
概述
适应性是自然界中最引人注目的现象之一。从章鱼通过改变皮肤颜色来融入环境,到人类大脑在受伤后重新连接,使个体能够恢复失去的功能并适应新的思维方式或运动方式。生物体展现出的适应性使得生命能够在多样且不断变化的环境中蓬勃发展。
在人工智能领域,适应性的概念同样具有吸引力。想象一下,一个机器学习系统能够动态调整自身的权重,以在不熟悉的环境中茁壮成长,这本质上展示了一个随着学习而进化的系统。自适应性的人工智能承诺更高的效率,并有可能实现与动态现实世界始终保持一致的终身模型。
这种自适应性人工智能的愿景是我们最新研究论文 Transformer²(“Transformer平方”)的核心,我们提出了一种能够为各种任务动态调整权重的机器学习系统。名称Transformer²反映了它的两步过程:首先,模型分析传入的任务以理解其需求,然后应用特定任务的调整以生成最佳结果。通过有选择地调整模型权重的关键组件,我们的框架使大语言模型(LLMs)能够实时动态适应新任务。Transformer²在各种任务(如数学、编码、推理和视觉理解)中展示了显著的进步,在效率和任务特定性能方面优于传统的静态方法(如LoRA),同时所需的参数数量大大减少。
我们的研究为未来提供了一个窥视,未来的AI模型将不再是静态的。这些系统将在测试时动态扩展其计算能力,以适应所遇到任务的复杂性,体现能够持续变化和终身学习的活体智能。我们相信自适应性不仅将改变AI研究,还将重新定义我们与智能系统的互动方式,创造一个适应性和智能并行的世界。

Transformer²是一种能够为各种任务动态调整权重的机器学习系统。适应性是一种显著的自然现象,就像章鱼如何改变颜色以融入环境,或者大脑在受伤后如何重新连接。我们相信,我们的新系统为新一代自适应AI模型铺平了道路,这些模型能够修改自身的权重和架构,以适应所遇到任务的性质,体现能够持续变化和终身学习的活体智能。
剖析大语言模型的“大脑”
就像人类大脑通过相互连接的神经通路存储知识和处理信息一样,大语言模型(LLMs)在其权重矩阵中存储知识。这些矩阵是LLM的“大脑”,包含了它从训练数据中学到的精髓。
理解这个“大脑”并确保它能够有效适应新任务,需要更深入地研究其内部结构。这就是奇异值分解(SVD)提供宝贵见解的地方。将SVD想象为一位外科医生,对LLM的大脑进行详细的手术。这位外科医生将LLM中存储的庞大而复杂的知识分解为更小、有意义且独立的部分(例如,数学、语言理解等不同路径或组件)。
SVD通过识别LLM权重矩阵的主成分来实现这一目的。在我们的研究中,我们发现增强这些成分中的一部分信号,同时抑制其他部分,可以提高LLM在下游任务中的表现。基于这一基础,Transformer²迈出了动态、任务特定适应的下一步,使LLM能够在多样且复杂的场景中表现出色。
介绍Transformer²
Transformer²是一种开创性的方法,通过两步过程重新定义了这些强大模型处理多样化任务的方式。其核心是能够动态调整其权重矩阵的关键组件。在训练时,我们引入了奇异值微调(SVF),这是一种使用强化学习(RL)来增强/抑制不同“大脑”组件信号的方法,适用于各种类型的下游任务。在推理时,我们采用三种不同的策略来检测任务的身份,并相应地调整模型的权重。下图概述了我们的方法。
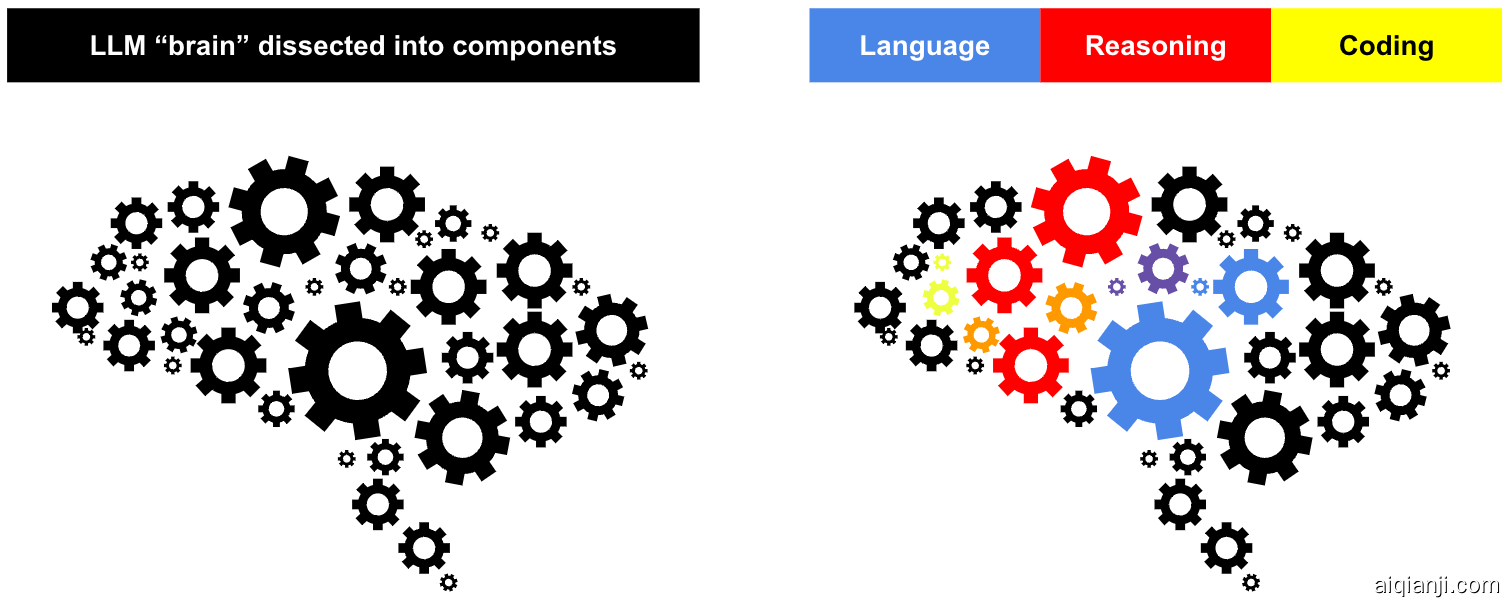
我们的方法示意图。 左:我们使用SVD将LLM的“大脑”(即权重矩阵)分解为几个独立的组件。右:我们使用RL来训练这些组件的组合,以应对各种任务。组件可以在不同任务之间共享。例如,在上图中,紫色齿轮由语言理解和推理共享。在推理时,我们识别任务类型,然后动态调整组件的组合。
使用SVF和RL进行训练
在训练时,SVF学习一组z-向量,每个下游任务一个。每个z-向量可以被视为某个任务的专家,它是一个紧凑的表示,指定了权重矩阵中每个组件的期望强度,充当一组“放大器”或“阻尼器”,以调节不同组件对模型行为的影响。
例如,假设SVD将一个权重矩阵分解为五个组件[A, B, C, D, E]。对于数学任务,学习到的z-向量可能是[1, 0.8, 0, 0.3, 0.5],这意味着组件A对数学至关重要,而组件C对其表现几乎没有影响。对于语言理解任务,z-向量可能是[0.1, 0.3, 1, 0.7, 0.5],这表明尽管组件C对数学任务不太有用,但它对语言理解任务至关重要。
SVF使用RL在一组预定义的下游任务上学习这些z-向量。学习到的z-向量使Transformer²能够适应各种新的下游任务,同时仅引入最少数量的额外参数(即z-向量)。
自适应性
在推理时,我们为我们的框架设计了一种两阶段适应策略,有效地结合了任务特定的z-向量集合。在第一次推理过程中,给定一个任务或单个输入提示,Transformer²使用以下三种适应方法之一分析其测试时条件。在第二次推理过程中,Transformer²通过结合z-向量相应地调整权重,生成最符合其新设置的最终响应。
我们总结了以下三种任务检测/适应方法:
- 基于提示的适应。 一个专门设计的适应提示对任务进行分类(例如,数学、编码)并选择一个预训练的z-向量。
- 基于分类器的适应。 一个使用SVF训练的任务分类器在推理过程中识别任务并选择适当的z-向量。
- 少样本适应。 通过加权插值结合多个预训练的z-向量。一个简单的优化算法基于少样本评估集的表现调整这些权重。
这三种方法共同确保Transformer²实现稳健且高效的任务适应,为在各种场景中取得卓越表现铺平了道路。详情请参阅我们的论文。
主要结果
我们将我们的方法应用于Llama和Mistral大语言模型,涵盖广泛的任务,包括数学(GSM8K, MATH)、编码(MBPP-Pro, HumanEval)、推理(ARC-Easy, ARC-Challenge)和视觉问答(TextVQA, OKVQA)。
我们首先通过SVF在这些任务上获得z-向量,并将其与LoRA进行比较。我们在下表中的结果显示,SVF在基于文本的任务上优于LoRA,特别是在GSM8K上表现尤为突出。这可以归因于我们的RL训练目标,它不需要每个问题的“完美解决方案”,这与LoRA的微调方法不同。右侧的直方图还展示了SVF在视觉领域的惊人能力。
SVF在广泛任务上的评估。 我们将每个任务分为训练集、验证集和测试集。我们使用pass@1作为MBPP-Pro的评估指标,使用准确率作为所有其他任务的评估指标。左:SVF在语言任务上的表现。标准化分数在括号中。右:SVF在VQA任务上的表现。

然后,我们在未见过的任务(特别是MATH、HumanEval和ARC-Challenge)上评估我们的适应框架与LoRA的对比。下表左侧显示,随着方法复杂性的增加,我们的策略在所有任务上都取得了越来越高的性能提升。
一个特别有趣的发现来自分析少样本学习如何结合不同的z-向量来应对任务,如右图所示。在解决MATH问题时,与预期相反,模型并不完全依赖其GSM8K(数学)专用的z-向量。这表明复杂的数学推理受益于结合数学、编程和逻辑推理能力。我们在其他任务和模型中观察到了类似的意外组合,突显了该框架综合不同类型专业知识以实现最佳表现的能力。
Transformer²的评估。 我们直接报告了在未见任务上的测试集表现。左:在未见任务上的自适应性。右:学习到的z-向量插值权重。

最后,我们探索了一个挑战AI开发传统观念的有趣问题:我们能否将一个模型的知识转移到另一个模型?令人兴奋的是,当我们将从Llama学习到的z-向量转移到Mistral时,我们观察到后者在大多数任务上的表现有所提高。详见下表。
尽管这些发现很有希望,但我们应该注意到,这两个模型具有相似的架构,这可能解释了它们的兼容性。这种知识共享是否能在更多样化的AI模型之间起作用仍然是一个悬而未决的问题。尽管如此,这些结果为解开和回收任务特定技能以用于更新/更大的模型提供了令人兴奋的可能性。
跨模型z-向量转移。 将从Llama3-8B-Instruct训练的“专家”转移到Mistral-7B-Instruct-v0.3并使用少样本适应的结果。

未来:从静态模型到活体智能
Transformer²代表了AI系统进化的一个重要里程碑。它能够实时动态适应未见任务,并增强组合性,展示了自适应性大语言模型在AI研究和应用中的革命性潜力。
但这仅仅是个开始。Transformer²为我们提供了一个窥视未来的机会,未来的AI系统将不再是针对固定任务训练的静态实体。相反,它们将体现“活体智能”,即能够持续学习、进化和适应的模型。想象一下,一个AI能够无缝整合新知识或在现实环境中实时调整其行为,而无需重新训练,就像人类如何应对新挑战一样。
未来的道路在于构建能够动态适应并与其他系统协作的模型,结合专门的能力来解决复杂的多领域问题。像Transformer²这样的自适应性系统弥合了静态AI和活体智能之间的差距,为高效、个性化和完全集成的AI工具铺平了道路,推动各行业和日常生活的进步。
