Breaking Free Transformer Models: Task-specific Context Attribution Promises Improved General iz ability Without Fine-tuning Pre-trained LLMs
突破Transformer模型限制:任务特定上下文归因承诺无需微调预训练大语言模型即可提升泛化能力
Abstract
摘要
Fine-tuning large pre-trained language models (LLMs) on particular datasets is a commonly employed strategy in Natural Language Processing (NLP) classification tasks. However, this approach usually results in a loss of models’ general iz ability. In this paper, we present a framework that allows for maintaining general iz ability, and enhances the performance on the downstream task by utilizing task-specific context attribution. We show that a linear transformation of the text representation from any transformer model using the task-specific concept operator results in a projection onto the latent concept space, referred to as context attribution in this paper. The specific concept operator is optimized during the supervised learning stage via novel loss functions. The proposed framework demonstrates that context attribution of the text representation for each task objective can improve the capacity of the disc rim in at or function and thus achieve better performance for the clas- sification task. Experimental results on three datasets, namely HateXplain, IMDB reviews, and Social Media Attributions, illustrate that the proposed model attains superior accuracy and general iz ability. Specifically, for the non-fine-tuned BERT on the HateXplain dataset, we observe $8%$ improvement in accuracy and $10%$ improvement in F1-score. Whereas for the IMDB dataset, fine-tuned state-of-the-art XLNet is outperformed by $1%$ for both accuracy and F1-score. Furthermore, in an out-of-domain cross-dataset test, DistilBERT fine-tuned on the IMDB dataset in conjunction with the proposed model improves the F1-score on the HateXplain dataset by $7%$ . For the Social Media Attributions dataset of YouTube comments, we observe $5.2%$ increase in F1- metric. The proposed framework is implemented with PyTorch and provided open-source on GitHub1.
在自然语言处理(NLP)分类任务中,对预训练大语言模型(LLM)进行特定数据集的微调是常用策略。然而,这种方法通常会导致模型泛化能力下降。本文提出一个既能保持泛化能力,又能通过任务特定上下文归因提升下游任务性能的框架。我们证明:使用任务特定概念算子对Transformer模型的文本表示进行线性变换,可将其投影到潜在概念空间(本文称为上下文归因)。该特定概念算子通过新型损失函数在监督学习阶段进行优化。实验表明,针对每个任务目标的文本表示上下文归因能提升判别函数能力,从而改善分类任务性能。在HateXplain、IMDB影评和社交媒体归因三个数据集上的实验结果显示,所提模型获得了更优的准确率和泛化能力。具体而言:
- 未微调BERT在HateXplain数据集上准确率提升8%,F1值提升10%
- 在IMDB数据集上,微调后的最先进XLNet模型被我们的方法在准确率和F1值上均超越1%
- 跨数据集测试中,基于IMDB微调的DistilBERT结合本模型使HateXplain的F1值提升7%
- YouTube评论的社交媒体归因数据集上F1指标提升5.2%
本框架采用PyTorch实现并在GitHub开源。
Introduction
引言
Currently, the domain of Language Models is one of the most rapidly developing areas of machine learning. Transformer architecture (Vaswani et al. 2017) has proven itself as a state-of-the-art approach towards the absolute majority of Natural Language Processing (NLP) domains (Maia et al. 2021). A particular strength of the language models is their general iz ability (Swamy, Jamatia, and Gamback 2019), (Blackledge and Atapour-Abarghouei 2021).
目前,语言模型领域是机器学习中发展最迅速的领域之一。Transformer架构 (Vaswani et al. 2017) 已被证明是应对绝大多数自然语言处理 (NLP) 领域任务的最先进方法 (Maia et al. 2021)。语言模型的一个显著优势在于其泛化能力 (Swamy, Jamatia, and Gamback 2019), (Blackledge and Atapour-Abarghouei 2021)。
By pre-training the model on a big chunk of semi-structured data and then fine-tuning with task-specific labeled data, we may obtain state-of-the-art performance in the problems of classification, regression, language translation, and more. However, the important note here is that the most crucial pre-training stage is usually costly, and repeating it for every new task is computationally inefficient. At the same time, the fine-tuning only downstream task specific head of pretrained models is time efficient and requires much less labeled data, preserving models’ general iz ability. On the other hand, this part of the pipeline might be a bottleneck to the process. Usually, single fine-tuning does not produce results on par with the complete model adaptation via training (Peters, Ruder, and Smith 2019). Explaining and adapting the results to the various downstream tasks is also tricky. To avoid any confusion in this paper, we are going to use term ”training” or ”model adaptation” referring to the process of full model retraining (adapting all of the weights), while for the head-only adaptation we are going to use term ”finetuning”. Fine-tuning is usually easier, faster and requires less data.
通过在大量半结构化数据上进行预训练,再用任务特定的标注数据进行微调,我们可以在分类、回归、语言翻译等问题上获得最先进的性能。但需要注意的是,最关键的预训练阶段通常成本高昂,且为每个新任务重复这一过程在计算上是低效的。与此同时,仅对预训练模型下游任务特定的头部进行微调则更省时,且所需标注数据量更少,同时保持了模型的泛化能力。另一方面,这一环节可能成为流程中的瓶颈。通常,单次微调的效果无法与完整模型训练(Peters、Ruder 和 Smith 2019)相媲美。将结果解释并适配到各种下游任务也颇具挑战性。为避免歧义,本文中"training"或"model adaptation"指代全模型重新训练(调整所有权重)的过程,而仅调整模型头部时则使用"finetuning"这一术语。微调通常更简单、更快速且所需数据更少。
As a potential solution to the problem, we propose a novel method of model fine-tuning. We call this approach the Space Model. The whole idea is to replace the classification head of the transformer model with a set of conceptual operators, projecting the contextual embeddings of the model to the set of concept spaces referred to as context attributions. The Space model is an additional model framework that plays the role of the pipeline’s original downstream task head. In this work, we limit ourselves to the review of the classification capabilities of the proposed approach, but generally, this is not a limitation to the technique in any way.
作为该问题的潜在解决方案,我们提出了一种新颖的模型微调方法。我们将这种方法称为空间模型 (Space Model)。其核心思想是用一组概念运算符替换 Transformer 模型的分类头,将模型的上下文嵌入投射到被称为上下文归因的概念空间集合中。空间模型是一个额外的模型框架,承担着原流程下游任务头的作用。在本工作中,我们仅针对所提方法的分类能力进行评估,但这并非该技术本身的局限性。
The model is designed in a way that a set of concepts describes different classes; such a set is called the “context attribution”. It is worth noting that we do not limit these concepts in terms of overlapping. Some context attributions might overlap if that makes sense in terms of the problem solved. This paper reviews one such task where overlapping context attributions are entirely appropriate. What we would like to avoid is allowing multiple concepts to converge to the same representation. For that type of regular iz ation, we introduce an additional loss called Intra-Space loss. Its goal is to make sure concepts in the context attribution are disjoint.
模型设计采用一组概念来描述不同类别,这类集合称为"上下文归因"。值得注意的是,我们并未限制这些概念的重叠性。在解决特定问题时,某些上下文归因出现重叠是合理的。本文探讨的任务就完全适用重叠的上下文归因。我们力求避免的是多个概念收敛到相同表征的情况。为此,我们引入了一种称为"空间内损失"的额外损失函数,其目的是确保上下文归因中的概念保持互斥。
As was stated previously, the Space Model is an external framework with a set of operators on top of the transformer model. Generally speaking, this is not limited to the transformer architecture either. Potentially, any technique that can produce embeddings may be used as the Space model’s base model, such as Word2Vec (Mikolov et al. 2013), Glove (Pennington, Socher, and Manning 2014), or RNN (Rumelhart, Hinton, and Williams 1986), (Ghosh et al. 2016). Further in this paper, whenever we refer to the base model, we mean the model that produces the embeddings for the space model. Some of the base models tested in this paper include BERT (Devlin et al. 2019), DistilBERT (Sanh et al. 2019), and XLNet (Yang et al. 2019).
如前所述,空间模型(Space Model)是一个外部框架,在Transformer模型之上定义了一组运算符。广义而言,这种架构并不局限于Transformer。理论上任何能生成嵌入(embedding)的技术都可以作为空间模型的基础模型,例如Word2Vec (Mikolov et al. 2013)、Glove (Pennington, Socher and Manning 2014)或RNN (Rumelhart, Hinton and Williams 1986)、(Ghosh et al. 2016)。本文后续提到基础模型(base model)时,均指为空间模型生成嵌入的模型。本文测试的部分基础模型包括BERT (Devlin et al. 2019)、DistilBERT (Sanh et al. 2019)和XLNet (Yang et al. 2019)。
The benchmarking and evaluation of the proposed solution are done with various configurations of the base models and across multiple datasets. We test performance for the specific task, fine-tuning the Space model for that particular downstream task, and we also test the performance of the model on the task that is related to the original semantically; however, it uses different data. The baseline for the comparison is mainly the performance of the original base model fine-tuned for the downstream task. During the experiments, we prove that besides an evident performance boost, the Space model also stabilizes the training process and generalizes better for the semantically close tasks. We also prove that the space model can achieve a significant performance boost even when using a smaller number of parameters than the base model fine-tuned on the downstream task.
对所提解决方案的基准测试和评估通过基础模型的不同配置及多个数据集完成。我们测试了特定任务的性能,针对该下游任务微调Space模型,同时也测试了模型在与原任务语义相关但使用不同数据的任务上的表现。对比基线主要是针对下游任务微调的原始基础模型性能。实验证明,除显著性能提升外,Space模型还能稳定训练过程,并对语义相近任务具有更好的泛化能力。我们还证实,即使使用比下游任务微调基础模型更少的参数,Space模型仍能实现显著的性能提升。
The datasets used for benchmarking are HateXplain (Mathew et al. 2021), IMDB reviews sentiment dataset (Maas et al. 2011), and Social Media Attributions dataset of YouTube comments, related to Chennai water crisis (Sarkar et al. 2020). The main reason for choosing corresponding datasets is that HateXplain is considered a very complex dataset, with imbalanced data, and labels “offensive” and “hateful” are conceptually very close. On the other hand, IMDB sentiment reviews are a semantically close dataset to the former one and are reasonably easily interpret able. Such a relation is essential since we would like to test the general iz ability of the proposed technique. Besides, in the Social Media Attributions paper, the authors apply a very similar approach to the one proposed in this paper, however, with additional manual labeling of the concepts and multiple runs. We would like to show that our approach achieves superior performance without additional manual labeling and via a single pass.
用于基准测试的数据集包括HateXplain (Mathew等人, 2021)、IMDB影评情感数据集 (Maas等人, 2011) 以及与金奈水危机相关的YouTube评论社交媒体归因数据集 (Sarkar等人, 2020)。选择这些数据集的主要原因是:HateXplain被认为是一个非常复杂的数据集,数据不平衡,且"冒犯性"和"仇恨性"标签在概念上非常接近;IMDB情感评论数据集在语义上与前者接近且易于解释,这种关联性对测试所提技术的泛化能力至关重要。此外,在《社交媒体归因》论文中,作者采用了与本文非常相似的方法,但需要额外的人工概念标注和多次运行。我们旨在证明,我们的方法无需额外人工标注且只需单次运行即可实现更优性能。
The impact and novelty of this paper include:
本文的影响力和创新点包括:
• A novel framework for Language Model fine-tuning, which outperforms the baseline score of the base models such as BERT, DistilBERT, and XLNet
• 一种新型的大语言模型微调框架,其性能超越了BERT、DistilBERT和XLNet等基础模型的基准分数
Related work
相关工作
The task of effective fine-tuning is one of the main tasks in the modern NLP. Cheaper and faster results of great quality are very appealing and a current trend in the domain. However, we are sourcing the inspiration for our framework not only from the latest NLP findings. The core idea has a root in a Psychological Belief Attribution Theory (Bem 1972), (Spilka, Shaver, and Kirkpatrick 1985). The theory revolves around the idea of attribution of certain concepts with corresponding behavior patterns. The concepts (sometimes also referred to as factors) may be external and internal. These factors are usually related to personal beliefs, and they affect the decisions and behavior of an individual. Researchers have also classified people based on these factors (e.g., pessimistic attribution, optimistic attribution, hostile attribution). We try to apply the same idea to language modeling, attributing certain concepts with class labels. In general, the idea of measuring and researching the belief attribution of language models is not novel. The authors of (Hase et al. 2023) have not only proved that certain language models possess the beliefs, but they have also provided metrics to measure such beliefs and a tool to update these beliefs, as well as visualization of beliefs graph.
有效微调任务是现代自然语言处理(NLP)的主要任务之一。以更低成本、更快速度获得高质量结果极具吸引力,也是当前领域的发展趋势。然而,我们框架的灵感来源不仅限于最新的NLP研究成果。其核心理念植根于心理学信念归因理论(Bem 1972)、(Spilka, Shaver, and Kirkpatrick 1985)。该理论围绕特定概念与相应行为模式的归因关系展开,这些概念(有时也称为因素)可分为外部和内部两类,通常与个人信念相关,并影响个体的决策和行为。研究者还基于这些因素对人进行分类(如悲观归因、乐观归因、敌意归因)。我们尝试将相同理念应用于语言建模,将特定概念归因于类别标签。总体而言,测量和研究语言模型的信念归因并非新概念。(Hase et al. 2023)的作者不仅证实了某些语言模型具有信念,还提供了测量这些信念的指标、更新信念的工具以及信念图的可视化方法。
It is very natural that semi-supervised solutions are mentioned when it comes to fine-tuning with the least resources. These also mainly include ensembling to achieve regularization when working with unsupervised data. One of the first such approaches addressing this issue is the COREG (Zhou and Li 2005). The technique uses two k-nearest-neighbor regressors with different distance metrics to label the data. The distance metric, in that case, would serve as the confidence label. This approach uses a fundamental idea that some features in some spaces are aligned with similar class labels and are further apart from the different class labels. This is an essential fact that is reused in the Space model.
在资源最少的情况下进行微调时,很自然会提到半监督解决方案。这些方法主要包括在使用无监督数据时通过集成实现正则化。最早解决这一问题的此类方法之一是COREG (Zhou and Li 2005)。该技术使用两个具有不同距离度量的k近邻回归器来标记数据。在这种情况下,距离度量将作为置信度标签。这种方法基于一个基本思想,即某些空间中的某些特征与相似的类标签对齐,并且与不同类标签的距离较远。这一基本事实在Space模型中得到了重用。
Another later technique involves minimal supervision for the labeling of the concept space, and then, based on this concept space, the model can autonomously label the unlabelled data (Chen tham arak shan et al. 2011). The key idea here is the knowledge extraction from the manually labeled concept space. It is claimed in the work that labeling a set of concepts and then running an algorithm on a set of documents to label them based on these supervised concepts is a superior technique. Our main takeaway from there is that we can extract knowledge from the supervised concept space for unlabelled data. Furthermore, what we would like to propose is testing if this concept space can help us make a prediction at the inference stage rather than during labeling.
另一种后续技术涉及对概念空间标记的最小监督,然后基于该概念空间,模型可以自主标记未标注数据 (Chen tham arak shan et al. 2011)。这里的核心思想是从人工标注的概念空间中提取知识。该研究声称,标注一组概念后,在文档集上运行算法以基于这些监督概念进行标注是一种更优的技术。我们的主要收获是,可以从监督概念空间中为未标注数据提取知识。此外,我们想提出的是测试这个概念空间是否能在推理阶段而非标注阶段帮助我们进行预测。
Social Media attributions in the Context of Water Crisis paper (Sarkar et al. 2020) is accomplishing a task very close to the one we are dealing with. However, unlike our approach, same as the previous one, their technique requires supervised sub-concept labeling. Besides, they measure the similarities between sub-concepts and the attention of the Language Model by feeding the sentence to the model multiple times, each time with a new sub-concept. However, they are using the similarity measure to find the concept subspace that best describes the given sentence and make the decision based on that. Our approach does this all in one pass and in an automated manner. We do not require manual labeling of the concept sub-spaces. We expect to learn them during the fine-tuning phase.
水资源危机背景下的社交媒体归因研究 (Sarkar et al. 2020) 所完成的任务与我们的工作非常接近。但与前述方法类似,他们的技术需要监督式的子概念标注。此外,他们通过多次将句子输入模型(每次附带一个新子概念)来测量子概念与大语言模型注意力机制之间的相似性。不过,他们使用相似性度量是为了找到最能描述给定句子的概念子空间,并据此做出决策。而我们的方法通过单次自动化处理即可完成全部流程,无需人工标注概念子空间——这些空间预期将在微调阶段自动学习获得。
In the paper on Interacting Conceptual Spaces (Bolt et al. 2019), the authors create all of the necessary mathematical background required to formulate the knowledge extraction process from the concept space. They converge the optimization task to the convex relations and prove that by means of optimizing the conceptual space and merging multiple concepts (or even spaces) together, one can extract new knowledge practical for the downstream task. They also provide an algebra language on how concepts are organized and interact and what it means mathematically when several concepts (or concept spaces) are combined. They put the conceptual representations in different compacts and explore the vectors’ behavior there. This is one of the ideas we are adopting in our paper, which we believe helps regularize the network. The concept spaces are encapsulated into a compact hypercube with the side 2. This is achieved due to the utilization of the tanh activation, which we will review in more detail in the methodology section.
在《交互式概念空间》(Bolt等人2019)的论文中,作者建立了从概念空间提取知识所需的全部数学基础。他们将优化任务收敛到凸关系,并证明通过优化概念空间及合并多个概念(甚至多个空间),可以提取对下游任务实用的新知识。论文还提出了一套代数语言,用于描述概念的组织与交互方式,以及多个概念(或概念空间)组合时的数学含义。作者将概念表征置于不同紧致集中,研究其中向量的行为特征。这正是我们本文借鉴的思路之一,我们认为这有助于网络的正则化。概念空间被封装在边长为2的超立方紧致集中,这是通过使用tanh激活函数实现的(我们将在方法论章节详细讨论)。
Methodology
方法
We are going to use the transformer architecture to extract the contextual embeddings from the input text. However, the methodology is not limited to transformers and may be reused with any architecture producing some kind of embeddings. In this specific research, we are focusing on the BERT family models (and some variations such as XLNet).
我们将使用Transformer架构从输入文本中提取上下文嵌入。不过,该方法并不局限于Transformer,任何能生成嵌入的架构都可复用。本项研究主要聚焦BERT系列模型(及XLNet等变体)。
Context Attribution
上下文归因
Context attribution - is a projection of a collection of contextual embeddings (vectors) or, simply, a matrix. Projection is done via a concept operator. When we train the model, we ensure that concept operators project disjoint concepts far away from similar concepts. We project the sentence in multiple context attributions and then find the similarity between the original sentence and the conceptual projections. This similarity tells how to classify the instance correctly. Note that in the actual implementation, we do not do the pairwise comparisons of the similarities or any other type of processing. Instead, we concatenate obtained projections into a single tensor and feed it to the classification layer. Thus, instead of manually defining the classification criteria, we specify it as a set of trainable parameters.
上下文归因 - 是对一组上下文嵌入(向量)或简单来说一个矩阵的投影。该投影通过概念算子实现。在训练模型时,我们会确保概念算子将不相交的概念投影到与相似概念相距较远的位置。我们将句子投影到多个上下文归因中,然后计算原始句子与概念投影之间的相似度。这种相似度指示了如何正确分类实例。需要注意的是,在实际实现中,我们不会进行相似度的两两比较或任何其他类型的处理。相反,我们将获得的投影连接成一个单一的张量,并将其输入到分类层中。因此,我们不是手动定义分类标准,而是将其指定为一组可训练参数。
Contextual word embeddings
上下文词嵌入
As it was already stated, the only assumption we impose on the base model is that it can create (contextual) embeddings from the input. Let $N_{s}$ be the sequence length, $d$ be the dimens ional it y of the contextual i zed embedding of the model. $E=[e_{1},e_{2},...,e_{N_{s}}]\in R^{N_{S}\times d}$ , $E_{N_{s}\times d}\in\overline{{R^{N_{S}\times d}}}$ is the contexual embedding matrix.
如前所述,我们对基础模型的唯一假设是它能够从输入生成(上下文相关的)嵌入向量。设 $N_{s}$ 为序列长度,$d$ 为模型上下文嵌入向量的维度。$E=[e_{1},e_{2},...,e_{N_{s}}]\in R^{N_{S}\times d}$ ,$E_{N_{s}\times d}\in\overline{{R^{N_{S}\times d}}}$ 为上下文嵌入矩阵。
In our research, we assume that the BERT-like models produce this embedding. So $N_{s}$ would be defined in the range between 256 and 512 (as a maximum sequence length used by the BERT architecture), and $d$ would be 768 for all of the base models and 1024 for the XLNet large.
在我们的研究中,我们假设类似BERT的模型生成这种嵌入。因此,$N_{s}$ 的定义范围在256到512之间(作为BERT架构使用的最大序列长度),而 $d$ 对于所有基础模型为768,对于XLNet大模型则为1024。
Conceptual projections
概念投影
For each of the classes in the classification problem, we assume a single concept space operator. This concept space operator transforms (projects) the contextual embeddings to the context attribution and produces new conceptual embeddings. The obtained representation of the embeddings is also called a latent representation. This representation’s dimensionality is defined as the latent space (target space for the projection). Let $m$ be the dimensionality of the latent space. We first define the projection operator as a matrix with trainable parameters: $\bar{P_{d\times m}}\in R^{d\times m}$ . Thus obtained projection matrix (context attribution) $C_{N_{s}\times m}\in R^{N_{s}\times m}$ .
对于分类问题中的每个类别,我们假设存在单一概念空间算子。该概念空间算子将上下文嵌入向量转换(投影)为上下文归因,并生成新的概念嵌入向量。所获得的嵌入表示也称为潜在表示,其维度被定义为潜在空间(投影的目标空间)。设 $m$ 为潜在空间的维度,我们首先将投影算子定义为含可训练参数的矩阵:$\bar{P_{d\times m}}\in R^{d\times m}$。由此得到的投影矩阵(上下文归因)为 $C_{N_{s}\times m}\in R^{N_{s}\times m}$。
Basically, context attribution is a new representation of the embeddings in the latent space, where the transformation operator is trained during fine-tuning. However, since we want to obtain proximity of the contextual i zed embedding to the context attribution, we introduce previously defined tanh operation as a similarity measure.
基本上,上下文归因(context attribution)是潜在空间中嵌入(embeddings)的一种新表示形式,其中变换算子(transformation operator)在微调(fine-tuning)过程中被训练。然而,由于我们希望获得上下文化嵌入(contextualized embedding)与上下文归因之间的接近性,因此引入了先前定义的tanh操作作为相似性度量。
$$
C_{N_{s}\times m}=t a n h(E_{N_{s}\times d}\times P_{d\times m})
$$
$$
C_{N_{s}\times m}=t a n h(E_{N_{s}\times d}\times P_{d\times m})
$$
tanh is applied element-wise. In that case, our conceptual matrix is a representation of how close a certain sentence is to the concept from the target context attribution (1 is very close, and -1 is from an orthogonal attribution). As an example, when we feed the word “terrible” to the context attribution that was predefined as “positive”, we expect to see $^-1$ in the conceptual representation and 1 for a word like “great”.
tanh 是逐元素应用的。在这种情况下,我们的概念矩阵表示某个句子与目标上下文归因 (context attribution) 中概念的接近程度 (1 表示非常接近,-1 表示来自正交归因)。例如,当我们向预定义为 "积极" 的上下文归因输入单词 "terrible" 时,我们期望在概念表示中看到 $^-1$,而对于像 "great" 这样的单词则期望看到 1。
The training objective of the model is, by taking into account multiple projections of the input embeddings, to find the projection that is most aligned with the sentence content.
模型的训练目标是通过考虑输入嵌入的多个投影,找到与句子内容最匹配的投影。
The similarity measure we are using is a slight modification of the cosine similarity, where normalizing the value by the vectors’ norms is replaced with the tanh.
我们使用的相似度度量是对余弦相似度的轻微修改,其中用tanh替代了向量范数的归一化。
$$
t a n h(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}
$$
$$
t a n h(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}
$$
Similarly to the original paper introducing LSTM (Hochreiter and Schmid huber 1997) , we use tanh to control the flow of the information in the network. It squashes the range, centers the values around zero, and introduces nonlinearity. This has also proven to be an excellent regularization technique, which reduces the instability, improves models’ general iz ability, and improves the results. This aspect is discussed in more detail in the results section.
与原论文引入LSTM (Hochreiter and Schmidhuber 1997) 类似,我们使用tanh函数控制网络中的信息流动。该函数能压缩数值范围、使值域集中在零附近并引入非线性。实践表明这也是一种优秀的正则化技术,可降低不稳定性、提升模型泛化能力并改善结果。具体分析详见结果章节。
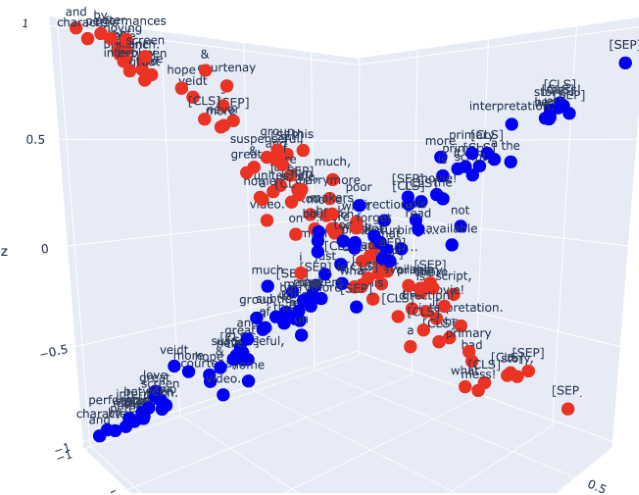
Figure 1: 3D projection of the space embeddings for the 2-class classification. After projecting the sentence onto different concept spaces, we expect these projections to be orthogonal if the classes are completely divergent. For the case between positive and negative sentiment, we expect that positive class projection would be orthogonal to the negative class projection.
图 1: 二分类任务中空间嵌入的三维投影。当句子被投射到不同概念空间时,若类别完全相异,我们预期这些投影应保持正交。以情感分析中的正负极性为例,正类投影应与负类投影呈现正交关系。
As a good side-effect of the tanh we add additional nonlinearity and squashing effect to the model. Thus, no additional normalization of values is required. Besides, we shrink our problem to the compact (hypercube with side 2, from -1 to 1). In Figure 1, one can find a benefit from such an approach. We can now easily interpret the outcome of the binary classification model. The visualization provided is the contextual embedding of the BERT model into 3- dimensional context attribution space for the IMDB classification task (this is done for test examples, so the model is not overfitted, and what we clearly see is the orthogonality of the negative and positive sentiment concepts).
作为 tanh 的一个良好副作用,我们为模型增加了额外的非线性和压缩效果。因此,无需对值进行额外归一化。此外,我们将问题缩小到紧凑空间 (边长为 2 的超立方体,范围从 -1 到 1)。在图 1 中,可以看到这种方法的优势。现在我们可以轻松解释二元分类模型的结果。提供的可视化是将 BERT 模型的上下文嵌入映射到 3 维上下文归因空间,用于 IMDB 分类任务 (这是针对测试样本完成的,因此模型没有过拟合,我们能清晰看到负面和正面情感概念的正交性)。
According to our definition, every target class has a unique context attribution for itself. So for $n$ classes classification problem:
根据我们的定义,每个目标类都有其独特的上下文归因。因此对于 $n$ 个类别的分类问题:
$$
C_{N_{s}\times m}^{i}=t a n h(E_{N_{s}\times d}\times P_{d\times m}^{i})
$$
$$
C_{N_{s}\times m}^{i}=t a n h(E_{N_{s}\times d}\times P_{d\times m}^{i})
$$
for $i\leq n$ . Where $C^{i}$ and $P^{i}$ are namely $i$ -th context attribution and concept projection operator.
对于 $i\leq n$ ,其中 $C^{i}$ 和 $P^{i}$ 分别是第 $i$ 个上下文归因 (context attribution) 和概念投影算子 (concept projection operator)。
Classification
分类
After we have projected the embeddings to all of the context attributions, we need to perform classification. In that case, since every projection is a set of vectors (where each vector is a conceptual embedding with latent size $m$ ) we would find the centroid of this representation for each context attribution and then concatenate these representations. This concatenated representation is then fed to the single linear layer for classification. This basically identifies the proximity of the embedding to the corresponding context attribution. Let $k_{i}$ represent $i$ -th context attribution centroid, and $c_{i,j}\textit{j}$ -th conceptual embedding vector ( $j$ -column) of the $i$ -th context attribution CiNs×m.
将嵌入向量投影到所有上下文属性后,我们需要进行分类。此时,由于每个投影都是一组向量(每个向量都是潜在维度为 $m$ 的概念嵌入),我们会计算每个上下文属性表征的质心,然后将这些表征连接起来。连接后的表征会被送入单层线性分类器,本质上是通过计算嵌入向量与对应上下文属性质心的接近度来完成分类。设 $k_{i}$ 表示第 $i$ 个上下文属性质心,$c_{i,j}\textit{j}$ 表示第 $i$ 个上下文属性 CiNs×m 的第 $j$ 列概念嵌入向量。
$$
k_{i}=\frac{1}{N_{s}}\cdot\sum_{j=0}^{N_{s}}c_{i,j}
$$
$$
k_{i}=\frac{1}{N_{s}}\cdot\sum_{j=0}^{N_{s}}c_{i,j}
$$
Loss function
损失函数
The loss that we are optimizing is primarily the CrossEntropy loss. To ensure that the conceptual embeddings don’t converge to the same embedding inside the conceptual space, we introduce an intra-space loss. This also adds additional regular iz ation and improves generalization. This is proved during the experiments. Controlling the weight of this loss compared to the cross entropy loss is another hyperparameter fine-tuning task. The intra-space loss is basically an inverse of the variance of the vectors inside the context attribution.
我们优化的损失函数主要是交叉熵损失 (CrossEntropy loss)。为了确保概念嵌入不会在概念空间内收敛到相同的嵌入,我们引入了空间内损失 (intra-space loss)。这还增加了额外的正则化并提高了泛化能力,这一点在实验中得到验证。控制该损失相对于交叉熵损失的权重是另一个超参数微调任务。空间内损失本质上是上下文归因中向量方差的倒数。
$$
\sigma^{2}=\sum_{i=1}^{m}\frac{1}{m}\cdot(c_{i}-\hat{c})^{2}
$$
$$
\sigma^{2}=\sum_{i=1}^{m}\frac{1}{m}\cdot(c_{i}-\hat{c})^{2}
$$
where $c_{i}$ is $i$ -th embedding $i$ -th column of the context attribution matrix) $C_{N_{s}\times m}$ and $\hat{c}$ is the mean vector of conceptual embedding matrix (column-wise).
其中 $c_{i}$ 是上下文归因矩阵 $C_{N_{s}\times m}$ 的第 $i$ 个嵌入(即第 $i$ 列),$\hat{c}$ 是概念嵌入矩阵的均值向量(按列计算)。
Results
结果
We evaluate our framework using 3 base models in 3 benchmarks with 3 different datasets. With benchmarks, we want to measure:
我们使用3个基础模型在3个基准测试中评估了我们的框架,涉及3个不同的数据集。通过基准测试,我们旨在衡量:
• Performance of the proposed Space Model • Generalization property of the novel technique • How does it compare with existing context attribution solutions which involve a manual process
- 提出的空间模型 (Space Model) 性能表现
- 新技术的泛化特性
- 与涉及人工流程的现有上下文归因解决方案的对比
To achieve that, we are going to use 3 datasets, namely HateXplain, IMDB reviews sentiment dataset, and Social Media Attributions dataset of YouTube comments related to the Chennai water crisis. IMDB sentiment reviews is a semantically close dataset to the HateXplain and is reasonably easily interpret able. Such a relation is essential since we would like to test the general iz ability of the proposed technique. Besides, in the Social Media Attributions paper, the authors do manual labeling of the concepts and measure similarity with the so-called Social Media Attributions; we would like to show that our approach achieves superior performance without additional manual labeling and via a single pass.
为此,我们将使用3个数据集:HateXplain、IMDB影评情感数据集,以及与金奈水危机相关的YouTube评论社交媒体归因数据集。IMDB情感评论是与HateXplain语义相近且易于解释的数据集,这种关联性至关重要,因为我们希望测试所提技术的泛化能力。此外,在《社交媒体归因》论文中,作者通过人工标注概念并测量其与所谓社交媒体归因的相似性;我们旨在证明,本方法无需额外人工标注且仅需单次处理即可实现更优性能。
The experiments are structured in a way that we have basic experiments with smaller models and simpler tasks. Additionally, we conducted experiments to compare the Space Model to the state-of-the-art model of the IMDB dataset. We also investigate and analyze various properties of the Space Model and explore some of the hyper parameters’ usage, with their respectful effect on the model performance. We explore the generalization property of the model by crosstesting it on the unseen dataset.
实验设计采用从小规模模型和简单任务的基础实验开始。此外,我们还进行了将Space模型与IMDB数据集最先进模型对比的实验。同时,我们研究分析了Space模型的多项特性,探索了部分超参数的使用及其对模型性能的影响。通过在新数据集上进行交叉测试,我们还探究了模型的泛化能力。
Preprocessing and settings
预处理与设置
BERT is a standard model that we use as a reference and a baseline. We only fully train the weights of this model once when compared with the Chennai water crisis data. For all of the other experiments, we preserve all of the generalizability and do not spend time on training. XLNet is the current state-of-the-art transformer for multiple benchmarks; in this specific work, we focus on the IMDB sentiment analysis dataset. By using this model and comparing the results with it, we want to prove that attaching the Space-model head to virtually any current state-of-the-art transformer would significantly boost performance.
BERT是我们用作参考和基准的标准模型。在与金奈水资源危机数据对比时,我们仅对该模型权重进行过一次完整训练。其余所有实验中,我们都保留其全部泛化能力且不进行训练。XLNet是当前多项基准测试中最先进的Transformer模型;本研究中我们专注于IMDB情感分析数据集。通过使用该模型并对比实验结果,我们旨在证明:为任何当前最先进的Transformer模型添加Space-model头部都能显著提升性能。
We are not conducting any data preprocessing for either of the datasets. We use cased models for all of the expriments except for the Social Media Attributions comparison. For the space model, the key idea is the contextual embedding generation. The entity doing this in our framework is called a base model; virtually any transformer model can play this role. We use cased DistliBERT, cased BERT, and cased XLNet.
我们对两个数据集均未进行任何数据预处理。除社交媒体归因(Social Media Attributions)对比实验外,所有实验均采用区分大小写(cased)模型。空间模型的核心思想在于上下文嵌入生成,在我们的框架中执行这一功能的实体称为基础模型(base model)——几乎所有Transformer模型都能胜任这一角色。实验使用了区分大小写的DistliBERT、BERT和XLNet模型。

Figure 2: 3D projection of the space embeddings for the 3-class classification (HateXplain). For the 3-class, similar to the 2-class, we expect to have 3 orthogonal projections. Here, we observe that if we review this image in multiple projections - some projections are clearly orthogonal, and some are more aligned. This is the effect that we have discussed previously, that contextual attributions might have overlapping concepts.
图 2: 3类分类(HateXplain)空间嵌入的3D投影。与2类情况类似,对于3类我们预期存在3个正交投影。此处可观察到,若从多角度审视该图像——部分投影明显正交,而另一些则更趋同向。这正是我们先前讨论过的效果:上下文归因可能存在概念重叠。
We use the base model configuration for all of the experiments except for the state-of-the-art establishment (12 layers for BERT and XLNet and 6 layers for DistilBERT). For the state-of-the-art performance, we trained large (24 layers) XLNet, which was used for reporting the results in the original paper. We use the Adam optimizer with a learning rate of $2\cdot1\dot{0}^{-4}$ for all experiments, except for the state-of-the-art establishment, since the original paper states that $10^{-5}$ was used to achieve the best results. Maximum sequence length and batch size is 256 for all of the basic experiments and is replaced with 512 and 4, respectively, for the XLNet large state-of-the-art results.
除建立最先进模型外( BERT和XLNet为12层,DistilBERT为6层),所有实验均采用基础模型配置。为达到最先进性能,我们训练了大型(24层)XLNet模型,该模型在原论文中被用于报告结果。所有实验均采用学习率为$2\cdot1\dot{0}^{-4}$的Adam优化器(建立最先进模型除外,因原论文指出使用$10^{-5}$可获得最佳结果)。基础实验的最大序列长度和批量大小均为256,而XLNet大型最先进模型结果则分别替换为512和4。
Since the original paper recommends using 32 as the batch size for the IMDB benchmark for the best results, and we could not fit that to the GPU memory, we used 8 gradient accumulation steps and adjusted the number of training steps accordingly. Even though the result does not precisely reproduce the original outcome, it is close, and the evident performance boost from the space model is transparent.
由于原论文建议在IMDB基准测试中使用32作为批次大小以获得最佳效果,而我们无法将其适配到GPU内存中,因此采用了8个梯度累积步长,并相应调整了训练步数。虽然结果未能完全复现原始成果,但已十分接近,且空间模型带来的显著性能提升清晰可见。
For the number of latent spaces, we use three for most experiments since this is enough to outperform significantly and is easy to visualize. As discussed previously, when we project the contextual embeddings onto the context attribution, we expect these projections to be orthogonal if the classes are different. That is what we observe in Figure 1 and Figure 2.
对于潜在空间的数量,我们在大多数实验中使用三个,因为这足以显著超越并易于可视化。如前所述,当我们将上下文嵌入投影到上下文归因上时,如果类别不同,我们期望这些投影是正交的。这正是我们在图1和图2中观察到的。
For the comparison with the Social Media Attributions, use the latent size of 64. For the state-of-the-art results using XLNet, we use 128 as the latent space size. We use a single Nvidia A5000 GPU for our training. Our model with various configurations may take from 30 seconds per epoch with DistilBERT to 25 minutes with XLNet large. A standard number of fine-tuning epochs is set to 5; however, for the XLNet large state-of-the-art results, we used only one epoch of training with one epoch of head fine-tuning to prevent over fitting.
与社交媒体归因(Social Media Attributions)对比时,使用64的潜在空间维度。对于采用XLNet的最先进结果,我们使用128作为潜在空间维度。训练使用单块Nvidia A5000 GPU。不同配置的模型每个epoch耗时从DistilBERT的30秒到XLNet large的25分钟不等。标准微调epoch数设为5;但针对XLNet large的最先进结果,为防止过拟合,我们仅训练1个epoch并微调头部1个epoch。
Evaluation Metrics
评估指标
Since we are evaluating the model between multiple benchmarks simultaneously, we want to adjust to both a perfectly balanced IMDB dataset and a less balanced HateXplain dataset. So, we report accuracy and f1-macro score. Our loss throughout the experiments is Cross-Entropy loss, sometimes combined with intra-space loss for better regularization. We also report the weight of the Intra-space loss in the experiments. This is usually set to a very low number to avoid dominance over the cross-entropy loss.
由于我们同时在多个基准之间评估模型,因此需要同时适应完全平衡的IMDB数据集和不太平衡的HateXplain数据集。为此,我们报告了准确率和f1宏平均分数。实验过程中使用的损失函数是交叉熵损失,有时会结合类内空间损失以获得更好的正则化效果。我们还报告了实验中类内空间损失的权重,该值通常设置得非常低,以避免其主导交叉熵损失。
Experimental Results
实验结果
Fine-tuning Space Model First, we ran a set of experiments on the IMDB benchmark dataset with the DistilBERT model as a base model (Table 1). We observe that the Space model is superior for both accuracy and f1-macro score. We also explore the number of trained parameters. With 3-time fewer parameters, the performance boost is already around $5%$ for both metrics. We also observe that with around 128 times fewer trainable parameters, the space model performs better by almost $2%$ .
微调空间模型
首先,我们在IMDB基准数据集上以DistilBERT模型为基础模型进行了一系列实验(表1)。我们观察到空间模型在准确率和f1-macro分数上均表现更优。我们还探究了训练参数量的影响:当参数量减少3倍时,两项指标性能提升约$5%$;当可训练参数量减少约128倍时,空间模型性能仍领先近$2%$。
Table 1: Comparative table of the results of the Space Model in different configurations with DistilBERT on the IMDB dataset and HateXplain dataset
表 1: 不同配置下 Space Model 与 DistilBERT 在 IMDB 数据集和 HateXplain 数据集上的结果对比
| 数据集 | 模型 | 训练参数量 | 准确率 | F1分数 (宏平均) | 召回率 | 空间内权重 |
|---|---|---|---|---|---|---|
| IMDB (训练集) | DistilBERT | 592130 | 0.7852 | 0.7819 | 0.6614 | N/A |
| IMDB (训练集) | SpaceModel | 197122 | 0.7917 | 0.7916 | 0.7728 | 0.001 |
| IMDB (训练集) | SpaceModel | 197122 | 0.8322 | 0.8320 | 0.8663 | 0 |
| HateXplain (零样本测试) | DistilBERT | 592130 | 0.6013 | 0.4450 | 0.0869 | N/A |
| HateXplain (零样本测试) | SpaceModel | 197122 | 0.5821 | 0.5187 | 0.2698 | 0.001 |
| HateXplain (零样本测试) | Space Model | 197122 | 0.5977 | 0.5040 | 0.2007 | 0 |
Table 2: BERT HateXplain (3-class) evaluation
表 2: BERT HateXplain (3-class) 评估
| 指标 | Space Model | BERT |
|---|---|---|
| 准确率 F1分数 (宏平均) 精确率 | 0.5296 0.4304 | 0.4485 0.3314 |
Then, we compare these results with the experiments for a much more complex HateXplain benchmark. The choice of the datasets is non-arbitrary in that case. We want data to have the evident polarization between classes, which is aligned cross-datasets, to prove the zero-short generalization component of our approach. BERT, DistilBERT, and XLNet are all evaluated with this benchmark against the Space Model in a 3-class and 2-class setting.
然后,我们将这些结果与更为复杂的HateXplain基准实验进行对比。在这种情况下,数据集的选择并非随意。我们希望数据在类别间具有明显的极化特征,并且这种特征在不同数据集间保持一致,以证明我们方法的零样本泛化能力。BERT、DistilBERT和XLNet都在3类和2类设置下,针对Space Model与该基准进行了评估。
General iz ability We take corresponding models and evaluate them on the HateXplain benchmark in a zero-shot manner (Table 1). For the sentiment analysis, negative labels are encoded as 0 and positive as 1; for the HateXplain, we encode Hateful and offensive labels as 0 and normal labels as 1. Here, we see that the Space model with intra-space loss is a top model in terms of f1-score, while the accuracy is the highest for the DistilBERT. However, accounting for the dataset imbalance, we see that DistilBERT is worse in terms of f1 by at least $6.7%$ and almost 4 times worse in terms of recall. Next, we compare the BERT model with the Space model and base BERT on the HateXplain benchmark with 3 classes. Here, we only train the classification head for BERT and contextual attribution operators for the Space model (as discussed previously). The results in Table 2 clearly show that the Space Model is superior in all of the metrics by at least $8%$ .
泛化能力
我们选取相应模型,在HateXplain基准上以零样本方式评估其表现(表1)。情感分析任务中,负面标签编码为0,正面为1;HateXplain任务中,仇恨和攻击性标签编码为0,普通标签为1。实验显示,采用空间内损失的Space模型在f1分数上表现最佳,而DistilBERT的准确率最高。但考虑数据集不平衡因素时,DistilBERT的f1分数至少低$6.7%$,召回率更是相差近4倍。
进一步在3分类的HateXplain基准上对比BERT与Space模型:仅训练BERT的分类头及Space模型的上下文归因算子(如前述)。表2结果明确显示,Space模型在所有指标上至少领先$8%$。
We then fine-tune the classification head and the space model with XLNet and BERT base models for the same HateXplain benchmark (Table 5) and observe that for BERT, the performance gap with identical training settings and identical base model is more than $16%$ on the f1-macro score. In comparison, for XLNet, this gap is around $6%$ .
随后,我们在相同的HateXplain基准测试上(表5),使用XLNet和BERT基础模型对分类头和空间模型进行微调,并观察到对于BERT模型,在相同的训练设置和相同基础模型下,f1-macro分数上的性能差距超过16%。相比之下,XLNet的差距约为6%。
To further prove the effect of the performance boost using the space model, we do the full training of the XLNet, a state-of-the-art model for the IMDB benchmark (Table 3). With almost identical settings to the original paper, we obtain a 0.9386 f1-score, while training the space model with the exact same settings gives us 0.9487 (all of the other metrics are also superior for the space model, except for the recall, which is again very different with precision for the vanilla model, and very close for the space model). We observe that the space model surpasses the state-of-the-art models in the tasks and is much more tolerant to the imbalanced data. The precision-recall trade-off is evident in most of the experiments. To prove this point further, we conducted the ablation study and researched how the space model stabilizes performance during training.
为了进一步证明空间模型带来的性能提升效果,我们对IMDB基准测试的先进模型XLNet进行了完整训练(表3)。在几乎与原始论文相同的设置下,我们获得了0.9386的f1分数,而使用完全相同设置训练的空间模型则达到0.9487(除召回率外,空间模型的所有其他指标均更优——原始模型的精确率与召回率差异显著,而空间模型两者数值非常接近)。我们观察到空间模型在各项任务中超越了当前最先进模型,且对数据不平衡具有更强的容忍度。精确率-召回率的权衡关系在大多数实验中表现明显。为深入验证这一点,我们进行了消融实验,研究空间模型如何在训练过程中稳定性能表现。
Table 3: State-of-the-art XLNet on IMDB
表 3: IMDB 上的最先进 XLNet 模型
| 指标 | Space eModel | XLNet |
|---|---|---|
| 准确率 F1分数 (宏平均) 精确率 召回率 | 0.9488 0.9487 0.9463 | 0.9387 0.9386 0.9106 0.9731 |
Social Media Attribution We compare our Space Model with the Social Media Attribution and observe $5.2%$ F1- score improvement on our own reproducing experiment and almost $2%$ F1-score improvement compared to the bestreported score from the original paper. The best result there was obtained on the adapted Indian BERT, while we used base uncased BERT without any adaptation, so this performance boost is not exhaustive.
社交媒体归因
我们将空间模型 (Space Model) 与社交媒体归因 (Social Media Attribution) 进行对比,在自行复现的实验中观察到 F1 分数提升了 5.2%,与原始论文报告的最佳成绩相比也提升了近 2%。原论文的最佳结果是通过调整后的印度版 BERT 获得的,而我们使用的是未经调整的基础无大小写 BERT 模型,因此这一性能提升并不彻底。
Table 4: Social Media Attribution BERT-uncased
表 4: 社交媒体归因 BERT-uncased
| 指标 | Space-model | BERT (uncased) |
|---|---|---|
| 准确率 | 0.8309 | 0.8220 |
| F1分数 (macro) | 0.8006 | 0.7484 |
| 精确率 | 0.7126 | 0.8876 |
| 召回率 | 0.7337 | 0.4674 |
Regular iz ation effect on fine-tuning
微调中的正则化效果
During the experiments, we observed that the space model has a much better ratio of recall/precision, which means that it handles imbalanced data much more efficiently. Another observation is that adding just a space model stabilizes the results during training, not allowing the performance to vary a lot between iterations. Find the visualization of the ablation study in Figure 3. Additionally, intra-space loss adds more regular iz ation and stabilization and ensures that the concepts in the context attribution will not converge to a single vector.
在实验过程中,我们观察到空间模型具有更优的召回率/精确度比率,这意味着它能更高效地处理不平衡数据。另一个发现是,仅添加空间模型就能稳定训练期间的结果,避免迭代间性能出现大幅波动。消融研究的可视化结果见图 3: 。此外,空间内损失函数进一步增强了正则化与稳定性,确保上下文归因中的概念不会收敛至单一向量。
Table 5: BERT and XLNet Comparison on HateXplain Dataset (2-class)
表 5: BERT 和 XLNet 在 HateXplain 数据集上的对比 (2分类)
| 指标 | 训练参数 | 准确率 | F1分数 (宏平均) | 精确率 | 召回率 |
|---|---|---|---|---|---|
| Space-model (XLNet) XLNet-base-cased | 4622 1538 | 0.8798 0.8160 | 0.8797 0.8156 | 0.8764 0.8421 | 0.8824 0.7750 |
| Space-model (BERT) BERT-base-cased | 4622 1538 | 0.8110 0.6588 | 0.8108 0.6555 | 0.8227 0.6919 | 0.7899 0.5649 |

Figure 3: DistilBERT (upper part) vs DistilBERT and Space Model (lower part) stabilization comparison
图 3: DistilBERT (上半部分) 与 DistilBERT 及空间模型 (下半部分) 的稳定性对比
Conclusion and discussion
结论与讨论
In conclusion, this research focused on the novel methodology towards conceptual embedding for classification with Language models. As an outcome of this research, we have conducted a set of experiments to empirically prove the efficiency of the proposed technique. We have also created the implementation of the proposed framework via PyTorch and provided an open-source GitHub repository to incivate and simplify future collaboration and exploration. We believe that the potential of this approach is yet to be discovered, and the goal of this paper was to provide some baseline ideas and understanding.
综上所述,本研究聚焦于大语言模型中概念嵌入(conceptual embedding)分类的新方法。通过一系列实验,我们实证验证了所提技术的有效性。基于PyTorch实现了该框架,并开源了GitHub仓库以促进后续协作探索。我们认为该方法潜力尚未完全发掘,本文旨在提供基础思路与研究起点。
We anticipate improvements by adding more complex transformations after the conceptual projection phase. We also believe that this technique should in no way be limited to classification problems only. The formulation of the regression problem is quite straightforward but needs to be additionally researched. With that, we also expect that 1-to-1 correspondence of the context attribution to the target class is an artificial limitation that we hold in this paper for the simplicity of interpretation. However, if domain knowledge suggests that having multiple context attributions (more than the number of classes) for the task makes sense - then this should also be an option. We would also like to explore further the potential of the interpretation capabilities of the framework and how we can use it to extract knowledge from the model.
我们预期通过在概念投影阶段后添加更复杂的变换来改进效果。同时认为该技术绝不应仅局限于分类问题,回归问题的公式化表达虽较为直接但仍需进一步研究。此外,我们认为将上下文归因与目标类别强制保持一对一对应关系是本文为简化解释而设置的人为限制——若领域知识表明为任务设置多个上下文归因(超过类别数量)具有合理性,这同样应成为可选方案。我们还将深入探索该框架的解释潜力,研究如何利用其从模型中提取知识。