Revealing Key Details to See Differences: A Novel Prototypical Perspective for Skeleton-based Action Recognition
揭示关键细节以识别差异:基于骨架的动作识别新原型视角
Abstract
摘要
In skeleton-based action recognition, a key challenge is distinguishing between actions with similar trajectories of joints due to the lack of image-level details in skeletal represent at ions. Recognizing that the differentiation of similar actions relies on subtle motion details in specific body parts, we direct our approach to focus on the fine-grained motion of local skeleton components. To this end, we introduce ProtoGCN, a Graph Convolutional Network (GCN)-based model that breaks down the dynamics of entire skeleton sequences into a combination of learnable prototypes representing core motion patterns of action units. By contrasting the reconstruction of prototypes, ProtoGCN can effectively identify and enhance the disc rim i native representation of similar actions. Without bells and whistles, ProtoGCN achieves state-of-the-art performance on multiple benchmark datasets, including NTU RGB+D, NTU RGB+D 120, Kinetics-Skeleton, and FineGYM, which demonstrates the effectiveness of the proposed method. The code is available at https://github.com/firework8/ProtoGCN.
在基于骨架的动作识别中,一个关键挑战是由于骨骼表示缺乏图像级细节,难以区分关节轨迹相似的动作。我们认识到相似动作的区分依赖于特定身体部位的细微运动细节,因此将方法重点放在局部骨架组件的细粒度运动上。为此,我们提出了ProtoGCN——一种基于图卷积网络(GCN)的模型,它将整个骨架序列的动态分解为可学习原型(prototype)的组合,这些原型代表动作单元的核心运动模式。通过对比原型重建,ProtoGCN能有效识别并增强相似动作的判别性表征。在未使用额外技巧的情况下,ProtoGCN在NTU RGB+D、NTU RGB+D 120、Kinetics-Skeleton和FineGYM等多个基准数据集上实现了最先进的性能,证明了该方法的有效性。代码已开源:https://github.com/firework8/ProtoGCN。
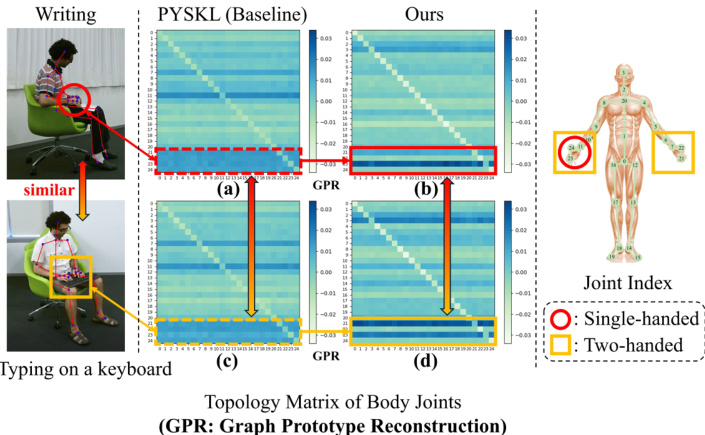
Figure 1. Illustration of the skeletons and learned topologies for similar actions Writing and Typing on a Keyboard (deeper color indicates stronger relationships between corresponding joints). As shown in (a) and (c), the baseline PYSKL [11] demonstrates its ability to focus on joints associated with hands, but falls short in revealing their distinctive motion characteristics. In contrast, the integration of the Graph Prototype Reconstruction mechanism facilitates a clearer differentiation between the two actions, as evidenced by the notably distinct motion patterns observed between (b) and (d). Please zoom in for a better view.
图 1: 相似动作"书写"与"键盘打字"的骨骼结构及学习到的拓扑关系示意图 (颜色越深表示对应关节间关联性越强)。如(a)和(c)所示,基线方法PYSKL [11]能聚焦手部相关关节,但未能揭示其差异化运动特征。相比之下,通过引入图原型重建(Graph Prototype Reconstruction)机制,(b)和(d)中观察到的显著差异运动模式证明该方法能更清晰区分这两个动作。建议放大查看细节。
1. Introduction
1. 引言
Human action recognition, a pivotal task with various realworld applications, has recently seen growing interest in skeleton-based methods due to their efficiency and robustness. Given the intrinsic graph structure of the human skeleton, Graph Convolutional Networks (GCNs) [6, 9, 19, 30, 40] are widely used to model the relationships between joints. However, despite their effectiveness in action recognition, these methods struggle to distinguish actions with similar motion patterns.
人体动作识别作为一项关键任务,在现实应用中具有广泛价值。近年来,基于骨骼数据的方法因其高效性和鲁棒性受到越来越多的关注。由于人体骨骼具有固有的图结构特性,图卷积网络 (GCNs) [6, 9, 19, 30, 40] 被广泛用于建模关节间的关系。然而,尽管这些方法在动作识别中表现优异,却难以区分具有相似运动模式的动作。
Specifically, existing methods face a key challenge in capturing the fine-grained details of crucial body parts, which are essential for distinguishing similar actions. Skeleton-based action recognition is primarily concerned with two tasks: identifying the key body parts involved and understanding their motion patterns. However, due to the lack of image-level information, current methods tend to capture coarse-grained motion patterns, effectively identifying the key parts but struggling to capture the subtle, discri mi native details that are crucial for distinguishing similar actions. This limitation arises because the patterns of similar actions often overlap significantly, with distinctive details representing only a small portion of the overall information, making it difficult for the classifier to differentiate between them.
具体而言,现有方法在捕捉关键身体部位的细粒度细节方面面临核心挑战,而这些细节对于区分相似动作至关重要。基于骨架的动作识别主要关注两个任务:识别涉及的关键身体部位和理解其运动模式。然而,由于缺乏图像层级信息,当前方法往往只能捕捉粗粒度的运动模式,虽能有效识别关键部位,却难以捕捉对区分相似动作起决定性作用的细微判别性细节。这一局限性的产生是因为相似动作的模式往往存在大量重叠,而具有区分性的细节仅占整体信息的一小部分,导致分类器难以有效区分它们。
As illustrated by the graph topologies in Fig. 1, PYSKL [11] successfully focuses on the hand-related joints when distinguishing between writing and typing on a keyboard. However, the high similarity between the graph topologies reveals its challenge in capturing the subtle distinctions in the motion characteristics of the attended joints. Specifically, in typing on a keyboard, both hands exhibit more balanced movement, whereas in writing, one hand is more actively engaged. Unfortunately, this difference is not well captured in the learned topologies shown in Fig. 1. Furthermore, intra-class variations, such as changes in viewpoint or motion amplitude, inevitably introduce noise into the acquired motion patterns. As a result, the task of capturing representative and disc rim i native motion features becomes more challenging, hindering the accurate classification of similar actions.
如图 1 中的图拓扑所示,PYSKL [11] 在区分写字和键盘打字时成功聚焦于手部相关关节。然而,图拓扑之间的高度相似性揭示了其在捕捉关注关节运动特征细微差异方面的挑战。具体而言,键盘打字时双手运动更平衡,而写字时单手活动更频繁。遗憾的是,图 1 所示的学习拓扑未能充分捕捉这一差异。此外,类内变化(如视角或运动幅度变化)不可避免地会为获取的运动模式引入噪声,这使得捕捉具有代表性且可区分的运动特征任务更具挑战性,从而阻碍了相似动作的准确分类。
The challenge outlined above has driven us to seek a represent ation that more effectively captures the intrinsic charact eris tics of actions with high disc rim i native power. To address this, we propose ProtoGCN, a novel graph prototype learning approach for skeleton-based action recognition. At the heart of ProtoGCN lies the Prototype Reconstruction Network, which explicitly enforces the representation to be formed as an associative combination of action prototypes stored in a memory module.
上述挑战促使我们寻求一种能更有效捕捉动作内在特征且具有高判别力的表征方式。为此,我们提出了ProtoGCN——一种基于骨架动作识别的创新图原型学习方法。ProtoGCN的核心是原型重建网络(Prototype Reconstruction Network),该网络显式强制表征由存储在记忆模块中的动作原型通过关联组合形成。
In specific, these prototypes represent diverse relationship patterns between all the human joints. The network samples and assembles the relevant prototypes via the associative response of input action features, producing the uniquely tailored representations. In addition, a motion topology enhancement module is incorporated to provide richer and more expressive features, facilitating prototype retrieval. Furthermore, we propose a class-specific contrastive learning strategy to accentuate the inter-class distinction, which compels the model to uncover distinctive prototypes to associate all action classes in the dataset. Such a prototype-based associative reconstruction process helps to enhance the disc rim i native capability of the resultant motion features and eliminate irrelevant distracting informa- tion. Both qualitative and quantitative analyses showcase the superior efficacy of ProtoGCN in acquiring discriminative representations and discerning similar actions.
具体而言,这些原型代表了人体所有关节之间的多样化关系模式。该网络通过输入动作特征的关联响应来采样并组装相关原型,生成定制化的独特表征。此外,我们引入了运动拓扑增强模块以提供更丰富、更具表现力的特征,从而促进原型检索。进一步地,我们提出了一种类特异性对比学习策略来强化类间差异,迫使模型发掘具有区分性的原型以关联数据集中的所有动作类别。这种基于原型的关联重建过程有助于增强最终运动特征的判别能力,并消除无关的干扰信息。定性与定量分析均表明ProtoGCN在获取判别性表征和区分相似动作方面具有卓越效能。
The main contributions are summarized as follows:
主要贡献总结如下:
• We introduce ProtoGCN, a novel graph prototype learning method that amplifies subtle distinctions for accurate differentiation of similar actions. • A Prototype Reconstruction Network is proposed to adaptively assemble prototypes, yielding distinctive representations under a contrastive objective. • Extensive experiments on four large-scale benchmarks (NTU $\mathrm{RGB}{+}\mathrm{D}$ , NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 120, Kinetics-Skeleton, and FineGYM) demonstrate that ProtoGCN consistently achieves state-of-the-art performance.
• 我们提出ProtoGCN,一种新颖的图原型学习方法,通过放大细微差异实现相似动作的精准区分。
• 提出原型重建网络 (Prototype Reconstruction Network),能够自适应地组装原型,在对比目标下生成具有区分度的表征。
• 在四个大规模基准数据集 (NTU $\mathrm{RGB}{+}\mathrm{D}$、NTU $\scriptstyle{\mathrm{RGB}}+{\mathrm{D}}$ 120、Kinetics-Skeleton和FineGYM) 上的大量实验表明,ProtoGCN始终达到最先进的性能水平。
2. Related Work
2. 相关工作
2.1. Skeleton-based Action Recognition with GCNs
2.1. 基于骨架的动作识别与图卷积网络 (GCNs)
Considering the intrinsic graph-like structure of human skeletons, the majority of GCN-based approaches [6, 7, 10, 25, 30, 40, 46] explicitly model the relationships using spatial-temporal graphs. ST-GCN [40] is the pioneering work integrating graph convolutions for comprehensive spatial-temporal modeling. Most subsequent studies adopt the main framework of ST-GCN and place greater emphasis on enhancing the capacity of GCNs. 2s-AGCN [30] proposes an adaptive GCN model to learn topological correlations. Following that, CTR-GCN [6] introduces the channel-wise graph convolution to explore topology-nonshared graphs. Similarly, InfoGCN [9] models contextdependent intrinsic topology, simultaneously leveraging an information-theoretic objective to represent latent information. HD-GCN [19] proposes the hierarchically decom- posed graph to model distant spatial relationships.
考虑到人体骨骼固有的图结构特性,大多数基于GCN的方法 [6, 7, 10, 25, 30, 40, 46] 都采用时空图显式建模关节点关系。ST-GCN [40] 是首个将图卷积网络应用于时空建模的开创性工作。后续研究大多沿袭ST-GCN的主体框架,更侧重于增强图卷积网络的表征能力。2s-AGCN [30] 提出自适应图卷积模型来学习拓扑关联;CTR-GCN [6] 随后引入通道式图卷积来探索非共享拓扑结构;InfoGCN [9] 则建模上下文相关的内在拓扑,同时利用信息论目标函数表征潜在信息;HD-GCN [19] 提出分层分解图结构以建模远距离空间关系。
Tracing the evolution of GCN-based approaches, the learning of graph topologies in GCNs plays a crucial role. Nevertheless, existing methods predominantly focus on general structural discrepancies in motion patterns, while frequently neglecting the nuanced details inherent in the motion features of specific key body parts. In contrast, we propose a novel graph prototype learning approach aimed at amplifying critical detail information and capturing nuanced motion patterns.
追溯基于GCN方法的演进历程,图拓扑结构的学习在GCN中起着关键作用。然而,现有方法主要关注运动模式中的通用结构差异,却常常忽视特定关键身体部位运动特征固有的细微细节。相比之下,我们提出了一种新颖的图原型学习方法,旨在增强关键细节信息并捕捉精细的运动模式。
2.2. Prototype Learning
2.2. 原型学习
Traditionally, prototype learning is a classical method that establishes a metric space and optimizes the most representative anchors from training data [20]. Due to the exemplardriven nature and simpler inductive bias, prototype learning has recently shown significant potential in a variety of tasks [26, 32, 34, 41, 42]. Interestingly, human vision itself deploys a remarkable prototyping ability, skillfully focusing on principal body joints while filtering out extraneous elements [13, 31]. In this context, we argue that movements of human body joints likewise exhibit noteworthy similarities, resulting in a collective of prototypes. Integrating prototype learning into the network facilitates the natural encapsulation of diverse dynamic characteristics, enhancing the capa- bility to discern similar actions.
传统上,原型学习 (prototype learning) 是一种经典方法,它通过建立度量空间并从训练数据中优化最具代表性的锚点 [20]。由于其示例驱动的特性以及更简单的归纳偏置,原型学习近年来在各种任务中展现出显著潜力 [26, 32, 34, 41, 42]。有趣的是,人类视觉本身就具备出色的原型化能力,能够巧妙聚焦于主要身体关节,同时过滤无关要素 [13, 31]。在此背景下,我们认为人体关节的运动同样表现出值得注意的相似性,从而形成原型集合。将原型学习融入网络,有助于自然封装多样化的动态特征,从而提升识别相似动作的能力。
Therefore, in this study, we employ prototype learning for diverse motion patterns through the utilization of the Prototype Reconstruction Network. Due to the considerable difficulty in directly learning highly detailed features for various actions, we represent them as combinations of learnable prototypes to highlight key information. The proposed method discovers and assembles the most representative prototypes, which can subsequently be employed to discern more fine-grained and distinct semantics.
因此,在本研究中,我们通过原型重建网络(Prototype Reconstruction Network)采用原型学习来捕捉多样化运动模式。由于直接学习各类动作的高度细节特征存在较大难度,我们将其表示为可学习原型的组合以突出关键信息。该方法能发现并组装最具代表性的原型,进而用于识别更细粒度、更具区分性的语义。
2.3. Contrastive Learning
2.3. 对比学习
Recently, contrastive learning has been widely applied in self-supervised learning studies [1, 5, 33]. Representative methods such as MoCo [15] and SimCLR [4], use the InfoNCE loss to pull the positive samples close while pushing them away from the negative samples in the embedding space. In skeleton-based action recognition, previous contrastive learning-based approaches [14, 21, 27, 43] concentrate on directly obtaining accurate skeleton representations. Under the supervised setting, these approaches [3, 16, 45] mainly focus on comparing the learned features to further optimize the model. Skeleton GCL [16] explicitly explores the global context across all sequences through contrastive learning. FR-Head [45] proposes contrastive feature refinement to obtain disc rim i native representations of skeletons. In contrast, we adopt the contrastive training objective as a form of regular iz ation, urging the reconstruction mechanism to identify and distinguish the distinctive prototypes.
最近,对比学习(contrastive learning)在自监督学习(self-supervised learning)研究中得到了广泛应用[1, 5, 33]。MoCo[15]和SimCLR[4]等代表性方法使用InfoNCE损失函数,在嵌入空间中将正样本拉近的同时使其远离负样本。在基于骨架的动作识别领域,先前基于对比学习的方法[14, 21, 27, 43]主要关注直接获取精确的骨架表征。在有监督设置下,这些方法[3, 16, 45]主要通过比较学习到的特征来进一步优化模型。Skeleton GCL[16]通过对比学习显式地探索所有序列间的全局上下文。FR-Head[45]提出对比特征精炼方法以获得骨架的判别性表征。与之不同,我们将对比训练目标作为一种正则化手段,促使重建机制识别并区分独特的原型。
3. Method
3. 方法
In this section, we first briefly introduce the preliminary concepts related to skeleton-based action recognition with GCNs, then provide a detailed description of the main components of ProtoGCN. An overview of the framework of ProtoGCN is presented in Fig. 2.
在本节中,我们首先简要介绍基于骨架的动作识别与图卷积网络 (GCN) 相关的初步概念,然后详细描述 ProtoGCN 的主要组成部分。图 2 展示了 ProtoGCN 框架的概览。
3.1. Preliminaries
3.1. 预备知识
Due to the intrinsic structural nature, the human skeleton is commonly represented as a graph $\mathcal{G}=(\mathcal{V},\mathcal{E})$ , where $\nu$ and $\mathcal{E}$ denote the joint and edge sets. The input skeleton sequence is represented as a feature tensor H ∈ RN×T ×C, where $N,T$ , and $C$ are the number of body joints, frames, and feature dimension, respectively. Generally, GCN models stacked graph convolutional layers ( $L$ layers in total) to extract the semantic feature of skeletons.
由于人体骨骼的固有结构特性,通常将其表示为图$\mathcal{G}=(\mathcal{V},\mathcal{E})$,其中$\nu$和$\mathcal{E}$分别表示关节点集合与边集合。输入骨骼序列以特征张量H ∈ RN×T ×C表示,其中$N,T$和$C$分别对应关节点数量、帧数及特征维度。一般而言,图卷积网络(GCN)通过堆叠多层图卷积层(共$L$层)来提取骨骼的语义特征。
For current adaptive methods, the translation function between the hidden variables in the $(l-1)^{\mathrm{th}}$ and $(l)^{\mathrm{th}}$ layer, i.e., $\mathbf{H}^{(l-1)}$ and $\mathbf{H}^{(l)}$ , can be formulated as
对于当前的自适应方法,$(l-1)^{\mathrm{th}}$ 层和 $(l)^{\mathrm{th}}$ 层隐藏变量之间的转换函数,即 $\mathbf{H}^{(l-1)}$ 和 $\mathbf{H}^{(l)}$,可以表示为
$$
\mathbf{H}^{(l)}=\sigma(\mathbf{A}^{(l)}\mathbf{H}^{(l-1)}\mathbf{W}^{(l)})
$$
$$
\mathbf{H}^{(l)}=\sigma(\mathbf{A}^{(l)}\mathbf{H}^{(l-1)}\mathbf{W}^{(l)})
$$
where ${\bf A}^{(l)}\in\mathbb{R}^{N\times N\times C}$ denotes the adaptive graph topology matrix, W(l) ∈ RC(l−1)×C(l) represents the learnable weight matrix utilized for feature projection, and $\sigma$ is the ReLU activation function 1. After obtaining the final hidden representation $\mathbf{H}^{(L)}$ , a classification network is employed to determine the prediction label $\hat{\mathbf{y}}\in\mathbb{R}^{c}$ ( $\mathit{\check{c}}$ denotes the total number of action classes). Finally, a cross-entropy loss $\mathcal{L}_{C E}$ is used to supervise the predicted action class
其中 ${\bf A}^{(l)}\in\mathbb{R}^{N\times N\times C}$ 表示自适应图拓扑矩阵,W(l) ∈ RC(l−1)×C(l) 代表用于特征投影的可学习权重矩阵,$\sigma$ 是 ReLU 激活函数。在获得最终隐藏表示 $\mathbf{H}^{(L)}$ 后,使用分类网络确定预测标签 $\hat{\mathbf{y}}\in\mathbb{R}^{c}$ ( $\mathit{\check{c}}$ 表示动作类别总数)。最后采用交叉熵损失 $\mathcal{L}_{C E}$ 监督预测动作类别
$$
\mathcal{L}{C E}=-\sum_{i}^{c}\mathbf{y_{i}}\log\hat{\mathbf{y_{i}}}
$$
$$
\mathcal{L}{C E}=-\sum_{i}^{c}\mathbf{y_{i}}\log\hat{\mathbf{y_{i}}}
$$
where $\mathbf{y_{i}}$ is the one-hot ground-truth action label. Following this routine, the approach adopted by ProtoGCN will be elaborated in the subsequent subsections.
其中 $\mathbf{y_{i}}$ 是独热编码的真实动作标签。按照这一流程,ProtoGCN采用的方法将在后续小节中详细阐述。
3.2. Prototype Reconstruction Network
3.2. 原型重建网络
As previously discussed, the essence of distinguishing similar actions lies in recognizing the variations in the motion patterns of involved body joints. However, effectively capturing these differences to create a disc rim i native representation poses a significant challenge. The nuanced nature of the corresponding joint movements often leads to these distinctions becoming obscured within the total body motion.
如前所述,区分相似动作的本质在于识别相关身体关节运动模式的变化。然而,如何有效捕捉这些差异以构建判别性表征仍面临重大挑战。由于相应关节运动的微妙性,这些差异往往在整体身体动作中变得模糊。
To tackle this issue, the model’s attention needs to be directed towards identifying the detailed joint-level motion characteristics. Therefore, we propose the Prototype Reconstruction Network (PRN) to obtain the fine-grained enhanced representations. This is achieved by decomposing the representations into a combination of the learned prototype vectors to highlight key details.
为了解决这一问题,模型需要将注意力集中在识别详细的关节级运动特征上。因此,我们提出了原型重建网络 (Prototype Reconstruction Network, PRN) 来获取细粒度的增强表征。这是通过将表征分解为学习到的原型向量组合来实现的,从而突出关键细节。
Specifically, the network consists of two parts: a memory module and a reconstruction module. The memory module stores the learned action prototypes that represent diverse relationship patterns between human body joints. Accordingly, the reconstruction module computes the response weights of input representations through an addressing mechanism. Last, the network samples and assembles the relevant prototypes via the response, producing uniquely tailored feature representations.
具体而言,该网络由两部分组成:记忆模块和重建模块。记忆模块存储学习到的动作原型(prototype),这些原型代表了人体关节之间多样化的关系模式。相应地,重建模块通过寻址机制计算输入表征的响应权重。最终,网络根据响应值对相关原型进行采样和组装,生成定制化的特征表征。
Memory Module. Given the input skeleton sequences, the learned graph representation, i.e., $\mathbf{A}\in\mathbb{R}^{N\times\tilde{N}\times C}$ , is first reshaped to $\mathbf{X}\in\overline{{\mathbb{R}^{N^{2}\times C}}}$ . The representation $\mathbf{X}$ can be intuitively interpreted as a feature aggregation that represents the correlations between joints. Then we implement memory as a learnable matrix $\mathbf{W_{memory}}\in\mathbb{R}^{n_{p r o}\times C}$ . The prototype vector $m_{i}$ (for $i\in{1,...,n_{p r o}})$ in each row of the matrix represents the learned relationship patterns between joints, where $n_{p r o}$ denotes the number of prototypes.
记忆模块。给定输入骨架序列,学习到的图表示 $\mathbf{A}\in\mathbb{R}^{N\times\tilde{N}\times C}$ 首先被重塑为 $\mathbf{X}\in\overline{{\mathbb{R}^{N^{2}\times C}}}$。该表示 $\mathbf{X}$ 可直观理解为表征关节间相关性的特征聚合。随后我们将记忆实现为可学习矩阵 $\mathbf{W_{memory}}\in\mathbb{R}^{n_{p r o}\times C}$,其中矩阵每行的原型向量 $m_{i}$ (对于 $i\in{1,...,n_{p r o}})$ 表示学习到的关节间关系模式,$n_{p r o}$ 为原型数量。
In practice, $\mathbf{W_{\mathrm{memory}}}$ is randomly initialized and the stored patterns are adaptively updated throughout training. Instead of fixed iterative updates, we make the network automatically exploit the clusters of these relationships through backward gradient, and learn the representative prototypes from the input graph embeddings. These learned prototypes can then be composed into unique enhanced representations under the response signals to be introduced below.
在实践中,$\mathbf{W_{\mathrm{memory}}}$ 被随机初始化,存储模式会在整个训练过程中自适应更新。不同于固定的迭代更新,我们让网络通过反向梯度自动利用这些关系的聚类,并从输入的图嵌入中学习代表性原型。这些学习到的原型随后可以在下文介绍的响应信号下组合成独特的增强表示。
Reconstruction Module. Our goal is to leverage the relevant prototype patterns to enhance the input feature, yielding more significant and disc rim i native representations. We use attention as the addressing mechanism. For the input graph representation, the module produces a response signal that represents a uniquely tailored linear combination of prototypes in the memory module.
重建模块。我们的目标是通过利用相关原型模式来增强输入特征,从而产生更具区分性的表征。我们采用注意力机制作为寻址方式。对于输入的图表征,该模块会生成一个响应信号,该信号代表记忆模块中原型的定制化线性组合。
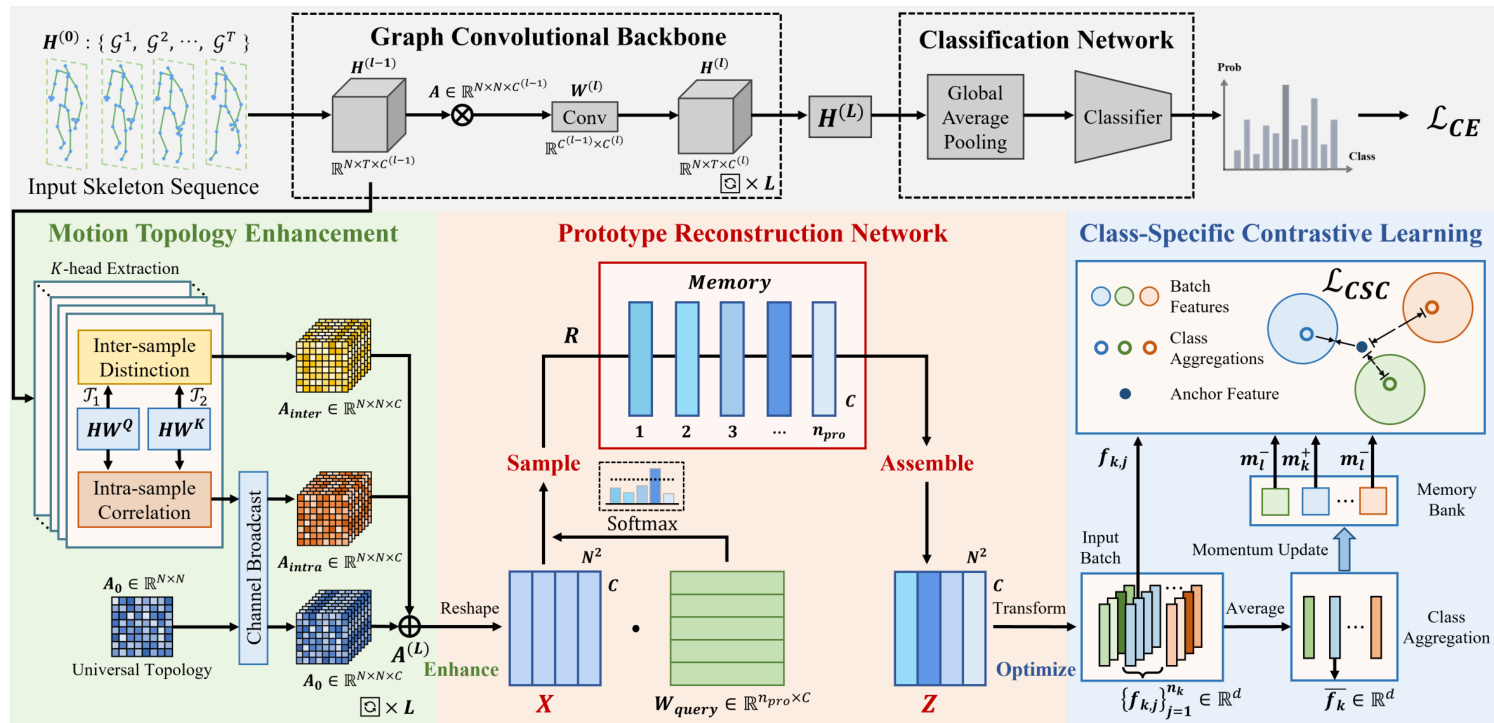
Figure 2. The overall architecture of ProtoGCN. A Prototype Reconstruction Network is proposed to transform the representation of graph topology X into a combination $\mathbf{Z}$ of learnable prototypes at the fine-grained joint level, thereby enhancing the distinctiveness of features. In specific, the prototypes represent diverse relationship patterns between all the human joints. Additionally, at each layer of the network, the Motion Topology Enhancement module is integrated to capture rich and expressive motion representations, establishing the foundation for prototype learning. Last, the outputs of the model are supervised by the classification loss and class-specific contrastive loss, respectively.
图 2: ProtoGCN的整体架构。该框架提出了原型重建网络 (Prototype Reconstruction Network) ,将图拓扑表示 X 转换为细粒度关节层级可学习原型的组合 $\mathbf{Z}$ ,从而增强特征区分度。具体而言,这些原型表征了人体各关节间多样化的关系模式。此外,在网络每一层集成了运动拓扑增强模块 (Motion Topology Enhancement) 以捕获丰富且具表现力的运动表征,为原型学习奠定基础。最终,模型输出分别通过分类损失和类对比损失进行监督。
Concretely, a learnable matrix $\mathbf{W_{query}}\in\mathbb{R}^{n_{p r o}\times C}$ serves as the key vectors projected from the input features, and then a softmax activation function is employed to compute the response signals. The addressing process could be further expressed as
具体来说,一个可学习的矩阵 $\mathbf{W_{query}}\in\mathbb{R}^{n_{p r o}\times C}$ 作为从输入特征投影得到的关键向量,随后采用 softmax 激活函数计算响应信号。该寻址过程可进一步表示为
$$
\mathbf{R}=\operatorname{softmax}(\mathbf{X}(\mathbf{W_{query}})^{\top})
$$
$$
\mathbf{R}=\operatorname{softmax}(\mathbf{X}(\mathbf{W_{query}})^{\top})
$$
where the signals $\mathbf{R}$ are used as weights to combine the prototypes. Here the softmax provides a weighted average of the target vectors based on the similarity between the query and the input. Then we can accomplish memory activation and obtain an enhanced output representation:
其中信号 $\mathbf{R}$ 被用作组合原型的权重。这里的 softmax 基于查询与输入之间的相似性提供了目标向量的加权平均。随后我们可以实现记忆激活并获得增强的输出表示:
The entire network could be considered as an encoderdecoder bottleneck model, where the memory is filled with the encoder output set. It is trained in an end-to-end supervised manner, with the memory updated while training along with the rest of the network parameters. Instead of relying on a pre-determined biological decomposition of the human skeleton, we enable the model to adaptively learn the composition of human actions. Given an input representation, the network generates tailored latent responses and then reconstructs the unique enhanced representation, i.e., X to Z. An illustration of this ‘sample-and-assemble process is provided in Fig. 2.
整个网络可以被视为一个编码器-解码器瓶颈模型,其中记忆单元存储着编码器输出集。该模型以端到端监督方式进行训练,在训练过程中记忆单元会随网络其他参数一同更新。不同于依赖预先确定的人体骨骼生物力学分解方式,我们让模型能够自适应学习人类动作的组成结构。给定输入表征时,网络会生成定制化的潜在响应,进而重建独特的增强表征(即X到Z的转换)。图2展示了这种"采样-组装"过程的示意图。
3.3. Motion Topology Enhancement
3.3. 运动拓扑增强
The quality of input topology representations $\mathbf{X}$ is vital since they determine the retrieval efficiency of the learned prototypes. Therefore, we present the Motion Topology Enhancement (MTE) module to augment the capacity to capture intricate motion details, resulting the abundant and expressive topologies.
输入拓扑表示 $\mathbf{X}$ 的质量至关重要,因为它们决定了学习原型(prototype)的检索效率。因此,我们提出运动拓扑增强(Motion Topology Enhancement, MTE)模块来提升捕捉复杂运动细节的能力,从而生成丰富且具有表现力的拓扑结构。
In practice, we start by mapping the input feature of each layer ${\bf H}\in\mathbb{R}^{N\times T\times\dot{C}}$ to $K$ sets of queries and keys with learnable matrices $\mathbf{W^{Q},W^{K}}\in\mathbb{R}^{C\times C^{\prime}}$ . The attention mechanism effectively establishes the global perceptual connections between different body joints. Multi-head configuration and mapping functions could further facilitate the diverse feature semantic with the dimension $C^{\prime}=[C/K]$ . Subsequently, we adopt average pooling to perform the aggregation of contextual temporal relations and squeeze the dimension $T$ . The projected features could be formulated as $H^{Q}=\mathbf{H}\mathbf{W}^{Q}\in\mathbf{\bar{\mathbb{R}}}^{\bar{N}\times\boldsymbol{C}^{\prime}}$ and $H^{K}=\mathbf{H}\mathbf{W}^{K}\in\mathbb{R}^{N\times C^{\prime}}$ .
在实践中,我们首先将每层的输入特征 ${\bf H}\in\mathbb{R}^{N\times T\times\dot{C}}$ 通过可学习矩阵 $\mathbf{W^{Q},W^{K}}\in\mathbb{R}^{C\times C^{\prime}}$ 映射到 $K$ 组查询(query)和键(key)。注意力机制有效建立了不同身体关节间的全局感知连接。多头配置和映射函数能进一步促进维度为 $C^{\prime}=[C/K]$ 的多样化特征语义。随后,我们采用平均池化来聚合上下文时序关系并压缩维度 $T$。投影特征可表示为 $H^{Q}=\mathbf{H}\mathbf{W}^{Q}\in\mathbf{\bar{\mathbb{R}}}^{\bar{N}\times\boldsymbol{C}^{\prime}}$ 和 $H^{K}=\mathbf{H}\mathbf{W}^{K}\in\mathbb{R}^{N\times C^{\prime}}$。
Then we model the nuanced relationships, which consist of two parts, the intra-sample correlations and the intersample distinctions. In delineating the details, intra-sample correlations exhibit skeleton-level comprehensive connections, requiring self-attention to identify their specific patterns. Moreover, for samples with inconsistent motion patterns, inter-sample distinctions could be captured by pairwise comparisons between joints. The differential realization eliminates extraneous noise, encouraging models to fo- cus on critical information.
然后我们对这些微妙关系进行建模,这些关系由两部分组成:样本内相关性和样本间差异性。具体而言,样本内相关性展现骨架级别的综合关联,需要自注意力机制来识别其特定模式。此外,对于运动模式不一致的样本,可以通过关节间的成对比较来捕捉样本间差异性。这种差分实现消除了无关噪声,促使模型专注于关键信息。
Specifically, the interdependence of intra-sample correlations is modeled by the inner product of projected features. For comparing distinctions, we adopt the transformation $\textstyle{\mathcal{T}}{d}(\cdot)$ to expand the tensor at its $d$ -th dimension and replicate the result $N$ times along that dimension. As a result, $\mathcal{T}{1}(H^{Q})$ and $\mathcal{T}_{2}(H^{K})$ have the same dimensions of $\mathbb{R}^{N\times N\times C^{\prime}}$ . The enhanced topology representations could be efficiently computed by
具体来说,样本内部相关性的相互依赖关系通过投影特征的内积建模。为比较差异,我们采用变换 $\textstyle{\mathcal{T}}{d}(\cdot)$ 在张量的第 $d$ 维度进行扩展,并沿该维度复制 $N$ 次。因此,$\mathcal{T}{1}(H^{Q})$ 和 $\mathcal{T}_{2}(H^{K})$ 具有相同的维度 $\mathbb{R}^{N\times N\times C^{\prime}}$。增强后的拓扑表征可通过以下方式高效计算:
$$
\begin{array}{r l}{\mathbf{A}{\mathrm{intra}}=\phi_{}(H^{Q}(H^{K})^{\top})}\ {\mathbf{A}{\mathrm{inter}}=\phi_{}({\mathcal{T}}{1}(H^{Q})-{\mathcal{T}}_{2}(H^{K}))}\end{array}
$$
$$
\begin{array}{r l}{\mathbf{A}{\mathrm{intra}}=\phi_{}(H^{Q}(H^{K})^{\top})}\ {\mathbf{A}{\mathrm{inter}}=\phi_{}({\mathcal{T}}{1}(H^{Q})-{\mathcal{T}}_{2}(H^{K}))}\end{array}
$$
where $\phi$ represents the activation function. Then these represent at ions are integrated into each GCN layer of ProtoGCN. They rely on specific input skeletons and delineate nuanced details of joints relevant to the corresponding action, thereby serving as a crucial component in distinguishing similar actions. In contrast, the original dynamic topology A is represented as $\mathbf{A_{0}}$ , which is utilized to represent the universal interconnections among human body joints and shared across all action classes.
其中 $\phi$ 表示激活函数。随后这些表征被整合到 ProtoGCN 的每个 GCN 层中。它们依赖于特定的输入骨架,并勾勒出与对应动作相关的关节细微细节,从而成为区分相似动作的关键组成部分。相比之下,原始动态拓扑 A 表示为 $\mathbf{A_{0}}$ ,用于表征人体关节间的通用连接关系,并在所有动作类别间共享。
Substituting the above decomposition of the graph topology into Eq. (1) gives the following translation function.
将上述图拓扑分解代入式(1)可得如下转换函数。
$$
\mathbf{H}^{(l)}=\sigma\big(\big(\mathbf{A_{0}}+\mathbf{A_{intra}}+\mathbf{A_{inter}}\big)\mathbf{H}^{(l-1)}\mathbf{W}^{(l)}\big)
$$
$$
\mathbf{H}^{(l)}=\sigma\big(\big(\mathbf{A_{0}}+\mathbf{A_{intra}}+\mathbf{A_{inter}}\big)\mathbf{H}^{(l-1)}\mathbf{W}^{(l)}\big)
$$
In this way, the network incorporates nuanced motion intricacies of the acquired topology, establishing the foundation for prototype learning.
通过这种方式,网络能够捕捉获取拓扑结构中的细微运动特征,为原型学习奠定基础。
3.4. Class-Specific Contrastive Learning
3.4. 类特定对比学习
Basically, in Eq. (4), $\mathbf{Z}$ could be regarded as the weighted sum of prototypes retrieved from $\mathbf{W_{\mathrm{memory}}}$ , where the weights are determined by the input-dependent probe R. However, the formulation itself does not ensure the represent at ive ness of learned prototypes or the discrimination of the resultant feature $\mathbf{Z}$ , and thus it may not necessarily lead to improved performance in classifying similar actions.
基本上,在式 (4) 中,$\mathbf{Z}$ 可视为从 $\mathbf{W_{\mathrm{memory}}}$ 检索出的原型的加权和,其权重由输入相关的探针 R 决定。然而,该公式本身并不能确保所学原型的代表性或结果特征 $\mathbf{Z}$ 的区分性,因此未必能提升相似动作的分类性能。
Therefore, to further accentuate the inter-class distinction of human actions, the class-specific contrastive learn- ing strategy is incorporated. Specifically, the strategy introduces two components: a compactness constraint that encourages samples to be close to their class-specific aggregations, and a dispersion contrastive loss that promotes the distinctions among different class aggregations.
因此,为了进一步突出人类动作的类间差异,我们引入了类特定对比学习策略。具体而言,该策略包含两个组件:一个紧凑性约束,促使样本靠近其类特定聚合点;以及一个分散对比损失,用于增强不同类聚合点之间的区分度。
In practice, a projection network is first utilized to embed $\mathbf{Z}$ into vectors within the contrastive feature space. We compress $\mathbf{Z}\in\mathbb{R}^{N^{2}\times C}$ along the channel dimension via an average pooling layer to obtain the one-dimensional vector $\mathbf{z}\in\bar{\mathbb{R}}^{N^{\bar{2}}}$ . Subsequently, a fully connected layer is further employed to transform $\mathbf{z}$ into $\mathbf{f_{\lambda}}\in\mathbb{R}^{d}$ , which is the input for the subsequent contrastive mechanism.
实践中,首先利用投影网络将 $\mathbf{Z}$ 嵌入到对比特征空间中的向量。我们通过平均池化层沿通道维度压缩 $\mathbf{Z}\in\mathbb{R}^{N^{2}\times C}$ ,得到一维向量 $\mathbf{z}\in\bar{\mathbb{R}}^{N^{\bar{2}}}$ 。随后,进一步使用全连接层将 $\mathbf{z}$ 转换为 $\mathbf{f_{\lambda}}\in\mathbb{R}^{d}$ ,作为后续对比机制的输入。
For the compactness constraint, considering that crossbatch graphs could enrich the cross-sequence context, a memory bank $\mathcal{M}$ of aggregated representations is constructed. The $k$ -th element $\mathbf{m}{k} \in~\mathcal{M}$ denotes the classspecific aggregation that embodies unique properties of the $k$ -th action class. In practice, $\mathcal{M}$ is randomly initialized and updated using a momentum update strategy. Given an input batch of samples, $\mathbf{m}_{k}$ is updated by
对于紧凑性约束,考虑到跨批次图可以丰富跨序列上下文,我们构建了一个聚合表征的记忆库 $\mathcal{M}$。其中第 $k$ 个元素 $\mathbf{m}{k} \in~\mathcal{M}$ 表示体现第 $k$ 个动作类别独特特性的类特定聚合。实际应用中,$\mathcal{M}$ 采用随机初始化并通过动量更新策略进行更新。给定一个输入样本批次,$\mathbf{m}_{k}$ 的更新方式为
$$
\mathbf{m}{k}=\alpha\cdot\mathbf{m}{k}+\left(1-\alpha\right)\cdot\overline{{\mathbf{f}_{k}}}
$$
$$
\mathbf{m}{k}=\alpha\cdot\mathbf{m}{k}+\left(1-\alpha\right)\cdot\overline{{\mathbf{f}_{k}}}
$$
where $\overline{{\mathbf{f}{k}}}$ is the average of ${\mathbf{f}{k,j}}{j=1}^{n_{k}}$ , i.e., the $n_{k}$ samples of class $k$ within input batch, and $\alpha$ is the momentum term. Along with the process, $\mathbf{m}_{k}$ gradually becomes a stable estimation of the clustering center for class $k$ .
其中 $\overline{{\mathbf{f}{k}}}$ 是 ${\mathbf{f}{k,j}}{j=1}^{n_{k}}$ 的平均值,即输入批次中类别 $k$ 的 $n_{k}$ 个样本,$\alpha$ 为动量项。在此过程中,$\mathbf{m}_{k}$ 会逐渐收敛为类别 $k$ 聚类中心的稳定估计值。
Then these class-specific aggregations are further optimized. Given the feature embedding $\mathbf{f}{k,j}$ of the $k$ -th class $(j$ is the batch index), the class-specific contrastive loss $\mathcal{L}_{C S C}$ could be formulated as
然后这些特定类别的聚合会进一步优化。给定第 $k$ 个类别的特征嵌入 $\mathbf{f}{k,j}$ ($j$ 是批次索引),特定类别的对比损失 $\mathcal{L}_{C S C}$ 可表示为
$$
\mathcal{L}{C S C}=-\log\frac{\exp(\mathbf{f}{k,j}\cdot\mathbf{m}{k}/\tau)}{\exp(\mathbf{f}{k,j}\cdot\mathbf{m}{k}/\tau)+\sum_{l\neq k}\exp(\mathbf{f}{k,j}\cdot\mathbf{m}_{l}/\tau)}
$$
$$
\mathcal{L}{C S C}=-\log\frac{\exp(\mathbf{f}{k,j}\cdot\mathbf{m}{k}/\tau)}{\exp(\mathbf{f}{k,j}\cdot\mathbf{m}{k}/\tau)+\sum_{l\neq k}\exp(\mathbf{f}{k,j}\cdot\mathbf{m}_{l}/\tau)}
$$
where $\mathbf{m}{k},\mathbf{m}{l}$ denotes the positive and negative class aggregation w.r.t. $\mathbf{f}_{k,j}$ , and $\tau$ is the temperature parameter.
其中 $\mathbf{m}{k},\mathbf{m}{l}$ 表示关于 $\mathbf{f}_{k,j}$ 的正负类聚合,$\tau$ 为温度参数。
Finally, the overall training objective function of ProtoGCN could be written as
最后,ProtoGCN的整体训练目标函数可表示为
$$
\mathcal{L}=\mathcal{L}{C E}+\lambda\mathcal{L}_{C S C}
$$
$$
\mathcal{L}=\mathcal{L}{C E}+\lambda\mathcal{L}_{C S C}
$$
where $\mathcal{L}_{C E}$ is the cross-entropy loss used to supervise the predicted action class, and $\lambda$ is the balance parameter.
其中 $\mathcal{L}_{C E}$ 是用于监督预测动作类别的交叉熵损失 (cross-entropy loss),$\lambda$ 是平衡参数。
3.5. Discussion
3.5. 讨论
The learning mechanism of our method is to make the network adaptively discover and assemble the learnable prototypes to generate more disc rim i native representations. Accordingly, enhancing $\mathbf{X}$ in Sec. 3.3 and optimizing $\mathbf{Z}$ in Sec. 3.4 could further facilitate this process. ProtoGCN especially improves classification for similar classes because it focuses more on specific characteristics to reveal the subtle differences of key body parts, which are essential for distinguishing these classes.
我们方法的学习机制是让网络自适应地发现并组装可学习的原型(prototype),以生成更具判别性的表征。因此,第3.3节中对$\mathbf{X}$的增强和第3.4节中对$\mathbf{Z}$的优化可以进一步促进这一过程。ProtoGCN尤其提升了相似类别的分类性能,因为它更关注特定特征以揭示关键身体部位的细微差异,这对区分这些类别至关重要。
Notably, the expression employed in Eq. (4) constrains the model to craft representations solely using learned prototypes stored in memory module. Driven by the contrastive learning objective, these representations are required to be disc rim i native, thereby amplifying the inter-class distinction in the feature space. Consequently, the building blocks, or prototypes, are expected to capture the characteristics of representative action units. After obtaining such principal components, the prototype reconstruction process naturally filters out motion patterns that are less disc rim i native, thereby suppressing noise and irrelevant information. Instead, the key action details are highlighted and revealed.
值得注意的是,式 (4) 中采用的表达式约束模型仅使用存储在记忆模块中的学习原型来构建表征。在对比学习目标的驱动下,这些表征需要具备区分性,从而增强特征空间中的类间差异。因此,这些基础构建块(即原型)有望捕捉代表性动作单元的特征。在获得这些主成分后,原型重建过程会自然过滤区分性较低的运动模式,从而抑制噪声和无关信息,转而突出并揭示关键动作细节。
Table 1. Performance comparisons against state-of-the-art methods on the NTU $\mathrm{RGB+D}$ , NTU $_\mathrm{RGB+D}$ 120, and Kinetics-Skeleton datasets in terms of classification accuracy $(%)$ .
表 1: 在 NTU $\mathrm{RGB+D}$、NTU $_\mathrm{RGB+D}$ 120 和 Kinetics-Skeleton 数据集上,与最先进方法在分类准确率 $(%)$ 方面的性能比较。
| 方法 | 发表 | NTU RGB+D X-Sub | NTU RGB+D X-View | NTU RGB+D 120 X-Sub | NTU RGB+D 120 X-Set | Kinetics-Skeleton Top-1 | Kinetics-Skeleton Top-5 |
|---|---|---|---|---|---|---|---|
| ST-GCN [40] | AAAI2018 | 81.5 | 88.3 | 70.7 | 73.2 | 30.7 | 52.8 |
| AS-GCN [22] | CVPR 2019 | 86.8 | 94.2 | 78.3 | 79.8 | 34.8 | 56.5 |
| 2s-AGCN [30] | CVPR 2019 | 88.5 | 95.1 | 82.5 | 84.2 | 36.1 | 58.7 |
| MS-G3D [25] | CVPR 2020 | 91.5 | 96.2 | 86.9 | 88.4 | 38.0 | 60.9 |
| DC-GCN+ADG [8] | ECCV 2020 | 90.8 | 96.6 | 86.5 | 88.1 | 一 | |
| MST-GCN [7] | AAAI2021 | 91.5 | 96.6 | 87.5 | 88.8 | 38.1 | 60.8 |
| CTR-GCN [6] | ICCV 2021 | 92.4 | 96.8 | 88.9 | 90.6 | ||
| STF [18] | AAAI2022 | 92.5 | 96.9 | 88.9 | 89.9 | 39.9 | |
| InfoGCN [9] | CVPR 2022 | 93.0 | 97.1 | 89.8 | 91.2 | ||
| PYSKL [11] | ACM MM 2022 | 92.6 | 97.4 | 88.6 | 90.8 | 49.1 | |
| SkeletonGCL [16] | ICLR 2023 | 92.8 | 97.1 | 89.8 | 91.2 | ||
| FR-Head [45] | CVPR 2023 | 92.8 | 96.8 | 89.5 | 90.9 | ||
| GAP [36] | ICCV 2023 | 92.9 | 97.0 | 89.9 | 91.1 | 一 | |
| HD-GCN [19] | ICCV 2023 | 93.4 | 97.2 | 90.1 | 91.6 | 40.9 | 63.5 |
| JT-GraphFormer [44] | AAAI2024 | 93.4 | 97.5 | 89.9 | 91.7 | ||
| DS-GCN [37] | AAAI2024 | 93.1 | 97.5 | 89.2 | 91.1 | 50.6 | |
| BlockGCN [46] | CVPR 2024 | 93.1 | 97.0 | 90.3 | 91.5 | ||
| ProtoGCN (2-ensemble) | 93.0 | 97.2 | 89.7 | 91.2 | 49.9 | 74.0 | |
| ProtoGCN (4-ensemble) | 93.5 | 97.5 | 90.4 | 91.9 | 51.3 | 75.1 | |
| ProtoGCN (6-ensemble) | 93.8 | 97.8 | 90.9 | 92.2 | 51.9 | 75.6 |
4. Experiments
4. 实验
4.1. Datasets
4.1. 数据集
NTU $\mathbf{RGB}{+}\mathbf{D}$ (NTU-60) [28] is a large-scale human ac- tion recognition dataset containing 56,880 skeleton action sequences, which are performed by 40 distinct subjects and classified into 60 classes. Each sequence is annotated with 25 body joints and guaranteed to have at most 2 subjects. This dataset recommends two benchmarks: (1) crosssubject (X-Sub): training data comes from 20 subjects, and testing data comes from other 20 subjects. (2) cross-view (X-View): training data comes from camera views 2 and 3, and testing data comes from camera view 1.
NTU $\mathbf{RGB}{+}\mathbf{D}$ (NTU-60) [28] 是一个大规模人体动作识别数据集,包含56,880个骨骼动作序列,由40名不同受试者执行并划分为60个类别。每个序列标注了25个身体关节点,且确保最多包含2名受试者。该数据集推荐两种基准:(1) 跨受试者 (X-Sub):训练数据来自20名受试者,测试数据来自另外20名受试者;(2) 跨视角 (X-View):训练数据来自摄像头视角2和3,测试数据来自摄像头视角1。
NTU $\mathbf{RGB}{+}\mathbf{D}$ 120 (NTU-120) [24] is an extended version of NTU $\mathrm{RGB}{+}\mathrm{D}$ , and contains 114,480 videos of 120 action classes. All skeleton sequences are performed by 106 subjects and captured from 32 different camera setups. Similarly, the two recommended settings are suggested: (1) cross-subject (X-Sub): training data comes from 53 subjects, and testing data comes from other 53 subjects. (2) cross-setup (X-Set): training data comes from 16 even setup IDs, and testing data comes from 16 odd setup IDs.
NTU $\mathbf{RGB}{+}\mathbf{D}$ 120 (NTU-120) [24] 是 NTU $\mathrm{RGB}{+}\mathrm{D}$ 的扩展版本,包含 120 个动作类别的 114,480 段视频。所有骨架序列由 106 名受试者完成,并通过 32 种不同的摄像机设置采集。同样推荐两种设置:(1) 跨受试者 (X-Sub):训练数据来自 53 名受试者,测试数据来自另外 53 名受试者;(2) 跨设置 (X-Set):训练数据来自 16 个偶数设置 ID,测试数据来自 16 个奇数设置 ID。
Kinetics-Skeleton (Kinetics) [17] is derived from Kinetics 400 video dataset using the pose estimation toolbox. It contains 240,436 training and 19,796 evaluation skeleton clips across 400 classes. At each time step, two people are selected for multi-person clips based on the average joint confidence. Regarding the experiments, we adopt the available skeletons provided by PYSKL [11]. Top-1 and Top-5 accuracies are used in the evaluation protocol.
Kinetics-Skeleton (Kinetics) [17] 源自 Kinetics 400 视频数据集,通过姿态估计工具箱生成。它包含 400 个类别的 240,436 个训练骨架片段和 19,796 个评估骨架片段。在每个时间步,基于关节平均置信度为多人片段选择两个人。在实验中,我们采用 PYSKL [11] 提供的可用骨架。评估协议采用 Top-1 和 Top-5 准确率。
FineGYM [29] is a recent large-scale fine-grained action recognition dataset with 29,000 videos of 99 gymnastic action classes, which requires action recognition methods to distinguish different sub-actions within the same video. We use the skeleton data provided by PYSKL [11]. The mean class Top-1 accuracy is reported in the evaluation protocol.
FineGYM [29] 是近期推出的大规模细粒度动作识别数据集,包含99个体操动作类别的29,000段视频,要求动作识别方法能够区分同一视频中的不同子动作。我们使用PYSKL [11]提供的骨骼数据,评估协议中报告的是平均类别Top-1准确率。
4.2. Implementation Details
4.2. 实现细节
In our experiments, ProtoGCN is trained for 150 epochs with the batch size set to 64. We employ PYSKL [11] as the baseline. The initial learning rate is set to 0.1, and we decay it using a cosine learning rate scheduler. The SGD optimizer is employed with a Nesterov momentum of 0.9 and a weight decay of $5\times10^{-4}$ . Following generic settings, momentum $\alpha$ is set to 0.9, and temperature $\tau$ is set to 0.125. The dimension $d$ for contrastive learning is set to 256. The learnable matrices are randomly initialized for topology modeling. We follow the data pre-processing procedures outlined in PYSKL [11]. All experiments are conducted on a single RTX 3090 GPU with PyTorch.
在我们的实验中,ProtoGCN训练150个周期(epoch),批量大小(batch size)设为64。我们采用PYSKL [11]作为基线方法。初始学习率设为0.1,并使用余弦学习率调度器进行衰减。采用SGD优化器,其Nesterov动量为0.9,权重衰减为$5\times10^{-4}$。按照通用设置,动量$\alpha$设为0.9,温度$\tau$设为0.125。对比学习的维度$d$设为256。用于拓扑建模的可学习矩阵采用随机初始化。我们遵循PYSKL [11]中概述的数据预处理流程。所有实验均在单块RTX 3090 GPU上使用PyTorch框架完成。
Table 2. Performance comparisons against state-of-the-art methods on FineGYM in terms of classification accuracy $(%)$ .
表 2: 在FineGYM数据集上分类准确率 $(%)$ 的先进方法性能对比
| 方法 | 模态 | FineGYM |
|---|---|---|
| I3D [2] | RGB | 64.4 |
| TSN [35] | RGB+Flow | 79.8 |
| TSM [23] | RGB+Flow | 81.2 |
| LT-S3D [38] | RGB | 88.9 |
| SkeletonMAE[39] | Skeleton | 91.8 |
| PYSKL [11] | Skeleton | 94.1 |
| PoseConv3D [12] | Skeleton+Limb | 94.3 |
| ProtoGCN (Ours) | Skeleton | 95.9 |

Figure 3. Ablation study on the influences of weight $\lambda$ and the memory capacity $n_{p r o}$ under the NTU-120 X-Sub setting.
图 3: 在NTU-120 X-Sub设置下,权重$\lambda$和记忆容量$n_{pro}$影响的消融研究。
4.3. Comparison with State-of-the-Art Methods
4.3. 与现有最优方法的对比
To improve recognition accuracy, recent state-of-the-art methods [6, 9, 19, 30] utilize the multi-stream fusion framework. For a fair comparison, we adopt the widely adopted six-stream ensemble strategy proposed in InfoGCN [9].
为提高识别准确率,当前最先进方法[6,9,19,30]采用多流融合框架。为确保公平比较,我们采用InfoGCN[9]提出的广泛使用的六流集成策略。
We compare ProtoGCN with extensive benchmark methods on four datasets, including NTU-60, NTU-120, Kinetics, and FineGYM. According to the results reported in Tab. 1 and Tab. 2, ProtoGCN consistently achieves the best accuracy and outperforms other approaches by a significant margin in all scenarios. On the NTU-60 dataset, the proposed method surpasses the performance of BlockGCN [46] by $0.7%$ on ${\tt X}{\tt-S u b}$ and $0.8%$ on X-View. Remarkably, ProtoGCN excels in performance on the challenging NTU-120 dataset, achieving accuracies of $90.9%$ on X-Sub and $92.2%$ on X-Set. As for Kinetics, ProtoGCN outperforms state-of-the-art method DS-GCN [37] by $1.3%$ . According to Tab. 2, ProtoGCN has achieved a significant improvement in fine-grained action recognition, further confirming the efficacy of our approach.
我们在NTU-60、NTU-120、Kinetics和FineGYM四个数据集上将ProtoGCN与多种基准方法进行了对比。根据表1和表2所示结果,ProtoGCN在所有场景中始终取得最佳准确率,并显著优于其他方法。在NTU-60数据集上,该方法在${\tt X}{\tt-S u b}$和X-View上分别以$0.7%$和$0.8%$的优势超越BlockGCN[46]的性能。值得注意的是,ProtoGCN在极具挑战性的NTU-120数据集上表现优异,在X-Sub和X-Set上分别达到$90.9%$和$92.2%$的准确率。对于Kinetics数据集,ProtoGCN以$1.3%$的优势超越当前最优方法DS-GCN[37]。根据表2所示,ProtoGCN在细粒度动作识别任务中实现了显著提升,进一步验证了我们方法的有效性。
4.4. Ablation Study
4.4. 消融实验
In this section, we conduct an experimental evaluation to assess the effectiveness of each component in the proposed method. The experiments are conducted under the X-Sub setting of NTU-120 with the bone modality.
在本节中,我们通过实验评估来验证所提方法中各组件的有效性。实验在NTU-120数据集的X-Sub配置下进行,采用骨骼模态。
Effectiveness of Each Module in ProtoGCN. We examine the contribution of each component of ProtoGCN as shown in Tab. 3. The baseline model is re-trained using the latest officially released code and achieved a performance of $87.8%$ . Subsequently, we observe a performance improvement of $0.3%$ with the Motion Topology Enhancement (MTE) module. Building upon the foundation provided by MTE, $\mathcal{L}_{C S C}$ could improve performance by $0.2%$ . Interestingly, the performance significantly improves by $0.7%$ (from $88.3%$ to $89.0%$ ) with the addition of Prototype Reconstruction Network (PRN). This indicates that PRN helps to capture the disc rim i native semantics through discovering diverse prototypes, thereby offering greater advantages for graph convolution learning. By integrating all components, we surpass the baseline model by $1.2%$ , demonstrating the effectiveness of the modules introduced in this work.
ProtoGCN中每个模块的有效性。我们研究了ProtoGCN各组成部分的贡献,如表3所示。基线模型使用最新官方发布的代码重新训练,达到了87.8%的性能。随后,我们发现运动拓扑增强(MTE)模块带来了0.3%的性能提升。在MTE的基础上,$\mathcal{L}_{C S C}$可以进一步提高0.2%的性能。有趣的是,加入原型重建网络(PRN)后性能显著提升了0.7%(从88.3%提升至89.0%),这表明PRN通过发现多样化原型有助于捕捉判别性语义,从而为图卷积学习提供更大优势。通过整合所有组件,我们最终以1.2%的优势超越了基线模型,证明了本文所提模块的有效性。
Table 3. Ablation study on the contribution of each component in ProtoGCN under the NTU-120 X-Sub setting.
表 3. ProtoGCN各组件贡献度消融实验 (NTU-120 X-Sub设置)
| Baseline | MTE | PRN | CSCL | Acc (%) |
|---|---|---|---|---|
| ✓ | ✗ | ✗ | ✗ | 87.8 |
| ✓ | ✓ | ✗ | ✗ | 88.1 (↑ 0.3) |
| ✗ | ✗ | ✓ | ✗ | 88.3 (↑ 0.5) |
| ✓ | ✗ | ✗ | ✓ | 88.5 (↑0.7) |
| ✓ | ✓ | ✓ | ✓ | 89.0 (↑1.2) |
Table 4. Comparison of classification accuracies $(%)$ based on (left) existing graph contrastive methods and (right) different enhanced topologies for the network.
表 4: 基于 (左) 现有图对比方法和 (右) 网络不同增强拓扑的分类准确率 $(%)$ 对比
| 方法 | 准确率 (%) | 方法 | 准确率 (%) |
|---|---|---|---|
| Baseline | 87.8 | ProtoGCN | 89.0 |
| w/SkeletonGCL[16] | 88.0 | w/o Aintra | 88.8 |
| w/ FR-Head [45] | 88.2 | w/o Ainter | 88.5 |
| Ours | 89.0 | w/o Aintra, Ainter | 88.4 |
Table 5. Average performance $(%)$ on different difficulty level classes sorted by accuracy under the NTU-120 X-Sub setting.
表 5: 不同难度级别类别在 NTU-120 X-Sub 设置下按准确率排序的平均性能 $(%)$。
| 难度级别 | 基线 | ProtoGCN | △ |
|---|---|---|---|
| class1-10 | 64.1 | 67.1 | +3.0 |
| class11-30 | 78.6 | 81.1 | +2.5 |
| class31-60 | 88.6 | 89.7 | +1.1 |
| class61-120 | 96.0 | 96.4 | +0.4 |
Effectiveness of Prototype Reconstruction. To underscore the efficacy of the reconstruction mechanism, we conduct the analysis between ProtoGCN and existing methods that employ graph contrastive objective, including SkeletonGCL [16] and FR-Head [45]. As shown in Tab. 4, while these methods facilitate the differentiation, the improvement of ProtoGCN is remarkable $(1.0%/0.8%)$ . This indicates that the mechanism of expressing features as the combinations of prototypes could further boost the accuracy.
原型重建的有效性。为强调重建机制的有效性,我们对 ProtoGCN 与现有采用图对比目标的方法(包括 SkeletonGCL [16] 和 FR-Head [45])进行了对比分析。如表 4 所示,虽然这些方法有助于区分,但 ProtoGCN 的改进显著 $(1.0%/0.8%)$。这表明将特征表达为原型组合的机制可以进一步提高准确性。

Figure 4. Visualization of the topologies learned by PYSKL [11] and ProtoGCN across four actions. Darker color indicates stronger correlation between corresponding joints.
图 4: PYSKL [11] 与 ProtoGCN 在四种动作中学习到的拓扑结构可视化。颜色越深表示对应关节间相关性越强。

Figure 5. Action classes with accuracy difference higher than $1%$ between our method and PYSKL [11] on the NTU-120 dataset.
图 5. 在 NTU-120 数据集上,我们的方法与 PYSKL [11] 之间准确率差异高于 $1%$ 的动作类别。
Influences of Topology Decomposition. We assess the influences of topology decomposition in the MTE module. We closely examine the effects of these terms and present their performance in Tab. 4. The results demonstrate that intricate motion details are advantageous for recognition, and removing them will detrimental ly affect performance.
拓扑分解的影响。我们评估了MTE模块中拓扑分解的影响,详细研究了这些项的作用,并在表4中展示了它们的性能表现。结果表明,复杂的运动细节有利于识别,移除这些细节会对性能产生负面影响。
Effect of Hyper parameters. We examine the effect of weight $\lambda$ and memory capacity $n_{p r o}$ related to Wmemory in Fig. 3. The optimal value for $\lambda$ is determined to be 0.3, corresponding to the peak accuracy. In addition, we explore the impact of varying $n_{p r o}$ . Intuitively, the memory capacity is closely related to representative patterns among all the joints. Through empirical investigation, we determine the optimal balance and set $n_{p r o}$ to 100 for the performance.
超参数影响。我们在图 3 中研究了与 Wmemory 相关的权重 $\lambda$ 和记忆容量 $n_{p r o}$ 的影响。$\lambda$ 的最佳值确定为 0.3,对应最高准确率。此外,我们探索了不同 $n_{p r o}$ 值的影响。直观来看,记忆容量与所有关节中的代表性模式密切相关。通过实验验证,我们确定了最佳平衡点,并将 $n_{p r o}$ 设为 100 以获得最佳性能。
Performance on Similar Classes. We conduct the analysis of the performance in discerning actions with differing degrees of similarity. To achieve this, we sorted 120 classes of NTU-120 based on accuracies, ranging from low to high according to the results obtained with the baseline. Subsequently, we categorized them into four difficulty levels and computed the average accuracy for each level. As shown in Tab. 5, ProtoGCN yields a more significant accuracy gain, especially in classes with higher difficulties. In Fig. 5, we further present the action classes that exhibit over $1%$ absolute accuracy difference with the baseline on the NTU-120 dataset. It is evident that ProtoGCN offers more pronounced improvements in a significantly greater number of classes.
相似类别上的性能表现。我们对区分不同相似度动作的性能进行了分析。为此,我们根据基线模型的结果将NTU-120的120个类别按准确率从低到高排序,并将其划分为四个难度等级,计算每个等级的平均准确率。如表5所示,ProtoGCN带来了更显著的准确率提升,尤其在较高难度的类别中。图5进一步展示了NTU-120数据集中与基线模型存在超过1%绝对准确率差异的动作类别。显然,ProtoGCN在更多类别上实现了更明显的性能改进。
Visualization. To visually demonstrate the effectiveness of ProtoGCN, in Fig. 4, we present the topologies for four different action classes. Each learned prototype is a pattern vector thus it would be difficult to understand its effect through the direct individual visualization. Instead, we visualize the combined prototypes, i.e., the reconstructed topologies, which are shown by averaging $\mathbb{R}^{N\times N\times C}$ along the $C$ dimension. By comparing the results of ProtoGCN with the baseline PYSKL, our method showcases an ability to effectively focus on the joints most relevant to the target motion. Furthermore, a closer inspection reveals that the proposed method can further accentuate the key motion details, such as color patterns or intensity fluctuations within the darkened rows. These fine-grained joint-level relationships are crucial for distinguishing similar actions.
可视化。为直观展示ProtoGCN的有效性,图4展示了四种不同动作类别的拓扑结构。每个学习到的原型都是一个模式向量,因此直接单独可视化难以理解其作用。我们转而可视化组合原型(即重构的拓扑结构),通过对$\mathbb{R}^{N\times N\times C}$沿$C$维度取平均得到。通过将ProtoGCN与基线方法PYSKL的结果对比,我们的方法展现出有效聚焦目标运动最相关关节的能力。进一步观察可见,该方法能强化关键运动细节(例如暗色行内的色彩模式或强度波动),这些细粒度关节级关系对于区分相似动作至关重要。
5. Conclusion
5. 结论
In this paper, we propose ProtoGCN, a novel GCN-based method for skeleton-based action recognition. ProtoGCN highlights its prototype reconstruction mechanism, aimed at revealing the fine-grained motion patterns essential for distinguishing similar actions. Through the addition of enhanced topology representations, ProtoGCN is empowered by the contrastive objective to learn and identify distinctive action units. Consequently, the reconstructed motion feature becomes sufficiently discernible, enabling the discrimination of similar actions. The effectiveness of ProtoGCN is substantiated by achieving state-of-the-art performance across four widely utilized benchmark datasets.
本文提出ProtoGCN,这是一种基于图卷积网络(GCN)的骨骼动作识别新方法。ProtoGCN的核心创新在于其原型重建机制,旨在揭示区分相似动作所需的细粒度运动模式。通过引入增强的拓扑表示,该方法借助对比学习目标来识别具有区分性的动作单元。最终重建的运动特征具有足够辨识度,能够有效区分相似动作。ProtoGCN在四个广泛使用的基准数据集上均实现了最先进的性能,验证了其有效性。