SST: Self-training with Self-adaptive Threshold ing for Semi-supervised Learning
SST: 基于自适应阈值的半监督学习自训练方法
A R T I C L E I N F O
文章信息
A B S T R A C T
摘要
Neural networks have demonstrated exceptional performance in supervised learning, benefiting from abundant high-quality annotated data. However, obtaining such data in real-world scenarios is costly and labor-intensive. Semi-supervised learning (SSL) offers a solution to this problem by utilizing a small amount of labeled data along with a large volume of unlabeled data. Recent studies, such as Semi-ViT and Noisy Student, which employ consistency regular iz ation or pseudo-labeling, have demonstrated significant achievements. However, they still face challenges, particularly in accurately selecting sufficient high-quality pseudo-labels due to their reliance on fixed thresholds. Recent methods such as FlexMatch and FreeMatch have introduced flexible or self-adaptive threshold ing techniques, greatly advancing SSL research. Nonetheless, their process of updating thresholds at each iteration is deemed time-consuming, computationally intensive, and potentially unnecessary. To address these issues, we propose Self-training with Self-adaptive Threshold ing (SST), a novel, effective, and efficient SSL framework. SST integrates with both supervised (Super-SST) and semi-supervised (Semi-SST) learning. SST introduces an innovative Self-Adaptive Threshold ing (SAT) mechanism that adaptively adjusts class-specific thresholds based on the model’s learning progress. SAT ensures the selection of high-quality pseudo-labeled data, mitigating the risks of inaccurate pseudo-labels and confirmation bias (where models reinforce their own mistakes during training). Specifically, SAT prevents the model from prematurely incorporating low-confidence pseudo-labels, reducing error reinforcement and enhancing model performance. Extensive experiments demonstrate that SST achieves state-ofthe-art performance with remarkable efficiency, generalization, and s cal ability across various architectures and datasets. Notably, Semi-SST-ViT-Huge achieves the best results on competitive ImageNet-1K SSL benchmarks (no external data), with $80.7%/84.9%$ Top-1 accuracy using only $1%%10%$ labeled data. Compared to the fully-supervised DeiT-III-ViT-Huge, which achieves $84.8%$ Top-1 accuracy using $100%$ labeled data, our method demonstrates superior performance using only $10%$ labeled data. This indicates a tenfold reduction in human annotation costs, significantly narrowing the performance disparity between semi-supervised and fullysupervised methods. These advancements pave the way for further innovations in SSL and practical applications where obtaining labeled data is either challenging or costly.
神经网络在监督学习中表现出色,这得益于大量高质量的标注数据。然而,在实际场景中获取此类数据成本高昂且费时费力。半监督学习(SSL)通过结合少量标注数据和大量未标注数据,为解决这一问题提供了方案。近期研究如Semi-ViT和Noisy Student采用一致性正则化或伪标签技术取得了显著成果,但仍面临挑战——尤其是依赖固定阈值导致难以准确选择足够高质量的伪标签。FlexMatch和FreeMatch等最新方法引入了灵活或自适应的阈值技术,极大推动了SSL研究,但其逐轮迭代更新阈值的过程被认为耗时、计算密集且可能非必要。
针对这些问题,我们提出了一种新颖、高效且有效的SSL框架——自适应阈值自训练(SST),该框架可同时集成监督学习(Super-SST)与半监督学习(Semi-SST)。SST创新性地设计了自适应阈值(SAT)机制,能够根据模型学习进度动态调整类别特定阈值,确保筛选高质量伪标注数据,从而降低错误伪标签和确认偏误(模型在训练中强化自身错误)的风险。具体而言,SAT能阻止模型过早引入低置信度伪标签,减少错误强化并提升性能。
大量实验表明,SST在不同架构和数据集上均以卓越的效率、泛化性和扩展性实现了最先进性能。值得注意的是,Semi-SST-ViT-Huge在竞争性ImageNet-1K SSL基准测试(无外部数据)中取得最佳结果:仅用$1%/10%$标注数据便达到$80.7%/84.9%$的Top-1准确率。相比使用$100%$标注数据达到$84.8%$准确率的全监督DeiT-III-ViT-Huge,我们的方法仅用$10%$标注数据即展现出更优性能,这意味着人类标注成本可降低十倍,显著缩小了半监督与全监督方法的性能差距。这些进展为SSL创新及标注数据获取困难或成本高昂的实际应用铺平了道路。
1. Introduction
1. 引言
Neural networks have demonstrated exceptional performance in various supervised learning tasks [1, 2, 3], benefiting from abundant high-quality annotated data. However, obtaining sufficient high-quality annotated data in real-world scenarios can be both costly and labor-intensive. Therefore, learning from a few labeled examples while effectively utilizing abundant unlabeled data has become a pressing challenge. Semi-supervised learning (SSL) [4, 5, 6, 7] offers a solution to this problem by utilizing a small amount of labeled data along with a large volume of unlabeled data.
神经网络在各种监督学习任务中表现卓越 [1, 2, 3],这得益于大量高质量的标注数据。然而,在现实场景中获取足够的高质量标注数据既昂贵又耗时。因此,如何从少量标注样本中学习,同时有效利用大量未标注数据,已成为亟待解决的挑战。半监督学习 (SSL) [4, 5, 6, 7] 通过结合少量标注数据和大量未标注数据,为解决这一问题提供了方案。
Consistency regular iz ation, pseudo-labeling, and self-training are prominent SSL methods. Consistency regularization [8, 9, 10, 11, 12, 13, 14, 15] promotes the model to yield consistent predictions for the same unlabeled sample under various perturbations, thereby enhancing model performance. Pseudo-labeling and self-training [16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 11, 6, 28, 29, 30, 31, 32, 33, 34] are closely related in SSL. Pseudo-labeling assigns labels to unlabeled data, while self-training iterative ly uses these pseudo-labels to enhance model performance.
一致性正则化 (Consistency regularization) 、伪标注 (pseudo-labeling) 和自训练 (self-training) 是半监督学习 (SSL) 中的主要方法。一致性正则化 [8, 9, 10, 11, 12, 13, 14, 15] 促使模型在不同扰动下对同一无标注样本产生一致的预测,从而提升模型性能。伪标注与自训练 [16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 11, 6, 28, 29, 30, 31, 32, 33, 34] 在半监督学习中紧密关联——伪标注为无标注数据分配标签,而自训练则迭代使用这些伪标签来优化模型性能。
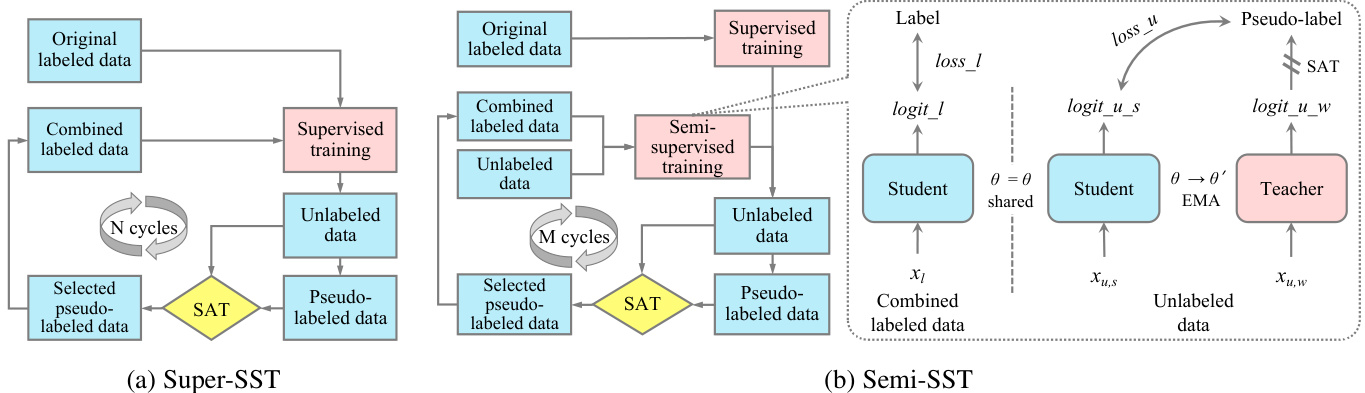
Figure 1: Illustration of the Self-training with Self-adaptive Threshold ing (SST) framework. Our SST can be integrated with either supervised or semi-supervised algorithms, referred to as Super-SST and Semi-SST, respectively. Self-Adaptive Threshold ing (SAT) is a core mechanism in our SST frameworks, accurately and adaptively adjusting class-specific thresholds according to the learning progress of the model. This ensures both high quality and sufficient quantity of selected pseudo-labeled data.
图 1: 自适应阈值自训练 (SST) 框架示意图。我们的 SST 可与监督或半监督算法结合使用,分别称为 Super-SST 和 Semi-SST。自适应阈值 (SAT) 是 SST 框架的核心机制,能根据模型学习进度精准动态调整各类别阈值,确保所选伪标签数据兼具高质量与足量性。
Recent studies, such as Semi-ViT [35] and Noisy Student [27], which employ consistency regular iz ation, pseudolabeling, or self-training, have demonstrated significant achievements. However, they still face challenges, particularly in accurately selecting sufficient high-quality pseudo-labels due to their reliance on fixed thresholds. Recent methods such as FlexMatch [31] and FreeMatch [36] have introduced flexible or self-adaptive threshold ing techniques, greatly advancing SSL research. Nonetheless, their process of updating thresholds at each iteration is deemed time-consuming, computationally intensive, and potentially unnecessary. Moreover, both FlexMatch and FreeMatch predict unlabeled data and update thresholds based on models that are still in training, rather than on converged models with high accuracy. During the early stages of training, using lower-performance models to predict unlabeled data inevitably introduces more inaccurate pseudo-labels, leading to a feedback loop of increasing inaccuracies. This amplifies and reinforces the confirmation bias [25, 37, 38] during training, ultimately resulting in suboptimal performance.
近期研究如Semi-ViT [35]和Noisy Student [27]通过采用一致性正则化、伪标签或自训练策略取得了显著成果。然而这些方法仍面临挑战,尤其是由于依赖固定阈值而难以准确筛选足够数量的高质量伪标签。FlexMatch [31]和FreeMatch [36]等最新技术引入了灵活或自适应的阈值调整机制,极大推动了半监督学习(SSL)研究进展。但它们在每次迭代时更新阈值的流程被认为存在耗时、计算密集且可能非必要的问题。此外,FlexMatch和FreeMatch都基于尚未收敛的训练中模型(而非高精度收敛模型)来预测未标注数据并更新阈值。在训练初期使用低性能模型预测未标注数据,必然会引入更多不准确的伪标签,形成误差不断累积的反馈循环。这种现象会放大并强化训练过程中的确认偏差(confirmation bias) [25,37,38],最终导致模型性能欠佳。
To address the aforementioned issues, we propose Self-training with Self-adaptive Threshold ing (SST), a novel, effective, and efficient SSL framework that significantly advances the field of SSL. As illustrated in Figure 1, our SST framework can be integrated with either supervised or semi-supervised algorithms. We refer to the combination of supervised training and SST as Super-SST, and the combination of semi-supervised training and SST as Semi-SST. Our SST introduces an innovative Self-Adaptive Threshold ing (SAT) mechanism, which accurately and adaptively adjusts class-specific thresholds according to the learning progress of the model. This approach ensures both high quality and sufficient quantity of selected pseudo-labeled data, mitigating the risks of inaccurate pseudo-labels and confirmation bias, thereby enhancing overall model performance.
为解决上述问题,我们提出了一种新颖、高效且有效的自监督学习框架——自适应阈值自训练(Self-training with Self-adaptive Thresholding,简称SST)。如图1所示,该框架可与监督或半监督算法结合使用,其中监督训练与SST的结合称为Super-SST,半监督训练与SST的结合称为Semi-SST。SST的核心创新在于自适应阈值机制(SAT),它能根据模型学习进度动态调整各类别阈值,确保所选伪标签数据兼具高质量与足量性,从而降低伪标签错误和确认偏差的风险,最终提升模型整体性能。
SAT differs from existing dynamic threshold ing methods like FlexMatch and FreeMatch in three key aspects:
SAT与现有动态阈值方法(如FlexMatch和FreeMatch)存在三个关键差异:
• Threshold Derivation: SAT adopts a confidence-based approach, applying a cutoff $C$ to filter out low-confidence probabilities per class, then averaging the remaining probabilities and scaling by a factor $S$ to derive class-specific thresholds. Unlike FlexMatch, which relies on curriculum learning based on predicted unlabeled sample counts and a global threshold, SAT avoids such dependencies. Unlike FreeMatch, which uses exponential moving averages (EMA) and a global threshold without low-confidence filtering, SAT introduces a cutoff mechanism while dispensing with both EMA and global threshold.
• 阈值推导:SAT采用基于置信度的方法,通过设定截断值$C$来过滤每类的低置信度概率,然后对剩余概率取平均值并用缩放因子$S$调整,从而得到类别特定阈值。不同于FlexMatch依赖基于预测未标记样本数量和全局阈值的课程学习机制,SAT避免了此类依赖。与FreeMatch使用指数移动平均(EMA)和全局阈值但未进行低置信度过滤不同,SAT在摒弃EMA和全局阈值的同时引入了截断机制。
• Threshold Updates: SAT updates thresholds once per training cycle using a well-trained model, limiting updates to single digits. This substantially reduces computational overhead and mitigates confirmation bias. In contrast, FlexMatch and FreeMatch update thresholds every iteration (e.g., over 1,000,000 updates) using a model still in training, incurring substantial computational cost and exacerbating confirmation bias during early training.
• 阈值更新: SAT 每个训练周期使用训练良好的模型更新一次阈值,将更新次数限制在个位数。这大幅降低了计算开销并缓解了确认偏差。相比之下,FlexMatch 和 FreeMatch 每次迭代(例如超过 1,000,000 次更新)都使用仍在训练中的模型更新阈值,导致巨大的计算成本并在训练早期加剧确认偏差。
• Empirical Advantages: Extensive empirical evaluations demonstrate SAT’s advantages across multiple benchmarks. For instance, on CIFAR-100 with 400, 2500, and 10000 labels, FreeMatch attains a mean error rate of $28.71%$ using about 240 GPU hours. In contrast, Super-SST and Semi-SST, powered by SAT’s mechanism, achieve lower mean error rates of $22.74%$ and $20.50%$ , respectively, with only 3 and 4 GPU hours, yielding speedups of $80\times$ and $60\times$ .
• 实证优势:大量实证评估表明,SAT在多个基准测试中均展现出优势。例如,在标注量为400、2500和10000的CIFAR-100数据集上,FreeMatch的平均错误率为$28.71%$,耗时约240 GPU小时;而基于SAT机制的Super-SST和Semi-SST仅用3/4 GPU小时就分别实现了$22.74%$和$20.50%$的更优平均错误率,计算效率提升达$80\times$和$60\times$。
Table 1 Comparison of Super-SST and Semi-SST.
表 1: Super-SST与Semi-SST对比
| 对比维度 | Super-SST | Semi-SST |
|---|---|---|
| 核心训练算法 | 监督训练算法 | 半监督训练算法 (EMA-Teacher) |
| 伪标签生成 | 仅离线 | 离线与在线 |
| SAT应用场景 | 离线伪标签筛选 | 离线与在线伪标签筛选 |
| 训练数据 | 离线混合标注数据 (原始数据+SAT筛选伪标签,视作人工标注) | 离线混合标注数据与在线伪标注数据 |
| 损失函数 | 交叉熵损失 (CE) 作用于离线混合标注数据 (L) | 总损失=离线混合标注数据交叉熵损失 + 在线伪标注数据加权交叉熵损失 (C = L + μLu) |
The Super-SST pipeline, illustrated in Figure 1a, consists of several steps: 1) Initialize the model with the original labeled data. 2) Utilize the well-trained, high-performance model to predict the unlabeled data. 3) Apply Self-Adaptive Threshold ing (SAT) to accurately generate or adjust class-specific thresholds. 4) Select high-confidence and reliable pseudo-labels using the class-specific thresholds, reducing inaccurate pseudo-labels and mitigating confirmation bias. 5) Expand the labeled training set by combining the original labeled data with the carefully selected pseudo-labeled data, treating them equally. 6) Optimize the model’s performance using the combined labeled data. 7) Iterative training by returning to step 2, continuously refining the model over multiple cycles until its performance converges.
Super-SST流程如图1a所示,包含以下步骤:1) 使用原始标注数据初始化模型;2) 调用训练完备的高性能模型预测未标注数据;3) 应用自适应阈值(SAT)精确生成或调整类特定阈值;4) 通过类特定阈值筛选高置信度可靠伪标签,减少错误标注并缓解确认偏差;5) 将原始标注数据与精选伪标签数据等权合并,扩展训练集;6) 基于混合标注数据优化模型性能;7) 返回步骤2进行迭代训练,通过多轮循环持续优化模型直至性能收敛。
As illustrated in Figure 1b, Semi-SST enhances Super-SST’s offline pseudo-labeling pipeline by integrating an EMA-Teacher model [35], introducing dynamic online pseudo-labeling to complement the offline process. Specifically, in EMA-Teacher, the teacher model dynamically generates pseudo-labels online, while the student model is trained on both offline combined labeled data and these online pseudo-labeled data. Semi-SST thus employs both offline and online pseudo-labeling mechanisms, with SAT applied in both cases to ensure the selection of high-confidence pseudo-labels. Table 1 outlines the primary distinctions between Super-SST and Semi-SST.
如图 1b 所示,Semi-SST 通过集成 EMA-Teacher 模型 [35] 增强了 Super-SST 的离线伪标注流程,引入动态在线伪标注作为离线流程的补充。具体而言,在 EMA-Teacher 中,教师模型动态生成在线伪标注,而学生模型则在离线组合标注数据和这些在线伪标注数据上进行训练。因此,Semi-SST 同时采用离线和在线伪标注机制,并在两种情况下应用 SAT (Selective Annotation Training) 以确保筛选高置信度的伪标注。表 1 概述了 Super-SST 与 Semi-SST 的主要区别。
Extensive experiments and results strongly confirm the effectiveness, efficiency, generalization, and s cal ability of our methods across both CNN-based and Transformer-based architectures and various datasets, including ImageNet-1K, CIFAR-100, Food-101, and i Naturalist. Compared to supervised and semi-supervised baselines, our methods achieve a relative improvement of $0.7%{-20.7%}$ $(0.2%{-}12.1%)$ in Top-1 accuracy with only $1%$ $(10%)$ labeled data. Notably, Semi-SST-ViT-Huge achieves the best results on competitive ImageNet-1K SSL benchmarks (no external data), with $80.7%/84.9%$ Top-1 accuracy using only $1%/10%$ labeled data. Compared to the fully-supervised DeiT-III-ViT-Huge, which achieves $84.8%$ Top-1 accuracy using $100%$ labeled data, our method demonstrates superior performance using only $10%$ labeled data. This indicates a tenfold reduction in human annotation costs, significantly reducing the performance disparity between semi-supervised and fully-supervised methods. Moreover, our SST methods not only achieve high performance but also demonstrate remarkable efficiency, resulting in an exceptional cost-performance ratio. Furthermore, on the ImageNet-1K benchmark, Super-SST’s accuracy outperforms FlexMatch and FreeMatch by $6.27%$ and $4.99%$ , respectively, requiring only 3 threshold updates, while FlexMatch and FreeMatch demand over 1,000,000 threshold updates.
大量实验和结果有力证实了我们的方法在CNN和Transformer架构以及多种数据集(包括ImageNet-1K、CIFAR-100、Food-101和iNaturalist)上的有效性、高效性、泛化性和可扩展性。与监督学习和半监督学习基线相比,我们的方法仅使用$1%$ ($10%$)标注数据时,Top-1准确率相对提升了$0.7%{-20.7%}$ ($0.2%{-}12.1%$)。值得注意的是,Semi-SST-ViT-Huge在竞争激烈的ImageNet-1K半监督学习基准测试(无外部数据)中取得了最佳结果,仅使用$1%/10%$标注数据就实现了$80.7%/84.9%$的Top-1准确率。相比之下,完全监督的DeiT-III-ViT-Huge使用$100%$标注数据才达到$84.8%$的Top-1准确率,而我们的方法仅需$10%$标注数据就展现出更优性能。这意味着人工标注成本降低了十倍,显著缩小了半监督与全监督方法之间的性能差距。此外,我们的SST方法不仅实现了高性能,还表现出卓越的效率,具有极佳的成本效益比。在ImageNet-1K基准测试中,Super-SST的准确率分别比FlexMatch和FreeMatch高出$6.27%$和$4.99%$,且仅需3次阈值更新,而FlexMatch和FreeMatch则需要超过1,000,000次阈值更新。
In summary, our contributions are three-fold:
总之,我们的贡献主要体现在三个方面:
• We propose an innovative Self-training with Self-adaptive Threshold ing (SST) framework, along with its two variations: Super-SST and Semi-SST, significantly advancing the SSL field. • SST introduces a novel Self-Adaptive Threshold ing (SAT) technique, which accurately and adaptively adjusts class-specific thresholds according to the model’s learning progress. This mechanism ensures both the high
• 我们提出了一种创新的自训练与自适应阈值(Self-training with Self-adaptive Thresholding,SST)框架及其两种变体:Super-SST和Semi-SST,显著推动了自监督学习(SSL)领域的发展。
• SST引入了一种新颖的自适应阈值(Self-Adaptive Thresholding,SAT)技术,能够根据模型的学习进度准确且自适应地调整类别特定阈值。这一机制既保证了高...
Algorithm 1 PyTorch-like Pseudo-code of SST
算法 1: SST 的类 PyTorch 伪代码
Step 1: Initialize the model with original labeled data model $=$ initialize model(labeled data)
步骤1:用原始标注数据初始化模型 model = initialize model(labeled data)
Set hyper parameters max_cycles = 6
设置超参数 max_cycles = 6
or cycle in range(max_cycles): # Step 2: Predict unlabeled data with the well-trained high-performance model outputs $=$ model.predict(unlabeled data) probabilities $=$ softmax(outputs)
或循环范围内(max_cycles): # 步骤2: 用训练好的高性能模型预测未标注数据
outputs $=$ model.predict(未标注数据)
probabilities $=$ softmax(outputs)
Step 3: Generate class-specific thresholds with Self-Adaptive Threshold ing (SAT) class specific thresholds $=$ self adaptive threshold ing(probabilities)
步骤3:通过自适应阈值法(SAT)生成类别特定阈值
类别特定阈值 = 自适应阈值法(概率)
Step 5: Combine labeled data with selected pseudo-labeled data combined labeled data $=$ labeled data $^+$ pseudo labeled data
步骤5:将标注数据与选定的伪标注数据结合
combined labeled data $=$ labeled data $^+$ pseudo labeled data
Step 6: Optimize the model’s performance with the combined labeled data model.train(combined labeled data) # In Semi-SST, unlabeled data is also required here # Step 7: Return to step 2 for iterative training until the model’s performance converges if model.has converged():
步骤6:使用合并的标注数据优化模型性能
model.train(combined labeled data)
在Semi-SST中,此处还需要未标注数据
步骤7:返回步骤2进行迭代训练,直到模型性能收敛
if model.has converged():
Self-trained model is ready for inference self trained model $=$ model
自训练模型已准备好进行推理 自训练模型 $=$ 模型
quality and sufficient quantity of selected pseudo-labeled data, mitigating the risks of inaccurate pseudo-labels and confirmation bias, thereby enhancing overall model performance.
所选伪标签数据的质量和足够数量,减轻了不准确伪标签和确认偏差的风险,从而提升了整体模型性能。
• SST achieves state-of-the-art (SOTA) performance across various architectures and datasets while demonstrating remarkable efficiency, resulting in an exceptional cost-performance ratio. Moreover, SST significantly reduces the reliance on human annotation, bridging the gap between semi-supervised and fully-supervised learning.
• SST 在各种架构和数据集上实现了最先进的 (SOTA) 性能,同时展现出卓越的效率,从而具备出色的性价比。此外,SST 显著降低了对人工标注的依赖,缩小了半监督学习与全监督学习之间的差距。
The organization of this paper is as follows: Section 2 outlines the study’s objectives. Section 3 details the methodology. Section 4 describes the experiments and reports the results. Section 5 reviews related works, highlighting the differences between our methods and previous approaches. Section 6 and 7 presents the limitation and conclusion, respectively.
本文结构如下:第2节概述研究目标。第3节详述方法论。第4节描述实验并报告结果。第5节回顾相关工作,重点说明本研究方法与先前方法的差异。第6节与第7节分别阐述局限性与结论。
2. Research objectives
2. 研究目标
The SSL methods previously discussed in Section 1 either rely on fixed threshold ing or use costly and performancelimited dynamic threshold ing techniques to select pseudo-labels. Both approaches tend to introduce more noisy labels during the early training stages, leading to a feedback loop of increasing inaccuracies and reinforcing confirmation bias, ultimately resulting in suboptimal performance. To overcome these challenges, we propose the SST framework and its core component, the SAT mechanism. These innovations aim to accurately select high-quality and sufficient pseudo-labeled data during training, minimizing the risks of inaccuracies and confirmation bias, thereby enhancing overall model performance. We hope this paper will inspire future research and provide cost-effective solutions for practical applications where acquiring labeled data is challenging or costly.
1.1节讨论的SSL方法要么依赖固定阈值,要么采用昂贵且性能受限的动态阈值技术来选择伪标签。这两种方法在训练初期都容易引入更多噪声标签,导致误差累积的恶性循环并强化确认偏误,最终影响模型性能。为应对这些挑战,我们提出SST框架及其核心组件SAT机制。这些创新旨在训练过程中精准筛选充足的高质量伪标签数据,最大限度降低误差和确认偏误风险,从而提升模型整体性能。我们希望本文能启发后续研究,并为标注数据获取困难或成本高昂的实际应用场景提供经济高效的解决方案。
3. Methodology
3. 方法论
Figure 1 provides a visual overview of SST, while Algorithm 1 presents its pseudo-code implementation. The algorithm is organized into several distinct steps:
图 1: SST的视觉概览,而算法 1 则展示了其伪代码实现。该算法分为以下几个不同步骤:
- Initialization. We initialize the model parameters $\theta$ using the original labeled samples . This initialization phase employs the standard Cross-Entropy (CE) loss Equation 1 to optimize the model’s initial parameters, ensuring a strong starting checkpoint for subsequent training phases.
- 初始化。我们使用原始标注样本 初始化模型参数 $\theta$。该初始化阶段采用标准交叉熵损失 (Cross-Entropy, CE) 公式1来优化模型的初始参数,为后续训练阶段提供稳健的起点。
$$
\mathcal{L}{l}=\frac{1}{N_{l}}\sum_{i=1}^{N_{l}}\mathbf{C}\mathbf{E}\left(f(x_{l i};\theta),y_{l i}\right)
$$
$$
\mathcal{L}{l}=\frac{1}{N_{l}}\sum_{i=1}^{N_{l}}\mathbf{C}\mathbf{E}\left(f(x_{l i};\theta),y_{l i}\right)
$$
- Prediction. We use the well-trained high-performance model $\theta$ to predict all unlabeled data , outputting the probabilities over $N_{c}$ classes.
- 预测。我们使用训练好的高性能模型 $\theta$ 预测所有未标注数据 ,输出 $N_{c}$ 个类别的概率分布。
$$
p_{u i}=\mathrm{softmax}(f(x_{u i};\theta))\quad\mathrm{for}\quad i=1,2,\ldots,N_{u}
$$
$$
p_{u i}=\mathrm{softmax}(f(x_{u i};\theta))\quad\mathrm{for}\quad i=1,2,\ldots,N_{u}
$$
This step produces an $N_{u}\times N_{c}$ probability matrix, where $N_{u}$ represents the number of unlabeled samples and $N_{c}$ denotes the total number of classes. Each element in this matrix corresponds to the predicted probability of a sample belonging to a particular class.
此步骤生成一个 $N_{u}\times N_{c}$ 的概率矩阵,其中 $N_{u}$ 表示未标记样本的数量,$N_{c}$ 代表类别总数。该矩阵中的每个元素对应样本属于特定类别的预测概率。
- Self-Adaptive Threshold ing (SAT). With the generated $N_{u}\times N_{c}$ probability matrix, we proceed to apply the SAT mechanism. The SAT mechanism is a pivotal component of the SST framework, designed to accurately and adaptively adjust class-specific thresholds according to the learning progress of the model. SAT mechanism involves several sub-steps.
- 自适应阈值调整 (SAT)。通过生成的 $N_{u}\times N_{c}$ 概率矩阵,我们开始应用SAT机制。该机制是SST框架的核心组件,旨在根据模型的学习进度精准且自适应地调整各类别特定阈值。SAT机制包含以下子步骤。
- Sorting: Given the $N_{u}\times N_{c}$ probability matrix $\mathbf{P}$ , where $\mathbf{P}{i,j}$ indicates the predicted probability of the $i\cdot$ -th unlabeled sample belonging to the $j$ -th class, we sort the probabilities for each class $j$ in descending order. Let $\mathbf{P}_{:,j}$ denote the vector of probabilities for class $j$ .
- 排序: 给定 $N_{u}\times N_{c}$ 概率矩阵 $\mathbf{P}$ ,其中 $\mathbf{P}{i,j}$ 表示第 $i$ 个未标记样本属于第 $j$ 个类别的预测概率。我们对每个类别 $j$ 的概率向量 $\mathbf{P}_{:,j}$ 进行降序排序。
$$
\mathbf{P}{:,j}^{\mathrm{sorted}}=\mathrm{sort}(\mathbf{P}_{:,j},\mathrm{descending})
$$
$$
\mathbf{P}{:,j}^{\mathrm{sorted}}=\mathrm{sort}(\mathbf{P}_{:,j},\mathrm{descending})
$$
$$
\mathbf{P}{:,j}^{\mathrm{filtered}}={p\in\mathbf{P}_{:,j}^{\mathrm{sorted}}\mid p>C}
$$
$$
\mathbf{P}{:,j}^{\mathrm{filtered}}={p\in\mathbf{P}_{:,j}^{\mathrm{sorted}}\mid p>C}
$$
- Average Calculation: We compute the average of the remaining probabilities for each class $j$ :
- 平均值计算:我们计算每个类别 $j$ 剩余概率的平均值:
$$
\bar{p}{j}=\frac{1}{|\mathbf{P}{:,j}^{\mathrm{filtered}}|}\sum_{p\in\mathbf{P}_{:,j}^{\mathrm{filtered}}}p
$$
$$
\bar{p}{j}=\frac{1}{|\mathbf{P}{:,j}^{\mathrm{filtered}}|}\sum_{p\in\mathbf{P}_{:,j}^{\mathrm{filtered}}}p
$$
where $\mathbf{\underline{{|}}P_{:,j}^{\mathrm{filtered}}|}$ is the number of filtered probabilities for class $j$ .
其中 $\mathbf{\underline{{|}}P_{:,j}^{\mathrm{filtered}}|}$ 表示类别 $j$ 的过滤后概率数量。
- |Thresho|ld Scaling: We then multiply the average value of each class $j$ by a scaling factor $S$ to obtain the class-specific thresholds 𝜏𝑗 :
- 阈值缩放 (Threshold Scaling): 我们将每个类别 $j$ 的平均值乘以缩放因子 $S$,得到类别特定阈值 𝜏𝑗:
$$
\tau_{j}=S\cdot\bar{p}{j}\quad\mathrm{for}\quad j=1,2,\dots,N_{c}
$$
$$
\tau_{j}=S\cdot\bar{p}{j}\quad\mathrm{for}\quad j=1,2,\dots,N_{c}
$$
The SAT mechanism ensures that lower, less reliable probabilities do not influence the threshold computation, thereby maintaining the reliability and quality of the pseudo-labeling process.
SAT机制确保较低且可靠性较差的概率不会影响阈值计算,从而维持伪标签过程的可靠性和质量。
- Selection. We use the class-specific thresholds to select high-confidence and reliable pseudo-labels, reducing the introduction of inaccurate pseudo-labels and mitigating confirmation bias. For each unlabeled sample ,p tlhe eisu dsoel-leacbteeld ias s par op d sue cued do -blya $\hat{y}{u i}=\arg\operatorname*{max}{j}p_{u i,j}$ .associated confidence $\hat{p}{u i}=\operatorname*{max}{j}p_{u i,j}$ . An $x_{u i}$ $\hat{p}{u i}>\tau_{\hat{y}_{u i}}$
- 选择。我们使用类别特定阈值 来筛选高置信度且可靠的伪标签,减少不准确伪标签的引入并缓解确认偏差。对于每个无标签样本 ,其伪标签被选择为 $\hat{y}{u i}=\arg\operatorname*{max}{j}p_{u i,j}$,关联置信度为 $\hat{p}{u i}=\operatorname*{max}{j}p_{u i,j}$。当 $\hat{p}{u i}>\tau_{\hat{y}{u i}}$ 时,样本 $x_{u i}$ 被选中。
$$
\hat{y}{u i}=\arg\operatorname*{max}{j}p_{u i,j}
$$
$$
\hat{y}{u i}=\arg\operatorname*{max}{j}p_{u i,j}
$$
$$
\hat{p}{u i}=\operatorname*{max}{j}p_{u i,j}
$$
$$
\hat{p}{u i}=\operatorname*{max}{j}p_{u i,j}
$$
- Combination. We combine the labeled data with the carefully selected high-confidence pseudo-labeled data, thereby expanding the labeled training set.
- 组合。我们将标注数据与精心筛选的高置信度伪标注数据相结合,从而扩展标注训练集。
$$
{(x_{i},y_{i})}{i=1}^{N_{l+u}}={(x_{l i},y_{l i})}{i=1}^{N_{l}}\cup{(x_{u i},\hat{y}{u i})\mid\hat{p}{u i}>\tau_{\hat{y}{u i}}}{i=1}^{N_{u}}
$$
$$
{(x_{i},y_{i})}{i=1}^{N_{l+u}}={(x_{l i},y_{l i})}{i=1}^{N_{l}}\cup{(x_{u i},\hat{y}{u i})\mid\hat{p}{u i}>\tau_{\hat{y}{u i}}}{i=1}^{N_{u}}
$$
- Optimization. In the Super-SST framework, the model is optimized on the offline combined labeled data using the standard CE loss, as defined in Equation 1. As discussed in Section 1, the high-confidence pseudo-labeled data included in the combined labeled data are selected offline via SAT and are treated as equally reliable as human-labeled data. In contrast, Semi-SST is built upon an EMA-Teacher framework, where the teacher model dynamically generates pseudo-labels during training, and the student model is trained on both offline combined labeled data and online pseudo-labeled data. We optimize the student model’s performance using the total loss function $\mathcal{L}$ , which consists of the CE loss for offline combined labeled data $\mathcal{L}{l}$ and the CE loss for online pseudo-labeled data $\mathcal{L}{u}$ , weighted by a factor $\mu$ to control the contribution of the $\mathcal{L}_{u}$ . This formulation ensures that the model benefits from both high-confidence offline pseudo-labels and dynamic online pseudo-labeling, with SAT filtering applied in both cases to maintain pseudo-label reliability.
- 优化。在Super-SST框架中,模型通过标准交叉熵损失(CE loss)在离线组合标注数据上进行优化,如公式1所定义。如第1节所述,组合标注数据中包含的高置信度伪标签数据是通过SAT离线筛选的,其可靠性被视为与人工标注数据等同。相比之下,Semi-SST基于EMA-Teacher框架构建,其中教师模型在训练期间动态生成伪标签,学生模型则在离线组合标注数据和在线伪标签数据上进行训练。我们使用总损失函数$\mathcal{L}$优化学生模型性能,该函数由离线组合标注数据的CE损失$\mathcal{L}{l}$和在线伪标签数据的CE损失$\mathcal{L}{u}$组成,并通过系数$\mu$控制$\mathcal{L}_{u}$的贡献权重。这种设计确保模型既能利用高置信度的离线伪标签,又能受益于动态在线伪标注技术,且两种情况下都应用SAT过滤机制以保证伪标签可靠性。
$$
\mathcal{L}=\mathcal{L}{l}+\mu\mathcal{L}_{u},
$$
$$
\mathcal{L}=\mathcal{L}{l}+\mu\mathcal{L}_{u},
$$
$$
\mathcal{L}{u}=\frac{1}{{{N}{u}}}\sum_{i=1}^{{N}{u}}\left[{\hat{p}{u i}}>{{\tau}{\hat{y}{u i}}}\right]\cdot\mathbb{C}\mathbb{E}\left({f({x}{u i};\theta),\hat{y}_{u i}}\right),
$$
$$
\mathcal{L}{u}=\frac{1}{{{N}{u}}}\sum_{i=1}^{{N}{u}}\left[{\hat{p}{u i}}>{{\tau}{\hat{y}{u i}}}\right]\cdot\mathbb{C}\mathbb{E}\left({f({x}{u i};\theta),\hat{y}_{u i}}\right),
$$
where $[\cdot]$ is the indicator function, and $\tau_{\hat{y}{u i}}$ is the threshold of class $\hat{y}_{u i}$ .
其中 $[\cdot]$ 是指示函数,$\tau_{\hat{y}{u i}}$ 是类别 $\hat{y}_{u i}$ 的阈值。
As illustrated in Figure 1b, for an unlabeled sample $x_{u}$ , both weak and strong augmentations are applied, generating $x_{u,w}$ and $x_{u,s}$ , respectively. The weakly-augmented $x_{u,w}$ is processed by the teacher network, outputting probabilities over classes. The pseudo-label is generated as described previously. The pseudo-labels selected by SAT can be used to guide the student model’s learning on the strongly-augmented $x_{u,s}$ , minimizing the CE loss. In Semi-SST’s semi-supervised training, we utilize the EMA-Teacher algorithm, updating the teacher model parameters $\theta^{\prime}$ through exponential moving average (EMA) from the student model parameters $\theta$ :
如图 1b 所示,对于未标记样本 $x_{u}$,同时应用弱增强和强增强,分别生成 $x_{u,w}$ 和 $x_{u,s}$。弱增强的 $x_{u,w}$ 通过教师网络处理,输出类别概率。伪标签的生成方式如前所述。SAT 筛选的伪标签可用于指导学生模型在强增强样本 $x_{u,s}$ 上的学习,从而最小化交叉熵损失。在 Semi-SST 的半监督训练中,我们采用 EMA-Teacher 算法,通过学生模型参数 $\theta$ 的指数移动平均 (EMA) 更新教师模型参数 $\theta^{\prime}$:
$$
\theta^{\prime}:=m\theta^{\prime}+(1-m)\theta,
$$
$$
\theta^{\prime}:=m\theta^{\prime}+(1-m)\theta,
$$
where the momentum decay $m$ is a number close to 1, such as 0.9999.
动量衰减 $m$ 是一个接近1的数,例如0.9999。
- Iterative training. Return to the prediction step for iterative training, continuously refining the model over multiple cycles until its performance converges. More details of the pipeline can be found in Figure 1 and Algorithm 1.
- 迭代训练。返回预测步骤进行迭代训练,通过多轮循环持续优化模型直至性能收敛。更多流程细节见图1和算法1。
4. Experiments and results
4. 实验与结果
4.1. Datasets and implementation details
4.1. 数据集与实现细节
Datasets. As shown in Table 2, we conduct experiments on eight publicly accessible benchmark datasets: ImageNet1K, Food-101, i Naturalist, CIFAR-100, CIFAR-10, SVHN, STL-10, and Clothing-1M. These datasets collectively provide a comprehensive benchmark for evaluating the performance of SSL algorithms across a wide variety of domains and complexities. All SSL experiments in this paper are performed on randomly sampled labeled data from the training set of each dataset.
数据集。如表 2 所示,我们在八个公开可用的基准数据集上进行了实验:ImageNet1K、Food-101、i Naturalist、CIFAR-100、CIFAR-10、SVHN、STL-10 和 Clothing-1M。这些数据集共同为评估自监督学习 (SSL) 算法在不同领域和复杂度下的性能提供了全面的基准。本文中所有 SSL 实验均在从各数据集训练集中随机采样的带标签数据上进行。
• ImageNet-1K [1] covers a broad spectrum of real-world objects, which is extensively used in computer vision tasks. It contains approximately 1.28M training images and 50K validation images, divided into 1,000 categories.
• ImageNet-1K [1] 涵盖了现实世界物体的广泛类别,被广泛应用于计算机视觉任务。它包含约128万张训练图像和5万张验证图像,划分为1000个类别。
Table 2 All experiments in this paper are performed on eight publicly accessible benchmark datasets.
表 2 本文所有实验均在八个公开可用的基准数据集上进行。
| 数据集 | 训练数据量 | 测试数据量 | 类别数 |
|---|---|---|---|
| ImageNet-1K[1] | 1,281,167 | 50,000 | 1,000 |
| iNaturalist [40] | 265,213 | 3,030 | 1,010 |
| Food-101[39] | 75,750 | 25,250 | 101 |
| CIFAR-100[41] | 50,000 | 10,000 | 100 |
| CIFAR-10[41] | 50,000 | 10,000 | 10 |
| SVHN [42] | 73,257 | 26,032 | 10 |
| STL-10 [43] | 5,000 | 8,000 | 10 |
| Clothing-1M [44] | 1,047,570 | 10,526 | 14 |
• Food-101 [39] consists of 101K food images across 101 categories. Each class contains 1,000 images, divided into 750 training images and 250 test images.
• Food-101 [39] 包含101个类别的10.1万张食物图像。每个类别包含1,000张图像,其中750张为训练图像,250张为测试图像。
• i Naturalist [40] is derived from the i Naturalist community, which documents biodiversity across the globe. It contains 256,213 training images and 3,030 test images, covering 1,010 classes of living organisms.
• i Naturalist [40] 源自记录全球生物多样性的 i Naturalist 社区,包含 256,213 张训练图像和 3,030 张测试图像,涵盖 1,010 类生物体。
• CIFAR-100 [41] covers a diverse range of real-world objects and animals. It contains 60K $32\times32$ images divided into 100 categories, with each class containing 500 training images and 100 testing images.
• CIFAR-100 [41] 涵盖了多样化的现实世界物体和动物。它包含 6 万张 $32\times32$ 图像,分为 100 个类别,每个类别包含 500 张训练图像和 100 张测试图像。
• CIFAR-10 [41] comprises 60K $32\times32$ color images divided into 10 distinct categories, with each class containing 5,000 training images and 1,000 testing images.
• CIFAR-10 [41] 包含 6 万张 $32\times32$ 的彩色图像,分为 10 个不同类别,每个类别包含 5,000 张训练图像和 1,000 张测试图像。
• SVHN [42] is a real-world dataset for digit recognition obtained from house numbers in Google Street View images. It contains 73,257 training samples and 26,032 testing samples across 10 digit classes, with an additional 531,131 supplementary images.
• SVHN [42] 是一个真实场景下的数字识别数据集,源自 Google 街景图像中的门牌号。它包含 10 个数字类别的 73,257 个训练样本和 26,032 个测试样本,另有 531,131 张补充图像。
• STL-10 [43] consists of 13K $.96\times96$ color images divided into 10 classes. Each category includes 500 labeled training images and 800 testing images, supplemented by 100K unlabeled images.
• STL-10 [43] 包含13,000张96×96像素的彩色图像,分为10个类别。每个类别包含500张带标注的训练图像和800张测试图像,并额外提供10万张未标注图像。
• Clothing-1M [44] is a large-scale dataset containing approximately 1 million images of clothing collected from online shopping websites. The images are annotated with noisy labels across 14 categories, and the dataset is split into 47,570 clean labeled training images, 1M noisy labeled training images, 14,313 validation images and 10,526 testing images, making it a challenging benchmark for learning with noisy labels.
• Clothing-1M [44] 是一个包含约100万张从购物网站收集的服装图像的大规模数据集。这些图像被标注了14个类别的噪声标签,数据集划分为47,570张干净标注的训练图像、100万张噪声标注的训练图像、14,313张验证图像和10,526张测试图像,使其成为带噪声标签学习的一个具有挑战性的基准。
Architectures. For transformer neural networks, we utilize the standard Vision Transformer (ViT) architectures [45], which consist of a stack of Transformer blocks. Each block includes a multi-head self-attention layer and a multi-layer perceptron (MLP) block. We use average pooling of the ViT output for classification. Following Semi-ViT, we directly use the pretrained ViT-Small from DINO [46], ViT-Base and ViT-Huge from MAE [47], which have learned useful visual representations for downstream tasks. For convolutional neural networks, we utilize the standard ConvNeXt architecture [48], which incorporates mixup strategy [49] for enhanced results, instead of the traditional ResNet [50]. Note that self-supervised pre training is optional in our methods. We train the ConvNeXt architecture from scratch without any pre training.
架构。对于Transformer神经网络,我们采用标准的Vision Transformer (ViT)架构[45],该架构由一系列Transformer模块堆叠而成。每个模块包含多头自注意力层和多层感知机(MLP)模块。我们使用ViT输出的平均池化进行分类。遵循Semi-ViT的做法,我们直接使用DINO[46]预训练的ViT-Small、MAE[47]提供的ViT-Base和ViT-Huge,这些模型已学习到对下游任务有用的视觉表征。对于卷积神经网络,我们采用标准ConvNeXt架构[48],该架构融合了mixup策略[49]以提升性能,而非传统的ResNet[50]。需注意自监督预训练在我们的方法中是可选项。ConvNeXt架构完全从头开始训练,未使用任何预训练权重。
Implementation details. Our training protocol largely follows the good practice in Semi-ViT, with minor differences. The optimization of model is performed using AdamW [51], with linear learning rate scaling rule [52] $l r=b a s e_l r\times b a t c h s i z e/256$ and cosine learning rate decay schedule [53]. Additionally, we incorporate label smoothing [54], drop path [55], and cutmix [56] in our experiments. For fair comparisons, we use a center crop of $224\times224$ during training and testing. The data augmentation strategy follows the methods described in [35, 57, 58]. Detailed hyper-parameter settings are provided in Table 10.
实现细节。我们的训练方案基本遵循 Semi-ViT 的良好实践,仅有细微差异。模型优化使用 AdamW [51] ,采用线性学习率缩放规则 [52] $l r=b a s e_l r\times b a t c h s i z e/256$ 和余弦学习率衰减策略 [53] 。此外,我们在实验中引入了标签平滑 [54] 、随机路径丢弃 [55] 和 CutMix [56] 。为确保公平比较,训练和测试阶段均采用 $224\times224$ 的中心裁剪。数据增强策略遵循 [35, 57, 58] 所述方法。详细超参数设置见 表 10 。
4.2. Comparison with baselines
4.2. 与基线对比
Table 3 presents a comparison of Super-SST against supervised baselines and Semi-SST against semi-supervised baselines. This comparison covers both CNN-based and Transformer-based architectures across various datasets, including ImageNet-1K, CIFAR-100, Food-101, and i Naturalist, with $1%$ and $10%$ labeled data. Due to computational resource constraints, we only performed experiments with ConvNeXt-T on $10%$ ImageNet-1K labels.
表 3: Super-SST与监督基线方法、Semi-SST与半监督基线方法的对比结果。该对比涵盖了基于CNN和Transformer的多种架构,涉及ImageNet-1K、CIFAR-100、Food-101及iNaturalist数据集,并测试了1%和10%标注数据比例。由于计算资源限制,我们仅在10%标注数据的ImageNet-1K上进行了ConvNeXt-T架构的实验。
Table 3 Comparison with both supervised and semi-supervised baselines across various datasets and architectures. The performance gaps to the baselines are indicated in brackets. The results of supervised baseline are implemented by us. Semi-ViT did not conduct experiments on CIFAR-100, resulting in the absence of corresponding results.
表 3 不同数据集和架构下有监督与半监督基线的对比。括号内表示与基线的性能差距。有监督基线结果由我们实现。Semi-ViT未在CIFAR-100上进行实验,故缺少相应结果。
| 数据集 | 架构 | 参数量 | 方法 | 1% | 10% |
|---|---|---|---|---|---|
| ImageNet-1K | ViT-Small | 22M | Supervised Super-SST (ours) | 60.3 70.4 (+10.1) | 74.3 78.3 (+4.0) |
| Semi-ViT Semi-SST (ours) | 68.0 71.4 (+3.4) | 77.1 78.6 (+1.5) | |||
| ViT-Huge | 632M | Supervised Super-SST (ours) | 73.7 80.3 (+6.6) | 81.8 84.8 (+3.0) | |
| Semi-ViT Semi-SST (ours) | 80.0 80.7 (+0.7) | 84.3 84.9 (+0.6) | |||
| ConvNeXt-T | 28M | Supervised Super-SST (ours) | 65.8 77.9 (+12.1) | ||
| Semi-ViT Semi-SST (ours) | 74.1 78.6 (+4.5) | ||||
| CIFAR-100 | ViT-Small | 22M | Supervised Super-SST (ours) | 53.7 68.1 (+14.4) | 79.8 84.1 (+4.3) |
| Semi-ViT Semi-SST (ours) | 72.3 | 84.7 | |||
| Food-101 | ViT-Base | 86M | Supervised Super-SST (ours) | 62.7 83.4 (+20.7) | 84.6 91.1 (+6.5) |
| Semi-ViT Semi-SST (ours) | 82.1 86.5 (+4.4) | 91.3 | |||
| iNaturalist | ViT-Base | 86M | Supervised Super-SST (ours) | 22.6 | 91.5 (+0.2) 57.5 |
| Semi-ViT Semi-SST (ours) | 25.6 (+3.0) 32.3 33.4 (+1.1) | 65.3 (+7.8) 67.7 68.1 (+0.4) |
Effectiveness and generalization. As shown in Table 3, both Super-SST and Semi-SST consistently outperform their respective supervised and semi-supervised baselines across various datasets, demonstrating strong generalization capabilities. Notably, both CNN and Transformer architectures benefit significantly from Super-SST and Semi-SST, underscoring their effectiveness and robustness across different architectures.
效果与泛化性。如表 3 所示,Super-SST 和 Semi-SST 在各类数据集上均稳定超越其对应的全监督与半监督基线方法,展现出强大的泛化能力。值得注意的是,CNN 和 Transformer 架构均显著受益于 Super-SST 和 Semi-SST,这印证了二者在不同架构间的有效性与鲁棒性。
Data Efficiency. Table 3 also demonstrates that both Super-SST and Semi-SST maintain robust performance improvements across different percentages of labeled data. They achieve a relative improvement of $0.7%-20.7%$ with $1%$ labeled data and $0.2%{-}12.1%$ with $10%$ labeled data in Top-1 accuracy. The improvements are more pronounced with a smaller percentage of labeled data $(e.g.,1%)$ , indicating that Super-SST and Semi-SST are particularly effective in low-data regimes, making them suitable for data-efficient learning. As the amount of labeled data increases from $1%$ to $10%$ , the relative improvements decrease, indicating diminishing returns with more labeled data.
数据效率。表 3 还表明,Super-SST 和 Semi-SST 在不同比例的标注数据下均保持了稳健的性能提升。在 Top-1 准确率上,它们使用 1% 标注数据时实现了 $0.7%-20.7%$ 的相对提升,使用 10% 标注数据时实现了 $0.2%{-}12.1%$ 的相对提升。标注数据比例较小时 (例如 1%),改进更为显著,这表明 Super-SST 和 Semi-SST 在低数据场景下特别有效,适用于高效数据学习。随着标注数据量从 $1%$ 增加到 $10%$,相对改进逐渐减小,表明更多标注数据带来的收益递减。
S cal ability. As presented in Table 3, both Super-SST and Semi-SST show significant improvements with larger architectures like ViT-Huge, indicating better s cal ability with increased model capacity. For example, with $1%/10%$ ImageNet-1K labeled data and ViT-Huge, Super-SST shows a $6.6%/3.0%$ relative improvement over the supervised baseline, while Semi-SST shows a $0.7%/0.6%$ relative improvement over the semi-supervised baseline.
可扩展性。如表 3 所示,Super-SST 和 Semi-SST 在使用 ViT-Huge 等更大架构时均显示出显著提升,表明模型容量增加时具有更好的可扩展性。例如,在 $1%/10%$ ImageNet-1K 标注数据和 ViT-Huge 条件下,Super-SST 相比监督基线实现了 $6.6%/3.0%$ 的相对提升,而 Semi-SST 在半监督基线上实现了 $0.7%/0.6%$ 的相对提升。
Super-SST vs. Semi-SST. Both Super-SST and Semi-SST demonstrate competitive performance across various datasets and architectures, with Semi-SST generally having a slight edge. As shown in Table 3, Semi-SST consistently achieves higher Top-1 accuracy compared to Super-SST. However, Super-SST typically delivers a larger relative improvement over its baselines. For example, using $1%$ ImageNet-1K labeled data and ViT-Small, Super-SST / Semi-SST achieves $70.4%/71.4%$ Top-1 accuracy, while the relative improvement over supervised / semi-supervised baseline is $10.1%/3.4%$ .
Super-SST vs. Semi-SST。Super-SST和Semi-SST在各类数据集与架构中均展现出竞争力,其中Semi-SST通常略占优势。如表3所示,Semi-SST的Top-1准确率始终高于Super-SST。但Super-SST相比其基线通常能带来更大的相对提升。例如,在使用$1%$ ImageNet-1K标注数据和ViT-Small架构时,Super-SST/Semi-SST分别达到$70.4%/71.4%$的Top-1准确率,而相较于监督/半监督基线的相对提升幅度为$10.1%/3.4%$。
Table 4 Comparison with previous SOTA SSL methods across both CNN-based and Transformer-based architectures on $1%$ and $10%$ ImageNet-1K labeled data. Our Super-SST and Semi-SST methods significantly outperform previous SOTA SSL counterparts.
表 4: 在基于 CNN 和 Transformer 架构的 $1%$ 和 $10%$ ImageNet-1K 标注数据上,与之前 SOTA (State-of-the-Art) SSL (自监督学习) 方法的对比。我们的 Super-SST 和 Semi-SST 方法显著优于之前的 SOTA SSL 方法。
| 方法 | 架构 | 参数量 | ImageNet-1K |
|---|---|---|---|
| 1% | |||
| NNO | |||
| UDA [11] | ResNet-50 | 26M | - |
| SimCLRv2 [59] | ResNet-50 | 26M | 60.0 |
| FixMatch [6] | ResNet-50 | 26M | - |
| MPL [28] | ResNet-50 | 26M | - |
| EMAN [29] | ResNet-50 | 26M | 63.0 |
| CoMatch [60] | ResNet-50 | 26M | 66.0 |
| PAWS [61] | ResNet-50 | 26M | 66.5 |
| SimMatch [62] | ResNet-50 | 26M | 67.2 |
| SimMatchV2 [63] | ResNet-50 | 26M | 71.9 |
| Semi-ViT [35] | ConvNeXt-T | 28M | 71.3 |
| Super-SST (ours) | ConvNeXt-T | 28M | 74.1 |
| Semi-SST (ours) | ConvNeXt-T | 28M | - |
| Transformer | |||
| SemiFormer [64] | ViT-S+Conv | 42M | - |
| SimMatchV2 [63] | ViT-Small | 22M | - |
| Semi-ViT [35] | ViT-Small | 22M | 63.7 |
| Semi-ViT [35] | ViT-Base | 86M | 68.0 |
| Semi-ViT [35] | ViT-Large | 307M | 71.0 |
| Semi-ViT [35] | ViT-Huge | 632M | 77.3 |
| - | ViT-Huge | 632M | 80.0 |
| Super-SST (ours) | ViT-Small | 22M | 70.4 |
| Super-SST (ours, distilled) | ViT-Small | 22M | 76.9 |
| Semi-SST (ours) | ViT-Small | 22M | 71.4 |
| Super-SST (ours) | ViT-Huge | 632M | 80.3 |
| Semi-SST (ours) | ViT-Huge | 632M | 80.7 |
In summary, Table 3 demonstrates that Super-SST and Semi-SST offer significant performance improvements across various datasets and architectures, particularly excelling in low-data scenarios and scaling well with model capacity. While Semi-SST often achieves higher Top-1 accuracy compared to Super-SST, Super-SST generally delivers larger improvement over its baselines. Our methods are effective, scalable, and broadly applicable, making them valuable for practical applications where labeled data is limited.
表 3 表明,Super-SST 和 Semi-SST 在各种数据集和架构上均实现了显著的性能提升,尤其在低数据场景下表现优异,并能随着模型容量扩展保持良好效果。虽然 Semi-SST 的 Top-1 准确率通常高于 Super-SST,但 Super-SST 相比其基线模型的改进幅度更大。我们的方法高效、可扩展且普适性强,对于标注数据有限的实际应用场景具有重要价值。
4.3. Comparison with SOTA SSL models
4.3. 与SOTA SSL模型的对比
Table 4 presents a comprehensive comparison between our methods and previous SOTA SSL methods, including UDA [11], SimCLRv2 [59], FixMatch [6], MPL [28], EMAN [29], CoMatch [60], PAWS [61], SimMatch [62], SimMatchV2 [63], and Semi-ViT [35], focusing on their performance with $1%$ and $10%$ ImageNet-1K labeled data. Our methods are evaluated across both CNN-based and Transformer-based architectures. Following Semi-ViT, we utilize the recently proposed ConvNeXt instead of the traditional ResNet.
表 4: 全面对比了我们的方法与先前 SOTA (state-of-the-art) SSL (半监督学习) 方法在 $1%$ 和 $10%$ ImageNet-1K 标注数据下的性能表现,包括 UDA [11]、SimCLRv2 [59]、FixMatch [6]、MPL [28]、EMAN [29]、CoMatch [60]、PAWS [61]、SimMatch [62]、SimMatchV2 [63] 和 Semi-ViT [35]。我们的方法在基于 CNN 和 Transformer 的架构上均进行了评估。遵循 Semi-ViT 的做法,我们采用最新提出的 ConvNeXt 替代传统 ResNet。
Superiority and robustness. For CNN-based models, Super-SST and Semi-SST achieve $77.9%$ and $78.6%$ Top-1 accuracy, respectively, with ConvNeXt-T on $10%$ ImageNet-1K labeled data, surpassing all previous counterparts. For Transformer-based models, Super-SST / Semi-SST achieves $70.4%\textit{/}71.4%$ Top-1 accuracy with ViT-Small on $1%$ labeled data, and $78.3%/78.6%$ on $10%$ labeled data, significantly outperforming previous counterparts. Both Super-SST and Semi-SST consistently outperform their counterparts across CNN-based and Transformer-based architectures, highlighting the superiority and robustness of our methods.
卓越性与鲁棒性。基于CNN的模型中,Super-SST和Semi-SST在ConvNeXt-T架构下仅使用10%的ImageNet-1K标注数据,分别取得77.9%和78.6%的Top-1准确率,超越所有同类方法。基于Transformer的模型中,Super-SST/Semi-SST在ViT-Small架构下仅用1%标注数据达到70.4%/71.4%的Top-1准确率,使用10%标注数据时提升至78.3%/78.6%,显著优于先前方法。无论是CNN还是Transformer架构,Super-SST与Semi-SST均展现出稳定的性能优势,证明了我们方法的卓越性和鲁棒性。
S cal ability and data-efficiency. Scalable and data-efficient algorithms are crucial to semi-supervised learning. As demonstrated in Table 4, both Super-SST and Semi-SST can easily scale up to larger architectures like ViT-Huge. Notably, Semi-SST-ViT-Huge achieves the best $80.7%/84.9%$ Top-1 accuracy on $1%/10%$ labeled data, setting new SOTA performance on the highly competitive ImageNet-1K SSL benchmarks without external data. Moreover, larger architectures like ViT-Huge generally achieve higher accuracy compared to smaller architectures, demonstrating that larger architectures are strong data-efficient learners. This trend is consistent in both $1%$ and $10%$ labeled data scenarios, underscoring the potential for larger models to better utilize scarce labeled data.
可扩展性和数据效率。可扩展且数据高效的算法对半监督学习至关重要。如表4所示,Super-SST和Semi-SST都能轻松扩展到ViT-Huge等更大架构。值得注意的是,Semi-SST-ViT-Huge在1%/10%标注数据上实现了80.7%/84.9%的Top-1准确率,在没有外部数据的情况下,在竞争激烈的ImageNet-1K SSL基准测试中创造了新的SOTA性能。此外,与较小架构相比,ViT-Huge等较大架构通常能获得更高准确率,表明较大架构是强大的数据高效学习器。这一趋势在1%和10%标注数据场景中保持一致,凸显了较大模型更好利用稀缺标注数据的潜力。
Table 5 Error Rates $(%)$ and Rankings on Classical SSL Benchmarks. The experimental settings in this table are consistent with those of SimMatchV2 [63] and USB [72], with all non-ours results directly sourced from these studies. Error rates and standard deviations are reported as the average over three runs. For each experimental setting, the best result is highlighted in bold, while the second-best is underlined.
表 5: 经典 SSL 基准测试的错误率 $(%)$ 和排名。本表中的实验设置与 SimMatchV2 [63] 和 USB [72] 保持一致,所有非本研究的实验结果均直接引自这些文献。错误率和标准差报告为三次运行的平均值。每种实验设置下的最佳结果以粗体标出,次优结果以下划线标出。
| Dataset | CIFAR-10 | CIFAR-100 | SVHN | STL-10 | Friedman Final | Mean | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #Label | 40 | 250 | 4000 | 400 | 2500 | 10000 | 40 | 250 | 1000 | 40 | 250 | 1000 | rank | rank | errorrate |
| Fully-Supervised | 4.57±0.06 | 18.96±0.06 | 2.14±0.01 | = | |||||||||||
| Supervised | 77.18±1.32 | 56.24±3.41 | 16.10±0.32 | 89.60±0.43 | 58.33±1.41 | 36.83±0.21 | 82.68±1.91 | 24.17±1.65 | 12.19±0.23 | 75.4±0.66 | 55.07±1.83 | 35.42±0.48 | |||
| 13.63±0.07 | 87.67±0.79 | 36.73±0.05 | 80.07±1.22 | 13.46±0.61 | 6.90±0.22 | 74.89±0.57 | 52.20±2.11 | 31.34±0.64 | 17 | ||||||
| II-Model Pseudo-Labeling | 76.35±1.69 | 48.73±1.07 | 15.32±0.35 | 88.18±0.89 | 56.40±0.69 | 9.37±0.42 | 51.90±1.87 | 16.17 | 48.20 | ||||||
| Mean Teacher | 75.95±1.86 72.42±2.10 | 51.12±2.91 | 8.29±0.10 | 79.96±0.53 | 55.37±0.48 44.37±0.60 | 36.58±0.12 | 75.98±5.36 | 16.47±0.59 3.44±0.02 | 3.28±0.07 | 74.02±0.47 72.90±0.83 | 49.30±2.09 | 30.77±0.04 | 16.08 13.67 | 16 14 | 48.42 40.01 |
| VAT | 78.58±2.78 | 37.56±4.90 28.87±3.62 | 10.90±0.16 | 83.60±4.21 | 46.20±0.80 | 31.39±0.11 32.14±0.31 | 49.34±7.90 84.12±3.18 | 3.38±0.12 | 2.87±0.18 | 73.33±0.47 | 57.78±1.47 | 27.92±1.65 40.98±0.96 | 14.67 | 15 | 45.23 |
| MixMatch | 35.18±3.87 | 13.00±0.80 | 6.55±0.05 | 64.91±3.34 | 39.29±0.13 | 27.74±0.27 | 27.77±5.43 | 4.69±0.46 | 3.85±0.28 | 49.84±0.58 | 32.05±1.16 | 20.17±0.67 | 12.92 | 13 | 27.09 |
| ReMixMatch | 8.13±0.58 | 6.34±0.22 | 4.65±0.09 | 41.60±1.48 | 25.72±0.07 | 20.04±0.13 | 16.43±3.77 | 5.65±0.35 | 5.36±0.58 | 27.87±3.85 | 11.14±0.52 | 6.44±0.15 | 9.50 | 12 | 14.95 |
| UDA | 10.01±3.34 | 5.23±0.08 | 4.36±0.09 | 45.48±0.37 | 27.51±0.28 | 23.12±0.45 | 5.28±4.02 | 1.93±0.03 | 1.94±0.02 | 40.094.03 | 10.11±1.15 | 6.23±0.28 | 8.00 | 10 | 15.11 |
| FixMatch | 12.66±4.49 | 4.95±0.10 | 4.26±0.01 | 45.38±2.07 | 27.71 ±0.42 | 22.06±0.10 | 3.37±1.01 | 1.97±0.01 | 2.02±0.03 | 38.19±4.76 | 8.64±0.84 | 5.82±0.06 | 6.83 | 7 | 14.75 |
| Dash | 9.29±3.28 | 5.16±0.28 | 4.36±0.10 | 47.49±1.05 | 27.47 ±0.38 | 21.89±0.16 | 5.26±2.02 | 2.01±0.01 | 2.08±0.09 | 42.00±4.94 | 10.50±1.37 | 6.30±0.49 | 8.25 | 11 | 15.32 |
| CoMatch | 6.51±1.18 | 5.35±0.14 | 4.27±0.12 | 53.41±2.36 | 29.78±0.11 | 22.11±0.22 | 8.20±5.32 | 2.16±0.04 | 2.01±0.04 | 13.74±4.20 | 7.63±0.94 | 5.71 ±0.08 | 7.17 | 8 | 13.41 |
| CRMatch | 13.62±2.62 | 4.61±0.17 | 3.65±0.04 | 37.76±1.45 | 24.13±0.16 | 19.89±0.23 | 2.60±0.77 | 1.98±0.04 | 1.95±0.03 | 33.73±1.17 | 14.87 ±5.09 | 6.53±0.36 | 5.67 | 4 | 13.78 |
| FlexMatch | 5.29±0.29 | 4.97 ±0.07 | 4.24±0.06 | 40.73±1.44 | 26.17±0.18 | 21.75±0.15 | 5.422.83 | 8.74±3.32 | 7.90±0.30 | 29.12±5.04 | 9.85±1.35 | 6.08±0.34 | 7.58 | 9 | 14.19 |
| AdaMatch | 5.09±0.21 | 5.13±0.05 | 4.36±0.05 | 37.08±1.35 | 26.66±0.33 | 21.99±0.15 | 6.14±5.35 | 2.13±0.04 | 2.02±0.05 | 19.95±5.17 | 8.59±0.43 | 6.01±0.02 | 6.00 | 5 | 12.10 |
| SimMatch | 5.38±0.01 | 5.36±0.08 | 4.41±0.07 | 39.32±0.72 | 26.21±0.37 | 21.50±0.11 | 7.60±2.11 | 2.48±0.61 | 2.05±0.05 | 16.98±4.24 | 8.27±0.40 | 5.74±0.31 | 6.58 | 6 | 12.11 |
| SimMatchV2 | 4.90±0.16 | 5.04±0.09 | 4.33±0.16 | 36.68±0.86 | 26.66±0.38 | 21.37±0.20 | 7.92±2.80 | 2.92±0.81 | 2.85±0.91 | 15.85±2.62 | 7.54±0.81 | 5.65±0.26 | 5.25 | 3 | 11.81 |
| Super-SST (ours) | 9.59±0.32 | 3.37±0.22 | 1.61±0.18 | 35.50±0.58 | 14.20±0.17 | 29.41±1.55 | 4.17±0.49 | 3.10±0.32 | |||||||
| Semi-SST (ours) | 6.35±0.28 | 2.42±0.13 | 1.41±0.10 | 31.39±0.47 | 18.51±0.36 16.62±0.28 | 13.50±0.14 | 23.18±1.38 | 3.36±0.17 | 2.97±0.11 | 7.33±0.31 3.920.20 | 1.59±0.12 1.40±0.10 | 1.45±0.10 1.36±0.08 | 5.08 3.58 | 2-1 | 10.82 8.99 |
Knowledge distillation. We have shown that larger architectures like ViT-Huge generally achieve higher accuracy than smaller ones, particularly in low-data scenarios. However, large models with high capacity require significant computational resources during deployment, making them impractical and uneconomical for real-world applications. Conversely, small models are easier to deploy but tend to perform worse compared to large models. This raises an important question: how can we train a small, high-performance model suitable for practical deployment in low-data scenarios? To address this, we conduct huge-to-small knowledge distillation [65, 66, 67, 68, 69, 70, 71] experiments. Initially, we train a teacher model (i.e., ViT-Huge) using Super-SST on $1%/10%$ original labeled data, achieving $80.3%/84.8%$ Top-1 accuracy. We then use the well-trained teacher model and SAT technique to obtain selected pseudo-labeled data. Finally, we distill the knowledge from the teacher model into the student model (i.e., ViT-Small). The student model was supervised trained on a combination of few original labeled data and selected pseudo-labeled data, achieving $76.9%$ and $80.3%$ Top-1 accuracy in $1%$ and $10%$ low-data scenarios, respectively. This represents a substantial $6.5%$ and $2.0%$ relative improvement over the Super-SST-ViT-Small. Thus, we successfully develop a compact, lightweight and high-performance model that is well-suited for practical deployment.
知识蒸馏。我们已经证明,像ViT-Huge这样的大型架构通常比小型架构获得更高的准确率,尤其是在低数据场景下。然而,高容量的大型模型在部署时需要大量计算资源,这使得它们在实际应用中不切实际且不经济。相反,小型模型更容易部署,但性能往往不如大型模型。这就引出了一个重要问题:如何在低数据场景下训练出适合实际部署的小型高性能模型?为了解决这个问题,我们进行了大模型到小模型的知识蒸馏[65, 66, 67, 68, 69, 70, 71]实验。首先,我们使用Super-SST在$1%/10%$的原始标记数据上训练教师模型(即ViT-Huge),达到了$80.3%/84.8%$的Top-1准确率。然后,我们使用训练好的教师模型和SAT技术获取选定的伪标记数据。最后,我们将教师模型的知识蒸馏到学生模型(即ViT-Small)中。学生模型在少量原始标记数据和选定伪标记数据的组合上进行监督训练,在$1%$和$10%$的低数据场景下分别达到了$76.9%$和$80.3%$的Top-1准确率。这相对于Super-SST-ViT-Small分别实现了显著的$6.5%$和$2.0%$的相对提升。因此,我们成功开发出了一个紧凑、轻量且高性能的模型,非常适合实际部署。
The results presented in Table 5 clearly highlight the superior performance of Semi-SST and Super-SST compared to existing SSL methods across multiple benchmarks. Notably, Semi-SST achieves the lowest mean error rate of $8.99%$ , ranking first overall, while Super-SST follows closely with a mean error rate of $10.82%$ , securing the second position. Notably, despite the availability of 531,131 additional training images in SVHN and 100,000 unlabeled images in STL-10, our method achieves competitive performance without leveraging these extra resources, underscoring its data-efficient learning capability. To further assess the statistical significance of our results, we conducted a Friedman test, which yielded a p-value of $3.11\times10^{-25}$ , indicating a statistically significant difference among the evaluated methods. The Friedman rankings for Semi-SST and Super-SST are 1st and 2nd, respectively, suggesting their consistent advantage across multiple benchmarks. These results provide strong statistical support for the effectiveness of our approach while reducing the likelihood that the observed improvements are due to random variation. Despite Semi-SST and Super-SST demonstrate strong overall performance, they exhibit relatively higher error rates on the SVHN dataset with only 40 labeled samples. This suggests that our methods, like other SSL techniques, may face challenges in scenarios with extremely limited labeled data. Future work could explore enhancements to further improve performance in such cases. To ensure consistency with the experimental configurations in this paper, we utilize a self-supervised pretrained ViT-Small from DINO, which differs from the architectures used in prior works such as SimMatchV2 [63] and USB [72]. While this setup may result in a less direct comparison, it contributes valuable data points to the research community, offering insights into the performance of transformer-based architectures in SSL.
表5所示结果清晰表明,Semi-SST和Super-SST在多项基准测试中均优于现有SSL方法。其中Semi-SST以$8.99%$的平均错误率位居榜首,Super-SST以$10.82%$紧随其后。值得注意的是,尽管SVHN提供额外531,131张训练图像且STL-10包含10万张未标注图像,我们的方法在不使用这些额外资源的情况下仍保持竞争力,凸显其高效的数据学习能力。Friedman检验得出$3.11\times10^{-25}$的p值,证实各方法间存在统计显著性差异——Semi-SST与Super-SST分列Friedman排名第一、二位,表明其在多基准测试中的稳定优势。这些结果为方法有效性提供了强统计支撑,同时降低观测改进源于随机变异的可能性。尽管整体表现优异,但Semi-SST和Super-SST在仅含40个标注样本的SVHN数据集上错误率相对较高,这说明与其他SSL技术类似,我们的方法在标注数据极度稀缺的场景仍存在挑战。未来工作可探索针对性优化方案。为确保实验配置一致性,我们采用DINO自监督预训练的ViT-Small架构,这与SimMatchV2 [63]、USB [72]等先前研究的架构存在差异。虽然这种设置可能导致对比不够直接,但为研究社区提供了Transformer架构在SSL中性能的宝贵数据参考。
Table 6 Comparison with fully-supervised methods on $100%$ , $10%$ , and $1%$ ImageNet-1K labeled data. † indicates result at a resolution of $224\times224$ for fair comparisons. Our methods significantly reduce the reliance on human annotation.
表 6: 在 $100%$、$10%$ 和 $1%$ ImageNet-1K 标注数据上与全监督方法的对比。† 表示分辨率为 $224\times224$ 的公平比较结果。我们的方法显著降低了对人工标注的依赖。
| 方法 | 架构 | 参数量 | ImageNet-1K |
|---|---|---|---|
| 100% | |||
| DeiT [73] | ViT-Small | 22M | 79.8 |
| Super-SST (ours) | ViT-Small | 22M | |
| Super-SST (ours, distilled) | ViT-Small | 22M | |
| Semi-SST (ours) | ViT-Small | 22M | - |
| DeiT-1llI [74] | ViT-Huge | 632M | 84.8 |
| Super-SST (ours) | ViT-Huge | 632M | 1 |
| Semi-SST (ours) | ViT-Huge | 632M |
Table 7 Comparison of efficiency and performance on ImageNet-1K. Following FlexMatch and FreeMatch, we use 4 NVIDIA Tesla V100 GPUs for experiments on ImageNet-1K.
表 7: ImageNet-1K 上的效率和性能对比。遵循 FlexMatch 和 FreeMatch 的设置,我们使用 4 块 NVIDIA Tesla V100 GPU 进行 ImageNet-1K 实验。
| 方法 | 架构 | 阈值更新次数 | 运行时间 (秒/迭代) | ImageNet-1K 100K |
|---|---|---|---|---|
| FixMatch [6] | ResNet-50 | 0 | 0.4 | 56.34 |
| FlexMatch [31] | ResNet-50 | 1,048,576 | 0.6 | 58.15 |
| FreeMatch [36] | ResNet-50 | 1,048,576 | 0.4 | 59.43 |
| Super-SST (本文) | ResNet-50 | 3 | 0.1 | 64.42 |
(a) Comparison of runtime and Top-1 accuracy on ImageNet-1K with 100K randomly sampled labeled data (i.e., 100 labels per class). The experimental setting follows FreeMatch [36] and FlexMatch [31] to maintain consistency. Following FlexMatch and FreeMatch, we train the ResNet-50 from scratch for fair comparisons. All other results are directly sourced from FreeMatch [36].
(b) Comparison of GPU days, memory and Top-1 accuracy on ImageNet-1K with $1%$ labels per class. The experimental setting follows SimMatchV2 [63] to maintain consistency. All other results are directly sourced from SimMatchV2.
(a) 在ImageNet-1K上使用10万随机采样的标注数据(即每类100个标签)的运行时间和Top-1准确率对比。实验设置遵循FreeMatch [36]和FlexMatch [31]以保持一致性。按照FlexMatch和FreeMatch的做法,我们从零开始训练ResNet-50以进行公平比较。所有其他结果直接来自FreeMatch [36]。
| 方法 | 架构 | 多裁剪策略 | GPU天数 | GPU内存 | ImageNet-1K 1% |
|---|---|---|---|---|---|
| CoMatch[60] | ResNet-50 | 10.3 | 81G | 61.1 | |
| SimMatch [62] | ResNet-50 | 7.7 | 40G | 61.2 | |
| PAWS [61] | ResNet-50 | 22.6 | 1048G | 63.8 | |
| SimMatchV2[63] | ResNet-50 | X | 7.8 | 42G | 63.7 |
| SimMatchV2[63] | ResNet-50 | 14.7 | 83G | 69.9 | |
| Super-SST (ours) | ViT-Small | × | 10.5 | 36G | 70.4 |
| Semi-SST (ours) | ViT-Small | 28.6 | 52G | 71.4 |
(b) 在ImageNet-1K上使用每类$1%$标签的GPU天数、内存和Top-1准确率对比。实验设置遵循SimMatchV2 [63]以保持一致性。所有其他结果直接来自SimMatchV2。
4.4. Comparison with fully-supervised models
4.4. 与全监督模型的对比
Table 6 compares our SST methods with fully-supervised methods such as DeiT [73] and DeiT-III [74] on ImageNet-1K. As shown, the fully-supervised DeiT-III-ViT-Huge model achieves $84.8%$ Top-1 accuracy using $100%$ labeled data. In comparison, our methods perform remarkably well even with significantly reduced labeled data. For instance, with only $10%$ labeled data and ViT-Huge, Super-SST and Semi-SST achieve the same $84.8%$ and higher $84.9%$ Top-1 accuracy, respectively, suggesting a tenfold reduction in human annotation costs, and highlighting the effectiveness of our methods in utilizing unlabeled data. This demonstrates that our methods can be highly effective in applications where obtaining labeled data is challenging or costly, thereby significantly narrowing the performance disparity between semi-supervised and fully-supervised methods. Moreover, using huge-to-small distillation, SuperSST-ViT-Small achieves an impressive $80.3%$ Top-1 accuracy on $10%$ labeled data, outperforming the fully-supervised DeiT-ViT-Small’s $79.8%$ Top-1 accuracy on $100%$ labeled data.
表 6 将我们的 SST 方法与全监督方法 (如 DeiT [73] 和 DeiT-III [74]) 在 ImageNet-1K 上进行了对比。如表所示,全监督的 DeiT-III-ViT-Huge 模型在使用 100% 标注数据时达到了 84.8% 的 Top-1 准确率。相比之下,我们的方法即使在标注数据大幅减少的情况下仍表现优异。例如,仅使用 10% 标注数据和 ViT-Huge 时,Super-SST 和 Semi-SST 分别达到了相同的 84.8% 和更高的 84.9% Top-1 准确率,这意味着人工标注成本降低了十倍,并凸显了我们的方法在利用未标注数据方面的有效性。这表明,在获取标注数据具有挑战性或成本高昂的应用场景中,我们的方法可以非常有效,从而显著缩小半监督与全监督方法之间的性能差距。此外,通过大模型到小模型的蒸馏,SuperSST-ViT-Small 在 10% 标注数据上实现了 80.3% 的 Top-1 准确率,优于全监督 DeiT-ViT-Small 在 100% 标注数据上 79.8% 的 Top-1 准确率。
Table 8 Comparison of GPU Hours and Mean Error Rates on CIFAR-10, CIFAR-100, SVHN, and STL-10. The reported results of FreeMatch and SoftMatch are directly sourced from their papers. Mean error rates represent the average over three runs. Following FreeMatch and SoftMatch, we use a single V100 GPU for experiments on these datasets.
表 8: CIFAR-10、CIFAR-100、SVHN 和 STL-10 的 GPU 耗时与平均错误率对比。FreeMatch 和 SoftMatch 的报告结果直接引自其论文。平均错误率为三次运行结果的均值。遵循 FreeMatch 和 SoftMatch 的设置,我们使用单块 V100 GPU 进行这些数据集的实验。
| 方法 | GPU 耗时 (小时) | 平均错误率 | |||
|---|---|---|---|---|---|
| CIFAR-10 | CIFAR-100 | SVHN | STL-10 | ||
| SoftMatch [75] | ~72 | ~168 | ~72 | ~168 | 13.11 |
| FreeMatch [36] | ~48 | ~240 | ~48 | ~240 | 12.51 |
| Super-SST (本文) | ~3 | ~3 | ~7 | ~2 | 12.41 |
| Semi-SST (本文) | ~4 | ~4 | ~15 | ~3 | 10.31 |
4.5. Comparison of efficiency
4.5. 效率对比
Table 7 presents a comparison of efficiency and performance between our methods and other SSL models on ImageNet-1K, focusing on threshold updates, runtime, GPU utilization, and Top-1 accuracy.
表 7: 我们的方法与其他SSL模型在ImageNet-1K上的效率和性能对比,重点关注阈值更新、运行时间、GPU利用率及Top-1准确率。
Comparison of threshold updates and runtime. Table 7a provides a detailed comparison of efficiency and performance between FixMatch, FlexMatch, FreeMatch, and Super-SST. Note that self-supervised pre training is optional in our methods. Following the same protocol as FlexMatch and FreeMatch, we train the ResNet-50 from scratch on 100K ImageNet-1K labeled data (i.e., 100 labels per class) for fair comparisons. As shown, FixMatch uses a predefined constant threshold, resulting in zero threshold updates. Both FlexMatch and FreeMatch update the class-specific thresholds at each iteration, leading to over 1,000,000 updates, making them computationally intensive and costly. Super-SST trains the ResNet-50 for 3 cycles and updates the class-specific thresholds only at each training cycle, resulting in just 3 updates. This vast difference in the number of updates makes Super-SST much more efficient in terms of time and computational costs. Additionally, Super-SST updates thresholds using a well-trained high-performance model, reducing erroneous predictions and confirmation bias. In contrast, FreeMatch and FlexMatch update thresholds using models that are still in training, leading to more inaccurate predictions during the early stages and amplifying confirmation bias, ultimately resulting in poorer performance. Super-SST achieves the fastest runtime of 0.1 seconds per iteration, compared to 0.4 seconds for FixMatch and FreeMatch, and 0.6 seconds for FlexMatch. This makes Super-SST the most efficient method with faster runtime and fewer threshold updates among those compared. Furthermore, Super-SST not only excels in efficiency but also achieves the highest Top-1 accuracy of $64.42%$ , significantly outperforming all counterparts by a substantial margin.
阈值更新与运行时间对比
表 7a 详细对比了 FixMatch、FlexMatch、FreeMatch 和 Super-SST 的效率和性能。需注意我们的方法中自监督预训练是可选项。为公平比较,我们遵循与 FlexMatch 和 FreeMatch 相同的协议,使用 100K ImageNet-1K 标注数据(即每类 100 个标签)从头训练 ResNet-50。数据显示:
- FixMatch 采用预定义常量阈值,阈值更新次数为零
- FlexMatch 和 FreeMatch 每迭代更新一次类别特定阈值,总更新量超 100 万次,计算成本高昂
- Super-SST 仅在每个训练周期(共 3 个周期)更新阈值,总更新仅 3 次
这种更新次数的巨大差异使得 Super-SST 在时间和计算成本上显著高效。此外,Super-SST 使用训练完备的高性能模型更新阈值,减少了错误预测和确认偏差;而 FreeMatch 和 FlexMatch 使用训练中的模型更新阈值,早期阶段预测准确性较低,会放大确认偏差,最终导致性能下降。
运行时间方面,Super-SST 每次迭代仅需 0.1 秒,显著快于 FixMatch 和 FreeMatch(0.4 秒)以及 FlexMatch(0.6 秒),成为对比方法中运行最快、阈值更新最少的方案。更重要的是,Super-SST 不仅效率突出,还以 $64.42%$ 的 Top-1 准确率大幅领先所有对比方法。
Comparison of GPU days and memory. Table 7b compares GPU days, GPU memory and Top-1 accuracy between CoMatch, SimMatch, PAWS, SimMatchV2, Super-SST, and Semi-SST on $1%$ ImageNet-1K labeled data. As shown, PAWS and SimMatchV2 use the multi-crop strategy, processing multiple cropped versions of each image, leading to better model performance but significantly higher computational demands and longer training time. For example, the training time of SimMatchV2 nearly doubles (from 7.8 to 14.7 days) when multi-crops are included, and its Top-1 accuracy significantly drops by $6.2%$ when multi-crops are excluded. Super-SST stands out for its excellent balance of efficiency and performance, achieving the second best Top-1 accuracy of $70.4%$ with the lowest GPU memory usage and relatively moderate GPU days, making it highly suitable for practical applications where both accuracy and efficiency are crucial. Semi-SST achieves the highest accuracy of $71.4%$ at the cost of high GPU days and moderate GPU memory usage, making it suitable for scenarios where maximum accuracy is required and computational resources are less of a constraint. Our methods outperform others in accuracy while maintaining reasonable resource usage, marking significant advancements in the SSL field.
GPU 天数和内存对比。表 7b 比较了 CoMatch、SimMatch、PAWS、SimMatchV2、Super-SST 和 Semi-SST 在 $1%$ ImageNet-1K 标注数据上的 GPU 天数、GPU 内存和 Top-1 准确率。结果显示,PAWS 和 SimMatchV2 采用多裁剪策略,处理每张图像的多个裁剪版本,虽然模型性能更优,但计算需求显著增加且训练时间更长。例如,SimMatchV2 包含多裁剪时训练时间几乎翻倍(从 7.8 天增至 14.7 天),而排除多裁剪时其 Top-1 准确率大幅下降 $6.2%$。Super-SST 在效率与性能间实现了出色平衡,以最低的 GPU 内存占用和相对适中的 GPU 天数取得了第二高的 Top-1 准确率 $70.4%$,非常适合对精度和效率均有严格要求的实际应用场景。Semi-SST 以较高的 GPU 天数和适中的 GPU 内存占用为代价,取得了 $71.4%$ 的最高准确率,适用于追求极致精度且计算资源不受限的场景。我们的方法在保持合理资源消耗的同时实现了更高的准确率,标志着自监督学习 (SSL) 领域的重大进展。
Comparison of GPU hours. Table 8 provides a comprehensive comparison of the computational efficiency and mean error rates of FreeMatch, SoftMatch, Super-SST, and Semi-SST across multiple benchmark datasets, including CIFAR-10, CIFAR-100, SVHN, and STL-10. When computing mean error rates, we reuse the experimental results from Table 5. It is important to note that FreeMatch and SoftMatch employ a slightly different set of benchmark configurations compared to our study, as well as SimMatchV2 and USB. Specifically, FreeMatch reports results for CIFAR-10 with 10 labels but does not provide results for STL-10 with 250 labels. Meanwhile, SoftMatch does not report results for SVHN and STL-10 with 250 labels. To align with USB and SimMatchV2, our study excludes CIFAR-10 with 10 labels but includes SVHN and STL-10 with 250 labels. To ensure a fair and consistent comparison, we consider the intersection of these benchmark configurations, ultimately including 10 settings: CIFAR-10 (with 40, 250, and 4000 labels), CIFAR-100 (with 400, 2500, and 10000 labels), SVHN (with 40 and 1000 labels), and
GPU 时耗对比
表 8: 全面对比了 FreeMatch、SoftMatch、Super-SST 和 Semi-SST 在 CIFAR-10、CIFAR-100、SVHN 和 STL-10 等多个基准数据集上的计算效率与平均错误率。计算平均错误率时,我们复用了表 5 的实验结果。需注意的是,FreeMatch 和 SoftMatch 采用的基准配置与本研究及 SimMatchV2、USB 略有不同:FreeMatch 报告了含 10 标签的 CIFAR-10 结果但未提供含 250 标签的 STL-10 结果,而 SoftMatch 未报告含 250 标签的 SVHN 和 STL-10 结果。为与 USB 和 SimMatchV2 保持一致,本研究排除了含 10 标签的 CIFAR-10 但纳入了含 250 标签的 SVHN 和 STL-10。为确保公平一致的比较,我们选取这些基准配置的交集,最终包含 10 种设定:CIFAR-10 (含 40、250、4000 标签)、CIFAR-100 (含 400、2500、10000 标签)、SVHN (含 40 和 1000 标签) 以及
Table 9 Comparison with supervised baseline on Clothing-1M dataset. The performance gap to the baseline is indicated in bracket. The result of supervised baseline is implemented by us.
表 9: Clothing-1M数据集上有监督基线的对比结果。括号内表示与基线的性能差距。有监督基线结果由我们实现。
| 数据集 | 架构 | 参数量 | 方法 | 5% | 100% |
|---|---|---|---|---|---|
| Clothing-1M | ViT-Small | 22M | 有监督 Super-SST (ours) | 71.28 75.69 (+4.41) | 78.99 |
STL-10 (with 40 and 1000 labels). As shown in Table 8, Super-SST and Semi-SST significantly reduce computational costs while maintaining superior performance. On CIFAR-100, FreeMatch requires approximately 240 GPU hours, whereas Super-SST and Semi-SST achieve better performance with about 3 and 4 GPU hours, respectively, representing speedups of $80\times$ and $60\times$ . Similarly, on STL-10, FreeMatch consumes about 240 GPU hours, while Super-SST and Semi-SST require approximately 2 and 3 GPU hours, respectively, reducing the computational cost by $120\times$ and $80\times$ A similar trend is observed on CIFAR-10 and SVHN, where Super-SST and Semi-SST consistently require an order of magnitude fewer GPU hours than FreeMatch and SoftMatch. Beyond efficiency, Semi-SST achieves the best overall performance, attaining a mean error rate of 10.31, which is lower than both SoftMatch (13.11), FreeMatch (12.51) and Super-SST (12.41). Notably, this improvement is achieved with drastically fewer GPU hours, further demonstrating the effectiveness of our approach in mitigating confirmation bias while maintaining a lightweight computational footprint. The results highlight the efficiency and effectiveness of our proposed SST methods. By significantly reducing training time while maintaining or surpassing state-of-the-art performance, our approach offers a compelling alternative to existing semi-supervised learning methods. These findings underscore the potential of SST as a highly cost-effective solution for large-scale SSL applications, particularly in scenarios where computational resources are constrained. Note that we use ViT-Small architecture, while FreeMatch and SoftMatch employ Wide ResNet (WRN) architecture [76], which may result in a less direct comparison.
STL-10 (含40和1000标签)。如表8所示,Super-SST和Semi-SST在保持卓越性能的同时显著降低了计算成本。在CIFAR-100上,FreeMatch需要约240 GPU小时,而Super-SST和Semi-SST分别仅需约3和4 GPU小时即可实现更优性能,提速达$80\times$和$60\times$。类似地,在STL-10上,FreeMatch消耗约240 GPU小时,而Super-SST和Semi-SST分别仅需约2和3 GPU小时,计算成本降低$120\times$和$80\times$。CIFAR-10和SVHN也呈现相同趋势,Super-SST和Semi-SST始终比FreeMatch和SoftMatch节省一个数量级的GPU小时。除效率外,Semi-SST取得了最佳综合性能,平均错误率10.31,低于SoftMatch (13.11)、FreeMatch (12.51) 和Super-SST (12.41)。值得注意的是,这一改进是在GPU小时数大幅减少的情况下实现的,进一步证明了我们的方法在保持轻量计算的同时有效缓解确认偏差。结果凸显了我们提出的SST方法的高效性。通过显著减少训练时间并保持或超越最先进性能,我们的方法为现有半监督学习方法提供了极具吸引力的替代方案。这些发现表明SST作为大规模SSL应用的高性价比解决方案的潜力,特别是在计算资源受限的场景中。需注意我们使用ViT-Small架构,而FreeMatch和SoftMatch采用Wide ResNet (WRN)架构[76],可能导致对比不够直接。
4.6. Class imbalance and label noise
4.6. 类别不平衡与标签噪声
Clothing-1M [44] is a large-scale dataset containing approximately 1 million clothing images collected from online shopping websites. The dataset exhibits both severe class imbalance and label noise, making it a particularly challenging benchmark for robust learning algorithms. The class distribution is highly skewed, with some common clothing categories (e.g., T-shirts, jackets) being vastly overrepresented, while others (e.g., swimwear, scarves) have significantly fewer samples. This imbalance, combined with noisy annotations, increases the difficulty of model training, as standard learning methods may be biased toward high-frequency categories and struggle to generalize to underrepresented classes. We randomly sample $5%$ samples from the clean-labeled training images, with the remaining images combined with 1M noisy samples as the unlabeled data. As shown in Table 9, Super-SST achieves $75.69%$ top-1 accuracy with only $5%$ of Clothing-1M clean-labeled data, surpassing the supervised baseline by $4.41%$ and demonstrating strong robustness to both class imbalance and label noise. Notably, this performance is close to the fully supervised upper bound of $78.99%$ , despite relying on significantly fewer labeled samples, further highlighting its effectiveness in real-world imbalanced scenarios.
Clothing-1M [44] 是一个包含约100万张从在线购物网站收集的服装图像的大规模数据集。该数据集同时存在严重的类别不平衡和标签噪声问题,使其成为鲁棒学习算法极具挑战性的基准。其类别分布高度倾斜,常见服装类别(如T恤、夹克)样本量极大,而其他类别(如泳装、围巾)样本量显著偏少。这种不平衡与噪声标注的结合增加了模型训练难度,因为标准学习方法可能偏向高频类别,难以泛化到低频类别。我们从干净标注的训练图像中随机采样$5%$作为标记数据,其余图像与100万噪声样本共同构成未标记数据。如表9所示,Super-SST仅使用Clothing-1M中$5%$的干净标注数据就达到$75.69%$的top-1准确率,超越监督基线$4.41%$,展现出对类别不平衡和标签噪声的双重鲁棒性。值得注意的是,该性能接近$78.99%$的全监督上限,尽管依赖的标记样本量显著更少,进一步凸显了其在现实不平衡场景中的有效性。
Similarly, i Naturalist [40] is a large-scale, real-world dataset that exhibits extreme class imbalance, as the number of images per class follows a long-tailed distribution. A few dominant species have thousands of images, while many rare species are represented by only a handful of samples. This highly skewed distribution poses significant challenges for learning algorithms, as models trained on i Naturalist tend to be biased toward majority classes, struggling to generalize to underrepresented species. Consequently, i Naturalist serves as a crucial benchmark for evaluating techniques designed to address long-tailed recognition, class-balanced learning, and data re weighting strategies. As shown in Table 3, our method achieves significant improvements under extreme class imbalance conditions. With $1%/10%$ labeled i Naturalist data and ViT-Base, Super-SST outperforms the supervised baseline by $3.0%/7.8%$ , while Semi-SST achieves a $1.1%/$ $0.4%$ relative improvement over the semi-supervised baseline. These results demonstrate that our method effectively mitigates the impact of class imbalance and enhances model generalization under highly skewed distributions, further reinforcing its applicability to real-world long-tailed learning challenges.
同样地,iNaturalist [40] 是一个呈现极端类别不平衡的大规模真实世界数据集,其每类图像数量遵循长尾分布。少数优势物种拥有数千张图像,而许多稀有物种仅由少量样本表示。这种高度倾斜的分布给学习算法带来了重大挑战,因为在iNaturalist上训练的模型往往偏向多数类,难以泛化到代表性不足的物种。因此,iNaturalist成为评估长尾识别、类别平衡学习和数据重加权策略技术的关键基准。如表3所示,我们的方法在极端类别不平衡条件下取得了显著改进。使用$1%/10%$标注的iNaturalist数据和ViT-Base时,Super-SST比监督基线高出$3.0%/7.8%$,而Semi-SST在半监督基线上实现了$1.1%/$$0.4%$的相对提升。这些结果表明,我们的方法有效缓解了类别不平衡的影响,并增强了模型在高度倾斜分布下的泛化能力,进一步巩固了其应对现实世界长尾学习挑战的适用性。
4.7. Ablation study
4.7. 消融研究
Figure 2 explores the impact of different cutoff values $C$ and scaling factors $S$ on Top-1 accuracy over multiple training cycles. Each subplot focuses on a specific variable while keeping the other constant to observe their individual effects on performance. All experiments are conducted with the same starting checkpoint (i.e., ViT-Small) that is supervised finetuned on $1%$ ImageNet-1K labeled data, achieving $60.3%$ Top-1 accuracy. As shown in Figure 2a, lower cutoff values ( $C{=}0.3$ and 0.5) lead to faster and higher improvements in accuracy. Higher cutoff value $(\mathrm{C}{=}0.7)$ under performs compared to lower cutoff values, indicating that a high cutoff value might hinder model performance. As shown in Figure 2b, lower scaling factor $(\mathrm{S}{=}0.6)$ leads to faster improvements in accuracy but quickly stabilizes at a lower level, indicating insufficient improvement over multiple training cycles. A higher scaling factor $(\mathrm{S}{=}1.0)$ results in slower improvements and lower peak accuracy. Moderate scaling factors ( $\mathrm{{}}\mathrm{=}0.8$ and 0.9) provide better performance. Based on these observations, we set $C$ to 0.5 and $S$ to 0.8 for ViT-Small and 0.9 for ViT-Huge on ImageNet-1K. Detailed hyper-parameter settings are provided in Table 10.
图 2: 探究不同截断值 $C$ 和缩放因子 $S$ 在多次训练周期中对 Top-1 准确率的影响。每个子图聚焦于特定变量,同时保持其他参数恒定以观察其单独对性能的影响。所有实验均采用相同的初始检查点(即 ViT-Small)进行,该模型在 $1%$ ImageNet-1K 标注数据上经过监督微调,达到 $60.3%$ 的 Top-1 准确率。如图 2a 所示,较低的截断值($C{=}0.3$ 和 0.5)能带来更快且更高的准确率提升。较高截断值 $(\mathrm{C}{=}0.7)$ 表现逊于较低截断值,表明高截断值可能阻碍模型性能。如图 2b 所示,较低缩放因子 $(\mathrm{S}{=}0.6)$ 能更快提升准确率但会迅速稳定在较低水平,表明多次训练周期中改进不足。较高缩放因子 $(\mathrm{S}{=}1.0)$ 会导致改进速度变慢且峰值准确率降低。中等缩放因子($\mathrm{{}}\mathrm{=}0.8$ 和 0.9)能提供更优性能。基于这些观察,我们在 ImageNet-1K 上为 ViT-Small 设置 $C$ 为 0.5、$S$ 为 0.8,为 ViT-Huge 设置 $S$ 为 0.9。详细超参数设置见表 10。

Figure 2: Influence of cutoff value $(C)$ and scaling factor $(S)$ in SAT. All experiments are conducted with the same starting checkpoint (ViT-Small) that is supervised finetuned on $1%$ ImageNet-1K labels, achieving $60.3%$ accuracy.
图 2: SAT 中截断值 $(C)$ 和缩放因子 $(S)$ 的影响。所有实验均使用相同的初始检查点 (ViT-Small) 进行,该检查点在 $1%$ ImageNet-1K 标签上进行了监督微调,准确率达到 $60.3%$。
Figure 3 presents a comprehensive comparison between Self-Adaptive Threshold ing (SAT) and various Fixed Threshold ing (FTH) settings for both Super-SST and Semi-SST. The metrics analyzed include Top-1 accuracy, classaverage threshold, quantity and accuracy of selected pseudo-labels (PLs) over multiple training cycles. All experiments are conducted with the same starting checkpoint (i.e., ViT-Small) that is supervised finetuned on $1%$ ImageNet-1K labeled data, achieving $60.3%$ Top-1 accuracy.
图 3: 展示了 Super-SST 和 Semi-SST 中自适应阈值 (SAT) 与多种固定阈值 (FTH) 设置的全面对比。分析指标包括 Top-1 准确率、类别平均阈值、多轮训练中筛选出的伪标签 (PLs) 数量及准确率。所有实验均采用相同的初始检查点 (即基于 1% ImageNet-1K 标注数据监督微调的 ViT-Small 模型),其 Top-1 准确率为 60.3%。
Top-1 accuracy. In Super-SST / Semi-SST, SAT starts with a Top-1 accuracy of $60.3%$ and shows a rapid increase to $66.3%/69.5%$ in Cycle 1, peaking at $70.4%/71.4%$ by Cycle 6 / 4. While the FTH settings exhibit similar upward trends, their final performance is lower than that of SAT.
Top-1准确率。在Super-SST/Semi-SST设置中,SAT初始Top-1准确率为$60.3%$,在周期1快速提升至$66.3%/69.5%$,并于周期6/4达到峰值$70.4%/71.4%$。尽管FTH设置呈现相似上升趋势,但其最终性能仍低于SAT。
Class-average threshold. In Super-SST and Semi-SST, SAT starts with a class-average threshold of 0.682, gradually increasing to 0.863 and 0.855, respectively. FTH methods maintain constant thresholds (i.e., 0.00, 0.25, 0.50, and 0.75) due to their fixed nature, with no variation across cycles. The dynamic nature of SAT allows it to accurately and adaptively adjust class-specific thresholds according to the model’s performance, providing a more robust and responsive learning process compared to the static FTH methods.
类平均阈值。在Super-SST和Semi-SST中,SAT初始类平均阈值为0.682,随后分别逐步提升至0.863和0.855。由于FTH方法采用固定阈值机制(即0.00、0.25、0.50和0.75),其阈值在各训练周期中保持不变。SAT的动态特性使其能根据模型表现精准自适应地调整各类别阈值,相比静态FTH方法提供了更具鲁棒性和响应性的学习过程。
Quantity and accuracy of selected PLs. The balance between high quality and sufficient quantity of selected PLs is crucial. In Super-SST / Semi-SST, SAT starts with $39.5%$ selected PLs and gradually increases to $88.0%/89.9%$ Additionally, the accuracy of the selected PLs begins at $89.5%$ and gradually decreases to $77.7%/78.1%$ , possibly due to the incorporation of more noisy labels. Our SAT mechanism stands out for its excellent balance of high quality and sufficient quantity of selected PLs. Compared to SAT, FTH methods struggle to balance the high quality and sufficient quantity of selected PLs. For instance, FTH-0.00 uses all PLs without discrimination, leading to the lowest accuracy of PLs. FTH-0.75 maintains similar accuracy of PLs to SAT but often selects fewer PLs than SAT.
所选伪标签 (PL) 的数量与准确性。在高质量与足量伪标签之间取得平衡至关重要。Super-SST/Semi-SST中,SAT初始选择39.5%的伪标签,逐步提升至88.0%/89.9%。同时,所选伪标签的准确率从89.5%开始,逐渐下降至77.7%/78.1%,这可能是由于引入了更多噪声标签。我们的SAT机制因其在高质量与足量伪标签间的出色平衡而表现突出。相比SAT,FTH方法难以兼顾伪标签的高质量与足量。例如FTH-0.00不加区分地使用全部伪标签,导致准确率最低;FTH-0.75虽能保持与SAT相近的伪标签准确率,但选取的伪标签数量往往少于SAT。
In summary, Figure 3 highlights the clear superiority of SAT over FTH methods in both Super-SST and Semi-SST frameworks. SAT’s dynamic threshold ing mechanism allows for consistent improvements in top-1 accuracy and effective balancing of the high quality and sufficient quantity of selected PLs, making it a superior choice for SSL tasks. The static nature of FTH methods means they cannot respond to the changing dynamics of training, resulting in either overly conservative or overly liberal PLs selection, leading to limited improvements in model performance.
总之,图3突显了SAT在Super-SST和Semi-SST框架中均明显优于FTH方法。SAT的动态阈值机制能持续提升top-1准确率,并有效平衡所选伪标签(Pseudo-Labels, PLs)的高质量与足量性,使其成为SSL任务的更优选择。而FTH方法的静态特性使其无法响应训练过程中的动态变化,导致伪标签选择要么过于保守、要么过于宽松,最终限制了模型性能的提升。

Figure 3: Self-Adaptive Threshold ing (SAT) vs. Fixed Threshold ing (FTH). In this figure, we set the cutoff value $C{=}0.5$ and scaling factor $S{=}0.8$ for SAT. For FTH, we set the constant thresholds to 0.00, 0.25, 0.50, and 0.75, respectively.
图 3: 自适应阈值 (SAT) 与固定阈值 (FTH) 对比。本图中,我们为 SAT 设置截断值 $C{=}0.5$ 和缩放因子 $S{=}0.8$。对于 FTH,我们分别将固定阈值设为 0.00、0.25、0.50 和 0.75。
5. Related work
5. 相关工作
5.1. Threshold ing techniques
5.1. 阈值技术
Our work is closely related to SSL methods that utilize threshold ing techniques [35, 29, 27, 31, 36, 6, 77, 78, 79, 80, 81, 82, 75]. Methods such as Semi-ViT [35], Noisy Student [27], UDA [11], and FixMatch [6] rely on fixed threshold ing strategy to select unlabeled samples with predicted confidence scores above a predefined constant. Dash [77] employs a gradually increasing threshold to incorporate more unlabeled data into early-stage training. Adsh [79] derives adaptive thresholds for imbalanced SSL by optimizing pseudo-label numbers per class. AdaMatch [78] uses an adaptively estimated relative threshold based on the EMA of labeled data confidence. FlexMatch [31] uses a higher constant as dataset-specific global threshold and adjusts it according to the number of confident unlabeled samples predicted to each class. FreeMatch [36] estimates a dataset-specific global threshold through the EMA of the unlabeled data confidence and further adjusts it based on the EMA expectation of each class’s predictions. SoftMatch [75] introduces a novel approach to semi-supervised learning by addressing the quantity-quality trade-off in pseudo-labeling, balancing the use of abundant low-confidence samples with high-confidence ones. By incorporating a soft threshold ing mechanism, SoftMatch effectively improves label efficiency and enhances model performance across various SSL benchmarks. USB [72] is a unified and challenging SSL benchmark with 15 tasks across computer vision, natural language processing, and audio for fair and consistent evaluations. USB provides the implementation of multiple SSL algorithms, including FixMatch, FlexMatch, SimMatch, SoftMatch, and FreeMatch.
我们的工作与采用阈值化技术的SSL方法密切相关[35, 29, 27, 31, 36, 6, 77, 78, 79, 80, 81, 82, 75]。Semi-ViT[35]、Noisy Student[27]、UDA[11]和FixMatch[6]等方法依赖固定阈值策略,选择预测置信度高于预设常数的未标记样本。Dash[77]采用逐渐增加的阈值,将更多未标记数据纳入早期训练。Adsh[79]通过优化每类的伪标签数量,为不平衡SSL推导自适应阈值。AdaMatch[78]基于标记数据置信度的指数移动平均(EMA)使用自适应估计的相对阈值。FlexMatch[31]采用更高的常数作为数据集特定全局阈值,并根据预测到每类的置信未标记样本数量进行调整。FreeMatch[36]通过未标记数据置信度的EMA估计数据集特定全局阈值,并进一步基于每类预测的EMA期望进行调整。SoftMatch[75]通过解决伪标签中的数量-质量权衡问题,平衡使用丰富低置信样本与高置信样本,提出了一种新颖的半监督学习方法。通过引入软阈值机制,SoftMatch有效提高了标签效率,并在各种SSL基准测试中提升了模型性能。USB[72]是一个统一且具有挑战性的SSL基准测试,包含计算机视觉、自然语言处理和音频领域的15项任务,用于公平一致的评估。USB提供了多种SSL算法的实现,包括FixMatch、FlexMatch、SimMatch、SoftMatch和FreeMatch。
Our SAT mechanism distinguishes itself from existing dynamic threshold ing techniques in three main aspects: generation mechanism, number of threshold updates, and performance improvement. SAT is a confidence-based method that initially uses a cutoff value $C$ to discard the lower and unreliable probabilities for each class. It then calculates the average of the remaining higher and reliable probabilities for each class and multiplies this by a scaling factor $S$ to obtain the class-specific thresholds. Unlike FlexMatch, our SAT does not rely on the number of unlabeled samples predicted to each class, nor does it use a dataset-specific global threshold. Unlike FreeMatch, SAT employs a cutoff mechanism that FreeMatch lacks. Additionally, SAT does not use EMA and global threshold as in FreeMatch. The most significant difference between SAT and FlexMatch or FreeMatch lies in the number of threshold updates. FlexMatch and FreeMatch update the thresholds at each iteration using a model that is still in training, leading to over 1,000,000 updates. This incurs extremely high computational and time costs and tends to amplify confirmation bias during the early stage of training, thereby leading to poorer model performance. In contrast, SAT updates the thresholds once per training cycle using a well-trained high-performance model, resulting in a single-digit number of updates and negligible computational and time costs. Detailed theoretical analysis and extensive experimental results strongly confirm the innovation, uniqueness, and superiority of SAT. These advantages enable SST to significantly outperform previous counterparts in both performance and efficiency, establishing it as a milestone in the field of SSL.
我们的SAT机制在生成方式、阈值更新次数和性能提升三方面区别于现有动态阈值技术。SAT采用基于置信度的方法,首先通过截断值$C$剔除各类别中较低且不可靠的概率,随后计算剩余高可靠概率的均值,并乘以缩放因子$S$得到类别专属阈值。与FlexMatch不同,SAT既不依赖预测到每类的未标注样本数量,也不使用数据集全局阈值;与FreeMatch相比,SAT引入了后者缺失的截断机制,且未采用EMA和全局阈值。SAT与FlexMatch/FreeMatch的核心差异在于阈值更新次数——后者使用训练中的模型每轮迭代更新阈值(超100万次),导致极高计算/时间成本,并易在训练初期放大确认偏误进而损害模型性能;而SAT采用训练完备的高性能模型,每个训练周期仅更新一次阈值(个位数次数),计算/时间成本可忽略。详细理论分析与大量实验结果有力佐证了SAT的创新性、独特性和优越性,这些优势使SST在性能与效率上显著超越前人工作,成为SSL领域的里程碑。
5.2. Self-training and pseudo-labeling
5.2. 自训练与伪标签
Self-training and pseudo-labeling are closely related methods in SSL, often used together. Self-training is a comprehensive framework that iterative ly uses pseudo-labeling along with other strategies to enhance the performance of model. Pseudo-labeling is a specific technique that generates pseudo-labels for unlabeled data, making it an integral part of self-training frameworks. The principles of self-training and pseudo-labeling, originating from early research [16, 17, 18, 19, 20, 22], have been revitalized in recent SSL studies [23, 24, 25, 26, 27, 11, 6, 28, 29, 30, 31, 32, 37, 36]. Pseudo-Labeling [22] utilizes hard pseudo-labels derived from model predictions to guide the self-training process on unlabeled data. Noisy Student [27] incorporates self-training with noise injection to enhance model performance. CBST [83] addresses the challenge of class imbalance in semantic segmentation by generating pseudo-labels with balanced class distribution. CReST [32] uses class-rebalancing technique that adjusts the number of pseudo-labeled samples per class based on class-specific sampling rates. Debiased Self-Training [37] aims to mitigate training bias in self-training by using independent heads for generating and utilizing pseudo-labels. $\mathrm{ST++}$ [84] extends traditional self-training methods by exploiting progressively refined pseudo-labels in a curriculum learning manner [85]. UDA [11] enhances SSL models by sharpening model predictions instead of converting them into hard pseudo-labels. FixMatch [6] converts weakly-augmented predictions into hard pseudo-labels for strongly-augmented data. Label Propagation [24] employs a trans duct ive approach, predicting the entire dataset to generate pseudo-labels. SimMatch [62] leverages a labeled memory buffer to propagate semantic and instance pseudo-labels.
自训练(Self-training)与伪标签(Pseudo-labeling)是半监督学习(SSL)中密切相关的两种方法,常结合使用。自训练是一个综合框架,通过迭代应用伪标签等技术提升模型性能;伪标签则是为无标注数据生成伪标签的具体技术,构成自训练框架的核心组件。这两项技术原理源于早期研究[16, 17, 18, 19, 20, 22],近年被SSL研究重新激活[23, 24, 25, 26, 27, 11, 6, 28, 29, 30, 31, 32, 37, 36]。
Pseudo-Labeling[22]采用模型预测生成的硬伪标签指导无标注数据的自训练过程。Noisy Student[27]通过注入噪声增强自训练效果。CBST[83]通过生成类别平衡的伪标签解决语义分割中的类别不平衡问题。CReST[32]采用基于类别采样率的伪标签数量调整技术实现类别再平衡。Debiased Self-Training[37]使用独立头部生成和使用伪标签以减轻训练偏差。$\mathrm{ST++}$[84]通过课程学习方式逐步优化伪标签来扩展传统自训练方法[85]。UDA[11]通过锐化模型预测而非生成硬伪标签来增强SSL模型。FixMatch[6]将弱增强预测转换为强增强数据的硬伪标签。Label Propagation[24]采用转导方法预测整个数据集以生成伪标签。SimMatch[62]利用标注记忆缓冲区传播语义和实例伪标签。
Our SST method stands out from traditional self-training and pseudo-labeling methods through several key innovations. The primary distinction is the combination of self-training with our innovative SAT mechanism, which accurately and adaptively adjusts class-specific thresholds according to the learning progress of the model. This mechanism ensures both high quality and sufficient quantity of selected pseudo-labels, reducing the risks of inaccuracies and confirmation bias, thereby enhancing overall model performance. Additionally, SST framework demonstrates significant flexibility as it can be integrated not only with supervised algorithms but also with semi-supervised algorithms like EMA-Teacher [29, 35]. This flexibility also distinguishes it from traditional self-training methods.
我们的SST方法通过多项关键创新,从传统自训练和伪标签方法中脱颖而出。主要区别在于将自训练与我们创新的SAT机制相结合,该机制能根据模型学习进度精准自适应地调整类别特定阈值。这一机制既保证了所选伪标签的高质量又确保了足够数量,降低了误差和确认偏误风险,从而提升整体模型性能。此外,SST框架展现出显著灵活性,不仅能与监督算法结合,还可集成EMA-Teacher[29,35]等半监督算法,这种灵活性也使其区别于传统自训练方法。
6. Limitation
6. 局限性
Despite the strong overall performance demonstrated by Semi-SST and Super-SST, they exhibit relatively higher error rates under extremely limited labeled data scenarios (e.g., SVHN with only 40 labeled samples). This suggests that our methods may face challenges in ultra-low-label scenarios. The limitation aligns with broader challenges in SSL, where extreme label scarcity amplifies the sensitivity to pseudo-label noise and model initialization. Future work could explore strategies to mitigate this issue. Furthermore, our method is specifically designed for computer vision tasks and is not currently configured for natural language processing (NLP) benchmarks. Although experiments on text data are of interest, adapting our framework to NLP tasks would require significant architectural modifications. Future research could investigate ways to generalize our approach to broader modalities, including NLP and multi-modal learning. Additionally, while we have conducted experiments on the Clothing-1M [44] dataset and provided corresponding results, our investigation into noisy data, class imbalance, and domain shift scenarios remains limited. Due to constraints on computational resources, our analysis of these challenges is not as comprehensive as desired. Future iterations of this work will aim to systematically explore these challenges, thereby offering deeper insights into SSL performance under more realistic and diverse conditions.
尽管Semi-SST和Super-SST展现出强劲的整体性能,但在极端有限标注数据场景下(如SVHN仅含40个标注样本)仍表现出较高的错误率。这表明我们的方法在超低标签场景中可能面临挑战,这与自监督学习(SSL)领域的普遍难题相吻合——极端标签稀缺会放大对伪标签噪声和模型初始化的敏感性。未来工作可探索缓解该问题的策略。此外,当前方法专为计算机视觉任务设计,尚未适配自然语言处理(NLP)基准测试。虽然文本数据实验具有研究价值,但将框架迁移至NLP任务需重大架构调整。未来研究可探索将该方法泛化至NLP和多模态学习等更广泛领域。尽管我们已在Clothing-1M[44]数据集上完成实验并给出相应结果,但对噪声数据、类别不平衡和域适应场景的探究仍显不足。受限于计算资源,对这些挑战的分析未达预期深度。后续研究将系统性地探索这些难题,从而为更真实多元条件下的SSL性能提供更深刻的见解。
7. Conclusion
7. 结论
In this paper, we introduce an innovative Self-training with Self-adaptive Threshold ing (SST) framework, along with its two variations: Super-SST and Semi-SST, significantly advancing the SSL field. The core innovation of our framework is the Self-Adaptive Threshold ing (SAT) mechanism, which accurately and adaptively adjusts class-specific thresholds according to the learning progress of the model. SAT mechanism ensures both high quality and sufficient quantity of selected pseudo-labeled data, mitigating the risks of inaccurate pseudo-labels and confirmation bias, thereby enhancing overall model performance. Extensive experiments and results strongly confirm the effectiveness, efficiency, generalization, and s cal ability of SST framework across various architectures and datasets. Notably, Semi-SST-ViTHuge achieves the best results on competitive ImageNet-1K SSL benchmarks, with $80.7%/84.9%$ Top-1 accuracy using only $1%/10%$ labeled data. Compared to the fully-supervised DeiT-III-ViT-Huge, which achieves $84.8%$ Top-1 accuracy using $100%$ labeled data, our method demonstrates superior performance using only $10%$ labeled data. This indicates a tenfold reduction in human annotation costs, significantly narrowing the gap between semi-supervised and fully-supervised learning. Moreover, SST achieves SOTA performance across various architectures and datasets while demonstrating remarkable efficiency, resulting in an exceptional cost-performance ratio. These advancements lay the groundwork for further innovations in SSL and practical applications where acquiring labeled data is difficult or expensive. In future research, we intend to extend our methods to more practical applications and enhance our threshold ing techniques and model optimization strategies. We anticipate that this work will motivate future studies and contribute valuable insights for the broader community.
本文提出了一种创新的自适应阈值自训练(SST)框架及其两种变体——Super-SST和Semi-SST,显著推动了自监督学习(SSL)领域的发展。该框架的核心创新是自适应阈值(SAT)机制,能根据模型学习进度精准动态调整各类别阈值。SAT机制在确保伪标签数据质量的同时保障选取数量,有效降低伪标签不准确和确认偏误风险,从而提升模型整体性能。大量实验结果表明,SST框架在不同架构和数据集上均展现出卓越的有效性、效率性、泛化性和可扩展性。其中,Semi-SST-ViTHuge在极具竞争力的ImageNet-1K SSL基准测试中取得最佳成绩,仅使用1%/10%标注数据就达到80.7%/84.9%的Top-1准确率。相较于使用100%标注数据达到84.8%准确率的全监督DeiT-III-ViT-Huge模型,我们的方法仅用10%标注数据就展现出更优性能,意味着人工标注成本降低十倍,大幅缩小了半监督与全监督学习之间的差距。此外,SST在各种架构和数据集上均实现SOTA性能,同时展现出显著的高效性,具有极佳的成本效益比。这些突破为SSL领域的进一步创新及标注数据获取困难场景的实际应用奠定了基础。未来我们将把该方法拓展至更多实际应用场景,并优化阈值技术和模型策略。期待本工作能为学界带来启发,为更广泛的研究社区贡献宝贵见解。
Broader impacts. Our methods have significant potential applications in fields where obtaining sufficient highquality labeled data is difficult or un affordable, such as medical research and defect detection. However, it is important to acknowledge that many people rely on providing annotation services for their livelihood, and reducing the need for these services may lead to decreased income or even unemployment for those individuals. Balancing the benefits of advanced SSL techniques with their socioeconomic impacts will be crucial as these technologies continue to develop.
更广泛的影响。我们的方法在难以获取足够高质量标注数据或成本过高的领域(如医学研究和缺陷检测)具有重要应用潜力。但必须认识到,许多人依靠提供标注服务维持生计,减少对这些服务的需求可能导致相关从业者收入下降甚至失业。随着这些技术的持续发展,在先进自监督学习(SSL)技术带来的益处与其社会经济影响之间取得平衡将至关重要。