ANALYSIS OF THE EVOLUTION OF ADVANCED TRANSFORMER-BASED LANGUAGE MODELS: EXPERIMENTS ON OPINION MINING
基于先进Transformer的语言模型演化分析:观点挖掘实验
Nour Eddine Zekaoui ∗
Nour Eddine Zekaoui ∗
Siham Yousfi
Siham Yousfi
Maryem Rhanoui
Maryem Rhanoui
ABSTRACT
摘要
Opinion mining, also known as sentiment analysis, is a subfield of natural language processing (NLP) that focuses on identifying and extracting subjective information in textual material. This can include determining the overall sentiment of a piece of text (e.g., positive or negative), as well as identifying specific emotions or opinions expressed in the text, that involves the use of advanced machine and deep learning techniques. Recently, transformer-based language models make this task of human emotion analysis intuitive, thanks to the attention mechanism and parallel computation. These advantages make such models very powerful on linguistic tasks, unlike recurrent neural networks that spend a lot of time on sequential processing, making them prone to fail when it comes to processing long text. The scope of our paper aims to study the behaviour of the cutting-edge Transformer-based language models on opinion mining and provide a high-level comparison between them to highlight their key particularities. Additionally, our comparative study shows leads and paves the way for production engineers regarding the approach to focus on and is useful for researchers as it provides guidelines for future research subjects.
意见挖掘,也称为情感分析,是自然语言处理(NLP)的一个子领域,专注于识别和提取文本材料中的主观信息。这可以包括确定一段文本的整体情感(例如,正面或负面),以及识别文本中表达的特定情绪或观点,涉及使用先进的机器和深度学习技术。最近,基于Transformer的语言模型使得人类情感分析任务变得直观,这得益于注意力机制和并行计算。这些优势使得此类模型在语言任务上非常强大,与循环神经网络不同,后者在顺序处理上花费大量时间,使其在处理长文本时容易失败。本文的范围旨在研究基于Transformer的最先进语言模型在意见挖掘中的行为,并提供它们之间的高层次比较,以突出它们的关键特性。此外,我们的比较研究为生产工程师提供了关于应关注的方法的线索,并为研究人员提供了未来研究主题的指导。
1 Introduction
1 引言
Over the past few years, interest in natural language processing (NLP) [1] has increased significantly. Today, several applications are investing massively in this new technology, such as extending recommend er systems [2], [3], uncovering new insights in the health industry [4], [5], and unraveling e-reputation and opinion mining [6], [7]. Opinion mining is an approach to computational linguistics and NLP that automatically identifies the emotional tone, sentiment, or thoughts behind a body of text. As a result, it plays a vital role in driving business decisions in many industries. However, seeking customer satisfaction is costly expensive. Indeed, mining user feedback regarding the products offered, is the most accurate way to adapt strategies and future business plans. In recent years, opinion mining has seen considerable progress, with applications in social media and review websites. Recommendation may be staff-oriented [2] or user-oriented [8] and should be tailored to meet customer needs and behaviors.
过去几年,人们对自然语言处理 (Natural Language Processing, NLP) [1] 的兴趣显著增加。如今,许多应用正在大力投资这项新技术,例如扩展推荐系统 [2]、[3],在健康行业中发现新的见解 [4]、[5],以及解析电子声誉和意见挖掘 [6]、[7]。意见挖掘是计算语言学和 NLP 的一种方法,能够自动识别文本背后的情感基调、情绪或思想。因此,它在许多行业中推动业务决策方面发挥着至关重要的作用。然而,追求客户满意度是成本高昂的。事实上,挖掘用户对提供产品的反馈是调整策略和未来业务计划的最准确方式。近年来,意见挖掘在社交媒体和评论网站中的应用取得了显著进展。推荐系统可以是面向员工的 [2] 或面向用户的 [8],并且应根据客户需求和行为进行定制。
Nowadays, analyzing people’s emotions has become more intuitive thanks to the availability of many large pre-trained language models such as bidirectional encoder representations from transformers (BERT) [9] and its variants. These models use the seminal transformer architecture [10], which is based solely on attention mechanisms, to build robust language models for a variety of semantic tasks, including text classification. Moreover, there has been a surge in opinion mining text datasets, specifically designed to challenge NLP models and enhance their performance. These datasets are aimed at enabling models to imitate or even exceed human level performance, while introducing more complex features.
如今,得益于许多大型预训练语言模型的可用性,例如基于 Transformer 的双向编码器表示 (BERT) [9] 及其变体,分析人们的情感变得更加直观。这些模型使用开创性的 Transformer 架构 [10],该架构完全基于注意力机制,为各种语义任务(包括文本分类)构建了强大的语言模型。此外,专门设计用于挑战 NLP 模型并提升其性能的意见挖掘文本数据集也大量涌现。这些数据集旨在使模型能够模仿甚至超越人类水平的表现,同时引入更复杂的特征。
Even though many papers have addressed NLP topics for opinion mining using high-performance deep learning models, it is still challenging to determine their performance concretely and accurately due to variations in technical environments and datasets. Therefore, to address these issues, our paper aims to study the behaviour of the cutting-edge transformerbased models on textual material and reveal their differences. Although, it focuses on applying both transformer encoders and decoders, such as BERT [9] and generative pre-trained transformer (GPT) [11], respectively, and their improvements on a benchmark dataset. This enable a credible assessment of their performance and understanding their advantages, allowing subject matter experts to clearly rank the models. Furthermore, through ablations, we show the impact of configuration choices on the final results.
尽管许多论文已经使用高性能深度学习模型探讨了情感挖掘的自然语言处理 (NLP) 主题,但由于技术环境和数据集的差异,具体且准确地评估其性能仍然具有挑战性。因此,为了解决这些问题,本文旨在研究基于 Transformer 的前沿模型在文本材料上的行为,并揭示它们之间的差异。尽管本文主要关注应用 Transformer 编码器和解码器,例如 BERT [9] 和生成式预训练 Transformer (GPT) [11],以及它们在基准数据集上的改进。这使得能够可信地评估它们的性能并理解其优势,从而让领域专家能够清晰地对这些模型进行排名。此外,通过消融实验,我们展示了配置选择对最终结果的影响。
2 Background
2 背景
2.1 Transformer
2.1 Transformer
The transformer [10], as illustrated in Figure 1, is an encoder-decoder model dispensing entirely with recurrence and convolutions. Instead, it leverages the attention mechanism to compute high-level contextual i zed embeddings. Being the first model to rely solely on attention mechanisms, it is able to address the issues commonly associated with recurrent neural networks, which factor computation along symbol positions of input and output sequences, and then precludes parallel iz ation within samples. Despite this, the transformer is highly parallel iz able and requires significantly less time to train. In the upcoming sections, we will highlight the recent breakthroughs in NLP involving transformer that changed the field overnight by introducing its designs, such as BERT [9] and its improvements.
Transformer [10],如图 1 所示,是一种完全摒弃了循环和卷积的编码器-解码器模型。相反,它利用注意力机制来计算高层次的上下文嵌入。作为第一个完全依赖注意力机制的模型,它能够解决通常与循环神经网络相关的问题,这些网络沿着输入和输出序列的符号位置进行因子计算,从而阻碍了样本内的并行化。尽管如此,Transformer 具有高度并行化的特性,并且训练所需的时间显著减少。在接下来的章节中,我们将重点介绍 Transformer 在 NLP 领域的最新突破,这些突破通过引入其设计(如 BERT [9] 及其改进)一夜之间改变了该领域。
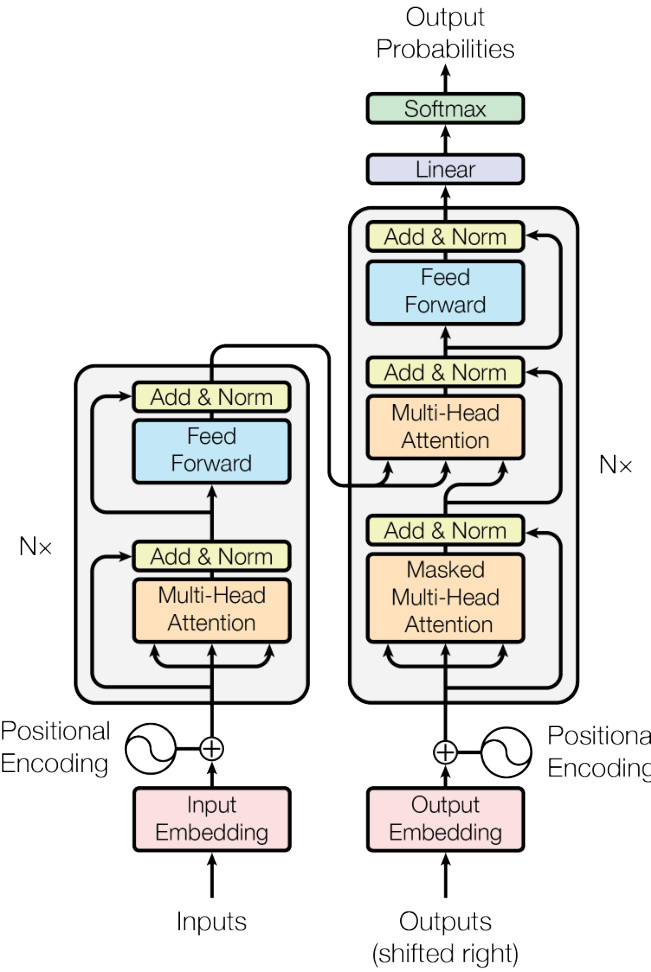
Figure 1: The transformer model architecture [10]
图 1: Transformer 模型架构 [10]
2.2 BERT
2.2 BERT
BERT [9] is pre-trained using a combination of Masked Language Modeling (MLM) and Next Sentence Prediction (NSP) objectives. It provides high-level contextual i zed embeddings grasping the meaning of words in different contexts through global attention. As a result, the pre-trained BERT model can be fine-tuned for a wide range of downstream tasks, such as question answering and text classification, without substantial task-specific architecture modifications.
BERT [9] 通过结合掩码语言建模 (Masked Language Modeling, MLM) 和下一句预测 (Next Sentence Prediction, NSP) 目标进行预训练。它通过全局注意力机制提供高层次的上下文嵌入,能够捕捉不同语境中单词的含义。因此,预训练的 BERT 模型可以在不需要大量任务特定架构修改的情况下,微调用于广泛的下游任务,例如问答和文本分类。
BERT and its variants allow the training of modern data-intensive models. Moreover, they are able to capture the contextual meaning of each piece of text in a way that traditional language models are unfit to do, while being quicker to develop and yielding better results with less data. On the other hand, BERT and other large neural language models are very expensive and computationally intensive to train/fine-tune and make inference.
BERT 及其变体使得现代数据密集型模型的训练成为可能。此外,它们能够以传统语言模型无法做到的方式捕捉每段文本的上下文含义,同时开发速度更快,且在使用较少数据的情况下产生更好的结果。另一方面,BERT 和其他大型神经语言模型在训练/微调和推理过程中非常昂贵且计算密集。
2.3 GPT-I, II, III
2.3 GPT-I, II, III
GPT [11] is the first causal or auto regressive transformer-based model pre-trained using language modeling on a large corpus with long-range dependencies. However, its bigger an optimized version called GPT-2 [12], was pre-trained on WebText. Likewise, GPT-3 [13] is architecturally similar to its predecessors. Its higher level of accuracy is attributed to its increased capacity and greater number of parameters, and it was pre-trained on Common Crawl. The OpenAI GPT family models has taken pre-trained language models by storm, they are very powerful on realistic human text generation and many other miscellaneous NLP tasks. Therefore, a small amount of input text can be used to generate large amount of high-quality text, while maintaining semantic and syntactic understanding of each word.
GPT [11] 是第一个基于因果或自回归 Transformer 的模型,通过在大规模语料库上进行语言建模预训练,具备长距离依赖能力。然而,其更大的优化版本 GPT-2 [12] 是在 WebText 上进行预训练的。同样,GPT-3 [13] 在架构上与其前代相似,其更高的准确性归功于其增加的容量和更多的参数,并在 Common Crawl 上进行预训练。OpenAI 的 GPT 系列模型在预训练语言模型领域引起了巨大轰动,它们在生成逼真的人类文本和许多其他 NLP 任务上表现出色。因此,只需少量输入文本即可生成大量高质量文本,同时保持对每个词语的语义和句法理解。
2.4 ALBERT
2.4 ALBERT
A lite BERT (ALBERT) [14] was proposed to address the problems associated with large models. It was specifically designed to provide contextual i zed natural language representations to improve the results on downstream tasks. However, increasing the model size to pre-train embeddings becomes harder due to memory limitations and longer training time. For this reason, this model arose.
轻量级 BERT (ALBERT) [14] 被提出以解决与大模型相关的问题。它专门设计用于提供上下文化的自然语言表示,以改善下游任务的结果。然而,由于内存限制和更长的训练时间,增加模型大小以预训练嵌入变得更加困难。因此,这个模型应运而生。
ALBERT is a lighter version of BERT, in which next sentence prediction (NSP) is replaced by sentence order prediction (SOP). In addition to that, it employs two parameter-reduction techniques to reduce memory consumption and improve training time of BERT without hurting performance:
ALBERT 是 BERT 的轻量版本,其中下一句预测 (NSP) 被替换为句子顺序预测 (SOP)。除此之外,它还采用了两种参数减少技术,以减少内存消耗并提高 BERT 的训练时间,同时不影响性能:
• Splitting the embedding matrix into two smaller matrices to easily grow the hidden size with fewer parameters, ALBERT separates the hidden layers size from the size of the vocabulary embedding by decomposing the embedding matrix of the vocabulary. • Repeating layers split among groups to prevent the parameter from growing with the depth of the network.
• 将嵌入矩阵分解为两个较小的矩阵,以便用更少的参数轻松增加隐藏层大小,ALBERT通过分解词汇表的嵌入矩阵,将隐藏层大小与词汇表嵌入大小分离。
• 重复分组层以防止参数随着网络深度的增加而增长。
2.5 RoBERTa
2.5 RoBERTa
The choice of language model hyper-parameters has a substantial impact on the final results. Hence, robustly optimized BERT pre-training approach (RoBERTa) [15] is introduced to investigate the impact of many key hyper-parameters along with data size on model performance. RoBERTa is based on Google’s BERT [9] model and modifies key hyper-parameters, where the masked language modeling objective is dynamic and the NSP objective is removed. It is an improved version of BERT, pre-trained with much larger mini-batches and learning rates on a large corpus using self-supervised learning.
语言模型超参数的选择对最终结果有重大影响。因此,引入了鲁棒优化的 BERT 预训练方法 (RoBERTa) [15] 来研究许多关键超参数以及数据大小对模型性能的影响。RoBERTa 基于 Google 的 BERT [9] 模型,并修改了关键超参数,其中掩码语言建模目标是动态的,并且移除了 NSP 目标。它是 BERT 的改进版本,使用自监督学习在大型语料库上以更大的小批量和学习率进行预训练。
2.6 XLNET
2.6 XLNET
The bidirectional property of transformer encoders, such as BERT [9], help them achieve better performance than auto regressive language modeling based approaches. Nevertheless, BERT ignores dependency between the positions masked, and suffers from a pretrain-finetune discrepancy when relying on corrupting the input with masks. In view of these pros and cons, XLNet [16] has been proposed. XLNet is a generalized auto regressive pre training approach that allows learning bidirectional dependencies by maximizing the anticipated likelihood over all permutations of the factorization order. Furthermore, it overcomes the drawbacks of BERT [9] due to its casual or auto regressive formulation, inspired from the transformer-XL [17].
Transformer 编码器的双向特性,如 BERT [9],帮助它们实现了比基于自回归语言建模方法更好的性能。然而,BERT 忽略了被掩盖位置之间的依赖关系,并且在依赖掩码破坏输入时存在预训练-微调差异。鉴于这些优缺点,XLNet [16] 被提出。XLNet 是一种广义的自回归预训练方法,通过最大化所有因子分解顺序排列的预期似然来学习双向依赖关系。此外,它克服了 BERT [9] 的缺点,因为它受到 Transformer-XL [17] 的启发,采用了因果或自回归的公式。
2.7 DistilBERT
2.7 DistilBERT
Unfortunately, the outstanding performance that comes with large-scale pretrained models is not cheap. In fact, operating them on edge devices under constrained computational training or inference budgets remains challenging. Against this backdrop, DistilBERT [18] (or Distilled BERT) has seen the light to address the cited issues by leveraging knowledge distillation [19].
遗憾的是,大规模预训练模型带来的卓越性能并不便宜。事实上,在边缘设备上以受限的计算训练或推理预算运行它们仍然具有挑战性。在此背景下,DistilBERT [18](或 Distilled BERT)应运而生,通过利用知识蒸馏 [19] 来解决上述问题。
DistilBERT is similar to BERT, but it is smaller, faster, and cheaper. It has $40%$ less parameters than BERT base, runs $40%$ faster, while preserving over $95%$ of BERT’s performance. It is trained using distillation of the pretrained BERT base model.
DistilBERT 与 BERT 类似,但它更小、更快且更便宜。它的参数量比 BERT base 少 40%,运行速度快 40%,同时保留了 BERT 95% 以上的性能。它是通过蒸馏预训练的 BERT base 模型进行训练的。
2.8 XLM-RoBERTa
2.8 XLM-RoBERTa
Pre-trained multilingual models at scale, such as multilingual BERT (mBERT) [9] and cross-lingual language models (XLMs) [20], have led to considerable performance improvements for a wide variety of cross-lingual transfer tasks, including question answering, sequence labeling, and classification. However, the multilingual version of RoBERTa [15] called XLM-RoBERTa [21], pre-trained on the newly created 2.5TB multilingual Common Crawl corpus containing 100 different languages, has further pushed the performance. It has shown strong improvements on low-resource languages compared to previous multilingual models.
大规模预训练的多语言模型,如多语言 BERT (mBERT) [9] 和跨语言语言模型 (XLMs) [20],已经在多种跨语言迁移任务中带来了显著的性能提升,包括问答、序列标注和分类。然而,基于新创建的 2.5TB 多语言 Common Crawl 语料库(包含 100 种不同语言)预训练的 XLM-RoBERTa [21](RoBERTa 的多语言版本 [15])进一步推动了性能的提升。与之前的多语言模型相比,它在低资源语言上表现出了显著的改进。
2.9 BART
2.9 BART
Bidirectional and auto-regressive transformer (BART) [22] is a generalization of BERT [9] and GPT [11], it takes advantage of the standard transformer [10]. Concretely, it uses a bidirectional encoder and a left-to-right decoder. It is trained by corrupting text with an arbitrary noising function and learning a model to reconstruct the original text. BART has shown phenomenal success when fine-tuned on text generation tasks such as translation, but also performs well for comprehension tasks like question answering and classification.
双向自回归 Transformer (Bidirectional and auto-regressive transformer, BART) [22] 是 BERT [9] 和 GPT [11] 的泛化版本,它利用了标准的 Transformer [10]。具体来说,它使用了一个双向编码器和一个从左到右的解码器。它通过使用任意的噪声函数破坏文本并训练模型来重建原始文本来进行训练。BART 在微调用于文本生成任务(如翻译)时表现出色,同时在理解任务(如问答和分类)中也表现良好。
2.10 ConvBERT
2.10 ConvBERT
While BERT [9] and its variants have recently achieved incredible performance gains in many NLP tasks compared to previous models, BERT suffers from large computation cost and memory footprint due to reliance on the global self-attention block. Although all its attention heads, BERT was found to be computationally redundant, since some heads simply need to learn local dependencies. Therefore, ConvBERT [23] is a better version of BERT [9], where self-attention blocks are replaced with new mixed ones that leverage convolutions to better model global and local context.
虽然 BERT [9] 及其变体在最近的许多 NLP 任务中相比之前的模型取得了显著的性能提升,但由于依赖于全局自注意力机制,BERT 的计算成本和内存占用较高。尽管 BERT 的所有注意力头都被使用,但研究发现它在计算上是冗余的,因为某些头只需要学习局部依赖关系。因此,ConvBERT [23] 是 BERT [9] 的改进版本,它将自注意力块替换为新的混合块,利用卷积更好地建模全局和局部上下文。
2.11 Reformer
2.11 Reformer
Consistently, large transformer [10] models achieve state-of-the-art results in a large variety of linguistic tasks, but training them on long sequences is costly challenging. To address this issue, the Reformer [24] was introduced to improve the efficiency of transformers while holding the high performance and the smooth training. Reformer is more efficient than transformer [10] thanks to locality-sensitive hashing attention and reversible residual layers instead of the standard residuals, and axial position encoding and other optimization s.
一致地,大型 Transformer [10] 模型在各种语言任务中取得了最先进的结果,但在长序列上训练它们既昂贵又具有挑战性。为了解决这个问题,Reformer [24] 被引入,以提高 Transformer 的效率,同时保持高性能和流畅的训练。Reformer 比 Transformer [10] 更高效,这得益于局部敏感哈希注意力机制和可逆残差层,而不是标准的残差层,以及轴向位置编码和其他优化方法。
2.12 T5
2.12 T5
Transfer learning has emerged as one of the most influential techniques in NLP. Its efficiency in transferring knowledge to downstream tasks through fine-tuning has given birth to a range of innovative approaches. One of these approaches is transfer learning with a unified text-to-text transformer (T5) [25], which consists of a bidirectional encoder and a left-to-right decoder. This approach is reshaping the transfer learning landscape by leveraging the power of being pre-trained on a combination of unsupervised and supervised tasks and reframing every NLP task into text-to-text format.
迁移学习已成为自然语言处理(NLP)中最具影响力的技术之一。它通过微调将知识迁移到下游任务中的高效性催生了一系列创新方法。其中一种方法是使用统一的文本到文本 Transformer (T5) [25] 进行迁移学习,该方法由双向编码器和从左到右的解码器组成。这种方法通过结合无监督和有监督任务进行预训练,并将每个 NLP 任务重新构建为文本到文本格式,正在重塑迁移学习的格局。
2.13 ELECTRA
2.13 ELECTRA
Masked language modeling (MLM) approaches like BERT [9] have proven to be effective when transferred to downstream NLP tasks, although, they are expensive and require large amounts of compute. Efficiently learn an encoder that classifies token replacements accurately (ELECTRA) [26] is a new pre-training approach that aims to overcome these computation problems by training two Transformer models: the generator and the disc rim in at or. ELECTRA trains on a replaced token detection objective, using the disc rim in at or to identify which tokens were replaced by the generator in the sequences. Unlike MLM-based models, ELECTRA is defined over all input tokens rather than just a small subset that was masked, making it a more efficient pre-training approach.
掩码语言建模 (Masked Language Modeling, MLM) 方法,如 BERT [9],已被证明在迁移到下游 NLP 任务时非常有效,尽管它们计算成本高昂且需要大量计算资源。高效学习准确分类 Token 替换的编码器 (Efficiently Learn an Encoder that Classifies Token Replacements Accurately, ELECTRA) [26] 是一种新的预训练方法,旨在通过训练两个 Transformer 模型(生成器和判别器)来克服这些计算问题。ELECTRA 通过替换 Token 检测目标进行训练,使用判别器来识别序列中哪些 Token 被生成器替换。与基于 MLM 的模型不同,ELECTRA 对所有输入 Token 进行定义,而不仅仅是对一小部分被掩码的 Token 进行处理,这使得它成为一种更高效的预训练方法。
2.14 Longformer
2.14 Longformer
While previous transformers were focusing on making changes to the pre-training methods, the long-document transformer (Longformer) [27] comes to change the transformer’s self-attention mechanism. It has became the de facto standard for tackling a wide range of complex NLP tasks, with an new attention mechanism that scales linearly with sequence length, and then being able to easily process longer sequences. Longformer’s new attention mechanism is a drop-in replacement for the standard self-attention and combines a local windowed attention with a task motivated global attention. Simply, it replaces the transformer [10] attention matrices with sparse matrices for higher training efficiency.
虽然之前的 Transformer 主要关注对预训练方法的改进,但长文档 Transformer (Longformer) [27] 则改变了 Transformer 的自注意力机制。它已成为处理各种复杂 NLP 任务的事实标准,其新的注意力机制与序列长度呈线性关系,从而能够轻松处理更长的序列。Longformer 的新注意力机制是对标准自注意力的直接替代,它将局部窗口注意力与任务驱动的全局注意力相结合。简而言之,它用稀疏矩阵替换了 Transformer [10] 的注意力矩阵,以提高训练效率。
2.15 DeBERTa
2.15 DeBERTa
DeBERTa [28] stands for decoding-enhanced BERT with disentangled attention. It is a pre-training approach that extends Google’s BERT [9] and builds on the RoBERTa [15]. Despite being trained on only half of the data used for RoBERTa, DeBERTa has been able to improve the efficiency of pre-trained models through the use of two novel techniques:
DeBERTa [28] 代表解码增强的 BERT(BERT with disentangled attention)。它是一种预训练方法,扩展了 Google 的 BERT [9] 并基于 RoBERTa [15]。尽管 DeBERTa 仅使用了 RoBERTa 一半的数据进行训练,但通过使用两种新技术,它能够提高预训练模型的效率:
• Disentangled attention (DA): an attention mechanism that computes the attention weights among words using disentangled matrices based on two vectors that encode the content and the relative position of each word respectively. • Enhanced mask decoder (EMD): a pre-trained technique used to replace the output softmax layer. Thus, incorporate absolute positions in the decoding layer to predict masked tokens for model pre-training.
- 解耦注意力机制 (Disentangled Attention, DA):一种注意力机制,通过使用基于两个向量的解耦矩阵计算单词之间的注意力权重,这两个向量分别编码每个单词的内容和相对位置。
- 增强掩码解码器 (Enhanced Mask Decoder, EMD):一种预训练技术,用于替换输出 softmax 层。因此,在解码层中引入绝对位置信息,以预测掩码 token 进行模型预训练。
3 Approach
3 方法
Transformer-based pre-trained language models have led to substantial performance gains, but careful comparison between different approaches is challenging. Therefore, we extend our study to uncover insights regarding their fine-tuning process and main characteristics. Our paper first aims to study the behavior of these models, following two approaches: a data-centric view focusing on the data state and quality, and a model-centric view giving more attention to the models tweaks. Indeed, we will see how data processing affects their performance and how adjustments and improvements made to the model over time is changing its performance. Thus, we seek to end with some takeaways regarding the optimal setup that aids in cross-validating a Transformer-based model, specifically model tuning hyper-parameters and data quality.
基于 Transformer 的预训练语言模型带来了显著的性能提升,但不同方法之间的仔细比较具有挑战性。因此,我们扩展了研究,以揭示有关其微调过程和主要特征的见解。本文首先旨在研究这些模型的行为,采用两种方法:一种是以数据为中心的观点,关注数据状态和质量;另一种是以模型为中心的观点,更多地关注模型的调整。我们将看到数据处理如何影响其性能,以及随着时间的推移对模型进行的调整和改进如何改变其性能。因此,我们希望通过一些关于优化设置的总结,帮助交叉验证基于 Transformer 的模型,特别是模型调优的超参数和数据质量。
3.1 Models Summary
3.1 模型总结
In this section, we present the base versions’ details of the models introduced previously as shown in Table A1. We aim to provide a fair comparison based on the following criteria: L-Number of transformer layers, H-Hidden state size or model dimension, A-Number of attention heads, number of total parameters, token iz ation algorithm, data used for pre-training, training devices and computational cost, training objectives, good performance tasks, and a short description regarding the model key points [29]. All these information will help to understand the performance and behaviors of different transformer-based models and aid to make the appropriate choice depending on the task and resources.
在本节中,我们将介绍之前提到的模型的基础版本详细信息,如表 A1 所示。我们旨在基于以下标准提供公平的比较:L-Transformer 层数、H-隐藏状态大小或模型维度、A-注意力头数、总参数数量、Token 化算法、预训练使用的数据、训练设备和计算成本、训练目标、表现良好的任务,以及关于模型关键点的简要描述 [29]。所有这些信息将有助于理解不同基于 Transformer 的模型的性能和行为,并根据任务和资源做出适当的选择。
3.2 Configuration
3.2 配置
It should be noted that we have used almost the same architecture building blocks for all our implemented models as shown in Figure 2 and Figure 3 for both encoder and decoder based models, respectively. In contrast, seq2seq models like BART are merely a bidirectional encoder pursued by an auto regressive decoder. Each model is fed with the three required inputs, namely input ids, token type ids, and attention mask. However, for some models, the position embeddings are optional and can sometimes be completely ignored (e.g RoBERTa), for this reason we have blurred them a bit in the figures. Furthermore, it is important to note that we uniformed the dataset in lower cases, and we tokenized it with tokenizers based on WordPiece [30], Sentence Piece [31], and Byte-pair-encoding [32] algorithms.
需要注意的是,我们为所有实现的模型使用了几乎相同的架构构建块,如图 2 和图 3 所示,分别用于基于编码器和解码器的模型。相比之下,像 BART 这样的 seq2seq 模型仅是一个双向编码器,后接一个自回归解码器。每个模型都接收三个必需的输入,即输入 ID (input ids)、Token 类型 ID (token type ids) 和注意力掩码 (attention mask)。然而,对于某些模型,位置嵌入是可选的,有时甚至可以完全忽略(例如 RoBERTa),因此我们在图中对它们进行了模糊处理。此外,值得注意的是,我们将数据集统一为小写,并使用基于 WordPiece [30]、Sentence Piece [31] 和字节对编码 (Byte-pair-encoding) [32] 算法的 Tokenizer 对其进行分词。
In our experiments, we used a highly optimized setup using only the base version of each pre-trained language model. For training and validation, we set a batch size of 8 and 4, respectively, and fine-tuned the models for 4 epochs over the data with maximum sequence length of 384 for the intent of correspondence to the majority of reviews’ lengths and computational capabilities. The AdamW optimizer is utilized to optimize the models with a learning rate of 3e-5 and the epsilon (eps) used to improve numerical stability is set to 1e-6, which is the default value. Furthermore, the weight decay is set to 0.001, while excluding bias, LayerNorm.bias, and LayerNorm.weight from the decay weight when fine-tuning, and not decaying them when it is set to 0.000. We implemented all of our models using PyTorch and transformers library from Hugging Face, and ran them on an NVIDIA Tesla P100-PCIE GPU-Persistence-M (51G) GPU RAM.
在我们的实验中,我们使用了高度优化的设置,仅使用每个预训练语言模型的基础版本。为了训练和验证,我们分别设置了批量大小为8和4,并在数据上对模型进行了4个周期的微调,最大序列长度为384,以符合大多数评论的长度和计算能力。我们使用AdamW优化器来优化模型,学习率为3e-5,用于提高数值稳定性的epsilon (eps)设置为1e-6,这是默认值。此外,权重衰减设置为0.001,同时在微调时排除偏差、LayerNorm.bias和LayerNorm.weight的衰减权重,当设置为0.000时不进行衰减。我们使用PyTorch和Hugging Face的transformers库实现了所有模型,并在NVIDIA Tesla P100-PCIE GPU-Persistence-M (51G) GPU RAM上运行。
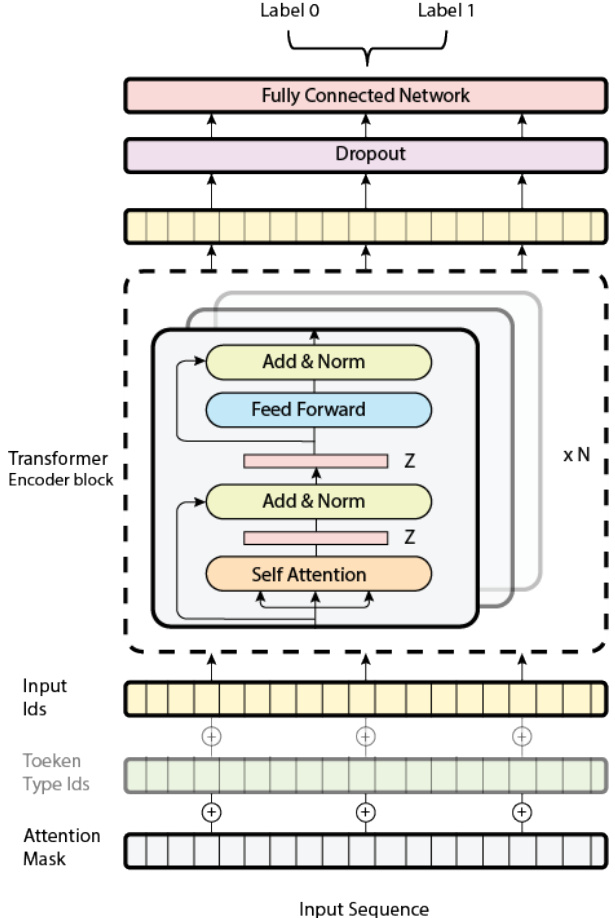
Figure 2: The Architecture of the Transformer Encoder-Based Models.
图 2: 基于 Transformer 编码器的模型架构。
3.3 Evaluation
3.3 评估
Dataset to fine-tune our models, we used the IMDb movie review dataset [33]. A binary sentiment classification dataset having 50K highly polar movie reviews labelled in a balanced way between positive and negative. We chose it for our study because it is often used in research studies and is a very popular resource for researchers working on NLP and ML tasks, particularly those related to sentiment analysis and text classification due to its accessibility, size, balance and pre-processing. In other words, it is easily accessible and widely available, with over 50K reviews well-balanced, with an equal number of positive and negative reviews as shown in Figure 4. This helps prevent biases in the trained model. Additionally, it has already been pre-processed with the text of each review cleaned and normalized.
为了微调我们的模型,我们使用了 IMDb 电影评论数据集 [33]。这是一个二元情感分类数据集,包含 50,000 条高度极化的电影评论,标签在正面和负面之间平衡分布。我们选择它进行研究是因为它经常被用于研究,并且是从事自然语言处理 (NLP) 和机器学习 (ML) 任务的研究人员非常流行的资源,特别是那些与情感分析和文本分类相关的研究,因为它易于获取、规模大、平衡且经过预处理。换句话说,它易于访问且广泛可用,拥有超过 50,000 条评论,且正负面评论数量均衡,如图 4 所示。这有助于防止训练模型中的偏差。此外,它已经过预处理,每条评论的文本都经过清理和规范化。
Metrics To assess the performance of the fine-tuned transformers on the IMDb movie reviews dataset, tracking the loss and accuracy learning curves for each model is an effective method. These curves can help detect incorrect predictions and potential over fitting, which are crucial factors to consider in the evaluation process. Moreover, widely-used metrics, namely accuracy, recall, precision, and F1-score are valuable to consider when dealing with classification problems. These metrics can be defined as:
指标
为了评估在 IMDb 电影评论数据集上微调的 Transformer 的性能,跟踪每个模型的损失和准确率学习曲线是一种有效的方法。这些曲线可以帮助检测错误的预测和潜在的过拟合,这是评估过程中需要考虑的关键因素。此外,在处理分类问题时,广泛使用的指标,即准确率、召回率、精确率和 F1 分数,是值得考虑的。这些指标可以定义为:

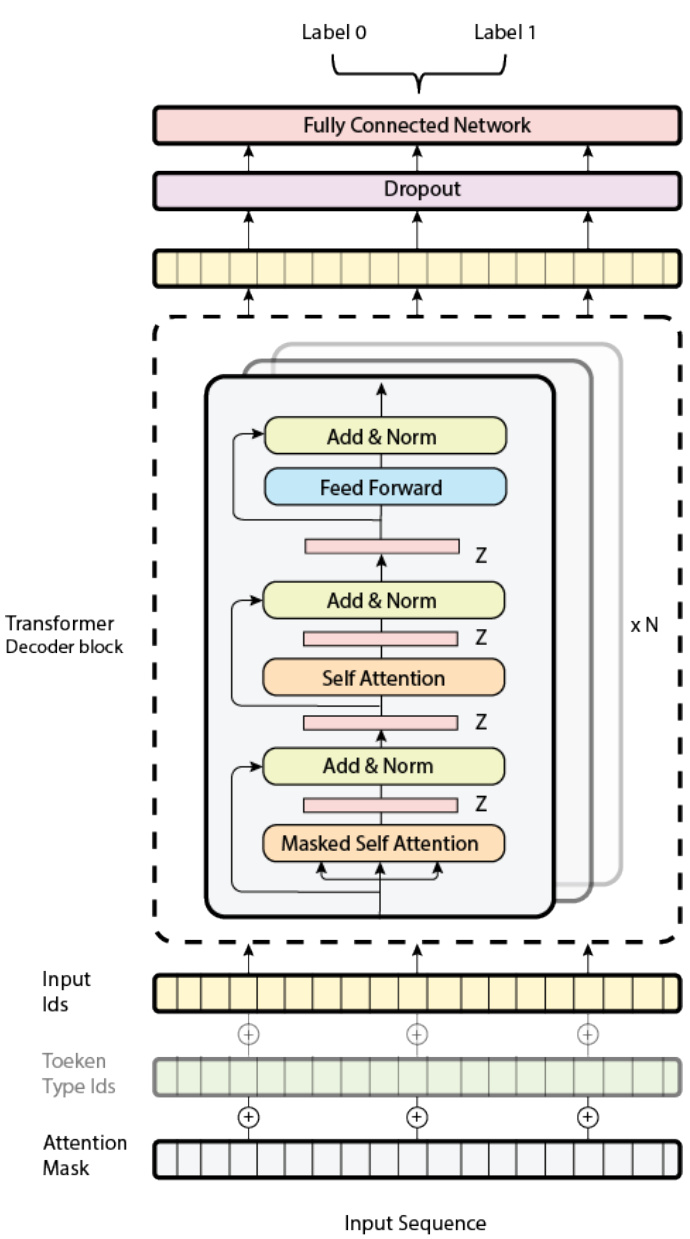
Figure 3: The Architecture of the Transformer Decoder-Based Models.
图 3: 基于 Transformer 解码器的模型架构。

Figure 4: Positive and negative reviews distribution
图 4: 正面和负面评论分布
Table 1: Transformer-based language models validation performance on the opinion mining IMDb dataset
表 1: 基于 Transformer 的语言模型在 IMDb 情感挖掘数据集上的验证性能
| 模型 | 召回率 (Recall) | 精确率 (Precision) | F1 分数 (F1) | 准确率 (Accuracy) |
|---|---|---|---|---|
| BERT | 93.9 | 94.3 | 94.1 | 94.0 |
| GPT | 92.4 | 51.8 | 66.4 | 53.2 |
| GPT-2 | 51.1 | 54.8 | 52.9 | 54.5 |
| ALBERT | 94.1 | 91.9 | 93.0 | 93.0 |
| RoBERTa | 96.0 | 94.6 | 95.3 | 95.3 |
| XLNet | 94.7 | 95.1 | 94.9 | 94.8 |
| DistilBERT | 94.3 | 92.7 | 93.5 | 93.4 |
| XLM-RoBERTA | 83.1 | 71.7 | 77.0 | 75.2 |
| BART | 96.0 | 93.3 | 94.6 | 94.6 |
| ConvBERT | 95.5 | 93.7 | 94.6 | 94.5 |
| DeBERTa | 95.2 | 95.0 | 95.1 | 95.1 |
| ELECTRA | 95.8 | 95.4 | 95.6 | 95.6 |
| Longformer | 95.9 | 94.3 | 95.1 | 95.0 |
| Reformer | 54.6 | 52.1 | 53.3 | 52.2 |
| T5 | 94.8 | 93.4 | 94.0 | 93.9 |
4 Results
4 结果
In this section, we present the fine-tuning main results of our implemented transformer-based language models on the opinion mining task on the IMDb movie reviews dataset. Typically, all the fine-tuned models perform well with fairly high performance, except the three auto regressive models: GPT, GPT-2, and Reformer, as shown in Table 1. The best model, ELECTRA, provides an F1-score of 95.6 points, followed by RoBERTa, Longformer, and DeBERTa, with an F1-score of 95.3, 95.1, and 95.1 points, respectively. On the other hand, the worst model, GPT-2 provide an F1-score of 52.9 points as shown in Figure 5 and Figure 6. From the results, it is clear that purely auto regressive models do not perform well on comprehension tasks like sentiment classification, where sequences may require access to bidirectional contexts for better word representation, therefore, good classification accuracy. Whereas, with auto encoding models taking advantage of left and right contexts, we saw good performance gains. For instance, the auto regressive XLNet model is our fourth best model in Table 1 with an F1 score of $94.9%$ , it incorporates modelling techniques from auto encoding models into auto regressive models while avoiding and addressing limitations of encoders. The code and fine-tuned models are available at [34].
在本节中,我们展示了基于 Transformer 的语言模型在 IMDb 电影评论数据集上的情感分析任务中的微调主要结果。通常情况下,除了三个自回归模型(GPT、GPT-2 和 Reformer)外,所有微调模型都表现良好,性能相当高,如表 1 所示。表现最好的模型 ELECTRA 的 F1 得分为 95.6 分,其次是 RoBERTa、Longformer 和 DeBERTa,F1 得分分别为 95.3、95.1 和 95.1 分。另一方面,表现最差的模型 GPT-2 的 F1 得分为 52.9 分,如图 5 和图 6 所示。从结果中可以明显看出,纯粹的自回归模型在情感分类等理解任务上表现不佳,这些任务可能需要访问双向上下文以获得更好的词表示,从而实现良好的分类准确性。而自编码模型利用左右上下文,我们看到了良好的性能提升。例如,自回归模型 XLNet 是我们表 1 中第四好的模型,F1 得分为 $94.9%$,它将自编码模型的建模技术融入到自回归模型中,同时避免并解决了编码器的局限性。代码和微调模型可在 [34] 获取。

Figure 5: Worst model: GPT-2 loss learning curve
图 5: 最差模型:GPT-2 损失学习曲线
5 Ablation Study
5 消融研究
In Table 2 and Figure 7, we demonstrate the importance of configuration choices through controlled trials and ablation experiments. Indeed, the maximum length of the sequence and data cleaning are particularly crucial. Thus, to make our ablation study credible, we fine-tuned our BERT model with the same setup, changing only the sequence length (max-len) initially and cleaning the data (cd) at another time to observe how they affect the performance of the model.
在表 2 和图 7 中,我们通过对照试验和消融实验展示了配置选择的重要性。实际上,序列的最大长度和数据清洗尤为关键。因此,为了使我们的消融研究可信,我们在相同的设置下微调了 BERT 模型,首先只改变序列长度 (max-len),然后在另一个时间清洗数据 (cd),以观察它们如何影响模型的性能。

Figure 6: Worst model: GPT-2 acc learning curve
图 6: 最差模型:GPT-2 准确率学习曲线
Table 2: Validation results of the BERT model based on different configurations, where cd stands for cleaned data, meaning that the latest model $\left(\mathrm{BERT}_{\mathrm{max-len}=384,c d}\right)$ is trained on an exhaustively cleaned text
表 2: 基于不同配置的 BERT 模型验证结果,其中 cd 表示清理后的数据,意味着最新模型 $\left(\mathrm{BERT}_{\mathrm{max-len}=384,c d}\right)$ 是在经过彻底清理的文本上训练的
| 模型 | 召回率 | 精确率 | F1 | 准确率 |
|---|---|---|---|---|
| BERTmax-len=64 | 86.8% | 84.7% | 85.8% | 85.6% |
| BERTmax-len=384 | 93.9% | 94.3% | 94.1% | 94.0% |
| BERTmax-len=384,cd | 92.6% | 91.6% | 92.1% | 92.2% |
5.1 Effects of Hyper-Parameters
5.1 超参数的影响
The gap between the performance of $\mathrm{BERT}{\mathrm{max-len=64}}$ and $\mathrm{BERT}{\mathrm{max-len}=384}$ on the IMDb dataset is an astounding 8.3 F1 points, as in Table 2, demonstrating how important this parameter is. Thereby, visualizing the distribution of tokens or words count is the ultimate solution for defining the optimal and correct value of the maximum length parameter that corresponds to all the training data points. Figure 8 illustrates the distribution of the number of tokens in the IMDb movie reviews dataset, it shows that the majority of reviews are between 100 and 400 tokens in length. In this context, we chose 384 as the maximum length reference to study the effect of the maximum length parameter, because it covers the majority of review lengths while conserving memory and saving computational resources. It should be noted that the BERT model can process texts up to 512 tokens in length. It is a consequence of the model architecture and can not be adjusted directly.
表 2 中显示,$\mathrm{BERT}{\mathrm{max-len=64}}$ 和 $\mathrm{BERT}{\mathrm{max-len}=384}$ 在 IMDb 数据集上的性能差距高达 8.3 F1 分,这表明该参数的重要性。因此,可视化 Token 或单词计数的分布是定义与所有训练数据点对应的最大长度参数的最佳和正确值的最终解决方案。图 8 展示了 IMDb 电影评论数据集中 Token 数量的分布,显示大多数评论的长度在 100 到 400 个 Token 之间。在这种情况下,我们选择 384 作为最大长度参考来研究最大长度参数的影响,因为它涵盖了大多数评论长度,同时节省内存和计算资源。需要注意的是,BERT 模型可以处理长度最多为 512 个 Token 的文本。这是模型架构的结果,无法直接调整。
5.2 Effects of Data Cleaning
5.2 数据清洗的影响
Traditional machine learning algorithms require extensive data cleaning before vector i zing the input sequence and then feeding it to the model, with the aim of improving both reliability and quality of the data. Therefore, the model can only focus on important features during training. Contrarily, the performance dropped down dramatically by 2 F1 points when we cleaned the data for the BERT model. Indeed, the cleaning carried out aims to normalize the words of each review. It includes lemma ti z ation to group together the different forms of the same word, stemming to reduce a word to its root, which is affixed to suffixes and prefixes, deletion of URLs, punctuation s, and patterns that do not contribute to the sentiment, as well as the elimination of all stop words, except the words “no", “nor", and “not", because their contribution to the sentiment can be tricky. For instance, “Black Panther is boring" is a negative review, but “Black Panther is not boring" is a positive review. This drop can be justified by the fact that BERT model and attention-based models need all the sequence words to better capture the meaning of words’ contexts. However, with cleaning, words may be represented differently from their meaning in the original sequence. Note that “not boring" and “boring" are completely different in meaning, but if the stop word “not" is removed, we end up with two similar sequences, which is not good in sentiment analysis context.
传统的机器学习算法在将输入序列向量化并输入模型之前,需要进行大量的数据清洗,目的是提高数据的可靠性和质量。因此,模型在训练过程中只能专注于重要的特征。相反,当我们为 BERT 模型清洗数据时,性能显著下降了 2 个 F1 点。实际上,清洗的目的是对每条评论中的单词进行标准化处理。它包括词形还原(lemmatization)以将同一单词的不同形式归为一组,词干提取(stemming)以将单词缩减为其词根(词根附加了后缀和前缀),删除 URL、标点符号以及对情感没有贡献的模式,以及删除所有停用词,除了“no”、“nor”和“not”,因为它们对情感的贡献可能比较复杂。例如,“Black Panther is boring”是一条负面评论,但“Black Panther is not boring”则是一条正面评论。这种性能下降可以解释为 BERT 模型和基于注意力机制的模型需要所有序列单词来更好地捕捉单词上下文的含义。然而,经过清洗后,单词的表示可能与原始序列中的含义不同。需要注意的是,“not boring”和“boring”在意义上是完全不同的,但如果删除了停用词“not”,我们最终会得到两个相似的序列,这在情感分析的情境中是不利的。
5.3 Effects of Bias and Training Data
5.3 偏见与训练数据的影响
Carefully observing the accuracy and the loss learning curves in Figure 9 and Figure 10, we notice that the validation loss starts to creep upward and the validation accuracy starts to go down. In this perspective, the model in question continues to lose its ability to generalize well on unseen data. In fact, the model is relatively biased due to the effect of the training data and data-drift issues related to the fine-tuning data. In this context, we assume that the model starts to overfit. However, setting different dropouts, reducing the learning rate, or even trying larger batches will not work. On the other hand, these strategies sometimes give worst results, then a more critical over fitting problem. For this reason, pre training these models on your industry data and vocabulary and then fine-tuning them may be the best solution.
仔细观察图 9 和图 10 中的准确率和损失学习曲线,我们注意到验证损失开始逐渐上升,验证准确率开始下降。从这个角度来看,该模型继续失去对未见数据的良好泛化能力。事实上,由于训练数据的影响以及与微调数据相关的数据漂移问题,该模型相对偏颇。在这种情况下,我们假设模型开始过拟合。然而,设置不同的 dropout、降低学习率,甚至尝试更大的批次都不会奏效。另一方面,这些策略有时会带来更糟糕的结果,进而导致更严重的过拟合问题。因此,在行业数据和词汇上对这些模型进行预训练,然后进行微调可能是最佳解决方案。

Figure 7: Validation accuracy history of BERT model based on different configurations
图 7: 基于不同配置的 BERT 模型验证准确率历史

Figure 8: Distribution of the number of tokens for a better selection of the maximum sequence length
图 8: Token 数量分布,用于更好地选择最大序列长度

Figure 9: Best model: ELECTRA loss learning curve
图 9: 最佳模型:ELECTRA 损失学习曲线

Figure 10: Best model: ELECTRA acc. learning curve
图 10: 最佳模型:ELECTRA 准确率学习曲线
6 Conclusion
6 结论
In this paper, we presented a detailed comparison to highlight the main characteristics of transformer-based pre-trained language models and what differentiates them from each other. Then, we studied their performance on the opinion mining task. Thereby, we deduce the power of fine-tuning and how it helps in leveraging the pre-trained models’ knowledge to achieve high accuracy on downstream tasks, even with the bias they came with due to the pre-training data. Experimental results show how performant these models are. We have seen the highest F1-score with the ELECTRA model with 95.6 points, across the IMDb dataset. Similarly, we found that access to both left and right contexts is necessary when it comes to comprehension tasks like sentiment classification. We have seen that auto regressive models like GPT, GPT-2, and Reformer perform poorly and fail to achieve high accuracy. Nevertheless, XLNet has reached good results even though it is an auto regressive model because it incorporates ideas taken from encoders characterized by their bidirectional property. Indeed, all performances were nearby, including DistilBERT, which helps to gain incredible performance in less training time thanks to knowledge distillation. For example, for 4 epochs, BERT took 70 minutes to train, while DistilBERT took 35 minutes, losing only 0.6 F1 points, but saving half the time taken by BERT. Moreover, our ablation study shows that the maximum length of the sequence is one of the parameters having a significant impact on the final results and must be carefully analyzed and adjusted. Likewise, data quality is a must for good performance, data that will do not need to be processed, since extensive data cleaning processes may not help the model capture local and global contexts in sequences, distilled sometimes with words removed or trimmed during cleaning. Besides, we notice, that the majority of the models we fine-tuned on the IMDb dataset start to overfit at a certain number of epochs, which can lead to biased models. However, good quality data is not even enough, but pre-training a model on large amounts of business problem data and vocabulary may help on preventing it from making wrong predictions and may help on reaching a high level of generalization.
在本文中,我们进行了详细的比较,以突出基于 Transformer 的预训练语言模型的主要特征及其之间的差异。接着,我们研究了它们在情感分析任务中的表现。由此,我们推断出微调的力量,以及它如何帮助利用预训练模型的知识在下游任务中实现高精度,即使这些模型因预训练数据而带有偏差。实验结果表明了这些模型的性能。我们在 IMDb 数据集上观察到 ELECTRA 模型的 F1 分数最高,达到了 95.6 分。同样,我们发现,在情感分类等理解任务中,访问左右上下文是必要的。我们发现像 GPT、GPT-2 和 Reformer 这样的自回归模型表现不佳,无法达到高精度。然而,XLNet 尽管是自回归模型,却取得了不错的结果,因为它结合了来自具有双向特性的编码器的思想。事实上,所有模型的性能都接近,包括 DistilBERT,它通过知识蒸馏在更短的训练时间内获得了令人难以置信的性能。例如,在 4 个 epoch 的情况下,BERT 需要 70 分钟进行训练,而 DistilBERT 仅需 35 分钟,仅损失了 0.6 个 F1 分数,但节省了 BERT 一半的时间。此外,我们的消融研究表明,序列的最大长度是对最终结果有显著影响的参数之一,必须仔细分析和调整。同样,数据质量对于良好的性能至关重要,数据不需要进行过多的处理,因为广泛的数据清洗过程可能无助于模型捕捉序列中的局部和全局上下文,有时在清洗过程中删除或修剪的词语可能会影响结果。此外,我们注意到,我们在 IMDb 数据集上微调的大多数模型在某个 epoch 数后开始过拟合,这可能导致模型偏差。然而,高质量的数据甚至还不够,但在大量业务问题数据和词汇上预训练模型可能有助于防止其做出错误的预测,并有助于达到高水平的泛化能力。
Acknowledgments
致谢
We are grateful to the Hugging Face team for their role in democratizing state-of-the-art machine learning and natural language processing technology through open-source tools. Their commitment to providing valuable resources to the research community is highly appreciated, and we acknowledge their vital contribution to the development of our article.
我们感谢 Hugging Face 团队通过开源工具在普及最先进的机器学习和自然语言处理技术方面所发挥的作用。他们为研究社区提供宝贵资源的承诺深受赞赏,我们承认他们对本文开发的重要贡献。
Appendix
附录
Appendix for “Analysis of the Evolution of Advanced Transformer-based Language Models: Experiments on Opining Mining"
“基于Transformer的高级语言模型演化分析:观点挖掘实验”附录
Table A1: Summary and comparison of transformer-based models.
表 A1: 基于 Transformer 模型的总结与比较
| 模型 | 简短描述 | 性能任务 | 训练目标 | 计算成本 | 训练数据 | Tokenization | 参数总数 | 全局注意力类型 | 层数 | 隐藏层大小 | 头数 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT | 第一个 Transformer-自回归模型 | 零样本、文本摘要、问题翻译、分类、语言推理、问答 | 自回归 | Cloud TPUs 在 Pod 配置中 | WebText2、Books2、Wikipedia | Byte-Pair Encoding | 117M | 全局 | 12 | 768 | 12 |
| ALBERT | 比 GPT 更大且优化,执行零样本任务 | 零样本、文本摘要、问题翻译、问答 | 自回归 | Cloud TPU V3 | Wikipedia、Book Corpus | WordPiece Encoding | 66M | 全局 | 12 | 768 | 12 |
| BERT | 第一个 Transformer-双向模型 | 文本摘要、问题翻译、问答 | 自编码 (MLM - NSP) | 512 TPUs | Wikipedia、Book Corpus | WordPiece Encoding | 110M | 全局 | 12 | 768 | 12 |
| GPT-2 | 比其前身更大 | 零样本、文本摘要、问题翻译、推理、语义相似性 | 自回归 | 8 16GB V100 GPUs | WebText2、Books2、Wikipedia | Byte-Pair Encoding | 1.5B | 全局 | 48 | 1600 | 25 |
| GPT-3 | 比 GPT-2 更大 | 零样本、文本摘要、问题翻译、推理、语义相似性 | 自回归 | 9 32GB V100 GPUs | WebText2、Books2、Wikipedia | Byte-Pair Encoding | 175B | 全局 | 96 | 12288 | 96 |
| DistilBERT | 比 BERT 更小且相似 | 文本摘要、问题翻译、问答 | 自编码 (MLM) | 32 小时在 8 16GB V100 GPUs 上 | Wikipedia、Book Corpus | WordPiece Encoding | 66M | 全局 | 6 | 768 | 12 |
| RoBERTa | 比 BERT 更大且优化 | 文本摘要、问题翻译、问答 | 自编码 (MLM) | 4 天在 512 TPUs 上 | Wikipedia、Book Corpus | Byte-Pair Encoding | 355M | 全局 | 24 | 1024 | 16 |
| 预训练目标 | XLM 证明了预训练方法在多语言语言建模目标上的表现尤为突出,XLM-RoBERTa 使用了 RoBERTa 的技巧,对强语料库和任务产生了影响。 |
|---|---|
| XLM 方法 | 它能够自行检测输入语言(100 种语言),通过替换 Token 检测目标解决了 MLM 问题,并在使用 RoBERTa 的基础上,结合解耦注意力和增强的掩码解码器,显著提高了模型在许多下游任务上的性能,仅使用了 RoBERTa 大型版本一半的数据。DeBERTa 在性能上表现优异,而 XLNet 则结合了这些方法。 |
| 翻译任务和跨语言基准 | 翻译任务和跨语言基准。自然语言理解(NLU) |
| 分析、推理 | DeBERTa 是第一个在 SuperGLUE 基准上取得最先进结果的模型,在 20 个下游任务上表现优于 BERT [38]。情感分析任务中,预训练的 DeBERTa 击败了 XLNet。 |
| 自编码、语言建模(CLM)、翻译语言建模(TLM) | 情感生成器(自动 Token 检测)和判别器(Electra:Token 预测)以及增强的掩码解码器。自回归、解耦机制、替换 Token 检测、掩码解码器。 |
| Volta 用于语言建模任务和 8 个 GPU | 64 个 V100 GPU 上运行 10 天。TPU 芯片。512 个 GPU。5.5 天。 |
| 100 种语言的 Wikipedia | XNLI 语言。CommonCrawl 语料库。 |
| SentencePiece、Byte-Pair 编码 | SentencePiece、WordPiece、Byte-Pair 编码。110M |
| 270M | 110M、125M、全局解耦注意力(Disentangled Attention) |
| 全局 | 全局 2 2 2 |
| 8 8 2048 768 | 768 768 768 |
| 2 2 | 2 2 |
| 2 | |
| ELECTRA、RoBERTa、XLM | DeBERTa、XLNet |
| 使用任意噪声函数将损坏的文本还原为原始文本。为了减少冗余并更好地建模全局和局部上下文,BERT 的自注意力图。01 训练 | 通过两种优化技术(哈希注意力和轴向位置编码)替换混合注意力,结合动态自注意力卷积,以更高效和更快的速度处理序列。为了涵盖大多数语言任务的多样性,T5 在监督和无监督任务的混合上进行了预训练,采用文本到文本格式。局部敏感的 Transformer 块和基于跨度的块 3 |
| BART 在生成任务上超越了其前身,类似于 RoBERTa 在判别任务(如问答和分类)上取得了最先进的结果。参数更少且成本更低,Con- 在下游任务上始终优于 BERT,训练成本更低,如翻译和 vBERT 各种 | Longformer 使用稀疏矩阵代替全矩阵,以应对 Coref- 挑战,通过 SuperGLUE 的问答任务,Longformer 在两个基准数据集 WikiHop 和 Entailement 上取得了最先进的结果,得益于注意力的复杂性减少。 |
| 任务。成本。01 删除 Token,填充和文档自编码,排列,生成序列,编码器掩码,序列句子旋转。编码器解码器,文本 Token | 自回归,到自回归,生成解码器。序列序列,编码器-解码器。解码器 |
| GPU 和 TPU | 在 8 个 GPU v3 TPU TPU 8.10 核心上进行并行化。云 Pods。 |
| Open WebText [39] BooksCorpus。维基百科, | 巨大的清洁语料库,英文维基百科,Open WebText [39] 抓取的书籍 (C4) |
| WordPiece 字节对编码 | SentencePiece SentencePiece 字节对编码 |
| 139M 124M | 编码 220M 149M |
| 全局 全局 | 注意力 149M 带局部敏感哈希的全局 |
| 16 2 | 2 2 |
| | 8 |
| 1024 768 768 | 768 768 |
| 2 | |
| 2 2 | 2 2 |
| | Reformer |
| | |
| | |
| ConvBERT BART | Longformer |