0.8% Nyquist computational ghost imaging via non-experimental deep learning
通过非实验性深度学习实现 0.8% 奈奎斯特计算鬼成像
We present a framework for computational ghost imaging based on deep learning and customized pink noise speckle patterns. The deep neural network in this work, which can learn the sensing model and enhance image reconstruction quality, is trained merely by simulation. To demonstrate the subNyquist level in our work, the conventional computational ghost imaging results, reconstructed imaging results using white noise and pink noise via deep learning are compared under multiple sampling rates at different noise conditions. We show that the proposed scheme can provide highquality images with a sampling rate of $0.8%$ even when the object is outside the training dataset, and it is robust to noisy environments. This method is excellent for various applications, particularly those that require a low sampling rate, fast reconstruction efficiency, or experience strong noise interference.
我们提出了一种基于深度学习和定制粉红噪声散斑图案的计算鬼成像框架。本工作中的深度神经网络可以通过模拟训练学习感知模型并提高图像重建质量。为了展示我们工作中的亚奈奎斯特水平,我们在不同噪声条件下比较了传统计算鬼成像结果、使用白噪声和粉红噪声通过深度学习重建的成像结果。我们表明,即使目标不在训练数据集中,所提出的方案也能在采样率为 $0.8%$ 时提供高质量图像,并且对噪声环境具有鲁棒性。该方法适用于各种应用,特别是那些需要低采样率、快速重建效率或经历强噪声干扰的应用。
I. INTRODUCTION
I. 引言
Ghost imaging (GI) [1–4] is an innovative method for measuring the spatial correlations between light beams. With GI, the signal light field interacts with the object and is collected by a single-pixel detector, and the reference light field, which does not interact with the object, falls onto the imaging detector. Therefore, the image information is not present in either beam alone but only revealed in their correlations. Computational ghost imaging (CGI) [5, 6] was proposed to further ameliorate and simplify this framework. In CGI, The reference arm that records the speckles is replaced by loading pre-generated patterns directly onto the spatial light modulator or the digital micro mirror device (DMD). The unconventional image is then revealed by correlating the sequentially recorded intensities at the single-pixel detector with the corresponding patterns. CGI finds a lot of applications such as wide spectrum imaging [7–9], remote sensing [10], and quantum-secured imaging [11].
鬼成像 (Ghost Imaging, GI) [1–4] 是一种用于测量光束之间空间相关性的创新方法。在鬼成像中,信号光场与物体相互作用并被单像素探测器收集,而参考光场不与物体相互作用,直接落在成像探测器上。因此,图像信息并不单独存在于任一光束中,而是通过它们之间的相关性显现出来。计算鬼成像 (Computational Ghost Imaging, CGI) [5, 6] 被提出以进一步改进和简化这一框架。在计算鬼成像中,记录散斑的参考臂被替换为直接将预生成的图案加载到空间光调制器或数字微镜器件 (DMD) 上。然后,通过将单像素探测器上顺序记录的强度与相应的图案相关联,揭示出非常规图像。计算鬼成像在广谱成像 [7–9]、遥感 [10] 和量子安全成像 [11] 等领域有广泛应用。
However, CGI generally requires a large number of samplings to reconstruct a high-quality image, or the signal would have been submerged under correlation fluctuations and environmental noise. To suppress the environmental noise and correlation fluctuations, the required minimum number of sampling is proportional to the total pixel number of the pattern applied on DMD, i.e., the Nyquist sampling limit [12, 13]. The image could have a meager quality with a limited sampling number. This demanding requirement hindered CGI from fully replacing conventional photography. A large number of schemes have been proposed to improve CGI’s speed and decrease the sampling rate (sub-Nyquist). For instance, compressive sensing imaging can reconstruct images with a relatively low sampling rate by exploiting the sparsity of the objects [14–17]. It nevertheless largely depends on the sparsity of objects and is sensitive to noise [18]. Ortho normalized noise patterns can be used to suppress the noise and improve the image’s quality under a limited sampling number [19, 20]. In particular, the ortho normalized colored noise patterns can break the Nyquist limit down to $\sim5%$ [20]. Fourier and sequence-ordered Walsh-Hadamard patterns, which are orthogonal to each other in time or spatial domain, were also applied to the sub-Nyquist imaging [21–23]. The Russian doll [24] and cake-cutting [25] ordering of Walsh-Hadamard patterns can minimize the sampling ratio to 5%-10% Nyquist limit.
然而,CGI通常需要大量采样才能重建高质量图像,否则信号会被相关性波动和环境噪声淹没。为了抑制环境噪声和相关性波动,所需的最小采样数与应用于DMD的图案的总像素数成正比,即奈奎斯特采样极限 [12, 13]。在采样数有限的情况下,图像质量可能非常差。这一苛刻的要求阻碍了CGI完全取代传统摄影。为了提高CGI的速度并降低采样率(亚奈奎斯特),已经提出了许多方案。例如,压缩感知成像可以通过利用物体的稀疏性以相对较低的采样率重建图像 [14–17]。然而,它在很大程度上依赖于物体的稀疏性,并且对噪声敏感 [18]。正交归一化噪声图案可用于在有限采样数下抑制噪声并提高图像质量 [19, 20]。特别是,正交归一化彩色噪声图案可以将奈奎斯特极限降低到 $\sim5%$ [20]。傅里叶和序列有序的沃尔什-哈达玛图案在时间或空间域中相互正交,也被应用于亚奈奎斯特成像 [21–23]。沃尔什-哈达玛图案的俄罗斯套娃 [24] 和切蛋糕 [25] 排序可以将采样率最小化到5%-10%的奈奎斯特极限。
Recently, the deep learning (DL) technique is employed to identify images [26, 27] and improve the quality of images with the deep neural network (DNN) [28–36]. Specifically, computational ghost imaging via deep learning (CGIDL) has shown a minimum ratio of Nyquist limit down to $\sim5%$ [29, 33]. However, such work’s DNNs are trained by experimental CGI results. Only when the training environment is highly identical to the environment used for image reconstruction can the DNN be effective. This limits its universal applications and restricts it to achieve quick reconstructions. Usually at least thousands of inputs have to be generated for the training, which would be very time-consuming if conducting experimental training each time. Some studies have been performed to test the effectiveness of non-experimental CGI training DNN, the minimum ratios of the Nyquist limit were up to a few percent [30, 31, 35]. However, the sampling ratio is much higher for objects outside of training dataset than those in the training dataset [33]. Therefore, despite the proliferation of numerous algorithms, retrieving high-quality images outside of the training group with a meager Nyquist limit ratio by non-experimental training remains a challenge for the CGIDL system.
最近,深度学习 (DL) 技术被用于识别图像 [26, 27] 并通过深度神经网络 (DNN) 提高图像质量 [28–36]。具体而言,基于深度学习的计算鬼成像 (CGIDL) 已显示出最低的奈奎斯特极限比率,低至 $\sim5%$ [29, 33]。然而,这些工作的 DNN 是通过实验 CGI 结果进行训练的。只有当训练环境与用于图像重建的环境高度一致时,DNN 才能有效工作。这限制了其通用应用,并限制了其实现快速重建的能力。通常,至少需要生成数千个输入用于训练,如果每次进行实验训练,这将非常耗时。一些研究已经测试了非实验 CGI 训练 DNN 的有效性,奈奎斯特极限的最低比率达到了几个百分点 [30, 31, 35]。然而,对于训练数据集之外的对象,采样比率远高于训练数据集中的对象 [33]。因此,尽管有许多算法涌现,但通过非实验训练在极低的奈奎斯特极限比率下从训练组之外检索高质量图像仍然是 CGIDL 系统的一个挑战。
This letter aims to minimize the necessary sampling number further and improve the imaging quality with the combination of DL and colored noise CGI. Recently, it has been shown that the synthesized colored noise patterns possess unique non-zero correlations between neighborhood pixels via amplitude modulation in the spatial frequency domain [37, 38]. In particular, The pink noise CGI owns positive cross-correlations in the second-order correlation [37]. It gives a good image quality under a boisterous environment or pattern distortion when the traditional CGI method fails. Combining DL with pink noise CGI shows that the imaging can be retrieved under an extremely low sampling rate $\mathrm{'\sim0.8%}$ ). We also show that we can get training patterns from the simulation without introducing the environmental noises, i.e., there is no need to get DNN training with a large number of experimental training inputs. The object used in the experiment can be independent of the training dataset, which can largely benefit CGIDL in the real application.
本信旨在进一步减少必要的采样数量,并通过结合深度学习(DL)和彩色噪声计算鬼成像(CGI)来提高成像质量。最近的研究表明,通过空间频域中的幅度调制,合成的彩色噪声模式在相邻像素之间具有独特的非零相关性 [37, 38]。特别是,粉红噪声 CGI 在二阶相关性中具有正交叉相关性 [37]。在传统 CGI 方法失效的嘈杂环境或模式失真情况下,它提供了良好的图像质量。将 DL 与粉红噪声 CGI 结合表明,可以在极低的采样率下($\mathrm{'\sim0.8%}$)恢复成像。我们还展示了可以从模拟中获取训练模式,而无需引入环境噪声,即无需通过大量实验训练输入来训练 DNN。实验中使用的对象可以与训练数据集无关,这在实际应用中极大地有利于 CGIDL。
II. DEEP LEARNING
II. 深度学习
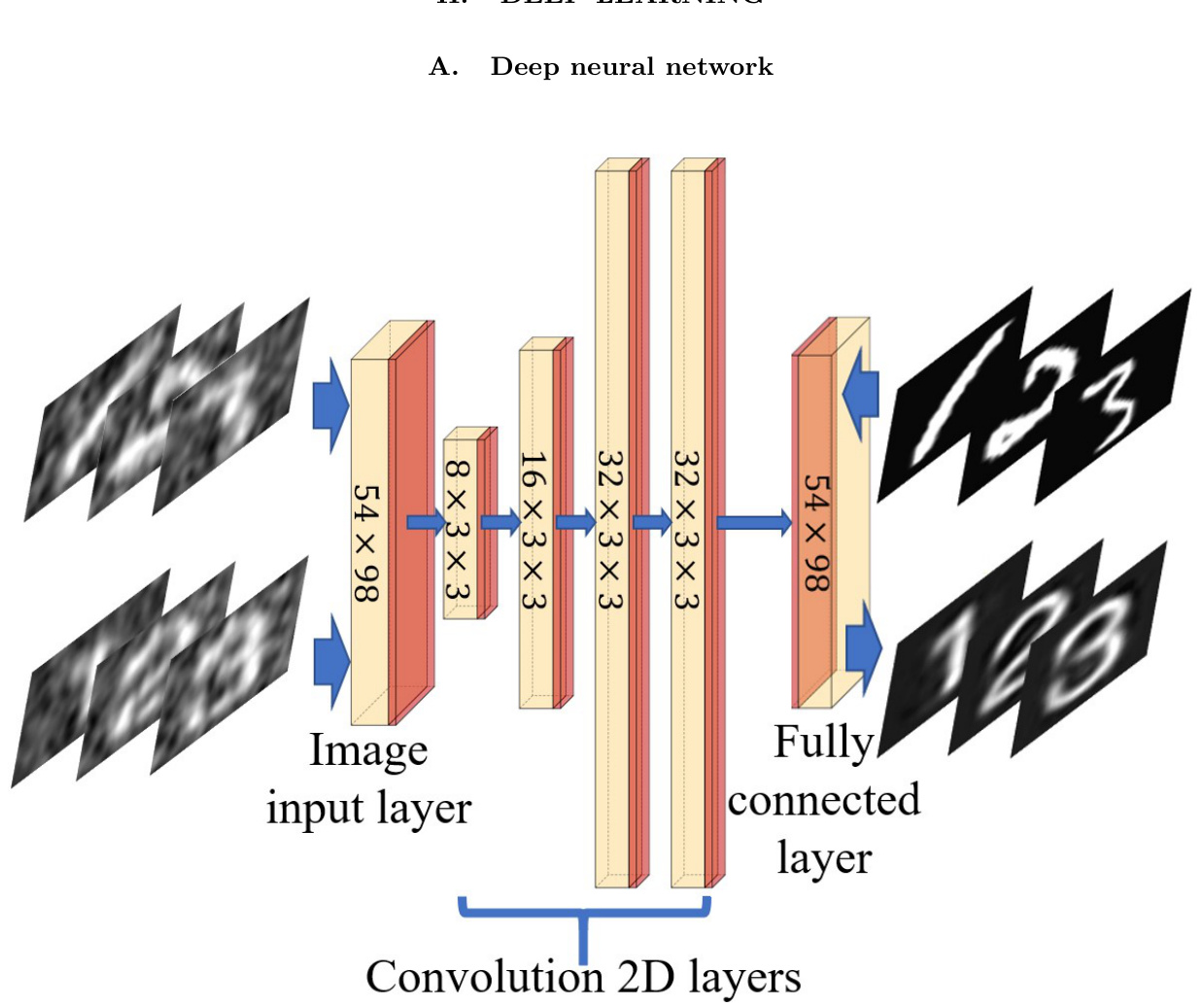
FIG. 1: Architecture of DNN. It consists of four convolution layers, one image input layer, one fully connected layer (yellow), the rectified linear unit, and the batch normalization layers (red). In the upper line are CGI results (training inputs) and handwriting ground truths (training labels); In the bottom line are CGI results from the experiment (test inputs) and CGIDL results (test outputs) with block style.
图 1: DNN 架构。它由四个卷积层、一个图像输入层、一个全连接层(黄色)、修正线性单元和批量归一化层(红色)组成。上排是 CGI 结果(训练输入)和手写真实值(训练标签);下排是实验中的 CGI 结果(测试输入)和 CGIDL 结果(测试输出),采用块状风格。
Our DNN model, as shown in Fig. 1, uses four convolution layers, one image input layer, and one fully connected layer. Small $3\times3$ receptive fields are applied throughout the whole convolution layers for better performance [39]. Batch normalization layers (BNL), rectified Linear Unit (ReLU) layers and zero padding are added between each convolution layer. The BNL is functioned to avoid internal covariate shift during the training process and speed up the training of DNN [40]. The ReLU layer applies a threshold operation to each element of the inputs [41]. The zero padding part was designed to maintain the characteristic of input images’ boundaries. To customize the size of training pictures, both the input and output layers are set to be $54\times98$ . The solver for training is employed by the Stochastic Gradient Descent with Momentum Optimizer (SGDMO) to reduce the oscillation via using momentum. The parameter vector can be updated via equation Eq. (1), which demonstrates the updating process during the iteration.
我们的 DNN 模型如图 1 所示,使用了四个卷积层、一个图像输入层和一个全连接层。为了获得更好的性能,整个卷积层都应用了小的 $3\times3$ 感受野 [39]。在每个卷积层之间添加了批量归一化层 (BNL)、修正线性单元 (ReLU) 层和零填充。BNL 的作用是避免训练过程中的内部协变量偏移,并加速 DNN 的训练 [40]。ReLU 层对输入的每个元素应用阈值操作 [41]。零填充部分旨在保持输入图像边界的特征。为了自定义训练图片的大小,输入层和输出层都设置为 $54\times98$。训练求解器采用带有动量的随机梯度下降优化器 (SGDMO),通过使用动量来减少振荡。参数向量可以通过公式 Eq. (1) 更新,该公式展示了迭代过程中的更新过程。

where $\ell$ is the iteration number, $\alpha$ is the learning rate, $\theta$ is the parameter vector, and $E(\theta)$ is the loss function, mean square error (MSE). The MSE is defined as
其中 $\ell$ 是迭代次数,$\alpha$ 是学习率,$\theta$ 是参数向量,$E(\theta)$ 是损失函数,即均方误差 (MSE)。MSE 定义为

Here, $G$ represents the pixel value of the resulted imaging. $G_{(o)}$ represents pixels that the light ought to be transmitted, i.e., the object area, while $G_{(b)}$ represents pixels that the light ought to be blocked, i.e., the background area. $X$ is the ground truth calculated by
这里,$G$ 表示生成图像的像素值。$G_{(o)}$ 表示光线应该透过的像素,即物体区域,而 $G_{(b)}$ 表示光线应该被阻挡的像素,即背景区域。$X$ 是通过计算得到的地面真值。

The third part on the right hand side of the equation is the feature of SGDMO, analog to the momentum where $\gamma$ determines the contribution of the previous gradient step to the current iteration [42]. Two strategies are applied to avoid over-fitting of training images. At the end of DNN, a dropout layer is applied with probability of dropping out input elements being 0.2, which is aimed to reduce the connection between convolution layers and the fully connected layer [43]. Meanwhile, we adopted a step decay schedule for the learning rate. The learning rate dropped from $10^{-3}$ to $10^{-4}$ after 75 epochs, which constrain the fitting parameters within a reasonable region. Lower the learning rate could avoid over fitting significantly with constant maximum epochs.
方程右侧的第三部分是 SGDMO 的特征,类似于动量,其中 $\gamma$ 决定了前一个梯度步骤对当前迭代的贡献 [42]。为了避免训练图像的过拟合,采用了两种策略。在 DNN 的末尾,应用了一个 dropout 层,丢弃输入元素的概率为 0.2,旨在减少卷积层和全连接层之间的连接 [43]。同时,我们采用了学习率的步进衰减策略。学习率在 75 个 epoch 后从 $10^{-3}$ 下降到 $10^{-4}$,从而将拟合参数限制在合理范围内。降低学习率可以在保持最大 epoch 不变的情况下显著避免过拟合。
B. Network training
B. 网络训练
The proposed CGIDL scheme requires a training process based on pre-prepared dataset. After training in simulation, it owns ability to reconstruct the images. We use a set of 10000 digits from the MNIST handwritten digit database [44] as training images. All images are resized and normalized to $54\times98$ to test the smaller sampling ratio. These training images are reconstructed by the CGI algorithm. The training images and reconstruction training images then feed the DNN model as inputs and outputs, respectively, as shown in Fig. 2(a). The white noise and pink noise speckle patterns are used separately for the training process, using exactly the same protocol. The maximum epochs are set as 100, and the training iteration is 31200. The program is implemented via MATLAB R2019a Update 5 (9.6.0.1174912, 64-bit), and the DNN is implemented through DL Toolbox. The GPU-chip NVIDIA GTX1050 is used to accelerate the speed of the computation.
所提出的CGIDL方案需要一个基于预准备数据集的训练过程。在模拟训练后,它具备了重建图像的能力。我们使用MNIST手写数字数据库[44]中的10000个数字作为训练图像。所有图像都被调整大小并归一化为$54\times98$,以测试较小的采样率。这些训练图像通过CGI算法进行重建。训练图像和重建的训练图像分别作为输入和输出馈送到DNN模型中,如图2(a)所示。白噪声和粉红噪声散斑图案分别用于训练过程,使用完全相同的协议。最大训练轮数设置为100,训练迭代次数为31200。程序通过MATLAB R2019a Update 5 (9.6.0.1174912, 64-bit)实现,DNN通过DL Toolbox实现。使用GPU芯片NVIDIA GTX1050来加速计算速度。
The trained DNN is then tested by simulation and used for retrieving CGI results in the experiments. In the testing part, the CGI algorithm generates reconstructed images from testing images with both the MNIST handwritten digits and block style digits, where the later set is different from images in the training group. As shown in Fig. 2(b), the trained DNN, fed with reconstruction testing images, generates CGIDL results. Comparing the difference between CGIDL and testing images, we could measure the quality of the trained DNN. Well-performed DNN can be used for retrieving CGI in the experiment.
训练后的深度神经网络 (DNN) 通过模拟进行测试,并在实验中用于检索计算鬼成像 (CGI) 结果。在测试部分,CGI 算法从测试图像中生成重建图像,这些图像包括 MNIST 手写数字和块状数字,其中后一组图像与训练组中的图像不同。如图 2(b) 所示,训练后的 DNN 在输入重建测试图像后生成 CGIDL 结果。通过比较 CGIDL 和测试图像之间的差异,我们可以评估训练后的 DNN 的质量。表现良好的 DNN 可用于在实验中检索 CGI。
The schematic of the experiment is shown in Fig. 2(c). A CW laser is used to illuminate the DMD, on which the noise patterns are loaded. The pattern generated by the DMD is then projected onto the object. In our experiment, the size of the noise patterns is $216\times392$ DMD pixels (54 $\times$ 98 independent pixels), in which the independent changeable mirrors count for $4\times4$ pixels. Each DMD pixel is $16\mu m\times16\mu m$ in size.
实验示意图如图 2(c) 所示。使用连续波 (CW) 激光器照射 DMD (数字微镜器件),并在其上加载噪声图案。DMD 生成的图案随后投射到物体上。在我们的实验中,噪声图案的大小为 $216\times392$ DMD 像素 (54 $\times$ 98 个独立像素),其中独立可变的微镜占 $4\times4$ 像素。每个 DMD 像素的大小为 $16\mu m\times16\mu m$。
In the CGI process, the quality of the images is proportional to the sampling rate, which is the ratio between the number of illumination patterns $N_{\mathrm{pattern}}$ and $N_{\mathrm{pixel}}$ [45, 46]:
在CGI(计算成像)过程中,图像质量与采样率成正比,采样率是照明模式数量 $N_{\mathrm{pattern}}$ 与像素数量 $N_{\mathrm{pixel}}$ 的比值 [45, 46]:

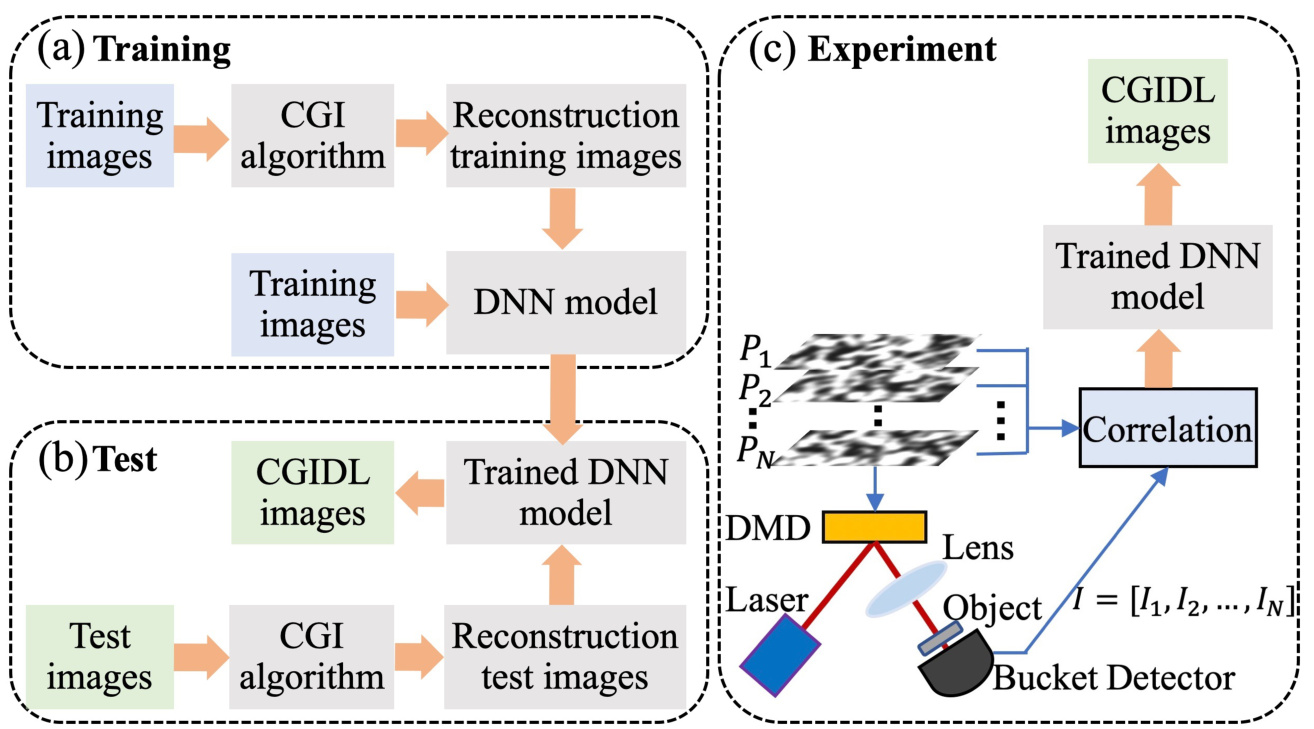
FIG. 2: The flow chart of CGIDL consists of three parts: (a) training, (b) test, and (c) experiment. The DNN model is trained with CGI results from database via simulation. The simulation testing process and experimental measuments use both the handwriting digits and block style digits. The experimental part for CGI uses pink noise and white noise speckle patterns, and their CGI results are ameliorated by trained DNN model.
图 2: CGIDL 的流程图由三部分组成:(a) 训练,(b) 测试,和 (c) 实验。DNN 模型通过仿真从数据库中获取的 CGI 结果进行训练。仿真测试过程和实验测量使用了手写数字和块状数字。CGI 的实验部分使用了粉红噪声和白噪声散斑图案,并通过训练后的 DNN 模型对其 CGI 结果进行了改进。
In the following, We compared the trained network using white noise speckle patterns (DL white) and pink noise speckle patterns (DL pink), as well as the conventional CGI (CGI white) in terms of reconstruction performance with respect to the sampling ratio $\beta$ .
在以下内容中,我们比较了使用白噪声散斑图案 (DL white) 和粉红噪声散斑图案 (DL pink) 训练的网络,以及传统 CGI (CGI white) 在采样比 $\beta$ 下的重建性能。
III. SIMULATION
III. 模拟
To test the robustness of our method to different datasets, noise, and its performs at different sampling rates, we performed a set of simulations. Two sets of testing images are used in the simulation. One of which is the handwriting digits 1-9 from the training set, the other is the block style digits 1-9, which are completely independent of training images. These images have $28\times28$ pixels and are resized into $54\times98$ by widening and amplification. We started our simulation from the comparison of the CGI white, DL white and DL pink without noise at $\beta=5%$ , as shown in Fig. 3. The upper part is with the handwriting digits 1-9, the lower part is with the block style digits 1-9. Apparently, at this low sampling rate, the traditional CGI method fails to retrieve the images in both cases. On the other hand, both DL methods work much better than the traditional CGI. For digits from the training dataset, both methods work almost equally well. For digits from outside the training dataset, DL pink works already better than DL white. For example, the DL white barely can distinguish digits ’3’ and ’8’, but DL pink can retrieve all the digits images.
为了测试我们的方法对不同数据集、噪声的鲁棒性以及在不同采样率下的表现,我们进行了一系列模拟实验。模拟中使用了两种测试图像集。其中一组是训练集中的手写数字1-9,另一组是块状风格的数字1-9,这些图像与训练图像完全独立。这些图像具有$28\times28$像素,并通过加宽和放大调整为$54\times98$像素。我们从无噪声情况下$\beta=5%$的CGI白、DL白和DL粉色的比较开始,如图3所示。上半部分为手写数字1-9,下半部分为块状风格数字1-9。显然,在这种低采样率下,传统的CGI方法在两种情况下都无法恢复图像。另一方面,两种DL方法的表现都远优于传统CGI。对于训练数据集中的数字,两种方法的表现几乎相同。对于训练数据集外的数字,DL粉色已经比DL白色表现更好。例如,DL白色几乎无法区分数字“3”和“8”,但DL粉色可以恢复所有数字图像。
In real application, there always exist noise in the measurement. It is therefore worthwhile checking the performances of different methods under the influence of noise. We then performed another set of simulations with added grayscale random noise. The signal-to-noise ratio (SNR) in logarithmic decibel scale is defined as
在实际应用中,测量中总是存在噪声。因此,检查不同方法在噪声影响下的性能是值得的。我们随后进行了另一组添加了灰度随机噪声的模拟。对数分贝尺度的信噪比 (SNR) 定义为
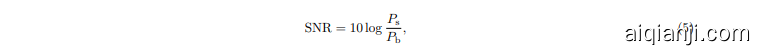
where $P_{\mathrm{s}}$ is the average signal and $P_{\mathrm{b}}$ is the average noise background. Here the SNR is set to be 4.77dB. As shown in Fig. 4, the upper part is the simulation with digits 2, 3, 5, and 6 from the training dataset, and the lower part is the simulation with digits 2, 3, 5, and 6 from the block style dataset. For both datasets, $\beta$ of $100%$ , $50%$ , and $10%$ are chosen for CGI white, $50%$ , $5%$ , and $1%$ for DL white, 5%, $0.8%$ , and $0.5%$ for DL pink. The image quality is better with the increase of $\beta$ for all cases, as expected. As for the CGI white case, it can only give marginally visible images when the sampling rate is beyond $50%$ . The DL white, can retrieve the digits from the training dataset when $\beta=1%$ . However, for the block style digits, it fails to do so even when $\beta=5%$ . Unlike the previous case with no noise, there is a significant difference between objects from the training dataset and outside the training dataset. Lastly, we note that the DL pink trained network can retrieve the training dataset when $\beta=0.5%$ . It can also retrieve clear images for the block style digits at $\beta=0.8%$ . If we compare the black style images at $\beta=5%$ for both DL white and DL pink with the no noise case in Fig. 3, it obvious that the quality of the former is largely affected by the noise, and the latter is barely affected.
其中 $P_{\mathrm{s}}$ 是平均信号,$P_{\mathrm{b}}$ 是平均噪声背景。这里信噪比 (SNR) 设置为 4.77dB。如图 4 所示,上半部分是对训练数据集中数字 2、3、5 和 6 的模拟,下半部分是对块样式数据集中数字 2、3、5 和 6 的模拟。对于这两个数据集,CGI 白色选择了 $\beta$ 为 $100%$、$50%$ 和 $10%$,DL 白色选择了 $\beta$ 为 $50%$、$5%$ 和 $1%$,DL 粉色选择了 $\beta$ 为 5%、$0.8%$ 和 $0.5%$。正如预期的那样,随着 $\beta$ 的增加,所有情况下的图像质量都更好。对于 CGI 白色情况,当采样率超过 $50%$ 时,只能给出勉强可见的图像。DL 白色在 $\beta=1%$ 时可以从训练数据集中恢复数字。然而,对于块样式数字,即使 $\beta=5%$ 也无法恢复。与之前无噪声的情况不同,训练数据集内外的对象之间存在显著差异。最后,我们注意到,DL 粉色训练的网络在 $\beta=0.5%$ 时可以恢复训练数据集。在 $\beta=0.8%$ 时,它还可以恢复块样式数字的清晰图像。如果我们将 DL 白色和 DL 粉色在 $\beta=5%$ 时的块样式图像与图 3 中的无噪声情况进行比较,很明显前者的质量受噪声影响较大,而后者几乎不受影响。

FIG. 3: Simulation results without noise. The upper part used handwriting digits 1-9 from the training dataset, and the lower part used block style digits 1-9, which is outside the training dataset. All the simulations are done at $\beta=5%$ . GT: ground truth.
图 3: 无噪声的仿真结果。上半部分使用了训练数据集中的手写数字 1-9,下半部分使用了训练数据集之外的方块风格数字 1-9。所有仿真均在 $\beta=5%$ 下完成。GT: 真实值。
IV. EXPERIMENT
IV. 实验
To further demonstrate the advantage and applicability of CGIDL with pink noise, we perform experiments with the non-experimental and one-time trained model. All the experiments are done with digits 2, 3, 5, and 6 with block style. The block style is chosen to better compare the different behaviors of all three methods. We manage to start from a relatively low noise level of $\mathrm{SNR}=14.90$ dB. The results are shown in upper part of Fig 5. We can see at this noise level, the CGI white method barely can distinguish the images from the noisy background even at $\beta=100%$ . The DL white trained network, while giving clear images at $\beta=50%$ , fails to fully image the digits at $\beta=5%$ . This is mainly due to the objects are outside the training set, reveal one of the shortcomings of the standard DL network. On the other hand, our DL pink trained network can still give clear results even when $\beta=0.5%$ .
为了进一步展示CGIDL在粉红噪声下的优势和适用性,我们使用非实验性和一次性训练的模型进行了实验。所有实验均使用数字2、3、5和6的块状风格进行。选择块状风格是为了更好地比较三种方法的不同行为。我们从相对较低的噪声水平$\mathrm{SNR}=14.90$ dB开始。结果如图5的上半部分所示。我们可以看到,在这个噪声水平下,CGI白噪声方法即使在$\beta=100%$时也难以从噪声背景中区分图像。DL白噪声训练的网络虽然在$\beta=50%$时给出了清晰的图像,但在$\beta=5%$时无法完全成像数字。这主要是由于对象不在训练集中,揭示了标准DL网络的一个缺点。另一方面,我们的DL粉红噪声训练的网络即使在$\beta=0.5%$时仍能给出清晰的结果。
We then increase the noise level to $\mathrm{SNR}=4.77$ dB, which is the same as the simulation case so we can have a fair comparison. The experimental results are shown in the lower part of Fig 5. The CGI white completely fail to image the digits even at $\beta=100%$ . The DL white trained network is also largely affected by the noisy environment, and not able to fully retrieve the images at $\beta=50%$ . On the other hand, the DL pink method can still image all digits at the sampling rate of $0.8%$ . If we compare these results to the corresponding low noise case, we can see that the image qualities do not change much, indicating our trained network is robust to noise. Also, the results with $\beta=0.8%$ is better than the standard DL white network at $\beta=50%$ , which is about two orders higher.
然后我们将噪声水平增加到 $\mathrm{SNR}=4.77$ dB,与模拟情况相同,以便进行公平比较。实验结果如图 5 的下半部分所示。CGI 白噪声方法在 $\beta=100%$ 时完全无法成像数字。DL 白噪声方法训练的网络在噪声环境中也受到很大影响,无法在 $\beta=50%$ 时完全恢复图像。另一方面,DL 粉红噪声方法在采样率为 $0.8%$ 时仍然能够成像所有数字。如果我们将这些结果与相应的低噪声情况进行比较,可以看到图像质量变化不大,表明我们训练的网络对噪声具有鲁棒性。此外,$\beta=0.8%$ 时的结果优于标准 DL 白噪声网络在 $\beta=50%$ 时的结果,后者大约高出两个数量级。
To quantitatively justify the quality of reconstructed block style images, we compare three evaluating indicators of image quality, i.e., the peak signal to noise ratio (PSNR), the visibility (VIS), and the correlation coefficient (CC):
为了定量评估重建块风格图像的质量,我们比较了三个图像质量评估指标,即峰值信噪比 (PSNR)、可见性 (VIS) 和相关系数 (CC):


FIG. 4: Simulation results of handwriting (top) and block style (bottom) digits 2, 3, 5, 6 with the SNR of 4.77 dB. The results of CGI white are done at $\beta$ of $10%$ , $50%$ , and $100%$ , DL white with $\beta$ of $1%$ , $5%$ , and $50%$ , and DL pink with $\beta$ of $0.5%$ , $0.8%$ , and $5%$ .
图 4: 信噪比 (SNR) 为 4.77 dB 时手写体 (上) 和印刷体 (下) 数字 2、3、5、6 的仿真结果。CGI 白色的结果在 $\beta$ 为 $10%$、$50%$ 和 $100%$ 时完成,DL 白色的结果在 $\beta$ 为 $1%$、$5%$ 和 $50%$ 时完成,DL 粉色的结果在 $\beta$ 为 $0.5%$、$0.8%$ 和 $5%$ 时完成。

FIG. 5: Experimental results with the SNR of 14.90 dB (upper) and 4.77 dB (lower). Objects are block style digits 2,3, 5, 6. Different sampling rates are shown for different methods: CGI white are done at $\beta$ of $10%$ , $50%$ , and $100%$ , DL white with $\beta$ of $1%$ , $5%$ , and $50%$ , and DL pink with $\beta$ of $0.5%$ , $0.8%$ , and $5%$ .
图 5: 信噪比 (SNR) 为 14.90 dB (上) 和 4.77 dB (下) 的实验结果。物体为块状数字 2、3、5、6。不同方法在不同采样率下的表现:CGI 白色背景在 $\beta$ 为 $10%$、$50%$ 和 $100%$ 时完成,DL 白色背景在 $\beta$ 为 $1%$、$5%$ 和 $50%$ 时完成,DL 粉色背景在 $\beta$ 为 $0.5%$、$0.8%$ 和 $5%$ 时完成。

Here MSE is defined in Eq. 2, $\mathrm{Var()}$ is the variance of its arguments, $\mathrm{Cov}()$ is the covariance of its arguments, $k$ is the gray level of the image, and in our experiment $k\equiv8$ .
这里 MSE 在公式 2 中定义,$\mathrm{Var()}$ 是其参数的方差,$\mathrm{Cov}()$ 是其参数的协方差,$k$ 是图像的灰度级别,在我们的实验中 $k\equiv8$。

FIG. 6: PSNR, VIS, and CC for simulation and experiments of the block style digits 2, 3, 5, 6 with three categories: CGI white $\beta$ of $10%$ , $50%$ , and $100%$ ), DL white ( $\beta$ of $1%$ , $5%$ , and $50%$ ), and DL pink ( $\beta$ of $0.5%$ , $0.8%$ , and $5%$ ).
图 6: 块状数字 2、3、5、6 的仿真和实验的 PSNR、VIS 和 CC,分为三类:CGI 白色 ($\beta$ 为 $10%$、$50%$ 和 $100%$)、DL 白色 ($\beta$ 为 $1%$、$5%$ 和 $50%$) 和 DL 粉色 ($\beta$ 为 $0.5%$、$0.8%$ 和 $5%$)。
The results for all cases including simulation without and with noise, experiment with high and low SNR, are shown in Fig. 6. The PSNR, VIS, and CC all indicate that the CGIDL methods are much better than the traditional CGI method. Indeed, as shown in the simulation case, the image quality of CGIDL at 5% is already better than CGI at full sampling rate for all the situations. When we compare the two DL methods, we see that in general DL pink is much better than DL white, as also suggested from Figs. 3, 4, and 5. Since the network is trained using MSE as the loss function, the PSNR of simulation without noise at 5% is very similar for both cases. However, when the noise increases, the PSNR of DL white starts to decrease, while the PSNR of DL pink does not change much. The VIS and CC also have similar behavior as PSNR. We note here that all three indicators suggest DL pink works better than the other two methods, in the experimental results with low SNR, DL pink of 5% sampling rate is already better than the DL white with $50%$ sampling rate.
所有情况下的结果,包括无噪声和有噪声的模拟、高信噪比和低信噪比的实验,如图 6 所示。PSNR、VIS 和 CC 均表明 CGIDL 方法远优于传统的 CGI 方法。实际上,如模拟案例所示,在所有情况下,CGIDL 在 5% 采样率下的图像质量已经优于 CGI 在全采样率下的图像质量。当我们比较两种 DL 方法时,我们发现 DL pink 通常远优于 DL white,正如图 3、图 4 和图 5 所示。由于网络使用 MSE 作为损失函数进行训练,因此在 5% 采样率下,无噪声模拟的 PSNR 在两种情况下非常相似。然而,当噪声增加时,DL white 的 PSNR 开始下降,而 DL pink 的 PSNR 变化不大。VIS 和 CC 也表现出与 PSNR 相似的行为。我们在此注意到,所有三个指标都表明 DL pink 优于其他两种方法,在低信噪比的实验结果中,5% 采样率的 DL pink 已经优于 50% 采样率的 DL white。
V. CONCLUSION
V. 结论
In conclusion, we have demonstrated a deep-learning imaging method with pink noise patterns. The DNN is trained using only simulation data from the handwriting dataset. The trained network can then be applied to various conditions, including objects outside the training set and experiments with strong noise. We have demonstrated imaging results with extremely low sampling rate both in simulation and experiments. We have also evaluated the quality of the images outside the training dataset for both simulation and experimental results, in terms of PSNR,
总之,我们展示了一种使用粉红噪声模式的深度学习成像方法。DNN仅使用手写数据集的模拟数据进行训练。训练后的网络可以应用于各种条件,包括训练集外的物体和强噪声实验。我们展示了在极低采样率下的模拟和实验成像结果。我们还评估了训练数据集外图像的质量,包括模拟和实验结果,以PSNR为衡量标准。
VIS, and CC.
VIS 和 CC。
All results suggest that the DL pink scheme has a great advantage, especially in the low sampling region. This one-time, noise-robust, and non-experimental training CGIDL is eligible to be implemented in various situations and has a wide range of application prospects. The pink noise speckle patterns, trained DNN with various sampling rates, and their raw encoding programs are encapsulated and uploaded online [48]. People who need a quick sampling function on CGIDL can utilize this universal system to get ameliorated results in other CGIDL systems. Further works can reach to other imaging and spectroscopy systems by loss function adjustment and speckle pattern optimization, in order to get spatial, frequency, or time-resolution. In addition to results amelioration, DL may also have great potential to generate optimized speckle patterns for a variety of tasks.
所有结果表明,DL粉红方案具有显著优势,尤其是在低采样区域。这种一次性、抗噪声且无需实验训练的CGIDL适用于多种场景,具有广泛的应用前景。粉红噪声散斑图案、不同采样率下训练的DNN及其原始编码程序已被封装并上传至网络 [48]。需要在CGIDL上快速采样功能的人可以利用这一通用系统,在其他CGIDL系统中获得改进的结果。通过损失函数调整和散斑图案优化,进一步的工作可以扩展到其他成像和光谱系统,以获得空间、频率或时间分辨率。除了结果改进外,DL在生成针对各种任务的优化散斑图案方面也可能具有巨大潜力。
Funding
资金
Air Force Office of Scientific Research (Award No. FA9550-20-1-0366 DEF), Office of Naval Research (Award No. N00014-20-1-2184), Robert A. Welch Foundation (Grant No. A-1261), National Science Foundation (Grant No. PHY-2013771).
空军科学研究办公室(奖项编号:FA9550-20-1-0366 DEF),海军研究办公室(奖项编号:N00014-20-1-2184),Robert A. Welch基金会(资助编号:A-1261),国家科学基金会(资助编号:PHY-2013771)。
Data availability.
数据可用性
The experimental and simulation data are available upon reasonable request. The trained DL networks and raw DL training and test codes are uploaded on the website: https://github.com/XJTU-TAMU-CGI/CGIDL.
实验和模拟数据可根据合理请求提供。训练好的深度学习网络及原始深度学习训练和测试代码已上传至网站:https://github.com/XJTU-TAMU-CGI/CGIDL。
Disclosures
披露
The authors declare no conflicts of interest.
作者声明无利益冲突。