VirTex: Learning Visual Representations from Textual Annotations
VirTex: 从文本标注中学习视觉表征
Karan Desai Justin Johnson University of Michigan kdexd,justincj @umich.edu
Karan Desai Justin Johnson 密歇根大学 kdexd,justincj @umich.edu
Abstract
摘要
The de-facto approach to many vision tasks is to start from pretrained visual representations, typically learned via supervised training on ImageNet. Recent methods have explored unsupervised pre training to scale to vast quantities of unlabeled images. In contrast, we aim to learn high-quality visual representations from fewer images. To this end we revisit supervised pre training, and seek dataefficient alternatives to classification-based pre training. We propose VirTex – a pre training approach using semantically dense captions to learn visual representations. We train convolutional networks from scratch on COCO Captions, and transfer them to downstream recognition tasks including image classification, object detection, and instance segmentation. On all tasks, VirTex yields features that match or exceed those learned on ImageNet – supervised or unsupervised – despite using up to ten times fewer images.
许多视觉任务的实际做法是从预训练的视觉表征开始,这些表征通常通过在ImageNet上进行监督训练学习得到。最近的方法探索了无监督预训练,以扩展到大量未标注图像。相比之下,我们的目标是从更少的图像中学习高质量的视觉表征。为此,我们重新审视了监督预训练,并寻找基于分类预训练的数据高效替代方案。我们提出了VirTex——一种使用语义密集的标注来学习视觉表征的预训练方法。我们在COCO Captions上从头开始训练卷积网络,并将它们迁移到下游识别任务,包括图像分类、目标检测和实例分割。在所有任务中,尽管使用的图像数量减少了十倍,VirTex生成的特征与在ImageNet上学习到的特征(无论是监督还是无监督)相当或更优。
1. Introduction
1. 引言
The prevailing paradigm for learning visual representations is first to pretrain a convolutional network [1, 2] to perform image classification on ImageNet [3, 4], then transfer the learned features to downstream tasks [5, 6]. This approach has been wildly successful, and has led to significant advances on a wide variety of computer vision problems such as object detection [7], semantic [8] and instance [9] segmentation, image captioning [10–12], and visual question answering [13, 14]. Despite its practical success, this approach is expensive to scale since the pre training step relies on images annotated by human workers.
学习视觉表征的主流范式是先在ImageNet [3, 4]上预训练卷积网络[1, 2]进行图像分类,然后将学习到的特征迁移到下游任务[5, 6]。这种方法取得了巨大成功,并在各类计算机视觉问题上实现了显著进展,例如目标检测[7]、语义分割[8]、实例分割[9]、图像描述生成[10–12]以及视觉问答[13, 14]。尽管实践效果显著,这种方法的扩展成本高昂,因为预训练步骤依赖于人工标注的图像。
For this reason, there has been increasing interest in unsupervised pre training methods that use unlabeled images to learn visual representations which are then transferred to downstream tasks [15–21]. Some recent approaches have begun to match or exceed supervised pre training on ImageNet [22–26], and have been scaled to hundreds of millions [22, 25, 27, 28] or billions [24] of images.
因此,利用无标注图像学习视觉表征的无监督预训练方法日益受到关注,这些表征随后可迁移至下游任务 [15–21]。近期一些方法已开始匹配甚至超越ImageNet上的监督式预训练效果 [22–26],并被扩展至数亿 [22, 25, 27, 28] 或数十亿 [24] 图像规模。
Continuing to scale unsupervised pre training to everlarger sets of unlabeled images is an important scientific goal. But we may also ask whether there are alternate ways of pre training that learn high-quality visual representations with fewer images. To do so, we revisit supervised pretraining and seek an alternative to traditional classification pre training that uses each image more efficiently.
持续扩大无监督预训练到更大规模的无标注图像集是一个重要的科学目标。但我们也需要探讨是否存在其他预训练方式,能够用更少的图像学习到高质量的视觉表征。为此,我们重新审视监督预训练,并寻找比传统分类预训练更高效利用每张图像的替代方案。

Figure 1: Learning visual features from language: First, we jointly train a ConvNet and Transformers using imagecaption pairs, for the task of image captioning (top). Then, we transfer the learned ConvNet to several downstream vision tasks, for example object detection (bottom).
图 1: 从语言中学习视觉特征:首先,我们使用图像-标题对联合训练一个卷积网络 (ConvNet) 和 Transformer,用于图像描述任务(上图)。然后,将学习到的卷积网络迁移到多个下游视觉任务中,例如目标检测(下图)。
In this paper we present an approach for learning Visual representations from Textual annotations (VirTex). Our approach is straightforward: first, we jointly train a ConvNet and Transformer [29] from scratch to generate natural language captions for images. Then, we transfer the learned features to downstream visual recognition tasks (Figure 1).
本文提出了一种从文本标注中学习视觉表示的方法(VirTex)。我们的方法简单直接:首先,我们从头开始联合训练一个卷积神经网络(ConvNet)和Transformer[29],为图像生成自然语言描述。然后,将学习到的特征迁移到下游视觉识别任务中(图1: )。
We believe that using language supervision is appealing due to its semantic density. Figure 2 compares different pretraining tasks for learning visual representations. Captions provide a semantically denser learning signal than unsupervised contrastive methods and supervised classification. Hence, we expect that using textual features to learn visual features may require fewer images than other approaches.
我们相信使用语言监督因其语义密度而具有吸引力。图 2: 比较了学习视觉表征的不同预训练任务。标题比无监督对比方法和有监督分类提供了语义更密集的学习信号。因此,我们预计使用文本特征学习视觉特征可能比其他方法需要更少的图像。
Another benefit of textual annotations is simplified data collection. To collect classification labels, typically human experts first build an ontology of categories [3, 4, 30, 31], then complex crowd sourcing pipelines are used to elicit labels from non-expert users [32, 33]. In contrast, natural language descriptions do not require an explicit ontology and can easily be written by non-expert workers, leading to a simplified data collection pipeline [34–36]. Large quantities of weakly aligned images and text can also be obtained from internet images [37–39].
文本标注的另一优势在于简化数据收集流程。传统分类标签收集需由人类专家先构建类别本体 (ontology) [3,4,30,31],再通过复杂的众包流程从非专业用户处获取标注 [32,33]。相比之下,自然语言描述既不需要明确定义的本体,也便于非专业人员撰写,从而简化数据收集流程 [34–36]。此外,大量弱对齐的图像文本数据可直接从网络图片中获取 [37–39]。
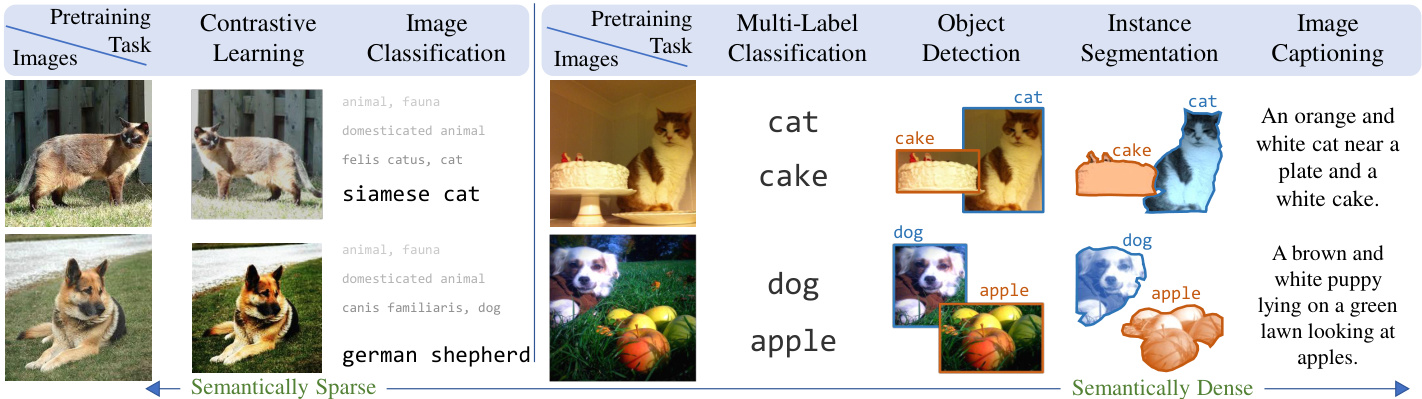
Figure 2: Comparison of pre training tasks for learning visual representations: Contrastive self-supervised learning methods provide a semantically sparse learning signal, encouraging different transforms of an image to have similar features. Image classification pairs an image with a single semantic concept, providing moderate semantic density. Multi-label classification, object detection, and instance segmentation increase semantic density by labeling and localizing multiple objects. Captions describe multiple objects, their attributes, relationships, and actions, giving a semantically dense learning signal. In this work, we aim to leverage this semantic density of captions to learn visual representations in a data-efficient manner.
图 2: 视觉表征学习的预训练任务对比:对比自监督学习方法提供语义稀疏的学习信号,鼓励图像的不同变换具有相似特征。图像分类将图像与单一语义概念配对,提供中等语义密度。多标签分类、目标检测和实例分割通过标记和定位多个对象来增加语义密度。描述文本则通过描述多个对象及其属性、关系和动作,提供语义密集的学习信号。本工作旨在利用描述文本的这种语义密度,以数据高效的方式学习视觉表征。
Our main contribution is to show that natural language can provide supervision for learning transferable visual representations with better data-efficiency than other approaches. We train models from scratch on the COCO Captions dataset [36], and evaluate the learned features on downstream tasks including image classification, object detection, instance segmentation, and low-shot recognition. On all tasks, VirTex matches or exceeds the performance of existing methods for supervised or unsupervised pretraining on ImageNet, despite using up to $10\times$ fewer images. Our code and pretrained models are available at https://github.com/kdexd/virtex
我们的主要贡献在于证明了自然语言能为学习可迁移的视觉表征提供监督信号,其数据效率优于其他方法。我们在COCO Captions数据集[36]上从头训练模型,并在图像分类、目标检测、实例分割和少样本识别等下游任务中评估所学特征。在所有任务中,VirTex匹配或超越了现有基于ImageNet有监督或无监督预训练方法的性能,且使用的图像数量最多减少10倍。代码和预训练模型已开源:https://github.com/kdexd/virtex
2. Related Work
2. 相关工作
Our work is related to recent efforts to move beyond supervised pre training on ImageNet using alternate data sources or pre training tasks.
我们的工作与最近利用替代数据源或预训练任务超越ImageNet监督式预训练的努力相关。
Weakly Supervised Learning scales beyond supervised pre training with a quantity over quality approach, and learns on large numbers of images with noisy labels from web services. Li et al. [40] trains visual N-gram models on the YFCC-100M dataset [41], that provides 100M Flickr images with user-provided tags. Recent works [42–44] also use JFT-300M [42] dataset, curated by automatic labeling of images from web signals using Google’s internal tooling. Weakly-supervised learning has also been studied on up to 3.5B Instagram images, using hashtags as labels [45, 46]. These approaches learn visual representations with large quantities of images with low-quality labels; in contrast we focus on using fewer images with high-quality annotations. Self-Supervised Learning focuses on learning visual represent at ions by solving pretext tasks defined on unlabeled images. Early works on self-supervised learning proposed hand-crafted pretext tasks, such as context prediction [15], color iz ation [17, 18], solving jigsaw puzzles [47], predicting rotation [19], inpainting [16], clustering [27], and generative modeling [48]. Recent works are based on contrastive learning [49, 50], encouraging similarity between image features under different random transformations on single input image [24–26, 51, 52]. Other approaches use contrastive losses based on context prediction [20, 23], mutual information maximization [21, 53, 54], predicting masked regions [55], and clustering [56–58].
弱监督学习 (Weakly Supervised Learning) 采用数量优先于质量的策略,突破了监督预训练的规模限制,通过从网络服务获取带有噪声标签的海量图像进行学习。Li等人[40]在YFCC-100M数据集[41]上训练视觉N-gram模型,该数据集包含1亿张带有用户标注标签的Flickr图片。近期研究[42–44]也使用JFT-300M[42]数据集,该数据集通过Google内部工具基于网络信号自动标注图像。弱监督学习的研究还扩展到35亿张Instagram图片,使用话题标签作为标注[45,46]。这些方法通过大量低质量标注图像学习视觉表征;相比之下,我们专注于使用少量高质量标注图像。
自监督学习 (Self-Supervised Learning) 通过定义在无标注图像上的代理任务来学习视觉表征。早期自监督学习研究提出了手工设计的代理任务,包括上下文预测[15]、着色[17,18]、拼图求解[47]、旋转预测[19]、图像修复[16]、聚类[27]和生成建模[48]。近期研究基于对比学习[49,50],通过单张输入图像的不同随机变换来增强图像特征的相似性[24–26,51,52]。其他方法采用基于上下文预测[20,23]、互信息最大化[21,53,54]、掩码区域预测[55]和聚类[56–58]的对比损失函数。
These methods lack semantic understanding as they rely on low-level visual cues (color, texture), whereas we leverage textual annotations for semantic understanding. Unlike these methods, our approach can leverage additional metadata such as text, when scaled to internet images [37–39].
这些方法缺乏语义理解,因为它们依赖于低层次的视觉线索(颜色、纹理),而我们利用文本注释来实现语义理解。与这些方法不同,我们的方法在扩展到互联网图像时能够利用文本等额外元数据 [37–39]。
Vision-and-Language Pre training attempts to learn joint representations of image-text paired data that can be transferred to multimodal downstream tasks such as visual question answering [13, 14, 59, 60], visual reasoning [61, 62], referring expressions [63], and language-based image retrieval [35]. Inspired by the success of BERT [64] in NLP, several recent methods use Transformers [29] to learn transferable joint representations of images and text [65–72].
视觉与语言预训练旨在学习图像-文本配对数据的联合表征,这些表征可迁移至多模态下游任务,例如视觉问答 [13, 14, 59, 60]、视觉推理 [61, 62]、指代表达 [63] 以及基于语言的图像检索 [35]。受 BERT [64] 在自然语言处理领域成功的启发,近期多种方法采用 Transformer [29] 来学习图像与文本的可迁移联合表征 [65–72]。
These methods employ complex pre training pipelines: they typically (1) start from an ImageNet-pretrained CNN; (2) extract region features using an object detector finetuned on Visual Genome [73], following [74]; (3) optionally start from a pretrained language model, such as BERT [64]; (4) combine the models from (2) and (3), and train a multimodal transformer on Conceptual Captions [37]; (5) fine-tune the model from (4) on the downstream task. In this pipeline, all vision-and-language tasks are downstream from the initial visual representations learned on ImageNet.
这些方法采用复杂的预训练流程:通常(1) 从ImageNet预训练的CNN开始;(2) 按照[74]的方法,使用在Visual Genome [73]上微调过的物体检测器提取区域特征;(3) 可选地从预训练的语言模型(如BERT [64])开始;(4) 结合(2)和(3)的模型,在Conceptual Captions [37]上训练一个多模态Transformer;(5) 在下游任务上对(4)的模型进行微调。在该流程中,所有视觉与语言任务都基于从ImageNet学到的初始视觉表示。
In contrast, we pretrain via image captioning, and put vision tasks downstream from vision-and-language pre training.
相比之下,我们通过图像描述进行预训练,并将视觉任务置于视觉与语言预训练的下游。
Concurrent Work: Our work is closest to Sariyildiz et al. [75] on learning visual representations from captions via image conditioned masked language modeling, with one major difference – we train our entire model from scratch, whereas they rely on pretrained BERT for textual features. Moreover, we evaluate on additional downstream tasks like object detection and instance segmentation. Our work is also closely related to Stroud et al. [76] on learning video representations using paired textual metadata, however they solely operate and evaluate their method on video tasks.
同期工作:我们的研究与Sariyildiz等人[75]最为接近,他们通过图像条件掩码语言建模从标题中学习视觉表征,但存在一个主要差异——我们从零开始训练整个模型,而他们依赖预训练的BERT获取文本特征。此外,我们还在目标检测和实例分割等下游任务上进行了评估。我们的工作也与Stroud等人[76]密切相关,他们利用配对的文本元数据学习视频表征,但仅针对视频任务进行操作和评估。
3. Method
3. 方法
Given a dataset of image-caption pairs, our goal is to learn visual representations that can be transferred to downstream visual recognition tasks. As shown in Figure 2, captions carry rich semantic information about images, including the presence of objects (cat, plate, cake); attributes of objects (orange and white cat); spatial arrangement of objects (cat near a plate); and their actions (looking at apples). Learned visual representations that capture such rich semantics should be useful for many downstream vision tasks.
给定一个图像-标题配对的数据集,我们的目标是学习可迁移至下游视觉识别任务的视觉表征。如图 2 所示,标题承载了关于图像的丰富语义信息,包括物体的存在(猫、盘子、蛋糕);物体的属性(橙白相间的猫);物体的空间排列(猫靠近盘子);以及它们的动作(看着苹果)。学习到能捕捉此类丰富语义的视觉表征,应当对许多下游视觉任务有所帮助。
To this end, we train image captioning models to predict captions from images. As shown in Figure 3, our model has two components: a visual backbone and a textual head. The visual backbone extracts visual features from an input image $I$ . The textual head accepts these features and predicts a caption $C=(c_{0},c_{1},\dots,c_{T},c_{T+1})$ token by token, where $c_{0}=[\mathsf{S}0\mathsf{S}]$ and $c_{T+1}=[\mathsf{E}0\mathsf{S}]$ are fixed special tokens indicating the start and end of sentence. The textual head performs bidirectional captioning (bi captioning): it comprises a forward model that predicts tokens left-to-right, and a backward model that predicts right-to-left. All model components are randomly initialized, and jointly trained to maximize the log-likelihood of the correct caption tokens
为此,我们训练了图像描述生成模型来从图像预测描述文本。如图 3 所示,我们的模型包含两个组件:视觉主干网络和文本头部网络。视觉主干网络从输入图像 $I$ 中提取视觉特征。文本头部网络接收这些特征并逐个 token 预测描述文本 $C=(c_{0},c_{1},\dots,c_{T},c_{T+1})$ ,其中 $c_{0}=[\mathsf{S}0\mathsf{S}]$ 和 $c_{T+1}=[\mathsf{E}0\mathsf{S}]$ 是表示句子开始与结束的固定特殊 token。文本头部网络执行双向描述生成(bi captioning):包含从左到右预测 token 的前向模型,以及从右到左预测的反向模型。所有模型组件均为随机初始化,并通过联合训练最大化正确描述文本 token 的对数似然。
$$
\begin{array}{r}{\mathcal{L}(\boldsymbol{\theta},\boldsymbol{\phi})=\displaystyle\sum_{t=1}^{T+1}\log\Big(p(c_{t}\mid c_{0:t-1},I;\phi_{f},\boldsymbol{\theta})\Big)}\ {+\displaystyle\sum_{t=0}^{T}\log\Big(p(c_{t}\mid c_{t+1:T+1},I;\phi_{b},\boldsymbol{\theta})\Big)}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}(\boldsymbol{\theta},\boldsymbol{\phi})=\displaystyle\sum_{t=1}^{T+1}\log\Big(p(c_{t}\mid c_{0:t-1},I;\phi_{f},\boldsymbol{\theta})\Big)}\ {+\displaystyle\sum_{t=0}^{T}\log\Big(p(c_{t}\mid c_{t+1:T+1},I;\phi_{b},\boldsymbol{\theta})\Big)}\end{array}
$$
where $\theta,\phi_{f}$ , and $\phi_{b}$ are the parameters of the visual back- bone, forward, and backward models respectively. After training, we discard the textual head and transfer the visual backbone to downstream visual recognition tasks.
其中$\theta,\phi_{f}$和$\phi_{b}$分别是视觉主干网络、前向模型和后向模型的参数。训练完成后,我们会丢弃文本头模块,并将视觉主干网络迁移至下游视觉识别任务。
Language Modeling: Our choice of pre training task is image captioning [10–12] – a well-studied vision-andlanguage task, so far kept downstream from vision-based pre training. We draw inspiration from recent work in NLP using language modeling as a pre training task to learn transferable text representations. This involves training massive language models – either unidirectional [77] or bidirectional [78–81], for predicting tokens one by one. However, following BERT [64], many large-scale models [82, 83] instead use masked language models (MLMs): some tokens are randomly masked and are predicted by the model.
语言建模:我们选择的预训练任务是图像描述生成 [10-12] —— 这是一个经过充分研究的视觉与语言任务,此前一直作为基于视觉的预训练的下游任务。我们从自然语言处理领域的最新工作中获得灵感,这些工作使用语言建模作为预训练任务来学习可迁移的文本表示。这涉及训练大规模语言模型 —— 无论是单向 [77] 还是双向 [78-81],用于逐个预测 token。然而,继 BERT [64] 之后,许多大规模模型 [82, 83] 转而使用掩码语言模型 (MLM):随机掩码部分 token 并由模型进行预测。
We performed preliminary experiments with MLMs, but like [64, 84] we observed that MLMs converge more slowly than directional models. We note that MLMs have poor sample efficiency, as they only predict a subset of tokens for each caption, while directional models predict all tokens. Due to computational constraints, we focus on directional models and leave MLMs to future work.
我们使用MLM(掩码语言模型)进行了初步实验,但和[64, 84]一样观察到MLM的收敛速度比定向模型慢。我们注意到MLM样本效率较低,因为它们只为每个标注预测部分token,而定向模型会预测所有token。由于计算资源限制,我们主要研究定向模型,将MLM留作未来工作。
Visual Backbone: The visual backbone is a convolutional network which computes visual features of images. It inputs raw image pixels, and outputs a spatial grid of image features. During pre training, these features are used to predict captions. In downstream tasks, we either train linear models on features extracted from the visual backbone, or fine-tune the visual backbone end-to-end.
视觉主干网络 (Visual Backbone):视觉主干网络是一个卷积网络,用于计算图像的视觉特征。它输入原始图像像素,输出图像特征的空间网格。在预训练阶段,这些特征用于预测描述文本。在下游任务中,我们既可以在视觉主干网络提取的特征上训练线性模型,也可以对视觉主干网络进行端到端微调。
In principle we could use any convolutional network architecture for the visual backbone. In our experiments we use a standard ResNet-50 [2] as the visual backbone to facilitate comparison with our baseline methods (Section 4). It accepts a $224\times224$ image and produces a $7\times7$ grid of 2048-dimensional features after the final convolutional layer. During pre training, we apply a linear projection layer to the visual features before passing them to the textual head to facilitate decoder attention over visual features. This projection layer is not used in downstream tasks.
原则上,我们可以使用任何卷积网络架构作为视觉主干。在实验中,为了便于与基线方法进行比较(第4节),我们采用标准的ResNet-50 [2]作为视觉主干。该网络接收$224\times224$尺寸的图像,并在最终卷积层后输出一个$7\times7$的2048维特征网格。在预训练阶段,我们会先对视觉特征应用线性投影层,再将其传递给文本头部,以便解码器能更好地关注视觉特征。该投影层在下游任务中不会被使用。
Textual Head: The textual head receives features from the visual backbone and predicts captions for images. It provides a learning signal to the visual backbone during pretraining. Our overall goal is not to predict high-quality captions, but instead to learn transferable visual features.
文本头:文本头接收来自视觉主干网络的特征,并为图像预测描述文本。在预训练过程中,它为视觉主干网络提供学习信号。我们的总体目标并非预测高质量描述文本,而是学习可迁移的视觉特征。
The textual head comprises two identical language models which predict captions in forward and backward di- rections respectively. Following recent advances in language modeling, we use Transformers [29], which use multiheaded self-attention both to propagate information along the sequence of caption tokens, as well as to fuse visual and textual features. We closely follow the transformer decoder architecture from [29], but use GELU [85] rather than ReLU, following [64, 79]. We briefly review the architecture here; refer to [29] for a more complete description.
文本头部由两个相同的语言模型组成,分别用于正向和反向预测描述文本。基于语言建模领域的最新进展,我们采用Transformer架构[29],该架构通过多头自注意力机制在描述文本token序列中传播信息,同时融合视觉与文本特征。我们严格遵循[29]提出的Transformer解码器架构,但根据[64,79]的研究改用GELU[85]激活函数替代ReLU。以下简要回顾该架构细节,完整说明请参阅[29]。
During training, the forward model receives two inputs: image features from the visual backbone, and a caption describing the image. Image features are a matrix of shape $N_{I}\times D_{I}$ giving a $D_{I}$ -dimensional vector for each of the $N_{I}=7~\times7$ positions in the final layer of the visual backbone. As described earlier, the caption $C=$ $(c_{0},c_{1},\dots,c_{T},c_{T+1})$ is a sequence of $T+2$ tokens, with $c_{0}=~[\mathsf{S0S}]$ and $c_{T+1}=[\mathsf{E}0\mathsf{S}]$ . It is trained to predict $C_{1:T+1}$ token-by-token, starting with $c_{0}$ . The prediction $c_{t}$ is causal – it only depends on past predictions $c_{0:t-1}$ and visual features. The backward model is similar; it operates right-to-left – trained to predict $C_{T:0}$ , given $c_{T+1}$ .
训练过程中,前向模型接收两个输入:视觉主干网络提取的图像特征矩阵(形状为 $N_{I}\times D_{I}$ ,对应视觉主干最后一层 $N_{I}=7~\times7$ 个位置的 $D_{I}$ 维向量)和描述图像的文本标注 $C=$ $(c_{0},c_{1},\dots,c_{T},c_{T+1})$ 。该标注序列包含 $T+2$ 个token,其中 $c_{0}=~[\mathsf{S0S}]$ 为起始符, $c_{T+1}=[\mathsf{E}0\mathsf{S}]$ 为终止符。模型以 $c_{0}$ 为起点逐token预测 $C_{1:T+1}$ ,当前预测 $c_{t}$ 仅依赖历史预测 $c_{0:t-1}$ 和视觉特征。后向模型结构类似但反向运作(从右至左),在给定 $c_{T+1}$ 的条件下预测 $C_{T:0}$ 。

Figure 3: VirTex pre training setup: Our model consists of a visual backbone (ResNet-50), and a textual head (two unidirectional Transformers). The visual backbone extracts image features, and textual head predicts captions via bidirectional language modeling (bi captioning). The Transformers perform masked multi headed self-attention over caption features, and multi headed attention over image features. Our model is trained end-to-end from scratch. After pre training, the visual backbone is transferred to downstream visual recognition tasks.
图 3: VirTex预训练框架: 我们的模型由视觉主干网络(ResNet-50)和文本头部网络(两个单向Transformer)组成。视觉主干网络提取图像特征,文本头部网络通过双向语言建模(双字幕生成)预测描述文本。Transformer对字幕特征执行掩码多头自注意力机制,并对图像特征进行多头注意力计算。该模型采用端到端方式从头训练。预训练完成后,视觉主干网络可迁移至下游视觉识别任务。
First, we convert the tokens of $C$ to vectors via learned token and positional embeddings, followed by element wise sum, layer normalization [86] and dropout [87]. Next, we process these vectors through a sequence of Transformer layers. As shown in Figure 3, each layer performs masked multi headed self-attention over token vectors, multi headed attention between token vectors and image vectors, and applies a two-layer fully-connected network to each vector. These three operations are each followed by dropout, wrapped in a residual connection, and followed by layer normalization. Token vectors interact only through selfattention; the masking in this operation maintains causal structure of the final predictions. After the last Transformer layer, we apply a linear layer to each vector to predict unnormalized log-probabilities over the token vocabulary.
首先,我们将 $C$ 的 token 通过学习的 token 和位置嵌入转换为向量,随后进行逐元素求和、层归一化 [86] 和 dropout [87]。接着,我们通过一系列 Transformer 层处理这些向量。如图 3 所示,每层对 token 向量执行掩码多头自注意力、token 向量与图像向量之间的多头注意力,并对每个向量应用一个两层的全连接网络。这三个操作各自后接 dropout,包裹在残差连接中,并跟随层归一化。token 向量仅通过自注意力交互;该操作中的掩码保持了最终预测的因果结构。在最后一个 Transformer 层之后,我们对每个向量应用线性层以预测 token 词汇表上的非归一化对数概率。
The forward and backward models consist of independent Transformer layers. However they share the same token embedding matrix (similar to [77]) which is also reused at the output layers of each model (similar to [88, 89]).
前向和后向模型由独立的Transformer层组成。但它们共享相同的token嵌入矩阵(类似于[77]),该矩阵也在每个模型的输出层重复使用(类似于[88, 89])。
Model Size: Several architectural hyper parameters control the size of our textual head. We can control the width of each Transformer layer by varying its hidden size $H$ , the number of attention heads $A$ used in multi headed attention, and the feed forward size $F$ of the fully-connected network. We follow [64] and always set $A=H/64$ and $F=4H$ ; this allows us to control the width of our textual head by varying $H$ . We can also control the depth of our textual head by varying the number of transformer layers $L$ .
模型大小:多个架构超参数控制着文本头的大小。我们可以通过调整每个Transformer层的隐藏大小$H$、多头注意力中使用的注意力头数量$A$,以及全连接网络的前馈大小$F$来控制其宽度。遵循[64]的做法,我们始终设置$A=H/64$和$F=4H$;这使得我们能够通过调整$H$来控制文本头的宽度。此外,我们还可以通过改变Transformer层的数量$L$来控制文本头的深度。
Token iz ation: We tokenize captions with SentencePiece [90] using the BPE algorithm [91]. Prior to tokenization we lowercase and strip accents from captions. We build a vocabulary of 10K tokens, including boundary ([SOS], [EOS]) and out-of-vocab ([UNK]) tokens. Following [79, 80] we restrict subword merges between letters and punctuation to prevent redundant tokens such as dog? and dog!. Compared to basic token iz ation schemes often used for image captioning that split on whitespace [10, 11], BPE makes fewer linguistic assumptions, exploits subword information, and results in fewer out-of-vocab tokens.
Token化处理:我们使用SentencePiece [90]和BPE算法 [91]对字幕进行Token化。在Token化之前,我们会将字幕转为小写并去除重音符号。我们构建了一个包含1万个Token的词汇表,其中包括边界Token([SOS]、[EOS])和未登录词Token([UNK])。参照[79, 80]的做法,我们限制了字母与标点符号之间的子词合并,以避免产生冗余Token(例如dog?和dog!)。与常用于图像字幕处理的基本Token化方案(基于空格分割 [10, 11])相比,BPE对语言假设的要求更低,能更好地利用子词信息,并减少未登录词Token的数量。
Training Details: We train on the train2017 split of the COCO Captions dataset [36], which provides $118K$ images with five captions each. During training we apply standard data augmentation: we randomly crop to $20–100%$ of the original image size, apply color jitter (brightness, contrast, saturation, hue), and normalize using the ImageNet mean color. We also apply random horizontal flips, also interchanging the words ‘left’ and ‘right’ in the caption.
训练细节:我们在COCO Captions数据集[36]的train2017分割上进行训练,该数据集提供11.8万张图像,每张图像配有5条标注。训练时采用标准数据增强方法:随机裁剪原始图像尺寸的20%–100%,应用色彩抖动(亮度、对比度、饱和度、色调),并使用ImageNet均值颜色进行归一化。同时实施随机水平翻转,并在标注中互换"左"和"右"的表述。
We train using SGD with momentum 0.9 [92, 93] and weight decay $10^{-4}$ wrapped in LookAhead [94] with $\alpha=$ 0.5 and 5 steps. Following [64], we do not apply weight decay to layer normalization and bias parameters in Transformers. We perform distributed training across 8 GPUs with batch normalization [95] per GPU, following [22]. We train with a batch size of 256 images (32 per GPU) for 500K iterations $\mathord{\approx}1080$ epochs). We use linear learning rate warmup [22] for the first 10K iterations followed by cosine decay [96] to zero. We found that the visual backbone required a higher LR than the textual head for faster convergence. The visual backbone uses a max LR of $2\times10^{-1}$ ; the textual head uses $10^{-3}$ . We implement our models using PyTorch [97] with native automatic mixed-precision [98].
我们使用带动量(momentum)0.9[92,93]和权重衰减(weight decay)$10^{-4}$的SGD进行训练,并采用LookAhead[94]包装器(参数$\alpha=$0.5,步数5)。参照[64],我们不对Transformer中的层归一化(layer normalization)和偏置(bias)参数应用权重衰减。按照[22]的方法,我们在8块GPU上采用每GPU批量归一化(batch normalization)[95]进行分布式训练。训练批大小为256张图像(每GPU 32张),共进行500K次迭代($\mathord{\approx}1080$个周期)。前10K次迭代使用线性学习率预热(warmup)[22],随后采用余弦衰减(cosine decay)[96]降至零。我们发现视觉主干网络需要比文本头部更高的学习率以实现更快收敛:视觉主干最大学习率为$2\times10^{-1}$,文本头部为$10^{-3}$。我们使用PyTorch[97]框架及其原生自动混合精度(automatic mixed-precision)[98]实现模型。
We observe that performance on image captioning has a positive but imprecise correlation with performance on downstream visual recognition tasks (Refer Appendix A.4). We thus perform early stopping based on the performance of our visual backbone on downstream PASCAL VOC [99] linear classification (see Section 4.1) since it is fast to evaluate and correlates well with our other downstream tasks.
我们观察到,图像描述(Image Captioning)性能与下游视觉识别任务性能呈正相关但不够精确(参考附录A.4)。因此我们基于视觉主干网络在下游PASCAL VOC [99]线性分类任务(见第4.1节)的表现进行早停(Early Stopping),因为该评估速度快且与其他下游任务相关性良好。
| Method | Annotations | Cost (hours)↑ | VOC07 | IN-1k |
| MoCo-COCO | self-sup. | 63.3 | 41.1 | |
| Multi-labelClf | labels | 11.1K [30] | 86.2 | 46.2 |
| InstanceSegmentation | masks | 30.0K [30] | 82.3 | 51.0 |
| VirTex(1 caption) | captions | 1.3K [100] | 84.2 | 50.2 |
| VirTex(5caption) | captions | 6.5K [100] | 88.7 | 53.8 |
| 方法 | 标注类型 | 成本 (小时)↑ | VOC07 | IN-1k |
|---|---|---|---|---|
| MoCo-COCO | 自监督 (self-sup.) | 63.3 | 41.1 | |
| Multi-labelClf | 标签 (labels) | 11.1K [30] | 86.2 | 46.2 |
| InstanceSegmentation | 掩码 (masks) | 30.0K [30] | 82.3 | 51.0 |
| VirTex(1 caption) | 描述文本 (captions) | 1.3K [100] | 84.2 | 50.2 |
| VirTex(5caption) | 描述文本 (captions) | 6.5K [100] | 88.7 | 53.8 |
Table 1: Annotation Cost Efficiency: We compare downstream performance of various pre training methods on COCO. VirTex outperforms all other methods trained on the same set of images with best performance vs. cost tradeoff. †: For COCO train2017 split, see Appendix A.1 for more details.
表 1: 标注成本效率: 我们在 COCO 数据集上比较了各种预训练方法的下游性能。VirTex 在相同图像集上训练的所有其他方法中表现最优,实现了最佳性能与成本平衡。†: 关于 COCO train2017 分割的详细信息,请参阅附录 A.1。
4. Experiments
4. 实验
In our experiments, we aim to demonstrate the effectiveness of learning visual features via natural language supervision. As described in Section 3, we jointly train a VirTex model from scratch on the COCO Captions [36] dataset. Here, we evaluate the features learned by visual backbone on six downstream vision tasks. We select these tasks based on two common mechanisms for transfer learning: where the visual backbone is either used as (a) frozen feature extractor, or (b) weight initialization for fine-tuning.
在我们的实验中,旨在验证通过自然语言监督学习视觉特征的有效性。如第3节所述,我们在COCO Captions [36]数据集上从头开始联合训练VirTex模型。此处评估视觉主干网络在六项下游视觉任务中学到的特征。这些任务根据两种常见的迁移学习机制选定:(a) 作为冻结特征提取器使用,或 (b) 作为微调的权重初始化。
4.1. Image Classification with Linear Models
4.1. 基于线性模型的图像分类
Our first set of evaluations involve training linear models on frozen visual backbones – we compare VirTex with various pre training methods to test our two hypotheses:
我们首先在冻结的视觉骨干网络上训练线性模型进行评估——将VirTex与各种预训练方法进行对比,以验证以下两个假设:
- Learning visual features via captions is cheaper than using other types of annotations, like labels and masks. 2. Using semantically dense captions helps with learning effective visual features using fewer training images.
- 通过标题学习视觉特征比使用标签和掩码等其他类型的标注更经济。
- 使用语义密集的标题有助于用更少的训练图像学习有效的视觉特征。
We evaluate on two datasets: PASCAL VOC [99] and ImageNet-1k [4]. We choose these tasks based on their simplicity and evaluation speed. We briefly describe the setup here. Refer Appendix A.1 for more details.
我们在两个数据集上进行评估:PASCAL VOC [99] 和 ImageNet-1k [4]。选择这些任务是基于其简单性和评估速度。此处简要描述实验设置,更多细节请参阅附录 A.1。
PASCAL VOC: We follow same protocol as SwAV [58] (highly similar to [22, 25]); we train on VOC07 trainval split (9K images, 20 classes) and report mAP on test split. We train per-class SVMs on 2048-dimensional global average pooled features extracted from the last layer of the visual backbone. For each class, we train SVMs for cost values $C\in{0.01,0.1,1,10}$ and select best $C$ by 3-fold cross- validation. Other SVM hyper parameters are same as [22].
PASCAL VOC: 我们遵循与SwAV [58]相同的协议(与[22,25]高度相似),在VOC07训练验证集(9K张图像,20个类别)上训练,并在测试集上报告mAP。我们从视觉主干网络的最后一层提取2048维全局平均池化特征,训练每类SVM。对每个类别,我们为成本值$C\in{0.01,0.1,1,10}$训练SVM,并通过3折交叉验证选择最佳$C$值。其他SVM超参数与[22]相同。
ImageNet-1k: We follow similar protocol as MoCo [24] and SwAV [58]: we train on the ILSVRC 2012 train split and report top-1 accuracy on val split. We train a linear classifier (fully connected layer $^+$ softmax) on 2048- dimensional global average pooled features extracted from the last layer of the visual backbone. We train with batch size 256 distributed across 8 GPUs for 100 epochs. We use SGD with momentum 0.9 and weight decay 0. We set the initial LR to 0.3 and decay it to zero by cosine schedule.
ImageNet-1k:我们采用与MoCo [24]和SwAV [58]相似的协议:在ILSVRC 2012训练集上进行训练,并在验证集上报告top-1准确率。我们在视觉主干网络最后一层提取的2048维全局平均池化特征上训练线性分类器(全连接层 $^+$ softmax)。训练时使用分布在8块GPU上的256批量大小,共100个周期。采用动量0.9、权重衰减0的SGD优化器,初始学习率设为0.3并按余弦调度衰减至零。

PASCAL VOC Linear Clf. (mAP)
PASCAL VOC 线性分类器 (mAP)

ImageNet-1k Linear Clf. (Top-1 Acc.) Figure 4: Data Efficiency: We compare VirTex and INsup models trained using varying amounts of images. VirTex closely matches or significantly outperforms IN-sup on downstream tasks despite using $10\times$ fewer images. IN-1k: Models using $\leq10^{5}$ images are mean of 5 trials, std dev. $\leq1.0$ .
图 4: 数据效率对比:我们比较了使用不同数量图像训练的VirTex和INsup模型。尽管VirTex使用的图像数量少10倍,但在下游任务中仍能接近或显著超越IN-sup。IN-1k:使用≤10^5图像的模型为5次试验均值,标准差≤1.0。
Annotation Cost Efficiency: We believe that using captions is appealing due to a simple and cost-efficient collection pipeline. Here, we test our first hypothesis by comparing various pre training methods on COCO, each drawing supervision from different annotation types (Figure 2):
标注成本效益:我们相信使用标题因其简单高效的收集流程而具有吸引力。此处通过在COCO数据集上比较不同预训练方法(每种方法采用不同标注类型作为监督信号)来验证第一个假设(图2):
– MoCo-COCO (self-supervised): We train a MoCo-v1 model on COCO images with default hyper parameters. – Multi-label Classification (labels): We use COCO object detection annotations (80 classes), and train a ResNet-50 backbone to predict a $K$ -hot vector with values $1/K$ with a KL-divergence loss, similar to [45]. – Instance Segmentation (masks): We use a pretrained Mask R-CNN from Detectron2 model zoo [101], and extract its ResNet-50 backbone for downstream tasks. This model is trained from scratch on COCO, following [102]. – VirTex (captions): We train a VirTex model on COCO Captions, with ResNet-50 visual backbone and $L=$ $1,H=2048$ textual head. Note that COCO Captions provides five captions per image, which effectively increases image-caption pairs by five-fold. Hence for a fair comparison, we also train an additional VirTex model using only one randomly selected caption per image.
– MoCo-COCO (自监督): 我们在COCO图像上使用默认超参数训练MoCo-v1模型。
– 多标签分类 (标签): 使用COCO目标检测标注(80个类别),训练ResNet-50骨干网络以KL散度损失预测值为$1/K$的$K$-hot向量,方法类似[45]。
– 实例分割 (掩码): 采用Detectron2模型库[101]的预训练Mask R-CNN,提取其ResNet-50骨干网络用于下游任务。该模型遵循[102]在COCO上从头训练。
– VirTex (描述文本): 我们在COCO Captions上训练VirTex模型,视觉骨干为ResNet-50,文本头参数$L=1$,$H=2048$。需注意COCO Captions每图提供5条描述文本,实际将图文对数量扩大五倍。为公平对比,我们额外训练仅使用每图随机单条描述的VirTex模型。
Results are shown in Table 1. We also compare annotation costs in terms of worker hours. For labels and masks, we use estimates reported by COCO [30]. For captions, we estimate the cost based on nocaps [100] 1, that follows a similar data collection protocol as COCO. We observe that VirTex outperforms all methods, and has the best performance vs. cost tradeoff, indicating that learning visual features using captions is more cost-efficient than labels or masks.
结果如表 1 所示。我们还以工时为单位比较了标注成本。对于标签和掩码,我们使用 COCO [30] 报告的估算值。对于描述文本,我们基于 nocaps [100] 1 进行成本估算,其数据收集流程与 COCO 类似。我们发现 VirTex 优于所有方法,且具有最佳的性价比,这表明使用描述文本来学习视觉特征比使用标签或掩码更具成本效益。
Data Efficiency: We believe that the semantic density of captions should allow VirTex to learn effective visual features from fewer images than other methods. To test our hypothesis, we compare VirTex and ImageNet-supervised models (IN-sup) trained using varying amount of images from COCO Captions and ImageNet-1k respectively.
数据效率:我们认为标题的语义密度应使VirTex能够比其他方法用更少的图像学习有效的视觉特征。为验证这一假设,我们比较了分别使用COCO Captions和ImageNet-1k中不同数量图像训练的VirTex与ImageNet监督模型(IN-sup)。
We train 4 VirTex models using ${10,20,50,100}%$ of COCO Captions (118K images) and 7 ResNet-50 models using ${1,2,5,10,20,50,100}%$ of ImageNet-1k (1.28M images). Similar to prior experiments, we also train 4 VirTex models using one randomly selected caption per image. All VirTex models use $L=1,H=2048$ textual heads.
我们使用 COCO Captions (11.8万张图像) 的 ${10,20,50,100}%$ 数据训练了4个VirTex模型,并使用 ImageNet-1k (128万张图像) 的 ${1,2,5,10,20,50,100}%$ 数据训练了7个ResNet-50模型。与先前实验类似,我们还为每张图像随机选择一个标题训练了4个VirTex模型。所有VirTex模型均采用 $L=1,H=2048$ 的文本头配置。
Table 2: Comparison with other methods: We compare downstream performance of VirTex with recent SSL methods and concurrent work. $^{\dagger}\cdot$ : Uses pretrained BERT-base.
| Method | Pretrain Images Annotations VOC07 | IN-1k | ||
| MoCo-IN v1 [24] | 1.28M | self-sup. | 79.4 | 60.8 |
| PCLv1[57] | 1.28M | self-sup. | 83.1 | 61.5 |
| SwAV (200 ep.)[58] | 1.28M | self-sup. | 87.9 | 72.7 |
| ICMLMatt-fc [75] t | 118K | captions | 87.5 | 47.9 |
| VirTex | 118K | captions | 88.7 | 53.8 |
表 2: 与其他方法的比较:我们将VirTex与近期自监督学习方法及同期工作进行下游性能对比。$^{\dagger}\cdot$:使用了预训练的BERT-base。
| 方法 | 预训练图像标注 VOC07 | IN-1k | ||
|---|---|---|---|---|
| MoCo-IN v1 [24] | 1.28M | 自监督 | 79.4 | 60.8 |
| PCLv1 [57] | 1.28M | 自监督 | 83.1 | 61.5 |
| SwAV (200 ep.) [58] | 1.28M | 自监督 | 87.9 | 72.7 |
| ICMLMatt-fc [75] t | 118K | 描述文本 | 87.5 | 47.9 |
| VirTex | 118K | 描述文本 | 88.7 | 53.8 |
We show results in Figure 4. On VOC07, VirTex-100% outperforms IN-sup-100% (mAP 88.7 vs 87.6), despite using $10\times$ fewer images (118K vs. 1.28M). When using similar amount of images, VirTex consistently outperforms INsup (blue, orange vs green), indicating superior data efficiency of VirTex. We also observe that given the same number of captions for training, it is better to spread them over more images – VirTex-50% (1 caption) significantly outperforms VirTex-10% (5 captions) (mAP 79.4 vs 69.3).
我们在图 4 中展示了结果。在 VOC07 数据集上,VirTex-100% 的表现优于 IN-sup-100% (mAP 88.7 vs 87.6),尽管使用的图像数量少了 $10\times$ (118K vs. 1.28M)。当使用相似数量的图像时,VirTex 始终优于 IN-sup (蓝色、橙色 vs 绿色),表明 VirTex 具有更优的数据效率。我们还观察到,在给定相同数量训练文本描述的情况下,将其分散到更多图像上效果更好——VirTex-50% (1 条描述)显著优于 VirTex-10% (5 条描述) (mAP 79.4 vs 69.3)。
Comparison with IN-sup on ImageNet-1k classification is unfair for VirTex, since IN-sup models are trained for the downstream task, using the downstream dataset. Even so, VirTex $100%$ outperforms IN-sup $10%$ (53.8 vs. 53.6, 118K vs. 128K images), and consistently outperforms it when both methods use fewer than 100K images.
在ImageNet-1k分类任务中与IN-sup进行比较对VirTex不公平,因为IN-sup模型是使用下游数据集为下游任务训练的。即便如此,VirTex $100%$ 的表现仍优于IN-sup $10%$ (53.8 vs. 53.6, 118K vs. 128K图像),且当两种方法使用的图像少于100K时,VirTex始终表现更优。
Comparison with other methods: Here, we compare VirTex with recent pre training methods that have demonstrated competitive performance on downstream tasks.
与其他方法的比较:在此,我们将VirTex与近期在下游任务中表现出竞争力的预训练方法进行对比。
– Self-supervised pre training: We choose three recent methods based on their availability and compatibility with our evaluation setup – MoCo [24], PCL [57], and SwAV [58]. We choose models trained with a similar compute budget as ours (8 GPUs, 200 ImageNet epochs). – ICMLM (Concurrent Work): We adapt numbers from Sariyildiz et al. [75]; evaluation may slightly differ. This model uses pretrained BERT [64] for textual features. – Note on vision-and-language pre training: Since we use captions, we also consider methods that learn multimodal representations for downstream vision-andlanguage tasks [65–72]). As described in Section 2, all these methods use an object detector trained on Visual Genome [73] (with ImageNet-pretrained backbone) to extract visual features, made available by [74]. These features are kept frozen, and do not learn from any textual supervision at all. Our comparison with ImageNetsupervised models subsumes this family of models.
- 自监督预训练:我们根据可用性和评估设置的兼容性选择了三种近期方法——MoCo [24]、PCL [57] 和 SwAV [58],所选模型的训练计算预算与我们相近(8块GPU,200个ImageNet训练周期)。
- ICMLM(同期工作):数据改编自Sariyildiz等人[75],评估可能存在细微差异。该模型使用预训练的BERT [64]提取文本特征。
- 视觉与语言预训练说明:由于使用字幕数据,我们还考虑了为下游视觉-语言任务学习多模态表征的方法[65–72]。如第2节所述,这些方法均采用在Visual Genome [73](基于ImageNet预训练主干网络)上训练的目标检测器提取视觉特征(由[74]提供),这些特征保持冻结状态且完全不依赖文本监督。我们与ImageNet监督模型的对比已涵盖此类模型。
Results are shown in Table 2. VirTex outperforms all methods on VOC07, despite being trained with much fewer images. On ImageNet-1k, comparison between selfsupervised models and VirTex is unfair on both ends, as the former observes downstream images during pre training, while the latter uses annotated images.
结果如表 2 所示。尽管 VirTex 使用的训练图像数量少得多,但在 VOC07 上仍优于所有方法。在 ImageNet-1k 上,自监督模型与 VirTex 的对比对双方都不公平,因为前者在预训练阶段会观察下游图像,而后者使用的是标注图像。

Figure 5: Ablations. (a) Pre training Tasks: Bi captioning improves over weaker pre training tasks – forward captioning, token classification and masked language modeling. (b) Visual Backbone: Bigger visual backbones improve downstream performance – both, wider $(\mathbf{R}{-}50~\mathbf{w}2{\times})$ and deeper (R-101). (c) Transformer Size: Larger transformers (wider and deeper) improve downstream performance.
图 5: 消融实验。(a) 预训练任务: 双向描述生成(Bi captioning)优于较弱的预训练任务——单向描述生成(forward captioning)、token分类和掩码语言建模。(b) 视觉主干网络: 更大的视觉主干网络提升下游性能——包括更宽的$(\mathbf{R}{-}50~\mathbf{w}2{\times})$和更深的(R-101)。(c) Transformer规模: 更大的Transformer(更宽更深)提升下游性能。
4.2. Ablations
4.2. 消融实验
The preceeding linear classification experiments demonstrate the effectiveness and data-efficiency of VirTex. In this section, we conduct ablation studies to isolate the effects of our pre training setup and modeling decisions, and uncover performance trends to seed intuition for future work. We evaluate all ablations on PASCAL VOC and ImageNet-1k linear classification, as described in Section 4.1.
前述线性分类实验验证了VirTex的有效性和数据效率。本节通过消融研究来分离预训练设置和建模决策的影响,并揭示性能趋势,为未来工作提供启发。我们按照第4.1节所述方法,在PASCAL VOC和ImageNet-1k线性分类任务上评估所有消融实验。
Pre training Task Ablations: We choose bi captioning task as it gives a dense supervisory signal per caption. To justify this choice, we form three pre training tasks with sparser supervisory signal and compare them with bi captioning:
预训练任务消融研究:我们选择双向字幕任务,因为该任务为每条字幕提供了密集的监督信号。为验证这一选择,我们构建了三种监督信号更稀疏的预训练任务并与双向字幕进行对比:
– Forward Captioning: We remove the backward transformer decoder and only perform left-to-right captioning. – Token Classification: We replace the textual head with a linear layer and perform multi-label classification (Table 1, row 2). We use the set of caption tokens as targets, completely ignoring the linguistic structure of captions. – Masked Language Modeling (MLM): We use a single bidirectional transformer in the textual head, and perform BERT-like masked language modeling. We randomly mask $15%$ of input tokens, and train the model to predict ground-truth tokens of masked positions.
- 前向字幕生成:移除反向Transformer解码器,仅执行从左到右的字幕生成。
- Token分类:将文本头替换为线性层,执行多标签分类(表1,第2行)。使用字幕Token集合作为目标,完全忽略字幕的语言结构。
- 掩码语言建模(MLM):在文本头中使用单一双向Transformer,执行类似BERT的掩码语言建模。随机掩码$15%$的输入Token,并训练模型预测被掩码位置的真实Token。
All textual heads with transformers have $L=1$ , $H=2048$ . Results are shown in Figure 5(a). Bi captioning outperforms forward captioning, indicating that denser supervi
所有基于Transformer的文本头均采用 $L=1$ 和 $H=2048$ 的配置。结果如图5(a)所示。双向字幕生成优于前向字幕生成,这表明更密集的监督
| Method | Pretrain Images | COCOInstanceSegmentation | LVISInstanceSegmentation | PASCALVOCDetection | iNat18 | |||||||||
| Apbbox all | Apbbox 50 | Apbbox 75 | Apmask all | Apmask 50 | Apmask 75 | Apmask all | Apmask 50 | APmask 75 | Apbbox all | Apbbox 50 | Apbbox 75 | Top-1 | ||
| 1)RandomInit | 36.7 | 56.7 | 40.0 | 33.7 | 53.8 | 35.9 | 17.4 | 27.8 | 18.4 | 33.8 | 60.2 | 33.1 | 61.4 | |
| 2) IN-sup | 1.28M | 41.1 | 62.0 | 44.9 | 37.2 | 59.1 | 40.0 | 22.6 | 35.1 | 23.7 | 54.3 | 81.6 | 59.7 | 65.2 |
| 3) )IN-sup-50% | 640K | 40.3_0.8 | 61.0-1.0 | 44.0_0.9 | 36.6_0.6 58.0-1.1 | 39.3_0.7 | 21.2-1.4 | 33.3-1.8 | 22.3-1.4 | 52.1-2.2 | 80.4-1.2 | 57.0-2.7 | 63.2_2.0 | |
| IN-sup-10% | 128K | 37.9_3.2 | 58.2-3.8 | 41.1-3.8 | 34.7-2.5 | 55.2-3.9 | 37.1-2.9 | 17.5-5.1 | 28.0_7.1 | 18.4-5.3 | 42.6-11.7 72.0-9.6 | 43.8-15.9 | 60.2_4.7 | |
| 5)MoCo-IN | 1.28M | 40.8_0.3 | 61.6_0.4 | 44.7-0.23 | 36.9_0.35 | 58.4_0.7 39.7_0.3 | 22.8+0.2 | 35.4+0.3 24.2+0.5 | 56.1+1.8 | 81.5_0.1 | 62.4+0.7 | 63.2-1.7 | ||
| 6) MoCo-COCO | 118K | 38.5-0.65 | 58.5-3.5 | 42.0_2.9 | 935.0_2.2 | 255.6-3.5 37.5-2.5 | 20.7-1.9 | 32.3_2.8 | 821.9-1.8 | 47.6-6.7 | 75.4-6.2 51.0-8.7 | 60.5_4.4 | ||
| 7) VirTex | 118K | 40.9_0.2 | 61.7_0.3 | 44.8_0.1 36.9-0.3 58.4-0.7 39.7-0.3 | 23.0+0.4 35.4+0.4 24.3+0.6 | 55.3+1.0 | 81.3_0.3 | 61.0+1.3 | 63.4-1.4 | |||||
| 方法 | 预训练图像数 | COCO实例分割 | LVIS实例分割 | PASCALVOC检测 | iNat18 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Apbbox all | Apbbox 50 | Apbbox 75 | Apmask all | Apmask 50 | Apmask 75 | Apmask all | Apmask 50 | APmask 75 | Apbbox all | Apbbox 50 | Apbbox 75 | Top-1 | ||
| 1) RandomInit | 36.7 | 56.7 | 40.0 | 33.7 | 53.8 | 35.9 | 17.4 | 27.8 | 18.4 | 33.8 | 60.2 | 33.1 | 61.4 | |
| 2) IN-sup | 1.28M | 41.1 | 62.0 | 44.9 | 37.2 | 59.1 | 40.0 | 22.6 | 35.1 | 23.7 | 54.3 | 81.6 | 59.7 | 65.2 |
| 3) IN-sup-50% | 640K | 40.3_0.8 | 61.0-1.0 | 44.0_0.9 | 36.6_0.6 58.0-1.1 | 39.3_0.7 | 21.2-1.4 | 33.3-1.8 | 22.3-1.4 | 52.1-2.2 | 80.4-1.2 | 57.0-2.7 | 63.2_2.0 | |
| 4) IN-sup-10% | 128K | 37.9_3.2 | 58.2-3.8 | 41.1-3.8 | 34.7-2.5 | 55.2-3.9 | 37.1-2.9 | 17.5-5.1 | 28.0_7.1 | 18.4-5.3 | 42.6-11.7 72.0-9.6 | 43.8-15.9 | 60.2_4.7 | |
| 5) MoCo-IN | 1.28M | 40.8_0.3 | 61.6_0.4 | 44.7-0.23 | 36.9_0.35 | 58.4_0.7 39.7_0.3 | 22.8+0.2 | 35.4+0.3 24.2+0.5 | 56.1+1.8 | 81.5_0.1 | 62.4+0.7 | 63.2-1.7 | ||
| 6) MoCo-COCO | 118K | 38.5-0.65 | 58.5-3.5 | 42.0_2.9 | 935.0_2.2 | 255.6-3.5 37.5-2.5 | 20.7-1.9 | 32.3_2.8 | 821.9-1.8 | 47.6-6.7 | 75.4-6.2 51.0-8.7 | 60.5_4.4 | ||
| 7) VirTex | 118K | 40.9_0.2 | 61.7_0.3 | 44.8_0.1 36.9-0.3 58.4-0.7 39.7-0.3 | 23.0+0.4 35.4+0.4 24.3+0.6 | 55.3+1.0 | 81.3_0.3 | 61.0+1.3 | 63.4-1.4 |
Table 3: Fine-tuning Tasks for Transfer: We compare VirTex with different pre training methods across four downstream tasks. For each task, all methods use the same architecture. We initialize the ResNet-50 backbone weights from pre training (except Random Init), which are then fine-tuned end-to-end. Performance gaps with IN-sup are shown on the side. On all tasks, VirTex significantly outperforms all methods that use similar amount of pre training images. VirTex closely matches or exceeds ImageNet supervised and self-supervised methods, despite using $10\times$ fewer pre training images.
表 3: 迁移微调任务: 我们在四个下游任务中比较VirTex与不同预训练方法的表现。所有方法在每个任务中使用相同架构,并基于预训练的ResNet-50骨干网络权重进行端到端微调(随机初始化除外)。右侧显示与IN-sup(ImageNet监督训练)的性能差距。在所有任务中,VirTex显著优于使用相似数量预训练图像的其他方法。尽管使用的预训练图像数量少 $10\times$ ,VirTex仍接近或超过ImageNet监督与自监督方法的性能。
sory signal from bidirectional modeling is beneficial. Bicaptioning and forward captioning both outperform token classification, demonstrating that learning to model the sequential structure of language improves visual features.
双向建模的辅助信号具有积极作用。双向描述生成和单向描述生成均优于token分类任务,这表明学习语言序列结构建模能提升视觉特征质量。
MLM performs quite worse than all three methods, possibly due to poor sample efficiency (discussed in Section 3) It may benefit from longer training schedules, however we leave this for future work due to computational constraints. Visual Backbone Ablations: Bigger visual backbones tend to show improvements on many vision tasks [2, 9, 103]. We investigate whether VirTex models with bigger visual backbones can improve downstream performance. We train three VirTex models with $L=1,H=1024$ textual heads, and different visual backbones: (a) ResNet-50 (default), (b) $\mathrm{ResNet}{-50}\mathrm{w}2\times[104]$ ( $2\times$ channel width), and (c) ResNet101 ( $2\times$ depth). We observe that bigger visual backbones better results on VOC07, however the trends are opposite on ImageNet (Figure 5(b)). We believe it to be an optimization issue. See Appendix A.2 for comparison on other tasks.
MLM的表现远逊于所有三种方法,可能是由于样本效率低下(第3节将讨论)。更长的训练周期可能带来提升,但由于计算资源限制,我们将此留待未来研究。视觉主干消融实验:更大的视觉主干通常能在多数视觉任务中带来提升 [2, 9, 103]。我们研究了采用更大视觉主干的VirTex模型是否能提升下游性能。我们训练了三个具有$L=1,H=1024$文本头、但采用不同视觉主干的VirTex模型:(a) ResNet-50(默认)、(b) $\mathrm{ResNet}{-50}\mathrm{w}2\times[104]$(2倍通道宽度)、以及(c) ResNet101(2倍深度)。发现更大的视觉主干在VOC07上表现更好,但在ImageNet上呈现相反趋势(图5(b))。我们认为这是优化问题所致,其他任务对比结果详见附录A.2。
Transformer Size Ablations: Prior work in language modeling has shown that larger Transformers tend to learn better textual features [80–83]. We investigate whether this holds for VirTex: do larger transformers in the textual head cause the visual backbone to learn better visual features? As discussed in Section 3, we may scale our textual head by increasing its width (hidden size $H$ ) or its depth (number of layers $L$ ). We investigate both, training VirTex models with: – Fixed $L=1$ , increasing $H\in{512,768,1024,2048}$ . – Fixed $H=1024$ , increasing $L\in{1,2,3,4}$ .
Transformer 规模消融实验:先前在语言建模中的研究表明,更大的 Transformer 往往能学习到更好的文本特征 [80-83]。我们探究这一结论是否适用于 VirTex:文本头中更大的 Transformer 是否会使视觉主干学习到更好的视觉特征?如第 3 节所述,我们可通过增加宽度(隐藏大小 $H$)或深度(层数 $L$)来扩展文本头。我们对两种方式都进行了研究,训练了以下 VirTex 模型:
- 固定 $L=1$,增加 $H\in{512,768,1024,2048}$。
- 固定 $H=1024$,增加 $L\in{1,2,3,4}$。
Results are shown in Figure 5(c) – increasing transformer size, both width and depth, generally improves downstream performance. Performance degrades slightly with very deep transformers $\mathit{\check{L}}=4$ ), indicating over fitting. We hope that massive transformers with billions of parameters will help when scaling VirTex to large-scale, more noisy image-text paired datasets [37–39] that are larger than COCO Captions.
结果如图5(c)所示——增大Transformer的宽度和深度通常能提升下游任务性能。当Transformer深度极大时( $\mathit{\check{L}}=4$ ),性能会轻微下降,这表明出现了过拟合。我们希望拥有数十亿参数的超大规模Transformer能助力VirTex在比COCO Captions更大规模、噪声更多的图文配对数据集[37-39]上实现扩展。
4.3. Fine-tuning Tasks for Transfer
4.3. 迁移学习的微调任务
So far we have evaluated VirTex using features extracted from frozen visual backbones. Another common mechanisms for transfer learning is fine-tuning, where the entire visual backbone is updated for the downstream task.
目前我们使用从冻结视觉主干网络提取的特征对VirTex进行了评估。另一种常见的迁移学习机制是微调 (fine-tuning),即针对下游任务更新整个视觉主干网络。
We evaluate features learned using VirTex on four downstream tasks with fine-tuning: (a) Instance Segmentation on COCO [30]; (b) Instance Segmentation on LVIS [31]; and (c) Object Detection on PASCAL VOC [99]; (d) Fine- grained Classification on i Naturalist 2018 [107]. In all these experiments, we use the VirTex model with ResNet-50 visual backbone and a textual head with $L=1,H=2048$ .
我们通过在四个下游任务上进行微调来评估使用VirTex学习到的特征:(a) COCO [30]上的实例分割;(b) LVIS [31]上的实例分割;(c) PASCAL VOC [99]上的目标检测;(d) iNaturalist 2018 [107]上的细粒度分类。在所有实验中,我们使用具有ResNet-50视觉主干和$L=1,H=2048$文本头的VirTex模型。
Baselines: Our main baselines are ImageNet-supervised (IN-sup) and MoCo. We consider three variants of IN-sup pretrained with ${10,50,100}%$ of ImageNet images (Figure 4). Similarly for MoCo, we consider both MoCo-IN (Table 2) and MoCo-COCO (Table 1). We also include Random Init baseline, trained from scratch on downstream task.
基线方法:我们的主要基线是ImageNet监督训练 (IN-sup) 和MoCo。我们考虑了使用${10,50,100}%$ ImageNet图像预训练的三种IN-sup变体 (图4)。对于MoCo,我们同时考虑了MoCo-IN (表2) 和MoCo-COCO (表1)。我们还包含了随机初始化基线,即在下游任务上从头开始训练。
We follow the same evaluation protocol as MoCo [24] for all four tasks. We use Detectron2 [101] for tasks (a,b,c). Our IN-sup $100%$ results are slightly better than those reported in [24] – we use pretrained ResNet-50 model from torch vision, whereas they used the MSRA ResNet-50 model from Detectron [108]. We briefly describe implementation details that differ from default Detectron2 settings. Refer Appendix A.3 for full details.
我们针对所有四项任务采用与MoCo [24]相同的评估协议。对于任务(a,b,c),我们使用Detectron2 [101]。我们的IN-sup $100%$结果略优于[24]报告的数据——我们采用torch vision预训练的ResNet-50模型,而他们使用Detectron [108]的MSRA ResNet-50模型。以下简要说明与默认Detectron2设置不同的实现细节,完整细节参见附录A.3。
COCO Instance Segmentation: We train Mask RCNN [9] models with ResNet-50-FPN backbones [109]. We initialize backbone with pretrained weights, train on train2017 split, and evaluate on val2017 split. We finetune all layers end-to-end with BN layers synchronized across GPUs [110] (SyncBN). We also use SyncBN in FPN layers. We train with batch size 16 distributed across 8 GPUs, following $2\times$ schedule (180K iterations with initial LR 0.02, multiplied by 0.1 at iterations 120K and 160K).
COCO实例分割:我们使用ResNet-50-FPN主干网络[109]训练Mask RCNN[9]模型。主干网络采用预训练权重初始化,在train2017数据集上训练,并在val2017数据集上评估。所有层均以端到端方式进行微调,BN层在GPU间同步[110] (SyncBN),FPN层同样使用SyncBN。训练批大小为16,分布在8块GPU上,遵循$2\times$调度方案(初始学习率0.02,18万次迭代中在第12万和16万次时乘以0.1)。
| Backbone Depth Width CIDEr SPICE |
| R-50 1 512 |
| 103.2 19.3 R-50 1 768 103.7 19.6 |
| R-50 1 1024 103.5 19.8 |
| R-50 1 2048 104.2 19.9 |
| R-50 1 1024 103.5 19.8 |
| R-50 2 1024 106.9 20.0 |
| R-50 3 1024 104.3 19.5 R-50 1024 103.8 19.2 |
| 4 |
| R-50w2x 1 1024 102.7 19.6 R-101 1 1024 106.6 20.1 |
| Backbone | Depth | Width | CIDEr | SPICE |
|---|---|---|---|---|
| R-50 | 1 | 512 | 103.2 | 19.3 |
| R-50 | 1 | 768 | 103.7 | 19.6 |
| R-50 | 1 | 1024 | 103.5 | 19.8 |
| R-50 | 1 | 2048 | 104.2 | 19.9 |
| R-50 | 1 | 1024 | 103.5 | 19.8 |
| R-50 | 2 | 1024 | 106.9 | 20.0 |
| R-50 | 3 | 1024 | 104.3 | 19.5 |
| R-50 | 4 | 1024 | 103.8 | 19.2 |
| R-50w2x | 1 | 1024 | 102.7 | 19.6 |
| R-101 | 1 | 1024 | 106.6 | 20.1 |
VirTex predicted captions (R-50, $L=1,H=512)$ , forward transformer decoder
VirTex预测标题(R-50,$L=1,H=512$),前向Transformer解码器

Figure 6: Image Captioning: We report image captioning performance (CIDEr [105] and SPICE [106]) of VirTex models on COCO val2017 split – all variants show modest performance. We also show some predicted captions on the right. For the highlighted word, we visualize decoder attention weights from the textual head on the input image. Our model focuses on relevant image regions to predict objects (shoes, desk), background (road) as well as actions (riding).
图 6: 图像描述生成:我们报告了VirTex模型在COCO val2017数据集上的图像描述性能(CIDEr [105]和SPICE [106])——所有变体都表现出适中的性能。右侧展示了一些预测描述。对于高亮显示的词语,我们可视化文本头在输入图像上的解码器注意力权重。我们的模型会聚焦于相关图像区域来预测物体(鞋子、桌子)、背景(道路)以及动作(骑行)。
LVIS Instance Segmentation: The LVIS dataset provides instance segmentation labels for a long tail of 1203 entrylevel object categories, and stresses the ability to recognize many object types from few training samples. We train Mask R-CNN models with ResNet-50-FPN backbones on train v1.0 and evaluate on val v1.0 split. Following MoCo settings, we keep BN parameters frozen for all INsup baselines. We train with $2\times$ schedule as COCO, use class resampling and test-time hyper parameters (0.0 score threshold and 300 detections per image) same as [31].
LVIS实例分割:LVIS数据集为1203个长尾基础物体类别提供了实例分割标注,重点考察模型从少量训练样本中识别多类物体的能力。我们在train v1.0上使用ResNet-50-FPN骨干网络训练Mask R-CNN模型,并在val v1.0划分集进行评估。遵循MoCo设置,所有INsup基线模型均保持BN参数冻结。训练采用与COCO相同的$2\times$调度方案,使用类别重采样及与[31]相同的测试时超参数(0.0分数阈值和每图300个检测)。
PASCAL VOC Detection: We train Faster R-CNN [111] models with ResNet-50-C4 backbones on trainval $.07\substack{+12}$ split, and evaluate on test2007 split. Like COCO, we finetune all models with SyncBN. We train for 24K iterations, including linear LR warmup for first 100 iterations. We set the maximum LR as 0.02, that is divided by 10 at iterations 18K and 22K. We distribute training across 8 GPUs, with batch size 2 per GPU. We use gradient check pointing [112, 113] to reduce the heavy memory footprint of these models and train them with desired batch size on our 12 GB GPUs.
PASCAL VOC 检测: 我们在 trainval $.07\substack{+12}$ 分割上使用 ResNet-50-C4 骨干网络训练 Faster R-CNN [111] 模型,并在 test2007 分割上进行评估。与 COCO 类似,我们使用 SyncBN 对所有模型进行微调。训练进行 24K 次迭代,包括前 100 次迭代的线性学习率预热。我们将最大学习率设为 0.02,在 18K 和 22K 次迭代时分别除以 10。我们在 8 个 GPU 上分布式训练,每个 GPU 的批次大小为 2。我们使用梯度检查点 [112, 113] 来减少这些模型的高内存占用,并在 12 GB GPU 上以所需的批次大小进行训练。
i Naturalist 2018 Fine-grained Classification: The iNaturalist 2018 dataset provides labeled images for 8142 finegrained categories, with a long-tailed distribution. We finetune the pretrained ResNet-50 with a linear layer end-toend. We train on train2018 split and evaluate on val2018 split, following training setup from torch vision – we train for 100 epochs using SGD with momentum 0.9 and weight decay $10^{-4}$ , and batch size 256 distributed across 8 GPUs. Fine-tuning uses LR 0.025 (and Random Init uses 0.1), which is multiplied by 0.1 at epochs 70 and 90.
iNaturalist 2018细粒度分类:iNaturalist 2018数据集为8142个细粒度类别提供标注图像,呈长尾分布。我们在预训练的ResNet-50上端到端微调线性层,遵循torch vision的训练设置——使用动量0.9、权重衰减$10^{-4}$的SGD优化器,在8块GPU上以256的批量大小训练100个周期。微调学习率为0.025(随机初始化时为0.1),并在第70和90周期时乘以0.1衰减。训练基于train2018划分,验证使用val2018划分。
Results: We show results in Table 3. VirTex matches or exceeds ImageNet-supervised pre training and MoCo-IN on all tasks (row 2,5 vs. 7) despite using $10\times$ fewer pre training images. Moreover, VirTex significantly outperforms methods that use similar, or more pre training images (row 3,4,6 vs. 7), indicating its superior data-efficiency. Among all tasks, VirTex shows significant improvements on LVIS, that shows the effectiveness of natural language annotations in capturing the long tail of visual concepts in the real world.
结果:我们在表3中展示了结果。尽管使用了$10\times$更少的预训练图像,VirTex在所有任务上的表现与ImageNet监督预训练和MoCo-IN相当或更优(第2、5行 vs. 第7行)。此外,VirTex显著优于使用相似或更多预训练图像的方法(第3、4、6行 vs. 第7行),表明其卓越的数据效率。在所有任务中,VirTex在LVIS上显示出显著提升,这证明了自然语言注释在捕捉现实世界中视觉概念长尾分布方面的有效性。
4.4. Image Captioning
4.4. 图像描述生成
Our goal is to learn transferable visual features via textual supervision. To do so, we use image captioning as a pre training task. Although our goal is not to advance the state-of-the-art in image captioning, in Figure 6 we show quantitative and qualitative results of VirTex models trained from scratch on COCO. All models show modest performance, far from current state-of-the-art methods, that commonly involve some pre training. However, captioning metrics are known to correlate weakly with human judgement – we surpass human performance on COCO.
我们的目标是通过文本监督学习可迁移的视觉特征。为此,我们使用图像描述生成作为预训练任务。虽然我们的目标并非提升图像描述生成的最先进水平,但在图6中我们展示了在COCO数据集上从头训练的VirTex模型的定量和定性结果。所有模型表现平平,远不及通常涉及某种预训练的当前最先进方法。然而,已知描述生成指标与人类判断相关性较弱——我们在COCO上超越了人类表现。
We show some predicted captions by VirTex (R-50, $L=$ $1,H=512)$ model. We apply beam search on the forward transformer decoder (5 beams) to decode most likely captions. The decoder attention module in this transformer attends over a $7\times7$ grid of image features through $A=8$ heads at each time-step for predicting a token. We average these $7\times7$ attention weights over all the heads, and overlay them on $224\times224$ input image (via bicubic upsampling).
我们展示了VirTex (R-50, $L=$ $1,H=512$) 模型预测的部分描述文本。我们在前向Transformer解码器上应用束搜索(beam search)(5束)来解码最可能的描述。该Transformer中的解码器注意力模块通过$A=8$个头在每个时间步关注$7\times7$的图像特征网格来预测一个Token。我们将所有头上这些$7\times7$的注意力权重进行平均,并将其叠加在$224\times224$的输入图像上(通过双三次上采样)。
In Figure 6, we show visualization s for some tokens. We observe that our model attends to relevant image regions for making predictions, indicating that VirTex learns meaningful visual features with good semantic understanding.
在图 6 中,我们展示了一些 token 的可视化结果。我们观察到,模型在预测时会关注相关的图像区域,这表明 VirTex 能够学习到具有良好语义理解能力的有意义视觉特征。
5. Conclusion
5. 结论
We have shown that learning visual representations using textual annotations can be competitive to methods based on supervised classification and self-supervised learning on ImageNet. We solely focus on downstream vision tasks – future works can explore other tasks that transfer both the visual backbone and the textual head. Finally, the usage of captions opens a clear pathway to scaling our approach to web-scale image-text pairs, that are orders of magnitude larger, albeit more noisy than COCO Captions.
我们证明了使用文本标注学习视觉表征的方法在ImageNet上可以与基于监督分类和自监督学习的方法相媲美。我们仅关注下游视觉任务——未来工作可以探索同时迁移视觉主干网络和文本头部的其他任务。最后,标题的使用为将我们的方法扩展到网络规模的图像-文本对开辟了一条清晰路径,这些数据量级比COCO Captions大得多,尽管噪声也更多。
Acknowledgments
致谢
We thank Harsh Agrawal, Mohamed El Banani, Richard Higgins, Nilesh Kulkarni and Chris Rockwell for helpful discussions and feedback on the paper. We thank Ishan Misra for discussions regarding PIRL/SwAV evaluation protocol; Saining Xie for discussions about replicating i Naturalist evaluation as MoCo; Ross Girshick and Yuxin Wu for help with Detectron2 model zoo; Georgia Gkioxari for suggesting the Instance Segmentation pre training task ablation; and Stefan Lee for suggestions on figure aesthetics. We thank Jia Deng for access to extra GPUs during project development; and UMich ARC-TS team for support with GPU cluster management. Finally, we thank all the Starbucks outlets in Ann Arbor for many hours of free WiFi. This work was partially supported by the Toyota Research Institute (TRI). However, note that this article solely reflects the opinions and conclusions of its authors and not TRI or any other Toyota entity.
我们感谢Harsh Agrawal、Mohamed El Banani、Richard Higgins、Nilesh Kulkarni和Chris Rockwell对本文的有益讨论和反馈。感谢Ishan Misra关于PIRL/SwAV评估协议的讨论;感谢Saining Xie关于在MoCo中复现iNaturalist评估的讨论;感谢Ross Girshick和Yuxin Wu在Detectron2模型库方面的帮助;感谢Georgia Gkioxari提出的实例分割预训练任务消融实验建议;感谢Stefan Lee对图表美学的建议。感谢Jia Deng在项目开发期间提供的额外GPU资源;感谢UMich ARC-TS团队在GPU集群管理方面的支持。最后,感谢安娜堡所有星巴克门店提供的长时间免费WiFi。本研究部分由丰田研究院(TRI)资助,但需说明:本文仅代表作者观点和结论,与TRI或丰田其他机构无关。
References
参考文献
Wang, and Chih-Jen Lin, “LIBLINEAR: A library for large linear classification,” Journal of machine learning research, 2008. 13
Wang 和 Chih-Jen Lin, "LIBLINEAR: 大规模线性分类库", 《机器学习研究期刊》, 2008. 13
Appendix A. Additional Experiments
附录 A. 补充实验
In this section, we describe additional implementation details about our experiments in Section 4. Our evaluation protocol is consistent with prior works on pre training visual representations – we report differences where applicable.
在本节中,我们将描述第4节实验的其他实现细节。我们的评估协议与视觉表征预训练领域的先前工作保持一致,并在适用之处报告差异。
A.1. Image Classification with Linear Models
A.1. 基于线性模型的图像分类
PASCAL VOC: We use standard data augmentation on images from both trainval and test split – we resize the shorter edge to 256 pixels, and take a $224\times224$ center crop. We normalize images by ImageNet color (RGB mean $=[0.485,0.456,0.406]$ , $\mathrm{std}=[0.229,0.224,0.225])$ .
PASCAL VOC: 我们对来自训练验证集和测试集的图像采用标准数据增强方法——将较短边调整为256像素,并截取 $224\times224$ 的中心区域。使用ImageNet颜色标准对图像进行归一化处理 (RGB均值 $=[0.485,0.456,0.406]$,标准差 $\mathrm{std}=[0.229,0.224,0.225]$)。
Prior works [22, 25, 58] train per-class SVMs for $C~\in$ $[2^{-19},2^{-4}]\cup[10^{-7},10^{-2}]$ (26 values), and choose best SVM based on 3-fold cross-validation. In our initial evaluations, we observed that the best performing SVMs are typically trained with cost values $C\in{0.01,0.1,1.0,10.0},$ . Based on this observation, we only use these values for faster evaluation. For training SVMs, we use scikitlearn [114] with LIBLINEAR [115] backend, default parameters are: LinearSVC(penalty $=^{\cdot}12^{\prime}$ , dual = True, max iter $=2000$ , tol ${=}1\mathsf{e}{-}4$ , class weigh = {1: 2,-1:1} , loss = squared hinge’).
先前的研究 [22, 25, 58] 为每个类别训练支持向量机 (SVM),参数范围 $C~\in$ $[2^{-19},2^{-4}]\cup[10^{-7},10^{-2}]$(共26个值),并通过3折交叉验证选择最佳SVM。在我们的初步评估中,观察到性能最佳的SVM通常使用成本值 $C\in{0.01,0.1,1.0,10.0}$ 进行训练。基于此观察,我们仅使用这些值以加速评估。训练SVM时,我们采用 scikitlearn [114] 和 LIBLINEAR [115] 后端,默认参数为:LinearSVC(penalty $=^{\cdot}12^{\prime}$ , dual = True, max iter $=2000$ , tol ${=}1\mathsf{e}{-}4$ , class weigh = {1: 2,-1:1} , loss = squared hinge’)。
ImageNet-1k: For data augmentation during training, we randomly crop $20{-}100%$ of the original image size, with a random aspect ratio in $(4/3,3/4)$ , resize to $224\times224$ , apply random flip, and normalization by ImageNet color. During evaluation, we resize the shorter edge to 256 pixels and take a $224\times224$ center crop. We initialize the weights of the linear layer as $N(0.0,0.01)$ , and bias values as 0.
ImageNet-1k:训练阶段的数据增强采用随机裁剪原始图像尺寸的20%-100%,随机长宽比控制在(4/3, 3/4)区间,缩放至224×224分辨率,实施随机翻转并按ImageNet标准进行色彩归一化。评估阶段将短边调整为256像素后截取中心224×224区域。线性层权重初始化为N(0.0,0.01)分布,偏置项初始值为0。
Note that we perform a small LR sweep separately for our VirTex model (ResNet-50 and $L=1,H=2048)$ , and ImageNet-supervised models. For Figure 4, best LR values for VirTex models is 0.3 (as mentioned in Section 4.1, and ImageNet-supervised models is 0.1.
请注意,我们分别对VirTex模型(ResNet-50和$L=1,H=2048$)和ImageNet监督模型进行了小幅学习率(LR)扫描。对于图4,VirTex模型的最佳学习率值为0.3(如第4.1节所述),ImageNet监督模型的最佳学习率值为0.1。
Annotation Cost Efficiency: Here, we provide details on our cost estimates for different methods in Table 1. For labels and masks, we use estimates reported by COCO [30], and for captions we use estimates reported by nocaps [100], collected in a similar fashion as COCO.
标注成本效率:我们在表 1 中提供了不同方法的成本估算细节。对于标签和掩码,我们使用了 COCO [30] 报告的估算值;对于描述文本,我们采用了与 COCO 类似方式收集的 nocaps [100] 报告估算值。
– Labels: We consider total time of Category Labeling and Instance Spotting steps in [30] $\mathord{\sim}30\mathrm{K}$ hours). This estimate corresponds to 328K images – we scale it for COCO Captions train2017 split (118K images).
- 标签:我们参考[30]中类别标注和实例标注步骤的总耗时(约30K小时)。该估算对应328K张图像——我们按COCO Captions train2017数据集划分(118K张图像)进行了等比缩放。
– Masks: As reported in [30], it takes 22 worker hours for collecting 1000 instance segmentation masks. We use this estimate to compute time for $\mathord{\sim}860\mathrm{K}$ masks in COCO train2017 split. The collection of masks is dependent on Category Labeling and Instance Spotting, we add the time for collecting labels in our total estimate.
- 掩码标注:如文献[30]所述,收集1000个实例分割掩码需要22个工时。我们据此估算COCO train2017数据集中$\mathord{\sim}860\mathrm{K}$个掩码的标注耗时。由于掩码收集依赖于类别标注和实例定位,我们将标签收集时间纳入总估算。
– Captions: We use the median time per caption (39.2 seconds) as reported in [100] $\mathord{\sim}151\mathrm{K}$ captions) to estimate the cost of collecting $(118\mathrm{K}\times5)$ captions in COCO.
– 说明:我们采用[100]中报告的每条说明的中位时间(39.2秒) ($\mathord{\sim}151\mathrm{K}$ 条说明)来估算COCO中收集$(118\mathrm{K}\times5)$条说明的成本。

Figure 7: Bi captioning vs. Masked Language Modeling: We compare $\mathrm{VOC07mAP}$ of Bi captioning and Masked LM pre training tasks. We observe that Masked LM converges slower than Bi captioning, indicating poor sample efficiency.
图 7: 双向描述生成与掩码语言建模对比:我们比较了双向描述生成和掩码语言建模预训练任务的 $\mathrm{VOC07mAP}$ 值。观察到掩码语言建模的收敛速度比双向描述生成慢,表明其样本效率较低。
Data Efficiency: We train our ImageNet-supervised models on randomly sampled subsets of ImageNet $1%$ , $2%5%$ , $10%$ , $20%$ , $50%$ ). We sample training examples such that the class distribution remains close to $100%$ ImageNet. For VirTex models, we randomly sample $10%$ , $20%$ , $50%$ , and $100%$ of COCO Captions [36] – we do not use any class labels to enforce uniform class distribution. Note that this may put ImageNet-supervised models at an advantage.
数据效率:我们在ImageNet的随机采样子集(1%、2%、5%、10%、20%、50%)上训练ImageNet监督模型。采样训练样本时保持类别分布接近100% ImageNet。对于VirTex模型,我们随机采样COCO Captions [36]的10%、20%、50%和100%数据——不使用任何类别标签来强制均匀类别分布。需注意这可能使ImageNet监督模型更具优势。
We train our ImageNet-supervised models by following the exact setup used to train the publicly available ResNet50 model in torch vision. We use SGD with momentum 0.9 and weight decay $10^{-4}$ . We use a batch size of 256, and perform distributed training across 8 GPUs (batch size 32 per GPU). We train for 90 epochs, with an initial learning rate 0.1, that is divided by 10 at epochs 30 and 60. We keep the number of training epochs fixed for models trained on smaller subsets of ImageNet (else they tend to overfit). For VirTex models, we scale training iterations according to the size of the sampled training set.
我们按照torch vision中训练公开可用的ResNet50模型所使用的相同设置来训练ImageNet监督模型。使用带动量0.9和权重衰减$10^{-4}$的SGD优化器,批大小为256,并在8个GPU上进行分布式训练(每个GPU批大小为32)。训练共进行90个周期,初始学习率为0.1,在第30和第60周期时学习率除以10。对于在ImageNet较小子集上训练的模型,我们保持训练周期数固定(否则容易过拟合)。对于VirTex模型,我们根据采样训练集的大小调整训练迭代次数。
Comparison: ImageNet vs. Cropped COCO. Note that the ImageNet images mostly contain a single object (commonly called iconic images). On the other hand, COCO dataset contains ${\sim}2.9$ object classes and ${\sim}5.7$ instances per image. It may seem that VirTex requires fewer images than ImageNet-supervised models as they contain multiple objects per image. Here, we make an additional comparison to control the varying image statistics between datasets.
对比:ImageNet与裁剪版COCO。需要注意的是,ImageNet图像大多包含单一对象(通常称为标志性图像)。而COCO数据集每张图像包含约2.9个对象类别和约5.7个实例。由于每张图像包含多个对象,VirTex似乎比ImageNet监督模型需要更少的图像。在此,我们进行了额外对比以控制数据集间不同的图像统计特征。
Specifically, we crop objects from COCO images and create a dataset of 860K iconic images. We randomly expand bounding boxes on all edges by 0–30 pixels before cropping, to mimic ImageNet-like images. We train a ResNet-50 with same hyper parameters as ImageNetsupervised models, described above. It achieves 79.1 VOC07 mAP (vs. 88.7 VirTex). This shows that the dataefficiency of VirTex does not entirely stem from using scene images with multiple objects.
具体来说,我们从COCO图像中裁剪物体,创建了一个包含86万张标志性图像的数据集。在裁剪前,我们在所有边缘随机将边界框扩展0-30像素,以模拟类似ImageNet的图像。我们使用与上述ImageNet监督模型相同的超参数训练了一个ResNet-50模型。该模型在VOC07上达到了79.1 mAP(VirTex为88.7)。这表明VirTex的数据效率并非完全源于使用包含多个物体的场景图像。
A.2. Ablations
A.2. 消融实验
Bi captioning vs. Masked Language Modeling. In our pre training task ablations (Section 4.2), we observed that Masked Language Modeling performs quite worse than all other pre training tasks on downstream linear classification performance. This issue arises from the poor sample efficiency of Masked LM, discussed in Section 3.
双向字幕生成与掩码语言建模对比。在我们的预训练任务消融实验中(第4.2节),我们观察到掩码语言建模在下游线性分类任务上的表现远逊于其他所有预训练任务。这一问题源于掩码语言建模较差的样本效率,如第3节所述。
For more evidence, we inspect $\mathrm{VOC07mAP}$ of Masked LM, validated periodically during training. In Figure 7, we compare this with VOC07 mAP of Bi captioning. Both models use $L=1,H=2048$ textual heads. We find that Masked LM indeed converges slower than bi captioning, as it receives weaker supervision per training caption – only corresponding to masked tokens. We believe that a longer training schedule may lead to MLM outperforming bicaptioning, based on its success in language pre training [64].
为获取更多证据,我们检测了训练期间定期验证的掩码语言模型 (Masked LM) 在 $\mathrm{VOC07mAP}$ 上的表现。在图 7 中,我们将其与双向描述生成 (Bi captioning) 的 VOC07 mAP 进行对比。两个模型均使用 $L=1,H=2048$ 的文本头。我们发现掩码语言模型的收敛速度确实慢于双向描述生成,因为每条训练描述对其监督信号较弱——仅对应被掩码的 token。基于掩码语言模型在语言预训练 [64] 中的成功表现,我们认为延长训练周期可能使 MLM 超越双向描述生成。
Additional Evaluation: Backbone Ablations. In our backbone ablations (Figure 5), we observed that larger visual backbones improve VOC07 classification performance. However, the performance trend for ImageNet-1k linear classification is opposite. We think this is an optimization issue – the hyper parameters chosen for ResNet-50 may not be optimal for other backbones. To verify our claims, we evaluate these models on PASCAL VOC object detection.
额外评估:主干网络消融实验
在我们的主干网络消融实验中(图5),我们观察到更大的视觉主干网络能提升VOC07分类性能。但ImageNet-1k线性分类的性能趋势却相反。我们认为这是优化问题——为ResNet-50选择的超参数可能不适用于其他主干网络。为验证这一观点,我们在PASCAL VOC目标检测任务上评估了这些模型。
In Table 4, we observe that the performance trends of PASCAL VOC object detection match with VOC07 classification. Hence, we conclude that using larger visual backbones can improve downstream performance.
在表4中,我们观察到PASCAL VOC目标检测的性能趋势与VOC07分类一致。因此,我们得出结论:使用更大的视觉主干网络(visual backbone)可以提升下游任务性能。
A.3. Fine-tuning Tasks for Transfer
A.3. 迁移学习的微调任务
We described the main details for downstream finetuning tasks in Section 4.3. We provide config files in Detectron2 [101] format to exactly replicate our downstream fine-tuning setup for COCO (Table 5), PASCAL VOC (Table 6), LVIS (Table 7). We apply modified hyper parameters on top of base config files available at:
我们在4.3节中描述了下游微调任务的主要细节。我们提供了Detectron2 [101]格式的配置文件,用于精确复现我们在COCO (表5)、PASCAL VOC (表6)、LVIS (表7)上的下游微调设置。我们在基础配置文件的基础上应用了修改后的超参数,这些基础配置文件可从以下网址获取:
Table 4: Additional Evaluations for Backbone Ablations. We compare VirTex models $(L=1,H=1024)$ with different visual backbones. We observe that larger backbones generally improve downstream performance. Table 5: COCO Instance Segmentation: Detectron2 config parameters that differ from base config file. Table 6: PASCAL VOC Object Detection: Detectron2 config parameters that differ from base config file.
| Backbone | VOC07 mAP | IN-1k Top-1 | PASCALVOC Detection | ||
| Apbbox | APbox | APbbox | |||
| ResNet-50 | 88.3 | 53.2 | 55.2 | 81.2 | 60.8 |
| ResNet-50w2x | 88.5+0.2 | 52.9_0.3 | 56.6+1.4 | 82.0+0.8 | 62.8+2.0 |
| ResNet-101 | 88.7+0.4 | 52.0-1.2 | 57.9+2.7 | 82.0+0.8 | 63.6+2.8 |
表 4: 骨干网络消融实验的额外评估。我们比较了不同视觉骨干网络的VirTex模型$(L=1,H=1024)$,发现更大的骨干网络通常能提升下游任务性能。
表 5: COCO实例分割:与基础配置文件不同的Detectron2配置参数。
表 6: PASCAL VOC目标检测:与基础配置文件不同的Detectron2配置参数。
| Backbone | VOC07 mAP | IN-1k Top-1 | Apbbox | APbox | APbbox |
|---|---|---|---|---|---|
| ResNet-50 | 88.3 | 53.2 | 55.2 | 81.2 | 60.8 |
| ResNet-50w2x | 88.5+0.2 | 52.9_0.3 | 56.6+1.4 | 82.0+0.8 | 62.8+2.0 |
| ResNet-101 | 88.7+0.4 | 52.0-1.2 | 57.9+2.7 | 82.0+0.8 | 63.6+2.8 |
github.com/facebook research/detectron2 @ b267c6 i Naturalist 2018 Fine-grained Classification: We use data augmentation and weight initialization same as ImageNet1k linear classification (Section A.1). Despite a long-tailed distribution like LVIS, we do not perform class balanced resampling, following the evaluation setup of MoCo [24].
github.com/facebook research/detectron2 @ b267c6 iNaturalist 2018细粒度分类任务:我们采用与ImageNet1k线性分类相同的数据增强和权重初始化策略(见章节A.1)。尽管存在类似LVIS的长尾分布问题,但遵循MoCo[24]的评估设置,我们未实施类别平衡重采样。
Table 7: LVIS Instance Segmentation: Detectron2 config parameters that differ from base config file.
| _BASE_: "BaSe-RCNN-FPN.yaml" INPUT: FORMAT:"RGB" DATASETS: TRAIN:("lvis_vl_train",) |
| TEST:("lvis_v1_val",) DATALOADER: SAMPLER_TRAIN: "RepeatFactorTrainingSampler |
| REPEAT_THRESHOLD:O.001 MODEL: WEIGHTS:"Loaded externally" |
| MASK_oN: True PIXEL_MEAN: [123.675, 116.280, 103.530] PIXEL_STD: [58.395, 57.120, 57.375] |
| BACKBONE: |
| FREEZE_AT:0 RESNETS: DEPTH: 50 NORM:"SyncBN" # For IN-sup: "FrozenBN" STRIDE_IN_1X1: False |
表 7: LVIS实例分割:与基础配置文件不同的Detectron2配置参数
| BASE: "BaSe-RCNN-FPN.yaml" INPUT: FORMAT:"RGB" DATASETS: TRAIN: ("lvis_vl_train",) |
| TEST: ("lvis_v1_val",) DATALOADER: SAMPLER_TRAIN: "RepeatFactorTrainingSampler" |
| REPEAT_THRESHOLD:O.001 MODEL: WEIGHTS:"Loaded externally" |
| MASK_oN: True PIXEL_MEAN: [123.675, 116.280, 103.530] PIXEL_STD: [58.395, 57.120, 57.375] |
| BACKBONE: |
| FREEZE_AT:0 RESNETS: DEPTH: 50 NORM:"SyncBN" # For IN-sup: "FrozenBN" STRIDE_IN_1X1: False |
LVIS v0.5 Instance Segmentation: In Section 4.3, we evaluated VirTex and baseline methods on LVIS Instance Segmentation task using LVIS v1.0 train and val splits. One of our baselines, MoCo, conducted this evaluation using LVIS v0.5 splits. For completeness, we report additional results on LVIS v0.5 split. The main changes in config (Table 7) following original LVIS v0.5 baselines are: NUM CLASSES: 1230 and SCORE THRESHOLD TEST: 0.0
LVIS v0.5实例分割:在第4.3节中,我们使用LVIS v1.0的训练和验证集划分评估了VirTex与基线方法在LVIS实例分割任务上的表现。其中一个基线方法MoCo采用了LVIS v0.5的划分标准进行评估。为保持完整性,我们补充报告了LVIS v0.5划分下的结果。主要配置变更(表7)遵循原始LVIS v0.5基线标准:类别数(NUM CLASSES)设为1230,测试分数阈值(SCORE THRESHOLD TEST)设为0.0。
Results are shown in Table 8. We observe the VirTex significantly outperforms all baseline methods on LVIS v0.5 split, similar to evaluation on LVIS v1.0 split.
结果如表 8 所示。我们观察到 VirTex 在 LVIS v0.5 分割上的表现显著优于所有基线方法,这与 LVIS v1.0 分割的评估结果相似。
A.4. Selecting Best Checkpoint by VOC07 mAP
A.4. 基于VOC07 mAP选择最佳检查点
As described in Section 3, we observed that image captioning performance has an imprecise correlation with performance on downstream vision tasks. Hence, we select our best checkpoint based on VOC07 classification mAP.
如第3节所述,我们观察到图像描述生成性能与下游视觉任务性能之间存在不精确的关联性。因此,我们基于VOC07分类mAP指标选择最佳检查点。
In Figure 8, we compare validation metrics of our best VirTex model (ResNet-50, $L=1,H=2048)$ . We observe the trends of $\mathrm{VOC07mAP}$ and CIDEr [105] score of the forward transformer decoder. We observe that an improvement in captioning performance indicates an improve
在图 8 中,我们比较了最佳 VirTex 模型 (ResNet-50, $L=1,H=2048$) 的验证指标。我们观察到前向 Transformer 解码器的 $\mathrm{VOC07mAP}$ 和 CIDEr [105] 分数变化趋势。结果表明,描述性能的提升意味着...
| Method | Pretrain Images | LVISv0.5InstanceSegmentation | ||
| Apbbox all | APbbox 50 | Apbbox 75 | ||
| 1)RandomInit | 22.5 | 34.8 | 23.8 | |
| 2) IN-sup | 1.28M | 24.5 | 38.0 | 26.1 |
| 3) IN-sup-50% | 640K | 23.7_0.8 | 36.7-1.3 | 25.1_1.0 |
| 4) IN-sup-10% | 128K | 20.5_4.0 | 32.8-6.2 | 21.7-5.2 |
| 5)MoCo-IN | 1.28M | 24.1_0.4 | 37.4_0.6 | 25.5_0.6 |
| 6) MoCo-COCO | 118K | 23.1-1.4 | 35.3_2.7 | 24.9-1.2 |
| 7) VirTex | 118K | 25.4+0.9 | 39.0+1.0 | 26.9+0.8 |
| 方法 | 预训练图像数量 | LVISv0.5实例分割 | ||
|---|---|---|---|---|
| APbbox all | APbbox 50 | APbbox 75 | ||
| 1) 随机初始化 | - | 22.5 | 34.8 | 23.8 |
| 2) IN监督 | 1.28M | 24.5 | 38.0 | 26.1 |
| 3) IN监督-50% | 640K | 23.7±0.8 | 36.7±1.3 | 25.1±1.0 |
| 4) IN监督-10% | 128K | 20.5±4.0 | 32.8±6.2 | 21.7±5.2 |
| 5) MoCo-IN | 1.28M | 24.1±0.4 | 37.4±0.6 | 25.5±0.6 |
| 6) MoCo-COCO | 118K | 23.1±1.4 | 35.3±2.7 | 24.9±1.2 |
| 7) VirTex | 118K | 25.4±0.9 | 39.0±1.0 | 26.9±0.8 |
Table 8: Downstream Evaluation: LVIS v0.5 Instance Segmentation. We compare VirTex with different pretraining methods for LVIS v0.5 Instance Segmentation. All methods use Mask R-CNN with ResNet-50-FPN backbone. Performance gaps with IN-sup are shown on the side. The trends are similar to LVIS v1.0 Table 3 – VirTex significantly outperforms all baseline methods.
表 8: 下游任务评估: LVIS v0.5 实例分割。我们将 VirTex 与不同预训练方法在 LVIS v0.5 实例分割任务上进行比较。所有方法均采用 ResNet-50-FPN 骨干网络的 Mask R-CNN。右侧显示了与 IN-sup (ImageNet监督训练) 的性能差距。其趋势与 LVIS v1.0 表 3 类似——VirTex 显著优于所有基线方法。

Figure 8: Validation metrics: VOC07 mAP and CIDEr. We compare VOC07 mAP and CIDEr score of VirTex (ResNet-50, ${\cal L}=1,{\cal H}=2048)$ model. We observe that captioning performance has a positive, yet imprecise correlation with downstream performance on vision tasks.
图 8: 验证指标: VOC07 mAP 和 CIDEr。我们比较了 VirTex (ResNet-50, ${\cal L}=1,{\cal H}=2048$) 模型的 VOC07 mAP 和 CIDEr 分数。观察到描述生成性能与视觉任务下游性能存在正向但非精确的相关性。
ment in downstream performance. However these are not strongly correlated – the best performing checkpoints according to these metrics occur at different iterations: 496K according to VOC07 mAP (88.7), and 492K according to CIDEr (105.8). Hence, we select the best checkpoint based on PASCAL VOC linear classification performance. We use this task as a representative downstream vision task for evaluation due to its speed and simplicity.
在下游任务性能上的提升。然而这些指标之间并不强相关——根据这些指标表现最佳的检查点出现在不同迭代次数:根据VOC07 mAP (88.7) 的最佳检查点在496K次迭代,而根据CIDEr (105.8) 的最佳检查点在492K次迭代。因此,我们基于PASCAL VOC线性分类性能选择最佳检查点。由于该任务的快速性和简单性,我们将其作为评估下游视觉任务的代表性任务。
Appendix B. Decoder Attention Visualization s for Caption Predictions
附录 B. 标题预测的解码器注意力可视化
In Figure 9 and Figure 10, we show more qualitative examples showing decoder attention weights overlaid on input images, similar to Section 4.4. All captions are decoded from $L=1,H=512$ VirTex model using beam search. We normalize the attention masks to [0, 1] to improve their contrast for better visibility.
在图9和图10中,我们展示了更多定性示例,这些示例显示了叠加在输入图像上的解码器注意力权重,类似于第4.4节。所有标题都是从$L=1,H=512$的VirTex模型使用束搜索解码得到的。我们将注意力掩码归一化到[0, 1]范围以提高对比度,从而获得更好的可视效果。

Figure 9: Attention visualization s per time step for predicted caption. We decode captions from the forward transformer of $L=1,H=512$ VirTex model using beam search.
图 9: 预测描述文本在各时间步的注意力可视化。我们使用束搜索从 $L=1,H=512$ 的 VirTex 模型前向 Transformer 解码描述文本。

Figure 10: We decode captions from the forward transformer of $L=1,H=512$ VirTex model using beam search. For the highlighted word, we visualize the decoder attention weights overlaid on the input image.
图 10: 我们使用束搜索从 $L=1,H=512$ 的 VirTex 模型前向 Transformer 中解码描述文字。对于高亮显示的单词,我们在输入图像上叠加可视化解码器的注意力权重。