ColBERT: Eficient and Efective Passage Search via Contextual i zed Late Interaction over BERT
ColBERT: 基于BERT上下文化延迟交互的高效有效段落搜索
Omar Khatab Stanford University okhatab@stanford.edu
Omar Khatab 斯坦福大学 okhatab@stanford.edu
Matei Zaharia Stanford University matei@cs.stanford.edu
Matei Zaharia 斯坦福大学 matei@cs.stanford.edu
ABSTRACT
摘要
Recent progress in Natural Language Understanding (NLU) is driving fast-paced advances in Information Retrieval (IR), largely owed to fne-tuning deep language models (LMs) for document ranking. While remarkably efective, the ranking models based on these LMs increase computational cost by orders of magnitude over prior approaches, particularly as they must feed each query–document pair through a massive neural network to compute a single relevance score. To tackle this, we present ColBERT, a novel ranking model that adapts deep LMs (in particular, BERT) for efcient retrieval. ColBERT introduces a late interaction architecture that independently encodes the query and the document using BERT and then employs a cheap yet powerful interaction step that models their fne-grained similarity. By delaying and yet retaining this fnegranular interaction, ColBERT can leverage the expressiveness of deep LMs while simultaneously gaining the ability to pre-compute document representations ofine, considerably speeding up query processing. Beyond reducing the cost of re-ranking the documents retrieved by a traditional model, ColBERT’s pruning-friendly interaction mechanism enables leveraging vector-similarity indexes for end-to-end retrieval directly from a large document collection. We extensively evaluate ColBERT using two recent passage search datasets. Results show that ColBERT’s ef ect ive ness is competitive with existing BERT-based models (and outperforms every nonBERT baseline), while executing two orders-of-magnitude faster and requiring four orders-of-magnitude fewer FLOPs per query.
自然语言理解(NLU)的最新进展正推动信息检索(IR)领域的快速发展,这主要归功于用于文档排序的深度语言模型(LM)微调技术。虽然基于这些大语言模型的排序模型效果显著,但其计算成本相比先前方法增加了数个数量级,尤其是需要将每个查询-文档对输入庞大的神经网络来计算单个相关性得分。为此,我们提出ColBERT——一种适配深度大语言模型(特别是BERT)的高效检索新型排序模型。ColBERT采用延迟交互架构:先使用BERT分别独立编码查询和文档,再通过一个计算量小但功能强大的交互步骤来建模它们的细粒度相似性。通过延迟并保留这种细粒度交互,ColBERT既能利用深度大语言模型的强大表达能力,又可离线预计算文档表示,从而显著加速查询处理。除了降低传统模型文档重排序成本外,ColBERT支持剪枝的交互机制还能直接在大规模文档集合上利用向量相似度索引进行端到端检索。我们使用两个最新段落搜索数据集对ColBERT进行了全面评估。结果表明,ColBERT的效果与现有基于BERT的模型相当(且优于所有非BERT基线),同时查询速度快两个数量级,每次查询所需的FLOPs减少四个数量级。
ACM Reference format:
ACM参考文献格式:
1 INTRODUCTION
1 引言
Over the past few years, the Information Retrieval (IR) community has witnessed the introduction of a host of neural ranking models, including DRMM [7], KNRM [4, 36], and Duet [20, 22]. In contrast to prior learning-to-rank methods that rely on hand-crafed features, these models employ embedding-based representations of queries and documents and directly model local interactions (i.e., fne-granular relationships) between their contents. Among them, a recent approach has emerged that fne-tunes deep pre-trained language models (LMs) like ELMo [29] and BERT [5] for estimating relevance. By computing deeply-contextual i zed semantic representations of query–document pairs, these LMs help bridge the pervasive vocabulary mismatch [21, 42] between documents and queries [30]. Indeed, in the span of just a few months, a number of ranking models based on BERT have achieved state-of-the-art results on various retrieval benchmarks [3, 18, 25, 39] and have been pro prieta ril y adapted for deployment by Google1 and $\mathrm{Bing^{2}}$ .
过去几年间,信息检索 (IR) 领域涌现了大量神经排序模型,包括 DRMM [7]、KNRM [4, 36] 和 Duet [20, 22]。与依赖手工特征的传统学习排序方法不同,这些模型采用基于嵌入 (embedding) 的查询和文档表示方式,直接建模内容间的局部交互 (即细粒度关系)。其中,最新趋势是通过微调深度预训练语言模型 (如 ELMo [29] 和 BERT [5]) 进行相关性估计。这些模型通过计算查询-文档对的深度上下文语义表征,有效缓解了文档与查询间普遍存在的词汇不匹配问题 [21, 42, 30]。事实上,短短数月内,基于 BERT 的多个排序模型已在各类检索基准测试中取得最先进成果 [3, 18, 25, 39],并被 Google 和 $\mathrm{Bing^{2}}$ 专有化适配投入实际应用。

Figure 1: Ef ect ive ness $(\mathbf{MRR}@\mathbf{10})$ versus Mean Qery Latency (log-scale) for a number of representative ranking models on MS MARCO Ranking [24]. Te fgure also shows ColBERT. Neural re-rankers run on top of the ofcial BM25 top-1000 results and use a Tesla V100 GPU. Methodology and detailed results are in $\S4$ .
图 1: 多个代表性排序模型在 MS MARCO Ranking [24] 数据集上的有效性 $(\mathbf{MRR}@\mathbf{10})$ 与平均查询延迟 (对数尺度) 的关系对比。图中同时展示了 ColBERT 的表现。神经重排序模型基于官方 BM25 top-1000 结果运行,并使用 Tesla V100 GPU。具体方法和详细结果见 $\S4$。
However, the remarkable gains delivered by these LMs come at a steep increase in computational cost. Hofstatter et al. [9] and MacAvaney et al. [18] observe that BERT-based models in the literature are $100–1000\times$ more computationally expensive than prior models—some of which are arguably not inexpensive to begin with [13]. Tis quality–cost tradeof is summarized by Figure 1, which compares two BERT-based rankers [25, 27] against a representative set of ranking models. Te fgure uses MS MARCO Ranking [24], a recent collection of 9M passages and 1M queries from Bing’s logs. It reports retrieval ef ect ive ness $(\mathrm{MRR}@10)$ on the ofcial validation set as well as average query latency (log-scale) using a high-end server that dedicates one Tesla V100 GPU per query for neural re-rankers. Following the re-ranking setup of MS MARCO, ColBERT (re-rank), the Neural Matching Models, and the Deep LMs re-rank the MS MARCO’s ofcial top-1000 documents per query.
然而,这些大语言模型带来的显著性能提升伴随着计算成本的大幅增加。Hofstatter等人[9]和MacAvaney等人[18]指出,文献中基于BERT的模型计算开销比先前模型高出$100–1000\times$——其中某些模型本身计算成本就不低[13]。图1总结了这种质量-成本的权衡关系,对比了两款基于BERT的排序模型[25, 27]与一组代表性排序模型。该实验采用MS MARCO排序数据集[24](来自Bing日志的900万段落和100万查询集合),在高端服务器(每查询配备一块Tesla V100 GPU用于神经重排序器)上报告了官方验证集的检索有效性$(\mathrm{MRR}@10)$及平均查询延迟(对数坐标)。按照MS MARCO重排序设置,ColBERT(重排序)、神经匹配模型和深度大语言模型对每个查询的官方Top-1000文档进行重排序。
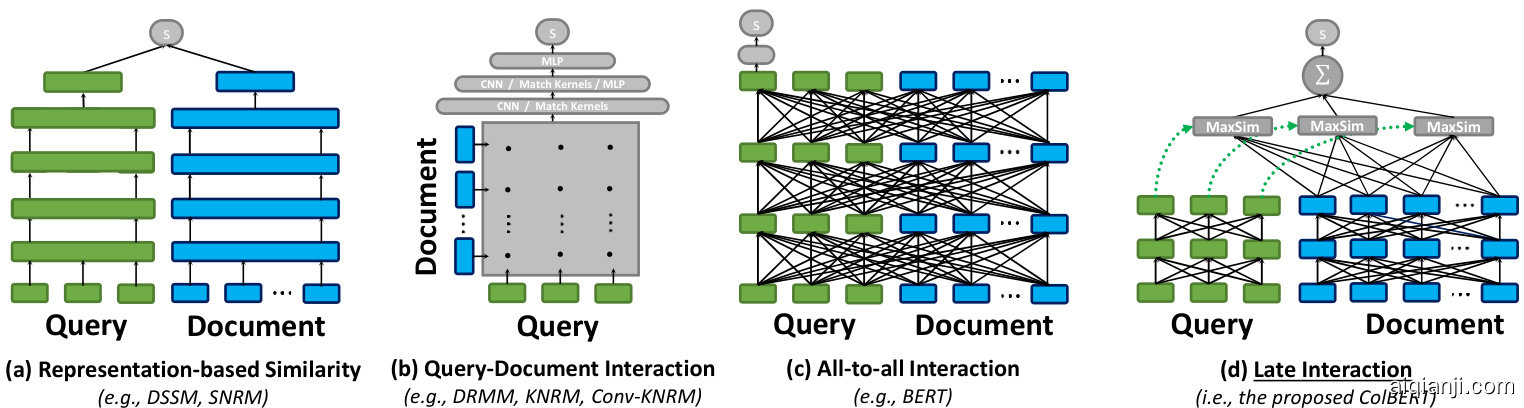
Figure 2: Schematic diagrams illustrating query–document matching paradigms in neural IR. Te fgure contrasts existing approaches (sub-fgures (a), (b), and (c)) with the proposed late interaction paradigm (sub-fgure (d)).
图 2: 神经信息检索中查询-文档匹配范式的示意图。该图对比了现有方法(子图(a)、(b)和(c))与提出的延迟交互范式(子图(d))。
Other methods, including ColBERT (full retrieval), directly retrieve the top-1000 results from the entire collection.
其他方法,包括ColBERT(全检索),直接从整个集合中检索前1000个结果。
As the fgure shows, BERT considerably improves search precision, raising MRR $@10$ by almost $7%$ against the best previous methods; simultaneously, it increases latency by up to tens of thousands of milliseconds even with a high-end GPU. Tis poses a challenging tradeof since raising query response times by as litle as $100\mathrm{ms}$ is known to impact user experience and even measurably diminish revenue [17]. To tackle this problem, recent work has started exploring using Natural Language Understanding (NLU) techniques to augment traditional retrieval models like BM25 [32]. For example, Nogueira et al. [26, 28] expand documents with NLU-generated queries before indexing with BM25 scores and Dai & Callan [2] replace BM25’s term frequency with NLU-estimated term importance. Despite successfully reducing latency, these approaches generally reduce precision substantially relative to BERT.
如图所示,BERT显著提升了搜索精度,将MRR $@10$ 比之前最佳方法提高了近 $7%$;与此同时,即使使用高端GPU,延迟也增加了数万毫秒。这带来了一个具有挑战性的权衡,因为已知查询响应时间仅增加 $100\mathrm{ms}$ 就会影响用户体验,甚至可测量地降低收入 [17]。为解决这一问题,近期研究开始探索使用自然语言理解(NLU)技术来增强传统检索模型如BM25 [32]。例如,Nogueira等人 [26, 28] 在基于BM25评分建立索引前,用NLU生成的查询扩展文档,而Dai & Callan [2] 则用NLU估计的词项重要性替代BM25的词频统计。尽管这些方法成功降低了延迟,但相对于BERT,它们通常大幅降低了精度。
To reconcile efciency and contextual iz ation in IR, we propose ColBERT, a ranking model based on contextual i zed late interaction over BERT. As the name suggests, ColBERT proposes a novel late interaction paradigm for estimating relevance between a query $q$ and a document d. Under late interaction, $q$ and $d$ are separately encoded into two sets of contextual embeddings, and relevance is evaluated using cheap and pruning-friendly computations between both sets—that is, fast computations that enable ranking without exhaustively evaluating every possible candidate.
为了兼顾信息检索(IR)中的效率与上下文关联性,我们提出了ColBERT——一个基于BERT上下文交互延迟的排序模型。顾名思义,ColBERT提出了一种新颖的延迟交互范式来评估查询$q$与文档$d$之间的相关性。在延迟交互机制下,$q$和$d$被分别编码为两组上下文嵌入向量,并通过两组向量间支持剪枝的低成本计算(即无需穷举评估所有候选结果的快速运算)来实现相关性评估。
Figure 2 contrasts our proposed late interaction approach with existing neural matching paradigms. On the lef, Figure 2 (a) illustrates representation-focused rankers, which independently compute an embedding for $q$ and another for $d$ and estimate relevance as a single similarity score between two vectors [12, 41]. Moving to the right, Figure 2 (b) visualizes typical interaction-focused rankers. Instead of summarizing $q$ and $d$ into individual embeddings, these rankers model word- and phrase-level relationships across $q$ and $d$ and match them using a deep neural network (e.g., with CNNs/MLPs [22] or kernels [36]). In the simplest case, they feed the neural network an interaction matrix that refects the similiar it y between every pair of words across $q$ and d. Further right, Figure 2 (c) illustrates a more powerful interaction-based paradigm, which models the interactions between words within as well as across $q$ and $d$ at the same time, as in BERT’s transformer architecture [25].
图 2: 对比了我们提出的延迟交互方法与现有神经匹配范式。左侧图 2 (a) 展示了以表征为中心的排序器,它们独立计算查询 $q$ 和文档 $d$ 的嵌入向量,并通过两个向量间的单一相似度分数评估相关性 [12, 41]。向右移动,图 2 (b) 展示了典型的以交互为中心的排序器。这类方法不将 $q$ 和 $d$ 压缩为独立嵌入,而是建模 $q$ 和 $d$ 之间的词级/短语级关系,并使用深度神经网络(如 CNN/MLP [22] 或核方法 [36])进行匹配。最简单情况下,它们向神经网络输入反映 $q$ 和 $d$ 间所有词对相似度的交互矩阵。最右侧图 2 (c) 展示了更强大的基于交互的范式,它能同时建模 $q$ 和 $d$ 内部及跨文档的词级交互,如 BERT 的 Transformer 架构 [25]。
Tese increasingly expressive architectures are in tension. While interaction-based models (i.e., Figure 2 (b) and (c)) tend to be superior for IR tasks [8, 21], a representation-focused model—by isolating the computations among $q$ and $d-$ makes it possible to precompute document representations ofine [41], greatly reducing the computational load per query. In this work, we observe that the fne-grained matching of interaction-based models and the precomputation of document representations of representation-based models can be combined by retaining yet judiciously delaying the query–document interaction. Figure 2 (d) illustrates an architec- ture that precisely does so. As illustrated, every query embedding interacts with all document embeddings via a MaxSim operator, which computes maximum similarity (e.g., cosine similarity), and the scalar outputs of these operators are summed across query terms. Tis paradigm allows ColBERT to exploit deep LM-based representations while shifing the cost of encoding documents offine and amortizing the cost of encoding the query once across all ranked documents. Additionally, it enables ColBERT to leverage vector-similarity search indexes (e.g., [1, 15]) to retrieve the top $k$ results directly from a large document collection, substantially improving recall over models that only re-rank the output of term-based retrieval.
这些日益富有表现力的架构之间存在张力。虽然基于交互的模型(即图2(b)和(c))在信息检索(IR)任务中往往更优[8,21],但专注于表示的模型——通过隔离$q$和$d-$之间的计算——使得可以离线预计算文档表示[41],大大降低了每个查询的计算负载。在这项工作中,我们观察到基于交互模型的细粒度匹配和基于表示模型的文档表示预计算可以通过保留但明智地延迟查询-文档交互来结合。图2(d)展示了一个精确实现这一点的架构。如图所示,每个查询嵌入通过MaxSim算子与所有文档嵌入交互,该算子计算最大相似度(例如余弦相似度),这些算子的标量输出在查询词项上求和。这种范式使ColBERT能够利用基于深度语言模型的表示,同时将文档编码成本转移到离线阶段,并将查询编码成本分摊到所有排序文档上。此外,它使ColBERT能够利用向量相似性搜索索引(例如[1,15])直接从大型文档集合中检索前$k$个结果,显著提高了仅对基于词项的检索输出进行重排的模型的召回率。
As Figure 1 illustrates, ColBERT can serve queries in tens or few hundreds of milliseconds. For instance, when used for reranking as in “ColBERT (re-rank)”, it delivers over $170\times$ speedup (and requires $14{,}000\times$ fewer FLOPs) relative to existing BERT-based models, while being more efective than every non-BERT baseline (§4.2 & 4.3). ColBERT’s indexing—the only time it needs to feed documents through BERT—is also practical: it can index the MS MARCO collection of 9M passages in about 3 hours using a single server with four GPUs (§4.5), retaining its ef ect ive ness with a space footprint of as litle as few tens of GiBs. Our extensive ablation study (§4.4) shows that late interaction, its implementation via MaxSim operations, and crucial design choices within our BERTbased encoders are all essential to ColBERT’s ef ect ive ness.
如图 1 所示,ColBERT 能在数十或数百毫秒内处理查询。例如,在作为 "ColBERT (re-rank)" 进行重排序时,相比现有的基于 BERT 的模型,它实现了超过 $170\times$ 的加速 (且所需 FLOPs 减少了 $14{,}000\times$ ),同时比所有非 BERT 基线更有效 (§4.2 & 4.3)。ColBERT 的索引过程——唯一需要将文档输入 BERT 的环节——同样实用:使用单台配备四块 GPU 的服务器,可在约 3 小时内完成包含 900 万段落的 MS MARCO 数据集索引 (§4.5),并以仅几十 GiB 的空间占用保持其有效性。我们详尽的消融研究 (§4.4) 表明,延迟交互、通过 MaxSim 运算的实现方式,以及基于 BERT 编码器中的关键设计选择,都对 ColBERT 的有效性至关重要。
Our main contributions are as follows.
我们的主要贡献如下。
2 RELATED WORK
2 相关工作
Neural Matching Models. Over the past few years, IR researchers have introduced numerous neural architectures for ranking. In this work, we compare against KNRM [4, 36], Duet [20, 22], ConvKNRM [4], and fastText $^+$ ConvKNRM [10]. KNRM proposes a diferent i able kernel-pooling technique for extracting matching signals from an interaction matrix, while Duet combines signals from exact-match-based as well as embedding-based similarities for ranking. Introduced in 2018, ConvKNRM learns to match $n$ - grams in the query and the document. Lastly, fastTex $^{\cdot+}$ ConvKNRM (abbreviated fT+ConvKNRM) tackles the absence of rare words from typical word embeddings lists by adopting sub-word token embeddings.
神经匹配模型。过去几年中,信息检索(IR)研究者提出了多种神经排序架构。本研究对比了KNRM [4, 36]、Duet [20, 22]、ConvKNRM [4]以及fastText$^+$ConvKNRM [10]。KNRM采用可微核池化技术从交互矩阵提取匹配信号,Duet则综合基于精确匹配和嵌入相似度的信号进行排序。2018年提出的ConvKNRM通过学习查询与文档中的$n$元语法(n-gram)实现匹配。最后,fastText$^{\cdot+}$ConvKNRM(简称fT+ConvKNRM)采用子词token嵌入技术,解决了传统词嵌入列表罕见词缺失的问题。
In 2018, Zamani et al. [41] introduced SNRM, a representationfocused IR model that encodes each query and each document as a single, sparse high-dimensional vector of “latent terms”. By producing a sparse-vector representation for each document, SNRM is able to use a traditional IR inverted index for representing documents, allowing fast end-to-end retrieval. Despite highly promising results and insights, SNRM’s ef ect ive ness is substantially outperformed by the state of the art on the datasets with which it was evaluated (e.g., see [18, 38]). While SNRM employs sparsity to allow using inverted indexes, we relax this assumption and compare a (dense) BERT-based representation-focused model against our late-interaction ColBERT in our ablation experiments in $\S4.4$ . For a detailed overview of existing neural ranking models, we refer the readers to two recent surveys of the literature [8, 21].
2018年,Zamani等人[41]提出了SNRM,这是一种专注于表示的IR(信息检索)模型,它将每个查询和每个文档编码为一个稀疏的高维"潜在词项"向量。通过为每个文档生成稀疏向量表示,SNRM能够使用传统的IR倒排索引来表示文档,从而实现快速的端到端检索。尽管取得了非常有前景的结果和见解,但SNRM的有效性在当时最先进的数据集上被明显超越(例如参见[18, 38])。虽然SNRM利用稀疏性来支持倒排索引的使用,但我们在消融实验($\S4.4$)中放宽了这一假设,并将基于BERT的(密集)表示模型与我们的延迟交互ColBERT进行了比较。关于现有神经排序模型的详细概述,我们建议读者参考最近的两篇文献综述[8, 21]。
Language Model Pre training for IR. Recent work in NLU emphasizes the importance pre-training language representation models in an unsupervised fashion before subsequently fne-tuning them on downstream tasks. A notable example is BERT [5], a bidirectional transformer-based language model whose fne-tuning advanced the state of the art on various NLU benchmarks. Nogueira et al. [25], MacAvaney et al. [18], and Dai & Callan [3] investigate incorporating such LMs (mainly BERT, but also ELMo [29]) on different ranking datasets. As illustrated in Figure 2 (c), the common approach (and the one adopted by Nogueira et al. on MS MARCO and TREC CAR) is to feed the query–document pair through BERT and use an MLP on top of BERT’s [CLS] output token to produce a relevance score. Subsequent work by Nogueira et al. [27] introduced duoBERT, which fne-tunes BERT to compare the relevance of a pair of documents given a query. Relative to their single-document BERT, this gives duoBERT a $1%$ MRR@10 advantage on MS MARCO while increasing the cost by at least $1.4\times$ .
信息检索的语言模型预训练。近期自然语言理解(NLU)领域的研究强调,在下游任务进行微调前,以无监督方式预训练语言表示模型的重要性。典型代表是BERT [5],这种基于双向Transformer的语言模型通过微调在多项NLU基准测试中实现了突破性进展。Nogueira等[25]、MacAvaney等[18]以及Dai & Callan [3]探索了将此类大语言模型(主要是BERT,也包括ELMo [29])应用于不同排序数据集的方法。如图2(c)所示,主流方法(也是Nogueira等在MS MARCO和TREC CAR数据集采用的方法)是将查询-文档对输入BERT,并在BERT的[CLS]输出token上使用多层感知机(MLP)生成相关性分数。Nogueira等[27]后续提出的duoBERT通过微调BERT来比较给定查询下文档对的相关性,相较于单文档BERT版本,该方法在MS MARCO数据集上获得1%的MRR@10提升,但计算成本至少增加1.4倍。
BERT Optimization s. As discussed in $\S1$ , these LM-based rankers can be highly expensive in practice. While ongoing efforts in the NLU literature for distilling [14, 33], compressing [40], and pruning [19] BERT can be instrumental in narrowing this gap, they generally achieve sign if cant ly smaller speedups than our redesigned architecture for IR, due to their generic nature, and more aggressive optimization s ofen come at the cost of lower quality.
BERT优化方案。如 $\S1$ 所述,这类基于语言模型的排序器在实际应用中可能成本极高。尽管自然语言理解领域持续涌现的BERT蒸馏[14,33]、压缩[40]和剪枝[19]研究有助于缩小这一差距,但由于其通用性质,这些方法通常只能实现远低于我们为信息检索重构架构的加速效果,且更激进的优化方案往往以质量下降为代价。
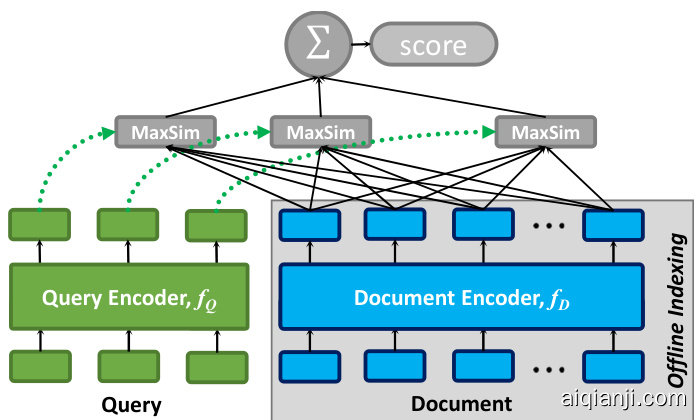
Figure 3: Te general architecture of ColBERT given a query $q$ and a document d.
图 3: 给定查询 $q$ 和文档 d 时 ColBERT 的通用架构。
Efcient NLU-based Models. Recently, a direction emerged that employs expensive NLU computation ofine. Tis includes doc2query [28] and DeepCT [2]. Te doc2query model expands each document with a pre-defned number of synthetic queries queries generated by a seq2seq transformer model that is trained to generate queries given a document. It then relies on a BM25 index for retrieval from the (expanded) documents. DeepCT uses BERT to produce the term frequency component of BM25 in a contextaware manner, essentially representing a feasible realization of the term-independence assumption with neural networks [23]. Lastly, doc TTT TT query [26] is identical to doc2query except that it fnetunes a pre-trained model (namely, T5 [31]) for generating the predicted queries.
高效基于自然语言理解(NLU)的模型。近期出现了一种利用离线NLU计算的研究方向,包括doc2query [28]和DeepCT [2]。doc2query模型通过预定义数量的合成查询来扩展每个文档,这些查询由经过训练的seq2seq transformer模型生成,该模型的任务是根据文档生成查询。随后它依赖BM25索引从(扩展后的)文档中进行检索。DeepCT则使用BERT以上下文感知的方式生成BM25的词频组件,本质上实现了用神经网络处理词项独立性假设的可行方案[23]。最后,docTTTTTquery [26]与doc2query类似,不同之处在于它对预训练模型(即T5 [31])进行了微调以生成预测查询。
Concurrently with our drafting of this paper, Hofstatter et al. [11] published their Transformer-Kernel (TK) model. At a high level, TK improves the KNRM architecture described earlier: while KNRM employs kernel pooling on top of word-embedding-based interaction, TK uses a Transformer [34] component for con textually encoding queries and documents before kernel pooling. TK establishes a new state-of-the-art for non-BERT models on MS MARCO (Dev); however, the best non-ensemble MRR $@10$ it achieves is $31%$ while ColBERT reaches up to $36%$ . Moreover, due to indexing document representations ofine and employing a MaxSim-based late interaction mechanism, ColBERT is much more scalable, enabling end-to-end retrieval which is not supported by TK.
在我们撰写本文的同时,Hofstatter等人[11]发表了他们的Transformer-Kernel (TK)模型。从高层次看,TK改进了前文所述的KNRM架构:KNRM在基于词嵌入(word-embedding)的交互层上采用核池化(kernel pooling),而TK则先通过Transformer[34]组件对查询和文档进行上下文编码,再进行核池化。TK在MS MARCO(Dev)数据集上创造了非BERT模型的新标杆,但其最佳非集成MRR@10仅为31%,而ColBERT可达36%。此外,由于ColBERT采用离线索引文档表征和基于MaxSim的延迟交互机制,其扩展性显著优于TK,支持端到端检索——这是TK无法实现的功能。
3 COLBERT
3 COLBERT
ColBERT prescribes a simple framework for balancing the quality and cost of neural IR, particularly deep language models like BERT. As introduced earlier, delaying the query–document interaction can facilitate cheap neural re-ranking (i.e., through pre-computation) and even support practical end-to-end neural retrieval (i.e., through pruning via vector-similarity search). ColBERT addresses how to do so while still preserving the ef ect ive ness of state-of-the-art models, which condition the bulk of their computations on the joint query–document pair.
ColBERT提出了一种平衡神经信息检索(IR)质量与成本的简单框架,尤其适用于BERT等深度语言模型。如前所述,延迟查询-文档交互能实现经济的神经重排序(即通过预计算),甚至支持实用的端到端神经检索(即通过向量相似性搜索进行剪枝)。ColBERT解决了如何在保持最先进模型效能的同时实现这一目标,这些模型将其大部分计算建立在联合查询-文档对的基础上。
Even though ColBERT’s late-interaction framework can be applied to a wide variety of architectures (e.g., CNNs, RNNs, transformers, etc.), we choose to focus this work on bi-directional transformerbased encoders (i.e., BERT) owing to their state-of-the-art efectiveness yet very high computational cost.
尽管ColBERT的延迟交互框架可应用于多种架构(如CNN、RNN、Transformer等),但由于双向Transformer编码器(即BERT)具有最先进的性能且计算成本极高,我们选择将本工作重点聚焦于此。
3.1 Architecture
3.1 架构
Figure 3 depicts the general architecture of ColBERT, which comprises: (a) a query encoder $f_{Q}$ , (b) a document encoder $f_{D}$ , and (c) the late interaction mechanism. Given a query $q$ and document $d$ , $f_{Q}$ encodes $q$ into a bag of fxed-size embeddings $E_{q}$ while $f_{D}$ encodes $d$ into another bag $E_{d}$ . Crucially, each embeddings in $E_{q}$ and $E_{d}$ is contextual i zed based on the other terms in $q$ or $d$ , respectively. We describe our BERT-based encoders in $\S3.2$ .
图 3: ColBERT 的通用架构包含:(a) 查询编码器 $f_{Q}$,(b) 文档编码器 $f_{D}$,以及 (c) 延迟交互机制。给定查询 $q$ 和文档 $d$,$f_{Q}$ 将 $q$ 编码为固定大小的嵌入集合 $E_{q}$,而 $f_{D}$ 将 $d$ 编码为另一个集合 $E_{d}$。关键的是,$E_{q}$ 和 $E_{d}$ 中的每个嵌入都分别基于 $q$ 或 $d$ 中的其他项进行了上下文处理。我们将在 $\S3.2$ 中描述基于 BERT 的编码器。
Using $E_{q}$ and $E_{d}$ , ColBERT computes the relevance score between $q$ and $d$ via late interaction, which we defne as a summation of maximum similarity (MaxSim) operators. In particular, we fnd the maximum cosine similarity of each $v\in E_{q}$ with vectors in $E_{d}$ , and combine the outputs via summation. Besides cosine, we also evaluate squared L2 distance as a measure of vector similarity. Intuitively, this interaction mechanism sofly searches for each query term $t_{q}\mathrm{-in}$ a manner that refects its context in the query—against the document’s embeddings, quantifying the strength of the “match” via the largest similarity score between $t_{q}$ and a document term $t_{d}$ . Given these term scores, it then estimates the document relevance by summing the matching evidence across all query terms.
使用 $E_{q}$ 和 $E_{d}$,ColBERT 通过延迟交互计算 $q$ 和 $d$ 之间的相关性得分,我们将其定义为最大相似度 (MaxSim) 算子的总和。具体而言,我们找到 $E_{q}$ 中每个 $v$ 与 $E_{d}$ 中向量的最大余弦相似度,并通过求和组合输出结果。除了余弦相似度,我们还评估了平方 L2 距离作为向量相似度的度量。直观上,这种交互机制以反映查询中上下文的方式,为每个查询词 $t_{q}$ 软搜索文档嵌入,并通过 $t_{q}$ 和文档词 $t_{d}$ 之间的最大相似度得分量化“匹配”强度。给定这些词项得分后,它通过汇总所有查询词的匹配证据来估计文档相关性。
While more sophisticated matching is possible with other choices such as deep convolution and atention layers (i.e., as in typical interaction-focused models), a summation of maximum similarity computations has two distinctive characteristics. First, it stands out as a particularly cheap interaction mechanism, as we examine its FLOPs in $\S4.2$ . Second, and more importantly, it is amenable to highly-efcient pruning for top $\cdot k$ retrieval, as we evaluate in $\S4.3$ . Tis enables using vector-similarity algorithms for skipping documents without materializing the full interaction matrix or even considering each document in isolation. Other cheap choices (e.g., a summation of average similarity scores, instead of maximum) are possible; however, many are less amenable to pruning. In $\S4.4$ , we conduct an extensive ablation study that empirically verifes the advantage of our MaxSim-based late interaction against alternatives.
虽然通过深度卷积层和注意力层等其他选择(例如典型的以交互为中心的模型)可以实现更复杂的匹配,但最大相似度计算的总和具有两个显著特点。首先,它是一种特别廉价的交互机制,我们将在 $\S4.2$ 中分析其浮点运算量 (FLOPs) 。其次,更重要的是,它非常适合针对 top $\cdot k$ 检索进行高效剪枝,我们将在 $\S4.3$ 中评估这一点。这使得可以利用向量相似度算法跳过文档,而无需生成完整的交互矩阵,甚至无需单独考虑每个文档。其他廉价选择(例如使用平均相似度得分而非最大值的总和)也是可行的,但其中许多方法较难进行剪枝。在 $\S4.4$ 中,我们进行了广泛的消融研究,通过实验验证了基于 MaxSim 的延迟交互相较于其他方案的优势。
deep transformer architecture, which computes a contextual i zed representation of each token.
深度Transformer架构,可计算每个Token的上下文表征。
We denote the padding with masked tokens as query augmentation, a step that allows BERT to produce query-based embeddings at the positions corresponding to these masks. Qery augmentation is intended to serve as a sof, diferent i able mechanism for learning to expand queries with new terms or to re-weigh existing terms based on their importance for matching the query. As we show in $\S4.4$ , this operation is essential for ColBERT’s ef ect ive ness.
我们将用掩码token进行填充的操作称为查询增强(query augmentation),这一步骤使得BERT能够在这些掩码对应的位置生成基于查询的嵌入向量。查询增强旨在作为一种柔性的、可微分机制,用于学习通过新词扩展查询或根据词语对查询匹配的重要性重新调整现有词语的权重。如$\S4.4$所示,该操作对ColBERT的效果至关重要。
Given BERT’s representation of each token, our encoder passes the contextual i zed output representations through a linear layer with no activation s. Tis layer serves to control the dimension of ColBERT’s embeddings, producing $m$ -dimensional embeddings for the layer’s output size $m$ . As we discuss later in more detail, we typically fx $m$ to be much smaller than BERT’s fxed hidden dimension.
给定BERT对每个Token的表示,我们的编码器将这些上下文化的输出表示通过一个无激活函数的线性层。该层用于控制ColBERT嵌入的维度,为层的输出尺寸$m$生成$m$维嵌入。稍后我们将详细讨论,通常我们会将$m$固定为远小于BERT固定隐藏维度的值。
While ColBERT’s embedding dimension has limited impact on the efciency of query encoding, this step is crucial for controlling the space footprint of documents, as we show in $\S4.5$ . In addition, it can have a signifcant impact on query execution time, particularly the time taken for transferring the document representations onto the GPU from system memory (where they reside before processing a query). In fact, as we show in $\S4.2$ , gathering, stacking, and transferring the embeddings from CPU to GPU can be the most expensive step in re-ranking with ColBERT. Finally, the output embeddings are normalized so each has L2 norm equal to one. Te result is that the dot-product of any two embeddings becomes equivalent to their cosine similarity, falling in the $[-1,1]$ range.
虽然ColBERT的嵌入维度对查询编码效率影响有限,但这一步骤对控制文档空间占用至关重要(如我们在$\S4.5$所示)。此外,它会对查询执行时间产生显著影响,尤其是将文档表示从系统内存(查询处理前的存储位置)传输到GPU所需的时间。实际上,如$\S4.2$所示,在ColBERT重排序过程中,从CPU收集、堆叠并传输嵌入向量可能是最耗时的环节。最终,输出嵌入会进行归一化处理,使每个向量的L2范数等于1。因此,任意两个嵌入的点积等价于它们的余弦相似度,其值落在$[-1,1]$范围内。
Document Encoder. Our document encoder has a very similar architecture. We frst segment a document $d$ into its constituent tokens $d_{1}d_{2}...d_{m}$ , to which we prepend BERT’s start token [CLS] followed by our special token [D] that indicates a document sequence. Unlike queries, we do not append [mask] tokens to documents. After passing this input sequence through BERT and the subsequent linear layer, the document encoder flters out the embeddings corresponding to punctuation symbols, determined via a pre-defned list. Tis fltering is meant to reduce the number of embeddings per document, as we hypothesize that (even contextual i zed) embeddings of punctuation are unnecessary for ef ect ive ness.
文档编码器。我们的文档编码器采用非常相似的架构。首先将文档 $d$ 分割为组成token序列 $d_{1}d_{2}...d_{m}$,并在其开头添加BERT的起始token [CLS]和表示文档序列的特殊token [D]。与查询处理不同,我们不会在文档后附加[mask] token。将该输入序列通过BERT及后续线性层后,文档编码器会基于预定义列表过滤掉标点符号对应的嵌入向量。此过滤操作旨在减少每个文档的嵌入数量,因为我们假设(即使是上下文相关的)标点符号嵌入对检索有效性并无必要。
In summary, given $q=q_{0}q_{1}...q_{l}$ and $d=d_{0}d_{1}...d_{n}$ , we compute the bags of embeddings $E_{q}$ and $E_{d}$ in the following manner, where # refers to the [mask] tokens:
综上所述,给定 $q=q_{0}q_{1}...q_{l}$ 和 $d=d_{0}d_{1}...d_{n}$,我们按以下方式计算嵌入包 $E_{q}$ 和 $E_{d}$,其中 # 代表 [mask] token:
3.2 Qery & Document Encoders
3.2 查询与文档编码器
Prior to late interaction, ColBERT encodes each query or document into a bag of embeddings, employing BERT-based encoders. We share a single BERT model among our query and document encoders but distinguish input sequences that correspond to queries and documents by prepending a special token [Q] to queries and another token [D] to documents.
在实现延迟交互之前,ColBERT 将每个查询或文档编码为一组嵌入向量,采用基于 BERT 的编码器。我们在查询和文档编码器之间共享同一个 BERT 模型,但通过在查询前添加特殊 token [Q] 和在文档前添加 token [D] 来区分对应的输入序列。
Qery Encoder. Given a textual query $q$ , we tokenize it into its BERT-based WordPiece [35] tokens $q_{1}q_{2}...q_{l}$ . We prepend the token [Q] to the query. We place this token right afer BERT’s sequencestart token [CLS]. If the query has fewer than a pre-defned number of tokens $N_{q}$ , we pad it with BERT’s special [mask] tokens up to length $N_{q}$ (otherwise, we truncate it to the frst $N_{q}$ tokens). Tis padded sequence of input tokens is then passed into BERT’s
查询编码器。给定一个文本查询 $q$,我们将其分词为基于BERT的WordPiece [35] tokens $q_{1}q_{2}...q_{l}$。我们在查询前添加[Q] token,并将其紧接在BERT序列起始token [CLS]之后。如果查询的token数量少于预设值 $N_{q}$,则用BERT的特殊[mask] token填充至长度 $N_{q}$(否则截断至前 $N_{q}$ 个token)。随后将这个填充后的输入token序列传入BERT的
$$
[
\begin{aligned}
E_q &:= \text{Norm}(\text{CNN}(\text{BERT}(Qq_0 \dots q_l))) \
E_d &:= \text{Filter}(\text{Norm}(\text{CNN}(\text{BERT}([D]d_0 \dots d_n^{\circ})))
\end{aligned}
$$
$$
[
\begin{aligned}
E_q &:= \text{Norm}(\text{CNN}(\text{BERT}(Qq_0 \dots q_l))) \
E_d &:= \text{Filter}(\text{Norm}(\text{CNN}(\text{BERT}([D]d_0 \dots d_n^{\circ})))
\end{aligned}
$$
3.3 Late Interaction
3.3 延迟交互
Given the representation of a query $q$ and a document $d$ , the relevance score of $d$ to $q$ , denoted as $S_{q,d}$ , is estimated via late interaction between their bags of contextual i zed embeddings. As mentioned before, this is conducted as a sum of maximum similarity computations, namely cosine similarity (implemented as dot-products due to the embedding normalization) or squared L2 distance.
给定查询 $q$ 和文档 $d$ 的表示,$d$ 对 $q$ 的相关性得分记为 $S_{q,d}$ ,通过两者上下文嵌入包 (contextualized embeddings) 的延迟交互 (late interaction) 进行估计。如前所述,这是通过最大相似度计算的总和来实现的,即余弦相似度 (由于嵌入归一化而实现为点积) 或平方 L2 距离。
$$
S_{q,d}:=\sum_{i\in[|E_{q}|]}\operatorname*{max}_ {j\in[|E_{d}|]}E_{q_{i}}\cdot E_{d_{j}}^{T}
$$
$$
S_{q,d}:=\sum_{i\in[|E_{q}|]}\operatorname*{max}_ {j\in[|E_{d}|]}E_{q_{i}}\cdot E_{d_{j}}^{T}
$$
ColBERT is diferent i able end-to-end. We fne-tune the BERT encoders and train from scratch the additional parameters (i.e., the linear layer and the [Q] and [D] markers’ embeddings) using the Adam [16] optimizer. Notice that our interaction mechanism has no trainable parameters. Given a triple $\langle q,d^{+},d^{-}\rangle$ with query $q$ , positive document $d^{+}$ and negative document $d^{-}$ , ColBERT is used to produce a score for each document individually and is optimized via pairwise sofmax cross-entropy loss over the computed scores of $d^{+}$ and $d^{-}$ .
ColBERT 的不同之处在于它是端到端可训练的。我们使用 Adam [16] 优化器对 BERT 编码器进行微调,并从头开始训练额外参数 (即线性层和 [Q]、[D] 标记的嵌入)。需要注意的是,我们的交互机制没有可训练参数。给定一个三元组 $\langle q,d^{+},d^{-}\rangle$,其中包含查询 $q$、正文档 $d^{+}$ 和负文档 $d^{-}$,ColBERT 会单独为每个文档生成分数,并通过在 $d^{+}$ 和 $d^{-}$ 计算得分上的成对 softmax 交叉熵损失进行优化。
3.4 Ofline Indexing: Computing & Storing Document Embeddings
3.4 离线索引:计算与存储文档嵌入向量
By design, ColBERT isolates almost all of the computations between queries and documents, largely to enable pre-computing document representations ofine. At a high level, our indexing procedure is straight-forward: we proceed over the documents in the collection in batches, running our document encoder $f_{D}$ on each batch and storing the output embeddings per document. Although indexing a set of documents is an ofine process, we incorporate a few simple optimization s for enhancing the throughput of indexing. As we show in $\S4.5$ , these optimization s can considerably reduce the ofine cost of indexing.
设计上,ColBERT 隔离了查询与文档间几乎所有的计算,主要是为了实现文档表征的离线预计算。我们的索引流程概览如下:以批处理方式遍历文档集,对每批文档运行文档编码器 $f_{D}$ 并存储各文档的输出嵌入。尽管文档集索引是离线过程,我们仍采用了几项简单优化策略来提升索引吞吐量。如 $\S4.5$ 所示,这些优化能显著降低索引的离线成本。
To begin with, we exploit multiple GPUs, if available, for faster encoding of batches of documents in parallel. When batching, we pad all documents to the maximum length of a document within the batch.3 To make capping the sequence length on a per-batch basis more efective, our indexer proceeds through documents in groups of $B$ (e.g., $B=100{,}000)$ documents. It sorts these documents by length and then feeds batches of $b$ (e.g., $b=128$ ) documents of comparable length through our encoder. Tis length-based bucketing is sometimes refered to as a Bucket Iterator in some libraries (e.g., allenNLP). Lastly, while most computations occur on the GPU, we found that a non-trivial portion of the indexing time is spent on pre-processing the text sequences, primarily BERT’s WordPiece tokenization. Exploiting that these operations are independent across documents in a batch, we parallel ize the pre-processing across the available CPU cores.
首先,我们利用多块GPU(如可用)来并行加速批量文档的编码处理。在批处理时,我们会将同一批次内的所有文档填充至该批次中最长文档的长度。为使基于批次的序列长度截断更高效,我们的索引器会按每组$B$份文档(例如$B=100{,}000$)进行处理:先将这些文档按长度排序,再将长度相近的$b$份文档(例如$b=128$)组成批次送入编码器。这种基于长度的分桶策略在某些库(如allenNLP)中被称为Bucket Iterator。最后,虽然大部分计算在GPU上执行,但我们发现索引时间的相当部分消耗在文本序列预处理(主要是BERT的WordPiece分词)上。通过利用批次内文档间预处理操作的独立性,我们在可用CPU核心上实现了并行预处理。
Once the document representations are produced, they are saved to disk using 32-bit or 16-bit values to represent each dimension. As we describe in $\S3.5$ and 3.6, these representations are either simply loaded from disk for ranking or are subsequently indexed for vector-similarity search, respectively.
生成文档表征后,会使用32位或16位数值表示每个维度并将其保存至磁盘。如我们在$\S3.5$和3.6节所述,这些表征要么直接从磁盘加载用于排序,要么随后被索引以支持向量相似性搜索。
3.5 Top $k$ Re-ranking with ColBERT
3.5 基于ColBERT的Top $k$重排序
Recall that ColBERT can be used for re-ranking the output of another retrieval model, typically a term-based model, or directly for end-to-end retrieval from a document collection. In this section, we discuss how we use ColBERT for ranking a small set of $k$ (e.g., $k=1000;$ documents given a query $q$ . Since $k$ is small, we rely on batch computations to exhaustively score each document (unlike our approach in $\S3.6$ ). To begin with, our query serving subsystem loads the indexed documents representations into memory, representing each document as a matrix of embeddings.
记得 ColBERT 既可用于对另一个检索模型(通常是基于术语的模型)的输出进行重排序,也可直接用于从文档集合中进行端到端检索。本节将讨论如何利用 ColBERT 对给定查询 $q$ 的小规模文档集 $k$(例如 $k=1000$)进行排序。由于 $k$ 值较小,我们依赖批量计算来穷举式评分每个文档(与 $\S3.6$ 中的方法不同)。首先,我们的查询服务子系统会将索引文档表示加载到内存中,将每个文档表示为嵌入矩阵。
Given a query $q$ , we compute its bag of contextual i zed embeddings $E_{q}$ (Equation 1) and, concurrently, gather the document representations into a 3-dimensional tensor $D$ consisting of $k$ document matrices. We pad the $k$ documents to their maximum length to facilitate batched operations, and move the tensor $D$ to the GPU’s memory. On the GPU, we compute a batch dot-product of $E_{q}$ and $D$ , possibly over multiple mini-batches. Te output materializes a 3-dimensional tensor that is a collection of cross-match matrices between $q$ and each document. To compute the score of each document, we reduce its matrix across document terms via a max-pool (i.e., representing an exhaustive implementation of our MaxSim computation) and reduce across query terms via a summation. Finally, we sort the $k$ documents by their total scores.
给定查询 $q$,我们计算其上下文嵌入包 $E_{q}$(公式1),同时将文档表示聚合为包含 $k$ 个文档矩阵的3维张量 $D$。我们将 $k$ 个文档填充至最大长度以支持批量操作,并将张量 $D$ 移至GPU内存。在GPU上计算 $E_{q}$ 与 $D$ 的批量点积(可能分多个小批次进行),最终生成一个3维张量,包含 $q$ 与每个文档的交叉匹配矩阵。为计算每个文档的得分,我们通过最大池化(即MaxSim计算的穷举实现)在文档词项维度归约,并通过求和操作在查询词项维度归约。最后按总分对 $k$ 个文档进行排序。
Relative to existing neural rankers (especially, but not exclusively, BERT-based ones), this computation is very cheap that, in fact, its cost is dominated by the cost of gathering and transferring the pre-computed embeddings. To illustrate, ranking $k$ documents via typical BERT rankers requires feeding BERT $k$ diferent inputs each of length $l=|q|+|d_{i}|$ for query $q$ and documents $d_{i}$ , where atention has quadratic cost in the length of the sequence. In contrast, ColBERT feeds BERT only a single, much shorter sequence of length $l=|q|$ . Consequently, ColBERT is not only cheaper, it also scales much beter with $k$ as we examine in $\S4.2$ .
相对于现有的神经排序器(尤其是但不限于基于BERT的模型),这种计算成本非常低,实际上其主要开销在于收集和传输预计算的嵌入向量。举例来说,使用典型的BERT排序器对$k$篇文档进行排序时,需要向BERT模型输入$k$个不同序列,每个序列长度为$l=|q|+|d_{i}|$(其中$q$为查询语句,$d_{i}$为文档),而注意力机制的计算成本与序列长度呈平方关系。相比之下,ColBERT只需向BERT输入单个更短的序列(长度为$l=|q|$)。因此如$\S4.2$所示,ColBERT不仅成本更低,在文档数量$k$增加时也展现出更优的扩展性。
3.6 End-to-end Top $k$ Retrieval with ColBERT
3.6 基于ColBERT的端到端Top $k$检索
As mentioned before, ColBERT’s late-interaction operator is specifcally designed to enable end-to-end retrieval from a large collection, largely to improve recall relative to term-based retrieval approaches. Tis section is concerned with cases where the number of documents to be ranked is too large for exhaustive evaluation of each possible candidate document, particularly when we are only interested in the highest scoring ones. Concretely, we focus here on retrieving the top $k$ results directly from a large document collection with $N$ (e.g., $N=10,000,000$ ) documents, where $k\ll N$ .
如前所述,ColBERT的延迟交互算子(late-interaction operator)专为实现大规模端到端检索而设计,主要为了提升基于术语检索方法的召回率。本节讨论待排序文档数量过大导致无法穷尽评估每个候选文档的情况,特别是当我们仅关注最高分文档时。具体而言,我们聚焦于从包含$N$份(例如$N=10,000,000$)文档的大型集合中直接检索前$k$个结果,其中$k\ll N$。
To do so, we leverage the pruning-friendly nature of the MaxSim operations at the backbone of late interaction. Instead of applying MaxSim between one of the query embeddings and all of one document’s embeddings, we can use fast vector-similarity data structures to efciently conduct this search between the query embedding and all document embeddings across the full collection. For this, we employ an of-the-shelf library for large-scale vector-similarity search, namely faiss [15] from Facebook. $^4\mathrm{{In}}$ particular, at the end of ofine indexing (§3.4), we maintain a mapping from each embedding to its document of origin and then index all document embeddings into faiss.
为此,我们利用延迟交互核心MaxSim操作对剪枝友好的特性。不同于在单个查询嵌入与某文档全部嵌入之间计算MaxSim,我们采用快速向量相似性数据结构,直接在查询嵌入与全量文档库的所有文档嵌入间高效执行搜索。具体实现中,我们使用Facebook开源的faiss [15]这一大规模向量相似性搜索库。$^4\mathrm{{In}}$ 特别地,在离线索引阶段(§3.4)结束时,我们会维护从每个嵌入到其源文档的映射关系,并将所有文档嵌入索引至faiss。
Subsequently, when serving queries, we use a two-stage procedure to retrieve the top $k$ documents from the entire collection. Both stages rely on ColBERT’s scoring: the frst is an approximate stage aimed at fltering while the second is a refnement stage. For the frst stage, we concurrently issue $N_{q}$ vector-similarity queries (corresponding to each of the embeddings in $E_{q}$ ) onto our faiss index. Tis retrieves the top $\cdot k^{\prime}$ (e.g., $k^{\prime}=k/2$ ) matches for that vector over all document embeddings. We map each of those to its document of origin, producing $N_{q}\times k^{\prime}$ document IDs, only $K\leq N_{q}\times k^{\prime}$ of which are unique. Tese $K$ documents likely contain one or more embeddings that are highly similar to the query embeddings. For the second stage, we refne this set by exhaustively re-ranking only those $K$ documents in the usual manner described in $\S3.5$ .
随后,在处理查询时,我们采用两阶段流程从整个文档集中检索前$k$篇文档。两个阶段均基于ColBERT评分机制:第一阶段为近似筛选阶段,第二阶段为精排阶段。在首阶段,我们并行地向faiss索引发起$N_{q}$次向量相似性查询(对应$E_{q}$中的每个嵌入向量),获取每个向量在所有文档嵌入中的前$\cdot k^{\prime}$个匹配项(例如$k^{\prime}=k/2$)。将这些匹配项映射回原始文档后,共得到$N_{q}\times k^{\prime}$个文档ID(实际唯一文档数$K\leq N_{q}\times k^{\prime}$)。这些$K$篇文档很可能包含与查询向量高度相似的嵌入项。在第二阶段,我们通过$\S3.5$所述的标准方法对这$K$篇文档进行 exhaustive 重排序来完成精排。
In our faiss-based implementation, we use an IVFPQ index (“inverted fle with product quantization”). Tis index partitions the embedding space into $P$ (e.g., $P=1000$ ) cells based on $k$ -means clustering and then assigns each document embedding to its nearest cell based on the selected vector-similarity metric. For serving queries, when searching for the top $\cdot k^{\prime}$ matches for a single query embedding, only the nearest $\boldsymbol{p}$ (e.g., $p=10$ ) partitions are searched. To improve memory efciency, every embedding is divided into s (e.g., $s=16$ ) sub-vectors, each represented using one byte. Moreover, the index conducts the similarity computations in this compressed domain, leading to cheaper computations and thus faster search.
在我们基于faiss的实现中,使用了IVFPQ索引("倒排文件与乘积量化")。该索引通过k均值聚类将嵌入空间划分为$P$个(例如$P=1000$)单元,然后根据选定的向量相似度度量将每个文档嵌入分配到最近的单元。处理查询时,当搜索单个查询嵌入的top $\cdot k^{\prime}$匹配项时,仅搜索最近的$\boldsymbol{p}$个(例如$p=10$)分区。为提高内存效率,每个嵌入被划分为s个(例如$s=16$)子向量,每个子向量用1字节表示。此外,索引在此压缩域内执行相似度计算,从而降低计算成本并实现更快的搜索。
4 EXPERIMENTAL EVALUATION
4 实验评估
We now turn our atention to empirically testing ColBERT, addressing the following research questions.
我们现在将注意力转向对ColBERT进行实证测试,以解决以下研究问题。
$\mathbf{RQ}_ {1}$ : In a typical re-ranking setup, how well can ColBERT bridge the existing gap (highlighted in $\S1$ ) between highly-efcient and highly-efective neural models? (§4.2) ${\bf R}{\bf Q}_ {2}$ : Beyond re-ranking, can ColBERT efectively support endto-end retrieval directly from a large collection? (§4.3) ${\bf R Q}_ {3}$ : What does each component of ColBERT (e.g., late interaction, query augmentation) contribute to its quality? (§4.4) ${\bf R Q}_{4}$ : What are ColBERT’s indexing-related costs in terms of ofine computation and memory overhead? (§4.5)
$\mathbf{RQ}_ {1}$: 在典型的重新排序场景中,ColBERT能在多大程度上弥合高效神经网络模型与高效果神经网络模型之间的现有差距(如$\S1$所述)?(§4.2)
${\bf R}{\bf Q}_ {2}$: 除了重新排序,ColBERT能否有效支持直接从大规模集合中进行端到端检索?(§4.3)
${\bf R Q}_ {3}$: ColBERT的各个组件(例如延迟交互、查询增强)对其质量有何贡献?(§4.4)
${\bf R Q}_{4}$: ColBERT在离线计算和内存开销方面的索引相关成本是多少?(§4.5)
4.1 Methodology
4.1 方法论
4.1.1 Datasets & Metrics. Similar to related work [2, 27, 28], we conduct our experiments on the MS MARCO Ranking [24] (henceforth, MS MARCO) and TREC Complex Answer Retrieval (TREC-CAR) [6] datasets. Both of these recent datasets provide large training data of the scale that facilitates training and evaluating deep neural networks. We describe both in detail below.
4.1.1 数据集与评估指标。与相关工作 [2, 27, 28] 类似,我们在 MS MARCO 排序数据集 [24] (以下简称 MS MARCO) 和 TREC 复杂答案检索数据集 (TREC-CAR) [6] 上进行了实验。这两个最新数据集均提供了大规模训练数据,足以支持深度神经网络的训练与评估。下文将详细描述这两个数据集。
MS MARCO. MS MARCO is a dataset (and a corresponding competition) introduced by Microsof in 2016 for reading comprehension and adapted in 2018 for retrieval. It is a collection of $8.8\mathrm{M}$ passages from Web pages, which were gathered from Bing’s results to 1M real-world queries. Each query is associated with sparse relevance judgements of one (or very few) documents marked as relevant and no documents explicitly indicated as irrelevant. Per the ofcial evaluation, we use $\mathrm{MRR}@10$ to measure ef ect ive ness.
MS MARCO。MS MARCO是由Microsoft于2016年推出的阅读理解数据集(及对应竞赛),2018年调整为检索任务。该数据集包含从Bing搜索结果中收集的880万条网页文本段落,对应100万条真实查询。每条查询关联着少量被标记为相关的文档稀疏相关性标注,且未明确标注不相关文档。根据官方评估标准,我们使用MRR@10衡量检索效果。
We use three sets of queries for evaluation. Te ofcial development and evaluation sets contain roughly 7k queries. However, the relevance judgements of the evaluation set are held-out by Microsof and ef ect ive ness results can only be obtained by submiting to the competition’s organizers. We submited our main re-ranking ColBERT model for the results in $\S4.2$ . In addition, the collection includes roughly 55k queries (with labels) that are provided as additional validation data. We re-purpose a random sample of 5k queries among those (i.e., ones not in our development or training sets) as a “local” evaluation set. Along with the ofcial development set, we use this held-out set for testing our models as well as baselines in $\S4.3$ . We do so to avoid submiting multiple variants of the same model at once, as the organizers discourage too many submissions by the same team.
我们使用三组查询进行评估。官方开发集和评估集包含约7k条查询。然而,评估集的相关性判断由Microsoft保留,只有通过向竞赛组织者提交才能获得有效性结果。我们提交了主要的重新排序ColBERT模型以获取$\S4.2$中的结果。此外,该集合还包含约55k条带标签的查询作为额外验证数据。我们从中随机抽取5k条查询(即不在开发集或训练集中的查询)重新用作"本地"评估集。除了官方开发集外,我们还使用这个保留集在$\S4.3$中测试模型及基线。这样做是为了避免一次性提交同一模型的多个变体,因为组织者不鼓励同一团队提交过多结果。
TREC CAR. Introduced by Dietz [6] et al. in 2017, TREC CAR is a synthetic dataset based on Wikipedia that consists of about 29M passages. Similar to related work [25], we use the frst four of fve pre-defned folds for training and the ffh for validation. Tis amounts to roughly 3M queries generated by concatenating the title of a Wikipedia page with the heading of one of its sections. Tat section’s passages are marked as relevant to the corresponding query. Our evaluation is conducted on the test set used in TREC 2017 CAR, which contains 2,254 queries.
TREC CAR。由Dietz [6]等人于2017年提出的TREC CAR是一个基于维基百科的合成数据集,包含约2900万段文本。与相关工作[25]类似,我们使用预先定义的五个折叠中的前四个进行训练,第五个用于验证。这相当于通过将维基百科页面标题与其某个章节的标题拼接生成约300万条查询,该章节的段落被标记为对应查询的相关内容。我们的评估在TREC 2017 CAR使用的测试集上进行,该测试集包含2254条查询。
4.1.2 Implementation. Our ColBERT models are implemented using Python 3 and PyTorch 1. We use the popular transformers library for the pre-trained BERT model. Similar to [25], we fne-tune all ColBERT models with learning rate $3\times10^{-6}$ with a batch size 32. We fx the number of embeddings per query at $N_{q}=32$ . We set our ColBERT embedding dimension $m$ to be 128; $\S4.5$ demonstrates ColBERT’s robustness to a wide range of embedding dimensions.
4.1.2 实现。我们的ColBERT模型使用Python 3和PyTorch 1实现。我们使用流行的transformers库加载预训练的BERT模型。与[25]类似,我们以学习率$3\times10^{-6}$和批量大小32对所有ColBERT模型进行微调。我们将每个查询的嵌入数量固定为$N_{q}=32$。ColBERT的嵌入维度$m$设为128;$\S4.5$展示了ColBERT对多种嵌入维度具有鲁棒性。
For MS MARCO, we initialize the BERT components of the ColBERT query and document encoders using Google’s ofcial pretrained $\mathrm{BERT_{base}}$ model. Further, we train all models for $200\mathrm{k\Omega}$ iterations. For TREC CAR, we follow related work [2, 25] and use a different pre-trained model to the ofcial ones. To explain, the ofcial BERT models were pre-trained on Wikipedia, which is the source of TREC CAR’s training and test sets. To avoid leaking test data into train, Nogueira and Cho’s [25] pre-train a randomly-initialized BERT model on the Wiki pages corresponding to training subset of TREC CAR. Tey release their $\mathrm{BERT_{large}}$ pre-trained model, which we fne-tune for ColBERT’s experiments on TREC CAR. Since fnetuning this model is sign if cant ly slower than $\mathrm{BERT_{base}}$ , we train on TREC CAR for only $125\mathrm{k\Omega}$ iterations.
对于MS MARCO数据集,我们使用谷歌官方预训练的$\mathrm{BERT_{base}}$模型来初始化ColBERT查询和文档编码器的BERT组件。此外,我们将所有模型训练$200\mathrm{k\Omega}$次迭代。对于TREC CAR数据集,我们遵循相关工作[2,25]的做法,采用与官方模型不同的预训练模型。具体而言,由于官方BERT模型是在维基百科上预训练的,而TREC CAR的训练集和测试集同样来源于维基百科,为避免测试数据泄露到训练过程中,Nogueira和Cho[25]在TREC CAR训练集对应的维基页面上对随机初始化的BERT模型进行了预训练。他们发布了$\mathrm{BERT_{large}}$预训练模型,我们在TREC CAR的ColBERT实验中对该模型进行微调。由于微调该模型的速度显著慢于$\mathrm{BERT_{base}}$,我们仅在TREC CAR上进行了$125\mathrm{k\Omega}$次迭代训练。
In our re-ranking results, unless stated otherwise, we use 4 bytes per dimension in our embeddings and employ cosine as our vectorsimilarity function. For end-to-end ranking, we use (squared) L2 distance, as we found our faiss index was faster at L2-based retrieval. For our faiss index, we set the number of partitions to $P=2,000$ , and search the nearest $p=10$ to each query embedding to retrieve $k^{\prime}=k=1000$ document vectors per query embedding. We divide each embedding into $s=16$ sub-vectors, each encoded using one byte. To represent the index used for the second stage of our end-to-end retrieval procedure, we use 16-bit values per dimension.
在我们的重排序结果中,除非另有说明,我们使用每个维度4字节的嵌入表示,并采用余弦作为向量相似度函数。对于端到端排序,我们使用(平方)L2距离,因为我们发现基于L2距离的faiss索引检索速度更快。对于faiss索引,我们将分区数设置为$P=2,000$,并为每个查询嵌入搜索最近的$p=10$个分区,以检索每个查询嵌入对应的$k^{\prime}=k=1000$个文档向量。我们将每个嵌入划分为$s=16$个子向量,每个子向量使用1字节编码。为了表示端到端检索流程第二阶段使用的索引,我们每个维度采用16位值表示。
4.1.3 Hardware & Time Measurements. To evaluate the latency of neural re-ranking models in $\S4.2$ , we use a single Tesla V100 GPU that has 32 GiBs of memory on a server with two Intel Xeon Gold 6132 CPUs, each with 14 physical cores (24 hyper threads), and 469 GiBs of RAM. For the mostly CPU-based retrieval experiments in $\S4.3$ and the indexing experiments in $\S4.5$ , we use another server with the same CPU and system memory spec if cations but which has four Titan V GPUs atached, each with 12 GiBs of memory. Across all experiments, only one GPU is dedicated per query for retrieval (i.e., for methods with neural computations) but we use up to all four GPUs during indexing.
4.1.3 硬件与时间测量
为评估$\S4.2$中神经重排序模型的延迟,我们使用配备单块Tesla V100 GPU(32 GiB显存)的服务器,该服务器搭载两颗Intel Xeon Gold 6132 CPU(每颗14物理核心/24超线程)和469 GiB内存。对于$\S4.3$中以CPU为主的检索实验及$\S4.5$中的索引实验,我们使用另一台相同CPU配置和系统内存规格的服务器,但配备四块Titan V GPU(每块12 GiB显存)。所有实验中,检索阶段每条查询仅使用单块GPU(涉及神经计算的方法),而索引阶段最多会调用全部四块GPU。
Table 1: “Re-ranking” results on MS MARCO. Each neural model re-ranks the ofcial top-1000 results produced by BM25. Latency is reported for re-ranking only. To obtain the end-to-end latency in Figure 1, we add the BM25 latency from Table 2.
| Method | MRR@10 (Dev) | MRR@10 (Eval) | Re-ranking Latency (ms) | FLOPs/query |
| BM25 (official) | 16.7 | 16.5 | ||
| KNRM | 19.8 | 19.8 | 3 | 592M (0.085x) |
| Duet | 24.3 | 24.5 | 22 | 159B (23×) |
| fastText+ConvKNRM | 29.0 | 27.7 | 28 | 78B (11×) |
| BERTbase [25] | 34.7 | 10,700 | 97T (13,900×) | |
| BERTbase (our training) | 36.0 | 10,700 | 97T (13,900x) | |
| BERTlarge [25] | 36.5 | 35.9 | 32,900 | 340T(48,600x) |
| ColBERT (over BERTbase) | 34.9 | 34.9 | 61 | 7B (1×) |
表 1: MS MARCO上的"重排序"结果。每个神经模型对BM25生成的官方top-1000结果进行重排序。延迟仅报告重排序部分。要获得图1中的端到端延迟,需加上表2中的BM25延迟。
| 方法 | MRR@10 (Dev) | MRR@10 (Eval) | 重排序延迟 (ms) | FLOPs/query |
|---|---|---|---|---|
| BM25 (官方) | 16.7 | 16.5 | ||
| KNRM | 19.8 | 19.8 | 3 | 592M (0.085x) |
| Duet | 24.3 | 24.5 | 22 | 159B (23×) |
| fastText+ConvKNRM | 29.0 | 27.7 | 28 | 78B (11×) |
| BERTbase [25] | 34.7 | 10,700 | 97T (13,900×) | |
| BERTbase (我们的训练) | 36.0 | 10,700 | 97T (13,900x) | |
| BERTlarge [25] | 36.5 | 35.9 | 32,900 | 340T(48,600x) |
| ColBERT (基于BERTbase) | 34.9 | 34.9 | 61 | 7B (1×) |
Table 2: End-to-end retrieval results on MS MARCO. Each model retrieves the top-1000 documents per query directly from the entire 8.8M document collection.
| Method | MRR@10(Dev) | MRR@10(LocalEval) | Latency (ms) | Recall@50 | Recall@200 | Recall@1000 |
| BM25 (official) | 16.7 | 81.4 | ||||
| BM25 (Anserini) | 18.7 | 19.5 | 62 | 59.2 | 73.8 | 85.7 |
| doc2query | 21.5 | 22.8 | 85 | 64.4 | 77.9 | 89.1 |
| DeepCT | 24.3 | 62 (est.) | 69 [2] | 82 [2] | 91 [2] | |
| docTTTTTquery | 27.7 | 28.4 | 87 | 75.6 | 86.9 | 94.7 |
| ColBERTL2 (re-rank) | 34.8 | 36.4 | 75.3 | 80.5 | 81.4 | |
| ColBERTL2 (end-to-end) | 36.0 | 36.7 | 458 | 82.9 | 92.3 | 96.8 |
表 2: MS MARCO端到端检索结果。每个模型直接从880万篇文档集合中为每个查询检索前1000篇文档。
| 方法 | MRR@10(Dev) | MRR@10(LocalEval) | 延迟(ms) | Recall@50 | Recall@200 | Recall@1000 |
|---|---|---|---|---|---|---|
| BM25 (官方) | 16.7 | 81.4 | ||||
| BM25 (Anserini) | 18.7 | 19.5 | 62 | 59.2 | 73.8 | 85.7 |
| doc2query | 21.5 | 22.8 | 85 | 64.4 | 77.9 | 89.1 |
| DeepCT | 24.3 | 62 (预估) | 69 [2] | 82 [2] | 91 [2] | |
| docTTTTTquery | 27.7 | 28.4 | 87 | 75.6 | 86.9 | 94.7 |
| ColBERTL2 (重排序) | 34.8 | 36.4 | 75.3 | 80.5 | 81.4 | |
| ColBERTL2 (端到端) | 36.0 | 36.7 | 458 | 82.9 | 92.3 | 96.8 |
4.2 Qality–Cost Tradeof: Top $k$ Re-ranking
4.2 质量-成本权衡:Top $k$ 重排序
In this section, we examine ColBERT’s efciency and ef ect ive ness at re-ranking the top $\cdot k$ results extracted by a bag-of-words retrieval model, which is the most typical seting for testing and deploying neural ranking models. We begin with the MS MARCO dataset. We compare against KNRM, Duet, and fastText $^{\cdot+}$ ConvKNRM, a representative set of neural matching models that have been previously tested on MS MARCO. In addition, we compare against the natural adaptation of BERT for ranking by Nogueira and Cho [25], in particular, $\mathrm{BERT_{base}}$ and its deeper counterpart $\mathrm{BERT_{large}}$ . We also report results for $^{\mathrm{{s}}\mathrm{}}\mathrm{BERT}_{\mathrm{base}}$ (our training)”, which is based on Nogueira and Cho’s base model (including hyper parameters) but is trained with the same loss function as ColBERT (§3.3) for $200\mathrm{k\Omega}$ iterations, allowing for a more direct comparison of the results.
在本节中,我们评估ColBERT在重排词袋检索模型提取的前$\cdot k$项结果时的效率与有效性——这是测试和部署神经排序模型最典型的场景。我们首先基于MS MARCO数据集展开实验,对比对象包括KNRM、Duet、fastText$^{\cdot+}$ConvKNRM等先前在该数据集测试过的代表性神经匹配模型。此外,我们还对比了Nogueira和Cho[25]提出的BERT自然排序适配方案,具体包括$\mathrm{BERT_{base}}$及其深层版本$\mathrm{BERT_{large}}$。同时汇报了$^{\mathrm{{s}}\mathrm{}}\mathrm{BERT}_{\mathrm{base}}$(我们的训练版本)"的结果:该模型基于Nogueira和Cho的基础模型(含超参数),但采用与ColBERT相同的损失函数(§3.3)训练$200\mathrm{k\Omega}$次迭代,使结果更具直接可比性。
We report the competition’s ofcial metric, namely $\mathrm{MRR}@10$ , on the validation set (Dev) and the evaluation set (Eval). We also report the re-ranking latency, which we measure using a single Tesla V100 GPU, and the FLOPs per query for each neural ranking model. For ColBERT, our reported latency subsumes the entire computation from gathering the document representations, moving them to the GPU, tokenizing then encoding the query, and applying late interaction to compute document scores. For the baselines, we measure the scoring computations on the GPU and exclude the CPU-based text preprocessing (similar to [9]). In principle, the baselines can pre-compute the majority of this preprocessing (e.g., document token iz ation) ofine and parallel ize the rest across documents online, leaving only a negligible cost. We estimate the FLOPs per query of each model using the torch prof le 6 library.
我们报告了比赛在验证集(Dev)和评估集(Eval)上的官方指标$\mathrm{MRR}@10$。同时报告了使用单个Tesla V100 GPU测量的重排序延迟,以及每个神经排序模型每次查询的FLOPs。对于ColBERT,报告的延迟包含从收集文档表示、将其移至GPU、对查询进行Token化编码到应用延迟交互计算文档分数的全过程。基线方法则仅测量GPU上的评分计算,不包括基于CPU的文本预处理(类似[9])。理论上,基线方法可以预先离线完成大部分预处理(如文档Token化),并在线并行处理剩余部分,仅产生可忽略的开销。我们使用torch prof le 6库估算每个模型每次查询的FLOPs。
We now proceed to study the results, which are reported in Table 1. To begin with, we notice the fast progress from KNRM in 2017 to the BERT-based models in 2019, manifesting itself in over $16%$ increase in $\mathrm{MRR}@10$ . As described in $\S1$ , the simultaneous increase in computational cost is difcult to miss. Judging by their rather monotonic patern of increasingly larger cost and higher effec ti ve ness, these results appear to paint a picture where expensive models are necessary for high-quality ranking.
我们现在开始研究表1中报告的结果。首先,我们注意到从2017年的KNRM到2019年基于BERT的模型取得了快速进展,体现在$\mathrm{MRR}@10$指标上超过$16%$的提升。如$\S1$所述,计算成本的同步增长不容忽视。从成本持续增加与效果提升之间近乎单调的规律来看,这些结果似乎描绘出高质量排序必须依赖昂贵模型的图景。
In contrast with this trend, ColBERT (which employs late interaction over $\mathrm{BERT_{base}}$ ) performs no worse than the original adaptation of $\mathrm{BERT_{base}}$ for ranking by Nogueira and Cho [25, 27] and is only marginally less efective than $\mathrm{BERT_{large}}$ and our training of $\mathrm{BERT_{base}}$ (described above). While highly competitive in efectiveness, ColBERT is orders of magnitude cheaper than $\mathrm{BERT_{base}}$ in particular, by over $170\times$ in latency and $13{,}900\times$ in FLOPs. Tis highlights the expressiveness of our proposed late interaction mechanism, particularly when coupled with a powerful pre-trained LM like BERT. While ColBERT’s re-ranking latency is slightly higher than the non-BERT re-ranking models shown (i.e., by 10s of milliseconds), this diference is explained by the time it takes to gather, stack, and transfer the document embeddings to the GPU. In particular, the query encoding and interaction in ColBERT consume only 13 milliseconds of its total execution time. We note that ColBERT’s latency and FLOPs can be considerably reduced by padding queries to a shorter length, using smaller vector dimensions (the MRR $@10$ of which is tested in $\S4.5_{,}$ ), employing quantization of the document vectors, and storing the embeddings on GPU if sufcient memory exists. We leave these directions for future work.
与这一趋势相反,ColBERT (采用基于 $\mathrm{BERT_{base}}$ 的延迟交互机制) 在排序任务上的表现不逊于 Nogueira 和 Cho [25, 27] 对 $\mathrm{BERT_{base}}$ 的原始适配方案,仅略逊于 $\mathrm{BERT_{large}}$ 及我们训练的 $\mathrm{BERT_{base}}$ (前文所述)。尽管效果极具竞争力,ColBERT 的计算成本比 $\mathrm{BERT_{base}}$ 低数个数量级——延迟降低超过 $170\times$,浮点运算量 (FLOPs) 减少 $13{,}900\times$。这凸显了我们提出的延迟交互机制的表达能力,尤其是与 BERT 这类强大预训练语言模型结合时。虽然 ColBERT 的重排序延迟略高于展示的非 BERT 重排序模型 (约几十毫秒),这种差异源于文档嵌入的收集、堆叠和传输至 GPU 的时间。实际上,ColBERT 的查询编码和交互阶段仅消耗总执行时间的 13 毫秒。值得注意的是,通过以下方法可显著降低 ColBERT 的延迟和 FLOPs:将查询填充至更短长度、使用更小的向量维度 (其 MRR $@10$ 测试结果见 $\S4.5_{,}$)、对文档向量进行量化处理,以及在 GPU 内存充足时直接存储嵌入。我们将这些优化方向留待未来研究。

Figure 4: FLOPs (in millions) and MRR $\mathbf{\varrho_{\mathbf{\Gamma}}}(\mathbf{\partial_{\theta}}$ as functions of the re-ranking depth $k$ . Since the ofcial BM25 ranking is not ordered, the initial top $k$ retrieval is conducted with Anserini’s BM25.
图 4: FLOPs (单位:百万次) 和 MRR $\mathbf{\varrho_{\mathbf{\Gamma}}}(\mathbf{\partial_{\theta}}$ 随重排序深度 $k$ 的变化关系。由于官方 BM25 排序结果无序,初始 top $k$ 检索采用 Anserini 的 BM25 实现。
Diving deeper into the quality–cost tradeof between BERT and ColBERT, Figure 4 demonstrates the relationships between FLOPs and ef ect ive ness $(\mathrm{MRR}@10)$ as a function of the re-ranking depth $k$ when re-ranking the top $\cdot k$ results by BM25, comparing ColBERT and $\mathrm{BERT_{base}}$ (our training). We conduct this experiment on MS MARCO (Dev). We note here that as the ofcial top-1000 ranking does not provide the BM25 order (and also lacks documents beyond the top-1000 per query), the models in this experiment re-rank the Anserini [37] toolkit’s BM25 output. Consequently, both MRR $@10$ values at $k=1000$ are slightly higher from those reported in Table 1.
深入探究 BERT 与 ColBERT 在质量与成本间的权衡关系,图 4 展示了在 MS MARCO (Dev) 数据集上,以 BM25 排序结果的前 $k$ 项进行重排序时,FLOPs 与有效性指标 $(\mathrm{MRR}@10)$ 随重排序深度 $k$ 的变化关系。实验对比了 ColBERT 与我们训练的 $\mathrm{BERT_{base}}$ 模型。需要注意的是,由于官方 top-1000 排序未提供 BM25 顺序(且每个查询仅包含前 1000 篇文档),本实验使用 Anserini [37] 工具包的 BM25 输出进行重排序。因此,当 $k=1000$ 时,两种模型的 MRR $@10$ 值均略高于表 1 中报告的结果。
Studying the results in Figure 4, we notice that not only is ColBERT much cheaper than BERT for the same model size (i.e., 12- layer “base” transformer encoder), it also scales beter with the number of ranked documents. In part, this is because ColBERT only needs to process the query once, irrespective of the number of documents evaluated. For instance, at $k=10$ , BERT requires nearly $180\times$ more FLOPs than ColBERT; at $k=1000$ , BERT’s overhead jumps to $13{,}900\times$ . It then reaches $23{,}000\times$ at $k=2000$ . In fact, our informal experimentation shows that this orders-of-magnitude gap in FLOPs makes it practical to run ColBERT entirely on the CPU, although CPU-based re-ranking lies outside our scope.
观察图4中的结果,我们注意到ColBERT不仅在相同模型规模(即12层"base"版Transformer编码器)下比BERT成本低得多,而且在处理文档数量增加时展现出更好的扩展性。这部分归因于ColBERT只需处理一次查询,与待评估文档数量无关。例如当k=10时,BERT所需的FLOPs(浮点运算次数)是ColBERT的180倍;当k=1000时,该差距扩大至13,900倍;在k=2000时进一步达到23,000倍。实际上,我们的非正式实验表明,这种数量级差距使得完全在CPU上运行ColBERT成为可能,尽管基于CPU的重排序不在本研究范围内。
| Method | MAP | MRR@10 |
| BM25 (Anserini) | 15.3 | |
| doc2query | 18.1 | |
| DeepCT | 24.6 | 33.2 |
| BM25+BERTbase | 31.0 | |
| BM25 + BERTlarge | 33.5 | |
| BM25+ColBERT | 31.3 | 44.3 |
Table 3: Results on TREC CAR.
| 方法 | MAP | MRR@10 |
|---|---|---|
| BM25 (Anserini) | 15.3 | |
| doc2query | 18.1 | |
| DeepCT | 24.6 | 33.2 |
| BM25+BERTbase | 31.0 | |
| BM25+BERTlarge | 33.5 | |
| BM25+ColBERT | 31.3 | 44.3 |
表 3: TREC CAR 实验结果。
Having studied our results on MS MARCO, we now consider TREC CAR, whose ofcial metric is MAP. Results are summarized in Table 3, which includes a number of important baselines (BM25, doc2query, and DeepCT) in addition to re-ranking baselines that have been tested on this dataset. Tese results directly mirror those with MS MARCO.
在研究了我们在 MS MARCO 上的结果后,现在转向 TREC CAR 数据集,其官方评估指标为 MAP。结果总结在表 3 中,除了在该数据集上测试过的重排序基线外,还包括多个重要基线 (BM25、doc2query 和 DeepCT)。这些结果与 MS MARCO 的结果直接对应。
4.3 End-to-end Top $k$ Retrieval
4.3 端到端Top $k$检索
Beyond cheap re-ranking, ColBERT is amenable to top $k$ retrieval directly from a full collection. Table 2 considers full retrieval, wherein each model retrieves the top-1000 documents directly from MS MARCO’s 8.8M documents per query. In addition to MRR $@10$ and latency in milliseconds, the table reports Recall@50, Recall@200, and Recall $@1000$ , important metrics for a full-retrieval model that essentially flters down a large collection on a per-query basis.
除了低成本的重排序外,ColBERT还能直接从完整集合中进行top $k$ 检索。表2展示了完整检索场景下各模型直接从MS MARCO每查询880万文档中检索top-1000文档的表现。除MRR $@10$ 和毫秒级延迟外,该表还报告了Recall@50、Recall@200和Recall $@1000$ 这些对全检索模型至关重要的指标,这类模型的核心功能正是基于每查询对海量集合进行筛选。
We compare against BM25, in particular MS MARCO’s ofcial BM25 ranking as well as a well-tuned baseline based on the Anserini toolkit. While many other traditional models exist, we are not aware of any that substantially outperform Anserini’s BM25 imple ment ation (e.g., see RM3 in [28], LMDir in [2], or Microsof’s proprietary feature-based RankSVM on the leader board).
我们对比了BM25算法,特别是MS MARCO官方BM25排序以及基于Anserini工具包优化过的基准模型。虽然存在许多其他传统模型,但我们尚未发现任何模型能显著超越Anserini的BM25实现(例如可参考[28]中的RM3、[2]中的LMDir或排行榜上Microsoft基于特征的专有RankSVM模型)。
We also compare against doc2query, DeepCT, and docTTTTTquery. All three rely on a traditional bag-of-words model (primarily BM25) for retrieval. Crucially, however, they re-weigh the frequency of terms per document and/or expand the set of terms in each document before building the BM25 index. In particular, doc2query expands each document with a pre-defned number of synthetic queries generated by a seq2seq transformer model (which d ocT TTT query replaced with a pre-trained language model, T5 [31]). In contrast, DeepCT uses BERT to produce the term frequency component of BM25 in a context-aware manner.
我们还对比了doc2query、DeepCT和docTTTTTquery。这三种方法都依赖传统的词袋模型(主要是BM25)进行检索。但关键在于,它们在构建BM25索引前会对每篇文档中的词项频率进行重新加权和/或扩展文档中的词项集合。具体而言,doc2query通过预定义数量的合成查询来扩展每篇文档,这些查询由seq2seq transformer模型生成(而docTTTTTquery则改用预训练语言模型T5[31])。相比之下,DeepCT使用BERT以上下文感知的方式生成BM25的词频组件。
For the latency of Anserini’s BM25, doc2query, and docTTTTquery, we use the authors’ [26, 28] Anserini-based implementation. While this implementation supports multi-threading, it only utilizes parallelism across diferent queries. We thus report single-threaded latency for these models, noting that simply parallel i zing their computation over shards of the index can substantially decrease their already-low latency. For DeepCT, we only estimate its latency using that of BM25 (as denoted by (est.) in the table), since DeepCT re-weighs BM25’s term frequency without modifying the index otherwise. As discussed in $\S4.1$ , we use $\mathrm{ColBERT_{L2}}$ for end-toend retrieval, which employs negative squared L2 distance as its vector-similarity function. For its latency, we measure the time for faiss-based candidate fltering and the subsequent re-ranking. In this experiment, faiss uses all available CPU cores.
关于Anserini的BM25、doc2query和docTTTTquery的延迟,我们采用了作者基于Anserini的实现[26, 28]。虽然该实现支持多线程,但仅在不同查询间实现并行化。因此我们报告这些模型的单线程延迟值,并指出只需对索引分片进行并行计算即可显著降低其本已较低的延迟。对于DeepCT,我们仅基于BM25的延迟进行估算(表中标记为(est.)),因为DeepCT仅重新加权BM25的词频而未修改索引结构。如$\S4.1$所述,我们采用$\mathrm{ColBERT_{L2}}$进行端到端检索,该模型使用负平方L2距离作为向量相似度函数。其延迟测量包含基于faiss的候选过滤及后续重排序耗时,本实验中faiss使用了全部可用CPU核心。
Looking at Table 2, we frst see Anserini’s BM25 baseline at 18.7 $\operatorname{MRR}@10$ , noticing its very low latency as implemented in Anserini (which extends the well-known Lucene system), owing to both very cheap operations and decades of bag-of-words top $k$ retrieval optimization s. Te three subsequent baselines, namely doc2query, DeepCT, and d ocT TTT query, each brings a decisive enhancement to ef ect ive ness. Tese improvements come at negligible overheads in latency, since these baselines ultimately rely on BM25-based retrieval. Te most efective among these three, d ocT TTT query, demonstrates a massive $9%$ gain over vanilla BM25 by fne-tuning the recent language model T5.
观察表2,我们首先看到Anserini的BM25基线结果为18.7 $\operatorname{MRR}@10$。由于Anserini(基于知名Lucene系统扩展)实现了极低成本的操作和数十年来词袋模型top $k$检索优化,其延迟非常低。随后的三个基线方法——doc2query、DeepCT和docTTTTquery——各自带来了决定性的效果提升。这些改进几乎不增加延迟开销,因为它们最终都依赖基于BM25的检索。其中效果最优的docTTTTquery通过微调最新语言模型T5,相比原始BM25实现了高达$9%$的性能提升。
Shifing our atention to ColBERT’s end-to-end retrieval efectiveness, we see its major gains in $\mathrm{MRR}@10$ over all of these end-toend models. In fact, using ColBERT in the end-to-end setup is superior in terms of MRR $@10$ to re-ranking with the same model due to the improved recall. Moving beyond $\mathrm{MRR}@10$ , we also see large gains in Recall@k for $k$ equals to 50, 200, and 1000. For instance, its Recall $@50$ actually exceeds the ofcial BM25’s Recall $@1000$ and even all but doc TTT TT query’s Recall@200, emphasizing the value of end-to-end retrieval (instead of just re-ranking) with ColBERT.
将注意力转向ColBERT的端到端检索效果,我们发现其在$\mathrm{MRR}@10$上显著优于所有同类端到端模型。实际上,由于召回率的提升,采用ColBERT进行端到端检索在MRR$@10$指标上甚至优于使用相同模型进行重排序。进一步观察$\mathrm{MRR}@10$之外的指标,当$k$取值为50、200和1000时,Recall@k也展现出大幅提升。例如,其Recall$@50$不仅超越了官方BM25的Recall$@1000$,甚至逼近doc TTT TT query的Recall@200,这凸显了ColBERT端到端检索(而非仅重排序)的价值。
4.4 Ablation Studies
4.4 消融实验

Figure 5: Ablation results on MS MARCO (Dev). Between brackets is the number of BERT layers used in each model.
图 5: MS MARCO (Dev) 消融实验结果。括号内为各模型使用的 BERT 层数。
Te results from $\S4.2$ indicate that ColBERT is highly efective despite the low cost and simplicity of its late interaction mechanism. To beter understand the source of this ef ect ive ness, we examine a number of important details in ColBERT’s interaction and encoder architecture. For this ablation, we report MRR $@10$ on the validation set of MS MARCO in Figure 5, which shows our main re-ranking ColBERT model [E], with $\mathrm{MRR}@10$ of $34.9%$ .
$\S4.2$ 的结果表明,ColBERT 尽管其后期交互机制成本低且简单,但效果显著。为了更好地理解这种有效性的来源,我们研究了 ColBERT 交互和编码器架构中的一些重要细节。对于这次消融实验,我们在图 5 中报告了 MS MARCO 验证集上的 MRR $@10$,其中展示了我们的主要重排序 ColBERT 模型 [E],其 $\mathrm{MRR}@10$ 为 $34.9%$。
Due to the cost of training all models, we train a copy of our main model that retains only the frst 5 layers of BERT out of 12 (i.e., model [D]) and similarly train all our ablation models for $200\mathrm{k\Omega}$ iterations with fve BERT layers. To begin with, we ask if the fnegranular interaction in late interaction is necessary. Model [A] tackles this question: it uses BERT to produce a single embedding vector for the query and another for the document, extracted from BERT’s [CLS] contextual i zed embedding and expanded through a linear layer to dimension 4096 (which equals $N_{q}\times128=32\times128)$ . Relevance is estimated as the inner product of the query’s and the document’s embeddings, which we found to perform beter than cosine similarity for single-vector re-ranking. As the results show, this model is considerably less efective than ColBERT, reinforcing the importance of late interaction.
由于训练所有模型的成本较高,我们训练了一个主模型的副本,仅保留BERT(共12层)的前5层(即模型[D]),并同样对所有消融模型进行 $200\mathrm{k\Omega}$ 次迭代训练,仅使用五层BERT。首先,我们探讨了延迟交互中的细粒度交互是否必要。模型[A]回答了这个问题:它使用BERT为查询生成一个嵌入向量,为文档生成另一个嵌入向量,这些向量从BERT的[CLS]上下文嵌入中提取,并通过线性层扩展到4096维(等于 $N_{q}\times128=32\times128$)。相关性估计为查询和文档嵌入向量的内积,我们发现对于单向量重新排序,内积比余弦相似度表现更好。结果显示,该模型的效果明显不如ColBERT,进一步证明了延迟交互的重要性。
Subsequently, we ask if our MaxSim-based late interaction is better than other simple alternatives. We test a model [B] that replaces ColBERT’s maximum similarity with average similarity. Te results suggest the importance of individual terms in the query paying special atention to particular terms in the document. Similarly, the fgure emphasizes the importance of our query augmentation mechanism: without query augmentation [C], ColBERT has a noticeably lower $\mathrm{MRR}@10$ . Lastly, we see the impact of end-to-end retrieval not only on recall but also on $\mathrm{MRR}@10$ . By retrieving directly from the full collection, ColBERT is able to retrieve to the top-10 documents missed entirely from BM25’s top-1000.
随后,我们探讨基于MaxSim的延迟交互是否优于其他简单替代方案。测试了用平均相似度替代ColBERT最大相似度的模型[B],结果表明查询中单个词项对文档特定词项专注的重要性。同样,该图强调了查询增强机制的关键作用:未使用查询增强[C]时,ColBERT的$\mathrm{MRR}@10$显著下降。最后,我们发现端到端检索不仅影响召回率,也影响$\mathrm{MRR}@10$——通过直接从完整集合检索,ColBERT能找回BM25前1000名中完全遗漏的前10名文档。

Figure 6: Efect of ColBERT’s indexing optimization s on the ofline indexing throughput.
图 6: ColBERT索引优化对离线索引吞吐量的影响。
4.5 Indexing Troughput & Footprint
4.5 索引吞吐量与存储占用
Lastly, we examine the indexing throughput and space footprint of ColBERT. Figure 6 reports indexing throughput on MS MARCO documents with ColBERT and four other ablation setings, which individually enable optimization s described in $\S3.4$ on top of basic batched indexing. Based on these through puts, ColBERT can index MS MARCO in about three hours. Note that any BERT-based model must incur the computational cost of processing each document at least once. While ColBERT encodes each document with BERT exactly once, existing BERT-based rankers would repeat similar computations on possibly hundreds of documents for each query.
最后,我们考察 ColBERT 的索引吞吐量和空间占用。图 6 展示了 ColBERT 与其他四种消融设置在 MS MARCO 文档上的索引吞吐量,这些设置均在基础批量索引之上启用了 $\S3.4$ 所述的优化。根据这些吞吐量数据,ColBERT 可在约三小时内完成 MS MARCO 的索引。需要注意的是,任何基于 BERT 的模型都至少需要对每篇文档进行一次计算处理。ColBERT 仅用 BERT 对每篇文档编码一次,而现有的基于 BERT 的排序器可能需要对每个查询涉及的数百篇文档重复类似计算。
| Setting | Dimension(m) | Bytes/Dim | Space(GiBs) | MRR@10 |
| Re-rankCosine | 128 | 4 | 286 | 34.9 |
| End-to-endL2 | 128 | 2 | 154 | 36.0 |
| Re-rankL2 | 128 | 2 | 143 | 34.8 |
| Re-rank Cosine | 48 | 4 | 54 | 34.4 |
| Re-rank Cosine | 24 | 2 | 27 | 33.9 |
Table 4: Space Footprint vs MRR@10 (Dev) on MS MARCO.
| 设置 | 维度(m) | 字节/维度 | 空间(GiBs) | MRR@10 |
|---|---|---|---|---|
| Re-rankCosine | 128 | 4 | 286 | 34.9 |
| End-to-endL2 | 128 | 2 | 154 | 36.0 |
| Re-rankL2 | 128 | 2 | 143 | 34.8 |
| Re-rank Cosine | 48 | 4 | 54 | 34.4 |
| Re-rank Cosine | 24 | 2 | 27 | 33.9 |
表 4: MS MARCO数据集上的空间占用与MRR@10 (开发集)对比。
Table 4 reports the space footprint of ColBERT under various setings as we reduce the embeddings dimension and/or the bytes per dimension. Interestingly, the most space-efcient seting, that is, re-ranking with cosine similarity with 24-dimensional vectors stored as 2-byte foats, is only $1%$ worse in $\mathrm{MRR}@10$ than the most space-consuming one, while the former requires only 27 GiBs to represent the MS MARCO collection.
表 4 报告了 ColBERT 在不同设置下的空间占用情况(包括降低嵌入维度和/或每维度字节数)。值得注意的是,最节省空间的设置(即使用 24 维 2 字节浮点数进行余弦相似度重排序)在 MRR@10 上仅比最耗空间的设置低 1%,而前者仅需 27 GiB 即可表示 MS MARCO 数据集。
5 CONCLUSIONS
5 结论
In this paper, we introduced ColBERT, a novel ranking model that employs contextual i zed late interaction over deep LMs (in particular, BERT) for efcient retrieval. By independently encoding queries and documents into fne-grained representations that interact via cheap and pruning-friendly computations, ColBERT can leverage the expressiveness of deep LMs while greatly speeding up query processing. In addition, doing so allows using ColBERT for end-toend neural retrieval directly from a large document collection. Our results show that ColBERT is more than $170\times$ faster and requires $14{,}000\times$ fewer FLOPs/query than existing BERT-based models, all while only minimally impacting quality and while outperforming every non-BERT baseline.
本文介绍了ColBERT,这是一种新颖的排序模型,通过深度大语言模型(特别是BERT)实现上下文感知的延迟交互,以实现高效检索。ColBERT将查询和文档独立编码为细粒度表示,并通过低成本且易于剪枝的计算进行交互,从而在保持深度大语言模型表达能力的同时显著加速查询处理。此外,这种方法使得ColBERT能够直接从大规模文档集合中进行端到端神经检索。实验结果表明,与现有基于BERT的模型相比,ColBERT的速度提升了170倍以上,每查询所需的FLOPs减少了14,000倍,同时对质量影响极小,且在所有非BERT基线模型中表现最优。
Acknowledgments. OK was supported by the Eltoukhy Family Graduate Fellowship at the Stanford School of Engineering. Tis research was supported in part by afliate members and other supporters of the Stanford DAWN project—Ant Financial, Facebook, Google, Infosys, NEC, and VMware—as well as Cisco, SAP, and the
致谢。OK 获得了斯坦福大学工程学院 Eltoukhy Family 研究生奖学金的支持。本研究部分由斯坦福 DAWN 项目的成员及其他支持者资助,包括蚂蚁金服、Facebook、Google、Infosys、NEC、VMware,以及思科、SAP 和...
NSF under CAREER grant CNS-1651570. Any opinions, fndings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily refect the views of the National Science Foundation.
美国国家科学基金会CAREER资助项目CNS-1651570。本材料中表达的任何观点、发现、结论或建议均为作者个人观点,并不一定反映美国国家科学基金会的立场。