Squeeze BERT: What can computer vision teach NLP about efficient neural networks?
Squeeze BERT:计算机视觉能为 NLP 提供哪些关于高效神经网络的启示?
Abstract
摘要
Humans read and write hundreds of billions of messages every day. Further, due to the availability of large datasets, large computing systems, and better neural network models, natural language processing (NLP) technology has made significant strides in understanding, proofreading, and organizing these messages. Thus, there is a significant opportunity to deploy NLP in myriad applications to help web users, social networks, and businesses. In particular, we consider smartphones and other mobile devices as crucial platforms for deploying NLP models at scale. However, today’s highly-accurate NLP neural network models such as BERT and RoBERTa are extremely computationally expensive, with BERT-base taking 1.7 seconds to classify a text snippet on a Pixel 3 smartphone. In this work, we observe that methods such as grouped convolutions have yielded significant speedups for computer vision networks, but many of these techniques have not been adopted by NLP neural network designers. We demonstrate how to replace several operations in self-attention layers with grouped convolutions, and we use this technique in a novel network architecture called Squeeze BERT, which runs $4.3\mathbf{X}$ faster than BERT-base on the Pixel 3 while achieving competitive accuracy on the GLUE test set. The Squeeze BERT code will be released.
人类每天阅读和书写数千亿条消息。此外,由于大规模数据集、大型计算系统和更好的神经网络模型的可用性,自然语言处理(NLP)技术在理解、校对和组织这些消息方面取得了显著进展。因此,在众多应用中部署 NLP 技术以帮助网络用户、社交网络和企业具有巨大的机会。特别是,我们认为智能手机和其他移动设备是规模化部署 NLP 模型的关键平台。然而,当今高度准确的 NLP 神经网络模型(如 BERT 和 RoBERTa)计算成本极高,BERT-base 在 Pixel 3 智能手机上分类一段文本需要 1.7 秒。在这项工作中,我们观察到诸如分组卷积等方法在计算机视觉网络中带来了显著的加速,但许多这些技术尚未被 NLP 神经网络设计者采用。我们展示了如何用分组卷积替换自注意力层中的多个操作,并将这一技术应用于一种名为 Squeeze BERT 的新型网络架构中,该架构在 Pixel 3 上比 BERT-base 快 $4.3\mathbf{X}$,同时在 GLUE 测试集上实现了具有竞争力的准确性。Squeeze BERT 代码将公开发布。
1 Introduction and Motivation
1 引言与动机
The human race writes over 300 billion messages per day [1, 2, 3, 4]. Out of these, more than half of the world’s emails are read on mobile devices, and nearly half of Facebook users exclusively access Facebook from a mobile device [5, 6]. Natural language processing (NLP) technology has the potential to aid these users and communities in several ways. When a person writes a message, NLP models can help with spelling and grammar checking as well as sentence completion. When content is added to a social network, NLP can facilitate content moderation before it appears in other users’ news feeds. When a person consumes messages, NLP models can help classify messages into folders, composing news feeds, prioritizing messages, and identifying duplicate messages.
人类每天撰写超过3000亿条消息 [1, 2, 3, 4]。其中,全球超过一半的电子邮件是在移动设备上阅读的,近一半的Facebook用户仅通过移动设备访问Facebook [5, 6]。自然语言处理 (Natural Language Processing, NLP) 技术有潜力以多种方式帮助这些用户和社区。当一个人撰写消息时,NLP模型可以帮助进行拼写和语法检查以及句子补全。当内容被添加到社交网络时,NLP可以在内容出现在其他用户的新闻推送之前进行内容审核。当一个人消费消息时,NLP模型可以帮助将消息分类到文件夹中,组成新闻推送,优先处理消息,并识别重复消息。
In recent years, the development and adoption of Attention Neural Networks has led to dramatic improvements in almost every area of NLP. In 2017, Vaswani et al. proposed the multi-head selfattention module, which demonstrated superior accuracy to recurrent neural networks on EnglishGerman machine language translation [7].1 These modules have since been adopted by GPT [8] and BERT [9] for sentence classification, and by GPT-2 [10] and CTRL [11] for sentence completion and generation. Recent works such as ELECTRA [12] and RoBERTa [13] have shown that larger datasets and more sophisticated training regimes can further improve the accuracy of self-attention networks.
近年来,注意力神经网络 (Attention Neural Networks) 的发展和应用几乎在自然语言处理 (NLP) 的每个领域都带来了显著的改进。2017 年,Vaswani 等人提出了多头自注意力模块 (multi-head self-attention module),在英德机器翻译任务中展示了比循环神经网络更高的准确性 [7]。这些模块随后被 GPT [8] 和 BERT [9] 用于句子分类,并被 GPT-2 [10] 和 CTRL [11] 用于句子补全和生成。最近的研究如 ELECTRA [12] 和 RoBERTa [13] 表明,更大的数据集和更复杂的训练机制可以进一步提高自注意力网络的准确性。
Considering the enormity of the textual data created by humans on mobile devices, a natural approach is to deploy NLP models themselves on the mobile devices themselves, embedding them in common apps that are used to read, write, and share text. Unfortunately, many of today’s best state-of-the-art NLP models may are often rather computationally expensive, often making mobile deployment impractical. For example, we observe that running the BERT-base network on a Google Pixel 3 smartphone approximately 1.7 seconds to classify a single text data sample.2 Much of the research on efficient self-attention networks for NLP has just emerged in the past year. However, starting with SqueezeNet [14], the mobile computer vision (CV) community has spent the last four years optimizing neural networks for mobile devices. Intuitively, it seems like there must be opport unities to apply the lessons learned from the rich literature of mobile CV research to accelerate mobile NLP. In the following we review what has already been applied and propose two additional techniques from CV that we will leverage for accelerating NLP.
考虑到人类在移动设备上创建的文本数据的庞大性,一个自然的方法是将 NLP 模型本身部署在移动设备上,并将其嵌入到用于阅读、写入和分享文本的常见应用中。不幸的是,当今许多最先进的 NLP 模型在计算上往往非常昂贵,通常使得移动部署变得不切实际。例如,我们观察到在 Google Pixel 3 智能手机上运行 BERT-base 网络大约需要 1.7 秒来分类单个文本数据样本。2 许多关于高效自注意力网络的研究在过去一年才出现。然而,从 SqueezeNet [14] 开始,移动计算机视觉 (CV) 社区在过去四年中一直在优化用于移动设备的神经网络。直觉上,似乎有机会将从丰富的移动 CV 研究文献中学到的经验应用于加速移动 NLP。接下来,我们将回顾已经应用的技术,并提出两种来自 CV 的额外技术,我们将利用这些技术来加速 NLP。
1.1 What has CV research already taught NLP research about efficient networks?
1.1 计算机视觉研究已经为自然语言处理研究提供了哪些关于高效网络的启示?
In recent months, novel self-attention networks have been developed with the goal of achieving faster inference. At present, the MobileBERT network defines the state-of-the-art in low-latency text classification for mobile devices [15]. MobileBERT takes approximately 0.6 seconds to classify a text sequence on a Google Pixel 3 smartphone. And, on the GLUE benchmark, which consists of 9 natural language understanding (NLU) datasets [16], MobileBERT achieves higher accuracy than other efficient networks such as DistilBERT [17], PKD [18], and several others [19, 20, 21, 22]. To achieve this, MobileBERT introduced two concepts into their NLP self-attention network that are already in widespread use in CV neural networks:
近几个月来,新型的自注意力网络(self-attention networks)被开发出来,旨在实现更快的推理速度。目前,MobileBERT网络在移动设备的低延迟文本分类领域定义了最先进的技术 [15]。在Google Pixel 3智能手机上,MobileBERT大约需要0.6秒来分类一个文本序列。此外,在由9个自然语言理解(NLU)数据集组成的GLUE基准测试中 [16],MobileBERT的准确率高于其他高效网络,如DistilBERT [17]、PKD [18] 以及其他几个网络 [19, 20, 21, 22]。为了实现这一点,MobileBERT在其NLP自注意力网络中引入了两个已经在计算机视觉(CV)神经网络中广泛使用的概念:
1.2 What else can CV research teach NLP research about efficient networks?
1.2 计算机视觉研究还能为大语言模型研究提供哪些关于高效网络的启示?
We are encouraged by the progress that MobileBERT has made in leveraging ideas that are popular in the CV literature to accelerate NLP.
我们对于 MobileBERT 在利用计算机视觉 (CV) 文献中流行的思想来加速自然语言处理 (NLP) 方面取得的进展感到鼓舞。
However, we are aware of two other ideas from CV, which weren’t used in MobileBERT, and that could be applied to accelerate NLP:
然而,我们注意到计算机视觉 (CV) 领域还有两个未被 MobileBERT 使用的想法,这些想法可以应用于加速自然语言处理 (NLP):
1.3 Squeeze BERT: Applying lessons learned from CV to NLP
1.3 Squeeze BERT:将计算机视觉的经验应用于自然语言处理
In this work, we describe how to apply convolutions and particularly grouped convolutions in the design of a novel self-attention network for NLP, which we call Squeeze BERT. Empirically, we
在本工作中,我们描述了如何在设计一种新型的自注意力网络(我们称之为 Squeeze BERT)中应用卷积,特别是分组卷积,用于自然语言处理(NLP)。
Table 1: How does BERT spend its time? This is a breakdown of computation (in floating-point operations, or FLOPs) and latency (on a Google Pixel 3 smartphone) in BERT-base, reported to three significant digits. The FC layers account for more than $97%$ of the FLOPs and over $88%$ of the latency.
表 1: BERT 的时间花在哪里?这是 BERT-base 中计算量(以浮点运算次数,即 FLOPs 为单位)和延迟(在 Google Pixel 3 智能手机上)的详细分解,数据保留三位有效数字。全连接层 (FC layers) 占据了超过 97% 的计算量和超过 88% 的延迟。
| 阶段 | 模块类型 | 计算量 (FLOPs) / 延迟 |
|---|---|---|
| 嵌入 | 嵌入 | 0.00% / 0.26% |
| 编码器 | 自注意力模块中的全连接层 | 24.3% / 18.9% |
| 编码器 | 自注意力模块中的 softmax | 2.70% / 11.3% |
| 编码器 | 前馈网络层中的全连接层 | 73.0% / 69.4% |
| 最终分类器 | 最终分类器中的全连接层 | 0.00% / 0.02% |
| 总计 | 100% / 100% |
find that Squeeze BERT runs at lower latency on a smartphone than BERT-base, MobileBERT, and several other efficient NLP models, while maintaining competitive accuracy.
我们发现,Squeeze BERT 在智能手机上的延迟低于 BERT-base、MobileBERT 和其他几种高效的自然语言处理 (NLP) 模型,同时保持了具有竞争力的准确性。
2 Implementing self-attention with convolutions
2 使用卷积实现自注意力 (Self-Attention)
In this section, first we review the basic structure of self-attention networks, next we identify that their biggest computational bottleneck is in their position-wise fully-connected (PFC) layers, and then we show that these PFC layers are equivalent to a 1D convolution with a kernel size of 1.
在本节中,首先我们回顾了自注意力网络的基本结构,接着指出其最大的计算瓶颈在于逐位置的全连接层 (PFC),然后我们证明这些 PFC 层等价于核大小为 1 的一维卷积。
2.1 Self-attention networks
2.1 自注意力网络
In most BERT-derived networks there are typically 3 stages: the embedding, the encoder, and the classifier [9, 13, 12, 15, 19]. 3 The embedding converts pre processed words (represented as integervalued tokens) into learned feature-vectors of floating-point numbers; the encoder is comprised of a series of self-attention and other layers; and the classifier produces the network’s final output. As we will see later in Table 1, the embedding and the classifier account for less than $1%$ of the runtime of a self-attention network, so we focus our discussion on the encoder.
在大多数基于 BERT 的网络中,通常有 3 个阶段:嵌入 (embedding)、编码器 (encoder) 和分类器 (classifier) [9, 13, 12, 15, 19]。嵌入将预处理后的单词(表示为整数值的 Token)转换为学习到的浮点数特征向量;编码器由一系列自注意力 (self-attention) 层和其他层组成;分类器生成网络的最终输出。正如我们稍后将在表 1 中看到的,嵌入和分类器占自注意力网络运行时间的不到 $1%$,因此我们将讨论重点放在编码器上。
We now describe the encoder that is used in BERT-base [9]. The encoder consists of a stack of blocks. Each block consists of a self-attention module followed by three position-wise fully-connected layers, known as feed-forward network (FFN) layers. Each self-attention module contains three seperate position-wise fully-connected (PFC) layers, which are used to generate the query $(Q)$ , key $(K)$ , and value $(V)$ activation vectors for each position in the feature embedding. Each of these PFC layers in self-attention applies the same operation to each position in the feature embedding independently. While neural networks traditionally multiply weights by activation s, a distinguishing factor of attention neural networks is that they multiply activation s by other activation s, which enables dynamic weighting of tensor elements to adjust based on the input data. Further, attention networks allow modeling of arbitrary dependencies irregardless of their distance in the input or output [7]. The self-attention module proposed by Vaswani et al. [7] (which is also used by GPT [8], BERT [9], RoBERTa [13], ELECTRA [12] and others) multiplies the $Q,K$ , and $V$ activation s together using the equation $\begin{array}{r}{s o f t m a x(\frac{Q K^{T}}{\sqrt{d_{k}}})V}\end{array}$ , where $d_{k}$ is the number of channels in one attention head.4
我们现在描述BERT-base [9]中使用的编码器。编码器由一系列块组成。每个块由一个自注意力模块和三个位置全连接层(称为前馈网络(FFN)层)组成。每个自注意力模块包含三个独立的位置全连接(PFC)层,用于为特征嵌入中的每个位置生成查询 $(Q)$、键 $(K)$ 和值 $(V)$ 激活向量。自注意力中的每个PFC层独立地对特征嵌入中的每个位置应用相同的操作。虽然传统神经网络将权重乘以激活,但注意力神经网络的一个显著特点是它们将激活乘以其他激活,这使得张量元素能够根据输入数据进行动态加权调整。此外,注意力网络允许对任意依赖关系进行建模,而不管它们在输入或输出中的距离如何 [7]。Vaswani等人 [7] 提出的自注意力模块(也被GPT [8]、BERT [9]、RoBERTa [13]、ELECTRA [12] 等使用)使用公式 $\begin{array}{r}{s o f t m a x(\frac{Q K^{T}}{\sqrt{d_{k}}})V}\end{array}$ 将 $Q,K$ 和 $V$ 激活相乘,其中 $d_{k}$ 是一个注意力头中的通道数。
2.2 Benchmarking BERT for mobile inference
2.2 移动设备推理中的 BERT 基准测试
To identify the parts of BERT that are time-consuming to compute, we profile BERT on a smartphone. Specifically, we measure the neural network’s latency using PyTorch [34] and Torch Script on a Google Pixel 3 smartphone, with an input sequence length of 128 and a batch size of 1. In Table 1, we show the breakdown of FLOPs and latency among the main components of the BERT network, and we observe that the $\begin{array}{r}{s o f t m a x(\frac{Q K^{T}}{\sqrt{d_{k}}})V}\end{array}$ calculations in the self-attention modules account for only 11.3 percent of the total latency. However, the PFC layers in the self-attention modules account for 18.9 percent, and the PFC layers in the feed-forward network modules account for 69.4 percent, and in total the PFC layers account for 88.3 percent of the latency. Given that the PFC layers account for the overwhelming majority of the latency, we now turn our focus to reducing the latency of the PFC layers.
为了识别BERT中计算耗时的部分,我们在智能手机上对BERT进行了性能分析。具体来说,我们使用PyTorch [34] 和 Torch Script在Google Pixel 3智能手机上测量了神经网络的延迟,输入序列长度为128,批量大小为1。在表1中,我们展示了BERT网络主要组件的FLOPs和延迟的分解情况,并观察到自注意力模块中的$\begin{array}{r}{s o f t m a x(\frac{Q K^{T}}{\sqrt{d_{k}}})V}\end{array}$计算仅占总延迟的11.3%。然而,自注意力模块中的PFC层占18.9%,前馈网络模块中的PFC层占69.4%,总计PFC层占延迟的88.3%。鉴于PFC层占据了绝大部分的延迟,我们现在将重点放在减少PFC层的延迟上。
2.3 Replacing the position-wise fully connected layers (PFC) with convolutions
2.3 使用卷积替换位置全连接层 (PFC)
To address this, we intend to replace the PFC layers with grouped convolutions, which have been shown to produce significant speedups in computer vision networks. As a first step in this direction, we now show that the fully-connected layers used throughout the BERT encoder are a special case of non-grouped 1D convolution. In the following, $f$ denotes the input feature vector, and $w$ denotes the weights. Given an input feature vector of dimensions $(P,C_{i n})$ with $P$ positions and $C_{i n}$ channels to generate an output of $(P,C_{o u t})$ features, the operation performed by the position-wise fullyconnected layer can be defined as follows:
为了解决这个问题,我们打算用分组卷积(grouped convolutions)替换 PFC 层,这种方法已被证明可以显著加速计算机视觉网络。作为这一方向的第一步,我们现在展示 BERT 编码器中使用的全连接层是非分组 1D 卷积的一种特殊情况。在下文中,$f$ 表示输入特征向量,$w$ 表示权重。给定一个维度为 $(P,C_{i n})$ 的输入特征向量,其中 $P$ 表示位置数,$C_{i n}$ 表示通道数,生成 $(P,C_{o u t})$ 维的输出特征,位置全连接层执行的操作可以定义如下:
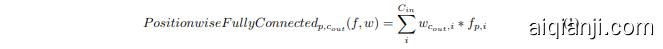
Then if we consider the definition of a 1D convolution with kernel size $K$ with the same input and output dimensions
如果我们考虑核大小为 $K$ 的一维卷积的定义,且输入和输出维度相同

we observe that the position-wise fully-connected operation is equivalent to a convolution with a kernel size of $k=1$ . Thus, the PFC layers of Vaswani et al. [7], GPT, BERT, and similar self-attention networks can be implemented using convolutions without changing the networks’ numerical properties or behavior.
我们观察到,逐位置全连接操作等价于核大小为 $k=1$ 的卷积。因此,Vaswani 等人 [7]、GPT、BERT 以及类似的自注意力网络中的 PFC 层可以使用卷积实现,而不会改变网络的数值属性或行为。
3 Incorporating grouped convolutions into self-attention
3 将分组卷积引入自注意力机制
Now that we have shown how to implement the expensive PFC layers in self-attention networks using convolutions, we can incorporate efficient grouped convolutions into a self-attention network. Grouped convolutions are defined as follows. Given an input feature vector of dimensions $(P,C_{i n})$ with $\mathrm{P}$ positions and $C_{i n}$ channels and outputting a vector with dimensions $(P,C_{o u t})$ , a 1d convolution with kernel size $K$ and $G$ groups can be defined as follows.
既然我们已经展示了如何使用卷积在自注意力网络中实现昂贵的 PFC 层,那么我们可以将高效的分组卷积引入自注意力网络。分组卷积定义如下。给定一个维度为 $(P,C_{i n})$ 的输入特征向量,其中 $\mathrm{P}$ 表示位置,$C_{i n}$ 表示通道数,并输出一个维度为 $(P,C_{o u t})$ 的向量,核大小为 $K$ 且分组数为 $G$ 的一维卷积可以定义如下。

This is equivalent to splitting the the input vector into $G$ separate vectors of size $\begin{array}{r}{(P,\frac{C_{i n}}{G})}\end{array}$ along the $P$ dimension and running $G$ separate convolutions with independent weights each computing vectors of size $\begin{array}{r}{(P,\frac{C_{o u t}}{G})}\end{array}$ . The grouped convolution, however, requires only $\textstyle{\frac{1}{G}}$ as many floating point operations (FLOPs) and $\textstyle{\frac{1}{G}}$ as many weights as an ordinary convolution, not counting the small (and unchanged) amount of operations needed for the channel-wise bias term that is often included in convolutional layers.5
这相当于将输入向量沿 $P$ 维度分割为 $G$ 个大小为 $\begin{array}{r}{(P,\frac{C_{i n}}{G})}\end{array}$ 的独立向量,并运行 $G$ 个独立的卷积,每个卷积使用独立的权重计算大小为 $\begin{array}{r}{(P,\frac{C_{o u t}}{G})}\end{array}$ 的向量。然而,分组卷积仅需要普通卷积的 $\textstyle{\frac{1}{G}}$ 浮点运算 (FLOPs) 和 $\textstyle{\frac{1}{G}}$ 权重,不包括卷积层中通常包含的通道偏置项所需的小量(且不变的)操作。
3.1 Squeeze BERT
3.1 Squeeze BERT
Now, we describe our proposed neural architecture called Squeeze BERT, which uses grouped convolutions. Squeeze BERT is much like BERT-base, but with PFC layers implemented as convolutions, and grouped convolutions for many of the layers. Recall from Section 2 that each block in the BERT-base encoder has a self-attention module with 3 PFC layers, plus 3 more PFC layers called feed-forward network layers $\mathrm{(FFN_{1}}$ , $\mathrm{FFN_{2}}$ , and $\mathrm{FFN_{3}}$ ). The FFN layers have the following dimensions: $\mathrm{FFN_{1}}$ has $C_{i n}=C_{o u t}=768$ , $\mathrm{FFN_{2}}$ has $C_{i n}~=~768$ and $C_{o u t}=3072$ , and $\mathrm{FFN_{3}}$ has
现在,我们描述我们提出的名为 Squeeze BERT 的神经架构,该架构使用分组卷积。Squeeze BERT 与 BERT-base 非常相似,但将 PFC 层实现为卷积,并且许多层使用分组卷积。回顾第 2 节,BERT-base 编码器中的每个块都有一个带有 3 个 PFC 层的自注意力模块,以及另外 3 个称为前馈网络层的 PFC 层 (FFN1, FFN2, 和 FFN3)。FFN 层具有以下维度:FFN1 有 Cin=Cout=768,FFN2 有 Cin=768 和 Cout=3072,FFN3 有
$C_{i n}=3072$ and $C_{o u t}=768$ . In all PFC layers of the self-attention modules, and in the $\mathrm{FFN_{2}}$ and $\mathrm{FFN_{3}}$ layers, we use grouped convolutions with $G=4$ . To allow for mixing across channels of different groups, we use $G=1$ in the less-expensive $\mathrm{FFN_{1}}$ layers. Note that in BERT-base, $\mathrm{FFN_{2}}$ and $\mathrm{FFN_{3}}$ each have 4 times more arithmetic operations than $\mathrm{FFN_{1}}$ . However, when we use $G=4$ in $\mathrm{FFN_{2}}$ and $\mathrm{FFN_{3}}$ , now all FFN layers have the same number of arithmetic operations.
$C_{i n}=3072$ 和 $C_{o u t}=768$。在自注意力模块的所有 PFC 层中,以及在 $\mathrm{FFN_{2}}$ 和 $\mathrm{FFN_{3}}$ 层中,我们使用 $G=4$ 的分组卷积。为了允许不同组通道之间的混合,我们在计算量较少的 $\mathrm{FFN_{1}}$ 层中使用 $G=1$。需要注意的是,在 BERT-base 中,$\mathrm{FFN_{2}}$ 和 $\mathrm{FFN_{3}}$ 的算术操作次数分别是 $\mathrm{FFN_{1}}$ 的 4 倍。然而,当我们在 $\mathrm{FFN_{2}}$ 和 $\mathrm{FFN_{3}}$ 中使用 $G=4$ 时,现在所有 FFN 层的算术操作次数都相同。
Finally, the embedding size (768), the number of blocks in the encoder (12), the number of heads per self-attention module (12), the tokenizer (WordPiece [35, 36]), and other aspects of Squeeze BERT are adopted from BERT-base. Aside from the convolution-based implementation and the adoption of grouped convolutions, the Squeeze BERT architecture is identical to BERT-base.
最后,Squeeze BERT 的嵌入大小 (768)、编码器中的块数 (12)、每个自注意力模块的头数 (12)、分词器 (WordPiece [35, 36]) 以及其他方面均采用了 BERT-base 的配置。除了基于卷积的实现和分组卷积的采用外,Squeeze BERT 的架构与 BERT-base 完全相同。
4 Experimental Methodology
4 实验方法
4.1 Datasets
4.1 数据集
Pre training Data. For pre training, we use a combination of Wikipedia and Books Corpus [37], setting aside $3%$ of the combined dataset as a test set. Following the ALBERT paper, we use Masked Language Modeling (MLM) and Sentence Order Prediction (SOP) as pre training tasks [19].
预训练数据。对于预训练,我们使用了 Wikipedia 和 Books Corpus [37] 的组合,并将组合数据集的 $3%$ 留作测试集。遵循 ALBERT 论文,我们使用掩码语言建模 (Masked Language Modeling, MLM) 和句子顺序预测 (Sentence Order Prediction, SOP) 作为预训练任务 [19]。
Finetuning Data. We finetune and evaluate Squeeze BERT (and other baselines) on the General Language Understanding Evaluation (GLUE) set of tasks. This benchmark consists of a diverse set of 9 NLU tasks; thanks to the structure and breadth of these tasks (see supplementary material for detailed task-level information), GLUE has become the standard evaluation benchmark for NLP research. A model’s performance across the GLUE tasks likely provides a good approximation of that model’s general iz ability (esp. to other text classification tasks).
微调数据。我们在通用语言理解评估(GLUE)任务集上对Squeeze BERT(及其他基线模型)进行微调和评估。该基准测试包含9个多样化的自然语言理解(NLU)任务;得益于这些任务的结构和广度(详见补充材料中的任务级别详细信息),GLUE已成为NLP研究的标准评估基准。模型在GLUE任务上的表现很可能很好地反映了该模型的泛化能力(尤其是对其他文本分类任务)。
4.2 Training Methodology
4.2 训练方法
Many of the recent papers on efficient NLP networks report results on models trained with bells and whistles such as distillation, adversarial training, and/or transfer learning across GLUE tasks. However, there is no standardization of these training schemes across different papers, making it difficult to distinguish the contribution of the model from the contribution of the training scheme to the final accuracy number. Therefore, we first train Squeeze BERT using a simple training scheme (described in Section 4.2.1, with results reported in Section 5.1), and then we train Squeeze BERT with distillation and other techniques (described in Section 4.2.2, with results reported in Section 5.2).
许多最近关于高效 NLP 网络的论文报告了使用蒸馏、对抗训练和/或跨 GLUE 任务的迁移学习等技术训练的模型结果。然而,不同论文中这些训练方案没有标准化,使得难以区分模型本身和训练方案对最终准确率的贡献。因此,我们首先使用简单的训练方案训练 Squeeze BERT(在第 4.2.1 节中描述,结果在第 5.1 节中报告),然后使用蒸馏和其他技术训练 Squeeze BERT(在第 4.2.2 节中描述,结果在第 5.2 节中报告)。
4.2.1 Training without bells and whistles
4.2.1 无额外修饰的训练
We pretrain Squeeze BERT from scratch (without distillation) using the LAMB optimizer, and we employ the hyper parameters recommended by the LAMB authors: a global batch size of 8192, a learning rate of $2.5\mathrm{e}{\cdot}3$ , and a warmup proportion of 0.28 [38]. Following the LAMB paper’s recommendations, we pretrain for $56\mathrm{k}$ steps with a maximum sequence length of 128 and then for 6k steps with a maximum sequence length of 512.
我们使用 LAMB 优化器从头开始预训练 Squeeze BERT(不进行蒸馏),并采用了 LAMB 作者推荐的超参数:全局批量大小为 8192,学习率为 $2.5\mathrm{e}{\cdot}3$,预热比例为 0.28 [38]。根据 LAMB 论文的建议,我们首先以最大序列长度 128 预训练 $56\mathrm{k}$ 步,然后以最大序列长度 512 预训练 6k 步。
For finetuning, we use the AdamW optimizer with a batch size of 16 without momentum or weight decay with $\beta_{1}=0.9$ and $\beta_{2}=0.999$ [39]. As is common in the literature, during finetuning for each task, we perform hyper parameter tuning on the learning rate and dropout rate. We present more details on this in the supplementary material. In the interest of a fair comparison, we also train BERT-base using the aforementioned pre training and finetuning protocol.
对于微调,我们使用 AdamW 优化器,批量大小为 16,不使用动量或权重衰减,$\beta_{1}=0.9$ 和 $\beta_{2}=0.999$ [39]。正如文献中常见的那样,在针对每个任务进行微调时,我们对学习率和 dropout 率进行超参数调优。我们在补充材料中提供了更多详细信息。为了公平比较,我们还使用上述预训练和微调协议训练了 BERT-base。
4.2.2 Training with bells and whistles
4.2.2 带附加功能的训练
We now review recent techniques for improving the training of NLP networks, and we describe the approaches that we will use for the training and evaluation of Squeeze BERT in Section 5.2.
我们现在回顾最近用于改进自然语言处理(NLP)网络训练的技术,并描述我们将在第5.2节中用于训练和评估Squeeze BERT的方法。
Distillation approaches used in other efficient NLP networks. While the term "knowledge distillation" was coined by Hinton et al. to describe a specific method and equation [40], the term "distillation" is now used in reference to a diverse range of approaches where a "student" network is trained to replicate a "teacher" network. Some researchers distill only the final layer of the network [17], while others also distill the hidden layers [15, 18, 22]. When distilling the hidden layers, some apply layer-by-layer distillation warmup, where each module of the student network is distilled independently while downstream modules are frozen [15]. Some distill during pre training [15, 17], some distill during finetuning [22], and some do both [18, 21].
其他高效 NLP 网络中使用的蒸馏方法。虽然“知识蒸馏”这一术语是由 Hinton 等人提出的,用于描述一种特定的方法和公式 [40],但现在“蒸馏”一词被广泛用于指代各种方法,其中“学生”网络被训练以复制“教师”网络。一些研究人员仅蒸馏网络的最后一层 [17],而另一些则还蒸馏隐藏层 [15, 18, 22]。在蒸馏隐藏层时,一些研究人员采用逐层蒸馏预热,其中学生网络的每个模块独立蒸馏,而下游模块被冻结 [15]。一些在预训练期间进行蒸馏 [15, 17],一些在微调期间进行蒸馏 [22],还有一些两者都进行 [18, 21]。
Table 2: Comparison of neural networks on the development set of the GLUE benchmark. denotes models trained by the authors of the present paper. Bells and whistles are: $A=$ adversarial training; $D=$ distillation of final layer; $E=$ distillation of encoder layers; $S=$ transfer learning across GLUE tasks (a.k.a. STILTs [41]); $W=$ per-layer warmup. In GLUE accuracy, a dash means that accuracy for this task is not provided in the literature.
表 2: GLUE 基准开发集上的神经网络比较。表示由本文作者训练的模型。附加功能包括:$A=$ 对抗训练;$D=$ 最后一层的蒸馏;$E=$ 编码器层的蒸馏;$S=$ 跨 GLUE 任务的迁移学习(也称为 STILTs [41]);$W=$ 每层预热。在 GLUE 准确率中,破折号表示文献中未提供该任务的准确率。
| GLUE 准确率效率 | 附加功能 MNLI-mm & | 延迟 (ms) #MParams MNLI-m 平均 GFLOPs 加速比 MRPC 附加功能 RTE 模型 S o B |
|---|---|---|
| 无附加功能的结果 | ||
| BERT-baset | 85.2 | 84.8 |
| MobileBERT[15] | 80.8 | 88.2 |
| ALBERT-base[19] | 81.6 | 90.3 |
| SqueezeBERTt | 51.1 | 7.42 |
| 有附加功能的结果 | ||
| DistilBERT 6/768[17] D | 82.2 | 88.5 |
| 一 D | 82.58 | 83.4 |
| Turc 6/768 [20] = | 2.1x | |
| Theseus6/768[22]DESW | 82.3 | 89.6 |
| MobileBERT[15]DEW | 84.4 | 91.5 |
| SqueezeBERTt DS | 51.1 | 7.42 |
Bells and whistles used for training Squeeze BERT (for results in Section 5.2). Distillation is not a central focus of this paper, and there is a large design space of potential approaches to distillation, so we select a relatively simple form of distillation for use in Squeeze BERT training. We apply distillation only to the final layer, and only during finetuning. On the GLUE sentence classification tasks, we use soft cross entropy loss with respect to a weighted sum of the teacher’s logits and a one-hot encoding of the ground-truth. Also note that GLUE has one regression task (STS-B text similarity), and for this task we replace the soft cross entropy loss with mean squared error. In addition to distillation, inspired by STILTS [41] and ELECTRA [12] we apply transfer learning from the MNLI GLUE task to other GLUE tasks as follows. The Squeeze BERT student model is pretrained using the approach described in Section 4.2.1, and then it is finetuned on the MNLI task. The weights from MNLI training are used as the initial student weights for other GLUE tasks except for CoLA.6 Similarly, the teacher model is a BERT-base model that is pretrained using the ELECTRA method and then finetuned on MNLI. Then, the teacher model is finetuned independently on each GLUE task, and these task-specific teacher weights are used for distillation.
用于训练 Squeeze BERT 的附加技巧(用于第 5.2 节的结果)。蒸馏并不是本文的核心重点,而且蒸馏方法的设计空间很大,因此我们选择了一种相对简单的蒸馏形式用于 Squeeze BERT 训练。我们仅在微调期间对最后一层应用蒸馏。在 GLUE 句子分类任务中,我们使用软交叉熵损失,该损失基于教师模型的 logits 和真实标签的 one-hot 编码的加权和。此外,GLUE 中有一个回归任务(STS-B 文本相似度),对于该任务,我们将软交叉熵损失替换为均方误差。除了蒸馏之外,受 STILTS [41] 和 ELECTRA [12] 的启发,我们应用了从 MNLI GLUE 任务到其他 GLUE 任务的迁移学习,具体如下。Squeeze BERT 学生模型使用第 4.2.1 节中描述的方法进行预训练,然后在 MNLI 任务上进行微调。MNLI 训练得到的权重被用作除 CoLA 之外的其他 GLUE 任务的初始学生权重。同样,教师模型是一个使用 ELECTRA 方法预训练并在 MNLI 上微调的 BERT-base 模型。然后,教师模型在每个 GLUE 任务上独立微调,这些特定任务的教师权重用于蒸馏。
5 Results
5 结果
We now turn our attention to comparing Squeeze BERT to other efficient neural networks.
我们现在将注意力转向比较 Squeeze BERT 与其他高效神经网络。
5.1 Results without bells and whistles
5.1 无额外修饰的结果
In the upper portions of Tables 2 and 3, we compare our results to other efficient networks on the dev and test sets of the GLUE benchmark. Note that relatively few of the efficiency-optimized networks report results without bells and whistles, and most such results are reported on the development (not test) set of GLUE. Fortunately, the authors of MobileBERT – a network which we will find in the next section compares favorably to other efficient networks with bells and whistles enabled – do provide development-set results without distillation on 4 of the GLUE tasks.7 We observe in the upper portion of Table 2 that, when both networks are trained without distillation, Squeeze BERT achieves higher accuracy than MobileBERT on all of these tasks. This provides initial evidence that the techniques from computer vision that we have adopted can be applied to NLP, and reasonable accuracy can be obtained. Further, we observe that Squeeze BERT is $4.3\mathbf{X}$ faster than BERT-base, while MobileBERT is $3.0\mathrm{x}$ faster than BERT-base.8
在表 2 和表 3 的上半部分,我们将我们的结果与 GLUE 基准测试的开发集和测试集上的其他高效网络进行了比较。需要注意的是,相对较少的高效优化网络报告了没有额外修饰的结果,而且大多数此类结果都是在 GLUE 的开发集(而非测试集)上报告的。幸运的是,MobileBERT 的作者——我们将在下一节中发现,该网络在启用额外修饰的情况下与其他高效网络相比表现优异——确实提供了在 4 个 GLUE 任务上未经蒸馏的开发集结果。我们在表 2 的上半部分观察到,当两个网络都在没有蒸馏的情况下训练时,Squeeze BERT 在所有任务上的准确率都高于 MobileBERT。这初步证明了我们从计算机视觉中采用的技术可以应用于 NLP,并且可以获得合理的准确率。此外,我们观察到 Squeeze BERT 比 BERT-base 快 $4.3\mathbf{X}$,而 MobileBERT 比 BERT-base 快 $3.0\mathrm{x}$。
Table 3: Comparison of neural networks on the test set of the GLUE benchmark. denotes models trained by the authors of the present paper. Bells and whistles are: $A=$ adversarial training; $D=$ distillation of final layer; $E=$ distillation of encoder layers; $S=$ transfer learning across GLUE tasks (a.k.a. STILTs [41]); $W=$ per-layer warmup.
表 3: GLUE 基准测试集上神经网络的比较。表示由本文作者训练的模型。附加功能包括:$A=$ 对抗训练;$D=$ 最终层蒸馏;$E=$ 编码器层蒸馏;$S=$ 跨 GLUE 任务的迁移学习(也称为 STILTs [41]);$W=$ 每层预热。
| GLUE 准确率效率 | |
|---|---|
| 附加功能 GLUE 分数 MNLI-mm & 3 C WNLI P S RTE | |
| MNLI-m 附加功能 模型 | #MParams GFLOPs 延迟( 加速比 S 0 T S 无附加功能的结果 |
| BERT-baset | |
| BERT-base [9] | |
| SqueezeBERT+ | |
| 有附加功能的结果 | |
| TinyBERT 4/312[21] DE | 82.5 81.8 87.792.6 43.3 79.9 62.9 65.1 14.5 1.2 |
| ELECTRA-Small++ [12] AS 81.6 81.5 81.0 79.8 | 118 14x 88.3 91.1 55.6 84.6 84.9 63.6 65.1 14.0 2.62 248 |
| PKD 6/768[18] DE | 6.8x 89.092.0 |
| Turc 6/768 [20] D Theseus 6/768[22]DESW | 82.5 65.1 67.0 011.3 814 2.1x 82.279.78 89.4 91.8 84.3 65.3 65.1 67.5 11.3 814 2.1x |
Due to the dearth of efficient neural network results on GLUE without bells and whistles, we also provide a comparison in Table 2 with the ALBERT-base network. ALBERT-base is a version of BERT-base that uses the same weights across multiple attention layers, and it has a smaller encoder than BERT. Due to these design choices, ALBERT-base has $9\mathrm{x}$ fewer parameters than BERT-base. However, ALBERT-base and BERT-base have the same number of FLOPs, and we observe in our measurements in Table 2 that ALBERT-base does not offer a speedup over BERT-base on a smartphone.9 Further, on the two GLUE tasks where the ALBERT authors reported the accuracy of ALBERT-base, MobileBERT and Squeeze BERT both outperform the accuracy of ALBERT-base.
由于在GLUE上没有花哨的高效神经网络结果,我们还在表2中提供了与ALBERT-base网络的比较。ALBERT-base是BERT-base的一个版本,它在多个注意力层中使用相同的权重,并且其编码器比BERT更小。由于这些设计选择,ALBERT-base的参数比BERT-base少$9\mathrm{x}$。然而,ALBERT-base和BERT-base的FLOPs数量相同,我们在表2中的测量中观察到,ALBERT-base在智能手机上并没有比BERT-base提供加速。此外,在ALBERT作者报告ALBERT-base准确率的两个GLUE任务中,MobileBERT和Squeeze BERT的准确率都优于ALBERT-base。
5.2 Results with bells and whistles
5.2 完整结果
Now, we turn our attention to comparing Squeeze BERT to other models, all trained with bellsand-whistles. In the lower portion of Table 3, we first observe that when trained with bells-andwhistles MobileBERT matches or outperforms the accuracy of the other efficient models (except Squeeze BERT) on 8 of the 9 GLUE tasks. Further, on 4 of the 9 tasks Squeeze BERT outperforms the accuracy of MobileBERT; on 4 of 9 tasks MobileBERT outperforms Squeeze BERT; and on 1 task (WNLI) all models predict the most frequently occurring category.10 Also, Squeeze BERT achieves an average score across all GLUE tasks that is within 0.4 percentage-points of MobileBERT. Given the speedup of Squeeze BERT over MobileBERT, we think it is reasonable to say that Squeeze BERT and MobileBERT each offer a compelling speed-accuracy tradeoff for NLP inference on mobile devices.
现在,我们将注意力转向比较 Squeeze BERT 与其他模型,所有模型都经过 bells-and-whistles 训练。在表 3 的下半部分,我们首先观察到,当经过 bells-and-whistles 训练后,MobileBERT 在 9 个 GLUE 任务中的 8 个任务上匹配或超越了其他高效模型(除了 Squeeze BERT)的准确率。此外,在 9 个任务中的 4 个任务上,Squeeze BERT 的准确率超过了 MobileBERT;在 9 个任务中的 4 个任务上,MobileBERT 的准确率超过了 Squeeze BERT;而在 1 个任务(WNLI)上,所有模型都预测了最常出现的类别。此外,Squeeze BERT 在所有 GLUE 任务上的平均得分与 MobileBERT 相差不到 0.4 个百分点。考虑到 Squeeze BERT 相对于 MobileBERT 的速度提升,我们认为可以说 Squeeze BERT 和 MobileBERT 各自为移动设备上的 NLP 推理提供了一个引人注目的速度-准确率权衡。
6 Related Work
6 相关工作
Quantization and Pruning. Quantization is a family of techniques which aims to reduce the number of bits required to store each parameter and/or activation in a neural network, while at the same time maintaining the accuracy of that network. This has been successfully applied to NLP in such works as [46, 47]. Pruning aims to directly eliminate certain parameters from the network while also maintaining accuracy, thereby reducing the storage and potentially computational cost of that network; for an application of this to NLP, please see [48]. These methods could be applied to Squeeze BERT to yield further efficiency improvements, but quantization and pruning are not a focus of this paper.
量化和剪枝。量化是一系列旨在减少神经网络中每个参数和/或激活所需的存储位数的技术,同时保持网络的准确性。这在[46, 47]等工作中已成功应用于自然语言处理(NLP)。剪枝旨在直接从网络中消除某些参数,同时保持准确性,从而减少网络的存储和潜在计算成本;有关其在NLP中的应用,请参见[48]。这些方法可以应用于Squeeze BERT以进一步提高效率,但量化和剪枝不是本文的重点。
Convolutions in self-attention networks for language-generation tasks. In this paper, our experiments focus on natural language understanding (NLU) tasks such as sentence classification. However, another widely-studied area is natural language generation (NLG), which includes the tasks of machine-translation (e.g., English-to-German) and language modeling (e.g., automated sentencecompletion). While we are not aware of work that adopts convolutions in self-attention networks for NLU, we are aware of such work in NLG. For instance, the Evolved Transformer and Lite Transformer architectures contain self-attention modules and convolutions in separate portions of the network [49, 50]. Additionally, LightConv shows that well-designed convolutional networks without self-attention produce comparable results to self-attention networks on certain NLG tasks [51]. Also, Wang et al. sparsify the self-attention matrix multiplication using a pattern of nonzeros that is inspired by dilated convolutions [52]. Finally, while not an attention network, Kim applied convolutional networks to NLU several years before the development of multi-head self-attention [53].
自注意力网络中的卷积用于语言生成任务。本文的实验主要集中在自然语言理解(NLU)任务上,例如句子分类。然而,另一个广泛研究的领域是自然语言生成(NLG),包括机器翻译(例如,英语到德语)和语言建模(例如,自动句子补全)任务。虽然我们不知道有工作在NLU中采用自注意力网络中的卷积,但我们知道在NLG中有这样的工作。例如,Evolved Transformer和Lite Transformer架构在网络的不同部分包含自注意力模块和卷积 [49, 50]。此外,LightConv表明,在某些NLG任务上,设计良好的无自注意力卷积网络可以产生与自注意力网络相当的结果 [51]。此外,Wang等人使用受膨胀卷积启发的非零模式稀疏化自注意力矩阵乘法 [52]。最后,虽然不是注意力网络,但Kim在多头自注意力发展之前几年就将卷积网络应用于NLU [53]。
7 Conclusions & Future Work
7 结论与未来工作
In this paper, we have studied how grouped convolutions, a popular technique in the design of efficient CV neural networks, can be applied to NLP. First, we showed that the position-wise fullyconnected layers of self-attention networks can be implemented with mathematically-equivalent 1D convolutions. Further, we proposed Squeeze BERT, an efficient NLP model which implements most of the layers of its self-attention encoder with 1D grouped convolutions. This model yields an appreciable ${>}4\mathbf{x}$ latency decrease over BERT-base when benchmarked on a Pixel 3 phone. We also successfully applied distillation to improve our approach’s accuracy to a level that is competitive with a distillation-trained MobileBERT and with the original version of BERT-base.
在本文中,我们研究了分组卷积(grouped convolutions)这一在高效计算机视觉(CV)神经网络设计中流行的技术如何应用于自然语言处理(NLP)。首先,我们展示了自注意力网络中的逐位置全连接层可以通过数学上等效的一维卷积来实现。此外,我们提出了Squeeze BERT,这是一种高效的NLP模型,它使用一维分组卷积实现了自注意力编码器的大部分层。在Pixel 3手机上进行的基准测试中,该模型相比BERT-base显著降低了${>}4\mathbf{x}$的延迟。我们还成功应用了蒸馏技术,将我们方法的准确率提升到了与经过蒸馏训练的MobileBERT以及原始版本的BERT-base相竞争的水平。
We now discuss some possibilities for future work in the directions outlined in this paper. There are several techniques in use in CV that could be applied to NLP which we have not covered in this paper. One very promising direction is down sampling strategies which decrease the sequence length of the activation s in the self-attention network as the layers progress. Extensions of this idea, such as U-Nets [54], as well as modifying channel sizes (hidden size) instead of and in addition to sequence length would also be promising directions. On this path of techniques, applying ideas such as BiFPNs [55], striding, and dilation [56] may also yield interesting results.
我们现在讨论一些未来工作的可能性,这些方向在本文中已经概述。计算机视觉(CV)中有几种技术可以应用于自然语言处理(NLP),但本文并未涵盖。一个非常有前景的方向是下采样策略,随着层数的增加,这些策略会减少自注意力网络中的激活序列长度。这一想法的扩展,例如 U-Nets [54],以及修改通道大小(隐藏大小)而不是仅仅修改序列长度,也将是有前景的方向。在这一技术路径上,应用诸如 BiFPNs [55]、步幅和扩张 [56] 等想法也可能产生有趣的结果。
The addition of all of these potential techniques opens up a significantly broader search-space of neural architecture designs for NLP. This motivates the application of automated neural architecture search (NAS) approaches such as those described in [57, 58].
所有这些潜在技术的加入为自然语言处理(NLP)的神经架构设计开辟了更广阔的搜索空间。这促使了自动化神经架构搜索(NAS)方法的应用,例如 [57, 58] 中描述的那些方法。
Broader Impact
更广泛的影响
Potential benefits of this work
本工作的潜在优势
We hope the techniques used in this paper will allow more efficient and practical deployment of selfattention based networks, particularly allowing more widespread use of these networks on mobile devices. Possible use cases include email sorting, chat analysis, spam detection, or hate-speech filtering. Facebook has begun using a self-attention based network to automatically detect and remove hate speech on their platform [59, 60]. Currently, companies usually run these models on the serverside, but some may be reticent to deploy them on a mass scale due to computation costs. Mobile inference wouldn’t require expensive server infrastructure and allows use in cases where privacy and security may be a concern. Running on the edge devices may allow more real-time or offline use cases such as grammar checking, or sentence completion.
我们希望本文中使用的技术能够更高效、更实际地部署基于自注意力机制的网络,特别是在移动设备上更广泛地使用这些网络。潜在的应用场景包括邮件分类、聊天分析、垃圾邮件检测或仇恨言论过滤。Facebook 已经开始使用基于自注意力机制的网络来自动检测并删除其平台上的仇恨言论 [59, 60]。目前,公司通常会在服务器端运行这些模型,但由于计算成本的原因,一些公司可能对大规模部署持保留态度。在移动设备上进行推理不需要昂贵的服务器基础设施,并且在隐私和安全可能成为问题的情况下也能使用。在边缘设备上运行可能支持更多实时或离线的应用场景,例如语法检查或句子补全。
Potential malicious uses of this work
本工作的潜在恶意用途
Given that we are releasing our model and training and inference code as free software, anyone can train our model on any dataset that they like. While we hope most practitioners will apply our work for altruistic or at least well-intention ed purposes, some may apply our work for ethically questionable or purely self-serving applications. For instance, low-cost mobile inference could allow "smart" key-loggers and eavesdropping viruses to be deployed, and for these devices to better avoid detection by computing locally and only uploading important information. And, while we hope that social networks and other text-centric portals will draw on our work to embed fair and just models into their mobile applications for content moderation, these companies could just as easily draw on our work to train and deploy models that censor content of political enemies or amplify only certain types of messages and voices.
鉴于我们正在将模型、训练和推理代码作为自由软件发布,任何人都可以在他们喜欢的任何数据集上训练我们的模型。虽然我们希望大多数从业者会将我们的工作应用于利他或至少是善意的目的,但有些人可能会将我们的工作应用于道德上有问题或纯粹自私的应用。例如,低成本的移动推理可能允许部署“智能”键盘记录器和窃听病毒,并使这些设备能够通过本地计算并仅上传重要信息来更好地避免检测。此外,虽然我们希望社交媒体和其他以文本为中心的门户网站能够利用我们的工作将公平和公正的模型嵌入到他们的移动应用程序中以进行内容审核,但这些公司同样可以轻松地利用我们的工作来训练和部署模型,以审查政治对手的内容或仅放大某些类型的消息和声音。
Potential effects of unintended bias in the neural network and its training data
神经网络及其训练数据中意外偏差的潜在影响
Models for NLP commonly suffer from biases regarding race and gender [61]. In our work, we have used standard datasets, and we are not aware of any experimental factors that would increase or decrease Squeeze BERT’s propensity for bias, as compared to the approaches used in similar self-attention research such as BERT and ELECTRA. The gender-related biases of our pre training corpora (Wikipedia and Books Corpus) are investigated by Tan et al. [61], and the gender biases of BERT and GPT models finetuned on the GLUE tasks are investigated by Baba ei anjel oda r et al. [62].
自然语言处理 (NLP) 模型通常存在种族和性别偏见 [61]。在我们的工作中,我们使用了标准数据集,并且与 BERT 和 ELECTRA 等类似自注意力研究中使用的方法相比,我们没有发现任何会增加或减少 Squeeze BERT 偏见倾向的实验因素。Tan 等人 [61] 研究了我们的预训练语料库(维基百科和书籍语料库)中的性别相关偏见,而 Baba ei anjel oda r 等人 [62] 研究了在 GLUE 任务上微调的 BERT 和 GPT 模型的性别偏见。
Aside from gender bias, we are not aware of studies that investigate other patterns of bias in the datasets that we used in our work. However, Sheng et al. investigate biases regarding race, gender, and sexual orientation in a GPT-2 self-attention model trained on a language-modeling (textgeneration) task [63]. Further, in the paper introducing the GPT-3 model, a study similar to that of Sheng et al. is performed [64].
除了性别偏见,我们尚未发现针对我们工作中使用的数据集中的其他偏见模式的研究。然而,Sheng 等人研究了在语言建模(文本生成)任务上训练的 GPT-2 自注意力模型中关于种族、性别和性取向的偏见 [63]。此外,在介绍 GPT-3 模型的论文中,进行了与 Sheng 等人类似的研究 [64]。
According to the taxonomy described in [65], the harms caused by biased NLP technology include:
根据[65]中描述的分类法,由有偏见的自然语言处理(NLP)技术造成的危害包括:
• Allocation al harms: These arise when an "automated system allocates resources (e.g., credit) or opportunities (e.g., jobs) unfairly to different social group." • Representational harms: These arise when "a system (e.g., a search engine) represents some social groups in a less favorable light than others, demeans them, or fails to recognize their existence altogether."
• 分配性伤害:当“自动化系统不公平地将资源(例如信贷)或机会(例如工作)分配给不同的社会群体”时,就会产生这种伤害。
• 代表性伤害:当“系统(例如搜索引擎)以不如其他社会群体的方式呈现某些社会群体,贬低他们,或完全未能承认他们的存在”时,就会产生这种伤害。
We direct the interested reader to work by Blodgett et al. [65] and Sun et al. [66] for more details and suggestions on how to minimize the bias in datasets and the neural networks that learn from them.
我们建议感兴趣的读者参考 Blodgett 等人的研究 [65] 和 Sun 等人的研究 [66],以获取更多关于如何最小化数据集及其训练的神经网络中的偏差的详细信息和建议。
Acknowledgments and Disclosure of Funding
致谢与资金披露
K. Keutzer’s research is supported by Alibaba, Amazon, Google, Facebook, Intel, and Samsung.
K. Keutzer 的研究得到了阿里巴巴、Amazon、Google、Facebook、Intel 和 Samsung 的支持。
References
参考文献
[63] E. Sheng, K.-W. Chang, P. Natarajan, and N. Peng, “The woman worked as a babysitter: On biases in language generation,” in Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019. [Online]. Available: https://www.aclweb.org/anthology/D19-1339
[63] E. Sheng, K.-W. Chang, P. Natarajan, 和 N. Peng, "The woman worked as a babysitter: On biases in language generation," 发表于 Conference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019. [在线]. 可访问: https://www.aclweb.org/anthology/D19-1339
Supplementary Material for Squeeze BERT
Squeeze BERT 补充材料
A Overview of GLUE tasks
GLUE任务概述
In this section we provide an overview of each of the tasks within the GLUE benchmark, their evaluation metrics, and their potential applications outside of the benchmark. For further information on the benchmark, please see [16], where it was originally proposed.
在本节中,我们将概述 GLUE 基准测试中的每个任务、它们的评估指标以及它们在基准测试之外的潜在应用。有关基准测试的更多信息,请参阅最初提出该基准测试的文献 [16]。
Note that some tasks have one evaluation metric, and some have two. The possible evaluation metrics are Accuracy (abbreviated below as acc), F1 [67], Matthews Correlation Coefficient (MCC) [68], Pearson Correlation (pearson), and Spearman Correlation (spearman).
请注意,某些任务有一个评估指标,而有些任务有两个。可能的评估指标包括准确率(Accuracy,下文缩写为 acc)、F1 [67]、马修斯相关系数(MCC)[68]、皮尔逊相关系数(pearson)和斯皮尔曼相关系数(spearman)。
MNLI: Multi-genre Natural Language Inference [69]. Given a pair of sentences (sentence 1 and sentence 2), the task is to predict whether sentence 2 entails sentence 1. Note that there are 2 test sets for this task: MNLI-matched (MNLI-m), and MNLI-mismatched (MNLI-mm). When computing an average score overall tasks, we follow the convention employed by the GLUE leader board, which is $\mathrm{\Lambda}^{\prime}\mathrm{acc}\left(\mathrm{MNLI-m}\right)+\mathrm{acc}\left(\mathrm{MNLI-mm}\right)\big)/2$ . Therefore, while MNLI-m and MNLI-mm are two columns in our results table, they only count as one task in the average GLUE score. Potential applications include helping users improve their writing by checking for repetitive sections based on whether certain sentences are entailed by other previous ones. This task contains 392,703 training examples.
MNLI:多类型自然语言推理 [69]。给定一对句子(句子1和句子2),任务是预测句子2是否蕴含句子1。需要注意的是,该任务有两个测试集:MNLI-matched (MNLI-m) 和 MNLI-mismatched (MNLI-mm)。在计算所有任务的平均分数时,我们遵循GLUE排行榜的惯例,即 $\mathrm{\Lambda}^{\prime}\mathrm{acc}\left(\mathrm{MNLI-m}\right)+\mathrm{acc}\left(\mathrm{MNLI-mm}\right)\big)/2$。因此,尽管MNLI-m和MNLI-mm在我们的结果表中是两列,但在平均GLUE分数中只算作一个任务。潜在的应用包括通过检查某些句子是否被之前的句子所蕴含,来帮助用户改进写作中的重复部分。该任务包含392,703个训练样本。
QQP: Quora Question Pairs [70, 71]. The goal of this task is to determine whether a pair of questions have the same meaning. In practical applications, such as organizing emails or organizing helpdesk tickets, this approach can be used to group similar questions together and only answer them once. There are 2 metrics for this task: acc and F1. In our results tables, we follow the approach of the GLUE leader board and compute QQP results as the average of these two metrics. We observe that, for most models, on the test set the F1 score is significantly lower than the accuracy score. For instance, previously reported BERT-base results are $_{\mathrm{F}1=71.2}$ and accuracy $=89.2$ . The TinyBERT paper [21] reports a TinyBERT QQP score of 71.3, relative to a BERT-base baseline of 71.2, so it appears that the TinyBERT paper only reports the QQP F1 (but not accuracy) score. Conversely, the ELECTRA [12] paper reports an ELECTRA-small QQP score of 88.0, relative to a BERT-base QQP score of 89.2, so it appears that the ELECTRA paper only reports the QQP accuracy (but not F1) score. Out of fairness, we have omitted the TinyBERT and ELECTRA-small QQP test-set results from our results table, as it appears that they are each using a metric different from our metric of $\mathrm{\Delta(acc(qQP)+F1(QQP))/2)}$ ). This task contains 363,871 training examples.
QQP: Quora Question Pairs [70, 71]。该任务的目标是确定一对问题是否具有相同的含义。在实际应用中,例如组织电子邮件或组织帮助台工单,这种方法可以用于将相似的问题分组在一起,并且只需回答一次。该任务有两个指标:准确率 (acc) 和 F1 分数。在我们的结果表中,我们遵循 GLUE 排行榜的方法,将 QQP 结果计算为这两个指标的平均值。我们观察到,对于大多数模型,在测试集上 F1 分数显著低于准确率。例如,之前报告的 BERT-base 结果是 $_{\mathrm{F}1=71.2}$ 和准确率 $=89.2$。TinyBERT 论文 [21] 报告的 TinyBERT QQP 分数为 71.3,相对于 BERT-base 基线为 71.2,因此似乎 TinyBERT 论文仅报告了 QQP 的 F1 分数(而非准确率)。相反,ELECTRA [12] 论文报告的 ELECTRA-small QQP 分数为 88.0,相对于 BERT-base QQP 分数为 89.2,因此似乎 ELECTRA 论文仅报告了 QQP 的准确率(而非 F1 分数)。出于公平性考虑,我们从结果表中省略了 TinyBERT 和 ELECTRA-small 的 QQP 测试集结果,因为它们似乎各自使用了与我们使用的指标 $\mathrm{\Delta(acc(qQP)+F1(QQP))/2)}$ 不同的指标。该任务包含 363,871 个训练样本。
QNLI: Question-answering Natural Language Inference. This task is derived from the dataset published in [72]. Specifically, it is reformulated as a two-class classification task, wherein the goal is to decide whether or not the given sentence does, or does not, contain the answer to a given question. In this way, QNLI bears some similarity to other entailment classification tasks such as MNLI. The evaluation metric used for QNLI is just acc(QNLI). In terms of applications, QNLI is useful for many of the same situations in which a standard question-answering dataset would be, such as in designing intelligent voice assistants which can respond to user questions. For instance, if an extractive or generative model is used to generate an answer to a question, a QNLI-trained model could be used as a sanity-check on whether the machine-generated response actually answers the question. Also, a QNLI-trained model could be used to check if an existing answer already answers a new question on a form or in a helpdesk database, thereby not requiring a new answer to be generated by a human. This task contains 104,744 training examples.
QNLI:问答自然语言推理 (Question-answering Natural Language Inference)。该任务源自 [72] 中发布的数据集。具体来说,它被重新表述为一个二分类任务,目标是判断给定的句子是否包含给定问题的答案。通过这种方式,QNLI 与其他蕴含分类任务(如 MNLI)有一些相似之处。QNLI 使用的评估指标是 acc(QNLI)。在应用方面,QNLI 适用于许多与标准问答数据集相同的场景,例如设计能够响应用户问题的智能语音助手。例如,如果使用抽取式或生成式模型生成问题的答案,则可以使用经过 QNLI 训练的模型来检查机器生成的响应是否真正回答了问题。此外,经过 QNLI 训练的模型可用于检查现有答案是否已经回答了表单或帮助台数据库中的新问题,从而无需人工生成新答案。该任务包含 104,744 个训练样本。
SST-2: Stanford Sentiment Treebank [73]. This is a sentiment classification dataset, with the goal being to predict whether a sentence has a positive or negative sentiment. The source data for SST-2 is hand-annotated movie review data. The metric used for this task is acc(SST-2). SST-2 applications include improving chatbot based systems which require responses that properly match the conversation context to be generated, and potentially triaging emails at helpdesks so that, for example, the ones with strong negative sentiments are prioritized. This task contains 67,350 training examples.
SST-2: Stanford Sentiment Treebank [73]。这是一个情感分类数据集,目标是预测句子是正面情感还是负面情感。SST-2 的源数据是手工标注的电影评论数据。该任务使用的指标是 acc(SST-2)。SST-2 的应用包括改进基于聊天机器人的系统,这些系统需要生成与对话上下文相匹配的响应,以及可能在帮助台中对电子邮件进行分类,例如,优先处理具有强烈负面情感的邮件。该任务包含 67,350 个训练样本。
CoLA: Corpus of Linguistic Acceptability [74]. This is a binary classification task, where the objective is to determine whether a given sentence meets the criteria for being a properly written English sentence. It is worth noting that CoLA is a binary classification task, and $69%$ of the data samples in the validation set are positive examples. The metric used for this task is different from the metrics used in other GLUE tasks: MCC(CoLA). A distinguishing feature of Matthews Correlation Coefficient (MCC) is that it effectively adjusts for class imbalance in the dataset. On the
CoLA: 语言可接受性语料库 (Corpus of Linguistic Acceptability) [74]。这是一个二分类任务,目标是判断给定的句子是否符合正确书写的英语句子的标准。值得注意的是,CoLA 是一个二分类任务,验证集中 $69%$ 的数据样本是正例。该任务使用的指标与其他 GLUE 任务不同:MCC(CoLA)。Matthews 相关系数 (MCC) 的一个显著特点是它能有效调整数据集中的类别不平衡。
CoLA validation set, where $69%$ of the samples are positive, predicting the majority class would produce an accuracy of $69%$ but an MCC of 0.0. Also note that MCC can be anywhere between and including $-1.0$ and 1.0, as opposed to 0.0 $(0%)$ and 1.0 $(100%)$ for acc. Models trained on CoLA could be used to provide feedback on the grammatical correctness of user-generated text, analogous to a spell-checker, but potentially with more nuanced understanding of grammar than a rule-based grammar checker. CoLA-trained models could also be used to verify the grammatical correctness of text generated by other neural networks. This task contains 8,551 training examples.
CoLA 验证集中,$69%$ 的样本为正例,预测多数类将产生 $69%$ 的准确率,但 MCC 为 0.0。还需注意的是,MCC 的取值范围在 $-1.0$ 到 1.0 之间,而准确率的取值范围为 0.0 $(0%)$ 到 1.0 $(100%)$。在 CoLA 上训练的模型可用于对用户生成文本的语法正确性提供反馈,类似于拼写检查器,但可能比基于规则的语法检查器对语法有更细致的理解。CoLA 训练的模型还可用于验证其他神经网络生成的文本的语法正确性。该任务包含 8,551 个训练样本。
STS-B: Semantic Textual Similarity Benchmark [75]. This dataset is built from several sources including news headlines data as well as captions data. The goal of this task is to predict the level of semantic similarity between two input sentences, on a scale of 1 (minimum similarity) to 5 (maximum similarity). Notably, this is a regression task. The overall evaluation metric used on the GLUE leader board, which we report in our results tables, is (spearman(STS-B) $^+$ pearson(STS-B))/2. STS-B could have applications in several areas, such as plagiarism detection, as well as potentially other applications which are mentioned above in the description of QQP. This task contains 5,750 training examples.
STS-B: 语义文本相似度基准 [75]。该数据集由多个来源构建,包括新闻标题数据和字幕数据。该任务的目标是预测两个输入句子之间的语义相似度水平,评分范围为1(最低相似度)到5(最高相似度)。值得注意的是,这是一个回归任务。我们在结果表中报告的GLUE排行榜上使用的总体评估指标是 (spearman(STS-B) $^+$ pearson(STS-B))/2。STS-B在多个领域可能有应用,例如抄袭检测,以及上述QQP描述中提到的其他潜在应用。该任务包含5,750个训练样本。
MRPC: Microsoft Research Paraphrase Corpus [76]. This is classification task where the goal is to predict whether or not the two input sentences have the same semantic meaning. The data itself comes from online news articles and is hand-annotated. The metric used for this task is ((acc(QQP) $^+$ F1(QQP))/2), consistent with the GLUE test set leader board. MRPC would have applications similar to STS-B, such as plagiarism detection and others. This task contains 3,669 training examples.
MRPC: Microsoft Research Paraphrase Corpus [76]。这是一个分类任务,目标是预测两个输入句子是否具有相同的语义。数据本身来自在线新闻文章,并经过人工标注。该任务使用的指标是 ((acc(QQP) $^+$ F1(QQP))/2),与 GLUE 测试集排行榜一致。MRPC 的应用场景与 STS-B 类似,例如抄袭检测等。该任务包含 3,669 个训练样本。
RTE: Recognizing Textual Entailment is a combination of several datasets from yearly challenges on entailment [77, 78, 79, 80]. RTE is a two-way classification task where the labels are entailment and not entail ment. The metric used for this task is acc(RTE). Potential applications of this dataset are similar to those of MNLI. This task contains 2,491 training examples.
RTE:文本蕴含识别 (Recognizing Textual Entailment) 是由多个年度蕴含挑战赛数据集组合而成的 [77, 78, 79, 80]。RTE 是一个二分类任务,标签为蕴含 (entailment) 和非蕴含 (not entailment)。该任务使用的评估指标是准确率 (acc(RTE))。该数据集的潜在应用与 MNLI 类似。该任务包含 2,491 个训练样本。
WNLI: Winograd Schema Challenge, reformulated as Winograd Natural Language Inference [81]. This goal of this task is for the model to predict the antecedent of a pronoun (out of a set of choices) given the input sentence containing that pronoun. The metric used for this task is acc(WNLI). As with other work in this area [9], we simply predict the majority class on this dataset, resulting in a test set accuracy of $65.1%$ . This task contains 636 training examples.
WNLI:Winograd Schema Challenge,重新表述为Winograd自然语言推理 [81]。该任务的目标是让模型在给定包含代词的输入句子后,预测代词的前指(从一组选项中选择)。该任务使用的指标是acc(WNLI)。与其他相关研究 [9] 一样,我们简单地预测该数据集中的多数类,测试集准确率为 $65.1%$。该任务包含636个训练样本。
In Listings 1 and 2, we show how we calculate overall scores for the GLUE development set and test set. Other than omitting WNLI from the development-set score (following [9]), these calculations adhere to the methodology used by the GLUE leader board.
在代码清单 1 和 2 中,我们展示了如何计算 GLUE 开发集和测试集的总体分数。除了在开发集分数中省略 WNLI(遵循 [9])之外,这些计算遵循 GLUE 排行榜使用的方法论。
Listing 1: Calculating average score on the GLUE development set.
列表 1: 计算 GLUE 开发集上的平均分数。
| dev_score= MEAN( | |
|------------------|--|
| | (acc(MNLI-m)+aCc(MNLI-mm))/2, |
| | (F1(QQP)+acc(QQP))/2, |
| 4 | acc(QNLI), |
| | acc(SST-2) |
| | MCC(CoLA), |
| 6 7 | |
| | (pearson(STS-B) + spearman(STS-B))/2, (F1(MRPC) +acc(MRPC))/2, |
| 9 | acc(RTE) |
| 01 | |
Listing 2: Calculating average score on the GLUE test set.
列表 2: 计算 GLUE 测试集上的平均分数。
| test_score= MEAN( |
|---|
| (acc(MNLI-m)+acc(MNLI-mm))/2, |
| (F1(QQP)+acc(QQP))/2, |
| acc(QNLI), |
| 4 |
| acc(SsT-2): |
| 6 |
| (pearson(STS-B) + spearman(STS-B))/2, (F1(MRPC)+aCc(MRPC))/2, |
| 9 |
| 10 |
| 11 |
B More training details and results
B 更多训练细节和结果
B.1 Training Hardware
B.1 训练硬件
We do all pre training and finetuning on an 8-GPU server without multi-server distributed training. Our server has 8 NVIDIA Titan RTX GPUs. The server also has an Intel Xeon Gold 6130 64-core CPU, and it has 256GB of RAM. Further, the data loading requirements for our NLP application are so small that we were able to use low-cost, low-bandwidth spinning-media (not flash) disks for storing the training data. We employed two of these servers for approximately 6 months to do various experiments, beginning with reproducing BERT-base, and then experimenting with various model architectures. No cloud computing resources or corporate computing resources were used for this research.
我们在一个8-GPU服务器上进行所有的预训练和微调,没有使用多服务器分布式训练。我们的服务器配备了8个NVIDIA Titan RTX GPU。服务器还配备了一个Intel Xeon Gold 6130 64核CPU,以及256GB的内存。此外,我们的NLP应用对数据加载的需求非常小,因此我们能够使用低成本、低带宽的机械硬盘(非闪存)来存储训练数据。我们使用了两个这样的服务器进行了大约6个月的实验,从复现BERT-base开始,然后尝试了各种模型架构。这项研究没有使用云计算资源或企业计算资源。
While we used our own computing resources for this work, we now consider what it would have cost to rent servers similar to ours from a cloud provider for the duration of our project. We can break this down into two types of costs, storage and computation:
虽然我们在这项工作中使用了自有的计算资源,但我们现在考虑如果从云服务提供商租用与我们类似的服务器,在项目期间的成本会是多少。我们可以将其分为两种类型的成本:存储和计算:
• Storage. The datasets are small (under 100GB total), and we typically retain a few hundred gigabytes of model parameters from various training checkpoints, so we imagine the cloud storage costs would be negligible: As of this writing, Amazon Web Services charges $\$0.023/0B$ for general-purpose storage [82], so storing a terabyte of data and model checkpoints would cost just $\$23$ per month, or $\$138$ for 6 months. There may be additional fees for data transfers within the AWS ecosystem, but we have studied these costs in detail. • Computation. As we mentioned earlier, to do the work in this project, including the initial work to reproduce baselines and the work to experiment with several potential neural network designs, we used 2 8-GPU servers for about 6 months. We estimate that renting this amount of computation from a cloud provider would cost around $\$100,000$ , calculated as (6 months) * ( $50%$ utilization) * (2 servers) $^ * $ (30 days per month) $^ * $ (24 hrs/day) $^*$ $\$24/\mathrm{hr}$ for an 8-GPU V100 machine from Amazon Web Services [83]).
• 存储。数据集较小(总计不到100GB),我们通常会保留来自不同训练检查点的几百GB模型参数,因此我们想象云存储成本可以忽略不计:截至本文撰写时,Amazon Web Services 对通用存储的收费为 $\$0.023/GB$ [82],因此存储1TB的数据和模型检查点每月仅需 $\$23$,6个月则为 $\$138$。在AWS生态系统内进行数据传输可能会有额外费用,但我们已经详细研究了这些成本。
• 计算。如前所述,为了完成本项目的工作,包括重现基线的初始工作和实验几种潜在神经网络设计的工作,我们使用了2台8-GPU服务器,持续约6个月。我们估计从云提供商租用这些计算资源将花费约 $\$100,000$,计算方式为(6个月)*($50%$ 利用率)*(2台服务器)$^ * $(每月30天)$^ * $(每天24小时)$^*$(Amazon Web Services 的8-GPU V100机器每小时 $\$24$ [83])。
So, while we used our computing resources for this work, doing this entire research project from beginning to end in the cloud would have cost around $\$100,000$ .
因此,虽然我们在这项工作中使用了我们的计算资源,但如果从头到尾都在云端完成整个研究项目,成本将约为 10 万美元。
Now, we consider what it would cost to reproduce the Squeeze BERT model from scratch using cloud hardware. The Squeeze BERT model can be reproduced in approximately 5 days: 4 days for pretraining, and then under one day for finetuning on all GLUE tasks with the optimal hyper parameters discovered by our hyper parameter search (see Section B.4). In total, this would cost approximately $\$2880$ , calculated as (5 days) * (24 hrs/day) $^*$ ( $\$24/\mathrm{hr}$ for one 8-V100 AWS machine).
现在,我们考虑使用云硬件从零开始复现 Squeeze BERT 模型的成本。Squeeze BERT 模型大约可以在 5 天内复现:4 天用于预训练,然后在所有 GLUE 任务上进行微调,使用我们通过超参数搜索发现的最佳超参数(见 B.4 节),微调时间不到一天。总成本大约为 $\$2880$,计算方式为 (5 天) * (24 小时/天) $^*$ (一台 8-V100 AWS 机器的成本为 $\$24/\mathrm{hr}$)。
B.2 Training Software
B.2 训练软件
Our PyTorch-based training and inference code draws heavily on the Hugging Face Transformers [84] and NVIDIA Deep Learning Examples [85] repositories. We perform pre training using 8 GPUs with 16-bit floating-point math, and we use the O2 optimization level in the NVIDIA Apex mixed-precision training primitives [86]. We perform finetuning on a single GPU with 32-bit floating-point math, and we concurrently run multiple finetuning tasks across the 8-GPU machine.
我们基于 PyTorch 的训练和推理代码大量借鉴了 Hugging Face Transformers [84] 和 NVIDIA 深度学习示例 [85] 的代码库。我们使用 8 个 GPU 进行 16 位浮点数数学运算的预训练,并在 NVIDIA Apex 混合精度训练原语 [86] 中使用 O2 优化级别。我们在单个 GPU 上进行 32 位浮点数数学运算的微调,并在 8-GPU 机器上同时运行多个微调任务。
B.3 Further details: distillation
B.3 进一步细节:蒸馏
In the distillation approach that we described in Section 4.2.2, we mentioned that we use teacher logits and one-hot ground-truth as the target output for our soft cross entropy loss. The weighting between the teacher logits and the ground-truth is controlled by a hyper parameter $\alpha$ . Let $\Psi_{t}$ represent the teacher logits and let $\Psi_{g}$ represent the one-hot encoding of the ground-truth. Formally, we write this weighted sum as:
在我们第4.2.2节中描述的蒸馏方法中,我们提到使用教师logits和one-hot真实标签作为软交叉熵损失的目标输出。教师logits和真实标签之间的权重由一个超参数$\alpha$控制。设$\Psi_{t}$表示教师logits,$\Psi_{g}$表示真实标签的one-hot编码。形式上,我们将这个加权和表示为:

In the next section, we will tune $\alpha$ as part of our hyper parameter tuning scheme.
在下一节中,我们将调整 $\alpha$ 作为超参数调优方案的一部分。
B.4 Details of hyper parameter search during finetuning on GLUE tasks
B.4 在GLUE任务微调期间的超参数搜索细节
We now present more details on the hyper parameter search approach that we used for training Squeeze BERT with bells and whistles. In Table 4, we present the space of possible hyperparameters over which we performed a grid-search. Note that the time to finetune the model using one set of hyper parameters varies significantly depending on the GLUE task, from 15 minutes for small datasets like RTE, to 14 hours for MNLI. For smaller datasets that require less training (e.g. RTE and MRPC), we use a broader search space and more epochs. And, for larger datasets (e.g. MNLI and QQP), we use a more narrow search space with fewer epochs.
我们现在详细介绍用于训练带有附加功能的 Squeeze BERT 的超参数搜索方法。在表 4 中,我们展示了进行网格搜索的可能超参数空间。需要注意的是,使用一组超参数微调模型的时间因 GLUE 任务的不同而有显著差异,从小数据集如 RTE 的 15 分钟,到 MNLI 的 14 小时不等。对于需要较少训练的小数据集(例如 RTE 和 MRPC),我们使用更广泛的搜索空间和更多的训练轮次。而对于较大的数据集(例如 MNLI 和 QQP),我们使用更窄的搜索空间和较少的训练轮次。
Table 4: Our hyper parameter search space.
表 4: 我们的超参数搜索空间。
| 超参数 | MNLI, QQP, QNLI, STS-2 | STS-B, MRPC, RTE | CoLA |
|---|---|---|---|
| [0.8, 0.9, 1.0] | [0.8, 0.9, 1.0] | [0.8, 0.9, 1.0] | |
| 学习率 | [1e-05, 2e-05, 3e-05, 4e-05] | [1e-05, 2e-05, 3e-05, 4e-05, 5e-05] | [1e-05, 2e-05, 3e-05, 4e-05, 5e-05] |
| 编码器丢弃率 | [0.0, 0.1] | [0.0, 0.1] | [0.0, 0.1] |
| 最终丢弃率 | [0.1, 0.2] | [0.1, 0.2] | [0.0, 0.1] |
| 训练轮数 | 5 | 10 | 20 |
| 批量大小 | 16 | 16 | [16, 32, 48] |
Table 5: Hyper parameters selected by our hyper parameter search when training Squeeze BERT with bells-and-whistles.
表 5: 在使用 bells-and-whistles 训练 Squeeze BERT 时,通过超参数搜索选择的超参数。
| 超参数 | MNLI-m | MNLI-mm | QQP | QNLI | STS-2 | CoLA | STS-B | MRPC | RTE |
|---|---|---|---|---|---|---|---|---|---|
| 1.0 | 1.0 | 0.8 | 1.0 | 0.8 | 1.0 | 0.8 | 0.9 | 0.8 | |
| 学习率 | 3e-05 | 3e-05 | 4e-05 | 3e-05 | 3e-05 | 2e-05 | 4e-05 | 3e-05 | 3e-05 |
| 编码器 Dropout | 0.0 | 0.0 | 0.1 | 0.0 | 0.1 | 0.0 | 0.1 | 0.1 | 0.1 |
| 最终 Dropout | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| 训练轮数 | 4 | 4 | 5 | 2 | 5 | 5 | 10 | 9 | 3 |
| 批量大小 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
Now, in Table 5, we present the best hyper parameters found in our search. We observe two interesting phenomena on this table. The first is regarding the use of distillation. Recall from Equation 4 that $\alpha$ is the hyper parameter that sets the weighting between the teacher logits and the ground-truth for distillation. When $\alpha=1.0$ , the teacher logits are ignored, and thus distillation is disabled. So, it is interesting to note that on three of the eight GLUE tasks in Table 5 (MNLI, QNLI, and CoLA), distillation did not produce superior results over non-distillation finetuning. The second interesting phenomenon in this table is that maximum accuracy was not necessarily achieved on final epoch. For example, on QNLI, Squeeze BERT converged to its maximum development-set accuracy after just two epochs.
现在,在表 5 中,我们展示了在搜索中找到的最佳超参数。我们在这个表中观察到了两个有趣的现象。第一个是关于蒸馏的使用。回想一下公式 4,$\alpha$ 是设置教师 logits 和真实标签之间权重的超参数。当 $\alpha=1.0$ 时,教师 logits 被忽略,因此蒸馏被禁用。因此,有趣的是,在表 5 中的八个 GLUE 任务中的三个(MNLI、QNLI 和 CoLA)上,蒸馏并没有产生优于非蒸馏微调的结果。表中的第二个有趣现象是,最大准确率并不一定在最后一个 epoch 达到。例如,在 QNLI 上,Squeeze BERT 仅在两个 epoch 后就达到了其最大开发集准确率。
C Further details: Inference on a smartphone
C 进一步细节:在智能手机上进行推理
To evaluate inference speed, we run the neural networks on a Google Pixel 3 smartphone. This phone contains the popular Qualcomm Snapdragon 845 processing chip, which is also used in popular smartphones from Samsung, Xiaomi, and Sony [87]. The phone also has 4GB of LPDDR4x memory. To run a neural network on the phone, we do the following. First, we export the network to Torch Script using the torch.jit.trace() command, which yields a standalone neural net that does not require Python to run. Then, we copy the network to the phone, and we run it using a modified version of the speed benchmark torch.cc file that is built into PyTorch. We report the average latency of 40 runs, using the CPU cores of the phone. Following the protocol of MobileBERT, each run operates on a length-128 input sequence and a batch size of 1.
为了评估推理速度,我们在 Google Pixel 3 智能手机上运行神经网络。该手机搭载了流行的 Qualcomm Snapdragon 845 处理器芯片,该芯片也被用于三星、小米和索尼等热门智能手机 [87]。该手机还配备了 4GB 的 LPDDR4x 内存。为了在手机上运行神经网络,我们执行以下步骤。首先,我们使用 torch.jit.trace() 命令将网络导出为 Torch Script,生成一个不需要 Python 语言即可运行的独立神经网络。然后,我们将网络复制到手机上,并使用 PyTorch 内置的修改版速度基准测试文件 torch.cc 来运行它。我们报告了使用手机 CPU 核心进行的 40 次运行的平均延迟。按照 MobileBERT 的协议,每次运行都使用长度为 128 的输入序列和批量大小为 1 的配置。
D More related work
D 更多相关工作
Efficient convolutional networks for CV. Convolutional neural networks lead the state-of-the-art on computer vision (CV) tasks such as image classification, object detection, and semantic segmentation. In the last five years, the community has developed efficient convolutional neural networks for CV that run efficiently and in real-time on mobile devices. On the ImageNet [28] image classification task, from the year 2016 (ResNet-101 [23]) to 2020 (Fix Efficient Net-D0 [88]), there is a $20\mathrm{x}$ reduction in the number of floating-point operations (FLOPs) required, while accuracy has actually improved.1112 Further, on the COCO [89] object detection task, from 2016 (FPN [90]) to
高效的卷积网络用于计算机视觉 (CV)。卷积神经网络在图像分类、目标检测和语义分割等计算机视觉任务中处于领先地位。在过去的五年中,社区开发了高效的卷积神经网络,能够在移动设备上高效且实时地运行。在 ImageNet [28] 图像分类任务中,从 2016 年 (ResNet-101 [23]) 到 2020 年 (Fix Efficient Net-D0 [88]),所需的浮点运算次数 (FLOPs) 减少了 $20\mathrm{x}$,而准确率实际上有所提高。1112 此外,在 COCO [89] 目标检测任务中,从 2016 年 (FPN [90]) 到
2020 (Efficient Det-D1 [55]), there is a $38\mathrm{x}$ reduction in the number of FLOPs and an improvement in accuracy.13 Finally, on the Cityscapes [91] semantic segmentation task, from 2016 (FCN-8s [92]) to 2020 (SqueezeNAS-MAC-Small [57]), there is a 334x reduction in the number of FLOPs, and an improvement in accuracy.14 Given that the datasets were, for the most part, held constant, to what do we owe these improvements? One factor that has helped is the design of new neural network architectures with superior FLOP-accuracy tradeoffs. There have been several innovations to neural architecture for CV, including dilated convolutions [56], creative approaches for multiscale recognition [90, 55], and long-range aggregation of skip-connections [94]. However, above all else, there is one influential design element that has been adopted by nearly all efficient convolutional neural network designs developed in the last three years: grouped convolutions. Grouped convolutions, which are form of structured sparsity in the channel dimension, have a hyper parameter $G$ , which reduces the number of parameters and the number of computations by $\textstyle{\frac{1}{G}}$ Grouped convolutions were proposed by Krizhevsky et al. in 2012 [26, 27], but they were largely forgotten, and they were not used by subsequent state-of-the-art networks such as VGG [95], Inception [96], and ResNet [23]. Grouped convolutions began to reemerge in the literature in 2016 with Xception [29] and ResNext [30]. For ImageNet image classification, MobileNet showed in 2017 that in certain cases grouped convolutions can preserve most of the accuracy (compared to a non-grouped baseline) while producing extreme reductions in FLOPs, particularly when setting $G=C$ (where $C$ is the number of channels) in certain layers [31].15 The efficient Fix Efficient Net, Efficient Det, and SqueezeNAS networks that we covered above all make extensive use of grouped convolutions.
2020年(Efficient Det-D1 [55]),FLOPs数量减少了38倍,同时准确率有所提升。最后,在Cityscapes [91]语义分割任务中,从2016年(FCN-8s [92])到2020年(SqueezeNAS-MAC-Small [57]),FLOPs数量减少了334倍,准确率也有所提升。考虑到数据集在大多数情况下保持不变,这些改进归功于什么?其中一个因素是设计了具有更好FLOP-准确率权衡的新型神经网络架构。计算机视觉领域的神经网络架构有多个创新,包括扩张卷积(dilated convolutions)[56]、多尺度识别的创造性方法 [90, 55] 以及跳跃连接(skip-connections)的远程聚合 [94]。然而,最重要的是,过去三年中几乎所有高效的卷积神经网络设计都采用了一个有影响力的设计元素:分组卷积(grouped convolutions)。分组卷积是通道维度上的一种结构化稀疏形式,具有一个超参数 $G$,它可以将参数数量和计算量减少 $\textstyle{\frac{1}{G}}$。分组卷积由Krizhevsky等人在2012年提出 [26, 27],但后来基本被遗忘,并未被后续的先进网络如VGG [95]、Inception [96] 和 ResNet [23] 使用。分组卷积在2016年随着Xception [29] 和 ResNext [30] 的提出重新出现在文献中。对于ImageNet图像分类,MobileNet在2017年表明,在某些情况下,分组卷积可以在大幅减少FLOPs的同时保持大部分准确率(与非分组基线相比),特别是在某些层中设置 $G=C$(其中 $C$ 是通道数)时 [31]。我们上面提到的Fix Efficient Net、Efficient Det和SqueezeNAS网络都广泛使用了分组卷积。
Improved training regimes. A number of techniques have been developed to train a given selfattention neural network to higher accuracy on sentence classification tasks. GPT and BERT proposed methods for self-supervised pre training of attention networks on large corpora such as Wikipedia to improve sentence classification accuracy [8, 9]. STILTS showed that, after performing the BERT pre training scheme, accuracy can be further improved by applying transfer learning across multiple sentence classification datasets [41]. Further, MT-DNN showed that training BERT to simultaneously perform multiple sentence classification tasks can yield higher accuracy on some tasks [97].16 In addition, RoBERTa showed that pre training BERT for more iterations on a larger dataset yields higher accuracy on NLU tasks [13]. Further, ELECTRA trained BERT using an adversarial generator-disc rim in at or method, and it achieved superior accuracy to RoBERTa without changing the design of the BERT encoder [12]. The RoBERTa and ELECTRA training regimes yield significant accuracy improvements when applied to both BERT-base and BERT-large, which suggests that these regimes improve the accuracy of larger (higher latency) as well as smaller (lower latency) network architectures. Finally, we believe it may be possible to further improve the accuracy of Squeeze BERT by pre training on more data and for more iterations (similar to RoBERTa) and by pre training with an adversarial method such as ELECTRA.
改进的训练机制。已经开发了许多技术来训练给定的自注意力神经网络,以提高在句子分类任务上的准确性。GPT 和 BERT 提出了在大规模语料库(如维基百科)上对注意力网络进行自监督预训练的方法,以提高句子分类的准确性 [8, 9]。STILTS 表明,在执行 BERT 预训练方案后,通过在多个句子分类数据集上应用迁移学习,可以进一步提高准确性 [41]。此外,MT-DNN 表明,训练 BERT 同时执行多个句子分类任务可以在某些任务上获得更高的准确性 [97]。RoBERTa 进一步表明,在更大的数据集上进行更多次数的预训练可以在自然语言理解 (NLU) 任务上获得更高的准确性 [13]。此外,ELECTRA 使用对抗性生成器-判别器方法训练 BERT,在不改变 BERT 编码器设计的情况下,实现了优于 RoBERTa 的准确性 [12]。RoBERTa 和 ELECTRA 的训练机制在应用于 BERT-base 和 BERT-large 时,都带来了显著的准确性提升,这表明这些机制不仅提高了较大(较高延迟)网络架构的准确性,也提高了较小(较低延迟)网络架构的准确性。最后,我们认为通过在更多数据上进行更多次数的预训练(类似于 RoBERTa)以及使用对抗性方法(如 ELECTRA)进行预训练,可能进一步提高 Squeeze BERT 的准确性。