CONTROL PREFIXES for Parameter-Efficient Text Generation
CONTROL PREFIXES 用于参数高效文本生成
Abstract
摘要
Prefix-tuning is a powerful lightweight technique for adapting a large pre-trained language model to a downstream application. However, it uses the same dataset-level tuned prompt for all examples in the dataset. We extend this idea and propose a dynamic method, CONTROL PREFIXES, which allows for the inclusion of conditional input-dependent information, combining the benefits of prompt tun- ing and controlled generation. The method incorporates attribute-level learnable representations into different layers of a pre-trained trans- former, allowing for the generated text to be guided in a particular direction. We provide a systematic evaluation of the technique and apply it to five datasets from the GEM benchmark for natural language generation (NLG). Although the aim is to develop a parameterefficient model, using only $0.1\mathrm{-}3%$ trainable parameters, we show CONTROL PREFIXES can even outperform full fine-tuning methods. We present state-of-the-art results on several data-to-text datasets, including WebNLG.
前缀调优 (Prefix-tuning) 是一种强大的轻量级技术,可将大型预训练语言模型适配到下游应用。然而,它对数据集中的所有样本使用相同的数据集级调优提示。我们扩展了这一思路,提出了一种动态方法 CONTROL PREFIXES,该方法支持融入条件性输入依赖信息,结合了提示调优 (prompt tuning) 和受控生成 (controlled generation) 的优势。该技术将属性级可学习表征嵌入预训练 Transformer 的不同层,从而引导生成文本朝特定方向发展。我们对该技术进行了系统评估,并将其应用于 GEM 基准测试中五个自然语言生成 (NLG) 数据集。尽管目标是通过仅使用 $0.1\mathrm{-}3%$ 可训练参数来开发参数高效模型,但实验表明 CONTROL PREFIXES 甚至能超越全参数微调方法。我们在 WebNLG 等多个文本生成数据集上取得了当前最优结果。
1 Introduction
1 引言
Recently, approaches in text generation have been dominated by adapting one large-scale, pre-trained language model (PLM) to various downstream tasks. Such adaptation is often performed via finetuning, which necessitates updating and storing all of the parameters, resulting in multiple new language models (LMs), one for each task. This poses a considerable challenge to the deployment of NLP systems in practice, especially as the scale of PLMs continues to climb from millions to billions of parameters. Moreover, full fine-tuning has been shown to be unnecessarily profligate through overwriting natural language understanding (NLU) that could otherwise be shared among tasks (Peters et al., 2019); it has also been shown that fine-tuned networks do not deviate substantially from the pretrained one in parameter space (Aghajanyan et al.,
近年来,文本生成方法主要依赖于将单一大规模预训练语言模型(PLM)适配到各种下游任务。这种适配通常通过微调(finetuning)实现,需要更新并存储所有参数,导致针对每个任务生成多个新语言模型(LM)。随着PLM参数量从百万级攀升至十亿级,这给NLP系统的实际部署带来了巨大挑战。此外,研究表明完整微调会不必要地覆盖本可在任务间共享的自然语言理解(NLU)能力(Peters等人,2019);另有证据表明,微调后的网络在参数空间内与预训练模型并无显著偏离(Aghajanyan等人,
2020; Radiya-Dixit and Wang, 2020), implying the existence of parameter efficient alternatives.
2020年; Radiya-Dixit和Wang, 2020), 暗示存在参数高效的替代方案。
Many researchers have sought to alleviate these issues by using fixed-LM techniques, where the parameters of the base LM remain unchanged. An ever-growing subset of these methods can be considered prompt tuning, where language models are adapted to downstream tasks with the aid of a tuned prompt accompanying the input. A recent survey on prompt tuning (Liu et al., 2021a), however, notes the dearth of research exploring dynamic prompts, which are input-dependent. This work fills this gap in the literature and considers such dynamic prompts. Existing controlled generation techniques either aim to generate text with specific target qualities, independent of overall task performance, or are methods that have the benefit of updating not only the attribute-level parameters but training all the parameters in the language model.
许多研究者试图通过固定语言模型 (fixed-LM) 技术来缓解这些问题,即保持基础大语言模型的参数不变。这些方法中日益增长的子集可归类为提示调优 (prompt tuning),即通过优化输入附带的提示来使语言模型适配下游任务。然而,Liu等人 (2021a) 最近的提示调优综述指出,学界缺乏对输入相关性动态提示 (dynamic prompts) 的探索。本研究填补了这一文献空白,重点研究此类动态提示。现有受控生成技术要么专注于生成具有特定目标属性的文本(与整体任务性能无关),要么是通过更新属性级参数并训练语言模型中全部参数的方法来实现优化。
We propose the dynamic prompting method CONTROL PREFIXES. The method extends prefixtuning and integrates static task-specific prompts at every layer of a model, adding only $0.1\mathrm{-}3%$ additional parameters to the base LM. With CON- TROL PREFIXES we aim to preserve the fixed-LM property, while also allowing datapoint-specific attributes to act as guidance signals at the input-level. This is done by employing modular control prefixes, which change alongside the input according to the guidance signal. Operating together with the static prompt parameters, these dynamic prompts can steer the frozen PLM to extend finer-grained control. The chosen attributes can provide additional information about the input, for example the domain of a data-to-text triple set, or it can specify some aspect of the desired output, such as the target length for text simplification.
我们提出动态提示方法 CONTROL PREFIXES。该方法扩展了前缀调优 (prefix-tuning) 技术,在模型的每一层集成静态任务特定提示,仅为基础大语言模型增加 $0.1\mathrm{-}3%$ 的额外参数量。通过 CONTROL PREFIXES,我们旨在保持固定语言模型的特性,同时允许数据点特定属性作为输入级的引导信号。这是通过采用模块化控制前缀实现的,这些动态前缀会根据引导信号随输入变化。与静态提示参数协同工作时,这些动态提示可以引导冻结的预训练语言模型实现更细粒度的控制。所选属性可以提供关于输入的附加信息(例如数据到文本三元组的领域),也可以指定期望输出的某些方面(例如文本简化的目标长度)。
We evaluate our method on an array of text generation tasks, leveraging additional input-level information specific to each dataset. Our results show that our parameter efficient architecture outperforms previous approaches, many of them based on full fine-tuning, according to the WebNLG (Gardent et al., 2017), DART (Radev et al., 2020) and E2E Clean (Dušek et al., 2019) data-to-text datasets. In addition, our method attains higher human-assessed performance than existing systems for sum mari z ation on XSum (Narayan et al., 2018). Although CONTROL PREFIXES no longer operates in the standard setting for NLG tasks, by being not confined to just using the textual input, we focus on datasets where the attribute-level information is available as part of the task.
我们在多种文本生成任务上评估了我们的方法,利用了每个数据集特有的额外输入级信息。结果表明,在WebNLG (Gardent et al., 2017)、DART (Radev et al., 2020) 和 E2E Clean (Dušek et al., 2019) 这三个数据到文本的数据集上,我们的参数高效架构优于以往基于完整微调的方法。此外,在XSum (Narayan et al., 2018) 摘要任务中,我们的方法获得了比现有系统更高的人工评估性能。尽管控制前缀 (CONTROL PREFIXES) 不再局限于仅使用文本输入的标准自然语言生成 (NLG) 任务设置,但我们重点关注那些属性级信息作为任务组成部分可用的数据集。
We also consider the common case where the attribute-level information is not available, and demonstrate that zero-shot learning with CONTROL PREFIXES can be effective. We show similar control prefix representations are learned by the model for semantically similar attribute labels.
我们还考虑了属性级信息不可用的常见情况,并证明使用 CONTROL PREFIXES 进行零样本学习是有效的。我们发现模型会为语义相似的属性标签学习到类似的控制前缀表示。
2 Related Work
2 相关工作
Prompt Tuning Unlike the discrete text prompts used by GPT-3 (Brown et al., 2020), in prompt tuning, soft prompts are learned through backpropagation to maximize the information from labelled data. This work focuses on tuning methods as zero-shot prompting performance lags far behind tuned models on supervised datasets (Lester et al., 2021). Several successive works (Logeswaran et al., 2020; Liu et al., 2021b; Lester et al., 2021) employ prompt-embedding tuning, which trains continuous embeddings prepended to the input embeddings. Li and Liang (2021) discovered that prefix-tuning was more effective than promptembedding tuning for text generation. In prefixtuning, additional trainable key-value pairs, which are fixed across all examples, are used to augment the left context in every attention computation. Therefore, the prompt has constituents at every layer rather than being confined to steer the frozen LM only through the input as in embedding tuning.
提示调优
与GPT-3 (Brown et al., 2020) 使用的离散文本提示不同,提示调优通过反向传播学习软提示 (soft prompts) 以最大化标注数据的信息量。由于零样本提示在监督数据集上的表现远逊于调优模型 (Lester et al., 2021),本研究聚焦于调优方法。多项后续研究 (Logeswaran et al., 2020; Liu et al., 2021b; Lester et al., 2021) 采用提示嵌入调优 (prompt-embedding tuning),该方法训练连续嵌入并前置到输入嵌入中。Li和Liang (2021) 发现前缀调优 (prefix-tuning) 在文本生成任务中比提示嵌入调优更有效。前缀调优通过在所有样本中固定的可训练键值对来增强每次注意力计算中的左侧上下文,因此提示能作用于每一层,而不像嵌入调优那样仅通过输入来引导冻结的大语言模型。
Controlled generation A complementary field to prompt learning is controlled generation, which aims to incorporate various types of guidance (e.g. length specifications (Kikuchi et al., 2016) or highlighted phrases (Grangier and Auli, 2018)) beyond the input text into the generation model. Johnson et al. (2016) successfully trained a multilingual translation model with control tokens to encode each language. Keskar et al. (2019) pre-trained a 1.63B parameter model, also alongside conditional control tokens, and demonstrated these learnt to govern style, content, and task-specific behaviour. However, these models require the whole underlying LM to be fine-tuned alongside the control tokens for a particular task.
可控生成
与提示学习互补的领域是可控生成,其目标是在输入文本之外,将各类引导信息(例如长度规范 (Kikuchi et al., 2016) 或高亮短语 (Grangier and Auli, 2018))融入生成模型。Johnson 等人 (2016) 通过控制 token 成功训练了多语言翻译模型以编码每种语言。Keskar 等人 (2019) 预训练了一个 16.3 亿参数的模型,同样结合条件控制 token,并证明这些 token 能学习控制风格、内容和任务特定行为。然而,这些模型需要针对特定任务对整个底层大语言模型及控制 token 进行微调。
Alternatives exist, such as plug-and-play perturbations of the LM hidden states towards a target attribute (Nguyen et al., 2016; Dathathri et al., 2020). These methods use fixed LMs and are able to control target qualities such as sentiment and topic. However, they are slow at inference time due to requiring multiple passes for a single batch. The shift in conditional probability has also been shown to increase text degeneration (Holtzman et al., 2019).
存在替代方案,例如对语言模型隐藏状态进行即插即用式扰动以实现目标属性控制 (Nguyen et al., 2016; Dathathri et al., 2020)。这类方法使用固定参数的语言模型,能够控制情感、主题等目标特性。但由于需要对单个批次进行多次计算,其推理速度较慢。研究还表明这种条件概率偏移会加剧文本退化现象 (Holtzman et al., 2019)。
Dynamic prompts There have been few works exploring dynamic prompts (Liu et al., 2021a; Tsim po uk ell i et al., 2021), which are inputdependent. Perhaps most similar to our work is work by Yu et al. (2021), who use an attribute alignment function to form dynamic prompts. Unlike our work, the prompt does not have a static component and aims to generate text with specific target attributes, independent of task performance. With CONTROL PREFIXES, the intention is to also maximize task-specific performance, which is why we maintain a large static prompt component to specify the task itself.
动态提示 (Dynamic prompts)
目前关于动态提示的研究较少 (Liu et al., 2021a; Tsimpo uk ell i et al., 2021),这类提示具有输入依赖性。与本文最接近的是Yu等人 (2021) 的工作,他们通过属性对齐函数构建动态提示。与我们的方法不同,该提示不包含静态组件,其目标是生成具有特定目标属性的文本,而不考虑任务性能。CONTROL PREFIXES的设计目标还包括最大化任务特定性能,因此我们保留了大型静态提示组件来明确任务本身。
3 CONTROL PREFIXES
3 控制前缀
3.1 Background
3.1 背景
This work considers sequence-to-sequence tasks where the objective is to model the conditional probability $P(Y\mid X)$ with $X$ and $Y$ representing the tokenized input and output sequences respectively. For example, in sum mari z ation, $X$ could be an article and $Y$ would be a short target summary.
本研究探讨序列到序列任务,其目标是对条件概率 $P(Y\mid X)$ 进行建模,其中 $X$ 和 $Y$ 分别表示经过分词的输入与输出序列。例如在摘要生成任务中,$X$ 可能是一篇文章,而 $Y$ 则是目标摘要。
In this work we experiment with T5-large (Raffel et al., 2020) and BARTLARGE (Lewis et al., 2020) as the underlying pre-trained LMs with parameters $\phi$ ; and as we consider fixed-LM methods, $\phi$ always remains frozen. These models are Transformer encoder-decoder models where decoding proceeds auto-regressive ly. Let us denote $d$ to represent the hidden state dimension and $L$ the number of layers. We use $(E,D c,D m)$ to denote the three classes of attention present in each layer: self-attention in the encoder $(E)$ , decoder cross-attention $(D c)$ and decoder masked-attention $(D m)$ . For an attention computation in the $l$ -th layer, the query, key and value matrices are denoted $Q_{l}\in\mathbb{R}^{N\times d}$ , and $K_{l}$ $,V_{l}\in\mathbb{R}^{M\times d}$ , where $N$ is the number of tokens in the series relating to queries, and $M$ is the number of tokens in the series relating to keys and values.
在本工作中,我们以T5-large (Raffel et al., 2020) 和BARTLARGE (Lewis et al., 2020) 作为底层预训练大语言模型进行实验,其参数为$\phi$。由于采用固定大语言模型方法,$\phi$始终保持冻结状态。这些模型均为Transformer编码器-解码器架构,解码过程采用自回归方式。设$d$表示隐藏状态维度,$L$为层数。我们用$(E,Dc,Dm)$表示每层存在的三类注意力机制:编码器自注意力$(E)$、解码器交叉注意力$(Dc)$和解码器掩码注意力$(Dm)$。对于第$l$层的注意力计算,查询矩阵、键矩阵和值矩阵分别记为$Q_{l}\in\mathbb{R}^{N\times d}$,以及$K_{l}$ $,V_{l}\in\mathbb{R}^{M\times d}$,其中$N$表示查询相关的token序列长度,$M$表示键值相关的token序列长度。
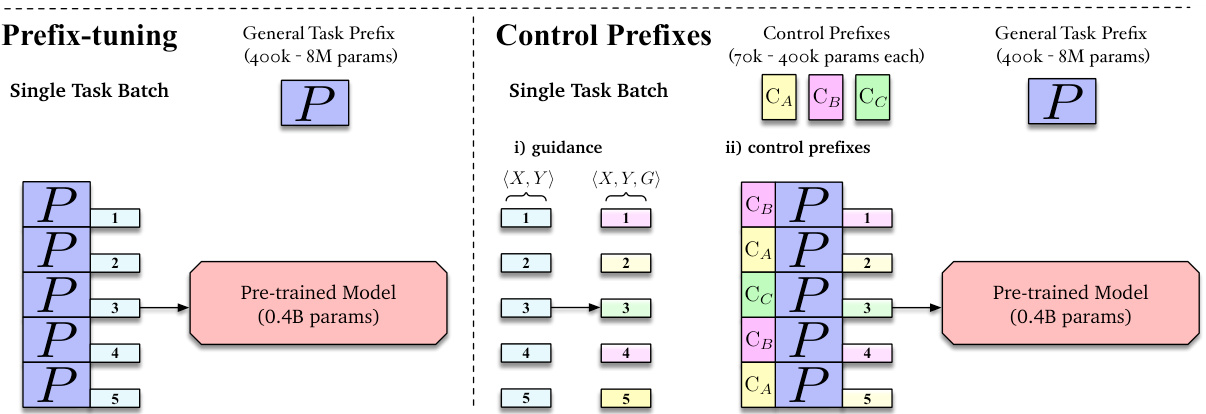
Figure 1: High-level diagram contrasting prefix-tuning and CONTROL PREFIXES in the single-task setup for a PLM such as BARTLARGE . The same single-task batch (examples 1,2,3,4 and 5) is considered for both setups. Left: Prefix-tuning has one general prefix $P$ for all examples. Right: CONTROL PREFIXES utilizes additional attribute information at the input-level, $G$ , in i). This conditional information is used in ii) to dictate which control prefix $(C_{A},C_{B},C_{C})$ to use for a particular example in a batch. This takes advantage of prefix-tuning’s capacity to include different prefixes in one forward pass.
图 1: 对比单任务设置中prefix-tuning与CONTROL PREFIXES的高层示意图(以BARTLARGE等PLM为例)。两种设置均考虑相同的单任务批次(示例1,2,3,4和5)。左:Prefix-tuning对所有示例使用单一通用前缀$P$。右:CONTROL PREFIXES在输入层面i)利用额外属性信息$G$,该条件信息在ii)中用于决定批次中特定示例应使用哪个控制前缀$(C_{A},C_{B},C_{C})$。这利用了prefix-tuning可在单次前向传播中容纳不同前缀的特性。
3.2 Intuition
3.2 直觉
Using a fixed PLM that captures broad natural language understanding provides the model with a parameter-efficient starting point which can be shared by many different tasks. Combining this with a trainable task representation allows the model to learn information relevant to one particular task. Furthermore, introducing attributelevel parameters allows us to guide the generationinto a required direction and provide the model with datapoint-level information. The general taskspecific parameters can themselves adapt to the modular control prefixes, which change according to the guidance signal for each input $X$ . This demarcation of parameters enables fine-grained con- trol to be extended to aid performance on downstream tasks. CONTROL PREFIXES can therefore leverage input-level information while being a fixed-LM, parameter efficient method.1 For this work, we only consider discrete labels as attributes for the guidance signal.
使用一个能捕捉广泛自然语言理解的固定PLM (预训练语言模型)为模型提供了参数高效的起点,该起点可被多种不同任务共享。将其与可训练的任务表征相结合,使得模型能够学习与特定任务相关的信息。此外,引入属性级参数使我们能够引导生成朝向所需方向,并为模型提供数据点级别的信息。通用的任务特定参数本身可以适应模块化控制前缀,这些前缀会根据每个输入$X$的引导信号而变化。这种参数划分使得细粒度控制得以扩展,从而提升下游任务性能。因此,控制前缀 (CONTROL PREFIXES) 能够在保持固定语言模型、参数高效方法的同时,利用输入级别的信息。本研究中,我们仅考虑将离散标签作为引导信号的属性。
3.3 Description
3.3 描述
The model uses a general task prefix $P_{\theta}$ ("taskspecific parameters") and also trains a set of control prefixes $C_{\theta}$ that change depending on the input ("attribute-level parameters"). This requires attribute-level information or guidance $G$ , to indicate which control prefixes to be used while processing a given input $X$ .2 Let us consider the parallel corpus where $G^{j}$ indicates all the conditional attribute-level information for the sample $j$ . The goal is to optimize through gradient descent the final inference parameters, $\theta$ , whilst the underlying $\phi$ parameters of the pre-trained LM remain frozen:
该模型使用一个通用任务前缀 $P_{\theta}$ ("任务特定参数"),并训练一组根据输入变化的控制前缀 $C_{\theta}$ ("属性级参数")。这需要属性级信息或指导 $G$ 来指示处理给定输入 $X$ 时应使用哪些控制前缀。其中 $G^{j}$ 表示样本 $j$ 的所有条件属性级信息。目标是通过梯度下降优化最终推理参数 $\theta$ ,同时保持预训练语言模型的底层 $\phi$ 参数冻结:
$$
\theta^{}=\arg\operatorname*{max}{\theta}\sum_{j=1}^{N}\log p\left(Y^{j}\mid X^{j},G^{j};P_{\theta},C_{\theta},\phi\right).
$$
$$
\theta^{}=\arg\operatorname*{max}{\theta}\sum_{j=1}^{N}\log p\left(Y^{j}\mid X^{j},G^{j};P_{\theta},C_{\theta},\phi\right).
$$
General Prefix For each attention class $(E,D c,D m)$ , a distinct prefix of key-value pairs is learnt, where $P_{l}\in$ $\mathbb{R}^{\rho\times2d}\forall l\in{1,\dots,L}$ . $P\in\mathbb{R}^{\rho\times2d L}$ and $\rho$ is the prompt length, i.e. the number of additional key-value pairs in each attention computation. In prefix-tuning3, for an attention computation in the $l$ -th layer, $K_{l}$ and $V_{l}$ are augmented to become
通用前缀 对于每个注意力类别 $(E,D c,D m)$,学习一个独特的键值对前缀,其中 $P_{l}\in$ $\mathbb{R}^{\rho\times2d}\forall l\in{1,\dots,L}$。$P\in\mathbb{R}^{\rho\times2d L}$ 且 $\rho$ 为提示长度,即每次注意力计算中额外键值对的数量。在prefix-tuning3中,对于第 $l$ 层的注意力计算,$K_{l}$ 和 $V_{l}$ 被扩展为
$$
K_{l}^{\prime}=\left[P_{l,K};K_{l}\right],V_{l}^{\prime}=\left[P_{l,V};V_{l}\right]
$$
$$
K_{l}^{\prime}=\left[P_{l,K};K_{l}\right],V_{l}^{\prime}=\left[P_{l,V};V_{l}\right]
$$
Control Prefixes Let us consider one attribute with $R$ possible labels4, such as the news domain of an article (e.g. sport, technology etc.),
控制前缀
考虑一个具有 $R$ 种可能标签的属性,例如文章的新闻领域(如体育、技术等)。
$C_{\theta}={C_{\theta,1},\ldots,C_{\theta,R}}$ , where $C_{\theta,r}\in\mathbb{R}^{\rho_{c}\times6d L}$ , $\forall r\in{1\ldots\ldots R}$ . $C_{\theta,r}$ represents the control prefix learnt for the $r$ -th attribute label and the parameter $\rho_{c}$ denotes the control prompt length for this particular attribute. Let $\mathcal{A}$ be a function which returns the corresponding control prefix for the attribute label indicated by $G$ . In CONTROL PREFIXES the $K_{l}$ and $V_{l}$ are augmented to become
$C_{\theta}={C_{\theta,1},\ldots,C_{\theta,R}}$ ,其中 $C_{\theta,r}\in\mathbb{R}^{\rho_{c}\times6d L}$ , $\forall r\in{1\ldots\ldots R}$ 。 $C_{\theta,r}$ 表示针对第 $r$ 个属性标签学习的控制前缀,参数 $\rho_{c}$ 表示该特定属性的控制提示长度。设 $\mathcal{A}$ 为返回由 $G$ 指示的属性标签对应控制前缀的函数。在 CONTROL PREFIXES 中, $K_{l}$ 和 $V_{l}$ 被扩展为
$$
\begin{array}{r l r}&{}&{K_{l}^{\prime\prime}=\left[\mathcal{A}(G){l,K};P_{l,K};K_{l}\right],}\ &{}&{V_{l}^{\prime\prime}=\left[\mathcal{A}(G)_{l,V};P_{l,V};V_{l}\right]}\end{array}
$$
$$
\begin{array}{r l r}&{}&{K_{l}^{\prime\prime}=\left[\mathcal{A}(G){l,K};P_{l,K};K_{l}\right],}\ &{}&{V_{l}^{\prime\prime}=\left[\mathcal{A}(G)_{l,V};P_{l,V};V_{l}\right]}\end{array}
$$
where K", V" E R(pe+p+M)xd
其中 K", V" ∈ R(pe+p+M)×d
Shared Re-parameter iz ation Li and Liang (2021) found that prefix optimization is stabilized by increasing the number of trainable parameters. This is achieved by introducing a feed-forward network to re-parameter ize the prefix. Rather than one network, we use three distinct two-layered large feed-forward neural networks for each attention class, applied row-wise. For each attention class $(E,D c,D m)$ , $P={\bf M L P}(\tilde{P})$ where $\Tilde{P}\in\mathbb{R}^{\rho\times d}$ is smaller than the matrix $P\in\mathbb{R}^{\rho\times2d L}$ , and each MLP has an intermediate dimension $k$ which we set to 800. The distinct MLPs and each $\tilde{P}$ are para meter i zed by training parameters $\tilde{\theta}$ ; thus, $\theta$ is a function of $\tilde{\theta}$ and $\vert\theta\vert<\vert\tilde{\theta}\vert$ . Once training is complete, the final $\theta$ parameters can be saved for use at inference and the re-parameter iz ation parameters dispensed with.
共享重参数化
Li和Liang (2021) 发现通过增加可训练参数数量可以稳定前缀优化。该方法通过引入前馈网络对前缀进行重参数化实现。我们为每类注意力机制 $(E,Dc,Dm)$ 使用三个独立的双层大型前馈神经网络(按行应用),而非单一网络。对于每类注意力机制,$P={\bf MLP}(\tilde{P})$,其中 $\tilde{P}\in\mathbb{R}^{\rho\times d}$ 小于矩阵 $P\in\mathbb{R}^{\rho\times2dL}$,且每个MLP的中间维度 $k$ 设为800。不同的MLP和每个 $\tilde{P}$ 通过训练参数 $\tilde{\theta}$ 进行参数化;因此 $\theta$ 是 $\tilde{\theta}$ 的函数,且 $\vert\theta\vert<\vert\tilde{\theta}\vert$。训练完成后,最终的 $\theta$ 参数可保存用于推理,此时可舍弃重参数化参数。
As described for the general prefix, $P_{\theta}$ , each control prefix, $C_{\theta,r}$ , comprises three constituents for each attention class: The re-parameter iz ation of $C_{\theta,r}$ occurs in the same manner as Pθ, sharing the same MLPE, MLPDc and $\mathbf{MLP}^{D m}$ . When using a disjoint set of reparameter iz at ions for the control prefixes, learning becomes unstable and performance degrades.5
如通用前缀 $P_{\theta}$ 所述,每个控制前缀 $C_{\theta,r}$ 包含三个注意力类别的组成部分。$C_{\theta,r}$ 的重参数化方式与 Pθ 相同,共享相同的 MLPE、MLPDc 和 $\mathbf{MLP}^{D m}$。若对控制前缀使用独立的重参数化集合,会导致学习不稳定且性能下降。5
Recent work by Buhai et al. (2020) show that over-parameter iz ation can smooth the optimization landscape. With this in mind, the three distinct re-parameter iz at ions compel each prefix element to coordinate control for the particular attention class. For example, the rows of $P^{E}$ and $C_{r}^{E}$ lie in a vector space better coordinated for moderating the processing of the input sequence $X$ than $P^{D m}$ and $C_{r}^{D m}$ . This is due to being formed from the shared mapping MLPE.
Buhai等人 (2020) 的最新研究表明,过参数化 (over-parameterization) 能够平滑优化地形。基于此,三种不同的重参数化迫使每个前缀元素协调控制特定的注意力类别。例如,$P^{E}$ 和 $C_{r}^{E}$ 的行向量所在空间比 $P^{D m}$ 和 $C_{r}^{D m}$ 更适于调节输入序列 $X$ 的处理,这是因为它们源自共享的映射MLPE层。
4 Experimental Setup
4 实验设置
4.1 Datasets, Guidance and Metrics
4.1 数据集、指导原则与评估指标
Examples of specific attribute labels for each task are found in the Appendix.6
各任务的具体属性标签示例见附录6。
Data-to-text The objective of data-to-text generation is to produce fluent text from structured input, such as a triple set (a set of subject-predicateobjects). Following Li and Liang (2021), we evaluate on the data-to-text datasets DART (Radev et al., 2020) and WebNLG (Gardent et al., 2017). However, we implement prefix-tuning for T5-large rather than GPT-2, as T5-large provides a stronger baseline and enables comparison with state-of-theart (SOTA) systems.7 We also report results on E2E Clean (Dušek et al., 2019), a dataset focused on the restaurant domain. We use the official evaluation scripts and report BLEU (Papineni et al., 2002), METEOR (Lavie and Agarwal, 2007), and TER (Snover et al., 2006) metrics.8
数据到文本生成的目标是从结构化输入(如三元组集合,即一组主谓宾关系)中生成流畅的文本。遵循 Li 和 Liang (2021) 的方法,我们在数据到文本数据集 DART (Radev et al., 2020) 和 WebNLG (Gardent et al., 2017) 上进行评估。不过,我们针对 T5-large 而非 GPT-2 实现了前缀调优 (prefix-tuning),因为 T5-large 提供了更强的基线,并可与当前最先进 (SOTA) 系统进行比较。我们还报告了在 E2E Clean (Dušek et al., 2019) 上的结果,这是一个专注于餐厅领域的数据集。我们使用官方评估脚本,并报告 BLEU (Papineni et al., 2002)、METEOR (Lavie and Agarwal, 2007) 和 TER (Snover et al., 2006) 指标。
WebNLG contains triple sets from DBPedia (Auer et al., 2007). The test set is divided into two partitions: “Seen”, which contains 10 DBpedia categories present in the training set, and “Unseen”, which covers 5 categories never seen during training.9 These categories, such as Airport or Food are used as a guidance signal in our experiments (indicated by $A_{1}$ in Table 1); our approach for unseen categories is discussed in $\S6.2$ .
WebNLG包含来自DBPedia (Auer et al., 2007)的三元组集合。测试集分为两个部分:"已见"分区包含训练集中出现的10个DBpedia类别,"未见"分区涵盖训练期间从未出现的5个类别。这些类别(如Airport或Food)在我们的实验中作为指导信号使用(见表1中的$A_{1}$);我们在$\S6.2$节讨论了针对未见类别的方法。
Providing the category explicitly as guidance with CONTROL PREFIXES may enable properties of triples belonging to a specific WebNLG category to be captured more effectively. This intuition is supported by studies showing a clear disparity in the performance of different model types between different categories (Moryossef et al., 2019; Castro Ferreira et al., 2020). DART is an opendomain, multi-source corpus, with six sources: internal and external human annotation of both Wikipedia tables and WikiSQL, as well as the two existing datasets WebNLG and E2E Clean. Radev et al. (2020) showed fine-tuning T5-large on the WebNLG dataset with only the human annotated portion of DART achieves SOTA performance, whilst using the whole DART dataset is not as effective. Nevertheless, this inspired the idea of using the six DART sub-dataset sources as a controllable attribute, represented by $A_{2}$ in Table 1. This strategy was inspired by previous work which incorporates auxiliary scaffold tasks (S way am dip ta et al., 2018; Cohan et al., 2019; Cachola et al., 2020).
通过控制前缀 (CONTROL PREFIXES) 显式提供类别作为引导,可以更有效地捕捉属于特定 WebNLG 类别的三元组属性。这一直觉得到研究支持:不同模型类型在不同类别间的性能存在明显差异 [Moryossef et al., 2019; Castro Ferreira et al., 2020]。DART 是一个开放领域、多来源的语料库,包含六个数据源:维基百科表格和 WikiSQL 的内部与外部人工标注,以及现有数据集 WebNLG 和 E2E Clean。Radev 等人 [2020] 研究表明,仅使用 DART 人工标注部分对 WebNLG 数据集微调 T5-large 即可实现 SOTA 性能,而使用完整 DART 数据集效果反而不佳。这启发了我们将 DART 的六个子数据集来源作为可控属性(表 1 中的 $A_{2}$),该策略受到先前整合辅助支架任务研究的启发 [Swayamdipta et al., 2018; Cohan et al., 2019; Cachola et al., 2020]。
Simplification We use WikiLarge (Zhang and Lapata, 2017) as the training data and evaluate on two simplification benchmarks: TurkCorpus (Xu et al., 2016) and ASSET (Alva-Manchego et al., 2020). Both benchmarks are composed of the same 2000 validation source and 359 test source sentences. However, the 10 ASSET references per source focus on a more diverse set of rewriting simplifications than the 8 TurkCorpus refer- ences per source. Martin et al. (2020) introduced ‘BARTLARGE with ACCESS’, which is a fine-tuned BARTLARGE model trained alongside control tokens to condition on four simplification-specific attributes, such as the length compression ratio (the length of the target sequence relative to the source sequence). We use the same controllable attributes in this work to directly compare with Martin et al. (2020) (Table 2). The control ratios are disc ret i zed into bins of fixed-width 0.05, capped to a maximum ratio of 2. At inference time, once the model has been trained with these oracle controls, the control ratios are set to desired values by tuning on the respective validation set.
简化
我们使用WikiLarge (Zhang and Lapata, 2017)作为训练数据,并在两个简化基准上进行评估:TurkCorpus (Xu et al., 2016)和ASSET (Alva-Manchego et al., 2020)。这两个基准均由相同的2000条验证源句子和359条测试源句子组成。然而,ASSET每条源句子有10条参考译文,比TurkCorpus每条源句子的8条参考译文更注重多样化的改写简化。
Martin et al. (2020)提出了"BARTLARGE with ACCESS",这是一个微调的BARTLARGE模型,训练时结合控制token以适配四个简化特定属性,例如长度压缩比(目标序列长度相对于源序列长度的比例)。在本工作中,我们使用相同的可控属性,以便与Martin et al. (2020)直接比较(表2)。控制比率被离散化为固定宽度0.05的分箱,最大比率上限为2。在推理阶段,一旦模型通过这些预设控制训练完成,控制比率将通过调整各自验证集设置为所需值。
We report the non-learned metrics SARI (Xu et al., 2016) and FKGL (Kincaid et al., 1975).10 Unlike previous studies, we also use the machinelearned Q&A metric QuestEval (Scialom et al., 2021) to assess our text simplification models.
我们报告了非学习型指标SARI (Xu等人, 2016) 和FKGL (Kincaid等人, 1975)。与之前的研究不同,我们还使用机器学习问答指标QuestEval (Scialom等人, 2021) 来评估文本简化模型。
Sum mari z ation As in Li and Liang (2021), we report results on the XSum dataset (Narayan et al., 2018) using BARTLARGE . XSum com- prises 226,711 British Broadcasting Corporation (BBC) articles coupled with their single-sentence summaries, where each sample corresponds to a unique URL. The URL contains information on whether the sub-directory is from the BBC Sport or BBC News page $[A_{1}$ in Table 3), and further subdirectory information ( $\mathrm{\Delta_{A_{2}}}$ in Table 3, where $A_{2}$ has 40 labels), for example (‘sport’, ‘formula1’) or (‘news’, ‘science’). The motivation for using this as guidance is that different sub-directories are likely to share properties relating to how the information is presented; journalists are also usually confined to one domain. We report on the customary ROUGE scores (Lin, 2004).
与Li和Liang (2021) 相同,我们使用BARTLARGE在XSum数据集 (Narayan et al., 2018) 上报告结果。XSum包含226,711篇英国广播公司 (BBC) 文章及其单句摘要,每个样本对应唯一的URL。URL包含子目录是否来自BBC体育或BBC新闻页面的信息 (表3中的$A_{1}$),以及更详细的子目录信息 (表3其中$A_{2}$包含40个标签),例如("sport", "formula1")或("news", "science")。以此为引导的动机在于,不同子目录可能共享信息呈现方式的相关属性;记者通常也局限于某一领域。我们报告了常规的ROUGE分数 (Lin, 2004)。
4.2 Training Details
4.2 训练细节
For the data-to-text datasets, we follow Ribeiro et al. (2020) and linearize the triples, prepending the special tokens ${<}\mathrm{H}>,{<}\mathrm{R}>$ , and ${<}\mathrm{T}>$ before the subject, predicate, and object of an individual triple.11 We also prepend “translate Graph to English: ” to every input (Raffel et al., 2020). Full training and hyper parameter details can be found in Appendix D.
对于数据到文本的数据集,我们遵循 Ribeiro 等人 (2020) 的方法,将三元组线性化,并在单个三元组的主语、谓语和宾语前添加特殊 token ${<}\mathrm{H}>、{<}\mathrm{R}>$ 和 ${<}\mathrm{T}>$。我们还在每个输入前添加 "translate Graph to English: " (Raffel 等人, 2020)。完整的训练和超参数细节可在附录 D 中找到。
5 Results
5 结果
5.1 Data-to-Text
5.1 数据到文本
Results in Table 1 show that for DART, both CONTROL PREFIXES $(A_{2})$ and prefix-tuning attain higher performance than the current SOTA, which is T5-large fined-tuned (Radev et al., 2020), by 1.29 and 0.54 BLEU points respectively. This indicates CONTROL PREFIXES can exert control over the frozen T5-large more effectively than prefixtuning.
表1中的结果显示,对于DART任务,CONTROL PREFIXES $(A_{2})$ 和前缀调优 (prefix-tuning) 的性能均优于当前最优方法 (即微调后的T5-large模型 [20]) ,分别高出1.29和0.54个BLEU分值。这表明CONTROL PREFIXES比前缀调优能更有效地控制冻结的T5-large模型。
The SOTA for WebNLG is a T5-large model fine-tuned on WebNLG and the human annotated portion of DART (Radev et al., 2020). Compared to this model, CONTROL PREFIXES achieves a 0.83 higher BLEU overall, and 1.33 on the Seen categories. Notably, CONTROL PREFIXES $(A_{1})$ outperforms CONTROL PREFIXES $(A_{1},A_{2})$ on the Seen component of the dataset, but does not generalize as well to the unseen categories. We argue that this illustrates the benefit of using both controllable attributes. The prefix-tuning model with additional DART data, like the SOTA, is trained on only the human annotated portion and yields a minor performance increase of 0.05 BLEU compared to prefix-tuning solely trained on WebNLG. We believe this indicates that for fine-tuning, training on a complementary type of additional data allows the PLM to maintain more NLU by not over-fitting a narrow distribution, leading to better LM generalization. In contrast, for prefix-tuning, much of
WebNLG的当前最佳性能(SOTA)是由基于WebNLG和DART人工标注部分(Radev等人,2020)微调的T5-large模型实现的。相比该模型,CONTROL PREFIXES整体BLEU提高了0.83,在Seen类别上提高了1.33。值得注意的是,CONTROL PREFIXES $(A_{1})$ 在数据集的Seen部分表现优于CONTROL PREFIXES $(A_{1},A_{2})$,但对未见类别的泛化能力较弱。我们认为这证明了同时使用两个可控属性的优势。与SOTA类似,额外加入DART数据的前缀调优模型仅使用人工标注部分训练,相比仅用WebNLG训练的前缀调优模型,BLEU仅提高了0.05。这表明在微调时,使用互补类型的额外数据进行训练,可以避免预训练语言模型(PLM)过度拟合狭窄分布,从而保留更多自然语言理解(NLU)能力,获得更好的语言模型泛化性能。而前缀调优则...
| Φ% | BLEU | METEOR | TER√ | Φ% | S | U | A | Φ% | BLEU | METEOR | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| T5-largefine-tuned | 100 | 50.66 | 40 | 43 | 100 | 64.89 | 54.01 | 59.95 | 100 | 41.83 | 38.1 |
| SOTA | 100 | 50.66 | 40 | 43 | 100 | 65.82 | 56.01 | 61.44 | 100 | 43.6 | 39 |
| Prefix-tuning | 1.0 | 51.20 | 40.62 | 43.13 | 1.0 | 66.95 | 55.39 | 61.73 | 1.0 | 43.66 | 39.0 |
| CONTROL PREFIXES (A1) | 1.4 | 67.32 | 55.38 | 61.94 | |||||||
| +Data:DART | |||||||||||
| Prefix-tuning | 1.0 | 51.20 | 40.62 | 43.13 | 1.0 | 67.05 | 55.37 | 61.78 | 1.0 | 43.04 | 38.7 |
| CONTROL PREFIXES(A2) | 1.1 | 51.95 | 41.07 | 42.75 | 1.0 | 66.99 | 55.56 | 61.83 | 1.0 | 44.15 | 39.2 |
| CONTROL PREFIXES(A1,A2) | 1.4 | 67.15 | 56.41 | 62.27 |
Table 1: Data-to-text test set results reported on the respective official evaluation scripts. $\phi%$ denotes the $%$ of additional parameters to the number of fixed-LM parameters required at inference time. T5-large fine-tuned results for WebNLG are from Ribeiro et al. (2020) and for DART are from Radev et al. (2020). Note the results in the main body of the GEM paper (Gehrmann et al., 2021) are reported on the validation set, rather than the test set as is done here. Several of the baseline results were only reported to the significant figures shown. $A_{1}$ signifies models trained with control prefixes for the WebNLG category attribute, and $A_{2}$ with control prefixes for the DART sub-dataset source attribute. For WebNLG, S, U and A refer to BLEU scores for the Seen, Unseen and $A l l$ portions of the dataset. The DART results are reported on the official evaluation script for v1.1.1, the same version as the official leader board. A CONTROL PREFIXES model attains state-of-the-art results for each dataset.
表 1: 数据到文本测试集结果基于各官方评估脚本报告。$\phi%$表示推理时所需额外参数占固定大语言模型参数的百分比。WebNLG的T5-large微调结果来自Ribeiro等人 (2020) ,DART的结果来自Radev等人 (2020) 。请注意GEM论文正文 (Gehrmann等人, 2021) 中的结果是基于验证集而非本表所用的测试集。部分基线结果仅显示有效数字。$A_{1}$表示使用WebNLG类别属性控制前缀训练的模型,$A_{2}$表示使用DART子数据集来源属性控制前缀训练的模型。对于WebNLG,S、U和A分别表示数据集中已见、未见和$All$部分的BLEU分数。DART结果基于v1.1.1官方评估脚本报告,与官方排行榜版本一致。控制前缀模型在每个数据集上都达到了最先进的成果。
this gain has already been realized by retaining the original frozen parameters.
这一增益已通过保留原始冻结参数得以实现。
The SOTA (Harkous et al., 2020) for E2E Clean consists of a fine-tuned GPT-2 with a semantic fidelity classifier trained on additional generated data. CONTROL PREFIXES $(A_{2})$ , which can leverage the heterogeneous DART datasets, outperforms this model in terms of the BLEU score.
E2E Clean的最先进技术 (Harkous et al., 2020) 包含一个经过微调的GPT-2模型和一个在额外生成数据上训练的语义保真度分类器。控制前缀 $(A_{2})$ 能够利用异构DART数据集,在BLEU分数上超越了该模型。
5.2 Simplification
5.2 简化
Table 2 reveals that prefix-tuning BART performs comparably to fine-tuning BART. When comparing our CONTROL PREFIXES to fine-tuned ‘BARTLARGE with ACCESS’ there is comparable performance in terms of SARI for ASSET, and better FKGL results on ASSET. For text simplification, Martin et al. (2020) indicate the gains from using the controllable attributes, as assessed by SARI and FKGL, are mostly due to being able to calibrate the length ratio, with validation and test sets being drawn from the same distribution, as opposed to the WikiLarge training distribution. CONTROL PREFIXES also achieves higher SARI and FKGL scores on TurkCorpus compared to the Gold Reference, which evaluates against other human annotators.
表 2 显示,前缀调优 (prefix-tuning) BART 的表现与微调 (fine-tuning) BART 相当。将我们的 CONTROL PREFIXES 与微调的 "BARTLARGE with ACCESS" 进行比较时,在 ASSET 数据集上的 SARI 指标表现相近,而在 ASSET 上的 FKGL 结果更优。对于文本简化任务,Martin 等人 (2020) [20] 指出,通过 SARI 和 FKGL 评估的可控属性收益主要源于能够校准长度比率,因为验证集和测试集来自相同分布,而非 WikiLarge 训练分布。与人工标注的黄金参考 (Gold Reference) 相比,CONTROL PREFIXES 在 TurkCorpus 上也取得了更高的 SARI 和 FKGL 分数,该参考标准用于评估其他人类标注者的表现。
5.3 Sum mari z ation
5.3 总结
There is considerable inconsistency regarding author-conducted human evaluation for NLG (van der Lee et al., 2021). Therefore, we opted to submit our CONTROL PREFIXES model outputs to an externally run evaluation framework, GENIE (Khashabi et al., 2021), which provides an unbiased attestation of performance. Their sample size of 300 examples is larger than the 50 or 100 examples that have been previously used for XSum and is typical of human evaluation experiments (Narayan et al., 2018; Dou et al., 2020). Both human evalu- ation and automated ROUGE metrics can be seen in Table 3. The confidence intervals indicate that this result is not necessarily definitive, but it also highlights that the quality of generations in this domain is not captured fully by ROUGE. For the datasets considered, the automatic metrics are the least reliable for XSum as it is the only dataset with a single gold reference.
关于NLG(自然语言生成)领域作者自行开展的人工评估存在较大不一致性(van der Lee等人,2021)。因此,我们选择将CONTROL PREFIXES模型输出提交至外部运行的评估框架GENIE(Khashabi等人,2021),该框架能提供无偏见的性能认证。其采用的300例样本量大于以往XSum任务使用的50或100例样本量(Narayan等人,2018;Dou等人,2020),符合人工评估实验的典型规模。人工评估与自动化ROUGE指标结果如表3所示。置信区间表明该结果并非绝对定论,但同时也凸显出ROUGE指标无法完全捕捉该领域生成文本的质量。就所研究的数据集而言,自动指标对XSum的可靠性最低,因为这是唯一仅含单组标准参考答案的数据集。
The results also show that CONTROL PREFIXES performs better than prefix-tuning in terms of ROUGE. We are not able to report the same humanassessment results for prefix-tuning, as each participant of GENIE is limited to one submission and there is no existing result for prefix-tuning.
结果还显示,CONTROL PREFIXES 在 ROUGE 指标上优于前缀调优 (prefix-tuning)。由于 GENIE 的每位参与者仅限提交一次,且没有现存的前缀调优人工评估结果,我们无法报告相同的人类评估数据。
6 Analysis
6 分析
6.1 Visualizing Control Prefixes
6.1 可视化控制前缀
Fig. 2 displays t-SNE (Maaten and Hinton, 2008) visualization s of the length compression control prefixes learnt as part of our simplification CONTROL PREFIXES model.13 We plot only the decoder self-attention constituent of each control prefix (comprising multiple key-value pairs at each layer) as the length ratio directly concerns the tar
图 2: 展示了作为我们简化控制前缀模型组成部分学习到的长度压缩控制前缀的t-SNE (Maaten and Hinton, 2008)可视化结果。我们仅绘制每个控制前缀的解码器自注意力成分(包含每层的多个键值对),因为长度比直接关系到目标...
Table 2: Simplification results on ASSET and TurkCorpus test sets. †This model is from Martin et al. (2020), where the authors fine-tuned BARTLARGE model alongside control tokens for the four attributes. The CONTROL PREFIXES model is trained with control prefixes for these same four attributes. Prefix-tuning and CONTROL PREFIXES use BARTLARGE as the fixed LM. The ∗ denotes baseline results calculated in this study—the model outputs of Martin et al. (2020) are publicly available. The BARTLARGE with ACCESS and CONTROL PREFIXES model are the average test set results over 5 random seeds. We bold the best results of parameter-efficient models in the results tables, while fully fine-tuned models and human performance are reported for reference.
表 2: ASSET和TurkCorpus测试集的简化结果。†该模型来自Martin等人 (2020) 的研究,作者针对四个属性微调了BARTLARGE模型并加入了控制token。CONTROL PREFIXES模型使用相同的四个属性控制前缀进行训练。Prefix-tuning和CONTROL PREFIXES均采用BARTLARGE作为固定语言模型。∗表示本研究中计算的基线结果——Martin等人 (2020) 的模型输出已公开。带ACCESS的BARTLARGE和CONTROL PREFIXES模型均为5次随机种子的测试集平均结果。我们在结果表中用粗体标出参数高效模型的最佳结果,同时列出全参数微调模型和人类表现作为参考。
| % | ASSET | TurkCorpus | |||||
|---|---|---|---|---|---|---|---|
| SARI | FKGL√ | QuestEval | SARI | FKGL√ | QuestEval | ||
| GoldReference | 44.87 | 6.49 | 0.63* | 40.04 | 8.77 | 0.66* | |
| BARTLARGE with ACCESSt | 100 | 43.63 | 6.25 | 0.64* | 42.62 | 6.98 | 0.66 |
| BARTLARGE fine-tuned | 100 | 39.91* | 7.73* | 39.55* | 7.73* | ||
| Prefix-tuning | 1.8 | 40.12 | 7.28 | 39.06 | 7.28 | ||
| CONTROL PREFIXES | 1.8 | 43.58 | 5.97 | 0.64 | 42.32 | 7.74 | 0.66 |
| Φ% | 人类总体评分 | 人类简洁性 | 人类流畅度 | 人类无幻觉性 | 人类信息量 | R-1 | ROUGE R-2 | R-3 | |
|---|---|---|---|---|---|---|---|---|---|
| BARTLARGE微调 | 100 | 0.49+0.03 0.04 | 0.50±0.03 0.03 | 0.50+0.03 0.03 | 45.14* | 22.27* | 37.25* | ||
| PEGASUS微调 | 100 | 0.49+0.03 0.03 | 0.52+0.02 0.03 | 0.49+0.03 0.02 | 0.49+0.03 0.03 | 0.49+0.03 -0.03 | 47.21* | 24.56* | 39.25* |
| T5(11B)微调 | 100 | 0.47+0.03 0.03 | 0.49+0.02 0.02 | 0.50±0.03 -0.03 | 0.49±0.03 0.03 | 0.48±0.03 0.03 | |||
| 前缀调优 | 3.0 | 43.53 | 20.66 | 35.63 | |||||
| 控制前缀(A1,A2) | 2.8 | 0.51+0.03 -0.03 | 0.53+0.02 -0.02 | 0.51+0.03 -0.03 | 0.53+0.03 -0.03 | 0.49+0.03 -0.03 | 43.81 | 20.84 | 35.81 |
Table 3: Sum mari z ation results on XSum. The human-assessed results are from the GENIE benchmark, where the $95%$ confidence intervals are computed with bootstrap re-sampling. Note the BARTLARGE and PEGASUS finetuned results for the human-assessed dimensions are transcribed from Khashabi et al. (2021), whilst the automatic metric results, indicated by ∗, are from Lewis et al. (2020) and Zhang et al. (2019). Prefix-tuning and CONTROL PREFIXES $(A_{1},A_{2})$ use BARTLARGE as the fixed LM. $A_{1}$ refers to the BBC news/sport page attribute and $A_{2}$ the further sub-directory attribute. We bold the best results of parameter-efficient models in the results tables for ROUGE, with fully fine-tuned models as reference. The public GENIE leader board is available at https: //leader board.allenai.org/genie-xsum/.
表 3: XSum数据集上的汇总结果。人工评估结果来自GENIE基准测试,其中95%置信区间通过自助重采样计算得出。需注意,BARTLARGE和PEGASUS在人工评估维度的微调结果转录自Khashabi等人 (2021) ,而带*号的自动指标结果来自Lewis等人 (2020) 和Zhang等人 (2019) 。前缀调优 (Prefix-tuning) 和控制前缀 (CONTROL PREFIXES) $(A_{1},A_{2})$ 均采用BARTLARGE作为固定语言模型。$A_{1}$ 指代BBC新闻/体育页面属性,$A_{2}$ 表示更深层子目录属性。我们在ROUGE结果表中将参数高效模型的最佳结果加粗显示,并以全参数微调模型作为参照基准。公开的GENIE排行榜详见https://leaderboard.allenai.org/genie-xsum/。
get.14 The relationship learnt by the control prefixes is very manifest, aided by the near uniform distribution of length ratios in the WikiLarge training dataset from 0 to 1.1.
get.14 控制前缀学习到的关系非常明显,这得益于WikiLarge训练数据集中长度比近乎均匀分布在0到1.1之间。
Fig. 2 establishes that for this simplistic attribute, different control prefixes corresponding to similar attribute labels (i.e. varying length ratios for the length attribute) share properties. Interestingly the decoder cross-attention of the control prefix is not as manifest. We believe this is due to BARTLARGE being accustomed to the same crossattention key-value pairs in each layer.
图 2: 研究表明,对于这个简单属性,对应相似属性标签的不同控制前缀(即长度属性中不同的长度比例)具有共享特性。有趣的是,控制前缀的解码器交叉注意力表现并不明显。我们认为这是由于 BARTLARGE 习惯了每层中相同的交叉注意力键值对所致。
6.2 Zero-shot Learning
6.2 零样本学习 (Zero-shot Learning)
We argue that even for more complicated attributes, such as the WebNLG category attribute, if the attribute labels are semantically similar, the respective control prefixes will similarly assist the general task-specific prefix and the frozen LM during generation. Previous work has discussed the notion of task similarity (Achille et al., 2019) for prompt learning methods (Lester et al., 2021); however, we argue prefixes concerning different labels of one attribute are more likely to overlap in terms of learnable properties than different tasks or whole datasets.
我们认为,即便是WebNLG类别属性这类更复杂的属性,只要属性标签在语义上相似,对应的控制前缀同样能在生成过程中辅助任务专用前缀和冻结的大语言模型。先前研究曾探讨过提示学习方法中的任务相似性概念 [20];但我们认为,同一属性不同标签对应的前缀在可学习特性上的重叠度,通常会高于不同任务或完整数据集之间的重叠度。

Figure 2: t-SNE visualization s for the decoder selfattention constituent of the simplification model’s length compression control prefixes. Each circle represents a control prefix corresponding to each length ratio (bins of fixed width 0.05, from 0 to 1.1).
图 2: 简化模型长度压缩控制前缀中解码器自注意力 (self-attention) 成分的 t-SNE 可视化。每个圆圈代表对应不同长度比率 (固定宽度 0.05 的分箱,范围从 0 到 1.1) 的控制前缀。
In the case of WebNLG, where although no examples of the unseen category are present during training, a textual label for the category exists. These labels were available to all competition participants. This gives us some prior on the properties of the unseen categories, which we show is enough to successfully zero-shot transfer with control prefixes. For each WebNLG model with the category attribute, we map each category’s textual label, including for the unseen categories, to a Glove embedding15 (Pennington et al., 2014). Then for each unseen category, we map to the seen category with the highest cosine similarity in embedding space, and use that control prefix at inference for the corresponding unseen sample. For example, the control prefix for the seen category SportsTeam is used for examples relating to the unseen category Athlete.16
在WebNLG的情况下,虽然训练期间未见类别的样本不存在,但该类别的文本标签是存在的。这些标签对所有竞赛参与者都可用。这为我们提供了一些关于未见类别属性的先验知识,我们证明这足以通过控制前缀成功实现零样本迁移。对于每个具有类别属性的WebNLG模型,我们将每个类别的文本标签(包括未见类别)映射到Glove嵌入[15] (Pennington et al., 2014)。然后对于每个未见类别,我们在嵌入空间中找到余弦相似度最高的已见类别,并在推理时使用对应的控制前缀处理未见样本。例如,已见类别SportsTeam的控制前缀被用于与未见类别Athlete相关的样本[16]。
Table 4 shows a comparison of using an out-ofvocabulary (OOV) control prefix for each example with an unseen category, and the zero-shot transfer method for both WebNLG datasets17. The OOV control prefix is trained on a random $2%$ of the data for each accumulated batch. These results indicate that zero-shot transfer is more promising than a learned OOV representation. The result fundamentally depends on the WebNLG categories, and if similar textual labels pertain to similar triple sets that CONTROL PREFIXES can utilize.
表4展示了在WebNLG两个数据集17上,针对未见类别分别采用超纲词(OOV)控制前缀和零样本迁移方法的对比。OOV控制前缀是在每个累积批次中随机抽取2%的数据进行训练的。结果表明,零样本迁移比学习到的OOV表征更具潜力。该结果本质上取决于WebNLG的类别划分,以及CONTROL PREFIXES能否利用与相似三元组集合相关联的文本标签。
6.3 Discussion
6.3 讨论
We also investigated a simpler architecture ‘prefixtuning $^+$ control tokens’ which informs the model of the identical guidance signal as in CONTROL PREFIXES, but with trainable control tokens instead of control prefixes. Appendix F reveals that CONTROL PREFIXES consistently outperforms prefixtuning $^+$ control tokens on the data-to-text and summarization datasets, while the results are both comparable to the Gold References on simplification datasets. This indicates that CONTROL PREFIXES is a superior parameter-efficient framework in leveraging additional information, whilst maintaining the fixed-LM property.
我们还研究了一种更简单的架构"前缀调优$^+$控制token",它向模型提供与CONTROL PREFIXES相同的引导信号,但使用可训练的控制token而非控制前缀。附录F显示,在数据到文本和摘要数据集上,CONTROL PREFIXES始终优于前缀调优$^+$控制token,而在简化数据集上两者的结果都与黄金参考相当。这表明CONTROL PREFIXES是一个更优秀的参数高效框架,既能有效利用额外信息,又能保持固定语言模型的特性。
Table 4: A comparison of the performance on the Unseen portions for WebNLG test sets, with i) a single OOV Control Prefix used for all samples from unseen categories, or ii) the zero-shot transfer approach outlined, utilizing the available textual labels.
表 4: WebNLG测试集在未见部分性能对比,其中i)对所有未见类别样本使用单一OOV控制前缀,ii)采用所述零样本迁移方法,利用可用文本标签。
| 未见组件 | #示例 | s#类别 | BLEU |
|---|---|---|---|
| WebNLG | 891 | 5 | |
| OOV表示法 | 56.35 | ||
| 零样本 | 56.41 | ||
| WebNLG+2020 | 896 | 3 | |
| OOV表示法 | 50.02 | ||
| 零样本 | 50.39 |
The alternative method is less expressive than CONTROL PREFIXES, by only exerting control through the embeddings rather than through each layer. CONTROL PREFIXES fundamentally depends on the strength of the guidance signal and by adding the constraint of attribute information being available with the dataset the guidance signal is naturally weaker. However, we show that CONTROL PREFIXES is a powerful general method which can utilize this signal to achieve a modest but consistent improvement across an array of tasks.
替代方法的表现力不及CONTROL PREFIXES,仅通过嵌入而非各层施加控制。CONTROL PREFIXES本质上依赖于引导信号的强度,由于添加了数据集需附带属性信息的约束条件,其引导信号天然较弱。但实验表明,CONTROL PREFIXES是一种强大的通用方法,能够利用该信号在一系列任务中实现虽有限但稳定的性能提升。
7 Conclusion
7 结论
We introduce CONTROL PREFIXES, a parameterefficient controlled generation technique, which integrates a task-specific prompt alongside dynamic prompts to leverage additional input-level information. The method extends prefix-tuning, enabling the model to have finer-grained control over generated text, and assists in maximizing downstream task performance.
我们介绍CONTROL PREFIXES,这是一种参数高效的受控生成技术,它将任务特定提示与动态提示相结合,以利用额外的输入级信息。该方法扩展了前缀调优(prefix-tuning),使模型能够对生成文本进行更细粒度的控制,并有助于最大化下游任务性能。
We demonstrate that CONTROL PREFIXES outperforms prefix-tuning and prefix-tuning with embedding level guidance, as well as existing approaches, on an array of natural language generation tasks. Our method attains state-of-theart results on several data-to-text datasets including WebNLG. This is despite learning $12%$ addi- tional parameters to the underlying LM parameters (which remain fixed). Additionally, our method holds the highest human evaluation ranking on the external platform GENIE for the sum mari z ation dataset XSum.
我们证明,在一系列自然语言生成任务中,CONTROL PREFIXES的表现优于前缀调优(prefix-tuning)和带有嵌入层引导的前缀调优,以及现有方法。我们的方法在包括WebNLG在内的多个数据到文本数据集上取得了最先进的结果,尽管需要学习比底层大语言模型参数多12%的额外参数(这些参数保持固定)。此外,在外部平台GENIE上,我们的方法在摘要数据集XSum上获得了最高的人类评估排名。
References
参考文献
Alessandro Achille, Michael Lam, Rahul Tewari, Avinash Ravi chandra n, Subhransu Maji, Charless Fowlkes, Stefano Soatto, and Pietro Perona. 2019. Task2vec: Task embedding for meta-learning. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 6429–6438.
Alessandro Achille、Michael Lam、Rahul Tewari、Avinash Ravi chandra n、Subhransu Maji、Charless Fowlkes、Stefano Soatto 和 Pietro Perona。2019. Task2vec:元学习的任务嵌入。见《2019年IEEE/CVF国际计算机视觉大会(ICCV)》,第6429–6438页。
Armen Aghajanyan, Luke Z ett le moyer, and Sonal Gupta. 2020. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. CoRR, abs/2012.13255.
Armen Aghajanyan、Luke Zettlemoyer 和 Sonal Gupta。2020. 语言模型微调有效性的内在维度解释。CoRR, abs/2012.13255。
Fernando Alva-Manchego, Louis Martin, Carolina Scarton, and Lucia Specia. 2019. Easse: Easier automatic sentence simplification evaluation. arXiv preprint arXiv:1908.04567.
Fernando Alva-Manchego、Louis Martin、Carolina Scarton和Lucia Specia。2019。Easse:更简便的自动句子简化评估。arXiv预印本arXiv:1908.04567。
Fernando Emilio Alva-Manchego, Louis Martin, An- toine Bordes, Carolina Scarton, Benoît Sagot, and Lucia Specia. 2020. ASSET: A dataset for tuning and evaluation of sentence simplification models with multiple rewriting transformations. CoRR, abs/2005.00481.
Fernando Emilio Alva-Manchego、Louis Martin、Antoine Bordes、Carolina Scarton、Benoît Sagot和Lucia Specia。2020。ASSET: 一个支持多重改写变换的句子简化模型调优与评估数据集。CoRR, abs/2005.00481。
Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives. 2007. Dbpedia: A nucleus for a web of open data. In The Semantic Web, pages 722–735, Berlin, Heidelberg. Springer Berlin Heidelberg.
Sören Auer、Christian Bizer、Georgi Kobilarov、Jens Lehmann、Richard Cyganiak 和 Zachary Ives。2007. DBpedia: 开放数据网络的核心。载于《语义网》,第722-735页,柏林/海德堡。Springer Berlin Heidelberg。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In NeurIPS.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever 和 Dario Amodei。2020。语言模型是少样本学习者。发表于 NeurIPS。
Rares-Darius Buhai, Yoni Halpern, Yoon Kim, Andrej Risteski, and David Sontag. 2020. Empirical study of the benefits of over parameter iz ation in learning latent variable models.
Rares-Darius Buhai、Yoni Halpern、Yoon Kim、Andrej Risteski 和 David Sontag。2020。过参数化在学习潜变量模型中优势的实证研究。
Isabel Cachola, Kyle Lo, Arman Cohan, and Daniel S. Weld. 2020. TLDR: extreme sum mari z ation of scientific documents. CoRR, abs/2004.15011.
Isabel Cachola、Kyle Lo、Arman Cohan 和 Daniel S. Weld。2020。TLDR: 科学文档的极限摘要。CoRR, abs/2004.15011。
Thiago Castro Ferreira, Claire Gardent, Nikolai Ilinykh, Chris van der Lee, Simon Mille, Diego Moussallem, and Anastasia Shimorina. 2020. The 2020 bilingual, bi-directional WebNLG $^+$ shared task: Overview and evaluation results (WebNLG $^{\ast}$ 2020). In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web $(W e b N L G+,$ ), pages 55–76, Dublin, Ireland (Virtual). Association for Computational Linguistics.
Thiago Castro Ferreira、Claire Gardent、Nikolai Ilinykh、Chris van der Lee、Simon Mille、Diego Moussallem和Anastasia Shimorina。2020。2020年双语双向WebNLG$^+$共享任务:概述与评估结果(WebNLG$^{\ast}$2020)。见《第三届语义网自然语言生成国际研讨会论文集》(WebNLG+), 第55-76页, 爱尔兰都柏林(线上)。计算语言学协会。
Arman Cohan, Waleed Ammar, Madeleine van Zuylen, and Field Cady. 2019. Structural scaffolds for citation intent classification in scientific publications. CoRR, abs/1904.01608.
Arman Cohan、Waleed Ammar、Madeleine van Zuylen 和 Field Cady。2019。科学出版物中引用意图分类的结构化支架。CoRR,abs/1904.01608。
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. 2020. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations.
Sumanth Dathathri、Andrea Madotto、Janice Lan、Jane Hung、Eric Frank、Piero Molino、Jason Yosinski 和 Rosanne Liu。2020。即插即用语言模型:一种简单的受控文本生成方法。见于 International Conference on Learning Representations。
Zi-Yi Dou, Pengfei Liu, Hiroaki Hayashi, Zhengbao Jiang, and Graham Neubig. 2020. Gsum: A general framework for guided neural abstract ive summarization. CoRR, abs/2010.08014.
Zi-Yi Dou、Pengfei Liu、Hiroaki Hayashi、Zhengbao Jiang 和 Graham Neubig。2020。GSum:一种通用的引导式神经抽象摘要框架。CoRR,abs/2010.08014。
Ondrej Dusek, David M. Howcroft, and Verena Rieser. 2019. Semantic noise matters for neural natural language generation. In Proc. of the 12th International Conference on Natural Language Generation, pages 421–426, Tokyo, Japan. Association for Computational Linguistics.
Ondrej Dusek、David M. Howcroft 和 Verena Rieser。2019. 神经自然语言生成中的语义噪声影响研究。载于《第12届国际自然语言生成会议论文集》,第421-426页,日本东京。计算语言学协会。
Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltr a chin i. 2017. The WebNLG challenge: Generating text from RDF data. In Proceedings of the 10th International Conference on Natural Language Generation, pages 124–133, Santiago de Compostela, Spain. Association for Computational Linguistics.
Claire Gardent、Anastasia Shimorina、Shashi Narayan和Laura Perez-Beltrachini。2017。WebNLG挑战赛:从RDF数据生成文本。载于《第10届国际自然语言生成会议论文集》,第124-133页,西班牙圣地亚哥德孔波斯特拉。计算语言学协会。
ebastian Gehrmann, Tosin P. Adewumi, Karmanya Aggarwal, Pawan Sasanka Amman a man chi, Aremu Anuoluwapo, Antoine Bosselut, Khyathi Raghavi Chandu, Miruna-Adriana Clinciu, Dipanjan Das, Kaustubh D. Dhole, Wanyu Du, Esin Durmus, Ondrej Dusek, Chris Emezue, Varun Gangal, Cristina Garbacea, Tatsunori Hashimoto, Yufang Hou, Yacine Jernite, Harsh Jhamtani, Yangfeng Ji, Shailza Jolly, Dhruv Kumar, Faisal Ladhak, Aman Madaan, Mounica Maddela, Khyati Mahajan, Saad Mahamood, Bodhi s at twa Prasad Majumder, Pedro Henrique Martins, Angelina McMillan-Major, Simon Mille, Emiel van Miltenburg, Moin Nadeem, Shashi Narayan, Vitaly Nikolaev, Rubungo An- dre Niyongabo, Salomey Osei, Ankur P. Parikh, Laura Perez-Beltr a chin i, Niranjan Ramesh Rao, Vikas Raunak, Juan Diego Rodriguez, Sashank Santhanam, João Sedoc, Thibault Sellam, Samira Shaikh, Anastasia Shimorina, Marco Antonio Sobrevilla Cabezudo, Hendrik Strobelt, Nishant Sub- ramani, Wei Xu, Diyi Yang, Akhila Yerukola, and Jiawei Zhou. 2021. The GEM benchmark: Natu- ral language generation, its evaluation and metrics. CoRR, abs/2102.01672.
Sebastian Gehrmann、Tosin P. Adewumi、Karmanya Aggarwal、Pawan Sasanka Ammanamanchi、Aremu Anuoluwapo、Antoine Bosselut、Khyathi Raghavi Chandu、Miruna-Adriana Clinciu、Dipanjan Das、Kaustubh D. Dhole、Wanyu Du、Esin Durmus、Ondrej Dusek、Chris Emezue、Varun Gangal、Cristina Garbacea、Tatsunori Hashimoto、Yufang Hou、Yacine Jernite、Harsh Jhamtani、Yangfeng Ji、Shailza Jolly、Dhruv Kumar、Faisal Ladhak、Aman Madaan、Mounica Maddela、Khyati Mahajan、Saad Mahamood、Bodhisattwa Prasad Majumder、Pedro Henrique Martins、Angelina McMillan-Major、Simon Mille、Emiel van Miltenburg、Moin Nadeem、Shashi Narayan、Vitaly Nikolaev、Rubungo Andre Niyongabo、Salomey Osei、Ankur P. Parikh、Laura Perez-Beltrachini、Niranjan Ramesh Rao、Vikas Raunak、Juan Diego Rodriguez、Sashank Santhanam、João Sedoc、Thibault Sellam、Samira Shaikh、Anastasia Shimorina、Marco Antonio Sobrevilla Cabezudo、Hendrik Strobelt、Nishant Subramani、Wei Xu、Diyi Yang、Akhila Yerukola 和 Jiawei Zhou。2021。GEM 基准:自然语言生成及其评估与指标。CoRR,abs/2102.01672。
David Grangier and Michael Auli. 2018. QuickEdit: Editing text & translations by crossing words out. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 272–282, New Orleans, Louisiana. Association for Computational Linguistics.
David Grangier和Michael Auli。2018。QuickEdit: 通过划词编辑文本与翻译。载于《2018年北美计算语言学协会人类语言技术会议论文集》第1卷(长论文),第272–282页,美国路易斯安那州新奥尔良。计算语言学协会。
Hamza Harkous, Isabel Groves, and Amir Saffari. 2020. Have your text and use it too! end-to-end neural datato-text generation with semantic fidelity. CoRR, abs/2004.06577.
Hamza Harkous、Isabel Groves 和 Amir Saffari。2020。鱼与熊掌兼得!端到端神经数据到文本生成与语义保真。CoRR, abs/2004.06577。
Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation.
Xiang Lisa Li 和 Percy Liang. 2021. 前缀调优 (Prefix-tuning): 面向生成的连续提示优化。
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Chin-Yew Lin. 2004. ROUGE: 自动摘要评估工具包。In Text Summarization Branches Out, pages 74-81, Barcelona, Spain. Association for Computational Linguistics.
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021a. Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing.
彭飞 刘、魏哲 袁、金兰 傅、正宝 蒋、Hiroaki Hayashi 和 Graham Neubig。2021a。预训练、提示与预测:自然语言处理中提示方法的系统综述。
Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021b. GPT understands, too. CoRR, abs/2103.10385.
Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021b. GPT也能理解. CoRR, abs/2103.10385.
Lajanugen Logeswaran, Ann Lee, Myle Ott, Honglak Lee, Marc’Aurelio Ranzato, and Arthur Szlam. 2020. Few-shot sequence learning with transformers. CoRR, abs/2012.09543.
Lajanugen Logeswaran、Ann Lee、Myle Ott、Honglak Lee、Marc'Aurelio Ranzato 和 Arthur Szlam。2020。基于Transformer的少样本序列学习。CoRR,abs/2012.09543。
Ilya Loshchilov and Frank Hutter. 2017. Fixing weight decay regular iz ation in adam. CoRR, abs/1711.05101.
Ilya Loshchilov 和 Frank Hutter. 2017. 修复 Adam 中的权重衰减正则化. CoRR, abs/1711.05101.
L. V. D. Maaten and Geoffrey E. Hinton. 2008. Visualizing data using t-sne. Journal of Machine Learning Research, 9:2579–2605.
L. V. D. Maaten 和 Geoffrey E. Hinton. 2008. 使用 t-SNE 可视化数据. Journal of Machine Learning Research, 9:2579–2605.
Louis Martin, Angela Fan, Éric de la Clergerie, An- toine Bordes, and Benoît Sagot. 2020. Multilingual unsupervised sentence simplification. CoRR, abs/2005.00352.
Louis Martin、Angela Fan、Éric de la Clergerie、Antoine Bordes 和 Benoît Sagot。2020。多语言无监督句子简化。CoRR,abs/2005.00352。
Amit Moryossef, Ido Dagan, and Yoav Goldberg. 2019. Improving quality and efficiency in plan-based neural data-to-text generation.
Amit Moryossef、Ido Dagan和Yoav Goldberg。2019。基于规划神经数据到文本生成的改进质量与效率。
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme sum mari z ation. CoRR, abs/1808.08745.
Shashi Narayan、Shay B. Cohen 和 Mirella Lapata。2018。无需细节,只需摘要!面向极端摘要的主题感知卷积神经网络。CoRR, abs/1808.08745。
Anh Nguyen, Jason Yosinski, Yoshua Bengio, Alexey Do sov it ski y, and Jeff Clune. 2016. Plug & play generative networks: Conditional iterative generation of images in latent space. CoRR, abs/1612.00005.
Anh Nguyen、Jason Yosinski、Yoshua Bengio、Alexey Dosovitskiy 和 Jeff Clune。2016. 即插即用生成网络:潜在空间中图像的条件迭代生成。CoRR, abs/1612.00005。
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL $\ '_{02}$ , page 311–318, USA. Association for Computational Linguistics.
Kishore Papineni, Salim Roukos, Todd Ward 和 WeiJing Zhu. 2002. Bleu: 一种机器翻译自动评估方法. 见《第40届计算语言学协会年会论文集》, ACL '02, 第311–318页, 美国. 计算语言学协会.
Nivranshu Pasricha, Mihael Arcan, and Paul Buitelaar. 2020. NUIG-DSI at the WebNLG $^+$ challenge: Leveraging transfer learning for RDF-to-text generation. In Proceedings of the 3rd International Workshop on Natural Language Generation from the Semantic Web ( $'W e b N L G+,$ ), pages 137–143, Dublin, Ireland (Virtual). Association for Computational Linguistics.
Nivranshu Pasricha、Mihael Arcan和Paul Buitelaar。2020. NUIG-DSI在WebNLG$^+$挑战赛:利用迁移学习实现RDF到文本生成。载于第三届语义网自然语言生成国际研讨会( $'WebNLG+$ )论文集,第137-143页,爱尔兰都柏林(线上)。计算语言学协会。
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, Doha, Qatar. Association for Computational Linguistics.
Jeffrey Pennington、Richard Socher 和 Christopher Manning。2014. GloVe: 全局词向量表示。载于《2014年自然语言处理实证方法会议论文集》(EMNLP),第1532–1543页,卡塔尔多哈。计算语言学协会。
Matthew E. Peters, Sebastian Ruder, and Noah A. Smith. 2019. To tune or not to tune? adapting pretrained representations to diverse tasks. In Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), pages 7–14, Flo- rence, Italy. Association for Computational Linguistics.
Matthew E. Peters、Sebastian Ruder 和 Noah A. Smith. 2019. 调还是不调?将预训练表征适配到多样化任务中. 收录于《第四届自然语言处理表征学习研讨会论文集》(RepL4NLP-2019), 第7-14页, 意大利佛罗伦萨. 计算语言学协会.
Dragomir R. Radev, Rui Zhang, Amrit Rau, Abhinand Sivaprasad, Chiachun Hsieh, Nazneen Fatema Rajani, Xiangru Tang, Aadit Vyas, Neha Verma, Pranav Krishna, Yang xiao kang Liu, Nadia Irwanto, Jessica Pan, Faiaz Rahman, Ahmad Zaidi, Murori Mutuma, Yasin Tarabar, Ankit Gupta, Tao Yu, Yi Chern Tan, Xi Victoria Lin, Caiming Xiong, and Richard Socher. 2020. DART: open-domain structured data record to text generation. CoRR, abs/2007.02871.
Dragomir R. Radev、Rui Zhang、Amrit Rau、Abhinand Sivaprasad、Chiachun Hsieh、Nazneen Fatema Rajani、Xiangru Tang、Aadit Vyas、Neha Verma、Pranav Krishna、Yang xiao kang Liu、Nadia Irwanto、Jessica Pan、Faiaz Rahman、Ahmad Zaidi、Murori Mutuma、Yasin Tarabar、Ankit Gupta、Tao Yu、Yi Chern Tan、Xi Victoria Lin、Caiming Xiong 和 Richard Socher。2020。DART:开放域结构化数据记录到文本生成。CoRR,abs/2007.02871。
Evani Radiya-Dixit and Xin Wang. 2020. How fine can fine-tuning be? learning efficient language models. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 2435–2443, Online. PMLR.
Evani Radiya-Dixit 和 Xin Wang. 2020. 微调能有多精细?学习高效的语言模型. 见《第二十三届国际人工智能与统计会议论文集》,第108卷《机器学习研究论文集》,第2435–2443页,在线. PMLR.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-totext transformer. Journal of Machine Learning Research, 21(140):1–67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu。2020。探索迁移学习的极限:统一的文本到文本Transformer。Journal of Machine Learning Research, 21(140):1–67。
Leonardo F. R. Ribeiro, Martin Schmitt, Hinrich Schütze, and Iryna Gurevych. 2020. Investigating pretrained language models for graph-to-text generation. arXiv.
Leonardo F. R. Ribeiro、Martin Schmitt、Hinrich Schütze 和 Iryna Gurevych。2020。探索预训练语言模型在图到文本生成中的应用。arXiv。
Thomas Scialom, Louis Martin, Jacopo Staiano, Éric Villemonte de la Clergerie, and Benoît Sagot. 2021. Rethinking automatic evaluation in sentence simplification. CoRR, abs/2104.07560.
Thomas Scialom、Louis Martin、Jacopo Staiano、Éric Villemonte de la Clergerie 和 Benoît Sagot。2021。重新思考句子简化中的自动评估。CoRR,abs/2104.07560。
Noam Shazeer and Mitchell Stern. 2018. Adafactor: Adaptive learning rates with sublinear memory cost. CoRR, abs/1804.04235.
Noam Shazeer 和 Mitchell Stern. 2018. Adafactor: 具有次线性内存成本的自适应学习率. CoRR, abs/1804.04235.
Matthew Snover, Bonnie Dorr, Richard Schwartz, Linnea Micciulla, and Ralph Weischedel. 2006. A study of translation error rate with targeted human annotation. In In Proceedings of the Association for Ma- chine Trans alt ion in the Americas (AMTA 2006.
Matthew Snover、Bonnie Dorr、Richard Schwartz、Linnea Micciulla 和 Ralph Weischedel。2006. 基于定向人工标注的翻译错误率研究。载于《美洲机器翻译协会会议论文集》(AMTA 2006)。
Swabha S way am dip ta, Sam Thomson, Kenton Lee, Luke Z ett le moyer, Chris Dyer, and Noah A. Smith. 2018. Syntactic scaffolds for semantic structures. In EMNLP.
Swabha Swayamdipta、Sam Thomson、Kenton Lee、Luke Zettlemoyer、Chris Dyer和Noah A. Smith。2018。语义结构的句法支架。载于EMNLP。
Maria Tsim po uk ell i, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals, and Felix Hill. 2021. Multimodal few-shot learning with frozen language models. CoRR, abs/2106.13884.
Maria Tsim po uk ell i, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals, and Felix Hill. 2021. 基于冻结语言模型的多模态少样本学习。CoRR, abs/2106.13884。
Chris van der Lee, Albert Gatt, Emiel Miltenburg, and Emiel Krahmer. 2021. Human evaluation of automatically generated text: Current trends and best practice guidelines. Computer Speech & Language, 67:101151.
Chris van der Lee、Albert Gatt、Emiel Miltenburg 和 Emiel Krahmer。2021。自动生成文本的人工评估:当前趋势与最佳实践指南。《计算机语音与语言》,67:101151。
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, Tim Rault, Rémi Louf, Morgan Funtow- icz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
Thomas Wolf、Lysandre Debut、Victor Sanh、Julien Chaumond、Clement Delangue、Anthony Moi、Pier-ric Cistac、Tim Rault、Rémi Louf、Morgan Funtowicz、Joe Davison、Sam Shleifer、Patrick von Platen、Clara Ma、Yacine Jernite、Julien Plu、Canwen Xu、Teven Le Scao、Sylvain Gugger、Mariama Drame、Quentin Lhoest 和 Alexander M. Rush。2020。Transformer:最先进的自然语言处理技术。载于《2020年自然语言处理实证方法会议:系统演示论文集》,第38-45页,线上。计算语言学协会。
Wei Xu, Courtney Napoles, Ellie Pavlick, Quanze Chen, and Chris Callison-Burch. 2016. Optimizing statistical machine translation for text simplification. Transactions of the Association for Computational Linguistics, 4:401–415.
Wei Xu、Courtney Napoles、Ellie Pavlick、Quanze Chen和Chris Callison-Burch。2016. 面向文本简化的统计机器翻译优化。计算语言学协会汇刊,4:401–415。
Dian Yu, Kenji Sagae, and Zhou Yu. 2021. Attribute alignment: Controlling text generation from pretrained language models. CoRR, abs/2103.11070.
Dian Yu、Kenji Sagae 和 Zhou Yu。2021. 属性对齐:控制预训练语言模型的文本生成。CoRR,abs/2103.11070。
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter J. Liu. 2019. PEGASUS: pre-training with extracted gap-sentences for abstract ive sum mari z ation. CoRR, abs/1912.08777.
Jingqing Zhang, Yao Zhao, Mohammad Saleh 和 Peter J. Liu. 2019. PEGASUS: 基于抽取式间隔句预训练的生成式摘要. CoRR, abs/1912.08777.
Xingxing Zhang and Mirella Lapata. 2017. Sentence simplification with deep reinforcement learning. arXiv preprint arXiv:1703.10931.
Xingxing Zhang 和 Mirella Lapata。2017。基于深度强化学习的句子简化。arXiv 预印本 arXiv:1703.10931。
A Additional Results
A 补充结果
Additional results using the official evaluation scripts for the data-to-text datasets are reported in Tables 5,6,7 to supplement the results in Table 1.
使用官方评估脚本对数据到文本数据集进行的额外结果如表5、6、7所示,作为表1结果的补充。
B WebNLG $^+$ 2020 Results
B WebNLG$^+$ 2020 结果
As NLG is notoriously challenging to evaluate, this work assesses model performance on five of the eleven datasets comprising GEM (Gehrmann et al., 2021), a benchmark that intends to provide robust datasets and reproducible standards across an array of NLG tasks. The GEM datasets used in this study are DART, E2E Clean, ASSET, TurkCorpus and WebNLG+ 2020.
由于自然语言生成(NLG)的评价 notoriously 具有挑战性,本研究选取了GEM基准测试(Gehrmann等人,2021)11个数据集中的5个来评估模型性能。GEM旨在为各类NLG任务提供稳健的数据集和可复现的标准。本实验采用的GEM数据集包括DART、E2E Clean、ASSET、TurkCorpus和WebNLG+ 2020。

Figure 3: t-SNE visualization s for the encoder constituent of control prefixes representing WebNLG categories seen during training. Each circle represents a category seen during training for the CONTROL PREFIXES $(A1)$ model. All 15 categories are seen categories in ${\mathrm{WebNLG+}}$ 2020, along with the category Company. $\mathrm{WebNLG}+2020$ has 3 additional unseen categories to those shown.
图 3: 控制前缀编码器部分在训练期间所见WebNLG类别的t-SNE可视化。每个圆圈代表CONTROL PREFIXES $(A1)$ 模型在训练期间见过的类别。所有15个类别均为 ${\mathrm{WebNLG+}}$ 2020数据集中的可见类别,包含Company类别。$\mathrm{WebNLG}+2020$ 另有3个未出现在本图的未见类别。
WebNLG $^+$ 2020 is not a component of DART—it was used for the second official WebNLG competition (Castro Ferreira et al., 2020). There are 16 training categories (the 15 categories from WebNLG, but with new examples), alongside 3 unseen categories. Table 8 displays ${\mathrm{WebNLG+}}$ 2020 results using the same model architectures as used for WebNLG. A similar pattern is revealed, in that CONTROL PREFIXES outperforms prefixtuning with CONTROL PREFIXES $(A_{1},A_{2})$ as the top-performing model. This illustrates again the benefit of using both controllable attributes.
WebNLG$^+$ 2020并非DART的组成部分——它被用于第二届官方WebNLG竞赛 (Castro Ferreira et al., 2020)。该数据集包含16个训练类别(沿用WebNLG的15个类别但新增示例)和3个未见类别。表8展示了使用与WebNLG相同模型架构的${\mathrm{WebNLG+}}$ 2020实验结果,其中CONTROL PREFIXES以$(A_{1},A_{2})$作为最佳模型的表现优于预调优前缀方法,这再次证明了同时使用两种可控属性的优势。
In the WebNLG and $\mathrm{WebNLG}+202\mathrm{C}$ training sets, for the same tripleset, multiple distinct lexic aliz at ions exist. In our experiments, the examples sharing identical tripleset inputs have the same triple order after linear iz ation. This is to aid in comparison with current systems for WebNLG, DART and E2E Clean. Future work would have to assess if architecture-independent improvement in test-set performance can arise by random permutation of the order of triples for training set examples with identical tripleset inputs. The motivation being that this may improve the general iz ability of the model, since the model would not learn the order of particular tripleset inputs.
在WebNLG和$\mathrm{WebNLG}+202\mathrm{C}$训练集中,对于相同的三元组集合,存在多种不同的词汇化表达。我们的实验中,共享相同三元组输入的例子在线性化后具有相同的三元组顺序。这是为了便于与当前WebNLG、DART和E2E Clean系统进行比较。未来工作需要评估:通过对训练集中相同三元组输入的例子进行随机顺序排列,是否能在测试集性能上带来与架构无关的改进。其动机在于,这可能提升模型的泛化能力,因为模型将不会学习特定三元组输入的顺序。
C Prefix-tuning
C 前缀调优 (Prefix-tuning)
We make two previously unremarked upon observations of the benefits conferred by using the keyvalue pair prefix-tuning described in $\S3.3$ compared to prefix-tuning involving augmenting the activation s directly (Hu et al., 2021) or promptembedding tuning of prompt length $\rho$ . i) The form discussed does not restrict the input length of the base LM. ii) The time complexity at inference time is reduced; for example, if we take a multi-head self-attention computation $\mathbf{\nabla}M\mathbf{\nabla}=$ $N)$ , the time complexity at inference time is $\mathcal{O}((N+\rho)N d+N d^{2})$ rather than the greater $\mathcal{O}((N+\rho)^{2}d+(N+\rho)d^{2})$ .
我们观察到,与直接增强激活(Hu等人,2021)或提示长度$\rho$的提示嵌入调优相比,采用$\S3.3$所述键值对前缀调优带来两个此前未被注意的优势:
i) 所述形式不限制基础大语言模型的输入长度。
ii) 推理时的时间复杂度降低。例如,对于多头自注意力计算$\mathbf{\nabla}M\mathbf{\nabla}=$$N)$,推理时间复杂度为$\mathcal{O}((N+\rho)N d+N d^{2})$,而非更高的$\mathcal{O}((N+\rho)^{2}d+(N+\rho)d^{2})$。
D Additional Training Details
D 额外训练细节
All implementations in this study are built on top of the Transformers library (Wolf et al., 2020). As T5 has relative position biases, we set these in all layers pertaining to offsets where the key is part of a prefix to zero. For BARTLARGE we adapt the orig- inal implementation (Li and Liang, 2021). Table 10 displays the hyper parameters used when training the models reported in this paper.
本研究中的所有实现均基于Transformers库 (Wolf等人, 2020) 。由于T5具有相对位置偏置,我们在所有与偏移量相关的层中将这些偏置设置为零,其中键是前缀的一部分。对于BARTLARGE,我们调整了原始实现 (Li和Liang, 2021) 。表10展示了本文报告模型训练时使用的超参数。
The general prompt length and each control prompt length are architecture-specific parameters that we choose based on performance on the validation set. We use gradient accumulation across batches to maintain an effective batch size above 64, a linear learning rate scheduler for all models and beam-search decoding. AdamW (Loshchilov and Hutter, 2017) and AdaFactor (Shazeer and Stern, 2018) were used for optimization. We chose the checkpoint with the highest validation score using BLEU for data-to-text, SARI for simplifica- tion and ROUGE-2 for sum mari z ation. For all tasks, we train our models on single Tesla V100- SXM2-16GB machines, with mixed precision for BARTLARGE based models (fp16) and full precision for T5-large based models (fp32).
通用提示长度和每个控制提示长度是基于架构特定的参数,我们根据验证集上的表现进行选择。我们采用跨批次的梯度累积来保持有效批次大小在64以上,为所有模型使用线性学习率调度器,并采用束搜索解码。优化过程中使用了AdamW (Loshchilov and Hutter, 2017)和AdaFactor (Shazeer and Stern, 2018)。我们根据BLEU(数据到文本)、SARI(简化任务)和ROUGE-2(摘要任务)选择验证分数最高的检查点。对于所有任务,我们均在单台Tesla V100-SXM2-16GB机器上训练模型,其中基于BARTLARGE的模型使用混合精度(fp16),基于T5-large的模型使用全精度(fp32)。
The CONTROL PREFIXES models with the DART sub-dataset source attribute $(A_{2})$ use DART as additional data and were trained in two stages: i) on DART, ii) solely on the downstream dataset. The WebNLG prefix-tuning model with DART data shown in Table 10 uses only the human annotated portion of DART. The prefix-tuning models using all of the DART data for WebNLG and E2E Clean were similarly trained in two stages, with identical hyper parameters to CONTROL PREFIXES models using $A_{2}$ . Training prefix-tuning on all of DART for WebNLG yielded lower performance than with only the human-annotated DART portion as additional data, so was not reported in Table 1.
使用DART子数据集源属性$(A_{2})$的CONTROL PREFIXES模型将DART作为附加数据,并分两个阶段进行训练:i) 在DART上训练,ii) 仅在下游数据集上训练。表10中展示的使用DART数据的WebNLG前缀调优模型仅采用了DART中人工标注的部分。对于WebNLG和E2E Clean任务,使用全部DART数据的前缀调优模型同样分两阶段训练,其超参数与采用$A_{2}$的CONTROL PREFIXES模型保持一致。在WebNLG任务中使用完整DART数据进行前缀调优时,性能低于仅采用人工标注DART部分作为附加数据的情况,因此未在表1中汇报。
Decoding specific parameters were not tuned—we instead mirrored what the topperforming fine-tuned based system used for the particular LM and dataset. For example, a beam width of 5 as in Ribeiro et al. (2020) for T5-large on all data-to-text datasets.
解码特定参数未进行调整,而是直接采用了在特定大语言模型和数据集上表现最佳的微调系统所使用的参数。例如,对于所有数据到文本数据集上的T5-large模型,采用了Ribeiro等人 (2020) 中使用的波束宽度为5的设置。
For XSum the source articles are truncated to 512 BPE tokens.
对于XSum数据集,源文章被截断至512个BPE token。
E Simplification Length Control
E 简化长度控制
Fig. 4 depicts the length compression ratio output distribution on the validation set for CONTROL PREFIXES, where a length control prefix of a specific attribute value (0.25,0.5,0.75,1.0) is specified. This clearly demonstrates CONTROL PREFIXES is capable of controlling the target length with respect to the input. Table 11 displays example output generations with each of the 0.25,0.5,0.75,1.0 values specified.
图 4 展示了 CONTROL PREFIXES 在验证集上的长度压缩比输出分布,其中指定了特定属性值 (0.25, 0.5, 0.75, 1.0) 的长度控制前缀。这清楚地表明 CONTROL PREFIXES 能够根据输入控制目标长度。表 11 展示了分别指定 0.25、0.5、0.75、1.0 值时的示例输出生成结果。
Fig. 5 is supplementary to $\S6.1$ , showing all constituents of the length compression control prefixes for all attribute values. In the WikiLarge training data, there are far fewer training samples where the simplified output is much longer than the complex, original input in WikiLarge. This explains why the representations are not as interpret able for values greater than 1.2.
图 5 是对 $\S6.1$ 的补充,展示了所有属性值的长度压缩控制前缀的组成成分。在WikiLarge训练数据中,简化输出比复杂原始输入长很多的训练样本要少得多。这解释了为什么大于1.2的值的表示不如小于1.2的值那样可解释。

Figure 4: Histogram illustrating the influence of different target length ratios on the actual length compression ratio output distribution for the simplification CONTROL PREFIXES model on the TurkCorpus validation set.
图 4: 柱状图展示了不同目标长度比例对TurkCorpus验证集上简化CONTROL PREFIXES模型实际长度压缩比输出分布的影响。
E.1 QuestEval
E.1 QuestEval
The Gold Reference results for Quest E val 18 are higher for TurkCorpus compared to ASSET in Table 2. We argue this is because the test set gold references are on average 114 characters for TurkCorpus, as opposed to 98 for ASSET. Therefore, the ASSET references contain less information to answer the generated queries during QuestEval evaluation; and thus, there is lower performance. We argue this shows a limitation with using QuestEval as a reference-less metric for simplification—by favouring longer generations.
表2中TurkCorpus的Quest Eval 18黄金参考结果高于ASSET。我们认为这是因为TurkCorpus测试集的黄金参考平均为114个字符,而ASSET仅为98个字符。因此,ASSET参考在QuestEval评估期间为回答生成查询提供的信息较少,从而导致性能较低。我们认为这表明了将QuestEval用作无参考简化指标的局限性——它更倾向于生成更长的文本。
F Prefix-tuning $^+$ Control Tokens
F Prefix-tuning $^+$ 控制 Token
We propose another architecture ‘prefix-tuning $^+$ control tokens’, where all of the original LM parameters, $\phi$ , still remain fixed, including the embedding matrix. Control has to be exerted through the few control embeddings and prefix-tuning’s ability to steer the frozen $\phi$ parameters through $<2%$ additional parameters. We use this method to inform the model of the same discrete guidance information as in CONTROL PREFIXES, but with control tokens instead of control prefixes.19 This alternative method is less expressive than CONTROL PREFIXES, in much the same way as prefix-tuning is more expressive than prompt-embedding tuning. Prefix-tuning $^+$ control tokens also does not benefit from the shared re-parameter iz at ions $(\S3.3)$ that we argue allow for more effective demarcation of control of the fixed LM in each attention class subspace.
我们提出另一种架构"前缀调优+控制token",其中所有原始大语言模型参数 $\phi$ 仍保持固定,包括嵌入矩阵。控制必须通过少量控制嵌入和前缀调优引导冻结 $\phi$ 参数的能力来实现,仅需增加 $<2%$ 的附加参数。该方法用于向模型传递与CONTROL PREFIXES相同的离散引导信息,但采用控制token而非控制前缀。19这种替代方法的表达能力弱于CONTROL PREFIXES,其差异程度类似于前缀调优优于提示嵌入调优。前缀调优+控制token也无法受益于共享重参数化 $(\S3.3)$ ,我们认为该机制能在每个注意力类子空间中更有效地划分对固定大语言模型的控制边界。

Figure 5: t-SNE visualization s for constituents of the length compression control prefixes learnt as part of the simplification CONTROL PREFIXES model. Each diagram depicts representations of control prefixes corresponding to each length value (41 bins of fixed width 0.05, from 0 to 2) for a particular attention mechanism. The dimension represented on the $\mathbf{X}$ -axis is stretched from a 1:1 to 2:1 aspect ratio for labelling clarity.
图 5: 作为简化控制前缀模型 (CONTROL PREFIXES) 组成部分学习的长度压缩控制前缀各成分的 t-SNE 可视化。每个图表描绘了特定注意力机制下对应各长度值 (从0到2的41个固定宽度0.05区间) 的控制前缀表征。为标注清晰起见,$\mathbf{X}$ 轴表示的维度从1:1拉伸至2:1的长宽比。
Table 9 reveals that CONTROL PREFIXES outperforms prefix-tuning $^+$ control tokens on the data-totext and sum mari z ation datasets, while the results are both comparable to the Gold References on simpli fi cation datasets. This indicates that CONTROL PREFIXES is better able to integrate and leverage guidance signal at the input-level, whilst maintaining the fixed-LM property, than prefix-tuning $^+$ con- trol tokens.
表 9 显示,在数据到文本和摘要数据集上,CONTROL PREFIXES 的表现优于前缀调优 $^+$ 控制 token,而在文本简化数据集上,两者的结果均与黄金参考 (Gold References) 相当。这表明,与前缀调优 $^+$ 控制 token 相比,CONTROL PREFIXES 能更好地在输入层面整合和利用引导信号,同时保持固定语言模型 (fixed-LM) 的特性。
G Varying Prompt Length
G 不同提示词长度

Figure 6: Prefix-tuning results of a model parameter search on several datasets for the optimal prompt length per dataset. These results are for the metric monitored per task on the respective validation sets indicated in the legend. $\phi%$ denotes the $%$ of additional parameters to the number of fixed-LM parameters required at inference time. The $y$ -axis is a relative measure: the validation set performance as a $%$ of the maximum attained in the parameter search.
图 6: 多个数据集上模型参数搜索的前缀调优结果,展示了每个数据集的最佳提示长度。这些结果对应图例中所示各验证集上监测的任务指标。$\phi%$ 表示推理时所需额外参数占固定大语言模型参数总量的百分比。$y$ 轴为相对度量:参数搜索中达到的最高性能的百分比表示的验证集性能。
Our research is not solely focused on parameter efficiency, but also on the effectiveness of adapting an already parameter efficient, fixed-LM method (adding ${<}3%$ additional parameters). The only way to add parameters with prefix-tuning is to increase the prompt length. XSum is the only dataset considered where performance does not plateau when increasing prompt length20, therefore we ensure
我们的研究不仅关注参数效率,还关注对已有参数高效、固定大语言模型方法的适配效果(仅增加${<}3%$额外参数)。通过前缀调优(prefix-tuning)增加参数的唯一方式是延长提示词长度。XSum是唯一一个在增加提示词长度时性能不会趋于平稳的数据集[20],因此我们确保
CONTROL PREFIXES does not have more parameters than prefix-tuning to ensure a fair comparison.
CONTROL PREFIXES 的参数数量不超过 prefix-tuning,以确保公平比较。
The only way to add parameters with prefixtuning is by increasing prompt length. Fig. 6 illustrates how performance saturation is observed—after a certain prompt length performance plateaus. Different datasets require varying prompt lengths to attain near maximum performance in a parameter search for prompt length. For the data-to- text datasets, near maximum performance $(>99%$ of the maximum validation score in the search) is reached with a prompt length of 1 or 2.
使用前缀调参 (prefixtuning) 增加参数的唯一方式是延长提示长度。图 6 展示了性能饱和现象——当提示长度超过某个阈值后性能趋于稳定。不同数据集在提示长度参数搜索中需要不同的提示长度才能接近最高性能。对于数据到文本 (data-to-text) 数据集,仅需 1 或 2 的提示长度即可达到接近最高性能 $(>99%$ 搜索中的最大验证分数)。
H Qualitative Examples
H 定性示例
For data-to-text, Table 13 displays example CONTROL PREFIXES output for WebNLG input belonging to unseen categories, along with the zero-shot procedure. Table 13 depicts example CONTROL PREFIXES $(A_{1},A_{2})$ output alongside prefix-tuning model output for $\mathrm{WebNLG}+2020$ input. For simpli fi cation, Table 12 compares the fixed-LM guided generations of CONTROL PREFIXES to the finetuned BARTLARGE with ACCESS (Martin et al., 2020). For sum mari z ation, Table 15 depicts cherrypicked CONTROL PREFIXES generated summaries for XSum input, alongside T5-large fine-tuned summaries that have higher ROUGE scores. This is to illustrate how CONTROL PREFIXES can achieve higher human assessment through GENIE than top-performing fine-tuned models, whilst attaining lower automatic metric scores.
在数据到文本任务中,表13展示了WebNLG未见类别输入的CONTROL PREFIXES零样本处理输出示例。表13呈现了CONTROL PREFIXES $(A_{1},A_{2})$ 输出与针对 $\mathrm{WebNLG}+2020$ 输入的prefix-tuning模型输出对比。为简化说明,表12将CONTROL PREFIXES的固定语言模型引导生成结果与经过ACCESS调优的BARTLARGE (Martin et al., 2020) 进行了比较。在摘要任务方面,表15精选展示了CONTROL PREFIXES为XSum输入生成的摘要,以及ROUGE分数更高的T5-large微调摘要。这旨在说明CONTROL PREFIXES如何通过GENIE获得比性能最佳的微调模型更高的人类评估分数,同时自动度量分数较低。
Table 5: Detailed results on the DART test set to complement Table 1. T5-large fine-tuned is the current SOTA (Radev et al., 2020). We report results on the official evaluation script for v1.1.1, the same version as the official leader board, available here: https://github.com/Yale-LILY/dart. *Results for this model were only reported to the significant figures shown. $\phi%$ denotes the $%$ of additional parameters to the number of fixed-LM parameters required at inference time.
表 5: DART测试集的详细结果,作为表1的补充。T5-large微调版本是当前的最先进技术(SOTA) (Radev et al., 2020)。我们使用v1.1.1官方评估脚本报告结果,该版本与官方排行榜相同,详见:https://github.com/Yale-LILY/dart。*该模型的结果仅显示有效数字。$\phi%$表示推理时所需额外参数占固定语言模型参数数量的百分比。
| Φ% | BLEU | METEOR | TER← | BERTScore(F1) | |
|---|---|---|---|---|---|
| T5-large fine-tuned* | 100 | 50.66 | 40 | 43 | 0.95 |
| Prefix-tuning | 1.0 | 51.20 | 40.62 | 43.13 | 0.95 |
| CONTROL PREFIXES (A1) | 1.1 | 51.95 | 41.07 | 42.75 | 0.95 |
Table 6: Detailed results on the WebNLG test set to complement Table 1. S, U and A refer to the Seen, Unseen and All portions of the WebNLG dataset. Several of the baseline results were only reported to the significant figures shown.
表 6: WebNLG测试集详细结果,作为表1的补充。S、U和A分别代表WebNLG数据集的Seen、Unseen和All部分。部分基线结果仅显示有效数字。
| Φ% | BLEU | METEOR | TER ↓ | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| S | U | A | S | U | A | S | U | A | ||
| T5-large | 100 | 64.89 | 54.01 | 59.95 | 46 | 43 | 44 | 34 | 41 | 37 |
| SOTA | 100 | 65.82 | 56.01 | 61.44 | 46 | 43 | 45 | 32 | 38 | 35 |
| Prefix-tuning | 1.0 | 66.95 | 55.39 | 61.73 | 46.73 | 42.71 | 44.87 | 31.34 | 39.01 | 34.86 |
| CONTROL PREFIXES (A1) | 1.4 | 67.32 | 55.38 | 61.94 | 46.78 | 42.77 | 44.92 | 30.96 | 39.01 | 34.65 |
| +Data:DART | ||||||||||
| Prefix-tuning | 1.0 | 67.05 | 55.37 | 61.78 | 46.69 | 42.82 | 44.90 | 31.36 | 38.79 | 34.77 |
| CONTROL PREFIXES (A2) | 1.0 | 66.99 | 55.56 | 61.83 | 46.67 | 42.87 | 44.91 | 31.37 | 38.53 | 34.65 |
| CONTROL PREFIXES (A1,A2) | 1.4 | 67.15 | 56.41 | 62.27 | 46.64 | 43.18 | 45.03 | 31.08 | 38.78 | 34.61 |
Table 7: Detailed results on the E2E Clean test set to complement Table 1. The SOTA baseline result was only reported to the significant figures shown.
表 7: E2E Clean测试集的详细结果,作为表1的补充。SOTA基线结果仅显示有效数字。
| Φ% | BLEU | NIST | METEOR | R-L | CIDEr | |
|---|---|---|---|---|---|---|
| T5-Large | 100 | 41.83 | 6.41 | 0.381 | 56.0 | 1.97 |
| SOTA | 100 | 43.6 | 0.39 | 57.5 | 2.0 | |
| Prefix-tuning | 1.0 | 43.66 | 6.51 | 0.390 | 57.2 | 2.04 |
| +Data:DART | ||||||
| Prefix-tuning | 1.0 | 43.04 | 6.46 | 0.387 | 56.8 | 1.99 |
| CONTROL PREFIXES (A2) | 1.0 | 44.15 | 6.51 | 0.392 | 57.3 | 2.04 |
| Φ% | BLEU | METEOR | chrF++ | TER↓ | BLEURT | |
|---|---|---|---|---|---|---|
| T5-large*t | 100 | 51.74 | 0.403 | 0.669 | 0.417 | 0.61 |
| Prefix-tuning | 1.0 | 54.74 | 0.417 | 0.693 | 0.399 | 0.62 |
| CONTROL PREFIXES (A1) | 1.6 | 54.97 | 0.417 | 0.693 | 0.398 | 0.62 |
| +Data:DART | ||||||
| CONTROL PREFIXES (A2) | 1.0 | 54.92 | 0.418 | 0.695 | 0.397 | 0.62 |
| CONTROL PREFIXES (A1,A2) | 1.6 | 55.41 | 0.419 | 0.698 | 0.392 | 0.63 |
Table 8 $\mathbf{\sigma}:\mathbf{WebNLG}+2\mathbf{0}2\mathbf{0}$ . The overall $\mathrm{WebNLG}+2020$ test set results using the official evaluation script. *As the model outputs are publicly available, we are able to run evaluation to achieve the same precision. †Results from Pasricha et al. (2020), who before fine-tuning on the ${\mathrm{WebNLG+}}$ data, further pre-train T5-large using a Mask Language Modelling objective (with $15%$ of the tokens masked) on the WebNLG corpus and a corpus of DBpedia. $A_{1}$ signifies models trained with control prefixes for the WebNLG category attribute, and $A_{2}$ with control prefixes for the DART sub-dataset source attribute.
表8 $\mathbf{\sigma}:\mathbf{WebNLG}+2\mathbf{0}2\mathbf{0}$。使用官方评估脚本的完整$\mathrm{WebNLG}+2020$测试集结果。*由于模型输出已公开,我们能够运行评估以获得相同精度。†结果来自Pasricha等人(2020)的研究,他们在对${\mathrm{WebNLG+}}$数据进行微调前,使用掩码语言建模目标(掩码$15%$的token)在WebNLG语料库和DBpedia语料库上对T5-large进行了进一步预训练。$A_{1}$表示使用WebNLG类别属性控制前缀训练的模型,$A_{2}$表示使用DART子数据集源属性控制前缀训练的模型。
Table 9: Prefix-tuning $^+$ Control Tokens. Comparison of our best CONTROL PREFIXES model for each dataset with prefix-tuning $^+$ control tokens for the same attributes. The guided simplification models are the average test set results over 5 random seeds.
表 9: Prefix-tuning $^+$ Control Tokens。我们在各数据集上表现最佳的CONTROL PREFIXES模型与相同属性下prefix-tuning $^+$ control tokens方法的对比结果。引导简化模型为5次随机种子的测试集平均结果。
| DART | WebNLG | E2E Clean | ASSET | TurkCorpus | XSum | |||
|---|---|---|---|---|---|---|---|---|
| BLEU | SARI | QuestEval | SARI | QuestEval | R-2 | |||
| Prefix-tuning + Control Tokens | 51.72 | 61.89 | 43.57 | 43.64 | 0.63 | 42.36 | 0.66 | 20.70 |
| CONTROL PREFIXES | 51.95 | 62.27 | 44.15 | 43.58 | 0.64 | 42.32 | 0.66 | 20.84 |
| 模型 | 阶段 | 学习率 | 优化器 | 预热步数 | 训练轮数 | 批次大小 | 有效批次 | 束宽 | LN-Q | 最小目标 | 最大目标 | 禁止重复三元组 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DART (T5-large) | ||||||||||||
| Prefix-tuning | 7e-5 | Ada | 2000 | 40 | 6 | 96 | 5 | 1 | 0 | 384 | 否 | |
| CONTROL PREFIXES (A1) | 7e-5 | Ada | 2000 | 40 | 6 | 96 | 5 | 1 | 0 | 384 | 否 | |
| E2E Clean (T5-large) | ||||||||||||
| Prefix-tuning | 8e-5 | Ada | 2000 | 50 | 9 | 96 | 5 | 1 | 0 | 384 | 否 | |
| CONTROL PREFIXES (A2) | 1 | 7e-5 | Ada | 2000 | 30 | 6 | 96 | 5 | 1 | 0 | 384 | 否 |
| 2 | 5e-5 | Ada | 2000 | 50 | 6 | 96 | 5 | 1 | 0 | 384 | 否 | |
| WebNLG (T5-large) | ||||||||||||
| Prefix-tuning | 7e-5 | Ada | 2000 | 30 | 6 | 96 | 5 | 1 | 0 | 384 | 否 | |
| CONTROL PREFIXES (A1) | 7e-5 | Ada | 2000 | 40 | 6 | 96 | 5 | 1 | 0 | 384 | 否 | |
| +Data: DART | ||||||||||||
| Prefix-tuning | 7e-5 | Ada | 2000 | 40 | 6 | 96 | 5 | 1 | 0 | 384 | 否 | |
| CONTROL PREFIXES (A2) | 7e-5 | Ada | 2000 | 30 | 6 | 96 | 5 | 1 | 0 | 384 | 否 | |
| 1 | 3e-5 | Ada | 2000 | 30 | 6 | 96 | 5 | 1 | 0 | 384 | 否 | |
| CONTROL PREFIXES (A1, A2) | 7e-5 | Ada | 2000 | 30 | 6 | 96 | 5 | 1 | 0 | 384 | 否 否 | |
| 3e-5 | Ada | 2000 | 30 | 6 | 96 | 5 | 1 | 0 | 384 | |||
| XSum (BARTLARGE) | ||||||||||||
| Prefix-tuning | 7e-5 | AdamW | 2000 | 40 | 8 | 128 | 6 | 1 | 10 | 09 | 人 | |
| CONTROL PREFIXES (A1, A2) | 7e-5 | AdamW | 2000 | 40 | 8 | 128 | 6 | 1 | 10 | 60 | √ | |
| ASSET& TurkCorpus (BARTLARGE) | ||||||||||||
| Prefix-tuning | 5e-5 | AdamW | 2000 | 30 | 8 | 9 | 6 | 0.8 | 3 | 100 | ||
| CONTROL PREFIXES) | 4e-5 | Ada | 5000 | 30 | 8 | 9 | 9 | 1 | 3 | 100 | √ √ |
Table 10: Hyper parameters. Detailed hyper parameter reporting for the models in this work. If the training procedure is multi-stage, each stage is indicated. L-rate is the learning rate, all learning follows a linear learning rate scheduler; Opt refers to the optimizer, Ada (Adafactor) or AdamW; Effective Batch $=$ Batch size x # of gradient accumulation batches; LN $\alpha$ refers to the $\alpha$ in length normalization during beam search.
表 10: 超参数。本工作中模型的详细超参数报告。若训练过程为多阶段,则每个阶段均会标明。L-rate 指学习率,所有学习均采用线性学习率调度器;Opt 指优化器,Ada (Adafactor) 或 AdamW;有效批次量 $=$ 批次大小 × 梯度累积批次数;LN $\alpha$ 指波束搜索中长度归一化的 $\alpha$ 参数。
Table 11: Controlled text simplification: a qualitative example from the ASSET Corpus validation set, with our corresponding CONTROL PREFIXES model outputs. Only the control prefix for the length control ratio is varied, depicted in red. †Note, this is one random gold reference out of 10.
表 11: 受控文本简化:来自ASSET Corpus验证集的定性示例,展示了我们对应的CONTROL PREFIXES模型输出。仅长度控制比例的控制前缀发生变化(以红色标出)。†注:这是10个随机黄金参考之一。
| ASSETCorpus | |
| 原文 | 西海岸蓝调(West Coast blues)是一种受爵士乐和跳跃蓝调影响、以强劲钢琴音色为主导并带有爵士风格吉他独奏的蓝调音乐类型,起源于20世纪40年代迁移至加利福尼亚的德克萨斯蓝调音乐人。 |
| 黄金参考 | 西海岸蓝调受爵士乐和跳跃蓝调影响,具有以钢琴为主导的音色和爵士风格的吉他独奏,起源于20世纪40年代迁往加利福尼亚的德克萨斯蓝调音乐人。 |
| CONTROL PREFIXES(A1:4) 长度控制:0.25 | 西海岸蓝调是美国的一种蓝调音乐类型。 |
| CONTROL PREFIXES(A1:4) 长度控制:0.5 | 西海岸蓝调是一种由20世纪40年代移居加利福尼亚的德克萨斯蓝调音乐人创造的蓝调音乐类型,具有爵士和跳跃蓝调的影响。 |
| CONTROL PREFIXES(A1:4) 长度控制:0.75 | 西海岸蓝调是一种起源于20世纪40年代德克萨斯的蓝调音乐类型,其特征包括受爵士和跳跃蓝调影响、以强劲钢琴音色为主导并带有爵士风格吉他独奏。 |
| CONTROL PREFIXES(A1:4) 长度控制:1.0 | 西海岸蓝调是一种受爵士乐和跳跃蓝调影响、以强劲钢琴音色为主导并带有爵士风格吉他独奏的蓝调音乐类型,起源于20世纪40年代迁移至加利福尼亚的德克萨斯蓝调音乐人 |
Table 12: Fixed-LM vs fine-tuned controlled text simplification. CONTROL PREFIXES and BARTLARGE with ACCESS (Martin et al., 2020) generated simplifications chosen from the ASSET Corpus test set. †Note, this is one random gold reference out of 10 for each example. The examples shown for CONTROL PREFIXES and BARTLARGE with ACCESS are also randomly selected from one of the five model outputs.
表 12: 固定语言模型 vs 微调控制的文本简化。CONTROL PREFIXES 和带 ACCESS 的 BARTLARGE (Martin et al., 2020) 生成的简化文本选自 ASSET Corpus 测试集。†注:每个示例的黄金参考是随机选取的10个中的一个。CONTROL PREFIXES 和带 ACCESS 的 BARTLARGE 的示例也是从五个模型输出中随机选取的。
| ASSETCorpus | |
|---|---|
| 原文 | The Great Dark Spot is thought to represent a hole in the methane cloud deck of Neptune. |
| 黄金参考 | The Great Dark Spot represents a hole in the methane cloud of Neptune. |
| CONTROL PREFIXES | It is thought that the Great Dark Spot is a hole in Neptune's methane cloud deck. |
| BARTLARGEWithACCESS | The Great Dark Spot looks like a hole in the methane cloud deck of Neptune. |
| 原文 | Fives is aBritish sport believed to derivefrom the same origins asmany racquet sports. |
| 黄金参考 | Fives is a British sport developed from the same origins as many racquet sports. |
| CONTROL PREFIXES | Fives is a British sport. It is believed to have its origins in racquet sports. |
| BARTLARGEWithACCESS | Fives is a British sport. It is thought to come from the same as many racquet sports. |
| 原文 | Nevertheless, Tagore emulated numerous styles, including craftwork from northern New Ireland, Haida carvings from the west coast of Canada (British Columbia),and woodcuts by Max Pechstein. |
| 黄金参考 | Canada and woodcuts byMaxPechstein. |
| CONTROL PREFIXES | Tagore emulated many different styles of art,including Haida carvings from the west coast of Canada (British Columbia),and woodcuts by Max Pechstein. |
| BARTLARGEWithACCESS | Tagore copied many styles. He copied craftwork from northern New Ireland, Haida carvings from the west coast of Canada (British Columbia),and woodcuts by MaxPechstein. |
WebNLG
未见类别:运动员 零样本 -> 运动队
源:
黄金
Valery Petrakov 是 FC Torpedo Moscow 的经理,主席是 Aleksandr Tukmanov。Aleksandr Chumakov 效力于该俱乐部,该俱乐部在 2014-15 赛季参加了俄罗斯超级联赛。
前缀调优
2014-15 赛季的超级联赛,主席是 Aleksandr Tukmanov。
控制前缀 (A1)
Aleksandr Chumakov 效力于由 Valery Petrakov 执教的 FC Torpedo Moscow。俱乐部主席是 Aleksandr Tukmanov,他们在 2014-15 赛季参加了俄罗斯超级联赛。
未见类别:交通工具 零样本 -> 机场
源:
黄金
Carnival Corporation & plc 是位于热那亚的 Costa Crociere 的母公司,后者拥有 AIDAstella。AIDAstella 由
前缀调优
Meyer Werft 建造,由 AIDA Cruises 运营。Costa Crociere 位于热那亚,归 Carnival Corporation & plc 所有。AIDAstella 由 AIDA Cruises 运营
控制前缀 (A1)
并由 Meyer Werft 建造。Costa Crociere 位于热那亚,归 AIDA Cruises 所有。AIDAstella 由 Meyer Werft 建造并由 AIDA Cruises 运营。Costa Crociere 的母公司是 Carnival Corporation & plc。
Table 13: WebNLG example generations: sources are shown in their linearized form, as fed to the T5-large based models, with prefix-tuning output and one of the gold references shown for comparison with CONTROL PREFIXES output. Triplesets are from WebNLG unseen categories and the zero-shot procedure is depicted using the textual category labels. As an example, for the unseen category Athlete, the closest Glove embedding belonging to a seen category label in embedding space is SportsTeam. Therefore the trained control prefix relating to SportsTeam is used for this example at inference time.
表 13: WebNLG示例生成:源数据以线性化形式展示(作为基于T5-large模型的输入),同时呈现前缀调优输出和一个黄金参考输出,用于与CONTROL PREFIXES输出进行对比。三元组来自WebNLG未见类别,零样本流程通过文本类别标签展示。例如,对于未见类别Athlete,在嵌入空间中最接近的已见类别标签Glove嵌入是SportsTeam。因此在推理阶段,该示例使用了与SportsTeam相关的训练控制前缀。
| WebNLG+2020 | |
|---|---|
| WebNLGMeanOfTransportation (Seen with UnseenEntities) | 来源: PontiacRageousproductionStartYear1997PontiacRageousassembly |
| Gold | Pontiac Rageous是一款由Pontiac生产的双门轿跑车型汽车。该车在密歇根州和底特律组装,于1997年开始生产,同年停产。 |
| Prefix-tuning | Pontiac Rageous是由Pontiac生产的双门轿跑车。它在密歇根州底特律组装,并于1997年开始生产。 |
| CONTROL PREFIXES(A1,A2) | 1997年。Pontiac Rageous采用双门轿跑车身设计。 |
| WebNLG (Unseen) Unseen Category: MusicalWork Zero-shot->Artist | 来源: BootlegSeriesVolume1:TheQuineTapesgenreRock musicBootlegSeriesVolume1:TheQuineTapesprecededBySqueeze The Velvet Underground albumBootlegSeriesVolume |
| Gold | recordedInSanFrancisco The Velvet Underground的专辑Squeeze之后发行了摇滚专辑Bootleg Series Volume 1: The Quine |
| Prefix-tuning | Tapes,由Polydor Records唱片公司在旧金山录制。Bootleg Series Volume 1: The Quine Tapes的唱片公司是Polydor Records。该专辑在旧金山录制 |
| CONTROL PREFIXES (A1,A2) | 并由The Velvet Underground的Squeeze专辑作为前作。其音乐类型为摇滚乐。 The Velvet Underground的Squeeze专辑前作为Bootleg Series Volume 1: The Quine Tapes,该专辑在旧金山录制并由Polydor Records发行。专辑类型为摇滚乐。 |
Table 14: $\mathbf{WebNLG}+2\mathbf{0}2\mathbf{0}$ generations: sources are shown in their linearized form as fed to the T5-large based models. The DART sub-dataset Source control prefix is highlighted, along with the final Category control prefix. The zero-shot procedure is depicted for the Unseen Category Musical Work. The closest embedding belonging to a Seen category in embedding space is Artist.
表 14: $\mathbf{WebNLG}+2\mathbf{0}2\mathbf{0}$ 生成结果: 数据源以线性化形式展示,作为基于 T5-large 模型的输入。DART 子数据集源控制前缀被高亮显示,同时标注了最终的类别控制前缀。针对未见类别 Musical Work 展示了零样本处理流程。在嵌入空间中最接近的已见类别嵌入是 Artist。
XSum
XSum
| news world | 喀拉拉邦警方周日拘留了Kamal C Chavara,起因是印度教民族主义政党BJP的青年组织在电影放映前举报。此后约有20人因在奏国歌时未起立而在喀拉拉邦和泰米尔纳德邦被拘。印度殖民时期的煽动叛乱法常被用于针对学生、记者、作家、社会活动人士及政府批评者。报道称BJP青年组织指控Chavara先生在Facebook发布的涉嫌侮辱国歌的帖文。该帖文显然节选自他... |
| Gold | ...的公职身份,从而对他人造成妨碍或骚扰"。金奈某影院内,警方称八名未向国歌起立者遭殴打辱骂。这八人后被控"对国歌不敬"。印度一位作家因涉嫌侮辱国歌被控煽动叛乱。 |
| T5-large微调模型(70.97/48.28/70.97) | |
| 控制前缀(A1,A2)(59.46/34.29/54.05) | 印度著名作家因抵制国歌被控煽动叛乱。一位印度作家兼活动人士因Facebook上涉嫌侮辱国歌的帖文被控煽动叛乱。 |
| sport horse-racing | 国歌。由David Mullins策骑、Mouse Morris训练的33倍冷门马,四月在安特里赛场夺冠,成为1958年以来首匹赢得该赛事的新秀马。这匹九岁赛驹隶属GigginstownHouse Stud马房,曾两次从骨盆骨折中康复。"我们不想让它负重重返安特里,这不公平,"Gigginstown赛事经理Eddie O'Leary表示,"它为我们赢得首个国家大赛冠军,我们永志难忘。"BBC赛马记者Cornelius Lysaght:"作为马主Michael O'Leary旗下首匹克服重伤问鼎大赛巅峰的赛驹,它已完成了使命。"Gigginstown本赛季虽在安特里、爱尔兰国家大赛和切尔滕纳姆金杯赛屡创佳绩,但代价沉重。"世界统治"已退役,金杯冠军Don Cossack能否复出亦存疑。 |
| Gold | 在安特里、爱尔兰国家大赛和切尔滕纳姆金杯赛取得佳绩,但代价不菲。"世界统治"已退役,金杯冠军Don Cossack能否再战成疑。 |
| T5-large微调模型(57.14/46.15/57.14) | 本届国家大赛冠军"世界统治"已退役。 |
Table 15: XSum generated summaries for T5-large fine-tuned and CONTROL PREFIXES based on BARTLARGE . These are presented alongside the source document and the sole gold reference. Source documents are truncated to 300 words if necessary. ROUGE-1/ROUGE-2/ROUGE-L are reported in bold. The news/sport control prefix and the related sub-directory control prefix are highlighted.
表 15: 基于BARTLARGE微调的T5-large和CONTROL PREFIXES生成的XSum摘要。这些摘要与源文档和唯一黄金参考摘要一同呈现。源文档在必要时被截断至300词。ROUGE-1/ROUGE-2/ROUGE-L分数以粗体显示。新闻/体育控制前缀及相关子目录控制前缀已高亮标注。