OmniVec2 - A Novel Transformer based Network for Large Scale Multimodal and Multitask Learning
OmniVec2 - 基于Transformer的新型大规模多模态多任务学习网络
Abstract
摘要
We present a novel multimodal multitask network and associated training algorithm. The method is capable of ingesting data from approximately 12 different modalities namely image, video, audio, text, depth, point cloud, time series, tabular, graph, X-ray, infrared, IMU, and hyperspectral. The proposed approach utilizes modality specialized tokenizers, a shared transformer architecture, and cross-attention mechanisms to project the data from different modalities into a unified embedding space. It addresses multimodal and multitask scenarios by incorporating modality-specific task heads for different tasks in respective modalities. We propose a novel pre training strategy with iterative modality switching to initialize the network, and a training algorithm which trades off fully joint training over all modalities, with training on pairs of modalities at a time. We provide comprehensive evaluation across 25 datasets from 12 modalities and show state of the art performances, demonstrating the effectiveness of the proposed architecture, pre training strategy and adapted multitask training.
我们提出了一种新颖的多模态多任务网络及配套训练算法。该方法能够处理约12种不同模态的数据,包括图像、视频、音频、文本、深度、点云、时间序列、表格、图结构、X光、红外、惯性测量单元(IMU)和高光谱数据。该方案采用模态专用分词器、共享Transformer架构和交叉注意力机制,将不同模态数据映射到统一嵌入空间。通过为各模态中的不同任务配备模态特定任务头,有效应对多模态与多任务场景。我们提出了一种基于迭代模态切换的新型预训练策略来初始化网络,并设计了一种训练算法,该算法在全局全模态联合训练与成对模态交替训练之间实现平衡。我们在12种模态的25个数据集上进行了全面评估,展示了最先进的性能表现,验证了所提架构、预训练策略和自适应多任务训练方法的有效性。
across various modalities, potentially reducing the need for extensive labeling in specific modalities for particular tasks.
跨多种模态,可能减少特定任务中对特定模态进行大量标注的需求。
In the present work, we extend such line of research and propose a multimodal multitask method which learns embeddings in a shared space across different modalities and then employs task specific sub-networks for solving specific tasks in specific modalities. The method utilizes a common transformer based bottleneck block to map the input to embeddings in a shared space, thus incorporating knowledge from multiple tasks associated with different respective modalities. This structure leads to learning of very robust representations informed and regularized by all tasks and modalities together. The embeddings are then used by the task heads to make required predictions.
在本研究中,我们扩展了这一研究方向,提出一种多模态多任务方法。该方法首先在不同模态的共享空间中学习嵌入表示,随后通过任务特定的子网络处理特定模态的专项任务。该方法采用基于Transformer的通用瓶颈模块将输入映射至共享嵌入空间,从而整合来自不同模态关联任务的多源知识。这种结构促使学习过程受到所有任务和模态的共同约束与信息共享,最终形成高度鲁棒的表征。任务头模块随后利用这些嵌入表示进行目标预测。
1. Introduction
1. 引言
Extracting meaningful representations from data is a central task in machine learning. Majority of the approaches proposed are usually specialized for specific modalities and tasks. The development of methods capable of handling multiple modalities, in a holistic way, has been an active topic of research recently [21, 34, 35, 45, 63, 105]. Multi task learning has a large body of literature [10], but has been traditionally limited to tasks from single modality. Learning a unified network that trains shared parameters across diverse tasks in different modalities, like image, video, depth maps, audio, has been shown to be more robust and give better generalization and reduce over fitting to a single task or modality [1, 24] cf. unimodal networks. Such joint learning also enables more efficient use of available labeled data
从数据中提取有意义的表征是机器学习的核心任务。现有方法大多针对特定模态和任务专门设计。近年来,开发能够以整体方式处理多模态的方法已成为活跃的研究课题 [21, 34, 35, 45, 63, 105]。多任务学习已有大量文献 [10],但传统上局限于单一模态内的任务。研究表明,与单模态网络相比,学习一个跨图像、视频、深度图、音频等不同模态任务共享参数的统一网络,具有更强鲁棒性、更好泛化能力,并能减少对单一任务或模态的过拟合 [1, 24]。这种联合学习还能更高效地利用现有标注数据
Previous research in generalized multimodal learning falls into three main categories. First, there are methods that process multiple heterogeneous modalities such as images, 3D, and audio, directly without using separate encoders for each modality, learning representations directly from these inputs [34, 35]. Second, some approaches use modality specific encoders and then learn generalized embeddings, for data from each modality, based on a unified objective in the latent space [5]. Third, there are methods focused on knowledge sharing across different modalities, employing either a single common encoder [21] or distinct encoders for each modality [1]. Our work aligns more closely with the third type of approaches, while incorporating elements from the first. We employ modality specific tokenizers and encoders, and have a bottleneck shared transformer backbone. Token iz ation is tailored to each modality, drawing inspiration from the Uni-Perceiver model but with key modifications detailed in Sec. 3. After token iz ation, transformer based network is used to obtain initial representations for the modalities which are passed through fully connected layers and then fused together with cross attention module. The fused representation then passes through the transformer backbone. The features from the transformer are then individually fused with original modality features using cross attention and are in turn fed to the modality specific task head.
广义多模态学习的前沿研究主要分为三类。第一类方法直接处理图像、3D模型和音频等异构模态数据,无需为各模态配备独立编码器,直接从原始输入学习表征 [34, 35]。第二类方法采用模态专用编码器,在潜在空间基于统一目标为各模态数据学习通用嵌入 [5]。第三类方法专注于跨模态知识共享,采用单一公共编码器 [21] 或为各模态设计独立编码器 [1]。我们的工作更接近第三类范式,同时融合了第一类方法的要素:我们使用模态专用分词器(Tokenizer)和编码器,但共享Transformer骨干网络作为瓶颈层。分词方案受Uni-Perceiver模型启发并针对各模态定制,具体改进见第3节。分词后通过基于Transformer的网络获取各模态初始表征,经全连接层处理后由交叉注意力模块融合。融合表征通过共享Transformer骨干网络后,其输出特征再次通过交叉注意力与原始模态特征交互,最终输入至各模态专用任务头。
The training procedure involves a dual-stage masked pre training and a full task based loss optimization. The first stage of masked pre training is the standard unsupervised masked pre-training with one modality at a time. The second state masked pre training involves masked pretraining with pairs of modalities at a time, employing a two stream setup as shown in Fig. 1. In this stage two modalities are used together, tokens are randomly masked and the full network is used to predict the masked tokens using the unmasked tokens for both modalities together. This allows for knowledge sharing across all modalities as the training proceeds by randomly sampling training batches from two modalities from all modalities. The final training step is then training for multiple tasks for different modalities. This is done similar to the second stage of masked pretraining, i.e. pairs of modalities are sampled, and a pair of tasks are sampled, one from each modality. Training batches are then constructed, half each from the two modality-task pairs. These are then used to optimize standard losses corresponding to the tasks, e.g. cross entropy for classification and $\ell_{2}$ loss for pixelwise prediction. The pre training and final task training using pairs of modalities is the key component of the training strategy, that enables the cross modal knowledge sharing across all modalities together, which we discuss more in the following.
训练流程包含双阶段掩码预训练和基于任务的完整损失优化。第一阶段掩码预训练采用标准单模态无监督掩码预训练。第二阶段掩码预训练采用双模态对掩码预训练,如图1所示的双流架构。该阶段联合使用两种模态,随机掩码token后,利用两种模态未掩码的token通过完整网络预测被掩码token。通过从所有模态中随机采样两种模态的训练批次,实现跨模态知识共享。最终训练阶段针对不同模态的多任务进行训练,其方式与第二阶段掩码预训练类似:采样模态对及对应任务对(每种模态各一个任务),构建各占一半比例的模态-任务对训练批次,随后优化任务对应的标准损失函数(如分类任务的交叉熵、像素级预测任务的$\ell_{2}$损失)。这种基于模态对的预训练和最终任务训练是训练策略的核心,实现了全模态间的跨模态知识共享,下文将展开讨论。
In summary, the contributions of the work are as follows. (i) We propose a multimodal multitask network based on transformer architectures with modality specific tokenizers, shared backbone, and task specific heads. (ii) We provide comprehensive empirical results on 25 benchmark datasets over 12 distinct modalities i.e. text, image, point cloud, audio and video along with applications to X-Ray, infrared, hyper spectral, IMU, graph, tabular, and time-series data. The method achieves better or close to state of the art performances on these datasets. (iii) We propose a novel multimodal pre training approach that alternates between a pair of modalities to enable crossmodal knowledge sharing. (iv) We propose a multimodal and multitask supervised training approach to leverage knowledge sharing between modalities for robust learning, simplifying the complex processes proposed in previous works on modality integration, e.g. [45, 94].
综上所述,本工作的贡献如下:(i) 我们提出了一种基于Transformer架构的多模态多任务网络,包含模态专用分词器、共享主干网络和任务专用头部。(ii) 我们在12种不同模态(包括文本、图像、点云、音频、视频以及X射线、红外、高光谱、IMU、图数据、表格数据和时间序列数据)的25个基准数据集上提供了全面的实证结果。该方法在这些数据集上达到或接近最先进性能。(iii) 我们提出了一种新颖的多模态预训练方法,通过交替训练模态对实现跨模态知识共享。(iv) 我们提出了一种多模态多任务监督训练方法,利用模态间知识共享实现鲁棒学习,简化了先前工作中模态整合的复杂流程,例如[45, 94]。
2. Related Works
2. 相关工作
In this section, we discuss similar works and various similar paradigms to our work.
在本节中,我们将讨论与本研究相关的类似工作及多种相似范式。
Multi-modal methods. Contemporary multi-modal methods predominantly employ modality-specific feature encoders [2, 36, 37, 63, 85], focusing on fusion techniques within their architectural designs. These networks usually vary across modalities, necessitating architectural modifications for combined usage. They must address challenges related to feature fusion timing, fine-tuning, and pre-training etc. [87]. Such complexities restrict the adaptability of universal frameworks like transformers for diverse domains, including point clouds, audio, and images.
多模态方法。当前的多模态方法主要采用特定模态的特征编码器 [2, 36, 37, 63, 85],其架构设计侧重于融合技术。这些网络通常因模态而异,需要调整架构以实现联合使用。它们必须解决特征融合时机、微调和预训练等挑战 [87]。此类复杂性限制了像 Transformer 这样的通用框架在点云、音频和图像等多样化领域的适应性。
Common network for multiple modalities. A growing body of research aims to learn from multiple modalities without modality-specific encoders [5, 7, 21, 35]. Notably, architectures like the perceiver [7, 34, 35] employ crossattention among latent queries to process multiple modalities together. The hierarchical perceiver [7] expands on this by structuring the input while maintaining locality. Other approaches, such as data2vec [5], use modality-specific encoders. Omnivore [21], with a common encoder, is limited to visual modalities only. Contrarily, VATT [1] employs a unified transformer backbone but processes each modality independently. These multi-modal methods have demonstrated enhanced robustness [1, 24].
多模态通用网络。越来越多的研究致力于无需特定模态编码器即可从多模态数据中学习 [5, 7, 21, 35]。值得注意的是,Perceiver [7, 34, 35] 等架构通过潜在查询间的交叉注意力机制实现多模态联合处理。分层感知器 [7] 在保持局部性的同时结构化输入,对此进行了扩展。而 data2vec [5] 等方法则采用模态专用编码器。Omnivore [21] 虽使用通用编码器,但仅限于视觉模态。相比之下,VATT [1] 采用统一 Transformer 主干网络,却对每个模态进行独立处理。这些多模态方法已展现出更强的鲁棒性 [1, 24]。
Multi-task learning. As explored in the preceding section, there has been a surge in methods that process multiple modalities. Perceive rIO[34] extends the capabilities of Perceiver [35] to facilitate learning multiple tasks with a singular network architecture. Although Perceive rIO is capable of multitasking, often separate networks are employed [98]. Various techniques [5, 11, 21, 32, 59] learn from raw representations of multiple modalities and are applicable to numerous tasks.
多任务学习。如前一节所述,处理多模态的方法激增。PerceiverIO[34]扩展了Perceiver[35]的能力,以促进使用单一网络架构学习多个任务。尽管PerceiverIO能够进行多任务处理,但通常仍会使用单独的网络[98]。多种技术[5, 11, 21, 32, 59]从多模态的原始表示中学习,并适用于众多任务。
Multi-modal masked pre training. Approaches such as [50, 79, 88] implement masked pre-training. This technique has proven beneficial for improving the performance of deep networks across different modalities and tasks[1, 4, 5, 20, 28, 95].
多模态掩码预训练。诸如[50, 79, 88]等方法实现了掩码预训练。该技术已被证明能有效提升深度网络在不同模态和任务中的性能[1, 4, 5, 20, 28, 95]。
Comparison to similar works. We draw motivations from Uni Perceive r [105], MetaFormer [16] and OmniVec [68]. Unlike Uni Perceive r line of methods, we do not use a unified task head definition, while similar to it we use task specific task heads. This allows our method to learn more robust and leverage fine details from each task depending upon the complexity of the tasks, which is important as each modality has distinct definition of complexity. For ex., in vision task, classification is a relatively simpler task as compared to segmentation, as segmentation tasks enforces networks to learn pixel level attention and learning better neighbourhood relationships [27, 69]. Further, MetaFormer uses unified tokenizers, and instead, we utilize modality specific tokenizers. Our experiments indicate that modality specific tokenizers perform better than MetaFormer’s unified tokenizer when training on multiple modalities. Further, OmniVec uses separate encoders for each modaity, that makes the network heavy and computationally expensive. In contrast, we use modality specific tokenizers with a shared backbone. Additionally, unlike other works, we train on multiple modalities in a multi task manner, allowing the network to learn from multiple modalities with varying task complexities simultaneously.
与同类工作的对比。我们的灵感来源于Uni Perceive r [105]、MetaFormer [16]和OmniVec [68]。与Uni Perceive r系列方法不同,我们未采用统一的任务头定义,但与其相似的是我们使用了任务特定的任务头。这使得我们的方法能够根据任务复杂度从每个任务中学习更鲁棒的特征并利用细微信息,这一点至关重要,因为每种模态对复杂度的定义各不相同。例如,在视觉任务中,分类相比分割是相对简单的任务,因为分割任务迫使网络学习像素级注意力并建立更好的邻域关系[27,69]。此外,MetaFormer采用统一的tokenizer,而我们则使用模态特定的tokenizer。实验表明,在多模态训练时,模态特定tokenizer的性能优于MetaFormer的统一tokenizer。再者,OmniVec为每种模态使用独立编码器,导致网络臃肿且计算成本高昂。相比之下,我们在共享主干网络上使用模态特定tokenizer。另外,不同于其他工作,我们以多任务方式训练多模态数据,使网络能同时从具有不同任务复杂度的多模态数据中学习。
3. Approach
3. 方法
Overview. We are interested in multimodal multitask learning. Say we have modalities indexed by $m\in[1,M]$ , and each modality has $T$ tasks indexed by $t\in[1,T]$ . Note that here we assume same number of tasks for all modalities for notational convenience, in practice different modalities would have different number of tasks. Examples of modality and their tasks could be classification into categories for point cloud modality, and dense pixel wise segmentation in image modality. We are interested in jointly learning classifiers $\phi_{m t}(\cdot|\theta_{m t})$ which take inputs $x_{m}$ from modality $m$ and make predictions for task $t$ , with $\theta_{m t}$ being the respective parameters. We assume that the learning is to happen by loss minimization where $\ell_{m t}(\cdot)$ denotes the loss for task $t$ on modality $m$ . Examples of such losses are cross entropy loss for classification tasks, and $\ell_{2}$ loss for dense image prediction tasks such as image segmentation. We would like to solve the following optimization.
概述。我们关注多模态多任务学习。假设模态索引为$m\in[1,M]$,每个模态包含$T$个任务,索引为$t\in[1,T]$。需说明的是,为表述简便此处假设所有模态任务数相同,实际场景中各模态任务数可能不同。例如点云模态的任务可能是类别分类,而图像模态的任务可能是密集像素级分割。我们的目标是联合学习分类器$\phi_{m t}(\cdot|\theta_{m t})$,这些分类器接收来自模态$m$的输入$x_{m}$并预测任务$t$的结果,其中$\theta_{m t}$为对应参数。假设学习过程通过损失最小化实现,$\ell_{m t}(\cdot)$表示模态$m$上任务$t$的损失函数。典型例子包括分类任务的交叉熵损失,以及图像分割等密集预测任务的$\ell_{2}$损失。我们需要求解以下优化问题。
$$
\Theta^{}=\operatorname*{min}{\Theta}\sum_{m,t}\ell_{m t}(\mathcal{T}_{m t}),
$$
$$
\Theta^{}=\operatorname*{min}{\Theta}\sum_{m,t}\ell_{m t}(\mathcal{T}_{m t}),
$$
where $\Theta={\theta_{m t}|m,t}$ are the parameters of all the pre- dictors, and $\tau_{m t}$ is the training set provided for task $t$ of modality $m$ . This is the extension of multiple task learning to multiple modalities as well.
其中 $\Theta={\theta_{mt}|m,t}$ 是所有预测器的参数集合,$\tau_{mt}$ 是为模态 $m$ 的任务 $t$ 提供的训练集。这是将多任务学习扩展到多模态的延伸。
We present a network and associated unsupervised pretraining and supervised training algorithm for the above task of multimodal multitask learning. The network consists of $M\times T$ modality specific tokenizers, followed by common feature transformation and feature fusion networks built with transformers, with cross attention modules in between, denoted by $f(\cdot),g(\cdot)$ in Fig. 1. The final part of the network are $M\times T$ task specific prediction heads, denoted by $h_{m t}(\cdot)$ for task $t$ on modality $m$ , which provide the final outputs for the tasks. At inference the prediction function is the composition of the three functions, i.e. $\phi(x)~=~h_{m t}\circ g\circ f(x)$ where $x$ is the tokenized form of the input. While training, we sample a pair of modalities from all the available modalities, and then sample one task each for the sampled modalities. We then construct training batch, half from each sampled task. Once the tokenization is done, the features $x_{i},x_{j}$ are passed into the first feature transformation subnetwork to obtain $f(x_{i}),f(x_{j})$ . These are then passed through the cross attention module to fuse them together. The fused features are then input to the second part of the network, i.e. $g(\cdot)$ . The output $\hat{x}{i j}=g\circ\mathcal{A}(f(x_{i}),f(x_{j}))$ , where $\mathcal{A}(\cdot)$ is the cross attention function, is then again fused with the respective input features $x_{i},x_{j}$ . These features, i.e. $\mathcal{A}(\hat{x}{i j},x_{i}),\mathcal{A}(\hat{x}{i j},x_{j})$ are then fed to the task predictors $h_{i q}$ and $h_{j r}$ , to obtain the final predictions for task $q,r$ on modalities $i,j$ respectively. The sum of losses $\ell_{i q}+\ell_{j r}$ are then minimized for the current batch by back propagation. Thus the learning proceeds by optimizing pairs of losses at a time, to stochastic ally minimize the sum over all the losses.
我们提出了一种网络及其相关的无监督预训练和有监督训练算法,用于上述多模态多任务学习任务。该网络由 $M\times T$ 个模态特定的分词器组成,随后是通过 Transformer 构建的通用特征转换和特征融合网络,中间穿插交叉注意力模块,在图 1 中用 $f(\cdot),g(\cdot)$ 表示。网络的最后部分是 $M\times T$ 个任务特定的预测头,对于模态 $m$ 上的任务 $t$ 表示为 $h_{m t}(\cdot)$,它们为任务提供最终输出。在推理时,预测函数是这三个函数的组合,即 $\phi(x)~=~h_{m t}\circ g\circ f(x)$,其中 $x$ 是输入的 Token 化形式。在训练时,我们从所有可用模态中采样一对模态,然后为每个采样的模态采样一个任务。接着我们构建训练批次,每个采样任务各占一半。完成分词后,特征 $x_{i},x_{j}$ 被传递到第一个特征转换子网络以获得 $f(x_{i}),f(x_{j})$。然后这些特征通过交叉注意力模块融合在一起。融合后的特征随后输入到网络的第二部分,即 $g(\cdot)$。输出 $\hat{x}{i j}=g\circ\mathcal{A}(f(x_{i}),f(x_{j}))$,其中 $\mathcal{A}(\cdot)$ 是交叉注意力函数,然后再次与各自的输入特征 $x_{i},x_{j}$ 融合。这些特征,即 $\mathcal{A}(\hat{x}{i j},x_{i}),\mathcal{A}(\hat{x}{i j},x_{j})$,随后被馈送到任务预测器 $h_{i q}$ 和 $h_{j r}$,以分别获得模态 $i,j$ 上任务 $q,r$ 的最终预测。然后通过反向传播最小化当前批次的损失总和 $\ell_{i q}+\ell_{j r}$。因此,学习过程通过一次优化一对损失来随机最小化所有损失的总和。
Along with the supervised multimodal joint training explained above, the learning also consists of two stages of unsupervised masked pre training with the first stage being unimodal and the second stage being multimodal pre training, to achieve knowledge sharing between tasks and modalities leading to regularized and robust predictors. We now present each of the components and the full training algorithm in detail.
除了上述有监督的多模态联合训练外,学习过程还包含两个阶段的无监督掩码预训练:第一阶段为单模态预训练,第二阶段为多模态预训练。这种设计旨在实现任务与模态间的知识共享,从而获得经过正则化且鲁棒的预测器。下面我们将详细阐述各组件及完整训练算法。
3.1. Network components
3.1. 网络组件
We now go through the network components sequentially from input to output.
我们现在按从输入到输出的顺序依次介绍网络组件。
Tokenizers. Each modality is tokenized using a modality specific tokenizer. The tokenizers are similar to those used in Uni-Perceiver [45], however, instead of attaching an embedding to the tokens, we provide transformer with one type of modality at a time. Further, Uni-Perceiver utilizes a combination of tokens from multiple modalities passed to a single transformer. This limits the Uni-perceiver to a limited set of modalities, i.e. text, image and videos. However, our method does not suffer from any such limitation. The details of specific tokenizers for the different modalities are provided in Supplementary.
Tokenizer。每种模态都使用特定的模态tokenizer进行处理。这些tokenizer与Uni-Perceiver [45] 中使用的类似,但我们不是为token附加嵌入,而是每次仅向transformer提供一种模态类型。此外,Uni-Perceiver将来自多种模态的token组合传递给单个transformer,这限制了Uni-Perceiver只能处理有限的模态集(即文本、图像和视频)。而我们的方法不受此类限制。不同模态的具体tokenizer细节见补充材料。
Feature transformation network. Once the features are tokenized, they are then passed through a transformer network. While the method can utilize any transformer backbone, in the current implementation we use a transformer based on BERT [13]. Here, the multi head attention involves standard self-attention [76], and GeLU [30] activation prior to the MLP layer. The output from the transformer network is passed to a fully connected neural network with three fully connected layers with ReLU activation. This transformer network along with the fully connected layers is denoted a $f(\cdot)$ in Fig. 1. The network could be used without the fully connected layers—we added the fully connected layers to reduce the dimensions of the features so that the computational complexity of the remaining part of the network could be reduced.
特征转换网络。特征被转换为token后,会输入一个transformer网络。虽然该方法可采用任何transformer主干网络,但在当前实现中我们使用了基于BERT[13]的transformer。其中多头注意力机制采用标准自注意力[76],并在MLP层前使用GeLU[30]激活函数。transformer网络的输出会传入一个包含三个全连接层(采用ReLU激活)的全连接神经网络。如图1所示,该transformer网络与全连接层共同表示为$f(\cdot)$。网络可不使用全连接层——我们添加全连接层是为了降低特征维度,从而减少网络剩余部分的计算复杂度。
Mixing features with cross attention. When training, we fuse the features from the two transformer streams, corresponding to two modalities, with cross attention module. The output fused features are then passed to another transformer network, denoted a $g(\cdot)$ in Fig. 1. The architecture of the transformer network is same as the transformers used in feature transformation network.
通过交叉注意力机制融合特征。在训练过程中,我们利用交叉注意力模块将来自两种模态的两个Transformer流特征进行融合。随后,这些融合后的特征会被传递到另一个Transformer网络(在图1中表示为$g(\cdot)$)。该Transformer网络的架构与特征转换网络中使用的Transformer相同。
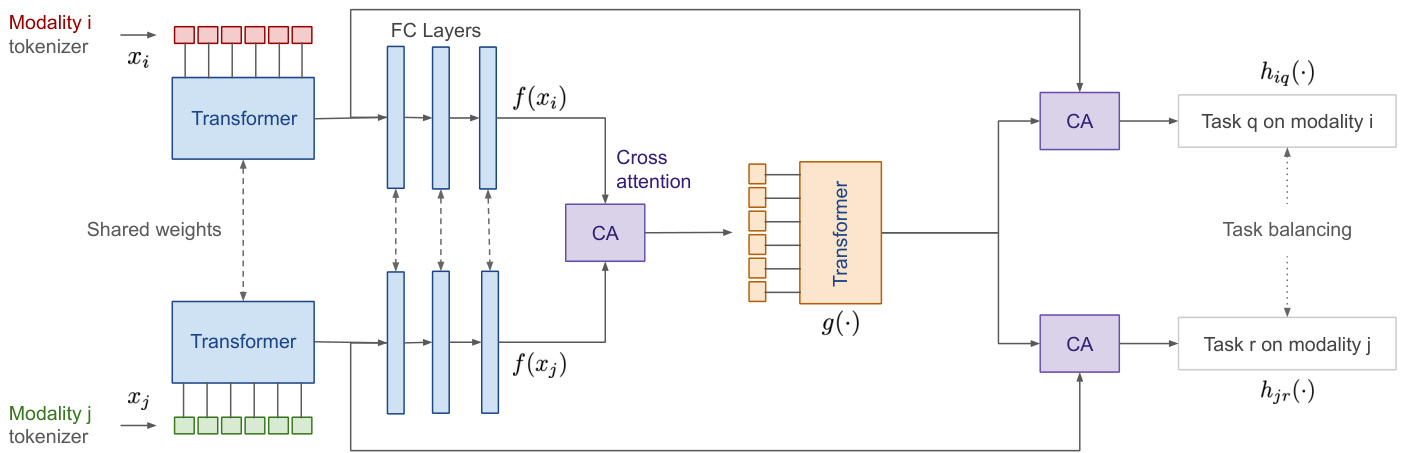
Figure 1. Overview of the proposed method. The proposed method consists of three parts, the feature transformation network $f(\cdot)$ which consists of a transformer followed by fully connected layers to reduce feature dimensions, another transformer $g(\cdot)$ and finally the task prediction heads $h_{m t}(\cdot)$ for task $t$ on modality $m$ . The input data is tokenized with corresponding modality specific tokenizer. While training, pairs of modalities are used and the features are fused between the two modalities using cross attention layers, in a two stream configuration as shown here. While making prediction, the network is a single stream with cross attention layers removed, and the output is $h_{m t}\circ g\circ f(x)$ where $_x$ is the output of the corresponding modality specific tokenizer.
图 1: 所提方法概述。该方法包含三部分:特征转换网络 $f(\cdot)$ (由Transformer和全连接层组成以降低特征维度)、另一个Transformer $g(\cdot)$,以及针对模态 $m$ 中任务 $t$ 的任务预测头 $h_{m t}(\cdot)$。输入数据通过对应模态的特定分词器进行Token化处理。训练时采用模态对,并通过交叉注意力层在双流配置中实现模态间特征融合(如图所示)。预测时网络为单流结构(移除交叉注意力层),输出为 $h_{m t}\circ g\circ f(x)$,其中 $_x$ 是对应模态特定分词器的输出。
Modality and task specific heads. The part of the network are the modality and task specific heads, denoted a $h_{m t}(\cdot)$ in Fig. 1. These task heads take as input, features from respective modality streams fused with features from the above network, fused with cross attention module. The task heads consist of a vanilla ViT-Tiny networks [82].
模态与任务特定头部。网络的这一部分为模态与任务特定头部,在图1中表示为 $h_{m t}(\cdot)$。这些任务头部接收来自各自模态流的特征作为输入,这些特征与上述网络通过交叉注意力模块融合后的特征相结合。任务头部由标准ViT-Tiny网络[82]构成。
3.2. Training
3.2. 训练
The training is done in three steps: (i) masked pre training iterating over modalities but doing masked prediction with one modality at a time, (ii) multimodal masked pre training where two modalities are simultaneously used to do masked prediction for each, and (iii) finally supervised task based training.
训练分为三个步骤:(i) 掩码预训练 (masked pre-training) 依次处理各模态,但每次仅对单一模态进行掩码预测;(ii) 多模态掩码预训练 (multimodal masked pre-training) 同时使用两种模态,分别对每种模态进行掩码预测;(iii) 最后进行基于监督任务的训练。
Stage 1 masked pre training. The first step in training is self supervised pre training of the transformer in the feature transformation network. We follow earlier works [1, 20, 68] and add a decoder for predicting masked tokens. Specifically, for an input modality with $P$ patches, we randomly mask $P_{m}$ patches, and feed non-masked patches and their positions to an encoder network attached in addition to the feature transformer. Further, we iterate between modalities while keeping the transformer network common, so that it learns to work with all modalities. Once this stage is complete we discard the decoder added, and keep only the encoder transformer.
阶段1:掩码预训练。训练的第一步是对特征转换网络中的Transformer进行自监督预训练。我们遵循先前的研究[1, 20, 68],添加了一个用于预测掩码Token的解码器。具体来说,对于包含$P$个补丁的输入模态,我们随机掩码$P_{m}$个补丁,并将未掩码的补丁及其位置输入到附加于特征Transformer的编码器网络中。此外,我们在保持Transformer网络通用的同时,在模态之间进行迭代,使其学会处理所有模态。此阶段完成后,我们将丢弃添加的解码器,仅保留编码器Transformer。
Stage 2 masked pre training. We engage the full network, except the task specific prediction heads. We take two inputs from two different modalities and pass them through the network till just before the task prediction heads. Instead of task prediction heads we add decoders to predict the masked tokens for respective input modalities. This process involves decoding the modalities in parallel, utilizing the outputs from the cross-attention modules and the modalityspecific feature vectors. This alternating approach is key to achieving effective multimodal masked pre training. Here also, we randomly mask tokens for both the modalities. Task balancing is not employed in this pre training stage. Such a multi task multi modality approach allows us to utilize unpaired data across modalities. As in stage 1 pretraining, once this stage of training is finished, we discard the decoders added and keep the trained network $f,g$ .
阶段2掩码预训练。我们启用整个网络(除任务特定的预测头外),从两种不同模态各取一个输入,让它们通过网络直至任务预测头之前。在此阶段,我们移除任务预测头并添加解码器来预测各自输入模态的掩码token。该过程通过并行解码各模态实现,利用交叉注意力模块的输出和模态特定特征向量。这种交替式训练是实现高效多模态掩码预训练的关键。本阶段同样会对两种模态的token进行随机掩码,且不采用任务平衡策略。这种多任务多模态方法使我们能够利用跨模态的非配对数据。与阶段1预训练相同,本阶段训练完成后,我们会移除新增的解码器,仅保留训练好的网络$f,g$。
3.2.1 Multimodal multitask supervised training
3.2.1 多模态多任务监督训练
In the final part of the training, we train for two tasks at a time from two different modalities. This lets up stochastically minimize the loss function in Eq. 1, but minimizing sum of two losses at a time instead of minimizing the sum of all of them. When we use two modalities, we use the network as shown in Fig. 1 in a two stream configuration. With the two modality features being fused together in the middle, passed through a transformer $g(\cdot)$ and then fused back with themselves, before finally being input to the task prediction heads. Such fusion of the the features from two modalities leads to knowledge sharing between the tasks of different modalies and makes the learning robust and regularized.
在训练的最后阶段,我们同时针对来自两种不同模态的任务进行训练。这种方法可以随机最小化公式1中的损失函数,但每次只最小化两个损失值的总和,而非所有损失的总和。当使用两种模态时,我们采用图1所示的网络结构进行双流配置:两种模态特征在中间层融合,通过Transformer模块$g(\cdot)$处理后重新与自身特征融合,最终输入任务预测头。这种跨模态特征融合实现了不同模态任务间的知识共享,使学习过程具有鲁棒性和正则化特性。
Given the varying complexities of these task pairs, as underscored in previous research [17], we found it essential to balance the complexity of tasks in a multitask learning setting. Hence, the we train while employing standard task balancing techniques. We adjust the loss magnitude for each task based on its convergence rate. As our ablation studies will demonstrate, this approach allows for random pairing of modalities, in contrast to the need for selecting specific pairs as suggested in prior works [45, 68, 94, 105]. We give details of such task balancing in the Supplementary material.
鉴于这些任务对的复杂度各不相同,如先前研究[17]所强调的,我们发现有必要在多任务学习环境中平衡任务的复杂度。因此,我们在训练时采用了标准的任务平衡技术,根据每个任务的收敛速度调整其损失幅度。正如我们的消融研究将展示的,这种方法允许随机配对模态,而不像先前工作[45, 68, 94, 105]所建议的那样需要选择特定配对。我们在补充材料中提供了此类任务平衡的详细信息。
3.2.2 Masked pre training for different modalities
3.2.2 不同模态的掩码预训练
We use the best practices when pre training with different modalities, following existing works. We use image, video, text, audio and 3D point clouds modalities for masked pretraining. We employ a consistent masking approach across visual and auditory modalities. We follow [65] for textual data, utilizing random sentence permutation [90]. We designate a fraction $f$ of tokens for prediction, following the 8:1:1 token masking ratio of BERT [13]. Our primary goal is to reduce the discrepancy between the input and the outputs of the decoder. For inputs such as images, videos, point clouds, and audio spec tro grams, we aim to minimize the $\ell_{2}$ distance between the predicted and actual target patches. Normalization to zero mean and unit variance is applied to visual inputs. For textual data, we utilize the permuted language modeling objective of XLNet [90].
我们采用不同模态预训练的最佳实践,遵循现有工作。使用图像、视频、文本、音频和3D点云模态进行掩码预训练,在视觉和听觉模态上采用一致的掩码方法。文本数据遵循[65]的随机句子置换策略[90],按BERT[13]的8:1:1 token掩码比例设定预测token占比$f$。核心目标是减小解码器输出与输入的差异:对图像、视频、点云和音频频谱图等输入,最小化预测块与实际目标块的$\ell_{2}$距离,视觉输入需归一化为零均值和单位方差;文本数据则采用XLNet[90]的置换语言建模目标。
3.2.3 Inference
3.2.3 推理
When doing prediction, the network is used as a single stream without the cross attention layers in Fig. 1. The input data is tokenized with the tokenizer for its modality, passed through the feature transformation network $f(\cdot)$ followed by the second transformer $g(\cdot)$ , and finally input to the task prediction head $h_{m t}(\cdot)$ , i.e. the full forward pass is $h_{m t}\circ g\circ f(x)$ where $x$ is the output of the tokenizer.
在进行预测时,网络作为单一流使用,不包含图1中的交叉注意力层。输入数据通过对应模态的分词器 (tokenizer) 进行分词,经特征转换网络 $f(\cdot)$ 处理后,输入第二个 Transformer $g(\cdot)$,最终传递至任务预测头 $h_{mt}(\cdot)$。完整前向传播过程为 $h_{mt}\circ g\circ f(x)$,其中 $x$ 是分词器的输出。
4. Experimental results
4. 实验结果
Masked pre training. We use AudioSet (audio) [19], Something-Something v2 (SSv2) (video) [25], English Wikipedia (text), ImageNet1K (image) [12], SUN RGB-D (depth maps) [66], ModelNet40 (3D point cloud) [84] for pre training the network. For Stage 1 of masked pre training (Sec. 3.2), we use the samples from the training set of the respective datasets. For Stage 2 of masked pre training, we randomly select two modalities, and sample data from them to pretrain the full network. Further, we randomly mask patches. For image, video and audio, we mask $95%$ of the patches. For point cloud and text, we mask $90%$ and $95%$ of the patches respectively. We perform pre training for 3000 epochs. We use fraction $f$ as $5%$ .
掩码预训练。我们使用AudioSet (音频) [19]、Something-Something v2 (SSv2) (视频) [25]、英文维基百科 (文本)、ImageNet1K (图像) [12]、SUN RGB-D (深度图) [66]、ModelNet40 (3D点云) [84] 进行网络预训练。在掩码预训练的第一阶段 (第3.2节),我们使用各数据集训练集中的样本。在掩码预训练的第二阶段,我们随机选择两种模态,并从中采样数据以预训练完整网络。此外,我们随机掩码图像块。对于图像、视频和音频,我们掩码 $95%$ 的图像块。对于点云和文本,我们分别掩码 $90%$ 和 $95%$ 的图像块。我们进行了3000个周期的预训练。使用分数 $f$ 为 $5%$。
Downstream tasks. We train the model on downstream tasks and report results. The datasets used for single modality methods are i Naturalist-2018 [75] (Image Recognition), Places-365 [100] (Scene Recognition), Kinetics-400 [38] (Video Action Recognition), Moments in Time [53] (Video Action Recognition), ESC50 [57] (Audio Event Classification), S3DIS [3] (3D point cloud segmentation), Dialogue
下游任务。我们在下游任务上训练模型并报告结果。单模态方法使用的数据集包括 iNaturalist-2018 [75](图像识别)、Places-365 [100](场景识别)、Kinetics-400 [38](视频动作识别)、Moments in Time [53](视频动作识别)、ESC50 [57](音频事件分类)、S3DIS [3](3D点云分割)、Dialogue
SUM [9] (Text sum mari z ation).
SUM [9] (文本摘要)
Adaptation on unseen datasets. To assess our method’s adaptability to datasets not seen at training, we report comparisons with image classification on Oxford-IIIT Pets [56], action recognition in videos using UCF-101 [67] and HMDB51 [41], 3D point cloud classification on ScanObjectNN [74], point cloud segmentation with NYU v2 seg [64], text sum mari z ation using the SamSum dataset [22]. As the number of classes and labels differ in each dataset as compared to the datasets used during pre training, we randomly sample $10%$ data from each of the training set. Further, we extract the embeddings using the pretrained network, and train two fully connected layers with task specific loss functions. This allows us to demonstrate the ability of the proposed method to generate embeddings which can generalize across datasets.
对未见数据集的适应。为评估我们方法对训练中未见数据集的适应能力,我们在以下任务中进行了对比实验:Oxford-IIIT Pets [56] 图像分类、基于 UCF-101 [67] 和 HMDB51 [41] 的视频动作识别、ScanObjectNN [74] 3D点云分类、NYU v2 seg [64] 点云分割、以及使用 SamSum 数据集 [22] 的文本摘要。由于这些数据集的类别数量和标签与预训练所用数据集存在差异,我们从每个训练集中随机采样 $10%$ 的数据,通过预训练网络提取嵌入特征后,使用两个全连接层配合任务特定损失函数进行训练。这验证了所提方法生成的嵌入特征具备跨数据集泛化能力。
Cross domain generalization. We follow prior work [1] and evaluate on video-text retrieval on two benchmark datasets i.e. YouCook2 [104], and MSR-VTT [86], for multiple modalities.
跨域泛化。我们遵循先前工作[1],在两个基准数据集 YouCook2[104]和 MSR-VTT[86]上针对多模态进行视频-文本检索评估。
Adaptation on unseen modalities. We also evaluate our method on unseen modalities. Specifically, we evaluate our method on the following (i) X-Ray scan, and hyper spectral data recognition, where we utilize the RegDB [54], Chest X-Ray [62], and Indian Pine datasets1. (ii) Time-series forecasting, where our experiments are based on the ETTh1 [103], Traffic2, Weather3, and Exchange datasets [42]. (iii) Graph understanding through the PCQM4M-LSC dataset [33], which comprises 4.4 million organic molecules with quantum-mechanical properties, focusing on predicting molecular properties with applications in drug discovery and material science. (iv)Tabular analysis, where we engage with the adult and bank marketing datasets from the UCI repository 4, (v) IMU recognition, where we conduct experiments on IMU sensor clas- sification using the Ego4D dataset [26], assessing the capability to understand inertial motion systems. We follow [16] for the train test splits and evaluation metrics on these datasets. Further, we use modality specific tokenizers and follow similar network settings as for generalization on unseen datasets.
对未见模态的适应性。我们还在未见模态上评估了我们的方法,具体包括:(i) X光扫描和高光谱数据识别,使用了RegDB [54]、Chest X-Ray [62]和Indian Pine数据集;(ii) 时间序列预测,实验基于ETTh1 [103]、Traffic、Weather和Exchange数据集 [42];(iii) 通过PCQM4M-LSC数据集 [33]进行图理解,该数据集包含440万个具有量子力学特性的有机分子,重点预测分子特性,应用于药物发现和材料科学;(iv) 表格分析,使用了UCI存储库中的adult和bank marketing数据集;(v) IMU识别,利用Ego4D数据集 [26]进行IMU传感器分类实验,评估理解惯性运动系统的能力。我们遵循[16]的方法进行数据集划分和评估指标设定,并采用模态特定的分词器,网络设置与未见数据集泛化实验保持一致。
We provide more details on the tokenizers used for each modality, description of task heads, and formulations of loss functions in the supplementary material.
我们在补充材料中提供了关于每种模态使用的分词器 (tokenizer)、任务头描述以及损失函数公式的更多细节。
Table 1. i Naturalist-2018 and Places365 top-1 accuracy.
表 1: iNaturalist-2018 和 Places365 的 top-1 准确率。
| 方法/数据集 | iN2018 | P365 |
|---|---|---|
| Omni-MAE [20] | 78.1 | 59.4 |
| Omnivore [21] | 84.1 | 59.9 |
| EfficientNetB8 [71] | 81.3 | 58.6 |
| MAE [29] | 86.8 | |
| MetaFormer [94] | 87.5 | 60.7 |
| InternImage [77] | 92.6 | 61.2 |
| OmniVec [68] | 93.8 | 63.5 |
| Ours | 94.6 | 65.1 |
Table 2. Kinetics-400 top-1 accuracy.
表 2: Kinetics-400 的 top-1 准确率
| 方法 | K400 |
|---|---|
| Omnivore [21] | 84.1 |
| VATT [1] Uniformerv2[46] | 90.0 |
| InternVideo[78] | 91.1 |
| TubeViT[58] | 90.9 |
| OmniVec[68] | 91.1 |
| Ours | 93.6 |
Table 3. Moments in time top-1 accuracy.
表 3: Moments in time top-1 准确率。
| 方法 | MIT |
|---|---|
| VATT [1] | 41.1 |
| Uniformerv2 [46] | 47.8 |
| CoCa [93] | 47.4 |
| CoCa-finetuned [93] | 49.0 |
| OmniVec [68] | 49.8 |
| Ours | 53.1 |
Table 4. ESC50 top-1 accuracy.
表 4: ESC50 top-1 准确率。
| 方法 | ESC50 |
|---|---|
| AST [23] | 85.7 |
| EAT-M [18] | 96.3 |
| HTS-AT [8] | 97.0 |
| BEATs [55] | 98.1 |
| OmniVec [68] | 98.4 |
| 我们的方法 | 99.1 |
Table 5. ModelNet40-C Error Rate.
表 5: ModelNet40-C 错误率
| 方法 | MN40C |
|---|---|
| PointNet++[60] | 0.236 |
| DGCN+PCM-R[97] | 0.173 |
| PCT+RSMIx[44] | 0.173 |
| PCT+PCM-R[70] | 0.163 |
| OmniVec[68] | 0.156 |
| 我们的方法 | 0.142 |
Table 6. Stanford Indoor Dataset mIoU.
表 6: Stanford Indoor 数据集 mIoU 对比
| 方法 | S3DIS |
|---|---|
| PointTransformer+CBL[72] | 71.6 |
| StratifiedTransformer[43] | 72.0 |
| PTv2[83] | 72.6 |
| Swin3D[89] | 74.5 |
| OmniVec[68] | 75.9 |
| 我们的方法 | 77.1 |
Table 7. Dialogue SUM text sum mari z ation ROGUE scores.
表 7: 对话摘要文本汇总 ROGUE 分数。
| 方法 | R-1 | R-2 | R-L | B-S |
|---|---|---|---|---|
| CODS[81] | 44.27 | 17.90 | 36.98 | 70.49 |
| SICK[39] | 46.2 | 20.39 | 40.83 | 71.32 |
| OmniVec[68] | 46.91 | 21.22 | 40.19 | 71.91 |
| Ours | 47.6 | 22.1 | 41.4 | 72.8 |
4.1. Comparison with state of the art methods
4.1. 与现有最优方法的对比
We performed masked pre training followed by training on multiple modalities and task groups as described in Section 3 for comparing with existing methods. We discuss the comparison on each modality below.
我们按照第3节所述,先进行了掩码预训练,然后针对多种模态和任务组进行训练,以便与现有方法进行对比。下面我们将逐一讨论各模态上的比较结果。
Image. Table 1 shows state of the art on i Naturalist 2018 and Places 365 datasets. On the i Naturalist 2018 dataset, our method achieves a top-1 accuracy of $94.6%$ , surpassing notable contenders such as OmniVec $(93.8%)$ , MetaFormer $(87.5%)$ , and MAE $(86.8%)$ . This superior accuracy demonstrates capability of the proposed method in accurately recognizing a diverse range of natural species. In the context of the Places 365 dataset, our method achieves an accuracy of $65.1%$ , notably outperforming OmniVec $(63.5%)$ , and significantly surpassing MetaFormer’s $60.7%$ and Omnivore’s $59.9%$ . The substantial margin of improvement, particularly in the challenging and variable environment of Places 365, underscores the robustness and adaptability of the proposed architecture. We also conduct experiments on ImageNet [12] (classification), MSCOCO [49] (object detection), and ADE-20K [101] (semantic segmentation) datasets (detailed table is in supplementary). $89.3%$ (accuracy) on ImageNet, 60.1 (AP) on MSCOCO and an mIoU of 58.5 on ADE-20K.
图。表 1 展示了在 iNaturalist 2018 和 Places 365 数据集上的最新成果。在 iNaturalist 2018 数据集上,我们的方法达到了 94.6% 的 top-1 准确率,超越了 OmniVec (93.8%)、MetaFormer (87.5%) 和 MAE (86.8%) 等显著竞争者。这一卓越的准确率证明了所提方法在准确识别多种自然物种方面的能力。在 Places 365 数据集上,我们的方法取得了 65.1% 的准确率,明显优于 OmniVec (63.5%),并显著超越了 MetaFormer 的 60.7% 和 Omnivore 的 59.9%。这一显著的提升幅度,尤其是在 Places 365 这一具有挑战性和多变性的环境中,凸显了所提架构的鲁棒性和适应性。我们还在 ImageNet [12](分类)、MSCOCO [49](目标检测)和 ADE-20K [101](语义分割)数据集上进行了实验(详细表格见补充材料),在 ImageNet 上达到了 89.3%(准确率),在 MSCOCO 上达到了 60.1(AP),在 ADE-20K 上达到了 58.5 的 mIoU。
Video. Table 2 and Table 3 show comparison against state of the art methods on Kinetics-400 and Moments in Time datasets.We observe that we outperform all the competing methods on both the datasets achieving top-1 accuracy of $93.6%$ and $53.1%$ respectively.
视频。表2和表3展示了在Kinetics-400和Moments in Time数据集上与现有最优方法的对比结果。我们观察到,在这两个数据集上我们的方法均优于所有竞争方法,分别达到了$93.6%$和$53.1%$的top-1准确率。
Audio. Table 4 shows our comparison with top-performing methods on the ESC50 dataset. We outperform competing methods, achieving an accuracy of $99.1%$ , significantly higher than the Audio Spec tr ogram Transformer (AST) at $85.7%$ , and OmniVec at $98.4%$ .
音频。表4展示了我们在ESC50数据集上与性能最佳方法的比较。我们的方法以99.1%的准确率超越其他竞争方案,显著高于Audio Spectrogram Transformer (AST)的85.7%和OmniVec的98.4%。
Point Cloud. Table 5 and Table 6 compare against state of the art methods on ModelNet40-C and S3DIS datasets respectively. On ModelNet40-C, we evaluate a classification task, while on S3DIS we evaluate semantic segmentation. On both the datasets, we outperform the competing methods. On ModelNet-C, we achieve an error rate of 0.142, which is notably lower than the rates observed in other contemporary methods. This is particularly evident when compared against methods like OmniVec, which recorded an error rate of 0.156, and $\mathrm{PCT+PCM{\mathrm{-}}R}$ , with an error rate of 0.163. On S3DIS, we achieve an mIoU of 77.1, which is the highest among all the methods evaluated c.f. 75.9 of OmniVec, and 74.5 of Swin3D. This demonstrates that the proposed method is able to obtain a robust performance with the shared backbone network across tasks.
点云 (Point Cloud)。表5和表6分别在ModelNet40-C和S3DIS数据集上对比了当前最优方法。在ModelNet40-C上我们评估分类任务,而在S3DIS上评估语义分割。两个数据集的实验结果表明,我们的方法均优于其他对比方法。在ModelNet-C上,我们实现了0.142的错误率,显著低于其他现有方法(如OmniVec的0.156错误率)和 $\mathrm{PCT+PCM{\mathrm{-}}R}$ (0.163错误率)。在S3DIS数据集上,我们取得了77.1的mIoU值(OmniVec为75.9,Swin3D为74.5),这是所有评估方法中的最高成绩。这表明所提出的方法能够通过共享主干网络在不同任务中获得鲁棒性能。
Text. Table 7 shows state of the art on Dialogue SUM dataset for text sum mari z ation. Our method surpasses other methods in all the metrics. Despite utilizing significantly fewer datasets for text in comparison to visual tasks , our method demonstrates strong performance. This suggests proposed method’s capacity to bridge the modality gap [48] across distinct domains in the latent space, even when the data distribution is skewed.
文本。表7展示了在Dialogue SUM数据集上文本摘要任务的最新技术水平。我们的方法在所有指标上都超越了其他方法。尽管与视觉任务相比使用的文本数据集显著减少,但我们的方法仍表现出强劲性能。这表明所提方法具备在潜在空间中跨越不同领域弥合模态差距[48]的能力,即使数据分布存在偏差时亦然。
Table 9 illustrates the experimental results on the GLUE benchmark for text understanding tasks, comparing various state-of-the-art methods such as BERT [13], RoBERTa [52], and ChatGPT. The comparison centers on paraphrasing, sentiment, duplication, inference, and answering tasks. We achieve second best performance on three out of five tasks demonstrating its capability to perform reasoning and adaptability to natural language tasks.
表 9: 展示了文本理解任务在GLUE基准上的实验结果,对比了BERT [13]、RoBERTa [52]和ChatGPT等前沿方法。该比较聚焦于复述、情感分析、重复检测、推理和问答任务。我们在五项任务中的三项上取得了第二名的性能,证明了其推理能力和对自然语言任务的适应性。
Table 8. Adaptation on unseen datasets. (Oxford-IIIT Pets, UCF-101, HMDB51, S can Object NN, NYUv2 Seg, SamSum), and crossdomain generalization (YouCook2, MSR-VTT). See supplementary for more detailed results.
| 数据集 | 模态 | 任务 | 指标 | 本文方法 | SOTA | 参考文献 |
|---|---|---|---|---|---|---|
| UCF-101 | 视频 | 动作识别 | 三折准确率 | 99.1 | 99.6 | OmniVec[68] |
| HMDB51 | 视频 | 动作识别 | 三折准确率 | 92.1 | 91.6 | OmniVec[68] |
| Oxford-IIIT Pets | 图像 | 细粒度分类 | Top-1准确率 | 99.6 | 99.2 | OmniVec[68] |
| ScanObjectNN | 3D点云 | 分类 | 准确率 | 97.2 | 96.1 | OmniVec[68] |
| NYUv2 | RGBD | 语义分割 | 平均交并比 | 63.6 | 60.8 | OmniVec[68] |
| SamSum | 文本 | 会议摘要生成 | ROGUE(R-L) | 55.4 | 54.6 | OmniVec[68] |
| YouCook2 | 视频+文本 | 零样本文本到视频检索 | Recall@10 | 69.9 | 64.2(预训练)/70.8(微调) | OmniVec[68] |
| MSR-VTT | 视频+文本 | 零样本文本到视频检索 | Recall@10 | 85.8 | 80.0(预训练)/90.8(微调) | SM[96] |
表 8: 未见过数据集的适应性测试 (Oxford-IIIT Pets, UCF-101, HMDB51, ScanObjectNN, NYUv2 Seg, SamSum) 及跨领域泛化能力 (YouCook2, MSR-VTT)。更多细节结果见补充材料。
Table 9. Text understanding on the GLUE benchmark. We compare existing advanced methods from paraphrasing, sentiment, duplication, inference, and answering tasks.
表 9. GLUE基准测试中的文本理解能力对比。我们比较了来自复述、情感分析、重复检测、推理和问答任务的现有先进方法。
| 方法 | GLUE基准测试 |
|---|---|
| SST-2情感分析 | |
| BiLSTM+ELMo+Attn | 90.4 |
| OpenAI GPT [61] | 91.3 |
| BERTBASE [13] | 88.0 |
| RoBERTaBAsE [52] | 96.0 |
| ChatGPT | 92.0 |
| Meta-Transformer-B16r[16] | 81.3 |
| Ours | 95.6 |
Comparison on pre training datasets. We fine tune our pretrained network on the respective training sets with related task heads. We obtain an mAP of 55.8 and 56.4 on AudioSet(A) and AudioSet $\left(\mathrm{A}+\mathrm{V}\right)$ respectively. Further, on SSv2, ImageNet-1K, SUN-RGBD, and ModelNet we achieve top-1 accuracies of $86.1%$ , $93.6%$ , $75.9%$ and $97.1%$ respectively. We outperform the competing state of the art methods on these datasets(detailed results are in supplementary).
预训练数据集对比。我们在各自训练集上使用相关任务头微调预训练网络,在AudioSet(A)和AudioSet $\left(\mathrm{A}+\mathrm{V}\right)$ 上分别获得55.8和56.4的mAP。此外,在SSv2、ImageNet-1K、SUN-RGBD和ModelNet上,我们分别实现了 $86.1%$ 、 $93.6%$ 、 $75.9%$ 和 $97.1%$ 的top-1准确率。我们在这些数据集上超越了当前最先进方法(详细结果见补充材料)。
4.2. Adaptation on unseen datasets
4.2. 在未见数据集上的适应
In Table 8 (rows 1-6), we observe that our method performs close to SoTA on all the datasets. Specifically, except on UCF-101, we outperform the SoTA (OmniVec) on all the datasets. We observe that on NYUv2, we obtain a performance improvement of $3%$ , while on an average perform better by approx $1%$ on other datasets. It must be noted that we freeze the base embeddings, and unlike other methods do not fine tune the full network, and use simpler task head for analysis on these datasets.
在表8 (第1-6行) 中,我们观察到该方法在所有数据集上的表现接近当前最优水平 (SoTA)。具体而言,除UCF-101外,我们在所有数据集上都超越了当前最优方法 (OmniVec)。值得注意的是,在NYUv2数据集上我们获得了 $3%$ 的性能提升,而在其他数据集上平均表现提升约 $1%$。需要强调的是,我们冻结了基础嵌入层,与其他方法不同,既没有微调整个网络,也没有使用更复杂的任务头来分析这些数据集。
4.3. Cross domain generalization
4.3. 跨领域泛化
Table 8 (rows 7,8) demonstrates results using our pretrained network on various tasks. On the YouCook2 dataset, our pretrained network surpasses the state of the art in zeroshot retrieval, achieving a Recall $@10$ of $69.9%$ compared to OmniVec’s $64.2%$ on pretrained network. Interestingly, we are very close to the full fine tuned OmniVec i.e. 70.8. This demonstrates that our method is able to leverage the cross domain information better potentially due to multi task pretraining while OmniVec sequentially trains on one modality at a time. On MSR-VTT, when compared with SM [96], our fine-tuned method has a Recall $@10$ of $89.4%$ cf. SM’s $80.0%$ (pretrained). It must be noted that SM uses internetscale data while our method utilizes significantly less data.
表 8 (第7,8行)展示了我们预训练网络在不同任务上的表现。在YouCook2数据集上,我们的预训练网络在零样本检索任务中超越了当前最优水平,Recall@10达到69.9%,而OmniVec预训练网络的结果为64.2%。值得注意的是,我们的结果非常接近完全微调的OmniVec模型(70.8)。这表明我们的方法能更好地利用跨领域信息,这可能是由于多任务预训练的优势,而OmniVec采用单模态顺序训练方式。在MSR-VTT数据集上,与SM[96]相比,我们微调后的方法Recall@10达到89.4%,而SM预训练模型为80.0%。需要特别说明的是,SM使用了互联网规模的数据,而我们的方法所需数据量显著更少。
4.4. Adaptation on Unseen Modalities
4.4. 未知模态的适配
Infrared, Hyper spectral, and X-Ray data. Table 10a presents the performance comparison on the RegDB dataset [54] for infrared image recognition. Our method achieves state of the art performance i.e. $\mathbf{R}\ @1$ of 86.21 c.f. 83.86 of MSCLNet, and mAP of 84.24 c.f. 78.57 of SMCL. This demonstrates that our method can transfer knowledge across unseen modalities. Specifically, we significantly outperform Meta-Transformer, which pretrains on similar modalities as ours. This could be potentially due to separate tokenizers for each modality allowing better integration with the transformer encoder as compared to a common tokenizer in meta-transformer.
红外、高光谱和X射线数据。表10a展示了RegDB数据集[54]在红外图像识别任务上的性能对比。我们的方法取得了最先进的性能表现,即$\mathbf{R}\ @1$达到86.21(对比MSCLNet的83.86),mAP达到84.24(对比SMCL的78.57)。这表明我们的方法能够在未见模态间实现知识迁移。值得注意的是,我们的方法显著优于采用类似预训练模态的Meta-Transformer,这可能是因为我们为每种模态设计了独立的tokenizer,相较于Meta-Transformer采用的通用tokenizer,能更好地与Transformer编码器进行整合。
In addition, Table 10b presents the performance on the Indian Pine dataset for hyper spectral image recognition. We achieve an overall accuracy of $90.6%$ , which is better than the Spectral Former $(81.76%)$ and significantly better than Meta-Transformer $(67.6%)$ . For X-Ray images (table in supplementary), our method achieves an accuracy of $98.1%$ , significantly outperforming competing methods.
此外,表10b展示了高光谱图像识别任务在Indian Pine数据集上的性能表现。我们取得了90.6%的整体准确率,优于Spectral Former (81.76%) ,并显著超过Meta-Transformer (67.6%) 。在X射线图像任务中(见补充材料表格),我们的方法达到了98.1%的准确率,显著优于其他竞争方法。
Graph and IMU Data. We show results in Table 11. We achieve performance close to the state of the art methods i.e. validate MAE of 0.1397 c.f. 0.1234 of Graphormer. It is important to note that our method was not designed for graphical data, while competing methods are designed to exploit graphical data. Meta-Transformer, which is a unified learning mechanism like ours, significantly lies behind with 0.8863 MAE cf. 0.1397 of ours.
图与IMU数据。我们在表11中展示了结果。我们的性能接近现有最优方法,即验证MAE为0.1397(对比Graphormer的0.1234)。值得注意的是,我们的方法并非专为图数据设计,而竞争方法都针对图数据进行了优化。与我们类似的统一学习机制Meta-Transformer表现显著落后,其MAE为0.8863(对比我们的0.1397)。
Time series forecasting. We achieve an MSE of 0.399,
时间序列预测。我们实现了0.399的均方误差(MSE)。
Table 10. Infrared and hyper spectral classification. Metrics are Rank-1 $(\mathrm{R}@1)$ , mean Average Precision (mAP), Overall Accuracy (OA), Average Accuracy (AA).
(a) SYSU-MM01 (infrared) (b) Indian Pine (hyper spectral)
表 10: 红外与高光谱分类。指标为 Rank-1 (R@1)、平均精度均值 (mAP)、总体准确率 (OA)、平均准确率 (AA)。
| 方法 | R@1(%) | mAP(%) |
|---|---|---|
| AGW[91] | 70.49 | 65.90 |
| SMCL[80] MSCLNet[99] | 83.05 83.86 | 78.57 78.31 |
| Meta-Transformer-B16r[16] | 73.50 | 65.19 |
| Ours | 86.21 | 84.24 |
(a) SYSU-MM01 (红外) (b) Indian Pine (高光谱)
Table 11. Graph data understanding . MAE on PCQM4M-LSC dataset.
表 11: 图数据理解。PCQM4M-LSC 数据集上的 MAE。
| 方法 | OA(%) | AA(%) |
|---|---|---|
| ViT [14] SpectralFormer31 SpectralFormer31 RPNet-RF[73] HyLITE[102] TC-GAN[6] | 71.86 78.55 81.76 90.23 89.80 | 78.97 84.68 87.81 |
| Meta-Transformer-B16r[16] Ours | 67.62 90.6 | 78.09 89.3 |
| 方法 | 训练集MAE | 验证集MAE |
|---|---|---|
| Graph Transformer[15] GraphTransformer-wide[15] GraphormersMALL[92] Graphormer[92] | 0.0944 | 0.1400 |
| 0.0955 | 0.1408 | |
| 0.0778 | 0.1264 | |
| 0.0582 | 0.1234 | |
| Meta-Transformer-B16F[16] 本文方法 | 0.8034 | 0.8863 |
| 0.0594 | 0.1397 |
0.601, 0.210, 0.330 on ETTh1, Traffic, Weather and Exchange datasets respectively, outperforming all the competing methods such as Pyraformer [51], Informer [103], LogTrans [47], Meta-former [94] and Reformer [40]. The detailed results are in supplementary.
在ETTh1、Traffic、Weather和Exchange数据集上分别达到0.601、0.210和0.330,性能优于Pyraformer [51]、Informer [103]、LogTrans [47]、Meta-former [94]和Reformer [40]等所有竞争方法。详细结果见补充材料。
Tabular Data. We achieve an accuracy of 88.1 and 92.3 on Adult and Bank Marketing datasets respectively, outperforming the competing methods (details in supplementary). Our method has never seen tabular data or structured textual information demonstrating its generalization ability to adapt to unseen patterns within data while providing better performance than competing methods.
表格数据。我们在Adult和Bank Marketing数据集上分别达到了88.1和92.3的准确率,优于其他竞争方法(详见补充材料)。我们的方法从未接触过表格数据或结构化文本信息,这证明了其在适应数据中未见模式方面的泛化能力,同时提供了优于竞争方法的性能。
4.5. Ablations
4.5. 消融实验
We study the impact of various components of the network in Table 12 on image (i Naturalist), video (Kinetics400) and audio (ESC50) modalities. Specifically, we study the impact of pre training with a single modality only, using the full pre training mechanism, and then fine tuning on the respective training set. We also study the impact of modality specific tokenizers compared to unified tokenizers of MetaFormer [94], and impact of utilizing multiple task heads as compared to unified task head design of Uni Perceive r-v2 [45]. For unimodal pre training (Table 12- row 1), we train the network on a single modality following Step 1 of Masked pre training (see Sec. 3.2). We use corresponding modality for each dataset i.e. for i Naturalist, we pretrain on ImageNet1K, for K400, we pretrain on SSv2 and for ESC50, we pretrain on AudioSet. For multimodal multitask pre training (Table 12-row 2), we pretrain using the full pre training discussed previously. For fine tuning, we utilize the respective train sets.
我们研究了表12中网络各组件对图像(i Naturalist)、视频(Kinetics400)和音频(ESC50)模态的影响。具体而言,我们研究了仅使用单一模态预训练(采用完整预训练机制)并在相应训练集上微调的效果,对比了MetaFormer[94]统一分词器与模态专用分词器的影响,以及Uni Perceive r-v2[45]统一任务头设计与多任务头设计的差异。对于单模态预训练(表12第1行),我们按照掩码预训练步骤1(见第3.2节)在单一模态上训练网络:i Naturalist使用ImageNet1K预训练,K400使用SSv2预训练,ESC50使用AudioSet预训练。对于多模态多任务预训练(表12第2行),我们采用前述完整预训练方案。微调阶段均使用各自对应的训练集。
Impact of unimodal vs. multimodal pre training We can observe that multimodal multitask pre training using our approach (row 5) provides a significant improvement in comparison to unimodal pre training (row 1). Specifically, it outperforms unimodal pre training by $\sim16%$ on i Naturalist and K400 datasets while is better by $\sim8%$ on ESC50. This demonstrates that the network is able to leverage the information from multiple modalities.
单模态与多模态预训练的影响
我们可以观察到,采用我们的方法进行多模态多任务预训练 (第5行) 相比单模态预训练 (第1行) 有显著提升。具体而言,在iNaturalist和K400数据集上表现优于单模态预训练约16%,在ESC50上则高出约8%。这表明网络能够有效利用来自多模态的信息。
Table 12. Ablation experiments. We vary the different components of the network to study the impact (Sec 4.5). Metric reported is top-1 accuracy.
表 12: 消融实验。我们调整网络的不同组件以研究其影响 (第4.5节)。报告的指标为top-1准确率。
| 模态 | Tokenizer | TaskHead | iN2018 | K400 | ESC50 |
|---|---|---|---|---|---|
| 单一 | 模态 | 自编码器 | 74.2 | 78.6 | 82.4 |
| 单一 | 统一[16] | 自编码器 | 74.1 | 78.3 | 82.1 |
| 多模态 | 统一[16] | 统一[45] | 80.1 | 81.8 | 82.7 |
| 多模态 | 模态 | 统一[45] | 85.4 | 84.8 | 86.8 |
| 多模态 | 统一[16] | 任务特定 | 86.1 | 85.2 | 87.0 |
| 多模态 | 模态 | 任务特定 | 90.3 | 88.4 | 92.4 |
Impact of modality specific tokenizer vs. unified tokenizer. We observe that the performance of unified tokenizer (row 3) lags behind that of a modality specific tokenizer (row 4) by an average of $\sim5%$ across all the tasks, while keeping unified heads. Similarly, while keeping task specific heads, and modality specific tokenizer (row 6) vs unified tokenizer (row 5), we observe an average performance gap of $4%$ in favour of modality specific tokenizer.
模态特定分词器与统一分词器的影响。我们观察到,在保持统一头的情况下,统一分词器(第3行)在所有任务中的表现平均落后于模态特定分词器(第4行)约$\sim5%$。类似地,在保持任务特定头的情况下,模态特定分词器(第6行)对比统一分词器(第5行)时,我们观察到模态特定分词器平均有$4%$的性能优势。
Multiple task heads vs unified task head. Comparing row 4 and row 6, we see that the the task specific heads contribute to an increase (average $3.5%$ ) in performance while keeping a modality specific tokenizer.
多任务头与统一任务头的对比。对比第4行和第6行可以看出,在保持模态特定分词器的情况下,任务专用头带来了平均3.5%的性能提升。
5. Conclusion
5. 结论
We presented a novel multimodal multitask network and associated training algorithm. The proposed method utilizes modality specific tokenizers and then uses shared transformers based backbone feeding to task specific heads. The traning proceeds in three stages, (i) masked pre training with one modality at a time, (ii) masked pre training with pairs of modalities together, and (iii) supervised traning for tasks with pairs of modalities together. The pairwise pre training and supervised training allows for knowledge sharing between tasks and modalities and leads to a robust and regularized network. We showed empirical results on 25 challenging benchmark datasets over 12 modalities obtaining better or close to existing state of the art results. The method can incorporate arbitrary number of modalities, with only the tokenizer and task heads being modality specific.
我们提出了一种新颖的多模态多任务网络及相应的训练算法。该方法首先利用模态特定的分词器(Tokenizer),然后通过基于共享Transformer的主干网络将特征馈送至任务特定的输出头。训练过程分为三个阶段:(i) 单模态掩码预训练,(ii) 多模态联合掩码预训练,(iii) 多模态联合监督训练。这种成对预训练和监督训练机制实现了跨任务和跨模态的知识共享,最终形成具有强鲁棒性和正则化特性的网络。我们在涵盖12种模态的25个高难度基准数据集上进行了实证验证,取得优于或接近现有最优水平的结果。该方法可扩展至任意数量的模态,仅需针对不同模态设计特定的分词器和任务输出头。
References [1] Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. Advances in Neural Information Processing Systems, 34:24206–24221, 2021. 1, 2, 4, 5, 6 [2] Relja Ar and j elo vic and Andrew Zisserman. Objects that sound. In Proceedings of the European conference on computer vision (ECCV), pages 435–451, 2018. 2 [3] Iro Armeni, Ozan Sener, Amir R Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1534–1543, 2016. 5 [4] Alan Baade, Puyuan Peng, and David Harwath. Maeast: Masked auto encoding audio spec tr ogram transformer. arXiv preprint arXiv:2203.16691, 2022. 2 [5] Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. Data2vec: A general framework for self-supervised learning in speech, vision and language. In International Conference on Machine Learning, pages 1298–1312. PMLR, 2022. 1, 2 [6] Jing Bai, Jiawei Lu, Zhu Xiao, Zheng Chen, and Licheng Jiao. Generative adversarial networks based on transformer encoder and convolution block for hyper spectral image classification. Remote Sensing, 14(14):3426, 2022. 8 [7] Joao Carreira, Skanda Koppula, Daniel Zoran, Adria Recasens, Catalin Ionescu, Olivier Henaff, Evan Shelhamer, Relja Ar and j elo vic, Matt Botvinick, Oriol Vinyals, et al. Hierarchical perceiver. arXiv preprint arXiv:2202.10890, 2022. 2 [8] Ke Chen, Xingjian Du, Bilei Zhu, Zejun Ma, Taylor BergKirkpatrick, and Shlomo Dubnov. Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 646–650. IEEE, 2022. 6 [9] Yulong Chen, Yang Liu, Liang Chen, and Yue Zhang. Dialogsum: A real-life scenario dialogue sum mari z ation dataset. arXiv preprint arXiv:2105.06762, 2021. 5 [10] Michael Crawshaw. Multi-task learning with deep neural networks: A survey. arXiv preprint arXiv:2009.09796, 2020. 1 [11] Yong Dai, Duyu Tang, Liangxin Liu, Minghuan Tan, Cong Zhou, Jingquan Wang, Zhangyin Feng, Fan Zhang, Xueyu Hu, and Shuming Shi. One model, multiple modalities: A sparsely activated approach for text, sound, image, video and code. arXiv preprint arXiv:2205.06126, 2022. 2 [12] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 5, 6 [13] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018. 3, 5, 7
参考文献
[1] Hassan Akbari, Liangzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. Vatt: 基于原始视频、音频和文本的多模态自监督学习Transformer. Advances in Neural Information Processing Systems, 34:24206–24221, 2021. 1, 2, 4, 5, 6
[2] Relja Ar and j elo vic and Andrew Zisserman. 发声物体. In Proceedings of the European conference on computer vision (ECCV), pages 435–451, 2018. 2
[3] Iro Armeni, Ozan Sener, Amir R Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese. 大规模室内空间的三维语义解析. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1534–1543, 2016. 5
[4] Alan Baade, Puyuan Peng, and David Harwath. 掩码自编码音频频谱Transformer. arXiv preprint arXiv:2203.16691, 2022. 2
[5] Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. Data2vec: 语音、视觉与语言的通用自监督学习框架. In International Conference on Machine Learning, pages 1298–1312. PMLR, 2022. 1, 2
[6] Jing Bai, Jiawei Lu, Zhu Xiao, Zheng Chen, and Licheng Jiao. 基于Transformer编码器与卷积块的高光谱图像分类生成对抗网络. Remote Sensing, 14(14):3426, 2022. 8
[7] Joao Carreira, Skanda Koppula, Daniel Zoran, Adria Recasens, Catalin Ionescu, Olivier Henaff, Evan Shelhamer, Relja Ar and j elo vic, Matt Botvinick, Oriol Vinyals, et al. 分层感知器. arXiv preprint arXiv:2202.10890, 2022. 2
[8] Ke Chen, Xingjian Du, Bilei Zhu, Zejun Ma, Taylor BergKirkpatrick, and Shlomo Dubnov. 基于层级Token语义的音频Transformer分类检测模型. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 646–650. IEEE, 2022. 6
[9] Yulong Chen, Yang Liu, Liang Chen, and Yue Zhang. Dialogsum: 现实场景对话摘要数据集. arXiv preprint arXiv:2105.06762, 2021. 5
[10] Michael Crawshaw. 深度神经网络多任务学习综述. arXiv preprint arXiv:2009.09796, 2020. 1
[11] Yong Dai, Duyu Tang, Liangxin Liu, Minghuan Tan, Cong Zhou, Jingquan Wang, Zhangyin Feng, Fan Zhang, Xueyu Hu, and Shuming Shi. 一体多模态: 文本、声音、图像、视频与代码的稀疏激活方法. arXiv preprint arXiv:2205.06126, 2022. 2
[12] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: 大规模层级图像数据库. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 5, 6
[13] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: 面向语言理解的深度双向Transformer预训练. arXiv preprint arXiv:1810.04805, 2018. 3, 5, 7
toine Miech, Lucas Smaira, Ross Hemsley, et al. Zorro: the masked multimodal transformer. arXiv preprint arXiv:2301.09595, 2023. 1, 2
toine Miech、Lucas Smaira、Ross Hemsley 等。Zorro: the masked multimodal transformer。arXiv 预印本 arXiv:2301.09595, 2023。1, 2