SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION
SELF-RAG: 通过自我反思学习检索、生成与评判
Akari Asai†, Zeqiu $\mathbf{W}\mathbf{u}^{\dagger}$ , Yizhong Wang†§, Avirup $\mathbf{Sil^{\ddagger}}$ , Hannaneh Hajishirzi†§ †University of Washington §Allen Institute for AI ‡IBM Research AI {akari,zeqiuwu,yizhongw,hannaneh}@cs.washington.edu, avi@us.ibm.com
赤岭明里†、吴泽秋†、王一舟†§、阿维鲁普·希尔‡、哈娜内·哈吉希尔齐†§
†华盛顿大学 §艾伦人工智能研究所 ‡IBM研究院人工智能部
{akari,zeqiuwu,yizhongw,hannaneh}@cs.washington.edu, avi@us.ibm.com
ABSTRACT
摘要
Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad hoc approach that augments LMs with retrieval of relevant knowledge, decreases such issues. However, indiscriminately retrieving and incorporating a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are relevant, diminishes LM versatility or can lead to unhelpful response generation. We introduce a new framework called Self-Reflective Retrieval-Augmented Generation (SELF-RAG) that enhances an LM’s quality and factuality through retrieval and self-reflection. Our framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using special tokens, called reflection tokens. Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements. Experiments show that SELFRAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks. Specifically, SELF-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.1
尽管大语言模型(LLM)具有卓越能力,但由于仅依赖其封装的参数化知识,生成的响应常包含事实性错误。检索增强生成(RAG)通过临时检索相关知识来增强语言模型,减少了此类问题。然而,无论检索是否必要或段落是否相关, indiscriminately检索并固定数量地合并段落会降低语言模型的灵活性,或导致生成无益的响应。我们提出了一种名为自反思检索增强生成(SELF-RAG)的新框架,通过检索和自反思提升语言模型的质量和事实性。该框架训练一个可自适应按需检索段落的通用语言模型,并使用称为反思token的特殊token来生成并对检索段落及自身生成内容进行反思。生成反思token使模型在推理阶段可控,能够根据不同任务需求调整行为。实验表明,SELF-RAG(70亿和130亿参数)在多样化任务上显著优于当前最先进的大语言模型和检索增强模型。具体而言,SELF-RAG在开放域问答、推理和事实核查任务上优于ChatGPT和检索增强版Llama2-chat,并在长文本生成的事实性和引用准确性方面较这些模型展现出显著提升。[20]
1 INTRODUCTION
1 引言
State-of-the-art LLMs continue to struggle with factual errors (Mallen et al., 2023; Min et al., 2023) despite their increased model and data scale (Ouyang et al., 2022). Retrieval-Augmented Generation (RAG) methods (Figure 1 left; Lewis et al. 2020; Guu et al. 2020) augment the input of LLMs with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks (Ram et al., 2023; Asai et al., 2023a). However, these methods may hinder the versatility of LLMs or introduce unnecessary or off-topic passages that lead to low-quality generations (Shi et al., 2023) since they retrieve passages indiscriminately regardless of whether the factual grounding is helpful. Moreover, the output is not guaranteed to be consistent with retrieved relevant passages (Gao et al., 2023) since the models are not explicitly trained to leverage and follow facts from provided passages. This work introduces Self-Reflective Retrieval-augmented Generation (SELF-RAG) to improve an LLM’s generation quality, including its factual accuracy without hurting its versatility, via on-demand retrieval and self-reflection. We train an arbitrary LM in an end-to-end manner to learn to reflect on its own generation process given a task input by generating both task output and intermittent special tokens (i.e., reflection tokens). Reflection tokens are categorized into retrieval and critique tokens to indicate the need for retrieval and its generation quality respectively (Figure 1 right). In particular, given an input prompt and preceding generations, SELF-RAG first determines if augmenting the continued generation with retrieved passages would be helpful. If so, it outputs a retrieval token that calls a retriever model on demand (Step 1). Subsequently, SELF-RAG concurrently processes multiple retrieved passages, evaluating their relevance and then generating corresponding task outputs (Step 2). It then generates critique tokens to criticize its own output and choose best one (Step 3) in terms of factuality and overall quality. This process differs from conventional RAG (Figure 1 left), which consistently retrieves a fixed number of documents for generation regardless of the retrieval necessity (e.g., the bottom figure example does not require factual knowledge) and never second visits the generation quality. Moreover, SELF-RAG provides citations for each segment with its self-assessment of whether the output is supported by the passage, leading to easier fact verification.
当前最先进的大语言模型在事实准确性方面仍存在不足 [Mallen et al., 2023; Min et al., 2023],尽管其模型和数据规模不断扩大 [Ouyang et al., 2022]。检索增强生成 (Retrieval-Augmented Generation, RAG) 方法 (图1左; [Lewis et al., 2020; Guu et al., 2020]) 通过检索相关段落来增强大语言模型的输入,从而减少知识密集型任务中的事实错误 [Ram et al., 2023; Asai et al., 2023a]。然而,这些方法可能会限制大语言模型的通用性,或引入不必要或偏离主题的段落,导致生成质量低下 [Shi et al., 2023],因为它们不加区分地检索段落,而不考虑事实依据是否有帮助。此外,由于模型没有经过明确训练以利用和遵循所提供段落中的事实,输出不能保证与检索到的相关段落一致 [Gao et al., 2023]。
本文提出自反思检索增强生成 (Self-Reflective Retrieval-augmented Generation, SELF-RAG),通过按需检索和自反思来提高大语言模型的生成质量,包括事实准确性,同时不损害其通用性。我们以端到端的方式训练任意语言模型,使其学会在给定任务输入时,通过生成任务输出和间歇性特殊标记 (即反思标记) 来反思自身的生成过程。反思标记分为检索标记和批评标记,分别表示检索需求和生成质量 (图1右)。具体而言,给定输入提示和之前的生成内容,SELF-RAG 首先判断是否需要用检索到的段落来增强后续生成。如果需要,它会输出一个检索标记,按需调用检索模型 (步骤1)。随后,SELF-RAG 并行处理多个检索到的段落,评估其相关性,然后生成相应的任务输出 (步骤2)。接着,它会生成批评标记,以批评自己的输出,并根据事实性和整体质量选择最佳输出 (步骤3)。这一过程不同于传统的 RAG (图1左),后者无论检索必要性如何 (例如,底部图例不需要事实知识) 都会固定检索一定数量的文档用于生成,并且不会二次检查生成质量。此外,SELF-RAG 为每个片段提供引用,并自我评估输出是否得到段落的支持,从而使事实验证更加容易。
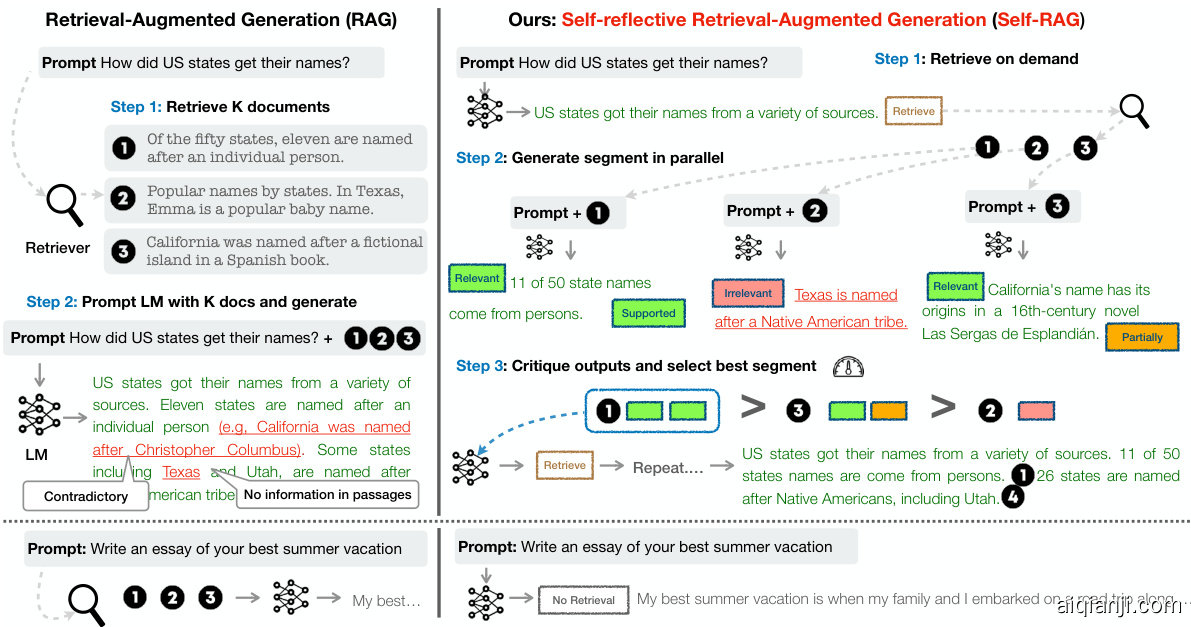
Figure 1: Overview of SELF-RAG. SELF-RAG learns to retrieve, critique, and generate text passages to enhance overall generation quality, factuality, and verifiability.
图 1: SELF-RAG 概览。SELF-RAG 通过学习检索、评价和生成文本来提升整体生成质量、事实性和可验证性。
SELF-RAG trains an arbitrary LM to generate text with reflection tokens by unifying them as the next token prediction from the expanded model vocabulary. We train our generator LM on a diverse collection of text interleaved with reflection tokens and retrieved passages. Reflection tokens, inspired by reward models used in reinforcement learning (Ziegler et al., 2019; Ouyang et al., 2022), are inserted offline into the original corpus by a trained critic model. This eliminates the need to host a critic model during training, reducing overhead. The critic model, in part, is supervised on a dataset of input, output, and corresponding reflection tokens collected by prompting a propriety LM (i.e., GPT-4; OpenAI 2023). While we draw inspiration from studies that use control tokens to start and guide text generation (Lu et al., 2022; Keskar et al., 2019), our trained LM uses critique tokens to assess its own predictions after each generated segment as an integral part of the generation output.
SELF-RAG通过将反思标记 (reflection token) 统一作为扩展模型词汇表中的下一个标记预测,训练任意大语言模型生成带有反思标记的文本。我们在交织了反思标记与检索段落的多样化文本集合上训练生成器模型。受强化学习中奖励模型的启发 (Ziegler等人, 2019; Ouyang等人, 2022) ,反思标记由训练好的评判模型 (critic model) 离线插入原始语料。这消除了训练期间托管评判模型的需求,降低了开销。评判模型的部分监督数据来自通过提示专有大语言模型 (如GPT-4; OpenAI 2023) 收集的输入、输出及对应反思标记数据集。虽然我们借鉴了使用控制标记启动和引导文本生成的研究 (Lu等人, 2022; Keskar等人, 2019) ,但经过训练的模型会将批判标记作为生成输出的组成部分,在每段生成后评估自身预测结果。
SELF-RAG further enables a customizable decoding algorithm to satisfy hard or soft constraints, which are defined by reflection token predictions. In particular, our inference-time algorithm enables us to (1) flexibly adjust retrieval frequency for different downstream applications and (2) customize models’ behaviors to user preferences by leveraging reflection tokens through segment-level beam search using the weighted linear sum of the reflection token probabilities as segment score.
SELF-RAG进一步支持可定制的解码算法,以满足由反思token预测定义的硬约束或软约束。具体而言,我们的推理时算法能够:(1) 针对不同下游应用灵活调整检索频率;(2) 通过分段级束搜索,利用反思token概率的加权线性和作为分段分数,根据用户偏好定制模型行为。
Empirical results on six tasks, including reasoning and long-form generation, demonstrate that SELFRAG significantly outperforms pre-trained and instruction-tuned LLMs that have more parameters and widely adopted RAG approaches with higher citation accuracy. In particular, SELF-RAG outperforms retrieval-augmented ChatGPT on four tasks, Llama2-chat (Touvron et al., 2023) and Alpaca (Dubois et al., 2023) on all tasks. Our analysis demonstrates the effectiveness of training and inference with reflection tokens for overall performance improvements as well as test-time model customization s (e.g., balancing the trade-off between citation previsions and completeness).
在六项任务(包括推理和长文本生成)上的实证结果表明,SELFRAG显著优于参数规模更大的预训练及指令调优大语言模型,以及引用准确率更高的主流RAG方法。特别值得注意的是,SELF-RAG在四项任务上超越检索增强型ChatGPT,在所有任务上均优于Llama2-chat (Touvron等人,2023)和Alpaca (Dubois等人,2023)。我们的分析证实:1) 使用反思token(reflection tokens)进行训练和推理能有效提升整体性能;2) 支持测试时模型定制(例如平衡引用精度与内容完整性的权衡)。
2 RELATED WORK
2 相关工作
Retrieval-Augmented Generation. Retrieval-Augmented Generation (RAG) augments the input space of LMs with retrieved text passages (Guu et al., 2020; Lewis et al., 2020), leading to large improvements in knowledge-intensive tasks after fine-tuning or used with off-the-shelf LMs (Ram et al., 2023). A more recent work (Luo et al., 2023) instruction-tunes an LM with a fixed number of retrieved passages prepended to input, or pre-train a retriever and LM jointly, followed by fewshot fine-tuning on task datasets (Izacard et al., 2022b). While prior work often retrieves only once at the beginning, Jiang et al. (2023) propose to adaptively retrieve passages for generation on top of a proprietary LLM or Schick et al. (2023) train an LM to generate API calls for named entities. Yet, the improved task performance of such approaches often comes at the expense of runtime efficiency (Mallen et al., 2023), robustness to irrelevant context (Shi et al., 2023), and lack of attributions (Liu et al., 2023a; Gao et al., 2023). We introduce a method to train an arbitrary LM to learn to use retrieval on-demand for diverse instruction-following queries and introduce controlled generation guided by reflections tokens to further improve generation quality and attributions.
检索增强生成 (Retrieval-Augmented Generation)。检索增强生成 (RAG) 通过检索到的文本段落来增强语言模型 (LM) 的输入空间 (Guu et al., 2020; Lewis et al., 2020),在微调或与现成语言模型配合使用时,能显著提升知识密集型任务的表现 (Ram et al., 2023)。近期研究 (Luo et al., 2023) 采用固定数量的检索段落作为输入前缀对语言模型进行指令微调,或联合预训练检索器与语言模型,再对任务数据集进行少样本微调 (Izacard et al., 2022b)。虽然先前工作通常仅在开始时检索一次,但 Jiang et al. (2023) 提出在专有大语言模型基础上自适应检索生成段落,Schick et al. (2023) 则训练语言模型生成命名实体的 API 调用。然而,这些方法提升任务性能的同时,往往牺牲了运行时效率 (Mallen et al., 2023)、对无关上下文的鲁棒性 (Shi et al., 2023),并缺乏归因能力 (Liu et al., 2023a; Gao et al., 2023)。我们提出一种方法,可训练任意语言模型学习根据多样化指令查询按需使用检索,并通过反思标记 (reflections tokens) 引导受控生成,进一步提升生成质量与归因能力。
Concurrent RAG work. A few concurrent works2 on RAG propose new training or prompting strategies to improve widely-adopted RAG approaches. Lin et al. (2023) fine-tune both the retriever and LM on instruction-tuning datasets in two steps. While we also train our model on diverse instruction-following datasets, SELF-RAG enables retrieval on demand and selection of the best possible model output via fine-grained self-reflection, making it widely applicable and more robust and controllable. Yoran et al. (2023) use a natural language inference model and $\mathrm{Xu}$ et al. (2023) use a sum mari z ation model to filter out or compress retrieved passages before using them to prompt the LM to generate the output. SELF-RAG processes passages in parallel and filters out irrelevant ones through self-reflection, without relying on external models at inference. Moreover, our self-reflection mechanism also evaluates other aspects of the model output quality including factuality. LATS (Zhou et al., 2023) prompt off-the-shelf LMs to search for relevant information for question answering tasks and to generate with tree search, guided by LM-generated value scores. While their value function simply indicates an overall score of each generation, SELF-RAG trains to an arbitrary LM to learn to generate fine-grained self-reflection and customizable inference.
并发RAG研究。近期几项关于RAG的并行研究提出了新的训练或提示策略来改进广泛采用的RAG方法。Lin等人(2023)分两步在指令微调数据集上同时微调检索器和大语言模型。虽然我们同样在多样化指令跟随数据集上训练模型,但SELF-RAG通过细粒度自我反思实现按需检索和最优模型输出选择,使其具有更广泛的适用性、更强健性和可控性。Yoran等人(2023)使用自然语言推理模型,而Xu等人(2023)采用摘要模型在提示大语言模型生成输出前过滤或压缩检索段落。SELF-RAG并行处理段落并通过自我反思过滤无关内容,无需在推理时依赖外部模型。此外,我们的自我反思机制还能评估模型输出质量的其他方面(包括事实性)。LATS(Zhou等人,2023)通过现成大语言模型生成的估值分数引导,提示模型为问答任务搜索相关信息并进行树搜索生成。虽然他们的估值函数仅给出每个生成的整体评分,但SELF-RAG通过训练使任意大语言模型学会生成细粒度自我反思和可定制推理。
Training and generating with critics. Training LLMs with reinforcement learning (e.g., Proximal Policy Optimization or PPO; Schulman et al. 2017) from human feedback (RLHF) has proven effective in aligning LLMs with human preferences (Ouyang et al., 2022). Wu et al. (2023) introduce fine-grained RLHF with multiple reward models. Though our work also studies fine-grained critique on retrieval and generation, we train our target LM on task examples augmented with reflection tokens from a critic model offline, with a far lower training cost compared to RLHF. In addition, reflection tokens in SELF-RAG enable controllable generation at inference, while RLHF focuses on human preference alignment during training. Other works use general control tokens to guide LM generation (Lu et al., 2022; Korbak et al., 2023), while SELF-RAG uses reflection tokens to decide the need for retrieval and to self-evaluate generation quality. Xie et al. (2023) propose a self-evaluationguided decoding framework, but they focus only on reasoning tasks with one evaluation dimension (reasoning path consistency) and without retrieval. Recent work on LLM refinement (Dhuliawala et al., 2023; Madaan et al., 2023; Paul et al., 2023) prompts a model to generate task output, natural language feedback and refined task output iterative ly, but at the cost of inference efficiency.
使用评论机制进行训练与生成。通过人类反馈强化学习(例如近端策略优化/PPO; Schulman等人2017)训练大语言模型(RLHF)已被证明能有效对齐人类偏好(Ouyang等人2022)。Wu等人(2023)提出了使用多重奖励模型的细粒度RLHF方法。虽然本研究同样探讨检索与生成的细粒度评论机制,但我们采用离线方式在任务样本中融入评论模型的反思标记(reflection tokens)来训练目标语言模型,其训练成本远低于RLHF。此外,SELF-RAG框架中的反思标记支持推理阶段的可控生成,而RLHF主要关注训练阶段的人类偏好对齐。其他研究使用通用控制标记引导语言模型生成(Lu等人2022; Korbak等人2023),而SELF-RAG则通过反思标记动态决策检索需求并自评生成质量。Xie等人(2023)提出自评估引导的解码框架,但仅针对单一评估维度(推理路径一致性)的推理任务且不含检索机制。近期关于大语言模型优化的研究(Dhuliawala等人2023; Madaan等人2023; Paul等人2023)通过迭代生成任务输出、自然语言反馈和优化结果来实现改进,但会显著影响推理效率。
3 SELF-RAG: LEARNING TO RETRIEVE, GENERATE AND CRITIQUE
3 SELF-RAG: 学习检索、生成与评判
We introduce Self-Reflective Retrieval-Augmented Generation (SELF-RAG), shown in Figure 1. SELF-RAG is a framework that enhances the quality and factuality of an LLM through retrieval and self-reflection, without sacrificing LLM’s original creativity and versatility. Our end-to-end training lets an LM $\mathcal{M}$ generate text informed by retrieved passages, if needed, and criticize the output by learning to generate special tokens. These reflection tokens (Table 1) signal the need for retrieval or confirm the output’s relevance, support, or completeness. In contrast, common RAG approaches retrieve passages indiscriminately, without ensuring complete support from cited sources.
我们介绍自反思检索增强生成(SELF-RAG),如图1所示。SELF-RAG是一个通过检索和自反思来提升大语言模型质量和事实性的框架,同时不牺牲其原有的创造力和多功能性。我们的端到端训练让语言模型$\mathcal{M}$在需要时基于检索到的段落生成文本,并通过学习生成特殊token来批判输出。这些反思token(表1)标志着检索需求或确认输出的相关性、支持度和完整性。相比之下,常见的RAG方法不加区分地检索段落,无法确保引用来源的完整支持。
3.1 PROBLEM FORMALIZATION AND OVERVIEW
3.1 问题形式化与概述
Formally, given input $x$ , we train $\mathcal{M}$ to sequentially generate textual outputs $y$ consisting of multiple segments $y=[y_{1},\dots,y_{T}]$ , where $y_{t}$ indicates a sequence of tokens for the $t$ -th segment.3 Generated tokens in $y_{t}$ include text from the original vocabulary as well as the reflection tokens (Table 1).
形式上,给定输入 $x$ ,我们训练 $\mathcal{M}$ 以顺序生成由多个片段组成的文本输出 $y=[y_{1},\dots,y_{T}]$ ,其中 $y_{t}$ 表示第 $t$ 个片段的token序列。 $y_{t}$ 中生成的token包括原始词汇表中的文本以及反思token (表 1)。
| Type | Input | Output | Definitions |
| Retrieve | c/x,y | {yes, no, continue} | DecideswhentoretrievewithR |
| ISREL | x,d | relevant,irrelevant} | d provides useful information to solve . |
| IsSUP | x,d,y | fully supported, partially supported, no support} | Allof theverification-worthystatementiny is supported by d. |
| IsUsE | x,y | {5,4,3,2,1} | y is auseful response to. |
| 类型 | 输入 | 输出 | 定义 |
|---|---|---|---|
| Retrieve | c/x,y | {是, 否, 继续} | 决定何时使用R进行检索 |
| ISREL | x,d | {相关, 不相关} | d为解决问题x提供了有用信息 |
| IsSUP | x,d,y | {完全支持, 部分支持, 不支持} | y中所有需要验证的陈述都得到了d的支持 |
| IsUsE | x,y | {5,4,3,2,1} | y是对x的有用回应 |
Table 1: Four types of reflection tokens used in SELF-RAG. Each type uses several tokens to represent its output values. The bottom three rows are three types of Critique tokens, and the bold text indicates the most desirable critique tokens. $x,y,d$ indicate input, output, and a relevant passage, respectively.
表 1: SELF-RAG中使用的四种反思token。每种类型使用多个token表示其输出值。底部三行是三种批判token,加粗文本表示最理想的批判token。$x,y,d$ 分别表示输入、输出和相关段落。
Algorithm 1 SELF-RAG Inference
算法 1 SELF-RAG 推理
Inference overview. Figure 1 and Algorithm 1 present an overview of SELF-RAG at inference. For every $x$ and preceding generation $y_{<t}$ , the model decodes a retrieval token to evaluate the utility of retrieval. If retrieval is not required, the model predicts the next output segment, as it does in a standard LM. If retrieval is needed, the model generates: a critique token to evaluate the retrieved passage’s relevance, the next response segment, and a critique token to evaluate if the information in the response segment is supported by the passage. Finally, a new critique token evaluates the overall utility of the response.4 To generate each segment, SELF-RAG processes multiple passages in parallel and uses its own generated reflection tokens to enforce soft constraints (Section 3.3) or hard control (Algorithm 1) over the generated task output. For instance, in Figure 1 (right), the retrieved passages $d_{1}$ is selected at the first time step since $d_{2}$ does not provide direct evidence ( ISREL is Irrelevant) and $d_{3}$ output is only partially supported while $d_{1}$ are fully supported.
推理概览。图1和算法1展示了SELF-RAG在推理阶段的整体流程。对于每个输入$x$和已生成内容$y_{<t}$,模型会解码一个检索token来评估检索的必要性。若无需检索,模型会像标准大语言模型那样预测下一个输出片段。若需检索,模型将依次生成:评估检索段落相关性的批判token、下一段响应内容、以及判断该响应内容是否得到检索段落支持的批判token。最后还会生成一个评估响应整体效用的批判token。SELF-RAG通过并行处理多个检索段落,并利用自生成的反思token对任务输出实施软约束(第3.3节)或硬控制(算法1)。例如在图1(右)中,首时间步选择检索段落$d_{1}$,因为$d_{2}$未提供直接证据(ISREL标记为无关),$d_{3}$的输出仅获部分支持,而$d_{1}$的内容获得完全支持。
Training overview. SELF-RAG enables an arbitrary LM to generate text with reflection tokens by unifying them as next token predictions from the expanded model vocabulary (i.e., the original vocabulary plus reflection tokens). Specifically, we train the generator model $\mathcal{M}$ on a curated corpus with interleaving passages retrieved by a retriever $\mathcal{R}$ and reflection tokens predicted by a critic model $\mathcal{C}$ (summarized in Appendix Algorithm 2). We train $\mathcal{C}$ to generate reflection tokens for evaluating retrieved passages and the quality of a given task output (Section 3.2.1). Using the critic model, we update the training corpus by inserting reflection tokens into task outputs offline. Subsequently, we train the final generator model $({\mathcal{M}})$ using the conventional LM objective (Section 3.2.2) to enable $\mathcal{M}$ to generate reflection tokens by itself without relying on the critic at inference time.
训练概览。SELF-RAG通过将反思标记(token)统一作为扩展模型词汇表(即原始词汇表加上反思标记)的下一个token预测,使任意大语言模型能够生成带有反思标记的文本。具体而言,我们在由检索器$\mathcal{R}$获取的交叉段落和评判模型$\mathcal{C}$预测的反思标记(附录算法2总结)组成的精选语料库上训练生成器模型$\mathcal{M}$。我们训练$\mathcal{C}$来生成用于评估检索段落和给定任务输出质量的反思标记(第3.2.1节)。利用评判模型,我们通过离线方式在任务输出中插入反思标记来更新训练语料库。随后,我们使用传统的大语言模型目标(第3.2.2节)训练最终生成器模型$({\mathcal{M}})$,使$\mathcal{M}$在推理时能够不依赖评判模型而自行生成反思标记。
3.2 SELF-RAG TRAINING
3.2 SELF-RAG训练
Here, we describe the supervised data collection and training of two models, the critic $\mathcal{C}$ (Section 3.2.1) and the generator $\mathcal{M}$ (Section 3.2.2).
在此,我们描述了两个模型的监督数据收集和训练过程:评论家 $\mathcal{C}$(第3.2.1节)和生成器 $\mathcal{M}$(第3.2.2节)。
3.2.1 TRAINING THE CRITIC MODEL
3.2.1 训练评论模型
Data collection for critic model. Manual annotation of reflection tokens for each segment is expensive (Wu et al., 2023). A state-of-the-art LLM like GPT-4 (OpenAI, 2023) can be effectively used to generate such feedback (Liu et al., 2023b). However, depending on such proprietary LMs can raise API costs and diminish reproducibility (Chen et al., 2023). We create supervised data by prompting GPT-4 to generate reflection tokens and then distill their knowledge into an in-house $\mathcal{C}$ . For each group of reflection tokens, we randomly sample instances from the original training data: ${X^{s a m p l e},Y^{s a m p l e}}\sim{X,Y}$ . As different reflection token groups have their own definitions and input, as shown in Table 1, we use different instruction prompts for them. Here, we use Retrieve as an example. We prompt GPT-4 with a type-specific instruction (“Given an instruction, make a judgment on whether finding some external documents from the web helps to generate a better response.”) followed by few-shot demonstrations $I$ the original task input $x$ and output $y$ to predict an appropriate reflection token as text: $p(r|I,x,y)$ . Manual assessment reveals that GPT-4 reflection token predictions show high agreement with human evaluations. We collect $4\mathrm{k}{-}20\mathrm{k}$ supervised training data for each type and combine them to form training data for $\mathcal{C}$ . Appendix Section $\mathrm{D}$ shows the full list of instructions, and A.1 contains more details and our analysis.
评论模型的数据收集。为每个片段手动标注反思标记(reflection tokens)成本高昂(Wu等人,2023)。使用GPT-4(OpenAI,2023)等先进大语言模型可以高效生成此类反馈(Liu等人,2023b)。但依赖此类专有模型会导致API成本上升并降低可复现性(Chen等人,2023)。我们通过提示GPT-4生成反思标记来创建监督数据,并将其知识蒸馏至内部模型$\mathcal{C}$。对于每组反思标记,我们从原始训练数据中随机采样实例:${X^{sample},Y^{sample}}\sim{X,Y}$。如表1所示,由于不同反思标记组有各自的定义和输入,我们为其使用不同的指令提示。以Retrieve为例,我们向GPT-4提供类型特定的指令("给定指令时,判断是否从网络查找外部文档有助于生成更好响应"),后接少样本演示$I$、原始任务输入$x$和输出$y$,以预测合适的文本形式反思标记:$p(r|I,x,y)$。人工评估显示GPT-4的反思标记预测与人类评估高度一致。我们为每类收集$4\mathrm{k}{-}20\mathrm{k}$条监督训练数据,合并形成$\mathcal{C}$的训练集。附录D节展示了完整指令列表,A.1章节包含更多细节和分析。

Figure 2: SELF-RAG training examples. The left example does not require retrieval while the right one requires retrieval; thus, passages are inserted. More examples are in Appendix Table 4.
图 2: SELF-RAG训练示例。左侧示例无需检索,右侧示例需要检索并插入相关段落。更多示例见附录表4。
Critic learning. After we collect training data $\mathcal{D}_ {c r i t i c}$ , we initialize $\mathcal{C}$ with a pre-trained LM and train it on $\mathcal{D}_{c r i t i c}$ using a standard conditional language modeling objective, maximizing likelihood:
评论家学习。收集训练数据 $\mathcal{D}_ {critic}$ 后,我们用预训练的大语言模型初始化 $\mathcal{C}$ ,并在 $\mathcal{D}_{critic}$ 上使用标准的条件语言建模目标进行训练,最大化似然:
$$
\operatorname*{max}_ {\mathcal{C}}\mathbb{E}_ {((x,y),r)\sim\mathcal{D}_ {c r i t i c}}\log p_{\mathcal{C}}(r|x,y),r\mathrm{for}\mathrm{reflectiontokens}.
$$
$$
\operatorname*{max}_ {\mathcal{C}}\mathbb{E}_ {((x,y),r)\sim\mathcal{D}_ {c r i t i c}}\log p_{\mathcal{C}}(r|x,y),r\mathrm{for}\mathrm{reflectiontokens}.
$$
Though the initial model can be any pre-trained LM, we use the same one as the generator LM (i.e., Llama 2-7B; Touvron et al. 2023) for $\mathcal{C}$ initialization. The critic achieves a higher than $90%$ agreement with GPT-4-based predictions on most reflection token categories (Appendix Table 5).
虽然初始模型可以是任何预训练的大语言模型,但我们使用与生成器大语言模型相同的模型(即Llama 2-7B;Touvron等人2023)进行$\mathcal{C}$初始化。该评判模型在大多数反思token类别上与基于GPT-4的预测达到了超过$90%$的一致性(附录表5)。
3.2.2 TRAINING THE GENERATOR MODEL
3.2.2 训练生成器模型
Data collection for generator. Given an input-output pair $(x,y)$ , we augment the original output $y$ using the retrieval and critic models to create supervised data that precisely mimics the SELFRAG inference-time process (Section 3.1). For each segment $y_{t}\in y$ , we run $\mathcal{C}$ to assess whether additional passages could help to enhance generation. If retrieval is required, the retrieval special token $\boxed{\mathrm{Retrieve}}=\Upsilon\in\mathbb{S}$ is added, and $\mathcal{R}$ retrieves the top $K$ passages, $\mathbf{D}$ . For each passage, $\mathcal{C}$ further evaluates whether the passage is relevant and predicts $\boxed{\mathbf{IsREL}}$ . If a passage is relevant, $\mathcal{C}$ further evaluates whether the passage supports the model generation and predicts $\boxed{\mathbf{IsSUP}}$ . Critique tokens ISREL and $\boxed{\mathbf{IsSUP}}$ are appended after the retrieved passage or generations. At the end of the output, $y$ (or $y_{T}$ ), $\mathcal{C}$ predicts the overall utility token $\boxed{\mathbf{IsUsE}}$ , and an augmented output with reflection tokens and the original input pair is added to $\mathcal{D}_{g e n}$ . See the example training data in Figure 2.
生成器数据收集。给定输入-输出对$(x,y)$,我们使用检索和评判模型增强原始输出$y$,创建精确模拟SELFRAG推理过程的有监督数据(第3.1节)。对于每个片段$y_{t}\in y$,运行$\mathcal{C}$评估是否需要额外文本来增强生成。若需检索,则添加检索特殊标记$\boxed{\mathrm{Retrieve}}=\Upsilon\in\mathbb{S}$,同时$\mathcal{R}$检索前$K$个文本$\mathbf{D}$。针对每个文本,$\mathcal{C}$进一步评估其相关性并预测$\boxed{\mathbf{IsREL}}$。若文本相关,$\mathcal{C}$继续评估其是否支持模型生成并预测$\boxed{\mathbf{IsSUP}}$。评判标记ISREL和$\boxed{\mathbf{IsSUP}}$被附加在检索文本或生成内容后。在输出$y$(或$y_{T}$)末尾,$\mathcal{C}$预测总体效用标记$\boxed{\mathbf{IsUsE}}$,最终将带有反思标记的增强输出与原始输入对加入$\mathcal{D}_{g e n}$。示例训练数据见图2。
Generator learning. We train the generator model $\mathcal{M}$ by training on the curated corpus augmented with reflection tokens $\mathcal{D}_{g e n}$ using the standard next token objective:
生成器学习。我们通过在增强了反思token (reflection tokens) $\mathcal{D}_{g e n}$ 的精选语料库上训练生成器模型 $\mathcal{M}$,使用标准的下一个token预测目标:
$$
\operatorname*{max}_ {\mathcal{M}}\mathbb{E}_ {(\boldsymbol{x},\boldsymbol{y},\boldsymbol{r})\sim\mathcal{D}_ {\boldsymbol{g e n}}}\log p_{\mathcal{M}}(\boldsymbol{y},\boldsymbol{r}|\boldsymbol{x}).
$$
$$
\operatorname*{max}_ {\mathcal{M}}\mathbb{E}_ {(\boldsymbol{x},\boldsymbol{y},\boldsymbol{r})\sim\mathcal{D}_ {\boldsymbol{g e n}}}\log p_{\mathcal{M}}(\boldsymbol{y},\boldsymbol{r}|\boldsymbol{x}).
$$
Unlike $\mathcal{C}$ training (Eq. 1), $\mathcal{M}$ learns to predict the target output as well as the reflection tokens. During training, we mask out the retrieved text chunks (surrounded by $\mathrm{\mathit{\Omega}}<\mathrm{\mathtt{p}}>$ and $</\mathtt{p}>$ in Figure 2) for loss calculation and expand the original vocabulary $\nu$ with a set of reflection tokens {$\boxed{\mathbf{Critique}}$, $\boxed{\mathbf{Retrieve}}$} .
与 $\mathcal{C}$ 训练(公式1)不同,$\mathcal{M}$ 需要学习预测目标输出以及反思token (reflection tokens)。训练时,我们会屏蔽检索到的文本块(图2中 $\mathrm{\mathit{\Omega}}<\mathrm{\mathtt{p}}>$ 和 $</\mathtt{p}>$ 包围的部分)以计算损失,并将原始词汇表 $\nu$ 扩展为一组反思token {$\boxed{\mathbf{Critique}}, \boxed{\mathbf{Retrieve}}$}。
Connections to prior work on learning with critique. Recent work incorporates additional critique (feedback) during training, e.g., RLHF (Ouyang et al. 2022) via PPO. While PPO relies on separate reward models during training, we compute critique offline and directly insert them into the training corpus, where the generator LM is trained with a standard LM objective. This significantly reduces training costs compared to PPO. Our work also relates to prior work that incorporates special tokens to control generation (Keskar et al., 2019; Lu et al., 2022; Korbak et al., 2023). Our SELF-RAG learns to generate special tokens to evaluate its own prediction after each generated segment, enabling the use of a soft re-ranking mechanism or hard constraints at inference (discussed next).
与带批判学习相关工作的联系。近期研究在训练过程中整合了额外批判(反馈),例如通过PPO实现的RLHF (Ouyang et al. 2022)。PPO依赖训练期间独立的奖励模型,而我们离线计算批判并直接将其插入训练语料,生成器大语言模型通过标准语言模型目标进行训练。相比PPO,这显著降低了训练成本。我们的工作还与通过特殊token控制生成的研究相关(Keskar et al., 2019; Lu et al., 2022; Korbak et al., 2023)。SELF-RAG学会在生成每个片段后输出特殊token来自我评估预测结果,从而在推理阶段实现软重排机制或硬约束应用(下文详述)。
3.3 SELF-RAG INFERENCE
3.3 SELF-RAG 推理
Generating reflection tokens to self-evaluate its own output makes SELF-RAG controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements. For tasks demanding factual accuracy (Min et al., 2023), we aim for the model to retrieve passages more frequently to ensure that the output aligns closely with the available evidence. Conversely, in more open-ended tasks, like composing a personal experience essay, the emphasis shifts towards retrieving less and prioritizing the overall creativity or utility score. In this section, we describe approaches to enforce control to meet these distinct objectives during the inference process.
生成反思token(Reflection Token)用于自我评估输出,使SELF-RAG在推理阶段具备可控性,能根据不同任务需求调整行为。对于需要事实准确性的任务[20],我们要求模型更频繁检索文本段落以确保输出与现有证据高度吻合;而在开放性任务(如撰写个人经历文章)中,则减少检索频率并优先考虑整体创意或效用分数。本节将阐述如何在推理过程中实施控制以满足这些差异化目标。
Adaptive retrieval with threshold. SELF-RAG dynamically decides when to retrieve text passages by predicting Retrieve . Alternatively, our framework allows a threshold to be set. Specifically, if the probability of generating the Retrieve =Yes token normalized over all output tokens in Retrieve surpasses a designated threshold, we trigger retrieval (details in Appendix Section A.3).
自适应阈值检索。SELF-RAG通过预测Retrieve动态决定何时检索文本段落。此外,我们的框架允许设置阈值。具体而言,若Retrieve中所有输出token生成Retrieve=Yes的概率归一化值超过指定阈值,则触发检索(详见附录A.3节)。
Tree-decoding with critique tokens. At each segment step $t$ , when retrieval is required, based either on hard or soft conditions, $\mathcal{R}$ retrieves $K$ passages, and the generator $\mathcal{M}$ processes each passage in parallel and outputs $K$ different continuation candidates. We conduct a segment-level beam search (with the beam $\mathrm{size}{=}B$ ) to obtain the top $\mathcal{B}$ segment continuations at each timestamp $t$ , and return the best sequence at the end of generation. The score of each segment $y_{t}$ with respect to passage $d$ is updated with a critic score $s$ that is the linear weighted sum of the normalized probability of each Critique token type. For each critique token group $G$ (e.g., ISREL ), we denote its score at timestamp $t$ as $\overline{{s_{t}^{G}}}$ , and we compute a segment score as follows:
基于批判性token的树形解码。在每个片段步骤$t$,当需要根据硬性或软性条件进行检索时,$\mathcal{R}$会检索$K$个段落,生成器$\mathcal{M}$并行处理每个段落并输出$K$个不同的延续候选。我们执行片段级束搜索(束宽$\mathrm{size}{=}B$)来获取每个时间戳$t$下的前$\mathcal{B}$个片段延续,并在生成结束时返回最佳序列。每个片段$y_{t}$相对于段落$d$的得分会通过批判性得分$s$进行更新,该得分为各批判性token类型归一化概率的线性加权和。对于每个批判性token组$G$(例如ISREL),我们将其在时间戳$t$的得分记为$\overline{{s_{t}^{G}}}$,并按如下方式计算片段得分:
$$
f(y_{t},d,\overrightarrow{\mathrm{[critique]}})=p(y_{t}|x,d,y_{<t}))+S(\overrightarrow{\mathrm{[critique]}}),\mathrm{where}
$$
$$
f(y_{t},d,\overrightarrow{\mathrm{[critique]}})=p(y_{t}|x,d,y_{<t}))+S(\overrightarrow{\mathrm{[critique]}}),\mathrm{where}
$$
$$
[
S([\overline{\mathrm{Critique}}])
= \sum_{G \in \mathcal{G}} w^{G} s_{t}^{G} \quad \text{for} \quad
\mathcal{G} = {[\overline{\mathrm{IsREL}}],[\overline{\mathrm{IsSUP}}],
\overline{\mathrm{IsUse}}}
]
$$
$$
[
S([\overline{\mathrm{Critique}}])
= \sum_{G \in \mathcal{G}} w^{G} s_{t}^{G} \quad \text{for} \quad
\mathcal{G} = {[\overline{\mathrm{IsREL}}],[\overline{\mathrm{IsSUP}}],
\overline{\mathrm{IsUse}}}
]
$$
where $\begin{array}{r}{s_{t}^{G}=\frac{p_{t}(\hat{r})}{\sum_{i=1}^{N^{G}}p_{t}(r_{i})}}\end{array}$ stands for the generation probability of the most desirable reflection token $\hat{r}$ (e.g., $\scriptstyle\boxed{\mathrm{IsREL}}=\mathrm{Re}\mathrm{1evant};$ ) for the critique token type $G$ with $N^{G}$ distinct tokens (that represent different possible values for $G$ ). The weights $w^{G}$ in Eq. 4 are hyper parameters that can be adjusted at inference time to enable customized behaviors at test time. For instance, to ensure that result $y$ is mostly supported by evidence, we can set a weight term for the $\boxed{\mathbf{IsSUP}}$ score higher, while relatively lowering weights for other aspects. Alternatively, we could further enforce hard constraints during decoding using $\boxed{\mathbf{Critique}}$ . Instead of using a soft reward function in Eq. 4, we could explicitly filter out a segment continuation when the model generates an undesirable Critique token (e.g., $\boxed{\mathbf{IsSUP}}=\mathbb{N}\circ$ support) . Balancing the trade-off between multiple preferences has been studied in RLHF (Touvron et al., 2023; Wu et al., 2023), which often requires training to change models’ behaviors. SELF-RAG tailors an LM with no additional training.
其中 $\begin{array}{r}{s_{t}^{G}=\frac{p_{t}(\hat{r})}{\sum_{i=1}^{N^{G}}p_{t}(r_{i})}}\end{array}$ 表示批判性token类型 $G$ (包含 $N^{G}$ 个不同token) 中最理想反射token $\hat{r}$ (例如 $\scriptstyle\boxed{\mathrm{IsREL}}=\mathrm{Re}\mathrm{1evant};$) 的生成概率。公式4中的权重 $w^{G}$ 是可调节超参数,支持在推理阶段定制化行为。例如,为确保结果 $y$ 主要基于证据,可调高 $\boxed{\mathbf{IsSUP}}$ 分数权重,同时降低其他维度权重。此外,还可通过 $\boxed{\mathbf{Critique}}$ 在解码阶段实施硬约束——当模型生成不理想的批判token (如 $\boxed{\mathbf{IsSUP}}=\mathbb{N}\circ$ support) 时,直接过滤掉该片段延续,而非使用公式4的软奖励函数。多偏好权衡问题在RLHF领域已有研究 [20][21],但通常需通过训练改变模型行为,而SELF-RAG无需额外训练即可实现大语言模型定制。
4 EXPERIMENTS
4 实验
4.1 TASKS AND DATASETS
4.1 任务与数据集
We conduct evaluations of our SELF-RAG and diverse baselines on a range of downstream tasks, holistic ally evaluating outputs with metrics designed to assess overall correctness, factuality, and fluency. Throughout these experiments, we conduct zero-shot evaluations, where we provide instructions describing tasks without few-shot demonstrations (Wei et al., 2022; Sanh et al., 2022). Details of our experiments’ settings, including test-time instructions, are available in the Appendix Section B.1.
我们对SELF-RAG及多种基线模型在一系列下游任务上进行了评估,通过衡量整体正确性、事实性和流畅性的指标对输出结果进行综合评价。所有实验均采用零样本评估方式,即仅提供任务说明而不展示少样本示例 (Wei et al., 2022; Sanh et al., 2022)。实验设置细节(包括测试阶段指令)详见附录B.1节。
Closed-set tasks include two datasets, i.e., a fact verification dataset about public health (PubHealth; Zhang et al. 2023) and a multiple-choice reasoning dataset created from scientific exams (ARC
闭集任务包含两个数据集,即公共卫生领域的事实核查数据集(PubHealth; Zhang et al. 2023)和基于科学考试构建的多选题推理数据集(ARC
Challenge; Clark et al. 2018). We use accuracy as an evaluation metric and report on the test set. We aggregate the answer probabilities of target classes for both of these datasets (Appendix Section B.2).
挑战;Clark等人2018)。我们使用准确率作为评估指标,并在测试集上报告结果。我们对这两个数据集的目标类别答案概率进行了汇总(附录B.2节)。
Short-form generations tasks include two open-domain question answering (QA) datasets, PopQA (Mallen et al., 2023) and TriviaQA-unfiltered (Joshi et al., 2017), where systems need to answer arbitrary questions about factual knowledge. For PopQA, we use the long-tail subset, consisting of 1,399 rare entity queries whose monthly Wikipedia page views are less than 100. As the TriviaQA-unfiltered (open) test set is not publicly available, we follow prior work’s validation and test split (Min et al., 2019; Guu et al., 2020), using 11,313 test queries for evaluation. We evaluate performance based on whether gold answers are included in the model generations instead of strictly requiring exact matching, following Mallen et al. (2023); Schick et al. (2023).
短文本生成任务包括两个开放域问答(QA)数据集:PopQA (Mallen et al., 2023) 和 TriviaQA-unfiltered (Joshi et al., 2017),系统需要回答关于事实性知识的任意问题。对于PopQA,我们使用长尾子集,包含1,399个月度维基百科页面浏览量少于100的稀有实体查询。由于TriviaQA-unfiltered(开放)测试集未公开,我们遵循先前工作的验证和测试划分(Min et al., 2019; Guu et al., 2020),使用11,313个测试查询进行评估。根据Mallen et al. (2023)和Schick et al. (2023)的方法,我们基于标准答案是否包含在模型生成结果中来评估性能,而非严格要求精确匹配。
Long-form generation tasks include a biography generation task (Min et al., 2023) and a long-form QA task ALCE-ASQA Gao et al. (2023); Stelmakh et al. (2022). We use FactScore (Min et al., 2023) to evaluate biographies, and we use official metrics of correctness (str-em), fluency based on MAUVE (Pillutla et al., 2021), and citation precision and recall (Gao et al., 2023) for ASQA. 5
长文本生成任务包括传记生成任务(Min et al., 2023)和长文本问答任务ALCE-ASQA(Gao et al., 2023; Stelmakh et al., 2022)。我们使用FactScore(Min et al., 2023)评估传记质量,对于ASQA则采用官方指标:正确性(str-em)、基于MAUVE(Pillutla et al., 2021)的流畅度,以及引文精确率与召回率(Gao et al., 2023)。5
4.2 BASELINES
4
Baselines without retrievals. We evaluate strong publicly available pre-trained LLMs, $\mathrm{Llama2}_ {78,138}$ (Touvron et al., 2023), instruction-tuned models, Alpaca7B,13B (Dubois et al., 2023) (our replication based on Llama2); and models trained and reinforced using private data, ChatGPT (Ouyang et al., 2022) and Llama2-chat $^{138}$ . For instruction-tuned LMs, we use the official system prompt or instruction format used during training if publicly available. We also compare our method to concurrent work, $\mathrm{CoVE_{65B}}$ (Dhuliawala et al., 2023), which introduces iterative prompt engineering to improve the factuality of LLM generations.
无检索基线。我们评估了公开可用的强预训练大语言模型:$\mathrm{Llama2}_ {78,138}$ (Touvron et al., 2023)、指令调优模型Alpaca7B/13B (Dubois et al., 2023) (基于Llama2的复现版本),以及使用私有数据训练和强化的模型ChatGPT (Ouyang et al., 2022)和Llama2-chat$^{138}$。对于指令调优的大语言模型,若官方系统提示或训练时使用的指令格式公开可用,我们均采用其原始配置。同时,我们将本方法与同期工作$\mathrm{CoVE_{65B}}$ (Dhuliawala et al., 2023)进行对比,该研究通过迭代式提示工程来提升大语言模型生成内容的真实性。
Baselines with retrievals. We evaluate models augmented with retrieval at test time or during training. The first category includes standard RAG baselines, where an LM (Llama2, Alpaca) generates output given the query prepended with the top retrieved documents using the same retriever as in our system. It also includes Llama2-FT, where Llama2 is fine-tuned on all training data we use without the reflection tokens or retrieved passages. We also report the result of retrieval-augmented baselines with LMs trained with private data: Ret-ChatGPT and Ret-Llama2-chat, which deploy the same augmentation technique above, as well as perplexity.ai, an Instruct GP T-based production search system. The second category includes concurrent methods that are trained with retrieved text passages, i.e., SAIL (Luo et al., 2023) to instruction-tune an LM on the Alpaca instruction-tuning data with top retrieved documents inserted before instructions, and Toolformer (Schick et al., 2023) to pre-train an LM with API calls (e.g., Wikipedia APIs).6
基于检索的基线模型。我们评估了在测试时或训练期间通过检索增强的模型。第一类包括标准的RAG (Retrieval-Augmented Generation) 基线,即大语言模型(Llama2、Alpaca)在查询前添加使用与我们系统相同检索器获取的顶部检索文档后生成输出。还包括Llama2-FT,即在所有训练数据上对Llama2进行微调(不包含反思token或检索段落)。我们还报告了基于私有数据训练的大语言模型的检索增强基线结果:Ret-ChatGPT和Ret-Llama2-chat(采用上述相同的增强技术)以及基于InstructGPT的生产搜索系统perplexity.ai。第二类包括与检索文本段落共同训练的方法,例如:SAIL [20](在Alpaca指令微调数据中,将顶部检索文档插入指令前进行大语言模型指令微调)和Toolformer [21](通过API调用(如维基百科API)预训练大语言模型)。
4.3 EXPERIMENTAL SETTINGS
4.3 实验设置
Training data and settings. Our training data consists of diverse instruction-following input-output pairs. In particular, we sample instances from Open-Instruct processed data (Wang et al., 2023) and knowledge-intensive datasets (Petroni et al., 2021; Stelmakh et al., 2022; Mihaylov et al., 2018). In total, we use 150k instruction-output pairs. We use Llama2 7B and 13B (Touvron et al., 2023) as our generator base LM, and we use Llama2 7B as our base critic LM. For the retriever model $\mathcal{R}$ , we use off-the-shelf Contriever-MS MARCO (Izacard et al., 2022a) by default and retrieve up to ten documents for each input. More training details are in the Appendix Section B.1.
训练数据与设置。我们的训练数据包含多样化的指令跟随输入-输出对。具体而言,我们从Open-Instruct处理数据(Wang et al., 2023)和知识密集型数据集(Petroni et al., 2021; Stelmakh et al., 2022; Mihaylov et al., 2018)中采样实例,共计使用15万条指令-输出对。采用Llama2 7B和13B(Touvron et al., 2023)作为生成器基础大语言模型,并选用Llama2 7B作为基础评判大语言模型。检索模型$\mathcal{R}$默认使用现成的Contriever-MS MARCO(Izacard et al., 2022a),每个输入最多检索十篇文档。更多训练细节见附录B.1节。
Inference settings. As a default configuration, we assign the weight terms $\boxed{\mathbf{IsREL}}$ , ISSUP , ISUSE values of 1.0, 1.0 and 0.5, respectively. To encourage frequent retrieval, we set the retrieval threshold to 0.2 for most tasks and to 0 for ALCE (Gao et al., 2023) due to citation requirements. We speed up inference using vllm (Kwon et al., 2023). At each segment level, we adopt a beam width of 2. For a token-level generation, we use greedy decoding. By default, we use the top five documents from Contriever-MS MARCO (Izacard et al., 2022a); for biographies and open-domain QA, we use additional top five documents retrieved by a web search engine, following Luo et al. (2023); for ASQA, we use the author-provided top 5 documents by GTR-XXL (Ni et al., 2022) across all baselines for a fair comparison.
推理设置。默认配置下,我们将权重项 $\boxed{\mathbf{IsREL}}$、ISSUP、ISUSE 分别设为1.0、1.0和0.5。为促进频繁检索,大多数任务设置检索阈值为0.2,而ALCE (Gao et al., 2023) 因引文要求设为0。我们使用vllm (Kwon et al., 2023) 加速推理。在每段层级采用束宽为2的搜索策略,Token级生成则使用贪心解码。默认采用Contriever-MS MARCO (Izacard et al., 2022a) 返回的前5篇文档;对于传记和开放域问答任务,遵循Luo et al. (2023) 的方法额外添加搜索引擎返回的前5篇文档;在ASQA任务中,为公平比较所有基线,统一使用作者提供的GTR-XXL (Ni et al., 2022) 检索前5篇文档。
Table 2: Overall experiment results on six tasks. Bold numbers indicate the best performance among non-proprietary models, and gray-colored bold text indicates the best proprietary model when they outperforms all non-proprietary models. ∗ indicates concurrent or recent results reported by concurrent work. – indicates numbers that are not reported by the original papers or are not applicable. Models are sorted based on scale. FS, em, rg, mau, prec, rec denote FactScore (factuality); str-em, rouge (correctness); MAUVE (fluency); citation precision and recall, respectively.
| Short-form | Closed-set | Long-form generations (with citations) | ||||||||
| LM | PopQA (acc) | TQA (acc) | Pub (acc) | ARC (acc) | Bio (FS) | (em) | (rg) | ASQA (mau) | (pre) | (rec) |
| LMswith hproprietarydata | ||||||||||
| Llama2-C13B | 20.0 | 59.3 | 49.4 | 38.4 | 55.9 | 22.4 | 29.6 | 28.6 | 一 | |
| Ret-Llama2-C13B | 51.8 | 59.8 | 52.1 | 37.9 | 79.9 | 32.8 | 34.8 | 43.8 | 19.8 | 36.1 |
| ChatGPT | 29.3 | 74.3 | 70.1 | 75.3 | 71.8 | 35.3 | 36.2 | 68.8 | 一 | |
| Ret-ChatGPT | 50.8 | 65.7 | 54.7 | 75.3 | 一 | 40.7 | 39.9 | 79.7 | 65.1 | 76.6 |
| Perplexity.ai | 一 | 一 | 71.2 | 一 | 一 | |||||
| Baselines withoutretrieval | ||||||||||
| Llama27B | 14.7 | 30.5 | 34.2 | 21.8 | 44.5 | 7.9 | 15.3 | 19.0 | ||
| Alpaca7B | 23.6 | 54.5 | 49.8 | 45.0 | 45.8 | 18.8 | 29.4 | 61.7 | 一 | |
| Llama213B | 14.7 | 38.5 | 29.4 | 29.4 | 53.4 | 7.2 | 12.4 | 16.0 | ||
| Alpaca13B | 24.4 | 61.3 | 55.5 | 54.9 | 50.2 | 22.9 | 32.0 | 70.6 | ||
| CoVE65B * | 一 | 71.2 | ||||||||
| Baselineswithretrieval | ||||||||||
| Toolformer*6B | 48.8 | |||||||||
| Llama27B | 38.2 | 42.5 | 30.0 | 48.0 | 78.0 | 15.2 | 22.1 | 32.0 | 2.9 | 4.0 |
| Alpaca7B | 46.7 | 64.1 | 40.2 | 48.0 | 76.6 | 30.9 | 33.3 | 57.9 | 5.5 | 7.2 |
| Llama2-FT7B | 48.7 | 57.3 | 64.3 | 65.8 | 78.2 | 31.0 | 35.8 | 51.2 | 5.0 | 7.5 |
| SAIL*7B | 69.2 | 48.4 | ||||||||
| Llama213B | 45.7 | 47.0 | 30.2 | 26.0 | 77.5 | 16.3 | 20.5 | 24.7 | 2.3 | 3.6 |
| Alpaca13B | 46.1 | 66.9 | 51.1 | 57.6 | 77.7 | 34.8 | 36.7 | 56.6 | 2.0 | 3.8 |
| Our SELF-RAG 7B | 54.9 | 66.4 | 72.4 | 67.3 | 81.2 | 30.0 | 35.7 | 74.3 | 66.9 | 67.8 |
| Our SELF-RAG 13B | 55.8 | 69.3 | 74.5 | 73.1 | 80.2 | 31.7 | 37.0 | 71.6 | 70.3 | 71.3 |
表 2: 六项任务的整体实验结果。加粗数字表示非专有模型中的最佳性能,灰色加粗文本表示专有模型在所有非专有模型中表现最佳时的结果。* 表示并发工作或近期研究报道的同期结果。– 表示原始论文未报告或不适用的数值。模型按规模排序。FS、em、rg、mau、prec、rec 分别代表 FactScore (事实性);str-em、rouge (正确性);MAUVE (流畅性);引用精确率和召回率。
| LM | PopQA (acc) | TQA (acc) | Pub (acc) | ARC (acc) | Bio (FS) | (em) | (rg) | ASQA (mau) | (pre) | (rec) |
|---|---|---|---|---|---|---|---|---|---|---|
| 使用专有数据的模型 | ||||||||||
| Llama2-C13B | 20.0 | 59.3 | 49.4 | 38.4 | 55.9 | 22.4 | 29.6 | 28.6 | – | – |
| Ret-Llama2-C13B | 51.8 | 59.8 | 52.1 | 37.9 | 79.9 | 32.8 | 34.8 | 43.8 | 19.8 | 36.1 |
| ChatGPT | 29.3 | 74.3 | 70.1 | 75.3 | 71.8 | 35.3 | 36.2 | 68.8 | – | – |
| Ret-ChatGPT | 50.8 | 65.7 | 54.7 | 75.3 | – | 40.7 | 39.9 | 79.7 | 65.1 | 76.6 |
| Perplexity.ai | – | – | – | – | 71.2 | – | – | – | – | – |
| 无检索的基线模型 | ||||||||||
| Llama27B | 14.7 | 30.5 | 34.2 | 21.8 | 44.5 | 7.9 | 15.3 | 19.0 | – | – |
| Alpaca7B | 23.6 | 54.5 | 49.8 | 45.0 | 45.8 | 18.8 | 29.4 | 61.7 | – | – |
| Llama213B | 14.7 | 38.5 | 29.4 | 29.4 | 53.4 | 7.2 | 12.4 | 16.0 | – | – |
| Alpaca13B | 24.4 | 61.3 | 55.5 | 54.9 | 50.2 | 22.9 | 32.0 | 70.6 | – | – |
| CoVE65B * | – | – | – | – | 71.2 | – | – | – | – | – |
| 带检索的基线模型 | ||||||||||
| Toolformer*6B | – | 48.8 | – | – | – | – | – | – | – | – |
| Llama27B | 38.2 | 42.5 | 30.0 | 48.0 | 78.0 | 15.2 | 22.1 | 32.0 | 2.9 | 4.0 |
| Alpaca7B | 46.7 | 64.1 | 40.2 | 48.0 | 76.6 | 30.9 | 33.3 | 57.9 | 5.5 | 7.2 |
| Llama2-FT7B | 48.7 | 57.3 | 64.3 | 65.8 | 78.2 | 31.0 | 35.8 | 51.2 | 5.0 | 7.5 |
| SAIL*7B | – | – | 69.2 | 48.4 | – | – | – | – | – | – |
| Llama213B | 45.7 | 47.0 | 30.2 | 26.0 | 77.5 | 16.3 | 20.5 | 24.7 | 2.3 | 3.6 |
| Alpaca13B | 46.1 | 66.9 | 51.1 | 57.6 | 77.7 | 34.8 | 36.7 | 56.6 | 2.0 | 3.8 |
| Our SELF-RAG 7B | 54.9 | 66.4 | 72.4 | 67.3 | 81.2 | 30.0 | 35.7 | 74.3 | 66.9 | 67.8 |
| Our SELF-RAG 13B | 55.8 | 69.3 | 74.5 | 73.1 | 80.2 | 31.7 | 37.0 | 71.6 | 70.3 | 71.3 |
5 RESULTS AND ANALYSIS
5 结果与分析
5.1 MAIN RESULTS
5.1 主要结果
Comparison against baselines without retrieval. Table 2 (top) presents the baselines without retrieval. Our SELF-RAG (bottom two rows) demonstrates a substantial performance advantage over supervised fine-tuned LLMs in all tasks and even outperforms ChatGPT in PubHealth, PopQA, biography generations, and ASQA (Rouge and MAUVE). Our approach also significantly outperforms a concurrent method that employs sophisticated prompt engineering; specifically, on the bio generation task, our 7B and 13B models outperform the concurrent CoVE (Dhuliawala et al., 2023), which iterative ly prompts Llama $2_{65\mathrm{B}}$ to refine output.
与无检索基线的对比。表2(上)展示了无检索的基线方法。我们的SELF-RAG(底部两行)在所有任务中都显著优于监督微调的大语言模型,甚至在PubHealth、PopQA、传记生成和ASQA(Rouge和MAUVE指标)上超越了ChatGPT。我们的方法也显著优于采用复杂提示工程的同期方法;具体而言,在传记生成任务中,我们的7B和13B模型优于同期CoVE(Dhuliawala等人,2023)方法,后者通过迭代提示Llama $2_{65\mathrm{B}}$ 来优化输出。
Comparison against baselines with retrieval. As shown in Tables 2 (bottom), our SELF-RAG also outperforms existing RAG in many tasks, obtaining the best performance among non-proprietary LM-based models on all tasks. While our method outperforms other baselines, on PopQA or Bio, powerful instruction-tuned LMs with retrieval (e.g., LLama2-chat, Alpaca) show large gains from their non-retrieval baselines. However, we found that these baselines provide limited solutions for tasks where we cannot simply copy or extract sub-strings of retrieved passages. On PubHealth and ARC-Challenge, baselines with retrieval do not improve performance notably from their noretrieval counterparts. We also observe that most baselines with retrieval struggle to improve citation accuracy. On ASQA, our model shows significantly higher citation precision and recall than all models except ChatGPT. Gao et al. (2023) found that ChatGPT consistently exhibits superior efficacy in this particular task, surpassing smaller LMs. Our SELF-RAG bridges this performance gap, even outperforming ChatGPT in citation precision, which measures whether the model-generated claim is fully supported by cited evidence. We also found that on the metrics for factual precision, SELF-RAG 7B occasionally outperforms our 13B due to the tendency of smaller SELF-RAG to often generate precisely grounded yet shorter outputs. Llama2- $\mathrm{FT}_{78}$ , which is the baseline LM trained on the same instruction-output pairs as SELF-RAG without retrieval or self-reflection and is retrieval-augmented at test time only, lags behind SELF-RAG. This result indicates SELF-RAG gains are not solely from training data and demonstrate the effectiveness of SELF-RAG framework.
基于检索的基线模型对比。如表2(底部)所示,我们的SELF-RAG模型在多数任务中优于现有RAG方法,在所有任务的非专有大语言模型(LM)中取得最佳性能。虽然本方法超越其他基线,但在PopQA和Bio任务上,采用检索机制的指令调优大语言模型(如LLama2-chat、Alpaca)较其无检索版本展现出显著提升。然而我们发现,这些基线模型对于无法直接复制或抽取检索文本子串的任务解决方案有限。在PubHealth和ARC-Challenge任务中,带检索的基线模型相比无检索版本未呈现明显改进。我们还观察到多数带检索的基线模型难以提升引用准确率。在ASQA任务上,除ChatGPT外,本模型的引用精确率与召回率显著优于所有模型。Gao等(2023)研究发现ChatGPT在该特定任务中始终表现出卓越效能,超越较小规模的大语言模型。我们的SELF-RAG弥合了这一性能差距,甚至在衡量生成主张是否完全被引用证据支持的引用精确率指标上超越ChatGPT。同时发现,在事实精确度指标方面,SELF-RAG 7B有时优于13B版本,这是因为较小模型倾向于生成更简短但精确接地的输出。Llama2-$\mathrm{FT}_{78}$作为仅在测试阶段采用检索增强、且训练数据与SELF-RAG相同(不含检索或自反思机制)的基线大语言模型,其表现落后于SELF-RAG。该结果表明SELF-RAG的优势不仅源于训练数据,更验证了SELF-RAG框架的有效性。

Figure 3: Analysis on SELF-RAG: (a) Ablation studies for key components of SELF-RAG training and inference based on our 7B model. (b) Effects of soft weights on ASQA citation precision and Mauve (fluency). (c) Retrieval frequency and normalized accuracy on PubHealth and PopQA.
图 3: SELF-RAG分析: (a) 基于7B模型对SELF-RAG训练和推理关键组件的消融研究。 (b) 软权重对ASQA引用精确率和Mauve(流畅度)的影响。 (c) PubHealth和PopQA上的检索频率和归一化准确率。
5.2 ANALYSIS
5.2 分析
Ablation studies. We conduct a set of ablations of our framework to identify which factors play key roles. We evaluate two model variants trained differently than our model: No Retriever trains an LM using the standard instruction-following method given instruction-output pairs, without retrieved passages; No Critic trains an LM trained with input-output pairs that are always augmented with the top one retrieved document without reflection tokens. This is similar to SAIL (Luo et al., 2023), and we use our instruction-output data instead of using the Alpaca dataset (Dubois et al., 2023), as in SAIL. We also conduct ablation on our inference-time algorithm, including No retrieval disables retrieval during inference; Hard constraints indicates the model performance that retrieves when Retrieve =Yes instead of using the adaptive threshold; Retrieve top 1 always retrieves and uses the top one document only, similar to standard RAG approaches; Remove ISSUP indicates the model performance that removes ISSUP score only during critique-guided beam search in Eq. 4. In this ablation experiment, we use a training instance size of $50\mathrm{k\Omega}$ for a more efficient exploration of training variations. Later in this section, we conduct an analysis of the effect of training data size. We conduct the ablation studies on three datasets, PopQA, PubHealth, and ASQA. On ASQA, we evaluate models on sampled 150 instances and exclude ablations involving adaptive or no retrieval processes.
消融实验。我们针对框架进行了一系列消融研究,以确定哪些因素起关键作用。我们评估了两种与模型训练方式不同的变体:No Retriever使用标准指令跟随方法训练大语言模型,仅提供指令-输出对而不使用检索段落;No Critic训练时始终用排名第一的检索文档增强输入-输出对,但不使用反思token,该方法类似SAIL (Luo et al., 2023),但我们采用自建指令-输出数据而非SAIL使用的Alpaca数据集 (Dubois et al., 2023)。我们还对推理算法进行消融:No retrieval在推理阶段禁用检索;Hard constraints表示模型仅在Retrieve=Yes时执行检索(不使用自适应阈值);Retrieve top 1始终仅检索并使用排名第一的文档(类似标准RAG方法);Remove ISSUP表示在公式4的批判引导束搜索中移除ISSUP评分。本实验采用$50\mathrm{k\Omega}$训练实例规模以高效探索训练变体,后续将分析训练数据规模的影响。消融实验在PopQA、PubHealth和ASQA三个数据集进行,其中ASQA仅评估150个采样实例,并排除涉及自适应/无检索流程的消融项。
We show in Table 3a the ablation results. The top part of the table shows results for training ablations, and the bottom part is for inference ablations. We see that all components play important roles. We also observe a large performance gap between SELF-RAG and No Retriever or Critic baselines across tasks, indicating that training an LM with those models largely contributes to the performance gain of SELF-RAG. Using the top passages regardless of their relevance (Retrieve top 1) as in conventional RAG approaches causes a large drop in PopQA and ASQA, and removing ISSUP during the beam search results hurts performance on ASQA. This demonstrates the effectiveness of SELF-RAG’s capabilities of carefully selecting generations based fine-grained multiple criterion, instead of naively using all of the top passages from the retrieval model or solely depending on relevance scores.
我们在表 3a 中展示了消融实验结果。表格上半部分为训练消融结果,下半部分为推理消融结果。可以看出所有组件都发挥着重要作用。我们还观察到 SELF-RAG 与无检索器或评判基准线在各任务间存在显著性能差距,这表明用这些模型训练大语言模型对 SELF-RAG 的性能提升贡献很大。像传统 RAG 方法那样不考虑相关性直接使用最高分段落 (Retrieve top 1) 会导致 PopQA 和 ASQA 性能大幅下降,而在束搜索中移除 ISSUP 会损害 ASQA 的表现。这证明了 SELF-RAG 基于细粒度多重标准谨慎选择生成内容的能力具有显著优势,而非简单地使用检索模型返回的所有高分段落或仅依赖相关性分数。
Effects of inference-time customization. One key benefit of our proposed framework is that it enables us to control how much each critique type affects the final generation sampling. We analyze the effects of different parameter weights on the top of our 7B model during inference time on ASQA, where multiple evaluation aspects are considered. Figure 3b shows the effects of changing the weighting term for $\boxed{\mathbf{IsSUP}}$ , which criticizes how supported the output is by the text passage. As the figure shows, increasing the weight leads to positive effects on the models’ citation precision since this puts more emphasis on whether model generation is supported by the evidence. On the contrary, a larger weight results in lower MAUVE scores: when generation gets longer and more fluent, there are often more claims that are not fully supported by citations, consistent with findings by Liu et al. (2023a). Our framework lets practitioners choose and customize models’ behaviors at test time by adjusting such parameters without requiring additional training.
推理时定制化的效果。我们提出的框架有一个关键优势,就是能够控制每种批评类型对最终生成采样的影响程度。我们在ASQA数据集上分析了推理时不同参数权重对7B模型顶部的影响,其中考虑了多个评估维度。图3b展示了改变$\boxed{\mathbf{IsSUP}}$权重项的效果,该指标用于批评输出结果在文本段落中的支持程度。如图所示,增加权重会提升模型的引用精确度,因为这更强调模型生成是否得到证据支持。相反,较大权重会导致MAUVE分数降低:当生成内容变得更长、更流畅时,往往会出现更多未被引用完全支持的声明,这与Liu等人(2023a)的发现一致。我们的框架允许实践者通过调整这些参数,在测试时选择和定制模型行为,而无需额外训练。

Figure 4: Training scale and Human analysis: (a) (b) (c) Training scale analysis shows the effect of the training data scale on PopQA, PubHealth and ASQA (citation precision), respectively. (d) Human analysis on SELF-RAG outputs as well as reflection tokens.
图 4: 训练规模与人工分析: (a) (b) (c) 训练规模分析分别展示了训练数据规模对PopQA、PubHealth和ASQA(引用精度)的影响。(d) 对SELF-RAG输出及反思token的人工分析。
Efficiency and accuracy trade-off. Using our framework, practitioners can adjust how often retrieval occurs using the token probability of reward tokens. We evaluate how this adaptive threshold affects overall accuracy and frequency of retrieval, and we evaluate the performance with varying numbers of threshold $\delta$ (larger $\delta$ results in less retrieval) on PubHealth and PopQA. Figure 3c shows that the model’s retrieval frequencies dramatically change on both datasets. as $\delta$ varies. On one hand, performance deterioration by retrieving less is smaller on PubHealth but larger in PopQA.
效率与准确性的权衡。通过我们的框架,实践者可以根据奖励token的token概率调整检索频率。我们评估了这种自适应阈值如何影响整体准确性和检索频率,并在PubHealth和PopQA数据集上测试了不同阈值$\delta$(较大的$\delta$会导致较少检索)下的性能表现。图3c显示,随着$\delta$的变化,模型在两个数据集上的检索频率发生显著改变。一方面,减少检索对PubHealth的性能影响较小,但在PopQA上影响较大。
Effects of training data size. We conduct an analysis of how the data scale affects the model’s performance. In particular, we randomly sample 5k, 10k, $20\mathrm{k\Omega}$ , and $50\mathrm{k\Omega}$ instances from our original $150\mathrm{k}$ training instances, and fine-tune four SELF-RAG $7\mathrm{B}$ variants on those subsets. Then, we compare the model performance on PopQA, PubHealth, and ASQA (citation precision) with our final SELFRAG trained on the full $150\mathrm{k}$ instances. We also evaluate Figures 4a, 4b and 4c shows the models’ performance trained on different amount of data. Across all datasets, increasing data size often shows upward trajectories and the improvements are significantly larger in PopQA and ASQA, while we do not observed such significant improvements on $\mathrm{Llama2-FT_{7B}}$ when increasing the training data from $50\mathrm{k\Omega}$ to $150\mathrm{k}$ . These results also indicate that further expanding the training data of SELF-RAG may lead to further improvements, although in this work we limit our training data size to 150k.
训练数据规模的影响。我们分析了数据规模如何影响模型性能,具体从原始150k训练实例中随机抽取5k、10k、$20\mathrm{k\Omega}$和$50\mathrm{k\Omega}$样本,并基于这些子集微调了四个SELF-RAG $7\mathrm{B}$变体。随后在PopQA、PubHealth和ASQA(引用精确度)上将这些模型与完整150k数据训练的最终SELF-RAG进行对比。图4a、4b和4c展示了不同数据量训练下的模型表现。所有数据集中,增大数据规模通常呈现上升趋势,其中PopQA和ASQA的提升尤为显著,而$\mathrm{Llama2-FT_{7B}}$在训练数据从$50\mathrm{k\Omega}$增至$150\mathrm{k}$时未观察到明显改进。这些结果表明,尽管本研究将训练数据限制在150k,但进一步扩展SELF-RAG的训练数据可能带来更大提升。
Human evaluations. We conduct small human evaluations on SELF-RAG outputs, as well as the reliability of predicted reflection tokens. In particular, we sampled 50 samples from PopQA and Bio results. Following Menick et al. (2022), human annotators evaluate S&P , which indicates whether the model output is plausible (i.e., the output is a reasonable and on-topic response to the question as if it were occurring in a conversation) and supported (i.e., the provided evidence is sufficient to verify the validity of the answer). For S&P, we do not consider the instances where SELF-RAG predicts irrelevant or no support. We then ask our annotators whether the model-predicted reflection tokens about $\boxed{\mathbf{IsREL}}$ and ISSUP match their inspections (e.g., whether the fully supported output is supported by the cited evidence). Human annotators find SELF-RAG answers are often plausible and supported by relevant passages with higher S&P scores on short-form PopQA, which is consistent with Menick et al. (2022). Human annotators also find ISREL and ISSUP reflection token predictions are mostly aligned with their assessments. Appendix Table 6 shows several annotated examples and explanations on assessments.
人工评估。我们对SELF-RAG的输出以及预测反射token的可靠性进行了小规模人工评估。具体而言,我们从PopQA和Bio结果中抽取了50个样本。参照Menick等人(2022)的方法,人工标注者评估了S&P指标,该指标衡量模型输出是否合理(即输出是对问题的合理且切题的回答,仿佛发生在对话中)且有依据(即提供的证据足以验证答案的有效性)。对于S&P评估,我们不考虑SELF-RAG预测为无关或没有支持的情况。然后,我们要求标注者判断模型预测的关于$\boxed{\mathbf{IsREL}}$和ISSUP的反射token是否与其检查结果一致(例如,完全支持的输出是否确实被引用的证据所支持)。人工标注者发现SELF-RAG的答案通常合理且由相关段落支持,在短格式PopQA上具有更高的S&P分数,这与Menick等人(2022)的结论一致。标注者还发现ISREL和ISSUP反射token的预测大多与其评估结果一致。附录表6展示了若干标注示例及评估说明。
6 CONCLUSION
6 结论
This work introduces SELF-RAG, a new framework to enhance the quality and factuality of LLMs through retrieval on demand and self-reflection. SELF-RAG trains an LM to learn to retrieve, generate, and critique text passages and its own generation by predicting the next tokens from its original vocabulary as well as newly added special tokens, called reflection tokens. SELF-RAG further enables the tailoring of LM behaviors at test time by leveraging reflection tokens. Our holistic evaluations on six tasks using multiple metrics demonstrate that SELF-RAG significantly outperforms LLMs with more parameters or with conventional retrieval-augmented generation approaches.
本研究提出了SELF-RAG框架,通过按需检索和自省机制提升大语言模型(LLM)的生成质量与事实准确性。该框架训练语言模型学习检索、生成及批判性评估文本段落,通过预测原始词汇表和新引入的特殊标记(称为反思标记)来优化自身输出。SELF-RAG还能在测试阶段利用反思标记灵活调整模型行为。我们在六大任务上的多维度评估表明,该框架显著优于参数量更大的LLM或传统检索增强生成方法。
ETHICAL CONCERNS
伦理关切
This work aims to improve the factuality of LLM outputs, the lack of which continues to cause numerous real-world problems (e.g., spread of misinformation and provision of incorrect and dangerous advice). While our method shows significant improvements in terms of performance, factuality, and citation accuracy, it can still generate outputs that are not fully supported by the citations. We hope that explicit self-reflection and fine-grained attribution may help users verify factual errors in the model outputs.
本研究旨在提升大语言模型(LLM)输出的真实性,该问题持续引发诸多现实困境(例如错误信息传播、提供不正确且危险的建议)。虽然我们的方法在性能、真实性和引用准确性方面展现出显著改进,但仍可能生成未被引用完全支持的输出。我们期望显式的自我反思和细粒度归因能帮助用户验证模型输出中的事实性错误。
ACKNOWLEDGMENTS
致谢
We thank Sewon Min, Scott Wen-tau Yih, Sean Welleck, and Kawin Ethayarajh for fruitful discussions in the early stages of this work. We thank Sewon Min, Joongwon (Daniel) Kim, and Sandy Kaplan for valuable feedback on the paper, and Tianyu Gao and Weijia Shi for their help on evaluations. Akari Asai is supported by the IBM Fellowship. We thank Stability AI for providing computing to train and evaluate the LMs in this work, and Microsoft Accelerate Foundation Models Research Program for the access to OpenAI APIs. This work was funded in part by the DARPA MCS program through NIWC Pacific (N66001-19-2-4031), NSF IIS-2044660, and gifts from AI2.
感谢 Sewon Min、Scott Wen-tau Yih、Sean Welleck 和 Kawin Ethayarajh 在本工作早期阶段的富有成效的讨论。感谢 Sewon Min、Joongwon (Daniel) Kim 和 Sandy Kaplan 对论文提出的宝贵意见,以及 Tianyu Gao 和 Weijia Shi 在评估方面的帮助。Akari Asai 获得了 IBM Fellowship 的支持。感谢 Stability AI 为本工作中的语言模型训练和评估提供的计算资源,以及 Microsoft Accelerate Foundation Models Research Program 提供的 OpenAI API 访问权限。本工作部分由 DARPA MCS 项目通过 NIWC Pacific (N66001-19-2-4031)、NSF IIS-2044660 以及 AI2 的捐赠资助。
REFERENCES
参考文献
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. Gpteval: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634, 2023b. URL https://arxiv.org/abs/2303.16634.
Yang Liu、Dan Iter、Yichong Xu、Shuohang Wang、Ruochen Xu 和 Chenguang Zhu。GPTEval: 使用 GPT-4 进行 NLG 评估并实现更好的人类对齐。arXiv 预印本 arXiv:2303.16634, 2023b。URL https://arxiv.org/abs/2303.16634。
APPENDIX
附录
D Full List of Instructions and Demonstrations for GPT-4 21
D GPT-4指令与演示全集 21
A SELF-RAG DETAILS
自反思检索增强生成(SELF-RAG)详解
A.1 REFLECTION TOKENS.
A.1 反思Token (Reflection Tokens)
Definitions of reflection tokens. Below, we provide a detailed definition of reflection type and output tokens. The first three aspects will be provided at each segment level, while the final aspect is only given at each output level.
反射Token的定义。下面我们详细定义反射类型和输出Token。前三个方面将在每个片段级别提供,而最后一个方面仅在每个输出级别给出。
• Retrieval-on-demand ( Retrieve ): Given an input and previous-step generation (if applicable), an LM determines whether the continuation requires factual grounding. No indicates retrieval is unnecessary as the sequence does not require factual grounding or may not be enhanced by knowledge retrieval, Yes indicates retrieval is necessary. We additionally have continue to use evidence, which indicates that a model can continue to use the evidence retrieved previously. For instance, a passage may contain rich factual information, and thus SELF-RAG generates multiple segments based on the passage.
• 按需检索 (Retrieve):给定输入和上一步生成内容(如适用),大语言模型判断后续内容是否需要事实依据。No表示无需检索,因为序列不需要事实依据或知识检索可能无法提升效果;Yes表示需要检索。我们还设置了继续使用证据选项,表示模型可以继续使用先前检索到的证据。例如,某段落可能包含丰富的事实信息,因此SELF-RAG会基于该段落生成多个片段。
• Relevant ( ISREL ): Retrieved knowledge may not be always relevant to the input. This aspect indicates whether the evidence provides useful information (Relevant) or not (Irrelevant).
• 相关性 (ISREL):检索到的知识可能并不总是与输入相关。这一指标用于判断证据是否提供了有用信息(相关)或无用信息(不相关)。
• Supported ( ISSUP ): Attribution is the concept of whether the output is fully supported by certain evidence (Menick et al., 2022; Bohnet et al., 2022). This aspect judges how much information in the output is entailed by the evidence. We evaluate attributions in three scale, Fully supported, Partially supported, and No support / Contradictory, following Yue et al. (2023); Nakano et al. (2021).
• 支持性 (ISSUP):归因 (Attribution) 指输出内容是否完全由特定证据支撑 (Menick et al., 2022; Bohnet et al., 2022)。该维度评估输出信息中有多少内容可被证据所蕴含。我们采用 Yue et al. (2023) 和 Nakano et al. (2021) 的三级评价标准:完全支持、部分支持、无支持/矛盾。
• Useful ( ISUSE ): Following the definitions from Liu et al. (2023a), we define the perceived utility as whether the response is a helpful and informative answer to the query, independently from whether it is in fact factual or not. This can be also viewed as plausibility in Menick et al. (2022). For usefulness, we use a five-scale evaluation (1 is the lowest and 5 is the highest).
• 有用性 (ISUSE): 根据 Liu 等人 (2023a) 的定义,我们将感知效用定义为回应是否为查询提供了有帮助且信息丰富的答案,而不论其是否真实。这也可以视为 Menick 等人 (2022) 中所说的合理性。对于有用性,我们采用五级评分 (1 为最低,5 为最高)。
Details of GPT-4-based data collections. We use the instruction and demonstration pairs to prompt GPT-4, listed in Section D. Following an official recommendation, we separate instructions and outputs with “##”. We use the temperature 1 and set the maximum output token counts to be 200. We discard instances where GPT-4 does not follow the designated output formats or output sequences that do not match our expected category names. As a result, we collected 1,2594 for Retrieve , 11,181 for ISSUP , 19,317 for relevance, 3,831 for utility.
基于GPT-4的数据收集细节。我们使用D节中列出的指令和演示对来提示GPT-4。根据官方建议,我们用"##"分隔指令和输出。设置温度参数为1,并将最大输出token数限制为200。我们剔除了GPT-4未遵循指定输出格式或输出序列与预期类别名称不匹配的实例。最终收集到12,594条Retrieve数据、11,181条ISSUP数据、19,317条relevance数据以及3,831条utility数据。
Manual analysis of the GPT-4 predictions. The authors of this paper manually assess randomly sampled 20 instances for each aspect and check if GPT-4 predictions match their assessments given the same instruction, demonstrations, and test instances. We found our assessments show high agreement with GPT-4 predictions, especially for relevance $(95%)$ , retrieval necessity $(95%)$ , and the degree of support $(90%)$ . Agreement was slightly lower in usefulness $(80%)$ , mostly due to the disagreement between 1 and 2 or 4 and 5.
对GPT-4预测结果的人工分析。本文作者针对每个评估维度随机抽样20个实例进行人工评估,检查在相同指令、示例和测试条件下GPT-4的预测是否符合人工判断。我们发现评估结果与GPT-4预测具有高度一致性,尤其在相关性 $(95%)$ 、检索必要性 $(95%)$ 和支持程度 $(90%)$ 方面。实用性 $(80%)$ 的一致性略低,主要源于评分1与2或4与5之间的分歧。
A.2 SELF-RAG TRAINING
A.2 SELF-RAG 训练
Overview of training. Algorithm 2 provides a high-level overview of our training.
训练概述。算法2提供了我们训练过程的高层概览。
Full list of seed datasets. To sample diverse input-output pairs, we sample instances of the OpenInstruct (Wang et al., 2023) dataset. In particular, we use their ShareGPT, GPT-4 Alpaca, Alpaca, Open Assistant, and FLAN subsets subsets. We also sample instances from a couple of knowledgeintensive datasets, Natural Questions (Kwiatkowski et al., 2019), Wizard of Wikipedia (Dinan et al., 2019) and FEVER (Thorne et al., 2018) from the KILT benchmark (Petroni et al., 2021), ASQA (Stelmakh et al., 2022) and multiple QA datasets including ARC-Easy and OpenBookQA (Mihaylov et al., 2018). Table 3 shows the full list of training instances, and in total, we use 145,619 instances.
种子数据集完整列表。为了采样多样化的输入-输出对,我们从OpenInstruct (Wang et al., 2023) 数据集中抽取实例,具体使用了其ShareGPT、GPT-4 Alpaca、Alpaca、Open Assistant和FLAN子集。同时从KILT基准测试 (Petroni et al., 2021) 的知识密集型数据集Natural Questions (Kwiatkowski et al., 2019)、Wizard of Wikipedia (Dinan et al., 2019)、FEVER (Thorne et al., 2018),以及ASQA (Stelmakh et al., 2022) 和多个问答数据集(包括ARC-Easy与OpenBookQA (Mihaylov et al., 2018))中采样实例。表3展示了全部训练实例列表,总计使用145,619个实例。
Performance of the Critic $\mathcal{C}$ . We evaluate the accuracy of reward predictions by splitting GPT-4 generated feedback into training, development, and test sets. The accuracy of the reward model is as follows. Table 5 shows the model performance of predicting GPT-4 judgments. As you can see, overall our fine-tuned reward model shows high prediction matching with GPT-4 predicted feedback.
评论家 $\mathcal{C}$ 的性能表现。我们通过将GPT-4生成的反馈数据划分为训练集、开发集和测试集来评估奖励预测的准确性。奖励模型的准确率如下所示。表5展示了预测GPT-4判断的模型性能。可以看出,经过微调的奖励模型整体上与GPT-4预测反馈具有高度匹配性。
表5:
Algorithm 2 SELF-RAG Training
算法 2 SELF-RAG 训练
Table 3: The generator LM $\mathcal{M}$ training data statistics.
| Datasetname | category | Datasource | thenumber ofinstances |
| GPT-4 Alpaca | Instruction-following | Open-Instruct | 26,168 |
| StanfordAlpaca | Instruction-following | Open-Instruct | 25,153 |
| FLAN-V2 | Instruction-following | Open-Instruct | 17,817 |
| ShareGPT | Instruction-following | Open-Instruct | 13,406 |
| OpenAssistant1 | Instruction-following | Open-Instruct | 9,464 |
| Wizard ofWikipedia | Knowledge-intensive | KILT | 17,367 |
| NaturalQuestions | Knowledge-intensive | KILT | 15,535 |
| FEVER | Knowledge-intensive | KILT | 9,966 |
| OpenBoookQA | Knowledge-intensive | HFDataset | 4,699 |
| Arc-Easy | Knowledge-intensive | HFDataset | 2,147 |
| ASQA | Knowledge-intensive | ASQA | 3,897 |
表 3: 生成器大语言模型 $\mathcal{M}$ 训练数据统计。
| 数据集名称 | 类别 | 数据来源 | 实例数量 |
|---|---|---|---|
| GPT-4 Alpaca | 指令跟随 | Open-Instruct | 26,168 |
| StanfordAlpaca | 指令跟随 | Open-Instruct | 25,153 |
| FLAN-V2 | 指令跟随 | Open-Instruct | 17,817 |
| ShareGPT | 指令跟随 | Open-Instruct | 13,406 |
| OpenAssistant1 | 指令跟随 | Open-Instruct | 9,464 |
| Wizard ofWikipedia | 知识密集型 | KILT | 17,367 |
| NaturalQuestions | 知识密集型 | KILT | 15,535 |
| FEVER | 知识密集型 | KILT | 9,966 |
| OpenBoookQA | 知识密集型 | HFDataset | 4,699 |
| Arc-Easy | 知识密集型 | HFDataset | 2,147 |
| ASQA | 知识密集型 | ASQA | 3,897 |
Figure 5: Reward prediction accuracy using GPT-4 predictions as ground-truth predictions.
| base LM | Retrieve | IsSUP | IsREL | IsUsE |
| Llama2-7B | 93.8 | 93.5 | 80.2 | 73.5 |
| FLAN-3B | 85.6 | 73.1 | 82.0 | 72.1 |
图 5: 使用 GPT-4 预测作为真实预测的奖励预测准确率
| base LM | Retrieve | IsSUP | IsREL | IsUsE |
|---|---|---|---|---|
| Llama2-7B | 93.8 | 93.5 | 80.2 | 73.5 |
| FLAN-3B | 85.6 | 73.1 | 82.0 | 72.1 |
While our final model uses Llama2-7B as a base LM, we also train and compare FLAN-3B (Wei et al., 2022) model on the same data, to investigate the effectiveness of different data sizes affect final reward predictions. In most aspects, our reward model shows higher than $80%$ accuracy, indicating the powerful ability of fine-tuned specialized LMs to evaluate text. While both models show relatively lower performance on $\boxed{\mathbf{IsUsE}}$ , this is because both models often confuse between the two highest cases (5 and 4), where human annotators can also disagree.
虽然我们的最终模型采用Llama2-7B作为基础大语言模型,但我们也使用相同数据训练并比较了FLAN-3B (Wei et al., 2022) 模型,以探究不同数据规模对最终奖励预测效果的影响。在多数评估维度上,我们的奖励模型准确率超过 $80%$ ,表明经过微调的专用大语言模型具备强大的文本评估能力。值得注意的是,两个模型在 $\boxed{\mathbf{IsUsE}}$ 指标上表现相对较弱,这源于模型常混淆最高两个评分等级(5和4)——该现象在人工标注时同样存在分歧。
Details of $\mathcal{M}$ data creation. Here, we provide detailed data creation procedures. Algorithm 3 summarizes the process. Here we set $y_{t}$ to $y$ for simplification. Once we train the critic model, we first run it on input data from the aforementioned datasets, to predict whether retrieval is needed or not. For the instances where the critic predicts $\scriptstyle\boxed{\mathbf{Retrieve}}=\mathrm{No}$ , we only predict the ISUSE given input and output. For the instances where the critic predicts $\scriptstyle\boxed{\mathrm{Retrieve}}=\Upsilon\in S$ , we first retrieve passages using the input and the entire output as queries, to find passages that are relevant to the entire output. We then split output sentences using Spacy.7 For each sentence, we run $\mathcal{C}$ to predict whether the retrieval is necessary or not, given the input, preceding segments, and the initial retrieved passage. If $\mathcal{C}$ predicts Retrieve =No, then do not insert any paragraph at the tth segment. If $\mathcal{C}$ predicts $\scriptstyle\boxed{\mathrm{Retrieve}}=\Upsilon\in S$ , then we use the original input and the tth segment as a retrieval query to find relevant passages for the $t$ -th segment. For each retrieved passage, we predict $\boxed{\mathbf{IsREL}}$ and $\boxed{\mathbf{IsSUP}}$ . If there is any passage and continuation with ISREL $=$ Relevant and $\scriptstyle\boxed{\mathrm{IsSUP}}=\scriptstyle\mathrm{Eul}\bot\mathrm{Y}$ Supported / ISSUP $=$ Partially
$\mathcal{M}$ 数据创建的细节。此处,我们提供详细的数据创建流程。算法3总结了该过程。为简化起见,这里我们将 $y_{t}$ 设为 $y$。训练完评判模型后,我们首先在上述数据集的输入数据上运行该模型,以预测是否需要检索。对于评判模型预测为 $\scriptstyle\boxed{\mathbf{Retrieve}}=\mathrm{No}$ 的实例,我们仅根据输入和输出来预测 ISUSE。对于评判模型预测为 $\scriptstyle\boxed{\mathrm{Retrieve}}=\Upsilon\in S$ 的实例,我们首先使用输入和整个输出作为查询来检索段落,以找到与整个输出相关的段落。然后,我们使用 Spacy 分割输出句子。7 对于每个句子,我们在给定输入、前序片段和初始检索段落的情况下,运行 $\mathcal{C}$ 来预测是否需要检索。如果 $\mathcal{C}$ 预测 Retrieve = No,则在第 $t$ 个片段处不插入任何段落。如果 $\mathcal{C}$ 预测 $\scriptstyle\boxed{\mathrm{Retrieve}}=\Upsilon\in S$,则我们使用原始输入和第 $t$ 个片段作为检索查询,为第 $t$ 个片段查找相关段落。对于每个检索到的段落,我们预测 $\boxed{\mathbf{IsREL}}$ 和 $\boxed{\mathbf{IsSUP}}$。如果有任何段落和延续满足 ISREL $=$ Relevant 且 $\scriptstyle\boxed{\mathrm{IsSUP}}=\scriptstyle\mathrm{Eul}\bot\mathrm{Y}$ Supported / ISSUP $=$ Partially
Supported, then we sample it as the continuation. If there is more than one passage satisfying this criterion, we use the one with the highest retrieval score. If there are only $\begin{array}{r}{\boxed{\mathbf{IsREL}}=\mathbb{T}}\end{array}$ rrelevant or $\boxed{\mathbf{IsSUP}}=\mathbb{N}\circ$ Support passages, we randomly sample one passage.
支持时,我们将其采样为续写内容。若存在多个满足该条件的段落,则选用检索分数最高的段落。若仅存在 $\begin{array}{r}{\boxed{\mathbf{IsREL}}=\mathbb{T}}\end{array}$ 无关或 $\boxed{\mathbf{IsSUP}}=\mathbb{N}\circ$ 支持段落,则随机采样一个段落。
Algorithm 3 M_gen Data creation
算法 3 $\mathcal{M}_{g e n}$ 数据生成
Training examples. Table 4 show several training examples used for $\mathcal{M}$ training.
训练样本。表4展示了用于$\mathcal{M}$训练的几个训练样本。
A.3 SELF-RAG INFERENCE
A.3 SELF-RAG 推理
Details of beam-search score calculations. We first compute scores for each critique type by taking the normalized probabilities of desirable tokens. For $\boxed{\mathbf{IsREL}}$ , we compute the score as follows:
束搜索得分计算细节。我们首先通过计算理想token的归一化概率来获得每种批评类型的得分。对于$\boxed{\mathbf{IsREL}}$,其得分计算方式如下:
$$
s(\boxed{\mathrm{IsReL}})=\frac{p(\boxed{\mathrm{IsReL}}=\mathrm{RELEVANT})}{p(\boxed{\mathrm{IsReL}}=\mathrm{RELEVANT})+p(\boxed{\mathrm{IsReL}}=\mathrm{IRRELEVANT})}.
$$
$$
s(\boxed{\mathrm{IsReL}})=\frac{p(\boxed{\mathrm{IsReL}}=\mathrm{RELEVANT})}{p(\boxed{\mathrm{IsReL}}=\mathrm{RELEVANT})+p(\boxed{\mathrm{IsReL}}=\mathrm{IRRELEVANT})}.
$$
For $\boxed{\mathbf{IsSUP}}$ , we compute the score as follows:
对于 $\boxed{\mathbf{IsSUP}}$ ,我们按如下方式计算得分:
$$
s(\mathrm{[IsReL]})=\frac{p(\mathrm{[IsSur]}=\mathrm{FULLY})}{S}+0.5\times\frac{p(\mathrm{[IsSur]}=\mathrm{PARTIALIY})}{S},
$$
$$
s(\mathrm{[IsReL]})=\frac{p(\mathrm{[IsSur]}=\mathrm{FULLY})}{S}+0.5\times\frac{p(\mathrm{[IsSur]}=\mathrm{PARTIALIY})}{S},
$$
where $\begin{array}{r}{S=\sum_{t\in{\mathrm{FULLY,PARTIALLY,No}}}p(\lbrack\rbrack\mathrm{sSup}\rbrack=t)}\end{array}$ . For $\boxed{\mathbf{IsUsE}}$ where we have a five-scale score, we compute th e weighted sum of the scores. We assigns weighted scores of $w={-1,-0.5,0,0.5,1}$ to the tokens $\boxed{\mathrm{IsUsE}}={1,2,3,4,5}$ , and compute the final scores as follows:
其中 $\begin{array}{r}{S=\sum_{t\in{\mathrm{FULLY,PARTIALLY,No}}}p(\lbrack\rbrack\mathrm{sSup}\rbrack=t)}\end{array}$。对于 $\boxed{\mathbf{IsUsE}}$ 的五级评分制,我们计算得分的加权和。为标记 $\boxed{\mathrm{IsUsE}}={1,2,3,4,5}$ 分配权重分数 $w={-1,-0.5,0,0.5,1}$,并按如下方式计算最终得分:
$$
s\big(\underline{{\mathrm{IsUsE}}}\big)=\sum_{i}^{5}w_{i}\frac{p(\big[\mathrm{IsUsE}\big]=i)}{S},
$$
$$
s\big(\underline{{\mathrm{IsUsE}}}\big)=\sum_{i}^{5}w_{i}\frac{p(\big[\mathrm{IsUsE}\big]=i)}{S},
$$
where $\begin{array}{r}{S=\sum_{t\in{1,2,3,4,5}}p(\boxed{\mathrm{IsUsE}}=t)}\end{array}$ .
其中 $\begin{array}{r}{S=\sum_{t\in{1,2,3,4,5}}p(\boxed{\mathrm{IsUsE}}=t)}\end{array}$ 。
Details of adaptive retrieval. For retrieval based on soft constraints, we trigger retrieval if the following condition is satisfied:
自适应检索的详细信息。对于基于软约束的检索,若满足以下条件则触发检索:
$$
\frac{p(\boldsymbol{\left[\mathrm{Retrieve}\right]}=\mathrm{YES})}{p(\boldsymbol{\left[\mathrm{Retrieve}\right]}=\mathrm{YES})+p(p(\boldsymbol{\left[\mathrm{Retrieve}\right]}=\mathrm{NO})}>\delta.
$$
$$
\frac{p(\boldsymbol{\left[\mathrm{Retrieve}\right]}=\mathrm{YES})}{p(\boldsymbol{\left[\mathrm{Retrieve}\right]}=\mathrm{YES})+p(p(\boldsymbol{\left[\mathrm{Retrieve}\right]}=\mathrm{NO})}>\delta.
$$
B EXPERIMENTAL DETAILS
B 实验细节
B.1 MORE DETAILS OF TRAINING
B.1 训练详情
More details of training and computations. We use 4 Nvidia A100 with 80GB memory to train our models. All models are trained for 3 epochs with a batch size of 128, a peak learning rate of 2e-5 with $3%$ warmup steps, and linear decay afterward. We set the maximum token length to be 2,048 for the 7B model, and 1,524 for the 13B model due to the memory constraint. We use Deepspeed stage 3 (Raj bh and ari et al., 2020) to conduct multi-GPU distributed training, with training precision Bfloat16 enabled. Flash Attention (Dao et al., 2022) is used to make the long-context training more efficient. We run inference of our trained models using 1-2 Quadro RTX 6000 GPUs with 24GB memory.
训练与计算的更多细节。我们使用4块80GB显存的Nvidia A100显卡训练模型。所有模型均训练3个周期,批次大小为128,峰值学习率为2e-5并采用$3%$预热步数,之后线性衰减。受内存限制,7B模型的最大token长度设为2,048,13B模型设为1,524。我们采用Deepspeed第三阶段(Raj bh和ari等人,2020)进行多GPU分布式训练,并启用Bfloat16训练精度。使用Flash Attention(Dao等人,2022)提升长文本训练效率。推理阶段采用1-2块24GB显存的Quadro RTX 6000显卡运行训练好的模型。
B.2 MORE DETAILS OF EVALUATIONS
B.2 评估的更多细节
Retrieval setup details. By default, we use Contriever-MS MARCO to retrieve the top five documents from Wikipedia, and use official Wikipedia embeddings based on 2018 English Wikipedia. On PopQA, where question and answer pairs are created based on WikiData in 2022, we found that the 2018 Wikipedia sometimes lacks articles about some entities that have been more recently added to Wikipedia. Therefore, for PopQA, we used the December 2020 pre processed Wikipedia corpus provided by Izacard et al. (2022b) and generated document embeddings.8 The issues of performance variance from different Wikipedia dumps have been reported by prior work (Asai et al., 2020; Izacard et al., 2022b). Yet, we observe limited effectiveness of such off-the-shelf retrieval models trained primarily on knowledge-intensive tasks for open-ended generation (e.g., instruction following). Recent or concurrent work studies instruction-tuning of retrieval systems (Asai et al., 2023b) or joint training of retrieval and LM components (Lin et al., 2023), while we leave exploring the effective s s of such appraoches for future work. For bio generation and open-domain QA tasks, we additionally retrieve five documents using Google Programmable Search9 and search documents from English Wikipedia. As this API only provides snippets, we retrieve Wikipedia introductory paragraphs for the corresponding entities.
检索设置细节。默认情况下,我们使用Contriever-MS MARCO从维基百科检索前5篇文档,并基于2018年英文维基百科的官方嵌入向量。在PopQA数据集上(其问答对基于2022年维基数据创建),我们发现2018年版维基百科有时缺少近期新增实体的条目。因此对于PopQA,我们采用了Izacard等人(2022b)提供的2020年12月预处理维基百科语料库并生成文档嵌入向量。不同维基百科数据版本导致的性能差异问题已被先前研究报道(Asai等人, 2020; Izacard等人, 2022b)。但我们观察到,这些主要在知识密集型任务上训练的现成检索模型对于开放式生成任务(如指令跟随)效果有限。近期或同期研究探索了检索系统的指令调优(Asai等人, 2023b)或检索与语言模型组件的联合训练(Lin等人, 2023),我们将此类方法的有效性探索留作未来工作。针对生物生成和开放域QA任务,我们还使用Google可编程搜索接口额外检索5篇文档,并从英文维基百科搜索文档。由于该接口仅返回摘要片段,我们检索了对应实体的维基百科导言段落。
Detailed experimental settings for individual datasets. For OpenQA datasets, we set the maximum new token number to 100 tokens. For closed-set tasks (PubHealth and ARC-C), we set the maximum new token length to 50 for all baselines. For SELF-RAG inference on PubHealth and ARC-C, instead of determining the output with the highest score 4 as in other tasks, we aggregate the scores for each option and select the answer option with the highest score. We found in zero-shot settings of fact checking, some LLMs can generate capitalized class labels (e.g., True) while our gold labels are lower-cased. Therefore, across different LMs, for fact checking, we lowercase the predictions. In multiple choice tasks, we found some models generate answers in slightly different ways (e.g., (A) instead of A). We slightly modify instructions for each LLM to avoid such format violations, and further conduct string matching between each candidate and model predictions if format violations still remain. After that processing, in closed set tasks, model predictions match one of the gold classes in almost all cases. For ALCE, we found that Llama2-chat tend to generate significantly lower outputs than other models (e.g., on average, their output is nearly 100 token, while ChatGPT generates 40 tokens on average), resulting in inflated str-em scores. We limit the maximum generation length to 100 tokens for all baselines to avoid this issue, rather than the original 300 tokens in the ALCE paper. Consequently, all of the baseline output length is within 30-60 tokens. For FactScore, we set the maximum new token length to 500 for baselines and 200 for SELF-RAG at each segment level.
各数据集的详细实验设置。对于OpenQA数据集,我们将最大新生成token数设为100。在闭集任务(PubHealth和ARC-C)中,所有基线模型的最大新token长度设置为50。对于PubHealth和ARC-C的SELF-RAG推理,我们不采用其他任务中选取最高分4的输出方式,而是汇总每个选项的分数并选择得分最高的答案选项。在零样本事实核查场景中,我们发现部分大语言模型会生成大写分类标签(如True),而我们的标准答案标签为小写。因此针对不同语言模型的事实核查任务,我们统一将预测结果转为小写。在多选题任务中,部分模型的答案生成格式存在细微差异(如(A)而非A)。我们为每个大语言模型微调指令以避免格式违规,若仍存在格式问题则进一步执行候选答案与模型预测的字符串匹配。经过该处理后,闭集任务中的模型预测结果几乎都能匹配到标准答案类别之一。针对ALCE任务,我们发现Llama2-chat模型的输出长度明显短于其他模型(例如平均输出约100token,而ChatGPT平均生成40token),导致str-em分数虚高。为避免该问题,我们将所有基线模型的最大生成长度限制为100token(而非ALCE论文原定的300token),最终所有基线输出长度均控制在30-60token范围内。对于FactScore任务,我们设置基线模型在每段级别的最大新token长度为500,SELF-RAG则为200。
Task-specific instructions. Table 5 shows the list of the instructions used during evaluations. For Open-domain QA, we do not provide explicit instructions.
任务特定指令。表5展示了评估过程中使用的指令列表。对于开放域问答(Open-domain QA),我们不提供明确指令。
C RESULTS
C 结果
C.1 ANALYSIS
C.1 分析
Reliance on parametric- and non-parametric memories. We conduct analysis on how frequently model answers come from retrieved passages (non-parametric memories) or their own parametric memories. On two open-domain QA datasets, TriviaQA and PopQA, we conduct the following analysis: 1) sample query models successfully answer correctly, 2) for each query in this group, check whether the matched ground-truth answer is a sub-string of the retrieved passage or not. We evaluate SELF-RAG 7B, Alpaca 7B, Alpaca 13B, and Llama2-Chat-13B. We found that SELF-RAG significantly less frequently generates answers that are not included in the provided evidence; in particular, in Alpaca 30B, $20%$ of the correct predictions are not included in the provided passages, followed by Llama2-chat 13B $(18%)$ and Alpaca $(15%)$ , while it is only $2%$ in SELF-RAG. When retrieved passages are not relevant, SELF-RAG generates $\scriptstyle\boxed{\mathrm{IsREL}}=\mathrm{Ir}\mathrm{r}\mathrm{c}\mathrm{l}\in\mathrm{vant}$ , indicating that the following answers may not be factually grounded, while those instruction-tuned models continue to generate plausible answers.
依赖参数化和非参数化记忆。我们分析了模型答案来自检索段落(非参数化记忆)或自身参数化记忆的频率。在两个开放域问答数据集TriviaQA和PopQA上进行了以下分析:1) 采样查询模型成功答对的样本,2) 对该组每个查询检查匹配的标准答案是否为检索段落的子串。评估对象包括SELF-RAG 7B、Alpaca 7B、Alpaca 13B和Llama2-Chat-13B。研究发现SELF-RAG显著减少了答案未包含在提供证据中的情况:Alpaca 30B有20%的正确预测未包含在提供段落中,Llama2-chat 13B(18%)和Alpaca(15%)次之,而SELF-RAG仅占2%。当检索段落不相关时,SELF-RAG会生成$\scriptstyle\boxed{\mathrm{IsREL}}=\mathrm{Ir}\mathrm{r}\mathrm{c}\mathrm{l}\in\mathrm{vant}$标记,表明后续答案可能缺乏事实依据,而经过指令调优的模型仍会生成看似合理的答案。
C.2 HUMAN EVALUATION EXAMPLES
C.2 人工评估示例
Table 6 shows examples with human evaluations on S&P and correctness of ISREL and ISSUP reflection tokens.
表 6: 展示了S&P人工评估示例及ISREL与ISSUP反思token的正确性。
C.3 QUALITATIVE EXAMPLES
C.3 定性分析示例
Table 7 shows several examples predicted by our SELF-RAG (13B). The first example is the model output to an ASQA question. The first reference states that Emperor Constantine made Sunday a day of rest from labor, and further the second citation supports the fact that the official adoption of Sunday as a day of rest by Constantine in AD 321. In the second example, the model predicts Contradictory to the first output as the output says the person has served as the CEO since 2010, while the passage says he stepped down as CEO in 2015. Indicating those factual contradictions as reflection tokens enables to enforcement of hard control and also verification of model outputs easily. In the third example, while the generation is mostly correct, SELF-RAG predicts Partially Support to the statement listing the name of the songs, as they were not explicitly mentioned.
表 7: 展示了我们的 SELF-RAG (13B) 预测的几个示例。第一个示例是针对 ASQA 问题的模型输出。第一处引用指出君士坦丁大帝将周日定为休息日,第二处引用进一步佐证了公元 321 年君士坦丁正式将周日定为休息日的事实。第二个示例中,模型预测与第一个输出存在矛盾,因为输出称该人物自 2010 年起担任 CEO,而文中提到他于 2015 年卸任 CEO 职位。将这些事实矛盾标记为反思 token (reflection tokens) 能够实现硬性控制,并便于验证模型输出。第三个示例中,虽然生成内容基本正确,但 SELF-RAG 对列出歌曲名称的声明预测为部分支持,因为这些歌曲名称并未被明确提及。
D FULL LIST OF INSTRUCTIONS AND DEMONSTRATIONS FOR GPT-4
D GPT-4 完整指令与演示列表
Here, we show the instructions and demonstrations used to prompt GPT-4 to collect reflection tokens. Table 8 shows the instructions and demonstrations for the initial retrieval token. Table 9 shows the instruction and demonstrations used to collect the three-way output tokens for Retrieve given instruction, preceding sentences, and previously retrieved passages. Due to the longer demonstration and test input, we only use a single demonstration. Table 10 shows an instruction and demonstrations used to collect the three-way output tokens for $\boxed{\mathbf{IsREL}}$ . Table 11 shows an instruction and demonstrations used to collect the three-way output tokens for ISREL . Table 12 shows an instruction and demonstrations used to collect the five-way output tokens for ISUSE
在此,我们展示了用于提示GPT-4收集反思token的指令和演示示例。表8展示了初始检索token的指令和演示示例。表9展示了用于收集Retrieve在给定指令、前文句子和先前检索段落情况下的三向输出token的指令和演示示例。由于演示和测试输入较长,我们仅使用单个演示示例。表10展示了用于收集$\boxed{\mathbf{IsREL}}$三向输出token的指令和演示示例。表11展示了用于收集ISREL三向输出token的指令和演示示例。表12展示了用于收集ISUSE五向输出token的指令和演示示例。
Input Identify the two types of computer memory. (from gpt4 alpaca)
输入 识别两种计算机内存类型。 (来自 gpt4 alpaca)
Output [ Retrieve =Yes]
Computer memory Computer memory – In computing, memory refers to the computer hardware integrated circuits that store information for immediate use in a computer; it is synonymous with the term “primary storage”. Computer memory operates at a high speed, for example random-access memory (RAM), as a distinction from storage that provides slow-to-access information but offers higher capacities. If needed, contents of the computer memory can be transferred to secondary storage; a very common way of doing this is through a memory management technique called “virtual memory”. An archaic synonym for memory is store. The term “memory”, meaning “primary storage” or “main memory”, $\scriptstyle\mathrm{is}<\mathrm{p}>[\scriptstyle\left[\scriptstyle\mathrm{IsREL}\right]=\mathrm{Re}\mathrm{1evant}]\mathrm{I}$ rimary memory, also known as main memory, is the memory that the computer can directly access and manipulate. [ ISSUP $=$ Fully Supported] [ Retrieve =Yes]
Computer memory–often associated with addressable semiconductor memory, i.e. integrated circuits consisting of silicon-based transistors, used for example as primary storage but also other purposes in computers and other digital electronic devices. There are two main kinds of semiconductor memory, volatile and non-volatile. Examples of non-volatile memory are flash memory (used as secondary memory) and ROM, PROM, EPROM and EEPROM memory (used for storing firmware such as BIOS). Examples of volatile memory are primary storage, which is typically dynamic random-access memory (DRAM), and fast CPU cache memory, which is typically static random-access memory (SRAM) that is fast but energy-consuming, offering lower memory ${\tt < p>}$ [ ISREL = Relevant]Primary memory can be accessed quickly, but it is volatile, meaning that the data is lost if the power is turned off.[ ISSUP $\mathrm{=P}$ artially Supported]...[ ISUSE :5]
输出 [检索=是]
计算机内存——在计算领域,内存指的是计算机中用于即时存储信息的硬件集成电路,它与“主存储器”这一术语同义。计算机内存运行速度极快,例如随机存取存储器(RAM),以此区别于访问速度较慢但容量更大的存储设备。如有需要,计算机内存的内容可转移至二级存储,最常见的实现方式是通过称为“虚拟内存”的内存管理技术。内存的旧式同义词为“存储器”。术语“内存”即指“主存储器”或“主内存”,$\scriptstyle\mathrm{是}<\mathrm{p}>[\scriptstyle\left[\scriptstyle\mathrm{IsREL}\right]=\mathrm{相关}]$主内存(又称主存储器)是计算机可直接访问和操作的内存。[支持程度=完全支持]
[检索=是]
计算机内存——通常与可寻址半导体存储器相关联,即由硅基晶体管组成的集成电路,不仅用作主存储器,也用于计算机及其他数字电子设备中的其他用途。半导体存储器主要分为易失性和非易失性两类。非易失性存储器的例子包括闪存(用作二级内存)以及ROM、PROM、EPROM和EEPROM存储器(用于存储BIOS等固件)。易失性存储器的例子包括主存储器(通常是动态随机存取存储器DRAM)和高速CPU缓存存储器(通常是静态随机存取存储器SRAM,速度快但能耗高,提供较低的内存${\tt < p>}$[相关性=相关]主内存访问速度快,但具有易失性,即断电后数据会丢失。[支持程度=部分支持]...[使用频率:5]
Input Give an example of a situation where you have to delegate tasks (from gpt4 alpaca)
输入 举一个必须委派任务的场景示例 (来自gpt4 alpaca)
Output [ Retrieve =No]The manager realizes that there is an extensive list of tasks that need to be completed in order to make the event a success.[ Retrieve =Yes]
Delegation–Delegation is the assignment of any responsibility or authority to another person (normally from a manager to a subordinate) to carry out specific activities. It is one of the core concepts of management leadership. However, the person who delegated the work remains accountable for the outcome of the delegated work. Delegation empowers a subordinate to make decisions, i.e. it is a shifting of decision-making authority from one organizational level to a lower one. Delegation, if properly done, is not fabrication. The opposite of effective delegation is micromanagement, where a manager provides too much input, $<_{\mathrm{P}}>$ [ ISREL $=$ Relevant]This includes tasks such as creating a guest list, designing and sending invitations, booking a venue, coordinating with vendors, planning the events program, and monitoring the budget.[ ISSUP $=$ Partially Supported][ Retrieve =No]Since it is not possible for the manager to handle everything alone, they must delegate tasks to their team members.[ Retrieve =No]The manager would then assign each team member specific responsibilities based on their individual skillsets and strengths.[ Retrieve =Yes]
Joint application design – Subject Matter Experts: These are the business users, the IS professionals, and the outside experts that will be needed for a successful workshop. This group is the backbone of the meeting
[ ISREL =I r re levant JFor instance, the teams graphic designer might be tasked with designing the invitations, while the event coordinator would be in charge of planning the program and working with vendors...[ Retrieve =No]By delegating tasks, the manager can ensure that all necessary tasks are completed in a timely manner, while also empowering their team members to take on responsibilities and contribute to the success of the event.[ ISUSE $=5]$
[检索=否]经理意识到,要确保活动成功举办,需要完成一系列繁重的任务清单。[检索=是]
授权——授权是指将任何责任或权力分配给他人(通常是从管理者到下属)以执行特定活动。这是管理领导力的核心概念之一。然而,授权者仍需对授权工作的结果负责。授权使下属能够自主决策,即将决策权从组织的一个层级转移到较低层级。如果操作得当,授权并非虚假行为。有效授权的反面是微观管理,即管理者提供过多输入,$<_{\mathrm{P}}>$[ISREL=相关]这些任务包括创建宾客名单、设计和发送邀请函、预订场地、与供应商协调、策划活动流程以及监控预算。[ISSUP=部分支持][检索=否]由于经理无法独自处理所有事务,必须将任务分配给团队成员。[检索=否]经理会根据每位成员的技能和优势分配具体职责。[检索=是]
联合应用设计——领域专家:包括业务用户、信息系统专业人员以及确保研讨会成功所需的外部专家。该群体是会议的核心支柱
[ISREL=不相关]例如,团队的平面设计师可能负责设计邀请函,而活动协调员则负责策划流程并与供应商对接...[检索=否]通过任务授权,经理既能确保所有必要任务按时完成,又能让团队成员承担责任并为活动成功贡献力量。[ISUSE=5]
Input Synthesize a poem based on this prompt:“The sun is setting” (from stanford alpaca)
根据提示创作一首诗:“夕阳西下”(来自斯坦福Alpaca)
Output [ Retrieve =No]The stars begin to twinkle bright the trees, scattered throughout the night; [ Retrieve =No]The stars begin to twinkle bright the trees, scattered throughout the night [ Retrieve =No] They flicker like a silent dance, A peaceful moment in its trance. [ Retrieve =No] They flicker like a silent dance, A peaceful moment in its trance. [ Retrieve =No] A chorus of crickets sing a lullaby, To every creature that roams the sky [ ISUSE $=5]$
[检索=否]繁星开始在树梢闪烁,点缀着整个夜空;
[检索=否]繁星开始在树梢闪烁,点缀着整个夜空
[检索=否]它们如静默的舞者摇曳,恍若凝驻的安宁瞬息。
[检索=否]它们如静默的舞者摇曳,恍若凝驻的安宁瞬息。
[检索=否]蟋蟀齐鸣唱起摇篮曲,献给所有翱翔天际的生灵 [ISUSE $=5]$
Input when did walking dead season 7 come out (from nq)
《行尸走肉》第七季何时播出(来自nq)
Output [ Retrieve =Yes]
The Walking Dead (season 7)–The Walking Dead (season 7) The seventh season of “The Walking Dead”, an American post-apocalyptic horror television series on AMC, premiered on October 23, 2016, and concluded on April 2, 2017, consisting of 16 episodes. Developed for television by Frank Darabont, the series is based on the eponymous series of comic books by Robert Kirkman, Tony Moore, and Charlie Adlard. ...
[ ISREL $=$ Relevant]October 23 , 2016[ ISSUP =Fully Supported][ ISUSE $=5]$
输出 [检索=是]
《行尸走肉》(第七季) – 《行尸走肉》(第七季) 第七季于2016年10月23日首播,2017年4月2日完结,共16集。该剧由Frank Darabont改编为电视剧,基于Robert Kirkman、Tony Moore和Charlie Adlard创作的同名漫画系列。
[是否相关=$=相关]2016年10月23日[是否支持=完全支持][是否使用=$=5]
Input Given a chat history separated by new lines, generates an informative, knowledgeable and engaging response: Hello, I love German shepherd dogs and you? – My favorite dog, they are officially known as German Shepherd Dogs? – Yes, I have a German shepherd in my house and she is pregnant (from wow)
输入 给定一个按换行符分隔的聊天记录,生成信息丰富、知识性强且引人入胜的回复:你好,我超爱德国牧羊犬,你呢?– 我最爱的犬种,它们正式名称就是German Shepherd Dogs对吧?– 是的,我家有只德国牧羊犬,而且它怀孕了 (来自wow)
Output hey also are easily trained, obedient, and intelligent.[ Retrieve =Yes]
German Shepherd – a simple are known for being easy to train and good for performing tasks and following instructions. They are especially well known for their police work, being used for tracking criminals, patrolling troubled areas and detecting and holding suspects.
[ ISREL = Relevant]Because of this, they are often used for disability assistance and for police work. [ ISSUP $\mathrm{=}\mathbb{P}$ artially Supported][ ISUSE $=2]$
输出 它们也容易训练、顺从且聪明。[检索=是]
德国牧羊犬——以易于训练、擅长执行任务和遵循指令而闻名。它们尤其以警用工作著称,被用于追踪罪犯、巡逻问题区域以及侦查和控制嫌疑人。
[ISREL = 相关]因此,它们常被用于残障辅助和警务工作。[ISSUP $\mathrm{=}\mathbb{P}$ 部分支持][ISUSE $=2$]
Table 4: List of the training examples.
表 4: 训练样本列表。
Table 5: Full list of instructions used during zero-shot evaluations. For open-domain QA, we don’t use any task specific instruction and simply use the original questions as input query.
| Dataset | Instruction |
| ARC-C | Givenfouranswer candidates,A,B,C andD,choosethebestanswerchoice.Please answer with the capitalized alphabet only, without adding any extra phrase or period. |
| PubHealth | Is the following statement correct or not? Say true if it's correct; otherwise, say false. Don't |
| BioGeneration | Tellmeabioabout[PersonName] |
| ASQA (baseline) Instruction: Write an accurate, engaging, and concise answer for the given question using only the provided search results (some of which might be irrelevant) and cite them properly. Use an unbiased and journalistic tone. Always cite for any factual claim. When citing several search results, use [1][2][3]. Cite at least one document and at most three documents in each sentence. If multiple documents support the sentence, only cite a minimum sufficient subset of | |
| ASQA (ours) | thedocuments. Answer the following question. The question may be ambiguous and have multiple correct answers, and in that case, you have to provide a long-form answer including all correct answers. |
表 5: 零样本评估期间使用的完整指令列表。对于开放域问答任务,我们不使用任何特定任务指令,仅将原始问题作为输入查询。
| 数据集 | 指令 |
|---|---|
| ARC-C | 给定四个候选答案A、B、C和D,选择最佳答案。请仅用大写字母回答,不要添加任何额外短语或句号。 |
| PubHealth | 以下陈述是否正确?如果正确请回答true,否则回答false。不要 |
| BioGeneration | 告诉我关于[人物姓名]的简介 |
| ASQA (基线) 指令:仅使用提供的搜索结果(部分可能无关)撰写准确、引人入胜且简洁的答案,并正确引用。保持中立和新闻化的语气。所有事实陈述都必须引用。引用多个搜索结果时使用[1][2][3]。每句话至少引用一个文档,最多三个文档。如果多个文档支持同一句话,只需引用最小充分子集的 | |
| ASQA (ours) | 文档。回答以下问题。问题可能存在歧义且存在多个正确答案,此时需要提供包含所有正确答案的长篇回答。 |
Input What genre is A Question and Answer Guide to Astronomy? (PopQA)
《天文学问答指南》属于什么类型?(PopQA)
Output $[\Big[\mathrm{Retrieve}\Big]{=}Yes\in{\mathrm{S}}]<\mathfrak{p}>;$ Reference [1] <$\mathsf{p}$>[ ISREL = Relevant] A Question and Answer Guide to Astronomy is a non-fiction book that falls under the genre of Astronomy and Cosmology. [ $ \mathbf{\bar{\rho}}_ {\mathrm{{IsSUP}}}=\mathbf{\mathbb{F}}\cup\mathbf{\mathbb{1}}\cup\mathbf{\bar{\rho}}_{\mathrm{{J}}}$ Supported][ $\underline{{\left[\mathbf{IsUsE}\right]}}=5\underline{{\mathrm{I}}}$
输出 $[\Big[\mathrm{Retrieve}\Big]{=}Yes\in{\mathrm{S}}]<\mathfrak{p}>;$ 参考文献 [1] <$\mathsf{p}$>[ ISREL = 相关]《天文学问答指南》是一本属于天文学与宇宙学领域的非虚构类书籍。[ $\mathbf{\bar{\rho}}_ {\mathrm{{IsSUP}}}=\mathbf{\mathbb{F}}\cup\mathbf{\mathbb{1}}\cup\mathbf{\bar{\rho}}_{\mathrm{{J}}}$ 支持][ $\underline{{\left[\mathbf{IsUsE}\right]}}=5\underline{{\mathrm{I}}}$
Reference [1] A Question and Answer Guide to Astronomy is a book about astronomy and cosmology, and is intended for a general audience. The book was written by Pierre-Yves Bely, Carol Christian, and Jean-Rene Roy, and published in English by Cambridge University Press in 2010. It was originally written in French. The content within the book is written using a question and answer format. It contains some 250 questions, which The Science Teacher states each are answered with a concise and well-formulated essay that is informative and readable. The Science Teacher review goes on to state that many of the answers given in the book are little gems of science writing. The Science Teacher summarizes by stating that each question is likely to be thought of by a student, and that the answers are informative, well constructed, and thorough. The book covers information about the planets, the Earth, the Universe, practical astronomy, history, and awkward questions such as astronomy in the Bible, UFOs, and aliens. Also covered are subjects such as the Big Bang, comprehension of large numbers, and the Moon illusion.
参考文献 [1] 《天文学问答指南》是一本面向大众的天文学与宇宙学书籍,由Pierre-Yves Bely、Carol Christian和Jean-Rene Roy合著,剑桥大学出版社于2010年出版英文版(原作为法语编写)。全书采用问答形式呈现,收录约250个问题。《科学教师》杂志评价称每个问题都配有简洁精炼、信息丰富且可读性强的短文解答,许多答案堪称科学写作的瑰宝。该书内容涵盖行星、地球、宇宙、实用天文学、历史等主题,并探讨了诸如《圣经》中的天文学、UFO与外星生命等争议性问题,同时涉及大爆炸理论、大数理解以及月亮错觉等专题。
S&P Supported and Plausible.
标普支持且合理。
Correctness of ISREL and ISSUP : Both ISREL and ISSUP are correct, as the Reference [1] provides detailed information of the book including the genre, and the model output is fully supported by the reference.
ISREL和ISSUP的正确性:ISREL和ISSUP都是正确的,因为参考文献[1]提供了包括书籍类型在内的详细信息,且模型输出完全得到该文献支持。
Output [ Retrieve =Yes]
Reference [1]
[ ISREL = Relevant] The author of The Lie is Sam Harris.[ ISSUP =Fully Supported][ ISUSE ${=}5$ ]
输出 [检索=是]
参考文献 [1]
[ISREL = 相关] 《谎言》的作者是Sam Harris。[ISSUP=完全支持][ISUSE ${=}5$]
Reference [1] Lying is a 2011 long-form essay book by American author and neuroscience expert Sam Harris. Harris argues that we can radically simplify our lives and improve society by merely telling the truth in situations where others often lie.
参考文献 [1] 《谎言》是美国作家兼神经科学专家Sam Harris于2011年出版的长篇随笔著作。Harris提出,在他人常撒谎的情境下,我们只需坚持说真话就能极大简化生活并改善社会。
Correctness of ISREL and ISSUP Both ISREL and ISSUP are incorrect, as the Reference [1] is about a different book whose title is similar to The Lie.
ISREL和ISSUP的正确性
ISREL和ISSUP都是错误的,因为参考文献[1]涉及的是另一本与《The Lie》书名相似的书籍。
Input Tell me a bio about Ronaldinho (Bio)
告诉我关于罗纳尔迪尼奥的简介
Output [ Retrieve =Yes] $<_ {\mathrm{P}}>$ Reference [1] $\mathsf{\Lambda}_{\mathrm{{cp}>[\Lambda}}$ [ ISREL $=$ Relevant] Ronaldinho is a retired professional footballer from Brazil.[ ISSUP $=$ Fully Supported][ Retrieve =Continue]He played as an attacking midfielder and was known for his technical skills, creativity, dribbling ability, and accuracy from free kicks[ Retrieve =Continue]He won two FIFA World Player of the Year awards and a Ballon d’Or.[ $\underline{{\boxed{\mathrm{IsUsE}}}}=5\mathrm{]}$ Reference [1] Ronaldo de Assis Moreira (born 21 March 1980), commonly known as Ronaldinho Gaucho or simply Ronaldinho, is a Brazilian retired professional footballer who played mostly as an attacking midfielder, but was also deployed as a winger. Considered one of the best players of his generation and regarded by many as one of the greatest of all time, Ronaldinho won two FIFA World Player of the Year awards and a Ballon d’Or. A global icon of the sport, he was renowned for his technical skills, creativity, dribbling ability and accuracy from free-kicks, as well as his use of tricks, feints, no-look passes and overhead...
输出 [检索=是] $<_ {\mathrm{P}}>$ 参考文献[1] $\mathsf{\Lambda}_{\mathrm{{cp}>[\Lambda}}$ [ISREL $=$ 相关] 罗纳尔迪尼奥是来自巴西的退役职业足球运动员。[ISSUP $=$ 完全支持][检索=继续]他司职攻击型中场,以技术能力、创造力、盘带技巧和任意球精准度著称。[检索=继续]他曾两次获得国际足联世界足球先生奖项和一次金球奖。[$\underline{{\boxed{\mathrm{IsUsE}}}}=5\mathrm{]}$ 参考文献[1] 罗纳尔多·德·阿西斯·莫雷拉(1980年3月21日出生),通常被称为罗纳尔迪尼奥·高乔或简称罗纳尔迪尼奥,是巴西退役职业足球运动员,主要司职攻击型中场,但也能胜任边锋位置。他被认为是同代最优秀的球员之一,并被许多人视为有史以来最伟大的球员之一。罗纳尔迪尼奥曾两次获得国际足联世界足球先生奖项和一次金球奖。作为这项运动的全球偶像,他以技术能力、创造力、盘带技巧、任意球精准度,以及运用花式动作、假动作、不看人传球和倒勾等技巧而闻名......
S&P Plausible and fully supported.
标普(S&P) 合理且证据充分。
Input Tell me a bio about Sergei Bodrov (Bio)
告诉我关于谢尔盖·波德罗夫 (Sergei Bodrov) 的简介

Table 6: Examples of human evaluation results.
表 6: 人工评估结果示例。
Input When did sunday became the seventh day of the week (asqa)
星期日何时成为一周的第七天 (asqa)
Instructions
指令
Given an instruction, please make a judgment on whether finding some external documents from the web (e.g., Wikipedia) helps to generate a better response. Please answer [Yes] or [No] and write an explanation.
给定一条指令,请判断从网络(例如 Wikipedia)查找外部文档是否有助于生成更好的回答。请回答[Yes]或[No]并写出解释。
Demonstrations
演示
Instruction Describe a time when you had to make a difficult decision.
描述一个你不得不做出艰难决定的时刻。
Explanation This instruction is asking about some personal experience and thus it does not require one to find some external documents.
解释 这条指令询问的是个人经历,因此不需要查找外部文件。
Instruction Write a short story in third person narration about a protagonist who has to make an important career decision.
以第三人称叙述写一篇关于主角必须做出重要职业决定的短篇故事。
Need retrieval? [No]
需要检索?[No]
Explanation This instruction asks us to write a short story, which does not require external evidence to verify.
说明 这条指令要求我们写一个短篇故事,无需外部证据验证。
Instruction Arrange the words in the given sentence to form a grammatically correct sentence. quickly the brown fox jumped
指令:将给定句子中的单词排列成语法正确的句子。quickly the brown fox jumped
Need retrieval? [No]
需要检索吗?[No]
Explanation This task doesn’t require any external evidence, as it is a simple grammatical question.
解释
该任务不需要任何外部证据,因为它是一个简单的语法问题。
Instruction Explain the process of cellular respiration in plants.
说明植物细胞呼吸的过程。
Need retrieval? [Yes]
需要检索?[Yes]
Explanation This instruction asks for a detailed description of a scientific concept, and is highly likely that we can find a reliable and useful document to support the response.
说明 该指令要求详细描述一个科学概念,极有可能找到可靠且有用的文档来支持回答。
Instructions
指令
You will be provided with an instruction, evidence, output sentence, and preceding sentences (optional). If the preceding sentence is given, the output should be the sentence that follows those preceding sentences. Your task is to determine whether the information in the output sentence can be fully verified by the evidence or if it requires further external verification. There are three cases:
你将收到一条指令、证据、输出句子及前文句子(可选)。若提供前文句子,输出应为紧随其后的句子。你的任务是判断输出句子中的信息是否能被证据完全验证,或是否需要进一步外部验证。存在三种情况:
- If the output sentence can be verified solely with the evidence, then respond with [Continue to Use Evidence].
- 如果输出语句仅凭证据即可验证,则回复 [Continue to Use Evidence]。
- If the sentence doesn’t require any factual verification (e.g., a subjective sentence or a sentence about common sense), then respond with [No Retrieval].
- 如果句子不需要任何事实核查(例如, 主观句子或关于常识的句子), 则回复[No Retrieval]。
Instruction Explain the use of word embeddings in Natural Language Processing.
指令 解释词嵌入(word embeddings)在自然语言处理(Natural Language Processing)中的应用。
Preceding sentences Word embeddings are one of the most powerful tools available for Natural Language Processing (NLP). They are mathematical representations of words or phrases in a vector space, allowing similarities between words and the context in which they are used to be measured.
前文句子 词嵌入 (Word embeddings) 是自然语言处理 (NLP) 领域最强大的工具之一。它们是将单词或短语映射到向量空间中的数学表示,能够度量词语之间的相似性及其使用语境。
Evidence: Word embedding
证据:词嵌入
Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers. Conceptually it involves a mathematical embedding from a space with one dimension per word to a continuous vector space with a much lower dimension. Output: Word embeddings are useful for tasks such as sentiment analysis, text classification, predicting the next word in a sequence, and understanding synonyms and analogies.
词嵌入 (Word embedding) 是自然语言处理 (NLP) 中一组语言建模和特征学习技术的统称,它将词汇表中的单词或短语映射到实数向量。从概念上讲,它涉及从每个单词对应一维的空间到维度低得多的连续向量空间的数学嵌入。输出:词嵌入可用于情感分析、文本分类、序列中下一个单词的预测以及理解同义词和类比等任务。
Rating [Retrieval]
评分 [检索]
Explanation The output discusses the applications of word embeddings, while the evidence only discusses the definitions of word embeddings and how they work. Therefore, we need to retrieve other evidence to verify whether the output is correct or not.
解释
输出内容讨论了词嵌入(word embeddings)的应用,而证据仅涉及词嵌入的定义及其工作原理。因此,我们需要检索其他证据来验证输出是否正确。
Table 9: Instructions and demonstrations for Retrieve aspect given the input, preceding generations, and retrieved passages.
表 9: 给定输入、先前生成内容和检索段落时针对Retrieve方面的指令与演示
Instructions
说明
You’ll be provided with an instruction, along with evidence and possibly some preceding sentences. When there are preceding sentences, your focus should be on the sentence that comes after them. Your job is to determine if the evidence is relevant to the initial instruction and the preceding context, and provides useful information to complete the task described in the instruction. If the evidence meets this requirement, respond with [Relevant]; otherwise, generate [Irrelevant].
你将收到一条指令,以及相关证据和可能的前置句子。当存在前置句子时,你的注意力应集中在紧随其后的句子上。你的任务是判断该证据是否与初始指令及前置上下文相关,并为完成指令描述的任务提供有用信息。若证据满足此要求,则回复[Relevant];否则生成[Irrelevant]。
Instruction Given four answer options, A, B, C, and D, choose the best answer. Input Earth’s rotating causes
指令 给定四个选项A、B、C和D,选择最佳答案。输入:地球自转导致
A: the cycling of AM and PM B: the creation of volcanic eruptions C: the cycling of the tides D: the creation of gravity
A: 昼夜交替
B: 火山喷发的形成
C: 潮汐循环
D: 重力的产生
Evidence Rotation causes the day-night cycle which also creates a corresponding cycle of temperature and humidity creates a corresponding cycle of temperature and humidity. Sea level rises and falls twice a day as the earth rotates.
地球自转导致昼夜更替,进而形成相应的温湿度循环周期。随着地球自转,海平面每天会出现两次涨落。
Rating [Relevant]
评分 [Relevant]
Explanation The evidence explicitly mentions that the rotation causes a day-night cycle, as described in the answer option A.
解释
证据明确提到,旋转导致了昼夜循环,如答案选项A所述。
Instruction age to run for US House of Representatives
竞选美国众议员的年龄要求
Evidence The Constitution sets three qualifications for service in the U.S. Senate: age (at least thirty years of age); U.S. citizenship (at least nine years); and residency in the state a senator represents at the time of election.
证据
美国宪法为担任参议员设定了三项资格要求:年龄(至少三十岁)、美国公民身份(至少九年)以及选举时需为所代表州的居民。
Rating [Irrelevant]
评分 [无关]
Explanation The evidence only discusses the ages to run for the US Senate, not for the House of Representatives.
解释
证据仅讨论了竞选美国参议员的年龄限制,未提及众议院的年龄要求。
Instructions
指令
You will receive an instruction, evidence, and output, and optional preceding sentences. If the preceding sentence is given, the output should be the sentence that follows those preceding sentences. Your task is to evaluate if the output is fully supported by the information provided in the evidence.
你将收到一条指令、证据、输出内容以及可选的前置句子。如果提供了前置句子,输出内容应为紧随这些前置句子之后的句子。你的任务是评估输出内容是否完全由证据中提供的信息所支持。
Use the following entailment scale to generate a score:
使用以下蕴含量表生成分数:
- [Fully supported] - All information in output is supported by the evidence, or extractions from the evidence. This is only applicable when the output and part of the evidence are almost identical.
- [完全支持] - 输出中的所有信息均有证据支持,或直接从证据中提取。仅当输出与部分证据几乎完全相同时适用。
- [Partially supported] - The output is supported by the evidence to some extent, but there is major information in the output that is not discussed in the evidence. For example, if an instruction asks about two concepts and the evidence only discusses either of them, it should be considered a [Partially supported].
- [部分支持] - 输出内容在一定程度上得到证据支持,但存在主要信息未在证据中讨论的情况。例如,若指令要求讨论两个概念而证据仅涉及其中之一,则应判定为[部分支持]。
- [No support / Contradictory] - The output completely ignores evidence, is unrelated to the evidence, or contradicts the evidence. This can also happen if the evidence is irrelevant to the instruction.
- [不支持/矛盾] - 输出完全忽略证据、与证据无关或与证据相矛盾。当证据与指令无关时也可能出现此情况。
Make sure to not use any external information/knowledge to judge whether the output is true or not. Only check whether the output is supported by the evidence, and not whether the output follows the instructions or not.
确保不要使用任何外部信息/知识来判断输出是否正确。仅检查输出是否有证据支持,而不关注输出是否遵循指令。
Instruction Explain the use of word embeddings in Natural Language Processing.
指令:解释词嵌入(word embeddings)在自然语言处理(NLP)中的应用。
Preceding sentences Word embeddings are one of the most powerful tools available for Natural Language Processing (NLP). They are mathematical representations of words or phrases in a vector space, allowing similarities between words and the context in which they are used to be measured.
前文提到,词嵌入(word embeddings)是自然语言处理(NLP)领域最强大的工具之一。它们通过向量空间中的数学形式表征单词或短语,从而量化词语间的相似性及其使用语境。
Output Word embeddings are useful for tasks such as sentiment analysis, text classification, predicting the next word in a sequence, and understanding synonyms and analogies.
词嵌入 (Word embeddings) 可用于情感分析、文本分类、序列下一词预测以及理解同义词和类比关系等任务。
Evidence Word embedding
词嵌入 (Word embedding)
Word embedding is the collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers. Conceptually it involves a mathematical embedding from a space with one dimension per word to a continuous vector space with a much lower dimension. Methods to generate this mapping include neural networks, dimensionality reduction on the word co-occurrence matrix, probabilistic models, explain able knowledge base method, and explicit representation in terms of the context in which words appear. Word and phrase embeddings, when used as the underlying input representation, have been shown to boost the performance in NLP tasks such as syntactic parsing, sentiment analysis, next token predictions as well and analogy detection.
词嵌入 (word embedding) 是自然语言处理 (NLP) 中语言建模和特征学习技术的统称,它将词汇表中的单词或短语映射到实数向量。从概念上讲,它涉及从每个单词对应一维的空间到维度低得多的连续向量空间的数学嵌入。生成这种映射的方法包括神经网络、词共现矩阵降维、概率模型、可解释知识库方法,以及根据词语出现上下文的显式表示。当作为底层输入表示时,词和短语嵌入已被证明能提升句法分析、情感分析、下一token预测以及类比检测等NLP任务的性能。
Score [Fully supported]
评分 [完全支持]
Explanation The output sentence discusses the application of word embeddings, and the evidence mentions all of the applications syntactic parsing, sentiment analysis, next token predictions as well as analogy detection as the applications. Therefore, the score should be [Fully supported].
解释
输出句子讨论了词嵌入(word embeddings)的应用,证据部分提到句法分析(syntactic parsing)、情感分析(sentiment analysis)、下一token预测(next token predictions)以及类比检测(analogy detection)等所有应用。因此评分应为[完全支持]。
Table 11: Instructions and demonstrations for ISSUP tokens.
表 11: ISSUP token的指令与演示示例。
| Instructions Given an instruction and an output, rate whether the response appears to be a helpful and informative answer to the query, from 1 (lowest) - 5 (highest). We call this score perceived utility. The detailed criterion is as follows: 5: The response provides a complete, highly detailed, and informative response to the query, fully satisfying the information needs. 4: The response mostly fulfills the need in the query, while there can be some minor improvements such as discussing more detailed information, having better structure of the response, or im- are needed to satisfy users’ needs. 2: The response still addresses the main request, but it is not complete or not relevant to the query. 1: The response is barely on-topic or completely |
| irrelevant. Instruction Who is the current prime minister of the UK as of 2023? Output Boris Johnson was the prime minister of the UK from 2019 - 2022. Perceived utility 2 Explanation While the output provides a factually correct statement about the UK prime minister from 2019 to 2022, this instruction asks who the prime minister is as of 2023, so it doesn't answer the instruction. Therefore, the utility is 2. |
| Instruction Given a description of a travel destination, recommend 10 tourist attrac- tions with detailed descriptions of each. The travel destination is Tokyo, Japan. Output Tokyo is a vibrant city full of exciting tourist attractions. Some must-see sights include the Tokyo Skytree, Tokyo Disneyland, Sensoji Temple, Meiji Shrine, Tsukiji Fish |
| Market, Harajuku, and Shinjuku Gyoen. Perceived utility 3 Explanation This output doesn't provide descriptions of each attraction and the number of the attractions is also less than 1o. While this output partially answers the instructions, it |
| 说明 | 给定一条指令和一个输出,根据1分(最低)到5分(最高)的标准,评估该回答是否为查询提供了有帮助且信息丰富的答案。我们将此评分称为感知效用。详细标准如下: |
|---|---|
| 5分 | 回答提供了完整、高度详细且信息丰富的内容,完全满足查询的信息需求。 |
| 4分 | 回答基本满足查询需求,但可能有一些小改进空间,例如提供更详细的信息、优化回答结构或提升准确性。 |
| 3分 | 回答部分满足查询需求,但存在明显不足,例如信息不完整、结构混乱或准确性不足,需要进一步改进以满足用户需求。 |
| 2分 | 回答仍涉及主要请求,但不完整或与查询无关。 |
| 1分 | 回答几乎不相关或完全无关。 |
| 指令 | 截至2023年,英国现任首相是谁? |
|---|---|
| 输出 | Boris Johnson在2019年至2022年期间担任英国首相。 |
| 感知效用 | 2分 |
| 解释 | 虽然输出提供了关于2019年至2022年英国首相的事实性正确陈述,但该指令询问的是截至2023年的首相,因此它没有回答指令。因此,效用为2分。 |
| 指令 | 给定一个旅游目的地的描述,推荐10个旅游景点,并对每个景点进行详细描述。旅游目的地是日本东京。 |
|---|---|
| 输出 | 东京是一个充满活力的城市,有许多令人兴奋的旅游景点。一些必看的景点包括东京晴空塔、东京迪士尼乐园、浅草寺、明治神宫、筑地鱼市场、原宿和新宿御苑。 |
| 感知效用 | 3分 |
| 解释 | 此输出未提供每个景点的描述,且景点数量也少于10个。虽然此输出部分回答了指令,但仍有明显不足。 |
Table 12: Instructions and demonstrations for ISUSE tokens.
表 12: ISUSE Token的指令与演示说明