AudioCLIP: Extending CLIP to Image, Text and Audio⋆
AudioCLIP: 将CLIP扩展到图像、文本和音频领域⋆
Abstract In the past, the rapidly evolving field of sound classification greatly benefited from the application of methods from other domains. Today, we observe the trend to fuse domain-specific tasks and approaches together, which provides the community with new outstanding models. In this work, we present an extension of the CLIP model that handles audio in addition to text and images. Our proposed model incorporates the ESResNeXt audio-model into the CLIP framework using the AudioSet dataset. Such a combination enables the proposed model to perform bimodal and unimodal classification and querying, while keeping CLIP’s ability to generalize to unseen datasets in a zero-shot inference fashion. AudioCLIP achieves new state-of-the-art results in the Environmental Sound Classification (ESC) task, out-performing other approaches by reaching accuracies of $90.07%$ on the Urban Sound 8 K and $97.15%$ on the ESC-50 datasets. Further it sets new baselines in the zero-shot ESCtask on the same datasets ( $68.78%$ and $69.40%$ , respectively).
摘要
过去,快速发展的声音分类领域极大地受益于其他领域方法的应用。如今,我们观察到将特定领域任务与方法相融合的趋势,这为学界提供了新的杰出模型。本文提出了一种CLIP模型的扩展版本,使其能够同时处理文本、图像和音频。我们提出的模型通过AudioSet数据集将ESResNeXt音频模型整合到CLIP框架中。这种组合使模型能够执行双模态和单模态分类及查询,同时保持CLIP以零样本推理方式泛化至未见数据集的能力。AudioCLIP在环境声音分类(ESC)任务中取得了新的最先进成果,在UrbanSound8K数据集上达到90.07%的准确率,在ESC-50数据集上达到97.15%的准确率,超越了其他方法。此外,它还在相同数据集的零样本ESC任务中设立了新基准(分别为68.78%和69.40%)。
Finally, we also assess the cross-modal querying performance of the proposed model as well as the influence of full and partial training on the results. For the sake of reproducibility, our code is published.
最后,我们还评估了所提出模型的跨模态查询性能,以及完整训练和部分训练对结果的影响。为了确保可复现性,我们的代码已公开。
Keywords: Multimodal learning · Audio classification · Zero-shot inference.
关键词:多模态学习 · 音频分类 · 零样本 (Zero-shot) 推理
1 Introduction
1 引言
The latest advances of the sound classification community provided many powerful audio-domain models that demonstrated impressive results. Combination of widely known datasets – such as AudioSet [7], Urban Sound 8 K [25] and ESC-50 [19] – and domain-specific and inter-domain techniques conditioned the rapid development of audio-dedicated methods and approaches [15,10,30].
声音分类领域的最新进展提供了许多强大的音频领域模型,展现出令人瞩目的成果。广为人知的数据集(如 AudioSet [7]、Urban Sound 8K [25] 和 ESC-50 [19])与领域专用及跨领域技术的结合,推动了音频专用方法和技术的快速发展 [15,10,30]。
Previously, researchers were focusing mostly on the classification task using the audible modality exclusively. In the last years, however, popularity of multimodal approaches in application to audio-related tasks has been increasing [14,2,34]. Being applied to audio-specific tasks, this implied the use of either textual or visual modalities in addition to sound. While the use of an additional modality together with audio is not rare, combination of more than two modalities is still uncommon in the audio domain. However, the restricted amount of qualitatively labeled data is constraining the development of the field in both, uni- and multimodal directions. Such a lack of data has challenged the research and sparked a cautious growth of interest for zero- and few-shot learning approaches based on contrastive learning methods that rely on textual descriptions [13,32,33].
此前,研究者主要专注于仅利用听觉模态的分类任务。然而近年来,多模态方法在音频相关任务中的应用日益普及[14,2,34]。在音频专项任务中,这意味着除了声音外还需结合文本或视觉模态。虽然音频与其他模态的结合并不罕见,但在音频领域同时使用两种以上模态仍属少见。然而,高质量标注数据的有限性制约着该领域在单模态和多模态方向的发展。这种数据匮乏的现状对研究提出了挑战,并促使基于文本描述的对比学习方法(如零样本和少样本学习)受到谨慎关注[13,32,33]。
In our work, we propose an approach to combine a high-performance audio model – ESResNeXt [10] – into a contrastive text-image model, namely CLIP [21], thus, obtaining a tri-modal hybrid architecture. The base CLIP model demonstrates impressive performance and strong domain adaptation capabilities that are referred as “zero-shot inference” in the original paper [21]. To keep consistency with the CLIP terminology, we use the term “zero-shot” in the sense defined in [21].
在我们的工作中,我们提出了一种将高性能音频模型——ESResNeXt [10]——与对比式文本-图像模型(即CLIP [21])相结合的方法,从而获得一个三模态混合架构。基础CLIP模型展现出令人印象深刻的性能和强大的领域适应能力,这些在原论文[21]中被称为"零样本(zero-shot)推理"。为保持与CLIP术语的一致性,我们采用[21]中定义的"零样本"概念。
As we will see, the joint use of three modalities during the training results in out-performance of previous models in environmental sound classification task, extends zero-shot capabilities of the base architecture to the audio modality and introduces an ability to perform cross-modal querying using text, image and audio in any combination.
正如我们将看到的,在训练过程中联合使用三种模态,使得模型在环境声音分类任务上超越了以往模型,将基础架构的零样本(Zero-shot)能力扩展至音频模态,并引入了能够以任意组合使用文本、图像和音频进行跨模态查询的能力。
The remainder of this paper is organized as follows. In Section 2 we discuss the current approaches to handle audio in a standalone manner as well as jointly with additional modalities. Then, we describe models that serve as a base of our proposed hybrid architecture in Section 3, its training and evaluation in Section 4 and the obtained results in Section 5. Finally, we summarize our work and highlight follow-up research directions in Section 6.
本文的剩余部分结构如下。第2节讨论当前单独处理音频及与其他模态联合处理的方法。接着,第3节介绍作为我们提出的混合架构基础模型,第4节描述其训练与评估过程,第5节展示实验结果。最后,第6节总结工作并展望后续研究方向。
2 Related Work
2 相关工作
In this section, we provide an overview of the audio-related tasks and approaches that are intersecting in our work. Beginning with description of the environmental sound classification task, we connect it to the zero-shot classification through the description of existing methods to handle multiple modalities in a single model.
在本节中,我们将概述工作中涉及的音频相关任务和方法。从环境声音分类任务的描述开始,通过介绍现有方法在单一模型中处理多模态的方式,将其与零样本分类联系起来。
The environmental sound classification task implies an assignment of correct labels given samples belonging to sound classes that surround us in the everyday life (e.g., “alarm clock”, “car horn”, “jackhammer”, “mouse clicking”, “cat”). To successfully solve this task, different approaches were proposed that included the use of one- [27,28] or two-dimensional Convolutional Neural Networks (CNN) operating on static [18,24,32,9,15,17,33,8,30] or trainable [23,10] time-frequency transformation of raw audio. While the first approaches relied on the task-specific design of models, the latter results confirmed that the use of domain adaptation from visual domain is beneficial [9,17,10]. However, the visual modality was used in a sequential way, implying the processing of only one modality simultaneously.
环境声音分类任务是指对日常生活中环绕我们的声音类别样本(如"闹钟"、"汽车喇叭"、"电钻"、"鼠标点击"、"猫叫")进行正确标注。为成功解决该任务,研究者提出了多种方法,包括使用一维[27,28]或二维卷积神经网络(CNN),这些网络基于原始音频的静态[18,24,32,9,15,17,33,8,30]或可训练[23,10]时频变换进行操作。早期方法依赖于针对特定任务的模型设计,而后来的研究结果证实,采用视觉领域的域适应技术具有优势[9,17,10]。然而,这些视觉模态的使用都是顺序式的,意味着每次只能处理单一模态。
The joint use of several modalities occurred first in video-related [14,34,6] tasks and was adapted to the sound classification task later [13,31]. However, despite the multimodal design, such approaches utilized two modalities simultaneously at most, while recent studies suggest that the use of more modalities is beneficial [2,1].
多种模态的联合使用最早出现在视频相关[14,34,6]任务中,后来被应用于声音分类任务[13,31]。然而,尽管采用了多模态设计,这类方法最多同时使用两种模态,而近期研究表明使用更多模态更有优势[2,1]。
The multimodal approaches described above share a common key idea of contrastive learning. Such a technique belongs to the branch of self-supervised learning that, among other features, helps to overcome the lack of qualitatively labeled data. That makes it possible to apply contrastive learning-based training to the zero-shot classification tasks [13,32,33].
上述多模态方法共享对比学习(contrastive learning)这一核心思想。该技术属于自监督学习的分支,其特性之一是可缓解高质量标注数据不足的问题。这使得基于对比学习的训练能够应用于零样本分类任务[13,32,33]。
Summarizing, our proposed model employs contrastive learning to perform training on textual, visual and audible modalities, is able to perform modalityspecific classification or, more general, querying and is implicitly enabled to generalize to previously unseen datasets in a zero-shot inference setup.
总结来说,我们提出的模型采用对比学习对文本、视觉和听觉模态进行训练,能够执行特定模态分类或更通用的查询任务,并隐式具备在零样本推理设置下泛化到未见数据集的能力。
3 Model
3 模型
In this section, we describe the key components that make up the proposed model and the way how it handles its input. On a high level, our hybrid architecture combines a ResNet-based CLIP model [21] for visual and textual modalities and an ESResNeXt model [10] for audible modality, as can be seen in Figure 1.
在本节中,我们将描述构成所提出模型的关键组件及其处理输入的方式。从高层次来看,我们的混合架构结合了基于ResNet的CLIP模型[21](用于视觉和文本模态)以及ESResNeXt模型[10](用于听觉模态),如图1所示。
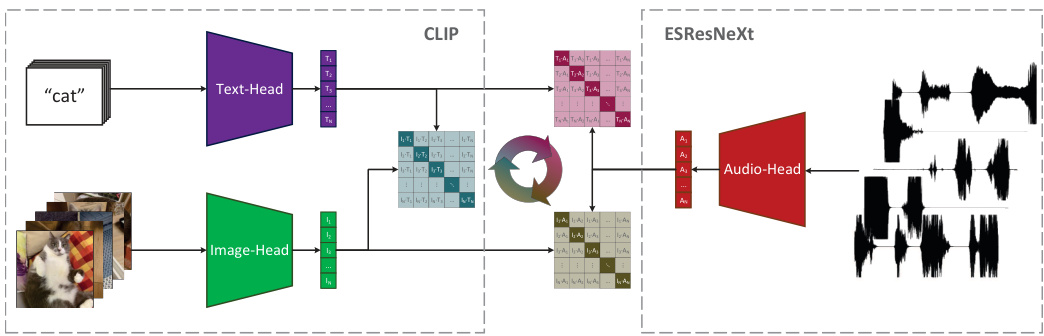
Figure 1. Overview of the proposed AudioCLIP model. On the left, the workflow of the text-image-model CLIP is shown. Performing joint training of the text- and imageheads, CLIP learns to align representations of the same concept in a shared multimodal embedding space. On the right, the audio-model ESResNeXT is shown. Here, the added audible modality interacts with two others, enabling the model to handle 3 modalities simultaneously.
图 1: 提出的 AudioCLIP 模型概览。左侧展示了文本-图像模型 CLIP 的工作流程。通过联合训练文本和图像编码头,CLIP 学会了在共享的多模态嵌入空间中对齐相同概念的表示。右侧展示了音频模型 ESResNeXT。这里新增的听觉模态与另外两种模态交互,使模型能够同时处理 3 种模态。
3.1 CLIP
3.1 CLIP
Conceptually, the CLIP model consists of two sub networks: text and image encoding heads. Both parts of the CLIP model were pre-trained jointly under natural language supervision [21]. Such a training setup enabled the model to generalize the classification ability to image samples that belonged to previously unseen datasets according to the provided labels without any additional finetuning.
从概念上讲,CLIP模型由两个子网络组成:文本编码头和图像编码头。该模型的两部分在自然语言监督下进行了联合预训练 [21] 。这种训练方式使模型能够根据提供的标签,将分类能力泛化到属于先前未见数据集的图像样本上,而无需任何额外的微调。
For the text encoding part, a slightly modified [22] Transformer [29] architecture was used [21]. For the chosen 12-layer model, the input text was represented by a lower-case byte pair encoding with a vocabulary of size 49 408 [21]. Due to computational constraints, the maximum sequence length was clipped at 76 [21].
在文本编码部分,采用了略微修改的[22] Transformer[29]架构[21]。对于选定的12层模型,输入文本通过小写字节对编码(BPE)表示,词表大小为49,408[21]。由于计算资源限制,最大序列长度被截断为76[21]。
For the image encoding part of the CLIP model, two different architectures were considered. One was a Vision Transformer (ViT) [21,5], whose architecture made it similar to the text-head. Another option was represented by a modified ResNet-50 [11], whose global average pooling layer was replaced by a QKVattention layer [21]. As we mentioned in Section 3.1, for the proposed hybrid model we chose the ResNet-based variant of the CLIP model because of its lower computational complexity, in comparison to the ViT-based one.
在CLIP模型的图像编码部分,我们考虑了两种不同架构。一种是Vision Transformer (ViT) [21,5],其架构使其与文本头(text-head)相似。另一种方案是改进版ResNet-50 [11],其全局平均池化层被替换为QKV注意力层(QKVattention layer) [21]。如第3.1节所述,由于基于ResNet的CLIP变体比基于ViT的版本具有更低计算复杂度,我们最终为混合模型选择了该方案。
Given an input batch (text-image pairs) of size $N$ , both CLIP-sub networks produce the corresponding embeddings that are mapped linearly into a multimodal embedding space of size $1024$ [21]. In a such setup, CLIP learns to maximize the cosine similarity between matching textual and visual representations, while minimizing it between incorrect ones, which is achieved using symmetric cross entropy loss over similarity measures [21].
给定一个大小为 $N$ 的输入批次(文本-图像对),两个CLIP子网络会生成相应的嵌入,这些嵌入被线性映射到一个大小为1024的多模态嵌入空间[21]。在这种设置下,CLIP学习最大化匹配文本和视觉表示之间的余弦相似度,同时最小化不匹配对之间的相似度,这是通过对相似度度量使用对称交叉熵损失来实现的[21]。
3.2 ESResNeXt
3.2 ESResNeXt
For the audio encoding part, we decided to apply ESResNeXt model [10] that is based on the ResNeXt-50 [3] architecture and consists of a trainable timefrequency transformation based on complex frequency B-spline wavelets [26]. The chosen model contains moderate number of parameters to learn ( $\sim30$ M), while performing competitive on a large-scale audio dataset, namely AudioSet [7], and providing state-of-the-art-level classification results on the Urban Sound 8 K [25] and ESC-50 [19] datasets. Additionally, the ESResNeXt model supports an implicit processing of a multi-channel audio input and provides improved robustness against additive white Gaussian noise and sample rate decrease [10].
在音频编码部分,我们决定采用基于ResNeXt-50架构的ESResNeXt模型[10],该模型包含基于复杂频率B样条小波的可训练时频变换[26]。所选模型具有适中的参数量(约3000万),在大规模音频数据集AudioSet[7]上表现优异,并在UrbanSound8K[25]和ESC-50[19]数据集上提供了最先进的分类结果。此外,ESResNeXt模型支持多通道音频输入的隐式处理,并提高了对加性高斯白噪声和采样率降低的鲁棒性[10]。
3.3 Hybrid Model – AudioCLIP
3.3 混合模型 – AudioCLIP
In this work, we introduce an additional – audible – modality into the novel CLIP framework, which is naturally extending the existing model. We consider the newly added modality as equally important as the originally present. Such a modification became possible through the use of the AudioSet [7] dataset that we found suitable for this, as described in Section 4.1.
在本工作中,我们向新颖的CLIP框架中引入了一个额外的可听模态,这自然扩展了现有模型。我们将新添加的模态视为与原有模态同等重要。如第4.1节所述,通过使用适用于此的AudioSet [7]数据集,这种修改成为可能。
Thus, the proposed AudioCLIP model incorporates three sub networks: text-, image- and audio-heads. In addition to the existing text-to-image-similarity loss term, there are two new ones introduced: text-to-audio and image-to-audio. The proposed model is able to process all three modalities simultaneously, as well as any pair of them.
因此,提出的AudioCLIP模型包含三个子网络:文本头、图像头和音频头。除了现有的文本-图像相似性损失项外,还引入了两个新的损失项:文本-音频和图像-音频。该模型能够同时处理所有三种模态,以及它们之间的任意两种组合。
4 Experimental Setup
4 实验设置
In this section, we describe datasets that were used, data augmentation methods we applied, the training process and its corresponding hyper-parameters, finalizing with the performance evaluation methods.
在本节中,我们将介绍所使用的数据集、采用的数据增强方法、训练流程及其对应超参数,最后说明性能评估方法。
4.1 Datasets
4.1 数据集
In this work, five image, audio and mixed datasets were used directly and indirectly. Here, we describe these datasets and define their roles in the training and evaluation processes.
在本研究中,直接或间接使用了五个图像、音频及混合数据集。以下将描述这些数据集,并明确它们在训练和评估过程中的作用。
Composite CLIP Dataset: In order to train CLIP, a new dataset was constructed by its authors. It consisted of roughly $400\mathrm{M}$ text-image pairs based on a set of $\sim500\mathrm{k\Omega}$ text-based queries, and each query covered at least $\sim20\mathrm{k\Omega}$ pairs [21]. In this work, the CLIP dataset was used indirectly as a weight initialize r of the text- and image-heads (CLIP model).
复合CLIP数据集:为了训练CLIP,其作者构建了一个新数据集。该数据集包含约$400\mathrm{M}$个文本-图像对,基于一组$\sim500\mathrm{k\Omega}$的文本查询构建,每个查询涵盖至少$\sim20\mathrm{k\Omega}$个配对[21]。本工作中,CLIP数据集被间接用作文本头和图像头(CLIP模型)的权重初始化器。
ImageNet: ImageNet is a large-scale visual datasets described in [4] that contains more than $1\mathrm{M}$ images across $1000$ classes. For the purposes of this work, the ImageNet dataset served as a weight initialize r of the ESResNeXt model and as a target for the zero-shot inference task.
ImageNet: ImageNet 是一个大规模视觉数据集 [4],包含超过 $1\mathrm{M}$ 张图像,涵盖 $1000$ 个类别。在本研究中,ImageNet 数据集用于初始化 ESResNeXt 模型的权重,并作为零样本推理任务的目标。
AudioSet: Being proposed in [7], the AudioSet dataset provides a large-scale collection ( $\sim1.8$ M $&\sim20\mathrm{k\Omega}$ evaluation set) of audible data organized into 527 classes in a non-exclusive way. Each sample is a snippet up to $\mathrm{10~s}$ long from a YouTube-video, defined by the corresponding ID and timings.
AudioSet:该数据集由[7]提出,提供了大规模可听数据集合(约180万样本和约2万欧姆评估集),以非排他方式划分为527个类别。每个样本是从YouTube视频中截取的最长10秒的片段,由对应ID和时间戳定义。
For this work, we acquired video frames in addition to audio tracks. Thus, the AudioSet dataset became the glue between the vanilla CLIP framework and our tri-modal extension on top of it. In particular, audio tracks and the respective class labels were used to perform image-to-audio transfer learning for the ESResNeXt model, and then, the extracted frames in addition to audio and class names served as an input for the hybrid AudioCLIP model.
在这项工作中,我们除了音频轨道外还采集了视频帧。因此,AudioSet数据集成为原始CLIP框架与我们基于其扩展的三模态模型之间的桥梁。具体而言,音频轨道和相应的类别标签被用于对ESResNeXt模型进行图像到音频的迁移学习,随后提取的帧与音频及类别名称共同作为混合AudioCLIP模型的输入。
During the training part, ten equally distant frames were extracted from a video recording, and one of them was picked randomly $(\sim\mathcal{U})$ and passed through the AudioCLIP model. In the evaluation phase, the same extraction procedure was performed, with the difference that only a central frame was presented to the model. Performance metrics are reported based on the evaluation set of the AudioSet dataset.
在训练阶段,从视频录制中提取了十个等距帧,并随机选取其中一帧 $(\sim\mathcal{U})$ 输入AudioCLIP模型。评估阶段采用相同的提取流程,区别在于仅向模型提供中央帧。性能指标基于AudioSet数据集的评估集进行报告。
Urban Sound 8 K: The Urban Sound 8 K dataset provides 8 732 mono- and binaural audio tracks sampled at frequencies in the range $16-48\mathrm{kHz}$ , each track is not longer than 4s. The audio recordings are organized into ten classes: “air conditioner”, “car horn”, “children playing”, “dog bark”, “drilling”, “engine idling”, “gun shot”, “jackhammer”, “siren”, and “street music”. To ensure correctness during the evaluation phase, the Urban Sound 8 K dataset was split by its authors into 10 non-overlapping folds [25] that we used in this work.
Urban Sound 8K:Urban Sound 8K数据集提供了8,732条单声道和双声道音频轨,采样频率范围为$16-48\mathrm{kHz}$,每条音频不超过4秒。录音内容分为十类:"空调声"、"汽车喇叭声"、"儿童嬉戏声"、"犬吠声"、"钻孔声"、"引擎空转声"、"枪声"、"破碎锤声"、"警笛声"和"街头音乐声"。为确保评估阶段准确性,该数据集作者将其划分为10个互不重叠的折叠[25],本研究采用了这一划分方式。
On this dataset, we performed zero-shot inference using the AudioCLIP model trained on AudioSet. Also, the audio encoding head was fine-tuned to the Urban Sound 8 K dataset in both, standalone and cooperative fashion, and the classification performance in both setups was assessed.
在该数据集上,我们使用基于AudioSet训练的AudioCLIP模型进行了零样本(zero-shot)推理。同时,音频编码头以独立和协同两种方式针对Urban Sound 8K数据集进行了微调,并评估了两种设置下的分类性能。
ESC-50: The ESC-50 dataset provides $2000$ single-channel 5 s long audio tracks sampled at 44.1 kHz. As the name suggests, the dataset consists of 50 classes that can be divided into 5 major groups: animal, natural and water, non-speech human, interior, and exterior sounds. To ensure correctness during the evaluation phase, the ESC-50 dataset was split by its author into 5 nonoverlapping folds [19] that we used in this work.
ESC-50: ESC-50数据集提供了2000条单声道、5秒长的音频片段,采样率为44.1 kHz。如其名称所示,该数据集包含50个类别,可分为5大类:动物声音、自然与水声、非语音人声、室内声音和室外声音。为确保评估阶段的准确性,ESC-50数据集作者将其划分为5个非重叠折叠[19],我们在本研究中采用了这一划分方式。
On this dataset, we performed zero-shot inference using the AudioCLIP model trained on AudioSet. Also, the audio encoding head was fine-tuned to the ESC-50 dataset in both, standalone and cooperative fashion, and the classification performance in both setups was assessed.
在该数据集上,我们使用基于AudioSet训练的AudioCLIP模型进行了零样本(zero-shot)推理。同时,音频编码头以独立和协同两种方式对ESC-50数据集进行了微调,并评估了两种设置下的分类性能。
4.2 Data Augmentation
4.2 数据增强
In comparison to the composite CLIP dataset (Section 4.1), the audio datasets provide two orders of magnitude less training samples, which makes over fitting an issue, especially for the Urban Sound 8 K and ESC-50 datasets. To address this challenge, several data augmentation techniques were applied that we describe in this section.
与复合CLIP数据集(第4.1节)相比,音频数据集提供的训练样本少了两个数量级,这会导致过拟合问题,尤其是在Urban Sound 8K和ESC-50数据集上。为解决这一挑战,我们采用了本节所述的多种数据增强技术。
Time Scaling: Simultaneous change of track duration and its pitch is achieved using random scaling along the time axis. This kind of augmentation combines two computationally expensive ones, namely time stretching and pitch shift. Being a faster alternative to the combination of the aforementioned techniques, the time scaling in the range of random factors [−1.5, 1.5], $\sim\mathcal{U}$ provides a lightweight though powerful method to fight over fitting [9].
时间缩放 (Time Scaling):通过在时间轴上随机缩放,实现音轨时长与音高的同步变化。这种数据增强方式融合了计算成本较高的时间拉伸 (time stretching) 和移调 (pitch shift) 技术。作为上述技术组合的快速替代方案,当随机因子范围控制在 [−1.5, 1.5]($\sim\mathcal{U}$)时,时间缩放能以轻量级方式有效抑制过拟合 [9]。
Time Inversion: Inversion of a track along its time axis relates to the random flip of an image, which is an augmentation technique that is widely used in the visual domain. In this work, random time inversion with the probability of 0.5 was applied to the training samples similarly to [10].
时间反转:沿时间轴反转音轨类似于图像的随机翻转,这是一种在视觉领域广泛使用的数据增强技术。在本研究中,我们以0.5的概率对训练样本进行随机时间反转,具体实现方式参照[10]。
Random Crop and Padding: Due to the requirement to align track duration before the processing through the model we applied random cropping or padding to the samples that were longer or shorter than the longest track in a non-augmented dataset, respectively. During the evaluation phase, the random operation was replaced by the center one.
随机裁剪与填充:由于需要通过模型处理前对齐音轨时长,我们对非增强数据集中时长超过或短于最长音轨的样本分别进行了随机裁剪或填充。在评估阶段,随机操作被替换为中心裁剪。
Random Noise: The addition of random noise was shown to be helpful to overcome over fitting in visual-realted tasks [12]. Also, the robustness evaluation of the ESResNeXt model suggested the improved sustainability of the chosen audio encoding model against the additive white Gaussian noise (AWGN) [10]. In this work, we extended the set of data augmentation techniques using AWGN, whose sound-to-noise ratio varied randomly ( $\sim\mathcal{U}$ ) from $10.0\mathrm{dB}$ to 120 dB. The probability of the presense of the noise was set to 0.25.
随机噪声:研究表明,在视觉相关任务中添加随机噪声有助于克服过拟合问题 [12]。此外,ESResNeXt模型的鲁棒性评估表明,所选音频编码模型对加性高斯白噪声 (AWGN) 具有更强的耐受性 [10]。本工作中,我们扩展了使用AWGN的数据增强技术集,其信噪比随机变化 ( $\sim\mathcal{U}$ ),范围从 $10.0\mathrm{dB}$ 到120 dB。噪声出现的概率设置为0.25。
4.3 Training
4.3 训练
The entire training process was divided into subsequent steps, which made acquisition of the final AudioCLIP model reliable and assured its high performance. As described in Section 3.1, we took a ResNet-based CLIP text-imagemodel pre-trained on its own dataset (Section 4.1) [21] and combined it with the ESResNeXt audio-model initialized using ImageNet weights and then pretrained on the AudioSet dataset [10].
整个训练过程分为多个后续步骤,这使得最终AudioCLIP模型的获取过程可靠且确保了其高性能。如第3.1节所述,我们采用了一个基于ResNet的CLIP文本-图像模型(该模型已在自有数据集上进行了预训练(见第4.1节)[21]),并将其与使用ImageNet权重初始化并在AudioSet数据集[10]上预训练的ESResNeXt音频模型相结合。
While the CLIP model was already pre-trained on text-image pairs, we decided to perform an extended AudioSet pre-training of the audio-head first, as it improved performance of the base ESResNeXt model (Table 1), and then to continue training in a tri-modal setting combining it with two other heads. Here, the whole AudioCLIP model was trained jointly on the AudioSet dataset using audio snippets, the corresponding video frames and the assigned textual labels.
虽然CLIP模型已经经过文本-图像对的预训练,但我们决定先对音频头进行扩展的AudioSet预训练(这提升了基础ESResNeXt模型的性能(表1)),再继续结合另外两个头进行三模态联合训练。整个AudioCLIP模型在AudioSet数据集上联合训练,使用音频片段、对应视频帧和分配的文本标签。
Finally, audio-head of the trained AudioCLIP model was fine-tuned on the Urban Sound 8 K and ESC-50 datasets in a bimodal manner (audio and text) using sound recordings and the corresponding textual labels.
最后,训练好的AudioCLIP模型的音频头部在Urban Sound 8K和ESC-50数据集上以双模态方式(音频和文本)进行了微调,使用了录音和相应的文本标签。
The trained AudioCLIP model and its audio encoding head were evaluated on the ImageNet dataset as well as on the three audio-datasets: AudioSet, Urban Sound 8 K, and ESC-50.
训练完成的AudioCLIP模型及其音频编码头在ImageNet数据集以及三个音频数据集(AudioSet、Urban Sound 8K和ESC-50)上进行了评估。
Audio-Head Pre-Training The initialization of the audio-head’s parameters was split into two steps. First, the ImageNet-initialized ESResNeXt model was trained on the AudioSet dataset in a standalone fashion. Then, the pre-trained audio-head was incorporated into the AudioCLIP model and trained further under the cooperative supervision of the text- and image-heads.
音频头预训练
音频头的参数初始化分为两步。首先,以独立方式在AudioSet数据集上训练ImageNet初始化的ESResNeXt模型。随后,将预训练好的音频头整合到AudioCLIP模型中,并在文本头和图像头的协同监督下进行进一步训练。
Standalone: The first pre-training step implied the use of the AudioSet dataset as a weight initialize r. Here, the ESResNeXt model was trained using the same setup as described in [10], with the difference in the number of training epochs. In this work, we increased the training time, which turned out into better evaluation performance on the AudioSet dataset and the subsequent downstream tasks, as described in Section 5.1 and independently quantified.
独立训练:第一步预训练阶段采用AudioSet数据集作为权重初始化器。此处ESResNeXt模型沿用[10]所述相同配置进行训练,仅调整了训练周期数。本研究通过延长训练时间,显著提升了模型在AudioSet数据集及后续下游任务(如第5.1节所述)的评估性能,该提升效果已通过独立量化验证。
Cooperative: The further pre-training of the audio-head was done jointly with the text- and image-heads. Here, the pre-trained (in a standalone manner) audio-head was modified slightly through the replacement of its classification layer with a randomly initialized one, whose number of output neurons was the same as the size of CLIP’s embedding space.
协作式:音频头部的进一步预训练是与文本和图像头部联合进行的。在此过程中,预训练(以独立方式完成)的音频头部经过轻微修改,将其分类层替换为随机初始化的新层,该层的输出神经元数量与CLIP嵌入空间的尺寸相同。
In this setup, the audio-head was trained as a part of the AudioCLIP model, which made its outputs compatible with the embeddings of the vanilla CLIP model. Parameters of the two other sub networks, namely text- and image-head, were frozen during the cooperative pre-training of the audio encoding head, thus, these heads served as teachers in a multi-modal knowledge distillation setup.
在此设置中,音频头(audio-head)作为AudioCLIP模型的一部分进行训练,使其输出与原始CLIP模型的嵌入兼容。在音频编码头的协同预训练过程中,另外两个子网络(即文本头和图像头)的参数被冻结,因此这些头在多模态知识蒸馏设置中充当教师角色。
The performance of the AudioCLIP model trained in such a fashion was assessed and is described in Section 5.
以这种方式训练的AudioCLIP模型性能评估结果见第5节。
AudioCLIP Training The joint training of the audio-head made it compatible with the vanilla CLIP model, however, the distribution of images and textual descriptions in the AudioSet dataset does not follow the one from the CLIP dataset. This could lead to suboptimal performance of the resulting AudioCLIP model on the target dataset as well as on the downstream tasks.
AudioCLIP训练
音频头部的联合训练使其与原始CLIP模型兼容,但AudioSet数据集中图像和文本描述的分布与CLIP数据集不一致。这可能导致最终AudioCLIP模型在目标数据集及下游任务中表现欠佳。
To address this issue, we decided to perform the training of the whole trimodal model on the AudioSet dataset. Here, all three modality-dedicated heads were tuned together, making the resulting model take into account the distributions of images and textual descriptions (video frames and names of the assigned AudioSet classes, respectively), in addition to the distribution of audio samples. The influence of the whole model training on the network’s performance in comparison to the audio-head-only training is described in Section 5.
为解决这一问题,我们决定在AudioSet数据集上训练整个三模态模型。在此过程中,三个模态专用头被联合调优,使得最终模型不仅考虑音频样本的分布,还兼顾图像和文本描述(分别为视频帧和AudioSet类别名称)的分布。与仅训练音频头相比,完整模型训练对网络性能的影响将在第5节详述。
Audio-Head Fine-Tuning The trained AudioCLIP model provides generalpurpose multimodal classification, or more general, querying abilities. However, under some conditions, it is required to acquire a more domain-specific model, which is able to distinguish concepts that differ just slightly.
音频头部微调
训练好的AudioCLIP模型提供了通用的多模态分类或更广义的查询能力。但在某些情况下,需要获得更具领域针对性的模型,以区分仅有细微差异的概念。
To address this need, we performed experiments on tuning of the audio encoding head to two target datasets: Urban Sound 8 K and ESC-50.
为了解决这一需求,我们在两个目标数据集上进行了音频编码头的调优实验:Urban Sound 8K和ESC-50。
Standalone: The ESResNeXt model that served as the audio-head demonstrated strong classification abilities on the chosen downstream tasks [10]. As we performed the AudioSet pre-training step instead of using a pre-trained ESResNeXt model, we fine-tuned it to the Urban Sound 8 K and ESC-50 datasets as well, in order to assess the change of the classification accuracy.
独立模型:作为音频处理核心的 ESResNeXt 模型在选定下游任务中展现出强大的分类能力 [10]。由于我们采用了 AudioSet 预训练步骤而非直接使用预训练 ESResNeXt 模型,因此还针对 Urban Sound 8K 和 ESC-50 数据集进行了微调,以评估分类准确率的变化。
The fine-tuning step was done the same way as in [10], which implied the replacement of the classification layer with a randomly initialized one, whose number of outputs was defined by the number of targets in the downstream task. We report the performance of the fine-tuned ESResNeXt model in Section 5.1.
微调步骤与[10]中的方法相同,即用随机初始化的分类层替换原有分类层,其输出数量由下游任务的目标数量决定。微调后的ESResNeXt模型性能将在第5.1节中报告。
Cooperative: During the fine-tuning of the AudioCLIP model to the downstream tasks, only the parameters of the audio-head were being updated, so the text- and image-heads were frozen at this step. In comparison to the AudioSet training, which implied a multi-label setup, the corresponding textual class labels from the Urban Sound 8 K and ESC-50 datasets were represented by one class per audio sample.
协作式:在对AudioCLIP模型进行下游任务微调时,仅更新音频头(audio-head)的参数,因此文本头(text-head)和图像头(image-head)在此步骤中被冻结。与采用多标签设置的AudioSet训练相比,Urban Sound 8K和ESC-50数据集中的对应文本类别标签每个音频样本仅代表一个类别。
For the fine-tuned AudioCLIP model, we assess the downstream classification performance as well as the querying performance, as described in Section 5.2.
对于微调后的AudioCLIP模型,我们按照第5.2节所述评估了下游分类性能和查询性能。
4.4 Hyper-Parameters
4.4 超参数
In this work, we trained our model on the AudioSet, Urban Sound 8 K and ESC-50 datasets. The required hyper-parameters are reported in the current section.
在本工作中,我们在AudioSet、Urban Sound 8K和ESC-50数据集上训练了模型。所需超参数将在本节中列出。
In all training phases, the model parameters were optimized using Stochastic Gradient Descent [20] optimizer with Nesterov’s momentum [16] of 0.9, weight decay of $5\cdot10^{-4}$ and batch size of 64.
在所有训练阶段,模型参数均使用随机梯度下降 (Stochastic Gradient Descent) [20] 优化器进行优化,其中 Nesterov 动量 (momentum) [16] 设为 0.9,权重衰减 (weight decay) 为 $5\cdot10^{-4}$,批量大小 (batch size) 为 64。
Table 1. Evaluation results of the ESResNeXt model trained on the AudioSet dataset for more epochs. In comparison to the original training, performance improves.
| Dataset | Score (%) | ESResNeXt Training | |
| [10] (5 epochs) | Our (30 epochs) | ||
| AudioSet | mAP | 28.17 | 34.14 |
| UrbanSound8K | 89.14 | 89.49 | |
| ESC-50 | accuracy | 95.20 | 95.90 |
表 1: 在AudioSet数据集上训练更多轮次的ESResNeXt模型评估结果。与原始训练相比,性能有所提升。
| 数据集 | 指标 (%) | ESResNeXt 训练 |
|---|---|---|
| [10] (5轮次) | ||
| AudioSet | mAP | 28.17 |
| UrbanSound8K | 89.14 | |
| ESC-50 | 准确率 | 95.20 |
The learning rate value decreased exponentially, varying its value $\eta$ and the decrease factor $\gamma$ from $10^{-4}$ and 0.95, respectively, during the standalone pretraining of the audio-head to $5\cdot10^{-5}$ and 0.98 during the fine-tuning of the AudioCLIP model to the downstream tasks.
学习率值呈指数下降,在音频头的独立预训练阶段,其值 $\eta$ 和下降因子 $\gamma$ 分别从 $10^{-4}$ 和 0.95 变化至 AudioCLIP 模型在下游任务微调阶段的 $5\cdot10^{-5}$ 和 0.98。
The number of epochs was set to 30 for the AudioSet-based training, and to 50 for the fine-tuning to the downstream tasks.
基于AudioSet的训练轮数(epoch)设为30,下游任务微调设为50。
4.5 Performance Evaluation
4.5 性能评估
The model performance was assessed based on two tasks: classification and querying. While the evaluation of the first was possible for both, audio-head itself and the full AudioCLIP model, the performance on the latter task was assessed for the multimodal network only.
模型性能基于分类和查询两项任务进行评估。虽然第一项任务可对音频头模块本身和完整AudioCLIP模型进行评测,但第二项任务仅针对多模态网络进行性能评估。
Classification The evaluation of the classification performance was done using the AudioCLIP model as well as its audio-head, namely ESResNeXt. The latter predicted the class labels directly, as the number of its outputs was equal to the number of targets in the datasets. For the AudioCLIP model, the classification task implied an intermediate step, which included construction of a target from textual labels [21].
分类
分类性能评估使用了AudioCLIP模型及其音频处理模块ESResNeXt。后者直接预测类别标签,因为其输出数量与数据集中的目标数量一致。对于AudioCLIP模型,分类任务包含一个中间步骤,即通过文本标签构建目标[21]。
In this work, the performance of the proposed model was evaluated after the training on the AudioSet dataset given audio and/or image as an input. For the Urban Sound 8 K and ESC-50 datasets, two downstream tasks were evaluated: classification after the training on the target dataset and without the training. The corresponding accuracies are reported in Section 5.1.
在本研究中,提出的模型在AudioSet数据集上以音频和/或图像作为输入进行训练后,对其性能进行了评估。对于Urban Sound 8K和ESC-50数据集,评估了两个下游任务:在目标数据集上训练后的分类以及未经训练的分类。相应的准确率在第5.1节中报告。
Querying The multimodal nature and symmetry of AudioCLIP allowed to perform querying of samples represented by another modality. Here, classification can be considered as a sub-task of querying, whose query consists of image and/or audio while the result is represented by text.
查询
AudioCLIP的多模态特性和对称性使其能够对由另一种模态表示的样本进行查询。在此过程中,分类可视为查询的子任务:查询由图像和/或音频构成,而结果以文本形式呈现。
In this work, we assessed the querying performance of the trained AudioCLIP model on the ImageNet, AudioSet, Urban Sound 8 K and ESC-50 datasets. The results include Top-1 Precision/Recall (P@1/R@1) and Mean Average Precision (mAP), and presented in Section 5.2.
在本工作中,我们评估了训练后的AudioCLIP模型在ImageNet、AudioSet、Urban Sound 8K和ESC-50数据集上的查询性能。结果包括Top-1精确率/召回率(P@1/R@1)和平均精度均值(mAP),具体内容见5.2节。
Table 2. Evaluation of AudioCLIP after partial (audio-head) and full training on AudioSet. The latter improves, in general, the results on the downstream tasks.
表 2: AudioCLIP在AudioSet上进行部分(音频头)和完整训练后的评估结果。后者通常能提升下游任务的表现。
| 数据集 | 模态 | 分数(%) | 训练方式 | 目标音频头训练 | 完整模型训练 |
|---|---|---|---|---|---|
| ImageNet | 图像 | 准确率 | 40.51 | 21.79 | |
| AudioSet | 图像 | mAP | 8.93 | 14.82 | |
| 音频 | mAP | 25.85 | 28.36 | ||
| 双模态 | mAP | 25.11 | 32.38 | ||
| UrbanSound8K | 音频 | 65.31 | 68.78 | ||
| 89.95 | 90.07 | ||||
| ESC-50 | 准确率 | 69.40 | 68.60 | ||
| 96.65 | 97.15 |
5 Results
5 结果
5.1 Classification
5.1 分类
Audio-Head Only The extended pre-training (30 epochs instead of 5) on the AudioSet dataset provided an audio encoding head that had increased performance, in comparison to the original training (from $28.17%$ to $34.14%$ , mAP). Such an improvement was also beneficial for the downstream tasks, making the newly trained audio-head to out-perform its base variant on the Urban Sound 8 K and ESC-50 datasets and achieving accuracy of $89.49%$ and $95.90%$ , respectively (Table 1).
仅音频头
在AudioSet数据集上进行扩展预训练(30轮而非5轮),相比原始训练(从$28.17%$提升至$34.14%$,mAP指标),提供了性能更优的音频编码头。这一改进对下游任务同样有益,使得新训练的音频头在Urban Sound 8K和ESC-50数据集上表现优于基础版本,分别达到$89.49%$和$95.90%$的准确率(表1)。
AudioCLIP Our tri-modal training setup – through the use of video frames introduced more diversity into audio-head’s target distribution, thus fighting the over fitting issue and further increasing performance in audio classification tasks, in comparison to the audio-only ESResNeXt model. Also, the joint training of all three heads provided an additional performance boost and the ability to use multiple modalities to perform classification, as well as the zero-shot inference capabilities on previously unseen datasets (Table 2).
AudioCLIP 我们的三模态训练设置——通过引入视频帧——为音频头(audio-head)的目标分布增加了更多多样性,从而解决了过拟合问题,并进一步提升了音频分类任务的性能,与纯音频的ESResNeXt模型相比。此外,三个头的联合训练不仅带来了额外的性能提升,还实现了利用多模态进行分类的能力,以及对未见数据集进行零样本推理的能力(表 2)。
Partial Training: The training of the audio-head under the supervision of the text- and image-heads already allows to out-perform current state-of-the-art results on the Urban Sound 8 K and ESC-50 datasets by achieving accuracy of $89.95%$ and $96.65%$ , respectively.
部分训练:在文本头和图像头的监督下训练音频头,已能在Urban Sound 8K和ESC-50数据集上以$89.95%$和$96.65%$的准确率超越当前最优结果。
Moreover, even the partial training of the AudioCLIP model sets new highest zero-shot classification accuracy on the ESC-50 dataset $(69.40%$ , Table 3) as well as out-performs performance of the commonly trained baseline CNN $(64.50%$ , Table 3).
此外,AudioCLIP模型的部分训练在ESC-50数据集上创下了零样本分类准确率的新高 $(69.40%$ ,表3),并优于常规训练的基线CNN $(64.50%$ ,表3)。
Full Training: The joint training of the AudioCLIP model provides further performance improvements in comparison to the partial one. Such a trained AudioCLIP model sets the new state-of-the-art classification accuracy on the
完整训练:与部分训练相比,AudioCLIP模型的联合训练能带来进一步的性能提升。经过完整训练的AudioCLIP模型在分类准确率上达到了新的最优水平。
Table 3. Evaluation results on Urban Sound 8 K (US8K) and ESC-50, accuracy ( $%$ ).
表 3. Urban Sound 8K (US8K) 和 ESC-50 的评估结果,准确率 ( $%$ )。
| 模型 | 来源 | 训练方式 | 目标数据集 |
|---|---|---|---|
| 目标域训练 | US8K | ||
| Human (2015) | [19] | ||
| Piczak-CNN (2015) | [18] | 73.70 | |
| SB-CNN (2017) | [24] | 79.00 | |
| VGGish + Word2Vec (2019) | [32] | ||
| ESResNet (2020) | [6] | 85.42 | |
| WEANET N4 (2020) | [15] | ||
| DenseNet-201 × 5,ensemble (2020) | [17] | 87.42 | |
| VGGish + Word2Vec + GloVe (2021) | [33] | ||
| ESResNeXt (2021) | [10] | 89.14 | |
| AST (2021) ERANN (2021) | [8] | √ | |
| Audio-Head (ESResNeXt, our training) Ours | [30] | ||
| AudioCLIP (partial training) | 89.49 | ||
| 65.31 | |||
| AudioCLIP (full training) | 89.95 | ||
| 68.78 | |||
| 90.07 |
Urban Sound 8 K and ESC-50 datasets ( $90.07%$ and $97.15%$ , respectively). Also, given the full model training setup, a new zero-shot classification baseline was set for the Urban Sound 8 K dataset ( $68.78%$ , Table 3).
Urban Sound 8K和ESC-50数据集(准确率分别为$90.07%$和$97.15%$)。此外,在完整模型训练设置下,为Urban Sound 8K数据集建立了新的零样本分类基线($68.78%$,表3)。
5.2 Querying
5.2 查询
The original CLIP model introduced the ability to perform querying using both supported modalities – text and image – in any direction. Given a query (e.g., text), model provided similarity scores for the samples represented by another (visual) modality. Thus, given a dataset and a modality, the set of queries was defined by the unique samples of the chosen modality. In this work, we added the support of audio, enabling the model to query between text, images and audio in any combination. We evaluated the querying performance on the ImageNet, AudioSet, Urban Sound 8 K and ESC-50 datasets and summarized it in Table 4.
原始CLIP模型支持在文本和图像两种模态之间进行任意方向的查询。给定一个查询(如文本),模型会为另一种(视觉)模态的样本提供相似度评分。因此,给定数据集和模态时,查询集由所选模态的唯一样本定义。本研究新增了音频模态支持,使模型能够在文本、图像和音频之间进行任意组合的跨模态查询。我们在ImageNet、AudioSet、Urban Sound 8K和ESC-50数据集上评估了查询性能,结果汇总于表4。
Image by Text: In this setup, all unique sets of class names assigned to the samples from a target dataset were collected and served as textual queries while the results were represented by images (ImageNet, AudioSet). Thus, only the visual samples possessing the same set of labels were considered as relevant results.
文本生成图像:在此设置中,收集了目标数据集中分配给样本的所有独特类别名称组合作为文本查询,而结果以图像形式呈现(如ImageNet、AudioSet)。因此,只有具有相同标签组合的视觉样本才会被视为相关结果。
For the AudioSet dataset, the full training contributed to the increase of the performance score measured by mAP. However, such a training led to the decrease of the querying performance on the ImageNet dataset, as its distribution is likely different from the AudioSet one.
对于AudioSet数据集,完整训练有助于提升以mAP衡量的性能得分。然而,这种训练导致在ImageNet数据集上的查询性能下降,因为其分布可能与AudioSet不同。
Table 4. Querying scores of AudioCLIP after partial and full training on AudioSet. The latter in general improves results on AudioSet and the downstream tasks.
表 4: AudioCLIP 在 AudioSet 上部分训练和完整训练后的查询分数。后者通常能提升 AudioSet 及下游任务的表现。
| 数据集 | 查询模态 | 目标模态 | Audio-Head (P@1 R@1 mAP) | Full Model (P@1 R@1 mAP) |
|---|---|---|---|---|
| ImageNet | text | image | 5.42 84.15 52.91 | 1.61 89.00 33.13 |
| AudioSet | text | image | 0.81 46.79 9.51 | 1.31 74.95 17.22 |
| text | audio | 2.51 84.38 23.54 | 5.33 76.13 30.79 | |
| audio | image | 0.62 56.39 5.45 | 1.03 52.12 7.22 | |
| UrbanSound8K | image | audio | 0.61 61.94 4.86 | 1.20 53.15 6.86 |
| ESC-50 | text | audio | 51.25 85.20 77.20 | 51.78 80.40 76.97 |
| 40.81 47.69 77.43 | 42.28 48.18 80.04 |
Audio by Text: Having the same type of query as in the previous setup, here, the result was represented by an audio recording and considered correct if the labels matched the query.
文本转音频:采用与先前设置相同的查询类型,此处结果以音频录制形式呈现,若标签与查询匹配则判定为正确。
On the AudioSet and Urban Sound 8 K datasets, the full training increases the querying performance. For the ESC-50 dataset it is not the case, however, the gap is not large and is close to be marginal.
在AudioSet和Urban Sound 8K数据集上,完整训练提升了查询性能。但对于ESC-50数据集并非如此,不过差距不大且接近边际。
Audio by Image and Vice Versa: For both types of queries – audio by image and image by audio – the full training of the AudioCLIP model was beneficial in terms of querying performance (mAP).
音频与图像的相互生成:对于两种查询类型——通过图像生成音频和通过音频生成图像,AudioCLIP模型的完整训练在查询性能(mAP)方面均显示出优势。
6 Conclusion
6 结论
In this work, we extended the CLIP model [21] from textual and visual modalities to audio using an effective sound classification model [10].
在这项工作中,我们通过一个有效的音频分类模型 [10] 将 CLIP 模型 [21] 从文本和视觉模态扩展到了音频领域。
The proposed AudioCLIP model achieves new state-of-the-art classification results on two datasets: Urban Sound 8 K $(90.07%)$ ) and ESC-50 $(97.15%$ ). To ease reproducibility, the details on hyper-parameters and implementation as well as weights of the trained models are made available for the community .
提出的AudioCLIP模型在两个数据集上取得了新的最先进分类结果:Urban Sound 8K $(90.07%)$) 和 ESC-50 $(97.15%$)。为便于复现,我们向社区公开了超参数、实现细节以及训练模型的权重。
Additionally, for the zero-shot inference, our model out-performs previous approaches on the ESC-50 dataset with a large gap $(69.40%$ ) and sets a baseline for the Urban Sound 8 K dataset $(68.78%$ ).
此外,在零样本 (Zero-shot) 推理任务中,我们的模型在 ESC-50 数据集上以显著优势 (69.40%) 超越先前方法,并在 Urban Sound 8K 数据集上 (68.78%) 建立了基准。
We also evaluated the performance of our model on cross-modal querying tasks as well as the influence of the partial and full training on the results in classification and querying tasks.
我们还评估了模型在跨模态查询任务中的性能,以及部分训练和完整训练对分类及查询任务结果的影响。
In the future, we would like to further investigate the performance of the proposed AudioCLIP model on a wider variety of datasets and tasks. Also, changing the backbones of image- and audio-heads to more powerful networks could further improve the model performance.
未来,我们希望能进一步研究提出的AudioCLIP模型在更广泛数据集和任务上的表现。同时,将图像和音频处理模块的骨干网络升级为更强大的架构有望进一步提升模型性能。