DIFFERENTIABLE PROMPT MAKES PRE-TRAINED LANGUAGE MODELS BETTER FEW-SHOT LEARNERS
可微提示使预训练语言模型成为更好的少样本学习器
Ningyu Zhang $^{1,2,3*}$ Luoqiu $\mathbf{Li}^{1,3*}$ Xiang Chen1,3 Shumin Deng1,3 Zhen $\mathbf{B}\mathbf{i}^{2,3}$ Chuanqi Tan5 Fei Huang 5 Huajun Chen1,3,4†
Ningyu Zhang $^{1,2,3*}$ Luoqiu $\mathbf{Li}^{1,3*}$ Xiang Chen1,3 Shumin Deng1,3 Zhen $\mathbf{B}\mathbf{i}^{2,3}$ Chuanqi Tan5 Fei Huang5 Huajun Chen1,3,4†
ABSTRACT
摘要
Large-scale pre-trained language models have contributed significantly to natural language processing by demonstrating remarkable abilities as few-shot learners. However, their effectiveness depends mainly on scaling the model parameters and prompt design, hindering their implementation in most real-world applications. This study proposes a novel pluggable, extensible, and efficient approach named DifferentiAble pRompT (DART), which can convert small language models into better few-shot learners. The main principle behind this approach involves reformulating potential natural language processing tasks into the task of a pre-trained language model and differential ly optimizing the prompt template as well as the target label with back propagation. Furthermore, the proposed approach can be: (i) Plugged to any pre-trained language models; (ii) Extended to widespread classification tasks. A comprehensive evaluation of standard NLP tasks demonstrates that the proposed approach achieves a better few-shot performance 1.
大规模预训练语言模型通过展现出卓越的少样本学习能力,为自然语言处理领域做出了重要贡献。然而,其效果主要依赖于模型参数规模的扩展和提示(prompt)设计,这阻碍了其在大多数实际应用中的落地。本研究提出了一种新颖的可插拔、可扩展且高效的方法——DifferentiAble pRompT (DART),能够将小型语言模型转化为更优秀的少样本学习器。该方法的核心原理是将潜在的自然语言处理任务重新表述为预训练语言模型的任务,并通过反向传播对提示模板和目标标签进行差异化优化。此外,所提出的方法具有以下特点:(i) 可适配任何预训练语言模型;(ii) 可扩展至广泛的分类任务。在标准NLP任务上的综合评估表明,该方法实现了更优异的少样本性能[20]。
1 INTRODUCTION
1 引言
The pre-train—fine-tune paradigm has become the de facto standard for natural language processing (NLP), and has achieved excellent results in several benchmarks (Devlin et al., 2019; Liu et al., 2019; Lewis et al., 2020; Dong et al., 2019; Bao et al., 2020a). The success of these pioneers seems to suggest that large-scale pre-trained models are always nothing short of a panacea for boosting machine intelligence. However, supervised fine-tuning is still prone to labeled data in practice and faces un ign or able challenges owing to the variations of domains, language, and tasks. These drawbacks lead to the research of an important technique, few-shot learning, which can significantly improve the learning capabilities of machine intelligence and practical adaptive applications by accessing only a small number of labeled examples.
预训练-微调范式已成为自然语言处理(NLP)的事实标准,并在多个基准测试中取得了优异成果 (Devlin et al., 2019; Liu et al., 2019; Lewis et al., 2020; Dong et al., 2019; Bao et al., 2020a)。这些先驱者的成功似乎表明,大规模预训练模型永远是提升机器智能的万能良药。然而,监督微调在实践中仍依赖标注数据,并因领域、语言和任务的差异而面临不容忽视的挑战。这些缺陷催生了一项重要技术——少样本学习的研究,该技术仅需少量标注样本就能显著提升机器智能的学习能力和实际自适应应用水平。
The GPT-3 model, introduced by Brown et al. (2020), exhibits impressive few-shot learning capabilities. Given a natural language prompt and 16 labeled samples as demonstrations in the contextual input, GPT-3 achieves $80%$ of the SOTA results. However, GPT-3 is a fully dense transformer model with 175B parameters, which makes it challenging to deploy in most real-world applications.
Brown等人(2020)提出的GPT-3模型展现了卓越的少样本学习能力。当给定自然语言提示和16个带标签样本作为上下文输入的演示时,GPT-3能达到SOTA结果的$80%$。然而,GPT-3是一个拥有1750亿参数的全稠密Transformer模型,这使得其在大多数实际应用中难以部署。
Recently, an emerging fine-tuning methodology has arisen to equip smaller language models (LMs) with few-shot capabilities: adapting the pre-trained LM directly as a predictor through completion of a cloze task (Schick & Schitze (2021; 2020); Ga0 et al. (2020); Liu et al. (2021c)), which treats the downstream task as a (masked) language modeling problem. These prompts can be used in finetuning to provide the classifier with additional task information, especially in the low-data regime.
最近,一种新兴的微调方法开始赋能较小规模的语言模型 (LM) 实现少样本学习能力:通过完形填空任务直接调整预训练语言模型作为预测器 (Schick & Schitze (2021; 2020); Ga0 et al. (2020); Liu et al. (2021c)),该方法将下游任务视为(掩码)语言建模问题。这些提示词可在微调过程中为分类器提供额外任务信息,尤其在低数据量场景下表现突出。
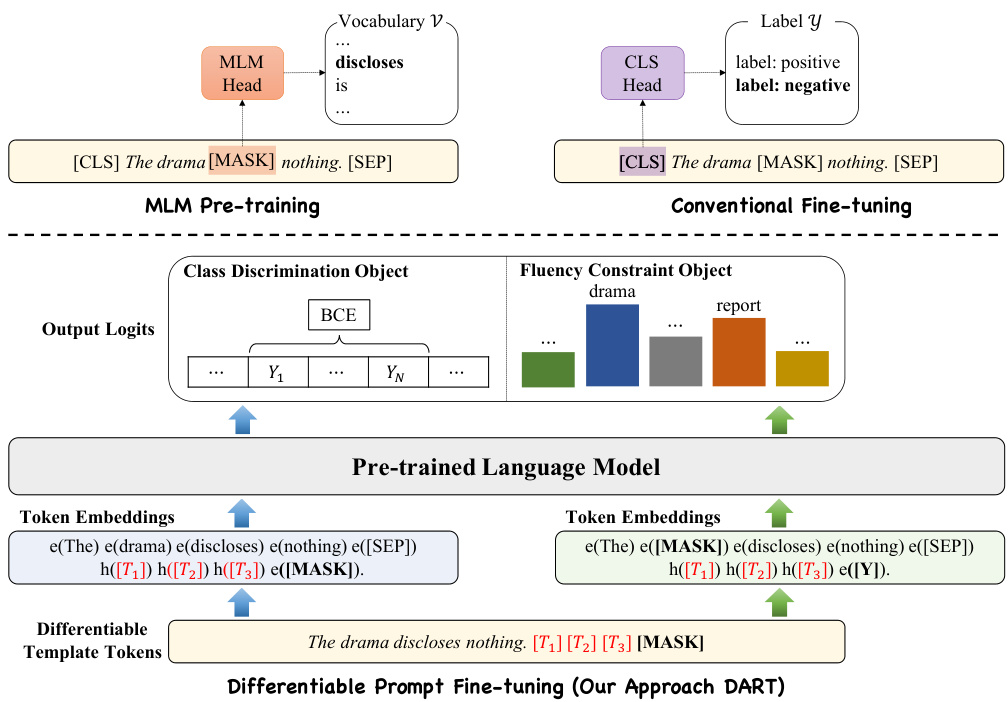
Figure 1: The architecture of DifferentiAble pRompT (DART) model comparing with MLM pretraining and conventional fine-tuning, where $T_{i}$ and $Y_{i}$ are unused or special tokens in the vocabulary. We leverage a few parameters within the language model as the template and label tokens and optimize them via back propagation without introducing additional parameters apart from the model.
图 1: DifferentiAble pRompT (DART) 模型架构与 MLM 预训练和常规微调的对比,其中 $T_{i}$ 和 $Y_{i}$ 是词汇表中未使用或特殊的 token。我们利用大语言模型中的少量参数作为模板 token 和标签 token,并通过反向传播优化它们,无需在模型之外引入额外参数。
Notably, Scao & Rush (2021) observe that prompting can often compensate for hundreds of data points on average across multiple classification tasks. However, determining the appropriate prompts requires domain expertise, and handcrafting a high-performing prompt often requires im practically large validation sets (Perez et al. (2021)). Recent studies (Lu et al. (2021); Zhao et al. (2021)) have reported that the manual prompt format can be sub-optimal, which would result in the accuracy varying from random guess performance to near the state-of-the-art. Therefore, previous approaches have attempted to search for discrete prompt tokens automatically. However, it is non-trivial for widespread classification tasks to obtain an optimized prompt template and target label token. For example, specific classification tasks such as relation extraction with the label of alternate name and country o f birth cannot specify a single label token in the vocabulary.
值得注意的是,Scao和Rush (2021) 研究发现,在多个分类任务中,提示 (prompting) 平均能替代数百个数据点的作用。然而,确定合适的提示需要领域专业知识,且手工设计高性能提示往往需要不切实际的大规模验证集 (Perez et al. (2021))。近期研究 (Lu et al. (2021); Zhao et al. (2021)) 指出,人工设计的提示格式可能并非最优,这会导致准确率在随机猜测水平到接近最先进水平之间波动。因此,先前的方法尝试自动搜索离散的提示token (prompt tokens)。但对于广泛的分类任务而言,获取优化的提示模板和目标标签token并非易事。例如,特定分类任务(如带有别名和出生国家标签的关系抽取)无法在词表中指定单一标签token。
In this paper, we propose a novel DifferentiAble pRompT (DART) fine-tuning approach, which is model-agnostic, parameter-efficient. As illustrated in Figure 1, the key idea is to leverage a few parameters (unused tokens) in the language model, which serve as the template and label tokens, and to optimize them in the continuous space using back propagation. Subsequently, we introduce differentiable prompt learning to obtain optimized prompt templates as well as labels. Since fine-tuning with limited samples can be affected by instability (Dodge et al. (2020); Zhang et al. (2021)), we propose an optimization algorithm to jointly learning templates as well as labels. We further introduce an auxiliary fluency constraint object to ensure the association among the prompt embeddings.
本文提出了一种新颖的可微分提示调优方法(DART),该方法与模型无关且参数高效。如图1所示,其核心思想是利用大语言模型中的少量参数(未使用的token)作为模板和标签token,并通过反向传播在连续空间中进行优化。随后,我们引入可微分提示学习来获得优化的提示模板和标签。由于有限样本下的微调可能受到不稳定性影响(Dodge et al. (2020); Zhang et al. (2021)),我们提出了一种联合学习模板和标签的优化算法。此外,我们还引入了一个辅助流畅性约束目标来确保提示嵌入之间的关联性。
We conduct extensive experiments on $15\mathrm{NLP}$ datasets. With only a few training samples across all the tasks, our approach (DART) can obtain a better performance. Notably, absolute performance improvement of up to $23.28%$ , over the conventional fine-tuning, is obtained on average in the setting of $K=8$ (and $1.55%$ for fully supervised settings) on relation extraction datasets with complex label semantics. Our approach can be applied to real-world classification tasks without the high cost of collecting and annotating a large amount of data. The main contributions of this study are as follows:
我们在15个自然语言处理(NLP)数据集上进行了大量实验。在所有任务中仅使用少量训练样本的情况下,我们的方法(DART)就能获得更好的性能。值得注意的是,在关系抽取数据集上,当K=8时(全监督设定下为1.55%),我们的方法相比传统微调平均获得了高达23.28%的绝对性能提升。该方法可应用于现实世界的分类任务,而无需承担收集和标注大量数据的高昂成本。本研究的主要贡献如下:
• We propose a new simple framework for few-shot learning, which is pluggable, extensible, and efficient. To the best of our knowledge, optimizing label tokens in continuous space is also a new branch of research that has not been explored in language model prompting.
• 我们提出了一种新的简单少样本学习框架,该框架可插拔、可扩展且高效。据我们所知,在连续空间中优化标签token也是语言模型提示中尚未探索的一个新研究方向。
• A systematic evaluation of $15\mathrm{NLP}$ tasks shows that the simple-yet-effective method contributes towards improvements across all these tasks. Remarkably, given only 8 labeled samples per class, our proposed approach can achieve $90%$ performance of the SOTA results (full dataset).
• 对15项自然语言处理(NLP)任务的系统评估表明,这种简单而有效的方法对所有任务都有改进作用。值得注意的是,在每类仅提供8个标注样本的情况下,我们提出的方法能达到当前最佳结果(SOTA) (全数据集) 90%的性能。
2 RELATED WORK
2 相关工作
Language Model Prompting. The language model prompting has emerged with the introduction of GPT-3 (Brown et al. (2020)), which demonstrates excellent few-shot performance (Liu et al. (2021b)). However, GPT-3 is not designed for fine-tuning; it mainly relies on the handcraft prompt (in-context learning (Liu et al. (2021a); Zhao et al. (2021); Ding et al. (2021); Min et al. (2021))). Thus, recent studies (Qin & Eisner (2021); Ham bard zum yan et al. (2021); Chen et al. (2021)) conducted in this field have been focused on automatically searching the prompts. Schick & Schitze (2021; 2020) propose the PET, which reformulates the NLP tasks as cloze-style questions and performs gradient-based fine-tuning. Tam et al. (2021) improve the PET with a denser supervision object during fine-tuning. Shin et al. (2020) propose the AUTOPROMPT to create prompts for a diverse set of tasks based on a gradient-guided search. Han et al. (2021) propose an approach called PTR, which leverages logic rules to construct prompts with sub-prompts for many-class text classification. Wang et al. (2021) reformulate potential NLP task into an entailment one, and then fine-tune the model with few-shot samples. Hu et al. (2021) propose an approach to incorporate external knowledge graph into the verbalizer with calibration. Additionally, Gao et al. (2020) present LM-BFF—better few-shot fine-tuning of language models, which leverages T5 (Raffel et al. (2020)) to generate templates and search label tokens in the vocabulary. However, the utilization of the generative model and the label search with validation is computation-intensive. Moreover, the prompt search over discrete space is sub-optimal due to the continuous nature of neural networks.
语言模型提示技术。语言模型提示技术随着GPT-3的推出而兴起(Brown等人(2020)),该模型展现出卓越的少样本性能(Liu等人(2021b))。然而GPT-3并非为微调设计,主要依赖手工构建的提示(上下文学习(Liu等人(2021a); Zhao等人(2021); Ding等人(2021); Min等人(2021)))。因此近期研究(Qin & Eisner (2021); Hambardzumyan等人(2021); Chen等人(2021))聚焦于自动搜索提示。Schick & Schütze (2021; 2020)提出PET方法,将NLP任务重构为完形填空式问题并进行基于梯度的微调。Tam等人(2021)通过引入更密集的监督目标改进了PET。Shin等人(2020)提出AUTOPROMPT,基于梯度引导搜索为多样化任务创建提示。Han等人(2021)提出PTR方法,利用逻辑规则构建包含子提示的提示方案来处理多类文本分类。Wang等人(2021)将潜在NLP任务重构为蕴含任务,再用少样本微调模型。Hu等人(2021)提出通过校准将外部知识图谱融入verbalizer的方法。Gao等人(2020)提出的LM-BFF框架改进了语言模型的少样本微调,利用T5(Raffel等人(2020))生成模板并在词表中搜索标签token。但生成模型的使用和带验证的标签搜索计算成本较高,且离散空间的提示搜索因神经网络的连续性本质而存在次优问题。
To overcome these limitations, Liu et al. (2021c) propose P-tuning, which employs trainable continuous prompt embeddings learned by an LSTM. Zhong et al. (2021) propose an effective continuous method called OPTIPROMPT to optimize prompts for factual probing. Liu et al. (2021c) propose prefix-tuning, which keeps language model parameters frozen but optimizes a small continuous taskspecific vector for natural language generation tasks. Lester et al. (2021) propose a mechanism for learning “soft prompts” to condition frozen language models to perform downstream tasks. However, these approaches still have to optimize the external parameters (e.g., LSTM in P-tuning) and are prone to complex label space.
为克服这些限制,Liu等人(2021c)提出P-tuning方法,采用LSTM训练得到的连续可训练提示嵌入。Zhong等人(2021)提出名为OPTIPROMPT的有效连续方法,用于优化事实探测任务的提示。Liu等人(2021c)提出前缀调优(prefix-tuning)方法,保持语言模型参数冻结的同时,针对自然语言生成任务优化小型连续任务特定向量。Lester等人(2021)提出学习"软提示"的机制,使冻结语言模型适应下游任务。然而这些方法仍需优化外部参数(如P-tuning中的LSTM),且易受复杂标签空间影响。
Conversely, this study aims to develop a novel few-shot learning framework based on pre-trained language models which can reduce the prompt engineering (including templates and labels) and external parameter optimization. Furthermore, the proposed approach only leverages the non invasive modification of the model, which can be plugged into any pre-trained language model and extended to the widespread classification task.
相反,本研究旨在开发一种基于预训练语言模型的新型少样本学习框架,该框架能够减少提示工程(包括模板和标签)和外部参数优化。此外,所提出的方法仅利用模型的无创修改,可插入任何预训练语言模型并扩展到广泛的分类任务。
Few-shot Learning. Few-shot learning can significantly improve the learning capabilities for machine intelligence and practical adaptive applications by accessing only a small number of labeled examples (Zhang et al. (2020)). The proposed approach corresponds to the other few-shot NLP methods, including: (1) Meta-learning (Yu et al. (2018); Bao et al. (2020b); Bansal et al. (2020); Deng et al. (2020b;a); Yu et al. (2020)), in which the quantities of the auxiliary tasks are optimized. (2) Intermediate training (Phang et al. (2018); Yin et al. (2020)), which supplements the pre-trained LMs with further training on the data-rich supervised tasks. (3) Semi-supervised learning (Miyato et al. (2017); Xie et al. (2020)), which leverages unlabeled samples. The proposed approach focuses on a more realistic few-shot setting (the number of labeled instances per class can be any variable).
少样本学习。少样本学习通过仅访问少量标注样本,可显著提升机器智能的学习能力和实际自适应应用能力 (Zhang et al. (2020))。所提出的方法对应于其他少样本自然语言处理方法,包括:(1) 元学习 (Yu et al. (2018); Bao et al. (2020b); Bansal et al. (2020); Deng et al. (2020b;a); Yu et al. (2020)),该方法优化了辅助任务的数量;(2) 中间训练 (Phang et al. (2018); Yin et al. (2020)),通过在数据丰富的监督任务上进行进一步训练来补充预训练语言模型;(3) 半监督学习 (Miyato et al. (2017); Xie et al. (2020)),该方法利用了未标注样本。所提出的方法侧重于更现实的少样本设置(每个类别的标注实例数量可以是任意变量)。
3 BACKGROUND
3 背景
Let $X_{\mathrm{in}}={x_{1},x_{2},...,x_{L}}$ be a sentence, where $x_{i}$ is the $i^{t h}$ token in the input sentence and $L$ is the number of tokens. Specifically, $X_{\mathrm{in}}$ is converted to a fixed token sequence $\tilde{X}{\mathrm{in}}$ and then mapped to a sequence of hidden vectors ${\mathbf{h}{k}\in\mathbb{R}^{d}}$ . Given the input sequence, $\tilde{X}_{\mathrm{in}}=~[\mathsf{C L S}]X_{\mathrm{in}}~[\mathsf{S E P}]$ , the conventional fine-tuning approaches leverage a generic head layer over [CLS] embeddings (e.g., an MLP layer) to predict an output class. For the prompt-based method, a task-specific pattern string (template $\mathcal{T}$ ) is designed to coax the model into producing a textual output corresponding to a given class (label token ${\mathcal{M}}(Y),$ )—we refer to these two things together as a prompt. Specifically, $X_{\mathrm{prompt}}$ containing one [MASK] token is directly tasked with the MLM input as:
设 $X_{\mathrm{in}}={x_{1},x_{2},...,x_{L}}$ 为一个句子,其中 $x_{i}$ 是输入句子中的第 $i^{t h}$ 个 token,$L$ 为 token 数量。具体而言,$X_{\mathrm{in}}$ 被转换为固定 token 序列 $\tilde{X}{\mathrm{in}}$,随后映射为隐藏向量序列 ${\mathbf{h}{k}\in\mathbb{R}^{d}}$。给定输入序列 $\tilde{X}_{\mathrm{in}}=~[\mathsf{C L S}]X_{\mathrm{in}}~[\mathsf{S E P}]$,传统微调方法通过在 [CLS] 嵌入上使用通用头部层(例如 MLP 层)来预测输出类别。对于基于提示词的方法,需设计任务特定的模式字符串(模板 $\mathcal{T}$)来引导模型生成与给定类别对应的文本输出(标签 token ${\mathcal{M}}(Y),$)——我们将这两者统称为提示词。具体地,包含一个 [MASK] token 的 $X_{\mathrm{prompt}}$ 直接作为 MLM 输入进行处理:

When the prompt is fed into the MLM, the model can obtain the probability distribution $p\big(\mathrm{[MASK]}\big|\big(X_{\mathrm{prompt}}\big)$ of the candidate class, $y\in Y$ as:
当提示输入到MLM时,模型可以获得候选类别 $y\in Y$ 的概率分布 $p\big(\mathrm{[MASK]}\big|\big(X_{\mathrm{prompt}}\big)$ 如下:
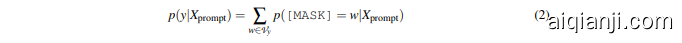
where $w$ represents the $w^{t h}$ label token of class $y$ .
其中 $w$ 表示类别 $y$ 的第 $w^{t h}$ 个标签 token。
4OUR APPROACH
4 我们的方法
4.1 MOTIVATION
4.1 动机
It can be observed from the previous empirical findings (Gao et al. (2020); Scao & Rush (2021)) that an optimal prompt is necessary for the improvement of the pre-trained language models for the few-shot learners. Since templates with discrete tokens may be sub-optimal and are insufficient to represent a specific class2, this study proposes DifferentiAble pRompT, referred to as DART, which can reduce the requirement of prompt engineering in order to improve the applicability of the proposed method in various domains.
从前人的实证研究 (Gao et al. (2020); Scao & Rush (2021)) 中可以发现,优化提示词 (prompt) 对于提升少样本学习场景下预训练语言模型的性能至关重要。由于基于离散token的模板可能存在次优性且难以充分表征特定类别2,本研究提出可微分提示 (DifferentiAble pRompT,简称DART),通过降低提示工程 (prompt engineering) 的门槛来提升该方法在多领域的适用性。
4.2 DIFFERENTIABLE TEMPLATE OPTIMIZATION
4.2 可微分模板优化
Since the language tokens are discrete variables, finding the optimal prompts with token searching is non-trivial and may easily fall into the local minima. To overcome these limitations, we utilize pseudo tokens to construct templates and then optimize them with back propagation. Specifically, given the template, $\mathcal{T}=\left{[\mathrm{T}{0:i}]\right.$ ,[MASK], $\big[\mathrm{T}{i+1:j}\big]}$ , which varies from the traditional discrete prompts, satisfying $\left[\mathrm{T}_{i}\right]\in\mathcal{V}$ and map $\mathcal{T}$ into:
由于语言token是离散变量,通过token搜索寻找最优提示并非易事,且容易陷入局部最小值。为克服这些限制,我们采用伪token构建模板,并通过反向传播进行优化。具体而言,给定模板$\mathcal{T}=\left{[\mathrm{T}{0:i}]\right.$,[MASK],$\big[\mathrm{T}{i+1:j}\big]}$(与传统离散提示不同),需满足$\left[\mathrm{T}_{i}\right]\in\mathcal{V}$并将$\mathcal{T}$映射至:
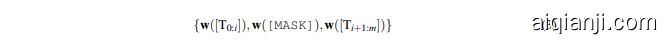
DART considers $[\mathrm{T}_{i}]$ as pseudo tokens and maps the template as follows:
DART将$[\mathrm{T}_{i}]$视为伪Token (pseudo tokens),并按以下方式映射模板:

where $h_{i}(0\leq i\leq j)$ are trainable parameters. Differentiable template optimization can obtain expressive templates beyond the original vocabulary $\mathcal{V}$ . Lastly, the templates, $h_{i}$ , are differential ly optimized by:
其中 $h_{i}(0\leq i\leq j)$ 是可训练参数。可微分模板优化能够获得超出原始词汇表 $\mathcal{V}$ 的表达性模板。最后,模板 $h_{i}$ 通过以下方式进行微分优化:

Note that the values of the prompt embeddings, $h_{i}$ , must be co-dependent with each other rather than independent. Unlike ${\bf P}.$ -tuning (Liu et al. (2021c)), which utilizes a bidirectional LSTM, DART leverages an auxiliary fluency constraint objective to associate the prompt embeddings with each other, thus stimulating the model to focus on context representation learning.
请注意提示嵌入 (prompt embeddings) 的值 $h_{i}$ 必须是相互依赖而非独立的。与使用双向 LSTM 的 ${\bf P}$-tuning (Liu et al. (2021c)) 不同,DART 通过辅助流畅度约束目标使提示嵌入相互关联,从而激励模型专注于上下文表示学习。
4.3 DIFFERENTIABLE LABEL OPTIMIZATION
4.3 可微分标签优化
Prompt-based fine-tuning requires filling in one word, and the masked word prediction is mapped to a verbalizer, which produces a class (i.e., ”Yes”: True. ”No”: False). For each class $c\in Y$ , the previous approaches such as LM-BFF (Gao et al. (2020)) estimate the conditional likelihood of the initial $\mathcal{L}$ on a pruned set $\mathcal{V}^{c}\subset\mathcal{V}$ of the top $k$ vocabulary words.
基于提示词(prompt)的微调需要填充一个单词,掩码词预测被映射到verbalizer,从而生成一个类别(例如"Yes":True,"No":False)。对于每个类别$c\in Y$,先前的方法如LM-BFF (Gao et al. (2020))会在前$k$个词汇表单词的修剪子集$\mathcal{V}^{c}\subset\mathcal{V}$上估计初始$\mathcal{L}$的条件似然。
However, the brute-forcing label searching: (1) is computationally intensive and tedious because the $\mathcal{D}_{\mathrm{dev}}$ is generally very large, requiring multiple rounds of evaluation. (2) has poor s cal ability with an increase in the class numbers (many classification datasets have more than 100 classes), the number of searches may be $k^{C}$ ( $C$ represents the total number of classes), which is exponential and thus intractable. Additionally, the labels of classes contain rich, complex semantic knowledge, and one discrete token may be insufficient to represent this information.
然而,暴力搜索标签的方法存在以下问题:(1) 计算量大且繁琐,因为开发集 $\mathcal{D}_{\mathrm{dev}}$ 通常规模庞大,需要多轮评估;(2) 可扩展性差,随着类别数量增加(许多分类数据集超过100个类别),搜索次数可能达到 $k^{C}$ ( $C$ 表示类别总数),这种指数级增长导致计算不可行。此外,类别标签蕴含丰富而复杂的语义知识,单个离散token可能不足以完整表征这些信息。
Specifically, with the labels, $Y={Y_{1},Y_{2},..,Y_{m}}$ , different from the previous approach which converts the class type $Y_{i}$ into a variable number of label tokens $\left{...,{\nu_{1}},..,{\nu_{k}},...\right}$ , DART maps the $Y_{j}$ to a continuous vocabulary space as follows:
具体而言,对于标签集 $Y={Y_{1},Y_{2},..,Y_{m}}$ ,不同于先前方法将类别 $Y_{i}$ 转换为可变数量的标签token $\left{...,{\nu_{1}},..,{\nu_{k}},...\right}$ 的做法,DART将 $Y_{j}$ 映射到连续词汇空间的方式如下:

where $m$ is the number of trainable embedding in template. To avoid optimizing any external parameters, ${h_{1},...,h_{m},..,h_{m+n}}_{.}$ is replaced with unused tokens (e.g., [unused1] or special tokens in vocabulary) in $\mathcal{V}$ to generate $\mathcal{V}^{\prime}$ , as shown in Figure 1.
其中 $m$ 是可训练嵌入模板的数量。为避免优化任何外部参数, ${h_{1},...,h_{m},..,h_{m+n}}_{.}$ 被替换为 $\mathcal{V}$ 中未使用的token (例如[unused1]或词表中的特殊token) 以生成 $\mathcal{V}^{\prime}$ ,如图 1 所示。
4.4 TRAINING OBJECTIVES
4.4 训练目标
Since the pseudo tokens in the prompt template must be co-dependent with each other, we introduce an auxiliary fluency constraint training without optimizing any other parameters inspired by Liu et al. (2021c); Tam et al. (2021). Overall, there are two objectives: the class discrimination objective $\mathcal{L}{C}$ and the fluency constraint objective $\mathcal{L}{F}$ .
由于提示模板中的伪Token必须相互依赖,我们受Liu等人 (2021c) 和Tam等人 (2021) 的启发,引入了一个不优化任何其他参数的辅助流畅性约束训练。总体而言,存在两个目标:类别区分目标 $\mathcal{L}{C}$ 和流畅性约束目标 $\mathcal{L}{F}$。
Class Discrimination Object The class discrimination objective is the main objective that aims to classify the sentences. As shown in Figure 1, given $(X_{\mathrm{in}},\mathcal{T})$ , we can generate $X_{\mathrm{prompt}}$ as:
类别区分目标
类别区分目标是旨在对句子进行分类的主要目标。如图 1 所示,给定 $(X_{\mathrm{in}},\mathcal{T})$ ,我们可以生成 $X_{\mathrm{prompt}}$ 为:

where CE is the cross-entropy loss function, $\mathcal{L}_{C}$ represents the class discrimination loss.
其中CE是交叉熵损失函数,$\mathcal{L}_{C}$代表类别判别损失。
Fluency Constraint Object To ensure the association among the template tokens and to maintain the ability of language understanding inherited from the PLMs, we leverage a fluency constraint object with the MLM. As shown in Figure 1, one token in the input sentence is randomly masked, and the masked language prediction is conducted. $x$ and $x^{\prime}$ are the original and masked sequences, respectively. Let $x^{m}$ be the target token that has been masked out in $x^{\prime}$ , and $g(x^{m}|x^{\prime},y)$ is maximized as follows3:
流畅性约束目标
为确保模板token之间的关联性,并保持从预训练语言模型(PLM)继承的语言理解能力,我们利用带掩码语言模型(MLM)的流畅性约束目标。如图1所示,随机掩码输入句子中的一个token,并进行掩码语言预测。$x$和$x^{\prime}$分别为原始序列和掩码序列。设$x^{m}$为$x^{\prime}$中被掩码的目标token,最大化$g(x^{m}|x^{\prime},y)$如下3:

By optimizing $\mathcal{L}_{F}$ , the language model can obtain a better contextual representation with a rich association among the template tokens. We have the following training object:
通过优化 $\mathcal{L}_{F}$,语言模型可以获得更好的上下文表示,其中模板token之间存在丰富的关联。我们有以下训练目标:

where $\lambda$ is the hyper-parameter. Lastly, we introduce the overall optimization procedure of DART. To mitigate the instability of the few-shot fine-tuning, we jointly optimize templates and labels. Note that our approach can reuse the same transformer architecture (rather than additional LSTM) so that it enjoys the beauty of simplicity for prompt-tuning.
其中 $\lambda$ 是超参数。最后,我们介绍 DART 的整体优化流程。为缓解少样本微调的不稳定性,我们联合优化模板和标签。值得注意的是,该方法可复用相同的 Transformer 架构(无需额外 LSTM),从而保持提示调优的简洁性优势。
| 模型 | SST-2 (准确率) | MR (准确率) | CR (准确率) | Subj (准确率) | TREC (准确率) |
|---|---|---|---|---|---|
| Majority' | 50.9 | 50.0 | 50.0 | 50.0 | 18.8 |
| 基于提示的零样本+ | 83.6 | 80.8 | 79.5 | 51.4 | 32.0 |
| "GPT-3" 上下文学习 | 84.8 (1.3) | 80.5 (1.7) | 87.4 (0.8) | 53.6 (1.0) | 26.2 (2.4) |
| 微调 | 81.4 (3.8) | 76.9 (5.9) | 75.8 (3.2) | 90.8 (1.8) | 88.8 (2.1) |
| LM-BFF | 92.3 (1.0) | 85.5 (2.8) | 89.0 (1.4) | 91.2 (1.1) | 88.2 (2.0) |
| P-Tuning | 92.2 (0.4) | 86.7 (1.2) | 91.8 (1.1) | 90.3 (2.2) | 86.3 (4.5) |
| DART | 93.5 (0.5) | 88.2 (1.0) | 91.8 (0.5) | 90.7 (1.4) | 87.1 (3.8) |
| 微调 (完整)* | 95.0 | 90.8 | 89.4 | 97.0 | 97.4 |
| 模型 | MNLI (准确率) | SNLI (准确率) | QNLI (准确率) | MRPC (F1) | QQP (F1) |
|---|---|---|---|---|---|
| Majority' | 32.7 | 33.8 | 49.5 | 81.2 | 0.0 |
| 基于提示的零样本* | 50.8 | 49.5 | 50.8 | 61.9 | 49.7 |
| "GPT-3" 上下文学习 | 52.0 (0.7) | 47.1 (0.6) | 53.8 (0.4) | 45.7 (6.0) | 36.1 (5.2) |
| 微调 | 45.8 (6.4) | 48.4 (4.8) | 60.2 (6.5) | 76.6 (2.5) | 60.7 (4.3) |
| LM-BFF | 68.3 (2.5) | 77.1 (2.1) | 68.3 (7.4) | 76.2 (2.3) | 67.0 (3.0) |
| P-Tuning | 61.5 (2.1) | 72.3 (3.0) | 64.3 (2.8) | 74.5 (7.6) | 65.6 (3.0) |
| DART | 67.5 (2.6) | 75.8 (1.6) | 66.7 (3.7) | 78.3 (4.5) | 67.8 (3.2) |
| 微调 (完整)* | 89.8 | 92.6 | 93.3 | 91.4 | 81.7 |
Table 1: Our main results with RoBERTa-large. †: the full training set is used. $^\ddagger$ : no training examples are used. Otherwise, we use $K=16$ (# examples per class). We report mean (and standard deviation) performance over 5 different splits. Majority: majority class “GPT $\beta^{,}$ in-context learning: using the in-context learning proposed in with RoBERTa-large (no parameter updates); LM-BFF: we report the performance in Gao et al. (2020). full: fine-tuning using full training set.
表 1: 使用 RoBERTa-large 的主要实验结果。†: 使用完整训练集。$^\ddagger$: 未使用训练样本。其余情况均采用 $K=16$ (每类样本数)。我们报告了5次不同数据划分的平均性能(及标准差)。Majority: 多数类基线。"GPT $\beta^{,}$"上下文学习: 采用RoBERTa-large进行上下文学习(不更新参数); LM-BFF: 数据来自Gao等人(2020)的报告结果。full: 使用完整训练集进行微调。
5 EXPERIMENTS
5 实验
In this section, we detail the comprehensive experimental results conducted on classification tasks. The promising results demonstrate that our proposed DART substantially outperforms the conventional fine-tuning method, thus, making pre-trained language models better few-shot learners.
在本节中,我们详细介绍了分类任务上的综合实验结果。优异的结果表明,我们提出的DART方法显著优于传统的微调方法,从而使预训练语言模型成为更好的少样本学习器。
5.1 DATASET STATISTICS
5.1 数据集统计
We conduct a comprehensive study across $15\mathrm{NLP}$ tasks, which covers sentiment analysis, natural language inference, paraphrases, sentence similarity, relation extraction, and event extraction (We only report event argument extraction performance). The evaluation consisted of 10 popular sentence classification datasets (SST-2, MR, CR, Subj, TREC, MNLI, SNLI, QNLI, MRPC, QQP).To further evaluate the effectiveness of the proposed approach with complex label space, we conduct experiments on the relation extraction and event extraction datasets, including SemEval-2010 Task 8 (Hendrickx et al., 2010), TACRED-Revisit (Alt et al. (2020)), Wiki $80^{4}$ (Han et al., 2019), ChemProt (Kringelum et al., 2016), and $\mathrm{ACE}{-}2005^{5}$ .
我们在15项自然语言处理(NLP)任务上进行了全面研究,涵盖情感分析、自然语言推理、复述、句子相似度、关系抽取和事件抽取(仅报告事件论元抽取性能)。评估包含10个常用句子分类数据集(SST-2、MR、CR、Subj、TREC、MNLI、SNLI、QNLI、MRPC、QQP)。为进一步评估所提方法在复杂标签空间的有效性,我们在关系抽取和事件抽取数据集上进行了实验,包括SemEval-2010 Task 8 (Hendrickx et al., 2010)、TACRED-Revisit (Alt et al. (2020))、Wiki80 (Han et al., 2019)、ChemProt (Kringelum et al., 2016)和ACE-2005。
5.2 SETTINGS
5.2 设置
The proposed model is implemented using Pytorch (Paszke et al. (2019)). Our experiments are conducted with the same setting following LM-BFF ( Gao et al. (2020)), which measures the average performance with a fixed set of seeds, $S_{\mathrm{seed}}$ , across five different sampled $\mathcal{D}{\mathrm{train}}$ for each task. We utilize a grid search over multiple hyper parameters and select the best result as measured on $\mathcal{D}{\mathrm{dev}}$ for each set ${\mathcal{D}{\mathrm{train}}^{s},\mathcal{D}{\mathrm{dev}}},s\in S_{\mathrm{seed}}$ . We employ AdamW as the optimizer. We conduct experiments with a RoBERTa-large (Liu et al. (2019)) on classification tasks for a fair comparison with LM-BFF. We leverage an uncased BERT-large (Devlin et al. (2019)) for relation extraction datasets, except that we use SCIBERT (Beltagy et al. (2019)) for the ChemProt dataset. We follow Soares et al. (2019) and use special entity markers uniformly to highlight the entity mentions for relation extraction.
所提出的模型采用Pytorch (Paszke等人 (2019)) 实现。实验设置遵循LM-BFF (Gao等人 (2020)) ,通过固定种子集 $S_{\mathrm{seed}}$ 对每个任务采样五种不同的 $\mathcal{D}{\mathrm{train}}$ 来测量平均性能。我们对多组超参数进行网格搜索,并在每组 ${\mathcal{D}{\mathrm{train}}^{s},\mathcal{D}{\mathrm{dev}}},s\in S{\mathrm{seed}}$ 上选取 $\mathcal{D}_{\mathrm{dev}}$ 表现最佳的结果。优化器选用AdamW。为与LM-BFF公平对比,分类任务采用RoBERTa-large (Liu等人 (2019)) 。关系抽取数据集使用uncased BERT-large (Devlin等人 (2019)) ,其中ChemProt数据集改用SCIBERT (Beltagy等人 (2019)) 。我们遵循Soares等人 (2019) 的方法,统一采用特殊实体标记符来突出关系抽取中的实体提及。
Table 2: Results on RE dataset WiKi80 (accuracy), while other datasets (micro $\mathrm{F}_{1}$ ). We use $K=8,16,32$ (# examples per class). Full represents the full training set is used.
表 2: RE数据集WiKi80上的结果(准确率),其他数据集为微观$\mathrm{F}_{1}$。我们使用$K=8,16,32$(每类样本数)。Full表示使用完整训练集。
| 数据集 | 模型 | K=8 | K=16 | K=32 | Full |
|---|---|---|---|---|---|
| SemEval | Fine-tuning LM-BFF DART | 26.3 43.2 51.8 (+25.5) | 43.8 62.0 67.2 (+23.4) | 64.2 72.9 77.3 (+13.1) | 87.8 88.0 89.1 (+1.3) |
| TACRED-Revisit | Fine-tuning LM-BFF DART | 7.4 21.0 25.8 (+18.4) | 15.5 23.7 30.1 (+14.6) | 25.8 27.1 31.8 (+6.0) | 75.0 76.4 77.8 (+2.8) |
| WiKi80 | Fine-tuning LM-BFF DART | 46.3 66.5 68.5 (+22.2) | 60.3 73.5 75.2 (+14.9) | 70.0 78.1 79.4 (+9.4) | 87.5 86.2 88.1 (+0.6) |
| ChemProt | Fine-tuning LM-BFF DART | 30.2 55.0 57.2 (+27.0) | 41.5 56.1 60.8 (+19.3) | 52.5 60.0 63.1 (+10.6) | 79.5 79.1 81.0 (+1.5) |
Table 3: Ablation of DART with different components on SemEval. ( $\mathrm{FT}=$ Fine tuning)
表 3: DART不同组件在SemEval上的消融实验 (FT=微调)
| 方法 | K=8 | K=16 | K=32 | Full |
|---|---|---|---|---|
| ConventionalFT | 26.3 | 43.8 | 64.2 | 87.8 |
| DART | 51.8 | 67.2 | 77.3 | 89.1 |
| -fluency constraint object | 50.3 (-1.5) | 66.1 (-1.1) | 76.0 (-1.3) | 88.2 (-0.9) |
| -differentiabletemplate | 49.8 (-2.0) | 66.3 (-0.9) | 76.2 (-1.1) | 88.4 (-0.7) |
| -differentiablelabel | 47.5 (-4.3) | 62.5 (-4.7) | 73.7 (-0.6) | 87.8 (-1.3) |
5.3 MAIN RESULTS
5.3 主要结果
As shown in Table 1, we observe that our approach obtains better performance than conventional fine-tuning and achieves comparable results with LM-BFF. Note that DART can reduce the prompt engineering without external models (e.g., T5 in LM-BFF) to generate templates that are readily easy to adapt to other datasets. DART can obtain $11.3%$ improvement with only 16 training samples per class on the MR dataset, comparable with LM-BFF, which leverages T5 to generate appropriate prompts. These results indicate that DART can better stimulate potential ability and makes the pretrained language model a better few-shot learner. We also notice that DART yields better performance than P-tuning, which indicates that label optimization is beneficial.
如表 1 所示,我们观察到该方法相比传统微调取得了更优性能,并与 LM-BFF 获得了相当的结果。值得注意的是,DART 无需依赖外部模型 (如 LM-BFF 中的 T5) 来生成模板即可减少提示工程的工作量,这些模板能轻松适配其他数据集。在 MR 数据集上,DART 仅需每类 16 个训练样本就能实现 11.3% 的性能提升,与利用 T5 生成提示的 LM-BFF 相当。这些结果表明 DART 能更好地激发预训练语言模型的潜在能力,使其成为更优秀的少样本学习器。我们还发现 DART 性能优于 P-tuning,这说明标签优化具有积极作用。
For the classification tasks with the complex label space, as shown in Table 2 and Figure 2(a), we observe that DART outperforms the conventional fine-tuning approach as well as LM-BFF with a large margin on relation extraction and event extraction datasets in both the few-shot and fully supervised settings. The proposed approach achieves an improvement of $2.8%$ of the absolute performance on the TACRED-Revisit dataset with full supervision and yields $18.4%$ gains with only 8 training samples per class. These findings also indicate that more relevant templates and labels can be determined without expert intervention, making it possible to generalize the proposed approach to other domains. We attribute the significant improvements to the fact that, unlike the GLUE datasets containing small categories, in relation extraction and event extraction tasks, the datasets consist of a large number of classes with complex label space, making it more challenging to obtain suitable label tokens. Furthermore, we notice that the improvement decays slowly when $K$ becomes larger (i.e., from 8 to 32). Our approach is a simple yet effective fine-tuning paradigm that can reduce prompt engineering within the complex label space, thus, making it possible to be an appropriate plug-in for some SOTA models.
对于具有复杂标签空间的分类任务,如表 2 和图 2(a) 所示,我们观察到 DART 在少样本和全监督设置下,于关系抽取和事件抽取数据集上均显著优于传统微调方法和 LM-BFF。该方法在 TACRED-Revisit 数据集上实现了全监督时绝对性能提升 $2.8%$,并在每类仅 8 个训练样本时获得 $18.4%$ 的性能增益。这些发现还表明,无需专家干预即可确定更相关的模板和标签,使得将该方法推广至其他领域成为可能。我们将显著改进归因于:与包含少量类别的 GLUE 数据集不同,关系抽取和事件抽取任务的数据集包含大量具有复杂标签空间的类别,这使得获取合适的标签 token 更具挑战性。此外,我们注意到当 $K$ 增大时(即从 8 到 32),性能提升衰减较慢。我们的方法是一种简单而有效的微调范式,可减少复杂标签空间内的提示工程,从而有望成为某些 SOTA 模型的适配插件。
5.4 ABLATION STUDY
5.4 消融研究
We conduct an ablation study to validate the effectiveness of the components in the proposed approach. We observe that DART exhibits a performance decay in the absence of any one of the modules, i.e., fluency constraint object, differentiable template, or differentiable label, demonstrating that all the modules are advantageous. Furthermore, we notice that differentiable label optimization is more sensitive to performance and is highly beneficial for DART, especially for low-resource settings. Since the proposed approach is the first approach that utilizes the differentiable label optimization, these findings illustrate that a suitable label token is important.
我们通过消融实验验证所提出方法中各组件的有效性。实验发现当缺失任一模块(流畅性约束目标、可微分模板或可微分标签)时,DART均会出现性能衰减,证明所有模块都具有积极作用。值得注意的是,可微分标签优化对性能更为敏感,尤其对低资源场景下的DART模型帮助显著。由于本研究是首个采用可微分标签优化的方法,这些发现表明选择合适的标签token至关重要。
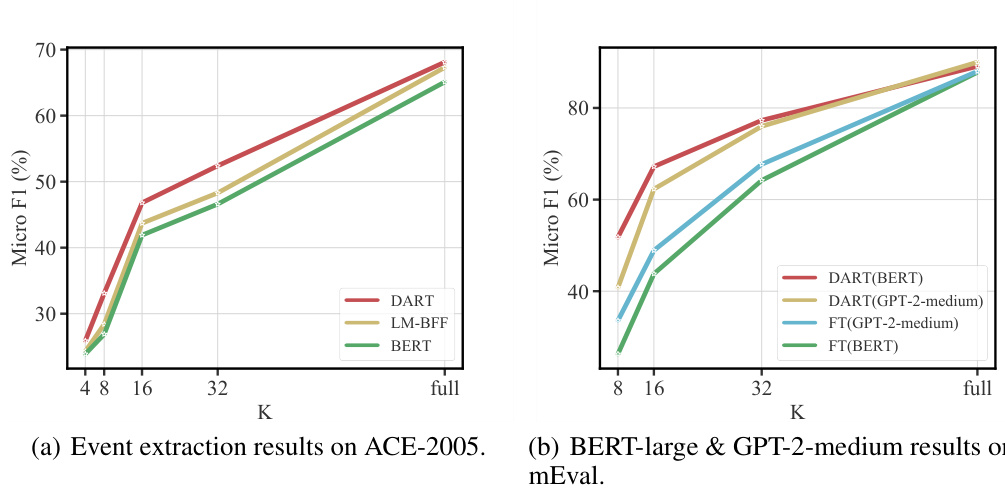
Figure 2: (a) Few-shot results using the ACE-2005. We used $\mathrm{K}=4$ , 8, 16, and 32 (# examples per class) with BERT. $\mathrm{FT}=$ Fine-tuning) (b) BERT-large vs. GPT-2-medium results for the SemEval. Moreover, for lower K, our method consistently outperforms conventional fine-tuning.
图 2: (a) 使用ACE-2005的少样本结果。我们采用BERT模型,设置 $\mathrm{K}=4$ 、8、16和32(每类样本数)。( $\mathrm{FT}=$ 微调) (b) BERT-large与GPT-2-medium在SemEval上的对比结果。此外,在较低K值时,我们的方法始终优于传统微调方案。
5.5 ANALYSIS AND DISCUSSION
5.5 分析与讨论
CAN DART BE APPLIED TO OTHER PRE-TRAINED LMS?
DART能否应用于其他预训练大语言模型?
To evaluate whether the proposed approach can be applied to other LMs, we conduct experiments using GPT-2-medium6 . From Figure 2(b), we observe that DART with GPT-2-medium yields better performance than the conventional fine-tuning approach. Furthermore, we notice that DART with GPT-2-medium can achieve performance on par with BERT-large, as observed by Liu et al. (2021c), indicating that the potential of GPT-style architectures for natural language understanding has been underestimated.
为了评估所提方法是否适用于其他大语言模型,我们使用GPT-2-medium6进行了实验。从图2(b)可以看出,采用GPT-2-medium的DART方法性能优于传统微调方法。此外,我们发现GPT-2-medium结合DART的性能可与BERT-large相媲美,这与Liu等人(2021c)的观察一致,表明GPT架构在自然语言理解方面的潜力可能被低估了。
WHY DO DIFFERENTIABLE PROMPTS YIELD BETTER PERFORMANCE?
为什么可微分提示能带来更好的性能?
To further analyze why our differentiable prompts method yields better performance compared with prompts with fixed templates and label tokens, we visualize the representation of masked tokens in the CR dataset during different training steps (from left to right) as shown in Figure 3 (fixed) and 4 (differentiable), respectively. While both methods learn separable hidden states, differentiable prompts’ representation is relatively more compact while the representation generated from fixed prompts is more scattered. This observation of differentiable prompts generating more disc rim i native representations than the fixed prompts method is supported by an indicator $R_{D}$ , the ratio between average intra-class and average inter-class distance. We believe the main reason behind its better performance lies in the more disc rim i native representation of the differentiable method. More details can be found in Appendix A.6.
为了进一步分析为什么我们的可微分提示方法比固定模板和标签token的提示表现更好,我们在CR数据集上对不同训练阶段(从左到右)的掩码token表征进行了可视化,如图3(固定)和图4(可微分)所示。虽然两种方法都学到了可分离的隐藏状态,但可微分提示的表征相对更紧凑,而固定提示生成的表征则更为分散。这一观察结果——可微分提示比固定提示方法生成更具判别性的表征——得到了指标$R_{D}$(类内平均距离与类间平均距离之比)的支持。我们认为其更优性能背后的主要原因在于可微分方法产生了更具判别性的表征。更多细节可参见附录A.6。
WHAT EXACTLY IS OPTIMIZED PROMPT?
优化提示词究竟是什么?
Since prompt templates and label tokens in the proposed approach are mapped as ${h_{1},...,h_{m},..,h_{m+n}}$ , we further analyze what exactly optimized label learned. We conduct a nearest-neighbor vocabulary embedding search to project the Top-3 optimized pseudo-label tokens in $\mathcal{V}$ to a readable natural language.We use $t$ -SNE (Van der Maaten & Hinton (2008)) with normalization to visualize labels on Wiki80 dataset. For example, “military branch” refers to as red $\star$ in Figure 5 represents the relation type, which is learned by optimizing the pseudo label in the continuous space, and the “volunteered”, “cor poral” and “buddies”, refers to as • are the tokens closest to the label. This finding indicates that the differentiable method generates better semantic representation.
由于所提方法中的提示模板和标签token被映射为${h_{1},...,h_{m},..,h_{m+n}}$,我们进一步分析了优化后标签的具体学习内容。通过最近邻词表嵌入搜索,将$\mathcal{V}$中优化后的Top-3伪标签token投影为可读的自然语言。我们采用经过归一化处理的$t$-SNE (Van der Maaten & Hinton (2008)) 在Wiki80数据集上可视化标签。例如,图5中红色$\star$标注的"military branch"表示通过连续空间优化伪标签学习得到的关系类型,而标注为•的"volunteered"、"cor poral"和"buddies"是与该标签最接近的token。这一发现表明可微分方法能生成更具语义性的表征。

Figure 3: Visualization of masked tokens’ representation in different training steps (with training 10, 30, 50, 70 steps from left to right) with fixed prompts.
图 3: 固定提示下不同训练步骤(从左到右分别为10、30、50、70步)中被遮蔽token的表示可视化。

Figure 4: Visualization of masked tokens’ representation in different training steps (with training 10, 30, 50, 70 steps from left to right) with differentiable prompts.
图 4: 使用可微分提示在不同训练步骤(从左到右分别为训练10、30、50、70步)中被遮蔽token的表示可视化
DART V.S. CONVENTIONAL FINE-TUNING
DART 与传统微调的对比
The ability of DART to perform few-shot learning can be attributed to the label and being a true language understanding task, that once the model is capable of performing it correctly, it can easily apply this knowledge to other tasks that are framed as such. Superficially, (i) DART does not optimize any new parameters; however, conventional fine-tuning should learn an explicit classifier head over [CLS] embeddings, which may fail in the low-data regime. (ii) DART has the same task setting as large-scale language model pre-training.
DART 能够进行少样本学习的能力可归因于其标签特性及作为真实语言理解任务的本质。一旦模型能正确执行该任务,就能轻松将这一知识迁移到其他类似框架的任务中。表面上看:(i) DART 不优化任何新参数,而传统微调需要在 [CLS] 嵌入上学习显式分类器头,这在低数据场景下可能失效;(ii) DART 的任务设置与大规模语言模型预训练完全一致。
6 CONCLUSION AND FUTURE WORK
6 结论与未来工作

Figure 5: A 3D visualization of several label representations learned in DART.
图 5: DART 中学习到的几种标签表示的 3D 可视化。
This paper presents DART, a simple yet effective finetuning approach that improves the fast-shot learning pretrained language model. The proposed approach can produce satisfactory improvements in the few-shot scenarios when compared to the conventional finetuning approaches. The proposed method is also pluggable for other language models (e.g., BART) and can be extended to other tasks, such as intent detection and sentiment analysis. Intuitively, the results obtained in this study can be used to stimulate future research directions in the few-shot or lifelong learning for NLP.
本文提出DART,一种简单而有效的微调方法,可提升预训练语言模型的少样本学习能力。与传统微调方法相比,该方法在少样本场景下能产生令人满意的改进效果。该方法还具有可插拔特性,可适配其他语言模型(如BART),并能扩展至意图识别和情感分析等任务。直观来看,本研究取得的成果可为NLP领域少样本学习或持续学习方向的未来研究提供启发。
ACKNOWLEDGMENTS
致谢
We want to express gratitude to the anonymous reviewers for their hard work and kind comments. This work is funded by National Key R&D Program of China (Funding No.SQ 2018 Y FC 000004), NSF CU 19 B 2027/NSF C 91846204, Zhejiang Provincial Natural Science Foundation of China (No. LG G 22 F 030011), Ningbo Natural Science Foundation (2021J190), and Yongjiang Talent Introduction Programme (2021A-156-G).
我们要感谢匿名评审专家的辛勤工作和宝贵意见。本研究由国家重点研发计划(资助号 SQ2018YFC000004)、国家自然科学基金(CU19B2027/C91846204)、浙江省自然科学基金(LGG22F030011)、宁波市自然科学基金(2021J190)及甬江人才工程(2021A-156-G)资助。
REPRODUCIBILITY STATEMENT
可复现性声明
Our code is available in https://github.com/zjunlp/DART for reproducibility. Hyperparameters are provided in the Appendix A.1.
我们的代码可在 https://github.com/zjunlp/DART 获取以确保可复现性。超参数详见附录 A.1。
REFERENCES
参考文献
Christoph Alt, Aleksandra Gabryszak, and Leonhard Hennig. TACRED revisited: A thorough evaluation of the TACRED relation extraction task. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel R. Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 1558–1569. Association for Computational Linguistics, 2020. doi: 10.18653/v1/2020.acl-main.142. URL https://doi. org/10.18653/v1/2020.acl-main.142.
Christoph Alt、Aleksandra Gabryszak 和 Leonhard Hennig。重审 TACRED:对 TACRED 关系抽取任务的全面评估。见 Dan Jurafsky、Joyce Chai、Natalie Schluter 和 Joel R. Tetreault (编), 《第 58 届计算语言学协会年会论文集》, ACL 2020, 线上, 2020 年 7 月 5-10 日, 第 1558–1569 页。计算语言学协会, 2020。doi: 10.18653/v1/2020.acl-main.142。URL https://doi.org/10.18653/v1/2020.acl-main.142。
Trapit Bansal, Rishikesh Jha, and Andrew McCallum. Learning to few-shot learn across diverse natural language classification tasks. In Donia Scott, Nuria Bel, and Chengqing Zong (eds.), Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, pp. 5108–5123. International Committee on Computational Linguistics, 2020. doi: 10.18653/v1/2020.coling-main.448. URL https://doi. org/10.18653/v1/2020.coling-main.448.
Trapit Bansal、Rishikesh Jha 和 Andrew McCallum. 在多样自然语言分类任务中学习少样本学习. 载于 Donia Scott、Nuria Bel 和 Chengqing Zong (编), 《第28届国际计算语言学会议论文集》, COLING 2020, 西班牙巴塞罗那(线上), 2020年12月8-13日, 第5108–5123页. 国际计算语言学委员会, 2020. doi: 10.18653/v1/2020.coling-main.448. URL https://doi.org/10.18653/v1/2020.coling-main.448.
Hangbo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Yang, Xiaodong Liu, Yu Wang, Jianfeng Gao, Songhao Piao, Ming Zhou, and Hsiao-Wuen Hon. Unilmv2: Pseudo-masked language models for unified language model pre-training. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pp. 642–652. PMLR, 2020a. URL http://proceedings.mlr. press/v119/bao20a.html.
Hangbo Bao、Li Dong、Furu Wei、Wenhui Wang、Nan Yang、Xiaodong Liu、Yu Wang、Jianfeng Gao、Songhao Piao、Ming Zhou 和 Hsiao-Wuen Hon。Unilmv2: 面向统一语言模型预训练的伪掩码语言模型。载于《第37届国际机器学习会议论文集》(ICML 2020),2020年7月13-18日,虚拟会议,《机器学习研究论文集》第119卷,第642-652页。PMLR,2020a。URL http://proceedings.mlr.press/v119/bao20a.html。
Yujia Bao, Menghua Wu, Shiyu Chang, and Regina Barzilay. Few-shot text classification with distribution al signatures. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020b. URL openreview.net/forum?id $=$ H1emfT4twB.
Yujia Bao, Menghua Wu, Shiyu Chang, and Regina Barzilay. 少样本文本分类与分布特征. In 第八届国际学习表征会议 (ICLR 2020), 埃塞俄比亚亚的斯亚贝巴, 2020年4月26-30日. OpenReview.net, 2020b. URL https://openreview.net/forum?id=H1emfT4twB.
Iz Beltagy, Kyle Lo, and Arman Cohan. Scibert: A pretrained language model for scientific text. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pp. 3613–3618. Association for Computational Linguistics, 2019. doi: 10.18653/v1/D19-1371. URL https://doi.org/10.18653/v1/D19-1371.
Iz Beltagy、Kyle Lo 和 Arman Cohan。SciBERT:面向科学文本的预训练语言模型。见 Kentaro Inui、Jing Jiang、Vincent Ng 和 Xiaojun Wan (编),《2019年自然语言处理实证方法会议暨第九届自然语言处理国际联合会议论文集》,EMNLP-IJCNLP 2019,中国香港,2019年11月3-7日,第3613–3618页。计算语言学协会,2019年。doi: 10.18653/v1/D19-1371。URL https://doi.org/10.18653/v1/D19-1371。
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin (eds.), Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/ 1457 c 0 d 6 bfc b 4967418 b fb 8 ac 142 f 64 a-Abstract.html.
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 语言模型是少样本学习者。见Hugo Larochelle, Marc'Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin (编), 《神经信息处理系统进展33: 2020年神经信息处理系统年会论文集》, NeurIPS 2020, 2020年12月6-12日, 线上会议, 2020. 网址 https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
Xiang Chen, Ningyu Zhang, Xin Xie, Shumin Deng, Yunzhi Yao, Chuanqi Tan, Fei Huang, Luo Si, and Huajun Chen. Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. arXiv preprint arXiv:2104.07650, 2021.
Xiang Chen, Ningyu Zhang, Xin Xie, Shumin Deng, Yunzhi Yao, Chuanqi Tan, Fei Huang, Luo Si, and Huajun Chen. 知识感知的提示调优与关系抽取协同优化. arXiv preprint arXiv:2104.07650, 2021.
Iris Hendrickx, Su Nam Kim, Zornitsa Kozareva, Preslav Nakov, Diarmuid O Séaghdha, Sebastian Pad6, Marco Penna c chi ott i, Lorenza Romano, and Stan Szpakowicz. Semeval-2010 task 8: Multiway classification of semantic relations between pairs of nominals. In Katrin Erk and Carlo Strapparava (eds.), Proceedings of the 5th International Workshop on Semantic Evaluation, SemEval@ACL 2010, Uppsala University, Uppsala, Sweden, July 15-16, 2010, pp. 33–38. The Association for Computer Linguistics, 2010. URL https://www.aclweb.org/anthology/S10-1006/.
Iris Hendrickx、Su Nam Kim、Zornitsa Kozareva、Preslav Nakov、Diarmuid O Séaghdha、Sebastian Pad6、Marco Penna c chi ott i、Lorenza Romano和Stan Szpakowicz。SemEval-2010任务8:名词对语义关系的多向分类。载于Katrin Erk和Carlo Strapparava(编),《第五届语义评估国际研讨会论文集》,SemEval@ACL 2010,2010年7月15-16日,瑞典乌普萨拉大学,第33-38页。计算机语言学协会,2010年。URL https://www.aclweb.org/anthology/S10-1006/。
Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 8024–8035, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/ bdb ca 288 fee 7 f 92 f 2 bf a 9 f 7012727740-Abstract.html.
第32届神经信息处理系统年会:2019年神经信息处理系统大会,NeurIPS 2019,2019年12月8-14日,加拿大不列颠哥伦比亚省温哥华,第8024–8035页,2019年。网址 https://proceedings.neurips.cc/paper/2019/hash/bdbca288fee7f92f2bfa9f7012727740-Abstract.html。
Our code is available in the supplementary materials for reproducibility. This section contains details about the training procedures and hyper parameters for each of the datasets. We utilize Pytorch (Paszke et al., 2019) to conduct experiments with 1 Nvidia 3090 GPUs. All optimization s are performed with the AdamW optimizer with a linear warmup of learning rate over the first $10%$ of gradient updates to a maximum value, then linear decay over the remainder of the training. Gradients are clipped if their norm exceeds 1.0, and weight decay on all non-bias parameters is set to 0.01. Early stopping is adopted to reduce over-fitting on the training set.
我们的代码可在补充材料中获取以确保可复现性。本节包含各数据集的训练流程和超参数细节。我们使用Pytorch (Paszke et al., 2019) 在1块Nvidia 3090 GPU上进行实验。所有优化均采用AdamW优化器,学习率在前$10%$梯度更新时线性预热至最大值,随后在剩余训练过程中线性衰减。若梯度范数超过1.0则进行裁剪,所有非偏置参数的权重衰减设为0.01。采用早停机制以减少训练集过拟合。
We follow LM-BFF (Gao et al., 2020) to measure the average performance of models trained on 5 different randomly sampled $\mathcal{D}{\mathrm{train}}$ and $\mathcal{D}{\mathrm{dev}}$ splits, and perform grid search for optimal hyper-parameter combinations on each split, including learning-rate, weight decay, and batch size.
我们遵循LM-BFF (Gao et al., 2020)的方法,在5组随机采样的$\mathcal{D}{\mathrm{train}}$和$\mathcal{D}{\mathrm{dev}}$划分上测量模型的平均性能,并在每组划分上通过网格搜索寻找最优超参数组合(包括学习率、权重衰减和批量大小)。
For P-tuning (Liu et al., 2021c), due to the limit of search space, we do not set anchor tokens in prompt tokens.
对于 P-tuning (Liu et al., 2021c),由于搜索空间的限制,我们没有在提示 token 中设置锚定 token。
For DART, we adopt joint optimization to acquire optimal prompts and fine-tune over global parameters. Note that we use base prompts as templates of pseudo tokens to accelerate convergence.
对于DART,我们采用联合优化来获取最优提示并微调全局参数。需要注意的是,我们使用基础提示作为伪token模板以加速收敛。
To compare fairly, we use RoBERTa-large (Liu et al., 2019) as pre-trained model for both DART and P-tuning framework, following LM-BFF (Gao et al., 2020). We also adopt the best discrete prompts together with label words in LM-BFF as base prompt settings for each framework, as stated below.
为了公平比较,我们遵循LM-BFF (Gao et al., 2020) 的做法,使用RoBERTa-large (Liu et al., 2019) 作为DART和P-tuning框架的预训练模型。如下所述,我们还采用了LM-BFF中最佳离散提示 (discrete prompts) 及标签词 (label words) 作为各框架的基础提示设置。
A.1 HYPER-PARAMETER SEARCH SPACE OF OUR METHOD IN GRID SEARCH
A.1 网格搜索中我们方法的超参数搜索空间
SST-2, MR, CR, Subj, TREC, QNLI, MRPC, QQP
SST-2、MR、CR、Subj、TREC、QNLI、MRPC、QQP
The hyper-parameter search space is (the optimal set of parameters may vary across different tasks and data splits):
超参数搜索空间为 (最优参数集可能因不同任务和数据划分而异):
• learning rate [1e-5, 5e-5, 1e-4, 2e-4] • weight decay [0.0, 0.01, 0.05, 0.10] • number epochs [20,30] • batch size: [4, 8, 16, 24, 32] • max seq length: 128 • gradient accumulation steps: [1, 2]
- 学习率 [1e-5, 5e-5, 1e-4, 2e-4]
- 权重衰减 [0.0, 0.01, 0.05, 0.10]
- 训练轮数 [20,30]
- 批量大小: [4, 8, 16, 24, 32]
- 最大序列长度: 128
- 梯度累积步数: [1, 2]
MNLI, SNLI
MNLI, SNLI
The hyper-parameter search space is (the optimal set of parameters may vary across different tasks and data splits):
超参数搜索空间如下(最优参数集可能因任务和数据划分而异):
TACRED-Revisit, WiKi80, SemEval
TACRED-Revisit, WiKi80, SemEval
The hyper-parameter search space are:
超参数搜索空间为:
ChemProt
ChemProt
The hyper-parameter search space are:
超参数搜索空间为:
DialogRE
DialogRE
The hyper-parameter search space is (the optimal set of parameters may vary across different tasks and data splits):
超参数搜索空间如下(最优参数集可能因任务和数据划分而异):
• learning rate [1e-5, 5e-5, 1e-4, 2e-4]
• 学习率 [1e-5, 5e-5, 1e-4, 2e-4]
A.2 BASE PROMPT AND LABEL WORDS
A.2 基础提示词与标签词
SST-2, MR, CR
SST-2、MR、CR
• prompt template $(l e n g t h=3)$ ) [”text”, ”it”, ”was”, ”
• 提示模板 $(length=3)$ ) [”text”, ”it”, ”was”, ”
• 标签词 ${\ '0\ '}$ : ”terrible”, ”1”: ”great”
Subj
主题
• prompt template $l e n g t h=3 $ ) [”text”, ”This”, ”is”, ”
• 提示模板 (prompt template) $length=3$ ) ["text", "This", "is", "
• 标签词 (label words) ${\ '0\ '}$ : "incorrect", "1": "correct"}
TREC
TREC
MNLI, SNLI
MNLI, SNLI
• prompt template(length $:=2$ ) [”texta”, ”?”, ”
• 提示模板(长度 $:=2$ ) [”texta”, ”?”, ”
• 标签词 {”contradiction”: ”No”, ”entailment”: ”Yes”, ”neutral”: ”Maybe”}
QNLI
QNLI
• prompt template $l e n g t h=2,$ ) [”texta”, ”?”, ”
• 提示模板 (prompt template) $length=2,$ ) [”texta”, ”?”, ”
• 标签词 ”非蕴含 (not entailment)”: ”No”, ”蕴含 (entailment)”: ”Yes”
MRPC, QQP
MRPC, QQP
• prompt template $\mathit{(l e n g t h=2)}$ ) [”texta”, ”?”, ”
• 提示模板 (length=2) ) [”texta”, ”?”, ”
• 标签词 {”0”: ”No” , ”1”: ”Yes”}
TACRED-Revisit, WiKi80, SemEval,DialogRE
TACRED-Revisit、WiKi80、SemEval、DialogRE
• prompt template $l e n g t h=3,$ ) [”text”, Entity1, ”is”, ”the”, ”
• 提示模板 (prompt template) $l e n g t h=3,$ ) [”text”, Entity1, ”is”, ”the”, ”
• 标签词 (label words) {”原产国 (country of origin)”, ”参赛队伍 (participating team)”, ”参与方 (participant of)”,...}
A.3 TEMPLATE LENGTH ANALYSIS
A.3 模板长度分析
| 模型 | 准确率 |
|---|---|
| DART (length = 2) | 92.6 (0.6) |
| DART (length = 3) | 93.5 (0.5) |
| DART T (length=5) | 91.2 (1.1) |
| DART (length = 10) | 90.6 (0.5) |
| Fine-tuning | 81.4 (3.8) |
Table 4: Few-shot performance on SST-2 task using templates with different length.
表 4: 使用不同长度模板在SST-2任务上的少样本性能
We define the length of a template as the number of tokens except for input sentence and
我们将模板长度定义为除输入句子和
A.4 PERFORMANCE ON FULL TRAINING SET
A.4 完整训练集上的性能
| 模型 | SST-2 (acc) | MR (acc) | CR (acc) | Subj (acc) | TREC (acc) |
|---|---|---|---|---|---|
| Fine-tuning | 95.0 | 90.8 | 89.4 | 97.0 | 97.4 |
| LM-BFF | 94.9 | 91.9 | 92.4 | 96.9 | 97.3 |
| DART | 94.6 | 91.3 | 93.8 | 96.6 | 95.6 |
| 模型 | MNLI (acc) | SNLI (acc) | QNLI (acc) | MRPC (F1) | QQP (F1) |
|---|---|---|---|---|---|
| Fine-tuning | 89.8 | 92.6 | 93.3 | 91.4 | 81.7 |
| LM-BFF | 89.6 | 90.3 | 92.8 | 91.7 | 86.4 |
| DART | 87.3 | 89.5 | 92.3 | 90.4 | 89.5 |
We conduct experiments and report the performance of DART with full-sized training data of GLUE tasks. From Table 5, we notice that DART obtain better or comparable results compared with the standard fine-tuning and LM-BFF, indicating that prompt-based tuning methods benefit less from full-sized data.
我们进行了实验,并报告了DART在GLUE任务全量训练数据上的性能。从表5可以看出,DART相比标准微调和LM-BFF取得了更好或相当的结果,这表明基于提示词调优的方法从全量数据中获益较少。
A.5 PERFORMANCE WITH CONSTRAINED LABEL TOKENS
A.5 受限标签Token下的性能
We conduct a nearest neighbor vocabulary embedding search to project the best optimized differentialble label token to a readable natural token. Those tokens are chosen based on cosine-similarity between all tokens’ embedding and the optimized differential ble label token of DART. We list them in descending order with similarity scores (i.e., the token ‘great‘ is chosen as its cosine-similarity score with trained positive label embedding of DART is the highest among all tokens, and the token ‘terrible‘ is the most similar token with the trained negative label embedding; the other tokens are selected and listed in descending order with similarity scores). From Table 6, we observe that the performance of fixed prompt models is related to the similarity score of the chosen label token and that the DART model learns more semantic representation for label tokens, thus, yield best performance.
我们通过最近邻词汇嵌入搜索,将最优化的可微分类标签token映射为可读的自然token。这些token的选取基于所有token嵌入与DART优化后的可微分类标签token之间的余弦相似度。我们按相似度分数降序列出这些token(例如,选择"great"是因为它与DART训练后的正向标签嵌入的余弦相似度在所有token中最高,而"terrible"是与训练后的负向标签嵌入最相似的token;其余token按相似度分数降序排列)。从表6可以看出,固定提示模型的性能与所选标签token的相似度分数相关,而DART模型能学习到标签token更丰富的语义表示,因此取得了最佳性能。
Table 5: Full training set results with RoBERTa-large. Fine-tuning: we reported same results as Gao et al. (2020). LM-BFF: we trained LM-BFF model (without demonstration) on full-training set. Table 6: Few-shot performance on CR task using constrained label tokens with DART.
表 5: 使用RoBERTa-large的完整训练集结果。微调: 我们报告了与Gao等人(2020)相同的结果。LM-BFF: 我们在完整训练集上训练了LM-BFF模型(无演示)。
表 6: 使用DART约束标签token在CR任务上的少样本性能。
| Labeltokens | Accuracy |
|---|---|
| differentiable token (DART) | 91.8 (0.5) |
| great/terrible | 91.5 (0.3) |
| fantastic/awful | 91.0 (0.6) |
| amazing/horrible | 90.2 (0.8) |
| good/bad | 89.6 (0.5) |

Figure 6: The $R_{D}$ ratio curve on dev set of CR task of fixed prompt and differentiable prompt during training.
图 6: CR任务开发集上固定提示 (fixed prompt) 和可微分提示 (differentiable prompt) 在训练过程中的 $R_{D}$ 比率曲线。
A.6 MORE EXPERIMENTS
A.6 更多实验
We numeralize our observation on representation of masked token with a ratio between the average intra-class distance and average inter-class distance of hidden state vectors as $\begin{array}{r}{R_{D}=\frac{\bar{D}{i n t r a}}{\bar{D}{i n t e r}}}\end{array}$ D¯ intra , where:
我们用隐藏状态向量的平均类内距离与平均类间距离之比 $\begin{array}{r}{R_{D}=\frac{\bar{D}{i n t r a}}{\bar{D}{i n t e r}}}\end{array}$ 来量化对掩码token表征的观测,其中:

where distance is the euclidean metric between two vectors, and $H_{c}[i]$ means the hidden state representation of masked token of $i\cdot$ -th sample from class $c$ . For disc rim i native representation, its average intra-class distance is low as data points within the same class tend to gather together, and its average inter-class distance is high as data points from different classes are separated, so its $R_{D}$ ratio should be close to 0.
其中距离是两个向量之间的欧几里得度量,$H_{c}[i]$ 表示类别 $c$ 中第 $i$ 个样本被遮蔽 token 的隐藏状态表示。对于判别性表示,其类内平均距离较低,因为同一类别的数据点倾向于聚集在一起;其类间平均距离较高,因为不同类别的数据点相互分离,因此其 $R_{D}$ 比值应接近 0。
As is shown in Figure 6, the $R_{D}$ ratio of the differentiable method grows lower than that of the fixed label method, which shows the hidden state representation trained in the differentiable method has better linear se par ability.
如图 6 所示,可微分方法的 $R_{D}$ 比值增长低于固定标签方法,这表明可微分方法训练的隐藏状态表征具有更好的线性可分性。
Note that in a masked language model, a linear transformation is performed on the hidden state representations, with a linear decoder sharing weights with the model’s word embeddings serving as the final token classifier. Hence it is evident that better linear se par ability of the representations leads to better performance. In our case, the differentiable method yields better performance due to its better linear se par ability.
需要注意的是,在掩码语言模型中,会对隐藏状态表示进行线性变换,其中线性解码器与模型词嵌入共享权重,作为最终的token分类器。因此显而易见,表示具有更好的线性可分性会带来更好的性能。在我们的案例中,可微分方法因其更优的线性可分性而表现出更好的性能。
A.7 LIMITATIONS
A.7 局限性
Our work may fail when the distribution of the task corpus varies from that of the pre-training corpus. For example, a general pre-trained language model may be fine-tuned with more training instances in a specific domain (e.g., medical domain). This issue can be addressed by intermediate training (Phang et al., 2018; Yin et al., 2020; Zhao et al., 2021), and will be analyzed in the future work. Besides, our work also shows an instability associated with hyper-parameters which is also observed by Dodge et al. (2020); Zhang et al. (2021); Perez et al. (2021) as volatility of few-shot learning in NLP. Overall, however, we believe our work will inspire future work to few-shot settings with more practical applications to low-data settings, e.g., that involve low-resource languages or expert annotation.
当任务语料库的分布与预训练语料库不同时,我们的方法可能会失效。例如,一个通用的预训练语言模型可能在特定领域(如医疗领域)使用更多训练实例进行微调。这一问题可以通过中间训练(Phang et al., 2018; Yin et al., 2020; Zhao et al., 2021)来解决,我们将在未来工作中进行分析。此外,我们的工作还揭示了与超参数相关的不稳定性,Dodge et al. (2020)、Zhang et al. (2021)和Perez et al. (2021)也观察到这种自然语言处理中少样本学习的波动性。不过总体而言,我们相信这项工作将启发未来研究在少样本设置下探索更多实际应用,特别是在低数据场景中,例如涉及低资源语言或专家标注的情况。
A.8 BROADER IMPACT
A.8 更广泛的影响
The pre-train-fine-tune approach has become the standard for natural language processing (NLP). However, supervised fine-tuning is still practically affected by labeled data. This study proposes a novel pluggable, extensible, and efficient approach named Differnt i Able pRompT (DART), which can convert small language models into better few-shot learners. We believe that our study makes a significant contribution to the literature because determining the appropriate prompts requires domain expertise, and handcrafting a high-performing prompt often requires im practically large validation sets, and these issues have been overcome with the use of the proposed method, which is model-agnostic, parameter-efficient. We experimentally verified our proposed approach on 13 standard NLP tasks, and it was seen to outperform several standard NLP platforms.
预训练-微调方法已成为自然语言处理 (NLP) 的标准范式。然而,监督式微调在实际应用中仍受限于标注数据。本研究提出了一种新颖的可插拔、可扩展且高效的方法——Differnt i Able pRompT (DART),能够将小语言模型转化为更优秀的少样本学习器。我们认为该研究对学术领域做出了重要贡献:由于确定合适的提示词需要领域专业知识,且手工构建高性能提示往往需要不切实际的大规模验证集,而这些问题通过我们提出的模型无关、参数高效的方法得到了解决。我们在13项标准NLP任务上进行了实验验证,结果表明该方法优于多个主流NLP平台。