.4 | 80.9 |
| CoCa-Large | 91.4 | 99.2 | 99.9 | 79.0 | 95.1 | 97.4 | 65.4 | 85.6 | 91.4 | 50.1 | 73.8 | 81.8 |
| CoCa | 92.5 | 99.5 | 99.9 | 80.4 | 95.7 | 97.7 | 66.3 | 86.2 | 91.8 | 51.2 | 74.2 | 82.0 |
表 3: 零样本图文检索结果在Flickr30K [62]和MSCOCO [63]数据集上的表现。
| 模型 | ImageNet | | ImageNet-A | | ImageNet-R | | ImageNet-V2 | | ImageNet-Sketch | | ObjectNet | |
| CLIP [12] | 76.2 | 77.2 | | 88.9 | 70.1 | | 60.2 | 72.3 | 平均 | 74.3 |
| ALIGN [13] | 76.4 | | 75.8 | 92.2 | | | 64.8 | | 72.2 | 74.5 |
| FILIP [61] | 78.3 | | | | | 70.1 | | | | | |
| Florence [14] | 83.7 | | | | | | | | | | |
| LiT [32] | 84.5 | | 79.4 | 93.9 | | 78.7 | | 81.1 | | | |
| BASIC [33] | 85.7 | 85.6 | | 95.7 | 80.6 | | | 76.1 | 78.9 | | 83.7 |
| CoCa-Base | 82.6 | | 76.4 | 93.2 | | 76.5 | 71.7 | 71.6 | | 78.7 |
| CoCa-Large | 84.8 | | 85.7 | 95.6 | | 79.6 | 75.7 | 78.6 | | 83.3 |
| CoCa | 86.3 | | 90.2 | 96.5 | | 80.7 | 77.6 | 82.7 | | 85.7 |
Table 4: Zero-shot image classification results on ImageNet [9], ImageNet-A [64], ImageNet-R [65], ImageNet-V2 [66], ImageNet-Sketch [67] and ObjectNet [68].
表 4: ImageNet [9]、ImageNet-A [64]、ImageNet-R [65]、ImageNet-V2 [66]、ImageNet-Sketch [67] 和 ObjectNet [68] 上的零样本图像分类结果。
Zero-Shot Image-Text Retrieval. We evaluate CoCa on the two standard image-text retrieval benchmarks: MSCOCO [63] and Flickr30K [62]. Following the CLIP setting [12], we first independently feed each image/text to the corresponding encoder and obtain embeddings for all image/text in the test set. We then retrieve based on cosine similarity scores over the whole test set. As shown in Table 3, CoCa significantly improves over prior methods on both image-to-text and text-to-image retrievals on all metrics. In addition, our model is parameter-efficient, with CoCa-Base already outperforming strong baselines (CLIP [12] and ALIGN [13]) and CoCa-Large outperforming Florence [14] (which contains a parameter count comparable to ViT-Huge). This shows that CoCa learns good unimodal representations and aligns them well across modalities.
零样本图像-文本检索。我们在两个标准图像-文本检索基准上评估CoCa:MSCOCO [63]和Flickr30K [62]。遵循CLIP的设置 [12],我们首先独立地将每张图像/文本输入对应的编码器,并获取测试集中所有图像/文本的嵌入表示。随后基于整个测试集的余弦相似度分数进行检索。如表3所示,CoCa在所有指标上均显著优于先前方法,无论是图像到文本还是文本到图像的检索任务。此外,我们的模型具有参数高效性,其中CoCa-Base已超越强基线模型(CLIP [12]和ALIGN [13]),而CoCa-Large则优于Florence [14](其参数量与ViT-Huge相当)。这表明CoCa能够学习优质的单模态表示,并能很好地跨模态对齐。
Zero-Shot Image Classification. Following prior work [12, 13], we use the aligned image/text embeddings to perform zero-shot image classification by matching images with label names without finetuning. We follow the exact setup in [12] and apply the same set of prompts used for label class names. As shown in Table 4, CoCa sets new state-of-the-art zero-shot classification results on ImageNet. Notably, CoCa uses fewer parameters than prior best model [33] while smaller CoCa variants already outperform strong baselines [12, 14], as shown in Figure 5b. In addition, our model demonstrates effective generalization under zero-shot evaluation, consistent with prior findings [12, 13], with CoCa improving on all six datasets considered. Lastly, while prior models [32, 33] found sequentially pre training with single-encoder and dual-encoder methods in multiple stages is crucial to performance gains, our results show it is possible to attain strong performance by unifying training objectives and datasets in a single-stage framework.
零样本图像分类。遵循先前工作 [12, 13],我们使用对齐的图像/文本嵌入来执行零样本图像分类,通过将图像与标签名称匹配而无需微调。我们完全按照 [12] 的设置,并应用相同的标签类名提示集。如表 4 所示,CoCa 在 ImageNet 上创造了新的最先进的零样本分类结果。值得注意的是,CoCa 使用的参数比先前的最佳模型 [33] 更少,而较小的 CoCa 变体已经超越了强基线 [12, 14],如图 5b 所示。此外,我们的模型在零样本评估下表现出有效的泛化能力,与先前的研究结果一致 [12, 13],CoCa 在所有考虑的六个数据集上都有所提升。最后,虽然先前的模型 [32, 33] 发现通过单编码器和双编码器方法在多阶段中进行顺序预训练对性能提升至关重要,但我们的结果表明,通过在单阶段框架中统一训练目标和数据集,也可以获得强大的性能。
Zero-Shot Video Retrieval. We evaluate video-text retrieval using CoCa on MSR-VTT [71] using the full split. Table 5 shows that CoCa produces the highest retrieval metrics for both text-to-video and video-to-text retrieval. It is important to note that MSR-VTT videos are sourced from YouTube, and we require the original videos to compute our embeddings. Many of the videos have been made explicitly unavailable [72], hence we compute retrieval over the subset of data that is publicly available at the time of evaluation. Using code3 provided by the authors of Socratic Models [70], we re-computed metrics on the available subset for those methods, indicated by “(subset)” for fairest comparison.
零样本视频检索。我们在MSR-VTT [71]完整分割数据集上使用CoCa评估视频-文本检索性能。表5显示,CoCa在文本到视频和视频到文本检索任务中均取得最高指标。需注意MSR-VTT视频源自YouTube,且计算嵌入向量需要原始视频文件。由于大量视频已被明确设为不可访问[72],我们仅在评估时公开可用的数据子集上进行检索计算。借助Socratic Models作者提供的代码[70],我们在相同可用子集上重新计算了对比方法的指标(标注为"(subset)")以确保公平性。
| MSR-VTT Full | ||||||
|---|---|---|---|---|---|---|
| Text → Video | Video → Text | |||||
| Method CLIP [69] | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| Socratic Models [70] | 21.4 | 41.1 | 50.4 | 40.3 | 69.7 | 79.2 |
| CLIP [69] (subset) | 23.3 | 44.2 | 53.6 | 43.3 | ||
| Socratic Models [70] (subset) | 46.9 | 73.3 | 81.8 | |||
| CoCa (subset) | 30.0 | 52.4 | 61.6 | 49.9 | 73.4 | |
| 表 5: MSR-VTT 零样本视频-文本检索 | 81.4 Full test set. |
| VQA | SNLI-VE | NLVR2 | ||||
|---|---|---|---|---|---|---|
| Model | test-dev | test-std | dev | test | dev | test-p |
| UNITER [26] | 73.8 | 74.0 | 79.4 | 79.4 | 79.1 | 80.0 |
| VinVL [27] | 76.6 | 76.6 | 82.7 | 84.0 | ||
| CLIP-ViL [73] | 76.5 | 76.7 | 80.6 | 80.2 | ||
| ALBEF [36] | 75.8 | 76.0 | 80.8 | 80.9 | 82.6 | 83.1 |
| BLIP [37] | 78.3 | 78.3 | 82.2 | 82.2 | ||
| OFA [17] | 79.9 | 80.0 | 90.3t | 90.2t | ||
| VLMo [30] | 79.9 | 80.0 | 85.6 | 86.9 | ||
| SimVLM [16] | 80.0 | 80.3 | 86.2 | 86.3 | 84.5 | 85.2 |
| Florence [14] | 80.2 | 80.4 | ||||
| METER [74] | 80.3 | 80.5 | ||||
| CoCa | 82.3 | 82.3 | 87.0 | 87.1 | 86.1 | 87.0 |
Table 6: Multimodal understanding results comparing vision-language pre training methods. †OFA uses both image and text premises as inputs while other models utilize the image only.
表 6: 多模态理解结果对比视觉语言预训练方法。†OFA 同时使用图像和文本作为输入,而其他模型仅使用图像。
4.2.3 Image Captioning and Multimodal Understanding Tasks
4.2.3 图像描述与多模态理解任务
Another key advantage of CoCa is its ability to process multimodal embeddings as an encoder-decoder model trained with the generative objective. Therefore, CoCa can perform both image captioning and multimodal understanding downstream tasks without any further fusion adaptation [73, 74]. Overall, experimental results suggest CoCa reaps the benefit of a encoder-decoder model to obtain strong multimodal understanding and generation capabilities, in addition to the vision and retrieval capabilities as a dual-encoder method.
CoCa的另一大优势是能够作为采用生成式目标训练的编码器-解码器模型处理多模态嵌入。因此,CoCa无需额外融合适配即可执行图像描述生成和多模态理解下游任务 [73, 74]。总体而言,实验结果表明CoCa通过编码器-解码器架构获得了强大的多模态理解与生成能力,同时兼具双编码器方法的视觉与检索优势。
Multimodal Understanding. As shown in [16], the output of encoder-decoder models can jointly encode image and text inputs, and can be used for tasks that require reasoning over both modalities. We consider three popular multimodal under stan ing benchmarks: visual question answering (VQA v2 [75]), visual entailment (SNLI-VE [76]), and visual reasoning (NLVR2 [77]). We mainly follow the settings in [16] and train linear class if i ers on top of the decoder outputs to predict answers (more details in Appendix B). Our results in Table 6 suggest that CoCa outperforms strong visionlanguage pre training (VLP) baselines and obtains state-of-the-art performance on all three tasks. While prior dual-encoder models [12, 14] do not contain fusion layers and thus require an additional VL pre training stage for downstream multimodal understanding tasks, CoCa subsumes the three pre training paradigms and obtains better performance on VL tasks with lightweight finetuning.
多模态理解。如[16]所示,编码器-解码器模型的输出可以联合编码图像和文本输入,并可用于需要跨模态推理的任务。我们评估了三个主流多模态理解基准:视觉问答(VQA v2 [75])、视觉蕴含(SNLI-VE [76])和视觉推理(NLVR2 [77])。我们主要遵循[16]的设置,在解码器输出端训练线性分类器来预测答案(详见附录B)。表6结果显示,CoCa在视觉语言预训练(VLP)基线中表现优异,三项任务均达到最先进水平。此前双编码器模型[12,14]因缺少融合层而需额外视觉语言预训练阶段来适应下游多模态理解任务,而CoCa整合了三种预训练范式,仅需轻量微调即可在视觉语言任务中获得更优性能。
Image Captioning. In addition to multimodal classification tasks, CoCa is also directly applicable to image captioning tasks as an encoder-decoder model. We finetune CoCa with the captioning loss ${\mathcal{L}}_{\mathrm{Cap}}$ only on MSCOCO [63] captioning task and evaluate on both MSCOCO Karpathy-test split and NoCaps [78] online evaluation. As shown by experiments in Table 7, CoCa outperforms strong baselines trained with cross-entropy loss on MSCOCO, and achieves results comparable to methods with CIDEr metric-specific optimization [79]. It is noteworthy that we do not use CIDEr-specific optimization [79] for simplicity. On the challenging NoCaps benchmark, CoCa obtains new stateof-the-art on both validation and test splits (generated examples shown in Figure 6). These results showcase the generative capability of CoCa as an image-text foundation model.
图像描述生成。除多模态分类任务外,CoCa作为编码器-解码器模型还可直接应用于图像描述生成任务。我们仅在MSCOCO [63]描述任务上使用描述损失${\mathcal{L}}_{\mathrm{Cap}}$微调CoCa,并在MSCOCO Karpathy测试集和NoCaps [78]在线评估上进行测试。如表7所示,CoCa在MSCOCO上超越使用交叉熵损失训练的强基线模型,其表现与采用CIDEr指标专项优化[79]的方法相当。值得注意的是,为简化流程,我们未采用CIDEr专项优化[79]。在具有挑战性的NoCaps基准测试中,CoCa在验证集和测试集上均取得最新最优性能(生成示例如图6所示)。这些结果展现了CoCa作为图文基础模型的生成能力。
Table 7: Image captioning results on MSCOCO and NoCaps (B@4: BLEU@4, M: METEOR, C: CIDEr, S: SPICE). †Models finetuned with CIDEr optimization.
表 7: MSCOCO和NoCaps数据集上的图像描述生成结果 (B@4: BLEU@4, M: METEOR, C: CIDEr, S: SPICE)。†表示使用CIDEr优化进行微调的模型。
| MSCOCO | NoCaps | |||||||
|---|---|---|---|---|---|---|---|---|
| B@4 | M | C | S | Valid | Test | |||
| C | S | C | S | |||||
| CLIP-ViL [73] | 40.2 | 29.7 | 134.2 | 23.8 | ||||
| BLIP [37] | 40.4 | 136.7 | 113.2 | 14.8 | ||||
| VinVL [27] | 41.0 | 31.1 | 140.9 | 25.4 | 105.1 | 14.4 | 103.7 | 14.4 |
| SimVLM [16] | 40.6 | 33.7 | 143.3 | 25.4 | 112.2 | 110.3 | 14.5 | |
| LEMON [80] | 41.5 | 30.8 | 139.1 | 24.1 | 117.3 | 15.0 | 114.3 | 14.9 |
| LEMONscsT [80]† | 42.6 | 31.4 | 145.5 | 25.5 | ||||
| OFA [17]† | 43.5 | 31.9 | 149.6 | 26.1 | ||||
| CoCa | 40.9 | 33.9 | 143.6 | 24.7 | 122.4 | 15.5 | 120.6 | 15.5 |

Figure 6: Curated samples of text captions generated by CoCa with NoCaps images as input.
图 6: 以NoCaps图像为输入的CoCa生成文本描述精选示例。
4.3 Ablation Analysis
4.3 消融分析
We extensively ablate the properties of CoCa on a smaller model variant. Specifically, we train CoCa-Base with a reduced 12 decoder layers and a total batch size of 4,096. We mainly evaluate using zero-shot image classification and VQA, since the former covers both visual representation quality and crossmodal alignment, while the later is representative for multimodal reasoning.
我们对CoCa的一个较小模型变体进行了广泛消融实验。具体而言,我们训练了CoCa-Base模型,其解码器层数减少至12层,总批量大小为4,096。主要评估指标采用零样本图像分类和视觉问答(VQA),因为前者能同时反映视觉表征质量和跨模态对齐能力,而后者代表了多模态推理性能。
Captioning vs. Classification. We first examine the effectiveness of captioning loss on image annotation datasets. To do this, we train a naive encoder-decoder model using ${\mathcal{L}}{\mathrm{Cap}}$ on the JFT-3B dataset, and compare with a standard ViT-Base single-encoder model trained with $\mathcal{L}{\mathrm{Cls}}$ in Table 8a. We find encoder-decoder models to perform on par with single-encoder pre training on both linear evaluation and finetuned results. This suggests that the generative pre training subsumes classification pre training, consistent with our intuition that $\mathcal{L}{\mathrm{Cls}}$ is a special case of ${\mathcal{L}}_{\mathrm{Cap}}$ when text vocabulary is the set of all possible class names. Thus, our CoCa model can be interpreted as an effective unification of the three paradigms. This explains why CoCa does not need a pretrained visual encoder to perform well.
标题生成与分类对比。我们首先在图像标注数据集上验证标题生成损失( ${\mathcal{L}}{\mathrm{Cap}}$ )的有效性。基于JFT-3B数据集训练朴素编码器-解码器模型,并与采用分类损失( $\mathcal{L}{\mathrm{Cls}}$ )的标准ViT-Base单编码器模型进行对比(表8a)。实验表明,在线性评估和微调结果上,编码器-解码器模型与单编码器预训练表现相当。这说明生成式预训练涵盖了分类预训练,符合"当文本词表为所有可能类别名称时 $\mathcal{L}{\mathrm{Cls}}$ 是 ${\mathcal{L}}_{\mathrm{Cap}}$ 特例"的直觉认知。因此,CoCa模型可视为对三种范式的有效统一,这也解释了为何CoCa无需预训练视觉编码器即可取得优异表现。
Training Objectives. We study the effects of the two training objectives and compare CoCa with single-objective variants in Table 8b. Compared to the contrastive-only model, CoCa significantly improves both zero-shot alignment and VQA (notice that the contrastive-only model requires additional fusion for VQA). CoCa performs on par with the captioning-only model on VQA while it additionally enables retrieval-style tasks such as zero-shot classification. Table 8c further studies loss ratios and suggests that the captioning loss not only improves VQA but also zero-shot alignment between modalities. We hypothesize that generative objectives learn fine-grained text representations that further improve text understanding. Finally, we compare training costs in Table 8b (measured in TPUv3-core-days; larger is slower) and find CoCa to be as efficient as the captioning-only model (a.k.a.naive encoder-decoder) due to the sharing of compute between two objectives. These suggest combining the two losses induces new capabilities and better performance with minimal extra cost.
训练目标。我们研究了两种训练目标的效果,并在表 8b 中将 CoCa 与单目标变体进行对比。相比纯对比学习模型,CoCa 在零样本对齐和 VQA 任务上均有显著提升(需注意纯对比模型需额外融合模块才能处理 VQA)。CoCa 在 VQA 任务上与纯描述生成模型表现相当,同时还能支持检索式任务(如零样本分类)。表 8c 进一步研究了损失比率,表明描述生成损失不仅能提升 VQA 性能,还能改善模态间的零样本对齐。我们推测生成式目标能学习细粒度文本表征,从而提升文本理解能力。最后通过表 8b 对比训练成本(以 TPUv3-core-days 计,数值越大速度越慢),发现由于双目标共享计算资源,CoCa 的效率与纯描述生成模型(即朴素编码器-解码器)相当。这表明结合两种损失函数能以极小额外代价获得新能力与性能提升。
Unimodal and Multimodal Decoders. CoCa introduces a novel decoder design and we ablate its components. In Table 8d, we vary the number of unimodal decoder layers (while keeping the total number of layers the same). Intuitively, fewer unimodal text layers leads to worse zero-shot classification due to lack of capacity for good unimodal text understanding, while fewer multimodal layers reduces the model’s power to reason over multimodal inputs such as VQA. Overall, we
单模态与多模态解码器。CoCa 提出了一种新颖的解码器设计,我们对其组件进行了消融实验。在表 8d 中,我们调整了单模态解码器层数(同时保持总层数不变)。直观来看,较少的单模态文本层会因缺乏良好的单模态文本理解能力而导致零样本分类性能下降,而较少的多模态层则会削弱模型处理 VQA 等多模态输入的推理能力。总体而言,我们
(a) Encoder-decoder vs. singleencoder models (trained on JFT).
(a) 编码器-解码器 vs. 单编码器模型 (在JFT上训练)
| 损失函数 | LE | FT |
|---|---|---|
| Lcls | 81.0 | 85.1 |
| LCap | 82.1 | 84.9 |
(b) Training objectives ablation.
| loss | ZS | VQA | TPU cost |
|---|---|---|---|
| LCon | 70.7 | 59.2 | 1x |
| LCap | - | 68.9 | 1.17x |
| LCoCa | 71.6 | 69.0 | 1.18x |
(b) 训练目标消融实验。
(c) Training objectives weights.
| 入Cap : 入Con | ZS VQA |
|---|---|
| 1:1 | 71.568.6 |
| 1:2 | 71.068.1 |
| 2:1 | 71.6 69.0 |
(c) 训练目标权重。
| Nuni | ZS | VQA |
|---|---|---|
| 3 | 70.2 | 69.0 |
| 6 | 71.6 | 69.0 |
| 9 | 71.4 | 68.8 |
| 变体 | AE MSCOCO |
|---|---|
| 1 [CLS] 80.7 | 41.4 |
| + text tokens 80.3 | 40.2 |
| 8[CLS] 80.3 | 36.9 |
| + text tokens 80.4 | 40.3 |
(d) Unimodal decoder layers.
(d) 单模态解码层。
(f) Attention al pooler design ablation.
| variant | ZS | VQA |
|---|---|---|
| parallel | 71.2 | 68.7 |
| cascade | 71.6 | 69.0 |
| Nquery =0 | 71.5 | 69.0 |
| Nquery =1 | 69.3 | 64.4 |
| nquery = 32 | 71.2 | 68.2 |
(f) 注意力池化器设计消融实验。
(e) Contrastive text embedding design ablation.
(e) 对比文本嵌入设计消融实验。
Table 8: CoCa ablation experiments. On ImageNet classification, we report top-1 accuracy for: zero-shot (ZS), linear evaluation (LE), attention al evaluation (AE) using pooler on frozen feature, and finetuning (FT). On MSCOCO retrieval, we report the average of image-to-text and text-to-image $\mathbf{R}\ @1$ . On VQA, we report the dev-set vqa score. The default CoCa setting is bold.
表 8: CoCa消融实验。在ImageNet分类任务中,我们报告了以下指标的top-1准确率:零样本 (ZS) 、线性评估 (LE) 、基于冻结特征的注意力池化评估 (AE) 以及微调 (FT) 。在MSCOCO检索任务中,我们报告了图像到文本和文本到图像 $\mathbf{R}\ @1$ 的平均值。在VQA任务中,我们报告了开发集的vqa分数。默认CoCa设置以粗体显示。
find decoupling the decoder in half maintains a good balance. One possibility is that global text representation for retrieval doesn’t require deep modules [33] while early fusion for shallow layers may also be unnecessary for multimodal understanding. Next, we explore various options to extract unimodal text embeddings. In particular, we experiment with the number of learnable [CLS] tokens as well as the aggregation design. For the later, we aggregate over either the [CLS] tokens only or the concatenation of [CLS] and the original input sentence. Interestingly, in Table 8e we find training a single [CLS] token without the original input is preferred for both vision-only and crossmodal retrieval tasks. This indicates that learning an additional simple sentence representation mitigates interference between contrastive and captioning loss, and is powerful enough for strong generalization.
发现将解码器解耦为两半能保持良好的平衡。一种可能的解释是,检索所需的全局文本表征不需要深层模块 [33],而浅层的早期融合对于多模态理解可能也非必要。接着,我们探索了提取单模态文本嵌入的多种方案,重点实验了可学习的 [CLS] token 数量以及聚合设计。对于后者,我们尝试仅聚合 [CLS] token 或同时聚合 [CLS] 与原始输入句子。有趣的是,表 8e 显示在纯视觉和跨模态检索任务中,单独训练单个 [CLS] token(不含原始输入)的效果更优。这表明学习额外的简单句子表征能缓解对比损失与描述损失之间的干扰,且足以支撑强大的泛化能力。
Attention al Poolers. CoCa exploits attention al poolers in its design both for different pre training objectives and objective-specific downstream task adaptations. In pre training, we compare a few design variants on using poolers for contrastive loss and generative loss: (1) the “parallel” design which extracts both contrastive and generative losses at the same time on Vision Transformer encoder outputs as shown in Figure 2, and (2) the “cascade” design which applies the contrastive pooler on top of the outputs of the generative pooler. Table 8f shows the results of these variants. Empirically, we find at small scale the “cascade” version (contrastive pooler on top of the generative pooler) performs better and is used by default in all CoCa models. We also study the effect of number of queries where $n_{\mathrm{query}}=0$ means no generative pooler is used (thus all ViT output tokens are used for decoder cross-attention). Results show that both tasks prefer longer sequences of detailed image tokens at a cost of slightly more computation and parameters. As a result, we use a generative pooler of length 256 to improve multimodal understanding benchmarks while still maintaining the strong frozen-feature capability.
注意力池化器。CoCa在其设计中利用了注意力池化器,既用于不同的预训练目标,也用于特定目标的下游任务适配。在预训练中,我们比较了几种使用池化器获取对比损失和生成损失的设计变体:(1) "并行"设计,如图2所示,同时在Vision Transformer编码器输出上提取对比损失和生成损失;(2) "级联"设计,在生成池化器输出之上应用对比池化器。表8f展示了这些变体的结果。经验表明,在小规模情况下,"级联"版本(在生成池化器之上应用对比池化器)表现更好,因此在所有CoCa模型中默认使用。我们还研究了查询数量的影响,其中$n_{\mathrm{query}}=0$表示不使用生成池化器(因此所有ViT输出token都用于解码器交叉注意力)。结果表明,两个任务都倾向于使用更长的详细图像token序列,尽管这会略微增加计算量和参数数量。因此,我们使用长度为256的生成池化器来提升多模态理解基准性能,同时仍保持强大的冻结特征能力。
5 Broader Impacts
5 更广泛的影响
This work presents an image-text pre training approach on web-scale datasets that is capable of transferring to a wide range of downstream tasks in a zero-shot manner or with lightweight finetuning. While the pretrained models are capable of many vision and vision-language tasks, we note that our models use the same pre training data as previous methods [13, 21, 32, 33] and additional analysis of the data and the resulting model is necessary before the use of the models in practice. We show CoCa models are more robust on corrupted images, but it could still be vulnerable to other image corruptions that are not yet captured by current evaluation sets or in real-world scenarios. For both the data and model, further community exploration is required to understand the broader impacts including but not limited to fairness, social bias and potential misuse.
本研究提出了一种基于网络规模数据集的图文预训练方法,能够以零样本方式或轻量微调迁移至广泛的下游任务。虽然预训练模型能胜任多种视觉和视觉-语言任务,但我们注意到这些模型使用的预训练数据与先前方法 [13, 21, 32, 33] 相同,实际应用前仍需对数据及所得模型进行额外分析。实验表明CoCa模型在受损图像上更具鲁棒性,但仍可能对当前评估集或现实场景中未涵盖的其他图像损坏类型存在脆弱性。针对数据和模型,需要进一步社区探索以理解包括但不限于公平性、社会偏见和潜在滥用等广泛影响。
6 Conclusion
6 结论
In this work we present Contrastive Captioners (CoCa), a new image-text foundation model family that subsumes existing vision pre training paradigms with natural language supervision. Pretrained on image-text pairs from various data sources in a single stage, CoCa efficiently combines contrastive and captioning objectives in an encoder-decoder model. CoCa obtains a series of state-of-the-art performance with a single checkpoint on a wide spectrum of vision and vision-language problems. Our work bridges the gap among various pre training approaches and we hope it motivates new directions for image-text foundation models.
在本工作中,我们提出了对比式描述生成模型 (Contrastive Captioners, CoCa) —— 一种通过自然语言监督融合现有视觉预训练范式的新型图文基础模型家族。通过单阶段预训练来自多源数据集的图文对,CoCa 在编码器-解码器架构中高效结合了对比学习与描述生成目标。仅用单一模型检查点,CoCa 就在广泛的视觉及视觉-语言任务中取得了一系列最先进性能。我们的工作弥合了不同预训练方法之间的鸿沟,希望能为图文基础模型开拓新的研究方向。
Acknowledgments
致谢
We would like to thank Yi-Ting Chen, Kaifeng Chen, Ye Xia, Zhen Li, Chao Jia, Yinfei Yang, Zhengdong Zhang, Wei Han, Yuan Cao, Tao Zhu, Futang Peng, Soham Ghosh, Zihang Dai, Junnan Li, Ning Wang, Xin Li, Anelia Angelova, Jason Baldridge, Izhak Shafran, Shengyang Dai, Abhijit Ogale, Zhifeng Chen, Claire Cui, Paul Natsev, Tom Duerig for helpful discussions, Andrew Dai for help with contrastive models, Christopher Fifty and Bowen Zhang for help with video models, Yuanzhong Xu for help with model scaling, Lucas Beyer for help with data preparation, Andy Zeng for help with MSR-VTT evaluation, Hieu Pham and Simon Kornblith for help with zero-shot evaluations, Erica Moreira and Victor Gomes for help with resource coordination, Tom Small for help with visual illustration, Liangliang Cao for proofreading, and others in the Google Brain team for support throughout this project.
我们要感谢Yi-Ting Chen、Kaifeng Chen、Ye Xia、Zhen Li、Chao Jia、Yinfei Yang、Zhengdong Zhang、Wei Han、Yuan Cao、Tao Zhu、Futang Peng、Soham Ghosh、Zihang Dai、Junnan Li、Ning Wang、Xin Li、Anelia Angelova、Jason Baldridge、Izhak Shafran、Shengyang Dai、Abhijit Ogale、Zhifeng Chen、Claire Cui、Paul Natsev、Tom Duerig的有益讨论,Andrew Dai在对比模型方面的帮助,Christopher Fifty和Bowen Zhang在视频模型方面的协助,Yuanzhong Xu在模型扩展方面的支持,Lucas Beyer在数据准备上的贡献,Andy Zeng对MSR-VTT评估的帮助,Hieu Pham和Simon Kornblith在零样本评估上的指导,Erica Moreira和Victor Gomes在资源协调上的协助,Tom Small在视觉展示上的支持,Liangliang Cao的校对工作,以及Google Brain团队其他成员在整个项目中的支持。
References
参考文献
A Visual Recognition Finetuning Details
视觉识别微调细节
Table 9: Hyper-parameters used in the visual recognition experiments.
| 超参数 | 固定特征微调 | 微调 | ImageNet | Kinetics-400/600/700 固定特征微调 | Moments-in-Time 固定特征微调 |
|---|---|---|---|---|---|
| 优化器 | Adafactor (带解耦权重衰减) | ||||
| 梯度裁剪 | 1.0 | ||||
| EMA衰减率 | 0.9999 | ||||
| 学习率衰减计划 | 余弦衰减至零 | ||||
| 损失函数 | Softmax | ||||
| MixUp | 无 | ||||
| CutMix | 无 | ||||
| AutoAugment | 无 | ||||
| RepeatedAugment | 无 | ||||
| RandAugment | 2,20 | 2,20 | 无 | 无 | 无 |
| 标签平滑 | 0.2 | 0.5 | 0.1 | 0.1 | 0.0 |
| 训练步数 | 200k | 200k | 120k | 120k | 120k |
| 训练批次大小 | 512 | 512 | 128 | 128 | 128 |
| 池化层学习率 | 5e-4 | 5e-4 | 5e-4 | 5e-4 | 5e-4 |
| 编码器学习率 | 0.0 | 5e-4 | 0.0 | 5e-4 | 0.0 |
| 预热步数 | 0 | 0 | 1000 | 1000 | 1000 |
| 权重衰减率 | 0.01 | 0.01 | 0.0 | 0.0 | 0.0 |
表 9: 视觉识别实验中使用的超参数。
In addition to zero-shot transfer, we evaluate frozen-feature and finetuning performance of CoCa on visual recognition tasks. For frozen-feature evaluation, we add an attention al pooling layer (pooler) on top of the output sequence of visual features and an additional softmax cross entropy loss layer to learn classification of images and videos. For finetuning, we adapt the same architecture as frozen-feature evaluation (thus also with poolers) and finetune both encoder and pooler. All learning hyper parameters are listed in Table 9.
除了零样本迁移外,我们还评估了CoCa在视觉识别任务中的冻结特征和微调性能。对于冻结特征评估,我们在视觉特征输出序列顶部添加了一个注意力池化层(pooler)和一个额外的softmax交叉熵损失层来学习图像和视频分类。对于微调,我们采用与冻结特征评估相同的架构(因此也包含poolers)并对编码器和pooler进行联合微调。所有学习超参数列于表9。
B Multimodal Understanding Finetuning Details
Table 10: Hyper-parameters used in the multimodal experiments.
B 多模态理解微调细节
| 超参数 | VQA | SNLI-VE | NLVR2 | MSCOCO | NoCaps |
|---|---|---|---|---|---|
| 优化器 | 带解耦权重衰减的Adafactor | ||||
| 梯度裁剪 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 学习率衰减策略 | 余弦衰减至零 | ||||
| RandAugment | 1,10 | 1,10 | 无 | 无 | 无 |
| 训练步数 | 100k | 50k | 50k | 50k | 10k |
| 训练批次大小 | 64 | 128 | 64 | 128 | 128 |
| Pooler学习率 | 5e-4 | 1e-3 | 5e-4 | 不适用 | 不适用 |
| 编码器学习率 | 2e-5 | 5e-5 | 2e-5 | 1e-5 | 1e-5 |
| 预热步数 | 1000 | 1000 | 1000 | 1000 | 1000 |
| 权重衰减率 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
表 10: 多模态实验中使用的超参数。
CoCa is an encoder-decoder model and the final decoder outputs can be used for multimodal understanding/generation. Thus, we evaluate on popular vision-language benchmarks. We mainly follow the same setup introduced in [16]. All hyper-parameters are listed in Table 10.
CoCa是一种编码器-解码器模型,其最终解码器输出可用于多模态理解/生成。因此,我们在流行的视觉语言基准上进行了评估,主要遵循[16]中介绍的相同设置。所有超参数列于表10。
For multimodal classification, we feed the image into the encoder and the corresponding text to the decoder. We then apply another attention al pooler with a single query to extract embedding from the decoder output, and train a linear classifier on top of the pooled embedding. For VQA v2 [75], we follow prior work and formulate the task as a classification problem over 3,129 most frequent answers in the training set. We additionally enable cotraining with the generative loss on the concatenated pairs of textual questions and answers to improve model robustness. Similarly for SNLI-VE, the image and the textual hypothesis are fed to encoder and decoder separately, and the classifier is trained to predict the relation between them as entailment, neutral or contradiction. For NLVR2, we create two input pairs of each image and the text description, and concatenate them as input to the classifier. We do not use image augmentation for NLVR2.
对于多模态分类任务,我们将图像输入编码器,对应文本输入解码器。随后采用带单查询的注意力池化器从解码器输出中提取嵌入特征,并在池化后的嵌入特征上训练线性分类器。针对VQA v2[75]任务,我们沿用先前工作方法,将其构建为对训练集中3,129个高频答案的分类问题。同时启用生成式损失协同训练机制,通过拼接文本问答对来提升模型鲁棒性。对于SNLI-VE任务,图像与文本假设分别输入编码器和解码器,分类器被训练用于预测两者间的蕴含、中立或矛盾关系。在NLVR2任务中,我们构建每张图像与文本描述的两个输入对,将其拼接后作为分类器输入(注:NLVR2任务未使用图像增强技术)。
For image captioning, we apply simple cross-entropy loss (same as the captioning loss used in pre training) and finetune the model on the training split of MSCOCO to predict for MSCOCO test split and NoCaps online evaluation.
对于图像描述任务,我们采用简单的交叉熵损失(与预训练中使用的描述损失相同),并在MSCOCO训练集上微调模型,以预测MSCOCO测试集和NoCaps在线评估结果。