PointGPT: Auto-regressive ly Generative Pre-training from Point Clouds
PointGPT: 点云的自回归生成式预训练
Abstract
摘要
Large language models (LLMs) based on the generative pre-training transformer (GPT) [44] have demonstrated remarkable effectiveness across a diverse range of downstream tasks. Inspired by the advancements of the GPT, we present PointGPT, a novel approach that extends the concept of GPT to point clouds, addressing the challenges associated with disorder properties, low information density, and task gaps. Specifically, a point cloud auto-regressive generation task is proposed to pre-train transformer models. Our method partitions the input point cloud into multiple point patches and arranges them in an ordered sequence based on their spatial proximity. Then, an extractor-generator based transformer decoder [25], with a dual masking strategy, learns latent representations conditioned on the preceding point patches, aiming to predict the next one in an auto-regressive manner. Our scalable approach allows for learning high-capacity models that generalize well, achieving state-of-the-art performance on various downstream tasks. In particular, our approach achieves classification accuracies of $94.9%$ on the ModelNet40 dataset and $93.4%$ on the S can Object NN dataset, outperforming all other transformer models. Furthermore, our method also attains new state-ofthe-art accuracies on all four few-shot learning benchmarks. Codes are available at https://github.com/CGuangyan-BIT/PointGPT.
基于生成式预训练Transformer (GPT) [44] 的大语言模型 (LLMs) 在多种下游任务中展现了显著的有效性。受GPT进展的启发,我们提出了PointGPT,这是一种将GPT概念扩展到点云的新方法,解决了与无序性、低信息密度和任务差距相关的挑战。具体来说,我们提出了一个点云自回归生成任务来预训练Transformer模型。我们的方法将输入点云划分为多个点块,并根据它们的空间邻近性将它们排列成一个有序序列。然后,基于提取器-生成器的Transformer解码器 [25] 采用双重掩码策略,学习以前序点块为条件的潜在表示,旨在以自回归的方式预测下一个点块。我们的可扩展方法允许学习具有良好泛化能力的高容量模型,在各种下游任务中实现了最先进的性能。特别是,我们的方法在ModelNet40数据集上达到了 $94.9%$ 的分类准确率,在Scan Object NN数据集上达到了 $93.4%$ 的准确率,优于所有其他Transformer模型。此外,我们的方法还在所有四个少样本学习基准上取得了新的最先进准确率。代码可在 https://github.com/CGuangyan-BIT/PointGPT 获取。
1 Introduction
1 引言
Point clouds are becoming widely adopted data structures in various application areas, such as autonomous driving and robotics, emphasizing the importance of acquiring informative and comprehensive 3D representations. However, current 3D-centric approaches [9; 38; 39; 56; 30] typically necessitate fully-supervised training from scratch, which entails labor-intensive human annotations. In natural language processing (NLP) and image analysis domains, self-supervised learning (SSL) [11; 18; 45; 5; 44] has emerged as a promising approach for acquiring latent representations without relying on annotations. Among these methods, the generative pre-training transformer (GPT) [44] has been particularly effective at learning representative features [7], where the task is to predict data in an auto-regressive manner. Due to its remarkable performance, we naturally ask the question: can the GPT be adapted to point clouds and serve as an effective 3D representation learner?
点云正在成为自动驾驶和机器人等各种应用领域中广泛采用的数据结构,这凸显了获取信息丰富且全面的3D表示的重要性。然而,当前以3D为中心的方法 [9; 38; 39; 56; 30] 通常需要从头开始进行全监督训练,这需要耗费大量人力进行标注。在自然语言处理 (NLP) 和图像分析领域,自监督学习 (SSL) [11; 18; 45; 5; 44] 已经成为一种无需依赖标注即可获取潜在表示的有前景的方法。在这些方法中,生成式预训练 Transformer (GPT) [44] 在学习代表性特征方面特别有效 [7],其任务是以自回归的方式预测数据。由于其卓越的性能,我们自然会问一个问题:GPT 能否适应点云并作为一种有效的3D表示学习器?
To answer this question, we exploit the GPT scheme for point cloud understanding. However, it is challenging to employ GPT on point clouds due to the following reasons: (I) Disorder properties. In contrast with the sequential arrangement of words in a sentence, a point cloud is a structure that lacks inherent order. To address this issue, point patches are arranged based on a geometric ordering, namely the Morton-order curve [34], which introduces sequential properties and preserves the local structures. (II) Information density differences. Languages are characterized by high information richness, therefore, the auto-regressive prediction task requires advanced language understanding. On the contrary, point clouds are natural signals with heavy redundancy, thereby the prediction task can be accomplished even without holistic comprehension. To address this disparity, a dual masking strategy is proposed, which additionally masks attending tokens for each token. This strategy effectively reduces redundancy and provides a challenging task that demands comprehensive understanding. (III) Gaps between generation and downstream tasks. Even though the model with a dual masking strategy exhibits sophisticated comprehension, the generation task primarily involves predicting individual points, which may result in the learned latent representations with a lower semantic level than downstream tasks. To mitigate this challenge, an extractor-generator architecture is introduced to the transformer decoder [25], such that the generation task is facilitated through the generator, thus enhancing the semantic level of the latent representations learned by the extractor.
为了回答这个问题,我们利用GPT方案进行点云理解。然而,由于以下原因,在点云上应用GPT具有挑战性:(I) 无序特性。与句子中单词的顺序排列不同,点云是一种缺乏固有顺序的结构。为了解决这个问题,点块基于几何顺序(即Morton-order曲线 [34])进行排列,从而引入顺序特性并保留局部结构。(II) 信息密度差异。语言具有高信息丰富性,因此自回归预测任务需要高级的语言理解能力。相反,点云是具有大量冗余的自然信号,因此即使没有整体理解,预测任务也可以完成。为了解决这种差异,提出了一种双重掩码策略,该策略额外为每个Token掩码了关注Token。这种策略有效地减少了冗余,并提供了一个需要全面理解的具有挑战性的任务。(III) 生成任务与下游任务之间的差距。尽管采用双重掩码策略的模型表现出复杂的理解能力,但生成任务主要涉及预测单个点,这可能导致学习到的潜在表示语义水平低于下游任务。为了缓解这一挑战,在Transformer解码器中引入了提取器-生成器架构 [25],使得生成任务通过生成器进行,从而提高了提取器学习到的潜在表示的语义水平。
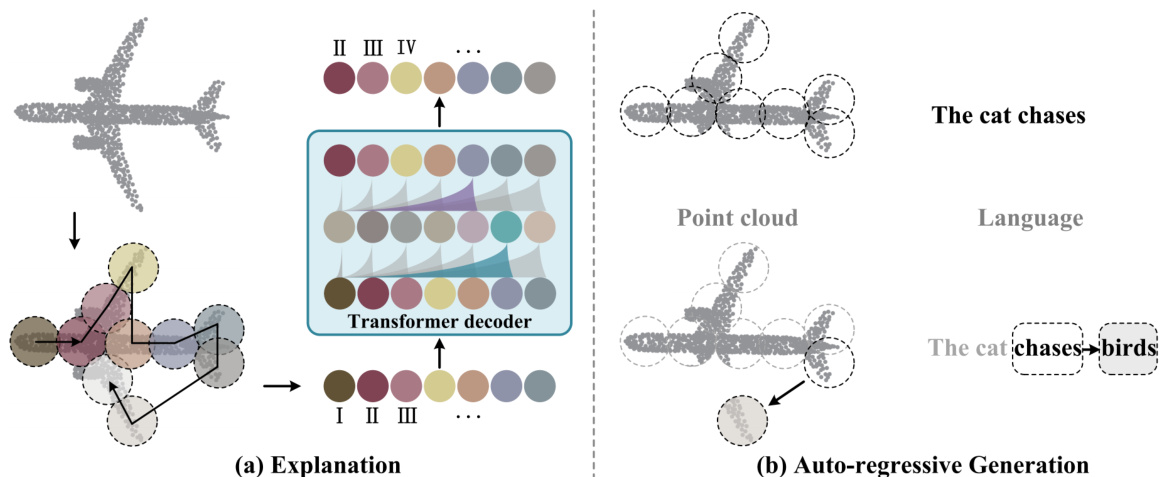
Figure 1: Illustration of our PointGPT. The transformer decoder is pre-trained to predict point patches in an auto-regressive manner. Such a design enables our method to predict patches without dedicated specifications and avoids positional information leakage, leading to improved generalization ability.
图 1: PointGPT 的示意图。Transformer 解码器以自回归的方式进行预训练,用于预测点云块。这种设计使我们的方法能够在无需专门规范的情况下预测块,并避免了位置信息泄露,从而提高了泛化能力。
Based on the above analysis, we propose a novel SSL framework for point clouds, called PointGPT. Specifically, our method partitions the input point cloud into multiple irregular point patches, which are subsequently organized using the Morton curve. Then, an extractor-generator based transformer decoder, with a dual masking strategy, processes the point patch sequences to learn latent representations conditioned on the unmasked preceding contents, and predicts the next point patches in an auto-regressive manner. Unlike recently developed masked point modeling approaches [64; 37; 66] that rely on positional information to specify reconstruction regions, resulting in the leakage of the overall object shape, our concise design, as illustrated in Figure 1, effectively circumvents the leakage of positional information and yields an enhanced generalization ability. Consequently, our PointGPT surpasses other single-modal SSL methods with comparable model sizes.
基于上述分析,我们提出了一种新颖的点云自监督学习(SSL)框架,称为 PointGPT。具体来说,我们的方法将输入点云划分为多个不规则的点块,随后使用 Morton 曲线进行组织。然后,基于提取器-生成器的 Transformer 解码器通过双重掩码策略处理点块序列,以学习基于未掩码前序内容的潜在表示,并以自回归方式预测下一个点块。与最近开发的依赖位置信息来指定重建区域的掩码点建模方法 [64; 37; 66] 不同,这些方法会导致整体物体形状的泄露,而我们的简洁设计(如图 1 所示)有效地避免了位置信息的泄露,并增强了泛化能力。因此,我们的 PointGPT 在模型大小相当的情况下超越了其他单模态 SSL 方法。
Inspired by the promising performance exhibited by our PointGPT, we endeavor to investigate its scaling property and push its performance limit further. However, a significant challenge arises due to the limited scale of the existing public point cloud datasets compared to NLP and images. This dataset size disparity introduces potential over fitting concerns. To alleviate this and fully unleash the power of PointGPT, a larger pre-training dataset is collected by mixing various point cloud datasets, such as ShapeNet [6] and S3DIS [3]. Moreover, a subsequent post-pre-training stage [55] is introduced, which involves performing supervised learning on the collected labeled dataset, enabling PointGPT to incorporate semantic information from multiple sources. Within this framework, our scaled models achieve state-of-the-art (SOTA) performance on various downstream tasks. In object classification tasks, our PointGPT achieves $94.9%$ accuracy on the ModelNet40 dataset and $93.4%$ accuracy on the S can Object NN dataset, outperforming all other transformer models. In few-shot learning tasks, our method also attains new SOTA performance on all four benchmarks.
受到我们的 PointGPT 所展现出的优异性能的启发,我们致力于研究其扩展特性并进一步推动其性能极限。然而,由于现有的公开点云数据集规模相较于自然语言处理(NLP)和图像领域较小,这一数据集规模的差异引发了潜在的过拟合问题。为了缓解这一问题并充分发挥 PointGPT 的潜力,我们通过混合多个点云数据集(如 ShapeNet [6] 和 S3DIS [3])收集了一个更大的预训练数据集。此外,我们还引入了一个后续的预训练后阶段 [55],该阶段涉及对收集到的标注数据集进行监督学习,使 PointGPT 能够整合来自多个来源的语义信息。在这一框架下,我们的扩展模型在各种下游任务中实现了最先进的(SOTA)性能。在物体分类任务中,我们的 PointGPT 在 ModelNet40 数据集上达到了 $94.9%$ 的准确率,在 ScanObjectNN 数据集上达到了 $93.4%$ 的准确率,超越了所有其他 Transformer 模型。在少样本学习任务中,我们的方法也在所有四个基准测试中取得了新的 SOTA 性能。
Our main contributions can be summarized as follows: (I) A novel GPT scheme, termed PointGPT, is proposed for point cloud SSL. PointGPT leverages a point cloud auto-regressive generation task while mitigating positional information leakage, outperforming other single-modal SSL methods. (II) A dual masking strategy is proposed to create an effective generation task, and an extractor-generator transformer architecture is introduced to enhance the semantic level of the learned representations. These designs boost the performance of PointGPT on downstream tasks. (III) A post-pre-training
我们的主要贡献可以总结如下:(I) 提出了一种新颖的 GPT 方案,称为 PointGPT,用于点云自监督学习 (SSL)。PointGPT 利用点云自回归生成任务,同时减轻位置信息泄露,优于其他单模态 SSL 方法。(II) 提出了一种双重掩码策略,以创建有效的生成任务,并引入了提取器-生成器 Transformer 架构,以增强学习表示的语义水平。这些设计提升了 PointGPT 在下游任务中的性能。(III) 一种后预训练
2 Related Work
2 相关工作
2.1 Self-supervised Learning for NLP and Image Processing
2.1 自监督学习在自然语言处理和图像处理中的应用
Self-supervised learning has attracted significant attention in recent years, especially in the fields of NLP and image processing, owing to its ability to learn useful representations without labeled data. The core idea of SSL is to design a pretext task to learn the distribution of the given data, obtaining beneficial features for the subsequent supervised modeling tasks [21; 13]. Contrastive learning [8; 15; 63; 36; 32; 42; 49] has been a popular disc rim i native self-supervised approach in both NLP and image processing, with the goal of grouping similar samples closer and diverse samples further apart. However, generative SSL methods [4; 18; 7; 11; 47; 44] have recently achieved more competitive performance. BERT [11] utilizes a bidirectional transformer to process the randomly masked text and reconstruct the original context. ELMo [47] adopts bidirectional LSTM [19] and generates subsequent words from left to right given representations of the previous contents. The GPT [44] also utilizes the auto-regressive prediction approach, but it employs a unidirectional transformer architecture, and the model is fine-tuned by updating all pre-trained parameters. In the computer vision field, BEiT [4] and MAE [18] randomly mask input patches, and pre-train models to recover the masked patches in the pixel space. Image-GPT [7] trains a sequence transformer to auto-regressive ly predict pixels without incorporating knowledge concerning the 2D input structure, exhibiting promising representation learning capabilities after pre-training.
近年来,自监督学习 (Self-supervised learning, SSL) 因其无需标注数据即可学习有用表示的能力,在自然语言处理 (NLP) 和图像处理领域引起了广泛关注。SSL 的核心思想是设计一个预训练任务来学习给定数据的分布,从而为后续的监督建模任务获取有益的特征 [21; 13]。对比学习 (Contrastive learning) [8; 15; 63; 36; 32; 42; 49] 是 NLP 和图像处理领域中一种流行的判别式自监督方法,其目标是将相似的样本聚集在一起,并将不同的样本分开。然而,生成式 SSL 方法 [4; 18; 7; 11; 47; 44] 最近取得了更具竞争力的性能。BERT [11] 使用双向 Transformer 处理随机掩码的文本并重建原始上下文。ELMo [47] 采用双向 LSTM [19],并根据先前内容的表示从左到右生成后续单词。GPT [44] 也使用自回归预测方法,但它采用单向 Transformer 架构,并通过更新所有预训练参数来微调模型。在计算机视觉领域,BEiT [4] 和 MAE [18] 随机掩码输入图像块,并预训练模型以在像素空间中恢复被掩码的图像块。Image-GPT [7] 训练一个序列 Transformer 来自回归预测像素,而不考虑 2D 输入结构的知识,在预训练后表现出有前景的表示学习能力。
2.2 Self-supervised Learning for Point Cloud
2.2 点云的自监督学习
The success of SSL in NLP and image processing has motivated researchers to develop SSL frameworks for point cloud representation learning. Among these methods, the contrastive methods [59; 67; 35; 20; 61] have been extensively investigated. Depth Contrast [67] constructs augmented depth maps and performs an instance discrimination task for the extracted global features. Similarly, MVIF [20] introduces cross-modal and cross-view invariance constraints to achieve self-supervised modal- and view-invariant feature learning. Another line of work [40; 12; 60] is proposed to integrate cross-modal information and leverage knowledge transferred from language or image models for 3D learning. ACT [12] employs cross-modal auto-encoders as teacher models to acquire knowledge from other modalities. Different from these methods, our work attempts to learn the intrinsic properties of point clouds without relying on cross-modal information and teacher models. Most relevant to our work are generative methods [22; 1; 48; 37; 64; 66; 31], especially recently proposed masked point modeling methods [37; 64; 66; 31]. Point-MAE extends the MAE by randomly masking point patches and reconstructing masked regions. Point-M2AE additionally utilizes a hierarchical transformer architecture and designs a corresponding masking strategy. However, masked point modeling methods still suffer from overall object shape leakage, which limits their ability to effectively generalize to downstream tasks. In this paper, we exploit the auto-regressive pre-training for point clouds and address unique challenges associated with the properties of point clouds. Our concise design avoids positional information leakage, thereby enhancing the generalization ability.
SSL(自监督学习)在自然语言处理(NLP)和图像处理领域的成功激励了研究人员开发用于点云表示学习的SSL框架。在这些方法中,对比学习方法 [59; 67; 35; 20; 61] 得到了广泛研究。Depth Contrast [67] 构建了增强的深度图,并对提取的全局特征执行实例判别任务。类似地,MVIF [20] 引入了跨模态和跨视角不变性约束,以实现自监督的模态和视角不变特征学习。另一类工作 [40; 12; 60] 提出整合跨模态信息,并利用从语言或图像模型转移的知识进行3D学习。ACT [12] 使用跨模态自编码器作为教师模型,从其他模态中获取知识。与这些方法不同,我们的工作试图在不依赖跨模态信息和教师模型的情况下学习点云的内在属性。与我们的工作最相关的是生成方法 [22; 1; 48; 37; 64; 66; 31],尤其是最近提出的掩码点建模方法 [37; 64; 66; 31]。Point-MAE 通过随机掩码点块并重建掩码区域扩展了MAE。Point-M2AE 进一步利用了分层Transformer架构,并设计了相应的掩码策略。然而,掩码点建模方法仍然存在整体物体形状泄露的问题,这限制了它们在下游任务中的有效泛化能力。在本文中,我们利用自回归预训练来处理点云,并解决与点云属性相关的独特挑战。我们的简洁设计避免了位置信息泄露,从而增强了泛化能力。
3 PointGPT
3 PointGPT
Given a point cloud $\pmb{X}={x_{1},x_{2},...,x_{M}}\subseteq\mathbb{R}^{3}$ , the overall pipeline of PointGPT during pre-training is illustrated in Fig. 2. The point cloud sequencer module is utilized to construct an ordered sequence of point patches. This is achieved by dividing the point cloud into irregular patches and arranging them in Morton order. The resulting sequence is then fed into the extractor to learn latent representations, and the generator predicts the subsequent point patches in an auto-regressive manner. After the pre-training stage, the generator is discarded, and the extractor without the use of a dual masking strategy, leverages the learned latent representations for downstream tasks.
给定一个点云 $\pmb{X}={x_{1},x_{2},...,x_{M}}\subseteq\mathbb{R}^{3}$,图 2 展示了 PointGPT 在预训练阶段的整体流程。点云序列化模块用于构建有序的点云块序列。这是通过将点云划分为不规则的块并按 Morton 顺序排列来实现的。生成的序列随后被输入到提取器中以学习潜在表示,生成器则以自回归的方式预测后续的点云块。在预训练阶段结束后,生成器被丢弃,提取器在不使用双重掩码策略的情况下,利用学习到的潜在表示进行下游任务。
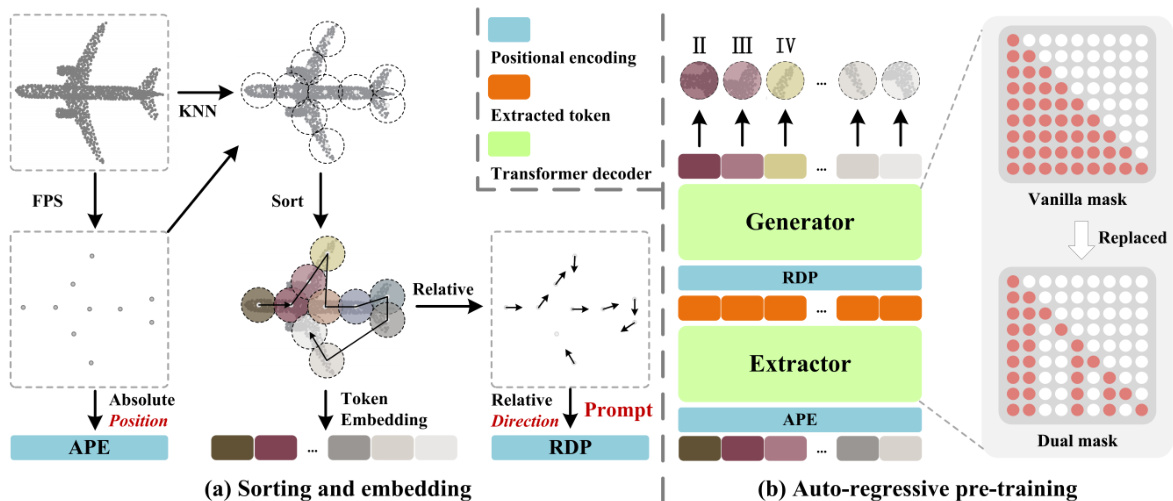
Figure 2: Overall architecture of our PointGPT. (a) The input point cloud is divided into multiple point patches, which are then sorted and arranged in an ordered sequence. (b) An extractor-generator based transformer decoder is employed along with a dual masking strategy for the auto-regressive ly prediction of the point patches. In this example, the additional mask of the dual masking strategy is applied to the same group of random tokens for better illustration purposes.
图 2: 我们的 PointGPT 的整体架构。(a) 输入的点云被划分为多个点块,然后排序并排列成一个有序序列。(b) 使用基于提取器-生成器的 Transformer 解码器以及双掩码策略进行点块的自回归预测。在这个例子中,双掩码策略的额外掩码被应用于同一组随机 Token 以便更好地说明。
3.1 Point Cloud Sequencer
3.1 点云序列器
In the field of NLP, the GPT approach benefits from an easily accessible language vocabulary and the inherent ordered properties of words. In contrast, the point cloud domain lacks a predefined vocabulary, and a point cloud is a sparse structure that exhibits a characteristic of the disorder. To overcome these challenges and obtain an ordered point cloud sequence with each component unit capturing rich geometric information, a three-stage process consisting of point patch partitioning, sorting, and embedding is employed.
在自然语言处理(NLP)领域,GPT方法受益于易于访问的语言词汇和单词固有的有序特性。相比之下,点云领域缺乏预定义的词汇,且点云是一种稀疏结构,表现出无序的特性。为了克服这些挑战并获得一个有序的点云序列,其中每个组成单元都能捕捉丰富的几何信息,采用了由点云块划分、排序和嵌入组成的三阶段过程。
Point patch partitioning: Taking the inherent sparsity and disorder properties of point clouds into account, the input point clouds are processed by farthest point sampling (FPS) and the K-nearest neighbors (KNN) algorithms to obtain center points and point patches. Given a point cloud $\boldsymbol{X}$ with $M$ points, we initially sample $n$ center points $C$ using FPS. Then, the KNN algorithm is utilized to construct $n$ point patches $_P$ by selecting the $k$ nearest points from $\boldsymbol{X}$ for each center point. In summary, the partitioning procedure is formulated as:
点云分块划分:考虑到点云固有的稀疏性和无序性,输入点云通过最远点采样 (FPS) 和 K 近邻 (KNN) 算法进行处理,以获得中心点和点块。给定一个包含 $M$ 个点的点云 $\boldsymbol{X}$,我们首先使用 FPS 采样 $n$ 个中心点 $C$。然后,利用 KNN 算法为每个中心点从 $\boldsymbol{X}$ 中选择 $k$ 个最近的点,构建 $n$ 个点块 $_P$。总结来说,划分过程可以表示为:
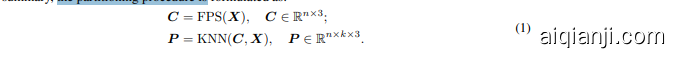
Sorting: To address the inherent disorder properties of point clouds, the obtained point patches are organized into a coherent sequence based on their center points. Concretely, the coordinates of the center points are encoded into one-dimensional space using Morton code [34], followed by sorting to determine the order $\mathcal{O}$ of these center points. The point patches are then arranged in the same order. The sorted center points $C^{s}$ and sorted point patches $P^{s}$ are obtained as follows:
排序:为了解决点云固有的无序性,获取的点块根据其中心点被组织成一个连贯的序列。具体来说,中心点的坐标使用Morton码 [34] 编码到一维空间,然后通过排序确定这些中心点的顺序 $\mathcal{O}$。点块随后按照相同的顺序排列。排序后的中心点 $C^{s}$ 和排序后的点块 $P^{s}$ 如下所示:
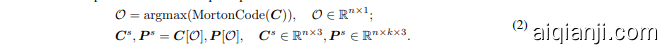
Embedding: Following Point-MAE [37], a PointNet [38] network is employed to extract rich geometric information for each point patch. To facilitate training convergence, the normalized coordinates of each point are utilized with respect to its center point. Specifically, the sorted point patches $P^{s}$ are embedded into $D$ -dimensional tokens $\mathbf{\delta}_{\mathbf{{T}}}$ as follows:
嵌入:遵循 Point-MAE [37],采用 PointNet [38] 网络为每个点块提取丰富的几何信息。为了促进训练收敛,使用每个点相对于其中心点的归一化坐标。具体来说,排序后的点块 $P^{s}$ 被嵌入到 $D$ 维的 Token $\mathbf{\delta}_{\mathbf{{T}}}$ 中,如下所示:
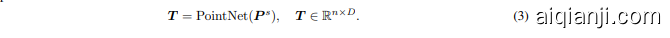
3.2 Transformer Decoder with a Dual Masking Strategy
3.2 采用双重掩码策略的 Transformer 解码器
A straightforward extension of the GPT [44] to point clouds can be achieved by utilizing the vanilla transformer decoder to auto-regressive ly predict point patches, followed by fine-tuning all pre-trained parameters for downstream tasks. Nevertheless, this approach suffers from low-level semantics due to the limited information density of point clouds and the gaps between generation and downstream tasks. To address this issue, a dual masking strategy is proposed to facilitate comprehensive understanding of point clouds. Additionally, an extractor-generator transformer architecture is introduced, where the generator is more specialized for the generation task and is discarded after pre-training, enhancing the semantic level of the latent representations that are learned by the extractor.
GPT [44] 在点云上的直接扩展可以通过使用原始 Transformer 解码器自回归地预测点云块,然后对所有预训练参数进行微调以用于下游任务来实现。然而,由于点云的信息密度有限以及生成任务与下游任务之间的差距,这种方法存在低层次语义的问题。为了解决这个问题,提出了一种双重掩码策略,以促进对点云的全面理解。此外,还引入了一种提取器-生成器 Transformer 架构,其中生成器更专注于生成任务,并在预训练后被丢弃,从而提高了提取器学习的潜在表示的语义水平。
Dual masking strategy: The vanilla masking strategy in the transformer decoder enables each token to receive information from all the preceding point tokens. To further encourage the learning of useful representations, the dual masking strategy is proposed, which additionally masks a proportion of the attending preceding tokens of each token during pre-training. The resulting dual mask $M^{d}$ is illustrated in Fig. 2(b), the self-attention process with a dual masking strategy can be represented as:
双掩码策略:Transformer解码器中的原始掩码策略使每个Token能够接收来自所有前序点Token的信息。为了进一步鼓励学习有用的表示,提出了双掩码策略,该策略在预训练期间额外屏蔽了每个Token的部分前序Token。结果的双掩码$M^{d}$如图2(b)所示,使用双掩码策略的自注意力过程可以表示为:

where $Q,K,V$ are $\mathbf{\delta}_{\mathbf{T}}$ encoded with different weights for the $D$ channels. The masked locations in $M^{d}$ are set to 0, while the unmasked locations are set to 1.
其中 $Q,K,V$ 是 $\mathbf{\delta}_{\mathbf{T}}$ 通过不同权重编码得到的 $D$ 通道。$M^{d}$ 中被掩码的位置设置为 0,而未掩码的位置设置为 1。
Extractor-generator: Our extractor is composed entirely of transformer decoder blocks with a dual masking strategy, obtaining latent representations $\tau$ , where each point token only attends to the unmasked preceding tokens. Considering that point patches are represented in normalized coordinates, and global structures of point clouds are essential for point cloud understanding, sinusoidal positional encodings [53] (PE) are utilized to map the coordinates of the sorted center points $C^{s}$ to the absolute positional encoding $(A P E)$ . Positional encodings are added to every transformer block to provide location information and incorporate global structural information.
提取器-生成器:我们的提取器完全由采用双重掩码策略的Transformer解码器块组成,获取潜在表示 $\tau$,其中每个点Token仅关注未掩码的前置Token。考虑到点块以归一化坐标表示,且点云的全局结构对于点云理解至关重要,我们利用正弦位置编码 [53] (PE) 将排序后的中心点 $C^{s}$ 的坐标映射到绝对位置编码 $(A P E)$。位置编码被添加到每个Transformer块中,以提供位置信息并融入全局结构信息。
The generator architecture is similar to the extractor architecture but contains fewer transformer blocks. It takes the extracted tokens $\tau$ as input and generates point tokens ${\pmb T}^{g}$ for the following prediction head. However, the patch order may be affected by the center point sampling process, inducing ambiguity when predicting the subsequent patches. This hinders the model from effectively learning meaningful point cloud representations. To address this issue, the directions relative to the subsequent point patches are provided in the generator, serving as prompts without revealing the locations of the masked patches and the overall object shapes of point clouds. The relative direction prompts $R D P$ are formulated as:
生成器架构与提取器架构类似,但包含较少的Transformer块。它以提取的Token $\tau$ 作为输入,并为后续的预测头生成点Token ${\pmb T}^{g}$。然而,补丁的顺序可能会受到中心点采样过程的影响,导致在预测后续补丁时产生歧义。这阻碍了模型有效学习有意义的点云表示。为了解决这个问题,生成器中提供了相对于后续点补丁的方向,作为提示而不揭示被遮蔽补丁的位置和点云的整体对象形状。相对方向提示 $R D P$ 的公式如下:

where $n^{\prime}=n{-}1$ . In summary, the procedure in the extractor-generator architecture is formulated as:
其中 $n^{\prime}=n{-}1$。总之,提取器-生成器架构中的过程可以表述为:

Prediction head. The prediction head is utilized to predict the subsequent point patches in the coordinate space. It consists of a two-layer MLP with two fully connected (FC) layers and rectified linear unit (ReLU) activation. The prediction head projects tokens ${\pmb T}^{g}$ to vectors, where the number of output channels equals the total number of coordinates in a patch. Then, these vectors are reshaped to construct the predicted point patches $P^{p d}$ :
预测头 (Prediction head)。预测头用于预测坐标空间中的后续点块 (point patches)。它由一个两层 MLP (多层感知机) 组成,包含两个全连接层 (FC) 和 ReLU (修正线性单元) 激活函数。预测头将 token ${\pmb T}^{g}$ 投影为向量,其中输出通道的数量等于一个点块中的坐标总数。然后,这些向量被重塑以构建预测的点块 $P^{p d}$:
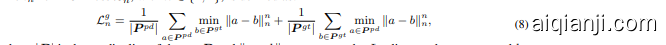
3.3 Generation Target
3.3 生成目标
The generation target for each point patch is to predict the coordinates of the points within the subsequent point patches. Given the predicted point patches $P^{p d}$ , as well as the ground-truth point patches $P^{g t}$ , which correspond to the last $n^{\prime}$ patches among the sorted point patches $P^{s}$ , the generation loss $\mathcal{L}^{g}$ is formulated using the $l_{1}$ -form and $l_{2}$ -form of the Chamfer distance (CD) [14], denoted as $\mathcal{L}{1}^{g}$ and $\mathcal{L}{2}^{g}$ , respectively. Specifically, the generation loss is computed as $\mathcal{L}^{g}=\mathcal{L}{1}^{g}+\mathcal{L}{2}^{g}$ . The $l_{n}$ -form CD loss ${\mathcal{L}}_{n}^{g}$ , with $n\in{1,2}$ , is defined as:
每个点块(point patch)的生成目标是预测后续点块中的点坐标。给定预测的点块 $P^{p d}$ 以及真实点块 $P^{g t}$ (对应于排序后的点块 $P^{s}$ 中的最后 $n^{\prime}$ 个块),生成损失 $\mathcal{L}^{g}$ 使用 Chamfer 距离(CD)[14] 的 $l_{1}$ 形式和 $l_{2}$ 形式计算,分别表示为 $\mathcal{L}{1}^{g}$ 和 $\mathcal{L}{2}^{g}$。具体而言,生成损失计算为 $\mathcal{L}^{g}=\mathcal{L}{1}^{g}+\mathcal{L}{2}^{g}$。$l_{n}$ 形式的 CD 损失 ${\mathcal{L}}_{n}^{g}$,其中 $n\in{1,2}$,定义如下:

where $|P|$ is the cardinality of the set $P$ and $|a-b|{n}$ represents the $L_{n}$ distance between $a$ and $b$ .
其中 $|P|$ 是集合 $P$ 的基数,$|a-b|{n}$ 表示 $a$ 和 $b$ 之间的 $L_{n}$ 距离。
We additionally find that incorporating the generation task into the fine-tuning process as an auxiliary objective can accelerate training convergence and improve the generalization ability of supervised models. This approach yields enhanced performance on downstream tasks, which is in line with the GPT [44]. Specifically, we optimize the following objective during the fine-tuning stage: $\mathcal{L}^{f}=$ $\mathcal{L}^{d}+\lambda\times\mathcal{L}^{\bar{g}}$ , where $\mathcal{L}^{d}$ represents the loss for the downstream task, $\mathcal{L}^{g}$ represents the generation loss as previously defined, and the parameter $\lambda$ balances the contribution of each loss term.
我们还发现,将生成任务作为辅助目标纳入微调过程可以加速训练收敛并提高监督模型的泛化能力。这种方法在下游任务中表现出了更好的性能,这与 GPT [44] 的结果一致。具体来说,我们在微调阶段优化以下目标:$\mathcal{L}^{f}=$ $\mathcal{L}^{d}+\lambda\times\mathcal{L}^{\bar{g}}$,其中 $\mathcal{L}^{d}$ 表示下游任务的损失,$\mathcal{L}^{g}$ 表示之前定义的生成损失,参数 $\lambda$ 用于平衡每个损失项的贡献。
3.4 Post-Pre-training
3.4 预训练后处理
Current point cloud SSL methods directly fine-tune pre-trained models on the target dataset, which may result in potential over fitting due to the limited semantic supervision information [55]. To alleviate this issue and facilitate training of high-capacity models, we adopt the intermediate finetuning strategy [55; 4; 27] and introduce a post-pre-training stage for PointGPT. In this stage, a labeled hybrid dataset is leveraged (Sec. 4.1), which collects and aligns multiple point cloud datasets with labels. By conducting supervised training on this dataset, semantic information is effectively incorporated from diverse sources. Subsequently, fine-tuning is performed on the target dataset to transfer the learned general semantics to task-specific knowledge.
当前的点云自监督学习 (SSL) 方法直接在目标数据集上微调预训练模型,这可能会由于有限的语义监督信息而导致潜在的过拟合 [55]。为了缓解这一问题并促进高容量模型的训练,我们采用了中间微调策略 [55; 4; 27],并为 PointGPT 引入了后预训练阶段。在此阶段,利用了一个带标签的混合数据集(第 4.1 节),该数据集收集并对齐了多个带标签的点云数据集。通过在该数据集上进行监督训练,有效地整合了来自不同来源的语义信息。随后,在目标数据集上进行微调,以将学习到的通用语义转移到任务特定的知识中。
4 Experiments
4 实验
This section begins by presenting the implementation and our pre-training setups. Subsequently, the effectiveness of our pre-trained models is evaluated across a range of downstream tasks. Finally, ablation studies are conducted to analyze the main properties of our PointGPT.
本节首先介绍实现和预训练设置。随后,在一系列下游任务中评估预训练模型的有效性。最后,进行消融研究以分析 PointGPT 的主要特性。
4.1 Implementation and Pre-training Setups
4.1 实现与预训练设置
Models: Following previous studies [37; 64], PointGPT is trained employing the ViT-S configuration [65] for the extractor module, referred to as PointGPT-S. Additionally, we investigate the high-capacity models by scaling the extractor to the ViT-B and ViT-L configurations, denoted as PointGPT-B and PointGPT-L, respectively. More details can be found in the appendix.
模型:根据之前的研究 [37; 64],PointGPT 使用 ViT-S 配置 [65] 进行训练,提取器模块称为 PointGPT-S。此外,我们通过将提取器扩展到 ViT-B 和 ViT-L 配置来研究高容量模型,分别称为 PointGPT-B 和 PointGPT-L。更多细节可以在附录中找到。
Data: PointGPT-S is pre-trained on the ShapeNet [6] dataset without subsequent post-pre-training. This is in line with the previous SSL methods [37; 64; 66; 24] to allow for a direct comparison with these prior approaches. ShapeNet contains over 50,000 unique 3D models across 55 object categories. Additionally, two datasets are collected to support the training of high-capacity PointGPT models (PointGPT-B and PointGPT-L): (I) an unlabeled hybrid dataset (UHD) for self-supervised pre-training, which collects point clouds from various datasets [50; 33; 6; 51; 3; 58; 16], such as ShapeNet [6], S3DIS [3] for indoor scenes, and Semantic3D [16] for outdoor scenes, etc. In total, the UHD contains approximately 300K point clouds; (II) a labeled hybrid dataset (LHD) for supervised post-pre-training, which aligns the label semantics of different datasets [50; 33; 6; 51; 3; 58], with 87 categories and approximately 200K point clouds in total. Further details are provided in the appendix.
数据:PointGPT-S 在 ShapeNet [6] 数据集上进行了预训练,没有进行后续的预训练后处理。这与之前的自监督学习方法 [37; 64; 66; 24] 一致,以便与这些先前的方法进行直接比较。ShapeNet 包含 55 个对象类别中的超过 50,000 个独特的 3D 模型。此外,还收集了两个数据集以支持高容量 PointGPT 模型(PointGPT-B 和 PointGPT-L)的训练:(I) 用于自监督预训练的无标签混合数据集 (UHD),该数据集从多个数据集 [50; 33; 6; 51; 3; 58; 16] 中收集了点云,例如 ShapeNet [6]、用于室内场景的 S3DIS [3] 和用于室外场景的 Semantic3D [16] 等。UHD 总共包含约 300K 个点云;(II) 用于监督预训练后处理的有标签混合数据集 (LHD),该数据集对齐了不同数据集 [50; 33; 6; 51; 3; 58] 的标签语义,包含 87 个类别,总共约 200K 个点云。更多细节见附录。
Pre-training setups: The input point clouds are obtained by sampling 1024 points from each raw point cloud. Afterward, each point cloud is partitioned into 64 point patches, with each patch consisting of 32 points. The PointGPT model is pre-trained for 300 epochs using an AdamW optimizer [29] with a batch size of 128, an initial learning rate of 0.001, and a weight decay of 0.05. Additionally, based on our empirical results, cosine learning rate decay [28] is employed.
预训练设置:输入点云通过从每个原始点云中采样1024个点获得。随后,每个点云被划分为64个点块,每个块包含32个点。PointGPT模型使用AdamW优化器 [29] 进行300个epoch的预训练,批量大小为128,初始学习率为0.001,权重衰减为0.05。此外,根据我们的实验结果,采用了余弦学习率衰减 [28]。
4.2 Downstream Tasks
4.2 下游任务
To demonstrate the performance of our method on different downstream tasks, we conduct experiments involving object classification on real-world and clean object datasets, few-shot learning, and part segmentation. The performance of PointGPT is evaluated using three different model capacities: PointGPT-S, which is pre-trained on the ShapeNet dataset without post-pre-training; and PointGPT-B and PointGPT-L, which undergo both pre-training and post-pre-training stages on the collected hybrid datasets. The impact of post-pre-training is further investigated and discussed in the appendix.
为了展示我们的方法在不同下游任务上的性能,我们进行了涉及现实世界和干净物体数据集上的物体分类、少样本学习以及部分分割的实验。PointGPT 的性能通过三种不同容量的模型进行评估:PointGPT-S,它在 ShapeNet 数据集上进行预训练,没有进行后预训练;以及 PointGPT-B 和 PointGPT-L,它们在收集的混合数据集上进行了预训练和后预训练阶段。后预训练的影响在附录中进一步研究和讨论。
Object classification on a real-world dataset: The performance of the proposed method on a real-world dataset is an important indicator of its practical applicability. Therefore, the pre-trained models are transferred to the S can Object NN dataset [52], which contains approximately 15,000 objects extracted from real-world indoor scans. The experiments are conducted under three different settings, OBJ-BG, OBJ-ONLY, and PB-T50-RS. The results are presented in Table 1, our PointGPT-S, which has similar capacities and training data to previous methods like Point-MAE, outperforms other single-modal SSL methods. Furthermore, even when compared to Recon and ULIP, which utilize cross-modal information and teacher models, our scaled PointGPT-B model achieves superior performance, and PointGPT-L achieves accuracy improvements of at least $1.8%$ .
真实数据集上的物体分类:所提出方法在真实数据集上的表现是其实际适用性的重要指标。因此,预训练模型被迁移到 S can Object NN 数据集 [52],该数据集包含从真实室内扫描中提取的大约 15,000 个物体。实验在三种不同的设置下进行:OBJ-BG、OBJ-ONLY 和 PB-T50-RS。结果如表 1 所示,我们的 PointGPT-S 在容量和训练数据上与 Point-MAE 等先前方法相似,但优于其他单模态自监督学习方法。此外,即使与利用跨模态信息和教师模型的 Recon 和 ULIP 相比,我们的扩展版 PointGPT-B 模型也表现出更优的性能,而 PointGPT-L 的准确率提升了至少 $1.8%$。
Table 1: Classification results on S can Object NN and ModelNet40 datasets. All results are expressed as percentages. Specifically, three variants are evaluated on the S can Object NN dataset. Additionally, The accuracy obtained on the ModelNet40 dataset is reported for both 1k and $\mathrm{8k}$ points. The symbols • and • denote larger pre-training dataset and post-pre-training stage, respectively.
表 1: S can Object NN 和 ModelNet40 数据集上的分类结果。所有结果均以百分比表示。具体来说,在 S can Object NN 数据集上评估了三种变体。此外,还报告了在 ModelNet40 数据集上获得的 1k 和 $\mathrm{8k}$ 点的准确率。符号 • 和 • 分别表示更大的预训练数据集和预训练后阶段。
| 方法 | 参考文献 | ScanObjectNN | ModelNet40 | |||
|---|---|---|---|---|---|---|
| OBJ_BG | OBJ_ONLY | PB_T50_RS | 1k P | 8k P | ||
| 仅监督学习 | ||||||
| PointNet [38] | CVPR2017 | 73.3 | 79.2 | 68.0 | 89.2 | 90.8 |
| DGCNN [56] | TOG 2019 | 82.8 | 86.2 | 78.1 | 92.9 | |
| PointCNN [23] | Neurips 2018 | 86.1 | 85.5 | 78.5 | 92.2 | |
| GBNet [43] | TMM 2021 | 一 | 81.0 | 93.8 | ||
| MVTN [17] | ICCV 2021 | 92.6 | 92.3 | 82.8 | 93.8 | |
| PointMLP [30] | ICLR 2022 | 85.4 | 94.5 | |||
| PointNeXt [41] | Neurips 2022 | 87.7 | 94.0 | |||
| P2P-RN101 [57] | Neurips 2022 | 87.4 | 93.1 | |||
| P2P-HorNet [57] | Neurips 2022 | 89.3 | 94.0 | |||
| 自监督表示学习 | ||||||
| Point-BERT [64] | CVPR 2022 | 87.4 | 88.1 | 83.1 | 93.2 | 93.8 |
| MaskPoint [24] | ECCV 2022 | 89.3 | 88.1 | 84.3 | 93.8 | |
| Point-MAE [37] | ECCV 2022 | 90.0 | 88.2 | 85.2 | 93.8 | 94.0 |
| Point-M2AE [66] | Neurips 2022 | 91.2 | 88.8 | 86.4 | 94.0 | |
| PointGPT-S | 91.6 | 90.0 | 86.9 | 94.0 | 94.2 | |
| PointGPT-B·· | 95.8 | 95.2 | 91.9 | 94.4 | 94.6 | |
| PointGPT-L •· | 97.2 | 96.6 | 93.4 | 94.7 | 94.9 | |
| 使用跨模态信息和教师模型的方法 | ||||||
| ACT [12] | ICLR 2023 | 93.3 | 91.9 | 88.2 | 93.7 | 94.0 |
| PointMLP+ULIP[60] | CVPR 2023 | 89.4 | 94.5 | 94.7 | ||
| ReCon [40] | ICML 2023 | 95.4 | 93.6 | 91.3 | 94.5 | 94.7 |
Object classification on a clean objects dataset: The pre-trained models are evaluated on the ModelNet40 dataset [58], which includes 12,311 clean 3D CAD models, covering 40 categories. To conduct fair comparisons, the standard voting method [26] is used during testing, and the input point clouds exclusively contain coordinate information, without additional normal information provided. The experimental results are presented in Table 1, our PointGPT-S surpasses other single-modal SSL methods. Even in comparison with Recon and ULIP, our PointGPT-L achieves superior performance.
在干净物体数据集上的物体分类:预训练模型在 ModelNet40 数据集 [58] 上进行评估,该数据集包含 12,311 个干净的 3D CAD 模型,涵盖 40 个类别。为了进行公平比较,测试期间使用了标准投票方法 [26],输入点云仅包含坐标信息,未提供额外的法线信息。实验结果如表 1 所示,我们的 PointGPT-S 超越了其他单模态自监督学习方法。即使与 Recon 和 ULIP 相比,我们的 PointGPT-L 也表现出更优的性能。
Few-shot learning: To intuitively demonstrate the generalization ability of our method, few-shot learning experiments are conducted on the ModelNet40 dataset without the post-pre-training stage. Following the protocols of previous studies [37; 64; 66], the few-shot learning experiments consist of four distinct tests, employing $w$ -way, $s$ -shot setting. Specifically, $w\in{5,10}$ represents the number of randomly selected classes, and $s\in{10,20}$ denotes the number of randomly sampled objects for each selected class. Each test is conducted with 10 independent trials. The results, as shown in Table 2, indicate that our method outperforms other methods in all tests, particularly in the 10-shot tests. This demonstrates the ability of PointGPT in acquiring knowledge for new tasks, even under the constraints of limited training data.
少样本学习:为了直观展示我们方法的泛化能力,我们在 ModelNet40 数据集上进行了少样本学习实验,且不进行后预训练阶段。遵循先前研究 [37; 64; 66] 的协议,少样本学习实验由四个不同的测试组成,采用 $w$ -way, $s$ -shot 设置。具体来说,$w\in{5,10}$ 表示随机选择的类别数量,$s\in{10,20}$ 表示每个选定类别中随机采样的对象数量。每个测试进行 10 次独立试验。结果如表 2 所示,表明我们的方法在所有测试中均优于其他方法,尤其是在 10-shot 测试中。这证明了 PointGPT 在有限训练数据约束下获取新任务知识的能力。
Part segmentation: The representation learning capability of our method is evaluated on the Shape Net Part [62] dataset, which consists of 16881 objects across 16 categories. The point clouds are sampled into 2048 points, and the segmentation head [37] concatenates the extracted features from layers $\textstyle{\frac{1\times t d}{3}}$ , $\frac{2\times t d}{3}$ , and $\frac{3\times t d}{3}$ of the extractor transformer blocks, with $t d$ representing the depth of the extractor. Subsequently, average pooling, max pooling, and upsampling are utilized to generate features for each point and an MLP is applied for label prediction. The experimental results, displayed in Table 3, demonstrate the superior performance of our PointGPT-L compared to all other methods.
部件分割:我们的方法在 Shape Net Part [62] 数据集上评估了表示学习能力,该数据集包含 16 个类别的 16881 个对象。点云被采样为 2048 个点,分割头 [37] 将提取器 Transformer 块的 $\textstyle{\frac{1\times t d}{3}}$、$\frac{2\times t d}{3}$ 和 $\frac{3\times t d}{3}$ 层的提取特征连接起来,其中 $t d$ 表示提取器的深度。随后,利用平均池化、最大池化和上采样为每个点生成特征,并应用 MLP 进行标签预测。实验结果如表 3 所示,表明我们的 PointGPT-L 相比所有其他方法具有更优越的性能。
Table 2: Few-shot classification results on the ModelNet40 dataset. In each experimental setting, 10 independent trials are conducted, and the mean accuracy $(%)$ is reported with its standard deviation. Symbol • denotes larger pre-training dataset, and the post-pre-training stage • is excluded.
表 2: ModelNet40 数据集上的少样本分类结果。在每个实验设置中,进行了 10 次独立试验,并报告了平均准确率 $(%)$ 及其标准差。符号 • 表示更大的预训练数据集,且排除了预训练后阶段 •。
| 方法 | 参考文献 | 5-way 10-shot | 5-way 20-shot | 10-way 10-shot | 10-way 20-shot |
|---|---|---|---|---|---|
| DGCNN [56] | TOG2019 | 31.6±2.8 | 40.8±4.6 | 19.9±2.1 | 16.9±1.5 |
| OcCo [54] | ICCV 2021 | 90.6±2.8 | 92.5±1.9 | 82.9±1.3 | 86.5±2.2 |
| 使用自监督表示学习的方法 | |||||
| Point-BERT[64] | CVPR 2022 | 94.6±3.1 | 96.3±2.7 | 91.0±5.4 | 92.7±5.1 |
| MaskPoint[24] | ECCV2022 | 95.0±3.7 | 97.2±1.7 | 91.4±4.0 | 93.4±3.5 |
| Point-MAE[37] | ECCV2022 | 96.3±2.5 | 97.8±1.8 | 92.6±4.1 | 95.0±3.0 |
| Point-M2AE[66] | Neurips 2022 | 96.8±1.8 | 98.3±1.4 | 92.3±4.5 | 95.0±3.0 |
| PointGPT-S | 96.8±2.0 | 98.6±1.1 | 92.6±4.6 | 95.2±3.4 | |
| PointGPT-B | 97.5±2.0 | 98.8±1.0 | 93.5±4.0 | 95.8±3.0 | |
| PointGPT-L | 98.0±1.9 | 99.0±1.0 | 94.1±3.3 | 96.1±2.8 | |
| 使用跨模态信息和教师模型的方法 | |||||
| ACT [12] | ICLR 2023 | 96.8±2.3 | 98.0±1.4 | 93.3±4.0 | 95.6±2.8 |
| ReCon [40] | ICML2023 | 97.3±1.9 | 98.9±1.2 | 93.3±3.9 | 95.8±3.0 |
Table 3: Part segmentation results on the Shape Net Part dataset. The mean intersection over union (mIoU) is reported across all classes (Cls.) and all instances (Inst.). Symbols $\bullet$ and • denote larger pre-training dataset and post-pre-training stage, respectively.
表 3: Shape Net Part 数据集上的部件分割结果。报告了所有类别 (Cls.) 和所有实例 (Inst.) 的平均交并比 (mIoU)。符号 $\bullet$ 和 • 分别表示更大的预训练数据集和预训练后阶段。
| 方法 | 参考文献 | Cls. mIoU(%) | Inst. mIoU(%) |
|---|---|---|---|
| PointNet[38] | CVPR2017 | 80.4 | 83.7 |
| PointNet++[39] | Neurips 2017 | 81.9 | 85.1 |
| DGCNN [56] | TOG 2019 | 82.3 | 85.2 |
| PointMLP [30] | ICLR 2022 | 84.6 | 86.1 |
| 使用自监督表示学习 | |||
| PointContrast[59] | ECCV2020 | 85.1 | |
| CrossPoint [2] | CVPR 2022 | 85.5 | |
| Point-BERT[64] | CVPR2022 | 84.1 | 85.6 |
| Point-MAE[37] | ECCV2022 | 86.1 | |
| PointGPT-S | 84.1 | 86.2 | |
| PointGPT-B | 84.5 | 86.5 | |
| PointGPT-L · | 84.8 | 86.6 | |
| 使用跨模态信息和教师模型的方法 | |||
| ACT [12] | ICLR 2023 | 84.7 | 86.1 |
| ReCon [40] | ICML2023 | 84.8 | 86.4 |
4.3 Ablation Studies
4.3 消融研究
Comprehensive ablation studies are conducted to investigate the fundamental designs of our PointGPT model. The impacts of these designs are evaluated by reporting the accuracy achieved by fine-tuning the model on the ModelNet40 dataset for object classification. To provide an intuitive representation of the results, ablation studies are conducted using the PointGPT-S model, which is pre-trained on the ShapeNet dataset and directly fine-tuned on the target dataset without post-pre-training.
我们对 PointGPT 模型的基本设计进行了全面的消融研究。通过在 ModelNet40 数据集上进行微调以评估这些设计的影响,并报告了模型在物体分类任务上的准确率。为了直观地展示结果,消融研究使用了在 ShapeNet 数据集上预训练的 PointGPT-S 模型,并在目标数据集上直接进行微调,而不进行后预训练。
Generator: Table 4(a) investigates the effect of varying the generator depth. The results demonstrate that the extractor-generator architecture facilitates the learning of strong semantic representations, particularly when combined with a deep generator, resulting in improved performance overall. However, due to the computational complexity associated with the deep generator, a depth of 4 is selected as the default setting for the generator.
生成器:表 4(a) 研究了生成器深度变化的影响。结果表明,提取器-生成器架构有助于学习强语义表示,特别是与深层生成器结合时,整体性能有所提升。然而,由于深层生成器带来的计算复杂性,生成器的默认设置选择为深度 4。
Generation targets: The generation objective is essential for enabling the model to learn the intrinsic characteristics of the given data. Table 4(b) exhibits four distinct generation targets, which can
生成目标:生成目标对于使模型能够学习给定数据的内在特征至关重要。表 4(b) 展示了四种不同的生成目标,这些目标可以
(a) Generator depth.
(a) 生成器深度。
Table 4: Ablation experiments with PointGPT-S pertaining on the ShapeNet dataset. The fine-tuned accuracy $(%)$ achieved without post-pre-training is reported. Default settings are marked in gray .
表 4: 在 ShapeNet 数据集上进行的 PointGPT-S 消融实验。报告了在没有进行后预训练的情况下实现的微调准确率 $(%)$。默认设置以灰色标记。
| Blocks | Acc. |
|---|---|
| 93.85% | |
| 2 | 94.08% |
| 4 | 94.21% |
| 6 | 94.24% |
| (d) 生成损失。 | |
| Loss | Acc. |
| CD 11 CD12 | 93.66% 94.13% |
| CD 11+l2 | 94.21% |
(c) Generation during fine-tuning.
(c) 微调期间的生成
(b) Generation targets.
(b) 生成目标
| 目标 | 准确率 |
|---|---|
| 坐标 | 94.21% |
| FPFH | 94.13% |
| PointNet | 94.31% |
| DGCNN | 94.35% |
| Coef. | Acc. |
|---|---|
| 0 1 | 94.01% 94.15% |
| 3 | 94.21% |
| 5 | 94.05% |
(e) Relative direction prompts.
(e) 相对方向提示。
(f) Dual masking strategy.
(f) 双重掩码策略。
| Case |
|---|
| None 93.69% 94.06% |
| Absolute position |
| Relative direction 94.21% |
| Ratio | Acc. | Ratio | Acc. |
|---|---|---|---|
| 0 | 93.68% | 5 | 94.01% |
| 1 | 93.70% | 7 | 94.21% |
| 3 | 93.85% | 9 | 93.66% |
be categorized into two groups: one-stage targets that can be directly obtained, including point coordinates and FPFH [46], and two-stage targets that are extracted by a trained deep network, including PointNet [38] and the DGCNN [56]. The experimental results indicate that the use of handcrafted FPFH features leads to under performance, which may be attributed to the over fitting of low-level geometric features. The variants with two-stage targets outperform the variant with point coordinate targets. However, the pre-training and inference processes of the teacher model inevitably incur an additional computational cost.
可以分为两类:一类是可以直接获取的单阶段目标,包括点坐标和FPFH [46];另一类是通过训练好的深度网络提取的两阶段目标,包括PointNet [38]和DGCNN [56]。实验结果表明,使用手工制作的FPFH特征会导致性能不佳,这可能归因于低级几何特征的过拟合。使用两阶段目标的变体优于使用点坐标目标的变体。然而,教师模型的预训练和推理过程不可避免地会产生额外的计算成本。
Generation task in the fine-tuning stage: The generation task is included as an auxiliary objective during the fine-tuning stage. Table 4(c) presents the obtained results when varying the coefficient $\lambda$ of the generation loss in the fine-tuning loss. The results signify that this auxiliary objective serves as a regular iz ation term and improves the generalization ability of supervised models. Furthermore, the results suggest that as the coefficient increases, the accuracy achieved in the classification task exhibits an increasing trend followed by a decreasing trend, reaching its highest value when $\lambda=3$ .
微调阶段的生成任务:在微调阶段,生成任务作为辅助目标被包含在内。表 4(c) 展示了在微调损失中改变生成损失系数 $\lambda$ 时获得的结果。结果表明,这一辅助目标起到了正则化项的作用,并提高了监督模型的泛化能力。此外,结果还表明,随着系数的增加,分类任务中的准确率呈现出先上升后下降的趋势,当 $\lambda=3$ 时达到最高值。
Generation loss: Table 4(d) presents the performance of variants using different generation loss functions, including the $l1$ -form CD loss, the l2-form CD loss, and the combination of both the $l1$ - and l2-forms CD loss. The results demonstrate that the combination of the $\mathrm{\nabla}l1.$ and l2-forms achieves superior performance. We analyze that the l2-form is more effective in guiding the network toward convergence and the $l1$ -form has better sparsity, thus the combination of both forms is more effective.
生成损失:表 4(d) 展示了使用不同生成损失函数的变体性能,包括 $l1$ 形式的 CD 损失、l2 形式的 CD 损失以及 $l1$ 和 l2 形式 CD 损失的组合。结果表明,$\mathrm{\nabla}l1.$ 和 l2 形式的组合实现了更优的性能。我们分析认为,l2 形式在引导网络收敛方面更有效,而 $l1$ 形式具有更好的稀疏性,因此两种形式的组合更为有效。
Relative direction prompts: The effect of utilizing relative direction prompts is analyzed in Table 4(e). The variant utilizing relative direction prompts outperforms the variants using absolute positional encoding and excluding positional encoding. We hypothesize that this improvement stems from the ability of relative direction prompts to prevent the model from over fitting to the patch order, thus enhancing the performance of PointGPT in downstream tasks.
相对方向提示:表 4(e) 分析了使用相对方向提示的效果。使用相对方向提示的变体优于使用绝对位置编码和排除位置编码的变体。我们假设这种改进源于相对方向提示能够防止模型对补丁顺序过拟合,从而提升 PointGPT 在下游任务中的表现。
Dual masking strategy: We conduct an analysis on the impact of the dual masking strategy and search for the proper mask ratio, as shown in Table 4(f). Decreasing the mask ratio to 0 corresponds to employing the vanilla masking strategy. The results indicate that both excessive and insufficient masking ratios lead to a decline in performance. The experimental results demonstrate that the dual masking strategy is effective in promoting beneficial representation learning and enhancing the generalization ability of the pre-trained model.
双掩码策略:我们对双掩码策略的影响进行了分析,并寻找合适的掩码比例,如表 4(f) 所示。将掩码比例降低到 0 相当于采用普通的掩码策略。结果表明,掩码比例过高或过低都会导致性能下降。实验结果证明,双掩码策略在促进有益的表示学习和增强预训练模型的泛化能力方面是有效的。
5 Conclusion
5 结论
In this paper, we present PointGPT, a novel approach that extends the GPT concept to point clouds, addressing the challenges associated with disorder properties, information density differences, and gaps between the generation and downstream tasks. Unlike recently proposed self-supervised masked point modeling approaches, our method avoids overall object shape leakage, attaining improved generalization ability. Additionally, we explore a high-capacity model training process and collect hybrid datasets for pre-training and post-pre-training. The effectiveness and strong generalization capabilities of our approach are verified on various tasks, indicating that our PointGPT outperforms other single-modal methods with similar model capacities. Furthermore, our scaled models achieve SOTA performance on various downstream tasks, without the need for cross-modal information and teacher models. Despite the promising performance exhibited by PointGPT, the data and model scales explored for PointGPT remain several orders of magnitude smaller than those in NLP [5; 10] and image processing [65; 27] domains. Our aspiration is that our research can stimulate further exploration in this direction and narrow the gaps between point clouds and these domains.
在本文中,我们提出了 PointGPT,这是一种将 GPT 概念扩展到点云的新方法,解决了与无序属性、信息密度差异以及生成任务与下游任务之间的差距相关的挑战。与最近提出的自监督掩码点建模方法不同,我们的方法避免了整体对象形状的泄露,从而获得了更好的泛化能力。此外,我们探索了一种高容量模型训练过程,并收集了混合数据集用于预训练和后预训练。我们的方法在各种任务上的有效性和强大的泛化能力得到了验证,表明 PointGPT 在模型容量相似的情况下优于其他单模态方法。此外,我们的扩展模型在各种下游任务上实现了 SOTA 性能,而无需跨模态信息和教师模型。尽管 PointGPT 表现出良好的性能,但其探索的数据和模型规模仍然比 NLP [5; 10] 和图像处理 [65; 27] 领域小几个数量级。我们希望我们的研究能够激发这一方向的进一步探索,并缩小点云与这些领域之间的差距。