Multi-Task Learning with LLMs for Implicit Sentiment Analysis: Data-level and Task-level Automatic Weight Learning
基于大语言模型的多任务学习在隐式情感分析中的应用:数据级与任务级自动权重学习
Abstract—Implicit sentiment analysis (ISA) presents significant challenges due to the absence of salient cue words. Previous methods have struggled with insufficient data and limited reasoning capabilities to infer underlying opinions. Integrating multi-task learning (MTL) with large language models (LLMs) offers the potential to enable models of varying sizes to reliably perceive and recognize genuine opinions in ISA. However, existing MTL approaches are constrained by two sources of uncertainty: datalevel uncertainty, arising from hallucination problems in LLMgenerated contextual information, and task-level uncertainty, stemming from the varying capacities of models to process contextual information. To handle these uncertainties, we introduce MT-ISA, a novel MTL framework that enhances ISA by leveraging the generation and reasoning capabilities of LLMs through automatic MTL. Specifically, MT-ISA constructs auxiliary tasks using generative LLMs to supplement sentiment elements and incorporates automatic MTL to fully exploit auxiliary data. We introduce data-level and task-level automatic weight learning (AWL), which dynamically identifies relationships and prioritizes more reliable data and critical tasks, enabling models of varying sizes to adaptively learn fine-grained weights based on their reasoning capabilities. We investigate three strategies for datalevel AWL, while also introducing homos ced a stic uncertainty for task-level AWL. Extensive experiments reveal that models of varying sizes achieve an optimal balance between primary prediction and auxiliary tasks in MT-ISA. This underscores the effectiveness and adaptability of our approach.
摘要—隐式情感分析(ISA)由于缺乏显著线索词而面临重大挑战。先前方法因数据不足和推理能力有限而难以推断潜在观点。将多任务学习(MTL)与大语言模型(LLM)相结合,有望使不同规模的模型可靠地感知和识别ISA中的真实观点。然而现有MTL方法受限于两类不确定性:数据级不确定性(源于LLM生成上下文信息时的幻觉问题)和任务级不确定性(源于模型处理上下文信息的能力差异)。为处理这些不确定性,我们提出MT-ISA——一种通过自动MTL利用LLM生成与推理能力来增强ISA的新型MTL框架。具体而言,MT-ISA利用生成式LLM构建辅助任务以补充情感要素,并采用自动MTL充分挖掘辅助数据。我们提出数据级与任务级自动权重学习(AWL),动态识别关系并优先处理更可靠的数据和关键任务,使不同规模模型能基于其推理能力自适应学习细粒度权重。我们研究了三种数据级AWL策略,同时为任务级AWL引入同方差不确定性。大量实验表明,不同规模模型在MT-ISA中实现了主要预测与辅助任务的最佳平衡,验证了我们方法的有效性与适应性。
Index Terms—Implicit sentiment analysis, Multi-task learning, Large language models.
索引词—隐式情感分析,多任务学习,大语言模型 (Large Language Model)。
I. INTRODUCTION
I. 引言
Aspect-based sentiment analysis (ABSA) aims to identify various sentiment elements, including target terms, aspect categories, opinion terms, and sentiment polarities [1]. As illustrated in Figure 1, these sentiment elements are evident in the explicit case to form a complete sentiment picture. Previous dominant research focused on detecting these elements independently. However, identifying a single sentiment element remains insufficient for a comprehensive understanding of aspect-level opinions [2]. To delve into more complex real
基于方面的情感分析 (ABSA) 旨在识别各种情感要素,包括目标词、方面类别、观点词和情感极性 [1]。如图 1 所示,这些情感要素在显式案例中形成完整的情感图景。先前的主流研究主要集中于独立检测这些要素。然而,仅识别单一情感要素仍不足以全面理解方面级观点 [2]。为探究更复杂的真实...
The research was supported by the Faculty Research Grant (DB24A4) at Lingnan University, Hong Kong. (Corresponding author: Haoran Xie.)
本研究由香港岭南大学教师研究基金 (DB24A4) 资助。(通讯作者: Haoran Xie。)
Wenna Lai is with the Department of Computing, Hong Kong Polytechnic University, Hong Kong SAR (email: winnelai05@gmail.com).
Wenna Lai 就职于香港理工大学计算学系,香港特别行政区 (email: winnelai05@gmail.com)。
Haoran Xie is with the School of Data Science, Lingnan University, Hong Kong (email: hrxie@ln.edu.hk).
Haoran Xie 就职于香港岭南大学数据科学学院 (email: hrxie@ln.edu.hk)。
Guandong Xu is with the School of Computer Science and the Data Science Institute, University of Technology Sydney, Sydney, NSW 2007, and also the Education University of Hong Kong, Hong Kong SAR (e-mail: gdxu@eduhk.hk).
许广东就职于悉尼科技大学计算机科学与数据科学学院(新南威尔士州悉尼市,邮编2007),同时兼任香港教育大学(香港特别行政区)教职(电子邮箱:gdxu@eduhk.hk)。
Qing Li is with the Department of Computing, Hong Kong Polytechnic University, Hong Kong SAR (e-mail: qing-prof.l $@$ polyu.edu.hk).
李青就职于香港特别行政区香港理工大学计算学系 (e-mail: qing-prof.l$@$polyu.edu.hk)。
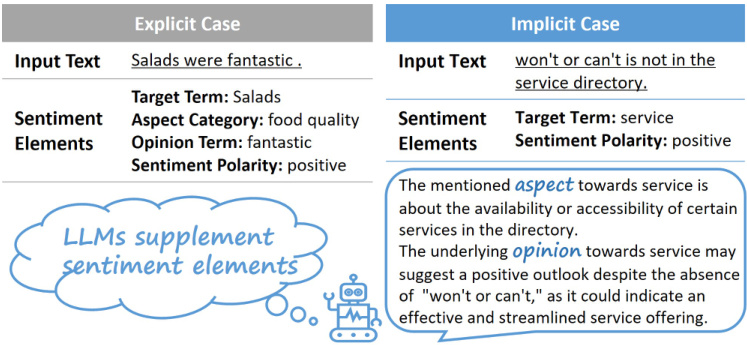
Fig. 1. The examples illustrate explicit (left) and implicit (right) cases in ABSA. LLMs help supplement sentiment elements in ISA.
图 1: 示例展示了 ABSA 中的显式 (左) 和隐式 (右) 情况。大语言模型 (LLM) 有助于补充 ISA 中的情感要素。
world scenarios, Li et al. [3] shed light on implicit sentiment analysis (ISA) and pointed out that previous studies have paid less attention to ISA, which presents greater challenges due to the absence of salient cue words in expressions. Unlike traditional ABSA tasks, ISA necessitates not only the extraction of dependencies between sentiment elements but also the capture of nuanced sentiment cues conveyed within texts [4].
现实场景中,Li等人[3]揭示了隐式情感分析(ISA)的重要性,并指出以往研究对ISA关注不足,由于表达中缺乏显性情感线索词,该任务面临更大挑战。与传统ABSA任务不同,ISA不仅需要提取情感元素间的依赖关系,还需捕捉文本中传递的微妙情感线索[4]。
The key challenges present in ISA are insufficient data to support pattern learning for implicit sentiments and limited reasoning capabilities of traditional models to incorporate common sense knowledge. In the evolving landscape of SA, researchers have increasingly focused on enhancing techniques for ISA. Li et al. [3] pre-trained on a large-scale sentimentannotated corpus, aiming to align implicit representations with explicit ones. However, their approach demands significant effort in constructing data sources and lacks generalization and interpret ability in reasoning deep-level sentiments. Recent advancements in large language models (LLMs) have exhibited their potential in addressing the challenges of ISA, particularly due to their remarkable performance in natural language generation and understanding [4], [5]. Figure 1 presents an example where LLMs supplement sentiment elements in the implicit case, demonstrating their capabilities for reasoning about sentiments. Fei et al. [6] directly conducted Chainof-Thought (CoT) fine-tuning to extract relevant sentiment elements for discerning implicit orientations in expressions. Although this approach achieved some performance improvements, it necessitates LLMs of a certain scale to exhibit emergent abilities [7] for step-by-step inference, limiting its broader application. Furthermore, LLMs are prone to hallucination problems, which can result in unfaithful reasoning and subsequently impair learning performance [8], [9].
隐式情感分析(ISA)面临的核心挑战在于:支持隐式情感模式学习的训练数据不足,以及传统模型缺乏融合常识知识的推理能力。随着情感分析领域的发展,研究者们日益聚焦于提升隐式情感分析技术。Li等人[3]通过在大规模情感标注语料库上进行预训练,试图对齐隐式与显式情感表征。但该方法需要耗费大量精力构建数据源,且在深层情感推理方面缺乏泛化性和可解释性。近年来,大语言模型(LLM)在自然语言生成与理解方面的卓越表现[4][5],展现出解决隐式情感分析难题的潜力。图1展示了LLM为隐式情感补充情感要素的案例,体现了其情感推理能力。Fei等人[6]直接采用思维链(CoT)微调技术来提取相关情感要素以识别表达中的隐式倾向。虽然该方法取得了一定效果提升,但需要特定规模的LLM才能展现逐步推理的涌现能力[7],限制了其广泛应用。此外,LLM容易产生幻觉问题,可能导致不可靠的推理进而影响学习性能[8][9]。
Apart from CoT fine-tuning, another prominent technique for integrating LLMs in reasoning is Multi-task learning (MTL), which has shown promise in various NLP tasks by leveraging shared representations across related reasoning tasks to improve overall performance [10], [11]. Notably, MTL with LLMs has demonstrated effectiveness even with smaller models [12], [13]. They typically use LLMs for auxiliary data generation and joint learning through MTL. However, traditional MTL approaches often require manual tuning of task weights [12], [13], which can be time-consuming and suboptimal due to two primary sources of uncertainty when applied with LLMs: data-level uncertainty, arising from the hallucination problems inherent in LLM-generated contextual information, and task-level uncertainty, stemming from the varying capacities of models to digest contextual information. It is critical to enhance the self-knowledge of LLMs [9] and handle these potential uncertainties, enabling models of different sizes to reliably perceive and recognize genuine opinions in ISA.
除了思维链 (CoT) 微调外,另一种将大语言模型 (LLM) 融入推理的突出技术是多任务学习 (MTL) 。该方法通过共享相关推理任务的表征来提升整体性能,已在多种自然语言处理任务中展现出潜力 [10], [11] 。值得注意的是,即使是较小规模的模型,采用 MTL 的大语言模型也表现出了有效性 [12], [13] 。这类方法通常利用大语言模型进行辅助数据生成,并通过 MTL 实现联合学习。
然而,传统 MTL 方法往往需要手动调整任务权重 [12], [13] ,这种方式既耗时又难以达到最优效果,主要源于大语言模型应用中的两类不确定性:数据级不确定性(由大语言模型生成上下文信息时固有的幻觉问题导致)和任务级不确定性(源于模型消化上下文信息的能力差异)。提升大语言模型的自我认知能力 [9] 并处理这些潜在不确定性至关重要,这能使不同规模的模型在 ISA 中可靠地感知和识别真实观点。
To tackle the above challenges and effectively harness the potential of LLMs for reliable reasoning, we introduce a novelMTL framework, MT-ISA, which leverages the generation and reasoning capabilities of LLMs, while also managing inherent uncertainties at both the data and task levels through automatic MTL. In MT-ISA, we construct auxiliary tasks by utilizing generative LLMs to supplement additional sentiment elements. By integrating MTL with LLMs, MT-ISA can fully exploit auxiliary data generated by LLMs, enabling backbone models to capture relationships between sentiment elements and effectively reason about implicit sentiments. To further enhance reasoning learning by managing inherent uncertainties, we employ data-level and task-level automatic weight learning (AWL) to dynamically adjust the focus on more reliable data and critical tasks, eliminating the need for extensive manual intervention. This allows models of varying sizes to adaptively learn fine-grained weights based on their reasoning capabilities. We explore three strategies for datalevel AWL and incorporate homos ced a stic uncertainty for task-level AWL, contributing to optimal reasoning learning performance in ISA.
为应对上述挑战并有效利用大语言模型(LLM)实现可靠推理,我们提出新型多任务学习(MTL)框架MT-ISA。该框架融合大语言模型的生成与推理能力,通过自动化多任务学习同步处理数据与任务层面的固有不确定性。在MT-ISA中,我们借助生成式大语言模型构建辅助任务以补充情感要素,通过多任务学习与大语言模型的协同,充分挖掘大语言模型生成的辅助数据,使主干模型能捕捉情感要素间关联并实现隐式情感的有效推理。为通过不确定性管理强化推理学习,我们采用数据级与任务级自动权重学习(AWL)动态聚焦更可靠数据与关键任务,无需大量人工干预,使不同规模模型能根据自身推理能力自适应学习细粒度权重。我们探索了三种数据级自动权重学习策略,并采用同方差不确定性实现任务级自动权重学习,最终在隐式情感分析(ISA)中实现最优推理学习性能。
In general, the key contributions of this work are as follows:
总的来说,本工作的主要贡献如下:
• We propose MT-ISA, a novel MTL framework for ISA that leverages the generation and reasoning capabilities of LLMs, while effectively handling inherent data-level and task-level uncertainties through automatic MTL. • MT-ISA incorporates data-level and task-level AWL to dynamically prioritize reliable data and critical tasks, enabling models of varying sizes to adaptively learn fine-grained weights based on their reasoning capabilities without manual intervention. • We investigate three strategies for data-level AWL, including Input (I), Output (O), and Input-Output (I-O) strategies. Extensive experiments demonstrate the efficacy of these strategies in enhancing automatic MTL performance, achieving state-of-the-art results in ISA.
• 我们提出了MT-ISA,一个面向ISA(图像情感分析)的新型多任务学习框架,该框架利用大语言模型(LLM)的生成与推理能力,并通过自动多任务学习有效处理数据级和任务级固有不确定性。
• MT-ISA结合数据级和任务级自适应权重学习(AWL),动态优先处理可靠数据和关键任务,使不同规模的模型能基于其推理能力自适应学习细粒度权重,无需人工干预。
• 我们研究了三种数据级AWL策略:输入(I)、输出(O)及输入-输出(I-O)策略。大量实验证明这些策略能显著提升自动多任务学习性能,在ISA任务中达到最先进水平。
The following sections are structured as follows. Section II will introduce related works in the field of ISA and MTL.
以下章节结构如下:第 II 部分将介绍 ISA (Instruction Set Architecture) 和 MTL (Multi-Task Learning) 领域的相关工作。
Then, Section III will detail the proposed MT-ISA framework, including auxiliary task construction and automatic weight learning. Subsequently, Section IV will present experimental evaluations conducted on two benchmark datasets. In section V, we will discuss alternative methods we have compared. Finally, conclusions are drawn in Section VI.
接着,第 III 部分将详细介绍提出的 MT-ISA 框架,包括辅助任务构建和自动权重学习。随后,第 IV 部分将展示在两个基准数据集上进行的实验评估。第 V 部分将讨论我们对比过的替代方法。最后,第 VI 部分给出结论。
II. RELATED WORKS
II. 相关工作
A. Implicit Sentiment Analysis
A. 隐式情感分析
Implicit sentiment analysis (ISA) presents greater challenges compared to sentiment classification tasks due to the absence of salient cue words in expressions [3], [14]–[16]. Some prior studies addressed ISA by enhancing feature representation at the sentence level [17], [18]. In 2021, the research team [3] divided the SemEval-2014 Restaurant and Laptop benchmarks into Explicit Sentiment Expression (ESE) slice and Implicit Sentiment Expression (ISE) slice based on the presence of opinion words, to facilitate a more fine-grained aspect-level analysis. Given that Pre-trained Language Models (PLMs) such as BERT [19] demonstrate exceptional performance in learning representations for classification tasks, many researchers have utilized PLMs for downstream tasks. They enhanced ISA through data augmentation [20] or advanced deep learning techniques like contrastive learning [3], graph learning [21]. In addition, casual intervention has proven to be an effective method for exploring implicit relationships [22]. With the triumph of LLMs in the NLP domain, the research community has experienced a paradigm shift towards the utilization of LLMs [4], [5]. Ouyang et al. [23] employed encoder-decoder style LLMs, with the encoder trained for data augmentation and the decoder for prediction purposes. Fei et al. [6] introduced THOR and applied Chain-of-Thought (CoT) fine-tuning in ISA by exploiting the emergent abilities in LLMs. However, THOR requires larger models to fully exhibit in-context learning and reasoning capacities, while smaller models achieve limited performance with CoT reasoning. In comparison, our approach enhances reasoning context using generative LLMs to self-refine [24] with label intervention for reliability control. Additionally, We capitalize on the strengths of LLMs via MTL employing data-level and task-level AWL to handle inherent uncertainties, which enables backbone models to deliver optimal results regardless of model size.
隐性情感分析 (ISA) 相比情感分类任务更具挑战性,因为表达中缺乏显著的情感线索词 [3], [14]-[16]。先前一些研究通过增强句子级别的特征表示来解决ISA问题 [17], [18]。2021年,研究团队 [3] 根据观点词的存在情况,将SemEval-2014 Restaurant和Laptop基准数据集划分为显式情感表达 (ESE) 切片和隐式情感表达 (ISE) 切片,以便进行更细粒度的方面级分析。鉴于预训练语言模型 (PLMs) 如BERT [19] 在分类任务的表示学习方面表现出色,许多研究者利用PLMs进行下游任务,通过数据增强 [20] 或对比学习 [3]、图学习 [21] 等先进深度学习技术来提升ISA性能。此外,因果干预已被证明是探索隐性关系的有效方法 [22]。
随着大语言模型在NLP领域的成功,研究界出现了向大语言模型应用的模式转变 [4], [5]。Ouyang等人 [23] 采用编码器-解码器风格的大语言模型,其中编码器用于数据增强训练,解码器用于预测目的。Fei等人 [6] 提出了THOR,并通过利用大语言模型中的涌现能力,在ISA中应用思维链 (CoT) 微调。然而,THOR需要更大模型才能充分展现上下文学习和推理能力,而较小模型通过CoT推理仅能获得有限性能。相比之下,我们的方法使用生成式大语言模型通过自我精炼 [24] 来增强推理上下文,并通过标签干预进行可靠性控制。此外,我们利用多任务学习 (MTL) 结合数据级和任务级自适应权重学习 (AWL) 来发挥大语言模型优势,处理固有不确定性,这使得骨干模型无论规模大小都能获得最优结果。
B. Multi-task Learning
B. 多任务学习
Multi-task learning (MTL) aims to enhance generalization performance by leveraging shared information across multiple related tasks [25]. It is a promising direction in NLP with various applications including information extraction, natural language understanding, and generation [11]. In ABSA, prior studies have explored joint learning of subtasks to improve the performance of sentiment polarity classification [26], [27]. Yang et al. [28] developed an MTL model to jointly extract aspects and predict their corresponding sentiments, achieving enhanced performance on both Chinese and English review datasets. Similarly, Yu et al. [29] proposed a multitask learning framework utilizing the pre-trained BERT model as a shared representation layer, but applied more complex tasks for joint learning including aspect-term SA and aspectcategory SA tasks. Zhao et al. [30] introduced MTABSA to learn aspect-term extraction and sentiment classification simultaneously, incorporating multi-head attention to associate dependency sequences with aspect extraction. In contrast, our approach focuses on a more granular level of joint task learning, where each sentiment element functions as a subtask and contributes to the primary sentiment polarity prediction task. In recent years, PLMs like T5 [31] have demonstrated exceptional generalization capabilities across numerous NLP tasks through multi-task learning via task prefixes. Models empowered by PLMs have shown promising results [6], [23], [32], [33]. Furthermore, LLMs with larger size have exhibited impressive complex reasoning abilities using Chain-of-Thought (CoT) prompting [34]–[38]. Some research has focused on jointly learning reasoning chains with prediction tasks [12], [13], [39]. Li et al. [13] explored multi-task learning with explanation and prediction, leveraging T5 as the backbone model with instruction learning. However, their approach assigns equal weight to each task, and the auxiliary explanation task may produce unfaithful explanations that could negatively impact prediction tasks. In contrast, our method conducts automatic MTL utilizing data-level and task-level AWL to focus on more reliable data and critical tasks, which achieve optimal performance by learning more fine-grained weights without extensive manual intervention.
多任务学习 (Multi-task learning, MTL) 旨在通过利用多个相关任务间的共享信息来提升泛化性能 [25]。这是自然语言处理 (NLP) 中一个前景广阔的方向,在信息抽取、自然语言理解和生成等领域有广泛应用 [11]。在方面级情感分析 (ABSA) 领域,先前研究已探索通过子任务联合学习来提升情感极性分类性能 [26][27]。Yang 等人 [28] 开发了一个 MTL 模型来联合抽取方面词并预测其对应情感,在中英文评论数据集上均取得了性能提升。类似地,Yu 等人 [29] 提出了一个以预训练 BERT 模型作为共享表示层的多任务学习框架,但采用了更复杂的联合学习任务,包括方面词情感分析和方面类别情感分析任务。Zhao 等人 [30] 提出的 MTABSA 模型通过多头注意力机制将依存序列与方面词抽取相关联,实现了方面词抽取和情感分类的同步学习。相比之下,我们的方法聚焦于更细粒度的联合任务学习,其中每个情感要素都作为子任务并服务于主情感极性预测任务。近年来,像 T5 [31] 这样的预训练语言模型 (PLM) 通过任务前缀的多任务学习,在众多 NLP 任务中展现出卓越的泛化能力。基于 PLM 的模型已取得显著成果 [6][23][32][33]。此外,更大规模的大语言模型通过思维链 (Chain-of-Thought, CoT) 提示展现出惊人的复杂推理能力 [34][38]。部分研究聚焦于将推理链与预测任务联合学习 [12][13][39]。Li 等人 [13] 以 T5 为骨干模型结合指令学习,探索了带有解释的预测多任务学习。但该方法对所有任务赋予同等权重,且辅助解释任务可能产生不忠实的解释从而影响预测任务。相较之下,我们的方法通过数据级和任务级自适应权重学习 (AWL) 实现自动化的 MTL,聚焦于更可靠的数据和关键任务,无需大量人工干预即可通过学习细粒度权重实现最优性能。
III. METHODOLOGY
III. 方法论
In this section, we delve into the proposed multi-task learning framework MT-ISA, as illustrated in Figure 2. MTISA leverages the generation and reasoning capabilities of LLMs through automatic MTL, which dynamically adjusts the weights between primary tasks and auxiliary tasks by concerning the confidence level of data and the importance of tasks. In the beginning, MT-ISA constructs additional sentiment elements as auxiliary tasks to form a comprehensive sentiment picture of a given expression. To prepare relevant sentiment elements conducive to the primary polarity inference task, an off-the-shelf LLM is employed to perform generation using a self-refine strategy with polarity label intervention, ensuring data relevance and quality. Moreover, confidence scores are obtained from the generation process, regarded as indicators of data-level uncertainty. To further enhance learning performance by handling inherent uncertainties that exist when applying MTL with LLMs, we introduce data-level and task-level automatic weight learning (AWL), enabling models of varying sizes to adaptively learn fine-grained weights based on their reasoning capabilities without manual intervention. The following section will provide a detailed explanation.
本节将深入探讨所提出的多任务学习框架MT-ISA,如图2所示。MT-ISA通过自动多任务学习(MTL)机制,利用大语言模型(LLM)的生成与推理能力,根据数据置信度和任务重要性动态调整主任务与辅助任务间的权重。该框架首先构建情感要素作为辅助任务,形成对给定表达式的完整情感画像。为准备有助于主极性推断任务的相关情感要素,采用现成大语言模型通过带极性标签干预的自优化策略进行生成,确保数据相关性与质量。生成过程中获得的置信度分数被视作数据级不确定性指标。为进一步提升学习性能并处理LLM多任务学习中固有的不确定性,我们引入了数据级和任务级自动权重学习(AWL)机制,使不同规模的模型能基于其推理能力自适应学习细粒度权重,无需人工干预。下文将对此进行详细阐述。
A. Task Definition
A. 任务定义
Denote a dataset $D={(x_{i},t_{i},y_{i})}^{N}$ , where $1\leq i\leq N,N$ is the number of data instance. Given an input sentence $x_{i}$ and its corresponding aspect term $t_{i}$ , where $t_{i}\subset x_{i}$ , the objective of ISA is to infer the sentiment polarity $y_{i}$ towards aspect term $t_{i}$ correctly. The relevant sentiment elements consist of aspect $a_{i}$ and opinion $o_{i}$ , which may not be explicitly included in the input sentence $x_{i}$ . In the setting of single-task fine-tuning with prompting approach, the LLM predicts the sentiment polarity $\hat{y_{i}}$ solely via $\hat{y_{i}}=a r g m a x p(y_{i}|x_{i},t_{i})$ . This approach may potentially limit the ability of models to capture complete sentiment information in input text without extra information about relevant sentiment elements.
给定一个数据集 $D={(x_{i},t_{i},y_{i})}^{N}$,其中 $1\leq i\leq N,N$ 表示数据实例的数量。给定输入句子 $x_{i}$ 及其对应的方面词 $t_{i}$(其中 $t_{i}\subset x_{i}$),隐式方面情感分析 (ISA) 的目标是正确推断针对方面词 $t_{i}$ 的情感极性 $y_{i}$。相关情感要素包括方面 $a_{i}$ 和观点 $o_{i}$,这些要素可能未明确包含在输入句子 $x_{i}$ 中。在采用提示方法的单任务微调设置中,大语言模型仅通过 $\hat{y_{i}}=a r g m a x p(y_{i}|x_{i},t_{i})$ 来预测情感极性 $\hat{y_{i}}$。这种方法可能会限制模型在没有相关情感要素额外信息的情况下,捕捉输入文本中完整情感信息的能力。
a) Primary Task: The objective of ISA is to infer implicit sentiment polarity $y_{i}$ towards a given target $t_{i}$ within a given input $x_{i}$ . Therefore, the primary task is polarity inference using a labeled dataset, aiming to predict $\hat{y_{i}}=a r g m a x p(y_{i}|x_{i},t_{i})$ . To optimize this task, the cross-entropy loss is calculated between the predicted label $\hat{y}{i}$ and the annotated label $y_{i}$ , then we have the prediction loss for sentiment polarity:
a) 主要任务: ISA (隐式情感分析) 的目标是从给定输入 $x_{i}$ 中推断出对指定目标 $t_{i}$ 的隐含情感极性 $y_{i}$。因此,主要任务是利用标注数据集进行极性推断,旨在预测 $\hat{y_{i}}=a r g m a x p(y_{i}|x_{i},t_{i})$。为了优化该任务,需要计算预测标签 $\hat{y}{i}$ 与标注标签 $y_{i}$ 之间的交叉熵损失,从而得到情感极性的预测损失:
$$
\mathcal{L}{p}=\frac{1}{N}\sum_{i=1}^{N}\ell_{C E}(\hat{y}{i},y_{i})
$$
$$
\mathcal{L}{p}=\frac{1}{N}\sum_{i=1}^{N}\ell_{C E}(\hat{y}{i},y_{i})
$$
B. Auxiliary Task Construction
B. 辅助任务构建
To facilitate the model understanding of implicit sentiment by providing a complete sentiment picture, we leverage generative LLMs to supplement additional sentiment elements that are conducive to enhancing the reasoning capacity for ISA. We construct two subtasks as auxiliary tasks focused on essential sentiment elements including aspect and opinion. Specifically, we prompt an off-the-shelf LLM using the self-refine strategy with polarity intervention. This approach ensures that the generated sentiment elements are rectified by golden polarity through an iterative refinement process, thereby enhancing the reliability of the generated content. Furthermore, we retrieve the confidence score for generated responses, serving as indicators of data-level uncertainty in Section III-C. The generation process is detailed in Algorithm 1 and the prompt templates are specified in Figure 5 with a case study to illustrate the whole process. We use teacher forcing to train our model for auxiliary tasks, minimizing the negative log-likelihood, which is expressed as follows:
为通过提供完整的情感图景促进模型理解隐含情感,我们利用生成式大语言模型补充有助于增强隐式情感分析 (ISA) 推理能力的情感要素。针对核心情感要素(包括方面和观点)构建了两个辅助子任务。具体而言,我们采用带极性干预的自优化策略提示现成大语言模型,该方法通过迭代优化过程确保生成的情感要素经黄金极性校正,从而提升生成内容的可靠性。此外,我们获取生成响应的置信度分数,作为第III-C节数据级不确定性的指标。生成过程详见算法1,提示模板详见图5并附案例说明全流程。对于辅助任务,我们采用教师强制训练模型以最小化负对数似然,其表达式如下:
$$
\mathcal{L}{N L L}=-\mathbb{E}l o g p(y|x)=-\mathbb{E}\sum_{t=1}^{T}l o g p(s_{t}|x,s_{<t})
$$
$$
\mathcal{L}{N L L}=-\mathbb{E}l o g p(y|x)=-\mathbb{E}\sum_{t=1}^{T}l o g p(s_{t}|x,s_{<t})
$$
$$
\mathcal{L}{a}=\mathcal{L}{o}=\mathcal{L}_{N L L}
$$
$$
\mathcal{L}{a}=\mathcal{L}{o}=\mathcal{L}_{N L L}
$$
where $L_{a}$ and $L_{p}$ are the loss for aspect and opinion auxiliary tasks respectively, $T$ is the length of target sequence $s$ , and $s_{<t}$ represents the sequence of outputs before time step $t$ .
其中 $L_{a}$ 和 $L_{p}$ 分别是方面和观点辅助任务的损失函数,$T$ 是目标序列 $s$ 的长度,$s_{<t}$ 表示时间步 $t$ 之前的输出序列。
C. Data-level Automatic Weight Learning (D-AWL)
C. 数据级自动权重学习 (D-AWL)
To encourage the model to prioritize data instances with high confidence levels in auxiliary tasks, we adopt three strategies for data-level AWL using the confidence scores obtained from Algorithm 1. These strategies help the model better manage uncertainty and noisy data, enabling it to learn more meaningful feature representations by mitigating the negative impact of noisy data on model training and enhancing learning efficiency and effectiveness. We also explored alternative methods for retrieving confidence scores, which are discussed in Section V. We select the prompt-based method due to
为鼓励模型优先处理辅助任务中高置信度的数据实例,我们采用三种基于数据级自适应权重学习 (AWL) 的策略,利用算法1获得的置信度分数。这些策略帮助模型更好地管理不确定性和噪声数据,通过减轻噪声数据对模型训练的负面影响,使其能够学习更具意义的特征表示,同时提升学习效率和效果。我们还探索了其他获取置信度分数的方法,具体讨论见第五节。最终选择基于提示 (prompt-based) 方法的原因是
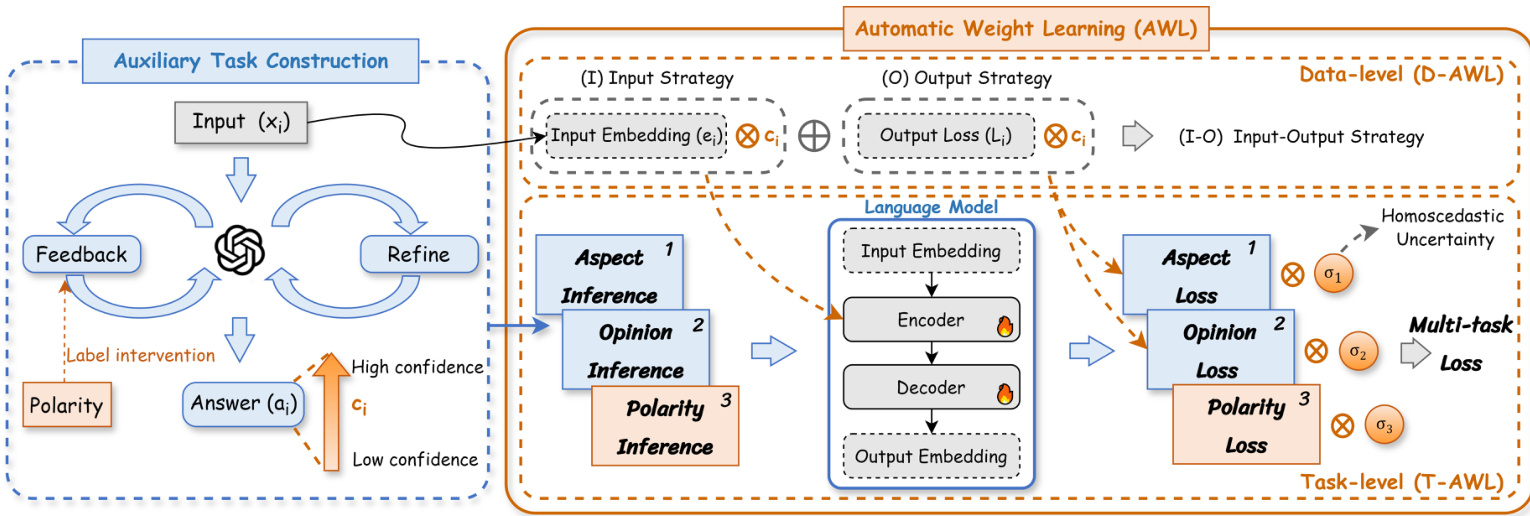
Fig. 2. The overview of proposed multi-task learning framework MT-ISA. The primary task is polarity inference originating from the given dataset. The auxiliary tasks are constructed by LLM generation using the self-refine strategy with polarity intervention to guide the generation for relevant sentiment elements, including aspect and opinion. The backbone model is trained using multi-task learning with automatic weight learning (AWL), which simultaneously considers auxiliary data confidence for data-level AWL and homos ced a stic uncertainty (i.e., task-level uncertainty) for task-level AWL to obtain fine-grained weights and achieve optimal learning performance.
图 2: 提出的多任务学习框架MT-ISA概述。主要任务是基于给定数据集的情感极性推断。辅助任务通过大语言模型生成,采用带极性干预的自优化策略来引导生成相关情感要素(包括评价对象和观点)。主干模型通过带自动权重学习(AWL)的多任务学习进行训练,同时考虑辅助数据置信度实现数据级AWL,以及同方差不确定性(即任务级不确定性)实现任务级AWL,从而获得细粒度权重并实现最优学习性能。
Algorithm 1 Auxilary Task Construction
算法 1: 辅助任务构建
Given: An original dataset $D={(x_{i},t_{i},y_{i})}^{N}$ . An off-theshelf LLM $\mathcal{F}$ and max refinement epoch $\mathcal{E}$ . A set of prompt template $\tau$ .
给定:原始数据集 $D={(x_{i},t_{i},y_{i})}^{N}$,现成大语言模型 $\mathcal{F}$,最大精炼轮次 $\mathcal{E}$,以及提示模板集 $\tau$。
Output: Sentiment element information including aspect $a_{i}$ with confidence score $c_{a_{i}}$ and opinion $o_{i}$ with confidence score $c_{o_{i}}$ . Auxiliary tasks data $D_{a}={(x_{i},t_{i},a_{i},c_{a_{i}})}^{N}$ and $D_{o}=$ ${(\stackrel{.}{x}_{i},t_{i},o_{i},c_{o_{i}})}^{N}$ .
输出:情感要素信息包括方面 $a_{i}$ (置信度得分 $c_{a_{i}}$)和观点 $o_{i}$ (置信度得分 $c_{o_{i}}$)。辅助任务数据 $D_{a}={(x_{i},t_{i},a_{i},c_{a_{i}})}^{N}$ 和 $D_{o}=$ ${(\stackrel{.}{x}_{i},t_{i},o_{i},c_{o_{i}})}^{N}$。
| 1: for (ci,ti, yi) in D do | |
| 2: Set auxiliary tasks data Da = {}, D。= {} | |
| Set initial prompt p = | |
| Set initial feedback f=None | |
| 4: 5: for e < ε do | |
| 6: Pi = T(ci,ti, fi) | |
| 7: ai,Cai = F(pi) | |
| 8: pi =T(ci,ta,ai, fi) | |
| 9: Oi, Coi = F(pi) | |
| 10: Pi = T(ci,ti, ai, Oi, fi) | |
| 11: yi = F(pi) > infer the polarity | |
| 12: if y = yi then | |
| 13: break | |
| 14: end if | |
| 15: Pi = T(ci,ti, ai, Oi,gi) > prompt for feedback | |
| 16: f; = F(pi) → infer the feedback for refinement | |
| end for | |
| 17: | |
| 18: Da ← Da U {(xi,ti,ai, Cai)} | |
| 19: D。←D。U {(ci,ti,Oi,Coi)} 20: end for |
| 1: for (ci,ti, yi) in D do |
|---|
| 2: 设置辅助任务数据 Da = {}, D。= {} |
| 3: 设置初始提示 p = |
| 4: 设置初始反馈 f=None |
| 5: for e < ε do |
| 6: Pi = T(ci,ti, fi) |
| 7: ai,Cai = F(pi) |
| 8: pi =T(ci,ta,ai, fi) |
| 9: Oi, Coi = F(pi) |
| 10: Pi = T(ci,ti, ai, Oi, fi) |
| 11: yi = F(pi) > 推断极性 |
| 12: if y = yi then |
| 13: break |
| 14: end if |
| 15: Pi = T(ci,ti, ai, Oi,gi) > 生成反馈提示 |
| 16: f; = F(pi) → 推断优化反馈 |
| 17: end for |
| 18: Da ← Da U {(xi,ti,ai, Cai)} |
| 19: D。←D。U {(ci,ti,Oi,Coi)} |
| 20: end for |
its more consistent distribution and superior performance in application. Specifically, we conduct an empirical study on three data-level AWL strategies as follows:
其分布更一致且在应用中表现更优。具体而言,我们对以下三种数据级AWL策略进行了实证研究:
- Input (I) Strategy: The first strategy is scaling the input embedding according to the data-level confidence scores retrieved from Algorithm 1, directly influencing the feature representations fed into the backbone model. Given the model embedding layer $E m b(\cdot)$ and input text $x_{i}$ with confidence score $c_{i}$ , we adapt the auxiliary task loss in equation (2) to get:
- 输入 (I) 策略:第一种策略是根据算法1获取的数据级置信度分数对输入嵌入进行缩放,直接影响输入骨干模型的特征表示。给定模型嵌入层 $Emb(\cdot)$ 和带有置信度分数 $c_i$ 的输入文本 $x_i$,我们调整方程(2)中的辅助任务损失得到:
$$
e_{i}={c_{i}}\cdot{E m b}{(x_{i})}
$$
$$
e_{i}={c_{i}}\cdot{E m b}{(x_{i})}
$$
$$
\mathcal{L}{N L L_{(I)}}=-\frac{1}{N}\sum_{i=1}^{N}\sum_{t=1}^{T}l o g p(s_{i,t}|e_{i},s_{i,<t})
$$
$$
\mathcal{L}{N L L_{(I)}}=-\frac{1}{N}\sum_{i=1}^{N}\sum_{t=1}^{T}l o g p(s_{i,t}|e_{i},s_{i,<t})
$$
where the re-weighting embedding $e_{i}$ will be fed into the backbone model instead of the original $x_{i}$ for auxiliary task training.
重加权嵌入 $e_{i}$ 将被输入到骨干模型中,替代原始的 $x_{i}$ 用于辅助任务训练。
- Output (O) Strategy : The second strategy is to re-weight the output loss with data-level confidence scores retrieved from Algorithm 1 while dealing with data instances equally, which adjusts more attention to data instances with higher confidence levels during optimization. In this way, the auxiliary loss in equation (2) becomes:
- 输出 (O) 策略:第二种策略是在平等处理数据实例的同时,使用从算法1中获取的数据级置信度分数对输出损失进行重新加权,从而在优化过程中更多地关注置信度较高的数据实例。这样,方程 (2) 中的辅助损失变为:
$$
\mathcal{L}{N L L_{(O)}}=-\frac{1}{N}\sum_{i=1}^{N}\sum_{t=1}^{T}c_{i}\cdot l o g p(s_{i,t}|x_{i},s_{i,<t})
$$
$$
\mathcal{L}{N L L_{(O)}}=-\frac{1}{N}\sum_{i=1}^{N}\sum_{t=1}^{T}c_{i}\cdot l o g p(s_{i,t}|x_{i},s_{i,<t})
$$
- Input-Output (I-O) Strategy : The third strategy simultaneously conducts confidence-guided re-weighting towards input embedding and output loss, which combines equation (5) & (6) to get:
- 输入-输出 (I-O) 策略:第三种策略同时对输入嵌入和输出损失进行置信度引导的重新加权,结合公式 (5) 和 (6) 得到:
$$
\mathcal{L}{N L L_{(I-O)}}=-\frac{1}{N}\sum_{i=1}^{N}\sum_{t=1}^{T}c_{i}\cdot l o g p(s_{i,t}|e_{i},s_{i,<t})
$$
$$
\mathcal{L}{N L L_{(I-O)}}=-\frac{1}{N}\sum_{i=1}^{N}\sum_{t=1}^{T}c_{i}\cdot l o g p(s_{i,t}|e_{i},s_{i,<t})
$$
D. Task-level Automatic Weight Learning (T-AWL)
D. 任务级自动权重学习 (T-AWL)
At the task level, we have each subtask represent one sentiment element. Instead of manually adjusting the weight between tasks, MT-ISA introduces homos ced a stic uncertainty [40] as the task-level uncertainty 1 to capture relative confidence among tasks. Subsequently, we develop an automatic loss function (ALF) for the multi-task loss in MT-ISA and train the model based on $A L F_{1}$ :
在任务层面,我们让每个子任务代表一个情感元素。MT-ISA没有手动调整任务间的权重,而是引入了同方差不确定性 (homoscedastic uncertainty) [40] 作为任务级不确定性1,以捕捉任务间的相对置信度。随后,我们为MT-ISA的多任务损失开发了一个自动损失函数 (ALF) ,并基于 $ALF_{1}$ 训练模型:
$$
\mathcal{L}=\frac{1}{{\sigma_{1}}^{2}}\mathcal{L}{a}+\frac{1}{{\sigma_{2}}^{2}}\mathcal{L}{o}+\frac{1}{{\sigma_{3}}^{2}}\mathcal{L}{p}+\sum_{i=1}^{k}l o g({\sigma_{i}}^{2})
$$
$$
\mathcal{L}=\frac{1}{{\sigma_{1}}^{2}}\mathcal{L}{a}+\frac{1}{{\sigma_{2}}^{2}}\mathcal{L}{o}+\frac{1}{{\sigma_{3}}^{2}}\mathcal{L}{p}+\sum_{i=1}^{k}l o g({\sigma_{i}}^{2})
$$
where $\sigma$ is a tunable observation noise parameter that measures task-level uncertainty, $l o g(\sigma^{2})$ is the regular iz ation term, and $k$ is the number of varied tasks.
其中$\sigma$是可调节的观测噪声参数,用于衡量任务级不确定性,$log(\sigma^{2})$是正则化项,$k$是任务变体数量。
However, to avoid negative values during optimization introduced by $l o g(\sigma^{2})$ when $\sigma^{2}<1$ , the regular iz ation term can be adapted to $l n(\sigma^{2}+1)$ as suggested by [42]. Then we adapt $A L F_{2}$ as follows:
然而,为了避免优化过程中当 $\sigma^{2}<1$ 时 $log(\sigma^{2})$ 引入负值,如 [42] 所建议,正则化项可调整为 $ln(\sigma^{2}+1)$。随后我们将 $ALF_{2}$ 调整如下:
$$
\mathcal{L}=\frac{1}{{\sigma_{1}}^{2}}\mathcal{L}{a}+\frac{1}{{\sigma_{2}}^{2}}\mathcal{L}{o}+\frac{1}{{\sigma_{3}}^{2}}\mathcal{L}{p}+\sum_{i=1}^{k}l n({\sigma_{i}}^{2}+1)
$$
$$
\mathcal{L}=\frac{1}{{\sigma_{1}}^{2}}\mathcal{L}{a}+\frac{1}{{\sigma_{2}}^{2}}\mathcal{L}{o}+\frac{1}{{\sigma_{3}}^{2}}\mathcal{L}{p}+\sum_{i=1}^{k}l n({\sigma_{i}}^{2}+1)
$$
In practice, we evaluate and compare both $A L F_{1}$ and $A L F_{2}$ as discussed in section V. Through the implementation of the above-developed loss function $\mathcal{L}$ for multi-task fine-tuning, we expect the model to dynamically adjust the task weight and model parameters simultaneously under D-AWL and T-AWL strategies.
在实践中,我们如第五节所述对 $ALF_{1}$ 和 $ALF_{2}$ 进行了评估比较。通过采用上述开发的多任务微调损失函数 $\mathcal{L}$ ,我们期望模型能在 D-AWL 和 T-AWL 策略下动态调整任务权重与模型参数。
IV. EXPERIMENT
IV. 实验
A. Setup
A. 设置
a) Datasets and Metrics: To evaluate the performance of ISA, We take experiments on Restaurant and Laptop datasets in SemEval-2014 [43] and follow the prior work [3] splitting annotated data into implicit and explicit classes. The evaluation metrics use accuracy and macro-F1 score.
a) 数据集和指标:为了评估 ISA (Implicit Sentiment Analysis) 的性能,我们在 SemEval-2014 [43] 的 Restaurant 和 Laptop 数据集上进行实验,并按照先前工作 [3] 将标注数据划分为隐式和显式类别。评估指标采用准确率 (accuracy) 和宏平均 F1 值 (macro-F1 score)。
b) Baselines: We compare our approach with state-ofthe-art ABSA baselines and recently reported prompt-based fine-tuning methods. Given that we utilize GPT-4o-mini for auxiliary task construction, we also include its zero-shot performance for reference. Additionally, we compare with MTL baselines to demonstrate the effectiveness of our automatic MTL approach. The baselines are as follows:
b) 基线方法: 我们将本方法与最先进的ABSA基线方法及近期报道的基于提示词(prompt-based)的微调方法进行对比。由于使用了GPT-4o-mini构建辅助任务,我们同时列出其零样本(zero-shot)性能作为参考。此外,通过与多任务学习(MTL)基线对比,验证本文自动构建MTL方法的有效性。具体基线方法包括:
ABSA Baselines:
ABSA基线:
$^1\mathrm{It}$ is also known as task-dependent uncertainty [41] proven to effectively reflect the task inherent uncertainties in the multi-task setting. Notably, this uncertainty remains constant across all input data but varies between tasks.
$^1\mathrm{It}$ 也被称为任务相关不确定性 (task-dependent uncertainty) [41],已被证明能有效反映多任务设置中任务固有的不确定性。值得注意的是,这种不确定性在所有输入数据中保持恒定,但在不同任务间存在差异。
– $\mathbf{\nabla}-\mathbf{B}\mathbf{ERT}_{A s p}{+}\mathbf{CEPT}$ [3]: Replaces contrastive learning with cross-entropy loss to post-train BERT with external corpora. – ABSA-ESA [23]: Augments implicit cases with explicit expressions using encoder-decoder models.
– $\mathbf{\nabla}-\mathbf{B}\mathbf{ERT}_{A s p}{+}\mathbf{CEPT}$ [3]: 用交叉熵损失替代对比学习,通过外部语料库对 BERT 进行后训练。
– ABSA-ESA [23]: 使用编码器-解码器模型,通过显式表达增强隐式案例。
• Prompt-based Fine-tuning:
• 基于提示的微调 (Prompt-based Fine-tuning):
MTL Methods:
MTL方法:
– BERT-MTL [29]: Simultaneously learns aspect-term and aspect-category sentiment analysis tasks. – MTABSA [30]: Jointly learns aspect term extraction and aspect polarity classification tasks. – MT-Re and MT-Ra [13]: Conduct MTL on LLMs by jointly learning rationales and question-answer pairs of original data. MT-Re derives rationales using reasoning (Re) prompts, whereas MT-Ra employs rationalization (Ra) prompts.
– BERT-MTL [29]: 同时学习方面术语(aspect-term)和方面类别(aspect-category)情感分析任务。
– MTABSA [30]: 联合学习方面术语提取(aspect term extraction)和方面极性分类(aspect polarity classification)任务。
– MT-Re和MT-Ra [13]: 通过联合学习原始数据的推理依据(rationales)和问答对(question-answer pairs),在大语言模型上进行多任务学习(MTL)。MT-Re使用推理(Re)提示(prompts)生成推理依据,而MT-Ra采用合理化(Ra)提示。
c) Models and Hyper parameters: We use an off-theshelf model, GPT-4o-mini, for auxiliary task construction applying a self-refine strategy [24] with polarity label intervention. For MTL, we use Flan-T5 [46] in encoder-decoder archi- tecture as the backbone model. We test different sizes of FlanT5 scaling from the base model (250M) to the XXL model (13B) to investigate their performance and behavior under data-level and task-level AWL. As our method applies AWL instead of manual adjustment, the task weights for different subtasks are tunable hyper parameters that are optimized along with model parameters. To maintain more stable training, we adopt $A L F_{2}$ as the multi-task loss objective to present the main results, and we discuss the results obtained with various $A L F$ in Section V.
c) 模型与超参数:我们采用现成模型GPT-4o-mini进行辅助任务构建,应用了带极性标签干预的自优化策略[24]。对于多任务学习(MTL),我们选用基于编码器-解码器架构的Flan-T5[46]作为主干模型,测试了从基础模型(250M)到XXL模型(13B)不同规模的FlanT5在数据级和任务级自适应权重学习(AWL)下的性能表现。由于采用AWL替代人工调整,不同子任务的任务权重是可训练超参数,与模型参数同步优化。为保持训练稳定性,我们采用$ALF_{2}$作为多任务损失目标呈现主要结果,并在第五节讨论不同$ALF$的对比结果。
B. Main Results
B. 主要结果
- Comparison with Baselines: The main results compared with baseline methods are shown in Table I. It can be seen that our method, MT-ISA, surpasses the current baselines and achieves state-of-the-art results in ISA, demonstrating the effectiveness of our proposed framework for learning relationships among sentiment elements. Notably, even the base-sized model with the input D-AWL strategy, $M T\ –I S A_{I}$ , outperforms most baselines, with the exception of $\mathrm{BERT}{A s p}$ $^+$ SCAPT [3]. Although $\mathrm{BERT}_{A s p}+\mathrm{SCAPT}$ is pre-trained on the large-scale aspect-aware annotated dataset and exhibits strong capabilities in ABSA, our method still shows superior performance on the Laptop dataset. In MT-ISA, we employed GPT-4o-mini for auxiliary task construction. We tested the zero-shot performance of GPT-4o-mini for reference and observed a gap between directly applying a strong model like GPT-4o-mini and fine-tuning a base model like Flan-T5-base in ISA. Furthermore, there is a performance degradation in both overall and implicit results when adopting GPT-4o-mini with the THOR method, where THOR uses CoT prompting to elicit relevant sentiment elements. This suggests that chainof-thought prompting requires the model to maintain context and coherence over multiple steps, which can be challenging for smaller models with less capacity for direct inference. In contrast, our method infers relevant sentiment elements with polarity inference as auxiliary tasks and applies multi-task learning with D-AWL and T-AWL techniques for more reliable and effective supervision of reasoning learning on primary tasks.
- 与基线方法的对比:主要实验结果如表1所示。可以看出我们的MT-ISA方法超越了现有基线,在ISA任务中取得了最先进成果,验证了所提框架在学习情感元素关系方面的有效性。值得注意的是,即使采用基础尺寸模型配合D-AWL输入策略的$MT–ISA_{I}$,其表现也优于多数基线方法(除$\mathrm{BERT}{Asp}$$^+$SCAPT [3]外)。虽然$\mathrm{BERT}_{Asp}+\mathrm{SCAPT}$在大规模方面感知标注数据集上进行了预训练,在ABSA任务中展现出强大能力,但我们的方法在Laptop数据集上仍保持优势。MT-ISA采用GPT-4o-mini构建辅助任务,测试其零样本性能作为参考时发现:直接应用GPT-4o-mini等强大模型与微调Flan-T5-base等基础模型在ISA任务中存在差距。此外,当GPT-4o-mini配合THOR方法(通过思维链提示激发相关情感元素)时,整体和隐含结果均出现性能下降,这表明思维链提示要求模型在多步推理中保持上下文连贯性,这对推理能力有限的小型模型具有挑战性。相比之下,我们的方法通过极性推理推断相关情感元素作为辅助任务,并应用D-AWL和T-AWL技术的多任务学习,为主任务的推理学习提供了更可靠有效的监督。
TABLE I MAIN RESULTS COMPARED WITH BASELINES ON RESTAURANT AND LAPTOP DATASETS. THE RESULTS WITH † AND ⋆ ARE OBTAINED FROM [3] AND [23], WHILE THE OTHER RESULTS ARE SELF-RERUN OR SELF-IMPLEMENTED. IN OUR METHODS, THE SUBSCRIPTS STAND FOR DATA-LEVEL AWL STRATEGIES: INPUT STRATEGY(I) AND OUTPUT STRATEGY $(O)$ , RESPECTIVELY. THE SUBSCRIPTS $A$ AND $F$ FOR EVALUATION METRICS REPRESENT THE ACCURACY AND MACRO-F1 SCORE.
表 1: 与基线方法在 Restaurant 和 Laptop 数据集上的主要结果对比。标注 † 和 ⋆ 的结果分别来自 [3] 和 [23],其余结果为自行复现或实现。在我们的方法中,下标表示数据级 AWL 策略:输入策略 (I) 和输出策略 (O)。评估指标下标 A 和 F 分别表示准确率和宏观 F1 分数。
| 方法 | 模型 | Restaurant14 | Laptop14 | ||||
|---|---|---|---|---|---|---|---|
| AllA | AllF | ISAA | AllA | AllF | ISAA | ||
| -State-of-the-art ABSA 基线 | |||||||
| BERT-SPC† [19] | BERT-Base (110M) | 83.57 | 77.16 | 65.54 | 78.22 | 73.45 | 69.54 |
| BERT-ADA† [44] | BERT-Base (110M) | 87.14 | 80.05 | 65.92 | 78.96 | 74.18 | 70.11 |
| RGAT† [21] | BERT-Base (110M) | 86.60 | 81.35 | 67.79 | 78.21 | 74.07 | 72.99 |
| BERTAsp + CEPT† [3] | BERT-Base (110M) | 87.50 | 82.07 | 67.79 | 81.66 | 78.38 | 75.86 |
| C3DA+ [20] | BERT-Base (110M) | 86.93 | 81.23 | 65.54 | 80.61 | 77.11 | 73.57 |
| ISAIV [22] | BERT-Base (110M) | 87.05 | 81.40 | - | 80.41 | 77.25 | - |
| BERTAsp + SCAPT† [3] | BERT-Base (110M) | 89.11 | 83.79 | 72.28 | 82.76 | 79.15 | 77.59 |
| ABSA-ESA⋆ [23] | T5-Base (220M) | 88.29 | 81.74 | 70.78 | 82.44 | 79.34 | 80.00 |
| RGAT† [21] | BERT-Large (340M) | 86.87 | 79.99 | 68.05 | 80.25 | 76.26 | 75.43 |
| -基于提示的微调 | |||||||
| 直接微调 | Flan-T5-Base (250M) | 86.88 | 79.78 | 65.17 | 81.98 | 77.93 | 73.71 |
| InstructABSA [45] | Tk-INSTRUCT (200M) | 80.89 | 38.26 | 47.19 | 79.31 | 46.29 | 73.71 |
| THOR [6] | Flan-T5-Base (250M) | 87.68 | 81.10 | 68.54 | 81.66 | 77.51 | 74.29 |
| 直接微调 | Flan-T5-XXL (11B) | 89.29 | 83.68 | 75.28 | 81.82 | 77.69 | 75.43 |
| THOR [6] | Flan-T5-XXL (11B) | 88.57 | 82.93 | 73.03 | 82.29 | 78.78 | 76.57 |
| -零样本基线 | |||||||
| GPT-4o-mini | - | 84.82 | 72.52 | 61.45 | 79.94 | 73.83 | 64.17 |
| GPT-4o-mini + THOR | - | 81.25 | 62.12 | 46.07 | 72.10 | 55.42 | 37.38 |
| -自动多任务学习 | |||||||
| MT-ISA₁ (Ours) | Flan-T5-Base (250M) | 88.21 | 82.45 | 70.41 | 82.91 | 79.86 | 80.57 |
| MT-ISAₒ (Ours) | Flan-T5-Base (250M) | 85.89 | 77.85 | 66.29 | 81.98 | 78.10 | 75.43 |
| MT-ISA₁ (Ours) | Flan-T5-XXL (11B) | 91.34 | 86.71 | 81.27 | 85.40 | 82.73 | 86.29 |
| MT-ISAₒ (Ours) | Flan-T5-XXL (11B) | 92.68 | 88.96 | 84.27 | 85.74 | 83.86 | 88.57 |
- Comparison with Multi-task Learning methods: To further compare with other multi-task learning methods, we demonstrate the results in Table II. We utilize the base size model for fair comparison. Our method $M T–I S A_{I}$ outperforms baseline methods that apply multi-task learning in ABSA. Among these, BERT-MTL [29] and MTABSA [30] construct auxiliary tasks from the perspective of different task types conducive to sentiment polarity inference. In contrast, our method builds auxiliary tasks intending to complete the sentiment picture and focus on semantic and sentiment correlation. We also implemented MT-Re and MT-Ra following [13], which jointly learn rationales with prediction tasks and similarly incorporate relevant sentiment element information in the rationales. However, they applied the multi-task loss by simply summing the loss from each task, lacking fine-grained control at both the data and task levels to enhance primary task performance. Overall, our method with a base-sized model significantly surpasses other multi-task learning methods by introducing AWL for data-level and task-level optimization.
- 与其他多任务学习方法的对比: 为进一步对比其他多任务学习方法,我们在表II中展示了结果。为保证公平比较,我们使用基础尺寸模型。我们的方法 $M T–I S A_{I}$ 在ABSA中应用多任务学习的基线方法上表现更优。其中,BERT-MTL [29] 和 MTABSA [30] 从有助于情感极性推断的不同任务类型角度构建辅助任务。相比之下,我们的方法旨在构建辅助任务以完善情感图景,并聚焦于语义与情感关联。我们还按照[13]实现了MT-Re和MT-Ra,它们将原理与预测任务联合学习,并在原理中类似地整合了相关情感元素信息。然而,它们仅通过简单求和各项任务损失来应用多任务损失,缺乏在数据和任务级别进行细粒度控制以提升主任务性能。总体而言,我们采用基础尺寸模型的方法通过引入AWL (Adaptive Weighted Loss) 进行数据级和任务级优化,显著超越了其他多任务学习方法。
TABLE II MAIN RESULTS OF ACCURACY COMPARED WITH OTHER MULTI-TASK LEARNING METHODS. THE RESULTS WITH † IS OBTAINED FROM [29] AND [30].
表 II 与其他多任务学习方法相比的主要准确率结果。带†的结果来自[29]和[30]。
| 方法 | 模型 | Restaurant14 | Laptop14 | ||
|---|---|---|---|---|---|
| All | ISA | All | ISA | ||
| BERT-MTL ↑[29] | BERT-Base | 84.60 | 80.30 | ||
| MTABSA + [30] | BERT-Base | 86.88 | 80.56 | ||
| MT-Re [13] | Flan-T5-Base | 86.25 | 63.67 | 81.35 | 77.14 |
| MT-Ra [13] | Flan-T5-Base | 86.96 | 64.05 | 82.29 | 76.00 |
| MT-ISAI | Flan-T5-Base | 88.21 | 70.41 | 82.91 | 80.57 |
- Comparison with D-AWL Strategies: We evaluate and compare different D-AWL strategies from two perspectives, one is learned task weights as shown in Table III, and another is the accuracy performance in ISA as illustrated in Figure 3. Results for both base-size and XXL-size models are included. It is observed that the base-size model learns more effectively with the input data-level AWL strategy while the XXL-size model performs better with the output data-level AWL strategy across both datasets. This is because the base-size models with less reasoning capacity may not be capable of digesting the auxiliary information as effectively as XXL-size models, leading them to assign less weight to auxiliary tasks. They benefit more from input-level adjustments which help the model focus on the most relevant features, compensating for its limited capacity to process and prioritize information. While XXL-size models with greater capacity can handle complex input data more effectively, all the strategies assign similarly higher weights for auxiliary tasks compared to that applied in base-size models. Output data-level AWL strategy allows XXL-size models to fine-tune their predictions by emphasizing more confident outputs, leveraging their ability to process and learn from a broader range of data. When it comes to the input-output strategy, it generally lags behind the other two strategies regardless of model size. It is possibly due to overadjustment, which introduces excessive attention or neglect of certain data by combining both input strategies. In general, these data-level AWL strategies can be conducive to preventing over-fitting problems during training and our method with finegrained automatic weight learning enables models of different sizes to select the most suitable strategy and achieve optimal performance
- 与D-AWL策略的比较:我们从两个角度评估比较不同的D-AWL策略,一是如表III所示的学习任务权重,二是如图3所示的ISA准确率性能。结果包含基础尺寸和XXL尺寸模型。观察发现,基础尺寸模型在输入数据级AWL策略下学习效果更好,而XXL尺寸模型在两个数据集上采用输出数据级AWL策略表现更优。这是因为推理能力较弱的基础尺寸模型无法像XXL尺寸模型那样有效消化辅助信息,导致它们对辅助任务分配较低权重。它们更受益于输入级调整,这有助于模型聚焦最相关特征,弥补其处理和优先处理信息的能力限制。而具备更强能力的XXL尺寸模型能更有效处理复杂输入数据,所有策略对辅助任务分配的权重均高于基础尺寸模型。输出数据级AWL策略使XXL尺寸模型能通过强调更高置信度的输出来微调预测,充分利用其处理和学习更广泛数据的能力。至于输入-输出组合策略,无论模型尺寸如何,其表现普遍落后于另外两种策略,可能是由于过度调整导致某些数据受到过多关注或被忽视。总体而言,这些数据级AWL策略有助于防止训练过程中的过拟合问题,我们提出的细粒度自动权重学习方法能让不同尺寸的模型选择最适合的策略以获得最佳性能。

Fig. 3. Com parisi on of performance with different D-AWL strategies, including input (I), output (O), and input-output (I-O) strategies. The metric uses the accuracy of implicit datasets.
图 3: 不同D-AWL策略的性能对比,包括输入(I)、输出(O)和输入-输出(I-O)策略。评估指标采用隐式数据集的准确率。
TABLE III TASKS WEIGHT LEARNED USING DIFFERENT DATA-LEVEL AUTOMATICWEIGHT LEARNING (D-AWL) STRATEGIES IN MT-ISA.
表 3: MT-ISA 中使用不同数据级自动权重学习 (D-AWL) 策略学习到的任务权重
| 策略 | Restaurant14 | Laptop14 | ||||
|---|---|---|---|---|---|---|
| Polarity | Aspect | Opinion | Polarity | Aspect | Opinion | |
| Base | 0.4 | 0.3 | 0.3 | 0.4 | 0.3 | 0.3 |
| ·Flan-T5-Base | ||||||
| D-AWL1 | 0.73 | 0.14 | 0.14 | 0.54 | 0.23 | 0.23 |
| D-AWLO | 0.43 | 0.28 | 0.28 | 0.41 | 0.29 | 0.29 |
| D-AWLI-O | 0.73 | 0.14 | 0.14 | 0.41 | 0.29 | 0.29 |
| ·Flan-T5-XXL | ||||||
| D-AWL1 | 0.34 | 0.33 | 0.33 | 0.34 | 0.33 | 0.33 |
| D-AWLO | 0.36 | 0.32 | 0.32 | 0.39 | 0.31 | 0.31 |
| D-AWL1-O | 0.43 | 0.28 | 0.28 | 0.39 | 0.31 | 0.31 |
- Model Size Effect: Figure 4 illustrates the effect of model size on MT-ISA with input and output D-AWL strategies. Both auxiliary task weights and implicit F1 score are compared. In most cases, the assigned weights for aspect and opinion auxiliary tasks overlap because they share the same construction process and task type. As model size increases, the performance of MT-ISA improves regardless of the datalevel AWL strategy employed. This is because larger models possess greater reasoning capacity, allowing them to benefit more from auxiliary tasks. For $M T–I S A_{I}$ , a similar trend is observed with the assigned task weights for auxiliary tasks. While $M T–I S A_{O}$ shows slight changes in task weights as model size increases. Since the ability to handle different complex input data can improve as model size increases under input DAWL strategy, while output D-AWL strategy maintains a focus on refining predictions, the relative importance of auxiliary tasks remains stable.
- 模型规模效应: 图4展示了模型规模对采用输入/输出D-AWL策略的MT-ISA的影响,对比了辅助任务权重与隐式F1分数。在多数情况下,方面和观点辅助任务的分配权重会重叠,因为它们共享相同的构建流程和任务类型。随着模型规模增大,无论采用何种数据级AWL策略,MT-ISA性能都会提升,这是因为更大模型具有更强的推理能力,能从辅助任务中获益更多。对于$MT–ISA_{I}$,辅助任务权重也呈现相似趋势;而$MT–ISA_{O}$的任务权重随模型规模增大仅出现轻微变化。由于在输入D-AWL策略下,处理不同复杂输入数据的能力会随模型规模提升而增强,而输出D-AWL策略始终专注于优化预测结果,因此辅助任务的相对重要性保持稳定。
C. Ablation Study
C. 消融实验
We conduct an ablation study for the proposed MT-ISA framework to investigate the effects of D-AWL and T-AWL. The best-performing models were evaluated: $\mathrm{MT-ISA}{I}$ with the base-size model, and $\mathrm{MT-ISA}_{I}$ with the XXL-size model. As shown in Table IV, MT-ISA without D-AWL exhibits a performance degradation of nearly $2%$ , with an even greater drop observed in the Restaurant ISA using the XXL-size model. This underscores the effectiveness of the D-AWL strategy in adjusting data-level attention and enhancing effective learning during multi-task fine-tuning. However, the performance decline of MT-ISA without T-AWL is more pronounced than without D-AWL. Given that multi-task learning can be sensitive to task weights, MT-ISA relying on grid search for optimal task weights may fail to achieve the fine-grained task weight optimization provided by T-AWL. T-AWL plays a crucial role in MT-ISA by balancing different tasks and adapting effectively to models of various sizes. Furthermore, when MT-ISA is applied without the assistance of D-AWL and T-AWL, where we refer collectively to AWL in the table, the performance decreases dramatically with a maximum drop of nearly 9 points in Restaurant ISA. This highlights the mutually reinforcing relationship between D-AWL and TAWL, where D-AWL supplements data-level adjustment and T-AWL manages task-level control accounting for the datalevel effects of D-AWL.
我们对提出的MT-ISA框架进行了消融实验,以研究D-AWL和T-AWL的影响。评估了性能最佳的模型:基于基础尺寸模型的$\mathrm{MT-ISA}{I}$和基于XXL尺寸模型的$\mathrm{MT-ISA}_{I}$。如表IV所示,未使用D-AWL的MT-ISA性能下降了近$2%$,而在使用XXL尺寸模型的Restaurant ISA中下降更为明显。这凸显了D-AWL策略在调整数据级注意力及增强多任务微调有效学习方面的作用。然而,未使用T-AWL的MT-ISA性能下降比未使用D-AWL更为显著。鉴于多任务学习对任务权重较为敏感,依赖网格搜索优化任务权重的MT-ISA可能无法实现T-AWL提供的细粒度任务权重优化。T-AWL通过平衡不同任务并有效适应不同尺寸模型,在MT-ISA中发挥着关键作用。此外,当MT-ISA在没有D-AWL和T-AWL辅助的情况下应用时(表中统称为AWL),性能急剧下降,Restaurant ISA最大降幅近9分。这体现了D-AWL与T-AWL的互补关系:D-AWL补充数据级调整,而T-AWL则通过考虑D-AWL的数据级效应来管理任务级控制。
D. Case Study
D. 案例研究
This section presents a case study for auxiliary task construction aimed at restoring aspect $a$ and opinion $o$ in ISA, as illustrated in Figure 5. This example involves two rounds of dialogue to achieve consensus with an off-the-shelf LLM, GPT4o-mini. During the process of inferring sentiment elements, the generated auxiliary data is appended to subsequent questions to serve as a reference. Additionally, the confidence score is elicited with each response. Through the implementation of a self-refine strategy with gold label intervention, GPT-4o-mini effectively refines its responses to align with the ground truth sentiments. Furthermore, the confidence scores exhibit a slight increase following this refinement process. This observation is consistent with the distribution of confidence scores discussed in Section V.
本节展示了一个辅助任务构建的案例研究,旨在恢复ISA中的方面$a$和观点$o$,如图5所示。该案例通过两轮对话与现成大语言模型GPT4o-mini达成共识。在推理情感要素过程中,生成的辅助数据会附加到后续问题中作为参考。每次响应时还会获取置信度分数。通过采用带黄金标签干预的自优化策略,GPT-4o-mini有效优化了其响应以匹配真实情感。此外,优化后的置信度分数呈现小幅提升,这一现象与第V节讨论的置信度分数分布规律一致。

Fig. 4. The model size effect for MT-ISA with input and output D-AWL strategies. Both auxiliary task weights and implicit F1 score are compared.
图 4: 采用输入输出D-AWL策略的MT-ISA模型尺寸效应对比。图中同时比较了辅助任务权重和隐式F1分数。
TABLE IV ABLATION STUDY FOR MT-ISA WITH THE MACRO-F1 SCORE METRIC. THE ABBREVIATIONS REPRESENT DATA-LEVEL AUTOMATIC WEIGHT LEARNING (D-AWL) AND TASK-LEVEL AUTOMATIC WEIGHT LEARNING (T-AWL).
表 4: 基于宏F1指标的MT-ISA消融研究。缩写代表数据级自动权重学习(D-AWL)和任务级自动权重学习(T-AWL)。
| 方法 | 模型 | Restaurant14 (All) | Restaurant14 (ISA) | Laptop14 (All) | Laptop14 (ISA) |
|---|---|---|---|---|---|
| MT-ISAI - w/o D-AWL | Flan-T5-Base | 82.45 | 69.21 | 79.86 | 73.83 |
| 80.60 | 67.04 | 77.82 | 71.38 | ||
| -w/o T-AWL | 80.28 | 66.91 | 77.80 | 70.56 | |
| -w/oL | 74.89 | 60.43 | 77.76 | 69.98 | |
| MT-ISAO | Flan-T5-XXL | 88.96 | 84.11 | 83.86 | 85.99 |
| - w/oD-AWL | 87.73 | 80.23 | 82.19 | 85.08 | |
| -w/oT-AWL | 85.78 | 79.92 | 82.91 | 82.76 | |
| -w/oAWL | 84.71 | 77.36 | 82.23 | 82.10 |
V. DISCUSSION
V. 讨论
We propose a multi-task learning framework MT-ISA, leveraging generative LLMs for auxiliary data construction to restore the complete sentiment picture. During optimization, we conduct D-AWL and T-AWL to enhance reliable reasoning and achieve optimal performance in ISA. Given the critical roles of data confidence score in D-AWL and automatic loss function in T-AWL, this section will discuss confidence score distribution in part V-A and automatic loss function in part V-B. We will evaluate alternative approaches and provide an in-depth analysis of their impact on the overall performance of the framework.
我们提出了一种多任务学习框架MT-ISA,利用生成式大语言模型进行辅助数据构建以恢复完整情感图景。在优化过程中,我们采用D-AWL和T-AWL来增强可靠推理能力,并在ISA任务中实现最优性能。鉴于数据置信度分数在D-AWL中的关键作用以及自动损失函数在T-AWL中的重要性,本节将在第V-A部分讨论置信度分数分布,在第V-B部分分析自动损失函数。我们将评估替代方案,并深入分析它们对框架整体性能的影响。
A. Confidence Score Distribution
A. 置信度分数分布
In the MT-ISA framework, we employ a prompt-based approach to derive confidence scores for data instances. The dominant research elicits confidence scores with prompt-based [47] or training-based approach. Figures 6 (a) and (b) illustrate the distribution of confidence scores across two benchmark datasets. Both datasets exhibit a similar distribution, with confidence scores ranging from 0.5 to 1.0, and the majority falling between 0.8 and 1.0. This trend is attributed to the tendency of the model to assign higher scores to its answerverified results following several epochs of self-refinement with label intervention. To compare with alternative confidence estimation methods, we investigate two additional approaches using the Laptop dataset, as depicted in Figures 6 (c) and (d):
在MT-ISA框架中,我们采用基于提示词(prompt-based)的方法来推导数据实例的置信度分数。主流研究通过基于提示词[47]或基于训练的方法来获取置信度分数。图6(a)和(b)展示了两个基准数据集中置信度分数的分布情况。两个数据集呈现出相似的分布特征,置信度分数范围在0.5至1.0之间,且多数集中在0.8至1.0区间。这一趋势归因于模型在经过多轮带标签干预的自优化后,倾向于为其验证通过的答案赋予更高分数。为与其他置信度估计方法进行对比,我们基于Laptop数据集研究了另外两种方法,如图6(c)和(d)所示:
From the confidence score distribution, the Markov Chain approach predominantly yields scores in the range of 0.5 to 1.0. In contrast, the Choice Token method produces scores mostly between 0.8 and 1.0, aligning closely with the promptbased method depicted in Figure 6 (b). However, both the Markov Chain and Choice Token distributions exhibit a longtail effect, where low confidence scores can lead to poor generation outcomes when input strategy is applied. Since the backbone models are pre-trained with a stable input distribution, very low confidence scores for input embedding re-weighting may result in the loss of significant information. This distortion can cause the model to misinterpret the input, leading to outputs that are nonsensical or garbled. In practice, we clip the scores to a minimum of 0.5, assuming that this threshold sufficiently reflects uncertainty to a certain extent. The performance results are presented in Table V. It is evident that the prompt-based method, with its more consistent confidence estimation, demonstrates superior performance compared to the other two methods. Even when identical auxiliary task weights are learned, variations in prediction performance persist. This observation underscores the critical importance of confidence calibration in facilitating data-level AWL in MTISA. Moreover, it highlights the effectiveness of the promptbased method in eliciting reliable confidence scores during the self-refinement process.
从置信分数分布来看,马尔可夫链方法生成的分数主要集中在0.5至1.0区间,而Choice Token方法产生的分数则集中在0.8至1.0范围,与图6(b)所示的基于提示的方法高度吻合。然而这两种方法都呈现长尾效应——当应用输入策略时,过低的置信分数会导致生成质量下降。由于骨干模型是在稳定输入分布下预训练的,输入嵌入重加权时的极低置信分数可能导致重要信息丢失。这种失真会使模型误解输入内容,产生无意义或混乱的输出。实践中我们将分数下限截断至0.5,假设该阈值能在一定程度上充分反映不确定性。性能结果如表V所示,可见基于提示的方法凭借更稳定的置信度估计展现出更优性能。即使学习到相同的辅助任务权重,预测性能仍存在差异。这一发现不仅印证了置信度校准在MTISA中实现数据级自适应权重学习的关键作用,更凸显了基于提示的方法在自优化过程中获取可靠置信分数的有效性。

Fig. 5. An example illustrates Algorithm 1 designed for constructing auxiliary data. This process generates both aspect $^{a}$ and opinion $^o$ using a self-refine strategy with gold label intervention. This example reaches a consensus with GPT-4o-mini after two runs.
图 5: 一个展示算法1的示例,该算法专为构建辅助数据而设计。此过程通过采用带黄金标签干预的自优化策略,同时生成方面 $^{a}$ 和观点 $^o$。该示例经过两次运行后与GPT-4o-mini达成一致。

Fig. 6. The distribution of confidence score retrieved with different methods:(a) Restaurant dataset with Prompt-based method, (b) Laptop dataset with Prompt-based method, (c) Laptop dataset with Markov Chain method, (d) Laptop dataset with Choice Token method.
图 6: 不同方法检索的置信度分数分布:(a) 基于提示方法 (Prompt-based) 的餐厅数据集,(b) 基于提示方法的笔记本数据集,(c) 马尔可夫链方法 (Markov Chain) 的笔记本数据集,(d) 选择 Token 方法 (Choice Token) 的笔记本数据集。
TABLE V COMPARISON OF PERFORMANCE ON LAPTOPS14 USING DIFFERENT METHODS FOR RETRIEVING CONFIDENCE SCORE. THE METRIC USES THEMACRO-F1 SCORE. AW REPRESENTS AUXILIARY TASK WEIGHT FORASPECT/OPINION TASK.
表 5: 不同置信度分数检索方法在LAPTOPS14数据集上的性能对比。评估指标采用宏F1分数(Macro-F1)。AW表示方面/观点任务的辅助任务权重。
| 方法 | 置信度 | 模型 | Laptop14 (All) | ISA | AW |
|---|---|---|---|---|---|
| MT-ISA1 | Prompt | Flan-T5-Base | 79.86 | 73.83 | 0.23 |
| MarkovChain | 77.19 | 70.89 | 0.23 | ||
| Choice Token | 76.60 | 71.48 | 0.30 | ||
| MT-ISAO | Prompt | Flan-T5-XXL | 83.86 | 85.99 | 0.31 |
| MarkovChain | 82.81 | 84.49 | 0.31 | ||
| ChoiceToken | 83.24 | 85.47 | 0.31 |
B. Automatic Loss Function
B. 自动损失函数
To facilitate T-AWL in multi-task scenarios, we extend the automatic loss function proposed by [41] and [42] to our multitask loss. The primary distinction between these approaches lies in the regular iz ation term, as shown in equations 8 and 9. However, their impact during the training process has not been previously explored. In this section, we compare $A L F_{1}$ with $A L F_{2}$ for T-AWL and evaluate their performance in the ISA scenario. The results are presented in Table VI. It is evident that MT-ISA with $A L F_{2}$ generally outperforms MT-ISA with $A L F_{1}$ across most scenarios. It is because $A L F_{1}$ carries the risk of introducing negative values when $\sigma$ is less than 1, potentially leading to instability in the training process or undesirable behavior. As observed in the results of $\mathrm{MT-ISA}{I}$ with $A L F_{1}$ in the Restaurant dataset, the learned weights for auxiliary tasks tend to approach very small values. This may be due to aggressive adjustments without enforcing a positive value in the regular iz ation term during training, causing the model to converge to a trivial solution. Even when both loss functions learn the same weights for auxiliary tasks, MTISA with $A L F_{1}$ demonstrates inferior performance. This is because the presence of negative values in the loss function can lead to erratic gradients or oscillations during training, affecting convergence behavior and resulting in suboptimal local minima. Overall, MT-ISA is sensitive to task weights and $A L F_{2}$ provides more stable training results, achieving optimal performance by effectively leveraging auxiliary tasks.
为在多任务场景中实现T-AWL,我们扩展了[41]和[42]提出的自动损失函数至多任务损失框架。两者的核心差异体现在正则项设计上(如公式8和9所示),但其在训练过程中的影响此前尚未被系统研究。本节通过对比$ALF_{1}$与$ALF_{2}$在T-AWL中的表现,评估了它们在ISA场景下的性能差异(结果见表6)。数据显示,采用$ALF_{2}$的MT-ISA在多数情况下优于$ALF_{1}$版本,这是因为当$\sigma$小于1时,$ALF_{1}$可能产生负值,进而引发训练过程不稳定或异常行为。例如在Restaurant数据集上,采用$ALF_{1}$的$\mathrm{MT-ISA}{I}$学得的辅助任务权重趋近于极小值——这源于训练过程中正则项未强制正值约束导致的激进调整,最终使模型收敛至平庸解。即便两种损失函数学得相同的辅助任务权重,$ALF_{1}$版本的MT-ISA仍表现欠佳,其损失函数中的负值可能引发梯度异常或训练震荡,影响收敛过程并陷入次优局部极小值。总体而言,MT-ISA对任务权重高度敏感,而$ALF_{2}$能提供更稳定的训练结果,通过有效利用辅助任务实现最优性能。
TABLE VI COMPARISON OF PERFORMANCE WHEN APPLYING T-AWL WITH $A L F_{1}$ AND $A L F_{2}$ IN MT-ISA. THE METRIC USES THE MACRO-F1 SCORE. AWREPRESENTS AUXILIARY TASK WEIGHT FOR ASPECT/OPINION TASK.
表 6: 在 MT-ISA 中应用 T-AWL 时 $ALF_{1}$ 和 $ALF_{2}$ 的性能对比。评估指标采用宏 F1 分数。AW 表示方面/观点任务的辅助任务权重。
| 方法 | 损失 | Restaurant14 | Laptop14 | ||||
|---|---|---|---|---|---|---|---|
| All | ISA | AW | All | ISA | AW | ||
| Flan-T5-Base | |||||||
| MT-ISAI | ALF1 | 81.81 | 68.34 | 0.08 | 79.41 | 74.52 | 0.21 |
| ALF2 | 82.45 | 69.21 | 0.14 | 79.86 | 73.83 | 0.23 | |
| Flan-T5-XXL | |||||||
| MT-ISAO | ALF1 | 85.88 | 79.32 | 0.32 | 84.81 | 83.85 | 0.32 |
| ALF2 | 88.96 | 84.11 | 0.32 | 83.86 | 85.99 | 0.31 |
VI. CONCLUSION
VI. 结论
In conclusion, we introduce a novel MTL framework, MT-ISA, designed to reason genuine underlying opinions in ISA by leveraging the generation and reasoning abilities of LLMs with automatic MTL. MT-ISA amically adjusts weights in MTL according to data-level and task-level uncertainties, enabling models of varying sizes to learn fine-grained weights based on their reasoning capabilities adaptively. We utilize an off-the-shelf LLM for auxiliary task construction, incorporating a self-refinement strategy with polarity label intervention to enhance the reliability of sentiment reasoning, where confidence scores are derived for responses to reflect data-level uncertainty. Our exploration includes threegies for data-level AWL, which are integrated with homos ced a stic uncertainty for task-level AWL. MT-ISA demonstrates stateof-the-art performance in ISA, highlighting its efficacy. Additionally, it is noteworthy that models of varying sizes exhibit distinct preferences and influences, yet they achieve optimal performance when employing the dynamic learning strategy. This finding underscores the robustness and adaptability of MT-ISA, suggesting its potential for broader applications.
综上所述,我们提出了一种新颖的多任务学习(MTL)框架MT-ISA,该框架通过结合大语言模型(LLM)的生成推理能力与自动多任务学习机制,旨在推理隐含情感分析(ISA)中的真实潜在观点。MT-ISA能根据数据级和任务级不确定性动态调整MTL权重,使不同规模的模型能基于其推理能力自适应学习细粒度权重。我们采用现成大语言模型构建辅助任务,通过引入极性标签干预的自优化策略增强情感推理的可靠性,其中置信度分数用于反映数据级不确定性。我们探索了三种数据级自适应权重学习(AWL)策略,并将其与任务级AWL的同方差不确定性相结合。MT-ISA在ISA任务中展现了最先进的性能,证明了其有效性。值得注意的是,不同规模的模型表现出差异化偏好和影响,但采用动态学习策略时均能获得最优性能。这一发现印证了MT-ISA的鲁棒性与适应性,表明其具备更广泛的应用潜力。
REFERENCES
参考文献

Wenna Lai is currently a Ph.D. student at the Department of Computing, Hong Kong Polytechnic University, under the supervision of Prof. Qing Li. She has been working closely with Prof. Guandong Xu at the School of Computer Science, University of Technology Sydney, and Prof. Haoran Xie at the School of Data Science, Lingnan University, Hong Kong. Before that, she received her Master’s degree in the Department of Electrical and Computer Engineering from the National University of Singapore. Her research interests include Affective Computing and NLP for Social Good.
温娜来目前是香港理工大学计算学系的博士生,师从李青教授。她与悉尼科技大学计算机科学学院的徐冠东教授以及香港岭南大学数据科学学院的谢浩然教授保持着密切合作。此前,她获得了新加坡国立大学电气与计算机工程系的硕士学位。她的研究兴趣包括情感计算和面向社会公益的自然语言处理。
Haoran Xie (Senior Member, IEEE) received a Ph.D. degree in Computer Science from City University of Hong Kong and an Ed.D degree in Digital Learning from the University of Bristol. He is currently a Professor and the Person-in-Charge at the Division of Artificial Intelligence, Director of LEO Dr David P. Chan Institute of Data Science, and Acting Associate Dean of the School of Data Science, Lingnan University, Hong Kong. His research interests include natural language processing, large language models, language learning, and AI in education. He has published 423 research publications, including 247 journal articles. He is the Editor-in-Chief of Natural Language Processing Journal, Computers & Education: Artificial Intelligence, and Computers & Education: X Reality. He has been selected as the World’s Top $2%$ Scientists by Stanford University.
谢浩然 (Senior Member, IEEE) 先后获得香港城市大学计算机科学博士学位和英国布里斯托大学数字学习教育博士学位。现任香港岭南大学数据科学学院人工智能学部主任、LEO Dr David P. Chan数据科学研究所所长、数据科学学院署理副院长,教授。研究领域涵盖自然语言处理、大语言模型、语言学习及教育人工智能。已发表423篇学术论著,其中期刊论文247篇。担任《Natural Language Processing Journal》《Computers & Education: Artificial Intelligence》和《Computers & Education: X Reality》三本期刊主编。入选斯坦福大学全球前2%顶尖科学家榜单。

Guandong Xu (Member, IEEE) received the Ph.D. degree in computer science from Victoria University, Melbourne, VIC, Australia, in 2009. He is currently a Professor and a Program Leader at the School of Computer Science and Data Science Institute, University of Technology Sydney, Sydney, NSW, Australia. His research interests include data science, data analytics, recommend er systems, web mining, user modeling, NLP, social network analysis, and social media mining.
徐广东 (IEEE会员) 于2009年获澳大利亚墨尔本维多利亚大学计算机科学博士学位。现任澳大利亚悉尼科技大学计算机科学学院教授兼数据科学研究所项目负责人。研究方向涵盖数据科学 (data science)、数据分析 (data analytics)、推荐系统 (recommender systems)、网络挖掘 (web mining)、用户建模 (user modeling)、自然语言处理 (NLP)、社交网络分析 (social network analysis) 及社交媒体挖掘 (social media mining)。


Qing Li (Fellow, IEEE) received the B.Eng. degree in Computer Science from Hunan Univeristy, Hunan, China, in 1982, and the M.S. and Ph.D. degrees in Computer Science from the University of Southern California, LA, California, USA, in 1985 and 1988, respectively. Qing Li is a Chair Professor and Head at the Department of Computing, The Hong Kong Polytechnic University. His research focuses on data science, web mining, and artificial intelligence. He is a Fellow of IET, a Fellow of IEEE, a member of ACM SIGMOD and IEEE Technical Committee on
Qing Li (IEEE Fellow) 于1982年获得中国湖南大学计算机科学学士学位,1985年和1988年分别获得美国南加州大学计算机科学硕士和博士学位。Qing Li现任香港理工大学计算学系讲座教授兼系主任,研究方向涵盖数据科学、网络挖掘和人工智能。他是英国工程技术学会会士(IET Fellow)、电气电子工程师学会会士(IEEE Fellow),并担任ACM SIGMOD成员及IEEE技术委员会成员。
Data Engineering. He is the chairperson of the Hong Kong Web Society, and is a steering committee member of DASFAA, ICWL, and WISE Society.
数据工程。他是香港网络学会主席,并担任DASFAA、ICWL及WISE学会的指导委员会委员。