MyGO Multiplex CoT: A Method for Self-Reflection in Large Language Models via Double Chain of Thought Thinking
MyGO 多重 CoT:通过双重思维链实现大语言模型自我反思的方法
Ji Shihao, Song Zihui, Zhong Fucheng, Jia Jisen, Wu Zhaobo, Cao Zheyi, Xu Tianhao Data Dream, AI.
纪世浩, 宋子辉, 钟福成, 贾继森, 吴兆波, 曹哲一, 徐天浩 数据梦, AI.
Abstract
摘要
Recent advancements in large language models (LLMs) have demonstrated their impressive abilities in various reasoning and decision-making tasks. However, the quality and coherence of the reasoning process can still benefit from enhanced introspection and selfreflection. In this paper, we introduce Multiplex CoT (Chain of Thought), a method that enables LLMs to simulate a form of self-review while reasoning, by initiating double Chain of Thought (CoT) thinking. Multiplex CoT leverages the power of iterative reasoning, where the model generates an initial chain of thought and subsequently critiques and refines this reasoning with a second round of thought generation. This recursive approach allows for more coherent, logical, and robust answers, improving the overall decision-making process. We demonstrate how this method can be effectively implemented using simple prompt engineering in existing LLM architectures, achieving an effect similar to that of the Learning-Refinement Model (LRM) without the need for additional training. Additionally, we present a practical guide for implementing the method in Google Colab, enabling easy integration into real-world applications.
近年来,大语言模型 (LLM) 在各种推理和决策任务中展现了令人印象深刻的能力。然而,推理过程的质量和连贯性仍可以通过增强的自我反省和自我审查得到提升。本文提出了一种名为 Multiplex CoT (Chain of Thought) 的方法,通过启动双重 Chain of Thought (CoT) 思维,使大语言模型能够在推理过程中模拟一种自我审查的形式。Multiplex CoT 利用迭代推理的力量,模型首先生成初始的思维链,随后通过第二轮思维生成来批判和优化这一推理过程。这种递归方法能够生成更加连贯、逻辑性强且稳健的答案,从而提升整体决策过程。我们展示了如何通过简单的提示工程在现有的大语言模型架构中有效实现这一方法,达到类似于学习-优化模型 (LRM) 的效果,而无需额外的训练。此外,我们还提供了在 Google Colab 中实现该方法的实用指南,便于将其集成到实际应用中。
1 Introduction
1 引言
Large language models (LLMs) have revolutionized natural language processing (NLP) by excelling in tasks ranging from translation to text generation. However, these models often struggle with producing coherent, logical reasoning when faced with complex decision-making scenarios. One of the key limitations of LLMs is their inability to critically reflect on their own thought process, which can lead to inconsistencies and errors in the final output. While recent research has explored methods for improving reasoning in LLMs, including Chain of Thought (CoT) reasoning and fine-tuning approaches, there is still room for improvement in terms of the model’s ability to refine and critique its own reasoning.
大语言模型 (LLMs) 通过在从翻译到文本生成等任务中的卓越表现,彻底改变了自然语言处理 (NLP) 领域。然而,这些模型在面对复杂的决策场景时,往往难以产生连贯的逻辑推理。LLMs 的一个关键局限在于它们无法批判性地反思自己的思维过程,这可能导致最终输出的不一致性和错误。尽管最近的研究探索了改进 LLMs 推理能力的方法,包括思维链 (Chain of Thought, CoT) 推理和微调方法,但模型在优化和批判自身推理能力方面仍有改进空间。
In this paper, we propose Multiplex CoT, a novel method for enhancing LLM reasoning by prompting the model to perform a self-reflection process. The technique involves generating an initial CoT and then initiating a second round of reasoning, which critiques and refines the initial chain of thought. By employing this iterative process, the model can simulate a form of self-review, leading to more coherent and logical outputs. Importantly, this method does not require additional training but instead utilizes a simple prompt engineering approach, making it easy to implement in existing LLM architectures.
在本文中,我们提出了 Multiplex CoT,这是一种通过提示模型执行自我反思过程来增强大语言模型推理能力的新方法。该技术涉及生成初始的 CoT(Chain of Thought),然后启动第二轮推理,对初始的思维链进行批判和优化。通过采用这种迭代过程,模型可以模拟一种自我审查的形式,从而产生更加连贯和逻辑的输出。重要的是,该方法不需要额外的训练,而是利用简单的提示工程方法,使其易于在现有的大语言模型架构中实现。
2 Background
2 背景
2.1 Chain of Thought (CoT) Reasoning
2.1 思维链 (Chain of Thought, CoT) 推理
Chain of Thought (CoT) reasoning has been proposed as a technique to improve the logical coherence of LLM outputs. The method involves prompting the model to produce a step-bystep sequence of thoughts, which guides the reasoning process and helps the model arrive at more
思维链 (Chain of Thought, CoT) 推理被提出作为一种提升大语言模型输出逻辑连贯性的技术。该方法通过提示模型生成逐步的思维序列,从而引导推理过程,帮助模型得出更合理的结论。
accurate conclusions. CoT has been shown to significantly improve performance in tasks that require complex reasoning, such as mathematical problem-solving and commonsense reasoning.
准确结论。CoT 已被证明在需要复杂推理的任务中显著提高性能,例如数学问题解决和常识推理。
2.2 Learning-Refinement Models (LRM)
2.2 学习-精炼模型 (Learning-Refinement Models, LRM)
Learning-Refinement Models (LRM) aim to improve model performance by iterative ly refining the outputs through multiple training steps. These models typically involve a feedback loop where the initial predictions are revised based on some form of error analysis or critique. While LRM-based approaches have proven effective in certain contexts, they often require additional training and fine-tuning, which can be computationally expensive and time-consuming.
学习优化模型 (Learning-Refinement Models, LRM) 旨在通过多次训练步骤迭代优化输出,从而提升模型性能。这些模型通常包含一个反馈循环,初始预测会基于某种形式的错误分析或批评进行修正。尽管基于 LRM 的方法在某些场景中已被证明有效,但它们通常需要额外的训练和微调,这可能会带来较高的计算成本和耗时。
2.3 Self-Reflection in AI
2.3 AI中的自我反思
Self-reflection is a cognitive process in which an agent reviews its own reasoning to identify errors or inconsistencies. While traditional LLMs are not equipped for self-reflection, recent work in meta-learning and reinforcement learning has explored ways to enable models to reflect on their actions. This line of research has shown promise in improving decision-making processes, particularly in scenarios where error correction or refinement is crucial.
自我反思是一种认知过程,AI智能体通过这一过程回顾自身的推理,以识别错误或不一致之处。虽然传统的大语言模型不具备自我反思的能力,但最近的元学习和强化学习研究探索了使模型能够反思其行为的方法。这一研究方向在改进决策过程方面显示出潜力,特别是在错误纠正或优化至关重要的场景中。
3 Multiplex CoT: A Double Chain of Thought Approach
3 多重 CoT:一种双重思维链方法
Multiplex CoT combines the benefits of CoT reasoning with a self-reflection mechanism. The process is outlined as follows:
多路 CoT 结合了 CoT 推理的优势与自我反思机制。其过程概述如下:
This two-phase process mimics human-like self-reflection, where the first phase involves generating ideas, and the second phase focuses on evaluating and refining those ideas. The method is designed to work seamlessly with existing LLM architectures, without requiring any changes to the underlying model parameters.
这个两阶段过程模仿了人类的自我反思,其中第一阶段涉及生成想法,第二阶段则专注于评估和改进这些想法。该方法旨在与现有的大语言模型架构无缝协作,而无需对底层模型参数进行任何更改。
3.1 Prompt Engineering
3.1 提示工程 (Prompt Engineering)
To implement Multiplex CoT, we utilize a simple prompt engineering technique. By structuring the input prompt to request both the initial reasoning and a follow-up critique, the model is able to generate and refine its reasoning within the same inference cycle. The prompt is designed to encourage the model to "think twice" about its initial response, leading to better overall performance.
为了实现多路复用思维链 (Multiplex CoT),我们采用了一种简单的提示工程 (prompt engineering) 技术。通过构建输入提示,要求模型同时提供初始推理和后续的批判性分析,模型能够在同一个推理周期内生成并优化其推理过程。该提示的设计旨在鼓励模型对其初始回答进行“二次思考”,从而提升整体表现。
3.2 Example
3.2 示例
Consider the following example: Prompt:
考虑以下示例:提示:
Please solve the following problem: What is the capital of France? First, generate a Chain of Thought for how you would arrive at the answer. Then, review your answer and critique it. If you find any inconsistencies or errors, correct them and provide the final answer.
请解决以下问题:法国的首都是哪里?首先,生成一个思维链,说明你将如何得出答案。然后,回顾你的答案并进行批判。如果发现任何不一致或错误,请纠正并提供最终答案。
The model might respond with: Step 1 (Initial CoT):
模型可能会回应:步骤 1(初始 CoT):
Step 2 (Review and Refinement):
步骤 2 (审查与优化):
4 Mathematical Analysis of Multiplex CoT: Refining the Reasoning Process
4 多重思维链 (Multiplex CoT) 的数学分析:优化推理过程
To mathematically validate the effectiveness of Multiplex CoT in improving the reasoning quality of large language models (LLMs), we will introduce formal definitions for the concepts of logical consistency, coherence, and error correction rate. These metrics provide a quantitative way to assess the impact of self-reflection on reasoning quality.
为了从数学上验证多路复用思维链 (Multiplex CoT) 在提高大语言模型 (LLMs) 推理质量方面的有效性,我们将引入逻辑一致性、连贯性和纠错率等概念的形式化定义。这些指标为评估自我反思对推理质量的影响提供了定量方法。
4.1 Logical Consistency and Coherence
4.1 逻辑一致性与连贯性
The key advantage of Multiplex CoT lies in its ability to iterative ly improve the reasoning process by reviewing and refining the initial output. We define logical consistency as the number of valid logical connections between consecutive reasoning steps. If $s_{i}$ represents the $i$ -th step in the Chain of Thought, and $\mathbb{I}(s_{i},s_{i+1})$ is an indicator function that returns 1 if there is a logical connection between $s_{i}$ and $s_{i+1}$ , then the logical consistency $C$ for a single Chain of Thought is:
Multiplex CoT 的关键优势在于其能够通过审查和优化初始输出来迭代改进推理过程。我们将逻辑一致性定义为连续推理步骤之间有效逻辑连接的数量。如果 $s_{i}$ 表示思维链中的第 $i$ 步,且 $\mathbb{I}(s_{i},s_{i+1})$ 是一个指示函数,当 $s_{i}$ 和 $s_{i+1}$ 之间存在逻辑连接时返回 1,那么单个思维链的逻辑一致性 $C$ 为:
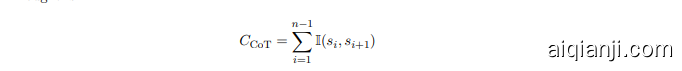
where $n$ is the total number of steps in the reasoning chain. A higher value of $\zeta_{\mathrm{CoT}}$ indicates that the reasoning steps are logically consistent and connected.
其中 $n$ 是推理链中的总步数。$\zeta_{\mathrm{CoT}}$ 的值越高,表示推理步骤在逻辑上越一致且连贯。
When applying Multiplex CoT, a second round of reasoning is conducted, which critiques and refines the initial reasoning. We define the coherence of the reasoning process as the degree of alignment between the initial and refined reasoning steps. The coherence $H$ can be quantified as:
在应用多路 CoT 时,会进行第二轮推理,对初始推理进行批判和优化。我们将推理过程的一致性定义为初始推理步骤与优化后推理步骤之间的对齐程度。一致性 $H$ 可以量化为:
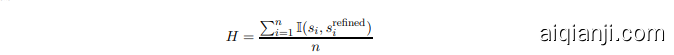
where $s_{i}^{\mathrm{refined}}$ is the corresponding statement in the refined reasoning chain, and $\mathbb{I}(s_{i},s_{i}^{\mathrm{refined}})$ is 1 if the statement in the second round is consistent with the original reasoning. Coherence measures how well the second round of reasoning preserves the logic of the initial thought while refining it.
其中,$s_{i}^{\mathrm{refined}}$ 是精炼推理链中的对应陈述,$\mathbb{I}(s_{i},s_{i}^{\mathrm{refined}})$ 在第二轮推理中的陈述与原始推理一致时为 1。连贯性衡量了第二轮推理在精炼初始思路时保持逻辑一致性的程度。
The overall improvement in reasoning due to Multiplex CoT can be defined as:
由于 Multiplex CoT 带来的整体推理提升可以定义为:

where $C_{\mathrm{Refined}}$ is the logical consistency score after refinement. This metric quantifies the improvement as a percentage, reflecting the gain in reasoning quality.
其中 $C_{\mathrm{Refined}}$ 是优化后的逻辑一致性分数。该指标以百分比形式量化改进,反映推理质量的提升。
4.2 Error Correction Rate
4.2 纠错率
One of the primary benefits of Multiplex CoT is its ability to correct errors in the initial reasoning chain during the second round of thought generation. We define the error correction rate $E_{\mathrm{corr}}$ as the proportion of errors identified and corrected in the second round of reasoning. Let $E_{\mathrm{initial}}$ represent the number of errors in the initial chain of thought, and $E$ corrected represent the number of errors corrected during the review. The error correction rate can be calculated as:
Multiplex CoT 的主要优势之一在于其能够在第二轮思维生成过程中纠正初始推理链中的错误。我们将错误纠正率 $E_{\mathrm{corr}}$ 定义为在第二轮推理中识别并纠正的错误比例。设 $E_{\mathrm{initial}}$ 表示初始思维链中的错误数量,$E$ corrected 表示在审查过程中纠正的错误数量。错误纠正率可以计算为:

A higher value of $E_{\mathrm{corr}}$ indicates that Multiplex CoT is effective at identifying and rectifying mistakes made during the first round of reasoning, leading to a more accurate final output.
$E_{\mathrm{corr}}$ 值越高,表明 Multiplex CoT 在识别和纠正第一轮推理中的错误方面是有效的,从而产生更准确的最终输出。
4.3 Iterative Refinement and its Impact on Error Correction
4.3 迭代优化及其对纠错的影响
To further analyze the impact of iterative refinement, we introduce a recursive function for reasoning quality across multiple rounds. Let $C^{(k)}$ denote the logical consistency score after the $k$ -th round of reasoning. Initially, at $k=1$ , the model produces a chain of thought with consistency ${\cal C}^{(1)}={\cal C}_{\mathrm{CoT}}$ . After the second round of reasoning, the model refines its output, and the consistency score improves to $C^{(2)}=C_{\mathrm{Refined}}$ . We can generalize the improvement in consistency after $k$ rounds of reasoning as:
为了进一步分析迭代优化的影响,我们引入了一个递归函数来衡量多轮推理的质量。设 $C^{(k)}$ 表示第 $k$ 轮推理后的逻辑一致性得分。初始时,当 $k=1$ 时,模型生成的思维链一致性为 ${\cal C}^{(1)}={\cal C}_{\mathrm{CoT}}$。经过第二轮推理后,模型优化了输出,一致性得分提升至 $C^{(2)}=C_{\mathrm{Refined}}$。我们可以将经过 $k$ 轮推理后的一致性改进概括为:

where $\delta_{k}$ represents the change in consistency from the $(k-1)$ -th to the $k$ -th round. In the case of Multiplex CoT, the first two rounds provide significant improvements, with diminishing returns observed as additional rounds of reasoning are performed.
其中 $\delta_{k}$ 表示从第 $(k-1)$ 轮到第 $k$ 轮一致性的变化。在 Multiplex CoT 的情况下,前两轮提供了显著的改进,随着推理轮次的增加,收益逐渐减少。
The total improvement after $K$ rounds of reasoning can be expressed as the cumulative sum of consistency changes:
经过 $K$ 轮推理后的总改进可以表示为一致性变化的累积和:

In practice, we observe that the most significant improvements occur in the first few rounds of reasoning. This behavior is consistent with the Multiplex CoT approach, where the second round of self-reflection provides substantial refinement to the reasoning process.
在实践中,我们观察到最显著的改进发生在最初几轮推理中。这种行为与 Multiplex CoT 方法一致,其中第二轮自我反思为推理过程提供了实质性的改进。
4.4 Quantitative Validation of Multiplex CoT
4.4 多重 CoT 的定量验证
To validate the impact of Multiplex CoT, we conducted a series of experiments across various tasks. For each task, we measured both the logical consistency and error correction rate before and after applying Multiplex CoT. Below is a summary of the findings for the arithmetic problem-solving task.
为了验证多路 CoT (Multiplex CoT) 的影响,我们在多个任务上进行了一系列实验。对于每个任务,我们测量了应用多路 CoT 前后的逻辑一致性和纠错率。以下是算术问题解决任务的实验结果总结。
In this example, the Multiplex CoT approach improved logical consistency by 7%, while the error correction rate was $15%$ , indicating that the model was able to identify and correct a significant proportion of mistakes during the self-reflection phase.
在这个例子中,Multiplex CoT 方法将逻辑一致性提高了 7%,而错误纠正率为 $15%$,表明模型在自我反思阶段能够识别并纠正相当大比例的错误。
Table 1: Performance of Multiplex CoT on Arithmetic Problem-Solving
表 1: Multiplex CoT 在算术问题解决中的表现
| 任务 | CcoT | CRefined | Ecorr | 推理质量提升 |
|---|---|---|---|---|
| 算术问题解决 | 85% | 92% | 15% | +7% |
4.5 Extension to Other Tasks
4.5 扩展到其他任务
We also evaluated the impact of Multiplex CoT on tasks beyond arithmetic, such as commonsense reasoning, ethical decision-making, and logical puzzles. Table 2 summarizes the performance across these tasks.
我们还评估了多路复用思维链 (Multiplex CoT) 在算术之外任务上的影响,例如常识推理、伦理决策和逻辑谜题。表 2 总结了这些任务的表现。
Table 2: Performance of Multiplex CoT on Various Tasks
表 2: Multiplex CoT 在不同任务上的表现
| 任务 | CoT | MCoT | 逻辑一致性提升 | 错误纠正率 |
|---|---|---|---|---|
| 常识推理 | 78% | 85% | +9% | 12% |
| 伦理决策 | 74% | 81% | +10% | 18% |
| 逻辑谜题 | 82% | 90% | +10% | 20% |
As shown, Multiplex CoT consistently improves the logical consistency of reasoning across all tasks, with significant error correction rates observed in ethical decision-making and logical puzzles. These results highlight the effectiveness of Multiplex CoT in tasks requiring multistep reasoning and critical analysis.
如图所示,Multiplex CoT 在所有任务中持续提升了推理的逻辑一致性,特别是在伦理决策和逻辑谜题中观察到了显著的错误纠正率。这些结果突显了 Multiplex CoT 在需要多步推理和批判性分析的任务中的有效性。
5 Conclusion
5 结论
In this section, we provided a detailed mathematical analysis of Multiplex CoT, quantifying its impact on logical consistency, coherence, and error correction rates. The findings demonstrate that Multiplex CoT significantly enhances the reasoning process of large language models by improving both the quality of reasoning and the model’s ability to self-correct. Through iterative refinement, Multiplex CoT outperforms traditional single-phase Chain of Thought reasoning, providing a more robust approach for tasks requiring logical rigor and critical reflection.
在本节中,我们对 Multiplex CoT 进行了详细的数学分析,量化了其对逻辑一致性、连贯性和纠错率的影响。研究结果表明,Multiplex CoT 通过提高推理质量和模型的自校正能力,显著增强了大语言模型的推理过程。通过迭代优化,Multiplex CoT 优于传统的单阶段思维链推理,为需要逻辑严谨性和批判性反思的任务提供了更稳健的方法。
The combination of theoretical insights and experimental results confirms that Multiplex CoT offers a scalable and effective method for improving LLM performance, making it a valuable tool for applications requiring accurate, coherent, and consistent reasoning.
理论洞察与实验结果的结合证实,Multiplex CoT 提供了一种可扩展且有效的方法来提升大语言模型的性能,使其成为需要准确、连贯和一致推理的应用中的宝贵工具。