Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents
ChatGPT擅长搜索吗?探究大语言模型作为重排序智能体的能力
Abstract
摘要
Large Language Models (LLMs) have demonstrated remarkable zero-shot generalization across various language-related tasks, including search engines. However, existing work utilizes the generative ability of LLMs for Information Retrieval (IR) rather than direct passage ranking. The discrepancy between the pretraining objectives of LLMs and the ranking objective poses another challenge. In this paper, we first investigate generative LLMs such as ChatGPT and GPT-4 for relevance ranking in IR. Surprisingly, our experiments reveal that properly instructed LLMs can deliver competitive, even superior results to state-of-the-art supervised methods on popular IR benchmarks. Furthermore, to address concerns about data contamination of LLMs, we collect a new test set called NovelEval, based on the latest knowledge and aiming to verify the model’s ability to rank unknown knowledge. Finally, to improve efficiency in real-world applications, we delve into the potential for distilling the ranking capabilities of ChatGPT into small special- ized models using a permutation distillation scheme. Our evaluation results turn out that a distilled 440M model outperforms a 3B supervised model on the BEIR benchmark. The code to reproduce our results is available at www.github.com/sunnweiwei/RankGPT.
大语言模型 (LLMs) 在各种语言相关任务中展现出卓越的零样本泛化能力,包括搜索引擎领域。然而现有研究主要利用LLMs的生成能力进行信息检索 (IR),而非直接用于段落排序。LLMs的预训练目标与排序目标之间的差异也带来了挑战。本文首次探究了ChatGPT、GPT-4等生成式LLMs在IR相关性排序中的应用。实验表明,经过恰当指令调优的LLMs在主流IR基准测试中能达到甚至超越最先进的监督学习方法。针对LLMs可能存在的数据污染问题,我们基于最新知识构建了NovelEval测试集,用于验证模型对未知知识的排序能力。为提升实际应用效率,我们深入研究了通过排列蒸馏方案将ChatGPT的排序能力迁移到小型专用模型的潜力。评估结果显示,经过蒸馏的440M参数模型在BEIR基准上超越了3B参数的监督模型。复现代码详见www.github.com/sunnweiwei/RankGPT。
1 Introduction
1 引言
Large Language Models (LLMs), such as ChatGPT and GPT-4 (OpenAI, 2022, 2023), are revolutionizing natural language processing with strong zero-shot and few-shot generalization. By pretraining on large-scale text corpora and alignment fine-tuning to follow human instructions, LLMs have demonstrated their superior capabilities in language understanding, generation, interaction, and reasoning (Ouyang et al., 2022).
大语言模型 (LLM),例如 ChatGPT 和 GPT-4 (OpenAI, 2022, 2023),凭借强大的零样本和少样本泛化能力正在彻底改变自然语言处理领域。通过在大规模文本语料库上进行预训练,并经过对齐微调以遵循人类指令,大语言模型已展现出其在语言理解、生成、交互和推理方面的卓越能力 (Ouyang et al., 2022)。

Figure 1: Average results of ChatGPT and GPT-4 (zero-shot) on passage re-ranking benchmarks (TREC, BEIR, and Mr.TyDi), compared with BM25 and previous best-supervised systems (SOTA sup., e.g., monoT5 (Nogueira et al., 2020)).
图 1: ChatGPT 和 GPT-4 (零样本) 在段落重排序基准测试 (TREC、BEIR 和 Mr.TyDi) 上的平均结果,与 BM25 及之前的最佳监督系统 (SOTA sup., 例如 monoT5 (Nogueira et al., 2020)) 的对比。
As one of the most successful AI applications, Information Retrieval (IR) systems satisfy user requirements through several pipelined sub-modules, such as passage retrieval and re-ranking (Lin et al., 2020). Most previous methods heavily rely on manual supervision signals, which require significant human effort and demonstrate weak generalizability (Campos et al., 2016; Izacard et al., 2022). Therefore, there is a growing interest in leveraging the zero-shot language understanding and reasoning capabilities of LLMs in the IR area. However, most existing approaches primarily focus on exploiting LLMs for content generation (e.g., query or passage) rather than relevance ranking for groups of passages (Yu et al., 2023; Microsoft, 2023).
作为最成功的人工智能应用之一,信息检索 (Information Retrieval, IR) 系统通过多个流水线子模块(如段落检索和重排序)满足用户需求 [20]。以往方法大多严重依赖人工监督信号,不仅需要大量人力投入,且泛化能力较弱 [6][12]。因此,如何利用大语言模型 (LLM) 的零样本语言理解和推理能力,正成为IR领域的研究热点。但现有方法主要聚焦于利用LLM生成内容(如查询或段落),而非对段落群进行相关性排序 [23][Microsoft, 2023]。
Compared to the common generation settings, the objectives of relevance re-ranking vary significantly from those of LLMs: the re-ranking agents need to comprehend user requirements, globally compare, and rank the passages based on their relevance to queries. Therefore, leveraging the LLMs’ capabilities for passage re-ranking remains a challenging and unanswered task.
与常见的生成设置相比,相关性重排序的目标与大语言模型(LLM)存在显著差异:重排序智能体需要理解用户需求,全局比较并根据段落与查询的相关性进行排序。因此,利用大语言模型的能力进行段落重排序仍是一项具有挑战性且尚未解决的任务。
To this end, we focus on the following questions:
为此,我们重点关注以下问题:
To answer the first question, we investigate prompting ChatGPT with two existing strategies (Sachan et al., 2022; Liang et al., 2022). However, we observe that they have limited performance and heavily rely on the availability of the log-probability of model output. Thus, we propose an alternative instructional permutation generation approach, instructing the LLMs to directly output the permutations of a group of passages. In addition, we propose an effective sliding window strategy to address context length limitations. For a comprehensive evaluation of LLMs, we employ three well-established IR benchmarks: TREC (Craswell et al., 2020), BEIR (Thakur et al., 2021), and My.TyDi (Zhang et al., 2021). Furthermore, to assess the LLMs on unknown knowledge and address concerns of data contamination, we suggest collecting a continuously updated evaluation testbed and propose NovelEval, a new test set with 21 novel questions.
为回答第一个问题,我们采用两种现有策略(Sachan等人,2022;Liang等人,2022)对ChatGPT进行提示研究。然而,我们发现这些策略性能有限且高度依赖模型输出的对数概率可用性。因此,我们提出了一种替代性的指令式排列生成方法,直接指导大语言模型输出一组段落的排列组合。此外,针对上下文长度限制问题,我们提出了一种有效的滑动窗口策略。为全面评估大语言模型,我们采用了三个成熟的IR基准测试:TREC(Craswell等人,2020)、BEIR(Thakur等人,2021)和My.TyDi(Zhang等人,2021)。为进一步评估大语言模型在未知知识上的表现并解决数据污染问题,我们建议收集持续更新的评估测试集,并提出了包含21个新颖问题的新测试集NovelEval。
To answer the second question, we introduce a permutation distillation technique to imitate the passage ranking capabilities of ChatGPT in a smaller, specialized ranking model. Specifically, we randomly sample 10K queries from the MS MARCO training set, and each query is retrieved by BM25 with 20 candidate passages. On this basis, we distill the permutation predicted by ChatGPT into a student model using a RankNet-based distillation objective (Burges et al., 2005).
为回答第二个问题,我们引入了一种排列蒸馏技术,用于在更小型的专业排序模型中模仿ChatGPT的段落排序能力。具体而言,我们从MS MARCO训练集中随机采样10K个查询,每个查询通过BM25检索出20个候选段落。在此基础上,使用基于RankNet的蒸馏目标 (Burges et al., 2005) 将ChatGPT预测的排列蒸馏到学生模型中。
Our evaluation results demonstrate that GPT-4, equipped with zero-shot instructional permutation generation, surpasses supervised systems across nearly all datasets. Figure 1 illustrates that GPT-4 outperforms the previous state-of-the-art models by an average nDCG improvement of 2.7, 2.3, and 2.7 on TREC, BEIR, and My.TyDi, respectively. Furthermore, GPT-4 achieves state-of-the-art performance on the new NovelEval test set. Through our permutation distillation experiments, we observe that a 435M student model outperforms the previous state-of-the-art monoT5 (3B) model by an average nDCG improvement of 1.67 on BEIR. Additionally, the proposed distillation method demonstrates cost-efficiency benefits.
我们的评估结果表明,配备零样本指令排列生成的GPT-4在几乎所有数据集上都超越了监督系统。图1显示,GPT-4在TREC、BEIR和My.TyDi上的平均nDCG分别提升了2.7、2.3和2.7,优于之前的先进模型。此外,GPT-4在新推出的NovelEval测试集上实现了最先进的性能。通过排列蒸馏实验,我们发现一个435M参数的学生模型在BEIR上的平均nDCG比之前的先进monoT5 (3B)模型提升了1.67。同时,所提出的蒸馏方法还展现出成本效益优势。
In summary, our contributions are tri-fold:
总之,我们的贡献体现在三个方面:
2 Related Work
2 相关工作
2.1 Information Retrieval with LLMs
2.1 基于大语言模型的信息检索
Recently, large language models (LLMs) have found increasing applications in information retrieval (Zhu et al., 2023). Several approaches have been proposed to utilize LLMs for passage retrieval. For example, SGPT (Mu en nigh off, 2022) generates text embeddings using GPT, generative document retrieval explores a differentiable search index (Tay et al., 2022; Cao et al., 2021; Sun et al., 2023), and HyDE (Gao et al., 2023; Wang et al., 2023a) generates pseudo-documents using GPT-3. In addition, LLMs have also been used for passage reranking tasks. UPR (Sachan et al., 2022) and SGPTCE (Mu en nigh off, 2022) introduce instructional query generation methods, while HELM (Liang et al., 2022) utilizes instructional relevance generation. LLMs are also employed for training data generation. InPars (Bonifacio et al., 2022) generates pseudo-queries using GPT-3, and Promptagator (Dai et al., 2023) proposes a few-shot dense retrieval to leverage a few demonstrations from the target domain for pseudo-query generation. Furthermore, LLMs have been used for content generation (Yu et al., 2023) and web browsing (Nakano et al., 2021; Izacard et al., 2023; Microsoft, 2023). In this paper, we explore using ChatGPT and GPT4 in passage re-ranking tasks, propose an instructional permutation generation method, and conduct a comprehensive evaluation of benchmarks from various domains, tasks, and languages. Recent work (Ma et al., 2023) concurrently investigated listwise passage re-ranking using LLMs. In comparison, our study provides a more comprehensive evaluation, incorporating a newly annotated dataset, and validates the proposed permutation distillation technique.
近年来,大语言模型(LLM)在信息检索领域的应用日益广泛(Zhu et al., 2023)。研究者们提出了多种利用LLM进行段落检索的方法:SGPT(Muennighoff, 2022)使用GPT生成文本嵌入,生成式文档检索探索了可微分搜索索引(Tay et al., 2022; Cao et al., 2021; Sun et al., 2023),HyDE(Gao et al., 2023; Wang et al., 2023a)则通过GPT-3生成伪文档。此外,LLM也被应用于段落重排序任务,UPR(Sachan et al., 2022)和SGPT-CE(Muennighoff, 2022)提出了指令式查询生成方法,而HELM(Liang et al., 2022)采用了指令式相关性生成技术。在训练数据生成方面,InPars(Bonifacio et al., 2022)使用GPT-3生成伪查询,Promptagator(Dai et al., 2023)则提出少样本密集检索方法,利用目标域的少量示例生成伪查询。LLM还被用于内容生成(Yu et al., 2023)和网页浏览(Nakano et al., 2021; Izacard et al., 2023; Microsoft, 2023)等场景。本文探索了ChatGPT和GPT-4在段落重排序任务中的应用,提出指令式排列生成方法,并对跨领域、多任务、多语言的基准测试进行了全面评估。近期研究(Ma et al., 2023)同步探索了基于LLM的列表式段落重排序,相较而言,本研究提供了更全面的评估框架,包含新标注数据集,并验证了提出的排列蒸馏技术。
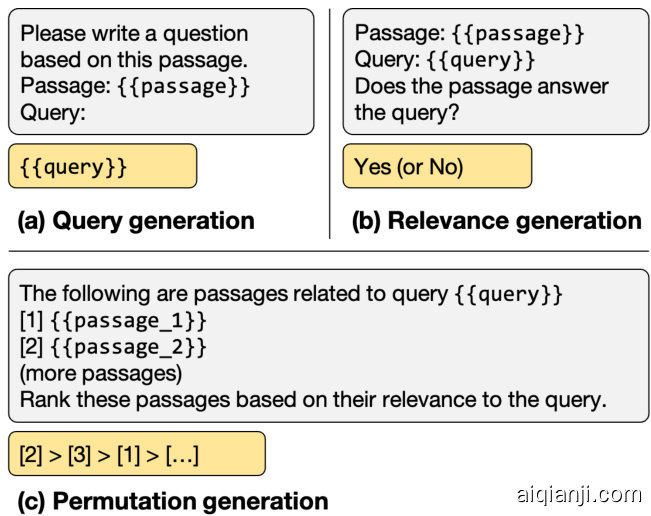
Figure 2: Three types of instructions for zero-shot passage re-ranking with LLMs. The gray and yellow blocks indicate the inputs and outputs of the model. (a) Query generation relies on the log probability of LLMs to generate the query based on the passage. (b) Relevance generation instructs LLMs to output relevance judgments. (c) Permutation generation generates a ranked list of a group of passages. See Appendix A for details.
图 2: 使用大语言模型进行零样本段落重排序的三种指令类型。灰色和黄色区块分别表示模型的输入和输出。(a) 查询生成依赖大语言模型根据段落生成查询的对数概率。(b) 相关性生成指导大语言模型输出相关性判断。(c) 排列生成针对一组段落生成排序列表。详见附录A。
2.2 LLMs Specialization
2.2 大语言模型 (LLM) 专业化
Despite their impressive capabilities, LLMs such as GPT-4 often come with high costs and lack opensource availability. As a result, considerable research has explored ways to distill the capabilities of LLMs into specialized, custom models. For instance, Fu et al. (2023) and Magister et al. (2023) have successfully distilled the reasoning ability of LLMs into smaller models. Self-instruct (Wang et al., 2023b; Taori et al., 2023) propose iterative approaches to distill GPT-3 using their outputs. Additionally, Sachan et al. (2023) and Shi et al. (2023) utilize the generation probability of LLMs to improve retrieval systems. This paper presents a permutation distillation method that leverages ChatGPT as a teacher to obtain specialized re-ranking models. Our experiments demonstrate that even with a small amount of ChatGPT-generated data, the specialized model can outperform strong supervised systems.
尽管GPT-4等大语言模型(LLM)能力出众,但其高昂成本与闭源特性限制了应用。为此,学界涌现了大量关于能力蒸馏的研究:Fu等人(2023)和Magister等人(2023)成功将大语言模型的推理能力迁移至小模型;Self-instruct(Wang等人,2023b;Taori等人,2023)提出利用模型输出迭代蒸馏GPT-3的方法;Sachan等人(2023)和Shi等人(2023)则利用大语言模型的生成概率优化检索系统。本文提出一种基于ChatGPT教师模型的置换蒸馏法,可训练出专用重排序模型。实验表明,仅需少量ChatGPT生成数据,专用模型性能即可超越强监督系统。
3 Passage Re-Ranking with LLMs
3 基于大语言模型的段落重排序
Ranking is the core task in information retrieval applications, such as ad-hoc search (Lin et al., 2020; Fan et al., 2022), Web search (Zou et al., 2021), and open-domain question answering (Karpukhin et al., 2020). Modern IR systems generally employ a multi-stage pipeline where the retrieval stage focuses on retrieving a set of candidates from a large corpus, and the re-ranking stage aims to re-rank this set to output a more precise list. Recent studies have explored LLMs for zero-shot re-ranking, such as instructional query generation or relevance generation (Sachan et al., 2022; Liang et al., 2022). However, existing methods have limited performance in re-ranking and heavily rely on the availability of the log probability of model output and thus cannot be applied to the latest LLMs such as GPT-4. Since ChatGPT and GPT-4 have a strong capacity for text understanding, instruction following, and reasoning, we introduce a novel instructional permutation generation method with a sliding window strategy to directly output a ranked list given a set of candidate passages. Figure 2 illustrates examples of three types of instructions; all the detailed instructions are included in Appendix A.
排序是信息检索应用中的核心任务,例如特定搜索 (Lin et al., 2020; Fan et al., 2022)、网络搜索 (Zou et al., 2021) 和开放域问答 (Karpukhin et al., 2020)。现代信息检索系统通常采用多阶段流程,其中检索阶段专注于从大规模语料库中获取候选集,而重排序阶段则旨在对该候选集重新排序以输出更精确的列表。近期研究探索了大语言模型在零样本重排序中的应用,例如指令式查询生成或相关性生成 (Sachan et al., 2022; Liang et al., 2022)。然而现有方法在重排序中性能有限,且严重依赖模型输出对数概率的可用性,因此无法应用于 GPT-4 等最新大语言模型。鉴于 ChatGPT 和 GPT-4 在文本理解、指令跟随和推理方面具有强大能力,我们提出了一种新颖的指令式排列生成方法,结合滑动窗口策略,直接根据候选段落集输出排序列表。图 2 展示了三类指令的示例,完整指令详见附录 A。
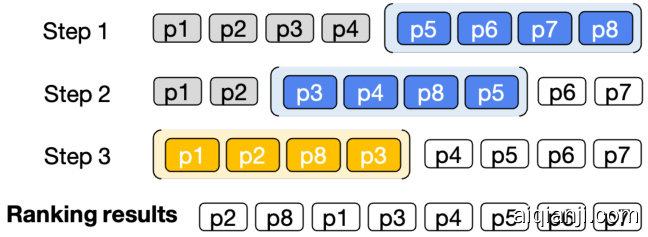
Figure 3: Illustration of re-ranking 8 passages using sliding windows with a window size of 4 and a step size of 2. The blue color represents the first two windows, while the yellow color represents the last window. The sliding windows are applied in back-to-first order, meaning that the first 2 passages in the previous window will participate in re-ranking the next window.
图 3: 使用窗口大小为4、步长为2的滑动窗口对8个段落进行重排序的示意图。蓝色表示前两个窗口,黄色表示最后一个窗口。滑动窗口按从后到前的顺序应用,即前一个窗口的前2个段落将参与下一个窗口的重排序。
3.1 Instructional Permutation Generation
3.1 指令排列生成
As illustrated in Figure 2 (c), our approach involves inputting a group of passages into the LLMs, each identified by a unique identifier (e.g., [1], [2], etc.). We then ask the LLMs to generate the permutation of passages in descending order based on their relevance to the query. The passages are ranked using the identifiers, in a format such as [2] $>[3]>[1]>\mid$ etc. The proposed method ranks passages directly without producing an intermediate relevance score.
如图 2 (c) 所示,我们的方法涉及将一组段落输入大语言模型 (LLM),每个段落都有一个唯一标识符 (例如 [1]、[2] 等)。然后,我们要求大语言模型根据段落与查询的相关性,以降序生成段落的排列顺序。段落使用标识符进行排序,格式如 [2] $>[3]>[1]>\mid$ 等。所提出的方法直接对段落进行排序,而无需生成中间的相关性分数。
3.2 Sliding Window Strategy
3.2 滑动窗口策略
Due to the token limitations of LLMs, we can only rank a limited number of passages using the permutation generation approach. To overcome this constraint, we propose a sliding window strategy. Figure 3 illustrates an example of re-ranking 8 passages using a sliding window. Suppose the firststage retrieval model returns $M$ passages. We rerank these passages in a back-to-first order using a sliding window. This strategy involves two hyperparameters: window size $(w)$ and step size $(s)$ . We first use the LLMs to rank the passages from the $(M-w)$ -th to the $M$ -th. Then, we slide the window in steps of $s$ and re-rank the passages within the range from the $(M-w-s)$ -th to the $(M-s)$ - th. This process is repeated until all passages have been re-ranked.
由于大语言模型的token限制,我们只能通过排列生成方法对有限数量的段落进行排序。为突破这一限制,我们提出滑动窗口策略。图3展示了使用滑动窗口对8个段落进行重排序的示例。假设第一阶段检索模型返回$M$个段落,我们采用首尾相接的滑动窗口方式对这些段落进行重排序。该策略涉及两个超参数:窗口大小$(w)$和步长$(s)$。首先使用大语言模型对第$(M-w)$至第$M$个段落进行排序,随后以$s$为步长滑动窗口,对第$(M-w-s)$至第$(M-s)$个段落进行重排序,重复该过程直至所有段落完成重排序。
4 Specialization by Permutation Distillation
4 基于排列蒸馏的专精化
Although ChatGPT and GPT-4 are highly capable, they are also too expensive to deploy in commercial search systems. Using GPT-4 to re-rank passages will greatly increase the latency of the search system. In addition, large language models suffer from the problem of unstable generation. Therefore, we argue that the capabilities of large language models are redundant for the re-ranking task. Thus, we can distill the re-ranking capability of large language models into a small model by specialization.
尽管ChatGPT和GPT-4能力强大,但其部署成本过高,难以应用于商业搜索系统。使用GPT-4对段落进行重排序会显著增加搜索系统的延迟。此外,大语言模型存在生成不稳定的问题。因此,我们认为大语言模型的能力对于重排序任务而言是冗余的。通过专业化处理,我们可以将大语言模型的重排序能力蒸馏到一个小型模型中。
4.1 Permutation Distillation
4.1 排列蒸馏
In this paper, we present a novel permutation distillation method that aims to distill the passage reranking capability of ChatGPT into a specialized model. The key difference between our approach and previous distillation methods is that we directly use the model-generated permutation as the target, without introducing any inductive bias such as consistency-checking or log-probability manipulation (Bonifacio et al., 2022; Sachan et al., 2023). To achieve this, we sample 10,000 queries from MS MARCO and retrieve 20 candidate passages using BM25 for each query. The objective of distillation aims to reduce the differences between the permutation outputs of the student and ChatGPT.
本文提出了一种新颖的排列蒸馏方法,旨在将ChatGPT的段落重排序能力蒸馏到一个专用模型中。我们的方法与以往蒸馏方法的关键区别在于:直接使用模型生成的排列作为目标,而不引入任何归纳偏置(如一致性检查或对数概率调整)(Bonifacio et al., 2022; Sachan et al., 2023)。为此,我们从MS MARCO中采样10,000个查询,并使用BM25为每个查询检索20个候选段落。蒸馏的目标是减少学生模型与ChatGPT在排列输出上的差异。
4.2 Training Objective
4.2 训练目标
Formally, suppose we have a query $q$ and $M$ passages $\left(p_{1},\ldots,p_{M}\right)$ retrieved by BM25 ( $M=20$ in our implementation). ChatGPT with instructional permutation generation could produce the ranking results of the $M$ passages, denoted as $R=\left(r_{1},...,r_{M}\right)$ , where $r_{i}\in[1,2,\dots,M]$ is the rank of the passage $p_{i}$ . For example, $r_{i}=3$ means $p_{i}$ ranks third among the $M$ passages. Now we have a specialized model $s_{i}=f_{\theta}(q,p_{i})$ with parameters $\theta$ to calculate the relevance score $s_{i}$ of paired $(q,p_{i})$ using a cross-encoder. Using the permutation $R$ generated by ChatGPT, we consider RankNet loss (Burges et al., 2005) to optimize the student model:
形式上,假设我们有一个查询 $q$ 和由 BM25 检索到的 $M$ 个段落 $\left(p_{1},\ldots,p_{M}\right)$ (在我们的实现中 $M=20$ )。带有指令排列生成功能的 ChatGPT 可以生成这 $M$ 个段落的排序结果,记为 $R=\left(r_{1},...,r_{M}\right)$ ,其中 $r_{i}\in[1,2,\dots,M]$ 是段落 $p_{i}$ 的排名。例如, $r_{i}=3$ 表示 $p_{i}$ 在 $M$ 个段落中排名第三。现在我们有一个专用模型 $s_{i}=f_{\theta}(q,p_{i})$ ,其参数为 $\theta$ ,用于通过交叉编码器计算配对 $(q,p_{i})$ 的相关性分数 $s_{i}$ 。利用 ChatGPT 生成的排列 $R$ ,我们采用 RankNet 损失 (Burges et al., 2005) 来优化学生模型:
$$
\mathcal{L}_ {\mathrm{RankNet}}=\sum_{i=1}^{M}\sum_{j=1}^{M}\mathbb{1}_ {r_{i}<r_{j}}\log(1+\exp(s_{j}-s_{i}))
$$
$$
\mathcal{L}_ {\mathrm{RankNet}}=\sum_{i=1}^{M}\sum_{j=1}^{M}\mathbb{1}_ {r_{i}<r_{j}}\log(1+\exp(s_{j}-s_{i}))
$$
RankNet is a pairwise loss that measures the correctness of relative passage orders. When using permutations generated by ChatGPT, we can construct $M(M-1)/2$ pairs.
RankNet是一种成对损失函数,用于衡量段落相对顺序的正确性。当使用ChatGPT生成的排列时,我们可以构建$M(M-1)/2$个配对。
4.3 Specialized Model Architecture
4.3 专用模型架构
Regarding the architecture of the specialized model, we consider two model structures: the BERT-like model and the GPT-like model.
关于专用模型的架构,我们考虑了两种模型结构:类似BERT的模型和类似GPT的模型。
4.3.1 BERT-like model.
4.3.1 类BERT模型
We utilize a cross-encoder model (Nogueira and Cho, 2019) based on DeBERTa-large. It concatenates the query and passage with a [SEP] token and estimates relevance using the representation of the [CLS] token.
我们采用基于DeBERTa-large的交叉编码器模型 (Nogueira and Cho, 2019) 。该模型通过[SEP] token连接查询和段落,并利用[CLS] token的表征来估计相关性。
4.3.2 GPT-like model.
4.3.2 类GPT模型
We utilize the LLaMA-7B (Touvron et al., 2023) with a zero-shot relevance generation instruction (see Appendix A). It classifies the query and passage as relevance or irrelevance by generating a relevance token. The relevance score is then defined as the generation probability of the relevance token.
我们采用LLaMA-7B (Touvron et al., 2023) 模型配合零样本相关性生成指令 (详见附录A) 。该模型通过生成一个相关性token (relevance token) 将查询和段落分类为相关或不相关,随后将相关性得分定义为该相关性token的生成概率。
Figure 5 illustrates the structure of the two types of specialized models.
图 5: 展示了两类专用模型的结构。
5 Datasets
5 数据集
Our experiments are conducted on three benchmark datasets and one newly collected test set NovelEval.
我们的实验在三个基准数据集和一个新收集的测试集NovelEval上进行。
5.1 Benchmark Datasets
5.1 基准数据集
The benchmark datasets include, TRECDL (Craswell et al., 2020), BEIR (Thakur et al., 2021), and Mr.TyDi (Zhang et al., 2021).
基准数据集包括 TRECDL (Craswell et al., 2020)、BEIR (Thakur et al., 2021) 和 Mr.TyDi (Zhang et al., 2021)。
TREC is a widely used benchmark dataset in IR research. We use the test sets of the 2019 and 2020 competitions: (i) TREC-DL19 contains 43 queries, (ii) TREC-DL20 contains 54 queries.
TREC是信息检索(IR)研究中广泛使用的基准数据集。我们使用2019年和2020年竞赛的测试集:(i) TREC-DL19包含43个查询,(ii) TREC-DL20包含54个查询。
BEIR consists of diverse retrieval tasks and domains. We choose eight tasks in BEIR to evaluate the models: (i) Covid: retrieves scientific articles for COVID-19 related questions. (ii) NFCorpus is a bio-medical IR data. (iii) Touche is an argument retrieval datasets. (iv) DBPedia retrieves entities from DBpedia corpus. (v) SciFact retrieves evidence for claims verification. (vi) Signal retrieves relevant tweets for a given news title. (vii) News retrieves relevant news articles for news headlines. (viii) Robust04 evaluates poorly performing topics.
BEIR包含多样化的检索任务和领域。我们选择了BEIR中的八项任务来评估模型:(i) Covid:检索与COVID-19相关问题相关的科学文章。(ii) NFCorpus是一个生物医学信息检索数据集。(iii) Touche是一个论点检索数据集。(iv) DBPedia从DBpedia语料库中检索实体。(v) SciFact为声明验证检索证据。(vi) Signal为给定新闻标题检索相关推文。(vii) News为新闻标题检索相关新闻文章。(viii) Robust04评估表现不佳的主题。
Mr.TyDi is a multilingual passages retrieval dataset of ten low-resource languages: Arabic, Bengali, Finnish, Indonesian, Japanese, Korean, Russian, Swahili, Telugu, and Thai. We use the first 100 samples in the test set of each language.
Mr.TyDi是一个包含十种低资源语言的多语言段落检索数据集,涵盖阿拉伯语、孟加拉语、芬兰语、印尼语、日语、韩语、俄语、斯瓦希里语、泰卢固语和泰语。我们使用每种语言测试集中的前100个样本。
5.2 A New Test Set – NovelEval
5.2 新测试集 – NovelEval
The questions in the current benchmark dataset are typically gathered years ago, which raises the issue that existing LLMs already possess knowledge of these questions (Yu et al., 2023). Furthermore, since many LLMs do not disclose information about their training data, there is a potential risk of contamination of the existing benchmark test set (OpenAI, 2023). However, re-ranking models are expected to possess the capability to comprehend, deduce, and rank knowledge that is inherently unknown to them. Therefore, we suggest constructing continuously updated IR test sets to ensure that the questions, passages to be ranked, and relevance annotations have not been learned by the latest LLMs for a fair evaluation.
当前基准数据集中的问题通常采集于多年前,这导致现有大语言模型可能已掌握这些问题知识 (Yu et al., 2023) 。此外,由于许多大语言模型未公开训练数据信息,现有基准测试集存在潜在的数据污染风险 (OpenAI, 2023) 。但重排序模型应具备理解、推理和排序其未知知识的能力,因此我们建议构建持续更新的信息检索测试集,确保其中问题、待排序段落及相关性标注未被最新大语言模型学习,以实现公平评估。
As an initial effort, we built NovelEval-2306, a novel test set with 21 novel questions. This test set is constructed by gathering questions and passages from 4 domains that were published after the release of GPT-4. To ensure that GPT-4 did not possess prior knowledge of these questions, we presented them to both gpt-4-0314 and gpt-4-0613. For instance, question "Which film was the 2023 Palme d’Or winner?" pertains to the Cannes Film Festival that took place on May 27, 2023, rendering its answer inaccessible to most existing LLMs. Next, we searched 20 candidate passages for each question using Google search. The relevance of these passages was manually labeled as: 0 for not relevant, 1 for partially relevant, and 2 for relevant. See Appendix C for more details.
作为初步尝试,我们构建了NovelEval-2306测试集,包含21道新颖问题。该测试集通过收集GPT-4发布后出版的4个领域的问题和段落构建而成。为确保GPT-4不具备这些问题的事先知识,我们同时向gpt-4-0314和gpt-4-0613提交了这些问题。例如,问题"2023年金棕榈奖获奖影片是哪部?"涉及2023年5月27日举办的戛纳电影节,其答案对现有大多数大语言模型而言均不可获取。随后,我们通过谷歌搜索为每个问题检索了20个候选段落,并人工标注段落相关性:0表示不相关,1表示部分相关,2表示相关。详见附录C。
6 Experimental Results of LLMs
6 大语言模型的实验结果
6.1 Implementation and Metrics
6.1 实现与指标
In benchmark datasets, we re-rank the top-100 passages retrieved by BM25 using pyserini and use $\mathrm{nDCG}@{1,5,10}$ as evaluation metrics. Since ChatGPT cannot manage 100 passages at a time, we use the sliding window strategy introduced in Section 3.2 with a window size of 20 and step size of 10. In NovelEval, we randomly shuffled the 20 candidate passages searched by Google and re-ranked them using ChatGPT and GPT-4 with permutation generation.
在基准数据集中,我们使用pyserini对BM25检索到的前100个段落进行重新排序,并采用$\mathrm{nDCG}@{1,5,10}$作为评估指标。由于ChatGPT无法一次性处理100个段落,我们采用第3.2节介绍的滑动窗口策略(窗口大小为20,步长为10)。在NovelEval中,我们对Google搜索到的20个候选段落进行随机打乱,并使用ChatGPT和GPT-4通过排列生成进行重新排序。
6.2 Results on Benchmarks
6.2 基准测试结果
On benchmarks, we compare ChatGPT and GPT-4 with state-of-the-art supervised and unsupervised passage re-ranking methods. The supervised baselines include: monoBERT (Nogueira and Cho, 2019), monoT5 (Nogueira et al., 2020), mmarcoCE (Bonifacio et al., 2021), and Cohere Rerank 2. The unsupervised baselines include: UPR (Sachan et al., 2022), InPars (Bonifacio et al., 2022), and Prompt a gator $^{++}$ (Dai et al., 2023). See Appendix E for more details on implementing the baseline.
在基准测试中,我们将ChatGPT和GPT-4与最先进的监督式和非监督式段落重排序方法进行比较。监督式基线包括:monoBERT (Nogueira and Cho, 2019)、monoT5 (Nogueira et al., 2020)、mmarcoCE (Bonifacio et al., 2021) 以及 Cohere Rerank 2。非监督式基线包括:UPR (Sachan et al., 2022)、InPars (Bonifacio et al., 2022) 以及 Promptagator$^{++}$ (Dai et al., 2023)。具体基线实现细节参见附录E。
Table 1 presents the evaluation results obtained from the TREC and BEIR datasets. The following observations can be made: (i) GPT-4, when equipped with the permutation generation instruction, demonstrates superior performance on both datasets. Notably, GPT-4 achieves an average improvement of 2.7 and 2.3 in $\mathrm{nDCG}@10$ on TREC and BEIR, respectively, compared to monoT5 (3B). (ii) ChatGPT also exhibits impressive results on the BEIR dataset, surpassing the majority of supervised baselines. (iii) On BEIR, we use only GPT-4 to re-rank the top-30 passages re-ranked by ChatGPT. The method achieves good results, while the cost is only 1/5 of that of only using GPT-4 for re-ranking.
表 1: 展示了从 TREC 和 BEIR 数据集获得的评估结果。可以得出以下观察:(i) 配备排列生成指令的 GPT-4 在两个数据集上均表现出更优性能。值得注意的是,与 monoT5 (3B) 相比,GPT-4 在 TREC 和 BEIR 上的 $\mathrm{nDCG}@10$ 分别平均提升了 2.7 和 2.3。(ii) ChatGPT 在 BEIR 数据集上也展现了令人印象深刻的结果,超越了大多数有监督基线。(iii) 在 BEIR 上,我们仅使用 GPT-4 对 ChatGPT 重排后的前 30 个段落进行二次重排。该方法取得了良好效果,而成本仅为仅使用 GPT-4 重排的 1/5。
Table 2 illustrates the results on Mr. TyDi of ten low-resource languages. Overall, GPT-4 outperforms the supervised system in most languages, demonstrating an average improvement of 2.65 nDCG over mmarcoCE. However, there are instances where GPT-4 performs worse than mmarcoCE, particularly in low-resource languages like Bengali, Telugu, and Thai. This may be attributed to the weaker language modeling ability of GPT-4 in these languages and the fact that text in lowresource languages tends to consume more tokens than English text, leading to the over-cropping of passages. Similar trends are observed with ChatGPT, which is on par with the supervised system in most languages, and consistently trails behind GPT-4 in all languages.
表 2: 展示了十种低资源语言在 Mr. TyDi 数据集上的评测结果。总体而言,GPT-4 在多数语言中表现优于监督系统 mmarcoCE,平均 nDCG 提升了 2.65。但在孟加拉语、泰卢固语和泰语等低资源语言中,GPT-4 表现不及 mmarcoCE,这可能源于 GPT-4 对这些语言的建模能力较弱,且低资源语言文本通常比英语消耗更多 token,导致段落被过度截断。ChatGPT 也呈现类似趋势,其在多数语言中与监督系统持平,但在所有语言中均落后于 GPT-4。
Table 1: Results $\mathbf{\Pi}(\mathbf{nDCG}@\mathbf{10})$ on TREC and BEIR. Best performing unsupervised and overall system(s) are marked bold. All models except InPars and Prompt a gator $^{++}$ re-rank the same BM25 top-100 passages. $^\dagger\mathrm{On}$ BEIR, we use gpt $^{-4}$ to re-rank the top-30 passages re-ranked by gpt $-3.5\cdot$ -turbo to reduce the cost of calling gpt $^{-4}$ API.
| Method | DL19 DL20|Covid NFCorpus Touche DBPedia SciFact Signal News Robust04|BEIR (Avg) | |||||||||
| BM25 | 50.58 47.96|59.47 | 30.75 | 44.22 | 31.80 | 67.89 | 33.05 39.52 | 40.70 | 43.42 | ||
| Supervised | ||||||||||
| monoBERT (340M) | 70.50 67.28 | 70.01 | 36.88 | 31.75 | 41.87 | 71.36 | 31.44 44.62 | 49.35 | 47.16 | |
| monoT5 (220M) | 71.48 66.99 | 78.34 | 37.38 | 30.82 | 42.42 | 73.40 | 31.67 46.83 | 51.72 | 49.07 | |
| monoT5 (3B) | 71.83 68.89 | 80.71 | 38.97 | 32.41 | 44.45 | 76.57 | 32.55 48.49 | 56.71 | 51.36 | |
| CohereRerank-v2 | 73.22 67.08 | 81.81 | 36.36 | 32.51 | 42.51 | 74.44 | 29.60 47.59 | 50.78 | 49.45 | |
| Unsupervised | ||||||||||
| UPR (FLAN-T5-XL) | 53.85 56.02 | 68.11 | 35.04 | 19.69 | 30.91 | 72.69 | 31.91 43.11 | 42.43 | 42.99 | |
| InPars (monoT5-3B) | 66.12 78.35 | |||||||||
| Promptagator++(few-shot) | 76.2 | 37.0 | 38.1 | 43.4 | 73.1 | |||||
| LLMAPI(Permutationgeneration) | ||||||||||
| gpt-3.5-turbo | 65.80 62.91 | 76.67 | 35.62 | 36.18 | 44.47 | 70.43 | 32.12 | 48.85 | 50.62 | 49.37 |
| gpt-4t | 75.59 70.56 | 85.51 | 38.47 | 38.57 | 47.12 | 74.95 | 34.40 52.89 | 57.55 | 53.68 | |
表 1: TREC 和 BEIR 上的 $\mathbf{\Pi}(\mathbf{nDCG}@\mathbf{10})$ 结果。表现最佳的无监督和整体系统以粗体标出。除 InPars 和 Promptagator$^{++}$ 外,所有模型都对相同的 BM25 前 100 段落进行重排序。$^\dagger\mathrm{在}$ BEIR 上,我们使用 gpt$^{-4}$ 对由 gpt$-3.5\cdot$-turbo 重排序的前 30 段落进行重排序,以降低调用 gpt$^{-4}$ API 的成本。
| 方法 | DL19 | DL20 | Covid | NFCorpus | Touche | DBPedia | SciFact | Signal | News | Robust04 | BEIR (Avg) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BM25 | 50.58 | 47.96 | 59.47 | 30.75 | 44.22 | 31.80 | 67.89 | 33.05 | 39.52 | 40.70 | 43.42 |
| 监督 | |||||||||||
| monoBERT (340M) | 70.50 | 67.28 | 70.01 | 36.88 | 31.75 | 41.87 | 71.36 | 31.44 | 44.62 | 49.35 | 47.16 |
| monoT5 (220M) | 71.48 | 66.99 | 78.34 | 37.38 | 30.82 | 42.42 | 73.40 | 31.67 | 46.83 | 51.72 | 49.07 |
| monoT5 (3B) | 71.83 | 68.89 | 80.71 | 38.97 | 32.41 | 44.45 | 76.57 | 32.55 | 48.49 | 56.71 | 51.36 |
| CohereRerank-v2 | 73.22 | 67.08 | 81.81 | 36.36 | 32.51 | 42.51 | 74.44 | 29.60 | 47.59 | 50.78 | 49.45 |
| 无监督 | |||||||||||
| UPR (FLAN-T5-XL) | 53.85 | 56.02 | 68.11 | 35.04 | 19.69 | 30.91 | 72.69 | 31.91 | 43.11 | 42.43 | 42.99 |
| InPars (monoT5-3B) | 66.12 | 78.35 | |||||||||
| Promptagator++ (few-shot) | 76.2 | 37.0 | 38.1 | 43.4 | 73.1 | ||||||
| LLMAPI (排列生成) | |||||||||||
| gpt-3.5-turbo | 65.80 | 62.91 | 76.67 | 35.62 | 36.18 | 44.47 | 70.43 | 32.12 | 48.85 | 50.62 | 49.37 |
| gpt-4t | 75.59 | 70.56 | 85.51 | 38.47 | 38.57 | 47.12 | 74.95 | 34.40 | 52.89 | 57.55 | 53.68 |
Table 2: Results (nDCG $@10$ ) on Mr.TyDi.
| Method | BM25 | mmarcoCE | gpt-3.5 | +gpt-4 |
| Arabic | 39.19 | 68.18 | 71.00 | 72.56 |
| Bengali | 45.56 | 65.98 | 53.10 | 64.37 |
| Finnish | 29.91 | 54.15 | 56.48 | 62.29 |
| Indonesian | 51.79 | 69.94 | 68.45 | 75.47 |
| Japanese | 27.39 | 49.80 | 50.70 | 58.22 |
| Korean | 26.29 | 44.00 | 41.48 | 49.63 |
| Russian | 34.04 | 53.16 | 48.75 | 53.45 |
| Swahili | 45.15 | 60.31 | 62.38 | 67.67 |
| Telugu | 37.05 | 68.92 | 51.69 | 62.22 |
| Thai | 44.62 | 68.36 | 55.57 | 63.41 |
| Avg | 38.10 | 60.28 | 55.96 | 62.93 |
表 2: Mr.TyDi 上的结果 (nDCG $@10$ )
| 方法 | BM25 | mmarcoCE | gpt-3.5 | +gpt-4 |
|---|---|---|---|---|
| Arabic | 39.19 | 68.18 | 71.00 | 72.56 |
| Bengali | 45.56 | 65.98 | 53.10 | 64.37 |
| Finnish | 29.91 | 54.15 | 56.48 | 62.29 |
| Indonesian | 51.79 | 69.94 | 68.45 | 75.47 |
| Japanese | 27.39 | 49.80 | 50.70 | 58.22 |
| Korean | 26.29 | 44.00 | 41.48 | 49.63 |
| Russian | 34.04 | 53.16 | 48.75 | 53.45 |
| Swahili | 45.15 | 60.31 | 62.38 | 67.67 |
| Telugu | 37.05 | 68.92 | 51.69 | 62.22 |
| Thai | 44.62 | 68.36 | 55.57 | 63.41 |
| Avg | 38.10 | 60.28 | 55.96 | 62.93 |
6.3 Results on NovelEval
6.3 NovelEval 实验结果
Table 3 illustrates the evaluation results on our newly collected NovelEval, a test set containing 21 novel questions and 420 passages that GPT-4 had not learned. The results show that GPT-4 performs well on these questions, significantly outperforming the previous best-supervised method, monoT5 (3B). Additionally, ChatGPT achieves a performance level comparable to that of monoBERT. This outcome implies that LLMs possess the capability to effectively re-rank unfamiliar information.
表 3: 展示了我们在新收集的 NovelEval 测试集上的评估结果,该测试集包含 21 个 GPT-4 未曾学习过的新颖问题和 420 篇文章。结果表明,GPT-4 在这些问题上表现良好,显著优于之前表现最佳的监督方法 monoT5 (3B)。此外,ChatGPT 达到了与 monoBERT 相当的性能水平。这一结果意味着大语言模型具备有效重排陌生信息的能力。
Table 3: Results on NovelEval.
| Method | nDCG@1 | nDCG@5 | nDCG@10 |
| BM25 | 33.33 | 45.96 | 55.77 |
| monoBERT (340M) | 78.57 | 70.65 | 77.27 |
| monoT5 (220M) | 83.33 | 77.46 | 81.27 |
| monoT5 (3B) | 83.33 | 78.38 | 84.62 |
| gpt-3.5-turbo | 76.19 | 74.15 | 75.71 |
| gpt-4 | 85.71 | 87.49 | 90.45 |
表 3: NovelEval 实验结果
| 方法 | nDCG@1 | nDCG@5 | nDCG@10 |
|---|---|---|---|
| BM25 | 33.33 | 45.96 | 55.77 |
| monoBERT (340M) | 78.57 | 70.65 | 77.27 |
| monoT5 (220M) | 83.33 | 77.46 | 81.27 |
| monoT5 (3B) | 83.33 | 78.38 | 84.62 |
| gpt-3.5-turbo | 76.19 | 74.15 | 75.71 |
| gpt-4 | 85.71 | 87.49 | 90.45 |
Table 4: Compare different instruction and API endpoint. Best performing system(s) are marked bold. PG, QG, RG denote permutation generation, query generation and relevance generation, respectively.
| Method | DL19 nDCG@1/5/10 | DL20 nDCG@1/5/10 |
| curie-001 | ||
| curie-001 | QG50.78/50.77/49.7650.00/48.36/48.73 | |
| curie-001 | ||
| gpt-3.5 | PG82.17/71.15/65.8079.32/66.76/62.91 | |
| gpt-4 | PG82.56/79.16/75.5978.40/74.11/70.56 |
表 4: 不同指令与API端点的比较。性能最佳的系统以粗体标注。PG、QG、RG分别表示排列生成 (permutation generation)、查询生成 (query generation) 和相关生成 (relevance generation)。
| Method | DL19 nDCG@1/5/10 | DL20 nDCG@1/5/10 |
|---|---|---|
| curie-001 | ||
| curie-001 | QG50.78/50.77/49.7650.00/48.36/48.73 | |
| curie-001 | ||
| gpt-3.5 | PG82.17/71.15/65.8079.32/66.76/62.91 | |
| gpt-4 | PG82.56/79.16/75.5978.40/74.11/70.56 |
6.4 Compare with Different Instructions
6.4 不同指令对比
We conduct a comparison with the proposed permutation generation (PG) with previous query generation (QG) (Sachan et al., 2022) and relevance gen- eration (RG) (Liang et al., 2022) on TREC-DL19. An example of the three types of instructions is in Figure 2, and the detailed implementation is in Appendix B. We also compare four LLMs provided in the OpenAI $\mathsf{A P I}^{3}$ : curie-001 - GPT-3 model with about 6.7 billion parameters (Brown et al., 2020); davinci-003 - GPT-3.5 model trained with RLHF and about 175 billion parameters (Ouyang et al., 2022); gpt-3.5-turbo - The underlying model of ChatGPT (OpenAI, 2022); gpt-4 - GPT4 model (OpenAI, 2023).
我们在TREC-DL19上对比了提出的排列生成(PG)方法与先前的查询生成(QG) (Sachan et al., 2022) 和相关性生成(RG) (Liang et al., 2022)。图2展示了三类指令的示例,具体实现详见附录B。同时比较了OpenAI $\mathsf{A P I}^{3}$ 提供的四种大语言模型:curie-001 - 约67亿参数的GPT-3模型 (Brown et al., 2020);davinci-003 - 采用RLHF训练、约1750亿参数的GPT-3.5模型 (Ouyang et al., 2022);gpt-3.5-turbo - ChatGPT底层模型 (OpenAI, 2022);gpt-4 - GPT4模型 (OpenAI, 2023)。
Table 5: Ablation study on TREC-DL19. We use gpt-3.5-turbo with permutation generation with different configuration.
| Method | nDCG@11 | nDCG@5 | nDCG@10 |
| BM25 gpt-3.5-turbo | 54.26 | 52.78 | 50.58 |
| 82.17 | 71.15 | 65.80 | |
| Initialpassageorder | |||
| (1) | Random order 26.36 | 25.32 | 25.17 |
| (2) Reverse order | 36.43 | 31.79 | 32.77 |
| Numberofre-ranking | |||
| (3) | Re-rank 2 times 78.29 | 69.37 | 66.62 |
| (4) Re-rank3times | 78.29 | 69.74 | 66.97 |
| (5) gpt-4Rerank | 80.23 | 76.70 | 73.64 |
表 5: TREC-DL19消融实验。我们使用gpt-3.5-turbo进行不同配置的排列生成。
| 方法 | nDCG@11 | nDCG@5 | nDCG@10 |
|---|---|---|---|
| BM25 gpt-3.5-turbo | 54.26 | 52.78 | 50.58 |
| 82.17 | 71.15 | 65.80 | |
| 初始段落顺序 | |||
| (1) 随机顺序 | 26.36 | 25.32 | 25.17 |
| (2) 逆序 | 36.43 | 31.79 | 32.77 |
| 重排次数 | |||
| (3) 重排2次 | 78.29 | 69.37 | 66.62 |
| (4) 重排3次 | 78.29 | 69.74 | 66.97 |
| (5) gpt-4重排 | 80.23 | 76.70 | 73.64 |
The results are listed in Table 4. From the results, we can see that: (i) The proposed PG method outperforms both QG and RG methods in instructing LLMs to re-rank passages. We suggest two explanations: First, from the result that PG has significantly higher top-1 accuracy compared to other methods, we infer that LLMs can explicitly compare multiple passages with PG, allowing subtle differences between passages to be discerned. Second, LLMs gain a more comprehensive understanding of the query and passages by reading multiple passages with potentially complementary information, thus improving the model’s ranking ability. (ii) With PG, ChatGPT performs comparably to GPT-4 on $\textstyle{\mathrm{nDCG}}\ @1$ , but lags behind it on $\mathrm{nDCG}@10$ . The Davinci model (text-davinci-003) performs poorly compared to ChatGPT and GPT-4. This may be because of the generation stability of Davinci and ChatGPT trails that of GPT-4. We delve into the stability analysis of Davinci, ChatGPT, and GPT-4 in Appendix F.
结果如表 4 所示。从结果可以看出:(i) 在指导大语言模型进行段落重排序时,所提出的 PG 方法优于 QG 和 RG 方法。我们提出两种解释:首先,PG 方法的 top-1 准确率显著高于其他方法,这表明大语言模型能通过 PG 显式比较多个段落,从而识别段落间的细微差异;其次,通过阅读可能包含互补信息的多个段落,大语言模型能更全面地理解查询和段落内容,从而提升排序能力。(ii) 使用 PG 方法时,ChatGPT 在 $\textstyle{\mathrm{nDCG}}\ @1$ 指标上与 GPT-4 表现相当,但在 $\mathrm{nDCG}@10$ 指标上落后。Davinci 模型 (text-davinci-003) 的表现远逊于 ChatGPT 和 GPT-4,这可能源于 Davinci 和 ChatGPT 的生成稳定性不及 GPT-4。我们在附录 F 中对 Davinci、ChatGPT 和 GPT-4 的稳定性进行了深入分析。
6.5 Ablation Study on TREC
6.5 TREC消融实验
We conducted an ablation study on TREC to gain insights into the detailed configuration of permutation generation. Table 5 illustrates the results.
我们在TREC上进行了消融研究,以深入了解排列生成的详细配置。表5展示了结果。
Initial Passage Order While our standard implementation utilizes the ranking result of BM25 as the initial order, we examined two alternative variants: random order (1) and reversed BM25 order (2). The results reveal that the model’s performance is highly sensitive to the initial passage order. This could be because BM25 provides a relatively good starting passage order, enabling satisfactory results with only a single sliding window re-ranking.
初始段落顺序
虽然我们的标准实现使用BM25的排序结果作为初始顺序,但我们研究了两种替代方案:随机顺序 (1) 和反向BM25顺序 (2)。结果表明,模型性能对初始段落顺序高度敏感。这可能是因为BM25提供了相对较好的初始段落顺序,仅需单次滑动窗口重排序即可获得满意结果。
Number of Re-Ranking Furthermore, we studied the influence of the number of sliding window passes. Models (3-4) in Table 5 show that reranking more times may improve $\mathrm{nDCG}@10$ , but it somehow hurts the ranking performance on top passages (e.g., $\textstyle{\mathrm{nDCG}}\ @1$ decreased by 3.88). Reranking the top 30 passages using GPT-4 showed notable accuracy improvements (see the model (5)). This provides an alternative method to combine ChatGPT and GPT-4 in passage re-ranking to reduce the high cost of using the GPT-4 model.
重排序次数
此外,我们研究了滑动窗口遍历次数的影响。表5中的模型(3-4)表明,增加重排序次数可能提升$\mathrm{nDCG}@10$,但会略微损害顶部段落排序性能(例如$\textstyle{\mathrm{nDCG}}\ @1$下降3.88)。使用GPT-4对前30个段落重排序显示出显著准确率提升(见模型(5))。这为结合ChatGPT和GPT-4进行段落重排序提供了一种替代方案,可降低GPT-4模型的高使用成本。
6.6 Results of LLMs beyond ChatGPT
6.6 超越ChatGPT的大语言模型成果
We further test the capabilities of other LLMs beyond the OpenAI series on TREC DL-19. As shown in Table 6, we evaluate the top-20 BM25 passage re-ranking nDCG of proprietary LLMs from OpenAI, Cohere, Antropic, and Google, and three open-source LLMs. We see that: (i) Among the proprietary LLMs, GPT-4 exhibited the highest reranking performance. Cohere Re-rank also showed promising results; however, it should be noted that it is a supervised specialized model. In contrast, the proprietary models from Antropic and Google fell behind ChatGPT in terms of re-ranking effectiveness. (ii) As for the open-source LLMs, we observed a significant performance gap compared to ChatGPT. One possible reason for this discrepancy could be the complexity involved in generating permutations of 20 passages, which seems to pose a challenge for the existing open-source models.
我们进一步测试了OpenAI系列之外的其他大语言模型在TREC DL-19上的能力。如表6所示,我们评估了来自OpenAI、Cohere、Antropic和Google的专有大语言模型以及三个开源大语言模型在top-20 BM25段落重排序nDCG上的表现。我们发现:(i) 在专有大语言模型中,GPT-4展现出最高的重排序性能。Cohere Re-rank也显示出不错的结果,但需注意它是一个有监督的专用模型。相比之下,Antropic和Google的专有模型在重排序效果上落后于ChatGPT。(ii) 至于开源大语言模型,我们观察到其性能与ChatGPT存在显著差距。造成这种差异的一个可能原因是生成20个段落排列所涉及的复杂性,这对现有开源模型似乎构成了挑战。
We analyze the model’s unexpected behavior in Appendix F, and the cost of API in Appendix H.
我们在附录 F 中分析了模型的意外行为,并在附录 H 中分析了 API 成本。
7 Experimental Results of Specialization
7 专业化的实验结果
As mentioned in Section 4, we randomly sample 10K queries from the MSMARCO training set and employ the proposed permutation distillation to distill ChatGPT’s predicted permutation into specialized re-ranking models. The specialized re-ranking models could be DeBERTa-v3-Large with a crossencoder architecture or LLaMA-7B with relevance generation instructions. We also implemented the specialized model trained using the original MS MARCO labels (aka supervised learning) for com
如第4节所述,我们从MSMARCO训练集中随机抽取10K个查询,并采用提出的排列蒸馏方法将ChatGPT预测的排列蒸馏到专用重排序模型中。专用重排序模型可以是采用交叉编码器架构的DeBERTa-v3-Large,或是带有相关性生成指令的LLaMA-7B。我们还实现了使用原始MS MARCO标签(即监督学习)训练的专用模型用于对比。
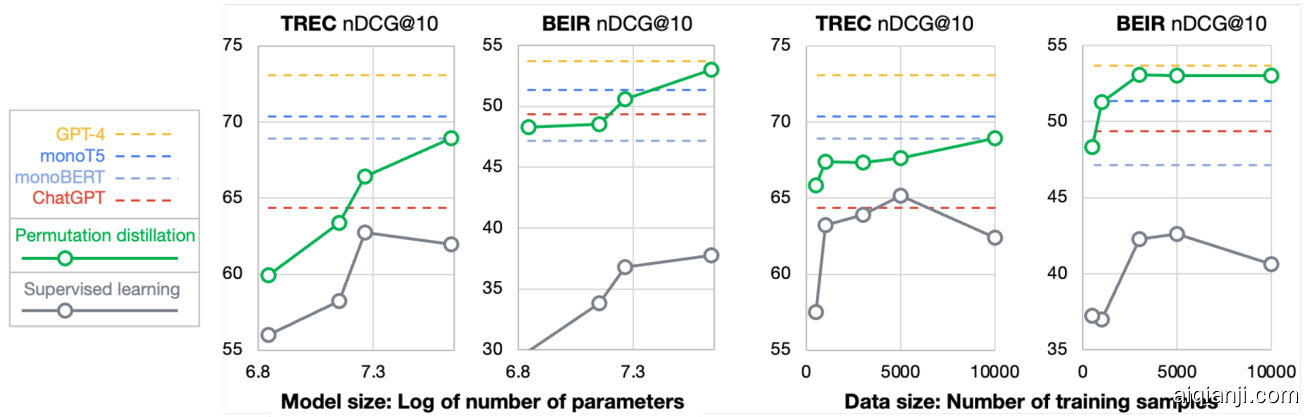
Figure 4: Scaling experiment. The dashed line indicates the baseline methods: GPT-4, monoT5, monoBERT, and ChatGPT. The solid green line and solid gray line indicate the specialized Deberta models obtained by the proposed permutation distillation and by supervised learning on MS MARCO, respectively. This figure compares the models’ performance on TREC and BEIR across varying model sizes (70M to 435M) and training data sizes (500 to 10K).
图 4: 缩放实验。虚线表示基线方法:GPT-4、monoT5、monoBERT 和 ChatGPT。绿色实线和灰色实线分别表示通过提出的排列蒸馏和在 MS MARCO 上进行监督学习获得的专用 Deberta 模型。该图比较了不同模型规模 (70M 至 435M) 和训练数据规模 (500 至 10K) 下模型在 TREC 和 BEIR 上的性能。
Table 6: Results of different LLMs on re-ranking top-20 passages on DL-19. ND{1,5,10} denote nDCG $@$ {1,5,10}, respectively.
| Method | ND1 | ND5 | ND10 |
| OpenAItext-davinci-003 | 70.54 | 61.90 | 57.24 |
| OpenAI gpt-3.5-turbo | 75.58 | 66.19 | 60.89 |
| OpenAI gpt-4 | 79.46 | 71.65 | 65.68 |
| Cohere rerank-english-v2.0 | 79.46 | 71.56 | 64.78 |
| Antropic claude-2 | 66.66 | 59.33 | 55.91 |
| Antropic claude-instant-1 | 81.01 | 66.71 | 62.23 |
| Google text-bison-001 | 69.77 | 64.46 | 58.67 |
| Go0gle bard-2023.10.21 | 81.01 | 65.57 | 60.11 |
| Google flan-t5-xxl | 52.71 | 51.63 | 50.26 |
| Tsinghua ChatGLM-6B | 54.26 | 52.77 | 50.58 |
| LMSYSVicuna-13B | 54.26 | 51.55 | 49.08 |
表 6: 不同大语言模型在DL-19数据集上对前20段落的重新排序结果。ND{1,5,10}分别表示nDCG $@$ {1,5,10}。
| 方法 | ND1 | ND5 | ND10 |
|---|---|---|---|
| OpenAI text-davinci-003 | 70.54 | 61.90 | 57.24 |
| OpenAI gpt-3.5-turbo | 75.58 | 66.19 | 60.89 |
| OpenAI gpt-4 | 79.46 | 71.65 | 65.68 |
| Cohere rerank-english-v2.0 | 79.46 | 71.56 | 64.78 |
| Antropic claude-2 | 66.66 | 59.33 | 55.91 |
| Antropic claude-instant-1 | 81.01 | 66.71 | 62.23 |
| Google text-bison-001 | 69.77 | 64.46 | 58.67 |
| Google bard-2023.10.21 | 81.01 | 65.57 | 60.11 |
| Google flan-t5-xxl | 52.71 | 51.63 | 50.26 |
| 清华 ChatGLM-6B | 54.26 | 52.77 | 50.58 |
| LMSYS Vicuna-13B | 54.26 | 51.55 | 49.08 |
Table 7: Results $\mathbf{\Pi}(\mathbf{nDCG}@\mathbf{10})$ of specialized models. Best performing specialized model(s) are marked bold. The label column denotes the relevance judgements used in model training, where MARCO denotes use MS MARCO annotation, ChatGPT denotes use the outputs of permutation generation instructed ChatGPT as labels. BEIR (Avg) denotes average nDCG on eight BEIR datasets, and the detailed results are at Table 13.
| Label | Method | DL19 DL20 | BEIR R(Avg) |
| BM25 | 50.58 47.96 | 43.42 | |
| ChatGPT | 65.80 62.91 | 49.37 | |
| MARCO | monoT5 (3B) | 71.83 68.89 | 51.36 |
| MARCO | DeBERTa-Large | 68.89 61.38 | 42.64 |
| MARCO | LLaMA-7B | 69.24 58.97 | 47.71 |
| ChatGPT | DeBERTa-Large | 70.66 67.15 | 53.03 |
| ChatGPT | LLaMA-7B | 71.78 66.89 | 51.68 |
表 7: 专用模型的 $\mathbf{\Pi}(\mathbf{nDCG}@\mathbf{10})$ 结果。表现最佳的专用模型已加粗标注。标签列表示模型训练中使用的相关性标注,其中MARCO表示使用MS MARCO标注,ChatGPT表示使用排列生成指令ChatGPT的输出作为标签。BEIR (Avg)表示八个BEIR数据集上的平均nDCG,详细结果见表13。
| 标签 | 方法 | DL19 DL20 | BEIR R(Avg) |
|---|---|---|---|
| BM25 | 50.58 47.96 | 43.42 | |
| ChatGPT | 65.80 62.91 | 49.37 | |
| MARCO | monoT5 (3B) | 71.83 68.89 | 51.36 |
| MARCO | DeBERTa-Large | 68.89 61.38 | 42.64 |
| MARCO | LLaMA-7B | 69.24 58.97 | 47.71 |
| ChatGPT | DeBERTa-Large | 70.66 67.15 | 53.03 |
| ChatGPT | LLaMA-7B | 71.78 66.89 | 51.68 |
parison4.
对比4.
7.1 Results on Benchmarks
7.1 基准测试结果
Table 7 lists the results of specialized models, and Table 13 includes the detailed results. Our findings can be summarized as follows: (i) Permutation distillation outperforms the supervised counterpart on both TREC and BEIR datasets, potentially because ChatGPT’s relevance judgments are more comprehensive than MS MARCO labels (Arabzadeh et al., 2021). (ii) The specialized DeBERTa model outperforms previous state-of-the-art (SOTA) baselines, monoT5 (3B), on BEIR with an average nDCG of 53.03. This result highlights the potential of distilling LLMs for IR since it is significantly more cost-efficient. (iii) The distilled specialized model also surpasses ChatGPT, its teacher model, on both datasets. This is probably because the re-ranking stability of specialized models is better than ChatGPT. As shown in the stability analysis in Appendix F, ChatGPT is very unstable in generating permutations.
表7列出了专用模型的结果,表13包含了详细结果。我们的发现可总结如下:(i) 在TREC和BEIR数据集上,排列蒸馏(permutation distillation)的表现优于监督学习对照方法,这可能是因为ChatGPT的相关性判断比MS MARCO标签更全面(Arabzadeh et al., 2021)。(ii) 专用DeBERTa模型在BEIR上以53.03的平均nDCG超越了先前的最先进(SOTA)基线monoT5(3B),这一结果凸显了用大语言模型进行信息检索(IR)蒸馏的潜力,因为其成本效益显著更高。(iii) 蒸馏后的专用模型在两个数据集上都超越了其教师模型ChatGPT,这可能是因为专用模型的重新排序稳定性优于ChatGPT。如附录F的稳定性分析所示,ChatGPT在生成排列时非常不稳定。
7.2 Analysis on Model Size and Data Size
7.2 模型规模与数据规模分析
In Figure 4, we present the re-ranking performance of specialized DeBERTa models obtained through permutation distillation and supervised learning of different model sizes (ranging from 70M to 435M) and training data sizes (ranging from 500 to 10K). Our findings indicate that the permutation-distilled models consistently outperform their supervised counterparts across all settings, particularly on the BEIR datasets. Notably, even with only 1K training queries, the permutation-distilled DeBERTa model achieves superior performance compared to the previous state-of-the-art monoT5 (3B) model on BEIR. We also observe that increasing the number of model parameters yields a greater improvement in the ranking results than increasing the training data. Finally, we find that the performance of supervised models is unstable for different model sizes and data sizes. This may be due to the presence of noise in the MS MARCO labels, which leads to over fitting problems (Arabzadeh et al., 2021).
在图4中,我们展示了通过排列蒸馏和监督学习获得的不同模型规模(从70M到435M)和训练数据规模(从500到10K)的专用DeBERTa模型的重新排序性能。我们的研究结果表明,排列蒸馏模型在所有设置中始终优于监督学习模型,尤其是在BEIR数据集上。值得注意的是,即使只有1K训练查询,排列蒸馏的DeBERTa模型在BEIR上的性能也优于之前最先进的monoT5(3B)模型。我们还观察到,增加模型参数数量比增加训练数据更能提高排序结果。最后,我们发现监督学习模型的性能在不同模型规模和数据规模下不稳定。这可能是由于MS MARCO标签中存在噪声,导致过拟合问题(Arabzadeh et al., 2021)。
8 Conclusion
8 结论
In this paper, we conduct a comprehensive study on passage re-ranking with LLMs. We introduce a novel permutation generation approach to fully explore the power of LLMs. Our experiments on three benchmarks have demonstrated the capability of ChatGPT and GPT-4 in passage re-ranking. To further validate LLMs on unfamiliar knowledge, we introduce a new test set called NovelEval. Additionally, we propose a permutation distillation method, which demonstrates superior effectiveness and efficiency compared to existing supervised approaches.
本文针对大语言模型(LLM)在段落重排序任务中的表现进行了全面研究。我们提出了一种新颖的排列生成方法,以充分挖掘大语言模型的潜力。在三个基准测试上的实验表明,ChatGPT和GPT-4具备出色的段落重排序能力。为了进一步验证大语言模型在陌生知识领域的表现,我们提出了名为NovelEval的新测试集。此外,我们还提出了一种排列蒸馏方法,与现有监督方法相比,该方法展现出更优的效能和效率。
Limitations
局限性
The limitations of this work include the main analysis for OpenAI ChatGPT and GPT-4, which are proprietary models that are not open-source. Although we also tested on open-source models such as FLAN-T5, ChatGLM-6B, and Vicuna-13B, the results still differ significantly from ChatGPT. How to further exploit the open-source models is a question worth exploring. Additionally, this study solely focuses on examining LLMs in the re-ranking task. Consequently, the upper bound of the ranking effect is contingent upon the recall of the initial passage retrieval. Our findings also indicate that the re-ranking effect of LLMs is highly sensitive to the initial order of passages, which is usually determined by the first-stage retrieval, such as BM25. Therefore, there is a need for further exploration into effectively utilizing LLMs to enhance the first-stage retrieval and improve the robustness of LLMs in relation to the initial passage retrieval.
本研究的局限性包括主要针对 OpenAI 的 ChatGPT 和 GPT-4 进行分析,这些是未开源的专有模型。尽管我们也测试了 FLAN-T5、ChatGLM-6B 和 Vicuna-13B 等开源模型,但结果仍与 ChatGPT 存在显著差异。如何进一步利用开源模型是一个值得探索的问题。此外,本研究仅关注大语言模型在重排序任务中的表现,因此排序效果的上限取决于初始段落检索的召回率。我们的研究结果还表明,大语言模型的重排序效果对段落的初始顺序高度敏感,而初始顺序通常由 BM25 等第一阶段检索决定。因此,需要进一步探索如何有效利用大语言模型来增强第一阶段检索,并提高大语言模型对初始段落检索的鲁棒性。
Ethics Statement
伦理声明
We acknowledge the importance of the ACM Code of Ethics and totally agree with it. We ensure that this work is compatible with the provided code, in terms of publicly accessed datasets and models. Risks and harms of large language models include the generation of harmful, offensive, or biased content. These models are often prone to generating incorrect information, sometimes referred to as halluci nations. We do not expect the studied model to be an exception in this regard. The LLMs used in this paper were shown to suffer from bias, hallucination, and other problems. Therefore, we are not recommending the use of LLMs for ranking tasks with social implications, such as ranking job candidates or ranking products, because LLMs may exhibit racial bias, geographical bias, gender bias, etc., in the ranking results. In addition, the use of LLMs in critical decision-making sessions may pose unspecified risks. Finally, the distilled models are licensed under the terms of OpenAI because they use ChatGPT. The distilled LLaMA models are further licensed under the non-commercial license of LLaMA.
我们认同ACM道德准则的重要性并完全遵守。我们确保本研究在公开数据集和模型使用方面符合该准则。大语言模型的风险与危害包括生成有害、冒犯性或带有偏见的内容,这些模型常会产生错误信息(即幻觉)。本文研究的大语言模型同样存在偏见、幻觉等问题,因此不建议将其用于具有社会影响的排序任务(如求职者排名或商品排名),因为其排序结果可能呈现种族偏见、地域偏见、性别偏见等。此外,大语言模型在关键决策环节的应用可能存在未明风险。最终,基于ChatGPT提炼的模型遵循OpenAI许可协议,而提炼的LLaMA模型额外受限于LLaMA非商业许可条款。
Acknowledgements
致谢
This work was supported by the Natural Science Foundation of China (62272274, 61972234, 62072279, 62102234, 62202271), the Natu- ral Science Foundation of Shandong Province (ZR2021QF129, ZR2022QF004), the Key Scien- tific and Technological Innovation Program of Shandong Province (2019 J ZZ Y 010129), the Fundamental Research Funds of Shandong University, the China Scholarship Council under grant nr. 202206220085.
本研究得到国家自然科学基金(62272274、61972234、62072279、62102234、62202271)、山东省自然科学基金(ZR2021QF129、ZR2022QF004)、山东省重点科技创新项目(2019JZZY010129)、山东大学基本科研业务费专项资金、国家留学基金委(202206220085)的资助。
References
参考文献
Negar Arabzadeh, Alexandra Vtyurina, Xinyi Yan, and Charles L. A. Clarke. 2021. Shallow pooling for sparse labels. Information Retrieval Journal, 25:365 – 385. Luiz Henrique Bonifacio, Hugo Queiroz Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. 2022. Inpars: Data augmentation for information retrieval using large language models. In SIGIR 2022. Luiz Henrique Bonifacio, Israel Campiotti, Roberto de Alencar Lotufo, and Rodrigo Nogueira. 2021. mmarco: A multilingual version of ms marco passage ranking dataset. ArXiv, abs/2108.13897. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens
Negar Arabzadeh、Alexandra Vtyurina、Xinyi Yan和Charles L. A. Clarke。2021。稀疏标签的浅层池化。信息检索期刊,25:365–385。
Luiz Henrique Bonifacio、Hugo Queiroz Abonizio、Marzieh Fadaee和Rodrigo Nogueira。2022。Inpars:利用大语言模型进行信息检索的数据增强。收录于SIGIR 2022。
Luiz Henrique Bonifacio、Israel Campiotti、Roberto de Alencar Lotufo和Rodrigo Nogueira。2021。mmarco:MS MARCO段落排序数据集的多语言版本。arXiv,abs/2108.13897。
Tom B. Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell、Sandhini Agarwal、Ariel Herbert-Voss、Gretchen Krueger、T. J. Henighan、Rewon Child、Aditya Ramesh、Daniel M. Ziegler、Jeff Wu、Clemens
Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In NeurIPS 2020.
Winter、Christopher Hesse、Mark Chen、Eric Sigler、Mateusz Litwin、Scott Gray、Benjamin Chess、Jack Clark、Christopher Berner、Sam McCandlish、Alec Radford、Ilya Sutskever 和 Dario Amodei。2020。大语言模型是少样本学习器。收录于 NeurIPS 2020。
Sebastian Bruch, Xuanhui Wang, Michael Bendersky, and Marc Najork. 2019. An analysis of the softmax cross entropy loss for learning-to-rank with binary relevance. In SIGIR 2019.
Sebastian Bruch, Xuanhui Wang, Michael Bendersky, and Marc Najork. 2019. 基于二元相关性的排序学习中Softmax交叉熵损失分析. 发表于SIGIR 2019.
Christopher J. C. Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Gregory N. Hullender. 2005. Learning to rank using gradient descent. In ICML 2005.
Christopher J. C. Burges、Tal Shaked、Erin Renshaw、Ari Lazier、Matt Deeds、Nicole Hamilton 和 Gregory N. Hullender。2005. 使用梯度下降学习排序。发表于 ICML 2005。
Daniel Fernando Campos, Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, Li Deng, and Bhaskar Mitra. 2016. Ms marco: A human generated machine reading comprehension dataset. ArXiv, abs/1611.09268.
Daniel Fernando Campos、Tri Nguyen、Mir Rosenberg、Xia Song、Jianfeng Gao、Saurabh Tiwary、Rangan Majumder、Li Deng 和 Bhaskar Mitra。2016. MS MARCO: 一个人类生成的机器阅读理解数据集。ArXiv, abs/1611.09268。
Nicola De Cao, Gautier Izacard, Sebastian Riedel, and Fabio Petroni. 2021. Auto regressive entity retrieval. In ICLR 2021.
Nicola De Cao、Gautier Izacard、Sebastian Riedel 和 Fabio Petroni。2021。自回归实体检索。收录于ICLR 2021。
Hyung Won Chung, Le Hou, S. Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Wei Yu, Vincent Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed Huai hsin Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. ArXiv, abs/2210.11416.
Hyung Won Chung、Le Hou、S. Longpre、Barret Zoph、Yi Tay、William Fedus、Eric Li、Xuezhi Wang、Mostafa Dehghani、Siddhartha Brahma、Albert Webson、Shixiang Shane Gu、Zhuyun Dai、Mirac Suzgun、Xinyun Chen、Aakanksha Chowdhery、Dasha Valter、Sharan Narang、Gaurav Mishra、Adams Wei Yu、Vincent Zhao、Yanping Huang、Andrew M. Dai、Hongkun Yu、Slav Petrov、Ed Huai hsin Chi、Jeff Dean、Jacob Devlin、Adam Roberts、Denny Zhou、Quoc V. Le 和 Jason Wei。2022。规模化指令微调的大语言模型。ArXiv,abs/2210.11416。
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Fernando Campos, and Ellen M. Voorhees. 2020. Overview of the trec 2020 deep learning track. ArXiv, abs/2102.07662.
Nick Craswell、Bhaskar Mitra、Emine Yilmaz、Daniel Fernando Campos 和 Ellen M. Voorhees。2020。TREC 2020深度学习赛道综述。ArXiv,abs/2102.07662。
Zhuyun Dai, Vincent Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith B. Hall, and Ming-Wei Chang. 2023. Prompt a gator: Few-shot dense retrieval from 8 examples. In ICLR 2023.
Zhuyun Dai、Vincent Zhao、Ji Ma、Yi Luan、Jianmo Ni、Jing Lu、Anton Bakalov、Kelvin Guu、Keith B. Hall和Ming-Wei Chang。2023。Prompt a gator:基于8个示例的少样本密集检索。发表于ICLR 2023。
Yixing Fan, Xiaohui Xie, Yinqiong Cai, Jia Chen, Xinyu Ma, Xiangsheng Li, Ruqing Zhang, and Jiafeng Guo. 2022. Pre-training methods in information retrieval. Foundations and Trends in Information Retrieval, 16:178–317.
范一兴、谢晓晖、蔡银琼、陈佳、马新宇、李祥生、张如青、郭家峰。2022。信息检索中的预训练方法。《信息检索的基础与趋势》,16:178–317。
Yao Fu, Hao-Chun Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. 2023. Specializing smaller language models towards multi-step reasoning. In ICML 2023.
Yao Fu、Hao-Chun Peng、Litu Ou、Ashish Sabharwal 和 Tushar Khot。2023. 面向多步推理的小型语言模型专业化研究。发表于 ICML 2023。
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. 2023. Precise zero-shot dense retrieval without relevance labels. In ACL 2023.
Luyu Gao、Xueguang Ma、Jimmy Lin 和 Jamie Callan。2023。无需相关性标签的精确零样本密集检索。载于 ACL 2023。
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Towards unsupervised dense information retrieval with contrastive learning. TMLR.
Gautier Izacard、Mathilde Caron、Lucas Hosseini、Sebastian Riedel、Piotr Bojanowski、Armand Joulin 和 Edouard Grave。2022。基于对比学习的无监督密集信息检索研究。TMLR。
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane A. Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research, 24(251):1–43.
Gautier Izacard、Patrick Lewis、Maria Lomeli、Lucas Hosseini、Fabio Petroni、Timo Schick、Jane A. Yu、Armand Joulin、Sebastian Riedel 和 Edouard Grave。2023。基于检索增强语言模型的少样本学习。《机器学习研究期刊》24(251):1–43。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Yu Wu, Sergey Edunov, Danqi Chen, and Wen tau Yih. 2020. Dense passage retrieval for open-domain question answering. In EMNLP 2020.
Vladimir Karpukhin、Barlas Oguz、Sewon Min、Patrick Lewis、Ledell Yu Wu、Sergey Edunov、Danqi Chen 和 Wen tau Yih。2020. 开放域问答的密集段落检索。载于 EMNLP 2020。
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Man- ning, Christopher R’e, Diana Acosta-Navas, Drew A. Hudson, E. Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu Ren, Huaxiu Yao, Jue Wang, Keshav Santhanam, Laurel J. Orr, Lucia Zheng, Mert Yuks ekg on ul, Mirac Suzgun, Nathan S. Kim, Neel Guha, Niladri S. Chatterji, O. Khattab, Peter Henderson, Qian Huang, Ryan Chi, Sang Michael Xie, Shibani Santurkar, Surya Ganguli, Tatsunori Hashimoto, Thomas F. Icard, Tianyi Zhang, Vishrav Chaudhary, William Wang, Xuechen Li, Yifan Mai, Yuhui Zhang, and Yuta Koreeda. 2022. Holistic evaluation of language models. ArXiv, abs/2211.09110.
Percy Liang、Rishi Bommasani、Tony Lee、Dimitris Tsipras、Dilara Soylu、Michihiro Yasunaga、Yian Zhang、Deepak Narayanan、Yuhuai Wu、Ananya Kumar、Benjamin Newman、Binhang Yuan、Bobby Yan、Ce Zhang、Christian Cosgrove、Christopher D. Manning、Christopher R'e、Diana Acosta-Navas、Drew A. Hudson、E. Zelikman、Esin Durmus、Faisal Ladhak、Frieda Rong、Hongyu Ren、Huaxiu Yao、Jue Wang、Keshav Santhanam、Laurel J. Orr、Lucia Zheng、Mert Yuksekgonul、Mirac Suzgun、Nathan S. Kim、Neel Guha、Niladri S. Chatterji、O. Khattab、Peter Henderson、Qian Huang、Ryan Chi、Sang Michael Xie、Shibani Santurkar、Surya Ganguli、Tatsunori Hashimoto、Thomas F. Icard、Tianyi Zhang、Vishrav Chaudhary、William Wang、Xuechen Li、Yifan Mai、Yuhui Zhang和Yuta Koreeda。2022。语言模型的整体评估。ArXiv,abs/2211.09110。
Jimmy J. Lin, Rodrigo Nogueira, and Andrew Yates. 2020. Pretrained transformers for text ranking: Bert and beyond. In WSDM 2020.
Jimmy J. Lin、Rodrigo Nogueira 和 Andrew Yates. 2020. 用于文本排序的预训练Transformer: BERT及其他. 收录于 WSDM 2020.
Xueguang Ma, Xinyu Crystina Zhang, Ronak Pradeep, and Jimmy Lin. 2023. Zero-shot listwise document reranking with a large language model. ArXiv, abs/2305.02156.
薛光马、Xinyu Crystina Zhang、Ronak Pradeep 和 Jimmy Lin。2023。使用大语言模型进行零样本列表式文档重排序。ArXiv, abs/2305.02156。
Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. 2023. Teaching small language models to reason. In ACL 2023.
Lucie Charlotte Magister、Jonathan Mallinson、Jakub Adamek、Eric Malmi和Aliaksei Severyn。2023。教会小语言模型推理。载于ACL 2023。
Microsoft. 2023. Confirmed: the new bing runs on openai’s gpt-4. https: //blogs.bing.com/search/march_2023/ Confirmed-the-new-Bing-runs-on-OpenAI% E2%80%99s-GPT-4.
Microsoft. 2023. 确认:新版Bing搭载OpenAI的GPT-4运行。https://blogs.bing.com/search/march_2023/Confirmed-the-new-Bing-runs-on-OpenAI% E2%80%99s-GPT-4.
Niklas Mu en nigh off. 2022. Sgpt: Gpt sentence embeddings for semantic search. ArXiv, abs/2202.08904.
Niklas Muennighoff. 2022. SGPT: 基于GPT的语义搜索句子嵌入. ArXiv, abs/2202.08904.
Reiichiro Nakano, Jacob Hilton, S. Arun Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin
Reiichiro Nakano, Jacob Hilton, S. Arun Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin
Chess, and John Schulman. 2021. Webgpt: Browserassisted question-answering with human feedback. ArXiv, abs/2112.09332.
Chess和John Schulman。2021。WebGPT:基于浏览器辅助与人类反馈的问答系统。arXiv,abs/2112.09332。
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage re-ranking with bert. ArXiv, abs/1901.04085.
Rodrigo Nogueira 和 Kyunghyun Cho. 2019. 基于BERT的段落重排序. ArXiv, abs/1901.04085.
Rodrigo Nogueira, Zhiying Jiang, Ronak Pradeep, and Jimmy Lin. 2020. Document ranking with a pretrained sequence-to-sequence model. In Findings of EMNLP 2020.
Rodrigo Nogueira、Zhiying Jiang、Ronak Pradeep 和 Jimmy Lin。2020。使用预训练序列到序列模型进行文档排序。收录于 EMNLP 2020 研究结果。
OpenAI. 2022. Introducing chatgpt. https://openai. com/blog/chatgpt.
OpenAI. 2022. 发布ChatGPT. https://openai.com/blog/chatgpt.
OpenAI. 2023. Gpt-4 technical report. ArXiv, abs/2303.08774.
OpenAI. 2023. GPT-4技术报告. ArXiv, abs/2303.08774.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welin- der, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. 2022. Training language models to follow instructions with human feedback. In NeurIPS 2022.
Long Ouyang、Jeff Wu、Xu Jiang、Diogo Almeida、Carroll L. Wainwright、Pamela Mishkin、Chong Zhang、Sandhini Agarwal、Katarina Slama、Alex Ray、John Schulman、Jacob Hilton、Fraser Kelton、Luke E. Miller、Maddie Simens、Amanda Askell、Peter Welinder、Paul Francis Christiano、Jan Leike 和 Ryan J. Lowe。2022。通过人类反馈训练语言模型遵循指令。发表于 NeurIPS 2022。
Devendra Singh Sachan, Mike Lewis, Mandar Joshi, Armen Aghajanyan, Wen tau Yih, Joëlle Pineau, and Luke Z ett le moyer. 2022. Improving passage retrieval with zero-shot question generation. In EMNLP 2022.
Devendra Singh Sachan、Mike Lewis、Mandar Joshi、Armen Aghajanyan、Wen tau Yih、Joëlle Pineau 和 Luke Zettlemoyer。2022。通过零样本问题生成改进段落检索。载于EMNLP 2022。
Devendra Singh Sachan, Mike Lewis, Dani Yogatama, Luke Z ett le moyer, Joëlle Pineau, and Manzil Zaheer. 2023. Questions are all you need to train a dense passage retriever. TACL, page 600–616.
Devendra Singh Sachan、Mike Lewis、Dani Yogatama、Luke Zettlemoyer、Joëlle Pineau和Manzil Zaheer。2023。训练密集段落检索器只需问题。TACL,第600–616页。
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Z ett le moyer, and Wen tau Yih. 2023. Replug: Retrieval-augmented black-box language models. ArXiv, abs/2301.12652.
Weijia Shi、Sewon Min、Michihiro Yasunaga、Minjoon Seo、Rich James、Mike Lewis、Luke Zettlemoyer 和 Wen tau Yih。2023。Replug: 检索增强的黑盒大语言模型。ArXiv, abs/2301.12652。
Weiwei Sun, Lingyong Yan, Zheng Chen, Shuaiqiang Wang, Haichao Zhu, Pengjie Ren, Zhumin Chen, Dawei Yin, M. de Rijke, and Zhaochun Ren. 2023. Learning to tokenize for generative retrieval. In NeruIPS 2023.
Weiwei Sun、Lingyong Yan、Zheng Chen、Shuaiqiang Wang、Haichao Zhu、Pengjie Ren、Zhumin Chen、Dawei Yin、M. de Rijke 和 Zhaochun Ren。2023. 面向生成式检索的分词学习。发表于 NeruIPS 2023。
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. github.com/tatsu-lab/stanford alpaca.
Rohan Taori、Ishaan Gulrajani、Tianyi Zhang、Yann Dubois、Xuechen Li、Carlos Guestrin、Percy Liang 和 Tatsunori B. Hashimoto。2023。斯坦福Alpaca:一个遵循指令的LLaMA模型。https://github.com/tatsu-lab/stanford_alpaca。
Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. 2022. Transformer memory as a differentiable search index. In NeurIPS 2022.
Yi Tay、Vinh Q. Tran、Mostafa Dehghani、Jianmo Ni、Dara Bahri、Harsh Mehta、Zhen Qin、Kai Hui、Zhe Zhao、Jai Gupta、Tal Schuster、William W. Cohen 和 Donald Metzler。2022。Transformer 记忆作为可微分搜索索引。发表于 NeurIPS 2022。
Nandan Thakur, Nils Reimers, Andreas Ruckl’e, Ab- hishek Srivastava, and Iryna Gurevych. 2021. Beir: A he t erogenous benchmark for zero-shot evaluation of information retrieval models. In NeurIPS 2021.
Nandan Thakur、Nils Reimers、Andreas Rücklé、Abhishek Srivastava 和 Iryna Gurevych。2021. BEIR: 信息检索模型零样本评估的异构基准。收录于 NeurIPS 2021。
A Instructions
A 说明
A.1 Query Generation Instruction
A.1 查询生成指令
The query generation instruction (Sachan et al., 2022) uses the log-probability of the query.
查询生成指令 (Sachan et al., 2022) 使用查询的对数概率。
A.2 Relevance Generation Instruction (few-shot)
A.2 相关性生成指令 (few-shot)
Following HELM (Liang et al., 2022), the relevance generation instruction use 4 in-context examples.
遵循HELM (Liang et al., 2022)的方法,相关性生成指令使用了4个上下文示例。
Given a passage and a query, predict whether the passage includes an answer to the query by producing either ‘Yes‘ or ‘No‘.
给定一段文本和一个查询,预测该文本是否包含对查询的答案,输出"是"或"否"。
Passage: RE: How many eyedrops are there in a $10~\mathrm{ml}$ bottle of Cosopt? My Kaiser pharmacy insists that 2 bottles should last me 100 days but I run out way before that time when I am using 4 drops per day.In the past other pharmacies have given me $3~10{-}\mathrm{ml}$ bottles for 100 days.E: How many eyedrops are there in a $10\mathrm{ml}$ bottle of Cosopt? My Kaiser pharmacy insists that 2 bottles should last me 100 days but I run out way before that time when I am using 4 drops per day.
回复:一瓶10毫升的Cosopt眼药水有多少滴?我的Kaiser药房坚持认为2瓶应该能用100天,但我每天用4滴时,总会在那之前就用完。过去其他药房给我3瓶10毫升的装量能用100天。
问题:一瓶10毫升的Cosopt眼药水有多少滴?我的Kaiser药房坚持认为2瓶应该能用100天,但我每天用4滴时,总会在那之前就用完。
Query: how many eye drops per ml Does the passage answer the query? Answer: No
查询:每毫升有多少滴眼药水
该段落是否回答了查询?答案:否
Passage: You can open a Wells Fargo banking account from your home or even online. It is really easy to do, provided you have all of the appropriate documentation. Wells Fargo has so many bank account options that you will be sure to find one that works for you. They offer free checking accounts with free online banking.
你可以在家中甚至在线开设富国银行(Wells Fargo)账户。只要准备好所有必要文件,操作非常简单。富国银行提供多种账户选择,总有一款适合你。他们提供免费支票账户及免费网上银行服务。
Query: can you open a wells fargo account online Does the passage answer the query?
查询:能否在线开通富国银行账户
该段落是否回答了查询?
Answer: Yes
回答:是
A.3 Relevance Generation Instruction (zero-shot)
A.3 相关性生成指令 (zero-shot)
This instruction is used to train LLaMA-7B specialized models.
本指令用于训练LLaMA-7B专用模型。
Given a passage and a query, predict whether the passage includes an answer to the query by producing either ‘Yes‘ or ‘No‘.
给定一段文本和一个查询,预测该文本是否包含对查询的答案,输出"Yes"或"No"。
A.4 Permutation Generation Instruction (Text)
A.4 排列生成指令 (文本)
Permutation generation (text) is used for text-davinci-003.
排列生成(文本)用于text-davinci-003。
This is RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query.
这是RankGPT,一个能根据文本与查询的相关性进行排序的智能助手。
The following are ${{\mathsf{n u m}}}$ passages, each indicated by number identifier []. I can rank them based on their relevance to query: ${{\mathsf{q u e r y}}}$
以下是 ${{\mathsf{n u m}}}$ 篇段落,每篇均以数字标识符 [] 标注。我可以根据它们与查询 ${{\mathsf{q u e r y}}}$ 的相关性进行排序。
[1] {{passage_1}}
[1] {{passage_1}}
[2] {{passage_2}}
[2] {{passage_2}}
(more passages) ...
...(更多段落)...
The search query is: ${{\mathsf{q u e r y}}}$
搜索查询是: ${{\mathsf{q u e r y}}}$
I will rank the ${{\mathsf{n u m}}}$ passages above based on their relevance to the search query. The passages will be listed in descending order using identifiers, and the most relevant passages should be listed first, and the output format should be $[]>[]>$ etc, e.g., $[1]>[2]>$ etc.
我将根据相关性对上述 ${{\mathsf{n u m}}}$ 篇文本进行排序。排序结果以降序列出标识符,最相关的文本应排在前面,输出格式为 $[]>[]>$ 等,例如 $[1]>[2]>$ 等。
The ranking results of the ${{\mathsf{n u m}}}$ passages (only identifiers) is:
${{\mathsf{n u m}}}$ 篇文章(仅标识符)的排序结果为:
A.5 Permutation Generation Instruction (Chat)
A.5 排列生成指令 (Chat)
Permutation generation instruction (chat) is used for gpt-3.5-turbo and gpt-4.
排列生成指令 (chat) 用于 gpt-3.5-turbo 和 gpt-4。
system:
system:
You are RankGPT, an intelligent assistant that can rank passages based on their relevancy to the query.
你是RankGPT,一个能根据查询相关性对文本段落进行排序的智能助手。
user:
用户:
I will provide you with ${{\mathsf{n u m}}}$ passages, each indicated by number identifier []. Rank them based on their relevance to query: ${{\mathsf{q u e r y}}}$ .
我将提供 ${{\mathsf{n u m}}}$ 段文本,每段以数字标识符 [] 标注。请根据它们与查询 ${{\mathsf{q u e r y}}}$ 的相关性进行排序。
assistant: Okay, please provide the passages.
好的,请提供需要翻译的段落内容。
user: [1] {{passage_1}}
用户: [1] {{passage_1}}
assistant: Received passage [1]
收到段落 [1]
user: [2] {{passage_2}}
用户: [2] {{passage_2}}
assistant: Received passage [2]
收到段落 [2]
(more passages) ...
...(更多段落)...
user
用户
Search Query: ${{\mathsf{q u e r y}}}$ .
搜索查询: ${{\mathsf{q u e r y}}}$
Rank the ${{\mathsf{n u m}}}$ passages above based on their relevance to the search query. The passages should be listed in descending order using identifiers, and the most relevant passages should be listed first, and the output format should be $[]>[]$ , e.g., $[1]>|$ [2]. Only response the ranking results, do not say any word or explain.
根据与搜索查询的相关性对上述 ${{\mathsf{n u m}}}$ 个段落进行排序。段落应按标识符降序列出,最相关的段落应排在前面,输出格式为 $[]>[]$,例如 $[1]>[2]$。仅返回排序结果,不要有任何其他文字或解释。
B Instructional Methods on LLMs as Rernaker
B 大语言模型 (LLM) 作为重塑者的教学方法
This paper focus on re-ranking task, given $M$ passages for a query $q$ , the re-ranking aims to use an agent $f(\cdot)$ to output their ranking results $\mathbf{R}=\left(r_{1},...,r_{M}\right)$ , where $r_{i}\in[1,2,...,M]$ denotes the rank of $p_{i}$ . This paper studies using the LLMs as $f(\cdot)$ .
本文聚焦于重排序任务,给定查询 $q$ 对应的 $M$ 个段落,重排序旨在使用智能体 $f(\cdot)$ 输出其排序结果 $\mathbf{R}=\left(r_{1},...,r_{M}\right)$ ,其中 $r_{i}\in[1,2,...,M]$ 表示 $p_{i}$ 的排名。本文研究将大语言模型 (LLM) 作为 $f(\cdot)$ 的应用。
B.1 Instructional Query Generation
B.1 教学式查询生成
Query generation has been studied in Sachan et al. (2022); Mu en nigh off (2022), in which the relevance between a query and a passage is measured by the log-probability of the model to generate the query based on the passage. Figure 2 (a) shows an example of instructional query generation.
查询生成已在Sachan等人(2022)和Muennighoff(2022)的研究中被探讨,其中查询与段落的相关性通过模型基于段落生成查询的对数概率来衡量。图2(a)展示了一个指令式查询生成的示例。
Formally, given query $q$ and a passage $p_{i}$ , their relevance score $s_{i}$ is calculated as:
给定查询 $q$ 和段落 $p_{i}$,其相关性得分 $s_{i}$ 的计算公式为:
$$
s_{i}=\frac{1}{|q|}\sum_{t}\log p(q_{t}|q_{<t},p_{i},\mathcal{Z}_{\mathrm{query}})
$$
$$
s_{i}=\frac{1}{|q|}\sum_{t}\log p(q_{t}|q_{<t},p_{i},\mathcal{Z}_{\mathrm{query}})
$$
where $|q|$ denotes the number of tokens in $q,q_{t}$ denotes the $t$ -th token of $q$ , and $\mathcal{T}_ {\mathrm{query}}$ denotes the instructions, referring to Figure 2 (a). The passages are then ranked based on relevance score $s_{i}$ .
其中 $|q|$ 表示 $q$ 中的 token 数量,$q_{t}$ 表示 $q$ 的第 $t$ 个 token,$\mathcal{T}_ {\mathrm{query}}$ 表示指令集 (参见图 2(a) )。段落随后根据相关性得分 $s_{i}$ 进行排序。
B.2 Instructional Relevance Generation
B.2 教学相关性生成
Relevance generation is employed in HELM (Liang et al., 2022). Figure 2 (b) shows an example of instructional relevance generation, in which LLMs are instructed to output "Yes" if the query and passage
相关性生成在HELM (Liang等人,2022) 中被采用。图 2 (b) 展示了一个指令相关性生成的示例,其中大语言模型被指示在查询和段落相关时输出"Yes"。
are relevant or "No" if they are irrelevant. The relevance score $s_{i}$ is measured by the probability of LLMs generating the word ’Yes’ or ’No’:
如果相关则输出"Yes",不相关则输出"No"。相关性分数$s_{i}$通过大语言模型生成"Yes"或"No"的概率来衡量:
$$
s_i = \begin{aligned}
&1 + p(\mathrm{Yes}), && \text{if output is Yes} \quad
&1 - p(\mathrm{No}), && \text{if output is No}
\end{aligned}.
$$
$$
s_i = \begin{aligned}
&1 + p(\mathrm{是}), & \text{若输出为是} \quad
&1 - p(\mathrm{否}), & \text{若输出为否}
\end{aligned}.
$$
where $p(\mathrm{Yes}/\mathrm{No})$ denotes the probability of LLMs generating Yes or No, and the relevance score is normalized into the range [0, 2].
其中 $p(\mathrm{Yes}/\mathrm{No})$ 表示大语言模型生成"Yes"或"No"的概率,相关性分数被归一化到[0, 2]范围内。
The above two methods rely on the log probability of LLM, which is often unavailable for LLM API. For example, at the time of writing, OpenAI’s Chat Completion API does not provide the log-probability of generation 5.
上述两种方法依赖于大语言模型的log probability,而LLM API通常无法提供该数据。例如,截至本文撰写时,OpenAI的Chat Completion API并未提供生成内容的log-probability [5]。
B.3 Instructional Permutation Generation
B.3 指令排列生成
The proposed instructional permutation generation is a listwise approach, which directly assigns each passage $p_{i}$ a unique ranking identifier $a_{i}$ (e.g., [1], [2]) and places it at the beginning of $p_{i}$ : $p_{i}^{\prime}=$ $\mathrm{Concat}(a_{i},p_{i})$ . Subsequently, a generative LLM is instructed to generate a permutation of these identifiers: $\mathbf{Perm}=f(q,p_{1}^{\prime},...,p_{M}^{\prime})$ , where the permutation Perm indicates the rank of the identifiers $a_{i}$ (e.g., [1], [2]). We then simply map the identifiers $a_{i}$ to the passages $p_{i}$ to obtain the ranking of the passages.
提出的指令排列生成是一种列表式方法,它直接为每个段落$p_{i}$分配一个唯一的排序标识符$a_{i}$ (例如 [1], [2]),并将其置于$p_{i}$的开头:$p_{i}^{\prime}=$$\mathrm{Concat}(a_{i},p_{i})$。随后,通过指令让生成式大语言模型生成这些标识符的排列:$\mathbf{Perm}=f(q,p_{1}^{\prime},...,p_{M}^{\prime})$,其中排列Perm表示标识符$a_{i}$ (例如 [1], [2]) 的排名。最后,我们只需将标识符$a_{i}$映射回段落$p_{i}$即可获得段落的排序。
Table 8: Questions and reference answers on NovelEval-2306.
| Domain Question | ReferenceAnswer | |
| Sport | What is Messi's annual income after transferring to Miami? | $50M-60M |
| Sport | How many goals did Haaland scored in the 2023 Champions League Final? | 0 |
| Sport | Where did Benzema go after leaving Real Madrid? | Saudi Arabia |
| Sport | Wherewas the 2023Premier LeagueFA CupFinal held? | WembleyStadium |
| Sport | Who won 2023 LaureusWorld Sportsman Of TheYear Award? | Lionel Messi |
| Sport | WhowinsNBAFinals 2023? | Denver Nuggets |
| Tech | What is the screen resolution of vision pro? | 4K with one eye |
| Tech | What is the name of the combined Deepmind and Google Brain? | Google DeepMind |
| Tech | How much video memory does the DGX GH200 have? | 144TB |
| Tech | What are the newfeatures ofPyTorch 2? | faster, low memory, dynamic shapes |
| Tech | Who will be the CEO of Twitter after Elon Musk is no longer the CEO? | Linda Yaccarino |
| Tech | What are the best papers of CVPR 2023? | Visual Programming: Compositional [..] |
| Movie | Who sang the theme song of Transformers Rise of the Beasts? | Notorious B.I.G |
| Movie | Who is the villain in The Flash? | EobardThawne/ProfessorZoom |
| Movie | How many different Spider-Men are there in Across the Spider-Verse? | 280 variations |
| Movie | Who does Momoa play in Fast X? | Dante |
| Movie | TheLittleMermaidfirstweekboxoffice? | $ 163.8 million worldwide |
| Movie | Whichfilmwas the2023Palmed'Or winner? | Anatomy of aFall |
| Other | WherewillBlackpink's 2023world tour concert inFrancebeheld? | theStadedeFrance |
| Other | What is the release date of songMiddle Ground? | May19,2023 |
| Other | Where did the G7Summit 2023 take place? | Hiroshima |
表 8: NovelEval-2306 的问题与参考答案
| 领域 | 问题 | 参考答案 |
|---|---|---|
| 体育 | 梅西转会迈阿密后的年收入是多少? | 5000万-6000万美元 |
| 体育 | 哈兰德在2023年欧冠决赛中进了多少球? | 0 |
| 体育 | 本泽马离开皇马后去了哪里? | 沙特阿拉伯 |
| 体育 | 2023年英超足总杯决赛在哪里举行? | 温布利球场 |
| 体育 | 谁获得了2023年劳伦斯世界体育奖年度最佳男运动员? | 莱昂内尔·梅西 |
| 体育 | 谁赢得了2023年NBA总冠军? | 丹佛掘金队 |
| 科技 | Vision Pro的屏幕分辨率是多少? | 单眼4K |
| 科技 | DeepMind和Google Brain合并后的名称是什么? | Google DeepMind |
| 科技 | DGX GH200有多少显存? | 144TB |
| 科技 | PyTorch 2有哪些新特性? | 更快、更低内存、动态形状 |
| 科技 | 埃隆·马斯克不再担任CEO后,谁将成为Twitter的CEO? | 琳达·亚卡里诺 |
| 科技 | CVPR 2023的最佳论文有哪些? | Visual Programming: Compositional [...] |
| 电影 | 谁演唱了《变形金刚:超能勇士崛起》的主题曲? | Notorious B.I.G |
| 电影 | 《闪电侠》中的反派是谁? | Eobard Thawne/Professor Zoom |
| 电影 | 《蜘蛛侠:纵横宇宙》中有多少个不同的蜘蛛侠? | 280个变体 |
| 电影 | 杰森·莫玛在《速度与激情10》中扮演谁? | 但丁 |
| 电影 | 《小美人鱼》首周全球票房是多少? | 1.638亿美元 |
| 电影 | 哪部电影获得了2023年戛纳电影节金棕榈奖? | 《坠落的审判》 |
| 其他 | Blackpink 2023世界巡回演唱会法国站将在哪里举行? | 法兰西体育场 |
| 其他 | 歌曲《Middle Ground》的发行日期是什么时候? | 2023年5月19日 |
| 其他 | 2023年G7峰会在哪里举行? | 广岛 |
C NovelEval-2306
C NovelEval-2306
Table 8 lists the collected 21 questions. These questions come from four domains and include hot topics from the past few months. For each question, we used Google search to obtain 20 passages. When using Google search, in order to avoid all pages containing the answer, we used not only the question itself as a search query, but also the entities that appear in the question as an alternative search query to obtain some pages that are relevant but do not contain the answer. For example, for the first question "What is Messi’s annual income after transferring to Miami?", we used "Messi" and "Messi transferring" as search queries to get some pages that do not contain the answer. When searching, we collected the highest-ranking web pages, news, and used a paragraph or paragraphs from the web pages related to the search term as candidate passages. Table 9 shows the statistical information of the data. All of the LLMs (including gpt-4-0314 and gpt-4-0613) we tested achieved $0%$ question-answering accuracy on the obtained test set.
表 8 列出了收集的 21 个问题。这些问题来自四个领域,包含了过去几个月内的热点话题。对于每个问题,我们使用 Google 搜索获取了 20 段文本。在使用 Google 搜索时,为了避免所有页面都包含答案,我们不仅使用问题本身作为搜索查询,还使用问题中出现的实体作为替代搜索查询,以获取一些相关但不包含答案的页面。例如,对于第一个问题 "梅西转会迈阿密后的年收入是多少?",我们使用 "梅西" 和 "梅西转会" 作为搜索查询来获取一些不包含答案的页面。在搜索时,我们收集了排名最高的网页、新闻,并使用与搜索词相关的网页中的一个或多个段落作为候选文本。表 9 展示了数据的统计信息。我们测试的所有大语言模型 (包括 gpt-4-0314 和 gpt-4-0613) 在获得的测试集上都实现了 $0%$ 的问答准确率。
We searched for 20 candidate passages for each question using Google search. These passages were manually labeled for relevance by a group of annotators, including the authors and their highly educated colleagues. To ensure consistency, the annotation process was repeated twice. Each passage was assigned a relevance score: 0 for not relevant, 1 for partially relevant, and 2 for relevant. When evaluating the latest LLMs, we found that all non-retrieval-augmented models tested achieved $0%$ accuracy in answering the questions on the test set. This test set provides a reasonable evaluation of the latest LLMs at the moment. Since LLMs may be continuously trained on new data, the proposed test set should be continuously updated to counteract the contamination of the test set by LLMs.
我们使用谷歌搜索为每个问题检索了20个候选段落。这些段落由包括作者及其高学历同事在内的一组标注者手动标注相关性。为确保一致性,标注过程重复进行了两次。每个段落被分配了相关性分数:0表示不相关,1表示部分相关,2表示相关。在评估最新的大语言模型时,我们发现所有未经检索增强的测试模型在测试集问题上的准确率均为$0%$。该测试集为当前最新大语言模型提供了合理评估。由于大语言模型可能持续在新数据上训练,建议定期更新测试集以抵消模型对测试集的污染效应。
Table 9: Data Statistics of NovelEval.
| Numberofquestions Number of passages Number ofrelevance annotation Average number words of passage | 21 420 420 149 |
| Number of score 0 | 290 |
| Numberofscore1 | 40 |
| Numberofscore2 | 90 |
表 9: NovelEval 数据统计
| 问题数量 | 段落数量 | 相关性标注数量 | 段落平均词数 |
|---|---|---|---|
| 21 | 420 | 420 | 149 |
| 评分0数量 | 290 | ||
| 评分1数量 | 40 | ||
| 评分2数量 | 90 |
D Implementation Details
D 实现细节
D.1 Training Configuration
D.1 训练配置
We use DeBERTa-V3-base, which concatenates the query and passage with a [SEP] token and utilizes the representation of the [CLS] token. To generate candidate passages, we randomly sample $10\mathrm{k\Omega}$ queries and use BM25 to retrieve 20 passages for each query. We then re-rank the candidate passages using the gpt-3.5-turbo API with permutation generation instructions, at a cost of approximately $\$40$ . During training, we employ a batch size of 32 and utilize the AdamW optimizer with a constant learning rate of $5\times10^{-5}$ . The model is trained for two epochs. Additionally, we implement models using the original MS MARCO labels for comparison.
我们采用DeBERTa-V3-base模型,该模型通过[SEP] token连接查询和段落,并利用[CLS] token的表征。为生成候选段落,我们随机采样$10\mathrm{k\Omega}$查询,使用BM25为每个查询检索20个段落,随后通过gpt-3.5-turbo API(花费约$\$40$)结合排列生成指令对候选段落进行重排序。训练阶段采用32的批次大小,使用学习率恒定为$5\times10^{-5}$的AdamW优化器,模型训练共两个周期。同时,我们使用原始MS MARCO标注数据构建对比模型。
The LLaMA-7B model is optimized with the AdamW optimizer, a constant learning rate of $5\times10^{-5}$ , and with mixed precision of bf16 and Deepspeed Zero3 strategy. All the experiments are conducted on 8 A100-40G GPUs.
LLaMA-7B模型采用AdamW优化器进行优化,恒定学习率为$5\times10^{-5}$,并混合使用bf16精度和Deepspeed Zero3策略。所有实验均在8块A100-40G GPU上完成。
Figure 5 illustrates the detailed model architecture of BERT-like and GPT-like specialized models.
图 5: 类BERT和类GPT专用模型的详细架构示意图

Figure 5: Model architecture of BERT-like and GPT-like specialized models.
图 5: 类BERT与类GPT专用模型的架构。
D.2 Training Objective
D.2 训练目标
Using the permutation generated by ChatGPT, we consider the following losses to optimize the student model:
使用ChatGPT生成的排列组合,我们考虑以下损失函数来优化学生模型:
Listwise Cross-Entropy (CE) (Bruch et al., 2019). Listwise CE is the wide-use loss for passage ranking, which considers only one positive passage and defines the list-wise softmax cross-entropy on all candidate’s passages:
列表交叉熵 (Listwise Cross-Entropy, CE) (Bruch et al., 2019)。列表交叉熵是段落排序任务中广泛使用的损失函数,它仅考虑一个正样本段落,并在所有候选段落上定义列表级softmax交叉熵:
$$
\mathcal{L}_ {\mathrm{Listwise_CE}}=-\sum_{i=1}^{M}\mathbb{1}_ {r_{i}=1}\log(\frac{\exp(s_{i})}{\sum_{j}\exp(s_{j})})
$$
$$
\mathcal{L}_ {\mathrm{Listwise_CE}}=-\sum_{i=1}^{M}\mathbb{1}_ {r_{i}=1}\log(\frac{\exp(s_{i})}{\sum_{j}\exp(s_{j})})
$$
where $\mathbb{1}$ is the indicator function.
其中 $\mathbb{1}$ 是指示函数。
RankNet (Burges et al., 2005). RankNet is a pairwise loss that measures the correctness of relative passage orders:
RankNet (Burges et al., 2005). RankNet 是一种成对损失函数,用于衡量段落相对顺序的正确性:
$$
\mathcal{L}_ {\mathrm{RankNet}}=\sum_{i=1}^{M}\sum_{j=1}^{M}\mathbb{1}_ {r_{i}<r_{j}}\log(1+\exp(s_{j}-s_{i}))
$$
$$
\mathcal{L}_ {\mathrm{RankNet}}=\sum_{i=1}^{M}\sum_{j=1}^{M}\mathbb{1}_ {r_{i}<r_{j}}\log(1+\exp(s_{j}-s_{i}))
$$
when using permutation generated by ChatGPT, we can construct $M(M-1)/2$ pairs.
使用ChatGPT生成的排列时,可以构建$M(M-1)/2$对。
LambdaLoss (Wang et al., 2018). The LambdaLoss further accounts for the nDCG gains of the model ranks. LambdaLoss uses the student model’s rank, denoted as $\pi=(\pi_{1},\cdots,\pi_{M})$ , where $\pi_{i}$ is the model predicted rank of $p_{i}$ with a similar definition with ChatGPT rank $R$ . The loss function is defined as:
LambdaLoss (Wang et al., 2018)。LambdaLoss 进一步考虑了模型排序的 nDCG 增益。该损失函数使用学生模型的排序结果 $\pi=(\pi_{1},\cdots,\pi_{M})$ ,其中 $\pi_{i}$ 表示模型对 $p_{i}$ 的预测排序,其定义与 ChatGPT 排序 $R$ 类似。损失函数定义为:
$$
\mathcal{L}_ {\mathrm{Lambda}}=\sum_{r_{i}<r_{j}}\Delta\mathrm{NDCG}\log_{2}(1+\exp(s_{j}-s_{i}))
$$
$$
\mathcal{L}_ {\mathrm{Lambda}}=\sum_{r_{i}<r_{j}}\Delta\mathrm{NDCG}\log_{2}(1+\exp(s_{j}-s_{i}))
$$
in which ∆NDCG is the delta of NDCG which could be compute as ∆NDCG = |Gi −Gj||D(1πi) − D(1πj)|, where $D(\pi_{i})$ and $D(\pi_{j})$ are the position discount functions and $G_{i}$ and $G_{j}$ are the gain functions used in NDCG (Wang et al., 2018).
其中∆NDCG是NDCG的变化量,可计算为∆NDCG = |Gi −Gj||D(1πi) − D(1πj)|,其中$D(\pi_{i})$和$D(\pi_{j})$为位置折扣函数,$G_{i}$和$G_{j}$为NDCG中使用的增益函数 (Wang et al., 2018)。
Pointwise Binary Cross-Entropy (BCE). We also include the Pointwise BCE as the baseline loss for supervised methods, which is calculated based on each query-document pair independently:
逐点二元交叉熵 (BCE)。我们将逐点 BCE 作为监督方法的基线损失函数,其计算基于每个查询-文档对的独立评估:
$$
\mathcal{L}_ {\mathrm{BCE}}=-\sum_{i=1}^{M}\mathbb{1}_ {r_{i}=1}\log\sigma(s_{i})+\mathbb{1}_ {r_{i}\neq1}\log\sigma(1-s_{i})
$$
$$
\mathcal{L}_ {\mathrm{BCE}}=-\sum_{i=1}^{M}\mathbb{1}_ {r_{i}=1}\log\sigma(s_{i})+\mathbb{1}_ {r_{i}\neq1}\log\sigma(1-s_{i})
$$
where $\begin{array}{r}{\sigma(x)=\frac{1}{1+\exp(-x)}}\end{array}$ is the logistic function.
其中 $\begin{array}{r}{\sigma(x)=\frac{1}{1+\exp(-x)}}\end{array}$ 是逻辑函数。
E Baselines Details
E 基线细节
We include state-of-the-art supervised and unsupervised passage re-ranking methods for comparison. The supervised baselines are:
我们纳入了当前最先进的监督式和非监督式段落重排序方法进行对比。监督基线方法包括:
The unsupervised baselines are:
无监督基线方法包括:
• UPR (Sachan et al., 2022): Unsupervised passage ranking with instructional query generation. Due to its superior performance, we use the FLAN-T5-XL (Chung et al., 2022) as the LLM of UPR. • InPars (Bonifacio et al., 2022): monoT5-3B trained on pseudo data generated by GPT-3. • Prompt a gator $^{++}$ (Dai et al., 2023): A 110M cross-encoder re-ranker trained on pseudo queries generated by FALN 137B.
• UPR (Sachan等人,2022): 基于指令式查询生成的无监督段落排序方法。因其卓越性能,我们采用FLAN-T5-XL (Chung等人,2022)作为UPR的大语言模型。
• InPars (Bonifacio等人,2022): 基于GPT-3生成伪数据训练的monoT5-3B模型。
• Promptagator$^{++}$ (Dai等人,2023): 使用FALN 137B生成伪查询训练的1.1亿参数交叉编码器重排序模型。
| Method | Repetition↓ | Missing | Rejection | RBO↑ |
| text-davinci-003 | 0 | 280 | 0 | 72.30 |
| gpt-3.5-turbo | 14 | 153 | 7 | 81.49 |
| gpt-4 | 0 | 1 | 11 | 82.08 |
| 方法 | 重复↓ | 缺失 | 拒绝 | RBO↑ |
|---|---|---|---|---|
| text-davinci-003 | 0 | 280 | 0 | 72.30 |
| gpt-3.5-turbo | 14 | 153 | 7 | 81.49 |
| gpt-4 | 0 | 1 | 11 | 82.08 |
Table 10: Analysis of model stability on TREC. Repetition refers to the number of times the model generates duplicate passage identifiers. Missing refers to the number of missing passage identifiers in model output. Rejection refers to the number of times the model rejects to perform the ranking. RBO, i.e., rank biased overlap, refers to the consistency of the model in ranking the same group of passages twice.
表 10: TREC数据集上的模型稳定性分析。重复(Repetition)指模型生成重复段落标识符的次数。缺失(Missing)指模型输出中遗漏段落标识符的数量。拒绝(Rejection)指模型拒绝执行排序的次数。RBO (rank biased overlap)表示模型对同一组段落进行两次排序时的一致性。
F Model Behavior Analysis
F 模型行为分析
In the permutation generation method, the ranking of passages is determined by the list of model-output passage identifiers. However, we have observed that the models do not always produce the desired output, as evidenced by occasional duplicates or missing identifiers in the generated text. In Table 10, we present quantitative results of unexpected model behavior observed during experiments with the GPT models.
在排列生成方法中,段落的排序由模型输出的段落标识符列表决定。然而我们观察到,模型并不总是产生预期输出,生成文本中偶尔会出现重复或缺失标识符的情况。表10展示了GPT模型实验中观测到的异常行为量化结果。
Repetition. The repetition metric measures the occurrence of duplicate passage identifiers generated by the model. The results indicate that ChatGPT produced 14 duplicate passage identifiers during re-ranking 97 queries on two TREC datasets, whereas text-davinci-003 and GPT-4 did not exhibit any duplicates.
重复性。重复性指标衡量模型生成的重复段落标识符的出现情况。结果表明,ChatGPT 在两个 TREC 数据集上对 97 个查询进行重排序时产生了 14 个重复段落标识符,而 text-davinci-003 和 GPT-4 未出现任何重复。
Missing. We conducted a count of the number of times the model failed to include all passages in the re-ranked permutation output9. Our findings revealed that text-davinci-003 has the highest number of missing passages, totaling 280 instances. ChatGPT also misses a considerable number of passages, occurring 153 times. On the other hand, GPT-4 demonstrates greater stability, with only one missing passage in total. These results suggest that GPT-4 has higher reliability in generating permutations, which is critical for effective ranking.
缺失情况统计。我们对模型在重排序输出中遗漏段落的总次数进行了统计[20]。结果显示,text-davinci-003的段落遗漏情况最为严重,共发生280次。ChatGPT也存在相当数量的遗漏,达到153次。相比之下,GPT-4表现最为稳定,仅出现1次段落遗漏。这些结果表明GPT-4在生成排列组合时具有更高的可靠性,这对实现有效排序至关重要。
Rejection. We have observed instances where the model refuses to re-rank passages, as evidenced by responses such as "None of the provided passages is directly relevant to the query ...". To quantify this behavior, we count the number of times this occurred and find that GPT-4 rejects ranking the most frequently, followed by ChatGPT, while the Davinci model never refused to rank. This finding suggests that chat LLMs tend to be more adaptable compared to completion LLMs, and may exhibit more subjective responses. Note that we do not explicitly prohibit the models from rejecting ranking in the instructions, as we find that it does not significantly impact the overall ranking performance.
拒绝行为。我们观察到模型有时会拒绝重新排序段落,例如出现"提供的段落中没有与查询直接相关的内容..."等回应。为量化该现象,我们统计了各模型的拒绝次数,发现GPT-4拒绝排序的频率最高,其次是ChatGPT,而Davinci模型从未拒绝排序。这一发现表明,对话类大语言模型相比补全类模型更具适应性,但可能表现出更多主观性响应。需说明的是,我们在指令中并未明确禁止模型拒绝排序,因为发现这对整体排序性能影响不大。
RBO. The sliding windows strategy involves re-ranking the top-ranked passages from the previous window in the next window. The models are expected to produce consistent rankings in two windows for the same group of passages. To measure the consistency of the model’s rankings, we use RBO (rank biased overlap10), which calculates the similarity between the two ranking results. The findings turn out that ChatGPT and GPT-4 are more consistent in ranking passages compared to the Davinci model. GPT-4 also slightly outperforms ChatGPT in terms of the RBO metric.
RBO。滑动窗口策略涉及在下一个窗口中重新排序前一个窗口中排名靠前的段落。模型预期在两个窗口中对同一组段落产生一致的排名。为了衡量模型排名的一致性,我们使用RBO (rank biased overlap10),它计算两个排名结果之间的相似度。结果表明,与Davinci模型相比,ChatGPT和GPT-4在段落排名上更为一致。在RBO指标方面,GPT-4也略优于ChatGPT。
G Analysis on Hyper parameters of Sliding Window
G 滑动窗口超参数分析
To analyze the influence of parameters of the sliding window strategy, we adjust the window size and set the step size to half of the window size. The main motivation for this setup is to keep the expected overhead of the method (number of tokens required for computation) low; i.e., most tokens in this setup are used for PG only twice. The experimental results are shown in Table $12^{11}$ . The results show that the effect varies over a certain range of arrivals for different values of window size: window size $\scriptstyle=20$ performs best in terms of $\mathrm{nDCG}@10$ , while window size $:=40$ performs best in terms of $\mathrm{nDCG}@5$ and $\textstyle\operatorname{nDCG}\ @1$ . We speculate that a larger window size will increase the model’s ranking horizon but will also present challenges in processing long contexts and large numbers of items.
为分析滑动窗口策略参数的影响,我们调整窗口大小并将步长设为窗口大小的一半。这种设置的主要动机是保持该方法预期开销(计算所需token数量)较低;即在此设置中大多数token仅被用于PG两次。实验结果如表$12^{11}$所示。结果表明,不同窗口尺寸值在特定到达范围内效果各异:窗口尺寸$\scriptstyle=20$在$\mathrm{nDCG}@10$指标上表现最佳,而窗口尺寸$:=40$在$\mathrm{nDCG}@5$和$\textstyle\operatorname{nDCG}\ @1$指标上表现最优。我们推测较大窗口尺寸会扩展模型的排序视野,但也会在处理长上下文和大量项目时带来挑战。
Table 11: Average token cost, number API request, and $\$0S D$ per query on TREC.
| API | Instruction | Tokens | Requests | $ USD |
| text-curie-001 | Relevance generation | 52,970 | 100 | 0.106 |
| text-curie-001 | Query generation | 10,954 | 100 | 0.022 |
| text-davinci-003 | Query generation | 11,269 | 100 | 0.225 |
| text-davinci-003 | Permutation generation | 17,370 | 10 | 0.347 |
| gpt-3.5-turbo | Permutation generation | 19,960 | 10 | 0.040 |
| gpt-4 | Permutation generation | 19,890 | 10 | 0.596 |
| - rerank top-30 | Permutation generation | 3,271 | 1 | 0.098 |
表 11: TREC 上每次查询的平均 token 成本、API 请求次数和 $\$0S D$。
| API | 指令 | Token数 | 请求次数 | 美元成本 |
|---|---|---|---|---|
| text-curie-001 | 相关性生成 | 52,970 | 100 | 0.106 |
| text-curie-001 | 查询生成 | 10,954 | 100 | 0.022 |
| text-davinci-003 | 查询生成 | 11,269 | 100 | 0.225 |
| text-davinci-003 | 排列生成 | 17,370 | 10 | 0.347 |
| gpt-3.5-turbo | 排列生成 | 19,960 | 10 | 0.040 |
| gpt-4 | 排列生成 | 19,890 | 10 | 0.596 |
| - rerank top-30 | 排列生成 | 3,271 | 1 | 0.098 |
Table 12: Analysis on Hyper parameters of Sliding Window on TREC-DL19.
| Windowsize | Stepsize | nDCG@1 | nDCG@5 | nDCG@10 |
| 20 | 10 | 75.58 | 70.50 | 67.05 |
| 40 | 20 | 78.30 | 71.32 | 65.51 |
| 60 | 30 | 75.97 | 69.23 | 65.03 |
| 80 | 40 | 72.09 | 70.59 | 65.57 |
表 12: TREC-DL19上滑动窗口超参数分析
| Windowsize | Stepsize | nDCG@1 | nDCG@5 | nDCG@10 |
|---|---|---|---|---|
| 20 | 10 | 75.58 | 70.50 | 67.05 |
| 40 | 20 | 78.30 | 71.32 | 65.51 |
| 60 | 30 | 75.97 | 69.23 | 65.03 |
| 80 | 40 | 72.09 | 70.59 | 65.57 |
H API Cost
H API 成本
In Table 11, we provide details on the average token cost, API request times, and USD cost per query. In terms of average token cost, the relevance generation method is the most expensive, as it requires 4 in-context demonstrations. On the other hand, the permutation generation method incurs higher token costs compared to the query generation method, as it involves the repeated processing of passages in sliding windows. Regarding the number of requests, the permutation generation method requires 10 requests for sliding windows, while other methods require 100 requests for re-ranking 100 passages. In terms of average USD cost, GPT-4 is the most expensive, with a cost of $\$0.596$ per query. However, using GPT-4 for re-ranking the top-30 passages can result in significant cost savings, with a cost of $\$0.098$ per query for GPT-4 usage, while still achieving good results. As a result, we only utilize GPT-4 for re-ranking the top 30 passages of ChatGPT on BEIR and Mr.TyDi. The total cost of our experiments with GPT-4 amounts to $\$556$ .
在表11中,我们提供了平均token消耗量、API请求次数和每次查询的美元成本详情。就平均token消耗而言,相关性生成方法成本最高,因为它需要4个上下文示例。相比之下,排列生成方法比查询生成方法消耗更多token,因其涉及滑动窗口中文本段的重复处理。在请求次数方面,排列生成方法需要10次滑动窗口请求,而其他方法需要对100个文本段进行重排序的100次请求。就平均美元成本而言,GPT-4最为昂贵,每次查询成本为$\$0.596$。但使用GPT-4对前30个文本段进行重排序可显著节省成本,GPT-4每次查询成本降至$\$0.098$,同时仍能获得良好效果。因此,我们仅在BEIR和Mr.TyDi数据集上使用GPT-4对ChatGPT生成的前30个文本段进行重排序。实验中GPT-4的总成本为$\$556$。
Since the experiments with ChatGPT and GPT-4 are conducted using the OpenAI API, the running time is contingent on the OpenAI service, e.g., API latency. Besides, the running time can also vary across different API versions and network environments. In our testing conditions, the average latency for API calls for gpt-3.5-turbo and gpt-4 was around 1.1 seconds and 3.2 seconds, respectively. Our proposed sliding window-based permutation generation approach requires 10 API calls per query to re-rank 100 passages. Consequently, the average running time per query is 11 seconds for gpt-3.5-turbo and 32 seconds for gpt-4.
由于ChatGPT和GPT-4的实验通过OpenAI API进行,运行时间取决于OpenAI服务(如API延迟)。此外,不同API版本和网络环境也会导致运行时间差异。在我们的测试条件下,gpt-3.5-turbo和gpt-4的API调用平均延迟分别约为1.1秒和3.2秒。我们提出的基于滑动窗口的排列生成方法每个查询需要10次API调用来对100个段落进行重排序,因此gpt-3.5-turbo的每查询平均运行时间为11秒,gpt-4为32秒。
I Results of Specialized Models
I 专用模型结果
Table 13 lists the detailed results of specialized models on TREC and BEIR.
表 13: TREC 和 BEIR 上专用模型的详细结果
| Method | DL19 DL20 Covid NFCorpus Touche DBPedia SciFact Signal News Robust04 BEIR (Avg) | |||||||
| BM25 | 50.58 47.96 59.47 | 30.75 | 44.22 | 31.80 | 67.89 | 33.05 39.52 | 40.70 | 43.42 |
| Supervised trainonMSMRACO | ||||||||
| monoBERT (340M) | 70.50 67.28 870.01 | 36.88 | 31.75 | 41.87 | 71.36 | 31.44 44.62 | 49.35 | 47.16 |
| monoT5 (220M) | 71.48 66.99 78.34 | 37.38 | 30.82 | 42.42 | 73.40 | 31.67 46.83 | 51.72 | 49.07 |
| monoT5 (3B) | 71.83 68.89 80.71 | 38.97 | 32.41 | 44.45 | 76.57 | 32.55 48.49 | 56.71 | 51.36 |
| Cohere Rerank-v2 | 73.22 67.08 81.81 | 36.36 | 32.51 | 42.51 | 74.44 | 29.60 47.59 | 50.78 | 49.45 |
| Unsupervised instructionalpermutationgeneration | ||||||||
| ChatGPT | 65.80 62.91 76.67 | 35.62 | 36.18 | 44.47 | 70.43 | 32.12 48.85 | 50.62 | 49.37 |
| GPT-4 | 75.59 70.56 85.51 | 38.47 | 38.57 | 47.12 | 74.95 | 34.40 52.89 | 57.55 | 53.68 |
| Specialized Models trainonMARCOlabelsorChatGPTpredictedpermutations | ||||||||
| MARCO Pointwise BCE | 65.57 56.72 70.82 | 33.10 | 17.08 | 32.28 | 55.37 | 19.30 41.52 | 46.00 | 39.43 |
| MARCO Listwise CE | 65.99 57.97 66.31 | 32.61 | 20.15 | 30.79 | 37.57 | 18.09 38.11 | 39.93 | 35.45 |
| MARCO RankNet | 66.34 58.51 70.29 | 34.23 | 20.27 | 29.62 | 49.01 | 23.22 39.82 | 43.87 | 38.79 |
| MARCO LambdaLoss | 64.82 56.16 72.86 | 34.20 | 19.51 | 32.55 | 51.88 | 26.22 42.47 | 45.28 | 40.62 |
| ChatGPT Listwise CE | 65.39 58.80 076.29 | 35.73 | 38.19 | 40.24 | 64.49 | 31.37 47.61 | 48.00 | 47.74 |
| ChatGPT RankNet | 65.75 59.34 81.26 | 36.57 | 39.03 | 42.10 | 68.77 | 31.55 52.54 | 52.44 | 50.53 |
| ChatGPT LambdaLoss | 67.17 60.56 80.63 | 36.74 | 36.73 | 43.75 | 68.21 | 32.58 49.00 | 50.51 | 49.77 |
| deberta-v3-xsmall (70M) | 64.75 55.07 78.21 67.85 58.84 478.88 | 35.95 36.55 | 35.42 36.16 | 41.37 40.99 | 67.86 66.66 | 30.04 47.68 49.17 | 49.91 | 48.31 |
| deberta-v3-small (142M) deberta-v3-base (184M) | 70.28 62.52 80.81 | 36.15 | 37.25 | 44.06 | 71.70 | 30.29 32.45 50.84 | 49.73 51.33 | 48.55 50.57 |
| deberta-v3-large (435M) | 70.66 67.15 84.64 | 38.48 | 39.27 | 47.36 | 74.18 | 32.53 51.19 | 56.55 | 53.03 |
| deberta-v3-large 5K | 70.93 64.32 84.43 | 38.66 | 40.72 | 46.28 | 73.88 | 31.93 52.24 | 55.89 | 53.00 |
| deberta-v3-large 3K | 70.79 63.91 84.21 | 38.73 | 39.83 | 45.74 | 74.41 | 31.92 52.29 | 57.42 | 53.07 |
| deberta-v3-large 1K | 69.90 64.81 83.38 | 38.94 | 36.65 | 44.46 | 71.96 | 30.19 50.73 | ||
| deberta-v3-large 500 | 69.71 62.00 83.54 | 37.23 | 33.68 | 44.56 | 70.48 | 28.70 45.64 | 53.74 | 51.26 |
| 42.67 | 48.31 | |||||||
| deberta-v3-large label 10K | 66.61 57.26 74.36 | 33.94 | 18.09 | 34.95 | 35.35 | 21.38 39.00 | 44.94 | 37.75 |
| deberta-v3-large label 5K | 68.98 61.38 80.73 | 35.68 | 20.48 | 37.34 | 54.63 | 24.25 36.94 | 51.13 | 42.64 |
| deberta-v3-large label 3K | 67.41 60.42 79.82 | 35.49 | 24.54 | 37.39 | 47.31 | 23.29 39.87 | 50.65 | 42.29 |
| deberta-v3-large label 1K | 65.55 60.93 77.70 | 33.29 | 23.36 | 36.38 | 31.10 | 21.71 34.28 | 38.31 | 37.01 |
| deberta-v3-large label 500 | 60.59 954.4576.20 | 32.93 | 19.66 | 31.54 | 45.66 | 13.99 33.48 | 44.49 | 37.24 |
| deberta-v3-large monoT5-3B deberta-v3-large chatgpt+label 72.42 | 73.05 68.82 84.78 | 38.55 | 34.43 | 43.61 | 75.45 | 30.75 49.85 | 56.80 | 51.78 |
| deberta-v3-base label 10k | 67.30 85.96 | 38.75 | 35.06 | 45.43 | 71.81 | 28.52 45.91 | 55.57 | 50.88 |
| deberta-v3-small label 10k | 65.66 59.84 71.63 63.63 52.83 68.17 | 34.65 30.48 | 16.53 18.12 | 32.59 31.72 | 34.65 33.62 | 22.64 37.60 18.02 34.57 | 44.02 36.09 | 36.79 33.85 |
| deberta-v3-xsmalllabel10k | 60.89 51.15 63.58 | 28.67 | 14.87 | 27.12 | 20.60 | 18.97 32.61 | 32.67 | 29.89 |
| llama-7b | 71.33 66.06 78.23 | 37.60 | 34.87 | 45.46 | 76.13 | 34.17 51.79 | 55.22 | 51.68 |
| vicuna-7b | 71.80 66.89 78.32 | 36.87 | 31.81 | 45.40 | 74.23 | 34.28 51.13 | 52.91 | 50.62 |
| llama-7b 10k label | 65.22 56.85 75.36 | 36.24 | ||||||
| 20.88 | 37.34 | 69.04 | 25.22 41.21 | 49.21 | 44.31 | |||
| llama-7b 5k label | 69.24 58.97 80.49 | 37.55 | 28.23 | 39.66 | 71.79 | 26.04 44.09 | 53.83 | 47.71 |
Table 13: Results $\mathbf{\Pi}(\mathbf{nDCG}@\mathbf{10})$ on TREC and BEIR. Best performing specialized and overall system(s) are marked bold. The specialized models are fine-tined on sampled queries using relevance judgements from MARCO or ChatGPT.
表 13: TREC 和 BEIR 数据集上的 $\mathbf{\Pi}(\mathbf{nDCG}@\mathbf{10})$ 结果。表现最佳的专用模型和整体系统已加粗标注。专用模型使用来自 MARCO 或 ChatGPT 的相关性判断对采样查询进行微调。
| 方法 | DL19 | DL20 | Covid | NFCorpus | Touche | DBPedia | SciFact | Signal News | Robust04 | BEIR (Avg) |
|---|---|---|---|---|---|---|---|---|---|---|
| BM25 | 50.58 | 47.96 | 59.47 | 30.75 | 44.22 | 31.80 | 67.89 | 33.05 | 39.52 | 40.70 |
| 监督训练 (MS MARCO) | ||||||||||
| monoBERT (340M) | 70.50 | 67.28 | 870.01 | 36.88 | 31.75 | 41.87 | 71.36 | 31.44 | 44.62 | 49.35 |
| monoT5 (220M) | 71.48 | 66.99 | 78.34 | 37.38 | 30.82 | 42.42 | 73.40 | 31.67 | 46.83 | 51.72 |
| monoT5 (3B) | 71.83 | 68.89 | 80.71 | 38.97 | 32.41 | 44.45 | 76.57 | 32.55 | 48.49 | 56.71 |
| Cohere Rerank-v2 | 73.22 | 67.08 | 81.81 | 36.36 | 32.51 | 42.51 | 74.44 | 29.60 | 47.59 | 50.78 |
| 无监督指令排列生成 | ||||||||||
| ChatGPT | 65.80 | 62.91 | 76.67 | 35.62 | 36.18 | 44.47 | 70.43 | 32.12 | 48.85 | 50.62 |
| GPT-4 | 75.59 | 70.56 | 85.51 | 38.47 | 38.57 | 47.12 | 74.95 | 34.40 | 52.89 | 57.55 |
| 专用模型 (基于 MARCO 标签或 ChatGPT 预测排列训练) | ||||||||||
| MARCO Pointwise BCE | 65.57 | 56.72 | 70.82 | 33.10 | 17.08 | 32.28 | 55.37 | 19.30 | 41.52 | 46.00 |
| MARCO Listwise CE | 65.99 | 57.97 | 66.31 | 32.61 | 20.15 | 30.79 | 37.57 | 18.09 | 38.11 | 39.93 |
| MARCO RankNet | 66.34 | 58.51 | 70.29 | 34.23 | 20.27 | 29.62 | 49.01 | 23.22 | 39.82 | 43.87 |
| MARCO LambdaLoss | 64.82 | 56.16 | 72.86 | 34.20 | 19.51 | 32.55 | 51.88 | 26.22 | 42.47 | 45.28 |
| ChatGPT Listwise CE | 65.39 | 58.80 | 076.29 | 35.73 | 38.19 | 40.24 | 64.49 | 31.37 | 47.61 | 48.00 |
| ChatGPT RankNet | 65.75 | 59.34 | 81.26 | 36.57 | 39.03 | 42.10 | 68.77 | 31.55 | 52.54 | 52.44 |
| ChatGPT LambdaLoss | 67.17 | 60.56 | 80.63 | 36.74 | 36.73 | 43.75 | 68.21 | 32.58 | 49.00 | 50.51 |
| DeBERTa 系列模型 | ||||||||||
| deberta-v3-xsmall (70M) | 64.75 | 55.07 | 78.21 | 67.85 | 58.84 | 478.88 | 35.95 | 36.55 | 35.42 | 36.16 |
| deberta-v3-small (142M) | 70.28 | 62.52 | 80.81 | 36.15 | 37.25 | 44.06 | 71.70 | 30.29 | 32.45 | 50.84 |
| deberta-v3-base (184M) | 70.66 | 67.15 | 84.64 | 38.48 | 39.27 | 47.36 | 74.18 | 32.53 | 51.19 | 56.55 |
| deberta-v3-large (435M) | 70.93 | 64.32 | 84.43 | 38.66 | 40.72 | 46.28 | 73.88 | 31.93 | 52.24 | 55.89 |
| deberta-v3-large 5K | 70.79 | 63.91 | 84.21 | 38.73 | 39.83 | 45.74 | 74.41 | 31.92 | 52.29 | 57.42 |
| deberta-v3-large 3K | 69.90 | 64.81 | 83.38 | 38.94 | 36.65 | 44.46 | 71.96 | 30.19 | 50.73 | |
| deberta-v3-large 1K | 69.71 | 62.00 | 83.54 | 37.23 | 33.68 | 44.56 | 70.48 | 28.70 | 45.64 | 53.74 |
| deberta-v3-large 500 | 42.67 | 48.31 | ||||||||
| DeBERTa 标签微调模型 | ||||||||||
| deberta-v3-large label 10K | 66.61 | 57.26 | 74.36 | 33.94 | 18.09 | 34.95 | 35.35 | 21.38 | 39.00 | 44.94 |
| deberta-v3-large label 5K | 68.98 | 61.38 | 80.73 | 35.68 | 20.48 | 37.34 | 54.63 | 24.25 | 36.94 | 51.13 |
| deberta-v3-large label 3K | 67.41 | 60.42 | 79.82 | 35.49 | 24.54 | 37.39 | 47.31 | 23.29 | 39.87 | 50.65 |
| deberta-v3-large label 1K | 65.55 | 60.93 | 77.70 | 33.29 | 23.36 | 36.38 | 31.10 | 21.71 | 34.28 | 38.31 |
| deberta-v3-large label 500 | 60.59 | 954.45 | 76.20 | 32.93 | 19.66 | 31.54 | 45.66 | 13.99 | 33.48 | 44.49 |
| 混合模型 | ||||||||||
| deberta-v3-large monoT5-3B | 73.05 | 68.82 | 84.78 | 38.55 | 34.43 | 43.61 | 75.45 | 30.75 | 49.85 | 56.80 |
| deberta-v3-large chatgpt+label | 72.42 | |||||||||
| deberta-v3-base label 10k | 67.30 | 85.96 | 38.75 | 35.06 | 45.43 | 71.81 | 28.52 | 45.91 | 55.57 | 50.88 |
| deberta-v3-small label 10k | 65.66 | 59.84 | 71.63 | 63.63 | 52.83 | 68.17 | 34.65 | 30.48 | 16.53 | 18.12 |
| deberta-v3-xsmall label 10k | 60.89 | 51.15 | 63.58 | 28.67 | 14.87 | 27.12 | 20.60 | 18.97 | 32.61 | 32.67 |
| 大语言模型 | ||||||||||
| llama-7b | 71.33 | 66.06 | 78.23 | 37.60 | 34.87 | 45.46 | 76.13 | 34.17 | 51.79 | 55.22 |
| vicuna-7b | 71.80 | 66.89 | 78.32 | 36.87 | 31.81 | 45.40 | 74.23 | 34.28 | 51.13 | 52.91 |
| llama-7b 10k label | 65.22 | 56.85 | 75.36 | 36.24 | 20.88 | 37.34 | 69.04 | 25.22 | 41.21 | 49.21 |
| llama-7b 5k label | 69.24 | 58.97 | 80.49 | 37.55 | 28.23 | 39.66 | 71.79 | 26.04 | 44.09 | 53.83 |