RTMDet: An Empirical Study of Designing Real-Time Object Detectors
RTMDet: 实时目标检测器设计的实证研究
Abstract
摘要
accuracy and efficiency of one-stage object detectors continuously.
一级目标检测器的准确性和效率不断提升。
In this paper, we aim to design an efficient real-time object detector that exceeds the YOLO series and is easily extensible for many object recognition tasks such as instance segmentation and rotated object detection. To obtain a more efficient model architecture, we explore an architecture that has compatible capacities in the backbone and neck, constructed by a basic building block that consists of large-kernel depth-wise convolutions. We further introduce soft labels when calculating matching costs in the dynamic label assignment to improve accuracy. Together with better training techniques, the resulting object detector, named RTMDet, achieves $52.8%$ AP on COCO with $3\pmb{\partial}\pmb{\partial}+F P S$ on an NVIDIA 3090 GPU, outperforming the current mainstream industrial detectors. RTMDet achieves the best parameter-accuracy trade-off with tiny/small/medium/large/extra-large model sizes for various application scenarios, and obtains new state-ofthe-art performance on real-time instance segmentation and rotated object detection. We hope the experimental results can provide new insights into designing versatile real-time object detectors for many object recognition tasks. Code and models are released at github.com/open-mmlab/mm detection/tree/ 3.x/configs/rtmdet.
本文旨在设计一种高效的实时目标检测器,其性能超越YOLO系列,并能轻松扩展至实例分割和旋转目标检测等多种目标识别任务。为获得更高效的模型架构,我们探索了一种在主干网络和颈部具有兼容容量的架构,该架构由基于大核深度卷积的基础构建块组成。在动态标签分配计算匹配成本时,我们进一步引入软标签以提升精度。结合更优的训练技术,所得目标检测器RTMDet在COCO数据集上达到52.8% AP,在NVIDIA 3090 GPU上实现300+FPS,超越当前主流工业检测器。RTMDet针对不同应用场景的极小/小/中/大/超大模型尺寸,实现了最佳的参数量-精度权衡,并在实时实例分割和旋转目标检测任务中取得最新最优性能。我们希望这些实验结果能为设计面向多目标识别任务的通用实时目标检测器提供新思路。代码和模型发布于https://github.com/open-mmlab/mmdetection/tree/3.x/configs/rtmdet。
1. Introduction
1. 引言
Optimal efficiency is always the primary pursuit in object detection, especially for real-world perception in autonomous driving, robotics, and drones. Toward this goal, YOLO series [3, 21, 25, 42, 63–65, 71] explore different model architectures and training techniques to improve the
最优效率始终是目标检测的首要追求,尤其是在自动驾驶、机器人和无人机等现实世界感知应用中。为实现这一目标,YOLO系列 [3, 21, 25, 42, 63–65, 71] 探索了不同的模型架构和训练技术以提升性能。
In this report, we aim to push the limits of the YOLO series and contribute a new family of Real-Time Models for object Detection, named RTMDet, which are also capable of doing instance segmentation and rotated object detection that previous works have not explored. The appealing improvements mainly come from better representation with large-kernel depth-wise convolutions and better optimization with soft labels in the dynamic label assignments.
在本报告中,我们致力于突破YOLO系列的极限,提出一个全新的实时目标检测模型家族RTMDet,该系列还能完成实例分割和旋转目标检测等前人未探索的任务。显著的改进主要来自两方面:采用大核深度可分离卷积( large-kernel depth-wise convolutions )提升表征能力,以及通过动态标签分配中的软标签( soft labels )优化训练过程。
Specifically, we first exploit large-kernel depth-wise convolutions in the basic building block of the backbone and neck in the model, which improves the model’s capability of capturing the global context [15]. Because directly placing depth-wise convolution in the building block will increase the model depth thus slowing the inference speed, we further reduce the number of building blocks to reduce the model depth and compensate for the model capacity by increasing the model width. We also observe that putting more parameters in the neck and making its capacity compatible with the backbone could achieve a better speedaccuracy trade-off. The overall modification of the model architectures allows the fast inference speed of RTMDet without relying on model re-parameter iz at ions [42, 71, 84].
具体来说,我们首先在模型的主干网络 (backbone) 和颈部网络 (neck) 的基础构建块中采用大核深度可分离卷积 (large-kernel depth-wise convolutions),这提升了模型捕获全局上下文的能力 [15]。由于直接在构建块中放置深度可分离卷积会增加模型深度从而降低推理速度,我们进一步减少构建块数量以降低模型深度,并通过增加模型宽度来补偿模型容量。我们还发现,在颈部网络中放置更多参数并使其容量与主干网络相匹配,能实现更好的速度-精度平衡。这些模型架构的整体修改使得 RTMDet 无需依赖模型重参数化技术 [42, 71, 84] 即可实现快速推理。
We further revisit the training strategies to improve the model accuracy. In addition to a better combination of data augmentations, optimization, and training schedules, we empirically find that existing dynamic label assignment strategies [19, 21] can be further improved by introducing soft targets instead of hard labels when matching ground truth boxes and model predictions. Such a design improves the discrimination of the cost matrix for high-quality matching but also reduces the noise of label assignment, thus improving the model accuracy.
我们进一步重新审视了提升模型准确性的训练策略。除了更好地结合数据增强、优化和训练计划外,我们通过实验发现,在匹配真实框 (ground truth boxes) 和模型预测时,引入软目标 (soft targets) 而非硬标签 (hard labels) 可以进一步改进现有的动态标签分配策略 [19, 21]。这种设计不仅提高了高质量匹配的成本矩阵 (cost matrix) 区分度,还减少了标签分配的噪声,从而提升了模型准确性。
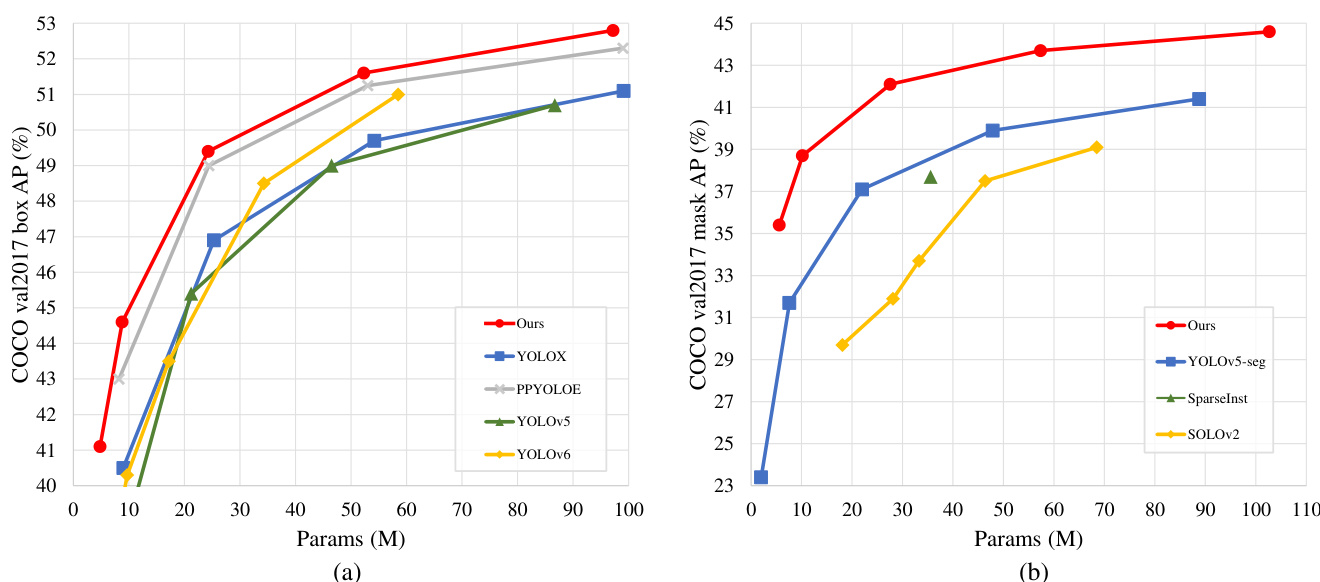
Figure 1. Comparison of parameter and accuracy. (a) Comparison of RTMDet and other state-of-the-art real-time object detectors. (b Comparison of RTMDet-Ins and other one-stage instance segmentation methods.
图 1: 参数量与精度对比。(a) RTMDet与其他先进实时目标检测器的对比。(b) RTMDet-Ins与其他单阶段实例分割方法的对比。
RTMDet is generic and can be easily extended to instance segmentation and rotated object detection with few modifications. By simply adding a kernel and a mask feature generation head [11,69], RTMDet can perform instance segmentation with only around $10%$ additional parameters. For rotated object detection, RTMDet only needs to extend the dimension (from 4 to 5) of the box regression layer and switch to a rotated box decoder. We also observe that the pre-training on general object detection datasets [48] is beneficial for rotated object detection in aerial scenarios [81].
RTMDet具有通用性,只需少量修改即可轻松扩展到实例分割和旋转目标检测。仅需添加一个核(kernel)和掩模特征生成头[11,69],RTMDet就能以约10%的额外参数量实现实例分割。对于旋转目标检测,RTMDet只需扩展边界框回归层的维度(从4到5)并切换为旋转框解码器。我们还发现,在通用目标检测数据集[48]上进行预训练对航拍场景中的旋转目标检测[81]具有增益效果。
We conduct extensive experiments to verify the effectiveness of RTMDet and scale the model size to provide tiny/small/medium/large/extra-large models for various application scenarios. As shown in Fig. 1, RTMDet achieves a better parameter-accuracy trade-off than previous methods and gains superior performance to previous models [3, 21, 25, 65]. Specifically, RTMDet-tiny achieves $41.1%$ AP at 1020 FPS with only 4.8M parameters. RTMDet-s yields $44.6%$ AP with 819 FPS, surpassing previous state-of-art small models. When extended to instance segmentation and rotated object detection, RTMDet obtained new stateof-the-art performance on the real-time scenario on both benchmarks, with $44.6%$ mask AP at $180\mathrm{FPS}$ on COCO val set and $81.33%$ AP on DOTA v1.0, respectively.
我们进行了大量实验来验证RTMDet的有效性,并通过调整模型规模为不同应用场景提供微型/小型/中型/大型/超大型模型。如图1所示,RTMDet相比之前的方法[3, 21, 25, 65]实现了更好的参数量-精度平衡,并获得了更优的性能。具体而言,RTMDet-tiny仅用480万参数就以1020 FPS的速度达到41.1% AP;RTMDet-s以819 FPS实现44.6% AP,超越了之前最先进的小型模型。当扩展到实例分割和旋转目标检测任务时,RTMDet在两个基准测试的实时场景中均取得最新最优性能:在COCO验证集上以180 FPS获得44.6%掩膜AP,在DOTA v1.0上达到81.33% AP。
2. Related Work
2. 相关工作
Efficient neural architecture for object detection. Object detection aims to recognize and localize objects in the scene. For real-time applications, existing works mainly explore anchor-based [47, 50, 64] or anchor-free [70, 98] onestage detectors, instead of two-stage detectors [5,24,59,66]. To improve the model efficiency, efficient backbone networks and model scaling strategies [3, 41, 71] and enhancement of multi-scale feature [7, 23, 36, 46, 49, 68] are explored either by handcrafted design or neural architecture search [10, 17, 23, 74]. Recent advances also explore model re-parameter iz ation [14,42,71,84] to improve the inference speed after model deployment. In this paper, we contribute an overall architecture with compatible capacity in the backbone and neck, constructed by a new basic building block with large-kernel depth-wise convolutions toward a more efficient object detector.
高效的目标检测神经网络架构。目标检测旨在识别和定位场景中的物体。针对实时应用,现有工作主要探索基于锚点(anchor-based) [47,50,64] 或无锚点(anchor-free) [70,98] 的单阶段检测器,而非两阶段检测器 [5,24,59,66]。为提高模型效率,研究者通过手工设计或神经架构搜索(NAS) [10,17,23,74] 探索了高效骨干网络、模型缩放策略 [3,41,71] 以及多尺度特征增强 [7,23,36,46,49,68]。最新进展还探索了模型重参数化(Reparameterization) [14,42,71,84] 以提升模型部署后的推理速度。本文提出了一种在骨干网络和颈部结构具有兼容能力的整体架构,该架构通过采用大核深度卷积的新型基础构建模块,实现更高效的目标检测。
Label assignment for object detection. Another dimension to improve the object detector is the design of label assignment and training losses. Pioneer methods [5,47,50,66] use IoU as a matching criterion to compare the ground truth boxes with model predictions or anchors in the label assignment. Later practices [37, 70, 95, 98] further explore different matching criteria such as object centers [70, 98]. Auxiliary detection heads are also explored [62, 71] to speed up and stabilize the training. Inspired by the Hungarian Assignment for end-to-end object detection [6], dynamic label assignment [19–21] are explored to significantly improve the convergence speed and model accuracy. Unlike these strategies that use matching cost functions precisely the same as losses, we propose to use soft labels when calculating the matching costs to enlarge the distinction between high and low-quality matches, thereby stabilizing training and accelerating convergence.
目标检测的标签分配。提升目标检测器的另一维度是标签分配和训练损失的设计。早期方法 [5,47,50,66] 使用交并比 (IoU) 作为匹配标准,在标签分配中比较真实框与模型预测或锚框。后续研究 [37,70,95,98] 进一步探索了不同匹配标准,例如物体中心 [70,98]。辅助检测头 [62,71] 也被用于加速和稳定训练。受端到端目标检测中匈牙利分配 [6] 的启发,动态标签分配 [19–21] 显著提升了收敛速度和模型精度。与这些使用与损失函数完全相同的匹配成本函数的策略不同,我们提出在计算匹配成本时使用软标签,以扩大高质量和低质量匹配之间的区分度,从而稳定训练并加速收敛。
Instance segmentation. Instance segmentation aims at predicting the per-pixel mask for each object of interest. Pioneer methods explore different paradigms to tackle this task, including mask classification [60, 61], ‘Top-Down’ [8, 31], and ‘Bottom-Up’ approaches [1, 39, 58]. Recent attempts perform instance segmentation in one stage with [4, 69] or without bounding boxes [76, 77, 96]. A representative of these attempts is based on dynamic kernels [69, 77, 96], which learn to generate dynamic kernels from either learned parameters [96] or dense feature maps [69,77] and use them to conduct convolution with mask feature maps. Inspired by these works, we extend RTMDet by kernel prediction and mask feature heads [69] to conduct instance segmentation.
实例分割。实例分割旨在为每个感兴趣的对象预测逐像素掩码。先驱方法探索了不同的范式来解决这一任务,包括掩码分类 [60, 61] 、"自上而下" [8, 31] 和 "自下而上" 方法 [1, 39, 58] 。近期尝试通过 [4, 69] 或无需边界框 [76, 77, 96] 的方式实现单阶段实例分割。这些尝试的代表性方法是基于动态核 [69, 77, 96] ,它们学习从学习参数 [96] 或密集特征图 [69,77] 生成动态核,并用这些核与掩码特征图进行卷积。受这些工作的启发,我们通过核预测和掩码特征头 [69] 扩展了 RTMDet 以执行实例分割。
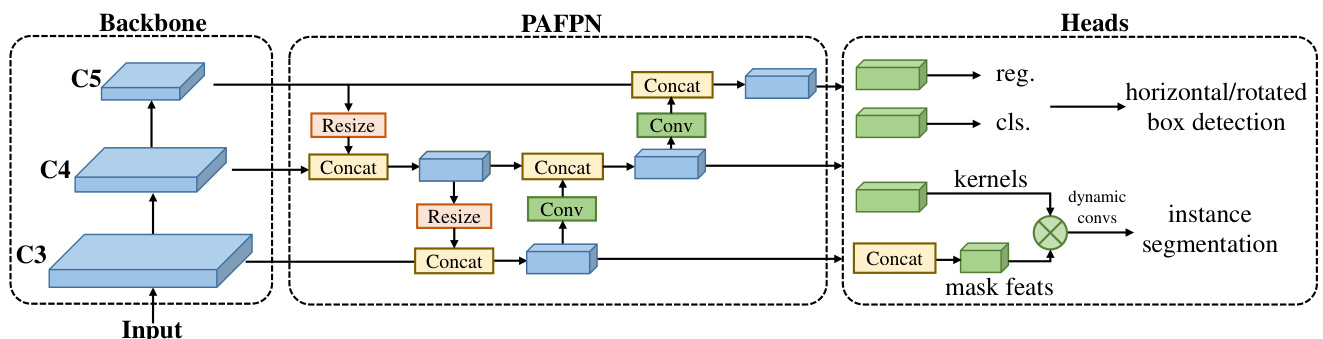
Figure 2. Macro architecture. We use CSP-blocks [72] with large kernel depth-wise convolution layers to build the backbone. The multilevel features, noted as $C3$ , $C4$ , and $C5$ , are extracted from the backbone and then fused in the CSP-PAFPN, which consists of the same block as the backbone. Then, detection heads with shared convolution weights and separated batch normalization (BN) layers are used to predict the classification and regression results for (rotated) bounding box detection. Extra heads can be added to produce dynamic convolution kernels and mask features for the instance segmentation task.
图 2: 宏观架构。我们采用带大核深度卷积层的 CSP 模块 [72] 构建主干网络。从主干网络提取的多层级特征 (标记为 $C3$、$C4$ 和 $C5$) 在由相同模块组成的 CSP-PAFPN 中进行融合。检测头采用共享卷积权重和独立批归一化 (BN) 层的设计,用于预测 (旋转) 边界框检测的分类与回归结果。可额外添加头部来生成动态卷积核和掩码特征,以支持实例分割任务。
Rotated object detection. Rotated object detection aims to predict further the orientation of objects in addition to their locations and categories. Based on an existing general object detector (e.g., RetinaNet [47] or Faster R-CNN [66]), different feature extraction networks are proposed to alleviate the feature misalignment [28, 29, 88] caused by object rotations. There are also various representations of rotated boxes explored (e.g., Gaussian distribution [89,90] and convex set [26, 44]) to ease the rotated bounding box regression task. Orthogonal to these methods, this paper only extends a general object detector with minimal modifications (i.e., adding an angle prediction branch and replacing the GIoU [67] loss by Rotated IoU Loss [97]) and reveals that a high-precision general object detector paves the way for high-precision rotated object detection through the model architecture and the knowledge learned on general detection dataset [48].
旋转目标检测。旋转目标检测旨在预测物体的方位,而不仅仅是它们的位置和类别。基于现有的通用目标检测器(如RetinaNet [47]或Faster R-CNN [66]),研究者提出了不同的特征提取网络来缓解由物体旋转引起的特征错位问题[28, 29, 88]。此外,还探索了多种旋转框的表示方法(如高斯分布[89, 90]和凸集[26, 44]),以简化旋转边界框回归任务。与这些方法不同,本文仅对通用目标检测器进行了最小限度的修改(即增加一个角度预测分支,并将GIoU [67]损失替换为旋转IoU损失[97]),并揭示了一个高精度的通用目标检测器通过模型架构和在通用检测数据集[48]上学到的知识,为高精度旋转目标检测铺平了道路。
3.1. Macro Architecture
3.1. 宏观架构
We decompose the macro architecture of a one-stage object detector into the backbone, neck, and head, as shown in Fig. 2. Recent advances of YOLO series [3, 21] typically adopt CSPDarkNet [3] as the backbone architecture, which contains four stages and each stage is stacked with several basic building blocks (Fig. 3.a). The neck takes the multiscale feature pyramid from the backbone and uses the same basic building blocks as the backbone with bottom-up and top-down feature pro pog ation [46, 49] to enhance the pyramid feature map. Finally, the detection head predicts object bounding boxes and their categories based on the feature map of each scale. Such an architecture generally applies to general and rotated objects, and can be extended for instance segmentation by the kernel and mask feature generation heads [69].
我们将一阶段目标检测器的宏观架构分解为骨干网络 (backbone)、颈部网络 (neck) 和检测头 (head),如图 2 所示。YOLO 系列 [3, 21] 的最新进展通常采用 CSPDarkNet [3] 作为骨干架构,该架构包含四个阶段,每个阶段由若干基本构建块堆叠而成 (图 3.a)。颈部网络接收来自骨干网络的多尺度特征金字塔,并采用与骨干网络相同的基本构建块,通过自底向上和自顶向下的特征传播 [46, 49] 来增强金字塔特征图。最后,检测头基于每个尺度的特征图预测目标边界框及其类别。该架构通常适用于通用目标和旋转目标,并可通过核与掩模特征生成头 [69] 扩展到实例分割任务。
To fully exploit the potential of the macro architecture, we first study more powerful basic building blocks. Then we investigate the computation bottleneck in the architecture and balance the depth, width, and resolution in the backbone and neck.
为充分发挥宏观架构的潜力,我们首先研究更强大的基础构建模块,随后分析架构中的计算瓶颈,并平衡主干网络与颈部结构的深度、宽度及分辨率。
3.2. Model Architecture
3.2. 模型架构
3. Methodology
3. 方法论
In this work, we build a new family of Real-Time Models for object Detection, named RTMDet. The macro architecture of RTMDet is a typical one-stage object detector (Sec. 3.1). We improve the model efficiency by exploring the large-kernel convolutions in the basic building block of backbone and neck, and balance the model depth, width, and resolution accordingly (Sec. 3.2). We further explore soft labels in dynamic label assignment strategies and a better combination of data augmentations and optimization strategies to improve the model accuracy (Sec. 3.3). RTMDet is a versatile object recognition framework that can be extended to instance segmentation and rotated object detection tasks with few modifications (Sec. 3.4).
在本工作中,我们构建了一个名为RTMDet的新型实时目标检测模型家族。RTMDet的宏观架构采用典型的一阶段目标检测器(第3.1节)。我们通过在主干网络和颈部基础构建块中探索大核卷积来提升模型效率,并相应平衡模型的深度、宽度和分辨率(第3.2节)。进一步研究了动态标签分配策略中的软标签技术,以及数据增强与优化策略的更好组合以提升模型精度(第3.3节)。RTMDet是一个多功能目标识别框架,只需少量修改即可扩展至实例分割和旋转目标检测任务(第3.4节)。
Basic building block. A large effective receptive field in the backbone is beneficial for dense prediction tasks like object detection and segmentation as it helps to capture and model the image context [56] more comprehensively. However, previous attempts (e.g., dilated convolution [92] and non-local blocks [75]) are computationally expensive, limiting their practical use in real-time object detection. Recent studies [15, 52] revisit the use of large-kernel convolutions, showing that one can enlarge the receptive field with a reasonable computational cost through depth-wise convolution [35]. Inspired by these findings, we introduce $5\times5$ depth-wise convolutions in the basic building block of CSPDarkNet [3] to increase the effective receptive fields (Fig. 3.b). This approach allows for more comprehensive contextual modeling and significantly improves accuracy.
基本构建模块。主干网络中较大的有效感受野对于目标检测和分割等密集预测任务非常有益,因为它有助于更全面地捕获和建模图像上下文 [56]。然而,之前的尝试(例如空洞卷积 [92] 和非局部块 [75])计算成本较高,限制了它们在实时目标检测中的实际应用。最近的研究 [15, 52] 重新审视了大核卷积的使用,表明通过深度卷积 [35] 可以在合理的计算成本下扩大感受野。受这些发现的启发,我们在 CSPDarkNet [3] 的基本构建模块中引入了 $5\times5$ 深度卷积,以增加有效感受野(图 3.b)。这种方法可以实现更全面的上下文建模,并显著提高准确性。
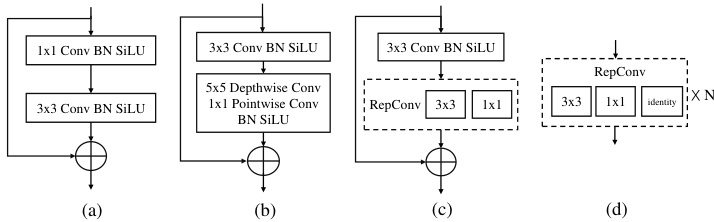
Figure 3. Different basic building blocks. (a) The basic bottleneck block of DarkNet used in [3, 21, 25, 65]. (b) The proposed bottleneck block with a large-kernel depth-wise convolution layer. (c) Bottleneck block of PPYOLO-E [84] that uses re-parameterized convolution. (d) The basic unit of YOLOv6 [42].
图 3: 不同基础构建模块。(a) DarkNet在[3, 21, 25, 65]中使用的基础瓶颈块。(b) 提出的带有大核深度卷积层的瓶颈块。(c) PPYOLO-E[84]使用的重参数化卷积瓶颈块。(d) YOLOv6[42]的基础单元。
It is noteworthy that some recent real-time object detectors [42, 71, 84] explore re-parameterized $3\times3$ convolutions [14] in the basic building block (Fig. 3.c&d). While the re-parameterized $3\times3$ convolutions is considered a free lunch to improve accuracy during inference, it also brings side effects such as slower training speed and increased training memory. It also increases the error gap after the model is quantized to lower bits, requiring compensation through re-parameter i zing optimizer [13] and quantizationaware training [42]. Large-kernel depth-wise convolution is a simpler and more effective option for the basic building block compared to re-parameterized $3\times3$ convolution, as they require less training cost and cause less error gaps after model quantization.
值得注意的是,近期一些实时目标检测器 [42, 71, 84] 在基础构建块中探索了重参数化的 $3\times3$ 卷积 [14] (图 3.c&d)。虽然重参数化的 $3\times3$ 卷积在推理时被视为提升精度的"免费午餐",但它也带来了训练速度下降、训练内存增加等副作用。此外,当模型被量化至低位宽时,这种结构会增大误差间隙,需要通过重参数优化器 [13] 和量化感知训练 [42] 进行补偿。相比之下,大核深度卷积作为基础构建块比重参数化的 $3\times3$ 卷积更简单高效,不仅训练成本更低,模型量化后产生的误差间隙也更小。
Balance of model width and depth. The number of layers in the basic block also increases due to the additional point-wise convolution following the large-kernel depthwise convolution (Fig. 3.b). This hinders the parallel computation of each layer and thus decreases inference speed. To address this issue, we reduce the number of blocks in each backbone stage and moderately enlarging the width of the block to increase the parallel iz ation and maintain the model capacity, which eventually improves inference speed without sacrificing accuracy.
模型宽度与深度的平衡。由于大核深度卷积后增加了逐点卷积(图 3.b),基础块中的层数也随之增加。这会阻碍各层的并行计算,从而降低推理速度。为解决这一问题,我们减少了每个主干阶段的块数,并适度扩大块的宽度以提高并行性,同时保持模型容量,最终在不牺牲精度的情况下提升了推理速度。
Balance of backbone and neck. Multi-scale feature pyramid is essential for object detection to detect objects at various scales. To enhance the multi-scale features, previous approaches either use a larger backbone with more parameters or use a heavier neck [36,68] with more connections and fusions among feature pyramid. However, these attempts also increase the computation and memory footprints. Therefore, we adopt another strategy that puts more parameters and computations from backbone to neck by increasing the expansion ratio of basic blocks in the neck to make them have similar capacities, which obtains a better computation-accuracy trade-off.
主干网络与颈部结构的平衡。多尺度特征金字塔对于目标检测任务至关重要,它能识别不同尺度的目标。为增强多尺度特征,先前方法要么采用参数量更大的主干网络,要么使用连接更密集、特征金字塔融合更复杂的重型颈部结构 [36,68]。但这些尝试会同时增加计算量和内存占用。因此,我们采用另一种策略:通过增大颈部基础模块的扩展率,使其具备与主干网络相近的容量,从而将更多参数和计算量从主干网络转移至颈部结构,最终实现更优的计算效率-精度平衡。
Shared detection head. Real-time object detectors typically utilize separate detection heads [3, 21, 25, 50, 65] for different feature scales to enhance the model capacity for higher performance, instead of sharing a detection head across multiple scales [47, 70]. We compare different design choices in this paper and choose to share parameters of heads across scales but incorporate different Batch Normalization (BN) layers to reduce the parameter amount of the head while maintaining accuracy. BN is also more efficient than other normalization layers such as Group Normalization [79] because in inference it directly uses the statistics calculated in training.
共享检测头。实时目标检测器通常为不同特征尺度使用独立的检测头 [3, 21, 25, 50, 65] 以提升模型性能,而非跨尺度共享检测头 [47, 70]。本文对比了不同设计方案,最终选择跨尺度共享检测头参数但引入独立的批量归一化 (Batch Normalization, BN) 层,在保持精度的同时减少检测头参数量。BN 相比组归一化 (Group Normalization) [79] 等归一化层更具效率,因其在推理时直接使用训练阶段计算的统计量。
3.3. Training Strategy
3.3. 训练策略
Label assignment and losses. To train the one-stage object detector, the dense predictions from each scale will be matched with ground truth bounding boxes through different label assignment strategies [19, 47, 70]. Recent advances typically adopt dynamic label assignment strategies [6, 20, 21] that use cost functions consistent with the training loss as the matching criterion. However, we find that their cost calculation have some limitations. Hence, we propose a dynamic soft label assignment strategy based on SimOTA [21], and its cost function is formulated as
标签分配与损失函数。为训练单阶段目标检测器,每个尺度上的密集预测将通过不同的标签分配策略 [19, 47, 70] 与真实边界框进行匹配。最新研究通常采用动态标签分配策略 [6, 20, 21],其使用与训练损失一致的成本函数作为匹配准则。然而,我们发现其成本计算存在一定局限性。因此,我们提出了一种基于 SimOTA [21] 的动态软标签分配策略,其成本函数公式为
$$
C=\lambda_{1}C_{c l s}+\lambda_{2}C_{r e g}+\lambda_{3}C_{c e n t e r},
$$
$$
C=\lambda_{1}C_{c l s}+\lambda_{2}C_{r e g}+\lambda_{3}C_{c e n t e r},
$$
where $C_{c l s}$ , $C_{c e n t e r}$ , and $C_{r e g}$ correspond to the classification cost, region prior cost, and regression cost, respectively, and $\lambda_{1}=1,\lambda_{2}=3$ , and $\lambda_{3}=1$ are the weights of these three costs by default. The calculation of the three costs is described below.
其中 $C_{cls}$、$C_{center}$ 和 $C_{reg}$ 分别对应分类成本、区域先验成本和回归成本,默认情况下 $\lambda_{1}=1$、$\lambda_{2}=3$ 和 $\lambda_{3}=1$ 是这三个成本的权重。这三种成本的计算方式如下所述。
Previous methods usually utilize binary labels to compute classification cost $C_{c l s}$ , which allows a prediction with a high classification score but an incorrect bounding box to achieve a low classification cost and vice versa. To solve this issue, we introduce soft labels in $C_{c l s}$ as
先前的方法通常利用二元标签来计算分类成本 $C_{cls}$,这使得分类得分高但边界框不正确的预测能够获得较低的分类成本,反之亦然。为解决这一问题,我们在 $C_{cls}$ 中引入软标签作为
$$
C_{c l s}=C E(P,Y_{s o f t})\times(Y_{s o f t}-P)^{2}.
$$
$$
C_{c l s}=C E(P,Y_{s o f t})\times(Y_{s o f t}-P)^{2}.
$$
The modification is inspired by GFL [45] that uses the IoU between the predictions and ground truth boxes as the soft label $Y_{s o f t}$ to train the classification branch. The soft classification cost in assignment not only reweights the matching costs with different regression qualities but also avoids the noisy and unstable matching caused by binary labels.
该改进方法受GFL [45]启发,使用预测框与真实框之间的交并比(IoU)作为软标签$Y_{soft}$来训练分类分支。分配过程中的软分类代价不仅根据不同回归质量重新加权匹配代价,还避免了二值标签带来的噪声和不稳定匹配问题。
When using Generalized IoU [67] as regression cost, the maximum difference between the best match and the worst match is less than 1. This makes it difficult to distinguish high-quality matches from low-quality matches. To make the match quality of different GT-prediction pairs more discri mi native, we use the logarithm of the IoU as the regression cost instead of GIoU used in the loss function, which amplifies the cost for matches with lower IoU values. The regression cost $C_{r e g}$ is calculated by
当使用广义交并比 (Generalized IoU) [67] 作为回归成本时,最佳匹配与最差匹配之间的最大差异小于1。这使得难以区分高质量匹配和低质量匹配。为了使不同真实值-预测值对的匹配质量更具区分性,我们使用交并比的对数作为回归成本,而非损失函数中使用的广义交并比,这放大了交并比较低匹配的成本。回归成本 $C_{r e g}$ 的计算公式为
$$
C_{r e g}=-l o g(I o U).
$$
$$
C_{r e g}=-l o g(I o U).
$$
For region cost $C_{c e n t e r}$ , we use a soft center region cost instead of a fixed center prior [20, 21, 95] to stabilize the matching of the dynamic cost as below
对于区域成本 $C_{center}$,我们采用软中心区域成本而非固定中心先验 [20, 21, 95] 来稳定动态成本的匹配,如下所示
$$
C_{c e n t e r}=\alpha^{|x_{p r e d}-x_{g t}|-\beta},
$$
$$
C_{c e n t e r}=\alpha^{|x_{p r e d}-x_{g t}|-\beta},
$$
where $\alpha$ and $\beta$ are hyper-parameters of the soft center region. We set $\alpha=10$ , $\beta=3$ by default.
其中 $\alpha$ 和 $\beta$ 是软中心区域的超参数。默认设置 $\alpha=10$,$\beta=3$。
Cached Mosaic and MixUp. Cross-sample augmentations such as MixUp [94] and CutMix [93] are widely adopted in recent object detectors [3, 21, 25, 42, 71]. These augmentations are powerful but bring two side effects. First, at each iteration, they need to load multiple images to generate a training sample, which introduces more data loading costs and slows the training. Second, the generated training sample is ‘noisy’ and may not belong to the real distribution of the dataset, which affects the model learning [21].
缓存式马赛克与混合增强。近年来,目标检测器 [3, 21, 25, 42, 71] 广泛采用 MixUp [94] 和 CutMix [93] 等跨样本增强技术。这类增强方法虽然效果显著,但会带来两个副作用:首先,每次迭代需要加载多张图像生成训练样本,增加了数据加载开销并拖慢训练速度;其次,生成的训练样本存在"噪声",可能偏离数据集的真实分布,从而影响模型学习 [21]。
We improve MixUp and Mosaic with the caching mechanism that reduces the demand for data loading. By utilizing cache, the time cost of mixing images in the training pipeline can be significantly reduced to the level of processing a single image. The cache operation is controlled by the cache length and popping method. A large cache length and random popping method can be regarded as equivalent to the original non-cached MixUp and Mosaic operations. Meanwhile, a small cache length and First-In-FirstOut (FIFO) popping method can be seen as similar to the repeated augmentation [2], allowing for the mixing of the same image with different data augmentation operations in the same or contiguous batches.
我们通过引入缓存机制改进了MixUp和Mosaic技术,从而降低数据加载需求。利用缓存可将训练流程中图像混合的时间成本显著降低至单张图像处理水平。缓存操作由缓存长度和弹出方式控制:较大缓存长度配合随机弹出方式可视为等效于原始无缓存MixUp和Mosaic操作;而较小缓存长度配合先进先出(FIFO)弹出方式则类似于重复增强[2],允许同一图像在相同或相邻批次中与不同数据增强操作进行混合。
Two-stage training. To reduce the side effects of ‘noisy’ samples by strong data augmentations, YOLOX [21] explored a two-stage training strategy, where the first stage uses strong data augmentations, including Mosaic, MixUp, and random rotation and shear, and the second stage use weak data augmentations, such as random resizing and flipping. As the strong augmentation in the initial training stage includes random rotation and shearing that cause misalignment between inputs and the transformed box annotations, YOLOX adds the L1 loss to fine-tune the regression branch in the second stage. To decouple the usage of data augmentation and loss functions, we exclude these data augmentations and increase the number of mixed images to 8 in each training sample in the first training stage of 280 epochs to compensate for the strength of data augmentation. In the last 20 epochs, we switch to Large Scale Jit- tering (LSJ) [22], allowing for fine-tuning of the model in a domain that is more closely aligned with the real data distributions. To further stabilize the training, we adopt AdamW [55] as the optimizer, which is rarely used in convolutional object detectors but is a default for vision transformers [16].
两阶段训练。为减少强数据增强带来的"噪声"样本副作用,YOLOX [21] 探索了双阶段训练策略:第一阶段采用包含Mosaic、MixUp、随机旋转和剪切等强数据增强,第二阶段使用随机缩放和翻转等弱数据增强。由于初始训练阶段的强增强包含会导致输入与变换后标注框错位的随机旋转和剪切,YOLOX在第二阶段添加L1损失来微调回归分支。为解耦数据增强与损失函数的使用,我们排除了这些数据增强方法,并在280轮次的第一阶段训练中,将每个训练样本的混合图像数量增至8张以补偿数据增强强度。最后20轮次切换至大规模抖动(LSJ) [22],使模型能在更贴近真实数据分布的领域进行微调。为进一步稳定训练,我们采用AdamW [55]作为优化器——该方案在卷积目标检测器中罕见使用,但却是视觉Transformer [16] 的默认选择。
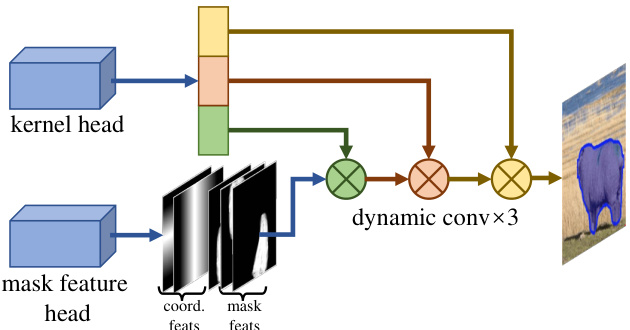
Figure 4. Instance segmentation branch in RTMDet-Ins. The mask feature head has 4 convolution layers and predicts mask features of 8 channels [69] from the multi-level features extracted from neck. Two relative coordinate features are concatenated with the mask features to generate instance masks. The kernel head predicts a 169-dimensional vector for each instance. The vector is divided into three parts (lengths are 88, 72, and 9 respectively), which are used to form the kernels of three dynamic convolution layers.
图 4: RTMDet-Ins中的实例分割分支。掩码特征头包含4个卷积层,并从颈部提取的多级特征中预测8通道的掩码特征 [69]。两个相对坐标特征与掩码特征拼接后生成实例掩码。内核头为每个实例预测169维向量,该向量被分为三部分(长度分别为88、72和9),用于构成三个动态卷积层的内核。
3.4. Extending to other tasks
3.4. 扩展到其他任务
Instance segmentation. We enable RTMDet for instance segmentation with a simple modification, denoted as RTMDet-Ins. As illustrated in Figure 4, based on RTMDet, an additional branch is added, consisting of a kernel prediction head and a mask feature head, similar to CondInst [69]. The mask feature head comprises 4 convolution layers that extract mask features with 8 channels from multi-level features. The kernel prediction head predicts a 169-dimensional vector for each instance, which is decomposed into three dynamic convolution kernels to generate instance segmentation masks through interaction with the mask features and coordinate features. To further exploit the prior information inherent in the mask annotations, we use the mass center of the masks when calculating the soft region prior in the dynamic label assignment instead of the box center. We use dice loss [57] as the supervision for the instance masks following typical conventions.
实例分割。我们通过简单修改使RTMDet具备实例分割能力,记为RTMDet-Ins。如图4所示,在RTMDet基础上新增一个分支,包含核预测头和掩码特征头,其结构与CondInst [69]类似。掩码特征头由4个卷积层组成,从多级特征中提取8通道的掩码特征。核预测头为每个实例预测169维向量,该向量被分解为三个动态卷积核,通过与掩码特征及坐标特征交互生成实例分割掩码。为更好地利用掩码标注的固有先验信息,我们在动态标签分配计算软区域先验时采用掩码质心而非框中心。遵循常规做法,我们使用dice loss [57]作为实例掩码的监督信号。
Rotated object detection. Due to the inherent similarity between rotated object detection and general (horizontal) object detection, it only takes 3 steps to adapt RTMDet to a rotated object detector, noted as RTMDet-R: (1) add a $1\times1$ convolution layer at the regression branch to predict the rotation angle; (2) modify the bounding box coder to support rotated boxes; (3) replace the GIoU loss with Rotated IoU loss. The highly optimized model architecture of RTMDet guarantees high performance of RTMDet-R on the rotated object detection tasks. Moreover, as RTMDetR shares most parameters of RTMDet, the model weights of RTMDet pre-trained on general detection dataset (e.g., COCO dataset) can serve as a good initialization for rotated object detection.
旋转目标检测。由于旋转目标检测与常规(水平)目标检测存在天然相似性,只需3步即可将RTMDet适配为旋转目标检测器(记为RTMDet-R):(1) 在回归分支添加 $1\times1$ 卷积层用于预测旋转角度;(2) 修改边界框编码器以支持旋转框;(3) 用旋转IoU损失替换GIoU损失。RTMDet高度优化的模型架构保证了RTMDet-R在旋转目标检测任务中的优异性能。此外,由于RTMDet-R与RTMDet共享大部分参数,在通用检测数据集(如COCO数据集)上预训练的RTMDet模型权重可作为旋转目标检测的良好初始化。
4. Experiments
4. 实验
4.1. Implementation Details
4.1. 实现细节
Object detection and instance segmentation. We conduct experiments on COCO dataset [48], which contains about 118K images in the train2017 set and 5K images in the val2017 set for training and validation, respectively. For ablation studies, we trained our models on the train2017 set for 300 epochs and validated them on the val2017 set. The hyper-parameters are in Table 1. All our object detection and instance segmentation models are trained on 8 NVIDIA A100 GPUs. We evaluate the model performance on object detection and instance segmentation by bbox AP and mask AP [48], respectively.
目标检测与实例分割。我们在COCO数据集[48]上开展实验,该数据集train2017子集包含约11.8万张训练图像,val2017子集包含5千张验证图像。消融研究中,模型在train2017子集上训练300个epoch并在val2017子集验证。超参数配置见表1。所有目标检测和实例分割模型均在8块NVIDIA A100 GPU上训练,分别通过边界框AP(bbox AP)和掩码AP(mask AP)[48]评估模型性能。
During the testing of object detection, the score threshold for filtering bounding boxes is set to 0.001 before nonmaximum suppression (NMS), and the top 300 boxes are kept for validation. This setting is consistent with previous studies [25,42,71] for a fair comparison. However, to accelerate the metric computation during ablation studies, we set the score threshold to 0.05 and the number of kept results to 100, which may degrade the accuracy by about $0.3%$ AP.
在目标检测测试中,非极大值抑制(NMS)前用于过滤边界框的分数阈值设为0.001,并保留前300个检测框用于验证。该设置与先前研究[25,42,71]保持一致以确保公平比较。但在消融实验阶段,为加速指标计算,我们将分数阈值调整为0.05且保留结果数降至100,这可能导致约$0.3%$ AP的精度下降。
Rotated object detection. We conduct experiments on DOTA dataset [81] which contains $2.8\mathrm{K}$ aerial images and 188K instances obtained from different sensors with multiple resolutions. The hyper-parameters are in Table 1. For single-scale training and testing, we crop the original images into $1024\times1024$ patches with an overlap of 256 pixels. For multi-scale training and testing, the original images are resized with the scale of 0.5, 1.0 and 1.5 and then cropped into $1024\times1024$ patches with an overlap of 500 pixels. Most of the rotated object detectors are trained by 1 NVIDIA V100 GPU except that the large model uses 2 NVIDIA V100 GPUs. For the evaluation metric, we adopt the same mAP calculation as that in PASCAL VOC2007 [18] but use rotated IoU to calculate the matched objects.
旋转目标检测。我们在DOTA数据集[81]上进行了实验,该数据集包含来自不同传感器的$2.8\mathrm{K}$张航拍图像和188K个实例,具有多种分辨率。超参数如表1所示。对于单尺度训练和测试,我们将原始图像裁剪为$1024\times1024$的块,重叠256像素。对于多尺度训练和测试,原始图像按0.5、1.0和1.5的比例调整大小,然后裁剪为$1024\times1024$的块,重叠500像素。大多数旋转目标检测器使用1块NVIDIA V100 GPU进行训练,大型模型除外,它使用2块NVIDIA V100 GPU。对于评估指标,我们采用与PASCAL VOC2007[18]相同的mAP计算方法,但使用旋转IoU来计算匹配对象。
Benchmark settings. The latency of all models is tested in the half-precision floating-point format (FP16) on an NVIDIA 3090 GPU with TensorRT 8.4.3 and cuDNN 8.2.0. The inference batch size is 1.
基准测试设置。所有模型的延迟测试均在NVIDIA 3090 GPU上以半精度浮点格式 (FP16) 进行,使用TensorRT 8.4.3和cuDNN 8.2.0。推理批次大小为1。
4.2. Benchmark Results
4.2. 基准测试结果
Object detection. We compare RTMDet with previous real-time object detectors including YOLOv5 [25], YOLOX [21], YOLOv6 [42], YOLOv7 [71], and PPY- OLOE [84]. For a fair comparison, all models are trained on 300 epochs without distillation nor pruning and the time of Non-Maximum Suppression (NMS) is not included in the latency calculation.
目标检测。我们将RTMDet与先前的实时目标检测器进行比较,包括YOLOv5 [25]、YOLOX [21]、YOLOv6 [42]、YOLOv7 [71]和PPYOLOE [84]。为确保公平比较,所有模型均训练300个epoch,未使用蒸馏或剪枝技术,且延迟计算中不包含非极大值抑制(NMS)的时间。
As shown in Table 2 and Fig. 1 (a), RTMDet achieves a better parameter-accuracy trade-off than previous methods. RTMDet-tiny achieves $41.1%$ AP with only 4.8M parameters, surpassing other models with a similar size by more than $5%$ AP. RTMDet-s has a higher accuracy with only half of the parameters and computation costs of YOLOv6- s. RTMDet-m and RTMDet-l also achieve excellent results in similar class models, with $44.6%$ and $49.4%$ AP respectively. RTMDet $\mathbf{\nabla}\cdot\mathbf{X}$ yields $52.8%$ AP with $300{+}\mathrm{FPS}$ , outperforming the current mainstream detectors. It is worth noting that both [25] and [71] use mask annotation to refine the bounding boxes after data augmentation, resulting in a gain of about $0.3%$ AP. We achieved superior results without relying on additional information beyond box annotation.
如表 2 和图 1 (a) 所示,RTMDet 在参数量与准确率的权衡上优于先前方法。RTMDet-tiny 仅用 4.8M 参数量就实现了 41.1% AP,比同规模模型高出超过 5% AP。RTMDet-s 仅需 YOLOv6-s 一半的参数量和计算成本,却获得了更高精度。RTMDet-m 和 RTMDet-l 在同类模型中也表现优异,分别达到 44.6% 和 49.4% AP。RTMDet $\mathbf{\nabla}\cdot\mathbf{X}$ 以 300+FPS 的速度实现 52.8% AP,优于当前主流检测器。值得注意的是,[25] 和 [71] 都通过数据增强后使用掩码标注来优化边界框,获得了约 0.3% AP 的提升。而我们仅依赖框标注信息就取得了更优结果。
Table 1. Training settings for object detection, instance segmentation and rotate object detection.
表 1: 目标检测、实例分割和旋转目标检测的训练设置。
| config | 目标检测和实例分割 | 旋转目标检测 |
|---|---|---|
| optimizer | AdamW [38] | AdamW |
| base learning rate | 0.004 | 0.00025 |
| weight decay | 0.05 (0 for bias and norm [33]) | 0.05 (0 for bias and norm) |
| optimizer momentum | 0.9 | 0.9 |
| batch size | 256 | 8 |
| learning rate schedule | Flat-Cosine | Flat-Cosine |
| training epochs | 300 | 36 |
| warmup iterations | 1000 | 1000 |
| input size | 640×640 | 1024×1024 |
| augmentation | cached Mosaic and MixUp (first 280 epochs); LSJ [22,80] (last 20 epochs) | random Flip and Rotate |
| EMA decay | 0.9998 | 0.9998 |
Instance segmentation. To evaluate the superiority of our label assignment strategy and loss, we first compare RTMDet-Ins with conventional methods using the standard ResNet50-FPN [46] backbone and the classic multi-scale 3x schedule [9, 80]. We adopt an auxiliary semantic seg- mentation head for faster convergence speed and a fair comparison with CondInst [69]. RTMDet outperforms CondInst by $1.5%$ mask AP (the first row in Table 3). However, we do not use the semantic segmentation branch when training RTMDet from scratch with heavy data augmentation because the auxiliary branch brings marginal improvements.
实例分割。为评估我们标签分配策略和损失函数的优越性,我们首先将RTMDet-Ins与采用标准ResNet50-FPN [46] 主干网络和经典多尺度3x训练策略 [9,80] 的传统方法进行对比。为加速收敛速度并与CondInst [69] 进行公平比较,我们采用了辅助语义分割头。RTMDet以1.5%的掩膜AP优势超越CondInst (表3第一行)。但在使用强数据增强从头训练RTMDet时,我们未采用语义分割分支,因为该辅助分支带来的提升有限。
Finally, we trained RTMDet-Ins $\mathrm{tiny/s/m/l/x}$ on the COCO dataset using the same data augmentation and optimization hyper-parameters as RTMDet for 300 epochs. RTMDet-Ins-x achieves $44.6%$ mask AP, surpasses the previous best practice YOLOv5-seg-x [25] by $3.2%$ AP, and still runs in real-time (second row in Table 3).
最后,我们在COCO数据集上使用与RTMDet相同的数据增强和优化超参数,对RTMDet-Ins $\mathrm{tiny/s/m/l/x}$ 进行了300个周期的训练。RTMDet-Ins-x实现了$44.6%$的掩码AP (average precision),比之前的最佳实践YOLOv5-seg-x [25]高出$3.2%$ AP,并且仍能保持实时运行(表3第二行)。
Rotated object detection. We compare RTMDet-R with previous state of the arts on the DOTA v1.0 dataset as shown in Table 4. With single-scale training and testing, RTMDet-R-m and RTMDet-R-l achieve $78.24%$ and $78.85%$ mAP, respectively, which outperforms almost all previous methods. With multi-scale training and testing, RTMDet-R-m and RTMDet-R-l further acheives $80.26%$ and $80.54%$ mAP, respectively. Moreover, RTMDet-R-l (COCO pre training) sets a new record ( $81.33%$ mAP) on the DOTA-v1.0 dataset. RTMDet-R also consistently outperforms PPYOLOE-R in all regimes of model sizes with much simpler modifications. Note that RTMDet-R avoids special operators in the architecture to achieve high precision, which makes it can be easily deployed on various hardware. We also compare RTMDet-R with other methods on HRSC2016 [53] and DOTA-v1.5 datasets in the appendix, and RTMDet-R also achieves superior performance.
旋转目标检测。我们在DOTA v1.0数据集上将RTMDet-R与现有先进方法进行对比,如表4所示。在单尺度训练和测试下,RTMDet-R-m和RTMDet-R-l分别达到78.24%和78.85% mAP,超越了此前几乎所有方法。采用多尺度训练和测试时,RTMDet-R-m和RTMDet-R-l进一步将mAP提升至80.26%和80.54%。值得注意的是,RTMDet-R-l (COCO预训练)在DOTA-v1.0数据集上创造了81.33% mAP的新记录。相较于PPYOLOE-R,RTMDet-R通过更简洁的改进,在所有模型尺寸下均保持性能优势。该架构避免使用特殊算子来保证高精度,使其能轻松部署于各类硬件平台。附录中还展示了RTMDet-R在HRSC2016 [53]和DOTA-v1.5数据集上的对比结果,其性能同样优于其他方法。
Table 2. Comparison of RTMDet with previous practices on the number of parameters, FLOPS, latency, and accuracy on COCO val2017 set. For a fair comparison, all models are trained for 300 epochs without using extra detection data or knowledge distillation. The inference speeds of all models are measured in the same environment. (LB) means LetterBox resize proposed in [25]. The results of the proposed RTMDet are marked in gray. The best results are in bold
表 2. RTMDet 与先前方法在参数量、FLOPS、延迟和 COCO val2017 数据集准确率上的对比。为公平比较,所有模型均训练 300 轮次,未使用额外检测数据或知识蒸馏。所有模型的推理速度均在相同环境下测量。(LB) 表示 [25] 提出的 LetterBox 缩放。提出的 RTMDet 结果以灰色标出,最佳结果以粗体显示。
| 模型 | 输入尺寸 | 参数量(M)↓ | FLOPs(G)↓ | 延迟(ms)↓ | AP(%)↑ | AP50(%)↑ |
|---|---|---|---|---|---|---|
| YOLOv5-n[25] | 640(LB) | 1.9 | 2.3 | 1.51 | 28.0 | 45.7 |
| YOLOX-tiny [21] | 416×416 | 5.1 | 3.3 | 0.82 | 32.8 | 50.3 |
| YOLOv6-n [42] | 640(LB) | 4.3 | 5.6 | 0.79 | 35.9 | 51.2 |
| YOLOv6-tiny | 640(LB) | 9.7 | 12.5 | 0.86 | 40.3 | 56.6 |
| RTMDet-tiny | 640×640 | 4.8 | 8.1 | 0.98 | 41.1 | 57.9 |
| YOLOv5-s | 640(LB) | 7.2 | 8.3 | 1.63 | 37.4 | 56.8 |
| YOLOX-s | 640×640 | 9.0 | 13.4 | 1.20 | 40.5 | 59.3 |
| YOLOv6-s | 640(LB) | 17.2 | 22.1 | 0.92 | 43.5 | 60.4 |
| PPYOLOE-s[84] | 640×640 | 7.9 | 8.7 | 1.34 | 43.0 | 59.6 |
| RTMDet-s | 640×640 | 8.99 | 14.8 | 1.22 | 44.6 | 61.9 |
| YOLOv5-m | 640(LB) | 21.2 | 24.5 | 1.89 | 45.4 | 64.1 |
| YOLOX-m | 640×640 | 25.3 | 36.9 | 1.68 | 46.9 | 65.6 |
| YOLOv6-m | 640(LB) | 34.3 | 41.1 | 1.21 | 48.5 | - |
| PPYOLOE-m | 640×640 | 23.4 | 25.0 | 1.75 | 49.0 | 65.9 |
| RTMDet-m | 640×640 | 24.7 | 39.3 | 1.62 | 49.4 | 66.8 |
| YOLOv5-l | 640(LB) | 46.5 | 54.6 | 2.46 | 49.0 | 67.3 |
| YOLOX-l | 640×640 | 54.2 | 77.8 | 2.19 | 49.7 | 68.0 |
| YOLOv6-l | 640(LB) | 58.5 | 72.0 | 1.91 | 51.0 | - |
| YOLOv7 [71] | 640(LB) | 36.9 | 52.4 | 2.63 | 51.2 | - |
| PPYOLOE-l | 640×640 | 52.2 | 55.0 | 2.57 | 51.4 | 68.6 |
| RTMDet-l | 640×640 | 52.3 | 80.2 | 2.40 | 51.5 | 68.8 |
| YOLOv5-x | 640(LB) | 86.7 | 102.9 | 2.92 | 50.7 | 68.9 |
| YOLOX-x | 640×640 | 99.1 | 141.0 | 2.98 | 51.1 | 69.4 |
| PPYOLOE-x | 640×640 | 98.4 | 103.3 | 3.07 | 52.3 | 69.5 |
| RTMDet-x | 640×640 | 94.9 | 141.7 | 3.10 | 52.8 | 70.4 |
4.3. Ablation Study of Model A rh it ec ture
4.3. 模型架构消融研究
Large kernel matters. We first compare the effectiveness of different kernel sizes in the basic building block of CSPDarkNet [3], with kernel sizes ranging from $3\times3$ to $7\times7.$ . A combination of $3\times3$ convolution and $5\times5$ kernel size depth-wise convolution achieves the optimal speed- accuracy trade-off (Table 5a).
大核至关重要。我们首先比较了CSPDarkNet[3]基础构建模块中不同卷积核尺寸的效果,核尺寸范围从$3\times3$到$7\times7$。结合$3\times3$卷积与$5\times5$核尺寸的深度可分离卷积,实现了最优的速度-精度平衡(表5a)。
Balance of multiple feature scales. Using depth-wise convolution also increases the depth and reduces the inference speed. Thus, we reduce the number of blocks in the 2nd and 3rd stages. As revealed in Table 5b, reducing the number of blocks from 9 to 6 results in a $20%$ reduction of latency but decreases accuracy by $0.5%$ AP. To compensate for this loss in accuracy, we incorporate Channel Attention (CA) at the end of each stage, achieving a better speed-accuracy tradeoff. Specifically, compared to the detector using 9 blocks in the second and third stages, the accuracy decreases by $0.1%$ AP, but with a $7%$ improvement in latency. Overall, our modification successfully reduce the latency of the detector without sacrificing too much accuracy.
多种特征尺度的平衡。使用深度可分离卷积 (depth-wise convolution) 也会增加深度并降低推理速度。因此,我们减少了第2和第3阶段的块数。如表 5b 所示,将块数从9减少到6会导致延迟降低 20%,但准确率下降 0.5% AP。为了弥补这一准确率损失,我们在每个阶段末尾加入了通道注意力 (Channel Attention, CA),实现了更好的速度-准确率权衡。具体而言,与在第2和第3阶段使用9个块的检测器相比,准确率下降了 0.1% AP,但延迟改善了 7%。总体而言,我们的修改成功地降低了检测器的延迟,而没有牺牲太多准确率。
Balance of backbone and neck. Following [3, 25, 42, 84], we utilize the same basic block as the backbone for building the neck. We empirically study whether it is more economic to put more computations in the neck. As shown in Table 5c, instead of increasing the complexity of the backbone, making the neck have similar capacity as the backbone can achieve faster speed with similar accuracy in both small and large real-time detectors.
骨干网络与颈部网络的平衡。参考 [3, 25, 42, 84],我们采用与骨干网络相同的基础模块构建颈部网络。通过实验验证,我们研究了将更多计算资源分配给颈部网络是否更具性价比。如表 5c 所示,相较于提升骨干网络复杂度,使颈部网络具备与骨干网络相近的容量,能在小型和大型实时检测器中实现更快的速度,同时保持相近的准确率。
Table 3. Comparison of RTMDet-Ins with previous instance segmentation methods on the number of parameters, FLOPS, latency, and accuracy on COCO val2017 set. (LB) means LetterBox resize proposed in [25]. The results of the proposed RTMDet-Ins are marked in gray. The best results are in bold. Different from the object detection model, box NMS and post-processing of top-100 masks are included in the speed measurement
表 3. RTMDet-Ins与现有实例分割方法在参数量、FLOPS、延迟和COCO val2017数据集准确率的对比。(LB)表示采用[25]提出的LetterBox缩放。所提RTMDet-Ins的结果以灰色标出,最优结果加粗显示。与目标检测模型不同,速度测试包含框NMS和前100掩码的后处理
| 模型 | 输入尺寸 | 训练轮次 | 参数量(M)↓ | FLOPs(G)↓ | 延迟(ms)↓ | 框AP(%)↑ | 掩码AP(%)↑ |
|---|---|---|---|---|---|---|---|
| SparseInst-R50 [11] | 640-853 | 147 | 31.6 | 99.1 | - | 34.2 | - |
| SOLOv2-R50-FPN[77] | 800-1333 | 36 | 46.4 | 253.5 | - | - | 37.5 |
| CondInst-R50-FPN[69] | 800-1333 | 36 | 33.9 | 240.8 | - | 42.6 | 38.2 |
| Cascade-R50-FPN [5] | 800-1333 | 36 | 77.1 | 403.6 | - | 44.3 | 38.5 |
| RTMDet-Ins-R50-FPN | 800-1333 | 36 | 35.9 | 295.2 | - | 45.3 | 39.7 |
| YOLOv5n-seg [25] | 640(LB) | 300 | 2.0 | 3.6 | 1.65 | 27.6 | 23.4 |
| YOLOv5s-seg | 640(LB) | 300 | 7.6 | 13.2 | 1.90 | 37.6 | 31.7 |
| YOLOv5m-seg | 640(LB) | 300 | 22 | 35.4 | 2.71 | 45.0 | 37.1 |
| YOLOv5l-seg | 640(LB) | 300 | 47.9 | 73.9 | 3.44 | 49.0 | 39.9 |
| YOLOv5x-seg | 640(LB) | 300 | 88.8 | 132.9 | 5.10 | 50.7 | 41.4 |
| RTMDet-Ins-tiny | 640×640 | 300 | 5.6 | 11.8 | 1.70 | 40.5 | 35.4 |
| RTMDet-Ins-s | 640×640 | 300 | 10.2 | 21.5 | 1.93 | 44.0 | 38.7 |
| RTMDet-Ins-m | 640×640 | 300 | 27.6 | 54.1 | 2.69 | 48.8 | 42.1 |
| RTMDet-Ins-l | 640×640 | 300 | 57.4 | 106.6 | 3.68 | 51.2 | 43.7 |
| RTMDet-Ins-x | 640×640 | 300 | 102.7 | 182.7 | 5.31 | 52.4 | 44.6 |
Table 4. Comparison of RTMDet-R with previous rotated object detection methods on the number of parameters, FLOPs, latency, and accuracy on DOTA-v1.0 test set. IN and COCO denote ImageNet pre training and COCO pre training. MAE means MAE unsupervised pre training [30] on the MillionAID [54]. R50 and X50 denote ResNet-50 and ResNeXt-50 (likewise for R101, R152 and X101). Re50 denotes ReResNet-50, RVSA denotes RVSA-ViTAE-B and CRN denotes CS PRep Res Net. MS means multi-scale training and testing. DOTA-v1.0 has 15 different object categories: plane (PL), baseball diamond (BD), bridge (BR), ground track field (GTF), small vehicle (SV), large vehicle (LV), ship (SH), tennis court (TC), basketball court (BC), storage tank (ST), soccer ball field (SBF), roundabout (RA), harbor (HA), swimming pool (SP), and helicopter (HC). The AP of each category is listed. The bold fonts indicate the best performance. The results of the proposed RTMDet-R are marked in gray
表 4. RTMDet-R 与先前旋转目标检测方法在参数量、FLOPs、延迟和 DOTA-v1.0 测试集精度上的对比。IN 和 COCO 分别表示 ImageNet 预训练和 COCO 预训练。MAE 表示在 MillionAID [54] 上进行的 MAE 无监督预训练 [30]。R50 和 X50 分别表示 ResNet-50 和 ResNeXt-50 (R101、R152 和 X101 同理)。Re50 表示 ReResNet-50,RVSA 表示 RVSA-ViTAE-B,CRN 表示 CS PRep Res Net。MS 表示多尺度训练和测试。DOTA-v1.0 包含 15 种不同目标类别:飞机 (PL)、棒球场 (BD)、桥梁 (BR)、田径场 (GTF)、小型车辆 (SV)、大型车辆 (LV)、船舶 (SH)、网球场 (TC)、篮球场 (BC)、储油罐 (ST)、足球场 (SBF)、环岛 (RA)、港口 (HA)、游泳池 (SP) 和直升机 (HC)。列出各类别的 AP。加粗字体表示最佳性能,提出的 RTMDet-R 结果用灰色标记。
| 方法 | 预训练 | 骨干网络 | MS | mAP(%) | PL | BD | BR | GTF | SV | LV SH | TC | BC | ST | SBF | RA | HA | SP | HC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Anchor-basedMethods | ||||||||||||||||||
| RoI Trans. [12] | IN | R101 [32] | √ | 69.56 | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 |
| Gliding Vertex [85] | IN | R101 | √ | 75.02 | 89.64 | 85.00 | 52.26 | 77.34 | 73.01 | 73.14 | 86.82 90.74 | 79.02 | 86.81 | 59.55 | 70.91 | 72.94 | 70.86 | 57.32 |
| CSL [87] | IN | R152 | √ | 76.17 | 90.25 | 85.53 | 54.64 | 75.31 | 70.44 | 73.51 | 77.62 90.84 | 86.15 | 86.69 | 69.60 | 68.04 | 73.83 | 71.10 | 68.93 |
| R′Det [88] | IN | R152 | 76.47 | 89.80 | 83.77 | 48.11 | 66.77 | 78.76 | 83.27 | 87.84 | 90.82 85.38 | 85.51 | 65.57 | 62.68 | 67.53 | 78.56 | 72.62 | |
| DCL [86] | IN | R152 | √ | 77.37 | 89.26 | 83.60 | 53.54 | 72.76 | 79.04 | 82.56 | 87.31 | 90.67 86.59 | 86.98 | 67.49 | 66.88 | 73.29 | 70.56 | 69.99 |
| S2ANet [28] | IN | R50 | 79.42 | 88.89 | 83.60 | 57.74 | 81.95 | 79.94 | 83.19 | 89.11 | 90.78 84.87 | 87.81 | 70.30 | 68.25 | 78.30 | 77.01 | 69.58 | |
| ReDet [29] | IN | Re50 [29] | 80.10 | 88.81 | 82.48 | 60.83 | 80.82 | 78.34 | 86.06 | 88.31 90.87 | 88.77 | 87.03 | 68.65 | 66.90 | 79.26 | 79.71 | 74.67 | |
| GWD [89] | IN | R152 | 80.23 | 89.66 | 84.99 | 59.26 | 82.19 | 78.97 | 84.83 | 87.70 90.21 | 86.54 | 86.85 | 73.47 | 67.77 | 76.92 | 79.22 | 74.92 | |
| KLD [90] | IN | R152 | 80.63 | 89.92 | 85.13 | 59.19 | 81.33 | 78.82 | 84.38 | 87.50 89.80 | 87.33 | 87.00 | 72.57 | 71.35 | 77.12 | 79.34 | 78.68 | |
| Oriented RCNN [83] | IN | R50 | 80.87 | 89.84 | 85.43 | 61.09 | 79.82 | 79.71 | 85.35 | 88.82 | 90.88 86.68 | 87.73 | 72.21 | 70.80 | 82.42 | 78.18 | 74.11 | |
| RoI Trans. + KFIoU [91] | IN | Swin-tiny [51] | 80.93 | 89.44 | 84.41 | 62.22 | 82.51 | 80.10 | 86.07 | 88.68 | 90.90 87.32 | 88.38 | 72.80 | 71.95 | 78.96 | 74.95 | 75.27 | |
| Oriented RCNN | MAE | RVSA [73] | 81.18 | 89.40 | 83.94 | 59.76 | 82.10 | 81.73 | 85.32 | 88.88 90.86 | 85.69 | 87.65 | 63.70 | 69.94 | 84.72 | 84.16 | 79.90 | |
| Anchor-freeMethods | ||||||||||||||||||
| CFA [27] | IN | R152 | 76.67 | 89.08 | 83.20 | 54.37 | 66.87 | 81.23 | 80.96 | 87.17 90.21 | 84.32 | 86.09 | 52.34 | 69.94 | 75.52 | 80.76 | 67.96 | |
| DAFNe [40] | IN | R101 | 76.95 | 89.40 | 86.27 | 53.70 | 60.51 | 82.04 | 81.17 | 88.66 90.37 | 83.81 | 87.27 | 53.93 | 69.38 | 75.61 | 81.26 | 70.86 | |
| SASM [34] | IN | RX101 [82] | 77.19 | 88.41 | 83.32 | 54.00 | 74.34 | 80.87 | 84.10 | 88.04 90.74 | 82.85 | 86.26 | 63.96 | 66.78 | 78.40 | 73.84 | 61.97 | |
| Oriented RepPoints [44] | IN | Swin-tiny | 77.63 | 89.11 | 82.32 | 56.71 | 74.95 | 80.70 | 83.73 | 87.67 90.81 | 87.11 | 85.85 | 63.60 | 68.60 | 75.95 | 73.54 | 63.76 | |
| PPYOLOE-R-s | IN | CRN-s [84] | 73.82 | 88.80 | 79.24 | 45.92 | 66.88 | 80.41 | 82.95 | 88.20 90.61 | 82.91 | 86.37 | 55.80 | 64.11 | 65.09 | 79.50 | 50.43 | |
| PPYOLOE-R-s | IN | CRN-s | 79.42 | 88.93 | 83.95 | 56.60 | 79.40 | 82.57 | 85.89 | 88.64 90.87 | 87.82 | 87.54 | 68.94 | 63.46 | 76.66 | 79.19 | 70.87 | |
| PPYOLOE-R-m | IN | CRN-m | 77.64 | 89.23 | 79.92 | 51.14 | 72.94 | 81.86 | 84.56 | 88.68 90.85 | 86.85 | 87.48 | 59.16 | 68.34 | 73.78 | 81.72 | 68.10 | |
| PPYOLOE-R-m | IN | CRN-m | 79.71 | 88.63 | 84.45 | 56.27 | 79.12 | 83.52 | 86.16 | 88.77 90.81 | 88.01 | 88.39 | 70.41 | 61.44 | 77.65 | 77.70 | 74.30 | |
| PPYOLOE-R-1 PPYOLOE-R-1 | IN IN | CRN-1 CRN-1 | 78.14 80.02 | 89.18 88.40 | 81.00 84.75 | 54.01 58.91 | 70.22 76.35 | 81.85 83.13 86.10 | 85.16 88.79 | 88.81 90.81 | 86.99 | 88.01 | 62.87 | 67.87 |
Table 5. Ablation studies of model architecture on COCO val2017 set. The proposed setting is marked in gray
表 5: 在 COCO val2017 数据集上的模型架构消融研究。所提出的设置以灰色标记
| (a) 卷积核大小的速度-精度权衡 | ||
|---|---|---|
| 卷积核大小 | 参数量↓ 计算量↓ 延迟↓ | AP(%)↑ |
| 3x3 | 50.80M 79.61G 2.10ms | 50.0 |
| 5x5 | 50.92M 79.70G 2.11ms | 50.9 |
| 7×7 | 51.10M 80.34G 2.73ms | 51.1 |
(c) Ablation study of backbone and neck proportions
(c) 主干与颈部比例消融研究
| 模型大小 | 主干:颈部比例 | 参数量↓ GFLOPs√ 延迟√ | AP(%)↑ |
|---|---|---|---|
| Small | 47% | 45% 8.54M | 15.76G 1.21ms |
| Small | 63% | 29% 9.01M | 15.85G 1.37ms |
| Large | 47% | 45% 50.92M | 79.70G 2.11ms |
| Large | 63% | 29% 57.43M | 93.73G 2.57ms |
(b) Speed-accuracy trade-off of the number of blocks
(b) 块数量的速度-精度权衡
| 块数量 | 参数量↓ GFLOPs↓ 延迟√ | AP(%)↑ | |
|---|---|---|---|
| 3-9-9-3 | 53.40M 86.28G | 2.60ms | 51.4 |
| 3-6-6-3 | 50.92M 79.70G | 2.11ms | 50.9 |
| 3-6-6-3W/CA | 52.30M 79.90G | 2.40ms | 51.3 |
(d) Design of the detection head
(d) 检测头设计
| 头类型 | 参数量√( | 计算量↓延迟 √ | AP(%)↑ | |
|---|---|---|---|---|
| 共享头 (SharedHead) | 52.32M | 80.23G | 2.44ms | 48.0 |
| 完全分离 (TotallySeparate) | 57.03M | 80.23G | 2.44ms | 51.2 |
| 分离BN (Separate BN) | 52.32M | 80.23G | 2.44ms | 51.3 |
Table 6. Ablation studies of label assignment on COCO val2017 set. The proposed setting is marked in gray
表 6: COCO val2017 数据集上标签分配的消融研究。所提设置以灰色标出
| Soft cls. cost | Soft ctr. prior | LogIoU cost | AP(%) ↑ |
|---|---|---|---|
| √ | 39.9 40.3 | ||
| √ | 人 | 40.8 | |
| √ | 人 | 41.3 |
(a) Ablation study of dynamic soft label assignment with ResNet50 1x schedule
(a) 基于 ResNet50 1x 训练计划的动态软标签分配消融实验
| 方法 | AP(%)↑ |
|---|---|
| ATSS[95] | 39.2 |
| PAA[37] | 40.4 |
| OTA [20] | 40.7 |
| TOOD [19] (w/o T-Head) | 40.7 |
| Ours | 41.3 |
(b) Comparison with other label assignment with ResNet50 1x schedule (c) Comparison with SimOTA label assignment on RTMDet-s with the same losses and other training strategies
(b) 与其他使用ResNet50 1x配置的标签分配方法对比
(c) 在相同损失函数及其他训练策略下,与RTMDet-s上的SimOTA标签分配方法对比
| 方法 | AP(%)↑ |
|---|---|
| SimOTA | 43.2 |
| 本文方法 | 44.5 |
Detection head. In Table 5d, we compare different sharing strategies of the detection head for multi-scale features. The results show that incorporating Batch Normalization (BN) into a shared-weight detection head causes a performance drop because of the statistical differences between different feature scales. Using different detection heads for different feature scales can solve this issue but significantly increases the parameter numbers. Using the same weights for different feature scales but different BN statistics yields the best parameter-accuracy trade-off.
检测头。在表 5d 中,我们比较了多尺度特征检测头的不同共享策略。结果表明,由于不同特征尺度间的统计差异,在共享权重的检测头中加入批量归一化 (BN) 会导致性能下降。为不同特征尺度使用不同检测头可以解决该问题,但会显著增加参数量。采用相同权重但不同 BN 统计量的方案能实现最佳的参数量-精度平衡。
4.4. Ablation Study of Training Strategy
4.4. 训练策略的消融研究
Label assignment. We then verify the effectiveness of each component in the proposed dynamic soft label assignment strategy. Following previous conventions, we use SimOTA [21] as our baseline and employ the FocalLoss [47] and GIoU [67], which are the same as the training losses, as the cost matrix. As shown in Table 6a, our baseline version can achieve an AP of $39.9%$ on ResNet50. Introducing IoU as a soft label in the classification cost improves the accuracy by $0.4%$ AP, reaching $40.3%$ AP. Replacing the fixed $3\times3$ center prior with a softened center prior further improves the accuracy to $40.8%$ AP. By replacing the GIoU cost with the logarithm IoU cost, the model obtains $41.3%$ AP.
标签分配。我们随后验证了所提出的动态软标签分配策略中每个组件的有效性。按照先前惯例,我们使用SimOTA [21]作为基线,并采用与训练损失相同的FocalLoss [47]和GIoU [67]作为成本矩阵。如表6a所示,我们的基线版本在ResNet50上可以达到$39.9%$的AP。在分类成本中引入IoU作为软标签,将准确率提高了$0.4%$ AP,达到$40.3%$ AP。将固定的$3\times3$中心先验替换为软化中心先验后,准确率进一步提升至$40.8%$ AP。通过将GIoU成本替换为对数IoU成本,模型获得了$41.3%$的AP。
The proposed label assignment strategy surpasses other high-performance strategies by $0.5%$ AP on the same model architecture with the same losses (Table 6b). When trained with a longer training schedule and stronger data augmentation, the proposed dynamic soft label assignment, together with the losses, surpasses SimOTA by $1.3%$ AP on RTMDet-s (Table 6c).
提出的标签分配策略在相同模型架构和损失函数下,比其他高性能策略高出 $0.5%$ AP (表 6b)。当采用更长训练周期和更强数据增强时,所提出的动态软标签分配方法结合损失函数,在RTMDet-s上比SimOTA高出 $1.3%$ AP (表 6c)。
Data augmentation. We then study different combinations of data augmentations at different training stages. The first and second training stage takes 280 and 20 epochs, respectively. When the data augmentation is the same in these two stages, it essentially forms a one-stage training. Following YOLOX, the range of random resizing in Mosaic for tiny and small models is (0.5, 2.0), while (0.1, 2.0) is used for larger models. As shown in Table $7\mathrm{a}$ , using largescale jittering (LSJ) [22] in all the stages is $0.4%$ AP better than using MixUp and Mosaic. The effect of cached Mosaic and MixUp is consistent with the original ones when there are sufficient cached samples. Still, the cache mechanism speeds up Mosaic and MixUp by $\sim3.6\times$ and $\sim1.5\times$ , respectively (Table 7b).
数据增强。我们随后研究了不同训练阶段采用不同数据增强方法的组合效果。第一和第二阶段分别训练280轮和20轮。当两个阶段采用相同的数据增强时,本质上构成单阶段训练。遵循YOLOX方案,针对微型和小型模型的Mosaic随机缩放范围为(0.5, 2.0),而大型模型使用(0.1, 2.0)。如表7a所示,在所有阶段采用大尺度抖动(LSJ)[22]比使用MixUp和Mosaic的AP指标高出0.4%。当缓存样本充足时,缓存版Mosaic和MixUp的效果与原始版本一致,同时缓存机制使Mosaic和MixUp分别加速约3.6倍和1.5倍(表7b)。
Using LSJ in the second stage instead of Mosaic and MixUp brings $2%$ AP and $1.5%$ improvement for RTMDets and RTMDet-l, respectively. This indicates that Mosaic and MixUp is a stronger augmentation than LSJ but also introduces more noise in training, which should be thrown in the second stage. We also observe that if the cache size
在第二阶段使用LSJ替代Mosaic和MixUp,分别使RTMDets和RTMDet-l的AP提升了2%和1.5%。这表明Mosaic和MixUp是比LSJ更强的数据增强方法,但也会在训练中引入更多噪声,因此应在第二阶段弃用。我们还观察到,若缓存大小
Table 7. Ablation studies of data augmentation on COCO val2017 set. The proposed settings are marked in gray was reduced to around 10 images and the First-In-First-Out (FIFO) popping method was applied, it is possible to mix the same image with different data augmentation operations in the same batch, which may have similar effects as repeated augmentation [2] and can slightly improve tiny and small models (by approximately $0.5%$ AP).
表 7: 在 COCO val2017 数据集上的数据增强消融实验。所提出的设置以灰色标出。当图像数量减少至约 10 张并应用先进先出 (FIFO) 弹出方法时,同一批次中可能混合了经过不同数据增强操作的相同图像,这可能产生与重复增强 [2] 类似的效果,并能略微提升微型和小型模型的性能 (约 $0.5%$ AP)。
(a) Comparison with large-scale jittering (LSJ) and Mosaic & MixUp of different setting. ”small” means using a small cache size and FIFO popping method
(b) The speed comparison with vanilla and cached Mosaic & MixUp
(a) 不同设置下大规模抖动 (LSJ) 与 Mosaic & MixUp 的对比。"small"表示使用较小的缓存大小和 FIFO 弹出方法
| 模型 | 第一阶段数据增强 | 第二阶段数据增强 | AP(%)↑ |
|---|---|---|---|
| RTMDet-s | LSJ [22] | LSJ Mosaic&MixUp | 42.3 |
| Mosaic&MixUp | LSJ Mosaic&MixUp | 41.9 | |
| Cached Mosaic&MixUp | CachedMosaic&MixUp | 41.9 | |
| Cached Mosaic&MixUp | LSJ | 43.9 | |
| Cached(small) Mosaic & MixUp | LSJ | 44.2 | |
| RTMDet-1 | LSJ | LSJ | 46.7 |
| Mosaic&MixUp | Mosaic & MixUp | 49.8 | |
| CachedMosaic&MixUp | CachedMosaic&MixUp | 49.8 | |
| Cached Mosaic & MixUp | LSJ | 51.3 | |
| Cached(small)Mosaic&MixUp | LSJ | 51.1 |
(b) 原始与缓存版 Mosaic & MixUp 的速度对比
| 使用缓存 | 毫秒/100张图片 ← | |
|---|---|---|
| Mosaic | 87.1 | |
| Mosaic | 是 | 24.0 |
| MixUp | 19.3 | |
| MixUp | √ | 12.4 |
Compared with YOLOX, we avoid random rotation and shearing in the first training stage because they cause misalignment between box annotations and the inputs. Instead, we increase the number of mixed images from 5 to 8 in each training sample to keep the strength of data augmentation in the first stage. Overall, the new combination of data augmentation explored in this paper is consistently better than those of YOLOX at different model sizes 7c.
与YOLOX相比,我们在第一训练阶段避免了随机旋转和剪切,因为这些操作会导致标注框与输入之间不对齐。取而代之的是,我们将每个训练样本中混合图像的数量从5张增加到8张,以保持第一阶段数据增强的强度。总体而言,本文探索的新数据增强组合在不同模型规模下均优于YOLOX [7c]。
Optimization strategy. We finally conduct experiments on the optimization strategies. The results in Table 8 indicate that SGD leads to unstable convergence progress with heavy data augmentation in training. As a result, we selected AdamW with a 0.05 weight decay and Cosine Annealing LR as our baseline. To avoid over fitting in the early or middle training progress due to the quickly reduced learning rate by Cosine Annealing, we adapt a flat-cosine approach, where a fixed learning rate is used in the first half of training epochs, and cosine annealing is then used in the second half. This modification improves the performance by $0.3%$ AP. Furthermore, inhibiting weight decay on normalization layers and biases following previous practices [33] brings $0.9%$ AP improvement. Finally, applying a pre-trained ImageNet backbone through the RSB [78] training strategy leads to (c) Comparison with data augmentation in YOLOX a further $0.3%$ increase in AP. The above-mentioned tricks syne r gic ally yield significant improvements of $1.5%$ AP.
优化策略。我们最终对优化策略进行了实验。表8的结果表明,在训练中使用大量数据增强时,SGD会导致收敛过程不稳定。因此,我们选择AdamW(权重衰减0.05)和余弦退火学习率作为基线。为避免因余弦退火导致学习率快速下降而在训练早期或中期出现过拟合,我们采用了平缓-余弦策略:在前半段训练周期使用固定学习率,后半段再启用余弦退火。这一改进使AP提升了$0.3%$。此外,依照先前实践[33]对归一化层和偏置项禁用权重衰减,带来了$0.9%$的AP提升。最后,通过RSB[78]训练策略加载预训练的ImageNet骨干网络,使AP进一步提高了$0.3%$。上述技巧协同作用最终实现了$1.5%$的AP显著提升。
| 模型 | 数据增强 (Data Aug.) | AP(%)↑ |
|---|---|---|
| RTMDet-s | YOLOX | 42.9 |
| RTMDet-s | Ours | 44.2 |
| RTMDet-l | YOLOX | 50.6 |
| RTMDet-l | Ours | 51.3 |
Table 8. Ablation study of optimization strategy based on RTMDet-s. The proposed setting is marked in gray
表 8: 基于RTMDet-s的优化策略消融实验。所提设置用灰色标记
| 优化器 | AP(%)↑ |
|---|---|
| SGD+CosineLR | 不稳定 |
| AdamW+CosineLR | 43.0 |
| AdamW+FlatCosineLR | 43.3 |
| + 去除归一化和偏置衰减 | 44.2 |
| + RSB预训练 | 44.5 |
4.5. Step-by-step Results
4.5. 分步结果
As demonstrated in Table 9, we have made successive modifications to YOLOX-s. By modifying the optimization strategy, the model accuracy is improved by $0.4%$ . The new architecture that has a similar capacity of backbone and neck, constructed by the new basic building block with large-kernel depth-wise convolutions, improves the model accuracy by $1.2%$ AP with marginal latency costs. Using a detection head with shared weights reduces the number of parameters significantly without hurting the accuracy. Subsequent enhancements to the label assignment strategy and training losses boost the performance by $1.1%$ AP. The new combination of data augmentations and the pre-training of backbone leads to $1.3%$ AP and $0.3%$ AP improvement, respectively. The synergy of these modifications results in the RTMDet-s, which outperforms the baseline by $4.3%$ AP.
如表 9 所示,我们对 YOLOX-s 进行了连续改进。通过修改优化策略,模型精度提升了 $0.4%$。采用大核深度卷积的新基础构建块构建的主干和颈部容量相近的新架构,以微小的延迟代价将模型精度提升了 $1.2%$ AP。使用共享权重的检测头显著减少了参数量且未损害精度。后续对标签分配策略和训练损失的增强使性能提升了 $1.1%$ AP。数据增强新组合与主干预训练分别带来 $1.3%$ AP 和 $0.3%$ AP 的提升。这些改进的协同作用最终形成了 RTMDet-s,其 AP 值比基线模型高出 $4.3%$。
Table 9. Step-by-step improvements from YOLOX-s baseline to RTMDet-s. The proposed setting is marked in gray
表 9: 从 YOLOX-s 基线到 RTMDet-s 的逐步改进。所提出的设置以灰色标记
| 模型 | 参数量(M) | 计算量(G)↓ | 延迟(ms) | AP(%)↑ |
|---|---|---|---|---|
| YOLOX基线 | 9.0M | 13.4G | 1.20ms | 40.2 |
| +AdamW&FlatCosineLR | 9.0M | 13.4G | 1.20ms | 40.6(+0.4) |
| +新架构 | 10.07M(+1.07) | 14.8G(+1.4) | 1.22ms | 41.8(+1.2) |
| +SepBNHead | 8.89M(-1.18) | 14.8G | 1.22ms | 41.8(+0.0) |
| +标签分配&损失 | 8.89M | 14.8G | 1.22ms | 42.9(+1.1) |
| +改进的数据增强 | 8.89M | 14.8G | 1.22ms | 44.2(+1.3) |
| +RSB预训练主干 | 8.89M | 14.8G | 1.22ms | 44.5(+0.3) |
5. Conclusion
5. 结论
In this paper, we empirically and comprehensively study each critical component in real-time object detectors, including model architectures, label assignment, data augmentations, and optimization. We further explore minimal adaptations of a high-precision real-time object detector for real-time instance segmentation and rotated object detection. The findings in the study result in a new family Real- Time Models for object Detection, named RTMDet, and its derivatives for different object recognition tasks. RTMDet demonstrates a superior trade-off between accuracy and speed in industrial-grade applications, with different model sizes for different object recognition tasks. We hope RTMDet, with the experimental results, can pave the way for future research and industrial development of real-time object recognition tasks.
本文通过实证研究全面分析了实时目标检测器的各个关键组成部分,包括模型架构、标签分配、数据增强和优化策略。我们进一步探索了将高精度实时目标检测器进行最小化适配,以应用于实时实例分割和旋转目标检测任务。这些研究成果催生了一个全新的实时目标检测模型家族——RTMDet,及其针对不同目标识别任务的衍生版本。RTMDet在工业级应用中展现出精度与速度的卓越平衡,针对不同任务需求提供多种模型规模。我们期望RTMDet及其实验结果能为实时目标识别任务的未来研究和工业发展铺平道路。
A. Appendix
A. 附录
A.1. Benchmark Results
A.1. 基准测试结果
Comparison with PPYOLOE-R. We further compare RTMDet-R with PPYOLOE-R in detail, and RTMDet-R is more competitive in accuracy and inference speed, as shown in Table A1. More surprisingly, RTMDet-R-m and RTMDet-R-l surpass PPYOLOE-R-l and PPYOLOE-R $\mathbf{\nabla}\cdot\mathbf{X}$ while being $18.5%$ and $20.8%$ faster, respectively. Code and models of RTMDet-R are released at MMRotate [99].
与PPYOLOE-R的对比。我们进一步详细比较了RTMDet-R与PPYOLOE-R的性能,如表A1所示,RTMDet-R在精度和推理速度上更具竞争力。更令人惊讶的是,RTMDet-R-m和RTMDet-R-l在分别提速18.5%和20.8%的同时,性能超越了PPYOLOE-R-l和PPYOLOE-R $\mathbf{\nabla}\cdot\mathbf{X}$。RTMDet-R的代码和模型已发布于MMRotate [99]。
Results on DOTA-v1.5. We further verify the effectiveness of RTMDet-R on DOTA-v1.5 dataset. DOTA-v1.5 contains the same images as DOTA-v1.0 but annotates extremely small instances (less than 10 pixels) with $215\mathrm{{k}}$ instances added, which makes it more challenging. For the DOTAv1.5 dataset, we use 4 NVIDIA A100 GPUs for training. Since we find that COCO pre training significantly improves the results on DOTA-v1.5, we use COCO pre training by default. Other settings are consistent with DOTA-v1.0. As shown in Table A2, RTMDet-R-l surpasses the previous best method ReDet [29] by $1.32%$ mAP.
DOTA-v1.5实验结果。我们进一步验证了RTMDet-R在DOTA-v1.5数据集上的有效性。DOTA-v1.5包含与DOTA-v1.0相同的图像,但标注了极小实例(小于10像素),新增了215k个实例,这使得任务更具挑战性。针对DOTAv1.5数据集,我们使用4块NVIDIA A100 GPU进行训练。由于发现COCO预训练能显著提升DOTA-v1.5的结果,我们默认采用COCO预训练。其他设置与DOTA-v1.0保持一致。如表A2所示,RTMDet-R-l以1.32% mAP的优势超越先前最佳方法ReDet [29]。
Results on HRSC2016. We also verify RTMDet-R on HRSC2016 dataset, a ship detection dataset containing 1K images and a total of 2.9K ships collected from Google Earth. For the HRSC2016 dataset, we do not change the aspect ratios of images. We train all the models with 108 epochs for HRSC2016 dataset. Other settings are consistent with those for DOTA-v1.0. RTMDet-R also obtains a new state-of-the-art performance and achieves $90.6%$ $\mathrm{mAP_{07}}$ (Table A3).
HRSC2016数据集上的结果。我们还在HRSC2016数据集上验证了RTMDet-R,该数据集是从Google Earth收集的包含1K图像和总计2.9K艘船只的船舶检测数据集。对于HRSC2016数据集,我们不改变图像的宽高比。我们在HRSC2016数据集上训练所有模型108个周期。其他设置与DOTA-v1.0保持一致。RTMDet-R也取得了新的最先进性能,达到了$90.6%$的$\mathrm{mAP_{07}}$(表A3)。
References
参考文献
Table A1. Comparison of RTMDet-R with PPYOLOE-R on the number of parameters, FLOPs, latency, and accuracy. The inference speeds of all models are measured in the same environment. The results of the proposed RTMDet-R is marked in gray. The best results are in bold
表 A1. RTMDet-R 与 PPYOLOE-R 在参数量、FLOPs、延迟和准确率上的对比。所有模型的推理速度均在相同环境下测量。提出的 RTMDet-R 结果以灰色标记,最佳结果以粗体显示。
| 模型 | 输入尺寸 | 参数量(M)↓ | FLOPs(G)↓ | 延迟(ms)↓ | mAP(%)↑ |
|---|---|---|---|---|---|
| RTMDet-R-tiny | 1024 | 4.88 | 20.45 | 3.04 | 75.36 |
| PPYOLOE-R-S | 1024 | 8.24 | 22.16 | 3.38 | 73.82 |
| RTMDet-R-s | 1024 | 8.86 | 37.62 | 3.44 | 76.93 |
| PPYOLOE-R-m | 1024 | 24.66 | 65.40 | 5.26 | 77.64 |
| RTMDet-R-m | 1024 | 24.67 | 99.76 | 5.79 | 78.24 |
| PPYOLOE-R-1 | 1024 | 55.17 | 145.88 | 7.09 | 78.14 |
| RTMDet-R-1 | 1024 | 52.27 | 204.21 | 8.20 | 78.85 |
| PPYOLOE-R-X | 1024 | 104.18 | 275.41 | 10.36 | 78.28 |
Table A2. Comparison with state-of-the-art methods on DOTA v1.5 dataset. MS means multi-scale training and testing. For the DOTA-v1.5 dataset, we use 4 NVIDIA A100 GPUs for training. Since we find that COCO pre training significantly improves the results on DOTA-v1.5, we use COCO pre training by default. DOTA-v1.5 has 16 different object categories: plane (PL), baseball diamond (BD), bridge (BR), ground track field (GTF), small vehicle (SV), large vehicle (LV), ship (SH), tennis court (TC), basketball court (BC), storage tank (ST), soccer ball field (SBF), roundabout (RA), harbor (HA), swimming pool (SP), helicopter (HC) and container crane (CC). The AP of each category is listed. The bold fonts indicate the best performance. The results of the proposed RTMDet-R are marked in gray
表 A2: DOTA v1.5 数据集上先进方法的对比。MS 表示多尺度训练和测试。对于 DOTA-v1.5 数据集,我们使用 4 块 NVIDIA A100 GPU 进行训练。我们发现 COCO 预训练显著提升了 DOTA-v1.5 的结果,因此默认使用 COCO 预训练。DOTA-v1.5 包含 16 个不同物体类别:飞机 (PL)、棒球场 (BD)、桥梁 (BR)、田径场 (GTF)、小型车辆 (SV)、大型车辆 (LV)、船舶 (SH)、网球场 (TC)、篮球场 (BC)、储罐 (ST)、足球场 (SBF)、环岛 (RA)、港口 (HA)、游泳池 (SP)、直升机 (HC) 和集装箱起重机 (CC)。列出了每个类别的 AP (Average Precision)。加粗字体表示最佳性能,所提出的 RTMDet-R 结果以灰色标记。
| 方法 | MS | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | CC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RetinaNet-OBB[47] | 71.43 | 77.64 | 42.12 | 64.65 | 44.53 | 56.79 | 73.31 | 90.84 | 76.02 | 59.96 | 46.95 | 69.24 | 59.65 | 64.52 | 48.06 | 0.83 | 59.16 | |
| FR-OBB [66] | 71.89 | 74.47 | 44.45 | 59.87 | 51.28 | 69.98 | 79.37 | 90.78 | 77.38 | 67.50 | 47.75 | 69.72 | 61.22 | 65.28 | 60.47 | 1.54 | 62.00 | |
| MASK RCNN[31] | 76.84 | 73.51 | 49.90 | 57.80 | 51.31 | 71.34 | 79.75 | 90.46 | 74.21 | 66.07 | 46.21 | 70.61 | 63.07 | 64.46 | 57.81 | 9.42 | 62.67 | |
| HTC [8] | 77.80 | 73.67 | 51.40 | 63.99 | 51.54 | 73.31 | 80.31 | 90.48 | 75.12 | 67.34 | 48.51 | 70.63 | 64.84 | 64.48 | 55.87 | 5.15 | 63.40 | |
| DAFNe | 71.99 | |||||||||||||||||
| OWSR[43] | 74.90 | |||||||||||||||||
| ReDet | 79.20 | 82.81 | 51.92 | 71.41 | 52.38 | 75.73 | 80.92 | 90.83 | 75.81 | 68.64 | 49.29 | 72.03 | 73.36 | 70.55 | 63.33 | 11.53 | 66.86 | |
| ReDet | 88.51 | 86.45 | 61.23 | 81.20 | 67.60 | 83.65 | 90.00 | 90.86 | 84.30 | 75.33 | 71.49 | 72.06 | 78.32 | 74.73 | 76.10 | 46.98 | 76.80 | |
| RTMDet-R-tiny | 77.79 | 83.03 | 48.45 | 73.37 | 59.33 | 81.30 | 88.89 | 90.88 | 80.73 | 76.26 | 51.81 | 71.59 | 75.81 | 75.19 | 54.36 | 20.01 | 69.30 | |
| RTMDet-R-tiny | 88.14 | 83.09 | 51.80 | 77.54 | 65.99 | 82.22 | 89.81 | 90.88 | 80.54 | 81.34 | 64.64 | 71.51 | 77.13 | 76.32 | 72.11 | 46.67 | 74.98 | |
| RTMDet-R-s | 80.05 | 84.36 | 50.65 | 72.04 | 59.54 | 81.79 | 89.22 | 90.90 | 83.07 | 76.27 | 56.82 | 72.13 | 76.25 | 77.04 | 65.66 | 32.84 | 71.79 | |
| RTMDet-R-s | 88.14 | 85.82 | 52.90 | 82.09 | 65.58 | 81.83 | 89.78 | 90.82 | 83.31 | 82.47 | 68.51 | 70.93 | 78.00 | 75.77 | 73.09 | 47.32 | 76.02 | |
| RTMDet-R-m | 80.34 | 86.00 | 54.02 | 72.98 | 63.21 | 82.09 | 89.46 | 90.87 | 85.12 | 76.69 | 63.12 | 72.14 | 77.91 | 76.04 | 71.57 | 32.24 | 73.36 | |
| RTMDet-R-m | 89.07 | 86.71 | 52.57 | 82.47 | 66.13 | 82.55 | 89.77 | 90.88 | 84.39 | 83.34 | 69.51 | 73.03 | 77.82 | 75.98 | 80.21 | 42.00 | 76.65 | |
| RTMDet-R-1 | 80.73 | 84.79 | 54.09 | 76.30 | 63.56 | 83.06 | 89.77 | 90.89 | 86.65 | 76.98 | 63.68 | 70.31 | 78.11 | 75.91 | 75.09 | 31.20 | 73.82 | |
| RTMDet-R-1 | 89.31 | 86.38 | 55.09 | 83.17 | 66.11 | 82.44 | 89.85 | 90.84 | 86.95 | 83.76 | 68.35 | 74.36 | 77.60 | 77.39 | 77.87 | 60.37 | 78.12 |
Table A3. Comparison with state-of-the-art methods on HRSC2016 dataset. $\mathrm{mAP_{07}}$ and $\mathrm{mAP_{12}}$ indicate that the results were evaluated under VOC2007 and VOC2012 metrics $(%)$ , respectively. We report both results for fair comparison. The results of the proposed RTMDet-R is marked in gray. The results of the proposed RTMDet is marked in gray. The best results are in bold
表 A3: 在HRSC2016数据集上与先进方法的对比。$\mathrm{mAP_{07}}$和$\mathrm{mAP_{12}}$分别表示采用VOC2007和VOC2012指标$(%)$评估的结果。为公平比较,我们同时报告两种结果。提出的RTMDet-R结果以灰色标出,提出的RTMDet结果以灰色标出。最佳结果以粗体显示
| 模型 | 输入尺寸 | mAP07 | mAP12 |
|---|---|---|---|
| Rol Trans. | 512-800 | 86.20 | |
| GlidingVertex | 512-800 | 88.20 | |
| R?Det | 800×800 | 89.26 | 96.01 |
| GWD | 800×800 | 89.85 | 97.37 |
| CSL | 800×800 | 89.62 | 96.10 |
| S²ANet | 512-800 | 90.17 | 95.01 |
| ReDet | 512-800 | 90.46 | 97.63 |
| OrientedRCNN | 800-1333 | 90.50 | 97.60 |
| RTMDet-R-tiny | 800×800 | 90.60 | 97.10 |