Towards General iz able Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy
迈向可泛化的视觉-语言机器人操作:基准与大语言模型引导的3D策略
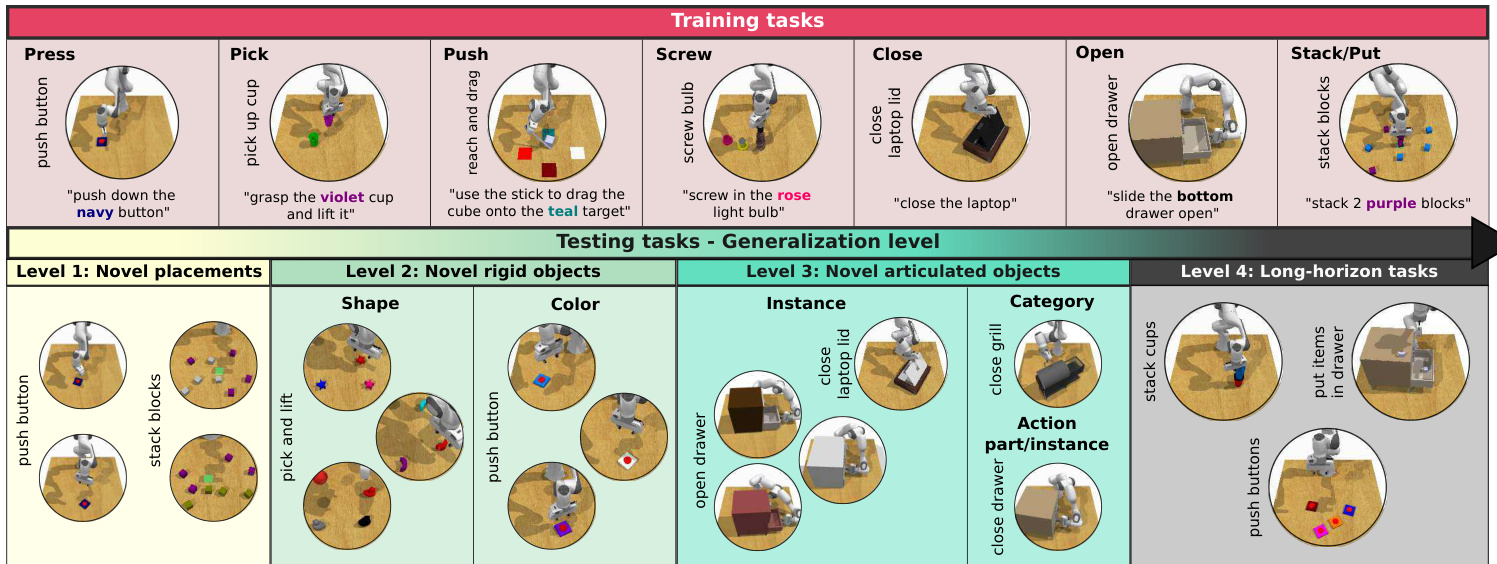
Fig. 1: GemBench benchmark for vision-language robotic manipulation. Top: GemBench comprises 16 training tasks with 31 variations, covering seven action primitives. Bottom: The testing set includes 44 tasks with 92 variations, which are organized into four progressively more challenging levels to systematically evaluate generalization capabilities.
图 1: 面向视觉语言机器人操作的GemBench基准。顶部:GemBench包含16个训练任务(共31种变体),涵盖7个动作基元。底部:测试集包含44个任务(共92种变体),分为四个难度递增的层级,用于系统评估泛化能力。
Abstract— Generalizing language-conditioned robotic policies to new tasks remains a significant challenge, hampered by the lack of suitable simulation benchmarks. In this paper, we address this gap by introducing GemBench, a novel benchmark to assess generalization capabilities of vision-language robotic manipulation policies. GemBench incorporates seven general action primitives and four levels of generalization, spanning novel placements, rigid and articulated objects, and complex long-horizon tasks. We evaluate state-of-the-art approaches on GemBench and also introduce a new method. Our approach 3D-LOTUS leverages rich 3D information for action prediction conditioned on language. While 3D-LOTUS excels in both efficiency and performance on seen tasks, it struggles with novel tasks. To address this, we present 3D-LOTUS $^{++}$ , a framework that integrates 3D-LOTUS’s motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs. 3D-LOT $\mathbf{U}\mathbf{S}++$ achieves state-ofthe-art performance on novel tasks of GemBench, setting a new standard for generalization in robotic manipulation. The benchmark, codes and trained models are available at https: //www.di.ens.fr/willow/research/gembench/.
摘要— 将语言条件化的机器人策略泛化到新任务仍是一个重大挑战,这主要受限于缺乏合适的仿真基准测试。本文通过推出GemBench这一评估视觉-语言机器人操作策略泛化能力的新型基准测试填补了这一空白。GemBench包含七种基础动作原语和四个泛化层级,涵盖新物体摆放、刚体和铰接物体操作以及复杂长周期任务。我们在GemBench上评估了前沿方法,并提出了一种新方法。我们的3D-LOTUS方法利用丰富的三维信息进行语言条件化的动作预测。虽然3D-LOTUS在已知任务上表现出优异的效率和性能,但其在新任务上仍有不足。为此,我们提出3D-LOTUS$^{++}$框架,该框架将3D-LOTUS的运动规划能力与大语言模型(LLM)的任务规划能力以及视觉语言模型(VLM)的物体定位精度相结合。3D-LOT$\mathbf{U}\mathbf{S}++$在GemBench的新任务上实现了最先进的性能,为机器人操作泛化设立了新标准。基准测试、代码及训练模型详见https://www.di.ens.fr/willow/research/gembench/。
I. INTRODUCTION
I. 引言
Vision-language robotic manipulation aims to train policies performing complex tasks based on visual inputs and language instructions [1], [2], [3], [4]. Given the vast diversity of real-world tasks, collecting data for every possible task is prohibitively expensive. Hence, it is critical to develop models that can effectively generalize to novel tasks.
视觉语言机器人操控旨在训练能够基于视觉输入和语言指令执行复杂任务的策略 [1]、[2]、[3]、[4]。鉴于现实世界任务的巨大多样性,为每个可能任务收集数据的成本极其高昂。因此,开发能有效泛化至新任务的模型至关重要。
A number of approaches have been proposed to improve the generalization ability of robotic policies. One prominent direction focuses on pre training visual and language represent at ions on large-scale web data for robotics [5], [6], [7], [8]. While these representations are more powerful, they do not directly translate into general iz able policies for new tasks. Another approach [1], [9], [10], [11], [12] pretrains entire robotic policies by combining robot data with web data, but these methods remain constrained by the limited size and diversity of available robot datasets [13]. More recently, foundation models such as large language models (LLMs) [14] and vision-language models (VLMs) [15] have been employed to enhance generalization of robot policies. For example, CaP [16] uses LLMs to generate codes that executes primitive actions, and VoxPoser [3] composes value maps with foundation models for action execution with classic motion planning. However, these approaches focus on simpler tasks like pick-and-place and often struggle with more complex manipulation like rotating objects.
为提升机器人策略的泛化能力,研究者提出了多种方法。一个重要方向是利用大规模网络数据预训练视觉与语言表征以应用于机器人领域 [5][6][7][8]。虽然这些表征能力更强,但无法直接转化为新任务的可泛化策略。另一类方法 [1][9][10][11][12] 通过结合机器人数据与网络数据来预训练完整策略,但仍受限于现有机器人数据集规模和多样性的不足 [13]。最近,大语言模型 (LLMs) [14] 和视觉语言模型 (VLMs) [15] 等基础模型被用于增强机器人策略的泛化能力。例如 CaP [16] 利用大语言模型生成执行基础动作的代码,VoxPoser [3] 则通过基础模型组合价值图,配合传统运动规划实现动作执行。但这些方法主要针对拾放等简单任务,在旋转物体等复杂操作上仍存在困难。
Furthermore, there is a notable lack of systematic benchmarks to evaluate the generalization capabilities of models. Though several simulation-based benchmarks have been developed for vision-language robotic manipulation [26], [21], [19], they primarily evaluate models on tasks seen during training, neglecting the crucial aspect of generalization. A few exceptions like VIMA-Bench [24] and Colosseum [25] attempt to evaluate generalization abilities. However, VIMABench is limited to relatively simple action skills, while Colosseum focuses more on environment perturbations like lighting changes rather than generalizing to new tasks.
此外,目前明显缺乏系统性基准来评估模型的泛化能力。尽管已开发出多个基于仿真的视觉语言机器人操作基准 [26][21][19] ,但这些基准主要评估模型在训练阶段已见任务上的表现,忽视了泛化这一关键维度。少数例外如 VIMA-Bench [24] 和 Colosseum [25] 尝试评估泛化能力,但 VIMA-Bench 仅局限于相对简单的动作技能,而 Colosseum 更关注光照变化等环境扰动,而非面向新任务的泛化能力。
TABLE I: Comparison of benchmarks for vision-and-language robotic manipulation. Multi-skill: covering multiple action primitives beyond pick and place. atc-obj: tasks involve interactions with articulated objects. Test generalization level to attr-obj: unseen size, color or texture of the object, act-obj: unseen action object combination, inst or cate: same action for unseen object instance or category respectively and long-horizon: unseen combination of multiple seen actions and objects.
表 1: 视觉与语言机器人操作基准对比。多技能: 涵盖抓取放置之外的多重动作基元。铰接物体: 任务涉及与铰接物体的交互。测试泛化级别包括: 属性-物体 (attr-obj) : 物体未见过的尺寸、颜色或纹理, 动作-物体 (act-obj) : 未见过的动作物体组合, 实例 (inst) 或类别 (cate) : 分别对未见过的物体实例或类别执行相同动作, 长视野 (long-horizon) : 未见过的多个已知动作和物体的组合。
| 基准 | 模拟器 | 物理引擎 | 训练任务数(变体) | 测试任务数(变体) | 多技能 | 铰接物体 | 属性-物体 | 动作-物体 | 实例 | 类别 | 长视野 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RLBench-74Task[17] | RLBench | 74 (74) | 74 (74) | √ | × | × | |||||
| RLBench-18Task[18] | RLBench | 18 (249) | 18 (249) | × | × | × | × | ||||
| VLMBench[19] | RLBench | 8 (233) | 8 (374) | < | × | ||||||
| ALFRED[20] | AI2-THOR | × | 7 (21,023) | 7 (1,529) | < | ||||||
| Calvin[21] | PyBullet | 34 | 34 (1000) | × | |||||||
| Ravens[22] | PyBullet | 10 | 10 | × | |||||||
| Arnold[23] | Isaac Sim | 8 (3571) | 8 (800) | ||||||||
| VIMA-Bench[24] | Ravens | 13 | 17 | × | × | ||||||
| Colosseum[25] | RLBench | 20 (280) | 20 (20,371) | < | |||||||
| GemBench (本工作) | RLBench | 16 (31) | 44 (92) | < |
In this work, we introduce GEMBench - a new simulation benchmark to evaluate GEneralization capabilities for vision-language robotic Manipulation. As shown in Figure 1, GemBench features two key improvements compared to prior work. First, it incorporates a wider range of complex tasks, involving seven core action skills: press, pick, push, screw, close, open and put. Secondly, it introduces a comprehensive suite of four generalization levels with increasing difficulty, focusing on generalization to novel placements, rigid objects, articulated objects, and long-horizon tasks respectively.
在这项工作中,我们推出了GEMBench——一个用于评估视觉语言机器人操作(GEneralization capabilities for vision-language robotic Manipulation)泛化能力的新型仿真基准。如图1所示,GEMBench相较于先前工作具有两大关键改进:首先,它整合了更广泛的复杂任务,涵盖按压(press)、抓取(pick)、推动(push)、旋转(screw)、关闭(close)、开启(open)和放置(put)七项核心动作技能;其次,它引入了一套完整的四级泛化难度体系,分别针对新物体布局、刚性物体、铰接物体和长时程任务的泛化能力进行评估。
To tackle the problem, we first propose a new 3D robotic manipulation policy - 3D-LOTUS with LanguagecOnditioned poinT cloUd tranSformer. By leveraging a strong 3D backbone and an effective action representation, 3D-LOTUS achieves state-of-the-art performance on existing vision-language manipulation benchmark [18] and Level 1 of GemBench, while significantly improving training efficiency. Nevertheless, 3D-LOTUS struggles to generalize to new tasks in GemBench, mainly due to limitations in planning for new tasks and grounding new objects. Therefore, we propose an enhanced version 3D-LOTUS $^{++}$ which integrates foundation models to boost generalization capabilities. Specifically, LLMs are employed for task planning, decomposing tasks into step-by-step actionable plans, and VLMs are used for object grounding which can localize new objects mentioned in the plan. With the grounded object and the primitive action in the plan, 3D-LOTUS serves as the motion controller to generate action trajectories. Experimental results demonstrate that $3\mathrm{D-LOTUS++}$ significantly improves generalization, outperforming 3D-LOTUS on Levels 2 to 4 of GemBench. To summarize, our contributions are three fold:
为解决这一问题,我们首先提出了一种新型3D机器人操作策略——3D-LOTUS (Language-conditioned Point Cloud Transformer)。通过强大的3D骨干网络和高效动作表示,3D-LOTUS在现有视觉语言操作基准[18]和GemBench第一级任务中实现了最先进性能,同时显著提升了训练效率。然而,3D-LOTUS难以泛化至GemBench中的新任务,主要受限于新任务规划和新物体定位能力。因此,我们提出增强版3D-LOTUS$^{++}$,通过集成基础模型提升泛化能力:利用大语言模型进行任务规划(将任务分解为可执行步骤),采用视觉语言模型实现物体定位(可识别计划中提及的新物体)。3D-LOTUS作为运动控制器,根据定位物体和规划动作生成运动轨迹。实验表明,$3\mathrm{D-LOTUS++}$显著提升了泛化能力,在GemBench 2-4级任务上全面超越3D-LOTUS。我们的贡献主要体现在三个方面:
We introduce a new benchmark GemBench to systematically evaluate generalization in vision-language robotic manipulation across four complexity levels.
我们推出了一个新的基准测试GemBench,用于系统评估视觉语言机器人操作在四个复杂度级别上的泛化能力。
• We propose an effective manipulation policy 3D-LOTUS and enhance its generalization ability with foundation models for task planning and object grounding $(3\mathrm{D-LOTUS++})$ .
• 我们提出了一种有效的操作策略 3D-LOTUS (3D-LOTUS++) ,并通过基础模型增强其在任务规划和物体定位方面的泛化能力。
Our models establish state of the arts on existing benchmark and GemBench, and also work reliably on a real robot.
我们的模型在现有基准测试和GemBench上达到了最先进水平,并在真实机器人上运行可靠。
II. RELATED WORK
II. 相关工作
Robotic manipulation benchmark. Significant progress has been made in the development of robot simulators such as RLBench [26], AI2-THOR [27] and Isaac Sim [28]. Leverag- ing these simulators, various benchmarks have emerged for robotic manipulation. Early benchmarks [17], [18] train and test policies on the same task set, overlooking the critical aspect of generalization to unseen scenarios. To address this, more recent benchmarks [19], [20], [21], [22], [23], [25], [24] have introduced generalization evaluations on new compositions of objects and colors, new object shapes, or even long-horizon tasks. Among them, VIMA-Bench [24] and Colosseum [25] are most similar to our work, aiming to systematically evaluate different generalization abilities. However, VIMA-Bench [24] is limited to pick-and-place tasks using a suction gripper, while Colosseum [25] emphasizes generalization to environment perturbations such as changes in lighting and camera angles. In contrast, GemBench covers more complex action skills and evaluate genera liz ation to entirely new tasks rather than perturbations of the seen tasks. Table I provides a comprehensive comparison of these benchmarks. We can observe that GemBench is most general among all of them.
机器人操作基准测试。在机器人模拟器开发方面已取得显著进展,例如RLBench [26]、AI2-THOR [27]和Isaac Sim [28]。依托这些模拟器,涌现出多种机器人操作基准测试。早期基准测试[17][18]在同一任务集上训练和测试策略,忽略了对未见场景泛化能力这一关键维度。为此,近期基准测试[19][20][21][22][23][25][24]引入了针对新物体颜色组合、新物体形状乃至长周期任务的泛化评估。其中VIMA-Bench [24]和Colosseum [25]与本研究最为相似,都致力于系统评估不同泛化能力。但VIMA-Bench [24]仅限于使用吸盘夹具的抓放任务,Colosseum [25]则侧重光照变化和摄像机角度等环境扰动的泛化能力。相比之下,GemBench涵盖更复杂的动作技能,并评估对全新任务(而非已见任务的变体)的泛化能力。表1提供了这些基准测试的全面对比,可见GemBench在其中最具普适性。
Vision-and-language robotic manipulation. Learning robotic manipulation conditioned on vision and language has received increasing attention [29], [30], [31]. The high dimensionality of manipulation action space makes it challenging to directly use reinforcement learning (RL) in training [32]. Therefore, most works rely on imitation learn- ing (IL) [33], [1], [17], [18], [34], [2], [8], [4], [35] using scripted trajectories [26] or tele-operation data [13]. Visual representation plays a crucial role in policy learning. Existing works [33], [1], [36], [17], [34], [37] mainly use 2D images to predict actions, though recent works have begun exploring 3D representations [38], [18], [2], [4], [35], [8]. In this work, we take advantage of rich spatial information of 3D point cloud for motion planning, while leaving object grounding in 2D to benefit from the generalization strength of pretrained 2D models [15], [39], [40].
视觉与语言机器人操控。基于视觉和语言的机器人操控学习正受到越来越多的关注 [29], [30], [31]。操控动作空间的高维度特性使得直接使用强化学习 (RL) 进行训练具有挑战性 [32]。因此,大多数研究依赖模仿学习 (IL) [33], [1], [17], [18], [34], [2], [8], [4], [35],使用脚本轨迹 [26] 或遥操作数据 [13]。视觉表征在策略学习中起着关键作用。现有工作 [33], [1], [36], [17], [34], [37] 主要使用 2D 图像预测动作,不过近期研究已开始探索 3D 表征 [38], [18], [2], [4], [35], [8]。本工作中,我们利用 3D 点云的丰富空间信息进行运动规划,同时将物体定位保留在 2D 空间以利用预训练 2D 模型 [15], [39], [40] 的泛化优势。
Foundation models for robotics. Learning-based robotic policies often struggle to generalize to new scenarios [41]. Inspired by the remarkable generalization capabilities of foundation models [39], [15], [42], recent work explores how to leverage these models for planning, perception and control in robotics. Huang et al. [43] use LLMs to decompose highlevel tasks into sub-steps. To ground plans in the visual world, SayCan [44] combine LLMs with value functions of pretrained skills. ViLa [45] replaces LLMs with a multimodal LLM GPT-4V [46]. CaP [16] instructs LLMs to write code which call tools for perception and control. However, these approaches rely on predefined motion skills, limiting applicability to broader tasks. To address this, VoxPoser [3] use LLMs to construct 3D voxel maps of affordance, constraint, rotation and velocity, which are fed into traditional motion planing algorithms to plan a trajectory. Nevertheless, VoxPoser only provides a coarse-grained understanding of the scene and struggles with precise robot control. In this work, we propose to combine the generalization ability of foundation models with strong motion control capabilities of 3D policies for robotic manipulation.
机器人基础模型。基于学习的机器人策略往往难以泛化到新场景[41]。受基础模型[39][15][42]卓越泛化能力的启发,近期研究探索如何利用这些模型实现机器人领域的规划、感知与控制。Huang等人[43]使用大语言模型将高层任务分解为子步骤。为实现视觉世界的规划落地,SayCan[44]将大语言模型与预训练技能的价值函数相结合。ViLa[45]采用多模态大语言模型GPT-4V[46]替代传统大语言模型。CaP[16]通过指令让大语言模型编写调用感知与控制工具的代码。然而这些方法依赖预定义的运动技能,限制了在更广泛任务中的适用性。为此,VoxPoser[3]利用大语言模型构建包含功能可供性、约束条件、旋转和速度的三维体素地图,将其输入传统运动规划算法生成轨迹。但VoxPoser仅能提供场景的粗粒度理解,且难以实现精确的机器人控制。本研究提出将基础模型的泛化能力与三维策略的强运动控制能力相结合,以实现机器人操控。
III. GEMBENCH: GENERAL IZ ABLE VISION-LANGUAGE ROBOTIC MANIPULATION BENCHMARK
III. GEMBENCH: 通用可泛化视觉语言机器人操作基准
This paper introduces the GemBench benchmark to system a tic ally evaluate generalization capabilities of vision-andlanguage robotic manipulation policies. It is built upon the RLBench simulator [26], which provides a wide range of visually and physically realistic tasks together with a framework to generate scripted demonstrations. In the following, we first describe training tasks in GemBench in Sec III-A and then present four levels of generalization for evaluation in Sec III-B. The details of the proposed GemBench are presented in Sec VI-A in the appendix.
本文介绍了GemBench基准测试,用于系统评估视觉与语言机器人操作策略的泛化能力。该基准基于RLBench模拟器[26]构建,该模拟器提供大量视觉和物理层面逼真的任务,并包含生成脚本演示的框架。下文首先在第III-A节描述GemBench中的训练任务,随后在第III-B节提出四个层级的泛化评估。GemBench的详细说明见附录第VI-A节。
A. Training tasks
A. 训练任务
We select 16 tasks (31 variations 1) from existing RLBench benchmarks [26], [18] to capture a diverse range of action primitives beyond simple pick-and-place. These tasks, shown in Figure 1 (top), include seven action primitives: press, pick, push, screw, close, open, and stack/put. Examples of training tasks are push button, pick up cup, reach and drag cube, screw light bulb in, close laptop lid, open drawer, stack blocks. Task variations cover 20 objects (e.g., cube, cup, fridge), 20 colors (e.g., red, blue, violet), and 3 object parts (e.g., top, middle, bottom). The training set is sufficiently diverse and should enable a robot to generalize to new tasks, such as novel attribute-object compositions, new actionobject pairings, or even entirely new shapes.
我们从现有RLBench基准测试[26][18]中选取了16项任务(含31种变体1),涵盖除简单抓放操作外的多样化动作基元。如图1(顶部)所示,这些任务包含七种动作基元:按压、抓取、推挤、旋拧、闭合、开启及堆叠/放置。训练任务示例包括按压按钮、拿起杯子、拖拽立方体、旋入灯泡、合上笔记本盖、拉开抽屉、堆叠积木。任务变体覆盖20种物体(如立方体、杯子、冰箱)、20种颜色(如红、蓝、紫)及3个物体部件(如顶部、中部、底部)。该训练集具备充分多样性,可使机器人泛化至新任务,例如新型属性-物体组合、新动作-物体配对,乃至全新形状。
B. Testing tasks with four levels of generalization
B. 包含四个泛化级别的测试任务
As shown in Figure 1 (bottom), the test set includes four levels of generalization that progressively increase the difficulty of vision-language robotic manipulation. The test set consists of a total of 44 tasks (92 variations), with 23 tasks selected from the original RLBench 100 tasks [26] and 21 newly scripted tasks. The test levels differ in object shape and color, object articulation and horizon of the tasks.
如图 1 (底部) 所示,测试集包含四个难度递增的视觉语言机器人操作泛化层级。该测试集共包含 44 项任务 (92 种变体),其中 23 项任务选自原始 RLBench 100 任务集 [26],21 项为新编写的脚本任务。测试层级在物体形状颜色、物体关节结构以及任务时间跨度等方面存在差异。
Level 1 - Novel placements: This level consists of the same 16 tasks (31 variations) as the training set, but with new object placements randomly sampled within the robot’s workspace. Additionally, some tasks feature new distractor objects with different colors. The objective is to evaluate whether a policy can perform well on seen tasks with minor configuration changes.
一级 - 新布局: 该级别包含与训练集相同的16个任务(31种变体),但物体位置在机器人工作空间内随机采样重新放置。此外,部分任务会加入不同颜色的新干扰物,旨在评估策略能否在配置微调后的已见任务中保持良好表现。
Level 2 - Novel rigid objects: This level comprises 15 unseen tasks (28 variations) where the robot interacts with novel rigid objects using actions such as press, pick, and put. There are two categories for generalization to rigid objects: 1) Novel object-color compositions. For instance, training tasks only manipulate yellow button and rose bulb, while the test task requires to operate a rose button. This level includes 20 new object-color compositions. 2) Novel object shapes. For example, picking a cube is learned in training, but the testing task is lifting a toy or a star-shaped item. There are 8 new object shapes in the evaluation.
二级 - 新型刚性物体:该级别包含15个未见任务(28种变体),机器人需通过按压、抓取、放置等动作与新型刚性物体交互。针对刚性物体的泛化分为两类:1) 新物体-颜色组合。例如训练任务仅操作黄色按钮和玫瑰色灯泡,而测试任务需操作玫瑰色按钮。此级别包含20种新物体-颜色组合。2) 新物体形状。例如训练学习抓取立方体,但测试任务需举起玩具或星形物品。评估中包含8种新物体形状。
Level 3 - Novel articulated objects: This set includes 18 new tasks (21 variations) where the robot interacts with articulated objects. Three categories are proposed: 1) Novel action-part compositions. For example, if trained to open bottom drawer and put item in middle shelf, it now needs to open middle drawer. There are 8 novel compositions. 2) Novel instances. For example, after being trained on a threedrawer unit, it must generalize to one with four drawers. This set includes 11 new object instances. 3) Novel categories. For example, it is trained to close a laptop lid but must generalize to closing a grill lid. This includes 2 new object categories. Level 4 - Novel Long-horizon tasks: This level presents the greatest challenge as it requires the robot to combine multiple actions learned during training. It includes 6 long-horizon tasks (12 variations). For example, the task “put items in drawer” involves a sequence of actions such as opening the drawer, picking up a sequence of items (a cube, a cylinder and a moon), and placing them inside according to the order specified by the variation instruction.
第3级 - 新型铰接物体:该组包含18项新任务(21种变体),涉及机器人与铰接物体的交互。分为三类:1) 新动作-部件组合。例如,若训练时学习打开底层抽屉并将物品放入中层搁板,则需泛化至打开中层抽屉的操作,共含8种新组合。2) 新物体实例。例如,在三抽屉柜体训练后需泛化至四抽屉柜体,包含11个新物体实例。3) 新物体类别。例如,训练关闭笔记本电脑屏幕后需泛化至关闭烤架盖板,包含2个新物体类别。
第4级 - 新型长周期任务:此级别挑战性最高,要求机器人组合训练期间学习的多个动作。包含6项长周期任务(12种变体)。例如"将物品放入抽屉"任务涉及一系列动作:打开抽屉、按顺序拾取物品(立方体、圆柱体和月形块),并根据变体指令指定的顺序将其放入抽屉。
IV. METHOD
IV. 方法
A. Problem formulation
A. 问题表述
The goal is to learn a policy $\pi(\boldsymbol{a}{t}|\boldsymbol{O}{t},L)$ for robotic manipulation, where $L$ is a language instruction, $O_{t}\in\mathbb{O},a_{t}\in$ A are the observation and action at step $t$ respectively, with $\mathbb{O}$ and A denoting the observation and action space.
目标是学习一个策略 $\pi(\boldsymbol{a}{t}|\boldsymbol{O}{t},L)$ 用于机器人操作,其中 $L$ 是语言指令,$O_{t}\in\mathbb{O},a_{t}\in$ A 分别是步骤 $t$ 的观察和动作,$\mathbb{O}$ 和 A 表示观察空间和动作空间。
The observation space $\mathbb{O}$ includes aligned RGB-D images from $K$ cameras, along with the robot’s proprio ce pti ve state consisting of joint and gripper poses. We assume the intrinsic and extrinsic camera parameters are known.
观测空间 $\mathbb{O}$ 包含来自 $K$ 个相机的对齐RGB-D图像,以及由关节和夹爪位姿组成的机器人本体感知状态。我们假设相机内外参已知。
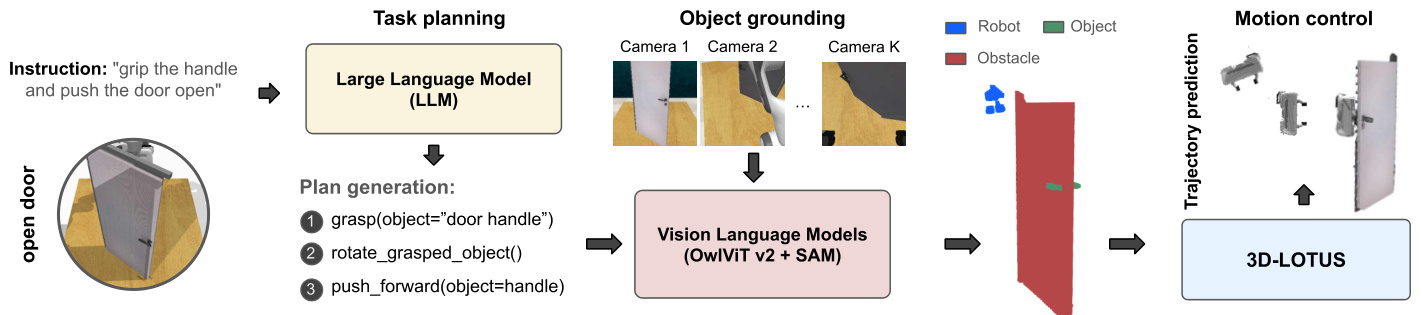
Fig. 2: Overview of ${\bf3D-L O T U S++}$ framework. It leverages generalization capabilities of foundation models for planning and perception, and strong action execution ability of 3D-LOTUS to perform complex tasks.
图 2: ${\bf3D-L O T U S++}$ 框架概览。该框架结合基础模型在规划与感知方面的泛化能力,以及3D-LOTUS强大的动作执行能力,以完成复杂任务。
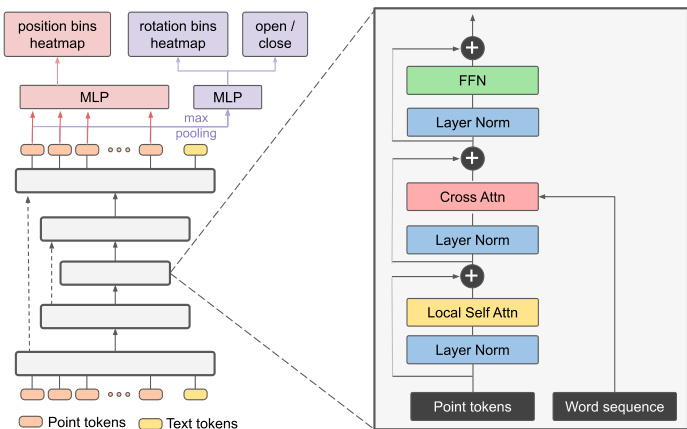
Fig. 3: 3D-LOTUS architecture. It takes point cloud and text as input to predict the next action.
图 3: 3D-LOTUS架构。它以点云(point cloud)和文本作为输入来预测下一个动作。
The action space A comprises the gripper’s position $a_{t}^{p}\in$ $\mathbb{R}^{3}$ , rotation $a_{t}^{r}\in\mathbb{R}^{3}$ , and open state $a_{t}^{o}\in{0,1}$ indicating if the gripper is open or closed. We utilize waypoint representation [38], [47], [17], [18] for action sequences. Inverse kinematics is used to move the robot from $a_{t-1}$ to $a_{t}$ .
动作空间A包含夹爪的位置 $a_{t}^{p}\in$ $\mathbb{R}^{3}$、旋转 $a_{t}^{r}\in\mathbb{R}^{3}$ 以及开合状态 $a_{t}^{o}\in{0,1}$(表示夹爪开启或闭合)。我们采用路径点表示法[38][47][17][18]来描述动作序列,并通过逆运动学控制机器人从 $a_{t-1}$ 移动到 $a_{t}$。
B. 3D-LOTUS policy
B. 3D-LOTUS 策略
As 3D point clouds provide rich spatial information to perceive object shapes and positions, we propose to effectively exploit the 3D information for robotic manipulation. The 3D-LOTUS policy is a 3D robotic manipulation policy with language-conditioned point cloud transformer. Figure 3 illustrates the architecture of the policy.
由于3D点云提供了丰富的空间信息来感知物体形状和位置,我们提出有效利用3D信息实现机器人操控。3D-LOTUS策略是一种基于语言条件点云Transformer (point cloud transformer) 的3D机器人操控策略。图3展示了该策略的架构。
Point cloud preprocessing. We follow PolarNet [2] to project multi-view RGB-D images into a unified point cloud in world coordinates, then downsample this point cloud to one point per $\mathrm{1cm^{3}}$ voxel [48]. We exclude points outside the robot’s workspace, and points on the robotic arm using a CAD model and joint poses of the arm, as these contribute little for manipulation. The resulting point cloud $V$ of $n$ points only covers the objects and robot gripper, significantly reducing the number of points and improving speed without compromising performance. Each point $\nu_{i}\in V$ consists of XYZ coordinates $\nu_{i}^{p}$ and additional feature $\nu_{i}^{o}$ such as RGB color and relative height to the table.
点云预处理。我们遵循PolarNet [2]的方法,将多视角RGB-D图像投影到世界坐标系下的统一点云中,然后对该点云进行下采样,确保每个$\mathrm{1cm^{3}}$体素[48]内仅保留一个点。通过CAD模型和机械臂关节位姿,我们排除了机器人工作空间外的点以及机械臂上的点,因为这些点对操作任务贡献甚微。最终得到的$n$个点组成的点云$V$仅覆盖物体和机器人夹爪,在保持性能的同时显著减少了点数并提升了处理速度。每个点$\nu_{i}\in V$包含XYZ坐标$\nu_{i}^{p}$和附加特征$\nu_{i}^{o}$(如RGB颜色和相对于桌面的高度)。
Language-conditioned point cloud transformer. We employ point cloud transformer v3 (PTV3) [49] as backbone to encode point cloud V . PTV3 adopts a U-Net [50] architecture with down sampling and upsampling blocks to efficiently compute point embeddings, where each block consists of transformer layers. For more details, please refer to the PTV3 paper [49]. We explore two variants to incorporate language information into the PTV3 model. Assuming the language instruction $L$ is encoded by a CLIP text encoder [39] and represented as a sequence of word embeddings $\left(w_{1},\cdots,w_{L}\right)$ . The first variant employs the adaptive normalization approach [51]. We compute a global language embedding $\overline{{w}}$ by weighted averaging $\left(w_{1},\cdots,w_{L}\right)$ , and use $\overline{{w}}$ to directly regress dimension-wise scale and shift parameters for each normalization layer in PTV3. The second variant utilizes a more conventional cross-attention mechanism [52]. A crossattention layer is added after each self-attention layer in PTV3, enabling each point to attend to the entire sequence of word embeddings $\left(w_{1},\cdots,w_{L}\right)$ .
语言条件点云Transformer。我们采用点云Transformer v3 (PTV3) [49] 作为主干网络来编码点云V。PTV3采用U-Net [50] 架构,包含下采样和上采样模块来高效计算点嵌入,其中每个模块由Transformer层构成。更多细节请参阅PTV3论文[49]。我们探索了两种将语言信息融入PTV3模型的变体。假设语言指令$L$通过CLIP文本编码器[39]编码为词嵌入序列$\left(w_{1},\cdots,w_{L}\right)$。第一种变体采用自适应归一化方法[51],通过加权平均$\left(w_{1},\cdots,w_{L}\right)$计算全局语言嵌入$\overline{{w}}$,并利用$\overline{{w}}$直接回归PTV3中每个归一化层的维度缩放和偏移参数。第二种变体采用更传统的交叉注意力机制[52],在PTV3每个自注意力层后添加交叉注意力层,使每个点都能关注整个词嵌入序列$\left(w_{1},\cdots,w_{L}\right)$。
Action prediction. Let $\nu_{i}^{e}$ denote the final point embedding for each point $\nu_{i}$ after the language-conditioned PTV3 model. We propose a new classification-based approach for action prediction, in contrast to the regression-based approach [17], [2], [8] or inefficient position classification over the whole 3D workspace [18], [4]. For position prediction, we predict the gripper’s location along the $X,Y,Z$ axes separately. We define sequential bins $\nu_{i,k,j}$ centered at each point’s location $\nu_{i}^{p}$ for each axis $k\in{X,Y,Z}$ , with $j\in[-m,m]$ representing the bin index. Each bin has a size of $b$ , so the position of bin $\nu_{i,k,j}$ along $k$ -axis is given by $\nu_{i,k}^{p}+b\times j$ . Using $\nu_{i}^{e}$ , we predict a heatmap for these bins at each point, and concatenate the bins across all points to form the final heatmap for each axis. During inference, we select the bin with the highest probability to determine the position for each axis. For rotation prediction, we also discretize the Euler angle for each axis into bins and use classification to predict the angles. The open state prediction remains a binary classification task. We apply max pooling over all points $\nu_{i}^{e}$ to predict rotation and open state. The cross entropy loss is employed to train position, rotation and open state classification. Further details are available in Sec VI-B in the appendix.
动作预测。设$\nu_{i}^{e}$表示经过语言条件化PTV3模型处理后每个点$\nu_{i}$的最终点嵌入。与基于回归的方法[17][2][8]或低效的全3D工作空间位置分类[18][4]不同,我们提出了一种新的基于分类的动作预测方法。对于位置预测,我们分别沿$X,Y,Z$轴预测夹爪位置。针对每个轴$k\in{X,Y,Z}$,以各点位置$\nu_{i}^{p}$为中心定义连续分箱$\nu_{i,k,j}$,其中$j\in[-m,m]$表示分箱索引。每个分箱尺寸为$b$,因此分箱$\nu_{i,k,j}$沿$k$轴的位置为$\nu_{i,k}^{p}+b\times j$。利用$\nu_{i}^{e}$,我们在每个点预测这些分箱的热力图,并将所有点的分箱拼接形成各轴的最终热力图。推理时选择概率最高的分箱确定各轴位置。对于旋转预测,我们同样将各轴欧拉角离散化为分箱并通过分类预测角度。开合状态预测仍作为二分类任务。通过对所有点$\nu_{i}^{e}$应用最大池化来预测旋转和开合状态。采用交叉熵损失训练位置、旋转和开合状态的分类任务。详见附录第六-B节。
C. 3D-LOTUS++ policy
C. 3D-LOTUS++ 策略
To accomplish a task specified by an instruction $L$ like ‘open the door’, the end-to-end policy 3D-LOTUS integrates multiple components into a single action prediction step. This includes task planning (e.g., first grasp the door handle), object grounding (e.g., localize the door handle in 3D space), and motion control (move to the localized door handle). This integration not only complicates error diagnosis, but also poses challenges in generalization to unseen scenarios, such as ‘open a new door’ or ‘close the door’.
为实现诸如"开门"这样的指令$L$所指定的任务,端到端策略3D-LOTUS将多个组件集成到单一动作预测步骤中。这包括任务规划(例如先抓住门把手)、物体定位(例如在3D空间中定位门把手)以及运动控制(移动到已定位的门把手处)。这种集成不仅增加了错误诊断的复杂度,还对未见过场景(如"打开新门"或"关门")的泛化能力提出了挑战。
To alleviate the above limitations, we propose enhancing 3D-LOTUS with foundation models. Existing LLMs [14] and VLMs [15], [39], [40], are able to generalize to unseen scenarios due to the training on massive data. Therefore, we introduce a modular framework that disentangles task planning, object grounding and motion control, leveraging the generalization capabilities of foundation models alongside the action execution abilities of 3D-LOTUS to achieve more general iz able robotic manipulation. Figure 2 illustrates the overall framework, comprising three modules: task planning with LLMs, object grounding with VLMs, and motion control with a modified version of 3D-LOTUS.
为缓解上述局限性,我们提出通过基础模型增强3D-LOTUS。现有的大语言模型[14]和视觉语言模型[15][39][40]凭借海量数据训练,能够泛化至未见场景。因此,我们引入模块化框架,将任务规划、物体定位与运动控制解耦,结合基础模型的泛化能力与3D-LOTUS的动作执行能力,实现更具普适性的机器人操作。图2展示了整体框架,包含三个模块:基于大语言模型的任务规划、基于视觉语言模型的物体定位,以及改进版3D-LOTUS的运动控制。
Task planning with LLM. Task planning aims to decompose the instruction $L$ into a sequence of steps $l_{1},\cdots,l_{T}$ . Each step corresponds to an action primitive that interacts with an object. In this work, we define six action primitives for object manipulation, covering a broad range of tasks, namely grasp(object), move grasped object(target), push down(object), push forward(object, target), release() and rotate grasped object(). We utilize the LLM LLaMa3- 8B [14] for task planning due to its strong commonsense knowledge and language reasoning capabilities. By providing prompts for the task requirement and several in-context examples, we guide the LLM to generate an plan for instruction L. Figure 2 presents an example of generated plans for the task of opening a door. The detailed prompts for LLMs are presented in Sec VI-C in the appendix.
使用大语言模型进行任务规划。任务规划旨在将指令 $L$ 分解为一系列步骤 $l_{1},\cdots,l_{T}$。每个步骤对应一个与物体交互的动作基元。在本工作中,我们定义了六种用于物体操控的动作基元,涵盖广泛的任务范围,包括抓取(对象)、移动抓取物体(目标)、下压(对象)、前推(对象, 目标)、释放()和旋转抓取物体()。我们采用LLaMa3-8B [14]作为任务规划的大语言模型,因其具备强大的常识知识和语言推理能力。通过提供任务需求提示和若干上下文示例,我们引导大语言模型为指令L生成规划方案。图2展示了开门任务的生成规划示例,详细的大语言模型提示内容见附录第六章节C部分。
Object grounding with VLMs. This module aims to localize an object given its text description in the generated plan. To achieve this, we leverage state-of-the-art VLMs to ensure robust generalization to new objects. First, we employ the open-vocabulary object detector OWLv2 [40] to detect bounding boxes with high objectiveness scores for each RGB image. OWLv2 also generates a semantic embedding for each bounding box, which is aligned with text embeddings from the CLIP text encoder [39]. Next, we use the Segment Anything Model (SAM) [15] to segment the object within each bounding box. This segmentation mask, combined with the corresponding RGB-D image, yields a 3D point cloud for each bounding box. To merge observations of the same object from different cameras, we compare semantic embeddings and point cloud distances. Pairs of objects are merged if their semantic and point cloud distances are below certain thresholds. In this way, we obtain object-centric representations for all objects in the scene, each object containing a merged point cloud and an averaged semantic embedding. Given the text description of an object, we compute its text embedding via CLIP and measure cosine similarities between this text embedding and all object semantic embeddings. The object with the highest cosine similarity is selected as the match.
基于视觉语言模型(VLM)的对象定位。该模块旨在根据生成计划中的文本描述定位对象。为此,我们采用最先进的视觉语言模型确保对新对象的强泛化能力。首先,使用开放词汇检测器OWLv2[40]为每张RGB图像检测具有高目标性得分的边界框。OWLv2还会为每个边界框生成与CLIP文本编码器[39]输出的文本嵌入对齐的语义嵌入。接着,利用Segment Anything Model(SAM)[15]对每个边界框内的对象进行分割。该分割掩码与对应的RGB-D图像结合,可为每个边界框生成3D点云。为合并来自不同摄像头的同一对象观测结果,我们比较语义嵌入和点云距离。若两个对象的语义距离和点云距离均低于特定阈值,则进行合并。通过这种方式,我们获得场景中所有对象的中心化表示,每个对象包含合并后的点云和平均语义嵌入。给定对象的文本描述时,通过CLIP计算其文本嵌入,并测量该文本嵌入与所有对象语义嵌入间的余弦相似度。选择具有最高余弦相似度的对象作为匹配结果。
Motion control. Given the action primitive name and input point cloud, the motion control module predicts a trajectory of actions to execute this actionable step. 3D-LOTUS can be easily modified for this purpose.
运动控制。给定动作基元名称和输入点云,运动控制模块预测执行该可操作步骤的动作轨迹。为此可轻松修改3D-LOTUS。
First, we change the input point feature $\nu_{i}^{o}$ by leveraging the output of the object grounding module, which segments the manipulated object and/or target location. This allows us to categorize points into four types: goal object, goal target, robot and obstacle. We treat points that do not belong to goal object, target and robot as obstacles. We then learn a look-up table to encode each point label and use this as point feature $\nu_{i}^{o}$ instead of RGB colors in addition to the XYZ coordinates $\nu_{i}^{p}$ . The new point feature help the model focus on geometry rather than textures during motion planning, thereby enhancing generalization to objects with novel textures.
首先,我们利用物体定位模块的输出改变输入点特征 $\nu_{i}^{o}$,该模块分割被操作物体和/或目标位置。这使得我们将点分为四种类型:目标物体、目标位置、机器人和障碍物。不属于目标物体、目标位置和机器人的点均视为障碍物。随后,我们学习一个查找表来编码每个点标签,并将其作为点特征 $\nu_{i}^{o}$ 使用,替代原有的RGB颜色信息,同时保留XYZ坐标 $\nu_{i}^{p}$。新的点特征帮助模型在运动规划过程中专注于几何结构而非纹理,从而增强对具有新纹理物体的泛化能力。
Second, instead of predicting a single action, we should generate a sequence of actions to complete the planned step. To achive this, we introduce a look-up table to encode the timestep index of actions in the trajectory, denoted as ${x_{t}}{t=1}^{s}$ . We concatenate the time embedding $x_{t}$ with the final point embedding $\nu_{i}^{e}$ to predict action for each timestep. The action prediction head is shared across all timesteps. As the number of actions varies for different plans, we also predict a stop probability to indiciate whether the trajectory should terminate at the current time step.
其次,我们不应预测单一动作,而应生成一系列动作来完成计划步骤。为此,我们引入一个查找表来编码轨迹中动作的时间步索引,记为 ${x_{t}}{t=1}^{s}$ 。将时间嵌入 $x_{t}$ 与最终点嵌入 $\nu_{i}^{e}$ 拼接后,用于预测每个时间步的动作。所有时间步共享同一个动作预测头。由于不同计划对应的动作数量不同,我们还预测了停止概率以判断轨迹是否应在当前时间步终止。
V. EXPERIMENTS
V. 实验
A. Experimental setup
A. 实验设置
Evaluation setup. We follow prior work [18], [2] and use $K=4$ cameras positioned at the front, left shoulder, right shoulder and wrist, with an image resolution of $256\times256$ . For training, we generate 100 demonstrations for each task variation, leading to a dataset of 3,100 demonstrations. During testing, we use different random seeds from training to ensure initial scene configurations are distinct from the training data. We evaluate 20 episodes per task variation per seed, and run the evaluation with 5 seeds, which results in $20\times5\times92$ evaluation episodes in total. The maximum number of steps per episode is set to 25. We measure the task performance by success rate (SR) of the evaluation episodes, which is 1 for success and 0 for failure of an episode. The average SR and standard derivation across seeds are reported. Implementation details. For the 3D-LOTUS model, we use 5 down sampling-upsampling blocks, each containing 1 transformer layer. The hidden sizes for these blocks are 64, 128, 256, 512, 768, respectively. For action prediction, the number of bins for position is 30 $(m=15\$ ) and bin size $b{=}1\mathrm{cm}$ . The number of bins for rotation is 72 with bin size of $5^{\circ}$ . In the modified 3D-LOTUS for trajectory prediction, the maximum trajectory length $s$ is set as 5. We train 3DLOTUS with batch size of 8 and initial learning rate of 1e-4 for $150\mathrm{k}$ iterations with linear learning rate decay. Training takes around 11 hours on a single Nvidia A100 GPU. A validation set of 20 episodes per task variation on Level 1 (different from testing episodes) is used to select the best checkpoint, evaluated every 10k iterations.
评估设置。我们遵循先前工作 [18]、[2],使用 $K=4$ 台分别位于正面、左肩、右肩和手腕的摄像头,图像分辨率为 $256\times256$。训练阶段,我们为每个任务变体生成100条演示数据,最终构建包含3,100条演示的数据集。测试时采用与训练不同的随机种子,确保初始场景配置区别于训练数据。每个任务变体在每个种子下评估20次 episode,共使用5个种子运行评估,总计 $20\times5\times92$ 次评估 episode。单次 episode 最大步数设为25步。通过 episode 成功率 (SR) 衡量任务表现,成功记为1,失败记为0。最终报告跨种子的平均 SR 及标准差。
实现细节。3D-LOTUS 模型采用5个下采样-上采样块,每个块含1个 transformer 层,隐藏层尺寸分别为64、128、256、512、768。动作预测中位置分箱数为30 $(m=15\$ ),箱尺寸 $b{=}1\mathrm{cm}$;旋转分箱数为72,箱尺寸 $5^{\circ}$。轨迹预测改进版中最大轨迹长度 $s$ 设为5。训练时 batch size 为8,初始学习率1e-4,线性衰减执行 $150\mathrm{k}$ 次迭代,单块 Nvidia A100 GPU 耗时约11小时。使用Level 1任务变体的20个验证 episode(区别于测试数据)每10k次迭代评估一次以选择最佳检查点。
TABLE II: Performance on RLBench-18Task. The Avg. Rank denotes the averaged rank of the model across tasks. Training time is the number of V100 GPU days for training.
表 II: RLBench-18任务性能表现。Avg. Rank表示模型在各任务中的平均排名。训练时间为V100 GPU训练天数。
| 方法 | Avg.SR↑ | Avg. Rank↓ | 训练时间↓ |
|---|---|---|---|
| C2F-ARM-BC[38] | 20.1 | 8.6 | - |
| Hiveformer[17] | 45.3 | 6.9 | - |
| PolarNet[2] | 46.4 | 6.4 | 8.9 |
| PerAct[18] | 49.4 | 6.2 | 128.0 |
| RVT[34] | 62.9 | 4.4 | 8.0 |
| Act3D[4] | 65.0 | 4.3 | 40.0 |
| RVT2[37] | 81.4 | 2.4 | 6.6 |
| 3Ddiffuser actor[35] | 81.3 | 2.3 | 67.6 |
| 3D-LOTUS | 83.1±0.8 | 2.2 | 2.23 |
TABLE III: Performance on four levels of GemBench.
表 III: GemBench四个级别的性能表现
| 方法 | L1 | L2 | L3 | L4 |
|---|---|---|---|---|
| Hiveformer [17] | 60.3±1.5 | 26.1±1.4 | 35.1±1.7 | 0.0±0.0 |
| PolarNet [2] | 77.7±0.9 | 37.1±1.4 | 38.5±1.7 | 0.1±0.2 |
| 3D diffuser actor[35] | 91.9±0.8 | 43.4±2.8 | 37.0±2.2 | 0.0±0.0 |
| RVT-2 [37] | 89.1±0.8 | 51.0±2.3 | 36.0±2.2 | 0.0±0.0 |
| 3D-LOTUS | 94.3±1.4 | 49.9±2.2 | 38.1±1.1 | 0.3±0.3 |
| 3D-LOTUS++ | 68.7±0.6 | 64.5±0.9 | 41.5±1.8 | 17.4±0.4 |
Baselines. We run four state-of-the-art methods on GemBench, including two 2D image based models2 (Hiveformer [17] and RVT-2 [37]), and two 3D-based models $(\mathrm{Po}-$ larnet [2] and 3D diffuser actor [35]). All the baselines use CLIP text encoder [39], while only 3D diffuser actor employs visual representations pretrained on large-scale datasets. We use official codes provided by the authors to validate the training pipeline on RLBench-18Task benchmark. After reproducing the results on RLBench-18Task, we apply the same configuration to train on our GemBench benchmark.
基准方法。我们在GemBench上运行了四种前沿方法,包括两种基于2D图像的模型 (Hiveformer [17] 和 RVT-2 [37]),以及两种基于3D的模型 $(\mathrm{Po}-$ larnet [2] 和 3D diffuser actor [35])。所有基准方法均采用CLIP文本编码器 [39],其中仅3D diffuser actor使用了基于大规模数据集预训练的视觉表征。我们使用作者提供的官方代码在RLBench-18Task基准上验证训练流程,复现结果后采用相同配置在GemBench基准上进行训练。
B. Comparison with state of the arts
B. 与现有技术的对比
RLBench-18Task. We first evaluate on the widely used RLBench-18Task benchmark [18], which contains the same 18 tasks (249 variations) for training and testing. The results are summarized in Table II, with a breakdown of performance on individual tasks provided in Table IX in the appendix. The 3D-LOTUS policy achieves state-of-the-art performance using significantly less training time, demonstrating strong action execution capability.
RLBench-18任务。我们首先在广泛使用的RLBench-18任务基准[18]上进行评估,该基准包含相同的18个任务(249种变体)用于训练和测试。结果总结在表II中,各任务性能细目见附录中的表IX。3D-LOTUS策略以显著更少的训练时间实现了最先进的性能,展现出强大的动作执行能力。
GemBench. Table III presents the results of different models across the four generalization levels in GemBench. Detailed results on individual tasks are shown in Sec VI-D in the appendix. As expected, Level 1 which only involves novel object placements, is easiest. The performance trend of different models are similar to those in RLBench-18Task. In Levels 2 to 4, we observe a significant drop in performance for the state-of-the-art methods, highlighting the limitations of existing methods in unseen generalization. Generalizing skills for articulated objects (Level 3) proves to be more challenging than for rigid objects (Level 2). Level 4, which features long-horizon tasks, is most difficult; the performance of all state-of-the-art methods drop to close to a $0%$ success rate. $3\mathrm{D-LOTUS++}$ significantly outperforms previous methods on more challenging generalization levels. Note that its performance is lower than the SOTA methods on Level 1. This can be explained by the zero-shot grounding models, which struggles to distinguish some objects in seen tasks such as ‘tuna can’ and ‘soup can’. The performance on Level 4 is suboptimal. Refer to the ablation study for an analysis.
GemBench。表 III 展示了不同模型在GemBench四个泛化层级上的表现结果,各任务详细结果见附录第六章节D部分。正如预期,仅涉及新物体摆放的Level 1难度最低,各模型表现趋势与RLBench-18Task相似。在Level 2至Level 4中,现有先进方法性能显著下降,凸显出现有方法在未知泛化场景中的局限性。铰接物体(Level 3)的技能泛化比刚性物体(Level 2)更具挑战性。包含长周期任务的Level 4难度最高,所有先进方法的成功率均降至接近$0%$。$3\mathrm{D-LOTUS++}$在更高难度的泛化层级上显著优于先前方法,但需注意其在Level 1的表现低于SOTA方法,这是由于零样本(Zero-shot)定位模型难以区分"金枪鱼罐头"和"汤罐头"等已知任务中的某些物体。Level 4的表现未达最优,具体分析参见消融实验。
TABLE IV: Ablation of 3D-LOTUS components.
表 IV: 3D-LOTUS组件的消融实验
| 动作 | 条件 | L1 | L2 | L3 | L4 |
|---|---|---|---|---|---|
| 回归 (Regression) | 自适应归一化 (AdaptiveNorm) | 83.3±0.7 | 29.3±1.9 | 34.5±1.0 | 0.0±0.0 |
| 分类 (Classification) | 自适应归一化 (AdaptiveNorm) | 90.8±0.7 | 47.8±0.6 | 37.9±1.5 | 0.0±0.0 |
| 分类 (Classification) | 交叉注意力 (CrossAttn) | 94.3±1.4 | 49.9±2.2 | 38.1±1.1 | 0.3±0.3 |
TABLE V: Ablations on $3\mathrm{D-LOTUS++}$ modules.
表 V: $3\mathrm{D-LOTUS++}$ 模块消融实验
| 任务规划 (Task Planning) | 对象定位 (Object Grounding) | L1 | L2 | L3 | L4 |
|---|---|---|---|---|---|
| GT | GT | 92.6±0.7 | 80.1±0.5 | 47.8±1.4 | 31.5±1.1 |
| GT | VLM | 71.0±1.7 | 66.3±0.9 | 46.0±1.5 | 19.4±1.5 |
| LLM | VLM | 68.7±0.6 | 64.5±0.9 | 41.5±1.8 | 17.4±0.4 |
C. Ablations
C. 消融实验
3D-LOTUS components. In Table IV, we ablate different components of 3D-LOTUS. Row 1 uses regression for action prediction. Its performance is worse than classification in Row 2 for all levels. Furthermore, it requires more iterations to converge. Row 2 and 3 compare two variants for language conditioning. The cross attention outperforms adaptive normalization method, though at a higher computation cost.
3D-LOTUS组件。在表IV中,我们对3D-LOTUS的不同组件进行了消融实验。第1行使用回归进行动作预测,其性能在所有层级上都逊于第2行的分类方法,且需要更多迭代次数才能收敛。第2行与第3行比较了两种语言条件化变体:交叉注意力机制虽计算成本较高,但性能优于自适应归一化方法。
3D-LOTUS $^{++}$ modules. The proposed $3\mathrm{D-LOTUS++}$ allows for detailed error analysis by isolating each module — task planning, object grounding, and motion control. To facilitate this, we manually annotate ground truth task plans and object grounding labels for each task, and evaluate the model’s performance with and without the ground truth information. The results are shown in Table V. We can see that the primary bottleneck in Levels 1 and 2 is the object grounding module, where ground truth object labels improve the performance by a large margin. In Levels 3 and 4, however, even when provided with all ground truth information, the performance remains suboptimal. The primary issue lies within the 3D-LOTUS motion control policy, specifically its struggle to generalize to long-horizon tasks where initial robot configurations deviate substantially from the training data. Task planning in Level 4 also suffers from reduced accuracy as the LLM operates without visual input. This lack of visual awareness can lead to incorrect assumptions about the environment. For example, for the task ’take shoes out of the box,’ the LLM cannot determine if the box is open or closed, potentially leading to an inefficient or failed plan.”
3D-LOTUS++模块。提出的3D-LOTUS++通过隔离每个模块——任务规划、物体定位和运动控制——实现了详细的错误分析。为此,我们手动标注了每个任务的真实任务计划和物体定位标签,并评估模型在有/无真实信息时的表现。结果如表V所示,可见Level 1和2的主要瓶颈在于物体定位模块,使用真实物体标签可大幅提升性能。但在Level 3和4中,即使提供全部真实信息,性能仍不理想。核心问题在于3D-LOTUS的运动控制策略,特别是其对初始机器人配置与训练数据差异较大的长周期任务的泛化能力不足。Level 4的任务规划也因大语言模型缺乏视觉输入而精度下降,这种视觉感知缺失可能导致对环境做出错误假设(例如执行"将鞋子拿出盒子"任务时,模型无法判断盒子是否打开,从而生成低效或失败的计划)。
D. Real world experiments
D. 真实世界实验
We further perform real world evaluations of our models.
我们进一步对模型进行了真实场景评估。

Fig. 4: Real robot tasks variations. The top row illustrates task variations used for model training. The bottom row presents new task variations to assess model’s generalization capabilities on the real robot.
图 4: 真实机器人任务变体。顶部行展示用于模型训练的任务变体。底部行呈现用于评估真实机器人上模型泛化能力的新任务变体。
TABLE VI: Performance of seen tasks with real robot.
表 VI: 真实机器人场景下的已知任务性能
| 任务 | PolarNet | 3D-LOTUS |
|---|---|---|
| 将黄色杯子叠放在粉色杯子中 | 10/10 | 9/10 |
| 将海军蓝杯子叠放在黄色杯子中 | 9/10 | 10/10 |
| 将草莓放入盒子 | 7/10 | 10/10 |
| 将桃子放入盒子 | 8/10 | 8/10 |
| 打开抽屉 | 6/10 | 9/10 |
| 将物品放入抽屉 | 1/10 | 3/10 |
| 悬挂马克杯 | 6/10 | 8/10 |
| 平均 | 6.7/10 | 8.1/10 |
Experimental setup. Our real robot setup includes a 6- DoF UR5 robotic arm equipped with three RealSense d435 cameras. We consider 7 variations across 5 tasks during training: stack cup (yellow in pink or navy in yellow), put fruit (strawberry or peach) in box, open drawer, put item in drawer and hang mug. For each task variation, we collect 20 human demonstrations via tele-operation. Then, we evaluate on the same 7 seen task variations with different objects placements and evaluate generalization capabilities on 7 new unseen task variations: put fruit (lemon and banana) in box, put food (tuna can then corn) in box and put fruits in plates (grapes in the yellow plate and banana in the pink plate). These tasks are illustrated in Figure 4. For each task variation we run models 10 times and report the success rate.
实验设置。我们的真实机器人配置包括一台配备三个RealSense d435相机的6自由度UR5机械臂。训练阶段涵盖5个任务的7种变体:叠杯子(黄杯套粉杯或蓝杯套黄杯)、将水果(草莓或桃子)放入盒子、拉开抽屉、将物品放入抽屉以及挂杯子。针对每个任务变体,我们通过远程操作收集了20组人类示范数据。随后,我们在相同7个已见任务变体(不同物体摆放)上评估模型性能,并在7个未见任务变体上测试泛化能力:将水果(柠檬和香蕉)放入盒子、将食品(金枪鱼罐头和玉米罐头)放入盒子、将水果摆盘(葡萄放黄盘和香蕉放粉盘)。这些任务如图4所示。每个任务变体运行模型10次并统计成功率。
TABLE VII: Performance of unseen tasks with real robot
表 VII: 真实机器人未见任务性能
| 任务 | 3D-LOTUS | 3D-LOTUS++ |
|---|---|---|
| 将红色杯子叠入黄色杯子 | 0/10 | 8/10 |
| 将黑色杯子叠入橙色杯子 | 0/10 | 7/10 |
| 将黄色杯子放入红色杯子内 | 0/10 | - |
| 然后将青色杯子叠放在顶部 | - | 7/10 |
| 将柠檬放入盒子 | 0/10 | 7/10 |
| 将香蕉放入盒子 | 0/10 | 9/10 |
| 将金枪鱼罐头放入盒子,再将玉米放入盒子 | 0/10 | 7/10 |
| 将葡萄放入黄色盘子 | 0/10 | 8/10 |
| 然后将香蕉放入粉色盘子 | 0/10 | 9/10 |
| 平均 | 0/10 | 7.9/10 |
VI. CONCLUSION
VI. 结论
In this work, we introduce a new benchmark and method for general iz able vision-language robotic manipulation. The proposed benchmark GemBench systematically evaluates four generalization levels: new placements, new rigid objects, new articulated objects, and long-horizon tasks. To improve generalization ability, we introduce $3\mathrm{D-LOTUS++}$ , a modular framework that leverages foundation models for task planning and object grounding alongside a strong 3Dbased motion plan policy 3D-LOTUS. Extensive experiments demonstrate the effectiveness of $3\mathrm{D-LOTUS++}$ on novel tasks. Our ablation studies highlight object grounding as a critical bottleneck and reveal the limitations of the motion control policy in complex scenarios. Future work will focus on addressing these two issues.
在本工作中,我们提出了一个可泛化视觉-语言机器人操作的新基准和方法。提出的GemBench基准系统评估了四种泛化层级:新摆放位置、新刚性物体、新铰接物体以及长周期任务。为提升泛化能力,我们引入$3\mathrm{D-LOTUS++}$模块化框架,该框架结合基础模型进行任务规划与物体定位,并搭载强大的基于3D的运动规划策略3D-LOTUS。大量实验验证了$3\mathrm{D-LOTUS++}$在新任务上的有效性。消融研究表明物体定位是关键瓶颈,并揭示了运动控制策略在复杂场景中的局限性。未来工作将重点解决这两个问题。
Table VI shows that our new method, 3D-LOTUS, outperforms PolarNet, achieving an average success rate of $8.1/10$ compared to PolarNet’s average performance of $6.7/10$ . However, when applying the same 3D-LOTUS model to new task variations, we observe a complete failure to generalize to the new objects and instructions as shown in Table VII. In contrast, our improved model, $3\mathrm{D-LOTUS++}$ , successfully addresses these new task variations, achieving an average success rate of $7.9/10$ .
表 VI 显示,我们的新方法 3D-LOTUS 优于 PolarNet,平均成功率达到 $8.1/10$,而 PolarNet 的平均表现仅为 $6.7/10$。然而,当将相同的 3D-LOTUS 模型应用于新任务变体时,我们观察到它完全无法泛化到新物体和指令,如表 VII 所示。相比之下,我们的改进模型 $3\mathrm{D-LOTUS++}$ 成功解决了这些新任务变体,平均成功率达到 $7.9/10$。
Acknowledgements. This work was partially supported by the HPC resources from GENCI-IDRIS (Grant 20XXAD011012122 and AD011014846). It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “France 2030” program, reference ANR-23-IACL-0008 (PR[AI]RIE-PSAI projet), and the ANR project Video Predict (ANR-21-FAI1- 0002-01). Cordelia Schmid would like to acknowledge the support by the Korber European Science Prize.
致谢。本研究部分使用了GENCI-IDRIS提供的高性能计算资源(资助编号20XXAD011012122和AD011014846)。经费部分来源于法国政府"法国2030"计划下由法国国家研究署(ANR)管理的ANR-23-IACL-0008(PR[AI]RIE-PSAI项目)和ANR-21-FAI1-0002-01(Video Predict项目)。Cordelia Schmid感谢Körber欧洲科学奖的支持。
REFERENCES
参考文献
APPENDIX
附录
A. The proposed GemBench benchmark
A. 提出的 GemBench 基准测试
Table VIII presents all the tasks and variations used in training and the four generalization levels in testing in the proposed GemBench.
表 VIII 展示了 GemBench 中训练阶段使用的所有任务及其变体,以及测试阶段的四种泛化级别。
B. Details of 3D-LOTUS policy
B. 3D-LOTUS 策略细节
- Point cloud preprocessing: We automatically filter out irrelevant points from the point cloud during preprocessing. To remove background and table points, we define the robot’s workspace and the table height, excluding all points outside these boundaries. For the robotic arm, we assign 3D bounding boxes to each of its links. Using the robot’s proprio ce pti ve state, we transform these bounding boxes based on the known poses and remove any points within them. As a result, the remaining point cloud contains only objects and the robotic gripper. Figure 5 illustrates the point cloud before and after the point removal step.
- 点云预处理:在预处理阶段,我们自动过滤点云中的无关点。为移除背景和桌面点云,我们定义了机器人工作空间及桌面高度,排除所有边界外的点。针对机械臂,我们为其每个连杆分配3D边界框,利用机器人本体感知状态,根据已知位姿变换这些边界框,并移除框内所有点。最终剩余点云仅包含目标物体和机械夹爪。图5展示了点云剔除步骤前后的对比效果。
D. Detailed evaluation results
D. 详细评估结果
- Action prediction: We discretize the ground truth position $a_{t}^{p}$ and rotation $a_{t}^{r}$ to train the model. For position prediction, let $b_{t,k}^{p}\in\mathbb{R}^{n\times2m}$ represent the position of the concatenated bins for all points along the $k$ axis, where $n$ is the number of points and $2m$ is the number of bins per point. We calculate the Euclidean distance between each bin and $a_{t,k}^{p}$ , defining the score for bin $i$ as:
- 动作预测:我们将真实位置 $a_{t}^{p}$ 和旋转 $a_{t}^{r}$ 离散化以训练模型。对于位置预测,令 $b_{t,k}^{p}\in\mathbb{R}^{n\times2m}$ 表示沿 $k$ 轴所有点的拼接区间位置,其中 $n$ 为点数,$2m$ 为每点的区间数。计算各区间与 $a_{t,k}^{p}$ 的欧氏距离,定义区间 $i$ 的得分为:
$$
\begin{array}{r}{\hat{p}{t,k,i}=\left{\begin{array}{l l}{0,\mathrm{ if~}\vert\vert b_{t,k,i}^{p}-a_{t,k}^{p}\vert\vert_{2}^{2}>0.01\mathrm{ or~}b_{t,k,i}^{p}\in\mathbb{B}}\ {\displaystyle\frac{1}{\vert\vert b_{t,k,i}^{p}-a_{t,k}^{p}\vert\vert_{2}^{2}},\mathrm{~otherwise.}}\end{array}\right.}\end{array}
$$
$$
\begin{array}{r}{\hat{p}{t,k,i}=\left{\begin{array}{l l}{0,\mathrm{ if~}\vert\vert b_{t,k,i}^{p}-a_{t,k}^{p}\vert\vert_{2}^{2}>0.01\mathrm{ or~}b_{t,k,i}^{p}\in\mathbb{B}}\ {\displaystyle\frac{1}{\vert\vert b_{t,k,i}^{p}-a_{t,k}^{p}\vert\vert_{2}^{2}},\mathrm{~otherwise.}}\end{array}\right.}\end{array}
$$
where $\mathbb{B}$ denotes the set of points that belong to the robot arm and gripper, and their scores are set to zero to ensure that the gripper’s position is predicted based only on the objects in the scene. The ground truth probability of position along the $k$ axis is then obtained by normalizing the scores $\widehat{p}_{t,k,i}$ via L1 norm. For rotation prediction, we simply use one-hot label along each axis.
其中 $\mathbb{B}$ 表示属于机械臂和夹爪的点集,其得分设为零以确保夹爪位置仅根据场景中的物体进行预测。沿 $k$ 轴位置的真实概率通过 L1 范数对得分 $\widehat{p}_{t,k,i}$ 进行归一化获得。对于旋转预测,我们直接沿每条轴使用独热编码标签。
C. Details policy
C. 策略细节
- Task planning: Figure 6 illustrates the prompts used in LLMs for task planning. For each task variation in the training set, we craft a corresponding example as shown in Figure 7. During inference, for each new instruction, we use Sentence Bert [?] to compute the sentence embedding of the instruction and compare it to the existing instructions. We then select the top 20 examples with the highest similarities to the query instruction as in-context examples to the LLM.
- 任务规划:图 6 展示了用于大语言模型任务规划的提示词。针对训练集中的每个任务变体,我们会按图 7 所示构建对应示例。在推理阶段,对于每条新指令,我们使用 Sentence Bert [?] 计算指令的句子嵌入向量,并与现有指令进行比对。随后选取与查询指令相似度最高的 20 个示例作为大语言模型的上下文示例。
- Object grounding: We use VLMs to detect the location of queried objects except for tasks requiring grounding different parts of articulated object like bottom drawer and top shelf. This limitation arises because our VLMs can only detect the whole object like drawer, but cannot ground the target level of the drawer. Therefore, we further leverage the LLM to predict the height range of the target object. We first obtain the overall height of the target object based on VLM’s prediction, then we use prompts presented in Figure 8 to guide the LLM in predicting the height range.
- 物体定位:我们使用视觉语言模型(VLM)来检测查询物体的位置,但对于需要定位铰接物体不同部分(如底层抽屉和顶层搁板)的任务除外。这一限制源于我们的视觉语言模型只能检测整体物体(如抽屉),而无法定位抽屉的具体层级。因此,我们进一步利用大语言模型来预测目标物体的高度范围:首先基于视觉语言模型的预测获得目标物体的整体高度,然后使用图8所示的提示词引导大语言模型预测高度范围。
RLBench-18Task. Table IX presents the detailed results of different models on each task in RLBench-18Task benchmark. Our 3D-LOTUS policy achieves better performances especially on tasks requiring high precision such as insert peg, place cups and stack cups.
RLBench-18任务。表 IX 展示了不同模型在RLBench-18任务基准测试中各项任务的详细结果。我们的3D-LOTUS策略表现更优,尤其在需要高精度的任务上,例如插入木钉 (insert peg)、放置杯子 (place cups) 和堆叠杯子 (stack cups)。
GemBench. Table $\mathrm{X}$ to XIII show the results of different models on the four generalization levels in GemBench respectively.
GemBench。表 $\mathrm{X}$ 至 XIII 分别展示了不同模型在 GemBench 四个泛化层级上的结果。
E. Detail task specification
E. 详细任务规范
We describe each task in detail along with its variations below, and highlight the newly created tasks in GemBench.
我们将在下文中详细描述每个任务及其变体,并重点介绍GemBench中新增的任务。
Close Laptop Lid
合上笔记本电脑盖
Close Microwave
关闭微波
Open Door
开门
Filename: open door.py Task: Pick up the door handle and open the door by pushing. New/Modified: Yes, modified to add new instructions. Objects: 1 door with a handle. Variations per level: Level 1: 0.
文件名: open door.py
任务: 拾取门把手并通过推动打开门。
新增/修改: 是,已修改并添加新指令。
对象: 1 扇带把手的门。
每级变化: 第 1 级: 0。
TABLE VIII: Training and testing tasks & variations in GemBench. The testing tasks contain four levels of generalization, where Level 1 evaluates the generalization to novel placements, Level 2 novel rigid objects, Level 3 novel articulated objects, and Level 4 novel long-horizon tasks.
表 VIII: GemBench中的训练与测试任务及变体。测试任务包含四个泛化级别,其中级别1评估对新摆放位置的泛化能力,级别2评估对新刚性物体的泛化能力,级别3评估对新铰接物体的泛化能力,级别4评估对新长周期任务的泛化能力。
| 训练/级别1 | 级别2 | 级别3 | 级别4 | |||||
|---|---|---|---|---|---|---|---|---|
| 任务 | 变体(栗色按钮) | 颜色 | 形状 | 实例 | 类别 | 动作部件 | 长周期(2按钮) | |
| 按压 | 按下按钮 | 海军蓝按钮 黄色按钮 | 天蓝按钮 玫瑰按钮 白色按钮 | 台灯开 | 3按钮 4按钮 | |||
| 拾取 | 拾取并举起 | 红色方块 青柠方块 青色方块 品红杯子 | 蓝绿方块 紫罗兰方块 黑色方块 灰色杯子 | 红色圆柱 红色星星 红色月亮 | ||||
| 拿起杯子 | 银色杯子 橙色杯子 绿色靶标 | 橄榄杯子 紫色杯子 粉色靶标 | 红色玩具 | |||||
| 推动 | 触及并拖动 | 蓝色靶标 蓝绿靶标 黑色靶标 天蓝罐子 | 黄色靶标 青色靶标 海军蓝靶标 蓝色罐子 | |||||
| 旋拧 | 关闭罐子 旋紧灯泡 关闭冰箱 | 紫罗兰罐子 玫瑰灯泡 白色灯泡 冰箱 | 绿色罐子 青柠灯泡 栗色灯泡 | |||||
| 关闭 | 合上笔记本盖 关闭微波炉 开门 | 笔记本盖 微波炉 100p | 冰箱2 笔记本盖2 微波炉2 门2 | 烤架 | 100p盒子 抽屉 冰箱 | 取出鞋子 | ||
| 打开 | 打开盒子 打开抽屉 | 盒子底部 顶层抽屉 第二层抽屉 2个灰色方块 | 盒子2 抽屉2, 抽屉3 带4层的长抽屉 | 马桶 | 笔记本盖 微波炉 中层抽屉 | 从盒中取出 将3件物品放入抽屉 堆叠3-4 | ||
| 堆叠方块 | 2个橄榄方块 2个紫色方块 | 2个橙色方块 2个银色方块 2个品红方块 | 方块 堆叠2个杯子 | |||||
| 放置/堆叠 | 放置杂货 | 饼干盒 汤罐头 | 芥末瓶 糖盒 | 放置所有杂货 | ||||
| 放置钱币 | 底层架子 中层架子 | 将立方体放入底层架子 | 顶层架子 |

Fig. 5: Automatic point removal. We use geometry information to automatically filter out irrelevant points in the scene
图 5: 自动点云剔除。我们利用几何信息自动过滤场景中的无关点
Success Metric: The handle has been rotated $25^{\mathrm{\circ}}$ to unlock the door and the revolute joint of the door has been rotated $25^{\mathrm{\circ}}$ .
成功指标:手柄已旋转25°以解锁门,且门的旋转关节已转动25°。
Open Box
Open Box
Success Metric: The revolute joint of the box lid has rotated $90^{\mathrm{\circ}}$ so that it is in the open configuration.
成功指标:盒盖的旋转关节已旋转 $90^{\mathrm{\circ}}$ ,使其处于打开状态。
Open Drawer
打开抽屉
Filename: open drawer.py Task: Open one of the three drawers: top, middle, or bottom. New/Modified: No. Objects: 1 drawer. Variations per level: Level 1: 0 (bottom) and 2 (top) and
文件名:open drawer.py
任务:打开三个抽屉中的一个:上层、中层或下层。
新增/修改:否。
对象:1个抽屉。
每层变化:
第1级:0(下层)和2(上层)
TABLE IX: Multi-Task Performance on RLBench. We report the success rate on all tasks in RLBench-18Task [18 benchmark. Our 3D-LOTUS outperforms all methods while having higher training speed.
表 IX: RLBench 上的多任务性能。我们报告了 RLBench-18Task [18] 基准测试中所有任务的成功率。我们的 3D-LOTUS 在保持更高训练速度的同时,性能优于所有方法。
Fig. 6: Prompts used in LLM for task planning. Level 3: 1(middle).
图 6: 大语言模型中用于任务规划的提示词。第三级:1(中)。
| 模型 | 平均成功率 ↑ | 平均排名 ↓ | 训练时间 (天) ↓ | 推理速度 (fps) ↑ | 关罐子 | 拖拽棍子 | 插入 | 取肉离烤架 | 打开 | 放置 | 放置 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| C2F-ARM-BC [38],[18] | 20.1 | 8.6 | - | - | 24 | 24 | 钉 4 | 20 | 抽屉 20 | 杯子 0 | 酒 8 |
| HiveFormer [17] | 45.3 | 6.9 | - | - | 52.0 | 76.0 | 0.0 | 100.0 | 52.0 | 0.0 | 80 |
| PolarNet [2] | 46.4 | 6.4 | 8.9 | - | 36.0 | 92.0 | 4.0 | 100.0 | 84.0 | 0.0 | 40 |
| PerAct [18] | 49.4 | 6.2 | 128.0 | 4.9 | 55.2±4.7 | 89.6±4.1 | 5.6±4.1 | 70.4±2.0 | 88.0±5.7 | 2.4±3.2 | 44.8±7.8 |
| RVT [34] | 62.9 | 4.4 | 8.0 | 11.6 | 52.0±2.5 | 99.2±1.6 | 11.2±3.0 | 88.0±2.5 | 71.2±6.9 | 4.0±2.5 | 91.0±5.2 |
| Act3D [4] | 65.0 | 4.3 | 40.0 | - | 92.0 | 92.0 | 27.0 | 94.0 | 93.0 | 3.0 | 80 |
| RVT-2 [37] | 81.4 | 2.4 | 6.6 | 20.6 | 100.0±0.0 | 99.0±1.7 | 40.0±0.0 | 99.0±1.7 | 74.0±11.8 | 38.0±4.5 | 95.0±3.3 |
| 3D diffuser actor [35] | 81.3 | 2.3 | 67.6 | - | 96.0±2.5 | 100.0±0.0 | 65.6±4.1 | 96.8±1.6 | 89.6±4.1 | 24.0±7.6 | 93.6±4.8 |
| 3D-LOTUS (ours) | 83.1 | 2.2 | 2.2 | 9.5 | 96.0±0.0 | 100.0±0.0 | 69.6±3.6 | 98.4±2.2 | 85.6±7.3 | 40.8±12.1 | 91.2±6.6 |
| 模型 | 按按钮 | 放入橱柜 | 放入 | 放入 | 拧螺丝 | 滑动 | 分类 | 堆叠 | 堆叠 | 扫入 | 转动 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| C2F-ARM-BC [38], [18] | 72 | 0 | 抽屉 4 | 保险箱 | 灯泡 | 积木 | 形状 | 积木 | 杯子 | 簸箕 | 水龙头 |
| HiveFormer [17] | 84 | 32.0 | 68.0 | 12 76.0 | 8 8.0 | 16 64.0 | 8 8.0 | 0 8.0 | 0 0.0 | 0 28.0 | 68 80 |
| PolarNet [2] | 96 | 12.0 | 32.0 | 84.0 | 44.0 | 56.0 | 12.0 | 4.0 | 8.0 | 52.0 | 80 |
| PerAct [18] | 92.8±3.0 | 28.0±4.4 | 51.2±4.7 | 84.0±3.6 | 17.6±2.0 | 74.0±13.0 | 16.8±4.7 | 26.4±3.2 | 2.4±2.0 | 52.0±0.0 | 88.0±4.4 |
| Act3D [4] | 99 | 51.0 | 90.0 | 95.0 | 47.0 | 93.0 | 8.0 | 12.0 | 9.0 | 92.0 | 94 |
| RVT [34] | 100.0±0.0 | 49.6±3.2 | 88.0±5.7 | 91.2±3.0 | 48.0±5.7 | 81.6±5.4 | - | 36.0±2.5 28.8±3.9 | 26.4±8.2 | 72.0±0.0 | 93.6±4.1 |
| RVT-2 [37] | 100.0±0.0 | 66.0±4.5 | 96.0±0.0 | 96.0±2.8 | 88.0±4.9 | 92.0±2.8 | - | 35.0±7.1 80.0±2.8 | 69.0±5.9 | 100.0±0.0 99.0±1.7 | - |
| 3D diffuser actor [35] | 98.4±2.0 | 85.6±4.1 | 96.0±3.6 | 97.6±2.0 | 82.4±2.0 | - | - | 97.6±3.2 44.0±4.4 68.3±3.3 47.2±8.58 | 84.0±4.4 99.2±1.6 | - | |
| 3D-LOTUS (ours) | 100.0±0.0 | 78.4±4.6 | 97.6±3.6 | 95.2±3.4 | 88.8±3.4 | - | 99.2±1.8 34.4±4.6 58.4±8.3 75.2±7.7 | - | - | 96.0±2.8 90.4±4.6 | - |
drawer is fully extended.
抽屉完全拉开。
Success Metric: The prismatic joint of the specified
成功指标:指定棱柱关节的

Fig. 7: In-context examples of each training task for task planning.
图 7: 任务规划中各训练任务的上下文示例。

Fig. 8: Prompts used in LLMs to predict the height range of an object.
图 8: 用于大语言模型预测物体高度范围的提示词。
TABLE X: Performance on GemBench Level 1.
表 X: GemBench Level 1 性能对比
| 方法 | 平均 | 关闭冰箱+0 | 关闭罐子+15 | 关闭罐子+16 | 关闭笔记本盖+0 | 关闭微波炉+0 | 灯泡安装+17 | 灯泡安装+19 | 打开盒子+0 | 开门+0 | 开抽屉+0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hiveformer [17] | 60.3±1.5 | 96±4.2 | 64±13.9 | 92±2.7 | 90±3.5 | 88±7.6 | 12±4.5 | 13±6.7 | 4±4.2 | 53±15.2 | 15±12.2 |
| PolarNet [2] | 77.6±0.9 | 99±2.2 | 99±2.2 | 99±2.2 | 95±3.5 | 98±2.7 | 72±12.5 | 71±6.5 | 32±11.5 | 69±8.9 | 61±12.4 |
| 3D diffuser actor [35] | 91.9±0.8 | 100±0.0 | 100±0.0 | 100±0.0 | 99±2.2 | 100±0.0 | 85±5.0 | 88±2.7 | 11±2.2 | 96±4.2 | 82±9.1 |
| RVT-2 [37] | 89.0±0.8 | 77±11.0 | 97±4.5 | 98±2.7 | 77±13.0 | 100±0.0 | 93±5.7 | 91±8.2 | 7±4.5 | 98±4.5 | 93±5.7 |
| 3D-LOTUS (ours) | 94.3±3.5 | 96±3.7 | 100±0.0 | 100±0.0 | 98±2.5 | 98±4.0 | 84±7.4 | 85±9.5 | 99±2.0 | 77±2.5 | 83±8.7 |
| 3D-LOTUS++ (ours) | 68.7±0.6 | 00+56 | 100±0.0 | 99±2.0 | 28±2.5 | 87±5.1 | 55±10.5 | 45±8.9 | 55±8.9 | 79±9.7 | 68±12.5 |
| 方法 | 开抽屉+2 | 拿起+0 | 拿起+2 | 拿起+7 | 拿起杯子+8 | 拿起杯子+9 | 拿起杯子+11 | 按按钮+0 | 按按钮+3 | 按按钮+4 | 放入橱柜+0 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hiveformer [17] | 86±4.2 | 61±19.8 | 34±8.2 | ||||||||
| PolarNet [2] | 59±7.4 | 90±7.1 | 92±9.1 | 92±6.7 | 84±7.4 | 93±2.7 | 88±5.7 | 83±7.6 | 82±7.6 | 69±12.9 | 79±4.2 |
| 3D diffuser actor [35] | 97±4.5 | 99±2.2 | 99±2.2 | 99±2.2 | 96±2.2 | 97±4.5 | 98±2.7 | 98±2.7 | 96±4.2 | 98±2.7 | 85±5.0 |
| RVT-2 [37] | 94±4.2 | 99±2.2 | 98±2.7 | 100±0.0 | 99±2.2 | 99±2.2 | 99±2.2 | 100±0.0 | 100±0.0 | 100±0.0 | 88±8.4 |
| 3D-LOTUS (ours) | 93±6.0 | 99±2.0 | 100±0.0 | 99±2.0 | 97±4.0 | 96±3.7 | 94±4.9 | 99±2.0 | 99±2.0 | 100±0.0 | 89±5.8 |
| 3D-LOTUS++ (ours) | 75±4.5 | 97±6.0 | 94±3.7 | 93±5.1 | 86±8.0 | 88±6.8 | 91±4.9 | 100±0.0 | 100±0.0 | 100±0.0 | 1±2.0 |
| 方法 | 放入橱柜+3 | 存钱+0 | 存钱+1 | 拖拽+14 | 拖拽+18 | 滑动方块+0 | 滑动方块+1 | 堆叠方块+30 | 堆叠方块+36 | 堆叠方块+39 |
|---|---|---|---|---|---|---|---|---|---|---|
| Hiveformer [17] | 6±5.5 | 34±10.8 | 37±5.7 | 32±7.6 | 99±2.2 | 100±0.0 | 91±12.4 | 0±0.0 | 7±4.5 | |
| PolarNet [2] | 74±6.5 | 88±4.5 | 85±3.5 | 93±4.5 | 88±2.7 | 95±5.0 | 37±5.7 | 99±2.2 | 32±7.6 | 99±2.2 |
| 3D diffuser actor [35] | 82±11.5 | 95±5.0 | 98±2.7 | 100±0.0 | 99±2.2 | 100±0.0 | 89±4.2 | 88±7.6 | 30±9.4 | 85±6.1 |
| RVT-2 [37] | 80±6.1 | 93±8.4 | 96±8.5 | 85±10.0 | 94±2.2 | 100±0.0 | 37±6.7 | 88±5.7 | 93±2.7 | 88±11.5 |
| 3D-LOTUS (ours) | 72±11.2 | 94±3.7 | 99±2.0 | 99±2.0 | 100±0.0 | 100±0.0 | 100±0.0 | 94±5.8 | 91±6.6 | 90±4.5 |
| 3D-LOTUS++ (ours) | 2±2.5 | 22±6.8 | 16±4.9 | 94±3.7 | 62±8.7 | 100±0.0 | 65±5.5 | 86±5.8 | 20±4.5 | 28±13.6 |
Pick and Lift
Pick and Lift
Filename: pick and lift.py
文件名:pick and lift.py
Task: Pick a colored cube and lift it to a red sphere target.
任务:选择一个彩色立方体并将其举到红色球体目标处。
New/Modified: No.
新增/修改:无。
Objects: 3 colored cubes, one with the specified color and the other two with different colors as distract or s.
物体:3个彩色立方体,其中一个为指定颜色,另外两个为不同颜色的干扰项。
Variations per level: Level 1: 0 (red), 2 (lime) and 7 (cyan) and Level 2: 14 (teal), 16 (violet) and 18 (black).
各层级变异数:层级1:0(红)、2(绿)和7(青);层级2:14(蓝绿)、16(紫)和18(黑)。
Success Metric: The cube of the specified color is grasped and next to the target red sphere.
成功指标:抓取指定颜色的立方体并将其放置在目标红色球体旁边。
Pick Up Cup
拿起杯子
Filename: pick up cup.py
文件名:pick up cup.py
Task: Pick the cup with the specified color and lift it from the table.
任务:拿起桌上指定颜色的杯子并将其从桌面抬起。
New/Modified: No.
新增/修改:编号
Objects: 3 tall colored cups.
物品:3个高脚彩色杯子。
Variations per level: Level 1: 8 (magenta), 9 (silver) and 11 (orange) and Level 2: 10 (gray), 12 (olive) and 13 (purple).
每级变体:第1级:8(品红)、9(银色)和11(橙色);第2级:10(灰色)、12(橄榄色)和13(紫色)。
Success Metric: The cup of the specified color is grasped and lifted from the table.
成功指标:从桌上抓取并抬起指定颜色的杯子。
Stack Blocks
Stack Blocks
Filename: stack blocks.py Task: Stack $N$ blocks of the specified color on the green
文件名:stack blocks.py 任务:将指定颜色的 $N$ 个方块堆叠在绿色方块上
TABLE XI: Performance on GemBench Level 2.
表 XI: GemBench Level 2 性能表现
| 方法 | 平均 | Push Button+13 | Push Button+15 | Push Button+17 | Pick& Lift+14 | Pick& Lift+16 | Pick& Lift+18 | PickUp Cup+10 | PickUp Cup+12 | PickUp Cup+13 |
|---|---|---|---|---|---|---|---|---|---|---|
| Hiveformer | 26.1±1.4 | 97±2.7 | 85±10.0 | 88±2.7 | 21±6.5 | 9±4.2 | 8±6.7 | 30±7.1 | 22±13.5 | 26±10.6 |
| PolarNet | 37.1±1.4 | 100±0.0 | 100±0.0 | 85±7.9 | 3±4.5 | 1±2.2 | 00干0 | 48±11.0 | 46±8.9 | 16±6.5 |
| 3D diffuser actor | 43.4±2.8 | 87±13.0 | 81±6.5 | 60±9.4 | 9±4.2 | 18±9.1 | 00干0 | 84±5.5 | 60±11.7 | 62±13.0 |
| RVT-2 | 51.0±2.3 | 100±0.0 | 100±0.0 | 100±0.0 | 47±7.6 | 29±9.6 | 8±4.5 | 81±8.2 | 59±9.6 | 72±9.7 |
| 3D-LOTUS (ours) | 49.9±2.2 | 99±2.0 | 100±0.0 | 100±0.0 | 3±2.5 | 18±8.7 | 33±9.3 | 89±3.7 | 78±8.7 | 57±7.5 |
| 3D-LOTUS++ (ours) | 64.5±0.9 | 99±2.0 | 100±0.0 | 99±2.0 | 94±3.7 | 96±3.7 | 95±3.2 | 79±4.9 | 89±9.7 | 84±10.2 |
| 方法 | Stack Blocks+24 | Stack Blocks+27 | Stack Blocks+33 | Slide Block+2 | Slide Block+3 | Close Jar+3 | Close Jar+4 | LightBulb In+1 | LightBulb In+2 | Lamp On+0 |
|---|---|---|---|---|---|---|---|---|---|---|
| Hiveformer | 00+0 | 4±4.2 | 00+0 | 00+0 | 00+0 | 00+0 | 4±4.2 | 00+0 | 7±4.5 | |
| PolarNet | 1±2.2 | 2±2.7 | 6±8.2 | 0±0.0 | 00+0 0±0.0 | 20±10.6 | 82±5.7 | 22±11.5 | 17±8.4 | 14±10.8 |
| 3D diffuser actor | 66±13.9 | 82±2.7 | 50±14.6 | 00+0 | 0±0.0 | 23±16.8 | 82±5.7 | 51±17.8 | 60±10.0 | 7±7.6 |
| RVT-2 | 18±4.5 | 56±16.7 | 45±13.7 | 00F0 | 1±2.2 | 7±7.6 | 77 ±5.7 | 68±14.4 | S"9千9 | 0±0.0 |
| 3D-LOTUS (ours) | 13±8.1 | 40±9.5 | 69±5.8 | 00+0 | 00+0 | 71±5.8 | 90±4.5 | 24±4.9 | 41±8.6 | 00+0 |
| 3D-LOTUS++ (ours) | 22±9.3 | 83±7.5 | 59±3.7 | 27±9.8 | 5±3.2 | 98±2.5 | 96±3.7 | 56±9.7 | 43±7.5 | 2±2.0 |
| 方法 | Reach& Drag+5 | Reach& Drag+7 | PutCube InSafe+0 | Pick&Lift Cylinder+0 | Pick&Lift Star+0 | Pick&Lift Moon+0 | Pick&Lift Toy+0 | PutIn Cupboard+7 | PutIn Cupboard+8 |
|---|---|---|---|---|---|---|---|---|---|
| Hiveformer | 1±2.2 | 00+0 | 4±2.2 | 78±5.7 | 73±7.6 | 88±2.7 | 87 ±4.5 | 00F0 | 00+0 |
| PolarNet | 61±8.2 | 10±6.1 | 40±14.1 | 93±6.7 | 88±8.4 | 93±6.7 | 90±3.5 | 00+0 | 00+0 |
| 3D diffuser actor | 00+0 | 64±6.5 | 3±2.7 | 99±2.2 | 43±17.9 | 91±9.6 | 30±9.4 | 00+0 | 3±4.5 |
| RVT-2 | 91±2.2 | 89±6.5 | 6±5.5 | 98±2.7 | 98±4.5 | 94±4.2 | 78±8.4 | 00F0 | 00+0 |
| 3D-LOTUS (ours) | 95±4.5 | 18±10.8 | 25±5.5 | 88±8.7 | 69±6.6 | 80±8.4 | 96±3.7 | 00+0 | 00+0 |
| 3D-LOTUS++ (ours) | 94±2.0 | 64±12.4 | 37±5.1 | 91±2.0 | 94±3.7 | 29±6.6 | 71±2.0 | 1±2.0 | 00干0 |
TABLE XII: Performance on GemBench Level 3.
表 XII: GemBench Level 3 性能表现
| 方法 | 平均 | 关门+0 | 关盒+0 | 关冰箱2+0 | 关笔记本盖2+0 | 关微波炉2+0 | 开门2+0 | 开盒2+0 |
|---|---|---|---|---|---|---|---|---|
| Hiveformer | 35.1±1.7 | 00+0 | 1±2.2 | 34±9.6 | 52±9.1 | 15±7.1 | 32±11.5 | 5±3.5 |
| PolarNet | 38.5±1.7 | 0±0.0 | 0±0.0 | 78±5.7 | 26±8.2 | 74±6.5 | 33±6.7 | 23±8.4 |
| 3D diffuser actor | 37.0±2.2 | 0±0.0 | 0±0.0 | 97±2.7 | 23±6.7 | 88±7.6 | 86±7.4 | 67±9.8 |
| RVT-2 | 36.0±2.2 | 1±2.2 | 2±2.7 | 72±6.7 | 42±14.0 | 71±8.9 | 79±6.5 | 5±6.1 |
| 3D-LOTUS (ours) | 38.1±1.1 | 0±0.0 | 58±8.1 | 36±9.7 | 54±10.7 | 85±7.1 | 42±6.8 | 11±6.6 |
| 3D-LOTUS++ (ours) | 41.5±1.8 | 1±2.0 | 29±8.6 | 93±2.5 | 50±9.5 | 99±2.0 | 52±10.3 | 16±8.0 |
| 方法 | 开抽屉2+0 | 开抽屉3+0 | 开长抽屉+0 | 开长抽屉+1 | 开长抽屉+2 | 开长抽屉+3 | 马桶盖抬起+0 | 开冰箱+0 |
|---|---|---|---|---|---|---|---|---|
| Hiveformer | 59±11.9 | 39±11.9 | 78±8.4 | 82±4.5 | 49±4.2 | 57±11.5 | 6±4.2 | 00+0 |
| PolarNet | 91±4.2 | 29±8.2 | 84±11.9 | 88±5.7 | 63±8.4 | 37±7.6 | 2±2.7 | 4±2.2 |
| 3D diffuser actor | 19±8.2 | 1±2.2 | 15±5.0 | 35±13.7 | 26±9.6 | 79±12.9 | 00+0 | 7±5.7 |
| RVT-2 | 81±11.9 | 0±0.0 | 84±8.2 | 39±10.8 | 11±8.9 | 75±6.1 | 7±5.7 | 00F0 |
| 3D-LOTUS (ours) | 90±3.2 | 22±8.1 | 56±13.9 | 33±11.2 | 17±8.1 | 75±6.3 | 0±0.0 | 4±5.8 |
| 3D-LOTUS++ (ours) | 70±5.5 | 41±4.9 | 72±4.0 | 52±10.8 | 23±8.1 | 78±5.1 | 8±5.1 | 00+0 |
| 方法 | 开笔记本盖+0 | 开微波炉+0 | 安全+2 | 开抽屉+1 | 关抽屉+0 | 关烤架+0 |
|---|---|---|---|---|---|---|
| Hiveformer | 100±0.0 | 00+0 | 0±0.0 | 00+0 | 83±5.7 | 44±10.8 |
| PolarNet | 100±0.0 | 00+0 | 1±2.2 | 4±4.2 | 29±11.9 | 42±11.5 |
| 3D diffuser actor | 100±0.0 | 0±0.0 | 2±4.5 | 0±0.0 | 66±7.4 | 65±13.7 |
| RVT-2 | 93±5.7 | 0±0.0 | 0±0.0 | 6±2.2 | 78±8.4 | 9±4.2 |
| 3D-LOTUS (ours) | 100±0.0 | 0±0.0 | 0±0.0 | 00F0 | 87±8.1 | 29±6.6 |
| 3D-LOTUS++ (ours) | 86±6.6 | 00F0 | 13±8.1 | 00T0 | 69±5.8 | 19±13.9 |
platform. There are always 4 blocks of the specified color, and 4 distractor blocks of another color. The block colors are sampled from the full set of 20 color instances.
平台。始终有4个指定颜色的方块和4个另一种颜色的干扰方块。方块颜色从全部20种颜色实例中采样。
New/Modified: No.
新增/修改:编号
Objects: 8 color blocks (4 are distract or s), and 1 green platform
对象:8个色块(其中4个为干扰项)和1个绿色平台
Variations per level: Level 1: 30 (2 gray blocks), 36 (2 olive blocks), 39 (2 purple blocks) and Level 2: 24 (2 orange blocks), 27 (2 silver blocks) and 33 (2 magenta blocks).
各级变体数量:
第1级:30种(2个灰色块)、36种(2个橄榄色块)、39种(2个紫色块);
第2级:24种(2个橙色块)、27种(2个银色块)、33种(2个品红色块)。
Success Metric: $N$ blocks are inside the area of the green platform.
成功指标:$N$ 个方块位于绿色平台区域内。
Put Groceries in Cupboard
将食品杂货放入橱柜
Filename: put groceries in cupboard.py
文件名:put groceries in cupboard.py
Task: Grab the specified object and put it in the cupboard above. The scene always contains 9 YCB objects that are randomly placed on the tabletop.
任务:抓取指定物体并将其放入上方的橱柜中。场景中始终随机摆放着9个YCB物体于桌面上。
New/Modified: Yes, modified the object names to include object category and therefore the instructions.
新增/修改:是,修改了对象名称以包含对象类别及相应说明。
Objects: 9 YCB objects, and 1 cupboard (that hovers in the air like magic).
物体:9个YCB物体和1个橱柜(像魔法一样悬浮在空中)。
Variations per level: Level 1: 0 (crackers box) and 3 (soup
每层级变化数:层级1:0(饼干盒)和3(汤罐头)
TABLE XIII: Performance on GemBench Level 4.
表 XIII: GemBench Level 4 性能表现
| 方法 | 平均 | 按下按钮4+1 | 按下按钮4+2 | 按下按钮4+3 | 从盒中取出鞋子+0 | 将物品放入抽屉+0 | 将物品放入抽屉+2 |
|---|---|---|---|---|---|---|---|
| Hiveformer | 00+0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| PolarNet | 0.1±0.2 | 1±2.2 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| 3Ddiffuser actor | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| RVT-2 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| 3D-LOTUS (ours) | 0.3±0.3 | 3±4.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0'0+0 |
| 3D-LOTUS++ (ours) | 17.4±0.4 | 76±7.4 | 49±8.6 | 37±8.1 | 0±0.0 | 0±0.0 | 0±0.0 |
| 方法 | 将物品放入抽屉+4 | 塔4+1 | 塔4+3 | 叠杯子+0 | 叠杯子+3 | 将所有杂货放入橱柜+0 |
|---|---|---|---|---|---|---|
| Hiveformer | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| PolarNet | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| 3Ddiffuseractor | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| RVT-2 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| 3D-LOTUS (ours) | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 | 0±0.0 |
| 3D-LOTUS++ (ours) | 0±0.0 | 17±10.8 | 30±13.4 | 0±0.0 | 0±0.0 | 0±0.0 |
can) and Level 2: 7 (mustard bottle) and 8 (sugar box).
1级:5(罐头)和2级:7(芥末瓶)与8(糖盒)。
Success Metric: The specified object is inside the cupboard.
成功指标:指定物品在橱柜内。
Put Money in Safe
把钱放进保险箱
Filename: put money in safe.py
文件名:put money in safe.py
Task: Pick up the stack of money and put it inside the safe on the specified shelf. The shelf has three placement locations: top, middle, bottom.
任务:拿起那叠钱并将其放入指定架子的保险箱内。架子有三个放置位置:顶部、中部、底部。
New/Modified: No.
新增/修改:无
Objects: 1 stack of money, and 1 safe.
物品:1叠钱和1个保险箱。
Variations per level: Level 1: 0 (bottom) and 1 (middle) and Level 2: 2 (top).
每层级变化:层级1:0(底部)和1(中部),层级2:2(顶部)。
Success Metric: The stack of money is on the specified shelf inside the safe.
成功指标:钱堆放在保险箱内指定的架子上。
Slide Block to Color Target
Slide Block to Color Target
Filename: slide block to color target peract.py
文件名:slide block to color target peract.py
Task: Slide the block on to one of the colored square targets. The target colors are limited to red, blue, pink, and yellow.
任务:将方块滑动到其中一个彩色方块目标上。目标颜色仅限于红色、蓝色、粉色和黄色。
New/Modified: Yes, modified as in RLBench-18Task [18]. The original slide block to target.py task contained only one target. Three other targets were added to make a total of 4 variations.
新增/修改:是,修改方式与RLBench-18Task [18]相同。原版slide_block_to_target.py任务仅包含一个目标,本次新增三个目标变体,使总变体数达到4种。
Objects: 1 block and 4 colored target squares.
物体:1个方块和4个彩色目标方块。
Variations per level: Level 1: 0 (green) and 1 (blue) and Level 2: 2 (pink) and 3 (yellow).
每层级变化:层级 1:0 (绿色) 和 1 (蓝色),层级 2:2 (粉色) 和 3 (黄色)。
Success Metric: Some part of the block is inside the specified target area.
成功指标:部分区块位于指定目标区域内。
Reach and Drag
触及与拖拽
Filename: reach and drag peract.py
文件名:reach_and_drag_peract.py
Task: Grab the stick and use it to drag the cube on to the specified colored target square. The target colors are sampled from the full set of 20 color instances.
任务:拿起棍子并用它将立方体拖到指定颜色的目标方块上。目标颜色从完整的20种颜色实例中采样。
New/Modified: Yes, modified as in RLBench-18Task [18]. The original reach and drag.py task contained only one target. Three other targets were added with randomized colors.
新增/修改:是,修改方式与RLBench-18Task [18]相同。原版reach和drag.py任务仅包含一个目标,现新增三个随机颜色的目标。
Objects: 1 block, 1 stick, and 4 colored target squares.
物体:1个方块、1根木棍和4个彩色目标方块。
Variations per level: Level 1: 14 (teal) and 18 (black) and Level 2: 5 (cyan) and 7 (navy).
每层变体数量:第一层:14种(青色)和18种(黑色);第二层:5种(浅蓝)和7种(深蓝)。
Success Metric: Some part of the block is inside the specified target area.
成功指标:方块部分位于指定目标区域内。
Close Jar
关紧罐子
Filename: close jar.py
文件名:close jar.py
Task: Put the lid on the jar with the specified color and screw the lid in. The jar colors are sampled from the full set of 20 color instances.
任务:将指定颜色的盖子盖在罐子上并拧紧。罐子颜色从20种颜色实例中随机选取。
New/Modified: No.
新增/修改:编号
Objects: 1 jar lid and 2 colored jars.
物品:1个罐盖和2个彩色罐子。
Variations per level: Level 1: 15 (azure) and 16 (violet) and Level 2: 3 (blue) and 4 (green).
各层级变体数量:第1级:15种(azure)和16种(violet);第2级:3种(blue)和4种(green)。
Success Metric: The lid is on top of the specified jar and the Franka gripper is not grasping anything.
成功指标:盖子位于指定罐子顶部且 Franka 夹爪未抓取任何物体。
Screw Bulb
螺旋灯泡
Filename: light bulb in.py
文件名:light bulb in.py
Task: Pick up the light bulb from the specified holder, and screw it into the lamp stand. The colors of holder are sampled from the full set of 20 color instances. There are always two holders in the scene – one specified and one distractor holder.
任务:从指定颜色的灯座中取出灯泡,并将其旋入灯架。灯座颜色从20种颜色实例中随机选取。场景中始终存在两个灯座——一个是指定灯座,另一个是干扰灯座。
Modified: No.
修改编号:
Objects: 2 light bulbs, 2 holders, and 1 lamp stand.
物品:2个灯泡、2个灯座和1个灯架。
Variations per level: Level 1: 17 (rose) and 19 (white) and Level 2: 1 (lime) and 2 (maroon).
各层级变体数量:
层级1:17种(玫瑰色)和19种(白色);
层级2:1种(青柠色)和2种(褐红色)。
Success Metric: The bulb from the specified holder is inside the lamp stand dock.
成功指标:指定灯座中的灯泡位于灯架底座内。
Close Door
关门
Filename: close door.py
文件名:close door.py
Task: Grab the handle of the door and pull to close the door.
任务:抓住门把手并拉动以关闭门。
Modified: Yes, modified to add new instructions.
修改:是,已修改以添加新指令。
Objects: 1 door with a handle.
对象:1扇带把手的门。
Variations per level: Level 3: 0.
每级变体数:第3级:0。
Success Metric: The revolute joint of the door is in the close configuration.
成功指标:门的旋转关节处于关闭状态。
Close Box
关闭窗口
Filename: close box.py Task: Grab the box lid and rotate to close the box.
文件名: close box.py 任务: 抓取盒盖并旋转以关闭盒子。
New/Modified: Yes, modified to add new instructions.
新增/修改:是,修改以添加新指令。
Objects: 1 box.
物品:1个箱子。
Variations per level: Level 3: 0.
每级变化数:第3级:0。
Success Metric: The revolute joint of the box lid has rotated so that it is in the closed configuration.
成功指标:盒盖的旋转关节已转动至闭合状态。
Close Drawer
关闭抽屉
Filename: close drawer.py
文件名:close drawer.py
Task: Close one of the three drawers: top, middle, or bottom.
任务:关闭三个抽屉中的一个:上层、中层或下层。
New/Modified: Yes, modified to add new instructions.
新增/修改:是,修改以添加新指令。
Objects: 1 drawer unit with 3 drawers.
1 个带 3 个抽屉的抽屉单元。
Variations per level: Level 3: 0.
每级变体数:3级:0。
Success Metric: The prismatic joint of the specified drawer is fully contracted.
成功指标:指定抽屉的棱柱关节完全收缩。
Open Fridge
Open Fridge
Filename: open fridge.py
文件名:open fridge.py
Task: Grab the handle of the fridge door and pull to open the fridge.
任务:抓住冰箱门的把手并拉开冰箱。
New/Modified: Yes, modified to add new instructions.
新增/修改:是,修改以添加新指令。
Objects: 1 fridge.
物品:1台冰箱。
Variations per level: Level 3: 0.
各层级变体数:第3级:0。
Success Metric: The revolute joint of the fridge door has rotated 70 degrees so that the fridge is open.
成功指标:冰箱门的旋转关节已转动70度,此时冰箱处于开启状态。
Open Laptop Lid
打开笔记本屏幕
Filename: open laptop lid.py
文件名:open laptop lid.py
Task: Grab the laptop lid and open it.
任务:抓住笔记本电脑的盖子并打开它。
New/Modified: Yes, we modified the close laptop lid task to add a new task where the laptop is already close and the goal is to open the lid instead of closing it.
新增/修改:是的,我们修改了合上笔记本屏幕的任务,新增了一个任务场景:当笔记本屏幕已处于闭合状态时,目标改为打开屏幕而非合上。
Objects: 1 laptop and 1 box.
物品:1台笔记本电脑和1个箱子。
Variations per level: Level 3: 0.
各层级变体数:第3级:0。
Success Metric: The revolute joint of the laptop lid reaches its minimum value so that the laptop is open.
成功指标:笔记本屏幕的旋转关节达到最小值,使笔记本处于打开状态。
Objects: 1 cube and 1 safe.
物品:1个立方体和1个保险箱。
Variations per level: Level 1: 0.
各层级变异数:第1级:0。
Success Metric: The cube is on the specified shelf inside the safe.
成功指标:立方体位于保险箱内指定的架子上。
Filename: close fridge2.py
文件名:close_fridge2.py
Task: Close the fridge door by pushing it.
任务:通过推动来关闭冰箱门。
New/Modified: Yes, new task based on close fridge where the fridge mesh and texture are completely changed.
新增/修改:是,基于关闭冰箱的新任务,其中冰箱的网格和纹理完全改变。
Objects: 1 microwave.
物品:1台微波炉。
Variations per level: Level 1: 0.
每级变异数:第1级:0。
Close Fridge2
关闭冰箱2
Success Metric: The revolute joint of the fridge door is in closed configuration and the door is in contact with the fridge cabinet.
成功指标:冰箱门的旋转关节处于闭合状态,且门与冰箱柜体接触。
Close Laptop Lid2
合上笔记本电脑盖2
Filename: close laptop lid2.py
文件名:close laptop lid2.py
Task: Grasp the laptop lid and rotate to close the laptop.
任务:抓住笔记本电脑的上盖并旋转以关闭电脑。
New/Modified: Yes, a new task based on close laptop lid task where the laptop is already close and the goal is to open the lid instead of closing it.
新增/修改项:是的,基于合上笔记本盖任务的新任务,此时笔记本已处于合盖状态,目标是打开盖子而非合上。
Objects: 1 box, 1 laptop.
物品:1个盒子,1台笔记本电脑。
Variations per level: Level 3: 0.
每级变体:3级:0。
Success Metric: The revolute joint of the laptop lid is in the close configuration.
成功指标:笔记本电脑盖板的旋转铰链处于闭合状态。
Close Microwave2
Close Microwave2
Filename: close microwave2.py
文件名:close_microwave2.py
Task: Close the microwave door.
任务:关闭微波炉门。
New/Modified: Yes, new task based on close microwave task where the microwave and handle meshes and textures are completely changed.
新增/修改:是,基于原有微波炉任务的新任务,其中微波炉和把手的网格模型及纹理全部更换。
Objects: 1 microwave.
物品:1台微波炉。
Variations per level: Level 3: 0.
每级变体数:第3级:0。
Success Metric: The revolute joint of the microwave is in the close configuration.
成功指标:微波炉的旋转关节处于闭合状态。
Open Microwave
Open Microwave
Filename: open microwave.py
文件名:open_microwave.py
Task: Grab the handle to pull and open the microwave door.
任务:抓住把手拉开微波炉门。
New/Modified: Yes, modified to add new instructions.
新增/修改:是,修改以添加新指令。
Objects: 1 microwave.
物品:1台微波炉。
Variations per level: Level 3: 0.
各级变化:3级:0。
Success Metric: The revolute joint of the microwave has rotated at least $80^{\mathrm{o}}$ .
成功指标:微波炉的旋转关节至少转动了$80^{\mathrm{o}}$。
Open Door2
Open Door2
Filename: open door2.py
文件名:open door2.py
Task: Pick up the door handle and open the door by pushing.
任务:拿起门把手并推开门。
New/Modified: Yes, a new task based on open door task where the door, door frame and handle meshes and textures are completely changed.
新增/修改:是的,基于开门任务的新任务,其中门、门框和把手的网格及纹理完全改变。
Objects: 1 door with a handle.
对象:1 扇带把手的门。
Variations per level: Level 3: 0.
每级变异数:第3级:0。
Success Metric: The handle has been rotated $25^{\mathrm{\circ}}$ to unlock the door and the revolute joint of the door has been rotated $20^{\circ}$ .
成功指标:手柄已旋转 $25^{\mathrm{\circ}}$ 以解锁门,且门的旋转关节已转动 $20^{\circ}$。
Put Cube In Safe
将方块放入保险箱
Filename: put cube in safe.py
文件名:put cube in safe.py
Task: Pick up the cube and put it inside the safe on the specified shelf. The shelf has three placement locations: top, middle, bottom.
任务:拿起立方体并将其放入指定架子上的保险箱内。架子有三个放置位置:顶部、中部、底部。
New/Modified: Yes, new task based on put money in safe where the bank note is changed by a cube.
新增/修改:是的,新任务基于将钱放入保险箱,其中纸币被替换为立方体。
Open Box2
Open Box2
Filename: open box2.py
文件名:open box2.py
Task: Open the box lid.
任务:打开盒盖。
New/Modified: Yes, a new task based on open box task where the box mesh and texture are changed.
新增/修改:是基于开箱任务的新任务,其中箱子的网格和纹理已更改。
Objects: 1 box with a lid.
物品:1个带盖的盒子。
Variations per level: Level 3: 0.
每级变体数:3级:0。
Success Metric: The revolute joint of the box lid has rotated $90^{\mathrm{\circ}}$ so that it is in the open configuration.
成功指标:盒盖的旋转关节已旋转 $90^{\mathrm{\circ}}$,使其处于打开状态。
Open Drawer2
Open Drawer2
Filename: open drawer2.py
文件名:open drawer2.py
Task: Open one of the three drawers: top, middle, or bottom.
任务:打开三个抽屉中的一个:顶部、中部或底部。
New/Modified: Yes, a new task based on open drawer task where the drawer handles and cabinet meshes, colors and textures are changed.
新增/修改:基于打开抽屉任务的新任务,其中抽屉把手、柜体网格、颜色和纹理均被更改。
Objects: 1 drawer.
对象:1个抽屉。
Variations per level: Level 3: 0 (bottom).
各层级变体:层级 3:0(底部)。
Success Metric: The revolute joint of the grill lid is in the close configuration.
成功指标:烤架盖板的旋转关节处于闭合状态。
Toilet Seat Up
马桶圈朝上
Filename: toilet seat up.py
文件名:toilet seat up.py
Task: Grasp the toilet seat and rotate it to move it up the toilet.
任务:抓住马桶座圈并旋转以将其向上移动。
New/Modified: No.
新增/修改:无。
Objects: 1 toilet.
物品:1个马桶。
Variations per level: Level 3: 0.
各层级变体数:第3级:0。
Success Metric: The revolute joint of the toilet seat is in the open configuration.
成功指标:马桶座圈旋转关节处于开启状态。
Success Metric: The prismatic joint of the specified drawer is fully extended.
成功指标:指定抽屉的棱柱关节完全伸展。
Open Drawer3
Open Drawer3
Filename: open drawer3.py
文件名:open drawer3.py
Task: Open one of the three drawers: top, middle, or bottom.
任务:打开三个抽屉中的一个:顶部、中部或底部。
New/Modified: Yes, a new task based on open drawer task where the drawer handles and cabinet meshes, colors and textures are changed and different to Open Drawer2.
新增/修改:是的,基于打开抽屉任务的新任务,其中抽屉把手、柜体网格、颜色和纹理均被更改,与Open Drawer2不同。
Objects: 1 drawer.
对象:1个抽屉。
Pick and Lift Cylinder
拾取与升降气缸
Filename: pick and lift cylinder.py
文件名:pick and lift cylinder.py
Task: Pick and lift the cylinder with the specified color.
任务:拾取并举起指定颜色的圆柱体。
New/Modified: Yes, a new task based on pick and lift task where cubes are changed with cylinders.
新增/修改:基于拾取和放置任务的新任务,将立方体替换为圆柱体。
Objects: 3 colored cylinders, one with the specified color and the other two with different colors as distract or s.
对象:3个彩色圆柱体,其中一个为指定颜色,另外两个为不同颜色的干扰项。
Variations per level: Level 2: 0 (red).
各层级变体:层级 2:0 (红色)。
Success Metric: The cylinder of the specified color is grasped and placed in the target red sphere.
成功指标:抓取指定颜色的圆柱体并将其放入目标红色球体中。
Variations per level: Level 3: 0 (bottom).
每层变体:第3层:0(底部)。
Success Metric: The prismatic joint of the specified drawer is fully extended.
成功指标:指定抽屉的棱柱关节完全伸展。
Open Drawer Long
Open Drawer Long
Filename: open drawer long.py
文件名:open drawer long.py
Task: Open one of the four drawers: top, top middle, bottom middle or bottom.
任务:打开四个抽屉中的一个:顶部、中上部、中下部或底部。
New/Modified: Yes, a new task based on open drawer task where the drawer unit has 4 drawers and and the handles and cabinet meshes, colors and textures are changed.
新增/修改:是的,基于打开抽屉任务的新任务,其中抽屉单元有4个抽屉,且把手、柜体网格、颜色和纹理均被更改。
Pick and Lift Star
拾取与抬升之星
Filename: pick and lift star.py
文件名:pick and lift star.py
Task: Pick and lift the star with the specified color.
任务:拾取并举起指定颜色的星星。
New/Modified: Yes, a new task based on pick and lift task where cubes are changed with stars.
新增/修改:是的,这是一个基于拾取和举起任务的新任务,其中立方体被替换为星形。
Objects: 3 colored stars, one with the specified color and the other two with different colors as distract or s.
对象:3颗彩色星星,其中一颗为指定颜色,另外两颗为不同颜色作为干扰项。
Variations per level: Level 2: 0 (red).
每级变体:2级:0(红色)。
Success Metric: The star of the specified color is grasped and placed in the target red sphere.
成功指标:将指定颜色的星星抓取并放入目标红色球体中。
Objects: 1 drawer.
对象:1个抽屉。
Variations per level: Level 3: 0 (bottom), 1 (bottom middle), 2 (top middle) and 3 (top).
各层级变体:层级3:0(底部)、1(中下)、2(中上)和3(顶部)。
Success Metric: The prismatic joint of the specified drawer is fully extended.
成功指标:指定抽屉的棱柱关节完全伸展。
Pick and Lift Moon
Pick and Lift Moon
Filename: pick and lift moon.py
文件名:pick and lift moon.py
Task: Pick and lift the moon with the specified color.
任务:拾取并举起指定颜色的月亮。
New/Modified: Yes, a new task based on pick and lift task where cubes are changed with moons.
新增/修改项:基于拾取和举升任务的新任务,将方块替换为月牙形物体。
Lamp On
灯亮
Filename: lamp on.py Task: Press the button to light on the lamp. New/Modified: No. Objects: 1 lamp, 1 button. Variations per level: Level 2: 0. Success Metric: The button is pressed and the lamp lig is on.
文件名: lamp on.py
任务: 按下按钮点亮灯。
新增/修改: 否。
对象: 1盏灯,1个按钮。
每级变化: 第2级: 0。
成功指标: 按钮被按下且灯亮起。
Objects: 3 colored moons, one with the specified color and the other two with different colors as distract or s.
对象:3个彩色月亮,1个为指定颜色,另外2个为不同颜色作为干扰项。
Variations per level: Level 2: 0 (red).
每级变体:2级:0(红色)。
Success Metric: The moon of the specified color is grasped and placed in the target red sphere.
成功指标:将指定颜色的月亮抓取并放入目标红色球体中。
Close Grill
关闭烤架
Pick and Lift Toy
抓取与举升玩具
Filename: pick and lift moon.py
文件名:pick and lift moon.py
Task: Pick and lift the duck rubber toy with the specified color
任务:拾取并举起指定颜色的橡皮鸭玩具
New/Modified: Yes, a new task based on pick and lift task where cubes are changed with duck rubber toys.
新增/修改:是的,这是一个基于抓取和举起任务的新任务,其中立方体被替换为橡皮鸭玩具。
Objects: 3 colored duck rubber toys, one with the specified color and the other two with different colors as distractors.
物品:3个彩色橡皮鸭玩具,其中1个为指定颜色,另外2个为不同颜色的干扰项。
Variations per level: Level 2: 0 (red).
每级变化:第2级:0(红色)。
Success Metric: The duck rubber toy of the specified color is grasped and placed in the target red sphere.
成功指标:抓取指定颜色的橡皮鸭玩具并将其放入目标红色球体中。
Push Buttons4
Push Buttons4
Filename: push buttons4.py
文件名:push_buttons4.py
Task: Push 2/3/4 buttons in the given color order.
任务:按照给定颜色顺序按下2/3/4个按钮。
New/Modified: Yes, a new task based on push button where there are 4 buttons instead of one, and the goal is change to follow a sequence of 2/3/4 buttons colors.
新增/修改:是的,这是一个基于按钮的新任务,共有4个按钮而非1个,目标改为遵循2/3/4个按钮颜色的顺序。
Objects: 4 colored buttons.
物品:4个彩色按钮。
Variations per level: Level 4: 1 (navy then teal), 2 (green then yellow then rose), 3 (maroon then blue then orange then magenta).
每级变化:4级:1种(海军蓝后接水鸭色),2种(绿色后接黄色再转玫瑰色),3种(栗色后接蓝色再转橙色最后洋红色)。
Success Metric: The buttons are pressed consecutively in the same order as specified by the instructions.
成功指标:按钮按照指令指定的顺序连续按下。
Take Shoes Out Of Box
将鞋子从盒中取出
Filename: take shoes out of box.py
文件名:take shoes out of box.py
Task: Open the box and then take both shoes and place them in the table.
任务:打开盒子,然后取出两只鞋并将它们放在桌子上。
New/Modified: No.
新增/修改:无。
Objects: 1 box and 2 shoes.
物品:1个盒子和2双鞋。
Variations per level: Level 4: 0.
每级变化:4级:0。
Success Metric: Both shoes are outside of the box and on top of the table.
成功指标:两只鞋子都在盒子外且位于桌面上。
Put Items In Drawer
将物品放入抽屉
Filename: put items in drawer.py
文件名:将物品放入抽屉.py
Task: Put a cube, a cylinder and a moon in the specified order and inside one of the three drawers: top, middle and bottom.
任务:将一个立方体、一个圆柱体和一个月亮按指定顺序放入三个抽屉(顶部、中部或底部)中的一个。
New/Modified: Yes. The task is a new long horizon task that combines open drawer task and put in drawer.
新增/修改:是。该任务是一个结合了拉开抽屉和放入抽屉的新增长周期任务。
Objects: 1 cube, 1 cylinder, 1 moon and a drawer.
物体:1个立方体、1个圆柱体、1个月亮和1个抽屉。
Variations per level: Level 4: 0 (cube then cylinder then moon in bottom drawer), 2 (cube then cylinder then moon in top drawer) and 4 (cube then moon then cylinder in middle drawer).
每级变化:第4级:0(立方体→圆柱体→月亮形,底层抽屉)、2(立方体→圆柱体→月亮形,顶层抽屉)和4(立方体→月亮形→圆柱体,中层抽屉)。
Success Metric: The cube, the cylinder and the moon have been placed in order inside the specified drawer.
成功指标:立方体、圆柱体和月亮已按顺序放入指定抽屉中。
Tower4
Tower4
Filename: tower4.py
文件名:tower4.py
Task: Stack 2, 3 or 4 cubes to create a tower on top of the green platform.
任务:将2、3或4个立方体堆叠在绿色平台上形成一座塔。
New/Modified: Yes, a new task based on stack blocks reducing the number of cubes to 4 blocks of different colors without repetitions.
新增/修改:是的,新任务基于堆叠积木,将立方体数量减少为4个不同颜色且不重复的积木块。
Objects: 4 cubes of different colors and a green platform.
物体:4个不同颜色的立方体和一个绿色平台。
Variations per level: Level 4: 1 (stack white then teal then blue) and 3 (stack orange then gray then lime then rose).
各层级变化:第4级:1(先堆叠白色,再堆叠蓝绿色,最后堆叠蓝色)和3(先堆叠橙色,再堆叠灰色,接着堆叠青柠色,最后堆叠玫瑰色)。
Success Metric: The cubes are stacked in the correct order and on top of the green platform.
成功指标:立方体按正确顺序堆叠并位于绿色平台上方。
Stack Cups
Stack Cups
Filename: stack cups.py
文件名:stack cups.py
Task: Stack all cups on top of the specified color cup. The cup colors are sampled from the full set of 20 color instances. The scene always contains three cups.
任务:将所有杯子叠放在指定颜色的杯子上。杯子颜色从20种颜色实例中随机选取,场景中始终包含三个杯子。
New/Modified: No.
新增/修改:无。
Objects: 3 tall cups.
物品:3个高杯子。
Variations per level: Level 4: 0 (red) and 3 (green).
每级变体:第4级:0(红色)和3(绿色)。
Success Metric: All other cups are inside the specified cup.
成功指标:所有其他杯子都在指定杯子内。
Put All Groceries In Cupboard
将所有食品杂货放入橱柜
Filename: put all groceries in cupboard.py
文件名:将所有食品放入橱柜.py
Task: Grab each one of the groceries and put them inside the cupboard until all of them are inside the cupboard.
任务:将所有杂货逐一取出并放入橱柜,直到全部放入为止。
New/Modified: Yes, modified to add new instructions and improve the groceries names.
新增/修改:是,修改以添加新指令并改进商品名称。
Objects: 6 YCB objects (1 crackers box, 1 chocolate jello box, 1 strawberry jello box, 1 soup can, 1 spam can, 1 mustard bottle and 1 sugar box), and 1 cupboard (that hovers in the air like magic).
物体:6个YCB物体(1个饼干盒、1个巧克力果冻盒、1个草莓果冻盒、1个汤罐头、1个午餐肉罐头、1个芥末瓶和1个糖盒),以及1个悬浮在空中的橱柜(如同魔法般)。
Variations per level: Level 4: 0.
每级变体数:4级:0。
Success Metric: All the groceries are set inside the cupboard.
成功指标:所有食品杂货都已放入橱柜。