Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models
Tree of Clarifications: 基于检索增强大语言模型的模糊问题解答
Gangwoo $\mathbf{Kim}^{1}$ Sungdong $\mathbf{Kim^{2,3,4}}$ Byeongguk Jeon1 Joonsuk Park2,3,5 Jaewoo Kang Korea University 1 NAVER Cloud2 NAVER AI Lab3 KAIST AI4 University of Richmond5 {gang woo kim, bkjeon1211, kangj}@korea.ac.kr sungdong.kim@navercorp.com park@joonsuk.org
Gangwoo $\mathbf{Kim}^{1}$ Sungdong $\mathbf{Kim^{2,3,4}}$ Byeongguk Jeon1 Joonsuk Park2,3,5 Jaewoo Kang 高丽大学1 NAVER Cloud2 NAVER AI Lab3 韩国科学技术院人工智能4 里士满大学5 {gang woo kim, bkjeon1211, kangj}@korea.ac.kr sungdong.kim@navercorp.com park@joonsuk.org
Abstract
摘要
Questions in open-domain question answering are often ambiguous, allowing multiple interpretations. One approach to handling them is to identify all possible interpretations of the ambiguous question (AQ) and to generate a long-form answer addressing them all, as suggested by Stelmakh et al. (2022). While it provides a comprehensive response without bothering the user for clarification, considering multiple dimensions of ambiguity and gathering corresponding knowledge remains a chal- lenge. To cope with the challenge, we propose a novel framework, TREE OF CLARIFICATIONS (TOC): It recursively constructs a tree of disambiguations for the AQ—via few-shot prompting leveraging external knowledge—and uses it to generate a long-form answer. TOC outperforms existing baselines on ASQA in a fewshot setup across all metrics, while surpassing fully-supervised baselines trained on the whole training set in terms of Disambig-F1 and Disambig-ROUGE. Code is available at github.com/gankim/tree-of-clarifications.
开放域问答中的问题往往具有歧义性,可能存在多种解读方式。Stelmakh等人(2022)提出的一种处理方法是识别歧义问题(AQ)的所有可能解释,并生成涵盖所有解释的长篇答案。虽然这种方法能在不打扰用户澄清的情况下提供全面回答,但如何考量歧义的多个维度并收集相应知识仍具挑战性。为此,我们提出了一个新颖框架——澄清树(TREE OF CLARIFICATIONS,TOC):它通过少样本提示结合外部知识,递归地为歧义问题构建消歧树,并利用该树生成长篇答案。在ASQA数据集上,TOC在少样本设置下的所有指标均优于现有基线方法,同时在Disambig-F1和Disambig-ROUGE指标上超越了使用完整训练集训练的完全监督基线。代码已开源:github.com/gankim/tree-of-clarifications。
1 Introduction
1 引言
In open-domain question answering (ODQA), users often ask ambiguous questions (AQs), which can be interpreted in multiple ways. To handle AQs, several approaches have been proposed, such as providing individual answers to disambiguate d questions (DQs) for all plausible interpretations of the given AQ (Min et al., 2020) or asking a clarification question (Guo et al., 2021). Among them, we adopt that of Stelmakh et al. (2022), which provides a comprehensive response without bothering the user for clarification: The task is to identify all DQs of the given AQ and generate a long-form answer addressing all the DQs (See Figure 1).
在开放域问答(ODQA)中,用户经常提出具有多义性的模糊问题(AQs)。针对这类问题,现有研究提出了多种解决方案:如为模糊问题的所有可能解释提供对应的明确问题(DQs)答案(Min等人, 2020),或通过澄清提问来消除歧义(Guo等人, 2021)。我们采用Stelmakh等人(2022)提出的方案,该方案无需用户澄清即可提供全面响应:其核心任务是识别给定模糊问题对应的所有明确问题,并生成涵盖所有明确问题的长文本答案(见图1)。
There are two main challenges to this task: (1) the AQ may need to be clarified by considering multiple dimensions of ambiguity. For example, the AQ “what country has the most medals in Olympic history” in Figure 1 can be clarified with respect to the type of medals—gold, silver, or bronze—or Olympics—summer or winter; and (2) substantial knowledge is required to identify DQs and respective answers. For example, it requires knowledge to be aware of the existence of different types of medals and the exact counts for each country.
该任务面临两大主要挑战:(1) 澄清模糊问题(AQ)可能需要考虑多维度歧义。例如图1中的AQ"奥运史上哪个国家奖牌最多",可以从奖牌类型(金牌、银牌或铜牌)或奥运会类型(夏季或冬季)进行澄清;(2) 识别衍生问题(DQ)及相应答案需要大量知识储备。例如需了解不同奖牌类型的存在,以及每个国家的具体奖牌数量。
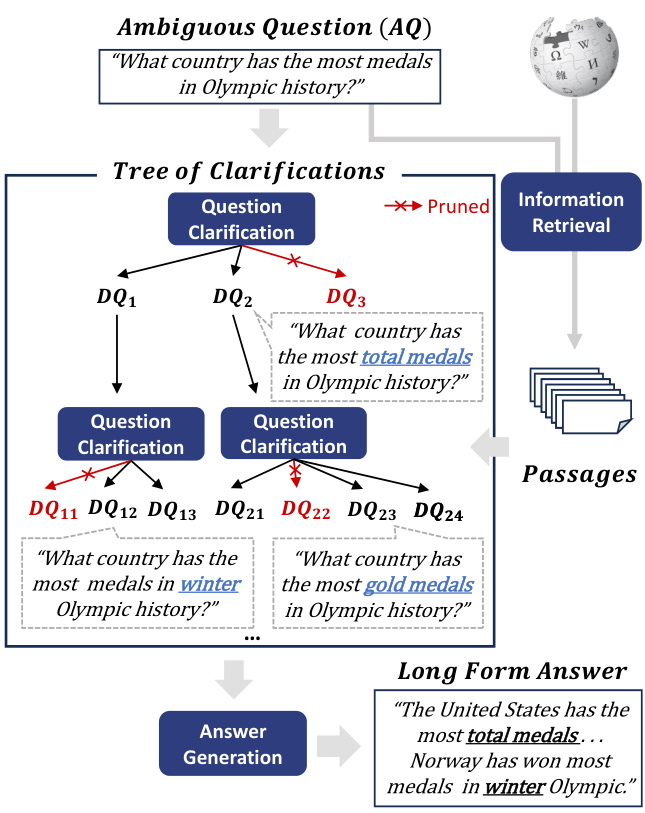
Figure 1: Overview of TREE OF CLARIFICATIONS. (1) relevant passages for the ambiguous question (AQ) are retrieved. (2) leveraging the passages, disambiguate d questions (DQs) for the AQ are recursively generated via few-shot prompting and pruned as necessary. (3) a long-form answer addressing all DQs is generated.
图 1: TREE OF CLARIFICATIONS 流程概览。(1) 检索与模糊问题 (AQ) 相关的文本段落。(2) 基于这些段落,通过少样本提示递归生成 AQ 的消歧问题 (DQs) 并按需剪枝。(3) 生成涵盖所有 DQs 的长篇回答。
To address the challenges and provide a longform answer to AQ, we propose a novel framework, TREE OF CLARIFICATIONS (TOC): It recursively constructs a tree of DQs for the AQ—via few-shot prompting leveraging external knowledge—and uses it to generate a long-form answer. More specifically, first, relevant passages for the AQ are retrieved. Then, leveraging the passages, DQs for the AQ are recursively generated via few-shot prompting and pruned as necessary. Lastly, a long-form answer addressing all DQs is generated. The tree structure promotes exploring DQs in targeting par- ticular dimensions of clarification, addressing the first challenge, and the external sources offer additional knowledge to cope with the second challenge.
为应对挑战并提供对AQ的长篇回答,我们提出了一种新颖框架——澄清树(TREE OF CLARIFICATIONS, TOC):它通过少样本提示利用外部知识,递归地为AQ构建DQ树,并以此生成长篇回答。具体而言,首先检索与AQ相关的段落;随后借助这些段落,通过少样本提示递归生成AQ的DQ并根据需要进行剪枝;最后生成解决所有DQ的长篇回答。该树状结构有助于探索针对特定澄清维度的DQ,应对第一个挑战,而外部知识源则为应对第二个挑战提供了额外信息。
Experiments demonstrate that our proposed use of LLMs with retrieval-augmentation and guidance to pursue diverse paths of clarification results in the new state-of-the-art on ASQA (Stelmakh et al., 2022)—a long-form QA benchmark for AQs. TOC outperforms existing baselines on ASQA in a few-shot setup across all metrics. In addition, this 5-shot performance surpasses that of the fullysupervised baselines trained on the whole training set by 7.3 and 2.9 in terms of Disambig-F1 and Disambig-ROUGE, respectively.
实验表明,我们提出的结合检索增强和引导策略使大语言模型(LLM)探索多样化澄清路径的方法,在ASQA (Stelmakh et al., 2022) 这个面向歧义问题的长文本问答基准上取得了最新最优性能。在少样本设定下,TOC在所有指标上均超越现有基线模型。此外,其5样本性能在Disambig-F1和Disambig-ROUGE指标上分别比完整训练集训练的全监督基线模型高出7.3和2.9分。
The main contribution of this work is proposing a novel framework, TREE OF CLARIFICATIONS (TOC), for generating long-form answers to AQs in ODQA, advancing the state-of-the-art on the ASQA benchmark. TOC introduces two main innovations:
这项工作的主要贡献是提出了一种新颖的框架——澄清树(Tree of Clarifications,TOC),用于在开放域问答(ODQA)中生成长篇答案,从而提升了ASQA基准的最先进水平。TOC引入了两大创新:
• It guides LLMs to explore diverse paths of clarification of the given AQ in a tree structure with the ability to prune unhelpful DQs. • To the best of our knowledge, it is the first to combine retrieval systems with LLM for generating long-form answers to AQs.
• 它引导大语言模型以树状结构探索给定澄清问题 (AQ) 的多样化解决路径,并具备剪枝无效澄清追问 (DQ) 的能力。
• 据我们所知,这是首次将检索系统与大语言模型结合用于生成针对澄清问题的长文本答案。
2 Related Work
2 相关工作
A line of studies (Min et al., 2020, 2021; Gao et al., 2021; Shao and Huang, 2022) extends retrieve-andread frameworks dominant in ODQA task (Chen et al., 2017; Karpukhin et al., 2020; Lewis et al., 2020; Izacard and Grave, 2021) to clarify AQ and generate DQs with corresponding answers to them. However, their approaches require fine-tuning models on the large-scale train set. On the other hand, our framework enables LLM to generate a comprehensive response addressing all DQs via few-shot prompting.
一系列研究 (Min et al., 2020, 2021; Gao et al., 2021; Shao and Huang, 2022) 扩展了开放域问答 (ODQA) 任务中主流的检索-阅读框架 (Chen et al., 2017; Karpukhin et al., 2020; Lewis et al., 2020; Izacard and Grave, 2021) ,通过澄清问题 (AQ) 并生成衍生问题 (DQ) 及其对应答案。然而,这些方法需要在大规模训练集上微调模型。相比之下,我们的框架通过少样本提示 (few-shot prompting) 使大语言模型能够生成涵盖所有衍生问题的综合回答。
Recent studies introduce LLM-based methods to generate a long-form answer to the AQ. Amplayo et al. (2023) suggest optimal prompts specifically engineered for the task. Kuhn et al. (2022) prompt LLMs to clarify ambiguous questions selectively. However, the studies do not utilize external information to ensure the factual correctness of the disambi gu at ions, thereby potentially increasing the risk of hallucinations from LLMs. Moreover, the results could be bounded by inherent parametric knowledge of LLM. Concurrently, Lee et al. (2023) automatically generate clarifying questions to resolve ambiguity.
近期研究提出了基于大语言模型(LLM)的方法来生成AQ的长篇回答。Amplayo等人(2023)提出了专门为该任务设计的最优提示模板。Kuhn等人(2022)通过提示大语言模型选择性地澄清模糊问题。然而这些研究都未利用外部信息来确保消歧的事实准确性,从而可能增加大语言模型产生幻觉的风险。此外,其结果可能受限于大语言模型固有的参数化知识。与此同时,Lee等人(2023)通过自动生成澄清性问题来解决歧义问题。
Our framework involves the recursive tree architecture, inspired by several prior studies. Min et al. (2021) propose the tree-decoding algorithm to auto regressive ly rerank passages in ambiguous QA. Gao et al. (2021) iterative ly explore additional interpretations and verify them in a round-trip manner. Concurrently, extending chain of thoughts (Wei et al., 2022) prompting, Yao et al. (2023) apply the tree architecture to reasoning tasks for deductive or mathematical problems. On the contrary, TOC recursively clarifies questions and introduces a self-verification method to prune unhelpful DQs.
我们的框架采用递归树结构,灵感来自多项先前研究。Min等人 (2021) 提出树解码算法,用于在模糊QA任务中自回归地重排段落。Gao等人 (2021) 通过迭代探索额外解释并以往返方式验证。与此同时,Yao等人 (2023) 在扩展思维链 (Wei等人, 2022) 提示的基础上,将树结构应用于演绎或数学问题的推理任务。与之相反,TOC通过递归澄清问题,并引入自验证方法来修剪无益的DQ。
3 Tree of Clarifications
3 澄清之树
We introduce a novel framework, TREE OF CLARIFICATIONS (TOC), as illustrated in Figure 1. We first devise retrieval-augmented clarification (RAC; Sec. 3.1), a basic component that clarifies AQ and generates DQs based on relevant passages. TOC explores various fine-grained interpretations, represented as a tree structure (TS; Sec. 3.2) by recursively performing RAC and pruning unhelpful DQs. Lastly, it aggregates the tree and generates a long-form answer addressing all valid interpreta- tions.
我们提出了一种新颖的框架——澄清树 (TREE OF CLARIFICATIONS, TOC) ,如图 1 所示。首先设计了检索增强澄清 (retrieval-augmented clarification, RAC;第 3.1 节) 这一基础组件,用于澄清初始问题 (AQ) 并根据相关段落生成细化问题 (DQ)。TOC 通过递归执行 RAC 并剪除无效的 DQ,以树形结构 (tree structure, TS;第 3.2 节) 探索多种细粒度解释。最后,框架会聚合整棵树并生成涵盖所有有效解释的长篇答案。
3.1 Retrieval-Augmented Clarification (RAC)
3.1 检索增强澄清 (RAC)
We first retrieve relevant Wikipedia documents for the AQ by using two retrieval systems, ColBERT (Khattab and Zaharia, 2020) and Bing search engine1. ColBERT is a recent dense retriever that has effective and efficient zero-shot search quality. Following Khattab et al. (2022), we use the off-the-shelf model pre-trained on MS-Marco (Bajaj et al., 2016). We additionally include the Bing search engine to promote the diversity of retrieved Wikipedia passages. Finally, we obtain over 200 passages by combining passages retrieved by each system.
我们首先使用两种检索系统ColBERT (Khattab and Zaharia, 2020)和Bing搜索引擎1为AQ检索相关的维基百科文档。ColBERT是近期提出的高效密集检索器,具有出色的零样本搜索性能。遵循Khattab等人(2022)的方法,我们直接使用在MS-Marco (Bajaj et al., 2016)上预训练的现成模型。为了提升检索维基百科段落的多样性,我们还加入了Bing搜索引擎。最终,通过合并两个系统检索到的段落,我们获得了超过200个相关段落。
After collecting a passage set for the AQ, we rerank and choose top $k$ passages and augment them to a prompt. We use Sentence BERT (Reimers and Gurevych, 2019) pre-trained on MS-Marco as the reranker backbone. For in-context learning setup, we dynamically choose $k$ -shot examples with the nearest neighbor search2 and add them to the prompt. We initiate with the instruction of Amplayo et al. (2023) and revise it for our setup. Given the prompt with relevant passages and AQs, LLM generates all possible DQs and their corresponding answers .
为AQ收集段落集后,我们重新排序并选择前$k$个段落,将其增强至提示词中。我们采用基于MS-Marco预训练的Sentence BERT (Reimers and Gurevych, 2019) 作为重排序主干模型。在上下文学习设置中,通过最近邻搜索动态选取$k$个少样本示例并加入提示词。初始指令基于Amplayo等人 (2023) 的研究,并根据我们的设置进行了调整。当提示词包含相关段落和AQ时,大语言模型会生成所有可能的DQ及其对应答案。
3.2 Tree Structure (TS)
3.2 树结构 (TS)
To effectively explore the diverse dimensions of ambiguity, we introduce a recursive tree structure of clarifications. Starting from the root node with AQ, it progressively inserts child nodes by recursively performing RAC, each of which contains a disambiguate d question-answer pair. In each expansion step, passages are reranked again regarding the current query. It allows each step to focus on its own DQ, encouraging TOC to comprehend a wider range of knowledge. Exploration of a tree ends when it satisfies termination conditions; it reaches the maximum number of valid nodes or the maximum depth. We choose the breadth-first search (BFS) by default, hence the resulting tree could cover the broader interpretations 4.
为了有效探索歧义的多元维度,我们引入了一种递归澄清树结构。从根节点AQ开始,通过递归执行RAC逐步插入子节点,每个子节点包含一个消歧后的问答对。在每次扩展步骤中,会根据当前查询重新对段落进行排序。这使得每一步都能专注于自身的DQ,促使TOC理解更广泛的知识范围。当满足终止条件时,树形探索结束;即达到有效节点的最大数量或最大深度。默认情况下我们选择广度优先搜索(BFS),因此生成的树能覆盖更广泛的解释[4]。
Pruning with Self-Verification To remove unhelpful nodes, we design a pruning method, inspired by current studies for self-verification (Kadavath et al., 2022; Cole et al., 2023). Specifically, we check the factual coherency between the answers in a target node and the AQ in the root node. By doing so, we discard the generated DQs that ask different or irrelevant facts from the original one. For example, given an AQ “Who will host the next world cup 2022?”, a generated disambiguation “DQ: Who hosted the world cup 2018? A: Russia” is a factually consistent question-answer pair but it changes the original scope of the $\mathrm{AQ}^{5}$ . We perform self-verification by prompting LLMs to determine whether the current node would be pruned or not. Prompted with AQ, the answer to the target DQ, and the answer-containing passage, LLM identifies
基于自验证的剪枝方法
为移除无效节点,我们受当前自验证研究 (Kadavath et al., 2022; Cole et al., 2023) 启发设计了一种剪枝方法。具体而言,我们检查目标节点答案与根节点歧义问题 (AQ) 之间的事实一致性,从而剔除那些询问不同或无关事实的生成消歧问题 (DQ)。例如,给定AQ"2022年下届世界杯由谁主办?",生成的消歧问题"DQ: 2018年世界杯由谁主办?A: 俄罗斯"虽是事实一致的问题-答案对,但改变了原始 $\mathrm{AQ}^{5}$ 的范畴。我们通过提示大语言模型判断当前节点是否应被剪枝来实现自验证:向大语言模型提供AQ、目标DQ的答案及包含答案的段落,由其进行判定。
| Model | D-F1 | R-L | DR |
| Fully-supervised | |||
| T5-Large Closed-Book | 7.4 | 33.5 | 15.7 |
| T5-Large w/JPR | 26.4 | 43.0 | 33.7 |
| PaLM w/Soft Prompt Tuning | 27.8 | 37.4 | 32.1 |
| Few-shotPrompting(5-shot) | |||
| PaLM* | 25.3 | 34.5 | 29.6 |
| GPT-3* | 25.0 | 31.8 | 28.2 |
| Tree of Clarifications (ToC; Ours) | |||
| GPT-3+RAC | 31.1 | 39.6 | 35.1 |
| GPT-3+RAC+TS | 32.4 | 40.0 | 36.0 |
| GPT-3 + RAC + TS w/Pruning | 33.7 | 39.7 | 36.6 |
from Amplayo et al. (2023)
| 模型 | D-F1 | R-L | DR |
|---|---|---|---|
| 全监督 | |||
| T5-Large Closed-Book | 7.4 | 33.5 | 15.7 |
| T5-Large w/JPR | 26.4 | 43.0 | 33.7 |
| PaLM w/Soft Prompt Tuning | 27.8 | 37.4 | 32.1 |
| 少样本提示(5-shot) | |||
| PaLM* | 25.3 | 34.5 | 29.6 |
| GPT-3* | 25.0 | 31.8 | 28.2 |
| 澄清树(ToC; 我们的方法) | |||
| GPT-3+RAC | 31.1 | 39.6 | 35.1 |
| GPT-3+RAC+TS | 32.4 | 40.0 | 36.0 |
| GPT-3 + RAC + TS w/Pruning | 33.7 | 39.7 | 36.6 |
来自 Amplayo 等人 (2023)
Table 1: Evaluation results for long-form QA on ambiguous questions from the development set of ASQA (Stelmakh et al., 2022). Baselines are either fully-supervised or 5-shot prompted. Note, TOC framework consists of retrieval-augmented clarification (RAC) and tree structure (TS).
表 1: ASQA开发集中模糊问题的长文本问答评估结果(Stelmakh等人, 2022)。基线方法采用全监督或5样本提示。请注意,TOC框架包含检索增强澄清(RAC)和树状结构(TS)。
if the given answer could be a correct answer to AQ.
如果给定答案可能是AQ的正确回答。
Answer Generation Once constructing the tree of clarifications, TOC aggregates all valid nodes and generates a comprehensive long-form answer to AQ. It selects the disambiguation s in retained nodes of the resulting tree with the relevant passages. If the number of nodes is insufficient, we undo the pruning steps from closer nodes to the root node in BFS order. Passages that contain the answers of valid nodes are prioritized. It finally generates a long-form answer, encoding AQ, selected disambiguation s, and relevant passages6.
答案生成
在构建澄清树后,TOC会聚合所有有效节点,并为AQ生成全面的长格式答案。它会从结果树的保留节点中选择消歧项及相关段落。若节点数量不足,则按广度优先搜索(BFS)顺序从靠近根节点的位置逐步撤销剪枝步骤。包含有效节点答案的段落会被优先处理。最终生成的长格式答案会编码AQ、选定的消歧项及相关段落[6]。
(注:根据策略要求,保留术语TOC/AQ/BFS不翻译,引用标记[6]保持原格式,段落结构与原文一致)
4 Experiment
4 实验
4.1 Experimental Setup
4.1 实验设置
Datasets All baselines and our framework are evaluated on ASQA (Stelmakh et al., 2022). It is a long-form QA dataset built upon the 6K ambiguous questions identified from AmbigNQ (Min et al., 2020). More details are in Appendix A.1
数据集
所有基线方法和我们的框架均在ASQA (Stelmakh et al., 2022) 数据集上进行评估。该数据集是一个长格式问答数据集,基于从AmbigNQ (Min et al., 2020) 中筛选出的6K个模糊问题构建。更多细节详见附录A.1。
Evaluation Metrics We use three evaluation metrics, following Stelmakh et al. (2022). (1) Disambig-F1 (D-F1) measures the factual correctness of generated predictions. It extracts short answers to each DQ and computes their F1 accuracy. (2) ROUGE-L (R-L) measures the lexical overlap between long-form answers from references and predictions. (3) DR score is the geometric mean of two scores, which assesses the overall performance. For validating intermediate nodes, we additionally use Answer-F1 that measures the accuracy of generated short answers in disambiguation. Further details are in Appendix A.2.
评估指标
我们采用Stelmakh等人 (2022) 提出的三项评估指标:(1) 消歧F1值 (D-F1) 用于衡量生成预测的事实准确性,通过提取每个DQ的简短答案并计算其F1准确率;(2) ROUGE-L (R-L) 用于衡量参考文本与预测文本之间长答案的词汇重叠度;(3) DR分数是两项分数的几何平均值,用于评估整体性能。针对中间节点验证,我们额外使用Answer-F1指标来评估消歧过程中生成的简短答案准确性。更多细节详见附录A.2。
Table 2: Ablation study on all components of retrievalaugmented clarification (RAC).
| Model | D-F1 | R-L | DR |
| GPT-3(Baseline) | 24.2 | 36.0 | 29.5 |
| GPT-3w/RAC | 31.1 | 39.6 | 35.1 |
| -Disambiguations | 30.5 | 37.3 | 33.7 |
| -Bing Search Engine | 28.5 | 37.4 | 32.7 |
| -RetrievalSystems | 25.6 | 35.1 | 30.0 |
表 2: 检索增强澄清(RAC)所有组件的消融研究
| 模型 | D-F1 | R-L | DR |
|---|---|---|---|
| GPT-3(基线) | 24.2 | 36.0 | 29.5 |
| GPT-3w/RAC | 31.1 | 39.6 | 35.1 |
| -消歧 | 30.5 | 37.3 | 33.7 |
| -Bing搜索引擎 | 28.5 | 37.4 | 32.7 |
| -检索系统 | 25.6 | 35.1 | 30.0 |
Baselines Stelmakh et al. (2022) propose finetuned baselines. They fine-tune T5-large (Raffel et al., 2020) to generate long-form answers on the whole train set. Models are evaluated in the closed-book setup or combined with JPR (Min et al., 2021), task-specific dense retriever for ambiguous QA by enhancing DPR (Karpukhin et al., 2020). On the other hand, Amplayo et al. (2023) propose a prompt engineering method to adapt LLMs to the ASQA benchmark. They employ PaLM (Chowdhery et al., 2022) and InstructGPT (Ouyang et al., 2022) that learn the soft prompts or adopt in-context learning with few-shot examples. They conduct experiments in the closedbook setup. Note that they share the same backbone with our models, GPT-3 with 175B parameters (text-davinci-002).
基线方法
Stelmakh等人(2022)提出了微调基线方法。他们在完整训练集上微调T5-large(Raffel等人,2020)来生成长篇答案。模型评估采用闭卷设置,或结合JPR(Min等人,2021)——通过增强DPR(Karpukhin等人,2020)实现的模糊问答任务专用密集检索器。另一方面,Amplayo等人(2023)提出了一种提示工程方法使大语言模型适配ASQA基准。他们采用PaLM(Chowdhery等人,2022)和InstructGPT(Ouyang等人,2022),通过学习软提示或采用少样本示例的上下文学习。实验在闭卷设置下进行。需要注意的是,这些模型与我们使用的GPT-3(text-davinci-002)具有相同的1750亿参数主干网络。
4.2 Experimental Results
4.2 实验结果
TOC outperforms fully-supervised and few-shot prompting baselines. Table 1 shows the long-form QA performance of baselines and TOC on the development set of ASQA. Among baselines, using the whole training set (Fully-supervised) achieves greater performances than Few-shot Prompting in all metrics. It implies that long-form QA task is challenging in the few-shot setup. In the closed-book setup, GPT-3 shows competitive performances with T5-large with JPR in D-F1 score, showing LLM’s strong reasoning ability over its inherent knowledge.
TOC 优于全监督和少样本提示基线。表 1 展示了基线和 TOC 在 ASQA 开发集上的长格式问答性能。在基线中,使用完整训练集 (全监督) 在所有指标上都优于少样本提示,这表明长格式问答任务在少样本设置中具有挑战性。在闭卷设置中,GPT-3 在 D-F1 分数上与采用 JPR 的 T5-large 表现相当,显示了大语言模型基于其固有知识的强大推理能力。
Among our models, LLM with RAC outperforms all other baselines in D-F1 and DR scores. It indicates the importance of leveraging external knowledge in clarifying AQs. Employing the tree structure (TS) helps the model to explore diverse interpretations, improving D-F1 and DR scores by
在我们的模型中,采用RAC的大语言模型在D-F1和DR分数上优于所有其他基线方法。这表明利用外部知识对澄清问题(AQ)的重要性。引入树结构(TS)有助于模型探索多样化解释,将D-F1和DR分数分别提升了
Table 3: Ablated results with and without pruning methods. The number of retained DQs after pruning and Answer-F1 are reported.
| Filtration | #(DQs) | Answer-F1 |
| w/o Pruning (None) | 12,838 | 40.9 |
| wPruning | ||
| +Deduplication | 10,598 | 40.1 |
| +Self-Verification | 4,239 | 59.3 |
表 3: 使用剪枝方法前后的消融实验结果。报告了剪枝后保留的 DQ (DQs) 数量及 Answer-F1 分数。
| Filtration | #(DQs) | Answer-F1 |
|---|---|---|
| w/o Pruning (None) | 12,838 | 40.9 |
| wPruning | ||
| +Deduplication | 10,598 | 40.1 |
| +Self-Verification | 4,239 | 59.3 |
1.3 and 0.9. When pruning the tree with our proposed self-verification (TS w/ Pruning), the model achieves state-of-the-art performance in D-F1 and DR score, surpassing the previous few-shot baseline by 8.4 and 7.0. Notably, it outperforms the best model in a fully-supervised setup (T5-large with JPR) by 7.3 and 2.9. In the experiment, T5-Large in a closed-book setup achieves comparable performance with LLM baselines in ROUGE-L score despite its poor D-F1 scores. It reconfirms the observation from Krishna et al. (2021) that shows the limitations of the ROUGE-L metric.
1.3和0.9。当使用我们提出的自验证方法进行剪枝时(TS w/ Pruning),该模型在D-F1和DR分数上达到了最先进的性能,比之前的少样本基线分别提高了8.4和7.0。值得注意的是,它比全监督设置下的最佳模型(T5-large with JPR)分别高出7.3和2.9。在实验中,封闭设置下的T5-Large尽管D-F1分数较低,但在ROUGE-L分数上与LLM基线取得了相当的性能。这再次印证了Krishna等人(2021)的研究发现,即ROUGE-L指标存在局限性。
Integrating retrieval systems largely contributes to accurate and diverse disambiguations. Table 2 displays the ablation study for measuring the contributions of each proposed component. When removing disambiguation s from fewshot training examples, the ROUGE-L score is significantly degraded, which shows the importance of the intermediate step to provide the complete answer. Integrating retrieval systems (i.e., Bing search engine and ColBERT) largely improves the model performance, especially in the D-F1 score. It indicates using external knowledge is key to enhancing the factual correctness of clarification. We report intrinsic evaluation for each retrieval system in Appendix B.
集成检索系统对提升消歧的准确性和多样性具有重要作用。表2展示了用于衡量各组件贡献的消融实验结果。移除少样本训练示例中的消歧步骤会导致ROUGE-L分数显著下降,这表明提供完整答案的中间步骤至关重要。集成检索系统(即Bing搜索引擎和ColBERT)大幅提升了模型性能,尤其在D-F1分数上表现突出,说明使用外部知识是增强澄清事实准确性的关键。各检索系统的内在评估结果详见附录B。
Our pruning method precisely identifies helpful disambiguation s from the tree. Table 3 shows intrinsic evaluation for generated disambiguation s, where all baselines are evaluated with Answer-F1 score that measures the F1 accuracy of the answer to the target DQ. Compared to the baseline, the valid nodes that pass self-verification contain more accurate disambiguation s, achieving much higher Answer-F1 score $(+18.4)$ . On the other hand, solely using de duplication does not advance the accuracy, indicating the efficacy of our proposed self-verification method.
我们的剪枝方法能精准识别树中有助于消歧的节点。表3展示了生成消歧结果的内部评估,所有基线模型均采用Answer-F1分数(衡量对目标DQ问题回答的F1准确率)进行评估。相比基线,通过自验证的有效节点包含更精确的消歧结果,Answer-F1分数显著提升$(+18.4)$。而仅使用去重策略并未提高准确率,这验证了我们提出的自验证方法的有效性。
5 Discussion
5 讨论
Ambiguity Detection TOC is designed to clarify AQs without bothering users; hence does not explicitly identify whether the given question is ambiguous or not. It tries to perform clarification even if the question cannot be disambiguate d anymore, often resulting in generating duplicate or irrelevant $\mathrm{DQs^{7}}$ . However, we could presume a question to be unambiguous if it can no longer be disambiguated8. In TOC, when it fails to disambiguate the given question or all generated disambiguation s are pruned, the question could be regarded as unambiguous.
歧义检测TOC旨在不打扰用户的情况下澄清模棱两可的问题(AQ),因此不会明确判断给定问题是否存在歧义。即使问题已无法进一步消歧,它仍会尝试进行澄清,这常导致生成重复或无关的消歧问题(DQ$^{7}$)。不过当问题无法被消歧时$^8$,我们可以推定该问题是无歧义的。在TOC中,当系统无法对给定问题消歧或所有生成的消歧选项都被剪枝时,该问题可被视为无歧义。
Computational Complexity Although TOC requires multiple LLM calls, its maximum number is less than 20 times per question. Exploration of the tree ends when it obtains the pre-defined number of valid nodes (10 in our experiments). Since the clarification process generates from two to five disambiguation s for each question, it satisfies the termination condition in a few steps without the pruning method. Failing to expand three times in a row also terminates the exploration. Pruning steps consume a smaller amount of tokens since they encode a single passage without few-shot exemplars. Compared to the existing ensemble methods such as self-consistency (Wei et al., 2022) which cannot be directly adopted to the generative task, ToC achieves a state-of-the-art performance with a comparable number of LLM calls.
计算复杂度
尽管TOC需要多次调用大语言模型,但每个问题的最大调用次数不超过20次。当获得预定义数量的有效节点(实验中设为10个)时,树探索即终止。由于澄清过程会为每个问题生成2到5个消歧选项,无需剪枝方法即可在几步内满足终止条件。连续三次扩展失败也会终止探索。剪枝步骤消耗的token较少,因为它们仅编码单个段落且不含少样本示例。与现有集成方法(如无法直接应用于生成任务的自洽方法 [20])相比,TOC在调用次数相近的情况下实现了最先进的性能。
General iz ability The key idea of ToC could be potentially generalized to other tasks and model architectures. It has a model-agnostic structure that could effectively explore diverse paths of recursive reasoning, which would be helpful for tasks that require multi-step reasoning, such as multi-hop QA. Future work might investigate the general iz ability of TOC to diverse tasks, datasets, and LM architectures.
泛化能力
ToC的核心思想可能推广到其他任务和模型架构。它具有与模型无关的结构,能有效探索递归推理的多样化路径,这对需要多步推理的任务(如多跳问答)很有帮助。未来工作可研究ToC在不同任务、数据集和大语言模型架构中的泛化能力。
6 Conclusion
6 结论
In this work, we propose a novel framework, TREE OF CLARIFICATIONS. It recursively builds a tree of disambiguation s for the AQ via few-shot prompting with external knowledge and utilizes it to generate a long-form answer. Our framework explores diverse dimensions of interpretations of ambiguity. Experimental results demonstrate TOC successfully guide LLMs to traverse diverse paths of clarification for a given AQ within tree structure and generate comprehensive answers. We hope this work could shed light on building robust clarification models, which can be generalized toward real-world scenarios.
在这项工作中,我们提出了一种新颖的框架——澄清树(TREE OF CLARIFICATIONS)。它通过少样本提示结合外部知识,为模糊问题(AQ)递归构建消歧树,并利用该结构生成长篇答案。我们的框架探索了模糊性解释的多个维度。实验结果表明,TOC能成功引导大语言模型在树状结构中遍历给定AQ的不同澄清路径,并生成全面答案。我们希望这项工作能为构建鲁棒的澄清模型提供启示,这些模型可推广至现实场景。
Limitations
局限性
Although TOC is a model-agnostic framework that could be combined with other components, our study is limited in demonstrating the genera liza bility of different kinds or sizes of LLMs. In addition, the experiments are only conducted on a benchmark, ASQA (Stelmakh et al., 2022). Although TOC enables LLM to explore diverse reasoning paths by iterative ly prompting LLM, the cost of multiple prompting is not negligible.
虽然TOC是一个与模型无关的框架,可以与其他组件结合使用,但我们的研究在展示不同类型或规模的大语言模型的通用性方面存在局限。此外,实验仅在ASQA基准测试(Stelmakh et al., 2022)上进行。尽管TOC通过迭代提示大语言模型使其能够探索多样化的推理路径,但多次提示的成本不容忽视。
We tried the recent prompting method, chain of thoughts (Wei et al., 2022), but failed to enhance the performance in our pilot experiments. It might indicate the disambiguation process requires external knowledge, which shows the importance of document-grounded or retrieval-augmented systems. Future work could suggest other pruning methods that identify unhelpful DQs more effec- tively. The performance could be further enhanced by using the state-of-the-art reranker in the answer sentence selection task, as proposed by recent works (Garg et al., 2020; Lauriola and Moschitti, 2021).
我们尝试了最新的提示方法——思维链 (Wei et al., 2022) ,但在初步实验中未能提升性能。这可能表明消歧过程需要外部知识,从而凸显了基于文档或检索增强系统的重要性。未来工作可以探索其他剪枝方法,以更有效地识别无用的DQ。通过采用答案句子选择任务中最先进的重新排序器 (如Garg et al., 2020和Lauriola and Moschitti, 2021提出的方案) ,性能有望得到进一步提升。
Acknowledgements
致谢
The first author, Gangwoo Kim, has been supported by the Hyundai Motor Chung Mong-Koo Foundation. This research was supported by the National Research Foundation of Korea (NRF2023R1A2C3004176, RS-2023-00262002), the MSIT (Ministry of Science and ICT), Korea, under the ICT Creative Cons i lien ce program (IITP-2022- 2020-0-01819) supervised by the IITP (Institute for Information & communications Technology Planning & Evaluation), and the Electronics and Telecommunications Research Institute (RS-2023- 00220195).
第一作者 Gangwoo Kim 获得了现代汽车郑梦九基金会的资助。本研究同时受到韩国国家研究基金会 (NRF2023R1A2C3004176, RS-2023-00262002) 、韩国科学技术信息通信部 (MSIT) 信息通信技术创新人才培育项目 (IITP-2022-2020-0-01819) 的资助 (项目主管单位:韩国信息通信技术规划评价院/IITP) ,以及韩国电子通信研究院 (RS-2023-00220195) 的资助。
References
参考文献
Reinald Kim Amplayo, Kellie Webster, Michael Collins, Dipanjan Das, and Shashi Narayan. 2023. Query refinement prompts for closed-book long-form question answering. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics.
Reinald Kim Amplayo、Kellie Webster、Michael Collins、Dipanjan Das 和 Shashi Narayan。2023。闭卷长文本问答中的查询优化提示。第61届计算语言学协会年会论文集。
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. 2016. Ms marco: A human generated machine reading comprehension dataset. 30th Conference on Neu- ral Information Processing Systems (NIPS 2016), Barcelona, Spain.
Payal Bajaj、Daniel Campos、Nick Craswell、Li Deng、Jianfeng Gao、Xiaodong Liu、Rangan Majumder、Andrew McNamara、Bhaskar Mitra、Tri Nguyen等。2016。MS MARCO:一个人工生成的机器阅读理解数据集。第30届神经信息处理系统大会(NIPS 2016),西班牙巴塞罗那。
Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. 2017. Reading wikipedia to answer opendomain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1870–1879.
Danqi Chen、Adam Fisch、Jason Weston和Antoine Bordes。2017。通过阅读维基百科回答开放域问题。见《第55届计算语言学协会年会论文集(第一卷:长论文)》,第1870–1879页。
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann 等. 2022. PaLM: 基于Pathways的大语言模型扩展. arXiv预印本 arXiv:2204.02311.
Jeremy R Cole, Michael JQ Zhang, Daniel Gillick, Ju- lian Martin Eisen schlo s, Bhuwan Dhingra, and Jacob Eisenstein. 2023. Selectively answering ambiguous questions. arXiv preprint arXiv:2305.14613.
Jeremy R Cole、Michael JQ Zhang、Daniel Gillick、Julian Martin Eisenschlos、Bhuwan Dhingra 和 Jacob Eisenstein。2023年。《选择性回答模糊问题》。arXiv预印本 arXiv:2305.14613。
Yifan Gao, Henghui Zhu, Patrick Ng, Cicero dos San- tos, Zhiguo Wang, Feng Nan, Dejiao Zhang, Ramesh Nallapati, Andrew O Arnold, and Bing Xiang. 2021. Answering ambiguous questions through generative evidence fusion and round-trip prediction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3263– 3276.
Yifan Gao, Henghui Zhu, Patrick Ng, Cicero dos Santos, Zhiguo Wang, Feng Nan, Dejiao Zhang, Ramesh Nallapati, Andrew O Arnold, Bing Xiang. 2021. 通过生成式证据融合与往返预测回答模糊问题. 见: 《第59届计算语言学协会年会暨第11届自然语言处理国际联合会议论文集(第一卷: 长论文)》, 第3263–3276页.
Siddhant Garg, Thuy Vu, and Alessandro Moschitti. 2020. Tanda: Transfer and adapt pre-trained transformer models for answer sentence selection. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7780–7788.
Siddhant Garg、Thuy Vu和Alessandro Moschitti。2020。Tanda:迁移与适配预训练Transformer模型用于答案句选择。载于《AAAI人工智能会议论文集》第34卷,第7780–7788页。
Meiqi Guo, Mingda Zhang, Siva Reddy, and Malihe Alikhani. 2021. Abg-coqa: Clarifying ambiguity in conversational question answering. In 3rd Conference on Automated Knowledge Base Construction.
梅琪·郭、明达·张、Siva Reddy和Malihe Alikhani。2021年。Abg-coqa:对话问答中的歧义澄清。收录于第三届自动知识库构建会议。
Gautier Izacard and Édouard Grave. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880.
Gautier Izacard 和 Édouard Grave. 2021. 利用生成式模型结合段落检索实现开放域问答. 载于《第16届欧洲计算语言学协会会议论文集: 主卷》, 第874–880页.
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535–547.
Jeff Johnson、Matthijs Douze 和 Hervé Jégou。2019。基于 GPU 的十亿级相似性搜索。《IEEE 大数据汇刊》7(3):535–547。
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield Dodds, Nova DasSarma, Eli Tran-Johnson, et al. 2022. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221.
Saurav Kadavath、Tom Conerly、Amanda Askell、Tom Henighan、Dawn Drain、Ethan Perez、Nicholas Schiefer、Zac Hatfield Dodds、Nova DasSarma、Eli Tran-Johnson 等. 2022. 语言模型 (大多) 知道自己知道什么. arXiv预印本 arXiv:2207.05221.
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for opendomain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781.
Vladimir Karpukhin、Barlas Oguz、Sewon Min、Patrick Lewis、Ledell Wu、Sergey Edunov、Danqi Chen和Wen-tau Yih。2020。开放域问答的密集段落检索。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第6769–6781页。
Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, and Matei Zaharia. 2022. Demonstrate-searchpredict: Composing retrieval and language models for knowledge-intensive nlp. arXiv preprint arXiv:2212.14024.
Omar Khattab、Keshav Santhanam、Xiang Lisa Li、David Hall、Percy Liang、Christopher Potts 和 Matei Zaharia。2022。演示-搜索-预测:组合检索与语言模型实现知识密集型自然语言处理。arXiv预印本 arXiv:2212.14024。
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextual i zed late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39– 48.
Omar Khattab和Matei Zaharia。2020。Colbert:基于BERT的情境化延迟交互实现高效段落搜索。见《第43届国际ACM SIGIR信息检索研究与发展会议论文集》,第39–48页。
Kalpesh Krishna, Aurko Roy, and Mohit Iyyer. 2021. Hurdles to progress in long-form question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4940–4957.
Kalpesh Krishna、Aurko Roy和Mohit Iyyer。2021。长形式问答中的进展障碍。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第4940–4957页。
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2022. Clam: Selective clarification for ambiguous questions with large language models. arXiv preprint arXiv:2212.07769.
Lorenz Kuhn、Yarin Gal 和 Sebastian Farquhar。2022。Clam: 大语言模型针对模糊问题的选择性澄清。arXiv预印本 arXiv:2212.07769。
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452– 466.
Tom Kwiatkowski、Jennimaria Palomaki、Olivia Redfield、Michael Collins、Ankur Parikh、Chris Alberti、Danielle Epstein、Illia Polosukhin、Jacob Devlin、Kenton Lee等。2019。自然问题(Natural Questions):问答研究的基准测试。《计算语言学协会汇刊》7:452–466。
Ivano Lauriola and Alessandro Moschitti. 2021. An- swer sentence selection using local and global context in transformer models. In European Conference on Information Retrieval, pages 298–312. Springer.
Ivano Lauriola 和 Alessandro Moschitti. 2021. 基于 Transformer 模型的局部与全局上下文答案句选择. 欧洲信息检索会议, 第 298–312 页. Springer.
Dongryeol Lee, Segwang Kim, Minwoo Lee, Hwanhee Lee, Joonsuk Park, Sang-Woo Lee, and Kyomin Jung. 2023. Asking clarification questions to handle ambiguity in open-domain qa. arXiv preprint arXiv:2305.13808.
Dongryel Lee、Segwang Kim、Minwoo Lee、Hwanhee Lee、Joonsuk Park、Sang-Woo Lee 和 Kyomin Jung。2023。通过澄清问题处理开放域问答中的歧义。arXiv预印本 arXiv:2305.13808。
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel等。2020。面向知识密集型NLP任务的检索增强生成。神经信息处理系统进展,33:9459–9474。
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Z ett le moyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pre training approach. arXiv preprint arXiv:1907.11692.
Yinhan Liu、Myle Ott、Naman Goyal、Jingfei Du、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zettlemoyer 和 Veselin Stoyanov。2019. RoBERTa: 一种鲁棒性优化的 BERT 预训练方法。arXiv 预印本 arXiv:1907.11692。
Sewon Min, Kenton Lee, Ming-Wei Chang, Kristina Toutanova, and Hannaneh Hajishirzi. 2021. Joint passage ranking for diverse multi-answer retrieval. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6997–7008.
Sewon Min、Kenton Lee、Ming-Wei Chang、Kristina Toutanova 和 Hannaneh Hajishirzi。2021. 面向多样化多答案检索的联合段落排序。载于《2021年自然语言处理实证方法会议论文集》,第6997–7008页。
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Z ett le moyer. 2020. Ambigqa: Answering ambiguous open-domain questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5783– 5797.
Sewon Min、Julian Michael、Hannaneh Hajishirzi 和 Luke Zettlemoyer。2020. AmbigQA: 回答模糊的开放领域问题。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第5783–5797页。
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
Long Ouyang、Jeffrey Wu、Xu Jiang、Diogo Almeida、Carroll Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray 等. 2022. 通过人类反馈训练语言模型遵循指令. Advances in Neural Information Processing Systems, 35:27730–27744.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu。2020。探索文本到文本Transformer迁移学习的极限。《机器学习研究期刊》21(1):5485–5551。
Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know what you don’t know: Unanswerable questions for squad. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 784–789.
Pranav Rajpurkar、Robin Jia和Percy Liang。2018。了解你所不知道的:SQuAD中的不可回答问题。载于《第56届计算语言学协会年会论文集(第二卷:短文)》,第784-789页。
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992.
Nils Reimers和Iryna Gurevych。2019. Sentence-BERT:使用孪生BERT网络的句子嵌入。载于《2019年自然语言处理实证方法会议暨第九届自然语言处理国际联合会议(EMNLP-IJCNLP)论文集》,第3982–3992页。
Zhihong Shao and Minlie Huang. 2022. Answering open-domain multi-answer questions via a recallthen-verify framework. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1825– 1838.
Zhihong Shao和Minlie Huang。2022。通过召回-验证框架回答开放域多答案问题。见《第60届计算语言学年会论文集(第一卷:长论文)》,第1825-1838页。
Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, and MingWei Chang. 2022. ASQA: Factoid questions meet long-form answers. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8273–8288, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Ivan Stelmakh、Yi Luan、Bhuwan Dhingra和MingWei Chang。2022。ASQA:事实型问题遇见长格式答案。载于《2022年自然语言处理实证方法会议论文集》,第8273–8288页,阿拉伯联合酋长国阿布扎比。计算语言学协会。
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. Minilm: Deep selfattention distillation for task-agnostic compression of pre-trained transformers. Advances in Neural Information Processing Systems, 33:5776–5788.
Wenhui Wang、Furu Wei、Li Dong、Hangbo Bao、Nan Yang 和 Ming Zhou。2020。MiniLM: 面向任务无关的预训练Transformer压缩深度自注意力蒸馏。Advances in Neural Information Processing Systems,33:5776–5788。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Fei Xia、Ed Chi、Quoc V Le、Denny Zhou 等. 2022. 思维链提示激发大语言模型中的推理能力. Advances in Neural Information Processing Systems, 35:24824–24837.
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601.
Shunyu Yao、Dian Yu、Jeffrey Zhao、Izhak Shafran、Thomas L Griffiths、Yuan Cao和Karthik Narasimhan。2023。思维之树:利用大语言模型进行深思熟虑的问题解决。arXiv预印本arXiv:2305.10601。
A Experimental Setup Details
实验设置详情
A.1 Ambiguous QA Datasets
A.1 模糊问答数据集
All baselines and our framework are evaluated on ASQA benchmark (Stelmakh et al., 2022). It is a long-form QA dataset built on the subset of ambiguous questions identified from AmbigNQ dataset (Min et al., 2020). It contains opendomain questions collected from Natural Questions (Kwiatkowski et al., 2019). ASQA consists of 6,316 ambiguous questions and their long-form answers with disambiguation s, split into 4,353, 948, and 1,015 train, development, and test set, respectively.
所有基线方法和我们的框架均在ASQA基准(Stelmakh等人,2022)上进行评估。该基准是基于AmbigNQ数据集(Min等人,2020)中识别出的模糊问题子集构建的长格式问答数据集,包含来自Natural Questions(Kwiatkowski等人,2019)的开放域问题。ASQA包含6,316个模糊问题及其带有消歧说明的长格式答案,分别划分为4,353、948和1,015个训练集、开发集和测试集。
A.2 Evaluation Metrics
A.2 评估指标
Following Stelmakh et al. (2022), we use three evaluation metrics on ASQA. First, ROUGE-L (R-L) measures the lexical overlap between long-form answers from references and system-generated predictions. Since the benchmark provides two groundtruth answers, we report the maximum ROUGE-L score. Disambig-F1 (D-F1) measures the factual correctness of generated predictions. A reading comprehension model, RoBERTa (Liu et al., 2019) trained on SQuADv2 (Rajpurkar et al., 2018), finds short answers to the ground-truth DQs from the generated long-form response. Then, F1 accuracy of the detected answer is calculated to check if the long-form answer contains accurate information. Disambiguation-ROUGE (DR) score is computed as the geometric mean of ROUGE-L and DisambigF1 to measure the overall performance. We additionally use Answer-F1 to validate the disambiguations. It computes the maximum F1 accuracy of answers to a single DQ. We use ground-truth dis- ambi gu at ions provided by AmbigNQ (Min et al., 2020).
遵循 Stelmakh 等人的方法 (2022),我们在 ASQA 上使用三种评估指标。首先,ROUGE-L (R-L) 用于衡量参考长答案与系统生成预测之间的词汇重叠度。由于基准测试提供了两个标准答案,我们报告最高 ROUGE-L 分数。Disambig-F1 (D-F1) 用于衡量生成预测的事实准确性。基于 SQuADv2 (Rajpurkar 等人, 2018) 训练的阅读理解模型 RoBERTa (Liu 等人, 2019) 会从生成长答案中找出标准歧义问题 (DQ) 的简短答案,然后计算检测答案的 F1 准确率以验证长答案是否包含准确信息。消歧-ROUGE (DR) 分数是 ROUGE-L 和 DisambigF1 的几何平均数,用于衡量整体性能。我们还使用 Answer-F1 来验证消歧效果,该指标计算单个 DQ 答案的最高 F1 准确率。我们采用 AmbigNQ (Min 等人, 2020) 提供的标准消歧结果。
A.3 Implementation Details
A.3 实现细节
A large portion of our implementation is based on the DSP library (Khattab et al., 2022). To dynami- cally find few-shot examples with the nearest neighbor search, we use pre-trained MiniLM (Wang et al., 2020) to obtain hidden representations of questions and compute similarity scores with Faiss library (Johnson et al., 2019). We add 5-shot training examples to the prompt, following Amplayo et al. (2023). It was the optimal number in our pilot experiment.
我们的大部分实现基于 DSP 库 (Khattab et al., 2022)。为了通过最近邻搜索动态寻找少样本示例,我们使用预训练的 MiniLM (Wang et al., 2020) 获取问题的隐藏表示,并利用 Faiss 库 (Johnson et al., 2019) 计算相似度分数。参照 Amplayo et al. (2023) 的方法,我们在提示中添加了 5 个少样本训练示例。这在我们初步实验中是最优数量。
For prompting LLM to perform RAC, we use top-5 relevant passages. To determine whether to prune the target node or not, we rerank and pick the most relevant passage among those containing the answer in the target node. In the answer generation process, we took ten valid disambiguation s in BFS order and five answer-containing passages. We use API served by OpenAI9 to employ GPT-3 as our backbone. We set max tokens as 300 and top $p$ as 1.0.
为引导大语言模型执行RAC任务,我们采用前5个相关段落。在判断是否剪枝目标节点时,我们对包含目标节点答案的段落进行重排序并选取最相关段落。答案生成过程中,我们按广度优先顺序选取10个有效消歧项和5个含答案段落。通过OpenAI提供的API使用GPT-3作为基础模型,设置最大token数为300,top $p$ 值为1.0。
Table 4: Intrinsic evaluation of retrieval systems. Answer coverage at $k$ $\left(\operatorname{AC}@k\right)$ measures the proportion of disambiguate d answers that are covered by top $k$ retrieved passages.
| Retrieval System | AC@10 | AC@30 | AC@100 |
| ColBERTv2 | 56.4 | 68.4 | 73.4 |
| w/Reranker | 56.8 | 69.0 | 73.4 |
| BingSearchEngine | 43.3 | 58.3 | 73.5 |
| w/Reranker | 62.7 | 68.0 | 72.8 |
| Combined w/Reranker | 64.2 | 77.4 | 80.1 |
表 4: 检索系统的内在评估。答案覆盖率 $k$ $\left(\operatorname{AC}@k\right)$ 衡量了前 $k$ 个检索段落覆盖的消歧答案比例。
| 检索系统 | AC@10 | AC@30 | AC@100 |
|---|---|---|---|
| ColBERTv2 | 56.4 | 68.4 | 73.4 |
| w/Reranker | 56.8 | 69.0 | 73.4 |
| BingSearchEngine | 43.3 | 58.3 | 73.5 |
| w/Reranker | 62.7 | 68.0 | 72.8 |
| Combined w/Reranker | 64.2 | 77.4 | 80.1 |
B Additional Experiment
B 补充实验
B.1 Intrinsic Evaluation for Retrieval Systems
B.1 检索系统的内在评估
We randomly sample 100 examples from ASQA dataset and report intrinsic evaluation results for retrieval systems. Since a single AQ has multiple ground-truth DQs and their answers, it is not trivial to check how many answers are covered by retrieved passages. Inspired by Min et al. (2021), we devise an evaluation proxy, answer coverage, for measuring the quality of retrieved passages in ambiguous QA tasks. We consider the retrieval as successful if the retrieved passages contain one of the answers to the target DQ. We calculate the proportion of success among DQs for a single AQ to check overall answer coverage.
我们从ASQA数据集中随机抽取100个样本,并报告检索系统的内在评估结果。由于单个模糊问题(AQ)对应多个真实衍生问题(DQ)及其答案,评估检索段落覆盖多少答案并非易事。受Min等人(2021)启发,我们设计了一个评估代理指标——答案覆盖率(answer coverage),用于衡量模糊QA任务中检索段落的质量。若检索段落包含目标DQ的任一答案,即视为检索成功。我们通过计算单个AQ对应DQ的成功比例,来评估整体答案覆盖率。
Table 4 compares retrieval systems in answer coverage $\left(\operatorname{AC@}k\right)$ of top $\cdot k$ passages. Bing search engine without reranker performs worst among baselines in $\mathrm{AC@10}$ and $\ @30$ . However, with reranker, its performances are greatly enhanced, outperforming ColBERT baselines. When combining two retrieval systems, it shows the best performances across all evaluation metrics; hence two results are complementary. It achieves 80.1 in $\mathrm{AC}@100$ scores, which indicates the passage set has sufficient information if properly explored.
表 4 比较了检索系统在 top-k 段落答案覆盖率 (AC@k) 的表现。未使用重排序器的 Bing 搜索引擎在 AC@10 和 AC@30 指标上表现最差。但经过重排序后,其性能显著提升,优于 ColBERT 基线模型。当结合两种检索系统时,所有评估指标均达到最佳表现,说明两种结果具有互补性。该系统在 AC@100 分数上达到 80.1,表明只要合理探索,该段落集合包含充足信息。
C Qualitative Analysis
C 定性分析
C.1 Prompt Format
C.1 提示格式
We add format descriptions to our prompt following Khattab et al. (2022). Table 5 displays the for- mat specifically designed to generate disambiguations for a given question based on external documents. The format description is augmented to prompts of both RAC and the answer generation. By using it, we encouarge LLM to comply with the format.
我们按照Khattab等人(2022)的方法在提示词中添加格式描述。表5展示了专门设计用于基于外部文档为给定问题生成消歧内容的格式。该格式描述被增强到RAC和答案生成的提示词中。通过使用它,我们鼓励大语言模型遵循该格式。
C.2 Question Clarification
C.2 问题澄清
Table 6 shows an example of RAC for the AQ. Retrieval systems provide the external knowledge. Leveraging it, LLM generates disambiguate d question-answer pairs. In RAC, long-form answers are also generated to follow the format but we do not use them in the later steps.
表 6 展示了 AQ 的 RAC 示例。检索系统提供外部知识,大语言模型利用这些知识生成消歧后的问答对。在 RAC 中,还会生成长篇答案以遵循格式要求,但后续步骤中我们并未使用这些长篇答案。
In Table 7, we observe the cases where TOC encounters unambiguous questions and fails to clarify them. It often asks different or irrelevant facts from them of original AQ.
表 7: 我们观察到TOC遇到明确问题却未能澄清的情况。它经常从原始AQ中询问不同或无关的事实。
C.3 Self Verification
C.3 自我验证
Table 8, 9 show examples of self-verification prompt. We prompt LLM to verify the current answer is factually coherent with AQ based on the relevant passage. It generates ‘True’ or ‘False’ to determine whether the node would be discarded or not. We do not provide few-shot training examples or formats.
表 8、9 展示了自验证提示的示例。我们提示大语言模型根据相关段落验证当前答案是否与 AQ 在事实上一致。模型会生成"True"或"False"来决定是否丢弃该节点。我们没有提供少样本训练示例或格式。
C.4 Answer Generation
C.4 答案生成
Table 10 depicts an example of answer generation prompt. We use a similar prompt to that of RAC except disambiguation s are given as inputs. It encodes up to ten disambiguation s and five relevant passages.
表 10: 答案生成提示示例。我们使用了与RAC类似的提示,区别在于消歧信息作为输入给出。该提示最多编码十条消歧信息和五段相关文本段落。
Follow the following format.
遵循以下格式。
Context:
上下文:
$\$$ {sources that may contain relevant content}
$\$$ {可能包含相关内容的数据源}
Question: $\$$ {ambiguous question to be disambiguate d}
问题: $\$$ {需要消歧义的模糊问题}
Answer: $\$$ thorough, detailed answer that explains the multiple interpretations of the original question and includes the appropriate disambiguation s, at least three sentences.}
答案:$\$$ 全面详细的解答,阐释原问题的多种理解方式,并包含适当的歧义消除说明,至少三句话。
Table 5: Format description for both RAC and the answer generation.
表 5: RAC与答案生成的格式描述
I will provide ambiguous questions that can have multiple answers based on their different possible interpretations. Clarify the given question into several disambiguate d questions and provide short factoid answers to each question. Subsequently, summarize them into a detailed long-form answer of at least three sentences. Here are some examples.
我将提供一些可能因不同解读而有多个答案的模糊问题。请将给定问题拆解为几个明确的子问题,并为每个子问题提供简短的事实性回答。随后将这些回答汇总成至少三句话的详细长答案。示例如下:
Context:
上下文:
Question: Who played the weasley brothers in harry potter?
问题:谁在《哈利·波特》中饰演韦斯莱兄弟?
Disambiguation s:
消歧义:
Answer: The Weasley brothers in the Harry Potter series were played by identical twin brothers James and other Oliver Phelps. The Phelps brothers are English actors who have appeared in films and TV shows together as a duo. Chris Rankin is the actor who played Percy Weasley in the Harry Potter series. Rankin is a British actor who has appeared in theatre, film, and TV.
答:哈利·波特系列中的韦斯莱兄弟由同卵双胞胎兄弟James和Oliver Phelps饰演。Phelps兄弟是英国演员,曾以组合形式共同出演多部影视作品。Chris Rankin则在哈利·波特系列中扮演珀西·韦斯莱。Rankin是一位活跃于戏剧、电影及电视领域的英国演员。
I will provide ambiguous questions that can have multiple answers based on their different possible interpretations. Clarify the given question into several disambiguate d questions and provide short factoid answers to each question. Subsequently, summarize them into a detailed long-form answer of at least three sentences. Here are some examples.
我将提供一些可能因不同解读而有多种答案的模糊问题。请将给定问题分解为几个明确的子问题,并为每个问题提供简短的事实性回答。随后将这些回答汇总成至少三句话的详细长答案。示例如下:
Follow the following format.
遵循以下格式。
Context:
上下文:
Question: When did Toronto host the MLB All-Star Game in 1991?
问题:多伦多在哪一年举办了1991年的MLB全明星赛?
Disambiguation s:
消歧义:
Answer: The 1991 Major League Baseball All-Star Game was
答:1991年美国职业棒球大联盟全明星赛
I will provide ambiguous questions that can have multiple answers based on their different possible interpretations. Clarify the given question into several disambiguate d questions and provide short factoid answers to each question. Subsequently, summarize them into a detailed long-form answer of at least three sentences. Here are some examples.
我将提供一些可能因不同解读而有多种答案的模糊问题。请将给定问题拆解为几个明确的子问题,并为每个子问题提供简短的事实性答案。随后将这些答案汇总成至少三句话的详细长格式回答。示例如下:
Follow the following format.
遵循以下格式。
Context:
上下文:
[1] Highest-paid NBA players by season | Highest-paid NBA players by season The highest-paid NBA players by season over ...
[1] NBA单赛季收入最高球员 | NBA单赛季收入最高球员 NBA单赛季收入最高的球员包括...
[5] Highest-paid NBA players by season | Highest-paid NBA players ...
[5] NBA球员单赛季收入排行榜 | NBA球员薪资之最...
Question: Who was the highest-paid NBA player in the 2017-2018 season?
问题:2017-2018赛季NBA收入最高的球员是谁?
Disambiguation s:
消歧义:
Answer: LeBron James was the highest-paid NBA player in the 2017-2018 season ...
答:勒布朗·詹姆斯是2017-2018赛季收入最高的NBA球员...
Correct Case 1 DQ: Who was selected to host the 2018 FIFA World Cup?
正确案例1 DQ:谁被选为2018年国际足联世界杯的主办国?
I will provide a question, relevant context, and proposed answer to it. Identify whether the proposed answer could be correct answers or not with only ‘True’ or ‘False’
我将提供一个提问、相关背景和对应的建议答案。请仅用"True"或"False"判断该建议答案是否可能是正确答案。
Context:
上下文:
2018 and 2022 FIFA World Cup bids | FIFA’s headquarters in Zurich. Russia was chosen to host the 2018 World Cup, and Qatar was chosen to host the 2022 World Cup. This made Russia the first Eastern European country to host the World Cup, while Qatar would be the first Middle Eastern country to host the World Cup. Blatter noted that the committee had decided to “go to new lands” and reflected a desire to “develop football” by bringing it to more countries. In each round a majority of twelve votes was needed. If no bid received 12 votes in a round, the bid with the fewest votes
2018年和2022年世界杯申办 | 位于苏黎世的国际足联总部。俄罗斯获选主办2018年世界杯,卡塔尔获选主办2022年世界杯。这使得俄罗斯成为首个举办世界杯的东欧国家,而卡塔尔将成为首个举办世界杯的中东国家。布拉特指出,委员会决定"开拓新大陆",并希望通过将赛事引入更多国家来"发展足球"。每轮投票需获得12票多数支持。若某轮无申办方获得12票,则得票最少的候选方...
Question: Who is hosting the next world cup 2022?
问题:2022年下一届世界杯由谁主办?
Proposed Answer: Russia
建议答案: Russia
Correct Case 2 DQ: Which player has won the most World Series in baseball?
正确案例2 DQ:哪位球员赢得了最多的棒球世界大赛冠军?
I will provide a question, relevant context, and proposed answer to it. Identify whether the proposed answer could be correct answers or not with only ‘True’ or ‘False’
我将提供一个提问、相关背景信息及其建议答案。请仅用"True"或"False"判断该建议答案是否可能正确
Context:
上下文:
World Series ring | on World Series rings. The New York Yankees Museum, located in Yankee Stadium, has an exhibit with replicas of all Yankees’ World Series rings, including the pocket watch given after the 1923 World Series. Yogi Berra won the most World Series rings with 10, as a player. Frankie Crosetti won 17 as a player and as a coach. Yogi Berra Museum and Learning Center. World Series ring A World Series ring is an award given to Major League Baseball players who win the World Series. Since only one Commissioner’s Trophy is awarded to the team, a World Series ring is
世界大赛戒指 | 关于世界大赛戒指。位于洋基体育场的纽约洋基队博物馆设有展览,陈列着所有洋基队世界大赛戒指的复制品,包括1923年世界大赛后颁发的怀表。Yogi Berra以球员身份赢得了最多的10枚世界大赛戒指,而Frankie Crosetti作为球员和教练共获得17枚。Yogi Berra博物馆与学习中心。世界大赛戒指是世界大赛冠军球队授予美国职棒大联盟球员的奖项。由于每支球队仅获颁一座联盟主席奖杯,世界大赛戒指便成为球员个人的荣誉象征。
Question: Who’s won the most world series in baseball?
问题:谁赢得了最多的棒球世界大赛冠军?
Proposed Answer: Yogi Berra
提议答案:Yogi Berra
True
真
Incorrect Case 1 DQ: Who is the highest goalscorer in world football in a single game?
错误案例1 DQ:谁是单场世界足球比赛中进球最多的球员?
I will provide a question, relevant context, and proposed answer to it. Identify whether the proposed answer could be correct answers or not with only ‘True’ or ‘False’
我将提供一个问题和相关背景信息及其建议答案。请仅用"True"或"False"判断该建议答案是否正确
Context:
上下文:
List of footballers with the most goals in a single game | This is a list of players with the most goals in a football game. The list only includes players who have scored the most multiple goals in first class or fully professional matches for country or club.The current world record for an international is held by Archie Thompson, who scored 13 goals against American Samoa in Australia’s 31–0 victory during the 2002 FIFA World Cup qualification. David Zdrilic scored 8 goals.In November 2022, Shokhan Nooraldin Salihi scored 15 goals in the match of Al-Hilal against Sama in the 2022–23 Saudi Women’s Premier League. In this match, Al-Hilal beat Sama 18-0.
单场进球最多的足球运动员列表 | 这是足球比赛中单场进球最多球员的列表。该列表仅包含在国家或俱乐部一级联赛及完全职业赛事中多次取得最高进球数的球员。目前国际比赛世界纪录由Archie Thompson保持,他在2002年世界杯预选赛澳大利亚31-0战胜美属萨摩亚的比赛中攻入13球。David Zdrilic在该场比赛中射入8球。2022年11月,Shokhan Nooraldin Salihi在2022-23赛季沙特女子超级联赛Al-Hilal对阵Sama的比赛中独中15球,最终Al-Hilal以18-0大胜对手。
Question: Who has the highest goals in world football?
问题:世界足坛谁的进球数最多?
Proposed Answer: Archie Thompson
建议答案:Archie Thompson
False
假
Incorrect Case 2 DQ: When was episode 113 of Dragon Ball Super released in the US?
错误案例2 DQ:美国何时播出了《龙珠超》第113集?
I will provide a question, relevant context, and proposed answer to it. Identify whether the proposed answer could be correct answers or not with only ‘True’ or ‘False’
我将提供一个问题和相关背景信息及其建议答案。请仅用"True"或"False"判断该建议答案是否可能是正确答案。
Context:
上下文:
Dragon Ball Super | would be available in the United States in summer 2017. Bandai has also announced the updated “Dragon Ball Super Card Game” that starts with one starter deck, one special pack containing 4 booster packs and a promotional Vegeta card and a booster box with 24 packs. It was released on July 28, 2017. A line of six “Dragon Ball Super” Happy Meal toys were made available at Japanese McDonald’s restaurants in May 2017. The average audience TV rating in Japan was $5.6%$ (Kanto region). The maximum audience rating was $8.4%$ (Episode 47) and the lowest rating was $3.5%$ (Episodes 109-110).
龙珠超 | 将于2017年夏季在美国上映。万代还宣布推出升级版"龙珠超卡牌游戏",首发包含一个起始卡组、一个内含4个补充包和限量贝吉塔促销卡的特殊套装,以及一个含24个补充包的整盒。该产品于2017年7月28日发售。2017年5月,日本麦当劳推出了六款"龙珠超"开心乐园餐玩具。该动画在日本的平均收视率为$5.6%$(关东地区),最高收视率达$8.4%$(第47集),最低收视率为$3.5%$(第109-110集)。
Question: When is episode 113 of dragon ball super coming out?
问题:龙珠超第113集什么时候播出?
Proposed Answer: November 5, 2017
建议答案:2017年11月5日
False
假
I will provide ambiguous questions that can have multiple answers based on their different possible interpretations. Clarify the given question into several disambiguate d questions and provide short factoid answers to each question. Subsequently, summarize them into a detailed long-form answer of at least three sentences. Here are some examples.
我将提供一些可能因不同解读而有多种答案的模糊问题。请将给定问题拆解成若干个明确的具体问题,并为每个问题提供简短的事实性回答。随后将这些回答汇总成至少包含三句话的详细长答案。以下是几个示例。
Context:
上下文:
[1] Game of Thrones | Game of Thrones Game of Thrones is an American fantasy drama television series created by David Benioff and D. B. Weiss. ... and its seventh season ended on August 27, 2017. The series will conclude with its eighth season [2] Game of Thrones | Game of Thrones is an American fantasy drama television series created by David Benioff and for HBO. It is an adaptation of "A Song of Ice and Fire", ... Set on the fictional continents of Westeros and Essos, "Game of Thrones" has a large ensemble cast [5] A Game of Thrones (comics) | A Game of Thrones (comics) A Game of Thrones is the comic book adaptation of George R. R. Martin’s fantasy novel "A Game of Thrones", . . . It is intended to follow the story and atmosphere of the novel closely, at a rate of about a page of art for each page of text, and
[1] 权力的游戏 | 权力的游戏
《权力的游戏》是由David Benioff和D.B. Weiss创作的美国奇幻剧集...第七季于2017年8月27日完结,最终第八季为系列终章。
[2] 权力的游戏 | 权力的游戏
《权力的游戏》是David Benioff为HBO打造的美国奇幻剧集,改编自《冰与火之歌》...故事以虚构大陆维斯特洛和厄索斯为背景,拥有庞大的演员阵容。
[5] 权力的游戏(漫画版) | 权力的游戏(漫画版)
《权力的游戏》漫画版改编自George R.R. Martin的奇幻小说《权力的游戏》...力求忠实还原原著情节与氛围,图文比例约为1页绘画对应1页文本。
Question: What kind of series is game of thrones?
问题:《权力的游戏》属于什么类型的剧集?
Disambiguation s:
消歧义:
Answer: There are multiple works that share the title Game of Thrones. The first is a television series that is a fantasy drama, the second is a comic book series that is fantasy, the third is a book series that is fantasy, and the fourth is a board game that is a strategy game.
答案:有多部作品共享《权力的游戏》这一标题。第一部是奇幻题材的电视剧,第二部是奇幻题材的漫画系列,第三部是奇幻题材的图书系列,第四部是策略类桌游。