STARS: Self-supervised Tuning for 3D Action Recognition in Skeleton Sequences
STARS: 面向骨骼序列3D动作识别的自监督调优
Abstract
摘要
Self-supervised pre training methods with masked prediction demonstrate remarkable within-dataset performance in skeleton-based action recognition. However, we show that, unlike contrastive learning approaches, they do not produce well-separated clusters. Additionally, these methods struggle with generalization in few-shot settings. To address these issues, we propose Self-supervised Tuning for 3D Action Recognition in Skeleton sequences (STARS). Specifically, STARS first uses a masked prediction stage using an encoder-decoder architecture. It then employs nearest-neighbor contrastive learning to partially tune the weights of the encoder, enhancing the formation of semantic clusters for different actions. By tuning the encoder for a few epochs, and without using hand-crafted data augmentations, STARS achieves state-of-the-art selfsupervised results in various benchmarks, including NTU60, NTU-120, and PKU-MMD. In addition, STARS exhibits significantly better results than masked prediction models in few-shot settings, where the model has not seen the actions throughout pre training. Project page: https: //so roush meh rab an.github.io/stars/
基于掩码预测的自监督预训练方法在基于骨架的动作识别中展现出优异的同数据集性能。但我们发现,与对比学习方法不同,这类方法无法形成良好分离的特征簇。此外,这些方法在少样本场景下的泛化能力较弱。为解决这些问题,我们提出骨架序列3D动作识别的自监督调优框架STARS。具体而言,STARS首先通过编码器-解码器架构进行掩码预测预训练,随后采用最近邻对比学习对编码器权重进行局部调优,从而增强不同动作语义簇的形成。仅需少量epoch的调优且无需人工设计数据增强,STARS便在NTU60、NTU-120和PKU-MMD等多个基准测试中取得了最先进的自监督性能。此外,在预训练阶段未见过动作类别的少样本场景下,STARS的表现显著优于纯掩码预测模型。项目页面: https://soroushmehraban.github.io/stars/
1. Introduction
1. 引言
Human action recognition is receiving growing attention in computer vision due to its wide applications in the real world, such as security, human-machine interaction, medical assistance, and virtual reality [20, 32, 42, 45]. While some previous works have focused on recognizing actions based on appearance information, other approaches have highlighted the benefits of using pose information. In comparison to RGB videos, Representing videos of human activities with 3D skeleton sequences offers advantages in privacy preservation, data efficiency, and excluding extraneous details such as background, lighting variations, or diverse clothing types. Recent models for 3D action recognition based on skeleton sequences have demonstrated impressive results [5, 10, 11, 21]. However, these models heavily depend on annotations, which are labor-intensive and timeconsuming to acquire. Motivated by this, in this study, we investigate the self-supervised representation learning of 3D actions.
人体动作识别因其在安防、人机交互、医疗辅助和虚拟现实等领域的广泛应用,正受到计算机视觉领域越来越多的关注 [20, 32, 42, 45]。早期研究多基于外观信息进行动作识别,而近年方法则强调姿态信息的优势。相较于RGB视频,采用3D骨骼序列表示人体活动视频具有隐私保护性强、数据效率高、能排除背景干扰、光照变化及服装多样性等无关细节的特点。基于骨骼序列的3D动作识别模型近期已取得显著成果 [5, 10, 11, 21],但这些模型严重依赖人工标注数据,其获取过程费时费力。受此启发,本研究探索3D动作的自监督表征学习方法。
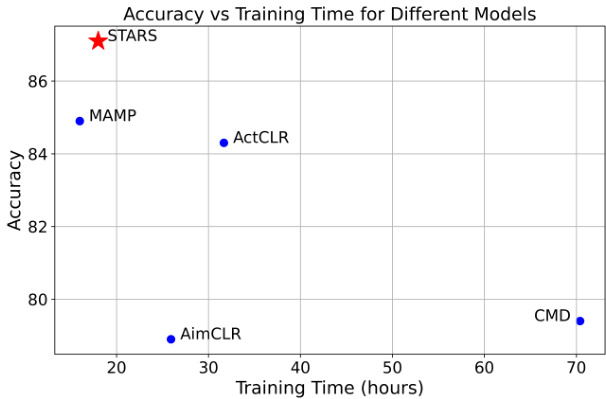
Figure 1. Comparison between training time and test-time accuracy on linear evaluation protocol. Training time is evaluated on a single NVIDIA GeForce RTX 3090 GPU.
图 1: 线性评估协议下训练时间与测试准确率的对比。训练时间在单块 NVIDIA GeForce RTX 3090 GPU 上评估。
Prior studies in self-supervised learning have employed diverse pretext tasks, such as predicting motion and recognizing jigsaw puzzles [24, 37, 49]. More recently, current research has shifted its focus towards contrastive learning [25, 29, 30] or Mask Autoencoders (MAE) [28, 43].
先前关于自监督学习的研究采用了多种代理任务,例如预测运动和识别拼图 [24, 37, 49]。最近,研究重点已转向对比学习 [25, 29, 30] 或掩码自编码器 (MAE) [28, 43]。
Contrastive learning approaches, although effective in learning representations, rely heavily on data augmentations to avoid focusing on spurious features. Without using data augmentations, they are prone to the problem of shortcut learning [14], leading to potential over fitting on extraneous features, such as a person’s height or the camera angle, which do not provide a valid cue to discriminate between different actions. As a result, some knowledge expert [40] is needed to design different augmentations of the same sequence; and methods that incorporate extreme augmentations in their pre training pipeline [16, 25] have shown significant improvements.
对比学习方法虽然在表征学习方面效果显著,但其高度依赖数据增强 (data augmentation) 来避免关注虚假特征。若不使用数据增强,这类方法容易陷入捷径学习 (shortcut learning) [14] 的问题,导致对外部特征(如人物身高或拍摄角度)的过拟合——这些特征并不能有效区分不同动作。因此,需要领域专家 [40] 来设计同一序列的不同增强版本;而采用极端增强策略的预训练方法 [16, 25] 已展现出显著性能提升。
MAE-based methods mask out a proportion of the input sequence and use an encoder-decoder architecture to reconstruct the missing information from the input based on the latent representation of unmasked regions. These approaches [28, 43] have recently outperformed their contrastive counterparts in within-dataset metrics. However, we show that representations learned by these models cannot separate different actions as effectively as contrastive learning-based methods in few-shot settings.
基于MAE的方法会遮蔽输入序列的一部分,并使用编码器-解码器架构根据未遮蔽区域的潜在表示来重建缺失信息。这些方法 [28, 43] 最近在数据集内指标上超越了对比学习方法。然而,我们发现这些模型学习到的表征在少样本设置下无法像基于对比学习的方法那样有效区分不同动作。
Despite the significant efforts that have been made, how to learn a more disc rim i native representation of skeletons is still an issue for skeleton-based action recognition. We believe that integrating MAE-based approaches with contrastive-learning methods can enhance the genera liza bility of representations, while preserving the strong performance of MAE models in within-dataset evaluations. To this end, we propose Self-supervised Tuning for 3D Action Recognition in Skeleton Sequences (STARS), a simple and efficient self-supervised framework for 3D action representation learning. It is a sequential approach that initially uses MAE as the pretext task. In the subsequent stage, it trains a contrastive head in addition to partially tuning the encoder for a few epochs, motivating the representation to form distinct and well-separated clusters. Fig. 1 shows that STARS requires significantly less resources during pretraining compared to contrastive learning approaches. In addition, STARS outperforms both MAE and contrastive learning approaches. In summary, our main contributions are as follows:
尽管已经付出了巨大努力,如何学习更具判别性的骨骼表征仍是基于骨骼动作识别的核心问题。我们认为将基于MAE的方法与对比学习方法相结合,既能保持MAE模型在数据集内评估中的优异性能,又能增强表征的泛化能力。为此,我们提出了骨骼序列3D动作识别的自监督调优框架STARS,这是一个简单高效的3D动作表征学习自监督框架。该框架采用分阶段策略:第一阶段以MAE作为前置任务;第二阶段在少量训练周期内,通过对比头训练与编码器部分调优,促使表征形成区分度良好的聚类簇。图1表明,STARS在预训练阶段所需的计算资源显著少于对比学习方法。此外,STARS在性能上同时超越了MAE和对比学习方法。我们的主要贡献可归纳为:
• We propose the STARS framework, a sequential approach that improves the MAE encoder output representation to create well-separated clusters, without any extra data augmentations, and with only a few epochs of contrastive tuning.
• 我们提出了STARS框架,这是一种通过改进MAE编码器输出表征来创建良好分离簇的序列化方法,无需任何额外数据增强,仅需少量对比调优周期。
• We show that, although MAE approaches excel in within-dataset evaluations, they exhibit a lack of genera liz ability in few-shot settings. Subsequently, we significantly enhance their few-shot capabilities while maintaining their strong within-dataset performance by employing our method.
• 我们发现,尽管MAE方法在数据集内评估中表现优异,但在少样本设置中展现出泛化能力不足的问题。随后,通过采用我们的方法,在保持其强大数据集内性能的同时,显著提升了它们的少样本能力。
• We validate the efficacy of our approach through extensive experiments and ablations on three large datasets for 3D skeleton-based action recognition, attaining state-of-the-art performance in most cases.
• 我们通过在三个大型3D骨架动作识别数据集上进行大量实验和消融研究,验证了方法的有效性,在多数情况下达到了最先进的性能水平。
2. Related Work
2. 相关工作
2.1. Self-supervised Skeleton-Based Action Recognition
2.1. 基于自监督的骨架动作识别
The objective of self-supervised action recognition is to train an encoder to discriminate sequences with different actions without providing any labels throughout the training. Methods such as LongTGAN [49] pretrain their model with 3D skeleton reconstruction using an encoder-decoder architecture; and P&C [37] improves the performance by employing a weak decoder. Color iz ation [46] represents the sequence as 3D point clouds and colorizes it based on the temporal and spatial orders in the original sequence.
自监督动作识别的目标是在整个训练过程中不提供任何标签的情况下,训练一个编码器来区分具有不同动作的序列。LongTGAN [49] 等方法使用编码器-解码器架构通过3D骨架重建预训练模型;P&C [37] 则通过采用弱解码器来提高性能。Colorization [46] 将序列表示为3D点云,并根据原始序列的时间和空间顺序对其进行着色。
Several studies explored various contrastive learning approaches, showing promising results [16, 23, 25, 29, 30]. CrosSCLR [23] applies the MoCo [17] framework and introduces cross-view contrastive learning. This approach aims to compel the model to maintain consistent decisionmaking across different views. AimCLR [16] improves the representation by proposing extreme augmentations. CMD [30] trains three encoders simultaneously and distills knowledge from one to another by introducing a new loss function. $\mathrm{I^{2}M D}$ [29] extends the CMD framework by introducing intra-modal mutual distillation, aiming to elevate its performance through incorporating local cluster-level contrasting. ActCLR [25] employs an unsupervised approach to identify actionlets, which are specific body areas involved in performing actions. The method distinguishes between actionlet and non-actionlet regions and applies more severe augmentations to non-actionlet regions.
多项研究探索了不同的对比学习方法,并展现出良好效果 [16, 23, 25, 29, 30]。CrosSCLR [23] 采用 MoCo [17] 框架并引入跨视图对比学习,旨在迫使模型在不同视图间保持一致的决策行为。AimCLR [16] 通过提出极端数据增强来改进表征质量。CMD [30] 同时训练三个编码器,并通过新设计的损失函数实现知识蒸馏。$\mathrm{I^{2}M D}$ [29] 在CMD框架基础上引入模态内互蒸馏机制,试图通过融入局部集群级对比来提升性能。ActCLR [25] 采用无监督方式识别动作元(actionlet),即执行动作时涉及的特定身体区域。该方法区分动作元与非动作元区域,并对非动作元区域施加更强烈的数据增强。
Recently, MAE-based approaches showed significant improvements. Skeleton MAE [43] reconstructs the spatial positions of masked tokens. MAMP [28] uses temporal motion as its reconstruction target and proposes a motionaware masking strategy. However, we show that MAEbased methods exhibit limited generalization in few-shot settings when compared to contrastive-learning based approaches.
最近,基于MAE的方法显示出显著改进。Skeleton MAE [43] 重建了被遮蔽token的空间位置。MAMP [28] 以时间运动作为重建目标,并提出了一种运动感知遮蔽策略。然而,我们发现与基于对比学习的方法相比,基于MAE的方法在少样本设置中表现出有限的泛化能力。
2.2. Combining Masked Auto encoders with Instance Discrimination
2.2. 结合掩码自编码器与实例判别
Some recent works in the image domain investigated the effect of combining MAE and Instance Discrimination (ID) methods [22, 31, 38, 41, 50]. iBOT [50] combines DINO [4] and BEiT [2] for the pretext task. RePre [41] extends the contrastive learning framework by adding pixel-level reconstruction loss. CAN [31] adds gaussian noise to the unmasked patches and it reconstructs the noise and masked patches, and adds a contrastive loss to the encoder output. MSN [1] aligns an image view featuring randomly masked patches with the corresponding unmasked image. SiameseIM [38] predicts dense representations from masked images in different views. MAE-CT [22] proposes a sequential training by adding contrastive loss after MAE training.
图像领域的一些近期工作研究了结合掩码自编码器 (MAE) 和实例判别 (Instance Discrimination, ID) 方法的效果 [22, 31, 38, 41, 50]。iBOT [50] 将 DINO [4] 和 BEiT [2] 结合用于预训练任务。RePre [41] 通过添加像素级重建损失扩展了对比学习框架。CAN [31] 向未掩码图像块添加高斯噪声,并重建噪声和掩码块,同时在编码器输出中添加对比损失。MSN [1] 将包含随机掩码块的图像视图与对应的未掩码图像对齐。SiameseIM [38] 从不同视图的掩码图像中预测密集表示。MAE-CT [22] 提出在 MAE 训练后添加对比损失进行序列训练。
Our work is a sequential self-supervised approach for pre training of skeleton sequences. It initially employs an MAE approach using an encoder-decoder architecture and further enhances the output representation of the encoder by tuning its weights using contrastive learning.
我们的工作提出了一种用于骨骼序列预训练的连续自监督方法。该方法首先采用基于编码器-解码器架构的MAE(Masked Autoencoder)方法,然后通过对比学习微调编码器权重来进一步增强其输出表征。
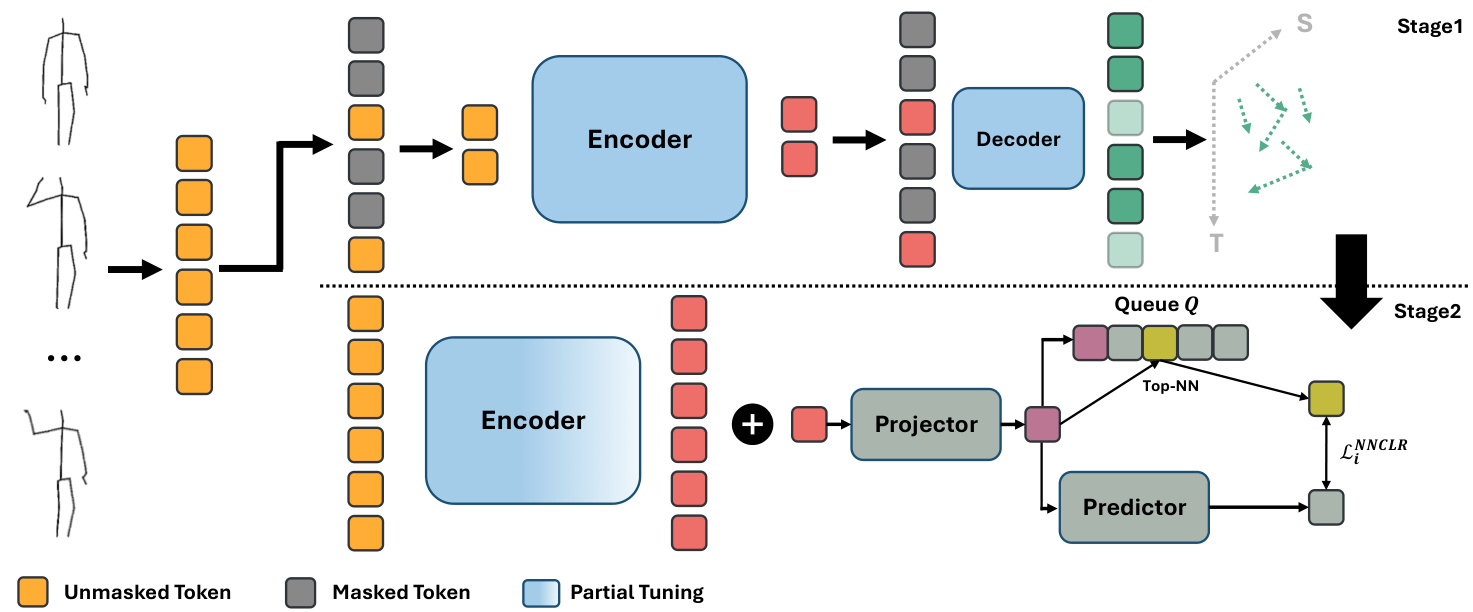
Figure 2. The overall pipeline of our proposed STARS framework. The first stage uses MAMP [28] to reconstruct the motion of masked tokens. The second stage trains parameters of the projector and predictor using a contrastive learning approach in addition to partially tuning the encoder weights.
图 2: 我们提出的STARS框架整体流程。第一阶段使用MAMP [28]重建被遮蔽token的运动。第二阶段通过对比学习方法训练投影器和预测器的参数,并部分调整编码器权重。
3. Method
3. 方法
3.1. Framework Overview
3.1. 框架概述
The overall framework of STARS is illustrated in Fig. 2. It is a sequential self-supervised approach consisting of two main stages. The first stage relies on an MAE-like framework to pretrain the weights of the encoder. We use MAMP [28] because it shows promising result in 3D ac- tion representation learning; however, any alternative MAEbased approach is also applicable. The next stage is designed to tune the parameters of the encoder using an instance discrimination method. Specifically, the second stage replaces the decoder with a projector and predictor [15]. It trains them in addition to the encoder using Nearest-Neighbor Contrastive Learning (NNCLR) [12] to converge to a representation capable of discriminating different sequences. This approach helps the encoder learn to output distinct clusters for different actions, improving its ability to discriminate between various sequences.
STARS的整体框架如图2所示。这是一种顺序自监督方法,包含两个主要阶段。第一阶段采用类似MAE的框架来预训练编码器权重。我们使用MAMP [28]方法,因为它在3D动作表征学习方面表现出色,但任何其他基于MAE的方法也同样适用。第二阶段旨在通过实例判别方法微调编码器参数。具体而言,该阶段将解码器替换为投影器和预测器 [15],并采用最近邻对比学习(NNCLR) [12] 同时训练它们与编码器,使模型收敛到能够区分不同序列的表征。这种方法帮助编码器学会为不同动作输出 distinct clusters,从而提升其区分各类序列的能力。
3.2. MAMP Pre-training (Stage 1)
3.2. MAMP 预训练 (阶段 1)
MAMP [28] uses a transformer encoder-decoder archi- tecture to reconstruct motions from the 3D skeleton sequence. It receives the input skeleton sequence $\begin{array}{r l}{S}&{{}\in}\end{array}$ $\bar{\mathbb{R}}^{T_{s}\times V\times C_{s}}$ , where $T_{s},V$ , and $C_{s}$ are the temporal length, number of joints, and coordinate channels, respectively. Next, the sequence is divided into non-overlapping segments $S^{\prime}\in\bar{\mathbb{R}^{T_{e}}}\times V\times l\cdot C_{s}$ , where $T_{e}=T_{s}/l$ and $l$ is the seg- ment length. This division results in having $T_{e}\times V$ tokens and reduces the temporal resolution by a factor of $l$ . Subsequently, the input joints are linearly projected into joint embedding $E\in\mathbb{R}^{T_{e}\times V\times C_{e}}$ where $C_{e}$ is the dimension of embedding features.
MAMP [28] 采用 Transformer 编码器-解码器架构从 3D 骨骼序列重建动作。其输入骨骼序列为 $\begin{array}{r l}{S}&{{}\in}\end{array}$ $\bar{\mathbb{R}}^{T_{s}\times V\times C_{s}}$ ,其中 $T_{s},V$ 和 $C_{s}$ 分别表示时间长度、关节数量和坐标通道数。随后,该序列被划分为无重叠片段 $S^{\prime}\in\bar{\mathbb{R}^{T_{e}}}\times V\times l\cdot C_{s}$ ,其中 $T_{e}=T_{s}/l$ , $l$ 为片段长度。此划分会生成 $T_{e}\times V$ 个 token ,并将时间分辨率降低 $l$ 倍。接着,输入关节通过线性投影转换为关节嵌入 $E\in\mathbb{R}^{T_{e}\times V\times C_{e}}$ ,其中 $C_{e}$ 为嵌入特征的维度。
As for the pre training objective and the masking strategy, MAMP leverages the motion information. Given an original sequence $S$ , the motion $M\in\mathbb{R}^{T_{s}\times V\times C_{s}}$ is derived by employing temporal difference on joint coordinates:
至于预训练目标和掩码策略,MAMP利用了运动信息。给定原始序列$S$,通过对关节坐标进行时间差分得到运动$M\in\mathbb{R}^{T_{s}\times V\times C_{s}}$:
$$
M_{i,:,:}=S_{i,:,:}-S_{i-m,:,:},\quad i\in m,m+1,...,T_{s}-1
$$
$$
M_{i,:,:}=S_{i,:,:}-S_{i-m,:,:},\quad i\in m,m+1,...,T_{s}-1
$$
where the step size of the motion is controlled by the hyperparameter $m$ . Specifically, MAMP uses a stride of $m=l$ to capture motion among different segments of the sequence.
运动步长由超参数 $m$ 控制。具体而言,MAMP采用 $m=l$ 的步长来捕捉序列不同区段间的运动。
For masking the input sequence based on the motion, the obtained motion $M$ should have the same dimension as the segmented sequence $S^{\prime}$ . Hence, the motion $M$ is padded by replicating the sequence and further reshaped into $M^{\prime}\in\mathbb{R}^{\bar{T_{e}}\times V\times l\times C_{s}}$ . Subsequently, to signify the importance of motion in each spatio-temporal segment, the motion intensity $I$ is calculated as follows:
为了基于运动对输入序列进行掩码处理,所获得的运动 $M$ 应与分割后的序列 $S^{\prime}$ 具有相同的维度。因此,通过复制序列对运动 $M$ 进行填充,并进一步重塑为 $M^{\prime}\in\mathbb{R}^{\bar{T_{e}}\times V\times l\times C_{s}}$。随后,为表征每个时空片段中运动的重要性,运动强度 $I$ 的计算方式如下:
$$
\begin{array}{r}{I=\displaystyle\sum_{i=0}^{l}\displaystyle\sum_{j=0}^{C_{i}}|M_{:,:,i,j}^{\prime}|\in\mathbb{R}^{T_{e}\times V},}\ {\quad\quad\quad\quad\quad\pi=\displaystyle\operatorname{Softmax}(I/\tau_{1}),}\end{array}
$$
$$
\begin{array}{r}{I=\displaystyle\sum_{i=0}^{l}\displaystyle\sum_{j=0}^{C_{i}}|M_{:,:,i,j}^{\prime}|\in\mathbb{R}^{T_{e}\times V},}\ {\quad\quad\quad\quad\quad\pi=\displaystyle\operatorname{Softmax}(I/\tau_{1}),}\end{array}
$$
where $\pi$ indicates the probability of masking each embedding feature, and $\tau_{1}$ is a temperature hyper parameter.
其中 $\pi$ 表示每个嵌入特征被掩码的概率,$\tau_{1}$ 是温度超参数。
Finally, to increase the diversity in mask selection, the Gumbel-Max trick is used:
最后,为了增加掩码选择的多样性,采用了Gumbel-Max技巧:
$$
\begin{array}{r}{g=-\log(-\log\epsilon),\epsilon\in U[0,1]^{T_{e}\times V},}\ {i d x^{\mathrm{mask}}=\mathrm{Index}\mathrm{-}\circ\pounds-\mathrm{Top}\mathrm{-}\mathrm{K}(\log\pi+g),}\end{array}
$$
$$
\begin{array}{r}{g=-\log(-\log\epsilon),\epsilon\in U[0,1]^{T_{e}\times V},}\ {i d x^{\mathrm{mask}}=\mathrm{Index}\mathrm{-}\circ\pounds-\mathrm{Top}\mathrm{-}\mathrm{K}(\log\pi+g),}\end{array}
$$
where $U[0,1]$ represents a uniform distribution ranging from 0 to 1, and $i d x^{\mathrm{mask}}$ denotes the masked indices.
其中 $U[0,1]$ 表示从0到1的均匀分布,$i d x^{\mathrm{mask}}$ 表示被遮蔽的索引。
On the joint embedding $E$ , spatio-temporal positional embedding is added and unmasked tokens are passed to the encoder. Following the computation of the encoder’s latent representations, learnable mask tokens are inserted to them according to the mask indices $i d x^{\mathrm{mask}}$ . The decoder then predicts the motion $M^{p r e d}$ and the reconstruction loss is computed by applying mean squared error (MSE) between the predicted motion M pred a nd the reconstruction target $M^{t a r g e t}$ , as follows:
在联合嵌入 $E$ 上添加时空位置嵌入,并将未掩码的token传递给编码器。计算编码器的潜在表示后,根据掩码索引 $i d x^{\mathrm{mask}}$ 向其中插入可学习的掩码token。解码器随后预测运动 $M^{p r e d}$ ,并通过在预测运动 $M^{pred}$ 与重建目标 $M^{target}$ 之间应用均方误差 (MSE) 来计算重建损失,如下所示:
$$
\mathcal{L}=\frac{1}{\lvert i d x^{\mathrm{mask}}\rvert}\sum_{(i,j)\in i d x^{\mathrm{mask}}}\lVert(M_{i,j,:}^{\mathrm{pred}}-M_{i,j,:}^{\mathrm{target}})\rVert_{2}^{2}.
$$
$$
\mathcal{L}=\frac{1}{\lvert i d x^{\mathrm{mask}}\rvert}\sum_{(i,j)\in i d x^{\mathrm{mask}}}\lVert(M_{i,j,:}^{\mathrm{pred}}-M_{i,j,:}^{\mathrm{target}})\rVert_{2}^{2}.
$$
3.3. Contrastive tuning (Stage 2)
3.3. 对比调优(第二阶段)
In the second stage, we replace the decoder with projection and prediction modules. The projection module aligns the encoder representation with a space targeted for contrastive loss. The prediction module takes one positive sample from a pair and generates a representation vector resembling the other sample in the positive pair to minimize the contrastive loss. More specifically, The encoder $f_{\theta}$ receives segmented sequence tokens $S^{\prime}$ and outputs representation tokens $Y_{\theta}=f_{\theta}(S^{\prime})$ . After applying average pooling of the output tokens, the projector $g_{\theta}$ aligns the result to the final representation vector $z_{\theta}=g_{\theta}(\bar{Y_{\theta}})$ . Following the NNCLR approach, vector $z_{\theta}$ is inserted into the queue $Q$ and is compared to sequence representations from previous iterations. From these representations, the top nearest neighbor is sampled as a positive sample in contrastive loss:
在第二阶段,我们用投影和预测模块替换了解码器。投影模块将编码器表示与对比损失的目标空间对齐。预测模块从正样本对中选取一个样本,生成与正样本对中另一个样本相似的表示向量,以最小化对比损失。具体来说,编码器 $f_{\theta}$ 接收分段序列 token $S^{\prime}$ 并输出表示 token $Y_{\theta}=f_{\theta}(S^{\prime})$。对输出 token 进行平均池化后,投影器 $g_{\theta}$ 将结果对齐到最终表示向量 $z_{\theta}=g_{\theta}(\bar{Y_{\theta}})$。根据 NNCLR 方法,向量 $z_{\theta}$ 被插入队列 $Q$,并与之前迭代的序列表示进行比较。从这些表示中,采样出最接近的邻居作为对比损失中的正样本:
$$
\mathbf{NN}(z,Q)=\arg\operatorname*{min}{q\in Q}||z-q||_{2}
$$
$$
\mathbf{NN}(z,Q)=\arg\operatorname*{min}{q\in Q}||z-q||_{2}
$$
Concurrently, the feature vector $z_{\theta}$ is given to predictor module to output the feature $z_{\theta}^{+}$ . Next, given positive pairs $(\mathbf{NN}(z,Q),z^{+})$ , we have:
同时,特征向量 $z_{\theta}$ 被输入预测模块以输出特征 $z_{\theta}^{+}$。接着,给定正样本对 $(\mathbf{NN}(z,Q),z^{+})$,我们得到:
$$
\mathcal{L}{i}^{\mathrm{NNCLR}}=-\log\frac{\exp\left(\mathrm{NN}(z_{i},Q)\cdot z_{i}^{+}/\tau_{2}\right)}{\sum_{k=1}^{n}\exp\left(\mathrm{NN}(z_{i},Q)\cdot z_{k}^{+}/\tau_{2}\right)}
$$
$$
\mathcal{L}{i}^{\mathrm{NNCLR}}=-\log\frac{\exp\left(\mathrm{NN}(z_{i},Q)\cdot z_{i}^{+}/\tau_{2}\right)}{\sum_{k=1}^{n}\exp\left(\mathrm{NN}(z_{i},Q)\cdot z_{k}^{+}/\tau_{2}\right)}
$$
where $\tau_{2}$ is a fixed temperature hyper parameter, $i$ is the sample index in batch of data, and $n$ is the batch size. Notably, in contrast to other contrastive learning approaches, our method operates more effectively with a single, unaltered view of the sequence, without relying on two different augmented views. Additionally, we show (later, in Fig. 4) that after training these two modules, the predictor output representation forms better cluster separation compared to the encoder trained with MAMP framework in previous stage.
其中 $\tau_{2}$ 是一个固定的温度超参数,$i$ 是数据批次中的样本索引,$n$ 是批次大小。值得注意的是,与其他对比学习方法不同,我们的方法仅需对序列进行单一未修改的视图即可更有效地运行,而无需依赖两种不同的增强视图。此外,我们(后文在图 4 中)将展示,在训练完这两个模块后,预测器输出的表征相比前一阶段使用 MAMP 框架训练的编码器能形成更好的聚类分离。
In addition to projector and predictor modules, we partially tune the encoder parameters to produce well-separated clusters. Specifically, we use layer-wise learning rate decay [7] to tune the second-half of the encoder parameters. This is formulated as:
除了投影器和预测器模块外,我们还对编码器参数进行部分微调以生成分离良好的聚类。具体来说,我们采用分层学习率衰减 [7] 来调整编码器的后半部分参数。其公式如下:
$$
\begin{array}{r}{L R_{i}=B a s e L R*\alpha^{(N-i)}}\end{array}
$$
$$
\begin{array}{r}{L R_{i}=B a s e L R*\alpha^{(N-i)}}\end{array}
$$
where $L R_{i}$ denotes learning rate of the $i^{\mathrm{th}}$ layer, $\alpha$ is the learning rate decay, and $N$ is the total number of layers.
其中 $LR_{i}$ 表示第 $i^{\mathrm{th}}$ 层的学习率,$\alpha$ 是学习率衰减系数,$N$ 是总层数。
4. Experiments
4. 实验
4.1. Datasets
4.1. 数据集
NTU-RGB $\mathbf{+D}$ 60 [35] is a large-scale dataset containing 56,880 3D skeleton sequences of 40 subjects performing 60 actions. In this study, we use the recommended crosssubject (X-sub) and cross-view (X-view) evaluation protocols. In the cross-subject scenario, half of the subjects are selected for the training set, and the remaining subjects are used for testing. For the cross-view evaluation, sequences captured by cameras 2 and 3 are employed for training, while camera 1 sequences are used for testing.
NTU-RGB $\mathbf{+D}$ 60 [35] 是一个大规模数据集,包含40名受试者执行60种动作的56,880个3D骨骼序列。在本研究中,我们采用推荐的跨受试者 (X-sub) 和跨视角 (X-view) 评估方案。在跨受试者场景中,选择一半受试者作为训练集,其余受试者用于测试。对于跨视角评估,使用摄像头2和3拍摄的序列进行训练,摄像头1的序列用于测试。
NTU-RGB $\mathbf{+D}$ 120 [27] is the extended version of NTU60, in which 106 subjects perform 120 actions in 114,480 skeleton sequences. The authors also substitute the crossview evaluation protocol with cross-setup (X-set), where sequences are divided into 32 setups based on camera distance and background. Samples from half of these setups are selected for training and the rest for testing.
NTU-RGB $\mathbf{+D}$ 120 [27] 是 NTU60 的扩展版本,其中 106 名受试者在 114,480 个骨骼序列中执行了 120 个动作。作者还将跨视角 (cross-view) 评估协议替换为跨设置 (X-set) 协议,根据相机距离和背景将序列划分为 32 种设置。其中一半设置的样本用于训练,另一半用于测试。
PKU-MMD [26] contains around 20,000 skeleton sequences of 52 actions. We follow the cross-subject protocol, where the training and testing sets are split based on subject ID. The dataset contains two phases: PKU-I and PKU-II. The latter is more challenging because of more noise introduced by larger view variations, with 5,332 sequences for training and 1,613 for testing.
PKU-MMD [26] 包含约20,000个骨骼动作序列,涵盖52种行为。我们采用跨受试者协议,根据受试者ID划分训练集和测试集。该数据集包含两个阶段:PKU-I和PKU-II。后者由于更大的视角变化引入更多噪声而更具挑战性,其中训练集包含5,332个序列,测试集包含1,613个序列。
4.2. Experimental Setup
4.2. 实验设置
Data Preprocessing: From an initial skeleton sequence, a consecutive segment is randomly trimmed with a proportion $p$ , where $p$ is sampled from the range [0.5, 1] during training and, similar to [28], remains fixed at 0.9 during testing. Subsequently, the segment is resized to a consistent length $T_{s}$ using bilinear interpolation. By default, $T_{s}$ is set to 120.
数据预处理:从初始骨架序列中,随机裁剪一个连续片段,比例为 $p$,其中 $p$ 在训练时从范围[0.5, 1]中采样,测试时则与[28]类似固定为0.9。随后,使用双线性插值将该片段调整为固定长度 $T_{s}$。默认情况下,$T_{s}$ 设为120。
Network Architecture: We adpoted the same network architecture as MAMP [28]. It uses a vanilla vision transformer (ViT) [9] as the backbone with $L_{e}=8$ transformer blocks and temporal patch size of 4. In each block, the embedding dimension is 256, number of multi-head attentions is 8, and hidden dimension of the feed-forward network is 1024. It also incorporates two spatial and temporal positional embeddings into the embedded inputs. The decoder used in first stage is similar to the transformer encoder except that it has $L_{d}~=~5$ layers. In the contrastive tuning modules used in the second stage, the projector module is solely a Batch Normalization [19], given the relatively small size of the 256-dimensional embedding space. The predictor module consists of a feed-forward network with a single hidden layer sized at 4096.
网络架构:我们采用了与MAMP [28]相同的网络架构。该架构使用标准视觉Transformer (ViT) [9]作为主干网络,包含$L_{e}=8$个Transformer块,时间块大小为4。每个块中,嵌入维度为256,多头注意力数量为8,前馈网络的隐藏维度为1024。该架构还将空间和时间位置嵌入整合到输入嵌入中。第一阶段使用的解码器与Transformer编码器类似,但具有$L_{d}~=~5$层。在第二阶段使用的对比调优模块中,考虑到256维嵌入空间相对较小,投影模块仅包含批归一化(Batch Normalization) [19]。预测模块则由一个单隐藏层的前馈网络组成,隐藏层大小为4096。
Pre-training: The first stage follows the same setting as MAMP [28]. For the second stage, we use the AdamW op- timizer with weight decay 0.01, betas (0.9, 0.95), and learning rate 0.001. In the second stage, we train the projection and prediction modules in addition to finetuning the encoder for 20 epochs. We employ layer-wise learning rate decay with a decay rate of 0.20. All the pre training experiments are conducted using PyTorch on four NVIDIA A40 GPUs with a batch size of 32 per GPU.
预训练:第一阶段遵循与 MAMP [28] 相同的设置。第二阶段,我们使用 AdamW 优化器,权重衰减为 0.01,betas 参数为 (0.9, 0.95),学习率为 0.001。在第二阶段,除了对编码器进行 20 个 epoch 的微调外,我们还训练投影和预测模块。我们采用分层学习率衰减策略,衰减率为 0.20。所有预训练实验均在四块 NVIDIA A40 GPU 上使用 PyTorch 完成,每块 GPU 的批次大小为 32。
4.3. Evaluation and Comparison
4.3. 评估与比较
In all evaluation protocols, we report on STARS, the method proposed in section 3, as well as STARS-3stage. STARS-3stage involves a three-stage pre training process. The second stage is divided into two parts: the Head Initi aliz ation stage, where only the projector and predictors are trained, and the contrastive tuning stage, where the encoder is fine-tuned along with the head modules. More details can be found in the supplementary materials.
在所有评估协议中,我们报告了第3节提出的STARS方法以及STARS-3stage。STARS-3stage采用三阶段预训练流程:第二阶段分为两部分——仅训练投影器和预测器的头部初始化阶段(Head Initialization stage),以及对编码器与头部模块联合微调的对比调优阶段(contrastive tuning stage)。更多细节详见补充材料。
Linear Evaluation Protocol: In this protocol, the weights of the pretrained backbone are frozen and a linear classifier is trained with supervision to evaluate the linearse par ability of the learned features. We train the linear classifier for 100 epochs with a batch size of 256 and a learning rate of 0.1, which is decreased to 0 by a cosine decay schedule. We evaluate the performance on the NTU60, NTU-120, and PKU-II datasets. As shown in Tab. 1, our proposed STARS outperforms other methods on both NTU benchmarks. On the PKU-II dataset, STARS achieves second-best result, and SkeAttnCLR [18] outperforms it using a three-stream input method.
线性评估协议:在该协议中,预训练骨干网络的权重被冻结,并通过监督训练一个线性分类器来评估所学特征的线性可分能力。我们以256的批量大小和0.1的学习率训练线性分类器100个周期,学习率通过余弦衰减计划降至0。我们在NTU60、NTU-120和PKU-II数据集上评估性能。如表1所示,我们提出的STARS在两个NTU基准测试中均优于其他方法。在PKU-II数据集上,STARS取得了第二好的结果,而SkeAttnCLR [18] 通过三流输入方法表现更优。
KNN Evaluation Protocol: An alternative way to evaluate the pretrained encoder is by directly applying a KNearest Neighbor (KNN) classifier to their output features. Following other works [29, 30, 37], each test sequence is compared to all training sequences using cosine similarity and the test prediction is based on the label of the most similar neighbor (i.e. KNN with $\mathrm{k}{=}1$ ). Tab. 2 compares different methods using KNN evaluation protocol. Notably, we find that MAMP cannot achieve competitive results compared to contrastive learning models, despite showing superior results on linear evaluation. We believe that this is because of the pre training objective of contrastive learning models, which, by pushing different samples into different areas of the representation space, results in better-separated clusters. Our STARS approach leverages contrastive tuning to enhance the feature representation of MAMP, outperforming all other methods. This demonstrates the superiority of contrastive tuning over contrastive learning approaches.
KNN评估协议:另一种评估预训练编码器的方法是直接对其输出特征应用K最近邻 (KNN) 分类器。遵循其他研究 [29, 30, 37],每个测试序列通过余弦相似度与所有训练序列进行比较,测试预测基于最相似邻居的标签 (即 KNN 设置 $\mathrm{k}{=}1$)。表 2 使用KNN评估协议比较了不同方法。值得注意的是,我们发现尽管MAMP在线性评估中表现出优越结果,但与对比学习模型相比仍无法取得竞争力。我们认为这是由于对比学习模型的预训练目标通过将不同样本推入表示空间的不同区域,从而形成更分离的簇。我们的STARS方法利用对比调优增强MAMP的特征表示,超越了所有其他方法。这证明了对比调优相对于对比学习方法的优越性。
Fine-tuned Evaluation Protocol: We follow MAMP and by adding MLP head on the pretrained backbone, the whole network is fine-tuned for 100 epochs with batch size of 48. The learning rate starts at 0 and is gradually raised to 3e-4 during the initial 5 warm-up epochs, after which it is reduced to 1e-5 using a cosine decay schedule. As shown in Tab. 3, both MAMP and STARS notably enhance the performance of their transformer encoder without pretraining. However, these results indicate that contrastive tuning following MAMP pre training does not impact the fine-tune evaluation, and MAMP and STARS achieve nearly identical results, both outperforming other approaches.
微调评估协议:我们遵循MAMP方法,在预训练骨干网络上添加MLP头部后,使用批量大小为48对整个网络进行100轮微调。学习率初始为0,在前5轮预热阶段逐步提升至3e-4,随后采用余弦衰减计划降至1e-5。如表3所示,MAMP和STARS均显著提升了未预训练的Transformer编码器性能。但结果表明,MAMP预训练后的对比微调不会影响最终评估效果,且MAMP与STARS取得近乎相同的结果,二者均优于其他方法。
Transfer Learning Protocol: In this protocol, the transferability of the learned representation is evaluated. Specifically, the encoder undergoes pre training on a source dataset using a self-supervised approach, followed by fine-tuning on a target dataset through a supervised method. In this study, NTU-60 and NTU-120 are selected as the source datasets, with PKU-II chosen as the target dataset. Tab. 4 shows that when fine-tuned on a new dataset, masked prediction techniques like Skeleton MAE and MAMP demonstrate superior transfer ability compared to contrastive learning methods. Moreover, STARS enhances performance when pre-trained on NTU-60, but its effectiveness diminishes when pre-trained on NTU-120.
迁移学习协议:该协议用于评估学习表征的可迁移性。具体而言,编码器先在源数据集上通过自监督方法进行预训练,再通过监督方法在目标数据集上进行微调。本研究选用NTU-60和NTU-120作为源数据集,PKU-II作为目标数据集。表4显示,在新数据集上微调时,Skeleton MAE和MAMP等掩码预测技术相比对比学习方法展现出更优的迁移能力。此外,STARS在NTU-60上预训练时性能有所提升,但在NTU-120上预训练时效果会减弱。
Few-shot Evaluation Protocol: This protocol evaluates the scenario where only a small number of samples are labeled in the target dataset. This is crucial in practical applications like education, sports, and healthcare, where actions may not be clearly defined in publicly available datasets. In this protocol, we pretrain the model on NTU-60 (XSub) and evaluate it on the evaluation set of 60 novel actions on NTU120 (XSub) using $n$ labeled sequences for each class in $n$ - shot setting. For the evaluation, we calculate the cosine distance between the test sequences and the exemplars, and use $n$ -nearest neighbors to determine the action. Tab. 5 compares different methods in the few-shot settings. Notably, MAMP demonstrates poor generalization performance, in contrast to its robust performance in transfer learning and evaluations within the dataset. By applying contrastive tuning, STARS surpasses contrastive learning approaches in all settings, demonstrating its strength in various evaluations.
少样本评估协议:该协议评估目标数据集中仅有少量样本被标记的场景。这在教育、体育和医疗等实际应用中至关重要,因为这些领域的动作可能在公开数据集中没有明确定义。在此协议中,我们在NTU-60 (XSub)上预训练模型,并在NTU120 (XSub)的60个新动作评估集上使用每个类别$n$个标记序列进行$n$-shot设置评估。评估时,我们计算测试序列与范例之间的余弦距离,并采用$n$-最近邻方法判定动作。表5比较了少样本设置下的不同方法。值得注意的是,MAMP表现出较差的泛化性能,与其在迁移学习和数据集内评估中的稳健表现形成反差。通过应用对比调优,STARS在所有设置中均超越对比学习方法,展现了其在各类评估中的优势。
Table 1. Performance comparison on NTU-60, NTU-120, and PKU-MMD in the linear evaluation protocol. Single-stream: Joint. Threestream: Joint $^+$ Bone+Motion. The best and second-best accuracies are in bold and underlined, respectively. * indicates that result is reproduced using our GPUs.
表 1. 在线性评估协议下 NTU-60、NTU-120 和 PKU-MMD 的性能对比。单流: 关节。三流: 关节 $^+$ 骨骼+运动。最佳和次佳准确率分别用粗体和下划线标出。* 表示该结果是使用我们的 GPU 复现的。
| 方法 | 输入 | NTU-60 XSub(%) | NTU-60 XView(%) | NTU-120 XSub(%) | NTU-120 XSet(%) | PKU-II XSub(%) |
|---|---|---|---|---|---|---|
| 其他预训练任务: | ||||||
| LongTGAN [49] | 单流 | 39.1 | 48.1 | 26.0 | ||
| 对比学习: | ||||||
| ISC [39] | 单流 | 76.3 | 85.2 | 67.1 | 67.9 | 36.0 |
| CrosSCLR [23] | 三流 | 77.8 | 83.4 | 67.9 | 66.7 | 21.2 |
| AimCLR [16] | 三流 | 78.9 | 83.8 | 68.2 | 68.8 | 39.5 |
| CPM [47] | 单流 | 78.7 | 84.9 | 68.7 | 69.6 | |
| PSTL [51] | 三流 | 79.1 | 83.8 | 69.2 | 70.3 | 52.3 |
| CMD [30] | 单流 | 79.4 | 86.9 | 70.3 | 71.5 | 43.0 |
| HaLP [34] | 单流 | 79.7 | 86.8 | 71.1 | 72.2 | 43.5 |
| HiCLR [48] | 三流 | 80.4 | 85.5 | 70.0 | 70.4 | |
| HiCo-Transformer [8] | 单流 | 81.1 | 88.6 | 72.8 | 74.1 | 49.4 |
| SkeAttnCLR [18] | 三流 | 82.0 | 86.5 | 77.1 | 80.0 | 55.5 |
| 1?MD [29] | 三流 | 83.4 | 88.0 | 73.1 | 74.1 | 49.0 |
| ActCLR [25] | 三流 | 84.3 | 88.8 | 74.3 | 75.7 | |
| 掩码预测: | ||||||
| SkeletonMAE [43] | 单流 | 74.8 | 77.7 | 72.5 | 73.5 | 36.1 |
| MAMP [28] | 单流 | 84.9 | 89.1 | 78.6 | 79.1 | 52.0* |
| 掩码预测+对比学习: | ||||||
| STARS-3stage (Ours) | 单流 | 86.3 | 90.7 | 79.3 | 80.6 | 52.2 |
| STARS (Ours) | 单流 | 87.1 | 90.9 | 79.9 | 80.8 | 52.7 |
Table 2. Performance comparison on NTU-60, NTU-120, and PKU-MMD in the KNN evaluation protocol $(\mathrm{K}{=}1)$ ).
表 2. 在 KNN 评估协议 $(\mathrm{K}{=}1)$ 下 NTU-60、NTU-120 和 PKU-MMD 的性能对比
| 方法 | NTU60 | NTU120 | ||
|---|---|---|---|---|
| XSub(%) | XView(%) | XSub(%) | XSet(%) | |
| P&C [37] | 50.7 | 75.3 | 42.7 | 41.7 |
| ISC [39] | 62.5 | 82.6 | 50.6 | 52.3 |
| MAMP [28] | 63.1 | 80.3 | 51.8 | 56.1 |
| CrosSCLR-B [23] | 66.1 | 81.3 | 52.5 | 54.9 |
| CMD [30] | 70.6 | 85.4 | 58.3 | 60.9 |
| 1°MD [29] | 75.9 | 83.8 | 62.0 | 64.7 |
| STARS-3Stage (Ours) | 76.9 | 88.0 | 65.7 | 68.0 |
| STARS (Ours) | 79.9 | 88.6 | 67.6 | 67.7 |
4.4. Ablation Study
4.4. 消融研究
Tuning Strategy Design: Tab. 6 compares the NNCLR strategy used in our STARS framework with DINO and MoCo. DINO [4] employs a student-teacher framework. It updates the student’s weights by relying on the teacher’s output, which is constructed using a momentum encoder, as the target. Unlike contrastive learning methods, DINO does not need negative samples for contrast and employs centring and sharpening techniques to prevent collapse. MoCo [17] is predominantly used by other contrastive learning approaches in action recognition [16, 23, 25]. It uses a memory bank to increase the negative samples in contrastive loss and a key encoder, which is updated via exponential moving average to maintain consistency. As shown in the Tab. 6, NNCLR significantly enhances KNN accuracy by forming better clusters for different actions, while not using any data augmentations. For the remaining two strategies, we also examined the impact of including augmentation through spatial flipping and rotation. Generally, adding augmentations helps the methods achieve better performance; espe- cially for MoCo, which relies on augmentations to construct the positive samples. Note that it is expected for the other two methods to further improve by incorporating more augmentations, which is not the focus of this study. Additional details about the hyper parameters in this ablation study are provided in the supplementary material.
调优策略设计:表 6 将我们的 STARS 框架中使用的 NNCLR 策略与 DINO 和 MoCo 进行了对比。DINO [4] 采用师生框架,通过依赖教师模型的输出(由动量编码器构建)作为目标来更新学生模型的权重。与对比学习方法不同,DINO 不需要负样本进行对比,并采用中心化和锐化技术防止崩溃。MoCo [17] 是动作识别领域其他对比学习方法 [16, 23, 25] 主要采用的方案,它通过记忆库增加对比损失中的负样本,并采用指数移动平均更新的键编码器来保持一致性。如表 6 所示,NNCLR 通过为不同动作形成更好的聚类显著提升了 KNN 准确率,且未使用任何数据增强。对于另外两种策略,我们还考察了加入空间翻转和旋转增强的影响。总体而言,添加增强有助于方法获得更好性能,特别是依赖增强构建正样本的 MoCo。需要注意的是,其他两种方法通过加入更多增强有望进一步提升性能,但这并非本研究重点。本消融实验中超参数的更多细节见补充材料。
Effect of Augmentation: Tab. 7 shows that applying augmentation results in a minor improvement in the KNN evaluation protocol. However, we chose not to use augmentation as our main method since the type of augmentation works heuristic ally and can result in different behavior in new scenarios, sometimes even degrading performance in cases such as shearing or axis masking. Additionally, we tested data augmentation on different evaluation protocols, such as linear evaluation, and did not observe any performance improvement.
增强效果的影响:表7显示,应用数据增强在KNN评估协议中仅带来小幅提升。但我们选择不将其作为主要方法,因为这类增强具有启发式特性,可能在新场景中导致不同行为(如剪切或轴掩码等情况下甚至会出现性能下降)。此外,我们在线性评估等其他协议上测试了数据增强,均未观察到性能提升。
Table 3. Performance comparison on NTU-60, NTU-120, and PKU-MMD in terms of the fine-tuning protocol. The best and second-best accuracies are in bold and underlined, respectively. * TF stands for Transformer.
表 3. NTU-60、NTU-120 和 PKU-MMD 在微调协议下的性能对比。最佳和次佳准确率分别用加粗和下划线标出。* TF 表示 Transformer (Transformer)。
| 方法 | 输入 | 主干网络 | NTU 60 XSub(%) | NTU 60 XView(%) | NTU 120 XSub(%) | NTU 120 XSet(%) |
|---|---|---|---|---|---|---|
| 其他预训练任务: | ||||||
| Colorization [46] | DGCNN | Three-stream | 88.0 | 94.9 | - | - |
| Hi-TRS [6] | Transformer | Three-stream | 90.0 | 95.7 | 85.3 | 87.4 |
| 对比学习: | ||||||
| CPM [47] | Single-stream | ST-GCN | 84.8 | 91.1 | 78.4 | 78.9 |
| CrosSCLR [23] | Three-stream | ST-GCN | 86.2 | 92.5 | 80.5 | 80.4 |
| 1²MD [29] | Single-stream | GCN-TF* | 86.5 | 93.6 | 79.1 | 80.3 |
| AimCLR [16] | Three-stream | ST-GCN | 86.9 | 92.8 | 80.1 | 80.9 |
| ActCLR [25] | Three-stream | ST-GCN | 88.2 | 93.9 | 82.1 | 84.6 |
| HYSP [13] | Three-stream | ST-GCN | 89.1 | 95.2 | 84.5 | 86.3 |
| 掩码预测: | ||||||
| SkeletonMAE [43] | Single-stream | STTFormer | 86.6 | 92.9 | 76.8 | 79.1 |
| SkeletonMAE [44] | Single-stream | STRL | 92.8 | 96.5 | 84.8 | 85.7 |
| MAMP [28] | Single-stream | Transformer | 93.1 | 97.5 | 90.0 | 91.3 |
| 掩码预测 + 对比学习: | ||||||
| W/o pre-training | Single-stream | Transformer | 83.1 | 92.6 | 76.8 | 79.7 |
| STARS-3stage (Ours) | Single-stream | Transformer | 93.2 | 97.5 | 89.8 | 91.3 |
| STARS (Ours) | Single-stream | Transformer | 93.0 | 97.5 | 89.9 | 91.4 |
Table 4. Performance comparison in the transfer learning protocol, where the source datasets are NTU-60 and NTU-120, and the target dataset is PKU-II.
表 4: 迁移学习协议下的性能对比,其中源数据集为 NTU-60 和 NTU-120,目标数据集为 PKU-II。
| 方法 | To PKU-II |
|---|---|
| NTU 60 | |
| LongTGAN [49] | 44.8 |
| MS2L [24] | 45.8 |
| ISC [39] | 51.1 |
| CMD [30] | 56.0 |
| HaLP+CMD [34] | 56.6 |
| SkeletonMAE [43] | 58.4 |
| MAMP [28] | 70.6 |
| STARS-3stage (Ours) | 71.8 |
| STARS (Ours) | 71.9 |
Layer-wise Learning Rate Decay: As shown in Fig. 3 (a), we observe a decrease in accuracy with higher learning decay. Our hypothesis is that increasing the decay causes the encoder to forget the robust representations learned in the initial stage, leading to performance degradation comparable to contrastive learning methods.
分层学习率衰减 (Layer-wise Learning Rate Decay):如图 3 (a) 所示,我们观察到随着学习率衰减幅度增大,准确率会下降。我们的假设是:增大衰减幅度会导致编码器遗忘初始阶段学习到的鲁棒特征表示,从而导致性能下降至与对比学习方法相当的水平。
Table 5. Performance comparison in the few-shot settings, where the model is pretrained on NTU-60 XSub and tested on 60 new samples of NTU-120 XSub.
表 5: 少样本设置下的性能对比,模型在NTU-60 XSub上预训练并在NTU-120 XSub的60个新样本上测试。
| Method | 1-shot | 2-shot | 5-shot |
|---|---|---|---|
| MAMP[28] | 47.6 | 44.4 | 48.4 |
| AimCLR [16] | 48.9 | 45.9 | 51.1 |
| HiCLR [48] | 51.7 | 49.6 | 53.8 |
| ISC [39] | 55.4 | 53.3 | 57.1 |
| HiCo-Transformer[8] | 60.0 | 58.2 | 60.9 |
| CMD [30] | 61.2 | 58.2 | 61.3 |
| STARS-3stage(Ours) | 59.3 | 57.8 | 61.5 |
| STARS (Ours) | 63.5 | 62.2 | 65.7 |
Queue size: Fig. 3 (b), shows that queue size has minimal influence in pre training, and 8k is used for all of our evaluations.
队列大小:图 3 (b) 显示队列大小在预训练阶段影响极小,我们所有评估均采用 8k 规模。
Qualitative Comparison: Fig. 4 compares the tSNE visualization of our proposed STARS method with AimCLR [16], CMD [30], HiCo-Transformer [8], and MAMP [28]. CMD adds cross-modal mutual distilla- tion loss to contrastive learning and by ensuring that various input modalities (joint, bone, and motion) exhibit the same neighborhood, it scatters actions across different areas of space and mitigates the impact of applying contrastive learning loss. On the other hand, AimCLR and
定性比较:图 4 将我们提出的 STARS 方法与 AimCLR [16]、CMD [30]、HiCo-Transformer [8] 和 MAMP [28] 的 tSNE 可视化结果进行了对比。CMD 在对比学习中加入了跨模态互蒸馏损失,通过确保不同输入模态(关节、骨骼和运动)具有相同的邻域关系,将动作分散在空间的不同区域,从而减轻了应用对比学习损失的影响。而 AimCLR 和
Table 6. Ablation study on the tuning strategy. The performance is evaluated on the NTU-60 XSub and NTU-60 XView datasets under the KNN evaluation protocol $(\mathrm{K}{=}10)$ .
表 6: 调优策略消融研究。性能评估基于NTU-60 XSub和NTU-60 XView数据集,采用KNN评估方案 $(\mathrm{K}{=}10)$ 。
| 调优策略 | NTU-60 XSub XView |
|---|---|
| DINO | 77.6 86.3 |
| DINO aug | 77.4 86.7 |
| MoCo | 72.2 86.7 |
| MoCoaug | 73.9 88.0 |
| NNCLR | 81.9 89.6 |
Table 7. Ablation study on the effect of augmentation. The performance is evaluated on the NTU-60 XSub and NTU-60 XView datasets under the KNN evaluation protocol $\scriptstyle(\mathrm{K}=10$ ).
表 7: 数据增强效果的消融研究。性能评估基于 NTU-60 XSub 和 NTU-60 XView 数据集,采用 KNN 评估协议 $\scriptstyle(\mathrm{K}=10$ ) 。
| 增强方式 | NTU-60 XSub | NTU-60 XView |
|---|---|---|
| Spatial Flip | 85.0 | 90.6 |
| Rotation | 84.8 | 90.1 |
| AxisMask | 81.2 | 89.0 |
| Shear | 83.2 | 90.4 |
| Spatial Flip + Rotation | 84.6 | 90.4 |
| No Augmentation | 84.5 | 89.6 |

Figure 3. Ablation study on (a) layer-wise learning decay (b) Queue size. The performance is evaluated on the NTU-60 XSub dataset under the KNN evaluation protocol $\scriptstyle(\mathrm{K}=10,$ ).
图 3: (a)分层学习衰减 (b)队列大小的消融研究。性能评估基于NTU-60 XSub数据集,采用KNN评估协议 $\scriptstyle(\mathrm{K}=10,$ )。
HiCo-Transformer create distinct clusters through the use of extreme augmentations and by applying contrastive loss at different hierarchical levels, respectively. When compared to MAMP, these two contrastive learning methods exhibit a higher inter-cluster distance than MAMP. Interestingly, actions involving interactions between two individuals, such as kicking, giving objects, and shaking hands, create a distinct higher-level cluster compared to actions involving a single person across various methods. Specifically, MAMP shows the highest distance between these two cluster groups, whereas within each group, the action clusters are closely situated. By employing contrastive tuning, STARS effectively minimizes intra-cluster distance (as seen in examples like sneeze/cough) while maximizing intercluster distance. This leads to the formation of clearly separated clusters, each representative of different actions.
HiCo-Transformer通过使用极端数据增强和在不同层级应用对比损失,分别创建了显著分离的聚类簇。与MAMP相比,这两种对比学习方法展现出更大的簇间距离。有趣的是,在所有方法中,涉及两人互动的动作(如踢腿、传递物品和握手)会形成明显的高层级聚类簇,而单人动作则分布在另一区域。具体而言,MAMP在这两类簇群间表现出最大距离,而每个簇群内部的动作聚类则紧密相邻。通过对比微调,STARS能有效最小化簇内距离(例如打喷嚏/咳嗽等动作)并最大化簇间距离,从而形成清晰分离、各自代表不同动作的聚类簇。

Figure 4. The t-SNE visualization of embedding features. We sample 15 action classes from the NTU-60 dataset and visualize the features extracted by our proposed STARS framework and compare it with AimCLR [16], CMD [30], HiCo-Transformer [8], and MAMP [28].
图 4: 嵌入特征的 t-SNE 可视化。我们从 NTU-60 数据集中采样了 15 个动作类别,并可视化由我们提出的 STARS 框架提取的特征,同时与 AimCLR [16]、CMD [30]、HiCo-Transformer [8] 和 MAMP [28] 进行了比较。
5. Conclusion
5. 结论
In this work, we proposed a sequential contrastive tuning method. We find that masked prediction methods, despite showing promising results in various within-dataset evaluations, cannot outperform contrastive learning based methods in few-shot settings. By using our STARS framework, we show that we can further enhance the masked prediction baseline while achieving competitive results in few-shot settings, outperforming other models in 5-shot setting. However, when the dataset size is limited for pre training and for evaluations when encoder is fine-tuned with supervision, STARS cannot add significant value to its baseline.
在本工作中,我们提出了一种序列对比调优方法。研究发现,尽管掩码预测方法在各类数据集内评估中表现良好,但在少样本设置下始终无法超越基于对比学习的方法。通过STARS框架,我们证明可以在提升掩码预测基线性能的同时,实现少样本场景下的竞争力表现——在5样本设置中超越了其他模型。然而,当预训练数据集规模受限或监督微调编码器时,STARS无法为其基线带来显著增益。
References
参考文献
A. 3-Stage Design
A. 三阶段设计
An alternative pre training method is to do it in 3 stages. Figure 5 shows the 3-stage design. Initially, when we initialize the projector and predictor modules, we freeze the encoder weights. In the second stage, we exclusively train the projector and predictor modules until they can effectively differentiate between different sequences using the NNCLR approach. Finally, in the third stage, we fine-tune the encoder weights using layer-wise learning rate decay.
另一种预训练方法是分三个阶段进行。图 5: 展示了三阶段设计。最初,在初始化投影器和预测器模块时,我们会冻结编码器的权重。第二阶段,我们专门训练投影器和预测器模块,直到它们能够使用 NNCLR 方法有效区分不同序列。最后,在第三阶段,我们使用分层学习率衰减对编码器权重进行微调。
B. Semi-supervised Evaluation Results
B. 半监督评估结果
In semi-supervised evaluation protocol, we follow previous works [23, 28, 30] and fine-tune the pretrained encoder in addition to a post-attached classifier while given a small fraction of the training dataset. Specifically, the performance on the NTU-60 is reported while using $1%$ and $10%$ of the training set. Since the training portions are selected randomly, we report the result averaged over 5 different runs as the final result. As shown in Tab. 9, STARS is more effective in all scenarios. Specifically, while using $1%$ of the training data, leading to an increase in accuracy for the MAMP baseline by $3.1%$ and $4.2%$ in cross-subject and cross-view evaluations, respectively.
在半监督评估协议中,我们遵循先前工作 [23, 28, 30],在给定小部分训练数据集的情况下,对预训练编码器和附加分类器进行微调。具体而言,当使用 $1%$ 和 $10%$ 的训练集时,报告了 NTU-60 的性能表现。由于训练部分是随机选择的,我们将 5 次不同运行的平均结果作为最终结果。如表 9 所示,STARS 在所有场景中都更为有效。具体而言,当使用 $1%$ 的训练数据时,MAMP 基线在跨主体和跨视角评估中的准确率分别提高了 $3.1%$ 和 $4.2%$。
Table 8. MoCo hyper parameters for ablation study in tuning strategy design.
表 8: MoCo消融研究中调优策略设计的超参数。
| 超参数 | 值 |
|---|---|
| 学习率 | 0.001 |
| 批大小 | 32 |
| 数据增强 | 镜像和旋转 |
| 队列大小 | 32,768 |
| 动量系数 | 0.999 |
| 温度参数 | 0.07 |
Table 9. Performance comparison on the NTU-60 dataset under the semi-supervised evaluation protocol, with the final performance reported as the average of five runs.
表 9. NTU-60数据集在半监督评估协议下的性能对比,最终性能报告为五次运行的平均值。
| 方法 | NTU-60 |
|---|---|
| XSub (1%) | |
| 其他前置任务: | |
| LongT GAN [49] | 35.2 |
| ASSL [36] 对比学习: | |
| MS?L [24] ISC [39] | 33.1 35.7 |
| 3s-CrosSCLR [23] 3s-Colorization [46] | 51.1 48.3 |
| CMD [30] | 50.6 |
| 3s-Hi-TRS [6] | 49.3 |
| 3s-AimCLR [16] | 54.8 |
| 3s-CMD [30] | 55.6 |
| CPM [47] | 56.7 |
| 掩码预测: | |
| SkeletonMAE [43] | |
| 54.4 | |
| MAMP [28] | 66.0 |
| 掩码预测 + 对比学习: | |
| STARS-3stage(本文) STARS (本文) | 68.6 69.1 |
C. Ablation Hyper-parameters
C. 消融实验超参数
Tab. 10 shows the hyper parameters used in DINOTuning strategy. For simplicity and because of limitation in resources, we used only two global views and did not use any local views in DINO. As shown in Tab. 11, we can see that incorporating local views led to a small improvement in performance. However, it came at the cost of significantly more resources. To be specific, we introduced two local views that randomly trimmed a section of the sequence between $40%$ and $80%$ and fed it only to the student network. With these additional views, we had to reduce the batch size to 16 and double the training time. Consequently, in our other experiments, we stuck to using only global views. We also used Sinkhorn-Knopp centering [3] a KoLeo regularizer [33] to help the convergence. Tab. 8 shows the hyperparameters used in MoCoTuning. Similar to previous approaches [16, 23], we used 32K as the queue size, 0.999 for the momentum and 0.07 for the temperature.
表 10 展示了 DINOTuning 策略中使用的超参数。出于简化和资源限制的考虑,我们仅使用了两个全局视图,而未在 DINO 中使用任何局部视图。如表 11 所示,引入局部视图带来了小幅性能提升,但代价是显著增加资源消耗。具体而言,我们引入了两个局部视图,随机截取序列中 $40%$ 至 $80%$ 的片段仅输入学生网络。由于这些额外视图,我们不得不将批量大小降至 16 并延长一倍训练时间。因此在其他实验中,我们坚持仅使用全局视图。我们还采用了 Sinkhorn-Knopp 中心化 [3] 和 KoLeo 正则化器 [33] 来促进收敛。表 8 列出了 MoCoTuning 使用的超参数,与先前方法 [16, 23] 类似,我们设置队列大小为 32K、动量系数为 0.999、温度参数为 0.07。
C.1. Algorithm psuedo code
C.1. 算法伪代码
Algorithm 1 demonstrates the process in PyTorch-style pseudo code.
算法 1 展示了 PyTorch 风格的伪代码流程。

Figure 5. The overall pipeline of our proposed STARS-3stage framework. The first stage uses MAMP [28] to reconstruct the motion of masked tokens. The second stage keeps the encoder parameters frozen and trains parameters of the projector and predictor using a contrastive learning approach. After these parameters have converged to well-separated clusters, the third stage involves partial-tuning of the encoder parameters. Algorithm 1 PyTorch-style pseudo-code of contrastive tuning in the second stage.
图 5: 我们提出的 STARS-3stage 框架整体流程。第一阶段使用 MAMP [28] 重建被遮蔽 token 的运动。第二阶段保持编码器参数冻结,通过对比学习方法训练投影器和预测器的参数。当这些参数收敛至良好分离的聚类后,第三阶段对编码器参数进行部分微调。算法 1: 第二阶段对比调优的 PyTorch 风格伪代码。
Table 10. DINOTuning hyper parameters for ablation study in tuning strategy design.
表 10: DINOTuning消融研究中的超参数设置(调优策略设计)
| 超参数 | 值 |
|---|---|
| 学习率 (Learning rate) | 0.001 |
| 批大小 (Batch size) | 32 |
| 数据增强 (Augmentations) | 镜像&旋转 |
| 中心化 (Centering) | Sinkhorn Knopp |
| KoLeo权重 | 0.1 |
| 全局视角数 (#Globalviews) | 2 |
| 局部视角数 (#Local views) | 0 |
| 学生温度 (Student temperature) | 0.1 |
| 教师温度 (Teacher temperature) | 0.04 |
| 教师动量 (Teacher momentum) | 0.996 |
Table 11. Effect of including local views on DINOTuning.
表 11: 包含局部视图对 DINOTuning 的影响
| 方法 | 10-NN | 20-NN | 40-NN |
|---|---|---|---|
| 不包含局部视图 | 77.4 | 77.1 | 77.0 |
| 包含局部视图 | 77.8 | 78.0 | 77.6 |
1 # f: MAMP Encoder. Only second-half is tuned. 2 # g: Projector. Batch normalization module 3 # h: Predictor. 2 layer MLP, hidden size 4096, output 256 4 # Q: Queue with length of 32,768 5 6 for x in loader: 7 y = f(x) # encoder forward pass 8 z = g(y) # projection forward pass 9 p = h(z) # prediction forward pass 10 z, p $=$ normalize(z, dim $=1$ ), normalize(p, dim $=1$ ) 11 nn $=$ top_nn(z, Q) # finding nearest-neighbor sample in Q 12 loss $=$ L(nn, p) 13 loss.backward() 14 optimizer.step() 15 update queue(Q, z) 16 17 18 def top_nn(z, Q): 19 similarities = z @ Q.T 20 idx $=$ similarities.max(dim $=1$ ) 21 return Q[idx] 22 23 def L(nn, p, temperatur $\div=0\cdot07$ ): 24 logits $=$ nn @ p.T 25 logits / $=$ temperature # sharpening 26 labels $=$ torch.arange(p.shape[0]) 27 loss $=$ cross entropy(logits, labels) 28 return loss
1 # f: MAMP编码器。仅后半部分进行调优
2 # g: 投影器。批归一化模块
3 # h: 预测器。2层MLP,隐藏层大小4096,输出256
4 # Q: 队列,长度32,768
6 for x in loader:
7 y = f(x) # 编码器前向传播
8 z = g(y) # 投影前向传播
9 p = h(z) # 预测前向传播
10 z, p $=$ normalize(z, dim $=1$), normalize(p, dim $=1$)
11 nn $=$ top_nn(z, Q) # 在Q中寻找最近邻样本
12 loss $=$ L(nn, p)
13 loss.backward()
14 optimizer.step()
15 update_queue(Q, z)
18 def top_nn(z, Q):
19 similarities = z @ Q.T
20 idx $=$ similarities.max(dim $=1$)
21 return Q[idx]
23 def L(nn, p, temperature $\div=0\cdot07$):
24 logits $=$ nn @ p.T
25 logits / $=$ temperature # 锐化
26 labels $=$ torch.arange(p.shape[0])
27 loss $=$ cross_entropy(logits, labels)
28 return loss
D. Confusion Matrix
D. 混淆矩阵
Fig. 6 illustrates the confusion matrix under KNN evaluation protocol when ${\tt K}\mathrm{=}10$ on NTU-60 XSub dataset. The errors depicted in the figure can be classified into two distinct categories. Firstly, there are errors stemming from a lack of contextual information. For instance, when only a skeletal sequence is provided, actions like ”play with phone/tablet” might be misinterpreted as ”reading” and ”writing.” Secondly, there are errors arising from subtle movements, such as distinguishing between ”clapping” and ”hand rubbing,” which pose challenges for the model in diffe rent i ation. In summary, these errors manifest due to either insufficient context or the intricacy of distinguishing minute actions, highlighting the complexities inherent in the task.
图 6: 展示了 NTU-60 XSub 数据集上 ${\tt K}\mathrm{=}10$ 时 KNN 评估协议下的混淆矩阵。图中所示的错误可分为两类:第一类源于上下文信息缺失,例如仅提供骨骼序列时,"玩手机/平板 (play with phone/tablet)" 可能被误判为 "阅读 (reading)" 和 "书写 (writing)";第二类由细微动作差异导致,例如区分 "鼓掌 (clapping)" 与 "搓手 (hand rubbing)" 对模型构成挑战。总体而言,这些错误反映了上下文不足或细微动作区分复杂性带来的任务固有难度。


Figure 6. Confusion matrix of KNN evaluation in NTU-60 XSub dataset $(\mathrm{k}{=}10)$ ).
图 6: NTU-60 XSub 数据集中 KNN 评估的混淆矩阵 $(\mathrm{k}{=}10)$ )。