olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models
olmOCR: 使用视觉语言模型解锁 PDF 中的数万亿 Token
Allen Institute for AI, Seattle, USA {jakep|kylel|lucas}@allenai.org
艾伦人工智能研究所,西雅图,美国 {jakep|kylel|lucas}@allenai.org
indicates core contributors.
核心贡献者。
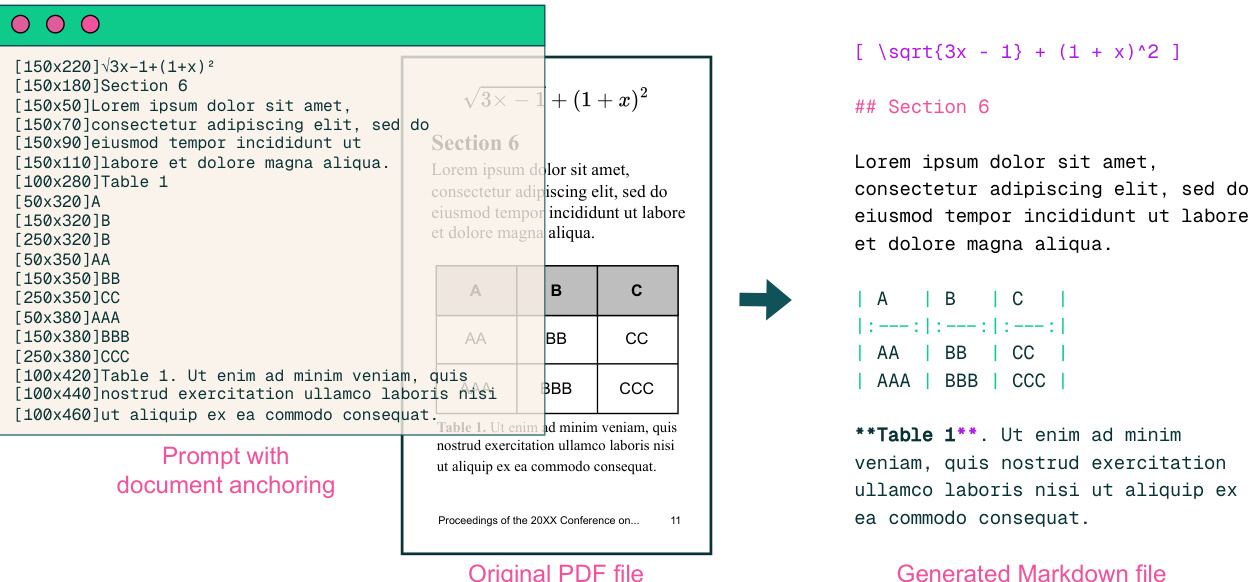
Abstract
摘要
PDF documents have the potential to provide trillions of novel, high-quality tokens for training language models. However, these documents come in a diversity of types with differing formats and visual layouts that pose a challenge when attempting to extract and faithfully represent the underlying content for language model use. We present olmOCR, an open-source Python toolkit for processing PDFs into clean, linearized plain text in natural reading order while preserving structured content like sections, tables, lists, equations, and more. Our toolkit runs a fine-tuned 7B vision language model (VLM) trained on a sample of 260,000 pages from over 100,000 crawled PDFs with diverse properties, including graphics, handwritten text and poor quality scans. olmOCR is optimized for large-scale batch processing, able to scale flexibly to different hardware setups and convert a million PDF pages for only $\$190$ USD. We release all components of olmOCR including VLM weights, data and training code, as well as inference code built on serving frameworks including vLLM and SGLang.
PDF 文档有潜力为训练大语言模型提供数万亿个新颖且高质量的 Token。然而,这些文档类型多样,格式和视觉布局各不相同,这在尝试提取并忠实地表示底层内容以供大语言模型使用时带来了挑战。我们推出了 olmOCR,这是一个开源的 Python语言 工具包,用于将 PDF 处理成干净、线性化的纯文本,使其符合自然阅读顺序,同时保留结构化内容,如章节、表格、列表、公式等。我们的工具包运行了一个微调的 7B 视觉语言模型(VLM),该模型在从 10 万多个爬取的 PDF 中抽取的 26 万页样本上进行训练,这些 PDF 具有多样化的属性,包括图形、手写文本和低质量扫描。olmOCR 针对大规模批处理进行了优化,能够灵活扩展到不同的硬件设置,并以仅 190 美元的成本转换一百万页 PDF。我们发布了 olmOCR 的所有组件,包括 VLM 权重、数据和训练代码,以及基于 vLLM 和 SGLang 等服务框架构建的推理代码。
Code allenai/olmocr Weights & Data allenai/olmocr Demo olmocr.allenai.org
代码 allenai/olmocr 权重和数据 allenai/olmocr 演示 olmocr.allenai.org
Introduction
简介
Access to clean, coherent textual data is a crucial component in the life cycle of modern language models (LMs). During model development, LMs require training on trillions of tokens derived from billions of documents (Soldaini et al., 2024; Penedo et al., 2024; Li et al., 2024); errors from noisy or low fidelity content extraction and representation can result in training instabilities or even worse downstream performance (Penedo et al., 2023; Li et al., 2024; OLMo et al., 2024). During inference, LMs are often prompted with plain text representations of relevant document context to ground user prompts; for example, consider information extraction (Kim et al., 2021) or AI reading assistance (Lo et al., 2024) over a user-provided document and cascading downstream errors due to low quality representation of the source document.
获取干净、连贯的文本数据是现代语言模型 (LMs) 生命周期中的关键组成部分。在模型开发过程中,LMs 需要从数十亿文档中提取的数万亿 Token 进行训练(Soldaini et al., 2024;Penedo et al., 2024;Li et al., 2024);由于噪声或低保真内容提取和表示导致的错误可能会引发训练不稳定性,甚至影响下游性能(Penedo et al., 2023;Li et al., 2024;OLMo et al., 2024)。在推理过程中,LMs 通常会被提示以相关文档上下文的纯文本表示来支持用户提示;例如,考虑在用户提供的文档上进行信息提取(Kim et al., 2021)或 AI 阅读辅助(Lo et al., 2024),以及由于源文档低质量表示而引发的级联下游错误。
While the internet remains a valuable source of textual content for language models, large amounts of content are not readily available through web pages. Electronic documents (e.g., PDF, PS, DjVu formats) and word processing files (e.g., DOC, ODT, RTF) are widely-used formats to store textual content. However, these formats present a unique challenge: unlike modern web standards, they encode content to facilitate rendering on fixed-size physical pages, at the expense of preserving logical text structure. For example, consider the PDF format, which originated as a means to specify how digital documents should be printed onto physical paper. As seen in Figure 1, PDFs store not units of text—headings, paragraphs, or other meaningful prose elements—but single characters alongside their spacing, placement, and any metadata used for visual rendering on a page. As more and more documents became digital, users have relied this file format to create trillions of documents (PDF Association staff, 2015); yet, these documents remain difficult to leverage in LM pipelines because PDFs lack basic structure necessary for coherent prose, such as ground truth reading order.
虽然互联网仍然是大语言模型获取文本内容的宝贵来源,但大量内容无法通过网页轻松获取。电子文档(例如 PDF、PS、DjVu 格式)和文字处理文件(例如 DOC、ODT、RTF)是广泛用于存储文本内容的格式。然而,这些格式带来了一个独特的挑战:与现代网页标准不同,它们对内容进行编码以促进在固定大小的物理页面上呈现,却以牺牲逻辑文本结构为代价。例如,考虑 PDF 格式,它最初是作为指定数字文档应如何打印到物理纸张上的手段而诞生的。如图 1 所示,PDF 存储的不是文本单元——标题、段落或其他有意义的内容元素——而是单个字符及其间距、位置和用于页面视觉呈现的任何元数据。随着越来越多的文档数字化,用户依靠这种文件格式创建了数万亿的文档(PDF Association staff, 2015);然而,这些文档在大语言模型管道中仍然难以利用,因为 PDF 缺乏连贯文本所需的基本结构,例如真实的阅读顺序。
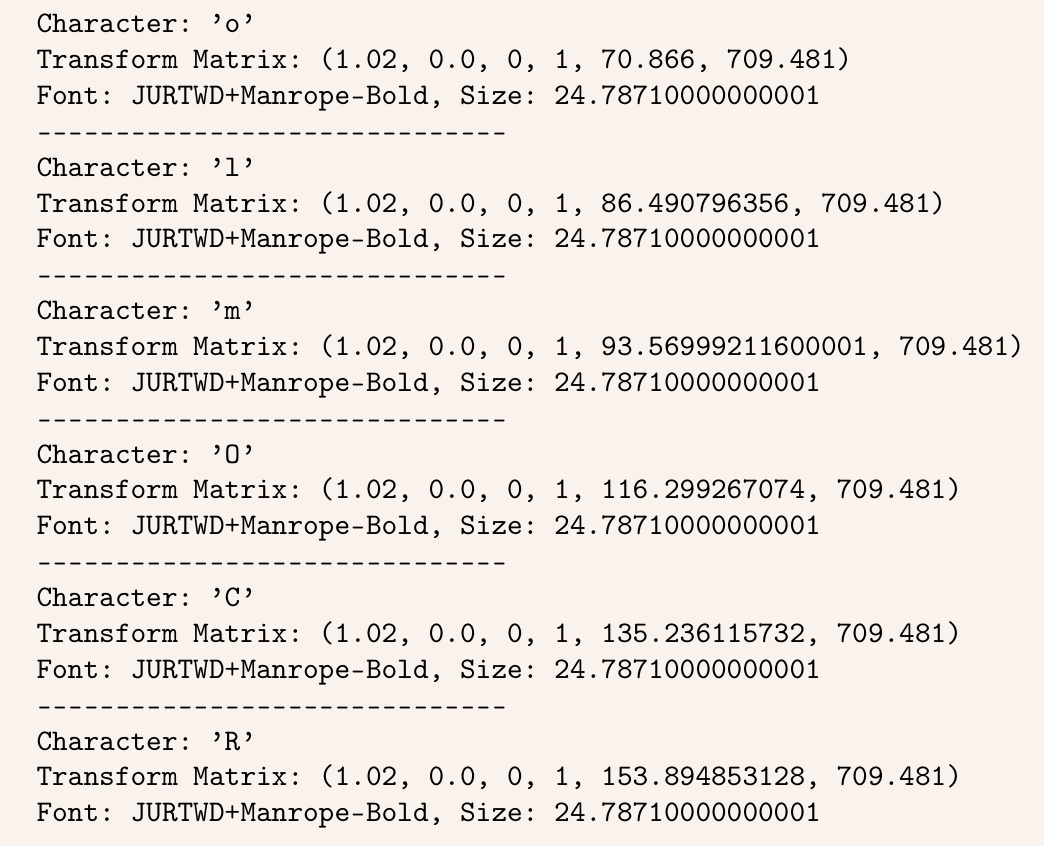
Figure 1 Example of how PDFs represent textual content, such as this paper title, as individual glyphs with metadata.
图 1: PDF 如何将文本内容(例如本文标题)表示为带有元数据的独立字形示例。
Faithful content extraction and representation of digitized print documents has long been of interest, with early research efforts in the 1950s, and first commercial optical character recognition (OCR) tools debuting in the late 1970s (Mori et al., 1992). The release of Tesseract in 2006 represented a significant milestone, as the first high-quality, open-source OCR toolkit (Smith, 2013). The current landscape of PDF extraction toolkits can be partitioned in pipeline-based systems and end-to-end models. Pipeline-based systems (MinerU, Wang et al. 2024a; Marker, Paruchuri 2025) are comprised of multiple ML components (e.g., section segmentation, table parsing) chained together; some, such as Grobid (GRO, 2008–2025), VILA (Shen et al., 2022), and PaperMage (Lo et al., 2023), are tailored to scientific papers. On the other hand, end-to-end models parse a document with a single model. For example, Nougat (Blecher et al., 2023) and GOT Theory 2.0 (Wei et al., 2024) take images of PDF pages as input, and return plain text. Notably, while pipeline-based systems have historically focused on simply faithful extraction, end-to-end-systems have also made strides to enable linear iz ation of this content—prescribing a flattening of this content to adhere to logical reading order—which can be quite challenging for layout-rich documents with many floating elements (e.g. multi-column documents with floating diagrams, headers, footnotes, and more). Recently, rapid advances in the proprietary LMs have led to significant improvements in end-to-end text extraction capabilities (Bai et al., 2025; Google, 2025). However, this capability comes at a steep price: for example, converting a million pages using GPT-4o can cost over \$6,200 USD.
长期以来,数字化印刷文档的忠实内容提取和表示一直备受关注,早在1950年代就有相关研究,而首个商用光学字符识别(OCR)工具则在1970年代末问世(Mori et al., 1992)。2006年Tesseract的发布标志着一个重要里程碑,它是首个高质量的开源OCR工具包(Smith, 2013)。当前的PDF提取工具包可以分为基于流水线的系统和端到端模型。基于流水线的系统(MinerU, Wang et al. 2024a; Marker, Paruchuri 2025)由多个机器学习组件(如章节分割、表格解析)串联而成;其中一些系统,如Grobid(GRO, 2008–2025)、VILA(Shen et al., 2022)和PaperMage(Lo et al., 2023),专门针对科学论文。另一方面,端到端模型使用单一模型解析文档。例如,Nougat(Blecher et al., 2023)和GOT Theory 2.0(Wei et al., 2024)将PDF页面的图像作为输入,并返回纯文本。值得注意的是,虽然基于流水线的系统历史上主要关注忠实的提取,但端到端系统也在内容的线性化方面取得了进展——将内容扁平化以遵循逻辑阅读顺序,这对于具有丰富布局的文档(例如带有浮动图表、页眉、脚注等的多栏文档)来说可能相当具有挑战性。最近,专有大语言模型的快速发展显著提升了端到端文本提取能力(Bai et al., 2025; Google, 2025)。然而,这种能力代价高昂:例如,使用GPT-4o转换一百万页文档的成本可能超过6,200美元。
We introduce olmOCR, a general-purpose context extraction and linear iz ation toolkit to convert PDFs or images of documents into clean plain text:
我们推出了 olmOCR,这是一个通用的上下文提取和线性化工具包,用于将 PDF 或文档图像转换为干净的纯文本:
2 Methodology
2 方法论
Approach Many end-to-end OCR models, such as GOT Theory 2.0 (Wei et al., 2024) and Nougat (Blecher et al., 2023), exclusively rely on rasterized pages to convert documents to plain text; that is, they process images of the document pages as input to auto regressive ly decode text tokens. This approach, while offering great compatibility with image-only digitization pipelines, misses the fact that most PDFs are born-digital documents, thus already contain either digitized text or other metadata that would help in correctly linear i zing the content.
方法
许多端到端的 OCR 模型,例如 GOT Theory 2.0 (Wei 等人, 2024) 和 Nougat (Blecher 等人, 2023),完全依赖光栅化页面将文档转换为纯文本;也就是说,它们将文档页面的图像作为输入,自回归地解码文本 Token。这种方法虽然与仅图像的数字化流程具有很好的兼容性,但却忽略了大多数 PDF 文件是原生数字文档的事实,因此已经包含了数字化文本或其他元数据,这些信息有助于正确线性化内容。
In contrast, the olmOCR pipeline leverages document text and metadata. We call this approach documentanchoring. Figure 2 provides an overview of our method; document-anchoring extracts coordinates of salient elements in each page (e.g., text blocks and images) and injects them alongside raw text extracted from the PDF binary file. Crucially, the anchored text is provide as input to any VLM alongside a rasterized image of the page.
相比之下,olmOCR 管道利用了文档文本和元数据。我们称这种方法为文档锚定。图 2 提供了我们方法的概述;文档锚定提取每个页面中显著元素(例如,文本块和图像)的坐标,并将它们与从 PDF 二进制文件中提取的原始文本一起注入。关键是,锚定文本与页面的光栅化图像一起作为输入提供给任何 VLM。
Our approach increases the quality of our content extraction. We apply document-anchoring when prompting GPT-4o to collect silver training samples, when fine-tuning olmOCR-7B-0225-preview, and when performing inference with the olmOCR toolkit.
我们的方法提高了内容提取的质量。我们在使用 GPT-4o 收集银样训练样本、微调 olmOCR-7B-0225-preview 以及使用 olmOCR 工具包进行推理时,应用了文档锚定技术。
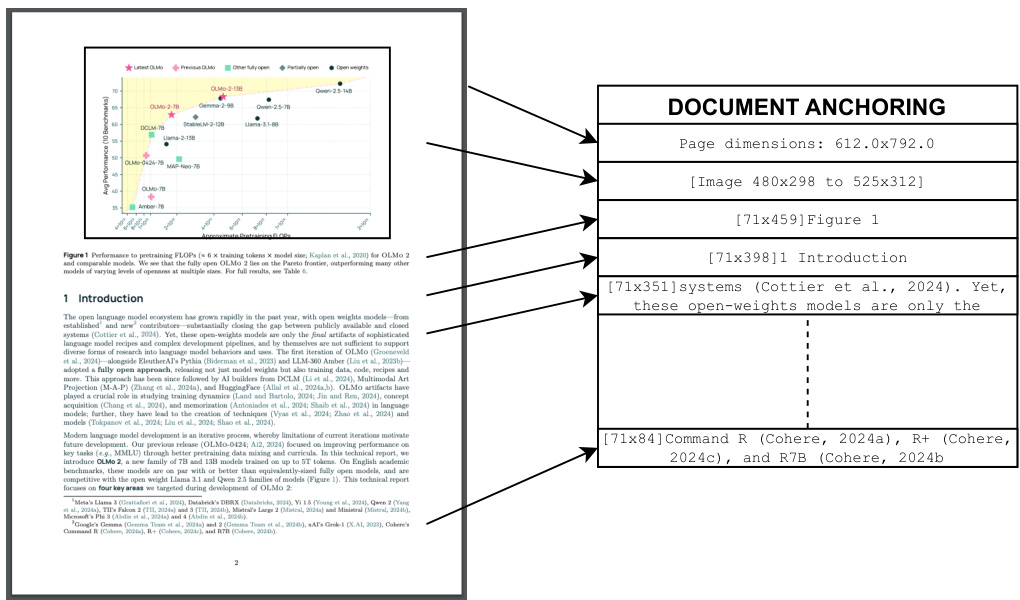
Figure 2 Example of how document-anchoring works for a typical page. Relevant image locations and text blocks get extracted, concatenated, and inserted into the model prompt. When prompting a VLM for a plain text version of the document, the anchored text is used in conjunction with the rasterized image of a page.
图 2: 文档锚定在典型页面中的工作原理示例。相关图像位置和文本块被提取、连接并插入到模型提示中。当为大语言模型 (VLM) 提示文档的纯文本版本时,锚定文本与页面的光栅化图像结合使用。
Implementation document-anchoring processes PDF document pages via the pypdf (PyPDF, 2012–2025) library to extract a representation of the page’s structure from the underlying PDF. All of the text blocks and images in the page are extracted, including position information. Starting with the most relevant text blocks and images2, these are sampled and added to the prompt of the VLM, up to a defined maximum character limit . This extra information is then available to the model when processing the document.
实现文档锚定流程:通过pypdf (PyPDF, 2012–2025) 库提取PDF文档页面的结构表示。页面中的所有文本块和图像都会被提取,包括位置信息。从最相关的文本块和图像开始,对这些内容进行采样,并将其添加到VLM的提示中,直至达到定义的最大字符限制。这样,模型在处理文档时便可利用这些额外信息。
Overall, we find that using prompts constructed using document-anchoring results in significantly fewer hallucinations. Prompting with just the page image was prone to models completing unfinished sentences, or to invent larger texts when the image data was ambiguous. Finally, while document-anchoring helps with quality on born-digital documents, our pipeline maintains high performance on documents that do not have any digital metadata encoded in them. In these cases, the model will not have the benefit of seeing the internal structure of the PDF document, instead relying on just the rasterized image of a page to process the underlying document.
总体而言,我们发现使用基于文档锚点构建的提示显著减少了幻觉现象。仅使用页面图像进行提示时,模型容易补全未完成的句子,或在图像数据模糊时虚构更长的文本。最后,虽然文档锚点有助于提高原生数字文档的质量,但我们的流程在没有任何数字元数据编码的文档上仍保持高性能。在这些情况下,模型将无法利用 PDF 文档的内部结构,而是仅依赖页面的光栅化图像来处理底层文档。
3 Fine-tuning Models for olmOCR
3 为olmOCR微调模型
While the document-anchoring method presented in Section §2 can be used to prompt any language model, we find that fine-tuning a smaller VLM on this linear iz ation task yields models that are as accurate as larger, general-purpose models and are much more efficient at inference time. In this section, we summarize the procedure we followed to distill the output of a larger VLM; Section §3.1 details how we collect the training data, while Section $\S3.2$ provides an overview of fine-tuning.
虽然第2节中提出的文档锚定方法可用于提示任何语言模型,但我们发现,在这个线性化任务上对较小的视觉语言模型 (VLM) 进行微调,可以产生与更大的通用模型一样准确的模型,并且在推理时效率更高。在本节中,我们总结了从更大的视觉语言模型输出中进行蒸馏的过程;第3.1节详细介绍了我们如何收集训练数据,而第3.2节则概述了微调的步骤。
3.1 Dataset
3.1 数据集
Choice of teacher model At the time of construction (October 2024), we evaluated several open-weights and API models to label our training data. Our analysis relied on qualitative assessment of linear iz ation performance on a small collection of PDF pages with moderately complicated layout. At this stage, we evaluated model outputs visually across a set of several PDF documents that were known to cause problems for traditional PDF content extraction tools, and contained varied elements such as equations, tables, multi-column layouts, and born-analog documents captured in poor lighting conditions.
教师模型的选择
在构建时(2024年10月),我们评估了几种开源权重和API模型来标注我们的训练数据。我们的分析依赖于对一组布局中等复杂的PDF页面的线性化性能进行定性评估。在此阶段,我们通过视觉评估了模型在一组已知会导致传统PDF内容提取工具出问题的PDF文档上的输出,这些文档包含多种元素,如公式、表格、多列布局以及在光线较差条件下捕获的模拟文档。
Among possible options, we found GPT-4o, GPT-4o mini, Gemini 1.5, and Claude Sonnet 3.5 to have acceptable performance. Gemini was discarded because a high proportion of prompts returned RECITATION errors, meaning that the output was too similar to Gemini’s own training data . Ultimately, we chose gpt-4o-2024-08-06 due to its high performance and relatively low cost in batch mode. GPT-4o mini produced too many hallucinations, and Claude Sonnet 3.5 was found to be cost prohibitive.
在可选的选项中,我们发现 GPT-4o、GPT-4o mini、Gemini 1.5 和 Claude Sonnet 3.5 的表现较为理想。Gemini 被排除,因为很大比例的提示返回了 RECITATION 错误,意味着输出与其训练数据过于相似。最终,我们选择了 gpt-4o-2024-08-06,因为它在批量模式下的高性能和相对较低的成本。GPT-4o mini 产生了过多的幻觉,而 Claude Sonnet 3.5 的成本过高。
Choice of PDF tools olmOCR leverages two tools for PDF raster iz ation and metadata manipulation: Poppler (2005–2025) transforms pages in a PDF to images; PyPDF (2012–2025) extracts text blocks, images, and their positions as part of document-anchoring.
PDF工具的选择
olmOCR 利用两种工具进行 PDF 栅格化和元数据操作:Poppler (2005–2025) 将 PDF 页面转换为图像;PyPDF (2012–2025) 提取文本块、图像及其位置作为文档锚定的一部分。
Prompting strategy We prompt GPT-4o with the image of a PDF page. We render each page using Poppler’s pdftoppm tool, at a resolution such that its longest edge is 2048 pixels, the largest supported by the GPT-4o model at the time. We report the full prompt in Appendix A, as augmented by our document-anchoring technique. As mentioned in Section §2, we found that this significantly reduced hallucinations. In contrast, prompting with just the page image was prone to complete unfinished sentences, or to produce unfaithful output when the image data was ambiguous.
提示策略
我们使用 PDF 页面的图像来提示 GPT-4o。我们使用 Poppler 的 pdftoppm 工具渲染每个页面,分辨率使其最长边为 2048 像素,这是 GPT-4o 模型当时支持的最大值。我们在附录 A 中报告了完整的提示,并通过我们的文档锚定技术进行了增强。正如第 2 节所述,我们发现这显著减少了幻觉。相比之下,仅使用页面图像进行提示容易补全未完成的句子,或在图像数据不明确时产生不忠实的输出。
Finally, we instruct GPT-4o to respond with structured output to our requests. We report the full JSON schema in Appendix A. It forces the model to first extract page metadata, such as language, page orientation, and presence of tables, before moving onto outputting the text of the page in a natural reading order. We believe the order of the fields in the structured schema is helpful in improving output quality, because it forces the model to analyze the page as a whole first before moving on to extracting the text. The output schema encourages the model to return no text at all, if appropriate: this aspect is necessary to prevent GPT-4o from visually describing the content of a PDF in cases where no text is found on the page (e.g., the page contains just a photographic image or non-textual diagram).
最后,我们指示 GPT-4o 以结构化输出响应我们的请求。我们在附录 A 中报告了完整的 JSON 模式。它强制模型首先提取页面元数据,如语言、页面方向和表格的存在,然后以自然阅读顺序输出页面文本。我们相信结构化模式中的字段顺序有助于提高输出质量,因为它强制模型首先将页面作为一个整体进行分析,然后再进行文本提取。输出模式鼓励模型在适当的情况下不返回任何文本:这一方面是必要的,以防止 GPT-4o 在页面上没有找到文本的情况下(例如,页面仅包含摄影图像或非文本图表)对 PDF 内容进行视觉描述。
Table 1 Training set composition by source. Web crawled PDFs are sampled from a set of over $240~\mathrm{mil}$ - lion documents crawled from public websites. Books in the Internet Archive set are in the public domain.
表 1 按来源划分的训练集组成。从公共网站爬取的 PDF 文件样本来自超过 $240~\mathrm{mil}$ 份文档。Internet Archive 中的书籍属于公共领域。
| 来源 | 唯一文档数 | 总页数 |
|---|---|---|
| 网络爬取的 PDF | 99,903 | 249,332 |
| Internet Archive 书籍 | 5,601 | 16,803 |
| 总计 | 105,504 | 266,135 |
Table2 Web PDFs breakdown by document type. Distribution is estimating by sampling 707 pages, which are classified using gpt-4o-2024-11-20. Details of the prompt used in Appendix A.
表 2: 按文档类型划分的 Web PDFs 分类。分布情况通过采样 707 页进行估算,并使用 gpt-4o-2024-11-20 进行分类。使用的提示详细信息见附录 A。
| 文档类型 | 占比 |
|---|---|
| 学术 | 60% |
| 宣传册 | 12% |
| 法律 | 11% |
| 表格 | 6% |
| 图表 | 5% |
| 幻灯片 | 2% |
| 其他 | 4% |
Data acquisition and page sampling To generate the primary training dataset, we sample 100,000 PDFs from an internal dataset of 240 million PDFs crawled from public internet sites. Using the Lingua package (Emond, 2025), we identify and filter out documents that were not in English. Further, we remove any document that failed to be parsed by pypdf, contains spam keywords, is a fillable form, or whose text is too short . We then sampled at most 3 pages uniformly at random from each PDF. This resulted in approximately 249,332 PDF pages. We also sampled 5,601 PDFs from a dataset public domain scanned books from the Internet Archive, and processed it similarly. Unlike the web crawled set, PDFs in this collection consist of image scans of book pages, as opposed to born-digital documents. We summarize the data distribution in Tables 1 and 2.
数据采集与页面采样
为了生成主要训练数据集,我们从从公共互联网站点爬取的2.4亿个PDF文件的内部数据集中抽取了10万个PDF文件。使用Lingua包 (Emond, 2025),我们识别并过滤掉了非英文文档。此外,我们还移除了任何无法通过pypdf解析、包含垃圾关键词、是可填充表单或文本过短的文档。然后,我们从每个PDF中随机均匀采样最多3页。这产生了大约249,332个PDF页面。我们还从Internet Archive的公共领域扫描书籍数据集中抽取了5,601个PDF文件,并进行了类似的处理。与网络爬取的数据集不同,该集合中的PDF文件由书籍页面的图像扫描组成,而不是天生数字化的文档。我们在表1和表2中总结了数据分布。
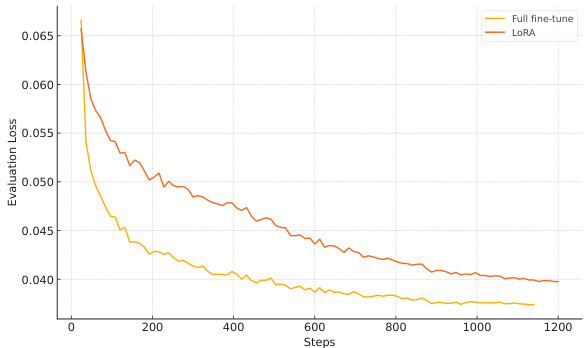
Figure 3 Validation Loss - Web PDFs
图 3: 验证损失 - Web PDFs
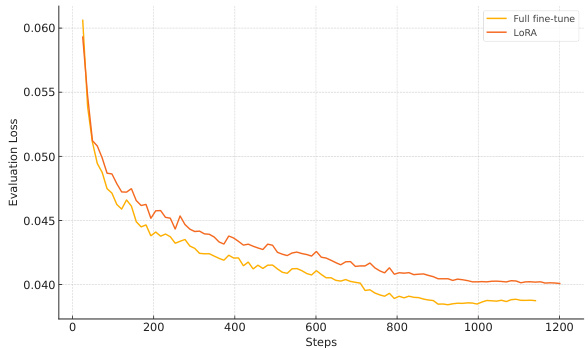
Figure 4 Validation Loss - Internet Archive Books
图 4: 验证损失 - Internet Archive Books
3.2 Model Training
3.2 模型训练
Fine-tuning olmOCR-7B-0225-preview is fine-tuned from a Qwen2-VL-7B-Instruct checkpoint. Training is implemented using Hugging Face’s transformers library (Wolf et al., 2020). Hyper parameters are set as follows: we use an effective batch size of 4 (batch size 1 with 4 gradient accumulation steps), a learning rate of $1e-6$ , AdamW optimizer, and a cosine annealing schedule for 10,000 steps (roughly 1.2 epochs). We use single node with 8 NVIDIA H100 GPUs. We experimented with both full fine-tuning as well as LoRA (Hu et al., 2021).
olmOCR-7B-0225-preview 是从 Qwen2-VL-7B-Instruct 检查点微调而来的。训练使用 Hugging Face 的 transformers 库 (Wolf et al., 2020) 实现。超参数设置如下:我们使用有效批大小为 4(批大小为 1,梯度累积步数为 4),学习率为 $1e-6$,AdamW 优化器,以及 10,000 步(大约 1.2 个 epoch)的余弦退火调度。我们使用单节点 8 个 NVIDIA H100 GPU 进行训练。我们尝试了全微调以及 LoRA (Hu et al., 2021) 两种方法。
Dataset formatting During fine-tuning, we slightly alter the prompt used for dataset labeling in Section §3.1. Namely, we remove some of the additional instructions from the prompt, and shrink the image size so that PDF pages get rendered to a maximum dimension of 1024 pixels on the longest edge. The simplified text prompt is listed in Appendix A. The prompt is capped to 6,000 characters, so a typical prompt uses about 1,000 tokens to encode a page image, 1,800 tokens for the anchor text, for about 3,000 total input tokens.
数据集格式化
在微调期间,我们对第3.1节中用于数据集标注的提示进行了一些调整。具体来说,我们删除了提示中的一些附加指令,并缩小了图像尺寸,使PDF页面的最长边渲染为最大1024像素。简化后的文本提示列在附录A中。提示被限制在6,000个字符内,因此一个典型的提示使用约1,000个Token来编码页面图像,1,800个Token用于锚文本,总共约3,000个输入Token。
We keep the same structured JSON output that was present in the outputs of olmOCR-mix-0225. Each training example was truncated to 8,192 tokens to cover cases when the prompt was unusually large, and the loss was masked so only the final response tokens participated in the loss calculation.
我们保持了与 olmOCR-mix-0225 输出中相同的结构化 JSON 格式。每个训练样本被截断至 8,192 个 Token,以应对提示(prompt)异常大的情况,并且损失被掩码,只有最终的响应 Token 参与损失计算。
To set hyper parameters and make other decisions during development, we relied on manual side-by-side evaluation as shown in Figure 5. A random selection of 20 to 50 documents were processed using two different methods, and were displayed side by side along with the render of the document page. We also open source our evaluation tool to support qualitative inspection of this visually-rich data.
在开发过程中,我们依靠手动并排评估来设置超参数并做出其他决策,如图 5 所示。使用两种不同方法随机处理 20 到 50 份文档,并并排显示文档页面的渲染结果。我们还开源了评估工具,以支持对这种视觉丰富的数据进行定性检查。
4 Deploying olmOCR
4 部署 olmOCR
4.1 Inference Pipeline
4.1 推理管道
To efficiently convert millions of documents, we develop the olmOCR pipeline using SGLang (Zheng et al., 2024) as the inference engine. The pipeline batches documents into work items of around 500 pages each. Each work item is then queued to run on a worker with access to a GPU for inference. Optionally, workers can coordinate using a shared cloud bucket6, allowing for batch jobs that scale from single nodes to hundreds of nodes without the need for complicated queue management.
为了高效转换数百万份文档,我们使用 SGLang (Zheng et al., 2024) 作为推理引擎开发了 olmOCR 管道。该管道将文档分批处理,每批约 500 页。然后将每个工作项排队,在具有 GPU 访问权限的工作节点上进行推理。可选地,工作节点可以通过共享的云存储桶6进行协调,从而实现从单节点扩展到数百节点的批处理作业,而无需复杂的队列管理。
To balance maintaining high GPU utilization while also ensuring work items are completed quickly, each worker queues up inference for all PDF pages in a work item simultaneously, and then waits until the SGLang server has no more pending requests before proceeding to another work item in the queue.
为了在保持高GPU利用率的同时确保工作项快速完成,每个工作器会同时将工作项中的所有PDF页面的推理任务加入队列,然后等待SGLang服务器没有更多待处理请求后再继续处理队列中的下一个工作项。

Figure 5 Example of side-by-side evaluation tool used during development. The software used to create these comparisons is released as open-source software as part of olmOCR. Table 3 Inference cost comparison against other OCR methods. A100 80GB Estimated at $\$1.89$ per hour, L40S Estimated at $\$0.79$ per hour, H100 80GB Estimated at $\$2.69$ per hour. Assuming $20%$ retries.
图 5: 开发过程中使用的并行评估工具示例。用于创建这些比较的软件已作为 olmOCR 的一部分发布为开源软件。表 3: 与其他 OCR 方法的推理成本比较。A100 80GB 每小时估计成本为 $\$1.89$,L40S 每小时估计成本为 $\$0.79$,H100 80GB 每小时估计成本为 $\$2.69$。假设有 $20%$ 的重试率。
| 模型 | 硬件 | Tokens/秒 | 页数/美元 | 每百万页成本 |
|---|---|---|---|---|
| GPT-40 | API | 80 | $12,480 | |
| GPT-40 | Batch | 160 | $6,240 | |
| marker | API | - | 800 | $1,250 |
| MinerU | L40s | 238 | 1678 | $596 |
| OLMOCR | A100 80GB | 1,487 | 3,700 | $270 |
| OLMOCR | L40S | 906 | 5,200 | $190 |
| OLMOCR | H100 80GB | 3,050 | 5,200 | $190 |
We summarize our efforts by comparing operational costs of olmOCR against other API and local models in Table 3. Overall, we find olmOCR to be significantly more efficient than other pipelines. It is over 32 times cheaper than GPT-4o in batch mode; compared to other purposed-built pipelines and models, olmOCR is over 6 times cheaper than MinerU, and $1/3^{r d}$ of the cost of marker.
我们在表 3 中通过比较 olmOCR 与其他 API 和本地模型的操作成本来总结我们的工作。总体而言,我们发现 olmOCR 比其他流程效率更高。它在批处理模式下比 GPT-4o 便宜超过 32 倍;与其他专用流程和模型相比,olmOCR 比 MinerU 便宜超过 6 倍,并且是 marker 成本的 $1/3^{r d}$。
4.2 Increasing Robustness
4.2 增强鲁棒性
We implement several heuristics to improve reliability of olmOCR without compromising its throughput.
我们实现了多种启发式方法来提高olmOCR的可靠性,同时不影响其吞吐量。
Prompt format During inference, we use the same abbreviated prompt described in Section §3.2. This keeps the test time examples looking the same as what the model was trained on. If the additional tokens generated by document-anchoring cause the overall prompt to exceed 8,192 tokens, then we continue regenerating the document-anchoring tokens with exponentially lower character limits until the overall prompt is of acceptable length.
提示格式
在推理过程中,我们使用与第3.2节中描述的相同缩写提示。这确保测试时的示例与模型训练时的示例保持一致。如果文档锚定生成的额外Token导致整体提示超过8,192个Token,则我们继续以指数级降低的字符限制重新生成文档锚定Token,直到整体提示达到可接受的长度。
Retries Unlike when we created olmOCR-mix-0225, we do not enforce a specific JSON schema during inference on our fine-tuned model. This is for two reasons: first, we find that open source tools designed to force decode a sequence into a particular schema are unreliable, and that enforcing a schema which is even slightly off from what the model expects can cause generations to go out-of-domain or collapse into repetitions. Second, and most importantly, we note that, since the model was extensively fine-tuned on the structured output, it reliably adheres to the required schema without constraints. For the rare cases when JSON parsing fails, we simply retry generating from the same input sequence.
重试
与创建 olmOCR-mix-0225 时不同,我们在微调模型的推理过程中并不强制执行特定的 JSON 模式。这有两个原因:首先,我们发现那些旨在强制将序列解码为特定模式的开源工具并不可靠,而且强制执行与模型预期略有偏差的模式可能导致生成结果超出领域或陷入重复。其次,也是最重要的,我们注意到,由于模型在结构化输出上进行了广泛微调,它能够可靠地遵循所需的模式而无需约束。对于 JSON 解析失败的罕见情况,我们只需从相同的输入序列重新生成即可。
Rotations The output JSON schema includes fields for is rotation valid and rotation correction. During inference, olmOCR pipeline reads these two fields and if is rotation valid is set to true it will rotate the page by the amount specified in rotation correction and reprocess the page.
旋转 输出 JSON 结构包含 is rotation valid 和 rotation correction 字段。在推理过程中,olmOCR 管道会读取这两个字段,如果 is rotation valid 设置为 true,则会根据 rotation correction 中指定的角度旋转页面并重新处理页面。
Decoding In developing olmOCR, the most common failure we experience is outputs degenerating into endless repetitions of the same token, line, or paragraph. This failure is caught automatically when the model’s output either exceeds the maximum context length, or does not validate against our JSON schema. We find that increasing generation temperature from $\tau=0.1$ up to $\tau=0.8$ reduces the likelihood of repetitions occurring. Further, we modify olmOCR to reprocess failed pages up to N times, falling back to a plain text-based PDF extraction if the pipeline repeatedly fails. This last mitigation is aided by the fact that document-anchoring randomly samples which anchors to include in the prompt; thus, resampling can sometimes help the page process correctly by removing potentially problematic meta tokens.
解码
在开发 olmOCR 时,我们遇到的最常见故障是输出退化为相同 Token、行或段落的无限重复。当模型的输出超过最大上下文长度或无法通过我们的 JSON 模式验证时,此故障会自动捕获。我们发现,将生成温度从 $\tau=0.1$ 提高到 $\tau=0.8$ 可以减少重复发生的可能性。此外,我们修改了 olmOCR,使其最多可重新处理失败的页面 N 次,如果管道反复失败,则回退到基于纯文本的 PDF 提取。最后一项缓解措施得益于文档锚定随机采样提示中包含的锚点;因此,重新采样有时可以通过删除可能有问题的元 Token 来帮助页面正确处理。
We note that one one limitation of this approach is that, if retries occur often, the total generation throughput could be significantly reduced. Further, letting generations repeat up to maximum sequence length uses significant memory within SGLang. In future work, we plan to detect repeated generations sooner than at the maximum context length limit, and abort promptly.
我们注意到这种方法的一个局限是,如果重试频繁发生,总生成吞吐量可能会显著降低。此外,让生成重复到最大序列长度会在SGLang中使用大量内存。在未来的工作中,我们计划在达到最大上下文长度限制之前更早地检测到重复生成,并及时中止。
5 Evaluating olmOCR
5 评估 olmOCR
We conduct three evaluations for olmOCR. First, we study how faithful olmOCR is to its teacher model (Section §5.1). Then, we compare olmOCR to other PDF text extraction systems through pairwise comparisons of their outputs (Section §5.2). Finally, we quantify the usefulness olmOCR for language modeling by continued pre training on an OLMo 2 checkpoint (OLMo et al., 2024) on content extracted and linearized with our toolkit (Section §5.3).
我们对 olmOCR 进行了三项评估。首先,我们研究了 olmOCR 对其教师模型的忠实度(第 5.1 节)。然后,我们通过对其输出进行两两比较,将 olmOCR 与其他 PDF 文本提取系统进行比较(第 5.2 节)。最后,我们通过在 OLMo 2 检查点(OLMo 等,2024)上使用我们的工具包提取和线性化的内容进行继续预训练,量化了 olmOCR 对语言建模的有用性(第 5.3 节)。
5.1 Alignment with Teacher Model
5.1 与教师模型的对齐
To compare the output of olmOCR-7B-0225-preview to the GPT-4o silver data in olmOCR-mix-0225, we build a document similarity metric which splits a document into words, uses Hirschberg’s algorithm to align those words, and counts what proportion match.
为了比较 olmOCR-7B-0225-preview 的输出与 olmOCR-mix-0225 中的 GPT-4o 参考数据,我们构建了一个文档相似度指标,该指标将文档拆分为单词,使用 Hirschberg 算法对这些单词进行对齐,并计算匹配的比例。
We report alignment scores in Table 4. Overall, we find that olmOCR-7B-0225-preview has good alignment, 0.875 on average, with its teacher model. To calibrate this result, we also report GPT-4o self-alignment score of 0.954, which is simply from calling the model again; imperfect alignment here is due to resampling differences. In fact, we find that our model actually better mimics the content extraction and linear iz ation of GPT-4o than its smaller counterpart GPT-4o mini.
我们在表 4 中报告了对齐分数。总体而言,我们发现 olmOCR-7B-0225-preview 与其教师模型具有良好的对齐性,平均为 0.875。为了校准这一结果,我们还报告了 GPT-4o 的自对齐分数为 0.954,这仅仅是通过再次调用模型得出的;这里的不完美对齐是由于重采样差异造成的。事实上,我们发现我们的模型在内容提取和线性化方面比其较小的对应物 GPT-4o mini 更好地模仿了 GPT-4o。
When partitioning scores in low, medium, and high alignment buckets (Table 5), we find that most documents parsed with olmOCR have medium to high alignment with GPT-4o. Increasing temperature un surprisingly leads to a wider distribution of alignment scores, as noted by the increase of low matches for $\tau=0.8$ .
当将分数划分为低、中、高对齐区间时(表 5),我们发现大多数使用 olmOCR 解析的文档与 GPT-4o 具有中到高的对齐度。不出所料,增加温度值会导致对齐分数的分布更广,如 $\tau=0.8$ 时低匹配数量的增加所示。
5.2 Intrinsic Human Evaluation
5.2 内在人类评估
Experimental setup To compare olmOCR against other common OCR methods, we collected pairwise human judgments of plain text produced by the three top ML-based PDF linear iz ation tools—Marker, MinerU, and GOT-OCR 2.0—and calculating ELO ratings.
实验设置
为了比较 olmOCR 与其他常见的 OCR 方法,我们收集了由三种顶尖基于机器学习的 PDF 线性化工具(Marker、MinerU 和 GOT-OCR 2.0)生成的纯文本的成对人类判断,并计算了 ELO 评分。
To create our evaluation set, we sample 2,017 new PDFs from the same distribution as used to create olmOCR-mix-0225 and run each PDF through olmOCR and the linear iz ation tools mentioned above. All
为了创建我们的评估集,我们从与创建 olmOCR-mix-0225 相同的分布中抽取了 2,017 个新的 PDF 文件,并通过 olmOCR 和上述的线性化工具处理每个 PDF。
| 模型 | 温度 T | 对齐度 |
|---|---|---|
| GPT-4o (自我对齐) | 0.1 | 0.954 |
| GPT-4o mini | 0.1 | 0.833 |
| OLMOCR | 0.8 | 0.859 |
| OLMOCR | 0.1 | 0.875 |
Table 4 Page-weighted alignment between GPT-4o, GPT-4o mini, and our fine-tuned model. We find that olmOCR-7B-0225-preview is more consistent with respect to its teacher than GPT-4o mini. Note that GPT-4o does not achieves a perfect alignment against itself due to the probabilistic nature of auto regressive decoding.
表 4: GPT-4o、GPT-4o mini 与我们的微调模型之间的页面加权对齐度。我们发现 olmOCR-7B-0225-preview 在其教师模型方面比 GPT-4o mini 更加一致。需要注意的是,由于自回归解码的概率性,GPT-4o 无法与自身实现完美对齐。
| 名称 | 低匹配 | 中匹配 | 高匹配 |
|---|---|---|---|
| GPT-4o (自我对齐) | 38 | 218 | 965 |
| GPT-4o mini | 214 | 478 | 529 |
| OLMOCR ( = 0.1) | 158 | 363 | 700 |
| OLMOCR (T = 0.8) | 195 | 390 | 636 |
Table 5 Match-up between olmOCR and different models compared to the olmOCR-mix-0225 dataset. Low match indicates $<70%$ alignment, Medium match is $70-95%$ alignment, High match is ${>}95%$ alignment.
表 5: olmOCR 与不同模型在 olmOCR-mix-0225 数据集上的匹配情况。低匹配表示 $<70%$ 的对齐,中匹配表示 $70-95%$ 的对齐,高匹配表示 ${>}95%$ 的对齐。
other linear iz ation tools were installed from either PyPI or Github according to their publicly available instructions as of January 14th, 2025. GOT-OCR 2.0 was configured in “format” mode, but otherwise all comparisons were done against default settings.
其他线性化工具根据截至2025年1月14日的公开说明,从PyPI或Github安装。GOT-OCR 2.0配置为“format”模式,但除此之外,所有比较均基于默认设置。
We then sampled 2,000 comparison pairs (same PDF, different tool). We asked 11 data researchers and engineers at Ai2 to assess which output was the higher quality representation of the original PDF, focusing on reading order, comprehensiveness of content and representation of structured information. The user interface used is similar to that in Figure 5. Exact participant instructions are listed in Appendix B.
我们随后抽取了 2,000 个对比对(相同的 PDF,不同的工具)。我们请 Ai2 的 11 位数据研究人员和工程师评估哪个输出更高质量地代表了原始 PDF,重点关注阅读顺序、内容的完整性以及结构化信息的呈现。用户界面与图 5 中的界面类似。详细的参与者说明列在附录 B 中。
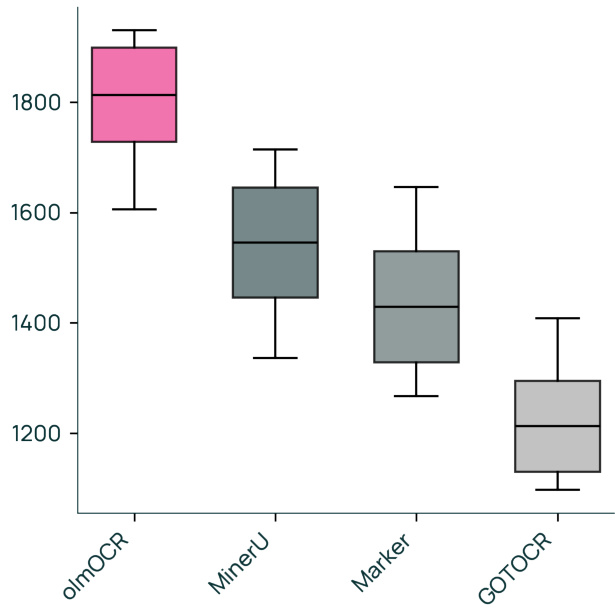
Figure 6 ELO ranking of olmOCR vs other popular PDF content extraction tools.
图 6: olmOCR 与其他流行的 PDF 内容提取工具的 ELO 排名。
Evaluation results We collected a total of 452 judgments where a participant expressed a preference between two models (the remaining 1,548 pairs were either skipped for being too similar, or marked as invalid). On average, this is 75 judgments per pair of tools. We calculate ELO ratings starting from a base of 1500 and report the average of 100 simulations to avoid ordering effects in ELO calculations; for 95% confidence intervals, we use boots trapping with 5000 resamples.
评估结果 我们总共收集了452条判断,其中参与者对两个模型表达了偏好(剩余的1548对要么因为太相似而被跳过,要么被标记为无效)。平均而言,每对工具有75条判断。我们从1500的基础分开始计算ELO评分,并报告100次模拟的平均值,以避免ELO计算中的顺序效应;对于95%的置信区间,我们使用5000次重采样的自助法。
We visualize our results in Figure 6. olmOCR achieves an ELO score over 1800, far exceeding all other PDF linear iz ation tools.
我们在图 6 中展示了我们的结果。olmOCR 的 ELO 分数超过 1800,远远超过了其他所有 PDF 线性化工具。
5.3 Downstream Evaluation
5.3 下游评估
Experimental setup To assess the impact of improved PDF linear iz ation, we experiment using the pre-midtraining checkpoint of OLMo-2-1124-7B and perform mid-training (that is, continued pre training while linearly decaying learning rate to zero) using content extracted from the same PDFs but with different linear iz ation tools. This procedure for assessing the quality of new data sources was introduced as domain upsampling in Blakeney et al. (2024), annealing in Gr atta fiori et al. (2024), and micro-annealing in OLMo et al. (2024).
实验设置
为了评估改进的PDF线性化的影响,我们使用OLMo-2-1124-7B的训练中期检查点进行实验,并通过从相同PDF中提取但使用不同线性化工具的内容进行中期训练(即在预训练过程中线性衰减学习率至零)。这种评估新数据源质量的方法在Blakeney等(2024)中被称为领域上采样,在Grattafiori等(2024)中被称为退火,在OLMo等(2024)中被称为微退火。
For our baseline, we use PDF extracted tokens from peS2o (Soldaini and Lo, 2023), a collection of over 58B tokens extracted from academic PDFs which were derived using Grobid in S2ORC (Lo et al., 2020) and further cleaned with heuristics for language modeling. To represent olmOCR, we identify the same documents used in peS2o, acquire their source PDFs from the upstream S2ORC pipeline, and reprocess them using olmOCR. For both of these, we perform 50B tokens worth of mid-training.
我们使用从 peS2o (Soldaini and Lo, 2023) 提取的 PDF token 作为基线,这些 token 是从学术 PDF 中提取的超过 580 亿个 token 的集合,这些 PDF 是通过 S2ORC (Lo et al., 2020) 中的 Grobid 获取的,并进一步通过启发式方法清理以用于语言建模。为了表示 olmOCR,我们识别出 peS2o 中使用的相同文档,从上游的 S2ORC 管道中获取它们的源 PDF,并使用 olmOCR 重新处理它们。对于这两种方法,我们进行了 500 亿个 token 的中期训练。
| PeS2oversion | Average | MMLU | ARCC | DROP | HSwag | NQ | WinoG |
|---|---|---|---|---|---|---|---|
| Grobid + rules (Soldaini and Lo, 2023) | 53.9 | 61.1 | 75.0 | 42.3 | 57.4 | 29.4 | 58.3 |
| OLMOCR | 55.2 | 61.1 | 76.4 | 43.7 | 62.6 | 29.1 | 58.0 |
Table 6 Comparison on OLMo et al. (2024) downstream evaluation tasks of OLMo-2-7B-1124 on 50B of original peS2o tokens vs 50B tokens from the same source PDFs but processed with olmOCR.
表 6: OLMo-2-7B-1124 在处理 50B 原始 peS2o Token 和经过 olmOCR 处理的同源 PDF 50B Token 的下游评估任务对比
Evaluation results We use the same downstream evaluation setup as in OLMo et al. (2024); results are in Table 6. Overall, we see an improvement in $+1.3$ percentage points on average across a number of core benchmark tasks, which most performance improvements in ARC Challenge and DROP.
评估结果
我们使用与OLMo等 (2024) 相同的下游评估设置;结果如表6所示。总体而言,我们在多个核心基准任务上平均提高了$+1.3$个百分点,其中ARC Challenge和DROP的性能提升最为显著。
6 Conclusion
6 结论
We introduce olmOCR, an open-source toolkit for converting PDF documents into clean plain text. Our approach combines document-anchoring, a novel prompting technique that leverages available metadata in born-digital PDFs, with a fine-tuned 7B parameter vision language model to achieve results competitive with closed commercial solutions at a fraction of the cost. Our efficient inference pipeline which ships as part of this release contains everything needed to start converting anything from single documents to million-page archives of PDFs. We hope olmOCR’s ability to efficiently process millions of documents will help unlock new sources of training data for language models, particularly from high-quality PDF documents that are currently underrepresented in existing datasets that rely heavily solely on crawled web pages.
我们介绍 olmOCR,一个将PDF文档转换为干净纯文本的开源工具包。我们的方法结合了文档锚定(document-anchoring)——一种利用原生数字PDF中的可用元数据的新型提示技术——以及一个经过微调的7B参数视觉语言模型,以较低的成本实现与封闭商业解决方案相媲美的结果。我们在此版本中提供的高效推理管道包含了从单个文档到百万页PDF档案转换所需的一切。我们希望 olmOCR 能够高效处理数百万份文档的能力,将有助于解锁新的语言模型训练数据来源,尤其是那些目前仅依赖爬取网页的现有数据集中代表性不足的高质量PDF文档。
Acknowledgments
致谢
This work would not be possible without the support of our colleagues at Ai2. We thank:
感谢 Ai2 同事们的支持。我们特别感谢:
We also thank Benjamin Charles Germain Lee for helpful feedback and suggestions around evaluation and potential use cases.
我们也感谢 Benjamin Charles Germain Lee 在评估和潜在用例方面提供的宝贵反馈和建议。
References
参考文献
GROBID. https://github.com/kermitt2/grobid, 2008–2025.
GROBID. https://github.com/kermitt2/grobid, 2008–2025.
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL technical report. arXiv [cs.CV], February 2025.
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL 技术报告. arXiv [cs.CV], 2025年2月.
Cody Blakeney, Mansheej Paul, Brett W. Larsen, Sean Owen, and Jonathan Frankle. Does your data spark joy? performance gains from domain upsampling at the end of training, 2024. https://arxiv.org/abs/2406.03476. ukas Blecher, Guillem Cucurull, Thomas Scialom, and Robert Stojnic. Nougat: Neural optical understanding for academic documents, 2023. https://arxiv.org/abs/2308.13418. atrick Emond. Lingua-py: Natural language detection for python, 2025. https://github.com/pemistahl/lingua-py. Accessed: 2025-01-06. oogle. Explore document processing capabilities with the gemini API. https://web.archive.org/web/ 20250224064040/https://ai.google.dev/gemini-api/docs/document-processing?lang=python, 2025. Accessed: 2025-2-23. aron Gr atta fiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathurx, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sra van kumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Bethany Biron, Binh Tang, Bobbie Chern, Charlotte Caucheteux, Chaya Nayak, Chloe Bi, Chris Marra, Chris McConnell, Christian Keller, Christophe Touret, Chunyang Wu, Corinne Wong, Cristian Canton Ferrer, Cyrus Nikolaidis, Damien Allonsius, Daniel Song, Danielle Pintz, Danny Livshits, Danny Wyatt, David Esiobu, Dhruv Choudhary, Dhruv Mahajan, Diego Garcia-Olano, Diego Perino, Dieuwke Hupkes, Egor Lakomkin, Ehab AlBadawy, Elina Lobanova, Emily Dinan, Eric Michael Smith, Filip Radenovic, Francisco Guzmán, Frank Zhang, Gabriel Synnaeve, Gabrielle Lee, Georgia Lewis Anderson, Govind Thattai, Graeme Nail, Gregoire Mialon, Guan Pang, Guillem Cucurell, Hailey Nguyen, Hannah Korevaar, Hu Xu, Hugo Touvron, Iliyan Zarov, Imanol Arrieta Ibarra, Isabel Kloumann, Ishan Misra, Ivan Evtimov, Jack Zhang, Jade Copet, Jaewon Lee, Jan Geffert, Jana Vranes, Jason Park, Jay Mahadeokar, Jeet Shah, Jelmer van der Linde, Jennifer Billock, Jenny Hong, Jenya Lee, Jeremy Fu, Jianfeng Chi, Jianyu Huang, Jiawen Liu, Jie Wang, Jiecao Yu, Joanna Bitton, Joe Spisak, Jongsoo Park, Joseph Rocca, Joshua Johnstun, Joshua Saxe, Junteng Jia, Kalyan Vasuden Alwala, Karthik Prasad, Kartikeya Upasani, Kate Plawiak, Ke Li, Kenneth Heafield, Kevin Stone, Khalid El-Arini, Krithika Iyer, Kshitiz Malik, Kuenley Chiu, Kunal Bhalla, Kushal Lakhotia, Lauren Rantala-Yeary, Laurens van der Maaten, Lawrence Chen, Liang Tan, Liz Jenkins, Louis Martin, Lovish Madaan, Lubo Malo, Lukas Blecher, Lukas Landzaat, Luke de Oliveira, Madeline Muzzi, Mahesh Pasupuleti, Mannat Singh, Manohar Paluri, Marcin Kardas, Maria Tsim po uk ell i, Mathew Oldham, Mathieu Rita, Maya Pavlova, Melanie Kambadur, Mike Lewis, Min Si, Mitesh Kumar Singh, Mona Hassan, Naman Goyal, Narjes Torabi, Nikolay Bashlykov, Nikolay Bogoychev, Niladri Chatterji, Ning Zhang, Olivier Duchenne, Onur Çelebi, Patrick Alrassy, Pengchuan Zhang, Pengwei Li, Petar Vasic, Peter Weng, Prajjwal Bhargava, Pratik Dubal, Praveen Krishnan, Punit Singh Koura, Puxin Xu, Qing He, Qingxiao Dong, Ragavan Srinivasan, Raj Ganapathy, Ramon Calderer, Ricardo Silveira Cabral, Robert Stojnic, Roberta Raileanu, Rohan Maheswari, Rohit Girdhar, Rohit Patel, Romain Sauvestre, Ronnie Polidoro, Roshan Sumbaly, Ross Taylor, Ruan Silva, Rui Hou, Rui Wang, Saghar Hosseini, Sahana Chen nab as appa, Sanjay Singh, Sean Bell, Seohyun Sonia Kim, Sergey Edunov, Shaoliang Nie, Sharan Narang, Sharath Raparthy, Sheng Shen, Shengye Wan, Shruti Bhosale, Shun Zhang, Simon Vanden he nde, Soumya Batra, Spencer Whitman, Sten Sootla, Stephane Collot, Suchin Gururangan, Sydney Borodinsky, Tamar Herman, Tara Fowler, Tarek Sheasha, Thomas Georgiou, Thomas Scialom, Tobias Speck bac her, Todor Mihaylov, Tong Xiao, Ujjwal Karn, Vedanuj Goswami, Vibhor Gupta, Vignesh Ramanathan, Viktor Kerkez, Vincent Gonguet, Virginie Do, Vish Vogeti, Vítor Albiero, Vladan Petrovic, Weiwei Chu, Wenhan Xiong, Wenyin Fu, Whitney Meers, Xavier Martinet, Xiaodong Wang, Xiaofang Wang, Xiaoqing Ellen Tan, Xide Xia, Xinfeng Xie, Xuchao Jia, Xuewei Wang, Yaelle Goldschlag, Yashesh Gaur, Yasmine Babaei, Yi Wen, Yiwen Song, Yuchen Zhang, Yue Li, Yuning Mao, Zacharie Delpierre Coudert, Zheng Yan, Zhengxing Chen, Zoe Papakipos, Aaditya Singh, Aayushi Srivastava, Abha Jain, Adam Kelsey, Adam Shajnfeld, Adithya Gangidi, Adolfo Victoria, Ahuva Goldstand, Ajay Menon, Ajay Sharma, Alex Boesenberg, Alexei Baevski, Allie Feinstein, Amanda Kallet, Amit Sangani, Amos Teo, Anam Yunus, Andrei Lupu, Andres Alvarado, Andrew Caples, Andrew Gu, Andrew Ho, Andrew Poulton, Andrew Ryan, Ankit Ram chan dani, Annie Dong, Annie Franco, Anuj Goyal, Aparajita Saraf, Arkabandhu Chowdhury, Ashley Gabriel, Ashwin Bharambe, Assaf Eisenman, Azadeh Yazdan, Beau James, Ben Maurer, Benjamin Leonhardi, Bernie Huang, Beth Loyd, Beto De Paola, Bhargavi Paranjape, Bing Liu, Bo Wu, Boyu Ni, Braden Hancock, Bram Wasti, Brandon Spence, Brani Stojkovic, Brian
Cody Blakeney, Mansheej Paul, Brett W. Larsen, Sean Owen, 和 Jonathan Frankle. 你的数据带来快乐吗?训练结束时的领域上采样性能提升, 2024. https://arxiv.org/abs/2406.03476.
Lukas Blecher, Guillem Cucurull, Thomas Scialom, 和 Robert Stojnic. Nougat: 学术文档的神经光学理解, 2023. https://arxiv.org/abs/2308.13418.
Patrick Emond. Lingua-py: Python语言的自然语言检测, 2025. https://github.com/pemistahl/lingua-py. 访问时间: 2025-01-06.
Google. 使用Gemini API探索文档处理能力. https://web.archive.org/web/20250224064040/https://ai.google.dev/gemini-api/docs/document-processing?lang=python, 2025. 访问时间: 2025-2-23.
Gamido, Britt Montalvo, Carl Parker, Carly Burton, Catalina Mejia, Ce Liu, Changhan Wang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tindal, Christoph Fei chten hofer, Cynthia Gao, Damon Civin, Dana Beaty, Daniel Kreymer, Daniel Li, David Adkins, David Xu, Davide Testuggine, Delia David, Devi Parikh, Diana Liskovich, Didem Foss, Dingkang Wang, Duc Le, Dustin Holland, Edward Dowling, Eissa Jamil, Elaine Montgomery, Eleonora Presani, Emily Hahn, Emily Wood, Eric-Tuan Le, Erik Brinkman, Esteban Arcaute, Evan Dunbar, Evan Smothers, Fei Sun, Felix Kreuk, Feng Tian, Filippos Kokkinos, Firat Ozgenel, Francesco Caggioni, Frank Kanayet, Frank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer, Georgia Swee, Gil Halpern, Grant Herman, Grigory Sizov, Guangyi, Zhang, Guna Lakshmi narayan an, Hakan Inan, Hamid Sho jan azeri, Han Zou, Hannah Wang, Hanwen Zha, Haroun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Hongyuan Zhan, Ibrahim Damlaj, Igor Molybog, Igor Tufanov, Ilias Leontiadis, Irina-Elena Veliche, Itai Gat, Jake Weissman, James Geboski, James Kohli, Janice Lam, Japhet Asher, Jean-Baptiste Gaya, Jeff Marcus, Jeff Tang, Jennifer Chan, Jenny Zhen, Jeremy Rei zen stein, Jeremy Teboul, Jessica Zhong, Jian Jin, Jingyi Yang, Joe Cummings, Jon Carvill, Jon Shepard, Jonathan McPhie, Jonathan Torres, Josh Ginsburg, Junjie Wang, Kai Wu, Kam Hou U, Karan Saxena, Kartikay Khandelwal, Katayoun Zand, Kathy Matosich, Kaushik Veera r agha van, Kelly Michelena, Keqian Li, Kiran Jagadeesh, Kun Huang, Kunal Chawla, Kyle Huang, Lailin Chen, Lakshya Garg, Lavender A, Leandro Silva, Lee Bell, Lei Zhang, Liangpeng Guo, Licheng Yu, Liron Moshkovich, Luca Wehrstedt, Madian Khabsa, Manav Avalani, Manish Bhatt, Martynas Mankus, Matan Hasson, Matthew Lennie, Matthias Reso, Maxim Groshev, Maxim Naumov, Maya Lathi, Meghan Keneally, Miao Liu, Michael L. Seltzer, Michal Valko, Michelle Restrepo, Mihir Patel, Mik Vyatskov, Mikayel Samvelyan, Mike Clark, Mike Macey, Mike Wang, Miquel Jubert Hermoso, Mo Metanat, Mohammad Rastegari, Munish Bansal, Nandhini Santhanam, Natascha Parks, Natasha White, Navyata Bawa, Nayan Singhal, Nick Egebo, Nicolas Usunier, Nikhil Mehta, Nikolay Pavlovich Laptev, Ning Dong, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar, Ozlem Kalinli, Parkin Kent, Parth Parekh, Paul Saab, Pavan Balaji, Pedro Rittner, Philip Bontrager, Pierre Roux, Piotr Dollar, Polina Zvyagina, Prashant Rat an chan dani, Pritish Yuvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Rafi Ayub, Raghotham Murthy, Raghu Nayani, Rahul Mitra, Rang a prabhu Part has ara thy, Raymond Li, Rebekkah Hogan, Robin Battey, Rocky Wang, Russ Howes, Ruty Rinott, Sachin Mehta, Sachin Siby, Sai Jayesh Bondu, Samyak Datta, Sara Chugh, Sara Hunt, Sargun Dhillon, Sasha Sidorov, Satadru Pan, Saurabh Mahajan, Saurabh Verma, Seiji Yamamoto, Sharadh Ramaswamy, Shaun Lindsay, Shaun Lindsay, Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shishir Patil, Shiva Shankar, Shuqiang Zhang, Shuqiang Zhang, Sinong Wang, Sneha Agarwal, Soji Sajuyigbe, Soumith Chintala, Stephanie Max, Stephen Chen, Steve Kehoe, Steve S a tter field, Sudarshan Govinda prasad, Sumit Gupta, Summer Deng, Sungmin Cho, Sunny Virk, Suraj Subramania n, Sy Choudhury, Sydney Goldman, Tal Remez, Tamar Glaser, Tamara Best, Thilo Koehler, Thomas Robinson, Tianhe Li, Tianjun Zhang, Tim Matthews, Timothy Chou, Tzook Shaked, Varun Vontimitta, Victoria Ajayi, Victoria Montanez, Vijai Mohan, Vinay Satish Kumar, Vishal Mangla, Vlad Ionescu, Vlad Poenaru, Vlad Tiberiu Mihailescu, Vladimir Ivanov, Wei Li, Wenchen Wang, Wenwen Jiang, Wes Bouaziz, Will Constable, Xiaocheng Tang, Xiaojian Wu, Xiaolan Wang, Xilun Wu, Xinbo Gao, Yaniv Kleinman, Yanjun Chen, Ye Hu, Ye Jia, Ye Qi, Yenda Li, Yilin Zhang, Ying Zhang, Yossi Adi, Youngjin Nam, Yu, Wang, Yu Zhao, Yuchen Hao, Yundi Qian, Yunlu Li, Yuzi He, Zach Rait, Zachary DeVito, Zef Rosnbrick, Zhaoduo Wen, Zhenyu Yang, Zhiwei Zhao, and Zhiyu Ma. The llama 3 herd of models, 2024. https://arxiv.org/abs/2407.21783. John Gruber. Markdown. https://daring fireball.net/projects/markdown/, 2004. Accessed: 2025-2-23. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. https://arxiv.org/abs/2106.09685. Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. In European Conference on Computer Vision, 2021. https://api.semantic scholar.org/CorpusID:250924870. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with paged attention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Mu en nigh off, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardner, Maciej Kilian, Hanlin Zhang, Rulin Shao, Sarah Pratt, Sunny Sanyal, Gabriel Ilharco, Giannis Daras, Kalyani Marathe, Aaron Gokaslan, Jieyu Zhang, Khyathi Chandu, Thao Nguyen, Igor Vasiljevic, Sham Kakade, Shuran Song, Sujay Sanghavi, Fartash Faghri, Sewoong Oh, Luke Z ett le moyer, Kyle Lo, Alaaeldin El-Nouby, Hadi Pouransari, Alexander Toshev, Stephanie Wang, Dirk Groeneveld, Luca Soldaini, Pang Wei Koh, Jenia Jitsev, Thomas Kollar, Alexandros G Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt, and Vaishaal Shankar. DataComp-LM: In search of the next generation of training sets for language models. arXiv [cs.LG], June 2024.
Gamido, Britt Montalvo, Carl Parker, Carly Burton, Catalina Mejia, Ce Liu, Changhan Wang, Changkyu Kim, Chao Zhou, Chester Hu, Ching-Hsiang Chu, Chris Cai, Chris Tindal, Christoph Feichtenhofer, Cynthia Gao, Damon Civin, Dana Beaty, Daniel Kreymer, Daniel Li, David Adkins, David Xu, Davide Testuggine, Delia David, Devi Parikh, Diana Liskovich, Didem Foss, Dingkang Wang, Duc Le, Dustin Holland, Edward Dowling, Eissa Jamil, Elaine Montgomery, Eleonora Presani, Emily Hahn, Emily Wood, Eric-Tuan Le, Erik Brinkman, Esteban Arcaute, Evan Dunbar, Evan Smothers, Fei Sun, Felix Kreuk, Feng Tian, Filippos Kokkinos, Firat Ozgenel, Francesco Caggioni, Frank Kanayet, Frank Seide, Gabriela Medina Florez, Gabriella Schwarz, Gada Badeer, Georgia Swee, Gil Halpern, Grant Herman, Grigory Sizov, Guangyi Zhang, Guna Lakshminarayanan, Hakan Inan, Hamid Shojanazeri, Han Zou, Hannah Wang, Hanwen Zha, Haroun Habeeb, Harrison Rudolph, Helen Suk, Henry Aspegren, Hunter Goldman, Hongyuan Zhan, Ibrahim Damlaj, Igor Molybog, Igor Tufanov, Ilias Leontiadis, Irina-Elena Veliche, Itai Gat, Jake Weissman, James Geboski, James Kohli, Janice Lam, Japhet Asher, Jean-Baptiste Gaya, Jeff Marcus, Jeff Tang, Jennifer Chan, Jenny Zhen, Jeremy Reizenstein, Jeremy Teboul, Jessica Zhong, Jian Jin, Jingyi Yang, Joe Cummings, Jon Carvill, Jon Shepard, Jonathan McPhie, Jonathan Torres, Josh Ginsburg, Junjie Wang, Kai Wu, Kam Hou U, Karan Saxena, Kartikay Khandelwal, Katayoun Zand, Kathy Matosich, Kaushik Veeraraghavan, Kelly Michelena, Keqian Li, Kiran Jagadeesh, Kun Huang, Kunal Chawla, Kyle Huang, Lailin Chen, Lakshya Garg, Lavender A, Leandro Silva, Lee Bell, Lei Zhang, Liangpeng Guo, Licheng Yu, Liron Moshkovich, Luca Wehrstedt, Madian Khabsa, Manav Avalani, Manish Bhatt, Martynas Mankus, Matan Hasson, Matthew Lennie, Matthias Reso, Maxim Groshev, Maxim Naumov, Maya Lathi, Meghan Keneally, Miao Liu, Michael L. Seltzer, Michal Valko, Michelle Restrepo, Mihir Patel, Mik Vyatskov, Mikayel Samvelyan, Mike Clark, Mike Macey, Mike Wang, Miquel Jubert Hermoso, Mo Metanat, Mohammad Rastegari, Munish Bansal, Nandhini Santhanam, Natascha Parks, Natasha White, Navyata Bawa, Nayan Singhal, Nick Egebo, Nicolas Usunier, Nikhil Mehta, Nikolay Pavlovich Laptev, Ning Dong, Norman Cheng, Oleg Chernoguz, Olivia Hart, Omkar Salpekar, Ozlem Kalinli, Parkin Kent, Parth Parekh, Paul Saab, Pavan Balaji, Pedro Rittner, Philip Bontrager, Pierre Roux, Piotr Dollar, Polina Zvyagina, Prashant Ratanchandani, Pritish Yuvraj, Qian Liang, Rachad Alao, Rachel Rodriguez, Rafi Ayub, Raghotham Murthy, Raghu Nayani, Rahul Mitra, Rangaprabhu Parthasarathy, Raymond Li, Rebekkah Hogan, Robin Battey, Rocky Wang, Russ Howes, Ruty Rinott, Sachin Mehta, Sachin Siby, Sai Jayesh Bondu, Samyak Datta, Sara Chugh, Sara Hunt, Sargun Dhillon, Sasha Sidorov, Satadru Pan, Saurabh Mahajan, Saurabh Verma, Seiji Yamamoto, Sharadh Ramaswamy, Shaun Lindsay, Shaun Lindsay, Sheng Feng, Shenghao Lin, Shengxin Cindy Zha, Shishir Patil, Shiva Shankar, Shuqiang Zhang, Shuqiang Zhang, Sinong Wang, Sneha Agarwal, Soji Sajuyigbe, Soumith Chintala, Stephanie Max, Stephen Chen, Steve Kehoe, Steve Satterfield, Sudarshan Govindaprasad, Sumit Gupta, Summer Deng, Sungmin Cho, Sunny Virk, Suraj Subramanian, Sy Choudhury, Sydney Goldman, Tal Remez, Tamar Glaser, Tamara Best, Thilo Koehler, Thomas Robinson, Tianhe Li, Tianjun Zhang, Tim Matthews, Timothy Chou, Tzook Shaked, Varun Vontimitta, Victoria Ajayi, Victoria Montanez, Vijai Mohan, Vinay Satish Kumar, Vishal Mangla, Vlad Ionescu, Vlad Poenaru, Vlad Tiberiu Mihailescu, Vladimir Ivanov, Wei Li, Wenchen Wang, Wenwen Jiang, Wes Bouaziz, Will Constable, Xiaocheng Tang, Xiaojian Wu, Xiaolan Wang, Xilun Wu, Xinbo Gao, Yaniv Kleinman, Yanjun Chen, Ye Hu, Ye Jia, Ye Qi, Yenda Li, Yilin Zhang, Ying Zhang, Yossi Adi, Youngjin Nam, Yu Wang, Yu Zhao, Yuchen Hao, Yundi Qian, Yunlu Li, Yuzi He, Zach Rait, Zachary DeVito, Zef Rosnbrick, Zhaoduo Wen, Zhenyu Yang, Zhiwei Zhao, and Zhiyu Ma. The llama 3 herd of models, 2024. https://arxiv.org/abs/2407.21783. John Gruber. Markdown. https://daringfireball.net/projects/markdown/, 2004. Accessed: 2025-2-23. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. https://arxiv.org/abs/2106.09685. Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. In European Conference on Computer Vision, 2021. https://api.semanticscholar.org/CorpusID:250924870. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with paged attention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023. Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muenighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardner, Maciej Kilian, Hanlin Zhang, Rulin Shao, Sarah Pratt, Sunny Sanyal, Gabriel Ilharco, Giannis Daras, Kalyani Marathe, Aaron Gokaslan, Jieyu Zhang, Khyathi Chandu, Thao Nguyen, Igor Vasiljevic, Sham Kakade, Shuran Song, Sujay Sanghavi, Fartash Faghri, Sewoong Oh, Luke Zettlemoyer, Kyle Lo, Alaaeldin El-Nouby, Hadi Pouransari, Alexander Toshev, Stephanie Wang, Dirk Groeneveld, Luca Soldaini, Pang Wei Koh, Jenia Jitsev, Thomas Kollar, Alexandros G Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt, and Vaishaal Shankar. DataComp-LM: In search of the next generation of training sets for language models. arXiv [cs.LG], June 2024.
A Appendix
附录
olmOCR-mix-0225 construction prompt for gpt-4o
olmOCR-mix-0225 构建提示词 for GPT-4o
The prompt below was used to create the silver dataset that was then used to fine-tune our model. The {base_text} is replaced with the output of document-anchoring.
以下提示用于创建银数据集,随后用于微调我们的模型。{base_text} 替换为文档锚定的输出。
JSON Schema
JSON Schema
" json schema ": { " name ": " page response ", " schema ": { " type ": " object ", " properties ": { " primary language ": { " type ": [" string ", " null "], " description ": " The primary language of the text using two - letter codes or null if there is no text at all that you think you should read .", }, " is rotation valid ": { " type ": " boolean ", " description ": "Is this page oriented correctly for reading ? Answer only considering the textual content , do not factor in the rotation of any charts , tables , drawings , or figures .", }, " rotation correction ": { " type ": " integer ", " description ": " Indicates the degree of clockwise rotation needed if the page is not oriented correctly .", " enum ": [0, 90, 180 , 270] , " default ": 0, }, " is_table ": { " type ": " boolean ", " description ": " Indicates if the majority of the page content is in tabular format ." , }, " is_diagram ": { " type ": " boolean ", " description ": " Indicates if the majority of the page content is a visual diagram ." , }, " natural text ": { " type ": [" string ", " null "], " description ": " The natural text content extracted from the page .", }, }, " additional Properties ": False
JSON Schema:{ "name": "页面响应", "schema": { "type": "object", "properties": { "主要语言": { "type": ["string", "null"], "description": "文本的主要语言,使用两字母代码表示,如果没有任何文本,则为null。" }, "旋转是否有效": { "type": "boolean", "description": "此页面是否正确定向以便阅读?仅考虑文本内容,不要考虑任何图表、表格、绘图或图形的旋转。" }, "旋转校正": { "type": "integer", "description": "如果页面未正确定向,则表示需要顺时针旋转的度数。", "enum": [0, 90, 180, 270], "default": 0 }, "是否为表格": { "type": "boolean", "description": "指示页面内容的大部分是否为表格格式。" }, "是否为图表": { "type": "boolean", "description": "指示页面内容的大部分是否为视觉图表。" }, "自然文本": { "type": ["string", "null"], "description": "从页面中提取的自然文本内容。" } }, "additionalProperties": false } }
"required":[
"primary_language"
"is_rotation_valid"
"rotation_correction"
"is_table"
"is_diagram"
"natural_text"
"strict":True, }
olmOCR-7B-0225-preview prompt
olmOCR-7B-0225-preview prompt
The prompt below is used to prompt the fine-tuned model, using the same rule to replace {base_text} with the output of document-anchoring.
以下提示用于提示微调后的模型,使用相同的规则将 {base_text} 替换为文档锚定的输出。
olmOCR-mix-0225 Classification Prompt
olmOCR-mix-0225 分类提示
The prompt and structured schema below was used to classify a sample of documents from olmOCR-mix-0225 as reported in Table 2.
表 2 中报告的分类使用了以下提示和结构化模式对 olmOCR-mix-0225 的文档样本进行分类。
| 这是一张文档页面的图片,请将其分类为最能概括其性质的以下类别之一:学术、法律、宣传册、幻灯片、表格、图表或其他。同时确定文档的主要语言以及你的分类置信度(0-1)。 | |||||
|---|---|---|---|---|---|
| class DocumentCategory(str, Enum): | |||||
| ACADEMIC= | "academic" | ||||
| LEGAL="legal" | |||||
| BROCHURE | = "brochure" | ||||
| SLIDESHOW | = "slideshow" | ||||
| TABLE | = "table" | ||||
| DIAGRAM | = "diagram" | ||||
| OTHER = | "other" | ||||
| class DocumentClassification(BaseModel): | |||||
| category: DocumentCategory | |||||
| language: str | confidence: float |
B ELO Evaluation Instructions
B ELO 评估指南
In Section 5.2, we asked participants to compare the output of various common OCR tools against olmOCR. Participants were given the instructions below, and presented with a document page, and the output of two random tools. They could then select which output was better, or select "Both Good", "Both Bad", or "Invalid PDF" any of which would not count the comparison in the ELO ranking.
在第 5.2 节中,我们要求参与者将各种常见 OCR 工具的输出与 olmOCR 进行比较。参与者被给予以下指示,并展示一个文档页面和两个随机工具的输出。然后,他们可以选择哪个输出更好,或者选择“两者都好”、“两者都差”或“无效 PDF”,其中任何一项都不会计入 ELO 排名。
Instructions to participants
参与者指南
ELO data
ELO 数据
Table 7 Pairwise Win/Loss Statistics Between Models
表 7: 模型之间的成对胜负统计
| 模型对 | 胜率 (%) |
|---|---|
| OLMOCR vs. MARKER 49/31 | 61.3 |
| OLMOCR vs. GOTOCR 41/29 | 58.6 |
| OLMOCR vs. MINERU 55/22 | 71.4 |
| MARKER vs. MINERU 53/26 | 67.1 |
| MARKER vs. GOTOCR 45/26 | 63.4 |
| GOTOCR vs. MINERU 38/37 | 50.7 |
| 总计 452 |
C Example output
C 示例输出
Below are some sample outputs on particularly challenging data. olmOCR, MinerU, GOT-OCR 2.0 and Marker run with default settings.
以下是一些在特别具有挑战性的数据上输出的示例。olmOCR、MinerU、GOT-OCR 2.0 和 Marker 均使用默认设置运行。

Christians behaving themselves like Mahomedans.
基督徒行为举止如穆斯林。
- The natives soon had reason to suspect the viceroy’s sincerity in his expressions of regret at the proceedings of which they complained. For about this time the Dominican friars, under pretence of building a convent, erected a fortress on the island of Solor, which, as soon as finished, the viceroy garrisoned with a strong force. The natives very naturally felt indignant at this additional encroachment, and took every opportunity to attack the garrison. The monks, forgetful of their peaceable profession, took an active part in these skirmishes, and many of them fell sword in hand.
- 当地人很快有理由怀疑总督对他们所控诉之事表达歉意的诚意。因为大约在这个时候,多明我会修士们以修建修道院为借口,在索洛尔岛上建造了一座堡垒,堡垒一完工,总督便派重兵驻守。当地人对这种额外的侵犯自然感到愤怒,并抓住一切机会攻击驻军。修士们忘记了他们原本和平的使命,积极参与了这些冲突,其中许多人手持利剑倒下。
The Mahomedan faith has been approp riat ely entitled, The religion of the sword; and with equal propriety may we so designate the religion of these belligerent friars. The Portuguese writers give an account of one of their missionaries, Fernando Vinagre, who was as prompt in the field of battle as at the baptismal font. This man, though a secular priest, undertook the command of a squadron that was sent to the assistance of the rajah of Tidore, on which occasion he is said to have acted in the twofold capacity of a great commander, and a great apostle, at one time appearing in armour, at another in a surplice; and even occasionally, baptizing the converts of his sword without putting off his armour, but covering it with his ecclesiastical vest. In this crusade he had two
马哈茂德信仰被恰当地称为“剑之宗教”;我们同样可以恰当地将这些好战的修道士的宗教称为“剑之宗教”。葡萄牙作家记载了其中一位传教士费尔南多·维纳格雷的事迹,他在战场上与在洗礼池旁一样迅速。这个人虽然是一位世俗牧师,却承担了一支被派去援助蒂多雷王公的中队的指挥任务。据说,他在这次任务中表现出了一位伟大指挥官和一位伟大使徒的双重身份,时而穿着盔甲,时而穿着法衣;甚至有时在不脱下盔甲的情况下为其剑下的皈依者施洗,只是用他的教会法衣覆盖盔甲。在这场十字军东征中,他有两个……
ININDIASY BOOKU Christians bchaving.themselves like Mahome dans.3
ININDIASY BOOKU Christians 表现得像 Mahome dans.3
4.The natives soon had reason to suspect ihe viceroy’s sincerity in his expressions of regret at the proceedings of which they complained. For about this time the Dominican friars,under pretenceof building a convent,erected a for tress on the island of Solorwhich,as soon as finishedthe viceroy garrisoned with a strong force. The natives very naturally felt indig nant at this additional encroachment, and took every pportunity to attack the garrison.The monks,forgetful of their peaceable profession took an activa part in these skirmishes, and many of tbein feil sword in hand.
不久,土著居民就有理由怀疑总督对他们所控诉之事表达歉意的诚意。因为大约在这个时候,多明我会修士们以建造修道院为借口,在索洛尔岛上建起了一座堡垒,堡垒一完工,总督便派重兵驻守。土著居民自然对这种额外的侵略行为感到愤怒,并抓住每一个机会攻击驻军。修士们忘记了他们和平的职业,积极参与这些冲突,许多人在战斗中手持刀剑倒下。
TheM a horned an faithhas been approp riat ely ntitled.The religion of the swordand with equal propriety may we so designate the region of these belligerent friars.The Portu gue s writers give an account of one of their mission a rz es,femando Vinagre,who was as prompt in the field of battle as at the baptismal font. This man, though a secular priest, undertook the command of a squadron that was sent to the assistance of the rajah of Tidore,4 on which occasion he is said to have acted in the twofold capacity of a great commander, and a great apostle, at one time appearing in armour, at another in a surplice;and even occasionally baptizing the converts of his sword without put ting off his armour, but covering it with his ecclesiastical vest.In this crusadehe had two
马霍恩德的信仰已被恰当地命名。剑的宗教,我们同样可以恰当地称这些好战的修道士的地区为剑的宗教。葡萄牙作家们记述了他们的传教士之一费尔南多·维纳格雷,他在战场上与在洗礼池旁一样迅速。这个人虽然是个世俗牧师,却承担了被派去协助蒂多雷王国拉贾的中队的指挥,据说他在这场合表现出了伟大指挥官和伟大使徒的双重身份,一时身着盔甲,一时又穿着法衣;甚至偶尔在未脱盔甲的情况下为他的剑下的皈依者施洗,只是用他的教会法衣覆盖盔甲。在这场十字军东征中,他有两个
IN INDIA: BOOK U 269 Christians behaving themselves like Mahome1670. 4. The natives son had reason to suspect the Viceroy’ s vice roy’ s sincerity in his expressions of regret in s in e eri ty at the proceedings of which they complained. fl it ars. For about this time the Dominican f mars, under pre ten ce of building a convent, erected a for- tress on the island of Sol or, which, as soon as finished, the vice roy garrisoned with a strong force. The natives very naturally felt indig- nant at this additional encroachment, and took every opportunity to attack the garrison. The monks, forgetful of their peaceable profession, took an active part in these skirmishes, and many of the n fell sword in hand. The Mh on med an faith has been appro- priately entitled. The religion of the sword; and with e ral Tropriety may we so designate the re- gian of these belligerent friars. The Port u- gue s writers give an account of one of their mission are s, Fer endo Vina gre, who was as prompt in the fe ld of battle as at the baptismal font. This man, though a secular priest, un- der took the command of a squadron that was sent to the assistance of the rajah of Tidore, on which occasion he is said to have acted in the twofold capacity of a great commander, and a great apostle, at one time appearing in armour, at another in a surplice; and even occasionally, baptizing the converts of his sword without put- ting off his armour, but covering it with his ecclesiastical vest. In this crusade he had two 3 Ged des History, & c. , pp. 24-27. P ude th aec opp rob ria nobis Vel die ipo tui sse. Called Tadur u or Daco, an island in the Indian Ocean, one of the Mol ucc as These a laDra goon conversions. Ged des History, p. 27.
在印度:BOOK U 269
基督徒像穆罕默德一样行事 1670。
4. 当地人有理由怀疑总督在其表达歉意时的诚意,因为他们对所抱怨的事件感到不满。大约在这个时候,多米尼加修士以建造修道院为借口,在索洛尔岛上建立了一座堡垒,一旦完工,总督便派重兵驻守。当地人自然对这一额外的侵占感到愤怒,并抓住一切机会攻击驻军。这些修士忘记了他们和平的职业,积极参加了这些冲突,许多人手持刀剑倒下。穆罕默德的信仰被恰当地称为“刀剑的宗教”;我们同样可以恰当地将这些好斗修士的宗教称为“刀剑的宗教”。葡萄牙作家记述了他们的一位传教士费尔南多·维纳格雷的事迹,他在战场上与在洗礼池旁一样迅速。尽管他是一位世俗牧师,但他指挥了一支被派去协助蒂多雷王公的舰队,据说他在这次行动中既是一位伟大的指挥官,也是一位伟大的使徒,时而穿着盔甲,时而穿着圣衣;甚至偶尔在不脱盔甲的情况下为他的刀剑下的皈依者施洗,只是用他的教会长袍覆盖盔甲。在这次远征中,他有两个……
Geddes History, & c., pp. 24-27.
Pude th aec opp rob ria nobis Vel die ipo tui sse.
被称为塔杜鲁或达科,印度洋中的一个岛屿,属于摩鹿加群岛之一。
这些被称为“龙”的皈依。
Geddes History, p. 27.
**IN INDIA *** BOOK TI. S69 Christians behaving themselves like Ma borne- a. dans.3 . $^5/0-^\mathbf>.$ .*
在印度 书籍 TI. S69 基督徒表现得像 Ma borne- a. dans.3 . $^5/0-^\mathbf>.$ .*
The natives soon had reason to suspect the viceroy, viceroy’s sincerity in his expressions of regret at the proceedings of which they complained. “n.“’ For about this time the Dominican friars, under pretence of building a. convent, erected a fortress on the island of Sol or, which, as soon as finished, the viceroy garrisoned with a strong force. The natives’ very naturally felt indig-S nant at this additional encroachment, and took every opportunity to attack the garrison. The monks, forgetful/ of their peaceable profession, took an active part in these skirmishes, and many of tbg.tr fell sword in hand. The i’lfinomedan faith has been approp riat ely entitled., ‘The religion of the sword’,; and with equal propriety may we so designate the re- . i’gv.m of these belligerent friars. The Portugu writers give an account of one of their ‘missionaries,’ Fernando Vinagre, who was as prompt in the field of battle as at the baptismal font. This man, though a secular priest, undertook the command of a squadron that was I sent to the assistance of the rajah of Tidore,4 on which occasion he is said to have acted in the twofold capacity of a great commander, and a great apostle, at one time appearing in armour, ; at another in a surplice; and even occasionally, baptizing the converts of his sword without putting off his armour, but covering it with his eccles iast ical vest. In this crusade5 he had two 3 Geddes History, &c., pp. 24—27. Pudet hæc opprobrianobis Vel dici potuisse. 4 Called ‘T a d u ra’ or ‘D a c o,’ an island in the Indian Ocean, one of the Moluccas 5 ‘These ‘a la D ra g o o n’ conversions.’ Geddes’ His- tory, p. 27.
当地居民很快有理由怀疑总督在他们所控诉事件中表达的歉意是否真诚。因为大约在这个时候,多明我会的修士们以建造修道院为借口,在索尔岛上建立了一座堡垒,一旦完工,总督便派重兵驻守。当地居民对这一额外的侵犯自然感到愤怒,并抓住一切机会攻击驻军。这些修士们忘记了他们和平的职业,积极参与了这些小规模冲突,其中许多人在战斗中手持刀剑倒下。穆斯林信仰被恰当地称为“剑的宗教”,我们同样可以如此称呼这些好战的修士们的宗教。葡萄牙作家记载了一位名为费尔南多·维纳格雷的“传教士”,他在战场上和在洗礼池边一样迅速。这个人虽然是个世俗牧师,却担任了一支被派去援助蒂多雷拉贾的中队的指挥,据说他在此场合既扮演了伟大指挥官的角色,又扮演了伟大使徒的角色,一时穿着盔甲,一时穿着白袍;甚至有时在未脱盔甲的情况下为他的刀剑下的皈依者施洗,只是用他的教袍覆盖盔甲。在这场十字军东征中,他有两个…

MinerU
MinerU
3.4 EXERCISES
3.4 练习
$#3.4$ EXERCISES
$#3.4$ 习题
Chapter 3 | Derivatives 273 3.4 EXERCISES For the following exercises, the given functions represent the position of a particle traveling along a horizontal line. a. Find the velocity and acceleration functions. b. Determine the time intervals when the object is slowing down or speeding up. 150. ${\bf s}({\bf t})=2{\bf t}3-3{\bf t}2$ $^{-12\mathrm{t}}+\mathrm{8}151$ . $\mathrm{s(t)=2t3-15t2+}$ 36t $-10\phantom{0}152$ . $\mathbf{s(t)}=\mathbf{t}\textbf{1}+\mathbf{t}2\mathbf{\beta}\mathbf{1}53$ A rocket is fired vertically upward from the ground. The distance s in feet that the rocket travels from the ground after t seconds is given by $\mathrm{\boldmath~s(t)~}=~-16\mathrm{t}2~+~560\mathrm{t}.$ . a. Find the velocity of the rocket 3 seconds after being fired. b. Find the acceleration of the rocket 3 seconds after being fired. 154. A ball is thrown downward with a speed of 8 ft/ s from the top of a 64-foot-tall building. After t seconds, its height above the ground is given by $\mathrm{s(t)=}$ $-16\mathbf{t}2\mathbf{\Omega}-8\mathbf{t}\mathbf{\Omega}+\mathbf{\Omega}64\mathbf{\Omega}$ . a. Determine how long it takes for the ball to hit the ground. b. Determine the velocity of the ball when it hits the ground. 155. The position function $\mathrm{s(t)=}$ $_{\textrm{t2}-3\textrm{t}-4}$ represents the position of the back of a car backing out of a driveway and then driving in a straight line, where s is in feet and t is in seconds. In this case, s(t) $=\mathrm{~0~}$ represents the time at which the back of the car is at the garage door, so is the starting position of the car, 4 feet inside the garage. a. Determine the velocity of the car when $\mathbf{s(t)}=\mathbf{0}$ . b. Determine the velocity of the car when $\mathbf{s(t)}=14$ . 156. The position of a hummingbird flying along a straight line in t seconds is given by $\mathbf{s}(\mathbf{t})=3\mathbf{t}3-7\mathbf{t}\textrm{222222222222}2$ 2 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 5 5 4 4 4 4 4 4 4 4 4 3 3 3 3 3 3 3 3 3 1 1 1 1 1 1 1 1 1 1 3 3 3 3 3 3 3 3 3 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 3 3 3 3 3 3 3 3 3 2 2 2 2 2 2 2 2 2 4 4 4 4 4 4 4 4 4 2 2 2 2 2 2 2 2 2 0 1 1 1 1 1 1 1 1 3 4 4 4 4 4 4 4 4 3 4 4 4 4 4 4 4 4 2 3 3 3 3 3 3 3 3 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 0 2 2 2 2 2 2 2 2 2 5 5 5 5 5 5 5 5 5 1 1 1 1 1 1 1 1 1 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5 5 3 3 3 3 3 3 3 3 3 5 5 5 5 5 5 5 5 5 2 2 2 2 2 2 2 2 2 a. Use the graph of the position function to determine the time intervals when the velocity is positive, negative, or zero. b. Sketch the graph of the velocity function. c. Use the graph of the velocity function to determine the time intervals when the acceleration is positive, negative, or zero. d. Determine the time in- tervals when the object is speeding ## $\yen3,4$ EXERCISES**For the following exercises, the given functions represent the position of a particle traveling along a horizontal line. - a. Find the velocity and acceleration functions. - b. Determine the time intervals when the object is slowing down or speeding up.
第3章 | 导数 273
3.4 习题
对于以下习题,给定函数表示粒子沿水平线运动的位置。
a. 求速度和加速度函数。
b. 确定物体减速或加速的时间区间。
- ${\bf s}({\bf t})=2{\bf t}3-3{\bf t}2$ $^{-12\mathrm{t}}+\mathrm{
8}151$ - $\mathrm{s(t)=2t3-15t2+}$ 36t $-10\phantom{0}152$
- $\mathbf{s(t)}=\mathbf{t}\textbf{1}+\mathbf{t}2\mathbf{\beta}\mathbf{1}53$
一枚火箭从地面垂直向上发射。火箭在 t 秒后离地面的距离 s(英尺)由 $\mathrm{\boldmaths(t)}=-16\mathrm{t}2+~560\mathrm{t}.$ 给出。
a. 求火箭在发射后 3 秒的速度。
b. 求火箭在发射后 3 秒的加速度。
- 一个球以 8 英尺/秒的速度从 64 英尺高的建筑物顶部向下抛出。t 秒后,其离地面的高度由 $\mathrm{s(t)=}$ $-16\mathbf{t}2\mathbf{\Omega}-8\mathbf{t}\mathbf{\Omega}+\mathbf{\Omega}64\mathbf{\Omega}$ 给出。
a. 确定球落地所需的时间。
b. 确定球落地时的速度。 - 位置函数 $\mathrm{s(t)=}$ $_{\textrm{t2}-3\textrm{t}-4}$ 表示汽车从车道倒车并沿直线行驶时车尾的位置,其中 s 的单位为英尺,t 的单位为秒。在这种情况下,s(t) $=\mathrm{~0~}$ 表示汽车车尾位于车库门的时间,因此是汽车的起始位置,车库内 4 英尺处。
a. 确定当 $\mathbf{s(t)}=\mathbf{0}$ 时汽车的速度。
b. 确定当 $\mathbf{s(t)}=14$ 时汽车的速度。 - 蜂鸟沿直线飞行在 t 秒内的位置由 $\mathbf{s}(\mathbf{t})=3\mathbf{t}3-7\mathbf{t}\textrm{222222222222}2$ 给出。
a. 使用位置函数的图像确定速度为正、负或零的时间区间。
b. 绘制速度函数的图像。
c. 使用速度函数的图像确定加速度为正、负或零的时间区间。
d. 确定物体加速的时间区间。
$$
150.s(t)=2t^{3}-3t^{2}-12t+8
$$
$$
150.s(t)=2t^{3}-3t^{2}-12t+8
$$
$$
s(t)=2t^{3}-15t^{2}+36t-10t
$$
$$
s(t)=2t^{3}-15t^{2}+36t-10t
$$
$$
152.s(t)={\frac{t}{1+t^{2}}}
$$
$$
152.s(t)={\frac{t}{1+t^{2}}}
$$

Marker
Marker
necuhve Mansion Vast- ington amany layor Seneral Hitchcocks Commissioner of Cachanges, is anthonged and directed to offer Bingadier General Trin prisoner of war in Fort Inctienny, in ex- change now w Major White, who is held as a preises at Richmond Ite is also directed to vand forwards the offer of exchange by Stenny in. Warfield, Eag. of Baltimore, under aflag 11 mice, and give him apass to tity Point. Abrakan Sincolus
necuhve大厦华盛顿amany layor Seneral Hitchcocks Cachanges专员,被授权并指示提供在Fort Inctienny的战俘Bingadier General Trin,以交换目前在Richmond被扣押的Major White。同时,指示通过来自巴尔的摩的Stenny in. Warfield, Eag.,在11只老鼠的旗帜下提出交换提议,并给他一张前往tity Point的通行证。Abrakan Sincolus
| olmOCR | MinerU | GOT-OCR2.0 | Mark |
|---|---|---|---|
| Executive Mansion, | No tertproduced. | 43571 Bachington City January 10th 1864.Major | necu |
| Washington City, January 15th,1864 | General Architect, Com- | ingto eral | |
| Major General Hitch- | missioner of aivachangera | sione | |
| cock,Commissioner of | is authorized and directed | anth | |
| Exchanges, is authorized | by ffeed Bngader General | ||
| and directed to offer | Trelmble, new a firemen of | too | |
| eral | |||
| Brigadier General Trim- | war in Fert nchery in ex- | in F | |
| ble, now a prisoner of | change for Mayor White, | chan | |
| war in Fort McHenry, | who held a a firemen at | Whit | |
| in exchange for Major | Hillmannd.He is aker | apr | |
| White, who is held as a | conducted by end forward | Ite | |
| prisoner at Richmond. | the offer of exchange by | vand | |
| He is also directed to | Henry in. Warfield, Lag. | ||
| send forwardthe offer | of Balthmore, under a fag | of ex | |
| Warf | |||
| of exchange by Henry | of three, and five him | more | |
| M.Warfield, Esq. of | afaies to City Bink. Abra- | and g | |
| Baltimore, under a fag | ham Lincoln | ||
| Point | |||
| of truce, and give him a | |||
| pass to City Point. | |||
| Abraham Lincoln |