Learning Dense Representations of Phrases at Scale
大规模短语密集表示学习
Abstract
摘要
Open-domain question answering can be reformulated as a phrase retrieval problem, without the need for processing documents on-demand during inference (Seo et al., 2019). However, current phrase retrieval models heavily depend on sparse representations and still underperform retriever-reader approaches. In this work, we show for the first time that we can learn dense representations of phrases alone that achieve much stronger performance in opendomain QA. We present an effective method to learn phrase representations from the supervision of reading comprehension tasks, coupled with novel negative sampling methods. We also propose a query-side fine-tuning strategy, which can support transfer learning and reduce the discrepancy between training and inference. On five popular open-domain QA datasets, our model Dense Phrases improves over previous phrase retrieval models by $15\mathrm{%-}$ $25%$ absolute accuracy and matches the performance of state-of-the-art retriever-reader models. Our model is easy to parallel ize due to pure dense representations and processes more than 10 questions per second on CPUs. Finally, we directly use our pre-indexed dense phrase representations for two slot filling tasks, showing the promise of utilizing Dense Phrases as a dense knowledge base for downstream tasks.1
开放域问答可以被重新表述为短语检索问题,而无需在推理过程中按需处理文档 (Seo et al., 2019)。然而,当前的短语检索模型严重依赖于稀疏表示,并且仍然表现不如检索器-阅读器方法。在这项工作中,我们首次展示了仅通过学习短语的密集表示,可以在开放域问答中实现更强的性能。我们提出了一种有效的方法,通过阅读理解任务的监督来学习短语表示,并结合新颖的负采样方法。我们还提出了一种查询端微调策略,支持迁移学习并减少训练与推理之间的差异。在五个流行的开放域问答数据集上,我们的模型 Dense Phrases 相比之前的短语检索模型,绝对准确率提高了 $15\mathrm{%-}$ $25%$,并与最先进的检索器-阅读器模型的性能相当。由于纯密集表示,我们的模型易于并行化,并且在 CPU 上每秒可以处理超过 10 个问题。最后,我们直接使用预索引的密集短语表示来完成两个槽填充任务,展示了将 Dense Phrases 作为下游任务的密集知识库的潜力。
1 Introduction
1 引言
Open-domain question answering (QA) aims to provide answers to natural-language questions using a large text corpus (Voorhees et al., 1999; Ferrucci et al., 2010; Chen and Yih, 2020). While a dominating approach is a two-stage retriever-reader approach (Chen et al., 2017; Lee et al., 2019; Guu et al., 2020; Karpukhin et al., 2020), we focus on a recent new paradigm solely based on phrase retrieval (Seo et al., 2019; Lee et al., 2020). Phrase retrieval highlights the use of phrase representations and finds answers purely based on the similarity search in the vector space of phrases.2 Without relying on an expensive reader model for processing text passages, it has demonstrated great runtime efficiency at inference time.
开放域问答 (Open-domain QA) 旨在通过使用大型文本语料库来回答自然语言问题 (Voorhees et al., 1999; Ferrucci et al., 2010; Chen and Yih, 2020)。虽然主流方法是两阶段的检索-阅读器方法 (Chen et al., 2017; Lee et al., 2019; Guu et al., 2020; Karpukhin et al., 2020),但我们关注的是最近一种仅基于短语检索的新范式 (Seo et al., 2019; Lee et al., 2020)。短语检索强调使用短语表示,并完全基于短语向量空间中的相似性搜索来找到答案。2 由于不依赖昂贵的阅读器模型来处理文本段落,它在推理时展现了极高的运行时效率。
Despite great promise, it remains a formidable challenge to build vector representations for every single phrase in a large corpus. Since phrase representations are decomposed from question represent at ions, they are inherently less expressive than cross-attention models (Devlin et al., 2019). Moreover, the approach requires retrieving answers correctly out of billions of phrases (e.g., $6\times10^{10}$ phrases in English Wikipedia), making the scale of the learning problem difficult. Consequently, existing approaches heavily rely on sparse representations for locating relevant documents and paragraphs while still falling behind retriever-reader models (Seo et al., 2019; Lee et al., 2020).
尽管前景广阔,但在大规模语料库中为每个短语构建向量表示仍然是一个巨大的挑战。由于短语表示是从问题表示中分解出来的,它们本质上不如交叉注意力模型(Devlin 等,2019)具有表现力。此外,该方法需要从数十亿个短语中正确检索答案(例如,英文维基百科中的 $6\times10^{10}$ 个短语),这使得学习问题的规模变得困难。因此,现有方法严重依赖稀疏表示来定位相关文档和段落,但仍然落后于检索-阅读器模型(Seo 等,2019;Lee 等,2020)。
In this work, we investigate whether we can build fully dense phrase representations at scale for opendomain QA. First, we aim to learn strong phrase representations from the supervision of reading comprehension tasks. We propose to use data augmentation and knowledge distillation to learn better phrase representations within a single passage. We then adopt negative sampling strategies such as inbatch negatives (Henderson et al., 2017; Karpukhin et al., 2020), to better discriminate the phrases at a larger scale. Here, we present a novel method called pre-batch negatives, which leverages preceding mini-batches as negative examples to compensate the need of large-batch training. Lastly, we present a query-side fine-tuning strategy that drastically improves phrase retrieval performance and allows for transfer learning to new domains, without re-building billions of phrase representations.
在本工作中,我们探讨了是否可以为开放域问答 (QA) 构建大规模的完全密集短语表示。首先,我们的目标是从阅读理解任务的监督中学习强短语表示。我们提出使用数据增强和知识蒸馏来在单个段落内学习更好的短语表示。然后,我们采用负采样策略,例如批次内负样本 (Henderson et al., 2017; Karpukhin et al., 2020),以在更大规模上更好地区分短语。在此,我们提出了一种称为预批次负样本的新方法,该方法利用前面的小批次作为负样本来弥补大规模批次训练的需求。最后,我们提出了一种查询端微调策略,该策略显著提高了短语检索性能,并允许在不重建数十亿短语表示的情况下进行跨领域迁移学习。
Table 1: Retriever-reader and phrase retrieval approaches for open-domain QA. The retriever-reader approach retrieves a small number of relevant documents or passages from which the answers are extracted. The phrase retrieval approach retrieves an answer out of billions of phrase representations pre-indexed from the entire corpus. Appendix B provides detailed benchmark specification. The accuracy is measured on the test sets in the opendomain setting. NQ: Natural Questions.
表 1: 开放域问答中的检索器-阅读器和短语检索方法。检索器-阅读器方法从少量相关文档或段落中检索出答案。短语检索方法从整个语料库中预索引的数十亿个短语表示中检索出答案。附录 B 提供了详细的基准规范。准确率是在开放域设置下的测试集上测量的。NQ: Natural Questions。
| 类别 | 模型 | 稀疏? | 存储 (GB) | #Q/秒 (GPU, CPU) | NQ (准确率) | SQuAD (准确率) |
|---|---|---|---|---|---|---|
| 检索器-阅读器 | DrQA (Chen et al., 2017) | 26 | 1.8, 0.6 | 29.8 | ||
| 检索器-阅读器 | BERTSerini (Yang et al., 2019) | 21 | 2.0, 0.4 | 38.6 | ||
| 检索器-阅读器 | ORQA (Lee et al., 2019) | × | 18 | 8.6, 1.2 | 33.3 | 20.2 |
| 检索器-阅读器 | REALMNews (Guu et al., 2020) | × | 18 | 8.4, 1.2 | 40.4 | |
| 检索器-阅读器 | DPR-multi (Karpukhin et al., 2020) | 76 | 0.9, 0.04 | 41.5 | 24.1 | |
| 短语检索 | DenSPI (Seo et al., 2019) | 1,200 | 2.9, 2.4 | 8.1 | 36.2 | |
| 短语检索 | DenSPI + Sparc (Lee et al., 2020) | 1,547 | 2.1, 1.7 | 14.5 | 40.7 | |
| 短语检索 | DensePhrases (Ours) | 320 | 20.6, 13.6 | 40.9 | 38.0 |
As a result, all these improvements lead to a much stronger phrase retrieval model, without the use of any sparse representations (Table 1). We evaluate our model, Dense Phrases, on five standard open-domain QA datasets and achieve much better accuracies than previous phrase retrieval models (Seo et al., 2019; Lee et al., 2020), with $15%-$ $25%$ absolute improvement on most datasets. Our model also matches the performance of state-ofthe-art retriever-reader models (Guu et al., 2020; Karpukhin et al., 2020). Due to the removal of sparse representations and careful design choices, we further reduce the storage footprint for the full English Wikipedia from $1.5\mathrm{TB}$ to 320GB, as well as drastically improve the throughput.
因此,所有这些改进使得短语检索模型变得更加强大,且无需使用任何稀疏表示(表 1)。我们在五个标准的开放域问答数据集上评估了我们的模型 Dense Phrases,并取得了比之前的短语检索模型(Seo et al., 2019; Lee et al., 2020)更好的准确率,在大多数数据集上实现了 $15%-$ $25%$ 的绝对提升。我们的模型还达到了最先进的检索-阅读器模型(Guu et al., 2020; Karpukhin et al., 2020)的性能。由于去除了稀疏表示并进行了精心的设计选择,我们进一步将整个英文维基百科的存储占用从 $1.5\mathrm{TB}$ 减少到 320GB,并大幅提高了吞吐量。
Finally, we envision that Dense Phrases acts as a neural interface for retrieving phrase-level knowledge from a large text corpus. To showcase this possibility, we demonstrate that we can directly use Dense Phrases for fact extraction, without rebuilding the phrase storage. With only fine-tuning the question encoder on a small number of subjectrelation-object triples, we achieve state-of-the-art performance on two slot filling tasks (Petroni et al., 2021), using less than $5%$ of the training data.
最后,我们设想 Dense Phrases 可以作为一种神经接口,用于从大型文本语料库中检索短语级知识。为了展示这种可能性,我们证明了可以直接使用 Dense Phrases 进行事实提取,而无需重建短语存储。仅通过对少量主语-关系-宾语三元组进行问题编码器的微调,我们在两个槽填充任务上实现了最先进的性能 (Petroni et al., 2021),使用的训练数据不到 $5%$。
2 Background
2 背景
We first formulate the task of open-domain question answering for a set of $K$ documents $\mathcal{D}=$ ${d_{1},\ldots,d_{K}}$ . We follow the recent work (Chen et al., 2017; Lee et al., 2019) and treat all of English Wikipedia as $\mathcal{D}$ , hence $K\approx5\times10^{6}$ . However, most approaches—including ours—are generic and could be applied to other collections of documents.
我们首先为一系列 $K$ 个文档 $\mathcal{D}=$ ${d_{1},\ldots,d_{K}}$ 定义了开放域问答任务。我们遵循最近的研究 (Chen et al., 2017; Lee et al., 2019),将整个英文维基百科视为 $\mathcal{D}$,因此 $K\approx5\times10^{6}$。然而,大多数方法——包括我们的方法——都是通用的,可以应用于其他文档集合。
The task aims to provide an answer $\hat{a}$ for the input question $q$ based on $\mathcal{D}$ . In this work, we focus on the extractive QA setting, where each answer is a segment of text, or a phrase, that can be found in $\mathcal{D}$ . Denote the set of phrases in $\mathcal{D}$ as $S({\mathcal{D}})$ and each phrase $s_{k}\in S(\mathcal{D})$ consists of contiguous words $w_{\mathrm{start}(k)},\ldots,w_{\mathrm{end}(k)}$ in its document $d_{\mathsf{d o c}(k)}$ . In practice, we consider all the phrases up to $L=20$ words in $\mathcal{D}$ and $S({\mathcal{D}})$ comprises a large number of $6\times10^{10}$ phrases. An extractive QA system returns a phrase $\hat{s}=\mathrm{argmax}_{s\in{\cal S}(\mathcal{D})}f(s|\mathcal{D},q)$ where $f$ is a scoring function. The system finally maps $\hat{s}$ to an answer string $\hat{a}$ $:\mathrm{TEXT}({\hat{s}})={\hat{a}}$ and the evaluation is typically done by comparing the predicted answer $\hat{a}$ with a gold answer $a^{*}$ .
该任务旨在基于 $\mathcal{D}$ 为输入问题 $q$ 提供一个答案 $\hat{a}$。在本工作中,我们专注于抽取式问答 (extractive QA) 设置,其中每个答案都是可以在 $\mathcal{D}$ 中找到的一段文本或短语。将 $\mathcal{D}$ 中的短语集合表示为 $S({\mathcal{D}})$,每个短语 $s_{k}\in S(\mathcal{D})$ 由其在文档 $d_{\mathsf{d o c}(k)}$ 中的连续单词 $w_{\mathrm{start}(k)},\ldots,w_{\mathrm{end}(k)}$ 组成。在实践中,我们考虑 $\mathcal{D}$ 中所有长度不超过 $L=20$ 个单词的短语,$S({\mathcal{D}})$ 包含大量短语,数量约为 $6\times10^{10}$。抽取式问答系统返回一个短语 $\hat{s}=\mathrm{argmax}_{s\in{\cal S}(\mathcal{D})}f(s|\mathcal{D},q)$,其中 $f$ 是一个评分函数。系统最终将 $\hat{s}$ 映射为一个答案字符串 $\hat{a}$ $:\mathrm{TEXT}({\hat{s}})={\hat{a}}$,评估通常通过比较预测答案 $\hat{a}$ 与标准答案 $a^{*}$ 来完成。
Although we focus on the extractive QA setting, recent works propose to use a generative model as the reader (Lewis et al., 2020; Izacard and Grave, 2021), or learn a closed-book QA model (Roberts et al., 2020), which directly predicts answers without using an external knowledge source. The extractive setting provides two advantages: first, the model directly locates the source of the answer, which is more interpret able, and second, phraselevel knowledge retrieval can be uniquely adapted to other NLP tasks as we show in $\S7.3$ .
尽管我们专注于抽取式问答 (extractive QA) 设置,但最近的研究提出使用生成式模型作为阅读器 (Lewis et al., 2020; Izacard and Grave, 2021),或者学习一个闭卷问答模型 (Roberts et al., 2020),该模型无需使用外部知识源即可直接预测答案。抽取式设置提供了两个优势:首先,模型直接定位答案的来源,更具可解释性;其次,短语级别的知识检索可以独特地适应其他 NLP 任务,正如我们在 $\S7.3$ 中展示的那样。
Retriever-reader. A dominating paradigm in open-domain QA is the retriever-reader approach (Chen et al., 2017; Lee et al., 2019; Karpukhin et al., 2020), which leverages a firststage document retriever $f_{\mathrm{retr}}$ and only reads top $K^{\prime}\ll K$ documents with a reader model $f_{\mathrm{read}}$ The scoring function $f(s\mid{\mathcal{D}},q)$ is decomposed as:
检索-阅读器。开放域问答中的一个主导范式是检索-阅读器方法 (Chen et al., 2017; Lee et al., 2019; Karpukhin et al., 2020),该方法利用第一阶段的文档检索器 $f_{\mathrm{retr}}$,并仅使用阅读器模型 $f_{\mathrm{read}}$ 读取前 $K^{\prime}\ll K$ 个文档。评分函数 $f(s\mid{\mathcal{D}},q)$ 被分解为:

where ${j_{1},\dots,j_{K^{\prime}}}\subset{1,\dots,K}$ and if $s\not\in$ $\mathcal{S}({d_{j_{1}},\ldots,d_{j_{K^{\prime}}}})$ , the score will be 0. It can easily adapt to passages and sentences (Yang et al., 2019; Wang et al., 2019). However, this approach suffers from error propagation when incorrect documents are retrieved and can be slow as it usually requires running an expensive reader model on every retrieved document or passage at inference time.
其中 ${j_{1},\dots,j_{K^{\prime}}}\subset{1,\dots,K}$,且如果 $s\not\in$ $\mathcal{S}({d_{j_{1}},\ldots,d_{j_{K^{\prime}}}})$,则得分为 0。这种方法可以轻松适应段落和句子 (Yang et al., 2019; Wang et al., 2019)。然而,当检索到错误的文档时,这种方法会面临错误传播的问题,并且可能会很慢,因为它通常需要在推理时对每个检索到的文档或段落运行昂贵的阅读器模型。
Phrase retrieval. Seo et al. (2019) introduce the phrase retrieval approach that encodes phrase and question representations independently and performs similarity search over the phrase representations to find an answer. Their scoring function $f$ is computed as follows:
短语检索。Seo 等人 (2019) 提出了短语检索方法,该方法独立编码短语和问题表示,并在短语表示上执行相似性搜索以找到答案。他们的评分函数 $f$ 计算如下:

where $E_{s}$ and $E_{q}$ denote the phrase encoder and the question encoder respectively. As $E_{s}(\cdot)$ and $E_{q}(\cdot)$ representations are de com pos able, it can support maximum inner product search (MIPS) and improve the efficiency of open-domain QA models. Previous approaches (Seo et al., 2019; Lee et al., 2020) leverage both dense and sparse vectors for phrase and question representations by taking their concatenation: $\begin{array}{r l}{E_{s}(s,\mathcal{D})}&{{}=}\end{array}$ $[E_{\mathrm{sparse}}(s,\mathcal{D}),E_{\mathrm{dense}}(s,\mathcal{D})]$ .3 However, since the sparse vectors are difficult to parallel ize with dense vectors, their method essentially conducts sparse and dense vector search separately. The goal of this work is to only use dense representations, i.e., $E_{s}(s,\mathcal{D})=E_{\mathrm{dense}}(s,\mathcal{D})$ , which can model $f(s\mid{\mathcal{D}},q)$ solely with MIPS, as well as close the gap in performance.
其中 $E_{s}$ 和 $E_{q}$ 分别表示短语编码器和问题编码器。由于 $E_{s}(\cdot)$ 和 $E_{q}(\cdot)$ 的表示是可分解的,因此它支持最大内积搜索 (MIPS) 并提高开放域问答模型的效率。先前的方法 (Seo et al., 2019; Lee et al., 2020) 通过连接密集向量和稀疏向量来利用短语和问题的表示:$\begin{array}{r l}{E_{s}(s,\mathcal{D})}&{{}=}\end{array}$ $[E_{\mathrm{sparse}}(s,\mathcal{D}),E_{\mathrm{dense}}(s,\mathcal{D})]$。然而,由于稀疏向量难以与密集向量并行化,他们的方法本质上分别进行稀疏和密集向量搜索。这项工作的目标是仅使用密集表示,即 $E_{s}(s,\mathcal{D})=E_{\mathrm{dense}}(s,\mathcal{D})$,它可以通过 MIPS 单独建模 $f(s\mid{\mathcal{D}},q)$,并缩小性能差距。
3 Dense Phrases
3 密集短语
3.1 Overview
3.1 概述
We introduce Dense Phrases, a phrase retrieval model that is built on fully dense representations. Our goal is to learn a phrase encoder as well as a question encoder, so we can pre-index all the possible phrases in $\mathcal{D}$ , and efficiently retrieve phrases for any question through MIPS at testing time. We outline our approach as follows:
我们介绍了 Dense Phrases,这是一种基于完全密集表示的短语检索模型。我们的目标是学习一个短语编码器和一个问题编码器,以便我们可以预索引 $\mathcal{D}$ 中所有可能的短语,并在测试时通过 MIPS 高效地检索任何问题的短语。我们的方法概述如下:
Before we present the approach in detail, we first describe our base architecture below.
在我们详细介绍方法之前,首先描述一下我们的基础架构。
3.2 Base Architecture
3.2 基础架构
Our base architecture consists of a phrase encoder $E_{s}$ and a question encoder $E_{q}$ . Given a passage $p=w_{1},\ldots,w_{m}$ , we denote all the phrases up to $L$ tokens as $S(p)$ . Each phrase $s_{k}$ has start and end in- dicies start $(k)$ and $\mathsf{e n d(}k\mathbf{)}$ and the gold phrase is $s^{*}\in S(p)$ . Following previous work on phrase or span representations (Lee et al., 2017; Seo et al., 2018), we first apply a pre-trained language model $\mathcal{M}{p}$ to obtain contextual i zed word representations for each passage token: $\mathbf{h}{1},\ldots,\mathbf{h}{m}\in\mathbb{R}^{d}$ . Then, we can represent each phrase $s{k}\in S(p)$ as the concatenation of corresponding start and end vectors:
我们的基础架构包括一个短语编码器 $E_{s}$ 和一个问题编码器 $E_{q}$。给定一个段落 $p=w_{1},\ldots,w_{m}$,我们将所有不超过 $L$ 个 Token 的短语表示为 $S(p)$。每个短语 $s_{k}$ 有起始和结束索引 start $(k)$ 和 $\mathsf{e n d(}k\mathbf{)}$,黄金短语为 $s^{*}\in S(p)$。根据之前关于短语或跨度表示的研究 (Lee et al., 2017; Seo et al., 2018),我们首先应用一个预训练的语言模型 $\mathcal{M}{p}$ 来获取每个段落 Token 的上下文词表示:$\mathbf{h}{1},\ldots,\mathbf{h}{m}\in\mathbb{R}^{d}$。然后,我们可以将每个短语 $s{k}\in S(p)$ 表示为相应起始和结束向量的拼接:

A great advantage of this representation is that we eventually only need to index and store all the word vectors (we use $\mathcal{W}(\mathcal{D})$ to denote all the words in $\mathcal{D})$ , instead of all the phrases $S({\mathcal{D}})$ , which is at least one magnitude order smaller.
这种表示方法的一个巨大优势是,我们最终只需要索引和存储所有的词向量(我们用 $\mathcal{W}(\mathcal{D})$ 表示 $\mathcal{D}$ 中的所有词),而不是所有的短语 $S({\mathcal{D}})$,这至少小了一个数量级。
Similarly, we need to learn a question encoder $E_{q}(\cdot)$ that maps a question $q=\tilde{w}{1},\ldots,\tilde{w}{n}$ to a vector of the same dimension as $E_{s}(\cdot)$ . Since the start and end representations of phrases are produced by the same language model, we use another two different pre-trained encoders $\mathcal{M}{q,\mathrm{start}}$ and $\mathcal{M}{q,\mathrm{end}}$ to differentiate the start and end positions. We apply ${\mathcal{M}}{q,{\mathrm{start}}}$ and $\mathcal{M}{q,\mathrm{end}}$ on $q$ separately and obtain representations $\mathbf{q}^{\mathrm{start}}$ and qend taken from the [CLS] token representations respectively. Finally, $E_{q}(\cdot)$ simply takes their concatenation:
同样,我们需要学习一个问题编码器 $E_{q}(\cdot)$,它将问题 $q=\tilde{w}{1},\ldots,\tilde{w}{n}$ 映射到与 $E_{s}(\cdot)$ 相同维度的向量。由于短语的起始和结束表示由相同的语言模型生成,我们使用另外两个不同的预训练编码器 $\mathcal{M}{q,\mathrm{start}}$ 和 $\mathcal{M}{q,\mathrm{end}}$ 来区分起始和结束位置。我们分别将 ${\mathcal{M}}{q,{\mathrm{start}}}$ 和 $\mathcal{M}{q,\mathrm{end}}$ 应用于 $q$,并分别从 [CLS] token 表示中获取表示 $\mathbf{q}^{\mathrm{start}}$ 和 qend。最后,$E_{q}(\cdot)$ 简单地取它们的拼接:
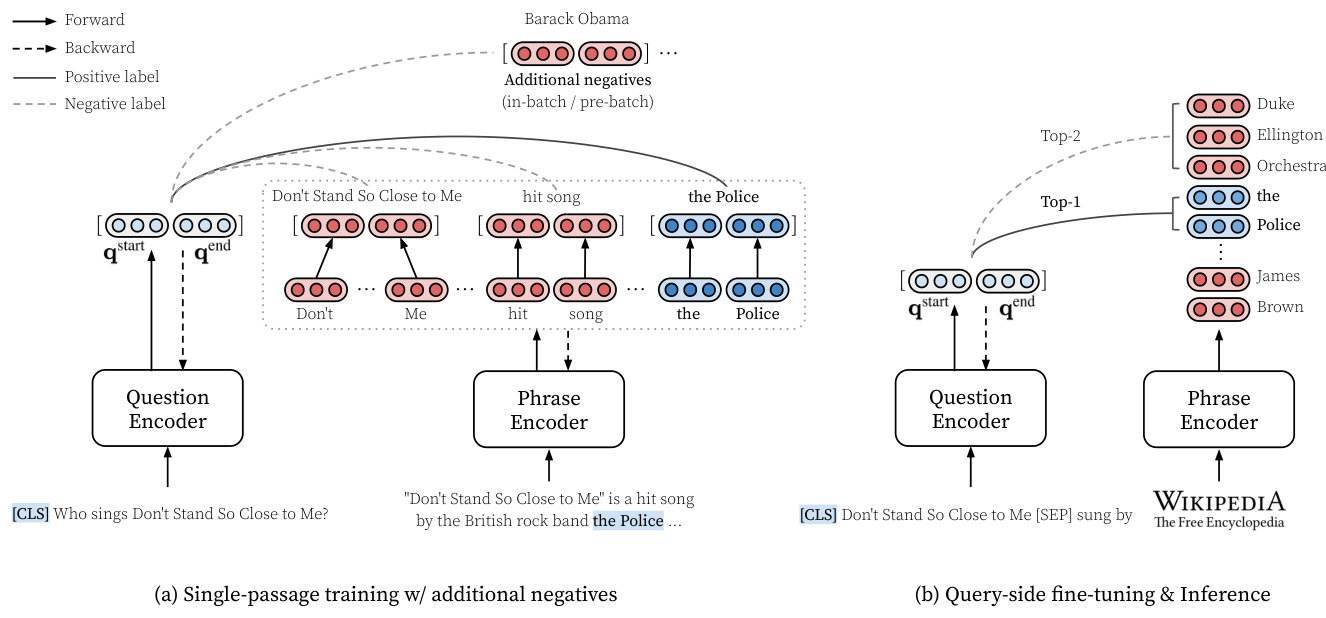
Figure 1: An overview of Dense Phrases. (a) We learn dense phrase representations in a single passage (§4.1) along with in-batch and pre-batch negatives $(\S4.2,\S4.3)$ . (b) With the top $k$ retrieved phrase representations from the entire text corpus (§5), we further perform query-side fine-tuning to optimize the question encoder (§6). During inference, our model simply returns the top-1 prediction.
图 1: Dense Phrases 概览。(a) 我们在单个段落中学习密集短语表示 (§4.1),并结合批次内和预批次负样本 $(\S4.2,\S4.3)$。(b) 通过从整个文本语料库中检索到的前 $k$ 个短语表示 (§5),我们进一步进行查询端微调以优化问题编码器 (§6)。在推理过程中,我们的模型仅返回前 1 个预测结果。

Note that we use pre-trained language models to initialize $\mathcal{M}{p}$ , $\mathcal{M}{q,\mathrm{start}}$ and $\mathcal{M}{q,\mathrm{end}}$ and they are fine-tuned with the objectives that we will define later. In our pilot experiments, we found that SpanBERT (Joshi et al., 2020) leads to superior performance compared to BERT (Devlin et al., 2019). SpanBERT is designed to predict the information in the entire span from its two endpoints, therefore it is well suited for our phrase representations. In our final model, we use SpanBERT-base-cased as our base LMs for $E{s}$ and $E_{q}$ , and hence $d=768.$ .5 See Table 5 for an ablation study.
请注意,我们使用预训练的语言模型来初始化 $\mathcal{M}{p}$、$\mathcal{M}{q,\mathrm{start}}$ 和 $\mathcal{M}{q,\mathrm{end}}$,并通过我们稍后定义的目标进行微调。在我们的初步实验中,我们发现 SpanBERT (Joshi et al., 2020) 相比 BERT (Devlin et al., 2019) 表现更优。SpanBERT 旨在从其两个端点预测整个跨度的信息,因此非常适合我们的短语表示。在我们的最终模型中,我们使用 SpanBERT-base-cased 作为 $E{s}$ 和 $E_{q}$ 的基础语言模型,因此 $d=768$。详见表 5 的消融研究。
4 Learning Phrase Representations
4 学习短语表示
In this section, we start by learning dense phrase representations from the supervision of reading comprehension tasks, i.e., a single passage $p$ contains an answer $a^{*}$ to a question $q$ . Our goal is to learn strong dense representations of phrases for $s\in S(p)$ , which can be retrieved by a dense represent ation of the question and serve as a direct answer (§4.1). Then, we introduce two different negative sampling methods $(\S4.2,\S4.3)$ , which encourage the phrase representations to be better discriminated at the full Wikipedia scale. See Figure 1 for an overview of Dense Phrases.
在本节中,我们首先从阅读理解任务的监督中学习密集短语表示,即单个段落 $p$ 包含问题 $q$ 的答案 $a^{*}$。我们的目标是为 $s\in S(p)$ 学习强密集短语表示,这些表示可以通过问题的密集表示进行检索,并作为直接答案(§4.1)。然后,我们介绍了两种不同的负采样方法 $(\S4.2,\S4.3)$,这些方法鼓励短语表示在全维基百科范围内更好地进行区分。有关 Dense Phrases 的概述,请参见图 1。
4.1 Single-passage Training
4.1 单段落训练
To learn phrase representations in a single passage along with question representations, we first maximize the log-likelihood of the start and end positions of the gold phrase $s^{}$ where $\operatorname{TEXT}(s^{})=a^{*}$ . The training loss for predicting the start position of a phrase given a question is computed as:
为了在单一段落中学习短语表示以及问题表示,我们首先最大化黄金短语 $s^{}$ 的起始和结束位置的对数似然,其中 $\operatorname{TEXT}(s^{})=a^{*}$。给定问题预测短语起始位置的训练损失计算如下:

We can define $\mathcal{L}_{\mathrm{end}}$ in a similar way and the final loss for the single-passage training is
我们可以用类似的方式定义 $\mathcal{L}_{\mathrm{end}}$,单段落训练的最终损失为
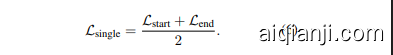
This essentially learns reading comprehension without any cross-attention between the passage and the question tokens, which fully decomposes phrase and question representations.
这本质上是在没有任何段落和问题Token之间的交叉注意力的情况下学习阅读理解,从而完全分解了短语和问题的表示。
Data augmentation Since the contextual i zed word representations $\mathbf{h}{1},\ldots,\mathbf{h}{m}$ are encoded in a query-agnostic way, they are always inferior to query-dependent representations in cross-attention models (Devlin et al., 2019), where passages are fed along with the questions concatenated by a special token such as [SEP]. We hypothesize that one key reason for the performance gap is that reading comprehension datasets only provide a few annotated questions in each passage, compared to the set of possible answer phrases. Learning from this supervision is not easy to differentiate similar phrases in one passage (e.g., $s^{*}=$ Charles, Prince of Wales and another $s=P_{\mathrm{}}$ rince George for a question $q=$ Who is next in line to be the monarch of England?).
数据增强 (Data Augmentation) 由于上下文化的词表示 $\mathbf{h}{1},\ldots,\mathbf{h}{m}$ 是以与查询无关的方式编码的,因此在交叉注意力模型 (Devlin et al., 2019) 中,它们总是劣于依赖于查询的表示。在这些模型中,段落与通过特殊 Token(如 [SEP])连接的问题一起输入。我们假设性能差距的一个关键原因是阅读理解数据集在每个段落中只提供了少量标注的问题,而可能的答案短语集合要大得多。从这种监督中学习很难区分一个段落中的相似短语(例如,对于问题 $q=$ 谁是英国王位的下一位继承人?,$s^{*}=$ 查尔斯王子和另一个 $s=P_{\mathrm{}}$ 乔治王子)。
Following this intuition, we propose to use a simple model to generate additional questions for data augmentation, based on a T5-large model (Raffel et al., 2020). To train the question genera- tion model, we feed a passage $p$ with the gold answer $s^{*}$ highlighted by inserting surrounding special tags. Then, the model is trained to maximize the log-likelihood of the question words of $q$ . After training, we extract all the named entities in each training passage as candidate answers and feed the passage $p$ with each candidate answer to generate questions. We keep the questionanswer pairs only when a cross-attention reading comprehension model6 makes a correct prediction on the generated pair. The remaining generated QA pairs ${(\bar{q}{1},\bar{s}{1}),(\bar{q}{2},\bar{s}{2}),\ldots,(\bar{q}{r},\bar{s}{r})}$ are directly augmented to the original training set.
基于这一直觉,我们提出使用一个简单的模型来生成额外的问题以进行数据增强,该模型基于 T5-large 模型 (Raffel et al., 2020)。为了训练问题生成模型,我们输入一个段落 $p$,并通过插入特殊标签来突出显示黄金答案 $s^{*}$。然后,模型被训练以最大化问题 $q$ 的单词的对数似然。训练完成后,我们提取每个训练段落中的所有命名实体作为候选答案,并将段落 $p$ 与每个候选答案一起输入以生成问题。只有当交叉注意力阅读理解模型6对生成的问答对做出正确预测时,我们才保留这些问答对。剩余的生成问答对 ${(\bar{q}{1},\bar{s}{1}),(\bar{q}{2},\bar{s}{2}),\ldots,(\bar{q}{r},\bar{s}{r})}$ 直接扩充到原始训练集中。
Distillation We also propose improving the phrase representations by distilling knowledge from a cross-attention model (Hinton et al., 2015). We minimize the Kullback–Leibler divergence between the probability distribution from our phrase encoder and that from a standard SpanBERT-base QA model. The loss is computed as follows:
蒸馏
我们还提出通过从交叉注意力模型 (Hinton et al., 2015) 中蒸馏知识来改进短语表示。我们最小化短语编码器的概率分布与标准 SpanBERT-base QA 模型的概率分布之间的 Kullback–Leibler 散度。损失计算如下:

where $P^{\mathrm{start}}$ (and $P^{\mathrm{end}}$ ) is defined in Eq. (5) and $P_{c}^{\mathrm{start}}$ and $P_{c}^{\mathrm{end}}$ denote the probability distributions used to predict the start and end positions of answers in the cross-attention model.
其中 $P^{\mathrm{start}}$ (和 $P^{\mathrm{end}}$ ) 在公式 (5) 中定义,$P_{c}^{\mathrm{start}}$ 和 $P_{c}^{\mathrm{end}}$ 表示用于预测跨注意力模型中答案开始和结束位置的概率分布。
4.2 In-batch Negatives
4.2 批次内负样本 (In-batch Negatives)
Eventually, we need to build phrase representations for billions of phrases. Therefore, a bigger challenge is to incorporate more phrases as negatives so the representations can be better discriminated at a larger scale. While Seo et al. (2019) simply sample two negative passages based on question similarity, we use in-batch negatives for our dense phrase representations, which has been shown to be effective in learning dense passage representations before (Karpukhin et al., 2020).
最终,我们需要为数十亿个短语构建短语表示。因此,更大的挑战是引入更多短语作为负样本,以便在大规模上更好地区分这些表示。虽然 Seo 等人 (2019) 仅基于问题相似性采样了两个负段落,但我们使用批次内负样本来构建密集短语表示,这在之前的学习密集段落表示中已被证明是有效的 (Karpukhin 等人, 2020)。
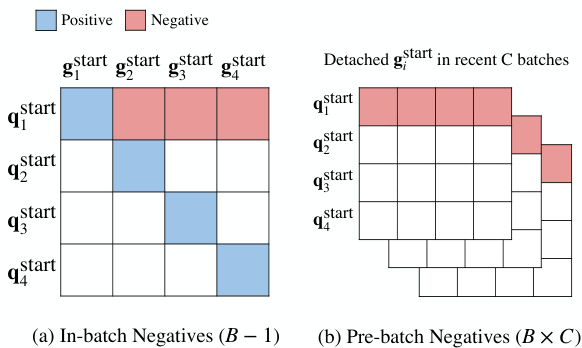
Figure 2: Two types of negative samples for the first batch item $(\mathbf{q}_{1}^{\mathrm{start}})$ in a mini-batch of size $B=4$ and $C=3$ . Note that the negative samples for the end representations $(\mathbf{q}_{i}^{\mathrm{end}})$ are obtained in a similar manner. See $\S4.2$ and $\S4.3$ for more details.
图 2: 在大小为 $B=4$ 和 $C=3$ 的小批量中,第一个批次项 $(\mathbf{q}_{1}^{\mathrm{start}})$ 的两种类型的负样本。注意,结束表示 $(\mathbf{q}_{i}^{\mathrm{end}})$ 的负样本以类似的方式获得。更多细节请参见 $\S4.2$ 和 $\S4.3$。
As shown in Figure 2 (a), for the $i$ -th example in a mini-batch of size $B$ , we denote the hidden representations of the gold start and end positions $\mathbf{h}{\mathit{s t a r t}}(s^{*})$ and $\mathbf{h}{\mathrm{end}(s^{*})}$ as $\mathbf{g}{i}^{\mathrm{start}}$ and $\mathbf{g}{i}^{\mathrm{end}}$ , as well as the question representation as $[\mathbf{q}{i}^{\mathrm{start}},\mathbf{q}{i}^{\mathrm{end}}]$ . Let ${\bf G}^{\mathrm{start}},{\bf G}^{\mathrm{end}},{\bf Q}^{\mathrm{start}},{\bf Q}^{\mathrm{end}}$ be the $B\times d$ matrices and each row corresponds to $\mathbf{g}{i}^{\mathrm{start}},\mathbf{g}{i}^{\mathrm{end}},\mathbf{q}{i}^{\mathrm{start}},\mathbf{q}{i}^{\mathrm{end}}$ respectively. Basically, we can treat all the gold phrases from other passages in the same mini-batch as negative examples. We compute $\mathbf{S}^{\mathrm{start}}=\mathbf{Q}^{\mathrm{start}}\mathbf{G}^{\mathrm{start}\intercal}$ and $\mathbf{S}^{\mathrm{end}}=$ $\mathbf{Q}^{\mathrm{end}}\mathbf{G}^{\mathrm{end}\top}$ and the $i$ -th row of $\mathbf{S}^{\mathrm{start}}$ and ${\bf S}^{\mathrm{end}}$ return $B$ scores each, including a positive score and $B{-}1$ negative scores: $s_{1}^{\mathrm{start}},\ldots,s_{B}^{\mathrm{start}}$ and sen d, $s_{1}^{\mathrm{end}},\ldots,s_{B}^{\mathrm{end}}$ Similar to Eq. (5), we can compute the loss function for the $i$ -th example as:
如图 2 (a) 所示,对于大小为 $B$ 的小批量中的第 $i$ 个样本,我们将黄金开始和结束位置的隐藏表示 $\mathbf{h}{\mathit{s t a r t}}(s^{*})$ 和 $\mathbf{h}{\mathrm{end}(s^{*})}$ 分别表示为 $\mathbf{g}{i}^{\mathrm{start}}$ 和 $\mathbf{g}{i}^{\mathrm{end}}$,并将问题表示表示为 $[\mathbf{q}{i}^{\mathrm{start}},\mathbf{q}{i}^{\mathrm{end}}]$。令 ${\bf G}^{\mathrm{start}},{\bf G}^{\mathrm{end}},{\bf Q}^{\mathrm{start}},{\bf Q}^{\mathrm{end}}$ 为 $B\times d$ 的矩阵,每行分别对应 $\mathbf{g}{i}^{\mathrm{start}},\mathbf{g}{i}^{\mathrm{end}},\mathbf{q}{i}^{\mathrm{start}},\mathbf{q}{i}^{\mathrm{end}}$。基本上,我们可以将同一小批量中其他段落的黄金短语视为负样本。我们计算 $\mathbf{S}^{\mathrm{start}}=\mathbf{Q}^{\mathrm{start}}\mathbf{G}^{\mathrm{start}\intercal}$ 和 $\mathbf{S}^{\mathrm{end}}=$ $\mathbf{Q}^{\mathrm{end}}\mathbf{G}^{\mathrm{end}\top}$,$\mathbf{S}^{\mathrm{start}}$ 和 ${\bf S}^{\mathrm{end}}$ 的第 $i$ 行分别返回 $B$ 个分数,包括一个正分数和 $B{-}1$ 个负分数:$s_{1}^{\mathrm{start}},\ldots,s_{B}^{\mathrm{start}}$ 和 $s_{1}^{\mathrm{end}},\ldots,s_{B}^{\mathrm{end}}$。类似于公式 (5),我们可以计算第 $i$ 个样本的损失函数为:

We also attempted using non-gold phrases from other passages as negatives but did not find a meaningful improvement.
我们还尝试使用其他段落中的非黄金短语作为负样本,但没有发现有意义的改进。
4.3 Pre-batch Negatives
4.3 预批负样本
The in-batch negatives usually benefit from a large batch size (Karpukhin et al., 2020). However, it is challenging to further increase batch sizes, as they are bounded by the size of GPU memory. Next, we propose a novel negative sampling method called pre-batch negatives, which can effectively utilize the representations from the preceding $C$ mini-batches (Figure 2 (b)). In each iteration, we maintain a FIFO queue of $C$ mini-batches to cache phrase representations $\mathbf{G}^{\mathrm{start}}$ and $\mathbf{G}^{\mathrm{end}}$ . The cached phrase representations are then used as negative samples for the next iteration, providing $B\times C$ additional negative samples in total.7
批次内负样本通常受益于较大的批次大小 (Karpukhin et al., 2020)。然而,进一步增加批次大小具有挑战性,因为它们受限于 GPU 内存的大小。接下来,我们提出了一种新的负采样方法,称为预批次负样本,它可以有效利用前 $C$ 个小批次的表示 (图 2 (b))。在每次迭代中,我们维护一个大小为 $C$ 的 FIFO 队列来缓存短语表示 $\mathbf{G}^{\mathrm{start}}$ 和 $\mathbf{G}^{\mathrm{end}}$。缓存的短语表示随后被用作下一次迭代的负样本,总共提供 $B\times C$ 个额外的负样本。
These pre-batch negatives are used together with in-batch negatives and the training loss is the same as Eq. (8), except that the gradients are not backpropagated to the cached pre-batch negatives. After warming up the model with in-batch negatives, we simply shift from in-batch negatives $(B-1$ negatives) to in-batch and pre-batch negatives (hence a total number of $B\times C+B-1$ negatives). For simplicity, we use $\mathcal{L}_{\mathrm{neg}}$ to denote the loss for both inbatch negatives and pre-batch negatives. Since we do not retain the computational graph for pre-batch negatives, the memory consumption of pre-batch negatives is much more manageable while allowing an increase in the number of negative samples.
这些预批次负样本与批次内负样本一起使用,训练损失与公式 (8) 相同,只是梯度不会反向传播到缓存的预批次负样本。在用批次内负样本预热模型后,我们简单地从批次内负样本($B-1$ 个负样本)切换到批次内和预批次负样本(因此总共有 $B\times C+B-1$ 个负样本)。为简单起见,我们使用 $\mathcal{L}_{\mathrm{neg}}$ 来表示批次内负样本和预批次负样本的损失。由于我们不保留预批次负样本的计算图,预批次负样本的内存消耗更加可控,同时允许增加负样本的数量。
4.4 Training Objective
4.4 训练目标
Finally, we optimize all the three losses together, on both annotated reading comprehension examples and generated questions from $\S4.1$ :
最后,我们在标注的阅读理解示例和 $\S4.1$ 生成的问题上同时优化所有三个损失函数:

where $\lambda_{1},\lambda_{2},\lambda_{3}$ determine the importance of each loss term. We found that $\lambda_{1}=1$ , $\lambda_{2}=2$ , and $\lambda_{3}=$ 4 works well in practice. See Table 5 and Table 6 for an ablation study of different components.
其中 $\lambda_{1},\lambda_{2},\lambda_{3}$ 决定了每个损失项的重要性。我们发现 $\lambda_{1}=1$ 、$\lambda_{2}=2$ 和 $\lambda_{3}=4$ 在实践中效果良好。关于不同组件的消融研究,请参见表 5 和表 6。
5 Indexing and Search
5 索引与搜索
Indexing After training the phrase encoder $E_{s}$ , we need to encode all the phrases $S({\mathcal{D}})$ in the entire English Wikipedia $\mathcal{D}$ and store an index of the phrase dump. We segment each document $d_{i}\in\mathcal{D}$ into a set of natural paragraphs, from which we obtain token representations for each paragraph using $E_{s}(\cdot)$ . Then, we build a phrase dump $\mathbf{H}=[\mathbf{h}{1},\dots,\mathbf{h}{|\mathcal{W}(\mathcal{D})|}]\in\mathbb{R}^{|\mathcal{W}(\mathcal{D})|\times d}$ by stacking the token representations from all the paragraphs in $\mathcal{D}$ . Note that this process is computationally expensive and takes about hundreds of GPU hours with a large disk footprint. To reduce the size of phrase dump, we follow and modify several techniques introduced in Seo et al. (2019) (see Appendix E for details). After indexing, we can use two rows $i$ and $j$ of $\mathbf{H}$ to represent a dense phrase representation $[\mathbf{h}{i},\mathbf{h}{j}]$ . We use faiss (Johnson et al., 2017) for building a MIPS index of $\mathbf{H}$ .8
索引
在训练短语编码器 $E_{s}$ 后,我们需要对整个英文维基百科 $\mathcal{D}$ 中的所有短语 $S({\mathcal{D}})$ 进行编码,并存储短语库的索引。我们将每个文档 $d_{i}\in\mathcal{D}$ 分割成一组自然段落,然后使用 $E_{s}(\cdot)$ 获取每个段落的 Token 表示。接着,我们通过堆叠 $\mathcal{D}$ 中所有段落的 Token 表示,构建一个短语库 $\mathbf{H}=[\mathbf{h}{1},\dots,\mathbf{h}{|\mathcal{W}(\mathcal{D})|}]\in\mathbb{R}^{|\mathcal{W}(\mathcal{D})|\times d}$。需要注意的是,这个过程计算量很大,需要数百个 GPU 小时,并且占用大量磁盘空间。为了减少短语库的大小,我们遵循并修改了 Seo 等人 (2019) 提出的几种技术(详见附录 E)。索引完成后,我们可以使用 $\mathbf{H}$ 的两行 $i$ 和 $j$ 来表示一个密集短语表示 $[\mathbf{h}{i},\mathbf{h}{j}]$。我们使用 faiss (Johnson 等人, 2017) 来构建 $\mathbf{H}$ 的 MIPS 索引。
Search For a given question $q$ , we can find the answer $\hat{s}$ as follows:
对于给定的问题 $q$,我们可以找到答案 $\hat{s}$ 如下:

where $s_{(i,j)}$ denotes a phrase with start and end indices as $i$ and $j$ in the index $\mathbf{H}$ . We can compute the argmax of $\mathbf{Hq}^{\mathrm{start}}$ and $\mathbf{Hq}^{\mathrm{end}}$ efficiently by performing MIPS over $\mathbf{H}$ with $\mathbf{q}^{\mathrm{start}}$ and $\mathbf{q}^{\mathrm{end}}$ . In practice, we search for the top $k$ start and top $k$ end positions separately and perform a constrained search over their end and start positions respectively such that $1\leq i\leq j<i+L\leq|\mathcal{W}(\mathcal{D})|$ .
其中 $s_{(i,j)}$ 表示在索引 $\mathbf{H}$ 中起始和结束索引分别为 $i$ 和 $j$ 的短语。我们可以通过在 $\mathbf{H}$ 上使用 $\mathbf{q}^{\mathrm{start}}$ 和 $\mathbf{q}^{\mathrm{end}}$ 执行 MIPS 来高效计算 $\mathbf{Hq}^{\mathrm{start}}$ 和 $\mathbf{Hq}^{\mathrm{end}}$ 的 argmax。在实际操作中,我们分别搜索前 $k$ 个起始位置和前 $k$ 个结束位置,并在它们的结束和起始位置上进行约束搜索,使得 $1\leq i\leq j<i+L\leq|\mathcal{W}(\mathcal{D})|$。
6 Query-side Fine-tuning
6 查询端微调
So far, we have created a phrase dump $\mathbf{H}$ that supports efficient MIPS search. In this section, we propose a novel method called query-side fine-tuning by only updating the question encoder $E_{q}$ to correctly retrieve a desired answer $a^{}$ for a question $q$ given $\mathbf{H}$ . Formally speaking, we optimize the marginal log-likelihood of the gold answer $a^{}$ for a question $q$ , which resembles the weakly-supervised QA setting in previous work (Lee et al., 2019; Min et al., 2019). For every question $q$ , we retrieve top $k$ phrases and minimize the objective:
到目前为止,我们已经创建了一个支持高效 MIPS 搜索的短语库 $\mathbf{H}$。在本节中,我们提出了一种称为查询端微调的新方法,通过仅更新问题编码器 $E_{q}$ 来正确检索给定 $\mathbf{H}$ 的问题 $q$ 的期望答案 $a^{}$。正式来说,我们优化了问题 $q$ 的黄金答案 $a^{}$ 的边际对数似然,这与之前工作中的弱监督 QA 设置类似 (Lee et al., 2019; Min et al., 2019)。对于每个问题 $q$,我们检索前 $k$ 个短语并最小化目标:

where $f(s|\mathcal{D},q)$ is the score of the phrase $s$ (Eq. (2)) and $\tilde{\cal S}(q)$ denotes the top $k$ phrases for $q$ (Eq. (10)). In practice, we use $k=100$ for all the experiments.
其中 $f(s|\mathcal{D},q)$ 是短语 $s$ 的得分(公式 (2)),$\tilde{\cal S}(q)$ 表示 $q$ 的前 $k$ 个短语(公式 (10))。在实际操作中,我们在所有实验中使用 $k=100$。
There are several advantages for doing this: (1) we find that query-side fine-tuning can reduce the discrepancy between training and inference, and hence improve the final performance substantially (§8). Even with effective negative sampling, the model only sees a small portion of passages compared to the full scale of $\mathcal{D}$ and this training objective can effectively fill in the gap. (2) This training strategy allows for transfer learning to unseen domains, without rebuilding the entire phrase index. More specifically, the model is able to quickly adapt to new QA tasks (e.g., Web Questions) when the phrase dump is built using SQuAD or Natural Questions. We also find that this can transfers to non-QA tasks when the query is written in a different format. In $\S7.3$ , we show the possibility of directly using Dense Phrases for slot filling tasks by using a query such as (Michael Jackson, is a singer of, $x_{.}$ ). In this regard, we can view our model as a dense knowledge base that can be accessed by many different types of queries and it is able to return phrase-level knowledge efficiently.
这样做有几个优势:(1) 我们发现查询端微调可以减少训练和推理之间的差异,从而显著提高最终性能(§8)。即使采用有效的负采样,模型也只能看到一小部分段落,而训练目标可以有效填补这一差距。(2) 这种训练策略允许在不重建整个短语索引的情况下进行跨领域迁移学习。具体来说,当使用 SQuAD 或 Natural Questions 构建短语库时,模型能够快速适应新的问答任务(例如 Web Questions)。我们还发现,当查询以不同格式编写时,这种方法也可以迁移到非问答任务中。在 $\S7.3$ 中,我们展示了通过使用诸如 (Michael Jackson, is a singer of, $x_{.}$) 的查询,直接使用 Dense Phrases 进行槽填充任务的可能性。在这方面,我们可以将我们的模型视为一个密集的知识库,可以通过多种不同类型的查询访问,并能够高效地返回短语级别的知识。
7 Experiments
7 实验
7.1Setup
7.1 设置
Datasets. We use two reading comprehension datasets: SQuAD (Rajpurkar et al., 2016) and Natural Questions (NQ) (Kwiatkowski et al., 2019) to learn phrase representations, in which a single gold passage is provided for each question. For the opendomain QA experiments, we evaluate our approach on five popular open-domain QA datasets: Natural Questions, Web Questions (WQ) (Berant et al., 2013), Curate dT REC (TREC) (Baudis and Sedivy, 2015), TriviaQA (TQA) (Joshi et al., 2017), and SQuAD. Note that we only use SQuAD and/or NQ to build the phrase index and perform query-side fine-tuning (§6) for other datasets.
数据集。我们使用两个阅读理解数据集:SQuAD (Rajpurkar et al., 2016) 和 Natural Questions (NQ) (Kwiatkowski et al., 2019) 来学习短语表示,其中每个问题都提供了一个黄金段落。对于开放域问答实验,我们在五个流行的开放域问答数据集上评估我们的方法:Natural Questions、Web Questions (WQ) (Berant et al., 2013)、Curated TREC (TREC) (Baudis and Sedivy, 2015)、TriviaQA (TQA) (Joshi et al., 2017) 和 SQuAD。请注意,我们仅使用 SQuAD 和/或 NQ 来构建短语索引并为其他数据集执行查询端微调 (§6)。
We also evaluate our model on two slot filling tasks, to show how to adapt our Dense Phrases for other knowledge-intensive NLP tasks. We focus on using two slot filling datasets from the KILT benchmark (Petroni et al., 2021): T-REx (Elsahar et al., 2018) and zero-shot relation extraction (Levy et al., 2017). Each query is provided in the form of “{subject entity} [SEP] {relation}" and the answer is the object entity. Appendix C provides the statistics of all the datasets.
我们还在两个槽填充任务上评估了我们的模型,以展示如何将我们的 Dense Phrases 适应其他知识密集型 NLP 任务。我们专注于使用来自 KILT 基准 (Petroni et al., 2021) 的两个槽填充数据集:T-REx (Elsahar et al., 2018) 和零样本关系抽取 (Levy et al., 2017)。每个查询以“{subject entity} [SEP] {relation}"的形式提供,答案是对象实体。附录 C 提供了所有数据集的统计信息。
Implementation details. We denote the training datasets used for reading comprehension (Eq. (9)) as $\mathcal{C}{\mathrm{phrase}}$ . For open-domain QA, we train two versions of phrase encoders, each of which are trained on $\ensuremath{\mathcal{C}}{\mathrm{phrase}}={\mathrm{SQuAD}}$ and ${\mathrm{NQ},\mathrm{SQuAD}}$ , respectively. We build the phrase dump H for the 2018-12-20 Wikipedia snapshot and perform queryside fine-tuning on each dataset using Eq. (11). For slot filling, we use the same phrase dump for opendomain QA, $\mathcal{C}_{\mathrm{phrase}}={\mathrm{NQ},\mathrm{SQuAD}}$ and perform query-side fine-tuning on randomly sampled 5K or 10K training examples to see how rapidly our model adapts to the new query types. See Appendix D for details on the hyper parameters and Appendix A for an analysis of computational cost.
实现细节。我们将用于阅读理解(公式 (9))的训练数据集表示为 $\mathcal{C}{\mathrm{phrase}}$。对于开放域问答(open-domain QA),我们训练了两个版本的短语编码器,分别使用 $\ensuremath{\mathcal{C}}{\mathrm{phrase}}={\mathrm{SQuAD}}$ 和 ${\mathrm{NQ},\mathrm{SQuAD}}$ 进行训练。我们为 2018-12-20 的维基百科快照构建了短语库 H,并使用公式 (11) 在每个数据集上进行查询端微调。对于槽填充任务,我们使用与开放域问答相同的短语库 $\mathcal{C}_{\mathrm{phrase}}={\mathrm{NQ},\mathrm{SQuAD}}$,并在随机采样的 5K 或 10K 训练样本上进行查询端微调,以观察我们的模型对新查询类型的适应速度。有关超参数的详细信息,请参见附录 D;有关计算成本的分析,请参见附录 A。
Table 2: Reading comprehension results, evaluated on the development sets of SQuAD and Natural Questions. Underlined numbers are estimated from the figures from the original papers. †: BERT-large model.
表 2: 阅读理解结果,基于 SQuAD 和 Natural Questions 的开发集进行评估。带下划线的数字是从原始论文的图表中估算的。†: BERT-large 模型。
| 模型 | SQuAD | SQuAD | NQ (Long) | NQ (Long) |
|---|---|---|---|---|
| EM | F1 | EM | F1 | |
| Query-Dependent | ||||
| BERT-base | 80.8 | 88.5 | 69.9 | 78.2 |
| SpanBERT-base | 85.7 | 92.2 | 73.2 | 81.0 |
| Query-Agnostic | ||||
| DilBERT (Siblini et al., 2020) | 63.0 | 72.0 | ||
| DeFormer (Ca0 et al., 2020) | 72.1 | |||
| DenSPIt | 73.6 | 81.7 | 68.2 | 76.1 |
| DenSPI+ Sparc | 76.4 | 84.8 | ||
| DensePhrases (ours) | 78.3 | 86.3 | 71.9 | 79.6 |
7.2 Experiments: Question Answering
7.2 实验:问答
Reading comprehension. In order to show the effectiveness of our phrase representations, we first evaluate our model in the reading comprehension setting for SQuAD and NQ and report its performance with other query-agnostic models (Eq. (9) without query-side fine-tuning). This problem was originally formulated by Seo et al. (2018) as the phrase-indexed question answering (PIQA) task.
阅读理解。为了展示我们短语表示的有效性,我们首先在 SQuAD 和 NQ 的阅读理解设置中评估我们的模型,并报告其与其他与查询无关的模型的性能(公式 (9) 未进行查询端微调)。这个问题最初由 Seo 等人 (2018) 提出,作为短语索引问答 (PIQA) 任务。
Compared to previous query-agnostic models, our model achieves the best performance of 78.3 EM on SQuAD by improving the previous phrase retrieval model (DenSPI) by $4.7%$ (Table 2). Al- though it is still behind cross-attention models, the gap has been greatly reduced and serves as a strong starting point for the open-domain QA model.
与之前的查询无关模型相比,我们的模型在 SQuAD 上实现了 78.3 EM 的最佳性能,将之前的短语检索模型 (DenSPI) 提高了 $4.7%$ (表 2)。尽管它仍然落后于交叉注意力模型,但差距已经大大缩小,并为开放域问答模型提供了一个强有力的起点。
Open-domain QA. Experimental results on open-domain QA are summarized in Table 3. Without any sparse representations, Dense Phrases outperforms previous phrase retrieval models by a large margin and achieves a $15%{-25%}$ absolute improvement on all datasets except SQuAD. Training the model of Lee et al. (2020) on $\mathcal{C}_{\mathrm{phrase}}=$ ${\mathrm{NQ},\mathrm{SQuAD}}$ only increases the result from $14.5%$ to $16.5%$ on NQ, demonstrating that it does not suffice to simply add more datasets for training phrase representations. Our performance is also competitive with recent retriever-reader models (Karpukhin et al., 2020), while running much faster during inference (Table 1).
开放域问答 (Open-domain QA)。开放域问答的实验结果总结在表 3 中。在没有使用任何稀疏表示的情况下,Dense Phrases 大幅超越了之前的短语检索模型,并在除 SQuAD 之外的所有数据集上实现了 $15%{-25%}$ 的绝对提升。在 $\mathcal{C}_{\mathrm{phrase}}=$ ${\mathrm{NQ},\mathrm{SQuAD}}$ 上训练 Lee 等人 (2020) 的模型,仅在 NQ 上将结果从 $14.5%$ 提升到 $16.5%$,这表明仅仅增加更多数据集来训练短语表示是不够的。我们的性能也与最近的检索-阅读器模型 (Karpukhin 等人, 2020) 相当,同时在推理过程中运行速度更快 (表 1)。
Table 3: Open-domain QA results. We report exact match (EM) on the test sets. We also show the additional training or pre-training datasets for learning the retriever models $(\mathcal{C}{\mathrm{retr}})$ and creating the phrase dump $(\mathcal{C}{\mathrm{phrase}})$ . ∗: no supervision using target training data (zero-shot). †: unlabeled data used for extra pre-training.
表 3: 开放域问答结果。我们报告了测试集上的精确匹配 (EM) 结果。我们还展示了用于学习检索器模型 $(\mathcal{C}{\mathrm{retr}})$ 和创建短语库 $(\mathcal{C}{\mathrm{phrase}})$ 的额外训练或预训练数据集。∗: 未使用目标训练数据进行监督 (零样本)。†: 用于额外预训练的无标签数据。
| 模型 | NQ | WQ | TREC | TQA | SQuAD | |
|---|---|---|---|---|---|---|
| 检索器-阅读器 | Cretr: (预)训练 | |||||
| DrQA (Chen et al., 2017) | 20.7 | 25.4 | 29.8 | |||
| BERT+BM25 (Lee et al., 2019) | 26.5 | 17.7 | 21.3 | 47.1 | 33.2 | |
| ORQA (Lee et al., 2019) | {Wiki.}† | 33.3 | 36.4 | 30.1 | 45.0 | 20.2 |
| REALM News (Guu et al., 2020) | {Wiki., CC-News} | 40.4 | 40.7 | 42.9 | ||
| DPR-multi (Karpukhin et al., 2020) | {NQ, WQ, TREC, TQA} | 41.5 | 42.4 | 49.4 | 56.8 | 24.1 |
| 短语检索 | Cphrase: 训练 | |||||
| DenSPI (Seo et al., 2019) | {SQuAD} | 8.1* | 11.1* | 31.6* | 30.7* | 36.2 |
| DenSPI + Sparc (Lee et al., 2020) | {SQuAD} | 14.5* | 17.3* | 35.7* | 34.4* | 40.7 |
| DenSPI + Sparc (Lee et al., 2020) | {NQ, SQuAD} | 16.5 | ||||
| DensePhrases (ours) | {SQuAD} | 31.2 | 36.3 | 50.3 | 53.6 | 39.4 |
| DensePhrases (ours) | {NQ, SQuAD} | 40.9 | 37.5 | 51.0 | 50.7 | 38.0 |
| 模型 | T-REx | ZsRE | ||
|---|---|---|---|---|
| Acc | F1 | Acc | F1 | |
| DPR+BERT | 4.47 | 27.09 | ||
| DPR+BART RAG | 11.12 23.12 | 11.41 23.94 | 18.91 36.83 | 20.32 39.91 |
| DensePhrases5K | 25.32 | 29.76 | 40.39 | 45.89 |
| DensePhrases 10K | 27.84 | 32.34 | 41.34 | 46.79 |
Table 4: Slot filling results on the test sets of T-REx and Zero shot RE (ZsRE) in the KILT benchmark. We report KILT-AC and KILT-F1 (denoted as Acc and $F I$ in the table), which consider both span-level accuracy and correct retrieval of evidence documents.
表 4: KILT 基准测试中 T-REx 和零样本关系抽取 (ZsRE) 测试集的槽填充结果。我们报告了 KILT-AC 和 KILT-F1 (表中表示为 Acc 和 $F I$),这两个指标同时考虑了片段级别的准确性和证据文档的正确检索。
7.3 Experiments: Slot Filling
7.3 实验:槽填充
Table 4 summarizes the results on the two slot filling datasets, along with the baseline scores provided by Petroni et al. (2021). The only extractive baseline is $\mathrm{DPR}+\mathrm{BERT}$ , which performs poorly in zero-shot relation extraction. On the other hand, our model achieves competitive performance on all datasets and achieves state-of-the-art performance on two datasets using only 5K training examples.
表 4 总结了两个槽填充数据集的结果,以及 Petroni 等人 (2021) 提供的基线分数。唯一的抽取式基线是 $\mathrm{DPR}+\mathrm{BERT}$,它在零样本关系抽取中表现不佳。另一方面,我们的模型在所有数据集上均取得了有竞争力的表现,并且仅使用 5K 训练样本就在两个数据集上达到了最先进的性能。
8 Analysis
8 分析
Ablation of phrase representations. Table 5 shows the ablation result of our model on SQuAD. Upon our choice of architecture, augmenting training set with generated questions $(\mathbf{Q}\mathbf{G}=\mathbf{\check{\Gamma}})$ and performing distillation from cross-attention models $({\mathrm{Distill}}={\checkmark})$ improve performance up to $\mathbf{EM}=$ 78.3. We attempted adding the generated questions to the training of the SpanBERT-QA model but find a $0.3%$ improvement, which validates that data sparsity is a bottleneck for query-agnostic models.
短语表示的消融实验。表 5 展示了我们的模型在 SQuAD 上的消融实验结果。在我们选择的架构基础上,通过生成的问题增强训练集 $(\mathbf{Q}\mathbf{G}=\mathbf{\check{\Gamma}})$ 以及从交叉注意力模型中进行蒸馏 $({\mathrm{Distill}}={\checkmark})$ ,性能提升至 $\mathbf{EM}=$ 78.3。我们尝试将生成的问题添加到 SpanBERT-QA 模型的训练中,但仅发现 $0.3%$ 的提升,这验证了数据稀疏性是查询无关模型的瓶颈。
Table 5: Ablation of Dense Phrases on the development set of SQuAD. Bb: BERT-base, Sb: SpanBERT-base, Bl: BERT-large. Share: whether question and phrase encoders are shared or not. Split: whether the full hidden vectors are kept or split into start and end vectors. QG: question generation (§4.1). Distill: distillation (Eq.(7)). DenSPI (Seo et al., 2019) also included a coherency scalar and see their paper for more details.
表 5: SQuAD 开发集上 Dense Phrases 的消融实验。Bb: BERT-base, Sb: SpanBERT-base, Bl: BERT-large。Share: 问题和短语编码器是否共享。Split: 是否保留完整的隐藏向量或将其拆分为起始和结束向量。QG: 问题生成 (§4.1)。Distill: 蒸馏 (Eq.(7))。DenSPI (Seo et al., 2019) 还包括一个一致性标量,更多细节请参见他们的论文。
| 模型 | M | Share | Split | QG Distill | EM | |
|---|---|---|---|---|---|---|
| DenSPI | Bb. | × | 70.2 | |||
| Sb. | 68.5 | |||||
| Bl. | × | 73.6 | ||||
| Dense | Bb. | × | × | × | 70.2 | |
| Phrases | Bb. | × | × | × | 71.9 | |
| Sb. | × | × | × | × | 73.2 | |
| Sb. | × | × | 76.3 | |||
| Sb. | × | 78.3 |
Effect of batch negatives. We further evaluate the effectiveness of various negative sampling methods introduced in $\S4.2$ and $\S4.3$ . Since it is computationally expensive to test each setting at the full Wikipedia scale, we use a smaller text corpus $\mathcal{D}_{\mathrm{small}}$ of all the gold passages in the development sets of Natural Questions, for the ablation study. Empirically, we find that results are generally well correlated when we gradually increase the size of $|\mathcal D|$ . As shown in Table 6, both in-batch and pre-batch negatives bring substantial improvements. While using a larger batch size $\mathit{\Theta}(B=84\$ ) is beneficial for in-batch negatives, the number of preceding batches in pre-batch negatives is optimal when $C=2$ . Surprisingly, the pre-batch negatives also improve the performance when $\mathcal{D}={p}$ .
批量负样本的影响。我们进一步评估了在 $\S4.2$ 和 $\S4.3$ 中介绍的各种负采样方法的有效性。由于在完整的维基百科规模上测试每个设置的计算成本较高,我们在消融研究中使用了一个较小的文本语料库 $\mathcal{D}_{\mathrm{small}}$,该语料库包含 Natural Questions 开发集中的所有黄金段落。经验表明,当我们逐渐增加 $|\mathcal D|$ 的大小时,结果通常是高度相关的。如表 6 所示,批内负样本和预批负样本都带来了显著的改进。虽然使用较大的批量大小 $\mathit{\Theta}(B=84\$ ) 对批内负样本有益,但当 $C=2$ 时,预批负样本中的前批数量是最优的。令人惊讶的是,当 $\mathcal{D}={p}$ 时,预批负样本也能提高性能。
Table 6: Effect of in-batch negatives and pre-batch negatives on the development set of Natural Questions. $B$ : batch size. $C$ : number of preceding mini-batches used in pre-batch negatives. $\mathcal{D}_{\mathrm{small}}$ : all the gold passages in the development set of NQ. ${p}$ : single passage.
表 6: 批内负样本和预批负样本对 Natural Questions 开发集的影响。$B$: 批大小。$C$: 预批负样本中使用的前置小批次数。$\mathcal{D}_{\mathrm{small}}$: NQ 开发集中的所有黄金段落。${p}$: 单一段落。
| 类型 | B | C D={p} | D = Dsmall |
|---|---|---|---|
| 无 | 48 | 70.4 | 35.3 |
| + 批内负样本 | 48 | 70.5 | 52.4 |
| 84 | 70.3 | 54.2 | |
| + 预批负样本 | 84 | 1 71.6 | 59.8 |
| 84 | 2 71.9 | 60.4 | |
| 84 | 4 71.2 | 59.8 |
Effect of query-side fine-tuning. We summarize the effect of query-side fine-tuning in Table 7. For the datasets that were not used for training the phrase encoders (TQA, WQ, TREC), we observe a $15%$ to $20%$ improvement after query-side finetuning. Even for the datasets that have been used (NQ, SQuAD), it leads to significant improvements (e.g., $32.6%{\rightarrow}40.9%$ on NQ for $\mathcal{C}_{\mathrm{phrase}}={\mathrm{NQ}})$ and it clearly demonstrates it can effectively reduce the discrepancy between training and inference.
查询端微调的效果。我们在表 7 中总结了查询端微调的效果。对于未用于训练短语编码器的数据集(TQA、WQ、TREC),我们观察到查询端微调后有 $15%$ 到 $20%$ 的提升。即使对于已经使用过的数据集(NQ、SQuAD),它也带来了显著的改进(例如,在 NQ 上从 $32.6%{\rightarrow}40.9%$,当 $\mathcal{C}_{\mathrm{phrase}}={\mathrm{NQ}}$ 时),这清楚地表明它可以有效减少训练和推理之间的差异。
9 Related Work
9 相关工作
Learning effective dense representations of words is a long-standing goal in NLP (Bengio et al., 2003; Collobert et al., 2011; Mikolov et al., 2013; Peters et al., 2018; Devlin et al., 2019). Beyond words, dense representations of many different granularities of text such as sentences (Le and Mikolov, 2014; Kiros et al., 2015) or documents (Yih et al., 2011) have been explored. While dense phrase represent at ions have been also studied for statistical machine translation (Cho et al., 2014) or syntactic parsing (Socher et al., 2010), our work focuses on learning dense phrase representations for QA and any other knowledge-intensive tasks where phrases can be easily retrieved by performing MIPS.
学习有效的词稠密表示是自然语言处理 (NLP) 领域的一个长期目标 (Bengio et al., 2003; Collobert et al., 2011; Mikolov et al., 2013; Peters et al., 2018; Devlin et al., 2019)。除了词之外,许多不同粒度的文本稠密表示也被探索过,例如句子 (Le and Mikolov, 2014; Kiros et al., 2015) 或文档 (Yih et al., 2011)。虽然稠密短语表示也曾在统计机器翻译 (Cho et al., 2014) 或句法解析 (Socher et al., 2010) 中被研究过,但我们的工作专注于为问答 (QA) 和其他知识密集型任务学习稠密短语表示,在这些任务中,短语可以通过执行 MIPS 轻松检索。
This type of dense retrieval has been also studied for sentence and passage retrieval (Humeau et al., 2019; Karpukhin et al., 2020) (see Lin et al., 2020 for recent advances in dense retrieval). While Dense Phrases is explicitly designed to retrieve phrases that can be used as an answer to given queries, retrieving phrases also naturally entails retrieving larger units of text, provided the datastore maintains the mapping between each phrase and the sentence and passage in which it occurs.
这种密集检索方法也被用于句子和段落检索 (Humeau et al., 2019; Karpukhin et al., 2020) (关于密集检索的最新进展,请参见 Lin et al., 2020)。虽然 Dense Phrases 明确设计用于检索可以作为给定查询答案的短语,但检索短语自然也涉及检索更大的文本单元,前提是数据存储库维护了每个短语与其所在的句子和段落之间的映射关系。
Table 7: Effect of query-side fine-tuning in Dense Phrases on each test set. We report EM of each model before $(\mathrm{QS}=X)$ and after $\boldsymbol{\mathrm{(QS=}\checkmark)}$ the query-side fine-tuning.
| QS | NQ | WQ TREC | TQA | SQuAD |
|---|---|---|---|---|
| Cphrase = {SQuAD} | ||||
| × √ | 12.3 31.2 | 11.8 36.3 | 36.9 34.6 50.3 53.6 | 35.5 39.4 |
| Cphrase = {NQ} | ||||
| x | 32.6 | 21.1 | 32.3 32.4 | 20.7 |
| 40.9 | 37.1 | 49.7 49.2 | 25.7 | |
| Cphrase = {NQ, SQuAD} | ||||
| 28.9 | 18.9 | 34.9 31.9 | 33.2 | |
| 40.9 | 37.5 | 51.0 50.7 | 38.0 |
表 7: Dense Phrases 中查询端微调对每个测试集的影响。我们报告了每个模型在查询端微调前 $(\mathrm{QS}=X)$ 和微调后 $\boldsymbol{\mathrm{(QS=}\checkmark)}$ 的 EM 值。
10 Conclusion
10 结论
In this study, we show that we can learn dense representations of phrases at the Wikipedia scale, which are readily retrievable for open-domain QA and other knowledge-intensive NLP tasks. We learn both phrase and question encoders from the supervision of reading comprehension tasks and introduce two batch-negative techniques to better discriminate phrases at scale. We also introduce query-side fine-tuning that adapts our model to different types of queries. We achieve strong performance on five popular open-domain QA datasets, while reducing the storage footprint and improving latency significantly. We also achieve strong performance on two slot filling datasets using only a small number of training examples, showing the possibility of utilizing our Dense Phrases as a knowledge base.
在本研究中,我们展示了可以在维基百科规模上学习短语的密集表示,这些表示可以轻松用于开放域问答(QA)和其他知识密集型 NLP 任务。我们从阅读理解任务的监督中学习短语和问题编码器,并引入了两种批量负样本技术,以更好地在大规模上区分短语。我们还引入了查询端微调,使我们的模型能够适应不同类型的查询。我们在五个流行的开放域 QA 数据集上取得了强劲的性能,同时显著减少了存储占用并改善了延迟。我们还仅使用少量训练样本在两个槽填充数据集上取得了强劲的性能,展示了利用我们的密集短语作为知识库的可能性。
Acknowledgments
致谢
We thank Sewon Min, Hyunjae Kim, Gyuwan Kim, Jungsoo Park, Zexuan Zhong, Dan Fried- man, Chris Sciavolino for providing valuable comments and feedback. This research was supported by a grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number: HR20C0021) and National Research Foundation of Korea (NRF-2020 R 1 A 2 C 3010638). It was also partly supported by the James Mi $\ast{}91$ Research Innovation Fund for Data Science and an Amazon Research Award.
我们感谢 Sewon Min、Hyunjae Kim、Gyuwan Kim、Jungsoo Park、Zexuan Zhong、Dan Friedman、Chris Sciavolino 提供的宝贵意见和建议。本研究得到了韩国健康产业开发院 (KHIDI) 通过韩国健康技术研发项目 (项目编号:HR20C0021) 以及韩国国家研究基金会 (NRF-2020 R 1 A 2 C 3010638) 的资助。部分研究也得到了 James Mi $\ast{}91$ 数据科学研究创新基金和 Amazon Research Award 的支持。
Ethical Considerations
伦理考量
Our work builds on standard reading comprehension datasets such as SQuAD to build phrase represent at ions. SQuAD, in particular, is created from a small number of Wikipedia articles sampled from top-10,000 most popular articles (measured by PageRanks), hence some of our models trained only on SQuAD could be easily biased towards the small number of topics that SQuAD contains. We hope that excluding such datasets during training or inventing an alternative pre-training procedure for learning phrase representations could mitigate this problem. Although most of our efforts have been made to reduce the computational complexity of previous phrase retrieval models (further detailed in Appendices A and E), leveraging our phrase retrieval model as a knowledge base will inevitably increase the minimum requirement for the additional experiments. We plan to apply vector quantization techniques to reduce the additional cost of using our model as a KB.
我们的工作基于标准的阅读理解数据集(如 SQuAD)来构建短语表示。特别是 SQuAD,它是从最受欢迎的 10,000 篇文章(通过 PageRanks 衡量)中抽取的少量维基百科文章创建的,因此我们仅在 SQuAD 上训练的一些模型可能会偏向于 SQuAD 包含的少量主题。我们希望在训练期间排除此类数据集,或发明一种替代的预训练程序来学习短语表示,以缓解这一问题。尽管我们的大部分努力都用于降低先前短语检索模型的计算复杂度(详见附录 A 和 E),但将我们的短语检索模型用作知识库将不可避免地增加额外实验的最低要求。我们计划应用向量量化技术来降低使用我们的模型作为知识库的额外成本。
References
参考文献
Kyunghyun Cho, Bart Van Mer ri n boer, Caglar Gul- cehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Empirical Methods in Natural Language Processing (EMNLP).
Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, 和 Yoshua Bengio. 2014. 使用 RNN 编码器-解码器学习短语表示以进行统计机器翻译. 在自然语言处理的经验方法 (EMNLP) 中.
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2017. Billion-scale similarity search with GPUs. arXiv preprint arXiv:1702.08734.
Jeff Johnson, Matthijs Douze, 和 Hervé Jégou. 2017. 使用 GPU 进行十亿级相似性搜索. arXiv 预印本 arXiv:1702.08734.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Z ett le moyer, and Omer Levy. 2020. SpanBERT: Improving pre-training by representing and predicting spans. Transactions of the Association of Computational Linguistics (TACL).
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, 和 Omer Levy. 2020. SpanBERT: 通过表示和预测跨度改进预训练. 计算语言学协会会刊 (TACL).
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Z ett le moyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Association for Computational Linguistics (ACL).
Mandar Joshi, Eunsol Choi, Daniel S Weld, 和 Luke Zettlemoyer. 2017. TriviaQA: 一个大规模远程监督的阅读理解挑战数据集. 在计算语言学协会 (ACL) 中.
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Empirical Methods in Natural Language Processing (EMNLP).
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, 和 Wen-tau Yih. 2020. 开放域问答中的密集段落检索. 在《自然语言处理经验方法》(EMNLP) 中.
Diederik P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR).
Diederik P Kingma 和 Jimmy Ba. 2015. Adam: 一种随机优化方法. 在国际学习表征会议 (ICLR) 上发表.
Ryan Kiros, Yukun Zhu, Russ R Salak hut dino v, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Skip-thought vectors. Advances in Neural Information Processing Systems (NIPS).
Ryan Kiros, Yukun Zhu, Russ R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, 和 Sanja Fidler. 2015. Skip-thought vectors. 神经信息处理系统进展 (NIPS).
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association of Computational Linguis- tics (TACL).
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, 等. 2019. 自然问题:问答研究的基准. 计算语言学协会会刊 (TACL).
Quoc Le and Tomas Mikolov. 2014. Distributed representations of sentences and documents. In International Conference on Machine Learning (ICML).
Quoc Le 和 Tomas Mikolov. 2014. 句子和文档的分布式表示 (Distributed representations of sentences and documents). 在国际机器学习会议 (ICML) 上.
Jinhyuk Lee, Minjoon Seo, Hannaneh Hajishirzi, and Jaewoo Kang. 2020. Contextual i zed sparse representations for real-time open-domain question answering. In Association for Computational Linguistics (ACL).
Jinhyuk Lee, Minjoon Seo, Hannaneh Hajishirzi, 和 Jaewoo Kang. 2020. 用于实时开放域问答的情境化稀疏表示。发表于计算语言学协会 (ACL)。
Kenton Lee, Ming-Wei Chang, and Kristina Toutanova. 2019. Latent retrieval for weakly supervised open domain question answering. In Association for Computational Linguistics (ACL).
Kenton Lee, Ming-Wei Chang 和 Kristina Toutanova. 2019. 弱监督开放域问答的潜在检索. 在计算语言学协会 (ACL).
Kenton Lee, Shimi Salant, Tom Kwiatkowski, Ankur Parikh, Dipanjan Das, and Jonathan Berant. 2017. Learning recurrent span representations for extractive question answering. In ICLR.
Kenton Lee, Shimi Salant, Tom Kwiatkowski, Ankur Parikh, Dipanjan Das, 和 Jonathan Berant. 2017. 学习用于抽取式问答的循环跨度表示。发表于 ICLR。
Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Z ett le moyer. 2017. Zero-shot relation extraction via reading comprehension. In Computational Natural Language Learning (CoNLL).
Omer Levy、Minjoon Seo、Eunsol Choi 和 Luke Zettlemoyer。2017。通过阅读理解进行零样本关系抽取。在《计算自然语言学习》(CoNLL) 中。
Patrick Lewis, Ethan Perez, Aleksandar a Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems (NeurIPS).
Patrick Lewis, Ethan Perez, Aleksandar a Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, 等. 2020. 检索增强生成用于知识密集型 NLP 任务. 发表于《神经信息处理系统进展》(NeurIPS).
Jimmy Lin, Rodrigo Nogueira, and Andrew Yates. 2020. Pretrained Transformers for text ranking: BERT and beyond. arXiv preprint arXiv:2010.06467.
Jimmy Lin、Rodrigo Nogueira 和 Andrew Yates. 2020. 用于文本排序的预训练 Transformer:BERT 及其他. arXiv 预印本 arXiv:2010.06467.
Lucian Vlad Lita, Abe Itty cheri ah, Salim Roukos, and Nanda Kambhatla. 2003. tRuEcasIng. In Association for Computational Linguistics (ACL).
Lucian Vlad Lita, Abe Ittycheriah, Salim Roukos, 和 Nanda Kambhatla. 2003. tRuEcasIng. 发表于计算语言学协会 (ACL).
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Cor- rado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems (NIPS).
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, 和 Jeff Dean. 2013. 单词和短语的分布式表示及其组合性. 在《神经信息处理系统进展》(NIPS) 中.
Sewon Min, Danqi Chen, Hannaneh Hajishirzi, and Luke Z ett le moyer. 2019. A discrete hard EM approach for weakly supervised question answering. In Empirical Methods in Natural Language Processing (EMNLP).
Sewon Min、Danqi Chen、Hannaneh Hajishirzi 和 Luke Zettlemoyer。2019。一种用于弱监督问答的离散硬 EM 方法。发表于《自然语言处理经验方法》(EMNLP)。
Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Z ett le moyer. 2018. Deep contextual i zed word representations. In North American Chapter of the Association for Computational Linguistics (NAACL).
Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, 和 Luke Zettlemoyer. 2018. 深度上下文词表示. 在北美计算语言学协会 (NAACL) 会议上.
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vassilis Plachouras, Tim Rock t s chel, et al. 2021. KILT: a benchmark for knowledge intensive language tasks. In North American Chapter of the Association for Computational Linguistics (NAACL).
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vassilis Plachouras, Tim Rocktäschel 等. 2021. KILT: 知识密集型语言任务的基准. 发表于北美计算语言学协会 (NAACL).
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140).
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu。2020。探索迁移学习的极限:统一的文本到文本 Transformer。机器学习研究杂志,21(140)。
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: $100{,}000+$ questions for machine comprehension of text. In Empirical Methods in Natural Language Processing (EMNLP).
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, 和 Percy Liang. 2016. SQuAD: 超过 $100{,}000$ 个问题的文本机器理解。发表于自然语言处理经验方法会议 (EMNLP)。
Adam Roberts, Colin Raffel, and Noam Shazeer. 2020. How much knowledge can you pack into the parameters of a language model? In Empirical Methods in Natural Language Processing (EMNLP).
Adam Roberts, Colin Raffel 和 Noam Shazeer. 2020. 你能将多少知识压缩到语言模型的参数中?发表于《自然语言处理经验方法》(EMNLP)。
Minjoon Seo, Tom Kwiatkowski, Ankur Parikh, Ali Farhadi, and Hannaneh Hajishirzi. 2018. Phraseindexed question answering: A new challenge for scalable document comprehension. In Empirical Methods in Natural Language Processing (EMNLP).
Minjoon Seo、Tom Kwiatkowski、Ankur Parikh、Ali Farhadi 和 Hannaneh Hajishirzi。2018。短语索引问答:可扩展文档理解的新挑战。载于《自然语言处理经验方法》(EMNLP)。
Minjoon Seo, Jinhyuk Lee, Tom Kwiatkowski, Ankur P Parikh, Ali Farhadi, and Hannaneh Hajishirzi. 2019. Real-time open-domain question answering with dense-sparse phrase index. In Association for Computational Linguistics (ACL).
Minjoon Seo, Jinhyuk Lee, Tom Kwiatkowski, Ankur P Parikh, Ali Farhadi, and Hannaneh Hajishirzi. 2019. 实时开放域问答与密集-稀疏短语索引. 发表于计算语言学协会 (ACL).
Wissam Siblini, Mohamed Challal, and Charlotte Pasqual. 2020. Delaying interaction layers in transformer-based encoders for efficient open domain question answering. arXiv preprint arXiv:2010.08422.
Wissam Siblini、Mohamed Challal 和 Charlotte Pasqual. 2020. 在基于 Transformer 的编码器中延迟交互层以实现高效的开放域问答. arXiv 预印本 arXiv:2010.08422.
Richard Socher, Christopher D Manning, and Andrew Y Ng. 2010. Learning continuous phrase representations and syntactic parsing with recursive neural networks. In Proceedings of the NIPS-2010 deep learning and unsupervised feature learning workshop.
Richard Socher、Christopher D Manning 和 Andrew Y Ng. 2010. 使用递归神经网络学习连续短语表示和句法解析。在 NIPS-2010 深度学习与无监督特征学习研讨会论文集上发表。
Ellen M Voorhees et al. 1999. The TREC-8 question answering track report. In Trec.
Ellen M Voorhees 等人. 1999. TREC-8 问答赛道报告. 在 Trec.
Zhiguo Wang, Patrick Ng, Xiaofei Ma, Ramesh Nallap- ati, and Bing Xiang. 2019. Multi-passage BERT: A globally normalized BERT model for open-domain question answering. In Empirical Methods in Natural Language Processing (EMNLP).
Zhiguo Wang, Patrick Ng, Xiaofei Ma, Ramesh Nallapati, 和 Bing Xiang. 2019. 多段落 BERT:一种用于开放域问答的全局归一化 BERT 模型. 在自然语言处理经验方法 (EMNLP) 中.
Wei Yang, Yuqing Xie, Aileen Lin, Xingyu Li, Luchen Tan, Kun Xiong, Ming Li, and Jimmy Lin. 2019. End-to-end open-domain question answering with bertserini. In North American Chapter of the Association for Computational Linguistics (NAACL).
Wei Yang, Yuqing Xie, Aileen Lin, Xingyu Li, Luchen Tan, Kun Xiong, Ming Li, 和 Jimmy Lin. 2019. 使用 Bertserini 进行端到端开放域问答. 在北美计算语言学协会 (NAACL) 会议上.
Wen-tau Yih, Kristina Toutanova, John C Platt, and Christopher Meek. 2011. Learning disc rim i native projections for text similarity measures. In Computational Natural Language Learning (CoNLL).
Wen-tau Yih, Kristina Toutanova, John C Platt, 和 Christopher Meek. 2011. 学习用于文本相似度度量的判别投影。在《计算自然语言学习》(CoNLL) 中。
A Computational Cost
计算成本
We describe the resources and time spent during inference (Table 1 and A.1) and indexing (Table A.1). With our limited GPU resources (24GB $\times4)$ , it takes about 20 hours for indexing the entire phrase representations. We also largely reduced the storage from 1,547GB to 320GB by (1) removing sparse representations and (2) using our sharing and split strategy. See Appendix E for the details on the reduction of storage footprint and Appendix B for the specification of our server for the benchmark.
我们描述了推理(表 1 和 A.1)和索引(表 A.1)过程中消耗的资源和时间。在我们有限的 GPU 资源(24GB $\times4$)下,对整个短语表示进行索引大约需要 20 小时。通过 (1) 移除稀疏表示和 (2) 使用我们的共享和拆分策略,我们还将存储空间从 1,547GB 大幅减少到 320GB。有关存储空间减少的详细信息,请参见附录 E;有关我们用于基准测试的服务器的规格,请参见附录 B。
Table A.1: Complexity analysis of three open-domain QA models during indexing and inference. For inference, we also report the minimum requirement of RAM and GPU memory for running each model with GPU. For computing #Q/s for CPU, we do not use GPUs but load all models on the RAM.
表 A.1: 三种开放域问答模型在索引和推理过程中的复杂度分析。对于推理,我们还报告了使用 GPU 运行每个模型所需的最小 RAM 和 GPU 内存要求。对于在 CPU 上计算 #Q/s,我们不使用 GPU,而是将所有模型加载到 RAM 上。
B Server Specifications for Benchmark
B 基准测试服务器规格
To compare the complexity of open-domain QA models, we install all models in Table 1 on the same server using their public open-source code. Our server has the following specifications:
为了比较开放域问答模型的复杂度,我们使用其公开的开源代码在相同服务器上安装了表 1 中的所有模型。我们的服务器具有以下规格:
Table B.2: Server specification for the benchmark
表 B.2: 基准测试的服务器规格
| 硬件 |
|---|
| Intel Xeon CPU E5-2630 v4 @ 2.20GHz 128GB RAM |
| 12GB GPU (TITAN Xp) × 2 |
| 2TB 970 EVO Plus NVMe M.2 SSD × 1 |
Table C.3: Statistics of five open-domain QA datasets and two slot filling datasets. We follow the same splits in open-domain QA for the two reading comprehension datasets (SQuAD and Natural Questions).
表 C.3: 五个开放域问答数据集和两个槽填充数据集的统计信息。我们遵循开放域问答中两个阅读理解数据集(SQuAD 和 Natural Questions)的相同划分。
| 索引方法 | 资源 | 存储 | 时间 |
|---|---|---|---|
| DPR | 32GB GPU ×8 | 76GB | 17h |
| DenSPI+Sparc | 24GB GPU ×4 | 1,547GB | 85h |
| DensePhrases | 24GB GPU ×4 | 320GB | 20h |
| 推理方法 | RAM/GPU | 每秒查询数(GPU, CPU) |
|---|---|---|
| DPR | 86GB/17GB | 0.9, 0.04 |
| DenSPI+Sparc | 27GB/2GB | 2.1, 1.7 |
| DensePhrases | 12GB/2GB | 20.6, 13.6 |
For DPR, due to its large memory consumption, we use a similar server with a 24GB GPU (TITAN RTX). For all models, we use 1,000 randomly sam- pled questions from the Natural Questions development set for the speed benchmark and measure #Q/sec. We set the batch size to 64 for all models except BERTSerini, ORQA and REALM, which do not allow a batch size of more than 1 in their open-source implementations. #Q/sec for DPR includes retrieving passages and running a reader model and the batch size for the reader model is set to 8 to fit in the 24GB GPU (retriever batch size is still 64). For other hyper parameters, we use the default settings of each model. We also exclude the time and the number of questions in the first five iterations for warming up each model. Note that despite our effort to match the environment of each model, their latency can be affected by various different settings in their implementations such as the choice of library (PyTorch vs. Tensorflow).
对于 DPR,由于其内存消耗较大,我们使用了一台配备 24GB GPU (TITAN RTX) 的类似服务器。对于所有模型,我们从 Natural Questions 开发集中随机抽取 1,000 个问题用于速度基准测试,并测量每秒处理的问题数 (#Q/sec)。我们将所有模型的批量大小设置为 64,除了 BERTSerini、ORQA 和 REALM,这些模型在其开源实现中不允许批量大小超过 1。DPR 的 #Q/sec 包括检索段落和运行阅读器模型,阅读器模型的批量大小设置为 8,以适应 24GB GPU(检索器的批量大小仍为 64)。对于其他超参数,我们使用每个模型的默认设置。我们还排除了前五次迭代中用于预热每个模型的时间和问题数量。请注意,尽管我们努力匹配每个模型的环境,但它们的延迟可能会受到其实现中各种不同设置的影响,例如库的选择 (PyTorch 与 Tensorflow)。
| 数据集 | 训练集 | 开发集 | 测试集 |
|---|---|---|---|
| NaturalQuestions | 79,168 | 8,757 | 3,610 |
| WebQuestions | 3,417 | 361 | 2,032 |
| CuratedTrec | 1,353 | 133 | 694 |
| TriviaQA | 78,785 | 8,837 | 11,313 |
| SQuAD | 78,713 | 8,886 | 10,570 |
| T-REx | 2,284,168 | 5,000 | 5,000 |
| Zero-ShotRE | 147,909 | 3,724 | 4,966 |
C Data Statistics and Pre-processing
C 数据统计与预处理
In Table C.3, we show the statistics of five opendomain QA datasets and two slot filling datasets. Pre-processed open-domain QA datasets are provided by Chen et al. (2017) except Natural Questions and TriviaQA. We use a version of Natural Questions and TriviaQA provided by Min et al. (2019); Lee et al. (2019), which are pre-processed for the open-domain QA setting. Slot filling datasets are provided by Petroni et al. (2021). We use two reading comprehension datasets (SQuAD and Natural Questions) for training our model on Eq. (9). For SQuAD, we use the original dataset provided by the authors (Rajpurkar et al., 2016). For Natural Questions (Kwiatkowski et al., 2019), we use the pre-processed version provided by Asai et al. (2020).9 We use the short answer as a ground truth answer $a^{*}$ and its long answer as a gold passage $p$ . We also match the gold passages in Natural Questions to the paragraphs in Wikipedia whenever possible. Since we want to check the performance changes of our model with the growing number of tokens, we follow the same split (train/dev/test) used in Natural Questions-Open for the reading comprehension setting as well. During the validation of our model and baseline models, we exclude samples whose answers lie in a list or a table from a Wikipedia article.
表 C.3 中展示了五个开放域问答数据集和两个槽填充数据集的统计信息。除了 Natural Questions 和 TriviaQA 之外,预处理后的开放域问答数据集由 Chen 等人 (2017) 提供。我们使用了 Min 等人 (2019) 和 Lee 等人 (2019) 提供的 Natural Questions 和 TriviaQA 版本,这些版本已经为开放域问答设置进行了预处理。槽填充数据集由 Petroni 等人 (2021) 提供。我们使用了两个阅读理解数据集 (SQuAD 和 Natural Questions) 来训练我们的模型,如公式 (9) 所示。对于 SQuAD,我们使用了作者 (Rajpurkar 等人, 2016) 提供的原始数据集。对于 Natural Questions (Kwiatkowski 等人, 2019),我们使用了 Asai 等人 (2020) 提供的预处理版本。我们将短答案作为真实答案 $a^{*}$,长答案作为黄金段落 $p$。我们还尽可能将 Natural Questions 中的黄金段落与 Wikipedia 中的段落进行匹配。由于我们希望检查模型在 Token 数量增加时的性能变化,我们在阅读理解设置中也遵循了 Natural Questions-Open 中使用的相同划分 (训练/开发/测试)。在验证我们的模型和基线模型时,我们排除了答案位于 Wikipedia 文章中的列表或表格中的样本。
D Hyper parameters
D 超参数
We use the Adam optimizer (Kingma and Ba, 2015) in all our experiments. For training our phrase and question encoders with Eq. (9), we use a learning rate of 3e-5 and the norm of the gradient is clipped at 1. We use a batch size of $B=84$ and train each model for 4 epochs for all datasets, where the loss of pre-batch negatives is applied in the last two epochs. We use SQuAD to train our QG model10 and use spaCy11 for extracting named entities in each training passage, which are used to generate questions. The number of generated questions is 327,302 and 1,126,354 for SQuAD and Natural Questions, respectively. The number of preceding batches $C$ is set to 2.
我们在所有实验中使用 Adam 优化器 (Kingma and Ba, 2015)。对于使用公式 (9) 训练短语和问题编码器,我们使用 3e-5 的学习率,并将梯度的范数裁剪为 1。我们使用批量大小 $B=84$,并在所有数据集上训练每个模型 4 个 epoch,其中在前两个 epoch 中应用了预批次负样本的损失。我们使用 SQuAD 训练我们的 QG 模型,并使用 spaCy 提取每个训练段落中的命名实体,这些实体用于生成问题。生成的 SQuAD 和 Natural Questions 的问题数量分别为 327,302 和 1,126,354。前批次数量 $C$ 设置为 2。
For the query-side fine-tuning with Eq. (11), we use a learning rate of 3e-5 and the norm of the gradient is clipped at 1. We use a batch size of 12 and train each model for 10 epochs for all datasets. The top $k$ for the Eq. (11) is set to 100. While we use a single 24GB GPU (TITAN RTX) for training the phrase encoders with Eq. (9), query-side fine-tuning is relatively cheap and uses a single 12GB GPU (TITAN Xp). Using the development set, we select the best performing model (based on EM) for each dataset, which are then evaluated on each test set. Since SpanBERT only supports cased models, we also truecase the questions (Lita et al., 2003) that are originally provided in the lowercase (Natural Questions and Web Questions).
对于使用公式 (11) 进行查询端微调,我们使用 3e-5 的学习率,并将梯度的范数裁剪为 1。我们使用 12 的批量大小,并在所有数据集上训练每个模型 10 个周期。公式 (11) 中的 top $k$ 设置为 100。虽然我们使用单个 24GB GPU (TITAN RTX) 来训练公式 (9) 的短语编码器,但查询端微调相对便宜,使用单个 12GB GPU (TITAN Xp)。使用开发集,我们为每个数据集选择表现最佳的模型(基于 EM),然后在每个测试集上进行评估。由于 SpanBERT 仅支持区分大小写的模型,我们还对原本以小写形式提供的问题(Natural Questions 和 Web Questions)进行了大小写转换 (Lita et al., 2003)。
E Reducing Storage Footprint
E 减少存储占用
As shown in Table 1, we have reduced the storage footprint from 1,547GB (Lee et al., 2020) to 320GB. We detail how we can reduce the storage footprint in addition to the several techniques introduced by Seo et al. (2019).
如表 1 所示,我们将存储占用从 1,547GB (Lee et al., 2020) 减少到了 320GB。我们详细介绍了除了 Seo 等人 (2019) 提出的几种技术之外,我们如何进一步减少存储占用。
First, following Seo et al. (2019), we apply a linear transformation on the passage token representations to obtain a set of filter logits, which can be used to filter many token representations from $\mathcal{W}(\mathcal{D})$ . This filter layer is supervised by applying the binary cross entropy with the gold start/end positions (trained together with Eq. (9)). We tune the threshold for the filter logits on the reading comprehension development set to the point where the performance does not drop significantly while maximally filtering tokens. In the full Wikipedia setting, we filter about $75%$ of tokens and store 770M token representations.
首先,按照 Seo 等人 (2019) 的方法,我们对段落 Token 表示应用线性变换,以获得一组过滤 logits,这些 logits 可用于从 $\mathcal{W}(\mathcal{D})$ 中过滤掉许多 Token 表示。该过滤层通过应用二元交叉熵与黄金开始/结束位置(与公式 (9) 一起训练)进行监督。我们在阅读理解开发集上调整过滤 logits 的阈值,直到性能不会显著下降,同时最大限度地过滤 Token。在全维基百科设置中,我们过滤了大约 $75%$ 的 Token,并存储了 770M 个 Token 表示。
Second, in our architecture, we use a base model (SpanBERT-base) for a smaller dimension of token representations $'d=768)$ and does not use any sparse representations including tf-idf or contextualized sparse representations (Lee et al., 2020). We also use the scalar quantization for storing float32 vectors as int4 during indexing.
其次,在我们的架构中,我们使用了一个基础模型(SpanBERT-base)来生成较小维度的Token表示($d=768$),并且不使用任何稀疏表示,包括tf-idf或上下文稀疏表示(Lee et al., 2020)。我们还在索引过程中使用标量量化将float32向量存储为int4。
Lastly, since the inference in Eq. (10) is purely based on MIPS, we do not have to keep the original start and end vectors which takes about 500GB. However, when we perform query-side fine-tuning, we need the original start and end vectors for reconstructing them to compute Eq. (11) since (the on-disk version of) MIPS index only returns the top $k$ scores and their indices, but not the vectors.
最后,由于公式 (10) 中的推理完全基于 MIPS (最大内积搜索),我们不需要保留原始的开始和结束向量,这些向量大约占用 500GB。然而,当我们进行查询端微调时,我们需要原始的开始和结束向量来重建它们以计算公式 (11),因为 (磁盘版本的) MIPS 索引只返回前 $k$ 个分数及其索引,而不返回向量。