TMCIR: Token Merge Benefits Composed Image Retrieval
TMCIR: Token Merge提升组合图像检索
Abstract
摘要
Composed Image Retrieval (CIR) retrieves target images using a multi-modal query that combines a reference image with text describing desired modifications. The primary challenge is effectively fusing this visual and textual information. Current cross-modal feature fusion approaches for CIR exhibit an inherent bias in intention interpretation. These methods tend to disproportionately emphasize either the reference image features (visual-dominant fusion) or the textual modification intent (text-dominant fusion through image-to-text conversion). Such an imbalanced representation often fails to accurately capture and reflect the actual search intent of the user in the retrieval results. To address this challenge, we propose TMCIR, a novel framework that advances composed image retrieval through two key innovations: 1) Intent-Aware CrossModal Alignment. We first fine-tune CLIP encoders contrastive ly using intent-reflecting pseudo-target images, synthesized from reference images and textual descriptions via a diffusion model. This step enhances the encoder ability of text to capture nuanced intents in textual descriptions. 2) Adaptive Token Fusion. We further fine-tune all encoders contrastive ly by comparing adaptive tokenfusion features with the target image. This mechanism dynamically balances visual and textual representations within the contrastive learning pipeline, optimizing the composed feature for retrieval. Extensive experiments on Fashion-IQ and CIRR datasets demonstrate that TMCIR significantly outperforms state-of-the-art methods, particularly in capturing nuanced user intent.
组合图像检索 (Composed Image Retrieval, CIR) 通过结合参考图像与描述修改需求的文本构成多模态查询,以此检索目标图像。其核心挑战在于如何有效融合视觉与文本信息。当前CIR的跨模态特征融合方法存在意图理解的固有偏差:这些方法往往过度侧重参考图像特征(视觉主导融合)或将文本修改意图通过图像转文本方式主导融合。这种不平衡的表示通常无法在检索结果中准确捕捉并反映用户的真实搜索意图。
为解决这一挑战,我们提出TMCIR框架,通过两项关键创新推动组合图像检索发展:1) 意图感知跨模态对齐。我们首先使用扩散模型根据参考图像和文本描述合成的意图反映伪目标图像,以对比学习方式微调CLIP编码器。这一步骤增强了文本编码器捕捉文本描述中细微意图的能力。2) 自适应Token融合。我们通过将自适应Token融合特征与目标图像进行对比,进一步以对比学习方式微调所有编码器。该机制在对比学习流程中动态平衡视觉与文本表示,优化检索所需的组合特征。在Fashion-IQ和CIRR数据集上的大量实验表明,TMCIR显著优于现有最优方法,尤其在捕捉用户细微意图方面表现突出。
CCS Concepts
CCS概念
• Composed Image Retrieval;
• 组合图像检索 (Composed Image Retrieval);
Keywords
关键词
Composed Image Retrieval, Contrastive Learning.
组合图像检索,对比学习。
1 Introduction
1 引言
Retrieving images based on a combination of a reference image and textual modification instructions defines the task of Composed ∼Image Retrieval (CIR) [5, 20, 37]. Specifically, the goal of CIR is to retrieve a target image from a candidate set that maintains overall visual similarity to the reference image while fulfilling the localized modification requirements specified in the textual description. CIR enables precise, interactive retrieval, making it valuable for applications like e-commerce and personalized web search.
基于参考图像和文本修改指令组合来检索图像的任务定义为组合图像检索 (Composed Image Retrieval, CIR) [5, 20, 37]。具体而言,CIR的目标是从候选集中检索出与参考图像保持整体视觉相似性,同时满足文本描述中指定的局部修改要求的目标图像。CIR支持精确的交互式检索,使其在电子商务和个性化网络搜索等应用中具有重要价值。
However, composed queries from two distinct modalities introduces unique challenges. Unlike text-to-image or image-to-image retrieval which rely on a single query type, CIR must interpret relative changes described textually and apply them to the specific visual content of the reference image. The core difficulty lies in effectively integrating these cross-modal signals into a unified representation for similarity comparison with candidate images. To achieve this integration, most current approaches predominantly employ visualdominant feature fusion mechanisms [1, 8, 11, 24]. which extract image and text features separately and then combining them. However, these methods exhibit two critical limitations: 1) They often fail to preserve essential visual details from the reference image; 2) They tend to inadvertently incorporate irrelevant background information (i.e., regions unrelated to the textual modifications) into the final query representation. These shortcomings become particularly pronounced in scenarios requiring fine-grained image modifications, such as precise color variations or localized texture alterations, where maintaining both visual fidelity and modification accuracy is paramount.
然而,组合来自两种不同模态的查询带来了独特的挑战。与依赖单一查询类型的文本到图像或图像到图像检索不同,CIR (Composed Image Retrieval) 必须解释文本描述的相对变化,并将其应用于参考图像的具体视觉内容。核心难点在于如何有效地将这些跨模态信号整合为统一的表示,以便与候选图像进行相似性比较。为实现这种整合,当前大多数方法主要采用视觉主导的特征融合机制 [1, 8, 11, 24],即分别提取图像和文本特征后再进行组合。但这些方法存在两个关键局限:1) 它们往往无法保留参考图像中的关键视觉细节;2) 容易将无关的背景信息(即与文本修改无关的区域)无意间融入最终查询表示。这些缺陷在需要细粒度图像修改的场景(如精确的颜色变化或局部纹理调整)中尤为突出,此时保持视觉保真度和修改准确性至关重要。
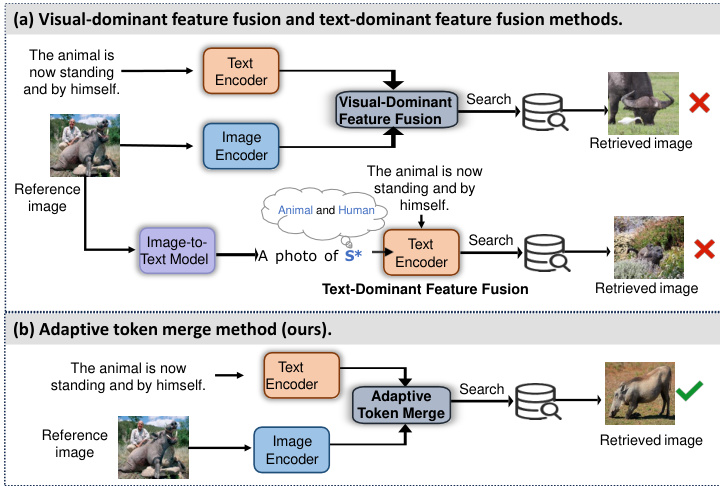
Figure 1: Workflows of existing CIR methods and our proposed TMCIR
图 1: 现有CIR方法与我们提出的TMCIR工作流程
Other recent approaches have adopted text-dominant fusion mechanisms that leverage CLIP-based image-to-text conversion [5, 12], where reference images are mapped to pseudo-word embeddings for integration with textual descriptions. While this paradigm benefits from established cross-modal alignment, it faces fundamental limitations: 1) The generated pseudo-word tokens primarily capture global image semantics while losing fine-grained visual details; 2) The constrained length of the word tokens restricts comprehensive visual representation. These factors lead to granularlevel discrepancies in the cross-modal representations, ultimately compromising retrieval accuracy.
其他近期研究采用了以文本为主导的融合机制,利用基于CLIP的图像到文本转换技术[5,12],将参考图像映射为伪词嵌入(pseudo-word embeddings)以整合文本描述。虽然该范式受益于成熟的跨模态对齐能力,但存在根本性局限:1) 生成的伪词token主要捕获全局图像语义,同时丢失细粒度视觉细节;2) 词token的长度限制制约了视觉表征的全面性。这些因素导致跨模态表征存在粒度级差异,最终影响检索精度。
As shown in Fig. 1(a), both the visual-dominant fusion and the text-dominant fusion methods are fail to accurately capture and reflect the actual search intent of the user in the retrieval results. To address these challenges, we propose a TMCIR framework. Our framework is carefully designed to preserve the critical visual information present in the reference image while accurately conveying the modification intent of the user as specified by textual description. The TMCIR comprises two key steps: 1) Intent-Aware Cross-Modal Alignment: This step is designed to precisely capture textual intent from descriptions, addressing a critical limitation in CIR. Conventional target images often contain extraneous variations (e.g., lighting conditions, irrelevant background objects, or stylistic inconsistencies) that deviate from the specified intent of text, making them suboptimal for fine-tuning. To overcome this, we introduce a pseudo-target generation module that leverages a diffusion model conditioned on both the reference image and the relative textual description. The generated pseudo-target image eliminates noise, serving as a cleaner supervisory signal that faithfully reflects the intended modifications. Using an image-text paired dataset constructed from these pseudo-targets and their corresponding descriptions, we perform contrastive fine-tuning of pre-trained visual and textual encoders. This approach ensures precise crossmodal token alignment in a shared embedding space, with a focused emphasis on text-intent preservation from the description. 2) Adaptive Token Fusion: Following alignment fine-tuning, we introduce an adaptive fusion strategy that computes token-wise cosine similarity between visual and textual encoder outputs, enhanced with positional encoding for weighted feature fusion (Fig. 1(b). This design serves two key purposes: 1) The positional cues establish explicit correspondences between textual concepts and their spatial counterparts in the image. 2) The similarity-weighted fusion preserves critical visual details while precisely encoding the nuanced modification intents specified in relative descriptions. The fused representations then drive a final contrastive fine-tuning stage, where we optimize all encoders by comparing the adaptive token-fusion features against target images. This dynamic balancing mechanism simultaneously refines both modalities within a unified contrastive framework, ultimately producing composite features that are optimally disc rim i native for retrieval tasks.
如图 1(a)所示,视觉主导融合和文本主导融合方法均无法在检索结果中准确捕捉和反映用户的真实搜索意图。为解决这些问题,我们提出了TMCIR框架。该框架通过精心设计,既能保留参考图像中的关键视觉信息,又能准确传达用户通过文本描述指定的修改意图。TMCIR包含两个关键步骤:
- 意图感知跨模态对齐:该步骤旨在从描述中精确捕捉文本意图,解决CIR中的关键局限。传统目标图像常包含与文本指定意图不符的干扰变化(如光照条件、无关背景对象或风格不一致),使其不适合微调。为此,我们引入基于参考图像和相对文本描述的扩散模型伪目标生成模块。生成的伪目标图像可消除噪声,作为忠实反映修改意图的纯净监督信号。利用这些伪目标图像与对应描述构建的图文配对数据集,我们对预训练视觉和文本编码器进行对比微调。该方法确保在共享嵌入空间实现精确的跨模态token对齐,重点保持描述中的文本意图。
- 自适应token融合:对齐微调后,我们引入自适应融合策略,计算视觉与文本编码器输出的token级余弦相似度,并通过位置编码增强加权特征融合(图 1(b)。该设计实现两大功能:(1) 位置线索建立文本概念与图像空间区域的显式对应关系;(2) 相似度加权融合在保留关键视觉细节的同时,精确编码相对描述中指定的细微修改意图。融合表征驱动最终对比微调阶段,通过比较自适应token融合特征与目标图像来优化所有编码器。这种动态平衡机制在统一对比框架中同步优化双模态,最终生成最适合检索任务的判别性复合特征。

Figure 2: Retrieval examples using the proposed TMCIR, CLIP4CIR [4] (visual-dominant feature fusion), and Pic2word [31] (text-dominant fusion) methods, respectively.
图 2: 分别使用提出的TMCIR方法、CLIP4CIR [4] (视觉主导特征融合)和Pic2word [31] (文本主导融合)方法进行检索的示例。
Experiments conducted on the Fashion-IQ and CIRR datasets demonstrate that our method achieves state-of-the-art performance on both benchmarks. As shown in Figure 2, a user provides a reference image of a black T-shirt accompanied by the relative description “change the black T-shirt to purple and add intricate patterns”.
在Fashion-IQ和CIRR数据集上进行的实验表明,我们的方法在两个基准测试中都达到了最先进的性能。如图2所示,用户提供了一张黑色T恤的参考图像,并附有相对描述"将黑色T恤改为紫色并添加复杂图案"。
The method of CLIP4CIR[4] employs visual-dominant feature fusion, which risks incorporating irrelevant visual elements (e.g., background clutter) that dilute the precise modification intent, leading to erroneous results. Conversely, the method of Pic2word[31] uses text-dominant fusion that may suppress relevant visual details while similarly weakening the intended modifications, resulting in comparable failures. Both approaches highlight the need for a balanced fusion strategy that preserves critical visual features while faithfully capturing textual intentions. Our adaptive token fusion approach analyzes the image in finer detail. It partitions the reference image, allowing visual tokens from different regions to be compared with keywords in the description. The mechanism can distinguish the T-shirt region from the background and, via cosine similarity, identify tokens highly correlated with keywords like “purple”, “T-shirt”, and “patterns”. Tokens from the T-shirt region receive higher weights, while background tokens are attenuated. Simultaneously, the textual information for “purple” guides the adjustment of the token representations associated with the T-shirt, generating a joint representation that accurately fulfills the modification requirements.
CLIP4CIR[4]方法采用视觉主导的特征融合策略,存在引入无关视觉元素(如背景杂波)的风险,这些干扰会稀释精确的修改意图,导致错误结果。相比之下,Pic2word[31]方法采用文本主导的融合方式,可能在抑制相关视觉细节的同时弱化预期修改效果,造成类似的失败案例。两种方法都凸显了平衡融合策略的必要性——既要保留关键视觉特征,又要忠实捕捉文本意图。我们的自适应token融合方案通过更精细的图像分析实现这一目标:对参考图像进行分区处理,使不同区域的视觉token能与描述中的关键词进行比对。该机制能区分T恤区域与背景,并通过余弦相似度识别与"purple"、"T-shirt"、"patterns"等关键词高度相关的token。T恤区域的token获得更高权重,背景token则被弱化。与此同时,"purple"的文本信息会引导调整T恤相关token的表征,最终生成准确满足修改需求的联合表征。
In summary, our contributions are as follows:
总之,我们的贡献如下:
• We propose a novel CIR approach that integrates intentaware cross-modal alignment (IACMA) and adaptive token fusion (ATF) to better capture user intent. The IACMA leverages a diffusion model to generate pseudo-target images that more accurately reflect user modification intent compared to potentially noisy real target images, providing a purer supervisory signal for encoder fine-tuning. The ATF adaptively fuse visual and textual tokens through weighted integration and positional encoding. This strategy ensures comprehensive preservation of key visual details while accurately capturing subtle user modification intent. • Experimental results on the Fashion-IQ and CIRR datasets indicate that our proposed method outperforms current stateof-the-art CIR approaches in both retrieval accuracy and robustness.
• 我们提出了一种新颖的组合图像检索(CIR)方法,该方法整合了意图感知跨模态对齐(IACMA)和自适应token融合(ATF)机制,以更好地捕捉用户意图。IACMA利用扩散模型生成能更准确反映用户修改意图的伪目标图像(相比可能存在噪声的真实目标图像),为编码器微调提供更纯净的监督信号。ATF通过加权集成和位置编码自适应融合视觉与文本token,该策略在全面保留关键视觉细节的同时,能精准捕捉用户细微的修改意图。
• 在Fashion-IQ和CIRR数据集上的实验结果表明,我们提出的方法在检索准确性和鲁棒性方面均优于当前最先进的CIR方法。
2 Related work
2 相关工作
Composed Image Retrieval. In current mainstream CIR methods, one category focuses on the reference image features, where the features of the reference image are fused with those of the relative caption. Then the fused feature is compared with those of all candidate images to determine the closest match [1, 9, 11, 24, 37]. Various feature fusion mechanisms [37] and attention mechanisms [9, 11] have exhibited prominent performance in CIR. Subsequently, capitalizing on the robust capabilities of pre-trained models, a number of CIR methods that adeptly amalgamate image and text features extracted from autonomously trained visual and text encoders [4, 13, 30]. Another category of approaches suggest to transform reference image into its pseudo-word embedding [3, 31], which is then combined with relative caption for text-to-image retrieval. However, the pseudo-word embeddings learned in this manner often capture only global semantic information while lacking fine-grained visual details, and their limited length makes it difficult to comprehensively represent the visual content of the reference image. Liu et al. created text with semantics opposite to that of the original text and add learnable tokens to the text to retrieve images in two distinct queries [26]. Nevertheless, this approach to fixed text prompt learning fails to modify the intrinsic information within the relative caption itself, thereby constraining retrieval performance. Although existing composed image retrieval methods have achieved varying degrees of visual and textual information fusion, they still fall short in fully preserving the detailed information in the reference image and accurately aligning with the user’s modification intent. Motivated by this, we propose the TMCIR framework, which effectively addresses the issues of information loss and insufficient cross-modal alignment through the generation of pseudo-target images, task-specific fine-tuning of encoders, and a similarity-based token fusion module. As a result, our approach achieves significant improvements in both retrieval accuracy and robustness.
组合图像检索。当前主流的CIR方法主要分为两类:一类侧重于参考图像特征,将参考图像特征与相关描述文本特征融合后,与候选图像特征进行匹配[1, 9, 11, 24, 37]。各类特征融合机制[37]和注意力机制[9, 11]在CIR中展现出卓越性能。随着预训练模型的强大能力,涌现出许多能巧妙融合自训练视觉编码器和文本编码器所提取特征的CIR方法[4, 13, 30]。另一类方法将参考图像转换为伪词嵌入(pseudo-word embedding)[3, 31],再结合文本描述进行图文检索。但这类伪词嵌入往往仅捕获全局语义信息而缺乏细粒度视觉细节,其有限长度也难以全面表征参考图像的视觉内容。Liu等人通过生成语义相反的文本并添加可学习token来实现双重查询[26],但固定文本提示学习无法修改原始描述的深层信息,限制了检索性能。现有方法虽实现了不同程度的视觉-文本信息融合,仍难以完整保留参考图像细节并精准对齐用户修改意图。为此,我们提出TMCIR框架,通过生成伪目标图像、任务导向的编码器微调以及基于相似度的token融合模块,有效解决信息丢失和跨模态对齐不足的问题,在检索精度和鲁棒性上取得显著提升。
Token Merge for Modal Fusion. Multi-modal fusion requires the compression of redundant features and efficient representation learning, both of which are critical for enhancing a model’s generalization and inference efficiency. Traditional multi-modal fusion approaches often suffer from redundant features and escalated computational costs due to overlapping information across modalities, particularly in resource-constrained settings. The Token Merge method was originally proposed for vision Transformers to reduce unnecessary computation by merging redundant or semantically similar tokens [6]. Subsequently, this method was adapted to multi-modal tasks where researchers attempted to dynamically fuse tokens from different modalities to construct a more compact and expressive joint representation. In tasks such as image–text retrieval, image–text generation, and video semantic understanding, Token Merge not only improves computational efficiency but also significantly alleviates the issues of information conflicts and semantic inconsistencies during cross-modal alignment [7, 23, 28, 32].
模态融合的Token Merge方法。多模态融合需要压缩冗余特征并实现高效表征学习,这两者对提升模型的泛化能力和推理效率至关重要。传统多模态融合方法常因跨模态信息重叠导致特征冗余和计算成本激增,在资源受限场景中尤为明显。Token Merge最初是为视觉Transformer设计的,通过合并冗余或语义相似的token来减少不必要计算[6]。随后该方法被引入多模态任务,研究者尝试动态融合来自不同模态的token,以构建更紧凑且表达能力更强的联合表征。在图文检索、图文生成和视频语义理解等任务中,Token Merge不仅能提升计算效率,还可显著缓解跨模态对齐时的信息冲突与语义不一致问题[7, 23, 28, 32]。
In the context of composed image retrieval, the Token Merge method is used to address the inconsistent granularity between cross-modal feature alignment and fusion. For example, Wang et al. [38] emphasized cross-modal entity alignment during fine-tuning by employing contrastive learning and entity-level masked modeling to promote effective information interaction and structural unification between image and text. To further exploit the potential of localized textual representations, NSFSE [39] adaptively delineated the boundaries between matching and non-matching samples by comprehensively considering the correspondence of positive and negative pairs.
在组合图像检索的背景下,Token Merge方法被用于解决跨模态特征对齐与融合粒度不一致的问题。例如,Wang等人[38]在微调阶段通过采用对比学习和实体级掩码建模,强调了跨模态实体对齐,以促进图像与文本之间的有效信息交互和结构统一。为了进一步挖掘局部化文本表征的潜力,NSFSE[39]通过综合考虑正负样本对的对应关系,自适应地划分匹配与非匹配样本的边界。
Furthermore, efficient inference and generation in multi-modal models can also be achieved by directly pruning labels in the language model. Huang [16] introduced a training-free method that minimizes video redundancy by merging spatio-temporal tokens, thereby enhancing model efficiency. Compared with traditional attention-intensive interaction mechanisms, Token Merge offers a more flexible and controllable computational pathway for multimodal fusion, with promising s cal ability and practical engineering prospects.
此外,通过直接剪枝语言模型中的标签也能实现多模态模型的高效推理与生成。Huang [16] 提出了一种无需训练的方法,通过合并时空 token (Token) 来最小化视频冗余,从而提升模型效率。与传统依赖密集注意力的交互机制相比,Token Merge 为多模态融合提供了更灵活可控的计算路径,具备良好的扩展性和实际工程前景。
In our work, we apply the Token Merge technique to the fusion of visual and textual information in composed image retrieval. By adaptively merging visual tokens and textual tokens, our approach better preserves essential visual details from the reference image and fine-grained semantic information from the text. This results in more precise cross-modal token alignment and fusion, ultimately enhancing the retrieval performance.
在我们的工作中,我们将Token Merge技术应用于组合图像检索中的视觉与文本信息融合。通过自适应合并视觉token和文本token,我们的方法能更好地保留参考图像中的关键视觉细节和文本中的细粒度语义信息。这实现了更精准的跨模态token对齐与融合,最终提升了检索性能。
3 Method
3 方法
3.1 Preliminary
3.1 初步准备
Assume that a composed image retrieval (CIR) dataset contains $N$ annotated triplet samples, where the 𝑖th triplet sample $x_{i}$ is represented as:
假设一个组合图像检索 (CIR) 数据集包含 $N$ 个标注的三元组样本,其中第 𝑖 个三元组样本 $x_{i}$ 表示为:
$$
x_{i}=(r_{i},m_{i},t_{i}),\quad r_{i},t_{i}\in\Omega,\quad m_{i}\in\mathcal{T}.
$$
$$
x_{i}=(r_{i},m_{i},t_{i}),\quad r_{i},t_{i}\in\Omega,\quad m_{i}\in\mathcal{T}.
$$
Here, $\textstyle r_{i},m_{i}$ , and $t_{i}$ denote the reference image, the relative description, and the target image of the 𝑖th triplet sample, respectively. The term relative emphasizes that $m_{i}$ specifies the modifications to be applied to $r_{i}$ to obtain the target image, capturing how the target image differs from the reference image. $\Omega$ represents the candidate image set that contains all reference and target images, and $\mathcal{T}$ denotes the text set containing all relative descriptions.
这里,$\textstyle r_{i},m_{i}$ 和 $t_{i}$ 分别表示第𝑖个三元组样本的参考图像、相对描述和目标图像。术语"相对"强调 $m_{i}$ 指定了要应用于 $r_{i}$ 以获得目标图像的修改,捕捉目标图像与参考图像的差异。$\Omega$ 表示包含所有参考图像和目标图像的候选图像集,$\mathcal{T}$ 表示包含所有相对描述的文本集。
In the CIR task, the query $q_{i}$ , which is composed of the reference image $r_{i}$ and the relative description $m_{i}$ , is used to retrieve the target image $t_{i}$ from the candidate set $\Omega$ . In the classical CIR training paradigm, multiple annotated triplet samples are first grouped into a mini-batch. Within the same batch, the reference images and relative descriptions are encoded into query representations by a query encoder $F(\cdot)$ , while the target images are encoded by an image encoder $G(\cdot)$ to obtain their embeddings. For brevity, we denote the representations of the triplet $\left({{r}{i}},{{m}{i}},t_{i}\right)$ as
在CIR任务中,查询$q_{i}$由参考图像$r_{i}$和相关描述$m_{i}$组成,用于从候选集$\Omega$中检索目标图像$t_{i}$。在经典的CIR训练范式中,首先将多个带标注的三元组样本分组为一个小批量。在同一批次内,参考图像和相关描述通过查询编码器$F(\cdot)$编码为查询表示,而目标图像则通过图像编码器$G(\cdot)$编码获取其嵌入向量。为简洁起见,我们将三元组$\left({{r}{i}},{{m}{i}},t_{i}\right)$的表示记为
$$
q_{i}=F(r_{i},m_{i})\quad\mathrm{and}\quad v_{i}=G(t_{i}),
$$
$$
q_{i}=F(r_{i},m_{i})\quad\mathrm{and}\quad v_{i}=G(t_{i}),
$$
where $v_{i}$ denotes the embedding of the target image. The cosine similarity function $f(\cdot,\cdot)$ computes the similarity between the query representation and the target image embedding. Most current methods adopt a contrastive learning paradigm, which pulls together the query and target image representations of positive pairs (i.e., the query paired with its matching target image) while pushing apart those of negative pairs (i.e., a query paired with a target image from a different triplet). The corresponding loss function is formulated as:
其中 $v_{i}$ 表示目标图像的嵌入向量。余弦相似度函数 $f(\cdot,\cdot)$ 用于计算查询表示与目标图像嵌入之间的相似度。当前大多数方法采用对比学习范式,该范式将正样本对(即查询与其匹配的目标图像配对)的查询和目标图像表示拉近,同时将负样本对(即查询与来自不同三元组的目标图像配对)的表示推远。对应的损失函数表示为:
$$
L_{c l}=\frac{1}{B}\sum_{i=1}^{B}-\log\left(\frac{\exp(f(q_{i},v_{i})/\tau)}{\sum_{j=1}^{B}\exp(f(q_{i},v_{j})/\tau)}\right),
$$
$$
L_{c l}=\frac{1}{B}\sum_{i=1}^{B}-\log\left(\frac{\exp(f(q_{i},v_{i})/\tau)}{\sum_{j=1}^{B}\exp(f(q_{i},v_{j})/\tau)}\right),
$$
where $B$ is the batch size and $\tau$ is the temperature hyper parameter, which controls the sharpness of the similarity distribution and thus regulates the strength of the contrastive signal.
其中 $B$ 是批量大小,$\tau$ 是温度超参数,用于控制相似度分布的锐度,从而调节对比信号的强度。
Our method follows the same contrastive learning paradigm.
我们的方法遵循相同的对比学习范式。
3.2 Overview
3.2 概述
As depicted in Figure 1, our proposed TMCIR pipeline comprises two steps:
如图 1 所示,我们提出的 TMCIR 流程包含两个步骤:
(1) Intent-Aware Cross-Modal Alignment. This step contains Pseudo Target Image Generation (PTIG) and Encoder FineTuning for Token Alignment (EFTTA) modules. In the PTIG module, a diffusion model, specifically Stable Diffusion 3, is utilized to generate a pseudo target image $p_{i}$ by conditioning on the reference image $r_{i}$ and the relative description $m_{i}$ . This pseudo target image accurately reflects the modification requirements specified in $m_{i}$ , ensuring a high level of control l ability and reproducibility. In the EFTTA module, we construct an image-text pair dataset from the relative description and the pseudo target image, then finetune the visual and text encoders of the CLIP model. This process promotes more consistent cross-modal token distributions in the shared embedding space. Here, token alignment refers to the process of harmonizing tokens from different modalities in the embedding space so that their semantic representations and attention patterns become more correlated and comparable.
(1) 意图感知的跨模态对齐。该步骤包含伪目标图像生成 (PTIG) 和面向Token对齐的编码器微调 (EFTTA) 模块。在PTIG模块中,我们采用扩散模型(具体为Stable Diffusion 3)基于参考图像 $r_{i}$ 和相对描述 $m_{i}$ 生成伪目标图像 $p_{i}$ 。该伪目标图像精确反映 $m_{i}$ 中指定的修改需求,确保高度可控性与可复现性。在EFTTA模块中,我们从相对描述和伪目标图像构建图文对数据集,并对CLIP模型的视觉与文本编码器进行微调。该过程促使共享嵌入空间中的跨模态Token分布更趋一致。此处Token对齐指在嵌入空间协调不同模态Token的过程,使其语义表示与注意力模式更具关联性和可比性。
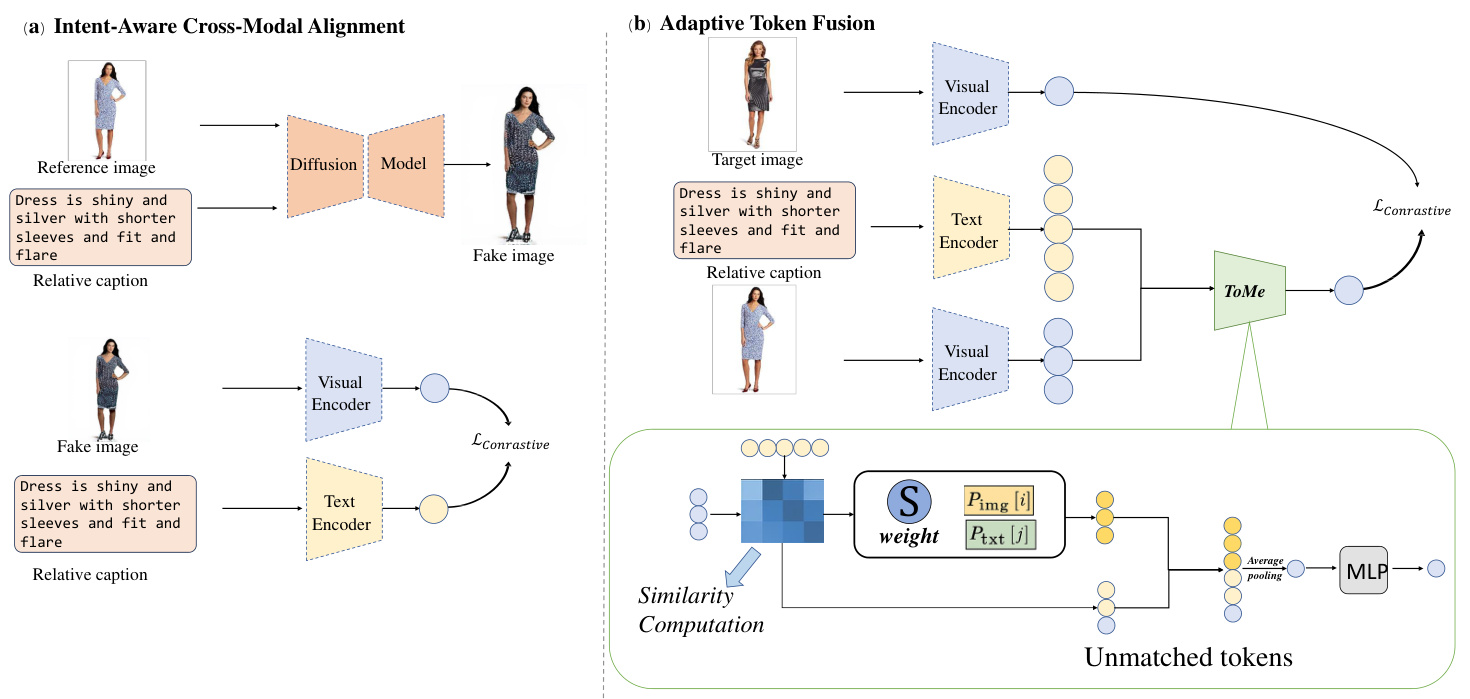
Figure 3: An Overview of the TMCIR Framework.It consists of two modules: the "Intent-Aware Cross-Modal Alignment" module and the "Adaptive Token Fusion" module. First, we input the reference image and the relative description into a diffusion model to generate a pseudo-target image. Through contrastive learning, we guide the visual and textual encoders to achieve cross-modal token distribution alignment. Then, the reference image and the relative description are fused using an adaptive token fusion strategy based on positional encoding and semantic similarity, generating a joint representation that captures both the user intent and the key visual information from the reference image.
图 3: TMCIR框架概述。该框架包含两个模块:"意图感知跨模态对齐"模块和"自适应Token融合"模块。首先,我们将参考图像和相对描述输入扩散模型生成伪目标图像,通过对比学习引导视觉和文本编码器实现跨模态Token分布对齐。随后,基于位置编码和语义相似度的自适应Token融合策略将参考图像与相对描述进行融合,生成同时捕捉用户意图和参考图像关键视觉信息的联合表征。
(2) Adaptive Token Fusion. After obtaining visual and text tokens from the fine-tuned bimodal encoder, we design an adaptive token fusion strategy. In our approach, token merging is performed on a token-by-token basis by computing the cosine similarity between individual tokens and incorporating positional encoding via weighted averaging. This fusion strategy constructs a unified and semantically rich cross-modal representation.
(2) 自适应Token融合。从微调后的双模态编码器获取视觉和文本Token后,我们设计了一种自适应Token融合策略。该方法通过计算单个Token之间的余弦相似度,并结合通过加权平均的位置编码,逐个Token进行融合。这种融合策略构建了统一且语义丰富的跨模态表征。
In the following subsections, we provide details for these two steps.
在以下小节中,我们将详细介绍这两个步骤。
3.3 Intent-Aware Cross-Modal Alignment
3.3 意图感知的跨模态对齐
The Intent-Aware Cross-Modal Alignment step aims to enhance the encoder ability of text to capture nuanced intents in textual descriptions, which includes pseudo target image generation and encoder fine-tuning for token alignment modules.
意图感知跨模态对齐步骤旨在增强文本编码器捕捉文本描述中细微意图的能力,包括伪目标图像生成和针对token对齐模块的编码器微调。
Pseudo Target Image Generation. Benefiting from large-scale training data comprising billions of image-text pairs, large-scale visual-language models (e.g., CLIP[29]) have demonstrated excellent generalization capabilities across numerous downstream tasks. This has inspired the application of such foundational models to the composite image retrieval (CIR) task. Existing methods typically rely on various modality fusion strategies to integrate the bimodal features extracted by the visual and text encoders. However, the visual encoder in pre-trained models primarily focuses on overall visual information, while the text encoder captures generic language features. Directly employing the original encoders often leads to inconsistent token distributions between the visual and text modalities in specific CIR datasets. This inconsistency results in suboptimal similarity computations during the token fusion phase, and consequently, inferior retrieval performance.
伪目标图像生成。得益于包含数十亿图像-文本对的大规模训练数据,大规模视觉语言模型(如CLIP[29])在众多下游任务中展现出卓越的泛化能力。这促使研究者将此类基础模型应用于组合图像检索(CIR)任务。现有方法通常依赖多种模态融合策略,以整合视觉编码器和文本编码器提取的双模态特征。然而,预训练模型中的视觉编码器主要关注整体视觉信息,而文本编码器捕获的是通用语言特征。直接使用原始编码器往往会导致特定CIR数据集中视觉与文本模态间的token分布不一致,这种不一致性使得token融合阶段的相似度计算欠佳,最终导致检索性能下降。
To address this issue, we first select image-text pairs from existing CIR datasets—typically sampling all available pairs or a fixed number per batch in our experiments—and perform task-specific fine-tuning of the visual and text encoders to achieve more consistent token representations from the reference image and the relative description. Considering that the manually collected triplet samples in current CIR datasets contain target images sourced from diverse origins (which may include background interference or noise not aligned with the modification description), we generate a pseudo target image ${\mathit{p}}{i}$ by conditioning a diffusion model $D$ on the reference image $r{i}$ and the relative description $m_{i}$ :
为解决这一问题,我们首先从现有的组合图像检索(CIR)数据集中选取图文对——通常在实验中采样所有可用对或每批次固定数量——并对视觉和文本编码器进行任务特定微调,以使参考图像和相对描述生成更一致的token表征。考虑到当前CIR数据集中人工收集的三元组样本包含来源各异的目标图像(可能含有与修改描述未对齐的背景干扰或噪声),我们通过以参考图像$r_{i}$和相对描述$m_{i}$为条件输入扩散模型$D$,生成伪目标图像${\mathit{p}}_{i}$:
$$
p_{i}=D(r_{i},m_{i}).
$$
$$
p_{i}=D(r_{i},m_{i}).
$$
The pseudo target image $p_{i}$ accurately embodies the modification requirements stipulated in $m_{i}$ , while excluding irrelevant background noise. This provides a purer and more precise supervisory signal for subsequent encoder fine-tuning. The pseudo target image $p_{i}$ and the relative description $m_{i}$ are then combined to form an image-text pair dataset $\mathcal{D}$ :
伪目标图像 $p_{i}$ 准确体现了 $m_{i}$ 中规定的修改要求,同时排除了无关的背景噪声。这为后续编码器微调提供了更纯净、更精确的监督信号。伪目标图像 $p_{i}$ 与相关描述 $m_{i}$ 随后被组合形成图文对数据集 $\mathcal{D}$:
$$
{\mathcal D}={(m_{i},p_{i})\mid i=1,2,\ldots,N}.
$$
$$
{\mathcal D}={(m_{i},p_{i})\mid i=1,2,\ldots,N}.
$$
We utilize $\mathcal{D}$ as a dedicated dataset in a distinct training stage for fine-tuning the encoders, separate from the original CIR training set.
我们利用 $\mathcal{D}$ 作为专用数据集,在独立于原始 CIR 训练集的单独训练阶段对编码器进行微调。
Encoder Fine-Tuning for Token Alignment. After constructing the image-text pair dataset $\mathcal{D}={(\bar{m_{i}},p_{i})}_{i=1}^{N}$ as described in Section 3.3, we adopt a contrastive learning strategy to fine-tune the CLIP-pretrained visual encoder and text encoder, thereby further enhancing their cross-modal representation and alignment abilities for the CIR task.
Token对齐的编码器微调。在按照第3.3节所述构建图文对数据集 $\mathcal{D}={(\bar{m_{i}},p_{i})}_{i=1}^{N}$ 后,我们采用对比学习策略对CLIP预训练的视觉编码器和文本编码器进行微调,从而进一步增强它们在CIR任务中的跨模态表示和对齐能力。
Specifically, for each image-text pair $(m i,p i)$ , the relative description $m_{i}$ is input into the text encoder $E_{T}$ to obtain the text feature vector:
具体来说,对于每个图文对$(m i,p i)$,将相对描述$m_{i}$输入文本编码器$E_{T}$以获取文本特征向量:
$$
t_{i}=E_{T}(m_{i})
$$
$$
t_{i}=E_{T}(m_{i})
$$
while the pseudo target image ${\mathit{p}}{i}$ is input into the visual encoder $E{V}$ to obtain the image feature vector:
伪目标图像 ${\mathit{p}}{i}$ 输入视觉编码器 $E{V}$ 后得到图像特征向量:
$$
v_{i}=E_{V}(p_{i})
$$
$$
v_{i}=E_{V}(p_{i})
$$
We then normalize these feature representations:
然后我们对这些特征表示进行归一化处理:
$$
\hat{t}{i}=\frac{t_{i}}{\lVert t_{i}\rVert_{2}},\quad\hat{v}{i}=\frac{v_{i}}{\lVert v_{i}\rVert_{2}}
$$
$$
\hat{t}{i}=\frac{t_{i}}{\lVert t_{i}\rVert_{2}},\quad\hat{v}{i}=\frac{v_{i}}{\lVert v_{i}\rVert_{2}}
$$
to facilitate subsequent cosine similarity calculations.
便于后续的余弦相似度计算。
Next, we optimize the model parameters using the InfoNCE lossfunction:
接下来,我们使用InfoNCE损失函数优化模型参数:
$$
\mathcal{L}=-\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp(\sin(\hat{v}_{i},\hat{t}_{i})/\tau)}{\sum_{j=1}^{N}\exp(\sin(\hat{v}_{i},\hat{t}_{j})/\tau)}
$$
$$
\mathcal{L}=-\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp(\sin(\hat{v}_{i},\hat{t}_{i})/\tau)}{\sum_{j=1}^{N}\exp(\sin(\hat{v}_{i},\hat{t}_{j})/\tau)}
$$
where $s\mathrm{i}\mathrm{m}(\cdot,\cdot)$ denotes the cosine similarity function and $\tau$ is a learnable temperature parameter that controls the smoothness of the similarity distribution.
其中 $s\mathrm{i}\mathrm{m}(\cdot,\cdot)$ 表示余弦相似度函数,$\tau$ 是可学习的温度参数,用于控制相似度分布的平滑度。
Following fine-tuning, the token representations produced by the visual and text encoders in the shared embedding space exhibit improved distribution consistency and cross-modal alignment, thereby providing a robust foundation for the subsequent token merging module.
经过微调后,视觉和文本编码器在共享嵌入空间生成的token表征展现出更强的分布一致性和跨模态对齐性,从而为后续的token合并模块奠定了坚实基础。
3.4 Adaptive Token Fusion
3.4 自适应Token融合
Following the fine-tuning of the visual and text encoders, the resulting visual tokens and text tokens are well-aligned in the shared embedding space. To effectively integrate the dual-modal information, we design a token merging module based on similarity computation.
视觉和文本编码器微调后,生成的视觉token和文本token在共享嵌入空间中对齐良好。为有效整合双模态信息,我们设计了一个基于相似度计算的token融合模块。
We then compute the similarity matrix $\mathbf{S_{\lambda}}\in\mathbb{R}^{L\times M}$ between the image token set $V$ and the text token set $T$ :
我们计算图像token集 $V$ 和文本token集 $T$ 之间的相似度矩阵 $\mathbf{S_{\lambda}}\in\mathbb{R}^{L\times M}$ :
$$
\mathbf{S}{i j}=\frac{\mathbf{v}{i}\cdot\mathbf{t}{j}}{|\mathbf{v}{i}|\cdot|\mathbf{t}_{j}|}.
$$
$$
\mathbf{S}{i j}=\frac{\mathbf{v}{i}\cdot\mathbf{t}{j}}{|\mathbf{v}{i}|\cdot|\mathbf{t}_{j}|}.
$$
For each text token, we iterate over each visual token, considering a pair $(\mathbf{v}{i},\mathbf{t}_{j})$ as a valid matching token pair if their similarity exceeds a preset threshold $\tau$ .
对于每个文本token,我们遍历每个视觉token,当它们的相似度超过预设阈值$\tau$时,将这对$(\mathbf{v}{i},\mathbf{t}_{j})$视为有效的匹配token对。
Fusion Strategy: For each matching token pair $(\mathbf{v}{i},\mathbf{t}{j})$ , we compute a weighted average using their similarity coefficient $\lambda$ as the weight and integrate their positional encodings $(\mathbf{P}{\mathrm{img}}[i]$ and $\mathbf{P}{\mathrm{txt}}[j],$ ) to preserve spatial information. The resulting fused representation $\mathbf{f}_{i,j}$ is calculated as:
融合策略:对于每个匹配的token对 $(\mathbf{v}{i},\mathbf{t}{j})$ ,我们使用它们的相似系数 $\lambda$ 作为权重计算加权平均值,并整合它们的位置编码 $(\mathbf{P}{\mathrm{img}}[i]$ 和 $\mathbf{P}{\mathrm{txt}}[j],$ ) 以保留空间信息。最终得到的融合表示 $\mathbf{f}_{i,j}$ 计算公式为:
$$
\mathbf{f}{i,j}=\frac{\mathbf{S}{i j}\cdot\mathbf{v}{i}+\mathbf{S}{i j}\cdot\mathbf{t}{j}}{2\mathbf{S}{i j}+\epsilon}+0.5\cdot\left(\mathbf{P}{\mathrm{img}}\big[i\big]+\mathbf{P}_{\mathrm{txt}}\big[j\big]\right),
$$
$$
\mathbf{f}{i,j}=\frac{\mathbf{S}{i j}\cdot\mathbf{v}{i}+\mathbf{S}{i j}\cdot\mathbf{t}{j}}{2\mathbf{S}{i j}+\epsilon}+0.5\cdot\left(\mathbf{P}{\mathrm{img}}\big[i\big]+\mathbf{P}_{\mathrm{txt}}\big[j\big]\right),
$$
where $\epsilon$ is a small constant to prevent division by zero.
其中 $\epsilon$ 是一个防止除以零的小常数。
For visual tokens and text tokens that do not find a matching counterpart, we retain them by directly adding their positional residuals:
对于未找到匹配项的视觉token和文本token,我们通过直接添加其位置残差来保留它们:
$$
\begin{array}{r}{\tilde{\mathbf{v}}{i}=\mathbf{v}{i}+0.5\cdot\mathbf{P}{\mathrm{img}}[i],\quad\mathrm{if}\mathbf{v}{i}\notin\mathrm{Matched},}\ {\mathrm{~}}\ {\tilde{\mathbf{t}}{j}=\mathbf{t}{j}+0.5\cdot\mathbf{P}{\mathrm{txt}}[j],\quad\mathrm{if}\mathbf{t}_{j}\notin\mathrm{Matched}.}\end{array}
$$
$$
\begin{array}{r}{\tilde{\mathbf{v}}{i}=\mathbf{v}{i}+0.5\cdot\mathbf{P}{\mathrm{img}}[i],\quad\mathrm{if}\mathbf{v}{i}\notin\mathrm{Matched},}\ {\mathrm{~}}\ {\tilde{\mathbf{t}}{j}=\mathbf{t}{j}+0.5\cdot\mathbf{P}{\mathrm{txt}}[j],\quad\mathrm{if}\mathbf{t}_{j}\notin\mathrm{Matched}.}\end{array}
$$
where $\boldsymbol{\mathcal M}$ denotes the set of matching pairs, while $\boldsymbol{\mathscr{M}}{I}$ and $\boldsymbol{\mathscr{M}}_{T}$ represent the matching indices for visual and text tokens, respectively. We then apply average pooling to $Z$ to obtain a single token representation $\mathbf{z}$ :
其中 $\boldsymbol{\mathcal M}$ 表示匹配对集合,$\boldsymbol{\mathscr{M}}{I}$ 和 $\boldsymbol{\mathscr{M}}_{T}$ 分别代表视觉token和文本token的匹配索引。我们对 $Z$ 应用平均池化以获得单个token表示 $\mathbf{z}$:
$$
\mathbf{z}=\frac{1}{N_{Z}}\sum_{n=1}^{N_{Z}}\mathbf{Z}_{n},
$$
$$
\mathbf{z}=\frac{1}{N_{Z}}\sum_{n=1}^{N_{Z}}\mathbf{Z}_{n},
$$
and pass it through a fully connected layer $\mathrm{F}$ to obtain the final cross-modal embedding vector $V_{Q}$ :
并将其通过全连接层 $\mathrm{F}$ 以获得最终的跨模态嵌入向量 $V_{Q}$:
$$
V_{Q}=\operatorname{F}(\mathbf{z}).
$$
$$
V_{Q}=\operatorname{F}(\mathbf{z}).
$$
Learning Objective: Our training objective for the composed image retrieval (CIR) task is to align the joint feature representation $V_{Q}$ of the mixed-modal query $(r,m)$ with the feature representation $V_{T}$ of the target image $t$ . In each training iteration, we process a mini-batch of samples:
学习目标:我们在组合图像检索 (CIR) 任务中的训练目标是将混合模态查询 $(r,m)$ 的联合特征表示 $V_{Q}$ 与目标图像 $t$ 的特征表示 $V_{T}$ 对齐。在每次训练迭代中,我们会处理一个小批量样本:
$$
{(V_{Q}^{(i)},V_{T}^{(i)})}{i=1}^{N_{B}},
$$
$$
{(V_{Q}^{(i)},V_{T}^{(i)})}{i=1}^{N_{B}},
$$
where $(V_{Q}^{(i)},V_{T}^{(i)})$ denotes the feature representations of the 𝑖th (mixed-modal query, target image) pair, and $N_{B}$ is the mini-batch size. The batch-based classification loss function is defined as:
其中 $(V_{Q}^{(i)},V_{T}^{(i)})$ 表示第 𝑖 个 (混合模态查询,目标图像) 对的特征表示,$N_{B}$ 是小批量大小。基于批量的分类损失函数定义为:
$$
L=\frac{1}{N_{B}}\sum_{i=1}^{N_{B}}-\log\frac{\exp(\lambda\cdot\mathrm{Sim}(V_{Q}^{(i)},V_{T}^{(i)}))}{\sum_{j=1}^{N B}\exp(\lambda\cdot\mathrm{Sim}(V_{Q}^{(j)},V_{T}^{(j)}))},
$$
$$
L=\frac{1}{N_{B}}\sum_{i=1}^{N_{B}}-\log\frac{\exp(\lambda\cdot\mathrm{Sim}(V_{Q}^{(i)},V_{T}^{(i)}))}{\sum_{j=1}^{N B}\exp(\lambda\cdot\mathrm{Sim}(V_{Q}^{(j)},V_{T}^{(j)}))},
$$
where $\mathrm{Sim(\cdot)}$ denotes the cosine similarity function and $\lambda$ is a temperature parameter.
其中 $\mathrm{Sim(\cdot)}$ 表示余弦相似度函数,$\lambda$ 是温度参数。
4 Experiment
4 实验
4.1 Experimental Setup
4.1 实验设置
Implementation Details. Our method is implemented in PyTorch and runs on an NVIDIA RTX A100 GPU with 80GB of memory. We adhere to the design principles of CLIP, initializing both the visual and text encoders from a CLIP pre-trained model based on the ViT-L architecture. The AdamW optimizer [27] is employed with a weight decay coefficient set to 0.05. Input images are resized to $224\times224$ pixels, and a padding ratio of 1.25 is applied for uniform processing [5]. The initial learning rates are set to 1e-5 and 2e-5 for the CIRR and Fashion-IQ datasets, respectively, and a cosine learning rate scheduling strategy is adopted. The similarity threshold $\tau$ is set to $0.7.1\mathrm{n}$ the Pseudo-Target Generation stage, the diffusion model FLUX.1-dev-edit-v0 is utilized.
实现细节。我们的方法基于PyTorch实现,运行在配备80GB显存的NVIDIA RTX A100 GPU上。遵循CLIP的设计原则,我们基于ViT-L架构的CLIP预训练模型初始化视觉和文本编码器。采用AdamW优化器[27],权重衰减系数设为0.05。输入图像统一调整为$224\times224$像素,并应用1.25的填充比例进行标准化处理[5]。CIRR和Fashion-IQ数据集的初始学习率分别设为1e-5和2e-5,采用余弦学习率调度策略。相似度阈值$\tau$设置为$0.7.1\mathrm{n}$。在伪目标生成阶段使用了扩散模型FLUX.1-dev-edit-v0。
Datasets and Metrics. We evaluate our method on two CIR benchmarks: (1) Fashion-IQ a fashion dataset with 77, 684 images forming 30, 134 triplets [41].We utilize Recall $\ @\mathrm{K}$ as the evaluation metric, which reflect the percentage of queries whose true target ranked within the top $K$ candidates.Since the ground-truth labels for the test set of this dataset have not been publicly disclosed, we adopt the results on the validation set for performance evaluation. (2) CIRR is a general image dataset that comprises 36, 554 triplets derived from 21, 552 images from the popular natural language inference dataset NLVR2 [34]. We randomly split this dataset into training, validation, and test sets in an $8:1:1$ ratio. This dataset encompasses rich object interactions, addressing the issues of overly narrow domains and high number of false-negatives in the Fashion-IQ dataset, thereby allowing for a comprehensive evaluation of the effectiveness of our proposed method. We report the results of the competing methods on this dataset at different levels, i.e., Recall@1, 5, 10, 50, and Recall subset@K [24].
数据集与评估指标。我们在两个CIR基准上评估方法:(1) Fashion-IQ时尚数据集包含77,684张图像构成的30,134组三元组[41],采用Recall@K作为评估指标,反映真实目标排名前K候选的查询百分比。由于该数据集测试集的真实标签未公开,我们使用验证集结果进行性能评估。(2) CIRR通用图像数据集包含从自然语言推理数据集NLVR2[34]的21,552张图像衍生的36,554组三元组,按8:1:1比例随机划分为训练集、验证集和测试集。该数据集涵盖丰富的物体交互关系,解决了Fashion-IQ领域过窄和假阴性率高的问题,可全面评估所提方法的有效性。我们报告了该数据集上不同层级(Recall@1/5/10/50和Recall subset@K[24])的对比方法结果。
Table 1: Ablation studies with regard to the impact of using pseudo versus real target images on retrieval performance.
表 1: 关于使用伪目标图像与真实目标图像对检索性能影响的消融研究。
| Method | FashionIQ | CIRR | |||
|---|---|---|---|---|---|
| R@10 | R@50 | R@1 | R@5 | Rsubset@1 | |
| Real | 54.85 | 75.43 | 53.62 | 83.62 | 79.05 |
| Pseudo | 56.57 | 76.55 | 54.12 | 84.27 | 82.64 |
Table 2: Ablation studies with regard to the performance differences between pre-trained and fine-tuned models.
表 2: 预训练与微调模型性能差异的消融研究
| 方法 | FashionIQ | CIRR | |||
|---|---|---|---|---|---|
| R@10 | R@50 | R@1 | R@5 | Rsubset@1 | |
| 预训练微调 | 54.42 56.57 | 75.67 76.55 | 53.22 54.12 | 83.47 84.27 | 79.16 82.64 |
4.2 Comparative study
4.2 对比研究
Results on Fashion-IQ Table 4 summarizes the evaluation of various competing methods on the Fashion-IQ dataset. As observed from Table 4, our proposed method, TMCIR, achieves the highest recall rates across all eight evaluation metrics for the three clothing categories. Specifically, compared to the second-best method SPRC, TMCIR improves the ${\mathrm{R}}\ @10$ metric from 54.92 to 56.57. More importantly, in the case of the text-to-image retrieval paradigm embodied by SPRC, our method demonstrates a significant enhancement on the "Shirt" category, with ${\mathrm{R}}\ @10$ increasing from 55.64 to 59.12 and $\mathrm{R}@50$ improving from 73.89 to 76.34. This improvement is primarily attributable to the fact that SPRC abstracts and converts a portion of the reference image information into textual prompts, and relies solely on a text-based retrieval model for matching. Such an indirect utilization of visual information is more prone to losing certain fine-grained visual details of the original reference image when compared to methods that directly fuse visual features. In contrast, our TMCIR method adaptively merges visual tokens and textual tokens via the token merging module, thereby producing a richer and more fine-grained multimodal fused representation. This enables the capture and exploitation of essential visual details in the reference image (e.g., specific patterns, textures, or styles within the "Shirt" category), resulting in improved retrieval performance.
Fashion-IQ数据集上的结果
表4总结了Fashion-IQ数据集上各种竞争方法的评估结果。从表4可以看出,我们提出的TMCIR方法在三个服装类别的所有八项评估指标中均取得了最高的召回率。具体而言,与第二名SPRC方法相比,TMCIR将${\mathrm{R}}\ @10$指标从54.92提升至56.57。更重要的是,在SPRC所体现的文本到图像检索范式下,我们的方法在"Shirt"类别上展现出显著提升:${\mathrm{R}}\ @10$从55.64增至59.12,$\mathrm{R}@50$从73.89提升至76.34。这一改进主要归因于SPRC将部分参考图像信息抽象转化为文本提示,并仅依赖基于文本的检索模型进行匹配。与直接融合视觉特征的方法相比,这种对视觉信息的间接利用更容易丢失原始参考图像的某些细粒度视觉细节。相比之下,我们的TMCIR方法通过token合并模块自适应融合视觉token和文本token,从而生成更丰富、更细粒度的多模态融合表示。这使得模型能够捕捉并利用参考图像中的关键视觉细节(例如"Shirt"类别中的特定图案、纹理或风格),进而提升检索性能。

Figure 4: Ablation studies in terms of average recalls with regards to different values of Similarity Threshold
图 4: 不同相似度阈值 (Similarity Threshold) 下的平均召回率消融研究
Table 3: Ablation studies with regard to the contribution of the token merging module to retrieval performance.
表 3: Token合并模块对检索性能贡献的消融研究
| 方法 | FashionIQ | CIRR | |||
|---|---|---|---|---|---|
| R@10 | R@50 | R@1 | R@5 | Rsubset@1 | |
| 无token合并 | 29.68 | 54.85 | 20.88 | 48.24 | 50.33 |
| token合并 | 56.57 | 76.55 | 54.12 | 84.27 | 82.64 |
Results on CIRR We further evaluated the effectiveness of our method on the more general CIRR dataset, with the results presented in Table 5. Compared to the existing text prompt-based method SPRC, our approach consistently demonstrates improvements on CIRR. For instance, Recall@1 increases from 51.96 to 54.12, Recall@5 from 82.12 to 84.27, Recall@10 from 89.74 to 91.06, and
CIRR数据集上的结果
我们进一步在更通用的CIRR数据集上评估了方法的有效性,结果如表5所示。与现有基于文本提示的方法SPRC相比,我们的方法在CIRR上持续展现出性能提升。例如,Recall@1从51.96提升至54.12,Recall@5从82.12提升至84.27,Recall@10从89.74提升至91.06。
Table 4: Quantitative comparison across competing methods on the Fashion-IQ validation set, where Average indicates the average results across all the metrics in the three different classes. The best results are marked in bold
表 4: Fashion-IQ验证集上各竞争方法的定量对比,其中Average表示三类别所有指标的平均结果。最佳结果以粗体标出
| Methods | Dress R@10 | Dress R@50 | Shirt R@10 | Shirt R@50 | Top&Tee R@10 | Top&Tee R@50 | Average R@10 | Average R@50 | Rmean |
|---|---|---|---|---|---|---|---|---|---|
| JVSM [8] | 10.70 | 25.90 | 12.00 | 27.10 | 13.00 | 26.90 | 11.90 | 26.60 | 19.26 |
| CIRPLANT [24] | 17.45 | 40.41 | 17.53 | 38.81 | 61.64 | 45.38 | 18.87 | 41.53 | 30.20 |
| TRACE w/BER [17] | 22.70 | 44.91 | 20.80 | 40.80 | 24.22 | 49.80 | 22.57 | 46.19 | 34.00 |
| VAL [9] w/GloVe | 22.53 | 44.00 | 22.38 | 44.15 | 27.53 | 51.68 | 24.15 | 46.61 | 35.38 |
| MAAF [11] | 23.80 | 48.60 | 21.30 | 44.20 | 27.90 | 53.60 | 24.30 | 48.80 | 36.60 |
| CurlingNet [42] | 26.15 | 53.24 | 21.45 | 44.56 | 30.12 | 55.23 | 25.90 | 51.01 | 34.36 |
| RTIC-GCN [33] | 29.15 | 54.04 | 23.79 | 47.25 | 31.61 | 57.98 | 28.18 | 53.09 | 40.64 |
| CoSMo [21] | 25.64 | 50.30 | 24.90 | 49.18 | 29.21 | 57.46 | 26.58 | 52.31 | 39.45 |
| ARTEMIS [10] | 27.16 | 52.40 | 21.78 | 43.64 | 29.20 | 53.83 | 26.05 | 50.29 | 38.04 |
| DCNet [19] | 28.95 | 56.07 | 23.95 | 47.30 | 30.44 | 58.29 | 27.78 | 53.89 | 40.84 |
| SAC w/BERT [17] | 26.52 | 51.01 | 28.02 | 51.86 | 32.70 | 61.23 | 29.08 | 54.70 | 41.89 |
| FashionVLP [13] | 32.42 | 60.29 | 31.89 | 58.44 | 38.51 | 68.79 | 34.27 | 62.51 | 48.39 |
| LF-CLIP(Combiner) [5] | 31.63 | 56.67 | 36.36 | 58.00 | 38.19 | 62.42 | 35.39 | 59.03 | 47.21 |
| LF-BLIP [22] | 25.31 | 44.05 | 25.39 | 43.57 | 26.54 | 44.48 | 25.75 | 43.98 | 34.88 |
| CASE[43] | 47.44 | 69.36 | 48.48 | 70.23 | 50.18 | 72.24 | 48.79 | 70.68 | 59.74 |
| AMC [36] | 31.73 | 59.25 | 30.67 | 59.08 | 36.21 | 66.06 | 32.87 | 61.64 | 47.25 |
| CoVR-BLIP [4] | 44.55 | 69.03 | 48.43 | 67.42 | 52.60 | 74.31 | 48.53 | 70.25 | 59.39 |
| CLIP4CIR [25] | 33.81 | 59.40 | 39.99 | 60.45 | 41.41 | 65.37 | 38.32 | 61.74 | 50.03 |
| BLIP4CIR+Bi [15] | 4209 | 67.33 | 41.76 | 64.28 | 46.61 | 70.32 | 43.49 | 67.31 | 55.04 |
| FAME-ViL[40] | 42.19 | 67.38 | 47.64 | 68.79 | 50.69 | 73.07 | 46.84 | 69.75 | 58.29 |
| TG-CIR [18] | 45.22 | 69.66 | 52.60 | 72.52 | 56.14 | 77.10 | 51.32 | 73.09 | 58.05 |
| Re-ranking [26] | 48.14 | 71.43 | 50.15 | 71.25 | 55.23 | 76.80 | 51.17 | 73.13 | 62.15 |
| CompoDiff [14] | 40.65 | 57.14 | 36.87 | 57.39 | 43.93 | 61.17 | 40.48 | 58.57 | 49.53 |
| SPRC [2] | 49.18 | 72.43 | 55.64 | 73.89 | 59.35 | 78.58 | 54.92 | 74.97 | 64.85 |
| TMCIR (Ours) | 50.67 | 73.86 | 59.12 | 76.34 | 59.93 | 79.46 | 56.57 | 76.55 | 66.56 |
Recall $@50$ from 97.69 to 98.43. Clearly, although the sentence-level prompts learned in SPRC enhance the relative textual information, they are unable to fully encode the subtle visual features present in the reference image. This shortcoming leads to suboptimal performance in categories requiring precise visual matching (e.g., "Shirt"), thereby resulting in a marked performance gap when compared to our method.
召回率 $@50$ 从 97.69 提升至 98.43。显然,尽管 SPRC 中学习的句子级提示增强了相对文本信息,但仍无法完全编码参考图像中存在的细微视觉特征。这一缺陷导致在需要精确视觉匹配的类别 (如 "Shirt") 中表现欠佳,从而与我们的方法相比存在显著性能差距。
In terms of the Recall subset $\ @\mathrm{K}$ metrics, our TMCIR also outperforms SPRC, for example: Recall@1 improves from 80.65 to 82.64, Recall $\ @2$ from 92.31 to 92.45, and Recall $\ @3$ from 96.60 to 96.77.
在召回率子集 $\ @\mathrm{K}$ 指标方面,我们的TMCIR同样优于SPRC,例如:Recall@1从80.65提升至82.64,Recall $\ @2$ 从92.31提升至92.45,Recall $\ @3$ 从96.60提升至96.77。
Moreover, when compared to the strongest CIR-LVLM baseline, our TMCIR still attains the highest recall rates. For example, on the three Recall subset $\ @\mathrm{K}$ metrics, SPRC yields increases of 3.52, 0.12 and 0.10, respectively, whereas our TMCIR, by introducing the similarity-based token fusion module and task-specific encoder fine-tuning, achieves significantly more effective multimodal information fusion. This enables a better understanding of complex composed image queries and, as a result, substantially enhances the accuracy of composed image retrieval.
此外,与最强的CIR-LVLM基线相比,我们的TMCIR仍保持着最高的召回率。例如,在三个Recall子集$\ @\mathrm{K}$指标上,SPRC分别提升了3.52、0.12和0.10,而我们的TMCIR通过引入基于相似度的token融合模块和任务特定编码器微调,实现了显著更有效的多模态信息融合。这使得模型能更好地理解复杂的组合图像查询,从而大幅提升了组合图像检索的准确性。
4.3 Ablation Study
4.3 消融研究
Pseudo-target Images vs. Real Target Images We investigate the impact of utilizing pseudo-target images generated by a diffusion model versus real target images from the Composed Image Retrieval (CIR) dataset during the encoder fine-tuning phase. Specifically, two training configurations are designed: one employs real target images as supervision signals, while the other uses pseudotarget images conditioned on the reference image and relative description. Experimental results on the CIRR dataset, as shown in Table 1, indicate that pseudo-target images more accurately capture the intended modifications, providing cleaner and more directive supervision. This enhances the alignment and robustness in subsequent token fusion stages. In contrast, real target images may introduce background noise and other distractions, hindering the model’s ability to capture fine-grained semantic differences, thereby affecting overall retrieval performance.
伪目标图像 vs. 真实目标图像
我们研究了在编码器微调阶段使用扩散模型生成的伪目标图像与来自组合图像检索(CIR)数据集的真实目标图像的影响。具体设计了两种训练配置:一种采用真实目标图像作为监督信号,另一种使用基于参考图像和相关描述生成的伪目标图像。如表1所示,CIRR数据集上的实验结果表明,伪目标图像能更准确地捕捉预期修改,提供更清晰、更具指导性的监督信号。这增强了后续token融合阶段的对齐能力和鲁棒性。相比之下,真实目标图像可能引入背景噪声等干扰因素,阻碍模型捕捉细粒度语义差异的能力,从而影响整体检索性能。
Impact of Similarity Threshold in Token Merging To assess the effect of the similarity threshold $\tau$ in the token merging module on cross-modal fusion and overall CIR performance, we experiment with various threshold settings (e.g., $\tau=0.5$ , 0.7, 0.9). As illustrated in Table 4, an optimal threshold (e.g., $\tau=0.7$ ) effectively filters out noisy tokens while retaining sufficient informative ones, leading to higher semantic consistency and disc rim i native power in the fused tokens. A lower threshold (e.g., $\tau=0.5$ ) admits excessive noisy tokens, degrading retrieval accuracy, whereas a higher threshold (e.g., $\tau=0.9$ ) results in the loss of valuable information. Eliminating the matching strategy altogether fails to leverage similarity information, causing significant performance drops due to ineffective cross-modal alignment.
Token合并中相似度阈值的影响
为评估token合并模块中相似度阈值$\tau$对跨模态融合和整体CIR性能的影响,我们测试了多种阈值设置(如$\tau=0.5$、0.7、0.9)。如表4所示,最优阈值(如$\tau=0.7$)能有效过滤噪声token同时保留足够信息量,使融合token具有更高的语义一致性和判别力。较低阈值(如$\tau=0.5$)会引入过多噪声token降低检索精度,而较高阈值(如$\tau=0.9$)会导致有效信息丢失。完全取消匹配策略则无法利用相似度信息,因跨模态对齐失效造成性能显著下降。
Table 5: Quantitative comparison across competing methods on the CIRR test set, where Avg. indicates the average results across all the metrics in the three different settings. The best results are marked in bold
表 5: CIRR测试集上各竞争方法的定量对比,其中Avg.表示三种不同设置下所有指标的平均结果。最佳结果以粗体标出
| Methods | Recall@K | Rsubset @K | Avg. | |||||
|---|---|---|---|---|---|---|---|---|
| K=1 | K=5 | K=10 | K=50 | K=1 | K=2 | K=3 | ||
| TIRG [37] | 14.61 | 48.37 | 64.08 | 90.03 | 22.67 | 44.97 | 65.14 | 35.52 |
| TIRG+LastConv [37] | 11.04 | 35.68 | 51.27 | 83.29 | 23.82 | 45.65 | 64.55 | 29.75 |
| MAAF [11] | 10.31 | 33.03 | 48.30 | 80.06 | 21.05 | 42.24 | 61.60 | 27.08 |
| MAAF-BERT [11] | 10.12 | 33.10 | 48.01 | 80.57 | 22.08 | 42.41 | 62.14 | 27.57 |
| MAAF-IT [11] | 9.90 | 32.86 | 48.83 | 80.27 | 21.17 | 40.91 | 60.91 | 27.02 |
| MAAF-RP [11] | 10.22 | 33.32 | 48.68 | 81.84 | 21.41 | 42.04 | 61.60 | 27.37 |
| CIRPLANT [24] | 19.55 | 52.55 | 68.39 | 92.38 | 39.20 | 63.03 | 79.49 | 45.88 |
| ARTEMIS [10] | 16.96 | 46.10 | 61.31 | 87.73 | 39.99 | 62.20 | 75.67 | 43.05 |
| LF-BLIP [5] | 20.89 | 48.07 | 61.16 | 83.71 | 50.22 | 69.39 | 86.82 | 60.58 |
| LF-CLIP [5] | 33.59 | 65.35 | 77.35 | 95.21 | 62.39 | 79.74 | 92.02 | 72.53 |
| CLIP4CIR [4] | 38.53 | 69.98 | 81.86 | 95.93 | 68.19 | 86.31 | 94.17 | 69.09 |
| BLIP4CIR+Bi[25] | 40.15 | 73.08 | 83.88 | 96.27 | 72.10 | 90.16 | 95.93 | 72.59 |
| CompoDiff [14] | 22.35 | 54.36 | 73.41 | 91.77 | 35.84 | 58.21 | 76.60 | 29.10 |
| CASE [22] | 48.00 | 79.11 | 87.25 | 97.57 | 75.88 | 94.67 | 96.00 | 77.50 |
| CASE Pre-LaSCo.CaT [22] | 49.35 | 80.02 | 88.75 | 97.47 | 76.48 | 95.03 | 95.71 | 78.25 |
| TG-CIR [40] | 45.25 | 78.29 | 87.16 | 97.30 | 72.84 | 89.25 | 95.13 | 75.57 |
| DRA [18] | 39.93 | 72.07 | 83.83 | 96.43 | 71.04 | 91.43 | 94.72 | 71.55 |
| CoVR-BLIP [36] | 49.69 | 78.60 | 86.77 | 94.31 | 75.01 | 91.07 | 93.16 | 80.81 |
| Re-ranking [26] | 50.55 | 81.75 | 89.78 | 97.18 | 80.04 | 94.29 | 96.80 | 80.90 |
| SPRC [2] | 51.96 | 82.12 | 89.74 | 97.69 | 80.65 | 92.31 | 96.60 | 81.39 |
| CIR-LVLM [35] | 53.64 | 83.76 | 90.60 | 97.93 | 79.12 | 92.33 | 96.67 | 81.44 |
| TMCIR (Ours) | 54.12 | 84.27 | 91.06 | 98.43 | 82.64 | 92.45 | 96.77 | 82.66 |
Pre-trained Models vs. Task-specific Fine-tuning To validate the efficacy of task-specific fine-tuning in CIR, we compare the performance of the pre-trained CLIP encoder against its fine-tuned counterpart. In the "no fine-tuning" setup, the CLIP model directly extracts representations for the reference image and relative description, followed by token fusion and similarity computation. In the "fine-tuning" setup, we construct image-text pairs using pseudotarget images and apply contrastive loss to fine-tune both the visual and textual encoders of CLIP, achieving precise cross-modal token alignment in a shared embedding space. The experimental results are shown in Table 2.Experimental results demonstrate that the finetuned model exhibits significant improvements across all metrics. For instance, Recal $@1$ increases by approximately $0.89%$ , indicating that task-specific fine-tuning effectively mitigates cross-modal alignment issues inherent in pre-trained models under specific data distributions. Moreover, the fine-tuned model shows enhanced consistency and robustness in token representations, better capturing the semantic modifications between the reference image and relative description. This ablation study underscores the importance of employing contrastive learning strategies to fine-tune pre-trained models for improved CIR performance.
预训练模型与任务特定微调的对比
为验证任务特定微调在CIR中的有效性,我们比较了预训练CLIP编码器与其微调版本的性能。在"无微调"设置中,CLIP模型直接提取参考图像和相对描述的表示,随后进行token融合与相似度计算。在"微调"设置中,我们使用伪目标图像构建图文对,并应用对比损失对CLIP的视觉和文本编码器进行微调,在共享嵌入空间中实现精确的跨模态token对齐。实验结果如表2所示。
实验结果表明,微调模型在所有指标上均有显著提升。例如Recall@1提高了约0.89%,说明任务特定微调能有效缓解预训练模型在特定数据分布下固有的跨模态对齐问题。此外,微调模型在token表示上展现出更强的一致性和鲁棒性,能更好捕捉参考图像与相对描述间的语义修改。该消融研究证实了采用对比学习策略微调预训练模型对提升CIR性能的重要性。
(注:根据规则要求,公式符号$@1$和百分比数值$0.89%$保留原格式,Table 2翻译为"表2",专业术语首次出现时标注英文如"CIR",后续直接使用中文表述)
Contribution of the Token Merging Module To evaluate the effectiveness of our proposed token merging module, we design two model variants: one incorporates the token merging strategy, which adaptively integrates cross-modal features by computing token similarities and performing weighted fusion; the other bypasses token matching and fusion, directly utilizing the original token sequences from the visual and textual encoders for subsequent average pooling and fully connected mapping.The experimental results are shown in Table 3. Experimental results reveal that the model without the token merging strategy exhibits noticeable declines in cross-modal image retrieval tasks, particularly in fine-grained semantic alignment and overall retrieval accuracy (e.g., Recall $\ @\mathrm{K}$ metrics). This validates the critical role of the token merging module in suppressing noise, enhancing inter-token mutual information, and improving the consistency of final cross-modal feature representations. Further analysis of feature distributions before and after token fusion indicates that the token merging module significantly reduces distribution al discrepancies between visual and textual tokens, thereby better supporting subsequent image retrieval tasks.
Token合并模块的贡献
为评估所提出的token合并模块的有效性,我们设计了两个模型变体:一种采用token合并策略,通过计算token相似度进行加权融合来自适应整合跨模态特征;另一种跳过token匹配与融合,直接使用视觉和文本编码器的原始token序列进行后续平均池化和全连接映射。实验结果如表3所示。实验结果表明,未采用token合并策略的模型在跨模态图像检索任务中表现明显下降,尤其在细粒度语义对齐和整体检索精度(如Recall $\ @\mathrm{K}$指标)方面。这验证了token合并模块在抑制噪声、增强token间互信息以及提升最终跨模态特征表示一致性方面的关键作用。对token融合前后特征分布的进一步分析表明,该模块显著减小了视觉与文本token间的分布差异,从而更好地支持后续图像检索任务。
5 Conclusion
5 结论
Addressing the challenge of biased feature fusion in Composed Image Retrieval (CIR), we introduced TMCIR. Our framework leverages Intent-Aware Cross-Modal Alignment (IACMA), using diffusion-generated pseudo-target images for cleaner encoder finetuning, and Adaptive Token Fusion (ATF), which merges tokens based on similarity and position to balance modalities. Extensive experiments demonstrate that TMCIR significantly outperforms state-of-the-art methods on the Fashion-IQ and CIRR benchmarks. By effectively preserving visual details while accurately capturing textual modification intent, TMCIR offers a more robust and precise solution for CIR.
针对组合图像检索(CIR)中存在的特征融合偏差问题,我们提出了TMCIR框架。该方案通过意图感知跨模态对齐(IACMA)技术,利用扩散模型生成的伪目标图像实现更纯净的编码器微调;同时采用自适应Token融合(ATF)机制,根据相似度和位置信息合并Token以实现模态平衡。在Fashion-IQ和CIRR基准测试上的大量实验表明,TMCIR显著优于现有最优方法。通过有效保留视觉细节并精准捕捉文本修改意图,TMCIR为CIR任务提供了更鲁棒精确的解决方案。
References
参考文献
images by natural language feedback. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition. 11307–11317. [42] Youngjae Yu, Seunghwan Lee, Yuncheol Choi, and Gunhee Kim. 2020. Curlingnet: Compositional learning between images and text for fashion iq data. arXiv preprint arXiv:2003.12299 (2020).
通过自然语言反馈编辑图像。载于IEEE/CVF计算机视觉与模式识别会议论文集。11307–11317。[42] Youngjae Yu、Seunghwan Lee、Yuncheol Choi和Gunhee Kim。2020。Curlingnet:面向时尚IQ数据的图像与文本组合学习。arXiv预印本arXiv:2003.12299 (2020)。
[43] Hongguang Zhu, Yunchao Wei, Yao Zhao, Chunjie Zhang, and Shujuan Huang. 2023. Amc: Adaptive multi-expert collaborative network for text-guided image retrieval. ACM Transactions on Multimedia Computing, Communications and Applications 19, 6 (2023), 1–22.
[43] Hongguang Zhu, Yunchao Wei, Yao Zhao, Chunjie Zhang, and Shujuan Huang. 2023. AMC: 面向文本引导图像检索的自适应多专家协同网络. ACM Transactions on Multimedia Computing, Communications and Applications 19, 6 (2023), 1–22.