ABSTRACT
摘要
Recent cross-lingual cross-modal works attempt to extend Vision-Language Pre-training (VLP) models to non-English inputs and achieve impressive performance. However, these models focus only on understanding tasks utilizing encoder-only architecture. In this paper, we propose ERNIE-UniX2, a unified cross-lingual cross-modal pre-training framework for both generation and understanding tasks. ERNIE-UniX2 integrates multiple pre-training paradigms (e.g., contrastive learning and language modeling) based on encoder-decoder architecture and attempts to learn a better joint representation across languages and modalities. Furthermore, ERNIE-UniX2 can be seamlessly fine-tuned for varieties of generation and understanding downstream tasks. Pre-trained on both multilingual text-only and image-text datasets, ERNIE-UniX2 achieves SOTA results on various cross-lingual cross-modal generation and understanding tasks such as multimodal machine translation and multilingual visual question answering.
近期跨语言跨模态工作致力于将视觉语言预训练 (Vision-Language Pre-training, VLP) 模型扩展至非英语输入并取得了显著性能。然而,这些模型仅聚焦于采用纯编码器架构的理解任务。本文提出ERNIE-UniX2——一个面向生成与理解任务的统一跨语言跨模态预训练框架。该框架基于编码器-解码器架构整合了对比学习、语言建模等多种预训练范式,试图学习跨语言与跨模态的更优联合表征。此外,ERNIE-UniX2可无缝微调用于各类生成与理解下游任务。通过在多语言纯文本和图文数据集上的预训练,ERNIE-UniX2在多模态机器翻译、多语言视觉问答等跨语言跨模态生成与理解任务中均取得了最先进 (State-of-the-Art, SOTA) 结果。
1 Introduction
1 引言
Pre-trained cross-modal models [1, 2, 3, 4, 5, 6, 7] have achieved impressive results across various vision-language understanding and generation tasks (e.g., image-text retrieval, visual question answering, image captioning). While most works are based on datasets in English, their models can not be easily used in cross-modal applications of non-English languages. While we are living in a multilingual world, it is worth exploring to build a unified model across languages and modalities.
预训练跨模态模型 [1, 2, 3, 4, 5, 6, 7] 在各类视觉-语言理解与生成任务 (例如图文检索、视觉问答、图像描述) 中取得了显著成果。虽然多数研究基于英语数据集构建模型,但这些模型难以直接应用于非英语语言的跨模态场景。身处多语言世界的我们,探索构建跨语言与跨模态的统一模型具有重要价值。
To tackle cross-modal tasks across languages, researchers have proposed cross-lingual cross-modal frameworks and achieved promising results, such as $\mathbf{M}^{\mathrm{3}}\mathbf{P}$ [8], and $\mathrm{{UC^{2}}}$ [9]. However, attempting to learn cross-lingual cross-modal representation through pre-training with bidirectional attention in encoder-only architecture, these frameworks can not easily be applied for generation tasks, such as multimodal machine translation.
为了应对跨语言的跨模态任务,研究人员提出了跨语言跨模态框架并取得了显著成果,例如 $\mathbf{M}^{\mathrm{3}}\mathbf{P}$ [8] 和 $\mathrm{{UC^{2}}}$ [9]。然而,这些框架试图通过仅编码器架构中的双向注意力预训练来学习跨语言跨模态表示,因此难以直接应用于生成任务,例如多模态机器翻译。
In this paper, we propose a unified cross-lingual cross-modal framework ERNIE-UniX2 integrating multiple generations and understanding pre-training paradigms, which can be seamlessly fine-tuned on downstream tasks. Figure 1 illustrates the main difference between ERNIE-UniX2 and previous cross-modal and cross-lingual cross-modal models. ERNIE $\mathrm{{UniX^{2}}}$ is built based on the encoder-decoder architecture, where the encoder fuse cross-lingual cross-modal feature with a token level interaction between aligned visual and language representation extracting two separated image/text encoder. To pre-train ERNIE-UniX2, we integrate multiple pre-training tasks to learn a joint cross-lingual cross-modal representation, focusing on both the capabilities for understanding and generation. For understanding pre-training tasks, we perform contrastive learning with dual-encoder architecture on bilingual texts and image-text pairs to learn global-level alignments across different languages and modalities, and feed the features to a cross-lingual cross-modal encoder to further learn the fine-grained alignments using two widely-used pre-training tasks in VLP (i.e., masking language modeling and image-text matching). To enhance the capabilities of our framework on generation tasks, we extend Prefix Language Modelling (PrefixLM) [1] to the multilingual scenario. While the PrefixLM only learns on monolingual inputs, we further adopt bilingual generation pre-training tasks to learn the joint alignment between bilingual texts and visual context. Besides, our framework adopts a more efficient image backbone ViT [10] with patch-level visual features instead of region-level visual features by a heavy object detector in previous works [8, 9]
本文提出了一种统一的多模态跨语言框架ERNIE-UniX2,整合了多种生成与理解预训练范式,可无缝适配下游任务微调。图1展示了ERNIE-UniX2与现有跨模态及跨语言跨模态模型的核心差异。ERNIE $\mathrm{{UniX^{2}}}$ 采用编码器-解码器架构,其编码器通过视觉与语言表征的对齐token交互,融合跨语言跨模态特征,最终输出独立的图像/文本编码器。在预训练阶段,我们整合多种预训练任务来学习联合的跨语言跨模态表征,同时兼顾理解与生成能力。针对理解任务,我们在双语文本和图文对上采用双编码器架构进行对比学习,获取跨语言跨模态的全局对齐特征,并将这些特征输入跨语言跨模态编码器,通过视觉语言预训练(VLP)中两个经典任务(掩码语言建模和图文匹配)进一步学习细粒度对齐。为增强框架的生成能力,我们将前缀语言建模(PrefixLM) [1] 扩展至多语言场景。除单语言输入外,我们还引入双语生成预训练任务来学习双语文本与视觉上下文的对齐关系。此外,本框架采用更高效的ViT [10] 图像主干网络提取图像块(patch)级视觉特征,取代了先前工作 [8,9] 中基于重型目标检测器的区域(region)级特征提取方案。
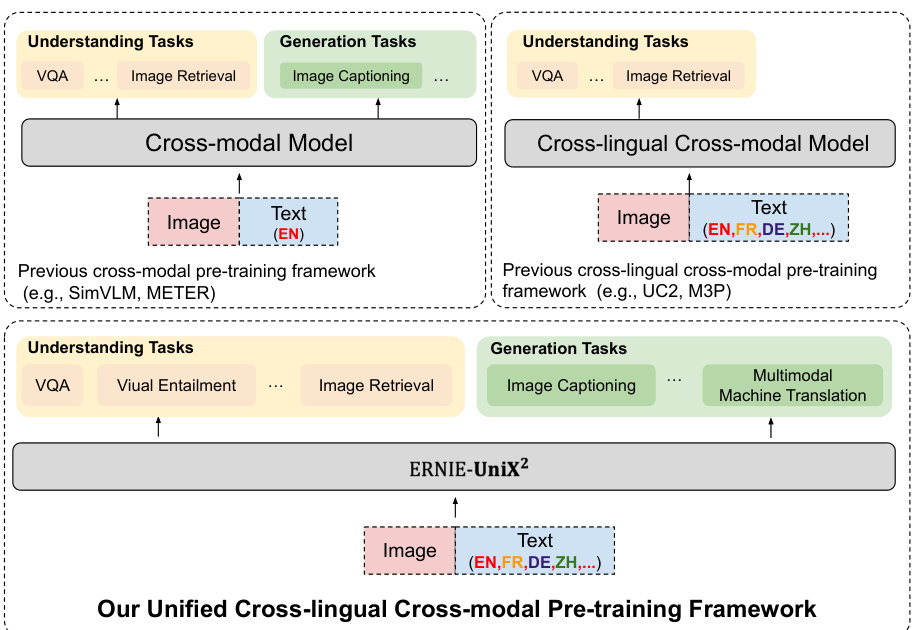
Figure 1: While existing unified cross-modal pre-trained models are mainly trained on English datasets and recent cross-lingual cross-modal pre-trained models can only be applied to understanding tasks, our proposed ERNIE-UniX2 is a unified pre-training framework, capable of tackling both understanding and generation tasks of cross-lingual cross-modal scenarios.
图 1: 现有统一跨模态预训练模型主要基于英语数据集训练,而近期跨语言跨模态预训练模型仅适用于理解任务。我们提出的 ERNIE-UniX2 是一个统一预训练框架,能够处理跨语言跨模态场景下的理解与生成任务。
We utilize text-only datasets (CC100 [11] and OPUS [12]) and image-text datasets (CC3M [13], CC12M [14] and WIT [15]) to train ERNIE-UniX2, in which we use translated CC3M and CC12M following $[9]^{2}$ . Transferred to understanding and generation downstream tasks, ERNIE-UniX2 achieves SOTA results for cross-lingual image-text retrieval, multimodal machine translation on Multi30K [16, 17], cross-lingual visual language reasoning on XVNLI [18]. Moreover, compared with previous SOTA VLP models pre-trained on large-scale datasets in well-resourced languages, ERNIE-UniX2 presents competitive results on image captioning on MSCOCO [19] and COCO-CN [20].
我们使用纯文本数据集(CC100 [11]和OPUS [12])以及图文数据集(CC3M [13]、CC12M [14]和WIT [15])来训练ERNIE-UniX2,其中CC3M和CC12M采用$[9]^{2}$中的翻译版本。迁移至理解与生成下游任务时,ERNIE-UniX2在跨语言图文检索、Multi30K [16, 17]上的多模态机器翻译、XVNLI [18]上的跨语言视觉语言推理等任务中取得了SOTA成果。此外,与先前在资源丰富语言的大规模数据集上预训练的SOTA VLP模型相比,ERNIE-UniX2在MSCOCO [19]和COCO-CN [20]的图片描述任务中展现出极具竞争力的表现。
Overall, our contributions fall into two parts:
总体而言,我们的贡献分为两部分:
2 Related Work
2 相关工作
Cross-modal Pre-trained Models In the past three years, numerous works [5, 3, 1, 21, 22, 4, 2] in Vision-Language Pre-training have shown their effectiveness in learning generic cross-modal representation and significantly improved the performance of various downstream cross-modal tasks. These works roughly fall into two categories.
跨模态预训练模型
过去三年间,大量视觉语言预训练研究 [5, 3, 1, 21, 22, 4, 2] 证明了其在学习通用跨模态表征方面的有效性,并显著提升了各类下游跨模态任务的性能。这些工作大致可分为两类。
The first category exploits cross-modal attention to learn fine-grained alignments between visual and textual tokens and presents superior performances on cross-modal tasks (especially for fine-grained vision-language tasks). However, most early works utilize region-level visual features with pre-trained detectors, which requires complicated pre-processing in training and inference. Motivated by an advanced image backbone ViT [10], recent works [22, 1, 2] propose more efficient pre-training frameworks directly extracting visual features via a simple linear projection of patches. Among these works, SimVLM [1] proposes a simple yet effective pre-training task PrefixLM and achieves impressive results on cross-modal tasks with an encoder-decoder architecture, exploiting bi-directional and left-to-right attention across languages and modalities simultaneously. Another category of work (e.g., ALIGN [4] and CLIP [23]) attempts to align vision and language using contrastive learning with parallel encoders (dual-encoder) and obtain robust vision and vision-language representation only leveraging web-crawled image-text datasets. However, these works utilize shallow cross-modal interactions, resulting in low performance on fine-grained vision-language tasks (e.g., VQA) requiring deeper multimodal understanding. To address these limitations, recent works [24, 25, 7] attempt to integrate contrastive learning and cross-modal attention with fine-grained interactions into one pre-training framework. In our framework, we integrate dual-encoder with contrastive learning into encoder-decoder architecture to be flexibly applied to various downstream tasks and focus on improving the performance of both cross-lingual cross-modal generation and understanding tasks.
第一类方法利用跨模态注意力 (cross-modal attention) 学习视觉与文本 token 之间的细粒度对齐,在跨模态任务(特别是细粒度视觉-语言任务)中表现出优越性能。然而,早期工作大多使用预训练检测器提取区域级视觉特征,这需要在训练和推理阶段进行复杂的预处理。受先进图像骨干网络 ViT [10] 的启发,近期研究 [22, 1, 2] 提出了更高效的预训练框架,通过简单的图像块线性投影直接提取视觉特征。其中 SimVLM [1] 提出简单有效的预训练任务 PrefixLM,采用编码器-解码器架构同时利用跨语言和跨模态的双向与左向右注意力,在跨模态任务上取得显著成果。另一类工作(如 ALIGN [4] 和 CLIP [23])尝试通过对比学习与并行编码器(双编码器)对齐视觉与语言,仅利用网络爬取的图文数据集就获得了鲁棒的视觉及视觉-语言表征。但这些方法采用浅层跨模态交互,导致在需要深层多模态理解的细粒度视觉-语言任务(如 VQA)上表现欠佳。为解决这些局限,近期研究 [24, 25, 7] 尝试将对比学习、跨模态注意力和细粒度交互整合到统一预训练框架中。我们的框架将双编码器与对比学习集成到编码器-解码器架构中,可灵活应用于各类下游任务,并着重提升跨语言跨模态生成与理解任务的双向性能。
Cross-lingual Cross-modal Pre-trained Models Cross-lingual cross-modal pre-training aims to generalize such success achieved by VLP to a wide range of non-English inputs. The pioneer work $\mathbf{M}^{3}\mathbf{P}$ [8] proposes cross-modal Code-switched Training (MCT) to learn a joint cross-lingual cross-modal representation leveraging English-only image-text pairs. Since MCT aligns images and multilingual texts with English as a pivot, $\mathrm{UC^{2}}$ [9] extended to multiple pivots (vision and languages) for enhancing the alignment by proposing Visual Translation Language Modeling (VTLM) and translating existing English-only image-text pairs into other languages. On the other hand, motivated by recent works on cross-modal retrieval using contrastive learning, MURAL [26] achieves significant improvements on cross-lingual image-text retrieval through pre-training on large-scale web-crawled multilingual image-text pairs with the dual-encoder architecture. While these works focus on understanding tasks, we attempt to tackle understanding and generation tasks with a unified pre-training framework across languages and modalities.
跨语言跨模态预训练模型
跨语言跨模态预训练旨在将视觉语言预训练(VLP)的成功推广到广泛的非英语输入场景。开创性工作$\mathbf{M}^{3}\mathbf{P}$[8]提出跨模态语码转换训练(MCT),利用纯英文图像-文本对学习联合跨语言跨模态表征。由于MCT以英语为枢纽对齐图像和多语言文本,$\mathrm{UC^{2}}$[9]通过提出视觉翻译语言建模(VTLM)并将现有纯英文图像-文本对翻译成其他语言,扩展到多枢纽(视觉和语言)以增强对齐。另一方面,受近期基于对比学习的跨模态检索研究启发,MURAL[26]采用双编码器架构,在大规模网络爬取的多语言图像-文本对上预训练,显著提升了跨语言图文检索性能。这些工作主要关注理解任务,而我们试图通过跨语言和跨模态的统一预训练框架,同时解决理解和生成任务。
3 Method
3 方法
In this section, we present a cross-lingual cross-modal framework ERNIE-UniX2 unifying generation and understanding tasks. We present the overview of our frameworks in Section 3.1, then describe the pre-training tasks in Section 3.2.
在本节中,我们提出了一种跨语言跨模态的框架 ERNIE-UniX2,统一了生成和理解任务。我们将在第 3.1 节介绍框架的概述,然后在第 3.2 节描述预训练任务。
3.1 Framework Overview
3.1 框架概述
As illustrated in Figure 2, we build ERNIE-UniX2 based on encoder-decoder architecture and incorporate three pretraining paradigms into a unified framework, which could seamlessly apply to varieties of understanding and generation downstream tasks with a unified framework across different languages.
如图 2 所示,我们基于编码器-解码器架构构建 ERNIE-UniX2,并将三种预训练范式整合到统一框架中。该框架可无缝适配跨语言多种理解与生成下游任务。
For understanding tasks, we employ Cross-lingual Contrastive learning (CLCL) and Cross-Modal Contrastive Learning (CMCL) with the dual-encoder for parallel bilingual text pairs and image-text pairs, respectively, to learn the coarsegrained alignment with shallow cross-modal interactions. Moreover, we exploit two widely-used Image-Text Matching (ITM) and Masked Language Modeling (MLM) to further learn a fine-grained vision-language alignment with the encoder. For generation tasks, we employ four pre-training tasks leveraging encoder-decoder, i.e., Prefix Language Modeling (PLM), visual Prefix Language Modeling (vPLM), Machine Translation (MT) and masked Multimodal Machine Translation (mMMT). vPLM and PLM attempt to enhance the generation capabilities of single languages with and without visual condition, and mMMT and MT aims to extend it to bilingual texts/text-image pairs.
在理解任务方面,我们分别采用跨语言对比学习(CLCL)和跨模态对比学习(CMCL)的双编码器结构,针对平行双语文本对和图文对进行粗粒度对齐学习,实现浅层跨模态交互。此外,我们利用图像文本匹配(ITM)和掩码语言建模(MLM)两项广泛使用的任务,通过编码器进一步学习细粒度的视觉-语言对齐。对于生成任务,我们采用基于编码器-解码器的四项预训练任务:前缀语言建模(PLM)、视觉前缀语言建模(vPLM)、机器翻译(MT)和掩码多模态机器翻译(mMMT)。其中vPLM和PLM分别尝试增强带视觉条件和不带视觉条件的单语言生成能力,而mMMT和MT则旨在将其扩展至双语文本/图文对的生成场景。
We note that, we adopt an end-to-end vision Transformer as our visual encoder to extract patch-level features from images instead of relying on region-level visual features with a pre-trained detector (e.g., BUTD [27]) used in previous works $\mathbf{M}^{3}\mathbf{P}$ [8] and $\mathrm{{UC^{2}}}$ [9].
我们注意到,我们采用端到端的视觉Transformer作为视觉编码器,从图像中提取patch级别的特征,而不是像之前的工作 $\mathbf{M}^{3}\mathbf{P}$ [8] 和 $\mathrm{{UC^{2}}}$ [9] 那样依赖预训练检测器(例如BUTD [27])提取区域级别的视觉特征。
3.2 Pre-training Tasks
3.2 预训练任务
ERNIE $\mathrm{{.UniX^{2}}}$ is trained on all pre-training tasks jointly with cross-lingual cross-modal mixed data stream sharing the same parameters. We construct data streams $D$ consisting of two main parts: text-only data stream $D^{\mathrm{[L]}}$ and image-text data stream $D^{\mathrm{VL}}$ . In each iteration, a specified task is selected to calculate its gradients with equal probabilities, and then we merge all the gradients for all tasks to update the parameters.
ERNIE $\mathrm{{.UniX^{2}}}$ 通过共享相同参数,在跨语言跨模态混合数据流上联合训练所有预训练任务。我们构建的数据流 $D$ 包含两个主要部分:纯文本数据流 $D^{\mathrm{[L]}}$ 和图文数据流 $D^{\mathrm{VL}}$。在每次迭代中,以等概率选择指定任务计算其梯度,随后合并所有任务的梯度进行参数更新。
3.2.1 Cross-lingual Cross-modal Contrastive Learning
3.2.1 跨语言跨模态对比学习
We adopt Cross-modal Contrastive Learning (CMCL) on cross-lingual text-image pairs and Cross-lingual Contrastive Learning (CLCL) on cross-lingual text pairs to learn robust representations across languages and modalities. Overall,
我们在跨语言文本-图像对上采用跨模态对比学习 (CMCL) ,在跨语言文本对上采用跨语言对比学习 (CLCL) ,以学习跨语言和跨模态的鲁棒表征。总体而言,
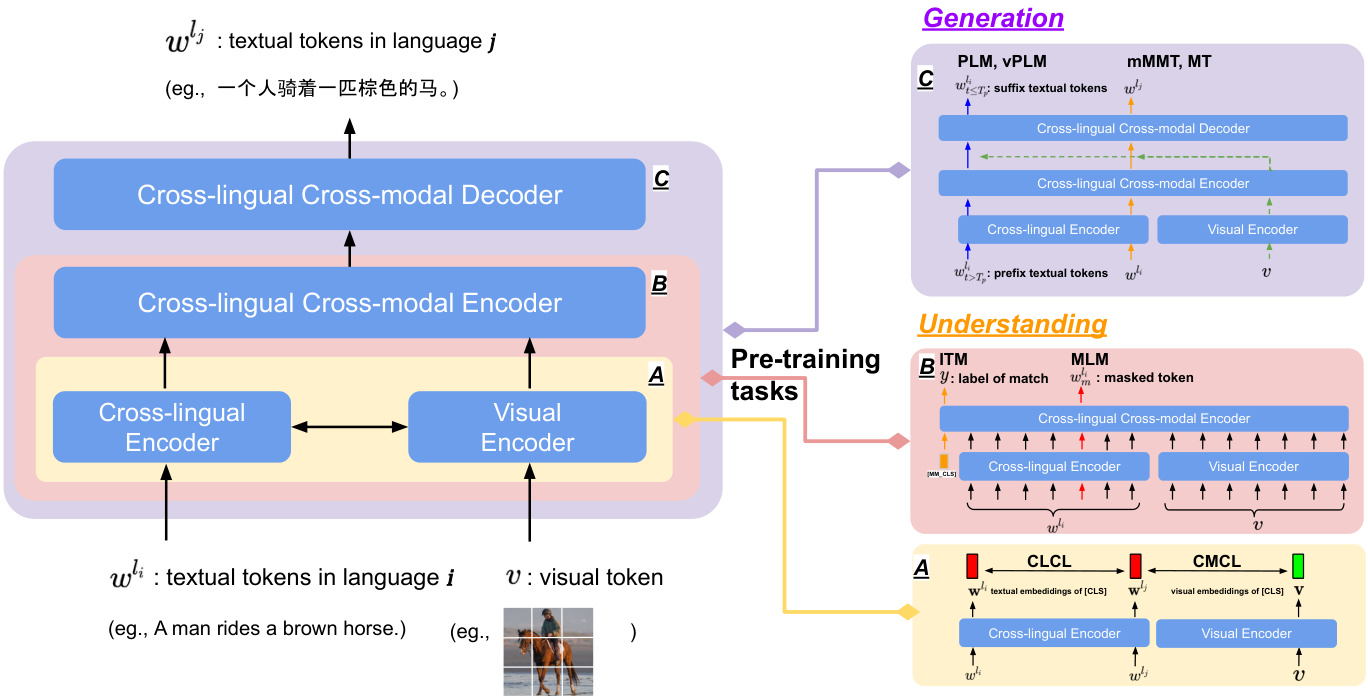
Figure 2: The overview of our proposed ERNIE $\mathbf{{.UniX^{2}}}$ framework. ERNIE $\mathbf{.UniX^{2}}$ integrates three pre-training paradigms on different components. 1) Pre-training on Component. A (dual-encoder architecture) with Cross-Lingual Contrative Learning (CLCL) for bilingual parallel texts and Cross-modal Contrastive Learning (CMCL) for text-image pairs. 2) Pre-training on Component. $\mathbfit{B}$ ( dual-encoder and encoder-decoder architecture) with Prefix Language Modeling (PLM) and Machine translation (MT) on cross-lingual texts, visual Prefix Language Modeling (vPLM) and Multimodal Machine Translation with masked textual tokens (mMMT) on cross-lingual image-text pairs. 3) Pre-training on Component. $c$ (encoder-only architecture) with Masked Language Modelling (MLM) and Image Text Matching $(\mathbf{ITM}).T_{p}$ denotes the length of prefix tokens.
图 2: 我们提出的 ERNIE $\mathbf{.UniX^{2}}$ 框架概览。ERNIE $\mathbf{.UniX^{2}}$ 在不同组件上整合了三种预训练范式:1) 组件A (双编码器架构) 采用跨语言对比学习 (CLCL) 处理双语平行文本,跨模态对比学习 (CMCL) 处理图文对;2) 组件 $\mathbfit{B}$ (双编码器与编码器-解码器架构) 采用前缀语言建模 (PLM) 和机器翻译 (MT) 处理跨语言文本,视觉前缀语言建模 (vPLM) 和带掩码文本token的多模态机器翻译 (mMMT) 处理跨语言图文对;3) 组件 $c$ (纯编码器架构) 采用掩码语言建模 (MLM) 和图文匹配 $(\mathbf{ITM})$。$T_{p}$ 表示前缀token的长度。
where $\mathbf{w}{a}^{l_{i}}$ and $\mathbf{v}{b}$ are the normalized [CLS] embeddings of a text in language $i$ for $a$ -th pairs and that of an image for the $b$ -th pairs at each batch, which denotes the global representations of texts and images. In each iteration, we sample $N$ image-text pairs $(w^{l_{i}},v)$ from $D^{\mathrm{[VL]}}$ as one mini-batch. $\tau$ is a learnable temperature to scale the logits.
其中 $\mathbf{w}{a}^{l_{i}}$ 和 $\mathbf{v}{b}$ 分别表示第 $a$ 个文本对中语言 $i$ 的归一化 [CLS] 嵌入向量,以及第 $b$ 个图像对在每个批次中的归一化 [CLS] 嵌入向量,它们代表文本和图像的全局表征。每次迭代时,我们从 $D^{\mathrm{[VL]}}$ 中采样 $N$ 个图文对 $(w^{l_{i}},v)$ 作为一个小批次。$\tau$ 是一个可学习的温度参数,用于缩放逻辑值。
We utilize Cross-lingual Contrastive Learning (CLCL) on multilingual parallel text pairs to generalize cross-modal cross-lingual capabilities to a wide range of languages with language pivot. Similar to CMCL, CLCL is utilized to learn the global alignment of parallel bilingual text pairs with loss as
我们利用跨语言对比学习 (Cross-lingual Contrastive Learning, CLCL) 在多语言平行文本对上训练,通过语言枢纽将跨模态跨语言能力泛化至多种语言。与 CMCL 类似,CLCL 通过损失函数学习平行双语文本对的全局对齐。
$$
\dot{\mathbf{\Psi}}{C L C L}=\mathbb{E}{(w^{l_{i}},w^{l_{i}})\sim D^{[L]}}-\frac{1}{N}(\underbrace{\sum_{a}^{N}\log\frac{\exp{\big({\mathbf{w}}{a}^{l_{i}}}^{\top}{\mathbf{w}}{a}^{l_{j}}/\tau\big)}{\sum_{b}^{N}\exp{\big({\mathbf{w}}{a}^{l_{i}}}^{\top}{\mathbf{w}}{b}^{l_{j}}/\tau\big)}}{\mathrm{language~}i-\mathrm{to-language~}j}+\underbrace{\sum_{a}^{N}\log\frac{\exp{\big({\mathbf{w}}{a}^{l_{j}}}^{\top}{\mathbf{w}}{a}^{l_{i}}/\tau\big)}{\sum_{b}^{N}\exp{\big({\mathbf{w}}{a}^{l_{j}}}^{\top}{\mathbf{w}}{b}^{l_{i}}/\tau\big)}}_{\mathrm{language~}j-\mathrm{to-language~}i})
$$
$$
\dot{\mathbf{\Psi}}{C L C L}=\mathbb{E}{(w^{l_{i}},w^{l_{i}})\sim D^{[L]}}-\frac{1}{N}(\underbrace{\sum_{a}^{N}\log\frac{\exp{\big({\mathbf{w}}{a}^{l_{i}}}^{\top}{\mathbf{w}}{a}^{l_{j}}/\tau\big)}{\sum_{b}^{N}\exp{\big({\mathbf{w}}{a}^{l_{i}}}^{\top}{\mathbf{w}}{b}^{l_{j}}/\tau\big)}}{\mathrm{language~}i-\mathrm{to-language~}j}+\underbrace{\sum_{a}^{N}\log\frac{\exp{\big({\mathbf{w}}{a}^{l_{j}}}^{\top}{\mathbf{w}}{a}^{l_{i}}/\tau\big)}{\sum_{b}^{N}\exp{\big({\mathbf{w}}{a}^{l_{j}}}^{\top}{\mathbf{w}}{b}^{l_{i}}/\tau\big)}}_{\mathrm{language~}j-\mathrm{to-language~}i})
$$
where $\mathbf{w}{a}^{l_{i}}$ and $\mathbf{w}{b}^{l_{j}}$ are the normalized [CLS] embedding of a text in the $a$ -th and $b$ -th bilingual pairs in language $i$ and language $j$ . $w^{l_{i}}$ and $w^{l_{j}}$ are translated texts between two languages.
其中 $\mathbf{w}{a}^{l_{i}}$ 和 $\mathbf{w}{b}^{l_{j}}$ 分别是语言 $i$ 和语言 $j$ 中第 $a$ 个和第 $b$ 个双语对文本的归一化 [CLS] 嵌入。$w^{l_{i}}$ 和 $w^{l_{j}}$ 是两种语言之间的翻译文本。
3.2.2 Cross-lingual Cross-modal fine-grained Understanding
3.2.2 跨语言跨模态细粒度理解
We employ two widely-used pre-training tasks in VLP (i.e., Image-Text Matching (ITM) and Masked Language Modeling (MLM) ) to further align vision and languages in a fine-grained semantic granularity. ITM attempts to predict whether the image-text pairs are matched or not. We use the outputs of a special token [MM_CLS] in the cross-lingual cross-modal encoder as the joint representation of image-text pairs and feed it into the binary classifier with sigmoid function to predict a match score of image-text pairs $s_{\theta}(\bar{\boldsymbol{w}}^{l_{i}},\boldsymbol{v})$ , $\theta$ is the learnable parameter of our framework. We use a binary cross-entropy loss as
我们在视觉语言预训练(VLP)中采用两种广泛使用的预训练任务(即图文匹配(Image-Text Matching, ITM)和掩码语言建模(Masked Language Modeling, MLM)),以在细粒度语义层面上进一步对齐视觉与语言。ITM旨在预测图文对是否匹配。我们使用跨语言跨模态编码器中特殊token [MM_CLS]的输出作为图文对的联合表征,并将其输入带有sigmoid函数的二分类器,以预测图文对的匹配分数$s_{\theta}(\bar{\boldsymbol{w}}^{l_{i}},\boldsymbol{v})$,其中$\theta$是我们框架的可学习参数。我们采用二元交叉熵损失作为...
$$
\mathcal{L}{I T M}(\theta)=\mathbb{E}{(w^{l_{i}},v)\sim D^{[\mathrm{VL}]}}-[y\log s_{\theta}(w^{l_{i}},v)+(1-y)\log(1-s_{\theta}(w^{l_{i}},v))]
$$
$$
\mathcal{L}{I T M}(\theta)=\mathbb{E}{(w^{l_{i}},v)\sim D^{[\mathrm{VL}]}}-[y\log s_{\theta}(w^{l_{i}},v)+(1-y)\log(1-s_{\theta}(w^{l_{i}},v))]
$$
where $y\in{0,1}$ denotes whether the image-text pairs is matched, and $w^{l_{i}}$ denotes texts in $i$ language. $(w^{l_{i}},v)$ consists of positive and negative pairs sampled from cross-lingual image-text pairs, and negative samples are constructed by replacing image or text in matched pairs. The loss function for MLM loss is
其中 $y\in{0,1}$ 表示图文对是否匹配,$w^{l_{i}}$ 表示第 $i$ 种语言的文本。$(w^{l_{i}},v)$ 由跨语言图文对中采样的正负样本对组成,负样本通过替换匹配对中的图像或文本来构建。MLM (Masked Language Modeling) 损失的损失函数为
$$
\mathcal{L}{M L M}(\theta)=\mathbb{E}{(w^{l_{i}},v)\sim D^{\mathrm{{[VL]}}}}-\sum_{m\in M}\log P_{\theta}(w_{m}^{l_{i}}|w_{\backslash m}^{l_{i}},v)
$$
$$
\mathcal{L}{M L M}(\theta)=\mathbb{E}{(w^{l_{i}},v)\sim D^{\mathrm{{[VL]}}}}-\sum_{m\in M}\log P_{\theta}(w_{m}^{l_{i}}|w_{\backslash m}^{l_{i}},v)
$$
where $w_{m}^{l_{i}}$ denotes the $m$ -th masked word, and $M$ is the set of masked words for each text-image pair. $w_{\backslash m}^{l_{i}}$ is texts with mask words.
其中 $w_{m}^{l_{i}}$ 表示第 $m$ 个被掩码的词,$M$ 是每个文本-图像对被掩码的词集合。$w_{\backslash m}^{l_{i}}$ 是带有掩码词的文本。
3.2.3 Cross-lingual Cross-modal Generation
3.2.3 跨语言跨模态生成
We use Prefix Language Modelling with and without the visual condition (vPLM and PLM) as generation pre-training tasks to learn cross-lingual cross-modal representation across monolingual texts and images. Specifically, Prefix Language Modeling (PLM) splits the multilingual texts of length $T$ into two parts (prefix sequence $w^{\hat{l}{i}}<T_{p}$ and suffix sequence $w^{l_{i}}\geq T_{p})$ , then feeds them to the encoder and decoder, respectively.
我们采用带视觉条件和不带视觉条件的前缀语言建模(vPLM和PLM)作为生成式预训练任务,以学习跨语言跨模态的单语文本和图像表示。具体而言,前缀语言建模(PLM)将长度为$T$的多语言文本分割为两部分(前缀序列$w^{\hat{l}{i}}<T_{p}$和后缀序列$w^{l_{i}}\geq T_{p}$),分别输入编码器和解码器。
, where $T_{p}$ is length of prefix sequence. vPLM and PLM attempt to generate the suffix sequence of texts $w^{l_{i}}$ given by the prefix sequence with or without visual condition. Moreover, $T_{p}$ is sampled as 0 or the length of $20%$ tokens of the whole sentence with equal probabilities. Therefore, vPLM acts as an image captioning task in a special case $T_{p}=0$ .
其中 $T_{p}$ 是前缀序列的长度。vPLM 和 PLM 尝试在给定前缀序列的情况下,生成文本的后缀序列 $w^{l_{i}}$ ,前者带有视觉条件而后者没有。此外,$T_{p}$ 以相等概率采样为 0 或整个句子 20% token 的长度。因此,在 $T_{p}=0$ 的特殊情况下,vPLM 充当了图像描述任务的角色。
Since vPLM learns cross-lingual cross-modal representation only with the visual pivot, we adopt Machine Translation (MT) and masked Multimodal Machine Translation (mMMT) to further enhance cross-lingual cross-modal learning leveraging bilingual text image-text pairs. Similarly, the mMMT is identical to machine translation with the visual condition, which aims to translate the source language with/without the images to the target language. Compared to conventional MMT, we employ mMMT by randomly replacing textual tokens in the source language with masked tokens (for such masked tokens, we also perform MLM on them) to enforce the interaction between images and texts in target language. For a similar purpose mentioned in Section 3.2.1 of extending to a wide range of languages, we follow standard Machine translation (MT) on the bilingual text pairs $(w^{l_{i}},w^{l_{j}})$ to enhance the cross-lingual alignment. The loss function for mMMT and MT is:
由于vPLM仅通过视觉枢纽学习跨语言跨模态表示,我们采用机器翻译(MT)和掩码多模态机器翻译(mMMT)技术,利用双语文本-图像对进一步增强跨语言跨模态学习。具体而言,mMMT是在视觉条件下进行的机器翻译,其目标是将源语言(无论是否包含图像)翻译为目标语言。与传统MMT相比,我们通过随机将源语言的文本token替换为掩码token(对这些掩码token同样执行MLM任务)来实现mMMT,从而加强目标语言中图像与文本的交互。出于与第3.2.1节所述相同的多语言扩展目的,我们对双语文本对$(w^{l_{i}},w^{l_{j}})$采用标准机器翻译(MT)来增强跨语言对齐。mMMT和MT的损失函数为:
$$
\begin{array}{r}{\mathcal{L}{\mathrm{mMMT}}(\theta)=\mathbb{E}{(w^{l_{i}},w^{l_{j}},v)\sim D^{[\mathrm{VL}]}}-\displaystyle\sum_{t=0}^{T_{j}}\log p_{\theta}(w_{t}^{l_{j}}|w_{[0,t)}^{l_{j}},w_{m}^{l_{i}},v),}\ {\mathcal{L}{\mathrm{MT}}(\theta)=\mathbb{E}{(w^{l_{i}},w^{l_{j}})\sim D^{[\mathrm{L}]}}-\displaystyle\sum_{t=0}^{T_{j}}\log p_{\theta}(w_{t}^{l_{j}}|w_{[0,t)}^{l_{j}},w^{l_{i}})}\end{array}
$$
$$
\begin{array}{r}{\mathcal{L}{\mathrm{mMMT}}(\theta)=\mathbb{E}{(w^{l_{i}},w^{l_{j}},v)\sim D^{[\mathrm{VL}]}}-\displaystyle\sum_{t=0}^{T_{j}}\log p_{\theta}(w_{t}^{l_{j}}|w_{[0,t)}^{l_{j}},w_{m}^{l_{i}},v),}\ {\mathcal{L}{\mathrm{MT}}(\theta)=\mathbb{E}{(w^{l_{i}},w^{l_{j}})\sim D^{[\mathrm{L}]}}-\displaystyle\sum_{t=0}^{T_{j}}\log p_{\theta}(w_{t}^{l_{j}}|w_{[0,t)}^{l_{j}},w^{l_{i}})}\end{array}
$$
Where $T_{j}$ is the length of target texts, $w_{t}^{l_{j}}$ is the $t$ -th token in target texts $w^{l_{j}}$ , and $w_{m}^{l_{i}}$ is source texts with masked tokens.
其中 $T_{j}$ 是目标文本的长度,$w_{t}^{l_{j}}$ 是目标文本 $w^{l_{j}}$ 中的第 $t$ 个 token,而 $w_{m}^{l_{i}}$ 是带有掩码 token 的源文本。
4 Experiment
4 实验
ERNIE-UniX2 is jointly trained on text-only and text-image datasets. We evaluate ERNIE-UniX2 across cross-lingual, cross-modal and cross-lingual cross-modal understanding and generation tasks. For understanding tasks, we evaluate on Multi30k [28] for cross-lingual cross-modal retrieval, XVNLI [18] and xGQA [29] from a new cross-lingual cross-modal benchmark IGLUE [30] for complex cross-lingual vision-language tasks. For generation tasks, we evaluate on COCO [19, 20] for image captioning in English and Chinese and Multi30k [28] for Multimodal Machine Translation (English-German). Moreover, we also evaluate our model on Tatoeba [31] for mono-modal cross-lingual text retrieval.
ERNIE-UniX2 在纯文本和文本-图像数据集上进行了联合训练。我们在跨语言、跨模态以及跨语言跨模态的理解与生成任务上评估了ERNIE-UniX2的性能。对于理解任务,我们使用Multi30k [28] 进行跨语言跨模态检索评估,采用来自新跨语言跨模态基准IGLUE [30] 的XVNLI [18] 和xGQA [29] 来测试复杂的跨语言视觉-语言任务。在生成任务方面,我们基于COCO [19, 20] 评估了中英文图像描述生成能力,并利用Multi30k [28] 进行多模态机器翻译(英德)测试。此外,还在Tatoeba [31] 上对模型进行了单模态跨语言文本检索的评估。
4.1 Pre-training Datasets
4.1 预训练数据集
Cross-lingual Image-text Datasets We utilize two cross-modal datasets, Conceptual Caption 3M (CC3M) and Conceptual 12M, (CC12M) [14] and one cross-lingual cross-modal dataset WIT [15] as our cross-lingual cross-modal dataset. We use translated caption of CC3M in $\bar{\mathrm{U}}\bar{\mathrm{C}}^{2}$ [9] and translate CC12M to five languages (German, French, Czech, Japanese, and Chinese). The Wikipedia-based Image-Text (WIT) [15] is mined from Wikipedia, including 37.6 million entity-rich image-text examples with 11.5 million unique images across 108 Wikipedia languages. We only use reference of WIT as the corresponding caption in our training datasets, which contain 14M unique image-text pairs due to removing invalid URLs. The total of cross-lingual cross-modal datasets is 29M (CC3M, CC12M, WIT).
跨语言图文数据集
我们采用两个跨模态数据集——Conceptual Caption 3M (CC3M) 和 Conceptual 12M (CC12M) [14],以及一个跨语言跨模态数据集 WIT [15] 作为跨语言跨模态数据源。使用 $\bar{\mathrm{U}}\bar{\mathrm{C}}^{2}$ [9] 中已翻译的 CC3M 字幕,并将 CC12M 翻译为五种语言(德语、法语、捷克语、日语和中文)。基于维基百科的图文数据集 WIT [15] 从维基百科中挖掘获得,包含 3760 万条实体丰富的图文样本,涵盖 108 种维基百科语言的 1150 万张独特图片。训练数据集中仅采用 WIT 的参考字幕作为对应标注,由于移除无效 URL 后共包含 1400 万组独特图文对。跨语言跨模态数据集总量达 2900 万(CC3M、CC12M、WIT)。
Multilingual Text-only Datasets To enhance learning in a wide range of languages, we use two text-only datasets CC100 and OPUS. CC100 corpus is a monolingual corpus [32] including 111 languages and 5 romanized languages. OPUS is a bilingual corpus collecting from OPUS [12], including MultiUN [33], IIT Bombay [34], and WikiMatrix [35].
多语言纯文本数据集
为增强多语言学习能力,我们采用两个纯文本数据集CC100和OPUS。CC100语料库是包含111种语言及5种罗马化语言的单语料库[32]。OPUS是从OPUS[12]收集的双语料库,包含MultiUN[33]、IIT Bombay[34]和WikiMatrix[35]。
We train ERNIE-UniX2 on these datasets using different pre-training tasks and list the details of each dataset used for pre-training tasks in Table 6.
我们在这些数据集上使用不同的预训练任务训练 ERNIE-UniX2,并在表 6 中列出了用于预训练任务的每个数据集的详细信息。
4.2 Downstream Tasks
4.2 下游任务
Cross-lingual Image-text Retrieval We evaluate ERNIE-UniX2 on Multi30k [28, 16, 17] for cross-lingual imagetext retrieval with zero-shot and fine-tuning settings. Multi30k [28] contains 31,783 images with four languages captions per image, extended from Flickr30K [36] by manually translating the English captions to German, French and Czech.
跨语言图文检索
我们在Multi30k [28, 16, 17]数据集上评估ERNIE-UniX2的零样本(zero-shot)和微调(fine-tuning)跨语言图文检索性能。Multi30k [28]包含31,783张图像,每张图像配有四种语言描述,该数据集通过人工将Flickr30K [36]的英文描述翻译为德语、法语和捷克语扩展而成。
Cross-lingual Visual Natural Language Entailment Recent cross-lingual cross-modal benchmark IGLUE [30] proposes a new task of Cross-lingual Visual Natural Language Inference (XVNLI), aiming to predict the relationship between given images and texts across different languages. XVNLI combines the text-only dataset SNLI [37] with its cross-modal [38] and cross-lingual [18] counterparts. Following the same zero-shot settings as IGLUE, we fine-tune ERNIE-UniX2 on training splits of XVNLI with English-only image-text pairs and transfer it to the other four languages with zero-shot settings.
跨语言视觉自然语言蕴含任务
近期提出的跨语言跨模态基准IGLUE [30]中新增了跨语言视觉自然语言推理(XVNLI)任务,旨在预测不同语言环境下图像与文本之间的关系。XVNLI将纯文本数据集SNLI [37]与其跨模态版本[38]及跨语言版本[18]相结合。我们沿用IGLUE的零样本设置,仅使用英文图文对在XVNLI训练集上微调ERNIE-UniX2模型,而后通过零样本方式迁移至其他四种语言。
Cross-lingual Grounded Question Answering The Cross-lingual Grounded Question Answering (xGQA) [29] dataset extends the established English GQA [39] dataset to 7 languages. We model xGQA as a multi-label classification task with 1,842 labels following IGLUE [30] benchmark. Following the same zero-shot settings as IGLUE, we fine-tune ERNIE-UniX2 on xGQA with English-only image-text pairs and transfer it to the other seven languages for zero-shot evaluation.
跨语言基础问答
跨语言基础问答(xGQA) [29]数据集将现有的英语GQA [39]数据集扩展到7种语言。我们按照IGLUE [30]基准将xGQA建模为包含1,842个标签的多标签分类任务。遵循与IGLUE相同的零样本设置,我们仅使用英语图文配对数据在xGQA上微调ERNIE-UniX2,并将其迁移至其他七种语言进行零样本评估。
Image Captioning The image captioning task attempts to generate natural language descriptions of input images. We consider two benchmarks named COCO-CN [20] and MSCOCO [19] to evaluate ERNIE-UniX2. For MSCOCO [19], we keep the same train/test split as the Karpathy split [40], including 123,000 images, each annotated with five sentences. COCO-CN [20] extends COCO captions to Chinese, which contains 20,342 images and 27,218 Chinese captions.
图像描述生成
图像描述生成任务旨在为输入图像生成自然语言描述。我们选用COCO-CN [20]和MSCOCO [19]两个基准数据集评估ERNIE-UniX2。对于MSCOCO [19],我们保持与Karpathy划分 [40]相同的训练/测试集拆分,包含123,000张图像,每张图像标注五句话。COCO-CN [20]将COCO描述扩展至中文,包含20,342张图像和27,218条中文描述。
Multimodal Machine Translation Multimodal machine translation aims to translate image captions from the source language to the target language, where the images are considered as grounding signals. We consider a benchmark Multi30k [28], which aims to translate English source sentences into its German human translation with the corresponding images.
多模态机器翻译
多模态机器翻译旨在将图像描述从源语言翻译为目标语言,其中图像被视为基础信号。我们采用基准数据集Multi30k [28],该数据集旨在将英语源句子与其对应的图像一起翻译为德语人工译文。
Cross-lingual Text Retrieval We use a subset of the Tatoeba [31] dataset to evaluate ERNIE $\mathrm{{.UniX^{2}}}$ on cross-lingual text retrieval, consisting of 1,000 English-aligned sentence pairs covering 36 languages for cross-lingual Sentence Retrieval.
跨语言文本检索
我们使用Tatoeba [31]数据集的一个子集来评估ERNIE $\mathrm{{.UniX^{2}}}$ 的跨语言文本检索能力,该子集包含1,000个英语对齐的句子对,涵盖36种语言,用于跨语言句子检索。
Table 1: The results of cross-lingual cross-modal pre-training methods on understanding downstream tasks. EN means that the results are obtained by fine-tuning the pre-trained model on English-only datasets, for XVNLI, xGQA, Retrieval. $\mathrm{X}$ -avg means the zero-shot results for the average of X languages with an English-only fine-tuned model. We use the average accuracy of 36 languages for Tatoeba. For image-text retrieval on Multi30k, meanRecall means the average of $\mathbf{R}\ @1$ , $\mathtt{R@5}$ , $\mathrm{\mathbf{R}}\ @10$ for image-to-text and text-to-image and avg means the average of meanRecall for four languages.
表 1: 跨语言跨模态预训练方法在下游理解任务上的结果。EN 表示通过在纯英文数据集上微调预训练模型获得的结果,适用于 XVNLI、xGQA 和检索任务。$\mathrm{X}$ -avg 表示使用纯英文微调模型在 X 种语言上的零样本平均结果。Tatoeba 任务采用 36 种语言的平均准确率。对于 Multi30k 的图文检索任务,meanRecall 表示图像到文本和文本到图像方向 $\mathbf{R}\ @1$、$\mathtt{R@5}$、$\mathrm{\mathbf{R}}\ @10$ 的平均值,avg 表示四种语言的 meanRecall 平均值。
| (1) (2) | 方法 | NLI | QA | 检索 |
|---|---|---|---|---|
| XVNLI EN | XGQA EN | EN | ||
| 准确率 | 4-avg | 7-avg准确率 | ||
| VECO | ||||
| (1) (2) | ERNIE-M | |||
| (3) | mUNITER | 76.38 | 53.69 | 54.68 |
| (4) | XUNITER | 75.77 | 58.48 | 54.83 |
| (5) | M²P | 76.38 | 58.25 | 55.19 |
| (6) | UC2 | 76.89 | 62.05 | 53.75 |
| (7) | MURALTrTrain(CC12m)+EOBT | |||
| (8) | ERNIE-UniX2 | 87.73 | 77.42 | 56.68 |
Table 2: Results on generation tasks of ERNIE-UniX2 compared to other single language cross-modal pre-training models. We use BLEU $\ @4$ for Multi30k on multimodal machine translation. We use BLEU $\ @4$ , METEOR, CIDEr and SPICE on MSCOCO and COCO-CN for image captioning. $\mathrm{B}@4$ : BLEU $\ @4$ , M: METEOR, C: CIDEr, S: SPICE)
表 2: ERNIE-UniX2 与其他单语言跨模态预训练模型在生成任务上的对比结果。我们在 Multi30k 多模态机器翻译任务上使用 BLEU $\ @4$ 指标,在 MSCOCO 和 COCO-CN 图像描述任务上使用 BLEU $\ @4$ 、METEOR、CIDEr 和 SPICE 指标。($\mathrm{B}@4$: BLEU $\ @4$, M: METEOR, C: CIDEr, S: SPICE)
| 图像描述 | 翻译 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| MSCOCO En | COCO-CN Zh | Multi30k En-De B@4 | |||||||
| B@4 | M | C | S | B@4 | M | R | C | ||
| (1) | OSCAR | 36.5 | 123.7 | ||||||
| (2) | E2E-VLP | 36.2 | 117.3 | ||||||
| (3) | ERNIE-ViLG | 50.0 | 31.6 | 60.3 | 138.2 | ||||
| (4) | SimVLM | 40.6 | 33.7 | 143.3 | 25.4 | ||||
| (5) | ERNIE-UniX2 | 40.7 | 39.8 | 133.1 | 27.0 | 48.3 | 30.1 | 58.7 | 133.5 |
4.3 Implementation Details
4.3 实现细节
4.3.1 Pre-training Settings
4.3.1 预训练设置
The cross-lingual cross-modal encoder-decoder of ERNIE-UniX2 are initialized from mBART [41]. For dual-encoder, we initialize the visual encoder with ViT-base [10] and the textual encoder with mBART. We train our model on 32 Nvidia A100 GPUs for 60K steps with a total batch size of 4096. We adopt Adam optimizer [42] with a base learning rate of $10^{-4}$ , which is warmed up linearly in 4K steps and decayed to $\mathrm{\dot{1}0^{-6}}$ with a cosine schedule. The detailed hyper parameter of our pre-trained model is in Table 5 in the appendix.
ERNIE-UniX2的跨语言跨模态编码器-解码器结构基于mBART [41]初始化。对于双编码器,我们分别采用ViT-base [10]初始化视觉编码器,mBART初始化文本编码器。模型在32块Nvidia A100 GPU上训练6万步,总批次大小为4096。我们使用Adam优化器 [42],基础学习率为$10^{-4}$,前4千步线性预热,随后按余弦调度衰减至$\mathrm{\dot{1}0^{-6}}$。预训练模型的详细超参数见附录中的表5。
4.3.2 Evaluation Settings
4.3.2 评估设置
We evaluated ERNIE $\mathrm{{.UniX^{2}}}$ on six cross-lingual cross-modal tasks with zero-shot and fine-tuning settings for generation and understanding. For cross-lingual image-text retrieval and cross-lingual text retrieval, we only employ dual encoders of ERNIE-UniX2 to evaluate our model both with zero-shot and fine-tuning settings. ERNIE-UniX2 is fine-tuned with encoder-only architecture on other understanding tasks (XVNLI and xGQA) through appending an MLP layer on outputs of the first special token [MM_CLS] to predict the target label. For generation tasks, image captioning and multimodal machine translation, we use the whole module of ERNIE-UniX2 with fine-tuning settings and generate the text with 4 beam size. The details of fine-tuning settings in Table 5.
我们在六项跨语言跨模态任务上评估了ERNIE $\mathrm{{.UniX^{2}}}$,包括生成和理解任务的零样本和微调设置。对于跨语言图文检索和跨语言文本检索任务,我们仅使用ERNIE-UniX2的双编码器,在零样本和微调设置下评估模型性能。在其他理解任务(XVNLI和xGQA)上,ERNIE-UniX2采用仅编码器架构进行微调,通过在首个特殊token [MM_CLS]的输出后添加MLP层来预测目标标签。对于生成任务(图像描述生成和多模态机器翻译),我们使用ERNIE-UniX2完整模块进行微调,并以4的束宽生成文本。具体微调设置详见表5。
4.4 Overall Results
4.4 总体结果
We evaluate ERNIE-UniX2 on several understanding and generation tasks compared to previous state-of-the-art (SOTA) methods.
我们在多项理解和生成任务上评估ERNIE-UniX2,并与之前的最先进 (SOTA) 方法进行对比。
For the understanding task, as shown in Table 1, ERNIE-UniX2 achieves new state-of-the-art results, outperforming VECO [43], ERNIE-M [44], mUNITER [45], xUNITER [45], $\mathbf{M}^{3}\mathbf{P}$ [8], $\mathrm{{UC^{2}}}$ [9] and MURAL [26]. Specifically, for zero-shot cross-lingual transfer, ERNIE-UniX2 substantially outperforms $\mathrm{{UC^{2}}}$ on XVNLI and xGQA, with an average improvement of over $15.37%$ and $11.28%$ . For the cross-lingual text retrieval task, ERNIE-UniX2 achieves a score of 93.82 in the Tatoeba dataset, outperforming the previous SOTA result of ERNIE-M. As well as, we use two different settings of zero-shot and all-language fine-tuning to compare ERNIE $\mathrm{{UniX^{2}}}$ with $\mathbf{M}^{3}\mathbf{P},$ $\mathrm{{UC^{2}}}$ and MURAL on Multi30k image-text retrieval. ERNIE-UniX2 also slightly outperforms MURAL, the prior state-of-the-art in the zero-shot by $0.65%$ averaged recall across four languages. This demonstrates that our unified pre-training approach is competitive with understanding-based models.
在理解任务方面,如表 1 所示,ERNIE-UniX2 取得了新的最先进 (state-of-the-art) 结果,超越了 VECO [43]、ERNIE-M [44]、mUNITER [45]、xUNITER [45]、$\mathbf{M}^{3}\mathbf{P}$ [8]、$\mathrm{{UC^{2}}}$ [9] 和 MURAL [26]。具体而言,在零样本跨语言迁移任务中,ERNIE-UniX2 在 XVNLI 和 xGQA 上显著优于 $\mathrm{{UC^{2}}}$,平均提升分别超过 $15.37%$ 和 $11.28%$。在跨语言文本检索任务中,ERNIE-UniX2 在 Tatoeba 数据集上取得了 93.82 的分数,超越了 ERNIE-M 之前的最优结果。此外,我们采用零样本和全语言微调两种不同设置,将 ERNIE $\mathrm{{UniX^{2}}}$ 与 $\mathbf{M}^{3}\mathbf{P}$、$\mathrm{{UC^{2}}}$ 和 MURAL 在 Multi30k 图文检索任务上进行对比。ERNIE-UniX2 在零样本设置下也以 $0.65%$ 的四语言平均召回率略微超越此前最优的 MURAL。这表明我们的统一预训练方法与基于理解的模型相比具有竞争力。
Table 3: The Ablation study of proposed pre-training tasks in ERNIE-UniX2. "ITM" refers to Image-Text Matching. "MLM" refers to Masked Language Modeling. "CMCL" refers to Cross-model Contrastive Learning. "mMMT" refers to masked Multimodal Machine Translation. "vPLM" refers to visual Prefix Language Modeling.
表 3: ERNIE-UniX2 中提出的预训练任务消融研究。"ITM"指图像-文本匹配。"MLM"指掩码语言建模。"CMCL"指跨模态对比学习。"mMMT"指掩码多模态机器翻译。"vPLM"指视觉前缀语言建模。
| Methods | xGQA EN | xGQA 7-avg | Multi30k retrieval meanRecall | MSCOCO B@4 | MSCOCO C | Multi30k translation B@4 | Avg |
|---|---|---|---|---|---|---|---|
| (0) ERNIE-UniX | 55.08 | 40.44 | 81.45 | 40.20 | 131.30 | 49.30 | 66.30 |
| (1) w/o ITM | 53.61 | 40.53 | 81.39 | 40.20 | 131.60 | 49.50 | 66.14 |
| (2) w/o MLM | 53.02 | 39.94 | 81.76 | 39.20 | 130.00 | 49.30 | 65.54 |
| (3) w/o CMCL | 53.45 | 38.73 | 68.94 | 38.90 | 127.80 | 49.00 | 62.80 |
| (4) w/o mMMT | 54.51 | 40.99 | 81.07 | 40.20 | 131.40 | 49.10 | 66.21 |
| (5) w/o vPLM | 52.09 | 39.30 | 81.63 | 39.60 | 128.80 | 48.90 | 65.05 |
For the generation task, as the results are shown in Table 1, ERNIE-UniX2 outperforms SimVLM [1] on 3 out of 4 metrics of the image captioning task on MS-CoCo. Our model also achieves comparable results to the previous SOTA model ERNIE-ViLG [46] for image captioning on COCO-CN. We note that ERNIE-ViLG is a 10 billion parameter model pre-trained on hundreds of millions of image-text pairs. In the image translation of Multi30k from English to German, ERNIE-UniX2 has a noticeable improvement compared to SimVLM by $1.70%$ , demonstrating that large and diverse translation pairs can learn better cross-lingual cross-modal encoder-decoder. These experiments demonstrate that our model can achieve superior performance through the unified cross-lingual cross-modal encoder-decoder architecture.
在生成任务中,如表1所示,ERNIE-UniX2在MS-CoCo图像描述任务的4项指标中有3项优于SimVLM [1]。我们的模型在COCO-CN图像描述任务上也取得了与之前SOTA模型ERNIE-ViLG [46]相当的结果。值得注意的是,ERNIE-ViLG是一个在数亿图文对上预训练的百亿参数模型。在Multi30k英德图像翻译任务中,ERNIE-UniX2相比SimVLM有1.70%的显著提升,这表明大规模多样化的翻译对可以学习到更好的跨语言跨模态编码器-解码器。这些实验证明,我们的模型通过统一的跨语言跨模态编码器-解码器架构能够实现更优的性能。
4.5 Ablation Studies
4.5 消融实验
The Effect of Pre-training Tasks To validate the effectiveness of pre-training tasks in ERNIE-UniX2, we conduct ablation studies and report results in Table 3. Concretely, we evaluate our ERNIE-UniX2 on two understanding tasks (i.e., cross-lingual image-text retrieval on Multi30k and xGQA) and two generation tasks (i.e., image captioning on MSCOCO and multimodal machine translation on Multi30k). For xGQA, following the same zero-shot settings as IGLUE, we present English-only fine-tuned results and transfer the model to other 7 languages to obtain zero-shot results. We present the all-language fine-tuned results on Multi30k for cross-lingual image-text retrieval across 7 languages. For generation tasks, we present fine-tuned results on image captioning on MSCOCO following Karpathy splits and multimodal machine translation on Multi30k. All compared models are pre-trained for 50K steps with a batch size of 512.
预训练任务的效果
为验证ERNIE-UniX2中预训练任务的有效性,我们进行了消融实验并在表3中报告了结果。具体而言,我们在两项理解任务(即Multi30k上的跨语言图文检索和xGQA)和两项生成任务(即MSCOCO上的图像描述生成和Multi30k上的多模态机器翻译)上评估了ERNIE-UniX2。对于xGQA,遵循与IGLUE相同的零样本设置,我们展示了仅英语微调的结果,并将模型迁移到其他7种语言以获得零样本结果。我们在Multi30k上展示了7种语言的跨语言图文检索全语言微调结果。对于生成任务,我们按照Karpathy划分展示了MSCOCO图像描述生成的微调结果,以及Multi30k上的多模态机器翻译结果。所有对比模型均以512的批量大小进行了50K步的预训练。
As shown in Table 3, ITM presents a significant improvement on English-only fine-tuning on xGQA yet a slight improvement across all tasks, which illustrates the importance of the fine-grained cross-modal alignment. Then, we analyze the effect of (2) MLM and (3) CMCL. The use of the CMCL objective significantly improved the performance of the Multi30k retrieval task. It is further proved that understanding and generation pre-training tasks are mutually reinforcing. Moreover, (4) mMMT improves multimodal machine translation and image-text retrieval. In addition, we study the contributions of (5) vPLM, and find it critical for all downstream tasks performance. These phenomenons indicate that the generation pre-training task improves not only the performance of the downstream generation task but also the performance of the downstream understanding task.
如表3所示,ITM在纯英文微调的xGQA上表现出显著提升,但在所有任务中仅有小幅改进,这说明了细粒度跨模态对齐的重要性。接着我们分析了(2) MLM和(3) CMCL的效果。使用CMCL目标显著提升了Multi30k检索任务的性能,进一步证明理解型与生成型预训练任务具有相互促进作用。此外,(4) mMMT改善了多模态机器翻译和图文检索性能。我们还研究了(5) vPLM的贡献,发现其对所有下游任务性能都至关重要。这些现象表明,生成式预训练任务不仅能提升下游生成任务的性能,还能增强下游理解任务的表现。
The Effect of ERNIE $\mathbf{U}\mathbf{n}\mathbf{i}\mathbf{X}^{2}$ Framework For a fair comparison with the previous best methods $(\mathbf{M}^{3}\mathbf{P},\mathbf{U}\mathbf{C}^{2})$ ), we reduce the parameters of ERNIE-UniX2 to the same size using fewer Transformer layers and the same pre-training datasets. As $\mathbf{M}^{3}\mathbf{P}$ and $\mathrm{{UC^{2}}}$ also initialize their 12-layer transformer model from XLM-R [11], we follow a similar initialization with the multilingual text encoder and cross-lingual cross-modal encoder initialized with the first and second 6 layers from XLM-R. As shown in Table 3, ERNIE $\cdot\mathrm{{UniX^{2}}}$ performs better than $\mathbf{M}^{3}\mathbf{P}$ and $\mathrm{{UC^{2}}}$ in both the Multi30k retrieval task and xGQA task, demonstrating the superiority of our proposed framework for cross-lingual cross-modal pre-training.
ERNIE $\mathbf{U}\mathbf{n}\mathbf{i}\mathbf{X}^{2}$ 框架的效果
为了与先前最佳方法 $(\mathbf{M}^{3}\mathbf{P},\mathbf{U}\mathbf{C}^{2})$ 进行公平比较,我们通过减少Transformer层数并使用相同的预训练数据集,将ERNIE-UniX2的参数规模调整至相同大小。由于 $\mathbf{M}^{3}\mathbf{P}$ 和 $\mathrm{{UC^{2}}}$ 也基于XLM-R [11]初始化其12层Transformer模型,我们采用类似的初始化方式:用XLM-R的前6层初始化多语言文本编码器,后6层初始化跨语言跨模态编码器。如表3所示,ERNIE $\cdot\mathrm{{UniX^{2}}}$ 在Multi30k检索任务和xGQA任务中均优于 $\mathbf{M}^{3}\mathbf{P}$ 和 $\mathrm{{UC^{2}}}$ ,验证了所提跨语言跨模态预训练框架的优越性。
Table 4: The zero-shot results on xGQA and Multi30K retrieval of ERNIE-UniX2 compared to previous cross-lingual cross-modal models $(\mathbf{M}^{3}\mathbf{P},$ UC2), under settings of comparable parameters size. For xGQA, we use the average accuracy of 7 languages with an English-only fine-tuned model. For Multi $30\mathrm{k\Omega}$ image-text, we use mR (meanRecall) that is the average meanRecall of four languages. $\dagger$ is initialized by XLM-R
表 4: ERNIE-UniX2 与先前跨语言跨模态模型 (M3P, UC2) 在参数规模可比设置下,于 xGQA 和 Multi30K 检索任务的零样本结果。对于 xGQA,我们使用仅英语微调模型在 7 种语言上的平均准确率。对于 Multi 30kΩ 图文检索,我们采用四种语言平均均值召回率 (mR)。$\dagger$ 表示模型由 XLM-R 初始化
5 Conclusion
5 结论
We present a unified framework ERNIE-UniX2 across languages, modalities, and tasks. ERNIE-UniX2 integrates multiple pre-training paradigms with encoder-decoder architecture, which can seamlessly be fine-tuned on various generation and understanding downstream tasks. ERNIE-UniX2 achieves SOTA results on several cross-lingual cross-modal generation and understanding tasks and competitive results for monolingual cross-modal generation in well-resourced language, which shows the effectiveness on varieties of downstream tasks. For the future work, we will further improve our unified framework through integrating more modalities and more pre-training paradigms. Also we will apply our model to single-modal tasks such as image classification for the visual modality.
我们提出了一个跨语言、跨模态、跨任务的统一框架ERNIE-UniX2。该框架通过编码器-解码器架构整合了多种预训练范式,可无缝适配各类生成与理解下游任务。ERNIE-UniX2在多项跨语言跨模态生成与理解任务中取得SOTA效果,在高资源语言的单语种跨模态生成任务中也展现出竞争力,验证了其在多样化下游任务中的有效性。未来工作将整合更多模态与预训练范式来完善框架,并尝试将模型应用于视觉模态的单模态任务(如图像分类)。
References
参考文献
Table 5: A summary of pre-training and fine-tuning hyper parameters in ERNIE-UniX2.
| 超参数 | 预训练 | 微调 | |||||
|---|---|---|---|---|---|---|---|
| xGQA | XVNLI | Multi30k retrieval | Multi30k translation | MSCOCO | COCO-CN | ||
| batch size | 4096 | 1024 | 1024 | 4096 | 256 | 256 | 256 |
| learning rate | 1e-4 | 5e-5 | 5e-5 | 5e-5 | 5e-5 | 5e-5 | 5e-5 |
| warmup updates | 4000 | 2000 | 2000 | 50 | |||
| learning rate schedule | Cosine Schedule Decaying to Zero | ||||||
| AdamW weight decay | 0.1 | ||||||
| AdamW β1 | 0.9 | ||||||
| AdamW β2 | 0.999 |
表 5: ERNIE-UniX2 中预训练和微调超参数总结。
Table 6: Statistics on the datasets of pre-training tasks. #Image,#Sample and #lang denote the number of unique images, samples and languages. *For language data, we report its storage following [44]
| 类型 | 预训练任务 | #图像 | #样本 | #语言 | |
|---|---|---|---|---|---|
| 图文数据 | CC3M | CMCL, ITM, MLM, vPLM, mMMT | 3M | 15M | 5 |
| CC12M | CMCL, ITM, MLM, vPLM, mMMT | 12M | 60M | 5 | |
| WIT | CMCL, ITM, MLM, vPLM, mMMT | 14M | 14M | 108 | |
| 文本数据 | OPUS | CLCL, MT | 55M | 99 | |
| CC100 | PLM, MLM | 1.5TB* | 96 |
表 6: 预训练任务数据集统计。#图像、#样本和#语言分别表示唯一图像数量、样本数量和语言数量。*对于语言数据,我们按照[44]报告其存储量
A Hyper parameters for Pre-training and Fine-tuning
预训练与微调的超参数
Table 5 lists the hyper parameters for pre-training and the fine-tuning on XVNLI, xGQA, MSCOCO, COCO-CN, Multi30k retrieval and translation.
表 5: 列出了在 XVNLI、xGQA、MSCOCO、COCO-CN、Multi30k 检索和翻译任务上进行预训练和微调的超参数。
B The datasets for Pre-training tasks
B 预训练任务的数据集
We list the pre-training tasks used for each dataset in Table 6.
我们在表6中列出了每个数据集使用的预训练任务。
C The results on XVNLI, xGQA and Tatoeba for each language
C 各语言在XVNLI、xGQA和Tatoeba上的结果
We report the performance of the zero-shot on XVNLI and xGQA in Tabel 7 and Tatoeba in Table 8 for each language.
我们在表7中报告了XVNLI和xGQA的零样本(Zero-shot)性能,在表8中报告了每种语言在Tatoeba上的表现。
Table 7: The zero-shot performance on xGQA and XVNLI with Accuracy. (i.e. English-only fine-tuning).
| 模型 | XVNLI | xGQA | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ARB | SPA | FRA | RUS | BEN | DEU | IND | KOR | POR | RUS | CMN | |
| mUNITER | 46.73 | 56.96 | 59.36 | 51.72 | 3.9 | 26.3 | 13.0 | 5.5 | 17.4 | 9.3 | 8.4 |
| xUNITER | 51.98 | 58.94 | 63.32 | 59.71 | 9.7 | 35.7 | 36.3 | 14.6 | 24.7 | 20.8 | 19.2 |
| M?P | 56.19 | 57.47 | 69.67 | 64.86 | 19.2 | 35.6 | 29.6 | 28.5 | 35.7 | 32.9 | 31.1 |
| UC2 | 55.24 | 58.85 | 56.36 | 62.54 | 20.8 | 45.1 | 28.1 | 24.3 | 27.6 | 31.9 | 33.9 |
| ERNIE-UniX2 | 74.08 | 78.86 | 81.04 | 75.73 | 25.9 | 49.7 | 41.5 | 37.0 | 43.6 | 40.4 | 46.4 |
表 7: xGQA 和 XVNLI 的零样本 (zero-shot) 准确率性能 (即仅用英语微调) 。
Table 8: The cross-lingual retrieval performance on Tatoeba results for each language.
| 模型 | af | ar | bg | bn | de | el | es | et | eu | fa | fi | fr | he | hi | hu | id | it | ja |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VECO | 80.9 | 85.1 | 91.3 | 78.1 | 98.5 | 89.5 | 97.4 | 94.8 | 79.8 | 93.1 | 95.4 | 93.7 | 85.8 | 94.2 | 93.8 | 93.0 | 92.2 | 92.8 |
| ERNIE-M | 92.6 | 94.3 | 96.6 | 89.2 | 99.7 | 96.8 | 98.8 | 92.5 | 87.4 | 96.0 | 97.1 | 96.5 | 90.1 | 97.9 | 95.5 | 95.7 | 95.2 | 96.9 |
| ERNIE-UNIX2 | 97.2 | 91.8 | 95.3 | 90.5 | 99.7 | 96.5 | 98.9 | 98.0 | 95.6 | 95.7 | 97.8 | 96.2 | 92.2 | 97.3 | 96.8 | 96.3 | 95.2 | 97.4 |
| 模型 | jv | ka | kk | ko | ml | mr | nl | pt | ru | SW | ta | te | th | tl | tr | ur | vi | zh |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VECO | 35.1 | 83.0 | 74.1 | 88.7 | 94.8 | 82.5 | 95.9 | 94.6 | 92.2 | 69.7 | 82.4 | 91.0 | 94.7 | 73.0 | 95.2 | 63.8 | 95.1 | 93.9 |
| ERNIE-M | 65.2 | 94.9 | 88.0 | 94.1 | 98.5 | 90.8 | 98.1 | 94.5 | 95.7 | 68.4 | 91.8 | 97.9 | 98.4 | 86.0 | 98.3 | 94.9 | 98.1 | 96.7 |
| ERNIE-UNIX2 | 60.0 | 92.1 | 85.9 | 93.0 | 98.4 | 92.5 | 97.4 | 95.6 | 95.1 | 79.0 | 90.2 | 96.2 | 97.5 | 90.5 | 98.3 | 92.9 | 98.2 | 96.7 |
表 8: 各语言在 Tatoeba 数据集上的跨语言检索性能。