Point-JEPA: A Joint Embedding Predictive Architecture for Self-Supervised Learning on Point Cloud
Point-JEPA:一种用于点云自监督学习的联合嵌入预测架构
Abstract
摘要
Recent advancements in self-supervised learning in the point cloud domain have demonstrated significant potential. However, these methods often suffer from drawbacks such as lengthy pre-training time, the necessity of reconstruction in the input space, and the necessity of additional modalities. In order to address these issues, we introduce PointJEPA, a joint embedding predictive architecture designed specifically for point cloud data. To this end, we introduce a sequencer that orders point cloud patch embeddings to efficiently compute and utilize their proximity based on their indices during target and context selection. The sequencer also allows shared computations of the patch embeddings’ proximity between context and target selection, further improving the efficiency. Experimentally, our method demonstrates state-of-the-art performance while avoiding the reconstruction in the input space or additional modality. In particular, Point-JEPA attains a classification accuracy of $\mathbf{93.7}\pm\mathbf{0.2~%}$ for linear SVM on ModelNet40 surpassing all other self-supervised models. Moreover, Point-JEPA also establishes new state-of-the-art performance levels across all four few-shot learning evaluation frameworks. The code is available at https://github.com/Ayumu-JS/Point-JEPA
点云领域自监督学习的最新进展展示了显著的潜力。然而,这些方法通常存在一些缺点,例如预训练时间长、需要在输入空间中进行重建以及需要额外的模态。为了解决这些问题,我们引入了 PointJEPA,这是一种专门为点云数据设计的联合嵌入预测架构。为此,我们引入了一个排序器,用于对点云补丁嵌入进行排序,以便在目标和上下文选择期间基于它们的索引高效计算和利用它们的邻近性。排序器还允许在上下文和目标选择之间共享补丁嵌入邻近性的计算,从而进一步提高效率。实验表明,我们的方法在避免输入空间重建或额外模态的情况下展示了最先进的性能。特别是,Point-JEPA 在 ModelNet40 上的线性 SVM 分类准确率达到 $\mathbf{93.7}\pm\mathbf{0.2~%}$,超越了所有其他自监督模型。此外,Point-JEPA 在所有四个少样本学习评估框架中也建立了新的最先进性能水平。代码可在 https://github.com/Ayumu-JS/Point-JEPA 获取。
1. Introduction
1. 引言
The growing accessibility of affordable consumer-grade 3D sensors has led to the widespread adoption of point clouds as a preferred data representation for capturing realworld environments. However, the existing point cloud understanding approaches [14] mostly rely on supervised training which requires time-consuming and labor-intensive manual annotations to semantically understand 3D environments. On the other hand, self-supervised learning (SSL) is an evolving paradigm that allows the model to learn a meaningful representation from unlabeled data. The success of self-supervised learning in advancing natural language processing and 2D computer vision has motivated its application in the point cloud domain for achieving state-of-the-art results on downstream tasks [17]. However, our initial inve stig ation found that they require a significant amount of pre-training time as shown in Fig. 1. The slow pre-training process can pose constraints in scaling to a larger dataset or complex and deeper models, hindering the key advantage of self-supervised learning; its capacity to learn a strong represent ation from a vast amount of data.
随着价格适中的消费级 3D 传感器日益普及,点云作为一种捕捉现实环境的优选数据表示方式得到了广泛应用。然而,现有的点云理解方法 [14] 大多依赖于监督训练,这需要耗时且劳动密集型的手动标注来语义理解 3D 环境。另一方面,自监督学习 (SSL) 是一种不断发展的范式,它允许模型从未标注的数据中学习有意义的表示。自监督学习在推动自然语言处理和 2D 计算机视觉方面的成功,激励了其在点云领域的应用,以在下游任务中实现最先进的结果 [17]。然而,我们的初步调查发现,它们需要大量的预训练时间,如图 1 所示。缓慢的预训练过程可能会对扩展到更大的数据集或更复杂和更深的模型造成限制,阻碍了自监督学习的关键优势;即从大量数据中学习强大表示的能力。
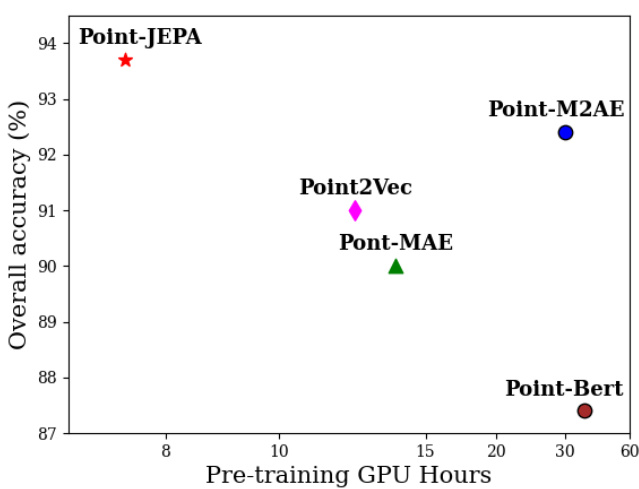
ModelNet40 Linear Evaluation vs Pre-train Hours Figure 1. ModelNet40 Linear Evaluation. Pre-training time on NVIDIA RTX A5500 and overall accuracy with SVM linear classifier on ModelNet40 [36]. We compare PointJEPA with previous methods utilizing standard Transformer architecture.
图 1: ModelNet40 线性评估。在 NVIDIA RTX A5500 上的预训练时间以及在 ModelNet40 [36] 上使用 SVM 线性分类器的总体准确率。我们将 PointJEPA 与之前使用标准 Transformer 架构的方法进行了比较。
The successful implementations of Joint-Embedding Predictive Architecture (JEPA) [18] for pre-training a model [2,3] show JEPA’s ability to learn strong semantic representations without the need for fine-tuning. The idea behind JEPA is to learn a representation by predicting the embedding of the input signal, called target, from another compatible input signal, called context, with the help of a predictor network. This allows learning in the representation space instead of the input space, leading to efficient learning. Inspired by I-JEPA [2], we aim to apply Joint-Embedding Predictive Architecture in the point cloud domain, which introduces a promising direction for self-supervised learning in the point cloud understanding. However, unlike images, unordered point clouds pose a unique challenge to applying JEPA due to their inherently permutation-invariant nature. The unordered nature of the point cloud data makes the context and target selection of the data difficult and inefficient, especially if we aim to select spatially contiguous patches similar to I-JEPA [2]. Therefore, we introduce Point-JEPA to overcome this challenge, while utilizing the full potential of Joint-Embedding Predictive Architecture for computational efficiency. Point-JEPA utilizes an efficient greedy sequencer to assist the model in selecting patch embeddings that are spatially adjacent. Our empirical studies indicate that Point-JEPA efficiently learns semantic representations from point cloud data with faster pre-training times compared to alternative state-of-the-art methods. The specific contributions of this work are as follows.
联合嵌入预测架构 (Joint-Embedding Predictive Architecture, JEPA) [18] 在模型预训练中的成功实现 [2,3] 展示了 JEPA 无需微调即可学习强语义表示的能力。JEPA 的核心思想是通过预测输入信号的嵌入(称为目标)来学习表示,该嵌入是从另一个兼容的输入信号(称为上下文)中借助预测网络生成的。这使得学习可以在表示空间而非输入空间中进行,从而实现高效学习。受 I-JEPA [2] 的启发,我们旨在将联合嵌入预测架构应用于点云领域,这为点云理解中的自监督学习引入了一个有前景的方向。然而,与图像不同,无序的点云由于其固有的排列不变性,给 JEPA 的应用带来了独特的挑战。点云数据的无序性使得数据的上下文和目标选择变得困难且低效,尤其是当我们希望选择类似于 I-JEPA [2] 的空间连续补丁时。因此,我们引入了 Point-JEPA 来克服这一挑战,同时充分利用联合嵌入预测架构的计算效率。Point-JEPA 利用一种高效的贪心排序器来帮助模型选择空间相邻的补丁嵌入。我们的实证研究表明,与现有的最先进方法相比,Point-JEPA 能够从点云数据中高效地学习语义表示,并且预训练时间更短。本文的具体贡献如下。
• We present a Joint-Embedding Predictive Architecture, called Point-JEPA, for point cloud selfsupervised learning. Point-JEPA efficiently learns a strong representation from point cloud data without reconstruction in the input space or additional modality. • We propose a point cloud patch embedding ordering method for Joint-Embedding Predictive Architecture, utilizing a greedy algorithm based on spatial proximity.
• 我们提出了一种名为 Point-JEPA 的联合嵌入预测架构 (Joint-Embedding Predictive Architecture),用于点云自监督学习。Point-JEPA 无需在输入空间进行重建或依赖额外模态,即可高效地从点云数据中学习到强表征。
• 我们提出了一种基于空间邻近度的贪心算法,用于联合嵌入预测架构的点云块嵌入排序方法。
2. Related Work
2. 相关工作
Recent advancements in self-supervised learning in 2D computer vision [2, 5, 8, 13, 15, 17, 23, 35] and natural language processing [4, 9, 28, 29] have inspired its application to point cloud processing. In this section, we review existing self-supervised learning methods in the point cloud domain and explore the concept of the Joint Embedding Predictive Architecture.
近年来,自监督学习在二维计算机视觉 [2, 5, 8, 13, 15, 17, 23, 35] 和自然语言处理 [4, 9, 28, 29] 领域的进展激发了其在点云处理中的应用。本节中,我们回顾了点云领域现有的自监督学习方法,并探讨了联合嵌入预测架构 (Joint Embedding Predictive Architecture) 的概念。
2.1. Generative Learning
2.1. 生成式学习 (Generative Learning)
Generative models learn representations by reconstructing the input signal within the same input space, capturing its underlying structure and features. For example, based on a popular NLP model Bert [9], Point-Bert [37] introduces generative pre training to the point cloud using a discrete variation al auto encoder to transform the point cloud into discrete point tokens. However, this model heavily relies on data augmentation and suffers from the early leakage of location information, which makes pre-training steps relatively complicated and computationally expensive. To overcome this issue, Point-MAE [25] presents a lightweight, flexible, and computationally efficient solution by bypassing the token iz ation and reconstructing the masked point cloud patches. On the other hand, PointGPT [7] introduces an auto-regressive learning paradigm in the point cloud domain. Such generative pre-training in the point cloud domain learns a robust representation; however, it suffers from computational inefficiency due to the reconstruction of the data in the input space.
生成模型通过在相同的输入空间内重建输入信号来学习表示,捕捉其底层结构和特征。例如,基于流行的 NLP 模型 Bert [9],Point-Bert [37] 引入了生成式预训练,使用离散变分自编码器将点云转换为离散的点 token。然而,该模型严重依赖数据增强,并且存在位置信息早期泄露的问题,这使得预训练步骤相对复杂且计算成本高。为了解决这个问题,Point-MAE [25] 提出了一种轻量级、灵活且计算高效的解决方案,通过绕过 token 化并重建被掩码的点云补丁。另一方面,PointGPT [7] 在点云领域引入了自回归学习范式。这种在点云领域的生成式预训练学习到了鲁棒的表示;然而,由于在输入空间中重建数据,它存在计算效率低下的问题。
2.2. Joint Embedding Architecture
2.2. 联合嵌入架构
Joint Embedding Architectures map the input data into a shared latent space that contains similar embeddings for semantically similar instances. These networks utilize regu lari z ation strategies such as contrastive learning and selfdistillation to learn meaningful representations. Contrastive learning generates embeddings that are close for positive pairs and distant for negative pairs. For example, Du et al. [10] introduces a contrastive learning approach that treats different parts of the same object as negative and positive examples. Unlike contrastive learning, a self-distillation network employs two identical networks with distinct parameters, commonly known as the teacher and student, where the teacher guides the student by providing its predictions as targets. For example, in Point2Vec [38], the teacher receives the patches of point clouds while the student receives a subset of these patches. Further, a shallow Transformer learns meaningful and robust representation from the masked positional information and the con- textual i zed embedding from the partial-view input. In selfdistillation networks, no reconstruction in the input space results in faster training than in generative models. However, as shown in Fig. 1, it requires longer training to learn a meaningful representation. On the other hand, contrastive learning excels in performance; however, its effectiveness highly depends on the careful selection of positive and negative samples as well as the data augmentation techniques to ensure transferable representations for downstream tasks [17].
联合嵌入架构将输入数据映射到一个共享的潜在空间,该空间包含语义相似实例的相似嵌入。这些网络利用对比学习和自蒸馏等正则化策略来学习有意义的表示。对比学习生成的嵌入在正样本对中接近,在负样本对中远离。例如,Du 等人 [10] 提出了一种对比学习方法,将同一对象的不同部分视为负样本和正样本。与对比学习不同,自蒸馏网络使用两个具有不同参数的相同网络,通常称为教师和学生,其中教师通过提供其预测作为目标来指导学生。例如,在 Point2Vec [38] 中,教师接收点云的补丁,而学生接收这些补丁的子集。此外,一个浅层 Transformer 从掩码位置信息和部分视图输入的上下文化嵌入中学习有意义且鲁棒的表示。在自蒸馏网络中,输入空间中没有重建,因此训练速度比生成模型更快。然而,如图 1 所示,学习有意义的表示需要更长的训练时间。另一方面,对比学习在性能上表现出色;然而,其有效性高度依赖于正负样本的精心选择以及数据增强技术,以确保下游任务的可迁移表示 [17]。
2.3. Joint Embedding Predictive Architecture (JEPA)
2.3. 联合嵌入预测架构 (Joint Embedding Predictive Architecture, JEPA)
A self-supervised learning architecture JEPA [24] learns representation using a predictor network that predicts one set of encoded signal $y$ based on another set of encoded signal $x$ , along with a conditional variable $z$ that controls the prediction. In the predictor network, encoders initially process both the target and the context signals to represent them in embedding space. Conceptually JEPA has a large similarity to generative models which are designed to reconstruct masked part of the input. However, instead of directly operating on the input space, JEPA makes predictions in the embedding space. This allows the elimination of unnecessary input details to focus on learning meaningful representations. As a result, the model can abstract and represent the data more efficiently. Closely related to our work, the specific application of the architecture in the image domain can be seen in I-JEPA [2]. In this work, the context signal is created by selecting a block of patches while the target signals are created by sampling the rest of unselected patches. Experiments show faster convergence of I-JEPA to learn highly semantic representation. Therefore, to ensure faster pre training in self-supervised learning for point cloud understanding, we aim to apply JEPA on point cloud data.
一种自监督学习架构 JEPA [24] 使用预测网络来学习表示,该网络基于另一组编码信号 $x$ 以及控制预测的条件变量 $z$ 来预测一组编码信号 $y$。在预测网络中,编码器首先处理目标和上下文信号,以在嵌入空间中表示它们。从概念上讲,JEPA 与生成模型有很大的相似性,生成模型旨在重建输入的掩码部分。然而,JEPA 不是在输入空间上直接操作,而是在嵌入空间中进行预测。这使得可以消除不必要的输入细节,专注于学习有意义的表示。因此,模型可以更高效地抽象和表示数据。与我们工作密切相关的是,该架构在图像领域的具体应用可以在 I-JEPA [2] 中看到。在这项工作中,上下文信号通过选择一组图像块创建,而目标信号则通过采样其余未选择的图像块创建。实验表明,I-JEPA 在学习高度语义表示时收敛速度更快。因此,为了确保在点云理解的自监督学习中更快地进行预训练,我们旨在将 JEPA 应用于点云数据。
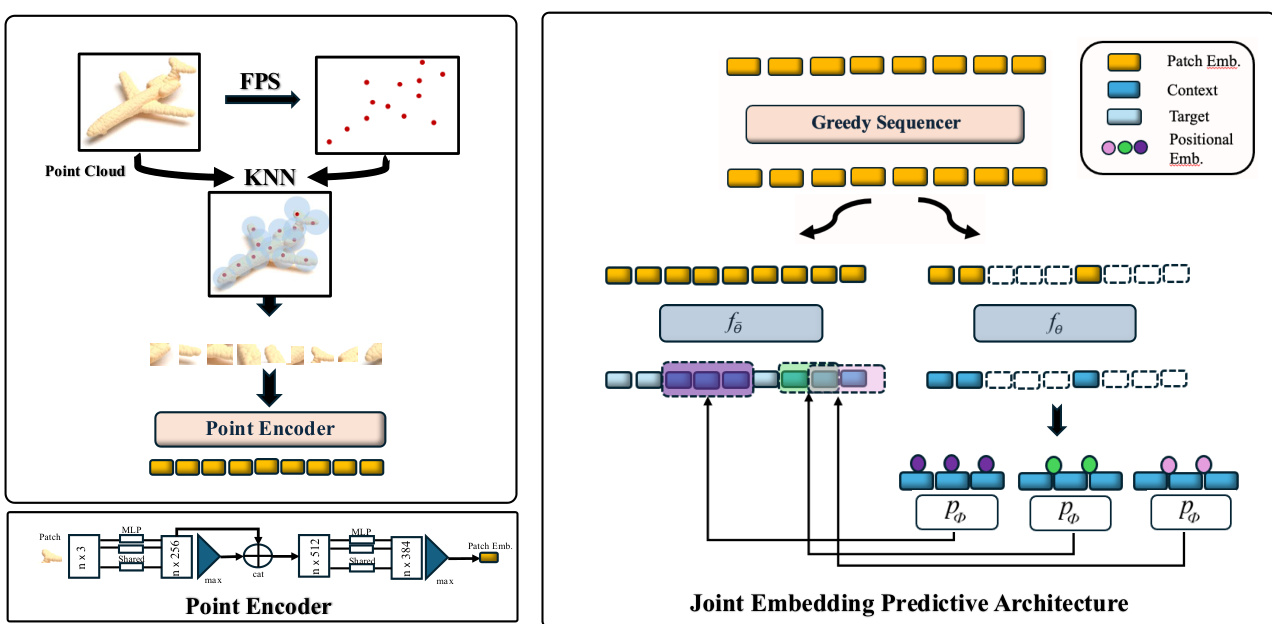
Figure 2. Schematic renderings illustrating the process of creating embeddings. (Top left), point encoder (bottom left) and PointJEPA (right). Point cloud patches are generated using furthest point sampling (FPS) [11] and $k$ -nearest neighbor (KNN) methods, a mini PointNet (Point Encoder) is used to generate patch embeddings which are subsequently fed to the JEPA architecture. We use standard Transformer [34] architecture for context $\left(f_{\theta}\right)$ and target $(f_{\overline{{\theta}}})$ encoders as well as predictor $(p_{\phi})$ .
图 2: 展示嵌入创建过程的示意图。(左上)点编码器(左下)和 PointJEPA(右)。点云补丁使用最远点采样 (FPS) [11] 和 $k$ 近邻 (KNN) 方法生成,一个迷你 PointNet(点编码器)用于生成补丁嵌入,随后将其输入到 JEPA 架构中。我们使用标准的 Transformer [34] 架构作为上下文 $\left(f_{\theta}\right)$ 和目标 $(f_{\overline{{\theta}}})$ 编码器以及预测器 $(p_{\phi})$。
3. Point-JEPA Architecture
3. Point-JEPA 架构
In this section, we describe our JEPA architecture for pre training in the point cloud domain. Our goal is to adapt JEPA [18] for use with point cloud data while evaluating its performance and implementation efficiency. The overall framework, as shown in Fig. 2, first converts the point cloud to a set of patch embeddings, then a greedy sequencer arranges them in sequence based on their spatial proximity to each other, and Joint-Embedding Predictive Architecture is applied to the ordered patch embeddings. We utilize a mini PointNet [26] architecture for encoding the grouped points and standard Transformer [34] architecture for the context and target encoder as well as the predictor. It is important to note that our JEPA architecture operates on embeddings instead of patches in order to share the point encoder network between context and target encoder for efficiency similar to
在本节中,我们描述了用于点云领域预训练的 JEPA 架构。我们的目标是调整 JEPA [18] 以适用于点云数据,同时评估其性能和实现效率。整体框架如图 2 所示,首先将点云转换为一组 patch 嵌入,然后贪婪排序器根据它们之间的空间邻近性将它们按顺序排列,并将联合嵌入预测架构(Joint-Embedding Predictive Architecture)应用于有序的 patch 嵌入。我们使用 mini PointNet [26] 架构对分组点进行编码,并使用标准 Transformer [34] 架构作为上下文和目标编码器以及预测器。需要注意的是,我们的 JEPA 架构在嵌入而不是 patch 上运行,以便在上下文和目标编码器之间共享点编码器网络以提高效率,类似于
Point2Vec [38].
Point2Vec [38]。
3.1. Point Cloud Patch Embedding
3.1. 点云块嵌入
Building on previous studies that utilize the standard Transformer architecture for point cloud objects [7, 25, 38], we adopt a process that embeds groups of points into patch embeddings. Given a point cloud object, $P\subset\mathbb{R}^{3}$ consisting of $n$ points, c center points are first sampled using the farthest point sampling [11]. Then we employ the $k$ -nearest neighbors algorithm to identify and select the $k$ closest points surrounding each of the $c$ designated center points. These point patches are then normalized by subtracting the center point coordinates from the coordinates of the points in the patches. This allows the separation between local structural information and the positional information of the patches. In order to embed the local point patches, we utilize a mini PointNet [26] architecture. This ensures that the patch embedding remains invariant to any permutations of data feeding order of points within the patch. Specifically, this PointNet contains two sets of a shared multi-layer perceptron (MLP) and a max-pooling layer as shown in Fig. 2. First, a shared MLP maps each point into a feature vector. Then, we apply max-pooling to these vectors and concatenate the result back to the original feature vector. Subsequently, a shared MLP processes these concatenated vectors, followed by a max-pooling operation to generate a set of patch embeddings $T$ of $P$ .
基于先前利用标准Transformer架构处理点云对象的研究[7, 25, 38],我们采用了一种将点组嵌入为补丁嵌入的过程。给定一个点云对象$P\subset\mathbb{R}^{3}$,由$n$个点组成,首先使用最远点采样[11]采样$c$个中心点。然后,我们采用$k$近邻算法识别并选择每个$c$个指定中心点周围的$k$个最近点。这些点补丁通过从补丁中的点坐标减去中心点坐标进行归一化。这使得局部结构信息与补丁的位置信息得以分离。为了嵌入局部点补丁,我们使用了一个小型PointNet[26]架构。这确保了补丁嵌入对补丁内点数据输入顺序的任何排列保持不变。具体来说,这个PointNet包含两组共享的多层感知器(MLP)和一个最大池化层,如图2所示。首先,一个共享的MLP将每个点映射到一个特征向量。然后,我们对这些向量应用最大池化,并将结果连接回原始特征向量。随后,一个共享的MLP处理这些连接后的向量,接着进行最大池化操作,生成一组补丁嵌入$T$。
Algorithm 1: Greedy sequencer strategy
算法 1: 贪婪序列策略
| 输入: 一组补丁嵌入 (patch emb.), T = {t1, t2, ..., tr} 输出: 一组空间连续的补丁嵌入, T' | |
|---|---|
| 1 | 找到初始补丁嵌入 t = minCoordSum(T); |
| 2 | 设置 T' = {t}; |
| 3 | T = T \ {t}; |
| 4 | 初始化 prev_t = t; |
| 5 | while T ≠ 0 do |
| 6 | 设置 closest = ∞; |
| 7 | for t ∈ T do |
| 8 | dis = |
| 9 | if dis ≤ closest then |
| 10 | 设置 closest = dis; |
| 11 | 设置 index = i; |
| 12 | end |
| 13 | end T' = T' ∪ {t_index}; |
| 14 | T = T \ {t_index}; |
| 15 | prev_t = t_index; |
| 16 | end |
3.2. Greedy Sequencer
3.2. 贪婪序列器
Due to the previously observed benefits of having targets and context clustered together in close spatial proximity, a configuration known as a block in I-JEPA [2], we aim to sample patch embeddings that are spatially close to each other. As previously mentioned, point cloud data is permutation invariant to data feeding order, which implies that even if the indices of patch embeddings are sequential, they might not be spatially adjacent. Furthermore, our approach involves the selection of $M$ spatially contiguous blocks of encoded embeddings as the target while ensuring that the context does not include the patch embeddings corresponding to these embedding vectors (details in the next paragraph). To address these challenges, we apply a greedy sequencer that is applied after producing patch embeddings similar to z-ordering in PointGPT [7]. This sequencer orders patch embeddings based on their associated center points ( Algorithm 1). The process is initiated by selecting the center point with the lowest sum of coordinates $(m i n C o o r S u m(T))$ as the starting point, along with its associated patch embedding. In each subsequent step, the center point closest to the one previously chosen and its associated patch embedding are selected. This is iterated until the sequencer visits all of the center points. The resulting arrangement of patch embeddings $(T^{'}={t_{1}^{'},t_{2}^{'},...,t_{r}^{'}})$ is in a sequence where contiguous elements are also spatially contiguous in most cases. This allows the shared computation of spatial proximity between context and target selection. At the same time, this also allows simpler implementation for context and target selection. It is worth noting, however, that selecting two adjacent patch embedding indices in this setting does not always guarantee spatial proximity; there might be a gap between them. While this is true, the experiment results show that this iterative ordering is effective enough in our JEPA architecture. Additionally, this rather simple approach is parallel i zed across batches, making it more efficient for large datasets or point clouds. Not only can we compute pairwise distances for all points within a batch in a single forward pass but also run the iterative process of simultaneously selecting the next closest point across the batch. This enables faster computation on modern GPUs, ensuring that the nearest points are selected efficiently while keeping the algorithm feasible even for large batch sizes.
由于之前观察到的目标和上下文在空间上紧密聚集在一起的好处,即 I-JEPA [2] 中称为块 (block) 的配置,我们的目标是采样在空间上彼此接近的补丁嵌入 (patch embeddings)。如前所述,点云数据对数据输入顺序是排列不变的,这意味着即使补丁嵌入的索引是连续的,它们在空间上也可能不相邻。此外,我们的方法涉及选择 $M$ 个空间连续的编码嵌入块作为目标,同时确保上下文不包括与这些嵌入向量对应的补丁嵌入(详见下一段)。为了解决这些挑战,我们应用了一种贪婪排序器 (greedy sequencer),该排序器在生成补丁嵌入后应用,类似于 PointGPT [7] 中的 z-ordering。该排序器根据补丁嵌入的相关中心点对它们进行排序(算法 1)。该过程通过选择坐标和最小的中心点 $(minCoordSum(T))$ 作为起点,并选择其相关的补丁嵌入。在随后的每一步中,选择与之前选择的中心点最接近的中心点及其相关的补丁嵌入。这个过程会迭代进行,直到排序器访问所有中心点。最终得到的补丁嵌入排列 $(T^{'}={t_{1}^{'},t_{2}^{'},...,t_{r}^{'}})$ 是一个序列,其中连续的元素在大多数情况下也是空间上连续的。这使得上下文和目标选择之间的空间接近性计算可以共享。同时,这也使得上下文和目标选择的实现更加简单。然而,值得注意的是,在这种设置下选择两个相邻的补丁嵌入索引并不总是保证空间上的接近性;它们之间可能存在间隙。尽管如此,实验结果表明,这种迭代排序在我们的 JEPA 架构中是足够有效的。此外,这种相对简单的方法在批次之间是并行化的,使其在处理大型数据集或点云时更加高效。我们不仅可以在一次前向传递中计算批次内所有点的成对距离,还可以同时跨批次运行选择下一个最近点的迭代过程。这使得在现代 GPU 上能够更快地进行计算,确保高效选择最近点,同时即使在大批量情况下也能保持算法的可行性。
3.3. JEPA Components
3.3. JEPA 组件
Context and Target Targets in Point-JEPA can be considered patch-level representations of the point cloud object, which the predictor aims to predict. As illustrated in Fig. 2, the target encoder initially encodes the patch embedding conventionally, and we randomly select $M$ possibly overlapping target blocks, which are sets of adjacent encoded embeddings. Specifically, we define $\boldsymbol{y}(i)={y_{j}}{j\in B{i}}$ as the $i^{\mathrm{th}}$ target representation block, where $B_{i}$ denotes the set of mask indices for the $i^{\mathrm{th}}$ block. Here, we denote the encoded embeddings as $y={y_{1},y_{2},...y_{n}}$ , where $y_{k}=f_{\overline{{\theta}}}(t_{k}^{'})$ is the representation associated with the $k^{t h}$ centre point. It is important to note that masking for the target is applied to the embedding vectors derived from the patch embeddings that have passed through the transformer encoder $f_{\overline{{\theta}}}$ . This ensures a high semantic level for the target representations.
上下文与目标
在 Point-JEPA 中,目标可以被视为点云对象的块级表示,预测器旨在预测这些目标。如图 2 所示,目标编码器首先对块嵌入进行常规编码,然后我们随机选择 $M$ 个可能重叠的目标块,这些块是相邻编码嵌入的集合。具体来说,我们将 $\boldsymbol{y}(i)={y_{j}}{j\in B{i}}$ 定义为第 $i^{\mathrm{th}}$ 个目标表示块,其中 $B_{i}$ 表示第 $i^{\mathrm{th}}$ 块的掩码索引集。在这里,我们将编码嵌入表示为 $y={y_{1},y_{2},...y_{n}}$,其中 $y_{k}=f_{\overline{{\theta}}}(t_{k}^{'})$ 是与第 $k^{t h}$ 个中心点相关的表示。需要注意的是,目标的掩码应用于通过 Transformer 编码器 $f_{\overline{{\theta}}}$ 的块嵌入生成的嵌入向量。这确保了目标表示的高语义水平。

Figure 3. Context and Targets. We visualize the corresponding grouped points of context and target blocks. Here, we use (0.15, 0.2) for the target selection ratio and (0.4, 0.75) for the context selection ratio.
图 3: 上下文与目标。我们可视化了上下文和目标块对应的分组点。这里,我们使用 (0.15, 0.2) 作为目标选择比例,使用 (0.4, 0.75) 作为上下文选择比例。
Context, on the other hand, is the representation of the point cloud object which is passed to the predictor to facilitate the reconstruction of target blocks. Unlike target blocks, masking is applied to the patch embeddings during the creation of context blocks. This allows the contextencoder $f_{\theta}$ to represent the uncertainties in the object’s represent at ions when certain parts are masked. Specifically, we first select a subset of patch embeddings $\hat{T}\subseteq T^{\prime}$ that are spatially contiguous. These selected embeddings are then fed to the context-encoder $f_{\theta}$ to generate a context block $x={x_{j}}{j\in B{x}}$ . To prevent trivial learning, we also ensure that the indices of patch embeddings chosen for the context differ from those for the targets. Furthermore, the patch embeddings $T^{\prime}$ are sorted such that embeddings that are adjacent in the data feeding order are also spatially close. This organization simplifies the selection of contiguous target and context blocks, despite the aforementioned complexities of point cloud data representation.
另一方面,上下文是传递给预测器的点云对象的表示,以促进目标块的重建。与目标块不同,在创建上下文块时,会对补丁嵌入应用掩码。这使得上下文编码器 $f_{\theta}$ 能够在某些部分被掩码时表示对象表示中的不确定性。具体来说,我们首先选择一个空间上连续的补丁嵌入子集 $\hat{T}\subseteq T^{\prime}$。然后将这些选定的嵌入输入到上下文编码器 $f_{\theta}$ 中,以生成一个上下文块 $x={x_{j}}{j\in B{x}}$。为了防止平凡学习,我们还确保为上下文选择的补丁嵌入的索引与为目标选择的索引不同。此外,补丁嵌入 $T^{\prime}$ 被排序,使得在数据输入顺序中相邻的嵌入在空间上也接近。这种组织简化了连续目标和上下文块的选择,尽管点云数据表示存在上述复杂性。
Predictor The task of predictor $p_{\phi}$ given targets $y$ and context $x$ is analogous to the task of supervised prediction. Given a context as input $x$ along with a certain condition, it aims to predict the target representations $y$ . Here, the condition involves the mask tokens, which are created from shared learned parameters, as well as positional encoding, created from centre points associated with the targets. That is
预测器任务 $p_{\phi}$ 在给定目标 $y$ 和上下文 $x$ 的情况下,类似于监督预测任务。给定一个上下文作为输入 $x$ 以及某个条件,它旨在预测目标表示 $y$。这里的条件包括从共享学习参数创建的掩码 Token,以及与目标相关的中心点创建的位置编码。
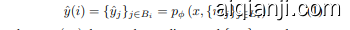
where $p_{\phi}\left(\cdot,\cdot\right)$ denotes the predictor and ${m_{j}}{j\in B{i}}$ denotes the mask token created from shared learnable parameter and positional encoding created from centre points.
其中 $p_{\phi}\left(\cdot,\cdot\right)$ 表示预测器,${m_{j}}{j\in B{i}}$ 表示由共享可学习参数创建的掩码 Token 以及由中心点创建的位置编码。
Loss Because the predictor’s task is to predict the representation produced by the target encoder, the loss can be defined to minimize the disagreement between the predictions and targets as follows.
损失
由于预测器的任务是预测目标编码器生成的表示,因此可以定义损失以最小化预测和目标之间的差异,如下所示。
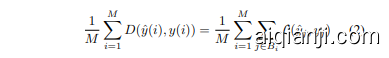
Similar to Point2Vec [38], we utilize Smooth L1 loss to measure the dissimilarity between each corresponding element of the target and predicted embedding because of its ability to be less sensitive to the outliers.
类似于 Point2Vec [38],我们利用 Smooth L1 损失来衡量目标和预测嵌入中每个对应元素之间的差异,因为它对异常值不太敏感。
Parameter Update We utilize AdamW [20] optimizer with cosine learning decay [19]. The target encoder and context encoder initially have identical parameters. The context encoder’s parameters are updated via back prop agation, while the target encoders’ parameters are updated us- ing the exponential moving average of the context encoder parameters, that is $\overline{{{\theta}}}\leftarrow\tau\overline{{{\theta}}}+(1\overline{{{-\tau}}})\theta$ where $\tau\in[0,1]$ denotes the decay rate.
参数更新
我们使用 AdamW [20] 优化器并结合余弦学习率衰减 [19]。目标编码器和上下文编码器最初具有相同的参数。上下文编码器的参数通过反向传播进行更新,而目标编码器的参数则使用上下文编码器参数的指数移动平均值进行更新,即 $\overline{{{\theta}}}\leftarrow\tau\overline{{{\theta}}}+(1\overline{{{-\tau}}})\theta$,其中 $\tau\in[0,1]$ 表示衰减率。
4. Experiments
4. 实验
In this section, we first describe the details of selfsupervised pre-training. Further, we compare the performance of the learned representation to the state-of-the-art self-supervised learning methods in the point cloud domain that utilizes the ShapeNet [6] dataset in pre-training. We specifically evaluate the learned representation using linear probing, end-to-end fine-tuning, and a few-shot learning setting. Finally, ablation experiments are conducted to gain insights into the principal characteristics of Point-JEPA.
在本节中,我们首先描述了自监督预训练的细节。接着,我们将学习到的表示与点云领域中最先进的自监督学习方法进行比较,这些方法在预训练中使用了 ShapeNet [6] 数据集。我们特别通过线性探测、端到端微调和少样本学习设置来评估学习到的表示。最后,我们进行了消融实验,以深入了解 Point-JEPA 的主要特性。
Table 1. Linear Evaluation on ModelNet40 [36]. We compare Point-JEPA to self-supervised learning methods pre-trained on ShapeNet [6]. * signifies the linear evaluation results as indicated in [39, 40]. ** signifies results with Transformer backbone.
表 1. ModelNet40 [36] 上的线性评估。我们将 Point-JEPA 与在 ShapeNet [6] 上预训练的自监督学习方法进行了比较。* 表示 [39, 40] 中所示的线性评估结果。** 表示使用 Transformer 骨干网络的结果。
| 方法 | 总体准确率 |
|---|---|
| Latent-GAN [1] | 85.7 |
| 3D-PointCapsNet [41] | 88.9 |
| STRL [16] | 90.3 |
| Sauder et al. [30] | 90.6 |
| Fu et al. [12] | 91.4 |
| Transformer-OcCo* [37] | 89.6 |
| Point-BERT* [37] | 87.4 |
| Point-MAE* [25] | 90.0 |
| Point-M2AE [39] | 92.9 |
| CluRender** [21] | 93.2 |
| Point-JEPA (Ours) | 93.7±0.2 |
4.1. Self-Supervised Pre-training
4.1 自监督预训练
We pre-train our model on training set of ShapeNet [6] following the previous studies utilizing the standard Transformer [34] architecture such as Point-MAE [25], PointM2AE [39], PointGPT [7], and Point2Vec [38] for the fair comparison. The dataset consists of 41952 3D point cloud instances created from synthetic 3D meshes from 55 categories. The standard Transformer [34] architecture is used for the context and target encoder as well as the predictor. During pre-training, we set the number of center points to 64 and the group size to 32. The point token iz ation is applied to the input point cloud containing 1024 points per object. We set the depth of the Transformer in the context and target encoder to 12 with the embedding width of 384 and 6 heads. For the predictor, we use the narrower dimension of 192 following I-JEPA [2]. The depth of the predictor is set to 6, and the number of heads is set to 6. Our experiments are conducted on NVIDIA RTX A5500 and NVIDIA A100 SXM4. We note that our method only takes 7.5 hours on RTX A5500 for pre training (see Fig. 1) which is less than half of that of PointM2AE [39] and about $60%$ of Point2Vec [38] time requirement for pre training. Adhering to the standard convention, we use overall accuracy for classification tasks and mean IoU for part segmentation tasks.
我们在ShapeNet [6] 的训练集上对模型进行了预训练,遵循了之前的研究,使用了标准的Transformer [34] 架构,如Point-MAE [25]、PointM2AE [39]、PointGPT [7] 和Point2Vec [38],以确保公平比较。该数据集由55个类别的合成3D网格生成的41952个3D点云实例组成。标准的Transformer [34] 架构用于上下文和目标编码器以及预测器。在预训练期间,我们将中心点的数量设置为64,组大小设置为32。点Token化应用于每个对象包含1024个点的输入点云。我们将上下文和目标编码器中的Transformer深度设置为12,嵌入宽度为384,头数为6。对于预测器,我们遵循I-JEPA [2] 使用较窄的维度192。预测器的深度设置为6,头数设置为6。我们的实验在NVIDIA RTX A5500和NVIDIA A100 SXM4上进行。我们注意到,我们的方法在RTX A5500上仅需7.5小时进行预训练(见图1),这不到PointM2AE [39] 的一半,约为Point2Vec [38] 预训练时间要求的60%。遵循标准惯例,我们使用整体准确率进行分类任务,使用平均IoU进行部分分割任务。
Table 2. End-to-End Classification. Overall accuracy on ModelNet40 [36] and ScanObjNN [32] with end-to-end fine-tuning. We specifically compare our methods to the method utilizing standard Transformer architecture pre-trained on ShapeNet [6] with only point cloud (no additional modality).
表 2: 端到端分类。在 ModelNet40 [36] 和 ScanObjNN [32] 上进行端到端微调的整体准确率。我们特别将我们的方法与仅在 ShapeNet [6] 上预训练的标准 Transformer 架构(仅使用点云,无额外模态)进行了比较。
| 方法 | 参考文献 | 整体准确率 | ModelNet40 | ScanObjNN | |||||
|---|---|---|---|---|---|---|---|---|---|
| #Points | +Voting | -Voting | #Points | OBJ-BG | OBJ-ONLY | OBJ-T50-RS | |||
| Point-BERT [37] | CVPR2022 | 1k | 93.2 | 92.7 | 1k | 87.4 | 88.1 | 83.1 | |
| Point-MAE [25] | ECCV2022 | 1k | 93.8 | 93.2 | 2k | 90.0 | 88.3 | 85.2 | |
| Point-M2AE [39] | NeurIPS2022 | 1k | 94.0 | 93.4 | 2k | 91.2 | 88.8 | 86.4 | |
| Point2Vec [38] | GCPR2023 | 1k | 94.8 | 94.7 | 2k | 91.2 | 90.4 | 87.5 | |
| PointGPT-S [7] | NeurIPS2023 | 1k | 94.0 | 2k | 91.6 | 90.0 | 86.9 | ||
| PointDiff [42] | CVPR2024 | 一 | 1k | 93.2 | 91.9 | 87.6 | |||
| Point-JEPA (Ours) | 1k | 94.1±0.1 | 93.8±0.2 | 2k | 92.9 ±0.4 | 90.1 ± 0.2 | 86.6 ± 0.3 |
4.2. Downstream Tasks
4.2. 下游任务
In this section, we report the performance of the learned representation on several downstream tasks. Following the previous studies [7, 37–39], we report the overall accuracy as a percentage. To account for variability across independent runs, we report the mean accuracy and standard deviation from 10 independent runs with different seeds, unless specified otherwise.
在本节中,我们报告了学习到的表示在多个下游任务中的表现。根据之前的研究 [7, 37–39],我们以百分比形式报告总体准确率。为了考虑独立运行之间的变异性,我们报告了10次不同种子独立运行的平均准确率和标准差,除非另有说明。
Linear Probing. After pre-training on ShapeNet [6], we evaluate the learned representation via linear probing on ModelNet40 [36]. Specifically, we freeze the learned context encoder and place the SVM classifier on top. To enforce invariance to geometric transformation, we utilize max and mean pooling on the output of the Transformer encoder [25, 38]. We utilize 1024 points for both training and test sets. As shown in Tab. 1, our method achieves state-of-theart accuracy, providing $+0.8%$ performance gain, showing the robustness of the learned representation.
线性探测。在 ShapeNet [6] 上进行预训练后,我们通过在 ModelNet40 [36] 上进行线性探测来评估学习到的表示。具体来说,我们冻结学习到的上下文编码器,并在其顶部放置 SVM 分类器。为了增强对几何变换的不变性,我们在 Transformer 编码器 [25, 38] 的输出上使用最大池化和平均池化。我们在训练集和测试集上均使用 1024 个点。如表 1 所示,我们的方法达到了最先进的准确率,提供了 $+0.8%$ 的性能提升,展示了学习到的表示的鲁棒性。
Few-Shot Learning We conduct few-shot learning experiments on Modelnet40 [36] in $m$ -way, $n$ -shot setting as shown in Tab. 3. Specifically, we randomly sample $n$ instances of $m$ classes for training and select 20 instances of $m$ support classes for evaluation. For one setting, we run 10 independent runs under a fixed random seed on 10 different folds of dataset and report mean and standard deviation of overall accuracy. As shown in Tab. 3, our method exceeds the performance of current state-of-the-art in all settings and yields a $+1.1%$ improvement in the most difficult 10-way 10-shot setting, showing the robustness of the learned representation of Point-JEPA, especially in the low-data regime.
少样本学习
我们在 Modelnet40 [36] 上进行了少样本学习实验,采用 $m$ 类 $n$ 样本的设置,如表 3 所示。具体来说,我们随机抽取 $m$ 个类别的 $n$ 个实例进行训练,并选择 $m$ 个支持类别的 20 个实例进行评估。对于每个设置,我们在固定随机种子下对数据集的 10 个不同折叠进行 10 次独立运行,并报告整体准确率的均值和标准差。如表 3 所示,我们的方法在所有设置中都超过了当前最先进方法的性能,并在最具挑战性的 10 类 10 样本设置中实现了 $+1.1%$ 的提升,展示了 Point-JEPA 学习到的表示的鲁棒性,尤其是在低数据量情况下。
End-to-end Fine-Tuning We also investigate the performance of the learned representation via end-to-end finetuning. After pre-training, we utilize the context encoder to extract the max and average pooled outputs. These outputs are then processed by a three-layer MLP for classification tasks. This class-specific head as well as the context encoder is fine-tuned end-to-end on ModelNet40 [36] and S can Object NN [32]. ModelNet40 consists of 12311 synthetic 3D objects from 40 distinct categories, while ScanObjectNN contains objects from 15 classes, each containing 2902 unique instances collected by scanning real-world objects. For ModelNet40, we sub-sample 1024 points per object and sample 64 center points with 32 points in each point patch. On the other hand, we utilize all 2048 points for the ScanObjNN dataset and sample 128 center points with 32 nearest neighbors for the grouped points. As shown in Tab. 2, our method achieves competitive results when compared to other state-of-the-art methods. Especially, in the OBJ-BG variant of the ScanObjNN [32] dataset, which presents a realistic representation of a point cloud that includes both the object and its background, our method achieves the overall accuracy marginally lower than PointDiff [42] while an improvement of $+1%$ over other SSL methods. This shows the learned representation obtained from pre-training with Point-JEPA can easily be transferred to a classification task.
端到端微调
我们还通过端到端微调研究了学习到的表示的性能。在预训练之后,我们利用上下文编码器提取最大池化和平均池化输出。这些输出随后通过一个三层 MLP 进行处理以进行分类任务。这个特定类别的头部以及上下文编码器在 ModelNet40 [36] 和 ScanObjectNN [32] 上进行了端到端微调。ModelNet40 包含来自 40 个不同类别的 12311 个合成 3D 对象,而 ScanObjectNN 包含来自 15 个类别的对象,每个类别包含 2902 个通过扫描真实世界对象收集的独特实例。对于 ModelNet40,我们对每个对象进行 1024 个点的子采样,并采样 64 个中心点,每个点块中包含 32 个点。另一方面,我们使用 ScanObjNN 数据集中的所有 2048 个点,并为分组点采样 128 个中心点和 32 个最近邻点。如表 2 所示,与其他最先进的方法相比,我们的方法取得了具有竞争力的结果。特别是在 ScanObjNN [32] 数据集的 OBJ-BG 变体中,该变体展示了包含对象及其背景的点云的逼真表示,我们的方法在整体准确率上略低于 PointDiff [42],但比其他自监督学习方法提高了 $+1%$。这表明通过 Point-JEPA 预训练获得的学习表示可以轻松迁移到分类任务中。
Table 3. Result of Few-Shot classification on ModelNet40 [36]. 10 independent trials are completed under one setting. We report mean and standard deviation over 10 trials. $^{**}$ signifies results with Transformer backbone.
表 3. ModelNet40 上少样本分类的结果 [36]。每种设置下完成了 10 次独立试验。我们报告了 10 次试验的平均值和标准差。$^{**}$ 表示使用 Transformer 骨干网络的结果。
| 方法 | 总体准确率 | 5-way | 10-way |
|---|---|---|---|
| 10-shot | 20-shot | 10-shot | |
| Point-BERT [37] Point-MAE[25] | 94.6±3.1 96.3±2.5 | 96.3±2.7 97.8±1.8 | 91.0±5.4 92.6±4.1 |
| Point-M2AE[39] | 96.8±1.8 | 98.3±1.4 | 92.3±4.5 |
| Point2Vec [38] | 97.0±2.8 | 98.7±1.2 | 93.9±4.1 |
| PointGPT-S [7] | 96.8±2.0 | 98.6±1.1 | 92.6±4.6 |
| CluRender** [21] | 97.2±2.3 | 98.4±1.3 | 93.7±4.0 |
| Point-JEPA (Ours) | 97.4±2.2 | 99.2±0.8 | 95.0±3.6 |
Table 4. Masking Strategies. Multi-block and single-block masking strategies and their effect on the learned representation.
表 4: 掩码策略。多块和单块掩码策略及其对学习表示的影响。
| 策略 | 比例 | 频率 | 上下文策略 | 比例 | Modelnet40Linear |
|---|---|---|---|---|---|
| random | (0.6, 0.6) | 1 | rest | 一 | 92.5 |
| contiguous | (0.6,0.6) | 1 | rest | 一 | 92.3 |
| contiguous | (0.15, 0.2) | 4 | contiguous | (0.4,0.75) | 93.7 |
Table 5. Part Segmentation on Shape Net Part [6]. $\mathrm{mIoU}{C}$ is the mean IoU for all part categories, and $\mathrm{mloU}{I}$ is the mean IoU for all instances.
表 5. Shape Net Part [6] 上的部件分割结果。$\mathrm{mIoU}{C}$ 是所有部件类别的平均 IoU,$\mathrm{mloU}{I}$ 是所有实例的平均 IoU。
| 方法 | mIoUc | mIoU1 |
|---|---|---|
| Transformer-OcCo[37] | 83.4 | 85.1 |
| Point-BERT [37] | 84.1 | 85.6 |
| Point-MAE [25] | 84.1 | 86.1 |
| Point-M2AE [39] | 84.9 | 86.5 |
| Point2Vec[38] | 84.6 | 86.3 |
| PointGPT-S [7] | 84.1 | 86.2 |
| Point-JEPA (Ours) | 83.9±0.1 | 85.8±0.1 |
Part Segmentation Following previous studies [7,25,37– 39], we report the performance of Point-JEPA in part segmentation task. Here, we utilize the Shape Net Part [6] dataset, consisting of 16881 objects from 16 categories. We utilize the identical architecture employed in Point2Vec [38] for this task. Specifically, we take the embeddings from $4^{\mathrm{th}},8^{\mathrm{th}}$ , and $12^{\mathrm{th}}$ Transformer block and take the average of them. Then, we apply mean and average pooling to this averaged output. The max and mean pooled embedding along with a one-hot encoded class label of an object is used as a global feature vector for the object. The original averaged output is also up-sampled using the PointNet+ $^{\cdot+}$ [27] feature propagation layer to create a feature vector for each point. Then, each feature vector is concatenated with the global feature vector. A shared MLP is utilized on this concatenated vector to predict the segmentation label for the given point. Although the Point-JEPA shows competitive results, as shown in Tab. 5, its performance is slightly worse than the state-of-the-art methods.
部件分割
遵循先前的研究 [7,25,37–39],我们报告了 Point-JEPA 在部件分割任务中的表现。这里,我们使用了 Shape Net Part [6] 数据集,该数据集包含来自 16 个类别的 16881 个对象。我们在此任务中使用了与 Point2Vec [38] 相同的架构。具体来说,我们从第 4、第 8 和第 12 个 Transformer 块中提取嵌入,并对它们取平均值。然后,我们对这个平均输出应用最大和平均池化。最大和平均池化嵌入以及对象的一热编码类别标签被用作对象的全局特征向量。原始的平均输出还通过 PointNet+ $^{\cdot+}$ [27] 特征传播层进行上采样,以创建每个点的特征向量。然后,每个特征向量与全局特征向量连接。在这个连接向量上使用共享的 MLP 来预测给定点的分割标签。尽管 Point-JEPA 显示出有竞争力的结果,如表 5 所示,但其性能略逊于最先进的方法。
Limitations Point-JEPA’s comparatively weaker performance in segmentation and its superior learned representation in classification indicate that the proposed approach emphasizes global features over local features. Additionally, the effectiveness of Point-JEPA for processing larger point clouds is uncertain due to redundancy in many areas in data and requires further study.
局限性
Point-JEPA 在分割任务中表现相对较弱,而在分类任务中学习到的表示效果较好,这表明该方法更注重全局特征而非局部特征。此外,由于数据中许多区域存在冗余,Point-JEPA 在处理更大规模点云时的有效性尚不确定,需要进一步研究。
4.3. Ablation Study
4.3. 消融研究
We conducted thorough ablation studies to understand the effect of moving parts of Point-JEPA. We pre-train Point-JEPA on the ShapeNet [6] dataset under various settings and evaluate the learned representation with linear probing on the ModelNet40 [36] dataset.
我们对 Point-JEPA 的各个部分进行了全面的消融研究,以了解其影响。我们在 ShapeNet [6] 数据集上以不同设置对 Point-JEPA 进行预训练,并在 ModelNet40 [36] 数据集上通过线性探测评估学习到的表示。
Masking Strategy. We investigate the impact of the masking type on the performance. We consider single-block masking and multi-block masking. For single-block masking strategies, we consider random masking and contiguous masking. For random masking, we randomly select the $60%$ of indices out of all encoded embedding vectors. Similarly, for contiguous masking, embedding vectors that are spatially contiguous are selected. In this setting, all patch embeddings not corresponding to the selected target blocks are used as context (denoted as rest). On the other hand, in the multi-block masking setting, we sample multiple possibly overlapping spatially contiguous embedding vectors as targets, and we remove the corresponding patch embeddings already selected for targets during context selection. In this setting, we set the ratio range of 0.15 to 0.2 for targets, while we set the ratio range of 0.4 to 0.75 for context. As shown in Tab. 4, the single-block masking achieves sub-optimal performance regardless of the spatial contiguity of the target embedding. It shows that our method learns stronger represent ation by utilizing a smaller amount of targets with a larger frequency.
掩码策略。我们研究了掩码类型对性能的影响。我们考虑了单块掩码和多块掩码。对于单块掩码策略,我们考虑了随机掩码和连续掩码。对于随机掩码,我们从所有编码的嵌入向量中随机选择 $60%$ 的索引。类似地,对于连续掩码,选择空间上连续的嵌入向量。在这种设置中,所有不对应于所选目标块的补丁嵌入都被用作上下文(表示为 rest)。另一方面,在多块掩码设置中,我们采样多个可能重叠的空间连续嵌入向量作为目标,并在上下文选择期间移除已选择为目标对应的补丁嵌入。在这种设置中,我们将目标的比例范围设置为 0.15 到 0.2,而将上下文的比例范围设置为 0.4 到 0.75。如表 4 所示,无论目标嵌入的空间连续性如何,单块掩码都实现了次优性能。这表明我们的方法通过利用较少的目标和更高的频率来学习更强的表示。
Sequencer At the heart of employing Point-JEPA for point cloud processing is the ability to translate point cloud data into a sequence of spatially contiguous patch embeddings. As shown in Tab. 6, we conduct the ablation experiment with different sequencer strategies including both the $z$ -order [22] and Hilbert-order [31] space-filling curves, as well as the proposed greedy sequencer. The greedy sequencer is evaluated in two versions: one starting with the point that has the minimum index in data feeding order, and the other starting with the point that has the minimum coordinate sum. The greedy sequencer with the minimum coordinate approach exhibits an overall accuracy improvement compared to all the other algorithms. Additionally, the greedy sequencer offers computational efficiency over z-order and Hilbert-order due to its ability to parallel ize computations, as mentioned previously. Notably, the greedy sequencer with minimum coordinate sum initial point guarantees that the starting center point in the sequencer lies near the edge of the object. As shown in Tab. 6, selecting the point near the edge of the object as the starting point helps the model learn a stronger representation.
在利用 Point-JEPA 进行点云处理的核心在于将点云数据转换为一系列空间连续的补丁嵌入。如表 6 所示,我们使用不同的序列化策略进行了消融实验,包括 $z$ 序 [22] 和 Hilbert 序 [31] 空间填充曲线,以及提出的贪婪序列化器。贪婪序列化器评估了两个版本:一个从数据输入顺序中索引最小的点开始,另一个从坐标和最小的点开始。与其他算法相比,采用最小坐标方法的贪婪序列化器在整体准确率上有所提升。此外,如前所述,由于能够并行化计算,贪婪序列化器在计算效率上优于 $z$ 序和 Hilbert 序。值得注意的是,以最小坐标和初始点开始的贪婪序列化器保证了序列化器中的起始中心点位于物体边缘附近。如表 6 所示,选择靠近物体边缘的点作为起始点有助于模型学习更强的表示。
Table 6. Experiment with different sequencers using the ModelNet40 linear evaluation and their corresponding training times on RTX 5500 GPU for 500 epochs.
表 6. 使用 ModelNet40 线性评估和 RTX 5500 GPU 上 500 个 epoch 的训练时间进行不同序列器的实验。
| 序列器 | ModelNet40 线性训练时间 |
|---|---|
| Z-ordering [22] | 93.4 8.30h |
| Hilbert ordering [31] | 91.8 10.78h |
| Greedy (min index) | 92.7 7.47h |
| Greedy (min coordinate) | 93.7 7.47h |

Figure 4. Embedding Visualization on ModelNet40 [36]. We visualize the context encoder’s learned representation with t-SNE [33].
图 4: ModelNet40 [36] 上的嵌入可视化。我们使用 t-SNE [33] 可视化了上下文编码器学习到的表示。
Number of Target Blocks. We also consider the effect of the number of blocks chosen for targets on the performance of the learned representation while we keep the ratio for targets and context fixed. As shown in Tab. 7, the performance increases as we increase the number of targets. However, the performance decreases as you increase the number of target blocks after a specific frequency. We observe that our method benefits from having a sufficient amount of patch embeddings available for context encoding.
目标块数量。我们还考虑了在保持目标和上下文比例固定的情况下,选择的目标块数量对学习表示性能的影响。如表 7 所示,随着目标块数量的增加,性能有所提升。然而,在达到特定频率后,随着目标块数量的增加,性能会下降。我们观察到,我们的方法受益于有足够的 patch embeddings 可用于上下文编码。
Table 7. Number of Target blocks. We change the number (frequency) of target blocks while keeping the other components fixed.
表 7. 目标块的数量。我们在保持其他组件不变的情况下改变目标块的数量(频率)。
| 目标 | 上下文 | OA |
|---|---|---|
| 比例 | 频率 | 比例 |
| (0.15, 0.2) | 1 | (0.85, 1.0) |
| (0.15, 0.2) | 2 | (0.85, 1.0) |
| (0.15, 0.2) | 3 | (0.4, 0.75) |
| (0.15, 0.2) | 4 | (0.4, 0.75) |
| (0.15, 0.2) | 5 | (0.4, 0.75) |
| (0.15, 0.2) | 6 | (0.4, 0.75) |
4.4. Visualization
4.4. 可视化
To qualitatively analyze the learned representation, we reduce the dimension of the learned representation by utilizing t-SNE [33]. We introduce max and mean pooling on the output of the context encoder, similar to the classification setup, and apply t-SNE on the pooled embedding. We visualize the learned representation on ModelNet40 [36] with no fine-tuning on the dataset. Despite being trained on the dataset, our context encoder produces disc rim i native features as shown in Fig. 4, showing the robustness of the learned representation.
为了定性分析学习到的表示,我们利用 t-SNE [33] 对学习到的表示进行降维。我们在上下文编码器的输出上引入了最大池化和平均池化,类似于分类设置,并对池化后的嵌入应用 t-SNE。我们在 ModelNet40 [36] 上对学习到的表示进行了可视化,且未对该数据集进行微调。尽管在数据集上进行了训练,我们的上下文编码器仍生成了判别性特征,如图 4 所示,展示了学习到的表示的鲁棒性。
5. Conclusion
5. 结论
This work introduced Point-JEPA, a joint embedding predictive architecture applied to point cloud objects. In order to efficiently select targets and context blocks even under the invariance property of point cloud data, we introduced a sequencer, which orders the center points and their corresponding patch embeddings by iterative ly selecting the next closest center point. This eliminates the necessity of computing spatial proximity between every pair of patch embeddings or encoded embeddings when sampling the targets and context. Point-JEPA achieves state-ofthe-art performance in downstream tasks, excelling in fewshot learning and linear evaluation. This makes Point-JEPA highly useful when there is a large amount of unlabeled data and a limited amount of labeled data. It is also worth noting that Point-JEPA converges much faster during pre-training, offering a more efficient pre-training alternative in the point cloud domain. Future work includes extending Point-JEPA for other downstream tasks such as object detection and scene level segmentation, and pre-training on large unlabeled hybrid datasets [7]. Additionally, the ability of JEPA to reduce dependency on large labeled datasets presents potential avenues for generating temporal predictive embeddings that anticipate point cloud evolution, thereby enhancing tasks like motion prediction, dynamic scene understanding, and anomaly detection.
本文介绍了Point-JEPA,一种应用于点云对象的联合嵌入预测架构。为了在点云数据的不变性特性下高效选择目标和上下文块,我们引入了一个排序器,通过迭代选择下一个最近的中心点来对中心点及其对应的补丁嵌入进行排序。这消除了在采样目标和上下文时计算每对补丁嵌入或编码嵌入之间空间邻近性的必要性。Point-JEPA在下游任务中实现了最先进的性能,在少样本学习和线性评估方面表现出色。这使得Point-JEPA在存在大量未标记数据和有限标记数据的情况下非常有用。值得注意的是,Point-JEPA在预训练期间收敛速度更快,为点云领域提供了更高效的预训练替代方案。未来的工作包括将Point-JEPA扩展到其他下游任务,如目标检测和场景级分割,并在大型未标记混合数据集上进行预训练 [7]。此外,JEPA减少对大型标记数据集依赖的能力为生成预测点云演化的时间预测嵌入提供了潜在途径,从而增强运动预测、动态场景理解和异常检测等任务。
References
参考文献
Point-JEPA: A Joint Embedding Predictive Architecture for Self-Supervised Learning on Point Cloud
Point-JEPA:一种用于点云自监督学习的联合嵌入预测架构
Supplementary Material
补充材料
A. Further Pre-training Details
A. 进一步预训练细节
Optimization We utilize AdamW [?] optimizer with cosine learning decay [?]. Starting from learning rate of $10^{-5}$ , we increase it to $10^{-3}$ in the first 30 epochs and decay it to $10^{-6}$ . The batch size for pre training is set to 512, and $\beta$ for Smooth L1 loss is set to 2, similar to Point2Vec [?]. The target encoder and context encoder initially have identical parameters. The context encoder’s parameters are updated via back propagation, while the target encoders’ parameters are updated using the exponential moving average of the context encoder parameters, that is $\overline{{{\theta}}}\leftarrow\dot{\tau}\overline{{{\theta}}}+(\dot{1}-\tau)\theta$ where $\tau\in[0,1]$ denotes the decay rate. We gradually increase the decay rate of the exponential moving average from 0.995 to 1.0 during pre training.
优化
我们使用 AdamW [?] 优化器,并采用余弦学习率衰减 [?]。学习率从 $10^{-5}$ 开始,在前 30 个 epoch 中逐渐增加到 $10^{-3}$,然后衰减到 $10^{-6}$。预训练的批量大小设置为 512,Smooth L1 损失的 $\beta$ 设置为 2,与 Point2Vec [?] 类似。目标编码器和上下文编码器最初具有相同的参数。上下文编码器的参数通过反向传播更新,而目标编码器的参数则使用上下文编码器参数的指数移动平均值更新,即 $\overline{{{\theta}}}\leftarrow\dot{\tau}\overline{{{\theta}}}+(\dot{1}-\tau)\theta$,其中 $\tau\in[0,1]$ 表示衰减率。在预训练过程中,我们逐渐将指数移动平均的衰减率从 0.995 增加到 1.0。
Masking and Ordering To determine the sequence of patch embeddings, we utilize the iterative ordering of associated center points, as previously mentioned. We chose the starting point in this sequence with the lowest sum of its coordinates. This method allows us to start the sequence from a point on the outer edge of the object rather than from a point within the object’s interior. This consistency in selecting the initial point is experimentally shown to deliver a slightly better learned representation than taking the first available index.
掩码与排序
为了确定补丁嵌入的顺序,我们利用之前提到的关联中心点的迭代排序。我们选择该序列中坐标和最小的点作为起点。这种方法使我们能够从对象的外边缘开始序列,而不是从对象内部的点开始。实验表明,这种选择初始点的一致性比直接使用第一个可用索引能够提供稍微更好的学习表示。
For masking, we define a range of ratios with both upper and lower limits similar to I-JEPA [?]. To start with, we clarify that the term “block” refers to a sequence of patch embeddings and their corresponding encoded embeddings that are contiguous. Because of the sequencing process applied before the target and context selection, most contiguous patch embeddings and encoded embeddings are also spatially contiguous. For the target, we randomly select 4 blocks of encoded embeddings processed by transformer blocks from within the 0.15 to 0.2 range. We then remove the corresponding patch embeddings of encoded embedding vectors that have already been chosen as targets for further selection. Following this, we choose a block of patch embeddings that is within the range of 0.4 to 0.75 out of available patch embeddings that are not concealed. Because some of the patch embeddings are not available for context selection, we note that context block usually consists of multiple sets of patch embeddings that are spatially contiguous. The selection of targets is completed on a per-batch basis, and we track the indices of these targets to ensure that the corresponding patch embeddings of these selected encoded embeddings are concealed in the context selection.
对于掩码处理,我们定义了一个与 I-JEPA [?] 类似的范围比例,包含上下限。首先,我们明确“块”指的是连续的 patch embedding 及其对应的编码 embedding。由于在目标和上下文选择之前应用了序列化处理,大多数连续的 patch embedding 和编码 embedding 在空间上也是连续的。对于目标,我们从 0.15 到 0.2 的范围内随机选择 4 个经过 Transformer 块处理的编码 embedding 块。然后,我们移除已被选为目标的编码 embedding 向量对应的 patch embedding,以便进一步选择。接着,我们从可用的未被遮蔽的 patch embedding 中选择一个在 0.4 到 0.75 范围内的块。由于部分 patch embedding 不可用于上下文选择,我们注意到上下文块通常由多个空间上连续的 patch embedding 组成。目标的选择是按批次完成的,我们跟踪这些目标的索引,以确保这些选定的编码 embedding 对应的 patch embedding 在上下文选择中被遮蔽。
The context is then selected using the available indices of patch embeddings also on a per-batch basis.
Table 1. Ratio Range for Target. The ratio of encoded embedding vectors selected for each target.
然后根据可用的 patch embeddings 索引在每个批次的基础上选择上下文。
| 目标 | 频率 | 上下文 | OA |
|---|---|---|---|
| 比率 | 频率 | 比率 | Modelnet40 Linear |
| (0.1, 0.2) | 4 | (0.85, 1.0) | 93.0 |
| (0.15, 0.2) | 4 | (0.85, 1.0) | 93.3 |
| (0.2,0.25) | 4 | (0.85, 1.0) | 93.2 |
| (0.25, 0.3) | 4 | (0.85, 1.0) | 92.4 |
| (0.3,0.35) | 4 | (0.85, 1.0) | 90.5 |
| (0.35, 0.4) | 4 | (0.85, 1.0) | 84.6 |
表 1: 目标比率范围。为每个目标选择的编码嵌入向量的比率。
B. Further Ablation
B. 进一步消融实验
Ratio of Targets. We change the ratio of the selected embedding vectors for the target selection while keeping the number of target blocks and the ratio of context patch embedding fixed. As shown in Tab. 1, the performance increases when you increase the ratio to a certain point. However, beyond this point, further increasing the ratio results in decreased performance. This implies that Point-JEPA does not require a large size for the target blocks and benefits from a sufficient amount of available patch embeddings for context selection.
目标比例。我们在保持目标块数量和上下文补丁嵌入比例固定的情况下,改变目标选择的嵌入向量比例。如表 1 所示,当比例增加到一定程度时,性能会提高。然而,超过这一点后,进一步增加比例会导致性能下降。这表明 Point-JEPA 不需要目标块的大小过大,并且受益于足够数量的可用补丁嵌入来进行上下文选择。
Table 2. Ratio Range for Context. The ratio of patch embeddings selected for context encoding.
| 目标 | 上下文 | OA |
|---|---|---|
| 比例 | 频率 | 比例 |
| (0.15, 0.2) | 4 | (0.85, 1.0) |
| (0.15, 0.2) | 4 | (0.75, 1.0) |
| (0.15, 0.2) | 4 | (0.65, 1.0) |
| (0.15, 0.2) | 4 | (0.45, 1.0) |
| (0.15, 0.2) | 4 | (0.6, 0.75) |
| (0.15, 0.2) | 4 | (0.5, 0.75) |
| (0.15, 0.2) | 4 | (0.4, 0.75) |
表 2: 上下文的比例范围。用于上下文编码的 patch embeddings 选择比例。
Ratio of Context. In this study, we change the ratio of patch embeddings selected for context encoding while keeping the number of targets and the ratio range for targets fixed. As shown in Table 2, having a relatively large difference between the lower and upper bound of the ratio can improve performance. In other words, Point-JEPA learns a better representation when the number of selected context patch embeddings varies more between training iterations. Additionally, when the upper bound of the ratio is somewhat constrained, we see increased performance.
上下文比例。在本研究中,我们改变了用于上下文编码的补丁嵌入比例,同时保持目标数量和目标比例范围不变。如表 2 所示,比例的下限和上限之间存在较大差异可以提高性能。换句话说,当训练迭代之间选择的上下文补丁嵌入数量变化较大时,Point-JEPA 能够学习到更好的表示。此外,当比例的上限受到一定限制时,我们观察到性能有所提升。

Figure 1. Confusion matrices illustrating model performance on ModelNet40 and another dataset, highlighting class-specific accuracies and challenges with similar categories.
图 1: 展示模型在 ModelNet40 和另一个数据集上性能的混淆矩阵,突出显示了类别特定的准确率以及在相似类别上的挑战。
Predictor Depth We also study the effect of the predictor’s depth on the learned representation. To this end, we vary the predictor depth and observe its effect on the linear evaluation accuracy. As shown in Table 3, Point-JEPA benefits from a deeper predictor.
预测器深度
我们还研究了预测器深度对学习表示的影响。为此,我们改变预测器的深度,并观察其对线性评估准确性的影响。如表 3 所示,Point-JEPA 受益于更深的预测器。
Class confusion on ModelNet40 and ScanObjNN To assess our model’s performance on the ModelNet40 [?] and ScanObjNN [?] datasets, we present two types of visualizations for each dataset. The first is a row-normalized confusion matrix, which illustrates the model’s sensitivity, indicating how well the model identifies each actual class. The second is a column-normalized confusion matrix, depicting the model’s specificity, which shows the correctness of predictions for each class assumed by the model. As illustrated in parts (a) and (b) of Fig. 1, the model fine-tuned on ModelNet40 demonstrates high accuracy. At the same time, errors predominantly arise from similar categories within the dataset. For instance, “flower pot” and “plant” are often mis classified, likely due to the presence of flowers in some of the flower pot models in the ModelNet40 dataset. Similarly, parts (c) and (d) of Fig. 1 show the aforementioned confusion matrices. As highlighted in the main paper, our model’s performance on S can Object NN dataset has room for enhancement compared to ModelNet40. The confusion matrix reveals some mis classifications, but it is encouraging to see that these errors predominantly occur between closely related classes, such as ‘table’ and ‘desk’ or ‘sofa’ and ‘bed’. This suggests that our model has a solid grasp of the key characteristics of these categories and that further refinement of the classification criteria could lead to significant improvements in overall accuracy.
ModelNet40 和 ScanObjNN 上的类别混淆
为了评估我们的模型在 ModelNet40 [?] 和 ScanObjNN [?] 数据集上的表现,我们为每个数据集提供了两种可视化方式。第一种是行归一化的混淆矩阵,展示了模型的敏感性,即模型识别每个实际类别的能力。第二种是列归一化的混淆矩阵,展示了模型的特异性,即模型对每个假设类别的预测准确性。
如图 1 的 (a) 和 (b) 部分所示,在 ModelNet40 上微调的模型表现出较高的准确性。同时,错误主要来自数据集中的相似类别。例如,“花盆”和“植物”经常被错误分类,这可能是由于 ModelNet40 数据集中一些花盆模型中存在花朵。
类似地,图 1 的 (c) 和 (d) 部分展示了上述混淆矩阵。正如主论文中所强调的,与 ModelNet40 相比,我们的模型在 ScanObjNN 数据集上的表现还有提升空间。混淆矩阵揭示了一些错误分类,但令人鼓舞的是,这些错误主要发生在密切相关的类别之间,例如“桌子”和“书桌”或“沙发”和“床”。这表明我们的模型对这些类别的关键特征有较好的把握,进一步细化分类标准可能会显著提高整体准确性。
Table 3. Predictor Depth. Predictor depth and its effect on learned representation.
表 3: 预测器深度。预测器深度及其对学习表示的影响。
| 预测器深度 | Modelnet40 线性 (OA) |
|---|---|
| 2 | 92.5 |
| 3 | 92.8 |
| 4 | 93.2 |
| 5 | 93.4 |
| 6 | 93.7 |