ABSTRACT
摘要
Transformers have recently emerged as a powerful tool for learning visual represent at ions. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ViT networks. The artifacts correspond to high-norm tokens appearing during inference primarily in low-informative background areas of images, that are repurposed for internal computations. We propose a simple yet effective solution based on providing additional tokens to the input sequence of the Vision Transformer to fill that role. We show that this solution fixes that problem entirely for both supervised and self-supervised models, sets a new state of the art for self-supervised visual models on dense visual prediction tasks, enables object discovery methods with larger models, and most importantly leads to smoother feature maps and attention maps for downstream visual processing.
Transformer 近期已成为学习视觉表征的强大工具。本文我们识别并描述了监督式与自监督式 ViT 网络特征图中的伪影现象。这些伪影表现为推理过程中主要出现在图像低信息量背景区域的高范数 token,它们被重新用于内部计算。我们提出了一种简单有效的解决方案:通过在 Vision Transformer 的输入序列中添加辅助 token 来承担该职能。研究表明,该方案能完全解决监督式和自监督式模型的这一问题,为自监督视觉模型在密集视觉预测任务上树立了新标杆,使目标发现方法能适配更大模型,最重要的是能为下游视觉处理生成更平滑的特征图和注意力图。
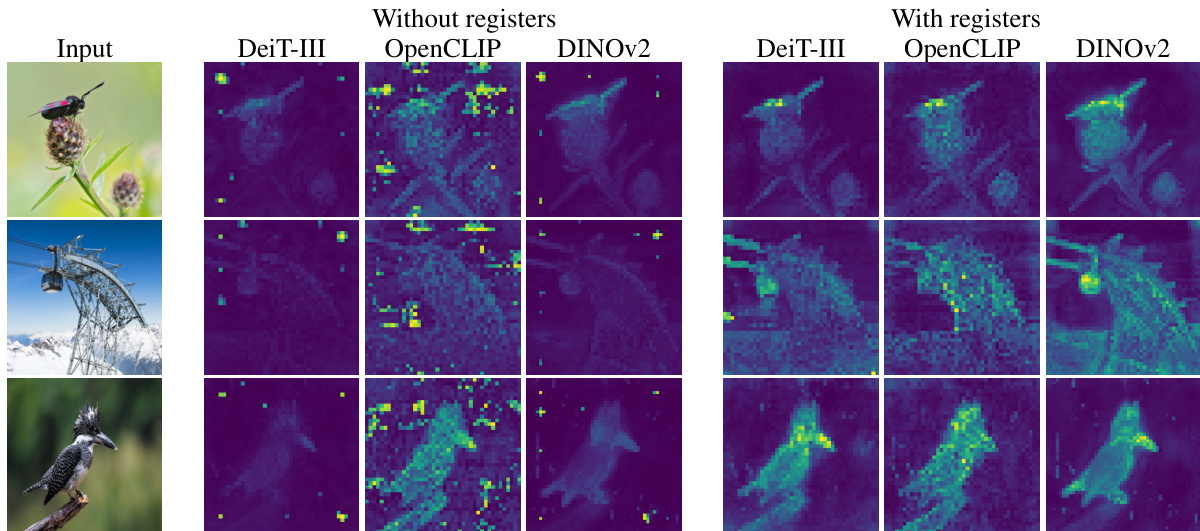
Figure 1: Register tokens enable interpret able attention maps in all vision transformers, similar to the original DINO method (Caron et al., 2021). Attention maps are calculated in high resolution for better visualisation. More qualitative results are available in appendix H.
图 1: 注册Token (Register tokens) 可在所有视觉Transformer中生成可解释的注意力图,类似于原始DINO方法 (Caron et al., 2021)。注意力图采用高分辨率计算以获得更佳可视化效果。更多定性结果见附录H。
1 INTRODUCTION
1 引言
Embedding images into generic features that can serve multiple purposes in computer vision has been a long-standing problem. First methods relied on handcrafted principles, such as SIFT (Lowe, 2004), before the scale of data and deep learning techniques allowed for end-to-end training. Pursuing generic feature embeddings is still relevant today, as collecting valuable annotated data for many specific tasks remains difficult. This difficulty arises because of the required expertise (e.g., medical data, or remote sensing) or the cost at scale. Today, it is common to pretrain a model for a task for which plenty of data is available and extract a subset of the model to use as a feature extractor. Multiple approaches offer this possibility; supervised methods, building on classification or text-image alignment, allow training strong feature models to unlock downstream tasks. Alternatively, self-supervised methods building on the Transformer architecture have attracted significant attention due to their high prediction performance on downstream tasks and the intriguing ability of some models to provide unsupervised segmentation s (Caron et al., 2021)
将图像嵌入到可用于计算机视觉多种用途的通用特征一直是个长期难题。早期方法依赖于手工设计原理,例如SIFT (Lowe, 2004),直到数据规模和深度学习技术实现了端到端训练。追求通用特征嵌入至今仍有重要意义,因为为许多特定任务收集有价值的标注数据仍然困难——无论是由于所需专业知识(如医疗数据或遥感数据)还是规模化成本。当前常见做法是针对数据充足的任务预训练模型,并提取模型子集作为特征提取器。多种方法支持这一思路:基于分类或图文对齐的监督方法可训练强大特征模型以支持下游任务;另一方面,基于Transformer架构的自监督方法因其在下游任务的高预测性能以及某些模型提供无监督分割的有趣能力 (Caron et al., 2021) 而备受关注。
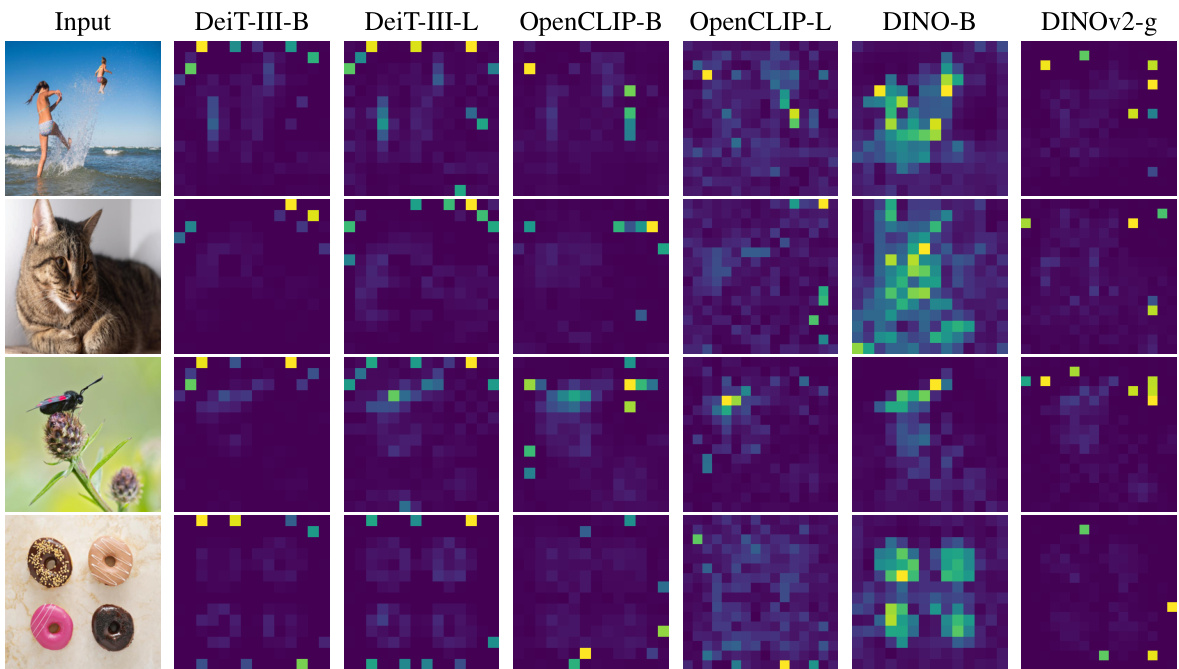
Figure 2: Illustration of artifacts observed in the attention maps of modern vision transformers. We consider ViTs trained with label supervision (DeiT-III), text-supervision (OpenCLIP) or selfsupervision (DINO and DINOv2). Interestingly, all models but DINO exhibit peaky outlier values in the attention maps. The goal of this work is to understand and mitigate this phenomenon.
图 2: 现代视觉 Transformer 注意力图中观察到的伪影示例。我们考察了通过标签监督 (DeiT-III) 、文本监督 (OpenCLIP) 或自监督 (DINO 和 DINOv2) 训练的 ViT。值得注意的是,除 DINO 外,所有模型在注意力图中均出现峰值异常值。本工作旨在理解和缓解这一现象。
In particular, the DINO algorithm is shown to produce models that contain explicit information about the semantic layout of an image. Indeed, qualitative results show that the last attention layer naturally focuses on semantically consistent parts of images and often produces interpret able attention maps. Exploiting these properties, object discovery algorithms such as LOsT (Siméoni et al., 2021) build on top of DINO. Such algorithms can detect objects without supervision by gathering information in attention maps. They are effectively unlocking a new frontier in computer vision.
特别是,DINO算法被证明能生成包含图像语义布局显式信息的模型。事实上,定性结果表明,最后的注意力层会自然地聚焦于图像中语义一致的部分,并经常产生可解释的注意力图。利用这些特性,LOsT (Siméoni et al., 2021) 等物体发现算法在DINO基础上构建。这类算法通过收集注意力图中的信息,无需监督即可检测物体,有效开启了计算机视觉的新前沿。
DINOv2 (Oquab et al., 2023), a follow-up to DINO, provides features that allow tackling dense prediction tasks. DINOv2 features lead to successful monocular depth estimation and semantic segmentation with a frozen backbone and linear models. Despite the strong performance on dense tasks, we observed that DINOv2 is surprisingly incompatible with LOST. When used to extract features, it delivers disappointing performance, only on par with supervised alternative backbones in this scenario. This suggests that DINOv2 behaves differently than DINO. The investigation described in this work notably exposes the presence of artefacts in the feature maps of DINOv2 that were not present in the first version of this model. These are observable qualitatively using straightforward methods. Also surprisingly, applying the same observations to supervised vision transformers exposes similar artifacts, as shown in Fig. 2. This suggests that DINO is, in fact, an exception, while DINOv2 models match the baseline behavior of vision transformers.
DINOv2 (Oquab等人,2023) 作为DINO的后续版本,提供了可处理密集预测任务的特征。DINOv2的特征使得在冻结主干网络和线性模型的情况下,成功实现了单目深度估计和语义分割。尽管在密集任务上表现强劲,但我们观察到DINOv2与LOST的兼容性出人意料地差。当用于提取特征时,其表现令人失望,仅与有监督替代主干网络相当。这表明DINOv2的行为与DINO不同。本工作的研究发现,DINOv2的特征图中存在该模型第一版本中未出现的伪影,这些伪影可通过简单方法定性观察到。同样令人惊讶的是,将有监督视觉Transformer (Vision Transformer) 应用相同观察时也暴露了类似伪影,如图 2 所示。这表明DINO实际上是一个例外,而DINOv2模型符合视觉Transformer的基线行为。
In this work, we set out to better understand this phenomenon and develop methods to detect these artifacts. We observe that they are tokens with roughly $10\mathrm{x}$ higher norm at the output and correspond to a small fraction of the total sequence (around $2%$ ). We also show that these tokens appear around the middle layers of the vision transformer, and that they only appear after a sufficiently long training of a sufficiently big transformer. In particular, we show that these outlier tokens appear in patches similar to their neighbors, meaning patches that convey little additional information.
在本研究中,我们旨在更好地理解这一现象并开发检测这些伪影的方法。我们观察到这些token在输出端具有约 $10\mathrm{x}$ 更高的范数,且仅占总序列的很小部分(约 $2%$ )。我们还证明这些token出现在视觉Transformer (Vision Transformer) 的中间层附近,并且仅在足够大规模Transformer经过充分训练后才会出现。特别地,我们发现这些异常token出现在与邻近patch相似的patch中,这意味着这些patch传递的额外信息极少。
As part of our investigation, we evaluate the outlier tokens with simple linear models to understand the information they contain. We observe that, compared to non-outlier tokens, they hold less information about their original position in the image or the original pixels in their patch. This observation suggests that the model discards the local information contained in these patches during inference. On the other hand, learning an image classifier on outlier patches yields significantly stronger accuracy than doing so on the other patches, suggesting that they contain global information about the image. We propose the following interpretation to these elements: the model learns to recognize patches containing little useful information, and recycle the corresponding tokens to aggregate global image information while discarding spatial information.
在我们的调查中,我们通过简单的线性模型评估异常Token(outlier tokens),以了解它们所包含的信息。我们发现,与非异常Token相比,这些Token所包含的关于其在图像中原始位置或图像块(patch)中原始像素的信息较少。这一观察表明,模型在推理过程中丢弃了这些图像块中包含的局部信息。另一方面,在异常图像块上学习图像分类器的准确率显著高于其他图像块,这表明它们包含了关于图像的全局信息。我们提出以下解释:模型学会识别包含少量有用信息的图像块,并回收相应的Token以聚合全局图像信息,同时丢弃空间信息。
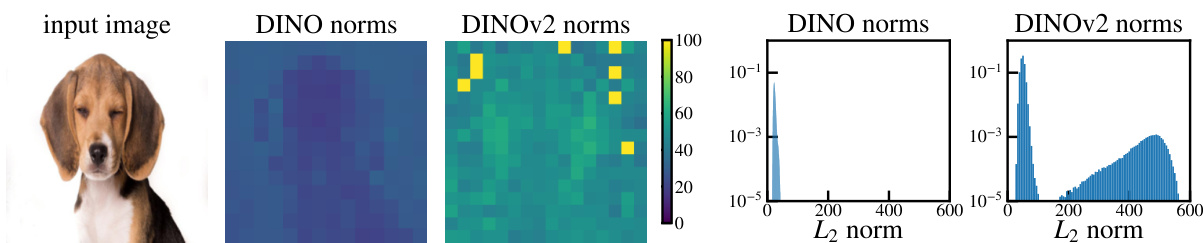
Figure 3: Comparison of local feature norms for DINO ViT-B/16 and DINOv2 ViT-g/14. We observe that DINOv2 has a few outlier patches, whereas DINO does not present these artifacts. For DINOv2, although most patch tokens have a norm between 0 and 100, a small proportion of tokens have a very high norm. We measure the proportion of tokens with norm larger than 150 at $2.37%$ .
图 3: DINO ViT-B/16 与 DINOv2 ViT-g/14 局部特征范数对比。我们观察到 DINOv2 存在少量异常图像块 (patch) ,而 DINO 未出现此类伪影。对于 DINOv2 ,虽然大多数图像块 token 的范数介于 0 至 100 之间,但仍有小部分 token 具有极高范数。我们测得范数超过 150 的 token 占比为 $2.37%$ 。
This interpretation is consistent with an inner mechanism in transformer models that allows performing computations within a restricted set of tokens. In order to test this hypothesis, we append additional tokens - that we call registers - to the token sequence, independent of the input image. We train several models with and without this modification and observe that the outlier tokens disappear from the sequence entirely. As a result, the performance of the models increases in dense prediction tasks, and the resulting feature maps are significantly smoother. These smooth feature maps enable object discovery methods like LOST mentioned above with the updated models.
这一解释与Transformer模型内部机制相符,该机制允许在有限的token集合内执行计算。为验证该假设,我们在输入图像无关的token序列后附加额外token(称为寄存器)。通过对比修改前后的多个模型训练结果,发现异常token会从序列中完全消失。这使得模型在密集预测任务中性能提升,生成的特征图显著平滑。改进后的模型配合上述LOST等方法,可利用这些平滑特征图实现目标发现。
2 PROBLEM FORMULATION
2 问题描述
As shown in Fig. 2, most modern vision transformers exhibit artifacts in the attention maps. The unsupervised DINO backbone (Caron et al., 2021) has been previously praised for the quality of local features and interpret ability of attention maps. Surprisingly, the outputs of the subsequent DINOv2 models have been shown to hold good local information but exhibit undesirable artifacts in attention maps. In this section, we propose to study why and when these artifacts appear. While this work focuses on alleviating artefacts in all vision transformers, we focus our analysis on DINOv2.
如图 2 所示,大多数现代视觉 Transformer 在注意力图中都表现出伪影 (artifacts)。无监督的 DINO 主干网络 (Caron et al., 2021) 曾因局部特征质量和注意力图可解释性而备受赞誉。但令人惊讶的是,后续 DINOv2 模型的输出虽保留了良好的局部信息,却在注意力图中出现了不理想的伪影。本节我们将探究这些伪影出现的原因和时机。尽管本研究致力于缓解所有视觉 Transformer 中的伪影问题,但分析重点仍放在 DINOv2 上。
2.1 ARTIFACTS IN THE LOCAL FEATURES OF DINOV2
2.1 DINOV2局部特征中的伪影
Artifacts are high-norm outlier tokens. We want to find a quantitative way of characterizing artefacts that appear in the local features. We observe that an important difference between “artifact” patches and other patches is the norm of their token embedding at the output of the model. In Fig. 3 (left), we compare the norm of local features for a DINO and DINOv2 model given a reference image. We clearly see that the norm of artifact patches is much higher than the norm of other patches. We also plot the distribution of feature norms over a small dataset of images in Fig. 3 (right), which is clearly bimodal, allowing us to choose a simple criterion for the rest of this section: tokens with norm higher than 150 will be considered as “high-norm” tokens, and we will study their properties relative to regular tokens. This hand-picked cutoff value can vary across models. In the rest of this work, we use “high-norm” and “outlier” interchangeably.
规则:
- 输出中文翻译部分时,仅保留翻译标题,不包含任何多余内容、重复或解释。
- 不输出与英文无关的内容。
- 保留原始段落格式及术语(如 FLAC、JPEG)、公司缩写(如 Microsoft、Amazon、OpenAI)。
- 人名不翻译。
- 保留论文引用格式(如 [20])。
- Figure 和 Table 翻译为“图”和“表”并保留原有编号(如“图 1: ”、“表 1: ”)。
- 全角括号替换为半角括号,左右括号前后添加半角空格。
- 专业术语首次出现时标注英文原文(如“生成式 AI (Generative AI)”),后续仅用中文。
- 常见 AI 术语对照:
- Transformer -> Transformer
- Token -> Token
- LLM/Large Language Model -> 大语言模型
- Zero-shot -> 零样本
- Few-shot -> 少样本
- AI Agent -> AI智能体
- AGI -> 通用人工智能
- Python -> Python语言
策略:
- 特殊字符和公式原样保留。
- HTML 表格转为 Markdown 格式。
- 翻译内容需符合中文表达习惯且无信息遗漏。
最终仅返回 Markdown 格式的翻译结果。
伪影 (artifact) 是高范数离群 Token。我们希望找到一种量化方法来描述局部特征中出现的伪影。观察到“伪影”补丁与其他补丁的关键区别在于模型输出端其 Token 嵌入的范数。在图 3 (左) 中,我们比较了给定参考图像时 DINO 和 DINOv2 模型的局部特征范数。可清晰看出伪影补丁的范数远高于其他补丁。图 3 (右) 还展示了小型图像数据集上特征范数的分布,该分布明显呈双峰,因此本节后续采用简单判定标准:范数高于 150 的 Token 视为“高范数”Token,并研究其相对于常规 Token 的特性。此手动设定的阈值可能因模型而异。后文中,“高范数”与“离群”将互换使用。
Outliers appear during the training of large models. We make several additional observations about the conditions in which these outlier patches appear during the training of DINOv2. This analysis is illustrated in Fig. 4. First, these high-norm patches seem to differentiate themselves from other patches around layer 15 of this 40-layer ViT (Fig. 4a). Second, when looking at the distribution of norms along training of DINOv2, we see that these outliers only appear after one third of training (Fig. 4b). Finally, when analyzing more closely models of different size (Tiny, Small, Base, Large, Huge and giant), we see that only the three largest models exhibit outliers (Fig. 4c).
在大模型训练过程中会出现异常值。我们对DINOv2训练过程中这些异常图像块(patches)出现的条件做了几点补充观察,该分析如图4所示:首先,这些高范数图像块似乎在这个40层ViT的第15层左右开始与其他图像块区分开来(图4a);其次,当观察DINOv2训练过程中的范数分布时,我们发现这些异常值仅在训练进行到三分之一阶段后才出现(图4b);最后,在更细致地分析不同尺寸模型(Tiny/Small/Base/Large/Huge/Giant)时,我们发现只有三个最大规模的模型会出现异常值(图4c)。
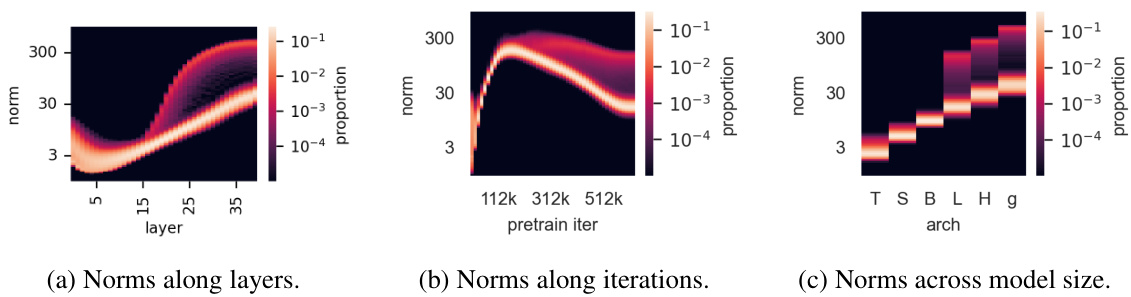
Figure 4: Illustration of several properties of outlier tokens in the 40-layer DINOv2 ViT-g model. (a): Distribution of output token norms along layers. (b): Distribution of norms along training iterations. (c): Distribution of norms for different model sizes. The outliers appear around the middle of the model during training; they appear with models larger than and including ViT-Large.
图 4: DINOv2 ViT-g 40层模型中离群Token的多项特性图示。(a): 各层输出Token范数分布。(b): 训练迭代过程中范数分布。(c): 不同模型尺寸下的范数分布。这些离群值在训练过程中出现在模型中部位置,且仅出现于ViT-Large及以上规模的模型中。
(b) Linear probing for local information.
| 位置预测 | 重建 | ||
|---|---|---|---|
| top-1 准确率 | 平均距离 ↓ | L2 误差 ← | |
| 正常 | 41.7 | 0.79 | 18.38 |
| 异常 | 22.8 | 5.09 | 25.23 |
(b) 局部信息的线性探测。
(a) Cosine similarity to neighbors.
(a) 与邻居的余弦相似度。
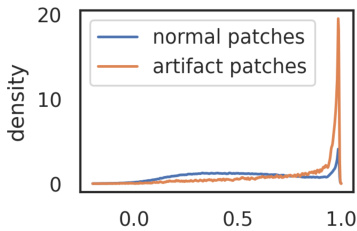
Figure 5: (a): Distribution of cosine similarity between input patches and their 4 neighbors. We plot separately artifact patches (norm of the output token over 150) and normal patches. (b): Local information probing on normal and outlier patch tokens. We train two models: one for predicting position, and one for reconstructing the input patch. Outlier tokens have much lower scores than the other tokens, suggesting they are storing less local patch information.
图 5: (a) 输入图像块与其4个邻域块之间余弦相似度的分布。我们分别绘制了伪影块(输出token范数超过150)和正常块的分布。(b) 对正常和异常图像块token的局部信息探测。我们训练了两个模型: 一个用于预测位置, 另一个用于重建输入图像块。异常token的得分远低于其他token, 表明它们存储的局部图像块信息更少。
High-norm tokens appear where patch information is redundant. To verify this, we measure the cosine similarity between high-norm tokens and their 4 neighbors right after the patch embedding layer (at the beginning of the vision transformer). We illustrate the density plot in Fig. 5a. We observe that high-norm tokens appear on patches that are very similar to their neighbors. This suggests that these patches contrain redundant information and that the model could discard their information without hurting the quality of the image representation. This matches qualitative observations (see Fig. 2) that they often appear in uniform, background areas.
高范数Token出现在图像块信息冗余的区域。为验证这一点,我们测量了视觉Transformer起始处(紧接图像块嵌入层后)高范数Token与其4个相邻Token的余弦相似度。如图5a所示密度图表明,高范数Token往往出现在与周边区域高度相似的图像块上。这说明这些图像块包含冗余信息,模型在丢弃这些信息时不会损害图像表征质量。该现象与定性观察结果一致(见图2),即高范数Token常出现于均匀的背景区域。
High-norm tokens hold little local information. In order to better understand the nature of these tokens, we propose to probe the patch embeddings for different types of information. For that we consider two different tasks: position prediction and pixel reconstruction. For each of these tasks, we train a linear model on top of the patch embeddings, and measure the performance of this model. We compare the performance achieved with high-norm tokens and with other tokens, to see if high-norm tokens contain different information than “normal” tokens.
高范数Token包含的局部信息较少。为了更好地理解这些Token的特性,我们提出探测不同信息类型的补丁嵌入。为此,我们考虑两项任务:位置预测和像素重建。针对每项任务,我们在补丁嵌入上训练线性模型,并测量该模型的性能。通过比较高范数Token与其他Token的性能表现,以验证高范数Token是否携带与"普通"Token不同的信息。
• Position prediction. We train a linear model to predict the position of each patch token in the image, and measure its accuracy. We note that this position information was injected in the tokens before the first ViT layer in the form of absolute position embeddings. We observe that high-norm tokens have much lower accuracy than the other tokens (Fig. 5b), suggesting they contain less information about their position in the image. • Pixel reconstruction. We train a linear model to predict the pixel values of the image from the patch embeddings, and measure the accuracy of this model. We observe again that high-norm tokens achieve much lower accuracy than other tokens (Fig. 5b). This suggests that high-norm tokens contain less information to reconstruct the image than the others.
• 位置预测。我们训练一个线性模型来预测图像中每个补丁(patch) token的位置,并测量其准确率。需要指出的是,这些位置信息是以绝对位置嵌入(absolute position embeddings)的形式在第一个ViT层之前注入到token中的。我们观察到高范数(high-norm) token的准确率远低于其他token(图5b),表明它们包含的图像位置信息较少。
• 像素重建。我们训练一个线性模型从补丁嵌入(patch embeddings)预测图像的像素值,并测量该模型的准确率。再次观察到高范数token的准确率远低于其他token(图5b)。这表明高范数token包含的图像重建信息比其他token更少。
Artifacts hold global information. In order to evaluate how much global information is gathered in the high-norm tokens, we propose to evaluate them on standard image representation learning
人工制品蕴含全局信息。为评估高范数Token中聚集的全局信息量,我们提出在标准图像表征学习任务中对其进行评估
| IN1k P205 Airc. CF10 CF100 CUB Cal101 Cars | DTD | 0 Flow.Food Pets SUN VOC | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [CLS] | 86.0 | 66.4 | 87.3 | 99.4 | 94.5 | 91.3 | 96.9 | 91.5 | 85.2 | 99.7 | 94.7 | 96.9 | 78.6 89.1 |
| normal | 65.8 | 53.1 | 17.1 | 97.1 | 81.3 | 18.6 | 73.2 | 10.8 | 63.1 | 59.5 | 74.2 | 47.8 37.7 | 70.8 |
| outlier | 69.0 | 55.1 | 79.1 | 99.3 | 93.7 | 84.9 | 97.6 | 85.2 | 84.9 | 99.6 | 93.5 94.1 | 78.5 | 89.7 |
Table 1: Image classification via linear probing on normal and outlier patch tokens. We also report the accuracy of class if i ers learnt on the class token. We see that outlier tokens have a much higher accuracy than regular ones, suggesting they are effectively storing global image information.
表 1: 通过正常和异常图像块token的线性探测进行图像分类。我们还报告了基于类别token学习的分类器准确率。结果显示异常token的准确率显著高于常规token,表明它们能有效存储全局图像信息。
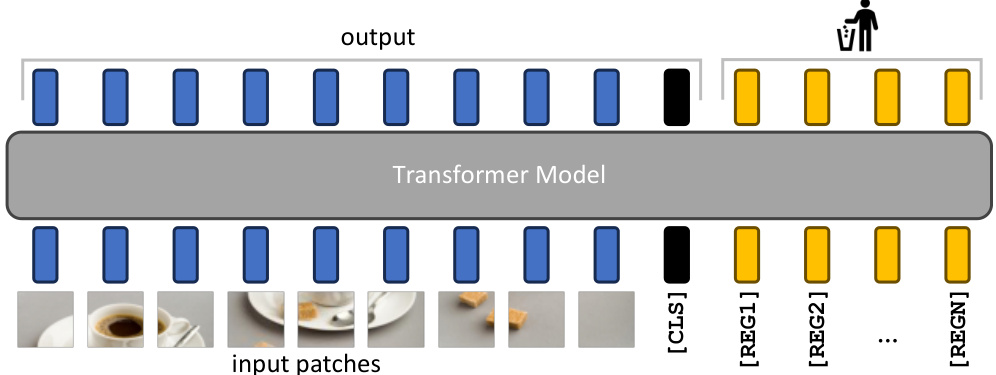
Figure 6: Illustration of the proposed remediation and resulting model. We add $N$ additional learnable input tokens (depicted in yellow), that the model can use as registers. At the output of the model, only the patch tokens and [CLS] tokens are used, both during training and inference.
图 6: 提出的修复方案及结果模型示意图。我们添加了 $N$ 个可学习的输入 Token (以黄色标示),模型可将这些 Token 用作寄存器。在模型输出端,无论是训练还是推理阶段,仅使用图像块 Token 和 [CLS] Token。
benchmarks. For each image in a classification dataset, we forward it through DINOv2- $\mathbf{\nabla}^{\cdot}\mathbf{g}$ and extract the patch embeddings. From those, we choose a single token at random, either high-norm or normal. This token is then considered as the image representation. We then train a logistic regression classifier to predict the image class from this representation, and measure the accuracy. We observe that the high-norm tokens have a much higher accuracy than the other tokens (Table 1). This suggests that outlier tokens contain more global information than other patch tokens.
基准测试。对于分类数据集中的每张图像,我们通过DINOv2- $\mathbf{\nabla}^{\cdot}\mathbf{g}$ 前向传播并提取补丁嵌入。从中随机选择一个高范数或普通token作为图像表征,随后训练逻辑回归分类器根据该表征预测图像类别并测量准确率。实验表明高范数token的准确率显著高于其他token(表1),这表明异常token比其他补丁token包含更全局的信息。
2.2 HYPOTHESIS AND REMEDIATION
2.2 假设与修复
Having made these observations, we make the following hypothesis: large, sufficiently trained models learn to recognize redundant tokens, and to use them as places to store, process and retrieve global information. Furthermore, we posit that while this behavior is not bad in itself, the fact that it happens inside the patch tokens is undesirable. Indeed, it leads the model to discard local patch information (Tab. 5b), possibly incurring decreased performance on dense prediction tasks.
基于上述观察,我们提出以下假设:经过充分训练的大型模型能够学会识别冗余token,并将其作为存储、处理和检索全局信息的载体。此外,我们认为虽然这种行为本身并无不妥,但问题在于它发生在图像块(patch)token内部。这会导致模型丢弃局部图像块信息(表5b),可能降低密集预测任务的性能。
We therefore propose a simple fix to this issue: we explicitly add new tokens to the sequence, that the model can learn to use as registers. We add these tokens after the patch embedding layer, with a learnable value, similarly to the [CLS] token. At the end of the vision transformer, these tokens are discarded, and the [CLS] token and patch tokens are used as image representations, as usual. This mechanism was first proposed in Memory Transformers (Burtsev et al., 2020), improving translation tasks in NLP. Interestingly, we show here that this mechanism admits a natural justification for vision transformers, fixing an interpret ability and performance issue that was present otherwise.
因此,我们针对该问题提出一个简单解决方案:显式地向序列中添加新token,使模型能够将其作为寄存器学习使用。这些token在补丁嵌入层之后以可学习值的形式添加,类似于[CLS] token的处理方式。在视觉Transformer末端,这些token会被丢弃,而[CLS] token和补丁token则照常作为图像表征使用。该机制最初由Memory Transformers (Burtsev et al., 2020) 提出,用于提升NLP中的翻译任务性能。值得注意的是,我们在此证明该机制能为视觉Transformer提供自然合理性,修复了原本存在的可解释性与性能问题。
We note that we have not been able to fully determine which aspects of the training led to the appearance of artifacts in different models. The pre training paradigm seems to play a role, as OpenCLIP and DeiT-III exhibit outliers both at size B and L (Fig. 2). However, the model size and training length also play important parts, as observed in Fig. 4.
我们注意到,目前尚无法完全确定训练过程中的哪些因素导致了不同模型中出现伪影 (artifacts) 。预训练范式似乎起到了一定作用,因为 OpenCLIP 和 DeiT-III 在 B 和 L 尺寸下都出现了异常值 (图 2) 。但如图 4 所示,模型规模和训练时长同样起着重要作用。
3 EXPERIMENTS
3 实验
In this section, we validate the proposed solution by training vision transformers with additional [reg] register tokens. We evaluate the effectiveness of our approach by a quantitative and qualitative analysis. We then ablate the number of registers used for training, to check that they do not
在本节中,我们通过训练带有额外[reg]寄存器token的视觉Transformer来验证所提出的解决方案。我们通过定量和定性分析评估方法的有效性,随后对训练所用寄存器数量进行消融实验,以验证其不会...

Figure 7: Effect of register tokens on the distribution of output norms on DINOv2, OpenCLIP and DeiT-III. Using register tokens effectively removes the norm outliers that were present previously.
图 7: 寄存器Token (register tokens) 对 DINOv2、OpenCLIP 和 DeiT-III 输出范数分布的影响。使用寄存器Token有效消除了先前存在的范数异常值。
cause a performance regression, evaluate an unsupervised object discovery method atop our features and finally provide a qualitative analysis of the patterns learnt by the registers.
导致性能下降,基于我们的特征评估一种无监督目标发现方法,最后对寄存器学习到的模式进行定性分析。
3.1 TRAINING ALGORITHMS AND DATA
3.1 训练算法与数据
As the proposed solution is a simple architectural change, we can easily apply it to any training procedure. We try it on three different state-of-the-art training methods for supervised, text-supervised, and unsupervised learning, shortly described below.
由于所提出的解决方案是一个简单的架构变更,我们可以轻松将其应用于任何训练流程。我们在以下三种最先进的训练方法上进行了验证:监督学习、文本监督学习和无监督学习,简要描述如下。
DEIT-III (Touvron et al., 2022) is a simple and robust supervised training recipe for classification with ViTs on ImageNet-1k and ImageNet-22k. We choose this method as an example of labelsupervised training as it is simple, uses the base ViT architecture, achieves strong classification results, and is easy to reproduce and modify with our improvements. We run this method on the ImageNet-22k dataset, using the ViT-B settings, as provided in the official repository 1.
DEIT-III (Touvron et al., 2022) 是一种简单且鲁棒的监督式训练方法,用于在 ImageNet-1k 和 ImageNet-22k 数据集上使用 ViT (Vision Transformer) 进行分类。我们选择该方法作为标签监督训练的示例,因为它简单易用,基于基础 ViT 架构,能取得强大的分类结果,并且易于复现和修改以适应我们的改进。我们按照官方代码库提供的 ViT-B 配置,在 ImageNet-22k 数据集上运行了该方法。
OpenCLIP (Ilharco et al., 2021) is a strong training method for producing text-image aligned models, following the original CLIP work. We chose this method as an example of text-supervised training because it is open-source, uses the base ViT architecture, and is easy to reproduce and modify with our improvements. We run the OpenCLIP method on a text-image-aligned corpus based on Shutter stock that includes only licensed image and text data. We use a ViT-B/16 image encoder, as proposed in the official repository 2.
OpenCLIP (Ilharco et al., 2021) 是一种强大的训练方法,用于生成文本-图像对齐模型,延续了原始 CLIP 的工作。我们选择该方法作为文本监督训练的示例,因为它是开源的,使用了基础的 ViT 架构,并且易于通过我们的改进进行复现和修改。我们在基于 Shutterstock 的文本-图像对齐语料库上运行 OpenCLIP 方法,该语料库仅包含经过授权的图像和文本数据。我们按照官方仓库的建议,使用了 ViT-B/16 图像编码器。
DINOv2 (Oquab et al., 2023) is a self-supervised method for learning visual features, following the DINO work. We apply our changes to this method as it is the main focus of our study. We run this method on ImageNet $22\mathrm{k}$ with the ViT-L configuration. We use the official repository 3.
DINOv2 (Oquab等人,2023) 是一种自监督的视觉特征学习方法,延续了DINO的工作。我们对此方法进行了改进,因为它是我们研究的主要焦点。我们在ImageNet $22\mathrm{k}$ 上使用ViT-L配置运行该方法,并采用了官方代码库3。
3.2 EVALUATION OF THE PROPOSED SOLUTION
3.2 所提方案的评估
As shown in Fig. 1, we get rid of the artifacts by training models with additional register tokens. In the appendix, we provide additional qualitative results for more images in Fig. 19. In order to quantitatively measure this effect, for each model, we probe the norm of features at the output of the model. We report these norms for all three algorithms with and without registers in Fig. 7. We see that when training with registers, models do not exhibit large-norm tokens at the output, which confirms the initial qualitative assessment.
如图1所示,我们通过使用额外注册token训练模型消除了伪影。附录的图19展示了更多图像的补充定性结果。为量化该效果,我们测量了各模型输出端特征的范数。图7对比展示了三种算法在使用/不使用注册token时的特征范数。结果表明:采用注册token训练时,模型输出端不会出现大范数token,这验证了初步的定性判断。
Performance regression. In the previous section, we have shown that the proposed approach removes artifacts from local feature maps. In this experiment, we want to check that the use of register tokens does not affect the representation quality of those features. We run linear probing on ImageNet classification, ADE20k Segmentation, and NYUd monocular depth estimation. We follow the experimental protocol outlined in Oquab et al. (2023). We summarize the performance of the models described in Sec. 3.1 with and without register tokens in Table 2a. We see that when using registers, models do not lose performance and sometimes even work better. For completeness, we also provided the zero-shot classification performance on ImageNet for OpenCLIP (Table 2b), which remains unchanged. Please note that the absolute performance of our OpenCLIP reproduction is lower due to the data source we used.
性能回归。上一节中,我们已证明所提方法能消除局部特征图(Feature Maps)的伪影。本实验旨在验证寄存器Token(Register Tokens)的使用不会影响这些特征的表征质量。我们在ImageNet分类、ADE20k分割和NYUd单目深度估计任务上进行了线性探测,遵循Oquab等人(2023)提出的实验方案。表2a汇总了第3.1节所述模型在使用/不使用寄存器Token时的性能表现。结果显示:使用寄存器时模型性能未下降,有时甚至表现更优。为完整起见,我们还提供了OpenCLIP在ImageNet上的零样本分类性能(表2b),其表现保持稳定。需注意由于数据源差异,我们复现的OpenCLIP绝对性能较低。
Table 2: Evaluation of downstream performance of the models that we trained, with and without registers. We consider linear probing of frozen features for all three models, and zero-shot evaluation for the OpenCLIP model. We see that using register not only does not degrade performance, but even improves it by a slight margin in some cases.
(a) Linear evaluation with frozen features.
表 2: 使用寄存器与不使用寄存器时,我们所训练模型的下游性能评估。我们对所有三个模型进行了冻结特征的线性探测,并对 OpenCLIP 模型进行了零样本评估。可以看到,使用寄存器不仅不会降低性能,在某些情况下甚至能略微提升性能。
| ImageNet Top-1 | ADE20k mIoU | NYUd rmse √ | |
|---|---|---|---|
| DeiT-III | 84.7 | 38.9 | 0.511 |
| DeiT-MI+reg | 84.7 | 39.1 | 0.512 |
| OpenCLIP | 78.2 | 26.6 | 0.702 |
| OpenCLIP+reg | 78.1 | 26.7 | 0.661 |
| DINOv2 | 84.3 | 46.6 | 0.378 |
| DINOv2+reg | 84.8 | 47.9 | 0.366 |
(a) 使用冻结特征的线性评估。
(b) Zero-shot classification.
| ImageNet Top-1 | |
|---|---|
| OpenCLIP | 59.9 |
| OpenCLIP+reg | 60.1 |
(b) 零样本分类。
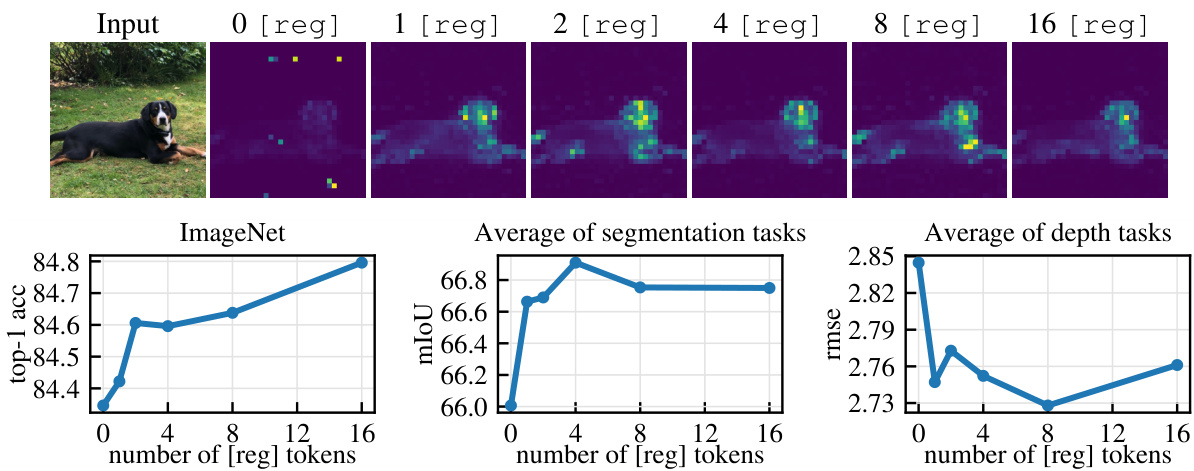
Figure 8: Ablation of the the number of register tokens used with a DINOv2 model. (top): qualitative visualization of artifacts appearing as a function of number of registers. (bottom): performance on three tasks (ImageNet, ADE $20\mathrm{k\Omega}$ and NYUd) as a function of number of registers used. While one register is sufficient to remove artefacts, using more leads to improved downstream performance.
图 8: DINOv2模型中使用的寄存器token数量消融实验。(top): 不同寄存器数量导致的伪影可视化。(bottom): 三个任务(ImageNet、ADE $20\mathrm{k\Omega}$和NYUd)性能随寄存器数量的变化趋势。单个寄存器即可消除伪影,但增加数量能提升下游任务性能。
Number of register tokens. As described in Sec. 2.2, we propose alleviating the feature maps’ artifacts by adding register tokens. In this experiment, we study the influence of the number of such tokens on local features and downstream performance. We train DINOv2 ViT-L/14 models with 0, 1, 2, 4, 8 or 16 registers. In Fig. 8, we report the results of this analysis. In Fig. 8(top), we qualitatively study the attention maps and observe that the visible artifacts disappear when adding at least one register. We then examine in Fig. 8(bottom) performance on downstream evaluation benchmarks, following the protocol from Oquab et al. (2023). There seems to be an optimal number of registers for dense tasks, and adding one brings most of the benefit. This optimum is likely explained by the disappearance of artifacts, leading to better local features. On ImageNet, however, performance improves when using more registers. In all our experiments, we kept 4 register tokens.
注册Token数量。如第2.2节所述,我们提出通过添加注册Token来缓解特征图伪影问题。本实验研究了此类Token数量对局部特征和下游性能的影响。我们训练了包含0、1、2、4、8或16个注册Token的DINOv2 ViT-L/14模型。图8展示了分析结果:在图8(顶部)中,我们定性研究了注意力图,发现添加至少一个注册Token时可见伪影会消失;在图8(底部)中,按照Oquab等人(2023)的评估协议测试了下游基准性能。稠密任务存在最优注册Token数量,而添加一个即可获得大部分收益,这很可能是因为伪影消失改善了局部特征。但在ImageNet上,使用更多注册Token时性能会持续提升。所有实验中我们均保留4个注册Token。
3.3 OBJECT DISCOVERY
3.3 目标发现
Recent unsupervised object discovery methods rely on the quality and smoothness of local feature maps (Siméoni et al., 2021; Wang et al., 2023). By leveraging DINO Caron et al. (2021), these methods have significantly surpassed the previous state of the art. However, the algorithm leads to poor performance when applied to modern backbones such as DINOv2 Oquab et al. (2023) or supervised ones Touvron et al. (2022). We posit that this can be alleviated by the method proposed in this work. We run LOST (Siméoni et al., 2021) on features extracted from backbones trained using the algorithms described in Sec.3.1 with and without registers. We run object discovery on PASCAL
最近的无监督物体发现方法依赖于局部特征图的质量和平滑度 (Siméoni et al., 2021; Wang et al., 2023)。通过利用 DINO (Caron et al., 2021),这些方法显著超越了之前的最先进水平。然而,当应用于现代骨干网络如 DINOv2 (Oquab et al., 2023) 或有监督骨干网络 (Touvron et al., 2022) 时,该算法表现不佳。我们认为,本文提出的方法可以缓解这一问题。我们在使用和不使用寄存器的情况下,对通过第3.1节描述的算法训练的骨干网络提取的特征运行 LOST (Siméoni et al., 2021),并在 PASCAL 上进行物体发现。
| VOC2007 | VOC2012 | COCO20k | |
|---|---|---|---|
| DeiT-III | 11.7 | 13.1 | 10.7 |
| DeiT-IMI+reg | 27.1 | 32.7 | 25.1 |
| OpenCLIP | 38.8 | 44.3 | 31.0 |
| OpenCLIP+reg | 37.1 | 42.0 | 27.9 |
| DINOv2 | 35.3 | 40.2 | 26.9 |
| DINOv2+reg | 55.4 | 60.0 | 42.0 |
Table 3: Unsupervised Object Discovery using LOST (Siméoni et al., 2021) on models with and without registers. We evaluated three types of models trained with various amounts of supervision on VOC 2007, 2012 and COCO. We measure performance using corloc. We observe that adding register tokens makes all models significantly more viable for usage in object discovery.
表 3: 使用 LOST (Siméoni et al., 2021) 在带/不带寄存器 (registers) 的模型上进行无监督目标发现。我们在 VOC 2007、2012 和 COCO 数据集上评估了三种经过不同监督程度训练的模型,采用 corloc 指标衡量性能。结果表明,添加寄存器 token 能显著提升所有模型在目标发现任务中的适用性。

Figure 9: Comparison of the attention maps of the [CLS] and register tokens. Register tokens sometimes attend to different parts of the feature map, similarly to slot attention (Locatello et al., 2020). This behaviour was never required from the model, and emerged naturally from training.
图 9: [CLS] Token 与 register token 的注意力图对比。register token 有时会关注特征图的不同区域,类似于 slot attention (Locatello et al., 2020)。这种行为从未被要求模型执行,而是在训练过程中自然涌现的。
VOC 2007 and 2012 and COCO 20k. We use values for DeiT and OpenCLIP, and for DINOv2, we use keys. Because the output features may have different conditioning, we manually add a bias to the gram matrix of features. The results of this experiment are presented in Table 3. For DINOv2 and DeiT-III, adding registers significantly improves the discovery performance. For OpenCLIP, the performance is slighty worse with registers (see Sec. C for analysis). The performance of DINOv2 on VOC2007 still does not match that of DINO as reported by Siméoni et al. (2021) (61.9 corloc). However, the model with registers gets an improvement of 20.1 corloc (55.4 versus 35.3).
VOC 2007和2012以及COCO 20k。我们使用DeiT和OpenCLIP的值,对于DINOv2则使用键。由于输出特征可能具有不同的条件化处理,我们手动为特征的格拉姆矩阵添加偏置。该实验结果如表3所示。对于DINOv2和DeiT-III,添加寄存器显著提升了发现性能。而OpenCLIP在使用寄存器时性能略有下降(分析见附录C)。DINOv2在VOC2007上的性能仍未达到Siméoni等人(2021)报告的DINO水平(61.9 corloc),但带寄存器的模型实现了20.1 corloc的提升(55.4对比35.3)。
3.4 QUALITATIVE EVALUATION OF REGISTERS
3.4 寄存器定性评估
In this final experiment, we qualitatively probe for the behavior of register tokens. We want to verify if they all exhibit similar attention patterns or whether a differentiation automatically emerges. To this end, we plot the attention maps of the class and register tokens to patch tokens. The result of this visualization is shown in Fig. 9. We see that registers do not have a completely aligned behavior. Some selected registers exhibit interesting attention patterns, attending to the different objects in the scene. While nothing enforced this behavior, their activation s had some natural diversity. We leave the study of the regular iz ation of registers for future work.
在最终实验中,我们定性探究了寄存器Token (register tokens) 的行为模式。旨在验证它们是否呈现相似的注意力分布,或是否会自动产生分化。为此,我们绘制了类别Token (class tokens) 和寄存器Token对图像块Token (patch tokens) 的注意力热图,可视化结果如图9所示。研究发现寄存器Token并未表现出完全一致的行为:部分被选中的寄存器Token展现出有趣的注意力模式,能够聚焦于场景中的不同物体。尽管模型未强制该行为,但其激活状态仍存在自然多样性。关于寄存器Token的规律化研究将留待未来工作。
4 RELATED WORK
4 相关工作
Feature extraction with pretrained models. Using pretrained neural network models for extracting visual features has stood the test of time since the AlexNet (Krizhevsky et al., 2012) CNN model pretrained on ImageNet-1k (Russ a kov sky et al., 2015). More recent models have upgraded the same setup with modern architectures, such as ResNets (used in, e.g., DETR, Carion et al., 2020) or even Vision Transformers. As Transformers are easily able to handle different modalities during training, off-the-shelf backbones are now commonly trained on label supervision (e.g., DeiT-III on ImageNet $22\mathrm{k\Omega}$ , Touvron et al., 2022) or text supervision (e.g., CLIP (Radford et al., 2021)), providing strong visual foundation models, scaling well with model sizes, and enabling excellent performance on a variety of tasks including detection (Carion et al., 2020) and segmentation (Zheng et al., 2021; Kirillov et al., 2023). In this context, supervision relies on annotations in the form of labels or text alignment; the dataset biases (Torralba & Efros, 2011) are not well characterized, yet they drive learning and shape the learned models. An alternative approach consists of not using supervision and letting the models learn from the data via a pretext task that is designed to require understanding the content of images (Doersch et al., 2015). This self-supervised learning paradigm was explored in multiple methods using Vision Transformers: MAE (He et al., 2022) trains a model at reconstructing pixel values of hidden areas of an image and then applies fine-tuning to address a new task. With a different approach, the self-distillation family of methods (He et al., 2020; Caron et al., 2021; Zhou et al., 2022) showcase strong performance using frozen backbones, allowing for more robustness to domain shifts for task-specific downstream models. In this work, we focused the analysis on selfsupervised learning, and more specifically on the DINOv2 approach (Oquab et al., 2023), which has shown to be particularly effective for learning local features. We showed that despite excellent benchmark scores, DINOv2 features exhibit undesirable artifacts and that correcting these artifacts in the learning process allows for further improvements in the benchmark performances. These phenomenon is even more surprising as DINOv2 builds upon DINO (Caron et al., 2021), which does not show signs of artifacts. We then further showed that the correction techniques hold for supervised paradigms by testing on DeiT-III and OpenCLIP.
基于预训练模型的特征提取。自AlexNet (Krizhevsky等, 2012) 在ImageNet-1k (Russakovsky等, 2015) 上预训练的CNN模型问世以来,使用预训练神经网络提取视觉特征的方法经受住了时间考验。现代架构如ResNets (如DETR采用, Carion等, 2020) 乃至Vision Transformers进一步升级了这一范式。由于Transformer能轻松处理训练中的多模态数据,现成骨干网络通常采用标签监督 (如DeiT-III在ImageNet-22k, Touvron等, 2022) 或文本监督 (如CLIP, Radford等, 2021) 训练,这些强大的视觉基础模型不仅随规模扩展表现优异,在检测 (Carion等, 2020) 和分割 (Zheng等, 2021; Kirillov等, 2023) 等任务中也有出色表现。此类监督依赖标签或文本对齐形式的标注,但数据集偏差 (Torralba & Efros, 2011) 尚未被充分表征,却主导着模型学习过程。另一种无监督方法通过设计需理解图像内容的代理任务 (Doersch等, 2015) 让模型从数据中自主学习。这种自监督范式在多项基于Vision Transformer的研究中得以探索:MAE (He等, 2022) 训练模型重建图像遮蔽区域的像素值,再通过微调适应新任务;而自蒸馏方法族 (He等, 2020; Caron等, 2021; Zhou等, 2022) 采用不同策略,在冻结骨干网络时仍展现强劲性能,使下游任务模型对领域偏移更具鲁棒性。本文重点分析自监督学习,特别是对局部特征学习尤为有效的DINOv2 (Oquab等, 2023),发现尽管其基准分数优异,但特征存在不良伪影,修正这些伪影可进一步提升性能。这一现象尤为意外,因为DINOv2基于未显示伪影迹象的DINO (Caron等, 2021) 构建。我们进一步通过对DeiT-III和OpenCLIP的测试表明,这些修正技术同样适用于监督学习范式。
Additional tokens in transformers. Extending the transformer sequence with special tokens was popularized in BERT (Devlin et al., 2019). However, most approaches add new tokens either to provide the network with new information as for example [SEP] tokens in BERT, provide opportunity to spend more computation on the input as seen with the tape tokens in AdaTape (Xue et al., 2023), or to gather information in these tokens, and use their output value as an output of the model: for classification, as [CLS] tokens in BERT and ViT (Do sov it ski y et al., 2021); for generative learning, as [MASK] in BERT and BEiT (Bao et al., 2021); for detection, as object queries in DETR (Carion et al., 2020), detection tokens in YOLOS (Fang et al., 2021), and ViDT (Song et al., 2021); or for accumulating information from possibly multiple modalities before decoding, as latent token arrays in Perceivers (Jaegle et al., 2021; 2022). Different to these works, the tokens we add to the sequence add no information, and their output value is not used for any purpose. They are simply registers where the model can learn to store and retrieve information during the forward pass. The Memory Transformer (Burtsev et al., 2020), closer to our work, presents a simple approach to improve transformer models using memory tokens added to the token sequence, improving translation performance. In follow-up work, Bulatov et al. (2022) address complex copy-repeat-reverse tasks. Sandler et al. (2022) extend this line to the vision domain for fine-tuning but observe that such tokens do not transfer well across tasks. In contrast, we do not perform fine-tuning and employ additional tokens during pre training to improve the features obtained for all tasks downstream. More importantly, our study contributes the following new insight in Sec. 2: the mechanism implemented through memory tokens already appears naturally in Vision Transformers; our study shows that such tokens allow us not to create but to isolate this existing behavior, and thus avoid collateral side-effects.
Transformer中的附加Token。BERT (Devlin et al., 2019) 推广了使用特殊Token扩展Transformer序列的方法。然而,大多数方法添加新Token的目的包括:为网络提供新信息(如BERT中的[SEP] Token)、增加对输入的计算机会(如AdaTape (Xue et al., 2023) 中的磁带Token),或通过收集这些Token的信息并将其输出值作为模型结果(例如分类任务中BERT和ViT (Dosovitskiy et al., 2021) 的[CLS] Token;生成式学习中BERT和BEiT (Bao et al., 2021) 的[MASK] Token;检测任务中DETR (Carion et al., 2020) 的对象查询、YOLOS (Fang et al., 2021) 的检测Token及ViDT (Song et al., 2021) 的检测Token);或在解码前聚合多模态信息的潜在Token数组(如Perceivers (Jaegle et al., 2021; 2022))。与这些工作不同,我们添加的Token不携带信息且其输出值不被使用,它们仅是模型在前向传播中学习存储和检索信息的寄存器。Memory Transformer (Burtsev et al., 2020) 与我们的工作更接近,提出通过向Token序列添加记忆Token来提升翻译性能。后续工作中,Bulatov et al. (2022) 解决了复杂复制-重复-反转任务,Sandler et al. (2022) 将其扩展至视觉领域微调,但发现此类Token跨任务迁移性较差。相比之下,我们不在微调阶段使用附加Token,而是在预训练中引入它们以提升下游任务特征质量。更重要的是,我们的研究在第2节揭示了新发现:记忆Token实现的机制已自然存在于视觉Transformer中;研究表明这些Token并非创建而是隔离了现有行为,从而避免了连带副作用。
Attention maps of vision transformers. Visual ising the attention map from [CLS] token to patch tokens was popularized in DINO (Caron et al., 2021). It was shown there that the attention maps of DINO were clean of artifacts, as opposed to the attention maps of previous vision transformers. Other works have since reported interesting attention maps using various techniques: by modifying the optimisation procedure (Chen et al., 2022), by steering the attention scores towards useful image parts (Shi et al., 2023), by modifying the architecture of the transformer layers (Yu et al., 2024), or by introducing a learnable pooling to produce the [CLS] token (Psomas et al., 2023).
视觉Transformer的注意力图。将[CLS] token到图像块token的注意力图可视化这一方法由DINO (Caron等人,2021)推广。研究表明,DINO的注意力图相比早期视觉Transformer更为纯净,没有伪影。后续研究通过多种技术展示了有趣的注意力图:例如修改优化流程 (Chen等人,2022)、引导注意力分数聚焦有效图像区域 (Shi等人,2023)、改造Transformer层架构 (Yu等人,2024),或引入可学习池化来生成[CLS] token (Psomas等人,2023)。
5 CONCLUSION
5 结论
In this work, we exposed artifacts in the feature maps of DINOv2 models, and found this phenomenon to be present in multiple existing popular models. We have described a simple method to detect these artifacts by observing that they correspond to tokens with an outlier norm value at the output of the Transformer model. Studying their location, we have proposed an interpretation that models naturally recycle tokens from low-informative areas and repurpose them into a different role for inference. Following this interpretation, we have proposed a simple fix, consisting of appending additional tokens to the input sequence that are not used as outputs, and have found that this entirely removes the artifacts, improving the performance in dense prediction and object discovery. Moreover, we have shown that the proposed solution also removes the same artifacts present in supervised models such as DeiT-III and OpenCLIP, confirming the generality of our solution.
在这项工作中,我们揭示了DINOv2模型特征图中的伪影现象,并发现该现象存在于多个现有流行模型中。我们提出了一种通过观察Transformer模型输出端具有离群范数值的token来检测这些伪影的简单方法。通过研究其位置分布,我们提出了一种解释:模型会自然回收低信息区域的token,并将其重新用于推理中的其他角色。基于这一解释,我们提出了一种简单修复方案——向输入序列添加不参与输出的额外token,实验表明该方法能完全消除伪影,提升密集预测和物体发现任务的性能。此外,我们还证实该解决方案同样能消除DeiT-III和OpenCLIP等监督式模型中的同类伪影,验证了方案的普适性。
ACKNOWLEDGMENTS
致谢
We thank Hu Xu, Oriane Siméoni, Mido Assran and Armand Joulin for their insightful discussions and help during the course of this work. We thank Pyrrhus for posing for fig 8. Julien Mairal was supported by ANR 3IA MIAI $@$ Grenoble Alpes (ANR-19-P3IA-0003) and by ERC grant number 101087696 (APHELEIA project).
我们感谢 Hu Xu、Oriane Siméoni、Mido Assran 和 Armand Joulin 在这项工作过程中富有洞察力的讨论和帮助。感谢 Pyrrhus 为图 8 摆拍。Julien Mairal 得到了 ANR 3IA MIAI $@$ Grenoble Alpes (ANR-19-P3IA-0003) 和 ERC 资助编号 101087696 (APHELEIA 项目) 的支持。

Figure 10: Feature norms along locations: proportion of tokens with norm larger than the cutoff value at a given location. Left: official DINOv2 model (no anti aliasing), right: our models (with anti aliasing). At some positions, more than $20%$ of tokens have a high norm.
图 10: 位置特征范数分布:各位置范数超过阈值的token比例。左图:官方DINOv2模型(无抗锯齿),右图:我们的模型(带抗锯齿)。在某些位置,超过$20%$的token具有高范数值。

Figure 11: Propagating unit gradients through a bicubic interpolation $(16\times16\to7\times7)$ without anti aliasing. We observe a striping pattern similar to the one of Fig. 10 (left).
图 11: 通过双三次插值 $(16\times16\to7\times7)$ 传播单位梯度且未进行抗锯齿处理时,我们观察到与图 10 (左) 类似的条纹图案。
A INTERPOLATION ARTIFACTS AND OUTLIER POSITION DISTRIBUTION
插值伪影与异常位置分布
We plot in Figure 10 (left) the proportion of outlier tokens, characterized by a norm larger than the cutoff value defined manually, following the distribution of norms shown in Fig. 3 (main text). We make two observations:
我们在图 10 (左) 中绘制了离群 token 的比例,这些 token 的特征是范数大于手动定义的截断值,遵循图 3 (正文) 所示的范数分布。我们得出两个观察结果:
First, the distribution has a vertical-striped pattern. We investigate this phenomenon and notice that in the original DINOv2 implementation, during training the position embeddings are interpolated from a $16\times16$ map into a $7\times7$ map, without anti aliasing. Propagating unit gradients through such an interpolation function (bicubic resize) leads to the following gradients, shown in Fig. 11. In this work, when producing results with DINOv2 (especially for the results in Tables 2a,3), we always apply anti aliasing in the interpolation operator, removing the striping pattern, which gives an updated distribution of outlier positions as shown in Fig. 10 (right).
首先,该分布呈现垂直条纹图案。我们研究这一现象时发现,在原始DINOv2实现中,训练期间位置嵌入从$16×16$图通过无抗锯齿处理插值为$7×7$图。通过这种插值函数(双三次调整大小)传播单位梯度会产生如图11所示的梯度模式。本工作中,当使用DINOv2生成结果时(特别是表2a和表3的结果),我们始终在插值算子中应用抗锯齿处理以消除条纹图案,从而得到更新后的异常值位置分布如图10(右)所示。
Second, the outliers tend to appear in areas closer to the border of the feature map rather than in the center. Our interpretation is that the base model tends to recycle tokens in low-informative areas to use as registers: pictures produced by people tend to be object-centric, and in this case the border areas often correspond to background, which contains less information than the center.
其次,异常值往往出现在靠近特征图边界的区域而非中心。我们认为这是因为基础模型倾向于重复利用低信息量区域的token作为寄存器:人类拍摄的照片通常以物体为中心,此时边缘区域往往对应背景信息,其信息量少于中心区域。
B COMPLEXITY ANALYSIS
B 复杂度分析
Since our proposed fix introduces new tokens, it also increases the number of learnable parameters and the FLOP count of the model. We show in Fig. 12 the relationship between number of registers and increase in model FLOP count and parameter count. We observe that adding registers induces a negligible change in number of parameters, and a slight change in FLOP count. Still, for $n=4$ registers, the increase in FLOPs stays below $2%$ .
由于我们提出的修复方案引入了新的token,因此也增加了模型的可学习参数数量和浮点运算量(FLOP)。图12展示了寄存器数量与模型FLOP量及参数数量增加之间的关系。我们观察到添加寄存器对参数数量的影响可以忽略不计,对FLOP量的影响也较小。即使使用n=4个寄存器时,FLOP的增加量仍低于2%。

Figure 12: Increase in model parameter and FLOP count when adding different numbers of registers. Adding registers can increase model FLOP count by up to $6%$ for 16 registers. However, in the more common case of using 4 registers, that we use in most of our experiments, this increase is below $2%$ . In all cases, the increase in model parameters is negligible.
图 12: 添加不同数量寄存器时模型参数量和 FLOP 数的增长情况。使用 16 个寄存器时,FLOP 数最多可增加 $6%$。但在我们大多数实验中采用的 4 寄存器配置下,FLOP 增幅低于 $2%$。所有情况下,模型参数量的增长均可忽略不计。

Figure 13: Illustration of the intermediate computations in the LOST algorithm for all models. Adding registers drastically improves the look of all intermediate steps for DeiT-III and DINOv2. The difference is less striking for the OpenCLIP model.
图 13: 所有模型在LOST算法中的中间计算过程图示。添加寄存器显著改善了DeiT-III和DINOv2的所有中间步骤效果。OpenCLIP模型的差异则不那么明显。
C ANALYSIS OF LOST PERFORMANCE
C 性能损失分析
The results presented in Sec. 3.3 show that adding registers allows us to obtain better object discovery performance with DINOv2 models. The conclusions for the two other models studied in this work could be more crisp. In order to understand why this is so, we qualitatively study the impact of removing artifacts on the intermediate computations in the LOST algorithm. We show the intermediate outputs of LOST for all models on a given input image in Fig. 13.
第3.3节的结果表明,添加寄存器能使DINOv2模型获得更好的目标发现性能。本文研究的另外两个模型的结论可能更为明确。为了理解其原因,我们定性研究了LOST算法中去除伪影对中间计算的影响。图13展示了所有模型在给定输入图像上LOST的中间输出结果。
Adding registers improves the scores and the resulting seed expansion for DeiT-III and DINOv2. This observation is coherent with the improved numbers reported in Table 3. For OpenCLIP, however, the LOST algorithm seems robust to the type of outliers observed in the local features. Adding registers does remove artifacts (as clearly shown in Fig. 20) but does not have much impact on the LOST score. It is also worth noting that OpenCLIP, with or without registers, provides comparable performance to DINOv2 without registers and DeiT-III with registers. The qualitative assessment is coherent with the numbers reported in Table 3.
添加寄存器提高了DeiT-III和DINOv2的分数及种子扩展效果。这一观察结果与表3中报告的性能提升数据一致。然而对于OpenCLIP而言,LOST算法对局部特征中出现的异常值类型表现出较强鲁棒性。添加寄存器确实能消除伪影(如图20清晰所示),但对LOST分数影响不大。值得注意的是,无论是否使用寄存器,OpenCLIP的性能都与未使用寄存器的DINOv2和使用寄存器的DeiT-III相当。定性评估结果与表3报告的数据相符。
A surprising observation is that despite the existence of high-norm patches in the output of OpenCLIP models without registers (as seen in Fig. 7), the seed expansion score in Fig. 13 looks smooth. In the LOST experiment with OpenCLIP models, we do not use the features directly, but the values from the computation of attention maps. In Fig. 14, we show the seed expansion score for OpenCLIP models with and without registers for keys, queries and values. We see that artifacts are clearly visible as spots in the background for keys and queries, for the model without registers. As soon as registers are used, the LOST score is focusing on the object, with a smoother score for values. We qualitatively observe that for the OpenCLIP model, the value projection filters out the outliers even without registers. This means that the outliers appear to live in the null space of the value projection layer; the investigation for this phenomenon is left for future work.
一个令人惊讶的观察是,尽管无寄存器版OpenCLIP模型的输出中存在高范数图像块(如图7所示),但图13中的种子扩展分数却显得平滑。在使用OpenCLIP模型的LOST实验中,我们并未直接使用特征,而是采用了注意力图计算中的数值。图14展示了带/不带寄存器的OpenCLIP模型在键(key)、查询(query)和值(value)上的种子扩展分数。可以明显观察到,无寄存器模型的键和查询会在背景中呈现斑点状伪影。而一旦使用寄存器,LOST分数就会聚焦于目标物体,且值的分数更为平滑。我们定性发现,对于OpenCLIP模型而言,值投影层即使在没有寄存器的情况下也能过滤异常值。这表明异常值似乎存在于值投影层的零空间中,这一现象的研究将留待未来工作。

Figure 14: Illustration of the seed expansion score in LOST for an OpenCLIP model with and without registers for the three types of features considered: keys, queries, and values. The score is qualitatively improved across all features, with fewer artifacts appearing. Interestingly, the seed expansion map computed using values does not exhibit artifacts with nor without registers.
图 14: 展示 LOST 中种子扩展分数在 OpenCLIP 模型中的对比情况(含/不含寄存器),针对三种特征类型:键(key)、查询(query)和值(value)。所有特征的得分在质量上均有所提升,伪影现象减少。值得注意的是,基于值(value)计算的种子扩展图无论是否使用寄存器均未出现伪影。
D BEHAVIOR OF MODELS TRAINED WITH REGISTERS
D 使用寄存器训练的模型行为
In order to better understand the phenomenon at hand, we examine the question of to what extent did the register tokens ”replace” the high-norm tokens and took on the same role.
为了更好地理解当前现象,我们研究了寄存器Token (register tokens) 在多大程度上"取代"了高规范Token (high-norm tokens) 并承担相同角色的问题。

Figure 15: Distribution of token norms for a DINOv2 model without (left) and with (right) 4 registers. Introducing registers entirely negates the high-norm outliers among the patch tokens.
图 15: 未使用寄存器(左)和使用4个寄存器(右)的DINOv2模型中token范数分布。引入寄存器完全消除了patch token中的高范数异常值。
In Fig. 15 we compare the distribution of token norms for a model with or without registers. This figure is similar to Fig. 7 but with a finer granularity, as we also plot the norm distribution of individual register tokens and [CLS] tokens. We observe the following: with registers, the norms of patch tokens do not contain outliers anymore, and the high-norm tokens are entirely contained in the set of registers. As a result, we conclude that the behavior leading to high-norm outliers in the model is effectively absorbed in the registers.
在图 15 中,我们比较了带或不带寄存器 (registers) 的模型的 token 范数分布。该图与图 7 类似,但粒度更细,因为我们还绘制了单个寄存器 token 和 [CLS] token 的范数分布。我们观察到以下现象:使用寄存器后,patch token 的范数不再包含异常值,而高范数 token 完全集中在寄存器集合中。因此,我们得出结论:模型中导致高范数异常值的行为被有效地吸收到了寄存器中。
An additional interesting observation is that the norms of the registers appear to be quantized, compared to the previous outliers; we leave the investigation of this phenomenon for future work.
另一个有趣的观察是,与前文的异常值相比,寄存器的范数似乎呈现量化特征。我们将这一现象的探究留待未来工作。
D.2 INFORMATION HELD BY TOKENS
D.2 Token 所包含的信息
We report on table 4 the linear probing performance of models trained with and without registers, when using different tokens as representations. We evaluate on the aircrafts dataset, as it showed clear conclusions in the similar table 1. We observe that adding a register does not significantly modify the scores obtained with the [CLS] or patch tokens. However, the outlier patches are removed, and their behavior is transferred to the newly added register.
我们在表4中报告了使用不同token作为表征时,带寄存器和不带寄存器训练的模型线性探测性能。评估在飞机数据集上进行,因为其在类似的表1中展现出明确结论。我们观察到添加寄存器不会显著改变使用[CLS]或图像块(patch)token获得的分数。但异常图像块会被移除,其行为特征会转移至新增的寄存器中。
| top-1准确率 | |
|---|---|
| #寄存器数 | [CLS] |
| 0 | 84.6 |
| 1 | 85.2 |
Table 4: Linear probing of models with and without registers on the Aircraft dataset, using various tokens as representation. We observe that the behavior of the outlier tokens, aggregating global information, is absorbed into the register.
表 4: 在Aircraft数据集上对带/不带寄存器(register)的模型进行线性探测(linear probing),使用不同token作为表征。我们观察到异常值token(聚合全局信息)的行为被吸收到寄存器中。
We further conduct an evaluation of the local information contained in the patch tokens of a model trained with and without registers (table 5). We observe that the non-outliers patches, in both cases, hold similar local information, confirming that the registers only remove the outlier behavior, without significantly modifying the information held by the other patches.
我们进一步评估了带寄存器和不带寄存器训练的模型中,图像块token所包含的局部信息(表5)。观察到在两种情况下,非异常图像块都持有相似的局部信息,这证实了寄存器仅移除了异常行为,并未显著改变其他图像块持有的信息。
| #registers | patches considered | position prediction top-1 acc | reconstruction L2 error √ |
|---|---|---|---|
| 0 | non-outliers | 66.3 | 15.9 |
| 4 | non-outliers s (ie all) | 65.8 | 16.0 |
Table 5: Linear probing for local information on the patch tokens of models trained without or with registers. We only consider patches considered ”normal”, i.e. not the high-norm outliers. We observe that adding registers does not significantly modify the scores of these patches.
表 5: 无寄存器训练模型与带寄存器训练模型在局部信息线性探测(patch tokens)上的对比。我们仅分析被判定为"正常"的图像块(即排除高范数离群值)。实验表明,添加寄存器不会显著改变这些图像块的得分。
D.3 POSITIONAL FOCUS
D.3 位置聚焦

Figure 16: Average attention map of registers and [CLS] token. There is a variability observed, with register 3 of this model focusing more on border areas. We also include the average attention map of a patch for comparison. The patch has a much more focused average attention.
图 16: 寄存器与[CLS] token的平均注意力分布图。观察到存在差异性,该模型的寄存器3更关注边缘区域。为便于对比,我们还展示了一个图像块(patch)的平均注意力图,其注意力分布明显更为集中。
In Fig. 16 we display the positional focus for the class token and the 4 registers of a DINOv2+reg model. We produce these plots by running the model on a random subset of ImageNet-22k, and averaging the attention maps for the corresponding tokens at the last layer. We note that ImageNet-22k contains mostly object-centric images rather than scenes, which explains why the average attention maps correspond to centered blobs.
在图 16 中,我们展示了 DINOv2+reg 模型的类 token (class token) 和 4 个寄存器 (registers) 的位置聚焦情况。这些图是通过在 ImageNet-22k 的随机子集上运行模型,并对最后一层对应 token 的注意力图进行平均得到的。我们注意到 ImageNet-22k 主要包含以物体为中心的图像而非场景,这解释了为什么平均注意力图呈现为中心化的斑块。
We make several observations. First, the attention maps for registers can be different of each other; for example, register 3 tends to focus on border areas, while the other registers tend to focus on more centered areas. Register 2 tends to focus slightly more on the upper areas of images that others. This is consistent with Fig. 9, where we show registers focusing on different large areas of the image, suggesting some level of specialization.
我们得出以下几点观察结果。首先,不同寄存器的注意力图可能各不相同:例如,寄存器3倾向于关注边缘区域,而其他寄存器更关注中心区域。寄存器2比其他寄存器更偏重图像上部区域。这与图9所示一致,图中显示各寄存器聚焦于图像的不同大区域,表明存在一定程度的专业化分工。
Second, by comparing the register maps to the [CLS] token map and to a patch token map, we observe that registers produce maps with a large support area, very similarly to the [CLS] token, and very different of a typical patch token which is more localized. As the [CLS] token is known to carry global information (as proven by the linear probing classification performance): this suggests that registers also carry global information.
其次,通过将寄存器映射与[CLS] token映射及图像块token映射进行对比,我们发现寄存器生成的映射具有大范围支持区域,这与[CLS] token高度相似,而与通常局限于局部区域的图像块token形成鲜明差异。由于[CLS] token已被证实承载全局信息(线性探测分类性能可佐证),这表明寄存器同样具备传递全局信息的能力。
E MASKED AUTO ENCODERS
E 掩码自编码器
Masked Auto encoding (He et al., 2022) is another common way of pre training self-supervised models. We observe in Fig. 17 that there are no artifacts in the maps produced by MAE: our hypothesis is that the absence of artifacts is due to the training procedure using only a local loss on the patch tokens, rather than an objective involving global aggregation of information. However, we also note that the performance of MAE models is very low for self-supervised representation learning $75%$ linear probing performance on ImageNet classification for ViT-Large), preventing it from being used as is, and making fine-tuning a requirement.
掩码自编码 (He et al., 2022) 是预训练自监督模型的另一种常见方法。我们在图 17 中观察到,MAE 生成的地图中没有伪影:我们的假设是,这种伪影的缺失源于训练过程仅对 patch token 使用局部损失函数,而非涉及全局信息聚合的目标函数。但我们也注意到,MAE 模型在自监督表征学习中的性能较低 (ViT-Large 在 ImageNet 分类上的线性探测准确率为 75%),这使其无法直接投入使用,必须进行微调。

Figure 17: First three principal components of the output feature map of a ViT-Large Masked Autoencoder.
图 17: ViT-Large掩码自编码器输出特征图的前三个主成分。
F BEHAVIOR PER ATTENTION HEAD
F 每个注意力头的行为
In this section, we investigate whether the artifacts appear only on the attention maps for specific heads of the last vision transformer block, or for all of them. We show in Fig. 18 the input image along with the attention maps for different heads. We observe that the artifacts appear for all attention heads, despite heads focusing on different areas of the object. We still observe that some heads focus more on artifacts than others.
在本节中,我们研究这些伪影是否仅出现在最后一个视觉Transformer (Vision Transformer) 块特定注意力头的注意力图上,还是所有注意力头都会出现。我们在图18中展示了输入图像以及不同注意力头的注意力图。我们观察到,尽管各注意力头聚焦于物体的不同区域,但所有注意力头都会出现伪影。同时仍可发现某些注意力头比其他头更集中于伪影区域。
G VARIANCE ON TOKEN INFORMATION PROBING
基于Token信息探测的G方差
The results presented in table 1 are obtained by taking a random patch token, either normal or outlier. However, the choice of this token adds a significant source of variance in the evaluation. For thoroughness, we report in table 6 the standard deviation of the scores obtained relative to this choice.
表1中的结果是通过随机选取一个普通或异常patch token获得的。然而,该token的选择为评估引入了显著的方差来源。为确保全面性,我们在表6中报告了与此选择相关的得分标准差。

Figure 18: Attention maps of the [CLS] token to the patch tokens, shown here separately per attention head. We produce these maps with a DINOv2-L model trained without registers.
图 18: [CLS] token 对图像块 (patch) token 的注意力热图,按注意力头分别展示。这些热图由未使用寄存器 (registers) 训练的 DINOv2-L 模型生成。
| dataset token | Airc. | CF10 | CF100 | CUB | Cal101 | Cars | DTD |
|---|---|---|---|---|---|---|---|
| normal outlier | 17.1±0.5 79.1±0.5 | 97.1±0.1 99.3±0.0 | 81.3±0.3 93.7±0.3 | 18.6±0.6 84.9±2.1 | 73.2±1.3 97.6±0.7 | 10.8±0.3 85.2±0.9 | 63.1±0.8 84.9±0.9 |
| [CLS] dataset | 87.3 Flow. | 99.4 Food | 94.5 IN1k | 91.3 P205 | 96.9 Pets | 91.5 SUN | 85.2 VOC |
| token | |||||||
| normal outlier | 59.5±1.2 | 74.2±0.3 | 65.8±0.1 | 53.1±0.3 | 47.8±0.5 94.1±0.2 | 37.7±0.3 78.5±0.2 | 70.8±0.5 89.7±0.1 |
| [CLS] | 99.6±0.0 99.7 | 93.5±0.2 94.7 | 69.0±0.7 86.0 | 55.1±1.0 66.4 | 96.9 | 78.6 | 89.1 |
Table 6: Image classification via linear probing on normal and outlier patch tokens. As we select the patch tokens randomly among the set of eligible tokens, this adds a source of variability. We report the standard deviation of this variability in grey along with the scores. This table is a detailed view of table 1.
表 6: 通过正常与异常图像块token的线性探测进行图像分类。由于我们在符合条件的token集合中随机选择图像块token,这增加了结果的可变性。我们在分数旁边以灰色标注了这种变异的标准差。本表是表 1 的详细展示。
H QUALITATIVE RESULTS
H 定性结果
We trained three popular models: DeiT-III, OpenCLIP, DINOv2 with and without the introduction of register tokens. We observe in Fig. 19 the attention maps in the last layer of the Vision Transformer, for all three cases. We see that our approach provides much cleaner attention maps, with considerably fewer artifacts, explaining the improvement on the downstream object discovery task mentioned in Sec. 3.3. The feature maps are also visibly improved, as shown in Fig. 20. Finally, we also show the norm of the patch tokens in Fig. 21, and confirm that in all three models, artifact patches correspond to norm outliers.
我们训练了三种流行模型:DeiT-III、OpenCLIP和DINOv2,分别测试引入寄存器token前后的效果。如图19所示,我们观察了三种情况下Vision Transformer最后一层的注意力图。结果表明,我们的方法能生成更清晰的注意力图,显著减少伪影,这也解释了第3.3节提到的下游物体发现任务的性能提升。特征图质量也有明显改善,如图20所示。最后,图21展示了图像块token的范数分布,证实三种模型中异常图像块都对应着范数离群值。

Figure 19: Attention maps of models trained without and with registers on various images.
图 19: 未使用和使用寄存器训练的模型在不同图像上的注意力图。

Figure 20: First principal component of the feature maps output by models trained without and with registers on various images. The components are whitened and the colormap covers the range $[-3\sigma,+3\sigma]$ .
图 20: 在不同图像上训练的无寄存器模型与带寄存器模型输出的特征图第一主成分。成分经过白化处理,色标范围覆盖 $[-3\sigma,+3\sigma]$。

Figure 21: Maps of token norms for models trained without and with registers on various images. The norm outliers are very visible for models trained without registers.
图 21: 未使用和使用寄存器训练的模型在不同图像上的token范数分布图。未使用寄存器训练的模型存在明显的范数异常值。