Hierarchical Prompting Taxonomy: A Universal Evaluation Framework for Large Language Models Aligned with Human Cognitive Principles
层次化提示分类法:符合人类认知原则的大语言模型通用评估框架
Devichand Budagam1, Ashutosh Kumar2, Mahsa Kho sh no odi 3, Sankalp $\mathbf{K}\mathbf{J}^{4}$ Vinija $\mathbf{Ja}\mathbf{in}^{5,7}$ , Aman Chadha6, 7
Devichand Budagam1、Ashutosh Kumar2、Mahsa Khoshno odi3、Sankalp $\mathbf{K}\mathbf{J}^{4}$、Vinija $\mathbf{Ja}\mathbf{in}^{5,7}$、Aman Chadha6,7
1Indian Institute of Technology Kharagpur, India 2Rochester Institute of Technology, USA 3 Researcher, Fatima Fellowship $^4\mathrm{\overline{{A}}I}$ Institute, University of South Carolina, USA 5Meta, USA 6Amazon GenAI, USA 7Stanford University, USA
1印度理工学院克勒格布尔分校,印度 2罗切斯特理工学院,美国 3法蒂玛奖学金研究员 $^4\mathrm{\overline{{A}}I}$ 研究所,南卡罗来纳大学,美国 5Meta,美国 6Amazon GenAI,美国 7斯坦福大学,美国
Abstract
摘要
Assessing the effectiveness of large language models (LLMs) in performing different tasks is crucial for understanding their strengths and weaknesses. This paper presents Hierarchical Prompting Taxonomy (HPT), grounded on human cognitive principles and designed to assess LLMs by examining the cognitive demands of various tasks. The HPT utilizes the Hierarchical Prompting Framework (HPF), which structures five unique prompting strategies in a hierarchical order based on their cognitive requirement on LLMs when compared to human mental capabilities. It assesses the complexity of tasks with the Hierarchical Prompting Index (HPI), which demonstrates the cognitive competencies of LLMs across diverse datasets and offers insights into the cognitive demands that datasets place on different LLMs. This approach enables a comprehensive evaluation of an LLM’s problem-solving abilities and the intricacy of a dataset, offering a standardized metric for task complexity. Extensive experiments with multiple datasets and LLMs show that HPF enhances LLM performance by $2%-63%$ compared to baseline performance, with GSM8k being the most cognitive ly complex task among reasoning and coding tasks with an average HPI of 3.20 confirming the effectiveness of HPT. To support future research and reproducibility in this domain, the implementations of HPT and HPF are available here.
评估大语言模型(LLM)在不同任务中的表现效果对于理解其优势与局限至关重要。本文提出基于人类认知原则的分层提示分类法(HPT),通过分析各类任务的认知需求来评估大语言模型。HPT采用分层提示框架(HPF),该框架根据LLM相较于人类心智能力的认知需求,将五种独特的提示策略按层级结构排列。系统通过分层提示指数(HPI)评估任务复杂度,该指数展示了LLM在不同数据集上的认知能力,并揭示了数据集对不同LLM的认知需求。这种方法能全面评估LLM的问题解决能力与数据集的复杂程度,为任务复杂度提供标准化度量指标。在多数据集和LLM上的大量实验表明,相比基线性能,HPF能将LLM表现提升$2%-63%$,其中GSM8k在推理和编码任务中认知复杂度最高,平均HPI达3.20,验证了HPT的有效性。为支持该领域未来研究及可复现性,HPT与HPF的实现代码已开源。
Code — https://github.com/de vich and 579/HPT
代码 — https://github.com/devichand579/HPT
1 Introduction
1 引言
Large Language Models (LLMs) have revolutionized natural language processing (NLP), enabling significant advancements in a wide range of applications. Conventional evaluation frameworks often apply a standard prompting approach to assess different LLMs, regardless of the complexity of the task, which may result in biased and suboptimal outcomes. Moreover, applying the same prompting approach across all samples within a dataset without considering each sample’s relative complexity adds to the unfair situation. To achieve a more balanced evaluation framework, it is essential to account for both the task-solving ability of LLMs and the varying cognitive complexities of the dataset samples. This limitation highlights the need for more sophisticated evaluation methods that can adapt to varying levels of task complex- ity. Within this study, complexity is defined as the cognitive demands associated with solving a task or the cognitive load introduced by a prompting strategy on LLMs. Henceforth, the term ”complexity” will be applied solely in this context. Task complexity, within the realm of human cognition, pertains to the cognitive requirements that a task imposes, which includes the diverse levels of mental effort necessary for processing, analyzing, and synthesizing information. According to Sweller (1988), tasks become more complex as they require greater cognitive resources, engaging working memory in more demanding processes such as reasoning and problem-solving. Similarly, Anderson et al. (2014) highlights that human cognitive abilities span a continuum from basic recall to higher-order thinking, with increasing difficulty correlating to tasks that demand analysis, synthesis, and evaluation. When applied to LLMs, the complexity of prompting strategies can be systematically evaluated by mapping them onto this human cognitive hierarchy. This alignment allows for an assessment of how LLMs perform tasks that reflect varying degrees of cognitive load, thereby providing a structured framework for understanding the cognitive demands associated with various tasks. By imposing this cognitive complexity framework on LLMs, this paper establishes a universal evaluation method, grounded in human cognitive principles, that enables more precise comparisons of model performance across tasks with varying levels of difficulty.
大语言模型 (LLM) 彻底改变了自然语言处理 (NLP) 领域,推动各类应用取得重大进展。传统评估框架通常采用标准提示方法评估不同大语言模型,而忽略任务复杂性差异,可能导致评估结果存在偏差且非最优。此外,对数据集中所有样本统一应用相同提示策略而不考虑样本间相对复杂度,进一步加剧了评估的不公平性。为实现更平衡的评估框架,必须同时考量大语言模型的任务解决能力与数据集样本的认知复杂度差异。这一局限性凸显了需要开发能适应不同任务复杂度的更精细评估方法。本研究将复杂度定义为:解决任务所需的认知需求,或提示策略给大语言模型带来的认知负荷。后文所述"复杂度"皆特指此定义。在人类认知领域,任务复杂度指任务对认知能力的要求,包括处理、分析和综合信息所需的不同层次脑力消耗。Sweller (1988) 指出,当任务需要更多认知资源(如涉及推理和问题解决等高要求工作记忆过程)时,其复杂度随之提升。Anderson et al. (2014) 同样强调,人类认知能力存在从基础记忆到高阶思维的连续统,任务难度随着对分析、综合和评估能力要求的提升而增加。将提示策略复杂度映射到人类认知层次体系,可系统评估大语言模型在不同认知负荷任务中的表现。这种对应关系为理解各类任务相关认知需求提供了结构化框架。通过将人类认知复杂度框架应用于大语言模型,本文建立了一种基于人类认知原理的通用评估方法,能更精准地比较模型在不同难度任务中的性能表现。
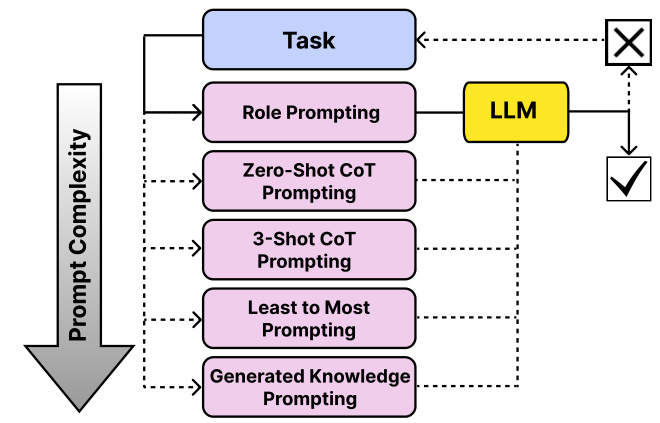
Figure 1: Hierarchical Prompting Framework includes five distinct prompting strategies, each designed for different levels of task complexity to ensure the appropriate prompt is selected for the given task. A $\checkmark$ indicates task completion, while $\mathrm{a}\times$ signifies task in completion.
图 1: 分层提示框架包含五种不同的提示策略,每种策略针对不同层次的任务复杂度设计,以确保为给定任务选择合适的提示。$\checkmark$ 表示任务完成,$\mathrm{a}\times$ 表示任务未完成。
This paper introduces the HPT, a set of rules that maps the human cognitive principles for assessing the complexity of different prompting strategies. It employs the HPF shown in Figure 1, a prompt selection framework that selects the prompt with the optimal cognitive load on LLM required in solving the task. HPF enhances the interaction with LLMs, and improves performance across various tasks by ensuring prompts resonate with human cognitive principles. The main contributions of this paper are as follows:
本文介绍了HPT,这是一套基于人类认知原则来评估不同提示策略复杂度的规则体系。该框架采用图1所示的HPF提示选择框架,能够根据任务需求选择对大语言模型(LLM)认知负荷最优的提示方案。HPF通过确保提示符合人类认知原则,不仅增强了大语言模型的交互体验,还提升了各类任务的表现。本文主要贡献如下:
HPF can be effectively compared to an ”Open Book” examination as shown in Figure 2, where questions represent tasks and textbooks serve as prompting strategies. In this analogy, the exam questions vary in complexity, from simple factual recall to intricate analytical problems, analogous to the tasks in HPT that are evaluated based on their cognitive demands. Similarly, textbooks provide structured guidance for solving these questions, much like the HPF organizes prompts in increasing levels of complexity to support LLMs. For example, a straightforward glossary lookup corresponds to a low-complexity task, while solving a multi-step analytical problem requiring synthesis of concepts represents a highcomplexity task. The effort a student invests in answering a question mirrors the HPI, which measures the cognitive load placed on the LLM. Just as students perform better with structured resources like textbooks, LLMs improve with welldesigned hierarchical prompting strategies, enabling them to tackle progressively complex tasks effectively.
HPF可以有效地比作"开卷考试",如图2所示,其中问题代表任务,教科书则充当提示策略。在这个类比中,考试题目复杂度各异,从简单的事实回忆到复杂的分析问题,类似于HPT中根据认知需求评估的任务。同样地,教科书为解答这些问题提供了结构化指导,就像HPF通过组织复杂度递增的提示来支持大语言模型。例如,简单的术语表查找对应低复杂度任务,而需要综合概念的多步骤分析问题则代表高复杂度任务。学生解答问题所付出的努力反映了HPI,即衡量大语言模型承受的认知负荷。正如学生在教科书等结构化资源的帮助下表现更好,大语言模型也能通过精心设计的层次化提示策略得到提升,从而有效处理日益复杂的任务。
The remainder of the paper is structured as follows: Section 2 reviews the related work on prompting and evaluation in LLMs. Section 3 details the HPT and its associated frameworks. Section 4 outlines the experimental setup, results, and ablation studies. Section 5 concludes the paper. Section 6 discusses the ethical impact of the work.
本文的其余部分结构如下:第2节回顾了大语言模型中提示 (prompting) 和评估的相关工作。第3节详细介绍了HPT及其相关框架。第4节概述了实验设置、结果和消融研究。第5节对全文进行总结。第6节讨论了本研究的伦理影响。
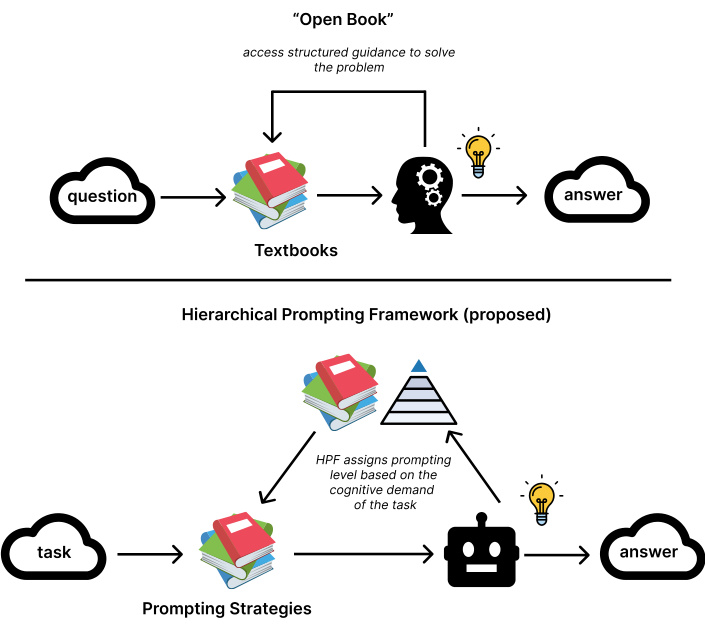
Figure 2: Analogical framework comparing the HPF with ”Open Book” examination methodology. The diagram illus- trates how HPF components (below) mirror traditional educational assessment elements (above), with parallel relationships between task complexity levels, resource utilization (prompts/textbooks), and performance metrics (HPI/student effort). This comparison demonstrates how LLM task complexity scales similarly to educational assessment complexity, from simple lookup tasks to complex synthesis problems
图 2: 类比框架对比HPF与"开卷考试"评估方法。该图展示了HPF组件(下方)如何对应传统教育评估要素(上方),包括任务复杂度层级、资源利用(提示词/教科书)和性能指标(HPI/学生努力程度)之间的平行关系。这一比较揭示了大语言模型任务复杂度与教育评估复杂度具有相似的递进规律,从简单查找任务到复杂综合问题。
2 Related Work
2 相关工作
The advent of LLMs has revolutionized NLP by demonstrating significant improvements in few-shot and zero-shot learning capabilities. Brown et al. (2020) introduced GPT-3, a 175 billion parameter auto regressive model, showcasing its ability to perform a wide range of tasks such as question-answering, reading comprehension, translation, and natural language inference without fine-tuning. This study highlighted the potential of very large models for in-context learning while also identifying limitations in commonsense reasoning and specific comprehension tasks. Similarly, Liu et al. (2021) surveyed prompt-based learning, emphasizing the role of prompt engineering in leveraging pre-trained models for few-shot and zero-shot adaptation to new tasks with minimal labeled data.
大语言模型(LLM)的出现通过显著提升少样本和零样本学习能力,彻底改变了自然语言处理领域。Brown等人(2020)提出的GPT-3是一个1750亿参数的自回归模型,展示了其在无需微调情况下执行问答、阅读理解、翻译和自然语言推理等广泛任务的能力。该研究凸显了超大规模模型在上下文学习方面的潜力,同时也指出了其在常识推理和特定理解任务上的局限性。类似地,Liu等人(2021)对基于提示的学习进行了综述,强调提示工程在利用预训练模型进行少样本和零样本适应新任务时的重要作用,仅需少量标注数据即可实现。
2.1 Prompt Engineering
2.1 提示工程 (Prompt Engineering)
Prompting plays a vital role in unlocking the full potential of LLMs. By designing specific input prompts, the LLM’s responses can be guided, significantly influencing the quality and relevance of the output. Effective prompting strategies have enhanced LLM performance on tasks ranging from simple question-answering to complex reasoning and problemsolving. Recent research has explored various approaches to prompting and reasoning evaluation in LLMs. Chain-ofThought (CoT) prompting (Wei et al. 2022b) elicits step-bystep reasoning, improving performance on complex tasks. Specializing smaller models (Fu et al. 2023) and using large models as reasoning teachers (Ho, Schmid, and Yun 2022) have demonstrated the potential for enhancing reasoning capabilities. Emergent abilities in LLMs, which appear suddenly at certain scale thresholds, have also been a topic of interest. Wei et al. (2022a) examined these abilities in fewshot prompting, discussing the underlying factors and implications for future scaling. Complementing this, Kojima et al. (2022) demonstrated that LLMs could exhibit multistep reasoning capabilities in a zero-shot setting by simply modifying the prompt structure, thus highlighting their potential as general reasoning engines. Yao et al. (2023) introduced the Tree-of-Thoughts framework, enabling LLMs to deliberate over coherent text units and perform heuristic searches for complex reasoning tasks. This approach generalizes over chain-of-thought prompting and has shown significant performance improvements in tasks requiring planning and search, such as creative writing and problem-solving games. Kong et al. (2024) introduced role-play prompting to improve zeroshot reasoning by constructing role-immersion interactions, which implicitly trigger chain-of-thought processes and enhance performance across diverse reasoning benchmarks. Progressive-hint prompting (Zheng et al. 2023) has been proposed to conceptualize answer generation and guide LLMs toward correct responses. Meta cognitive prompting (Wang and Zhao 2024) incorporates self-aware evaluations to enhance understanding abilities.
提示工程在释放大语言模型全部潜力方面起着至关重要的作用。通过设计特定的输入提示,可以引导大语言模型的响应,显著影响输出的质量和相关性。从简单的问答到复杂的推理和问题解决,有效的提示策略已提升了大语言模型在各种任务上的表现。
近期研究探索了大语言模型中多种提示与推理评估方法。思维链 (Chain-of-Thought, CoT) 提示 (Wei et al. 2022b) 通过逐步推理提示,提升了复杂任务的表现。专业化小型模型 (Fu et al. 2023) 以及使用大模型作为推理教师 (Ho, Schmid, and Yun 2022) 的方法,都展示了增强推理能力的潜力。
大语言模型在特定规模阈值突然显现的涌现能力也备受关注。Wei等 (2022a) 研究了少样本提示中的这些能力,探讨了其内在因素及对未来扩展的影响。Kojima等 (2022) 进一步证明,仅通过修改提示结构,大语言模型就能在零样本设置中展现多步推理能力,凸显其作为通用推理引擎的潜力。
Yao等 (2023) 提出的思维树框架使大语言模型能够对连贯文本单元进行推敲,并为复杂推理任务执行启发式搜索。该方法推广了思维链提示,在需要规划和搜索的任务(如创意写作和解题游戏)中展现出显著性能提升。
Kong等 (2024) 引入角色扮演提示技术,通过构建角色沉浸式交互来改进零样本推理,隐式触发思维链过程并提升跨领域推理基准的表现。渐进式提示 (Zheng et al. 2023) 被提出用于概念化答案生成并引导大语言模型给出正确响应。元认知提示 (Wang and Zhao 2024) 则通过自我感知评估来增强理解能力。
These works collectively highlight the advancements in leveraging LLMs through innovative prompting techniques, addressing their emergent abilities, reasoning capabilities, interaction strategies, robustness, and evaluation methodologies. Despite significant advancements, the current LLM research reveals several limitations, particularly in terms of prompt design, handling complex reasoning tasks, and evaluating model performance across diverse scenarios. While promising, the emergent abilities of LLMs often lack predictability and control, and the robustness of these LLMs in the face of misleading prompts remains a concern.
这些研究共同凸显了通过创新提示技术利用大语言模型所取得的进展,涉及模型的涌现能力、推理性能、交互策略、鲁棒性以及评估方法。尽管取得了重大进展,当前大语言模型研究仍存在若干局限性,尤其在提示设计、处理复杂推理任务以及跨场景模型性能评估方面。虽然前景广阔,但大语言模型的涌现能力往往缺乏可预测性和可控性,且这些模型在面对误导性提示时的鲁棒性仍令人担忧。
2.2 Prompt Optimization and Selection
2.2 提示优化与选择
The challenge of optimizing prompts for LLMs has been addressed in several key studies, each contributing unique methodologies to enhance model performance and efficiency. Shen et al. (2023) introduce PFLAT, a metric utilizing flatness regular iz ation to quantify prompt utility, which leads to improved results in classification tasks. Do et al. (2024) propose a structured three-step methodology that contains data clustering, prompt generation, and evaluation, effectively balancing generality and specificity in prompt selection. ProTeGi (Pryzant et al. 2023) offers a non-parametric approach inspired by gradient descent, leveraging natural language ”gradients” to iterative ly refine prompts. Wang et al. (2024) present PromISe, which transforms prompt optimization into an explicit chain of thought, employing self-introspection and refinement techniques. Zhou et al. (2023b) proposed DYNAICL, a framework for efficient prompting that dynamically allocates in-context examples based on a meta-controller’s predictions, achieving better performance-efficiency tradeoffs compared to uniform example allocation.
优化大语言模型提示词的挑战已在多项关键研究中得到解决,这些研究各自提出了独特方法来提升模型性能和效率。Shen等人(2023)提出PFLAT指标,通过平坦度正则化量化提示效用,在分类任务中取得更好效果。Do等人(2024)设计了包含数据聚类、提示生成与评估的三步法,有效平衡提示选择的通用性与特异性。ProTeGi(Pryzant等人2023)受梯度下降启发提出非参数方法,利用自然语言"梯度"迭代优化提示词。Wang等人(2024)开发的PromISe将提示优化转化为显式思维链,采用自省与精炼技术。Zhou等人(2023b)提出DYNAICL框架,通过元控制器预测动态分配上下文示例,相比均匀分配实现了更优的性能-效率平衡。
These studies aim to automate prompt design, moving away from traditional manual trial-and-error methods while emphasizing efficiency and s cal ability across various tasks and models. They report significant improvements in LLMs performance, with enhancements ranging from $5%$ to $31%$ across different benchmarks. This body of work underscores the increasing importance of prompt optimization and selection in unlocking the potential of LLMs and points toward future research avenues, such as exploring theoretical foundations, integrating multiple optimization techniques, and distinguishing between task-specific and general-purpose strategies.
这些研究旨在实现提示设计的自动化,摒弃传统的手动试错方法,同时强调跨任务和模型的高效性与可扩展性。研究显示大语言模型性能显著提升,在不同基准测试中提升幅度达 $5%$ 至 $31%$。该系列工作凸显了提示优化与选择在释放大语言模型潜力方面日益增长的重要性,并为未来研究方向指明路径,例如探索理论基础、整合多种优化技术,以及区分任务专用策略与通用策略。
2.3 Evaluation Benchmarks
2.3 评估基准
To facilitate the evaluation and understanding of LLM capabilities, Zhu et al. (2024) introduced Prompt Bench, a unified library encompassing a variety of LLMs, datasets, evaluation protocols, and adversarial prompt attacks. This modular and extensible tool aims to support collaborative research and advance the comprehension of LLM strengths and weaknesses. Further exploring reasoning capabilities, Qiao et al. (2023) categorized various prompting methods and evaluated their effectiveness across different model scales and reasoning tasks, identifying key open questions for achieving robust and general iz able reasoning. (Wang et al. 2021) introduced a multi-task Benchmark for robustness Evaluation of LLMs extends the original GLUE (Wang et al. 2018) benchmark to assess model robustness against adversarial inputs. It incorporates perturbed versions of existing GLUE tasks, such as paraphrasing, negation, and noise, to test models’ abilities with challenging data. The study highlights that despite their success on clean datasets, state-of-the-art models often struggle with adversarial examples, underscoring the importance of robustness evaluations in model development.
为便于评估和理解大语言模型的能力,Zhu等人 (2024) 提出了Prompt Bench,这是一个包含多种大语言模型、数据集、评估协议和对抗性提示攻击的统一库。这个模块化且可扩展的工具旨在支持协作研究,并增进对大语言模型优缺点理解。Qiao等人 (2023) 进一步探索推理能力,对各种提示方法进行分类,并评估它们在不同模型规模和推理任务中的有效性,指出了实现稳健且可泛化推理的关键开放性问题。(Wang等人 2021) 引入了一个用于大语言模型鲁棒性评估的多任务基准,将原始GLUE (Wang等人 2018) 基准扩展到评估模型对抗对抗性输入的鲁棒性。它整合了现有GLUE任务的扰动版本,如释义、否定和噪声,以测试模型在处理挑战性数据时的能力。研究强调,尽管最先进的模型在干净数据集上表现优异,但在对抗性样本上往往表现不佳,这凸显了模型开发中鲁棒性评估的重要性。
3 Hierarchical Prompting Taxonomy 3.1 Governing Rules
3 分层提示分类法 3.1 基本规则
Figure 3 illustrates the HPT, a taxonomy that systematically reflects human cognitive functions as outlined in Bloom (1956). Each rule embodies complex cognitive processes based on established principles from learning and psychology.
图 3: 展示了HPT (Human Process Taxonomy)分类体系,该系统化地反映了Bloom (1956)提出的人类认知功能框架。每条规则都基于学习和心理学既定原则,体现了复杂的认知处理过程。
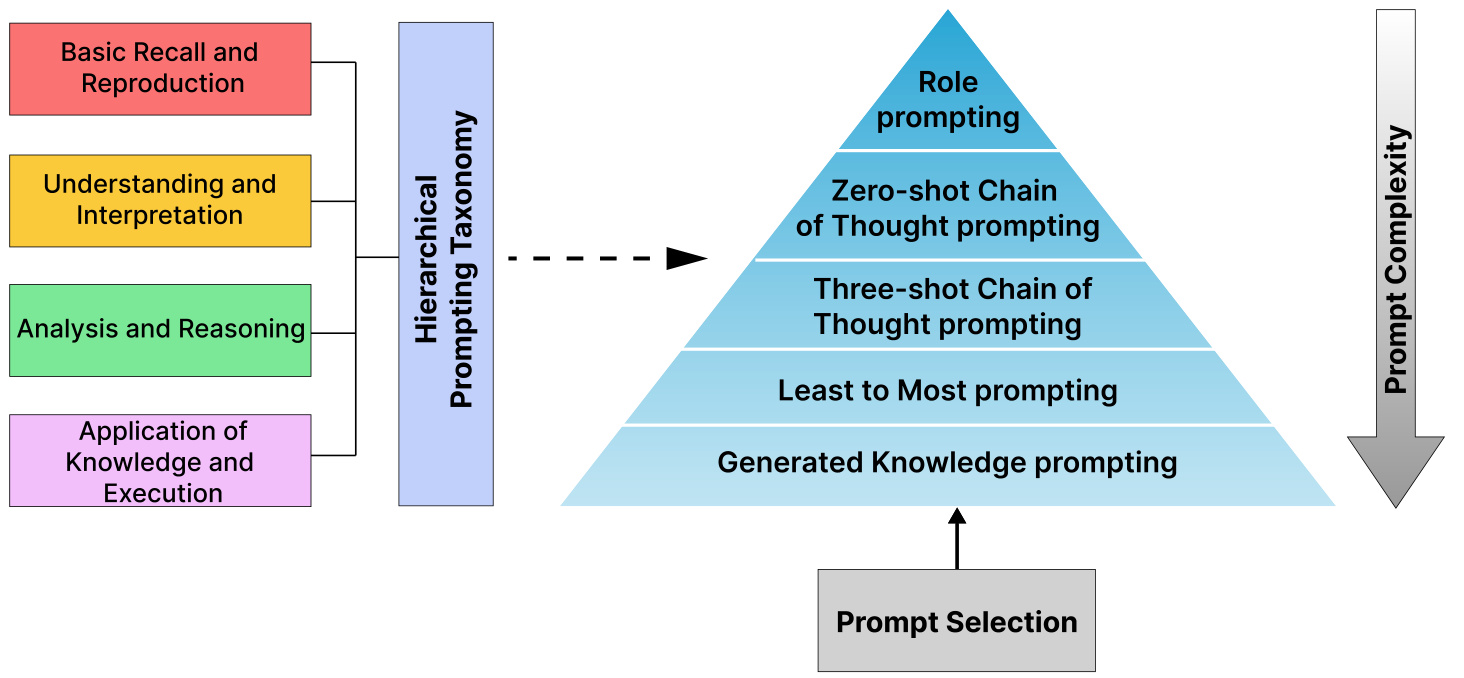
Figure 3: Hierarchical Prompting Taxonomy: A taxonomy designed to assess the complexity of prompting strategies based on the criteria: Basic Recall and Reproduction, Understanding and Interpretation, Analysis and Reasoning, and Application of Knowledge and Reasoning.
图 3: 分层提示分类法: 一种基于以下标准设计的提示策略复杂度评估分类体系: 基础记忆与复现、理解与解释、分析与推理、知识应用与推理。
than mere understanding because it requires examining structure and identifying patterns and connections.
超越单纯理解,因为它需要审视结构并识别模式和关联。
- Application of Knowledge and Execution: This mirrors the application and evaluation stages of (Bloom 1956), where individuals must not only understand and analyze but also use knowledge to perform multi-step tasks, solve complex problems, and execute decisions. It represents the most cognitive ly complex tasks, which require synthesis of information and practical decision-making, highlighting the critical leap from understanding theory to executing it in practice.
- 知识与执行的应用:这对应于 (Bloom 1956) 中的应用和评估阶段,个体不仅需要理解和分析,还必须运用知识完成多步骤任务、解决复杂问题并执行决策。它代表了认知复杂度最高的任务,要求综合信息并进行实际决策,突显了从理论理解到实践执行的关键跨越。
In HPT, the progression from basic recall to application of knowledge reflects increasing cognitive complexity, consistent with educational and cognitive frameworks, where more advanced cognitive processes build on foundational ones, demanding deeper engagement and mental effort.
在HPT中,从基础记忆到知识应用的进阶过程反映了认知复杂度的提升,这与教育和认知框架一致——更高级的认知过程建立在基础认知之上,需要更深层次的投入和心智努力。
3.2 Hierarchical Prompting Framework
3.2 分层提示框架
The HPF consists of five prompting strategies, each assigned a complexity level. These levels are determined by the degree to which the strategies are shaped by the four principles of the HPT. The complexity levels of the prompting strategies are assigned based on human assessment of their relative cognitive loads over a set of 7 different tasks, guaranteeing that the cognitive abilities of LLMs are in harmony with those of humans. This approach enables the assessment of tasks in terms of their complexity and the cognitive load they impose on both humans and LLMs by utilizing HPI. Section 4.4 examines the hierarchical structure of the HPF in conjunction with the LLM-as-a-Judge framework, validating that the cognitive demands on LLMs can be aligned with those of
HPF包含五种提示策略,每种策略都分配了一个复杂度等级。这些等级由策略受HPT四项原则影响的程度决定。提示策略的复杂度等级基于人类对7种不同任务中相对认知负荷的评估而设定,确保大语言模型的认知能力与人类保持一致。该方法通过利用HPI,能够从任务复杂度及其对人类和大语言模型施加的认知负荷角度进行评估。第4.4节结合LLM-as-a-Judge框架研究了HPF的层次结构,验证了大语言模型的认知需求可与人类需求对齐。
humans.
人类。
The set of five prompting strategies were chosen from a diverse range of existing strategies to populate the framework, guided by a human judgment policy, prioritizing comprehensiveness in cognitive demands rather than the sheer number of strategies. See Appendix A for more details. Consequently, the HPF can be replicated or expanded with other relevant prompting strategies that exhibit similar cognitive demands, making the framework adaptable. The five prompting strategies, listed from least to most complex, are as follows:
从现有策略中精选出五种提示策略来构建该框架,这些策略的选择基于人工判断原则,优先考虑认知需求的全面性而非策略数量。更多细节见附录A。因此,HPF框架可通过其他具有相似认知需求的相关提示策略进行复制或扩展,从而保持框架的适应性。这五种提示策略按复杂度从低到高依次为:
This approach requires recalling prior prompts, interpreting previous responses, and analyzing them to effectively solve the task, resulting in a highly cognitive ly demanding strategy.
这种方法需要回忆先前的提示、解读之前的响应并对其进行分析,才能有效解决任务,从而形成一种认知要求极高的策略。
- Generated Knowledge Prompting (GKP) (Liu et al. 2022): Prompts that require integrating external knowledge to generate relevant information represent the most complex and cognitive ly demanding strategy. This approach is strongly influenced by rules 2, 3, and 4, as it involves correlating knowledge with the prompt and applying and analyzing external information, making it the most cognitive ly demanding within the HPT framework. In the experiments, Llama-3 8B is used to generate external knowledge.
- 生成式知识提示 (GKP) (Liu et al. 2022): 需要整合外部知识以生成相关信息的提示代表了最复杂且认知需求最高的策略。该方法受规则2、3和4的强烈影响,因为它涉及将知识与提示相关联,并应用和分析外部信息,使其成为HPT框架中认知需求最高的方法。实验中使用了Llama-3 8B来生成外部知识。
3.3 Hierarchical Prompting Index
3.3 分层提示索引
HPI is an evaluation metric for assessing the task complexity of LLMs over different datasets, which is influenced by the HPT rules. A lower HPI for a dataset suggests that the corresponding LLM is more adept at solving the task with fewer cognition processes. For each dataset instance, we begin with the least complex prompting strategy and progressively move through the HPF prompting strategies until the instance is resolved. The HPI corresponds to the complexity level of the prompting strategy where the LLM first tackles the instance.
HPI是一种用于评估大语言模型(LLM)在不同数据集上任务复杂度的指标,其数值受HPT规则影响。数据集的HPI值越低,表明对应的大语言模型能以更少的认知过程熟练解决该任务。对于每个数据集实例,我们从复杂度最低的提示策略开始,逐步尝试HPF提示策略,直至该实例被解决。HPI对应大语言模型首次解决该实例时所使用的提示策略复杂度等级。
Algorithm 1: HPI Metric
算法 1: HPI 评估指标
| HPI_List= 对于评估数据集中的样本i执行 对于HPF中的层级r执行 如果大语言模型解决了任务则 HPI_List[]= 跳出循环 结束条件 结束循环 如果大语言模型未能解决任务则 |
| HPIList[]= m + HPIDataset 结束条件 结束循环 |
| HPI = ≥=1 HPI-List[] |
$m$ is the total number of levels in the HPF, and $n$ is the total number of samples in the evaluation dataset. $\mathsf{H P I}_{D a t a s e t}$ represents the penalty introduced into the framework by human assessments. For further details on human annotation, see Appendix A.
$m$ 是HPF中的总层数,$n$ 是评估数据集中的总样本数。$\mathsf{H P I}_{D a t a s e t}$ 表示人类评估给框架引入的惩罚项。关于人工标注的更多细节,请参阅附录A。
4 Results
4 结果
4.1 Experimental Setup Datasets
4.1 实验设置数据集
The experiments utilized a diverse set of datasets, including MMLU, GSM8k, HumanEval, BoolQ, CSQA, SamSum, and IWSLT en-fr covering areas such as reasoning, coding, mathematics, question-answering, sum mari z ation, and machine translation, to evaluate the framework’s robustness and applicability. For further details on evaluation dataset sizes, see
实验采用了多样化的数据集,包括 MMLU、GSM8k、HumanEval、BoolQ、CSQA、SamSum 和 IWSLT en-fr,涵盖推理、编程、数学、问答、摘要和机器翻译等领域,以评估框架的鲁棒性和适用性。有关评估数据集规模的更多详情,请参阅
Appendix A.
附录 A.
Reasoning: MMLU (Hendrycks et al. 2021) includes multiple-choice questions across 57 subjects, covering areas like humanities, social sciences, physical sciences, basic mathematics, U.S. history, computer science, and law. CommonSenseQA (CSQA) (Talmor et al. 2019) contains 12,000 questions to assess commonsense reasoning.
推理:MMLU (Hendrycks et al. 2021) 包含57个学科的多选题,涵盖人文、社会科学、自然科学、基础数学、美国历史、计算机科学和法律等领域。CommonSenseQA (CSQA) (Talmor et al. 2019) 包含12,000个用于评估常识推理的问题。
Coding: HumanEval (Chen et al. 2021a) features 164 coding challenges, each with a function signature, docstring, body, and unit tests, designed to avoid training data overlap with LLMs.
编码:HumanEval (Chen et al. 2021a) 包含164个编程挑战,每个挑战包含函数签名、文档字符串、函数体和单元测试,旨在避免与大语言模型的训练数据重叠。
Mathematics: Grade School Math 8K (GSM8k) (Cobbe et al. 2021) comprises 8.5K diverse math problems for multi-step reasoning, focusing on basic arithmetic and early Algebra.
数学:小学数学8K (GSM8k) (Cobbe et al. [2021]) 包含8500道多样化数学题,用于多步推理训练,侧重基础算术和初级代数。
Question-Answering: BoolQ (Clark et al. 2019) consists of 16,000 True/False questions based on Wikipedia passages for binary reading comprehension.
问答:BoolQ (Clark等人, 2019) 包含16,000个基于维基百科段落的真/假问题,用于二元阅读理解。
Sum mari z ation: SamSum (Gliwa et al. 2019) features 16,000 human-generated chat logs with summaries for dialogue sum mari z ation.
摘要:SamSum (Gliwa et al. 2019) 包含16,000条人工生成的聊天记录及对话摘要。
Machine Translation: IWSLT-2017 en-fr (IWSLT) (Cettolo et al. 2017) is a parallel corpus with thousands of EnglishFrench sentence pairs from TED Talks for translation tasks.
机器翻译:IWSLT-2017 en-fr (IWSLT) (Cettolo et al. 2017) 是一个包含数千个英法语句对的平行语料库,语料源自TED演讲的翻译任务。
Large Language Models
大语言模型
For the evaluation, LLMs with parameter sizes ranging from 7 billion to 12 billion from top open-source models and top proprietary models were selected to determine the effectiveness of the proposed framework across varied parameter scales and architectures.
在评估中,我们选取了参数规模从70亿到120亿的顶级开源大语言模型和专有大语言模型,以验证所提框架在不同参数规模和架构下的有效性。
Additional Evaluation Metrics
附加评估指标
• Coding: The Pass $\ @\mathrm{k}$ (Chen et al. 2021b) metric measures the probability of at least one correct solution among the top k outputs, used for evaluating code generation. • Sum mari z ation: ROUGE-L (Lin 2004) evaluates the longest common sub sequence between generated text and reference, focusing on sequence-level similarity for summaries and translations. • Machine Translation: BLEU (Papineni et al. 2002) is a precision-based metric that assesses machine-generated text quality by comparing n-grams with reference texts.
• 编码:Pass $\ @\mathrm{k}$ (Chen et al. 2021b) 指标衡量前k个输出中至少存在一个正确解的概率,用于评估代码生成质量。
• 摘要:ROUGE-L (Lin 2004) 通过计算生成文本与参考文本的最长公共子序列来评估摘要和翻译的序列级相似性。
• 机器翻译:BLEU (Papineni et al. 2002) 是基于精确度的指标,通过对比n-gram与参考文本来评估机器生成文本的质量。
In the experiments, thresholds of 0.15, and 0.20 were established for sum mari z ation and machine translation tasks to define the conditions required for task completion at each complexity level of the HPF. These thresholds allowed for iterative refinement of HPF prompting strategies.
在实验中,为摘要(summarization)和机器翻译任务设定了0.15和0.20的阈值,用于定义HPF每个复杂度级别完成任务所需的条件。这些阈值允许对HPF提示策略进行迭代优化。
4.2 Results on Standard Benchmarks: MMLU, GSM8K, and Humaneval
4.2 标准基准测试结果:MMLU、GSM8K和Humaneval
The evaluation of HPF effectiveness as shown in Figure 4 spans three standard benchmarks: MMLU, GSM8k, and HumanEval. On the MMLU benchmark, which tests general knowledge across multiple domains, all models showed notable improvements over their baseline performance. MistralNemo 12B demonstrated the most substantial MMLU enhancement $(+21.8%)$ , while Claude 3.5 Sonnet achieved a consistent improvement of $3.5%$ . In mathematical reasoning, assessed through GSM8k, the results revealed a correlation with the model scale. Larger models like GPT-4 and Claude 3.5 Sonnet showed modest gains $(+4.4%$ and $+1.3%$ respectively), while smaller models exhibited more variable performance. The HumanEval benchmark, which assesses code generation capabilities, revealed the most dramatic improvements across all models. Mistral 7B achieved an exception $62.5%$ improvement in HumanEval scores, followed by Mistral-Nemo 12B with an impressive $51.4%$ improvement, and Gemma-2 9B with a $50.8%$ enhancement. These findings indicate that HPF improves performance across all benchmarks for most of the LLMs, its impact is particularly pronounced in programming tasks, suggesting that the technique may be especially valuable for enhancing code-related capabilities.
如图 4 所示,HPF 有效性评估涵盖三个标准基准测试:MMLU、GSM8k 和 HumanEval。在测试跨领域通用知识的 MMLU 基准中,所有模型相较基线表现均有显著提升。MistralNemo 12B 展现出最大的 MMLU 提升幅度 $(+21.8%)$,Claude 3.5 Sonnet 则保持 $3.5%$ 的稳定改进。通过 GSM8k 评估的数学推理任务显示,结果与模型规模存在相关性:GPT-4 和 Claude 3.5 Sonnet 等大模型提升幅度较小 $(+4.4%$ 和 $+1.3%$),小模型则表现波动较大。在评估代码生成能力的 HumanEval 基准中,所有模型均取得最显著进步:Mistral 7B 以 $62.5%$ 的异常增幅领先,Mistral-Nemo 12B 紧随其后达 $51.4%$,Gemma-2 9B 也有 $50.8%$ 的提升。这些发现表明 HPF 能提升大多数大语言模型在所有基准测试中的表现,其对编程任务的增强效果尤为突出,暗示该技术对提升代码相关能力具有特殊价值。
Table 1 highlights the improved performance of various LLMs on MMLU, with all models showing an HPI index below three. This indicates that reasoning over most MMLU samples requires minimal cognitive effort for these models, compared to baseline multi-shot CoT methods (5 shot), which typically require more than five examples and are more cognitively demanding according to HPT. Interestingly, while Claude 3.5 Sonnet achieves the highest MMLU accuracy, GPT-4o records the best HPI score, showing that minimal cognitive effort does not necessarily equate to the best performance. The enhancement in GSM8k is relatively smaller compared to MMLU, with decreased performances for both Mistral 7B and Gemma 7B. The high HPI values for Gemma 7B and Mistral 7B indicate that none of the five prompting strategies in HPF posed significant cognitive challenges for these LLMs, highlighting a limitation of the HPF. As shown in Table 2, Claude 3.5 Sonnet achieves a perfect pass $@1$ of 1.00 with low HPI values, outperforming GPT-4o, which scores 0.95 but has a higher HPI. Gemma 7B struggles with the lowest pass $@1$ of 0.79 and the highest HPI of 3.71, indicating a need for more complex prompting strategy.
表 1: 展示了各大大语言模型在MMLU上的性能提升,所有模型的HPI指数均低于3。这表明相较于基线多样本思维链(CoT)方法(5样本),这些模型对大多数MMLU样本进行推理时所需的认知努力更少。根据HPT指标,基线方法通常需要超过五个示例且认知需求更高。有趣的是,虽然Claude 3.5 Sonnet取得了最高的MMLU准确率,但GPT-4o获得了最佳的HPI分数,说明最低认知努力并不一定等同于最佳性能。与MMLU相比,GSM8k的提升幅度相对较小,Mistral 7B和Gemma 7B的性能均有所下降。Gemma 7B和Mistral 7B的高HPI值表明,HPF中的五种提示策略均未对这些大语言模型构成显著认知挑战,这凸显了HPF的局限性。如表 2所示,Claude 3.5 Sonnet以1.00的完美pass@1分数和低HPI值表现最优,优于得分为0.95但HPI更高的GPT-4o。Gemma 7B表现最差,pass@1分数仅为0.79且HPI高达3.71,表明其需要更复杂的提示策略。
Interestingly, HPF significantly enhanced the performance of most LLMs across three benchmark datasets, even when the HPI difference was less than 1 relative to the best performing LLMs. This highlights that tailoring the prompting strategy to align with the complexity of each dataset instance can lead to substantial improvements, achieving performance levels comparable to state-of-the-art LLMs such as GPT-4o and Claude 3.5 Sonnet on these benchmarks.
有趣的是,HPF显著提升了大多数大语言模型在三个基准数据集上的表现,即使其HPI差异与表现最佳的大语言模型相比不到1。这表明,根据每个数据集实例的复杂性定制提示策略可以带来显著改进,使性能达到与GPT-4o和Claude 3.5 Sonnet等先进大语言模型相当的水平。
4.3 Results on Other Datasets
4.3 其他数据集上的结果
Table 1 presents the performance of LLMs on the BoolQ and CSQA datasets. Notably, no significant insights emerge from the results, aside from GPT-4o performing unexpectedly poorly, which contrasts with its typical performance. With most LLMs achieving near-perfect scores, the BoolQ dataset appears to lack the complexity needed to serve as an effective benchmark for modern LLMs, as they perform exceptionally well even with minimal cognitive prompting strategies. This underscores the utility of HPF in evaluating dataset complexities relative to an LLM, offering researchers valuable insights for designing more challenging and robust benchmarks.
表 1: 展示了大语言模型在BoolQ和CSQA数据集上的性能表现。值得注意的是,除了GPT-4o表现意外不佳(与其典型性能形成对比)外,结果中并未出现显著洞见。由于大多数大语言模型都获得了接近满分的成绩,BoolQ数据集似乎缺乏作为现代大语言模型有效基准所需的复杂度——即便采用最低限度的认知提示策略,它们也能表现优异。这凸显了HPF在评估数据集相对于大语言模型复杂度方面的实用性,为研究者设计更具挑战性和鲁棒性的基准提供了宝贵洞见。
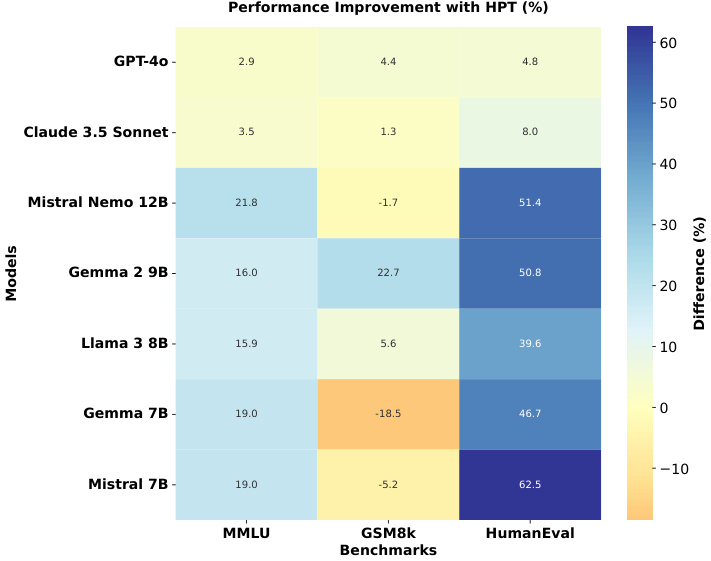
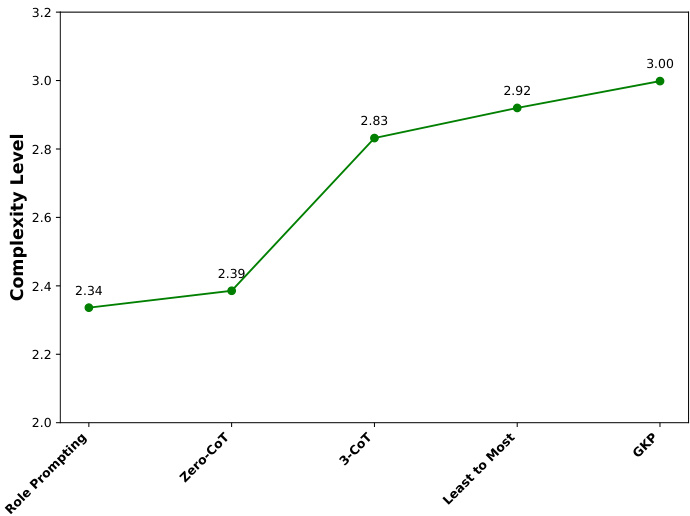
Figure 4: Performance Comparison of HPT-based Evaluation vs. Standard Evaluation: Performance improvements (in $%$ ) when using HPT-based evaluation compared to standard evaluation across three benchmarks: MMLU, GSM8k, and HumanEval. Positive values indicate performance gains with HPT, while negative values indicate performance decreases. The baseline standard evaluation scores are sourced from Hugging Face leader board and official research reports. Figure 5: Hierarchy of prompting strategies with LLM-as-aJudge framework with GPT-4o as the judge.
图 4: 基于HPT的评估与标准评估性能对比:在MMLU、GSM8k和HumanEval三个基准测试中,使用基于HPT的评估相比标准评估的性能提升(以$%$计)。正值表示HPT带来性能增益,负值表示性能下降。基线标准评估分数来源于Hugging Face排行榜和官方研究报告。
图 5: 以GPT-4o为评判者的LLM-as-aJudge框架提示策略层级结构。
Table 3 presents the performance of LLMs on IWSLT and SamSum datasets at varying thresholds. GPT-4o consistently achieved the highest scores across all thresholds, while most models, except Gemma 7B, performed similarly. Interestingly, Claude 3.5 Sonnet, which excelled in reasoning tasks, did not perform as strongly in sum mari z ation and translation tasks. The threshold selection is guided by the observed performance plateau across most LLMs as the threshold increases. For a detailed explanation of the threshold selection process, please refer to Appendix B.
表 3: 展示了不同阈值下大语言模型在IWSLT和SamSum数据集上的性能表现。GPT-4o在所有阈值下均保持最高得分,除Gemma 7B外,其他模型表现相近。值得注意的是,在推理任务中表现出色的Claude 3.5 Sonnet在摘要和翻译任务中表现相对较弱。阈值选择依据大多数大语言模型性能随阈值增长进入平台期的现象,具体选择过程详见附录B。
Table 1: HPI (lower is better) and accuracy of LLMs across MMLU, GSM8K, BoolQ, and CSQA datasets. Blue indicates datasets where the LLM with the best HPI does not achieve the best performance. Green indicates the LLM with the best performance over the maximum number of datasets.
表 1: HPI (数值越低越好) 和大语言模型在MMLU、GSM8K、BoolQ和CSQA数据集上的准确率。蓝色表示HPI最佳的大语言模型未达到最高性能的数据集。绿色表示在最多数据集上性能最佳的大语言模型。
| DATASETS Models | MMLU HPI | MMLU Accuracy | GSM8k HPI | GSM8k Accuracy | BoolQ HPI | BoolQ Accuracy | CSQA HPI | CSQA Accuracy |
|---|---|---|---|---|---|---|---|---|
| GPT-40 | 1.81 | 91.61 | 1.71 | 96.43 | 1.32 | 96.82 | 1.65 | 92.54 |
| Claude3.5Sonnet | 1.84 | 92.16 | 1.35 | 97.72 | 1.20 | 99.81 | 2.01 | 86.15 |
| Mistral-Nemo12B | 2.45 | 89.75 | 3.01 | 86.80 | 1.75 | 99.87 | 2.06 | 90.17 |
| Gemma-29B | 2.34 | 87.28 | 2.17 | 91.28 | 1.30 | 98.28 | 1.94 | 88.86 |
| Llama-38B | 2.84 | 82.63 | 2.34 | 86.20 | 1.37 | 99.30 | 2.43 | 84.76 |
| Gemma 7B | 2.93 | 83.31 | 6.70 | 27.88 | 1.45 | 99.42 | 2.50 | 83.78 |
| Mistral 7B | 2.89 | 81.45 | 5.11 | 46.93 | 1.41 | 98.07 | 2.49 | 82.06 |
Table 2: HPI (lower is better) and Pass $@1$ of LLMs on the HumanEval dataset. Blue indicates datasets where the LLM with the best HPI does not achieve the best performance. Green indicates the LLMs with the best performance over the dataset.
表 2: HumanEval数据集上大语言模型的HPI(数值越低越好)和Pass@1指标。蓝色标注表示HPI最佳的大语言模型未在该数据集上取得最佳性能,绿色标注表示在该数据集上性能最佳的大语言模型。
| DATASET Models | HumanEval |
|---|---|
| HPI | |
| GPT-40 | 2.25 |
| Claude3.5Sonnet | 1.04 |
| Mistral-Nemo12B | 2.07 |
| Gemma-29B | 1.01 |
| Llama-38B | 1.03 |
| Gemma 7B | 3.71 |
| Mistral 7B | 1.10 |
4.4 Complexity Levels with LLM-as-a-Judge
4.4 基于大语言模型的复杂度分级
This study evaluated prompting strategies by assessing how GPT-4o, as the LLM judge, replicates the hierarchical complexity levels of these strategies using a systematic scoring approach across tasks. Figure 5 shows a consistent hierarchy with less variability than human judges, indicating a strong alignment between LLM and human judgment. These results validate the proposed framework and demonstrate the corresponden ce between human cognitive principles and LLM behavior. Figure 6 shows the scoring distribution across the four HPT rules for each strategy. Further details related to dataset specifications and scoring method are in Appendix C.
本研究通过评估作为大语言模型裁判的GPT-4o如何采用系统性评分方法在各任务中复现提示策略的层级复杂度,对不同提示策略进行了评价。图5显示该模型呈现出比人类裁判更稳定的一致性层级结构,表明大语言模型与人类判断具有高度一致性。这些结果验证了所提出的框架,并证实了人类认知原则与大语言模型行为之间的对应关系。图6展示了各策略在四条HPT规则下的评分分布情况。关于数据集规范与评分方法的详细信息见附录C。
4.5 Parallels with System 1 and System 2 Thinking
4.5 与系统1和系统2思维的类比
HPF align closely with the principles of System 1 and System 2 thinking from dual-process cognitive theories (Booch et al. 2021). HPT categorizes tasks and HPF structures prompts based on their cognitive complexity, mirroring how humans allocate cognitive resources. For tasks with low cognitive demands, HPF employs simple prompts that parallel System 1 thinking. These tasks, like fact recall or basic classification, require minimal reasoning, allowing the LLM to respond quickly and efficiently without extensive computation. For instance, asking an LLM to ”identify the capital of a coun- try” is analogous to a person retrieving a familiar fact using System 1.
HPF与双过程认知理论中的系统1和系统2思维原则高度契合 (Booch et al. 2021)。HPT对任务进行分类,HPF则根据认知复杂度构建提示词,这种机制模拟了人类分配认知资源的方式。对于低认知需求的任务,HPF采用类似系统1思维的简单提示词。这类任务(如事实回忆或基础分类)只需极少推理,使得大语言模型无需大量计算即可快速高效响应。例如让大语言模型"识别某国首都",就如同人类通过系统1调取常识信息。
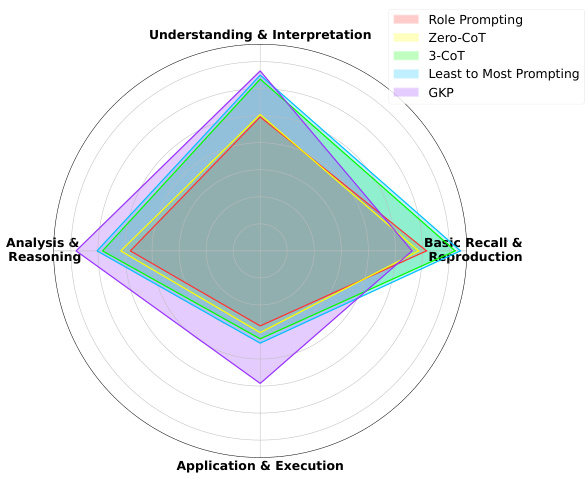
Figure 6: Scoring distribution for each of the four rules of the HPT for the prompting strategies in the HPF.
图 6: HPF中不同提示策略在HPT四项规则下的得分分布
In contrast, tasks with high cognitive demands involve prompts that guide the LLM through complex reasoning, abstraction, or multi-step problem-solving—analogous to System 2 thinking. Examples include generating logical arguments or solving intricate problems, where deliberate and resource-intensive processes are necessary. Just as System 2 engages when a problem exceeds the capacity of System 1, higher levels of HPF are invoked for tasks requiring deeper analysis.
相比之下,高认知需求的任务需要提示词引导大语言模型进行复杂推理、抽象或多步骤问题解决,类似于系统2思维。例如生成逻辑论证或解决复杂问题,这些任务需要深思熟虑且消耗资源的处理过程。正如当问题超出系统1能力范围时系统2会介入,需要深度分析的任务会调用更高级别的HPF。
HPF explicitly measures this transition with HPI, assessing the cognitive load required for each task. By tailoring prompting strategies to task complexity, HPF optimizes LLM performance, much like humans adaptively switch between System 1 and System 2 based on the situation. This parallel highlights how HPT bridges computational strategies with human-like cognitive models, enabling more nuanced task evaluation and resource allocation.
HPF通过HPI明确衡量这种转变,评估每项任务所需的认知负荷。通过根据任务复杂度定制提示策略,HPF优化了大语言模型的性能,类似于人类根据情境在系统1和系统2之间自适应切换。这一相似性凸显了HPT如何将计算策略与类人认知模型相连接,从而实现更细致的任务评估和资源分配。
Table 3: HPI (lower is better), BLEU score for IWSLT, and ROUGE-L score for SamSum, of LLMs with threshold
| 数据集 | IWSLT | SamSum | ||||||
|---|---|---|---|---|---|---|---|---|
| HPI | BLEU | HPI | ROUGE-L | |||||
| 模型 | 0.15 | 0.20 | 0.15 | 0.20 | 0.15 | 0.20 | 0.15 | 0.20 |
| GPT-40 | 2.66 | 3.08 | 0.32 | 0.32 | 1.11 | 1.21 | 0.30 | 0.29 |
| Claude 3.5 Sonnet | 4.63 | 4.87 | 0.20 | 0.20 | 1.25 | 1.60 | 0.23 | 0.23 |
| Mistral-Nemo12B | 2.87 | 3.40 | 0.27 | 0.27 | 1.19 | 1.47 | 0.23 | 0.24 |
| Gemma-29B | 4.40 | 4.75 | 0.21 | 0.20 | 1.30 | 1.86 | 0.22 | 0.22 |
| Llama-3 8B | 3.40 | 3.92 | 0.24 | 0.23 | 1.30 | 1.72 | 0.22 | 0.22 |
| Gemma 7B | 5.39 | 5.84 | 0.08 | 0.09 | 3.31 | 5.03 | 0.11 | 0.10 |
| Mistral 7B | 3.52 | 4.14 | 0.22 | 0.22 | 1.26 | 1.68 | 0.21 | 0.22 |
表 3: 大语言模型在 IWSLT 数据集上的 HPI (越低越好) 和 BLEU 分数,以及在 SamSum 数据集上的 ROUGE-L 分数,阈值为
4.6 Adaptive HPF
4.6 自适应HPF
The Adaptive HPF automates the selection of the optimal complexity level in the HPF using a prompt-selector, Llama $38\mathrm{B}$ in a zero-shot setting, bypassing iterative steps. Figure 7 shows that Adaptive HPF yields higher HPI but lower evaluation scores than the standard HPF. This suggests that Adaptive HPF struggles to select the optimal complexity level, likely due to hallucinations by the prompt-selector when choosing the prompting strategy. For more results and ablation studies, see Appendix E.
自适应HPF (Adaptive HPF) 通过提示选择器 (prompt-selector) 在零样本 (zero-shot) 设置下自动选择HPF中的最佳复杂度级别,绕过了迭代步骤。图7显示,自适应HPF比标准HPF产生更高的HPI但更低的评估分数。这表明自适应HPF难以选择最佳复杂度级别,可能是由于提示选择器在选择提示策略时产生幻觉 (hallucinations) 所致。更多结果和消融研究见附录E。
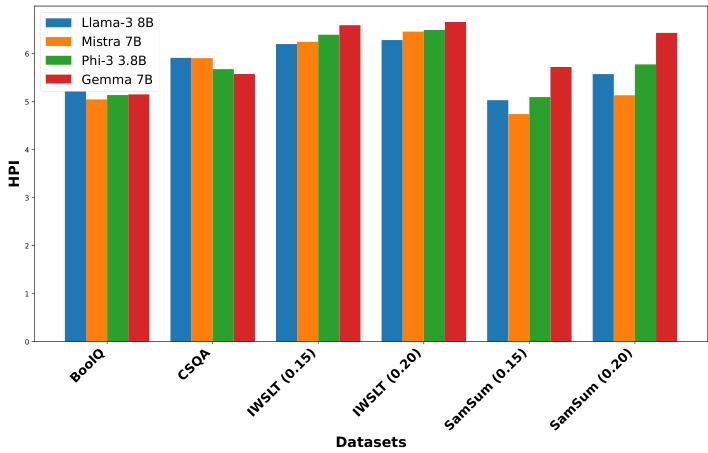
Figure 7: HPI of datasets for LLMs in Adaptive HPF.
图 7: 自适应HPF中大语言模型数据集的HPI指标
5 Conclusion
5 结论
The HPT provides a strong and efficient approach for assessing LLMs by focusing solely on the cognitive demands of different tasks. The results emphasize that the HPF is effective in evaluating diverse datasets, using the most cognitive ly effective prompting strategies tailored to task complexity, which results in improved LLM performance across multiple datasets. This method not only offers an in-depth insight into LLM’s problem-solving abilities but also suggests that dynamically choosing suitable prompting strategies can enhance LLM performance, setting the stage for future improvements in LLM evaluation methods. This study paves the way for formulating and designing evaluation methods grounded in human cognitive principles, aligning them with the problem-solving capabilities of LLMs. Additionally, it facilitates the development of more robust benchmarks and in-context learning methodologies to effectively assess LLM performance across various tasks.
HPT通过专注于不同任务的认知需求,为评估大语言模型提供了一种强大而高效的方法。结果表明,HPF能有效评估多样化数据集,通过采用针对任务复杂度量身定制、最具认知效率的提示策略,从而提升大语言模型在多个数据集上的表现。该方法不仅深入揭示了大语言模型的问题解决能力,还表明动态选择合适提示策略可增强模型性能,为未来改进大语言模型评估方法奠定基础。本研究为基于人类认知原理制定评估方法开辟了道路,使其与大语言模型的问题解决能力相匹配。此外,它促进了更健壮的基准测试和上下文学习方法的开发,以有效评估大语言模型在各种任务中的表现。
6 Ethical Statement
6 伦理声明
The $\mathsf{H P I}_{D a t a s e t}$ assigned by experts to the datasets: MMLU, GSM8k, Humaneval, BoolQ, CSQA, IWSLT, and SamSum may introduce bias into the comparative analysis. This potential bias stems from the subjective nature of expert scoring, which can be influenced by individual experience and perspective. Despite this, the datasets utilized in this study are publicly available and widely recognized in the research community, thereby minimizing the risk of unanticipated ethical issues. Nevertheless, it is crucial to acknowledge the possibility of scoring bias to ensure transparency and integrity in the analysis.
专家为MMLU、GSM8K、Humaneval、BoolQ、CSQA、IWSLT和SamSum数据集分配的$\mathsf{H P I}_{D a t a s e t}$可能会在比较分析中引入偏差。这种潜在偏差源于专家评分的主观性,可能受到个人经验和观点的影响。尽管如此,本研究所用数据集均为公开可用且在研究界广泛认可,从而将意外伦理问题的风险降至最低。然而,必须承认评分偏差的可能性,以确保分析的透明性和完整性。
References
参考文献
AI@Meta. 2024. Llama 3 Model Card. https://github.com/ meta-llama/llama3/blob/main/MODEL CARD.md.
AI@Meta. 2024. Llama 3 模型卡。https://github.com/meta-llama/llama3/blob/main/MODEL CARD.md。
Anderson, L.; Krathwohl, D.; Cruikshank, K.; Airasian,P.; Raths, J.; Pintrich, P.; Mayer, R.; and Wittrock, M. 2014. A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s. Always learning. Pearson. ISBN 9781292042848. Anthropic. 2024. Claude 3.5 Sonnet. https://www.anthropic. com/claude-3-5-sonnet. Accessed: 2024-09-16. Bloom, B. 1956. Taxonomy of Educational Objectives: The Classification of Educational Goals. Number v. 1 in Taxonomy of Educational Objectives: The Classification of Educational Goals. Longmans, Green. ISBN 9780679302094. Booch, G.; Fabiano, F.; Horesh, L.; Kate, K.; Lenchner, J.; Linck, N.; Loreggia, A.; Murgesan, K.; Mattei, N.; Rossi, F.; et al. 2021. Thinking fast and slow in AI. In Proceedings of
Anderson, L.; Krathwohl, D.; Cruikshank, K.; Airasian,P.; Raths, J.; Pintrich, P.; Mayer, R.; Wittrock, M. 2014. 学习、教学和评估的分类学: 布鲁姆分类法的修订版. Always learning. Pearson. ISBN 9781292042848.
Anthropic. 2024. Claude 3.5 Sonnet. https://www.anthropic.com/claude-3-5-sonnet. 访问日期: 2024-09-16.
Bloom, B. 1956. 教育目标分类学: 教育目标的分类. Number v. 1 in Taxonomy of Educational Objectives: The Classification of Educational Goals. Longmans, Green. ISBN 9780679302094.
Booch, G.; Fabiano, F.; Horesh, L.; Kate, K.; Lenchner, J.; Linck, N.; Loreggia, A.; Murgesan, K.; Mattei, N.; Rossi, F.; et al. 2021. AI中的快与慢思考. In Proceedings of
A Human Annotation and Judgement Policy A.1 Human Annotation Policy
人工标注与评判策略
A.1 人工标注策略
$\mathsf{H P I}{D a t a s e t}$ is introduced to penalize the HPI of tasks or samples unsolvable by the LLM, aligning the framework more closely with human cognitive demands and enhancing its comprehensiveness. We implemented a rigorous human annotation process to ensure the quality of $\mathsf{H P I}{D a t a s e t}$ scored by human experts for the datasets. Human annotators were tasked with calculating the HPI for each sample in a given dataset. The HPI quantifies the cognitive demands imposed on human expert proficiency in completing a task, based on the HPT, where higher values indicate greater cognitive demands. Each sample was scored on a scale from $I$ (lowest complexity level) to 5 (highest complexity level) for the following criteria:
$\mathsf{H P I}{D a t a s e t}$ 用于惩罚大语言模型无法解决的任务或样本的HPI,使框架更贴近人类认知需求并增强其全面性。我们实施了严格的人工标注流程来确保由人类专家为数据集评分的 $\mathsf{H P I}{D a t a s e t}$ 质量。标注人员的任务是为给定数据集中的每个样本计算HPI。该指标基于HPT量化了完成任务时对人类专家专业能力的认知需求,数值越高表示认知需求越大。每个样本按以下标准从 $I$(最低复杂度等级)到5(最高复杂度等级)进行评分:
Higher scores for the four rules signify a stronger influence of the respective rules, indicating that completing the task requires greater cognitive effort. The $\mathsf{H P I}_{D a t a s e t}$ for each dataset, as shown in Table 4, was calculated by taking the mean of the values from these four criteria, acknowledging the challenge of estimating or computing the individual weights of the influence of each rule.
四项规则的得分越高,表明相应规则的影响越强,意味着完成任务需要更大的认知努力。如表 4 所示,每个数据集的 $\mathsf{H P I}_{D a t a s e t}$ 是通过这四个标准的平均值计算得出的,这承认了估算或计算每条规则影响权重的挑战。
The Representative Set Size in Table 4 refers to the subset of the dataset evaluated by human annotators, ensuring that the assessment reflects the overall task. Human annotation, while time-consuming and costly, provides a gold standard for calibrating the evaluation process of this paper. Selecting $5%$ of the dataset as the representative set size balances quality assessment and feasibility, capturing the dataset’s diversity and ensuring that human annotations encompass a broad range of cases without needing to annotate every sample.
表4中的代表集大小是指由人工标注员评估的数据集子集,确保评估能反映整体任务。人工标注虽然耗时且成本高昂,但为本文评估过程的校准提供了黄金标准。选择数据集的$5%$作为代表集大小,在质量评估和可行性之间取得了平衡,既能捕捉数据集的多样性,又无需标注每个样本就能确保人工标注涵盖广泛案例。
Table 4: ${\sf H P I}{D a t a s e t}$ scores across datasets evaluated by human annotators. The table lists the evaluation set size, representative set size, and $\mathsf{H P I}{D a t a s e t}$ for various datasets. $\mathsf{H P I}_{D a t a s e t}$ scores provide a measure of task complexity relative to human annotators.
表 4: ${\sf H P I}{D a t a s e t}$ 在不同数据集上由人工标注者评估的得分。该表列出了各数据集的评估集大小、代表集大小以及 $\mathsf{H P I}{D a t a s e t}$ 。 $\mathsf{H P I}_{D a t a s e t}$ 得分提供了任务复杂度相对于人工标注者的衡量标准。
| Dataset | Evaluation Set Size | Representative SetSize | HPIDataset |
|---|---|---|---|
| MMILU | 14500 | 725 | 3.03 |
| GSM8K | 1320 | 66 | 2.14 |
| Humaneval | 160 | 8 | 4.68 |
| BoolQ | 3270 | 162 | 1.71 |
| CSQA | 1221 | 60 | 2.52 |
| IWSLT | 890 | 45 | 1.92 |
| SamSum | 819 | 40 | 2.23 |
A.2 Human Judgement Policy
A.2 人工评判策略
To populate the HPF with relevant prompting strategies across a wide range of strategies, human annotators who adhered to the annotation policy for assessing $\mathsf{H P I}_{D a t a s e t}$ were instructed to follow a judgment policy for a predefined set of prompting strategies. They were instructed to evaluate the influence of the four rules of the HPT on solving the annotated tasks using each prompting strategy, rating their influence as
为了在HPF中填充涵盖广泛策略的相关提示策略,遵循$\mathsf{H P I}_{数据集}$评估标注政策的人工标注员,被要求按照预定义提示策略集的判断政策执行。他们需评估HPT四条规则对使用每种提示策略解决标注任务的影响程度,并将其影响评级为
High (H), Moderate (M), or Low (L). It’s important to note that a high rating on rule 4 has a greater influence than a high rating on rule 3, and similarly for the other two rules. Considering the rating as shown in Table 5 and varying influences of these rules, five prompting strategies that prioritize comprehensive coverage of cognitive demands while ensuring the set optimally widens the variation across complexity levels were selected for populating the HPF.
高 (H)、中 (M) 或低 (L)。需要注意的是,规则4的高评级比规则3的高评级影响更大,其他两条规则也类似。根据表5所示的评级及这些规则的不同影响,我们选择了五种提示策略来填充HPF,这些策略优先考虑全面覆盖认知需求,同时确保集合能最大限度地扩大复杂度级别的变化范围。
| 提示策略 | 规则1 | 规则2 | 规则3 | 规则4 |
|---|---|---|---|---|
| 角色提示 (Role Prompting) | L | L | L | L |
| 情感提示 (Emotion) | L | L | M | L |
| 零样本思维链提示 (Zero-shot CoT) | L | L | M | L |
| 元提示 (Meta Prompting) | M | H | M | L |
| 三样本思维链提示 (Three-shot CoT) | H | H | M | L |
| 五样本思维链提示 (Five-shot CoT) | H | H | H | L |
| 验证链提示 (Chain-of-Verification) | H | H | H | H |
| 渐进式提示 (Least-to-Most) | H | H | H | L |
| 自洽提示 (Self-Consistency) | H | H | H | M |
| 通用知识提示 (GKP) | L | H | H | H |
Table 5: Human judgment of influence of the rules of taxonomy on different prompting strategies in solving the tasks of the representative set. The ratings are provided based on a voting system involving all human annotators. Green represents the prompting strategies selected for populating the complexity levels of the HPF.
表 5: 人类对分类规则在不同提示策略解决代表性任务集时影响力的评判。评分基于所有人工标注员参与的投票系统得出。绿色表示被选入填充HPF复杂度等级的提示策略。
B Threshold Selection for Sum mari z ation and Translation Tasks
B 摘要和翻译任务的阈值选择
In addition to the 0.15 and 0.20 thresholds presented in the main paper, extended evaluations were conducted on the IWSLT and SamSum datasets using thresholds of 0.25 and 0.30 with GPT-4o, Mistral-Nemo 12B, and Llama-3 to assess the impact of varying thresholds on LLM performance.
除主论文中提到的0.15和0.20阈值外,还在IWSLT和SamSum数据集上使用0.25和0.30阈值对GPT-4o、Mistral-Nemo 12B和Llama-3进行了扩展评估,以研究不同阈值对大语言模型性能的影响。
B.1 Sum mari z ation Task
B.1 摘要任务
In the sum mari z ation task, increasing the threshold evaluates an LLM’s ability to condense content while retaining key information. Higher thresholds like 0.25 and 0.30 reveal the trade-offs between conciseness and informative ness. However, as shown in Figure 8, there was no significant improvement in ROUGE-L, except for a slight increase with GPT-4o. The experiments showed a sharp rise in HPI, reflecting the increased task complexity. These results suggest that LLM performance has plateaued, with no further gains at higher thresholds. This validates the use of 0.15 and 0.20 thresholds in the main paper are sufficient for optimal LLM performance.
在摘要任务中,提高阈值可评估大语言模型在保留关键信息的同时压缩内容的能力。0.25和0.30等高阈值揭示了简洁性与信息量之间的权衡。然而如图8所示,除GPT-4o有轻微提升外,ROUGE-L指标未见显著改善。实验显示HPI值急剧上升,反映出任务复杂度的增加。这些结果表明大语言模型性能已进入平台期,更高阈值下无法获得额外收益。这验证了主论文采用0.15和0.20阈值已足以实现大语言模型的最佳性能。

Figure 8: Comparison of HPI and ROUGE-L score across different threshold values in sum mari z ation task.
图 8: 摘要任务中不同阈值下 HPI 和 ROUGE-L 分数的对比。
B.2 Translation Task
B.2 翻译任务
In machine translation, higher thresholds (0.25 and 0.30) impose stricter evaluations, assessing how well models capture the nuances of the source text. Lower thresholds (0.15 and 0.20) focus on general adequacy, while higher ones test performance under more challenging conditions. As shown in Figure 9, no BLEU improvements were observed across any LLMs, with models either reaching saturation or showing decreased performance alongside a rapid rise in HPI. This validates the selection of 0.15 and 0.20 thresholds in the main paper as sufficient for optimal LLM performance.
在机器翻译中,较高阈值(0.25和0.30)会实施更严格的评估,检验模型对源文本细微差别的捕捉能力。较低阈值(0.15和0.20)侧重整体达意程度,而较高阈值则测试模型在更具挑战性条件下的表现。如图9所示,所有大语言模型均未观察到BLEU指标提升,模型要么达到性能饱和,要么在HPI快速上升的同时表现出性能下降。这验证了主论文选择0.15和0.20阈值足以实现大语言模型的最佳性能。

Figure 9: Comparison of HPI and BLEU score across different threshold values in the translation task.
图 9: 翻译任务中不同阈值下 HPI 和 BLEU 分数的对比。
C LLM-as-a-Judge
C 大语言模型即评委 (LLM-as-a-Judge)
C.1 Scoring Prompt Template
C.1 评分提示模板
The system prompt is designed to guide the LLM judge in evaluating different prompting strategies based on four specific criteria: Basic Recall and Reproduction, Understanding and Interpretation, Analysis and Reasoning, and Application of Knowledge and Execution. Each criterion is scored on a scale of 1-5. The evaluation uses GPT-4o as a judge, with the following system prompt:
系统提示词旨在引导大语言模型(LLM)评审员根据四项具体标准评估不同的提示策略:基础记忆与复现、理解与阐释、分析与推理、知识应用与执行。每项标准按1-5分制评分。评估采用GPT-4o作为评审员,系统提示词如下:
You are a judge evaluating different prompting strategies and you need to score these prompting strategies based on pre-defined criteria. Different prompting strategies leverage varied amounts of intelligence from the model to achieve the required answer. So, assign the scores very carefully based on your analysis of the prompt and its effect on your intelligence to achieve the given answer as well as the number of multi-step prompts which increases the complexity of execution.
你是一名评估不同提示策略的裁判,需要根据预定义标准对这些提示策略进行评分。不同的提示策略利用模型不同程度的智能来获得所需答案。因此,请根据你对提示的分析及其对实现给定答案所需智能的影响,以及增加执行复杂性的多步提示数量,谨慎分配分数。
score1: Basic Recall and Reproduction Definition: The need of the model to remember and reproduce factual information without interpretation or analysis to answer the prompt Range: 1-5
score1: 基础记忆与复现
定义: 模型需要记忆并复现事实信息,无需解释或分析即可回答提示
范围: 1-5
C.2 Hybrid Dataset
C.2 混合数据集
The hybrid dataset is composed of 1106 samples uniformly distributed over seven different task-specific datasets, covering a wide range of language understanding and generation tasks. This diversity allows for a comprehensive evaluation of the prompting strategies across various problem types. The evaluation uses a hybrid dataset composed of samples from various task-specific datasets and each dataset contributes specific types of tasks:
混合数据集由1106个样本组成,均匀分布在七个不同的任务专用数据集上,涵盖了广泛的语言理解和生成任务。这种多样性使得能够全面评估不同问题类型下的提示策略。评估使用了一个混合数据集,该数据集由来自各个任务专用数据集的样本组成,每个数据集贡献特定类型的任务:
C.3 Scoring Method
C.3 评分方法
For each prompting strategy (Role Prompting, Zero-shot CoT, Three-shot CoT, Least to Most Prompting, Generated Knowledge Prompting), the system:
对于每种提示策略(角色提示、零样本思维链、少样本思维链、最少到最多提示、生成知识提示),系统:
This study ensured that both the human judge and the LLM judge utilized the same scoring methodology to eliminate any potential bias in the comparison.
本研究确保人类评审员和大语言模型评审员采用相同的评分方法,以消除比较中的潜在偏差。
D Limitations
D 局限性
Human Annotation Constraints: A limitation of this study is the reliance on human evaluation for inducing the $\mathsf{H P I}_{D a t a s e t}$ penalty into the HPF. While this study assessed $5%$ of the datasets, expanding coverage would offer a more comprehensive analysis. However, due to constraints in human resources for manual annotation, we could not include a larger portion. Future work could address this by increasing manpower or automating parts of the evaluation process.
人工标注限制:本研究的一个局限在于依赖人工评估来将$\mathsf{H P I}_{D a t a s e t}$惩罚引入HPF。虽然本研究评估了$5%$的数据集,但扩大覆盖范围将提供更全面的分析。然而,由于人工标注的人力资源限制,我们无法纳入更大比例的数据。未来工作可以通过增加人力或自动化部分评估流程来解决这一问题。
HPF Optimization: The effectiveness of the HPF heavily relies on the quality of the prompts used at each level of the taxonomy. Crafting high-quality prompts that accurately reflect the subtleties of each level demands considerable expertise and repeated refinement. This study only investigated a limited set of prompting strategies within the HPF, indicating a need for further research into creating diverse structural frameworks and incorporating additional prompting strategies.
HPF优化:HPF的有效性在很大程度上依赖于分类体系每个层级所使用的提示词质量。要制作出准确反映各层级细微差异的高质量提示词,需要相当的专业知识和反复优化。本研究仅探讨了HPF框架内有限的提示策略,表明未来需要进一步研究构建多样化结构框架并整合更多提示策略。
Zero-shot Prompt Selection: HPF dynamically determines the optimal cognitive complexity level by iterating through the framework’s levels, which leads to increased inference time. While this study investigated Adaptive HPF for zeroshot prompt selection, it faced considerable hallucinations. Future research should focus on automating HPF using finetuning or reinforcement learning-based approaches to select the appropriate complexity level without manual iteration. This strategy would optimize inference time and improve overall performance.
零样本提示选择:HPF通过迭代框架的层级动态确定最佳认知复杂度水平,这会导致推理时间增加。虽然本研究探索了自适应HPF在零样本提示选择中的应用,但仍存在明显的幻觉问题。未来研究应侧重于通过微调或基于强化学习的方法来自动化HPF,从而无需手动迭代即可选择合适的复杂度水平。这一策略将优化推理时间并提升整体性能。
E Adaptive HPF
E 自适应高通滤波器 (Adaptive HPF)
E.1 HPI for Adaptive HPF
E.1 自适应HPF的HPI
The prompt-selector can dynamically select the most suitable prompting strategy for a given task’s complexity from the HPF’s hierarchy of complexity levels. To determine the most effective prompting strategy to complete the task, the prompt-selector was given a maximum number of iterations equivalent to the number of levels in the manual HPF. The score for ith iteration is $i+x$ , where $x$ is the complexity level by the prompt-selector. If the LLM fails to complete the task after all iterations, it is assigned a penalty, $\mathsf{H P I}_{D a t a s e t}$ . $x$ represents the level of the HPF selected by prompt-selector at ith iteration at which the task is addressed, $m$ represents the total number of levels in the HPF, and $n$ denotes the total number of samples in the evaluation set.
提示选择器 (prompt-selector) 能够根据任务复杂度从手动构建的层次化提示框架 (HPF) 中动态选择最合适的提示策略。为确定完成任务的最有效提示策略,系统设置了与手动HPF层级数相等的最大迭代次数。第i次迭代得分为 $i+x$ ,其中 $x$ 代表提示选择器判定的复杂度层级。若大语言模型在全部迭代后仍未能完成任务,则会被施加惩罚项 $\mathsf{H P I}_{D a t a s e t}$ 。变量 $x$ 表示第i次迭代时提示选择器选定的HPF层级, $m$ 表示HPF总层数, $n$ 代表评估集样本总数。
Algorithm 2: Prompt-Selector for Adaptive HPF
算法 2: 自适应HPF提示选择器
| HPI_List = 对于评估数据集中的样本j do 已解决 = False 对于迭代次数 i = 1 到 m do 选择层级c的提示策略 如果大语言模型在迭代i完成任务 then |
| HPIList[]=+ 已解决=True |
| break end if |
| end for |
| if 已解决=False then HPI-List[j] = m + HPIDataset |
| end if end for |
| HPIAdaptive = ≥=1 HPI-List[] |
E.2 Hallucination in Adaptive HPF
E.2 自适应HPF中的幻觉现象
Hallucinations in prompt-selector refer to instances where the LLM generates incorrect or misleading prompting levels or nonsensical information that is not supported by the HPF. These hallucinations can occur across various tasks, including question answering, multiple-choice questions, translation, and sum mari z ation.
提示选择器中的幻觉 (Hallucinations) 指的是大语言模型生成错误或误导性的提示级别,或产生不受HPF支持的无意义信息。这些幻觉可能出现在各种任务中,包括问答、选择题、翻译和摘要生成。
For the BoolQ task, the prompt-selector initially struggles, indicated by the iterations where it reaches Level 4 with hallucinations (represented by ’...’). However, by the fourth iteration, Llama-3 8B manages to answer correctly at Level 2. For the CSQA task, prompt-selector exhibits hallucinations initially, shown by Level 4 and Level 0 (not included in HPF) responses. Eventually, it corrects itself by the third iteration, providing the correct answer at Level 2. For the IWSLT task, prompt-selector demonstrates a consistent pattern of hallucinations across multiple iterations. Even though Llama-3 8B attempts the translation at Level 2 multiple times, it ultimately fails to provide a correct translation, indicating a persistent hallucination. For the SamSum task, prompt-selector shows initial hallucinations in the first three iterations (Level 4). However, by the fourth and fifth iterations, the promptselector starts producing lower levels. Finally, Llama-3 8B achieves the correct answer at Level 2 in the last iteration .
在BoolQ任务中,提示选择器(prompt-selector)最初表现不佳,通过带有幻觉(以"..."表示)的Level 4迭代可见。但到第四次迭代时,Llama-3 8B成功在Level 2给出正确答案。对于CSQA任务,提示选择器初期出现Level 4和Level 0(未包含在HPF中)的幻觉响应,直到第三次迭代才自我修正,在Level 2提供正确答案。在IWSLT任务中,提示选择器表现出持续的多轮次幻觉模式,尽管Llama-3 8B多次尝试Level 2的翻译,但始终未能产出正确译文,显示顽固性幻觉问题。SamSum任务中,提示选择器在前三次迭代(Level 4)呈现初始幻觉,但从第四、五次迭代开始产生较低层级响应,最终Llama-3 8B在末次迭代的Level 2获得正确答案。
The results in Table 6 and Table 7 indicate that the promptselector exhibits hallucinations in selecting complexity levels across various tasks and iterations resulting in higher HPI for Adaptive HPF, with performance varying significantly. While the LLM can eventually produce correct answers, as seen in the BoolQ and SamSum tasks, it often requires multiple attempts and may still fail in tasks like IWSLT translation.
表6和表7的结果表明,提示选择器(promptselector)在不同任务和迭代中选择复杂度级别时会出现幻觉,导致自适应HPF (Adaptive HPF)的HPI更高,且性能差异显著。虽然大语言模型最终能生成正确答案(如BoolQ和SamSum任务所示),但通常需要多次尝试,并且在IWSLT翻译等任务中仍可能失败。
Table 6: HPI (lower is better) of LLMs across datasets (with thresholds) for Adaptive HPF.
表 6: 大语言模型在不同数据集上的自适应HPF HPI值(越低越好) (带阈值)
| Model | BoolQ | CSQA | IWSLT (0.15) | IWSLT (0.20) | SamSum (0.15) | SamSum 1 (0.20) |
|---|---|---|---|---|---|---|
| Llama-38B | 5.2173 | 5.9136 | 6.2006 | 6.2841 | 5.0316 | 5.5756 |
| Mistra 7B | 5.0483 | 5.9073 | 6.2478 | 6.4604 | 4.7423 | 5.1336 |
| Phi-33.8B | 5.1386 | 5.6793 | 6.3955 | 6.4936 | 5.0961 | 5.7778 |
| Gemma 7B | 5.1514 | 5.5771 | 6.5947 | 6.6605 | 5.7229 | 6.4347 |
Table 7: Performance scores of LLMs across datasets for Adaptive HPF.
| 数据集 | 指标 | 阈值 | Llama-38B | Phi-33.8B | Mistral7B | Gemma 7B |
|---|---|---|---|---|---|---|
| BoolQ | 准确率 | - | 0.88577 | 0.91115 | 0.91752 | 0.91166 |
| CSQA | 准确率 | - | 0.59451 | 0.68019 | 0.60111 | 0.68549 |
| IWSLT | BLEU | 0.15 | 0.21140 | 0.15557 | 0.20000 | 0.08447 |
| 0.2 | 0.21146 | 0.15354 | 0.20568 | 0.07730 | ||
| 0.15 | 0.24407 | 0.20586 | 0.26910 | 0.16023 | ||
| SamSum | ROUGE-1 | 0.2 | 0.24981 | 0.21580 | 0.28335 | 0.16179 |
表 7: 大语言模型在自适应 HPF 各数据集上的性能得分
E.3 Prompt Template for Prompt-Selector
E.3 提示选择器 (Prompt-Selector) 的提示模板
The prompt-selector in adaptive HPF selects the prompting level based on the task complexity to address the task. Llama $38\mathbf{B}$ serves as the prompt-selector in the experiments. The prompt template was meticulously designed to ensure maximum clarity, aiming to reduce hallucinations and select the most effective prompting strategy.
自适应HPF中的提示选择器会根据任务复杂度选择提示级别来处理任务。实验中使用Llama $38\mathbf{B}$作为提示选择器。提示模板经过精心设计以确保最大清晰度,旨在减少幻觉并选择最有效的提示策略。
Prompt Template: Choose the most effective prompting strategy among five available strategies for the task. Begin with the lowest indexed strategy and progress to higher indexed strategies if the earlier ones are not effective. For a given task, the prompting strategies are:
提示模板:从五种可用策略中选择最适合该任务的提示策略。从编号最低的策略开始尝试,若无效则逐步尝试更高编号的策略。给定任务的提示策略包括:
Select only the index (do not provide the name) of the most effective prompting strategy.
只选择最有效提示策略的索引(不要提供名称)。
F Computational Budget
F 计算预算
All evaluation experiments and ablation studies were conducted on V100 GPUs (16GB and 32GB variants), utilizing a total of around 9,000 computation hours, this equates to approximate ly 1.125 petaflop-hours of computational resources.
所有评估实验和消融研究均在V100 GPU(16GB和32GB版本)上进行,总计使用了约9,000计算小时,相当于约1.125千万亿次浮点运算小时的计算资源。
G Large Language Models Used for Evaluation
用于评估的大语言模型
The HPF supports leading open source and proprietary LLMs and includes mechanisms for optimizing performance through advanced quantization techniques. The experiments were conducted on the following instruction-tuned LLMs, and the model description and licenses are discussed in Table 8.
HPF支持领先的开源和专有大语言模型,并通过先进的量化技术优化性能。实验在以下经过指令调优的大语言模型上进行,模型描述和许可信息见表8。
The LLMs were loaded in 4-bit precision format, with a maximum generation limit of 1024 tokens per run to ensure concise outputs. The temperature was set to 0.6 to control prediction randomness, while top-p sampling $(\mathtt{p}{=}0.9)$ enabled the exploration of diverse continuations. Additionally, a repetition penalty was applied to discourage the generation of repeated phrases, promoting coherent and varied text output.
大语言模型以4位精度格式加载,每次运行最多生成1024个token以确保输出简洁。温度参数设为0.6以控制预测随机性,同时采用top-p采样 (p=0.9) 实现多样化的续写探索。此外,通过重复惩罚机制抑制重复短语生成,从而提升文本输出的连贯性与多样性。
H Prompt Templates
H 提示词模板
H.1 Level 1: Role Prompting
H.1 第一级:角色提示
Role prompting represents the most basic interaction with an LLM, assigning it a specific role or task without additional context or examples. This approach relies solely on the initial instruction to guide responses. For instance, asking the LLM to “act as a translator” prompts it to translate text based on its training data. While straightforward, this method may lack depth, resulting in less accurate or nuanced outputs. Table 9 shows the prompt templates used for role prompting across all datasets in the experiments.
角色提示 (Role prompting) 代表与大语言模型最基本的交互方式,即为其分配特定角色或任务而不提供额外上下文或示例。该方法仅依靠初始指令来引导响应。例如,要求大语言模型"扮演翻译角色"会促使其基于训练数据执行文本翻译。虽然操作简单,但这种方法可能缺乏深度,导致输出结果准确性或细腻度不足。表9展示了实验中所有数据集使用的角色提示模板。
H.2 Level 2: Zero-shot Chain-of-Thought Prompting
H.2 第二级: 零样本思维链提示
Zero-shot Chain-of-Thought (CoT) prompting enhances basic role prompting by requiring the LLM to generate a reasoning process for a task, despite not being explicitly trained on similar examples. This method encourages the LLM to break down the problem and solve it step-by-step using its internal knowledge, improving response quality through logical progression and coherence. Table 10 displays the prompt templates used for Zero-CoT across all datasets in the experiments.
零样本思维链 (Zero-shot Chain-of-Thought) 提示通过要求大语言模型为任务生成推理过程,增强了基础角色提示的效果,尽管模型并未针对类似示例进行明确训练。这种方法鼓励大语言模型分解问题并逐步利用其内部知识解决问题,通过逻辑推进和连贯性提高响应质量。表 10 展示了实验中所有数据集使用的零样本思维链提示模板。
Table 8: License information for LLMs used in the experiments.
表 8: 实验中使用的LLM许可信息
| 模型 | 许可类型 | 使用限制 |
|---|---|---|
| GPT-40 | 专有许可 | 商业用途需付费API访问,受OpenAI服务条款约束 |
| Claude 3.5 Sonnet | 专有许可 | 商业用途需付费API访问,受Anthropic服务条款约束 |
| Mistral-Nemo12B | 专有许可 | 使用可能仅限于授权合作伙伴或特定用例 |
| Gemma-2 9B Llama-3 8B | 研究许可 | 仅限非商业用途,用于研究目的 |
| 研究许可 | 可能适用特定限制,通常仅限非商业研究用途 | |
| Mistral 7B | 开源许可 | 允许广泛使用,必须包含原始许可和声明 |
| Gemma 7B | 开源/研究许可 | 根据许可类型,可能允许广泛使用或存在非商业限制 |
| Phi-3 3.8B | 开源许可 | 允许广泛使用,必须包含原始许可和声明 |
Table 9: Prompt templates of different datasets for Role Prompting.
表 9: 角色提示(Role Prompting)不同数据集的提示模板。
| 数据集 | 提示 |
|---|---|
| BoolQ | 作为一个全知者,根据文章:"passage",回答以下问题的真/假:"question"。 |
| CSQA | 作为一个批判性思考者,选择答案:"question",A."option 1",B."option 2",C. ,'. ,' , |
| IWSLT | 作为一名翻译人员,将"english text"翻译成法语。 |
| SamSum | 作为一名总结者,总结对话:"dialogue"。 |
| GSM8k | 作为一名专业数学家,根据问题:"question",计算出问题的数值答案。 |
| HumanEval | 一名专业程序员。 |
| MMLU | 作为一个批判性思考者,选择答案:' uodo,, ''" uodo,, ''uosnb,, :amsue 'option 3",D. "option 4"。 |
H.3 Level 3: Three-Shot Chain-of-Thought Prompting
H.3 第三级:三样本思维链提示
Three-shot Chain-of-Thought (CoT) prompting builds on the zero-shot approach by providing the LLM with three task examples, including the reasoning steps used to reach the solution. These examples help the LLM grasp the required structure and logic, enabling it to better replicate the problemsolving process and produce more accurate, con textually relevant responses. Table 11 shows the prompt templates used for 3-CoT across all datasets in the experiments.
三样本思维链 (Chain-of-Thought, CoT) 提示法在零样本基础上扩展,通过为大语言模型提供三个任务示例(包含推导步骤)来增强理解。这种方法帮助模型掌握解题结构和逻辑,从而更准确地复现推理过程并生成符合语境的回答。表11展示了实验中所有数据集使用的3-CoT提示模板。
H.4 Level 4: Least-to-Most Prompting
H.4 第四级:从易到难提示法 (Least-to-Most Prompting)
Least-to-most prompting is an advanced technique that gradually increases prompt complexity, starting with simpler tasks and progressing to more complex challenges. This method allows the LLM to build confidence and leverage insights from easier prompts to tackle harder ones, enhancing its ability to generalize from straightforward examples to intricate scenarios. Table 12 displays the prompt templates used for Least-to-Most Prompting across all datasets in the experiments.
由简至繁提示 (Least-to-most prompting) 是一种进阶技术,它从简单任务开始逐步增加提示复杂度,最终处理复杂挑战。该方法让大语言模型能够建立信心,并利用简单提示的洞见来解决更难的问题,从而提升其从简单示例泛化到复杂场景的能力。表12展示了实验中所有数据集使用的由简至繁提示模板。
H.5 Level 5: Generated Knowledge Prompting
H.5 第5级:生成知识提示 (Generated Knowledge Prompting)
Generated Knowledge prompting is one of the most complex techniques in HPF, where the LLM not only addresses the task but also integrates relevant additional information to enhance its response. This method prompts another LLM to produce auxiliary knowledge, creating a richer context for understanding and solving the problem. By leveraging self-generated insights, the LLM can deliver more detailed, accurate, and nuanced answers. Table 13 shows the prompt templates used for Generated Knowledge Prompting across all datasets in the experiments.
生成知识提示 (Generated Knowledge prompting) 是HPF中最复杂的技术之一,大语言模型不仅完成任务,还会整合相关附加信息以提升回答质量。该方法会提示另一个大语言模型生成辅助知识,为问题理解和解决创建更丰富的上下文。通过利用自生成洞察,大语言模型能提供更详细、准确且细致的答案。表13展示了实验中所有数据集使用的生成知识提示模板。
Table 10: Prompt templates of different datasets for Zero-shot Chain-of-Thought Prompting.
表 10: 零样本思维链提示 (Zero-shot Chain-of-Thought Prompting) 不同数据集的提示模板。
| 数据集 | 提示模板 |
|---|---|
| BoolQ | sb s ss, ss s ‘‘question"。让我们一步步思考。 |
| CSQA | ‘‘option 4",E. ‘‘option 5"。让我们一步步思考。 |
| IWSLT | |
| SamSum GSM8k | 基于问题: "question",计算问题的数值答案。让我们一步步思考。 |
| HumanEval | 让我们一步步思考。 |
| MMLU | ‘‘option 3",D. ‘‘option 4"。让我们一步步思考。 |
Table 11: Prompt templates of different datasets for Three-Shot Chain-of-Thought Prompting.
表 11: 三样本思维链提示(Chain-of-Thought Prompting)各数据集提示模板。
| 数据集 | 提示模板 |
|---|---|
| BoolQ | 根据段落:"passage2",判断问题:"question2"的真假。回答:"answer2"。解释:"explaination2"。基于段落:"passage3",判断问题:"option1-1",B."option2-1",C.的真假。 |
| CSQA | 选择答案:"questionl",A."option3-1",D."option4-1",E.解释:"explaination1"。(A."option1-2",B."option2-2",C."option5-2",回答:"answer2","option3-3",D."option4-3",E.解释:"explaination3"。4",E.‘option5"。选择答案:"question2","option3-2",D."option4-2",E.解释:"explaination2"。"option5-3",回答:"answer3",选择答案:"question"。 |
| IWSLT | 将"english text2"翻译为法语。法语:"french text2"。将"english text3"翻译为法语。法语:"french text3"。将"english text"翻译为法语。 |
| SamSum | 总结对话:"dialogue1"。摘要:"summary1"。总结对话:"dialogue2"。摘要:"summary2"。总结对话:"dialogue3"。摘要:"summary3"。总结对话:"dialogue"。基于问题:"gsm8k-question1",计算数值"gsm8k_ans1"。 |
| GSM8k | 回答问题:"gsm8k-question2",计算数值答案。回答:"gsm8k_ans2"。基于问题:"gsm8k_question3",计算数值答案。回答:"gsm8k-ans3"。基于问题:"question",计算数值答案。 |
| HumanEval | 根据约束条件:"humaneval_code1",补全代码。代码:"humaneval-sol1"。根据约束条件:"humaneval_code2",补全代码。根据约束条件:"humaneval_code3",补全代码。代码:"humaneval-sol3"。 |
| MMLU | ‘option3",D.‘option4"。A.错误,错误。B.错误,正确。C.正确,错误。D.正确,正确。回答:B解释:"mmlu-exp3"。选择问题:"mmlu-ques3"。A.被告陈述是非自愿的。B.被告陈述是自愿的。C.被告陈述时未被拘留。D. |
Table 12: Prompt templates of different datasets for Least-to-Most Prompting.
表 12: 不同数据集在Least-to-Most Prompting中的提示模板
| 数据集 | 提示模板 |
|---|---|
| BoolQ | prompt 1: 总结这段话的要点:"passage"。prompt b t b "question",文章:"passage"。prompt 4: 根据文章内容,回答这个问题:'question",相关信息:"previous response"。 |
| CSQA | prompt 1: 分析这个问题:"question"。Cs e o "‘option 5"。prompt 3: 根据分析:"previous response",排除错误选项,正确选项可能是:A.‘‘option 1",B.‘‘option 2",C.‘‘option 3",D.‘‘option 4",E.‘‘option 5"。prompt 4: 从选项中选择正确答案:A.‘‘option 1",B.‘ uod,,' odo,,'‘ uo,,' odo,, |
| IWSLT | prompt 2: 识别并列出这段文本中的关键短语或术语:'english text"。r response'"。关键短语的翻译:"previous response"。 |
| SamSum | prompt 1: 列出这段对话中的要点或关键想法:"dialogue"。prompt 2: 详细说明以下要点,提供更多细节或背景:"previous response"。prompt 3: 使用列出的要点及其详细说明,为这段文本起草一个简洁的摘要:"dialogue"。prompt 4: 改进这份摘要草稿,使其更加简洁 |
| GSM8k | 分析问题:"question"。将问题分解为子问题:"question"。计算问题的子问题答案:"pred"。根据之前的计算,计算这个问题的数值答案:"question":"pred" |
| HumanEval | 根据提到的约束条件编写代码:"code"根据之前的计算:"pred" |
| MMLU | 问题:"question",选项:A."option 1" B."option 2" C."option 3" D. "option 4"。根据分析:"question",排除错误选项 D."option 4"。 |
Table 13: Prompt templates of different datasets for Generated Knowledge Prompting.
表 13: 不同数据集在生成知识提示(Generated Knowledge Prompting)中使用的提示模板。
| 数据集 | 提示 |
|---|---|
| BoolQ | 知识生成提示: 生成关于段落的背景知识: "passage"。 |
| CSQA | sutsn uodo,, ‘'" uotdo,,'a' uodo,, ‘'" uoado,, 关于问题的知识:"knowledge" 知识生成提示: 生成关于问题的背景知识: "question"。 |
| IWSLT | 关键词定义:"knowledge" 知识生成提示: 为文本中的每个单词生成法语定义: "english text"。 |
| SamSum | 推理提示: 使用对话的解读:"knowledge" 来总结对话: "dialogue" 知识生成提示: 生成关于对话的解读: "dialogue"。 |
| GSM8K | 基于问题:"question",使用对问题的解读:"pred" 来计算问题的数值答案 |
| HumanEval | 基于提到的约束条件:"code" 使用约束条件的知识:"pred" 来完成代码 |
| MMLU | 选择答案。 "question", 选项: A. "option 1" B. "option 2" C. |