Toward Efficient Language Model Pre training and Downstream Adaptation via Self-Evolution: A Case Study on SuperGLUE
通过自我进化实现高效语言模型预训练与下游适配:以SuperGLUE为例
Abstract
摘要
This technical report briefly describes our JDExplore d-team’s Vega v2 submission on the SuperGLUE leader board 1. SuperGLUE is more challenging than the widely used general language understanding evaluation (GLUE) benchmark, containing eight difficult language understanding tasks, including question answering, natural language inference, word sense disambiguation, co reference resolution, and reasoning. [Method] Instead of arbitrarily increasing the size of a pretrained language model (PLM), our aim is to 1) fully extract knowledge from the input pre training data given a certain parameter budget, e.g., 6B, and 2) effectively transfer this knowledge to downstream tasks. To achieve goal 1), we propose self-evolution learning for PLMs to wisely predict the informative tokens that should be masked, and supervise the masked language modeling (MLM) process with rectified smooth labels. For goal 2), we leverage the prompt transfer technique to improve the low-resource tasks by transferring the knowledge from the foundation model and related downstream tasks to the target task. [Results] According to our submission record (Oct. 2022), with our optimized pre training and fine-tuning strategies, our 6B Vega method achieved new state-of-the-art performance on 4/8 tasks, sitting atop the SuperGLUE leader board on Oct. 8, 2022, with an average score of 91.3.
本技术报告简要介绍了我们JDExplore d-team在SuperGLUE排行榜上的Vega v2提交方案。SuperGLUE比广泛使用的通用语言理解评估(GLUE)基准更具挑战性,包含八项困难的语言理解任务,涵盖问答、自然语言推理、词义消歧、共指消解和推理等领域。[方法] 我们并未盲目增大预训练语言模型(PLM)的规模,而是致力于:1) 在给定参数量(如60亿)下充分提取输入预训练数据的知识;2) 高效将该知识迁移至下游任务。为实现目标1),我们提出PLM的自进化学习机制,智能预测应被掩码的信息化token,并通过修正平滑标签监督掩码语言建模(MLM)过程。针对目标2),我们采用提示迁移技术,通过从基础模型和相关下游任务转移知识来提升低资源目标任务的性能。[结果] 根据2022年10月的提交记录,我们优化的预训练与微调策略使60亿参数的Vega方法在8项任务中4项取得最先进性能,于2022年10月8日以91.3的平均分位居SuperGLUE榜首。
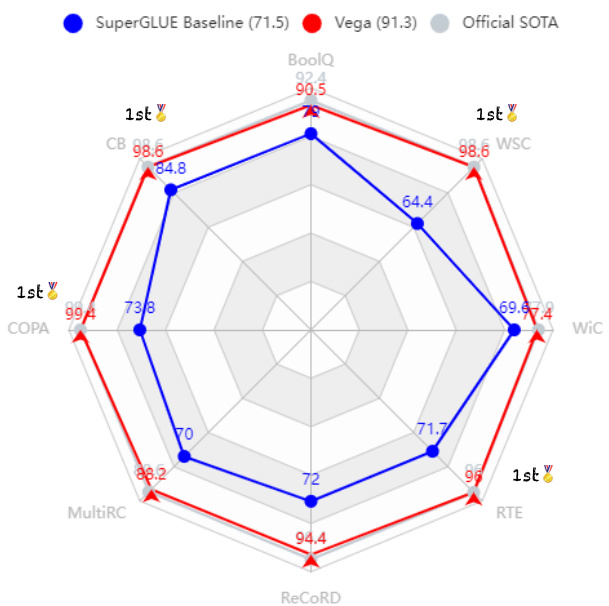
Figure 1: Vega v2 achieves state-of-the-art records on 4 out of 8 tasks among all submissions, producing the best average score of 91.3 and significantly outperforming the competitive official SuperGLUE Baseline (Wang et al., 2019a, BERT $^{++}$ ).
图 1: Vega v2 在所有提交中,在 8 项任务中的 4 项上达到了最先进的记录,取得了 91.3 的最佳平均分,显著优于竞争性的官方 SuperGLUE 基线 (Wang et al., 2019a, BERT$^{++}$)。
1 Introduction
1 引言
The last several years have witnessed notable progress across many natural language processing (NLP) tasks, led by pretrained language models (PLMs) such as bidirectional encoder representations from transformers (BERT) (Devlin et al., 2019), OpenAI GPT (Radford et al., 2019) and its most renowned evolution GPT3 (Brown et al., 2020). The unifying theme of the above methods is that they conduct self-supervised learning with massive easy-to-acquire unlabelled text corpora during the pre training stage and effectively fine-tune on a few labeled data in target tasks. Such a “pre training-fine-tuning” paradigm has been widely adopted by academia and industry, and the main research and development direction involves scaling the sizes of foundation models up to extremely large settings, such as Google’s 540B PaLM (Chowdhery et al., 2022b), to determine the upper capacity bounds of foundation models.
过去几年,自然语言处理(NLP)领域在预训练语言模型(PLM)的引领下取得了显著进展,代表性模型包括Transformer双向编码表示(BERT) (Devlin等人,2019)、OpenAI GPT (Radford等人,2019)及其最著名的演进版本GPT3 (Brown等人,2020)。这些方法的共同特点是在预训练阶段利用海量易获取的无标注文本语料进行自监督学习,并在目标任务中使用少量标注数据进行有效微调。这种"预训练-微调"范式已被学术界和工业界广泛采用,当前主要研发方向是将基础模型规模扩展至极大参数级别,例如谷歌5400亿参数的PaLM (Chowdhery等人,2022b),以探索基础模型的能力上限。
In such a context, the SuperGLUE (Wang et al., 2019a) (a more challenging version of the general language understanding evaluation (GLUE) benchmark (Wang et al., 2018)) has become the most influential and prominent evaluation benchmark for the foundation model community. Most highperforming models on the GLUE/ SuperGLUE leader board bring new insights and better practices to properly guide future research and applications.
在此背景下,SuperGLUE (Wang et al., 2019a) (通用语言理解评估基准GLUE (Wang et al., 2018) 的进阶挑战版) 已成为基础模型领域最具影响力和代表性的评估基准。GLUE/SuperGLUE排行榜上多数高性能模型都为未来研究和应用提供了新见解与更佳实践方案。
We recently submitted our 6B Vega v2 model to the SuperGLUE leader board and, as seen in Figure 1, obtained state-of-the-art records on 4 out of 8 tasks, sitting atop the leader board as of Oct. 8, 2022, with an average score of 91.3. Encouragingly, our 6B model with deliberately optimized pre training and downstream adaptation strategies substantially outperforms 540B PaLM (Chowdhery et al., 2022b), showing the effectiveness and parameter-efficiency of our Vega model. This technical report briefly describes how we build our powerful model under a certain parameter budget, i.e., 6B, from different aspects, including backbone framework (§2.1), the efficient pre training process (§2.2), and the downstream adaptation approach (§2.3). To fully extract knowledge from the given pre training data to PLMs, we propose a self-evolution learning (in Figure 2) mechanism to wisely predict the informative tokens that should be masked and supervise the mask language modeling process with rectified smooth labels. To effectively transfer the knowledge to different downstream tasks, especially the low-resource tasks, e.g., CB, COPA, and WSC, we design a knowledge distillation-based prompt transfer method (Zhong et al., 2022b) (in Figure 3) to achieve better performance with improved robustness.
我们近期将6B Vega v2模型提交至SuperGLUE排行榜。如图1所示,该模型在8项任务中斩获4项最先进指标,并以91.3的平均分位列2022年10月8日榜单首位。值得注意的是,通过精心优化的预训练与下游适配策略,我们的6B模型显著超越了540B参数的PaLM (Chowdhery et al., 2022b),彰显了Vega模型的高效性与参数利用率。本技术报告从主干框架(§2.1)、高效预训练流程(§2.2)和下游适配方法(§2.3)等维度,阐述了如何在6B参数预算内构建强大模型。为充分挖掘预训练数据价值,我们提出自演进学习机制(图2),智能预测需遮蔽的信息化token,并通过平滑修正标签监督掩码语言建模过程。针对下游任务(特别是CB、COPA、WSC等低资源任务)的知识迁移,我们设计了基于知识蒸馏的提示迁移方法(Zhong et al., 2022b)(图3),在提升鲁棒性的同时获得更优性能。
The remainder of this paper is designed as follows. We introduce the major utilized approaches in Section 2. In Section 3, we review the task descriptions and data statistics and present the experimental settings and major results. Conclusions are described in Section 4.
本文剩余部分结构如下:第2节介绍主要采用的方法;第3节回顾任务描述与数据统计,并展示实验设置与核心结果;第4节给出结论。
2 Approaches
2 方法
In this section, we describe the main techniques in our model, including the backbone framework in $\S2.1$ , the efficient pre training approaches in $\S2.2$ , and the downstream adaptation technique in $\S2.3$ .
在本节中,我们将介绍模型的主要技术,包括主干框架($\S2.1$)、高效预训练方法($\S2.2$)以及下游适配技术($\S2.3$)。
2.1 Backbone Framework
2.1 骨干框架
Vanilla transformers (Vaswani et al., 2017) enjoy appealing s cal ability as large-scale PLM backbones (Devlin et al., 2019; Raffel et al., 2020; Brown et al., 2020; Zan et al., 2022b); for example, T5 and GPT3 flexibly scale their feed forward dimensions and layers up to 65,534 and 96, respectively. We hereby employ a vanilla transformer, i.e., multihead self-attention followed by a fully connected feed forward network, as our major backbone framework. As encoder-only PLMs have an overwhelming advantage over the existing methods on the SuperGLUE leader board, we train our large model in an encoder-only fashion to facilitate downstream language understanding tasks. According to our PLM parameter budget – 6 Billion, we empirically set the model as follows: 24 layers, 4096 as the hidden layer size, an FFN of size 16,384, 32 heads, and 128 as the head size. In addition, He et al. (2021) empirically demonstrated the necessity of computing self-attention with disentangled matrices based on their contents and relative positions, namely disentangled attention2, which is adopted in Vega v2.
Vanilla transformers (Vaswani等人,2017) 作为大规模预训练语言模型 (PLM) 的主干网络展现出卓越的可扩展性 (Devlin等人,2019; Raffel等人,2020; Brown等人,2020; Zan等人,2022b)。例如,T5和GPT3可灵活扩展其前馈网络维度至65,534,层数至96层。本文采用标准Transformer架构 (即多头自注意力机制后接全连接前馈网络) 作为主干框架。鉴于仅编码器型PLM在SuperGLUE榜单上对现有方法的压倒性优势,我们以仅编码器模式训练大模型以提升下游语言理解任务性能。根据6 Billion的PLM参数量预算,我们经验性地设置模型结构如下:24层网络,隐藏层维度4096,前馈网络维度16,384,32个注意力头,头维度128。此外,He等人 (2021) 通过实验验证了基于内容与相对位置解耦矩阵 (即解耦注意力2) 计算自注意力的必要性,该机制被Vega v2采用。
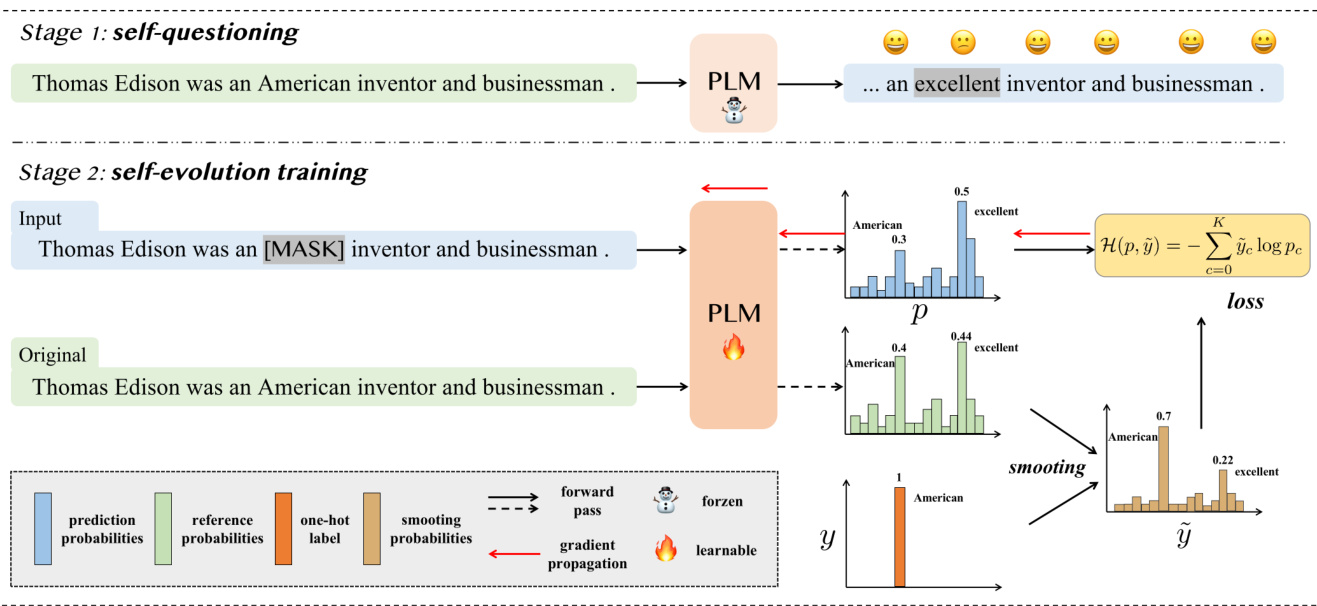
Figure 2: Overview of the proposed self-evolution learning mechanism for PLMs.
图 2: 提出的PLMs自进化学习机制概览。
2.2 Efficient Pre training
2.2 高效预训练
Recall that our aim is not to arbitrarily increase the model scales, but to facilitate storing the informative derived knowledge from the pre training data in PLMs. To approach this goal, we first revisit the representative self-supervision objective – masked language modeling (Devlin et al., 2019) (MLM), and propose a novel self-evolution learning mechanism to enable our PLM to wisely predict the informative tokens that should be masked, and train the model with smooth self-evolution labels.
需要明确的是,我们的目标并非随意扩大模型规模,而是促进预训练语言模型(PLM)高效存储从预训练数据中提取的信息化知识。为实现这一目标,我们首先重新审视了经典的掩码语言建模(MLM)自监督目标 [20],并提出创新的自进化学习机制:使PLM能够智能预测应当被掩码的信息化token,同时采用平滑自进化标签进行模型训练。
Masked Language Modeling MLM is a widely used self-supervision objective when conducting largescale pre training on large amounts of text to learn contextual word representations. In practice, MLM randomly selects a subset of tokens from a sentence and replaces them with a special mask token, i.e., [MASK]. However, such a random masking procedure is usually suboptimal, as the masked tokens are sometimes too easy to guess with only local cues or shallow patterns. Hence, some prior works focused on more informative masking strategies, such as span-level masking (Joshi et al., 2020), entity-level masking (Sun et al., 2019), and pointwise mutual information (PMI)-based masking (Sadeq et al., 2022). These efforts achieved better performance than vanilla random masking, which inspires us to explore more approaches for fully extracting knowledge from pre training data.
掩码语言建模 (Masked Language Modeling, MLM) 是一种广泛使用的自监督目标,用于在大规模文本预训练中学习上下文词表征。实践中,MLM 会从句子中随机选取部分 token 并用特殊掩码标记 [MASK] 替换。然而,这种随机掩码策略通常并非最优,因为被掩码的 token 有时仅通过局部线索或浅层模式就能轻易推测。因此,部分先前研究聚焦于更具信息量的掩码策略,例如基于片段级掩码 (Joshi et al., 2020)、实体级掩码 (Sun et al., 2019) 和点间互信息 (PMI) 的掩码 (Sadeq et al., 2022)。这些方法相比原始随机掩码取得了更好的性能,这启发我们探索更多方法以充分提取预训练数据中的知识。
Self-Evolution Learning Based on the above motivations, we propose a novel self-evolution learning mechanism for PLMs, as illustrated in Figure 2. Different from the prior works that designed masking strategies to train language models from scratch, our self-evolution learning approach aims to encourage the given “naive” PLMs to find patterns (tokens) that are not learned well but are more informative, and then fix them. Specifically, there are two stages in our self-evolution learning mechanism, as follows.
基于上述动机,我们提出了一种新颖的自进化学习机制用于预训练语言模型 (PLM) ,如图 2 所示。与之前通过设计掩码策略从头训练语言模型的工作不同,我们的自进化学习方法旨在促使给定的"初始"预训练语言模型发现那些未充分学习但信息量更大的模式 (token) ,进而修复它们。具体而言,我们的自进化学习机制包含以下两个阶段:
Stage 1 is self-questioning. Given a vanilla PLM (e.g., trained with the random masking objective), we first feed the original training samples into the PLM and make it re-predict the output probabilities for each token. As the PLM has seen these samples and learned from them in the pre training stage, it can make deterministic and correct predictions for most of the tokens, which we denote as learned tokens. However, for some tokens, such as “American” in the sentence “Thomas Edison was an American inventor and businessman”, the PLM tends to predict this token as “excellent” (the probability of “excellent” is 0.44, while the probability of “American” is 0.4). We attribute this phenomenon to the fact that the PLM does not learn this knowledge-intense pattern but only makes its prediction based on the local cues. We refer to these harder and more informative tokens as neglected tokens. After all training samples are fed into the PLM, we can obtain a set of neglected tokens for each training sample. Note that this procedure is conducted offline and does not update the parameters of the original PLM.
阶段1是自提问阶段。给定一个基础PLM(例如采用随机掩码目标训练的模型),我们首先将原始训练样本输入PLM,使其重新预测每个token的输出概率。由于PLM在预训练阶段已见过这些样本并从中学习,它能对大多数token做出确定且正确的预测,这些token我们称为已学习token。但对于部分token(如句子"Thomas Edison was an American inventor and businessman"中的"American"),PLM更倾向于预测为"excellent"("excellent"概率为0.44,而"American"概率为0.4)。我们将这种现象归因于PLM未能学习这种知识密集型模式,仅基于局部线索进行预测。这类难度较高且信息量更大的token被称为被忽视token。当所有训练样本输入PLM后,可为每个训练样本获得一组被忽视token。需注意的是,此过程为离线操作,不会更新原始PLM的参数。
| Algorithm 1: Transductive Fine-tuning | |
| Input: Finetuned (FT) Model M, DownstreamSeedD Output: Transductively FT Model M | |
| 1 t:=0 while not convergence do | |
| 3 | Estimate D with M and get DM |
| 4 | Tune M on DU DM and get M', then M = M |
| I+=: | |
| 6end | |
算法 1: 传导式微调 (Transductive Fine-tuning)
输入: 微调 (FT) 模型 M, 下游种子数据 D
输出: 传导式微调模型 M
1 t:=0
2 while 未收敛 do
3 | 用 M 估计 D 得到 DM
4 | 在 DU DM 上微调 M 得到 M', 然后 M = M
5 | t+=1
6 end
Stage 2 is self-evolution training. Given the neglected tokens (obtained in stage 1), we can select them for masking and then encourage the PLM to learn from these informative patterns, thus continuously improving the capability of the PLM. Intuitively, we can make the PLM learn how to predict these tokens, by minimizing the loss between the predicted probabilities and one-hot labels. However, considering the diversity of the neglected token, if we force the PLM to promote one specified ground truth over others, the other reasonable “ground truths” (for a given masking token, there can be more than one reasonable prediction) become false negatives that may plague the training process or cause a performance decrease (Li et al., 2022).
阶段2是自进化训练。给定被忽略的token(在阶段1中获得),我们可以选择它们进行掩码处理,然后促使预训练语言模型(PLM)从这些信息丰富的模式中学习,从而持续提升PLM的能力。直观上,我们可以通过最小化预测概率与独热标签之间的损失,让PLM学习如何预测这些token。然而,考虑到被忽略token的多样性,如果我们强制PLM提升某个特定真实标签而忽略其他,其他合理的"真实标签"(对于给定的掩码token,可能存在多个合理的预测)就会变成假阴性,这可能会干扰训练过程或导致性能下降 [20]。
Hence, we propose a novel self-evolution training method to help the PLM learn from the informative tokens, without damaging the diversification ability of the PLM. In practice, we feed the masked sentence and original sentence into the PLM, and obtain the prediction probabilities $p$ and reference probabilities $r$ for the [MASK] token. Then, we merge the $r$ and the one-hat label $y$ as $\tilde{y}=(1-\alpha)y+\alphar$ , where $\tilde{y}$ denotes the smoothing label probabilities and $\alpha$ is a weighting factor that is empirically set as 0.5. Finally, we use the cross-entropy loss function to minimize the difference between $p$ and $\tilde{y}$ . In this way, different from the strong-headed supervision of the one-hot labels $y$ , the PLM can benefit more from the smooth and informative labels $\tilde{y}$ .
因此,我们提出了一种新颖的自进化训练方法,帮助预训练语言模型 (PLM) 从信息丰富的token中学习,同时不损害PLM的多样化能力。具体实现时,我们将掩码句子和原始句子输入PLM,分别获得[MASK] token的预测概率$p$和参考概率$r$。接着,我们将$r$与one-hot标签$y$融合为$\tilde{y}=(1-\alpha)y+\alphar$,其中$\tilde{y}$表示平滑后的标签概率,$\alpha$为权重因子(经验值设为0.5)。最后采用交叉熵损失函数最小化$p$与$\tilde{y}$之间的差异。这种方式不同于one-hot标签$y$的强监督信号,PLM能从更平滑且信息丰富的标签$\tilde{y}$中获得更大收益。
2.3 Downstream Adaptation
2.3 下游适配
In addition to the above efficient pre training methods, we also introduce some useful fine-tuning strategies for effectively adapting our Vega v2 to downstream tasks. Specifically, there are two main problems that hinder the adaptation performance of a model. 1) The first concerns the domain gaps between the training and test sets, which lead to poor performance on target test sets. 2) The second is the use of limited training data, e.g., the CB task, which only consists of 250 training samples, as limited data can hardly update the total parameters of PLMs effectively. Note that in addition to the strategies listed below, we have also designed and implemented other methods from different perspectives to improve the generalization and efficiency of models, e.g. the FSAM optimizer for PLMs (Zhong et al., 2022c), Sparse Adapter (He et al., 2022), and continued training with downstream data (Zan et al., 2022a). Although these approaches can help to some extent, they do not provide complementary benefits compared to the listed approaches, so they are not described here.
除了上述高效的预训练方法外,我们还引入了一些实用的微调策略,以有效适配Vega v2至下游任务。具体而言,阻碍模型适配性能的主要有两个问题:1) 首先是训练集与测试集之间的领域差距,这会导致目标测试集上表现不佳;2) 其次是使用有限的训练数据,例如CB任务仅包含250个训练样本,有限的数据难以有效更新预训练语言模型(PLM)的全部参数。需要注意的是,除以下列出的策略外,我们还从不同角度设计并实现了其他方法来提升模型的泛化能力和效率,例如用于PLM的FSAM优化器(Zhong et al., 2022c)、稀疏适配器(Sparse Adapter)(He et al., 2022)以及下游数据持续训练(Zan et al., 2022a)。尽管这些方法在一定程度上有所帮助,但与所列方法相比并未提供互补优势,因此在此不做赘述。
Trans duct ive Fine-tuning Regrading the domain or linguistic style gap between the training and test sets (the first problem), we adopt a trans duct ive fine-tuning strategy to improve the target domain performance, which is a common practice in machine translation evaluations (Wu et al., 2020; Ding and Tao, 2021) and some domain adaptation applications (Liu et al., 2020). The proposed trans duct ive fine-tuning technique is shown in Algorithm 1. Whether we should conduct trans duct ive fine-tuning depends on the practical downstream performance achieved.
传导式微调
针对训练集与测试集之间的领域或语言风格差异(第一个问题),我们采用传导式微调策略来提升目标领域性能。该策略在机器翻译评估(Wu et al., 2020; Ding and Tao, 2021)和部分领域适应应用(Liu et al., 2020)中已有成熟实践。算法1展示了所提出的传导式微调技术。是否执行传导式微调需根据实际下游任务表现决定。
(注:根据术语处理规则,"transductive fine-tuning"首次出现时本应标注英文原文,但用户提供的术语表中未包含该词条,故按默认策略保留不译。若需补充术语对应关系,请提供该词条的中文译法。)
Prompt-Tuning To address the second problem, we replace the vanilla fine-tuning process with a more parameter-efficient method, prompt-tuning (Lester et al., 2021), for low-resource tasks. Despite the success of prompts in many NLU tasks (Wang et al., 2022; Zhong et al., 2022a), directly using prompttuning might lead to poor results, as this approach is sensitive to the prompt’s parameter initialization settings (Zhong et al., 2022b). An intuitive approach, termed as prompt transfer (Vu et al., 2022), is to initialize the prompt on the target task with the trained prompts from similar source tasks. Unfortunately, such a vanilla prompt transfer approach usually achieves suboptimal performance, as (i) the prompt transfer process is highly dependent on the similarity of the source-target pair and (ii) directly tuning a prompt initialized with the source prompt on the target task might lead to forgetting the useful general knowledge learned from the source task.
提示调优 (Prompt-Tuning)
为解决第二个问题,我们针对低资源任务采用参数效率更高的提示调优方法 (Lester et al., 2021) 替代传统微调。尽管提示在众多自然语言理解任务中成效显著 (Wang et al., 2022; Zhong et al., 2022a),直接使用提示调优可能效果欠佳,因为该方法对提示参数的初始化设置极为敏感 (Zhong et al., 2022b)。一种直观的解决方案是提示迁移 (Vu et al., 2022),即使用相似源任务的训练后提示来初始化目标任务的提示。然而,这种基础提示迁移方法往往表现欠佳,原因在于:(i) 提示迁移过程高度依赖源任务-目标任务的相似度;(ii) 直接在目标任务上微调源自源任务的初始化提示,可能导致遗忘从源任务中学到的有用通用知识。
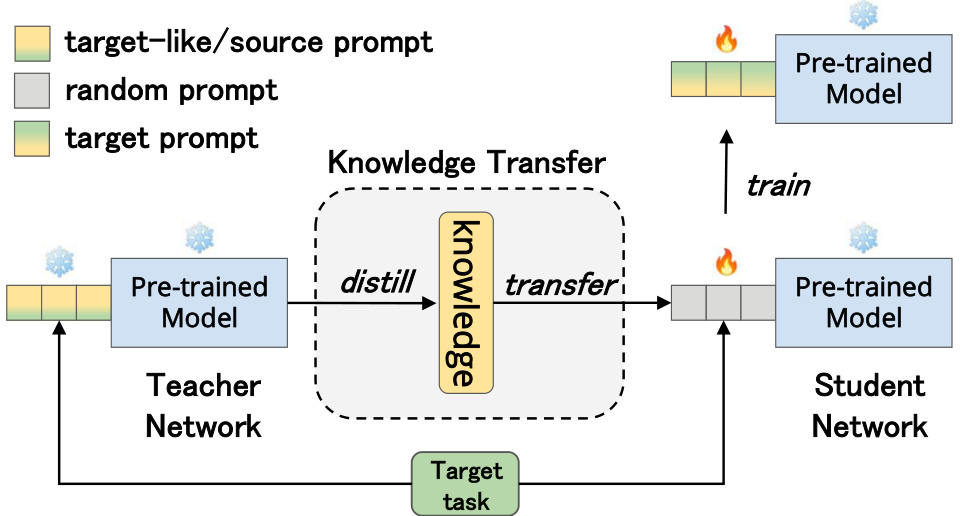
Figure 3: The architecture of our proposed KD-based prompt transfer method.
图 3: 我们提出的基于知识蒸馏 (KD) 的提示迁移方法架构。
To this end, we introduce a novel prompt transfer framework (Zhong et al., 2022b) to tackle the above problems. For (i), we propose a new metric to accurately predict prompt transfer ability. In practice, the metric first maps the source/target tasks into a shared semantic space to obtain their task embeddings based on the source/target soft prompts and then measures the prompt transfer ability via the similarity of corresponding task embeddings. In our primary experiments, we found that this metric could make appropriately choose which source tasks should be used for a target task. For instance, to perform prompt transfer among the SuperGLUE tasks, WSC is a better source task for the CB task, while COPA benefits more from the RTE task.
为此,我们引入了一种新颖的提示迁移框架 (Zhong et al., 2022b) 来解决上述问题。针对问题 (i),我们提出了一种新指标来准确预测提示迁移能力。该指标首先将源/目标任务映射到共享语义空间,基于源/目标软提示获取任务嵌入,然后通过对应任务嵌入的相似度来衡量提示迁移能力。在初步实验中,我们发现该指标能合理选择适用于目标任务的源任务。例如,在SuperGLUE任务间进行提示迁移时,WSC是CB任务更优的源任务,而COPA则从RTE任务中获益更多。
Regarding (ii), inspired by the knowledge distillation (KD) paradigm (Hinton et al., 2015; Liu et al., 2021; Rao et al., 2022) that leverages a powerful teacher model to guide the training process of a student model, we propose a KD-based prompt transfer method that leverages the KD technique to transfer the knowledge from the source prompt to the target prompt in a subtle manner, thus effectively alleviating the problem of prior knowledge forgetting. An illustration of our proposed method is shown in Figure 3. More specifically, our KD-based prompt transfer approach first uses the PLM with the source prompt as the teacher network and the PLM with the randomly initialized prompt as the student network. Then, the student network is trained using the supervision signals from both the ground-truth labels in the target task and the soft targets predicted by the teacher network. Note that we only update the parameters of the student prompt, while keeping the other parameters fixed. Furthermore, to adaptively control the knowledge transfer process in our approach, we use the prompt similarity predicted by our metric as the balancing factor between the two supervision signals for each source-target pair.
关于(ii),受知识蒸馏 (knowledge distillation, KD) 范式 (Hinton et al., 2015; Liu et al., 2021; Rao et al., 2022) 的启发,我们提出了一种基于KD的提示迁移方法。该方法利用KD技术以巧妙的方式将知识从源提示迁移到目标提示,从而有效缓解先验知识遗忘问题。图3展示了我们提出的方法示意图。具体而言,我们的基于KD的提示迁移方法首先将带有源提示的PLM作为教师网络,将带有随机初始化提示的PLM作为学生网络。然后,使用来自目标任务中真实标签和教师网络预测的软目标的双重监督信号来训练学生网络。需要注意的是,我们仅更新学生提示的参数,同时固定其他参数。此外,为了自适应地控制我们方法中的知识迁移过程,我们使用该度量预测的提示相似度作为每个源-目标对之间两个监督信号的平衡因子。
Adversarial Fine-Tuning In addition to the above trans duct ive FT and prompt-tuning processed for deliberately solving the training-testing domain gap and low downstream resource problem, respectively, we also adopt the advanced adversarial fine-tuning algorithm (Miyato et al., 2019; Jiang et al., 2020) designed for PLMs, i.e., SiFT (He et al., 2021), to improve the training stability of our approach. In practice, we follow He et al. (2021) by applying the perturbations to the normalized word embeddings when tuning our Vega foundation model on downstream tasks, where we first normalize the embedding vectors into stochastic vectors and then apply the perturbations to the normalized embedding vectors.
对抗性微调
除了上述分别用于针对性解决训练-测试领域差距和下游资源不足问题的转导式微调 (transductive FT) 和提示调优 (prompt-tuning) 外,我们还采用了专为预训练语言模型设计的先进对抗性微调算法 (Miyato et al., 2019; Jiang et al., 2020) ——即SiFT (He et al., 2021) ——以提升我们方法的训练稳定性。具体实现时,我们遵循He等人 (2021) 的方法,在下游任务微调Vega基础模型时对归一化后的词嵌入施加扰动:首先将嵌入向量归一化为随机向量,再对归一化后的嵌入向量施加扰动。
Table 1: Results obtained on the SuperGLUE test sets, which are scored by the SuperGLUE evaluation server. We obtained the results from https://super.glue benchmark.com on October 8, 2022. The best results (except the those of human baselines) are shown in bold.
表 1: SuperGLUE测试集上的结果,由SuperGLUE评估服务器评分。我们于2022年10月8日从https://super.gluebenchmark.com获取结果。最佳结果(除人类基线外)以粗体显示。
| 模型 | BoolQ Acc | CB F1 | CB Acc | COPA Acc | COPA F1 | MultiRC EM | MultiRC F1 | ReCoRD Acc. | ReCoRD F1 | WiC Acc | WSC Acc | 总分 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SuperGLUE基线 | 79.0 | 84.8 | 90.4 | 73.8 | 70.0 | 24.1 | 72.0 | 71.3 | 79.0 | 69.6 | 64.4 | 71.5 |
| SuperGLUE人类基线 | 89.0 | 95.8 | 98.9 | 100.0 | 81.8 | 51.9 | 91.7 | 91.3 | 93.6 | 80.0 | 100.0 | 89.8 |
| PaLM 540B (Chowdhery et al., 2022a) | 91.9 | 94.4 | 96.0 | 99.0 | 88.7 | 63.6 | 94.2 | 93.3 | 94.1 | 77.4 | 95.9 | 90.4 |
| ERNIE 3.0 (Sun et al., 2021) | 91.0 | 98.6 | 99.2 | 97.4 | 88.6 | 63.2 | 94.7 | 94.2 | 92.6 | 77.4 | 97.3 | 90.6 |
| Turing NLR v5 (Bajaj et al., 2022) | 92.0 | 95.9 | 97.6 | 98.2 | 88.4 | 63.0 | 96.4 | 95.9 | 94.1 | 77.1 | 97.3 | 90.9 |
| ST-MoE-32B (Zoph et al., 2022) | 92.4 | 96.9 | 98.0 | 99.2 | 89.6 | 65.8 | 95.1 | 94.4 | 93.5 | 77.7 | 96.6 | 91.2 |
| Vegav2(本工作) | 90.5 | 98.6 | 99.2 | 99.4 | 88.2 | 62.4 | 94.4 | 93.9 | 96.0 | 77.4 | 98.6 | 91.3 |
3 Experiments
3 实验
3.1 Implementation
3.1 实现
For pre training, we follow many prior works (Liu et al., 2019; He et al., 2021) and use Wikipedia3 (the English Wikipedia dump, 10 GB), BookCorpus (Zhu et al., $2015)^{4}$ (6 GB), Open web Text 5 (38 GB), Stories6 (31 GB) and CC-News (Trinh and Le, 2018) (76 GB) as pre training datasets, and use 40 NVIDIA DGX nodes with 320 A100 GPUs to train our Vega v2 model. It takes 30 days to finish phase-1 (pre training, i.e., MLM) with 1 M steps. For phase-2, i.e., self-evolution training, we continuously train Vega v2 for 50K steps. During fine-tuning, we only apply our KD-based prompt transfer strategy to the low-resource tasks, e.g., CB, COPA, and WSC. For the other tasks, the vanilla full-parameter model-tuning method with adversarial and trans duct ive fine-tuning is used. We use AdamW (Loshchilov and Hutter, 2018) as the optimizer for both pre training and fine-tuning.
在预训练阶段,我们遵循多项先前研究 (Liu et al., 2019; He et al., 2021) ,采用 Wikipedia3(英文维基百科转储文件,10GB)、BookCorpus (Zhu et al., $2015)^{4}$(6GB)、OpenWebText5(38GB)、Stories6(31GB)和 CC-News (Trinh and Le, 2018)(76GB)作为预训练数据集,并使用40个配备320块A100 GPU的NVIDIA DGX节点训练Vega v2模型。第一阶段(预训练,即MLM)耗时30天完成100万步训练。第二阶段(自进化训练)继续训练Vega v2模型5万步。在微调阶段,我们仅对低资源任务(如CB、COPA和WSC)应用基于知识蒸馏 (Knowledge Distillation) 的提示迁移策略,其他任务则采用常规全参数模型调优方法(结合对抗式与传导式微调)。预训练和微调均使用AdamW优化器 (Loshchilov and Hutter, 2018) 。
3.2 Tasks
3.2 任务
To validate the effectiveness of Vega v2, we use the SuperGLUE benchmark (Wang et al., 2019b) for model evaluation purposes. As one of the most popular NLU benchmarks, SuperGLUE consists of eight challenging NLU tasks, including question answering (BoolQ, Clark et al. (2019), MultiRC, Khashabi et al. (2018), ReCoRD, Zhang et al. (2018)), natural language inference (CB, de Marneffe et al. (2019), RTE, Dagan et al. (2006; Bar Haim et al. (2006; Gia m piccolo et al. (2007; Bentivogli et al. (2009)), word sense disambiguation (WIC, Pilehvar and Camacho-Collados (2019)), co reference resolution (WSC, Levesque et al. (2012)), and reasoning (COPA, Roemmele et al. (2011)). More detailed data statistics and examples for the above tasks can be found in Appendix Tables 3 and 4.
为验证Vega v2的有效性,我们采用SuperGLUE基准测试 (Wang et al., 2019b) 进行模型评估。作为最流行的自然语言理解(NLU)基准之一,SuperGLUE包含八项具有挑战性的NLU任务:问答系统(BoolQ, Clark et al. (2019), MultiRC, Khashabi et al. (2018), ReCoRD, Zhang et al. (2018))、自然语言推理(CB, de Marneffe et al. (2019), RTE, Dagan et al. (2006; Bar Haim et al. (2006; Gia m piccolo et al. (2007; Bentivogli et al. (2009))、词义消歧(WIC, Pilehvar and Camacho-Collados (2019))、共指消解(WSC, Levesque et al. (2012))以及推理任务(COPA, Roemmele et al. (2011))。各任务的详细数据统计与示例见附录表3和表4。
3.3 Main Results
3.3 主要结果
Table 1 reports the test results obtained by our Vega v2 and other cutting-edge models on the SuperGLUE benchmark7. Vega v2 significantly surpasses the powerful human baselines in terms of average score (91.3 vs. 89.8) and achieves state-of-the-art performance on four (relatively) low-resource tasks, i.e., CB, COPA, RTE, and WSC. We attribute this success to the novel self-evolution learning mechanism and KD-based prompt transfer method. More specifically, the former enhances Vega v2’s ability to extract informative patterns, while the latter alleviates the problem of over fitting and boosts the model performance on low-resource tasks.
表 1: 报告了我们的 Vega v2 和其他前沿模型在 SuperGLUE 基准测试7上获得的测试结果。Vega v2 在平均得分 (91.3 vs. 89.8) 方面显著超越了强大的人类基线,并在四个(相对)低资源任务(CB、COPA、RTE 和 WSC)上实现了最先进的性能。我们将这一成功归功于新颖的自进化学习机制和基于知识蒸馏 (KD) 的提示迁移方法。更具体地说,前者增强了 Vega v2 提取信息模式的能力,而后者缓解了过拟合问题并提升了模型在低资源任务上的表现。
In addition, compared to the other larger PLMs, e.g., PaLM (Chowdhery et al., 2022b) which consists of 540 billion parameters, our 6-billion-parameter Vega v2 can achieve competitive or even better performance on the SuperGLUE benchmark. This inspires us to conclude that scaling PLMs to larger model sizes arbitrarily might not be cost-effective, but would encourage the PLMs to fully extract knowledge from the pre training data when given a certain parameter budget.
此外,与其他更大的预训练语言模型 (PLM) 相比,例如包含 5400 亿参数的 PaLM (Chowdhery et al., 2022b),我们的 60 亿参数 Vega v2 在 SuperGLUE 基准测试中能够达到相当甚至更优的性能。这启发我们得出结论:盲目地将 PLM 扩展到更大的模型规模可能并不划算,但在给定一定参数预算的情况下,应鼓励 PLM 从预训练数据中充分提取知识。
4 Conclusion
4 结论
This paper presents the JD Explore Academy large-scale Vega v2 PLM for the SuperGLUE benchmark. Based on an advanced transformer backbone with disentangled attention and a series of advanced finetuning strategies, we propose two novel techniques. The first is a self-evolution learning mechanism that fully exploits the knowledge contained in data for a PLM in two steps: 1) the PLM performs selfquestioning to determine hard and informative words, and then 2) supervises the MLM process with rectified smooth labels. The second is a prompt transfer strategy for efficiently adapting downstream tasks (especially low-resource tasks) by leveraging the knowledge acquired from the foundation model and related downstream tasks.
本文介绍了京东探索研究院针对SuperGLUE基准的大规模Vega v2预训练语言模型(PLM)。基于采用解耦注意力机制的先进Transformer主干网络和一系列微调策略,我们提出了两项新技术:首先是自进化学习机制,通过两个步骤充分挖掘数据中的知识——1) PLM执行自提问以识别困难且信息丰富的词汇,2) 使用修正平滑标签监督掩码语言建模(MLM)过程;其次是提示迁移策略,通过利用基础模型和相关下游任务获取的知识,高效适配下游任务(特别是低资源任务)。
We show that these techniques significantly improve the efficiency of model pre training and the performance achieved on downstream tasks. The Vega v2 model with 6 billion parameters achieves state-of-the-art records on 4 out of 8 tasks and ranks the first in terms of the macro-average score. Our experience with building Vega v2 demonstrates the necessity of 1) fully improving the parameter efficiency of PLMs, and 2) wisely preforming downstream adaptation.
我们证明这些技术能显著提升模型预训练效率和下游任务性能。60亿参数的Vega v2模型在8项任务中刷新了4项最优记录,并以宏观平均分位列第一。构建Vega v2的经验表明:1) 必须全面提升预训练语言模型(PLM)的参数效率;2) 需明智实施下游适配。
Acknowledgments
致谢
The authors wish to thank the leader board maintainer of SuperGLUE for their great construction efforts and their prompt responses to our questions. The authors also especially thank Mr. Yukang Zhang (JD Explore Academy), who kindly supports maintaining a stable computing platform.
作者感谢SuperGLUE排行榜维护团队的卓越建设工作及对我们问题的及时回应。特别感谢张宇康先生(京东探索研究院)对稳定计算平台维护的大力支持。
References
参考文献
Takeru Miyato, Shin ichi Maeda, Masanori Koyama, and Shin Ishii. 2019. Virtual adversarial training: A regu lari z ation method for supervised and semi-supervised learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41:1979–1993.
Takeru Miyato, Shin ichi Maeda, Masanori Koyama, and Shin Ishii. 2019. 虚拟对抗训练: 一种用于监督和半监督学习的正则化方法. IEEE Transactions on Pattern Analysis and Machine Intelligence, 41:1979–1993.
Table 2: Results of Top-10 models on SuperGLUE leader board (https://super. glue benchmark.com/leader board), on October 8, 2022.
表 2: 2022年10月8日SuperGLUE排行榜(https://super.gluebenchmark.com/leaderboard)前十名模型结果
| #Rank | Model | BoolQ Acc | CB F1 | CB Acc | COPA Acc | MultiRC F1 | MultiRC EM | ReCoRD F1 | ReCoRD Acc. | RTE Acc | WiC Acc | WSC Acc | Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Vegav2 (Ours) | 90.5 | 98.6 | 99.2 | 99.4 | 88.2 | 62.4 | 94.4 | 93.9 | 96.0 | 77.4 | 98.6 | 91.3 |
| 2 | ST-MoE-32B | 92.4 | 96.9 | 98.0 | 99.2 | 89.6 | 65.8 | 95.1 | 94.4 | 93.5 | 77.7 | 96.6 | 91.2 |
| 3 | Turing NLR v5 | 92.0 | 95.9 | 97.6 | 98.2 | 88.4 | 63.0 | 96.4 | 95.9 | 94.1 | 77.1 | 97.3 | 90.9 |
| 4 | ERNIE3.0 | 91.0 | 98.6 | 99.2 | 97.4 | 88.6 | 63.2 | 94.7 | 94.2 | 92.6 | 77.4 | 97.3 | 90.6 |
| 5 | PaLM540B | 91.9 | 94.4 | 96.0 | 99.0 | 88.7 | 63.6 | 94.2 | 93.3 | 94.1 | 77.4 | 95.9 | 90.4 |
| 6 | T5+UKG,Single Model | 91.4 | 95.8 | 97.6 | 98.0 | 88.3 | 63.0 | 94.2 | 93.5 | 93.0 | 77.9 | 96.6 | 90.4 |
| 7 | DeBERTa/TuringNLRv4 | 90.3 | 95.7 | 97.6 | 98.4 | 88.2 | 63.7 | 94.5 | 94.1 | 93.2 | 77.5 | 95.9 | 90.3 |
| 8 | SuperGLUEHumanBaselines | 89.0 | 95.8 | 98.9 | 100.0 | 81.8 | 51.9 | 91.7 | 91.3 | 93.6 | 80.0 | 100.0 | 89.8 |
| 9 | T5 | 91.2 | 93.9 | 96.8 | 94.8 | 88.1 | 63.3 | 94.1 | 93.4 | 92.5 | 76.9 | 93.8 | 89.3 |
| 10 | FrozenT5 1.1+SPoT | 91.1 | 95.8 | 97.6 | 95.6 | 87.9 | 61.9 | 93.3 | 92.4 | 92.9 | 75.8 | 93.8 | 89.2 |
Table 3: Data statistics of different tasks included in SuperGLUE according to their original paper (Wang et al., 2019a). WSD stands for word sense disambiguation, NLI is natural language inference, coref. is co reference resolution, and $Q A$ is question answering. For MultiRC, we list the number of total answers for 456/83/166 train/dev/test questions.
表 3: SuperGLUE基准中各任务的数据统计 (Wang et al., 2019a) 。WSD表示词义消歧,NLI表示自然语言推理,coref.指共指消解,$Q A$代表问答。对于MultiRC任务,我们列出了456/83/166个训练集/开发集/测试集问题对应的总答案数量。
| 语料库 | 训练集 | 开发集 | 测试集 | 任务类型 | 评估指标 | 文本来源 |
|---|---|---|---|---|---|---|
| BoolQ | 9427 | 3270 | 3245 | 问答 | 准确率 | 谷歌搜索、维基百科 |
| CB | 250 | 57 | 250 | 自然语言推理 | 准确率/F1值 | 多源数据 |
| COPA | 400 | 100 | 500 | 问答 | 准确率 | 博客、摄影百科 |
| MultiRC | 5100 | 953 | 1800 | 问答 | F1值/精确匹配 | 多源数据 |
| ReCoRD | 101k | 10k | 10k | 问答 | F1值/精确匹配 | 新闻(CNN、每日邮报) |
| RTE | 2500 | 278 | 300 | 自然语言推理 | 准确率 | 新闻、维基百科 |
| WiC | 6000 | 638 | 1400 | 词义消歧 | 准确率 | WordNet/VerbNet/Wiktionary |
| WSC | 554 | 104 | 146 | 共指消解 | 准确率 | 小说书籍 |
Table 4: Task examples from the valid set in SuperGLUE (Wang et al., 2019a). Bold text represents part of the example format for each task. Text in italics is part of the model input. Underlined text is specially marked in the input. Text in a monospaced font represents the expected model output.
表 4: SuperGLUE验证集中的任务示例 (Wang et al., 2019a)。加粗文本表示每个任务示例格式的部分内容。斜体文本是模型输入的一部分。带下划线文本在输入中有特殊标记。等宽字体文本代表预期的模型输出。
| Bool | 段落:Barq's-Barq's是一种美国软饮料。其根汁啤酒品牌因含有咖啡因而闻名。Barq's由Edward Barq创建并于20世纪之交开始灌装,归Barq家族所有但由可口可乐公司灌装。2012年前它被称为Barq's Famous Olde Tyme Root Beer。问题:barq's根汁啤酒是百事产品吗 答案:否 文本:B:但是,呃,我希-我希望看到雇主能提供帮助。比如在工作场所设立儿童托管中心之类的。A:嗯。B:你怎么看,你觉得我们在... |
| COPA | 引领潮流吗?假设:他们正在引领潮流 蕴含关系:未知 前提:我的身体在草地上投下阴影。问题:造成这种现象的原因是什么? |
| MultiRC | 选项1:太阳正在升起。选项2:草被割了。正确答案:1 段落:Susan想举办生日派对。她给所有朋友打了电话。她有五个朋友。她妈妈说Susan可以邀请所有人。第一个朋友因病无法参加。第二个朋友要出城。第三个朋友不确定父母是否同意。第四个朋友说可能来。第五个朋友确定能参加。Susan有点难过。派对当天,五个朋友都出现了。 |
| ReCoRD | 每个朋友都给Susan带了礼物。Susan很开心,第二周给每个朋友寄了感谢卡。问题:Susan生病的朋友康复了吗?候选答案:是的,她康复了(T),否(F),是的(T),不,她没有康复(F),是的,她参加了Susan的派对(T) 段落:(CNN)波多黎各周日以压倒性票数支持成为美国州。但只有国会能批准新州加入,最终决定这个美国自治邦的地位是否改变。州选举委员会97%的结果显示。这是第五次此类州地位公投。"今天我们波多黎各人民向美国国会...也向全世界...发出强烈明确的信息..." |
| RTE | 周日支持成为美国州 查询 首先,他们可以诚实地说:"别怪我,我没投票给他们",当讨论iplaceholder总统任期时 正确实体:美国 文本:根据克里斯托弗·里夫基金会消息,演员克里斯托弗·里夫的遗孀Dana Reeve因肺癌去世,享年44岁。 |
| WSC | 假设:克里斯托弗·里夫发生过事故。蕴含关系:假 上下文1:食宿。上下文2:他用木板钉住了窗户。语义匹配:假 |
| | 文本:Mark向Pete说了很多关于自己的谎言,Pete把这些写进了书里。他本该更诚实的。共指关系:假 |