SwapNet: Image Based Garment Transfer
SwapNet: 基于图像的服装迁移

Fig. 1. SwapNet can interchange garment appearance between two single view images (A and B) of people with arbitrary shape and pose.
图 1: SwapNet可以在任意形状和姿势的两个人单视图图像(A和B)之间交换服装外观。
Abstract. We present Swapnet, a framework to transfer garments across images of people with arbitrary body pose, shape, and clothing. Garment transfer is a challenging task that requires (i) disentangling the features of the clothing from the body pose and shape and (ii) realistic synthesis of the garment texture on the new body. We present a neural network architecture that tackles these sub-problems with two task-specific sub-networks. Since acquiring pairs of images showing the same clothing on different bodies is difficult, we propose a novel weaklysupervised approach that generates training pairs from a single image via data augmentation. We present the first fully automatic method for garment transfer in un constrained images without solving the difficult 3D reconstruction problem. We demonstrate a variety of transfer results and highlight our advantages over traditional image-to-image and analogy pipelines.
摘要。我们提出Swapnet框架,用于在任意身体姿态、形状和着装的真人图像间实现服装迁移。服装迁移是一项具有挑战性的任务,需要:(i) 从身体姿态和形状中解耦服装特征;(ii) 在新身体上实现服装纹理的真实合成。我们提出一种神经网络架构,通过两个任务专用子网络分别解决这些子问题。由于获取同一服装在不同身体上成对图像的难度较大,我们提出一种新颖的弱监督方法,通过数据增强从单张图像生成训练对。我们首次实现了非约束图像中完全自动化的服装迁移,而无需解决复杂的3D重建问题。通过多样化的迁移结果展示,我们突显了相较于传统图像到图像和类比流程的优势。
1 Introduction
1 引言
Imagine being able to try on different types of clothes from celebrities’ red carpet appearance within the comfort of your own home, within minutes, and without hours of shopping. In this work, we aim to fulfill this goal with an algorithm to transfer garment information between two single view images depicting people in arbitrary pose, shape, and clothing (Figure 1). Beyond virtual fitting room applications, such a system could be useful as an image editing tool. For example, after a photo-shoot a photographer might decide that the subject would look better in a different outfit for the photographic setting and lighting condition. Garment transfer is also useful for design ideation to answer questions like “how does this style of clothing look on different body shapes and proportions?”
想象一下,只需几分钟就能在家中舒适地试穿明星红毯造型的各种服饰,无需耗时购物。本研究旨在通过一种算法实现这一目标,该算法能在任意姿势、体型和着装的两张单人图像间迁移服装信息(图 1)。除虚拟试衣应用外,此类系统还可作为图像编辑工具。例如,摄影师在拍摄后可能认为模特换套服装会更契合场景与光线条件。服装迁移还能辅助设计构思,解答"这类款式在不同身材比例上的效果如何"等问题。
These applications require solving the challenging problem of jointly inferring the body pose, shape, and clothing of a person. Most virtual try-on applications address this challenge by making simplifying assumptions. They either use predefined virtual avatars in a small set of allowed poses or require an accurate 3D scan of the individual to demonstrate a limited selection of clothes using physical cloth simulation [1]. The recent approach for garment recovery and transfer [2] involves 3D reconstruction of the human body and estimation of the parameters of pre-defined cloth templates. The proposed model fitting approach is computationally expensive and the quality is limited by the representational power of the pre-defined templates. None of these approaches address the problem of transferring arbitrary clothes to an arbitrary person and pose in the image space.
这些应用需要解决联合推断人体姿态、体型和衣物的难题。大多数虚拟试穿应用通过简化假设应对这一挑战:要么使用有限预设姿态的虚拟化身,要么依赖精确的3D人体扫描配合物理布料模拟来展示少量服装 [1]。近期服装复原与迁移方法 [2] 需进行人体三维重建,并估算预设服装模板参数。该模型拟合方法计算成本高昂,且质量受限于预设模板的表现力。现有方案均未实现图像空间中任意服装向任意姿态人体的迁移。
Transferring garment information between images inherently requires solving three sub-problems. First, the garment pieces need to be identified from the input images. Second, the shape, e.g., the outline of each garment piece, needs to be transferred across two bodies with potentially different pose and shape. Finally, the texture of the garment needs to be synthesized realistically in this new shape. Our approach focuses on solving the last two stages, warping (Figure 2) and texturing (Figure 6), using a learning approach.
在图像间传递服装信息本质上需要解决三个子问题。首先,需要从输入图像中识别出服装部件。其次,服装的形状(例如每个服装部件的轮廓)需要在可能具有不同姿势和体型的两个身体之间进行转移。最后,服装的纹理需要在这个新形状中逼真地合成。我们的方法侧重于使用学习方式解决后两个阶段:变形(图2)和纹理合成(图6)。
Assume we have an image $A$ , depicting the desired clothing, and B, showing the target body and pose. Learning to directly transfer detailed clothing from $A$ to $B$ is challenging due to large differences in body shape, cloth outlines, and pose between the two images. Instead, we propose to first transfer the clothing segmentation $A_{c s}$ of $A$ , based on the body segmentation $\mathit{B}{\mathit{b s}}$ of $B$ to generate the appropriate warped clothing segmentation $B_{c s}^{\prime}$ which is different from $B$ ’s original clothing segmentation $B_{c s}$ . This segmentation warping operation is easier to learn since it does not require the transfer of high frequency texture details. Once the desired clothing segmentation $B_{c s}^{\prime}$ is generated, we next transfer the clothing details from $A$ to $B$ conditioned on $B_{c s}^{\prime}$ for final result.
假设我们有一张描绘目标服装的图像 $A$,以及展示目标身体和姿态的图像 $B$。由于两幅图像在体型、服装轮廓和姿态上存在较大差异,直接学习将服装细节从 $A$ 迁移到 $B$ 具有挑战性。为此,我们提出首先基于 $B$ 的身体分割 $\mathit{B}{\mathit{b s}}$ 迁移 $A$ 的服装分割 $A_{c s}$,生成与之不同的变形服装分割 $B_{c s}^{\prime}$(不同于 $B$ 的原始服装分割 $B_{c s}$)。这种分割变形操作更易学习,因为它不需要迁移高频纹理细节。一旦生成目标服装分割 $B_{c s}^{\prime}$,我们便以 $B_{c s}^{\prime}$ 为条件将服装细节从 $A$ 迁移至 $B$ 以得到最终结果。
In the ideal scenario, given pairs of photos $(A,B)$ of people in different poses with different proportions wearing the exact same clothing, we could train a 2- stage pipeline in a supervised manner. However, such a dataset is hard to obtain and therefore we propose a novel weakly supervised approach where we use a single image and its augmentations as exemplars of $A$ and $B$ to train warping and text uri zing networks. We introduce mechanisms to prevent the networks from learning the identity mapping such that warping and text uri zing can be applied when $A$ and $B$ depict different individuals at test time. At both training and test time, we assume that we have access to the body and clothing segmentation of the image from state-of-the-art human parsing pipelines.
理想情况下,给定人物穿着完全相同服装但姿态和比例不同的照片对$(A,B)$,我们可以用监督方式训练一个两阶段流程。然而这类数据集难以获取,因此我们提出了一种新颖的弱监督方法:使用单张图像及其增强版本作为$A$和$B$的样本来训练形变网络和纹理生成网络。我们引入了防止网络学习恒等映射的机制,使得测试时$A$和$B$描绘不同个体时仍能应用形变和纹理生成技术。在训练和测试阶段,我们都假设能够通过最先进的人体解析流程获取图像的躯干与服装分割结果。

Fig. 2. Demonstration of clothing transfer.
图 2: 服装迁移效果展示。
No previous works address the problem we have at hand – transferring garment from the picture of one person to the picture of another with no constraints on identity, poses, body shapes and clothing categories in the source and target images. We argue that garment transfer in our un constrained setting is a more challenging task. It requires disentangling the target clothing from the corresponding body and re tar getting it to a different body where ideal training data for supervised learning are hard to obtain.
以往的研究均未解决我们当前面临的问题——将服装从一个人的照片转移到另一个人的照片上,且对源图像和目标图像中的身份、姿势、体型及服装类别均无限制。我们认为,在这种无约束场景下的服装迁移是一项更具挑战性的任务:它需要从对应身体中分离目标服装,并将其重新适配到另一具身体上,而这类监督学习的理想训练数据难以获取。
To summarize, we make the following contributions: (1) We present the first method that operates in image-space to transfer garment information across images with arbitrary clothing, body poses, and shapes. Our approach eschews the need for 3D reconstruction or parameter estimation of cloth templates. (2) With the absence of ideal training data for supervision, we introduce a weakly supervised learning approach to accomplish this task.
总结来说,我们的贡献如下:(1) 我们提出了首个在图像空间运行的方法,能够在任意服装、身体姿态和形状的图像间传递衣物信息。该方法无需进行3D重建或布料模板的参数估计。(2) 在缺乏理想监督训练数据的情况下,我们引入了一种弱监督学习方法来完成该任务。
2 Related Work
2 相关工作
Human parsing and understanding. There is significant work in the computer vision community for human understanding from monocular images. We can group the related work under two main methodologies, where, one line of work explicitly focuses on parsing clothing items from images [3], while the other approaches focus on modeling the human body in terms of 2D pose [4], body part segmentation [5], 3D pose [6], or 3D body shape [7]. A few approaches tackle the problem of jointly modeling the 3D body shape and garments but require additional information in the form of depth scans [8, 9]. The recent work of
人体解析与理解。计算机视觉领域在单目图像的人体理解方面有大量研究。相关工作可分为两大方法论:一类研究专注于从图像中解析服装物品 [3],另一类则聚焦于通过2D姿态 [4]、身体部位分割 [5]、3D姿态 [6] 或3D体型 [7] 来建模人体。少数方法尝试联合建模3D体型与服装,但需要深度扫描等额外信息 [8, 9]。近期研究...
Yang et al. [2] is the first automatic method to present high-resolution garment transfer results from a single image. However, this approach relies on the existence of a deformable body model and a database of cloth templates. It solves a computationally expensive optimization that requires priors for regular iz ation. In contrast, our method operates fully in the image space, learns to disentangle the garment features from the human body pose and shape in a source image and transfers the garment to another image with arbitrary pose and shape.
Yang等人在文献[2]中首次提出了从单张图像实现高分辨率服装迁移的自动化方法。但该方法依赖于可变形人体模型和服装模板数据库的存在,并通过计算成本高昂的优化过程求解,需要正则化先验知识。相比之下,我们的方法完全在图像空间运作,能够从源图像中学习解耦服装特征与人体姿态及形状,并将服装迁移至具有任意姿态和形状的其他图像。
Generative adversarial networks (GANs). Generative adversarial networks [10–13] and variation al auto-encoders [14, 15] have recently been used for image-based generation of faces [16–18], birds [19], and scenes [12]. Conditional GANs have been particularly popular for generating images based on various kinds of conditional signals such as class information [20], attributes [21], sketch [22–24], text [19, 25], or pose [26]. Image-to-image translation networks [22, 27] have demonstrated image synthesis conditioned on images. The texturing stage of our framework is inspired from the U-Net architecture [28]. However, we have two conditioning images where one provides the desired garment and the other shows the desired body pose and shape.
生成对抗网络 (GAN)。生成对抗网络 [10-13] 和变分自编码器 [14, 15] 最近被用于基于图像的生成任务,如人脸 [16-18]、鸟类 [19] 和场景 [12]。条件生成对抗网络 (Conditional GANs) 尤其受欢迎,它能基于各类条件信号生成图像,例如类别信息 [20]、属性 [21]、草图 [22-24]、文本 [19, 25] 或姿态 [26]。图像到图像转换网络 [22, 27] 展示了基于图像条件的图像合成能力。我们框架的纹理生成阶段受到 U-Net 架构 [28] 的启发。但我们的模型有两个条件图像输入:一个提供目标服装,另一个显示目标身体姿态和体型。
Image-based garment synthesis. Several recent works attempt to solve problems similar to ours. The work by Lassneret al. [29] presents an approach to generate images of people in arbitrary clothing conditioned on pose. More recent methods [30, 26] propose a framework to modify the viewpoint or the pose of a person from an image while keeping the clothing the same. Some recent works [31, 32] attempt to transfer a stand-alone piece of clothing to an image of a person, whilst another work [33] solves the opposite task of generating a standalone piece of clothing given a person image. Finally, the work of Zhu et al. [34] generates different clothing from a given image based on textual descriptions, whilst retaining the pose of the original image. Yang et al, [2] propose a pipeline different from generative models, which involves estimation of the 3D body model followed by cloth simulation. Ma et al. [35] propose an approach to disentangle pose, foreground, and background from an image in an unsupervised manner such that different disentangled representations can be used to generate new images. They did not solve our exact problem of transferring the garment from source to target while maintaining the target picture’s identity. In fact, the identity is often lost in their transfer process. Another difference is that they represent the desired pose to transfer garments to as silhouette derived from sparse pose key points while we operate on individual cloth segments. Clothing segmentation provides more informative signals than pose key points, which allows us to transfer the garment from source to target more precisely.
基于图像的服装合成。近期多项研究尝试解决与我们类似的问题。Lassner等人[29]提出了一种根据姿势生成任意着装人物图像的方法。较新的方法[30,26]提出了在保持服装不变的情况下,从单张图像修改人物视角或姿态的框架。部分最新研究[31,32]尝试将独立服装转移到人物图像上,而另一项研究[33]则解决了反向任务——根据人物图像生成独立服装。Zhu等人[34]的工作基于文本描述生成与原始图像姿势一致的不同服装。Yang等人[2]提出了一条不同于生成模型的流程,涉及3D人体模型估计及布料模拟。Ma等人[35]提出以无监督方式从图像中解耦姿势、前景和背景,从而利用不同解耦表征生成新图像。他们并未解决我们在保持目标图像身份的同时将服装从源图像转移到目标图像的核心问题——事实上,其转移过程常导致身份信息丢失。另一区别在于,他们将目标姿态表示为稀疏姿态关键点衍生的剪影,而我们直接操作独立服装分割区域。服装分割比姿态关键点提供更具信息量的信号,使我们能更精确地完成跨图像服装转移。
Visual analogies. There has been recent interest in visual analogy pipelines which synthesize an image by inferring the transformation between a pair of images and then applying that transformation to a new image. The work by Reed et al. [36] generates the analogous image for a particular input instance given the relationship between a similar pair of images. They show good generation results on simple 2D shapes, 3D car models and video game sprites. The more recent work by Liao et al. [37] presents a framework that, given two images, A and B’, generates two additional images A’ and B, such that each input and output image form an analogical pair (A, A’) and (B, B’). Our work is similar in spirit to this work in that, given two full-body images of people in clothing, we can transfer the clothing between the pair of images. However, our formulation is more challenging, as the system has to reason about the concept of clothing explicitly.
视觉类比。近期出现了通过推断图像对之间的变换关系并应用于新图像来合成图像的视觉类比流程研究。Reed等人[36]的工作能在给定相似图像对关系的情况下,为特定输入实例生成类比图像,其在简单2D形状、3D汽车模型和游戏精灵上展示了良好的生成效果。Liao等人[37]的最新研究提出一个框架:给定图像A和B',能生成另外两幅图像A'和B,使输入输出图像形成类比对(A, A')和(B, B')。我们的工作与之理念相似——给定穿着服装的人物全身图像对,可实现服装互换。但我们的任务更具挑战性,因为系统需要显式推理服装概念。
3 SwapNet
3 SwapNet
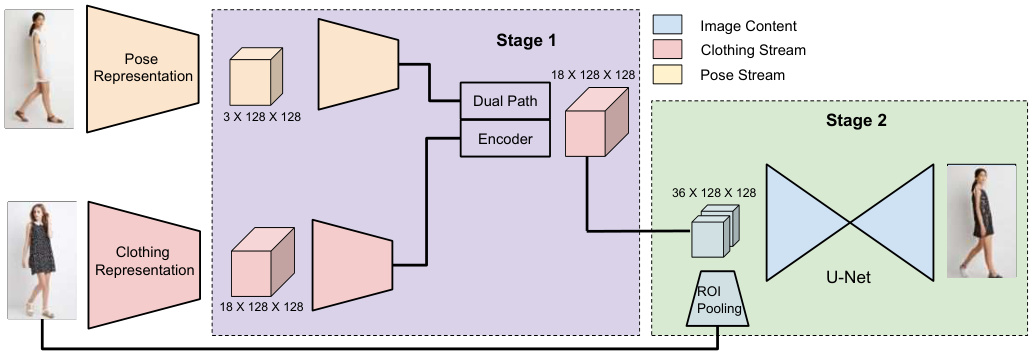
Fig. 3. Our pipeline consists of two stages: (1) the warping stage, which generates a clothing segmentation consistent with the desired pose and (2) the texturing stage, which uses clothing information from desired clothing image to synthesize detailed clothing texture consistent with the clothing segmentation from the previous stage.
图 3: 我们的流程包含两个阶段:(1) 变形阶段,生成与目标姿态一致的服装分割;(2) 纹理化阶段,利用目标服装图像的服装信息合成与前一阶段服装分割一致的细节纹理。
We present a garment transfer system that can swap clothing between a pair of images while preserving the pose and body shape. We achieve this by disentangling the concept of clothing from that of body shape and pose, so that we can change either the person or the clothing and recombine them as we desire.
我们提出了一种服装迁移系统,能够在保留姿态和体型的同时交换两张图像中的服装。通过将服装概念与体型、姿态解耦,我们可以自由更换人物或服装并按需重新组合。
Given an image $A$ containing a person wearing desired clothing and an image $B$ portraying another person in the target body shape and pose, we generate an image $B^{\prime}$ composed of the same person as in $B$ wearing the desired clothing in $A$ . Note that $A$ and $B$ can depict different persons of diverse body shape and pose wearing arbitrary clothing.
给定一张包含穿着目标服装的人物图像 $A$ 和一张展示目标体型与姿态的另一人物图像 $B$ ,我们生成图像 $B^{\prime}$ ,其中人物与 $B$ 相同但穿着 $A$ 中的目标服装。需注意 $A$ 和 $B$ 可呈现不同体型、姿态且穿着任意服装的个体。
Increasingly popular conditional generative models use encoder-decoder types of network architectures to transform an input image to produce output pixels directly. Recent work such as pix2pix and Scribbler [27, 22] have shown high quality results on image translation tasks where the structure and shape in the output does not deviate much from the input. However, our garment transfer task presents unique challenges. A successful transfer involves significant structural changes to the input images. As shown in previous work [34], directly transferring both the shape and the texture details of the desired clothing to a target body gives the network too much burden resulting in poor transfer quality.
日益流行的条件生成模型采用编码器-解码器网络架构,直接将输入图像转换为输出像素。pix2pix和Scribbler[27, 22]等近期研究在图像转换任务中展示了高质量成果,这些任务的输出结构与输入偏差较小。然而,我们的服装迁移任务面临独特挑战:成功的迁移需要对输入图像进行显著结构改变。如先前研究[34]所示,若直接将目标服装的版型和纹理细节迁移至目标人体,会给网络带来过大负担,导致迁移质量下降。
We propose a two-stage pipeline (Figure 3) to tackle the shape and texture synthesis separately. Specifically, we argue that clothing and body segmentation s provide a concise and necessary representation of the desired clothing and the target body. Thus, we first operate on these segmentation s to perform the desired shape change, i.e., generate a clothing segmentation in the target body shape and pose of $B$ but with the clothing in $A$ . We assume the clothing segmentation of image $A$ and the body segmentation of image $B$ are given or are computed by previous work [7, 3]. In a second stage, we propose a text uri z ation network that takes as input the synthesized clothing segmentation and image of the desired clothing to generate the final transfer result.
我们提出一个两阶段流程 (图 3) 来分别处理形状和纹理合成。具体而言,我们认为服装和人体分割图能简洁且必要地表达目标服装和人体。因此,我们首先在这些分割图上进行操作以实现目标形状变化,即在 $B$ 的身体形状和姿态下生成包含 $A$ 服装的分割图。我们假设图像 $A$ 的服装分割图和图像 $B$ 的人体分割图已通过先前工作 [7, 3] 提供或计算得出。在第二阶段,我们提出一个纹理化网络,以合成的服装分割图和目标服装图像作为输入,生成最终的迁移结果。
3.1 Warping Module
3.1 变形模块
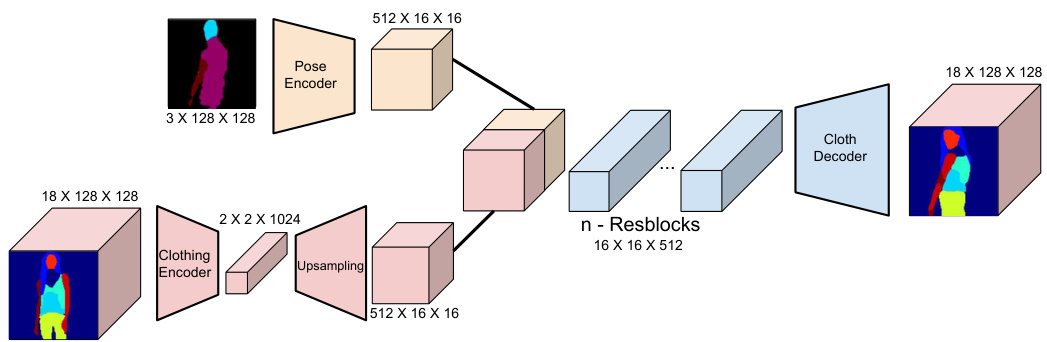
Fig. 4. Architecture of stage 1 module. The warp module consists of a dual-path U-net strongly conditioned on the body segmentation and weakly conditioned on the clothing segmentation.
图 4: 第一阶段模块架构。变形模块采用双路径U-net结构,其强约束条件为人体分割,弱约束条件为服装分割。
The first stage of our pipeline, which we call the warping module, operates on $A_{c s}$ , the clothing segmentation of $A$ , and $\mathit{B}{b s}$ , the body segmentation of $B$ , to generate $B_{c s}^{\prime}$ , a clothing segmentation of $B$ consistent with the segmentation shapes and labels in $A$ while strictly following the body shape and pose in $B$ as given in Figure 4. We pose this problem as a conditioned generative process where the clothing should be conditioned on $A_{c s}$ whereas the body is conditioned on $\mathit{B}_{b s}$ .
我们流程的第一阶段称为变形模块,该模块基于 $A$ 的服装分割 $A_{c s}$ 和 $B$ 的身体分割 $\mathit{B}{b s}$ 进行操作,生成与 $A$ 中分割形状和标签一致、同时严格遵循 $B$ 中身体形状和姿态的服装分割 $B_{c s}^{\prime}$ ,如图 4 所示。我们将此问题表述为条件生成过程,其中服装应以 $A_{c s}$ 为条件,而身体则以 $\mathit{B}_{b s}$ 为条件。
We use a dual path [28] network to address the dual conditioning problem. The dual path network consists of two streams of encoders, one for the body and one for the clothing, and one decoder that combines the two encoded hidden representations to generate the final output. We represent the clothing with a 18- channel segmentation mask where we exclude small accessories such as belts or glasses. Given this 18-channel segmentation map where each channel contains the probability map of one clothing category, the cloth encoder produces a feature map of size $512\times16\times16$ ( $16\times16$ features of size 512). Given a color-coded 3- channel body segmentation, the body encoder similarly produces a feature map of size $512\times16\times16$ to represent the target body. These encoded feature maps are concatenated and passed through 4 residual blocks. The resulting feature map is then up-sampled to generate the desired 18-channel clothing segmentation.
我们采用双路径 [28] 网络来解决双重条件问题。该双路径网络包含两条编码器流(分别针对身体和服装)以及一个解码器,后者将两个编码后的隐藏表征结合以生成最终输出。我们使用18通道的分割掩码表示服装,其中排除了腰带或眼镜等小配饰。给定这个18通道分割图(每个通道包含一个服装类别的概率图),服装编码器会生成尺寸为$512\times16\times16$的特征图(即$16\times16$个512维特征)。对于彩色编码的3通道身体分割图,身体编码器同样会生成尺寸为$512\times16\times16$的特征图来表示目标身体。这些编码后的特征图被拼接后通过4个残差块处理,最终将结果特征图上采样以生成所需的18通道服装分割图。
The generated image is strongly conditioned on the body segmentation and weakly conditioned on the clothing segmentation. This is achieved by encoding the clothing segmentation into a narrow representation of $2\times2\times1024$ , before upsampling it to a feature map of the required size. This compact representation encourages the network to distill high-level information such as the types of clothing items (top, bottom, shoes, skin, etc.) and the general shape of each item from the clothing stream, whilst restricting the generated segmentation to closely follow the target pose and body shape embedded in the body segmentation.
生成的图像主要受身体分割的强约束,同时受服装分割的弱约束。这一效果是通过将服装分割编码为 $2\times2\times1024$ 的紧凑表示实现的,随后将其上采样至所需尺寸的特征图。这种压缩表示促使网络从服装流中提取高级信息(如上装、下装、鞋履、皮肤等衣物类型及各部位的大致形状),同时限制生成的分割结果严格遵循身体分割中嵌入的目标姿态和体型。
To supervise the training, ideally we need ground-truth triplets $\mathit{\Delta}{\mathit{B}{b s}}+\mathit{A}{c s}$ $\Rightarrow B_{c s}^{\prime}$ ) as in [26]. However, such a dataset is hard to obtain and is often not scalable for larger variation in clothing. Instead, we use a self-supervised approach to generate the required triplets. Specifically, given a single image $B$ , we consider the triplet ( $B_{b s}+B_{c s}\Rightarrow B_{c s}^{\prime}$ ) for which we can directly supervise. With this setting, however, there is a danger for the network to learn the identity mapping since $B_{c s}=B_{c s}^{\prime}$ . To avoid this, we use augmentations of $B_{c s}$ instead. We perform random affine transformations (including random crops and flips). This encourages the network to discard locational cues from $B_{c s}$ and pick up only high-level cues regarding the types and structures of the clothing segments.
为了监督训练过程,理想情况下我们需要真实三元组 $\mathit{\Delta}{\mathit{B}{b s}}+\mathit{A}{c s}$ $\Rightarrow B_{c s}^{\prime}$ ) 如文献[26]所述。然而,此类数据集难以获取,且难以适应服装变化的更大规模。因此,我们采用自监督方法生成所需三元组。具体而言,给定单张图像 $B$ ,我们构建可直接监督的三元组 ( $B_{b s}+B_{c s}\Rightarrow B_{c s}^{\prime}$ )。但此设置存在网络学习恒等映射的风险,因为 $B_{c s}=B_{c s}^{\prime}$ 。为避免该问题,我们改用 $B_{c s}$ 的增强版本,通过随机仿射变换(包括随机裁剪和翻转)促使网络摒弃 $B_{c s}$ 的位置线索,仅捕捉服装片段类型与结构的高层特征。
We choose to represent the clothing segmentation as a 18-channel probability map instead of a 3-channel color-coded segmentation image to allow the model more flexibility to warp each individual segment separately. During training, each channel of the segmentation image undergoes a different affine transform, and hence the network should learn higher level relational reasoning between each channel and the corresponding body segment. For the body segmentation, in contrast, we use the 3-channel color-coded image, similar to Lassner et al. [29] as we observe a more fine-grained encoding of the body segmentation does not offer much more information. The color-coded body segmentation image also provides guidance as to where each clothing segment should be aligned, which overall provides a stronger cue about body shape and pose. Additionally, since clothing segments span over multiple body segments, keeping the structure of the entire body image is more beneficial than splitting the body segment into individual channels.
我们选择用18通道概率图而非3通道彩色编码分割图像来表示服装分割,这样能让模型更灵活地单独变形每个分割区域。训练时,分割图像的每个通道会经历不同的仿射变换,因此网络需要学习各通道与对应身体部位之间的高层关系推理。而对于身体分割,我们采用与Lassner等人[29]类似的3通道彩色编码图像,因为更精细的身体分割编码并未带来更多有效信息。这种彩色编码的身体分割图还能指导各服装区域的对齐位置,从而提供更明确的身体形态和姿势线索。此外,由于服装区域会跨越多个身体部位,保持整体身体图像结构比将身体分割拆分为独立通道更具优势。
The warping module is trained with the combination of cross entropy loss and GAN loss. Specifically, our warping module $z_{c s}=f1(A_{c s},B_{b s})$ has the the following learning objectives:
扭曲模块通过交叉熵损失和GAN损失的组合进行训练。具体来说,我们的扭曲模块 $z_{c s}=f1(A_{c s},B_{b s})$ 具有以下学习目标:
$$
\begin{array}{r l}&{\mathcal{L}{C E}=-\displaystyle\sum_{c=1}^{18}\mathbb{1}(A_{c s}(i,j)=c)(\log(z_{c s}(i,j))}\ &{\mathcal{L}{a d v}=\mathbb{E}{x\sim p(A_{c s})}[D(x)]+\mathbb{E}{z\sim p(f1_{e n c}(A_{c s},B_{b s}))}[1-D(f1_{d e c}(z))]}\ &{\mathcal{L}{w a r p}=\mathcal{L}{C E}+\lambda_{a d v}\mathcal{L}_{a d v}}\end{array}
$$
$$
\begin{array}{r l}&{\mathcal{L}{C E}=-\displaystyle\sum_{c=1}^{18}\mathbb{1}(A_{c s}(i,j)=c)(\log(z_{c s}(i,j))}\ &{\mathcal{L}{a d v}=\mathbb{E}{x\sim p(A_{c s})}[D(x)]+\mathbb{E}{z\sim p(f1_{e n c}(A_{c s},B_{b s}))}[1-D(f1_{d e c}(z))]}\ &{\mathcal{L}{w a r p}=\mathcal{L}{C E}+\lambda_{a d v}\mathcal{L}_{a d v}}\end{array}
$$
where $\lambda_{a d v}L_{a d v}$ refers to the adversarial component of the loss and $f1_{e n c}$ and $f1_{d e c}$ are the encoder and decoder components of the warp module. The weights of each component are tuned such that the gradient contribution from each loss is around the same order of magnitude. In our experiments, we observe that adding a small adversarial weight helps produce better convergence and shape retention of the generated segmentation.
其中 $\lambda_{a d v}L_{a d v}$ 表示损失的对抗成分,$f1_{e n c}$ 和 $f1_{d e c}$ 是变形模块的编码器和解码器部分。各成分的权重经过调整,使得每个损失的梯度贡献量级大致相同。实验中我们观察到,添加较小的对抗权重有助于生成分割结果获得更好的收敛性和形状保持性。
Finally, to train and test this network, we use the Deep Fashion dataset [38], where we use the LIP SSL pretrained network [3] to generate clothing segmentations and use “Unite the People” [39] to obtain the body segmentation as in Figure 5
最后,为了训练和测试该网络,我们使用Deep Fashion数据集[38],其中采用LIP SSL预训练网络[3]生成服装分割,并利用"Unite the People"[39]获取如图5所示的人体分割。

Fig. 5. Stage 1 segmentation visualization. (a) Clothing segmentation of A; (b) Body segmentation of B; (c) Generated clothing segmentation for B by warping module; (d) Original clothing segmentation of B.
图 5: 第一阶段分割可视化。(a) A的服装分割;(b) B的身体分割;(c) 通过变形模块生成的B的服装分割;(d) B的原始服装分割。
3.2 Texturing Module
3.2 纹理模块
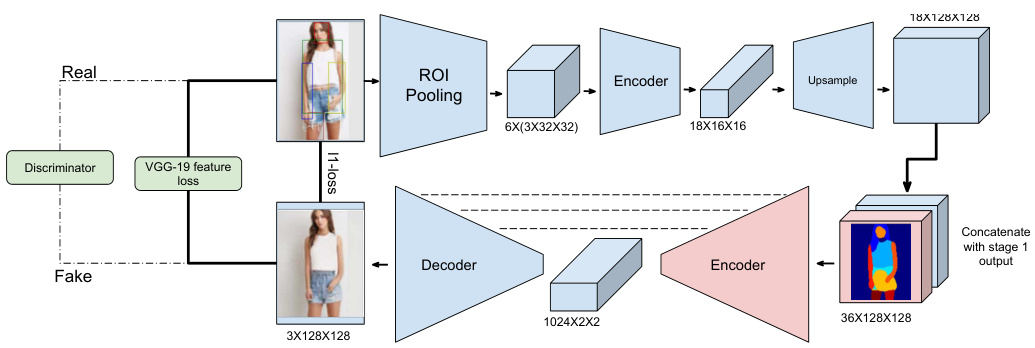
Fig. 6. Architecture of the stage 2 module. The texturing module is trained in a self supervised manner. The shape information input to the encoder is obtained from clothing segmentation and the texture information is obtained using ROI pooling.
图 6: 第二阶段模块架构。纹理模块以自监督(self supervised)方式进行训练。编码器输入的形状信息来自服装分割,纹理信息通过ROI池化获取。
Our second stage network, the texturing module, is a U-Net architecture trained to generate texture details given the clothing segmentation at the desired body shape and pose, $B_{c s}^{\prime}$ , and an embedding of the desired clothing shown in image $A$ . We obtain this embedding by ROI pooling on each of the 6 body parts (main body, left arm, right arm, left leg, right leg and face) of $A$ and generating feature maps of size $3\times16\times16$ , which are then upsampled to the original image size. We stack these feature maps with $B_{c s}^{\prime}$ before feeding them into the U-Net. The idea is to use the clothing segmentation to control the high-level structure and shape and use the clothing embedding to guide the hallucination of low-level color and details.
我们的第二阶段网络(即纹理模块)采用U-Net架构,其训练目标是根据目标体型姿态下的服装分割图$B_{cs}^{\prime}$和图像$A$中目标服装的嵌入特征生成纹理细节。我们通过对图像$A$的6个身体部位(躯干、左臂、右臂、左腿、右腿和面部)进行ROI池化来获取嵌入特征,生成尺寸为$3\times16\times16$的特征图,随后上采样至原始图像尺寸。这些特征图与$B_{cs}^{\prime}$拼接后输入U-Net。该设计通过服装分割图控制高层结构与形状,同时利用服装嵌入特征引导底层色彩与细节的生成。
Similar to the first stage, we train the texturing module in a weakly supervised way. Specifically, given an input image $B$ , we consider the inputs to be ( $B_{c s}+$ embedding of the clothing in $B\Rightarrow B$ ). To avoid learning the identity mapping, we compute an embedding of the desired clothing from augmentations of $B$ by performing random flips and crops. We use the L1 reconstruction loss, feature loss (VGG-19) and the GAN loss with DRAGAN gradient penalty [40] which has been shown to improve the sharpness of the results and stabilize the training of GANs. The learning objective of the second stage texturing module $f2$ is given as follows:
与第一阶段类似,我们以弱监督方式训练纹理模块。具体而言,给定输入图像$B$,我们认为输入是($B_{c s}+$ $B$中服装的嵌入$\Rightarrow B$)。为避免学习恒等映射,我们通过对$B$进行随机翻转和裁剪增强来计算目标服装的嵌入。我们使用L1重建损失、特征损失(VGG-19)以及带DRAGAN梯度惩罚[40]的GAN损失,该惩罚已被证明能提升结果锐度并稳定GAN训练。第二阶段纹理模块$f2$的学习目标如下:
$$
\begin{array}{l}{\lefteqn{\mathcal{L}{L1}=||f2(z_{c s}^{\prime},A)-A||{1}}}\ {\mathcal{L}{f e a t}=\sum_{l}\lambda_{l}||\phi_{l}(f2(z_{c s}^{\prime},A))-\phi_{l}(A)||{2}}\ {\mathcal{L}{a d v}=\mathbb{E}{x\sim p(A)}[D(x)]+\mathbb{E}{z\sim p(f2_{e n c})}[1-D(f2_{d e c}(z))]}\end{array}
$$
$$
\begin{array}{l}{\lefteqn{\mathcal{L}{L1}=||f2(z_{c s}^{\prime},A)-A||{1}}}\ {\mathcal{L}{f e a t}=\sum_{l}\lambda_{l}||\phi_{l}(f2(z_{c s}^{\prime},A))-\phi_{l}(A)||{2}}\ {\mathcal{L}{a d v}=\mathbb{E}{x\sim p(A)}[D(x)]+\mathbb{E}{z\sim p(f2_{e n c})}[1-D(f2_{d e c}(z))]}\end{array}
$$
where, $\phi_{l}$ accounts for loss w.r.t activation s of some layer of a pretrained VGG-19 network. The disc rim in at or for this stage has the following objective:
其中,$\phi_{l}$ 表示预训练 VGG-19 网络某层激活值对应的损失。该阶段的判别器 (discriminator) 目标函数如下:
$$
\begin{array}{r}{\mathcal{L}{a d v_{d}}=\mathbb{E}{{x}\sim p(A)}[D(x)]+\mathbb{E}{z\sim p(f2_{e n c})}[1-D(f2_{d e c}(z))]+\lambda_{g p}\mathbb{E}{z\sim P(z)}[||\nabla_{z}D(z)||_{2}]}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{a d v_{d}}=\mathbb{E}{{x}\sim p(A)}[D(x)]+\mathbb{E}{z\sim p(f2_{e n c})}[1-D(f2_{d e c}(z))]+\lambda_{g p}\mathbb{E}{z\sim P(z)}[||\nabla_{z}D(z)||_{2}]\end{array}
$$
During testing, we use the clothing segmentation generated by the previous stage. Note that we flatten the 18 channel segmentation map by performing an argmax operation across the channels. This is done mainly to prevent artifacts due to output of stage 1 having non-zero values in more than 1 channel at a particular pixel location. This step is non-differentiable, and therefore disallows end-to-end training. However, we can perform an end-to-end fine-tuning of these pretrained networks by skipping the argmax step and employing a softmax instead. We would like to point out that our framework is robust to the noise in the input clothing and body segmentation. The second stage operates on noisy clothing segmentation generated from the first stage and learns to ignore the noise while filling in textures and colors.
测试阶段,我们使用前一阶段生成的服装分割图。需注意的是,我们通过对18通道分割图执行argmax操作来将其展平,此举主要是为了避免因第一阶段输出在特定像素位置存在多个通道非零值而导致的伪影。该步骤不可微分,因此无法实现端到端训练。但我们可以通过跳过argmax步骤并改用softmax,对这些预训练网络进行端到端微调。需要指出的是,我们的框架对输入服装和人体分割图中的噪声具有鲁棒性。第二阶段处理第一阶段生成的含噪服装分割图时,能够学习在填充纹理和色彩时忽略这些噪声。
The major advantage of our network lies in the fact that unlike [29] the clothing segmentation and body segmentation need not be very clean for our framework to be effective. Our segmentation s are obtained by state of the art human parsing and body parsing models, however the predictions of these are still noisy and often have holes. Our network however, can learn to compensate for the noise in these intermediate representation. The noisy clothing and body segmentation s provide a very rich and structured signal as opposed to pose keypoints whilst not being as restrictive as inputs to pix2pix and Scribbler that require precise sketches or segmentation as input to generate reasonable results.
我们网络的主要优势在于,与[29]不同,我们的框架不需要非常干净的衣物分割和人体分割也能有效工作。我们的分割结果是通过最先进的人体解析和身体解析模型获得的,但这些预测结果仍然存在噪声且常有孔洞。然而,我们的网络能够学会补偿这些中间表示中的噪声。与姿态关键点相比,带有噪声的衣物和人体分割提供了非常丰富且结构化的信号,同时又不像pix2pix和Scribbler的输入那样严格——后者需要精确的草图或分割作为输入才能生成合理结果。
Additionally, we perform some post processing on the output of the first stage to preserve the identity of the target individual before feeding it into the second stage. In particular, in the generated clothing segmentation $B_{c s}^{\prime}$ , we replace the “face” and “hair” segments with corresponding segments in the original clothing segmentation $B_{c s}$ . Similarly, at the end of the second stage, we copy the face and hair pixels from $B$ into the result. Without these steps, the whole framework becomes akin to reposing the same individual instead of re-targeting the clothing to a different individual.
此外,我们对第一阶段的输出进行了一些后处理,以在输入第二阶段前保留目标人物的身份特征。具体而言,在生成的服装分割图 $B_{cs}^{\prime}$ 中,我们将"面部"和"头发"区域替换为原始服装分割图 $B_{cs}$ 中的对应区域。类似地,在第二阶段结束时,我们将 $B$ 中的面部和头发像素复制到最终结果中。若不进行这些步骤,整个框架将更近似于对同一个人进行姿态调整,而非将服装重定向到不同个体。
4 Experiments
4 实验
In this section, we show results of each stage and provide detailed quantitative and qualitative comparisons with baselines. We first explain the baseline methods and then discuss our findings.
在本节中,我们展示了各阶段的结果,并与基线方法进行了详细的定量和定性比较。首先介绍基线方法,随后讨论我们的发现。
4.1 Qualitative evaluation
4.1 定性评估

Fig. 7. Ablation study showing the need for various augmentations. Results from models trained with (a) no augmentations, (b) no flips $^+$ affine transforms, (c) flips $^+$ small affine transforms, (d) flips $+$ large affine transforms (e) no flip on stage 2
图 7: 消融实验展示各类数据增强的必要性。模型训练结果对比:(a) 无数据增强,(b) 无翻转+仿射变换,(c) 翻转+小幅仿射变换,(d) 翻转+大幅仿射变换,(e) 第二阶段无翻转
Need for Augmentation: To analyze the effects of different types of augmentation, we present an ablation study (Figure 7), where stage 1 is trained (a) with no augmentation, (b) with only affine transforms, (c) with random flips and small affine transforms and (d) with flips and large affine transforms. While flips help to handle cases when source and target are on different regions of the frame, affine transformations are necessary in part to handle scale changes between source and target. We also show that crops and flips reduce leaking artifacts for the second stage (e).
数据增强的必要性:为分析不同类型数据增强的效果,我们进行了消融实验(图 7),其中第一阶段分别采用以下训练方式:(a) 无增强,(b) 仅仿射变换,(c) 随机翻转配合小幅仿射变换,(d) 翻转配合大幅仿射变换。翻转操作能有效处理源目标位于画面不同区域的情况,而仿射变换则部分解决了源目标间的尺度变化问题。实验还表明,裁剪与翻转操作能减少第二阶段训练中的渗色伪影(e)。

Fig. 8. Com parisi on with PG2. (a) Source pose, (b) Target Pose, (c) Ours (d) PG2.
图 8: 与 PG2 的对比。(a) 源姿势, (b) 目标姿势, (c) 我们的方法 (d) PG2。
Comparison with PG2: We compare SwapNet with the work of Ma et al. [26] on their provided test split (Figure 8). We notice visible high frequency artifacts as a result of the second stage network in PG2. In contrast, as demonstrated by many previous work, adding feature loss makes the generated quality better because we match higher level feature statistics in addition to the color of the clothing component. Furthermore, we see that a “learned” representation of pose, such as body segmentation, provides richer guidance to the original target pose, as opposed to extracting a hand engineered mask from pose keypoints as in [26]. Additionally, body segmentation s allow for just as much control as pose keypoints, whilst still being constrained by the body shape (similar to a deformable parts model). We evaluate the performance of SwapNet in this setting, and since we have direct supervision as to what the generated image should look like, we can calculate the SSIM metric and perceptual distance (1)
与PG2的对比:我们将SwapNet与Ma等人[26]在其提供的测试集上的工作进行对比(图8)。我们注意到PG2第二阶段网络会产生明显的高频伪影。相反,正如许多先前研究所示,添加特征损失(feature loss)能提升生成质量,因为除了服装组件的颜色外,我们还匹配了更高层次的特征统计量。此外,我们发现"学习"得到的姿态表征(如人体分割图)能为原始目标姿态提供比[26]中从姿态关键点提取手工设计掩模更丰富的指导。同时,人体分割图在保持与身体形状约束(类似于可变形部件模型)的前提下,能提供与姿态关键点同等的控制力。我们在该设定下评估SwapNet的性能,由于对生成图像外观有直接监督,可计算SSIM指标和感知距离(1)

Fig. 9. Com parisi on with PG2. (a) Source pose, (b) Target Pose, (c) Ours, (d) Ours after user corrects intermediate clothing segmentation (e) PG2.
图 9: 与PG2的对比。(a) 源姿势, (b) 目标姿势, (c) 我们的方法, (d) 用户修正中间服装分割后的结果, (e) PG2。
on this matched pair of images. Additionally, We also demonstrate the advantage of using clothing segmentation as an intermediate representation (Figure 9(d)). In cases where the clothing segment is ambiguous, the user can edit the intermediate representation to better fit the clothing.
在这对匹配图像上。此外,我们还展示了使用服装分割作为中间表示的优势(图 9(d))。当服装分割结果模糊时,用户可以编辑中间表示以更好地适配服装。
Comparison with VITON and visual analogy:
与VITON和视觉类比对比:

Fig. 10. Results of SwapNet, VITON and Visual Analogy on the Zolando dataset. Additional results on SwapNet-Feat (trained without Feature loss) and SwapNet-Gan (trained without GAN loss)
图 10: SwapNet、VITON和Visual Analogy在Zolando数据集上的结果。SwapNet-Feat(未使用特征损失训练)和SwapNet-Gan(未使用GAN损失训练)的附加结果
We present additional comparisons with VITON[32] and Deep Visual Analogy[37]. VITON transfers a product image of a clothing item onto an image of an individual using a two-stage approach, where the first stage involves generating a coarse transferred image using an Encoder-decoder network, and the second stage involves refining the generated image by warping the product image. Deep Visual Analogies produce images to complete analogies of the form A:A’::B:B’.
我们提供了与VITON[32]和Deep Visual Analogy[37]的额外对比。VITON采用两阶段方法将服装产品的图像转移到个人图像上:第一阶段通过编码器-解码器网络生成粗略的转移图像,第二阶段通过扭曲产品图像来优化生成结果。Deep Visual Analogies则通过生成图像来完成"A:A’::B:B’"形式的类比。
Particularly, it generates images A’ and B, given style and content image A and B’. We highlight that VITON and Deep Visual Analogy are not strict baselines since our target task of swapping clothing between portrait images in the wild is different from the task of VITON (virtual try-on based on product image) and Deep Visual Analogy (Style transfer). We cannot find other previous work addressing the same problem as ours, so we modify our problem setting slightly to compare with these related but different works. We use the test split used by VITON for fair comparison. VITON demonstrates clothing transfer on the Zolando dataset[32]. We observe that our model trained on the Deep Fashion dataset is able to generalize to the Zolando dataset without additional finetuning.
具体来说,它根据风格图像A和内容图像B'生成图像A'和B。需要强调的是,VITON和Deep Visual Analogy并非严格意义上的基线方法,因为我们的目标任务(在自然场景人像间进行服装替换)与VITON(基于商品图像的虚拟试穿)及Deep Visual Analogy(风格迁移)的任务存在差异。由于未发现其他前人工作与我们研究相同问题,我们略微调整问题设置以与这些相关但不同的工作进行对比。为公平比较,我们采用VITON使用的测试集划分。VITON在Zolando数据集[32]上展示了服装迁移效果。我们观察到,基于Deep Fashion数据集训练的模型无需额外微调即可泛化至Zolando数据集。
4.2 Quantitative Results
4.2 定量结果
We present the performance of different models on some of the common metrics for evaluating generative models. The inception score is a measure of how realistic images from a set look and how diverse they are. We also present the SSIM on a subset of data for which we have paired information.
我们展示了不同模型在评估生成模型的若干常见指标上的表现。初始分数 (inception score) 用于衡量一组图像的逼真程度和多样性。此外,我们还针对具有配对信息的数据子集提供了结构相似性 (SSIM) 指标。
Additionally, we use the VGG perceptual metric (PD) as suggested by [41]. We present PD(TP) – the perceptual distance to the target pose and PD(TC) – the perceptual distance to the target clothing image.
此外,我们采用[41]提出的VGG感知度量(PD),分别计算目标姿态感知距离PD(TP)和目标服装图像感知距离PD(TC)。
Table 1. Quantitative metrics for different models. Higher score is better for IS and SSIM and smaller is better for PD
表 1: 不同模型的量化指标。IS和SSIM分数越高越好,PD分数越小越好
| 模型 | SSIM | PD(TP) | PD(TC) |
|---|---|---|---|
| CGAN | 2.11 3.06 | ||
| PG2 | 0.09 | ||
| Ours (w/o GAN w/o feat) | 2.63 ± 0.061 | 0.84 0.075 0.82 | 0.114 |
| Ours (w/ofeat) | 2.72 ± 0.032 | 0.057 | 0.100 |
| Ours (w/o GAN) | 2.75 ± 0.13 | 0.81 0.061 0.83 | 0.101 |
| Ours | 3.04±0.052 | 0.056 | 0.099 |
| Dataset | 3.28 |
For the most part we see that scores of all methods are clustered around similar values. The IS and SSIM metrics provide a good proxy to measure the performance but are not a true measurement of how well the model is performing the required task. The perceptual losses provide some more insights about the transfer performance. Particularly, we see that the SSIM scores favourably for a model trained without the GAN loss and feature loss. Since the network is trained with only L1 loss, the SSIM predicts that the generations are very close to ground truth. However, with the perceptual metric it can be clearly seen that the model w/o GAN and w/o feature loss performs worse perceptual ly. We see that our SwapNet model performs the best both in terms of inception score and the perceptual distance on the task of reposing a given clothing image.
大部分情况下,我们看到所有方法的得分都集中在相似值附近。IS (Inception Score) 和 SSIM (结构相似性) 指标能较好地衡量性能,但并非模型执行任务效果的真实度量。感知损失 (perceptual loss) 为迁移性能提供了更多洞见。值得注意的是,SSIM 分数更倾向于未使用 GAN 损失和特征损失训练的模型。由于该网络仅用 L1 损失训练,SSIM 预测生成结果非常接近真实值。然而通过感知度量可以明显看出,未使用 GAN 和特征损失的模型在感知层面表现更差。我们的 SwapNet 模型在给定服装图像重姿态任务上,无论是初始分数还是感知距离都表现最佳。
4.3 Limitations
4.3 局限性

Fig. 11. Limitations of SwapNet for clothing transfer. First row demonstrates extreme pose changes (DP: Desired pose; DC: Desired clothing; Gen: Generated image) . Second row demonstrates occlusion by rare classes (hat, purse).
图 11: SwapNet在服装迁移中的局限性。第一行展示了极端姿态变化 (DP: 目标姿态;DC: 目标服装;Gen: 生成图像)。第二行展示了罕见类别(帽子、手提包)造成的遮挡。
Our framework has difficulty handling large pose changes between source and target images (top row of Figure 11). If one of the images contain a truncated body and the other contains a full body, our model is not able to hallucinate appropriate details for the missing lower limbs. Furthermore, our framework is sensitive to occlusions by classes like hats and sunglasses, and might generate blending artifacts (the bottom row Figure 11). The third row in Figure 10 also shows that the network is sometimes unable to handle partial self occlusion.
我们的框架难以处理源图像与目标图像之间的大幅度姿态变化(图 11 顶部行)。若其中一张图像包含截断的身体而另一张包含完整身体,我们的模型无法为缺失的下肢生成合理的细节。此外,该框架对帽子、太阳镜等遮挡物敏感,可能产生混合伪影(图 11 底部行)。图 10 第三行也表明,网络有时无法处理部分自遮挡情况。
5 Conclusion
5 结论
We present SwapNet, a framework for single view garment transfer. We motivate the need for a two-stage approach as opposed to a traditional “end-to-end” training pipeline and highlight the use of split channel segmentation as an intermediary stage for garment transfer. Additionally, we employ a novel weakly supervised training procedure to train the warping and text uri z ation modules in the absence of supervised data for same clothing in different poses. In the future we aim to leverage a supervised subset that could potentially enable the model to handle larger pose and scale variations. We could also leverage approaches like warping as in [32], to further improve the details in the generated clothing. Acknowledgements: This work was partially funded by Adobe Research and NSF award 1561968
我们提出SwapNet框架,用于单视角服装迁移。与传统"端到端"训练流程不同,我们论证了采用两阶段方法的必要性,并重点介绍了分割通道作为服装迁移中间阶段的应用。此外,我们采用新型弱监督训练方法,在缺乏不同姿势下相同服装监督数据的情况下训练形变和纹理生成模块。未来我们计划利用监督数据子集,使模型能够处理更大范围的姿势和尺度变化。还可借鉴[32]等形变方法进一步提升生成服装的细节。致谢:本研究部分由Adobe Research和美国国家科学基金会奖项1561968资助
References
参考文献
16 A. Raj, P. Sangkloy, H, Chang, J. Hays, D. Ceylan, J. Lu
16 A. Raj, P. Sangkloy, H. Chang, J. Hays, D. Ceylan, J. Lu