FACE: FAST, ACCURATE AND CONTEXT-AWARE AUDIO ANNOTATION AND CLASSIFICATION
FACE: 快速、准确且上下文感知的音频标注与分类
ABSTRACT
摘要
This paper presents a context-aware framework for feature selection and classification procedures to realize a fast and accurate audio event annotation and classification. The context-aware design starts with exploring feature extraction techniques to find an appropriate combination to select a set resulting in remarkable classification accuracy with minimal computational effort. The exploration for feature selection also embraces an investigation of audio Tempo representation, an advantageous feature extraction method missed by previous works in the environmental audio classification research scope. The proposed annotation method considers outlier, inlier, and hard-to-predict data samples to realize context-aware Active Learning, leading to the average accuracy of $90%$ when only $15%$ of data possess initial annotation. Our proposed algorithm for sound classification obtained average prediction accuracy of $98.\bar{0}5%$ on the Urban Sound 8 K dataset. The notebooks containing our source codes and implementation results are available at https://github.com/gitmehrdad/FACE.
本文提出了一种用于特征选择和分类流程的情境感知框架,旨在实现快速准确的音频事件标注与分类。该情境感知设计首先探索特征提取技术,通过寻找合适的组合来选取一组能在最小计算成本下实现显著分类准确率的特征。特征选择过程中还研究了音频节奏(Tempo)表征——这一在环境音频分类研究领域被以往工作忽略的优势特征提取方法。所提出的标注方法综合考虑离群值、内点及难预测数据样本,实现了情境感知的主动学习(Active Learning),在仅15%数据具备初始标注时仍能达到90%的平均准确率。我们提出的声音分类算法在Urban Sound 8K数据集上取得了98.05%的平均预测准确率。包含源代码和实现结果的Notebook已发布于https://github.com/gitmehrdad/FACE。
Keywords Context-aware Machine Learning $\cdot$ Active Learning $\cdot$ Sound Classification $\cdot$ Audio Annotation $\cdot$ Audio Tempo Representation (Tempogram) $\cdot$ Semi-supervised Audio Classification $\cdot$ Feature Selection
关键词 上下文感知机器学习 (Context-aware Machine Learning) $\cdot$ 主动学习 (Active Learning) $\cdot$ 声音分类 (Sound Classification) $\cdot$ 音频标注 (Audio Annotation) $\cdot$ 音频速度表征 (Tempogram) $\cdot$ 半监督音频分类 (Semi-supervised Audio Classification) $\cdot$ 特征选择 (Feature Selection)
1 Introduction
1 引言
In recent years, sound event classification has gained attention due to its application in audio analysis, music information retrieval, noise monitoring, animal call classification, and speech enhancement [1, 2, 3]. The development in the mentioned fields requires annotated recordings [3] and larger datasets instead of the smaller ones [4]. Since labeling audio is time-consuming and expensive, establishing a large-scale labeled audio dataset is arduous [5]. So, it seems necessary to develop reliable methods to label the datasets. There are several methods of determining the labels of unlabeled data. Some papers, including [1, 4, 5, 6, 7, 8] pursue Semi-supervised Learning, and some works, including [2, 3, 9, 10, 11, 12] seek to utilize Active Learning. Regarding the superior annotation accuracy of Active Learning-based approaches, this paper also focuses on Active Learning to determine the labels of audio samples. In certainty-based Active learning, a small portion of data with deterministic labels trains a classifier at first. Then, the classifier labels the unlabeled data, and audio samples with the highest classification certainties join the training set. The cycle of classifier training, classification, and updating the training set continues until the complete annotation of all audio samples.
近年来,声音事件分类因其在音频分析、音乐信息检索、噪声监测、动物叫声分类和语音增强等领域的应用而受到关注 [1, 2, 3]。上述领域的发展需要标注录音 [3] 和更大规模的数据集而非小型数据集 [4]。由于音频标注耗时且昂贵,建立大规模标注音频数据集十分艰巨 [5]。因此,开发可靠的数据集标注方法显得尤为必要。
现有多种方法可用于确定未标注数据的标签。部分论文(如 [1, 4, 5, 6, 7, 8])采用半监督学习 (Semi-supervised Learning),另一些研究(如 [2, 3, 9, 10, 11, 12])则尝试利用主动学习 (Active Learning)。鉴于基于主动学习的方法具有更高的标注准确性,本文同样聚焦于通过主动学习确定音频样本的标签。
在基于确定性的主动学习中,首先使用少量带确定标签的数据训练分类器。随后,分类器对未标注数据进行标注,并将分类确定性最高的音频样本加入训练集。分类器训练、分类和训练集更新的循环将持续进行,直至完成所有音频样本的标注。
Solutions proposed for the problem of audio event classification examine several methods. In [1, 4, 5, 7, 8], they suggested utilizing deep multi-layer neural networks to classify the data. The main issue challenging some Deep Learning solutions is the low prediction accuracy, in the case of the model over fitting, due to the scarcity of training data. In the audio classification task, where usually a propitious amount of training samples are available, we won’t face the model over fitting; however, in the audio annotation task, where the labels are available only for a small portion of data, the over fitting problem makes the deep multi-layer neural networks less attractive. In [2, 3, 6], they have employed classic machine learning class if i ers to classify the data. These methods are potentially less susceptible to over fitting since they have fewer unknown parameters that should get determined during the training. Nevertheless, the classic machine learning approaches suffer from the fixed input size issue.
针对音频事件分类问题提出的解决方案探讨了多种方法。文献[1,4,5,7,8]建议采用深度多层神经网络进行数据分类。某些深度学习方案面临的主要挑战是由于训练数据稀缺导致模型过拟合时的预测准确率低下问题。在通常具备充足训练样本的音频分类任务中不会出现过拟合现象,但在仅能获取少量数据标签的音频标注任务中,过拟合问题使得深度多层神经网络的吸引力下降。文献[2,3,6]则采用经典机器学习分类器进行数据处理。由于需要训练的未知参数较少,这些方法对过拟合的敏感性相对较低。然而,经典机器学习方法存在固定输入尺寸的限制性问题。
Regarding the considerable achievements of Context-aware Machine Learning [13], this paper proposes some contextaware solutions for the addressed problems. A context-aware design considers the current situation for decision-making. As a case in point, based on the system’s status, a context-aware Machine Learning system might dynamically renew the model fine-tuning and hyper parameter adjustment. The first research contribution of this paper includes a heuristic approach for context-aware feature selection to provide summarized fixed-size input vectors to gain a fast, accurate, and over fitting-resistant classification model. The investigation of the audio signal’s Cyclic Tempogram feature would be another contribution of this work in the audio signal classification task. The proposal of a context-aware Active Learning-based method for audio signal annotation is the third research contribution of this paper. The fourth research contribution is the context-aware classifier design to obtain optimum classification results. Section 2 describes the mentioned contributions in data preparation and feature extraction, data annotation, and audio classification. Section 3 discusses the implementation results for the proposed methods. Section 4 concludes the paper.
鉴于上下文感知机器学习 (Context-aware Machine Learning) [13] 取得的显著成果,本文针对所述问题提出了一些上下文感知解决方案。上下文感知设计会综合考虑当前情境进行决策。例如,基于系统状态,上下文感知机器学习系统可动态更新模型微调与超参数调整。本文的第一项研究贡献是提出了一种启发式上下文感知特征选择方法,通过生成固定长度的摘要化输入向量,从而获得快速、准确且抗过拟合的分类模型。在音频信号分类任务中探索循环时变谱 (Cyclic Tempogram) 特征是本研究的另一项贡献。第三项研究贡献是提出了基于上下文感知的主动学习 (Active Learning) 音频信号标注方法。第四项贡献是通过上下文感知分类器设计实现最优分类结果。第2章详细阐述了在数据准备、特征提取、数据标注和音频分类方面的上述贡献。第3章讨论了所提方法的实现结果。第4章对全文进行总结。
2 The proposed Method
2 所提出的方法
2.1 Data Preparation and Feature Extraction
2.1 数据准备与特征提取
Assume a dataset of audio signals with a duration of four seconds under the sampling rate of $22.05K H z$ . Since each audio signal consists of $4\times22050$ samples, the input vector of a classifier operating on that dataset should contain 88200 variables. These variables might distinguish audio signals from each other; however, processing those lengthy input vectors requires large amounts of memory and expensive computational resources. Besides, as the classifier’s input vector’s length grows, the trained model tends to be more susceptible to over fitting [14]. So, instead of regarding the time contents of an audio signal as the classifier’s input vector, some distinctive features extracted from the signal’s time contents would form the input vector. A context-aware feature extraction provides good classification accuracy and low model over fitting possibility.
假设有一个采样率为 $22.05K H z$ 的四秒音频信号数据集。由于每个音频信号包含 $4\times22050$ 个样本,基于该数据集的分类器输入向量应包含88200个变量。这些变量可能区分不同音频信号,但处理如此冗长的输入向量需要大量内存和高昂计算资源。此外,随着分类器输入向量长度增加,训练模型更容易出现过拟合 [14]。因此,与其将音频信号的时间内容作为分类器输入向量,不如从信号时间内容中提取一些显著特征来构成输入向量。上下文感知的特征提取能提供良好的分类精度和较低的模型过拟合可能性。
Some previous works, including [15, 16, 17, 18], discussed the various feature extraction methods applicable to the sound event classification task. Following a context-aware approach, we evaluate different feature extraction methods to find the most effective selection among that methods. Since this paper desires fast classification, we overlooked the evaluation of some methods with remarkable classification accuracy gain, like the Scattering Transform, because of their low feature extraction speed. The setup for the ablation study on the features contains a dataset, a feature extraction method, and a classifier.
包括[15, 16, 17, 18]在内的先前研究讨论了适用于声音事件分类任务的各种特征提取方法。基于上下文感知的方法,我们评估了不同特征提取方法以从中找出最有效的选择。由于本文追求快速分类,我们忽略了对某些分类精度提升显著但特征提取速度较慢的方法(如散射变换(Scattering Transform))的评估。特征消融研究的实验设置包含数据集、特征提取方法和分类器三部分。
The employed dataset is Urban Sound 8 K (US8K) presented in [19], which consists of 10 classes of urban environment’s audio events, including air conditioner, car horn, children playing, dog bark, drilling, engine idling, gunshot, jackhammer, siren, and street music. Each class consists of various counts of audio samples, and different-class data are arduous to distinguish for at least half the data classes. There are 8732 audio samples with different sampling rates and a maximum duration of 4 seconds. In this paper, the first step of data preparation is resampling the audio signals with the $22.05K H z$ sampling rate to obtain a uniform dataset. Data compression often ensues signal resampling since the sampling rate of audio signals usually exceeds $22.05K H z$ . Since the US8K dataset does not specify a validation set, we regard $10%$ of the training samples as the validation samples. All context-aware decisions in this paper are made based on the mentioned validation set. The examined features contain local auto correlation of the onset strength envelope (Tempogram), Chromagram, Mel-scaled Spec tr ogram, Mel-frequency cepstral coefficients (MFCCs), Spectral Contrast, Spectral flatness, Spectral bandwidth, Spectral centroid, Roll-off frequency, RMS value for each frame of audio samples, tonal centroid features (Tonnetz), and zero-crossing rate of an audio time series. Regarding the lack of investigation history in the environmental sound classification papers, this paper studies the Tempogram, proposed in [20], for the first time.
采用的数据集为文献[19]提出的Urban Sound 8K (US8K),包含10类城市环境音频事件:空调声、汽车喇叭声、儿童嬉戏声、犬吠声、钻孔声、引擎空转声、枪击声、破碎锤声、警笛声和街头音乐声。每类音频样本数量不等,其中半数以上类别的数据存在显著区分难度。该数据集共含8732个采样率各异、最长4秒的音频样本。本文数据预处理的第一步是将所有音频信号重采样至22.05kHz统一采样率。由于原始音频采样率通常超过22.05kHz,重采样过程常伴随数据压缩。鉴于US8K未预设验证集,我们划拨10%训练样本作为验证样本,本文所有上下文感知决策均基于该验证集得出。
研究的特征包括:起始强度包络局部自相关(Tempogram)、色度图(Chromagram)、梅尔频谱图(Mel-scaled Spectrogram)、梅尔频率倒谱系数(MFCCs)、频谱对比度(Spectral Contrast)、频谱平坦度(Spectral flatness)、频谱带宽(Spectral bandwidth)、频谱质心(Spectral centroid)、滚降频率(Roll-off frequency)、音频帧均方根值(RMS)、音调质心特征(Tonnetz)以及音频时间序列过零率。针对环境音分类领域的研究空白,本文首次探讨了文献[20]提出的Tempogram特征。
Most of the mentioned feature extraction methods operate based on windowing an audio signal, so the extracted features are referred to as static since they represent the information of the signal’s specific windows. The delta and delta-delta coefficients of the audio signal feature, which respectively indicate the first-order and second-order derivatives of the features, are referred to as dynamic features. The delta features show the speech rate, and the delta-delta features indicate the speech’s acceleration [21]. Some feature extraction methods generate a Spec tr ogram, a visual representation of the audio signal’s spectrum of frequencies. Regarding the Spec tr ogram as an image, we can exert some feature extraction properties from the Computer Vision scope, so we apply a Gaussian filter to the feature vectors before taking derivatives. In [14], feature selection helps to overcome the over fitting problem of the model by reducing the input vector’s dimensions and to obliviate the fixed input size issue mentioned in the previous section. The input vector’s length depends on the number of windows used during the feature extraction. When the windows’ count gets too high, the information represented by consecutive windows won’t differ substantially, and when the windows’ count gets too low, the amount of the extracted features won’t suffice to distinguish different audio samples easily. To reduce the data dimensions, the mean and the variance of the extracted features per window would replace the original data. A similar replacement happens for the delta and delta-delta vectors. So, the final feature vector embraces six vectors of floating-point numbers, containing the mean and the variance values for the original feature and first-order and second-order derivatives of it. In this paper, we used the feature extraction tools available by Librosa, a Python package, where most arguments of the feature extraction function are left untouched with their default values. Nevertheless, some function arguments, including the window length and the number of samples per window, got adjusted using the validation data. Before the experiments, we transformed features using Quantiles information into the standard vectors where the value of all elements lies in the range of (-1,1).
上述大多数特征提取方法基于对音频信号进行分窗操作,因此提取的特征被称为静态特征,因为它们代表了信号特定窗口的信息。音频信号特征的一阶导数(delta系数)和二阶导数(delta-delta系数)则被称为动态特征:delta特征反映语速变化,delta-delta特征体现语音加速度[21]。部分特征提取方法会生成声谱图(Spectrogram)——即音频信号频率谱的可视化表示。将声谱图视为图像时,我们可以引入计算机视觉领域的特征提取方法,例如在求导前对特征向量应用高斯滤波。文献[14]指出,特征选择通过降低输入向量维度有助于缓解模型过拟合问题,并规避前文提到的固定输入尺寸限制。输入向量长度取决于特征提取时使用的窗口数量:窗口过多会导致相邻窗口信息高度冗余,窗口过少则难以区分不同音频样本。为降低数据维度,我们用每个窗口提取特征的均值与方差替代原始数据,并对delta和delta-delta向量进行同样处理。最终特征向量包含六个浮点数向量,分别对应原始特征及其一阶、二阶导数的均值与方差值。本文使用Python语言音频处理库Librosa进行特征提取,大部分函数参数保持默认值,但窗长和每窗样本数等关键参数通过验证数据进行了调整。实验前,我们基于分位数信息将特征标准化至(-1,1)区间。
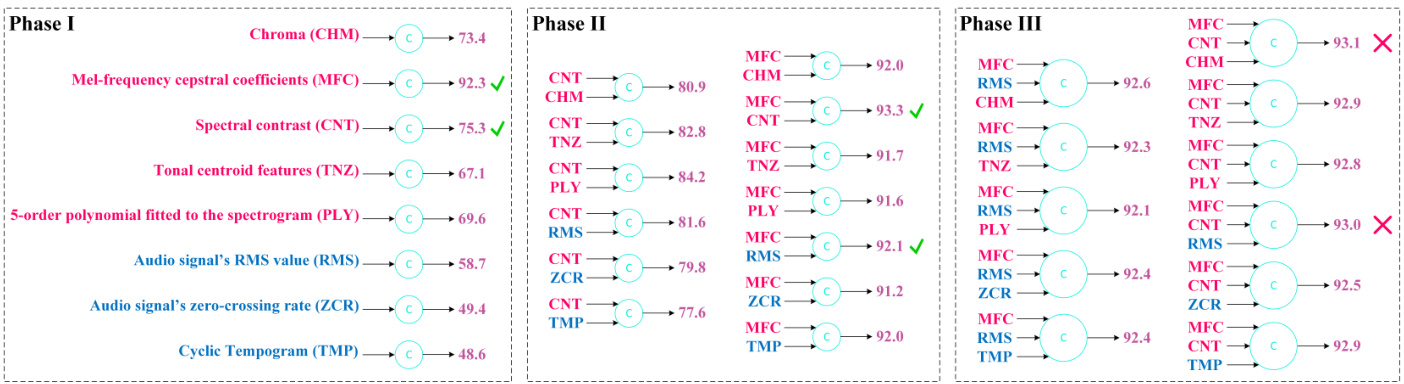
Figure 1: Feature selection resutls based on the proposed heuristic approach
图 1: 基于所提启发式方法的特征选择结果
A context-aware choice for the classifier would be the one holding the best capability to distinguish the data. There is a dilemma in feature and classifier selection: a classifier might hide the distinction some features provide, while a feature set might hide the resolution some class if i ers provide. So, initially, we explore various extracted features using a specific classifier chosen based on our speculation of the data distribution. After feature selection, we try to find the best classifier to distinguish the data.
上下文感知分类器的选择应基于其区分数据的最佳能力。特征与分类器选择存在两难困境:分类器可能掩盖某些特征提供的区分度,而特征集也可能掩盖某些分类器提供的分辨率。因此,我们首先基于对数据分布的推测选择特定分类器,探索各类提取特征。完成特征选择后,再尝试寻找区分数据的最佳分类器。
As the t-SNE plot for the Urban Sound 8 K dataset samples represented in [22] shows, the data distribution in the features space is heterogeneous and sparse. In a heterogeneous data distribution, the neighborhood of each data sample embraces some data samples with different class labels. Sparse data have a distribution in which the same-class data samples don’t shape dense areas. Assuming that the feature selection in our work also results in heterogeneous and sparse data distribution, we search for a classifier to separate the data classes. Class if i ers drawing a linear decision boundary fail to separate sparse and heterogeneous data, and class if i ers utilizing non-linear kernels require expensive computational effort. So, a decision tree classifier with an appropriate depth seems profitable. The high potential of model over fitting utilizing the decision tree classifier necessitates using an ensemble of tree class if i ers. Despite the improvements, the model over fitting still overshadows the accuracy of the mentioned classifier, so the XGBoost classifier proposes a solution by moving the decision boundaries utilizing regular iz ation [14]. Inspired by the One-vs-All approach that avails the application of binary class if i ers for multi-class classification, we propose to employ the One-vs-All XGBoost classifier. In fact, instead of a single multi-class XGBoost classifier, multiple binary XGBoost class if i ers draw the decision boundaries, where each classifier tries to separate the members of a specific class from all other data. Regarding the light duty of a binary XGBoost compared to a multi-class XGBoost, the computational overhead of the proposed method would not be an issue.
如[22]中所示的Urban Sound 8K数据集样本t-SNE图所示,特征空间中的数据分布呈现异质性和稀疏性。在异质性数据分布中,每个数据样本的邻域内会包含不同类别标签的样本。稀疏数据则表现为同类样本无法形成密集区域。鉴于本研究的特征选择同样可能导致异质稀疏的数据分布,我们需寻找能有效分离数据类别的分类器。
采用线性决策边界的分类器难以分割稀疏异质数据,而使用非线性核函数的分类器又面临高昂计算成本。因此,具有适当深度的决策树分类器成为较优选择。但决策树分类器存在较高的过拟合风险,这促使我们采用树分类器集成方法。尽管有所改进,过拟合问题仍会影响分类器精度,为此XGBoost分类器通过正则化[14]调整决策边界提供了解决方案。
受"一对多"(One-vs-All)方法启发(该方法使二分类器能处理多分类问题),我们提出采用一对多XGBoost分类器。具体而言,该方法使用多个二分类XGBoost替代单一多分类XGBoost,每个分类器负责将特定类别样本与其他所有数据分离。由于二分类XGBoost的计算负荷远低于多分类版本,该方法不会带来显著的计算开销。
Figure 1 depicts the feature selection results. To avoid the examination of all features permutations, we followed a heuristic approach, which consists of adding one new feature to each feature set at each phase, reporting the validation sample’s classification accuracy, moving the top-two feature sets to the next study phase, and dropping further investigations when the classification accuracy stopped enhancement. In Figure 1, the results of Phase III don’t show improvement compared to Phase II; therefore, we pick the MFC+CNT combination from Phase II as our final selection. Figure 1 depicts methods’ abbreviations in Phase II and Phase III of the experiment and shows the time-domain features in blue and the frequency-domain features in red. Figure 1 doesn’t represent the Mel-scaled Spec tr ogram feature extraction results since MFCC features are not only convertible to the Mel-scaled Spec tr ogram features but also capable of providing more classification accuracy. Some methods like Spectral flatness, Spectral bandwidth, Spectral centroid, and Roll-off frequency got excluded from Figure 1 because of their poor classification accuracy results. Please note that the reported accuracies belong to a simple classification procedure where no Active Learning or other accuracy optimization techniques are applied. As seen in Figure 1, the remarkable accuracy the MFCC feature provides alone clarifies the reason behind the widespread use of that feature in most previous works. The feature vector of the selected combination consists of 810 floating-point numbers, substantially reducing the computational resources required for the annotation and the classification tasks because it is sufficient to check 810 features instead of 88200 features.
图 1: 特征选择结果。为避免检查所有特征排列组合,我们采用启发式方法:在每阶段向特征集添加一个新特征,记录验证样本的分类准确率,将前两名特征集推进至下一研究阶段,当分类准确率停止提升时终止研究。图 1 显示第三阶段结果相对第二阶段未有改进,因此我们选择第二阶段的 MFC+CNT 组合作为最终方案。图中标注了实验第二、三阶段的方法缩写,蓝色表示时域特征,红色表示频域特征。
由于梅尔倒谱系数 (MFCC) 不仅能转换为梅尔频谱特征,还能提供更高分类准确率,图 1 未展示梅尔频谱特征提取结果。频谱平坦度、频谱带宽、频谱质心、滚降频率等方法因分类准确率不佳未被纳入图示。需注意报告准确率来自基础分类流程,未应用主动学习或其他准确率优化技术。
如图 1 所示,MFCC 特征单独展现的优异准确率解释了其被广泛采用的原因。所选组合的特征向量由810个浮点数构成,相比检查88200个特征,该方案显著降低了标注与分类任务所需的计算资源。
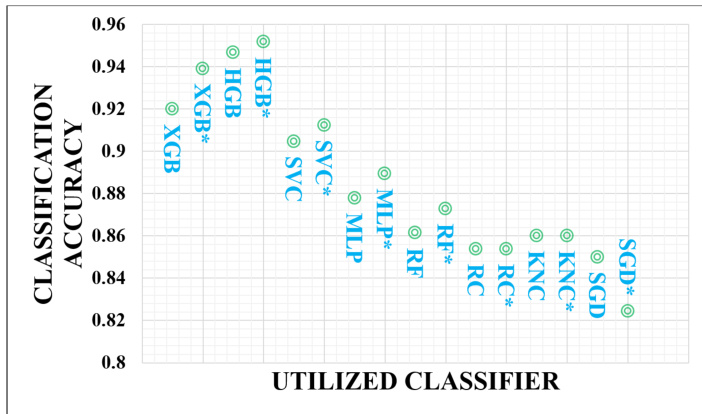
Figure 2: The classification accuracy vs. the utilized classifier
图 2: 分类准确率与所用分类器的关系
Utilizing various class if i ers, Figure 2 shows the classification results where no Active Learning or other accuracy optimization techniques are applied. The experiment focuses on finding the best classifier for the annotation task, so it explores only the classic machine-learning methods. In Figure 2, XGB, HGB, SVC, MLP, RF, RC, KNC, and SGD, respectively, denote the XGBoost, the Histogram-based Gradient Boosting Classifier, the Support Vector Machine, the Multi-layer Perceptron, the Random Forest, the Ridge Classifier, the K-nearest-neighbors Classifier, and the Regularized Linear SVM with Stochastic Gradient Descent learning. In Figure 2, the asterisk sign after the classifier’s name indicates using the classifier in the One-vs-All scheme. Each classifier uses our defined validation set as the test set and the rest of the samples in the US8K dataset as the training set. Figure 2 shows the results in which class if i ers succeed in obtaining at least $80%$ classification accuracy, so it does not contain class if i ers like Decision Tree, Gaussian Naive Bayes, AdaBoost, and QDA, which fail to reach $80%$ classification accuracy. The results of Figure 2 corroborate our speculation of the data distribution and the context-aware classifier selection to separate the classes. As shown in Figure 2, the HGB classifier outperforms the XGB classifier in terms of classification accuracy, but the XGB classifier operates faster. So, for the annotation tasks, we will use a One-vs-All XGBoost classifier, a context-aware choice that provides satisfying classification accuracy on the validation set.
图 2: 展示了使用不同分类器且未应用主动学习(Active Learning)或其他精度优化技术时的分类结果。实验旨在为标注任务寻找最佳分类器,因此仅探索经典机器学习方法。在图 2 中,XGB、HGB、SVC、MLP、RF、RC、KNC 和 SGD 分别代表 XGBoost、基于直方图的梯度提升分类器(Histogram-based Gradient Boosting Classifier)、支持向量机(Support Vector Machine)、多层感知器(Multi-layer Perceptron)、随机森林(Random Forest)、岭分类器(Ridge Classifier)、K近邻分类器(K-nearest-neighbors Classifier)以及采用随机梯度下降学习的正则化线性 SVM(Regularized Linear SVM with Stochastic Gradient Descent learning)。图 2 中分类器名称后的星号表示该分类器采用"一对多"(One-vs-All)方案。所有分类器均使用我们定义的验证集作为测试集,并将 US8K 数据集中其余样本作为训练集。图 2 仅展示分类精度达到至少 $80%$ 的分类器,因此未包含决策树(Decision Tree)、高斯朴素贝叶斯(Gaussian Naive Bayes)、AdaBoost 和 QDA 等未能达到 $80%$ 分类精度的算法。图 2 结果验证了我们关于数据分布及上下文感知分类器选择的推测。如图所示,HGB 分类器在分类精度上优于 XGB 分类器,但 XGB 分类器运行速度更快。因此,在标注任务中我们将采用"一对多"XGBoost 分类器——这种基于上下文感知的选择能在验证集上提供令人满意的分类精度。
2.2 Data Annotation
2.2 数据标注
For the annotation task, conventionally, it is assumed that a human annotator provides the labels for a small proportion of the data. Such an assumption leads us to avoid using deep neural network class if i ers to annotate new samples because the low number of training samples and the high number of model parameters expose the model to over fitting, which in turn causes the prediction accuracy to drop. So, based on the results observed in Section 2.1, we will annotate the data using a One-vs-All XGBoost classifier, a context-aware choice that provides good classification accuracy. Another manifestation of a context-aware framework, realized in our proposed annotation method, is specifying the data the human labeler should annotate. Algorithm 1 shows our proposed annotation method. The Local Outlier Factor (LOF) method, proposed in [23], finds the inlier samples having the least Euclidean distances from their nearest neighbor. The Active Learner, a Python tool from the modAL package, detects hard-to-predict data that are samples with minimum prediction certainty. According to what is shown from line 1 to line 8 of Algorithm 1, a human annotator determines the labels for inlier samples, hard-to-predict samples, and some random samples, uniformly chosen from every different class. The maximum number of selected inlier, hard-to-predict, and random samples are respectively limited to $2.5%$ , $5%$ , and $7.5%$ of the total sample count in the datatset. The philosophy behind choosing inlier samples for initial annotation is that there is a good chance that the neighborhood of the inlier samples embraces the same class samples. The reason behind adding some random data samples to the inlier samples is the possible imbalance in the count of data samples of different classes in the inlier samples. Another reason for adding random samples is to find different-class data samples adjacent to the inlier samples.
在标注任务中,传统做法是假设人工标注者为小部分数据提供标签。这种假设导致我们避免使用深度神经网络分类器来标注新样本,因为训练样本数量少而模型参数多会使模型容易过拟合,进而导致预测准确率下降。因此,根据第2.1节观察到的结果,我们将采用一对多XGBoost分类器进行数据标注,这是一种能提供良好分类准确率的上下文感知选择。我们提出的标注方法还体现了上下文感知框架的另一个特征,即明确指定人工标注者应标注的数据。算法1展示了我们提出的标注方法。文献[23]提出的局部离群因子(LOF)方法会找到与最近邻欧氏距离最小的内围样本。来自modAL包的Python工具Active Learner则能检测出预测难度大的数据,即预测确定性最低的样本。根据算法1第1至8行所示,人工标注者需要确定内围样本、难预测样本以及从每个不同类别中均匀选取的随机样本的标签。所选内围样本、难预测样本和随机样本的最大数量分别限制为数据集中总样本数的$2.5%$、$5%$和$7.5%$。选择内围样本进行初始标注的核心理念是,这些样本的邻域很可能包含同类样本。在内围样本中添加随机数据样本的原因,一是内围样本中不同类别的数据量可能存在不平衡,二是为了发现与内围样本相邻的不同类别数据样本。
In Algorithm 1, line 9 to line 27 indicate the proposed context-aware Active Learning method. The method consists of five stages of data labeling where the predicted samples with reliable prediction accuracy also help determine the labels. In this work, a reliable prediction possesses at least $70%$ prediction accuracy score. The number of Active Learning stages and the threshold of accepting a prediction as a reliable one are the problem’s hyper parameters, depending on various factors, including the audio samples count, the data se par ability, the classifier’s accuracy, and the classification’s certainty. The problem’s hyper parameters got adjusted using a validation set, $10%$ of the unlabeled samples. The major innovation in our method is that it overlooks labeling outlier samples until the last stage of labeling because we believe the presence of outlier data samples among the training samples decreases the labeling accuracy. In the first stage of Active Learning-based labeling, we train a classifier using human-labeled data. Then the trained classifier predicts the labels of dataset samples. Next, the reliable predictions reach the final prediction list and the set of training samples for the class if i ers of the further labeling stages. In the last stage of the labeling procedure, the labels predicted for the outlier samples and the remainder of unlabeled data reach the final prediction list unconditionally.
在算法1中,第9至27行描述了提出的上下文感知主动学习方法。该方法包含五个阶段的数据标注流程,其中预测准确率可靠的样本也会参与标签确定。本研究中,可靠预测需至少达到70%的准确率分数。主动学习的阶段数量及接受预测为可靠的阈值是该问题的超参数,其取值取决于音频样本数量、数据可分性、分类器准确率和分类确定性等多重因素。这些超参数通过验证集(占未标注样本的10%)进行调整。本方法的核心创新在于:直至标注最后阶段才处理离群样本,因为我们认为训练样本中的离群数据会降低标注准确率。在基于主动学习的第一阶段标注中,我们使用人工标注数据训练分类器,随后该分类器预测数据集样本标签。可靠的预测结果将进入最终预测列表,并作为后续标注阶段的分类器训练样本集。在标注流程的最后阶段,为离群样本和剩余未标注数据预测的标签将无条件进入最终预测列表。
2.3 Data Classification
2.3 数据分类
Figure 3 shows the proposed neural network for audio classification. Figure 3 demonstrates the convolutional blocks in blue and the locally connected convolutional blocks in green. The locally connected convolutional blocks work similarly to convolutional blocks; however, unlike convolutional blocks, a different set of filters is applied at each input patch selected by the kernel window. The number on each block indicates the kernel size for that block, and the number above each column of blocks shows the number of filters. All blocks enjoy Batch Normalization, followed by a LeakyReLU activation function. We merge the outputs of five parallel streams, depicted in Figure 3, by an addition operation. The last layers of the neural network are two fully-connected layers, joined together through a dropout layer. We adjusted the neural network’s hyper parameters, including filter count, kernel sizes, dropout ratio, and the number of training epochs, using a validation set containing $10%$ of training samples. In the neural network design, we preferred in-width extension to in-depth expansion, which makes the neural network operate faster by providing the opportunity for parallel computations of five parallel streams.
图 3: 展示了用于音频分类的神经网络架构。图中蓝色部分表示卷积块,绿色部分表示局部连接卷积块。局部连接卷积块的工作原理与常规卷积块类似,但不同之处在于:内核窗口选中的每个输入区块会应用不同的滤波器组。每个区块上的数字表示该区块的内核尺寸,区块列上方的数字则显示滤波器数量。所有区块均采用批归一化(Batch Normalization)处理,并接LeakyReLU激活函数。如图 3所示,我们通过加法运算合并五个并行支路的输出。神经网络最后两层是全连接层,中间通过丢弃层(dropout layer)连接。我们使用包含$10%$训练样本的验证集调整了神经网络超参数,包括滤波器数量、内核尺寸、丢弃率和训练周期数。在网络设计中,我们采用宽度扩展而非深度扩展策略,通过五个并行支路的同步计算显著提升了运算速度。

Figure 3: The proposed Neural Network for the audio classification task
图 3: 用于音频分类任务的神经网络
Table 1: Annotation Accuracy Results with a Labeling Budget of $15%$
表 1: 标注预算为 $15%$ 时的标注准确率结果
| 方法 | 策略 | 准确率 |
|---|---|---|
| SSCDE[6] | 半监督学习 (Semi-supervised Learning) | 35 |
| CRTAL+SSL[9,10] | 主动学习与半监督学习 | 50 |
| LDAL[11] | 基于词典的主动学习 | 55 |
| DBAL[12] | 基于词典的主动学习 | 57 |
| MAL[3] | 主动学习 (Active Learning) | 61 |
| 本工作 (FACE) | 上下文感知的主动学习 | 90 |
3 Implementation Results
3 实现结果
Following the convention of this paper’s references, [3, 6, 9, 10, 11, 12], we have tested our proposed context-aware annotation method on the Urban Sound 8 K dataset. As mentioned in Section 2, we assume a labeling budget of $15%$ , meaning that the labels are deterministic for only $15%$ of the data before the labeling process. Table 1 shows the labeling accuracy results, indicating $90%$ of accuracy, which is improved by $29%$ compared to the best previously reported works.
遵循本文参考文献[3, 6, 9, 10, 11, 12]的惯例,我们在Urban Sound 8K数据集上测试了提出的上下文感知标注方法。如第2节所述,我们假设标注预算为$15%$,即在标注过程前仅有$15%$的数据具有确定性标签。表1展示了标注准确率结果,达到$90%$的准确率,较先前最佳报道成果提升了$29%$。
For the sound classification task, we trained our neural network in 25 epochs using a $S G D$ optimizer with a learning rate of 0.01. We determine the maximum number of training epochs and the optimizer settings such that the classification accuracy on the validation data, $10%$ of the training set, reaches its highest value. Regarding the popularity of the Urban Sound 8 K dataset for the audio classification task, Table 2 shows the classification accuracy results on the Ura ban Sound 8 K dataset. As the results of Table 2 indicate, our proposed method achieved the classification accuracy of $98.05%$ , which is higher than any other reported works to date. Presenting another measure for our classification method’s quality assessment, Figure 4 depicts the classification confusion matrix for the Urban Sound 8 K dataset. To study the effect of Active Learning on classification accuracy enhancement, we let the Active Learner, a Python tool from the modAL package, inquire about the labels of some test set samples. We observed that it is possible to achieve $100%$ classification accuracy by providing the data labels for only $0.9%$ of the test data.
在声音分类任务中,我们使用学习率为0.01的$SGD$优化器对神经网络进行了25个周期的训练。通过调整最大训练周期数和优化器设置,确保验证数据(占训练集的$10%$)的分类准确率达到最高值。针对音频分类任务中广泛使用的Urban Sound 8K数据集,表2展示了在该数据集上的分类准确率结果。如表2所示,我们提出的方法实现了$98.05%$的分类准确率,高于目前所有已报道的研究成果。作为分类方法质量评估的另一项指标,图4呈现了Urban Sound 8K数据集的分类混淆矩阵。为研究主动学习(Active Learning)对分类准确率的提升效果,我们使用modAL包中的Python工具Active Learner对部分测试集样本的标签进行查询。实验表明,仅需标注$0.9%$的测试数据即可实现$100%$的分类准确率。
The notebooks containing our source codes and implementation results are available at https://github.com/gitmehrdad/FACE.
包含我们源代码和实现结果的笔记本可在 https://github.com/gitmehrdad/FACE 获取。
4 Conclusion
4 结论
This paper presented a fast, accurate, and context-aware method that can get employed to annotate and classify the audio signals. A context-aware approach utilized in feature selection, classifier design, and annotation algorithm design remarkably improves our methods’ accuracy in both annotation and classification tasks. The compact extracted features vector and the computationally efficient classification scheme avail a fast labeler, annotating nearly 8000 audio samples with $90%$ of accuracy in less than a minute using a free computing platform of Google Co laboratory. Our proposed method obtained an average classification accuracy of $98.05%$ on the US8K dataset. The achieved classification accuracy is the best-reported one compared to previous works. An Active Learning procedure boosts the classification accuracy to the value of $100%$ by asking for the labels of only $0.9%$ of the test data.
本文提出了一种快速、准确且上下文感知的方法,可用于音频信号的标注与分类。通过在特征选择、分类器设计和标注算法设计中采用上下文感知策略,我们的方法在标注和分类任务中的准确性得到显著提升。紧凑的特征向量提取和高效的计算分类方案使得标注速度大幅提高——在Google Colab免费计算平台上,仅用不到一分钟即可完成近8000个音频样本的标注(准确率达90%)。在US8K数据集上,本方法平均分类准确率达到98.05%,这是目前文献报道的最高水平。通过主动学习(Active Learning)流程,仅需标注0.9%的测试数据标签,即可将分类准确率提升至100%。
Table 2: Classification Accuracy Results
表 2: 分类准确率结果
| 方法 | 准确率 |
|---|---|
| MAL[3] | 65 |
| CRTAL+SSL[9,10] | 65 |
| DBAL[12] | 67 |
| LDAL[11] | 68 |
| CDSS[5] | 78 |
| AemNet-DW[24] | 83.6 |
| Graphwo/FFOntology[22] | 89.0 |
| TFCNN[25] | 93.1 |
| SacNet-8[18] | 95.3 |
| TSCNN[26] | 95.7 |
| TSCNN-DS[17] | 97.2 |
| MHAT[15] | 97.5 |
| Thiswork(FACE) | 98.05 |
| This work (FACE + Active Learning) | 100 |

Figure 4: The classification confusion matrix on the US8K dataset
图 4: US8K数据集上的分类混淆矩阵