A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection
基于统一Transformer框架的群组分割:协同分割、协同显著性检测与视频显著目标检测
Abstract—Humans tend to mine objects by learning from a group of images or several frames of video since we live in a dynamic world. In the computer vision area, many researches focus on co-segmentation (CoS), co-saliency detection (CoSD) and video salient object detection (VSOD) to discover the co-occurrent objects. However, previous approaches design different networks on these similar tasks separately, and they are difficult to apply to each other, which lowers the upper bound of the transfer ability of deep learning frameworks. Besides, they fail to take full advantage of the cues among inter- and intra-feature within a group of images. In this paper, we introduce a unified framework to tackle these issues, term as UFO (Unified Framework for Co-Object Segmentation). Specifically, we first introduce a transformer block, which views the image feature as a patch token and then captures their long-range dependencies through the self-attention mechanism. This can help the network to excavate the patch structured similarities among the relevant objects. Furthermore, we propose an intra-MLP learning module to produce self-mask to enhance the network to avoid partial activation. Extensive experiments on four CoS benchmarks (PASCAL, iCoseg, Internet and MSRC), three CoSD benchmarks (Cosal2015, CoSOD3k, and CocA) and four VSOD benchmarks $\mathbf{(DAVIS_{16}}$ , FBMS, ViSal and SegV2) show that our method outperforms other state-of-the-arts on three different tasks in both accuracy and speed by using the same network architecture , which can reach 140 FPS in realtime. Code is available at https://github.com/suyukun666/UFO
摘要—人类倾向于通过从一组图像或视频的若干帧中学习来挖掘物体,因为我们生活在一个动态的世界中。在计算机视觉领域,许多研究关注于协同分割 (CoS)、协同显著性检测 (CoSD) 和视频显著目标检测 (VSOD) 以发现共现物体。然而,先前的方法针对这些相似任务分别设计了不同的网络,难以相互迁移应用,从而降低了深度学习框架迁移能力的上限。此外,它们未能充分利用一组图像中特征间和特征内的线索。本文提出一个统一框架来解决这些问题,称为 UFO (Unified Framework for Co-Object Segmentation)。具体而言,我们首先引入一个 Transformer 模块,将图像特征视为 patch token,并通过自注意力机制捕获其长程依赖关系。这有助于网络挖掘相关物体间的 patch 结构化相似性。此外,我们提出一个 intra-MLP 学习模块来生成自掩码,以增强网络避免部分激活的能力。在四个 CoS 基准 (PASCAL、iCoseg、Internet 和 MSRC)、三个 CoSD 基准 (Cosal2015、CoSOD3k 和 CocA) 以及四个 VSOD 基准 (DAVIS16、FBMS、ViSal 和 SegV2) 上的大量实验表明,我们的方法在使用相同网络架构的情况下,在三个不同任务的准确性和速度上均优于其他最先进方法,实时速度可达 140 FPS。代码发布于 https://github.com/suyukun666/UFO
Index Terms—Co-object, Long-range Dependency, Transformer, Activation.
索引词—共现对象 (Co-object),长程依赖 (Long-range Dependency),Transformer,激活 (Activation)。
I. INTRODUCTION
I. 引言
BJECT segmentation [1], [2], [3] and detection [4], [5] are the core tasks in computer vision. In our real world, the continuous emergence of massive group-based data and dynamic multi-frame data make deep learning more in the direction of human vision. As a result, more and more studies focus on co-segmentation (CoS) [6], [7], co-saliency detection (CoSD) [8], [9] and video salient object detection (VSOD) [10], [11]. Among them, these tasks all share the common objects with the same attributes given a group of relevant images or within several adjacent frames in the video. They all essentially aim to discover and segment the co-occurrent object by imitating the human vision system.
目标分割 [1]、[2]、[3] 与检测 [4]、[5] 是计算机视觉的核心任务。现实世界中,海量群体数据与动态多帧数据的持续涌现,推动深度学习进一步贴近人类视觉方向。因此,越来越多研究聚焦于协同分割 (CoS) [6]、[7]、协同显著性检测 (CoSD) [8]、[9] 以及视频显著目标检测 (VSOD) [10]、[11]。这些任务的共性在于:给定一组相关图像或视频中若干相邻帧时,它们均需处理具有相同属性的共同目标。其本质都是通过模拟人类视觉系统来发现并分割共现目标。
However, as shown in Fig 1 top, previous methods tend to design different networks on these tasks in isolation, which may
然而,如图 1 顶部所示,先前的方法倾向于孤立地为这些任务设计不同的网络,这可能
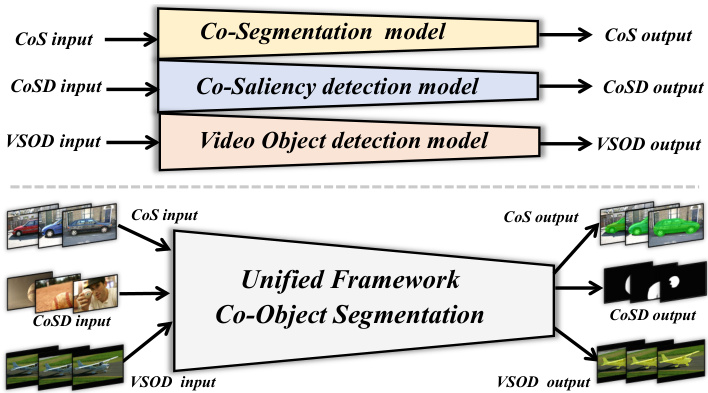
Fig. 1: The main purpose of our proposed framework. The co-object images can be fed into our network to yield the accurate masks in real-time using the same architecture.
图 1: 我们提出框架的主要目标。通过相同架构,可将共目标图像输入我们的网络以实时生成精确掩码。
lower the upper bound on the ease of usage of deep learning frameworks. Besides, the transfer ability and applicability of these methods are relatively poor. For example, some of the CoS [6], [12], CoSD [13], [8] and VSOD methods [10], [11] are well-trained on the same dataset [14], [15], they fail to achieve comparable performance on all benchmarks but only their tasktargeted benchmarks. This illustrates that there may exist some limitations in previous approaches. To be specific, most of the co-object segmentation and saliency detection networks are based on matching strategies [16], [17], which enable the network to extract and propagate the feature representation not only to express the images individual properties but also reflect the relevance and interaction among group-based images. Some recent works [18], [6] utilize spectral clustering [19] to mine the corresponding object regions. However, such methods are unstable and they are deeply dependent on the upper stream extracted features. Some researches [8], [20] adopt distance measure metric [21], [22] to model the relationship among image pixels, but they can only handle the pair-wise information and it is cumbersome to address group-wise relationships. Some others, like [9], [13] try to use the CNNbased attention technique to establish the relationships among group-based images. However, convolution operations produce local receptive fields and experience difficulty to capture longrange feature dependencies among pixels, which may affect the learning representation of co-object regions. Furthermore, some of the VSOD approaches [11], [23] capture the pair-wise feature between frames with the help of optical flow [24], which greatly increases the network running cost and reduces the convenience of using the networks.
降低深度学习框架易用性的上限。此外,这些方法的迁移能力和适用性相对较差。例如,部分CoS [6][12]、CoSD [13][8]和VSOD方法 [10][11]虽然在相同数据集 [14][15] 上训练良好,却无法在所有基准测试中取得可比性能,仅在其任务目标基准上表现尚可。这表明先前方法可能存在某些局限性。具体而言,多数共目标分割和显著性检测网络基于匹配策略 [16][17],这些策略使网络不仅能提取和传递特征表征以表达图像个体属性,还能反映组内图像间的关联性与交互作用。近期研究 [18][6] 采用谱聚类 [19] 挖掘对应目标区域,但此类方法不稳定且高度依赖上游提取特征。另有研究 [8][20] 使用距离度量指标 [21][22] 建模图像像素间关系,但仅能处理成对信息,难以应对组间关系。其他方法如 [9][13] 尝试利用基于CNN的注意力技术建立组内图像关联,然而卷积操作的局部感受野特性使其难以捕捉像素间长程特征依赖,可能影响共目标区域的学习表征。此外,部分VSOD方法 [11][23] 借助光流 [24] 捕获帧间成对特征,这显著增加了网络运行成本并降低了使用便捷性。
To this end, we design a unified framework as shown in Fig 1 bottom, term as UFO (Unified Framework for CoObject Segmentation), to jointly address the aforementioned drawbacks. Specifically, to better reflect the relationships among group-based images, we first introduce a transformer block to insert into our network. It splits the image feature as a patch token and then captures their global dependency thanks to the self-attention mechanism and Multilayer Perceptron (MLP) structure. This can help the network learn complex spatial features and reflect long-range semantic correlations to excavate the patch structured similarities among the relevant objects. The inherent global feature interaction capability of the visual transformer [25] frees us from the computationally expensive similarity matrices as some previous methods [6]. Therefore, our method can achieve real-time performance. In addition to improving inter-collaboration in group-based images, we also propose an intra-MLP learning module to enhance the single image. As it is common that the encoder of the network only focuses on the most disc rim i native part of the objects [26], in order to avoid partial activation, we add the intra-MLP operation to produce global receptive fields. For each query pixel, it will match with its top $K$ potentially corresponding pixels, which can help the network learn diver gently. Then we produce the self-masks and add them to the decoder to enhance the network. Finally, extensive experiments on four CoS benchmarks (i.e., PASCAL, iCoseg, Internet and MSRC), three CoSD benchmarks (i.e., Cosal2015, CoSOD3k, and CocA) and four VSOD benchmarks (i.e., $\mathrm{DAVIS_{16}}$ , FBMS, ViSal and ${\mathrm{SegV}}2 ) $demonstrate the superiority of our approach and it can outperform the state-of-the-arts in both accuracy and speed by using the same network architecture.
为此,我们设计了一个统一框架(如图1底部所示),命名为UFO(Unified Framework for CoObject Segmentation),以共同解决上述缺陷。具体而言,为更好反映组内图像间的关系,我们首先在网络中引入了一个transformer模块。它将图像特征分割为patch token,借助自注意力机制和多层感知机(MLP)结构捕获全局依赖关系。这能帮助网络学习复杂的空间特征,并反映长程语义关联,从而挖掘相关对象间的结构化相似性。视觉transformer[25]固有的全局特征交互能力,使我们无需像先前某些方法[6]那样计算昂贵的相似度矩阵,因此本方法可实现实时性能。
除提升组内图像协作外,我们还提出了一个intra-MLP学习模块来增强单张图像。由于网络编码器通常只关注对象最具判别力的部分[26],为避免局部激活,我们添加intra-MLP操作来生成全局感受野。每个查询像素会与其Top $K$ 个潜在对应像素匹配,这有助于网络进行多样化学习。随后生成自掩码并加入解码器以增强网络。最终,在四个CoS基准数据集(PASCAL、iCoseg、Internet和MSRC)、三个CoSD基准数据集(Cosal2015、CoSOD3k和CocA)以及四个VSOD基准数据集($\mathrm{DAVIS_{16}}$、FBMS、ViSal和${\mathrm{SegV}}2$上的大量实验表明,本方法在使用相同网络架构时,在精度和速度上均优于现有最优技术。
The main contributions of our paper are the following:
我们论文的主要贡献如下:
II. RELATED WORK
II. 相关工作
Co-Segmentation (CoS). Co-Segmentation is introduced by Rother et al. [27], which aims to segment the common objects in pair images. Early conventional works like Gabor filters [28] and SIFT [29] try to extract low-level image features and then detect image foreground. As deep learning recently emerges and demonstrates the success in many computer vision applications, more and more recent studies adopt deep visual features to train object co-segmentation. Chen et al. [30] and Li et al. [31] first propose the siamese fully convolutional network to solve the object co-segmentation task with a mutual correlation layer. However, both of them can not achieve satisfactory performance and they can only deal with pair-wise images. Later, Li et al. [12] and Zhang [7] et al. both propose groupwise networks using LSTM [32]. Although they can improve the performance, they are computationally expensive because of the serial structure of recurrent neural network. Besides, training such methods will have a risk such as forgetting historical information. More recently, Chen et al. [33] proposes a matching strategy to jointly complete semantic matching and object Co-segmentation. Such a method is targeted for bipartite matching, which is hard to apply to group-based segmentation. Zhang [6] later designs a spatial-semantic network with subcluster optimizing. The cluster results are deeply dependent on the upper extracted features and thus, it may make the training unstable.
共分割 (CoS)。共分割由Rother等人[27]提出,旨在分割成对图像中的共同对象。早期传统方法如Gabor滤波器[28]和SIFT[29]尝试提取低级图像特征以检测前景。随着深度学习近年兴起并在众多计算机视觉应用中取得成功,越来越多研究采用深度视觉特征进行对象共分割训练。Chen等人[30]与Li等人[31]首次提出连体全卷积网络,通过互相关层解决对象共分割任务。但二者均未能达到理想性能,且仅能处理成对图像。随后,Li等人[12]与Zhang等人[7]均提出采用LSTM[32]的分组网络。虽能提升性能,但循环神经网络的串行结构导致计算成本高昂。此外,此类方法训练存在遗忘历史信息的风险。最近,Chen等人[33]提出联合完成语义匹配与对象共分割的匹配策略,但该方法针对二分匹配设计,难以应用于分组分割。Zhang[6]后续设计了具有子聚类优化的空间语义网络,其聚类结果高度依赖上层提取特征,可能导致训练不稳定。
Co-Saliency Detection (CoSD). Co-Saliency Detection is similar to Co-Segmentation. The main difference between them lies in that salient detection mimics the human vision system to distinguish the most visually distinctive regions [34], [8]. Previous standard methods [35], [36], [37] try to use hand-crafted cues or super-pixels prior to discover the cosaliency from the images. Later, researchers pay more attention to explore the deep-based models in a data-driven manner in various ways, i.e., co-category semantic fusion [38], [6], gradient-induced [34] and CNN-based self-attention [9], [13], etc. However, these works do not fully consider the global correlation among the group-based images since the convolution local receptive fields. Some recent works [39], [18] exploit GCN to solve the non-local problem in CNN. However, in these methods, a large number of similarity matrices and adjacency matrices need to be constructed for the graph, which will slow down the networks and are computational costly. Zhang et al. [8] proposes to use GW distance [40] to build the dense correlation volumes for image pixels. However, it has to select a target image and source images, which ignore the attention on the target image itself. Moreover, the distance metric problem in the network needs a sub-solver to optimize. This will cost more time for matching. Compared to it, for a query patch, our transformer block can capture the relationships of both inter-pixel within group-based images and intra-pixel within a single image, which can model the global long-range semantic correlations rapidly.
共显著性检测 (CoSD)。共显著性检测与共分割类似,两者主要区别在于显著性检测通过模拟人类视觉系统来识别最具视觉区分度的区域 [34][8]。早期传统方法 [35][36][37] 主要采用手工特征或超像素先验从图像中发现共显著性。后续研究转向以数据驱动方式探索深度模型,包括共类别语义融合 [38][6]、梯度诱导 [34] 和基于CNN的自注意力机制 [9][13] 等多种途径。然而由于卷积操作的局部感受野限制,这些工作未能充分考虑图像组间的全局关联性。近期研究 [39][18] 尝试用图卷积网络 (GCN) 解决CNN的非局部性问题,但需要为图结构构建大量相似度矩阵和邻接矩阵,导致网络速度下降且计算成本高昂。Zhang等人 [8] 提出使用GW距离 [40] 构建图像像素的密集关联体,但该方法需指定目标图像与源图像,忽略了目标图像自身的注意力机制,且网络中的距离度量问题需要子优化器求解,显著增加了匹配耗时。相比之下,我们的Transformer模块能同时捕捉组内图像间的像素级关联和单幅图像内的像素级关联,可快速建模全局长程语义相关性。
Video Salient Object Detection (VSOD). In video salient object detection, since the content of each frame is highly correlated, it can be considered whose purpose is to capture long-range feature information among the adjacency frame. Traditional methods [41], [42], [43], [44] are usually based on classic heuristics in image salient object detection area. Subsequently, some works [45], [46] rely on 3D-convolution to capture the temporal information. However, the 3D convolution operation is very time-costly. In recent, more and more schemes [11], [47], [43] propose to combine optical flow [24] to locate the representative salient objects in video frames.
视频显著目标检测 (VSOD)。在视频显著目标检测中,由于每帧内容高度相关,其目标可视为捕捉相邻帧间的长程特征信息。传统方法 [41]、[42]、[43]、[44] 通常基于图像显著目标检测领域的经典启发式算法。随后,部分研究 [45]、[46] 采用 3D 卷积捕捉时序信息,但该操作耗时严重。近年来,越来越多方案 [11]、[47]、[43] 提出结合光流 [24] 来定位视频帧中的代表性显著目标。
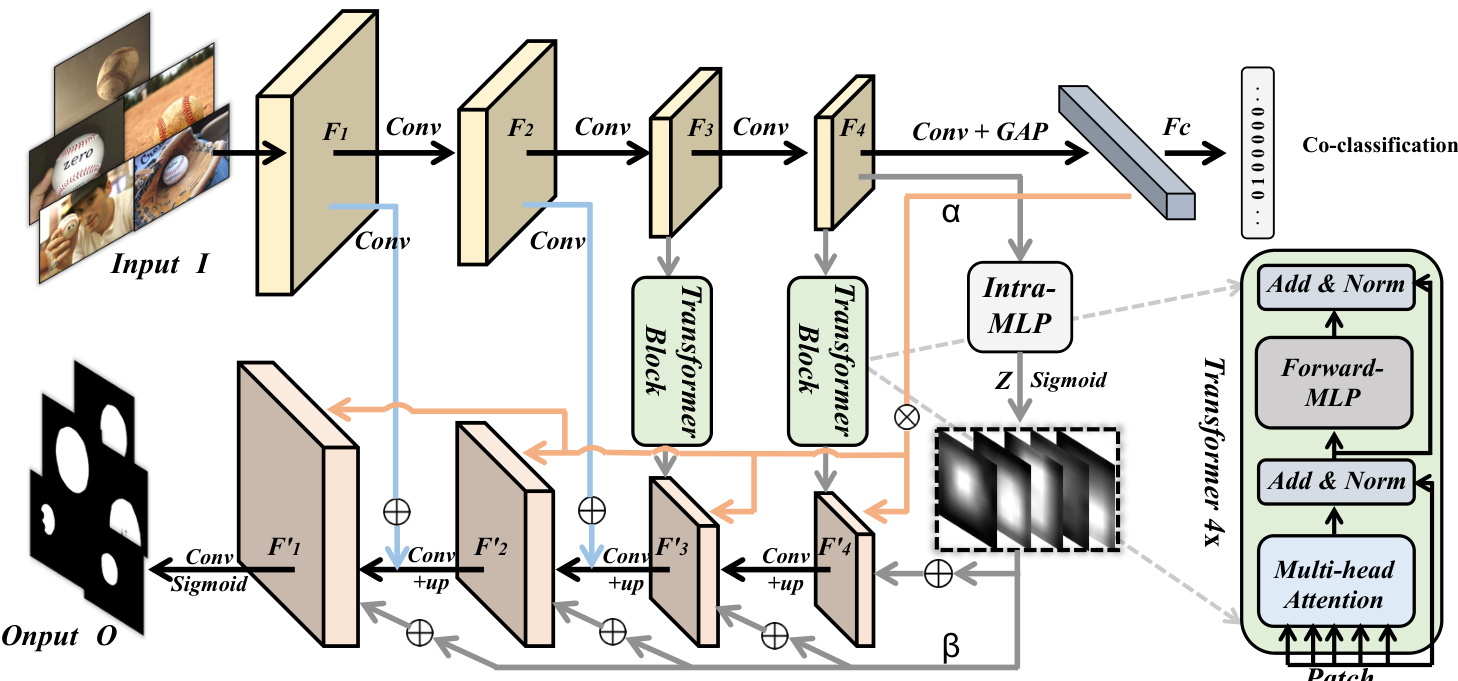
Fig. 2: The pipeline of our proposed method. The given group-based input images $\mathcal{T}$ are first fed into the encoder, yielding the multi-scale feature maps $F$ . Then we employ transformer blocks (see Fig 3 for more details) on the last two layers to capture the images long-range correlations to model the patch structured similarities among the relevant objects, which will output the updated co-attention layers $F^{\prime}$ . In addition, the last layer feature are passed through a classification sub-network and an intra-MLP module. The former exploits the co-category associated information and the latter produce the self-masks. Finally, they are combined with the updated co-attention layers to enhance the co-object semantic-aware regions in the pyramid network structure-like decoder to produce the output $\mathcal{O}$ .
图 2: 我们提出方法的流程。给定的基于分组的输入图像 $\mathcal{T}$ 首先被送入编码器,生成多尺度特征图 $F$。随后我们在最后两层应用transformer块(详见 图 3)来捕获图像的长程相关性,以建模相关对象间的块结构相似性,这将输出更新后的共注意力层 $F^{\prime}$。此外,最后一层特征通过分类子网络和内部MLP模块处理。前者利用共类别关联信息,后者生成自掩码。最终,它们与更新后的共注意力层结合,在金字塔网络结构的解码器中增强共对象语义感知区域,生成输出 $\mathcal{O}$。
In practical usage, obtaining additional prior information such as optical flow will make the deep learning network inconvenient, which can not be a real sense of end-to-end network. More recently, some approaches exploit attentionbased mechanisms to better establish the pair-wise relation in the area in consecutive frames. Fan et al. [48] and Gu et al. [10] propose a visual-attention-consistent module and a pyramid constrained self-attention block to better capture the temporal dynamics cues, respectively. However, these models can not transfer well to the above tasks. Therefore, in this paper, we propose a unified framework to solve these problems in a more comprehensive way.
在实际应用中,获取光流等额外先验信息会导致深度学习网络使用不便,无法实现真正意义上的端到端网络。近期,一些研究采用基于注意力 (attention) 的机制来更好地建立连续帧区域间的成对关系。Fan等人[48]和Gu等人[10]分别提出了视觉注意力一致性模块和金字塔约束自注意力块 (self-attention) ,以更好地捕捉时序动态特征。然而,这些模型难以迁移至上述任务。为此,本文提出统一框架以更全面地解决这些问题。
III. METHODOLOGY
III. 方法论
A. Architecture Overview
A. 架构概述
Given a group of $N$ images that contain cooccurrent objects, our target is to produce the accurate masks output $O=\dot{{O^{n}}}{n=1}^{N}$ that represent the share foregrounds. To achieve this goal, we propose a unified framework for co-object segmentation (UFO). As depicted in Fig 2, the overall architecture of our network is based on an encoder (i.e., VGG16 [49]) to extract multi-scale layer features ${F_{1},F2,F3,F_{4}}$ . The transformer blocks in the last two layers are responsible for matching the co-objects similarities in multi-resolution feature maps, producing the enhanced co-attention maps ${F_{3}^{\prime},F_{4}^{\prime}}$ . Besides, the intra-MLP learning representation and the co-category semantic guidance are leveraged to combine with the updated maps in the decoder to enhance co-object regions. Specifically, the co-category embedding response $\alpha$ is multiplied by the decoder features, and the intra self-masks $\beta$ are added to the decoder features. The encoder-decoder structure in our network is similar to the feature pyramid network [50], whose top-level features are fused by upsampling with low-level features in skip connection. Furthermore, the input of our network can be not only a group of images with relevant objects but also a multi-frame video.
给定一组包含共现物体的 $N$ 张图像 ,我们的目标是生成表示共享前景的精确掩码输出 $O=\dot{{O^{n}}}{n=1}^{N}$ 。为实现这一目标,我们提出了一个统一的共目标分割框架 (UFO) 。如图 2 所示,网络的整体架构基于编码器 (即 VGG16 [49]) 来提取多尺度层特征 ${F_{1},F2,F3,F_{4}}$ 。最后两层中的 Transformer 模块负责匹配多分辨率特征图中的共目标相似性,生成增强的共注意力图 ${F_{3}^{\prime},F_{4}^{\prime}}$ 。此外,利用内部 MLP 学习表示和共类别语义引导与解码器中的更新特征图结合,以增强共目标区域。具体而言,共类别嵌入响应 $\alpha$ 与解码器特征相乘,而内部自掩码 $\beta$ 则与解码器特征相加。网络中的编码器-解码器结构类似于特征金字塔网络 [50] ,其顶层特征通过上采样与跳跃连接中的低层特征融合。此外,网络的输入不仅可以是一组相关物体的图像,还可以是多帧视频。
B. Transformer Block
B. Transformer 模块
Preliminaries. In visual transformer [25], in order to handle 2D images, an input image will be divided into a sequence of flattened 2D patches. The transformer uses a constant latent vector size $D$ in all its layers for each token embedding. Each layer consists of a multi-head self-attention layer and a Multilayer Perceptron (MLP) operation. Compared to other group-based image matching strategies and feature extraction methods, we consider that transformer block has two main advantages: (1) Although transformer is not specially designed for image matching, it has the intrinsic ability to capture global cues across all input patch tokens, which we have mentioned in Sec.II. (2) The transformer parallel ize s the patch tokens, which is faster than some of the serial processing methods and can achieve real-time performance.
预备知识。在视觉Transformer [25]中,为了处理2D图像,输入图像会被分割成一系列扁平化的2D图像块。Transformer在每一层中为每个token嵌入使用恒定大小的潜在向量$D$。每层由多头自注意力层和多层感知机(MLP)操作组成。与其他基于分组的图像匹配策略和特征提取方法相比,我们认为transformer模块具有两个主要优势:(1) 尽管transformer并非专为图像匹配设计,但其具备捕获所有输入图像块token间全局线索的内在能力,正如我们在第II节所述。(2) transformer并行处理图像块token,比某些串行处理方法更快,能够实现实时性能。
Semantic Patch Collaboration. The detailed workflow of the transformer block is shown in Fig 3 left. Since we employ transformer blocks both on $F_{3}$ and $F_{4}$ layers in multiresolution feature maps, for simplicity, we omit $F_{3}$ in the following. Concretely, we first reshape $F_{4}\in\mathbb{R}^{B\ast N\times C\times h\times w}$ ( $w$ and $h$ denote the spatial size of the feature map, $C$ is the feature dimension, $B$ and $N$ denote the batch size and group size, respectively) into a sequence flattened patch tokens $\bar{\boldsymbol{T}}\in\mathbf{\bar{\mathbb{R}}}^{B\times C\times P}$ , where $P=Nhc$ . All these tokens are then fed into the transformer blocks and yield the updated patch embeddings by:
语义补丁协作。Transformer 模块的详细工作流程如图 3 左侧所示。由于我们在多分辨率特征图的 $F_{3}$ 和 $F_{4}$ 层均采用了 Transformer 模块,为简化表述,下文将省略 $F_{3}$ 部分。具体而言,我们首先将 $F_{4}\in\mathbb{R}^{B\ast N\times C\times h\times w}$ (其中 $w$ 和 $h$ 表示特征图的空间尺寸,$C$ 为特征维度,$B$ 和 $N$ 分别代表批处理大小和分组大小) 重塑为展平的补丁 Token 序列 $\bar{\boldsymbol{T}}\in\mathbf{\bar{\mathbb{R}}}^{B\times C\times P}$,其中 $P=Nhc$。随后将所有 Token 输入 Transformer 模块,通过以下运算得到更新后的补丁嵌入 :
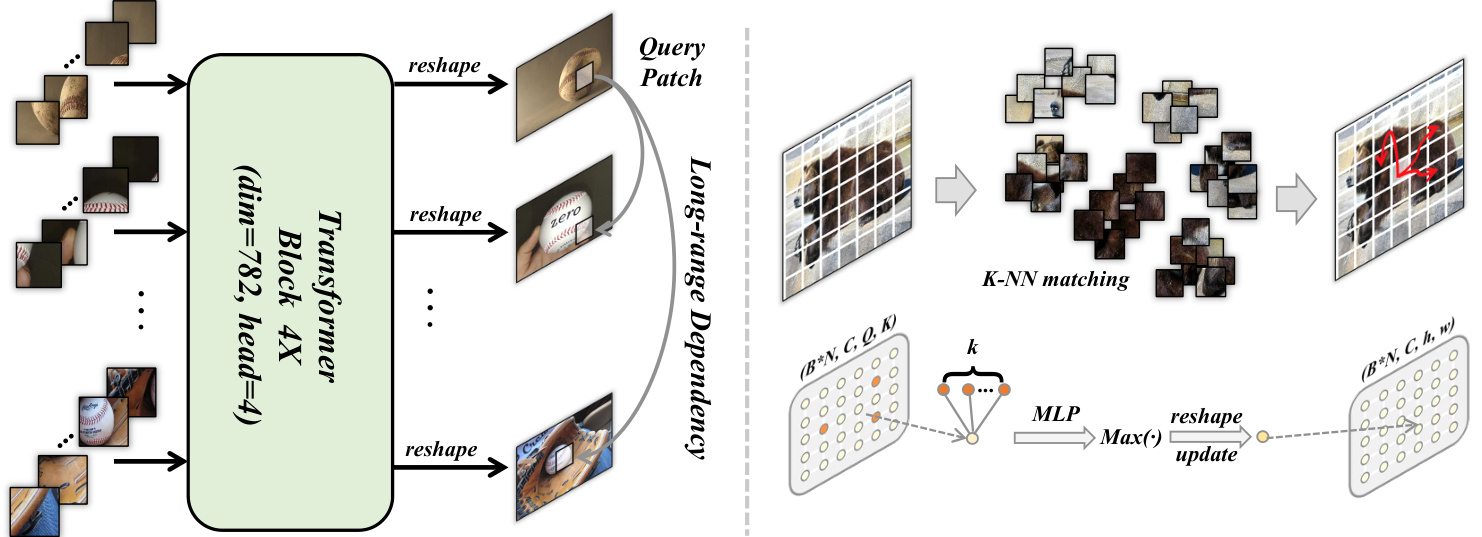
Fig. 3: Detailed illustration of the transformer block and the intra-MLP learning module. Left: A group of images $\mathcal{T}$ are reshaped into patches. The transformer encoder will output the enhanced patch embeddings implemented by the multi-head MLP. We then reshape all the patches into image-like feature maps. Right: For each query image feature patch, it will match with its top $\mathcal{K}$ potentially corresponding patches. Then, it will be updated by aggregating different sub-region representations using MLP operation.
图 3: Transformer模块和内部MLP学习模块的详细图示。左侧: 一组图像$\mathcal{T}$被重塑为图像块。Transformer编码器将通过多头MLP输出增强后的图像块嵌入表示。随后我们将所有图像块重塑为类图像特征图。右侧: 对于每个查询图像特征块,它会与其top $\mathcal{K}$个潜在对应块进行匹配。然后通过MLP操作聚合不同子区域表示来更新该特征块。
$$
T^{\prime}=\mathbf{M}\mathbf{u}\mathbf{l}\mathbf{t}\mathbf{i}-\mathbf{H}\mathbf{e}\mathbf{a}\mathbf{d}(\mathbf{M}\mathbf{L}\mathbf{P}(T)),
$$
$$
T^{\prime}=\mathbf{M}\mathbf{u}\mathbf{l}\mathbf{t}\mathbf{i}-\mathbf{H}\mathbf{e}\mathbf{a}\mathbf{d}(\mathbf{M}\mathbf{L}\mathbf{P}(T)),
$$
where the trainable linear projection maps the patches from the original $C$ dimensions to $D$ dimensions, and back to $C$ dimensions. Afterward, we reshape $T^{\prime}$ back into an imagelike feature map $F_{4}^{\prime}\in\mathbb{R}^{B\ast N\times C\times h\times w}$ . Due to the inductive bias [51] of convolution, the features extracted by the encoder convolution layers are not sensitive to the global location of features but only care about the existence of decisive features. The proposed transformer block can complement convolution and enhance the representations of the global co-object regions.
其中可训练的线性投影将图像块从原始的 $C$ 维映射到 $D$ 维,再映射回 $C$ 维。随后,我们将 $T^{\prime}$ 重新变形为类似图像的特征图 $F_{4}^{\prime}\in\mathbb{R}^{B\ast N\times C\times h\times w}$。由于卷积的归纳偏置 [51],编码器卷积层提取的特征对特征的全局位置不敏感,只关注决定性特征的存在。所提出的Transformer模块可以补充卷积,并增强全局共现目标区域的表征。
What it learns? Fig 4 shows what the transformer blocks learn (the output is from $F_{3}^{\prime}$ ). As can be seen in the $3^{r d}$ row, the corresponding image patches of the co-object regions are highly activated after operated by the transformer block comparing to the $2^{n d}$ row, which illustrates that the attention mechanism in transformer projection function can adaptively pay attention to the targeted areas and assign more weights to capture the global cues from all the images. In addition, we also visualize the query attention of the picked image patch (i.e., the endpoints of the “banana” and the “head” of the penguin) to show what it will match. The qualitative visualization s in the $3^{r d}$ row further validate that the transformer block can help the network model the long-range dependencies among different location pixels.
它学到了什么?图4展示了Transformer模块学习到的内容(输出来自$F_{3}^{\prime}$)。如第3行所示,经过Transformer模块处理后,共现物体区域对应的图像块激活程度显著高于第2行,这表明Transformer投影函数中的注意力机制能自适应关注目标区域,并为捕捉全局线索分配更高权重。此外,我们还可视化选定图像块(即"香蕉"末端和企鹅"头部")的查询注意力,展示其匹配对象。第3行的定性可视化进一步验证了Transformer模块能帮助网络建模不同位置像素间的长程依赖关系。
C. Intra-MLP module
C. 内部MLP模块
In addition to the image inter-collaboration, we also propose an intra-MLP learning module to activate more self-object areas within a single image. As shown in Fig 3 right, the top layer feature map from the encoder are viewed as different patches. We consider that different patches will not just match with their nearest ones as in CNN (local receptive fields) since the long-distance patch features may share some similar responses (i.e., color and texture). Motivated by this, we can fuse the non-local semantic information to improve the object learning representation. Concretely, the top layer feature $F_{4}\in$ $\mathbb{R}^{BN\times C\times\bar{h}\times w}$ is reshaped into $\overline{{F}}{4}\in\overline{{\mathbb{R}}}^{B\ast N\times C\times Q}$ , where $Q=h*w$ is the number of patches. We then construct a matrix $M$ that represents the similarity of each patch within a single image. Specifically, we use $\ell_{2}$ - distance to measure the relationship between the two arbitrary patches. Since we use normalized channel features, by removing the constant, the matrix $\boldsymbol{M}\in\mathbb{R}^{B\ast N\times Q\times Q}$ can be formulated as:
除了图像间的协同合作,我们还提出了一种内部MLP学习模块,用于激活单张图像中更多的自对象区域。如图3右侧所示,编码器的顶层特征图被视为不同图像块。我们认为,不同于CNN(局部感受野)中图像块仅与最近邻匹配,远距离图像块特征可能共享某些相似响应(如颜色和纹理)。受此启发,我们可以融合非局部语义信息来提升对象学习的表征能力。具体而言,顶层特征$F_{4}\in$$\mathbb{R}^{BN\times C\times\bar{h}\times w}$被重塑为$\overline{{F}}{4}\in\overline{{\mathbb{R}}}^{B\ast N\times C\times Q}$,其中$Q=h*w$表示图像块数量。随后构建表征单张图像内各图像块相似度的矩阵$M$,采用$\ell_{2}$距离度量任意两个图像块的关系。由于使用归一化通道特征,去除常数项后,矩阵$\boldsymbol{M}\in\mathbb{R}^{B\ast N\times Q\times Q}$可表示为:
$$
M={\overline{{F}}}{4}^{T}{\overline{{F}}}_{4}.
$$
$$
M={\overline{{F}}}{4}^{T}{\overline{{F}}}_{4}.
$$
To avoid the patches match with themselves, the diagonal elements of the matrix are set to $-I N F$ . For each query patch, we perform $K N N$ operation on the matrix to select its potentially corresponding target patches. Then, it will output a tensor in $Q\times K$ shape, which indicates the patches along with their top $K$ semantically related patches. After that, we can acquire the $\hat{F}_{4}\in\mathbb{R}^{BN\times C\times Q\times K}$ , and then we perform MLP with $M A X(\cdot)$ operations on it to get the updated feature $Z\in\mathbb{R}^{B*N\times C\times Q}$ as:
为避免图像块与自身匹配,矩阵的对角线元素被设置为 $-I N F$。对于每个查询图像块,我们在矩阵上执行 $K N N$ 操作以选择其潜在对应的目标图像块。随后,系统将输出一个形状为 $Q\times K$ 的张量,该张量标识了各图像块及其语义关联度最高的前 $K$ 个图像块。通过此过程,我们可获得 $\hat{F}_{4}\in\mathbb{R}^{BN\times C\times Q\times K}$,继而对其执行带 $M A X(\cdot)$ 操作的多层感知机处理,最终得到更新后的特征 $Z\in\mathbb{R}^{B*N\times C\times Q}$,其计算方式如下:
$$
Z={\bf M A X}({\bf M L P}(\hat{F}_{4})),
$$
$$
Z={\bf M A X}({\bf M L P}(\hat{F}_{4})),
$$
where $M A X$ is the element-wise maximum operation. This guarantees that the combination of MLP and symmetric function can arbitrarily approximate any continuous set function [52]. The purpose of this step is to combine the target feature with its top $K$ features appearance change information and learn through the perceptron. Finally, we reshape $Z\in\mathbb{R}^{B\ast N\times C\times Q}$ back into $\mathbf{\bar{Z}}\in\bar{\mathbb{R}}^{B*N\times C\times h\times w}$ and employ $S i g m o i d(\cdot)$ to $Z$ to yield the self-masks $\beta$ .
其中 $MAX$ 为逐元素取最大值操作。这保证了多层感知机 (MLP) 与对称函数的组合可以任意逼近任何连续集函数 [52]。此步骤的目的是将目标特征与其前 $K$ 个特征的外观变化信息相结合,并通过感知机进行学习。最后,我们将 $Z\in\mathbb{R}^{B\ast N\times C\times Q}$ 重塑回 $\mathbf{\bar{Z}}\in\bar{\mathbb{R}}^{B*N\times C\times h\times w}$ 并对 $Z$ 应用 $Sigmoid(\cdot)$ 函数生成自掩码 $\beta$。
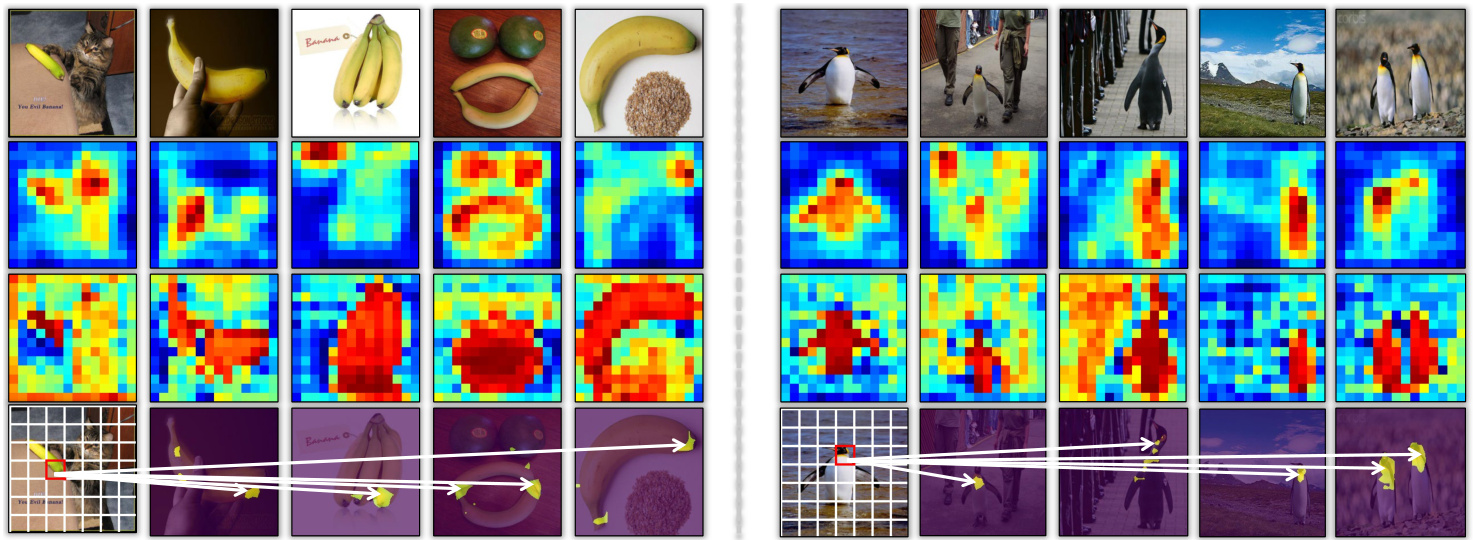
Fig. 4: Analysis of the transformer block. The $1^{s t}$ row: original group-based images input, note that we deliberately pick some hard examples with complex backgrounds and multi-objects. The $2^{n d}$ row: the responded maps before transformer. The $3^{r d}$ row: the responded maps of the patch tokens after transformer. The $4^{t h}$ row: the corresponding attention maps of the selected patches (marked with red rectangles in the query images).
图 4: Transformer模块分析。第1行:原始分组图像输入(注意我们刻意选取了具有复杂背景和多目标的困难样本)。第2行:经过Transformer前的响应图。第3行:经过Transformer后patch token的响应图。第4行:所选patch(查询图像中用红色矩形标出)对应的注意力图。
D. Network Training
D. 网络训练
Moreover, since the co-category information can also be used, the top layer $F_{4}$ is thus passed through a convolutional layer as [38], [6], following a $G A P$ layer to yield a vector $\alpha$ . And the $F C$ layer classifies the embedding $\alpha$ to predict the co-category labels $\hat{y}$ . Then we combine both the $\alpha$ and self-masks $\beta$ to enhance the decoder layer in a conditional normalization way [53] modulated with learned scale and bias. Specifically, the variables $\alpha$ are the learned scale modulation parameters that exclude the distract or s in co-objects regions by using the rich semantic-aware clues. The variables $\beta$ serve as the bias parameters complement and highlight the object targets by endowing spatial-aware information. The decoder leverages the skip connection structure to fuse the low-resolution layer features from the encoder. Ultimately, it outputs the co-object masks.
此外,由于还可以利用共类别信息,顶层 $F_{4}$ 会像 [38]、[6] 那样经过一个卷积层,再通过一个 $GAP$ 层生成向量 $\alpha$。接着,$FC$ 层会对嵌入向量 $\alpha$ 进行分类,以预测共类别标签 $\hat{y}$。然后,我们将 $\alpha$ 和自掩码 $\beta$ 结合起来,通过条件归一化方式 [53] 增强解码器层,并利用学习到的缩放和偏置进行调制。具体来说,变量 $\alpha$ 是学习到的缩放调制参数,通过利用丰富的语义感知线索来排除共物体区域中的干扰物。变量 $\beta$ 则作为偏置参数,通过赋予空间感知信息来补充并突出目标物体。解码器利用跳跃连接结构融合编码器的低分辨率层特征,最终输出共物体掩码。
Objective Function. Firstly, classification loss is used to update the gradient propagation for the semantic information as:
目标函数。首先,分类损失用于更新语义信息的梯度传播,公式如下:
$$
\mathcal{L}{c l s}=\mathcal{L}_{c e}(y,\hat{y}),
$$
$$
\mathcal{L}{c l s}=\mathcal{L}_{c e}(y,\hat{y}),
$$
where $\mathcal{L}_{c e}$ is the cross-entropy loss, $y$ is the ground-truth class label and $\hat{y}$ is the prediction. Besides, the Weighted Binary Cross-Entropy (WBCE) loss for pixel-wise segmentation is also adopted as:
其中 $\mathcal{L}_{c e}$ 是交叉熵损失 (cross-entropy loss),$y$ 是真实类别标签,$\hat{y}$ 是预测值。此外,还采用了加权二元交叉熵损失 (Weighted Binary Cross-Entropy, WBCE) 进行像素级分割:
$$
\begin{array}{c}{\mathcal{L}{w b c e}=-\displaystyle\frac{1}{H W}\sum_{i=1}^{H}\sum_{j=1}^{W}\gamma G(i,j)l o g(P(i,j))}\ {-\displaystyle(1-\gamma)(1-G(i,j))l o g(1-P(i,j)),}\end{array}
$$
$$
\begin{array}{c}{\mathcal{L}{w b c e}=-\displaystyle\frac{1}{H W}\sum_{i=1}^{H}\sum_{j=1}^{W}\gamma G(i,j)l o g(P(i,j))}\ {-\displaystyle(1-\gamma)(1-G(i,j))l o g(1-P(i,j)),}\end{array}
$$
where $H$ and $W$ denote the height and width of the image. $G(i,j)\in{0,1}$ is the ground truth mask and $P(i,j)$ is the predicted probability. $\gamma$ is the ratio of all positive pixels over all pixels in images. Moreover, similar to [54], [9], IoU loss is also widely used to evaluate segmentation accuracy as follows:
其中 $H$ 和 $W$ 表示图像的高度和宽度。$G(i,j)\in{0,1}$ 是真实掩码,$P(i,j)$ 是预测概率。$\gamma$ 是图像中所有正像素与总像素的比率。此外,类似于 [54]、[9],IoU (Intersection over Union) 损失也广泛用于评估分割精度,公式如下:
$$
\mathcal{L}{i o u}=1-\frac{\sum_{i=1}^{H}\sum_{j=1}^{W}P(i,j)G(i,j)}{\sum_{i=1}^{H}\sum_{j=1}^{W}[P(i,j)+G(i,j)-P(i,j)G(i,j)]}.
$$
$$
\mathcal{L}{i o u}=1-\frac{\sum_{i=1}^{H}\sum_{j=1}^{W}P(i,j)G(i,j)}{\sum_{i=1}^{H}\sum_{j=1}^{W}[P(i,j)+G(i,j)-P(i,j)G(i,j)]}.
$$
The whole framework is optimized by integrating all the aforementioned loss functions in an end-to-end manner:
整个框架通过端到端方式整合所有上述损失函数进行优化:
$$
\mathcal{L}{t o t a l}=\mathcal{L}{c l s}+\mathcal{L}{w b c e}+\mathcal{L}_{i o u}.
$$
$$
\mathcal{L}{t o t a l}=\mathcal{L}{c l s}+\mathcal{L}{w b c e}+\mathcal{L}_{i o u}.
$$
IV. EXPERIMENTS
IV. 实验
Datasets. Following [7], [6], we conduct experiments on four co-segmentation benchmarks including: PASCAL-VOC [55], iCoseg [56], Internet [29] and MSRC [57]. Among them, PASCAL-VOC is the most challenging dataset with 1,037 images of 20 categories. For co-saliency detection, our method is evaluated on the three largest and most challenging benchmark datasets, including Cosal2015 [58], CoCA [34], and CoSOD3k [59]. The $\mathrm{CoSOD3k}$ is the largest evaluation benchmark for real-world co-saliency proposed recently, which has a total of 160 categories with 3,316 images. And all of them contain multiple objects against a complex background. In terms of video salient object detection, we benchmark our method on four public datasets, i.e., $\mathrm{DAVIS_{16}}$ [60] (30 videos training and 20 videos validation), FBMS [61] (29 training videos and 30 testing videos), ViSal [62] (consists of 17 video sequences for testing) and $\mathrm{SegV}2$ [63] (consists of 13 clips for testing).
数据集。根据[7]、[6]的研究,我们在四个共分割基准数据集上进行实验,包括:PASCAL-VOC[55]、iCoseg[56]、Internet[29]和MSRC[57]。其中PASCAL-VOC是最具挑战性的数据集,包含20个类别的1,037张图像。对于共显著性检测任务,我们的方法在三个最大且最具挑战性的基准数据集上进行评估,包括Cosal2015[58]、CoCA[34]和CoSOD3k[59]。$\mathrm{CoSOD3k}$是近期提出的最大规模真实场景共显著性评估基准,包含160个类别的3,316张图像,所有图像均包含复杂背景下的多个目标。在视频显著目标检测方面,我们在四个公开数据集上测试方法性能,包括$\mathrm{DAVIS_{16}}$[60](30个训练视频和20个验证视频)、FBMS[61](29个训练视频和30个测试视频)、ViSal[62](包含17个测试视频序列)和$\mathrm{SegV}2$[63](包含13个测试片段)。
TABLE I: Analysis of different modules and their combinations.
表 1: 不同模块及其组合的分析。
| Baseline | Trans | PASCAL | iCoseg | ||||
|---|---|---|---|---|---|---|---|
| P | J | P | C | ||||
| √ | 81.2 | 36.8 | 85.2 | 52.8 | |||
| √ | 92.4 | 68.1 | 95.3 | 87.9 | |||
| √ | 82.9 | 37.6 | 86.0 | 53.3 | |||
| √ | 92.1 | 69.5 | 95.6 | 86.4 | |||
| √ | 92.5 | 68.6 | 95.3 | 88.1 | |||
| 95.0 | 72.7 | 96.9 | 89.8 | ||||
| 92.8 | 69.6 | 95.9 | 87.1 | ||||
| ? | 95.4 | 73.6 | 97.6 | 90.9 |
TABLE II: Analysis of the block and multi-head number in transformer.
表 II: Transformer中块数和多头数的分析
| Transformer | PASCAL | iCoseg | ||
|---|---|---|---|---|
| P | J | P | J | |
| Block =2 | ||||
| Head =2 | 94.0 | 71.8 | 95.9 | 89.1 |
| Head = 4 | 94.2 | 72.5 | 96.3 | 89.4 |
| Head =6 | 94.6 | 73.0 | 96.4 | 89.9 |
| Block = 4 | ||||
| Head =2 | 94.8 | 72.9 | 97.3 | 90.4 |
| Head = 4 | 95.4 | 73.6 | 97.6 | 90.9 |
| Head = :6 | 95.0 | 73.5 | 97.5 | 90.2 |
| Block =6 | ||||
| Head =2 | 95.1 | 72.9 | 97.1 | 90.6 |
| Head = 4 | 95.6 | 72.8 | 97.3 | 90.2 |
| Head = 6 | 95.0 | 73.1 | 97.5 | 90.4 |
Evaluation Metrics. Two widely used measures, Precision $(\mathcal{P})$ and Jaccard index $(\mathcal{I})$ , are used to evaluate the performance of object co-segmentation. For co-saliency detection and video salient object detection, we adopt four evaluation metrics for comparison, including the mean absolute error MAE [64], Fmeasure $\mathrm{F}{\beta}$ [65], E-measure $\mathrm{E}{m}$ [66], and S-measure $\boldsymbol{\mathrm{S}}_{m}$ [67].
评估指标。采用两种广泛使用的度量标准来评估对象共分割的性能:精确率 $(\mathcal{P})$ 和杰卡德指数 $(\mathcal{I})$ 。对于共显著性检测和视频显著目标检测,我们采用四种评估指标进行比较,包括平均绝对误差 MAE [64]、F 度量 $\mathrm{F}{\beta}$ [65]、E 度量 $\mathrm{E}{m}$ [66] 和 S 度量 $\boldsymbol{\mathrm{S}}_{m}$ [67]。
Training Details. The input image group $\mathcal{T}$ contains $N=5$ images. The mini-batch size is set to $8\times N$ . For fair comparisons, we strictly follow the same settings as [34], [9] to use VGG16 [49] as backbone and the images are all resized to $224\times224$ for training and testing unless otherwise stated. We use 4 transformer blocks with 4 multi-heads and $K$ is set to 4 by default. And the feature dimension of the transformer linear projection function is 782. (1): On both co-segmentation (CoS) and co-saliency detection (CoSD) tasks, we follow [38], [13] to use the COCO-SEG [14] for training, which contains 200, 000 images belonging to 78 groups. And each image has a manually-labeled binary mask with co-category labels. We leverage the Adam algorithm [68] as the optimization strategy with $\beta_{1}=0.9$ and $\beta_{2}=0.999$ . The learning rate is initially set to 1e-5 and reduces by a half every 25,000 steps. The whole training takes about 20 hours for total 100,000 steps. (2): On video salient detection task (VSOD), the common practice for most methods [10], [11] are first pre-trained on the static saliency dataset. Following this scheme, we first load the weights pre-trained on $\mathrm{CoS}$ and CoSD tasks and use DUT [15] dataset to train our network to avoid over-fitting. And then we frozen the co-classification layer since we do not have class labels in VSOD task. Lastly, we train on the training
训练细节。输入图像组 $\mathcal{T}$ 包含 $N=5$ 张图像。小批量大小设置为 $8\times N$。为公平比较,我们严格遵循 [34]、[9] 的设置,使用 VGG16 [49] 作为主干网络,所有图像均调整为 $224\times224$ 进行训练和测试(除非另有说明)。我们使用 4 个 Transformer 块(含 4 个头),默认 $K$ 值为 4。Transformer 线性投影函数的特征维度为 782。(1) 在共分割 (CoS) 和共显著性检测 (CoSD) 任务中,我们遵循 [38]、[13] 的方法,使用包含 20 万张图像(分属 78 个组)的 COCO-SEG [14] 进行训练,每张图像都有带共类别标签的手动标注二值掩码。采用 Adam 算法 [68] 作为优化策略($\beta_{1}=0.9$,$\beta_{2}=0.999$),初始学习率为 1e-5,每 25,000 步减半,总计 100,000 步的训练耗时约 20 小时。(2) 在视频显著目标检测任务 (VSOD) 中,多数方法 [10]、[11] 会先在静态显著性数据集上预训练。遵循该方案,我们首先加载在 $\mathrm{CoS}$ 和 CoSD 任务上预训练的权重,并使用 DUT [15] 数据集训练网络以避免过拟合。由于 VSOD 任务没有类别标签,随后冻结共分类层,最后在训练集...
TABLE III: Analysis of the features from different stages in the encoder.
表 III: 编码器不同阶段特征分析
| 方法 | PASCAL | iCoseg | ||
|---|---|---|---|---|
| P | J | P | J | |
| F3 only | 92.1 | 69.8 | 94.6 | 86.4 |
| F4 only | 94.1 | 72.8 | 96.2 | 88.7 |
| F3 and F4 | 95.4 | 73.6 | 97.6 | 90.9 |
TABLE IV: Analysis of different operations for self-masks production.
表 IV: 自掩码生成不同操作的分析
| 方法 | PASCAL iCoseg |
|---|---|
| P J | |
| Conv | 94.8 72.3 |
| Non-Local [69] | 95.1 72.9 |
| Intra-MLP | 95.4 73.6 |
| 方法 | 时间 (毫秒) |
|---|---|
| Cluster [6] | 49.1 |
| Graph [18] | 50.2 |
| GW-Distance [8] | >50 |
| Transformer | 5.4 |
TABLE V: Analysis of different methods’ matching time cost.
表 V: 不同方法匹配时间成本分析
set of $\mathrm{DAVIS_{16}}$ (30 clips) and FBMS (29 clips) as [11] and it takes about 4 hours. All the experiments are conducted on a RTX 3090 GPU. For all the runtime analysis, we report the results tested on Titan $\mathrm{Xp}$ GPU as in [10] for fair comparisons.
我们采用与[11]相同的 $\mathrm{DAVIS_{16}}$ (30个片段)和FBMS (29个片段)数据集进行测试,整个过程耗时约4小时。所有实验均在RTX 3090 GPU上完成。为了公平比较,所有运行时间分析结果均按照[10]的方法在Titan $\mathrm{Xp}$ GPU上进行测试。
A. Ablation Studies
A. 消融实验
To explore each component of our proposed method, we conduct several ablation studies on the CoS (PASCAL-VOC and iCoseg) datasets to demonstrate their effectiveness.
为了探究我们提出方法中各个组件的有效性,我们在CoS (PASCAL-VOC和iCoseg) 数据集上进行了多项消融实验。
Comparisons to Baseline: In Tab I, we investigate the effect of different proposed modules including co-category information $\alpha$ , intra-MLP masks $\beta$ , transformer blocks and their combinations. As can be seen, each module can boost the performance of the baseline model to different degrees. Specifically, the proposed transformer block provides the main contributions to help improve the network performances. Whether used alone or in combination with the other two modules, it can outperform other alternatives by a large margin. This illustrates the effectiveness of each component in our framework.
与基线对比:在表 I 中,我们研究了不同提出模块的效果,包括共类别信息 $\alpha$、内部MLP掩码 $\beta$、Transformer块及其组合。可以看出,每个模块都能不同程度地提升基线模型的性能。具体而言,提出的Transformer块对提升网络性能贡献最大。无论是单独使用还是与其他两个模块组合,它都能大幅优于其他方案。这说明了我们框架中每个组件的有效性。
Settings in Transformer: Tab II shows the exploration of using different block and multi-head numbers in the transformer. We find that network performance can be improved when increasing the number of blocks and the multi-head attention mechanisms. However, keep increasing both the block and head numbers does not always bring gains to the network (i.e., block $=6$ ), which will also cost much computational resources. We conjecture that large block and multi-head numbers will bring more parameter and redundant information for network
Transformer中的设置:表 II展示了在transformer中使用不同块数和多头数的探索。我们发现,增加块数和多头注意力机制可以提升网络性能。然而,持续增加块数和头数并不总能带来网络增益(例如块数$=6$),同时会消耗大量计算资源。我们推测,过大的块数和多头数会为网络引入更多参数和冗余信息

Fig. 5: Qualitative results of our proposed network for “Bus”, “Ballon” and “Bottle” objects.
图 5: 我们提出的网络在"Bus"、"Ballon"和"Bottle"对象上的定性结果。
| 方法 | Backbone | 尺寸 | PASCAL-P | PASCAL-J | iCoseg-P | iCoseg-J | Internet-P | Internet-J | MSRC-P | MSRC-J |
|---|---|---|---|---|---|---|---|---|---|---|
| Jerripothula et al.[70]TMM'2016 | 85.2 | 45.0 | 91.9 | 72.0 | 88.9 | 64.0 | 88.7 | 71.0 | ||
| Jerripothula et al.[71]cvpR'2017 | 80.1 | 40.0 | ||||||||
| Wang et al.[72]TIP'2017 | ResNet50 | 300×300 | 84.3 | 52.0 | 93.8 | 77.0 | 90.9 | 73.0 | ||
| Hsu et al.[73]u1CAr2018 | VGG16 | 384×384 | 91.0 | 60.0 | 96.5 | 84.0 | 92.3 | 69.8 | ||
| Chen et al.[30]Accv'2018 | VGG16 | 512×512 | 59.8 | 84.0 | 73.1 | 77.7 | ||||
| Li et al.[31]Accv'2018 | VGG16 | 512×512 | 94.2 | 64.5 | 95.1 | 84.2 | 93.5 | 72.6 | 95.2 | 82.9 |
| CARNN[12]1cCV'2019 | VGG19 | 224×224 | 94.1 | 63.0 | 97.9 | 89.0 | 97.1 | 84.0 | ||
| SSNM[6]AAAI2020 | VGG16 | 224×224 | 93.7 | 66.0 | 96.5 | 88.0 | 92.3 | 67.0 | 94.3 | 76.3 |
| Chen et al.[33]TPAMI'2020 | ResNet101 | 240×240 | 93.9 | 61.0 | 93.5 | 70.0 | ||||
| CycleSegNet[7]TIP'2021 | ResNet34 | 512×512 | 96.8 | 73.6 | 92.1 | 86.2 | 97.6 | 89.6 | ||
| GCoNett[9]cvPR'2021 | VGG16 | 224×224 | 93.5 | 69.2 | 96.9 | 89.7 | 92.5 | 70.5 | 94.0 | 80.8 |
| CADCt[13]iccv'2021 | VGG16 | 256×256 | 94.1 | 71.8 | 97.1 | 90.2 | 92.8 | 71.9 | 94.4 | 81.6 |
| UFO (Ours) | VGG16 | 224×224 | 95.4 | 73.6 | 97.6 | 90.9 | 93.3 | 73.7 | 95.8 | 83.2 |
| UFO (Ours) | VGG16 | 256×256 | 96.9 | 75.7 | 98.1 | 92.3 | 95.2 | 74.6 | 97.8 | 84.3 |
TABLE VI: Comparisons of our method with the other state-of-the-arts on $\mathrm{CoS}$ datasets. $\dagger$ denotes the results using the publicly released code to re-complete. The best two results on each dataset are shown in red and blue.
表 VI: 我们的方法与其他先进方法在 $\mathrm{CoS}$ 数据集上的对比。$\dagger$ 表示使用公开代码重新复现的结果。每个数据集上最优的两个结果分别用红色和蓝色标出。
learning. Therefore, we set both block and multi-head numbers to 4 in our paper.
因此,我们在论文中将块数和多头数均设为4。
Multi-Scale Features: In our method, we adopt transformer blocks on different top-level layers (i.e., $F_{3}$ and $F_{4}$ ). Since the low-level (i.e., $F_{1}$ and $F_{2}$ ) feature maps are large, we do not consider to using them. Tab III reveals that using both the features from the last two layers is better than using the features alone. This indicates that different level features can provide some vital coarse-to-fine information in the co-object segmentation task.
多尺度特征:在我们的方法中,我们在不同的顶层(即 $F_{3}$ 和 $F_{4}$)上采用了 Transformer 模块。由于低层(即 $F_{1}$ 和 $F_{2}$)的特征图较大,我们不考虑使用它们。表 III 显示,同时使用最后两层的特征比单独使用某一层特征效果更好。这表明在协同目标分割任务中,不同层级的特征能够提供从粗到细的关键信息。
Self-Mask Production: In Tab IV, we compare our intraMLP learning module to standard convolution operation and non-local [69]. We can observe that both our method and non-local can improve the performance by accepting more receptive fields to activate object regions compared to the standard convolution. Moreover, although non-local operation can improve the original convolution, it essentially uses some $1\times1$ convolutions to extract features and then reshape and multiply to get the output, which is still worse than our method.
自掩膜生成:在表 IV 中,我们将内部MLP学习模块与标准卷积运算和非局部操作[69]进行了比较。可以观察到,与标准卷积相比,我们的方法和非局部操作都能通过接受更大感受野来激活目标区域,从而提升性能。此外,尽管非局部操作能改进原始卷积,但其本质上仍使用一些 $1\times1$ 卷积提取特征后通过重塑和乘法得到输出,效果仍逊于我们的方法。
Matching Time: We also exhibit the matching time of different methods in co-object regions mining in Tab V. The results illustrate that our proposed method can not only better model co-object long-distance similarities, but also achieve the best performance in speed, which further validates the claim of the advantage of transformer block. More other analysis can be referred to the supplementary material.
匹配时间:我们在表5中展示了不同方法在共目标区域挖掘中的匹配时间。结果表明,我们提出的方法不仅能更好地建模共目标长距离相似性,还在速度上实现了最佳性能,这进一步验证了Transformer模块的优势主张。更多其他分析可参考补充材料。
B. Comparison with State-of-the-arts
B. 与最先进技术的对比
Co-Segmentation. Tab VI presents the comparisons of our method with other existing CoS methods. Note that there is no standard specification for unifying the various methods on this task, and thus, we point out the respective backbone and input resolution in the table. By using the VGG16 [49] backbone, our framework outperforms all the other methods using the same backbone, even though some of them use a larger input size. Besides, compared to the stronger backbone methods like Chen et al. [33] and CycleS eg Net [7], we can also achieve relatively comparable performance and even outperforms them. CARNN [12] adopts the VGG19 backbone and achieves the top precision on the Internet dataset. However, it is trained on the full COCO dataset. It contains $9\mathrm{k\Omega}$ images belonging to 118 groups, which is much larger than our training set. Furthermore, we also report the performance of some state-of-the-art methods in the co-saliency detection task (i.e., GCoNet [9] and CADC [13]). The results show that our method can also outperform them, which reflects that the transfer ability of such co-saliency detection methods is poor and they are unsuitable for co-segmentation. In general, our method achieves 5 best results and 2 second-best results on 4 benchmarks, which is competitive. Fig 5 shows some qualitative results and more visualization results can be referred to the supplementary.
协同分割。表 VI 展示了我们的方法与其他现有协同分割 (CoS) 方法的对比。需要注意的是,该任务尚无统一各类方法的标准规范,因此我们在表中标明了各方法所用的主干网络和输入分辨率。使用 VGG16 [49] 主干网络时,我们的框架优于所有采用相同主干网络的其他方法,即使其中部分方法使用了更大的输入尺寸。此外,与 Chen 等人 [33] 和 CycleSeg Net [7] 等采用更强主干网络的方法相比,我们也能取得与之相当甚至更优的性能。CARNN [12] 采用 VGG19 主干网络,在 Internet 数据集上取得了最高精度,但该方法是在完整 COCO 数据集上训练的。该数据集包含 $9\mathrm{k\Omega}$ 张图像,分属 118 个组别,规模远大于我们的训练集。我们还对比了协同显著性检测任务中的若干先进方法 (如 GCoNet [9] 和 CADC [13]),结果表明我们的方法同样优于它们,这反映出此类协同显著性检测方法的迁移能力较差,不适用于协同分割任务。总体而言,我们的方法在 4 个基准测试中取得了 5 项最优和 2 项次优结果,具有显著竞争力。图 5 展示了一些定性结果,更多可视化结果可参考补充材料。

Fig. 6: Qualitative results of our method compared with other state-of-the-art methods and the PR and F-measure curves on three benchmark datasets.
图 6: 我们的方法与其他最先进方法的定性对比结果,以及三个基准数据集上的PR和F-measure曲线。
| 方法 | 类型 | Cosal2015 | CoSOD3k | CoCA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | Sm ↑ | Em ↑ | Fβ↑ | MAE↓ | Sm ↑ | Em ↑ | Fβ ↑ | MAE↓ | Sm ↑ | Em ↑ | Fβ↑ | ||
| BASNet[54]cvPR'2019 | Sin | 0.097 | 0.820 | 0.846 | 0.784 | 0.122 | 0.753 | 0.791 | 0.696 | 0.195 | 0.589 | 0.623 | 0.397 |
| PoolNet[74]cvPR'2019 | Sin | 0.094 | 0.820 | 0.851 | 0.785 | 0.120 | 0.763 | 0.797 | 0.704 | 0.179 | 0.599 | 0.631 | 0.401 |
| EGNet[75]1ccv'2019 | Sin | 0.099 | 0.818 | 0.842 | 0.782 | 0.119 | 0.762 | 0.796 | 0.703 | 0.179 | 0.594 | 0.637 | 0.389 |
| SCRN[76]1ccv'2019 | Sin | 0.097 | 0.814 | 0.854 | 0.789 | 0.118 | 0.773 | 0.806 | 0.717 | 0.166 | 0.610 | 0.658 | 0.416 |
| RCAN[77]1JCAI'2019 | Co | 0.126 | 0.779 | 0.842 | 0.764 | 0.130 | 0.744 | 0.808 | 0.688 | 0.160 | 0.616 | 0.702 | 0.422 |
| CSMG[78]cvPR'2019 | Co | 0.130 | 0.774 | 0.818 | 0.777 | 0.157 | 0.711 | 0.723 | 0.645 | 0.124 | 0.632 | 0.734 | 0.503 |
| GICD[34]ECCV'2020 | Co | 0.071 | 0.842 | 0.884 | 0.834 | 0.089 | 0.778 | 0.831 | 0.743 | 0.125 | 0.658 | 0.701 | 0.513 |
| SSNM[6]AAAI'2020 | Co | 0.102 | 0.788 | 0.843 | 0.794 | 0.120 | 0.726 | 0.756 | 0.675 | 0.116 | 0.628 | 0.741 | 0.482 |
| GCAGC[18]cvPR'2020 | Co | 0.085 | 0.817 | 0.866 | 0.813 | 0.100 | 0.785 | 0.816 | 0.740 | 0.111 | 0.669 | 0.754 | 0.523 |
| CoEGNet[59]TPAMI2021 | Co | 0.077 | 0.836 | 0.882 | 0.832 | 0.092 | 0.762 | 0.825 | 0.736 | 0.106 | 0.612 | 0.717 | 0.493 |
| DeepACG[8]cvPR'2021 | Co | 0.064 | 0.854 | 0.892 | 0.842 | 0.089 | 0.792 | 0.838 | 0.756 | 0.102 | 0.688 | 0.771 | 0.552 |
| GCoNet[9]cvPR'2021 | Co | 0.068 | 0.845 | 0.887 | 0.847 | 0.071 | 0.802 | 0.860 | 0.777 | 0.105 | 0.673 | 0.760 | 0.544 |
| CADCt[13]1ccv'2021 | Co | 0.064 | 0.866 | 0.906 | 0.862 | 0.096 | 0.801 | 0.840 | 0.759 | 0.132 | 0.681 | 0.744 | 0.548 |
| UFO (Ours) | Co | 0.064 | 0.860 | 0.906 | 0.865 | 0.073 | 0.819 | 0.874 | 0.797 | 0.095 | 0.697 | 0.782 | 0.571 |
TABLE VII: Comparisons of our method with the other state-of-the-arts on CoSD datasets. “Sin” and “Co” denote single and co-object image saliency object detection methods, respectively. $\dagger$ denotes the results using a larger input size $(256\times256)$ and copy and paste augmentation strategy. The best two results on each dataset are shown in red and blue.
表 VII: 在CoSD数据集上我们的方法与其他最先进方法的对比。"Sin"和"Co"分别表示单目标和协同目标图像显著性目标检测方法。$\dagger$表示使用更大输入尺寸$(256\times256)$和复制粘贴增强策略的结果。每个数据集上最好的两个结果分别用红色和蓝色标出。
Co-Saliency Detection. Likewise, Tab VII presents the comparisons of our method with other state-of-the-arts in CoSD. Note that all methods use the VGG16 as backbone and the input size is $224\times224$ for fair comparisons unless otherwise specified. We can observe that our framework can also outperform other methods except for two second-best (i.e., $S_{m}~=~0.860$ in Cosal2015 and $M A E=0.073$ in CoSOD3k) results, and all the rest results are ranked the first. It is worth mentioning that unlike some of the previous methods (i.e., GCAGC [18] and CADC [13]), we do not require additional data [15], [93] and data augmentation strategies like Jigsaw in GICD [34] and copyand-paste in CACD [13] to train the network. Moreover, we visualize the results of some examples (i.e., pumpkin and soap) with complex backgrounds and some foreground distract or s in Fig 6 top. Our method can yield more accurate co-object masks compared to other approaches, which validates the robustness and effectiveness of our method. Fig 6 bottom shows the PR and the ROC curves of the compared methods, and our curves are higher than the other methods on the three challenging benchmarks.
协同显著性检测。同样地,表 VII 展示了我们的方法与其他最先进方法在 CoSD 上的比较。需要注意的是,除非另有说明,所有方法均使用 VGG16 作为主干网络,输入尺寸为 $224\times224$ 以保证公平比较。我们可以观察到,除了两项次优结果(即 Cosal2015 中的 $S_{m}~=~0.860$ 和 CoSOD3k 中的 $M A E=0.073$),我们的框架在其他所有指标上均优于其他方法,其余结果均排名第一。值得一提的是,与之前的一些方法(如 GCAGC [18] 和 CADC [13])不同,我们不需要额外的数据 [15][93] 或数据增强策略(如 GICD [34] 中的 Jigsaw 和 CACD [13] 中的 copy-and-paste)来训练网络。此外,我们在图 6 顶部展示了复杂背景(如南瓜和肥皂)及前景干扰物的可视化结果。与其他方法相比,我们的方法能生成更准确的共目标掩码,验证了其鲁棒性和有效性。图 6 底部展示了对比方法的 PR 和 ROC 曲线,我们的曲线在三个具有挑战性的基准测试中均高于其他方法。
Video Salient Object Detection. We further evaluate our method on VSOD benchmarks. As is shown in Tab VIII, our proposed framework can once again achieve the best results on FBMS, ViSal and $\mathrm{SegV}2$ datasets by using the VGG16 backbone and small input resolution but without optical flow. This shows that our method can effectively extract the object’s spatial appearance information and long-range temporal dependencies, which can also reach 140 FPS for real-time inference. Moreover, the proposed framework is an unsupervised VSOD method, which can outperform some semi-supervised methods [87], [88], [47] without any bells and whistles. The reason why we fail to achieve the best results
视频显著目标检测。我们进一步在VSOD基准上评估了所提方法。如表VIII所示,使用VGG16主干网络和小输入分辨率且无需光流的情况下,我们的框架在FBMS、ViSal和$\mathrm{SegV}2$数据集上再次取得了最佳结果。这表明我们的方法能有效提取目标的空间外观信息和长程时序依赖,实时推理速度可达140 FPS。此外,该框架作为无监督VSOD方法,无需任何花哨技巧即可超越部分半监督方法[87][88][47]。我们未能取得最佳成绩的原因...

Fig. 7: Qualitative results of our proposed framework on DAVIS, FBMS, ViSal and SegV2 datasets, respectively. More visualization s can be referred to the supplementary material.
图 7: 我们提出的框架在 DAVIS、FBMS、ViSal 和 SegV2 数据集上的定性结果。更多可视化内容可参考补充材料。
| 方法 | 设置 | OF | Sup | RT | DAVIS16 MAE↓ | Sm↑ | F3↑ | FBMS MAE↓ | Sm↑ | Fβ↑ | ViSal MAE↓ | Sm↑ | Fβ↑ | SegV2 MAE↓ | Sm↑ | Fβ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SCOM[79]TIP'2018 | DCL[80] | U | 38.8 | 0.048 | 0.832 | 0.783 | 0.079 | 0.794 | 0.797 | 0.122 | 0.762 | 0.831 | 0.030 | 0.815 | 0.764 | |
| MBNM[81]eccv2018 | DeepLab | U | 2.6 | 0.031 | 0.887 | 0.861 | 0.047 | 0.857 | 0.816 | 0.020 | 0.898 | 0.883 | 0.026 | 0.809 | 0.716 | |
| PDBM[82]EcCV"2018 | Res50-473 | × | U | 0.05 | 0.028 | 0.882 | 0.855 | 0.064 | 0.851 | 0.821 | 0.032 | 0.907 | 0.888 | 0.024 | 0.864 | 0.800 |
| SRP[83]TIP'2019 | U | 17.0 | 0.070 | 0.662 | 0.660 | 0.134 | 0.648 | 0.671 | 0.092 | " | 0.752 | 0.095 | 0.683 | |||
| MESO[23]TMM2019 | > | U | 50.3 | 0.070 | 0.718 | 0.660 | 0.134 | 0.635 | 0.618 | |||||||
| LTSI[84]TIP2019 | VGG16-500 | U | 1.4 | 0.034 | 0.876 | 0.850 | 0.087 | 0.805 | 0.799 | 0.027 | 0.922 | 0.909 | 0.028 | 0.827 | 0.862 | |
| RSE[43]rcsvT2019 | U | 48.2 | 0.063 | 0.748 | 0.698 | 0.128 | 0.670 | 0.652 | ||||||||
| SSAV[48]cvPR2019 | Res50-473 | U | 0.05 | 0.028 | 0.893 | 0.861 | 0.040 | 0.879 | 0.865 | 0.020 | 0.943 | 0.939 | 0.023 | 0.851 | 0.801 | |
| RCR[47]iccv2019 | Res50-448 | S | 0.04 | 0.027 | 0.886 | 0.848 | 0.053 | 0.872 | 0.859 | |||||||
| CAS[85]TNNLS*2020 | Res50 | × | U | 0.032 | 0.873 | 0.860 | 0.056 | 0.856 | 0.863 | 0.029 | 0.820 | 0.847 | ||||
| PCSA[10]AAAr2020 | MobV3-448 | U | 0.009 | 0.022 | 0.902 | 0.880 | 0.040 | 0.868 | 0.837 | 0.017 | 0.946 | 0.940 | 0.025 | 0.865 | 0.810 | |
| DFNet[86]eccv"2020 | DeepLab | U | 0.018 | 0.899 | 0.054 | 0.833 | 0.017 | 0.927 | ||||||||
| FSNet[11Jccv2021 | Res101-352 | U | 0.08 | 0.020 | 0.920 | 0.907 | 0.041 | 0.890 | 0.888 | 0.023 | 0.870 | 0.772 | ||||
| ReuseVOS+[87]cvPR'2021 | Res18-480 | S | 0.02 | 0.019 | 0.883 | 0.865 | 0.027 | 0.888 | 0.884 | 0.020 | 0.928 | 0.933 | 0.025 | 0.844 | 0.832 | |
| TransVOS+[88]rePrint'2021 | Res50-240 | S | 0.06 | 0.018 | 0.885 | 0.869 | 0.038 | 0.867 | 0.886 | 0.021 | 0.917 | 0.928 | 0.024 | 0.816 | 0.800 | |
| UFO (Ours) | VGG16-224 | × | U | 0.007 | 0.036 | 0.864 | 0.828 | 0.028 | 0.894 | 0.890 | 0.011 | 0.953 | 0.940 | 0.022 | 0.892 | 0.863 |
| UFO (Ours) | VGG16-224 | U | 0.01 | 0.015 | 0.918 | 0.906 | 0.031 | 0.891 | 0.888 | 0.013 | 0.959 | 0.951 | 0.013 | 0.899 | 0.869 |
TABLE VIII: Comparisons of our method with the other state-of-the-arts on VSOD datasets. The majority of the results are borrowed from [11]. $o F$ denotes the optical flow. RT denotes the runtime (s). “U”: unsupervised method. “S”: semi-supervised method. “Res” denotes ResNet [89], “Mob” denotes Moiblenet [90], and the number behind them is the input resolution. $\dagger$ denotes video segmentation methods trained on DAVIS17 [91] and YouTube-VOS [92] datasets, whose results are acquired from their released code weights. The best two results on each dataset are shown in red, blue.
表 VIII: 我们的方法与其他先进方法在VSOD数据集上的对比。大部分结果引自[11]。$o F$表示光流(optical flow),RT表示运行时间(秒)。"U"表示无监督方法,"S"表示半监督方法。"Res"代表ResNet[89],"Mob"代表MobileNet[90],其后数字表示输入分辨率。$\dagger$表示在DAVIS17[91]和YouTube-VOS[92]数据集上训练的视频分割方法,其结果来自其公开的代码权重。每个数据集上最优的两个结果分别用红色和蓝色标出。
on the DAVIS is that in some cases the background of cooccurring objects is incorrectly segmented (e.g., foreground: the dancing girl; background: the audience. They all belong to the object of “people”). To alleviate this issue, we combine the flow cues to make our network pay more attention to the foreground moving salient objects and using optical flow in our network is straightforward. Specifically, the images and their corresponding optical flow are passed through the shareencoder at the same time, and the enhanced image features to be fed into subsequent networks can be obtained by multiplying the flow features. More details of the usage of optical flow can be referred to the supplementary material. The quantitative results show that we can achieve new satisfactory results. The performances on FBMS drop a little since the acquired optical flow information are poor. Note that using the optical flow is not our framework’s main purpose and contribution, we recommend using the multi-frame images alone, which can already achieve state-of-the-art performance in most tasks. Some qualitative results on the 4 VSOD datasets are shown in Fig 7.
在DAVIS数据集上的问题是,某些情况下共现物体的背景会被错误分割(例如,前景:跳舞的女孩;背景:观众。它们都属于"人"这一类别)。为了缓解这一问题,我们结合光流线索使网络更关注前景运动的显著物体,在网络上使用光流是直接的。具体来说,图像及其对应的光流同时通过共享编码器,通过将光流特征相乘可获得增强的图像特征以供后续网络使用。光流使用的更多细节可参考补充材料。定量结果表明我们能够取得令人满意的新结果。由于获取的光流信息质量较差,FBMS数据集上的性能略有下降。需要注意的是,使用光流并非我们框架的主要目的和贡献,我们建议仅使用多帧图像,这已在大多数任务中达到最先进的性能。图7展示了在4个VSOD数据集上的一些定性结果。
V. CONCLUSION
V. 结论
In this paper, we propose a unified framework for groupbased image segmentation, which can conduct co-segmentation, co-saliency detection and video salient object detection tasks. The proposed transformer block and intra-MLP module can both help the network well capture the inter-collaborative and intra-activated information. The competitive results on 11 benchmarks validate the effectiveness of our method. We take an early attempt to unify the deep learning network for different tasks, and we hope this finding will encourage the development of more follow-up research that simplifies the network in other domains.
本文提出了一种基于分组的图像分割统一框架,能够执行协同分割、协同显著性检测和视频显著目标检测任务。所提出的Transformer块和内部MLP模块都能有效帮助网络捕捉跨协作和内部激活信息。在11个基准测试上的优异结果验证了我们方法的有效性。我们率先尝试用统一深度学习网络处理不同任务,希望这一发现能推动其他领域简化网络的后续研究发展。
ACKNOWLEDGMENT
致谢
This work was supported by National Natural Science Foundation of China (NSFC) 61876208, Key-Area Research and Development Program of Guangdong Province 2018 B 010108002, and the National Research Foundation, Singapore under its AI Singapore Programme (AISG Award No: AISG-RP-2018-003), and the MOE Tier-1 research grants: RG28/18 (S), RG22/19 (S) and RG95/20.
本研究得到国家自然科学基金 (NSFC) 61876208、广东省重点领域研发计划2018B010108002、新加坡国家研究基金会人工智能新加坡计划 (AISG Award No: AISG-RP-2018-003) 以及新加坡教育部Tier-1研究基金 (RG28/18 (S)、RG22/19 (S) 和 (RG95/20) 的资助。
REFERENCES
参考文献
Supplementary Material
补充材料
This supplementary material contains more details of the network, including the details of using optical flow, more training details, more analysis, more downstream applications and more additional qualitative results in our paper “A Unified Transformer Framework for Group-based Segmentation: CoSegmentation, Co-Saliency Detection and Video Salient Object Detection”.
本补充材料包含网络的更多细节,包括光流使用细节、更多训练细节、更多分析、更多下游应用以及我们论文《A Unified Transformer Framework for Group-based Segmentation: CoSegmentation, Co-Saliency Detection and Video Salient Object Detection》中更多附加定性结果。
A. Details of Using Optical Flow
A. 光流使用细节
As we have discussed in our main paper, optical flow is optional to add into our network, and applying flow cues to our network is straightforward. First of all, let us first introduce why optical flow can help us. As is shown in Fig 8, when we directly use the optical flow as input, the output predictions are comparable. This is because the optical flows reflect the foreground moving salient objects without any complicated backgrounds, and thus, our network can well extract their features and yields the masks. Based on this, we consider that combing the optical flow features with the origin image feature can help the network focus on more foreground salient objects. Fig 9 shows us the overall architecture of using the optical flow information. Specifically, we maintain the transformer block, intra-MLP learning module, and decoder unchanged but slightly modify the encoder features. We take both the optical flows generated by FlowNet2.0 [24] and adjacent frames as input, and they share the same encoder. The enhanced features of the group-based images to be fed into the subsequent network can be formulated as:
正如我们在主论文中讨论的那样,光流(optical flow)是可选择加入网络的模块,将光流线索应用于网络非常简单。首先,让我们解释光流为何能带来帮助。如图8所示,当直接使用光流作为输入时,输出预测结果具有可比性。这是因为光流反映了前景运动显著物体而不含复杂背景,因此我们的网络能很好地提取其特征并生成掩膜。基于此,我们认为将光流特征与原始图像特征结合可以帮助网络更关注前景显著物体。图9展示了使用光流信息的整体架构:我们保持Transformer块、内部MLP学习模块和解码器不变,仅对编码器特征进行微调。具体采用FlowNet2.0 [24]生成的光流与相邻帧作为输入,它们共享同一编码器。输入后续网络的增强型分组图像特征可表示为:
$$
\begin{array}{r}{F_{3_i m g}=F_{3_f l o w}\times F_{3_i m g},}\ {F_{4_i m g}=F_{4_f l o w}\times F_{4_i m g}.}\end{array}
$$
$$
\begin{array}{r}{F_{3_i m g}=F_{3_f l o w}\times F_{3_i m g},}\ {F_{4_i m g}=F_{4_f l o w}\times F_{4_i m g}.}\end{array}
$$
This operation enables the image features to pay more attention to the targeted regions by combining flow cues regardless of the distracting background items. Note that our method of using optical flow may not be the optimal way, maybe using a separate optical flow branch and a unique combination can further improve the network performance. However, using the optical flow is not our framework’s main purpose and contribution, we can already achieve state-ofthe-art performance on three benchmarks (i.e., FBMS [61], ViSal [62] and $\mathrm{SegV}2$ [63]) without using it. We will continue to refine and research possible ways to improve our network in future work.
该操作通过结合光流线索,使图像特征能更专注于目标区域,而不受干扰背景元素的影响。需要注意的是,我们使用光流的方法可能并非最优方案,或许采用独立的光流分支和独特组合能进一步提升网络性能。但光流并非本框架的核心目的与贡献,即便不使用光流,我们已在FBMS [61]、ViSal [62]和$\mathrm{SegV}2$ [63]三个基准测试中实现了最先进的性能。未来工作中我们将持续优化并研究可能的网络改进方案。
B. More Training Details
B. 更多训练细节
For object co-segmentation (CoS) and co-saliency detection (CoSD), unlike the previous methods (i.e., GCAGC [18], CADC [13]) that are trained on both COCO-SEG [14] and other saliency datasets (i.e., MSRA-B [93], DUTS [15]), we train our method only using COCO-SEG [14] dataset and without using data augmentation like copy-and-paste in CADC [13], Jigsaw in GICD [34]. For video salient object detection (VSOD), we follow the previous works (i.e., FSNet [11], PCSA [10]) that employ the random flip, random rotation and multi-scale ${0.75,1,1.25}$ training strategy in the training phase.
对于物体协同分割(CoS)和协同显著性检测(CoSD),不同于先前方法(即GCAGC [18]、CADC [13])同时在COCO-SEG [14]和其他显著性数据集(即MSRA-B [93]、DUTS [15])上训练,我们仅使用COCO-SEG [14]数据集训练,且未采用CADC [13]中的复制粘贴、GICD [34]中的拼图等数据增强技术。在视频显著性目标检测(VSOD)方面,我们沿用FSNet [11]、PCSA [10]等先前工作采用的训练策略:随机翻转、随机旋转以及多尺度${0.75,1,1.25}$训练。

Fig. 8: The predictions of the direct optical flow input.
| Method | PASCAL | iCoseg | ||
| P | J | P | J | |
| K=2 | 94.5 | 72.8 | 97.1 | 90.2 |
| K=4 | 95.4 | 73.6 | 97.6 | 90.9 |
| K=6 | 95.2 | 73.3 | 97.5 | 90.6 |
图 8: 直接光流输入的预测结果。
| 方法 | PASCAL | iCoseg | ||
|---|---|---|---|---|
| P | J | P | J | |
| K=2 | 94.5 | 72.8 | 97.1 | 90.2 |
| K=4 | 95.4 | 73.6 | 97.6 | 90.9 |
| K=6 | 95.2 | 73.3 | 97.5 | 90.6 |
TABLE IX: Analysis of the $K$ number in intra-MLP learning module.
表 IX: 分析 MLP 内部学习模块中的 $K$ 值
| 方法 | PASCAL | iCoseg | ||
|---|---|---|---|---|
| P | J | P | J | |
| D = 512 | 94.7 | 72.3 | 96.5 | 89.5 |
| D = 782 | 95.4 | 73.6 | 97.6 | 90.9 |
| D = 1024 | 94.9 | 73.1 | 97.0 | 90.3 |
TABLE X: Analysis of the dim channel in transformer projection function.
表 X: Transformer投影函数中暗通道分析。
C. More Analysis
C. 更多分析
The number of $K$ . We here explore the effect of the $K$ number we use in the intra-MLP learning module. As shown in Tab IX, we find that when $K=4$ , our network can achieve the best performance. We conjecture that a small or too large $K$ number may make the network learn less useful corresponding semantic information or redundant information that harms the network.
$K$ 的数量。我们在此探讨了在内部MLP学习模块中使用的 $K$ 值的影响。如表 IX 所示,我们发现当 $K=4$ 时,我们的网络能够达到最佳性能。我们推测,$K$ 值过小或过大可能会导致网络学习到较少有用的对应语义信息或冗余信息,从而损害网络性能。
The Dim Channels. We further conduct an additional experiment to analyze the effect of the dim channel in our transformer block projection function. Since the top-level output features map channels are 512, and thus, we explore ${D=512,782,1024}$ , respectively. Tab X shows that when $D=782$ the network performs the best. Note that keep enlarging the dim channel will not only bring no gain to the network, but also consume computing resources.
暗通道 (Dim Channels)。我们进一步开展额外实验来分析暗通道在 Transformer 块投影函数中的作用。由于顶层输出特征图的通道数为512,因此我们分别探索了 ${D=512,782,1024}$ 。表 X 显示当 $D=782$ 时网络性能最佳。值得注意的是,持续扩大暗通道不仅不会为网络带来增益,还会消耗计算资源。
Stronger Backbone. Furthermore, we adopt a stronger backbone HRNet [94] to conduct experiments on VSOD tasks, whose results are shown in Tab XI. Although using a more powerful backbone can improve the performance of the network, the execution time will also increase at the same time. As we mentioned in our main paper, using vgg16 backbone can already achieve the state-of-the-art performance and the execution speed can also reach real-time. Therefore, we recommend
更强的骨干网络。此外,我们采用更强的骨干网络HRNet [94]在VSOD任务上进行实验,其结果如表XI所示。虽然使用更强大的骨干网络可以提升网络性能,但执行时间也会相应增加。如主论文所述,使用vgg16骨干网络已能实现最先进的性能,且执行速度可达实时。因此我们推荐

Fig. 9: The overall architecture of combing the optical flow information.
图 9: 结合光流信息的整体架构
| 方法 | 设置 | OF | Sup | RT | DAVIS16 MAE↓ | Sm↑ | F3↑ | FBMS MAE↓ | Sm↑ | F3↑ | ViSal MAE↓ | Sm↑ | F3↑ | SegV2 MAE↓ | Sm↑ | Fg↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UFO (Ours) | HRNet-224 | U | 0.01 | 0.028 | 0.881 | 0.842 | 0.026 | 0.899 | 0.893 | 0.012 | 0.958 | 0.948 | 0.018 | 0.897 | 0.866 | |
| UFO (Ours) | HRNet-224 | U | 0.03 | 0.013 | 0.921 | 0.907 | 0.033 | 0.888 | 0.887 | 0.011 | 0.962 | 0.956 | 0.012 | 0.901 | 0.867 |
TABLE XI: OF denotes the optical flow. RT denotes the runtime (s). “U”: unsupervised method. The number behind the backbone is the input resolution.
表 XI: OF 表示光流 (optical flow)。RT 表示运行时间 (s)。"U":无监督方法。骨干网络后的数字表示输入分辨率。
using vgg16, which can already meet most of the needs in our tasks.
使用 VGG16,它已经能满足我们任务中的大部分需求。
D. More Downstream Applications
D. 更多下游应用
Co-Localization. We try to conduct an additional experiment on CUB-2011 [95] dataset for co-localization task, which is also aims to simultaneously localize objects of the same class across a set of distinct images [96]. As shown in Fig 11, we first generate the object masks on the co-objects. Then, we obtain the green predated box according to the binary masks. As can be seen, our predicted bounding boxes are closed to the GT bounding boxes.
共定位 (Co-Localization)。我们尝试在CUB-2011 [95]数据集上进行共定位任务的额外实验,该任务旨在跨一组不同图像同时定位同一类别的对象 [96]。如图11所示,我们首先生成共对象的掩码。然后,根据二值掩码获得绿色预测框。可以看出,我们的预测边界框与GT边界框非常接近。
Real-Time Video Salient Object Detection. Our framework can be applied to detect the salient object in the video without using optical flow, therefore, it can be easily to conduct this task. We use a video sample from the public website1 for our demo. The result are provided in our publicly released code page. Note that we do not train our network on YouTubeVOS [92] dataset, and the competitive result of the randomly selected demo video shows the superiority of our proposed method.
实时视频显著目标检测。我们的框架可用于检测视频中的显著目标而无需使用光流,因此可以轻松执行该任务。我们使用来自公共网站1的视频样本进行演示,结果发布于我们公开的代码页面。请注意,我们的网络未在YouTubeVOS [92]数据集上训练,随机选取的演示视频所呈现的竞争性结果证明了我们提出方法的优越性。

Fig. 10: Visualization s of object matching flow.
图 10: 物体匹配流的可视化。
Bullet-Chat Blocking. Bullet-chat blocking aims to prevent the salient objects in the video from being occluded by the viewer’s barrage. It has to segment out the object and yield a accurate mask that provides to block the bullet-chat text in the foreground. To validate the generality of our method, we use a video sample from the public website2. And then we adopt the OpenCV [97] toolbox to generate some pseudo bullet-chat that constantly slides over the video. Finally, we can produce a new bullet-chat blocking video as we provide in our publicly released code page.
弹幕遮挡。弹幕遮挡旨在防止视频中的显著物体被观众的弹幕所遮盖。该方法需要分割出物体并生成精确的掩膜,用于在前景中遮挡弹幕文字。为验证本方法的通用性,我们使用来自公共网站2的视频样本,并采用OpenCV [97]工具箱生成持续滑过视频的伪弹幕。最终,我们可生成如公开代码页所示的新弹幕遮挡视频。

Fig. 11: Visualization s of co-localization. The $1^{s t}$ row are the input images, the $2^{n d}$ row are our predicted masks, and the $3^{r d}$ row are the localization results. The ground-truth bounding box is in red and predicted bounding box is green.
图 11: 共定位可视化结果。$1^{s t}$ 行是输入图像,$2^{n d}$ 行是我们的预测掩码,$3^{r d}$ 行是定位结果。真实边界框为红色,预测边界框为绿色。
E. More Visualization s
E. 更多可视化内容
Matching. To further provide the network interpret ability, we visualize how group-based images match features with each other during network learning. Fig 10 shows the highly correlated patches in different images, which illustrates that our network can well capture the object similarities and discover the object regions.
匹配。为了进一步增强网络的可解释性,我们可视化了基于分组的图像在网络学习过程中如何相互匹配特征。图10展示了不同图像中高度相关的图像块,这表明我们的网络能够很好地捕捉目标相似性并发现目标区域。
Co-Segmentation. Fig 12 shows more visualization s on CoS task.
共分割。图 12 展示了更多关于 CoS (共分割) 任务的可视化结果。
Co-Saliency Detection. Fig 13 shows more visualization s on CoSD tasks.
共显著性检测。图 13 展示了更多关于 CoSD 任务的可视化结果。
Video Salient Object Detection. Fig 14 shows more visualizations on VSOD tasks.
视频显著目标检测。图 14 展示了更多 VSOD 任务的视觉化结果。
Note that all the predicted results can be found and downloaded in our project page: https://github.com/suyukun666/UFO.
请注意,所有预测结果均可在我们的项目页面找到并下载:https://github.com/suyukun666/UFO。

Fig. 12: Visualization s of co-segmentation.
图 12: 协同分割可视化结果。

Fig. 13: Visualization s of co-saliency detection.
图 13: 协同显著性检测的可视化效果。

Fig. 14: Visualization s of video salient object detection.
图 14: 视频显著性目标检测的可视化效果。