LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
大语言模型增强检索:通过语言模型和文档级嵌入提升检索模型
Mingrui Wu Meta mingruiwu@meta.com
吴明瑞 Meta mingruiwu@meta.com
Abstract
摘要
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-ofwords based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
最近,基于嵌入的检索(embedding-based retrieval)或密集检索(dense retrieval)相比传统的稀疏或词袋(bag-of-words)方法展现了最先进的成果。本文通过大语言模型(LLM)增强,提出了一种与模型无关的文档级嵌入框架。此外,它还改进了检索模型训练过程中的一些重要组件,如负采样、损失函数等。通过实施这一LLM增强的检索框架,我们显著提升了广泛使用的检索模型(如双编码器Bi-encoders (Contriever, DRAGON))和延迟交互模型(late-interaction models (ColBERTv2))的效果,从而在LoTTE数据集和BEIR数据集上取得了最先进的成果。
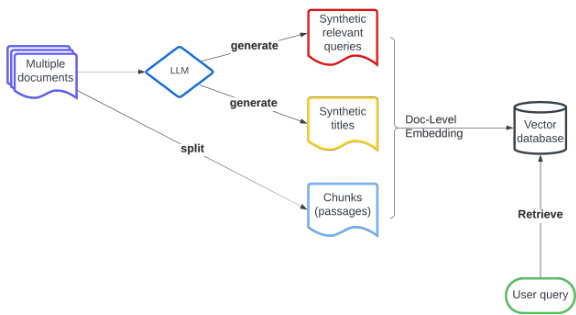
Figure 1: Overall view on LLM-augmented retrieval framework. Synthetic relevant queries and synthetic titles are generated from LLM and then assembled into doc-level embedding together with chunks (passages) split from the original document. The final retrieval is based on the similarity between user query and the doc-level embedding.
图 1: 大语言模型增强检索框架整体视图。通过大语言模型生成合成相关查询和合成标题,随后与原始文档分块(段落)共同组装为文档级嵌入向量。最终检索基于用户查询与文档级嵌入向量之间的相似度完成。
1 Introduction
1 引言
The Bi-encoder (Karpukhin et al., 2020) is a type of neural network architecture that is widely used in information retrieval. It consists of two encoders, typically in the form of transformer models (Vaswani et al., 2017), which encode an vector representation for user queries and potential documents or passages respectively. These two encoders can be shared or using two separate models. The similarity between these two embedding vectors can then be computed, often using dot product or cosine similarity, to determine the relevance of the document or passage to the user’s query.
双编码器 (Bi-encoder) (Karpukhin et al., 2020) 是一种广泛应用于信息检索的神经网络架构。它由两个编码器组成,通常采用Transformer模型 (Vaswani et al., 2017) 的形式,分别对用户查询和潜在文档/段落进行向量表征编码。这两个编码器可以共享参数,也可以使用两个独立模型。随后通过点积或余弦相似度计算这两个嵌入向量的相似度,从而确定文档/段落与用户查询的相关性。
Cross-encoders (Nogueira and Cho, 2019), unlike bi-encoders, amalgamate the inputs at an early stage, allowing for a more intricate interaction between user queries and documents. Here the user query and the document are concatenated, based on which a joint embedding vector is computed. The joint embedding vector is then used to make predictions, such as the relevance of a document to a query in an information retrieval task. Crossencoders often outperform bi-encoders in tasks requiring a nuanced understanding of the interplay between inputs.
交叉编码器 (Cross-encoders) [20] 与双编码器不同,它们在早期阶段就将输入融合,允许用户查询和文档之间进行更复杂的交互。具体而言,用户查询和文档会被拼接起来,并基于此计算出一个联合嵌入向量。该联合嵌入向量随后用于预测任务,例如信息检索中文档与查询的相关性。在需要细致理解输入间相互作用的场景中,交叉编码器通常优于双编码器。
Late-interaction models, such as ColBERT (Khattab and Zaharia, 2020), ColBERTv2 (Santhanam et al., 2021) or SPALDE $^{++}$ (Formal et al., 2022), are model architectures that hybrids crossencoder models and bi-encoder models. Queries and documents are independently encoded into token-level vector representations. So in some sense, this is a bag of embedding vectors model. The interaction between these representations, which constitutes the “late interaction”, involves computing the cosine similarity or dot product scores over the token-level vector embedding.
延迟交互模型 (late-interaction models) ,例如 ColBERT (Khattab and Zaharia, 2020) 、ColBERTv2 (Santhanam et al., 2021) 或 SPALDE$^{++}$ (Formal et al., 2022) ,是一种融合交叉编码器 (crossencoder) 和双编码器 (bi-encoder) 的混合架构。查询和文档被独立编码为 Token 级别的向量表示,因此在某种意义上属于嵌入向量集合模型。这些表示之间的交互(即"延迟交互")通过计算 Token 级别向量嵌入的余弦相似度或点积得分来实现。
All the model architectures require informative embedding of user queries and target documents. While we cannot control the user queries during retrieval tasks, we hypothesize that enriching the embedding of documents can improve the quality and robustness of text retrieval.
所有模型架构都需要对用户查询和目标文档进行信息丰富的嵌入。虽然在检索任务中我们无法控制用户查询,但我们假设通过增强文档的嵌入可以提升文本检索的质量和鲁棒性。
This work makes the following contributions:
本工作做出以下贡献:
-
We propose LLM-augmented retrieval, a model-agnostic framework that enriches the
-
我们提出了LLM增强检索 (LLM-augmented retrieval),这是一个与模型无关的框架,能够丰富
2 Background & Related Work
2 背景与相关工作
To the best of our knowledge, there’s no existing work on constructing a unified LLM-augmented framework for doc-level embedding. Therefore, we summarized some related knowledge that’s important to our work.
据我们所知,目前尚无关于构建统一的大语言模型增强文档级嵌入框架的现有研究。因此,我们总结了一些对本工作至关重要的相关知识。
2.1 Data Augmentation in Information Retrieval
2.1 信息检索中的数据增强
Data augmentation is a widely used technique in information retrieval training. In Contrastive Learning (Izacard et al., 2021), inverse cloze task, inde- pendent cropping, as well as random word deletion, replacement or masking are introduced to enrich the diversity of training data. While in training the DRAGON model, (Lin et al., 2023), not only query augmentation by query generation models are studied, but also label augmentation methods with diverse supervision are discussed and compared.
数据增强是信息检索训练中广泛使用的技术。在对比学习 (Izacard et al., 2021) 中,通过引入逆完形填空任务、独立裁剪以及随机词删除、替换或掩码来增加训练数据的多样性。而在训练 DRAGON 模型时 (Lin et al., 2023),不仅研究了通过查询生成模型进行查询增强的方法,还讨论并比较了多种监督方式的标签增强技术。
Large pre-trained language models are good at generating text data of high quality (Anaby-Tavor et al., 2020; Papa nikola ou and Pierleoni, 2020; Yang et al., 2020; Kumar et al., 2020; Schick and Schütze, 2021; Meng et al., 2022). Some past work has been done to utilize the generation capability of language models to create synthetic training data for retriever models (Bonifacio et al., 2022; Wang et al., 2023).
大型预训练语言模型擅长生成高质量的文本数据 (Anaby-Tavor et al., 2020; Papanikolaou and Pierleoni, 2020; Yang et al., 2020; Kumar et al., 2020; Schick and Schütze, 2021; Meng et al., 2022)。已有研究利用语言模型的生成能力为检索模型创建合成训练数据 (Bonifacio et al., 2022; Wang et al., 2023)。
2.2 Pseudo Queries Generation
2.2 伪查询生成
Pre-generated pseudo queries are proved to be effective in improving retrieval performance. Previously the similarity of pseudo-queries and userqueries are calculated through BM25 or BERT model in determining the final relevance score of the query to document through relevance score fusion (Chen et al., 2021; Wen et al., 2023). An alternative method to generate pseudo queries is to generate pseudo query embedding through Kmeans clustering algorithm (Tang et al., 2021).
预生成的伪查询被证明能有效提升检索性能。此前研究通过BM25或BERT模型计算伪查询与用户查询的相似度,再通过相关性分数融合确定查询对文档的最终相关性评分 (Chen et al., 2021; Wen et al., 2023)。另一种生成伪查询的方法是使用Kmeans聚类算法生成伪查询嵌入向量 (Tang et al., 2021)。
2.3 Retrieval Augmented Generation (RAG)
2.3 检索增强生成 (RAG)
In a Retrieval Augmented Generation (RAG) system (Lewis et al., 2020), a dedicated retriever module is introduced to retrieve relevant documents from a set of corpus based on the input query, and the retrieved documents are then integrated by a language model as part of the context, in order to refine its final response generation. This approach can be applied to not only decoder-only models but also encoder-decoder architectures (Yu, 2022).
在检索增强生成 (Retrieval Augmented Generation, RAG) 系统中 (Lewis et al., 2020),系统会引入专门的检索模块来根据输入查询从一组语料库中检索相关文档,检索到的文档随后由语言模型整合为上下文的一部分,从而优化其最终响应生成。这种方法不仅适用于仅解码器 (decoder-only) 模型,也可应用于编码器-解码器 (encoder-decoder) 架构 (Yu, 2022)。
2.4 Similarity Scores
2.4 相似度评分
Having the embedding vectors of input query and target document, we need to compute the similarity score between these two vectors to determine the relevance between them (Jones and Furnas, 1987). Dense retrievers like Contriever (Izacard et al., 2021) and DRAGON (Lin et al., 2023) use dot products to measure the similarity of query and document in the text embedding space. SPLADE (Formal et al., 2021b) and SPLADEv2 (Formal et al., 2021a) use dot products as well while ColBERT (Khattab and Zaharia, 2020) and ColBERTv2 (Santhanam et al., 2021) use cosine similarity scores. The main difference between cosine similarity and dot product is the sensitivity to the magnitude of the embedding vectors. And dot product is computationally cheaper and more stable.
在获得输入查询和目标文档的嵌入向量后,我们需要计算这两个向量之间的相似度得分以确定它们的相关性 (Jones and Furnas, 1987)。像Contriever (Izacard et al., 2021) 和DRAGON (Lin et al., 2023) 这样的密集检索器使用点积来衡量查询和文档在文本嵌入空间中的相似度。SPLADE (Formal et al., 2021b) 和SPLADEv2 (Formal et al., 2021a) 也使用点积,而ColBERT (Khattab and Zaharia, 2020) 和ColBERTv2 (Santhanam et al., 2021) 则使用余弦相似度得分。余弦相似度和点积之间的主要区别在于对嵌入向量大小的敏感性。点积在计算上更便宜且更稳定。
2.5 Training
2.5 训练
The contrastive InfoNCE loss (Izacard et al., 2021; Lin et al., 2023) is widely adopted in dense retrieval training and is defined as:
对比式InfoNCE损失函数 (Izacard et al., 2021; Lin et al., 2023) 被广泛应用于稠密检索训练,其定义为:
$$
\begin{array}{r}{L(q,d_{+})=-\frac{e x p(s(q,d_{+})/\tau)}{e x p(s(q,d_{+})/\tau)+\sum_{i=1}^{K}e x p(s(q,d_{i})/\tau)}}\end{array}
$$
$$
\begin{array}{r}{L(q,d_{+})=-\frac{e x p(s(q,d_{+})/\tau)}{e x p(s(q,d_{+})/\tau)+\sum_{i=1}^{K}e x p(s(q,d_{i})/\tau)}}\end{array}
$$
where $\tau$ is the temperature, $s$ is the similarity score function, $q$ is the input query, $d_{i}$ is any candidate document and $d_{+}$ is the relevant document. Other popular loss functions include point-wise Binary Cross Entropy (Sun et al., 2023), list-wise Cross En- tropy (Bruch, 2021), RankNet (Burges et al., 2005) and LambdaLoss (Wang et al., 2018). Pointwise Binary Cross Entropy is calculated based on each of the query-document pairs independently. Listwise Cross-Entropy loss is widely used in passage ranking and minimizes list-wise softmax cross entropy on all passages. RankNet is used to calculate the pair-wise relevant order of passages.
其中 $\tau$ 是温度参数,$s$ 是相似度评分函数,$q$ 是输入查询,$d_{i}$ 是任意候选文档,$d_{+}$ 是相关文档。其他常用损失函数包括逐点二元交叉熵 (Sun et al., 2023)、列表交叉熵 (Bruch, 2021)、RankNet (Burges et al., 2005) 和 LambdaLoss (Wang et al., 2018)。逐点二元交叉熵基于每个查询-文档对独立计算。列表交叉熵损失广泛用于段落排序,最小化所有段落的列表级softmax交叉熵。RankNet用于计算段落的成对相关顺序。
3 LLM-augmented Retrieval
3 大语言模型增强检索 (LLM-augmented Retrieval)
In this section, we first discuss the components of the LLM-augmented retrieval framework. After that, we explain how this framework can be adapted to different retriever model architectures. In particular, we propose doc-level embedding for bi-encoders and late-interaction encoders under the LLM-augmented retrieval framework and demonstrate how it is applied to enhance the end-to-end retrieval quality.
在本节中,我们首先讨论大语言模型增强检索框架的组成部分。随后,我们将解释如何将该框架适配到不同的检索器模型架构中。具体而言,我们提出了在大语言模型增强检索框架下为双编码器和延迟交互编码器设计的文档级嵌入方法,并展示其如何应用于提升端到端检索质量。
3.1 LLM-Augmented Retrieval Framework
3.1 大语言模型增强检索框架
3.1.1 Synthetic Relevant Queries
3.1.1 合成相关查询
The inspiration for this concept was drawn from web search techniques (Xue et al., 2004; Guo et al., 2009a,b; Chuklin et al., 2022). To illustrate the idea, let us consider an example on a user query of "MIT". Without prior knowledge, it is challenging to figure out that "Massachusetts Institute of Technology" and "MIT" are equivalent. Nevertheless, in web search, we can observe that the home page of "Massachusetts Institute of Technology" has received numerous clicks from the query "MIT", allowing us to infer that the home page of "Massachusetts Institute of Technology" must be closely associated with the query "MIT". On the other side, we typically don’t have click data for each user query in the scenario of contextual retrieval. However, large language models are good at generating synthetic queries (Anaby-Tavor et al., 2020; Papa nikola ou and Pierleoni, 2020; Yang et al., 2020; Kumar et al., 2020; Schick and Schütze, 2021; Meng et al., 2022) so we can use the synthetic queries as proxy “click data” to direct user queries to related documents.
这一概念的灵感来源于网页搜索技术 (Xue et al., 2004; Guo et al., 2009a,b; Chuklin et al., 2022)。举例说明,假设用户查询"MIT"。在没有先验知识的情况下,很难判断"Massachusetts Institute of Technology"和"MIT"是等价的。然而在网页搜索中,我们可以观察到"Massachusetts Institute of Technology"主页通过"MIT"查询获得了大量点击,从而推断该主页必然与查询词"MIT"高度相关。另一方面,在上下文检索场景中,我们通常没有每个用户查询的点击数据。但大语言模型擅长生成合成查询 (Anaby-Tavor et al., 2020; Papa nikola ou and Pierleoni, 2020; Yang et al., 2020; Kumar et al., 2020; Schick and Schütze, 2021; Meng et al., 2022),因此可将合成查询作为代理"点击数据",将用户查询导向相关文档。
An important point is that in traditional retrieval tasks, we are using similarity to express relevance (Jones and Furnas, 1987). The similarity score is mathematically defined as either dot product or cosine of the encoded vectors of user query and documents. However, sometimes this similarity score might not reflect semantic relevance (Rao et al., 2019). For example, “Who is the first president of the United States?” might be very close, in terms of similarity score, to “Who became the first president of America?”. But our target answer might be a Wiki page or autobiography about “George
一个重要观点是,在传统检索任务中,我们使用相似度来表示相关性 (Jones and Furnas, 1987)。相似度分数在数学上定义为用户查询与文档编码向量的点积或余弦值。然而,这种相似度分数有时可能无法反映语义相关性 (Rao et al., 2019)。例如,"谁是美国第一任总统?"与"谁成为了美国首位总统?"在相似度分数上可能非常接近,但我们的目标答案可能是关于"乔治·华盛顿"的维基页面或自传。
Washington”, whose similarity score to the query is not that high. While if we use Washington’s autobiography to create synthetic queries, “Who became the first president of America?” may be one of them. The user query “Who is the first president of the United States?” can easily match to the relevant query through similarity scores. And the latter points to the target document (Washington’s autobiography). Therefore the generated synthetic queries express the semantic of the original document from different angles which are helpful to match the relevant queries.
华盛顿”,其与查询的相似度得分并不高。而如果我们用华盛顿的自传来生成合成查询,“谁成为美国第一任总统?”可能是其中之一。用户查询“美国第一任总统是谁?”可以通过相似度得分轻松匹配到相关查询,后者指向目标文档(华盛顿的自传)。因此生成的合成查询从不同角度表达了原始文档的语义,有助于匹配相关查询。
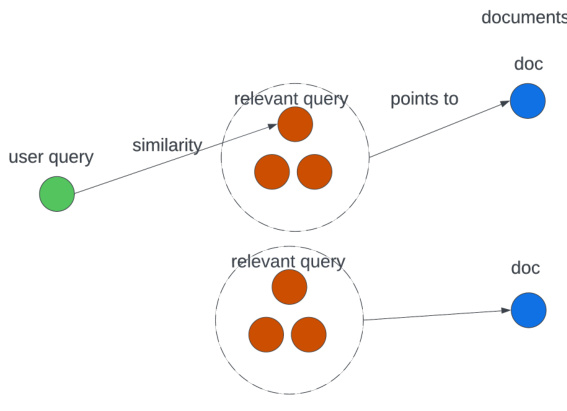
Figure 2: Through synthetic relevant queries, the relevance relationship is not solely expressed by the similarity now but also expressed by the augmentation steps of the large language models
图 2: 通过合成相关查询,相关性关系不再仅由相似性表达,还通过大语言模型的增强步骤来体现
3.1.2 Title
3.1.2 标题
The title of a document plays a crucial role in determining its relevance and usefulness to a user’s query. The title is often the first piece of information that a user sees when searching for documents, and it can greatly influence their decision to click on a particular result. A well-crafted title can provide important context and keywords that help users quickly understand the content and purpose of a document. If the original document has a title, we can use them directly. If it does not, we can leverage the large language models to generate a synthetic title for a that document.
文档标题在决定其与用户查询的相关性和实用性方面起着至关重要的作用。标题通常是用户搜索文档时看到的第一条信息,它能极大地影响用户点击特定结果的决策。精心设计的标题可以提供重要的上下文和关键词,帮助用户快速理解文档的内容和目的。如果原始文档有标题,我们可以直接使用;如果没有,则可以借助大语言模型为该文档生成一个合成标题。
3.1.3 Chunks (Passages)
3.1.3 块 (段落)
Chunking refers to the process of dividing a large document or piece of text into smaller, more manageable units. These units, known as "chunks," or "passages", are typically created by grouping together related pieces of information. Due to the limitation of the context window of retriever models, (in other words, max length of the model input), we typically divide a long document into several chunks whose number of tokens is below the context window limit. The chunk data is from original documents and is not from LLM-augmentation. The optimal chunking size is different for various retriever models. For bi-encoders like Contriever and DRAGON, we found the optimal chunking size to be 64 after empirical studies. For tokenlevel late-interaction models such as ColBERT and ColBERTv2, since it’s already calculating the similarity score at token-level, it’s not necessary to chunk the original documents unless the context window limit is reached.
分块 (chunking) 指将大型文档或文本分割为更小、更易处理的单元的过程。这些被称为"块"或"段落"的单元通常通过将相关信息分组创建。由于检索模型 (retriever models) 的上下文窗口限制 (即模型输入的最大长度),我们通常会将长文档分割为多个token数量低于上下文窗口限制的块。分块数据来自原始文档,而非通过大语言模型增强生成。不同检索模型的最佳分块大小各异:对于Contriever和DRAGON等双编码器 (bi-encoders),经实证研究得出最佳分块大小为64;而对于ColBERT和ColBERTv2等token级延迟交互模型 (token-level late-interaction models),由于它们已在token级别计算相似度分数,除非达到上下文窗口限制,否则无需对原始文档进行分块。
3.2 Doc-level embedding
3.2 文档级嵌入
In this section, we will first introduce the high level idea of doc-level embedding for information retrieval, and then use bi-encoders and token-level late-interaction models to illustrate how the doclevel embedding can be adaptive to different retriever model structures.
在本节中,我们将首先介绍文档级嵌入 (doc-level embedding) 用于信息检索的核心思想,随后通过双编码器 (bi-encoders) 和 Token 级延迟交互模型 (token-level late-interaction models) 来说明文档级嵌入如何适配不同的检索器模型结构。
Document fields. For convenience, we call the above mentioned information source, synthetic queries, title and chunk, fields of a document. These fields express the semantic of the original document from different angles and will be composed into the doc-level embedding of a document which is static and can be pre-computed and cached for information retrieval. Embedding indexes can be pre-built to speed up the retrieval inference, and each doc-level embedding points to the original document.
文档字段。为方便起见,我们将上述提到的信息来源、合成查询、标题和文本块称为文档的字段。这些字段从不同角度表达了原始文档的语义,并将组合成文档级别的嵌入表示 (doc-level embedding)。这种嵌入是静态的,可预先计算并缓存以支持信息检索。通过预构建嵌入索引可加速检索推理过程,每个文档级别嵌入都指向原始文档。
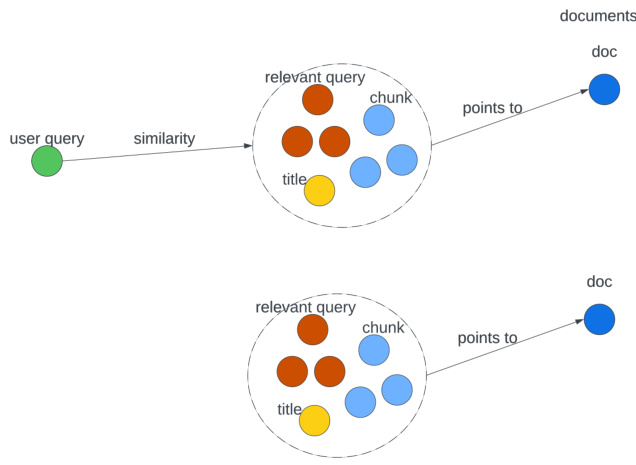
Figure 3: The graphic representation of "relevance" in doc-level embedding
图 3: 文档级嵌入中"相关性"的图示
3.2.1 For Bi-encoders
3.2.1 双编码器 (Bi-encoders)
Bi-encoders are typically “Two-Tower” model structures. Given a query and a document, a query encoder and a doc encoder are applied to compute the embedding vectors for the query and the document respectively. Then these two embedding vectors are fed into the dot products (or cosine similarity) to compute the similarity scores between the query and the document. As we want to enrich the document embedding vectors by injecting the synthetic queries and titles, we propose to compute the similarity as the following:
双编码器通常采用"双塔"模型结构。给定查询(query)和文档(document),分别通过查询编码器和文档编码器计算两者的嵌入向量,然后将这两个嵌入向量输入点积运算(或余弦相似度)来计算查询与文档之间的相似度分数。为了通过注入合成查询和标题来丰富文档嵌入向量,我们提出按以下方式计算相似度:
$$
\begin{array}{r}{s i m(q,d)=m a x_{i}s(q,c_{i})+\sum_{f}w_{f}\times s(q,e_{f})}\end{array}
$$
$$
\begin{array}{r}{s i m(q,d)=m a x_{i}s(q,c_{i})+\sum_{f}w_{f}\times s(q,e_{f})}\end{array}
$$
The first term on the right hand side calculates the maximum similarity score of query chunk embedding pairs, where $s$ is the similarity score function, $q$ is the embedding vector of the input query, $c_{i}$ is the embedding vector of the $i$ -th chunk in the document. This term is commonly used in current embedding based retrievals, which determines the similarity between a query and a document based on the query and the most relevant chunk in the document.
右侧第一项计算查询块嵌入对的最大相似度得分,其中 $s$ 是相似度得分函数, $q$ 是输入查询的嵌入向量, $c_{i}$ 是文档中第 $i$ 个块的嵌入向量。这一项在当前基于嵌入的检索中常用,它根据查询和文档中最相关的块来确定查询与文档之间的相似度。
The second term is innovative and considers more information, where $e_{f}$ is the embedding vector of each document field. The similarity scores between the query embedding and each field embedding are computed and combined together, each with a field weight parameter $w_{f}$ . As described before, those document fields include the synthetic query, title and chunk fields.
第二项具有创新性且考虑了更多信息,其中$e_{f}$是每个文档字段的嵌入向量。计算查询嵌入与每个字段嵌入之间的相似度得分并将其组合在一起,每个字段都有一个权重参数$w_{f}$。如前所述,这些文档字段包括合成查询、标题和文本块字段。
Now let’s consider how to compute the query field embedding $e_{f}$ for each field. For the title field, which just contains one phase or sentence, it is straightforward. We just apply the doc encoder to compute the embedding vector of the title as the title field embedding.
现在让我们考虑如何计算每个字段的查询字段嵌入 $e_{f}$。对于仅包含一个短语或句子的标题字段,这很简单。我们只需应用文档编码器来计算标题的嵌入向量作为标题字段嵌入。
For the chunk field which may contain multiple doc chunks, we can compute the embedding vector of each chunk with the doc encoder. The question is how to combine these embedding vectors to represent the whole document? Actually people have already considered a similar problem for sentence embedding: having the embedding vectors of all the tokens in one sentence, how to come up with a representation of the whole sentence? A simple but effective idea was proposed in (Arora et al., 2017) for this problem. Here we adapt this idea to the doc embedding problem. Namely we compute the average of all the chunk embedding vectors as the chunk field embedding. Similarly, for the synthetic query field, we compute the embedding vector of each query with the query encoder, and then compute the average of these embedding vectors as the query field embedding. This simple approach works very well in our experiments, while clearly more advanced approaches can be explored here in the future.
对于可能包含多个文档块的块字段,我们可以使用文档编码器计算每个块的嵌入向量。问题在于如何组合这些嵌入向量来代表整个文档?实际上人们已经考虑过句子嵌入的类似问题:当获得一个句子中所有token的嵌入向量后,如何生成整个句子的表示?(Arora et al., 2017) 针对该问题提出了一个简单但有效的解决方案。这里我们将该思路适配到文档嵌入问题上。具体来说,我们计算所有块嵌入向量的平均值作为块字段的嵌入表示。类似地,对于合成查询字段,我们先用查询编码器计算每个查询的嵌入向量,再取这些向量的平均值作为查询字段的嵌入表示。这个简单方法在我们的实验中表现优异,当然未来还可以探索更先进的方案。
Furthermore, as the similarity function is linear1, the above equation can be simplified as the following:
此外,由于相似度函数是线性的,上述等式可简化为:
$$
s i m(q,d)=m a x_{i}s(q,c_{i}+\textstyle\sum_{f}w_{f}\times e_{f})
$$
$$
s i m(q,d)=m a x_{i}s(q,c_{i}+\textstyle\sum_{f}w_{f}\times e_{f})
$$
Therefore, we can treat $\begin{array}{r}{c_{i}+\sum_{f}w_{f}\times e_{f}}\end{array}$ as the chunk embedding vector of each chunk $c_{i}$ of the original document, and still apply the algorithms like approximate nearest neighbors (Indyk and Motwani, 1998) to retrieve the most relevant documents.
因此,我们可以将 $\begin{array}{r}{c_{i}+\sum_{f}w_{f}\times e_{f}}\end{array}$ 视为原始文档每个分块 $c_{i}$ 的分块嵌入向量,并继续应用近似最近邻 (approximate nearest neighbors) [Indyk and Motwani, 1998] 等算法来检索最相关的文档。
3.2.2 For Token-Level Late-Interaction Models
3.2.2 Token级延迟交互模型
Instead of using a single embedding vector for query and a single embedding vector for each document, late-interaction models such as ColBERT and ColBERTv2 use token-level embedding and the embedding vectors of all the tokens are kept and will participate in computing the similarity score between the query and document.
与使用单个嵌入向量表示查询和每个文档不同,ColBERT和ColBERTv2等延迟交互模型采用token级嵌入,所有token的嵌入向量都会被保留并参与计算查询与文档之间的相似度得分。
$$
s i m(q,d)=\sum_{i}m a x_{j}s(q_{i},t_{j})
$$
$$
s i m(q,d)=\sum_{i}m a x_{j}s(q_{i},t_{j})
$$
where $q_{i}$ and $t_{j}$ are token-level embedding vectors for the input query and document respectively. Therefore, for each query token, the most similar token from the document is identified, and their similarity score is recorded. All these scores are summed up over all the query tokens to obtain the overall similarity between the query and the document. Since the similarity score calculation is done at token-level, we can concatenate the synthetic queries and titles to the original document passages. After that, we decide whether to chunk the concatenated documents if the number of tokens reaches the context window limit.
其中 $q_{i}$ 和 $t_{j}$ 分别是输入查询和文档的token级别嵌入向量。因此,对于每个查询token,系统会从文档中识别最相似的token,并记录它们的相似度分数。所有这些分数会在所有查询token上求和,从而得到查询与文档之间的整体相似度。由于相似度计算是在token级别进行的,我们可以将合成查询和标题与原始文档段落拼接起来。之后,若token数量达到上下文窗口限制,则决定是否对拼接后的文档进行分块处理。
4 Experiments
4 实验
In this section we will introduce our experiment set up, the datasets and the models used in our experiments.
在本节中,我们将介绍实验设置、所用数据集及模型。
4.1 Datasets
4.1 数据集
BEIR Data The BEIR (Benchmark for Evaluating Information Retrieval) dataset (Thakur et al., 2021), provides a comprehensive benchmark for evaluating and comparing different IR models, particularly in the context of out-of-domain tests. BEIR is designed to address the limitations of other previous datasets by offering a more diverse and extensive range of queries and passages. It encompasses a wide array of topics, thereby facilitating a more robust and comprehensive evaluation of IR models.
BEIR数据
BEIR (Benchmark for Evaluating Information Retrieval) 数据集 (Thakur et al., 2021) 为评估和比较不同信息检索 (IR) 模型提供了全面的基准测试,尤其专注于跨领域测试场景。该数据集通过提供更丰富多样的查询和文本段落,旨在解决以往数据集的局限性。其涵盖广泛的主题领域,从而支持对IR模型进行更全面、更鲁棒的评估。
LoTTE Data LoTTE data (Santhanam et al., 2021) is a dataset specifically designed for Long-Tail Topic-stratified Evaluation. The primary focus of LoTTE is on natural user queries that are associated with long-tail topics, which may not be adequately covered by an entity-centric knowledge base such as Wikipedia. LoTTE is composed of 10 distinct test sets, each containing 500 – 2,000 queries and 100,000 – 2,000,000 passages. These test sets are divided by topic, and each is accompanied by a validation set comprising related yet disjoint queries and passages. In this experiment we are using the test split sorely for evaluation.
LoTTE 数据
LoTTE 数据 (Santhanam et al., 2021) 是一个专为长尾主题分层评估 (Long-Tail Topic-stratified Evaluation) 设计的数据集。该数据集的核心关注点是与长尾主题相关的自然用户查询,这些主题可能无法被以实体为中心的知识库 (如 Wikipedia) 充分覆盖。LoTTE 包含 10 个不同的测试集,每个测试集包含 500 – 2,000 条查询和 100,000 – 2,000,000 条文本段落。这些测试集按主题划分,每个测试集还附带一个验证集,其中包含相关但互不重叠的查询和段落。本实验仅使用测试集拆分进行评估。
4.2 Models
4.2 模型
Contriever For Contriever we use the Robertabase (Liu et al., 2019) model architecture, the checkpoint is trained on Wiki passages (Karpukhin et al., 2020) and CC100 (Conneau et al., 2019) data through Contrastive Learning. It has 125M parameters, a context window of 512 tokens, with 12 layers, 768 hidden dimensions, and 12 attention heads. We use the single Roberta-base model for query encoder and context encoder, namely the “Two Tower” of the bi-encoder is shared in model architecture.
Contriever 我们采用 Robertabase (Liu et al., 2019) 的模型架构,该检查点通过对比学习在 Wiki 段落 (Karpukhin et al., 2020) 和 CC100 (Conneau et al., 2019) 数据上训练得到。模型包含 1.25 亿参数,512 token 的上下文窗口,12 层结构,768 维隐藏层及 12 个注意力头。查询编码器与上下文编码器共享单个 Roberta-base 模型,即双编码器的"双塔"结构在模型架构中实现参数共享。
DRAGON For DRAGON we also use the Robertabase model architecture, the checkpoint is trained by the author and released publicly. Different from the Contriever model, DRAGON has separate Roberta-base models for query encoder and context encoder.
DRAGON
对于DRAGON,我们同样采用Robertabase模型架构,该检查点由作者训练并公开发布。与Contriever模型不同,DRAGON的查询编码器和上下文编码器使用独立的Roberta-base模型。
ColBERTv2 For ColBERTv2, we use bert-baseuncased model architecture, the same as the default settings in the original paper. It has 110M parameters and a context window of 256 tokens, with 12 layers, 768 hidden dimensions, and 12 heads. The checkpoint is trained on the MSMARCO dataset (Nguyen et al., 2016) from the author’s checkpoint.
ColBERTv2
对于ColBERTv2,我们采用bert-base-uncased模型架构,与原始论文的默认设置相同。该模型包含1.1亿参数、256个token的上下文窗口、12层网络结构、768维隐藏层及12个头注意力机制。检查点基于作者提供的预训练权重,在MSMARCO数据集 (Nguyen等人, 2016) 上完成训练。
4.3 Implementation Details
4.3 实现细节
We choose open source Llama-70B (Touvron et al., 2023a,b) for synthetic query generation and title generation. The prompt templates used for generating synthetic queries and titles are in Table 9 and 10.
我们选择开源的Llama-70B (Touvron et al., 2023a,b) 用于合成查询生成和标题生成。生成合成查询和标题所使用的提示模板见表9和表10。
For Bi-encoders, we implemented the doclevel embedding as above mentioned and chose $w_{q u e r y}{=}1.0$ , $w_{t i t l e}{=}0.5$ , $w_{c h u n k}{=}0.1$ for the Contriever model and $w_{q u e r y}{=}0.6$ , $w_{t i t l e}{=}0.3$ $w_{c h u n k}{=}0.3$ for the DRAGON model. We chose chunk_ $\scriptstyle{\mathit{s i z e}}=64$ after empirical experiments and found 64 normally performed the best in retrieval results for Bi-encoders. Note these hyperparameters of field weights are not fully optimized. They are chosen according to the performance of Bi-encoder models on the single LoTTE-lifestyleforum dataset, and then fixed for the evaluations on all the other datasets.
对于双编码器(Bi-encoders),我们实现了上述文档级嵌入方法,并为Contriever模型选择权重$w_{query}{=}1.0$、$w_{title}{=}0.5$、$w_{chunk}{=}0.1$,为DRAGON模型选择$w_{query}{=}0.6$、$w_{title}{=}0.3$、$w_{chunk}{=}0.3$。经过实验验证,我们选定chunk_$\scriptstyle{\mathit{size}}=64$,发现64通常在双编码器的检索结果中表现最佳。需要注意的是,这些字段权重的超参数并未完全优化,它们是根据双编码器模型在单个LoTTE-lifestyleforum数据集上的表现选定,之后在所有其他数据集评估中保持固定。
For ColBERTv2, as mentioned previously, we concatenate the title with all the synthetic queries for each document and make it an additional “passage” of the original document. Thus there’s no field weights hyper-parameters in these experiments. There could be other better assembling methods for composing the doc-level embedding under a late-interaction model architecture. We set index_bits $_{=8}$ when building the ColBERT index.
对于ColBERTv2,如前所述,我们将每个文档的标题与所有合成查询拼接起来,使其成为原始文档的一个额外"段落"。因此在这些实验中不存在字段权重超参数。在延迟交互模型架构下,可能还存在其他更好的组合方法来构建文档级嵌入。我们在构建ColBERT索引时设置index_bits$_{=8}$。
5 Results
5 结果
The result on LoTTE and BEIR data for all three models can be seen in Table 1, 2 and 3. We can observe that the LLM augmented retrieval and doc-level embeddings boost the recall $\ @3$ and recall $@10$ of Bi-encoders (Contriever and DRAGON) significantly. For token-level lateinteraction models (ColBERTv2), the increase on the LoTTE and BEIR Dataset is still clear, although not as much as on Bi-encoders. We hypothesis this due to that the baselines for token-level lateinteraction models are much higher than those of Bi-encoders.
所有三个模型在LoTTE和BEIR数据集上的结果见表1、表2和表3。我们可以观察到,大语言模型增强检索和文档级嵌入显著提升了双编码器(Contriever和DRAGON)的召回率$\ @3$和召回率$@10$。对于Token级延迟交互模型(ColBERTv2),在LoTTE和BEIR数据集上的提升虽然不如双编码器明显,但仍清晰可见。我们推测这是由于Token级延迟交互模型的基线性能原本就远高于双编码器。
Moreover, the performance of the LLMaugmented Contriver has exceeded the performance of the vanilla DRAGON in most datasets. Similarly, the LLM-augmented DRAGON even exceeds vanilla ColBERTv2 on BEIR-ArguAna,
此外,LLM增强版Contriver在多数数据集上的表现已超越基础版DRAGON。同样地,LLM增强版DRAGON在BEIR-ArguAna数据集上甚至优于基础版ColBERTv2。
BEIR-SciDocs and BEIR-CQ AD up stack-English datasets and greatly reduce the performance gap in the remaining datasets, although ColBERTv2 introduces a more complex late-interaction architecture than DRAGON. Therefore, we can see that, after enriching the embedding of documents with LLM augmentation, we can greatly improve the retriever models recall performance without further fine-tuning.
BEIR-SciDocs和BEIR-CQ AD up stack-English数据集上大幅缩小了性能差距,尽管ColBERTv2引入了比DRAGON更复杂的延迟交互架构。由此可见,通过大语言模型增强技术丰富文档嵌入后,无需进一步微调即可显著提升检索模型的召回性能。
6 Ablation Studies
6 消融研究
In this section, we want to see how the chunk, query and title fields impact the retrieval quality of different retriever models. For Bi-encoders (Contriever and DRAGON), we further control the field weights of chunk, synthetic query and title to see how those parameters can affect the performance. For the token-level late-interaction model (ColBERTv2), we just control the model to use one of the chunk, query or title field only to see how the they affect the end-to-end retrieval quality.
在本节中,我们想观察分块(chunk)、查询(query)和标题(title)字段如何影响不同检索器模型的检索质量。对于双编码器(Bi-encoder)模型(Contriever和DRAGON),我们进一步控制分块、合成查询(synthetic query)和标题的字段权重,以观察这些参数如何影响性能。对于Token级延迟交互模型(ColBERTv2),我们仅控制模型使用分块、查询或标题中的一个字段,以观察它们如何影响端到端检索质量。
For the Contriever model (Table 4), we have observed that most of the time the synthetic queries play the most critical role in boosting the recall performance, comparing to the other two fields, while in BEIR-SciDocs and BEIR-Scifact, synthetic queries’ importance is smaller. Therefore, a weighted sum of multiple fields in doc-level embedding yields better performance in most cases. And these weights can be further tuned as hyperparameters.
对于Contriever模型(表4),我们观察到大多数情况下,与其他两个字段相比,合成查询对提升召回性能起着最关键作用,而在BEIR-SciDocs和BEIR-Scifact数据集中,合成查询的重要性较低。因此,在文档级嵌入中对多字段进行加权求和,在大多数情况下能获得更好的性能表现。这些权重还可作为超参数进一步调优。
For the DRAGON model (Table5), there’s less strong pattern that which field plays a more important role in doc-level embedding. In the LoTTE dataset it’s more driven by the title field. However, the chunk field matters more in datasets of BEIR-ArguAna, BEIR-Quora and BEIR-SciFact. Once again, a weighted sum of multiple document fields in doc-level embedding yields better performance in most cases. For the different patterns we have observed in DRAGON vs Contriever, one reason might be that DRAGON uses separate query and context encoders, while Contriever uses shared query and context encoders in our setup. Thus Contriever is better at identifying similarity instead of relevance and that’s why the synthetic query field has a more significant impact in the Contriever model, since it better transforms similarity to relevance as explained before.
对于DRAGON模型(表5),在文档级嵌入中哪个字段起更重要作用并没有特别明显的规律。在LoTTE数据集中,标题字段的影响更大;而在BEIR-ArguAna、BEIR-Quora和BEIR-SciFact数据集中,文本块字段更为关键。同样地,在大多数情况下,对文档多个字段进行加权求和的文档级嵌入方法表现更优。关于DRAGON与Contriever模型表现出的不同模式,一个可能的原因是:DRAGON采用分离的查询编码器和上下文编码器,而我们的实验设置中Contriever使用共享的查询与上下文编码器。因此Contriever更擅长识别相似性而非相关性,这也解释了为什么合成查询字段在Contriever模型中影响更显著——如前所述,该字段能更好地将相似性转化为相关性。
For ColBERTv2 (Table 6), we have observed from the LoTTE dataset that further chunking the passages actually hurts the performance. This may be because the similarity calculation is done at token-level so chunking the passages (meanwhile increasing the number of chunks) will not help the ColBERTv2 model digest the granular contextual information. Therefore we did not evaluate the chunk-only scenario on the BEIR dataset. The synthetic queries are more critical than titles for ColBERTv2 across the datasets, while combining them all often yields even better recall results. Note again there’s no field weights hyper-parameters for token-level late-interaction models.
对于ColBERTv2 (表6),我们从LoTTE数据集中观察到,进一步分块处理段落实际上会损害性能。这可能是因为相似性计算是在token级别进行的,因此分块段落(同时增加块数)无助于ColBERTv2模型消化细粒度的上下文信息。因此我们未在BEIR数据集上评估纯分块场景。在各数据集中,合成查询对ColBERTv2的重要性超过标题,而组合所有要素通常能带来更好的召回结果。需再次说明,token级延迟交互模型不存在字段权重超参数。
Table 1: Results on Contriever: The performance of LLM-augmented Contriver has greatly exceeded the vanilla Contriever on both LoTTE and BEIR dataset, and even exceeds the performance of the vanilla DRAGON in most datasets. * means base model plus the doc-level embedding $(w_{q u e r y}{=}1.0$ , $w_{t i t l e}{=}0.5$ , $w_{c h u n k}{=}0.1$ ).
| LoTTEDataset | ||||||||||||||
| Model | Recall | Lifestyle Forum | Lifestyle Search | Recreation Forum | Recreation Search | Science Forum | Science Search | Technology Forum | Technology Search | Writing Forum | Writing Search | |||
| Contriever | recall@3 | 0.4366 | 0.3358 | 0.3486 | 0.1948 | 0.1046 | 0.1005 | 0.1826 | 0.1242 | 0.3950 | 0.2745 | |||
| recall@10 | 0.6149 | 0.4690 | 0.4895 | 0.2857 | 0.1706 | 0.1637 | 0.3174 | 0.1896 | 0.5390 | 0.3950 | ||||
| Contriever* | recall@3 | 0.6244 | 0.6021 | 0.5455 | 0.4610 | 0.2395 | 0.2901 | 0.3663 | 0.3557 | 0.5970 | 0.5724 | |||
| recall@10 | 0.7622 | 0.7821 | 0.6948 | 0.6320 | 0.3570 | 0.4684 | 0.5494 | 0.5017 | 0.7365 | 0.6919 | ||||
| Model | BEIR Dataset | |||||||||||||
| Recall | ArguAna | FIQA | Quora | SciDocs | SciFact | CQADupstackCQADupstack | ||||||||
| English | Physics | |||||||||||||
| Contriever Contriever* | recall@3 | 0.2589 | 0.1895 | 0.8654 | 0.1580 | 0.5410 | 0.2261 | 0.1723 | ||||||
| recall@10 recall@3 | 0.5206 0.2468 | 0.2993 0.3690 | 0.9463 0.8687 | 0.2950 0.2440 | 0.6934 0.5996 | 0.3089 | 0.3417 | 0.2551 | ||||||
表 1: Contriever实验结果: 经过大语言模型增强的Contriever在LoTTE和BEIR数据集上的性能远超原始Contriever,在多数数据集上甚至超过了原始DRAGON的表现。*表示基础模型加上文档级嵌入 $(w_{query}{=}1.0$ , $w_{title}{=}0.5$ , $w_{chunk}{=}0.1$ )。
| 模型 | 召回率 | 生活方式论坛 | 生活方式搜索 | 娱乐论坛 | 娱乐搜索 | 科学论坛 | 科学搜索 | 技术论坛 | 技术搜索 | 写作论坛 | 写作搜索 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Contriever | recall@3 | 0.4366 | 0.3358 | 0.3486 | 0.1948 | 0.1046 | 0.1005 | 0.1826 | 0.1242 | 0.3950 | 0.2745 |
| recall@10 | 0.6149 | 0.4690 | 0.4895 | 0.2857 | 0.1706 | 0.1637 | 0.3174 | 0.1896 | 0.5390 | 0.3950 | |
| Contriever* | recall@3 | 0.6244 | 0.6021 | 0.5455 | 0.4610 | 0.2395 | 0.2901 | 0.3663 | 0.3557 | 0.5970 | 0.5724 |
| recall@10 | 0.7622 | 0.7821 | 0.6948 | 0.6320 | 0.3570 | 0.4684 | 0.5494 | 0.5017 | 0.7365 | 0.6919 |
| 模型 | 召回率 | ArguAna | FIQA | Quora | SciDocs | SciFact | CQADupstack英语 | CQADupstack物理 |
|---|---|---|---|---|---|---|---|---|
| Contriever | recall@3 | 0.2589 | 0.1895 | 0.8654 | 0.1580 | 0.5410 | 0.2261 | 0.1723 |
| recall@10 | 0.5206 | 0.2993 | 0.9463 | 0.2950 | 0.6934 | 0.3089 | 0.3417 | |
| Contriever* | recall@3 | 0.2468 | 0.3690 | 0.8687 | 0.2440 | 0.5996 | 0.2551 | - |
| recall@10 | - | - | - | - | - | - | - |
Table 2: Results on DRAGON: The performance of LLM-augmented DRAGON has greatly exceeded the vanilla DRAGON on both LoTTE and BEIR dataset, and even exceeds vanilla ColBERTv2 on BEIR-ArguAna, BEIRSciDocs and BEIR-CQ AD up stack-English datasets, as well as greatly reduces the performance gap in the remaining datasets. * means base model plus the doc-level embedding $\scriptstyle w_{q u e r y}=0.6$ , $w_{t i t l e}{=}0.3$ , $w_{c h u n k}{=}0.3$ ).
| LoTTEDataset | |||||||||||
| Model | Recall | Lifestyle | Lifestyle | Recreation | Recreation | Science | Science | Technology | Technology | Writing | Writing |
| Forum | Search | Forum | Search | Forum | Search | Forum | Search | Forum | Search | ||
| DRAGON | recall@3 | 0.5270 | 0.5598 | 0.4560 | 0.4253 | 0.2578 | 0.2601 | 0.2854 | 0.3591 | 0.5300 | 0.5798 |
| recall@10 | 0.6798 | 0.7035 | 0.5949 | 0.5325 | 0.3704 | 0.3938 | 0.4232 | 0.5101 | 0.6675 | 0.7311 | |
| DRAGON* | recall@3 recall@10 | 0.6883 0.8172 | 0.7625 | 0.6079 | 0.6472 | 0.3099 | 0.4498 | 0.4192 | 0.5285 | 0.6520 | 0.7031 |
| 0.8911 | 0.7468 | 0.7944 BEIRDataset | 0.4427 | 0.6062 | 0.6038 | 0.7097 | 0.7725 | 0.8170 | |||
| Model | |||||||||||
| Recall | ArguAna | FIQA | Quora | SciDocs | SciFact | CQADupstack CQADupstack | |||||
| DRAGON | recall@3 | English | Physics | ||||||||
| 0.1408 0.4040 | 0.3327 | 0.8465 | 0.1800 | 0.4743 0.5996 | 0.2605 | 0.1877 | |||||
| DRAGON* | recall@10 recall@3 | 0.3663 | 0.4514 | 0.9419 | 0.3260 | 0.3599 | 0.2916 | ||||
| recall@10 | 0.6764 | 0.4255 0.5635 | 0.8638 0.9527 | 0.3040 0.4800 | 0.6610 0.7710 | 0.4618 0.5662 | 0.5342 | 0.3936 | |||
表 2: DRAGON实验结果:增强版大语言模型DRAGON在LoTTE和BEIR数据集上的性能远超原始DRAGON,甚至在BEIR-ArguAna、BEIR-SciDocs和BEIR-CQADupstack-English数据集上超越了原始ColBERTv2,同时大幅缩小了其他数据集的性能差距。(*表示基础模型加文档级嵌入 $\scriptstyle w_{query}=0.6$ , $w_{title}=0.3$ , $w_{chunk}=0.3$)
| 模型 | 召回率 | Lifestyle论坛 | Lifestyle搜索 | Recreation论坛 | Recreation搜索 | Science论坛 | Science搜索 | Technology论坛 | Technology搜索 | Writing论坛 | Writing搜索 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DRAGON | recall@3 | 0.5270 | 0.5598 | 0.4560 | 0.4253 | 0.2578 | 0.2601 | 0.2854 | 0.3591 | 0.5300 | 0.5798 |
| recall@10 | 0.6798 | 0.7035 | 0.5949 | 0.5325 | 0.3704 | 0.3938 | 0.4232 | 0.5101 | 0.6675 | 0.7311 | |
| DRAGON* | recall@3 | 0.6883 | 0.7625 | 0.6079 | 0.6472 | 0.3099 | 0.4498 | 0.4192 | 0.5285 | 0.6520 | 0.7031 |
| recall@10 | 0.8172 | 0.8911 | 0.7468 | 0.7944 | 0.4427 | 0.6062 | 0.6038 | 0.7097 | 0.7725 | 0.8170 |
BEIR数据集
| 模型 | 召回率 | ArguAna | FIQA | Quora | SciDocs | SciFact | CQADupstack英语 | CQADupstack物理 |
|---|---|---|---|---|---|---|---|---|
| DRAGON | recall@3 | 0.1408 | 0.3327 | 0.8465 | 0.1800 | 0.2605 | 0.1877 | 0.4040 |
| recall@10 | 0.3663 | 0.4514 | 0.9419 | 0.3260 | 0.3599 | 0.2916 | 0.4743 | |
| DRAGON* | recall@3 | 0.4255 | 0.5635 | 0.8638 | 0.3040 | 0.4618 | 0.3936 | 0.5996 |
| recall@10 | 0.6764 | 0.9527 | 0.9527 | 0.4800 | 0.5662 | 0.5342 | 0.7710 |
| Model | LoTTEDataset | |||||||||||||
| Recall | Lifestyle | Lifestyle | Recreation | Recreation | Science | Science | TechnologyTechnology | Writing | Writing | |||||
| ColBERTv2 | Forum | Search | Forum | Search | Forum | Search | Forum | Search | Forum | Search | ||||
| recall@3 | 0.6988 0.8087 | 0.7927 | 0.6344 | 0.6677 | 0.3932 | 0.5073 | 0.4496 | 0.5940 | 0.6960 | 0.7423 | ||||
| ColBERTv2* | recall@10 | 0.7308 | 0.8911 | 0.7498 | 0.7868 | 0.5285 | 0.6613 | 0.6292 | 0.7315 | 0.8050 | 0.8366 | |||
| recall@3 recall@10 | 0.8447 | 0.8003 0.9107 | 0.6753 0.7862 | 0.7100 0.8268 | 0.4026 0.5558 | 0.5024 | 0.4626 | 0.5956 | 0.7145 | 0.7544 0.8571 | ||||
| BEIRDataset | 0.6726 | 0.6517 | 0.7383 | 0.8260 | ||||||||||
| Model Recall | ArguAna | |||||||||||||
| ColBERTv2 | FIQA | Quora | SciDocs | SciFact | English | CQADupstackCQADupstack Physics | ||||||||
| recall@3 | 0.3542 | 0.4469 | 0.9048 | 0.2990 | 0.6691 | 0.4484 | 0.4052 | |||||||
| ColBERTv2* | recall@10 | 0.6287 | 0.5787 | 0.9643 | 0.4780 | 0.7755 | 0.5369 | 0.5380 | ||||||
| recall@3 | 0.3592 0.6344 | 0.4666 0.6018 | 0.9067 | 0.3000 | 0.6862 | 0.4822 | 0.4196 | |||||||
Table 3: Results on ColBERTv2: The performance of LLM-augmented ColBERTv2 has greatly exceeded the performance of vanilla ColBERTv2 on both LoTTE and BEIR dataset. * means base model plus the doc-level embedding.
| 模型 | LoTTE数据集 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 召回率 | 生活方式 | 生活方式 | 休闲娱乐 | 休闲娱乐 | 科学 | 科学 | 科技 | 写作 | 写作 | ||||
| ColBERTv2 | 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | |||
| recall@3 | 0.6988 0.8087 | 0.7927 | 0.6344 | 0.6677 | 0.3932 | 0.5073 | 0.4496 | 0.5940 | 0.6960 | 0.7423 | |||
| ColBERTv2* | recall@10 | 0.7308 | 0.8911 | 0.7498 | 0.7868 | 0.5285 | 0.6613 | 0.6292 | 0.7315 | 0.8050 | 0.8366 | ||
| recall@3 recall@10 | 0.8447 | 0.8003 0.9107 | 0.6753 0.7862 | 0.7100 0.8268 | 0.4026 0.5558 | 0.5024 | 0.4626 | 0.5956 | 0.7145 | 0.7544 0.8571 | |||
| BEIR数据集 | 0.6726 | 0.6517 | 0.7383 | 0.8260 | |||||||||
| 模型 召回率 | ArguAna | ||||||||||||
| ColBERTv2 | FIQA | Quora | SciDocs | SciFact | 英语 | CQADupstack 物理 | |||||||
| recall@3 | 0.3542 | 0.4469 | 0.9048 | 0.2990 | 0.6691 | 0.4484 | 0.4052 | ||||||
| ColBERTv2* | recall@10 | 0.6287 | 0.5787 | 0.9643 | 0.4780 | 0.7755 | 0.5369 | 0.5380 | |||||
| recall@3 | 0.3592 0.6344 | 0.4666 0.6018 | 0.9067 | 0.3000 | 0.6862 | 0.4822 | 0.4196 |
表 3: ColBERTv2实验结果: 经过大语言模型增强的ColBERTv2在LoTTE和BEIR数据集上的性能均大幅超越原始ColBERTv2。*表示基础模型加上文档级嵌入。
7 Supervised Fine-tuning
7 监督式微调
The above studies are all based on zero-shot evaluation, namely the checkpoints in (Lin et al., 2023; Santhanam et al., 2021) are directly used in evaluation. Actually our LLM-augmented retrieval and doc-level embedding also support supervised finetuning on domain-specific datasets. Some popular training methods include picking hard negatives, constructing in-batch or cross-batch negatives, and calculating InfoNCE loss as training loss (Izacard et al., 2021; Lin et al., 2023). In this section, we propose some effective training techniques for fine-tuning which we used internally on proprietary dataset and performed better than the common methods mentioned above.
上述研究均基于零样本(zero-shot)评估,即直接使用(Lin et al., 2023; Santhanam et al., 2021)中的检查点进行评估。实际上,我们的大语言模型增强检索和文档级嵌入也支持在特定领域数据集上进行监督微调。常见的训练方法包括选取困难负样本、构建批内或跨批负样本,以及计算InfoNCE损失作为训练损失(Izacard et al., 2021; Lin et al., 2023)。本节我们将提出一些有效的微调训练技术,这些技术已在内部专有数据集上应用,并取得了优于上述常规方法的效果。
7.1 Adaptive Negative Sampling
7.1 自适应负采样
The process of acquiring negative docs for each query can be approached in several ways. A straightforward method involves the random sampling of doc contexts, excluding the ground truth. Alternatively, a model such as BM25 (Robertson et al., 2004, 2009) could be employed to select “strong” negative doc contexts that have been assigned high ranking scores by the model. However, for more effective training, it is advantageous to obtain “difficult” negative doc contexts. To this end, an adaptive negative sampling approach was developed. The retrieval model under training is used to rank all doc contexts for each query. The doc contexts ranked in the top positions, excluding the ground truth doc contexts, are selected and then represented as the most challenging negative examples that could potentially confound our retrieval model. Consequently, it is imperative to train the retrieval model to effectively handle these samples.
为每个查询获取负样本文档的过程可以通过多种方式实现。一种简单的方法是随机采样文档上下文(排除真实答案)。另一种方法是使用BM25 (Robertson et al., 2004, 2009) 等模型来选择"强"负样本文档上下文(即模型给出高排序分数的文档)。但为了更有效的训练,获取"困难"负样本文档上下文更具优势。为此,我们开发了一种自适应负采样方法:使用训练中的检索模型对每个查询的所有文档上下文进行排序,选取排名靠前(排除真实答案文档)的文档上下文作为最具挑战性的负样本。这些样本可能干扰检索模型的判断,因此必须训练模型有效处理这类样本。
A significant challenge of this approach is the time and space complexity. For each query (or batch of queries), it is necessary to re-compute the embedding for all doc contexts to identify the top negative examples. These doc context embedding cannot be pre-calculated due to the continuous updating of the model parameters during training, which correspondingly alters the doc context embedding. To address this issue, we can periodically pre-calculate and update the top negative samples for multiple training batches simultaneously.
该方法面临的一个重大挑战是时间和空间复杂度问题。对于每个查询(或批量查询),都需要重新计算所有文档上下文的嵌入(embedding)以确定最佳负例。由于训练过程中模型参数持续更新会相应改变文档上下文嵌入,这些嵌入无法预先计算。为解决这个问题,我们可以定期预计算并同时更新多个训练批次的最佳负样本。
7.2 Loss Function
7.2 损失函数
In supervised training, for each training query, each doc has a binary label: relevant or not relevant.
在有监督训练中,每个训练查询对应的文档都有一个二元标签:相关或不相关。
In the context of binary label problems, the crossentropy loss function is a prevalent choice. However, the cross-entropy is primarily for classification problems. This is due to its requirement for model output scores to be maximized for positive examples and minimized for negative examples. Within the realm of information retrieval, the primary challenge lies in the task of ranking of target documents. The absolute numerical values of output scores are not the primary focus. Instead, the focus is on the relative order and gaps between the model outputs of positive and negative doc contexts. Consequently, we adopted the margin ranking loss function (Nayyeri et al., 2019), which aims to maximize the "margin" between the scores of positive and negative examples.
在二分类标签问题的背景下,交叉熵损失函数 (cross-entropy loss) 是一种普遍选择。然而交叉熵主要适用于分类问题,因为它要求模型对正例输出高分、对负例输出低分。在信息检索领域,核心挑战在于目标文档的排序任务,输出分数的绝对数值并非关注重点,而是正负文档上下文模型输出间的相对顺序与差距。因此我们采用间隔排序损失函数 (margin ranking loss) [20],其目标是最大化正负例分数之间的"间隔"。
$$
L o s s(o_{1},o_{2},y)=m a x(0,-y(o_{1}-o_{2})+m a r g i n)
$$
$$
L o s s(o_{1},o_{2},y)=m a x(0,-y(o_{1}-o_{2})+m a r g i n)
$$
In the above equation, $O_{1},O_{2}$ are model output scores, the value of $y$ equals 1 or $^-1$ , indicating whether $O_{1}$ should be larger or smaller than $O_{2}$ respectively. For example, when $y{=}1$ , and the gap between $O_{1}$ and $O_{2}$ is larger than the “margin” parameter, the loss value is 0. Otherwise, the smaller the gap between $O_{1}$ and $O2$ , the larger the loss value. Our experiments showed that this margin loss was better than the cross entropy loss on proprietary domain data fine-tuning.
在上述等式中,$O_{1},O_{2}$ 是模型输出分数,$y$ 的值为1或$^-1$,分别表示 $O_{1}$ 是否应大于或小于 $O_{2}$。例如,当 $y{=}1$ 时,若 $O_{1}$ 与 $O_{2}$ 的差值大于"margin"参数,则损失值为0;反之,$O_{1}$ 与 $O_{2}$ 的差值越小,损失值越大。实验表明,在专有领域数据微调任务中,这种边界损失函数效果优于交叉熵损失函数。
8 Conclusion
8 结论
This paper presents a novel framework, LLMaugmented retrieval, which significantly improves the performance of existing retriever models by enriching the embedding of documents through large language model augmentation. The proposed framework includes a doc-level embedding that encodes contextual information from synthetic queries, titles, and chunks, which can be adapted to various retriever model architectures. The proposed approach has achieved state-of-the-art results across different models and datasets, demonstrating its effectiveness in enhancing the quality and robustness of neural information retrieval. Future research could explore further enhancements to the LLM-augmented retrieval framework, such as the integration of additional contextual information into doc-level embedding, the application of more advanced similarity score measures, more complicated approaches to combine the embedding of multiple chunks/queries into one chunk/query field embedding, etc.
本文提出了一种新颖的框架——大语言模型增强检索(LLMaugmented retrieval),该框架通过大语言模型增强来丰富文档嵌入,显著提升了现有检索模型的性能。该框架包含一个文档级嵌入(doc-level embedding),可编码来自合成查询、标题和文本块的上下文信息,并能适配多种检索模型架构。所提出的方法在不同模型和数据集上均取得了最先进的结果,证明了其在提升神经信息检索质量和鲁棒性方面的有效性。未来研究可探索对该框架的进一步优化,例如:将更多上下文信息整合到文档级嵌入中、应用更先进的相似度评分指标、采用更复杂的方法将多个文本块/查询的嵌入合并为单个文本块/查询字段嵌入等。
9 Limitations
9 局限性
One limitation of study include the extra computation resources it required in augmenting relevant queries and titles for original documents and sometimes to size of augmented texts can be comparable to the size of the original documents. This computational limitation may restrict the usage of this approach where computational resource is limited.
该研究的一个局限在于,增强原始文档相关查询和标题需要额外的计算资源,有时增强文本的规模可能与原始文档相当。这种计算限制可能会在计算资源有限的情况下制约该方法的使用。
Another limitation or risk is that the hallucination in large language models may pose extra inaccuracy in augmented corpus to the original documents. Hallucination remains an unsolved problem in the field of large language model’s study.
另一个限制或风险在于,大语言模型中的幻觉 (hallucination) 可能会对原始文档的增强语料库造成额外的不准确性。幻觉仍是大语言模型研究领域中一个尚未解决的问题。
References
参考文献
Thibault Formal, Carlos Lassance, Benjamin Piwowarski, and Stéphane Clinchant. 2021a. Splade v2: Sparse lexical and expansion model for information retrieval. arXiv preprint arXiv:2109.10086.
Thibault Formal、Carlos Lassance、Benjamin Piwowarski和Stéphane Clinchant. 2021a. SPLADE v2: 信息检索的稀疏词法与扩展模型. arXiv预印本 arXiv:2109.10086.
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel等。2020。面向知识密集型NLP任务的检索增强生成。神经信息处理系统进展,33:9459–9474。
Sheng-Chieh Lin, Akari Asai, Minghan Li, Barlas Oguz, Jimmy Lin, Yashar Mehdad, Wen-tau Yih, and Xilun Chen. 2023. How to train your dragon: Diverse augmentation towards general iz able dense retrieval. arXiv preprint arXiv:2302.07452.
盛杰林 (Sheng-Chieh Lin)、浅井朱里 (Akari Asai)、李明翰 (Minghan Li)、巴拉斯·奥古兹 (Barlas Oguz)、林志明 (Jimmy Lin)、雅沙尔·梅达德 (Yashar Mehdad)、温涛义 (Wen-tau Yih) 和陈曦伦 (Xilun Chen)。2023。如何训练你的龙:面向通用化稠密检索的多样化增强。arXiv预印本 arXiv:2302.07452。
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Z ett le moyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pre training approach. arXiv preprint arXiv:1907.11692.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: 一种稳健优化的BERT预训练方法. arXiv preprint arXiv:1907.11692.
Yu Meng, Jiaxin Huang, Yu Zhang, and Jiawei Han. 2022. Generating training data with language models: Towards zero-shot language understanding. Advances in Neural Information Processing Systems, 35:462–477.
Yu Meng、Jiaxin Huang、Yu Zhang和Jiawei Han。2022。使用语言模型生成训练数据:迈向零样本语言理解。Advances in Neural Information Processing Systems,35:462–477。
Mojtaba Nayyeri, Xiaotian Zhou, Sahar Vahdati, Hamed Shariat Yazdi, and Jens Lehmann. 2019. Adaptive margin ranking loss for knowledge graph embeddings via a corr entropy objective function. arXiv preprint arXiv:1907.05336.
Mojtaba Nayyeri、Xiaotian Zhou、Sahar Vahdati、Hamed Shariat Yazdi 和 Jens Lehmann。2019. 基于相关熵目标函数的知识图谱嵌入自适应边界排序损失。arXiv预印本 arXiv:1907.05336。
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. Ms marco: A human generated machine reading comprehension dataset. choice, 2640:660.
Tri Nguyen、Mir Rosenberg、Xia Song、Jianfeng Gao、Saurabh Tiwary、Rangan Majumder 和 Li Deng。2016. MS MARCO: 一个由人类生成的机器阅读理解数据集。《choice》,2640:660。
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage re-ranking with bert. arXiv preprint arXiv:1901.04085.
Rodrigo Nogueira 和 Kyunghyun Cho. 2019. 基于BERT的段落重排序. arXiv预印本 arXiv:1901.04085.
Yannis Papa nikola ou and Andrea Pierleoni. 2020. Dare: Data augmented relation extraction with gpt-2. arXiv preprint arXiv:2004.13845.
Yannis Papa nikola ou 和 Andrea Pierleoni. 2020. Dare: 基于 GPT-2 的数据增强关系抽取. arXiv 预印本 arXiv:2004.13845.
Jinfeng Rao, Linqing Liu, Yi Tay, Wei Yang, Peng Shi, and Jimmy Lin. 2019. Bridging the gap between relevance matching and semantic matching for short text similarity modeling. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5370–5381.
Jinfeng Rao、Linqing Liu、Yi Tay、Wei Yang、Peng Shi和Jimmy Lin。2019. 弥合短文本相似性建模中相关性匹配与语义匹配的差距。2019年自然语言处理实证方法会议暨第九届自然语言处理国际联合会议论文集(EMNLP-IJCNLP),第5370–5381页。
Stephen Robertson, Hugo Zaragoza, and Michael Taylor. 2004. Simple bm25 extension to multiple weighted fields. In Proceedings of the thirteenth ACM international conference on Information and knowledge management, pages 42–49.
Stephen Robertson、Hugo Zaragoza和Michael Taylor。2004。简单BM25扩展到多加权字段。在第十三届ACM国际信息与知识管理会议论文集,第42-49页。
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389.
Stephen Robertson, Hugo Zaragoza, 等. 2009. 概率相关性框架: BM25 及其扩展. Foundations and Trends® in Information Retrieval, 3(4):333–389.
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2021. Colbertv2: Effective and efficient retrieval via lightweight late interaction. arXiv preprint arXiv:2112.01488.
Keshav Santhanam、Omar Khattab、Jon Saad-Falcon、Christopher Potts 和 Matei Zaharia。2021。Colbertv2: 通过轻量级延迟交互实现高效检索。arXiv 预印本 arXiv:2112.01488。
Timo Schick and Hinrich Schütze. 2021. Generating datasets with pretrained language models. arXiv preprint arXiv:2104.07540.
Timo Schick和Hinrich Schütze。2021。使用预训练语言模型生成数据集。arXiv预印本arXiv:2104.07540。
Weiwei Sun, Lingyong Yan, Xinyu Ma, Pengjie Ren, Dawei Yin, and Zhaochun Ren. 2023. Is chatgpt good at search? investigating large language models as re-ranking agent. arXiv preprint arXiv:2304.09542.
Weiwei Sun, Lingyong Yan, Xinyu Ma, Pengjie Ren, Dawei Yin, and Zhaochun Ren. 2023. ChatGPT擅长搜索吗?探究大语言模型作为重排序智能体的能力。arXiv preprint arXiv:2304.09542.
Hongyin Tang, Xingwu Sun, Beihong Jin, Jingang Wang, Fuzheng Zhang, and Wei Wu. 2021. Improving document representations by generating pseudo query embeddings for dense retrieval. arXiv preprint arXiv:2105.03599.
Hongyin Tang、Xingwu Sun、Beihong Jin、Jingang Wang、Fuzheng Zhang 和 Wei Wu。2021。通过生成伪查询嵌入改进密集检索的文档表示。arXiv预印本 arXiv:2105.03599。
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. Beir: A he t erogenous benchmark for zero-shot evaluation of information retrieval models. arXiv preprint arXiv:2104.08663.
Nandan Thakur、Nils Reimers、Andreas Rücklé、Abhishek Srivastava 和 Iryna Gurevych。2021。BEIR:一个用于信息检索模型零样本评估的异构基准。arXiv预印本 arXiv:2104.08663。
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
Hugo Touvron、Thibaut Lavril、Gautier Izacard、Xavier Martinet、Marie-Anne Lachaux、Timothée Lacroix、Baptiste Rozière、Naman Goyal、Eric Hambro、Faisal Azhar 等. 2023a. Llama: 开放高效的基础语言模型. arXiv预印本 arXiv:2302.13971.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Hugo Touvron、Louis Martin、Kevin Stone、Peter Albert、Amjad Almahairi、Yasmine Babaei、Nikolay Bashlykov、Soumya Batra、Prajjwal Bhargava、Shruti Bhosale 等. 2023b. Llama 2: 开放基础与微调对话模型. arXiv预印本 arXiv:2307.09288.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Łukasz Kaiser 和 Illia Polosukhin。2017。Attention is all you need。《神经信息处理系统进展》,30。
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2023. Improving text embeddings with large language models. arXiv preprint arXiv:2401.00368.
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2023. 基于大语言模型改进文本嵌入技术. arXiv preprint arXiv:2401.00368.
Xuanhui Wang, Cheng Li, Nadav Golbandi, Michael Bendersky, and Marc Najork. 2018. The lambdaloss framework for ranking metric optimization. In Proceedings of the 27th ACM international conference on information and knowledge management, pages 1313–1322.
Xuanhui Wang, Cheng Li, Nadav Golbandi, Michael Bendersky, Marc Najork. 2018. 排序指标优化的LambdaLoss框架. 见: 第27届ACM国际信息与知识管理会议论文集, 第1313–1322页.
Xueru Wen, Xiaoyang Chen, Xuanang Chen, Ben He, and Le Sun. 2023. Offline pseudo relevance feedback for efficient and effective single-pass dense retrieval. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2209–2214.
温雪茹、陈晓阳、陈宣昂、何贲、孙乐。2023。高效单次密集检索的离线伪相关反馈。载于《第46届国际ACM SIGIR信息检索研究与发展会议论文集》,第2209–2214页。
Gui-Rong Xue, Hua-Jun Zeng, Zheng Chen, Yong Yu, Wei-Ying Ma, WenSi Xi, and WeiGuo Fan. 2004. Optimizing web search using web click-through data. In Proceedings of the thirteenth ACM international conference on Information and knowledge management, pages 118–126.
薛贵荣, 曾华军, 陈政, 俞勇, 马维英, 奚文斯, 范伟国. 2004. 利用网页点击数据优化网络搜索. 见: 第十三届ACM国际信息与知识管理会议论文集, 第118-126页.
Yiben Yang, Chaitanya Malaviya, Jared Fernandez, Swabha S way am dip ta, Ronan Le Bras, Ji-Ping Wang, Chandra Bhaga va tula, Yejin Choi, and Doug Downey. 2020. Generative data augmentation for commonsense reasoning. arXiv preprint arXiv:2004.11546.
Yiben Yang、Chaitanya Malaviya、Jared Fernandez、Swabha Swayamdipta、Ronan Le Bras、Ji-Ping Wang、Chandra Bhagavatula、Yejin Choi 和 Doug Downey。2020。常识推理的生成式数据增强 (Generative Data Augmentation for Commonsense Reasoning)。arXiv预印本 arXiv:2004.11546。
Wenhao Yu. 2022. Retrieval-augmented generation across heterogeneous knowledge. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop, pages 52–58.
Wenhao Yu. 2022. 跨异构知识的检索增强生成. 见《2022年北美计算语言学协会会议: 人类语言技术: 学生研究研讨会论文集》, 第52-58页.
Appendix
附录
Here we share the ablation studies’ results and the prompts we used in generating synthetic queries and titles using Llama-70B.
我们在此分享消融研究的结果,以及使用Llama-70B生成合成查询和标题时所采用的提示词。
| LoTTEDataset | ||||||||||||
| Model | Recall | Lifestyle | Lifestyle | Recreation | Recreation | Science | Science | Technology | Technology | Writing | Writing | |
| Forum | Search | Forum | Search | Forum | Search | Forum | Search | Forum | Search | |||
| Contriever Wchunk=1.0 | recall@3 | 0.4476 | 0.4342 | 0.3871 | 0.2695 | 0.1358 | 0.1896 | 0.2116 | 0.1879 | 0.4425 | 0.3968 | |
| recall@10 | 0.6459 | 0.6172 | 0.5415 | 0.4145 | 0.2196 | 0.3063 | 0.3693 | 0.3003 | 0.600 | 0.5369 | ||
| Contriever | recall@3 | 0.6194 | 0.6967 | 0.5355 | 0.4437 | 0.2335 | 0.2901 | 0.3523 | 0.3305 | 0.5860 | 0.5472 | |
| Wquery=1.0 | recall@10 | 0.7762 | 0.7837 | 0.6863 | 0.6115 | 0.3461 | 0.4295 | 0.5180 | 0.4883 | 0.7410 | 0.6910 | |
| Contriever | recall@3 | 0.5310 | 0.4902 | 0.4975 | 0.3789 | 0.2345 | 0.1896 | 0.3468 | 0.2668 | 0.5315 | 0.4809 | |
| Wtitle=1.0 | recall@10 | 0.6958 | 0.6641 | 0.6404 | 0.5314 | 0.3421 | 0.3241 | 0.5200 | 0.4077 | 0.6725 | 0.6153 | |
| Contriever* | recall@3 recall@10 | 0.6244 0.7622 | 0.6021 0.7821 | 0.5455 0.6948 | 0.4610 0.6320 | 0.2395 0.3570 | 0.2901 0.4684 | 0.3663 0.5494 | 0.3557 0.5017 | 0.5970 0.7365 | 0.5724 0.6919 | |
| Model Recall | ArguAna | FIQA | BEIR Dataset Quora SciDocs | SciFact | CQADupstackCQADupstack | |||||||
| English | Physics | |||||||||||
| Contriever Wchunk=1.0 | recall@3 0.2240 | 0.2623 | 0.8653 | 0.1980 0.6177 0.7466 | 0.2605 | 0.2156 | ||||||
| Contriever | recall@10 | 0.5391 | 0.4031 | 0.9463 | 0.3360 | 0.3580 | 0.3292 | |||||
| recall@3 | 0.2347 | 0.3580 | 0.8622 | 0.2180 0.5888 | 0.3860 | 0.3330 | ||||||
| Wquery=1.0 Contriever | recall@10 | 0.5718 | 0.5045 | 0.8088 | 0.3720 | 0.7322 0.5013 | 0.4629 | |||||
| recall@3 | 0.2063 | 0.3180 | 0.7555 | 0.2600 | 0.5573 | 0.3338 0.2926 | ||||||
| Wtitle=1.0 Contriever* | recall@10 | 0.5192 | 0.4595 | 0.8791 | 0.4120 | 0.7051 0.4369 | 0.4100 | |||||
| recall@3 | 0.2468 | 0.3690 | 0.8687 | 0.2440 | 0.5996 0.3822 | 0.3417 | ||||||
| recall@10 | 0.5825 | 0.5174 | 0.9517 | 0.4030 | 0.7259 0.5025 | 0.4658 | ||||||
Table 4: Ablation study on doc-level embedding with Contriever. In most cases the ensemble of relevant queries, title and chunks gives the best results. * means base model plus the doc-level embedding (chunk:0.1, query:1.0, title:0.5).
表 4: 基于Contriever的文档级嵌入消融研究。在多数情况下,结合相关查询(query)、标题(title)和文本块(chunk)的集成方法能取得最佳效果。*表示基础模型加上文档级嵌入(文本块:0.1,查询:1.0,标题:0.5)。
| 模型 | 召回率 | 生活方式 | 生活方式 | 休闲娱乐 | 休闲娱乐 | 科学 | 科学 | 技术 | 技术 | 写作 | 写作 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | ||
| Contriever Wchunk=1.0 | recall@3 | 0.4476 | 0.4342 | 0.3871 | 0.2695 | 0.1358 | 0.1896 | 0.2116 | 0.1879 | 0.4425 | 0.3968 |
| recall@10 | 0.6459 | 0.6172 | 0.5415 | 0.4145 | 0.2196 | 0.3063 | 0.3693 | 0.3003 | 0.6000 | 0.5369 | |
| Contriever Wquery=1.0 | recall@3 | 0.6194 | 0.6967 | 0.5355 | 0.4437 | 0.2335 | 0.2901 | 0.3523 | 0.3305 | 0.5860 | 0.5472 |
| recall@10 | 0.7762 | 0.7837 | 0.6863 | 0.6115 | 0.3461 | 0.4295 | 0.5180 | 0.4883 | 0.7410 | 0.6910 | |
| Contriever Wtitle=1.0 | recall@3 | 0.5310 | 0.4902 | 0.4975 | 0.3789 | 0.2345 | 0.1896 | 0.3468 | 0.2668 | 0.5315 | 0.4809 |
| recall@10 | 0.6958 | 0.6641 | 0.6404 | 0.5314 | 0.3421 | 0.3241 | 0.5200 | 0.4077 | 0.6725 | 0.6153 | |
| Contriever* | recall@3 | 0.6244 | 0.6021 | 0.5455 | 0.4610 | 0.2395 | 0.2901 | 0.3663 | 0.3557 | 0.5970 | 0.5724 |
| recall@10 | 0.7622 | 0.7821 | 0.6948 | 0.6320 | 0.3570 | 0.4684 | 0.5494 | 0.5017 | 0.7365 | 0.6919 |
| 模型 | 召回率 | ArguAna | FIQA | BEIR数据集 Quora SciDocs | SciFact | CQADupstack英语 | CQADupstack物理 |
|---|---|---|---|---|---|---|---|
| Contriever Wchunk=1.0 | recall@3 | 0.2240 | 0.2623 | 0.8653 | 0.1980 0.6177 0.7466 | 0.2605 | 0.2156 |
| Contriever Wquery=1.0 | recall@10 | 0.5391 | 0.4031 | 0.9463 | 0.3360 0.3580 | 0.3292 | |
| recall@3 | 0.2347 | 0.3580 | 0.8622 | 0.2180 0.5888 | 0.3860 | 0.3330 | |
| recall@10 | 0.5718 | 0.5045 | 0.8088 | 0.3720 0.7322 0.5013 | 0.4629 | ||
| Contriever Wtitle=1.0 | recall@3 | 0.2063 | 0.3180 | 0.7555 | 0.2600 0.5573 | 0.3338 0.2926 | |
| recall@10 | 0.5192 | 0.4595 | 0.8791 | 0.4120 0.7051 0.4369 | 0.4100 | ||
| Contriever* | recall@3 | 0.2468 | 0.3690 | 0.8687 | 0.2440 0.5996 0.3822 | 0.3417 | |
| recall@10 | 0.5825 | 0.5174 | 0.9517 | 0.4030 0.7259 0.5025 | 0.4658 |
Table 5: Ablation study on doc-level embedding with DRAGON. In most cases the ensemble of relevant queries, title and chunks gives the best results. * means base model plus the doc-level embedding (chunk:0.3, query:0.6, title:0.3).
| LoTTEDataset | ||||||||||
| Model | Recall | Lifestyle | Lifestyle | Recreation | Recreation | Science | Science | Technology | Technology Writing | Writing |
| Forum | Search Forum | Search | Forum | Search | Forum | Search | Forum | Search | ||
| DRAGON | recall@3 | 0.6244 | 0.7126 | 0.5375 | 0.5779 | 0.2385 0.3695 | 0.3239 | 0.4362 | 0.6190 | 0.6471 |
| Wchunk=1.0 | recall@10 | 0.7627 | 0.8636 | 0.6813 | 0.7359 0.3738 | 0.5462 | 0.5010 | 0.6023 | 0.7620 | 0.7871 |
| DRAGON | recall@3 | 0.6583 | 0.7247 | 0.5839 | 0.6071 0.2707 | 0.3647 | 0.3892 | 0.4866 | 0.6235 | 0.6583 |
| Wquery=1.0 | recall@10 | 0.8017 | 0.8654 | 0.7108 | 0.7478 0.3991 | 0.5219 | 0.5704 | 0.6812 | 0.7420 | 0.7656 |
| DRAGON | recall@3 | 0.6913 | 0.7610 | 0.6294 | 0.6472 0.3565 | 0.4408 | 0.4616 | 0.5436 | 0.6550 | 0.6928 |
| Wtitle=1.0 | recall@10 | 0.8167 | 0.8790 | 0.7458 | 0.7879 | 0.4834 0.5948 | 0.6477 | 0.7064 | 0.7690 | 0.8011 |
| DRAGON* | recall@3 recall@10 | 0.6883 0.8172 | 0.7625 0.8911 | 0.6079 0.7468 | 0.6472 0.3099 0.7944 0.4427 | 0.4498 0.6062 | 0.4192 0.6038 | 0.5285 0.7097 | 0.6520 0.7725 | 0.7031 0.8170 |
| BEIR Dataset | ||||||||||
| Model | Recall | ArguAna | FIQA Quora | SciDocs | SciFact | CQADupstack CQADupstack | ||||
| English | Physics | |||||||||
| DRAGON Wchunk=1.0 | recall@3 | 0.3919 | 0.3681 0.8587 0.5196 | 0.2860 | 0.6601 0.7827 | 0.4331 | 0.3638 | |||
| recall@10 recall@3 | 0.6863 | 0.9478 | 0.4700 | 0.6032 | 0.5338 | 0.4966 | ||||
| DRAGON Wquery=1.0 | recall@10 | 0.3265 0.3875 0.6472 | 0.8267 | 0.2820 0.4470 | 0.7403 | 0.4318 | 0.3503 | |||
| DRAGON | 0.5220 0.3208 | 0.9283 0.8039 | 0.2940 | 0.5344 0.6375 | 0.4889 | |||||
| Wtitle=1.0 | recall@3 recall@10 | 0.4310 0.6230 0.5692 | 0.9139 | 0.4770 0.7556 | 0.4516 0.5567 | 0.4081 0.5274 | ||||
| DRAGON* | recall@3 | 0.3663 0.4255 | 0.8638 | 0.3040 | 0.4618 | 0.3936 | ||||
| recall@10 | 0.6764 0.5635 | 0.9527 | 0.4800 | 0.6610 0.7710 | 0.5662 | 0.5342 | ||||
表 5: 基于DRAGON的文档级嵌入消融研究。在大多数情况下,相关查询、标题和文本块的组合能取得最佳效果。*表示基础模型加上文档级嵌入(chunk:0.3, query:0.6, title:0.3)。
| 模型 | Recall | Lifestyle Forum | Lifestyle Search | Recreation Forum | Recreation Search | Science Forum | Science Search | Technology Forum | Technology Search | Writing Forum | Writing Search |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DRAGON Wchunk=1.0 | recall@3 | 0.6244 | 0.7126 | 0.5375 | 0.5779 | 0.2385 | 0.3695 | 0.3239 | 0.4362 | 0.6190 | 0.6471 |
| recall@10 | 0.7627 | 0.8636 | 0.6813 | 0.7359 | 0.3738 | 0.5462 | 0.5010 | 0.6023 | 0.7620 | 0.7871 | |
| DRAGON Wquery=1.0 | recall@3 | 0.6583 | 0.7247 | 0.5839 | 0.6071 | 0.2707 | 0.3647 | 0.3892 | 0.4866 | 0.6235 | 0.6583 |
| recall@10 | 0.8017 | 0.8654 | 0.7108 | 0.7478 | 0.3991 | 0.5219 | 0.5704 | 0.6812 | 0.7420 | 0.7656 | |
| DRAGON Wtitle=1.0 | recall@3 | 0.6913 | 0.7610 | 0.6294 | 0.6472 | 0.3565 | 0.4408 | 0.4616 | 0.5436 | 0.6550 | 0.6928 |
| recall@10 | 0.8167 | 0.8790 | 0.7458 | 0.7879 | 0.4834 | 0.5948 | 0.6477 | 0.7064 | 0.7690 | 0.8011 | |
| DRAGON* | recall@3 | 0.6883 | 0.7625 | 0.6079 | 0.6472 | 0.3099 | 0.4498 | 0.4192 | 0.5285 | 0.6520 | 0.7031 |
| recall@10 | 0.8172 | 0.8911 | 0.7468 | 0.7944 | 0.4427 | 0.6062 | 0.6038 | 0.7097 | 0.7725 | 0.8170 |
| 模型 | Recall | ArguAna | FIQA | Quora | SciDocs | SciFact | CQADupstack English | CQADupstack Physics |
|---|---|---|---|---|---|---|---|---|
| DRAGON Wchunk=1.0 | recall@3 | 0.3919 | 0.3681 | 0.8587 | 0.2860 | 0.6601 | 0.4331 | 0.3638 |
| recall@10 | 0.6863 | 0.9478 | 0.5196 | 0.4700 | 0.7827 | 0.5338 | 0.4966 | |
| DRAGON Wquery=1.0 | recall@3 | 0.3265 | 0.3875 | 0.6472 | 0.2820 | 0.7403 | 0.4318 | 0.3503 |
| recall@10 | 0.5220 | 0.8267 | 0.9283 | 0.4470 | 0.5344 | 0.4889 | 0.6375 | |
| DRAGON Wtitle=1.0 | recall@3 | 0.3208 | 0.8039 | 0.2940 | 0.7556 | 0.4516 | 0.4081 | 0.5274 |
| recall@10 | 0.6230 | 0.9139 | 0.4770 | 0.5692 | 0.5567 | 0.5274 | 0.5274 | |
| DRAGON* | recall@3 | 0.3663 | 0.4255 | 0.8638 | 0.3040 | 0.4618 | 0.3936 | 0.3936 |
| recall@10 | 0.6764 | 0.9527 | 0.5635 | 0.4800 | 0.7710 | 0.5662 | 0.5342 |
| Model | LoTTEDataset | ||||||||||
| Recall | Lifestyle | Lifestyle | Recreation | Recreation | Science | Science | TechnologyTechnologyWriting | Writing | |||
| ColBERTv2 chunk64 only | Forum | Search | Forum | Search | Forum | Search | Forum | Search | Forum | Search | |
| recall@3 | 0.6184 | 0.7474 | 0.5949 | 0.6245 | 0.3535 | 0.4797 | 0.3927 | 0.5168 | 0.6680 | 0.7199 | |
| recall@10 | 0.7537 | 0.8759 | 0.7258 | 0.7586 | 0.4819 | 0.6353 | 0.5758 | 0.6846 | 0.7945 | 0.8273 | |
| ColBERTv2 query only | recall@3 | 0.7088 | 0.7413 | 0.6479 | 0.6580 | 0.3634 | 0.4327 | 0.3643 | 0.4530 | 0.6835 | 0.7274 |
| ColBERTv2 title only | recall@10 | 0.8222 | 0.8759 | 0.7642 | 0.7727 | 0.4948 | 0.5997 | 0.5259 | 0.5419 | 0.7890 | 0.8254 |
| recall@3 | 0.6004 | 0.6218 | 0.5210 | 0.5487 | 0.3128 | 0.3695 | 0.4336 | 0.4715 | 0.5425 | 0.5780 | |
| recall@10 | 0.7368 | 0.7458 | 0.6479 | 0.6937 | 0.4378 | 0.5024 | 0.5968 | 0.6141 | 0.6505 | 0.6853 | |
| ColBERTv2* | recall@3 | 0.7308 | 0.8003 | 0.6753 | 0.7100 | 0.4026 | 0.5024 | 0.4626 | 0.5956 | 0.7145 | 0.7544 |
| recall@10 | 0.8447 0.9107 | 0.7862 | 0.8268 | 0.5558 | 0.6726 | 0.6517 | 0.7383 | 0.8260 | 0.8571 | ||
| BEIRDataset | |||||||||||
| Model | Recall | ArguAna | FIQA | Quora | SciDocs | SciFact | CQADupstackCQADupstack | ||||
| English | Physics | ||||||||||
| ColBERTv2 query only | recall@3 | 0.3122 | 0.4299 | 0.8037 | 0.2680 | 0.6041 | 0.4503 | 0.4187 | |||
| recall@10 | 0.5711 | 0.5654 | 0.9102 | 0.4170 | 0.7214 | 0.5357 | 0.5342 | ||||
| ColBERTv2 title only | recall@3 | 0.2091 | 0.3372 | 0.7149 | 0.2580 | 0.4806 | 0.3344 | 0.3494 | |||
| ColBERTv2* | recall@10 | 0.3947 | 0.4588 | 0.8265 | 0.4060 | 0.6005 | 0.4248 | 0.4716 | |||
| recall@3 | 0.3592 | 0.4666 | 0.9067 | 0.3000 | 0.6862 | 0.4822 | 0.4196 | ||||
| recall@10 | 0.6344 | 0.6018 | 0.9663 | 0.4850 | 0.7917 | 0.5694 | 0.5611 | ||||
| 模型 | LoTTE数据集 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 召回率 | 生活方式 | 生活方式 | 休闲娱乐 | 休闲娱乐 | 科学 | 科学 | 技术 | 技术 | 写作 | 写作 | |
| 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | 论坛 | 搜索 | ||
| ColBERTv2 chunk64 only | recall@3 | 0.6184 | 0.7474 | 0.5949 | 0.6245 | 0.3535 | 0.4797 | 0.3927 | 0.5168 | 0.6680 | 0.7199 |
| recall@10 | 0.7537 | 0.8759 | 0.7258 | 0.7586 | 0.4819 | 0.6353 | 0.5758 | 0.6846 | 0.7945 | 0.8273 | |
| ColBERTv2 query only | recall@3 | 0.7088 | 0.7413 | 0.6479 | 0.6580 | 0.3634 | 0.4327 | 0.3643 | 0.4530 | 0.6835 | 0.7274 |
| ColBERTv2 title only | recall@10 | 0.8222 | 0.8759 | 0.7642 | 0.7727 | 0.4948 | 0.5997 | 0.5259 | 0.5419 | 0.7890 | 0.8254 |
| recall@3 | 0.6004 | 0.6218 | 0.5210 | 0.5487 | 0.3128 | 0.3695 | 0.4336 | 0.4715 | 0.5425 | 0.5780 | |
| recall@10 | 0.7368 | 0.7458 | 0.6479 | 0.6937 | 0.4378 | 0.5024 | 0.5968 | 0.6141 | 0.6505 | 0.6853 | |
| ColBERTv2* | recall@3 | 0.7308 | 0.8003 | 0.6753 | 0.7100 | 0.4026 | 0.5024 | 0.4626 | 0.5956 | 0.7145 | 0.7544 |
| recall@10 | 0.8447 | 0.9107 | 0.7862 | 0.8268 | 0.5558 | 0.6726 | 0.6517 | 0.7383 | 0.8260 | 0.8571 |
| 模型 | BEIR数据集 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 召回率 | ArguAna | FIQA | Quora | SciDocs | SciFact | CQADupstack | CQADupstack | ||||
| English | Physics | ||||||||||
| ColBERTv2 query only | recall@3 | 0.3122 | 0.4299 | 0.8037 | 0.2680 | 0.6041 | 0.4503 | 0.4187 | |||
| recall@10 | 0.5711 | 0.5654 | 0.9102 | 0.4170 | 0.7214 | 0.5357 | 0.5342 | ||||
| ColBERTv2 title only | recall@3 | 0.2091 | 0.3372 | 0.7149 | 0.2580 | 0.4806 | 0.3344 | 0.3494 | |||
| recall@10 | 0.3947 | 0.4588 | 0.8265 | 0.4060 | 0.6005 | 0.4248 | 0.4716 | ||||
| ColBERTv2* | recall@3 | 0.3592 | 0.4666 | 0.9067 | 0.3000 | 0.6862 | 0.4822 | 0.4196 | |||
| recall@10 | 0.6344 | 0.6018 | 0.9663 | 0.4850 | 0.7917 | 0.5694 | 0.5611 |
Table 6: Ablation study on doc-level embedding with ColBERTv2. In all cases the ensemble of relevant queries title and chunks gives the best results. * means base model plus the doc-level embedding.
表 6: 基于ColBERTv2的文档级嵌入消融研究。在所有情况下,相关查询标题与文本块的组合均能获得最佳结果。*表示基础模型加文档级嵌入。
Table 7: Statistical description of BEIR dataset
| QuestionSet | #Questions | #Passages |
| ArguAna | 1406 | 8674 |
| FIQA | 6648 | 57600 |
| Quora | 15000 | 522929 |
| SciDocs | 1000 | 25313 |
| SciFact | 1109 | 5183 |
| CQADupstack English | 1570 | 40221 |
| CQADupstack Physics | 1039 | 38316 |
表 7: BEIR数据集统计描述
| 问题集 | 问题数量 | 段落数量 |
|---|---|---|
| ArguAna | 1406 | 8674 |
| FIQA | 6648 | 57600 |
| Quora | 15000 | 522929 |
| SciDocs | 1000 | 25313 |
| SciFact | 1109 | 5183 |
| CQADupstack English | 1570 | 40221 |
| CQADupstack Physics | 1039 | 38316 |
| QuestionSet | #Questions | #Passages | Subtopics |
| LifestyleSearch LifestyleForum | 661 | 219k | Cooking,Sports,Travel |
| RecreationSearch | 2002 924 | 167k | Gaming,Anime,Movies |
| RecreationForum ScienceSearch | 2002 617 | ||
| ScienceForum TechnologySearch | 2017 596 | 1.694M | Math,Physics,Biology |
| TechnologyForum | 2004 | 639k | Apple,Android,UNIX,Security |
| WritingSearch WritingForum | 1071 2000 | 200k | English |
| QuestionSet | #Questions | #Passages | Subtopics |
|---|---|---|---|
| LifestyleSearch LifestyleForum | 661 | 219k | Cooking, Sports, Travel |
| RecreationSearch | 2002 924 | 167k | Gaming, Anime, Movies |
| RecreationForum ScienceSearch | 2002 617 | ||
| ScienceForum TechnologySearch | 2017 596 | 1.694M | Math, Physics, Biology |
| TechnologyForum | 2004 | 639k | Apple, Android, UNIX, Security |
| WritingSearch WritingForum | 1071 2000 | 200k | English |
Table 8: Statistical description of LoTTE Test dataset Table 9: Prompt for generating relevant queries for documents Table 10: Prompt for generating titles for documents.
| I will give you an article below. Create a title for the below article. |
| Thisisthearticle:{document} |
| question. Don't write empty title. |
表 8: LoTTE测试数据集的统计描述
表 9: 为文档生成相关查询的提示
表 10: 为文档生成标题的提示
| 我将提供一篇文章。请为以下文章创建一个标题。 |
| 这是文章内容: {document} |
| 问题。不要生成空标题。 |