From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
从 RAG 到记忆:大语言模型的非参数持续学习
Bernal Jimenez Gutiérrez * 1 Yiheng $\mathbf{Shu}^{*1}$ Weijian Qi 1 Sizhe Zhou 2 Yu Su 1
Bernal Jimenez Gutiérrez * 1 Yiheng $\mathbf{Shu}^{*1}$ Weijian Qi 1 Sizhe Zhou 2 Yu Su 1
Abstract
摘要
1. Introduction
1. 引言
Our ability to continuously acquire, organize, and leverage knowledge is a key feature of human intelligence that AI systems must approximate to unlock their full potential. Given the challenges in continual learning with large language models (LLMs), retrieval-augmented generation (RAG) has become the dominant way to introduce new information. However, its reliance on vector retrieval hinders its ability to mimic the dynamic and interconnected nature of human long-term memory. Recent RAG approaches augment vector embeddings with various structures like knowledge graphs to address some of these gaps, namely sense-making and associativity. However, their performance on more basic factual memory tasks drops considerably below standard RAG. We address this unintended deteri oration and propose HippoRAG 2, a framework that outperforms standard RAG comprehensively on factual, sense-making, and associative memory tasks. HippoRAG 2 builds upon the Personalized PageRank algorithm used in HippoRAG and enhances it with deeper passage integration and more effective online use of an LLM. This combination pushes this RAG system closer to the effectiveness of human long-term memory, achieving a $7%$ improvement in associative memory tasks over the state-of-the-art embedding model while also exhibiting superior factual knowledge and sense-making memory capabilities. This work paves the way for non-parametric continual learning for LLMs. Our code and data will be released at https://github.com/ OSU-NLP-Group/HippoRAG.
我们持续获取、组织和利用知识的能力是人类智能的一个关键特征,AI 系统必须接近这一特征才能充分发挥其潜力。鉴于大语言模型 (LLMs) 在持续学习中的挑战,检索增强生成 (RAG) 已成为引入新信息的主要方式。然而,其对向量检索的依赖阻碍了其模拟人类长期记忆的动态和互连性的能力。最近的 RAG 方法通过知识图谱等各种结构增强向量嵌入,以解决其中的一些差距,即意义构建和关联性。然而,它们在更基本的事实记忆任务上的表现远低于标准的 RAG。我们解决了这种意外的退化问题,并提出了 HippoRAG 2,这是一个在事实、意义构建和关联记忆任务上全面优于标准 RAG 的框架。HippoRAG 2 建立在 HippoRAG 中使用的个性化 PageRank 算法的基础上,并通过更深层次的段落整合和更有效的在线使用 LLM 来增强它。这种组合使该 RAG 系统更接近人类长期记忆的有效性,在关联记忆任务上比最先进的嵌入模型提高了 7%,同时还表现出卓越的事实知识和意义构建记忆能力。这项工作为 LLMs 的非参数持续学习铺平了道路。我们的代码和数据将在 https://github.com/OSU-NLP-Group/HippoRAG 发布。
In an ever-evolving world, the ability to continuously absorb, integrate, and leverage knowledge is one of the most important features of human intelligence. From lawyers navigating shifting legal frameworks to researchers tracking multifaceted scientific progress, much of our productivity relies on this incredible capacity for continual learning. It is imperative for AI systems to approximate this capability in order to become truly useful human-level assistants.
在不断变化的世界中,持续吸收、整合和利用知识的能力是人类智能最重要的特征之一。从律师应对不断变化的法律框架到研究人员追踪多方面的科学进展,我们的生产力很大程度上依赖于这种持续学习的惊人能力。对于AI系统来说,近似这种能力至关重要,以便成为真正有用的人类级助手。
In recent years, large language models (LLMs) have made remarkable progress in many aspects of human intelligence. However, efforts to endow these models with our evolving long-term memory capabilities have faced significant challenges in both fully absorbing new knowledge (Zhong et al., 2023; Hoelscher-Obermaier et al., 2023) and avoiding catastrophic forgetting (Cohen et al., 2024; Gu et al., 2024), due to the complex distribution al nature of their parametric knowledge. Retrieval-augmented generation (RAG) has emerged as a way to circumvent these obstacles and allow LLMs to access new information in a non-parametric fashion without altering an LLM’s parametric representation. Due to their simplicity and robustness (Zhong et al., 2023; Xie et al., 2024), RAG has quickly become the de facto continual learning solution for production LLM systems. However, their reliance on simple vector retrieval results in the inability to capture two vital aspects of our interconnected long-term memory system: sense-making (Klein et al. (2006); the ability to interpret larger, more complex, or uncertain contexts) and associativity (Suzuki (2005); the capacity to draw multi-hop connections between disparate pieces of knowledge).
近年来,大语言模型(LLMs)在人类智能的许多方面取得了显著进展。然而,由于参数化知识的复杂分布性,赋予这些模型我们不断发展的长期记忆能力的努力在完全吸收新知识(Zhong et al., 2023; Hoelscher-Obermaier et al., 2023)和避免灾难性遗忘(Cohen et al., 2024; Gu et al., 2024)方面面临重大挑战。检索增强生成(RAG)作为一种绕过这些障碍的方式应运而生,使大语言模型能够以非参数化的方式访问新信息,而无需改变其参数化表示。由于其简单性和鲁棒性(Zhong et al., 2023; Xie et al., 2024),RAG迅速成为生产级大语言模型系统的事实上的持续学习解决方案。然而,它们对简单向量检索的依赖导致无法捕捉我们相互关联的长期记忆系统的两个重要方面:意义建构(Klein et al. (2006); 解释更大、更复杂或不确定上下文的能力)和关联性(Suzuki (2005); 在不同知识片段之间建立多跳连接的能力)。
Several RAG frameworks that engage an LLM to explicitly structure its retrieval corpus have been recently proposed to address these limitations. To enhance sense-making, such structure-augmented RAG methods allow an LLM to either generate summaries (Edge et al., 2024; Sarthi et al., 2024; Chen et al., 2023) or a knowledge graph (KG) structure (Guo et al., 2024) to link groups of disparate but related passages, thereby improving the RAG system’s ability to understand longer and more complex discourse such as long stories. To address the associativity gap, the authors of HippoRAG (Gutiérrez et al., 2024) use the Personalized
为了解决这些限制,最近提出了几种利用大语言模型(LLM)明确构建其检索语料库的 RAG 框架。为了增强意义理解,这种结构增强的 RAG 方法允许大语言模型生成摘要(Edge 等人,2024;Sarthi 等人,2024;Chen 等人,2023)或知识图谱(KG)结构(Guo 等人,2024),以链接不同但相关的段落组,从而提高 RAG 系统理解更长、更复杂话语(如长故事)的能力。为了解决关联性差距,HippoRAG 的作者(Gutiérrez 等人,2024)使用了个性化
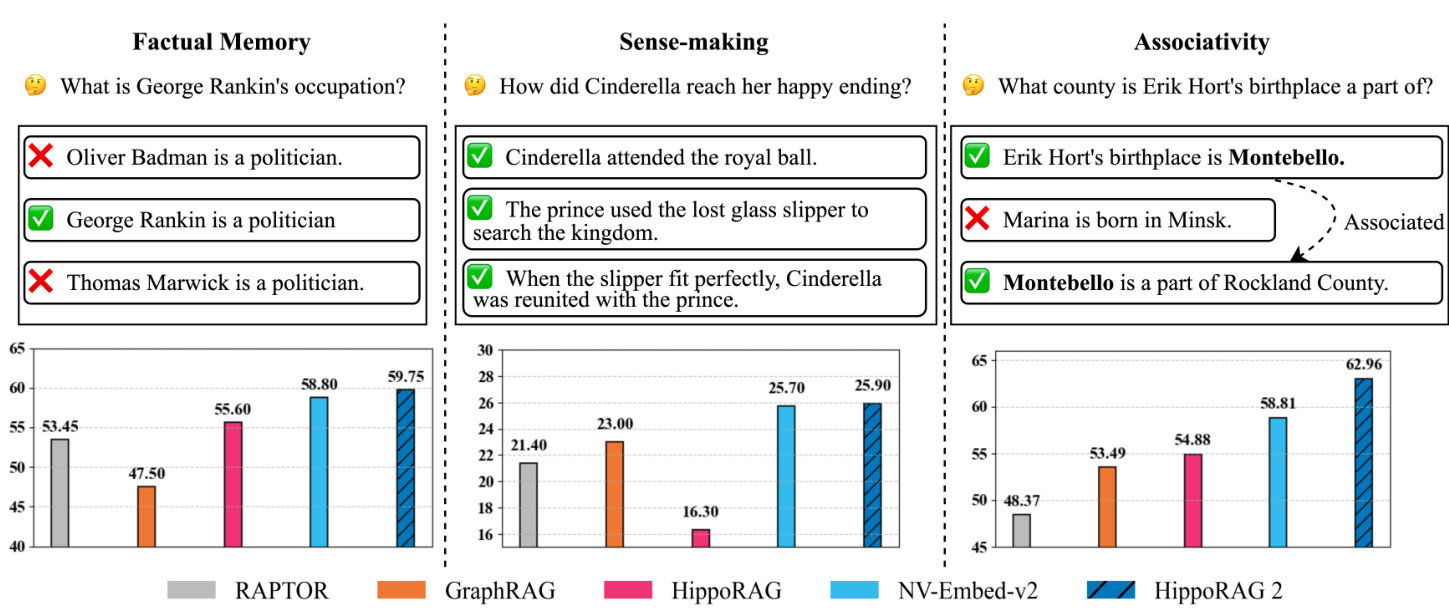
Figure 1. Evaluation of continual learning capabilities across three key dimensions: factual memory (Natural Questions, PopQA), sensemaking (Narrative QA), and associativity (MuSiQue, 2Wiki, HotpotQA, and LV-Eval). HippoRAG 2 surpasses other methods across all benchmark categories, bringing it one step closer to a true long-term memory system.
图 1: 持续学习能力在三个关键维度上的评估:事实记忆(Natural Questions, PopQA)、意义理解(Narrative QA)和关联性(MuSiQue, 2Wiki, HotpotQA, 和 LV-Eval)。HippoRAG 2 在所有基准类别中均优于其他方法,使其更接近真正的长期记忆系统。
PageRank algorithm (Haveliwala, 2002) and an LLM’s ability to automatically construct a KG and endow the retrieval process with multi-hop reasoning capabilities.
PageRank算法 (Haveliwala, 2002) 以及大语言模型自动构建知识图谱 (KG) 并为检索过程赋予多跳推理能力。
Although these methods demonstrate strong performance in both of these more challenging memory tasks, bringing RAG truly closer to human long-term memory requires robustness across simpler memory tasks as well. In order to understand whether these systems could achieve such robustness, we conduct comprehensive experiments that not only simultaneously evaluate their associativity and sensemaking capacity through multi-hop QA and large-scale discourse understanding, but also test their factual memory abilities via simple QA tasks, which standard RAG is already well-equipped to handle.
尽管这些方法在更具挑战性的记忆任务中表现出色,但要让 RAG 真正接近人类的长期记忆,还需要在更简单的记忆任务中具备鲁棒性。为了了解这些系统是否能实现这种鲁棒性,我们进行了全面的实验,不仅通过多跳问答和大规模语篇理解同时评估它们的关联性和意义构建能力,还通过简单的问答任务测试它们的事实记忆能力,而标准的 RAG 已经能够很好地应对这些任务。
As shown in Figure 1, our evaluation reveals that all previous structure-augmented methods under perform against the strongest embedding-based RAG methods available on all three benchmark types. Perhaps un surprisingly, we find that each method type experiences the largest performance decay in tasks outside its own experimental setup. For example, HippoRAG’s performance drops most on large-scale discourse understanding due to its lack of query-based contextual iz ation, while RAPTOR’s performance deteriorates substantially on the simple and multi-hop QA tasks due to the noise introduced into the retrieval corpora by its LLM sum mari z ation mechanism.
如图 1 所示,我们的评估显示,所有以前的结构增强方法在所有三种基准类型上都表现不如最强的基于嵌入的 RAG 方法。或许并不令人意外的是,我们发现每种方法类型在其自身实验设置之外的任务中都会经历最大的性能衰减。例如,HippoRAG 由于缺乏基于查询的上下文,其在大规模话语理解上的表现下降最多,而 RAPTOR 由于大语言模型摘要机制在检索语料库中引入了噪声,其在简单和多跳 QA 任务上的表现大幅下降。
In this work, we leverage this experimental setting to help us address the robustness limitations of these innovative approaches while avoiding the pitfalls of focusing too narrowly on just one task. Our proposed method, HippoRAG 2, leverages the strength of HippoRAG’s OpenIE and Personalized PageRank (PPR) methodologies while addressing its querybased contextual iz ation limitations by integrating passages into the PPR graph search process, involving queries more deeply in the selection of KG triples as well as engaging an LLM in the online retrieval process to recognize when retrieved triples are irrelevant.
在本工作中,我们利用这一实验设置来帮助我们解决这些创新方法的鲁棒性限制,同时避免了过于狭隘地只关注单一任务的陷阱。我们提出的方法 HippoRAG 2,结合了 HippoRAG 的 OpenIE 和个性化 PageRank (PPR) 方法的优势,同时通过将段落整合到 PPR 图搜索过程中,解决了其基于查询的上下文化限制,使查询在 KG 三元组选择中更深入地参与,并在在线检索过程中引入大语言模型来识别检索到的三元组是否无关。
Through extensive experiments, we find that this design provides HippoRAG 2 with consistent performance improvements over the most powerful standard RAG methods across the board. More specifically, our approach achieves an average 7 point improvement over standard RAG in associativity tasks while showing no deterioration and even slight improvements in factual memory and sense-making tasks. Furthermore, we show that our method is robust to different retrievers as well as to the use of strong open-source and proprietary LLMs, allowing for a wide degree of usage flexibility. All of these results suggest that HippoRAG 2 is a promising step in the development of a more human-like non-parametric continual learning system for LLMs.
通过大量实验,我们发现这一设计使 HippoRAG 2 在各方面都优于最强大的标准 RAG 方法。具体而言,我们的方法在关联性任务中比标准 RAG 平均提高了 7 分,而在事实记忆和意义理解任务中不仅没有退化,甚至还有轻微提升。此外,我们证明了该方法对不同检索器以及使用强大的开源和专有大语言模型具有鲁棒性,允许广泛的灵活性。所有这些结果表明,HippoRAG 2 是开发更接近人类的非参数化持续学习系统的重要一步。
2. Related Work
2. 相关工作
2.1. Continual Learning for LLMs
2.1. 大语言模型的持续学习
Continual learning methods applied to LLMs aim to allow them to acquire and integrate new knowledge over time while preserving past information. Given the high computational cost of full-scale LLM pre training, various techniques have been used to achieve this goal. These approaches generally fall into three categories: continual fine-tuning, model editing, and RAG (Shi et al., 2024).
应用于大语言模型的持续学习方法旨在使其能够随着时间的推移获取并整合新知识,同时保留过去的信息。鉴于全面大语言模型预训练的高计算成本,已采用多种技术来实现这一目标。这些方法通常分为三类:持续微调、模型编辑和 RAG (Shi et al., 2024)。
Continual fine-tuning involves periodically training an LLM on new data. This can be achieved through methods like continual pre training (Jin et al., 2022), instruction tuning (Zhang et al., 2023), and alignment fine-tuning (Zhang et al., 2024). While effective in incorporating new linguistic patterns and reasoning skills, continual fine-tuning suffers from catastrophic forgetting (Huang et al., 2024), where previously learned knowledge is lost as new data is introduced. Moreover, its computational expense makes frequent updates impractical for real-world applications.
持续微调涉及定期在大语言模型 (LLM) 上使用新数据进行训练。这可以通过持续预训练 (Jin et al., 2022)、指令调优 (Zhang et al., 2023) 和对齐微调 (Zhang et al., 2024) 等方法实现。虽然持续微调在融入新的语言模式和推理技能方面有效,但它存在灾难性遗忘问题 (Huang et al., 2024),即引入新数据时先前学到的知识会丢失。此外,其计算成本使得在实际应用中频繁更新变得不切实际。
Model editing techniques (Yao et al., 2023) provide a more lightweight alternative by directly modifying specific parameters in the model to update its knowledge. However, these updates have been found to be highly localized, having little effect on information associated with the update that should also be changed.
模型编辑技术(Yao等,2023)提供了一种更轻量化的替代方案,通过直接修改模型中的特定参数来更新其知识。然而,这些更新被发现具有高度局部性,对应当随之更改的相关信息影响甚微。
RAG has emerged as a scalable and practical alternative for continual learning. Instead of modifying the LLM itself, RAG retrieves relevant external information at inference time, allowing for real-time adaptation to new knowledge. We will discuss several aspects of this non-parametric continual learning solution for LLMs in the next section.
RAG 已成为持续学习的一种可扩展且实用的替代方案。与直接修改大语言模型本身不同,RAG 在推理时检索相关外部信息,从而能够实时适应新知识。我们将在下一节中讨论这种非参数化持续学习解决方案的多个方面。
2.2. Non-Parametric Continual Learning for LLMs
2.2. 大语言模型的非参数持续学习
Encoder model improvements, particularly with LLM backbones, have significantly enhanced RAG systems by generating high-quality embeddings that better capture semantic relationships, improving retrieval quality for LLM generation. Recent models (Li et al., 2023; Mu en nigh off et al., 2024; Lee et al., 2025) leverage LLMs, large corpora, improved architectures, and instruction fine-tuning for notable retrieval gains. NV-Embed-v2 (Lee et al., 2025) serves as the primary comparison in this paper.
编码器模型的改进,特别是采用大语言模型作为骨干网络,显著提升了 RAG 系统的性能。这些改进通过生成高质量的嵌入,更好地捕捉语义关系,从而提高了大语言模型生成的检索质量。最近的模型(Li 等,2023;Mu en nigh off 等,2024;Lee 等,2025)利用大语言模型、大规模语料库、改进的架构以及指令微调,取得了显著的检索效果提升。本文主要对比的模型是 NV-Embed-v2(Lee 等,2025)。
Sense-making is the ability to understand large-scale or complex events, experiences, or data (Koli et al., 2024). Standard RAG methods are limited in this capacity since they require integrating information from disparate passages, and thus, several RAG frameworks have been proposed to address it. RAPTOR (Sarthi et al., 2024) and GraphRAG (Edge et al., 2024) both generate summaries that integrate their retrieval corpora. However, they follow distinct processes for detecting what to summarize and at what granularity. While RAPTOR uses a Gaussian Mixture Model to detect document clusters to summarize, GraphRAG uses a graph community detection algorithm that can summarize documents, entity clusters with relations, or a combination of these elements. LightRAG (Guo et al., 2024) employs a dual-level retrieval mechanism to enhance comprehensive information retrieval capabilities in both low-level and highlevel knowledge, integrating graph structures with vector retrieval.
意义构建 (Sense-making) 是理解大规模或复杂事件、经历或数据的能力 (Koli et al., 2024)。标准的 RAG 方法在这方面存在局限性,因为它们需要整合来自不同段落的信息,因此,已经提出了几种 RAG 框架来解决这一问题。RAPTOR (Sarthi et al., 2024) 和 GraphRAG (Edge et al., 2024) 都生成了整合其检索语料库的摘要。然而,它们在检测摘要内容和粒度方面遵循不同的流程。RAPTOR 使用高斯混合模型 (Gaussian Mixture Model) 来检测需要摘要的文档集群,而 GraphRAG 使用图社区检测算法 (graph community detection algorithm),可以摘要文档、具有关系的实体集群或这些元素的组合。LightRAG (Guo et al., 2024) 采用双级检索机制,以增强低层次和高层次知识的综合信息检索能力,将图结构与向量检索相结合。
Although both GraphRAG and LightRAG use a KG just like our HippoRAG 2 approach, our KG is used to aid in the retrieval process rather than to expand the retrieval corpus itself. This allows HippoRAG 2 to introduce less LLM-generated noise, which deteriorates the performance of these methods in single and multi-hop QA tasks.
尽管GraphRAG和LightRAG都像我们的HippoRAG 2方法一样使用了知识图谱(KG),但我们的KG用于辅助检索过程,而不是扩展检索语料库本身。这使得HippoRAG 2能够引入较少的大语言模型(LLM)生成的噪声,这些噪声会降低这些方法在单跳和多跳问答任务中的性能。
Associativity is the capacity to draw multi-hop connections between disparate facts for efficient retrieval. It is an important part of continual learning, which standard RAG cannot emulate due to its reliance on independent vector retrieval. HippoRAG (Gutiérrez et al., 2024) is the only RAG framework that has addressed this property by leveraging the PPR algorithm over an explicitly constructed open KG. HippoRAG 2 is closely inspired by HippoRAG, which allows it to perform very well on multi-hop QA tasks. However, its more comprehensive integration of passages, queries, and triples allows it to have a more comprehensive performance across sense-making and factual memory tasks as well.
关联性是指在不同事实之间建立多跳连接以便高效检索的能力。它是持续学习的重要组成部分,而标准检索增强生成 (RAG) 由于其依赖于独立的向量检索而无法模拟这一特性。HippoRAG (Gutiérrez et al., 2024) 是唯一一个通过利用明确构建的开放知识图谱上的个性化网页排序算法 (PPR) 来解决这一特性的 RAG 框架。HippoRAG 2 受到了 HippoRAG 的启发,使其在多跳问答任务上表现非常出色。然而,它更全面地将段落、查询和三元组整合在一起,使其在意义构建和事实记忆任务上也具备更全面的表现。
3. HippoRAG 2
3. HippoRAG 2
3.1. Overview
3.1. 概述
HippoRAG (Gutiérrez et al., 2024) is a neuro biologically inspired long-term memory framework for LLMs, with each component designed to emulate aspects of human memory. The framework consists of three primary components: the artificial neocortex (LLM), the para hippo camp al region (PHR encoder), and the artificial hippocampus (open KG). These components collaborate to replicate the interactions observed in human long-term memory.
HippoRAG (Gutiérrez et al., 2024) 是一种受神经生物学启发的大语言模型长期记忆框架,每个组件都旨在模拟人类记忆的各个方面。该框架由三个主要组件组成:人工新皮层 (LLM)、旁海马区 (PHR 编码器) 和人工海马体 (开放知识图谱)。这些组件协同工作,以复制在人类长期记忆中观察到的交互。
For HippoRAG offline indexing, an LLM processes passages into KG triples, which are then incorporated into the artificial hippo camp al index. Meanwhile, the PHR is responsible for detecting synonymy to interconnect information. For HippoRAG online retrieval, the LLM neocortex extracts named entities from a query, while the PHR encoder link these entities to the hippo camp al index. Then, the Personalized PageRank (PPR) algorithm on the KG is conducted for context-based retrieval. Although HippoRAG seeks to construct memory from non-parametric RAG, its effectiveness is hindered by a critical flaw: an entity-centric approach that causes context loss during both indexing and inference, as well as difficulties in semantic matching.
对于 HippoRAG 的离线索引,大语言模型将段落处理为知识图谱三元组,随后将其整合到人工海马体索引中。同时,PHR 负责检测同义词以互连信息。在 HippoRAG 的在线检索中,大语言模型新皮质从查询中提取命名实体,而 PHR 编码器将这些实体链接到海马体索引。接着,在知识图谱上执行个性化 PageRank (PPR) 算法以进行基于上下文的检索。尽管 HippoRAG 试图从非参数化 RAG 构建记忆,但其有效性受到一个关键缺陷的阻碍:以实体为中心的方法在索引和推理过程中导致上下文丢失,并且在语义匹配方面也面临困难。
Built on the neuro biologically inspired long-term memory framework proposed in HippoRAG (Gutiérrez et al., 2024), the structure of HippoRAG 2 follows a similar two-stage process: offline indexing and online retrieval, as shown in Figure 2. Additionally, however, HippoRAG 2 introduces several key refinements that improve its alignment with human memory mechanisms: 1) It seamlessly integrates conceptual and contextual information within the open KG, enhancing the comprehensiveness and atomicity of the constructed index (§3.2). 2) It facilitates more context-aware retrieval by leveraging the KG structure beyond isolated KG nodes (§3.3). 3) It incorporates recognition memory to improve seed node selection for graph search (§3.4). In the following sections, we introduce the pipeline in more detail and elaborate on each of these refinements.
基于 HippoRAG (Gutiérrez 等, 2024) 提出的神经生物学启发的长期记忆框架,HippoRAG 2 的结构遵循了类似的两阶段过程:离线索引和在线检索,如图 2 所示。然而,HippoRAG 2 还引入了几个关键改进,以更好地与人类记忆机制对齐:1) 它在开放的 KG 中无缝整合了概念和上下文信息,增强了构建索引的全面性和原子性 (§3.2)。2) 它通过利用 KG 结构而不仅仅是孤立的 KG 节点,促进了更具上下文感知的检索 (§3.3)。3) 它引入了识别记忆,以改进图搜索的种子节点选择 (§3.4)。在以下部分中,我们将更详细地介绍这一流程,并详细阐述这些改进。
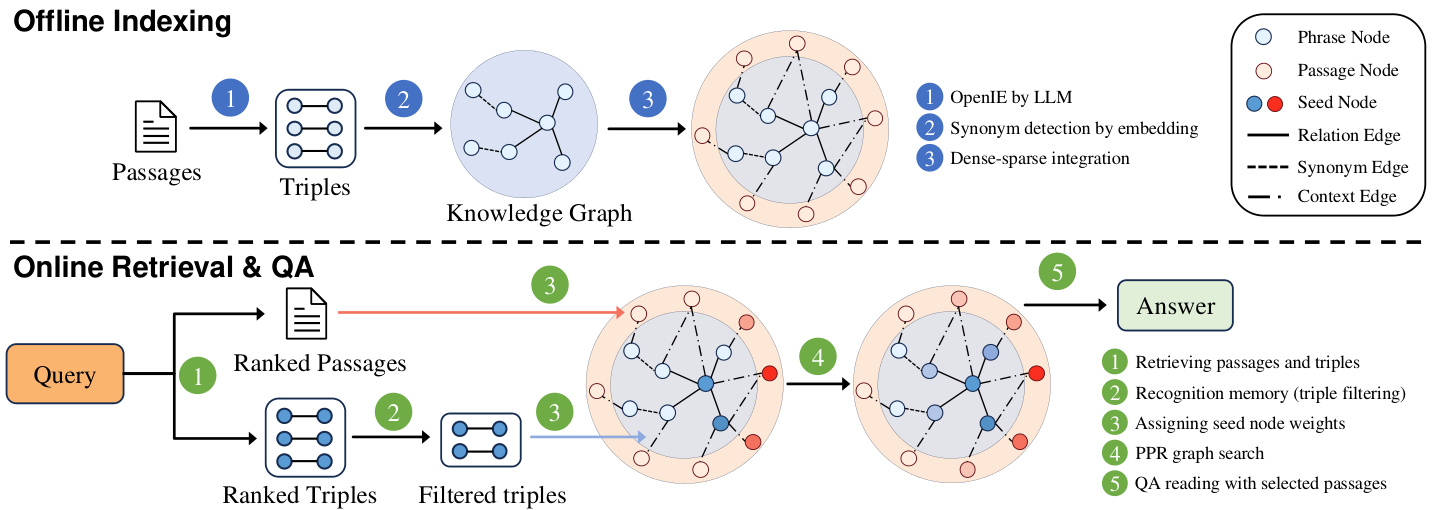
Figure 2. HippoRAG 2 methodology. For offline indexing, we use an LLM to extract open KG triples from passages, with synonym detection applied to phrase nodes. Together, these phrases and passages form the open KG. For online retrieval, an embedding model scores both the passages and triples to identify the seed nodes of both types for the Personalized PageRank (PPR) algorithm. Recognition memory filters the top triples using an LLM. The PPR algorithm then performs context-based retrieval on the KG to provide the most relevant passages for the final QA task. The different colors shown in the KG nodes above reflect their probability mass; darker shades indicate higher probabilities induced by the PPR process.
图 2: HippoRAG 2 方法论。在离线索引阶段,我们使用大语言模型从段落中提取开放知识图谱三元组,并对短语节点应用同义词检测。这些短语和段落共同构成开放知识图谱。在线检索阶段,嵌入模型对段落和三元组进行评分,以识别两种类型的种子节点,供个性化 PageRank (PPR) 算法使用。识别记忆通过大语言模型过滤出最相关的三元组。随后,PPR 算法在知识图谱上执行基于上下文的检索,为最终的问答任务提供最相关的段落。上图知识图谱节点中的不同颜色反映了它们的概率质量;较深的色调表示 PPR 过程诱导的较高概率。
Table 1. Dataset statistics
表 1: 数据集统计
| NQ | PopQA | MuSiQue | 2Wiki | HotpotQA | LV-Eval | NarrativeQA | |
|---|---|---|---|---|---|---|---|
| 查询数量 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 124 | 293 |
| 段落数量 | 9,633 | 8,676 | 11,656 | 6,119 | 9,811 | 22,849 | 4,111 |
Offline Indexing. 1) HippoRAG 2 leverages an LLM to extract triples from each passage and integrates them into a schema-less open KG. We call the subject or object of these triples phrase and the edge connecting them relation edge. 2) Next, the encoder identifies synonyms by evaluating phrase pairs within the KG, detecting those with vector similarity above a predefined threshold, and adding synonym edge between such pair. This process enables the KG to link synonyms across different passages, facilitating the integration of both old and new knowledge during learning. 3) Finally, this phrase-based KG is combined with the original passages, allowing the final open KG to incorporate both conceptual and contextual information (§3.2).
离线索引
- HippoRAG 2 利用大语言模型从每段文本中提取三元组,并将其集成到一个无模式的开放知识图谱 (KG) 中。我们将这些三元组的主语或宾语称为短语 (phrase),连接它们的边称为关系边 (relation edge)。
- 接着,编码器通过评估知识图谱中的短语对,检测向量相似度超过预定义阈值的短语对,并在这些短语对之间添加同义词边 (synonym edge)。这一过程使得知识图谱能够链接不同段落中的同义词,促进学习过程中新旧知识的整合。
- 最后,这个基于短语的知识图谱与原始段落相结合,使得最终的开放知识图谱能够融合概念和上下文信息 (§3.2)。
Online Retrieval. 1) The query is linked to relevant triples and passages using the encoder, identifying potential seed nodes for graph search (§3.3). 2) During triple linkage, the recognition memory functions as a filter, ensuring only relevant triples are retained from the retrieved set (§3.4). 3) Given seed nodes, the PPR algorithm is then applied for context-aware retrieval, refining the linking results to retrieve the most relevant passages. 4) Finally, the retrieved passages serve as contextual inputs for the final QA task. Next, we describe each of the improvements in HippoRAG 2 in more detail.
在线检索。1) 使用编码器将查询与相关的三元组和段落进行链接,识别图搜索的潜在种子节点(§3.3)。2) 在三元组链接过程中,识别记忆充当过滤器,确保从检索集中只保留相关的三元组(§3.4)。3) 给定种子节点后,应用PPR算法进行上下文感知检索,优化链接结果以检索最相关的段落。4) 最后,检索到的段落作为最终QA任务的上下文输入。接下来,我们将更详细地描述HippoRAG 2中的每项改进。
3.2. Dense-Sparse Integration
3.2. 稠密-稀疏集成
The nodes in the HippoRAG KG primarily consist of phrases describing concepts, which we refer to as phrase nodes in this paper. This graph structure introduces limitations related to the concept-context tradeoff. Concepts are concise and easily general iz able but often entail information loss. In contrast, context provide specific circumstances that shape the interpretation and application of these concepts, enriching semantics but increasing complexity. However, in human memory, concepts and contexts are intricately interconnected. The dense and sparse coding theory offers insights into how the brain represents and processes information at different granular i ties (Beyeler et al., 2019). Dense coding encodes information through the simultaneous activation of many neurons, resulting in a distributed and redundant representation. Conversely, sparse coding relies on minimal neural activation, engaging only a small subset of neurons to enhance efficiency and storage compactness.
HippoRAG KG中的节点主要由描述概念的短语组成,我们在本文中称之为短语节点。这种图结构引入了概念与上下文权衡相关的限制。概念简洁且易于泛化,但往往伴随着信息丢失。相比之下,上下文提供了塑造这些概念解释和应用的具体情境,丰富了语义但增加了复杂性。然而,在人类记忆中,概念和上下文是错综复杂地相互关联的。密集和稀疏编码理论为我们提供了关于大脑如何在不同粒度上表示和处理信息的见解 (Beyeler et al., 2019)。密集编码通过同时激活许多神经元来编码信息,从而产生分布式和冗余的表示。相反,稀疏编码依赖于最少的神经激活,仅激活一小部分神经元以提高效率和存储紧凑性。
Inspired by the dense-sparse integration observed in the human brain, we treat the phrase node as a form of sparse coding for the extracted concepts, while incorporating dense coding into our KG to represent the context from which these concepts originate. First, we adopt an encoding approach similar to how phrases are encoded, using the embedding model. These two types of coding are then integrated in a specific manner within the KG. Unlike the document ensemble in HippoRAG, which simply aggregates scores from graph search and embedding matching, we enhance the KG by introducing passage nodes, enabling more seamless integration of contextual information. This approach retains the same offline indexing process as HippoRAG while enriching the graph structure with additional nodes and edges related to passages during construction. Specifically, each passage in the corpus is treated as a passage node, with the context edge labeled “contains” connecting the passage to all phrases derived from this passage.
受人类大脑中密集-稀疏集成的启发,我们将短语节点视为提取概念的稀疏编码形式,同时将密集编码纳入我们的知识图谱(KG)中以表示这些概念的来源上下文。首先,我们采用与短语编码类似的编码方法,使用嵌入模型。这两种编码方式随后在KG中以特定方式集成。与HippoRAG中简单的图搜索和嵌入匹配分数聚合不同,我们通过引入段落节点来增强KG,从而实现更无缝的上下文信息集成。这种方法保留了与HippoRAG相同的离线索引过程,同时在构建过程中丰富了与段落相关的额外节点和边的图结构。具体来说,语料库中的每个段落都被视为一个段落节点,带有标记为“包含”的上下文边,将该段落与其派生的所有短语连接起来。
3.3. Deeper Contextual iz ation
3.3. 更深入的上下文化
Building upon the discussion of the concept-context tradeoff, we observe that query parsing in HippoRAG, which relies on Named Entity Recognition (NER), is predominantly concept-centric, often overlooking the contextual alignment within the KG. This entity-focused approach to extraction and indexing introduces a strong bias toward concepts, leaving many contextual signals under utilized (Gutiérrez et al., 2024). To address this limitation, we explore and evaluate different methods for linking queries to the KG, aiming to more effectively align query semantics with the starting nodes of graph searches. Specifically, we consider three approaches: 1) NER to Node: This is the original method used in HippoRAG, where entities are extracted from the query and subsequently matched with nodes in the KG using text embeddings. 2) Query to Node: Instead of extracting individual entities, we leverage text embeddings to match the entire query directly to nodes in the KG. 3) Query to Triple: To incorporate richer contextual information from the KG, we match the entire query to triples within the graph using text embeddings. Since triples encapsulate fundamental contextual relationships among concepts, this method provides a more comprehensive understanding of the query’s intent. By default, HippoRAG 2 adopts the query-to-triple approach, and we evaluate all three methods later (§6.1).
在讨论概念-上下文权衡的基础上,我们观察到 HippoRAG 中的查询解析依赖于命名实体识别 (NER),主要是以概念为中心的,往往忽略了知识图谱 (KG) 中的上下文对齐。这种以实体为中心的提取和索引方法引入了强烈的概念偏向,导致许多上下文信号未被充分利用 (Gutiérrez et al., 2024)。为了解决这一限制,我们探索并评估了将查询链接到 KG 的不同方法,旨在更有效地将查询语义与图搜索的起始节点对齐。具体来说,我们考虑了三种方法:1) NER 到节点:这是 HippoRAG 中使用的原始方法,其中从查询中提取实体,随后使用文本嵌入与 KG 中的节点匹配。2) 查询到节点:我们利用文本嵌入将整个查询直接与 KG 中的节点匹配,而不是提取单个实体。3) 查询到三元组:为了从 KG 中整合更丰富的上下文信息,我们使用文本嵌入将整个查询与图中的三元组匹配。由于三元组封装了概念之间的基本上下文关系,因此该方法提供了对查询意图的更全面理解。默认情况下,HippoRAG 2 采用了查询到三元组的方法,我们将在后面评估所有三种方法 (§6.1)。
3.4. Recognition Memory
3.4. 识别记忆
Recall and recognition are two complementary processes in human memory retrieval (Uner & Roediger III, 2022). Recall involves actively retrieving information without external cues, while recognition relies on identifying information with the help of external stimuli. Inspired by this, we model the query-to-triple retrieval as a two-step process. 1) Query to Triple: We use the embedding model to retrieve the top $\mathbf{\nabla\cdot}\mathbf{k}$ triples $T$ of the graph as described in $\S3.3$ . 2) Triple Filtering: We use LLMs to filter retrieved $T$ and generate triples $T^{\prime}\subseteq T$ . The detailed prompts are shown in Appendix A.
回忆和识别是人类记忆检索中的两个互补过程 (Uner & Roediger III, 2022)。回忆涉及在没有外部线索的情况下主动检索信息,而识别则依赖于借助外部刺激来识别信息。受此启发,我们将查询到三元组的检索建模为一个两步过程。1) 查询到三元组:我们使用嵌入模型检索图的顶部 $\mathbf{\nabla\cdot}\mathbf{k}$ 个三元组 $T$,如 $\S3.3$ 所述。2) 三元组过滤:我们使用大语言模型过滤检索到的 $T$ 并生成三元组 $T^{\prime}\subseteq T$。详细的提示信息见附录 A。
3.5. Online Retrieval
3.5. 在线检索
We summarize the online retrieval process in HippoRAG 2 after introducing the above improvements. The task involves selecting seed nodes and assigning reset probabilities for retrieval. HippoRAG 2 identifies phrase nodes from filtered triples generated by query-to-triple and recognition memory. If no triples are available, it directly retrieves top-ranked passages using the embedding model. Otherwise, up to $k$ phrase nodes are selected based on their average ranking scores across filtered triples they originate. All passage nodes are also taken as seed nodes, as broader activation improves multi-hop reasoning. Reset probabilities are assigned based on ranking scores for phrase nodes, while passage nodes receive scores proportional to their embedding similarity, adjusted by a weight factor (§6.2) to balance the influence between phrase nodes and passage nodes. The PPR search is then executed, and passages are ranked by their PageRank scores, with the top-ranked passages used for downstream QA. An example of the pipeline is in Appendix B and the PPR initialization is detailed in Appendix G.1,
在引入上述改进后,我们总结了HippoRAG 2中的在线检索流程。该任务涉及选择种子节点并为检索分配重置概率。HippoRAG 2从由query-to-triple和识别记忆生成的过滤三元组中识别短语节点。如果没有可用的三元组,它则直接使用嵌入模型检索排名最高的段落。否则,根据它们在过滤三元组中的平均排名得分,选择最多$k$个短语节点。所有段落节点也被选为种子节点,因为更广泛的激活有助于多跳推理。重置概率根据短语节点的排名得分分配,而段落节点的得分则与其嵌入相似度成比例,并通过权重因子(§6.2)进行调整,以平衡短语节点和段落节点之间的影响。随后执行PPR搜索,段落根据其PageRank得分进行排名,排名最高的段落用于下游的问答任务。管道的一个示例见附录B,PPR初始化的详细信息见附录G.1。
4. Experimental Setup
4. 实验设置
4.1. Baselines
4.1. 基线
We select three types of comparison methods: 1) The classic retrievers BM25 (Robertson & Walker, 1994), Contriever (Izacard et al., 2022) and GTR (Ni et al., 2022). 2) Large embedding models that perform well on the BEIR leaderboard (Thakur et al., 2021), including Alibaba-NLP/GTEQwen2-7B-Instruct (Li et al., 2023), GritLM/GritLM- 7B (Mu en nigh off et al., 2024), and nvidia/NV-Embedv2 (Lee et al., 2025). 3) Structure-augmented RAG methods, including RAPTOR (Sarthi et al., 2024), GraphRAG (Edge et al., 2024), LightRAG (Guo et al., 2024), and HippoRAG (Gutiérrez et al., 2024).
我们选择了三种类型的比较方法:1) 经典检索器 BM25 (Robertson & Walker, 1994)、Contriever (Izacard et al., 2022) 和 GTR (Ni et al., 2022)。2) 在 BEIR 排行榜上表现优异的大型嵌入模型 (Thakur et al., 2021),包括 Alibaba-NLP/GTEQwen2-7B-Instruct (Li et al., 2023)、GritLM/GritLM-7B (Mu en nigh off et al., 2024) 和 nvidia/NV-Embedv2 (Lee et al., 2025)。3) 结构增强的 RAG 方法,包括 RAPTOR (Sarthi et al., 2024)、GraphRAG (Edge et al., 2024)、LightRAG (Guo et al., 2024) 和 HippoRAG (Gutiérrez et al., 2024)。
4.2. Datasets
4.2. 数据集
To evaluate how well RAG systems retain factual memory while enhancing associativity and sense-making, we select datasets that correspond to three critical challenge types: 1) Simple QA primarily evaluates the ability to recall and retrieve factual knowledge accurately. 2) Multi-hop QA measures associativity by requiring the model to connect multiple pieces of information to derive an answer. 3) Discourse understanding evaluates sense-making by testing the capability to interpret and reason over lengthy, complex narratives. The statistics for our sampled dataset are summarized in Table 1.
为了评估RAG系统在增强关联性和意义理解的同时保留事实记忆的能力,我们选择了对应三种关键挑战类型的数据集:1) 简单问答主要评估准确回忆和检索事实知识的能力。2) 多跳问答通过要求模型连接多条信息来推导答案,从而衡量关联性。3) 话语理解通过测试对冗长复杂叙述的解释和推理能力来评估意义理解。我们采样数据集的统计数据总结在表 1 中。
Table 2. QA performance (F1 scores) on RAG benchmarks using Llama-3.3-70B-Instruct as the QA reader. No retrieval means evaluating the parametric knowledge of the readers. HippoRAG (and HippoRAG 2) uses Llama-3.3-70B-Instruct as the extractor (and the triple filter) and NV-Embed-v2 as the retriever. This table, along with the following ones, highlight the best and second-best results.
表 2: 使用 Llama-3.3-70B-Instruct 作为 QA 阅读器在 RAG 基准测试中的问答性能 (F1 分数)。无检索意味着评估阅读器的参数知识。HippoRAG (和 HippoRAG 2) 使用 Llama-3.3-70B-Instruct 作为提取器 (和三元过滤器),并使用 NV-Embed-v2 作为检索器。本表以及后续表格均突出显示了最佳和次佳结果。
| 检索方法 | NQ | PopQA | MuSiQue | 2Wiki | HotpotQA | LV-Eval | NarrativeQA | 平均 |
|---|---|---|---|---|---|---|---|---|
| 简单基线 | ||||||||
| 无 | 54.9 | 32.5 | 26.1 | 42.8 | 47.3 | 6.0 | 12.9 | 38.4 |
| Contriever (Izacard et al., 2022) | 58.9 | 53.1 | 31.3 | 41.9 | 62.3 | 8.1 | 19.7 | 46.9 |
| BM25 (Robertson & Walker, 1994) | 59.0 | 49.9 | 28.8 | 51.2 | 63.4 | 5.9 | 18.3 | 47.7 |
| GTR (T5-base) (Ni et al., 2022) | 59.9 | 56.2 | 34.6 | 52.8 | 62.8 | 7.1 | 19.9 | 50.4 |
| 大嵌入模型 | ||||||||
| GTE-Qwen2-7B-Instruct (Li et al., 2023) | 62.0 | 56.3 | 40.9 | 60.0 | 71.0 | 7.1 | 21.3 | 54.9 |
| GritLM-7B (Muennighoff et al., 2024) | 61.3 | 55.8 | 44.8 | 60.6 | 73.3 | 9.8 | 23.9 | 56.1 |
| NV-Embed-v2 (7B) (Lee et al., 2025) | 61.9 | 55.7 | 45.7 | 61.5 | 75.3 | 9.8 | 25.7 | 57.0 |
| 结构增强RAG | ||||||||
| RAPTOR (Sarthi et al., 2024) | 50.7 | 56.2 | 28.9 | 52.1 | 69.5 | 5.0 | 21.4 | 48.8 |
| GraphRAG (Edge et al., 2024) | 46.9 | 48.1 | 38.5 | 58.6 | 68.6 | 11.2 | 23.0 | 49.6 |
| LightRAG (Guo et al., 2024) | 16.6 | 2.4 | 1.6 | 11.6 | 2.4 | 1.0 | 3.7 | 6.6 |
| HippoRAG (Gutiérrez et al., 2024) | 55.3 | 55.9 | 35.1 | 71.8 | 63.5 | 8.4 | 16.3 | 53.1 |
| HippoRAG 2 | 63.3 | 56.2 | 48.6 | 71.0 | 75.5 | 12.9 | 25.9 | 59.8 |
Table 3. Retrieval performance (passage recall $\ @{\cdot}$ 5) on RAG benchmarks. * denotes the report from the original paper. The compared structure-augmented RAG methods are reproduced with the same LLM and retriever as ours for a fair comparison. GraphRAG and LightRAG are not presented because they do not directly produce passage retrieval results.
表 3: RAG基准测试中的检索性能 (段落召回率 $\ @{\cdot}$ 5) 。* 表示原始论文中的报告。为了公平比较,结构增强的RAG方法与我们的方法使用相同的LLM和检索器进行了复现。GraphRAG和LightRAG未展示,因为它们不直接生成段落检索结果。
| SimpleQA | Multi-Hop QA | Avg | ||||
|---|---|---|---|---|---|---|
| NQ | PopQA | MuSiQue | 2Wiki | HotpotQA | ||
| SimpleBaselines | ||||||
| BM25 (Robertson & Walker, 1994) | 56.1 | 35.7 | 43.5 | 65.3 | 74.8 | 55.1 |
| Contriever (Izacard et al., 2022) | 54.6 | 43.2 | 46.6 | 57.5 | 75.3 | 55.4 |
| GTR (T5-base) (Ni et al., 2022) | 63.4 | 49.4 | 49.1 | 67.9 | 73.9 | 60.7 |
| LargeEmbeddingModels | ||||||
| GTE-Qwen2-7B-Instruct (Li et al., 2023) | 74.3 | 50.6 | 63.6 | 74.8 | 89.1 | 70.5 |
| GritLM-7B (Muennighoff et al., 2024) | 76.6 | 50.1 | 65.9 | 76.0 | 92.4 | 72.2 |
| NV-Embed-v2 (7B) (Lee et al., 2025) | 75.4 | 51.0 | 69.7 | 76.5 | 94.5 | 73.4 |
| Structure-Augmented RAG | ||||||
| RAPTOR (Sarthi et al., 2024) | 68.3 | 48.7 | 57.8 | 66.2 | 86.9 | 65.6 |
| HippoRAG* (Gutiérrez et al., 2024) | 51.9 | 89.1 | 77.7 | |||
| HippoRAG (reproduced) | 44.4 | 53.8 | 53.2 | 90.4 | 77.3 | 63.8 |
| HippoRAG 2 | 78.0 | 51.7 | 74.7 | 90.4 | 96.3 | 78.2 |
Simple QA. This common type of QA task primarily involves questions centered around individual entities, making it particularly well-suited for embedding models to retrieve relevant contextual information intuitively. We randomly collect $1,000$ queries from the Natural Questions (NQ) dataset (collected by Wang et al. (2024)), which contains real user questions with a wide range of topics. Additionally, we select 1, 000 queries from PopQA (Mallen et al., 2023), with the corpus derived from the December 2021 Wikipedia dump.1 Both datasets offer straightforward QA pairs, enabling evaluation of single-hop QA capabilities in RAG systems. Notably, PopQA from Wikipedia is especially entity-centric, with entities being less frequent than Natural Questions, making it an excellent resource for evaluating entity recognition and retrieval in simple QA tasks.
简单问答 (Simple QA)。这种常见的问答任务主要围绕单个实体展开问题,因此特别适合嵌入模型直观地检索相关上下文信息。我们从自然问题 (Natural Questions, NQ) 数据集中随机收集了 $1,000$ 个查询 (由 Wang 等人 (2024) 收集),该数据集包含广泛主题的真实用户问题。此外,我们从 PopQA (Mallen 等人, 2023) 中选取了 1,000 个查询,语料库来自 2021 年 12 月的 Wikipedia 数据。这两个数据集都提供了简单的问答对,能够评估 RAG 系统中的单跳问答能力。值得注意的是,来自 Wikipedia 的 PopQA 尤其以实体为中心,其实体出现的频率比自然问题低,因此它是评估简单问答任务中实体识别和检索的绝佳资源。
Multi-hop QA. We randomly collect 1, 000 queries from MuSiQue, 2 Wiki Multi hop QA, and HotpotQA following HippoRAG (Gutiérrez et al., 2024), all requiring multi-passage reasoning. Additionally, we include all 124 queries from LV-Eval (hot pot wiki qa-mixup $256\mathrm{k}$ ) (Yuan et al., 2024), a challenging dataset designed to minimize knowledge leakage and reduce over fitting through keyword and phrase replacements. Thus, unlike Wikipedia-based datasets, LV-Eval better evaluates the model’s ability to synthesize knowledge from different sources effectively. For corpus collection, we segment long-form contexts of LVEval into shorter passages while maintaining the same RAG setup as other multi-hop datasets.
多跳问答 (Multi-hop QA)。我们按照 HippoRAG (Gutiérrez et al., 2024) 的方法,从 MuSiQue、2 Wiki Multi hop QA 和 HotpotQA 中随机收集了 1, 000 个查询,所有这些查询都需要多段落推理。此外,我们还纳入了 LV-Eval (hot pot wiki qa-mixup $256\mathrm{k}$) (Yuan et al., 2024) 中的所有 124 个查询,这是一个具有挑战性的数据集,旨在通过关键词和短语替换来最小化知识泄漏并减少过拟合。因此,与基于维基百科的数据集不同,LV-Eval 更好地评估了模型从不同来源有效综合知识的能力。在语料库收集方面,我们将 LV-Eval 的长篇上下文分割成较短的段落,同时保持与其他多跳数据集相同的 RAG 设置。
Table 4. Ablations: passage recall $\ @5$ on multi-hop benchmarks.
表 4: 消融实验:多跳基准测试中的段落召回率 $\ @5$
| MuSiQue | 2Wiki | HotpotQA | Avg | |
|---|---|---|---|---|
| HippoRAG 2 | 74.7 | 90.4 | 96.3 | 87.1 |
| w/NERtonode | 53.8 | 91.2 | 78.8 | 74.6 |
| w/Querytonode | 44.9 | 65.5 | 68.3 | 59.6 |
| w/o Passage Node | 63.7 | 90.3 | 88.9 | 81.0 |
| w/oFilter | 73.0 | 90.7 | 95.4 | 86.4 |
Table 5. Passage recall $\ @5$ with different weight factors for passage nodes on our MuSiQue dev set and Natural Questions (NQ) dev set, where each set has 1, 000 queries.
表 5. 在不同权重因子下,我们的MuSiQue开发集和Natural Questions (NQ)开发集上的段落召回率 $\ @5$,每个集合包含1,000个查询。
| 权重 | 0.01 | 0.05 | 0.1 | 0.3 | 0.5 |
|---|---|---|---|---|---|
| MuSiQue | 79.9 | 80.5 | 79.8 | 78.4 | 77.9 |
| NQ | 75.6 | 76.9 | 76.9 | 76.7 | 76.4 |
Discourse Understanding. This category consists of only Narrative QA, a QA dataset that contains questions requiring a cohesive understanding of a full-length novel. This dataset’s focus on large-scale discourse understanding allows us to leverage it in our evaluation of sense-making in our chosen baselines and our own method. We randomly select 10 lengthy documents and their corresponding 293 queries from Narrative QA and collect a retrieval corpus just as in the above LV-Eval dataset.
话语理解。这一类别仅包含 Narrative QA,这是一个问答数据集,其中的问题需要对整部小说有连贯的理解。该数据集专注于大规模话语理解,使我们能够在评估所选基线方法和我们自身方法的意义构建时利用它。我们从 Narrative QA 中随机选择 10 篇长文档及其对应的 293 个查询,并按照上述 LV-Eval 数据集的方式收集检索语料库。
4.3. Metrics
4.3. 指标
Following HippoRAG (Gutiérrez et al., 2024), we use passage recall $\ @5$ to evaluate the retrieval task. For the QA task, we follow evaluation metrics from MuSiQue (Trivedi et al., 2022) to calculate F1 scores for the final answer.
遵循 HippoRAG (Gutiérrez et al., 2024),我们使用段落召回率 $\ @5$ 来评估检索任务。对于问答任务,我们采用 MuSiQue (Trivedi et al., 2022) 的评估指标来计算最终答案的 F1 分数。
4.4. Implementation Details
4.4. 实现细节
For HippoRAG 2, we use the open-source Llama-3.3-70BInstruct (AI $@$ Meta, 2024) as both the extraction (NER and OpenIE) and triple filtering model, and we use nvidia/NVEmbed-v2 as the retriever. We also reproduce the compared structure-augmented RAG methods using the same extractor and retriever for a fair comparison. For the triple filter, we use DSPy (Khattab et al., 2024) MIPROv2 optimizer and Llama-3.3-70B-Instruct to tune the prompt, including the instructions and demonstrations. The resulting prompt is shown in Appendix A. We use top-5 triples ranked by retriever for filtering. For hyper parameters, we follow the default settings from HippoRAG. More implementation and hyper parameter details can be found in Appendix G.
对于 HippoRAG 2,我们使用开源的 Llama-3.3-70BInstruct (AI @ Meta, 2024) 作为提取(NER 和 OpenIE)和三元组过滤模型,并使用 nvidia/NVEmbed-v2 作为检索器。为了公平比较,我们还使用相同的提取器和检索器复现了对比的结构增强 RAG 方法。对于三元组过滤器,我们使用 DSPy (Khattab et al., 2024) MIPROv2 优化器和 Llama-3.3-70B-Instruct 来调整提示,包括指令和演示。生成的提示如附录 A 所示。我们使用检索器排名前 5 的三元组进行过滤。对于超参数,我们遵循 HippoRAG 的默认设置。更多实现细节和超参数信息见附录 G。
Table 6. Passage recall $\ @5$ on MuSiQue subset. HippoRAG 2 supports different dense retrievers.
表 6: MuSiQue 子集上的段落召回率 $\ @5$。HippoRAG 2 支持不同的密集检索器。
| 检索器 | 密集检索 | HippoRAG 2 |
|---|---|---|
| GTE-Qwen2-7B-Instruct | 63.6 | 68.8 |
| GritLM-7B | 66.0 | 71.6 |
| NV-Embed-v2 (7B) | 69.7 | 74.7 |
5. Results
5. 结果
We now present our main QA and retrieval experimental results, where the QA process uses retrieved results as its context. More detailed experimental results are presented in Appendix C. The statistics for all constructed KGs are shown in Appendix A.
我们现在展示主要的问答和检索实验结果,其中问答过程使用检索结果作为其上下文。更详细的实验结果见附录C。所有构建的知识图谱的统计信息见附录A。
QA Performance. Table 2 presents the QA performance of various retrievers across multiple RAG benchmarks using Llama-3.3-70B-Instruct as the QA reader. HippoRAG 2 achieves the highest average F1 score, demonstrating robustness across different settings. Large embedding models outperform smaller ones, with NV-Embed-v2 (7B) scoring $6.6%$ higher on average than GTR (T5-base). These models also surpass structure-augmented RAG methods with lower computational costs but excel mainly in simple QA while struggling in complex cases. N otably, HippoRAG 2 outperforms NV-Embed-v2 by $9.5%$ F1 on 2Wiki and by $3.1%$ on the challenging LV-Eval dataset. Compared to HippoRAG, HippoRAG 2 shows even greater improvements, validating its neuropsychology-inspired approach. These results highlight HippoRAG 2 as a state-of-the-art RAG system that enhances both retrieval and QA performance while being effectively powered by an open-source model. Table 8 in Appendix C presents additional QA results (EM and F1) using Llama or GPT-4o-mini as the QA reader, along with an extractor or triple filter. GPT-4o-mini follows Llama’s trend, with NV-Embed-v2 outperforming structureaugmented methods in most cases, except for HippoRAG in multi-hop QA. HippoRAG 2 consistently outperforms all other methods across nearly all settings.
QA性能。表2展示了使用Llama-3.3-70B-Instruct作为QA阅读器的多个RAG基准测试中各种检索器的QA性能。HippoRAG 2取得了最高的平均F1分数,展示了在不同设置下的鲁棒性。大型嵌入模型优于较小的模型,其中NV-Embed-v2 (7B)平均比GTR (T5-base)高出$6.6%$。这些模型还超越了结构增强的RAG方法,并且在计算成本较低的情况下,主要在简单QA中表现出色,但在复杂案例中表现不佳。值得注意的是,HippoRAG 2在2Wiki上的F1分数比NV-Embed-v2高出$9.5%$,在具有挑战性的LV-Eval数据集上高出$3.1%$。与HippoRAG相比,HippoRAG 2展示了更大的改进,验证了其受神经心理学启发的方法。这些结果突显了HippoRAG 2作为最先进的RAG系统,在增强检索和QA性能的同时,有效地由开源模型驱动。附录C中的表8展示了使用Llama或GPT-4o-mini作为QA阅读器,以及提取器或三元过滤器的额外QA结果(EM和F1)。GPT-4o-mini遵循了Llama的趋势,在大多数情况下,NV-Embed-v2优于结构增强方法,除了在多跳QA中的HippoRAG。HippoRAG 2在几乎所有设置中始终优于其他所有方法。
Retrieval Performance. We report retrieval results for datasets with supporting passage annotations and models that explicitly retrieve passages in Table 3. Large embedding models (7B) significantly outperform classic smaller LM-based models like Contriever and GTR, achieving at least a $9.8%$ higher F1 score. While our reproduction of HippoRAG using Llama-3.3-70B-Instruct and NV-Embed-v2 shows slight improvements over the original paper, the gains are minimal, with only a $1.3%$ increase in F1. Although HippoRAG excels in entity-centric retrieval, achieving the highest recall $\ @5$ on PopQA, it generally lags behind recent dense retrievers and HippoRAG 2. Notably, HippoRAG 2 achieves the highest recall scores across most datasets, with substantial improvements of $5.0%$ and $13.9%$ in Recall $\ @5$ on MuSiQue and 2Wiki, respectively, compared to the strongest dense retriever, NV-Embed-v2. Additionally, the cost and efficiency analysis is presented in Appendix F.
检索性能。我们在表 3 中报告了带有支持段落注释的数据集以及明确检索段落的模型的检索结果。大型嵌入模型(7B)显著优于基于经典小语言模型的 Contriever 和 GTR,F1 分数至少提高了 $9.8%$。虽然我们使用 Llama-3.3-70B-Instruct 和 NV-Embed-v2 复现的 HippoRAG 显示了对原论文的轻微改进,但收益微乎其微,F1 仅提高了 $1.3%$。尽管 HippoRAG 在以实体为中心的检索方面表现出色,在 PopQA 上达到了最高的召回率 $\ @5$,但它通常落后于最近的密集检索器和 HippoRAG 2。值得注意的是,HippoRAG 2 在大多数数据集上实现了最高的召回分数,与最强的密集检索器 NV-Embed-v2 相比,在 MuSiQue 和 2Wiki 上的召回率 $\ @5$ 分别提高了 $5.0%$ 和 $13.9%$。此外,成本与效率分析见附录 F。
Table 7. We show exemplary retrieval results (the title of passages) from HippoRAG 2 and NV-Embed-v2 on different types of questions. Bolded items denote the titles of supporting passages.
表 7: 展示了 HippoRAG 2 和 NV-Embed-v2 在不同类型问题上的示例检索结果(段落的标题)。加粗项表示支持段落的标题。
| 问题 | NV-Embed-v2 结果 | HippoRAG 2 过滤三元组 | HippoRAG 2 结果 | |
|---|---|---|---|---|
| 简单问答 | I.P.Paul 出生在哪个城市? | 1. 1. P. Paul 2.Yinka Ayefele -早期生活 3. Paul Parker (歌手) | (I. P. Paul, 来自, Thrissur) (I. P. Paul, 曾担任市长, Thrissur 市政公司) | 1.1.P.Paul 2. Thrissur 3.YinkaAyefele |
| 多跳问答 | Erik Hort 的出生地属于哪个县? | 1.Erik Hort 2.Horton Park (圣保罗 明尼苏达) 3.Hertfordshire | (Erik Hort, 出生在, Montebello) (Erik Hort, 出生在, 纽约) | 1.Erik Hort 2.Horton Park (圣保罗, 明尼苏达) 3.Monstebello, 纽约 |
6. Discussions
6. 讨论
6.1. Ablation Study
6.1. 消融研究
We design ablation experiments for the proposed linking method, graph construction method, and triple filtering method, with the results reported in Table 4. Each introduced mechanism boosts HippoRAG 2. First, the linking method with deeper contextual iz ation leads to significant performance improvements. Notably, we do not apply a filtering process to the NER-to-node or query-to-node methods; however, the query-to-triple approach, regardless of whether filtering is applied, consistently outperforms the other two linking strategies. On average, query-to-triple improves Recall $\ @5$ by $12.5%$ compared to NER-to-node. Moreover, query-to-node does not provide an advantage over NER-to-node, as queries and KG nodes operate at different levels of granularity, whereas both NER results and KG nodes correspond to phrase-level representations.
我们为提出的链接方法、图构建方法和三元组过滤方法设计了消融实验,结果如表 4 所示。每种引入的机制都提升了 HippoRAG 2 的性能。首先,具有更深层次上下文信息的链接方法显著提升了性能。值得注意的是,我们没有对 NER-to-node 或 query-to-node 方法应用过滤过程;然而,无论是否应用过滤,query-to-triple 方法始终优于其他两种链接策略。与 NER-to-node 相比,query-to-triple 平均提高了 Recall $\ @5$ $12.5%$。此外,query-to-node 并未比 NER-to-node 提供优势,因为查询和知识图谱节点在不同的粒度层次上操作,而 NER 结果和知识图谱节点都对应于短语级表示。
6.2. Controlling Reset Probabilities
6.2. 控制重置概率
When setting the reset probability before starting PPR, we find that it is necessary to balance the reset probabilities between two types of nodes: phrase nodes and passage nodes. Specifically, the reset probability of all passage nodes is multiplied by a weight factor to balance the importance of two types of nodes during PPR. Here, we present the results obtained on the validation set in Table 5, which shows that this factor is crucial for the PPR results. Considering the model performance across different scenarios, we set the factor to be 0.05 by default.
在开始 PPR 之前设置重置概率时,我们发现有必要在两种节点之间平衡重置概率:短语节点和段落节点。具体来说,所有段落节点的重置概率乘以一个权重因子,以平衡 PPR 过程中两种节点的重要性。表 5 展示了在验证集上获得的结果,表明该因子对 PPR 结果至关重要。考虑到不同场景下的模型性能,我们默认将该因子设置为 0.05。
6.3. Dense Retriever Flexibility
6.3. 密集检索器的灵活性
The dense retriever employed by HippoRAG 2 is fully plugand-play, offering seamless integration. As demonstrated in Table 6, HippoRAG 2 consistently surpasses direct dense retrieval across various retrievers. Notably, these performance gains remain robust regardless of the specific dense retriever used.
HippoRAG 2 采用的密集检索器完全即插即用,提供无缝集成。如表 6 所示,HippoRAG 2 在多种检索器上始终优于直接密集检索。值得注意的是,无论使用哪种具体的密集检索器,这些性能提升都保持稳健。
6.4. Qualitative Analysis
6.4. 定性分析
We show examples from PopQA and MuSiQue in Table 7. For the first example, “In what city was I. P. Paul born?”, NV-Embed-v2 ranks the entity mentioned in the query “I. P. Paul” as the top 1, where the passage is enough to answer this question. But HippoRAG 2 does even better. It directly finds the answer “Thrissur” when linking the triples, and during the subsequent graph search, it places the passage corresponding to that entity in the second position, which is a perfect retrieval result. For the second multi-hop question, “What county is Erik Hort’s birthplace a part of?” NV-Embed-v2 also easily identifies the person mentioned, “Erik Hort.” However, since this question requires two-step reasoning, it is not sufficient to fully answer the question. In contrast, HippoRAG 2 retrieves a passage titled “Montebello” during the query-to-triple step, which contains geographic information that implies the answer to the question. In the subsequent graph search, this passage is also ranked at the top. Apart from this, the error analysis of HippoRAG 2 is detailed in Appendix E.
我们在表 7 中展示了来自 PopQA 和 MuSiQue 的示例。对于第一个示例,“I. P. Paul 出生在哪个城市?”,NV-Embed-v2 将查询中提到的实体“I. P. Paul”排名第一,该段落足以回答这个问题。但 HippoRAG 2 表现更好。它在链接三元组时直接找到了答案“Thrissur”,并在随后的图搜索中将该实体对应的段落排在第二位,这是一个完美的检索结果。对于第二个多跳问题,“Erik Hort 的出生地属于哪个县?”,NV-Embed-v2 也轻松识别了提到的人物“Erik Hort”。然而,由于这个问题需要两步推理,因此不足以完全回答这个问题。相比之下,HippoRAG 2 在查询到三元组的步骤中检索到了一篇题为“Montebello”的段落,其中包含的地理信息暗示了问题的答案。在随后的图搜索中,该段落也排在了首位。除此之外,HippoRAG 2 的错误分析详见附录 E。
7. Conclusion
7. 结论
We introduced HippoRAG 2, a novel framework designed to address the limitations of existing RAG systems in approximating the dynamic and interconnected nature of human long-term memory. It combining the strengths of the Personalized PageRank algorithm, deeper passage integration, and effective online use of LLMs. HippoRAG 2 opens new avenues for research in continual learning and long-term memory for LLMs by achieving comprehensive improvements over standard RAG methods across factual, sensemaking, and associative memory tasks, showing capabilities that previous methods have either overlooked or been incapable of achieving in a thorough evaluation. Future work could consider leveraging graph-based retrieval methods to further enhance the episodic memory capabilities of LLMs in long conversations.
我们介绍了 HippoRAG 2,这是一种新颖的框架,旨在解决现有 RAG 系统在近似人类长期记忆的动态和互连性方面的局限性。它结合了个性化 PageRank 算法、更深层次的段落集成以及大语言模型的有效在线使用的优势。HippoRAG 2 通过在事实、意义构建和关联记忆任务上对标准 RAG 方法进行全面改进,展示了大语言模型在持续学习和长期记忆研究中的新途径,显示了先前方法在全面评估中要么忽略要么无法实现的能力。未来的工作可以考虑利用基于图的检索方法,进一步增强大语言模型在长对话中的情景记忆能力。
Impact Statement
影响声明
This paper presents work on Retrieval-Augmented Generation (RAG) to advance the field of long-term memory for large language models. While our work may have various societal implications, we do not identify any concerns that warrant specific emphasis beyond those generally associated with large language models and information retrieval systems.
本文介绍了检索增强生成(Retrieval-Augmented Generation, RAG)的研究工作,以推动大语言模型在长期记忆领域的发展。尽管我们的工作可能产生各种社会影响,但我们并未发现任何需要特别强调的问题,除了那些通常与大语言模型和信息检索系统相关的问题。
Acknowledgments
致谢
We would also like to extend our appreciation to colleagues from the OSU NLP group for their constructive comments. This work is supported in part by ARL W 911 NF 2220144, NSF 2112606, and a gift from Cisco. We also thank the Ohio Supercomputer Center for providing computational resources. The views and conclusions contained herein are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. government. The U.S. government is authorized to reproduce and distribute reprints for government purposes notwithstanding any copyright notice herein.
我们还要感谢 OSU NLP 组的同事提出的建设性意见。本工作部分由 ARL W 911 NF 2220144、NSF 2112606 和 Cisco 的捐赠支持。我们还感谢俄亥俄超级计算机中心提供的计算资源。本文中的观点和结论仅代表作者本人,不应被解释为美国政府的官方政策,无论是明示还是暗示的。美国政府有权为政府目的复制和分发本文的重印本,不论本文中的任何版权声明。
References
参考文献
dense information retrieval with contrastive learning. Trans. Mach. Learn. Res., 2022, 2022. URL https: //openreview.net/forum?id $\equiv$ jKN1pXi7b0.
基于对比学习的密集信息检索。Trans. Mach. Learn. Res., 2022, 2022. URL https://openreview.net/forum?id $\equiv$ jKN1pXi7b0.
Jin, X., Zhang, D., Zhu, H., Xiao, W., Li, S.-W., Wei, X., Arnold, A., and Ren, X. Lifelong pre training: Continually adapting language models to emerging corpora. In Carpuat, M., de Marneffe, M.-C., and Meza Ruiz, I. V. (eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4764–4780, Seattle, United States, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022. naacl-main.351. URL https://a cl anthology. org/2022.naacl-main.351/.
Jin, X., Zhang, D., Zhu, H., Xiao, W., Li, S.-W., Wei, X., Arnold, A., and Ren, X. 终身预训练:持续将语言模型适应新兴语料库。载于 Carpuat, M., de Marneffe, M.-C., 和 Meza Ruiz, I. V. (编), 《2022年北美计算语言学协会会议论文集:人类语言技术》, 第4764–4780页, 美国西雅图, 2022年7月。计算语言学协会。doi: 10.18653/v1/2022.naacl-main.351。URL https://aclanthology.org/2022.naacl-main.351/。
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., Santhanam, K., Var d haman an, S., Haq, S., Sharma, A., Joshi, T. T., Moazam, H., Miller, H., Zaharia, M., and Potts, C. DSPy: Compiling declarative language model calls into self-improving pipelines. 2024.
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., Santhanam, K., Var d haman an, S., Haq, S., Sharma, A., Joshi, T. T., Moazam, H., Miller, H., Zaharia, M., and Potts, C. DSPy: 将声明式大语言模型调用编译为自我改进的管道。2024。
Klein, G., Moon, B., and Hoffman, R. R. Making sense of sense making 1: Alternative perspectives. IEEE intelligent systems, 21(4):70–73, 2006.
Klein, G., Moon, B., and Hoffman, R. R. 理解意义建构 1: 替代视角. IEEE 智能系统, 21(4):70–73, 2006.
Koli, V., Yuan, J., and Dasgupta, A. Sense making of socially-mediated crisis information. In Blodgett, S. L., Cercas Curry, A., Dev, S., Madaio, M., Nenkova, A., Yang, D., and Xiao, Z. (eds.), Proceedings of the Third Workshop on Bridging Human–Computer Interaction and Natural Language Processing, pp. 74– 81, Mexico City, Mexico, June 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024. hcinlp-1.7. URL https://a cl anthology.org/ 2024.hcinlp-1.7/.
Koli, V., Yuan, J., 和 Dasgupta, A. Sense making of socially-mediated crisis information. In Blodgett, S. L., Cercas Curry, A., Dev, S., Madaio, M., Nenkova, A., Yang, D., 和 Xiao, Z. (eds.), Proceedings of the Third Workshop on Bridging Human–Computer Interaction and Natural Language Processing, pp. 74–81, Mexico City, Mexico, June 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.hcinlp-1.7. URL https://aclanthology.org/2024.hcinlp-1.7/.
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with paged attention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. 大语言模型服务中的分页注意力高效内存管理。在ACM SIGOPS第29届操作系统原理研讨会论文集, 2023.
Lee, C., Roy, R., Xu, M., Raiman, J., Shoeybi, M., Catan- zaro, B., and Ping, W. NV-Embed: Improved techniques for training llms as generalist embedding models, 2025. URL https://arxiv.org/abs/2405.17428.
Lee, C., Roy, R., Xu, M., Raiman, J., Shoeybi, M., Catanzaro, B., 和 Ping, W. NV-Embed: 改进训练大语言模型作为通用嵌入模型的技术, 2025. URL https://arxiv.org/abs/2405.17428.
Li, Z., Zhang, X., Zhang, Y., Long, D., Xie, P., and Zhang, M. Towards general text embeddings with multi-stage contrastive learning. arXiv preprint arXiv:2308.03281, 2023.
Li, Z., Zhang, X., Zhang, Y., Long, D., Xie, P., and Zhang, M. 面向通用文本嵌入的多阶段对比学习。arXiv preprint arXiv:2308.03281, 2023.
Lu, X. H. BM25S: Orders of magnitude faster lexical search via eager sparse scoring, 2024. URL https://arxiv. org/abs/2407.03618.
Lu, X. H. BM25S: 通过急切稀疏评分实现数量级更快的词汇搜索, 2024. URL https://arxiv.org/abs/2407.03618.
Mallen, A., Asai, A., Zhong, V., Das, R., Khashabi, D., and Hajishirzi, H. When not to trust language models: Investigating effectiveness of parametric and nonparametric memories. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pp. 9802–9822, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.546. URL https: //a cl anthology.org/2023.acl-long.546/.
Mallen, A., Asai, A., Zhong, V., Das, R., Khashabi, D., and Hajishirzi, H. 何时不信任语言模型:探究参数化和非参数化记忆的有效性。收录于 Rogers, A., Boyd-Graber, J., 和 Okazaki, N. (编), 第61届计算语言学协会年会论文集 (第1卷:长论文), 第9802–9822页, 加拿大多伦多, 2023年7月. 计算语言学协会. doi: 10.18653/v1/2023.acl-long.546. URL https://acl anthology.org/2023.acl-long.546/.
Mu en nigh off, N., Su, H., Wang, L., Yang, N., Wei, F., Yu, T., Singh, A., and Kiela, D. Generative representational instruction tuning. CoRR, abs/2402.09906, 2024. doi: 10.48550/ARXIV.2402.09906. URL https://doi. org/10.48550/arXiv.2402.09906.
Mu en nigh off, N., Su, H., Wang, L., Yang, N., Wei, F., Yu, T., Singh, A., and Kiela, D. 生成式表征指令调优。CoRR, abs/2402.09906, 2024. doi: 10.48550/ARXIV.2402.09906. URL https://doi.org/10.48550/arXiv.2402.09906.
Ni, J., Qu, C., Lu, J., Dai, Z., Hernandez Abrego, G., Ma, J., Zhao, V., Luan, Y., Hall, K., Chang, M.-W., and Yang, Y. Large dual encoders are general iz able retrievers. In Goldberg, Y., Kozareva, Z., and Zhang, Y. (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 9844–9855, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main. 669. URL https://a cl anthology.org/2022. emnlp-main.669/.
Ni, J., Qu, C., Lu, J., Dai, Z., Hernandez Abrego, G., Ma, J., Zhao, V., Luan, Y., Hall, K., Chang, M.-W., and Yang, Y. 大型双编码器是通用的检索器。在 Goldberg, Y., Kozareva, Z., 和 Zhang, Y. (编), 《2022 年自然语言处理经验方法会议论文集》, 第 9844–9855 页, 阿拉伯联合酋长国阿布扎比, 2022 年 12 月. 计算语言学协会. doi: 10.18653/v1/2022.emnlp-main.669. URL https://aclanthology.org/2022.emnlp-main.669/.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E. Z., DeVito, Z., Raison, M., Tejani, A., Chi lam kurt hy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. PyTorch: An imperative style, high-performance deep learning library. In Wallach, H. M., Larochelle, H., Bey gel zi mer, A., d'Alché-Buc, F., Fox, E. B., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 8024– 8035, 2019. URL https://proceedings. neurips.cc/paper/2019/hash/ bdb ca 288 fee 7 f 92 f 2 bf a 9 f 7012727740-Abstra html.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E. Z., DeVito, Z., Raison, M., Tejani, A., Chi lam kurt hy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. PyTorch: 一种命令式风格的高性能深度学习库。 In Wallach, H. M., Larochelle, H., Bey gel zi mer, A., d'Alché-Buc, F., Fox, E. B., and Garnett, R. (eds.), 《神经信息处理系统进展 32: 2019年神经信息处理系统年会》, NeurIPS 2019, 2019年12月8-14日, 加拿大不列颠哥伦比亚省温哥华, 第8024–8035页, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/bdbca288fee7f92f2bfa9f7012727740-Abstra.html.
Robertson, S. E. and Walker, S. Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval. In Croft, W. B. and van Rijsbergen, C. J. (eds.), Proceedings of the 17th Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval. Dublin, Ireland, 3-6 July 1994 (Special Issue of the SIGIR Forum), pp. 232–241. ACM/Springer, 1994. doi: 10.1007/978-1-4471-2099-5\ 24.
Robertson, S. E. 和 Walker, S. 一些简单有效的近似方法用于概率加权检索的 2-Poisson 模型。见 Croft, W. B. 和 van Rijsbergen, C. J. (编), 第 17 届国际 ACM-SIGIR 研究与开发会议论文集。爱尔兰都柏林, 1994 年 7 月 3-6 日 (SIGIR 论坛特刊), 第 232–241 页。ACM/Springer, 1994. doi: 10.1007/978-1-4471-2099-5\ 24.
Sarthi, P., Abdullah, S., Tuli, A., Khanna, S., Goldie, A., and Manning, C. D. RAPTOR: recursive abstract ive processing for tree-organized retrieval. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/ forum?id $\underline{{\underline{{\mathbf{\Pi}}}}}$ GN921JHCRw.
Sarthi, P., Abdullah, S., Tuli, A., Khanna, S., Goldie, A., and Manning, C. D. RAPTOR: 面向树结构检索的递归抽象处理。在第十二届国际学习表示会议 (ICLR 2024),奥地利维也纳,2024年5月7-11日。OpenReview.net, 2024。URL https://openreview.net/ forum?id $\underline{{\underline{{\mathbf{\Pi}}}}}$ GN921JHCRw.
Shi, H., Xu, Z., Wang, H., Qin, W., Wang, W., Wang, Y., Wang, Z., Ebrahimi, S., and Wang, H. Continual learning of large language models: A comprehensive survey. arXiv preprint arXiv:2404.16789, 2024.
Shi, H., Xu, Z., Wang, H., Qin, W., Wang, W., Wang, Y., Wang, Z., Ebrahimi, S., and Wang, H. 大语言模型的持续学习:全面综述. arXiv preprint arXiv:2404.16789, 2024.
Suzuki, W. A. Associative learning and the hippocampus. Psychological Science Agenda, February 2005.
Suzuki, W. A. 联想学习与海马体。心理科学议程,2005年2月。
Thakur, N., Reimers, N., Ruckle, A., Srivastava, A., and Gurevych, I. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URL https://openreview.net/forum? id $=$ w Cu 6 T 5 xF je J.
Thakur, N., Reimers, N., Ruckle, A., Srivastava, A., 和 Gurevych, I. BEIR: 一个用于信息检索模型零样本评估的异构基准。在第三十五届神经信息处理系统会议数据集与基准赛道(第二轮), 2021. URL https://openreview.net/forum? id $=$ w Cu 6 T 5 xF je J.
Trivedi, H., Bala subramania n, N., Khot, T., and Sabharwal, A. MuSiQue: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554, 2022. doi: 10. 1162/tacl a 00475. URL https://a cl anthology. org/2022.tacl-1.31/.
Trivedi, H., Bala subramania n, N., Khot, T., and Sabharwal, A. MuSiQue: 通过单跳问题组合的多跳问题. Transactions of the Association for Computational Linguistics, 10:539–554, 2022. doi: 10.1162/tacl_a_00475. URL https://acl anthology.org/2022.tacl-1.31/.
Uner, O. and Roediger III, H. L. Do recall and recognition lead to different retrieval experiences? The American Journal of Psychology, 135(1):33–43, 2022.
Uner, O. 和 Roediger III, H. L. 回忆和再认是否导致不同的检索体验?《美国心理学杂志》, 135(1):33–43, 2022.
Wang, Y., Ren, R., Li, J., Zhao, X., Liu, J., and Wen, J. REAR: A relevance-aware retrieval-augmented framework for open-domain question answering. In AlOnaizan, Y., Bansal, M., and Chen, Y. (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pp. 5613–5626. Association for Computational Linguistics, 2024. URL a cl anthology.org/2024.emnlp-main.321.
Wang, Y., Ren, R., Li, J., Zhao, X., Liu, J., 和 Wen, J. REAR: 一种基于相关性感知的检索增强框架,用于开放域问答。在 AlOnaizan, Y., Bansal, M., 和 Chen, Y. (编), 2024年自然语言处理经验方法会议论文集,EMNLP 2024, 美国佛罗里达州迈阿密, 2024年11月12-16日, 第5613–5626页。计算语言学协会, 2024. 网址 a cl anthology.org/2024.emnlp-main.321.
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtow- icz, M., and Brew, J. Hugging face’s transformers: State-of-the-art natural language processing. CoRR, abs/1910.03771, 2019. URL http://arxiv.org/ abs/1910.03771.
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., and Brew, J. Hugging Face 的 Transformers:最先进的自然语言处理。CoRR, abs/1910.03771, 2019. URL http://arxiv.org/abs/1910.03771.
Xie, J., Zhang, K., Chen, J., Lou, R., and Su, Y. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/ forum?id $=$ auKAUJZMO6.
Xie, J., Zhang, K., Chen, J., Lou, R., and Su, Y. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/ forum?id $=$ auKAUJZMO6.
Yao, Y., Wang, P., Tian, B., Cheng, S., Li, Z., Deng, S., Chen, H., and Zhang, N. Editing large language models: Problems, methods, and opportunities. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 10222–10240, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main. 632. URL https://a cl anthology.org/2023. emnlp-main.632/.
Yao, Y., Wang, P., Tian, B., Cheng, S., Li, Z., Deng, S., Chen, H., and Zhang, N. 大语言模型编辑:问题、方法与机遇。在 Bouamor, H., Pino, J., 和 Bali, K. (编), 《2023年自然语言处理实证方法会议论文集》, 第10222–10240页, 新加坡, 2023年12月. 计算语言学协会. doi: 10.18653/v1/2023.emnlp-main.632. URL https://aclanthology.org/2023.emnlp-main.632/.
Yuan, T., Ning, X., Zhou, D., Yang, Z., Li, S., Zhuang, M., Tan, Z., Yao, Z., Lin, D., Li, B., Dai, G., Yan, S., and Wang, Y. LV-Eval: A balanced long-context benchmark with 5 length levels up to 256k, 2024. URL https: //arxiv.org/abs/2402.05136.
Yuan, T., Ning, X., Zhou, D., Yang, Z., Li, S., Zhuang, M., Tan, Z., Yao, Z., Lin, D., Li, B., Dai, G., Yan, S., and Wang, Y. LV-Eval: 一个长度级别多达256k的平衡长上下文基准,2024. URL https://arxiv.org/abs/2402.05136.
Zhang, H., Gui, L., Zhai, Y., Wang, H., Lei, Y., and Xu, R. Copr: Continual learning human preference through optimal policy regular iz ation, 2024. URL arxiv.org/abs/2310.15694.
Zhang, H., Gui, L., Zhai, Y., Wang, H., Lei, Y., and Xu, R. Copr: 通过最优策略正则化持续学习人类偏好, 2024. URL https://arxiv.org/abs/2310.15694.
Zhang, Z., Fang, M., Chen, L., and Namazi-Rad, M.- R. CITB: A benchmark for continual instruction tuning. In Bouamor, H., Pino, J., and Bali, K. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 9443–9455, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp. 633. URL https://a cl anthology.org/2023. findings-emnlp.633/.
Zhang, Z., Fang, M., Chen, L., and Namazi-Rad, M.- R. CITB: 持续指令调优的基准。In Bouamor, H., Pino, J., and Bali, K. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 9443–9455, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.633. URL https://aclanthology.org/2023.findings-emnlp.633/.
Zhong, Z., Wu, Z., Manning, C., Potts, C., and Chen, D. MQuAKE: Assessing knowledge editing in language models via multi-hop questions. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 15686–15702, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main. 971. URL https://a cl anthology.org/2023. emnlp-main.971/.
Zhong, Z., Wu, Z., Manning, C., Potts, C., and Chen, D. MQuAKE: 通过多跳问题评估语言模型中的知识编辑。In Bouamor, H., Pino, J., and Bali, K. (eds.), 2023年自然语言处理实证方法会议论文集, pp. 15686–15702, 新加坡, 2023年12月. 计算语言学协会. doi: 10.18653/v1/2023.emnlp-main. 971. URL https://a cl anthology.org/2023. emnlp-main.971/.
Appendices
附录
Within this supplementary material, we elaborate on the following aspects:
在本补充材料中,我们详细阐述了以下方面:
A. LLM Prompts
A. 大语言模型提示
We show LLM prompts for triple filter in Figure 3, including the instruction, the few-shot demonstrations and the input format.
我们在图 3 中展示了大语言模型的三重过滤提示,包括指令、少样本演示和输入格式。
B. Pipeline Example
B. 管道示例
We show a pipeline example of HippoRAG 2 online retrieval in Figure 4, including query-to-triple, triple filtering and using seed nodes for PPR.
图 4: HippoRAG 在线检索流程示例,包括查询到三元组、三元组过滤以及使用种子节点进行 PPR。
C. Detailed Experimental Results
C. 详细实验结果
We show QA performance and retrieval performance with the proprietary model GPT-4o-mini as well as more metrics here, as shown in Table 8 and Table 9.
我们展示了使用专有模型 GPT-4o-mini 的问答性能和检索性能,以及更多指标,如表 8 和表 9 所示。
QA Performance As shown in Table 8, when using GPT-4o-mini for indexing and QA reading, HippoRAG 2 consistently achieves competitive EM and F1 scores across most datasets. Notably, it leads in the MuSiQue and 2Wiki benchmarks. Our method also demonstrates superior performance in the Narrative QA and LV-Eval tasks. When compared to the strong NV-Embed-v2 retriever, HippoRAG 2 exhibits comparable or enhanced F1 scores, particularly excelling in the LV-Eval dataset with reduced knowledge leakage.
QA性能
如表 8 所示,当使用 GPT-4o-mini 进行索引和 QA 阅读时,HippoRAG 2 在大多数数据集上始终保持着具有竞争力的 EM 和 F1 分数。值得注意的是,它在 MuSiQue 和 2Wiki 基准测试中领先。我们的方法在 Narrative QA 和 LV-Eval 任务中也表现出卓越的性能。与强大的 NV-Embed-v2 检索器相比,HippoRAG 2 表现出相当或更高的 F1 分数,尤其是在 LV-Eval 数据集中,显著减少了知识泄漏。
Retrieval Performance As shown in Table 9, the improvement trend of HippoRAG 2 in recall $\ @2$ is similar to that in recall $\ @5$ .
检索性能如表 9 所示,HippoRAG 2 在召回率 $\ @2$ 上的提升趋势与召回率 $\ @5$ 上的提升趋势相似。
D. Graph Statistics
D. 图统计
We show the knowledge graph statistics using Llama-3.3-70B-Instruct or GPT-4o-mini for OpenIE in Table 10.
表 10: 使用 Llama-3.3-70B-Instruct 或 GPT-4o-mini 进行 OpenIE 的知识图谱统计
E. Error Analysis
E. 错误分析
We provide an error analysis of 100 samples generated by HippoRAG 2 with recall $\ @5$ less than 1.0. Among these samples, $26%$ , $41%$ , and $33%$ are classified as 2-hop, 3-hop, and 4-hop questions, respectively. Triple filtering and the graph search algorithm are the two main sources of errors.
我们对 HippoRAG 2 生成的召回率 $\ @5$ 小于 1.0 的 100 个样本进行了错误分析。在这些样本中,$26%$、$41%$ 和 $33%$ 分别被分类为 2-hop、3-hop 和 4-hop 问题。三元组过滤和图搜索算法是错误的两大主要来源。
Recognition Memory In $7%$ of the samples, no phrase from the supporting documents is matched with the phrases obtained by the query-to-triple stage before triple filtering. In $26%$ of the samples, no phrase from the supporting documents is matched with the phrases after triple filtering. After the triple filtering step, $8%$ of the samples show a decrease in the proportion of phrases in the triples that match phrases from the supporting passages. For instance, the first case from Table 11 shows an empty list after triple filtering, which eliminates all relevant phrases. Additionally, $18%$ of the samples are left with zero triples after filtering. Although not necessarily an error in filtering, this indicates that the attempt to link to
在 $7%$ 的样本中,在通过查询到三元组阶段获得的三元组过滤之前,没有从支持文档中匹配到短语。在 $26%$ 的样本中,三元组过滤后没有从支持文档中匹配到短语。在三元组过滤步骤后,$8%$ 的样本显示三元组中与支持段落匹配的短语比例下降。例如,表 11 中的第一个案例在三元组过滤后显示为空列表,这消除了所有相关短语。此外,$18%$ 的样本在过滤后没有剩余的三元组。虽然这不一定是过滤错误,但这表明尝试链接到
Triple Filter
三重过滤
Instruction:
指令:
You are a critical component of a high-stakes question-answering system used by top researchers and decision-makers worldwide. Your task is to filter facts based on their relevance to a given query, ensuring that the most crucial information is presented to these stakeholders. The query requires careful analysis and possibly multi-hop reasoning to connect different pieces of information.
你是全球顶尖研究人员和决策者使用的高风险问答系统的关键组成部分。你的任务是根据与给定查询的相关性筛选事实,确保向这些利益相关者呈现最关键的信息。该查询需要仔细分析,并可能需要进行多步推理以连接不同的信息片段。
You must select up to 4 relevant facts from the provided candidate list that have a strong connection to the query, aiding in reasoning and providing an accurate answer.
你必须从提供的候选列表中选出最多4个与查询有强关联的相关事实,以辅助推理并提供准确答案。
The output should be in JSON format, e.g., {"fact": [["s1", "p1", "o1"], ["s2", "p2", "o2"]]}, and if no facts are relevant, return an empty list, {"fact": []}.
输出应为JSON格式,例如{"fact": [["s1", "p1", "o1"], ["s2", "p2", "o2"]]},如果没有相关事实,则返回空列表{"fact": []}。
The accuracy of your response is paramount, as it will directly impact the decisions made by these high-level stakeholders. You must only use facts from the candidate list and not generate new facts. The future of critical decisionmaking relies on your ability to accurately filter and present relevant information.
你回答的准确性至关重要,因为它将直接影响这些高层决策者的决策。你只能使用候选列表中的事实,而不能生成新的事实。关键决策的未来依赖于你准确筛选和呈现相关信息的能力。
Demonstration:
演示:
Question: Are Imperial River (Florida) and Amaradia (Dolj) both located in the same country?
问题:Imperial River(佛罗里达州)和 Amaradia(多尔日县)是否位于同一个国家?
Fact Before Filter: "{"fact": [["imperial river", "is located in", "florida"], ["imperial river", "is a river in", "united states"], ["imperial river", "may refer to", "south america"], ["amaradia", "flows through", "ro ia de amaradia"], ["imperial river", "may refer to", "united states"]]}",
筛选前的事实:"{"fact": [["imperial river", "is located in", "florida"], ["imperial river", "is a river in", "united states"], ["imperial river", "may refer to", "south america"], ["amaradia", "flows through", "ro ia de amaradia"], ["imperial river", "may refer to", "united states"]]}"
Fact After Filter: "{"fact":[["imperial river","is located in","florida"],["imperial river","is a river in","united states"],["amaradia","flows through","ro ia de amaradia"]]}”
过滤后的事实:{"fact":[["imperial river","is located in","florida"],["imperial river","is a river in","united states"],["amaradia","flows through","ro ia de amaradia"]]}
Question: When is the director of film The Ancestor 's birthday?
电影《The Ancestor》导演的生日是什么时候?
Fact Before Filter: "{"fact": [["jean jacques annaud", "born on", "1 october 1943"], ["tsui hark", "born on", "15 february 1950"], ["pablo trapero", "born on", "4 october 1971"], ["the ancestor", "directed by", "guido brignone"], ["benh zeitlin", "born on", "october 14 1982"]]}
事实优先过滤:"{"fact": [["Jean Jacques Annau", "出生于", "1943年10月1日"], ["徐克", "出生于", "1950年2月15日"], ["Pablo Trapero", "出生于", "1971年10月4日"], ["The Ancestor", "由", "Guido Brignone执导"], ["Benh Zeitlin", "出生于", "1982年10月14日"]]}"
Fact After Filter: "{"fact":[["the ancestor","directed by","guido brignone"]]}"
过滤后的事实:"{"fact":[["the ancestor","directed by","guido brignone"]]}"
Question: In what geographic region is the country where Teafuone is located? Fact Before Filter: "{"fact": [["teafuaniua", "is on the", "east"], ["motuloa", "lies between", "teafuaniua"], ["motuloa", "lies between", "teafuanonu"], ["teafuone", "is", "islet"], ["teafuone", "located in", "nukufetau"]]} Fact After Filter: "{"fact":[["teafuone","is","islet"],["teafuone","located in","nukufetau"]]}"
问题:Teafuone 所在的国家位于哪个地理区域?
过滤前的事实:{"fact": [["teafuaniua", "is on the", "east"], ["motuloa", "lies between", "teafuaniua"], ["motuloa", "lies between", "teafuanonu"], ["teafuone", "is", "islet"], ["teafuone", "located in", "nukufetau"]]}
过滤后的事实:{"fact":[["teafuone","is","islet"],["teafuone","located in","nukufetau"]]}
Question: What is the date of death of the director of film The Old Guard (1960 Film)?
问题:电影《The Old Guard》(1960年电影)的导演的去世日期是什么?
Fact Before Filter: "{"fact": [["the old guard", "is", "1960 french comedy film"], ["gilles grangier", "directed", "the old guard"], ["the old guard", "directed by", "gilles grangier"], ["the old fritz", "directed by", "gerhard lamprecht"], ["oswald albert mitchell", "directed", "old mother riley series of films"]]}
事实筛选前: "{"fact": [["the old guard", "是", "1960年法国喜剧电影"], ["gilles grangier", "导演", "the old guard"], ["the old guard", "导演是", "gilles grangier"], ["the old fritz", "导演是", "gerhard lamprecht"], ["oswald albert mitchell", "导演", "old mother riley系列电影"]]}"
Fact After Filter: "{"fact":[["the old guard","is","1960 french comedy film"],["gilles grangier","directed","the old guard"],["the old guard","directed by","gilles grangier"]]}"
事实过滤后结果:{"fact":[["the old guard","是","1960年法国喜剧电影"],["gilles grangier","执导了","the old guard"],["the old guard","由","gilles grangier 执导"]]}
Question: When is the composer of film Aulad (1968 Film) 's birthday?
问题:电影《Aulad》(1968 年电影)的作曲者生日是什么时候?
Fact Before Filter: "{"fact": [["aulad", "has music composed by", "chitra gupta shri vast ava"], ["aadmi sadak ka", "has music by", "ravi"], ["ravi shankar sharma", "composed music for", "hindi films"], ["gulzar", "was born on", $ ^{\prime\prime}18$ august 1934"], ["aulad", "is a", "1968 hindi language drama film"]]}
筛选前的事实:{"fact": [["aulad", "的音乐由", "chitra gupta shri vast ava" 创作], ["aadmi sadak ka", "的音乐由", "ravi" 创作], ["ravi shankar sharma", "为", "印地语电影" 创作了音乐], ["gulzar", "出生于", $ ^{\prime\prime}18$ 1934年8月"], ["aulad", "是一部", "1968年印地语剧情片"]]}
Fact After Filter: "{"fact":[["aulad","has music composed by","chitra gupta shri vast ava"],["aulad","is a","1968 hindi language drama film"]]}"
过滤后的事实:"{"fact":[["aulad","的音乐由","chitra gupta shri vast ava"创作],["aulad","是一部","1968年印地语剧情片"]]}"
Input:
输入:
Question: {} Fact Before Filter: ${}$ Fact After Filter: {}
问题: {} 过滤前事实: ${}$ 过滤后事实: {}
Figure 3. LLM prompts for triple filtering (recognition memory).
图 3: 大语言模型的三重过滤提示(识别记忆)。
Query to Triple
查询到三元组
PPR Seed Nodes
PPR 种子节点
Seed Phrase Nodes ("Montebello", 1.0), ("Erik Hort", 0.995), ("New York", 0.989) Seed Passage Nodes (Title) ("Erik Hort", 0.05), ("Horton Park (Saint Paul, Minnesota)", 0.031), ("Hertfordshire”, 0.028), …
种子短语节点 ("Montebello", 1.0), ("Erik Hort", 0.995), ("New York", 0.989) 种子段落节点 (标题) ("Erik Hort", 0.05), ("Horton Park (Saint Paul, Minnesota)", 0.031), ("Hertfordshire", 0.028), …
Returned Top Passages
返回的顶部段落
1. Erik Hort
1. Erik Hort
Erik Hort (born February 16, 1987 in Montebello, New York) is an American soccer player who is currently a Free Agent.
Erik Hort(1987年2月16日出生于纽约州蒙特贝罗)是一名美国足球运动员,目前是自由球员。
2. Horton Park (Saint Paul, Minnesota)
2. Horton Park (圣保罗,明尼苏达州)
Horton Park is a small arboretum in Saint Paul, Minnesota, United States. Known primarily for its variety of trees, Horton Park has become a symbol of the Saint Paul Midway community.
霍顿公园是位于美国明尼苏达州圣保罗市的一个小型植物园。霍顿公园以其多样的树木而闻名,已成为圣保罗中途社区的一个象征。
3. Montebello, New York
3. 蒙特贝洛,纽约
Montebello (Italian: "Beautiful mountain") is an incorporated village in the town of Ramapo, Rockland County, New York, United States. It is located north of Suffern, east of Hillburn, south of Wesley Hills, and west of Airmont. The population was 4,526 at the 2010 census.
Montebello (意大利语: "美丽的山") 是美国纽约州罗克兰县拉马波镇的一个合并村庄。它位于 Suffern 以北, Hillburn 以东, Wesley Hills 以南, Airmont 以西。2010 年人口普查显示,该村人口为 4,526 人。
4. Hertfordshire
4. 赫特福德郡
Hertfordshire is the county immediately north of London and is part of the East of England region, a mainly statistical unit. A significant minority of the population across all districts are City of London commuters. To the east is Essex, to the west is Buckinghamshire and to the north are Bedfordshire and Cambridgeshire.
赫特福德郡紧邻伦敦北部,属于英格兰东部地区,主要是一个统计单位。所有地区中都有相当一部分人口是伦敦市通勤者。东边是埃塞克斯郡,西边是白金汉郡,北边是贝德福德郡和剑桥郡。
5. Hull County, Quebec
5. 魁北克赫尔县
Hull County, Quebec is an historic county of Quebec, Canada. It was named after the town of the same name (Hull or Kingston-upon-Hull) in East Yorkshire, England. It is located on the north shore of the Ottawa River and is part of the Outaouais, one of roughly 12 historical regions of Québec.
魁北克省赫尔县是加拿大魁北克省的一个历史悠久的县。它得名于英格兰东约克郡的同名城镇(赫尔或金斯顿赫尔)。它位于渥太华河北岸,是魁北克省大约12个历史区域之一的乌塔韦地区的一部分。
Figure 4. An example of HippoRAG 2 pipeline.
图 4: HippoRAG 2 流程示例。
Table 8. QA performance (EM / F1 scores) on RAG benchmarks. No retrieval means evaluating the parametric knowledge of the readers. HippoRAG (and HippoRAG 2) uses the denoted LLM for OpenIE (triple filtering) and QA reading.
表 8: RAG 基准上的 QA 性能 (EM / F1 分数)。无检索意味着评估读者的参数知识。HippoRAG (以及 HippoRAG 2) 使用指定的大语言模型进行 OpenIE(三元组过滤)和 QA 阅读。
| 检索方法 | NQ | PopQA | MuSiQue | 2Wiki | HotpotQA | LV-Eval | NarrativeQA | 平均 |
|---|---|---|---|---|---|---|---|---|
| Llama-3.3-70B-Instruct | ||||||||
| 无 | 40.2/54.9 | 28.2/32.5 | 17.6/26.1 | 36.5/42.8 | 37.0/47.3 | 4.0/6.0 | 3.4/12.9 | 29.7/38.4 |
| Contriever (Izacard et al., 2022) | 45.0/58.9 | 41.6/53.1 | 24.0/31.3 | 38.1/41.9 | 51.3/62.3 | 5.7/8.1 | 6.5/19.7 | 37.4/46.9 |
| BM25 (Robertson & Walker, 1994) | 44.7/59.0 | 39.1/49.9 | 20.3/28.8 | 47.9/51.2 | 52.0/63.4 | 4.0/5.9 | 4.4/18.3 | 38.0/47.7 |
| GTR(T5-base)(Nietal., 2022) | 45.5/59.9 | 43.2/56.2 | 25.8/34.6 | 49.2/52.8 | 50.6/62.8 | 4.8/7.1 | 6.8/19.9 | 40.0/50.4 |
| GTE-Qwen2-7B-Instruct(Li et al., 2023) | 46.6/62.0 | 43.5/56.3 | 30.6/40.9 | 55.1/60.0 | 58.6/71.0 | 5.7/7.1 | 7.9/21.3 | 43.8/54.9 |
| GritLM-7B (Muennighoff et al., 2024) | 46.8/61.3 | 42.8/55.8 | 33.6/44.8 | 55.8/60.6 | 60.7/73.3 | 7.3/9.8 | 8.2/23.9 | 44.9/56.1 |
| NV-Embed-v2 (7B)(Lee et al., 2025) | 47.3/61.9 | 42.9/55.7 | 34.7/45.7 | 57.5/61.5 | 62.8/75.3 | 7.3/9.8 | 8.9/25.7 | 45.9/57.0 |
| RAPTOR(Sarthi et al., 2024) | 36.9/50.7 | 43.1/56.2 | 20.7/28.9 | 47.3/52.1 | 56.8/69.5 | 2.4/5.0 | 5.1/21.4 | 38.1/48.8 |
| GraphRAG (Edge et al., 2024) | 30.8/46.9 | 31.4/48.1 | 27.3/38.5 | 51.4/58.6 | 55.2/68.6 | 4.8/11.2 | 6.8/23.0 | 36.7/49.6 |
| LightRAG (Guo et al., 2024) | 8.6/16.6 | 2.1/2.4 | 0.5/1.6 | 9.4/11.6 | 2.0/2.4 | 0.8/1.0 | 1.0/3.7 | 4.2/6.6 |
| HippoRAG (Gutiérrez et al., 2024) HippoRAG 2 | 43.0/55.3 | 42.7/55.9 42.9/56.2 | 26.2/35.1 | 65.0/71.8 | 52.6/63.5 | 6.5/8.4 | 4.4/16.3 | 42.8/53.1 |
| 48.6/63.3 | 37.2/48.6 | 65.0/71.0 | 62.7/75.5 | 9.7/12.9 | 8.9/25.9 | 48.0/59.8 | ||
| GPT-4o-mini | ||||||||
| 无 | 35.2/52.7 | 16.1/22.7 | 11.2/22.0 | 30.2/36.3 | 28.6/41.0 | 3.2/5.0 | 2.7/14.1 | 22.6/33.1 |
| NV-Embed-v2 (7B)(Lee et al., 2025) | 43.5/59.9 | 41.7/55.8 | 32.8/46.0 | 54.4/60.8 | 57.3/71.0 | 7.3/10.0 | 5.1/24.2 | 42.9/55.7 |
| RAPTOR(Sarthi et al., 2024) | 37.8/54.5 | 41.9/55.1 | 27.7/39.2 | 39.7/48.4 | 50.6/64.7 | 5.6/9.2 | 4.1/21.8 | 36.9/49.7 |
| GraphRAG (Edge et al., 2024) | 38.0/55.5 | 30.7/51.3 | 27.0/42.0 | 45.7/61.0 | 51.4/67.6 | 4.9/11.0 | 5.4/20.9 | 36.0/52.6 |
| LightRAG (Guo et al., 2024) | 2.8/15.4 | 1.9/14.8 | 2.0/9.3 | 2.5/12.1 | 9.9/20.2 | 0.9/5.0 | 1.0/9.0 | 3.6/13.9 |
| HippoRAG (Gutiérrez et al., 2024) | 37.2/52.2 | 42.5/56.2 | 24.0/35.9 | 59.4/67.3 | 46.3/60.0 | 4.8/7.6 | 2.1/16.1 | 38.9/51.2 |
| HippoRAG 2 | 43.4/60.0 | 41.7/55.7 | 35.0/49.3 | 60.5/69.7 | 56.3/71.1 | 10.5/14.0 | 5.8/25.2 | 44.3/58.1 |
the triples has failed, where HippoRAG 2 directly uses the results from dense retrieval as a substitute. Overall, though recognition memory is an essential component, the precision of the triple filter has room for further improvement.
三元组过滤失败,HippoRAG 2 直接使用密集检索的结果作为替代。总体而言,虽然识别记忆是一个重要组成部分,但三元组过滤器的精度还有进一步提升的空间。
Graph Construction Graph construction is challenging to evaluate, but we find that only $2%$ of the samples do not contain any phrases from the supporting passages within the one-hop neighbors of the linked nodes. Given our dense-sparse integration, we can assume that the graphs we construct generally include most of the potentially exploit able information.
图构建
图构建的评估具有挑战性,但我们发现,在链接节点的一跳邻居中,只有 $2%$ 的样本不包含任何支持段落中的短语。鉴于我们的密集-稀疏集成方法,可以假设我们构建的图通常包含大多数潜在可利用的信息。
Personalized PageRank In $50%$ of the samples, at least half of the linked phrase nodes appear in the supporting documents. However, the final results remain unsatisfactory due to the graph search component. For example, in the second case from Table 11, the recognition memory identifies the key phrase "Philippe, Duke of Orléans” from the query, but the graph search fails to return perfect results among the top-5 retrieved passages.
个性化 PageRank (Personalized PageRank) 在 $50%$ 的样本中,至少有一半的链接短语节点出现在支持文档中。然而,由于图搜索组件的不足,最终结果仍然不尽如人意。例如,在表 11 的第二个案例中,识别记忆从查询中识别出关键短语 "Philippe, Duke of Orléans",但图搜索未能在前 5 个检索到的段落中返回完美结果。
F. Cost and Efficiency
F. 成本与效率
For LLM deployment, we run Llama-3.3-70B-Instruct on a machine equipped with four NVIDIA H100 GPUs, utilizing tensor parallelism via vLLM (Kwon et al., 2023). We also employ the gpt-4o-mini-2024-07-18 model from OpenAI’s official endpoint, leveraging its batch $\mathsf{A P I}^{2}$ . For offline indexing, we execute NER and Open IE on the MuSiQue corpus (11, 656 passages). Processing each passage takes approximately 1.1 seconds using Llama-3.3-70B-Instruct, while utilizing the gpt-4o-mini batch API allows indexing to complete within 24 hours at a cost of under $\$2\$ USD.
对于大语言模型的部署,我们在配备四块 NVIDIA H100 GPU 的机器上运行 Llama-3.3-70B-Instruct,并通过 vLLM (Kwon et al., 2023) 利用张量并行。我们还使用了 OpenAI 官方端点的 gpt-4o-mini-2024-07-18 模型,并利用其批处理 $\mathsf{A P I}^{2}$ 。对于离线索引,我们在 MuSiQue 语料库(11, 656 段落)上执行 NER 和 Open IE。使用 Llama-3.3-70B-Instruct 处理每个段落大约需要 1.1 秒,而利用 gpt-4o-mini 的批处理 API 可以在 24 小时内完成索引,成本低于 $\$2\$ 美元。
Comparison With Structure-Augmented RAG Methods We count the token usage across different structure-augmented RAG methods when indexing the MuSiQue corpus using the Llama-3.3-70B-Instruct model, and we compare the number of input and output tokens against RAPTOR (Sarthi et al., 2024), LightRAG (Guo et al., 2024), and GraphRAG (Edge et al., 2024) in Table 12. HippoRAG 2 not only outperforms these RAG methods in QA and retrieval performance but also uses much fewer tokens compared to LightRAG and GraphRAG.
与结构增强的RAG方法对比
G. Implementation Details and Hyper parameters
G. 实现细节与超参数
G.1. HippoRAG 2
G.1. HippoRAG 2
We provide a detailed explanation of the PPR initialization process used in HippoRAG 2 here. The key goal is to determine the seed nodes for the PPR search and assign appropriate reset probabilities to ensure an effective retrieval process.
我们在此详细解释 HippoRAG 2 中使用的 PPR (Personalized PageRank) 初始化过程。关键目标是确定 PPR 搜索的种子节点,并分配适当的重置概率,以确保有效的检索过程。
Table 9. Passage recall $\textstyle{\mathcal{@2/\mathrm{~}}}\langle\alpha\rangle$ on RAG benchmarks. * denotes the report from the original paper while we reproduce the HippoRAG results with aligned LLM and retriever.
表 9. 在 RAG 基准测试中的段落召回率 $\textstyle{\mathcal{@2/\mathrm{~}}}\langle\alpha\rangle$。* 表示原始论文中的报告,而我们使用对齐的 LLM 和检索器重现了 HippoRAG 的结果。
| Simple | Multi-hop | Avg | ||||
|---|---|---|---|---|---|---|
| NQ | PopQA | MuSiQue | 2Wiki | HotpotQA | ||
| SimpleBaselines | ||||||
| Contriever (Izacard et al.,2022) | 29.1/ 54.6 | 27.0/43.2 | 34.8/ 46.6 | 46.6/ 57.5 | 58.4/ 75.3 | 39.2/55.4 |
| BM25 (Robertson & Walker,1994) | 28.2/56.1 | 24.0 / 35.7 | 32.4/43.5 | 55.3/65.3 | 57.3/74.8 | 39.4/55.1 |
| GTR (T5-base) (Ni et al.,2022) | 35.0/63.4 | 40.1 / 49.4 | 37.4/ 49.1 | 60.2/ 67.9 | 59.3/73.9 | 46.4/ 60.7 |
| LargeEmbeddingModels | ||||||
| GTE-Qwen2-7B-Instruct (Liet al.,2023) | 44.7/74.3 | 47.7/50.6 | 48.1/ 63.6 | 66.7/ 74.8 | 75.8/ 89.1 | 56.6 / 70.5 |
| GritLM-7B (Muennighoff et al., 2024) | 46.2/ 76.6 | 44.0 / 50.1 | 49.7/ 65.9 | 67.3/ 76.0 | 79.2/92.4 | 57.3/72.2 |
| NV-Embed-v2 (7B) (Lee et al.,2025) | 45.3/ 75.4 | 45.3 / 51.0 | 52.7/ 69.7 | 67.1/ 76.5 | 84.1/94.5 | 58.9/ 73.4 |
| Structure-augmented RAG | ||||||
| RAPTOR (GPT-4o-mini) | 40.5 / 69.4 | 37.2 / 48.1 | 49.1/ 61.0 | 58.4/ 66.0 | 78.6/ 90.2 | 52.8 / 67.0 |
| RAPTOR (Llama-3.3-70B-Instruct) | 40.3/68.3 | 40.2/ 48.7 | 47.0/57.8 | 58.3/66.2 | 76.8/ 86.9 | 52.5 / 65.6 |
| HippoRAG* (Gutiérrez et al., 2024) | 40.9/51.9 | 70.7/ 89.1 | 60.5/ 77.7 | |||
| HippoRAG (GPT-4o-mini) | 21.6 / 45.1 | 36.5/52.2 | 41.8/52.4 | 68.4/ 87.0 | 60.1/ 78.5 | 45.7/ 63.0 |
| HippoRAG (Llama-3.3-70B-Instruct) | 21.3 / 44.4 | 40.0/53.8 | 41.2/53.2 | 71.9/90.4 | 60.4/ 77.3 | 47.0/63.8 |
| HippoRAG 2 (GPT-4o-mini) | 44.4 / 76.4 | 43.5/ 52.2 | 53.5/74.2 | 74.6/ 90.2 | 80.5/ 95.7 | 59.3/ 77.7 |
| HippoRAG 2 (Llama-3.3-70B-Instruct) | 45.6/ 78.0 | 43.9/51.7 | 56.1/74.7 | 76.2/90.4 | 83.5/96.3 | 61.1/78.2 |
Seed Node Selection The seed nodes for the PPR search are categorized into two types: phrase nodes and passage nodes. All the scores given by the embedding model below use normalized embedding to calculate. 1) Phrase Nodes: These seed nodes are selected from the phrase nodes within the filtered triples, which are obtained through the recognition memory component. If recognition memory gives an empty triple list and no phrase node is available, HippoRAG 2 directly returns top passages using the embedding model without any graph search. Otherwise, we keep at most 5 phrase nodes as the seed nodes, and the ranking score of each phrase node is computed as the average score of all filtered triples it appears in. 2) Passage Nodes: Each passage node is initially scored using an embedding-based similarity, and these scores are processed as follows. All passage nodes are taken as seed nodes since we find that activating a broader set of potential passages is more effective for uncovering passages along multi-hop reasoning chains compared to focusing only on the top-ranked passages.
种子节点选择
PPR搜索的种子节点分为两种类型:短语节点和段落节点。下面嵌入模型给出的所有分数都使用归一化嵌入来计算。
- 短语节点:这些种子节点从过滤后的三元组中的短语节点中选择,这些三元组是通过识别记忆组件获得的。如果识别记忆给出一个空的三元组列表并且没有可用的短语节点,HippoRAG 2会直接使用嵌入模型返回顶级段落,而不进行任何图搜索。否则,我们最多保留5个短语节点作为种子节点,每个短语节点的排名分数计算为它出现的所有过滤三元组的平均分数。
- 段落节点:每个段落节点最初使用基于嵌入的相似性进行评分,这些分数按如下方式处理。所有段落节点都作为种子节点,因为我们发现,与仅关注排名靠前的段落相比,激活更广泛的潜在段落集对于揭示多跳推理链中的段落更为有效。
Reset Probability Assignment After determining the seed nodes, we assign reset probabilities to control how likely the PPR algorithm will return to these nodes during the random walk. The rules are: 1) Phrase nodes receive reset probabilities directly as their ranking scores. 2) Passage nodes receive reset probabilities proportional to their embedding similarity scores, i.e., to balance the influence of phrase nodes and passage nodes, we apply a weight factor to the passage node scores. Specifically, the passage node scores are multiplied by the weight factor discussed in Section 6.2. This ensures that passage nodes and phrase nodes contribute appropriately to the retrieval process.
重置概率分配
PPR Execution and Passage Ranking Once the seed nodes and their reset probabilities are initialized, we run PPR over the constructed graph. The final ranking of passages is determined based on the PageRank scores of the passage nodes. Top-ranked passages are then used as inputs for the downstream QA reading process. We manage our KG and run the PPR algorithm using the python-igraph library.3
PPR执行与段落排序
一旦种子节点及其重置概率初始化完成,我们在构建的图上运行PPR。段落的最终排序基于段落节点的PageRank分数。排名靠前的段落随后用作下游问答阅读过程的输入。我们使用python-igraph库管理知识图谱并运行PPR算法。
By incorporating both phrase nodes and passage nodes into the PPR initialization, our approach ensures a more effective retrieval of relevant passages, especially for multi-hop reasoning tasks.
通过将短语节点和段落节点结合到PPR初始化中,我们的方法确保了更有效的相关段落检索,特别是对于多跳推理任务。
Hyper parameters We perform hyper parameter tuning on 100 examples from MuSiQue’s training data. The hyper para meters are listed in Table 13.
超参数 (Hyper parameters)
我们在 MuSiQue 的训练数据中选取了 100 个示例进行超参数调优。具体超参数列于表 13 中。
G.2. Comparison Methods
G.2. 对比方法
We use PyTorch (Paszke et al., 2019) and Hugging Face (Wolf et al., 2019) for dense retrievers and BM25s (Lu, 2024) for the BM25 implementation. For GraphRAG (Edge et al., 2024) and LightRAG (Guo et al., 2024), we adhere to their
我们使用 PyTorch (Paszke et al., 2019) 和 Hugging Face (Wolf et al., 2019) 来实现密集检索器,并使用 BM25s (Lu, 2024) 来实现 BM25。对于 GraphRAG (Edge et al., 2024) 和 LightRAG (Guo et al., 2024),我们遵循其
Table 10. Knowledge graph statistics using different LLMs for OpenIE. The nodes and triples are counted based on unique values.
表 10: 使用不同大语言模型进行 OpenIE 的知识图谱统计。节点和三元组基于唯一值进行计数。
| NQ | PopQA | MuSiQue | 2Wiki | HotpotQA | LV-Eval | NarrativeQA | |
|---|---|---|---|---|---|---|---|
| Llama-3.3-70B-Instruct | |||||||
| # of phrase nodes | 68,375 | 76,539 | 85,288 | 44,004 | 81,200 | 175,195 | 9,224 |
| # of passage nodes | 9,633 | 8,676 | 11,656 | 6,119 | 9,811 | 22,849 | 4,111 |
| # of total nodes | 78,008 | 85,215 | 96,944 | 50,123 | 91,011 | 198,044 | 13,335 |
| # of extracted edges | 125,777 | 124,579 | 140,830 | 68,881 | 130,058 | 314,324 | 26,208 |
| # of synonym edges | 899,031 | 845,014 | 1,125,951 | 593,298 | 994,187 | 2,674,833 | 72,494 |
| # of context edges | 126,757 | 118,909 | 132,586 | 64,132 | 122,437 | 375,424 | 33,395 |
| # of total edges | 1,151,565 | 1,088,502 | 1,399,367 | 726,311 | 1,246,682 | 3,364,581 | 132,097 |
| GPT-4o-mini | |||||||
| # of phrase nodes | 86,904 | 85,744 | 101,641 | 49,544 | 95,105 | 217,085 | 15,365 |
| # of passage nodes | 9,633 | 8,676 | 11,656 | 6,119 | 9,811 | 22,849 | 4,111 |
| # of total nodes | 96,537 | 94,420 | 113,297 | 55,663 | 104,916 | 239,934 | 19,476 |
| # of extracted edges | 114,900 | 108,989 | 125,903 | 62,626 | 119,630 | 303,491 | 24,373 |
| # of synonym edges | 1,094,651 | 901,528 | 1,304,605 | 715,763 | 1,126,501 | 3,268,084 | 14,075 |
| # of context edges | 142,419 | 127,568 | 146,293 | 68,348 | 133,220 | 404,210 | 38,632 |
| # of total edges | 1,351,970 | 494,082 | 1,576,801 | 846,737 | 1,379,351 | 3,975,785 | 77,080 |
Table 11. Two examples from MuSiQue where passage recall $\ @5$ is less than 1.0.
表 11. MuSiQue 中两个段落召回率 $\ @5$ 小于 1.0 的示例。
| 查询答案 | 想要改革并解决 Bernhard Lichtenberg 宗教问题的人在他去世前宣讲 Marian devotion 的区位于哪里?萨克森-安哈尔特 |
|---|---|
| 支持段落(标题) 检索段落(标题) | 1. Mary, mother of Jesus 2. Reformation 3. Wittenberg (district) 4. Bernhard Lichtenberg 1. Bernhard Lichtenberg 2. Mary, mother of Jesus 3. Ambroise-Marie Carre 4. Reformation 5. Henry Scott Holland (Recall@5 为 0.75) |
| 查询到三元组(Top-5) | ("Bernhard Lichtenberg", "was","Roman Catholic Priest") ("Bernhard Lichtenberg", "beatified by", "Catholic Church") ("Bernhard Lichtenberg", "died on", "5 November 1943") ("Catholic Church", "beatified", "Bernhard Lichtenberg") ("Bernhard Lichtenberg", "was","Theologian") |
| 过滤后的三元组 | 以上所有主语和宾语均出现在支持段落中 空 |
| 查询答案 | Philippe, Duke of Orléans 的祖母是谁?Mariede'Medici |
| 支持段落(标题) 检索段落(标题) | 1. Philippe I, Duke of Orléans 2. Leonora Dori 1. Philippe I, Duke of Orléans 2. Louise Elisabeth d'Orléans 3. Philip IMI of Spain 4. Anna of Lorraine 5. Louis Philippe I (Recall@5 为 0.5) |
| 查询到三元组(Top-5) | ("Bank of America","purchased","Fleetboston Financial") ("Fleetboston Financial", "was acquired by", "Bank of America") ("Bank of America", "acquired", "Fleetboston Financial") ("Bank of America","announced purchase of","Fleetboston Financial") ("Bank of America", "merged with", "Fleetboston Financial") |
| 过滤后的三元组 | ("Bank of America", "purchased", "Fleetboston Financial") ("Fleetboston Financial","was acquired by","Bank of America") |
Table 12. Token usage of different structure-augmented RAG methods for indexing the MuSiQue corpus (11, 656 passages) and their relative proportions.
表 12: 不同结构增强的RAG方法在索引MuSiQue语料库 (11, 656段落) 时的Token使用情况及其相对比例。
| HippoRAG 2 | RAPTOR | LightRAG | GraphRAG | |
|---|---|---|---|---|
| 输入Token | 9.2M (100.0%) | 1.7M (18.5%) | 68.5M (744.6%) | 115.5M (1255.4%) |
| 输出Token | 3.0M (100.0%) | 0.2M (6.7%) | 18.3M (610.0%) | 36.1M (1203.3%) |
Table 13. Hyper parameters set on HippoRAG 2
表 13. HippoRAG 2 的超参数设置
| 超参数 | 值 |
|---|---|
| 同义词阈值 (Synonym Threshold) | 0.8 |
| PPR 阻尼因子 (Damping Factor of PPR) | 0.5 |
| 温度 (Temperature) | 0.0 |
default hyper parameters and prompts. To ensure a consistent evaluation, the same QA prompt that HippoRAG 2 adopts from HippoRAG (Gutiérrez et al., 2024) is applied to rephrase the original response of GraphRAG and LightRAG.
默认超参数和提示。为了确保评估的一致性,HippoRAG 2 采用的与 HippoRAG (Gutiérrez et al., 2024) 相同的 QA 提示被应用于重新表述 GraphRAG 和 LightRAG 的原始响应。
Hyper parameters We keep the default indexing hyper parameters for LightRAG and GraphRAG. For QA, we perform hyper parameter tuning on the same 100 samples as Appendix G.1.
超参数
Table 14. Hyper parameters set on LightRAG and GraphRAG
表 14: LightRAG 和 GraphRAG 的超参数设置
| 超参数 | LightRAG | GraphRAG |
|---|---|---|
| 模式 | Local | Local |
| 响应类型 | Shortphrase | Shortphrase |
| 用于 QA 的 Top-k 短语 | 60 | 60 |
| ChunkTokenSize | 1,200 | 1,200 |
| Chunk Overlap Token Size | 100 | 100 |
| 社区报告最大长度 | 2,000 | |
| 最大输入长度 | 8,000 | |
| 最大集群大小 | 10 | |
| 实体摘要最大 Token 数 | 500 |