Anytime Active Learning
随时主动学习
Abstract
摘要
A common bottleneck in deploying supervised learning systems is collecting human-annotated examples. In many domains, annotators form an opinion about the label of an example increment ally — e.g., each additional word read from a document or each additional minute spent inspecting a video helps inform the annotation. In this paper, we investigate whether we can train learning systems more efficiently by requesting an annotation before inspection is fully complete — e.g., after reading only 25 words of a document. While doing so may reduce the overall annotation time, it also introduces the risk that the annotator might not be able to provide a label if interrupted too early. We propose an anytime active learning approach that optimizes the annotation time and response rate simultaneously. We conduct user studies on two document classification datasets and develop simulated annotators that mimic the users. Our simulated experiments show that anytime active learning outperforms several baselines on these two datasets. For example, with an annotation budget of one hour, training a classifier by annotating the first 25 words of each document reduces classification error by $17%$ over annotating the first 100 words of each document.
部署监督学习系统的一个常见瓶颈是收集人工标注的示例。在许多领域中,标注者会逐步形成对示例标签的看法——例如,从文档中读取的每个额外单词或检查视频时花费的每一分钟都有助于标注。在本文中,我们研究了是否可以通过在检查完全完成之前请求标注来更高效地训练学习系统——例如,在仅读取文档的25个单词后。虽然这样做可能会减少整体标注时间,但也引入了标注者如果被过早中断可能无法提供标签的风险。我们提出了一种随时主动学习方法,同时优化标注时间和响应率。我们在两个文档分类数据集上进行了用户研究,并开发了模拟标注者来模仿用户行为。我们的模拟实验表明,随时主动学习在这两个数据集上优于多个基线方法。例如,在一小时的标注预算下,通过标注每个文档的前25个单词来训练分类器,相比标注每个文档的前100个单词,分类错误减少了17%。
Introduction
引言
Active learning is a machine learning approach that seeks to maximize classifier accuracy while minimizing the effort of human annotators (Settles 2012). This is typically done by prioritizing example annotation according to the utility to the classifier.
主动学习是一种机器学习方法,旨在最大化分类器的准确性,同时最小化人工标注者的工作量 (Settles 2012)。这通常通过根据分类器的效用优先标注示例来实现。
In this paper, we begin with the simple observation that in many domains human annotators form an opinion about the label of an example increment ally. For example, while reading a document, an annotator makes a more informed deci- sion about the topic assignment as each word is read. Similarly, in video classification the annotator becomes more certain of the class label the longer she watches the video.
在本文中,我们从一个简单的观察开始:在许多领域中,人类标注者会逐步形成对示例标签的看法。例如,在阅读文档时,标注者每读一个词,都会对主题分配做出更明智的决定。同样,在视频分类中,标注者观看视频的时间越长,对类别标签的确定性就越高。
The question we ask is whether we can more efficiently train a classifier by interrupting the annotator to ask for a label, rather than waiting until the annotator has fully completed her inspection. For example, in document classification the active learner may request the label after the annotator has read the first 50 words of the document. For video classification, the active learner may decide to show only a short clip. We refer to this approach as anytime active learning (AAL), by analogy to anytime algorithms, whose execution may be interrupted at any time to provide an answer.
我们提出的问题是,是否可以通过打断标注者以请求标签来更高效地训练分类器,而不是等待标注者完全完成检查。例如,在文档分类中,主动学习器可能在标注者阅读了文档的前50个词后请求标签。对于视频分类,主动学习器可能决定只展示一个简短的片段。我们将这种方法称为随时主动学习 (AAL),类似于随时算法,其执行可以在任何时间中断以提供答案。
If the decision of when to interrupt the annotator is made optimally, we can expect to reduce total annotation effort by eliminating unnecessary inspection time that does not affect the returned label. However, the annotator may not be able to provide a label if interrupted too early – e.g., the annotator will not know how to label a document after seeing only the first word. AAL strategies, then, must balance two competing objectives: (1) the time spent annotating an instance (annotation cost); (2) the likelihood that the annotator will be able to produce a label (annotation response rate). In this paper, we propose and evaluate a number of anytime active learning strategies applied to the domain of document classification. In this domain, it is natural to implement this approach by revealing only the first $k$ words to the annotator, which we refer to as a sub instance.
如果能够最优地决定何时中断标注者,我们可以通过消除不影响返回标签的不必要检查时间来减少总标注工作量。然而,如果过早中断标注者,标注者可能无法提供标签——例如,标注者在只看到第一个单词时不知道如何标注文档。因此,AAL(Anytime Active Learning)策略必须平衡两个相互竞争的目标:(1) 标注一个实例所花费的时间(标注成本);(2) 标注者能够生成标签的可能性(标注响应率)。在本文中,我们提出并评估了多种应用于文档分类领域的随时主动学习策略。在该领域中,自然可以通过仅向标注者展示前 $k$ 个单词来实现这种方法,我们将其称为子实例。
We first conduct user studies to estimate annotation times and response rates, and then create simulated oracles that mimic the human annotators. We perform simulated-oracle experiments on two document classification tasks, comparing two classes of anytime active learning strategies: (1) static strategies select sub instances of a fixed size; (2) dynamic strategies select sub instances of varying sizes, optimizing cost and response rate simultaneously. Our research questions and answers are as follows:
我们首先进行用户研究以估计标注时间和响应率,然后创建模拟标注器来模仿人类标注者。我们在两个文档分类任务上进行了模拟标注器实验,比较了两类随时主动学习策略:(1) 静态策略选择固定大小的子实例;(2) 动态策略选择不同大小的子实例,同时优化成本和响应率。我们的研究问题和答案如下:
RQ1. How does sub instance size affect human annotation time and response rate? We conducted a user study in which each user labeled 480 documents from two domains under different interruption conditions (e.g., seeing only the first $k$ words). We find that as sub instance sizes increase, both response rates and annotation times increase (non-linearly), and that the rate of increase varies by dataset. RQ2. How do static AAL strategies compare with traditional active learning? We find that simple static strategies result in significantly more efficient learning, even with few words shown per document. For example, with an annotation budget of one hour, labeling only the first 25 words of each document reduces classification error by $17%$ compared with labeling the first 100 words of each document.
RQ1. 子实例大小如何影响人工标注时间和响应率?我们进行了一项用户研究,其中每个用户在不同中断条件下(例如,仅看到前 $k$ 个词)标注了来自两个领域的 480 份文档。我们发现,随着子实例大小的增加,响应率和标注时间都会增加(非线性),并且增加的速度因数据集而异。
RQ2. 静态 AAL 策略与传统主动学习相比如何?我们发现,即使每份文档只显示少量词语,简单的静态策略也能显著提高学习效率。例如,在标注预算为一小时的情况下,仅标注每份文档的前 25 个词比标注每份文档的前 100 个词能将分类错误减少 $17%$。
RQ3. How do dynamic AAL strategies compare with static strategies? The drawback of the static strategy is that we must select a sub instance size ahead of time; however, we find that the optimal size varies by dataset. Instead, we formulate a dynamic AAL algorithm to minimize cost while maximizing response rates. We find that this dynamic approach performs as well or better than the best static strategy, without the need for additional tuning.
RQ3. 动态 AAL 策略与静态策略相比如何?静态策略的缺点是我们必须提前选择一个子实例大小;然而,我们发现最佳大小因数据集而异。相反,我们制定了一种动态 AAL 算法,以在最大化响应率的同时最小化成本。我们发现,这种动态方法与最佳静态策略表现相当或更好,且无需额外调整。
The remainder of the paper is organized as follows: we first formalize the anytime active learning problem, then propose static and dynamic solutions. Next, we describe our user studies and how they are used to inform our simulation experiments. Finally, we present the empirical results and discuss their implications.
本文的剩余部分组织如下:我们首先形式化随时主动学习问题,然后提出静态和动态解决方案。接着,我们描述了用户研究以及它们如何用于指导我们的模拟实验。最后,我们展示了实证结果并讨论了其意义。
Anytime Active Learning (AAL)
随时主动学习 (Anytime Active Learning, AAL)
In this section, we first review standard active learning and then formulate our proposed anytime extension.
在本节中,我们首先回顾标准的主动学习 (active learning),然后阐述我们提出的随时扩展 (anytime extension)。
Problem Formulation
问题定义
Let $\mathcal{L}={(\mathbf{x}{i},y{i})}_{i=1}^{l}$ be a labeled dataset where $\mathbf{x}_{i}\in\mathbb{R}^{d}$ is a $d$ -dimensional feature vector and $y_{i}\in{y^{0},y^{1}}$ is its class label.1 Let $\mathcal{U}={\mathbf{x}_{i}}_{i=l+1}^{m}$ be a set of unlabeled examples. Let $P_{\mathcal{L}}(y|\mathbf{x})$ be the conditional probability of $y$ given $\mathbf{x}$ according to a classifier trained on $\mathcal{L}$ .
设 $\mathcal{L}={(\mathbf{x}{i},y{i})}_{i=1}^{l}$ 为一个带标签的数据集,其中 $\mathbf{x}_{i}\in\mathbb{R}^{d}$ 是一个 $d$ 维特征向量,$y_{i}\in{y^{0},y^{1}}$ 是其类别标签。设 $\mathcal{U}={\mathbf{x}_{i}}_{i=l+1}^{m}$ 为一组未标记的样本。设 $P_{\mathcal{L}}(y|\mathbf{x})$ 为根据在 $\mathcal{L}$ 上训练的分类器得到的给定 $\mathbf{x}$ 时 $y$ 的条件概率。
Typical pool-based active learning selects instances ${{\mathcal{U}}^{}}\subseteq$ $\mathcal{U}$ to be labeled by a human annotator (oracle) and appended to $\mathcal{L}$ . Assuming a pre specified annotation budget $B$ and an annotation cost function $C(\mathbf{x})$ , the goal of the active learning algorithm (student) is to select $\mathcal{U}^{}$ to minimize the classifier’s generalization error subject to the budget constraints:
典型的基于池的主动学习选择实例 ${{\mathcal{U}}^{}}\subseteq$ $\mathcal{U}$ 由人类标注者(oracle)进行标注,并将其附加到 $\mathcal{L}$ 中。假设预定义的标注预算为 $B$,标注成本函数为 $C(\mathbf{x})$,主动学习算法(student)的目标是在预算约束下选择 $\mathcal{U}^{}$ 以最小化分类器的泛化误差:
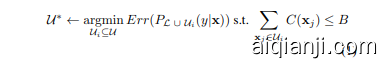
Equation 1 is typically optimized by greedy algorithms, selecting one or more examples at a time according to some heuristic criterion that estimates the utility of each labeled example. A common approach is to request a label for the unlabeled instance that maximizes benefit-cost ratio: $\mathbf{x}{i}^{}\gets$ $\begin{array}{r}{\operatorname{max}{\mathbf{x}{i}\in\mathcal{U}}\frac{U(\mathbf{x}{i})}{C(\mathbf{x}_{i})}}\end{array}$
公式 1 通常通过贪心算法进行优化,根据某些启发式准则一次选择一个或多个样本,这些准则用于估计每个已标注样本的效用。常见的方法是请求对未标注实例进行标注,以最大化效益成本比:$\mathbf{x}{i}^{}\gets$ $\begin{array}{r}{\operatorname{max}{\mathbf{x}{i}\in\mathcal{U}}\frac{U(\mathbf{x}{i})}{C(\mathbf{x}_{i})}}\end{array}$
Various definitions of utility $U(\cdot)$ are used in the literature, such as expected error reduction (Roy and McCallum 2001) and classifier uncertainty (Lewis and Gale 1994).
文献中使用了多种效用 $U(\cdot)$ 的定义,例如预期误差减少 (Roy and McCallum 2001) 和分类器不确定性 (Lewis and Gale 1994)。
We propose an alternative formulation of the active learning problem in which the student has the added capability of interrupting the human oracle to request a label while the annotation of $\mathbf{x}_{i}$ is being performed. For example, in video classification, the student may request a label after the oracle has spent only one minute watching the video. Similarly, in document classification the student may request a label after the oracle has read only the first ten words of a document.
我们提出了一种主动学习问题的替代公式,其中学生具备在标注 $\mathbf{x}_{i}$ 时打断人类标注者以请求标签的额外能力。例如,在视频分类中,学生可能在标注者仅观看视频一分钟后就请求标签。同样,在文档分类中,学生可能在标注者仅阅读文档的前十个单词后就请求标签。
Let $\mathbf{x}{i}^{k}$ indicate this abbreviated instance, which we call a sub instance. The nature of sub instances will vary by domain. For example, $k$ could indicate the time allotted to inspect the instance. In this paper, we focus on document classification, where it is natural to let $\mathbf{x}{i}^{k}$ be the first $k$ words of document $\mathbf{x}_{i}$ .
令 $\mathbf{x}{i}^{k}$ 表示这个简化的实例,我们称之为子实例。子实例的性质会因领域而异。例如,$k$ 可以表示检查实例所分配的时间。在本文中,我们专注于文档分类,其中自然地让 $\mathbf{x}{i}^{k}$ 表示文档 $\mathbf{x}_{i}$ 的前 $k$ 个词。
The potential savings from this approach arises from the assumption that $C(\mathbf{x}{i}^{k})<C(\mathbf{x}{i})$ ; that is, sub instances are less costly to label than instances. While the magnitude of these savings are data-dependent, our user studies below show substantial savings for document classification.
这种方法潜在的节省来自于假设 $C(\mathbf{x}{i}^{k})<C(\mathbf{x}{i})$ ;也就是说,子实例的标注成本低于实例。虽然这些节省的幅度取决于数据,但我们下面的用户研究表明,在文档分类中可以节省大量成本。
The immediate problem with this approach is that $\mathbf{x}{i}^{k}$ may be considerably more difficult for the oracle to label. We therefore must account for imperfect oracles (Donmez and Carbonell 2008; Yan et al. 2011). There are at least two scenarios to consider — (1) a noisy oracle produces a label for any $\mathbf{x}{i}^{k}$ , but that label may be incorrect; (2) a reluctant oracle may decide not to produce a label for some examples, but labels that are produced are assumed to be correct. Our user studies below suggests that the latter case is more common; thus, in this paper, we restrict our attention to reluctant oracles, leaving noisy oracles for future work.
这种方法的一个直接问题是,$\mathbf{x}{i}^{k}$ 可能对预言机来说更难标注。因此,我们必须考虑不完美的预言机 (Donmez and Carbonell 2008; Yan et al. 2011)。至少有两种情况需要考虑:(1) 一个嘈杂的预言机会为任何 $\mathbf{x}{i}^{k}$ 生成一个标签,但该标签可能是错误的;(2) 一个犹豫的预言机可能会决定不为某些样本生成标签,但生成的标签被认为是正确的。我们下面的用户研究表明,后一种情况更为常见;因此,在本文中,我们将注意力限制在犹豫的预言机上,将嘈杂的预言机留给未来的工作。
In each interaction between the student and oracle, the student presents a sub instance $\mathbf{x}{i}^{k}$ to the oracle, and the oracle returns an answer $a\in{y^{0},y^{1},n}$ , where the answer can be either the correct label $y$ or neutral, $n$ , which represents an “I don’t know” answer. If the oracle returns a non-neutral answer $a$ for $\mathbf{x}{i}^{k}$ , the student adds $\mathbf{x}{i}$ and the returned label $\overset{\cdot}{y}^{0}$ or $y^{1}.$ ) to its training data and updates its classifier. If $n$ is returned, the labeled data is unchanged. In either case, the annotation cost $C(\mathbf{x}{i}^{k})$ is deducted from the student’s budget because the oracle spends time inspecting $\mathbf{x}_{i}^{k}$ even if she returns a neutral label. To choose the optimal sub instance, the student must consider both the cost of the sub instance as well as the likelihood that a non-neutral label will be returned. Below, we propose two AAL strategies.
在学生与预言机(oracle)的每次交互中,学生向预言机提交一个子实例 $\mathbf{x}{i}^{k}$,预言机返回一个答案 $a\in{y^{0},y^{1},n}$,其中答案可以是正确的标签 $y$ 或中性标签 $n$,后者表示“我不知道”的答案。如果预言机为 $\mathbf{x}{i}^{k}$ 返回一个非中性答案 $a$,学生将 $\mathbf{x}{i}$ 和返回的标签 $\overset{\cdot}{y}^{0}$ 或 $y^{1}$ 添加到其训练数据中,并更新其分类器。如果返回的是 $n$,则标注数据保持不变。无论哪种情况,标注成本 $C(\mathbf{x}{i}^{k})$ 都会从学生的预算中扣除,因为即使预言机返回中性标签,她也会花费时间检查 $\mathbf{x}_{i}^{k}$。为了选择最优的子实例,学生必须同时考虑子实例的成本以及返回非中性标签的可能性。接下来,我们提出了两种主动学习(AAL)策略。
Static AAL Strategies
静态AAL策略
We first consider a simple, static approach to AAL that decides a priori on a fixed sub instance size $k$ . For example, the student fixes $k=10$ and presents the oracle sub instances $\mathbf{x}_{i}^{10}$ (please see Algorithm 1).
我们首先考虑一种简单、静态的AAL方法,该方法预先决定一个固定的子实例大小$k$。例如,学生固定$k=10$,并向预言机展示子实例$\mathbf{x}_{i}^{10}$(请参见算法1)。
Let $\mathcal{U}^{k}={x_{i}^{k}}_{i=l+1}^{m}$ be the set of all unlabeled subinstances of fixed size $k$ . In SELECT SUB INSTANCE (line 3), the student picks $\mathbf{x}_{i}^{k*}$ as follows:
设 $\mathcal{U}^{k}={x_{i}^{k}}_{i=l+1}^{m}$ 为固定大小 $k$ 的所有未标记子实例的集合。在 SELECT SUB INSTANCE (第 3 行) 中,学生选择 $\mathbf{x}_{i}^{k*}$ 如下:

Note that the utility is computed from the full instance $\mathbf{x}{i}$ , not the sub instance, since $\mathbf{x}{i}$ will be added to our labeled set (line 8). In our experiments, we consider two utility functions: uncertainty $(\mathtt{s t a t i c-k-u n c})$ , which sets $U\bar{(}\mathbf{x}{i}^{k})=$ $1-\operatorname*{max}{y}P_{\mathcal{L}}(\dot{y}|\mathbf{x}{i})$ , and constant $(s\mathtt{t a t i c-k-c o n s t})$ , which sets the utility of each sub instance to one, $U(\mathbf{x}{i}^{k})=1$ . We use static-k-const as a baseline for other AAL methods because it is an anytime version of random sampling.
请注意,效用是从完整实例 $\mathbf{x}{i}$ 计算的,而不是子实例,因为 $\mathbf{x}{i}$ 将被添加到我们的标记集中(第8行)。在我们的实验中,我们考虑了两个效用函数:不确定性 $(\mathtt{s t a t i c-k-u n c})$ ,它设置 $U\bar{(}\mathbf{x}{i}^{k})=$ $1-\operatorname*{max}{y}P_{\mathcal{L}}(\dot{y}|\mathbf{x}{i})$ ,以及常数 $(s\mathtt{t a t i c-k-c o n s t})$ ,它将每个子实例的效用设置为1, $U(\mathbf{x}{i}^{k})=1$ 。我们使用 static-k-const 作为其他 AAL 方法的基线,因为它是随机采样的随时版本。
Algorithm 1 Static Anytime Active Learning
算法 1 静态随时主动学习
| | 1: 输入:已标注数据 L;未标注数据 U;预算 B:分类器 P(y|x);子实例大小 k |
| | 2: while B > 0 do |
| 3: | x ← SELECTSUBINSTANCE(U, k) |
| 4: | u ← u \ {xi} |
| 5: | α ← QUERYORACLE(x) |
| 6: 7: | B ← B - C(x) if α then // 非中性响应 |
| 8: | C ← L ∪ (xi, α) |
| 9: | P(y|X) ← UPDATECLASSIFIER(C, P) |
Algorithm 2 Dynamic Anytime Active Learning
算法 2: 动态随时主动学习
1: 输入:标注数据 L;未标注数据 U;预算 B:中性标注数据 L²←0。
2: while B > 0 do
3: 分类器 P(y|x);中性分类器 Q(z|x);中性 x ← SELECTSUBINSTANCE(U)
Table 1: User study results reporting average annotation time in seconds and percent of neutral labels by sub instance size.
表 1: 用户研究结果,报告了按子实例大小划分的平均注释时间(秒)和中性标签的百分比。
| 大小 | IMDB 时间 (秒) | SRAA 时间 (秒) | IMDB 中性标签百分比 (%) | SRAA 中性标签百分比 (%) |
|---|---|---|---|---|
| 10 | 5.7 | 5.2 | 53 | 50 |
| 25 | 8.2 | 6.5 | 33 | 38 |
| 50 | 10.9 | 7.6 | 24 | 42 |
| 75 | 15.9 | 9.1 | 12 | 22 |
| 100 | 16.7 | 10.3 | 13 | 13 |
used to train the neutrality classifier $Q(z|\mathbf{x}_{k}^{i})$ (line 11). Algorithm 2 outlines this approach, where ISNEUTRAL maps the oracle answer to $z$ (i.e., $n$ or $\neg n$ ). As in the static strategy, we consider two settings of the utility function: uncertainty (dynamic-unc) and constant (dynamic-const). While both dynamic-unc and dynamic-const consider the cost of annotation, dynamic-unc balances utility with the chance of receiving a non-neutral label, while dynamic-const simply maximizes the chance of a nonneutral label.
用于训练中立分类器 $Q(z|\mathbf{x}_{k}^{i})$ (第 11 行)。算法 2 概述了这种方法,其中 ISNEUTRAL 将预言机答案映射到 $z$ (即 $n$ 或 $\neg n$ )。与静态策略一样,我们考虑了效用函数的两种设置:不确定性 (dynamic-unc) 和常数 (dynamic-const)。虽然 dynamic-unc 和 dynamic-const 都考虑了标注成本,但 dynamic-unc 在效用与获得非中性标签的机会之间进行权衡,而 dynamic-const 则简单地最大化非中性标签的机会。
Experimental Evaluation
实验评估
Our experiments use two datasets: (1) IMDB: A collection of 50K reviews from IMDB.com labeled with positive or negative sentiment (Maas et al. 2011); (2) SRAA: A collection of 73K Usenet articles labeled as related to aviation or auto documents (Nigam et al. 1998).
我们的实验使用了两个数据集:(1) IMDB:来自 IMDB.com 的 50K 条评论,标注为正面或负面情感 (Maas et al. 2011);(2) SRAA:包含 73K 篇 Usenet 文章,标注为与航空或汽车文档相关 (Nigam et al. 1998)。
Dynamic AAL Strategies
动态AAL策略
The static strategy ignores the impact that $k$ has on the likelihood of obtaining a neutral label from the oracle. In this section, we propose a dynamic strategy that models this probability directly and uses it to guide sub instance selection (see Algorithm 2).
静态策略忽略了 $k$ 对从预言机获取中性标签可能性的影响。在本节中,我们提出了一种动态策略,直接建模这一概率,并利用它来指导子实例选择(见算法 2)。
Let $Q(z|\mathbf{x}{i}^{k})$ be the probability distribution that models whether the oracle will return an “I don’t know” answer (i.e. a neutral label) for the sub instance $\mathbf{x}{i}^{k}$ , where $z\in$ ${n,\neg n}$ . The objective of SELECT SUB INSTANCE (line 3) is to select the sub instance that maximizes utility and the probability of obtaining a non-neutral label, $\neg n$ , while minimizing cost.
设 $Q(z|\mathbf{x}{i}^{k})$ 为建模预言机是否会对子实例 $\mathbf{x}{i}^{k}$ 返回“我不知道”答案(即中性标签)的概率分布,其中 $z\in$ ${n,\neg n}$。SELECT SUB INSTANCE(第3行)的目标是选择能够最大化效用和获得非中性标签 $\neg n$ 的概率,同时最小化成本的子实例。
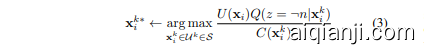
In contrast to the static approach, the dynamic algorithm searches over an expanded set of $p$ different sub instance sizes: ${\cal S}={\mathcal{U}^{k_{1}}\dots\dot{\mathcal{U}}^{k_{p}}}$ .
与静态方法不同,动态算法在扩展的 $p$ 个不同子实例大小集合 ${\cal S}={\mathcal{U}^{k_{1}}\dots\dot{\mathcal{U}}^{k_{p}}}$ 上进行搜索。
The immediate question is how to estimate $Q(z|\mathbf{x}{k}^{i})$ . We propose a supervised learning approach using the previous interactions with the oracle as labeled examples. That is, we maintain an auxiliary binary labeled dataset $\mathcal{L}^{z}$ containing $(\mathbf{x}{i}^{k},z_{i})$ pairs (line 10), indicating whether subinstance $\mathbf{x}_{i}^{k}$ received a neutral label or not.2 This dataset is
当前的问题是,如何估计 $Q(z|\mathbf{x}{k}^{i})$ 。我们提出了一种监督学习方法,利用与预言机(oracle)的先前交互作为标注示例。也就是说,我们维护一个辅助的二元标注数据集 $\mathcal{L}^{z}$ ,其中包含 $(\mathbf{x}{i}^{k},z_{i})$ 对(第10行),表示子实例 $\mathbf{x}_{i}^{k}$ 是否收到了中性标签。
User Studies
用户研究
To estimate the real-world relationships among sub instance size, annotation time, and response rate, we first performed several user studies in which subjects were shown document sub instances of varying sizes and asked to provide a correct label or an “I don’t know” answer (i.e., a neutral label).
为了估计子实例大小、标注时间和响应率之间的实际关系,我们首先进行了几项用户研究,在这些研究中,受试者被展示不同大小的文档子实例,并被要求提供正确的标签或“我不知道”的答案(即中性标签)。
Each user performed six classification tasks per dataset, labeling document sub instances of sizes ${10,25,50,75,100,\mathrm{All}}$ . For example, to create the 50-word task, we truncated the documents to the first 50 words. For each classification task, the users were asked to annotate 20 randomly-chosen documents from each class, resulting in 40 annotations per task. The documents were presented to the users in random order. For every sub instance, we recorded the annotation time, the number of words seen, and the label. We used the average over five users on the IMDB and three users on the SRAA data.
每个用户在每个数据集上执行六项分类任务,标注大小为 ${10,25,50,75,100,\mathrm{All}}$ 的文档子实例。例如,为了创建 50 个单词的任务,我们将文档截断为前 50 个单词。对于每个分类任务,用户被要求为每个类别的 20 个随机选择的文档进行标注,每项任务共产生 40 个标注。文档以随机顺序呈现给用户。对于每个子实例,我们记录了标注时间、看到的单词数量和标签。我们在 IMDB 数据集上使用了五名用户的平均值,在 SRAA 数据集上使用了三名用户的平均值。
Table 1 shows the average annotation time (in seconds) and average percentage of neutral labels returned for each sub instance size. We find that the annotation time varies by sub instance size and dataset. For instance, in IMDB annotation time of sub instances of size 50 is $25%$ greater than for sub instances of size 25. These responses are influenced by the user experience and domain knowledge familiarity, among other factors.
表 1 展示了每个子实例大小的平均标注时间(以秒为单位)和返回的中性标签的平均百分比。我们发现标注时间因子实例大小和数据集而异。例如,在 IMDB 数据集中,大小为 50 的子实例的标注时间比大小为 25 的子实例多 $25%$。这些响应受到用户体验和领域知识熟悉度等因素的影响。
Intuitively, the annotator will be more likely to provide a non-neutral label when he can see more of a document. This intuition was confirmed by our user studies. Table 1 shows that the percentage of neutral labels decreases as sub instance size increases. However, the rate at which the neutral answer decreases differs by dataset. For example, there was approximately a $50%$ neutral rate on both datasets for sub instances with 10 words; yet for 75 words the neutral responses were $12%$ on IMDB and $22%$ on SRAA. We speculate that the SRAA dataset is a more specialized domain, whereas classifying movie reviews (IMDB) is easier for non-expert human annotators.
直觉上,当标注者能看到文档的更多内容时,他们更有可能提供非中立的标签。我们的用户研究证实了这一直觉。表 1 显示,随着子实例大小的增加,中立标签的百分比下降。然而,中立答案下降的速度因数据集而异。例如,对于包含 10 个单词的子实例,两个数据集的中立率约为 $50%$;而对于 75 个单词的子实例,IMDB 的中立响应率为 $12%$,SRAA 的中立响应率为 $22%$。我们推测 SRAA 数据集是一个更专业的领域,而对电影评论(IMDB)进行分类对于非专业的人类标注者来说更容易。
Simulations
模拟
We use the results of the user study to inform our large-scale studies on the two datasets.
我们利用用户研究的结果来指导我们在两个数据集上的大规模研究。
Oracle In order to compare many AAL strategies at scale, it is necessary to simulate the actions of the human annotators. Specifically, we must simulate for which examples the annotator will return a neutral label. We wanted to better reflect the fact that the lexical content of each sub instance influences its neutrality instead of random neutrality — e.g., if a sub instance has strong sentiment words it is not likely to be labeled neutral. To accomplish this, we trained two oracles (one per dataset) that mimic the human annotators. We simulated the oracle with a classifier trained on held-out data; a neutral label is returned when the class posterior probability for a sub instance $\mathbf{x}_{i}^{k}$ is below a specified threshold. We tune this classifier so that the pattern of neutral labels matches that observed in the user study.
为了大规模比较多种主动学习策略,有必要模拟人类标注者的行为。具体来说,我们必须模拟标注者在哪些示例上会返回中性标签。我们希望更好地反映每个子实例的词汇内容对其中立性的影响,而不是随机中立性——例如,如果一个子实例包含强烈的情感词汇,它不太可能被标记为中性。为了实现这一点,我们训练了两个模拟人类标注者的oracle(每个数据集一个)。我们通过在保留数据上训练的分类器来模拟oracle;当子实例 $\mathbf{x}_{i}^{k}$ 的类别后验概率低于指定阈值时,返回中性标签。我们调整这个分类器,以使中性标签的模式与用户研究中观察到的模式相匹配。
At the start of each experiment we fit a logistic regression classifier on a held-out labeled dataset (25K examples for IMDB; 36K for SRAA). We use L1 regular iz ation controlled by penalty $C$ to encourage sparsity. When the oracle is asked to label a sub instance $\mathbf{x}{i}^{k}$ , we compute the posterior probability with respect to this classifier and compute oracle’s uncertainty on $\mathbf{\dot{x}}{i}^{k}$ as $1-\operatorname*{max}{y}P(y|\mathbf x{i}^{k})$ . If the uncertainty is greater than a specified threshold $T$ , then the oracle returns a neutral label. Otherwise, the true label is returned.
在每次实验开始时,我们会在一个保留的带标签数据集上拟合一个逻辑回归分类器(IMDB 为 25K 个样本;SRAA 为 36K 个样本)。我们使用由惩罚参数 $C$ 控制的 L1 正则化来鼓励稀疏性。当请求预言机为子实例 $\mathbf{x}{i}^{k}$ 打标签时,我们根据该分类器计算后验概率,并计算预言机对 $\mathbf{\dot{x}}{i}^{k}$ 的不确定性为 $1-\operatorname*{max}{y}P(y|\mathbf x{i}^{k})$。如果不确定性大于指定的阈值 $T$,则预言机返回一个中性标签。否则,返回真实标签。
For each of the datasets, we set $C$ and $T$ so that the distribution of neutral labels by sub instance size most closely matches the results of the user study. We searched values $C~\in~[0.001,3]$ with 0.001 step and $T\in[0.3,0.45]$ with 0.05 step, selecting $C~=0.3,T=~0.4$ for IMDB and $C=0.01,T=0.3$ for SRAA. Figures 1(a) and 1(b) show the simulated distribution of neutral labels by sub instance size over the same documents from the user study, indicating a close match with human behavior.
对于每个数据集,我们设置 $C$ 和 $T$,使得按子实例大小的中性标签分布最接近用户研究的结果。我们搜索了 $C~\in~[0.001,3]$,步长为 0.001,以及 $T\in[0.3,0.45]$,步长为 0.05,最终选择 $C~=0.3,T=~0.4$ 用于 IMDB 数据集,$C=0.01,T=0.3$ 用于 SRAA 数据集。图 1(a) 和图 1(b) 展示了按子实例大小的中性标签在用户研究相同文档上的模拟分布,表明与人类行为非常接近。
To simulate the cost of each annotation, we used a fixed cost equal to the average annotation time from the user study for sub instances of that size — e.g., for all sub instances of size 10 for IMDB, the cost is the average annotation time for all sub instances of size 10 in the IMDB user study. In future work, we will consider modeling annotation time as a function of the lexical content of the sub instance.
为了模拟每次标注的成本,我们使用了一个固定成本,该成本等于用户研究中该大小子实例的平均标注时间。例如,对于IMDB中所有大小为10的子实例,成本是IMDB用户研究中所有大小为10的子实例的平均标注时间。在未来的工作中,我们将考虑将标注时间建模为子实例词汇内容的函数。
Student For the student, we use a logistic regression classifier with L1 regular iz ation using the default parameter $C=1$ , seeded with a labeled set of two examples. At each round of active learning, a subsample of 250 examples are selected uniformly from the unlabeled set $\mathcal{U}$ . Following the user study, sub instances of sizes ${10,25,50,75,100}$ are created for each example in the subsample and scored according to the appropriate strategy (Equation 2 for static; Equation 3 for dynamic). We reserve half of the data for testing, and use the remaining to simulate active learning. For all methods, we report the average result of 10 trials.
对于学生,我们使用带有 L1 正则化的逻辑回归分类器,默认参数为 $C=1$,并使用两个带标签的样本作为初始集。在每一轮主动学习中,从未标记集 $\mathcal{U}$ 中均匀选择 250 个样本的子集。根据用户研究,为子集中的每个样本创建大小为 ${10,25,50,75,100}$ 的子实例,并根据适当的策略进行评分(静态策略使用公式 2;动态策略使用公式 3)。我们保留一半的数据用于测试,并使用剩余数据模拟主动学习。对于所有方法,我们报告 10 次试验的平均结果。
For both datasets, we used documents that at least contain 100 words. We created binary feature representations of the documents, using stemmed n-grams (sizes one to three), pruning n-grams appearing in fewer than five documents. In SRAA, we filtered header information, preserving only the subject line and body of the messages.
对于这两个数据集,我们使用了至少包含100个单词的文档。我们创建了文档的二进制特征表示,使用词干提取的n-gram(大小为1到3),并剪枝出现在少于五个文档中的n-gram。在SRAA中,我们过滤了头部信息,仅保留了消息的主题行和正文。
Results and Discussion
结果与讨论
With an oracle simulation and annotation cost in place, we explored the performance of several AAL strategies. We examined learning curves for accuracy and area under the ROC curve (AUC) and observed the same trends and behaviors for each; therefore we include only AUC results here. We summarize our findings below.
在设置了预言机模拟和标注成本后,我们探索了几种主动学习 (AAL) 策略的性能。我们检查了准确率和 ROC 曲线下面积 (AUC) 的学习曲线,并观察到每种策略的趋势和行为相同;因此,这里仅包含 AUC 结果。我们在下面总结了我们的发现。
Smaller sub instances generally outperform larger sub instances. Figure 2 shows the performance of static-k-const for IMDB and SRAA datasets. These results consistently show that savings can be achieved by selecting smaller sub instances. For example, after an hour of annotation (3600 seconds) on IMDB, inspecting the first 100 words of each document results in an AUC of .752; whereas labeling only the first 25 words results in an AUC of .792, a $17%$ reduction in error. This suggests that while a smaller $k$ results in a high neutral percentage, the time saved by reading shorter documents more than make up for the losses. The results for static-k-unc are similar but are omitted due to space limitations.
较小的子实例通常优于较大的子实例。图 2 展示了 IMDB 和 SRAA 数据集上 static-k-const 的性能。这些结果一致表明,通过选择较小的子实例可以实现节省。例如,在 IMDB 上进行一小时的标注(3600 秒)后,检查每篇文档的前 100 个词得到的 AUC 为 0.752;而仅标注前 25 个词得到的 AUC 为 0.792,误差减少了 17%。这表明,虽然较小的 $k$ 会导致较高的中性比例,但通过阅读较短的文档所节省的时间足以弥补损失。static-k-unc 的结果类似,但由于篇幅限制,此处省略。
The optimal sub instance size varies by dataset. Comparing Figure 2(a) to Figure 2(b) indicates that the optimal $k^{}$ varies by dataset $\mathit{\Omega}^{\prime}k^{}=25$ for IMDB, $k^{*}~=~50$ for SRAA). This follows from the observed differences between these datasets in the user study (Table 1); i.e., the annotation cost rises more slowly with sub instance size in SRAA. Thus, somewhat bigger sub instances are worth the small additional cost to reduce the likelihood of a neutral label.
最优子实例大小因数据集而异。比较图 2(a) 和图 2(b) 可以看出,最优的 $k^{}$ 因数据集而异(对于 IMDB,$\mathit{\Omega}^{\prime}k^{}=25$;对于 SRAA,$k^{*}~=~50$)。这与用户研究中观察到的这些数据集之间的差异一致(表 1);即,在 SRAA 中,子实例大小的增加导致标注成本的上升速度较慢。因此,稍大的子实例值得付出较小的额外成本,以减少中性标签的可能性。
dynamic-unc does better than or equal to the best static AAL algorithm. Given the fact that the optimal sub instance size varies by dataset, we examine how the dynamic approach compares to the static approach. Figure 3 compares the dynamic approach with uncertainty and constant utility (dynamic-unc, dynamic-const) with the best static methods. We find that the dynamic-unc outperforms the best static method for the IMDB dataset (Figure 3(a)). In Figure 3(b), the static and dynamic approaches are comparable; however, the advantage of dynamic-unc is that there is no need to specify $k$ ahead of time.
动态不确定性方法(dynamic-unc)优于或等于最佳的静态AAL算法。鉴于最优子实例大小因数据集而异,我们研究了动态方法与静态方法的比较。图3比较了带有不确定性和恒定效用的动态方法(dynamic-unc,dynamic-const)与最佳静态方法。我们发现,对于IMDB数据集,dynamic-unc优于最佳静态方法(图3(a))。在图3(b)中,静态和动态方法相当;然而,dynamic-unc的优势在于无需提前指定$k$。
Dynamic approaches tend to pick a mixture of subinstance sizes. To better understand the behavior of the dynamic approaches, Figure 4 plots the distribution of subinstance sizes selected by both approaches. As we can see, the dynamic approaches select a mixture of sub instance sizes, but heavily favor smaller sizes. Combining this observation with the results that dynamic-unc is either able to outperform or perform comparable to static approaches, this suggests that the dynamic approach is able to pick small subinstances that receive non-neutral labels.
动态方法倾向于选择不同大小的子实例组合。为了更好地理解动态方法的行为,图 4 展示了两种方法选择的子实例大小的分布情况。从图中可以看出,动态方法选择了不同大小的子实例组合,但更倾向于选择较小的子实例。结合动态方法在性能上能够优于或与静态方法相当的实验结果,这表明动态方法能够选择那些获得非中性标签的较小子实例。

IMDB -‐ Percentage of Neutral Responses by Size
图 1: IMDB - 中性响应百分比随规模变化

SRAA -‐ Percentage of Neutral Responses by Size
SRAA - 按规模划分的中性响应百分比

Figure 1: A comparison of the proportion of neutral responses by sub instance size for the user studies and the simulated oracles.
图 1: 用户研究和模拟预言机中子实例大小的中性响应比例比较。

Figure 2: AUC learning curves for static-k-const. The trends for static-k-unc are similar. The optimal $k^{}$ depends on the domain. For IMDB, $k^{}=25$ while for SRAA, $k^{*}=50$ .
图 2: 静态-k-const 的 AUC 学习曲线。静态-k-unc 的趋势类似。最优的 $k^{}$ 取决于领域。对于 IMDB,$k^{}=25$,而对于 SRAA,$k^{*}=50$。
Figure 3: Comparing dynamic AAL to the best of the static AAL approaches. dynamic-unc outperforms all methods for IMDB whereas it is comparable to the best static approaches for SRAA.
图 3: 动态 AAL 与最佳静态 AAL 方法的比较。dynamic-unc 在 IMDB 上优于所有方法,而在 SRAA 上与最佳静态方法相当。
Table 2 further investigates this by comparing the proportion of neutral labels observed with the expected proportion based on the user study. That is, by combining the data from
表 2: 通过比较观察到的中性标签比例与基于用户研究的预期比例,进一步探讨了这一点。即通过结合数据
Table 1 and Figure 4, we compute the proportion of neutral labels we expect to see for the observed distribution of sub instance sizes. We can see that the neutrality classifier $Q(z|\mathbf{x}_{i}^{k})$ enables the dynamic approach to select small sub instances while limiting the impact of neutral labels.
表 1 和图 4 中,我们计算了在观察到的子实例大小分布中预期看到的中性标签比例。我们可以看到,中性分类器 $Q(z|\mathbf{x}_{i}^{k})$ 使动态方法能够选择小的子实例,同时限制中性标签的影响。

IMDB -‐ AAL Proportion of Sub instances by Size SRAA -‐ AAL Proportion of Sub instances by Size Figure 4: Proportion of sub instance sizes selected by dynamic AAL.
图 4: 动态 AAL 选择的子实例大小的比例
Table 2: The percentage of observed neutral labels for dynamic-unc and dynamic-const, compared with what is expected for sub instances of the observed sizes.
表 2: dynamic-unc 和 dynamic-const 的中性标签观察百分比,与观察大小的子实例预期值的比较。
| Obs. | Exp. | ||
|---|---|---|---|
| IMDB | const unc | 15% 34% | 48% 45% |
| SRAA | const unc | 2% 37% | 50% 45% |
Uncertainty improves the exploration of AAL algorithms. In general, we find that using uncertainty outperforms constant utility. For example, in Figure 3, dynamic-unc outperforms dynamic-const on both datasets. This supports prior work showing the benefits of uncertainty sampling. Additionally, we find that the uncertainty term of the objective balances the neutrality term, enabling a better exploration of the sample space. For example, in the SRAA dataset, Figure 3(b) shows that dynamic-const stops learning after a few rounds of active learning. Interestingly, analysis of this result showed that the $Q(z|\mathbf{x}{i}^{k})$ model quickly learned in the first iterations a strong correlation between non-neutral response and certain terms, e.g. “GPL” (proper name indicating class “auto”) in the subject line; dynamic-const selected sub instances with those terms thereafter obtaining non-neutral labels for those sub instances. Thus, $Q(z|\mathbf{x}{i}^{k})$ was further reinforced to predict the sub instances that contain the word “GPL” as nonneutral. This prevented the neutrality model from exploring other terms and the student did not receive a diverse set of documents to improve learning. Including the uncertainty term encouraged the student to seek a more diverse set of examples, thus avoiding this problem.
不确定性提升了 AAL 算法的探索能力。总体而言,我们发现使用不确定性优于恒定效用。例如,在图 3 中,dynamic-unc 在两个数据集上都优于 dynamic-const。这支持了先前关于不确定性采样优势的研究。此外,我们发现目标函数的不确定性项平衡了中性项,从而更好地探索样本空间。例如,在 SRAA 数据集中,图 3(b) 显示 dynamic-const 在几轮主动学习后停止了学习。有趣的是,对这一结果的分析表明,$Q(z|\mathbf{x}{i}^{k})$ 模型在前几次迭代中迅速学习到了非中性响应与某些术语之间的强相关性,例如主题行中的“GPL”(表示类别“auto”的专有名词);dynamic-const 随后选择了包含这些术语的子实例,从而为这些子实例获得了非中性标签。因此,$Q(z|\mathbf{x}{i}^{k})$ 进一步强化了预测包含“GPL”一词的子实例为非中性的能力。这阻碍了中性模型探索其他术语,学生也没有获得多样化的文档集来提升学习效果。引入不确定性项鼓励学生寻找更多样化的示例,从而避免了这一问题。
This is further supported by Table 2, which shows that dynamic-const primarily selects instances for which it is very likely to receive a non-neutral label. E.g., in SRAA, only $2%$ of instances receive a neutral label for dynamic-const; Figure 3(b) shows this to be an ineffective strategy, since the student observes only a homogeneous subset of examples. While dynamic-unc increases the rate of neutral labels, this additional cost is worth the greater diversity of labeled data.
表 2 进一步支持了这一点,它表明 dynamic-const 主要选择那些极有可能获得非中性标签的实例。例如,在 SRAA 中,只有 $2%$ 的实例获得了 dynamic-const 的中性标签;图 3(b) 显示这是一种无效的策略,因为学生只能观察到同质的示例子集。虽然 dynamic-unc 增加了中性标签的比例,但这一额外成本值得换取更丰富的标注数据多样性。
Related Work
相关工作
There has been a significant amount of work on noisy and reluctant oracles for traditional active learning scenarios without anytime capability (Donmez and Carbonell 2008; Donmez, Carbonell, and Schneider 2009; Fang, Zhu, and Zhang 2012; Wallace et al. 2011; Yan et al. 2011). Much of this work considered which instance to show to which oracle, and the oracle’s quality is fixed. In the anytime framework that we propose in this paper, the student has control over how much time an oracle should spend on an instance, thus controlling the quality of the label.
在传统主动学习场景中,已有大量关于噪声和犹豫不决的标注者(oracle)的研究,这些研究并未考虑实时能力(Donmez 和 Carbonell 2008;Donmez、Carbonell 和 Schneider 2009;Fang、Zhu 和 Zhang 2012;Wallace 等 2011;Yan 等 2011)。这些研究大多关注于向哪个标注者展示哪个实例,且标注者的质量是固定的。而在本文提出的实时框架中,学习者可以控制标注者在每个实例上花费的时间,从而控制标签的质量。
There has also been a significant amount of work on cost-sensitive active learning (Settles, Craven, and Friedland 2008; Donmez and Carbonell 2008; Haertel et al. 2008; Kapoor, Horvitz, and Basu 2007; Tomanek and Hahn 2010). The common strategy is to use a utility-cost ratio to determine the most cost-effective instances. We follow the same strategy and use utility-cost ratio, with the additional multiplicative factor of probability of non-neutrality.
在成本敏感型主动学习方面也有大量工作 (Settles, Craven, and Friedland 2008; Donmez and Carbonell 2008; Haertel et al. 2008; Kapoor, Horvitz, and Basu 2007; Tomanek and Hahn 2010)。常见的策略是使用效用成本比来确定最具成本效益的实例。我们遵循相同的策略并使用效用成本比,并额外乘以非中性概率的乘数因子。
We build on our previous work (Ramirez-Loaiza, Culotta, and Bilgic 2013) about the problem of searching over subinstances with some notable differences: i) we conducted user studies to determining annotation time, whereas they assumed a linear cost function, ii) we allow the oracles to return a neutral label and model neutrality.
我们在之前的工作 (Ramirez-Loaiza, Culotta, and Bilgic 2013) 基础上,针对子实例搜索问题进行了研究,但有以下几个显著差异:i) 我们通过用户研究来确定标注时间,而他们假设了一个线性成本函数;ii) 我们允许预言者返回中性标签并对中性进行建模。
Conclusions and Future Work
结论与未来工作
We present an anytime active learning framework in which the student is allowed to interrupt the oracle to save annotation time. User studies were conducted to quantify the relationship between sub instance size, annotation time, and response rate. These were used to inform a large-scale simulated study on two document classification tasks, which showed that although interruption can cause the oracle return neutral labels, interrupting at the right time can lead to significantly more efficient learning. We found that optimal interruption time depends on the domain and proposed a dynamic AAL strategy that is better than or comparable to the best static strategy that uses a fixed interruption time.
我们提出了一种随时可中断的主动学习框架,其中学生可以中断标注者以节省标注时间。通过用户研究量化了子实例大小、标注时间和响应率之间的关系。这些研究结果被用于指导在两个文档分类任务上进行的大规模模拟研究,研究表明,尽管中断可能导致标注者返回中性标签,但在适当的时间中断可以显著提高学习效率。我们发现最佳中断时间取决于领域,并提出了一种动态的随时可中断主动学习策略,该策略优于或等同于使用固定中断时间的最佳静态策略。
In the future, we will expand our model of annotation time to account for lexical content. Moreover, we assumed in this paper that the annotator reads the document serially starting from the beginning and hence created sub instances that correspond to the first $k$ words of the document. As future work, we will consider alternative techniques of interruption, such as structured reading (e.g., the first and last sections of a document) and text sum mari z ation to speed up annotation.
未来,我们将扩展标注时间的模型,以考虑词汇内容。此外,我们在本文中假设标注者从文档的开头开始顺序阅读,因此创建了与文档前 $k$ 个词对应的子实例。作为未来的工作,我们将考虑其他中断技术,例如结构化阅读(例如,文档的第一部分和最后部分)以及文本摘要,以加快标注速度。
multiple expert active learning. In Proc. of the SIAM International Conference on Data Mining (SDM). Yan, Y.; Fung, G. M.; Rosales, R.; and Dy, J. G. 2011. Active learning from crowds. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), 1161– 1168.
多专家主动学习。在 SIAM 国际数据挖掘会议 (SDM) 上。Yan, Y.; Fung, G. M.; Rosales, R.; 和 Dy, J. G. 2011. 从众包中主动学习。在第 28 届国际机器学习会议 (ICML-11) 上,1161–1168。