Transformers are Short-text Class if i ers
Abstract. Short text classification is a crucial and challenging aspect of Natural Language Processing. For this reason, there are numerous highly specialized short text class if i ers. A variety of approaches have been employed in short text class if i ers such as convolutional and recurrent networks. Also many short text classifier based on graph neural networks have emerged in the last years. However, in recent short text research, State of the Art (SOTA) methods for traditional text classification, particularly the pure use of Transformers, have been un exploited. In this work, we examine the performance of a variety of short text class if i ers as well as the top performing traditional text classifier on benchmark datasets. We further investigate the effects on two new real-world short text datasets in an effort to address the issue of becoming overly dependent on benchmark datasets with a limited number of characteristics. The datasets are motivated from a real-world use case on classifying goods and services for tax auditing. NICE is a classification system for goods and services that divides them into 45 classes and is based on the Nice Classification of the World Intellectual Property Organization. The Short Texts Of Products and Services (STOPS) dataset is based on Amazon product descriptions and Yelp business entries. Our experiments unambiguously demonstrate that Transformers achieve SOTA accuracy on short text classification tasks, raising the question of whether specialized short text techniques are necessary. The NICE dataset showed to be particularly challenging and makes a good benchmark for future advancements.
摘要:短文本分类是自然语言处理(Natural Language Processing)中关键且具有挑战性的任务。为此,业界已开发出众多高度专业化的短文本分类器,采用了包括卷积网络和循环网络在内的多种方法。近年来还涌现出许多基于图神经网络(graph neural networks)的短文本分类器。然而在当前短文本研究中,传统文本分类的最先进(State of the Art)方法——尤其是单纯使用Transformer的方案——尚未得到充分探索。本研究评估了多种短文本分类器及表现最佳的传统文本分类器在基准数据集上的性能,并进一步在两个新的现实世界短文本数据集上验证效果,以解决过度依赖特征有限的基准数据集的问题。这些数据集源自税务审计中商品服务分类的实际用例:NICE分类系统将商品服务划分为45个类别,其基础是世界知识产权组织的《尼斯分类》;而商品服务短文本(STOPS)数据集则基于Amazon产品描述和Yelp商家条目。实验明确表明,Transformer在短文本分类任务上达到了最先进精度,这引发了"是否需要专用短文本技术"的思考。其中NICE数据集展现出特别的挑战性,为未来研究提供了优质基准。
Source code is available here: https://github.com/FKarl/short-text-classification
源代码可在此处获取:https://github.com/FKarl/short-text-classification
Keywords: Text Classification · Transformer · BERT · GNN
关键词:文本分类 · Transformer · BERT · GNN
1 Introduction
1 引言
Text classification is a crucial aspect of Natural Language Processing (NLP), and extensive research in this field is being conducted. Many researchers are working to improve the speed, accuracy, or robustness of their algorithms. Traditional text classification, however, does not take some traits into account that appear in numerous real-world applications, such as short text. Therefore, studies have been conducted specifically on short texts [37,46]. From user-generated content like social media to business data like accounting records, short text covers a wide range of topics. For example, the division into goods and services (see Section 4.1) is an important part of the tax audit. Currently, an auditor checks whether the element descriptions match the appropriate class of good or service. Since this can be very time-consuming, it is desirable to bring it into a semiautomatic context with the help of class if i ers. Also, the subdivision into more specific classes can be useful for determining whether a given amount for an entry in the accounting records is reasonable.
文本分类是自然语言处理(NLP)的关键领域,该领域正在进行广泛研究。许多研究者致力于提升算法的速度、准确性或鲁棒性。然而传统文本分类未考虑现实应用中的某些特征,例如短文本。因此已有研究专门针对短文本展开[37,46]。从社交媒体用户生成内容到会计记录等商业数据,短文本涵盖广泛主题。例如商品与服务分类(见4.1节)是税务审计的重要环节。目前审计员需人工核对条目描述是否匹配正确的商品或服务类别。由于该过程极其耗时,借助分类器实现半自动化处理成为迫切需求。此外,将条目细分至更具体的类别有助于判断会计记录中金额的合理性。
Since short texts are typically only one to two sentences long, they lack context and therefore pose a challenge for text classification. In order to get better results, many short text class if i ers also operate in a trans duct ive setup [40,37,42], which includes the test set during training. However, as they need to be retrained each time new data needs to be classified, those trans duct ive models are not very suitable for real-world applications. The results of both trans duct ive and the generally more useful inductive short text classifier are typically unsatisfactory due to the challenge that short text presents. Recent studies on short texts have emphasized specialized models [40,32,46,35,37,42] to address the issues associated with the short text length. However, State of the Art (SOTA) text classification methods, particularly the pure use of Transformers, have been un exploited. In this work, the effectiveness on short texts is examined and tested by means of benchmark datasets. We also introduce two new, realistic datasets in the domain of goods and services descriptions. Our contributions are in summary:
由于短文本通常只有一到两句话的长度,缺乏上下文信息,因此对文本分类提出了挑战。为了获得更好的结果,许多短文本分类器采用转导式 (transductive) 设置 [40,37,42],即在训练过程中包含测试集。然而,由于每次对新数据进行分类时都需要重新训练,这些转导式模型并不太适合实际应用。无论是转导式还是通常更有用的归纳式 (inductive) 短文本分类器,由于短文本本身的挑战,其结果通常都不尽如人意。最近关于短文本的研究强调了专用模型 [40,32,46,35,37,42] 来解决与短文本长度相关的问题。然而,最先进的 (SOTA) 文本分类方法,特别是纯使用 Transformer 的方法,尚未得到充分探索。在这项工作中,我们通过基准数据集检验和测试了短文本上的有效性。我们还引入了两个新的、现实中的商品和服务描述领域的数据集。我们的贡献总结如下:
Below, we summarize the related work. Section 3 provides a description of the models that were selected for our experiments. The experimental apparatus is described in Section 4. An overview of the achieved results is reported in Section 5. Section 6 discusses the results, before we conclude.
下文我们将对相关工作做总结。第3节介绍了实验所选模型的描述。第4节阐述了实验装置。第5节概述了实验结果。第6节对结果进行了讨论,最后得出结论。
2 Related Work
2 相关工作
Despite the fact that Bag of Words (BoW)-based models have long represented the cutting edge in text classification, attention has recently shifted to sequencebased and, more recently, graph-based concepts. However, BoW-based models continue to offer a solid baseline [7]. For example in fastText [12] the average of the trained word representations are used as text representation and then fed into a linear classifier. This results in an efficient model for text classification. To give an overview of the various concepts, Section 2.1 provides various works in the field of sequence-based models, Section 2.2 discusses graph-based models, and Section 2.3 examines how these concepts are applied to short text. Finally, a summary of the findings from the related work is presented in Section 2.4.
尽管基于词袋 (BoW) 的模型长期以来一直是文本分类领域的尖端技术,但近年来的关注点已转向基于序列的方法,以及更近期的图结构模型。不过,基于词袋的模型仍能提供可靠的基线性能 [7]。例如 fastText [12] 采用训练词向量的平均值作为文本表征,再输入线性分类器,从而构建出高效的文本分类模型。为全面梳理不同技术路线,第 2.1 节将介绍基于序列模型的相关研究,第 2.2 节讨论图结构模型,第 2.3 节分析这些方法在短文本场景的应用。最终,第 2.4 节将对相关工作进行总结性评述。
2.1 Sequence-based Models
2.1 基于序列的模型
For any NLP task, Recurrent Neural Networks (RNN) and Long short-term memory (LSTM) are frequently used and a logical choice because both models learn historical information while taking location information for all words into account [16,22]. Since RNNs must be computed sequentially and cannot be computed in parallel, the use of Convolutional Neural Networks (CNNs) is also common [16,33]. The text must be represented as a set of vectors that are concatenated into a matrix in order to be used by CNNs. The standard CNN convolution and pooling operations can then be applied to this matrix. TextCNN [14] uses this in combination with pretrained word embeddings for sentence-level classification tasks. While CNN-based models extract the characteristics from the convolution kernels, the relationship between the input words is captured by RNN-based models [16]. An important turning point in the advancement of NLP technologies was the introduction of Bidirectional Encoder Representations from Transformers (BERT) [34]. By performing extensive pre-training in an unsupervised manner and automatically mining semantic knowledge, BERT learns to produce contextual i zed word vectors that have a global semantic representation. The effectiveness of BERT-like models for text classification is demonstrated by Galke and Scherp [7].
对于任何自然语言处理(NLP)任务,循环神经网络(RNN)和长短期记忆网络(LSTM)都是常用且合理的选择,因为这两种模型在学习历史信息的同时会考虑所有词语的位置信息[16,22]。由于RNN必须顺序计算且无法并行化,卷积神经网络(CNN)的使用也很普遍[16,33]。文本需要被表示为向量集合并拼接成矩阵才能供CNN使用。随后可以对此矩阵应用标准的CNN卷积和池化操作。TextCNN[14]将此方法与预训练词嵌入相结合,用于句子级分类任务。基于CNN的模型通过卷积核提取特征,而基于RNN的模型则捕捉输入词语之间的关系[16]。NLP技术发展的一个重要转折点是Transformer双向编码器表征(BERT)[34]的提出。通过以无监督方式进行大规模预训练并自动挖掘语义知识,BERT学会了生成具有全局语义表征的上下文词向量。Galke和Scherp[7]证明了类BERT模型在文本分类中的有效性。
2.2 Graph-based Models
2.2 基于图 (Graph) 的模型
Recently, text classification has paid a lot of attention to graph-based models, particularly Graph Neural Networks (GNNs) [3,36,27]. This is due to the fact that tasks with rich relational structures benefit from the powerful representation capabilities of GNNs, which preserve global structure information [36]. The task of text classification offers this rich relational structure because text can be modeled as edges and nodes in a graph structure. There are different ways to represent the documents in a graph structure, but two main approaches have emerged [36,37]. The first approach builds a graph for each document using words as nodes and structural data, such as word co-occurence data, as edges. However, only local structural data is used. The task is constructed as a whole graph classification problem in order to classify the text. A popular document-level approach is HyperGAT [5] which uses a dual attention mechanism and hyper graphs applied to documents to learn text embeddings. The second approach creates a graph for the entire corpus using words and documents as nodes. The text classification task is now a node classification task for the unlabeled document nodes. The drawback of this method is that models using it are inherently transductive. For example, TextGCN [41] uses this concept by employing a standard Graph Convolutional Networks (GCN) on this heterogeneous graph. Following TextGCN, Lin et al. [18] propose BertGCN, a model that makes use of BERT to initialize representations for the document nodes in order to combine the benefits of both the large-scale pre training of BERT and the trans duct ive TextGCN. However, the increase provided by this method is limited to datasets with long average text lengths. Zeng et al. [43] also experiment with combining TextGCN and BERT in the form of TextGCN-Bert-serial-SB, a Simplified-Boosting Ensemble, where BERT is only trained on the TextGCN’s mis classification. Which model is applied to which document is determined by a heuristic based on the node degree of the test document. However, TextGCN-CNN-serial-SB, which substitutes TextCNN for BERT, yields better results. By using a joint training mechanism, TextING [45] and BERT are trained on sub-word tokens and base their predictions on the results of the two models. In contrast to applying each model separately, this produces better results. Another approach combining graph class if i ers with BERT is Cont TextING [11]. Cont TextING utilizes a joint training mechanism to create a unified model that incorporates both documentwise contextual information from a BERT-style model and node interactions within a document through the use of a GNN module. The predictions for the text classification task are determined by combining the output from both of these modules.
近年来,文本分类领域对基于图结构的模型尤其是图神经网络(GNNs) [3,36,27]给予了极大关注。这是因为具有丰富关联结构的任务能受益于GNNs强大的表征能力,这种能力可以保留全局结构信息[36]。文本分类任务恰好提供了这种丰富的关联结构,因为文本可以被建模为图结构中的边和节点。
现有两种主要的文档图结构表示方法[36,37]:第一种方法以单词为节点,以词共现等结构数据为边,为每个文档构建独立图。但这种方法仅利用局部结构数据,并将任务构建为整体图分类问题。典型的文档级方法是HyperGAT[5],它采用双重注意力机制和应用于文档的超图来学习文本嵌入。
第二种方法以单词和文档为节点,为整个语料库构建单一图。此时文本分类任务转化为对未标注文档节点的节点分类任务。这种方法的局限在于模型本质上是直推式的。例如TextGCN[41]就在这种异质图上应用标准图卷积网络(GCN)。Lin等人[18]提出的BertGCN通过BERT初始化文档节点表示,结合了BERT的大规模预训练优势与TextGCN的直推特性,但该方法仅在长文本数据集上表现提升有限。
Zeng等人[43]尝试以TextGCN-Bert-serial-SB(简化提升集成)形式结合TextGCN与BERT,其中BERT仅针对TextGCN的误分类进行训练。测试文档的节点度启发式决定模型选择,但用TextCNN替代BERT的TextGCN-CNN-serial-SB效果更佳。TextING[45]采用联合训练机制,在子词token上同步训练并与BERT共同预测,相比单独应用模型效果更好。另一结合图分类器与BERT的方法是ContTextING[11],它通过联合训练构建统一模型,既包含BERT式模型的文档上下文信息,又通过GNN模块捕获文档内节点交互,最终结合两个模块输出进行文本分类预测。
2.3 Short Text Models
2.3 短文本模型
Of course, short texts can also be classified using the methods discussed above. However, this is challenging because short texts tend to lack context and adhere to less strict syntactic structure [37]. This has led to the emergence of specialized techniques that focus on improving the results for short text. Early works focused on sentence classification using methods like Support Vector Machines (SVM) [28]. A survey by Galke et al. [6] compared SVM and other classical methods like Naive Bayes and $k$ NN with multi-layer perceptron models (MLP) on short text classification. Other works on sentence classification used Convolutional Neural Networks (CNN) [35,44,13], which showed strong performance on benchmark datasets. Recently, also methods exploiting graph neural networks were adopted to the needs of short text. For instance, Heterogeneous Graph Attention networks (HGAT) [40] is a powerful semi-supervised short text classifier. This was the first attempt to model short texts as well as additional information like topics gathered from a Latent Dirichlet Allocation (LDA) [1] and entities retrieved from Wikipedia with a Heterogeneous Information Network (HIN). To achieve this, a HIN embedding with a dual-level attention mechanism for nodes and their relations was used. For the semantic sparsity of short text, both the additional information and the captured relations are beneficial. A trans duct ive and an inductive HGAT model were released, with the trans duct ive model being better on every dataset. NC-HGAT [32] expands the HGAT model to produce a more robust variant. Neighbor contrastive learning is based on the premise that documents that are connected have a higher likelihood of sharing a class label and, as a result, should therefore be closer in feature space. In order to represent the additional information, SHINE [37] also makes use of a he t erogenous graph. In contrast, SHINE generates component graphs in the form of word, entity, and Part Of Speech (POS) graphs and creates a dynamically learned short document graph by employing hierarchical pooling over all component graphs. In the semi-supervised setting, SHINE outperforms HGAT as a strong transductive model. SimpleSTC (Simple Short Text Classification) [47] is a graph-based method for short-text classification similar to SHINE. But instead of constructing the word-graph only over the data corpus itself, SimpleSTC employs a global corpus to create a reference graph that shall enrich and help to understand the short text in the smaller corpus. As global corpus, articles from Wikipedia are used. The authors sample 20 labeled documents per class as training set and validation set. Short-Text Graph Convolutional Networks (STGCN) [42] is an additional short text classifier. A graph of topics, documents, and unique words is the foundation of STGCN. Although the STGCN results by themselves are not particularly strong, the impact of pre-trained word vectors obtained by BERT was also examined. The classification of the STGCN is significantly enhanced by the combination of STGCN with BERT and a Bi-LSTM.
当然,短文本也可以使用上述方法进行分类。然而,这具有挑战性,因为短文本往往缺乏上下文且语法结构较松散 [37]。这催生了专注于提升短文本分类效果的专门技术。早期研究采用支持向量机(SVM) [28]等方法进行句子分类。Galke等人的综述 [6] 在短文本分类任务中对比了SVM、朴素贝叶斯、$k$近邻等传统方法与多层感知机(MLP)模型的表现。其他句子分类研究使用了卷积神经网络(CNN) [35,44,13],这些模型在基准数据集上表现出色。近期,图神经网络方法也被适配于短文本场景。例如异构图注意力网络(HGAT) [40]就是一种强大的半监督短文本分类器,首次尝试通过异质信息网络(HIN)同时建模短文本、从潜在狄利克雷分配(LDA) [1]提取的主题特征以及维基百科实体信息。该模型采用具有节点和关系双重注意力机制的HIN嵌入,有效缓解了短文本语义稀疏性问题。研究者发布了直推式和归纳式HGAT模型,其中直推式模型在所有数据集上表现更优。NC-HGAT [32]对HGAT进行扩展,通过邻居对比学习(假设相连文档更可能共享类别标签,因而在特征空间应更接近)构建了更鲁棒的变体。SHINE [37]同样采用异构图结构,但通过构建词图、实体图和词性(POS)图等组件图,并实施分层池化操作来动态生成短文档图。在半监督场景下,SHINE作为强直推模型超越了HGAT。SimpleSTC [47]是与SHINE类似的基于图的短文本分类方法,其创新在于使用维基百科文章构建全局语料参考图(而非仅依赖目标语料构建词图)来增强对小规模语料的理解。作者采用每类20个标注文档作为训练验证集。短文本图卷积网络(STGCN) [42]是另一分类器,其基础是由主题、文档和唯一词构成的图结构。尽管STGCN本身效果一般,但研究发现结合BERT预训练词向量和双向LSTM能显著提升其分类性能。
2.4 Summary
2.4 小结
Graph neural network-based methods are widely used in short text classification. However, in recent short text research, SOTA text classification methods, particularly the pure use of Transformers, have been un exploited. The majority of short text models are trans duct ive. The crucial drawback of being trans duct ive is that every time new data needs to be classified, the model must be retrained.
基于图神经网络的方法在短文本分类中被广泛使用。然而,在近期的短文本研究中,SOTA文本分类方法(特别是纯Transformer的使用)尚未得到充分探索。大多数短文本模型都是直推式的。直推式方法的关键缺陷在于,每当需要对新数据进行分类时,模型都必须重新训练。
3 Selected Models for Our Comparison
3 我们选择的对比模型
We begin with models for short text classification in Section 3.1 and then Section 3.2 introduces a selection of top-performing models for text classification. Following Galke and Scherp [7], we have excluded works that employ nonstandard datasets only, use different measures, or are otherwise not comparable. For example, regarding short text classification there are works that are applied on non-standard datasets only [10,48].
我们从第3.1节的短文本分类模型开始,随后第3.2节介绍了一系列在文本分类任务中表现优异的模型。遵循Galke和Scherp [7]的方法,我们排除了那些仅使用非标准数据集、采用不同评估指标或无法直接比较的研究。例如,在短文本分类领域,存在仅应用于非标准数据集的工作[10,48]。
3.1 Models for Short Text Classification
3.1 短文本分类模型
The models listed below either make claims about their ability to categorize short texts or were designed with that specific goal. The SECNN [35] is a text classification model built on CNNs that was created specifically for short texts with few and insufficient semantic features. Wang et al. [35] suggested four components to address this issue. In order to achieve better coverage on the word vector table, they used an improved Jaro-Winkler similarity during preprocessing to identify any potential spelling mistakes. Second, they use a CNN model built on the attention mechanism to look for words that are related. Third, in order to accomplish the goal of short text semantic expansion, the external knowledge base Probase [38] is used to enhance the semantic features of short text. Finally, the classification process is performed using a straightforward CNN with a Softmax output layer.
以下列出的模型要么声称具备对短文本进行分类的能力,要么就是专为该目标而设计。SECNN [35] 是一种基于 CNN (卷积神经网络) 的文本分类模型,专门针对语义特征稀少且不足的短文本而创建。Wang 等人 [35] 提出了四个组件来解决这一问题。首先,为了在词向量表上实现更好的覆盖,他们在预处理阶段使用改进的 Jaro-Winkler 相似度来识别潜在的拼写错误。其次,他们采用基于注意力机制的 CNN 模型来查找相关词汇。第三,为了实现短文本语义扩展的目标,利用外部知识库 Probase [38] 来增强短文本的语义特征。最后,使用带有 Softmax 输出层的简单 CNN 完成分类过程。
The Sequential Graph Neural Network (SGNN) [46] is a GNN-based model that emphasizes the propagation of features based on sequences. By training each document as a separate graph, it is possible to learn the words’ local and sequential features. GloVe’s [23] pre-trained word embedding is utilized as a semantic feature of words. In order to update the feature matrix for each document graph, a Bi-LSTM is used to extract the contextual feature of each word. After that, a simplified GCN aggregates the features of neighboring word nodes. Additionally, Zhao et al. [46] introduce two variants: Extended-SGNN (ESGNN), in which the initial contextual feature of words is preserved, and C-BERT, in which the Bi-LSTM is swapped for BERT.
序列图神经网络 (SGNN) [46] 是一种基于 GNN 的模型,强调基于序列的特征传播。通过将每个文档作为单独的图进行训练,可以学习单词的局部和序列特征。该模型采用 GloVe [23] 预训练词向量作为单词的语义特征。为了更新每个文档图的特征矩阵,使用 Bi-LSTM 提取每个单词的上下文特征。随后,通过简化的 GCN 聚合相邻词节点的特征。此外,Zhao 等人 [46] 提出了两种变体:保留单词初始上下文特征的扩展版 ESGNN,以及用 BERT 替换 Bi-LSTM 的 C-BERT。
The Deep Attention Diffusion Graph Neural Network (DADGNN) [21] is a graph-based method that combats the over smoothing problem of GNNs and allows stacking more layers by utilizing attention diffusion and decoupling techniques. This decoupling technique is also very advantageous for short texts because it obtains distinct hidden features in deep graph networks.
深度注意力扩散图神经网络 (DADGNN) [21] 是一种基于图的方法,通过利用注意力扩散和解耦技术解决了 GNN 的过度平滑问题,并允许堆叠更多层。这种解耦技术对短文本也非常有利,因为它能在深度图网络中获取不同的隐藏特征。
The Long short-term memory (LSTM) [9], which is frequently used in text classification, has a bidirectional variant called Bi-LSTM [19]. Due to its strong results for short texts [46,22] and years of use as the SOTA method for many tasks, this model is a good baseline for our purpose.
长短期记忆网络 (LSTM) [9] 在文本分类中应用广泛,其双向变体称为 Bi-LSTM [19]。由于该模型在短文本任务中表现优异 [46,22] 且多年来被用作多项任务的 SOTA (state-of-the-art) 方法,因此很适合作为本研究的基线模型。
3.2 Top-performing Models for Text Classification
3.2 文本分类的顶尖模型
An overview of the top text classification models that excel on texts of all lengths and were not specifically created with short texts in mind is provided in this section. We employ the base models for the Transformers.
本节概述了适用于各种长度文本且非专为短文本设计的顶级文本分类模型。我们采用基于Transformer的模型。
The Bidirectional Encoder Representations from Transformers (BERT) [4] is a language representation model that is based on the Transformer architecture [34]. Encoder-only models, such as BERT, rely solely on the encoder component of the Transformer architecture, whereby the text sequences are converted into rich numerical representations [33]. These models are well suited for text classification due to this representation. BERT is designed to incorporate a token’s left and right contexts into its computed representation. This is commonly referred to as bidirectional attention.
基于Transformer的双向编码器表征(BERT)[4]是一种基于Transformer架构[34]的语言表征模型。仅含编码器的模型(如BERT)完全依赖Transformer架构中的编码器组件,将文本序列转换为丰富的数值表征[33]。由于这种表征特性,这类模型非常适用于文本分类任务。BERT的设计特点是将token的左右上下文信息整合到其计算表征中,这种机制通常被称为双向注意力机制。
The Robustly optimized BERT approach (RoBERTa) [20] is a systematically improved BERT adaptation. In the Robustly optimized BERT approach (RoBERTa) model, the pre-training strategy was changed and training was done on larger batches with more data, to increase BERT’s performance.
鲁棒优化BERT方法(RoBERTa)[20]是对BERT模型的系统性改进。在RoBERTa模型中,通过改变预训练策略并使用更大批次和更多数据进行训练,从而提升了BERT的性能。
To improve BERT and RoBERTa models, Decoding-enhanced BERT with disentangled attention (DeBERTa) [8] makes two architectural adjustments. The first is the disentangled attention mechanism, which encodes the content and location of each word using two vectors. The content of the token at position $i$ is represented by $H_{i}$ and the relative position $i|j$ between the token at position $i$ and $j$ are represented by $P_{i|j}$ . The equation for determining the cross s a etc te on n tdi oand jsucsotrem eisn ta iss foalnlo ewns:h $A_{i,j}=H_{i}H_{j}^{\prime\prime}+H_{i}P_{j\mid i}^{\prime}+P_{i\mid j}H_{j_{-}}^{\prime\prime}+P_{i\mid j}P_{j\mid i}^{\prime}$ .i tiTohnes in the decoding layer to predict masked tokens during pre-training. For masked token prediction, DeBERTa includes the absolute position after the transform layers but before the softmax layer. In contrast, BERT incorporates the position embedding into the input layer. As a result, DeBERTa is able to capture the relative position in all Transformer layers.
为改进BERT和RoBERTa模型,解码增强型解耦注意力BERT(DeBERTa)[8]进行了两项架构调整。首先是解耦注意力机制,该机制使用两个向量分别编码每个词的内容和位置。位置$i$处token的内容由$H_{i}$表示,位置$i$与$j$之间token的相对位置$i|j$由$P_{i|j}$表示。交叉注意力得分计算公式为:$A_{i,j}=H_{i}H_{j}^{\prime\prime}+H_{i}P_{j\mid i}^{\prime}+P_{i\mid j}H_{j_{-}}^{\prime\prime}+P_{i\mid j}P_{j\mid i}^{\prime}$。该机制在解码层用于预训练期间预测被遮蔽的token。对于遮蔽token预测,DeBERTa在变换层之后、softmax层之前加入了绝对位置信息,而BERT则将位置嵌入整合到输入层。因此,DeBERTa能够在所有Transformer层中捕获相对位置信息。
Sun et al. [31] proposed ERNIE 2.0, a continuous pre-training framework that builds and learns pre-training tasks through continuous multi-task learning. This allows the extraction of additional valuable lexical, syntactic, and semantic information in addition to co-occurring information, which is typically the focus.
孙等人[31]提出了ERNIE 2.0,这是一个通过持续多任务学习构建并学习预训练任务的连续预训练框架。该框架除了通常关注的共现信息外,还能提取额外的有价值的词汇、句法和语义信息。
The concept behind DistilBERT [25] is to leverage knowledge distillation to produce a more compact and faster version of BERT while retaining most of its language understanding capacities. DistilBERT reduces the size of BERT by $40%$ , is $60%$ faster, and still retains 97% of its language understanding capabilities. In order to accomplish this, DistilBERT optimizes the following three objectives while using the BERT model as a teacher: (1) Distillation loss: The model was trained to output probabilities equivalent to those of the BERT base model. (2) Masked Language Modeling (MLM): As described by Devlin et al. [4] for the BERT model, the common pre-training using masked language modeling is being used. (3) Cosine embedding loss: The model was trained to align the DistilBERT and BERT hidden state vectors.
DistilBERT [25] 的设计理念是通过知识蒸馏技术,在保留BERT大部分语言理解能力的同时,生成更精简、更快速的版本。DistilBERT将BERT的规模缩小了40%,速度提升60%,仍保持97%的语言理解能力。为实现这一目标,DistilBERT以BERT模型为教师模型,优化了以下三个目标:(1) 蒸馏损失:训练模型输出与BERT基础模型等同的概率分布;(2) 掩码语言建模 (MLM):采用Devlin等人[4]为BERT模型描述的常规预训练方法,使用掩码语言建模;(3) 余弦嵌入损失:训练模型使DistilBERT与BERT的隐藏状态向量对齐。
A Lite BERT (ALBERT) [15] is a Transformer that uses two parameterreduction strategies to save memory and speed up training by sharing the weights of all layers across its Transformer. This model is therefore particularly effective for longer texts. During pre training, ALBERTv2 employs MLM and SentenceOrder Prediction (SOP), which predicts the sequence of two subsequent text segments.
轻量级BERT (ALBERT) [15] 是一种采用两种参数压缩策略的Transformer,通过跨层共享权重来节省内存并加速训练。该模型因此特别适用于长文本处理。在预训练阶段,ALBERTv2采用了掩码语言建模(MLM)和句子顺序预测(SOP)技术,后者用于预测两个连续文本段的顺序关系。
WideMLP [7] is a BoW-Based Multilayer Perceptron (MLP) with a single wide hidden layer of $1,024$ Rectified Linear Units (ReLUs). This model serves as a useful benchmark against which we can measure actual scientific progress.
WideMLP [7] 是一种基于词袋模型(BoW)的多层感知机(MLP),具有一个包含1024个修正线性单元(ReLU)的宽隐藏层。该模型可作为衡量实际科学进展的有效基准。
InducTive Graph Convolutional Networks for Text classification (InducTGCN) [36] is a GCN-based method that categorically rejects any information or statistics from the test set. To achieve the inductive setup, InducT-GCN represents document vectors with a weighted sum of word vectors and applies TF-IDF weights instead of representing document nodes with one-hot vectors. A two-layer GCN is employed for training, with the first layer learning the word embeddings and the second layer in the dimension of the dataset’s classes outputs into a softmax activation function.
用于文本分类的归纳图卷积网络 (InducTGCN) [36] 是一种基于 GCN 的方法,它明确拒绝来自测试集的任何信息或统计数据。为了实现归纳设置,InducT-GCN 使用词向量的加权和来表示文档向量,并应用 TF-IDF 权重,而不是用独热向量表示文档节点。该方法采用双层 GCN 进行训练,其中第一层学习词嵌入,第二层在数据集类别维度上输出到 softmax 激活函数。
4 Experimental Apparatus
4 实验装置
4.1 Datasets
4.1 数据集
First, we describe the benchmark datasets. Second, we introduce our new datasets in the domain of goods and services. The characteristics are denoted in Table 1.
首先,我们介绍基准数据集。其次,我们在商品和服务领域引入新的数据集。相关特征如表 1 所示。
Benchmark Datasets Six short text benchmark datasets, namely R8, MR, Search Snippets, Twitter, TREC, and SST-2, are used in our experiments. The following gives a detailed description of them. R8 is an 8-class subset of the Reuters 21578 news dataset1. It is not a classical short text scenario with an average length of 65.72 tokens but offers the ability to set the methods in comparison to traditional text classification. $\mathbf{M}\mathbf{R}^{2}$ is a widely used dataset for text classification. It contains movie-review documents with an average length of 20.39 tokens and is therefore suitable for short text classification. The dataset Search Snippets $^3$ , which is made up of snippets returned by a search engine and has an average length of 18.10 tokens, was released by Phan et al. [24]. Twitter $^4$ is a collection of $10,000$ tweets that are split into the categories negative and positive based on sentiment. The length of those tweets is on average 11.64 tokens. TREC5, which was introduced by Li and Roth [17], is a question type classification dataset with six classifications for questions. It provides the shortest texts in our collection of benchmark datasets, with an average text length of 10.06 tokens. SST $\mathbf{2}^{6}$ [29] or SST-binary is a subset of the Stanford Sentiment Treebank, a fine-grained sentiment analysis dataset, in which neutral reviews have been removed and the data has either a positive or negative label. The average number of tokens in the texts is 20.32.
基准数据集
我们实验中使用了六个短文本基准数据集:R8、MR、Search Snippets、Twitter、TREC和SST-2。以下是它们的详细描述。
R8是Reuters 21578新闻数据集1的一个8类子集。虽然其平均长度为65.72个token,不属于典型的短文本场景,但能为传统文本分类方法提供对比基准。
$\mathbf{M}\mathbf{R}^{2}$是一个广泛使用的文本分类数据集,包含平均长度为20.39个token的电影评论文档,适合短文本分类任务。
Search Snippets$^3$由Phan等人[24]发布,包含搜索引擎返回的摘要片段,平均长度为18.10个token。
Twitter$^4$包含$10,000$条推文,根据情感分为负面和正面两类,平均长度为11.64个token。
TREC5由Li和Roth[17]提出,是一个包含六类问题类型的问题分类数据集。其文本平均长度仅为10.06个token,是我们基准数据集中最短的。
SST $\mathbf{2}^{6}$[29](或称SST-binary)是斯坦福情感树库的子集。该细粒度情感分析数据集剔除了中性评论,仅保留正面或负面标签的文本,平均token数为20.32。
Table 1: Characteristics of short text datasets. #C refers to the number of classes. Avg. L is the average document length.
表 1: 短文本数据集特性。#C表示类别数量,Avg. L表示平均文档长度。
| Benchmarks | #Doc | #Train | #Test | #C | Avg. L |
|---|---|---|---|---|---|
| R8 | 7,674 | 5,485 | 2,189 | 8 | 65.72 |
| MR | 10,662 | 7,108 | 3,554 | 2 | 20.39 |
| SearchSnippets | 12,340 | 10,060 | 2,280 | 8 | 18.10 |
| 10,000 | 7,000 | 3,000 | 2 | 11.64 | |
| TREC | 5,952 | 5,452 | 500 | 6 | 10.06 |
| SST-2 | 9,613 | 7,792 | 1,821 | 2 | 20.32 |
| Goods&Services | #Doc | #Train | #Test | #C | Avg. L |
| NICE-45 | 9,593 | 6,715 | 2,878 | 45 | 3.75 |
| NICE-2 | 9,593 | 6,715 | 2,878 | 2 | 3.75 |
| STOPS-41 | 200,341 | 140,238 | 60,103 | 41 | 5.64 |
| STOPS-2 | 200,341 | 140,238 | 60,103 | 2 | 5.64 |
Goods and Services Datasets In order to evaluate the performance on data with real world applications, we introduce two new datasets that are focused on the distinction between goods and services. Although there are already datasets for product classification, such as the WDC-LSPM7, to the best of our knowledge, our datasets are the first to combine goods and services. NICE is a classification system for goods and services that divides them into 45 classes and is based on the Nice Classification 8 of the World Intellectual Property Organization (WIPO). There are 11 classes for various service types and 34 categories for goods. With 9, 593 documents, NICE-45 is comparable in size to the benchmark datasets. This dataset, which has texts with an average length of 3.75 tokens, is an excellent example of extremely short text. For the division into goods and services, there is also the binary version NICE-2. Short Texts Of Products and Services (STOPS) is the second dataset we offer. With 200, 341 documents and an average length of 5.64 tokens, STOPS-41 is a reasonably large dataset. The data set was derived from a potential use case in the form of Amazon descriptions and Yelp business entries, making it the most realistic. Like NICE, STOPS has a binary version STOPS-2. Both datasets provide novel characteristic properties that the benchmark datasets did not cover. In particular, the number of fine-granular classes presents a challenge that is not addressed by common benchmarks. For details on the class distribution of these datasets, please refer to Figure 1.
商品与服务数据集
为评估模型在现实应用数据上的表现,我们引入了两个专注于区分商品与服务的新数据集。尽管现有产品分类数据集(如WDC-LSPM7)已存在,但据我们所知,我们的数据集首次实现了商品与服务的结合。
NICE是基于世界知识产权组织(WIPO)《尼斯分类》8建立的商品与服务分类系统,包含45个类别(11个服务类型和34个商品类别)。NICE-45数据集拥有9,593份文档,其规模与基准数据集相当。该数据集文本平均长度仅3.75个token,是超短文本的典型代表。我们还提供了二元版本NICE-2用于商品/服务划分。
第二个数据集STOPS(产品与服务短文本)包含200,341份文档,平均长度5.64个token。STOPS-41的数据源来自亚马逊商品描述和Yelp商家条目,具有高度真实性。与NICE类似,STOPS也提供二元版本STOPS-2。
这两个数据集均具备基准数据集未覆盖的新特性,特别是细粒度类别数量带来的挑战未被现有基准解决。数据集类别分布详见 图1: 。
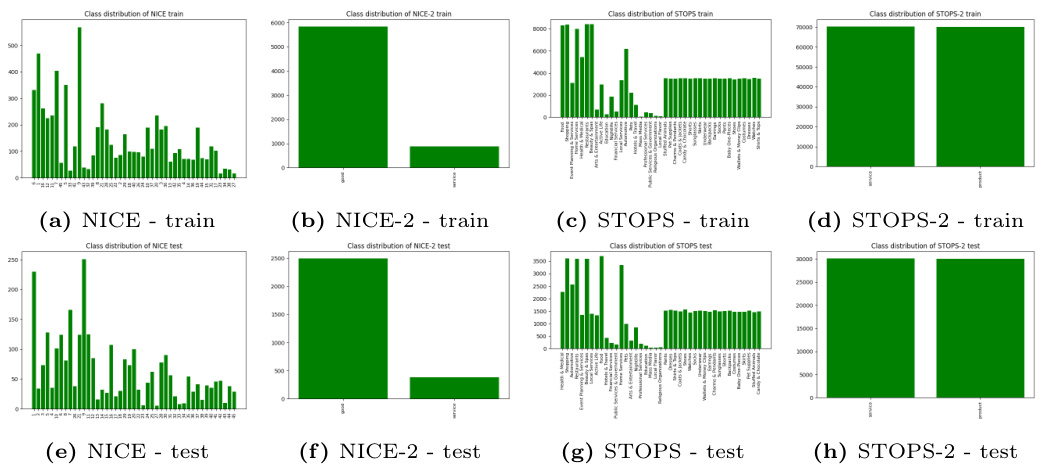
Fig. 1: Class distribution of our new datasets (separated by train and test split)
图 1: 我们新数据集的类别分布 (按训练集和测试集划分)
4.2 Preprocessing
4.2 预处理
To create NICE, the WIPO $^{9}$ classification data was converted to lower case, all punctuation was removed, and side information that was enclosed in brackets was also removed. Additionally, accents were dropped. Following a random shuffle, the data was divided into $70%$ train and $30%$ test.
为创建NICE,WIPO$^{9}$分类数据被转换为小写,移除所有标点符号及括号内的附加信息,同时去除重音符号。经过随机打乱后,数据按70%训练集和30%测试集划分。
As product and service entries for STOPS, we use the product descriptions of MAVE $\cdot^{\mathrm{10}}$ [39] and the business names of YELP $_{11}$ . Due to the different data sources, these also had to be pre processed differently. All classes’ occurrences in the MAVE data were counted, and $5,000$ sentences from each of the 20 most common classes were chosen. The multi-label categories for the YELP data were broken down into a list of single label categories, and the sentences were then mapped to the most common single label that each one has. In order to prevent any label from taking up too much of the dataset, the data was collected such that there is a maximum of 1, 200 documents per label. After that, all punctuation was dropped, the data was converted to lower case, and accents were also dropped. The data was split into train and test in a $70:30$ ratio after being randomly shuffled.
作为STOPS的产品和服务条目,我们使用了MAVE $\cdot^{\mathrm{10}}$ [39]的产品描述和YELP $_{11}$ 的商业名称。由于数据来源不同,这些数据也需要进行不同的预处理。我们对MAVE数据中所有类别的出现次数进行了统计,并从20个最常见类别中各选取了$5,000$条句子。YELP数据的多标签类别被分解为单标签类别列表,然后将句子映射到每个句子最常见的单标签上。为了防止任何标签占据过多数据集,我们进行了数据收集,确保每个标签最多包含1,200个文档。之后,删除了所有标点符号,将数据转换为小写,并去除了重音符号。数据在随机打乱后按$70:30$的比例划分为训练集和测试集。
4.3 Procedure
4.3 流程
The best short text classifier and text classification models were retrieved from the literature (see description of the models in Section 3). The accuracy scores were extracted in order to establish a comparison. Own experiments, particularly using various Transformers, were conducted in order to compare them. Investigations into the impacts of hyper parameters on short texts were performed. More details about these are provided in Section 4.4. In order to test the methods in novel contexts, we also created two new datasets, whereby STOPS stands out due to its much higher quantity of documents.
从文献中检索了最佳短文本分类器和文本分类模型(模型描述见第3节)。提取准确率分数以建立对比基准。为进行比较,我们自行开展了多项实验,特别是使用不同Transformer架构的测试。研究还探讨了超参数对短文本的影响,具体细节见第4.4节。为测试方法在新场景的适用性,我们创建了两个新数据集,其中STOPS因其文档数量优势而表现突出。
4.4 Hyper parameter Optimization
4.4 超参数优化
Our experiments for BERT, DistilBERT, and WideMLP used the hyperparameter from Galke and Scherp [7]. The parameters for BERT and DistilBERT are a learning rate of $5\cdot10^{-5}$ , a batch size of 128, and fine-tuning for 10 epochs. WideMLP was trained for 100 epochs with a learning rate of $10^{-3}$ , a batch size of 16, and a dropout of 0.5. For ERNIE 2.0 and ALBERTv2, we make use of the SST-2 values that Sun et al. [31] and Lan et al. [15], respectively, published. For our hyper parameter selection for DeBERTa and RoBERTa, we used the BERT values from Galke and Scherp [7] as a starting point and investigated the effect of smaller learning rates. This resulted in learning rates of $2\cdot10^{-5}$ for DeBERTa and $4\cdot10^{-5}$ for RoBERTa while maintaining the other parameters. For comparison, we followed the same procedure to create ERNIE 2.0 (optimized), which yields a learning rate of $25\cdot10^{-6}$ . The Bi-LSTM values from Zhao et al. [46] were used for both the LSTM and the Bi-LSTM model. We used DADGNN with the default parameters of 0.5 dropout, $10^{-6}$ weight decay, and two attention heads for all datasets.
我们在BERT、DistilBERT和WideMLP上的实验采用了Galke和Scherp [7]的超参数设置。BERT和DistilBERT的参数为:学习率$5\cdot10^{-5}$,批量大小128,微调10个周期。WideMLP训练100个周期,学习率$10^{-3}$,批量大小16,dropout率为0.5。对于ERNIE 2.0和ALBERTv2,我们分别采用了Sun等人[31]和Lan等人[15]发布的SST-2参数值。在DeBERTa和RoBERTa的超参数选择上,我们以Galke和Scherp[7]的BERT值为起点,研究了较小学习率的影响,最终确定DeBERTa学习率为$2\cdot10^{-5}$,RoBERTa为$4\cdot10^{-5}$,其他参数保持不变。作为对比,我们采用相同流程创建了ERNIE 2.0(优化版),其学习率为$25\cdot10^{-6}$。LSTM和Bi-LSTM模型均采用Zhao等人[46]的Bi-LSTM参数。DADGNN采用默认参数:dropout率0.5,权重衰减$10^{-6}$,所有数据集均使用两个注意力头。
4.5 Metrics
4.5 指标
Accuracy is used to measure the classification of short text. For multi-class cases, the subset accuracy is calculated.
准确率用于衡量短文本分类效果。在多分类情况下,计算子集准确率。
5 Results
5 结果
The accuracy scores for the text classification models on the six benchmark datasets are shown in Table 2. The findings demonstrate that the relatively straightforward models LSTM, Bi-LSTM, and WideMLP provide a strong baseline across all datasets. This comparison clearly demonstrates the limitations of some models, with InducT-GCN falling short in all datasets except SearchSnippets, SECNN under performing on TREC, and DADGNN producing weak MR results in our own experiment. The Transformer models, on the other hand, are the best performing across all datasets with the exception of Search Snippets. With consistently strong performance across all datasets, DeBERTa stands out in particular. The graph-based models from Zhao et el. [46], SGNN, ESGNN, and C-BERT, all perform well for the datasets for which results are available and ESGNN even outperforms all other models for Search Snippets. It is important to note that Zhao et al. [46] used a modified training split and additional preprocessing. While an increase of about 5 percentage points for MR could be obtained by extending ESGNN with BERT in C-BERT, the increase is not noticeable for other datasets. When applied to short texts, the inductive models even outperform trans duct ive models. On Twitter, ERNIE 2.0 and ALBERTv2 reach a performance of $99.97%$ , and when using BERT on the TREC dataset, a performance of $99.4%$ is obtained. Non-Transformer models also perform well on TREC, although Transformers outperform them. For the graph-based models SHINE and InducT-GCN, we also calculated the mean and standard deviation of the accuracy scores across 5 runs. This is motivated from the observation that models based on graph-neural networks are susceptible to the initialization of the embeddings [26]. SHINE had a generally high standard deviation of up to nearly 5 points, indicating greater variance in its performance. In comparison, InducT-GCN has a rather small variance of always below 1 point.
文本分类模型在六个基准数据集上的准确率分数如表 2 所示。研究结果表明,相对简单的模型 LSTM、Bi-LSTM 和 WideMLP 在所有数据集上都提供了强有力的基线。这一对比清晰地揭示了一些模型的局限性:InducT-GCN 除 SearchSnippets 外在所有数据集表现欠佳,SECNN 在 TREC 上表现不佳,而 DADGNN 在我们的实验中 MR 结果较弱。另一方面,Transformer 模型在除 SearchSnippets 外的所有数据集上表现最佳,其中 DeBERTa 凭借在所有数据集上持续强劲的表现尤为突出。Zhao 等人 [46] 提出的基于图的模型 SGNN、ESGNN 和 C-BERT 在可获得结果的数据集上都表现良好,ESGNN 甚至在 SearchSnippets 上超越了所有其他模型。值得注意的是,Zhao 等人 [46] 使用了修改后的训练分割和额外预处理。虽然通过用 BERT 扩展 ESGNN 构建的 C-BERT 能使 MR 提升约 5 个百分点,但其他数据集的提升并不明显。当应用于短文本时,归纳模型甚至超越了转导模型。在 Twitter 上,ERNIE 2.0 和 ALBERTv2 达到了 $99.97%$ 的性能,而在 TREC 数据集上使用 BERT 时获得了 $99.4%$ 的性能。非 Transformer 模型在 TREC 上也有不错表现,但仍逊色于 Transformer 模型。对于基于图的模型 SHINE 和 InducT-GCN,我们还计算了 5 次运行的准确率分数的平均值和标准差。这一做法源于观察到基于图神经网络的模型容易受到嵌入初始化影响 [26]。SHINE 的标准差普遍较高,最高接近 5 分,表明其性能波动较大。相比之下,InducT-GCN 的方差始终低于 1 分,波动较小。
The accuracy results for our newly introduced datasets, NICE and STOPS, are shown in Table 3. New characteristics covered by NICE and STOPS include shorter average lengths and the ability to distinguish between classes at a fine-granular level in NICE-45 and STOPS-41. The investigation of more documents is also conducted in the case of STOPS. As a result, NICE-45 and STOPS-41 reveal that DADGNN encounters issues when dealing with more classes, even falling around 20 and 60 percent points behind the baseline models. While still performing worse than the baseline models, InducT-GCN outperforms DADGNN on all four datasets. Transformers once again demonstrate their strength and rank as the top performing models across all datasets on this dataset. There are also significant drops. ERNIE 2.0 performs worse than the baseline models with 45.55% on NICE-45. However, ERNIE 2.0 (optimized), which uses different hyper parameter values (see Section 4.4), comes in third with $67.65%$
我们新引入的数据集NICE和STOPS的准确率结果如表3所示。NICE和STOPS涵盖的新特性包括:在NICE-45和STOPS-41中具有更短的平均长度,以及能在细粒度级别区分类别。STOPS还进行了更多文档的调查。结果显示,NICE-45和STOPS-41表明DADGNN在处理更多类别时遇到问题,甚至比基线模型落后约20和60个百分点。虽然表现仍不及基线模型,但InducT-GCN在所有四个数据集上都优于DADGNN。Transformer再次展现出其优势,成为该数据集上所有数据集中表现最佳的模型。也存在显著下降的情况,ERNIE 2.0在NICE-45上的表现仅为45.55%,低于基线模型。然而,使用不同超参数值(见第4.4节)的ERNIE 2.0(优化版)以$67.65%$的成绩位列第三。
Table 2: Accuracy on short text classification datasets. The “Short?” column indicates whether the model makes claims about its ability to categorize short texts. Provenance refers to the source of the accuracy scores.
1 With a batch size of 32 and for DeBERTa of 16. 2 With only 40 randomly selected documents per class. 3 Not reproducible. Authors have been contacted twice without a response. 4 Using a modified training split of 8, 636 training and 3, 704 test documents and further preprocessing. 5 Employing very low train ratios $0.38%$ to $6.22%$ ). 6 Uni-gram model with extensive pre-processing, use of WordNet, etc. and 60 hand-coded rules 7 Removed phrases of length less than 4 from the training set 8 Using a slightly different split of 6,920 sentences for training, 872 for development, and 1,821 for test 9 Samples 20 labeled documents per class as training set and validation set
表 2: 短文本分类数据集准确率。"Short?"列表示模型是否宣称具备短文本分类能力。Provenance列指准确率分数来源。
| Short? | R8 | MR | Snippets | TREC | SST-2 | Provenance | ||
|---|---|---|---|---|---|---|---|---|
| Inductive Models | ||||||||
| Transformer Models BERT | N | 98.171 | 86.94 | 88.20 | 99.96 | 99.4 | 91.37 | Own experiment |
| RoBERTa | N | 98.171 | 89.42 | 85.22 | 99.9 | 98.6 | 94.01 | Own experiment |
| DeBERTa | N | 98.451 | 90.21 | 86.14 | 98.8 | 94.78 | ||
| 98.041 | 99.93 | Own experiment | ||||||
| ERNIE 2.0 | N | 98.171 | 88.97 | 89.12 | 99.97 | 98.8 | 93.36 | Own experiment |
| ERNIE 2.0 (optimized) | N | 97.981 | 89.53 | 89.17 | 99.97 | 99 | 94.07 | Own experiment |
| DistilBERT ALBERTv2 | N N | 97.62 | 85.31 86.02 | 89.69 87.68 | 99.96 99.97 | 99 98.6 | 90.49 91.54 | Own experiment |
| Own experiment | ||||||||
| BoW Models | ||||||||
| SVM WideMLP | Y | 956 | Silva et al. [28] | |||||
| fastText | N N | 96.98 96.13 | 76.48 75.14 | 67.28 | 99.86 | 26 | 82.26 | Own experiment |
| 88.564 | Zhao et al. [46] | |||||||
| Graph-based Models | ||||||||
| HGAT2 NC-HGAT2 | Y | 62.75 | 82.36 | 63.21 | Yang et al. [40] | |||
| Y | 62.46 | 63.76 | Sun et al. [32] | |||||
| SGNN3 | Y | 98.09 | 80.58 | 90.684 | Zhao et al. [46] | |||
| ESGNN3 | Y | 98.23 | 80.93 | 90.804 | Zhao et al. [46] | |||
| C-BERT (ESGNN+BERT)3 | Y | 98.28 | 86.06 | 90.434 | Zhao et al. [46] | |||
| DADGNN | Y | 98.15 | 78.64 | 97.99 | 84.32 | Liu et al. [21] | ||
| DADGNN | Y | 97.28 | 74.54 | 84.91 | 98.16 | 97.54 | 82.81 | Own experiment |
| HyperGAT | N | 97.97 | 78.32 | Ding et al. [5] | ||||
| InducT-GCN ConTextING-BERT | N | 96.68 | 75.34 | 76.67 | 88.56 | 92.50 | 79.97 | Own experiment |
| ConTextING-RoBERTa | N N | 97.91 98.13 | 86.01 89.43 | Huang et al. [11] | ||||
| CNN and LSTMs | Huang et al. [11] | |||||||
| SECNN3 | ||||||||
| MGNC-CNN | Y | 83.89 | 91.34 | 87.37 | Wang et al. [35] | |||
| DCNN | Y | 86.808 | 95.52 | 88.307 | Zhang et al. [44] | |||
| LSTM (BERT) | Y | 75.10 | 93 | Kalchbr. et al. [13] | ||||
| Bi-LSTM (BERT) | Y | 94.28 | 75.30 | 65.13 | 99.83 | 97 | 81.38 | Own experiment |
| LSTM (GloVe) | Y | 95.52 | 74.99 | 66.79 | 99.76 | 97.2 | 80.83 | Own experiment |
| Bi-LSTM (GloVe) | Y Y | 96.34 96.84 | 75.32 | 67.67 68.15 | 95.23 95.53 | 97.4 97.2 | 79.95 80.17 | Own experiment |
| Bi-LSTM (GloVe) | Y | 96.31 | 77.68 | 84.814 | Own experiment Zhao et al. [46] | |||
| Transductive Models | ||||||||
| Short? | R8 | MR | Snippets | TREC | SST-2 | Provenance | ||
| Graph-based Models SHINE5 | Y | 64.58 | ||||||
| SHINE | Y | 79.80 | 62.05 | 82.39 82.14 | 72.54 70.64 | 79.90 | 61.71 | Wang et al. [37] Own experiment |
| STGCN | Y | 97.2 | 78.2 | — | Ye et al. [42] | |||
| STGCN+BiLSTM | Y | 78.5 | Ye et al. [42] | |||||
| STGCN+BERT+BiLSTM | Y | 98.5 | 82.5 | Ye et al. [42] | ||||
| SimpleSTC9 | Y | 62.27 | 80.96 | 62.19 | Zheng et al. [47] | |||
| TextGCN | N | 97.07 | 76.74 | 83.49 | Zhao et al. | |||
| TextGCN | N | 97.07 | 76.74 | 91.40 | 81.02 | [46] Liu et al. | ||
| BertGCN | N | 98.1 | 86.0 | [21] Lin et al. [18] | ||||
| RoBERTaGCN | N |
1 批处理大小为32,DeBERTa为16。2 每类仅随机选择40个文档。3 不可复现。已联系作者两次未获回复。4 使用修改后的训练集划分:8,636训练文档和3,704测试文档,并进行额外预处理。5 采用极低训练比例(0.38%至6.22%)。6 采用一元模型配合大量预处理、WordNet使用及60条手工编码规则。7 从训练集中移除长度小于4的短语。8 使用稍有不同的划分:6,920句训练集,872句开发集和1,821句测试集。9 每类采样20个标注文档作为训练集和验证集
Table 3: Accuracy on our own short text classification datasets. The “Short?” column indicates whether the model makes claims about its ability to categorize short texts. Provenance refers to the source of the accuracy scores.
表 3: 自建短文本分类数据集的准确率。"Short?"列表示模型是否声称具备短文本分类能力。Provenance指准确率分数的来源。
| 归纳模型 | 短文本 | NICE-45 | NICE-2 | STOPS-41 | STOPS-2 |
|---|---|---|---|---|---|
| Transformer模型 | |||||
| BERT | N | 72.79 | 99.72 | 89.4 | 99.87 |
| RoBERTa | N | 66.09 | 99.76 | 89.56 | 99.86 |
| DeBERTa | N | 59.42 | 99.72 | 89.73 | 99.85 |
| ERNIE 2.0 | N | 45.55 | 99.69 | 89.39 | 99.85 |
| ERNIE 2.0 (优化版) | N | 67.65 | 99.72 | 89.65 | 99.88 |
| DistilBERT | N | 69.28 | 99.75 | 89.32 | 99.85 |
| ALBERTv2 | N | 59.24 | 99.51 | 88.58 | 99.83 |
| BoW模型 | |||||
| WideMLP | N | 58.99 | 96.76 | 88.2 | 97.05 |
| 图模型 | |||||
| DADGNN | Y | 28.51 | 91.15 | 26.75 | 97.48 |
| InducT-GCN | N | 47.06 | 94.98 | 86.08 | 97.74 |
| CNN和LSTM | |||||
| LSTM (BERT) | Y | 47.81 | 96.63 | 86.27 | 96.05 |
| Bi-LSTM (BERT) | Y | 52.39 | 96.63 | 85.93 | 98.54 |
| LSTM (GloVe) | Y | 52.64 | 96.17 | 87.4 | 99.46 |
| Bi-LSTM (GloVe) | Y | 55.35 | 95.93 | 87.38 | 99.43 |
6 Discussion
6 讨论
Graph-based models are computationally expensive because they require not only the creation of the graph but also its training, which can be resource- and time-intensive, especially for word-document graphs with $\mathcal{O}(N^{2})$ space [7]. On STOPS, this drawback becomes very apparent. We could observe that DADGNN required roughly 30 hours of training time, while BERT only took 30 minutes to fine-tune with the same resources. Although in the case of BERT, the pretraining was already very expensive, transfer learning allows this effort to be used for a variety of tasks. Nevertheless, the Transformers outperform the inductive graph-based models as well as the short text models, with just one exception. The best model for Search Snippets is ESGNN, but additional preprocessing and a modified training split were employed. Our Bi-LSTM results, obtained without additional preprocessing, differ by 16.66 percentage points from the Bi-LSTM results from Zhao et el. [46]. This indicates that preprocessing, and not a better model, is primarily responsible for the strong outcomes of the Search Snippets experiments. Another interesting discovery can be made using the sentiment datasets. In comparison to other datasets, the Transformers outperform graphbased models that do not utilize a Transformer themselves by a large margin. This demonstrates that graph-based models may not be as effective at sentiment prediction tasks. In contrast, the CNN-based models show strong performance on the sentiment analysis task SST-2. Still, the best CNN model is more than 6 points below the best transformer. However, it should be noted that not all Transformers are consistently excellent. For instance, for NICE-45, one can observe a lower performance with ERNIE 2.0. But the absence of this performance decrease in our optimized version of ERNIE 2.0 (optimized) suggests that choosing suitable hyper parameters is crucial in this case.
基于图的模型在计算上成本高昂,因为它们不仅需要创建图结构,还需进行训练,这会消耗大量资源和时间,特别是对于空间复杂度为$\mathcal{O}(N^{2})$的词-文档图[7]。在STOPS任务中,这一缺陷尤为明显。我们观察到DADGNN需要约30小时的训练时间,而BERT在相同资源下仅需30分钟完成微调。尽管BERT的预训练阶段本身成本极高,但迁移学习使其能够将这一投入复用于多种任务。Transformer模型在绝大多数情况下优于归纳式图模型和短文本模型,仅有一个例外:Search Snippets任务的最佳表现者是ESGNN,但该结果使用了额外的预处理和改进的训练集划分。我们未经额外预处理获得的Bi-LSTM结果与Zhao等人[46]的报告相差16.66个百分点,这表明Search Snippets实验的优异表现主要归功于预处理而非模型改进。情感数据集揭示了另一个有趣现象:与其他数据集相比,Transformer对未采用Transformer架构的图模型形成了显著优势,这说明图模型在情感预测任务中可能效果欠佳。相比之下,基于CNN的模型在情感分析任务SST-2上表现强劲,但最佳CNN模型仍落后顶尖Transformer超过6个百分点。值得注意的是,并非所有Transformer都表现稳定,例如ERNIE 2.0在NICE-45任务中性能较低,但经过优化的ERNIE 2.0版本未出现这种性能下降,表明选择合适的超参数在此情况下至关重要。
6.1 Key Results
6.1 关键结果
Our experiments unambiguously demonstrate that Transformers achieve SOTA accuracy on short text classification tasks. This raises the question of whether specialized short text techniques are necessary given that the performance of the existing models is insufficient. This observation is especially interesting because many of the short text models used are from 2021 [40,46,21,35] or 2022 [32]. Most short text models attempt to enrich the documents with some kind of external context, such as a knowledge base or POS tags. However, one could argue that Transformers implicitly contain context in their weights through their pre-training.
我们的实验明确表明,Transformer在短文本分类任务上达到了SOTA准确率。这引发了一个问题:鉴于现有模型性能不足,是否还需要专门的短文本技术?这一发现尤为有趣,因为许多使用的短文本模型来自2021年[40,46,21,35]或2022年[32]。大多数短文本模型试图通过某种外部上下文(如知识库或词性标注)来丰富文档内容。然而,可以认为Transformer通过预训练在其权重中隐式包含了上下文信息。
Those short text models that compare themselves to Transformers assert that they outperform them. For instance, Ye et al. [42] claim to outperform BERT by 2.2 percentage points on MR, but their fine-tuned BERT only achieves $80.3%$ . In contrast, our own experiments show that BERT achieves $86.94%$ . With $85.86%$ on MR, Zhao et al. [46] achieve better BERT results, but only to beat it by a meager $0.2%$ with C-BERT. Given the low surplus, they would no longer outperform it with a marginally better selection of hyper parameters for BERT. Therefore, it is reasonable to assume that the importance of good hyper parameters for Transformers is underestimated and that they are often not properly optimized. ERNIE 2.0 (optimized), which outperforms ERNIE 2.0 on every dataset, also demonstrates the effect of better hyper parameters. Finally, Zhao et al. [46] is already outperformed by other transformers like RoBERTa and DeBERTa by 3 and 4 points, respectively.
那些自称优于Transformer的短文本模型声称自己表现更出色。例如,Ye等人[42]宣称在MR任务上比BERT高出2.2个百分点,但他们微调的BERT仅达到$80.3%$。相比之下,我们的实验显示BERT实际可达到$86.94%$。Zhao等人[46]在MR任务上取得$85.86%$的BERT成绩,但使用C-BERT仅以微弱优势$0.2%$险胜。考虑到如此微小的优势,若为BERT选择稍优的超参数,他们的模型便不再具有优势。因此可以合理推断:Transformer模型优质超参数的重要性被低估,且往往未得到充分优化。ERNIE 2.0(优化版)在所有数据集上都优于原版ERNIE 2.0,也印证了优质超参数的效果。最后,Zhao等人[46]的结果已被RoBERTa和DeBERTa等其他Transformer模型超越,分别落后3分和4分。
Additionally, there is a need for new short text datasets because the widely used benchmark datasets share many characteristics and fall short in many use cases. The common benchmark datasets all contain around $10,000$ documents, distinguish only a few classes, and frequently have a similar average length. Furthermore, many of them cover the same tasks. For instance, MR, Twitter, and SST-2 all perform sentiment prediction, which makes sense given how much short text is produced by social media. In this paper, we introduce two new datasets with distinctive attributes to cover more cases in NICE and STOPS. New and intriguing findings are produced by the new characteristics that are investigated using these datasets. Particularly, the ability to distinguish between classes at a fine-granular level reveals the shortcomings of various models, like
此外,还需要新的短文本数据集,因为广泛使用的基准数据集具有许多共同特征,且在许多应用场景中存在不足。常见的基准数据集通常包含约$10,000$篇文档,仅区分少数类别,且平均长度往往相近。更重要的是,其中许多数据集覆盖相同任务。例如,MR、Twitter和SST-2都用于情感预测,这符合社交媒体产生大量短文本的特点。本文通过引入两个具有独特属性的新数据集(NICE和STOPS)来覆盖更多案例。利用这些数据集研究的新特性产生了新颖而有趣的发现。特别值得注意的是,细粒度分类能力揭示了各类模型(如...
DADGNN or ERNIE 2.0. NICE-45 in particular proved to be challenging for all models, making it a good benchmark for future advancements.
DADGNN或ERNIE 2.0。其中NICE-45对所有模型都极具挑战性,这使其成为衡量未来进展的良好基准。
6.2 Threats to Validity
6.2 有效性威胁
In our study, each experiment was generally conducted once. The rationale is the extremely low standard deviation for text classification tasks observed in previous studies [7,46,21]. However, it has been reported in the literature on models using graph neural networks (GNN) that they generally have high standard deviation in their performance, which has been attributed among others to the influence of the random initialization in the evaluation [26]. Thus, we have run our experiments for SHINE and InducT-GCN five times and report averages and standard deviation. The high standard deviation observed in SHINE’s performance adds to the evidence of the need for caution when interpreting the results of GNNs [26].
在我们的研究中,每个实验通常只进行一次。其依据是先前研究中观察到的文本分类任务极低的标准差 [7,46,21]。然而,关于使用图神经网络 (GNN) 的模型的文献报告称,它们的性能通常具有较高的标准差,这被归因于评估中随机初始化的影响 [26]。因此,我们对 SHINE 和 InducT-GCN 进行了五次实验,并报告平均值和标准差。SHINE 性能中观察到的高标准差进一步证明在解释 GNN 结果时需要谨慎 [26]。
We acknowledge that STOPS contains user-generated labels, some of which may not be entirely accurate. However, given that this occurs frequently in numerous use cases, it is also crucial to test the models in these scenarios.
我们承认STOPS包含用户生成的标签,其中一些可能不完全准确。然而,鉴于这种情况在许多用例中频繁发生,在这些场景下测试模型也至关重要。
6.3 Parameter Count of Models
6.3 模型参数量
Table 4 lists the parameter counts of selected Transformer models, the BoWbased baseline methods WideMLP, and graph-based methods used in our experiments. Generally, the top performing Transformer models have a similar size between 110M to 130M parameters. Although DistilBERT is only have of that size and ALBERTv2 only about a tens, our experiments show still comparable accuracy scores on R8, Snippets, Twitter, and TREC. ALBERTv2 with its 12M parameters outperforms the WideMLP baseline with 31.3M parameters on all datasets, some with a large margin. The graph-based model ConTextINGRoBERTa has a similar parameter count compared to the pure Transformer models, since the RoBERTa transformer is used internally. It is the top-performer among the graph-based models on R8 and MR but cannot outperform the pure Transformer models.
表 4 列出了实验中选用的 Transformer 模型、基于词袋 (BoW) 的基线方法 WideMLP 以及基于图的方法的参数数量。总体而言,性能最佳的 Transformer 模型参数量级相近,均在 1.1亿至1.3亿参数之间。尽管 DistilBERT 参数量仅为前者一半,ALBERTv2 参数量仅约其十分之一,但实验表明它们在 R8、Snippets、Twitter 和 TREC 数据集上仍能取得相当的准确率。参数量为1200万的 ALBERTv2 在所有数据集上均优于参数量3130万的 WideMLP 基线模型,部分数据集优势显著。基于图的模型 ConTextINGRoBERTa 因内部采用 RoBERTa 作为 Transformer 组件,其参数量与纯 Transformer 模型相近。该模型在 R8 和 MR 数据集上是基于图方法中的最优模型,但仍无法超越纯 Transformer 模型。
6.4 Generalization
6.4 泛化
As we cover in our experiments a range of diverse domains, with sentiment analysis on various themes (MR, SST-2, Twitter), question type classification (TREC), news (R8), and even search queries (Search Snippets), we expect to find equivalent results on other short text classification datasets. Additionally, the categorization of goods and services is covered by our new datasets NICE and STOPS. They include additional features not covered by the benchmark datasets, including a significantly larger amount of training data in STOPS, a shorter average length, and the capacity to differentiate between a wider range of classes. By using an example from a business problem, STOPS specifically demonstrates how the knowledge gained here can be applied in corporate use.
由于我们的实验涵盖了多个不同领域,包括各类主题的情感分析(MR、SST-2、Twitter)、问题类型分类(TREC)、新闻(R8)甚至搜索查询(Search Snippets),我们预期在其他短文本分类数据集上也能得到类似结果。此外,商品与服务分类任务由我们新构建的NICE和STOPS数据集覆盖。这些数据集包含基准数据集未涉及的特征:STOPS拥有明显更多的训练数据、更短的平均文本长度,并能区分更广泛的类别。通过商业问题示例,STOPS特别展示了如何将本研究获得的知识应用于企业场景。
Table 4: Parameter counts for selected methods used in our experiments
表 4: 实验中选用方法的参数量统计
| 模型 | 参数量 |
|---|---|
| Transformer模型 | |
| BERT | 110M |
| RoBERTA | 123M |
| DeBERTA | 134M |
| ERNIE 2.0 | 110M |
| DistilBERT | 66M |
| ALBERTv2 | 12M |
| 基于BoW的方法 | |
| WideMLP | 31.3M |
| 基于图的方法 | |
| HyperGAT | LDA参数 + 3.1M |
| ConTextING-RoBERTa | 129M |
In this work, we cover a variety of models for each architecture, particularly the most popular and best-performing ones. Our findings are consistent with the studies by Galke and Scherp [7], which demonstrate the tremendous power of Transformers for traditional text classification.
在本研究中,我们涵盖了每种架构的多种模型,特别是最受欢迎和性能最佳的模型。我们的发现与Galke和Scherp [7]的研究一致,该研究证明了Transformer在传统文本分类中的强大能力。
7 Conclusion and Future Work
7 结论与未来工作
Our experiments unequivocally demonstrate the outstanding capability of Transformers for short text classification tasks. Additional research on our newly released datasets, NICE and STOPS, supports these findings and highlights the issue of becoming overly dependent on benchmark datasets with a limited number of characteristics. In conclusion, our study raises the question of whether specialized short text techniques are required given the lower performance of current models.
我们的实验明确证明了Transformer在短文本分类任务中的卓越能力。针对我们新发布的数据集NICE和STOPS的进一步研究支持了这些发现,并突显出过度依赖特征有限的基准数据集的问题。总之,鉴于当前模型性能较低,我们的研究提出了是否需要专门短文本技术的问题。
Future research on improving the performance of Transformers on short text could be to do pre-training on short texts or on in-domain texts (i. e., pre-training in the same domain as the target task) [30,33,2], multi-task fine-tuning [30,33], or an ensemble of multiple Transformer models [49].
未来关于提升Transformer在短文本上性能的研究方向可能包括:在短文本或领域内文本(即与目标任务相同领域的预训练)上进行预训练[30,33,2]、多任务微调[30,33]、或采用多个Transformer模型的集成方法[49]。
Acknowledgement. This work is co-funded under the 2LIKE project by the German Federal Ministry of Education and Research (BMBF) and the Ministry of Science, Research and the Arts Baden-W rttemberg within the funding line Artificial Intelligence in Higher Education. We thank Till Blume and Felix Krieger from Ernst & Young (EY) for the discussion of the problem statement that motivated this work. We are grateful to Liu et al. [21] for providing the unreleased DADGNN source code.
致谢。本研究由德国联邦教育与研究部(BMBF)和巴登-符腾堡州科学、研究与艺术部在"高等教育人工智能"资助计划下通过2LIKE项目共同资助。我们感谢安永(EY)的Till Blume和Felix Krieger对激发本研究的议题讨论。感谢Liu等人[21]提供未公开的DADGNN源代码。