Learning to Trust Your Feelings: Leveraging Self-awareness in LLMs for Hallucination Mitigation
学会信任你的感受:利用大语言模型中的自我意识缓解幻觉问题
Yuxin Liang*1, Zhuoyang Song2, Hao Wang1, Jiaxing Zhang2 1X2Robot 2 International Digital Economy Academy liang yu x in 42@gmail.com, wanghao@x2robot.com {song zhuo yang, zhang jia xing}@idea.edu.cn
Yuxin Liang*1, Zhuoyang Song2, Hao Wang1, Jiaxing Zhang2 1X2Robot 2国际数字经济学院 liangyuxin42@gmail.com, wanghao@x2robot.com {songzhuoyang, zhangjiaxing}@idea.edu.cn
Abstract
摘要
We evaluate the ability of Large Language Models (LLMs) to discern and express their inter- nal knowledge state, a key factor in countering factual hallucination and ensuring reliable application of LLMs. We observe a robust selfawareness of internal knowledge state in LLMs, evidenced by over $85%$ accuracy in knowledge probing. However, LLMs often fail to express their internal knowledge during generation, leading to factual hallucinations. We develop an automated hallucination annotation tool, Dream Catcher, which merges knowledge probing and consistency checking methods to rank factual preference data. Using knowledge preference as reward, We propose a Rein for cement Learning from Knowledge Feedback (RLKF) training framework, leveraging reinforcement learning to enhance the factuality and honesty of LLMs. Our experiments across multiple models show that RLKF training effectively enhances the ability of models to utilize their internal knowledge state, boosting performance in a variety of knowledge-based and honesty-related tasks.
我们评估了大语言模型(LLM)识别和表达其内部知识状态的能力,这是对抗事实幻觉(factual hallucination)并确保大语言模型可靠应用的关键因素。实验发现大语言模型对其内部知识状态具有高度自我认知,在知识探测(knowledge probing)中准确率超过$85%$。然而,大语言模型在生成过程中往往无法正确表达其内部知识,从而导致事实幻觉。我们开发了自动幻觉标注工具Dream Catcher,通过结合知识探测与一致性检查方法,对事实偏好数据进行排序。以知识偏好作为奖励信号,我们提出了基于知识反馈的强化学习(RLKF)训练框架,利用强化学习提升大语言模型的事实性和诚实度。在多个模型上的实验表明,RLKF训练能有效增强模型利用内部知识状态的能力,显著提升各类知识型和诚实度相关任务的性能。
1 Introduction
1 引言
Large Language Models (LLMs), including notable examples such as GPT-3 (Brown et al., 2020), LLaMA (Touvron et al. (2023a), Touvron et al. (2023b)), and PaLM (Chowdhery et al., 2023), have emerged as a transformative tool in diverse fields due to their robust capabilities in various tasks. However, despite this significant progress and success, an inherent challenge continues to persist: their tendency to "hallucinate", i.e., generate content misaligned with actual facts. This issue is particularly problematic in critical applications, such as clinical or legal scenarios, where the generation of reliable and accurate text is vital. Therefore, mitigating hallucinations in LLMs is a crucial step toward enhancing their practical application scope and improving the overall trust in these emerging technologies.
大语言模型 (LLMs),包括GPT-3 (Brown et al., 2020)、LLaMA (Touvron et al. (2023a), Touvron et al. (2023b)) 和PaLM (Chowdhery et al., 2023) 等知名模型,因其在各种任务中的强大能力已成为多领域的变革性工具。然而,尽管取得了重大进展和成功,一个固有挑战仍然存在:它们倾向于"幻觉"(hallucinate),即生成与实际事实不符的内容。这一问题在临床或法律等关键应用中尤为突出,因为这些场景需要生成可靠且准确的文本。因此,减少大语言模型中的幻觉是扩大其实际应用范围、提升对这些新兴技术整体信任度的关键一步。
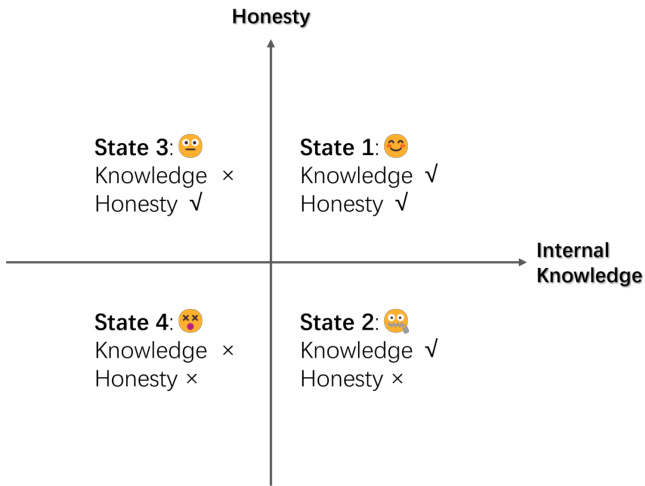
Figure 1: Internal knowledge state categorization of LLM, based on the possession of corresponding internal knowledge and the capacity to express it honestly.
图 1: 大语言模型(LLM)的内部知识状态分类,基于其是否拥有相应的内部知识以及能否诚实表达这些知识。
Hallucinations of LLMs can be categorized into three types (Zhang et al., 2023b): input conflict, context conflict, and factual conflict. This paper focus on the issue of fact-conflicting hallucination, where LLM produces fluent and seemingly plausible content, but conflicts with real-world facts, pose risks of misleading users and compromise the models’ fact-based reasoning.
大语言模型的幻觉可分为三种类型 (Zhang et al., 2023b):输入冲突、上下文冲突和事实冲突。本文聚焦于事实冲突型幻觉问题,即大语言模型生成流畅且看似合理的内容,却与现实世界事实相矛盾,存在误导用户和损害模型基于事实推理能力的风险。
Commonly used hallucination mitigation methods, such as retrieval augmentation generation (RAG), address fact-conflict hallucination of LLM by bringing in external knowledge, but at the cost of introducing a costly and complex retrieval system. In this paper, we propose to mitigate the factual hallucination problem from the perspective of enhancing the model’s utilization of internal knowledge.
常用的幻觉缓解方法,如检索增强生成 (RAG),通过引入外部知识来解决大语言模型的事实冲突幻觉,但代价是引入昂贵且复杂的检索系统。本文提出从增强模型内部知识利用的角度来缓解事实幻觉问题。
Previous works (Kadavath et al. (2022), Azaria and Mitchell (2023), Agrawal et al. (2023)) have shown that LLMs have the capability to discern the validity of factual statements, supported further by Kadavath et al. (2022) suggesting these models capacity to assess their ability in responding to specific questions. Nevertheless, the universality and extent of models’ self-awareness of their knowledge remains an open question. In light of this, we conducted exploratory experiments to probe the knowledge state of various models across different scales, employing linear probes to ascertain the accuracy of models’ judgments regarding their internal knowledge states. The results revealed that all models under analysis demonstrated proficient accuracy in recognizing whether they have the internal knowledge about certain facts.
先前的研究 (Kadavath et al. (2022), Azaria and Mitchell (2023), Agrawal et al. (2023)) 表明,大语言模型具备辨别事实陈述有效性的能力,Kadavath et al. (2022) 进一步指出这些模型能够评估自身回答特定问题的能力。然而,模型对自身知识状态的普遍认知程度仍是一个悬而未决的问题。为此,我们通过探索性实验探究了不同规模模型的知识状态,采用线性探针技术验证模型对其内部知识状态判断的准确性。结果显示,所有被分析模型在识别自身是否掌握特定事实的内部知识时均表现出较高的准确度。
However, during generation, such accurate judgments do not translate into honest output; instead, in the absence of specific internal knowledge, models often manifest a tendency towards hallucinations. Therefore, to mitigate factual hallucinations, it is crucial that models leverage their self-assessed judgments concerning their knowledge status.
然而,在生成过程中,这种精确判断并不会转化为诚实的输出;相反,在缺乏特定内部知识的情况下,模型往往表现出幻觉倾向。因此,为减少事实性幻觉,关键在于模型需利用其关于自身知识状态的自我评估判断。
We propose a training framework named rein for cement learning from knowledge feedback (RLKF) to improve the factuality and honesty of LLM with reinforcement learning using factual preferences as reward. Through the hallucination annotation method Dream Catcher – a blend of knowledge probing and consistencybased judgments – we rank the knowledge-based Question-Answering (QA) data adhering to a preference hierarchy delineated as: factuality $>$ uncertainty $>$ hallucination. This factual preference data is then utilised to train the reward model which is deployed to optimize the Large Language Model via Proximal Policy Optimisation (PPO) algorithm.
我们提出了一个名为REIN的训练框架,用于通过知识反馈进行强化学习(RLKF),以利用事实偏好作为奖励,通过强化学习提升大语言模型的事实性和诚实度。通过幻觉标注方法Dream Catcher——结合知识探测和基于一致性的判断——我们对基于知识的问答(QA)数据进行排序,遵循如下偏好层级:事实性 > 不确定性 > 幻觉。这些事实偏好数据随后被用于训练奖励模型,并通过近端策略优化(PPO)算法来优化大语言模型。
The primary contributions of this paper are articulated as follows:
本文的主要贡献如下:
- We carried out extensive experiments on different models’ capacity to discern their own internal knowledge. The results indicate that LLMs are highly adept at discerning their internal knowledge, with an impressive accuracy over $85%$ in most cases with a limited amount of data.
- 我们在不同模型辨识自身内部知识的能力上进行了大量实验。结果表明,大语言模型 (LLM) 在辨识内部知识方面表现优异,在数据量有限的情况下,大多数场景准确率超过 $85%$。
- We develop Dream Catcher 1, an automatic hallucination detection tool for scoring the degree of hallucination in LLM generations. Dream Catcher integrates knowledge probing methods and consistency judgments, achieving $81%$ agreement with human annotator.
- 我们开发了Dream Catcher 1,这是一个用于评估大语言模型生成内容幻觉程度的自动检测工具。Dream Catcher结合了知识探测方法和一致性判断,与人工标注者达到了81%的一致性。
- We introduce the Reinforcement Learning from Knowledge Feedback (RLKF) training framework to optimize LLM against the factual preference. The experiment results on multiple knowledge and reasoning tasks indicate that RLKF not only enhances the honesty and factuality of LLMs but also improves their general capabilities.
- 我们提出了基于知识反馈的强化学习 (RLKF) 训练框架,用于针对事实偏好优化大语言模型。在多项知识与推理任务上的实验结果表明,RLKF不仅能提升大语言模型的诚实性和事实性,还能增强其通用能力。
2 Problem Setup
2 问题设定
Hallucination, in the context of Large Language Models, refers to a set of inconsistencies during model generation. The central focus of this paper is exploring the fact-conflict hallucination which is defined as the inconsistency between the generated content of the model and the established facts. Although the definition provides a description of the generation results, the causes underlying this phenomenon are multifaceted.
在大语言模型的语境中,幻觉(Hallucination)指模型生成过程中出现的一系列不一致现象。本文聚焦于事实冲突型幻觉(fact-conflict hallucination),即模型生成内容与既定事实之间的不一致性。虽然该定义描述了生成结果,但这种现象背后的成因是多方面的。
In general, LLMs encode factual knowledge into parameters during training and utilize this internal knowledge for generation during inference. However, LLMs do not always honestly express the knowledge in its parameters, which is one of the major causes of fact-conflict hallucination.
通常,大语言模型在训练过程中将事实知识编码到参数中,并在推理时利用这些内部知识进行生成。然而,大语言模型并不总是如实表达其参数中的知识,这是导致事实冲突幻觉的主要原因之一。
For a given question that requires factual knowledge, the model output can be classified into one of four states, depending on the model’s internal knowledge and its honesty. These states are illustrated in Figure 1:
对于一个需要事实性知识的给定问题,根据模型的内部知识及其诚实性,模型输出可归类为四种状态之一。这些状态如图1所示:
State 1: The model has relevant internal knowledge and expresses it faithfully.
状态1:模型具备相关内部知识并忠实地表达出来。
State 2: Despite having the relevant internal knowledge, the model fails to express it honestly. This discrepancy could be due to various factors such as the decoding strategy (Lee et al., 2022; Chuang et al., 2023), hallucination snowballing (Zhang et al., 2023a), or misalignment issues (Schulman, 2023).
状态2:模型虽然具备相关内部知识,却未能如实表达。这种差异可能由多种因素导致,例如解码策略 (Lee et al., 2022; Chuang et al., 2023)、幻觉累积效应 (Zhang et al., 2023a) 或对齐偏差问题 (Schulman, 2023)。
State 3: The model lacks the necessary internal knowledge but honestly indicates un awareness.
状态 3: 模型缺乏必要的内部知识,但诚实地表明未意识到。
State 4: The model lacks the necessary internal knowledge and instead produces a hallucinated response.
状态4:模型缺乏必要的内部知识,转而产生幻觉性响应。
Outputs in State 2 and State 4 are both considered forms of hallucination, despite the differing conditions of internal knowledge.
状态2和状态4的输出都被视为幻觉形式,尽管内部知识条件不同。
In the upper section of Figure 1, the model’s outputs are devoid of hallucinations, honestly mirroring its internal knowledge reservoir. Here, State 1 stands out as the most desirable state, where the model both possesses and faithfully produces the relevant knowledge.
在图 1 的上半部分,模型的输出没有幻觉,真实反映了其内部知识储备。其中,状态 1 是最理想的状态,模型不仅拥有相关知识,还能忠实地生成这些知识。
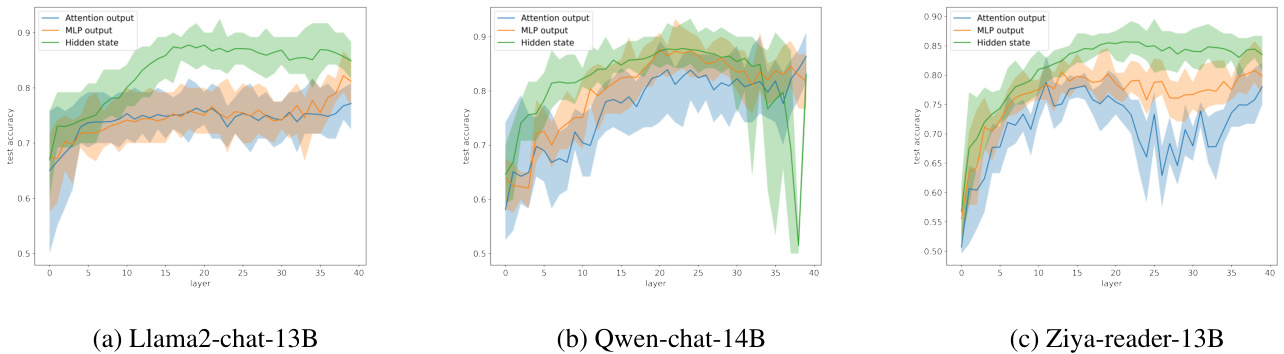
Figure 2: Accuracy of knowledge state probing across different models with different internal representations. The light-colored area in the figure shows the range of accuracy for ten repetitions of the experiment, and the solid line shows the mean accuracy. More results shown in A.2
图 2: 不同模型内部表征的知识状态探测准确率。图中浅色区域显示十次实验重复的准确率范围,实线表示平均准确率。更多结果见附录A.2
Many efforts have been deployed to transition model toward state 1.
已投入大量努力将模型过渡至状态1。
Retrieval-augmented generation (RAG) attempts to bypass the lack of internal knowledge by providing knowledge via context, thereby enabling the model to transition from State 3/4 to State 1. On another front, certain strategies, like those of Li et al. (2023b) and Chuang et al. (2023), seek to move the model from State 2 to State 1 by intervening the model’s internal representation or the decoding process during inference. While these methods improve the model’s capacity to express existing internal knowledge, they disregard scenarios where the model lacks relevant internal knowledge. Also, interference at inference time can potentially lead to unpredictable effects on other types of tasks.
检索增强生成 (RAG) 试图通过上下文提供知识来绕过内部知识缺失的问题,从而使模型从状态3/4过渡到状态1。另一方面,某些策略(如 Li et al. (2023b) 和 Chuang et al. (2023) 提出的方法)通过在推理过程中干预模型的内部表示或解码过程,试图将模型从状态2推进到状态1。虽然这些方法提升了模型表达现有内部知识的能力,但忽略了模型缺乏相关内部知识的情况。此外,推理阶段的干预可能对其他类型任务产生不可预知的影响。
Without the introduction of external knowledge, the mitigation of the model’s fact-conflict hallucination correspond to an upward movement of the state in Figure 1. In essence, this symbolizes the enhancement of the model’s capacity to accurately represent its internal knowledge state. A critical question, then, is how to discern the internal knowledge state of a model?
在不引入外部知识的情况下,缓解模型的事实冲突幻觉(fact-conflict hallucination)对应于图1中状态的上移。本质上,这象征着模型准确表征其内部知识状态能力的提升。于是,一个关键问题随之而来:如何辨别模型的内部知识状态?
3 Knowledge State Probing
3 知识状态探测
This section delves into the complexities of discerning a model’s internal knowledge state. It comprises two perspectives. The first, an external perspective, discuss how to determine if a model possesses specific knowledge based on the model generations; The second perspective, an internal view, questions if it is possible to determine whether a model possesses specific knowledge by its internal activation.
本节深入探讨了识别模型内部知识状态的复杂性,包含两个视角。第一个是外部视角,讨论如何根据模型输出来判断其是否具备特定知识;第二个是内部视角,探讨能否通过模型的内部激活状态来确定其是否拥有特定知识。
For the following pilot experiments, we have selected three families of models with different sizes: Llama2-chat(Touvron et al., 2023b) (13B and 7B); Qwen-chat(Bai et al., 2023) (14B and 7B); Ziya-reader(Junqing et al., 2023) (13B).
在以下试点实验中,我们选择了三种不同规模的模型系列:Llama2-chat (Touvron et al., 2023b) (13B和7B)、Qwen-chat (Bai et al., 2023) (14B和7B)、Ziya-reader (Junqing et al., 2023) (13B)。
As for data, We randomly select passages from Chinese and English Wikipedia and instruct GPT3.5 to generate a knowledge-related questionanswer pair. The answer generated by GPT3.5 based on the original Wikipedia is considered as the correct answer. We refer to the QA pairs obtained by this method as wiki-QA in this paper. Examples of instructions and corresponding output are shown in Appendix A.1.
至于数据部分,我们从中文和英文维基百科中随机选取段落,并指导GPT3.5生成与知识相关的问题-答案对。GPT3.5基于原始维基百科生成的答案被视为正确答案。本文中将通过此方法获得的问答对称为wiki-QA。指令示例及相应输出见附录A.1。
3.1 External perspective
3.1 外部视角
Determining whether a model has specific knowledge through its generation is a straightforward way. But it is challenging to accurately assess the model’s knowledge state through a singular generation result, due to the uncertainty of generation caused by sampling (Lee et al., 2022) and different generation tendencies (Chuang et al., 2023). Multiple generation results can more faithfully reflect the knowledge state of the model.
通过模型的生成结果来判断其是否具备特定知识是一种直接的方法。但由于采样带来的不确定性 (Lee et al., 2022) 和不同的生成倾向 (Chuang et al., 2023),仅凭单次生成结果难以准确评估模型的知识状态。多次生成结果能更真实地反映模型的知识状态。
In the presence of a correct answer, the consistency of the model’s multiple generation with the correct answer is a reliable method for assessing knowledge state. The consistency of model generation with the correct answer can be computed using methods such as unigram overlap and cosine similarity of text representation.
在存在正确答案的情况下,模型多次生成与正确答案的一致性可作为评估知识状态的可靠方法。模型生成与正确答案的一致性可通过unigram重叠度、文本表征余弦相似度等方法计算。
However, the correct answer is hard to obtain in many scenarios, in which case self-consistency becomes a critical tool for assessing the validity of the generation. As evidenced by multiple research (Manakul et al. (2023), Agrawal et al. (2023), Hase et al. (2023), Elaraby et al. (2023)), there is a general conclusion that higher consistency across multiple generations is often indicative of validity of the generation. Intuitively, if the model has the corresponding knowledge, multiple generation are likely to contain consistent facts, resulting in higher consistency. Whereas, the contents of the hallucinations often varies, leading to lower self-consistency. We evaluate the self-consistency of a certain generation by the average of the cosine similarity representations among other generated answers.
然而,在许多场景中难以获得正确答案,此时自洽性成为评估生成结果有效性的关键工具。多项研究 (Manakul et al. (2023), Agrawal et al. (2023), Hase et al. (2023), Elaraby et al. (2023)) 表明,普遍结论认为多次生成结果间更高的自洽性通常意味着生成内容的有效性。直观而言,若模型具备相关知识,多次生成很可能包含一致的事实,从而产生更高的自洽性;而幻觉内容往往多变,导致自洽性较低。我们通过计算某次生成与其他生成答案表征间余弦相似度的平均值来评估其自洽性。
3.2 Internal perspective
3.2 内部视角
Previous work (Azaria and Mitchell (2023), Kadavath et al. (2022), Li et al. (2023b)) prove that LLMs can discern the factual accuracy of certain statements, even when the false statements are selfgenerated. This supports the existence of state 2 in Figure 1 where the model has the corresponding knowledge but generates incorrect outputs. But are LLMs capable of discerning its own state of knowledge? The question can be rephrased as follows: for a given knowledge-related question, can a model discern its capability to output the correct answer before the actual generation of an answer? The following linear probing experiments on multiple models implies that the answer is yes.
先前的研究 (Azaria和Mitchell (2023)、Kadavath等人 (2022)、Li等人 (2023b)) 证明,大语言模型能够辨别某些陈述的事实准确性,即便这些错误陈述是模型自行生成的。这支持了图1中状态2的存在,即模型具备相关知识却生成错误输出。但大语言模型能否识别自身的知识状态?该问题可重新表述为:对于给定的知识相关问题,模型能否在实际生成答案前判断自身输出正确答案的能力?以下对多个模型的线性探测实验表明答案是肯定的。
We sample questions from the wiki-QA data, and LLM generates $k=5$ answers for each question separately. We use the consistency method described earlier to pre-label the questions. The sum of these normalized consistency scores computed to derive the final score.
我们从wiki-QA数据中抽取问题样本,由大语言模型为每个问题分别生成$k=5$个答案。采用前文所述的一致性方法对问题进行预标注,通过计算这些归一化一致性分数的总和得出最终得分。
To categorize the questions, straightforward thresholds are utilized. The upper threshold is set at the 65th percentile score, and the lower at the 35th percentile score. Under this setup, responses with scores exceeding the upper threshold are labeled as correct, while those falling below the lower threshold are labeled as incorrect. If all of the k generated responses related to a specific question are deemed correct, the model is presumed to possess the relevant internal knowledge, and thus the question is labeled as ’Known’. Conversely, if all k responses are incorrect, the model is considered to lack the necessary internal knowledge, and hence the question is labeled as ’Unknown’.
为对问题进行分类,采用了简单的阈值法。上阈值设为第65百分位分数,下阈值为第35百分位分数。在此设置下,得分超过上阈值的回答标记为正确,低于下阈值的则标记为错误。若某问题的全部k个生成回答均被判定为正确,则假定模型具备相关内部知识,该问题标记为"已知";反之,若所有k个回答均错误,则认为模型缺乏必要内部知识,该问题标记为"未知"。
A single linear layer classifier (probe) is trained on the internal representation corresponding to the last token of each question. Its task is to predict the corresponding Known/Unknown label.
在对应每个问题最后一个token的内部表征上训练一个单层线性分类器(探针),其任务是预测相应的已知/未知标签。
For our experiments, we select three types of internal representations:
在我们的实验中,我们选择了三种类型的内部表征:
The attention output, which refers to the output of the dot product attention and before the attention linear layer in the decoder layer. This setup aligns with the probe’s positioning within Li et al. (2023b); The MLP output, i.e., the feed-forward layer’s output within the decoder layer, occurring prior to residual linkage; The hidden states, defined as each decoder layer’s output.
注意力输出,即解码器层中点积注意力(dot product attention)的输出,位于注意力线性层之前。这一设置与Li等人(2023b) 中探针的定位一致;MLP输出,即解码器层中前馈层的输出,出现在残差连接之前;隐藏状态,定义为每个解码器层的输出。
The results of the internal knowledge probe experiment are shown in Figure 2, which presents the accuracy of the trained probes across different models with different internal representation and at different layers.
内部知识探针实验结果如图2所示,该图展示了不同模型、不同内部表示及不同层级的训练探针准确率。
Comparative analysis of the experimental results across models of varying sizes yields consistent observations:
不同规模模型的实验结果对比分析得出一致结论:
- The linear probes of the internal state accurately predict the knowledge representation of the model. The probes’ maximum accuracy surpasses 0.85 in most setups. This suggests that information about whether the model has the corresponding knowledge is linearly encoded in the internal representation of the model with high accuracy.
- 内部状态的线性探针能准确预测模型的知识表征。在多数实验设置中,探针最高准确率超过0.85。这表明模型是否具备相应知识的信息,以高精度线性编码在其内部表征中。
- The accuracy of the probes increases rapidly in the early to middle layer, indicating that the model needs some layers of computation before it can determine its own knowledge states.
- 探针的准确率在早期到中间层迅速提升,表明模型需要经过若干层计算后才能确定自身的知识状态。
- Hidden state probes exhibit the highest accuracy in discerning the knowledge state of the model, sustaining high accuracy from the middle layer to the output layer, which opens up the possibility of utilizing internal knowledge state when generating responses.
- 隐藏状态探针 (hidden state probes) 在识别模型知识状态方面表现出最高准确率,从中层到输出层始终保持高精度,这为利用内部知识状态生成响应提供了可能性。
3.3 Dream Catcher
3.3 梦境捕捉器
We integrated the above methods of knowledge state probing and consistency judgments to develop an automatic hallucination labeling tool, DreamCatcher.
我们将上述知识状态探测与一致性判断方法相结合,开发了自动幻觉标注工具DreamCatcher。
We start by collect the LLMs generation for each question in the question set, in our case, the wikiQA dataset. This process features two modes: normal generation and uncertainty generation. Normal generation is when the prompt contains only the question and model generates k responses, while uncertainty generation refers to where the prompt contains a request for the model to output answers that show uncertainty or lack of knowledge.
我们首先收集大语言模型对问题集中每个问题的生成结果,在本研究中即wikiQA数据集。该过程包含两种模式:常规生成和不确定性生成。常规生成模式下提示词仅包含问题,模型生成k个响应;而不确定性生成模式下提示词会要求模型输出表达不确定或缺乏知识的答案。
Subsequently, we assess the degree of hallucination of the generated responses using multiple scorers using the methods described above. Concretely, we compute the following scores:
随后,我们采用上述方法通过多位评分者评估生成回答的幻觉程度。具体计算以下分数:
$$
\begin{array}{r l}{s_{s2g}}&{=\arg_{i j}(\cos(\mathbf{r}_ {G_{i}},\mathbf{r}_ {G_{j}}))}\ {s_{p}}&{=\mathrm{probe}(\mathbf{r}_ {Q})}\ {s_{o2a}}&{=\mathrm{count}(t o k e n_{o v e r l a p})/\mathrm{count}(t o k e n_{A})}\ {s_{s2a}}&{=\cos(\mathbf{r}_ {G},\mathbf{r}_{A})}\end{array}
$$
$$
\begin{array}{r l}{s_{s2g}}&{=\arg_{i j}(\cos(\mathbf{r}_ {G_{i}},\mathbf{r}_ {G_{j}}))}\ {s_{p}}&{=\mathrm{probe}(\mathbf{r}_ {Q})}\ {s_{o2a}}&{=\mathrm{count}(t o k e n_{o v e r l a p})/\mathrm{count}(t o k e n_{A})}\ {s_{s2a}}&{=\cos(\mathbf{r}_ {G},\mathbf{r}_{A})}\end{array}
$$
where $Q$ denotes the question, $A$ the correct answer, $G$ the generation and $\mathbf{r}$ the embedding represent ation of text.
其中 $Q$ 表示问题,$A$ 表示正确答案,$G$ 表示生成内容,$\mathbf{r}$ 表示文本的嵌入表示。
$s_{p}$ (Probe Score): rates the questions by utilizing the probes trained in Section 3.2, which are intended to discern the model’s knowledge state for the corresponding questions.
$s_{p}$ (探针得分):利用第3.2节训练的探针对问题评分,旨在识别模型对相应问题的知识状态。
$s_{O2a}$ (Overlap with Answer Score): calculates the ratio of token overlap between the generated output and the correct answer $(A)$ .
$s_{O2a}$ (与答案重叠度评分): 计算生成输出与正确答案$(A)$之间的token重叠比例。
$s_{s2a}$ (Similarity to Answer Score): computes the cosine similarity between the embedding of the generated response $(G)$ and the correct answer $(A)$ , using the bge-large model for text embedding.
$s_{s2a}$ (答案相似度得分): 使用bge-large模型计算生成回答$(G)$与正确答案$(A)$嵌入向量间的余弦相似度。
The scores are normalized and summed to provide an overall factuality score for each generation. The generations are then classified as "correct" or "incorrect" based on whether their total score is above or below the median score, respectively. Questions are categorized as "Known", "Unknown", or "Mixed" based on whether the responses are consistently correct, incorrect, or a combination of correct and incorrect across multiple generations, with "Mixed" being a less frequent occurrence.
分数经过归一化处理并求和,为每个生成结果提供总体事实性评分。随后,根据总分是否高于或低于中位数,将生成结果分别归类为"正确"或"错误"。问题则根据多轮生成中回答的一致性被划分为"已知"、"未知"或"混合"三类——若回答持续正确归为"已知",持续错误归为"未知",正确与错误混杂时归为出现频率较低的"混合"类别。
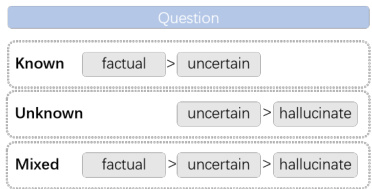
The categories correspond to three ranking hierarchies as shown in Figure 3: Known (corresponding to state 1 in Fig. 1): factual $>$ uncertainty; Mixed (state 2): factual $>$ uncertainty $>$ hallucination; Unknown (state 4): uncertainty $>$ hallucination. Here, "factual" refers to the generation with the highest factuality score, while "hallucination" denotes the generation with the lowest score.
这些类别对应如图3所示的三个排序层次:已知(对应图1中的状态1):事实性 $>$ 不确定性;混合(状态2):事实性 $>$ 不确定性 $>$ 幻觉;未知(状态4):不确定性 $>$ 幻觉。其中,"事实性"指事实性得分最高的生成内容,"幻觉"则表示得分最低的生成内容。
We randomly sampled 200 entries, half Chinese and half English, from the Dream Catcher labeled data. Then the human annotator annotate the same data, without access to the labels of Dream Catcher. The consistency between Dream Catcher and human annotator is shown in Table 1, with an overall accuracy of $81%$ .
我们从Dream Catcher标注数据中随机抽取了200条条目,中英文各半。随后由人工标注者在无法查看Dream Catcher标签的情况下对相同数据进行标注。Dream Catcher与人工标注者的一致性如表1所示,总体准确率为$81%$。
| Language | Accuracy | Precision | Recall |
| All | 81% | 77% | 86% |
| Chinese | 77% | 79% | 76% |
| English | 86% | 76% | 98% |
| 语言 | 准确率 | 精确率 | 召回率 |
|---|---|---|---|
| 全部 | 81% | 77% | 86% |
| 中文 | 77% | 79% | 76% |
| 英文 | 86% | 76% | 98% |
Table 1: The consistency between Dream Catcher and human annotator. For precision and recall, we treat "correct" as a positive label and "incorrect" as negative.
表 1: Dream Catcher与人工标注者的一致性。对于精确率和召回率,我们将"正确"视为正标签,"错误"视为负标签。
4 Method
4 方法
From the above knowledge-probing experiments, we discover that LLMs are capable of evaluating their own knowledge states in response to specific knowledge-based questions. This implies that LLMs demonstrate a self-awareness of their knowledge state, which does not consistently translate into their generational output.
从上述知识探测实验中发现,大语言模型能够针对特定知识性问题评估自身的知识状态。这表明大语言模型展现出对知识状态的自我认知能力,但这种认知并不总能转化为其生成输出。
Frequently, when faced with questions outside of internal knowledge, LLMs tends to generate hallucinations. Additionally, even with questions within internal knowledge, LLMs may potentially generate incorrect responses due to other influences. One possible explanation could be that LLMs did not learn to generate with respect to the internal knowledge state during model training. Instead, the fine-tuning process often requires the model to generate seemingly reasonable answers to all factual questions.
当面对超出内部知识范围的问题时,大语言模型(LLM)往往会产生幻觉性回答。此外,即使对于内部知识范围内的问题,大语言模型也可能因其他影响而生成错误响应。一种可能的解释是:在模型训练过程中,大语言模型并未学会根据内部知识状态生成内容,相反,微调过程通常要求模型对所有事实性问题生成看似合理的答案。
We therefore emphasize on enhancing the model’s utilization of internal knowledge state so that the model can choose to rely on internal knowledge to answer or honestly express its lack of relevant knowledge.2
因此,我们强调增强模型对内部知识状态的利用,使模型能够选择依赖内部知识作答或如实表达其缺乏相关知识。 [20]
Consequently, we propose the RLKF (Reinforce Learning from Knowledge Feedback) training framework. This introduces model knowledge state assessments into the reinforcement learning feedback mechanism, enhancing model honesty and factuality. The RLKF training process shares similarities with the standard RLHF (Reinforce Learning from Human Feedback), and can integrate smoothly with the existing RLHF framework, but reduces data collection costs by substituting human labeling with automatic knowledge labeling.
因此,我们提出了RLKF(基于知识反馈的强化学习)训练框架。该框架将模型知识状态评估引入强化学习反馈机制,从而提升模型的诚实性和事实性。RLKF训练流程与标准RLHF(基于人类反馈的强化学习)具有相似性,可无缝集成现有RLHF框架,并通过用自动知识标注替代人工标注来降低数据收集成本。
The RLKF training framework consists of the following components, as shown in Figure 3.
RLKF训练框架包含以下组件,如图3所示。
Dream catcher ranks multiple generations of each question by factuality.
梦境捕捉器根据事实性对每个问题的多代答案进行排序
Using factuality ranked data to train reward model.
使用真实性分级数据训练奖励模型
Optimize LLM against the factuality reward model using reinforcement learning.
基于强化学习优化大语言模型 (LLM) 的事实性奖励模型
LLM generates multiple responses for each wiki-QA question.
大语言模型为每个维基问答问题生成多个回答。
Dream catcher scores generation using consistency methods and knowledge probes.
使用一致性方法和知识探针生成捕梦网分数。
Dream catcher ranks responses using knowledge states and factuality scores.
捕梦网通过知识状态和事实性评分对回答进行排序。

Data ranked by Dream catcher:
梦境捕捉器排名数据:
Sample prompt from wiki-QA question, LLM generate answer,RM calculates reward.
来自wiki-QA问题的示例提示,大语言模型生成答案,奖励模型计算奖励。
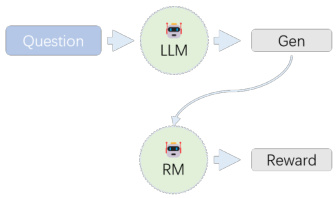
Train reward model with f actuality preference:
训练奖励模型以符合事实偏好:
Optimize LLM with the reward using PPO with guidance.
使用PPO算法通过奖励优化大语言模型(LLM)并加入指导。
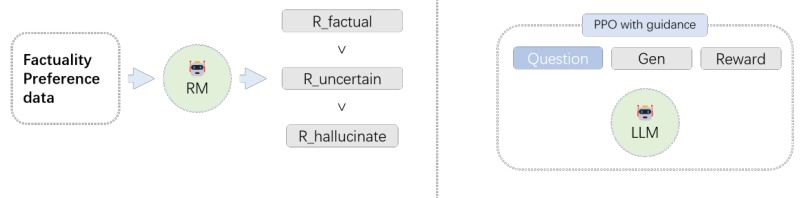
Figure 3: RLKF training
图 3: RLKF训练
Knowledge state annotation: We annotate factual preference data using the Dream catcher tool.
知识状态标注:我们使用Dream catcher工具对事实偏好数据进行标注。
Knowledge Feedback Modeling: Having obtained the factual preference data, we train the reward model following Ouyang et al., 2022. The language modelling head in reward model is replaced with a linear layer to produce a scalar output, corresponding to the reward of the generated response. In line with (Köpf et al., 2023), an additional regularization parameter is introduced to prevents the predicted values from diverging too much.
知识反馈建模:在获取事实偏好数据后,我们按照Ouyang等人[20]的方法训练奖励模型。该奖励模型中的语言建模头被替换为线性层,以生成标量输出,对应生成响应的奖励值。参照Köpf等人[20]的做法,我们引入额外正则化参数以防止预测值过度发散。
By initiating the PPO Policy training and the reward model training from the same model, we can ensure that the Reward model can leverage the same internal knowledge.
通过从同一模型启动PPO策略训练和奖励模型训练,我们可以确保奖励模型能够利用相同的内部知识。
PPO Optimizing: Based on our factual reward model, we optimize the policy, i.e., the initial generative model, using the PPO algorithm once again following Ouyang et al., 2022. To improve the efficiency of model exploration towards honesty, we use guidance technique in reinforcement learning. Concretely, we concatenate the first few tokens of the preferred responses to the input prompts in a portion of the training data. The added tokens do not participate in the loss calculation, but can guide the model to generate desired responses, thus improving learning efficiency.
PPO优化:基于我们的事实奖励模型,我们按照Ouyang等人[20]的方法再次使用PPO算法优化策略(即初始生成模型)。为了提高模型向诚实方向探索的效率,我们在强化学习中采用了引导技术。具体而言,我们将部分训练数据中偏好回复的前几个token拼接到输入提示词后。这些新增token不参与损失计算,但能引导模型生成期望回复,从而提升学习效率。
The core of the training framework is to establish the factual preference reward mechanism. The reinforcement learning algorithms in the RLKF framework can also be replaced by other optimization algorithms such as DPO (Rafailov et al., 2023), reject sampling, etc. We choose PPO to be consistent with the common practice in RLHF training.
训练框架的核心是建立事实偏好奖励机制。RLKF框架中的强化学习算法也可替换为DPO (Rafailov et al., 2023) 、拒绝采样等其他优化算法。我们选择PPO是为了与RLHF训练的常规做法保持一致。
5 Experiments
5 实验
In the following experiments, We chose three different models of varying sizes: llama2-chat (13B and 7B); Qwen-chat (14B and 7B); and Ziya-reader (13B), which is consistent with the choice of models for the knowledge-probing experiments detailed in Section 3.
在以下实验中,我们选择了三种不同规模的模型:llama2-chat (13B和7B)、Qwen-chat (14B和7B) 以及Ziya-reader (13B),这与第3节所述知识探测实验的模型选择保持一致。
Table 2: Accuracy of trained reward model for each knowledge state category.
| Model | Known | Unknown | Mixed |
| Qwen-chat-14B | 82.7% | 87.1% | 77.8% |
| Qwen-chat-7B | 65.7% | 81.6% | 61.1% |
| Llama2-chat-13B | 85.4% | 85.4% | 60.0% |
| Llama2-chat-7B | 78.9% | 89.2% | 57.6% |
| Ziya-reader-13B | 93.5% | 82.4% | 64.5% |
表 2: 各知识状态类别下训练奖励模型的准确率
| 模型 | 已知 | 未知 | 混合 |
|---|---|---|---|
| Qwen-chat-14B | 82.7% | 87.1% | 77.8% |
| Qwen-chat-7B | 65.7% | 81.6% | 61.1% |
| Llama2-chat-13B | 85.4% | 85.4% | 60.0% |
| Llama2-chat-7B | 78.9% | 89.2% | 57.6% |
| Ziya-reader-13B | 93.5% | 82.4% | 64.5% |
5.1 Data collection
5.1 数据收集
We used the wiki-QA data collection method same as in Section 3, obtaining about 7,000 QA pairs each for Chinese and English. To add variety to the questions, we have also modified the prompt to include multiple choice question types. Since our approach relies on the internal knowledge of the models and the boundaries of the internal knowledge are different for each model, we need to perform automatic annotation for each model individually. The generated responses are labeled using Dreamcatcher to obtain factual preference data. The statistics of the factual preference data are shown in Table 7.
我们采用了与第3节相同的wiki-QA数据收集方法,分别获取了约7000对中英文问答数据。为了增加问题多样性,我们还修改了提示词以包含多选题题型。由于我们的方法依赖于模型内部知识,而不同模型的内部知识边界存在差异,因此需要为每个模型单独进行自动标注。使用Dreamcatcher对生成回答进行标注,最终获得事实偏好数据。事实偏好数据的统计信息如表7所示。
Table 3: Evaluation of RLKF-trained models on various knowledge and reasoning related tasks: MMLU (Hendrycks et al., 2020), WinoGrande (Sakaguchi et al., 2021), ARC (Chollet, 2019), BBH (Suzgun et al., 2022), GSM8K (Cobbe et al., 2021), MATH (Hendrycks et al., 2021), C-Eval (Huang et al., 2023), CMMLU(Li et al., 2023a). Tasks are evaluated by the open-source evaluation tool TLEM (SUSTech, 2023), employing a 0-shot setting with greedy generation.
| Models | MMLU | WinoGrande | ARC | BBH | GSM8K | MATH | C-Eval | CMMLU | Avg | |
| Qwen-chat-14B | before | 64.2% | 53.8% | 76.5% | 34.5% | 47.3% | 18.9% | 65.0% | 64.1% | 53.0% |
| after | 64.5% | 59.1% | 87.2% | 37.3% | 49.9% | 20.3% | 64.6% | 66.4% | 56.2% | |
| Qwen-chat-7B | before | 54.2% | 49.6% | 63.1% | 28.8% | 50.0% | 12.6% | 57.8% | 58.1% | 46.8% |
| after | 55.3% | 52.2% | 75.4% | 28.1% | 50.9% | 12.5% | 57.5% | 56.0% | 48.5% | |
| Llama2-chat-13B | before | 52.3% | 51.9% | 72.4% | 21.7% | 35.2% | 3.2% | 34.6% | 34.5% | 38.2% |
| after | 52.8% | 54.3% | 72.1% | 23.4% | 35.6% | 3.1% | 34.3% | 34.6% | 38.8% | |
| Llama2-chat-7B | before | 45.9% | 51.5% | 59.2% | 23.3% | 25.9% | 1.6% | 32.1% | 31.6% | 33.9% |
| after | 46.2% | 52.4% | 61.1% | 24.4% | 23.7% | 2.0% | 34.0% | 32.1% | 34.5% | |
| Ziya-reader-13B | before | 49.5% | 50.8% | 64.7% | 44.7% | 29.3% | 4.3% | 44.7% | 46.1% | 41.7% |
| after | 50.3% | 51.9% | 67.9% | 42.6% | 33.2% | 3.8% | 42.6% | 45.1% | 42.2% | |
表 3: RLKF训练模型在各类知识与推理任务上的评估结果:MMLU (Hendrycks et al., 2020) 、WinoGrande (Sakaguchi et al., 2021) 、ARC (Chollet, 2019) 、BBH (Suzgun et al., 2022) 、GSM8K (Cobbe et al., 2021) 、MATH (Hendrycks et al., 2021) 、C-Eval (Huang et al., 2023) 、CMMLU (Li et al., 2023a) 。任务通过开源评估工具TLEM (SUSTech, 2023) 采用零样本设置下的贪婪生成策略进行评估。
| 模型 | 阶段 | MMLU | WinoGrande | ARC | BBH | GSM8K | MATH | C-Eval | CMMLU | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen-chat-14B | before | 64.2% | 53.8% | 76.5% | 34.5% | 47.3% | 18.9% | 65.0% | 64.1% | 53.0% |
| after | 64.5% | 59.1% | 87.2% | 37.3% | 49.9% | 20.3% | 64.6% | 66.4% | 56.2% | |
| Qwen-chat-7B | before | 54.2% | 49.6% | 63.1% | 28.8% | 50.0% | 12.6% | 57.8% | 58.1% | 46.8% |
| after | 55.3% | 52.2% | 75.4% | 28.1% | 50.9% | 12.5% | 57.5% | 56.0% | 48.5% | |
| Llama2-chat-13B | before | 52.3% | 51.9% | 72.4% | 21.7% | 35.2% | 3.2% | 34.6% | 34.5% | 38.2% |
| after | 52.8% | 54.3% | 72.1% | 23.4% | 35.6% | 3.1% | 34.3% | 34.6% | 38.8% | |
| Llama2-chat-7B | before | 45.9% | 51.5% | 59.2% | 23.3% | 25.9% | 1.6% | 32.1% | 31.6% | 33.9% |
| after | 46.2% | 52.4% | 61.1% | 24.4% | 23.7% | 2.0% | 34.0% | 32.1% | 34.5% | |
| Ziya-reader-13B | before | 49.5% | 50.8% | 64.7% | 44.7% | 29.3% | 4.3% | 44.7% | 46.1% | 41.7% |
| after | 50.3% | 51.9% | 67.9% | 42.6% | 33.2% | 3.8% | 42.6% | 45.1% | 42.2% |
5.2 RLKF Training
5.2 RLKF训练
We train the reward model using the factual preference data in Table 7. To maintain the generalization of the RM, we include same amount of general purpose data as the wiki-QA data in the training. Accuracy of the trained RM on factual preference data testset are shown in Table 2. Interestingly, the reward model is able to quickly achieve high accuracy for both known/unknown categories during training, suggesting that reward model may utilize the internal knowledge state of the initial model to determine whether the uncertainty response should be preferred.
我们使用表7中的事实偏好数据训练奖励模型。为保持奖励模型的泛化能力,我们在训练中加入了与wiki-QA数据等量的通用数据。训练后的奖励模型在事实偏好数据测试集上的准确率如表2所示。有趣的是,奖励模型在训练过程中能快速对已知/未知类别都达到较高准确率,这表明奖励模型可能利用初始模型的内部知识状态来判断是否应优先选择不确定性响应。
Using the trained reward model, the RL process optimizes policy model using the PPO algorithm, where policy model is initialized from the same base model as reward model. The detailed training settings and hyper-parameters are described in A.4.
利用训练好的奖励模型,强化学习过程使用PPO算法优化策略模型,其中策略模型初始化自与奖励模型相同的基础模型。具体训练设置和超参数详见A.4节。
We conduct an evaluation of the trained model, focusing on its factuality and truthfulness. A comparative analysis of the models is performed between pre- and post- RLKF training on various tasks related to knowledge and reasoning as shown in Table 3. The RLKF-trained models demonstrate improvements on the majority of the benchmarks. While RLHF typically results in a reduction of benchmark performance, termed as ’alignment tax’ (Askell et al., 2021), RLKF avoids this decline specifically on knowledge-related tasks, and even lead to improvements. Note that our training methodology does not employ any benchmark data, and the overall volume of training data utilized is small.
我们对训练后的模型进行了评估,重点关注其事实性和真实性。如表3所示,我们在与知识和推理相关的各项任务上,对RLKF训练前后的模型进行了对比分析。经过RLKF训练的模型在大多数基准测试中表现出提升。虽然RLHF通常会导致基准性能下降(这种现象被称为"对齐税"(alignment tax) [20]),但RLKF特别在知识相关任务上避免了这种下降,甚至带来了改进。需要注意的是,我们的训练方法没有使用任何基准数据,且使用的训练数据总量较少。
| Models | ||
| Qwen-chat-14B | before | 43.7% |
| after | 49.1% | |
| Qwen-chat-7B | before | 49.1% |
| after | 50.3% | |
| Llama2-chat-13B | before | 21.5% |
| after | 20.9% | |
| Llama2-chat-7B | before | 27.5% |
| after | 28.3% | |
| Ziya-reader-13B | before | 34.8% |
| after | 37.9% | |
Table 4: Evaluation of RLKF-trained models on TruthfulQA, again using TLEM (SUSTech, 2023), employing a 0-shot setting with greedy generation.
| 模型 | 阶段 | 准确率 |
|---|---|---|
| Qwen-chat-14B | 优化前 | 43.7% |
| Qwen-chat-14B | 优化后 | 49.1% |
| Qwen-chat-7B | 优化前 | 49.1% |
| Qwen-chat-7B | 优化后 | 50.3% |
| Llama2-chat-13B | 优化前 | 21.5% |
| Llama2-chat-13B | 优化后 | 20.9% |
| Llama2-chat-7B | 优化前 | 27.5% |
| Llama2-chat-7B | 优化后 | 28.3% |
| Ziya-reader-13B | 优化前 | 34.8% |
| Ziya-reader-13B | 优化后 | 37.9% |
表 4: 采用RLKF训练模型在TruthfulQA上的评估结果 (使用TLEM方法 (SUSTech, 2023), 零样本设置配合贪婪生成策略)
Regarding the truthfulness of trained models, we evaluated their performance using the widely recognized TruthfulQA task. Notably, all models, with the exception of llama2-chat-13B, show increase in honesty, as shown in Table 4.
关于训练模型的真实性,我们使用广泛认可的TruthfulQA任务评估了它们的性能。值得注意的是,除llama2-chat-13B外,所有模型都显示出诚实度的提升,如表4所示。
6 Related Work
6 相关工作
Hallucination in large language models (LLMs) has been the focal point of research, spanning its causes, detection, and mitigation. Our work relates to all three aspects.
大语言模型(LLM)中的幻觉问题一直是研究的焦点,涵盖其成因、检测和缓解方法。我们的工作涉及这三个方面。
Causes of hallucination: Studies have linked LLM hallucination to various causes. McKenna et al. (2023) ascribes it to memorization of training data, indicating a direct correlation between the training data and the resultant hallucination. Other works such as Schulman (2023) pinpoint improper model fine-tuning as contrib uti ve, and Perez et al. (2022) argues that RLHF induce model "sycophancy" which in turn degrades honesty.
幻觉的成因:研究表明大语言模型(LLM)幻觉与多种因素相关。McKenna等人(2023)将其归因于训练数据的记忆效应,指出训练数据与最终产生的幻觉存在直接关联。Schulman(2023)等研究指出不当的模型微调是诱因之一,而Perez等人(2022)则认为基于人类反馈的强化学习(RLHF)会导致模型"谄媚行为",进而降低回答的真实性。
Other studies link hallucinations to the generation process. For example, Lee et al. (2022) sug- gests that sampling-induced randomness could be responsible. One perspective provided by Chuang et al. (2023) proposes that "lower-level" prior layer information might overshadow factual information from subsequent layers. Furthermore, some works relate hallucinations to the over confidence of LLMs (Ren et al., 2023).
其他研究将幻觉( hallucination )与生成过程联系起来。例如,Lee等人(2022)提出采样引入的随机性可能是原因之一。Chuang等人(2023)提出的观点认为,"较低层级"的前置层信息可能会掩盖后续层的事实信息。此外,部分研究将幻觉与大语言模型的过度自信相关联(Ren等人,2023)。
Hallucination detecting: In terms of detecting hallucination, the consistency of multiple generations has been recognized as an effective indicator. Self Check GP T (Manakul et al., 2023) capitalizes on the consistent nature of internal knowledgebased generations compared to the variable nature of hallucination, leading to the proposal of several consistency checks to identify hallucinations. The idea is echoed by Agrawal et al. (2023), who suggest evaluating the generation consistency of generated references to spot hallucination. Similarly, Elaraby et al. (2023) proposes a metric involving the calculation of sentence-level entailment between response pairs as a measure of hallucination.
幻觉检测:在检测幻觉方面,多轮生成的一致性已被视为有效指标。Self Check GPT (Manakul等人,2023) 利用基于内部知识的生成具有一致性、而幻觉具有多变性的特点,提出了若干一致性检查方法来识别幻觉。Agrawal等人 (2023) 同样主张通过评估生成参考文献的一致性来发现幻觉。类似地,Elaraby等人 (2023) 提出通过计算响应对之间的句子级蕴涵关系作为幻觉度量指标。
Employing large language models (LLMs) to recognize their own hallucinations has been suggested in Saunders et al. (2022), suggesting that discrimination is more accurate than generation for LLMs (G-D gap). This notion is furthered by Kadavath et al. (2022) and Agrawal et al. (2023) by directly prompting LLMs to assess the validity of their own output.
利用大语言模型(LLM)识别自身幻觉的方法在Saunders等人(2022)的研究中被提出,该研究表明对于大语言模型而言,判别任务比生成任务更准确(G-D差距)。Kadavath等人(2022)和Agrawal等人(2023)通过直接提示大语言模型评估自身输出的有效性,进一步验证了这一观点。
Another approach examines the factual ness of statements by analyzing the model’s internal represent ation. Studies Li et al. (2023b) and Burns et al. (2022) identify a "factual ness" direction in the model’s internal representation, with Li et al. (2023b) showcasing a high accuracy attention head through linear probing, and Burns et al. (2022) locating factual ness direction through consistency of facts. Additionally, Kadavath et al. (2022) trains the model to predict the probability that it knows. Base on these works, we shifts focus onto the model’s self-evaluation of knowledge state.
另一种方法通过分析模型的内部表征来检验陈述的事实性。研究 Li et al. (2023b) 和 Burns et al. (2022) 在模型的内部表征中识别出一个"事实性"方向,其中 Li et al. (2023b) 通过线性探测展示了一个高精度的注意力头,而 Burns et al. (2022) 通过事实一致性定位了事实性方向。此外,Kadavath et al. (2022) 训练模型预测其知晓概率。基于这些工作,我们将研究重点转向模型对知识状态的自我评估。
Hallucination mitigation: The common approach of hallucination mitigation involves enhancing the model with additional information. Elaraby et al. (2023) propose the use of larger models to provide additional information when hallucinations is detected.
幻觉缓解:缓解幻觉的常见方法是通过增强模型附加信息。Elaraby等人(2023)提出在检测到幻觉时使用更大模型来提供额外信息。
Some research efforts focus on the optimization of decoding strategies to address hallucinations. Chuang et al. (2023) suggests that contrastive decoding can augment the factual ness of model generation. Others leverage the direction of factual ness in the model representation space; Li et al. (2023b) enhances factual ness by adjusting the output of attention heads along the direction of factual ness during inference. Our work seeks to optimizes the utilization of the model’s internal knowledge state, in line with the direction proposed by Schulman (2023) leveraging reinforcement learning to tackle hallucinations.
一些研究致力于优化解码策略以解决幻觉问题。Chuang等人 (2023) 提出对比解码可以增强模型生成的事实性。其他研究则利用模型表征空间中的事实性方向;Li等人 (2023b) 通过在推理过程中沿事实性方向调整注意力头输出来提升事实性。我们的工作旨在优化模型内部知识状态的利用方式,这与Schulman (2023) 提出的利用强化学习解决幻觉问题的方向一致。
7 Conclusion
7 结论
In our research, we have thoroughly explored the capability of large language models (LLMs) to discern and express their internal knowledge, a key factor in mitigating factual hallucinations and ensuring reliable applications. Our research, manifested through a series of knowledge probing experiments, identifies the model’s self-awareness of its knowledge state. We released the open-source tool Dream Catcher which scores and labels the degree of hallucination in the LLM’s response to knowledge-oriented question and rank responses based on their factuality.
在我们的研究中,我们深入探索了大语言模型(LLM)识别和表达其内部知识的能力,这是减少事实幻觉并确保可靠应用的关键因素。通过一系列知识探测实验,我们的研究识别了模型对其知识状态的自我认知。我们发布了开源工具Dream Catcher,该工具对大语言模型在知识导向问题回答中的幻觉程度进行评分和标记,并根据事实性对回答进行排序。
We further validated our findings through the introduction of a training framework: Reinforcement Learning from Knowledge Feedback (RLKF). Utilizing Dream Catcher to annotate factual preference data, we trained a reward model and leveraging rein for cement learning to enhances LLM’s factuality and truthfulness. Our results indicate RLKF’s effec ti ve ness in improving the model’s utilization of its internal knowledge state, enhancing its performance in various knowledge and honesty related tasks. We posit that RLKF is a promising solution to address LLM’s hallucination issues and, combined with RLHF, offers significant potential for enhancing the model’s overall capabilities.
我们通过引入一个训练框架进一步验证了我们的发现:基于知识反馈的强化学习 (RLKF)。利用 Dream Catcher 标注事实偏好数据,我们训练了一个奖励模型,并运用强化学习来增强大语言模型的事实性和真实性。结果表明,RLKF 能有效提升模型对其内部知识状态的利用,改善其在各类知识与诚信相关任务中的表现。我们认为,RLKF 是解决大语言模型幻觉问题的可行方案,与基于人类反馈的强化学习 (RLHF) 结合后,将为提升模型整体能力带来显著潜力。
References
参考文献
Ayush Agrawal, Lester Mackey, and Adam Tauman Kalai. 2023. Do language models know when they’re hallucinating references? arXiv preprint arXiv:2305.18248.
Ayush Agrawal、Lester Mackey 和 Adam Tauman Kalai。2023。语言模型知道自己何时在虚构参考文献吗?arXiv 预印本 arXiv:2305.18248。
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. 2021. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861.
Amanda Askell、Yuntao Bai、Anna Chen、Dawn Drain、Deep Ganguli、Tom Henighan、Andy Jones、Nicholas Joseph、Ben Mann、Nova DasSarma等. 2021. 通用语言助手作为对齐研究的实验平台. arXiv预印本 arXiv:2112.00861.
Amos Azaria and Tom Mitchell. 2023. The internal state of an llm knows when its lying. arXiv preprint arXiv:2304.13734.
Amos Azaria 和 Tom Mitchell. 2023. 大语言模型的内部状态知道何时在说谎. arXiv 预印本 arXiv:2304.13734.
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609.
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, 等. 2023. Qwen技术报告. arXiv预印本 arXiv:2309.16609.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell等. 2020. 大语言模型是少样本学习者. 神经信息处理系统进展, 33:1877–1901.
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. 2022. Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827.
Collin Burns、Haotian Ye、Dan Klein 和 Jacob Steinhardt。2022。无监督发现语言模型中的潜在知识。arXiv预印本 arXiv:2212.03827。
François Chollet. 2019. On the measure of intelligence. arXiv preprint arXiv:1911.01547.
François Chollet. 2019. 论智能的衡量标准. arXiv preprint arXiv:1911.01547.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann等. 2023. PaLM: 基于Pathways扩展的语言建模. 机器学习研究期刊, 24(240):1–113.
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. 2023. Dola: Decoding by contrasting layers improves factuality in large language models. arXiv preprint arXiv:2309.03883.
Yung-Sung Chuang、Yujia Xie、Hongyin Luo、Yoon Kim、James Glass 和 Pengcheng He。2023。Dola: 通过对比层解码提升大语言模型的事实性 (Decoding by contrasting layers improves factuality in large language models)。arXiv预印本 arXiv:2309.03883。
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
Karl Cobbe、Vineet Kosaraju、Mohammad Bavarian、Mark Chen、Heewoo Jun、Lukasz Kaiser、Matthias Plappert、Jerry Tworek、Jacob Hilton、Reiichiro Nakano 等。2021。训练验证器解决数学应用题。arXiv预印本 arXiv:2110.14168。
Mohamed Elaraby, Mengyin Lu, Jacob Dunn, Xueying Zhang, Yu Wang, and Shizhu Liu. 2023. Halo: Estimation and reduction of hallucinations in opensource weak large language models. arXiv preprint arXiv:2308.11764.
Mohamed Elaraby、Mengyin Lu、Jacob Dunn、Xueying Zhang、Yu Wang和Shizhu Liu。2023。Halo:开源弱大语言模型中的幻觉估计与减少。arXiv预印本arXiv:2308.11764。
Peter Hase, Mona Diab, Asli Cel i kyi l maz, Xian Li, Zornitsa Kozareva, Veselin Stoyanov, Mohit Bansal, and Srinivasan Iyer. 2023. Methods for measuring, updating, and visualizing factual beliefs in language models. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2706–2723.
Peter Hase、Mona Diab、Asli Celikyilmaz、Xian Li、Zornitsa Kozareva、Veselin Stoyanov、Mohit Bansal 和 Srinivasan Iyer。2023。语言模型中事实信念的测量、更新与可视化方法。载于《第17届欧洲计算语言学协会会议论文集》,第2706–2723页。
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
Dan Hendrycks、Collin Burns、Steven Basart、Andy Zou、Mantas Mazeika、Dawn Song和Jacob Steinhardt。2020。测量大规模多任务语言理解。arXiv预印本arXiv:2009.03300。
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical prob- lem solving with the math dataset. arXiv preprint arXiv:2103.03874.
Dan Hendrycks、Collin Burns、Saurav Kadavath、Akul Arora、Steven Basart、Eric Tang、Dawn Song 和 Jacob Steinhardt。2021。使用数学数据集衡量数学问题解决能力。arXiv预印本 arXiv:2103.03874。
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, et al. 2023. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322.
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, 等. 2023. C-Eval: 面向基础模型的多层级多学科中文评估套件. arXiv预印本 arXiv:2305.08322.
He Junqing, Pan Kunhao, Dong Xiaoqun, Song Zhuoyang, Liu Yibo, Liang Yuxin, Wang Hao, Sun Qianguo, Zhang Songxin, Xie Zejian, et al. 2023. Never lost in the middle: Improving large language models via attention strengthening question answering. arXiv preprint arXiv:2311.09198.
贺俊清, 潘坤浩, 董晓群, 宋卓阳, 刘一博, 梁雨欣, 王浩, 孙乾果, 张松鑫, 谢泽健等. 2023. 大语言模型注意力强化问答机制研究: 解决"中间信息丢失"问题. arXiv预印本 arXiv:2311.09198.
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. 2022. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221.
Saurav Kadavath、Tom Conerly、Amanda Askell、Tom Henighan、Dawn Drain、Ethan Perez、Nicholas Schiefer、Zac Hatfield-Dodds、Nova DasSarma、Eli Tran-Johnson 等。2022。语言模型(大多)知道它们知道什么。arXiv预印本 arXiv:2207.05221。
Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris An agno s tid is, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, et al. 2023. Open assistant conversations–democratizing large language model alignment. arXiv preprint arXiv:2304.07327.
Andreas Köpf、Yannic Kilcher、Dimitri von Rütte、Sotiris Anagnostidis、Zhi-Rui Tam、Keith Stevens、Abdullah Barhoum、Nguyen Minh Duc、Oliver Stanley、Richárd Nagyfi 等。2023。开放助手对话——大语言模型对齐的民主化。arXiv预印本 arXiv:2304.07327。
Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pascale N Fung, Mohammad Shoeybi, and Bryan Catanzaro. 2022. Factuality enhanced language models for open-ended text generation. Advances in Neural Information Processing Systems, 35:34586–34599.
Nayeon Lee、Wei Ping、Peng Xu、Mostofa Patwary、Pascale N Fung、Mohammad Shoeybi 和 Bryan Catanzaro。2022。面向开放式文本生成的事实性增强语言模型。神经信息处理系统进展,35:34586–34599。
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. 2023a. Cmmlu: Measuring massive multitask language understanding in chinese. arXiv preprint arXiv:2306.09212.
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. 2023a. CMMLU: 中文海量多任务语言理解评估基准. arXiv预印本 arXiv:2306.09212.
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023b. Inferencetime intervention: Eliciting truthful answers from a language model. arXiv preprint arXiv:2306.03341.
Kenneth Li、Oam Patel、Fernanda Viégas、Hanspeter Pfister 和 Martin Wattenberg。2023b。推理时干预:从语言模型中引出真实答案。arXiv预印本 arXiv:2306.03341。
Potsawee Manakul, Adian Liusie, and Mark JF Gales. 2023. Self check gp t: Zero-resource black-box hallucination detection for generative large language models. arXiv preprint arXiv:2303.08896.
Potsawee Manakul、Adian Liusie 和 Mark JF Gales。2023。SelfCheckGPT:面向生成式大语言模型的零资源黑箱幻觉检测。arXiv预印本 arXiv:2303.08896。
Nick McKenna, Tianyi Li, Liang Cheng, Mohammad Javad Hosseini, Mark Johnson, and Mark Steedman. 2023. Sources of hallucination by large language models on inference tasks. arXiv preprint arXiv:2305.14552.
Nick McKenna、Tianyi Li、Liang Cheng、Mohammad Javad Hosseini、Mark Johnson 和 Mark Steedman。2023。大语言模型在推理任务中的幻觉来源。arXiv预印本 arXiv:2305.14552。
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
Long Ouyang、Jeffrey Wu、Xu Jiang、Diogo Almeida、Carroll Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray 等。2022。基于人类反馈的指令微调语言模型训练方法。《神经信息处理系统进展》,35:27730–27744。
Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Bhosale等人2023b. Llama 2: 开放基础与精调对话模型. arXiv预印本arXiv:2307.09288.
Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A Smith. 2023a. How language model hallucinations can snowball. arXiv preprint arXiv:2305.13534.
Muru Zhang、Ofir Press、William Merrill、Alisa Liu 和 Noah A Smith. 2023a. 大语言模型幻觉如何滚雪球式增长. arXiv 预印本 arXiv:2305.13534.
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. 2023b. Siren’s song in the ai ocean: A survey on hallucination in large language models. arXiv preprint arXiv:2309.01219.
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, 等. 2023b. AI海洋中的塞壬之歌: 大语言模型幻觉问题综述. arXiv预印本 arXiv:2309.01219.
A Appendix A.1 Example of wiki-QA Instruction A.2 More probing results
A 附录 A.1 wiki-QA 指令示例 A.2 更多探测结果

Figure 4: Accuracy of knowledge state probing in 7B models. The light-colored area in the figure shows the range of accuracy for ten repetitions of the experiment, and the solid line shows the mean accuracy.
图 4: 7B 模型知识状态探测的准确率。图中浅色区域显示实验重复十次的准确率范围,实线表示平均准确率。
A.3 Statistics of factual preference data
A.3 事实偏好数据统计
A.4 RLKF Training details
A.4 RLKF 训练细节
We use the AdamW optimizer, with $\beta_{1}=0.9$ , $\beta_{2}=0.99$ , $e p s=1e-5$ for all models. The learning rate for reward model training is $5e-6$ with $1%$ warmup and linear decay scheduler. The batch size is 16 for 13/14B models and 64 for 7B models. We train the reward model for 1 epoch. For PPO training, we use learning rate of $1e-6$ with cosine scheduler. The batch size is 32 for 13/14B models and 64 for 7B models. We set the KL penalty to 0 for all models.
我们使用 AdamW 优化器,对所有模型设置 $\beta_{1}=0.9$、$\beta_{2}=0.99$、$eps=1e-5$。奖励模型训练的学习率为 $5e-6$,采用 $1%$ 预热和线性衰减调度器。13B/14B 模型的批次大小为 16,7B 模型为 64。奖励模型训练 1 个周期。对于 PPO 训练,我们使用 $1e-6$ 的学习率并采用余弦调度器。13B/14B 模型的批次大小为 32,7B 模型为 64。所有模型的 KL 惩罚项均设为 0。
A.5 More Observation
A.5 更多观察
We observe that, some of the responses to the unknown questions are indicating uncertainty in RLHFtrained models, but there is also a significant percentage of responses that are hallucinations. This indicates an increase in model honesty achieved through RLHF, but there is still room for improvement.
我们观察到,对于未知问题的部分回答表明RLHF训练模型存在不确定性,但也有相当比例的回应是幻觉。这表明通过RLHF实现了模型诚实度的提升,但仍有改进空间。
Instruction template:
指令模板:
Based on the following Wikipedia article snippet, ask a knowledge-based question and provide a corresponding answer.
基于以下维基百科文章片段,提出一个知识型问题并提供相应答案。
Article snippet: {Wikipedia passage} Requirements:
文章片段:{维基百科段落} 要求:
- there is a unique correct answer to the question, and the answer can be found in the given article fragment.
- 问题有唯一正确答案,且答案可在给定的文章片段中找到。
- the question can be answered independently of the article fragment, i.e. the answer to the question cannot depend on contextual information, e.g. a question about a character in a literature needs to specify the work to which the character belongs, and a question such as "What is the article about?" cannot be asked.
- 问题可以独立于文章片段回答,即问题的答案不能依赖于上下文信息。例如,关于文学作品中角色的问题需要指明该角色所属的作品,而像"文章讲的是什么?"这样的问题则不能提出。
- Provide the question, answer, and category (e.g., literature, physics, etc.) at the same time, and reply in the following format: {"question":question,"answer":answer,"type":category}.
- 同时提供问题、答案和类别(如文学、物理等),并按以下格式回复: {"question":question,"answer":answer,"type":category}。
If you are unable to ask a question that meets the above requirements, you can simply reply "Unable to ask".
如果你无法提出符合上述要求的问题,可以直接回复"无法提问"。
Reply:
回复:
Wikipedia passage:
维基百科条目:
House Arrest (1996 film) House Arrest is a 1996 American comedy film directed by Harry Winer, written by Michael Hitchcock, and starring Jamie Lee Curtis, Kevin Pollak, Jennifer Tilly, Christopher McDonald, Wallace Shawn, and Ray Walston with supporting roles done by Kyle Howard, Amy Sakasitz, Mooky Arizona, Russel Harper, and an up-and-coming Jennifer Love Hewitt. It tells the story of two children who trap their parents in their basement upon their plans for a separation as the other children they know get involved by trapping their respective problem parents as well. The film was released on August 14, 1996 and went on to gross just over $\text{\$}7$ million at the box office. The film was panned by critics. The film was shot at various locations in the U.S. states of California and Ohio. Monrovia, California was the location for several exterior house scenes while most interior shots were done at the CBS/Radford lot in Studio City, California. The story was set in Defiance, Ohio, although another town, Chagrin Falls, Ohio, actually doubled for it.
《看管严苛》(1996年电影)
《看管严苛》是1996年由Harry Winer执导的美国喜剧片,编剧为Michael Hitchcock,主演包括Jamie Lee Curtis、Kevin Pollak、Jennifer Tilly、Christopher McDonald、Wallace Shawn和Ray Walston,配角由Kyle Howard、Amy Sakasitz、Mooky Arizona、Russel Harper以及新秀Jennifer Love Hewitt出演。影片讲述两个孩子因父母计划分居而将他们关在地下室,随后其他孩子也效仿,各自囚禁了有问题的父母。该片于1996年8月14日上映,票房仅收获700余万美元,并遭到影评人的严厉批评。
拍摄地涵盖美国加利福尼亚州和俄亥俄州多地:加州蒙罗维亚用于外景房屋镜头,而大部分内景在加州Studio City的CBS/Radford片场完成。故事设定在俄亥俄州Defiance,但实际取景地由俄亥俄州Chagrin Falls替代。
GPT3.5 response:
GPT3.5 回应:
{"question":"Who directed the film House Arrest?","answer":"Harry Winer","type":"film"}
{"question":"电影《House Arrest》的导演是谁?","answer":"Harry Winer","type":"film"}
Instruction template:
指令模板:
根据下面的维基百科文章片段,提出一个简短的知识型问题并给出对应回答,要求这个问题存在唯一正确答案,并且答案可以在给出的文章片段中找到。
根据下面的维基百科文章片段,提出一个简短的知识型问题并给出对应回答,要求这个问题存在唯一正确答案,并且答案可以在给出的文章片段中找到。
文章片段:
文章片段:
{Wikipedia passage}
维基百科词条
问题需要在脱离文章片段的情况下仍能够被回答,例如针对文学作品中人物提问需要指明所属的作品,以免引起歧义。问题的回答不能依赖于上下文的信息,不能提出类似“这篇文章的内容是什么?”的问题。同时给出问题,回答和问题分类(比如文学类或物理类等),按如下格式回复:{"question":问题,"answer":回答,"type":分类}。如果无法提出满 足上述要求的问题,可以直接回复“无法提问”。
{"question": "问题需要在脱离文章片段的情况下仍能够被回答,例如针对文学作品中人物提问需要指明所属的作品,以免引起歧义。问题的回答不能依赖于上下文的信息,不能提出类似“这篇文章的内容是什么?”的问题。同时给出问题,回答和问题分类(比如文学类或物理类等),按如下格式回复:{"question":问题,"answer":回答,"type":分类}。如果无法提出满足上述要求的问题,可以直接回复“无法提问”。", "answer": "无法提问", "type": "指令说明"}
回复:
回复:
Wikipedia passage:
维基百科条目:
M25
M25
M25,也称为IC 4725,是一个由恒星组成,在南天人马座的疏散星团。Philippe Loys de Chéseaux在1745年对这个星团进行了第一次有记录的观测,查尔斯·梅西耶1764年将它收录进他的星云天体清单[6]。这个星团位于模糊的特征附近,因此有一条暗带通过中心附近[3]。
M25,也称为IC 4725,是一个由恒星组成、位于南天人马座的疏散星团。Philippe Loys de Chéseaux于1745年首次对该星团进行了有记录的观测,查尔斯·梅西耶在1764年将其收录进他的星云天体清单 [6]。该星团靠近模糊特征区域,因此有一条暗带穿过其中心附近 [3]。
M25距离地球大约2,000光年,年龄约为6,760万岁[2]。这个星团在空间的维度大约是13光年,估计质量是1,937 M,其中大约24%是星际物质[4]。星团成员中的人马座U是一颗分类为造父变星的变星[7],还有两颗红巨星,且其中一颗是联星系统[8]。
M25距离地球大约2,000光年,年龄约为6,760万岁[2]。这个星团在空间的维度大约是13光年,估计质量是1,937 M,其中大约24%是星际物质[4]。星团成员中的人马座U是一颗分类为造父变星的变星[7],还有两颗红巨星,且其中一颗是联星系统[8]。
GPT3.5 response:
GPT3.5 回复:
{"question":"M25是位于哪个星座的疏散星团?","answer":"南天人马 座","type":"天文学"}
{"question":"M25是位于哪个星座的疏散星团?","answer":"南天人马座","type":"天文学"}
Table 6: Example of instruction and corresponding GPT3.5 output of Chinese wiki-QA.
| Model | Total | Known | Unknown | Mixed |
| Qwen-chat-14B | 12799 | 49% | 43% | 8% |
| Qwen-chat-7B | 7201 | 52% | 40% | 8% |
| Llama2-chat-13B | 6600 | 48% | 44% | 8% |
| Llama2-chat-7B | 6680 | 45% | 45% | 10% |
| Ziya-reader-13B | 12558 | 49% | 41% | 10% |
Table 7: Statistics of factual preference data and percentage of each knowledge state category used for reward modeling. The Llama2 models use English-only wiki-QA data, Qwen-chat-7B uses Chinese-only data, and Qwen-chat-14B and Ziya-reader-13B use a mixture of English and Chinese data.
表 6: 中文维基问答的指令示例及对应 GPT3.5 输出。
| 模型 | 总数 | 已知 | 未知 | 混合 |
|---|---|---|---|---|
| Qwen-chat-14B | 12799 | 49% | 43% | 8% |
| Qwen-chat-7B | 7201 | 52% | 40% | 8% |
| Llama2-chat-13B | 6600 | 48% | 44% | 8% |
| Llama2-chat-7B | 6680 | 45% | 45% | 10% |
| Ziya-reader-13B | 12558 | 49% | 41% | 10% |
表 7: 用于奖励建模的事实偏好数据统计及各知识状态类别占比。Llama2 模型使用纯英文维基问答数据,Qwen-chat-7B 使用纯中文数据,Qwen-chat-14B 和 Ziya-reader-13B 使用中英文混合数据。