UNIK: A Unified Framework for Real-world Skeleton-based Action Recognition
UNIK: 面向真实场景骨骼动作识别的统一框架

Figure 1. Skeleton-based action recognition. In this paper we introduce a generic skeleton-based action recognition model UNIK, and report significant improvements by using our model pre-trained on Posetics, a real-world, large, human skeleton video dataset.
图 1: 基于骨架的动作识别。本文提出通用骨架动作识别模型UNIK,通过使用在真实世界大规模人体骨架视频数据集Posetics上预训练的模型,报告了显著性能提升。
Abstract
摘要
Action recognition based on skeleton data has recently witnessed increasing attention and progress. State-of-theart approaches adopting Graph Convolutional networks (GCNs) can effectively extract features on human skeletons relying on the pre-defined human topology. Despite associated progress, GCN-based methods have difficulties to generalize across domains, especially with different human topological structures. In this context, we introduce UNIK*, a novel skeleton-based action recognition method that is not only effective to learn spatio-temporal features on human skeleton sequences but also able to generalize across datasets. This is achieved by learning an optimal dependency matrix from the uniform distribution based on a multi-head attention mechanism. Subsequently, to study the cross-domain general iz ability of skeleton-based action recognition in real-world videos, we re-evaluate state-ofthe-art approaches as well as the proposed UNIK in light of a novel Posetics dataset. This dataset is created from Kinetics-400 videos by estimating, refining and filtering poses. We provide an analysis on how much performance improves on smaller benchmark datasets after pre-training on Posetics for the action classification task. Experimental results show that the proposed UNIK, with pre-training on Posetics, generalizes well and outperforms state-of-theart when transferred onto four target action classification datasets: Toyota Smarthome, Penn Action, NTU-RGB+D 60 and NTU-RGB+D 120.
基于骨骼数据的动作识别近来受到越来越多的关注并取得了进展。采用图卷积网络(GCNs)的最先进方法能够基于预定义的人体拓扑结构有效提取人体骨骼特征。尽管相关研究取得了进展,基于GCN的方法在跨域泛化方面仍存在困难,特别是面对不同人体拓扑结构时。为此,我们提出了UNIK*——一种新型的基于骨骼的动作识别方法,不仅能有效学习人体骨骼序列的时空特征,还具备跨数据集泛化能力。该方法通过多头注意力机制从均匀分布中学习最优依赖矩阵来实现这一目标。随后,为研究现实视频中基于骨骼的动作识别跨域泛化能力,我们基于新型Posetics数据集重新评估了现有最优方法及提出的UNIK方案。该数据集通过Kinetics-400视频的姿态估计、优化和筛选创建而成。我们分析了在Posetics上预训练后,动作分类任务在较小基准数据集上的性能提升程度。实验结果表明,经过Posetics预训练的UNIK模型展现出优异的泛化能力,在转移至四个目标动作分类数据集(Toyota Smarthome、Penn Action、NTU-RGB+D 60和NTU-RGB+D 120)时均超越现有最优方法。
1. Introduction
1. 引言
As skeleton-based human action recognition methods rely on 2D or 3D positions of human key joints only, they are able to filter out noise caused, for instance, by background clutter, changing light conditions, and to focus on the action being performed [36, 45, 35, 47, 42, 16, 1, 43, 18, 31, 9, 32, 25, 30, 21]. Recent approach, namely Graph Convolutional Networks (GCNs) [43], models human joints, as well as their natural connections (i.e., bones) in skeleton spatio-temporal graphs to carry both, spatial and temporal inferences. Consequently, several successors, applying Adaptive GCNs (AGCNs), with optimized graph construction strategies to extract multi-scale structural features on skeletons and long-range dependencies between joints have been proposed and shown encouraging results. Promising examples are graph convolutions with learnable adjacency matrix [31], higher-order polynomials of adjacency matrix [18] and separate multi-scale subsets of adjacency matrix [21]. All these adjacency matrices are manually predefined to represent the relationships between joints according to human topology. Nevertheless, compared with RGBbased methods such as spatio-temporal Convolutional Neural Networks (CNNs) [4, 11] that are pre-trained on Kinetics [4] to boost accuracy in downstream datasets and tasks, GCN-based models are limited as they are always trained individually on the target dataset (often small) from scratch. Our insight is that, the generalization abilities of these approaches are hindered by the need for different adaptive adjacency matrices when different topological human structures are used (e.g., joints number, joints order, bones), as in the case of the three datasets of Fig. 2. However, we note that such adaptive sparse adjacency matrices are transformed to fully dense matrices in deeper layers in order to capture long-range dependencies between joints. This new structure contradicts the initial and original topological skeleton structure.
基于骨架的人体动作识别方法仅依赖于人体关键关节的2D或3D位置,因此能够过滤掉由背景杂乱、光线变化等因素引起的噪声,并专注于正在执行的动作 [36, 45, 35, 47, 42, 16, 1, 43, 18, 31, 9, 32, 25, 30, 21]。近期提出的图卷积网络 (GCNs) [43] 将人体关节及其自然连接(即骨骼)建模为骨架时空图,以同时进行空间和时间推理。随后,研究者们提出了多种采用自适应图卷积网络 (AGCNs) 的改进方法,通过优化图构建策略来提取骨架上的多尺度结构特征和关节间的长程依赖关系,并取得了令人鼓舞的成果。典型的例子包括具有可学习邻接矩阵的图卷积 [31]、邻接矩阵的高阶多项式 [18] 以及邻接矩阵的独立多尺度子集 [21]。这些邻接矩阵均根据人体拓扑结构手动预定义以表示关节间的关系。然而,与基于RGB的方法(如在Kinetics [4] 上预训练以提升下游数据集和任务准确率的时空卷积神经网络 (CNNs) [4, 11])相比,基于GCN的模型存在局限性,因为它们总是在目标数据集(通常较小)上从头开始单独训练。我们的观点是,当使用不同拓扑人体结构(如关节数量、关节顺序、骨骼)时,这些方法的泛化能力会因需要不同的自适应邻接矩阵而受到阻碍,如图 2 中的三个数据集所示。但值得注意的是,这些自适应稀疏邻接矩阵在更深层次中被转换为完全稠密矩阵,以捕获关节间的长程依赖关系。这种新结构与初始的原始拓扑骨架结构相矛盾。
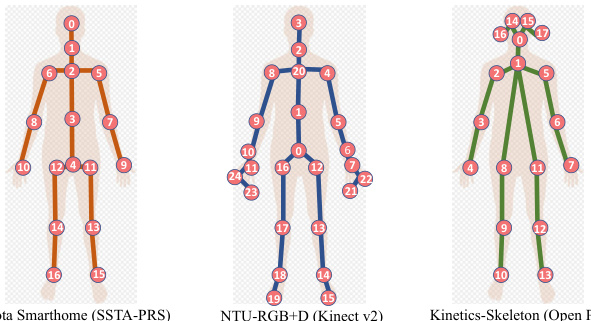
Figure 2. Human joint labels of three datasets: Toyota Smarthome (left), NTU $_\mathrm{RGB+D}$ (middle) and Kinetics-Skeleton (right). We note the different numbers, orders and locations of joints.
图 2: 三个数据集中的人体关节标注:Toyota Smarthome (左)、NTU $_\mathrm{RGB+D}$ (中) 和 Kinetics-Skeleton (右)。我们注意到关节的数量、顺序和位置存在差异。
Based on these considerations and as the human-intrinsic graph representation is deeply modified during training, we hypothesize that there should be a more optimized and generic initialization strategy that can replace the adjacency matrix. To validate this hypothesis, we introduce UNIK, a novel unified framework for skeleton-based action recognition. In UNIK, the adjacency matrix is initialized into a uniformly distributed dependency matrix where each element represents the dependency weight between the corresponding pair of joints. Subsequently, a multi-head aggregation is performed to learn and aggregate multiple dependency matrices by different attention maps. This mechanism jointly leverages information from several representation sub-spaces at different positions of the dependency matrix to effectively learn the spatio-temporal features on skeletons. The proposed UNIK does not rely on any topology related to the human skeleton, makes it much easier to transfer onto other skeleton datasets. This opens up a great design space to further improve the recognition performance by transferring a model pre-trained on a sufficiently large dataset.
基于这些考虑,由于人类固有图表示在训练过程中会被深度修改,我们假设应存在一种更优化且通用的初始化策略来替代邻接矩阵。为验证这一假设,我们提出UNIK——一个基于骨架动作识别的新型统一框架。在UNIK中,邻接矩阵被初始化为均匀分布的依赖矩阵,其中每个元素表示对应关节对之间的依赖权重。随后通过多头聚合机制,利用不同注意力图学习并聚合多个依赖矩阵。该机制联合利用了依赖矩阵不同位置多个表示子空间的信息,从而有效学习骨架的时空特征。所提出的UNIK不依赖于任何与人体骨骼相关的拓扑结构,使其更易于迁移到其他骨架数据集。这为通过迁移预训练于大型数据集的模型来进一步提升识别性能开辟了广阔的设计空间。
In addition, another difficulty for model generalization is that many skeleton datasets have been captured in lab environments with RGBD sensors (e.g., NTU-RGB $+\mathrm{D}$ [29,
此外,模型泛化的另一难点在于许多骨骼数据集是在实验室环境下通过RGBD传感器(如NTU-RGB $+\mathrm{D}$ [29])采集的。
20]). Then, the action recognition accuracy significantly decreases, when the pre-trained models on the sensor data are transferred to the real-world videos, where skeleton data encounters a number of occlusions and truncation s of the body. To address this, we create Posetics dataset by estimating and refining poses, as well as filtering, purifying and categorizing videos and annotations based on the real-world Kinetics-400 [4] dataset. To this aim, we apply multi-expert pose estimators [2, 8, 27] and a refinement algorithm [44]. Our experimental analysis confirms: pre-training on Posetics improves state-of-the-art skeleton-based action recognition methods, when transferred and fine-tuned on all evalu- ated datasets [6, 46, 29, 20].
[20])。然而,当基于传感器数据预训练的模型迁移至真实世界视频时,由于骨架数据存在大量肢体遮挡和截断问题,动作识别准确率显著下降。为此,我们基于真实场景的Kinetics-400数据集[4],通过姿态估计与优化、视频过滤净化及标注分类构建了Posetics数据集。具体采用多专家姿态估计器[2,8,27]和优化算法[44]进行处理。实验分析表明:在全部评估数据集[6,46,29,20]上迁移微调时,基于Posetics的预训练能提升当前最优骨架动作识别方法的性能。
In summary, the contributions of this paper are:
本文的贡献总结如下:
2. Related Work
2. 相关工作
Skeleton-Based Action Recognition. Early skeletonbased approaches using Recurrent Neural Networks (RNNs) [45, 35, 47, 33, 42] or Temporal Convolutional Networks (TCNs) [14] were proposed due to their high representation capacity. However, these approaches ignore the spatial semantic connectivity of the human body. Subsequently, [16, 1, 45] proposed to map the skeleton as a pseudo-image (i.e., in a 2D grid structure to represent the spatial-temporal features) based on manually designed transformation rules and to leverage 2D CNNs to process the spatio-temporal local dependencies within the skeleton sequence by considering a partial human-intrinsic connectivity. ST-GCN [43] used spatial graph convolutions along with interleaving temporal convolutions for skeleton-based action recognition. This work considered the topology of the human skeleton, however ignored the important longrange dependencies between the joints. In contrast, recent AGCN-based approaches [18, 31, 9, 30, 25, 32, 21] have seen significant performance boost, by the advantage of improving the representation of human skeleton topology to process long-range dependencies for action recognition. Specifically, 2s-AGCN [31] introduced an adaptive graph convolutional network to adaptively learn the topology of the graph with self-attention, which was shown beneficial in action recognition. Associated extension, MS-AAGCN [32] incorporated multi-stream adaptive graph convolutional networks that used attention modules and 4-stream ensemble based on 2s-AGCN [31]. These approaches primarily focused on spatial modeling. Consequently, MS-G3D Net [21] presented a unified approach for capturing complex joint correlations directly across space and time. However, the accuracy depends on the scale of the temporal segments, which should be carefully tuned for different datasets, preventing transfer learning. Thus, previous approaches [31, 32, 21] learn adaptive adjacency matrices from the sub-optimal initialized human topology. In contrast, our work proposes an optimized and unified dependency matrix that can be learned from the uniform distribution by a multi-head attention process for skeleton-based action recognition without the constraint of human topology and a limited number of attention maps in order to improve performance, as well as generalization capacity.
基于骨架的动作识别。早期基于骨架的方法利用循环神经网络(RNNs)[45,35,47,33,42]或时序卷积网络(TCNs)[14]因其强大的表征能力被提出。然而这些方法忽视了人体的空间语义连接性。随后[16,1,45]提出通过人工设计的转换规则将骨架映射为伪图像(即用二维网格结构表示时空特征),并借助二维CNNs在考虑部分人体固有连接性的情况下处理骨架序列中的时空局部依赖关系。ST-GCN[43]采用空间图卷积与交错时序卷积相结合的方式进行骨架动作识别,该方法虽考虑了人体骨架拓扑结构,却忽略了关节间重要的长程依赖关系。相比之下,近期基于AGCN的方法[18,31,9,30,25,32,21]通过改进人体骨架拓扑表征来处理动作识别中的长程依赖,获得了显著的性能提升。具体而言,2s-AGCN[31]引入自适应图卷积网络,通过自注意力机制自适应学习图拓扑结构,被证明对动作识别有益。其扩展工作MS-AAGCN[32]在2s-AGCN[31]基础上整合了多流自适应图卷积网络,采用注意力模块和四流集成策略。这些方法主要聚焦于空间建模。为此,MS-G3D Net[21]提出直接在时空维度捕获复杂关节关联的统一方法,但其精度受限于需针对不同数据集精细调参的时序片段尺度,阻碍了迁移学习。因此先前方法[31,32,21]都是从次优初始化的人体拓扑中学习自适应邻接矩阵。相比之下,我们的工作提出了一种可通过多头注意力过程从均匀分布中学习的优化统一依赖矩阵,不受人体拓扑限制和有限注意力图数量的约束,从而提升基于骨架动作识别的性能与泛化能力。
Model Generalization. Previous methods [43, 31, 32, 21] were only evaluated on the target datasets, trained from scratch without taking advantages of fine-tuning on a pretrained model. To explore the transfer ability for action recognition using human skeleton, recent research [34, 17] proposed view-invariant 2D or 3D pose embedding algorithms with pre-training performed on lab datasets [13, 20] that do not correspond to real-world and thus these techniques struggle to improve the action recognition performance on downstream tasks with large-scale real-world videos [6, 19]. To the best of our knowledge, we are the first to explore the skeleton-based pre-training and fine-tuning strategies for real-world videos.
模型泛化性。先前的方法 [43, 31, 32, 21] 仅在目标数据集上进行评估,从头开始训练而未利用预训练模型的微调优势。为了探索基于人体骨架的动作识别的迁移能力,近期研究 [34, 17] 提出了视角不变的 2D 或 3D 姿态嵌入算法,并在实验室数据集 [13, 20] 上进行预训练,但这些数据与真实场景不符,导致这些技术难以提升大规模真实世界视频下游任务的动作识别性能 [6, 19]。据我们所知,我们是首个探索面向真实世界视频的基于骨架的预训练与微调策略的研究。
3. Proposed Approach
3. 提出的方法
3.1. Unified Architecture (UNIK)
3.1. 统一架构 (UNIK)
In this section we present UNIK, a unified spatiotemporal dependencies learning network for skeleton-based action recognition.
在本节中,我们提出UNIK,一种基于骨架动作识别的统一时空依赖学习网络。
Skeleton Sequence Modeling. As shown in Fig. 4 (a), the sequence of the input skeletons is modeled by a 3D spatiotemporal matrix, noted as $\mathbf{f_{in}}$ . For each frame, the 2D or 3D body joint coordinates are arranged in a vector within the spatial dimension in any order as long as the order is consistent with other frames in the same video. For the temporal dimension, the same body joints in two consecutive frames are connected. $T,V$ , and $C_{i n}$ represent the length of the video, the number of joints of the skeleton in one frame, as well as the input channels (2D or 3D at the beginning and expanded within the building blocks), respectively. The input $\mathbf{f_{in}}$ and the output $\mathbf{f_{out}}$ for each building block (see 3.1)
骨架序列建模。如图4(a)所示,输入骨架序列通过一个3D时空矩阵建模,记为$\mathbf{f_{in}}$。对于每一帧,2D或3D身体关节坐标按任意顺序排列在空间维度的向量中,只要该顺序与同一视频中其他帧保持一致即可。在时间维度上,连接两连续帧中的相同身体关节。$T,V$和$C_{in}$分别表示视频长度、单帧骨架关节数以及输入通道数(初始为2D或3D,并在构建块内扩展)。每个构建块(见3.1节)的输入$\mathbf{f_{in}}$和输出$\mathbf{f_{out}}$
are represented by a matrix in $\mathbb{R}^{C_{i n}\times T\times V}$ and a matrix in $\mathbb{R}^{C_{o u t}\times T\times V}$ , respectively.
分别由 $\mathbb{R}^{C_{i n}\times T\times V}$ 和 $\mathbb{R}^{C_{o u t}\times T\times V}$ 矩阵表示。
Overall Architecture. The overall architecture is composed of $K$ building blocks (see Fig. 3). Key components of each block constitute the Spatial Long-short Dependency learning Unit (S-LSU), as well as the Temporal Long-short Dependency learning Unit (T-LSU) that extract both spatial and temporal multi-scale features on skeletons over a large receptive field. The building block $\mathrm{ST-LS_{\mathrm{block}}}$ is formulated as follows:
总体架构。整体架构由 $K$ 个基础模块构成(见图 3)。每个模块的核心组件包含空间长短期依赖学习单元 (S-LSU) 和时序长短期依赖学习单元 (T-LSU),用于在骨骼数据的大感受野上提取空间与时序的多尺度特征。基础模块 $\mathrm{ST-LS_{\mathrm{block}}}$ 的数学表达如下:
$$
\mathbf{f_{out}}=\mathrm{ST-LS_{block}}(\mathbf{f_{in}})=\mathrm{T-LSU}\left(\mathrm{S-LSU}(\mathbf{f_{in}})\right)
$$
$$
\mathbf{f_{out}}=\mathrm{ST-LS_{block}}(\mathbf{f_{in}})=\mathrm{T-LSU}\left(\mathrm{S-LSU}(\mathbf{f_{in}})\right)
$$
S-LSU and T-LSU are followed by a 2D Batch normalization layer respectively. A 1D Batch normalization layer is added in the beginning for normalizing the flattened input data. Given a skeleton sequence, the modeled data is fed into the building blocks. After the last block, global average pooling is performed to pool feature maps of different samples to the same size. Finally, the fully connected classifier outputs the prediction of the human action. The number of blocks $K$ and the number of output channels should be adaptive to the size of the training set, as a large network cannot be trained with a small dataset. However, in this work, we do not need to adjust $K$ , as we propose to pre-train the model on a large, generic dataset (see 4). We set $K=10$ with the number of output channels: 64, 64, 64, 64, 128, 128, 128, 256, 256, 256 (see Fig. 3). In order to stabilize the training and ease the gradient propagation, a residual connection is added for each block.
S-LSU和T-LSU后分别接一个2D批量归一化层。网络起始处添加了1D批量归一化层用于规范化展平的输入数据。给定骨骼序列,建模后的数据被送入构建块中。经过最后一个块后,执行全局平均池化以使不同样本的特征图尺寸统一。最终全连接分类器输出人体动作的预测结果。构建块数量$K$和输出通道数需根据训练集规模自适应调整,因为小数据集无法训练大型网络。然而本工作无需调整$K$,因为我们提出在大型通用数据集上进行预训练(见第4节)。设定$K=10$,对应输出通道数为:64、64、64、64、128、128、128、256、256、256(见图3)。为稳定训练并促进梯度传播,每个块都添加了残差连接。
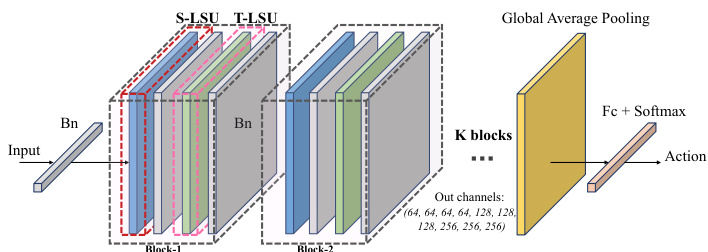
Figure 3. Overall architecture. There are K blocks with a 1D Batch normalization layer at the beginning, a global average pooling layer and a fully connected classifier at the end. Each block contains a Spatial Long-short dependency Unit (S-LSU), a Temporal Long-short dependency Unit (T-LSU) and two Batch normalization layers.
图 3: 整体架构。包含K个模块,起始处为一维批归一化层,末端为全局平均池化层和全连接分类器。每个模块包含一个空间长短依赖单元 (S-LSU)、一个时序长短依赖单元 (T-LSU) 以及两个批归一化层。
Spatial Long-short Dependency Unit (S-LSU). To aggregate the information from a larger spatial-temporal receptive field, a sliding temporal window of size $\tau$ is set over the input matrix. At each step, the input $\mathbf{f_{in}}$ across $\tau$ frames in the window becomes a matrix in $\mathbb{R}^{C_{i n}\times T\times\tau V}$ . For the purpose of spatial modeling, we use a multi-head and residual based S-LSU (see Fig. 4 (b)) and formulated as follows:
空间长短期依赖单元 (S-LSU)。为了聚合更大时空感受野的信息,我们在输入矩阵上设置了一个大小为 $\tau$ 的滑动时间窗口。在每一步中,窗口内跨越 $\tau$ 帧的输入 $\mathbf{f_{in}}$ 会形成一个 $\mathbb{R}^{C_{i n}\times T\times\tau V}$ 维度的矩阵。针对空间建模的需求,我们采用了基于多头和残差结构的 S-LSU (见图 4(b)) ,其公式如下:
$$
\mathbf{f_{out}}=\mathrm{S-LSU}(\mathbf{f_{in}})=\sum_{i=1}^{N}\mathbf{E}_{i}\cdot\left(\mathbf{f_{in}}\times\left(\mathbf{W}_{i}+\mathbf{A}_{i}\right)\right),
$$
$$
\mathbf{f_{out}}=\mathrm{S-LSU}(\mathbf{f_{in}})=\sum_{i=1}^{N}\mathbf{E}_{i}\cdot\left(\mathbf{f_{in}}\times\left(\mathbf{W}_{i}+\mathbf{A}_{i}\right)\right),
$$
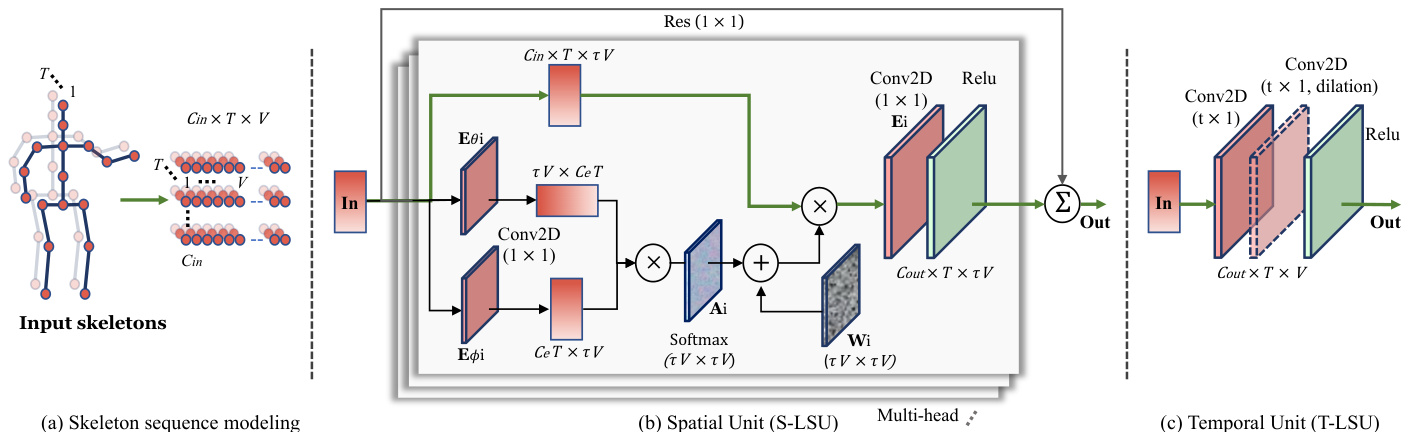
Figure 4. Unified Spatial-temporal Network. (a) The input skeleton sequence is modeled into a matrix with $C_{i n}$ channels $\times T$ frames $\times V$ joints. (b) In each head of the S-LSU, the input data over a temporal sliding window $(\tau)$ is multiplied by a dependency matrix which are obtained from the unified, uniformly initialized $\mathbf{W_{i}}$ and the self-attention based $\mathbf{A_{i}}$ . $\mathbf{E}{i}$ , ${\bf E}{\theta i}$ and $\mathbf{E}{\phi i}$ are for the channel embedding from $C_{i n}$ to $C_{o u t}/C_{e}$ respectively by $(1\times1)$ convolutions. The final output is the sum of the outputs from all the heads. (c) The T-LSU is composed of convolutional layers with $(t\times1)$ kernels . $d$ denotes the dilation coefficient which can be different in each block.
图 4: 统一时空网络。(a) 输入骨骼序列被建模为具有 $C_{i n}$ 通道 $\times T$ 帧 $\times V$ 关节的矩阵。(b) 在S-LSU的每个头中,时间滑动窗口 $(\tau)$ 内的输入数据与依赖矩阵相乘,该矩阵由统一均匀初始化的 $\mathbf{W_{i}}$ 和基于自注意力机制的 $\mathbf{A_{i}}$ 获得。$\mathbf{E}{i}$、${\bf E}{\theta i}$ 和 $\mathbf{E}{\phi i}$ 分别通过 $(1\times1)$ 卷积将通道从 $C_{i n}$ 嵌入到 $C_{o u t}/C_{e}$。最终输出是所有头输出的总和。(c) T-LSU由具有 $(t\times1)$ 核的卷积层组成。$d$ 表示每个块中可不同的膨胀系数。
where $N$ represents the number of heads. $\mathbf{E}{i}\in$ RCout×Cin×1×1 denotes the 2D convolutional weight matrix with $1\times1$ kernel size, which embeds the features from $C_{i n}$ to $C_{o u t}$ by the dot product. $\mathbf{W}{i}\in\mathbb{R}^{\tau V\times\tau V}$ is the “dependency matrix” mentioned in Sec. 1 to process the dependencies for every pair of spatial features. Note that $\mathbf{W}_{i}$ is learnable and uniformly initialized as random values within bounds (Eq. 3).
其中 $N$ 表示头数。$\mathbf{E}{i}\in$ RCout×Cin×1×1 表示核大小为 $1\times1$ 的二维卷积权重矩阵,通过点积将特征从 $C_{i n}$ 嵌入到 $C_{o u t}$。$\mathbf{W}{i}\in\mathbb{R}^{\tau V\times\tau V}$ 是第1节提到的"依赖矩阵",用于处理每对空间特征的依赖关系。注意 $\mathbf{W}_{i}$ 是可学习的,并统一初始化为有界随机值 (式3)。
$$
\mathbf{W}_{i}=\mathrm{Uniform}(-b o u n d,b o u n d),
$$
$$
\mathbf{W}_{i}=\mathrm{Uniform}(-b o u n d,b o u n d),
$$
where
其中
$$
b o u n d=\sqrt{\frac{6}{(1+a^{2})V}},
$$
$$
b o u n d=\sqrt{\frac{6}{(1+a^{2})V}},
$$
where $a$ denotes a constant indicating the negative slope [12]. In this work, we take $a={\sqrt{5}}$ as the initialization strategy of the fully connected layers, in order to efficiently find the optimized dependencies [12].
其中 $a$ 表示一个指示负斜率的常数 [12]。在本工作中,我们采用 $a={\sqrt{5}}$ 作为全连接层的初始化策略,以高效找到优化依赖关系 [12]。
Self-attention Mechanism. The matrix $\mathbf{A}{i}$ in Eq. 2 represents the non-local self attention map that adapts the dependency matrix $\mathbf{W}{i}$ dynamically to the target action. This adaptive attention map is learned end-to-end with the action label. In more details, given the input feature map $\mathbf{f_{in}}\in\mathbb{R}^{C_{i n}\times T\times\tau V}$ , we first embed it into the space $\mathbb{R}^{C_{e}\times T\times\tau V}$ by two convolutional layers with $1\times1$ kernel size. The convolutional weights are denoted as $\mathbf{E}{\theta i}\in$ $\mathbb{R}^{C_{e}\times C_{i n}\times1\times1}$ and $\mathbf{E}{\phi i}\in\mathbb{R}^{C_{e}\times\bar{C}{i n}\times1\times1}$ , respectively. The two embedded feature maps are reshaped to $\tau V\times C_{e}T$ and $C_{e}T\times\tau V$ dimensions. They are then multiplied to obtain the attention map $\mathbf{A}{i}\in\mathbb{R}^{\tau V\times\tau V}$ , whose elements represent the attention weights between each two joints adapted to different actions. The value of the matrix is normalized to $0\sim1$ using a softmax function. We can formulate $\mathbf{A}_{i}$ as:
自注意力机制 (Self-attention Mechanism)。式2中的矩阵 $\mathbf{A}{i}$ 表示非局部自注意力图,能够根据目标动作动态调整依赖矩阵 $\mathbf{W}{i}$。这种自适应注意力图与动作标签端到端联合学习。具体而言,给定输入特征图 $\mathbf{f_{in}}\in\mathbb{R}^{C_{i n}\times T\times\tau V}$,我们首先通过两个核尺寸为 $1\times1$ 的卷积层将其嵌入到空间 $\mathbb{R}^{C_{e}\times T\times\tau V}$。卷积权重分别记为 $\mathbf{E}{\theta i}\in$ $\mathbb{R}^{C_{e}\times C_{i n}\times1\times1}$ 和 $\mathbf{E}{\phi i}\in\mathbb{R}^{C_{e}\times\bar{C}{i n}\times1\times1}$。两个嵌入特征图被重塑为 $\tau V\times C_{e}T$ 和 $C_{e}T\times\tau V$ 维度,随后相乘得到注意力图 $\mathbf{A}{i}\in\mathbb{R}^{\tau V\times\tau V}$,其元素表示适应不同动作的关节间注意力权重。通过softmax函数将矩阵值归一化至 $0\sim1$ 范围。$\mathbf{A}_{i}$ 可表示为:
$$
\mathbf{A}{i}=\mathrm{Softmax}\left((\mathbf{E}{\theta i}^{\mathbf{T}}\cdot\mathbf{f_{in}^{\mathbf{T}}})\times\left(\mathbf{E}{\phi i}\cdot\mathbf{f_{in}}\right)\right).
$$
$$
\mathbf{A}{i}=\mathrm{Softmax}\left((\mathbf{E}{\theta i}^{\mathbf{T}}\cdot\mathbf{f_{in}^{\mathbf{T}}})\times\left(\mathbf{E}{\phi i}\cdot\mathbf{f_{in}}\right)\right).
$$
Temporal Long-short Dependency Unit (T-LSU). For the temporal dimension, the video length is generally large. If we use the same method as spatial dimension, i.e., establishing dependencies by $T\times T$ weights for every pair of frames, it will consume too much calculation. Therefore, we leverage multiple 2D convolutional layers with kernels of different dilation coefficient $d$ and temporal size $t$ on the $C_{o u t}\times T\times N$ feature maps to learn the multi-scale longshort term dependencies (see Fig. 4 (c)). The T-LSU can be formulated as:
时序长短依赖单元 (T-LSU)。在时间维度上,视频长度通常较大。若采用与空间维度相同的方法(即为每对帧建立 $T\times T$ 权重依赖关系),将消耗过多计算量。因此,我们在 $C_{o u t}\times T\times N$ 特征图上采用多个具有不同膨胀系数 $d$ 和时间尺度 $t$ 的2D卷积层,以学习多尺度长短时序依赖关系(见图4(c))。T-LSU可表述为:
$$
\mathbf{f_{out}}=\mathrm{T}\mathrm{-LSU}(\mathbf{f_{in}})=\mathrm{Conv}{2D(t\times1,d)}(\mathbf{f_{in}}).
$$
$$
\mathbf{f_{out}}=\mathrm{T}\mathrm{-LSU}(\mathbf{f_{in}})=\mathrm{Conv}{2D(t\times1,d)}(\mathbf{f_{in}}).
$$
Joint-bone Two-stream Fusion. Inspired by the twostream methods [31, 30, 21], we use a two-stream framework where a separate model with identical architecture is trained using the bone features initialized as vector differences of adjacent joints directed away from the body center. The softmax scores from the joint and bone models are summed to obtain final prediction scores.
关节-骨骼双流融合。受双流方法 [31, 30, 21] 启发,我们采用双流框架,其中使用相同架构的独立模型通过以远离身体中心的相邻关节向量差初始化的骨骼特征进行训练。将关节模型和骨骼模型的softmax分数相加以获得最终预测分数。
3.2. Design Strategy
3.2. 设计策略
In this section, we present our design strategy that goes beyond GCNs by using a generic dependency matrix $\mathbf{W}{i}$ (see Eq. 2) and the attention mechanism $\mathbf{A}_{i}$ to model the relations between joints in our unified formulation.
在本节中,我们提出了一种超越GCN的设计策略,通过使用通用依赖矩阵$\mathbf{W}{i}$(见式2)和注意力机制$\mathbf{A}_{i}$,在我们的统一框架中对关节间关系进行建模。
Dependency Matrix. For many human actions, the natural connectivity between joints are not the most appropriate to be used to extract features on skeletons (e.g., for “drinking”, the connectivity between the head and the hand should be considered, but the original human topology does not include this connectivity). Hence, it is still an open question what kind of adjacency matrix can represent the opti- mal dependencies between joints for effective feature extraction. Recent works [18, 31, 21] aim at optimizing the adjacency matrices to increase the receptive field of graph convolutions, by higher-order polynomials to make distant neighbors reachable [18] or leveraging an attention mechanism to guide the learning process of the adjacency matrix [31, 21]. Specifically, they decompose the adjacency matrix into a certain number of subsets according to the distances between joints [21] or according to the orientation of joints to the gravity (i.e., body center) [31], so that each subset is learned individually by the self-attention. The learned feature maps are then aggregated together for the action classification. However, the number of subsets is constrained by the body structure. Moreover, we note that the manually pre-defined subsets of the adjacency matrix with prior knowledge (i.e., pre-defined body topology) are all sparse. At the initial learning stage, this spatial convolution relies on a graph-representation, while at the deeper stage, the relations coded within the adjacency matrix are no more sparse and the joint connections are represented by a complete-graph, which corresponds to a fully connected layer in the narrow sense. Finally, the dependencies converge to a sparse representation again, which is locally optimal but completely different from the original topological connectivity of the human body (see Fig. 5). This motivates us, in this work, to revise the “adjacency matrix” by a generic “dependency matrix” that is prospectively initialized with a fully dense and uniform distribution (Eq. 3) to better reach the globally optimal representation.
依赖矩阵。对于许多人类动作而言,关节间的自然连接性并非提取骨骼特征的最佳选择(例如"喝水"动作应考虑头部与手部的连接,但原始人体拓扑并不包含这种连接)。因此,如何构建能表征关节间最优依赖关系的邻接矩阵以进行有效特征提取,仍是一个开放性问题。近期研究[18,31,21]尝试通过高阶多项式使远端节点可达[18],或采用注意力机制引导邻接矩阵学习[31,21]来优化邻接矩阵,从而扩大图卷积的感受野。具体而言,这些方法根据关节间距[21]或关节相对重力方向(即身体中心)[31]将邻接矩阵分解为若干子集,每个子集通过自注意力独立学习,最终聚合特征图进行动作分类。然而子集数量受人体结构限制,且基于先验知识(预定义人体拓扑)手动划分的邻接矩阵子集均为稀疏矩阵。在学习初始阶段,空间卷积依赖于图表示;而在深层阶段,邻接矩阵编码的关系转为稠密,关节连接呈现为完全图,狭义上等同于全连接层。最终依赖关系会再次收敛为稀疏表示,这种局部最优解与人体原始拓扑连接截然不同(见图5)。这促使我们在本工作中将"邻接矩阵"改进为通用"依赖矩阵",初始采用完全稠密的均匀分布(公式3)以实现全局最优表征。
Multi-head Aggregation. With our proposed initialization strategy, we can repeat the self-attention mechanism by leveraging multiple dependency matrices and sum the outputs to automatically aggregate the features focusing on different body joints (Eq. 2). As the number of attention maps (i.e., heads) $N$ is no longer limited by the human topology, we can use it as a flexible hyper-parameter to improve the model. In the ablation study (see Fig. 5 and Tab. 1), our insight has been verified. Overall, our design strategy makes the architecture more flexible, effective and generic, which facilitates the study of cross-domain transfer learning in this field for datasets using different joint distributions (see Fig. 2).
多头聚合 (Multi-head Aggregation)。通过我们提出的初始化策略,可以借助多个依赖矩阵重复执行自注意力机制 (self-attention),并将输出结果求和以自动聚合关注不同身体关节的特征(公式2)。由于注意力图(即头)数量$N$不再受人体拓扑结构限制,可将其作为灵活的超参数来改进模型。消融实验(见图5和表1)验证了我们的观点。总体而言,该设计策略使架构更具灵活性、高效性和通用性,有助于针对采用不同关节分布的数据集开展跨领域迁移学习研究(见图2)。
4. Posetics Skeleton Dataset
4. Posetics 骨骼数据集
In this section, we introduce Posetics, a novel large-scale pre-training dataset for skeleton-based action recognition (as illustrated in Fig. 1). The Posetics dataset is created to study the transfer learning on skeleton-based action recognition. It contains 142,000 real-world video clips with the corresponding 2D and 3D poses including 17 body joints. All video clips in Posetics dataset are filtered from Kinetics400 [4], to contain at least one human pose over $50%$ of frames.
在本节中,我们介绍Posetics——一个面向骨骼动作识别的大规模预训练数据集(如图1所示)。Posetics数据集旨在研究骨骼动作识别的迁移学习能力,包含142,000个真实世界视频片段,每个片段均配有包含17个身体关节点在内的2D和3D姿态数据。该数据集所有视频片段均从Kinetics400 [4]中筛选而出,确保至少50%的帧数包含有效人体姿态。
Motivation and Data Collection. Recent skeleton-based action recognition methods on NTU-RGB $+\mathrm{D}$ [29, 20] can perform similarly or better compared to RGB-based methods. However, as laboratory indoor datasets may not contain occlusions, it is difficult to use such datasets to pretrain a generic model that can be transferred onto real-world videos, where skeleton data encounters a number of occlusions and truncation s of the body. On the other hand, the accuracy based on skeleton data on the most popular realworld pre-training dataset, Kinetics [4], is still far below the accuracy on other datasets. The main problems are: (i) the skeleton data is hard to obtain by pose estimators as Kinetics is not human-centric. Human body may be missing or truncated by the image boundary in many frames. (ii) Many action categories are highly related to objects rather than human motion (e.g., “making cakes”, “making sushi” and “making pizza”). These make it difficult to effectively learn the human skeleton representation for recognizing actions. Hence, recent datasets [20, 43] are unable to significantly boost the action recognition performance when applied to different datasets. In order to better study the general iz ability of skeleton-based models in the real-world, we extract the pose (i.e., skeleton) data on Kinetics-400 [4] videos. Specifically, we compare the recent pose estimators and extract pose data from RGB videos through multiple pose estimation systems. Then we apply SSTA-PRS [44], a pose refinement system, for obtaining higher quality pose data in real-world videos. This system aggregates the poses of three off-the-shelf pose estimators [27, 2, 8], as pseudo ground-truth and retrain LCRNet+ $^{\cdot+}$ [27] to improve the estimation performance. Moreover, for the problem (i), we filter out the videos where no body detected, and for the problem (ii), we slightly and manually modify the video category labels of Kinetics-400, and place emphasis on relating verbs to poses. (e.g., For “making cakes”, “making sushi” and “making pizza”, we collectively chose the label “making food”, whereas “washing clothes”, “washing feet”, and “washing hair” remain with the original labels). All in one, we organize 320 action categories for Posetics and this dataset can be more appropriately used for studying the real-world general iz ability of skeleton-based action recognition models across datasets by transfer learning.
动机与数据收集。近期基于骨架的动作识别方法在NTU-RGB $+\mathrm{D}$ [29, 20]上的表现已与基于RGB的方法相当甚至更优。然而实验室室内数据集通常不含遮挡场景,难以用于预训练可迁移至真实视频的通用模型——真实场景中骨架数据常面临肢体遮挡与截断问题。另一方面,当前最流行的真实世界预训练数据集Kinetics [4]上,基于骨架数据的识别准确率仍远低于其他数据集,主要存在两大问题:(i) 由于Kinetics非以人物为中心,姿态估计器难以获取骨架数据,许多帧中人体可能缺失或被图像边界截断;(ii) 大量动作类别与物体关联度高于人体运动(如"做蛋糕"、"做寿司"、"做披萨"),导致难以有效学习用于动作识别的人体骨架表征。因此现有数据集[20, 43]应用于不同数据集时均未能显著提升动作识别性能。
为更好地研究骨架模型在真实世界中的泛化能力,我们从Kinetics-400 [4]视频中提取姿态(即骨架)数据。具体而言,我们对比最新姿态估计器,通过多套姿态估计系统从RGB视频提取姿态数据,并采用姿态优化系统SSTA-PRS [44]提升真实视频中的姿态数据质量。该系统聚合三种现成姿态估计器[27, 2, 8]的结果作为伪真值,通过重训练LCRNet+$^{\cdot+}$ [27]来提升估计性能。针对问题(i),我们过滤未检测到人体的视频;针对问题(ii),我们人工微调Kinetics-400的视频类别标签,重点建立动词与姿态的关联(例如将"做蛋糕"、"做寿司"、"做披萨"统一标记为"制作食物",而"洗衣服"、"洗脚"、"洗头"保留原标签)。最终我们为Posetics数据集整理出320个动作类别,该数据集更适用于通过迁移学习来研究跨数据集的骨架动作识别模型在真实世界中的泛化能力。
5. Experiments and Analysis
5. 实验与分析
5.1. Experimental Settings
5.1. 实验设置
Overview. Extensive experiments are conducted on 5 action classification datasets: Toyota Smarthome (Smarthome) [6], Penn Action [46], NTU-RGB $\mathbf{+D}$ 60 (NTU-60) [29], NTU $\mathbf{RGB}{+}\mathbf{D}$ 120 (NTU-120) [20] and the proposed Posetics. See the supplementary material for datasets and implementation details pertaining to all experiments. Firstly, we perform (i) exhaustive ablation study on Smarthome and NTU-60 without pre-training to verify the effectiveness of our proposed dependency matrix and multihead attention. Then we (ii) demonstrate the impact of pre-training on Posetics by both linear evaluation and finetuning on Smarthome and Penn Action. (iii) We re-evaluate state-of-the-art models [43, 31, 21], as well as our model on the proposed Posetics dataset (baselines are shown in Tab. 6), proceed to provide an analysis on how much performance improves on target datasets: Smarthome, Penn Action, NTU-60 and NTU-120, after pre-training on Posetics. We demonstrate that our model generalizes well and benefits the most from pre-training. (iv) Final fine-tuned models are evaluated on all datasets to compare with the other stateof-the-art approaches for action recognition.
概述。我们在5个动作分类数据集上进行了广泛实验:Toyota Smarthome (Smarthome) [6]、Penn Action [46]、NTU-RGB $\mathbf{+D}$ 60 (NTU-60) [29]、NTU $\mathbf{RGB}{+}\mathbf{D}$ 120 (NTU-120) [20]以及新提出的Posetics数据集。所有实验涉及的数据集和实现细节详见补充材料。首先,我们(i)在Smarthome和NTU-60上进行了无预训练的详尽消融实验,以验证所提出的依赖矩阵和多头注意力机制的有效性;接着(ii)通过线性评估和微调在Smarthome和Penn Action上展示了Posetics预训练的影响;(iii)重新评估了最先进模型[43,31,21]及我们模型在Posetics数据集上的表现(基线结果如 表6 所示),进而分析了在Posetics预训练后目标数据集(Smarthome、Penn Action、NTU-60和NTU-120)的性能提升幅度,证明我们的模型泛化能力优异且从预训练中获益最大;(iv)最终在所有数据集上评估微调后的模型,与其他最先进动作识别方法进行对比。
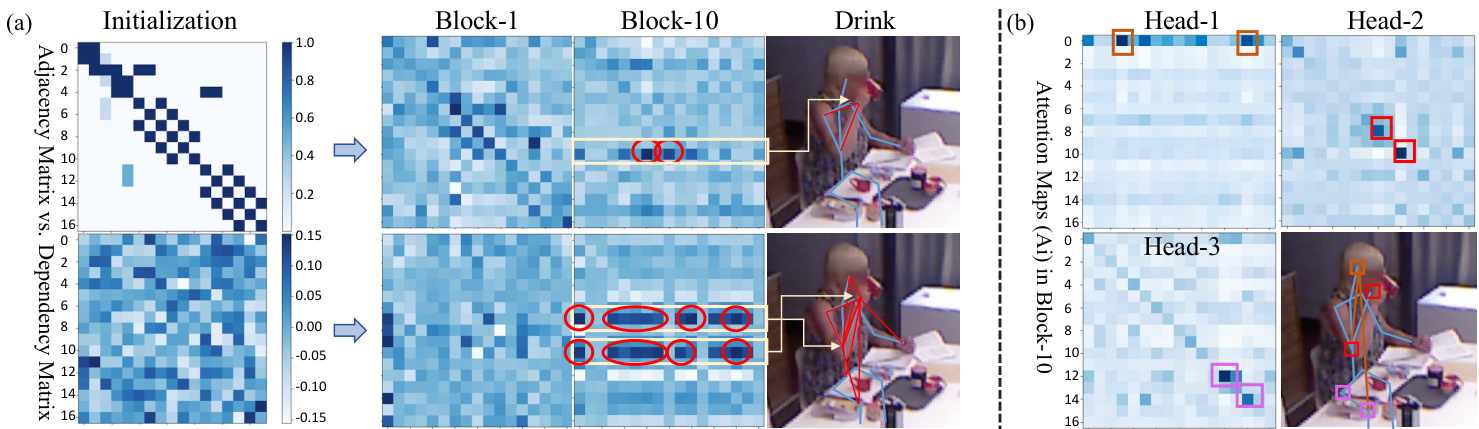
Figure 5. (a) Adaptive Adjacency Matrix [31] (top) vs. Dependency Matrix (bottom) in different blocks for action ”Drink” of Smarthome (right). They have different initial distributions. During training, the dependencies will become optimized representations, that are salient and more sparse in the deeper blocks, while our proposed matrix represents longer range dependencies (indicated by the red circles and red lines). (b) Multi-head attention maps in Block-10. Similar to dependency matrices, attention maps are salient and sparse in the deep block. The different heads automatically learn the relationships between the different body joints (as shown in the boxes and lines with different colors) to process long-range dependencies between joints instead of using pre-defined adjacency matrices.
图 5: (a) 自适应邻接矩阵 [31] (上) 与依赖矩阵 (下) 在 Smarthome 动作"Drink"不同区块中的对比 (右)。它们具有不同的初始分布。在训练过程中,依赖关系会逐渐优化为深层区块中更显著且稀疏的表示,而我们提出的矩阵能表征更长程的依赖关系 (如红圈和红线所示)。 (b) Block-10 中的多头注意力图。与依赖矩阵类似,注意力图在深层区块中呈现显著且稀疏的特性。不同注意力头自动学习身体关节间的关联关系 (如不同颜色的方框和连线所示),从而处理关节间的长程依赖,而非使用预定义的邻接矩阵。
Evaluation Protocols. For Posetics, we split the dataset into 131,268 training clips and 10,669 test clips. We use Top-1 and Top-5 accuracy as evaluation metrics [43]. With respect to real-word settings, 2D poses extracted from images and videos tend to be more accurate than 3D poses, which are more prone to noise. Therefore, we only use 2D data for evaluation and comparison of the models on Posetics. We note that for pre-training, both can be used, 2D and 3D data, in order to obtain different models that can be transferred to datasets with different skeleton data. For the other datasets, we evaluate cross-subject (CS on Smarthome, NTU-60 and 120), cross-view (CV1 and CV2 on Smarthome and CV on NTU-60), cross-setup (CSet on NTU-120) protocols and the standard protocol (on Penn Action). Unless stated, we use 2D data on Smarthome and Penn Action, 3D data on NTU-60 and 120.
评估协议。对于Posetics数据集,我们将其划分为131,268个训练片段和10,669个测试片段。采用Top-1和Top-5准确率作为评估指标[43]。在实际场景中,从图像和视频提取的2D姿态通常比3D姿态更精确,后者更容易受噪声影响。因此,在Posetics上我们仅使用2D数据进行模型评估与比较。需说明的是,预训练阶段可同时使用2D和3D数据,以获得可迁移至不同骨架数据集的多样化模型。其他数据集的评估协议包括:跨主体(CS,用于Smarthome、NTU-60和120)、跨视角(CV1/CV2用于Smarthome,CV用于NTU-60)、跨设置(CSet用于NTU-120)以及标准协议(用于Penn Action)。除非特别说明,Smarthome和Penn Action使用2D数据,NTU-60和120使用3D数据。
5.2. Ablation Study of UNIK
5.2. UNIK消融实验
Impact of Dependency Matrix. Here we compare the dependency matrices with the adaptive adjacency matrices. In order to verify our analysis in Sec. 3.2, we visualize the adjacency matrices [31] before and after learning. As shown in Fig. 5 (a)-top, we find that the previous learned graph [31] becomes a complete-graph, whose relationships are represented by weights that are well distributed over the feature maps. In contrast, our method is able to explore longer range dependencies, while being based on a dependency matrix with self-attention, which freely searches for dependencies of the skeleton from the beginning without graph-representation (see Fig. 5 (a)-bottom). Quantitatively, results in Tab. 1 show the effectiveness of the Dependency Matrix. Overall, we conclude that, both our method and AGCN-based methods are fully connected layers with different initialization strategies and attention mechanisms in the spatial dimension, both are better than using a fixed graph [43]. It becomes evident that for skeleton-based tasks, where the number of nodes (i.e., spatial body joints) is not large, multi-head attention based dependency matrix learning along with temporal convolutions can be a more generic and effective way to learn spatio-temporal dependencies compared with graph convolution.
依赖矩阵的影响。这里我们将依赖矩阵与自适应邻接矩阵进行比较。为验证第3.2节的分析,我们可视化学习前后的邻接矩阵[31]。如图5(a)-顶部所示,先前学习得到的图[31]变成了完全图,其关系通过均匀分布在特征图上的权重表示。相比之下,我们的方法基于自注意力机制的依赖矩阵,无需图表示即可自由探索骨骼的远距离依赖关系(见图5(a)-底部)。定量分析结果如表1所示,验证了依赖矩阵的有效性。总体而言,我们的方法与基于AGCN的方法都是空间维度上采用不同初始化策略和注意力机制的全连接层,二者性能均优于使用固定图的方法[43]。显然,对于节点数(即空间关节点)不多的骨骼任务,基于多头注意力的依赖矩阵学习与时序卷积相结合,相比图卷积能更通用有效地学习时空依赖关系。
Table 1. Impact of Dependency Matrix on Smarthome CS and NTU-60 CS using joint (J) data only. F-AdjM: Fixed Adjacency Matrix (ST-GCN), A-AdjM: Adaptive Adjacency Matrix (AGCNs), DepM: Dependency Matrix (Ours).
表 1: 仅使用关节(J)数据时依赖矩阵(Dependency Matrix)对Smarthome CS和NTU-60 CS的影响。F-AdjM: 固定邻接矩阵(Fixed Adjacency Matrix)(ST-GCN), A-AdjM: 自适应邻接矩阵(Adaptive Adjacency Matrix)(AGCNs), DepM: 依赖矩阵(Dependency Matrix)(Ours)。
| 数据集(J) | 矩阵 | ||
|---|---|---|---|
| F-AdjM | (N = 3,T = 1) A-AdjM | DepM | |
| Smarthome CS (%) NTU-60 CS (%) | 50.4 84.3 | 55.7 86.1 | 58.5 87.3 |
Table 2. Impact of Multi-head Attention on Smarthome CS and NTU-60 CS using joint (J) data only.
| 数据集 (J) | #Heads-N (T = 1) | ||||
|---|---|---|---|---|---|
| 0 | 1 | 3 | 6 | 12 | |
| Smarthome CS (%) NTU-60 CS (%) | 56.8 86.8 | 58.1 87.0 | 58.5 87.3 | 57.9 87.1 | 58.1 88.0 |
表 2: 仅使用关节 (J) 数据时多头注意力对 Smarthome CS 和 NTU-60 CS 的影响。
Table 3. Impact of TW and TD on Smarthome CS and NTU-60 CS using joint (J) data only. TW: Temporal window size $(\tau)$ . TD: Temporal dilation.
| 数据集 (J) | TW-T (N=3) | TD (N=3, T=1) | |||
|---|---|---|---|---|---|
| 1 | 2 | 6 | |||
| Smarthome CS (%) NTU-60 CS (%) | 58.5 87.3 | 57.0 87.0 | 56.2 87.8 | 58.5 87.3 | 58.9 87.8 |
表 3: 仅使用联合 (J) 数据时 TW 和 TD 对 Smarthome CS 及 NTU-60 CS 的影响。TW: 时间窗口大小 $(\tau)$。TD: 时间膨胀。
Table 4. Mean per-class accuracy on Smarthome and Top-1 classification accuracy on Penn Action by Fine-tuning (Backbone not fixed) and Linear classification (Backbone fixed) for evaluation of extracted features by pre-training. “ $\mathrm{\Delta}^{\mathrm{6}}\mathrm{J+B"}$ : Joint and Bone two stream fusion.
| UNIK | 预训练 (Pre-training) | Smarthome (J+B) | Smarthome (J+B) | Smarthome (J+B) | Smarthome (J+B) | Penn Action (J+B) | Penn Action (J+B) |
|---|---|---|---|---|---|---|---|
| #Params | CS(%) | CV1(%) | CV2(%) | #Params | Accuracy (%) | ||
| 微调 (Fine-tuning) | 从头训练 (Scratch) | 3.45M | 63.1 | 22.9 | 61.2 | 3.45M | 94.0 |
| 微调 (Fine-tuning) | Posetics | 3.45M | 64.3 | 36.1 | 65.2 | 3.45M | 97.9 |
| 线性分类 (Linear classification) | 从头训练 (Scratch) | 7.97K | 24.6 | 17.2 | 20.7 | 3.85K | 29.8 |
| 线性分类 (Linear classification) | Posetics | 7.97K | 51.9 | 35.2 | 52.2 | 3.85K | 97.3 |
表 4: 通过微调 (不固定主干网络) 和线性分类 (固定主干网络) 评估预训练提取特征在Smarthome上的平均每类准确率及Penn Action上的Top-1分类准确率。"$\mathrm{\Delta}^{\mathrm{6}}\mathrm{J+B"}$"表示关节与骨骼双流融合。
Table 5. General iz ability study of state-of-the-art by comparing the impact of transfer learning on Smarthome, Penn Action, NTU-60 and 120 datasets. The blue values indicate the best general iz abilities that can take the most advantage of pre-training on Posetics. “*” indicates that we only use 17 main joints adapted to the pre-trained model on Posetics.
| 方法 | 预训练 | Smarthome e() | Penn Action (J) Top-1 Acc. (%) | *NTU-60 (J+B) | *NTU-120 (J+B) | ||||
|---|---|---|---|---|---|---|---|---|---|
| CS (%) | CV1 (%) | CV2 (%) | CS (%) | CV (%) | CS (%) | CSet (%) | |||
| 2s-AGCN [31] | Scratch | 55.7 | 21.6 | 53.3 | 89.5 | 84.2 | 93.0 | 78.2 | 82.9 |
| MS-G3D [21] | Scratch | 55.9 | 17.4 | 56.7 | 88.5 | 86.0 | 94.1 | 80.2 | 86.1 |
| UNIK (Ours) | Scratch | 58.9 | 21.9 | 58.7 | 90.1 | 85.1 | 93.6 | 79.1 | 83.5 |
| 2s-AGCN [31] | Posetics | 58.8 | 32.2 | 57.9 | 96.4 | 85.8 | 93.4 | 79.7 | 85.0 |
| MS-G3D [21] | Posetics | 59.1 | 26.6 | 60.1 | 92.2 | 86.2 | 94.1 | 80.6 | 86.4 |
| UNIK (Ours) | Posetics | 62.1 | 33.4 | 63.6 | 97.2 | 86.8 | 94.4 | 80.8 | 86.5 |
表 5: 通过比较迁移学习对 Smarthome、Penn Action、NTU-60 和 120 数据集的影响,对现有技术进行的泛化能力研究。蓝色数值表示最能利用 Posetics 预训练的最佳泛化能力。"*"表示我们仅使用适应于 Posetics 预训练模型的 17 个主要关节。
Impact of Multi-head Attention. In this section, we visualize the multi-head attention maps and analyze the impact of the number of heads $N$ for UNIK with $N=$ $1,3,6,12$ . As shown in Fig. 5, our multi-head aggregation mechanism can automatically learn the relationships between different positions of body joints by conducting the spatial processing (see Eq. 3) using the unified dependency matrices with a uniform initialization. Quantitative results in Tab. 2 show that obtaining a correct number of heads $N$ is instrumental in improving the accuracy in a given dataset, but weakens the generalization ability across datasets (e.g., the model benefits predominantly from $N=12$ for NTU60, and $N:=:3$ for Smarthome). Consequently, we set $N~=~3$ as a unified setting for all experiments and all datasets in order to balance the efficiency and performance of the model, as well as the generalization ability.
多头注意力机制的影响。本节我们可视化多头注意力图,并分析UNIK模型中头数$N$(取值为$1,3,6,12$)的影响。如图5所示,我们的多头聚合机制通过使用统一初始化依赖矩阵进行空间处理(见公式3),能自动学习身体关节不同位置间的关系。表2的定量结果表明:在特定数据集中,选取合适的头数$N$能显著提升精度,但会削弱跨数据集泛化能力(例如NTU60数据集在$N=12$时表现最优,而Smarthome数据集在$N=3$时效果最好)。因此,为平衡模型效率、性能及泛化能力,我们在所有实验和数据集统一采用$N=3$的设定。
Other Ablations. For further analysis, results in Tab. 3 also show that (i) similar to [21], the size of the sliding window (see 3.1) $\tau$ can help to improve the performance, however weakening the general iz ability of the model. (ii) Temporal dilated convolution contributes to minor boosts.
其他消融实验。进一步分析表明,表3中的结果还显示:(i) 与[21]类似,滑动窗口(见3.1节)的尺寸$\tau$有助于提升性能,但会削弱模型的泛化能力;(ii) 时间扩张卷积仅带来小幅性能提升。
5.3. Impact of Pre-training.
5.3. 预训练的影响
Transfer Learning. In this section, we evaluate the features of skeletons extracted by UNIK pre-trained on Posetics by transfer learning. For linear classification, we freeze the UNIK backbone pre-trained on Posetics, then retrain linear class if i ers on smaller benchmarks: Smarthome and Penn Action. The results in Tab. 4 demonstrate the effectiveness of transfer learning with fewer parameters compared with classification from scratch. Fine-tuning (i.e., UNIK backbone not fixed) results are also shown. In addition, we visualize the training curve for the Top-1 accuracy with training steps during fine-tuning (see Fig. 6). From the curves, we deduce that at the beginning of training steps, the pre-training has a significant boost for all transferred datasets. This suggests that the weights of the model are well pre-trained on Posetics, providing a strong transfer ability i.e., pre-trained on Posetics is generic and can be used for extracting features of skeleton sequences.
迁移学习。本节我们通过迁移学习评估在Posetics数据集上预训练的UNIK模型提取的骨骼特征。对于线性分类任务,我们冻结预训练的UNIK主干网络,仅在小型基准数据集Smarthome和Penn Action上重新训练线性分类层。表4结果显示,与从头训练相比,迁移学习能以更少的参数取得更好效果,同时展示了微调(即不固定UNIK主干网络)的结果。此外,我们绘制了微调过程中Top-1准确率随训练步数的变化曲线(见图6)。曲线表明:在训练初期,预训练权重对所有迁移数据集都产生显著提升,这说明模型在Posetics上的预训练权重具有强迁移能力,即Posetics预训练具有通用性,可用于提取骨骼序列特征。
General iz ability Study. In this section, we report the classification results on all the four target datasets to demonstrate the impact of pre-training and compare the generalization capacities (i.e., benefits by fine-tuning compared to training from scratch) with state-of-the-art methods. Specifically, we pre-train respectively [31, 21] and our proposed UNIK in a unified setting $(N=3,K=10,\tau=1)$ ). Note that for pre-training GCN-based models [31, 21], we need to manually calibrate the different human topological structures in different datasets to keep the pre-defined graphs unified. Note that unless otherwise stated, we use the consistent skeleton data (2D on Smarthome, Penn Action and 3D on NTU-60, 120), number of joints (17 main joints) for fair comparison of all models. On NTU-60 and 120, we use both joint (J) and bone (B) data to compare the full models with two-stream fusion. The results suggest that pre- training consistently boosts all models, see Tab. 5, in particular, small benchmarks (e.g., Smarthome CV and Penn Action with $5%\sim12%$ improvement), as we do not have sufficiently large training data. Previous work [21] has a weak transfer capacity, due to the dataset-specific model settings (e.g., the number of GCN scales and G3D scales) not always being able to adapt to the transferred datasets. On NTU-60, we take the main 17 joints for fine-tuning as we estimate and refine the main 17 joints on Posetics, and our pre-trained model outperforms state-of-the-art model [21]. Therefore, we conclude that our pre-trained model is the most generic-applicable especially for real-world scenarios.
泛化能力研究。本节我们报告了四个目标数据集的分类结果,以展示预训练的影响,并将微调相比从头训练的泛化能力提升与前沿方法进行对比。具体而言,我们在统一设置$(N=3,K=10,\tau=1)$下分别对[31, 21]和提出的UNIK进行预训练。需注意的是,基于GCN的模型[31, 21]预训练时需要手动校准不同数据集中的人体拓扑结构差异以保持预定义图的统一性。除非特别说明,我们采用一致的骨架数据(Smarthome和Penn Action使用2D数据,NTU-60和120使用3D数据)和关节点数量(17个主要关节)以确保模型对比公平性。在NTU-60和120数据集上,我们同时使用关节(J)和骨骼(B)数据,通过双流融合对比完整模型。结果表明预训练对所有模型均有稳定提升(见表5),尤其在小型基准测试中(如Smarthome CV和Penn Action提升$5%\sim12%$),这是因为训练数据量不足。先前工作[21]由于数据集特定的模型设置(如GCN尺度和G3D尺度数量)无法适应迁移数据集,导致迁移能力较弱。在NTU-60上,我们选取17个主要关节进行微调(这些关节在Posetics数据集上进行了估计和优化),预训练模型性能超越了当前最优模型[21]。由此我们得出结论:本文预训练模型具有最优的通用适用性,尤其适合真实场景应用。
Table 6. Comparison with state-of-the-art methods on the Posetics, Toyota Smarthome and Penn Action dataset. The best results using RGB data are marked in blue for reference.
| 方法 | RGB | 姿态 | 预训练 | Posetics Top-1(%) | Posetics Top-5(%) | Smarthome CS(%) | Smarthome CV1(%) | Smarthome CV2(%) | Penn Action 准确率(%) |
|---|---|---|---|---|---|---|---|---|---|
| I3D [4] | Kinetics-400 | 53.5 | 78.0 | 53.4 | 34.9 | 45.1 | |||
| AssembleNet++ [28] | Kinetics-400 | 63.6 | |||||||
| NPL [26] | Kinetics-400 | 39.6 | 54.6 | ||||||
| Separable STA [6] | √ | Kinetics-400 | 54.2 | 35.2 | 50.3 | ||||
| VPN [7] | √ | Kinetics-400 | 60.8 | 43.8 | 53.5 | ||||
| Multi-task [22] | √ | Scratch | - | - | - | 97.4 | |||
| LSTM [23] | Scratch | - | 42.5 | 13.4 | 17.2 | ||||
| ST-GCN [43] | Scratch | 43.3 | 67.3 | 53.8 | 15.5 | 51.1 | 89.6 | ||
| 2s-AGCN [31] | Scratch | 47.0 | 70.8 | 60.9 | 22.5 | 53.5 | 93.1 | ||
| MS-G3D Net [21] | √ | Scratch | 47.1 | 70.0 | 61.1 | 17.5 | 59.4 | 92.7 | |
| UNIK (Ours) | Scratch | 47.6 | 71.3 | 63.1 | 22.9 | 61.2 | 94.0 | ||
| Pr-ViPE [34] | Human3.6M | 97.5 | |||||||
| UNIK (Ours) | Posetics(Ours) | 64.3 | 36.1 | 65.0 | 97.9 |
表 6. 在Posetics、Toyota Smarthome和Penn Action数据集上与最先进方法的比较。使用RGB数据的最佳结果以蓝色标出供参考。

Figure 6. Validation accuracy with the training steps on Smarthome, Penn Action and NTU-60 datasets for demonstrating the impact of Pre-training on Posetics. Pre-training on Kinetics-Skeleton [43] (i.e., 2D Openpose on Kinetics-400) is shown for reference.
图 6: 在Smarthome、Penn Action和NTU-60数据集上展示预训练对Posetics影响的验证准确率随训练步骤变化情况。作为参考,同时展示了在Kinetics-Skeleton[43] (即Kinetics-400上使用2D Openpose)的预训练结果。
5.4. Comparison with State-of-the-art
5.4. 与最先进技术的对比
We compare our full model (i.e., Joint+Bone fusion) with and without pre-training to state-of-the-art methods, reporting results in Tab. 6 (Posetics, Smarthome and Penn Action). Note that for fair comparison, we use the same skeleton data (2D and 17 joints) for all models. For real-world benchmarks using estimated skeleton data (e.g., Posetics, Smarthome and Penn Action), our model without pre-training outperforms all state-of-the-art methods [23, 43, 31, 21] in skeleton (i.e., pose) stream and with pretraining, outperforms the embedding-based method [34] that pre-trained on Human3.6M [13]. On NTU-60 and 120 (see Tab. 5), we compare the most impressive twostream graph-based methods [31, 21] and our model performs competitively without pre-training. We argue that, we simplify our model as generically as possible without data-specific settings, which can improve the performance but weaken the transfer behavior (e.g., the setting of $N$ and $\tau$ ). Subsequently, we further compare RGB-based methods [4, 6, 28, 26, 7, 22] for reference, that can be pre-trained on Kinetics-400 [4]. It suggests that previous skeleton-based methods [23, 43, 31, 21] without leveraging the pre-training are limited by the poor general iz ability and the paucity of pre-training data. In contrast, our proposed framework, UNIK with pre-training on the Posetics dataset, outperforms state-of-the-art using RGB and even both RGB and pose data on the downstream tasks (e.g., Smarthoma and Penn Action).
我们将完整模型(即Joint+Bone融合)在有无预训练情况下与最先进方法进行比较,结果如表6所示(Posetics、Smarthome和Penn Action)。请注意,为公平比较,所有模型均使用相同骨架数据(2D和17个关节)。在使用估计骨架数据的真实基准测试中(如Posetics、Smarthome和Penn Action),未经预训练的模型在骨架(即姿态)流上优于所有最先进方法[23,43,31,21];经预训练后则优于基于Human3.6M[13]预训练的嵌入方法[34]。在NTU-60和120数据集(见表5)上,我们对比了最优秀的双流图方法[31,21],未经预训练的模型仍具竞争力。我们认为,本模型通过尽可能通用的简化设计(避免数据特定设置,如$N$和$\tau$的配置)虽可能提升性能但会削弱迁移能力。随后,我们进一步对比了基于RGB的方法[4,6,28,26,7,22]作为参考,这些方法可在Kinetics-400[4]上预训练。结果表明,既往未采用预训练的骨架方法[23,43,31,21]受限于泛化能力不足和预训练数据匮乏。相比之下,我们提出的UNIK框架通过在Posetics数据集预训练,在下游任务(如Smarthome和Penn Action)中超越了仅使用RGB或同时使用RGB与姿态数据的最先进方法。
6. Conclusion
6. 结论
In this paper, we have proposed UNIK, a unified framework for real-world skeleton-based action recognition. Our experimental analysis shows that UNIK is effective and has a strong generalization ability to transfer across datasets. In addition, we have introduced Posetics, a large-scale realworld skeleton-based action recognition dataset featuring high quality skeleton annotations. Our experimental results demonstrate that pre-training on Posetics improves performance of the action recognition approaches. Future work involves an analysis of our framework for additional tasks involving skeleton sequences (e.g., 2D-to-3D pose estimation).
本文提出了UNIK,一个面向现实世界基于骨架动作识别的统一框架。实验分析表明UNIK具有出色的跨数据集迁移泛化能力。此外,我们发布了Posetics数据集——一个具备高质量骨架标注的大规模现实世界动作识别数据集。实验证明基于Posetics的预训练能显著提升动作识别方法的性能。未来工作将探索该框架在其他骨架序列任务中的应用(如2D到3D姿态估计)。
References
参考文献
Appendix
附录
In this supplementary material we provide additional details w.r.t., our experimental analysis provided in the main paper. In section A, we provide details pertaining to the datasets, the implementation of our framework. In section B, we provide more details on the proposed Posetics dataset including the comparison to other related datasets.
在本补充材料中,我们提供了与主论文中实验分析相关的额外细节。在A部分,我们详细说明了数据集及框架的实现细节。在B部分,我们进一步阐述了所提出的Posetics数据集,包括与其他相关数据集的对比分析。
A. Experimental Details
A. 实验细节
A.1. Datasets
A.1. 数据集
Toyota Smarthome. Toyota Smarthome [6] (Smarthome) is a real-world dataset for daily living action classification, recorded in an apartment, where 18 older subjects carry out tasks of daily living during a day. The dataset contains 16,115 videos of 31 action classes, and the videos are taken from 7 different camera viewpoints. All actions are performed in a natural way without strong prior instructions. It provides RGB videos and two versions of skeleton data, which is extracted either from $\mathrm{LCRNet++}$ [27] (v1) or from SSTA-PRS [44] (v2). In this work, we use the skeletonv2 for all experiments and comparisons in skeleton stream. Unless stated, we only use 2D data for the experiments. For the evaluation on this dataset, we follow the cross-subject (CS) and cross-view (CV1 and CV2) evaluation protocols.
丰田智能家居 (Toyota Smarthome) [6] 是一个真实场景的日常生活动作分类数据集,录制于公寓环境中,由18位老年受试者在一天内执行日常生活任务。该数据集包含16,115个视频片段,涵盖31个动作类别,视频采集自7个不同摄像机视角。所有动作均以自然方式完成,未给予严格预设指令。数据集提供RGB视频和两个版本的骨骼数据,分别通过 $\mathrm{LCRNet++}$ [27] (v1版) 和 SSTA-PRS [44] (v2版) 提取。本研究中,我们在骨骼数据流的所有实验和对比中均采用skeletonv2版本。除非特别说明,实验仅使用2D数据。针对该数据集的评估,我们遵循跨受试者 (CS) 和跨视角 (CV1与CV2) 评估协议。
Penn Action. Penn Action dataset [46] contains 2,326 video sequences of 15 different actions and human joint annotations for each sequence. Given that annotated skeletons have a large number of missing joints due to occlusions and truncation s, we use $\mathrm{LCRNet++}$ [27] to obtain the 2D skeletons for experiments. We report Top-1 accuracy following the standard train-test split.
Penn Action。Penn Action数据集[46]包含15种不同动作的2,326个视频序列及每段序列的人体关节标注。由于标注的骨骼数据存在大量因遮挡和截断导致的关节缺失,我们使用$\mathrm{LCRNet++}$[27]获取2D骨骼数据进行实验。按照标准训练-测试划分报告Top-1准确率。
NTU $\mathbf{\nabla}\cdot\mathbf{R}\mathbf{G}\mathbf{B}{+}\mathbf{D}\mathbf{6}\mathbf{0},$ . NTU-RGB $+\mathrm{D}60$ [29] (NTU-60) is a largescale multi-modality dataset which consists of 56,880 sequences of high-quality 2D and 3D skeletons with 25 joints, associated with depth maps, RGB and IR frames captured by the Microsoft Kinect v2 sensor. We only use sequences of 3D skeletons in this work and we follow the cross-subject (CS) and cross-view (CV) evaluation protocols.
NTU $\mathbf{\nabla}\cdot\mathbf{R}\mathbf{G}\mathbf{B}{+}\mathbf{D}\mathbf{6}\mathbf{0},$ 。NTU-RGB $+\mathrm{D}60$ [29] (NTU-60) 是一个大规模多模态数据集,包含56,880个高质量2D和3D骨骼序列(25个关节点),并附带由Microsoft Kinect v2传感器采集的深度图、RGB帧和红外帧。本工作仅使用3D骨骼序列,并遵循跨主体(CS)和跨视角(CV)评估协议。
NTU-RGB $\mathbf{+D}$ 120. NTU-RGB $+\mathrm{D}$ 120 [20] (NTU-120)dataset extends the number of action classes and videos of NTU $\mathrm{RGB}{+}\mathrm{D}6(\$ 0 to 120 classes 114,480 videos. Similarly, we use only sequences of 3D skeletons and we follow the cross-subject (CS) and cross-set (CSet) evaluation protocols.
NTU-RGB $\mathbf{+D}$ 120. NTU-RGB $+\mathrm{D}$ 120 [20] (NTU-120) 数据集将 NTU $\mathrm{RGB}{+}\mathrm{D}60$ 的动作类别和视频数量扩展至 120 个类别 114,480 段视频。同样,我们仅使用 3D 骨架序列,并遵循跨主体 (CS) 和跨场景 (CSet) 评估协议。
A.2. Implementation Details
A.2. 实现细节
Implementation of UNIK. Unless otherwise stated in the ablation study, all UNIK models have $N=3,\tau=1$ for S-LSU, and $t=9$ , $d=1,3,3,3,3,1,1,1,1,1$ , in each block respectively for T-LSU. We use SGD for training with momentum 0.9, an initial learning rate of 0.1 for 50, 30, 50, 60, and 65 epochs with step LR decay with a factor of 0.1 at epochs ${30,40}$ , $\lbrace10,20\rbrace$ , ${30,40}$ , ${30,50}$ , and ${45,55}$ for Smarthome, Penn Action, NTU-60, NTU-120, and Posetics, respectively. Weight decay is set to 0.0001 for final models. For NTU-60 and 120, all skeleton sequences are padded to 300 frames by replaying the actions. For
UNIK的实现。除非消融研究中另有说明,所有UNIK模型的S-LSU参数均为$N=3,\tau=1$,T-LSU各模块参数分别为$t=9$、$d=1,3,3,3,3,1,1,1,1,1$。训练使用带动量0.9的SGD优化器,初始学习率0.1,针对Smarthome、Penn Action、NTU-60、NTU-120和Posetics数据集分别训练50/30/50/60/65个epoch,并在${30,40}$、${10,20}$、${30,40}$、${30,50}$和${45,55}$epoch时按0.1系数进行阶梯学习率衰减。最终模型权重衰减设为0.0001。对于NTU-60和120数据集,所有骨骼序列通过动作回放填充至300帧。
Smarthome, Penn Action, Posetics, we randomly choose 400, 150, 150 frames respectively for each training epoch and all frames for test. 2D and 3D inputs are pre-processed with normalization and centering following [24], [31] respectively. As we have both 2D and 3D skeleton data on Posetics, we pre-train two models for transferring to benchmarks with different types of skeleton data. Note that for ablation study of UNIK (Sec. 5.2), we train all models from scratch, without pre-training.
在Smarthome、Penn Action和Posetics数据集上,我们分别为每个训练周期随机选取400、150和150帧,测试时则使用全部帧。2D和3D输入数据分别遵循[24]和[31]进行归一化和中心化预处理。由于Posetics同时包含2D和3D骨骼数据,我们预训练了两个模型以适配不同骨骼数据类型的基准测试。需注意,在UNIK消融研究(第5.2节)中,所有模型均为从头训练,未采用预训练方案。
Number of Joints. SSTA-PRS [44] and LCRNet $^{-+}$ [27] provide 13 joints of the main body. We add ”hip”, ”chest”, ”neck” and ”nose” by interpolation and obtain 17 joints for all experiments of real-world datasets (i.e., Posetics, Smarthome, Penn Action). On NTU-60 and 120, we use 3D Kinect skeleton data with 25 joints for ablation study of UNIK (Sec. 5.2) while 17 main body joints for general iz ability study (Sec. 5.3) to adapt to the pre-trained model on Posetics.
关节数量。SSTA-PRS [44] 和 LCRNet$^{-+}$[27] 提供了躯干的13个关节。我们通过插值添加了"髋部"、"胸部"、"颈部"和"鼻子",在所有现实世界数据集(即Posetics、Smarthome、Penn Action)实验中获得了17个关节。在NTU-60和120上,我们使用带有25个关节的3D Kinect骨架数据进行UNIK的消融研究(第5.2节),同时为通用性研究(第5.3节)使用17个主要躯干关节以适应Posetics上的预训练模型。
B. Details of Posetics Dataset
B. Posetics数据集详情
In this section, we first review the recent skeleton-based action recognition datasets and then compare the most impressive ones with Posetics by (i) the benefit of pre-training for smaller datasets and (ii) skeleton quality obtained by different pose estimators.
在本节中,我们首先回顾了近期基于骨架的动作识别数据集,随后通过以下两方面将最具代表性的数据集与Posetics进行对比:(i) 预训练对小数据集的增益效果,(ii) 不同姿态估计器获得的骨架质量。
Review of Skeleton Datasets. Tab. 7 shows an overview of pertinent skeleton-based action recognition datasets, which we proceed to describe. To evaluate methods in 3D human action recognition, [29, 20, 37] were recorded in laboratory conditions, where acquired actions were performed by actors under strict guidance. In contrast, [6, 46, 43, 10, 19] aimed to explore real-world action recognition using estimated or handcrafted annotated skeleton data. As the largest real-world dataset, Kinetics-Skeleton [43] provides poses extracted using OpenPose [2]. GCNs were applied on the real-world videos [4] using pseudo 3D data i.e., 2D data and confidence [2]. However, the pose quality is limited due to occlusions and truncation s. Skeletics-152 [10] addressed this issue by applying VIBE [15] to obtain higher-quality skeleton data from Kinetics-700 [3] and manually scaled down the dataset by omitting the object-oriented action categories. However, there are still videos with missing skeletons. Deviating from the above, the higher-quality skeleton data in our dataset is calculated using pose refinement method [44] which aims at real-world pose estimation [6]. Instead of omitting the samples in object-oriented action categories, we merge action categories that are incompatible with skeleton-based action recognition to keep the scale and we filter out the non-skeleton videos. Our large-scale dataset can be more effectively used for pre-training and transferring onto other simulated [29, 20] and real-world [6, 46] scenarios. Besides, our dataset can be used for human action video generation [39, 38, 40, 41, 5] towards augmenting existing datasets.
骨架数据集综述。表7展示了相关基于骨架的动作识别数据集概览,我们将对此进行描述。为评估3D人体动作识别方法,[29, 20, 37]在实验室环境下采集数据,由演员在严格指导下完成规定动作。与之相反,[6, 46, 43, 10, 19]致力于通过估计或人工标注的骨架数据探索真实场景动作识别。作为最大规模的现实世界数据集,Kinetics-Skeleton [43]提供了通过OpenPose [2]提取的姿态数据。研究者将图卷积网络(GCN)应用于真实场景视频[4],使用伪3D数据(即2D数据与置信度[2])。但由于遮挡和截断问题,姿态质量存在局限。Skeletics-152 [10]通过应用VIBE [15]从Kinetics-700 [3]获取更高质量的骨架数据,并手动剔除面向对象的动作类别来缩减数据集规模,但仍存在骨架缺失的视频。不同于上述方法,本数据集采用姿态优化方法[44]计算更高质量的骨架数据,该方法专为真实场景姿态估计[6]设计。我们通过合并不适用于骨架识别的动作类别(而非直接剔除)来保持数据规模,并过滤非骨架视频。本大规模数据集能更有效地用于预训练及迁移至其他模拟场景[29, 20]和真实场景[6, 46]。此外,本数据集还可用于人体动作视频生成[39, 38, 40, 41, 5]以增强现有数据集。
Comparison of Pre-training. In this section, we compare Posetics with NTU-120 [20] and Kinetics-Skeleton [43] datasets by fine-tuning performances after pre-training. We note that we only have 2D skeletons on Kinetics-Skeleton for pre-training. Consequently, we use 2D data of NTU-60 for fine-tuning. Results in Tab. 8 demonstrate the effectiveness of our Posetics dataset (i.e., pre-training on Posetics boosts the most on target datasets).
预训练效果对比。本节通过微调性能比较Posetics与NTU-120 [20]和Kinetics-Skeleton [43]数据集。需注意Kinetics-Skeleton仅提供2D骨架数据进行预训练,因此我们使用NTU-60的2D数据进行微调。表8结果显示Posetics数据集的有效性(即在Posetics上预训练能最大程度提升目标数据集性能)。
Table 7. A survey of recent datasets for skeleton-based action recognition. “RW”: Real-world. “Intrpl.”: Interpolation.
| 数据集 | RW | 2D | 3D | 视频数量 | 类别数 | 关节点数 | 骨骼数据来源 | 骨骼质量 | 年份 |
|---|---|---|---|---|---|---|---|---|---|
| Human3.6M [13] | √ | √ | 209 | 15 | 24 | 动作捕捉系统 | 高 | 2014 | |
| NTU-RGB+D 60 [29] | 56,880 | 60 | 25 | Kinect v2.0 | 高 | 2016 | |||
| NTU-RGB+D 120 [20] | × | √ | 114,480 | 120 | 25 | Kinect v2.0 | 高 | 2019 | |
| Penn Action [46] | √ | × | 2,326 | 15 | 13 | 手工标注 | 中 | 2013 | |
| UAV-Human [19] | √ | × | 21,224 | 155 | 17 | AlphaPose [8] | 中 | 2021 | |
| Kinetics-Skeleton [43] | √ | × | 260,232 | 400 | 18 | OpenPose [2] | 低 | 2018 | |
| ToyotaSmarthome [6] | √ | √ | 16,115 | 31 | 13 | LCRNet++ [44] | 低 | 2019 | |
| Skeletics-152 [10] | 125,621 | 152 | 25 | VIBE [15] | 高 | 2021 | |||
| Posetics (Ours) | 142,000 | 320 | 25 | SSTA-PRS [44]+插值 | 高 | 2021 |
表 7: 基于骨骼的动作识别近期数据集调研。"RW": 真实场景。"Intrpl.": 插值。
Table 8. Comparison of datasets by pre-training (top) and impact of two-stream fusion (bottom). “J”/“B”: Joint/Bone stream. “ ”: The input data (2D) is different from other competitors (3D) on NTU-60 due to the lack of 3D data on Kinetics-Skeleton. “*”: We only use 17 main joints.
表 8: 预训练数据集对比 (上) 和双流融合效果对比 (下) 。"J"/"B": 关节流/骨骼流。" ": 由于Kinetics-Skeleton缺乏3D数据,NTU-60的输入数据(2D)与其他竞争者(3D)不同。"*": 我们仅使用17个主要关节。
| 方法 | 预训练 | Smarthome CS(%) CV1(%) CV2(%) | PennAction Top-1 Acc.(%) | *NTU-60 CS(%) |
|---|---|---|---|---|
| UNIK-J | NTU-RGB+D120 | 59.2 28.3 59.7 | 91.7 | 82.5 |
| UNIK-J | Kinetics-Skeleton | 58.9 29.5 60.6 | 95.4 | - |
| UNIK-J | Posetics (Ours) | 62.1 33.4 63.6 | 97.2 | 85.3 |
| UNIK-B | Posetics (Ours) | 61.1 31.3 62.5 | 97.4 | 84.9 |
| UNIK-J&B | Posetics (Ours) | 64.3 36.1 65.0 | 97.9 | 86.8 |
Comparison of Pose Estimators. In this section, we compare Posetics with Kinetics-Skeleton [43] and Skeletics-152 [10] by the pose (i.e., skeleton) quality. While [43], [10] use OpenPose [2] and VIBE [15] respectively to estimate poses, Posetics uses SSTA-PRS [44] that integrates the advantages of three pose estimators including OpenPose [2]. Hence, Posetics has higher quality poses, in particular in cases of occlusions and truncation s (see Fig. 7 and Fig. 8 for qualitative comparison). For quantitative comparison, we lack ground-truth poses, and hence we indirectly evaluate the quality of poses through the performance of action recognition. Towards this, we use all clips of Posetics and Smarthome with different 2D pose data for action recognition. Experimental results in Tab. 9 show that the performance using SSTA-PRS poses is higher than that using other poses.
姿态估计器对比。本节通过姿态(即骨架)质量将Posetics与Kinetics-Skeleton [43]和Skeletics-152 [10]进行对比。[43]和[10]分别使用OpenPose [2]和VIBE [15]进行姿态估计,而Posetics采用整合了OpenPose [2]等三种姿态估计器优势的SSTA-PRS [44]。因此Posetics能获得更高质量的姿态数据,尤其在遮挡和截断场景下(定性对比见图7和图8)。由于缺乏真实姿态数据,我们通过动作识别性能间接评估姿态质量:使用Posetics和Smarthome的所有片段搭配不同2D姿态数据进行动作识别。表9的实验结果表明,采用SSTA-PRS姿态数据的识别性能优于其他姿态数据。
| UNIK | Posetics(JB) | Smarthome(J) CS(%) | |
|---|---|---|---|
| Top-1(%) | Top-5(%) | ||
| OpenPose [2] | 45.9 | 69.5 | |
| VIBE-Pose[15] | 42.5 | ||
| VIBE-Mesh[15] | 43.2 | ||
| SSTA-PRS [44] | 47.6 | 71.3 | 58.9 |
Table 9. Classification accuracy of UNIK using different poses on Posetics and Smarthome.
表 9: UNIK 在 Posetics 和 Smarthome 数据集上使用不同姿态的分类准确率

Figure 7. Visualization of pose data-I in Posetics (left) and Kinetics-Skeleton (right) in the case of occlusions and truncation s.
图 7: 遮挡和截断情况下 Posetics (左) 和 Kinetics-Skeleton (右) 的姿态数据-I 可视化。

Figure 8. Visualization of pose data-II in Posetics (left) and Kinetics-Skeleton (right) in the case of occlusions and truncation s.
图 8: 遮挡和截断情况下 Posetics (左) 与 Kinetics-Skeleton (右) 的姿态数据-II 可视化