Feature Fusion Transfer ability Aware Transformer for Unsupervised Domain Adaptation
特征融合迁移能力感知Transformer在无监督域适应中的应用
Abstract
摘要
Unsupervised domain adaptation (UDA) aims to leverage the knowledge learned from labeled source domains to improve performance on the unlabeled target domains. While Convolutional Neural Networks (CNNs) have been dominant in previous UDA methods, recent research has shown promise in applying Vision Transformers (ViTs) to this task. In this study, we propose a novel Feature Fusion Transfer ability Aware Transformer (FFTAT) to enhance ViT performance in UDA tasks. Our method introduces two key innovations: First, we introduce a patch discriminator to evaluate the transfer ability of patches, generating a transfer ability matrix. We integrate this matrix into self-attention, directing the model to focus on transferable patches. Second, we propose a feature fusion technique to fuse embeddings in the latent space, enabling each embedding to incorporate information from all others, thereby improving generalization. These two components work in synergy to enhance feature representation learning. Extensive experiments on widely used benchmarks demonstrate that our method significantly improves UDA performance, achieving state-of-the-art (SOTA) results.
无监督域适应 (UDA) 旨在利用从带标签的源域学到的知识提升无标签目标域的性能。虽然卷积神经网络 (CNN) 在以往的 UDA 方法中占据主导地位,但近期研究表明视觉 Transformer (ViT) 在该任务中具有潜力。本研究提出了一种新颖的特征融合迁移能力感知 Transformer (FFTAT) 来增强 ViT 在 UDA 任务中的表现。我们的方法包含两项关键创新:首先,引入一个 patch 判别器来评估各 patch 的迁移能力,生成迁移能力矩阵。我们将该矩阵整合到自注意力机制中,引导模型关注可迁移性强的 patch。其次,提出一种特征融合技术,在潜在空间融合嵌入表示,使每个嵌入都能整合其他所有嵌入的信息,从而提升泛化能力。这两个组件协同工作以增强特征表示学习。在广泛使用的基准测试上进行的大量实验表明,我们的方法显著提升了 UDA 性能,达到了当前最优 (SOTA) 水平。
1. Introduction
1. 引言
Deep neural networks (DNNs) have achieved remarkable breakthroughs across various application fields owing to their impressive automatic feature extraction capabilities. However, such success often relies on the availability of large labeled datasets, which can be challenging to acquire in many real-world scenarios due to the significant time and labor required. Fortunately, unsupervised domain adaptation (UDA) techniques [40] offer a promising solution by harnessing rich labeled data from a source domain and transferring knowledge to target domains with limited or no labeled examples. The essence of UDA lies in identifying discriminant and domain-invariant features shared between the source domain and target domain within a common latent space [44]. Over the past decade, as interests in domain adaptation research have grown, numerous UDA methods have emerged and evolved [20, 24, 50], such as adversarial adaptation, which focuses on discriminating domain-invariant and domain-variant features and acquiring domain-invariant feature representations through adversarial learning [24, 52]. Besides, deep unsupervised domain adaptation techniques usually employ a pre-trained Convolutional Neural Network (CNN) backbone [19].
深度神经网络 (DNN) 凭借其出色的自动特征提取能力,在各个应用领域取得了显著突破。然而,这种成功通常依赖于大规模标注数据集的可用性,而由于需要大量时间和人力,这在许多现实场景中可能难以获取。幸运的是,无监督域适应 (UDA) 技术 [40] 提供了一种有前景的解决方案,它利用源域中丰富的标注数据,并将知识迁移到标注样本有限或没有标注样本的目标域。UDA 的核心在于在共同的潜在空间中识别源域和目标域之间共享的判别性和域不变特征 [44]。过去十年间,随着域适应研究兴趣的增长,涌现并发展了许多 UDA 方法 [20, 24, 50],例如对抗适应,它专注于区分域不变和域变特征,并通过对抗学习获取域不变特征表示 [24, 52]。此外,深度无监督域适应技术通常采用预训练的卷积神经网络 (CNN) 骨干网络 [19]。
Recently, the self-attention mechanism and vision transformer (ViT) [7,41,48] have received growing interest in the vision community. Unlike convolutional neural networks that gather information from local receptive fields of the given image, ViTs leverage the self-attention mechanism to capture long-range dependencies among patch features through a global view. In ViT and many of its variants, each image is partitioned into a series of non-overlapping fixedsize patches, which are then projected into a latent space as patch tokens and combined with position embeddings. A class token, representing the entire image, is prepended to the patch tokens. All tokens are then fed into a specific number of transformer layers to learn visual representations of the input image. Leveraging the superior global content capture capability of the self-attention mechanism, ViTs have demonstrated impressive performance across various vision tasks, including image classification [7], video under standing [11], and object detection [1].
最近,自注意力机制和视觉Transformer (ViT) [7,41,48] 在视觉领域引起了越来越多的关注。与从给定图像的局部感受野收集信息的卷积神经网络不同,ViT利用自注意力机制通过全局视角捕捉图像块特征之间的长距离依赖关系。在ViT及其众多变体中,每张图像被分割成一系列不重叠的固定大小图像块,随后这些图像块被投影到潜在空间作为图像块token,并与位置编码相结合。一个代表整张图像的类别token会被添加到图像块token之前。所有token随后被输入特定数量的Transformer层以学习输入图像的视觉表示。凭借自注意力机制卓越的全局内容捕捉能力,ViT在图像分类 [7]、视频理解 [11] 和目标检测 [1] 等多种视觉任务中展现出了令人印象深刻的性能。
Despite increasing interest, only a few studies have explored the application of ViTs for unsupervised domain adaptation tasks [34, 43, 44, 50]. In this work, we introduce a novel Feature Fusion Transfer ability Aware Transformer, designed for unsupervised domain adaptation. FFTAT builds upon TVT [44], the first ViT-based UDA model, by introducing two key components: (1) a transfer ability graph-guided self-attention (TG-SA) mechanism that enhances information from highly transferable features while suppressing information from less transferable features, and (2) a carefully designed features fusion (FF) operation that makes each embedding incorporate information from other embeddings in the same batch. Fig. 1 illustrates the transferability graph guided self-attention and feature fusion.
尽管兴趣日益增长,但仅有少数研究探索了ViT在无监督域适应任务中的应用[34, 43, 44, 50]。本文提出了一种新颖的特征融合迁移感知Transformer (Feature Fusion Transfer ability Aware Transformer),专为无监督域适应设计。FFTAT基于首个ViT域适应模型TVT[44],通过引入两个关键组件:(1) 迁移能力图引导的自注意力机制 (TG-SA),该机制增强高迁移性特征的信息,同时抑制低迁移性特征的信息;(2) 精心设计的特征融合 (FF) 操作,使每个嵌入能整合同批次其他嵌入的信息。图1展示了迁移能力图引导的自注意力与特征融合机制。
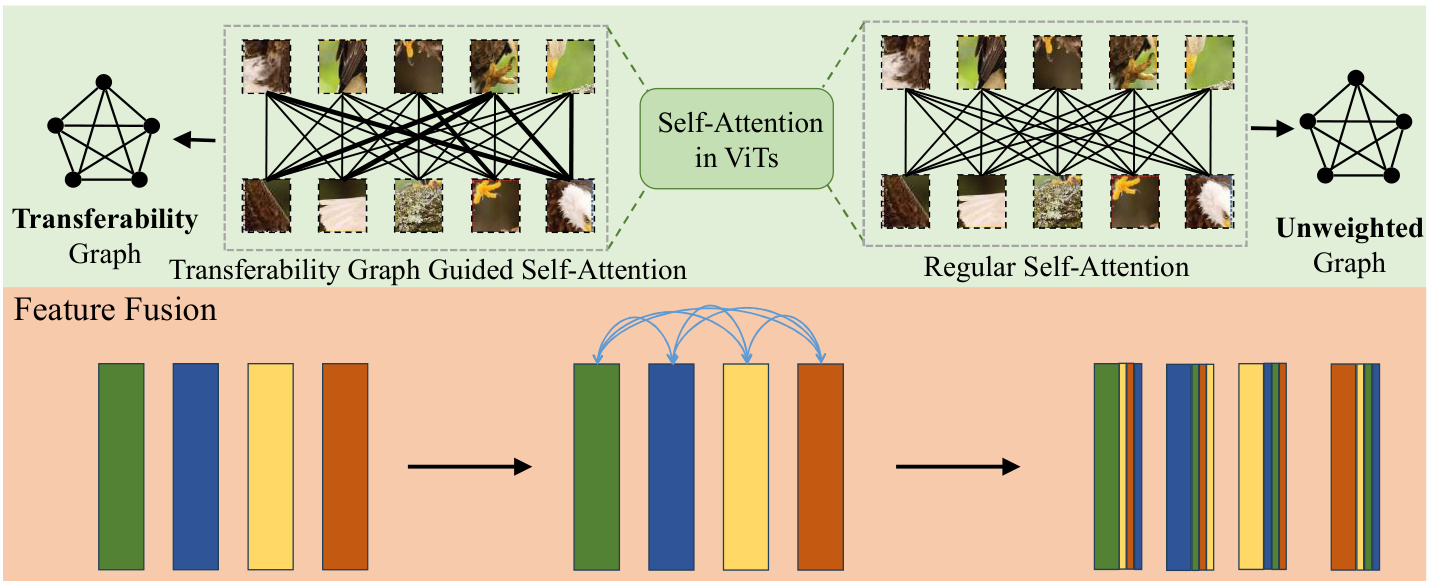
Figure 1. Illustration of transfer ability graph-guided self-attention and feature fusion. The section above (green) shows the transfer ability graph guided self-attention and compares it with vanilla self-attention. The section below (orange) illustrates the feature fusion mechanism, where the features of each sample are summed with the features of all other images in the same batch. Each bar represents the features of a sample.
图 1: 迁移能力图引导的自注意力与特征融合示意图。上方绿色区域展示了迁移能力图引导的自注意力机制,并与普通自注意力进行对比。下方橙色区域说明了特征融合机制,其中每个样本的特征会与同批次中所有其他图像的特征相加。每根柱状条代表一个样本的特征。
From a graph view, vanilla self-attention among patches can be seen as an unweighted graph, where the patches are considered as nodes, and the attention between nodes is regarded as the edge connecting them. Unlike vanilla selfattention, our proposed transfer ability graph guided selfattention is controlled by a weighted graph, where the information communication between highly transferable patches is emphasized via a large-weight edge, and the information communication between less transferable patches is attenuated by a small-weight edge [47, 48]. The transfer ability graph is automatically learned and updated through learning iterations in the transfer ability-aware layer, where we design a patch disc rim in at or to evaluate the transfer ability of each patch. The TG-SA allows for integrative information processing, facilitating the model to focus on domain- invariant features shared between domains and gather important information for domain adaptation. The Feature Fusion (FF) operation enables each embedding to integrate information from other embeddings. Different from recent work PMTrans [53] for unsupervised domain adaptation, our feature fusion occurs in the latent space rather than on the image level.
从图的角度来看,原始的自注意力机制(vanilla self-attention)可以视为一个无权图,其中图像块(patches)作为节点,节点间的注意力被视为连接它们的边。与原始自注意力不同,我们提出的迁移能力图引导自注意力(transfer ability graph guided selfattention)由加权图控制,其中高迁移性图像块间的信息交流通过大权重边强调,而低迁移性图像块间的信息交流则通过小权重边弱化 [47, 48]。迁移能力图在迁移能力感知层(transfer ability-aware layer)中通过学习迭代自动更新,该层设计了图像块判别器(patch discriminator)来评估每个图像块的迁移能力。TG-SA 支持整合性信息处理,促使模型聚焦于跨域共享的域不变特征,并收集对域适应重要的信息。特征融合(Feature Fusion, FF)操作使每个嵌入能够整合来自其他嵌入的信息。与近期无监督域适应工作 PMTrans [53] 不同,我们的特征融合发生在潜在空间而非图像层面。
These two new components synergistic ally enhance robust feature representation learning and generalization in UDA tasks. Extensive experiments on widely used UDA benchmarks demonstrate that FFTAT significantly improves UDA performance, achieving new state-of-the-art results. In summary, our contributions are as follows:
这两个新组件协同增强了UDA任务中的鲁棒特征表示学习和泛化能力。在广泛使用的UDA基准测试上的大量实验表明,FFTAT显著提升了UDA性能,达到了新的最先进水平。总之,我们的贡献如下:
• We introduce a novel transfer ability graph-guided attention mechanism in ViT architecture for UDA, enhanc- ing performance by promoting attention between highly transferable features while suppressing attention between less transferable ones. • We propose a feature fusion technique that enhances feature learning and generalization capabilities for UDA. • Our proposed model, FFTAT, integrates transfer ability graph-guided attention and feature fusion mechanisms, resulting in notable advancements and state-of-the-art performance on widely used UDA benchmarks.
• 我们在ViT架构中引入了一种新颖的迁移能力图引导注意力机制 (transfer ability graph-guided attention mechanism) 用于无监督域适应 (UDA),通过促进高迁移性特征间的注意力同时抑制低迁移性特征间的注意力来提升性能。
• 我们提出了一种特征融合技术 (feature fusion technique) 来增强UDA任务中的特征学习和泛化能力。
• 我们提出的FFTAT模型整合了迁移能力图引导注意力和特征融合机制,在广泛使用的UDA基准测试中取得了显著进步和最优性能。
2. Related Work
2. 相关工作
2.1. Unsupervised Domain Adaptation
2.1. 无监督域适应
UDA aims to learn transferable knowledge across the source and target domains with different distributions [25,
UDA旨在从具有不同分布的源域和目标域中学习可迁移的知识[25,
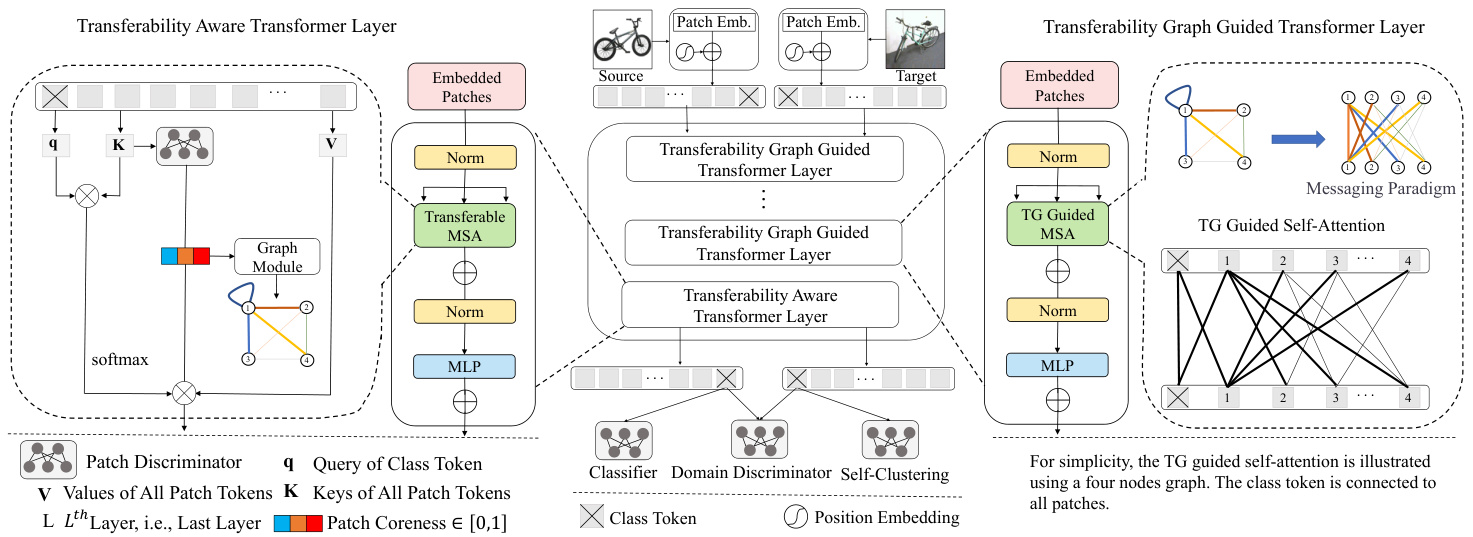
Figure 2. The overview of the FFTAT framework. In FFTAT, source and target images are divided into non-overlapping fixed-size patches which are linearly projected into the latent space and concatenated with positional information. A class token is prepended to the image tokens. The tokens are subsequently processed by a transformer encoder. The Feature Fusion Layer mixes the features as illustrated in Fig. 1. The patch disc rim in at or assesses the transfer ability of each patch and generates a transfer ability graph, which is used to guide the attention mechanism in the transformer layers. The classifier head and self-clustering module operate on source domain images and target domain images, respectively. The Domain Disc rim in at or predicts whether an image belongs to the source or target domain.
图 2: FFTAT框架概览。在FFTAT中,源图像和目标图像被划分为不重叠的固定大小图像块(patch),经线性投影嵌入潜在空间并与位置信息拼接。一个类别token(class token)被添加到图像token序列前端。这些token随后通过Transformer编码器进行处理。特征融合层(Feature Fusion Layer)按图1所示方式混合特征。图像块判别器(patch discriminator)评估每个图像块的迁移能力并生成迁移能力图(transfer ability graph),用于指导Transformer层中的注意力机制。分类器头(classifier head)和自聚类模块(self-clustering module)分别处理源域图像和目标域图像。域判别器(domain discriminator)预测图像属于源域还是目标域。
39]. Various techniques for UDA have been proposed. For example, the discrepancy techniques measure the distribution divergence between source and target domains [24, 33, 35]. Adversarial adaptation discriminates domaininvariant and domain-specific representations by playing an adversarial game between the feature extractor and a domain disc rim in at or [9,44]. Metric learning aims to optimize new metrics that explicitly capture both the intra-class domain variation and the inter-class domain variation [16, 54]. While prevailing UDA methods focus on learning domaininvariant (transferable) features, another line of work emphasizes the importance of domain-specific features [31].
39]。针对无监督域适应 (UDA) 已提出了多种技术。例如,差异度量技术通过计算源域与目标域之间的分布散度来实现迁移 [24, 33, 35];对抗式适应方法通过特征提取器与域判别器之间的对抗博弈来区分域不变特征与域特定特征 [9,44];度量学习则致力于优化能同时捕获域内类间差异和跨域类间差异的新度量标准 [16, 54]。当前主流UDA方法主要关注学习域不变(可迁移)特征,另有研究强调了域特定特征的重要性 [31]。
3. Method
3. 方法
3.1. Preliminaries
3.1. 预备知识
Let $D_{s}={(x_{i}^{s},y_{i}^{s})}_{i=1}^{n_{s}}$ represents data in the labeled source domain, where $\boldsymbol{x}_{i}^{s}$ denotes the images, $y_{i}^{s}$ denotes the corresponding labels, and $n_{s}$ denotes the number of samples in labeled source domain. Similarly, let Dt = {(xit)}jnt=1 represents data in the target domain, consisting $n_{t}$ images but no labels. UDA algorithms aim to learn transferable knowledge to minimize domain discrepancy, thereby achieving the desired prediction performance on unlabeled target data. A common approach is to devise an objective function that jointly learns feature embeddings and a classifier. This objective function is formulated as follows:
设 $D_{s}={(x_{i}^{s},y_{i}^{s})}_{i=1}^{n_{s}}$ 表示带标签源域数据,其中 $\boldsymbol{x}_{i}^{s}$ 表示图像,$y_{i}^{s}$ 表示对应标签,$n_{s}$ 表示带标签源域样本数量。类似地,设 $D_{t} = {(x_{i}^{t})}_{j=1}^{n_{t}}$ 表示目标域数据,包含 $n_{t}$ 张图像但无标签。无监督域适应 (UDA) 算法的目标是学习可迁移知识以最小化域差异,从而在未标记目标数据上实现预期预测性能。常见方法是设计同时学习特征嵌入和分类器的目标函数,其数学表达如下:
2.2. Data Augmentation
2.2. 数据增强
Data Augmentation has been an integral part of modern deep learning vision models. The general idea is to transform the given data without severely altering the semantics. Common data augmentation techniques include random flip and crop [17], MixUp [51], CutOut [6], AutoAugment [14] Rand Augment [3] and so on. While these techniques are generally employed in the image space, recent works have explored data augmentation in the embedding space and found promising outcomes in different applications, such as supervised image classification [37, 46] and semi-supervised learning [15]. Our feature fusion can be viewed as data augmentation in embedding space for unsupervised domain adaptation.
数据增强 (Data Augmentation) 是现代深度学习视觉模型的重要组成部分。其核心思想是在不严重改变语义的情况下对给定数据进行变换。常见的数据增强技术包括随机翻转和裁剪 [17]、MixUp [51]、CutOut [6]、AutoAugment [14]、Rand Augment [3] 等。虽然这些技术通常应用于图像空间,但最近的研究探索了在嵌入空间进行数据增强,并在监督图像分类 [37, 46] 和半监督学习 [15] 等不同应用中取得了良好效果。我们的特征融合可视为无监督域适应 (unsupervised domain adaptation) 中嵌入空间的数据增强。
$$
{\cal L}={\cal L}{C E}+\alpha{\cal L}_{d i s}
$$
$$
{\cal L}={\cal L}{C E}+\alpha{\cal L}_{d i s}
$$
where $L_{C E}$ is the standard cross-entropy loss supervised in the source domain, while $L_{d i s}$ denotes the divergence loss, which varies in implementation across different algorithms. Hyper parameter $\alpha$ is used to balance the weight of $L_{d i s}$ .
其中 $L_{C E}$ 是源域监督的标准交叉熵损失,而 $L_{d i s}$ 表示散度损失,其实现方式因算法而异。超参数 $\alpha$ 用于平衡 $L_{d i s}$ 的权重。
3.2. Overview of FFTAT
3.2. FFTAT概述
We aim to advance ViT-based solutions for Unsupervised Domain Adaptation. Fig. 2 illustrates the overall framework of our proposed FFTAT. The framework employs a vision transformer backbone, consisting of a domain discriminator for the images (using the class tokens), a patch discriminator for assessing the transfer ability of the patches, a selfclustering module, and a classifier head. The vision transformer backbone is equipped with our proposed transferability graph-guided attention mechanism (comprising the Transfer ability Graph Guided Transformer Layer and the Transfer ability Aware Transformer Layer in Fig. 2), and a feature fusion mechanism (implemented as the Feature Fusion Layer, as shown in Fig. 2).
我们致力于推进基于ViT的无监督域适应解决方案。图2展示了我们提出的FFTAT整体框架。该框架采用视觉Transformer主干网络,包含用于图像的域判别器(使用类别token)、评估图像块迁移能力的块判别器、自聚类模块和分类器头。视觉Transformer主干网络配备了我们提出的可迁移性图引导注意力机制(由图2中的可迁移性图引导Transformer层和可迁移性感知Transformer层组成)以及特征融合机制(实现为图2所示的特征融合层)。
During training, both the source and target images are used. Each image is divided into non-overlapping fixed-size patches which are linearly projected into the latent space and concatenated with positional information. A class token is prepended to the patch tokens. All tokens are subsequently processed by the vision transformer backbone. From a graph view, we consider the patches as nodes and the attention between the patches as edges. This allows us to manipulate the strength of self-attention among patches by adaptively learning a transfer ability graph during the training process. In the first iteration, we initialize the transfer ability graph as an unweighted graph. At the end of each iteration, the patch disc rim in at or evaluates the transfer ability score of the patches and updates the transferability graph. The learned transfer ability graph is used to rescale the self-attention in the Transfer ability Aware Transformer Layer and the Transfer ability Graph Guided Transformer Layers, amplifying information from highly transferable features while damping the less transferable ones.
训练过程中会同时使用源图像和目标图像。每张图像被划分为不重叠的固定尺寸图块(patch),这些图块经过线性投影嵌入潜在空间并与位置信息拼接。在图块token前会添加一个类别token(class token)。所有token随后由视觉Transformer主干网络进行处理。
从图(graph)的视角来看,我们将图块视为节点(node),图块间的注意力(attention)视为边(edge)。这使得我们能够通过在训练过程中自适应学习迁移能力图(transfer ability graph),来调控图块间自注意力(self-attention)的强度。在首次迭代时,我们将迁移能力图初始化为无权图(unweighted graph)。每次迭代结束时,图块判别器(patch discriminator)会评估各图块的迁移能力分数并更新可迁移性图(transferability graph)。
学习得到的迁移能力图将用于重缩放"迁移感知Transformer层"(Transfer ability Aware Transformer Layer)和"迁移图引导Transformer层"(Transfer ability Graph Guided Transformer Layers)中的自注意力机制——放大高可迁移特征的信息,同时抑制低可迁移特征。
The Feature Fusion Layer is placed before the Transferability Aware Layer to mix patch token embeddings for better generalization. The classifier head predicts class labels based on the output class token of the labeled source domain images, while the domain disc rim in at or predicts whether images belong to the source or target domain for output class token embeddings of both domains. The selfclustering module utilizes the class token of the target domain to encourage the clustering of learned target domain image representation. Details are introduced below.
特征融合层位于可迁移感知层之前,用于混合图像块token嵌入以提升泛化能力。分类器头部基于标记源域图像的输出类别token预测类别标签,而域判别器则通过两个域的输出类别token嵌入来预测图像属于源域还是目标域。自聚类模块利用目标域的类别token促进学习到的目标域图像表征聚类。具体细节如下所述。
3.3. Transfer ability Aware Transformer Layer
3.3. 迁移能力感知 Transformer 层
The patch tokens correspond to partial regions of the image and capture visual features as fine-grained local representations. Existing work [44, 45, 49] shows that the patch tokens are of different semantic importance. In this work, we define the transfer ability score on a patch to assess its transfer ability (detailed definition below). A patch with a higher transfer ability score is more likely to correspond to the highly transferable features.
补丁Token (patch tokens) 对应图像的局部区域,并以细粒度局部表征形式捕捉视觉特征。现有研究 [44,45,49] 表明,不同补丁Token具有差异化的语义重要性。本文通过定义补丁迁移能力分数 (transfer ability score) 来评估其迁移能力(具体定义见下文),分数越高的补丁越可能对应高迁移性特征。
To obtain the transfer ability score of patch tokens, we adopt a patch-level domain disc rim in at or $D_{l}$ to evaluate the local features with a loss function:
为了获取补丁token的迁移能力分数,我们采用了一个补丁级别的域判别器 $D_{l}$ ,通过损失函数评估局部特征:
$$
L_{p a t}(x,y^{d})=-\frac{1}{n P}\sum_{x_{i}\in D}\sum_{p=1}^{P}L_{C E}\left(D_{l}\left(G_{f}\left(x_{i p}\right)\right),y_{i p}^{d}\right)
$$
$$
L_{p a t}(x,y^{d})=-\frac{1}{n P}\sum_{x_{i}\in D}\sum_{p=1}^{P}L_{C E}\left(D_{l}\left(G_{f}\left(x_{i p}\right)\right),y_{i p}^{d}\right)
$$
where $P$ is the number of patches, $D=D_{s}\cup D_{t}$ , $G_{f}$ is the feature encoder, implemented as ViT, $n~=~n_{s}+n_{t}$ , is the total number of images in $D$ , ip denotes the $p$ th patch of the i th image, yidp denotes the domain label of the $p$ th token of the $i$ th image, i.e., $y_{i p}^{d}=1$ means source domain, else the target domain. $D_{l}\left(f_{i p}\right)$ gives the probability of the patch belonging to the source domain, where $f_{i p}$ denotes the features of the $p$ th token of the ith image, i.e., $f_{i p}=G_{f}\left(x_{i p}\right)$ . During the training process, $D_{l}$ tries to discriminate the patches correctly, assigning 1 to patches from the source domain and 0 to those from the target domain.
其中 $P$ 是图像块数量,$D=D_{s}\cup D_{t}$,$G_{f}$ 是特征编码器(采用 ViT 实现),$n~=~n_{s}+n_{t}$ 表示 $D$ 中的图像总数,ip 表示第 i 张图像的第 $p$ 个块,yidp 表示第 i 张图像第 $p$ 个 token 的域标签(即 $y_{i p}^{d}=1$ 代表源域,否则为目标域)。$D_{l}\left(f_{i p}\right)$ 给出该图像块属于源域的概率,其中 $f_{i p}$ 表示第 i 张图像第 $p$ 个 token 的特征(即 $f_{i p}=G_{f}\left(x_{i p}\right)$)。训练过程中 $D_{l}$ 会尝试正确判别图像块,为源域块分配 1,为目标域块分配 0。
Empirically, patches that cannot be easily distinguished by the patch disc rim in at or (e.g., $D_{l}$ is around 0.5) are more likely to correspond to highly transferable features. These highly transferable features capture underlying patterns that remain consistent despite variations in the data distribution between the source and target domains. In the paper, we use the phrase “transfer ability” to capture this property. We define the transfer ability score of a patch as:
经验表明,那些难以被补丁判别器(例如 $D_{l}$ 值接近0.5)区分的补丁,往往对应着高可迁移性特征。这些高可迁移性特征捕捉了源域与目标域之间数据分布变化下仍保持一致的底层模式。在论文中,我们使用"可迁移性(transfer ability)"这一术语来描述该特性,并将补丁的可迁移性得分定义为:
$$
c\left(f_{i p}\right)=H\left(D_{l}\left(f_{i p}\right)\right)\in[0,1]
$$
$$
c\left(f_{i p}\right)=H\left(D_{l}\left(f_{i p}\right)\right)\in[0,1]
$$
where $H\left(\cdot\right)$ is the standard entropy function. If the output of the patch disc rim in at or $D_{l}$ is around 0.5, then the transfer ability score is close to 1, indicating that the features in the patch are highly transferable. A high transfer ability score means that the features in a patch are highly transferable, and vice versa. Assessing the transfer ability of patches allows a finer-grained view of the image, separating an image into highly transferable and less transferable patches. Features from highly transferable patches will be amplified while features from less transferable patches will be suppressed.
其中 $H\left(\cdot\right)$ 是标准熵函数。若图像块判别器 $D_{l}$ 的输出值接近0.5,则迁移能力分数趋近于1,表明该图像块中的特征具有高度可迁移性。高迁移能力分数意味着图像块特征可迁移性强,反之则弱。通过评估图像块的迁移能力,可以更细粒度地观察图像,将其划分为高可迁移性和低可迁移性区域。高可迁移性图像块的特征将被增强,而低可迁移性图像块的特征则会被抑制。
Let $\mathcal{C}{i}={c_{i1},...,c_{i p}}$ be the transfer ability scores of patches of image $i$ . The adjacency matrix of the transferability graph can be formulated as:
设 $\mathcal{C}{i}={c_{i1},...,c_{i p}}$ 为图像 $i$ 各区块的迁移能力得分。迁移性图的邻接矩阵可表示为:
$$
M_{t s}=\frac{1}{B\mathcal{H}}\sum_{h=1}^{\mathcal{H}}\sum_{i=1}^{B}\left[\mathcal{C}_{i}^{T}\mathcal{C}_{i}\right]_{\times}
$$
$$
M_{t s}=\frac{1}{B\mathcal{H}}\sum_{h=1}^{\mathcal{H}}\sum_{i=1}^{B}\left[\mathcal{C}_{i}^{T}\mathcal{C}_{i}\right]_{\times}
$$
$B$ is the batch size, $\mathcal{H}$ is the number of heads, $[\cdot]{\times}$ means no gradients back-propagation for the adjacency matrix of the generated transfer ability graph. $M_{t s}$ controls the connection strength of attention between patches.
$B$ 是批次大小,$\mathcal{H}$ 是注意力头数,$[\cdot]{\times}$ 表示对生成的迁移能力图的邻接矩阵不进行梯度回传。$M_{ts}$ 控制图像块间注意力的连接强度。
The vanilla Self-Attention (SA) can then be reformulated as Transfer ability Aware Self-Attention (TSA) in the Transferability Aware Transformer Layer by integrating with transfer ability scores:
原始的自注意力机制 (Self-Attention, SA) 可通过整合迁移能力分数重新表述为迁移感知自注意力机制 (Transfer ability Aware Self-Attention, TSA) ,形成迁移感知 Transformer 层 (Transferability Aware Transformer Layer) :
$$
T S A(q_{c l s},K,V)=s o f t m a x({\frac{q_{c l s}K^{T}}{\sqrt{d}}})\odot[1;C_{K_{p a t c h}}]V
$$
$$
T S A(q_{c l s},K,V)=s o f t m a x({\frac{q_{c l s}K^{T}}{\sqrt{d}}})\odot[1;C_{K_{p a t c h}}]V
$$
where $q_{c l s}$ is the query of the class token, $K$ represents the key of all tokens, including the class token and patch tokens, $K_{p a t c h}$ is the key of the patch tokens, $C_{K_{p a t c h}}$ denotes the transfer ability scores of the patch tokens, $\odot$ is the dot product, and $[;]$ is the concatenation operation. TSA encourages the class token to take more information from highly transferable patches with higher transfer ability scores while suppressing information from patches with low transferability scores. The Transfer ability Aware Multi-head SelfAttention is therefore defined as:
其中 $q_{c l s}$ 是类别 token 的查询向量,$K$ 表示所有 token 的键向量(包括类别 token 和图像块 token),$K_{p a t c h}$ 是图像块 token 的键向量,$C_{K_{p a t c h}}$ 表示图像块 token 的迁移能力分数,$\odot$ 是点积运算,$[;]$ 是拼接操作。迁移能力敏感注意力机制 (TSA) 促使类别 token 从具有较高迁移能力分数的图像块中获取更多信息,同时抑制来自低迁移能力图像块的信息。因此迁移能力敏感多头自注意力 (Transfer ability Aware Multi-head SelfAttention) 定义为:
$$
T-M S A(q_{c l s},K,V)=C o n c a t(h e a d_{1},...,h e a d_{h})W^{O}
$$
$$
T-M S A(q_{c l s},K,V)=C o n c a t(h e a d_{1},...,h e a d_{h})W^{O}
$$
where $h e a d_{i}=T S A\left(q_{c l s}W_{i}^{q_{c l s}},K W_{i}^{K},V W_{i}^{V}\right)$ . Taking them together, the operations in the transfer ability aware transformer layer can be formulated as:
其中 $h e a d_{i}=T S A\left(q_{c l s}W_{i}^{q_{c l s}},K W_{i}^{K},V W_{i}^{V}\right)$ 。综合起来,迁移能力感知 Transformer (Transformer) 层的操作可表述为:
$$
\begin{array}{l}{{\hat{z}^{l}=T\ –M S A\left(L N\left(z^{l-1}\right)\right)+z^{l-1}}}\ {{z^{l}=M L P\left(L N\left(\hat{z}^{l}\right)\right)+\hat{z}^{l}}}\end{array}
$$
$$
\begin{array}{l}{{\hat{z}^{l}=T\ –M S A\left(L N\left(z^{l-1}\right)\right)+z^{l-1}}}\ {{z^{l}=M L P\left(L N\left(\hat{z}^{l}\right)\right)+\hat{z}^{l}}}\end{array}
$$
where $z^{l-1}$ are output from previous layer. In this way, the Transfer ability Aware Transformer Layer focuses on finegrained features that are highly transferable and are discriminative for classification. Here $l=L$ , $L$ is the total number of transformer layers in ViT architecture.
其中 $z^{l-1}$ 来自前一层的输出。通过这种方式,可迁移性感知 Transformer 层 (Transfer ability Aware Transformer Layer) 专注于高度可迁移且对分类具有区分性的细粒度特征。这里 $l=L$,$L$ 是 ViT 架构中 Transformer 层的总数。
3.4. Feature Fusion
3.4. 特征融合
Emerging evidence shows that adding perturbations enhances model robustness [15,34,46]. To enhance the robustness of the generated transfer ability graphs and to make the model resistant to noisy perturbations, we propose a novel feature fusion technique into our FFTAT framework, implemented as a Feature Fusion Layer, placed before the Transferability Aware Transformer Layer. Given an image $x_{i}$ , let $b_{i}={b_{i1},\cdot\cdot\cdot,b_{i p}}$ denote the embeddings of its patches. As illustrated in Fig. 1, each embedding is perturbed by incorpora ting information from all the other embeddings. We perform the embedding fusion for the source and target domain separately, as instructed in [46]:
新兴证据表明,添加扰动能增强模型鲁棒性[15,34,46]。为提升生成迁移能力图的鲁棒性并使模型抵抗噪声扰动,我们在FFTAT框架中提出了一种新颖的特征融合技术,通过特征融合层(Feature Fusion Layer)实现,该层位于迁移感知Transformer层(Transferability Aware Transformer Layer)之前。给定图像$x_{i}$,令$b_{i}={b_{i1},\cdot\cdot\cdot,b_{i p}}$表示其图像块嵌入。如图1所示,每个嵌入通过融合其他所有嵌入信息进行扰动。我们按照文献[46]的方法,分别对源域和目标域执行嵌入融合:
$$
\left{\begin{array}{l}{{\tilde{b}}{i p}^{s}={\frac{2}{B+1}}b_{i p}^{s}+{\frac{1}{B+1}}\sum_{j=1}^{B}b_{j p}^{s},j\neq i}\ {{\tilde{b}}{i p}^{t}={\frac{2}{B+1}}b_{i p}^{t}+{\frac{1}{B+1}}\sum_{j=1}^{B}b_{j p}^{t},j\neq i}\end{array}\right.
$$
$$
\left{\begin{array}{l}{{\tilde{b}}{i p}^{s}={\frac{2}{B+1}}b_{i p}^{s}+{\frac{1}{B+1}}\sum_{j=1}^{B}b_{j p}^{s},j\neq i}\ {{\tilde{b}}{i p}^{t}={\frac{2}{B+1}}b_{i p}^{t}+{\frac{1}{B+1}}\sum_{j=1}^{B}b_{j p}^{t},j\neq i}\end{array}\right.
$$
where $B$ is the batch size, $s$ and $t$ indicate the source and target domain. The FF aids in generating more robust transferability graphs and improves model general iz ability.
其中 $B$ 是批量大小,$s$ 和 $t$ 分别表示源域和目标域。FF (Feed Forward) 有助于生成更具鲁棒性的可迁移图,并提升模型的泛化能力。
3.5. Transfer ability Graph Guided Transformer Layer
3.5. 迁移能力图引导的 Transformer 层
As introduced in Section 3.2, we consider the patches as nodes and the attention between patches as edges. The learned transfer ability information can be effectively and conveniently integrated into the self-attention mechanism by updating the graph, as illustrated in the right part of Fig. 2. With the guidance of the transfer ability graph, the self-attention in Transfer ability Graph Guided Transformer
如第3.2节所述,我们将图像块视为节点,块间注意力视为边。通过更新图结构,习得的迁移能力信息可高效便捷地融入自注意力机制,如图2右侧所示。在迁移能力图的引导下,自注意力机制在迁移能力图引导的Transformer中
Layers will focus on the patches with more transferable features, thus steering the model to learn transferable knowledge across the source and target domain.
各层将聚焦于具有更多可迁移特征的补丁,从而引导模型学习源域和目标域之间的可迁移知识。
The transfer ability graph can be represented by $\mathcal{G}~=$ $(\nu,\mathcal{E})$ , with nodes $\begin{array}{r l r}{\mathcal{V}}&{{}=}&{{\nu_{1},...,\nu_{n}}}\end{array}$ , edges $\varepsilon\mathrm{~\quad~}=$ ${(\nu_{p},\nu_{\tilde{p}})|\nu_{p},\nu_{\tilde{p}}\in\mathcal{V}}$ , and adjacency matrix $M_{t s}$ . The transfer ability graph-guided self-attention for a specific patch $p$ at $l$ -th layer in the Transfer ability Graph Guided Transformer Layer is:
迁移能力图可表示为 $\mathcal{G}~=$ $(\nu,\mathcal{E})$,其中节点 $\begin{array}{r l r}{\mathcal{V}}&{{}=}&{{\nu_{1},...,\nu_{n}}}\end{array}$,边 $\varepsilon\mathrm{~\quad~}=$ ${(\nu_{p},\nu_{\tilde{p}})|\nu_{p},\nu_{\tilde{p}}\in\mathcal{V}}$,邻接矩阵为 $M_{t s}$。在迁移能力图引导的Transformer层中,第 $l$ 层特定图像块 $p$ 的迁移能力图引导自注意力计算为:
$$
b_{p}^{(l+1)}=\sigma^{(l)}(\frac{q_{p}^{(l)}(K_{\tilde{p}}^{(l)})^{T}}{\sqrt{d_{k}}})\odot C_{K_{\tilde{p}}^{(l)}}V_{\tilde{p}}^{(l)},~\tilde{p}\in N(p)\cup p
$$
$$
b_{p}^{(l+1)}=\sigma^{(l)}(\frac{q_{p}^{(l)}(K_{\tilde{p}}^{(l)})^{T}}{\sqrt{d_{k}}})\odot C_{K_{\tilde{p}}^{(l)}}V_{\tilde{p}}^{(l)},~\tilde{p}\in N(p)\cup p
$$
where $\sigma(\cdot)$ is the activation function, which is usually the softmax function in ViTs, $q_{p}^{(l)}$ is the query of the $p$ th patch ( $\overset{\cdot}{p}$ th node in $\mathcal{G}$ ), $N(p)$ are the neighborhood nodes of node $p,d_{k}$ is the scale factor with the same dimension of queries and keys, K(l) and V (l) are the key and value of nodes $\tilde{p}$ , and $C_{K_{\tilde{p}}^{(l)}}$ denotes the transfer ability scores. Therefore, the transfer ability graph guided self-attention that is conducted at the patch level can be formulated as:
其中 $\sigma(\cdot)$ 是激活函数,在ViT中通常为softmax函数,$q_{p}^{(l)}$ 表示第 $p$ 个图像块(即图 $\mathcal{G}$ 中第 $\overset{\cdot}{p}$ 个节点)的查询向量,$N(p)$ 是节点 $p$ 的邻域节点集合,$d_{k}$ 是与查询和键向量维度相同的缩放因子,$K^{(l)}$ 和 $V^{(l)}$ 分别表示节点 $\tilde{p}$ 的键和值向量,$C_{K_{\tilde{p}}^{(l)}}$ 代表迁移能力分数。因此,基于图像块级别的迁移能力图引导自注意力机制可表示为:
$$
T G-S A(Q,K,V,M_{t s})=s o f t m a x(\frac{Q K^{T}\odot M_{t s}}{\sqrt{d_{k}}})V
$$
$$
T G-S A(Q,K,V,M_{t s})=s o f t m a x(\frac{Q K^{T}\odot M_{t s}}{\sqrt{d_{k}}})V
$$
where queries, keys, and values of all patches are packed into matrices $Q,K$ , and $V$ , respectively, $M_{t s}$ is the adjacency matrix defined in $\mathrm{Eq}4$ . The transfer ability graph guided multi-head attention is then formulated as:
其中,所有补丁的查询(query)、键(key)和值(value)分别打包成矩阵 $Q,K$ 和 $V$ , $M_{t s}$ 是式4中定义的邻接矩阵。转移能力图引导的多头注意力公式如下:
$$
M S A(Q,K,V,M_{t s})=C o n c a t(h e a d_{1},...,h e a d_{h})W^{o}
$$
$$
M S A(Q,K,V,M_{t s})=C o n c a t(h e a d_{1},...,h e a d_{h})W^{o}
$$
where $h e a d_{i}=T G-S A(Q W_{i}^{Q},K W_{i}^{K},V W_{i}^{V},M_{t s})$ . The learnable parameter matrices $\boldsymbol{W}{i}^{Q}$ , $W{i}^{K}$ , $W_{i}^{V}$ and $W^{O}$ are the projections. Multi-head attention helps the model to jointly aggregate information from different representation subspaces at various positions. In this work, we apply the transfer ability guidance to each representation subspace.
其中 $h e a d_{i}=T G-S A(Q W_{i}^{Q},K W_{i}^{K},V W_{i}^{V},M_{t s})$ 。可学习参数矩阵 $\boldsymbol{W}{i}^{Q}$ 、 $W{i}^{K}$ 、 $W_{i}^{V}$ 和 $W^{O}$ 为投影矩阵。多头注意力机制使模型能够从不同位置的不同表示子空间联合聚合信息。本工作中,我们将迁移能力指导应用于每个表示子空间。
3.6. Overall Objective Function
3.6. 总体目标函数
Since our proposed FFTAT has a classifier head, a selfclustering module, a patch disc rim in at or, and a domain discriminator, there are four terms in the overall objective function. The classification loss is formulated as:
由于我们提出的FFTAT具有分类器头、自聚类模块、补丁判别器和域判别器,总体目标函数包含四项。分类损失公式如下:
$$
L_{c l c}\left(x^{s},y^{s}\right)=\frac{1}{n_{s}}\sum_{x_{i}\in D_{s}}L_{C E}\left(G_{c}\left(G_{f}\left(x_{i}^{s}\right)\right),y_{i}^{s}\right)
$$
$$
L_{c l c}\left(x^{s},y^{s}\right)=\frac{1}{n_{s}}\sum_{x_{i}\in D_{s}}L_{C E}\left(G_{c}\left(G_{f}\left(x_{i}^{s}\right)\right),y_{i}^{s}\right)
$$
where $G_{c}$ is the classifier head, and $G_{f}$ is the feature extractor, i.e., the ViT with transfer ability graph-guided selfattention and feature fusion in our work.
其中 $G_{c}$ 是分类器头,$G_{f}$ 是特征提取器,即本工作中具有迁移能力的图引导自注意力 (self-attention) 和特征融合 (feature fusion) 的 ViT。
The domain disc rim in at or takes the class token of images from the source and target domain and tries to discriminate
域判别器提取源域和目标域图像的类别token并尝试进行区分
Table 1. Comparison with SOTA methods on the Office-Home dataset. The best performance is marked in bold. The methods above the horizontal line are CNN-based methods, while the methods below the horizontal line are ViT-based methods.
表 1: Office-Home数据集上与SOTA方法的对比。最佳性能以粗体标出。水平线上方为基于CNN的方法,下方为基于ViT的方法。
| 方法 | Ar→Cl | Ar→Pr | Ar→Re | Cl→Ar | Cl→Pr | Cl→Re | Pr→Ar | Pr→Cl | Pr→Re | Re→Ar | Re→Cl | Re→Pr | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 [13] | 44.9 | 66.3 | 74.3 | 51.8 | 61.9 | 63.6 | 52.4 | 39.1 | 71.2 | 63.8 | 45.9 | 77.2 | 59.4 |
| MinEnt [12] | 51.0 | 71.9 | 77.1 | 61.2 | 69.1 | 70.1 | 59.3 | 48.7 | 77.0 | 70.4 | 53.0 | 81.0 | 65.8 |
| SAFN [42] | 52.0 | 71.7 | 76.3 | 64.2 | 69.9 | 71.9 | 63.7 | 51.4 | 77.1 | 70.9 | 57.1 | 81.5 | 67.3 |
| CDAN+E [24] | 54.6 | 74.1 | 78.1 | 63.0 | 72.2 | 74.1 | 61.6 | 52.3 | 79.1 | 72.3 | 57.3 | 82.8 | 68.5 |
| DCAN [18] | 54.5 | 75.7 | 81.2 | 67.4 | 74.0 | 76.3 | 67.4 | 52.7 | 80.6 | 74.1 | 59.1 | 83.5 | 70.5 |
| BNM [4] | 56.7 | 77.5 | 81.0 | 67.3 | 76.3 | 77.1 | 65.3 | 55.1 | 82.0 | 73.6 | 57.0 | 84.3 | 71.1 |
| SHOT [20] | 57.1 | 78.1 | 81.5 | 68.0 | 78.2 | 78.1 | 67.4 | 54.9 | 82.2 | 73.3 | 58.8 | 84.3 | 71.8 |
| ATDOC-NA [21] | 58.3 | 78.8 | 82.3 | 69.4 | 78.2 | 78.2 | 67.1 | 56.0 | 82.7 | 72.0 | 58.2 | 85.5 | 72.2 |
| ViT [7] | 54.7 | 83.0 | 87.2 | 77.3 | 83.4 | 85.6 | 74.4 | 50.9 | 87.2 | 79.6 | 54.8 | 88.8 | 75.5 |
| TVT [44] | 74.9 | 86.8 | 89.5 | 82.8 | 88.0 | 88.3 | 79.8 | 71.9 | 90.1 | 85.5 | 74.6 | 90.6 | 83.6 |
| CDTrans [43] | 68.8 | 85.0 | 86.9 | 81.5 | 87.1 | 87.3 | 79.6 | 63.3 | 88.2 | 82.0 | 66.0 | 90.6 | 80.5 |
| SSRT [34] | 75.2 | 89.0 | 91.1 | 85.1 | 88.3 | 90.0 | 85.0 | 74.2 | 91.3 | 85.7 | 78.6 | 91.8 | 85.4 |
| PMTrans [53] | 81.3 | 92.9 | 92.8 | 88.4 | 93.4 | 93.2 | 87.9 | 80.4 | 93.0 | 89.0 | 80.9 | 84.8 | 89.0 |
| FFTAT (ours) | 83.2 | 92.9 | 95.2 | 91.1 | 93.5 | 95.2 | 89.7 | 85.0 | 94.9 | 93.0 | 87.5 | 95.9 | 91.4 |
Table 2. Comparison with SOTA methods on Visda-2017. The best performance is marked in bold. The methods above the horizontal line are CNN-based methods, while the methods below the horizontal line are ViT-based methods.
| 方法 | 飞机 | 自行车 | 公交车 | 汽车 | 马 | 刀 | 摩托车 | 人 | 植物 | 滑板 | 火车 | 卡车 | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 [13] | 55.1 | 53.3 | 61.9 | 59.1 | 80.6 | 17.9 | 79.7 | 31.2 | 81.0 | 26.5 | 73.5 | 8.5 | 52.4 |
| DANN [9] | 81.9 | 77.7 | 82.8 | 44.3 | 81.2 | 29.5 | 65.1 | 28.6 | 51.9 | 54.6 | 82.8 | 7.8 | 57.4 |
| MinEnt [12] | 80.3 | 75.5 | 75.8 | 48.3 | 77.9 | 27.3 | 69.7 | 40.2 | 46.5 | 46.6 | 79.3 | 16.0 | 57.0 |
| SAFN [42] | 93.6 | 61.3 | 84.1 | 70.6 | 94.1 | 79.0 | 91.8 | 79.6 | 89.9 | 55.6 | 89.0 | 24.4 | 76.1 |
| CDAN+E [24] | 85.2 | 66.9 | 83.0 | 50.8 | 84.2 | 74.9 | 88.1 | 74.5 | 83.4 | 76.0 | 81.9 | 38.0 | 73.9 |
| BNM [4] | 89.6 | 61.5 | 76.9 | 55.0 | 89.3 | 69.1 | 81.3 | 65.5 | 90.0 | 47.3 | 89.1 | 30.1 | 70.4 |
| CGDM [8] | 93.7 | 82.7 | 73.2 | 68.4 | 92.9 | 94.5 | 88.7 | 82.1 | 93.4 | 82.5 | 86.8 | 49.2 | 82.3 |
| SHOT [20] | 94.3 | 88.5 | 80.1 | 57.3 | 93.1 | 93.1 | 80.7 | 80.3 | 91.5 | 89.1 | 86.3 | 58.2 | 82.9 |
| ViT [7] | 97.7 | 48.1 | 86.6 | 61.6 | 78.1 | 63.4 | 94.7 | 10.3 | 87.7 | 47.7 | 94.4 | 35.5 | 67.1 |
| TVT [44] | 92.9 | 85.6 | 77.5 | 60.5 | 93.6 | 98.2 | 89.4 | 76.4 | 93.6 | 92.0 | 91.7 | 55.7 | 83.9 |
| CDTrans [43] | 97.1 | 90.5 | 82.4 | 77.5 | 96.6 | 96.1 | 93.6 | 88.6 | 97.9 | 86.9 | 90.3 | 62.8 | 88.4 |
| SSRT [34] | 98.9 | 87.6 | 89.1 | 84.8 | 98.3 | 98.7 | 96.3 | 81.1 | 94.9 | 97.9 | 94.5 | 43.1 | 88.8 |
| PMTrans [53] | 99.4 | 88.3 | 88.1 | 78.9 | 98.8 | 98.3 | 95.8 | 70.3 | 94.6 | 98.3 | 96.3 | 48.5 | 88.0 |
| FFTAT (ours) | 99.7 | 98.5 | 93.1 | 81.1 | 99.8 | 99.5 | 97.8 | 89.6 | 95.7 | 99.8 | 98.7 | 72.4 | 93.8 |
表 2: Visda-2017 数据集上的 SOTA 方法对比。最佳性能以粗体标出。横线上方为基于 CNN 的方法,横线下方为基于 ViT 的方法。
the class token, i.e., the representation of the entire image, to the source or target domain:
类别Token (class token),即整个图像的表示,到源域或目标域:
$$
L_{d i s}\left(x,y^{d}\right)=-\frac{1}{n}\sum_{x_{i}\in D}L_{c e}\left(D_{g}\left(G_{f}\left(x_{i}\right),y_{i}^{d}\right)\right)
$$
$$
L_{d i s}\left(x,y^{d}\right)=-\frac{1}{n}\sum_{x_{i}\in D}L_{c e}\left(D_{g}\left(G_{f}\left(x_{i}\right),y_{i}^{d}\right)\right)
$$
where ${\cal D}g$ is the domain disc rim in at or, and $y_{i}^{d}$ is the the domain label (i.e., $y_{i}^{d}=1$ means source domain, $y_{i}^{d}=0$ is target).
其中 ${\cal D}g$ 是域判别器,$y_{i}^{d}$ 是域标签 (即 $y_{i}^{d}=1$ 表示源域,$y_{i}^{d}=0$ 表示目标域)。
The self-clustering module is inspired by the cluster assumption [2] for images from the target domain without labels and the probability $\mathrm{{p}}^{t}=s o f t m a x\left(G_{c}\left(G_{f}\left(x^{t}\right)\right)\right)$ of target image $x^{t}$ is optimized to maximize the mutual information with $x^{t}$ [44]. The self-clustering loss term is formulated as:
自聚类模块的灵感来源于针对无标签目标域图像的聚类假设 [2],目标图像 $x^{t}$ 的概率 $\mathrm{{p}}^{t}=s o f t m a x\left(G_{c}\left(G_{f}\left(x^{t}\right)\right)\right)$ 通过优化使其与 $x^{t}$ 的互信息最大化 [44]。自聚类损失项公式如下:
$$
I\left(\mathrm{p}^{t};x^{t}\right)=H\left(\bar{\mathrm{p}^{t}}\right)-\frac{1}{n_{t}}\sum_{i=1}^{n_{t}}H\left(\mathrm{p}_{i}^{t}\right)
$$
$$
I\left(\mathrm{p}^{t};x^{t}\right)=H\left(\bar{\mathrm{p}^{t}}\right)-\frac{1}{n_{t}}\sum_{i=1}^{n_{t}}H\left(\mathrm{p}_{i}^{t}\right)
$$
where $\bar{\mathrm{p}^{t}}=\mathbb{E}\left[\mathrm{p}^{t}\right]$ . The self-clustering loss encourages the model to learn clustered target features.
其中 $\bar{\mathrm{p}^{t}}=\mathbb{E}\left[\mathrm{p}^{t}\right]$。自聚类损失促使模型学习聚类目标特征。
Take classification loss (Eq. 12), domain discrimination loss (Eq. 13), patch discrimination loss (Eq. 2), and selfclustering loss (Eq. 14) together, the overall objective function is therefore formulated as:
分类损失(Eq. 12)、域判别损失(Eq. 13)、图像块判别损失(Eq. 2)和自聚类损失(Eq. 14)共同构成了整体目标函数:
$$
L_{c l c}\left(x^{s},y^{s}\right)+\alpha L_{d i s}\left(x,y^{d}\right)+\beta L_{p a t}(x,y^{d})-\gamma I\left(p^{t};x^{t}\right)
$$
$$
L_{c l c}\left(x^{s},y^{s}\right)+\alpha L_{d i s}\left(x,y^{d}\right)+\beta L_{p a t}(x,y^{d})-\gamma I\left(p^{t};x^{t}\right)
$$
where $\alpha,\beta$ , and $\gamma$ are the hyper parameters that control the influence of each term on the overall function.
其中 $\alpha,\beta$ 和 $\gamma$ 是控制各项对整体函数影响的超参数。
4. Experiments
4. 实验
4.1. Dataset and Setting
4.1. 数据集与实验设置
We evaluate our proposed FFTAT on widely used UDA benchmarks, including Office-31 [30], Office-Home [36], Visda-2017 [27], and DomainNet [26]. Office-31 contains 4,652 images of 31 categories collected from three domains, i.e., Amazon (A), DSLR (D), and Webcam (W). Office-Home has 15,500 images of 65 classes from four domains: Artistic (Ar), Clip Art (Cl), Product $(\mathrm{Pr})$ , and Real-world (Re) images. Visda2017 is a simulation-to-real dataset, with more than 0.2 million images in 12 classes. DomainNet dataset has the largest scale containing around 0.6 million images of 345 classes in 6 domains: Quickdraw (qdr), Real (rel), Sketch (skt), Clipart (clp), Infograph (inf), Painting (pnt).
我们在广泛使用的无监督域适应 (UDA) 基准上评估提出的 FFTAT 方法,包括 Office-31 [30]、Office-Home [36]、Visda-2017 [27] 和 DomainNet [26]。Office-31 包含从三个域(Amazon (A)、DSLR (D) 和 Webcam (W))收集的 31 个类别共 4,652 张图像。Office-Home 包含来自四个域(Artistic (Ar)、Clip Art (Cl)、Product $(\mathrm{Pr})$ 和 Real-world (Re))的 65 个类别共 15,500 张图像。Visda2017 是一个仿真到真实场景的数据集,包含 12 个类别超过 20 万张图像。DomainNet 数据集规模最大,涵盖 6 个域(Quickdraw (qdr)、Real (rel)、Sketch (skt)、Clipart (clp)、Infograph (inf)、Painting (pnt))中 345 个类别约 60 万张图像。
Table 3. Comparison with SOTA methods on DomainNet. The best performance is marked in bold. PMTrans takes advantage of a different data partitioning strategy. Our FFTAT adheres to the same data partitioning strategy as SSRT and CDTrans.
表 3. DomainNet上与SOTA方法的对比。最佳性能以粗体标出。PMTrans采用了不同的数据划分策略,而我们的FFTAT遵循与SSRT和CDTrans相同的数据划分策略。
| ResNet101 | clp | inf | pnt | ipb | rel | skt | Avg. | MIMTFL | clp | inf | pnt | pb | rel | skt Avg. | CGDM [8] | clp | inf | pnt | ipb | rel | skt | Avg. | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [13] | 19.3 | 37.5 | 11.1 | 52.2 41.1 | 32.2 | [10] clp | - 15.1 | 35.6 | 10.7 | 51.5 | 43.1 | 31.2 | clp | 16.9 | 35.3 | 10.8 | 53.5 | 36.9 | 30.7 | |||||
| clp inf | - 30.2 | - | 31.2 | 3.6 | 44.0 | 27.9 | 27.4 | inf | 32.1 - | 31.0 | 2.9 | 48.5 | 31.0 | 29.1 | inf | 27.8 | - | 28.2 | 4.4 | 48.2 | 22.5 | 26.2 | ||
| pnt | 39.6 | 18.7 | - | 4.9 | 54.5 | 36.3 | 30.8 | pnt | 40.1 | 14.7 | 4.2 | 55.4 | 36.8 | 30.2 | pnt | 37.7 | 14.5 | 4.6 | 59.4 | 33.5 | 30.0 | |||
| pb | 7.0 | 0.9 | 1.4 | - | 4.1 | 8.3 | 4.3 | pb | 18.8 3.1 | 5.0 | - | 16.0 | 13.8 | 11.3 | pb | 14.9 | 1.5 | 6.2 | 10.9 | 10.2 | 8.7 | |||
| rel | 48.4 | 22.2 | 49.4 | 6.4 | 38.8 | 33.0 | rel | 48.5 | 19.0 | 47.6 | 5.8 | 39.4 | 22.1 | rel | 49.4 | 20.8 | 47.2 | 4.8 | 38.2 | 32.0 | ||||
| skt | 46.9 | 15.4 | 37.0 | 10.9 | 47.0 | - | 31.4 | skt | 51.7 | 16.5 | 40.3 | 12.3 | 53.5 | 34.9 | skt | 50.1 | 16.5 | 43.7 | 11.1 | 55.6 | 35.4 | |||
| Avg. | 34.4 | 15.3 | 31.3 | 7.4 | 40.4 | 30.5 | 26.6 | Avg. | 38.2 13.7 | 31.9 | 7.2 | 45.0 | 32.8 | 28.1 | Avg. | 36.0 | 14.0 | 32.1 | 7.1 | 45.5 | 28.3 | 27.2 |
| MDD+SCDA | | clp | inf | pnt | pb | rel | skt Avg. | | ViT-Base | clp inf | pnt | | pb | rel skt | Avg. | | CDTrans | clp | inf | | | | | | |
|-----------|-----|-----|-----|----|-----|---------|-|----------|-------|-----|----|----|--------|------|-|--------|-----|-----|-----|-----|-----|-----|------|
| [19] clp | | | 20.4 | | | | | | [7] | | | | | | | | [43] | | | pnt | pb | rel | skt | Avg. |
| inf | | 32.7 | | 43.3 34.5 | 15.2 6.3 | 59.3 47.6 | 46.5 29.2 | 36.9 30.1 | clp inf | 51.4 | 27.2 | 53.1 49.3 | 13.2 4.0 | 71.2 | 53.3 41.1 | 43.6 42.4 | clp inf | 57.0 | 29.4 | 57.2 | 26.0 | 72.6 | 58.1 | 48.7 |
| pnt | | 46.4 | 19.9 | | 8.1 | 58.8 | 42.9 | 35.2 | pnt | 53.1 25.6 | - | | 4.8 | 66.3 70.0 | 41.8 39.1 | | pnt | 62.9 | 27.4 | 54.4 | 12.8 | 69.5 | 48.4 | 48.4 |
| pb | 31.1 | | 6.6 | 18.0 | = | 28.8 | 22.0 | 21.3 | pb | 30.5 4.5 | | 16.0 | | 27.0 | 19.3 19.5 | | pb | 44.6 | 8.9 | - | 15.8 | 72.1 | 53.9 | 46.4 |
| rel | | 55.5 23.7 | | 52.9 | 9.5 | | 45.2 | 37.4 | rel | 58.4 29.0 | | 60.0 | 6.0 | | 45.8 39.9 | | rel | 66.2 | 31.0 | 29.0 61.5 | | 42.6 | 28.5 | 30.7 |
| skt | | 55.8 20.1 | | 46.5 | 15.0 | 56.7 | | 38.8 | skt | 63.9 23.8 | 52.3 | | 14.4 | 67.4 | 44.4 | | skt | 69.0 | 29.6 | 59.0 | 16.2 27.2 | 72.5 | 52.9 | 45.6 |
| Avg. | | 44.3 18.1 | | 39.0 | 10.8 | 50.2 | 37.2 | 33.3 | Avg. | 51.5 22.0 | | 46.1 | 8.5 | 60.4 40.3 | 38.1 | | Avg. | 59.9 | 25.3 | 52.2 | 19.6 | 65.9 | 48.4 | 51.5 45.2 |
| SSRT [43] | clp inf | | pnt | pb | rel | skt | Avg. | PMTrans* | clp | inf | pnt | pb | rel | skt | Avg. | FFTAT | clp | inf | pnt | | | | | | |
|-----------|---------|-----|-----|----|-----|-----|------|----------|-----|-----|-----|----|-----|-----|------|-------|-----|-----|-----|-----|-----|-----|------|
| clp | 33.8 | | 60.2 | 19.4 | 75.8 | 59.8 | 49.8 | [53] | | 34.2 | 62.7 | 32.5 | | 63.7 | 54.5 | (ours) clp | | 39.4 | 70.3 | | pb 25.5 | rel 81.9 | skt 70.9 | Avg. 57.6 |
| inf | 55.5 - | | 54.0 | 9.0 | 68.2 | 44.7 | 46.3 | clp inf | 67.4 | | 61.1 | 22.2 | 79.3 78.0 |
Table 4. Comparison with SOTA methods on Office-31. The best performance is marked in bold. The methods above the horizontal line are CNN-based methods, while the methods below the horizontal line are ViT-based methods.
表 4: Office-31数据集上与SOTA方法的对比。最佳性能以粗体标注。横线上方为基于CNN的方法,横线下方为基于ViT的方法。
| 方法 | A→W | D→W | W→D | A→D | D→A | W→A | 平均 |
|---|---|---|---|---|---|---|---|
| ResNet-50[13] DANN[9] | 68.4 82.0 | 96.7 96.9 | 99.3 68.9 99.1 79.7 | 62.5 68.2 | 60.7 67.4 | 76.1 82.2 | |
| rRGrad+CAT[5] | 94.4 | 98.0 | 100.0 90.8 99.8 | 72.2 | 70.2 | 87.6 | |
| SAFN+ENT[42] | 90.1 95.7 | 98.6 98.7 | 90.7 100.0 | 73.0 | 70.2 | 87.1 | |
| CDAN+TN[38] | 94.0 93.2 | 73.4 | 74.2 | 89.3 | |||
| TAT[22] | 92.5 | 99.3 | 100.0 | 73.1 | 72.1 | 88.4 | |
| SHOT[20] | 90.1 | 98.4 | 99.9 | 94.0 | 74.7 74.3 | 88.6 | |
| MDD+SCDA[19] | 95.3 | 99.0 | 100.0 | 95.4 | 77.2 75.9 | 90.5 | |
| ViT[7] | 91.2 | 99.2 | 100.0 | 93.6 | 80.7 80.7 | ||
| TVT[44] | 96.4 | 99.4 | 100.0 | 91.1 | |||
| 96.7 | 99.0 | 96.4 | 84.9 86.1 | 93.9 | |||
| CDTrans[43] | 100.0 | 97.0 81.1 | 81.9 | 92.6 | |||
| SSRT[34] | 97.7 | 99.2 | 100.0 | 98.6 83.5 | 82.2 | 93.5 | |
| PMTrans[53] | 99.5 | 99.4 | 100.0 | 99.8 86.7 | 86.5 | 95.3 | |
| FFTAT (ours) | 97.6 | 99.2 | 100.0 | 97.8 | 90.2 91.0 | 96.0 |
We use the ViT-base with a $16\times16$ patch size (ViT-B/16) [7] [32], pre-trained on ImageNet [29], as the backbone. We use minibatch Stochastic Gradient Descent (SGD) optimizer [28] with a momentum of 0.9 as the optimizer. The batch size is set to 16 for Office-31, Office-Home, Visda2017, and DomainNet by default. We initialized the learning rate as 0 and linearly warm up to 0.06 after 500 training steps then a cosine decay strategy is applied. For small to middle-scale datasets Office-31 and Office-Home, the training step is set to 5000. For large-scale datasets Visda-2017 and DomainNet, the training step is set to 20000. The hyper parameters $\alpha$ , $\beta$ , and $\gamma$ are set to [1.0, 0.01, 0.1] for Office-31 and Office-Home, and to [0.1, 0.1, 0.1] for Visda2017 and DomainNet by default, but can be adjusted for optimal performance on specific tasks.
我们采用基于 $16\times16$ 图像块大小的 ViT-base (ViT-B/16) [7][32] 作为主干网络,该模型已在 ImageNet [29] 上完成预训练。优化器选用小批量随机梯度下降 (Stochastic Gradient Descent, SGD) [28],动量参数设为 0.9。默认情况下,Office-31、Office-Home、Visda2017 和 DomainNet 数据集的批量大小均设置为 16。学习率初始化为 0,经过 500 次训练步数后线性预热至 0.06,随后采用余弦衰减策略。对于中小规模数据集 Office-31 和 Office-Home,训练步数设为 5000;对于大规模数据集 Visda-2017 和 DomainNet,训练步数设为 20000。超参数 $\alpha$、$\beta$ 和 $\gamma$ 在 Office-31 和 Office-Home 上默认设为 [1.0, 0.01, 0.1],在 Visda2017 和 DomainNet 上默认设为 [0.1, 0.1, 0.1],但可根据具体任务需求调整以获得最佳性能。
4.2. Results
4.2. 结果
Table 1 presents the evaluation results on the OfficeHome dataset. The methods listed above the horizontal line are based on CNN architectures, while those below the horizontal line utilize Transformer architectures. Compared to its predecessor, TVT [44], which was the first to adopt the Transformer architecture for UDA, our proposed method, FFTAT, achieves a significant performance improvement of $7.8%$ . FFTAT represents the first work to surpass an average accuracy exceeding $90%$ on the Office-Home dataset. Additionally, it is noteworthy that FFTAT outperforms existing methods in each domain adaptation task as well as in the average results by a considerable margin.
表 1: 展示了 OfficeHome 数据集上的评估结果。水平线上方列出的方法基于 CNN (Convolutional Neural Network) 架构,而下方的方法采用 Transformer 架构。与首次将 Transformer 架构应用于无监督域适应 (UDA) 的 TVT [44] 相比,我们提出的 FFTAT 方法实现了 $7.8%$ 的显著性能提升。FFTAT 是首个在 Office-Home 数据集上平均准确率超过 $90%$ 的工作。此外值得注意的是,FFTAT 在每个域适应任务以及平均结果上都以较大优势超越了现有方法。

Figure 3. The learned transfer ability graphs (adjacency matrices) from randomly selected domain adaptation tasks. The weight increases with the intensity of red colors while decreasing with the intensity of blue colors.
图 3: 从随机选取的领域自适应任务中学习到的迁移能力图(邻接矩阵)。权重随红色加深而增加,随蓝色加深而减小。
Table 2 shows results on the Visda-2017 dataset. We can observe that the FFTAT achieves impressive performance on average results and in most adaptation tasks. Compared to TVT, FFTAT increased performance by $9.9%$ . Even when compared to the latest work, PMTrans [53], our method outperforms it in every task, and by $5.8%$ in average accuracy. It is worth noting that PMTrans utilizes the more powerful architecture of S win Transformer [23] with pre-trained weights from ImageNet-21K. FFTAT is the first work to achieve an average accuracy exceeding $93%$ on the Visda-2017 dataset, where the performances of other methods are below $89%$ . FFTAT also achieves SOTA results on Office-31, with an average accuracy of $96%$ as shown in Table 4.
表 2 展示了 Visda-2017 数据集上的结果。我们可以观察到,FFTAT 在平均结果和大多数适应任务中均取得了令人印象深刻的性能。与 TVT 相比,FFTAT 将性能提升了 $9.9%$。即使与最新工作 PMTrans [53] 相比,我们的方法在每项任务中都优于它,平均准确率高出 $5.8%$。值得注意的是,PMTrans 采用了更强大的 Swin Transformer [23] 架构,并使用了 ImageNet-21K 的预训练权重。FFTAT 是首个在 Visda-2017 数据集上平均准确率超过 $93%$ 的工作,而其他方法的性能均低于 $89%$。FFTAT 在 Office-31 上也取得了 SOTA 结果,如表 4 所示,其平均准确率达到 $96%$。
Experimental results on DomainNet, the largest dataset, are presented in Table 3. The performance of the vanilla ViT baseline, standing at $38.1%$ , is far from satisfactory. In contrast, FFTAT achieves significant improvements across all domain adaptation tasks, with an average accuracy of $51.9%$ . FFTAT surpasses recent Transformer-based methods like CDTrans and SSRT, and remains competitive with the latest work, PMTrans 1.
在最大的数据集DomainNet上的实验结果如表3所示。普通ViT基线的性能仅为38.1%,远不能令人满意。相比之下,FFTAT在所有领域适应任务中都取得了显著提升,平均准确率达到51.9%。FFTAT超越了近期基于Transformer的方法如CDTrans和SSRT,并与最新工作PMTrans 1保持竞争力。
Overall, the results highlight the superior performance of Transformer-based over CNN-based models, owing to their robust transferable feature representations. Our FFTAT achieves state-of-the-art results across these benchmarks, demonstrating its effectiveness for UDA tasks.
总体而言,这些结果突显了基于Transformer的模型优于基于CNN模型的表现,这归功于其强大的可迁移特征表示能力。我们的FFTAT在这些基准测试中取得了最先进的成果,证明了其在无监督领域自适应(UDA)任务中的有效性。
4.3. Learned Transfer ability Graphs
4.3. 学习迁移能力图
The Transfer ability Aware Transformer Layer dynamically learns transfer ability graphs in a data driven manner. To gain insights into the identified patterns, we visualize the adjacency matrices of the learned transfer ability graphs from two randomly selected domain adaptation tasks across Office-31, Office-Home, and DomainNet datasets. Since the Visda-2017 dataset only consists of two domains (simulation-to-real), there is a single learned transfer ability graph for Visda-2017. The selected transfer ability graphs are shown in Fig. 3. We observe variations in learned transferability patterns for different domain adaptation tasks. For instance, in the $\mathrm{Pr}$ to Cl domain adaptation task within the Office-Home dataset, the red-colored area appears large and dense, indicating a significant number of highly transferable patches. Conversely, in the Ar to Pr domain adaptation task, the red-colored area appears sparse and less intense compared to the $\mathrm{Pr}$ to Cl task, suggesting fewer highly transferable patches.
迁移能力感知Transformer层以数据驱动的方式动态学习迁移能力图。为深入理解所识别的模式,我们从Office-31、Office-Home和DomainNet数据集中随机选取两个域适应任务,可视化其学习到的迁移能力图的邻接矩阵。由于Visda-2017数据集仅包含两个域(模拟到真实),因此该数据集仅对应单一迁移能力图。所选迁移能力图如图3所示。我们观察到不同域适应任务学习到的可迁移性模式存在差异:例如在Office-Home数据集的Pr到Cl域适应任务中,红色区域大而密集,表明存在大量高可迁移性图像块;而在Ar到Pr任务中,相较于Pr到Cl任务,红色区域稀疏且强度较低,说明高可迁移性图像块较少。
Table 5. Ablation study on the influence of feature fusion and transfer ability graph-guided self-attention on model performance across four datasets.
表 5: 特征融合和迁移能力图引导自注意力对四个数据集模型性能影响的消融研究
| Office-31 | Office-Home | eVisda2017 | DomainNet | ||
|---|---|---|---|---|---|
| FFTAT | 96.0 | 91.4 | 93.8 | 51.9 | |
| w/oFF | 92.7 | 84.5 | 84.5 | 43.6 | |
| w/oTG-SA | 95.8 | 90.6 | 93.5 | 49.5 |
4.4. Ablation Studies
4.4. 消融实验
We conducted comprehensive ablation studies to assess the impact of the two key components, TG-SA and FF, on model performance across these four datasets. Each component was removed individually to isolate its effect. It is noteworthy that removing the transfer ability graph-guiding mechanism restores vanilla self-attention in the regular ViT. Table 5 reports the average accuracy across all tasks in each dataset. On average, the removal of Feature fusion or Transferability Graph Guidance leads to performance degradation. These findings demonstrate that each component con- tributes to the final performance of FFTAT.
我们对两个关键组件(TG-SA和FF)在这四个数据集上对模型性能的影响进行了全面的消融研究。通过单独移除每个组件来隔离其影响。值得注意的是,移除迁移能力图引导机制会恢复常规ViT中的原始自注意力机制。表5报告了各数据集中所有任务的平均准确率。平均而言,移除特征融合或可迁移性图引导均会导致性能下降。这些结果表明每个组件都对FFTAT的最终性能有所贡献。
5. Conclusion
5. 结论
In this study, we introduce FFTAT, a novel ViT-based solution tailored for unsupervised domain adaptation. FFTAT leverages transfer ability graphs to guide self-attention (TGSA) within the Vision Transformer framework, enhancing the emphasis on highly transferable features. and the Feature Fusion (FF) operation to intentionally perturb embeddings, thereby promoting robust feature learning. Extensive experiments demonstrate the efficacy of the Transfer a bility Graph Guided Self-Attention and the Feature Fusion, paving the way for further advancements in this field.
在本研究中,我们提出了FFTAT,这是一种基于Vision Transformer (ViT)的新型解决方案,专为无监督域适应而设计。FFTAT利用可迁移性图来指导Vision Transformer框架中的自注意力机制(TGSA),从而加强对高可迁移特征的关注,并通过特征融合(FF)操作有意扰动嵌入,进而促进鲁棒特征学习。大量实验证明了可迁移性图引导自注意力和特征融合的有效性,为该领域的进一步发展铺平了道路。