Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation
Separate and Reconstruct: 语音分离的非对称编码器-解码器结构
Abstract
摘要
In speech separation, time-domain approaches have successfully replaced the time-frequency domain with latent sequence feature from a learnable encoder. Conventionally, the feature is separated into speaker-specific ones at the final stage of the network. Instead, we propose a more intuitive strategy that separates features earlier by expanding the feature sequence to the number of speakers as an extra dimension. To achieve this, an asymmetric strategy is presented in which the encoder and decoder are partitioned to perform distinct processing in separation tasks. The encoder analyzes features, and the output of the encoder is split into the number of speakers to be separated. The separated sequences are then reconstructed by the weight-shared decoder, which also performs cross-speaker processing. Without relying on speaker information, the weight-shared network in the decoder directly learns to discriminate features using a separation objective. In addition, to improve performance, traditional methods have extended the sequence length, leading to the adoption of dual-path models, which handle the much longer sequence effectively by segmenting it into chunks. To address this, we introduce global and local Transformer blocks that can directly handle long sequences more efficiently without chunking and dual-path processing. The experimental results demonstrated that this asymmetric structure is effective and that the combination of proposed global and local Transformer can sufficiently replace the role of interand intra-chunk processing in dual-path structure. Finally, the presented model combining both of these achieved state-of-the-art performance with much less computation in various benchmark datasets.
在语音分离领域,时域方法已成功利用可学习编码器的潜在序列特征替代了时频域方法。传统上,特征分离是在网络最终阶段进行的。我们提出了一种更直观的策略:通过将特征序列扩展为说话者数量作为额外维度,实现更早的特征分离。为此,我们采用非对称策略——将编码器和解码器划分以执行不同的分离任务处理。编码器负责分析特征,其输出会按待分离说话者数量进行分割。随后,权重共享的解码器会重建分离后的序列,同时执行跨说话者处理。该解码器中的权重共享网络不依赖说话者信息,而是直接通过分离目标学习区分特征。此外,传统方法为提升性能会延长序列长度,这促使双路径模型通过分块处理超长序列。针对此问题,我们引入全局和局部Transformer模块,无需分块和双路径处理即可直接高效处理长序列。实验结果表明:这种非对称结构具有有效性,且所提出的全局与局部Transformer组合足以替代双路径结构中块间/块内处理的作用。最终,结合这两项技术的模型以更少计算量在多个基准数据集上实现了最先进性能。
1 Introduction
1 引言
For the well-known cocktail party problem [14, 3], single channel speech separation [30] has been improved since the introduction of time-domain audio separation network (TasNet) [46, 47], which processes the audio separation in the latent space instead of the short-time Fourier transform (STFT) domain, as shown in Figure 1(a). In particular, in most speech separation methods, the process of separating the feature sequence for each speaker is typically positioned at the final stage of the network, as shown in Figure 1(b), which we refer to as late split. Therefore, a single feature sequence must encode all the information for all speakers to be separated. In addition, experimental results have shown that TasNet employing a convolution-based audio encoder/decoder performs better when the kernel length of the audio encoder is shortened [47, 45], which requires modeling a long sequence. Indeed, expanding the sequence in channel and temporal dimensions is necessarily beneficial, since the separation process must include all the information for all speakers in the feature sequence.
针对著名的鸡尾酒会问题 [14, 3],自时域音频分离网络 (TasNet) [46, 47] 提出以来,单通道语音分离 [30] 技术得到了显著提升。该网络在潜在空间而非短时傅里叶变换 (STFT) 域中进行音频分离处理,如图 1(a) 所示。值得注意的是,大多数语音分离方法中,为每个说话人分离特征序列的过程通常位于网络的最后阶段(如图 1(b) 所示),我们称之为"延迟拆分"。因此,单一特征序列必须编码所有待分离说话人的完整信息。此外,实验结果表明:当基于卷积的音频编码器/解码器的核长度缩短时,采用该结构的 TasNet 表现更优 [47, 45],这需要对长序列进行建模。实际上,在通道和时间维度上扩展序列必然具有优势,因为分离过程需要特征序列包含所有说话人的完整信息。
As a solution to modeling long sequences, DPRNN [45] was proposed using a dual path model, in which it segments long sequences into chunks and processes in terms of intra-chunk and inter-chunk to model the local and global contexts. As a result, due to promising performances in modeling long sequences, many TasNet-based approaches have adopted the dual-path model and repeatedly achieved state-of-the-art performances in monaural speech separation [9, 66, 37, 38, 92, 57, 60, 51]. Meanwhile, some studies have tackled the high computational complexity of long sequences in the time domain approach and proposed using multi-scaled sequence models based on the recurrent or stacked U-Net structure [70, 32, 42]. They reduced the computations to some extent, however, they still could not show competitive performance compared to the dual-path method.
作为长序列建模的解决方案,DPRNN [45] 提出了一种双路径模型,将长序列分割成块,并通过块内和块间处理来建模局部和全局上下文。由于在长序列建模方面表现出色,许多基于 TasNet 的方法采用了这种双路径模型,并在单声道语音分离任务中屡次取得最先进的性能 [9, 66, 37, 38, 92, 57, 60, 51]。与此同时,一些研究针对时域方法中长序列的高计算复杂度问题,提出了基于循环或堆叠 U-Net 结构的多尺度序列模型 [70, 32, 42]。这些方法在一定程度上降低了计算量,但与双路径方法相比仍未能展现出竞争力。
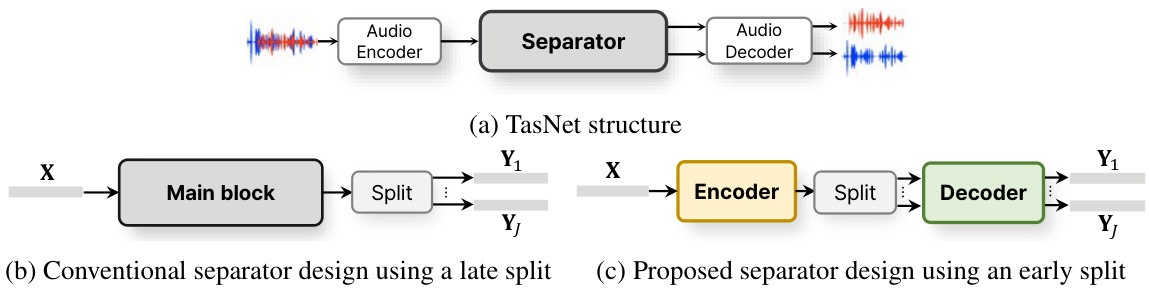
Figure 1: Block diagrams of (a) TasNet and separator designs of the (b) conventional and (c) proposed networks. The proposed network consists of separation encoder and reconstruction decoder based on weight sharing. After an encoder, separated features are independently processed by a decoder network.
图 1: (a) TasNet及(b)传统网络与(c)所提网络分离器设计的框图。所提网络基于权重共享由分离编码器和重建解码器构成。编码后,分离特征由解码器网络独立处理。
However, most studies have focused on handling long sequences rather than addressing the fundamental inefficiency of TasNet’s late split structure, where a single feature sequence must encode all speaker information without discrimination, creating an information bottleneck. Also, forcing the separator to generate all separated features at once before the audio decoder makes the task difficult and can easily lead to local minima during training. To alleviate this challenge, we propose a more intuitive approach: expanding the feature sequence to include a dimension for the number of speakers in advance, as an early split. By splitting features earlier in the separator (Figure 1(c)), we adopt an asymmetric strategy where the encoder and decoder perform distinct roles. The encoder process a single feature sequence before the split layer, similar to conventional separators. After splitting into multiple sequences, the decoder focuses on capturing disc rim i native characteristics between features using weight-sharing blocks [4, 11]. By employing this early split with a shared decoder (ESSD) structure, we ease the burden on the separator’s encoder. This approach aligns with common practices in multi-channel speech processing, where processing is divided into two stages. Coarse separation is achieved through spatial filtering [31, 85, 24], followed by post-enhancement to refine results [80, 8, 81, 41].
然而,大多数研究集中于处理长序列,而非解决TasNet后期分割结构的根本低效问题。该结构要求单一特征序列不加区分地编码所有说话者信息,从而形成信息瓶颈。此外,强制分离器在音频解码前一次性生成所有分离特征,不仅增加了任务难度,还容易导致训练陷入局部最优。为缓解这一挑战,我们提出一种更直观的方法:提前扩展特征序列以包含说话人数量的维度,实现早期分割。通过在分离器中更早分割特征(图1(c)),我们采用非对称策略,使编码器和解码器承担不同角色。编码器在分割层前处理单一特征序列,与传统分离器类似。分割为多序列后,解码器通过权重共享模块[4,11]专注于捕捉特征间的区分性特性。这种采用共享解码器的早期分割(ESSD)结构减轻了分离器编码器的负担。该方法符合多通道语音处理的常见实践,即将处理分为两阶段:通过空间滤波实现粗分离[31,85,24],再通过后增强优化结果[80,8,81,41]。
Furthermore, dual-path model itself also has redundancy because the segmentation process may increase the amount of computation by twice when the overlap between adjacent chunks is set to $50%$ . Also, the inter-chunk blocks in the dual-path model are inefficient because their role is mainly to capture the global context. Therefore, we design unit blocks for both global and local processing, integrating them effectively to replace the dual-path model and directly process long sequences without chunking. Both of global and local blocks are based on Transformer block structure [23] where multi-head self-attention (MHSA) module and feed-foward network (FFN) module are stacked. As a global Transformer block, we modified MHSA module in Transformer block as an efficient gated attention (EGA) module to mainly capture the global dependency without redundancy. On the other hand, as a local block, the MHSA is replaced with convolutional local attention (CLA) to capture local contexts.
此外,双路径模型本身也存在冗余,因为当相邻分块的重叠比例设为$50%$时,分段处理可能使计算量翻倍。同时,双路径模型中的分块间模块效率较低,因其主要功能仅是捕获全局上下文。为此,我们设计了兼具全局与局部处理能力的单元模块,通过高效整合替代双路径模型,无需分块即可直接处理长序列。全局模块和局部模块均基于Transformer块结构[23],采用多头自注意力(MHSA)模块与前馈网络(FFN)模块的堆叠形式。在全局Transformer块中,我们将MHSA模块改进为高效门控注意力(EGA)模块,以无冗余方式捕获全局依赖关系;而在局部模块中,则用卷积局部注意力(CLA)替代MHSA来捕捉局部上下文。
Consequently, we present the Separation-Reconstruction Transformer (Sep Reformer) for more efficient time-domain separation. Based on the ESSD framework and efficient global and local Transformer unit block, the Sep Reformer employs an asymmetric encoder-decoder structure with skip connections based on a temporally multi-scaled sequence model. The encoder processes a single feature at different temporal resolutions, and each intermediate feature is used for skip connection. The decoder then gradually reconstructs fine-grained information from the temporal bottleneck features, focusing on the disc rim i native characteristics of separated speech with auxiliary loss. To achieve this, the weight-shared decoder is trained to discriminate between the features separated by the encoder. In addition, a cross-speaker block is utilized in the decoder to facilitate information interaction between sequences, as described in [15, 40]. Furthermore, we design unit blocks for both global and local processing, integrating them effectively to replace the dual-path model and directly process long sequences without chunking. The experimental results demonstrated that the ESSD is effective especially with a small network. Also, comprising the separator network with the proposed global and local blocks can sufficiently replace the inter- and intra-chunk processing in dual-path structure, suggesting effectiveness for long feature sequence processing in speech separation. As a consequence, the proposed Sep Reformer that includes both of these achieved state-of-the-art (SOTA) performance with much less computation than before in various benchmark datasets.
因此,我们提出了分离-重构Transformer (Sep Reformer) 以实现更高效的时域分离。基于ESSD框架和高效的全局-局部Transformer单元块,Sep Reformer采用基于时间多尺度序列模型的非对称编码器-解码器结构,并带有跳跃连接。编码器在不同时间分辨率下处理单一特征,每个中间特征均用于跳跃连接。解码器则逐步从时序瓶颈特征中重建细粒度信息,通过辅助损失聚焦分离语音的判别性特征。为此,权重共享的解码器被训练用于区分编码器分离的特征。此外,如[15,40]所述,解码器中采用了跨说话人模块以促进序列间信息交互。我们同时设计了全局与局部处理的单元块,通过有效整合替代双路径模型,无需分块即可直接处理长序列。实验结果表明ESSD尤其在小规模网络中效果显著,且所提全局-局部模块构成的分离网络能充分替代双路径结构的块间/块内处理,验证了其在语音分离长特征序列处理中的有效性。最终,融合上述技术的Sep Reformer在多个基准数据集上以远低于先前的计算量实现了最先进(SOTA)性能。
2 Related Works
2 相关工作
TasNet Conventional source separation has been performed in the STFT domain [30, 36, 12, 44]. In the time-frequency representation, a separator is modeled to estimate mask values or direct output representations. Then, the inverse STFT (iSTFT) is operated for the output representations to obtain separated signals [30, 36]. On the other hand, TasNet [46] replaces STFT with a 1D convolutional layer. Based on the encoder representation, mask values or direct output representations [65, 59, 40] are obtained in the separator. Then, the output representations are decoded by the audio decoder of 1D transposed convolution instead of iSTFT. Also, unlike the STFT, the convolutional encoder turns out to work well in a much shorter kernel size. Therefore, TasNet requires the separator to process the much longer sequences. Therefore, instead of an LSTM-based separator [46], Conv-TasNet [47] is proposed based on a temporal convolutional network (TCN) [71, 39] to design a separator for longer sequence, showing impressive separation results.
TasNet 传统源分离方法通常在短时傅里叶变换 (STFT) 域进行 [30, 36, 12, 44]。在时频表示中,分离器被建模用于估计掩码值或直接输出表征,随后通过逆短时傅里叶变换 (iSTFT) 处理输出表征以获得分离信号 [30, 36]。而 TasNet [46] 使用一维卷积层替代 STFT,基于编码器表征在分离器中获取掩码值或直接输出表征 [65, 59, 40],再通过一维转置卷积的音频解码器(而非 iSTFT)解码输出表征。与 STFT 不同,卷积编码器在更小的卷积核尺寸下仍表现优异,因此 TasNet 要求分离器处理更长的序列。为此,Conv-TasNet [47] 基于时序卷积网络 (TCN) [71, 39] 提出替代 LSTM 分离器 [46] 的方案,专为长序列分离设计,展现出卓越的分离效果。
Dual-path model for long sequence After Conv-TasNet, the dual-path model is extensively employed to handle long sequences. In the dual-path model, the sequence is segmented into smaller chunks, and the sequence is processed alternately as intra-chunk and inter-chunk, effectively interleaving between local and global contexts. This dual-path strategy has shown promising performance in TasNet and has been repeatedly adopted [9, 66, 37, 38, 92, 57, 60, 51, 53, 34]. Especially, it is shown that, compared to various efficient attention mechanisms [76, 2, 35], using the dual-path model with the original self-attention mechanism of Transformer [72] is effective for long sequence [67] in speech separation. However, modeling with the dual-path method can double computational costs due to the $50%$ overlap between adjacent chunks. The inter-chunk blocks in this model are somewhat redundant since they mainly capture global context. To reduce this redundancy, the quasi-dual-path network (QDPN) [59] replaces inter-chunk processing with down sampling. Inspired by QDPN, we design EGA and CLA modules to capture the global and local contexts without chunking process.
长序列的双路径模型
在Conv-TasNet之后,双路径模型被广泛用于处理长序列。该模型将序列分割为较小片段,通过交替处理片段内和片段间信息,有效融合局部与全局上下文。这种双路径策略在TasNet中表现出优异性能,并被多次采用[9, 66, 37, 38, 92, 57, 60, 51, 53, 34]。特别地,研究表明相较于各类高效注意力机制[76, 2, 35],在语音分离任务中,采用Transformer原始自注意力机制[72]的双路径模型对长序列处理更有效[67]。但由于相邻片段存在50%重叠,双路径建模会使计算成本翻倍。该模型的片段间处理模块存在冗余,因其主要捕获全局上下文。为降低冗余,准双路径网络(QDPN)[59]通过降采样替代片段间处理。受QDPN启发,我们设计EGA和CLA模块,无需分块即可捕获全局与局部上下文。
Multi-scale model for efficiency Instead of the dual-path model, based on U-Net structure [61], some studies have suggested using multi-scaled sequence model [65, 49, 21, 32, 42, 7]. SuDoRM-RF model [70] used a stacked U-Net structure to reduce the computational cost. The SuDoRM-RF approach can be regarded as a substitution of the TCN block in Conv-TasNet with U-ConvBlock as UNet sub-block. Although SuDoRM-RF reduces the computational cost, it still has the disadvantages of having a fixed receptive field size and not considering the global context. More recently, TDANet [42] has efficiently improved performance with top-down attention and unfolding as in A-FCRNN [32]. However, these conventional methods with multi-scaled sequences prefer stacked or recurrent structures with U-Net sub-block to improve performance. Instead, we consider a single U-Net architecture and explicitly divide the roles of encoder and decoder as separation and reconstruction.
多尺度高效模型
部分研究建议采用基于U-Net结构[61]的多尺度序列模型[65, 49, 21, 32, 42, 7]来替代双路径模型。SuDoRM-RF模型[70]通过堆叠U-Net结构降低计算成本,其本质是将Conv-TasNet中的TCN模块替换为以U-ConvBlock作为UNet子模块的方案。尽管SuDoRM-RF减少了计算量,但仍存在感受野大小固定、未考虑全局上下文等缺陷。最新提出的TDANet[42]借鉴A-FCRNN[32]的自顶向下注意力和展开机制显著提升了性能。但这些传统多尺度序列方法倾向于采用堆叠式或循环式结构配合U-Net子模块来优化性能。与之不同,我们采用单一U-Net架构,并明确划分编码器(分离)与解码器(重建)的职能分工。
Disc rim i native learning Weight-sharing neural networks widely used in modern contrastive learning [11, 6, 25] including speaker verification [90, 58, 17]. On the other hand, some studies on speech separation proposed to exploit speaker identity as disc rim i native information to address the case that the similar voices are mixed [52, 51, 89]. Therefore, we utilized the weight-shared network to reconstruct separated speech by extracting distinct speech representations for corresponding speakers. To separate the mixture, weight-shared decoder directly learns to focus disc rim i native features without the need for additionally designed, for example, speaker loss using an additional speaker embedding extractor. As a result, based on disc rim i native learning, the weight-shared network in the decoder strengthens the dominant speaker’s components on each separated sequence, respectively.
判别式学习
权重共享神经网络在现代对比学习[11, 6, 25]中广泛应用,包括说话人验证[90, 58, 17]。另一方面,一些语音分离研究提出利用说话人身份作为判别信息,以解决相似声音混合的情况[52, 51, 89]。因此,我们利用权重共享网络通过为对应说话人提取不同的语音表征来重建分离的语音。为了分离混合语音,权重共享解码器直接学习聚焦判别特征,而无需额外设计(例如使用额外说话人嵌入提取器的说话人损失)。最终,基于判别式学习,解码器中的权重共享网络分别强化了每个分离序列上主导说话人的成分。
3 Method
3 方法
3.1 Overall pipeline
3.1 整体流程
When input mixture $\mathbf{x}\in\mathbb{R}^{1\times N}$ , the 1D convolution audio encoder, followed by GELU activation [28], encodes $\mathbf{x}$ to the input representation, as $\mathbf{X}=\mathcal{E}(\mathbf{x})\in\mathbb{R}^{F_{o}\times T}$ ,where $F_{o}$ and $T$ denote the number of convolutional filter of encoder and the number of frames, respectively. The kernel and stride size are
当输入混合信号 $\mathbf{x}\in\mathbb{R}^{1\times N}$ 时,一维卷积音频编码器(后接GELU激活函数 [28])将 $\mathbf{x}$ 编码为输入表示 $\mathbf{X}=\mathcal{E}(\mathbf{x})\in\mathbb{R}^{F_{o}\times T}$ ,其中 $F_{o}$ 和 $T$ 分别表示编码器的卷积滤波器数量和帧数。卷积核大小与步长分别为
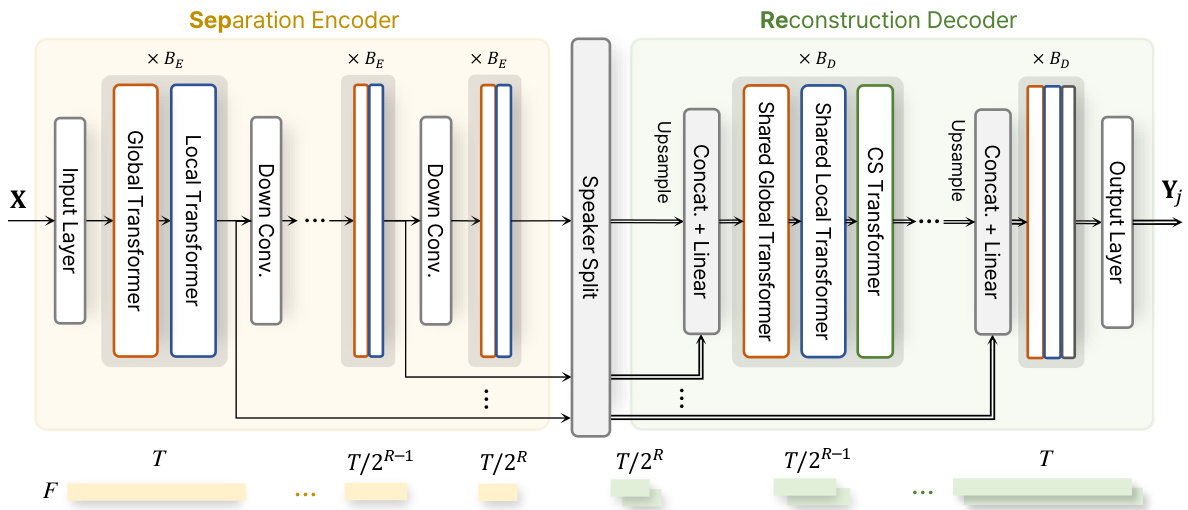
Figure 2: The architecture of the separator in the proposed Sep Reformer. The separator consists of three parts: separation encoder, speaker split module, and reconstruction decoder.
图 2: 所提 Sep Reformer 中分离器的架构。该分离器由三部分组成:分离编码器 (separation encoder)、说话人分割模块 (speaker split module) 和重构解码器 (reconstruction decoder)。
$L$ and $H$ , respectively. Then, the $J$ output representations $\mathbf{Y}{j}$ are estimated from the separator and decoded by the audio decoder, expressed as $\hat{\mathbf{s}}{j}=\mathcal{D}(\mathbf{Y}_{j})\in\mathbb{R}^{1\times N},1\leq j\leq J.$ Following the recent works [60, 79], we design the separator to directly map the output signals instead of masking.
$L$ 和 $H$。然后,通过分离器估计出 $J$ 个输出表示 $\mathbf{Y}{j}$,并由音频解码器解码,表达式为 $\hat{\mathbf{s}}{j}=\mathcal{D}(\mathbf{Y}_{j})\in\mathbb{R}^{1\times N},1\leq j\leq J.$ 根据近期研究 [60, 79],我们将分离器设计为直接映射输出信号而非掩码。
3.2 Architecture of separator
3.2 分离器架构
The detailed architecture of the separator of the proposed Sep Reformer is illustrated in Figure 2. The separator is constructed on the basis of the ESSD framework with a separation encoder and a reconstruction decoder in temporally multi-scaled U-Net structure.
所提出的Sep Reformer分离器的详细架构如图2所示。该分离器基于ESSD框架构建,采用时间多尺度U-Net结构,包含分离编码器和重建解码器。
Separation encoder The input representation is first projected to $F$ dimension by the input layer. The input layer is composed of the linear layer and Layer Normalization (LN) [1] applied to each frame independently. In the encoder, the projected feature sequence is successively down sampled $R$ times from the sequence length of $T$ to ${\bar{T}}/2^{\bar{R}}$ . The down sampling is performed by a 1D depth-wise convolution (Dconv) layer with a stride of 2 and a kernel size of 5, followed by Batch Normalization (BN) and GELU activation [28]. Each encoder stage processes the single sequence feature by $B_{E}$ stacks of global and local Transformer blocks.
分离编码器
输入表示首先通过输入层投影到 $F$ 维。输入层由线性层和独立应用于每帧的层归一化 (LN) [1] 组成。在编码器中,投影后的特征序列从长度 $T$ 连续下采样 $R$ 次至 ${\bar{T}}/2^{\bar{R}}$。下采样通过步长为2、核大小为5的一维深度卷积 (Dconv) 层实现,后接批归一化 (BN) 和 GELU 激活函数 [28]。每个编码器阶段通过 $B_{E}$ 个全局与局部 Transformer 块堆栈处理单序列特征。
Speaker split The encoded features in all stages of the encoder are expanded by the number of speakers $J$ to transmit the speaker-wise features from the encoder to the decoder. Therefore, the speaker split layer is placed in the middle, and it commonly separates the intermediate encoder features used for skip connections as well as the bottleneck feature. As shown in Figure 3, this module consists of two linear layers with gated linear unit (GLU) activation [20]. Each feature is then normalized by LN and processed by the decoder.
说话人分离
编码器所有阶段的编码特征都通过说话人数量 $J$ 进行扩展,以将说话人相关特征从编码器传递到解码器。因此,说话人分离层位于中间位置,通常既分离用于跳跃连接的中间编码器特征,也分离瓶颈特征。如图 3 所示,该模块由两个带有门控线性单元 (GLU) 激活的线性层组成 [20]。每个特征随后通过层归一化 (LN) 进行标准化,并由解码器处理。
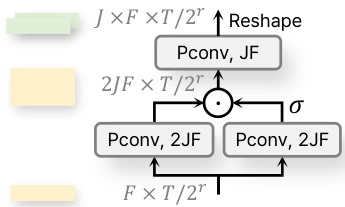
Figure 3: Speaker split module
图 3: 说话人分割模块
Reconstruction decoder For temporal reconstruction, the upsampled sequence feature from the previous stage is concatenated with the skip connection followed by linear layer. Then, $B_{D}$ stacks of global and local Transformer blocks process the $J$ feature sequences as a weight-sharing network to discriminate between the separated features. By incorporating the separation objective function into the weight-sharing decoder, the network directly learns to capture the disc rim i native features. Then, the output of the last decoder stage is projected back to $F_{o}$ dimension by an output layer. The output layer consists of two linear layers with GLU activation.
重建解码器
在时序重建阶段,前一阶段的上采样序列特征会与跳跃连接(skip connection)拼接,随后通过线性层处理。接着,$B_{D}$组全局与局部Transformer块会以权重共享网络的形式处理$J$个特征序列,以区分分离后的特征。通过将分离目标函数融入权重共享解码器,网络能直接学习捕捉判别性特征。最终解码器阶段的输出会通过输出层投影回$F_{o}$维度,该输出层由两个带GLU激活函数的线性层构成。
Cross-speaker (CS) Transformer During the discrimination process by the weight-sharing decoder, speech elements can be mistakenly clustered into other speaker channels. As a result, it would be beneficial to attend to each other in order to effectively recover the distorted speech elements. Therefore, to improve the interaction of contexts between speakers within the decoder, we incorporate a Transformer-based CS module as in [15, 40]. Based on MHSA module without positional encoding, the CS block performs an attention operation on speaker dimension while temporal dimension is processed independently. Therefore, the CS block learns to identify the interfering components of the opposing sequences within the same temporal frame. For convenience, we call ESSD with CS as a separation-and-reconstruction (SepRe) method.
跨说话人 (CS) Transformer
在权重共享解码器的判别过程中,语音元素可能会被错误地聚类到其他说话人通道。因此,通过相互关注来有效恢复失真的语音元素将大有裨益。为此,我们借鉴 [15, 40] 的方法,在解码器中引入基于 Transformer 的 CS 模块以增强说话人间的上下文交互。该 CS 模块基于无位置编码的多头自注意力 (MHSA) 机制,在说话人维度执行注意力运算,同时独立处理时序维度。这使得 CS 模块能够学习识别同一时间帧内对立序列的干扰成分。为便于表述,我们将带有 CS 模块的 ESSD 称为分离-重建 (SepRe) 方法。
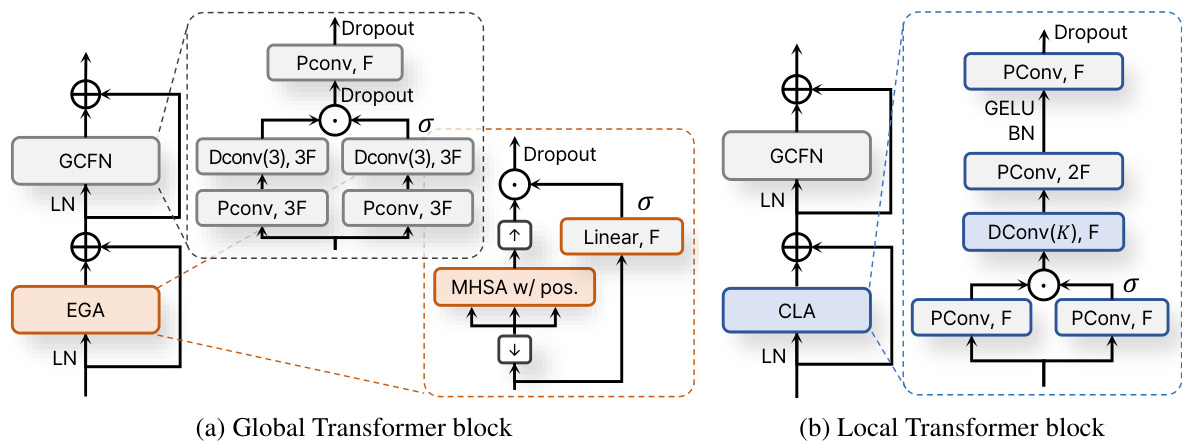
Figure 4: Block diagrams of global and local Transformer for sequence processing. $\downarrow$ and $\uparrow$ in EGA denote down sampling with average pooling and upsampling with nearest interpolation. Note that the point-wise convolution (Pconv) layer performs an equivalent operation to the linear layer as channel mixing. The hidden dimension of GCFN is set to $3F$ after GLU to maintain a similar parameter size to the FFN with a hidden size of $4F$ . Therefore, while the FFN has parameter size of $8F^{2}$ , GCFN has a slightly larger size of about $9F^{2}$ .
图 4: 序列处理的全局与局部Transformer结构框图。EGA中的 $\downarrow$ 和 $\uparrow$ 分别表示平均池化下采样和最近邻插值上采样。需注意点卷积(Pconv)层作为通道混合时执行与线性层等效的操作。GCFN的隐藏维度在GLU后设为 $3F$ ,以保持与隐藏维度为 $4F$ 的FFN相近的参数规模。因此FFN参数量为 $8F^{2}$ 时,GCFN参数量略大约 $9F^{2}$ 。
3.3 Global and local Transformer for long sequences
3.3 面向长序列的全局与局部Transformer
Instead of the dual-path model based on chunking, we directly process a long sequence using global and local processing blocks, similar to QDPN [59] or Conformer [27]. In particular, global and local blocks replace inter- and intra-chunk processing, respectively. The design of the blocks follows a Transformer block structure to ensure structural effectiveness [23, 68, 86, 29]. This structure consists of two sub-modules: temporal mixing and frame-wise channel mixing. These modules are stacked together with a pre-norm residual unit [75, 55] and LayerScale [69] to facilitate faster training of deep networks. Also, in all residual units, we apply dropout [64] for regular iz ation.
我们摒弃了基于分块的双路径模型,直接采用全局与局部处理块来处理长序列,类似QDPN [59]或Conformer [27]的方案。具体而言,全局块和局部块分别替代了分块间与分块内的处理流程。这些模块的设计遵循Transformer块结构以确保架构有效性 [23, 68, 86, 29],其核心由两个子模块构成:时序混合模块和逐帧通道混合模块。这些模块通过前置归一化残差单元 [75, 55] 和LayerScale [69] 进行堆叠,以加速深层网络的训练。此外,所有残差单元中都应用了dropout [64] 技术来实现正则化。
Gated convolutional feed-forward network (GCFN) Instead of using the conventional feedforward network (FFN) [23, 72] for channel mixing, we improve it by incorporating temporal Dconv with a small kernel size of 3 and substituting GELU with GLU activation [20] as shown in Figure 4(a). This GCFN can effectively process channel features by considering the adjacent frame context. Several studies also have demonstrated the effectiveness of these enhancements in FFN [63, 87, 77].
门控卷积前馈网络 (GCFN)
我们通过引入核大小为3的时序Dconv,并将GELU激活替换为GLU激活[20](如图4(a)所示),改进了传统的用于通道混合的前馈网络 (FFN) [23, 72]。这种GCFN能够通过考虑相邻帧上下文来有效处理通道特征。多项研究也证明了这些改进在FFN中的有效性[63, 87, 77]。
Global Transformer with efficient global attention (EGA) In Figure 4(a), the global block consists of an EGA module for temporal mixing and GCFN. The EGA module is based on the MHSA with relative positional encoding [19]. However, to reduce the computation and focus on global information in the attention layer, the down sampled sequence is processed and upsampled back. Sequences $T/2^{r}$ at all stages $0\leq r\leq R-1$ are down sampled to $\dot{T^{\prime}}{2^{R}}$ , which is equal to the length in the bottleneck. To compensate for down sampling, the upsampled features are multiplied by the gate value obtained from an additional branch with a linear layer and sigmoid function $\sigma$ . The simple strategy allows the effective capture of global contexts while maintaining local contexts.
全局Transformer与高效全局注意力 (EGA)
在图 4(a) 中,全局块包含用于时序混合的EGA模块和GCFN。EGA模块基于带相对位置编码的MHSA [19]。然而,为了减少计算量并聚焦注意力层的全局信息,会对下采样序列进行处理并重新上采样。所有阶段 $0\leq r\leq R-1$ 的序列 $T/2^{r}$ 被下采样至 $\dot{T^{\prime}}{2^{R}}$ ,该长度与瓶颈层一致。为补偿下采样,上采样特征会乘以通过附加分支(含线性层和Sigmoid函数 $\sigma$ )获取的门控值。这一简单策略能在保持局部上下文的同时有效捕获全局上下文。
Local Transformer with convolutional local attention (CLA) For the local block, we design a CLA module based on 1D temporal convolution with a large kernel of $K$ in Figure 4(b). Inspired by [27, 84], the CLA module first processes the feature with the Pconv layer and GLU activation to facilitate capturing local contexts attentively. After the temporal Dconv, two Pconv layers are used. They have a hidden dimension of $2F$ and employ BN and GELU activation.
局部Transformer与卷积局部注意力(CLA)
对于局部块,我们基于一维时序卷积设计了一个CLA模块,其大核尺寸为$K$,如图4(b)所示。受[27, 84]启发,CLA模块首先通过Pconv层和GLU激活处理特征,以专注捕捉局部上下文。在时序Dconv之后,使用了两个Pconv层。它们具有$2F$的隐藏维度,并采用BN和GELU激活。
3.4 Boosting disc rim i native learning by multi-loss
3.4 通过多损失提升判别式学习
The objective function is given as scale-invariant signal-to-noise ratio (SI-SNR) [62, 46] defined as
目标函数由尺度不变信噪比 (SI-SNR) [62, 46] 给出,其定义为
$$
\mathcal{L}=-\sum_{j=1}^{J}\operatorname*{min}\left(20\log_{10}\frac{|\gamma_{j}{\bf s}{j}|{2}}{|\gamma_{j}{\bf s}{j}-\hat{\bf s}{j}|_{2}},\tau\right),
$$
$$
\mathcal{L}=-\sum_{j=1}^{J}\operatorname*{min}\left(20\log_{10}\frac{|\gamma_{j}{\bf s}{j}|{2}}{|\gamma_{j}{\bf s}{j}-\hat{\bf s}{j}|_{2}},\tau\right),
$$
where $\gamma_{j}=\hat{\mathbf{s}}{j}^{T}\mathbf{s}{j}/\Vert\mathbf{s}{j}\Vert_{2}^{2}$ and $|\cdot|{2}$ denotes L2-norm. The clipping value of $\tau$ limits the influence of the best training prediction [89, 83]. Notably, the output of the decoder stages can be trained for progressive reconstruction as the feature sequences are already separated in the decoder stages as in the progressive multi-stage strategy [54, 91, 88, 16]. In particular, weight-sharing decoder in each stage can be trained clearly for disc rim i native learning with stage-specific separation objective. This multiloss strategy is also considered to guide intermediate features in audio separation [53, 5, 59, 60, 40]. Therefore, the source signal can be estimated as $\hat{\mathbf{s}}{j,r}=\mathcal{D}{r}(\mathbf{X}\odot\mathbf{M}{j,r})\in\mathbb{R}^{1\times N}$ when $\mathbf{M}{j,r}\in\mathbb{R}^{F_{o}\times T}$ is estimated with additional output layers for $\mathbf{L}{j,r}$ and the nearest upsampling. $\odot$ denotes an elementwise multiplication, and $\mathcal{D}_{\boldsymbol{r}}(\cdot)$ is an auxiliary audio decoder, which is also additional required with additional output layers. Therefore, we can set the auxiliary objective function as
其中 $\gamma_{j}=\hat{\mathbf{s}}{j}^{T}\mathbf{s}{j}/\Vert\mathbf{s}{j}\Vert_{2}^{2}$ ,$|\cdot|{2}$ 表示 L2 范数。截断值 $\tau$ 限制了最佳训练预测的影响 [89, 83]。值得注意的是,由于特征序列已在解码器阶段实现分离(如渐进式多阶段策略 [54, 91, 88, 16] 所示),解码器阶段的输出可被训练用于渐进式重建。特别是,每个阶段的权重共享解码器可通过阶段特异性分离目标进行明确的判别性学习。这种多损失策略也被认为能引导音频分离中的中间特征 [53, 5, 59, 60, 40]。因此,当 $\mathbf{M}{j,r}\in\mathbb{R}^{F_{o}\times T}$ 通过 $\mathbf{L}{j,r}$ 的额外输出层和最近邻上采样估计时,源信号可表示为 $\hat{\mathbf{s}}{j,r}=\mathcal{D}{r}(\mathbf{X}\odot\mathbf{M}{j,r})\in\mathbb{R}^{1\times N}$ 。其中 $\odot$ 表示逐元素乘法,$\mathcal{D}_{\boldsymbol{r}}(\cdot)$ 是辅助音频解码器,同样需要配备额外输出层。因此,我们可以将辅助目标函数设为
$$
\mathcal{L}{r}=-\sum_{j=1}^{J}\operatorname*{min}\left(20\log_{10}\frac{|\gamma_{j,r}\mathbf{s}{j}|{2}}{|\gamma_{j,r}\mathbf{s}{j}-\hat{\mathbf{s}}{j,r}|_{2}},\tau\right),
$$
$$
\mathcal{L}{r}=-\sum_{j=1}^{J}\operatorname*{min}\left(20\log_{10}\frac{|\gamma_{j,r}\mathbf{s}{j}|{2}}{|\gamma_{j,r}\mathbf{s}{j}-\hat{\mathbf{s}}{j,r}|_{2}},\tau\right),
$$
where $\gamma_{j,r}=\hat{\mathbf{s}}{j,r}^{T}\mathbf{s}{j}/|\mathbf{s}{j}|{2}^{2}$ . Note that, when calculating the output from intermediate features, we opt for masking instead of direct estimation because the temporal resolutions of the feature sequences are deficient. Then, the multi-loss can be set to $\begin{array}{r}{\hat{\mathcal{L}}=(\hat{1}-\alpha)\mathcal{L}+\alpha\sum_{r=1}^{R}\mathcal{L}{r}/R}\end{array}$ . Moreover, we alternatively calculate the intermediate loss $\mathcal{L}{r}$ using the magnitude val ues of $\mathbf{s}{j}$ and $\hat{\bf s}_{j}$ in the STFT domain as it provided more stable training and no actual separated signals are required from the intermediate outputs.
其中 $\gamma_{j,r}=\hat{\mathbf{s}}{j,r}^{T}\mathbf{s}{j}/|\mathbf{s}{j}|{2}^{2}$。需要注意的是,在计算中间特征输出时,我们选择掩蔽而非直接估计,因为特征序列的时间分辨率不足。此时可将多任务损失函数设为 $\begin{array}{r}{\hat{\mathcal{L}}=(\hat{1}-\alpha)\mathcal{L}+\alpha\sum_{r=1}^{R}\mathcal{L}{r}/R}\end{array}$。此外,我们采用STFT域中 $\mathbf{s}{j}$ 和 $\hat{\bf s}{j}$ 的幅度值来计算中间损失 $\mathcal{L}_{r}$,这种方法能提供更稳定的训练效果,且无需从中间输出获取实际分离信号。
4 Experimental Settings
4 实验设置
4.1 Dataset
4.1 数据集
We evaluated our proposed Sep Reformer on WSJ0-2Mix [30], WHAM! [82], WHAMR! [50], and LibriMix [18], which are popular datasets for monaural speech separation. To ensure generality, the mixtures in the test set were generated by the speakers that were not seen during training. For all the datasets, networks were trained with 4-s-long segments at a 8-kHz sampling rate while the model processes inputs of varying lengths in the evaluation.
我们在 WSJ0-2Mix [30]、WHAM! [82]、WHAMR! [50] 和 LibriMix [18] 这些单声道语音分离的常用数据集上评估了提出的 Sep Reformer。为确保泛化性,测试集中的混合语音均由训练阶段未出现的说话人生成。对于所有数据集,网络均以 8 kHz 采样率的 4 秒片段进行训练,而模型在评估阶段可处理可变长度的输入。
WSJ0-2Mix WSJ0-2Mix is the most popular dataset to benchmark the monaural speech separation task. It contains 30, 10, and 5 hours for training, validation, and evaluation sets, respectively. Each mixture was artificially generated by randomly selecting different speakers from the corresponding set and mixing them at a random relative signal-to-noise ratio (SNR) between -5 and 5 dB.
WSJ0-2Mix
WSJ0-2Mix是单声道语音分离任务最常用的基准数据集,包含30小时训练集、10小时验证集和5小时测试集。每个混合音频均通过从对应集合中随机选取不同说话人,并以-5至5 dB之间的随机相对信噪比(SNR)混合生成。
WHAM!/WHAMR! WHAM!/WHAMR! is a noisy/noisy-reverb e rant version of the WSJ0-2Mix dataset. In the WHAM! dataset, speeches were mixed with noise recorded in scenes such as cafes, restaurants, and bars. The noise was added to get mixtures at SNRs uniformly sampled between -6dB and 3dB, making the mixtures more challenging than those in the WSJ0-2Mix.
WHAM!/WHAMR!
WHAM!/WHAMR! 是 WSJ0-2Mix 数据集的带噪/带混响版本。在 WHAM! 数据集中,语音与咖啡馆、餐厅和酒吧等场景录制的噪声混合。噪声以均匀采样于 -6dB 至 3dB 之间的信噪比 (SNR) 添加到混合音频中,使得混合结果比 WSJ0-2Mix 中的更具挑战性。
Libri2Mix In Libri2Mix dataset, the target speech in each mixture was randomly selected from a subset of Libri Speech’s train-100 [56] for faster training. Each source was mixed with uniformly sampled Loudness Units relative to Full Scale (LUFS) to get a mixture at an SNR between -25 and -33 dB. We used the clean version as in previous studies [9, 42].
Libri2Mix
在Libri2Mix数据集中,每个混合音频的目标语音均从Libri Speech的train-100子集[56]中随机选取以加速训练。各源信号通过均匀采样的满刻度相对响度单位(LUFS)混合,生成信噪比(SNR)介于-25至-33 dB的混合音频。如先前研究[9,42]所示,我们采用了纯净版本。
4.2 Training and model configuration
4.2 训练与模型配置
We trained the proposed Sep Reformer for a maximum of 200 epochs with an initial learning rate of $1.0e^{-3}$ . We used a warm-up training scheduler for the first epoch, and then the learning rate decayed by a factor of 0.8 if the validation loss did not improve in three consecutive epochs. As optimizer, AdamW [43] was used with a weight decay of 0.01, and gradient clipping with a maximum L2-norm of 5 was applied for stable training. All models were trained with Permutation Invariant Training (PIT) [36]. When the multi-loss in Subsection 3.4 was applied, the $\alpha$ was set to 0.4, and after 100 epochs, it decayed by a factor of 0.8 at every five epochs. $\tau$ was set to 30 as in [89]. SI-SNRi and SDRi [73] were used as evaluation metrics. Also, we compared the parameter size and the number of multiply-accumulate operations (MACs) for 16000 samples. The number of heads in MSHA was commonly set to 8, and the kernel size $K$ in the local block was set to 65. Also, we evaluated our model in various model sizes as follows:
我们训练所提出的Sep Reformer最多200个周期,初始学习率为$1.0e^{-3}$。第一个周期采用预热训练调度器,之后若验证损失连续三个周期未改善,学习率衰减因子为0.8。优化器采用AdamW [43],权重衰减为0.01,并为稳定训练应用了最大L2范数为5的梯度裁剪。所有模型均采用排列不变训练(PIT) [36]进行训练。当应用第3.4节的多重损失时,$\alpha$设为0.4,100个周期后每五个周期衰减因子为0.8。$\tau$如[89]所述设为30。评估指标采用SI-SNRi和SDRi [73]。同时,我们比较了16000个样本的参数规模和乘加运算(MACs)数量。MSHA中的头数通常设为8,局部块中的核大小$K$设为65。此外,我们还评估了以下不同模型尺寸的表现:
• Sep Reformer-T/B/L: $F=64/128/256.$ $F_{o}=256$ , $L=16$ , H = 4, $R=4$ • Sep Reformer-S/M: $F=64/128$ , $F_{o}=256$ , $L=8$ , $H=2$ , $R=5$
• Sep Reformer-T/B/L: $F=64/128/256$, $F_{o}=256$, $L=16$, H = 4, $R=4$
• Sep Reformer-S/M: $F=64/128$, $F_{o}=256$, $L=8$, $H=2$, $R=5$
We used a longer encoder length of $L=32$ in the Large model when evaluating the WHAMR dataset to account for reverberation. Note that we did not train the models multiple times, as the deviations in the results are negligible below the significant digits. All experiments were conducted on a server with GeForce RTX $3090\times6$ .
在评估WHAMR数据集时,我们为大型模型采用了更长的编码器长度$L=32$以应对混响效应。需要注意的是,我们没有对模型进行多次训练,因为结果差异在小数位以下可忽略不计。所有实验均在配备GeForce RTX $3090\times6$的服务器上完成。
Table 1: Experimental evaluation of SepRe method on the WSJ0-2Mix dataset. ML denotes the multi-loss. In (a), all the methods were trained with ML, and the numbers in the left and right of the $\because/{}^{\star}$ symbol were obtained for the tiny and base models, respectively. In (b), when ML was used for training, we indicated the numbers of parameters including the additional output layer for an auxiliary output for $\hat{\bf s}_{j}$ , which were denoted with asterisk ∗. Note that the additional output layers were not required during inference.
(a) Decoder design. (b) Effects of multi-loss.
表 1: SepRe方法在WSJ0-2Mix数据集上的实验评估。ML表示多损失函数。(a) 中所有方法均采用ML训练,$\because/{}^{\star}$符号左右两侧数值分别对应微型和基础模型。(b) 当使用ML训练时,我们标出了包含$\hat{\bf s}_{j}$辅助输出额外输出层的参数量(带星号∗标注)。注意推理阶段不需要这些额外输出层。
| Case | MACs (G/s) | Param. (M) | SI-SNRi (dB) | Case | ML | Param.SISNRi (M) (dB) |
|---|---|---|---|---|---|---|
| late split+ origin dec. | 5.0/18.3 | 2.8/11.6 | 19.0/21.6 | late split+origin dec. | 11.6 | 21.2 |
| late split + large dec. | 9.0/33.7 | 4.9/20.1 | 19.7/22.0 | late split+origin dec. | 13.2 | 21.6 |
| early split+ multi dec. | 7.9/29.5 | 4.5/18.4 | 19.8/22.1 | early split+shared dec. | 11.6 | 22.4 |
| early split+shared dec. | 7.9/29.5 | 2.8/11.6 | 21.3/23.1 | early split+ shared dec. | 12.2 | 23.1 |
| early split+ shared dec. +CS | 10.4/39.8 | 3.5/14.2 | 22.4/23.8 | early split+shared dec.+CS | 14.2 14.8* | 22.6 |
| early split+ shared dec.+CS √ | 23.8 |
(a) 解码器设计 (b) 多损失函数效果
Table 2: Application of SepRe to other networks. From the original separator of Conv-TasNet and Sepformer, we applied the SepRe method with multi-loss (ML) and evaluated on the WSJ0-2Mix dataset.
(a) Conv-TasNet with SepRe method. (b) Sepformer with SepRe method.
表 2: SepRe 在其他网络中的应用。我们从 Conv-TasNet 和 Sepformer 的原始分离器出发,应用了多损失 (ML) 的 SepRe 方法,并在 WSJ0-2Mix 数据集上进行了评估。
| 案例 | ESSD | CS | ML | 参数量 (M) | SI-SNRi (dB) | 案例 | ESSD | CS | ML | 参数量 (M) | SI-SNRi (dB) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 (原始) | 5.1 | 15.3 | 1 (原始) | 26.0 | 20.4 | ||||||
| 2 | √ | 5.4 | 17.5 | 2 | √ | 27.1 | 21.3 | ||||
| 3 | 5.5 | 17.8 | 3 | 人 | √ | 27.2 | 22.0 | ||||
| 4 (SepRe) | √ | 5.7 | 19.2 | 4 (SepRe) | √ | √ | 28.0 | 21.6 | |||
| 5 (SepRe) | √ | 5.7 | 19.5 | 5 (SepRe) | √ | 28.0 | 22.7 |
(a) 应用 SepRe 方法的 Conv-TasNet。(b) 应用 SepRe 方法的 Sepformer。
5 Results
5 结果
5.1 Ablation studies of SepRe method
5.1 SepRe方法的消融研究
Decoder Design In Table 1(a), we evaluated various decoder structures (See Appendix A for detailed structures) to validate the effectiveness of weight-sharing decoder structure. As shown in Table 1(a), the computations increases about twice by using large decoder in late split or using early split methods. In particular, the model using multiple decoders after an early split yielded a performance comparable to that of using a large decoder after a late split. In contrast, by sharing a decoder after an early split, the separation result increased significantly, suggesting that the ESSD structure effectively discriminates between the separated features. This impact was more noticeable in the tiny models by showing increase of $1.5\mathrm{dB}$ . Applying CS to ESSD improved the performance especially on the tiny model, leading to the SepRe mechanism. Although changing from a late split structure to an ESSD structure can increase computation if the channel size is kept constant, reducing the channel size allows us to still achieve better performance. This adjustment significantly improves computational efficiency in relation to performance. This is particularly evident when comparing the base model with late split to the tiny model with the proposed $\mathrm{ESSD+CS}$ (SepRe) structure. The latter model achieves a higher performance, with an SI-SNRi of $22.4:\mathrm{dB}$ compared to 21.6 dB, while using fewer computations and a smaller model size, clearly demonstrating the efficiency of the model architecture.
解码器设计
在表 1(a) 中,我们评估了多种解码器结构(详细结构见附录 A)以验证权重共享解码器结构的有效性。如表 1(a) 所示,采用延迟分割的大解码器或早期分割方法会使计算量增加约两倍。特别是,在早期分割后使用多个解码器的模型性能与延迟分割后使用大解码器的模型相当。相比之下,通过早期分割后共享解码器,分离结果显著提升,表明 ESSD 结构能有效区分分离特征。这一影响在微型模型中更为明显,性能提升了 $1.5\mathrm{dB}$。将 CS 应用于 ESSD 进一步提升了性能(尤其在微型模型上),从而形成了 SepRe 机制。
若保持通道尺寸不变,从延迟分割结构转向 ESSD 结构会增加计算量,但通过减小通道尺寸仍可实现更优性能。这一调整显著提升了计算效率与性能的平衡。对比延迟分割的基础模型与采用 $\mathrm{ESSD+CS}$(SepRe)结构的微型模型时尤为明显:后者以更少的计算量和更小的模型尺寸实现了更高性能(SI-SNRi 为 $22.4:\mathrm{dB}$,优于前者的 21.6 dB),充分证明了该架构的高效性。
Effects of multi-loss Furthermore, we experimented with the effects of multi-loss on various decoder structures in Table 1(b). Compared to a late split, the case with an early split increased more significantly with multi-loss because an early split structure could be trained with a clearer objective for disc rim i native learning using an intermediate loss at each stage. In particular, while applying only CS without multi-loss resulted in a marginal improvement, combining CS with multi-loss led to a substantial gain. The results demonstrated that stage-specific objective functions induce each CS-equipped weight-sharing decoder stage to effectively learn simultaneously how to discriminate between and attend to each other. As a result, our proposed SepRe method using ESSD and CS significantly improved separation performance by applying stage-specific objective functions and inducing progressive reconstruction of separated feature sequences.
多损失效果
此外,我们在表1(b)中实验了多损失对不同解码器结构的影响。与延迟分割相比,早期分割结构在多损失下的提升更为显著,因为早期分割结构可以通过每个阶段的中间损失,以更清晰的目标进行判别性学习。特别是,仅应用通道共享(CS)而不使用多损失时效果提升有限,但将CS与多损失结合则带来了显著增益。结果表明,阶段特定的目标函数能使每个配备CS的权重共享解码器阶段有效学习如何同时进行判别和相互关注。因此,我们提出的SepRe方法通过使用早期阶段共享解码器(ESSD)和CS,应用阶段特定目标函数并引导分离特征序列的渐进重建,显著提升了分离性能。
Table 3: Ablation studies for unit blocks on our Sep Reformer-B on the WSJ0-2Mix dataset. Various configurations of $B_{E}$ and $B_{D}$ were evaluated to assess the relative importance of encoder and decoder. Also, we validated the proposed EGA and GCFN modules.
(a) Depth of encoder-decoder. (b) EGA module design. (c) FFN module design.
表 3: 在WSJ0-2Mix数据集上对我们的Sep Reformer-B进行单元模块消融研究。评估了$B_{E}$和$B_{D}$的不同配置以衡量编码器和解码器的相对重要性。同时,我们验证了提出的EGA和GCFN模块。
| (BE,BD) | Param. (M) | SI-SNRi (dB) | Case | Param.SI-SNRi (M) | Case (dB) | Param.SI-SNRi (M) (dB) | |
|---|---|---|---|---|---|---|---|
| (1, 4) | 14.6 | 23.6 | MHSAw/d.s&u.s | 13.9 | 23.3 | FFN [23] | 13.3 |
| (2,3) | 14.2 | 23.8 | EGA w/o linear gate | 13.9 | 23.2 | FFNw/Dconv | 13.4 14.1 |
| (3,2) (4, 1) | 13.8 13.4 | 22.8 21.7 | EGA | 14.2 | 23.8 | FFN w/ GLU GCFN | 14.2 |
(a) 编码器-解码器深度 (b) EGA模块设计 (c) FFN模块设计
Table 4: Comparison with various long sequence models in speech separation of WSJ0-2Mix. MS denotes multi-scale. For our model, global and local blocks were repeated 22 times with $F=128$ .
| 分离器 | 长序列模型 | 参数量 (百万) | MACs (G/s) | SI-SNRi (dB) |
|---|---|---|---|---|
| Conv-TasNet[47] | TCN [71] | 5.1 | 10.5 | 15.6 |
| DPRNN [45] | 双路径+BLSTM | 2.6 | 88.5 | 18.8 |
| SuDoRM-RF[70] | 多尺度+卷积 | 6.4 | 10.1 | 18.9 |
| Sepformer[66] | 双路径+Transformer | 26.0 | 86.9 | 20.4 |
| TDANet[42] | 多尺度+Transformer | 2.3 | 9.1 | 18.5 |
| MossFormer(S)[92] | GAU [33] | 10.8 | 44.0 | 20.9 |
| S4M [7] | 多尺度+SSM[26] | 3.6 | 38.4 | 20.5 |
| 本方法 | 全局-局部Transformer | 11.9 | 43.1 | 21.3 |
| 本方法+U-Net | 多尺度+全局-局部Transformer | 11.6 | 18.3 | 21.2 |
表 4: WSJ0-2Mix语音分离任务中各类长序列模型的对比。MS表示多尺度。本模型的全局和局部模块重复22次 ($F=128$)。
5.2 Effects of the SepRe method in other networks
5.2 SepRe方法在其他网络中的效果
To validate the general applicability of the SepRe method, we incorporated the SepRe method with multi-loss into the original separators of Conv-TasNet [47] and Sepformer [66] and conducted experiments on WSJ0-2MIX. The experimental results in Table 2 demonstrated a significant performance improvement when ESSD was applied for both networks. Also, applying CS and multi-loss in addition to the ESSD framework improved the performance further, which confirms the effectiveness of SepRe with multi-loss.
为验证SepRe方法的通用性,我们将多损失SepRe方法融入Conv-TasNet [47]和Sepformer [66]的原始分离器,并在WSJ0-2MIX数据集上进行实验。表2的实验结果表明,当ESSD应用于两种网络时均取得显著性能提升。此外,在ESSD框架基础上结合CS和多损失策略可进一步提升性能,这验证了多损失SepRe方法的有效性。
5.3 Ablation studies of unit blocks
5.3 单元模块消融研究
Depth of encoder-decoder In Table 3(a), we experimented the depth of encoder and decoder to determine the optimal configuration in terms of the number of block repetition $B_{E}$ and $B_{D}$ . Generally, experimental results showed that using more blocks in the reconstruction decoder had a greater impact on performance improvement than in the separation encoder. It demonstrate that it is more important to discriminate the features more elaborately in weight-sharing decoder than to analyze the features in encoder in speech separation. In particular, optimal performance was achieved with $B_{E}=2$ and $B_{D}=3$ , which were used as the common configuration for subsequent experiments.
编码器-解码器深度
在表 3(a) 中,我们通过实验探索了编码器和解码器的深度,以确定块重复次数 $B_{E}$ 和 $B_{D}$ 的最佳配置。总体而言,实验结果表明:与分离编码器相比,在重建解码器中使用更多块对性能提升的影响更大。这说明在语音分离任务中,权重共享解码器对特征的精细化判别比编码器的特征分析更为关键。特别是当 $B_{E}=2$ 和 $B_{D}=3$ 时达到最优性能,该配置被作为后续实验的统一设定。
EGA module design Next, we validated our proposed EGA module by ablating its components (see Appendix B for detailed structures) in Table 3(b). First of all, using vanilla MHSA on a long sequence without chunking was infeasible due to the extremely large computational requirements. Therefore, one approach was to perform down sampling before applying MHSA, similar to the method used in QDPN [59]. However, this naive approach had the drawback of losing detailed frame-wise information. Although another consideration was to simply multiply the features to reflect the finegrained frame-wise information, this method still could not significantly improve performance. In contrast, the optimal performance was achieved by estimating gate values based on a linear layer and a sigmoid function. As a result, it is shown that our proposed global Transformer with EGA module and local Transformer with CLA module have effectively replaced conventional sequence models with smaller computations.
EGA模块设计
接下来,我们通过消融实验验证了所提出的EGA模块各组件(详细结构见附录B),结果如表3(b)所示。首先,由于计算量过大,在长序列上直接使用标准MHSA(未分块)是不可行的。因此,一种解决方案是在应用MHSA前进行降采样,类似QDPN [59]采用的方法。但这种简单方法会丢失细粒度的逐帧信息。另一种思路是通过特征相乘来反映精细的逐帧信息,但性能提升仍不明显。相比之下,基于线性层和sigmoid函数估计门控值的方法取得了最优性能。实验表明,我们提出的带EGA模块的全局Transformer与带CLA模块的局部Transformer,以更小的计算量有效替代了传统序列模型。
FFN module design Also, by improving the design of FFN with Dconv and GLU activation, we could achieve the significant improvement of performance with slight increase of parameters as shown in Table 3(c).
FFN模块设计
此外,通过采用Dconv和GLU激活改进FFN设计,我们能够以参数量的轻微增加实现显著的性能提升,如表3(c)所示。
Comparison with various long sequence models In Table 4, we evaluated the network by stacking our proposed global-local Transformer blocks to assess the performance of modeling a long sequence.
与各种长序列模型的比较
在表4中,我们通过堆叠提出的全局-局部Transformer块来评估网络对长序列建模的性能。
| 系统 | 参数量 (M) | MACs (G/s) | WSJ0-2Mix | WHAM! | Libri2Mix |
|---|---|---|---|---|---|
| SI-SNRi (dB) | SDRi (dB) | SI-SNRi (dB) | |||
| Conv-TasNet [47] | 5.1 | 10.5 | 15.3 | 15.6 | 12.7 |
| SuDoRM-RF [70] | 6.4 | 10.1 | 18.9 | 13.7 | |
| TDANet [42] | 2.3 | 9.1 | 18.5 | 18.7 | 15.2 |
| Sandglasset [38] | 2.3 | 28.8 | 20.8 | 21.0 | |
| S4M [7] | 3.6 | 38.4 | 20.5 | 20.7 | |
| SepReformer-T | 3.5 | 10.4 | 22.4 | 22.6 | 17.2 |
| SepReformer-S | 4.3 | 21.3 | 23.0 | 23.1 | 17.3 |
| DPRNN [45] | 2.6 | 88.5 | 18.8 | 19.0 | 13.7 |
| DPTNet [9] | 2.7 | 102.5 | 20.2 | 20.3 | 14.9 |
| Sepformer [66] | 26.0 | 86.9 | 20.4 | 20.5 | 14.7 |
| WaveSplitt [89] | 29.0 | 21.0 | 21.2 | 16.0 | |
| A-FRCNN [32] | 6.1 | 125.0 | 18.3 | 18.6 | 14.5 |
| SFSRNet [60] | 59.0 | 124.2 | 22.0 | 22.1 | |
| ISCITt [51] | 58.4 | 252.2 | 22.4 | 22.5 | 16.4 |
| QDPN[59] | 200.0 | 22.1 | |||
| TF-GridNet [79] | 14.5 | 460.8 | 23.5 | 23.6 | |
| SepReformer-B | 14.2 | 39.8 | 23.8 | 23.9 | 17.6 |
| SepReformer-M | 17.3 | 81.3 | 24.2 | 24.4 | 17.8 |
(a) Comparison of Sep Reformer to existing models. Table 5: Evaluation on various benchmark dataset of WSJ0-2MIX, WHAM!, WHAMR!, and Libri2Mix. "†" denotes that the networks use additional speaker information.
(b) Comparison of Sep Reformer-L to existing large models with DM
(a) Sep Reformer与现有模型的对比
表 5: 在WSJ0-2MIX、WHAM!、WHAMR!和Libri2Mix等多个基准数据集上的评估。"†"表示网络使用了额外的说话人信息。
| System | Params. (M) | MACs (G/s) | WSJ0-2Mix SI-SNRi (dB) | WSJ0-2Mix SDRi (dB) | WHAM! SI-SNRi (dB) | WHAM! SDRi (dB) | WHAMR! SI-SNRi (dB) | WHAMR! SDRi (dB) |
|---|---|---|---|---|---|---|---|---|
| Sepformer [67] | 26.0 | 86.9 | 22.3 | 22.5 | 16.4 | 16.7 | 14.0 | 13.0 |
| WaveSplit [89] | 29.0 | - | 21.0 | 21.2 | - | - | 13.2 | 12.2 |
| SFSRNet [60] | 59.0 | 466.2 | 24.0 | 24.1 | 1 | 1 - | - | - |
| ISCIT [51] | 58.4 | 252.2 | 24.3 | 24.4 | 16.9 | 17.2 | - | - |
| QDPN [59] | 200.0 | - | 23.6 | - | - | - | 14.4 | - |
| Mossformer(L) [92] | 42.1 | 86.1 | 22.8 | - | 17.3 | - | 16.3 | - |
| Mossformer2(L) [93] | 55.7 | 1 | 24.1 | - | 18.1 | - | 17.0 | - |
| Separate And Diffuse [48] | - | - | 23.9 | - | - | - | - | - |
| SepReformer-L | 59.4 | 155.5 | 25.1 | 25.2 | 18.4 | 18.7 | 17.2 | 16.0 |
(b) Sep Reformer-L与现有大型DM模型的对比
Note that we did not apply the ESSD structure and multi-loss to our separator in this experiment. We could observe that the network based on dual-path sequence models requires high computation resources in terms of MACs while multi-scale sequence models are more efficient. The recently proposed Mossformer based on efficient gate attention unit (GAU) mechanism [33] showed improved performance with relatively smaller computations compared to the networks with dual-path model. In particular, the proposed model showed improved separation performance with similar MACs, which demonstrated the capacity as a model for a long sequence. It also suggested that the proposed block can sufficiently replace the dual-path models with fewer computations. Furthermore, by combining the U-Net structure into global-local Transformer blocks, the network became more efficient with the similar separation performance.
需要注意的是,在本实验中我们并未对分离器应用ESSD结构和多损失函数。可以观察到,基于双路径序列模型的网络在MACs运算量方面要求较高,而多尺度序列模型效率更优。最近提出的基于高效门控注意力单元(GAU)机制的Mossformer[33]相比双路径模型网络,在计算量较小的情况下展现了更好的性能。特别地,所提出的模型在相近MACs条件下实现了分离性能提升,证明了其作为长序列模型的能力。这也表明所提出的模块能够以更少计算量充分替代双路径模型。此外,通过将U-Net结构融入全局-局部Transformer模块,网络在保持相近分离性能的同时进一步提升了效率。
5.4 Comparison with existing models
5.4 与现有模型的对比
Finally, we compared our Sep Reformer models with existing separation models on various benchmark datasets in Table 5. Although we evaluated Sep Reformer trained with standard pairs from the training set in Table 5(a), Sep Reformer-L was trained with dynamic mixing (DM) [89, 66] for data augmentation and compared to other existing large models with DM in Table 5(b). When traind with DM, we set an initial learning rate of $2.0e^{-4}$ and fixed during first 50 epoch. In Table 5(a), with almost the smallest computational loads in terms of MACs, our tiny model showed the best performance except for TF-GridNet in the WSJ0-2Mix dataset which was a powerful model recently proposed. It demonstrated the efficiency of the SepRe method in speech separation. Also, Sep Reformer-M without DM in Table 5(a) showed competitive separation performance on WSJ0-2Mix compared to the large models with data augmentation in Table 5(b). In particular, Sep Reformer-L with DM achieved the SOTA performance of $25\mathrm{dB}$ of SI-SNRi on WSJ0-2Mix, showing significantly improved performance over other conventional methods.
最后,我们在表5中将Sep Reformer模型与现有分离模型在多个基准数据集上进行了比较。虽然在表5(a)中我们评估了使用训练集标准配对训练的Sep Reformer,但表5(b)中的Sep Reformer-L采用了动态混合(DM)[89,66]进行数据增强,并与其他采用DM的大型模型进行了对比。使用DM训练时,我们设置初始学习率为$2.0e^{-4}$,并在前50个epoch保持固定。表5(a)显示,在MACs计算量几乎最小的情况下,我们的微型模型在WSJ0-2Mix数据集上表现最佳(仅次于近期提出的强大模型TF-GridNet),证明了SepRe方法在语音分离中的高效性。此外,表5(a)中未使用DM的Sep Reformer-M在WSJ0-2Mix上的分离性能,与表5(b)中采用数据增强的大型模型相比仍具竞争力。特别值得注意的是,采用DM的Sep Reformer-L在WSJ0-2Mix上实现了SI-SNRi达$25\mathrm{dB}$的SOTA性能,较传统方法有显著提升。

Figure 5: Si-SNRi results on WSJ0-2Mix versus MACs $\bf(G/s)$ for the conventional methods and the proposed Sep Reformer. The check mark in the circle indicates the use of DM method for training. The radius of circle is proportional to the parameter size of the networks.
图 5: WSJ0-2Mix数据集上Si-SNRi结果与MACs $\bf(G/s)$ 的对比,展示了传统方法与提出的Sep Reformer。圆圈中的对勾标记表示使用了DM方法进行训练。圆圈半径与网络参数量成正比。
In Table 5(a), the smallest Sep Reformer-T among the proposed models even showed significant improvements on WHAM! and Libri2Mix datasets compared to the conventional methods. It suggested that the proposed SepRe method can be efficiently applied to a speech separation task in general. Also, Sep Reformer-L with DM showed the SOTA performance on WHAM! and WHAMR! datasets, as well as WSJ0-2Mix, which demonstrated that the proposed method can be trained effectively in a large model. Figure 5 compares the separation performance of various existing methods in terms of SI-SNRi versus MACs on WSJ0-2MIX. From the figure, we can observe the significant effectiveness of the proposed Sep Reformer in the speech separation task with high computational efficiency. Especially, it is noteworthy that the Sep Reformer-T models outperformed the conventional Sepformer trained with DM with 10 times smaller computations.
在表5(a)中,所提模型中最小的Sep Reformer-T相比传统方法在WHAM!和Libri2Mix数据集上仍显示出显著提升。这表明所提出的SepRe方法可高效应用于通用语音分离任务。此外,采用DM训练的Sep Reformer-L在WHAM!、WHAMR!及WSJ0-2Mix数据集上均实现了SOTA性能,证明该方法能在大模型中有效训练。图5对比了WSJ0-2MIX数据集上各现有方法在SI-SNRi与MACs指标下的分离性能。由图可见,所提Sep Reformer在保持高计算效率的同时,展现出显著的语音分离效能。特别值得注意的是,Sep Reformer-T模型以10倍于DM训练的传统Sepformer更小的计算量实现了更优性能。
6 Conclusion
6 结论
In this work, we introduced the SepRe method, in which the asymmetric encoder and decoder perform separation and reconstruction, respectively. The encoder analyzes and separates a feature sequence, and the separated sequences are reconstructed by a weight-sharing network and a cross-speaker network. We demonstrated that the SepRe method can be applied to conventional separators in general and utilizing multi-loss significantly improves the performance. Moreover, we replaced the dual-path model with presented global and local Transformer blocks to address a long sequence. The separator using the presented unit blocks has shown enhanced separated results efficiently, and combining a U-Net structure to exploit the multi-scale sequence model has further increased the efficiency. Finally, not only did our presented Sep Reformer outperform the most conventional methods in speech separation even with almost the smallest computational resources, but our large models achieved SOTA performance with large margins compared to the conventional models on various speech separation datasets.
在本工作中,我们提出了SepRe方法,其非对称编码器与解码器分别执行分离和重建任务。编码器分析并分离特征序列,分离后的序列通过权重共享网络和跨说话人网络进行重建。我们证明了SepRe方法可普遍应用于传统分离器,且采用多损失函数能显著提升性能。此外,我们采用提出的全局与局部Transformer模块替代双路径模型,以处理长序列问题。使用该单元模块的分离器能高效提升分离效果,结合U-Net结构利用多尺度序列建模进一步提高了效率。最终,我们提出的Sep Reformer不仅以近乎最小的计算资源在语音分离任务中超越多数传统方法,大型模型更在多个语音分离数据集上以显著优势刷新了SOTA(State-of-the-art)性能。
Limitations and future work. Our study focuses on 2-speaker mixture situation to assess our models in various model sizes and in the extensive datasets including noise and reverberation. Consequently, we believe that further investigation is needed to validate for more than 2-speaker mixture scenarios. Also, an important future direction is to separate mixtures for an unknown number of speakers as it is impractical to assume that the number of speakers to be separated is known in advance. Finally, although we experimentally validated our SepRe method, we believe that further investigation is necessary to figure out its underlying mechanism.
局限性与未来工作。我们的研究聚焦于双人混合语音场景,以评估不同规模模型在包含噪声和混响的广泛数据集中的表现。因此,我们认为需要进一步研究来验证超过两人混合场景的适用性。另一个重要方向是分离未知说话人数量的混合语音,因为预先知道待分离的说话人数量在实际中往往不现实。最后,尽管我们通过实验验证了SepRe方法的有效性,但仍需深入研究其内在机制。