Cross-modal Local Shortest Path and Global Enhancement for Visible-Thermal Person Re-Identification
跨模态局部最短路径与全局增强的可见光-热成像行人重识别
Abstract—In addition to considering the recognition difficulty caused by human posture and occlusion, it is also necessary to solve the modal differences caused by different imaging systems in the Visible-Thermal cross-modal person re-identification (VTReID) task. In this paper,we propose the Cross-modal Local Shortest Path and Global Enhancement (CM-LSP-GE) modules, a two-stream network based on joint learning of local and global features. The core idea of our paper is to use local feature alignment to solve occlusion problem, and to solve modal difference by strengthening global feature. Firstly, Attentionbased two-stream ResNet network is designed to extract dualmodality features and map to a unified feature space. Then, to solve the cross-modal person pose and occlusion problems, the image are cut horizontally into several equal parts to obtain local features and the shortest path in local features between two graphs is used to achieve the fine-grained local feature alignment. Thirdly, a batch normalization enhancement module applies global features to enhance strategy, resulting in difference enhancement between different classes. The multi granularity loss fusion strategy further improves the performance of the algorithm. Finally, joint learning mechanism of local and global features is used to improve cross-modal person re-identification accuracy. The experimental results on two typical datasets show that our model is obviously superior to the most state-of-the-art methods. Especially, on SYSU-MM01 datasets, our model can achieve a gain of $2.89%$ and $7.96%\mathbf{in}$ all search term of Rank-1 and mAP. The source code will be released soon.
摘要—在可见光-热红外跨模态行人重识别(VTReID)任务中,除了考虑人体姿态和遮挡带来的识别困难外,还需解决不同成像系统导致的模态差异。本文提出基于局部与全局特征联合学习的双流网络框架CM-LSP-GE模块,核心思想是通过局部特征对齐解决遮挡问题,通过全局特征增强解决模态差异。首先设计基于注意力机制的双流ResNet网络提取双模态特征并映射至统一特征空间;其次将图像水平切分为若干等份获取局部特征,通过计算两图局部特征间最短路径实现细粒度局部特征对齐,以解决跨模态行人姿态与遮挡问题;第三采用批归一化增强模块对全局特征实施增强策略,从而扩大类间差异;多粒度损失融合策略进一步提升了算法性能;最终通过局部与全局特征的联合学习机制提升跨模态行人重识别准确率。在两个典型数据集上的实验结果表明,本模型显著优于现有最优方法,特别是在SYSU-MM01数据集的全搜索模式下,Rank-1和mAP指标分别获得2.89%和7.96%的提升。源代码即将开源。
Index Terms—Visible-Thermal person re-identification, crossmodal, Local feature alignment, Multi-branch
索引术语—可见光-热成像行人重识别,跨模态,局部特征对齐,多分支
I. INTRODUCTION
I. 引言
D ERSON re-identification(Re-ID) [1]is an important technology in video tracking, which mainly studies matching person images from different camera perspectives. The traditional Re-ID mainly focuses on the visible modality, but in the actual application environment, there are often problems that cannot be identified due to low illumination, so that full-time tracking cannot be realized. In order to obtain the information of pedestrian identification at night, researchers turned to VT-Reid [2]research which mainly studies the matching of pedestrian images from one modality (infrared) to another modality (visible), which is a cross-modal tracking technology for intelligent tracking of pedestrians in full time.
行人重识别 (Re-ID) [1]是视频跟踪中的一项重要技术,主要研究从不同摄像机视角匹配行人图像。传统Re-ID主要关注可见光模态,但在实际应用环境中常因光照不足导致无法识别,从而无法实现全天候跟踪。为获取夜间行人识别信息,研究者转向VT-Reid [2]研究,该技术主要研究从一种模态(红外)到另一种模态(可见光)的行人图像匹配,是实现全天候行人智能跟踪的跨模态追踪技术。
As shown in Figure 1, now the main challenge of VT-Reid is not only to solve the problem of pedestrian posture difference and body part occlusion, but also to solve the problem of image inconsistency caused by modal difference.
如图 1 所示,当前 VT-Reid 的主要挑战不仅在于解决行人姿态差异和身体部位遮挡问题,还需解决由模态差异导致的图像不一致性问题。
In order to improve the accuracy of cross modal pedestrian re-recognition, researchers have proposed machine learning models that based on hand-designed feature and deep learning network. Because manual features can only represent limited pedestrian low-level features which are only part of all features , the machine learning methods such as HOG [3],LOMO [4] cannot fulfill the re-identification task satisfactorily. At present, deep learning is widely used to solve the re-identification problem and its common solution is to encode the pedestrian characteristics of different modes into a common feature space for similarity measurement.
为提高跨模态行人重识别的准确性,研究者们提出了基于手工设计特征和深度学习网络的机器学习模型。由于手工特征仅能表示有限的行人底层特征(这些特征只是全部特征的一部分),诸如HOG [3]、LOMO [4]等机器学习方法无法令人满意地完成重识别任务。当前,深度学习被广泛应用于解决重识别问题,其常见解决方案是将不同模态的行人特征编码至公共特征空间进行相似性度量。
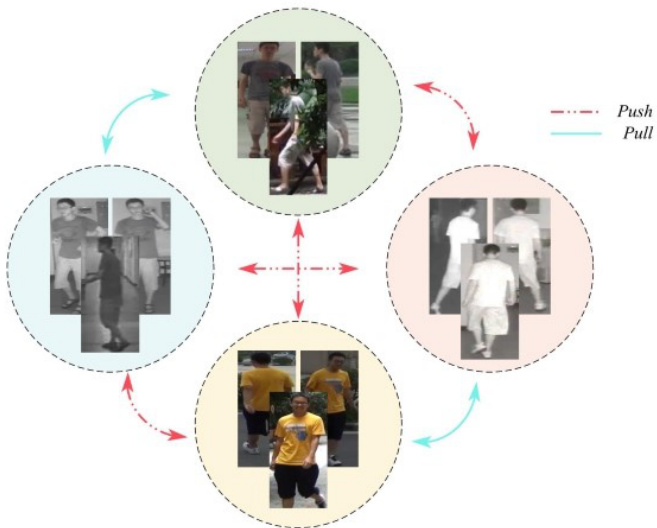
Fig. 1: The cross-modal person re-identification technology difficulties. Sample images from SYSU-MM01 dataset [2]
图 1: 跨模态行人重识别技术难点。样本图像来自SYSU-MM01数据集 [2]
To alleviate the modal differences in cross matching, in this paper we use the attention-based two-stream ResNet network to extract the features of pedestrians in visible and infrared images, and map them to the unified feature space for similarity measurement.
为了缓解跨模态匹配中的模态差异,本文采用基于注意力机制的双流ResNet网络提取可见光和红外图像中行人的特征,并将其映射到统一的特征空间进行相似性度量。
Most of the work only focuses on the global coarse grained feature extraction process and ignore the research on the feature enhancement method after extraction, in this paper we design a feature enhancement module based on batch normalization to enhance the global feature after extraction and improve the feature representation of different pedestrians.
大多数工作仅关注全局粗粒度特征提取过程,而忽略了提取后特征增强方法的研究。本文设计了一个基于批归一化 (batch normalization) 的特征增强模块,用于提升提取后的全局特征并改善不同行人的特征表示。
However, it is not enough to focus only on the global features, local features are also play an important role in VTReID task. When the body parts are missed due to pedestrian occlusion, it is difficult to extract the global features from these images and truly characterize this person, which is easy to lead incorrect classification. Considering that local information(e.g., head, body) of pedestrians in the images can be well distinguished and aids global feature learning, so in this paper, the pedestrian images under two different modes are segmented equally in the horizontal direction, and then the shortest path algorithm is used to achieve cross-modal local feature alignment. Finally, the joint learning mechanism based on local and global features can effectively improve the algorithm performance.
然而,仅关注全局特征是不够的,局部特征在跨模态行人重识别(VTReID)任务中也起着重要作用。当行人因遮挡导致身体部位缺失时,难以从这些图像中提取全局特征并真实表征该行人,容易导致错误分类。考虑到图像中行人的局部信息(如头部、躯干)能够被良好区分并辅助全局特征学习,本文对两种不同模态下的行人图像进行水平方向等分切割,随后采用最短路径算法实现跨模态局部特征对齐。最终,基于局部与全局特征的联合学习机制能有效提升算法性能。
Finally, different backbone networks in the classification task can affect the final classification accuracy. In this context, we investigate the impact of different variants of the ResNet two-stream feature extraction network on the final identification accuracy to further promote the performance of the network. In summary, the contributions of this paper are:
最后,分类任务中不同的主干网络会影响最终的分类准确率。为此,我们研究了ResNet双流特征提取网络的不同变体对最终识别准确率的影响,以进一步提升网络性能。综上所述,本文的贡献在于:
We propose an attention-based two-stream ResNet network for VT cross-modal feature acquisition. • We propose a method for cross-modal local feature alignment based on the shortest path (CM-LSP), which effectively solves the occlusion problem in cross-modal pedestrian re-identification and improves the robustness of the algorithm. • We design a batch normalized global feature enhancement (BN-GE) method to solve the problem of insufficient global feature discrimination and propose a multi granularity loss fusion strategy to guide network learning. • Ours method achieves preferably results on datasets SYSU-MM01 and RegDB. This can be used as a research baseline to improve the quality of future research.
我们提出了一种基于注意力机制的双流ResNet网络,用于可见光-热红外(VT)跨模态特征提取。
• 我们提出了一种基于最短路径的跨模态局部特征对齐方法(CM-LSP),有效解决了跨模态行人重识别中的遮挡问题,提升了算法鲁棒性。
• 我们设计了批归一化全局特征增强方法(BN-GE)以解决全局特征区分度不足的问题,并提出多粒度损失融合策略来指导网络学习。
• 本方法在SYSU-MM01和RegDB数据集上取得了优异效果,可作为提升未来研究质量的基准方案。
II. RELATED WORK
II. 相关工作
In order to improve cross-modal recognition accuracy in VTReID not only needs to solve the problem of pedestrian posture and occlusion, but also needs to break through the dilemma of cross-modal discrepancy. Machine learning based on artificial features has proved poor performance since they represent only some low-level pedestrian features. Therefore, Researchers turn to more powerful methods, Deep Learning, for feature acquisition and the mainstream approaches include: image generation-based methods, feature extractor-based methods and metric learning-based methods.
为了提高VTReID中的跨模态识别准确率,不仅需要解决行人姿态和遮挡问题,还需突破跨模态差异的困境。基于人工特征的机器学习方法已被证明效果不佳,因为它们仅能表示一些低层次的行人特征。因此,研究者转向更强大的深度学习方法进行特征提取,主流方法包括:基于图像生成的方法、基于特征提取器的方法以及基于度量学习的方法。
Image Generation Based Methods fulfil the reidentification task by generating fake images through generative adversarial network (GAN) to reduce the difference between cross-patterns from the image level. Vladimir $\mathrm{[5]_{et}}$ al.firstly proposed ThermalGAN to transform visible images into infrared images and then accomplish pedestrian recognition in the infrared modality. Zhang [6]et al.considered a teacher-student GAN model (TS-GAN) which used modal transitions to better guide the learning of disc rim i native features. Xia [7]et al.pointed out an image modal panning network which performed image modal transformation through a cycle consistency adversarial network. The above methods all use GAN to generate fake images reducing cross-modal differences from the image level. However, multiple seemingly reasonable images may be generated due to the change of the color attribute of the pedestrian appearance. It is difficult to determine which generated target is correct,resulting in a false identification process. The methods based on image generation often have the problem of algorithm performance uncertainty.
基于图像生成的方法通过生成对抗网络 (GAN) 生成虚假图像,从图像层面减少跨模态差异,从而完成重识别任务。Vladimir $\mathrm{[5]_{et}}$ 等人首次提出 ThermalGAN,将可见光图像转换为红外图像,进而在红外模态下完成行人识别。Zhang [6]等人提出师生式 GAN 模型 (TS-GAN),利用模态转换更好地指导判别特征学习。Xia [7]等人设计了一种图像模态平移网络,通过循环一致性对抗网络实现图像模态转换。上述方法均利用 GAN 生成虚假图像,从图像层面减小跨模态差异。但由于行人外观颜色属性的变化,可能生成多个看似合理的图像,难以确定哪个生成目标正确,导致识别过程出现错误。基于图像生成的方法往往存在算法性能不确定性问题。
Feature Extractor Based Methods are mainly used to extract the distinction and consistency characteristics from different modes according to the discrepancy of different modes. Therefore, the extraction of rich features is the key of the algorithm. $\mathrm{Wu}^{[2]}\mathrm{et}$ al.analyzed the performance of different network structures, which include one-stream and twostream networks, and proposed deep zero-padding for training one-stream network towards automatically evolving domainspecific nodes in the network for cross-modality matching. Kang [8] et al.rendered a one-stream model that placed visible and infrared images in different channels or created input images by connecting different channels. Fan [9]et al.advanced a cross-spectral bi-subspace matching one-stream model to solve the matching difference between cross-modal classes. All three of the above single-stream algorithms have low accuracy due to the single-stream network structure defects, which can only extract some common features and cannot extract the disc rim i native features in dual-modality.
基于特征提取器的方法主要用于根据不同模态间的差异,从不同模态中提取区分性与一致性特征。因此,丰富特征的提取是算法的核心。Wu[2]等人分析了一流网络和双流网络等不同网络结构的性能,提出了深度零填充技术,通过训练一流网络实现跨模态匹配中领域特定节点的自动演化。Kang[8]团队提出的一流模型将可见光与红外图像置于不同通道,或通过通道连接构建输入图像。Fan[9]等人提出的跨光谱双子空间匹配一流模型,则用于解决跨模态类别间的匹配差异问题。上述三种单流算法由于网络结构缺陷,仅能提取部分共性特征而无法捕获双模态中的判别性特征,导致准确率较低。
On the contrary to single stream network, the two-stream can extract different modal features by using the parallel network, so that the network has the advantage of extracting distinguishing features. Ye [10] et al. applied the two-stream AlextNet network to gain the dual-mode features, and then project these features into the public feature space. Based on this, Jiang [11]et al. designed a multi-granularity attention network to extract coarse-grained features separately. Ran [12]et al. mapped global features to the same feature space and added local disc rim i native feature learning and the algorithms performance were improved to some extent.To verify the effect of the network flow structure to acquire features ability on the performance of the algorithm, Emrah Basaran [13]designed a four-stream ResNet network framework which composed of gray flow and LZM upon the two-stream network. However, the experiment result showed that this method has large amount of calculation, high training cost and unsatisfactory experimental results. Overall, the two-stream network performs best in the structure of VT-ReID tasks.
与单流网络相反,双流网络通过并行架构提取不同模态特征,使网络具备提取区分性特征的优势。Ye [10] 等人采用双流AlexNet网络获取双模态特征,并将这些特征投影到公共特征空间。基于此,Jiang [11] 团队设计了多粒度注意力网络分别提取粗粒度特征。Ran [12] 团队将全局特征映射到同一特征空间,并加入局部判别特征学习模块,使算法性能得到一定提升。为验证网络流结构对特征获取能力的影响,Emrah Basaran [13] 在双流网络基础上设计了包含灰度流和LZM的四流ResNet框架。但实验表明该方法计算量大、训练成本高且效果欠佳。总体而言,双流网络在VT-ReID任务结构中表现最优。
Most of the above methods use ResNet as the feature extraction network. However, the variants of ResNet, like SE [14], CBAM [15], GC [16], SK [17], ST [18], NAM [19], ResNetXT [20]and SN [21]are widely used in classification and recognition tasks, and have achieved good accuracy improvement.
上述方法大多采用ResNet作为特征提取网络。然而,ResNet的变体如SE [14]、CBAM [15]、GC [16]、SK [17]、ST [18]、NAM [19]、ResNetXT [20]和SN [21]被广泛应用于分类与识别任务,并取得了显著的精度提升。
Metric Learning Based Methods are mainly focus on forcibly shortening the distance between similar samples across models and widening the distance between different samples by designing loss function. Based on the hierarchical feature extraction of the two-stream network, Ye [22], [23]et al. designed the dual-constrained top-ranking loss and the Bidirectional exponential angular triplet loss from the global feature. Zhu [24]et al.proposed to use the Hetero-center loss to constrain the intra-class center distance between two heterogeneous modes to monitor the learning of cross-modal invariant information from the perspective of global features.Ling [25]et al.advanced a center-guided metric learning method for enforcing the distance constraints among cross-modal class centers and samples. Liu [26]et al.raised a dual-modality triplet loss which considering both inter-mode difference and intra-mode change and introduced a mid-level feature fusion module. Hao [27]et al.projected an end-to-end two-stream hyper sphere manifold embedding network with classification and identification losses, which constrained the intra-mode change and cross-mode change on the hyper sphere. Zhao [28]et al. introduced difficult sample quintuple loss which is used to guide global feature learning. Liu [29], [30]et al. introduced heterogeneous center-based triple loss and dual-granularity triple loss from cross-modal global feature alignment, and coarsegrained feature learning as well as part-level feature extraction block. Ling [31]et al. designed the Earth Mover’s Distance can alleviate the impact of the intra-identity variations during modality alignment, and the Multi-Granularity Structure is designed to enable it to align modalities from both coarse-and fine-grained features. In order to find the nuances features, $\mathrm{Wu}^{[\bar{3}2]}\mathrm{et}$ al. proposed the center clustering loss, separation loss and the mode alignment module to find the nuances of different modes in an unsupervised manner.
基于度量学习的方法主要关注通过设计损失函数强制缩短跨模型相似样本间的距离,同时扩大不同样本间的距离。基于双流网络的分层特征提取,Ye [22][23]等人从全局特征出发设计了双约束顶级排序损失和双向指数角度三元组损失。Zhu [24]团队提出使用异质中心损失约束两种异构模态间的类内中心距离,从全局特征角度监控跨模态不变信息的学习。Ling [25]等人提出中心引导的度量学习方法,用于加强跨模态类中心与样本间的距离约束。Liu [26]团队提出同时考虑模态间差异与模态内变化的双模态三元组损失,并引入中层特征融合模块。Hao [27]等人设计了端到端的双流超球面流形嵌入网络,通过分类与识别损失在超球面上约束模态内变化与跨模态变化。Zhao [28]团队引入困难样本五元组损失指导全局特征学习。Liu [29][30]等人从跨模态全局特征对齐、粗粒度特征学习及局部特征提取模块出发,提出基于异构中心的三元组损失和双粒度三元组损失。Ling [31]团队设计的推土机距离(EMD)可减轻模态对齐过程中身份内部变异的影响,并通过多粒度结构实现从粗粒度到细粒度特征的跨模态对齐。为捕捉细微差异特征,Wu [32]等人提出中心聚类损失、分离损失和模态对齐模块,以无监督方式发现不同模态的细微差异。
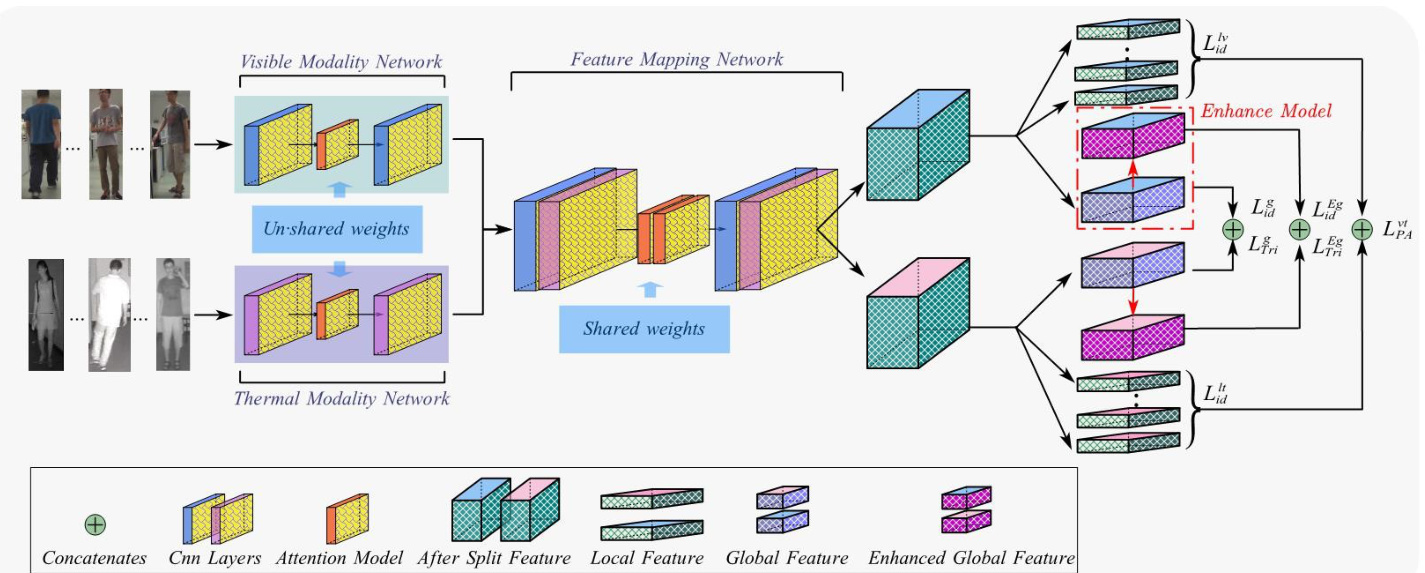
Fig. 2: The model proposed in this paper consists of three main components, an attention-based two-stream backbone network, the cross-modal local feature alignment module and a global feature enhancement module. Firstly, attention-based two-stream networks extract bimodal features and map them to the same feature space. Segmentation by FMN output features to obtain unimodal After Split Feature, the segmented features continue to be divided into unimodal global features and local features containing a certain number of horizontal cuts.
图 2: 本文提出的模型包含三个主要组件:基于注意力机制的双流主干网络、跨模态局部特征对齐模块和全局特征增强模块。首先,基于注意力的双流网络提取双模态特征并将其映射到同一特征空间。通过FMN输出特征进行分割得到单模态分割特征后,这些特征继续被划分为单模态全局特征和包含若干水平切片的局部特征。
From the above literature, it is known that coarse-grained global feature plays a major role in recognition, while finegrained local feature is a very good help in addition to global features to improve the ReID accuracy. In order to solve the problem of occlusion and modal difference in cross-modal VTReID, we use multi-granularity fusion loss to guide network learning. Firstly, in order to solve the modal difference, we design the classification loss based on global features and the loss of hard sample triples from the overall level. At the same time, the classification loss based on local features is designed from the partial level. Secondly, in order to solve the problem of component occlusion and ensure the shortest distance between components of the same kind, a part alignment loss is devised. Finally, multi-granularity loss is used to jointly constrain feature learning.
从上述文献可知,粗粒度的全局特征在识别中起主导作用,而细粒度的局部特征作为全局特征的补充能有效提升ReID精度。为解决跨模态VTReID中的遮挡问题和模态差异,我们采用多粒度融合损失指导网络学习。首先,为消除模态差异,从整体层面设计了基于全局特征的分类损失和困难样本三元组损失;同时从局部层面设计了基于局部特征的分类损失。其次,为解决部件遮挡问题并确保同类部件间距离最近,设计了部件对齐损失。最终通过多粒度损失联合约束特征学习。
III. METHODOLOGY
III. 方法论
Overview. In this section, we propose a CM-LSP-GE method. As shown in Fig. 2.this model mainly consists of four parts:(1) Attention-based two-stream network includes thermal mode network (TMN), visible mode network (VMN)and fusion module network (FMN). (2) Cross-modal local feature alignment module.(3) Batch normalized global feature enhancement module. (4) The multi-granularity fusion loss.
概述。在本节中,我们提出了一种CM-LSP-GE方法。如图2所示,该模型主要由四部分组成:(1) 基于注意力的双流网络,包括热模态网络(TMN)、可见模态网络(VMN)和融合模块网络(FMN);(2) 跨模态局部特征对齐模块;(3) 批归一化全局特征增强模块;(4) 多粒度融合损失。
A. Attention-based two-stream network
A. 基于注意力机制的双流网络
In cross-modal person re-identification project, the twostream network is often used for feature extraction due to its excellent characteristics of disc rim i native learning of different modal features, which mainly include feature extraction and feature mapping. At present, most of the mainstream methods use ResNet50 as the backbone for feature extraction. However, some of the latest improved ResNet have achieved better performance in image classification, recognition and so on. Therefore, it is necessary to find a better backbone for VTReid task, and provide a new reference for future research.
在跨模态行人重识别项目中,双流网络因其对不同模态特征的判别性学习优势常被用于特征提取,主要包括特征提取和特征映射两个部分。当前主流方法大多采用ResNet50作为特征提取主干网络,但部分最新改进版ResNet在图像分类、识别等任务中已展现出更优性能。因此,有必要为VTReid任务寻找更优主干网络,为后续研究提供新参考。
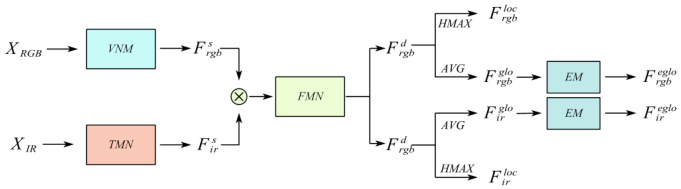
Fig. 3: Schematic diagram of two-stream characteristic flow
图 3: 双流特征流示意图
As shown in Fig. 3, We will introduce how to obtain the feature of sample. Assume that the visible and infrared image are respectively defined as $X_{r g b}$ and $X_{i r}$ , they are respectively fed into the VMN and TMN networks for feature learning to obtain shallow features $F_{r g b}^{s}$ and $F_{i r}^{s}$ ,then the two shallow features are connected as new features, which are input into the FMN network for fusion feature learning and feature mapping , and then the segmented features F rdgb and F idr represented in a uniform feature space are obtained. The segmentation features are processed by the adaptive average pooling layer to obtain the global featuresF rgglbo rgb’ , $F_{i r}^{g l o}$ ,while the local features $F_{r g b}^{l o c}$ and $F_{i r}^{l o c}$ are obtained via the horizontal adaptive maximum pooling layer. Finally, the global features are enhanced by the EM module to get the enhanced features $F_{r g b}^{e g l o}$ and $F_{i r}^{e j l o}$ .In the network inference stage, the distance matrix is constructed using the F eglo for similarity analysis.
如图 3 所示,我们将介绍如何获取样本特征。假设可见光图像和红外图像分别定义为 $X_{r g b}$ 和 $X_{i r}$,它们分别输入 VMN 和 TMN 网络进行特征学习,得到浅层特征 $F_{r g b}^{s}$ 和 $F_{i r}^{s}$,然后将这两个浅层特征连接为新特征,输入 FMN 网络进行融合特征学习和特征映射,最终得到统一特征空间中的分割特征 $F_{rdgb}$ 和 $F_{idr}$。分割特征通过自适应平均池化层处理得到全局特征 $F_{rgglbo\ rgb}$ 和 $F_{i r}^{g l o}$,而局部特征 $F_{r g b}^{l o c}$ 和 $F_{i r}^{l o c}$ 则通过水平自适应最大池化层获得。最后,全局特征通过 EM 模块增强,得到增强特征 $F_{r g b}^{e g l o}$ 和 $F_{i r}^{e j l o}$。在网络推理阶段,使用 $F_{eglo}$ 构建距离矩阵进行相似性分析。
B. Cross-modal Local Feature Alignment Module
B. 跨模态局部特征对齐模块
When pedestrian occlusion occurs, it is difficult to truly recognize the global pedestrian features using missing components as distinguishing features. Therefore, we designed the shortest path alignment module based on local features, which achieves component alignment by equalizing the image segmentation and calculating the shortest path between local features in the two graphs.
当行人遮挡发生时,很难真正利用缺失部分作为区分特征来识别全局行人特征。因此,我们设计了基于局部特征的最短路径对齐模块,通过均衡图像分割并计算两图中局部特征之间的最短路径来实现组件对齐。
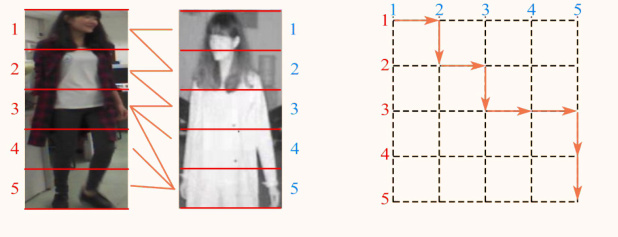
Fig. 4: Cross-modal Local Feature Alignment
图 4: 跨模态局部特征对齐
As shown in Fig. 4, the visible and infrared images are equally divided into five parts, then the local feature represent ation is defined as F rlogcb $\bar{\cal F}{r g b}^{\mathrm{loc}}={f_{r}^{1},f_{r}^{2}...f_{r}^{i}}$ and $F_{i r}^{\mathrm{loc}}=$ $\big{f_{t}^{1},f_{t}^{2}...f_{t}^{i}\big}$ ,where the visible local features are calculated as Eq. 1
如图 4 所示,可见光与红外图像被均分为五部分,局部特征表示定义为 $F_{r g b}^{\mathrm{loc}}={f_{r}^{1},f_{r}^{2}...f_{r}^{i}}$ 和 $F_{i r}^{\mathrm{loc}}={f_{t}^{1},f_{t}^{2}...f_{t}^{i}}$ ,其中可见光局部特征计算公式如式 (1) 所示。
$$
f_{r}^{i}=\operatorname*{\o}{H M a x}{i\in(1,2,...,h)}(F_{r g b}^{d})_{[i\times\mathrm{d}]}d=2^{n}&n\in(0,1,2,...,11)
$$
$$
f_{r}^{i}=\operatorname*{\o}{H M a x}{i\in(1,2,...,h)}(F_{r g b}^{d})_{[i\times\mathrm{d}]}d=2^{n}&n\in(0,1,2,...,11)
$$
where $i$ is the horizontal feature position, $d$ is the local feature dimension, $h$ is height of the input image.
其中 $i$ 为水平特征位置,$d$ 为局部特征维度,$h$ 为输入图像高度。
When using similar methods to calculate infrared local features, we obtain the local feature representation of the bimodal state and subsequently define the Eq. 2for calculating the distance between the two graphs. The distance equation is defined as:
在采用类似方法计算红外局部特征时,我们获得了双模态状态的局部特征表示,随后定义了用于计算两图间距离的公式2。该距离方程定义为:
$$
d_{i,j}=\left|\frac{f_{r}^{i}-M e a n(f_{r}^{i})}{M a x(f_{r}^{i})-M i n(f_{r}^{i})}-\frac{f_{\mathrm{t}}^{j}-M e a n(f_{t}^{j})}{M a x(f_{t}^{j})-M i n(f_{t}^{j})}\right|_{1}
$$
$$
d_{i,j}=\left|\frac{f_{r}^{i}-M e a n(f_{r}^{i})}{M a x(f_{r}^{i})-M i n(f_{r}^{i})}-\frac{f_{\mathrm{t}}^{j}-M e a n(f_{t}^{j})}{M a x(f_{t}^{j})-M i n(f_{t}^{j})}\right|_{1}
$$
where $i,j\in(1,2,3,...,h)$ are the respective parts of the images. $d_{i,j}$ is the distance between local features of different modes.
其中 $i,j\in(1,2,3,...,h)$ 表示图像的各个部分,$d_{i,j}$ 是不同模态局部特征之间的距离。
Then, we construct the distance matrix $D$ from $d_{i,j}$ ,and define $S_{i,j}$ is the total distance between the local features of the two images as the shortest distance from $(1,1)$ to $(H,H)$ .the shortest path between two graphs is calculated by the Eq. 3
接着,我们根据 $d_{i,j}$ 构建距离矩阵 $D$,并定义 $S_{i,j}$ 为两幅图像局部特征之间的总距离,即从 $(1,1)$ 到 $(H,H)$ 的最短距离。两个图之间的最短路径通过公式 3 计算。
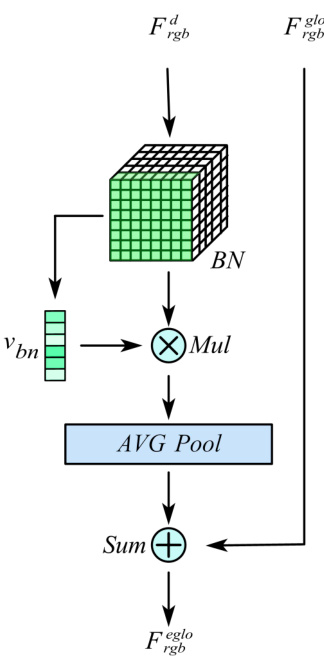
Fig. 5: Global feature enhancement module
图 5: 全局特征增强模块
C. Batch normalized global feature enhancement module
C. 批量归一化全局特征增强模块
It is no doubt that global features play an important role in person re-identification, and a BN-based global feature enhancement module is designed to further improve the discri mi nation of different pedestrian global representations under cross-modality. As shown in Fig. 5, taking the visible mode as an example.
毫无疑问,全局特征在行人重识别中起着重要作用。为了进一步提升跨模态下不同行人全局表征的区分能力,我们设计了一个基于批归一化(BN)的全局特征增强模块。如图 5 所示,以可见光模态为例。
Firstly, the unified spatial output features F rdgb are normalized through the batch-normalization layer (BN) At the same time, the vector $v_{b n}$ is calculated according to the BN weights. Normalize the features F rdgb using BN and multiply them with $v_{b n}$ to obtain a new feature and use this feature to obtain a new weight matrix by adaptive averaging pooling layer. To obtain the final F reggblo , we linearly sum F rgglbo and this feature.
首先,统一的空域输出特征F_rdgb通过批归一化层(BN)进行归一化处理。同时,根据BN权重计算向量$v_{bn}$。使用BN对特征F_rdgb进行归一化后,将其与$v_{bn}$相乘得到新特征,并通过自适应平均池化层生成新的权重矩阵。最终通过线性叠加F_rgglbo与该特征,获得F_reggblo。
Then, we derive the calculation process from the perspective of the formula. We first define the BN layer calculation, as in Eq. 4:
接着,我们从公式角度推导计算过程。首先定义BN层计算,如式4所示:
$$
B N(x)=\gamma\frac{x-\mu_{b}}{\sqrt{\sigma_{b}^{2}+\varepsilon}}+\beta
$$
where $\gamma$ is scale factor and $\beta$ is translation factor, $\mu_{b}$ and $\sigma_{b}^{2}$ is mean and variance of one batch, respectively. $\varepsilon$ is a hyper parameter.
其中 $\gamma$ 是缩放因子,$\beta$ 是平移因子,$\mu_{b}$ 和 $\sigma_{b}^{2}$ 分别表示一个批次的均值和方差,$\varepsilon$ 是一个超参数。
We define the weight vector $v_{b n}=\lambda_{j}/\sum_{j=0}\lambda_{j}$ ,where $\lambda_{j}$ is the weight factor in the BN layer.
我们将权重向量定义为 $v_{b n}=\lambda_{j}/\sum_{j=0}\lambda_{j}$ ,其中 $\lambda_{j}$ 是 BN (Batch Normalization) 层中的权重因子。
Finally, The enhanced global features are calculated as in Eq. 5:
最后,增强的全局特征按式5计算:
$$
F_{r g b}^{e g l o}=F_{r g b}^{g l o}+A v g(v_{b n}\bullet B N(F_{r g b}^{d}))
$$
$$
F_{r g b}^{e g l o}=F_{r g b}^{g l o}+A v g(v_{b n}\bullet B N(F_{r g b}^{d}))
$$
where $A v g$ is adaptive average pooling calculation process.
其中 $A v g$ 是自适应平均池化 (adaptive average pooling) 的计算过程。
$D$ . The Multi-granularity Fusion Loss
$D$ . 多粒度融合损失
The multi-granularity fusion loss proposed in this paper is described in detail below. We use two-stream networks to obtain global and local features, and then use them to compute classification loss and triple loss. Classification loss is widely used in the Reid task to calculate cross-entropy loss mainly by pedestrian identity labels, which is referred to as id loss in this paper.
本文提出的多粒度融合损失函数详述如下。我们采用双流网络分别提取全局和局部特征,随后利用这些特征计算分类损失(classification loss)和三重损失(triple loss)。分类损失在行人重识别任务中广泛应用,主要通过行人身份标签计算交叉熵损失,本文将其称为id损失。
Firstly, we define the global and local classification losses as $L_{i d}^{g}$ and $L_{i d}^{l v}$ , respectively, as Eq. 6 and Eq. 7:
首先,我们将全局和局部分类损失分别定义为 $L_{i d}^{g}$ 和 $L_{i d}^{l v}$ ,如式6和式7所示:
$$
L_{i d}^{g}=\sum_{i=1}^{N}-q_{i}\log(p_{i}^{g})
$$
$$
L_{i d}^{g}=\sum_{i=1}^{N}-q_{i}\log(p_{i}^{g})
$$
$$
L_{i d}^{l v}=\sum_{j=2}^{S}\sum_{i=1}^{N}-q_{i}\log(p_{i}^{j})
$$
$$
L_{i d}^{l v}=\sum_{j=2}^{S}\sum_{i=1}^{N}-q_{i}\log(p_{i}^{j})
$$
where $N$ is the total number of categories in the training dataset, $q_{i}$ is the sample true probability distribution , $S$ is the number of horizontal slices, $p_{i}^{j}$ and $p_{i}^{g}$ are the predicted probability distributions.
其中 $N$ 是训练数据集中类别的总数,$q_{i}$ 是样本的真实概率分布,$S$ 是水平切片的数量,$p_{i}^{j}$ 和 $p_{i}^{g}$ 是预测的概率分布。
For each of $P$ that randomly selected person identities, $K$ visible images and $K$ thermal images are randomly sampled, totally are $2\times P\times K$ images, We define the heterogeneous center-based triad loss as Eq. 8
对于随机选取的 $P$ 个人物身份,各随机采样 $K$ 张可见光图像和 $K$ 张热成像图像,总计 $2\times P\times K$ 张图像。我们将基于异构中心的三元组损失定义为式 (8)
$$
\begin{array}{r}{L_{T r i}^{g}=\displaystyle\sum_{i=1}^{P}\left[m_{g}+\left|f c_{v}^{i}-f c_{t}^{i}\right|_{2}-\displaystyle\operatorname*{min}_{k\in{v,t}}\left|f c_{v}^{i}-f c_{k}^{j}\right|_{2}\right]}\ {+\displaystyle\sum_{i=1}^{P}\left[m_{g}+\left|f c_{t}^{i}-f c_{v}^{i}\right|_{2}-\displaystyle\operatorname*{min}_{k\in{v,t}}\left|f c_{t}^{i}-f c_{k}^{j}\right|_{2}\right]_{+}}\end{array}
$$
$$
\begin{array}{r}{L_{T r i}^{g}=\displaystyle\sum_{i=1}^{P}\left[m_{g}+\left|f c_{v}^{i}-f c_{t}^{i}\right|_{2}-\displaystyle\operatorname*{min}_{k\in{v,t}}\left|f c_{v}^{i}-f c_{k}^{j}\right|_{2}\right]}\ {+\displaystyle\sum_{i=1}^{P}\left[m_{g}+\left|f c_{t}^{i}-f c_{v}^{i}\right|_{2}-\displaystyle\operatorname*{min}_{k\in{v,t}}\left|f c_{t}^{i}-f c_{k}^{j}\right|_{2}\right]_{+}}\end{array}
$$
where $m_{g}$ is a hyper parameter. $\begin{array}{r}{f c_{v}^{i}=\frac{1}{K}\sum_{j=1}^{K}f_{v,j}^{i}}\end{array}$ and $\begin{array}{r c l}{f c_{t}^{i}}&{=}&{\frac{1}{K}\sum_{j=1}^{K}f_{t,j}^{i}}\end{array}$ are the features centersP of different modality. $f c_{v}^{j}$ and $f c_{t}^{\j}$ represent pedestrian features in different modality respectively.
其中 $m_{g}$ 是超参数。$\begin{array}{r}{f c_{v}^{i}=\frac{1}{K}\sum_{j=1}^{K}f_{v,j}^{i}}\end{array}$ 和 $\begin{array}{r c l}{f c_{t}^{i}}&{=}&{\frac{1}{K}\sum_{j=1}^{K}f_{t,j}^{i}}\end{array}$ 是不同模态的特征中心。$f c_{v}^{j}$ 和 $f c_{t}^{\j}$ 分别代表不同模态下的行人特征。
Considering the auxiliary role of local features to the performance of the algorithm, the cross-modal local feature alignment loss $L_{P A}^{v t}$ is designed in this paper and defined as Eq. 9:
考虑到局部特征对算法性能的辅助作用,本文设计了跨模态局部特征对齐损失 $L_{P A}^{v t}$ ,其定义如式 9 所示:
$$
\begin{array}{r}{L_{P A}^{v t}=\displaystyle\sum_{i=1}^{P}\displaystyle\sum_{a=1}^{2K}\displaystyle\sum_{j=2}^{H}\left[m_{l}+\displaystyle\operatorname*{max}_{k\in{v,t}}\left|f_{i.j}^{k a}-f_{i,j}^{k p}\right|_{2}\right.}\ {-\displaystyle\left.\operatorname*{min}_{k\in{v,t}}\left|f_{i,j}^{k a}-f_{i,j}^{k n}\right|_{2}\right]}\end{array}
$$
$$
\begin{array}{r}{L_{P A}^{v t}=\displaystyle\sum_{i=1}^{P}\displaystyle\sum_{a=1}^{2K}\displaystyle\sum_{j=2}^{H}\left[m_{l}+\displaystyle\operatorname*{max}_{k\in{v,t}}\left|f_{i.j}^{k a}-f_{i,j}^{k p}\right|_{2}\right.}\ {-\displaystyle\left.\operatorname*{min}_{k\in{v,t}}\left|f_{i,j}^{k a}-f_{i,j}^{k n}\right|_{2}\right]}\end{array}
$$
where $m_{l}$ is a hyper parameter, $f_{i.j}^{k a}$ is the infrared/visible modal local features, f ik,jp is the visible/infrared mode with the most distant positive sample, $f_{i,j}^{k n}$ is the visible/infrared mode distance nearest negative sample and $k$ represents different modes. In this paper, the total loss $L_{t o t a l}$ is defined by the Eq. 10:
其中 $m_{l}$ 是一个超参数,$f_{i.j}^{k a}$ 是红外/可见光模态的局部特征,$f_{ik,jp}$ 是可见光/红外模态中最远的正样本,$f_{i,j}^{k n}$ 是可见光/红外模态距离最近的负样本,$k$ 表示不同的模态。本文中,总损失 $L_{total}$ 由公式 10 定义:
$$
L_{t o t a l}=\overbrace{L_{i d}^{g}+L_{i d}^{e g}}^{G l o b a l i d}+\overbrace{L_{T r i}^{g}+L_{T r i}^{e g}}^{G l o b a l T r i}+\overbrace{L_{i d}^{l v}+L_{i d}^{l t}}^{L o c a l i d}+\overbrace{L_{P A}^{v t}}^{L o c a l T r i}
$$
$$
L_{t o t a l}=\overbrace{L_{i d}^{g}+L_{i d}^{e g}}^{G l o b a l i d}+\overbrace{L_{T r i}^{g}+L_{T r i}^{e g}}^{G l o b a l T r i}+\overbrace{L_{i d}^{l v}+L_{i d}^{l t}}^{L o c a l i d}+\overbrace{L_{P A}^{v t}}^{L o c a l T r i}
$$
IV. EXPERIMENT
IV. 实验
A. Experimental settings
A. 实验设置
Datasets. SYSU-MM01 is the first cross-modal pedestrian dataset built by Wu et al. All data are collected from 4 RGB cameras and $2\mathrm{IR}$ cameras, including a total of 491 different pedestrians. 395 people are included in the training set, with a total of 19,659 visible images and 12,792 IR images, and 96 people are included in the test set, including full-scene search and indoor scene search. For indoor search only search in cameras1,2,3and6, while the full scene uses all images.
数据集。SYSU-MM01是Wu等人构建的首个跨模态行人数据集。所有数据通过4台RGB相机和$2\mathrm{IR}$红外相机采集,共包含491名不同行人。训练集涵盖395人,含19,659张可见光图像与12,792张红外图像;测试集包含96人,分为全场景搜索与室内场景搜索两种模式。室内搜索仅使用摄像头1、2、3和6的数据,全场景搜索则使用全部图像。
RegDB [33 ] contains 412 individuals, each with 10 images from the visible camera and 10 images from the infrared camera.
RegDB [33] 包含412个个体,每个个体有10张可见光相机拍摄的图像和10张红外相机拍摄的图像。
Evaluation metrics. The CMC (Cumulative Matching Characteristics), the mINP (mean inverse negative penalty) and mAP (mean Average Precision) are used to evaluate the retrieval performance. For CMC, we report the rank-1, rank10, and rank-20 precision.
评估指标。采用CMC (Cumulative Matching Characteristics)、mINP (mean inverse negative penalty) 和mAP (mean Average Precision) 评估检索性能。对于CMC指标,我们报告了rank-1、rank-10和rank-20的精度。
Official method evaluation was performed on the SYSUMM 01 data set, based on 10 replicate random splits of the query set dataset and the mean of the group to be tested. RegDB results were based on 10 replicate random splits of the training and test sets and the mean was calculated.
官方方法评估在SYSUMM 01数据集上进行,基于查询集数据集的10次重复随机划分及待测组别的均值。RegDB结果基于训练集和测试集的10次重复随机划分并计算均值。
Implementation Details. We implemented our model with Pytorch. The training input images are first padded with 10 and randomly cropped to $288\times144$ ,random horizontal flipping is further imposed as data augmentation. The train-batch size is set to 120. We set the ImageNet pre-trained CNN part as 0.01 and the classifier as 0.1, optimized them via SGD. The learning rate decreases by a factor of 10 every 10 epochs.
实现细节。我们使用Pytorch实现了模型。训练输入图像首先填充10像素并随机裁剪至$288\times144$,随后采用随机水平翻转作为数据增强。训练批次大小设为120。将ImageNet预训练的CNN部分学习率设为0.01,分类器部分设为0.1,通过SGD进行优化。学习率每10个epoch下降10倍。
Re-ranking. In recent studies [13], [34], [35], the Re-ranking algorithm ,which is an algorithm for reordering Retrieval Results, contributes significantly to person Re-Identification, so that we used ECN [35](Expanded Cross Neighborhood) as a post-processing algorithm in the inference phase. We used the relevant parameter sources in 35.
重排序。近期研究[13][34][35]表明,重排序算法(一种对检索结果重新排序的算法)在行人重识别任务中效果显著,因此我们在推理阶段采用ECN[35](Expanded Cross Neighborhood)作为后处理算法,相关参数设置参照文献[35]。
B. Comparison with The State-of-The-Art Algorithms
B. 与最先进算法的对比
To demonstrate the superiority of our method, we compared it against the state-of-the-art approaches on SYSU-MM01 and RegDB. These methods include:traditional characterization:HOG [3],LOMO [4],deep learning:HCML [10],LZM [13],IPVT $+.$ MSR [8].
为验证本方法的优越性,我们在SYSU-MM01和RegDB数据集上与当前最优方法进行了对比。这些方法包括:传统特征提取方法:HOG [3]、LOMO [4];深度学习方法:HCML [10]、LZM [13]、IPVT $+.$ MSR [8]。
Metric Learning Methods: HC [24],DCTR [23],CML [25] ,EDFL [26],HSME [27],HPILN [28],DGTL [29],Hc- Tri [30],CM-EMD [31],MPANet [32].
度量学习方法:HC [24]、DCTR [23]、CML [25]、EDFL [26]、HSME [27]、HPILN [28]、DGTL [29]、Hc-Tri [30]、CM-EMD [31]、MPANet [32]。
Image generation methods:cmGAN [36],AlignGAN [37], JSIA [39], CoSiGAN [38],TS-GAN [6]. The experimental results respectively correspond to Tabel II and Tabel I.
图像生成方法:cmGAN [36]、AlignGAN [37]、JSIA [39]、CoSiGAN [38]、TS-GAN [6]。实验结果分别对应表 II 和表 I。
Results on SYSU-MM01. The results are shown in Tabel I. Our method respectively obtains $76.28%$ and $76.52%$ of Rank1 and mAP accuracy in the full scene search, and obtain $82.31%$ and $85.16%$ of Rank-1 and mAP accuracy in the indoor search. The test results are better than the latest methods.
SYSU-MM01数据集上的结果。结果如表1所示。我们的方法在全场景搜索中分别获得了76.28%的Rank1准确率和76.52%的mAP准确率,在室内场景搜索中获得了82.31%的Rank1准确率和85.16%的mAP准确率。测试结果优于现有最新方法。
Results on RegDB. We use the method of this paper on the RegDB dataset to compare with the current state-of-theart methods, and the results are shown in Tabel II. In VisibleThermal test results, our method achieves Rank-1 accuracy of $94.13%$ and mAP accuracy of $88.86%$ , and in Thermal-Visible test our method obtains Rank-1 accuracy of $93.16%$ and mAP accuracy of $87.26%$ . In VT test, the results are basically the same as the latest literature CM-EMD [31] results were essentially unchanged and in the TV test, $0.39%$ improvement was achieved on Rank-1 and $0.41%$ improvement on mAP.
RegDB数据集上的结果。我们将本文方法应用于RegDB数据集,并与当前最优方法进行对比,结果如表II所示。在可见光-热成像(VT)测试中,我们的方法取得了94.13%的Rank-1准确率和88.86%的mAP准确率;在热成像-可见光(TV)测试中,获得了93.16%的Rank-1准确率和87.26%的mAP准确率。VT测试结果与最新文献CM-EMD[31]基本持平,TV测试则在Rank-1指标上提升0.39%,mAP指标提升0.41%。
TABLE I: Comparison with the state-of-the-art methods on the SYSU-MM01 dataset.
表 1: SYSU-MM01数据集上现有最优方法的对比
| 方法 | 时间 | rank-1 | rank-10 | rank-20 | mAP | mINP | rank-1 | rank-10 | rank-20 | mAP | mINP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| HOG [3] | 2005 | 2.76 | 18.25 | 31.91 | 4.24 | - | 3.22 | 24.68 | 44.52 | 7.25 | |
| LOMO [4] | 2015 | 3.64 | 23.18 | 37.28 | 4.53 | - | 5.75 | 34.35 | 57.90 | 10.19 | |
| HCML [10] | 2018 | 14.32 | 53.16 | 69.17 | 16.16 | 20.58 | 63.38 | 85.79 | 26.92 | - | |
| DCTR [23] | 2018 | 17.01 | 55.43 | 71.96 | 19.66 | - | |||||
| cmGAN [36] | 2018 | 26.97 | 67.51 | 80.56 | 31.49 | 31.63 | 77.23 | 89.62 | 42.46 | ||
| HSME [27] | 2019 | 20.68 | 62.74 | 77.95 | 23.12 | - | - | ||||
| IPVT+MSR [8] | 2019 | 23.20 | 51.20 | 61.70 | 22.50 | - | |||||
| AlignGAN [37] | 2019 | 51.50 | 89.40 | 95.70 | 33.90 | - | 57.10 | 92.70 | 97.40 | 45.30 | |
| CoSiGAN [38] | 2020 | 35.55 | 81.54 | 90.43 | 38.33 | - | |||||
| EDFL [26] | 2020 | 36.94 | 84.52 | 93.22 | 40.77 | ||||||
| HPILN [28] | 2020 | 41.36 | 84.78 | 94.51 | 42.95 | 45.77 | 91.82 | 98.46 | 56.52 | ||
| JSIA [39] | 2020 | 45.10 | 85.70 | 93.80 | 29.50 | 52.70 | 91.10 | 96.40 | 42.70 | ||
| CML [25] | 2020 | 56.27 | 94.08 | 98.12 | 43.39 | 60.42 | 95.88 | 99.5 | 53.52 | ||
| HC [24] | 2020 | 59.96 | 91.50 | 96.82 | 54.95 | 59.74 | 92.07 | 96.22 | 64.91 | ||
| HcTri [30] | 2020 | 61.68 | 93.10 | 97.17 | 57.51 | 39.54 | 63.41 | 91.69 | 95.28 | 68.10 | 64.26 |
| LZM [13] | 2020 | 63.05 | 93.62 | 96.30 | 67.13 | 69.06 | 96.30 | 97.16 | 76.95 | ||
| TS-GAN [6] | 2021 | 55.90 | 91.20 | 96.60 | 39.70 | 59.30 | 91.80 | 97.90 | 50.90 | - | |
| AGW [7] | 2021 | 56.52 | 90.26 | 95.59 | 57.47 | 38.75 | 68.72 | 94.61 | 97.42 | 75.11 | 64.22 |
| DGTL [29] | 2021 | 57.34 | 55.13 | 63.11 | 69.2 | ||||||
| MPANet [32] | 2021 | 70.58 | 96.21 | 98.80 | 68.24 | 76.74 | 98.21 | 99.57 | 80.95 | ||
| CM-EMD [31] | 2022 | 73.39 | 96.24 | 98.82 | 68.56 | - | 80.53 | 98.31 | 99.91 | 82.71 | |
| CM-GE | - | 58.59 | 87.14 | 92.64 | 54.95 | 39.00 | 65.84 | 93.22 | 96.95 | 67.31 | 61.99 |
| CM-LSP-GE | 60.91 | 89.03 | 94.43 | 57.12 | 41.39 | 69.38 | 95.14 | 98.25 | 70.3 | 65.14 | |
| CM-LSP-GE-RK | 76.28 | 94.38 | 97.08 | 76.52 | 42.03 | 82.31 | 98.12 | 99.91 | 85.16 | 66.51 |
TABLE II: Comparison with the state-of-the-art methods on the RegDB dataset.
表 II: RegDB数据集上最新方法的对比
| 方法 | 时间 | 可见光-热成像 rank-1 | 可见光-热成像 mAP | 热成像-可见光 rank-1 | 热成像-可见光 mAP |
|---|---|---|---|---|---|
| HCML [10] | 2018 | 24.44 | 20.08 | 21.70 | 22.24 |
| DCTR [29] | 2018 | 33.47 | 31.83 | 32.72 | 31.10 |
| HSME [27] | 2019 | 50.85 | 47.00 | 50.15 | 46.16 |
| AlignGAN [37] | 2019 | 57.9 | 53.6 | 56.3 | 53.4 |
| CoSiGAN [38] | 2020 | 47.18 | 46.16 | ||
| EDFL [26] | 2020 | 52.58 | 52.98 | 51.89 | 52.13 |
| CML [25] | 2020 | 59.81 | 60.86 | ||
| HcTri [30] | 2020 | 91.05 | 83.28 | 89.3 | 81.46 |
| LZM [13] | 2020 | 60.58 | 63.36 | 57.17 | 57.56 |
| AGW [7] | 2021 | 78.3 | 70.37 | 75.22 | 67.28 |
| DGTL [29] | 2021 | 83.92 | 73.78 | 81.59 | 71.65 |
| MPANet [32] | 2021 | 83.7 | 80.9 | 82.8 | 80.7 |
| CM-EMD [31] | 2022 | 94.37 | 88.23 | 92.77 | 86.85 |
| CM-GE | |||||
| CM-LSP-GE | 92.32 94.13 | 85.35 88.86 | 90.16 93.16 | 83.43 87.26 |
Compared with HcTri [30], our method has better performance in all aspects.
与HcTri [30]相比,我们的方法在所有方面都具有更好的性能。
C. Evaluation.
C. 评估
Effectiveness of attention mechanism. In order to study the effect of different attention methods on re-identification accuracy, the following eight different methods are selected for experimental study. such as SEResNet based on channel attention, CBAMResNet based on convolutional block attention, GCResNet based on full-text information, ResNetST based on scattered attention, NAMResNet based on normalized attention, SKResNet based on selective kernel, ResNetXT based on design aggregated residual block, ResNetSN based on switchable normalized layer. As shown in Fig. 6, the experimental results prove the improved backbone network based on GC attention mechanism has the best performance.
注意力机制的有效性。为了研究不同注意力方法对重识别准确率的影响,我们选取了以下八种方法进行实验研究:基于通道注意力的SEResNet、基于卷积块注意力的CBAMResNet、基于全文信息的GCResNet、基于分散注意力的ResNetST、基于归一化注意力的NAMResNet、基于选择性核的SKResNet、基于聚合残差块设计的ResNetXT,以及基于可切换归一化层的ResNetSN。如图6所示,实验结果证明基于GC注意力机制改进的主干网络性能最佳。
Effectiveness of GE. To verify the effectiveness of the GE module designed in this paper, we select global features and enhanced global features in the network for visualization and analysis which are shown in Figure 7. We randomly select 20 different pedestrians from the SYSU-MM01 query dataset, and take 10 images of each person separately for visualization and analysis. In Fig. 7 (a) the image is mapped to a two-dimensional plane using PCA, (b) shows the global features mapped onto the plane visualization and (c) shows the enhanced global features. Comparing (b) and (c), it can be found that the distance between different classes is farther after global feature enhancement.
GE模块的有效性。为验证本文设计的GE模块有效性,我们选取网络中的全局特征和增强全局特征进行可视化分析,如图7所示。我们从SYSU-MM01查询数据集中随机选取20个不同行人,每人各取10张图像进行可视化分析。图7(a)展示使用PCA将图像映射到二维平面,(b)显示映射到平面的全局特征可视化,(c)显示增强后的全局特征。对比(b)和(c)可发现,全局特征增强后不同类别间的距离更远。
Effectiveness of CM-LSP. In order to verify the effectiveness of the proposed method for cross-modal local feature alignment based on the shortest path the cutting quantity experiment on SYSU-MM01 is firstly carried out. From the result in Tabel III.it can be found that the best result is obtained by dividing the body image into three equal parts.
CM-LSP的有效性。为了验证所提出的基于最短路径的跨模态局部特征对齐方法的有效性,首先在SYSU-MM01数据集上进行了切割数量实验。从表III的结果可以看出,将人体图像划分为三等分时获得了最佳效果。
We chose the number of parts in Tabel III. as 2 for the validation dimension experiment and selectively verified that the dimensions 128, 256, 516 and 1024. As shown in Tabel IV, we found that the 1024 dims features have the best performance from the combined results.
我们在表 III 中选择部件数量为 2 进行验证维度实验,并选择性验证了维度 128、256、516 和 1024。如表 IV 所示,从综合结果来看,1024 维特征表现最佳。
Experimental results demonstrated that joint learning using global and local features is superior to global features alone, and with the help of local features, the network pays more attention to the similarity of pedestrian body parts in images rather than over fitting background information.
实验结果表明,结合全局和局部特征的联合学习优于仅使用全局特征,且在局部特征的辅助下,网络会更关注图像中行人身体部位的相似性,而非过度拟合背景信息。

Fig. 6: (a) Impacts of Backbone in terms of Rank-1,(b) Impacts of Backbone in terms of mAP, (c) Impacts of Backbone in terms of mINP
图 6: (a) 主干网络对Rank-1指标的影响, (b) 主干网络对mAP指标的影响, (c) 主干网络对mINP指标的影响

Fig. 7: (a) Impacts of Backbone in terms of Rank-1,(b) Impacts of Backbone in terms of mAP, (c) Impacts of Backbone in terms of mINP
图 7: (a) 主干网络对Rank-1指标的影响, (b) 主干网络对mAP指标的影响, (c) 主干网络对mINP指标的影响
TABLE III: Comparison with Part quantity in SYSU-MM01 do indoor search.
表 III: 与SYSU-MM01数据集部分数量在室内搜索中的对比
| 部件数量 | Rank-1 | mAP | mINP |
|---|---|---|---|
| 无 | 65.84 | 67.31 | 61.99 |
| 2 | 67.26 | 68.08 | 62.52 |
| 3 | 69.38 | 70.30 | 65.14 |
| 4 | 68.55 | 69.47 | 64.09 |
| 5 | 66.66 | 68.22 | 62.42 |
| 6 | 67.82 | 68.80 | 63.28 |
| 7 | 67.76 | 68.56 | 62.62 |
| 8 | 67.17 | 68.21 | 62.90 |
| 9 | 66.02 | 67.52 | 62.50 |
TABLE IV: Comparison with two Part and differ Dim in SYSU-MM01 do indoor search.
表 IV: SYSU-MM01 数据集不同维度和部件在室内搜索场景下的性能对比
| Dim | rank-1 | rank-10 | rank-20 | mAP | mINP |
|---|---|---|---|---|---|
| 128 | 67.26 | 93.79 | 97.15 | 68.08 | 62.52 |
| 256 | 65.25 | 93.96 | 97.21 | 66.65 | 60.92 |
| 512 | 65.58 | 93.51 | 97.40 | 66.88 | 61.04 |
| 1024 | 67.13 | 93.72 | 97.35 | 68.72 | 62.78 |
V. CONCLUSION
V. 结论
Identification network in this paper, called Cross-modal Local Shortest path and Batch Normalized Global Enhancement (CM-LSP-GE), which can mitigate cross-modal differences and resolve occlusion problems in images. Moreover, we introduce four different methods to facilitate the CM-LSPGE proposed in this paper, which are the attention-based twostream network, cross-modal local feature alignment based on the shortest path (CM-LSP),batch normalized global feature enhancement (GE) and the multi-granularity fusion loss.CMLSP can ensure that the model learns pedestrian details in the image without over fitting the background at a fine-grained level, while GE can enhance the global feature representation of the image at a coarse-grained level. Loss function guides network learning from global and local levels. Eventually, the accuracy is effectively improved, and our method achieves better results on RegDB and SYSU-MM01.
本文提出的识别网络称为跨模态局部最短路径与批量归一化全局增强 (CM-LSP-GE),能够缓解跨模态差异并解决图像中的遮挡问题。此外,我们引入了四种不同方法来优化本文提出的CM-LSPGE,分别是基于注意力的双流网络、基于最短路径的跨模态局部特征对齐 (CM-LSP)、批量归一化全局特征增强 (GE) 以及多粒度融合损失函数。CMLSP能确保模型在细粒度层面学习图像中的行人细节而不过度拟合背景,而GE可在粗粒度层面增强图像的全局特征表示。损失函数从全局和局部两个层面指导网络学习,最终有效提升了识别准确率,我们的方法在RegDB和SYSU-MM01数据集上取得了更优的结果。
REFERENCES
参考文献
Considering the important role of feature fusion of global and local features for the overall re-identification task accuracy improvement,we proposed a novel Visible-Thermal person re
考虑到全局和局部特征融合对整体重识别任务精度提升的重要作用,我们提出了一种新颖的可见光-热成像行人重识别方法