Abstract
摘要
Background: Deep learning (DL)-based predictive models from electronic health records (EHRs) deliver good performance in many clinical tasks. Large training cohorts, however, are often required to achieve high accuracy, hindering the adoption of DL-based models in scenarios with limited training data size. Recently, bidirectional encoder representations from transformers (BERT) and related models have achieved tremendous successes in the natural language processing (NLP) domain. The pre-training of BERT on a very large training corpus generates contextual i zed embeddings that can be applied to smaller data sets with fine-tuning that can substantially boost their performance with these data sets. Because EHR data are analogous to text data, as both are sequential over a large vocabulary, we explore whether this “pre-training, fine tuning”? paradigm can improve the performance of EHR-based predictive modeling.
背景:基于电子健康记录(EHR)的深度学习(DL)预测模型在许多临床任务中表现良好。然而,通常需要大量训练队列才能实现高精度,这阻碍了基于DL的模型在训练数据规模有限场景中的应用。近年来,来自Transformer的双向编码器表示(BERT)及相关模型在自然语言处理(NLP)领域取得了巨大成功。BERT在超大规模训练语料上的预训练能生成情境化嵌入,通过微调可应用于较小数据集,从而显著提升这些数据集的性能。由于EHR数据与文本数据具有相似性(两者都是基于大词汇表的序列数据),我们探索这种"预训练-微调"范式是否能提升基于EHR的预测建模性能。
Objective: To investigate whether pre-trained contextual i zed embeddings on large-scale structured EHRs can benefit downstream disease-prediction tasks and to share the pre-trained model and relevant tools with the public.
目的:研究基于大规模结构化电子健康记录(EHR)预训练的上下文嵌入是否能提升下游疾病预测任务的性能,并向公众开放预训练模型及相关工具。
Method: We propose Med-BERT, which adapts the BERT framework for pre-training contextual i zed embedding models on structured EHR data. We improve the layer representations of BERT to make it more suitable for modeling the data structure of EHRs and design a domainspecific pre-training task to better capture the underlying semantics in the clinical data. Fine-tuning experiments are conducted on two disease-prediction tasks: (1) prediction of heart failure in patients with diabetes and (2) prediction of pancreatic cancer as well as on three cohorts from two EHR databases. The general iz ability of the model on different sizes of fine-tuning training samples is tested. Further, the dependency relations among the EHRs of each patient as presented by different attention heads in the Med-BERT model are visualized.
方法:我们提出Med-BERT,该模型基于BERT框架进行改进,用于在结构化电子健康记录(EHR)数据上预训练上下文嵌入模型。我们优化了BERT的层表示,使其更适合建模EHR的数据结构,并设计了一个特定领域的预训练任务以更好地捕捉临床数据中的潜在语义。在两个疾病预测任务上进行了微调实验:(1) 糖尿病患者心力衰竭预测 (2) 胰腺癌预测,以及来自两个EHR数据库的三个队列数据。测试了模型在不同规模微调训练样本上的泛化能力。此外,我们还可视化了Med-BERT模型中不同注意力头所呈现的患者EHR之间的依赖关系。
Results: Med-BERT, pre-trained using a 28,490,650 patient EHR data set, substantially improves the prediction performance with the three fine-tuning cohorts, boosting the area under receiver operating characteristics (AUC) by $2.67{-}3.92%$ $3.20{-}7.12%$ ,and $2.02–4.71%$ ,respectively,for three popular predictive models, i.e., GRU, Bi-GRU, and RETAIN. In particular, pre-trained MedBERT considerably improved performance with very small fine-tuning training sets with only 300-500 samples, bringing their performance on par with a training set 10 times larger without pre-trained Med-BERT. Leveraging the parameters of Med-BERT, we also observe meaningful connections between clinical codes through dependency analysis.
结果:Med-BERT通过预训练2849万患者电子健康记录(EHR)数据集,在三个微调队列中显著提升预测性能,使GRU、Bi-GRU和RETAIN这三种主流预测模型的受试者工作特征曲线下面积(AUC)分别提升$2.67{-}3.92%$、$3.20{-}7.12%$和$2.02–4.71%$。特别值得注意的是,预训练后的Med-BERT在仅含300-500样本的极小规模微调训练集上仍能大幅提升性能,使其达到未使用预训练Med-BERT时10倍规模训练集的同等效果。通过依赖分析,我们还发现Med-BERT参数能有效揭示临床编码间的关联性。
Conclusion: Med-BERT is the first pre-trained contextual i zed embedding model that delivers a meaningful performance boost for real-world disease-prediction problems as compared to stateof-the-art models. Because it is especially helpful when only a small amount of data is available, it enables the pre-training, fine-tuning paradigm to be applied to solve various EHR-based problems. We share our pre-trained model to benefit disease-prediction tasks for researchers with small local training datasets. We believe that Med-BERT has great potential to help reduce data collection expenses and accelerate the pace of artificial intelligence (AI)-aided diagnosis.
结论:Med-BERT是首个预训练上下文嵌入模型,相比最先进模型,它能显著提升真实世界疾病预测问题的性能表现。该模型在仅有少量数据时尤为有效,使得预训练-微调范式可应用于解决各类基于电子健康记录(EHR)的问题。我们开源预训练模型,以帮助拥有小型本地训练数据集的研究者开展疾病预测任务。我们相信Med-BERT在降低数据收集成本、加速人工智能(AI)辅助诊断进程方面具有巨大潜力。
INTRODUCTION
引言
Artificial intelligence (AI)-aided disease prediction has undergone considerable development in recent years [1-3]. At present, it can improve the precision of diagnosis, enable disease prevention by early warning, streamline clinical decision making, and reduce healthcare costs [4-7]. Powerful AI tools, advanced conventional machine learning [8-10], and deep-learning [11-14] approaches also have been widely applied in clinical predictive modeling and have gained numerous successes. Given enough training samples, deep-learning models can achieve comparable or even better performance than domain experts in the diagnosis of certain diseases [15-19]. One prerequisite of typical deep-learning-based methods is the availability of large and high-quality annotated datasets, which are used to cover the underlying complex semantics of the input domain as much as possible and to avoid the under-fitting of model training [20,21]. Big EHR data, however, often are not accessible for numerous reasons, including the limited number of cases for new or rare conditions; difficulty in data cleaning and annotation, especially if collected from different sources; and some governance issues that hinder the data acquisition [22].
人工智能 (AI) 辅助疾病预测近年来取得了长足发展 [1-3]。目前,该技术能提升诊断精度、通过早期预警实现疾病预防、优化临床决策并降低医疗成本 [4-7]。强大的AI工具、先进的传统机器学习 [8-10] 和深度学习方法 [11-14] 也已被广泛应用于临床预测建模,并取得诸多成功。在训练样本充足的情况下,深度学习模型对某些疾病的诊断表现可媲美甚至超越领域专家 [15-19]。典型深度学习方法的前提是具备大规模高质量标注数据集,这些数据需尽可能覆盖输入域的潜在复杂语义,以避免模型训练中出现欠拟合 [20,21]。然而,由于新发/罕见病症案例有限、多源数据清洗标注困难,以及数据治理等障碍 [22],大规模电子健康档案 (EHR) 数据往往难以获取。
Transfer learning was developed to address the issue whereby some representations were first pretrained on large volumes of un annotated datasets and then further adapted to guide other tasks [23]. A recent trend in transfer learning is to use self-supervised learning over large general datasets to derive a general-purpose pre-trained model that captures the intrinsic structure of the data, which can be applied to a specific task with a specific dataset by fine-tuning. This pre-training-fine-tuning paradigm has been proven to be extremely effective in natural language processing (NLP) [24-30] and, recently, computer visions [31,32]. Among the models, bidirectional encoder representations from transformers (BERT) are one of the most popular ones for handling sequential inputs, e.g., texts, with numerous variations [33-39]. BERT also has been applied to the clinical domain, where there already were publicly available models pre-trained on clinical texts [33,34,40].
迁移学习 (Transfer Learning) 的开发旨在解决某些表征首先在大量未标注数据集上进行预训练,然后进一步调整以指导其他任务的问题 [23]。迁移学习的最新趋势是在大型通用数据集上使用自监督学习 (self-supervised learning),以得到一个能捕捉数据内在结构的通用预训练模型,该模型可以通过微调 (fine-tuning) 应用于特定任务和数据集。这种预训练-微调范式已被证明在自然语言处理 (NLP) [24-30] 和最近的计算机视觉 (computer vision) [31,32] 领域极为有效。在这些模型中,基于 Transformer 的双向编码器表征 (BERT) 是处理序列输入(如文本)最流行的模型之一,并衍生出许多变体 [33-39]。BERT 也已应用于临床领域,目前已有基于临床文本预训练的公开模型 [33,34,40]。
Structured EHRs, as a primary input source for disease prediction, offer rich and well-structured information that reflects the disease progression of each patient and are one of the most valuable resources for health data analysis [41,42]. Adapting the BERT framework to structured EHRs is a natural idea based on the analogy between natural language texts and EHRs; i.e., both texts and EHRs are sequential modalities for tokens from a large vocabulary. Generally, the tokens in language texts are “"words,” and the corresponding tokens in EHRs are medical codes (e.g., diagnosis code, medication code, procedure code). In addition, whereas the token orders in texts are natural and self-evident, the orders in EHRs are usually sequential specific to the clinical domain, such as the temporal relationship between visits.
结构化电子健康记录(EHR)作为疾病预测的主要输入源,提供了反映每位患者疾病进展的丰富且结构化的信息,是健康数据分析中最有价值的资源之一[41,42]。基于自然语言文本与EHR之间的类比关系,将BERT框架适配于结构化EHR是一个自然的思路;即文本和EHR都是来自大型词汇表的token的序列模态。通常,语言文本中的token是"单词",而EHR中对应的token则是医疗代码(如诊断代码、药物代码、操作代码)。此外,文本中的token顺序是自然且不言自明的,而EHR中的顺序通常遵循临床领域的特定序列,例如就诊之间的时间关系。
In addition, adapting BERT to structured EHRs, however, is non-trivial due to the essential differences between EHRs and texts. For example, how to organize the EHRs to efficiently match the structured inputs of BERT is still uncertain, and whether there are any applicable domainspecific pre-training tasks is still under investigation. As a result, successful research in this field is still lacking.
此外,由于电子健康记录(EHR)与文本之间存在本质差异,将BERT适配到结构化电子健康记录并非易事。例如,如何组织电子健康记录以高效匹配BERT的结构化输入仍不明确,是否存在适用的领域特定预训练任务也仍在研究中。因此,该领域目前仍缺乏成功的研究成果。
To the best of our knowledge, there are only two relevant studies in literature: BEHRT [43] and G-BERT [44]. These models, however, are limited in the following ways. BEHRT aimed to develop pre-trained models to predict the existence of any medical codes in certain visits. It uses positional embeddings to distinguish different visits and adds an age layer to imply temporal orders. The authors’ definition of the area under receiver operating characteristics (AUC), however, was a non-standard one, making it difficult to compare the findings with those of previous predictive modeling studies. G-BERT applied a graph neural network (GNN) model to expand the context of each clinical code through ontologies and jointly trained the GNN and BERT embeddings. GBERT modified the masked language model (Masked LM) pre-training task into domain-specific ones, including maximizing the gap between the existing and non-existing codes and using different types of codes to predict each other. G-BERT's inputs, however, are all single-visit samples, which are insufficient to capture long-term contextual information in EHRs. In addition, the size for their pre-training dataset is not large, making it difficult to evaluate its full potential. Neither BEHRT nor G-BERT uses disease-prediction tasks as the evaluation of their pre-trained model by fine-tuning.
据我们所知,目前文献中仅有两项相关研究:BEHRT [43] 和 G-BERT [44]。但这些模型存在以下局限性:BEHRT 旨在开发预训练模型以预测特定就诊中是否存在任何医疗代码,它通过位置嵌入区分不同就诊记录,并添加年龄层来隐含时间顺序。然而作者对受试者工作特征曲线下面积 (AUC) 的定义采用非标准方式,导致难以与既往预测建模研究结果进行对比。G-BERT 应用图神经网络 (GNN) 模型通过本体论扩展临床代码的上下文,并联合训练 GNN 与 BERT 嵌入。该研究将掩码语言模型 (Masked LM) 预训练任务调整为领域专用任务,包括最大化存在与不存在代码间的差异,以及利用不同类型代码相互预测。但 G-BERT 的输入均为单次就诊样本,不足以捕捉电子健康档案 (EHR) 中的长期上下文信息。此外,其预训练数据集规模较小,难以评估模型的全部潜力。BEHRT 和 G-BERT 均未通过微调方式将疾病预测任务作为预训练模型的评估标准。
To alleviate the aforementioned issues and to evaluate a pre-trained contextual i zed embedding model specific to disease prediction, we designed Med-BERT, a variation of BERT for structured EHRs. We compare Med-BERT with BEHRT and G-BERT in Table 1. The main feature of MedBERT is that it has a much larger vocabulary size and pre-training cohort size than do the other two models, which will help to provide a reality check of BERT-based models. In Med-BERT, larger cohort size and longer visit sequences will greatly benefit the model in learning more comprehensive contextual semantics. We also believe that, by using a large and publicly accessible vocabulary, i.e., International Classification of Diseases (ICD)-9 plus ICD-10, Med-BERT will likely be deployable to different institutions and clinical scenarios. Further, only Med-BERT tested the utility of the pre-trained model on an external data source (Truven), and the results showed that our model has good s cal ability.
为缓解上述问题并评估专为疾病预测设计的预训练上下文嵌入模型,我们开发了针对结构化电子健康记录(EHR)的BERT变体Med-BERT。表1展示了Med-BERT与BEHRT、G-BERT的对比。Med-BERT的核心优势在于其词汇表规模与预训练队列规模远超另外两个模型,这将有助于验证基于BERT模型的实际效能。在Med-BERT中,更大的队列规模和更长的就诊序列能显著提升模型学习全面上下文语义的能力。我们认为,通过采用国际通用的标准化词汇表(即ICD-9与ICD-10编码体系),该模型可适配不同医疗机构与临床场景。此外,只有Med-BERT在外部数据源(Truven)上验证了预训练模型的实用性,结果表明我们的模型具备良好的可扩展性。
Similar to BEHRT and G-BERT, we used code embeddings to represent each clinical code, visit embeddings to differentiate visits, and the transformer structure to capture the inter-correlations between codes. Within each visit, we defined serialization embeddings to denote the relative order of each code, whereas neither BEHRT nor G-BERT introduced code ordering within a visit. Specifically, we designed a domain-specific pre-training task prediction of prolonged length of stay in hospital (Prolonged LOS), which is a popular clinical problem that requires contextual information modeling to evaluate the severity of a patient's health condition according to the disease progression. We expect that the addition of this task can help the model to learn more clinical and more contextual i zed features for each visit sequence and facilitate certain tasks. Evaluations (fine-tuning)' were conducted on two disease-prediction tasks: the prediction of heart failure among patients with diabetes (DHF) and the prediction of onset of pancreatic cancer $\mathrm{(PaCa)}$ , and three patient cohorts from two different EHR databases, Cerner Health Facts $\mathfrak{B}^{2}$ and Truven Health MarketScan $\textcircled{8}$ .3 These tasks are different from the pre-training prediction tasks (Masked LM and Prolonged LOS) and, thus, are good tests for the general iz ability of the pretrained model. In addition, we chose these tasks because they capture more complexity, not merely the existence of certain diagnosis codes, and are based on phe no typing algorithms that further integrate multiple pieces of information, such as constraints on time window, code occurrence times, medications, and lab test values (see below).
与BEHRT和G-BERT类似,我们使用代码嵌入(code embeddings)表示每个临床代码,用就诊嵌入(visit embeddings)区分不同就诊记录,并采用Transformer结构捕捉代码间的相互关系。在每个就诊记录内部,我们定义了序列化嵌入(serialization embeddings)来标识代码的相对顺序,而BEHRT和G-BERT都未引入就诊内部的代码排序机制。具体而言,我们设计了一个领域特定的预训练任务——预测住院时长延长(Prolonged LOS),这是一个需要根据病情进展建模上下文信息来评估患者健康状况严重程度的常见临床问题。我们期望通过该任务的加入,能帮助模型学习更具临床意义和上下文特征的就诊序列表示,从而提升特定任务的性能。
评估(微调阶段)在两个疾病预测任务上进行:糖尿病患者心力衰竭预测(DHF)和胰腺癌发病预测(PaCa),数据来自Cerner Health Facts $\mathfrak{B}^{2}$ 和Truven Health MarketScan $\textcircled{8}$ 两个电子健康记录(EHR)数据库的三个患者队列。这些任务与预训练任务(掩码语言模型和住院时长预测)存在差异,因此能有效检验预训练模型的泛化能力。我们选择这些任务的原因在于:它们不仅涉及特定诊断代码的存在性判断,还需要处理更复杂的临床表型算法——这些算法需要整合时间窗口约束、代码出现频次、用药记录和实验室检测值等多维度信息(详见下文)。
Experiments were conducted in three steps: (1) test the performance gains by adding Med-BERT on three state-of-the-art predictive models; (2) compare Med-BERT with a pre-trained clinical word2vec-style embedding [47]; and (3) test to see how much Med-BERT would contribute to disease predictions with different training sizes.
实验分三步进行:(1) 在三种前沿预测模型上测试添加Med-BERT带来的性能提升;(2) 将Med-BERT与预训练的临床word2vec式嵌入[47]进行对比;(3) 测试不同训练数据量下Med-BERT对疾病预测的贡献程度。
Table 1. Comparison of Med-BERT with BEHRT and G-BERT from multiple perspectives.
| Criteria | BEHRT | G-BERT | Med-BERT |
| Type of input code | Caliber code for diagnosis developed by a college in London | Selected ICD-9 code for diagnosis + ATC code for medication | ICD-9 + ICD-10 code for diagnosis |
| Vocabulary size | 301 | <4K | 82K |
| Pre-training data source | CPRD (primary care data) [45] | MIMIC II (ICU data) [46] | Cerner HealthFacts (general EHRs) |
| Input structure | Code + visit + age embeddings | Code embeddings from ontology + visit embeddings | Code + visit + code serialization embeddings |
| Pre-training sample unit | Patient's visit sequence | Single visit | Patient's visit sequence |
| Total number of pre- training patients | 1.6M | 20K | 20M |
| Average number of visits for each patient for pre-training | Not reported but > 5 | <2 | 8 |
| Pre-training task | Masked LM | Modified Masked LM | Masked LM + prediction of prolonged length of stay in hospital |
| Evaluation task | Diagnosis code prediction in different time windows | Medication code prediction | Disease predictions according to strict inclusion/exclusion criteria |
| Total number of patients in evaluation tasks | 699K, 391K, and 342K for different time windows | 7K | 50K, 20K, and 20K for three task cohorts |
表 1. Med-BERT与BEHRT和G-BERT的多角度对比
| 标准 | BEHRT | G-BERT | Med-BERT |
|---|---|---|---|
| 输入编码类型 | 伦敦某学院开发的诊断用Caliber编码 | 精选的诊断用ICD-9编码 + 用药ATC编码 | 诊断用ICD-9 + ICD-10编码 |
| 词表大小 | 301 | <4K | 82K |
| 预训练数据来源 | CPRD (初级诊疗数据) [45] | MIMIC II (ICU数据) [46] | Cerner HealthFacts (通用电子健康档案) |
| 输入结构 | 编码 + 就诊 + 年龄嵌入 | 本体论中的编码嵌入 + 就诊嵌入 | 编码 + 就诊 + 编码序列化嵌入 |
| 预训练样本单元 | 患者就诊序列 | 单次就诊 | 患者就诊序列 |
| 预训练患者总数 | 1.6M | 20K | 20M |
| 预训练中每位患者的平均就诊次数 | 未报告但>5 | <2 | 8 |
| 预训练任务 | 掩码语言模型 (Masked LM) | 改进版掩码语言模型 | 掩码语言模型 + 预测住院时长延长 |
| 评估任务 | 不同时间窗口的诊断编码预测 | 用药编码预测 | 根据严格纳入/排除标准的疾病预测 |
| 评估任务中的患者总数 | 不同时间窗口分别699K、391K和342K | 7K | 三个任务队列分别50K、20K和20K |
Our primary contributions are summarized as follows:
我们的主要贡献总结如下:
- This work is the first proof-of-concept demonstration that a BERT-style model for structured EHRs can deliver a meaningful performance boost in real-world-facing predictive modeling tasks.
- 本研究首次通过概念验证证明,针对结构化电子健康记录(EHR)的BERT风格模型能在面向真实世界的预测建模任务中带来显著性能提升。
METHODS
方法
Data Preparation
数据准备
We extracted our cohorts from two databases. Cerner Health Facts was used for both pretraining and evaluation tasks, and Truven Health MarketScan $\textcircled{8}$ was used only during evaluation. Appendix A the includes details of different cohort definitions and data sources. Finally, we had one cohort for pre-training from Cerner and three phenotyped cohorts for evaluation, two of which were from Cerner (DHF-Cerner and PaCa-Cerner) and one from Truven (PaCa-Truven). The descriptive analysis of the cohorts used is shown in Table 2.
我们从两个数据库中提取了研究队列。Cerner Health Facts 同时用于预训练和评估任务,而 Truven Health MarketScan $\textcircled{8}$ 仅用于评估阶段。附录 A 包含不同队列定义和数据源的详细信息。最终,我们获得了一个来自 Cerner 的预训练队列,以及三个用于评估的表型队列,其中两个来自 Cerner (DHF-Cerner 和 PaCa-Cerner),一个来自 Truven (PaCa-Truven)。所用队列的描述性分析如 表 2 所示。

Figure 1. Selection pipeline for the pre-training cohort.
图 1: 预训练队列的筛选流程。
Table 2. Descriptive analysis of the cohorts.
| Characteristic | Pre-training | DHF- Cerner | PaCa- Cerner | PaCa- Truven |
| Cohort size (n) | 28,490,650 | 672,647 | 29,405 | 42,721 |
| Average number of visits per patient | 8 | 17 | 7 | 19 |
| Average number of codes per patient | 15 | 33 | 14 | 18 |
| Vocabulary size | 82,603 | 26,427 | 13,071 | 7,002 |
| ICD-10 codes (%) | 33.8% | 13.3% | 20.7% | 0% |
表 2: 队列描述性分析
| 特征 | 预训练队列 | DHF-Cerner队列 | PaCa-Cerner队列 | PaCa-Truven队列 |
|---|---|---|---|---|
| 队列规模(n) | 28,490,650 | 672,647 | 29,405 | 42,721 |
| 患者平均就诊次数 | 8 | 17 | 7 | 19 |
| 患者平均编码数量 | 15 | 33 | 14 | 18 |
| 词汇表规模 | 82,603 | 26,427 | 13,071 | 7,002 |
| ICD-10编码占比(%) | 33.8% | 13.3% | 20.7% | 0% |
Med-BERT
Med-BERT
Figure 2 shows the Med-BERT structure with an input example (the dotted part). Three types of embeddings were taken as inputs. These embeddings were projected from diagnosis codes, the order of codes within each visit, and the position of each visit and named, respectively, code embeddings, serialization embeddings, and visit embeddings. Code embeddings are the lowdimensional representations of each diagnosis code; serialization embeddings denote the relative order of each code in each visit; and visit embeddings are used to distinguish each visit in the sequence.
图 2: 展示了带有输入示例(虚线部分)的Med-BERT结构。模型接收三种类型的嵌入向量作为输入: 诊断代码(code embeddings)、每次就诊中代码的顺序(serialization embeddings)以及每次就诊的位置(visit embeddings)。代码嵌入是每个诊断代码的低维表示;序列化嵌入表示每次就诊中各代码的相对顺序;就诊嵌入则用于区分序列中的每次就诊。
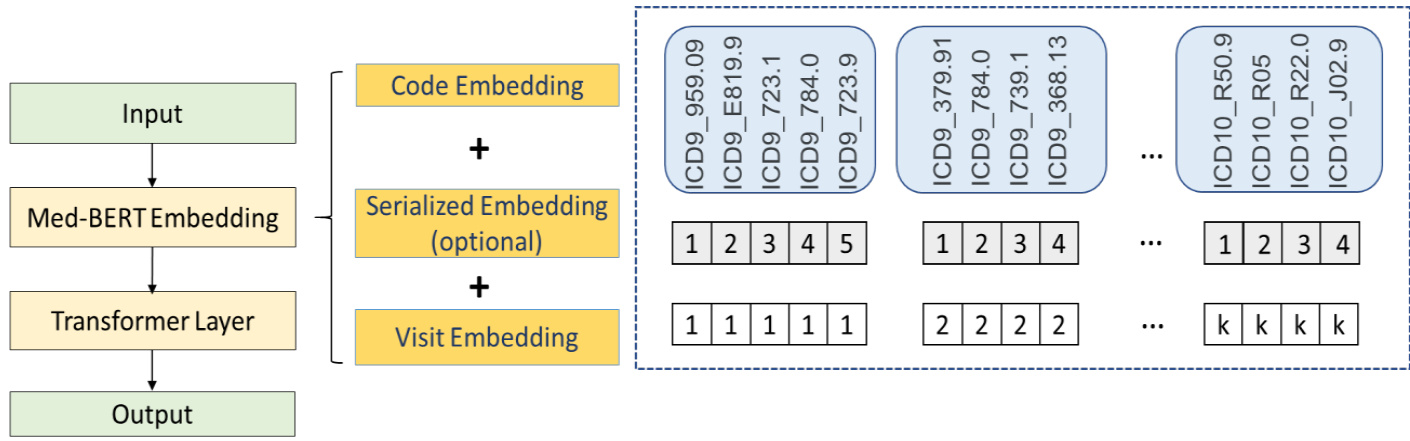
Figure 2. Med-BERT structure.
图 2: Med-BERT结构。
Unlike BERT, we did not use the specific tokens $[C L S]$ and $[S E P]$ at the input layer, attributed mainly to the differences in the input formats of EHRs and text. In BERT, there are only two adjacent sentences, and the token $[S E P]$ behaves as a separator to distinguish the two sentences for the pre-training task of next sentence prediction. Next sentence prediction, however, was not involved in our tasks (as explained in the next subsection). We consider that the visit embeddings can separate well each visit and that adding $[S E P]$ would only be redundant. In BERT, the token $[C L S]$ was used mainly to summarize the information from the two sentences; however, EHR sequences are usually much longer; e.g., a sequence may contain 10 more visits, and simply using one token will inevitably lead to huge information loss. Therefore, for both the Prolonged LOS task and the downstream disease-prediction tasks where the information of the whole sequence is usually needed, we added a feed-forward layer (FFL) to average the outputs from all of the visits to represent a sequence, instead of using only a single token.
与BERT不同,我们在输入层没有使用特定的token $[C L S]$ 和 $[S E P]$,这主要归因于电子健康记录(EHR)与文本输入格式的差异。在BERT中,只有两个相邻的句子,token $[S E P]$ 作为分隔符来区分这两个句子,用于下一句预测的预训练任务。然而,我们的任务并不涉及下一句预测(如下一小节所述)。我们认为就诊嵌入(visit embeddings)能很好地分隔每次就诊,添加 $[S E P]$ 只会显得冗余。在BERT中,token $[C L S]$ 主要用于汇总两个句子的信息;但EHR序列通常要长得多,例如一个序列可能包含10次以上的就诊,仅使用一个token将不可避免地导致大量信息丢失。因此,对于需要整个序列信息的长期住院(LOS)任务和下游疾病预测任务,我们添加了一个前馈层(FFL)来平均所有就诊的输出以表示一个序列,而不是仅使用单个token。
Similar to BERT, transformers also were employed to model the structures of diagnosis codes for each patient. Bidirectional transformer blocks in the transformer layer take advantage of multi head attention operations to encode the codes and the visits [48].
与BERT类似,Transformer也被用于建模每位患者的诊断代码结构。Transformer层中的双向Transformer块利用多头注意力操作对代码和就诊记录进行编码 [48]。
Pre-training
预训练
Two tasks were involved in our pre-training step, on the code level and the patient level, respectively:
在我们的预训练步骤中涉及两个任务,分别在代码层面和患者层面:
(1) Masked Language Model (Masked LM)
(1) 掩码语言模型 (Masked LM)
This model was directly inherited from the original BERT paper, which was used to predict the existence of code, given its context. In detail, there was an $80%$ chance that a code was replaced
该模型直接继承自原始BERT论文,用于根据上下文预测代码是否存在。具体而言,代码被替换的概率为$80%$
by $[M A S K]$ ,a $10%$ chance that the code was replaced by a random code, and another $10%$ chance that it was kept unchanged. This task is the core of the contextual i zed embedding model.
通过 $[M A S K]$,代码有 $10%$ 的概率被随机代码替换,另有 $10%$ 的概率保持不变。该任务是上下文嵌入模型的核心。
(2) Prediction of prolonged length of stay (Prolonged LOS) in hospital
(2) 住院时间延长预测 (Prolonged LOS)
For the classification task, instead of using the question-answer pairs, we decided to choose a clinical problem with a relatively high prevalence in our pre-training dataset and one that is not disease-specific to ensure better general iz ability of our pre-trained model. The three most commonly used quality-of-care indicators, mortality, early read mission, and prolonged LOS, were selected and tested. Through testing that used different cohort definitions, we found that assessing each patient for whether a prolonged hospital visit ( $\mathrm{LOS}>7$ days) had ever occurred was associated with lower masking loss during the pre-training phase. Prolonged LOS involves the determination of whether a patient has experienced any prolonged LOS in his or her visit history based on the EHR sequence. A prolonged LOS is any hospital visit that is a longer than a seven-day stay, according to the difference between the admission and discharge dates. We used a simplified version of prolonged LOS prediction by targeting the patient level rather than the visit level to reduce the pre-training complexity.
对于分类任务,我们决定不使用问答对,而是选择一个在预训练数据集中患病率相对较高且非疾病特异性的临床问题,以确保预训练模型具备更好的泛化能力。我们选取并测试了三种最常用的医疗质量指标:死亡率、早期再入院率和住院时间延长(LOS)。通过采用不同队列定义的测试,我们发现评估患者是否曾有过住院时间延长( $\mathrm{LOS}>7$ 天)的情况,与预训练阶段较低的掩码损失相关。住院时间延长的判定是基于电子健康记录(EHR)序列,判断患者在其就诊历史中是否经历过任何住院时间延长的情况。根据入院和出院日期的差值,任何住院时间超过7天的就诊都被视为住院时间延长。我们采用了简化版的住院时间延长预测方法,将目标设定在患者层面而非就诊层面,以降低预训练的复杂度。
The natural semantics of Prolonged LOS also can maximize the utility of the bidirectional structure of Med-BERT, as the task inherently indicates the severity of illness of each patient, which could be measured by the EHR from both directions (forward and backward), whereas tasks such as mortality always will be terminated at the last visit of the patient sequence, the input data of which can be constructed in only one direction. Similarly, early read mission will be based mainly on the pieces of visits involved, as they reflect the quality of care received and contribute more than the patient's health status in evaluating read mission.
延长住院时间 (Prolonged LOS) 的自然语义还能最大化 Med-BERT 双向结构的效用,因为该任务本身表明了每位患者的疾病严重程度,可通过电子健康记录 (EHR) 从两个方向 (前向和后向) 进行测量。而像死亡率这类任务总是终止于患者序列的最后一次就诊,其输入数据只能单向构建。同理,早期再入院主要基于相关就诊片段进行评估,因为这些片段反映了所接受的护理质量,在评估再入院时比患者健康状况更具参考价值。
Evaluation
评估
The pre-trained model can be further fine-tuned to better fit downstream tasks, which is known as transfer learning. In our study, we conducted evaluations on two different diseaseprediction tasks on three cohorts from two databases. The two tasks are heart failure in diabetes patients (DHF-Cerner) and pancreatic cancer (PaCa-Cerner, PaCa-Truven); the detailed cohort definitions are presented in the Supplementary Materials. Different from BEHRT and G-BERT, for which the evaluation tasks are simply the prediction of certain codes and are different from the tasks in pre-training, the definition of a certain disease is more complex, as it requires the phe no typing from multiple perspectives, e.g., the existence of certain diagnosis codes, drug prescriptions, procedures, lab-test values, and, sometimes, the frequency of events in predefined time windows. Therefore, we claim that our evaluation might be more realistic (compared with BEHRT) and more helpful in proving the general iz ability of Med-BERT.
预训练模型可以通过微调更好地适应下游任务,这一过程称为迁移学习。在我们的研究中,我们基于两个数据库的三个队列,对两种不同的疾病预测任务进行了评估。这两个任务分别是糖尿病患者心力衰竭(DHF-Cerner)和胰腺癌(PaCa-Cerner、PaCa-Truven),详细的队列定义见补充材料。与BEHRT和G-BERT不同(它们的评估任务仅是对某些代码的预测,且与预训练任务不同),特定疾病的定义更为复杂,因为它需要从多个角度进行表型分析,例如某些诊断代码的存在、药物处方、手术、实验室检测值,有时还包括预定义时间窗口内事件发生的频率。因此,我们认为我们的评估可能更贴近实际(与BEHRT相比),也更有利于证明Med-BERT的泛化能力。
For each evaluation cohort, we randomly selected a subset of the original cohort and further split it into training, validation, and testing sets. The numbers of patients in the testing sets are all 5K for each task, and the sizes of training sets are 50K, 20K, and 20K for DHF-Cerner, PaCa-Cerner, and PaCa-Truven, respectively. The validation sets were set up according to a fixed ratio of the training sets, with $10%$ for the full training sets (e.g., 50K for DHF-Cerner) and $25%$ forother training sizes (e.g., training sets in Ex-3, introduced below). For performance measurement, we used AUC as our primary evaluation metric, which has been widely adopted by many previous studies of disease prediction [12,14,49].
对于每个评估队列,我们从原始队列中随机选取一个子集,并将其进一步划分为训练集、验证集和测试集。各任务的测试集患者数均为5K,训练集规模分别为DHF-Cerner 50K、PaCa-Cerner 20K和PaCa-Truven 20K。验证集根据训练集的固定比例设置:完整训练集(如DHF-Cerner 50K)采用10%的比例,其他训练规模(如下文介绍的Ex-3训练集)采用25%的比例。性能评估方面,我们采用AUC作为主要评价指标,该指标已被许多既往疾病预测研究广泛采用[12,14,49]。
For all three tasks, we conducted three experiments: (1) Ex-1: evaluate how Med-BERT can contribute to three state-of-the-art methods; (2) Ex-2: compare Med-BERT with one state-of-theart clinical word2vec-style embedding, t-W2V (trained on the full Cerner cohort) [47]; and (3) Ex3: investigate how much the pre-trained model can help in transfer learning, i.e., when only a proportion of training samples are available. For Ex-1 and Ex-2, we adopted GRU [50], Bi-GRU [51], and RETAIN [12] as our base models. Performances were compared through running the base models and adding pre-trained models as initialization s and further fine-tuning, including tW2V and Med-BERT. We also list the results by using Med-BERT only; i.e., only FFL was appended on top of the sequential output. For Ex-3, we selected different sizes of samples from the training data for each cohort for fine-tuning. Intuitively, the pre-trained model would be more helpful when the training size is smaller, as it helps inject a broader scope of knowledge. Therefore, the motivation of this stepwise experiment is to investigate how “small' our training set can be for achieving satisfying results with the addition of Med-BERT. For each training size (except the maximum size, which was randomly initialized 10 times), we conducted a random bootstrap sampling 10 times and reported the average AUC and standard deviation for each cohort.
针对这三项任务,我们进行了三个实验:(1) 实验1:评估Med-BERT如何提升三种前沿方法的性能;(2) 实验2:将Med-BERT与当前最优的临床word2vec式嵌入方法t-W2V(基于完整Cerner队列训练)[47]进行对比;(3) 实验3:探究预训练模型在迁移学习中的助力程度,即仅使用部分训练样本时的表现。实验1和实验2中,我们采用GRU[50]、Bi-GRU[51]和RETAIN[12]作为基线模型,通过运行基线模型并添加预训练模型(包括t-W2V和Med-BERT)进行初始化及微调来比较性能。我们还列出了仅使用Med-BERT(即在序列输出端仅附加FFL)的结果。实验3中,我们从每个队列的训练数据中选取不同规模的样本进行微调。直观而言,训练规模越小时预训练模型的作用越大,因其能注入更广泛的知识。因此,本阶梯实验旨在探究:加入Med-BERT后,训练集规模"多小"仍能获得满意结果。针对每个训练规模(除最大规模随机初始化10次外),我们进行了10次随机自助采样,并报告各队列的平均AUC和标准差。
Implementation Details
实现细节
For pre-training we used mainly the BERT recommended parameters [29]. We had six attention heads, each with a 32-dimensional attention vector, and, thus, our hidden and embedding dimensions are 192. We used the default BERT optimizer, Adam Weight decay optimizer. We used the recommended learning rate of 5e-5, a dropout rate of 0.1, and 6 BERT layers. We set the maximum sequence length as 512 and masked only one diagnosis code per patient during Masked LM.
在预训练阶段,我们主要采用了BERT推荐的参数[29]。模型配置包含6个注意力头,每个注意力头的向量维度为32,因此隐藏层和嵌入维度均为192。我们使用了默认的BERT优化器——Adam Weight decay优化器,采用推荐学习率5e-5、丢弃率(dropout)0.1及6层BERT结构。最大序列长度设为512,在掩码语言模型(Masked LM)训练中每位患者仅掩码一个诊断码。
We used the Google TensorFlow code for pre-training (February 2019 version),4 and, for finetuning, we converted the pre-trained model to the PyTorch version, using the Hugging face package (version 2.3) [52]. For pre-training, we used a single Nvidia Tesla V100 GPU of 32GB graphics memory capacity, and we trained the model for a week for more than 45 million steps, for which each step consists of 512 disease code (maximum sequence length) $^\ast32$ patients (batch size) . For the evaluation tasks, we used GPUs Nvidia GeForce RTX 2080 Ti of 12GB memory.
我们使用Google TensorFlow代码进行预训练(2019年2月版本),并在微调阶段通过Hugging face包(2.3版)[52]将预训练模型转换为PyTorch版本。预训练采用单块32GB显存的Nvidia Tesla V100 GPU,以512个疾病代码(最大序列长度)*32名患者(批次大小)为单步训练量,经过超过4500万步训练(耗时一周)。评估任务使用12GB显存的Nvidia GeForce RTX 2080 Ti GPU。
To facilitate reproducibility and benefit other EHR-based studies, we shared our pre-trained model as well as our visualization tool on https://github.com/ZhiGroup/Med-BERT. [The codes for all steps will be available to the public after the paper is accepted.]
为促进研究可复现性并惠及其他基于电子健康记录(EHR)的研究,我们在https://github.com/ZhiGroup/Med-BERT上共享了预训练模型及可视化工具。[论文录用后,所有步骤的代码将向公众开放。]
RESULTS
结果
Performance boost of Med-BERT on fine-tuning tasks
Med-BERT在微调任务上的性能提升
Table 3 presents the AUCs for Ex-1 on the three evaluation tasks. We tagged the top-three AUCs for each task as bold with different colors (top-1, top-2, top-3). For DHF-Cerner, it is notable thatBi-GRU $+$ Med-BERT andRETAIN $^+$ Med-BERT obtain the best results and perform comparably, followed by Med-BERT_only and GRU+Med-BERT. For each base model, adding t-W2V (except GRU) will generally achieve better results, but adding Med-BERT improves the results much further. It is worth mentioning that, for those powerful deep-learning models, such as Bi-GRU and RETAIN, that can obtain over 80 on AUC with relatively large training data, e.g..
表 3 展示了 Ex-1 在三个评估任务上的 AUC 值。我们将每项任务中排名前三的 AUC 值用不同颜色加粗标注 (top-1, top-2, top-3)。值得注意的是,在 DHF-Cerner 数据集上,Bi-GRU $+$ Med-BERT 和 RETAIN $^+$ Med-BERT 取得了最佳且表现相近的结果,其次是 Med-BERT_only 和 GRU+Med-BERT。对于每个基础模型,添加 t-W2V (GRU 除外) 通常能获得更好的结果,但添加 Med-BERT 能进一步提升性能。值得一提的是,对于那些强大的深度学习模型 (如 Bi-GRU 和 RETAIN),在训练数据量较大时 (例如) 可以获得超过 80 的 AUC 值。
50K samples, adding Med-BERT still makes considerable contributions, i.e., over $2.5%$ . Using Med-BERT_only can beat any model without Med-BERT.
50K样本下,加入Med-BERT仍能带来显著提升(即超过$2.5%$)。仅使用Med-BERT_only即可超越任何未采用Med-BERT的模型。
Table 3. Average AUC values and standard deviations for the different methods for the three evaluation tasks.
| Model | DHF-Cerner | PaCa-Cerner | PaCa -Truven |
| GRU | 78.85 (1.65) | 78.05 (1.47) | 75.25 (0.47) |
| GRU+t-W2V | 74.72 (3.08) | 78.02 (0.89) | 74.57 (0.60) |
| GRU+Med-BERT | 82.77 (0.18) | 82.40 (0.16) | 79.27 (0.17) |
| Bi-GRU | 80.20 (0.21) | 77.76 (0.33) | 74.46 (0.19) |
| Bi-GRU+t-W2V | 80.72 (0.14) | 80.75 (0.16) | 75.23 (0.33) |
| Bi-GRU+Med-BERT | 83.15 (0.14) | 82.63 (0.22) | 79.17 (0.17) |
| RETAIN | 80.47 (0.22) | 78.83 (0.43) | 76.17 (0.25) |
| RETAIN+t-W2V | 82.38 (0.14) | 82.30 (0.18) | 78.60 (0.14) |
| RETAIN+Med-BERT | 83.14 (0.06) | 82.03 (0.17) | 78.19 (0.31) |
| Med-BERT_only(FFL) | 82.79 (0.12) | 82.41 (0.33) | 78.65 (0.2) |
表 3. 三种评估任务下不同方法的平均AUC值及标准差。
| 模型 | DHF-Cerner | PaCa-Cerner | PaCa-Truven |
|---|---|---|---|
| GRU | 78.85 (1.65) | 78.05 (1.47) | 75.25 (0.47) |
| GRU+t-W2V | 74.72 (3.08) | 78.02 (0.89) | 74.57 (0.60) |
| GRU+Med-BERT | 82.77 (0.18) | 82.40 (0.16) | 79.27 (0.17) |
| Bi-GRU | 80.20 (0.21) | 77.76 (0.33) | 74.46 (0.19) |
| Bi-GRU+t-W2V | 80.72 (0.14) | 80.75 (0.16) | 75.23 (0.33) |
| Bi-GRU+Med-BERT | 83.15 (0.14) | 82.63 (0.22) | 79.17 (0.17) |
| RETAIN | 80.47 (0.22) | 78.83 (0.43) | 76.17 (0.25) |
| RETAIN+t-W2V | 82.38 (0.14) | 82.30 (0.18) | 78.60 (0.14) |
| RETAIN+Med-BERT | 83.14 (0.06) | 82.03 (0.17) | 78.19 (0.31) |
| Med-BERT_only(FFL) | 82.79 (0.12) | 82.41 (0.33) | 78.65 (0.2) |
For PaCa-Cerner, similar trends also were observed, whereby Bi-GRU+Med-BERT, MedBERT_only, and GRU $+$ Med-BERT outperformed methods without Med-BERT, and adding MedBERT enhanced the AUCs of base models by $3-7%$ . For PaCa-Truven, the best AUC was obtained byGRU $^+$ Med-BERT, whereas the other Med-BERT-related models also have better results than do other models. On this Truven dataset, we still observed performance gains of $2.02–4.02%$ although the average AUCs appear to be a bit lower than those on $\mathrm{PaCa}$ -Cerner. Nevertheless, we consider it enough to demonstrate that Med-BERT can be generalized well to a different dataset whose data distributions might be quite different from Cerner—the one it pre-trained on.
在PaCa-Cerner数据集上,我们也观察到了类似的趋势:Bi-GRU+Med-BERT、MedBERT_only和GRU $+$ Med-BERT的表现优于未使用Med-BERT的方法,加入MedBERT使基础模型的AUC提升了 $3-7%$。对于PaCa-Truven数据集,GRU $^+$ Med-BERT取得了最佳AUC值,其他与Med-BERT相关的模型也表现优于其他模型。在这个Truven数据集上,尽管平均AUC略低于$\mathrm{PaCa}$-Cerner,但我们仍观察到 $2.02–4.02%$ 的性能提升。这足以证明Med-BERT能够很好地泛化到与预训练数据分布差异较大的其他数据集。
A clear trend reflected by the results of these three tasks is that the addition of Med-BERT was more helpful on simpler models, i.e., $\mathrm{GRU}>\mathrm{Bi}\mathrm{-GRU}>\mathrm{RETA}$ IN, compared with the addition of t-W2V to the base models. The addition of t-W2V shows promising improvements on RETAIN and Bi-GRU, but neither helps nor hurts the performance of GRU. For RETAIN, the performance by adding t-W2V and Med-BERT is comparable on the PC tasks.
这三项任务的结果反映出一个明显趋势:与在基础模型中加入t-W2V相比,Med-BERT对简单模型的提升效果更显著,即 $\mathrm{GRU}>\mathrm{Bi}\mathrm{-GRU}>\mathrm{RETA}$ IN。t-W2V的加入在RETAIN和Bi-GRU上表现出良好的改进效果,但对GRU的性能既无提升也无损害。对于RETAIN而言,在PC任务中添加t-W2V和Med-BERT的性能表现相当。
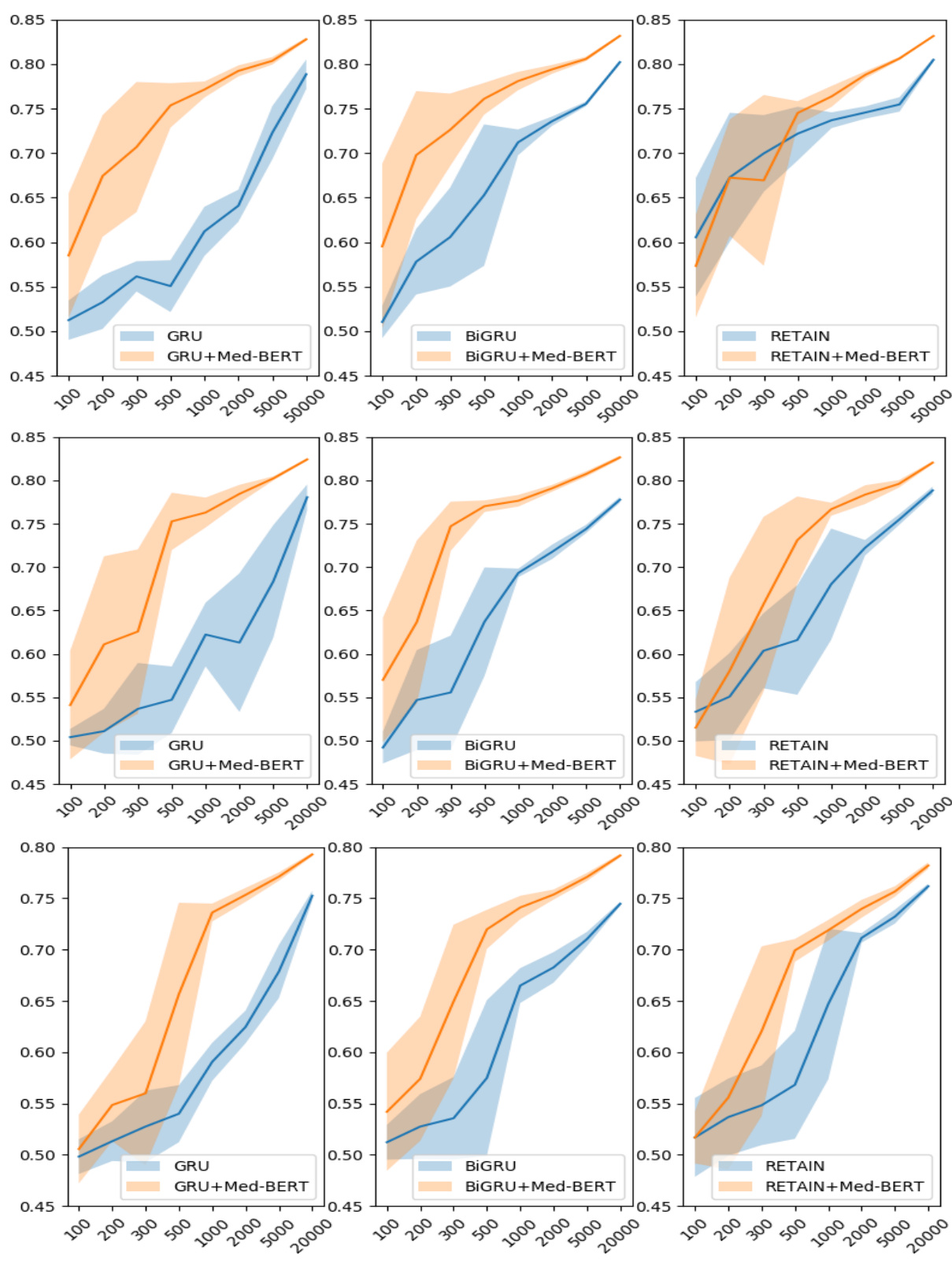
Figure 3. Prediction results for the evaluation sets by training on different sizes of data on DHFCerner (top), PaCa-Cerner (middle), and PaCa-Truven (bottom). The shadows indicate the standard deviations.
图 3: 在DHFCerner(上)、PaCa-Cerner(中)和PaCa-Truven(下)数据集上使用不同规模训练数据得到的评估集预测结果。阴影区域表示标准差。
Figure 3 shows the results in the three cohorts on the transfer-learning paradigm. We used different training sizes to test how much Med-BERT can help boost the prediction performance of the base models by incorporating more contextual information as prior knowledge. In the line chart of DHFCerner, we notice that, without Med-BERT, it is difficult for GRU only to exceed 0.65 when given fewer than 2,000 training samples. The addition of Med-BERT, however, greatly increases the A UC s by about $20%$ and helps the model to reach 0.75, even when training on 500 samples. For Bi-GRU, considerable improvements also can be observed, but they are not as high as those for GRU. For RETAIN, Med-BERT seems to be more helpful when the training set contains more than 500 samples. For smaller training sizes, the standard deviations show heavy overlaps between the two curves, indicating that the results are not quite stable; thus, it is difficult to determine which model is absolutely better than the other.
图 3 展示了三个队列在迁移学习范式下的结果。我们使用不同的训练规模来测试 Med-BERT 通过融入更多上下文信息作为先验知识,能在多大程度上提升基础模型的预测性能。在 DHFCerner 的折线图中,我们注意到,在没有 Med-BERT 的情况下,当训练样本少于 2,000 个时,GRU 模型很难超过 0.65。然而,加入 Med-BERT 后,AUC 值显著提升了约 20%,即使仅用 500 个样本训练,模型也能达到 0.75。对于 Bi-GRU 模型,同样可以观察到明显的改进,但提升幅度不如 GRU 显著。对于 RETAIN 模型,当训练集超过 500 个样本时,Med-BERT 的帮助更为明显。在训练规模较小时,两条曲线的标准差显示出较大重叠,表明结果不太稳定,因此难以确定哪个模型绝对优于另一个。
For PaCa-Cerner, the results demonstrate large improvements by adding Med-BERT to GRU and Bi-GRU on almost all training sizes. In particular, for Bi-GRU, Med-BERT enables the AUC to reach 0.75 when training on only 300 samples. For RETAIN, when training on 100 samples adding Med-BERT reduces the performance a bit, but the two curves overlap heavily based on standard deviations. The charts for PaCa-Truven show similar trends, but the overall AUC values are lower compared to those on PaCa-Cerner.
对于PaCa-Cerner数据集,结果表明在几乎所有训练规模下,通过将Med-BERT添加到GRU和Bi-GRU中都带来了显著提升。特别是对于Bi-GRU,仅使用300个样本训练时,Med-BERT使AUC达到了0.75。对于RETAIN,当使用100个样本训练时,添加Med-BERT会使性能略有下降,但基于标准差的两条曲线高度重叠。PaCa-Truven数据集的图表显示出相似趋势,但整体AUC值低于PaCa-Cerner数据集。
Visualization of attention patterns in Med-BERT
Med-BERT中的注意力模式可视化
Med-BERT not only offers improvement for prediction accuracy but also enables prediction interpretation. It is interesting and meaningful to explore how the pre-trained model has learned using the complex structure and a huge volume of data. We show several examples of how codes are connected with each other according to the attention weights from the transformer layers, the core component of Med-BERT.
Med-BERT不仅提高了预测准确性,还能实现预测可解释性。探索这个预训练模型如何通过复杂结构和海量数据进行学习,具有重要研究价值。我们通过Transformer层(Med-BERT的核心组件)的注意力权重,展示了多个医疗代码间关联关系的典型案例。
The bertviz tool [53] was adopted and improved to better visualize the attention patterns in each layer of the pre-trained model. We observed distinct patterns in different layers of the model. In the pre-trained model, among the six layers of the BERT transformer model, the connections of the first two layers are mostly syntactic, some attention heads are restricted within a visit, and some point to the same codes across different visits. In the middle two layers, some medically meaningful attention patterns that capture contextual and visit-dependent information emerge. For the final couple of layers, the attention patterns become diffused and difficult to interpret.
采用并改进了bertviz工具[53],以更好地可视化预训练模型中每一层的注意力模式。我们观察到模型不同层中存在明显不同的模式。在预训练模型中,BERT transformer模型的六层中,前两层的连接大多是语法性的,部分注意力头被限制在单次就诊范围内,还有一些指向不同就诊间的相同代码。中间两层开始出现具有医学意义的注意力模式,能够捕捉上下文和就诊依赖信息。而在最后几层中,注意力模式变得分散且难以解释。

Figure 4. Example of different connections of the same code, “type 2 diabetes mellitus," in different visits.
图 4: 同一代码"2型糖尿病(type 2 diabetes mellitus)"在不同就诊中的不同连接示例。
Figure 4 is an example of the same code in different visits, showing different attention patterns. This demonstrates the ability of Med-BERT to learn contextual i zed representations. The earlier code for type 2 diabetes mellitus focuses mainly on the code for the long-term use of insulin within the same visit, but the later diabetes code focuses on the insulin code, both in the current and the previous visits. This could potentially indicate that the model learns the temporal relationship between visits through the segment embedding. More examples are provided in Appendix B.
图 4: 展示了同一段代码在不同就诊中的示例,呈现了不同的注意力模式。这证明了 Med-BERT 能够学习情境化表征 (contextualized representations)。早期的 2 型糖尿病代码主要关注同一就诊中胰岛素长期使用的代码,而后期的糖尿病代码则同时关注当前和既往就诊中的胰岛素代码。这可能表明模型通过片段嵌入 (segment embedding) 学习了就诊间的时间关系。更多示例见附录 B。
The attention patterns of the fine-tuned model are different. The fine-tuned models express distinct task-dependent patterns across different layers, showing the general iz ability and adaptability of the model for learning different levels of knowledge in the real-world scenarios. Figure 5 provides an example of the Med-BERT model fine-tuned on the DHF-Cerner dataset with attention converging onto several related codes in the second layer. Figure 6 is an example of the attention pattern in the fourth layer of the Med-BERT model fine-tuned on the PaCa-Cerner dataset, capturing the relevant correlation between diagnostic codes. Additional visualization patterns can be seen in the Supplementary Materials. We believe that these kinds of visualization patterns can help us to better understand the inner workings of the neural network model and to build trust and better communication of health information.
微调模型的注意力模式有所不同。经过微调的模型在不同层级展现出与任务相关的独特模式,体现了模型在现实场景中学习不同层次知识的泛化能力和适应性。图5展示了在DHF-Cerner数据集上微调的Med-BERT模型示例,其第二层注意力会聚焦于若干相关代码。图6则呈现了在PaCa-Cerner数据集上微调的Med-BERT模型第四层注意力模式示例,该层能捕捉诊断代码间的相关性。更多可视化模式可参见补充材料。我们认为这类可视化模式有助于更好地理解神经网络模型的内部运作机制,从而建立对健康信息的信任并促进更有效的沟通。

Figure 5. Example of the dependency connections in the DHF-Cerner cohort.
图 5: DHF-Cerner 队列中的依赖连接示例。

Figure 6. Example of the dependency connections in the PaCa-Cerner cohort.
图 6: PaCa-Cerner队列中的依赖连接示例。
DISCUSSION
讨论
Med-BERT shows its power in helping to improve the prediction performance on multiple tasks with different configurations, and it is particularly effective in the “extreme transfer learning? paradigms, i.e., fine-tuning on only several hundreds of samples. Deep-learning-based predictive models usually require at least thousands of samples. These models need to learn complex semantics through feeding samples that convey different underlying disease progressions and variation al context information so that they can be capable of dealing with intricate unseen cases. However, most deep-learning algorithms are insufficient in modeling the data comprehensively due to their limitation in an in-depth understanding of the inputs. Pre-trained models can well address this issue by using more sophisticated structures to better capture the complex semantics of inputs, behaving as a knowledge container, and injecting the knowledge into new tasks. Similar to pre-trained models on other domains, Med-BERT, by using its bidirectional transformer and deep structures as well as big data, also have been shown in this study to be extremely helpful when transferring to new tasks.
Med-BERT在提升多种任务配置下的预测性能方面展现出强大能力,尤其在"极端迁移学习"场景中表现突出——仅需数百样本进行微调即可生效。基于深度学习的预测模型通常需要至少数千样本,这些模型必须通过输入反映不同潜在疾病进展和变异上下文信息的样本,才能学习复杂语义以应对未见过的复杂病例。然而,多数深度学习算法因对输入理解深度不足,难以全面建模数据。预训练模型通过更复杂的结构捕获输入数据的深层语义,作为知识容器将学习到的知识注入新任务,能有效解决这一问题。与其它领域的预训练模型类似,本研究证明Med-BERT凭借双向Transformer架构、深层结构及大数据优势,在任务迁移时表现出显著优势。
Masked LM and Prolonged LOS were designed and included to reinforce the modeling of contextual information and to help collect sequential dependencies. Labels for both can be generated in an unsupervised way, i.e., without human annotations. In Masked LM, the goal is to predict a masked code using the sequential information from forward and backward directions. In Prolonged LOS, the goal is to determine whether a patient is associated with any visit that is a prolonged stay, which also relies on cumulative contexts. We believe that, by including the prediction tasks from both the code level and the patient (sequence) level, Med-BERT can further strengthen the representation learning of EHR sequences from different granular i ties.
掩码语言模型 (Masked LM) 和长住院预测 (Prolonged LOS) 的设计旨在强化上下文信息建模并捕捉序列依赖关系。两者的标签均可通过无监督方式生成 (即无需人工标注)。在掩码语言模型中,目标是通过双向序列信息预测被遮蔽的医疗代码;在长住院预测中,目标是通过累积上下文判断患者是否存在超长住院记录。我们认为,通过同时包含代码层级和患者 (序列) 层级的预测任务,Med-BERT 能够从不同粒度加强电子健康记录序列的表征学习。
Med-BERT also can improve several points when training on large cohorts. Intuitively, deeplearning methods can fit the data quite well if enough training data is available. We consider 50K and 20K as acceptable scales of samples for training satisfactory deep-learning models. When we added Med-BERT, however, significant improvements also could be observed. For example, RETAIN obtains the best performance on all the three tasks, but adding Med-BERT brings further improvements by $2.02–3.20%$ . In addition, for GRU and Bi-GRU, whose model structures are simpler than that of RETAIN, the improvements are much larger, which bring these simple models to a comparable level of RETAIN. Further, according to the results of Med-BERT_only, which also achieves good performance, we may conclude that Med-BERT will potentially release researchers from developing complex models for disease-prediction problems.
Med-BERT在大规模队列训练时还能提升多个指标。直观来看,深度学习方法只要有足够训练数据就能很好拟合数据。我们认为5万和2万样本量足以训练出令人满意的深度学习模型。但加入Med-BERT后仍能观察到显著提升:例如RETAIN虽然在所有三项任务中表现最佳,但引入Med-BERT后其性能又提升了$2.02–3.20%$。此外,对于模型结构比RETAIN更简单的GRU和Bi-GRU,提升幅度更为显著,使这些简单模型达到了与RETAIN相当的水平。值得注意的是,仅使用Med-BERT_only也取得了良好效果,这表明Med-BERT有望让研究者不必再为疾病预测问题开发复杂模型。
In comparison, t-W2V behaves more usefully in RETAIN but has limited contributions in Bi-GRU and GRU and even hurts the performance of GRU. A probable explanation is that t-W2V has limitations in modeling sequential information, considering its shallow structure and that it cannot be guaranteed to act well in all situations.
相比之下,t-W2V在RETAIN中表现更有效,但对Bi-GRU和GRU的贡献有限,甚至降低了GRU的性能。一个可能的解释是,考虑到其浅层结构,t-W2V在建模序列信息方面存在局限性,无法保证在所有情况下都表现良好。
Ex-3 proves the effectiveness of transferring Med-BERT into realistic disease-prediction tasks. Most of the charts in Figure 3 reflect that Med-BERT has made an immense contribution to training base models on small samples. The only exception is RETAIN, where there are heavy overlaps of the two curves, e.g., under 500 samples in the third sub-chart of DHF-Cerner. A possible explanation is that RETAIN has a well-designed structure (two layers of self-attention) that is powerful in capturing some important features in these datasets and can get good results, whereas adding Med-BERT involves more parameters and more difficulties to fine-tuning. Note that the
Ex-3证明了将Med-BERT迁移到真实疾病预测任务中的有效性。图3中的大部分图表反映出Med-BERT在小样本训练基础模型方面做出了巨大贡献。唯一的例外是RETAIN,在DHF-Cerner第三子图中500样本以下时两条曲线存在严重重叠。可能的原因是RETAIN具有精心设计的结构(两层自注意力),能够有效捕捉这些数据集中的重要特征并获得良好结果,而加入Med-BERT会引入更多参数并增加微调难度。需要注意的是
AUCs on those training sizes have large standard deviations, indicating that the data distribution might be uneven and that these results are not sufficiently stable.
在训练规模上的AUC值存在较大标准差,表明数据分布可能不均匀,且这些结果不够稳定。
Further in practice, Med-BERT will significantly help to reduce the data annotation cost, which can be seen in comparing the sizes of training samples required to achieve certain AUC levels. For example, in the first sub-chart of PaCa-Cerner in Figure 3, if we draw a horizontal line across the y-tick of 0.75, we will see a requirement of 500 samples for GRU $+$ Med-BERT and over 5,000 samples for GRU only. Thus, Med-BERT brought the model performance on par with a training set almost 10 times larger. The data acquisition cost of these over 4,500 samples, which sometimes can be quite expensive, will be substantially saved by using Med-BERT. In this situation, with Med-BERT, researchers and clinicians are able to quickly get a general and acceptable understanding of the progressions of new diseases before collecting enough annotated samples.
在实践中,Med-BERT将显著降低数据标注成本,这可以通过比较达到特定AUC水平所需的训练样本量看出。例如,在图3的PaCa-Cerner第一子图中,若在y轴刻度0.75处画一条水平线,可观察到GRU $+$ Med-BERT仅需500个样本,而单独使用GRU则需要超过5,000个样本。因此,Med-BERT使模型性能达到了近10倍训练集规模的效果。使用Med-BERT可大幅节省获取这4,500多个样本的数据采集成本(有时可能相当昂贵)。在这种情况下,研究人员和临床医生能够在收集足够标注样本前,借助Med-BERT快速获得对新疾病进展的基本且可接受的认知。
The vocabulary of the current version of Med-BERT is the combination of ICD-9 and ICD-10 codes. Compared with BEHRT and G-BERT, our vocabulary is more acceptable and has broader coverage. We believe that it will greatly facilitate the mode transfer ability, as the ICD is the global health information standard recommended by the World Health Organization and is used by over 100 countries around the world.5 This can be demonstrated in our PaCa-Truven evaluation, for which we tested models using a cohort extracted from a health insurance dataset.
当前版本Med-BERT的词库( vocabulary )由ICD-9和ICD-10编码组合而成。相较于BEHRT和G-BERT,我们的词库更具普适性且覆盖范围更广。由于ICD是世界卫生组织推荐的全球健康信息标准,已被100多个国家采用[5],我们相信这将极大提升模型的迁移能力。这一点在我们的PaCa-Truven评估中得到验证——该测试使用从健康保险数据集中提取的队列来检验模型性能。
There are still several limitations of the current work. First, we used only the diagnosis information in the ICD format at present. Second, we did not include the length of time intervals between visits in this study but, instead, used only the relative position, which may cause some temporal information loss. Third, we did not fully explore the order of concepts within each visit, and the current setting based on code priorities might not be sufficiently reliable. In the future, more research on designing different pre-training tasks will be conducted, and different types of evaluation tasks, other than disease prediction, also will be tested. We also plan to include other sources, such as time, medications, procedures, and laboratory tests, as inputs of Med-BERT. In addition, task-specific visualization s and interpretations are other areas that we plan to explore.
当前工作仍存在一些局限性。首先,我们目前仅使用了ICD格式的诊断信息。其次,本研究未纳入就诊间隔时长,仅采用相对位置信息,可能导致部分时间信息丢失。第三,我们未充分探索单次就诊中各类概念的顺序关系,当前基于代码优先级的设置可能不够可靠。未来将开展更多预训练任务设计研究,并测试除疾病预测外的其他评估任务类型。我们还计划纳入时间、药物、诊疗程序和实验室检测等其他数据源作为Med-BERT的输入。此外,针对特定任务的可视化与解释性研究也是我们计划探索的方向。
CONCLUSION
结论
We proposed Med-BERT, a contextual i zed embedding model pre-trained on a large volume of structured EHRs, and further evaluated the model in disease-prediction tasks. Domainspecific input formats and pre-trained tasks were elaborately designed. Extensive experiments demonstrated that Med-BERT has the capacity to help boost the prediction performance of baseline deep-learning models on different sizes of training samples and can obtain promising results, even training on very few samples. The visualization module enabled us to look deeper into the underlying semantics of the data and working mechanisms of the model, in which we observed meaningful examples. Those examples were further verified by clinical experts, indicating that Med-BERT can well model the semantics among EHRs during both pre-training and evaluation. We believe that our model also can be beneficial in solving other clinical problems.
我们提出了Med-BERT,这是一种基于大量结构化电子健康记录(EHR)预训练的上下文嵌入模型,并在疾病预测任务中进一步评估了该模型。我们精心设计了领域特定的输入格式和预训练任务。大量实验表明,Med-BERT能够帮助提升基线深度学习模型在不同规模训练样本上的预测性能,即使在极少量样本上训练也能获得良好结果。可视化模块使我们能够深入探究数据底层语义和模型工作机制,其中我们观察到了具有临床意义的示例。这些示例经过临床专家验证,表明Med-BERT在预训练和评估阶段都能很好地建模EHR之间的语义关系。我们相信该模型也能有益于解决其他临床问题。
ACKNOWLEDGMENTS
致谢
We are grateful for our collaborators, David Aguilar, MD, Masayuki Nigo, MD, and Bijun S. Kannadath, MBBS, MS, for the helpful discussions on cohorts definitions and results evaluation. This research was undertaken with the assistance of resources and services from the School of Biomedical Informatics Data Service, which is supported in part by CPRIT Grant RP170668. Specifically, we would like to acknowledge the use of Cerner Health Facts and the IBM Truven Marketplace TM datasets as well as the assistance provided by the UTHealth SBMI Data Service team to extract the data. The Nvidia GPU hardware is partly supported through Xiaoqian Jiang's UT star award. We are also grateful to the NVIDIA Corporation for supporting our research by donating a Tesla K40 GPU.
我们感谢合作者 David Aguilar、Masayuki Nigo 和 Bijun S. Kannadath 在队列定义和结果评估方面提供的宝贵讨论。本研究得到了生物医学信息学院数据服务部门的资源和服务支持,该部门部分由 CPRIT 资助 RP170668 资助。特别感谢使用 Cerner Health Facts 和 IBM Truven Marketplace TM 数据集,以及 UTHealth SBMI 数据服务团队在数据提取方面提供的协助。Nvidia GPU 硬件部分由 Xiaoqian Jiang 的 UT star 奖项支持。同时感谢 NVIDIA 公司捐赠 Tesla K40 GPU 对我们的研究予以支持。
Authors Contributions
作者贡献
LR, YX, ZX, and DZ designed the methods. LR led the implementation of the methods, with substantial inputs from YX and ZX. YX and DZ led the design of experiments. LR conducted the experiments and produced results. ZX led the visualization. YX led the writing, with substantial inputs from LR, DZ, ZX, and CT. YX, DZ, and CT supervised the execution of the project. DZ initialized the conceptualization of the project.
LR、YX、ZX 和 DZ 设计了方法。LR 主导了方法的实现,YX 和 ZX 提供了重要支持。YX 和 DZ 主导了实验设计。LR 进行了实验并生成结果。ZX 主导了可视化工作。YX 主导了论文撰写,LR、DZ、ZX 和 CT 提供了重要贡献。YX、DZ 和 CT 监督了项目执行。DZ 提出了项目的初始概念。
Funding Support
资金支持
CT and DZ are partly supported by the Cancer Prevention and Research Institute of Texas (CPRIT) Grant RP170668. LR is supported by UTHealth Innovation for Cancer Prevention Research Training Program Pre-Doctoral Fellowship (CPRIT Grant RP160015). CT and YX are supported by the National Institutes of Health (NIH) Grants R 01 A I 130460 and R 01 LM 011829.
CT和DZ部分由德克萨斯州癌症预防与研究所(CPRIT)资助RP170668支持。LR受UTHealth癌症预防研究培训计划创新预博士奖学金(CPRIT资助RP160015)支持。CT和YX获得美国国立卫生研究院(NIH)资助R01AI130460和R01LM011829支持。
Disclaimer
免责声明
The content is solely the responsibility of the authors and does not necessarily represent the official views of the Cancer Prevention and Research Institute of Texas. The authors have no competing interests to declare.
内容仅代表作者个人观点,未必反映德克萨斯州癌症预防与研究所 (Cancer Prevention and Research Institute of Texas) 的官方立场。作者声明无利益冲突。
REFERENCES
参考文献
Supplementary Materials
补充材料
Appendix A: Data Extraction and Preparation
附录 A: 数据提取与准备
A.1. Med-BERT pre training cohort
A.1. Med-BERT预训练队列
Cerner Health Facts (version 2017) is a de-identified EHR database that consists of over 600 hospitals and clinics in the United States, represents over 68 million unique patients, and includes longitudinal data from 2000 to 2017. The database consists of patient-level data, including demographics, encounters, diagnoses, procedures, lab results, medication orders, medication administration, vital signs, microbiology, surgical cases, other clinical observations, and health systems attributes. Data in Health Facts is extracted directly from the EMR of hospitals with which Cerner has a data use agreement. Encounters may include pharmacy, clinical and microbiology laboratory, admission, and billing information from affiliated patient care locations. All admissions, medication orders and dispensing, laboratory orders, and specimens are date and time stamped, providing a temporal relationship between treatment patterns and clinical information. Cerner Corporation has established Health Insurance Portability and Accountability Act-compliant operating policies to establish de-identification for Health Facts.
Cerner Health Facts(2017版)是一个去标识化的电子健康记录(EHR)数据库,涵盖美国600多家医院和诊所,代表超过6800万独立患者,包含2000年至2017年的纵向数据。该数据库包含患者层级数据,涵盖人口统计、就诊记录、诊断、手术、实验室结果、用药医嘱、给药记录、生命体征、微生物检测、手术案例、其他临床观察及医疗系统属性。Health Facts的数据直接从与Cerner签订数据使用协议的医院电子病历(EMR)中提取,就诊记录可能包含来自关联医疗机构的药房、临床与微生物实验室、入院及账单信息。所有入院记录、用药医嘱与配药、实验室检验单及样本均标注日期时间,可追踪治疗模式与临床信息的时序关系。Cerner公司已制定符合《健康保险可携性和责任法案》(HIPAA)的操作政策,确保Health Facts的去标识化处理。
During the pre training cohort data preprocessing, for each patient, we organized the visits in temporal order and ranked the diagnosis codes within each visit according to three criteria: (1) the diagnosis was flagged as present on admission; (2) the diagnosis was captured during the visit (e.g., hospitalization) or only at the billing phase; and (3) the diagnosis priority is provided by the Cerner database, indicating some priorities of the diagnoses, e.g., principal/secondary diagnosis (the priority is provided by the database, but it might not be a perfect priority ranking)
在预训练队列数据预处理阶段,我们对每位患者按时间顺序整理就诊记录,并根据以下三个标准对每次就诊的诊断代码进行排序:(1) 诊断被标记为入院时存在;(2) 诊断是在就诊期间(如住院)捕获的还是仅在结算阶段记录;(3) Cerner数据库提供的诊断优先级,用于指示诊断的主次关系(例如主要/次要诊断)。该优先级由数据库提供,但可能并非完美的排序标准。
For each visit, we extracted the diagnosis codes (represented by ICD, Ninth Revision, Clinical Modification (ICD-9) and ICD, Tenth Revision, Clinical Modification (ICD-10) and the length of stay in hospital. We then ranked the codes in each visit according to the above three criteria and determined the order by using $(1)\rightarrow(2)\rightarrow(3)$ in sequence. We observed only very limited performance gains, however, by adding the code order during the evaluation, compared with randomly scattering the codes. Hence, we set it as a placeholder here and assume that more effective orders will be defined in the future.
每次就诊时,我们提取了诊断代码(由ICD-9-CM和ICD-10-CM表示)以及住院时长。随后,我们根据上述三个标准对每次就诊的代码进行排序,并按$(1)\rightarrow(2)\rightarrow(3)$的顺序确定优先级。然而在评估过程中发现,与随机排列代码相比,添加代码顺序带来的性能提升非常有限。因此,我们暂时将其设为占位项,并假设未来会定义更有效的排序方式。
Patients with fewer than three diagnosis codes in their records as well as those with wrong recorded time information, e.g., discharge date before admission date, were removed from the selection. In total, we had 28,490,650 unique patients (Figure 1), which were further separated into training, valid, and testing sets by the ratio of 7:1:2 on both the pre-training and evaluation phases.
从筛选过程中排除了记录中诊断代码少于三个的患者以及时间信息记录错误的患者(例如出院日期早于入院日期)。最终,我们获得了28,490,650名独立患者(图1),这些患者在预训练和评估阶段均按7:1:2的比例进一步划分为训练集、验证集和测试集。
A.2. Diabetes heart failure cohort (DHF)
A.2. 糖尿病心力衰竭队列 (DHF)
We originally identified 3,668,780 patients with at least one encounter with a diabetes diagnosis, based on the associated ICD-9/10 codes. We decided to exclude patients with any history of diabetes insipidus, gestation al diabetes, secondary diabetes, neonatal diabetes mellitus, or type I diabetes mellitus (DM) from our cohort, as we focus on patients with type II DM and need to avoid any chance of wrong coding, taking into consideration that most of the EHR data are based on user manual entries and that there is a high associated chance of data entry mistakes. For the same reason, we decided to include patients who have more than one encounter with a diabetes diagnosis code. In addition, for type II DM patients, we verified that the patients’ A1C reading is ${\underline{{>}}}6.5$ or that they are taking an anti diabetic agent, including metformin, chl or prop amide, g lime piri de, glyburide, glipizide, to l but amide, tolazamide, pio gl it a zone, rosi gl it a zone, s it agli pt in, sax agli pt in, alogliptin, lin agli pt in, rep agli ni de, nate gl in ide, miglitol, acarbose, or insulin.
我们最初根据相关ICD-9/10编码识别出3,668,780名至少有一次糖尿病诊断记录的患者。考虑到电子健康记录(EHR)数据大多基于人工录入且存在较高错误概率,我们决定从队列中排除有尿崩症、妊娠糖尿病、继发性糖尿病、新生儿糖尿病或I型糖尿病(DM)病史的患者,以专注于II型DM患者并避免编码错误。基于同样原因,我们仅纳入具有多次糖尿病诊断编码记录的患者。对于II型DM患者,我们进一步验证其糖化血红蛋白(A1C)读数${\underline{{>}}}6.5$或正在服用降糖药物(包括二甲双胍、氯磺丙脲、格列美脲、格列本脲、格列吡嗪、甲苯磺丁脲、妥拉磺脲、吡格列酮、罗格列酮、西格列汀、沙格列汀、阿格列汀、利格列汀、瑞格列奈、那格列奈、米格列醇、阿卡波糖或胰岛素)。
For these cases, we identified patients with incidences of heart failure (using ICD-9 code equivalents, such as 428, 0r in 404.03, 404.13, 402.11, 404.11, 402.01, 404.01, 402.91, 398.91, 404.93, and 404.91, or ICD-10 code equivalents, such as $150%$ , 0r in 111.0, 109.81, 113.2, 197.13, 197.131, 113.0, and 197.130). In addition, we verified that the eligible cases are either prescribed a diuretic agent, had high B-type na tr iure tic peptide (BNP), or had been subjected to relevant procedures, including dialysis or an artificial heart-associated procedure. We included only those patients who reported heat failure (HF) at least 30 days after their first encounter with a type II DM code and excluded patients with only one HF encounter.
针对这些情况,我们识别出心力衰竭患者(使用ICD-9等效代码,如428、404.03、404.13、402.11、404.11、402.01、404.01、402.91、398.91、404.93和404.91,或ICD-10等效代码,如$150%$、111.0、109.81、113.2、197.13、197.131、113.0和197.130)。此外,我们确认符合条件的病例需满足以下条件之一:开具利尿剂处方、B型钠尿肽(BNP)水平偏高,或接受过相关治疗(包括透析或人工心脏相关手术)。我们仅纳入首次出现II型糖尿病(DM)代码后至少30天报告心力衰竭(HF)的患者,并排除仅有一次HF记录的患者。
Further data cleaning included exclusion of patients with incorrect or incomplete data, for example, patients who were recorded as expired in between their first encounter and our event (first HF encounter for cases or last encounter for controls) as well as patients who are younger than 18 years old at their first diabetes diagnosis. The final cohort is shown in Supplementary Figure 1 and includes 39,727 cases and 632,920 controls.
进一步的数据清理包括排除数据错误或不完整的患者,例如记录在首次就诊与我们的研究事件(病例组的首次心衰就诊或对照组的末次就诊)之间死亡的患者,以及首次糖尿病诊断时年龄小于18岁的患者。最终队列如补充图1所示,包含39,727例病例和632,920例对照。

Supplemental Figure 1. Flowchart for the DHF cohort definition.
图 1: DHF队列定义的流程图。
A.3. Pancreatic cancer cohort (PaCa)
A.3. 胰腺癌队列 (PaCa)
Using ICD-9 codes that start with 157 and ICD-10 codes that start with C25, we originally identified around 45,000 pancreatic cancer patients from the Cerner Health Facts dataset, of which 11,486 cases of individuals 45 years or older did not report any other cancer disease before their first pancreatic cancer diagnosis were eligible for inclusion in this cohort. Further details of the cohort definition are seen in Supplementary Figure 2.
使用以157开头的ICD-9编码和以C25开头的ICD-10编码,我们最初从Cerner Health Facts数据集中识别出约45,000名胰腺癌患者,其中11,486例45岁及以上且在首次胰腺癌诊断前未报告任何其他癌症疾病的个体符合纳入本队列的条件。队列定义的更多细节见补充图2。

Supplemental Figure 2. Flowchart for the PC cohort definition.
补充图 2: PC队列定义的流程图。
Similarly, we extracted a cohort from Truven Health MarketScan $\textcircled{8}$ Research Databases for evaluation purposes. The Truven Health MarketScan $\textcircled{8}$ Research Databases (version 2015) are a family of research data sets that fully integrate de-identified patient-level health data (medical, drug, and dental), productivity (workplace absence, short- and long-term disability, and workers' compensation), laboratory results, health risk assessments, hospital discharges, and electronic medical records into datasets available for healthcare research. It captures person-specific clinical utilization, expenditures, and enrollment across inpatient, outpatient, prescription drug, and carveout services. The annual medical databases include private-sector health data from approximately 350 payers. Historically, more than 20 billion service records are available in the MarketScan databases. These data represent the medical experience of insured employees and their dependents for active employees, early retirees, Consolidated Omnibus Budget Reconciliation Act (COBRA) continuees, and Medicare-eligible retirees with employer-provided Medicare Supplemental plans. Most of the diagnosis codes in Truven are ICD-9 codes, as the version of the database that we used is 2015, but the implementation of ICD-10 started in October 2015 [54].
同样地,我们从Truven Health MarketScan $\textcircled{8}$ 研究数据库中提取了一个队列用于评估。Truven Health MarketScan $\textcircled{8}$ 研究数据库(2015版)是一系列完全整合了去标识化患者级健康数据(医疗、药品和牙科)、生产力数据(职场缺勤、短期与长期残疾及工伤赔偿)、实验室结果、健康风险评估、医院出院记录和电子病历的研究数据集,可供医疗健康研究使用。该数据库覆盖了住院、门诊、处方药及专项服务中个人层面的临床资源使用、支出和参保情况。年度医疗数据库包含约350家支付方的私营部门健康数据。历史上,MarketScan数据库累计拥有超过200亿条服务记录。这些数据代表了在职员工及其家属、提前退休人员、《综合预算调节法案》(COBRA)延续参保者,以及享有雇主提供的医疗保险补充计划的退休人员的医疗经历。由于我们使用的数据库版本为2015年,Truven中大部分诊断代码为ICD-9编码,但ICD-10已于2015年10月开始实施[54]。
Appendix B: Additional Visualization Example
附录 B: 其他可视化示例
Supplemental Figure 3 provides an example of the attention connections from the first three transformer layers. In the first layer, several heads show short-range attention patterns, and each token attends mainly to the nearby tokens that are within the same visit. In the second layer, some attention heads learn to make the correspondence between the same tokens. The third layer has the most interpret able patterns. A token in the third layer will focus strongly on other relevant tokens but mostly within the same visit. After the third layer, the attention becomes more diffuse and less explain able; however, there are still some heads that show long-range attention patterns.
补充图3展示了前三个Transformer层的注意力连接示例。在第一层中,多个注意力头呈现短程关注模式,每个Token主要关注同一就诊记录内的邻近Token。第二层中,部分注意力头学会了建立相同Token间的对应关系。第三层展现出最具可解释性的模式——该层Token会强烈聚焦于其他相关Token,但主要仍限于同一就诊记录内。经过第三层后,注意力分布变得更为分散且难以解释,但仍存在部分注意力头表现出长程关注模式。

Supplemental Figure 3. Attention connections from the first three transformer layers (a top-down direction) of a sample patient sequence.
补充图 3: 某患者序列前三个Transformer层的注意力连接 (自上而下方向)。