ABSTRACT
摘要
Traditional diagnosis of chronic diseases involves in-person consultations with physicians to identify the disease. However, there is a lack of research focused on predicting and developing application systems using clinical notes and blood test values. We collected five years of Electronic Health Records (EHRs) from Taiwan's hospital database between 2017 and 2021 as an AI database. Furthermore, we developed an EHR-based chronic disease prediction platform utilizing Large Language Multimodal Models (LLMMs), successfully integrating with frontend web and mobile applications for prediction. This prediction platform can also connect to the hospital's backend database, providing physicians with real-time risk assessment diagnostics. The demonstration link can be found at https://www.youtube.com/watch?v $=$ o qm L 9 DE DF gA.
传统慢性病诊断需要医生面对面问诊以确定病情。但目前缺乏利用临床记录和血液检测值进行预测并开发应用系统的研究。我们从台湾医院数据库中收集了2017至2021年间的五年电子健康档案(EHRs)作为AI数据库。此外,我们基于大语言多模态模型(LLMMs)开发了慢性病预测平台,成功整合了前端网页和移动应用进行预测。该预测平台还可连接医院后端数据库,为医生提供实时风险评估诊断。演示链接详见:https://www.youtube.com/watch?v=oqmL9DEDFgA。
CCS CONCEPTS
CCS概念
· Applied computing $\rightarrow$ Health care information systems; · Computing methodologies $\rightarrow$ Artificial intelligence; $\bullet$ Software and its engineering $\rightarrow$ Integrated and visual development environments;
· 应用计算 (Applied computing) → 医疗保健信息系统 (Health care information systems)
· 计算方法论 (Computing methodologies) → 人工智能 (Artificial intelligence)
· 软件及其工程 (Software and its engineering) → 集成可视化开发环境 (Integrated and visual development environments)
KEYWORDS
关键词
Electronic Health Records, Large Language Models, Chronic Disease Prediction System
电子健康档案、大语言模型、慢性病预测系统
ACM Reference Format:
ACM 参考文献格式:
Chun-Chieh Liaot, Wei-Ting Kuot, I-Hsuan Hu, Jun-En Ding, Feng Liu, Yen-Chen Shih, and Fang-Ming Hung*. 2024. EHR-Based Mobile and Web Platform for Chronic Disease Risk Prediction Using Large Language Multimodal Models.In Proceedings of Make sure to enter the correct conference title from your rights confirmation email (Conference acronym'Xx). ACM, New York, NY, USA, 5 pages. https://doi.org/XXXXXXX.XXXXXXX
廖俊杰、郭威廷、胡怡萱、丁俊恩、刘峰、施彦辰和洪芳明*。2024。基于电子健康记录(EHR)的移动和Web平台:利用大语言多模态模型进行慢性病风险预测。见:请确保从您的权限确认邮件中输入正确的会议标题(会议缩写'Xx)。ACM,美国纽约州纽约市,5页。https://doi.org/XXXXXXX.XXXXXXX
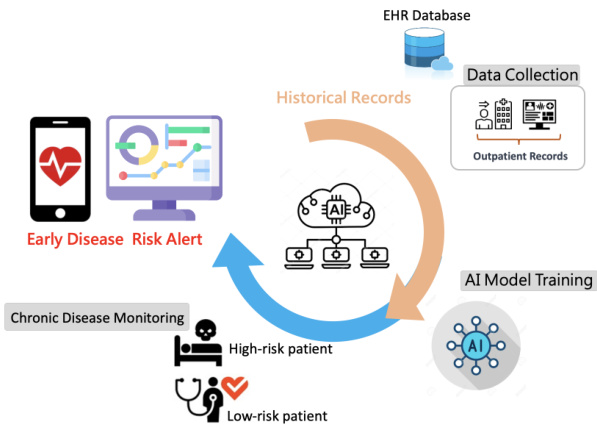
Figure 1: An overview of the AI-driven disease prediction and alert system.
图 1: AI驱动的疾病预测与预警系统概览。
1 INTRODUCTION
1 引言
Chronic diseases such as diabetes, high blood pressure, and heart disease are all diseases of concern in many countries [2, 14]. These chronic diseases are also associated with a high incidence of mortality [4, 13]. Traditional diagnosis of chronic diseases involves in-person consultation with a physician to identify the disease. However, this will result in a significant waste of time and medical resources.
糖尿病、高血压和心脏病等慢性疾病是许多国家关注的疾病 [2, 14]。这些慢性疾病还与高死亡率相关 [4, 13]。传统的慢性疾病诊断需要与医生面对面咨询以确定疾病。然而,这将导致时间和医疗资源的巨大浪费。
In the hospital diagnosis system, most patient records are stored in digital format using Electronic Health Records (EHRs), including patient clinical notes, blood test results, and pathology reports. Clinical notes are typically recorded in the database by doctors after they have seen the patient. Particularly, EHRs encompass multimodal data, including numerical values (e.g., blood test results) and categorical data (e.g., gender, age). In recent years, advancements in deep learning technology have significantly enhanced natural language processing (NLP), making it a primary focus in the research of disease classification within clinical notes . NLP techniques have demonstrated considerable potential in comprehending the contextual information embedded in medical domain sentences [9, 10].
在医院诊断系统中,大多数患者记录以电子健康档案(EHRs)形式数字化存储,包括患者临床记录、血液检测结果和病理报告。临床记录通常由医生接诊后录入数据库。特别值得注意的是,电子健康档案包含多模态数据,涵盖数值型数据(如血液检测结果)和分类数据(如性别、年龄)。近年来,深度学习技术的进步显著提升了自然语言处理(NLP)能力,使其成为临床记录疾病分类研究的主要方向。NLP技术在理解医疗领域句子中的上下文信息方面展现出巨大潜力[9, 10]。
In recent years, large language models have demonstrated remarkable performance in medical question answering and diagnosis, as well as in using NLP to predict various diseases [6, 15, 16]. For various unstructured data types, multimodal NLP has been increasingly applied to diagnose and classify diseases by integrating clinical notes and medical images with different domain features [1]. In the EHR data remote monitoring platform, a mobile system has been established for sharing lung and health data, allowing for the remote monitoring of patients’ conditions [7]. However, there is a paucity of research focused on predicting and developing application systems using clinical notes and blood test values. In this study, we present several key contributions:
近年来,大语言模型在医疗问答诊断以及利用自然语言处理(NLP)预测各类疾病方面展现出卓越性能[6, 15, 16]。针对各类非结构化数据类型,多模态NLP通过整合临床记录与具有不同领域特征的医学影像,正日益广泛应用于疾病诊断与分类[1]。在电子健康档案(EHR)数据远程监测平台中,已建立用于共享肺部及健康数据的移动系统,实现对患者病情的远程监控[7]。然而,目前鲜有研究专注于利用临床记录和血液检测值进行预测并开发应用系统。本研究的主要贡献包括:
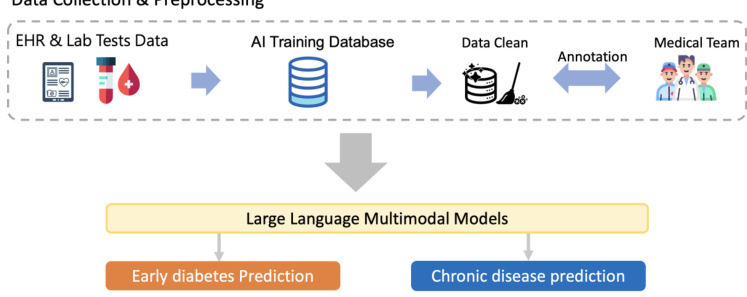
Data Collection & Preprocessing Figure 2: The workflow of building AI database and LLMMs training and inference tasks.
图 2: 构建AI数据库与大语言模型训练及推理任务的工作流程
2 DATA COLLECTION
2 数据收集
In this study, we collected five-year EHRs from the Far Eastern Memorial Hospital (FEMH) Taiwan hospital database from 2017 to 2021, including 1,420,596 clinical notes, 387,392 laboratory results, and more than 1,505 laboratory test items. The database included clinical notes and laboratory results. The study was approved by the FEMH Research Ethics Review Committee (https://www.femhirb.org/) and data has been de-identified. We first conducted data processing and physician annotation and established a comprehensive database integrated with the AI server system. Finally, we developed a complete architecture for the user interface (UI) and mobile end, as shown in Figure 1.
在本研究中,我们从台湾远东纪念医院 (FEMH) 2017至2021年的医疗数据库中收集了五年电子健康记录 (EHR),包含1,420,596份临床记录、387,392份实验室检测结果以及超过1,505项实验室检测项目。该数据库涵盖临床记录与实验室检测结果。研究已通过远东纪念医院研究伦理审查委员会 (https://www.femhirb.org/) 批准,数据均经过去标识化处理。我们首先进行数据处理和医师标注,建立了与AI服务器系统集成的综合数据库,最终开发出完整的用户界面 (UI) 和移动端架构,如图 1 所示。
2.1 Large Language Multimodal Models
2.1 大语言多模态模型 (Large Language Multimodal Models)
In our study, we utilized clinical notes and blood test data related to common chronic diseases such as diabetes, heart disease, and hy pertension to conduct multimodal model training. Specifically, we employed widely used language models such as BERT [5], BiomedBERT [8], Flan-T5-large-770M [3], and GPT-2 [12] as a text feature extractor. Next, we integrate clinical notes from a single modality as input into LLMMs to extract text feature embeddings and fuse them using an attention module for the final prediction task, as shown in Figure 2.
在我们的研究中,我们利用与糖尿病、心脏病和高血压等常见慢性病相关的临床记录和血液检测数据进行多模态模型训练。具体而言,我们采用了广泛使用的语言模型,如BERT [5]、BiomedBERT [8]、Flan-T5-large-770M [3]和GPT-2 [12]作为文本特征提取器。接着,我们将单一模态的临床记录作为输入整合到大语言模型中,提取文本特征嵌入,并通过注意力模块进行融合以完成最终预测任务,如图2所示。
2.2 Multi modality and Data Fusion
2.2 多模态与数据融合
For the blood test data, we build a Deep Neural Network (DNN) to obtain the blood presentation. To better integrate the two modalities, we utilized a multi-head attention layer to compute the attention
对于血液检测数据,我们构建了一个深度神经网络(DNN)来获取血液表征。为了更好地整合这两种模态,我们采用了多头注意力层来计算注意力
scores and matrices for the embeddings from both domains. Finally, fully connected layers were employed to predict multiple diseases.
来自两个领域的嵌入分数和矩阵。最后,使用全连接层来预测多种疾病。
2.3 Model Evaluation
2.3 模型评估
To better evaluate the unimodal performance of LLMs. Table 1 shows that the performance of LLMMs varies depending on the positive rate of different samples, including diabetes $20.4%$ ,heart disease $(22.57%)$ ,hypertension $(3.3%)$ . It is worth noting that when classifying certain specific diseases, especially those with a lower positive class, the performance of GPT-2 is not particularly well. In contrast, BiomedBERT with prior knowledge achieve an precision of 0.35 for hypertension. In contrast, in classes with higher positive rates, such as diabetes, the combination of LLMMs's modality data with GPT-2 achieved an precisoin of 0.70, a recall of 0.71, and an F1 score of 0.70. For heart disease, GPT-2 showed a significant improvement, reaching a precision of 0.81, a recall of 0.85, and an F1 score of 0.83. Based on the experimental findings, we determined that applying distinct unimodal language models with DNN to various diseases within LLMMs generate different impacts and achieved more stable and superior performance in multiclass prediction.
为了更好地评估大语言模型(LLM)的单模态性能。表1显示,LLMMs的性能因不同样本的阳性率而异,包括糖尿病(20.4%)、心脏病(22.57%)和高血压(3.3%)。值得注意的是,在对某些特定疾病进行分类时,尤其是阳性类别较低的疾病,GPT-2的表现并不特别理想。相比之下,具有先验知识的BiomedBERT对高血压的精确度达到了0.35。相反,在阳性率较高的类别中,如糖尿病,LLMMs的模态数据与GPT-2结合实现了0.70的精确度、0.71的召回率和0.70的F1分数。对于心脏病,GPT-2表现出显著改善,达到了0.81的精确度、0.85的召回率和0.83的F1分数。根据实验结果,我们确定在LLMMs中对不同疾病应用具有DNN的独特单模态语言模型会产生不同的影响,并在多类预测中实现了更稳定和更优的性能。
Table 1: Evaluation of LLMMs with various unimodal language models as backbones and laboratory values for classifying multiple diseases.
| 疾病类型 | 模型 | 精确率 (Precision) | 召回率 (Recall) | F1值 |
|---|---|---|---|---|
| 高血压 (n=1,230) | BERT BiomedBERT Flan-T5-large-770M GPT-2 | 0.35 0.35 0.29 | 0.32 0.29 0.16 | 0.33 0.32 0.20 |
| 心脏病 (n=6,929) | BERT BiomedBERT Flan-T5-large-770M GPT-2 | 0.29 0.71 0.76 0.70 | 0.21 0.76 0.75 0.78 | 0.25 0.52 0.75 0.74 |
| BERT | 0.81 0.66 | 0.85 0.58 | 0.83 0.62 | |
| 糖尿病 (n=7,208) | BiomedBERT Flan-T5-large-770M GPT-2 | 0.63 0.65 0.70 | 0.72 0.64 0.71 | 0.67 0.64 0.70 |
| 表 1: 基于不同单模态语言模型作为骨干的大语言模型对多种疾病分类的评估及实验室指标 |
3 SYSTEM DESIGN
3 系统设计
3.1 Patient Query System
3.1 患者查询系统
The overall system design is depicted in Figure 3. Our web application boasts a React-built frontend hosted on AWS EC2 and deployed using Docker containers. The user interface consists of five distinct pages: 1. Login portal, 2. Patient record management, 3. Chronic disease prediction, 4. Potential chronic disease risk alert, and 5. Early diabetes prediction.
整体系统设计如图3所示。我们的Web应用采用React构建前端,托管在AWS EC2上,并通过Docker容器部署。用户界面包含五个独立页面:(1) 登录门户,(2) 患者记录管理,(3) 慢性病预测,(4) 潜在慢性病风险预警,(5) 早期糖尿病预测。
The back end of our system includes three components. The primary component utilizes the Django MVC framework, which is deployed on AWS with Docker. This segment manages all API requests from the front end and defines the schema for the Post greSQL database, which is hosted on a separate virtual machine. Additionally, serverless endpoints are established for necessary LLMM computations.
我们系统的后端包含三个组件。主要组件采用Django MVC框架,通过Docker部署在AWS上。该部分负责处理来自前端的所有API请求,并定义托管在独立虚拟机上的PostgreSQL数据库架构。此外,还建立了无服务器端点用于必要的大语言模型(LLM)计算。
During patient data entry, the front end transmits it to the Django server. The back end takes charge, utilizing an API to forward
在患者数据录入期间,前端将其传输至Django服务器。后端负责通过API转发

Figure 3: The system design architecture that mobile and web apps interact with a Flask server for user management and LLM inference, communicating with a PostgreSQL database and an LLMs inference server.
图 3: 移动端和网页应用与Flask服务器交互的系统设计架构,用于用户管理和大语言模型(LLM)推理,并与PostgreSQL数据库及大语言模型推理服务器通信。

Figure 4: The interface of the medical diagnostic Web system
图 4: 医疗诊断Web系统界面
the data to the LLMMs endpoint for processing asynchronously. Simultaneously, the back-end organizes and uploads the data to the database server. Once processing is complete, the back-end retrieves the processed data from the LLMMs endpoint and stores it in the database. When the front end requests specific patient predictions, the back end fetches the processed data in real-time and delivers it back to the user interface.
将数据发送至大语言模型(LLM)端点进行异步处理。同时,后端系统会整理数据并上传至数据库服务器。处理完成后,后端从大语言模型端点获取处理结果并存入数据库。当前端请求特定患者预测时,后端实时调取处理数据并返回至用户界面。

Figure 5: The real-time medical appointment and diagnosis mobile platform.
图 5: 实时医疗预约与诊断移动平台。
In addition to developing a web-based front-end, we also created a six-page Android application. The mobile application includes five user interface pages and one patient list page. This patient list page enables physicians to directly access and select patients for whom they have previously entered data. We will further describe our platform details in subsection 3.2.
除了开发基于网页的前端,我们还创建了一个六页面的安卓应用。该移动应用包含五个用户界面页面和一个患者列表页面。患者列表页面能让医生直接访问并选择他们此前录入过数据的患者。我们将在3.2小节进一步描述平台细节。
3.2 Demonstration
3.2 演示
3.2.1 Medical Diagnostic Web Platform. In our chronic disease prediction platform, we demonstrate a web interface that can retrieve historical EHRs of three diseases based on the patient ID from PostgreSQL. The retrieved data can be synchronized and sent to the backend, where trained LLMMs return the risk probabilities for three disease risks to the frontend UI interface, as shown in Figure 4(a).
3.2.1 医疗诊断网络平台
在我们的慢性病预测平台中,我们展示了一个基于患者ID从PostgreSQL检索三种疾病历史电子健康记录(EHR)的网页界面。检索到的数据可同步发送至后端,经训练的大语言模型(LLM)将三种疾病风险概率返回至前端UI界面,如图4(a)所示。
3.2.2 New-Onset Diabetes Prediction System. To address the clinically early diabetes risk, we designed the platform to return predictions of early diabetes risk according to different new-onset disease days from LLMMs to the front. As shown in Figure 4 (b), for diabetes prediction, we provide early risk predictions for 90, 180, 270, and 360 days. To better visualize risk in web interface, we created a bar chart that shows the probabilities of diabetes occurrence at different periods based on the EHRs of a single patient with diabetes.
3.2.2 新发糖尿病预测系统
为解决临床早期糖尿病风险问题,我们设计该平台通过大语言模型(LLM)向前端返回不同新发天数对应的早期糖尿病风险预测结果。如图4(b)所示,针对糖尿病预测,我们提供90天、180天、270天和360天的早期风险预测。为在网页界面更直观展示风险,我们基于单例糖尿病患者电子健康档案(EHRs)数据,创建了显示不同时期糖尿病发生概率的柱状图。
3.2.3 Explain able EHR Risk Assessment. Specifically, our LLMMs framework can effectively use Shapley Additive exPlanations (SHAP) values [11] to highlight the risk levels in clinical notes as shown in Figure 4 (c). The SHAP was developed from game theory and generate Shapley values for explaining the importance of features. We first pre-train the LLMMs to focus on word position during encoding, enabling the calculation of attention scores. Subsequently, we utilize SHAP values to analyze the combined corpus of clinical notes and textual laboratory data. This visualization tool helps us understand the individual contributions of words within the corpus. By highlighting each word's positive or negative influence on predicting specific clinical terms from the LLMMs output, SHAP values enhance the model's clinical interpret ability.
3.2.3 可解释的电子健康记录(EHR)风险评估。具体而言,我们的LLMMs框架能有效利用Shapley加性解释(SHAP)值[11]来突出临床记录中的风险等级,如图4(c)所示。SHAP源自博弈论,通过生成Shapley值来解释特征重要性。我们首先预训练LLMMs在编码时关注词位置,从而计算注意力分数。随后利用SHAP值分析临床记录与文本实验室数据的组合语料库。该可视化工具帮助我们理解语料库中每个词语的独立贡献度。通过突显每个词语对LLMMs输出中特定临床术语预测的正负向影响,SHAP值增强了模型的临床可解释性。
Finally, as illustrated in Figure 4 (d) of our presented web interface, we designed a allowing physicians to freely upload patients' blood test items of health records and send them back to the server. Our model can then perform modality predictions based on the same patient's record.
最后,如图4(d)所示,我们设计的网页界面允许医生自由上传患者血液检查项目等健康记录,并将其发送回服务器。随后我们的模型可以基于同一患者的记录进行模态预测。
3.2.4 Mobile Platform. In this work, we designed a flexible mobile patient query system platform that can synchronize with the server and update with the backend server. As shown in Figure 5 (a), the mobile interface provides doctors with a list of patients′ appointments throughout the day. Subsequently, in Figure 5 (b), historical clinical notes can be retrieved in real time using the patient ID for LLMMs inference. Figures 5 (c) and (d) demonstrate the real-time of predictions with the web interface. Additionally, Figure 5 (e) also shows how real-time blood test data can be submitted to the mobile app. This data is then synchronized with the web interface and used to update the database.
3.2.4 移动平台。在本研究中,我们设计了一个灵活的移动患者查询系统平台,可与服务器同步并随后端服务器更新。如图5(a)所示,移动界面为医生提供全天患者预约列表。随后,在图5(b)中,可通过患者ID实时调取历史临床记录用于大语言模型推理。图5(c)和(d)展示了与网页界面同步的实时预测功能。此外,图5(e)还演示了如何通过移动应用提交实时血液检测数据,这些数据将与网页界面同步并用于更新数据库。
4 CONCLUSION
4 结论
In this paper, we propose a medical diagnosis system platform that integrates multimodal data into LLMMs with Flask and PostgreSQL. This allows us to update patient EHR information more effectively on web and mobile platforms in real time to implement a chronic disease alert system. Furthermore, our system in the future can also provide users and clinicians with an interactive platform and disease prevention effects.
本文提出了一种集成多模态数据到大语言模型(LLM)的医疗诊断系统平台,采用Flask框架与PostgreSQL数据库。该平台能实时更新患者在网页端和移动端的电子健康档案(EHR)信息,实现慢性病预警系统。未来该系统还将为用户和临床医生提供交互平台及疾病预防效果评估功能。